⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-09 更新
OpenS2S: Advancing Open-Source End-to-End Empathetic Large Speech Language Model
Authors:Chen Wang, Tianyu Peng, Wen Yang, Yinan Bai, Guangfu Wang, Jun Lin, Lanpeng Jia, Lingxiang Wu, Jinqiao Wang, Chengqing Zong, Jiajun Zhang
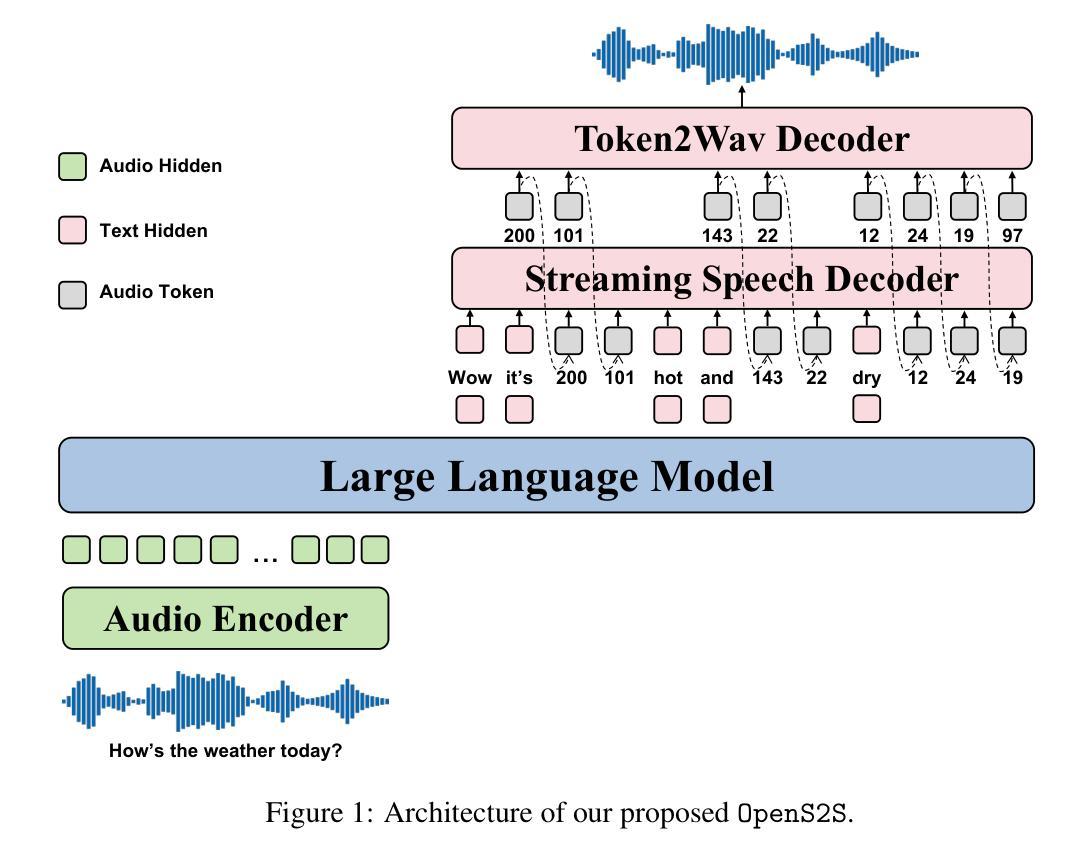
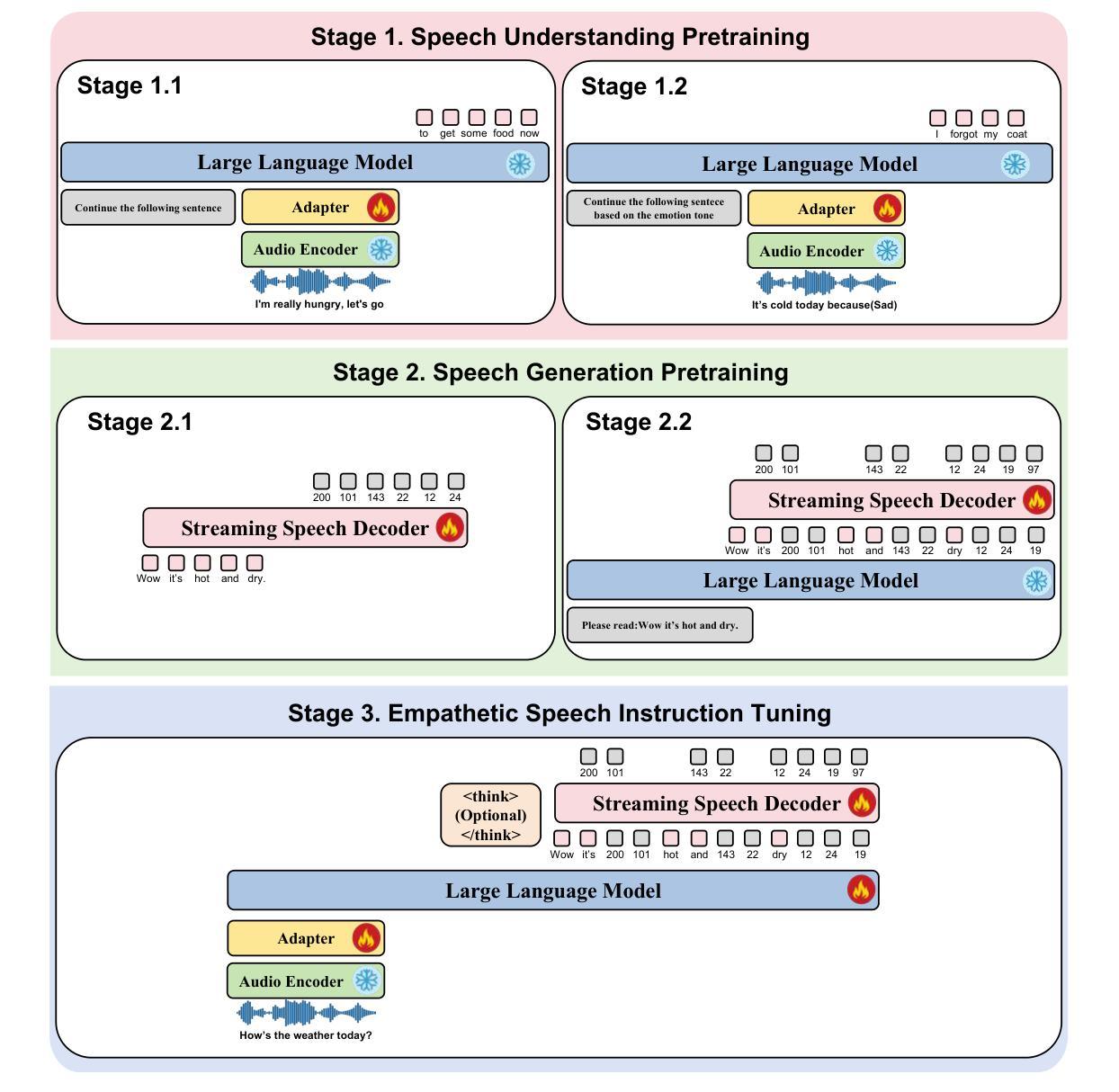
Empathetic interaction is a cornerstone of human-machine communication, due to the need for understanding speech enriched with paralinguistic cues and generating emotional and expressive responses. However, the most powerful empathetic LSLMs are increasingly closed off, leaving the crucial details about the architecture, data and development opaque to researchers. Given the critical need for transparent research into the LSLMs and empathetic behavior, we present OpenS2S, a fully open-source, transparent and end-to-end LSLM designed to enable empathetic speech interactions. Based on our empathetic speech-to-text model BLSP-Emo, OpenS2S further employs a streaming interleaved decoding architecture to achieve low-latency speech generation. To facilitate end-to-end training, OpenS2S incorporates an automated data construction pipeline that synthesizes diverse, high-quality empathetic speech dialogues at low cost. By leveraging large language models to generate empathetic content and controllable text-to-speech systems to introduce speaker and emotional variation, we construct a scalable training corpus with rich paralinguistic diversity and minimal human supervision. We release the fully open-source OpenS2S model, including the dataset, model weights, pre-training and fine-tuning codes, to empower the broader research community and accelerate innovation in empathetic speech systems. The project webpage can be accessed at https://casia-lm.github.io/OpenS2S
共情交互是人类与机器通信的基石,这是因为需要理解包含副语言线索的语音并产生情感和表达性反应。然而,最强大的共情LSLM(大型语言模型)日益封闭,使研究者对架构、数据和发展等重要细节无从得知。考虑到对LSLM和共情行为透明研究的迫切需求,我们推出了OpenS2S,这是一个完全开源、透明和端到端的LSLM,旨在实现共情的语音交互。OpenS2S基于我们的共情语音到文本模型BLSP-Emo,并进一步采用流式交织解码架构来实现低延迟的语音生成。为了促进端到端的训练,OpenS2S引入了一个自动数据构建管道,以低成本合成多样、高质量的共情语音对话。通过利用大型语言模型来生成共情内容,并借助可控的文本到语音系统来引入发言者和情感变化,我们构建了一个具有丰富的副语言多样性和最小人工监督的可扩展训练语料库。我们公开了完全开源的OpenS2S模型,包括数据集、模型权重、预训练和微调代码,以支持更广泛的研究群体并加速共情语音系统的创新。项目网页可访问https://casia-lm.github.io/OpenS2S。
论文及项目相关链接
PDF Technical Report
Summary
基于人类情感交互的重要性以及对理解富含副语言特征的语音和生成情感表达回应的需求,本文介绍了OpenS2S,一个完全开源、透明的端到端LSLM模型,旨在实现富有同情心的语音交互。OpenS2S基于BLSP-Emo的同情语音转文本模型,并采用流式交织解码架构实现低延迟语音生成。为了促进端到端的训练,OpenS2S利用自动化数据构建管道,低成本合成多样、高质量的同情语音对话。通过利用大型语言模型生成同情内容以及可控的文本转语音系统引入说话者和情感变化,构建了一个丰富的副语言多样性和最小人工监督的可扩展训练语料库。本文公开了完全开源的OpenS2S模型,包括数据集、模型权重、预训练和微调代码等,以激发更广泛的研究群体兴趣并加速同情语音系统的创新。项目网页可通过以下链接访问:https://casia-lm.github.io/OpenS2S。
Key Takeaways
- empathetic interaction是人与机器通信的重要基础,这需要理解副语言特征丰富的语音和生成情感表达回应。
- OpenS2S是一个旨在实现富有同情心的语音交互的完全开源、透明的端到端LSLM模型。
- OpenS2S采用流式交织解码架构实现低延迟语音生成。
- 通过自动化数据构建管道低成本合成多样、高质量的同情语音对话,建立丰富且可扩展到语料库。
- 利用大型语言模型和可控的文本转语音系统,可以生成富有同情心的内容和引入说话者和情感变化。
- OpenS2S模型完全开源,包括数据集、模型权重和预训练及微调代码等。
点此查看论文截图


TTS-CtrlNet: Time varying emotion aligned text-to-speech generation with ControlNet
Authors:Jaeseok Jeong, Yuna Lee, Mingi Kwon, Youngjung Uh
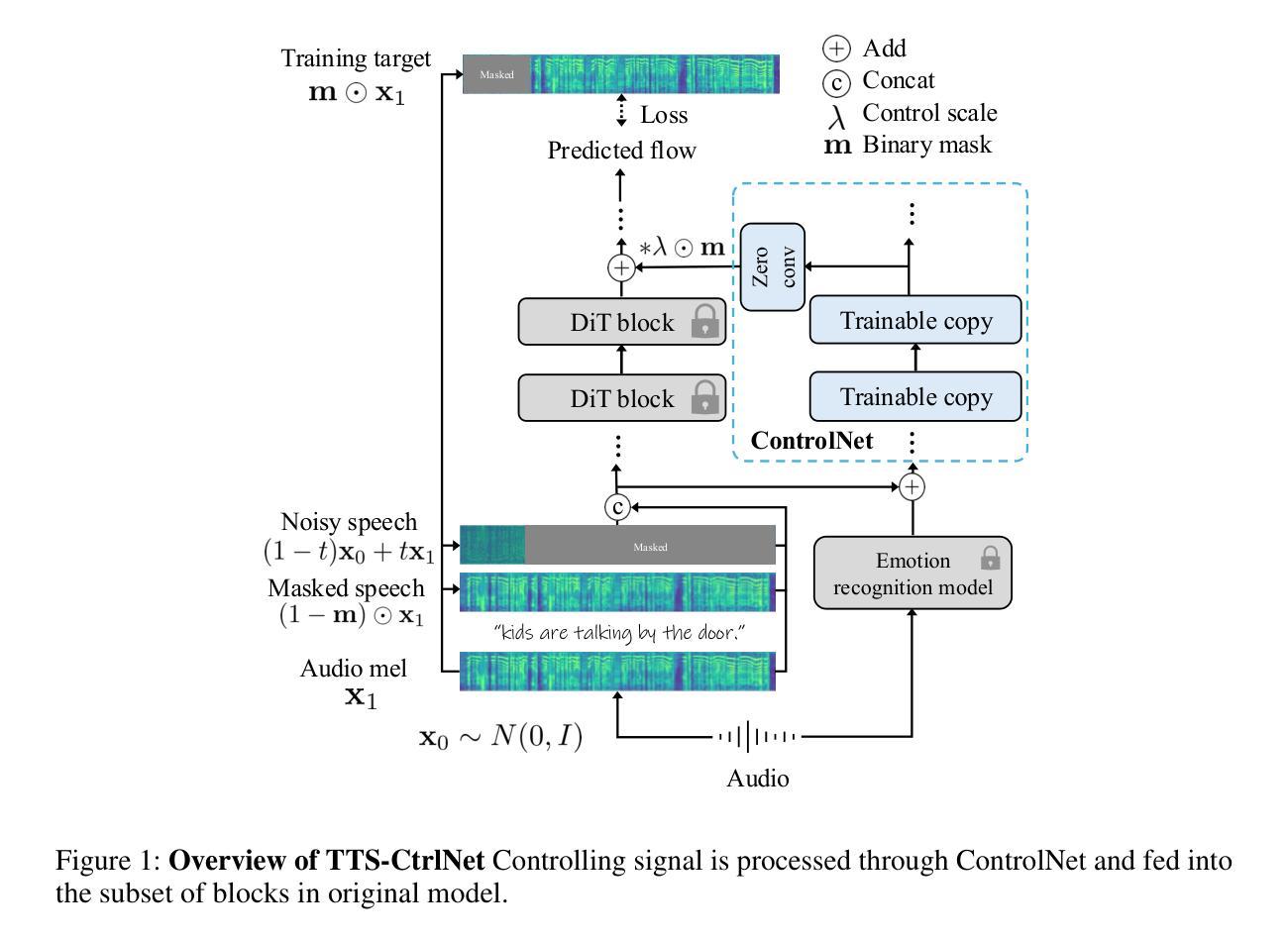
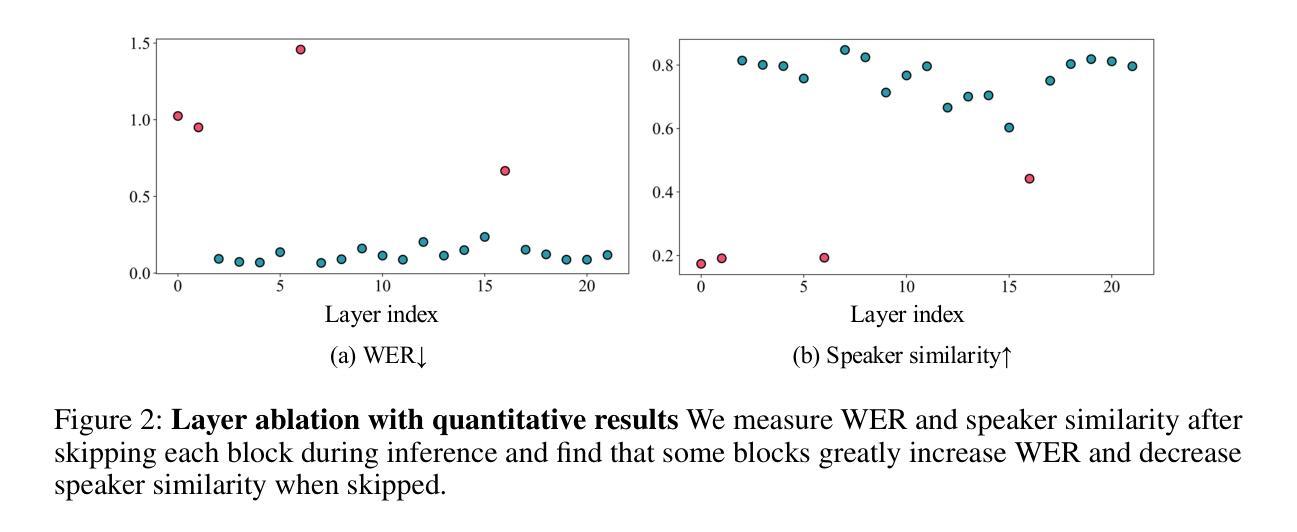
Recent advances in text-to-speech (TTS) have enabled natural speech synthesis, but fine-grained, time-varying emotion control remains challenging. Existing methods often allow only utterance-level control and require full model fine-tuning with a large emotion speech dataset, which can degrade performance. Inspired by adding conditional control to the existing model in ControlNet (Zhang et al, 2023), we propose the first ControlNet-based approach for controllable flow-matching TTS (TTS-CtrlNet), which freezes the original model and introduces a trainable copy of it to process additional conditions. We show that TTS-CtrlNet can boost the pretrained large TTS model by adding intuitive, scalable, and time-varying emotion control while inheriting the ability of the original model (e.g., zero-shot voice cloning & naturalness). Furthermore, we provide practical recipes for adding emotion control: 1) optimal architecture design choice with block analysis, 2) emotion-specific flow step, and 3) flexible control scale. Experiments show that ours can effectively add an emotion controller to existing TTS, and achieves state-of-the-art performance with emotion similarity scores: Emo-SIM and Aro-Val SIM. The project page is available at: https://curryjung.github.io/ttsctrlnet_project_page
近期文本到语音(TTS)的进展已经实现了自然的语音合成,但精细的时间变化情感控制仍然具有挑战性。现有方法通常只允许语句级别的控制,并且需要大规模情感语音数据集进行全模型微调,这可能会降低性能。受ControlNet(Zhang等人,2023)中引入条件控制的启发,我们提出了基于ControlNet的可控流程匹配TTS(TTS-CtrlNet)方法。该方法冻结了原始模型并引入了一个可训练的副本来处理额外的条件。我们展示了TTS-CtrlNet可以通过添加直观、可扩展和时间变化的情感控制来提升预训练的大型TTS模型的性能,同时继承了原始模型的能力(例如零样本声音克隆和自然性)。此外,我们还提供了添加情感控制的实用配方:1)通过块分析进行最佳架构设计选择,2)针对情感的流程步骤,以及3)灵活的控制规模。实验表明,我们的方法可以有效地为现有的TTS添加情感控制器,并在情感相似度得分方面达到最新性能:Emo-SIM和Aro-Val SIM。项目页面可访问于:https://curryjung.github.io/ttsctrlnet_project_page 。
论文及项目相关链接
Summary
本文介绍了基于ControlNet的TTS可控流匹配技术(TTS-CtrlNet)。该技术通过引入可训练的模型副本来处理额外的条件,实现了对预训练大型TTS模型的直观、可扩展和时间可变的情感控制,同时继承了原始模型的零样本语音克隆和自然度。该技术能够有效提升情感控制的灵活性并实现了最先进的性能。
Key Takeaways
- TTS-CtrlNet是一种基于ControlNet的TTS技术,旨在实现精细粒度的情感控制。
- 该技术通过引入可训练的模型副本处理额外的条件,使得情感控制更为直观、可扩展和时间可变。
- TTS-CtrlNet能够在预训练的大型TTS模型上添加情感控制器,同时保留原始模型的性能,如零样本语音克隆和自然度。
- 通过优化架构设计选择、情感特定流步骤和灵活的控制尺度,提供了实用的情感控制配方。
- 实验表明,TTS-CtrlNet能够有效添加情感控制器到现有的TTS系统中,并实现了最先进的性能表现。
- 该技术实现了情感相似性评分的高性能表现,包括Emo-SIM和Aro-Val SIM。
点此查看论文截图

PresentAgent: Multimodal Agent for Presentation Video Generation
Authors:Jingwei Shi, Zeyu Zhang, Biao Wu, Yanjie Liang, Meng Fang, Ling Chen, Yang Zhao
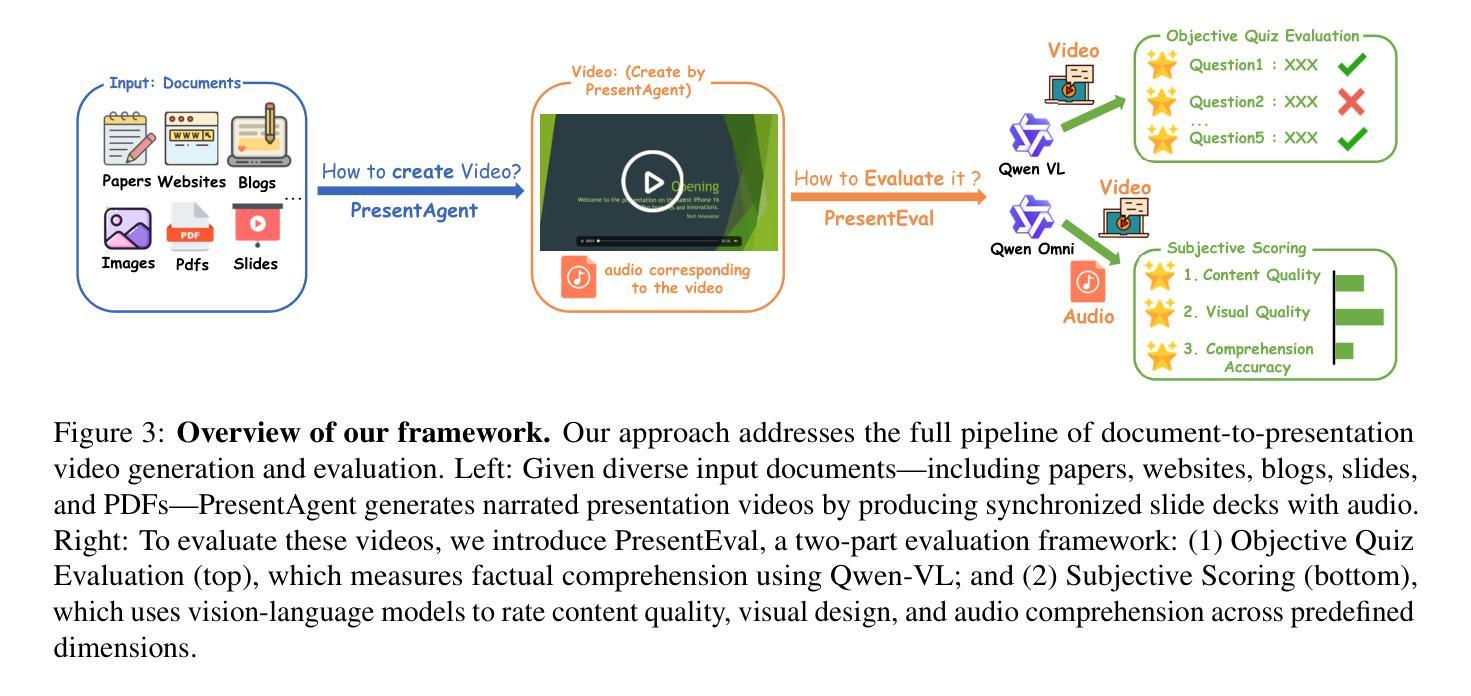
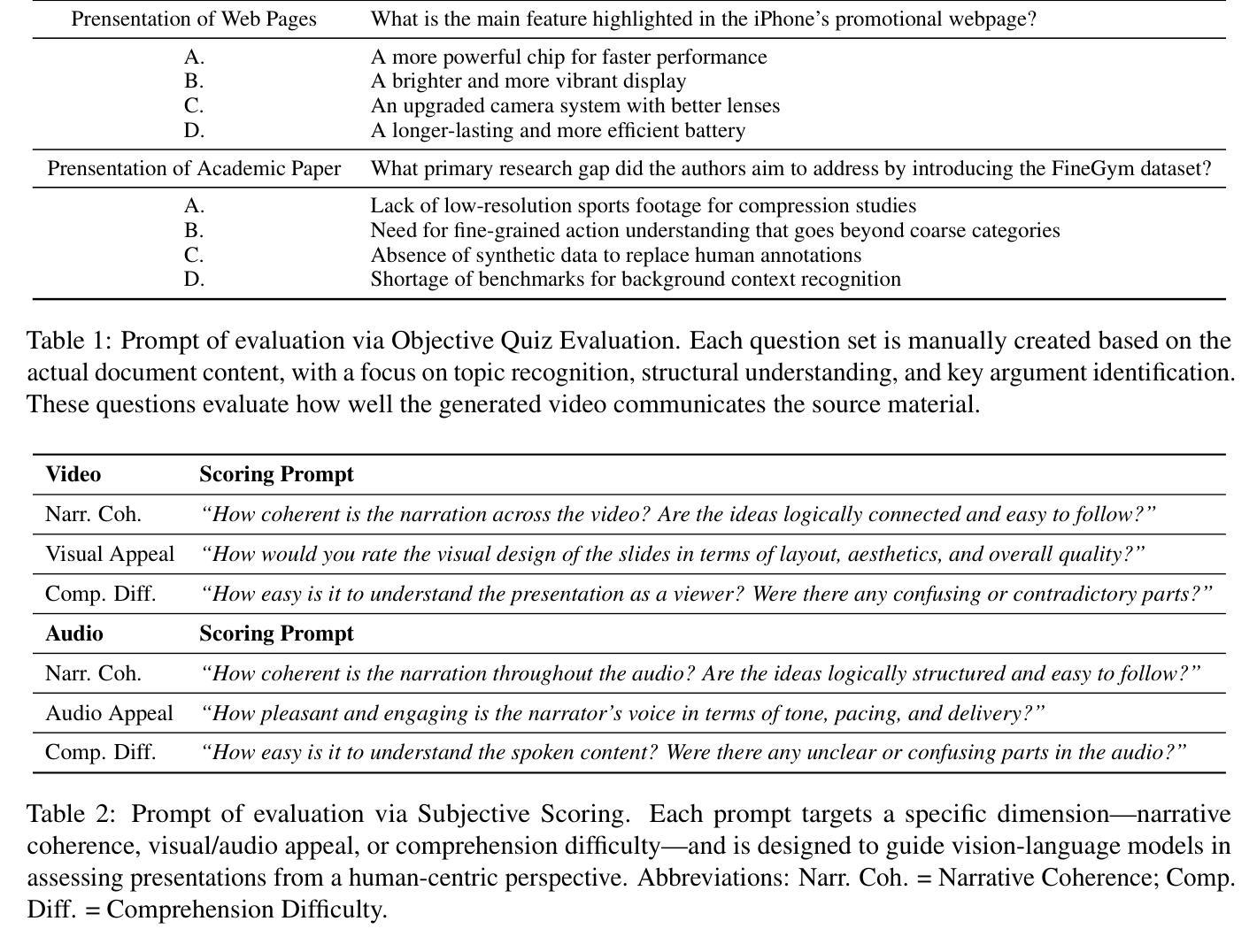
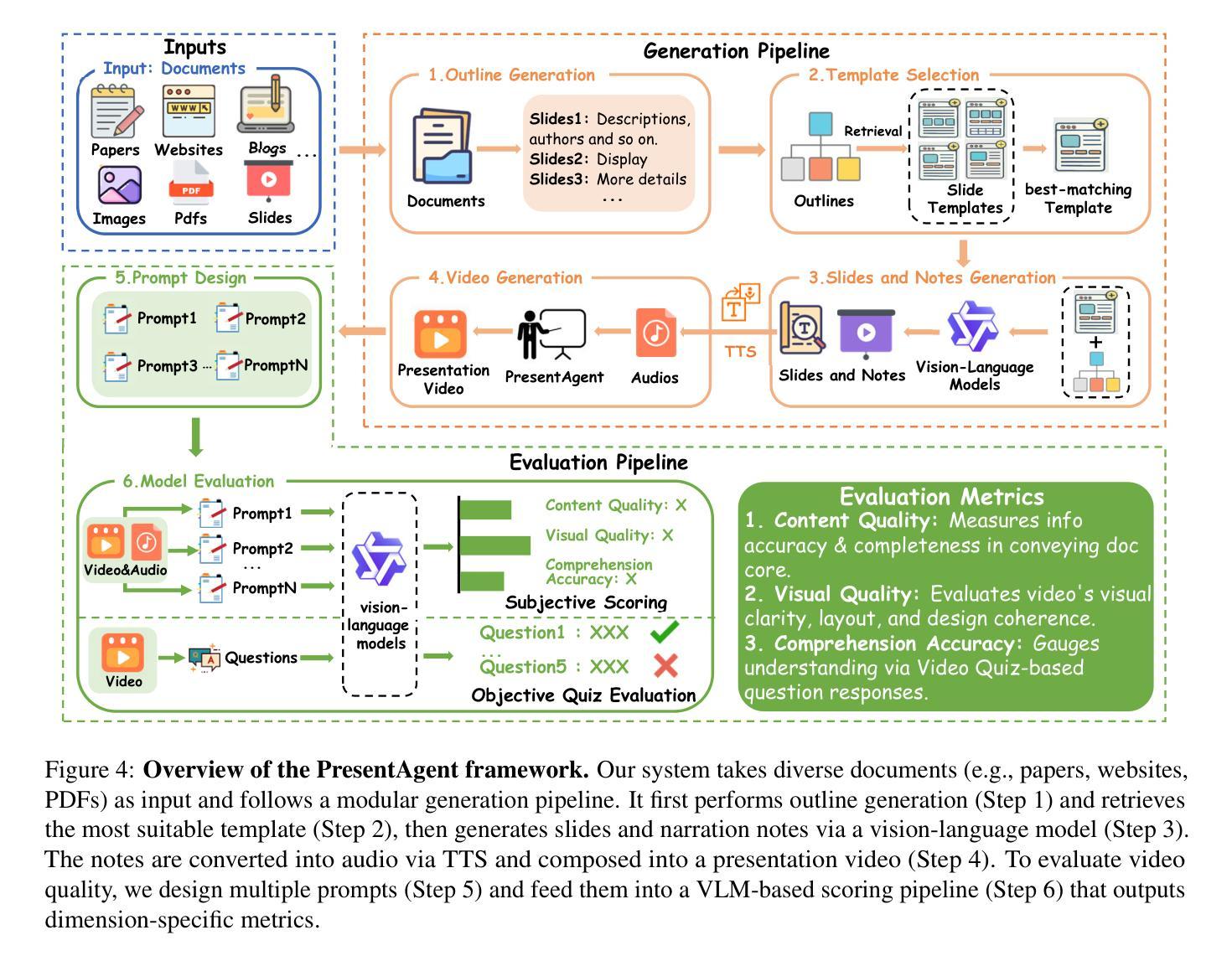
We present PresentAgent, a multimodal agent that transforms long-form documents into narrated presentation videos. While existing approaches are limited to generating static slides or text summaries, our method advances beyond these limitations by producing fully synchronized visual and spoken content that closely mimics human-style presentations. To achieve this integration, PresentAgent employs a modular pipeline that systematically segments the input document, plans and renders slide-style visual frames, generates contextual spoken narration with large language models and Text-to-Speech models, and seamlessly composes the final video with precise audio-visual alignment. Given the complexity of evaluating such multimodal outputs, we introduce PresentEval, a unified assessment framework powered by Vision-Language Models that comprehensively scores videos across three critical dimensions: content fidelity, visual clarity, and audience comprehension through prompt-based evaluation. Our experimental validation on a curated dataset of 30 document-presentation pairs demonstrates that PresentAgent approaches human-level quality across all evaluation metrics. These results highlight the significant potential of controllable multimodal agents in transforming static textual materials into dynamic, effective, and accessible presentation formats. Code will be available at https://github.com/AIGeeksGroup/PresentAgent.
我们推出了PresentAgent,这是一款能够将长篇文档转换为叙述式演示视频的多模式代理。虽然现有方法仅限于生成静态幻灯片或文本摘要,但我们的方法通过生成完全同步的视听内容,紧密模仿人类风格的演示,超越了这些限制。为了实现这种集成,PresentAgent采用模块化管道,系统地分割输入文档,规划和呈现幻灯片式视觉框架,利用大型语言模型和文本到语音模型生成上下文相关的口语叙述,无缝地组合出最终的精确音视频对齐的视频。考虑到评估这种多模式输出的复杂性,我们引入了PresentEval,这是一个由视觉语言模型驱动的统一评估框架,全面地对视频进行三个关键维度的评分:内容忠实度、视觉清晰度和观众理解度,通过基于提示的评估。我们在精选的包含30个文档演示对的数据集上进行实验验证,结果表明PresentAgent在所有评估指标上达到了人类水平的质量。这些结果凸显了可控多模式代理在将静态文本材料转换为动态、有效和可访问的演示格式方面的巨大潜力。代码将在https://github.com/AIGeeksGroup/PresentAgent上提供。
论文及项目相关链接
Summary
PresentAgent能够将长文档转化为叙述型展示视频。与现有生成静态幻灯片或文本摘要的方法不同,PresentAgent通过生成完全同步的视觉和语音内容,紧密模仿人类风格的展示,从而超越了这些限制。它采用模块化管道实现文档的系统分段、幻灯片风格视觉帧的计划和渲染、使用大型语言模型和语音合成模型生成上下文语音叙述,并将最终视频无缝组合成精确的视频语音对齐。为了评估这种多媒体输出的复杂性,我们引入了PresentEval评估框架,通过视觉语言模型全面地对视频在内容忠实度、视觉清晰度和观众理解度三个关键维度进行评分。在精选的包含30篇文档演示对数据集的实验验证显示,PresentAgent在所有评估指标上都达到了接近人类水平的品质。这突显了可控多媒体代理在将静态文本材料转化为动态、高效和可访问的展示形式方面的巨大潜力。
Key Takeaways
- PresentAgent是一个多模态代理,能将长文档转化为叙述型展示视频。
- 与其他方法相比,PresentAgent能生成完全同步的视觉和语音内容,模仿人类风格的展示。
- PresentAgent采用模块化管道处理文档的多个阶段,包括分段、视觉帧计划、语音叙述生成和视频组合。
- 为了评估多媒体输出的复杂性,引入了PresentEval评估框架。
- PresentEval框架从内容忠实度、视觉清晰度和观众理解度三个关键维度对视频进行全面评分。
- 在实验验证中,PresentAgent在所有评估指标上都达到了接近人类水平的品质。
点此查看论文截图


Pronunciation Editing for Finnish Speech using Phonetic Posteriorgrams
Authors:Zirui Li, Lauri Juvela, Mikko Kurimo
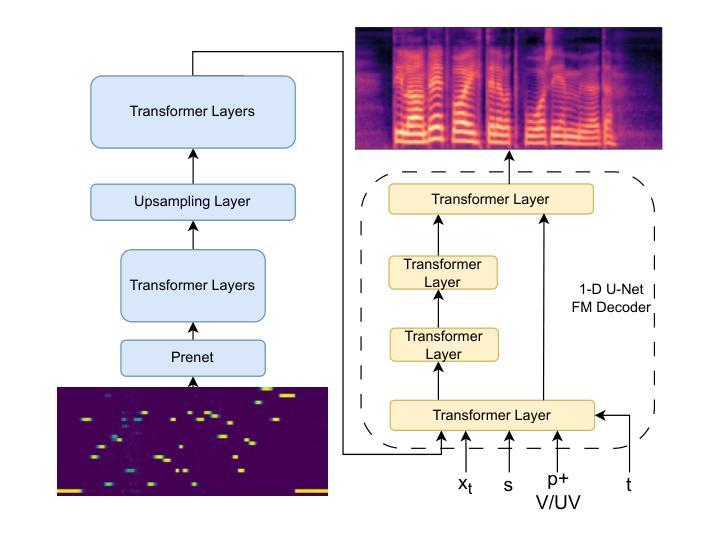
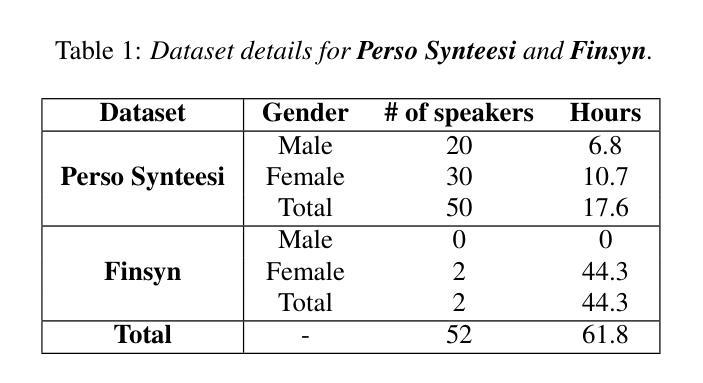
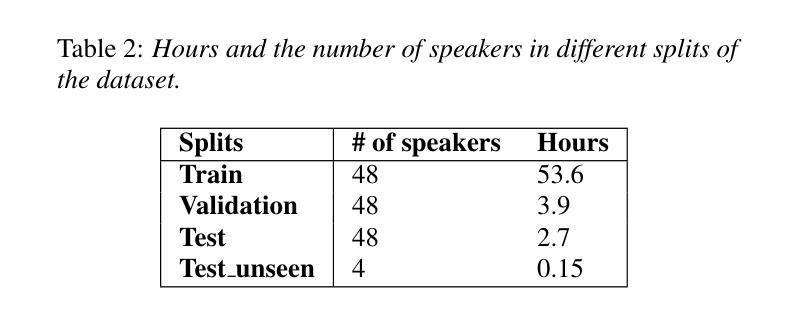
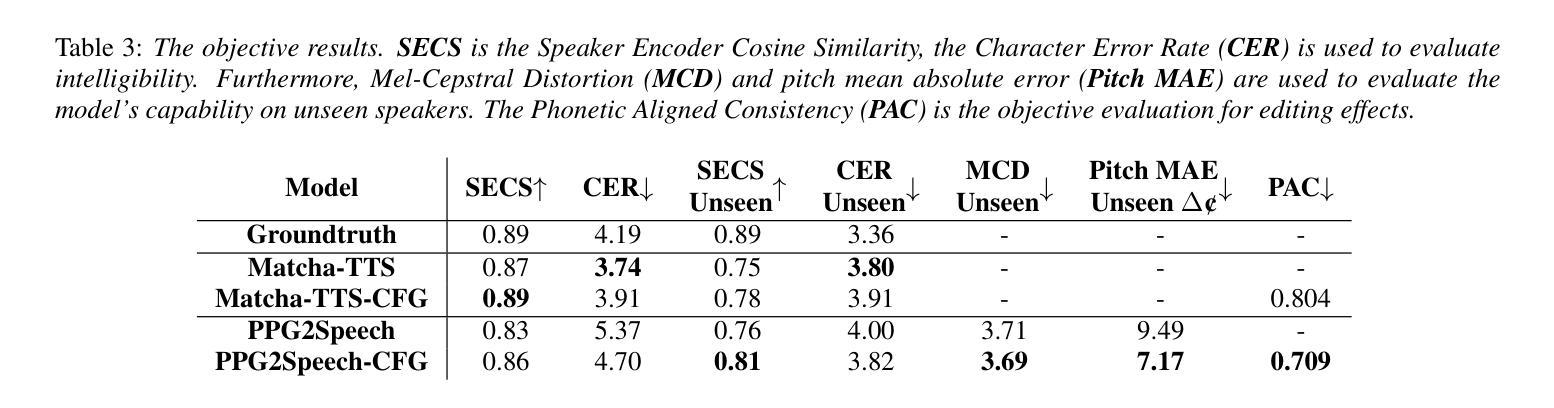
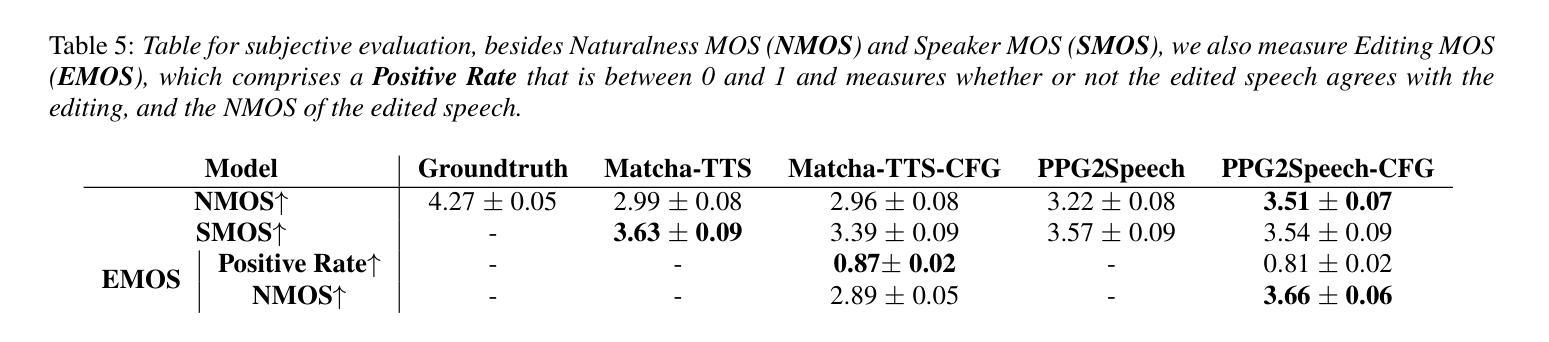
Synthesizing second-language (L2) speech is potentially highly valued for L2 language learning experience and feedback. However, due to the lack of L2 speech synthesis datasets, it is difficult to synthesize L2 speech for low-resourced languages. In this paper, we provide a practical solution for editing native speech to approximate L2 speech and present PPG2Speech, a diffusion-based multispeaker Phonetic-Posteriorgrams-to-Speech model that is capable of editing a single phoneme without text alignment. We use Matcha-TTS’s flow-matching decoder as the backbone, transforming Phonetic Posteriorgrams (PPGs) to mel-spectrograms conditioned on external speaker embeddings and pitch. PPG2Speech strengthens the Matcha-TTS’s flow-matching decoder with Classifier-free Guidance (CFG) and Sway Sampling. We also propose a new task-specific objective evaluation metric, the Phonetic Aligned Consistency (PAC), between the edited PPGs and the PPGs extracted from the synthetic speech for editing effects. We validate the effectiveness of our method on Finnish, a low-resourced, nearly phonetic language, using approximately 60 hours of data. We conduct objective and subjective evaluations of our approach to compare its naturalness, speaker similarity, and editing effectiveness with TTS-based editing. Our source code is published at https://github.com/aalto-speech/PPG2Speech.
合成第二语言(L2)语音对于L2语言学习经验和反馈具有潜在的高价值。然而,由于缺乏L2语音合成数据集,很难为资源较少的语言合成L2语音。在本文中,我们提供了一种编辑原生语音以近似L2语音的实用解决方案,并介绍了PPG2Speech,这是一种基于扩散的多人语音Phonetic-Posteriorgrams-to-Speech模型,能够在无需文本对齐的情况下编辑单个音素。我们使用Matcha-TTS的流式匹配解码器作为骨干,将语音音素后效图(PPGs)转换为梅尔频谱图,并根据外部说话人嵌入和音调进行条件化。PPG2Speech通过无分类指导(CFG)和摇摆采样强化了Matcha-TTS的流式匹配解码器。我们还提出了一种新的针对特定任务的客观评价指标——语音编辑效果的音素对齐一致性(PAC),这是通过对比编辑后的PPGs与合成语音中提取的PPGs来衡量的。我们在芬兰语这种资源匮乏、几乎音素的语言上验证了我们的方法,使用了大约60小时的数据。我们对我们的方法进行了客观和主观评估,比较其在自然度、说话人相似性和编辑效果方面的表现与基于TTS的编辑方法。我们的源代码已发布在https://github.com/aalto-speech/PPG2Speech。
论文及项目相关链接
PDF 5 pages; 1 figure; Accepted to Speech Synthesis Workshop 2025 (SSW13)
Summary
本文提出了一种编辑原生语音以近似第二语言语音的实用解决方案,并介绍了PPG2Speech模型,该模型是基于扩散的多说话者音素后验图(PPGs)转语音模型,能够在无需文本对齐的情况下编辑单个音素。通过使用Matcha-TTS的流匹配解码器作为主干,将音素后验图(PPGs)转换为以外部说话者嵌入和音调为条件的梅尔频谱图。PPG2Speech通过无分类指导(CFG)和摇摆采样强化了Matcha-TTS的流匹配解码器。此外,本文还提出了一种针对编辑任务的新目标评估指标——音素对齐一致性(PAC),用于评估编辑后的PPGs与合成语音中提取的PPGs之间的对齐一致性。在芬兰语这种低资源、近乎音素的语言上验证了该方法的有效性,使用了大约60小时的数据。
Key Takeaways
- 第二语言语音合成对于语言学习经验和反馈具有潜在的高价值。
- 缺乏第二语言语音合成数据集使得为低资源语言合成第二语言语音变得困难。
- 本文提出了一种编辑原生语音以近似第二语言语音的实用解决方案。
- 介绍了PPG2Speech模型,该模型是基于扩散的多说话者音素后验图转语音模型,可编辑单个音素而无需文本对齐。
- PPG2Speech使用了Matcha-TTS的流匹配解码器作为主干技术。
- 引入了无分类指导(CFG)和摇摆采样来强化模型性能。
点此查看论文截图