⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-09 更新
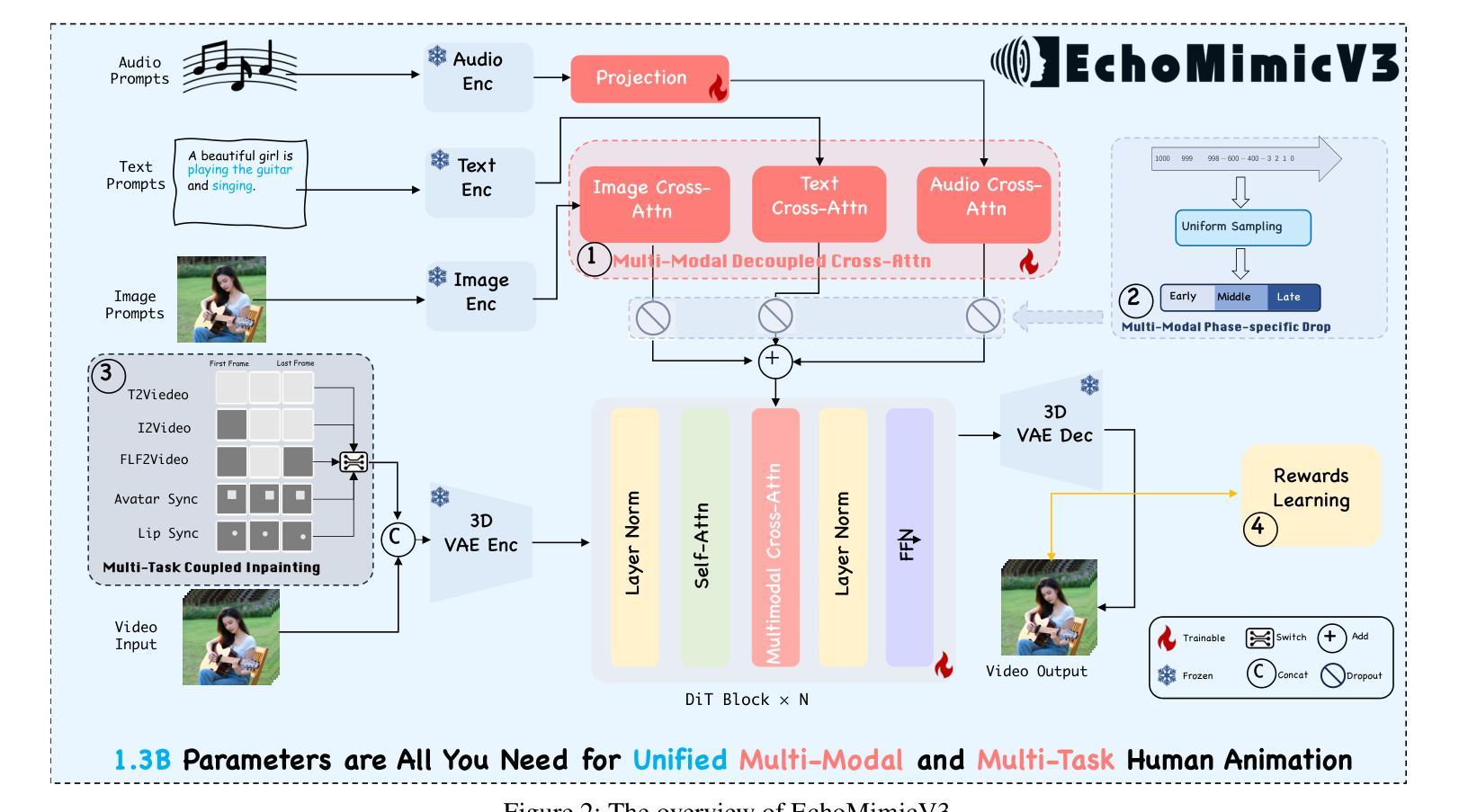
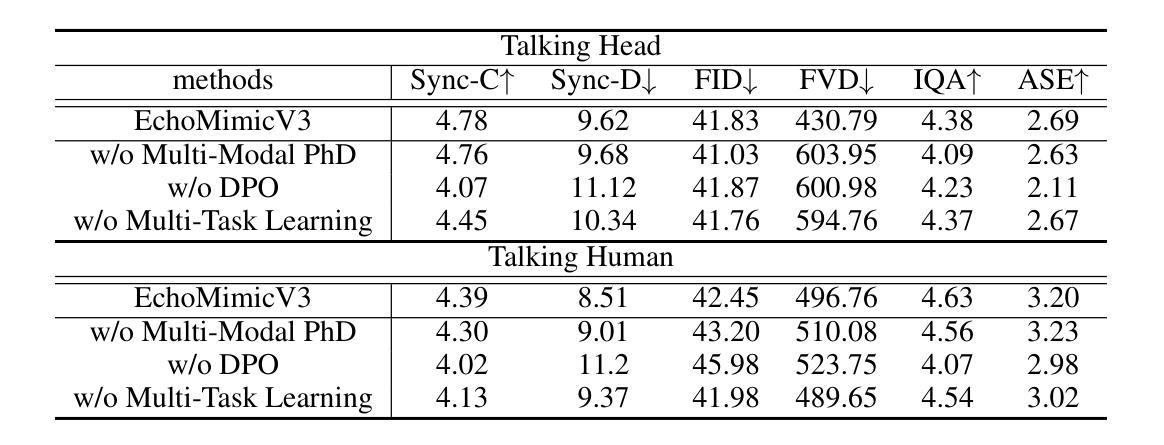
EchoMimicV3: 1.3B Parameters are All You Need for Unified Multi-Modal and Multi-Task Human Animation
Authors:Rang Meng, Yan Wang, Weipeng Wu, Ruobing Zheng, Yuming Li, Chenguang Ma
Human animation recently has advanced rapidly, achieving increasingly realistic and vivid results, especially with the integration of large-scale video generation models. However, the slow inference speed and high computational cost of these large models bring significant challenges for practical applications. Additionally, various tasks in human animation, such as lip-syncing, audio-driven full-body animation, and video generation from start and end frames, often require different specialized models. The introduction of large video models has not alleviated this dilemma. This raises an important question: Can we make human animation Faster, Higher in quality, Stronger in generalization, and make various tasks Together in one model? To address this, we dive into video generation models and discover that the devil lies in the details: Inspired by MAE, we propose a novel unified Multi-Task paradigm for human animation, treating diverse generation tasks as spatial-temporal local reconstructions, requiring modifications only on the input side; Given the interplay and division among multi-modal conditions including text, image, and audio, we introduce a multi-modal decoupled cross-attention module to fuse multi-modals in a divide-and-conquer manner; We propose a new SFT+Reward alternating training paradigm, enabling the minimal model with 1.3B parameters to achieve generation quality comparable to models with 10 times the parameters count. Through these innovations, our work paves the way for efficient, high-quality, and versatile digital human generation, addressing both performance and practicality challenges in the field. Extensive experiments demonstrate that EchoMimicV3 outperforms existing models in both facial and semi-body video generation, providing precise text-based control for creating videos in a wide range of scenarios.
人类动画技术最近发展迅速,特别是在大规模视频生成模型的融合下,实现了越来越真实和生动的效果。然而,这些大型模型的推理速度慢和计算成本高,给实际应用带来了重大挑战。此外,人类动画中的各项任务,如语音同步、音频驱动全身动画、从起始帧生成视频等,通常需要不同的专用模型。大型视频模型的引入并未缓解这一困境。这就引发了一个重要问题:我们能否使人类动画更快、质量更高、泛化能力更强,并且在一个模型中完成各种任务?为了解决这个问题,我们深入研究视频生成模型,发现细节是魔鬼:受到MAE的启发,我们提出了人类动画的统一多任务范式,将各种生成任务视为空间时间的局部重建,只需在输入端进行修改;考虑到包括文本、图像和音频在内的多模态条件之间的相互作用和分工,我们引入了一个多模态解耦交叉注意模块,以分而治之的方式融合多模态;我们提出了一种新的SFT+Reward交替训练范式,使具有1.3B参数的最小模型就能达到与参数数量十倍模型的生成质量相当。通过这些创新,我们的工作为人效高、质量好的数字人类生成铺平了道路,解决了该领域的性能和实用性挑战。大量实验表明,EchoMimicV3在面部和半身视频生成方面超越了现有模型,为各种场景的视频创建提供了精确的文本控制。
论文及项目相关链接
摘要
本文探讨了人类动画领域的最新进展,特别是大规模视频生成模型在提升动画真实感和生动性方面的作用。然而,这些大型模型的推理速度慢和计算成本高,给实际应用带来了挑战。文章针对这一难题提出了一个新的统一多任务范式用于人类动画生成的新方法,以细节作为突破口。新模型受到MAE启发,将各种生成任务视为空间时间局部重建,只需在输入端进行修改。考虑到文本、图像和音频等多模态条件的相互作用和划分,引入多模态解耦交叉注意力模块进行协同工作;提出了一种新型的SFT+Reward交替训练范式,能在只有较少的模型参数的情况下达到很高的生成质量。实验证明,该模型在面部和半身视频生成方面都优于现有模型,能在多种场景下创建精准的文字控制视频。这些创新不仅提升了数字人动画的效率和实用性,还进一步拓宽了其应用范围。本文的研究成果对于解决性能问题和实用性挑战具有重要意义。总结为一句话就是:“人类动画领域的重大突破,统一多任务范式实现了高质量、高效率且通用性强的数字人生成。”此模型的革新策略涵盖了新提出的多任务范式和多个技术创新,显示出巨大潜力。但基于已有技术和当前语境的挑战及未来的发展预测将要求继续对该领域的研究投入更多的精力与探索更多可能的技术突破点。虽然取得了一定的进展,但在细节及真实度的改进、泛化能力的提高等方面仍有提升空间。未来的研究需要进一步关注模型的实际应用效果以及优化模型结构等方面的问题。总体来说,这是一个重要的突破和创新的领域,具有巨大的潜力。随着技术的不断进步和创新,未来有望看到更多令人惊叹的成果问世。
关键见解
点此查看论文截图



Advancing Talking Head Generation: A Comprehensive Survey of Multi-Modal Methodologies, Datasets, Evaluation Metrics, and Loss Functions
Authors:Vineet Kumar Rakesh, Soumya Mazumdar, Research Pratim Maity, Sarbajit Pal, Amitabha Das, Tapas Samanta
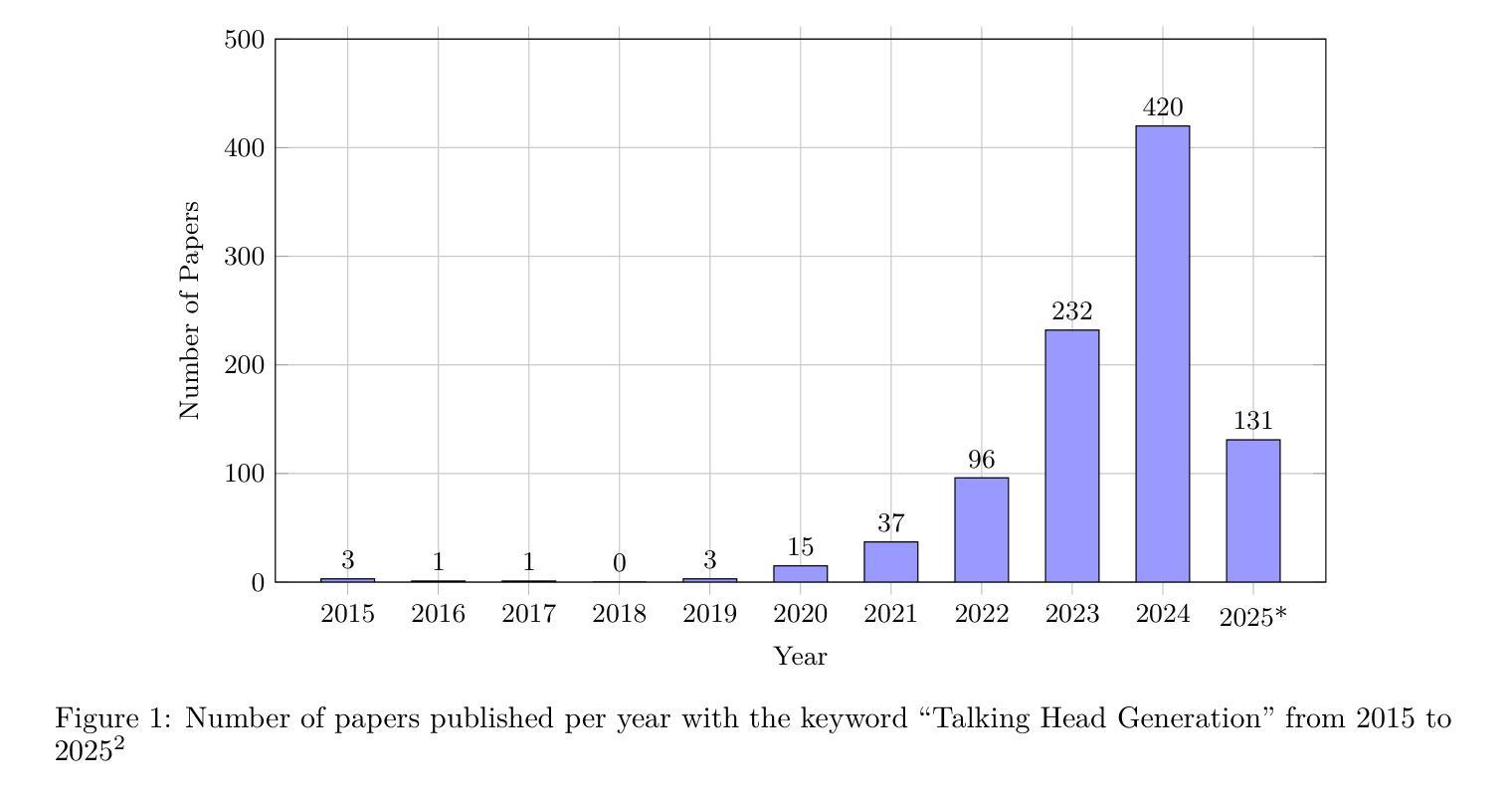
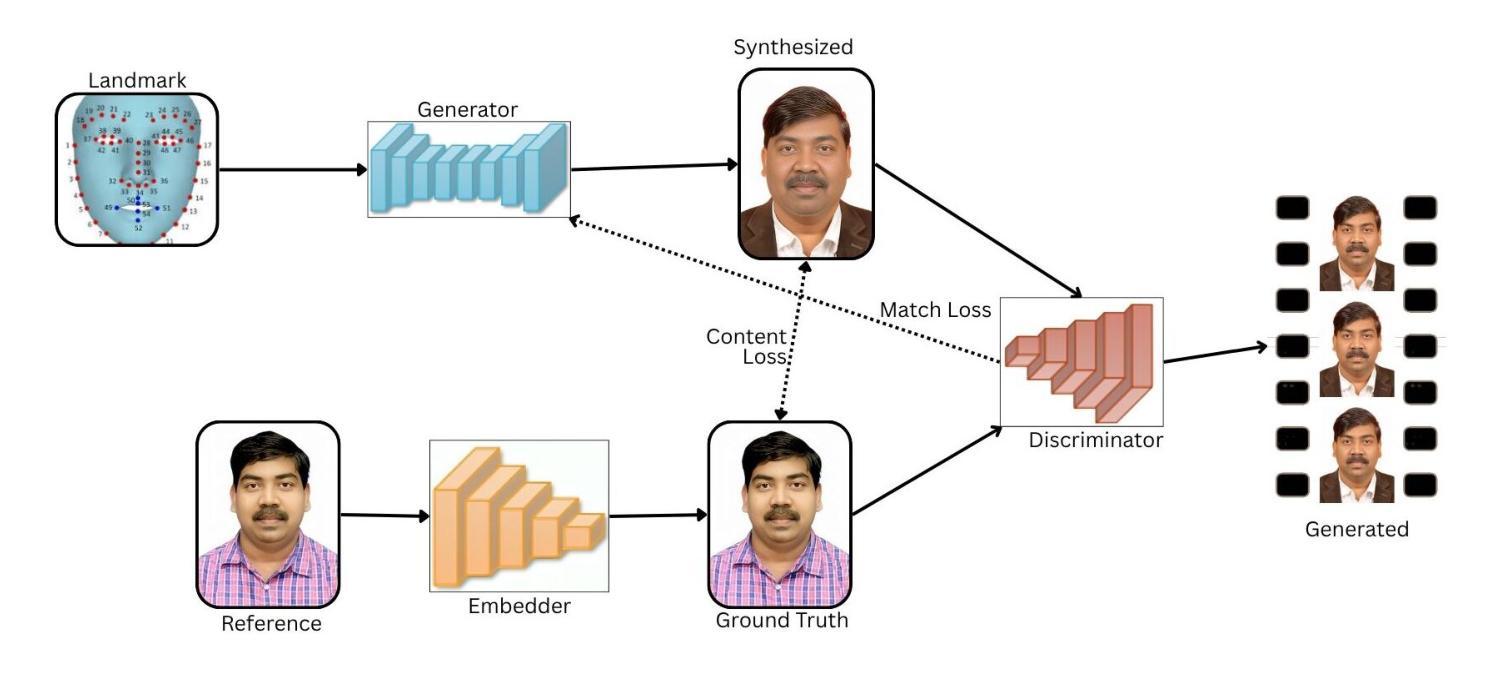
Talking Head Generation (THG) has emerged as a transformative technology in computer vision, enabling the synthesis of realistic human faces synchronized with image, audio, text, or video inputs. This paper provides a comprehensive review of methodologies and frameworks for talking head generation, categorizing approaches into 2D–based, 3D–based, Neural Radiance Fields (NeRF)–based, diffusion–based, parameter-driven techniques and many other techniques. It evaluates algorithms, datasets, and evaluation metrics while highlighting advancements in perceptual realism and technical efficiency critical for applications such as digital avatars, video dubbing, ultra-low bitrate video conferencing, and online education. The study identifies challenges such as reliance on pre–trained models, extreme pose handling, multilingual synthesis, and temporal consistency. Future directions include modular architectures, multilingual datasets, hybrid models blending pre–trained and task-specific layers, and innovative loss functions. By synthesizing existing research and exploring emerging trends, this paper aims to provide actionable insights for researchers and practitioners in the field of talking head generation. For the complete survey, code, and curated resource list, visit our GitHub repository: https://github.com/VineetKumarRakesh/thg.
谈话头部生成(THG)作为一项变革性技术,已经在计算机视觉领域崭露头角。它能够实现与图像、音频、文本或视频输入同步的真实人类面部的合成。本文全面回顾了谈话头部生成的方法论和框架,将方法分为基于2D的、基于3D的、基于神经辐射场(NeRF)的、基于扩散的、参数驱动技术以及其他许多技术。它评估了算法、数据集和评价指标,同时突出了数字化身、视频配音、超低比特率视频会议和在线教育等应用中感知真实感和技术效率方面的进展。该研究确定了面临的挑战,如依赖预训练模型、极端姿势处理、多语言合成和时序一致性等。未来发展方向包括模块化架构、多语言数据集、混合预训练和任务特定层的混合模型,以及创新的损失函数。本文通过综合现有研究和探索新兴趋势,旨在为谈话头部生成领域的研究人员和实践者提供可操作的见解。有关完整的调查、代码和精选资源列表,请访问我们的GitHub仓库:https://github.com/VineetKumarRakesh/thg。
论文及项目相关链接
Summary
新一代说话人头部生成技术已成为计算机视觉领域中的变革性技术。本文全面综述了说话人头部生成的方法论和框架,包括基于二维、三维、神经辐射场、扩散技术等多种方法,并评价了算法、数据集和评价指标。本文强调了感知真实性和技术效率在数字化身、视频配音、超低比特率视频会议和在线教育等领域中的重要性。未来发展方向包括模块化架构、多语言数据集、混合模型和新颖的损失函数等。关注本文可获得有关说话人头部生成领域的实用见解和资源。
Key Takeaways
- 说话头生成技术已成为计算机视觉领域的变革性技术。
- 综述了多种说话头生成方法论和框架,包括二维、三维、神经辐射场等。
- 感知真实性和技术效率在数字化身等领域至关重要。
- 现有挑战包括依赖预训练模型、极端姿态处理和多语言合成等。
- 未来发展方向包括模块化架构、多语言数据集和混合模型等。
点此查看论文截图