⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-10 更新
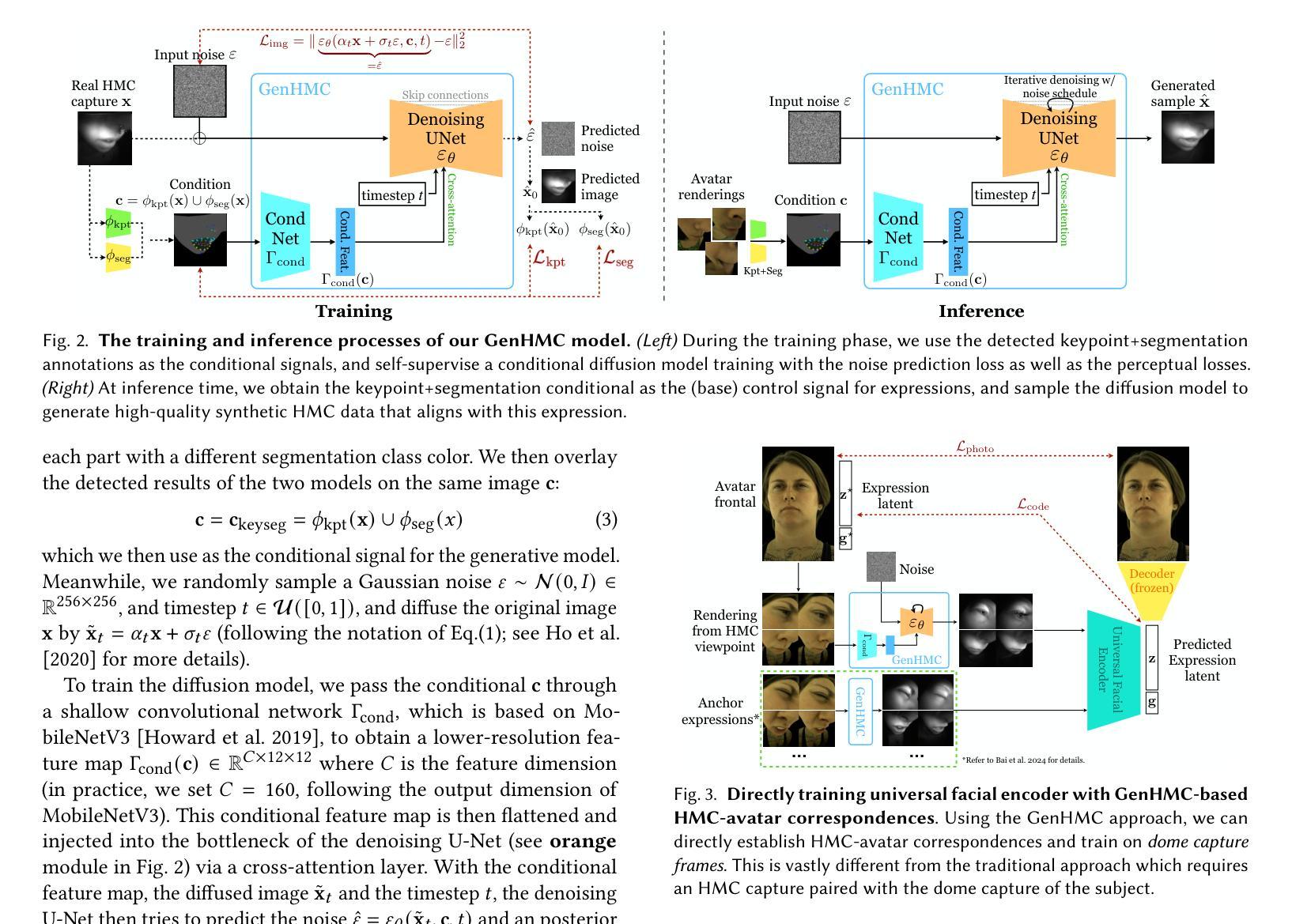
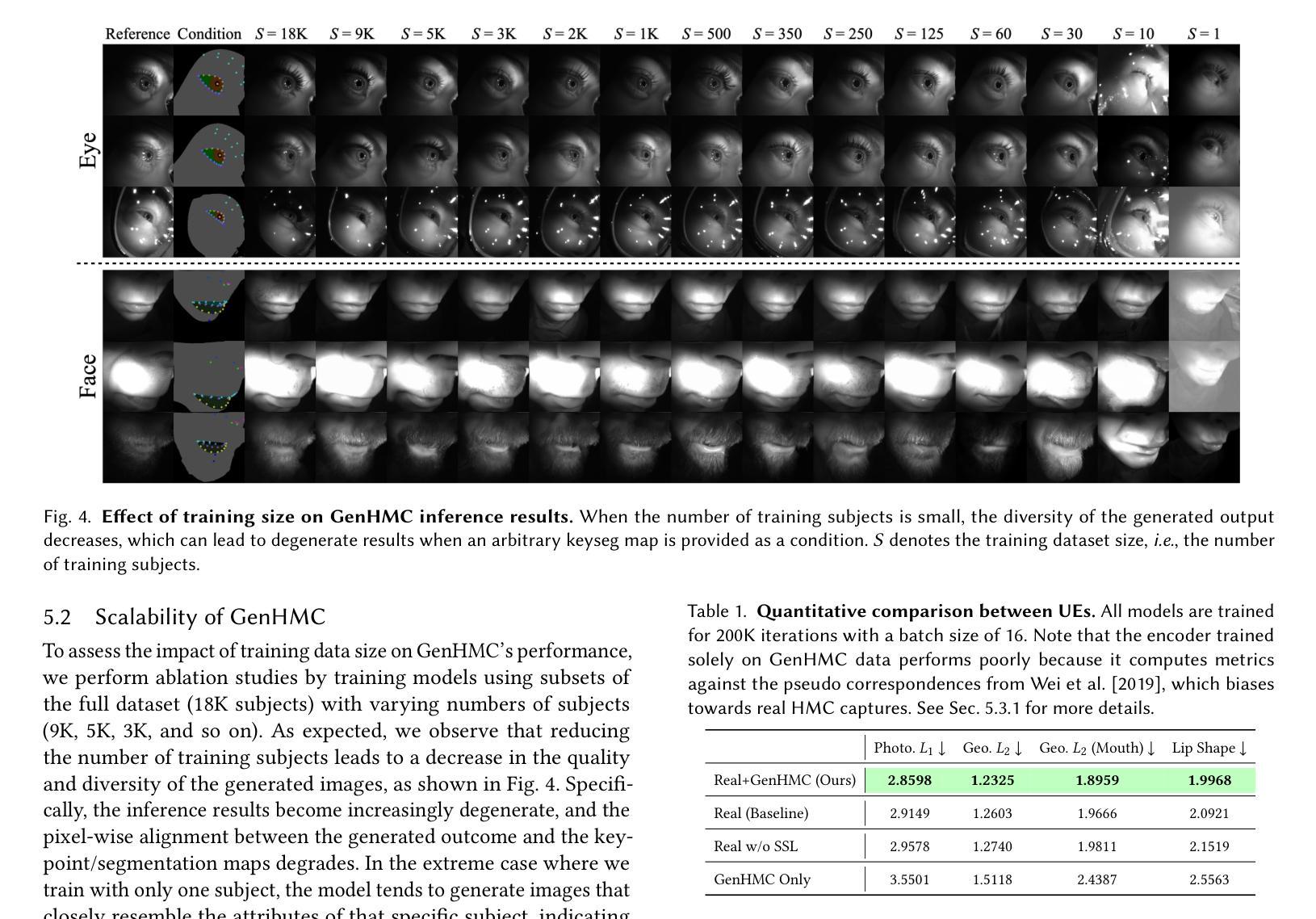
Generative Head-Mounted Camera Captures for Photorealistic Avatars
Authors:Shaojie Bai, Seunghyeon Seo, Yida Wang, Chenghui Li, Owen Wang, Te-Li Wang, Tianyang Ma, Jason Saragih, Shih-En Wei, Nojun Kwak, Hyung Jun Kim
Enabling photorealistic avatar animations in virtual and augmented reality (VR/AR) has been challenging because of the difficulty of obtaining ground truth state of faces. It is physically impossible to obtain synchronized images from head-mounted cameras (HMC) sensing input, which has partial observations in infrared (IR), and an array of outside-in dome cameras, which have full observations that match avatars’ appearance. Prior works relying on analysis-by-synthesis methods could generate accurate ground truth, but suffer from imperfect disentanglement between expression and style in their personalized training. The reliance of extensive paired captures (HMC and dome) for the same subject makes it operationally expensive to collect large-scale datasets, which cannot be reused for different HMC viewpoints and lighting. In this work, we propose a novel generative approach, Generative HMC (GenHMC), that leverages large unpaired HMC captures, which are much easier to collect, to directly generate high-quality synthetic HMC images given any conditioning avatar state from dome captures. We show that our method is able to properly disentangle the input conditioning signal that specifies facial expression and viewpoint, from facial appearance, leading to more accurate ground truth. Furthermore, our method can generalize to unseen identities, removing the reliance on the paired captures. We demonstrate these breakthroughs by both evaluating synthetic HMC images and universal face encoders trained from these new HMC-avatar correspondences, which achieve better data efficiency and state-of-the-art accuracy.
在虚拟和增强现实(VR/AR)中实现逼真的虚拟形象动画一直是一个挑战,因为获取面部真实状态非常困难。从头戴式相机(HMC)获取同步图像在物理上是不可能的,因为HMC对红外有局部观察,而外部穹顶相机阵列具有与虚拟形象外观相匹配的全局观察。早期依赖分析合成方法的工作可以生成准确的真实值,但它们在个性化训练中表情和风格的分离并不完美。对同一主题的大量配对捕获(HMC和穹顶)的依赖,使得收集大规模数据集变得操作成本高昂,并且不能在不同的HMC观点和照明中重复使用。在这项工作中,我们提出了一种新型生成方法,即生成式HMC(GenHMC),它利用更容易收集的大量未配对HMC捕获,根据穹顶捕获的任何条件虚拟形象状态直接生成高质量的合成HMC图像。我们证明我们的方法能够恰当地分离输入条件信号,该信号指定面部表情和视角,而不会影响面部外观,从而产生更准确的真实值。此外,我们的方法可以推广到未见过的身份,不再依赖配对捕获。我们通过评估合成HMC图像和从这些新的HMC-虚拟形象对应关系训练的通用面部编码器来证明这些突破,这些编码器实现了更好的数据效率和最先进的准确性。
简化解释
论文及项目相关链接
PDF 15 pages, 16 figures
Summary
该文主要介绍了在虚拟和增强现实(VR/AR)中启用真实感角色动画的挑战。由于难以获取面部真实状态,因此存在困难。先前的工作采用分析合成方法生成准确真实状态,但存在表情与风格间的不完全分离问题。本文提出一种新型生成方法——生成式头显相机(GenHMC),利用大量未配对的头显相机捕获数据,直接生成高质量合成头显相机图像,给定任何条件角色状态。该方法能正确分离面部表情和视点输入信号,与面部外观分离,获得更准确真实状态。此外,该方法可推广至未见身份,不再依赖配对捕获。通过评估合成头显相机图像和通用面部编码器证明这些突破,达到更好的数据效率和最先进的准确性。
Key Takeaways
- VR/AR中的真实感角色动画面临获取面部真实状态的挑战。
- 现有方法依赖分析合成生成准确真实状态,但存在表情与风格混淆问题。
- 提出新型生成式头显相机(GenHMC)方法,利用大量未配对头显相机捕获数据,直接生成高质量合成图像。
- GenHMC能分离面部表情和视点输入信号,与面部外观分离,获得更准确真实状态。
- GenHMC方法可推广至未见身份,无需配对捕获。
- 通过合成头显相机图像评估证明该方法的有效性。
点此查看论文截图

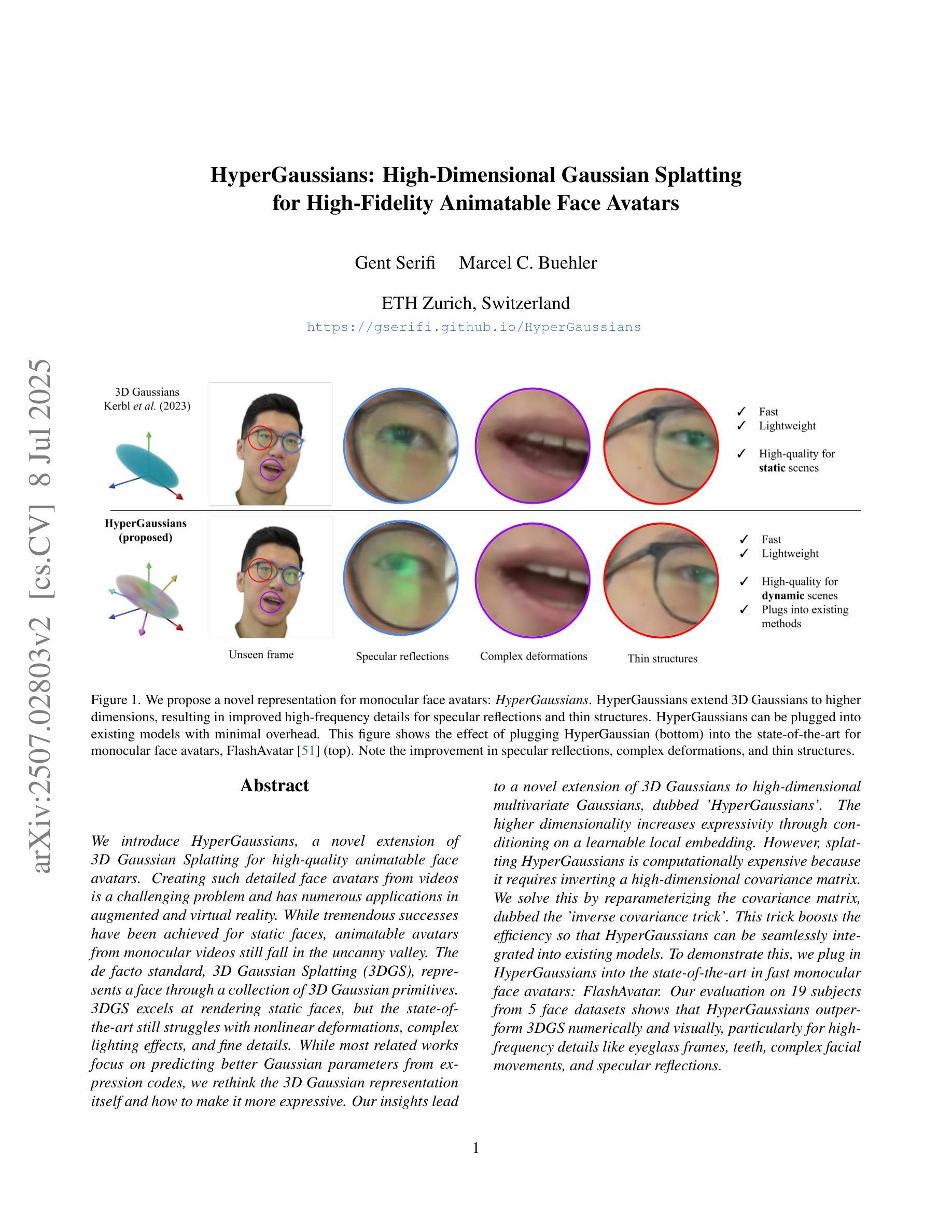
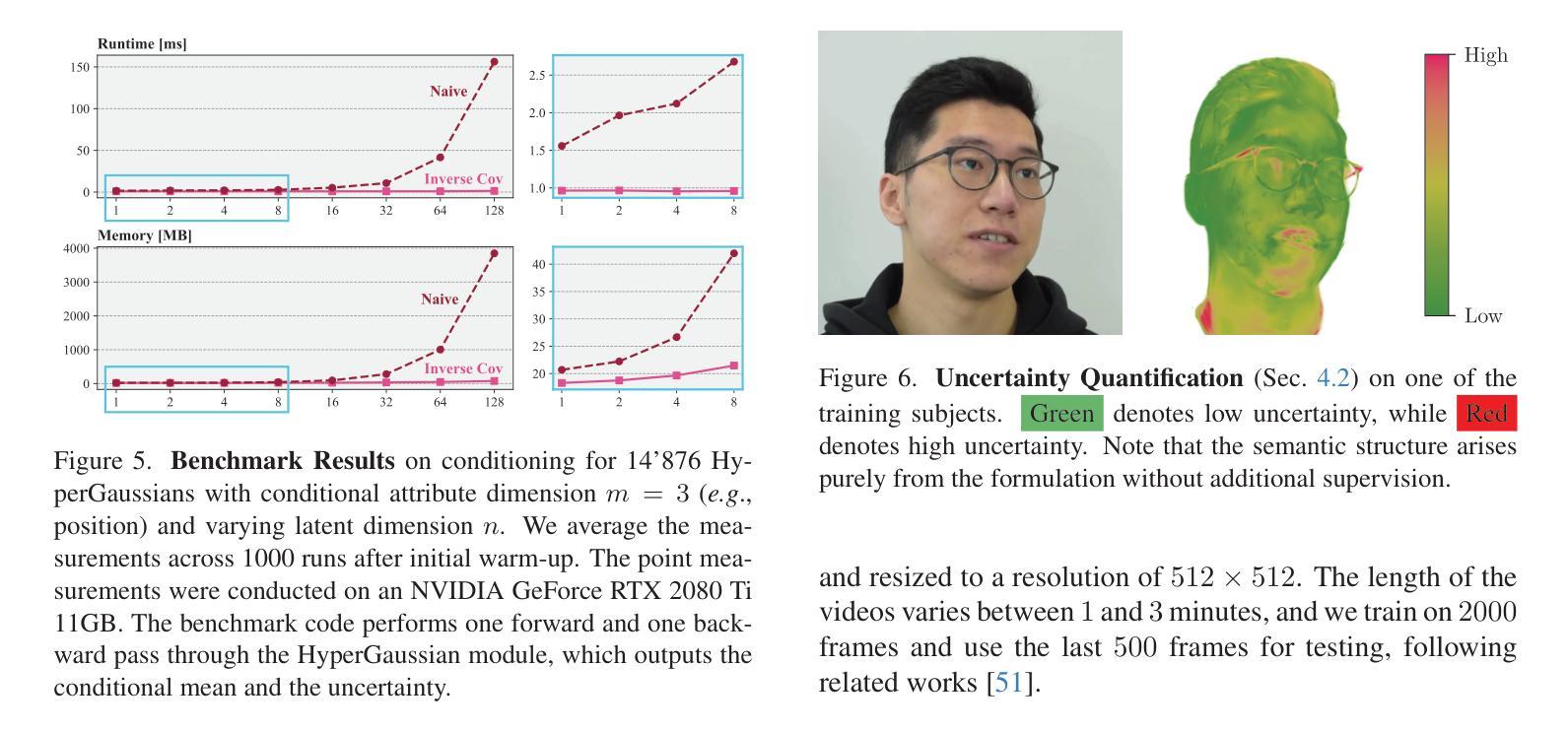
HyperGaussians: High-Dimensional Gaussian Splatting for High-Fidelity Animatable Face Avatars
Authors:Gent Serifi, Marcel C. Bühler
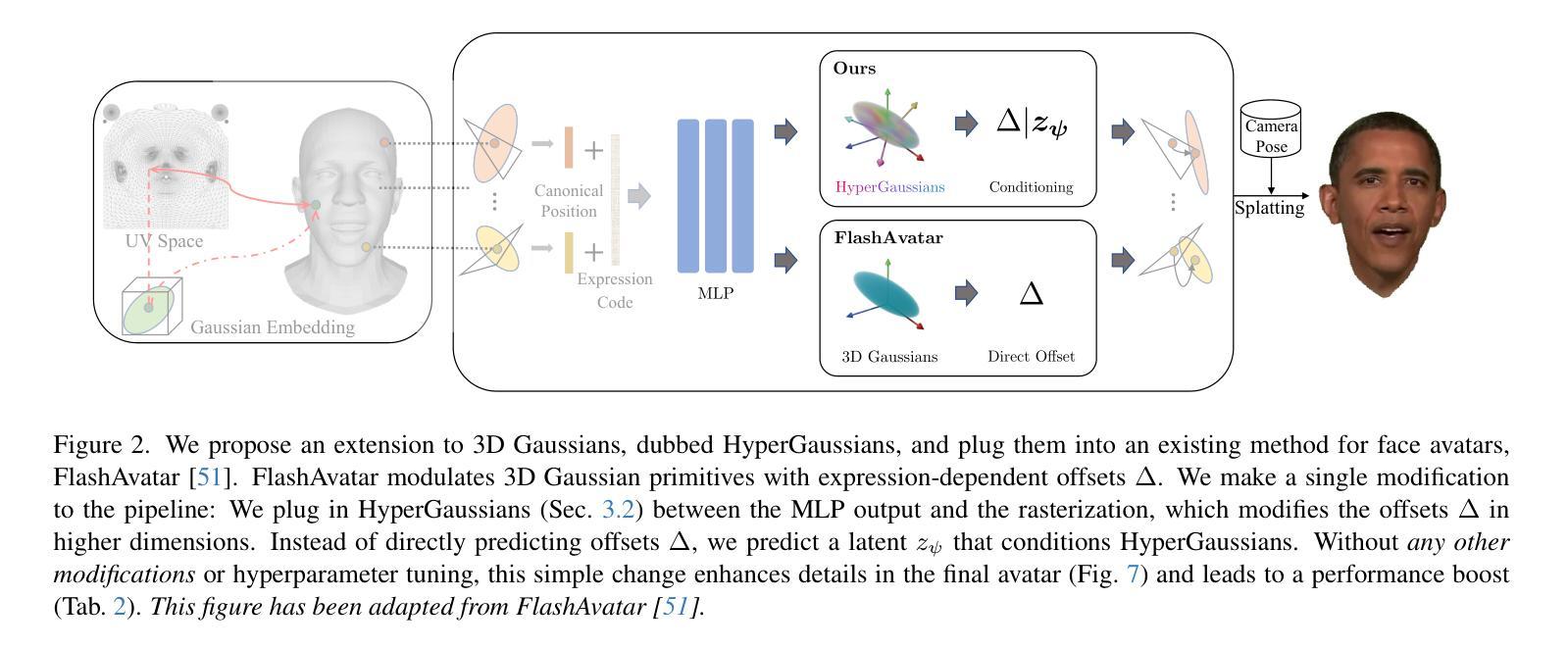
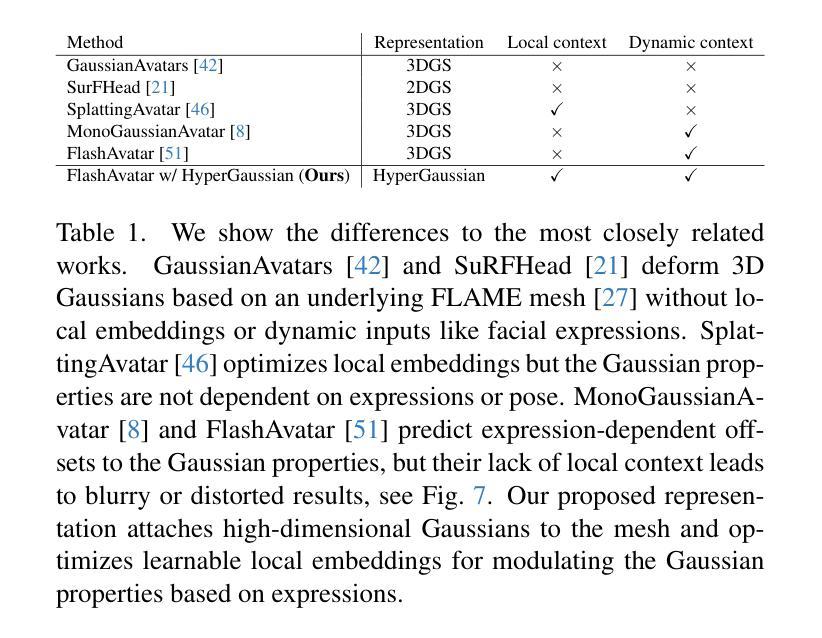
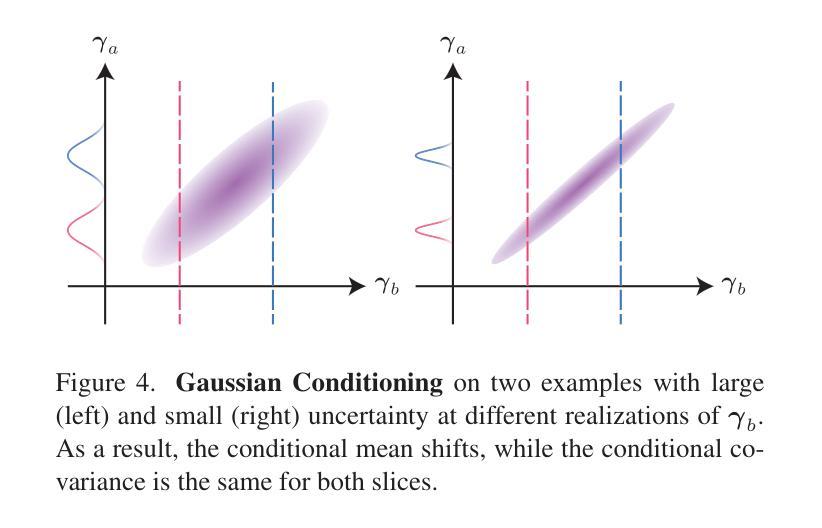
We introduce HyperGaussians, a novel extension of 3D Gaussian Splatting for high-quality animatable face avatars. Creating such detailed face avatars from videos is a challenging problem and has numerous applications in augmented and virtual reality. While tremendous successes have been achieved for static faces, animatable avatars from monocular videos still fall in the uncanny valley. The de facto standard, 3D Gaussian Splatting (3DGS), represents a face through a collection of 3D Gaussian primitives. 3DGS excels at rendering static faces, but the state-of-the-art still struggles with nonlinear deformations, complex lighting effects, and fine details. While most related works focus on predicting better Gaussian parameters from expression codes, we rethink the 3D Gaussian representation itself and how to make it more expressive. Our insights lead to a novel extension of 3D Gaussians to high-dimensional multivariate Gaussians, dubbed ‘HyperGaussians’. The higher dimensionality increases expressivity through conditioning on a learnable local embedding. However, splatting HyperGaussians is computationally expensive because it requires inverting a high-dimensional covariance matrix. We solve this by reparameterizing the covariance matrix, dubbed the ‘inverse covariance trick’. This trick boosts the efficiency so that HyperGaussians can be seamlessly integrated into existing models. To demonstrate this, we plug in HyperGaussians into the state-of-the-art in fast monocular face avatars: FlashAvatar. Our evaluation on 19 subjects from 4 face datasets shows that HyperGaussians outperform 3DGS numerically and visually, particularly for high-frequency details like eyeglass frames, teeth, complex facial movements, and specular reflections.
我们介绍了HyperGaussians,这是3D高斯涂抹术的一种新型扩展,用于创建高质量的可动画面部化身。从视频中创建如此详细的面部化身是一个具有挑战性的问题,并且在增强和虚拟现实中具有许多应用。虽然静态面孔已经取得了巨大的成功,但从单目视频中创建的可动画化身仍然处于令人尴尬的境地。现有的标准3D高斯涂抹术(3DGS)通过一组3D高斯原始数据来呈现面部。3DGS在呈现静态面孔方面表现出色,但现有技术仍难以处理非线性变形、复杂的灯光效果和细节。虽然大多数相关工作都集中在从表情代码中预测更好的高斯参数上,但我们重新思考了3D高斯表示本身以及如何使其更具表现力。我们的见解导致了对高维多元高斯的新型扩展,称为“HyperGaussians”。更高的维度通过依赖于可学习的局部嵌入来增加表现力。然而,涂抹HyperGaussians的计算成本很高,因为它需要反转高维协方差矩阵。我们通过重新参数化协方差矩阵来解决这个问题,这被称为“协方差逆变换技巧”。这一技巧提高了效率,使得HyperGaussians可以无缝地集成到现有模型中。为了证明这一点,我们将HyperGaussians插入到快速单目面部化身中的最新技术:FlashAvatar。我们对来自四个面部数据集的19名受试者进行了评估,结果表明HyperGaussians在数值和视觉上均优于3DGS,特别是在眼镜框、牙齿、复杂面部动作和镜面反射等高频细节方面。
论文及项目相关链接
PDF Project page: https://gserifi.github.io/HyperGaussians, Code: https://github.com/gserifi/HyperGaussians
Summary
提出一种名为HyperGaussians的新型三维高斯扩展技术,用于创建高质量的可动画面部化身。该技术解决了从视频创建详细面部化身的问题,并广泛应用于增强和虚拟现实。HyperGaussians通过引入高维多元高斯分布提高了三维高斯表示的表达能力,解决了现有技术面临的非线性变形、复杂光照和精细细节等挑战。通过重新参数化协方差矩阵提高了计算效率,并成功集成到现有模型中。在快速单目面部化身领域,HyperGaussians的表现超越了当前技术水平,特别是在处理眼镜框、牙齿、复杂面部动作和镜面反射等高频细节方面。
Key Takeaways
- HyperGaussians是3D Gaussian Splatting的新扩展,用于创建高质量的可动画面部化身。
- HyperGaussians解决了现有技术在处理非线性变形、复杂光照和精细细节方面的挑战。
- 通过引入高维多元高斯分布,HyperGaussians提高了三维高斯表示的表达能力。
- 通过重新参数化协方差矩阵(即“逆协方差技巧”),解决了HyperGaussians计算效率问题。
- HyperGaussians可无缝集成到现有模型中。
- HyperGaussians在快速单目面部化身领域的表现超越了当前技术水平。
点此查看论文截图