⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-10 更新
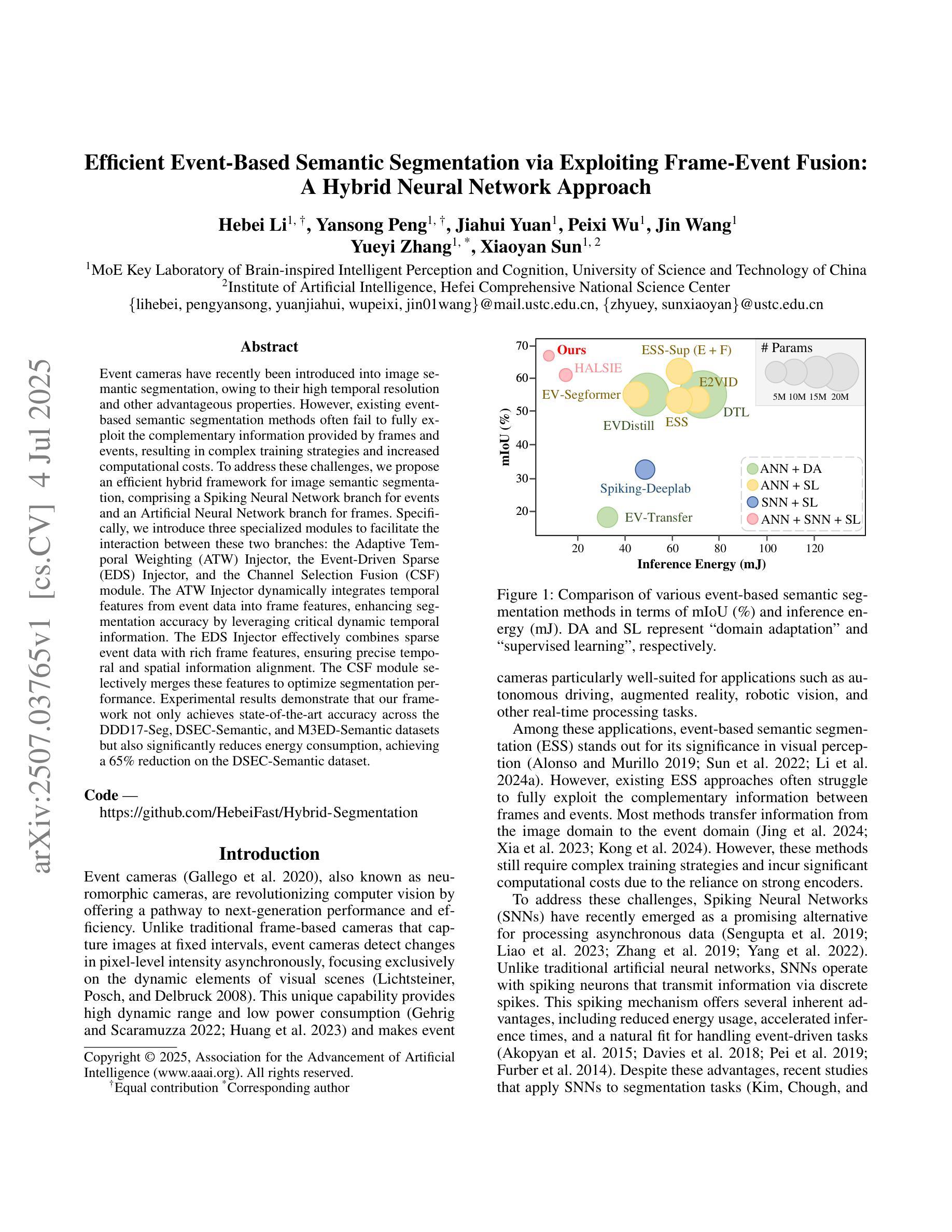
Efficient Event-Based Semantic Segmentation via Exploiting Frame-Event Fusion: A Hybrid Neural Network Approach
Authors:Hebei Li, Yansong Peng, Jiahui Yuan, Peixi Wu, Jin Wang, Yueyi Zhang, Xiaoyan Sun
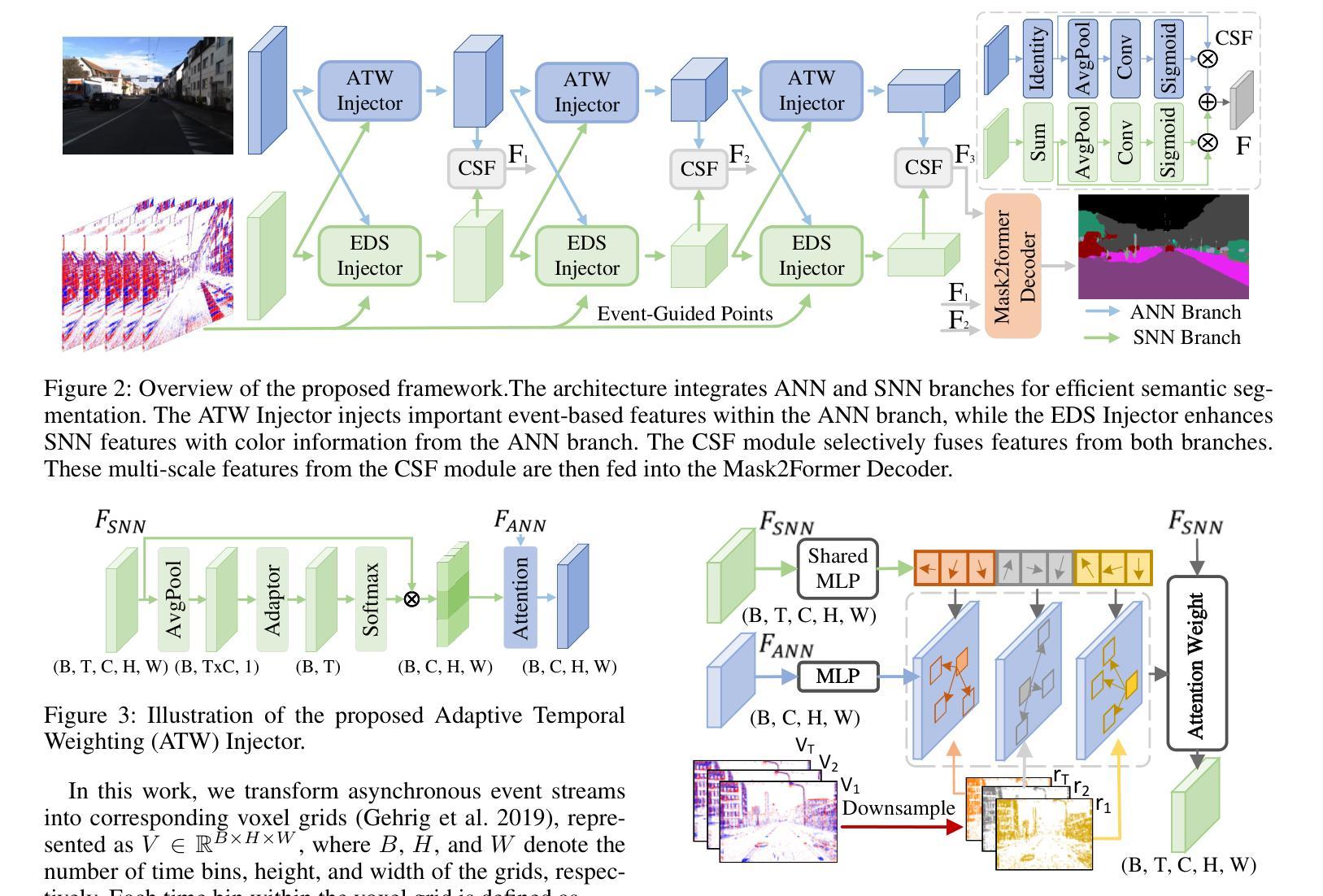
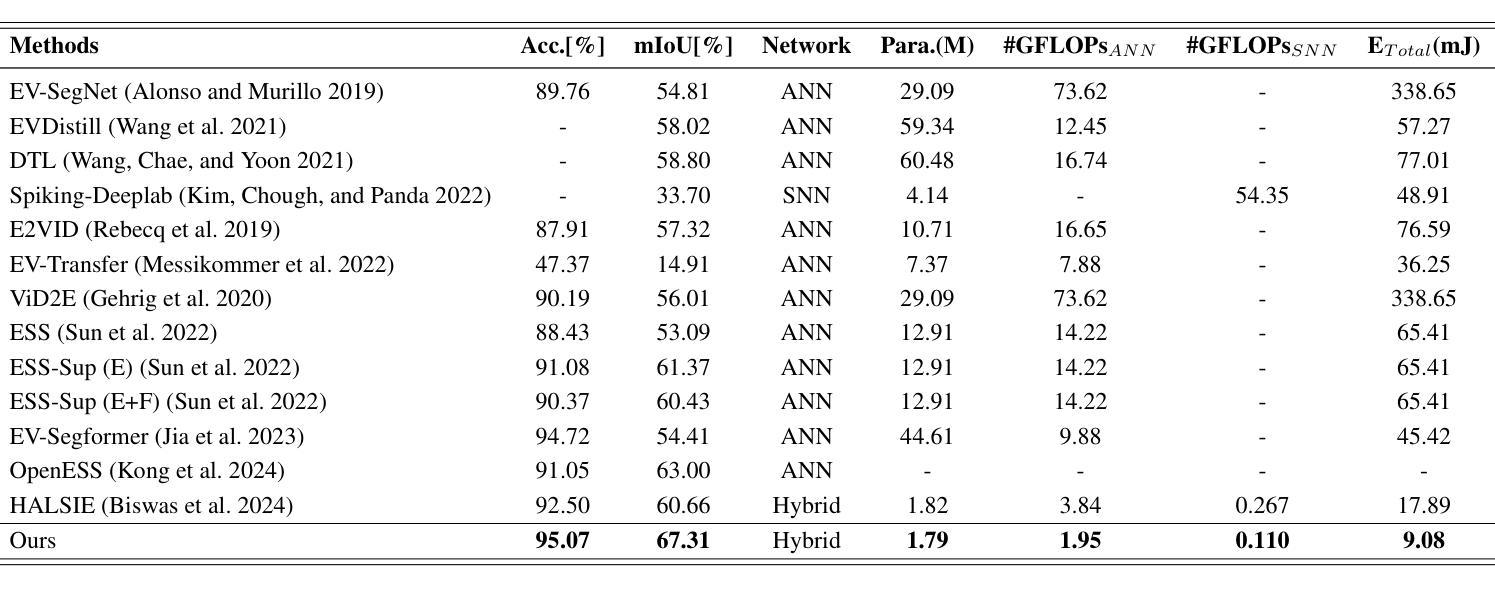
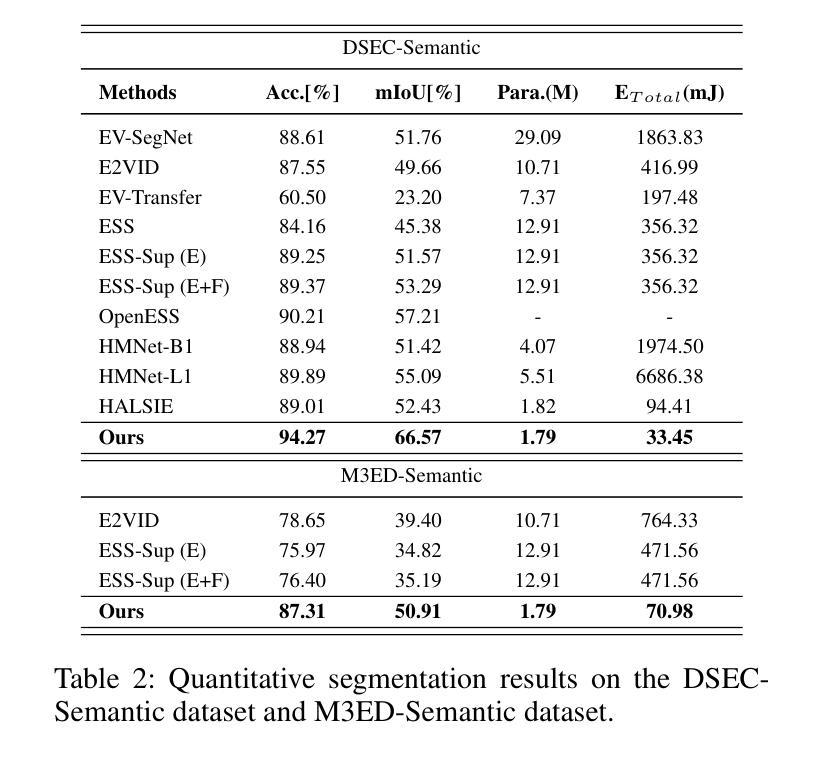
Event cameras have recently been introduced into image semantic segmentation, owing to their high temporal resolution and other advantageous properties. However, existing event-based semantic segmentation methods often fail to fully exploit the complementary information provided by frames and events, resulting in complex training strategies and increased computational costs. To address these challenges, we propose an efficient hybrid framework for image semantic segmentation, comprising a Spiking Neural Network branch for events and an Artificial Neural Network branch for frames. Specifically, we introduce three specialized modules to facilitate the interaction between these two branches: the Adaptive Temporal Weighting (ATW) Injector, the Event-Driven Sparse (EDS) Injector, and the Channel Selection Fusion (CSF) module. The ATW Injector dynamically integrates temporal features from event data into frame features, enhancing segmentation accuracy by leveraging critical dynamic temporal information. The EDS Injector effectively combines sparse event data with rich frame features, ensuring precise temporal and spatial information alignment. The CSF module selectively merges these features to optimize segmentation performance. Experimental results demonstrate that our framework not only achieves state-of-the-art accuracy across the DDD17-Seg, DSEC-Semantic, and M3ED-Semantic datasets but also significantly reduces energy consumption, achieving a 65% reduction on the DSEC-Semantic dataset.
事件相机因其高时间分辨率和其他优势属性而最近被引入到图像语义分割中。然而,现有的基于事件的语义分割方法往往未能充分利用帧和事件提供的互补信息,导致复杂的训练策略和计算成本增加。为了应对这些挑战,我们提出了一种用于图像语义分割的高效混合框架,该框架包括用于事件的脉冲神经网络分支和用于帧的人工神经网络分支。具体来说,我们引入了三个专用模块来促进这两个分支之间的交互:自适应时间加权(ATW)注入器、事件驱动稀疏(EDS)注入器和通道选择融合(CSF)模块。ATW注入器动态地将事件数据的临时特征融合到帧特征中,利用关键动态临时信息提高分割精度。EDS注入器有效地将稀疏事件数据与丰富的帧特征相结合,确保精确的临时和空间信息对齐。CSF模块有选择地合并这些特征以优化分割性能。实验结果表明,我们的框架不仅在DDD17-Seg、DSEC-Semantic和M3ED-Semantic数据集上达到了最先进的精度,而且在DSEC-Semantic数据集上实现了65%的能耗减少。
论文及项目相关链接
摘要
事件相机因其高时间分辨率和其他优势特性最近已被引入图像语义分割领域。然而,现有的基于事件语义分割方法未能充分利用帧和事件提供的互补信息,导致复杂的训练策略和增加的计算成本。为解决这些挑战,我们提出了一种高效的混合框架,包括用于事件的脉冲神经网络分支和用于帧的人工神经网络分支。具体地,我们引入了三个专业模块来促进这两个分支之间的交互:自适应时间加权(ATW)注入器、事件驱动稀疏(EDS)注入器和通道选择融合(CSF)模块。ATW注入器动态地将事件数据的时间特征集成到帧特征中,利用关键动态时间信息提高分割精度。EDS注入器有效地将稀疏事件数据与丰富的帧特征相结合,确保精确的时间和空间信息对齐。CSF模块选择性地合并这些特征以优化分割性能。实验结果表明,我们的框架不仅在DDD17-Seg、DSEC-Semantic和M3ED-Semantic数据集上实现了最先进的精度,而且显著降低了能耗,在DSEC-Semantic数据集上实现了65%的能耗减少。
关键见解
- 事件相机因其高时间分辨率和其他优势特性被引入图像语义分割领域。
- 现有方法未能充分利用事件和帧的互补信息。
- 提出的混合框架包括脉冲神经网络分支和人工神经网络分支。
- 引入三个专业模块:ATW注入器、EDS注入器和CSF模块,以促进框架内两个分支的交互。
- ATW注入器通过集成事件数据的时间特征提高分割精度。
- EDS注入器确保事件数据和帧特征的时空信息精确对齐。
点此查看论文截图

Leveraging Out-of-Distribution Unlabeled Images: Semi-Supervised Semantic Segmentation with an Open-Vocabulary Model
Authors:Wooseok Shin, Jisu Kang, Hyeonki Jeong, Jin Sob Kim, Sung Won Han
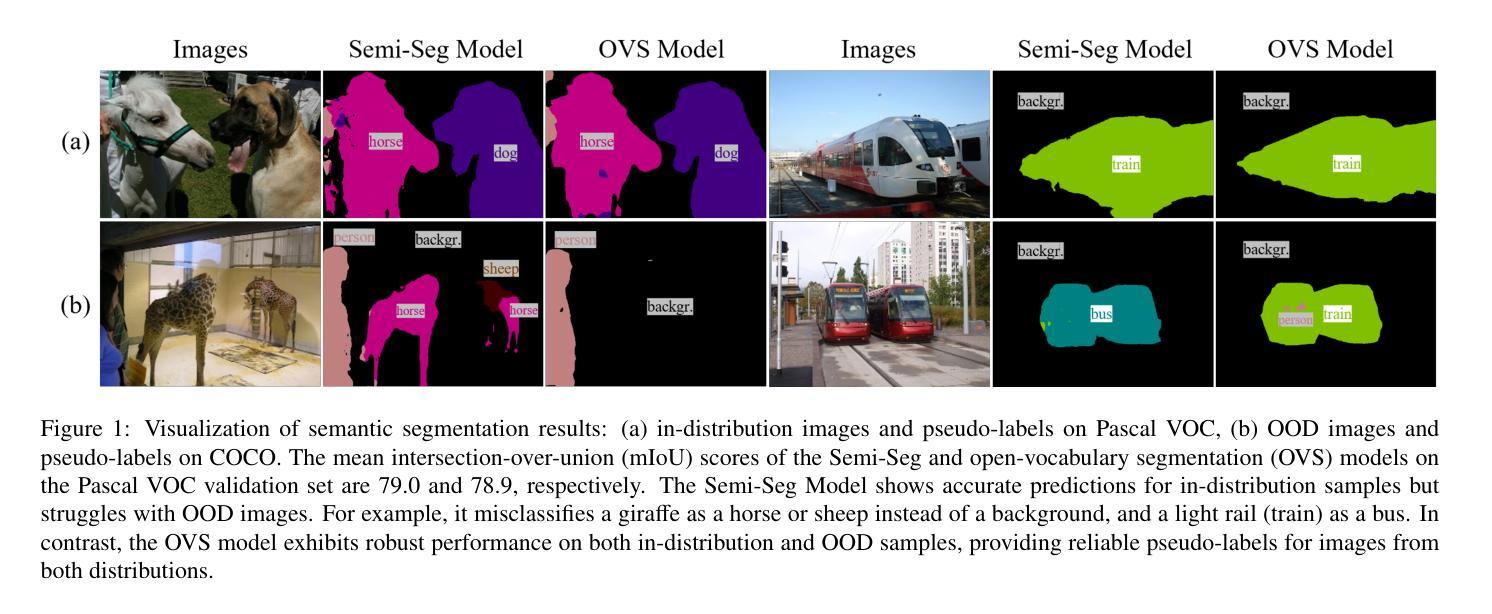
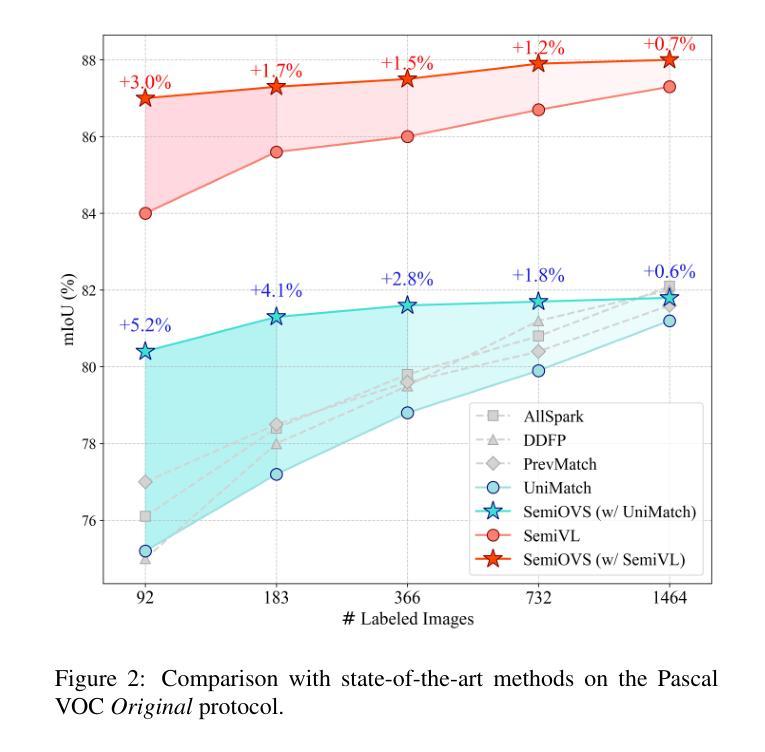
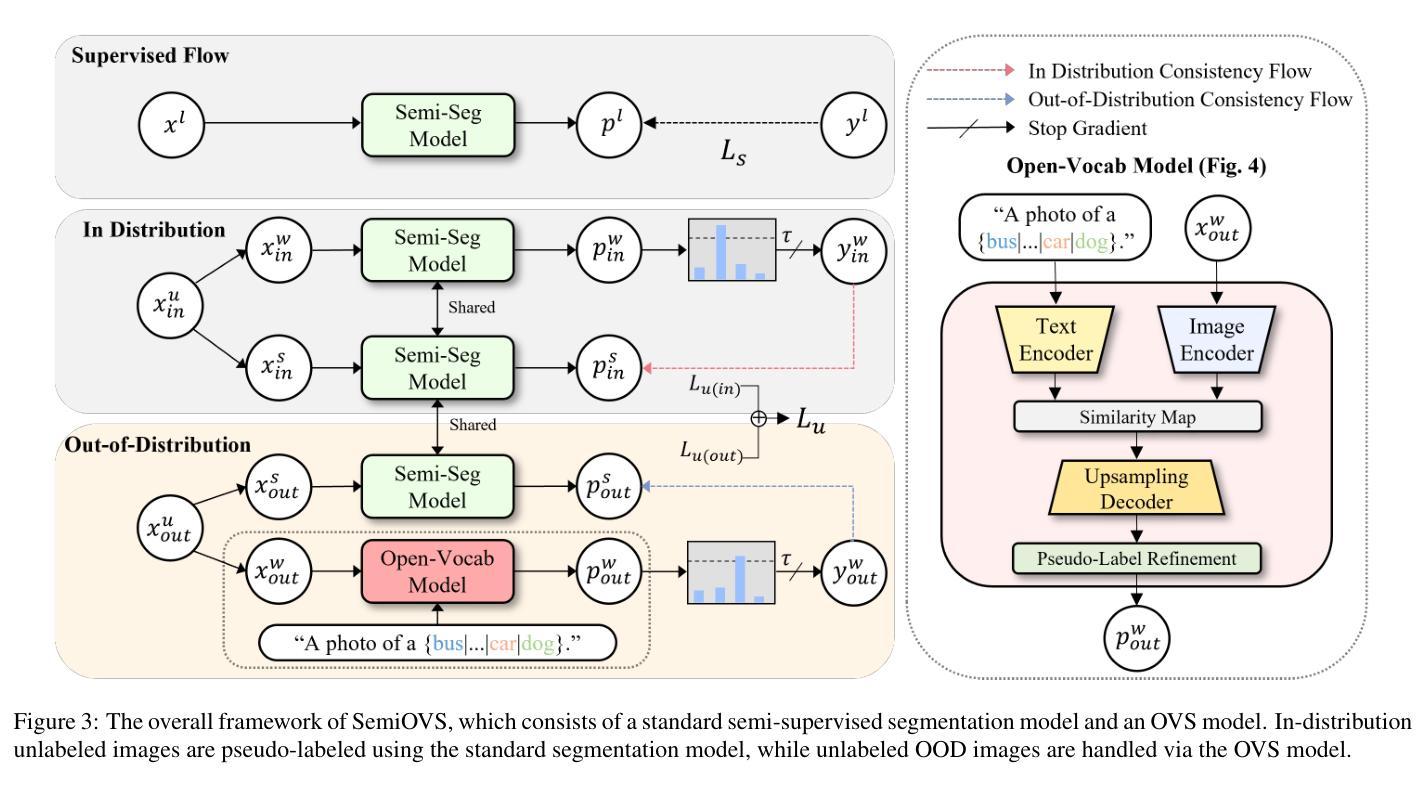
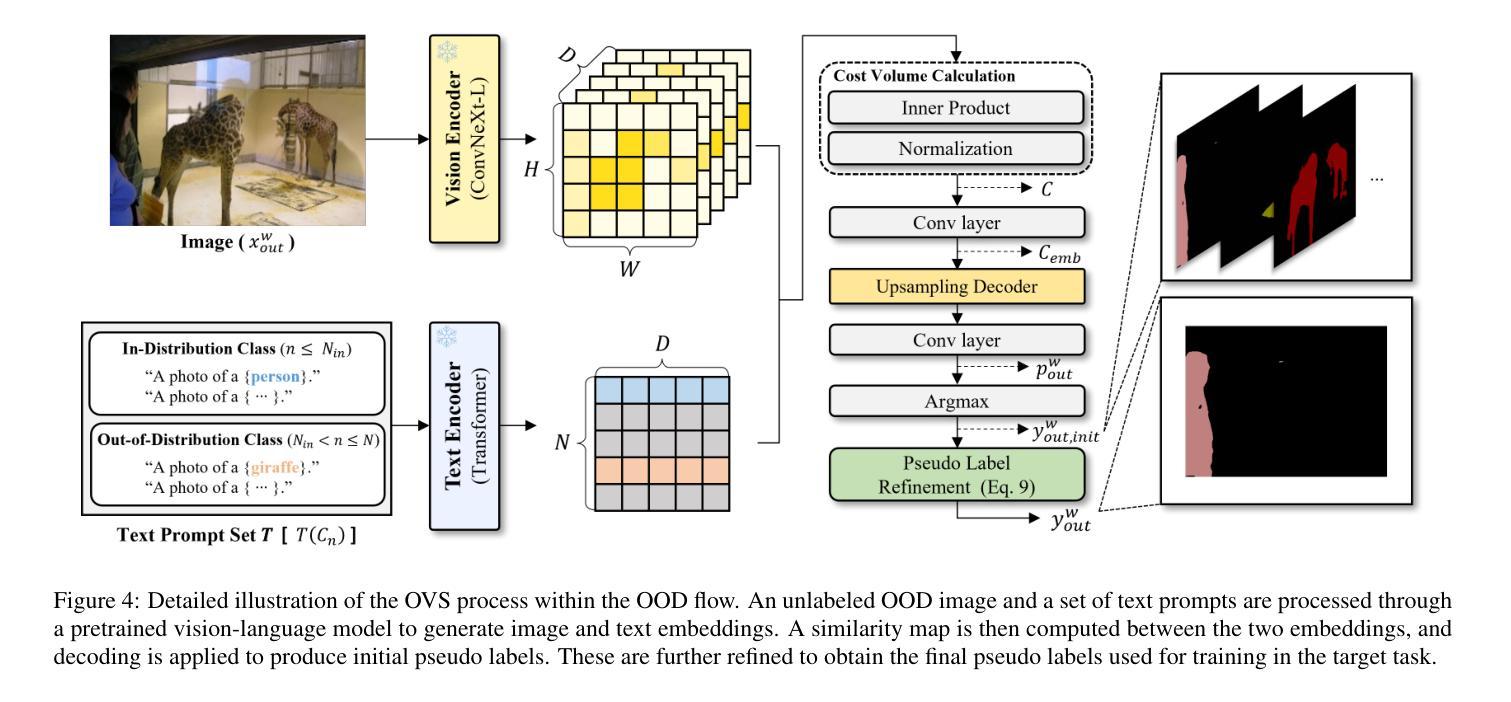
In semi-supervised semantic segmentation, existing studies have shown promising results in academic settings with controlled splits of benchmark datasets. However, the potential benefits of leveraging significantly larger sets of unlabeled images remain unexplored. In real-world scenarios, abundant unlabeled images are often available from online sources (web-scraped images) or large-scale datasets. However, these images may have different distributions from those of the target dataset, a situation known as out-of-distribution (OOD). Using these images as unlabeled data in semi-supervised learning can lead to inaccurate pseudo-labels, potentially misguiding network training. In this paper, we propose a new semi-supervised semantic segmentation framework with an open-vocabulary segmentation model (SemiOVS) to effectively utilize unlabeled OOD images. Extensive experiments on Pascal VOC and Context datasets demonstrate two key findings: (1) using additional unlabeled images improves the performance of semi-supervised learners in scenarios with few labels, and (2) using the open-vocabulary segmentation (OVS) model to pseudo-label OOD images leads to substantial performance gains. In particular, SemiOVS outperforms existing PrevMatch and SemiVL methods by +3.5 and +3.0 mIoU, respectively, on Pascal VOC with a 92-label setting, achieving state-of-the-art performance. These findings demonstrate that our approach effectively utilizes abundant unlabeled OOD images for semantic segmentation tasks. We hope this work can inspire future research and real-world applications. The code is available at https://github.com/wooseok-shin/SemiOVS
在半监督语义分割领域,现有研究在基准数据集的控制分割中已显示出令人鼓舞的结果。然而,利用大量未标记图像的优势仍未被探索。在真实世界场景中,大量未标记的图像通常可以从在线来源(网络爬取的图像)或大规模数据集中获得。但这些图像的分布可能与目标数据集的分布不同,这种情况被称为分布外(OOD)。将这些图像作为半监督学习的未标记数据可能导致不准确的伪标签,从而可能误导网络训练。
论文及项目相关链接
PDF 19pages, 8 figures
Summary
本文提出了一种新的半监督语义分割框架,利用开放词汇分割模型(SemiOVS)有效利用未标记的OOD图像。实验表明,使用额外的未标记图像在标签较少的情况下提高了半监督学习者的性能,使用开放词汇分割模型对OOD图像进行伪标签标注带来了显著的性能提升。该方法在Pascal VOC数据集上实现了最先进的性能。
Key Takeaways
- 现有半监督语义分割研究主要在学术设置下对基准数据集进行受控分割,但利用大量未标记图像的优势尚未被完全探索。
- 在现实世界中,可以从在线来源(如网络抓取图像)或大规模数据集获得大量未标记图像,但这些图像可能与目标数据集分布不同,即出现OOD情况。
- 使用未标记的OOD图像进行半监督学习可能导致不准确的伪标签,从而误导网络训练。
- 本文提出了一种新的半监督语义分割框架(SemiOVS),能有效利用未标记的OOD图像。
- 实验表明,使用额外未标记图像在标签有限的情况下能提高半监督学习者性能。
- 使用开放词汇分割模型(OVS)对OOD图像进行伪标签标注,带来了显著的性能提升。
点此查看论文截图

MaSS13K: A Matting-level Semantic Segmentation Benchmark
Authors:Chenxi Xie, Minghan Li, Hui Zeng, Jun Luo, Lei Zhang
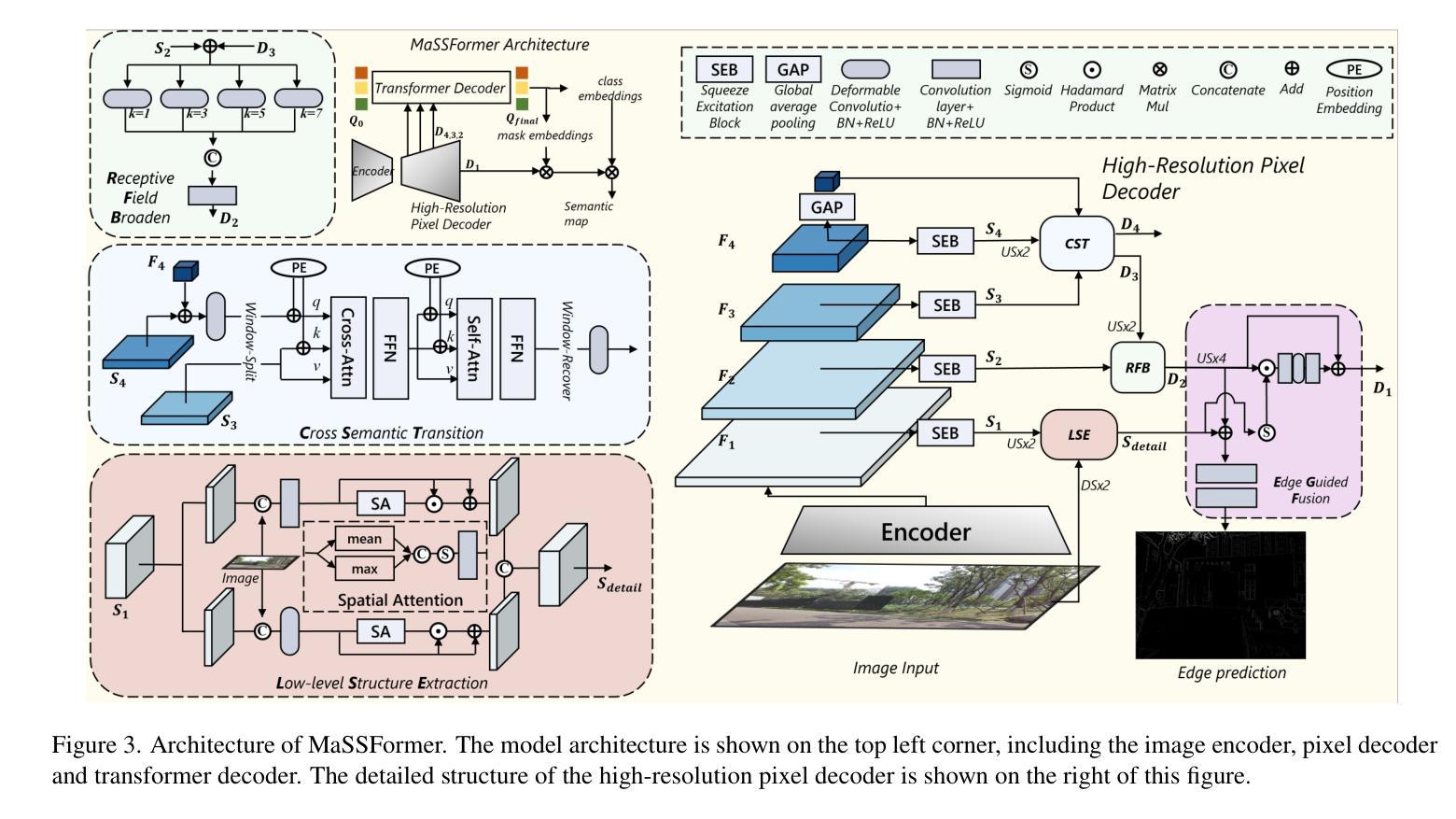
High-resolution semantic segmentation is essential for applications such as image editing, bokeh imaging, AR/VR, etc. Unfortunately, existing datasets often have limited resolution and lack precise mask details and boundaries. In this work, we build a large-scale, matting-level semantic segmentation dataset, named MaSS13K, which consists of 13,348 real-world images, all at 4K resolution. MaSS13K provides high-quality mask annotations of a number of objects, which are categorized into seven categories: human, vegetation, ground, sky, water, building, and others. MaSS13K features precise masks, with an average mask complexity 20-50 times higher than existing semantic segmentation datasets. We consequently present a method specifically designed for high-resolution semantic segmentation, namely MaSSFormer, which employs an efficient pixel decoder that aggregates high-level semantic features and low-level texture features across three stages, aiming to produce high-resolution masks with minimal computational cost. Finally, we propose a new learning paradigm, which integrates the high-quality masks of the seven given categories with pseudo labels from new classes, enabling MaSSFormer to transfer its accurate segmentation capability to other classes of objects. Our proposed MaSSFormer is comprehensively evaluated on the MaSS13K benchmark together with 14 representative segmentation models. We expect that our meticulously annotated MaSS13K dataset and the MaSSFormer model can facilitate the research of high-resolution and high-quality semantic segmentation. Datasets and codes can be found at https://github.com/xiechenxi99/MaSS13K.
高分辨率语义分割对于图像编辑、散景成像、增强现实/虚拟现实等应用至关重要。然而,现有数据集往往分辨率有限,缺乏精确的掩膜细节和边界。在这项工作中,我们构建了一个大规模、材质级别的语义分割数据集,名为MaSS13K,由13348张真实世界的4K分辨率图像组成。MaSS13K提供了高质量的对象掩膜注释,这些对象被分为七大类:人类、植被、地面、天空、水、建筑和其他。MaSS13K的掩膜非常精确,其平均掩膜复杂度比现有语义分割数据集高20-50倍。因此,我们提出了一种专门用于高分辨率语义分割的方法,名为MaSSFormer,它采用高效的像素解码器,跨三个阶段聚合高级语义特征和低级纹理特征,旨在以最小的计算成本生成高分辨率掩膜。最后,我们提出了一种新的学习范式,它将给定的七类的高质量掩膜与来自新类别的伪标签相结合,使MaSSFormer能够将准确的分割能力迁移到其他类别的对象上。MaSSFormer在MaSS13K基准测试上与14种代表性的分割模型进行了全面评估。我们希望我们的精心标注的MaSS13K数据集和MaSSFormer模型能够促进高分辨率和高质量语义分割的研究。数据集和代码可在https://github.com/xiechenxi99/MaSS13K找到。
论文及项目相关链接
PDF CVPR2025
Summary
本文构建了一个大规模、成像级别语义分割数据集MaSS13K,包含13,348张真实世界的4K图像,提供高质量的对象掩膜标注,分为七大类。同时提出了一种针对高分辨率语义分割的方法MaSSFormer,采用高效像素解码器聚合高级语义特征和低级纹理特征,并引入新的学习范式,利用高质量掩膜和伪标签提升分割能力。MaSS13K数据集和MaSSFormer模型有助于高分辨率和高质量语义分割的研究。
Key Takeaways
1. 构建了一个大规模的高分辨率语义分割数据集MaSS13K,包含真实世界的图像,分辨率高达4K。
2. MaSS13K数据集提供了高质量的对象掩膜标注,分为七大类:人类、植被、地面、天空、水域、建筑和其他。
3. MaSS13K数据集的掩膜精度高于现有语义分割数据集,平均复杂度高出20-50倍。
4. 提出了一种针对高分辨率语义分割的方法MaSSFormer,能有效聚合高级语义特征和低级纹理特征。
5. MaSSFormer采用新的学习范式,结合高质量掩膜和伪标签,提高了对新类别对象的准确分割能力。
6. MaSSFormer在MaSS13K基准测试上进行了全面评估,并与其他代表性分割模型进行了比较。
点此查看论文截图


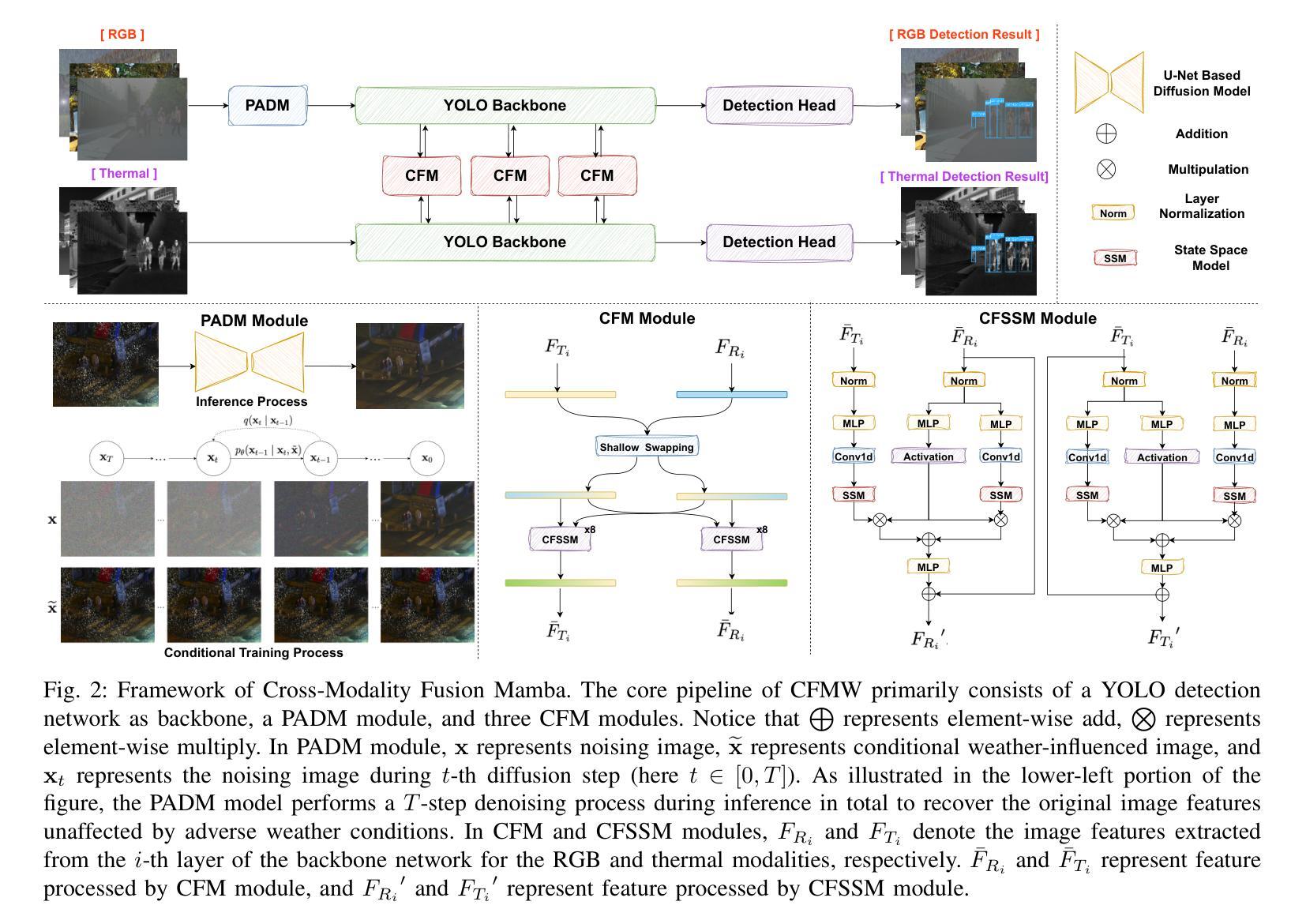
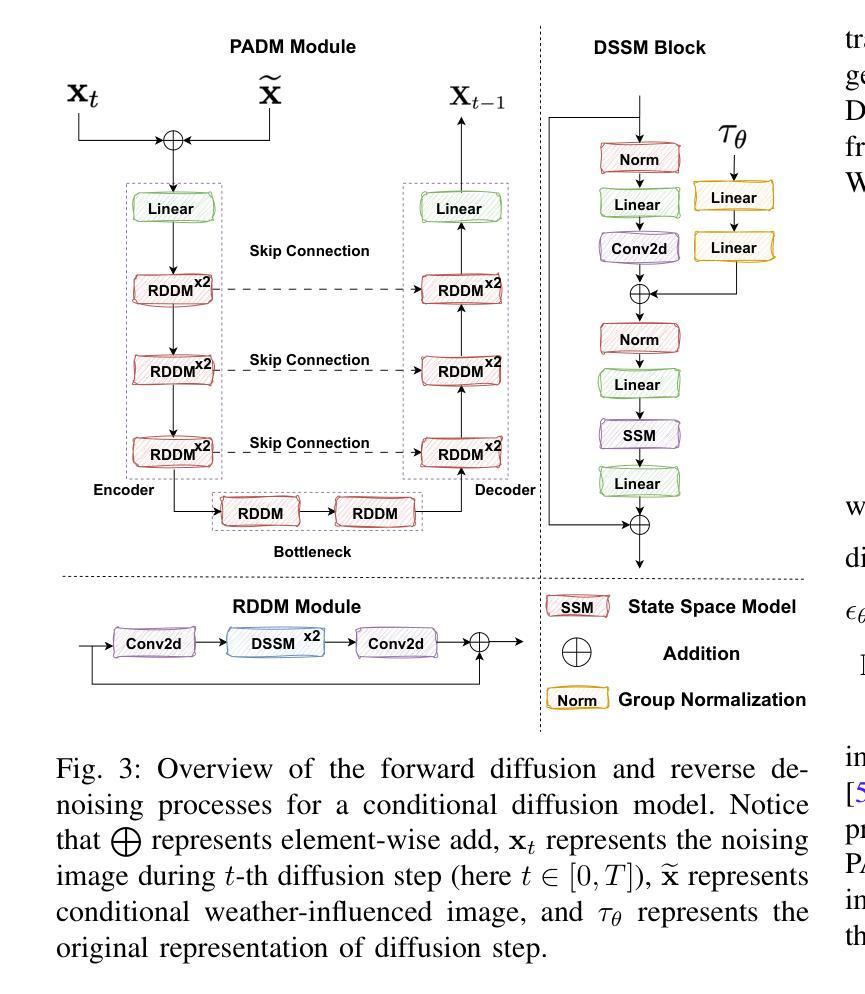
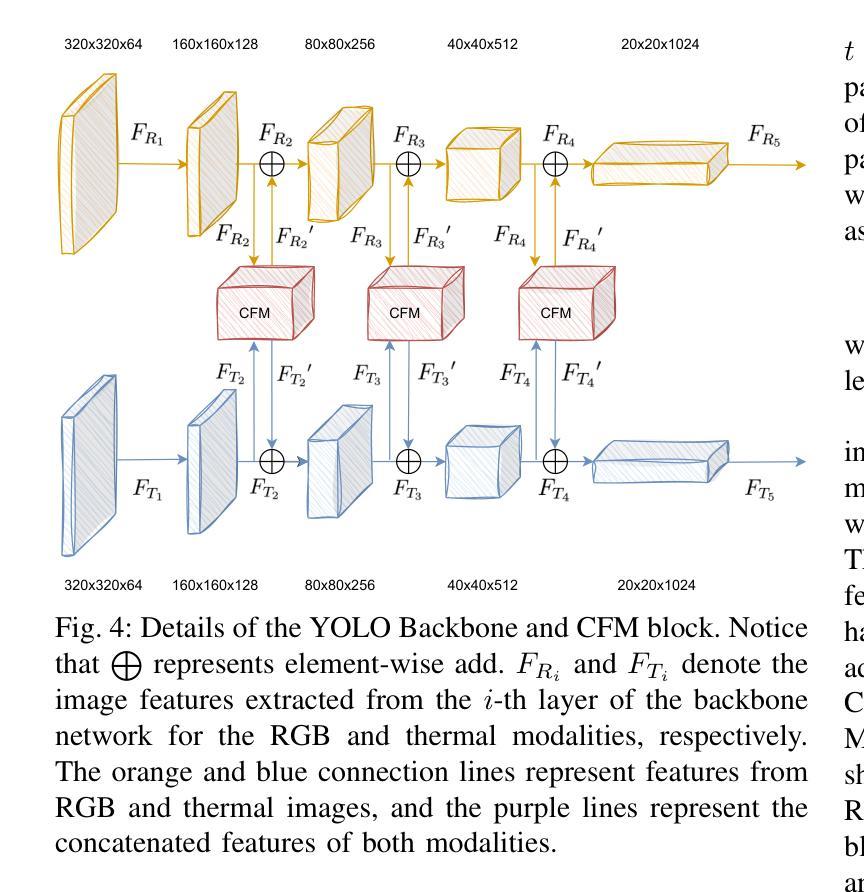
CFMW: Cross-modality Fusion Mamba for Robust Object Detection under Adverse Weather
Authors:Haoyuan Li, Qi Hu, Binjia Zhou, You Yao, Jiacheng Lin, Kailun Yang, Peng Chen
Visible-infrared image pairs provide complementary information, enhancing the reliability and robustness of object detection applications in real-world scenarios. However, most existing methods face challenges in maintaining robustness under complex weather conditions, which limits their applicability. Meanwhile, the reliance on attention mechanisms in modality fusion introduces significant computational complexity and storage overhead, particularly when dealing with high-resolution images. To address these challenges, we propose the Cross-modality Fusion Mamba with Weather-removal (CFMW) to augment stability and cost-effectiveness under adverse weather conditions. Leveraging the proposed Perturbation-Adaptive Diffusion Model (PADM) and Cross-modality Fusion Mamba (CFM) modules, CFMW is able to reconstruct visual features affected by adverse weather, enriching the representation of image details. With efficient architecture design, CFMW is 3 times faster than Transformer-style fusion (e.g., CFT). To bridge the gap in relevant datasets, we construct a new Severe Weather Visible-Infrared (SWVI) dataset, encompassing diverse adverse weather scenarios such as rain, haze, and snow. The dataset contains 64,281 paired visible-infrared images, providing a valuable resource for future research. Extensive experiments on public datasets (i.e., M3FD and LLVIP) and the newly constructed SWVI dataset conclusively demonstrate that CFMW achieves state-of-the-art detection performance. Both the dataset and source code will be made publicly available at https://github.com/lhy-zjut/CFMW.
可见光红外图像对提供了互补信息,提高了现实世界场景中目标检测应用的可靠性和稳健性。然而,大多数现有方法在面对复杂天气条件下保持稳健性的挑战时存在局限性,这限制了其适用性。同时,模态融合中对注意力机制的依赖引入了显著的计算复杂性和存储开销,尤其是在处理高分辨率图像时。为了应对这些挑战,我们提出了跨模态融合Mamba带天气移除(CFMW)方案,以提高恶劣天气条件下的稳定性和成本效益。通过利用提出的扰动自适应扩散模型(PADM)和跨模态融合Mamba(CFM)模块,CFMW能够重建受恶劣天气影响的视觉特征,丰富了图像细节的表示。通过高效架构设计,CFMW的速度是Transformer风格融合(例如CFT)的3倍。为了填补相关数据集的空白,我们构建了一个新的恶劣天气可见光红外(SWVI)数据集,涵盖了雨、雾、雪等多种恶劣天气场景。该数据集包含64281对可见光红外图像,为未来的研究提供了宝贵的资源。在公开数据集(即M3FD和LLVIP)和新构建的SWVI数据集上的大量实验表明,CFMW实现了最先进的检测性能。数据集和源代码将在https://github.com/lhy-zjut/CFMW上公开提供。
论文及项目相关链接
PDF Accepted to IEEE Transactions on Circuits and Systems for Video Technology (TCSVT). The dataset and source code will be made publicly available at https://github.com/lhy-zjut/CFMW
Summary:
可见光红外图像对提供了互补信息,提高了对象检测应用的可靠性和稳健性。然而,现有方法在面对复杂天气条件时,往往面临保持稳健性的挑战。为此,我们提出了跨模态融合Mamba与去天气化(CFMW)方案,旨在增强恶劣天气下的稳定性和成本效益。通过利用扰动自适应扩散模型(PADM)和跨模态融合Mamba(CFM)模块,CFMW能够重建受恶劣天气影响的视觉特征,丰富图像细节表示。此外,我们还构建了一个新的严重天气可见光红外(SWVI)数据集,包含各种恶劣天气场景,如降雨、雾霾和雪。实验结果证明,CFMW在公共数据集和新建的SWVI数据集上均实现了最先进的检测性能。
Key Takeaways:
- 可见光红外图像对提供互补信息,增强对象检测的可靠性和稳健性。
- 现有方法在复杂天气条件下面临稳健性挑战。
- 跨模态融合Mamba与去天气化(CFMW)方案旨在增强恶劣天气下的稳定性和成本效益。
- CFMW利用扰动自适应扩散模型和跨模态融合模块,能重建受恶劣天气影响的视觉特征。
- CFMW效率更高,是Transformer风格融合的3倍速度。
- 构建了一个新的严重天气可见光红外(SWVI)数据集,包含多样化的恶劣天气场景。
点此查看论文截图

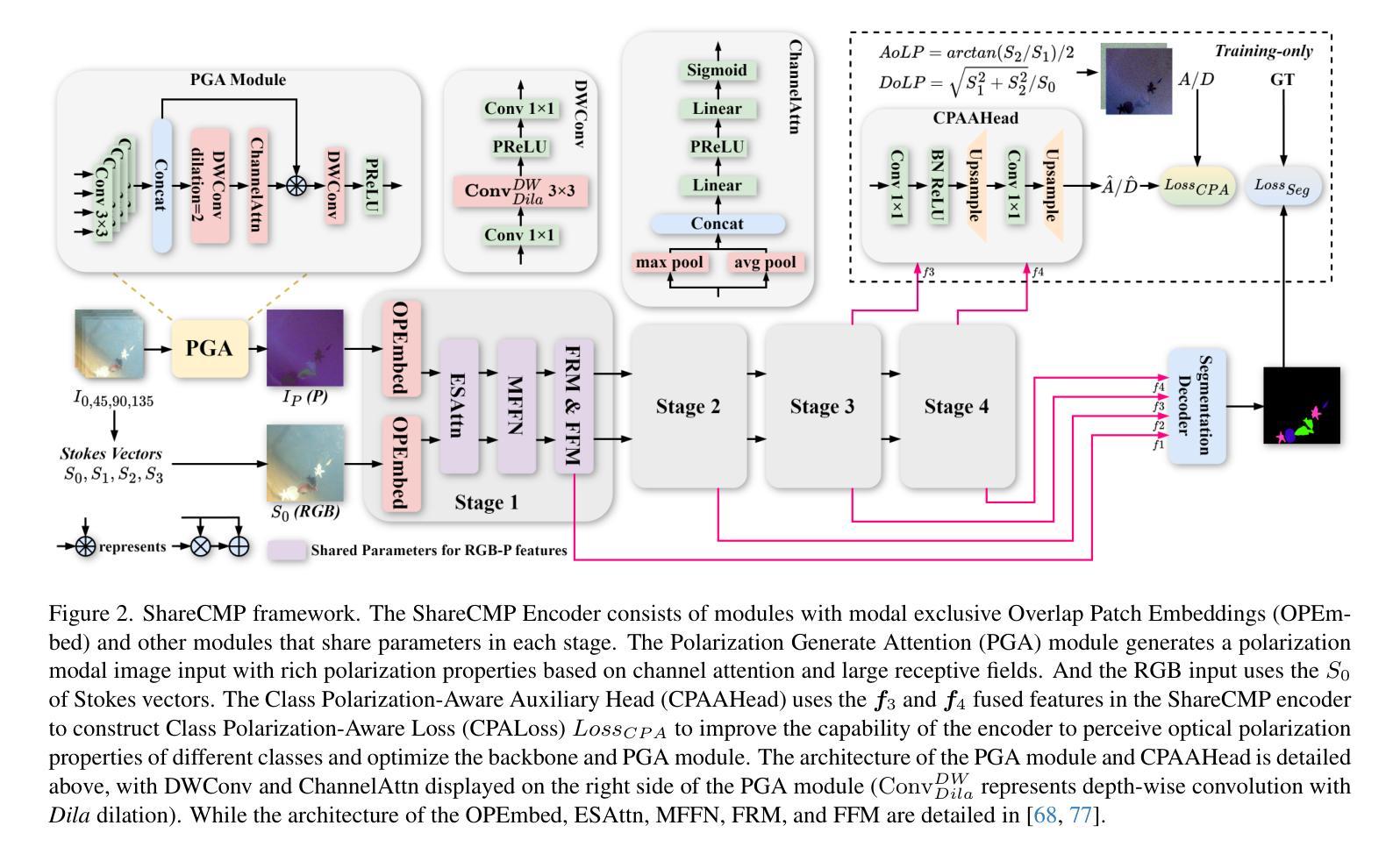
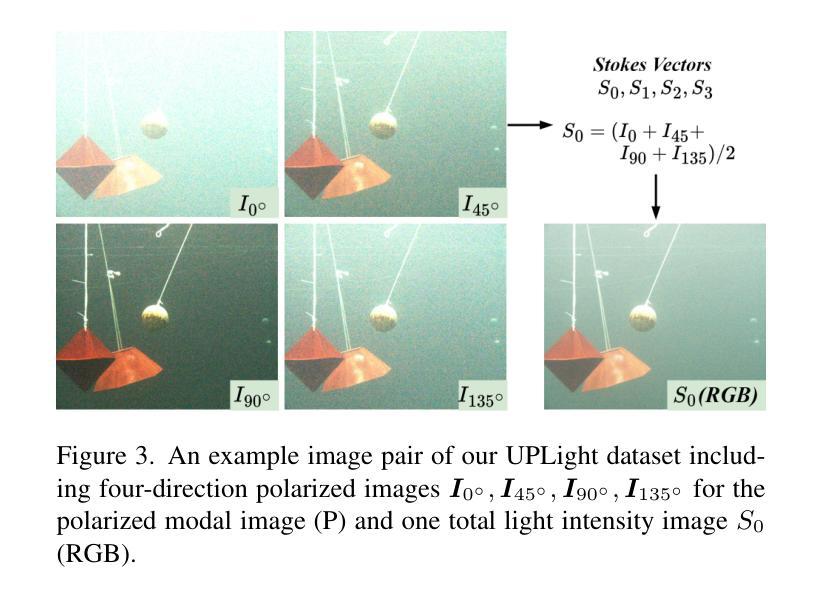
ShareCMP: Polarization-Aware RGB-P Semantic Segmentation
Authors:Zhuoyan Liu, Bo Wang, Lizhi Wang, Chenyu Mao, Ye Li
Multimodal semantic segmentation is developing rapidly, but the modality of RGB-\textbf{P}olarization remains underexplored. To delve into this problem, we construct a UPLight RGB-P segmentation benchmark with 12 typical underwater semantic classes. In this work, we design the ShareCMP, an RGB-P semantic segmentation framework with a shared dual-branch architecture (ShareCMP Encoder), which reduces the parameters and memory space by about 33.8% compared to previous dual-branch models. It encompasses a Polarization Generate Attention (PGA) module designed to generate polarization modal images with richer polarization properties for the encoder. In addition, we introduce the Class Polarization-Aware Loss (CPALoss) with Class Polarization-Aware Auxiliary Head (CPAAHead) to improve the learning and understanding of the encoder for polarization modal information and to optimize the PGA module. With extensive experiments on a total of three RGB-P benchmarks, our ShareCMP achieves the best performance in mIoU with fewer parameters on the UPLight (92.45{\small (+0.32)}%), ZJU (92.7{\small (+0.1)}%), and MCubeS (50.99{\small (+1.51)}%) datasets. And our ShareCMP (w/o PGA) achieves competitive or even higher performance on other RGB-X datasets compared to the corresponding state-of-the-art RGB-X methods. The code and datasets are available at https://github.com/LEFTeyex/ShareCMP.
多模态语义分割正在迅速发展,但RGB-偏振模态仍未得到充分探索。为了深入研究这一问题,我们构建了UPLight RGB-P分割基准测试集,包含12个典型的水下语义类别。在这项工作中,我们设计了ShareCMP,这是一个RGB-P语义分割框架,采用共享双分支架构(ShareCMP Encoder),与之前的双分支模型相比,参数和内存空间减少了约33.8%。它包含一个偏振生成注意力(PGA)模块,该模块旨在生成具有更丰富偏振属性的偏振模态图像,以供编码器使用。此外,我们引入了类偏振感知损失(CPALoss)和类偏振感知辅助头(CPAAHead),以提高编码器对偏振模态信息的学习和理解,并优化PGA模块。我们在三个RGB-P基准测试集上进行了大量实验,ShareCMP在UPLight(提升0.32%,达到92.45%)、ZJU(提升0.1%,达到92.7%)和MCubeS(提升1.51%,达到50.99%)数据集上取得了最佳的性能。并且我们的ShareCMP(不含PGA)在其他RGB-X数据集上的性能与最新的RGB-X方法相比具有竞争力,甚至更高。相关代码和数据集可通过https://github.com/LEFTeyex/ShareCMP获取。
论文及项目相关链接
PDF 17 pages, 8 figures, 12 tables, accepted by IEEE TCSVT
Summary
RGB-P模态的多模态语义分割发展快速,但仍被较少探索。为解决这个问题,本文构建了UPLight RGB-P分割基准测试集,包含12类典型水下语义类别。提出了ShareCMP框架,采用共享双分支架构,相较于之前的方法,参数和内存占用减少了约33.8%。设计Polarization Generate Attention(PGA)模块,生成具有更丰富极化属性的极化模态图像。引入Class Polarization-Aware Loss(CPALoss)和CPAAHead,提高编码器对极化模态信息的学习和理解,优化PGA模块。在三个RGB-P基准测试集上的实验表明,ShareCMP在参数更少的情况下实现了最佳性能。
Key Takeaways
- RGB-P模态在多模态语义分割中的研究仍然不足,需要更多关注。
- 本文构建了UPLight RGB-P分割基准测试集,涵盖多种水下语义类别。
- 引入ShareCMP框架,采用共享双分支架构降低参数和内存占用。
- PGA模块用于生成具有更丰富极化属性的极化模态图像。
- CPALoss和CPAAHead的设计旨在提高编码器对极化模态信息的学习和性能优化。
- 在多个RGB-P基准测试集上,ShareCMP实现了最佳性能。
点此查看论文截图