⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-10 更新
MCAM: Multimodal Causal Analysis Model for Ego-Vehicle-Level Driving Video Understanding
Authors:Tongtong Cheng, Rongzhen Li, Yixin Xiong, Tao Zhang, Jing Wang, Kai Liu
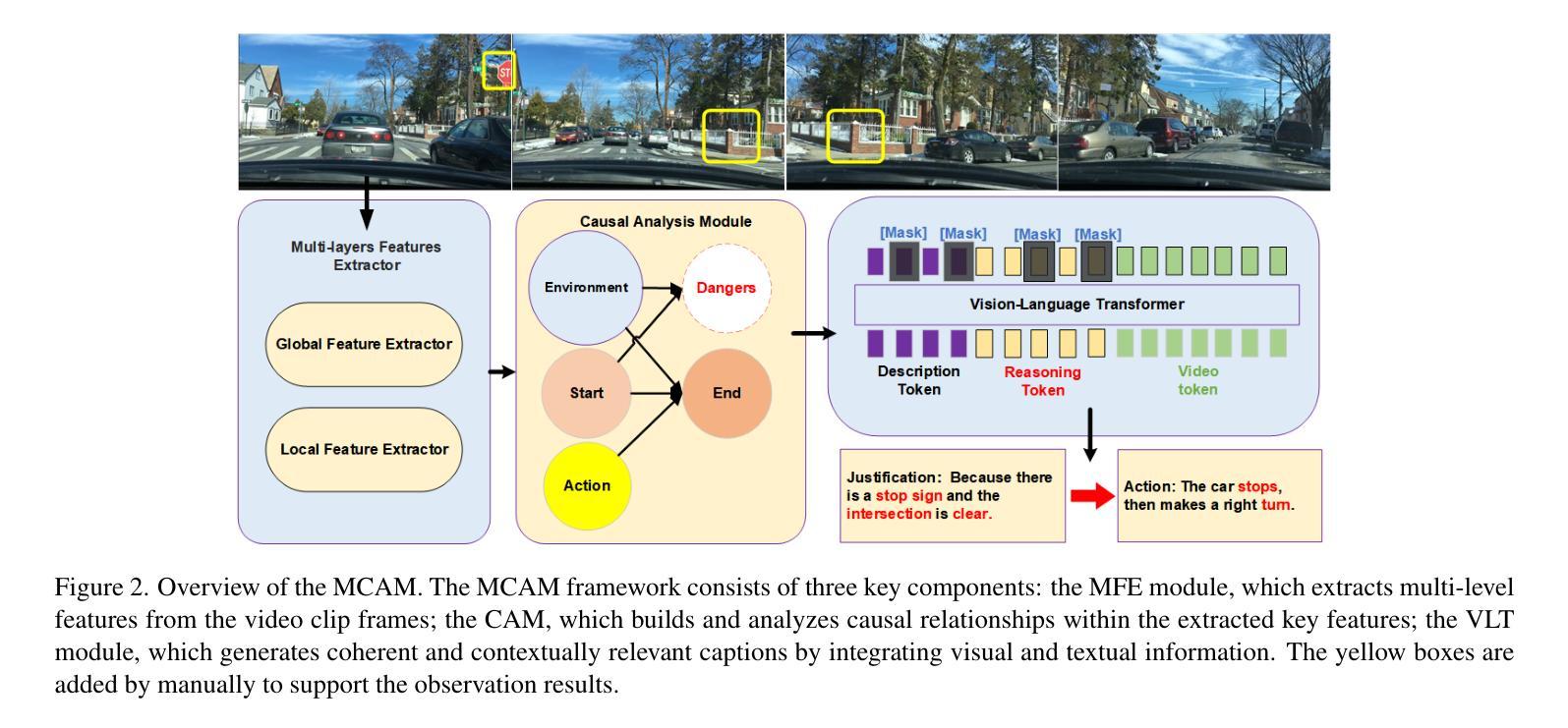
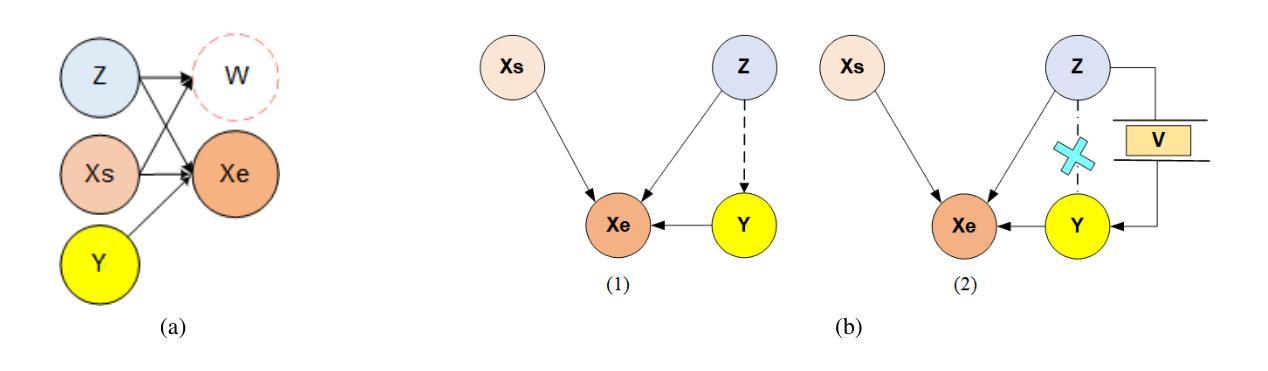
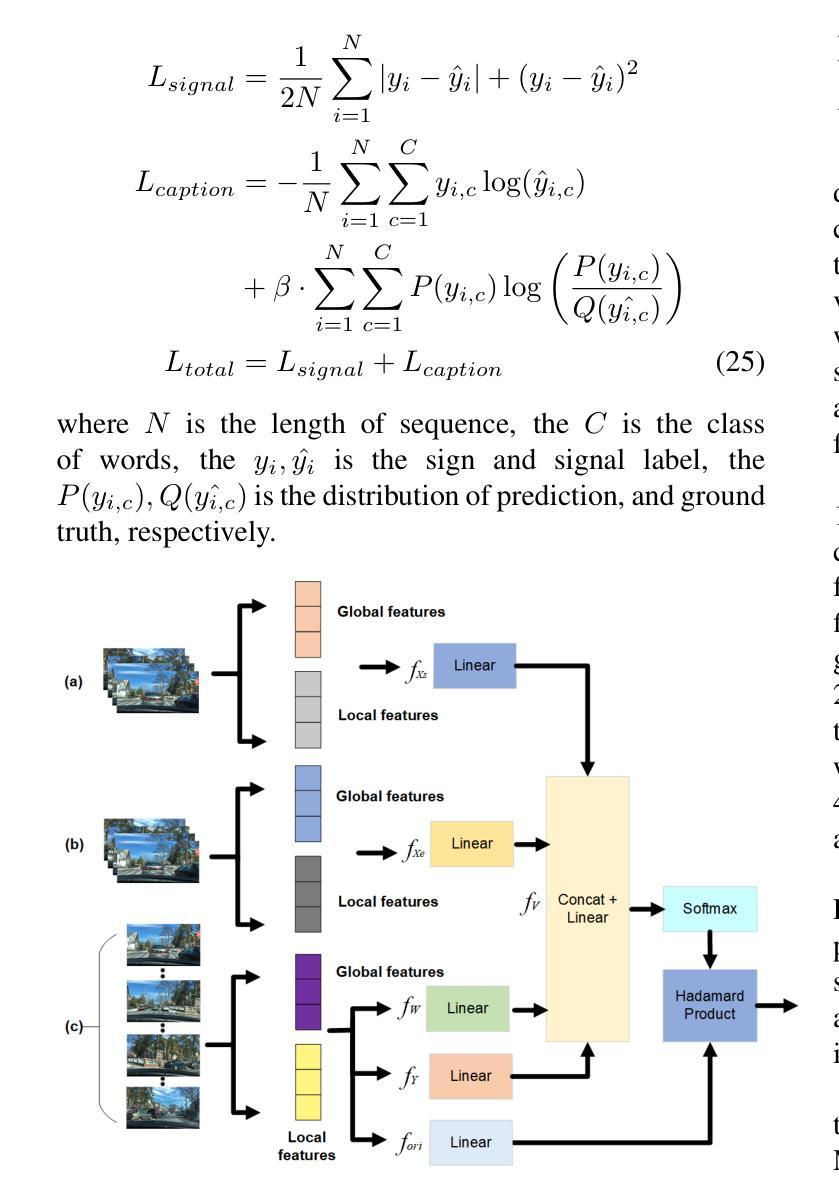
Accurate driving behavior recognition and reasoning are critical for autonomous driving video understanding. However, existing methods often tend to dig out the shallow causal, fail to address spurious correlations across modalities, and ignore the ego-vehicle level causality modeling. To overcome these limitations, we propose a novel Multimodal Causal Analysis Model (MCAM) that constructs latent causal structures between visual and language modalities. Firstly, we design a multi-level feature extractor to capture long-range dependencies. Secondly, we design a causal analysis module that dynamically models driving scenarios using a directed acyclic graph (DAG) of driving states. Thirdly, we utilize a vision-language transformer to align critical visual features with their corresponding linguistic expressions. Extensive experiments on the BDD-X, and CoVLA datasets demonstrate that MCAM achieves SOTA performance in visual-language causal relationship learning. Furthermore, the model exhibits superior capability in capturing causal characteristics within video sequences, showcasing its effectiveness for autonomous driving applications. The code is available at https://github.com/SixCorePeach/MCAM.
准确识别与解析驾驶行为对于自动驾驶视频理解至关重要。然而,现有方法往往倾向于挖掘浅层因果关系,无法处理跨模态的偶然关联,并忽略了车辆本身的因果建模。为了克服这些局限性,我们提出了一种新型的多模态因果分析模型(MCAM),该模型构建了视觉和语言模态之间的潜在因果结构。首先,我们设计了一种多层次特征提取器来捕捉长期依赖关系。其次,我们设计了一个因果分析模块,该模块使用驾驶状态的定向无环图(DAG)动态模拟驾驶场景。最后,我们利用视觉语言转换器将关键视觉特征与相应的语言表达进行对齐。在BDD-X和CoVLA数据集上的大量实验表明,MCAM在视觉语言因果关系学习中取得了最先进的性能。此外,该模型在捕捉视频序列中的因果特征方面表现出卓越的能力,展示了其在自动驾驶应用中的有效性。代码可在https://github.com/SixCorePeach/MCAM获取。
论文及项目相关链接
Summary
本文提出一种多模态因果分析模型(MCAM),用于构建视觉和语言模态之间的潜在因果结构。该模型通过设计多层次特征提取器捕捉长距离依赖关系,利用因果分析模块动态建模驾驶场景,并采用视觉语言转换器对齐关键视觉特征与对应的语言表达。在BDD-X和CoVLA数据集上的实验表明,MCAM在视觉语言因果关系学习中达到SOTA性能,并展现出捕捉视频序列内因果特性的卓越能力,适用于自动驾驶应用。
Key Takeaways
- 准确驾驶行为识别和推理对于自动驾驶视频理解至关重要。
- 现有方法往往挖掘浅层因果关系,忽略跨模态的偶然关联和车辆级别因果建模。
- 提出多模态因果分析模型(MCAM),构建视觉和语言模态之间的潜在因果结构。
- MCAM通过多层次特征提取器捕捉长距离依赖关系。
- 利用因果分析模块动态建模驾驶场景,采用视觉语言转换器对齐关键视觉特征和语言表达。
- 在BDD-X和CoVLA数据集上的实验显示MCAM达到SOTA性能。
点此查看论文截图