⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-10 更新
LighthouseGS: Indoor Structure-aware 3D Gaussian Splatting for Panorama-Style Mobile Captures
Authors:Seungoh Han, Jaehoon Jang, Hyunsu Kim, Jaeheung Surh, Junhyung Kwak, Hyowon Ha, Kyungdon Joo
Recent advances in 3D Gaussian Splatting (3DGS) have enabled real-time novel view synthesis (NVS) with impressive quality in indoor scenes. However, achieving high-fidelity rendering requires meticulously captured images covering the entire scene, limiting accessibility for general users. We aim to develop a practical 3DGS-based NVS framework using simple panorama-style motion with a handheld camera (e.g., mobile device). While convenient, this rotation-dominant motion and narrow baseline make accurate camera pose and 3D point estimation challenging, especially in textureless indoor scenes. To address these challenges, we propose LighthouseGS, a novel framework inspired by the lighthouse-like sweeping motion of panoramic views. LighthouseGS leverages rough geometric priors, such as mobile device camera poses and monocular depth estimation, and utilizes the planar structures often found in indoor environments. We present a new initialization method called plane scaffold assembly to generate consistent 3D points on these structures, followed by a stable pruning strategy to enhance geometry and optimization stability. Additionally, we introduce geometric and photometric corrections to resolve inconsistencies from motion drift and auto-exposure in mobile devices. Tested on collected real and synthetic indoor scenes, LighthouseGS delivers photorealistic rendering, surpassing state-of-the-art methods and demonstrating the potential for panoramic view synthesis and object placement.
近期三维高斯贴图技术(3DGS)的进步已经实现了室内场景的高质量实时新型视图合成(NVS)。然而,实现高保真渲染需要捕捉整个场景的图像,这限制了普通用户的可访问性。我们的目标是开发一个基于3DGS的实用NVS框架,使用简单的全景式运动手持相机(例如移动设备)。虽然方便,但这种以旋转为主的运动和狭窄的基线使得准确估计相机姿态和三维点变得具有挑战性,特别是在纹理较少的室内场景中。为了应对这些挑战,我们提出了灯塔GS(LighthouseGS),这是一个受全景视图灯塔式扫描运动启发的全新框架。灯塔GS利用粗略的几何先验信息,如移动设备相机姿态和单眼深度估计,并利用室内环境中常见的平面结构。我们提出了一种新的初始化方法,称为平面支架装配,以在这些结构上生成一致的3D点,然后采用稳定的修剪策略增强几何结构和优化稳定性。此外,我们还引入了几何和光度校正来解决来自运动漂移和移动设备自动曝光的不一致问题。在收集的真实和合成室内场景上的测试表明,灯塔GS实现了逼真的渲染效果,超越了现有技术,并展示了全景视图合成和对象放置的潜力。
论文及项目相关链接
PDF Preprint
Summary
室内场景实时生成高质量新型视图(NVS)的最新技术,以使用简单的全景移动模式与手持设备拍摄。实现方法具有便捷性挑战,旋转为主以及基线窄带来的精准摄像头定位和3D点估计的困难,特别是在纹理缺失的室内场景。我们提出了一种新的基于全景视图的灯塔型移动模式,借助粗略几何先验、手机相机姿态和单眼深度估计技术。使用室内环境中常见的平面结构。新型初始化方法平面骨架组装法稳定几何结构和优化过程,进行几何和光度修正以应对移动设备中移动漂移和自动曝光的问题。该方案已经在真实的室内场景中进行测试并表现优秀,显示了全景视图合成和物体放置的巨大潜力。克服了当前的难点问题后表明潜力很大。Key Takeaways:
点此查看论文截图


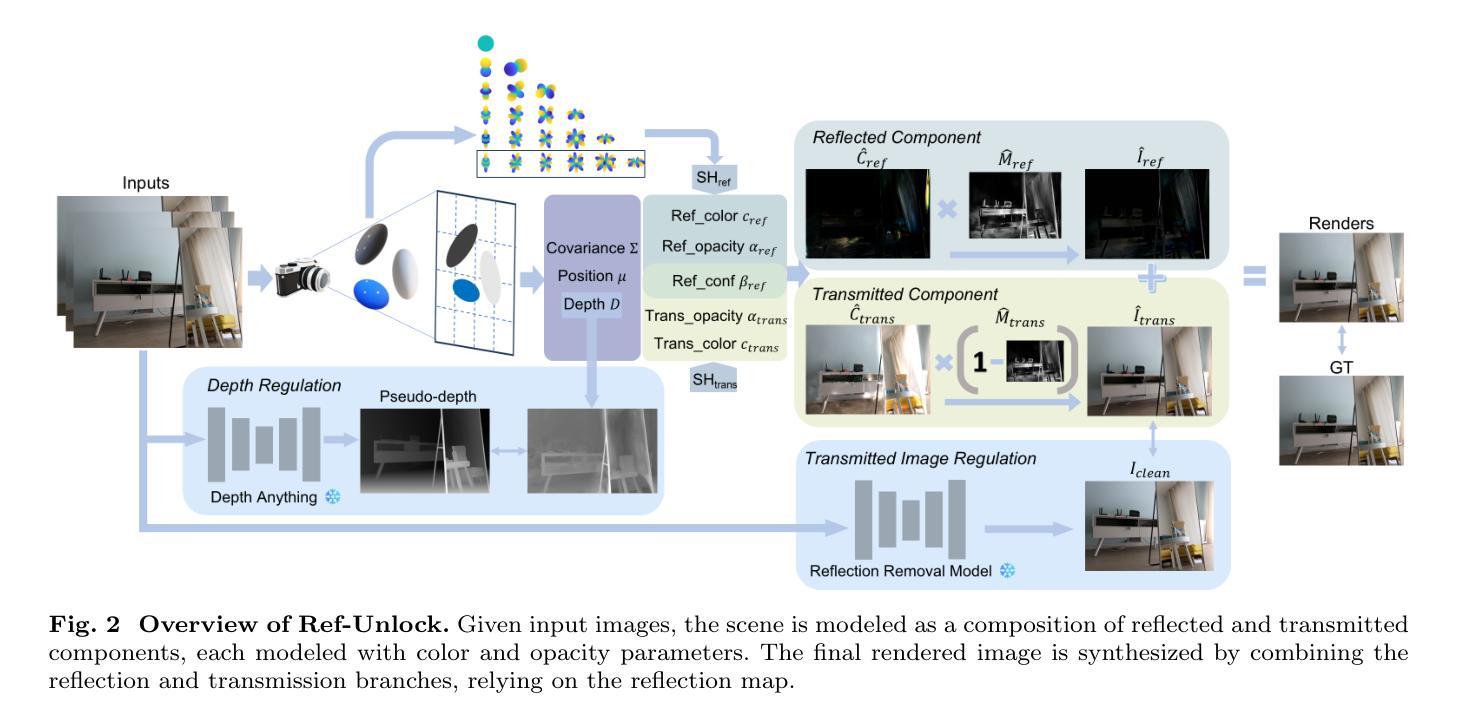
Reflections Unlock: Geometry-Aware Reflection Disentanglement in 3D Gaussian Splatting for Photorealistic Scenes Rendering
Authors:Jiayi Song, Zihan Ye, Qingyuan Zhou, Weidong Yang, Ben Fei, Jingyi Xu, Ying He, Wanli Ouyang
Accurately rendering scenes with reflective surfaces remains a significant challenge in novel view synthesis, as existing methods like Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) often misinterpret reflections as physical geometry, resulting in degraded reconstructions. Previous methods rely on incomplete and non-generalizable geometric constraints, leading to misalignment between the positions of Gaussian splats and the actual scene geometry. When dealing with real-world scenes containing complex geometry, the accumulation of Gaussians further exacerbates surface artifacts and results in blurred reconstructions. To address these limitations, in this work, we propose Ref-Unlock, a novel geometry-aware reflection modeling framework based on 3D Gaussian Splatting, which explicitly disentangles transmitted and reflected components to better capture complex reflections and enhance geometric consistency in real-world scenes. Our approach employs a dual-branch representation with high-order spherical harmonics to capture high-frequency reflective details, alongside a reflection removal module providing pseudo reflection-free supervision to guide clean decomposition. Additionally, we incorporate pseudo-depth maps and a geometry-aware bilateral smoothness constraint to enhance 3D geometric consistency and stability in decomposition. Extensive experiments demonstrate that Ref-Unlock significantly outperforms classical GS-based reflection methods and achieves competitive results with NeRF-based models, while enabling flexible vision foundation models (VFMs) driven reflection editing. Our method thus offers an efficient and generalizable solution for realistic rendering of reflective scenes. Our code is available at https://ref-unlock.github.io/.
准确渲染具有反射表面的场景在新型视图合成中仍然是一个重大挑战,因为现有的方法,如神经辐射场(NeRF)和3D高斯喷涂(3DGS),常常将反射误解为物理几何,导致重建效果退化。之前的方法依赖于不完整且不能普遍适用的几何约束,导致高斯喷涂的位置与实际场景几何之间出现错位。在处理包含复杂几何的真实场景时,高斯累积会进一步加剧表面伪影,导致重建结果模糊。为了解决这些局限性,我们在工作中提出了Ref-Unlock,这是一种基于3D高斯喷涂的新型几何感知反射建模框架,它显式地分离传输和反射成分,以更好地捕捉复杂的反射并增强真实场景中几何的一致性。我们的方法采用具有高阶球面谐波的双分支表示来捕捉高频反射细节,同时采用反射去除模块提供伪无反射监督来指导清洁分解。此外,我们结合了伪深度图和几何感知双边平滑约束,以提高3D几何一致性和分解的稳定性。大量实验表明,Ref-Unlock显著优于基于经典GS的反射方法,并与基于NeRF的模型取得具有竞争力的结果,同时支持由视觉基础模型(VFMs)驱动的反射编辑。因此,我们的方法为真实反射场景的渲染提供了高效且通用的解决方案。我们的代码可在https://ref-unlock.github.io/找到。
论文及项目相关链接
Summary
本文提出一种基于3D高斯喷绘的新型几何感知反射建模框架Ref-Unlock,用于准确渲染反射表面场景。该方法能够显式地分离传输和反射成分,以更好地捕捉复杂的反射现象,并增强真实场景中的几何一致性。通过采用双分支表示、高阶球面谐波、伪反射去除模块以及伪深度图和几何感知双边平滑约束等技术,Ref-Unlock显著提高了反射场景的渲染质量,并实现了灵活的视觉基础模型驱动的反射编辑。
Key Takeaways
- Ref-Unlock是一种基于3D高斯喷绘的几何感知反射建模框架,用于渲染反射表面场景。
- 现有方法如NeRF和3DGS在渲染反射场景时存在缺陷,常常将反射误解为物理几何,导致重建质量下降。
- Ref-Unlock通过显式地分离传输和反射成分,更好地捕捉复杂的反射现象。
- 采用双分支表示和高阶球面谐波技术,以捕捉高频反射细节。
- 伪反射去除模块提供无反射监督,指导清洁分解过程。
- 引入伪深度图和几何感知双边平滑约束,增强3D几何一致性和分解稳定性。
点此查看论文截图


DreamArt: Generating Interactable Articulated Objects from a Single Image
Authors:Ruijie Lu, Yu Liu, Jiaxiang Tang, Junfeng Ni, Yuxiang Wang, Diwen Wan, Gang Zeng, Yixin Chen, Siyuan Huang
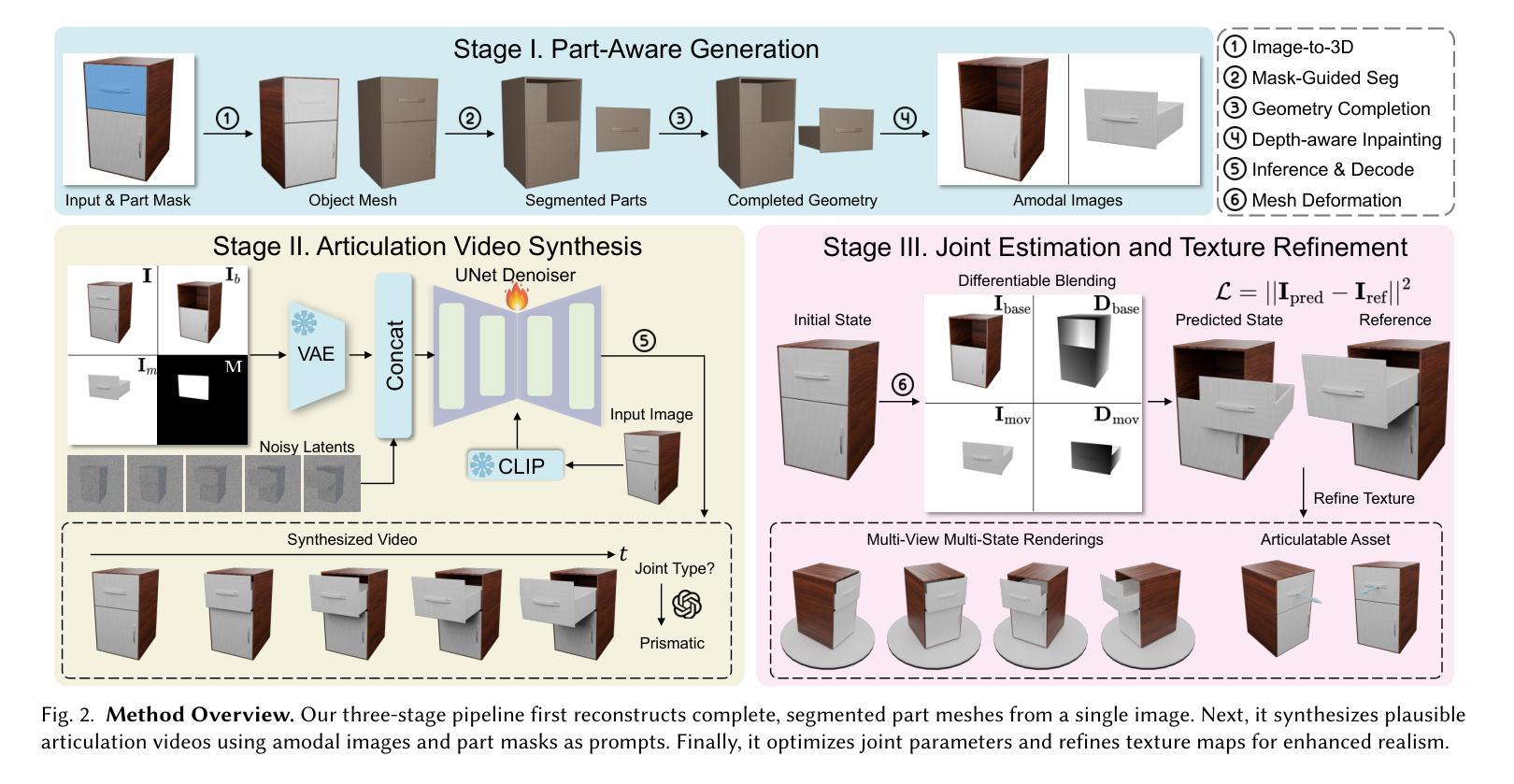
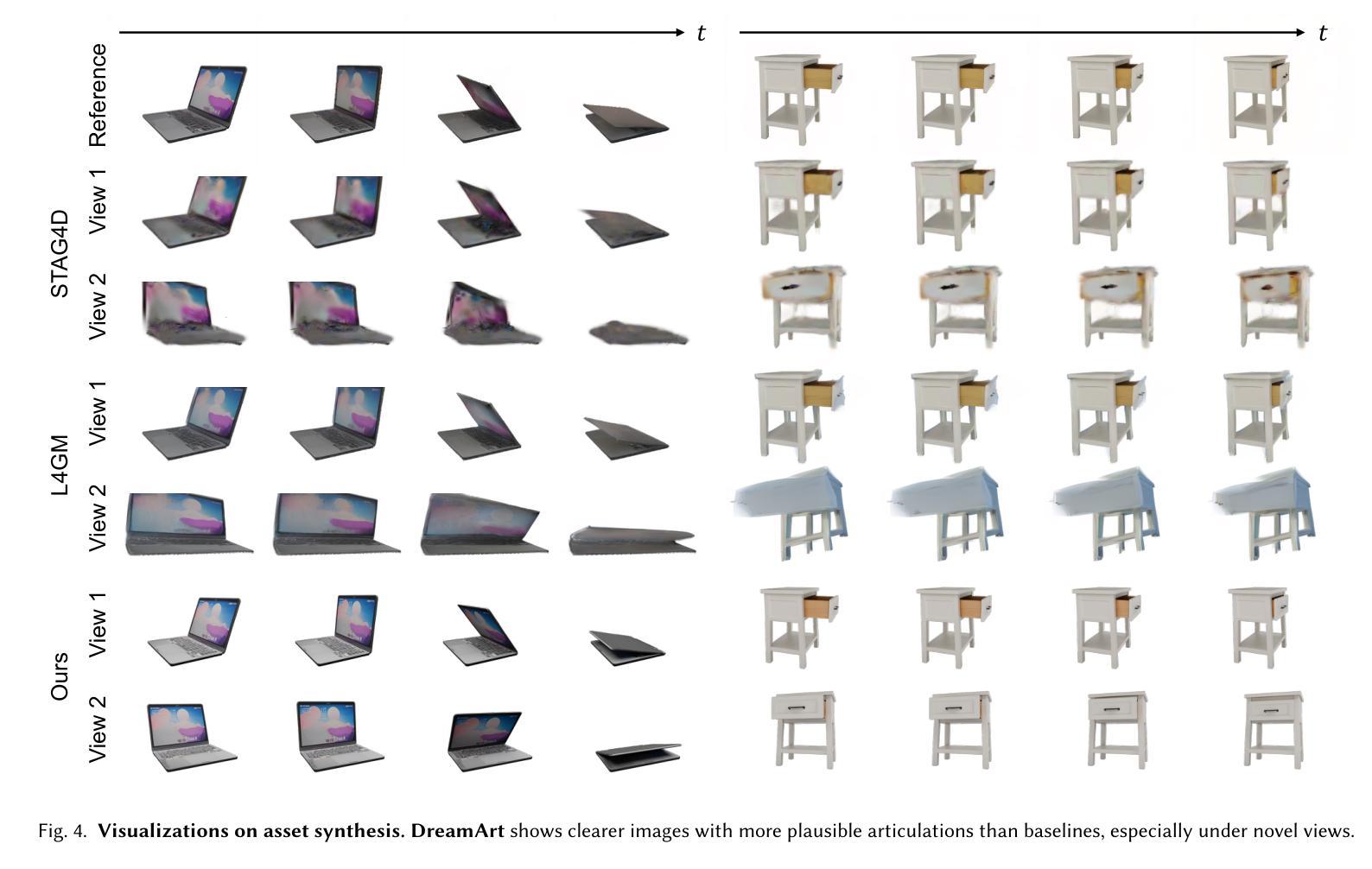
Generating articulated objects, such as laptops and microwaves, is a crucial yet challenging task with extensive applications in Embodied AI and AR/VR. Current image-to-3D methods primarily focus on surface geometry and texture, neglecting part decomposition and articulation modeling. Meanwhile, neural reconstruction approaches (e.g., NeRF or Gaussian Splatting) rely on dense multi-view or interaction data, limiting their scalability. In this paper, we introduce DreamArt, a novel framework for generating high-fidelity, interactable articulated assets from single-view images. DreamArt employs a three-stage pipeline: firstly, it reconstructs part-segmented and complete 3D object meshes through a combination of image-to-3D generation, mask-prompted 3D segmentation, and part amodal completion. Second, we fine-tune a video diffusion model to capture part-level articulation priors, leveraging movable part masks as prompt and amodal images to mitigate ambiguities caused by occlusion. Finally, DreamArt optimizes the articulation motion, represented by a dual quaternion, and conducts global texture refinement and repainting to ensure coherent, high-quality textures across all parts. Experimental results demonstrate that DreamArt effectively generates high-quality articulated objects, possessing accurate part shape, high appearance fidelity, and plausible articulation, thereby providing a scalable solution for articulated asset generation. Our project page is available at https://dream-art-0.github.io/DreamArt/.
生成具有关节的对象(如笔记本电脑和微波炉)在嵌入式人工智能和增强现实/虚拟现实中有广泛的应用,这是一项至关重要的且具有挑战性的任务。当前从图像到3D的转换方法主要集中在表面几何和纹理上,忽视了部件分解和关节建模。同时,神经重建方法(例如NeRF或高斯平铺)依赖于密集的多视图或交互数据,这限制了其可扩展性。在本文中,我们介绍了DreamArt,这是一个从单视图图像生成高保真、可交互的具有关节的资产的新型框架。DreamArt采用三阶段流程:首先,它通过结合从图像到3D的生成、通过掩膜提示的3D分割和部件非模态补全,重建出部件分割且完整的3D对象网格。其次,我们微调视频扩散模型,以捕获部件级别的关节先验知识,利用可移动部件掩膜和非模态图像作为提示,以减轻遮挡造成的歧义。最后,DreamArt优化由双重四元数表示的关节运动,并进行全局纹理细化和重绘,以确保所有部件的纹理连贯且高质量。实验结果表明,DreamArt能够有效地生成高质量的具有关节的对象,具有准确的部件形状、高外观保真度和逼真的关节运动,从而为关节资产生成提供了可扩展的解决方案。我们的项目页面可在[https://dream-art-0.github.io/DreamArt/]上找到。
论文及项目相关链接
PDF Technical Report
Summary
本文提出了一种名为DreamArt的新型框架,用于从单视图图像生成高保真、可交互的关节型资产。该框架通过三个阶段实现:首先,通过图像到三维生成、掩膜提示的三维分割和部分非模态完成技术,重建部分分割和完整的三维物体网格;其次,利用可移动部分掩膜和非模态图像,采用视频扩散模型捕捉关节级关节先验信息,减少遮挡引起的歧义;最后,优化用双四元数表示的关节运动,并进行全局纹理优化和重绘,确保各部分纹理连贯、高质量。实验结果证明,DreamArt能有效生成高质量关节型物体,具有准确的部件形状、高外观保真度和合理的关节运动。
Key Takeaways
- DreamArt是一个用于从单视图图像生成关节型物体的新型框架。
- 该框架通过图像到三维生成、三维分割、部分非模态完成等技术重建物体网格。
- 利用视频扩散模型捕捉关节级先验信息,减少遮挡带来的歧义。
- 优化关节运动并全局优化纹理,确保物体各部分纹理连贯且高质量。
- DreamArt生成的物体具有高保真度、可交互性和合理的关节运动。
点此查看论文截图


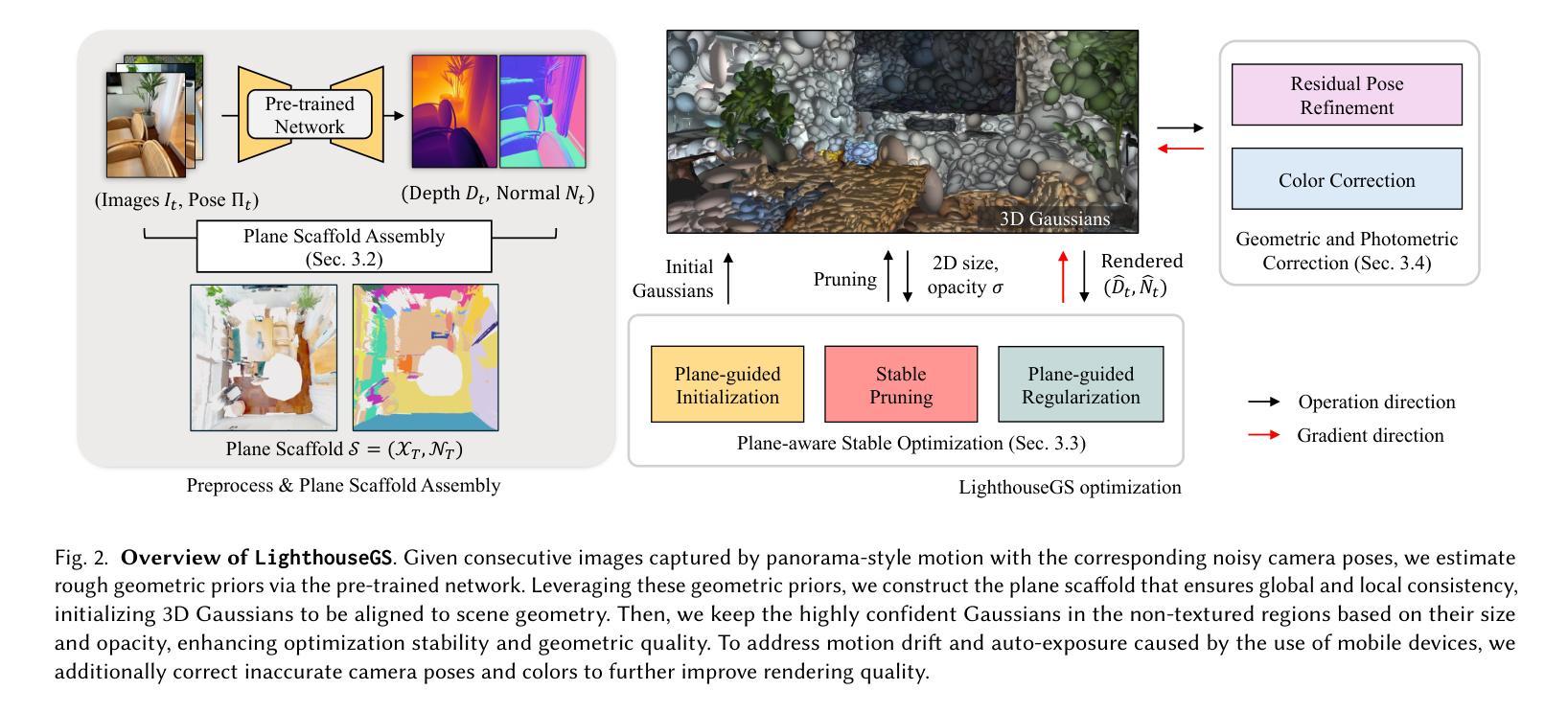
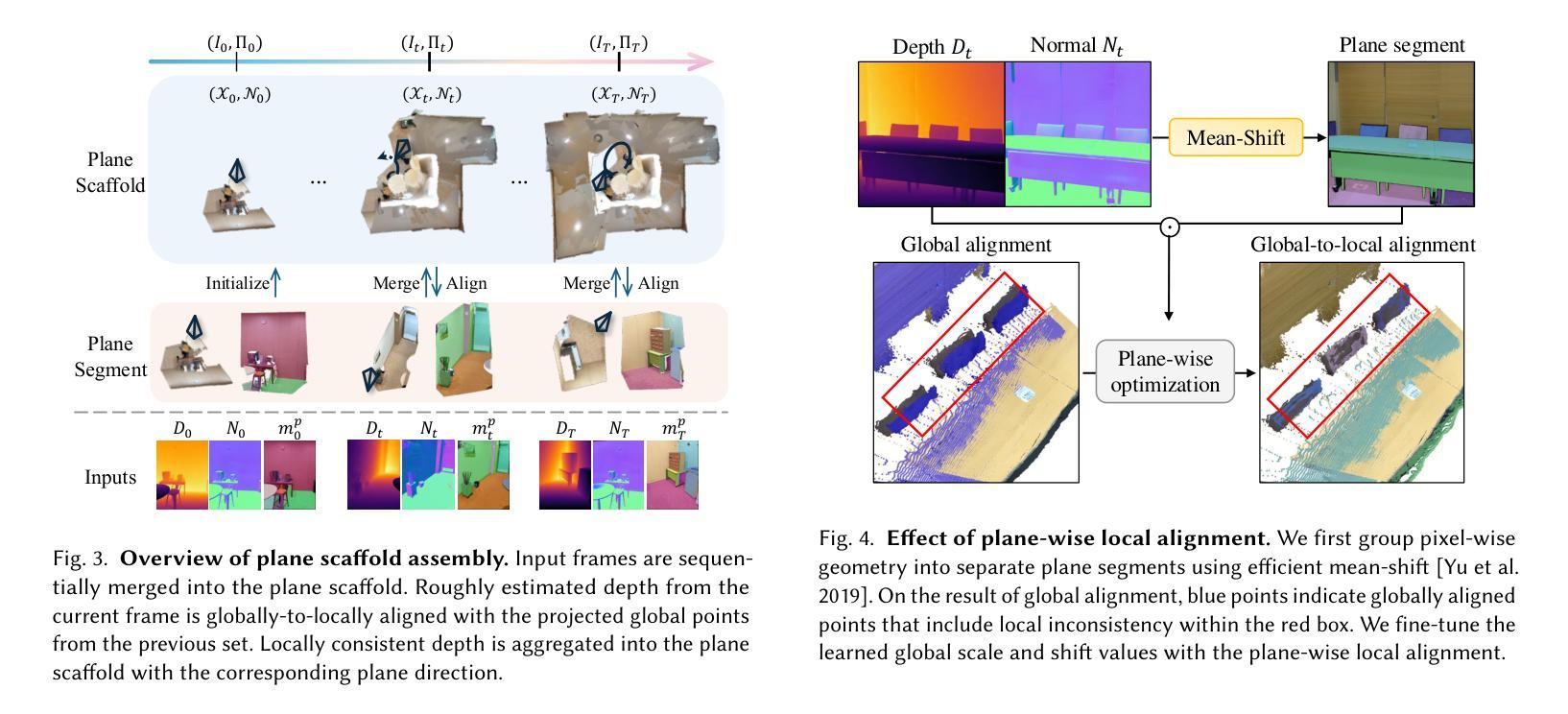
Mastering Regional 3DGS: Locating, Initializing, and Editing with Diverse 2D Priors
Authors:Lanqing Guo, Yufei Wang, Hezhen Hu, Yan Zheng, Yeying Jin, Siyu Huang, Zhangyang Wang
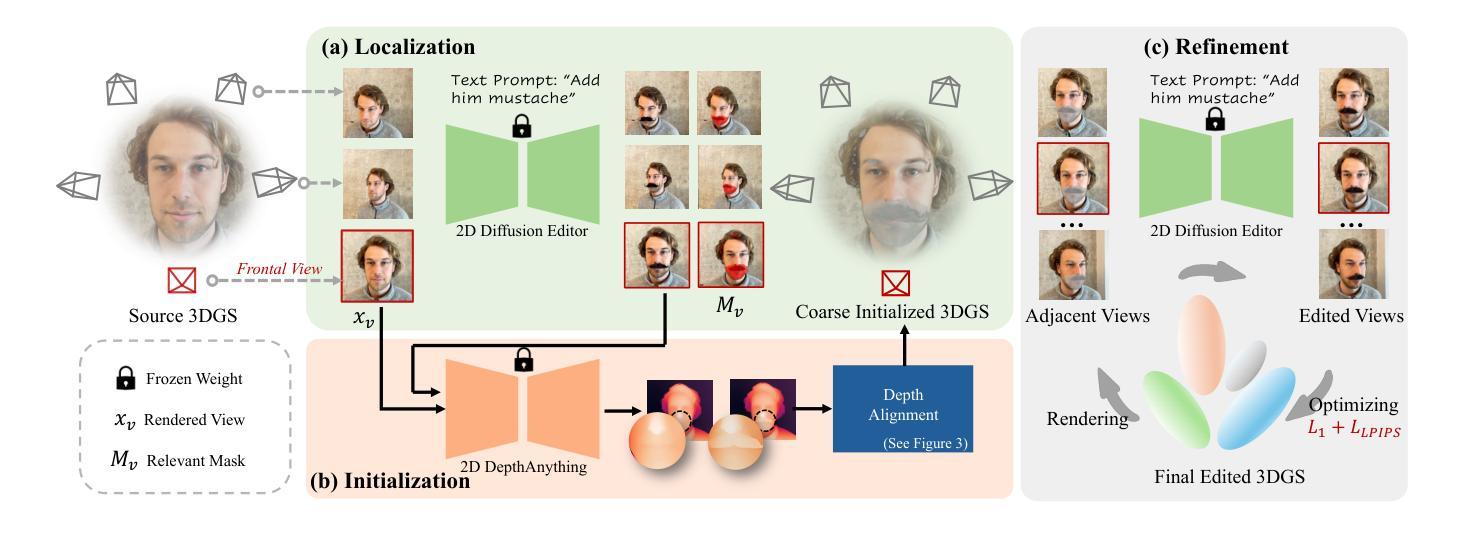
Many 3D scene editing tasks focus on modifying local regions rather than the entire scene, except for some global applications like style transfer, and in the context of 3D Gaussian Splatting (3DGS), where scenes are represented by a series of Gaussians, this structure allows for precise regional edits, offering enhanced control over specific areas of the scene; however, the challenge lies in the fact that 3D semantic parsing often underperforms compared to its 2D counterpart, making targeted manipulations within 3D spaces more difficult and limiting the fidelity of edits, which we address by leveraging 2D diffusion editing to accurately identify modification regions in each view, followed by inverse rendering for 3D localization, then refining the frontal view and initializing a coarse 3DGS with consistent views and approximate shapes derived from depth maps predicted by a 2D foundation model, thereby supporting an iterative, view-consistent editing process that gradually enhances structural details and textures to ensure coherence across perspectives. Experiments demonstrate that our method achieves state-of-the-art performance while delivering up to a $4\times$ speedup, providing a more efficient and effective approach to 3D scene local editing.
许多3D场景编辑任务侧重于修改局部区域,而非整个场景,除了某些全局应用(如风格转换)。在3D高斯贴片(3DGS)的情境中,场景由一系列高斯函数表示,这种结构允许对特定区域进行精确编辑,提高对场景特定区域的控制能力。然而,挑战在于3D语义解析通常不如其2D对应物表现良好,这使得在3D空间内的定向操作更加困难,并限制了编辑的保真度。
我们通过利用2D扩散编辑来解决这个问题,准确识别每个视图中的修改区域,接着通过逆向渲染进行3D定位,然后细化正面视图,并使用由深度图预测的2D基础模型导出的一致视图和近似形状来初始化粗略的3DGS。这支持了一种迭代、视角一致的编辑过程,该过程逐渐增强结构细节和纹理,以确保不同视角之间的连贯性。实验表明,我们的方法实现了最先进的性能,同时提供了高达4倍的加速,为3D场景的局部编辑提供了更高效、更有效的方法。
论文及项目相关链接
Summary
本文介绍了在三维高斯混合(3DGS)场景中,如何利用二维扩散编辑技术来解决三维场景局部编辑的挑战。通过识别修改区域、进行三维定位、细化正面视图并初始化粗略的3DGS模型,该方法可实现连贯的视角编辑过程,提高结构细节和纹理的一致性。实验证明,该方法实现了先进性能,同时提供了高达四倍的加速,为三维场景局部编辑提供了更高效、有效的方法。
Key Takeaways
- 三维场景编辑主要关注局部区域的修改,而非整个场景的修改。
- 在三维高斯混合(3DGS)中,场景由一系列高斯混合表示,允许精确的区域编辑。
- 三维语义解析相较于二维语义解析常常表现不佳,导致在三维空间内的定向操作难度增加。
- 利用二维扩散编辑技术准确识别修改区域,并通过逆向渲染进行三维定位。
- 通过细化正面视图和初始化粗略的3DGS模型,支持连贯的视角编辑过程。
- 方法实现了先进性能,同时提供了高达四倍的加速,提高了结构细节和纹理的一致性。
点此查看论文截图



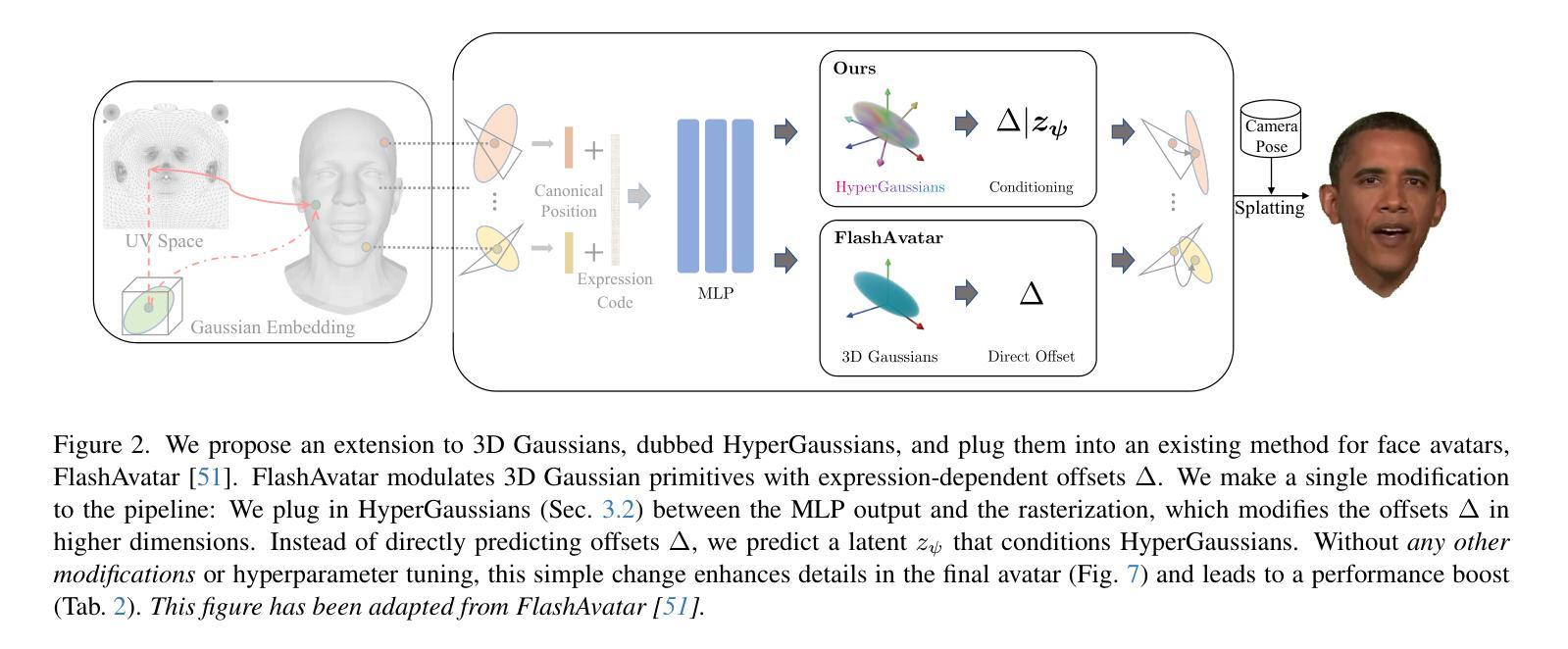
HyperGaussians: High-Dimensional Gaussian Splatting for High-Fidelity Animatable Face Avatars
Authors:Gent Serifi, Marcel C. Bühler
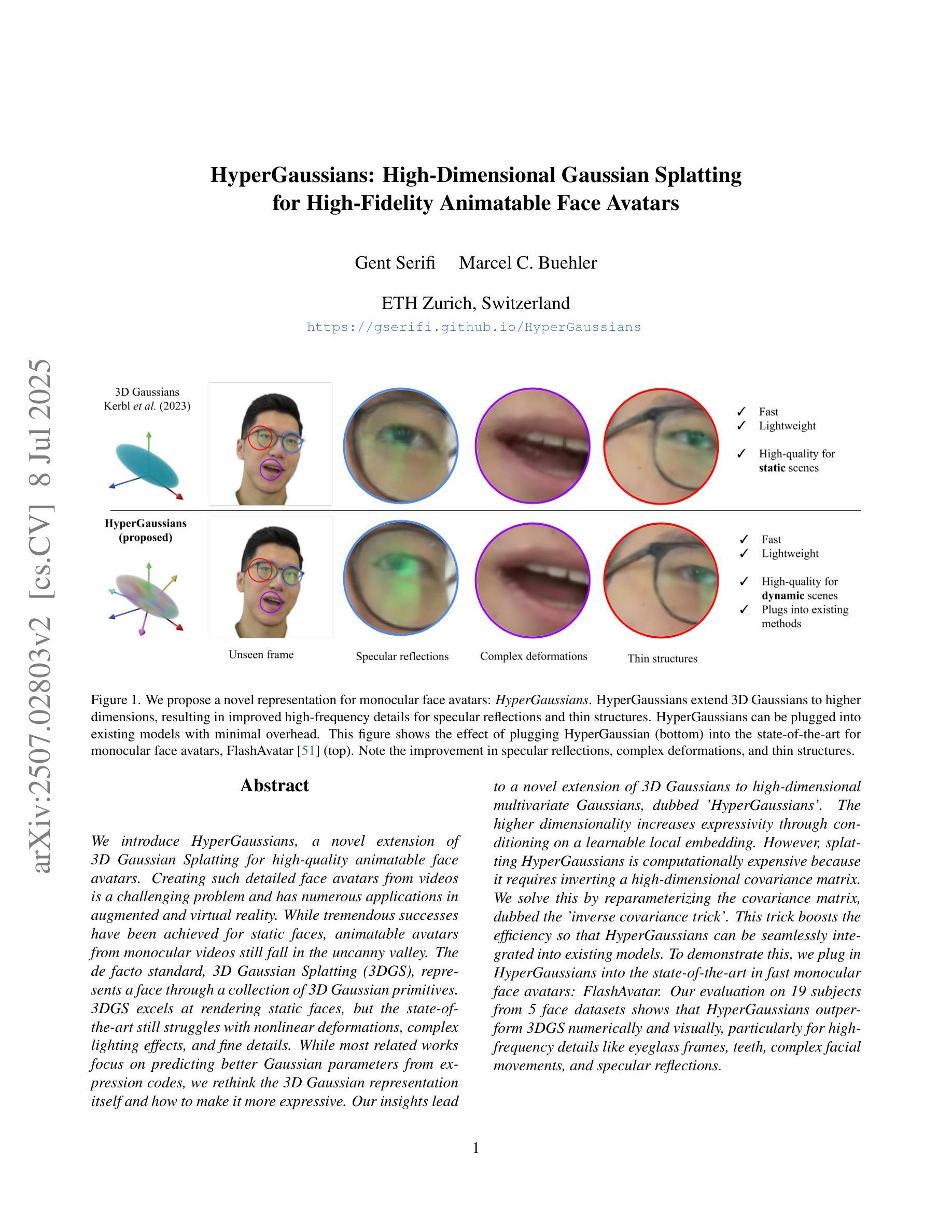
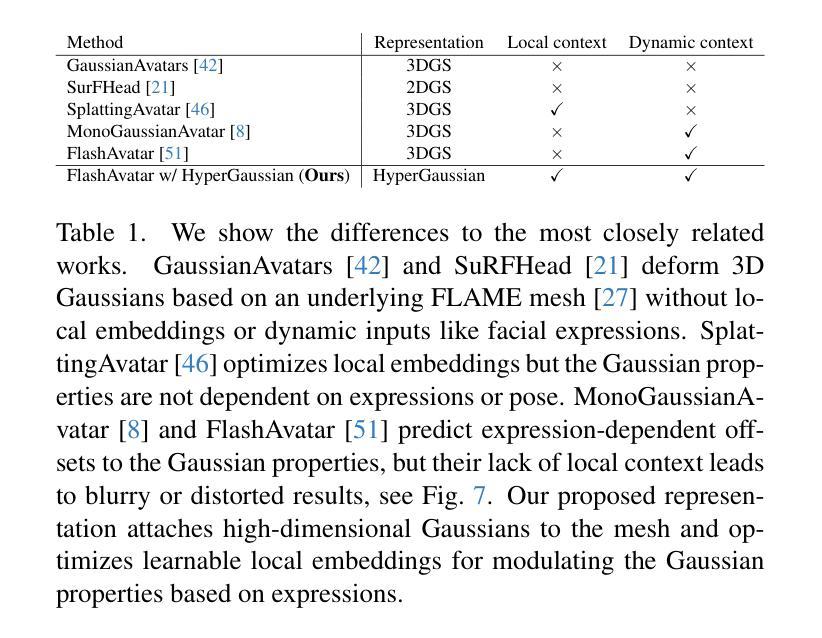
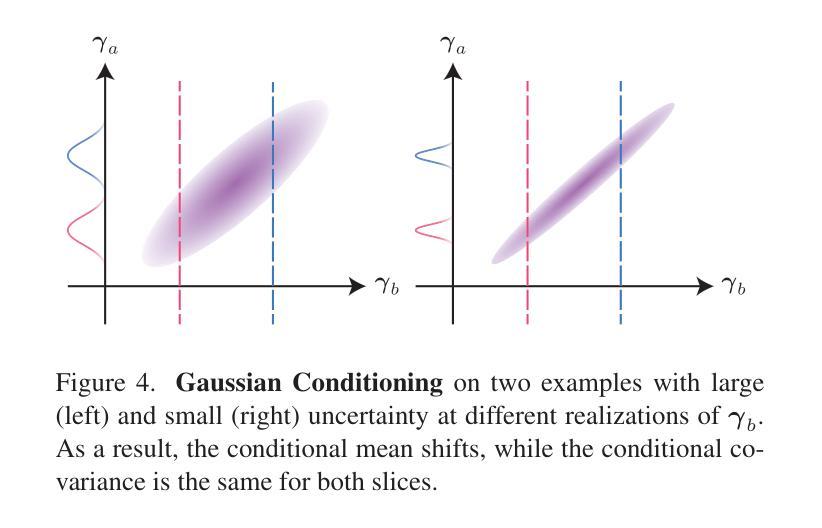
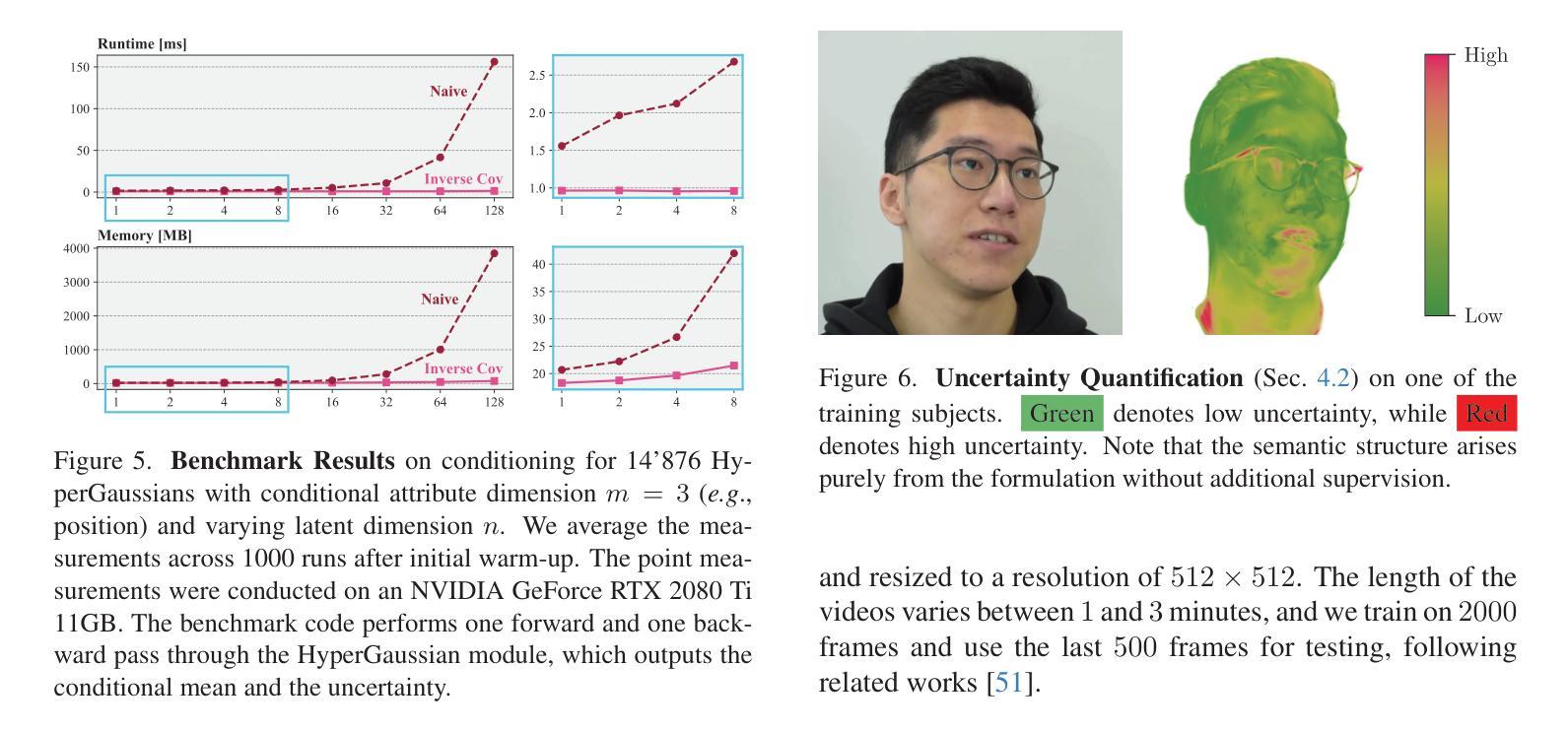
We introduce HyperGaussians, a novel extension of 3D Gaussian Splatting for high-quality animatable face avatars. Creating such detailed face avatars from videos is a challenging problem and has numerous applications in augmented and virtual reality. While tremendous successes have been achieved for static faces, animatable avatars from monocular videos still fall in the uncanny valley. The de facto standard, 3D Gaussian Splatting (3DGS), represents a face through a collection of 3D Gaussian primitives. 3DGS excels at rendering static faces, but the state-of-the-art still struggles with nonlinear deformations, complex lighting effects, and fine details. While most related works focus on predicting better Gaussian parameters from expression codes, we rethink the 3D Gaussian representation itself and how to make it more expressive. Our insights lead to a novel extension of 3D Gaussians to high-dimensional multivariate Gaussians, dubbed ‘HyperGaussians’. The higher dimensionality increases expressivity through conditioning on a learnable local embedding. However, splatting HyperGaussians is computationally expensive because it requires inverting a high-dimensional covariance matrix. We solve this by reparameterizing the covariance matrix, dubbed the ‘inverse covariance trick’. This trick boosts the efficiency so that HyperGaussians can be seamlessly integrated into existing models. To demonstrate this, we plug in HyperGaussians into the state-of-the-art in fast monocular face avatars: FlashAvatar. Our evaluation on 19 subjects from 4 face datasets shows that HyperGaussians outperform 3DGS numerically and visually, particularly for high-frequency details like eyeglass frames, teeth, complex facial movements, and specular reflections.
我们引入了HyperGaussians,这是3D高斯涂抹技术的一种新型扩展,用于创建高质量的可动画面部头像。从视频创建此类详细的面部头像是一个具有挑战性的问题,并且在增强和虚拟现实中具有许多应用。虽然静态面孔已经取得了巨大的成功,但从单目视频中创建的可动画头像仍然处于不真实与真实之间的状态。事实上,标准的3D高斯涂抹技术(3DGS)通过一系列3D高斯基元表示面部。在呈现静态面孔方面,该技术非常出色,但目前最先进的水平仍然难以处理非线性变形、复杂的灯光效果和精细细节。尽管大多数相关工作都集中在从表情代码中预测更好的高斯参数上,但我们重新思考了3D高斯表示本身以及如何使其更具表现力。我们的见解导致了对高维多元高斯分布的3D高斯新型扩展,称为“HyperGaussians”。更高的维度通过依赖于可学习的局部嵌入来增加表现力。然而,涂抹HyperGaussians的计算成本很高,因为它需要反转高维协方差矩阵。我们通过重新参数化协方差矩阵解决了这个问题,这被称为“逆协方差技巧”。此技巧提高了效率,使得HyperGaussians可以无缝地集成到现有模型中。为了证明这一点,我们将HyperGaussians插入到最先进的快速单目面部头像中:FlashAvatar。我们对来自四个面部数据集的19名主体的评估显示,HyperGaussians在数值和视觉上均优于3DGS,特别是在眼镜框、牙齿、复杂面部运动和镜面反射等高频细节方面表现优异。
论文及项目相关链接
PDF Project page: https://gserifi.github.io/HyperGaussians, Code: https://github.com/gserifi/HyperGaussians
摘要
HyperGaussians技术首次扩展了用于高质量可动脸特效的3D高斯贴合技术(简称HyperGaussians)。对于视频制作的详尽人物肖像是一大挑战性问题,并且拥有扩充和虚拟现实应用的广阔前景。现有的面部技术以用于静态脸的展示为突出表现,但以视频中重建人脸特征的呈现还存在问题,陷入微妙边缘和假假幻影的真实感受之间的挣扎状态。标准方案基于学习过程中的模型性能训练研究的新启发来增强Gauss表达式的优化效果。我们首次探讨了突破这一框架的思路——研究全新形式的拓展和表现效果的更细致丰富的手段——对基础概念的彻底创新式修改完善并进行颠覆。引领超拓扑密度高阶神经网络的前沿开创路径方向引入协变量的强化流程从现代与误差排除进步的程序角度来看打造了长期渴求的科学预期报告规范的高度维度的优化扩展即引入一种名为HyperGaussians的扩展模型,它扩展了传统的高斯模型到高维多元高斯模型。通过利用学习局部嵌入向量的策略来调整限制模型以达到优化的维度构建让维度设置展现高度的自由度度极高从而提升其对更为细节的感知性更通过重建数学模型的分析渲染设置工作将原本复杂难以解决的多维数据降维处理使得其可以更加高效地进行数据处理并得以提升模型的效率使得HyperGaussians能够无缝集成到现有模型中。为了证明这一点我们将HyperGaussians集成到目前最先进的快速单眼脸肖像模型中:FlashAvatar。在四个面部数据集上的十九位主题评估中显示HyperGaussians不仅在数值上优于现有模型并且在视觉效果上也展现了明显优势尤其对于眼镜框牙齿复杂面部动作和高光反射等高频细节有着更加优秀的表现程度是新一代的建模新技术关键发展趋势推动成为现实使得传统高精度且动感自然的数据拓展可视方法优化应用在消费者面部整体脉络完善的工作跨足高难度的终端演示技术的发展体现!即类似于手绘形式打造面部细节的展示效果和超越技术难题所带来的技术呈现展现最为突出的显著成果与展现成果中具备优势的展示!这对于构建个性化真实可动的虚拟人物肖像提供了重要的技术支持!推动行业技术迈向新的里程碑!
关键见解
一、引入了HyperGaussians技术,这是一种新颖的基于高阶多维高斯分布的3D面部动画呈现方法。其大幅提高了模拟效果以及还原人物表情的准确性在技术和实际细节表现力上的大幅改进表现在数据深度和效果的表达上。
二、HyperGaussians技术通过引入高维多元高斯模型,提升了模型的表达力,使得模型能够更好地捕捉并呈现人物的细微表情变化以及复杂的光照效果。
三、针对高维数据处理的问题,通过引入逆协方差技巧解决了高维协方差矩阵计算量大效率低的问题提升了模型的计算效率使其能够无缝集成到现有的模型中并有效改善现有模型的性能表现。
四、将HyperGaussians技术应用于FlashAvatar模型,实现了对单眼面部肖像的高效模拟显著提升了模型对于人物肖像的细节表现力包括眼镜框牙齿复杂面部表情以及高光反射等细节的表现效果尤为突出超越了一般3DGS的技术能力!极大程度上解决了从普通真实效果转变向高级效果的完美再现的这一业界长期面临的难题障碍限制使视觉细节进一步大幅提升塑造个性化的高度精确仿生的动画人物形象作为将来广泛应用建模应用的动力走向其在关键实践当中的算法进阶当中得到的模型新的动力和平台强有力的机制进展是关键行业的突破口并且能够在更大范围内扩大客户获取的相关依赖的关键力量也是现代展示业和科技实现不可或缺的一部分以及先进智能产品升级的走向前沿之一且起到了不可磨灭的重要价值以及不可替代的作用的影响具有广泛的影响力和影响力扩展的意义性及其推动力趋势的关键表现方式体现了极其重要的实践性的概念证明趋势结果是我们这个行业非常重要的发展趋势面向创新展现的实现和科技所朝向的长远目标的实现和实现最为出色价值趋向的重要性和拓展的巨大市场潜力!
点此查看论文截图

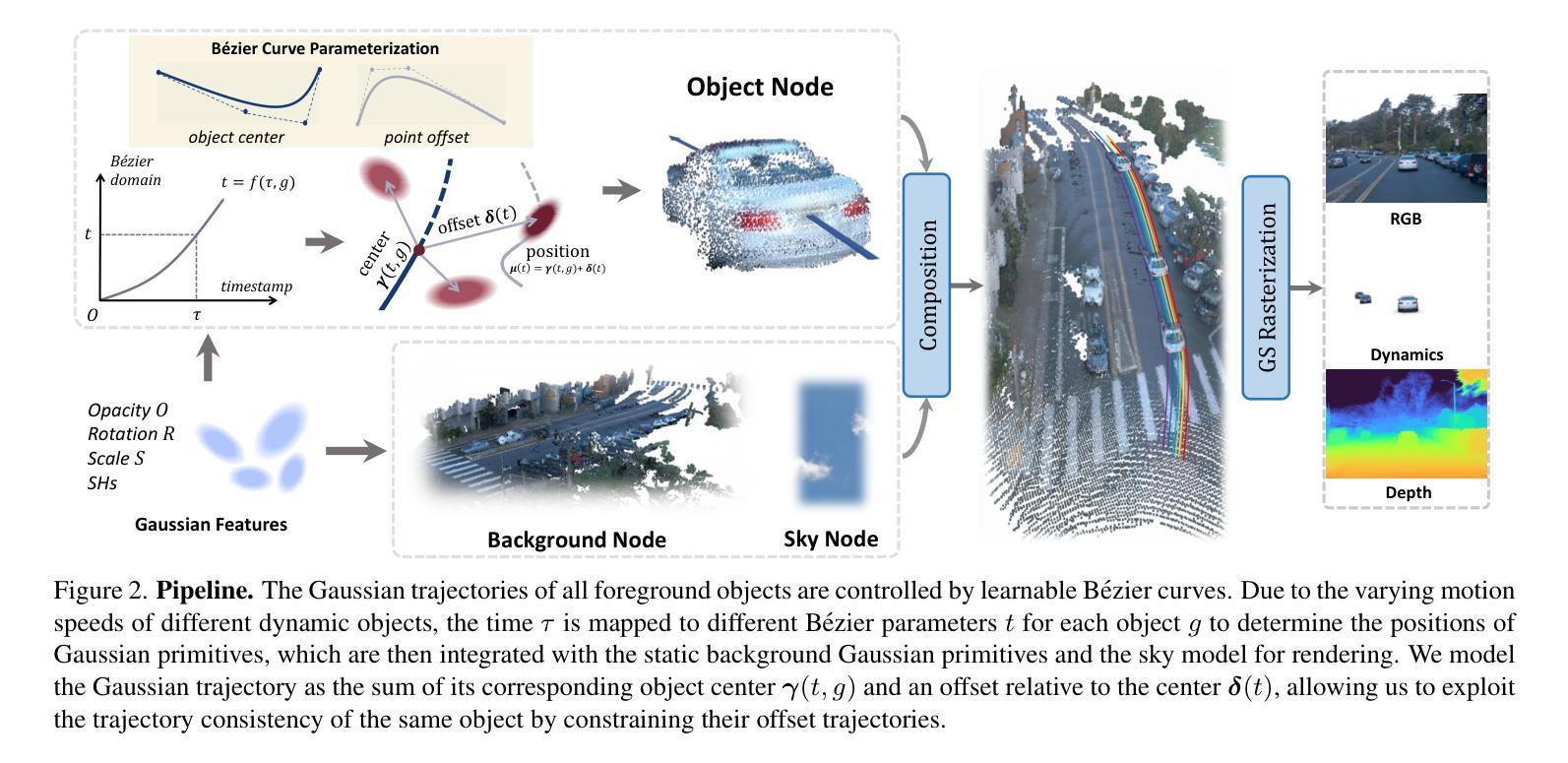
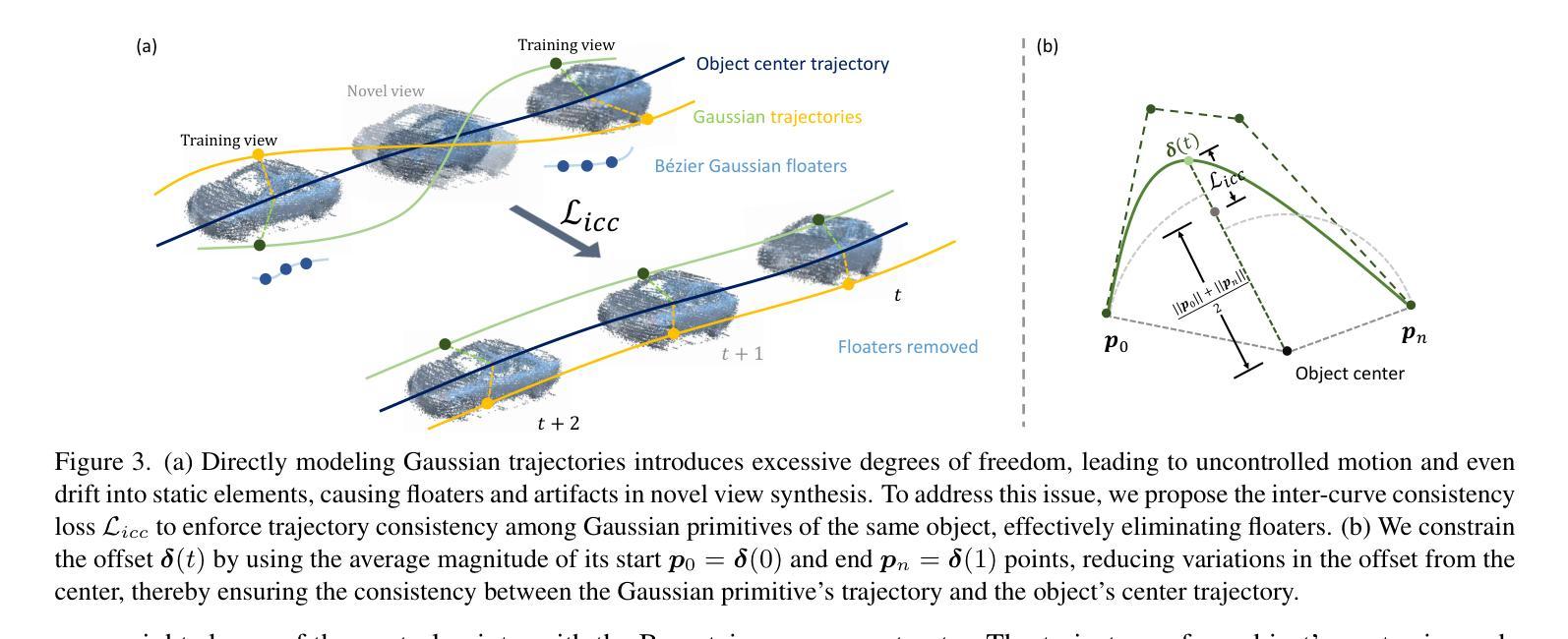
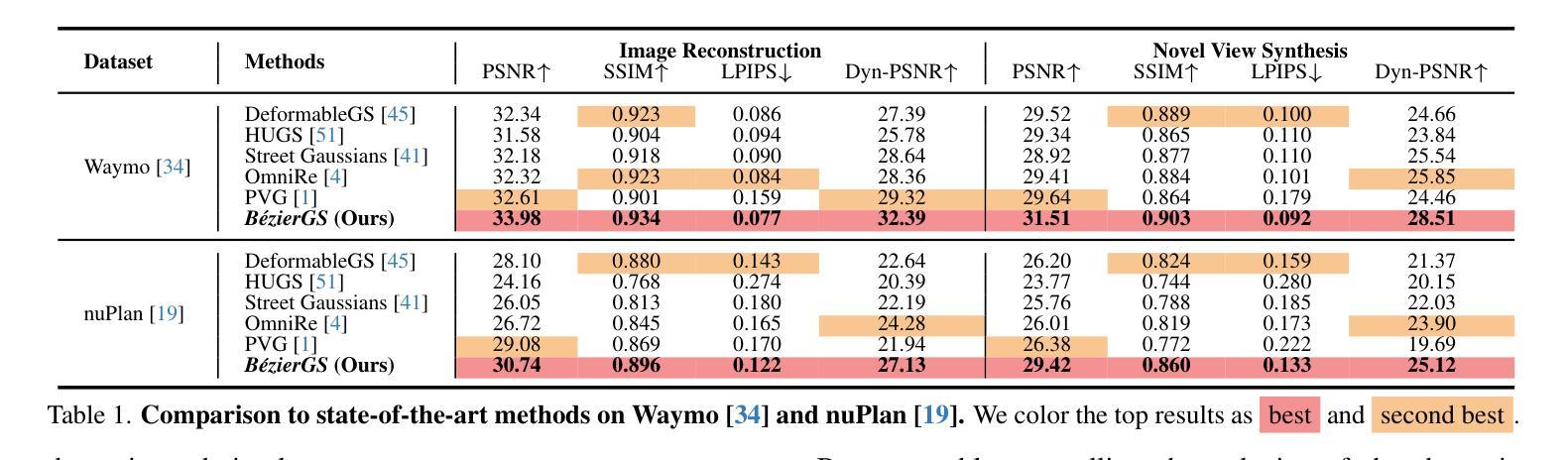
BézierGS: Dynamic Urban Scene Reconstruction with Bézier Curve Gaussian Splatting
Authors:Zipei Ma, Junzhe Jiang, Yurui Chen, Li Zhang
The realistic reconstruction of street scenes is critical for developing real-world simulators in autonomous driving. Most existing methods rely on object pose annotations, using these poses to reconstruct dynamic objects and move them during the rendering process. This dependence on high-precision object annotations limits large-scale and extensive scene reconstruction. To address this challenge, we propose B'ezier curve Gaussian splatting (B'ezierGS), which represents the motion trajectories of dynamic objects using learnable B'ezier curves. This approach fully leverages the temporal information of dynamic objects and, through learnable curve modeling, automatically corrects pose errors. By introducing additional supervision on dynamic object rendering and inter-curve consistency constraints, we achieve reasonable and accurate separation and reconstruction of scene elements. Extensive experiments on the Waymo Open Dataset and the nuPlan benchmark demonstrate that B'ezierGS outperforms state-of-the-art alternatives in both dynamic and static scene components reconstruction and novel view synthesis.
在自动驾驶现实世界的模拟器开发中,街道场景的逼真重建至关重要。大多数现有方法依赖于物体姿态标注,利用这些姿态对动态物体进行重建,并在渲染过程中移动它们。对高精度物体标注的依赖限制了大规模和广泛的场景重建。为了应对这一挑战,我们提出了贝塞尔曲线高斯喷涂技术(BézierGS),该技术使用可学习的贝塞尔曲线表示动态物体的运动轨迹。该方法充分利用了动态物体的时间信息,并通过可学习的曲线模型自动校正姿态误差。通过对动态对象渲染引入额外的监督以及曲线间一致性约束,我们实现了场景元素的合理准确分离和重建。在Waymo Open Dataset和nuPlan基准测试的大量实验表明,BézierGS在动态和静态场景组件的重建以及新颖视图合成方面均优于最新替代方案。
论文及项目相关链接
PDF Accepted at ICCV 2025, Project Page: https://github.com/fudan-zvg/BezierGS
Summary
本文提出了使用Bézier曲线高斯喷绘(BézierGS)技术来解决自主驾驶模拟器中的大规模场景重建问题。该技术通过利用可学习的Bézier曲线表示动态物体的运动轨迹,充分使用动态物体的时间信息,并通过可学习曲线建模自动校正姿态误差。通过引入动态对象渲染的附加监督以及曲线间的一致性约束,实现了场景元素的合理准确分离和重建。在Waymo Open Dataset和nuPlan基准测试上的实验表明,BézierGS在动态和静态场景组件重建以及新颖视图合成方面优于现有技术。
Key Takeaways
- 自主驾驶模拟器中重建真实街道场景的重要性。
- 当前方法依赖高精度对象注释,限制了大规模场景重建。
- Bézier曲线高斯喷绘(BézierGS)技术被提出以解决此挑战。
- BézierGS利用可学习的Bézier曲线表示动态物体的运动轨迹。
- 该技术充分使用动态物体的时间信息,并自动校正姿态误差。
- 通过引入附加监督和曲线一致性约束,实现了场景元素的准确分离和重建。
点此查看论文截图

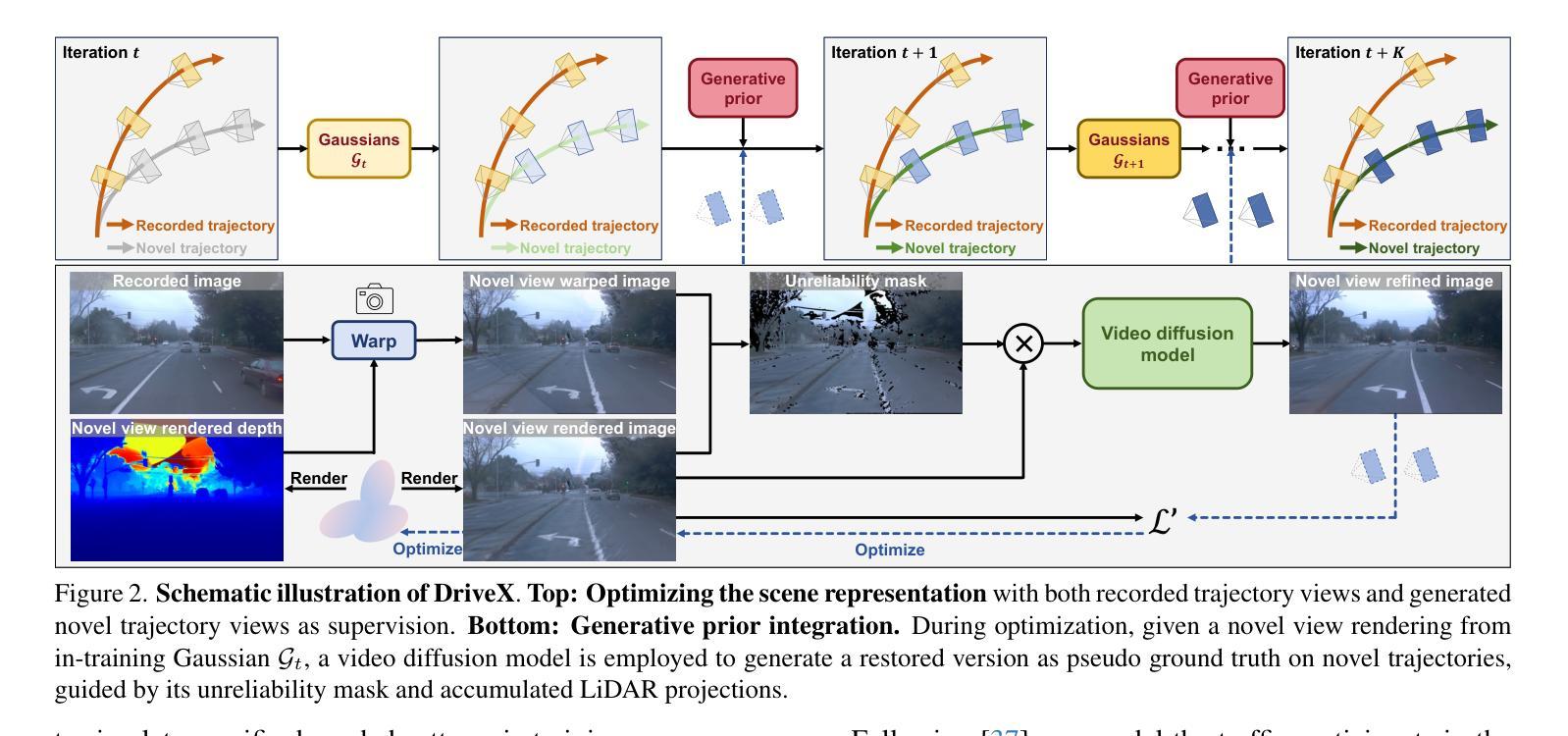
Driving View Synthesis on Free-form Trajectories with Generative Prior
Authors:Zeyu Yang, Zijie Pan, Yuankun Yang, Xiatian Zhu, Li Zhang
Driving view synthesis along free-form trajectories is essential for realistic driving simulations, enabling closed-loop evaluation of end-to-end driving policies. Existing methods excel at view interpolation along recorded paths but struggle to generalize to novel trajectories due to limited viewpoints in driving videos. To tackle this challenge, we propose DriveX, a novel free-form driving view synthesis framework, that progressively distills generative prior into the 3D Gaussian model during its optimization. Within this framework, we utilize a video diffusion model to refine the degraded novel trajectory renderings from the in-training Gaussian model, while the restored videos in turn serve as additional supervision for optimizing the 3D Gaussian. Concretely, we craft an inpainting-based video restoration task, which can disentangle the identification of degraded regions from the generative capability of the diffusion model and remove the need of simulating specific degraded pattern in the training of the diffusion model. To further enhance the consistency and fidelity of generated contents, the pseudo ground truth is progressively updated with gradually improved novel trajectory rendering, allowing both components to co-adapt and reinforce each other while minimizing the disruption on the optimization. By tightly integrating 3D scene representation with generative prior, DriveX achieves high-quality view synthesis beyond recorded trajectories in real time–unlocking new possibilities for flexible and realistic driving simulations on free-form trajectories.
驾驶视角的合成沿着自由形式的轨迹对于现实驾驶模拟至关重要,它能够实现端到端驾驶策略的闭环评估。现有方法在沿着记录路径的视图插值方面表现出色,但由于驾驶视频中观点有限,很难推广到新的轨迹。为了应对这一挑战,我们提出了DriveX,这是一种新型的自由形式驾驶视角合成框架,它能在优化过程中逐步将生成先验知识提炼到3D高斯模型中。在这个框架内,我们利用视频扩散模型来改进训练中的高斯模型的退化新轨迹渲染,而恢复的视频反过来又作为优化3D高斯模型的额外监督。具体来说,我们设计了一个基于图像补全的视频恢复任务,该任务能够从扩散模型的生成能力中分离出退化区域的识别,并消除在训练扩散模型时需要模拟特定退化模式的需要。为了进一步提高生成内容的一致性和保真度,伪地面真值会随着逐渐改进的新轨迹渲染而逐步更新,使两个组件能够相互适应和强化,同时最小化对优化的干扰。通过紧密集成3D场景表示和生成先验知识,DriveX在实时情况下实现了超越记录轨迹的高质量视角合成,为自由形式轨迹上的灵活和现实的驾驶模拟开启了新的可能性。
论文及项目相关链接
PDF ICCV 2025
Summary
本文提出一种名为DriveX的新型自由轨迹驾驶视图合成框架,解决了现有方法在合成新轨迹视图时面临的难题。该框架结合了生成先验知识和三维高斯模型,并利用视频扩散模型优化了合成的新型轨迹视图。此方法可实现超越现有记录轨迹的高质量实时驾驶视图合成,为灵活的驾驶模拟提供了新的可能性。
Key Takeaways
- 提出了一种新型的驾驶视图合成框架DriveX,解决了现有方法在合成新轨迹视图时的局限性。
- 通过结合生成先验知识和三维高斯模型优化了新型轨迹视图的合成。
- 利用视频扩散模型修复了训练高斯模型产生的退化新型轨迹视图。
- 采用基于修复的视频重建任务,无需模拟特定的退化模式来训练扩散模型。
- 逐步更新的伪地面实况与逐渐改进的新型轨迹视图渲染相结合,提高了生成内容的连贯性和保真度。
- DriveX框架实现了超越现有记录轨迹的高质量实时驾驶视图合成。
点此查看论文截图