⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-10 更新
Conditional Multi-Stage Failure Recovery for Embodied Agents
Authors:Youmna Farag, Svetlana Stoyanchev, Mohan Li, Simon Keizer, Rama Doddipatla
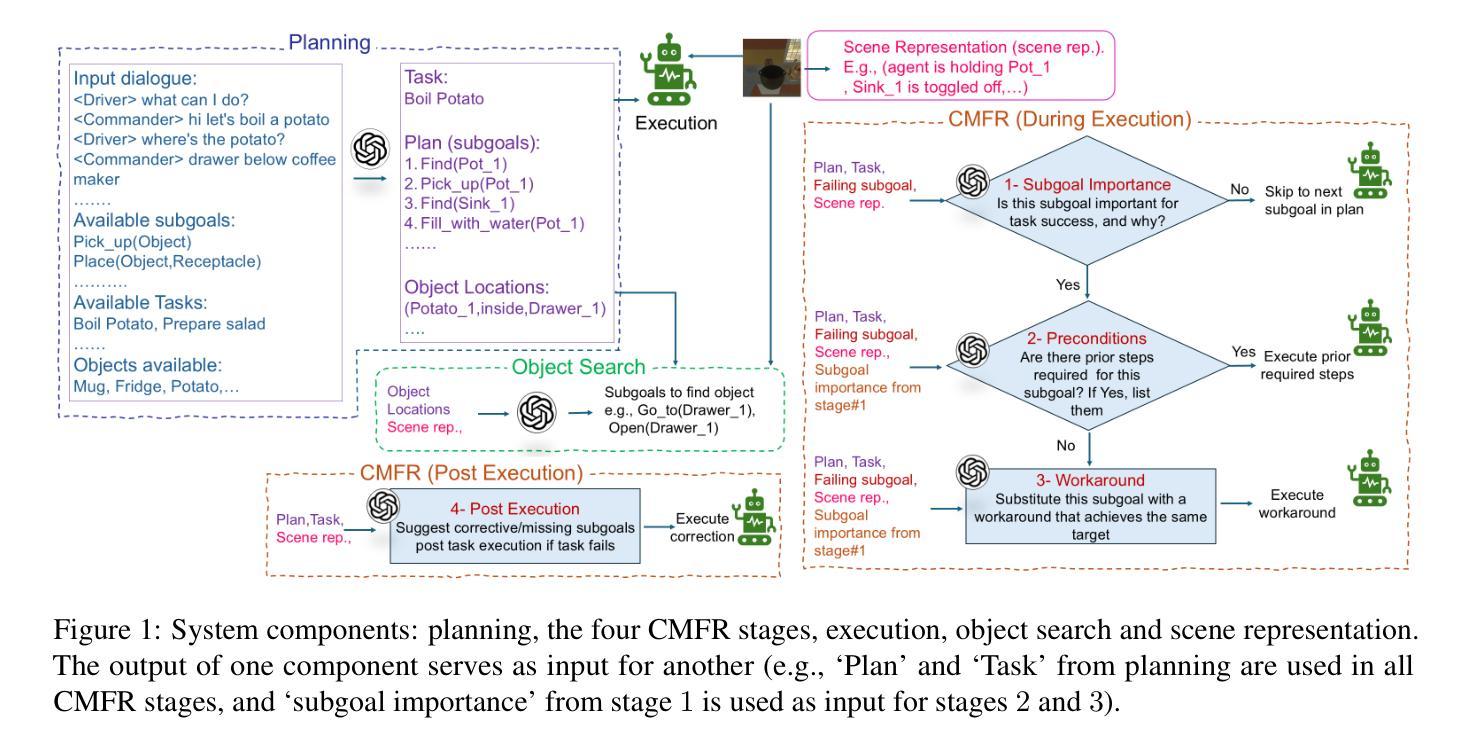
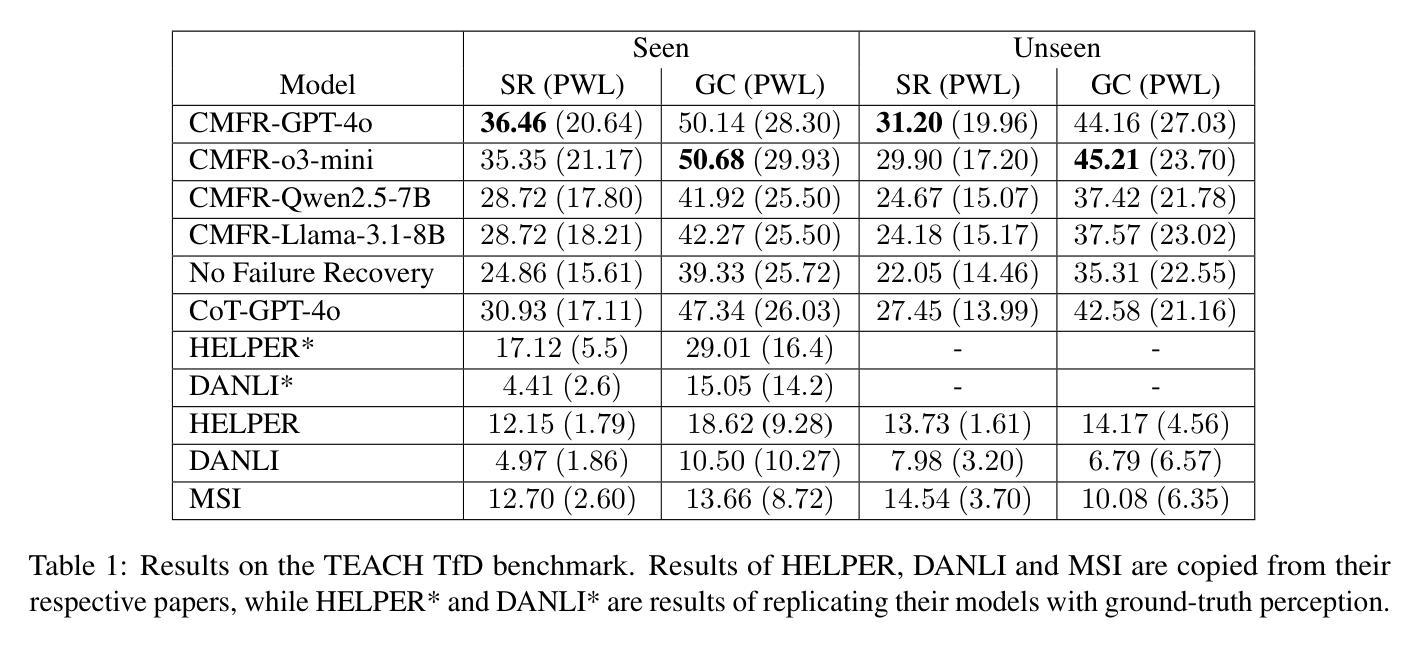
Embodied agents performing complex tasks are susceptible to execution failures, motivating the need for effective failure recovery mechanisms. In this work, we introduce a conditional multistage failure recovery framework that employs zero-shot chain prompting. The framework is structured into four error-handling stages, with three operating during task execution and one functioning as a post-execution reflection phase. Our approach utilises the reasoning capabilities of LLMs to analyse execution challenges within their environmental context and devise strategic solutions. We evaluate our method on the TfD benchmark of the TEACH dataset and achieve state-of-the-art performance, outperforming a baseline without error recovery by 11.5% and surpassing the strongest existing model by 19%.
执行复杂任务的实体代理容易出现执行失败的情况,这激发了对于有效故障恢复机制的需求。在这项工作中,我们引入了一个采用零样本链提示的条件多阶段故障恢复框架。该框架被构建为四个错误处理阶段,其中三个阶段在任务执行期间运行,一个阶段作为执行后的反思阶段发挥作用。我们的方法利用大型语言模型的推理能力来分析其在环境背景下的执行挑战,并设计战略性的解决方案。我们在TEACH数据集的TfD基准上评估了我们的方法,实现了最先进的性能表现,相对于没有错误恢复的基线提高了11.5%,并超越了最强的现有模型高达19%。
论文及项目相关链接
PDF Accepted at REALM 2025
Summary
本文介绍了一个基于零样本链提示的多阶段故障恢复框架,用于处理执行复杂任务的实体代理中的执行失败问题。该框架分为四个错误处理阶段,其中三个阶段在任务执行期间运行,另一个阶段作为执行后反思阶段。通过利用大语言模型的分析能力和推理能力,该方法能够在环境背景下分析执行挑战并设计战略解决方案。在TEACH数据集的TfD基准测试中进行了评估,取得了最先进的性能表现。相较于无错误恢复基准提高了11.5%,并超越了现有的最佳模型,提高了19%。
Key Takeaways
- 实体代理在执行复杂任务时可能会遇到执行失败的问题。
- 介绍了一个基于零样本链提示的多阶段故障恢复框架来处理这些失败。
- 该框架包含四个错误处理阶段,包括任务执行期间的三个阶段和执行后的反思阶段。
- 利用大语言模型的推理能力来分析执行挑战并设计解决方案。
- 在TEACH数据集的TfD基准测试上进行了评估,性能超越现有模型。
- 与无错误恢复基准相比,性能提高了11.5%。
点此查看论文截图

From General Relation Patterns to Task-Specific Decision-Making in Continual Multi-Agent Coordination
Authors:Chang Yao, Youfang Lin, Shoucheng Song, Hao Wu, Yuqing Ma, Shang Han, Kai Lv
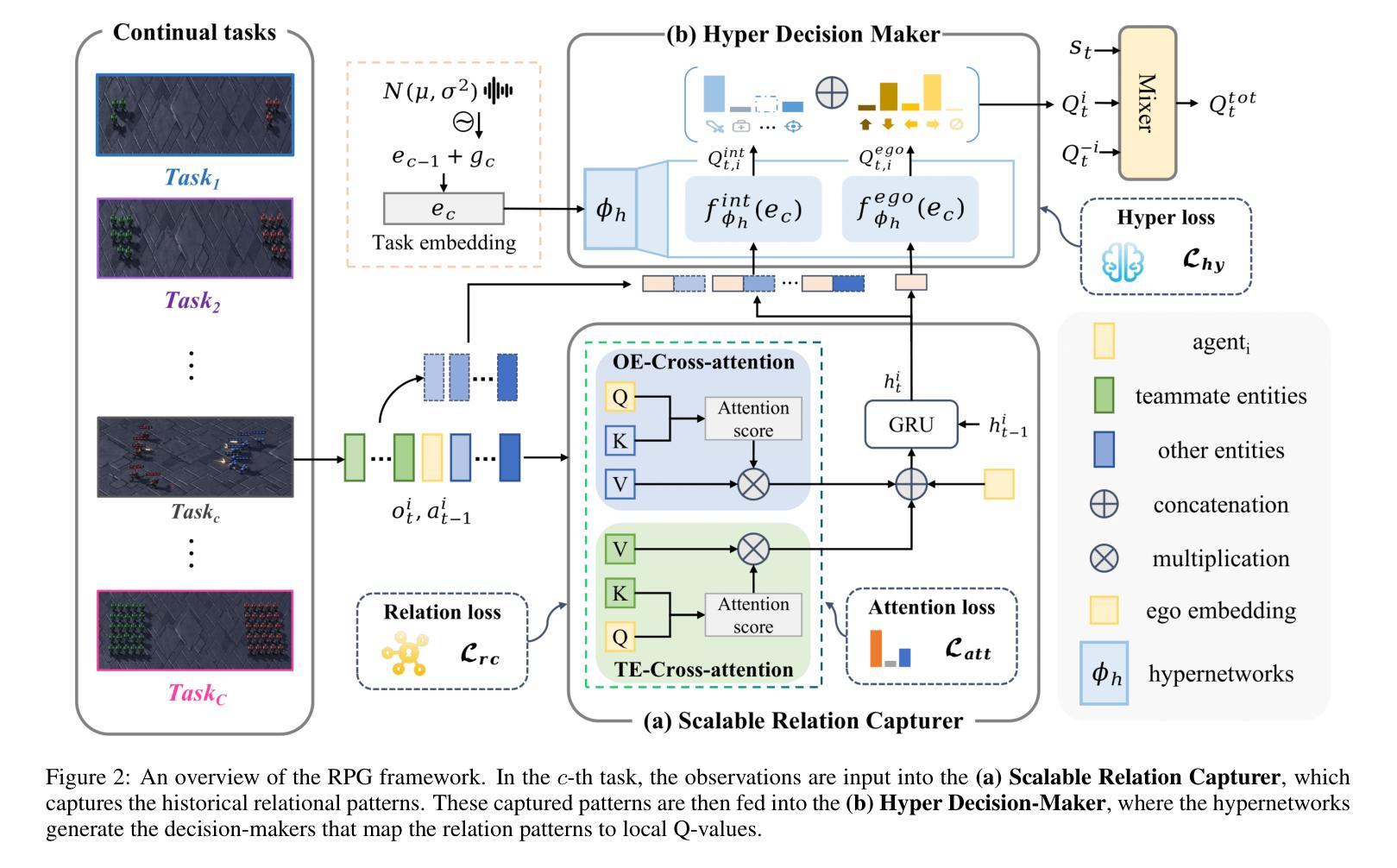
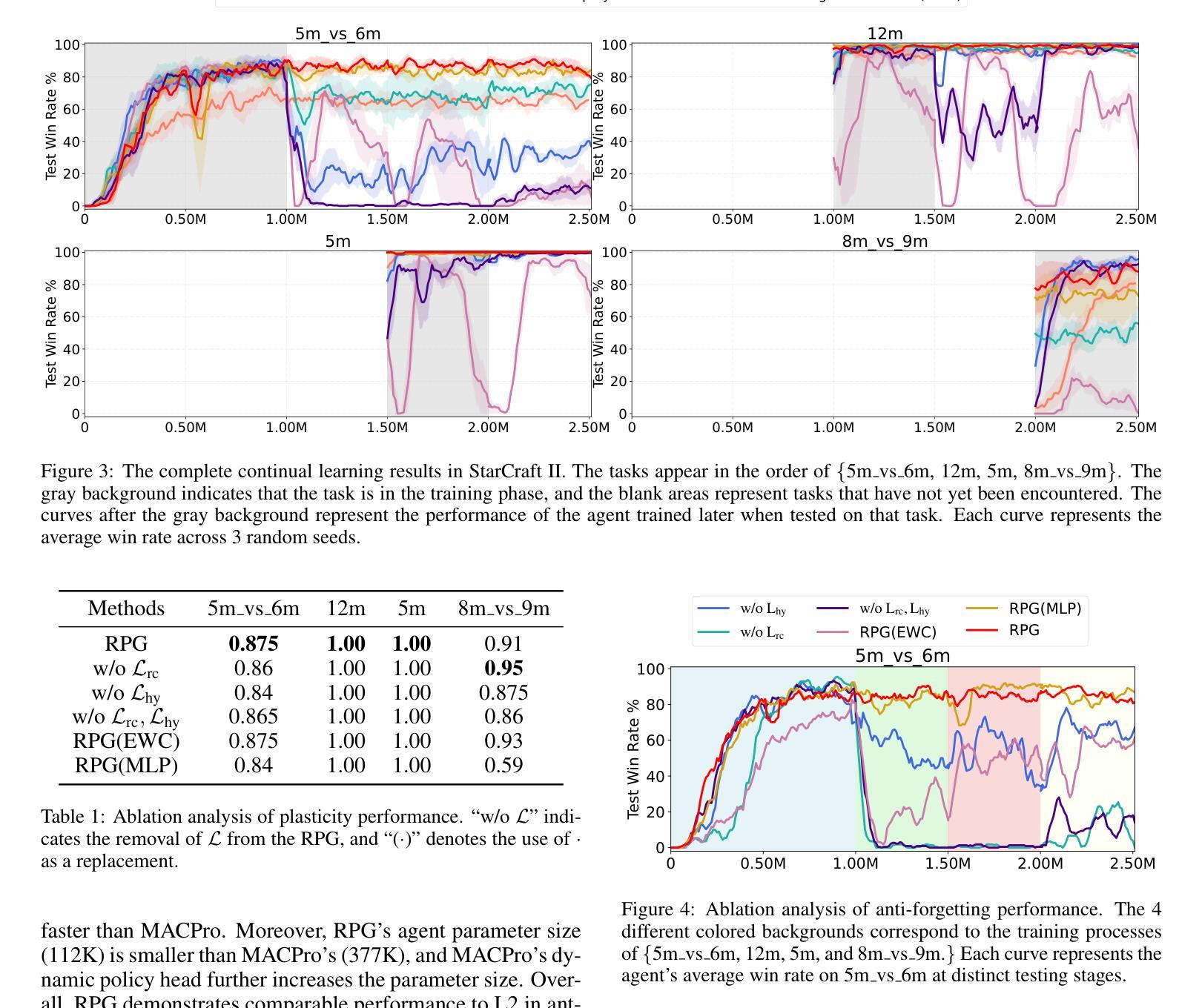
Continual Multi-Agent Reinforcement Learning (Co-MARL) requires agents to address catastrophic forgetting issues while learning new coordination policies with the dynamics team. In this paper, we delve into the core of Co-MARL, namely Relation Patterns, which refer to agents’ general understanding of interactions. In addition to generality, relation patterns exhibit task-specificity when mapped to different action spaces. To this end, we propose a novel method called General Relation Patterns-Guided Task-Specific Decision-Maker (RPG). In RPG, agents extract relation patterns from dynamic observation spaces using a relation capturer. These task-agnostic relation patterns are then mapped to different action spaces via a task-specific decision-maker generated by a conditional hypernetwork. To combat forgetting, we further introduce regularization items on both the relation capturer and the conditional hypernetwork. Results on SMAC and LBF demonstrate that RPG effectively prevents catastrophic forgetting when learning new tasks and achieves zero-shot generalization to unseen tasks.
持续多智能体强化学习(Co-MARL)要求智能体在团队动态中学习新的协调策略时解决灾难性遗忘问题。在本文中,我们深入探讨了Co-MARL的核心,即关系模式,它是指智能体对交互的一般理解。除了普遍性之外,当映射到不同的动作空间时,关系模式还表现出任务特异性。为此,我们提出了一种名为通用关系模式引导的任务特定决策制定者(RPG)的新方法。在RPG中,智能体使用关系捕获器从动态观测空间中提取关系模式。这些与任务无关的关系模式然后通过由条件超网络生成的任务特定决策制定者映射到不同的动作空间。为了对抗遗忘,我们在关系捕获器和条件超网络上进一步引入了正则化项。在SMAC和LBF上的结果表明,RPG在学习新任务时有效地防止了灾难性遗忘,并对未见任务实现了零射击泛化。
论文及项目相关链接
PDF IJCAI 2025 Accepted
Summary
本文探讨了持续多智能体强化学习(Co-MARL)中的核心问题,即智能体之间的交互关系模式。文章提出了一个名为RPG的新方法,该方法通过关系捕获器从动态观测空间中提取关系模式,并通过条件超网络将其映射到不同的动作空间。同时,为了克服遗忘问题,对关系捕获器和条件超网络都进行了正则化。在SMAC和LBF上的实验结果表明,RPG在学习新任务时能有效防止灾难性遗忘,并实现了对未见任务的零样本泛化。
Key Takeaways
- Co-MARL面临的主要挑战是灾难性遗忘问题,需要在学习新协调策略时保持对之前知识的记忆。
- 关系模式是Co-MARL的核心,体现了智能体之间的交互理解,具有通用性和任务特异性。
- 本文提出了RPG方法,通过关系捕获器提取关系模式,利用条件超网络将其映射到动作空间。
- RPG通过正则化项来防止智能体在学习过程中的遗忘。
- 在SMAC和LBF实验上,RPG展示了其有效性,能够在学习新任务时防止灾难性遗忘。
- RPG实现了对未见任务的零样本泛化,表明其良好的适应性和泛化能力。
点此查看论文截图

SciMaster: Towards General-Purpose Scientific AI Agents, Part I. X-Master as Foundation: Can We Lead on Humanity’s Last Exam?
Authors:Jingyi Chai, Shuo Tang, Rui Ye, Yuwen Du, Xinyu Zhu, Mengcheng Zhou, Yanfeng Wang, Weinan E, Yuzhi Zhang, Linfeng Zhang, Siheng Chen
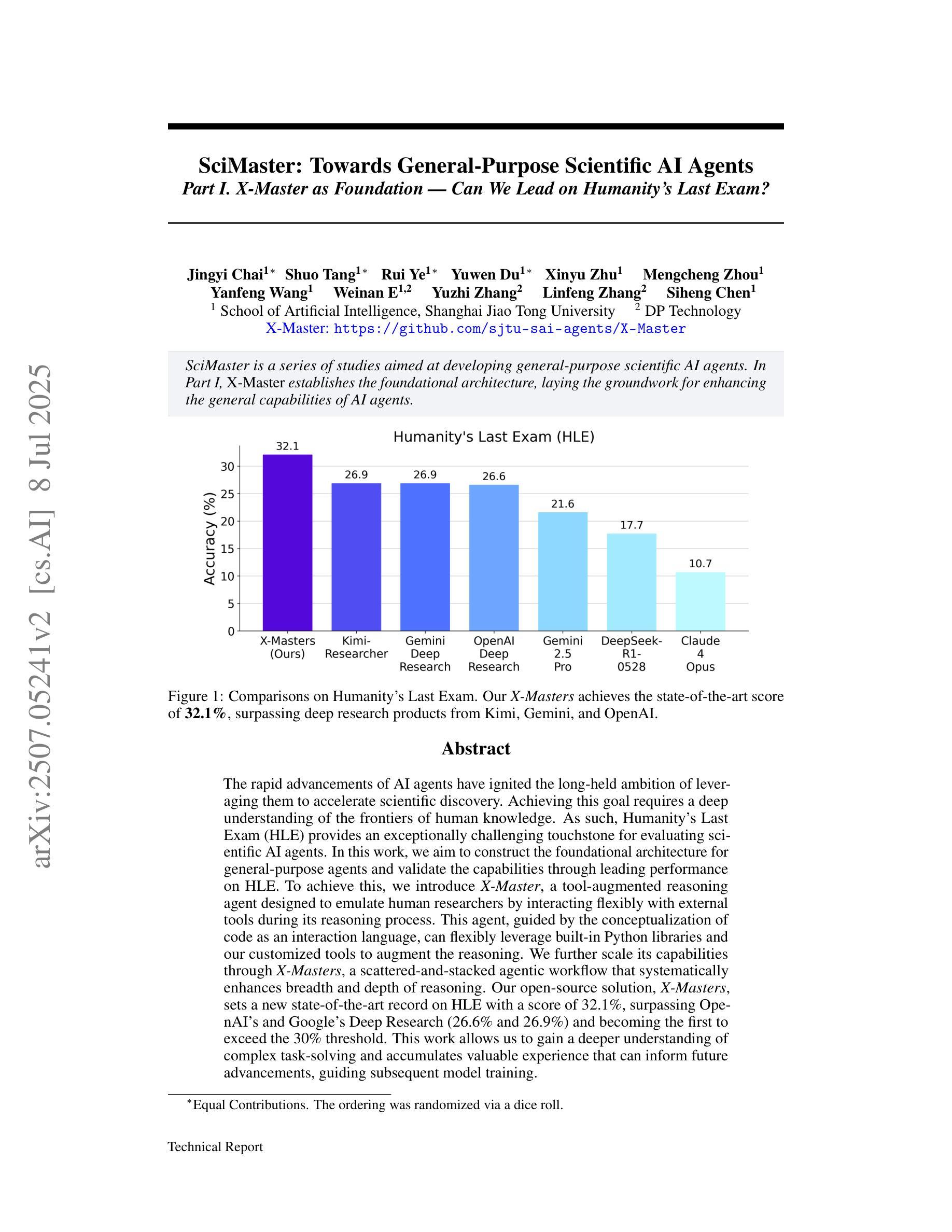
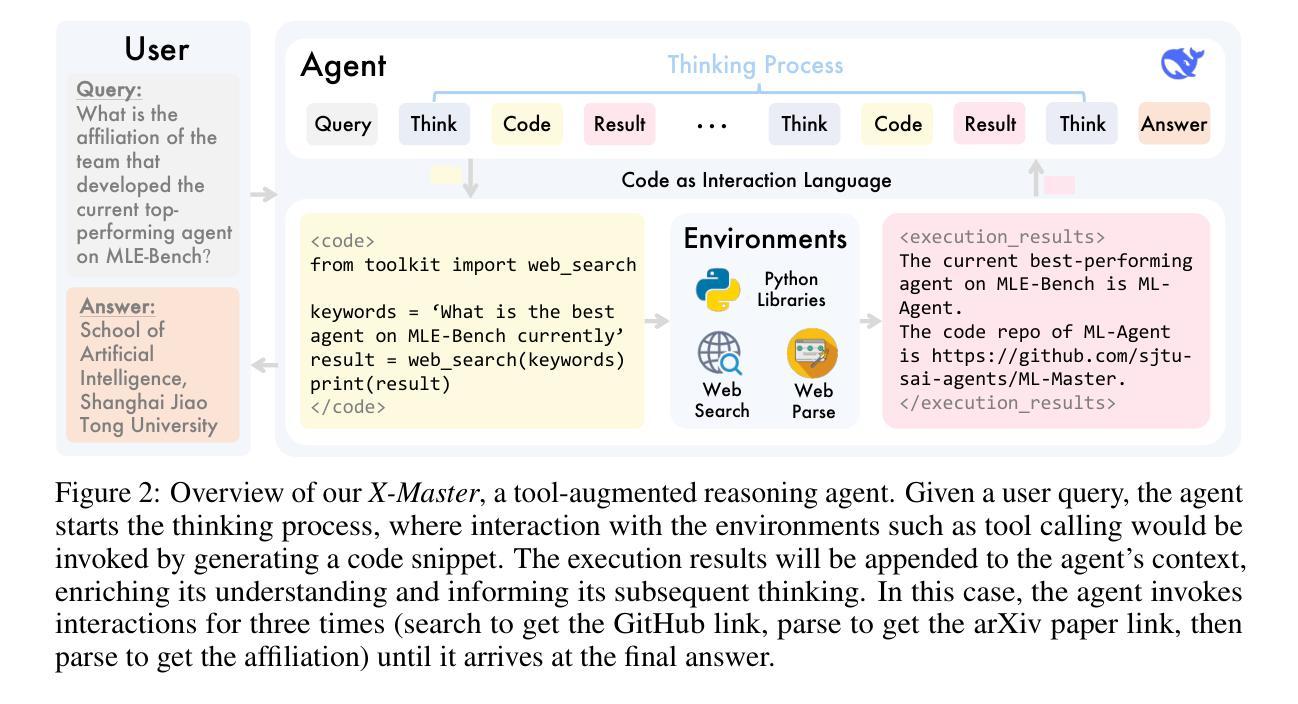
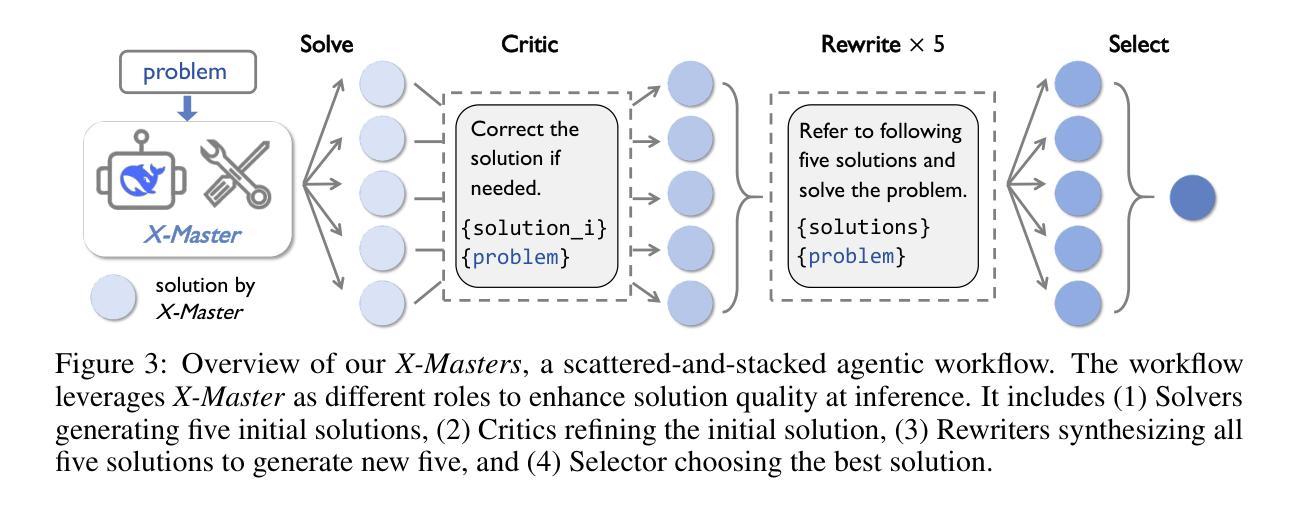
The rapid advancements of AI agents have ignited the long-held ambition of leveraging them to accelerate scientific discovery. Achieving this goal requires a deep understanding of the frontiers of human knowledge. As such, Humanity’s Last Exam (HLE) provides an exceptionally challenging touchstone for evaluating scientific AI agents. In this work, we aim to construct the foundational architecture for general-purpose agents and validate the capabilities through leading performance on HLE. To achieve this, we introduce X-Master, a tool-augmented reasoning agent designed to emulate human researchers by interacting flexibly with external tools during its reasoning process. This agent, guided by the conceptualization of code as an interaction language, can flexibly leverage built-in Python libraries and our customized tools to augment the reasoning. We further scale its capabilities through X-Masters, a scattered-and-stacked agentic workflow that systematically enhances breadth and depth of reasoning. Our open-source solution, X-Masters, sets a new state-of-the-art record on HLE with a score of 32.1%, surpassing OpenAI’s and Google’s Deep Research (26.6% and 26.9%) and becoming the first to exceed the 30% threshold. This work allows us to gain a deeper understanding of complex task-solving and accumulates valuable experience that can inform future advancements, guiding subsequent model training.
人工智能代理的快速进步激发了人们长久以来利用它们来加速科学发现的愿望。实现这一目标需要对人类知识的前沿有深刻的理解。因此,Humanity’s Last Exam(HLE)为评估科学人工智能代理提供了一个极具挑战性的试金石。在这项工作中,我们的目标是构建通用代理的基础架构,并通过在HLE上的领先性能来验证其能力。为了实现这一点,我们引入了X-Master,这是一个工具增强型推理代理,设计用于通过其在推理过程中灵活地与外部工具进行交互来模拟人类研究者。该代理以代码作为一种交互语言的理念为指导,可以灵活地利用内置的Python库和我们的定制工具来增强推理。我们进一步通过X-Masters(一种分散和堆叠的代理工作流程)来扩展其能力,系统地提高推理的广度和深度。我们的开源解决方案X-Masters在HLE上创下了新的最高纪录,得分为32.1%,超越了OpenAI和Google Deep Research(分别为26.6%和26.9%),并成为首个突破30%门槛的团队。这项工作使我们能够更深入地了解复杂任务解决,并积累了宝贵的经验,可以为未来的进步提供指导,为后续的模型训练提供指引。
论文及项目相关链接
PDF 15 pages, 10 figures
Summary:随着人工智能技术的迅速发展,人工智能已被广泛用于科学研究中以加快知识探索的速度。为应对挑战性评价人工智能的工作,《Humanity’s Last Exam》提出了X-Master的通用架构作为设计方向。此推理工具的设计可以灵活地与外部工具互动来模拟人类研究者。通过构建代码交互语言的概念,X-Master能够灵活利用内置Python库和定制工具来增强自身推理能力。该方案的规模化使用(被称为X-Masters)设置了全新的最新状态纪录——《Humanity’s Last Exam》得分达到32.1%,超越了OpenAI和谷歌深度研究的数据(分别为26.6%和26.9%)。这项工作让我们能深入理解复杂的任务解决方式并积累了宝贵经验。展望未来的人工智能研究时,可为后续的模型训练提供指导。
Key Takeaways:
- AI技术快速发展,推动其在科学发现中的应用。
- 《Humanity’s Last Exam》成为评估人工智能性能的重要标准。
- X-Master设计旨在模拟人类研究者,灵活利用外部工具进行推理。
- X-Master通过构建代码交互语言概念,利用Python库和定制工具增强推理能力。
- X-Masters系统提升人工智能推理能力广度与深度。
- X-Masters方案首次突破《Humanity’s Last Exam》的30%阈值,达到新的记录水平。
点此查看论文截图
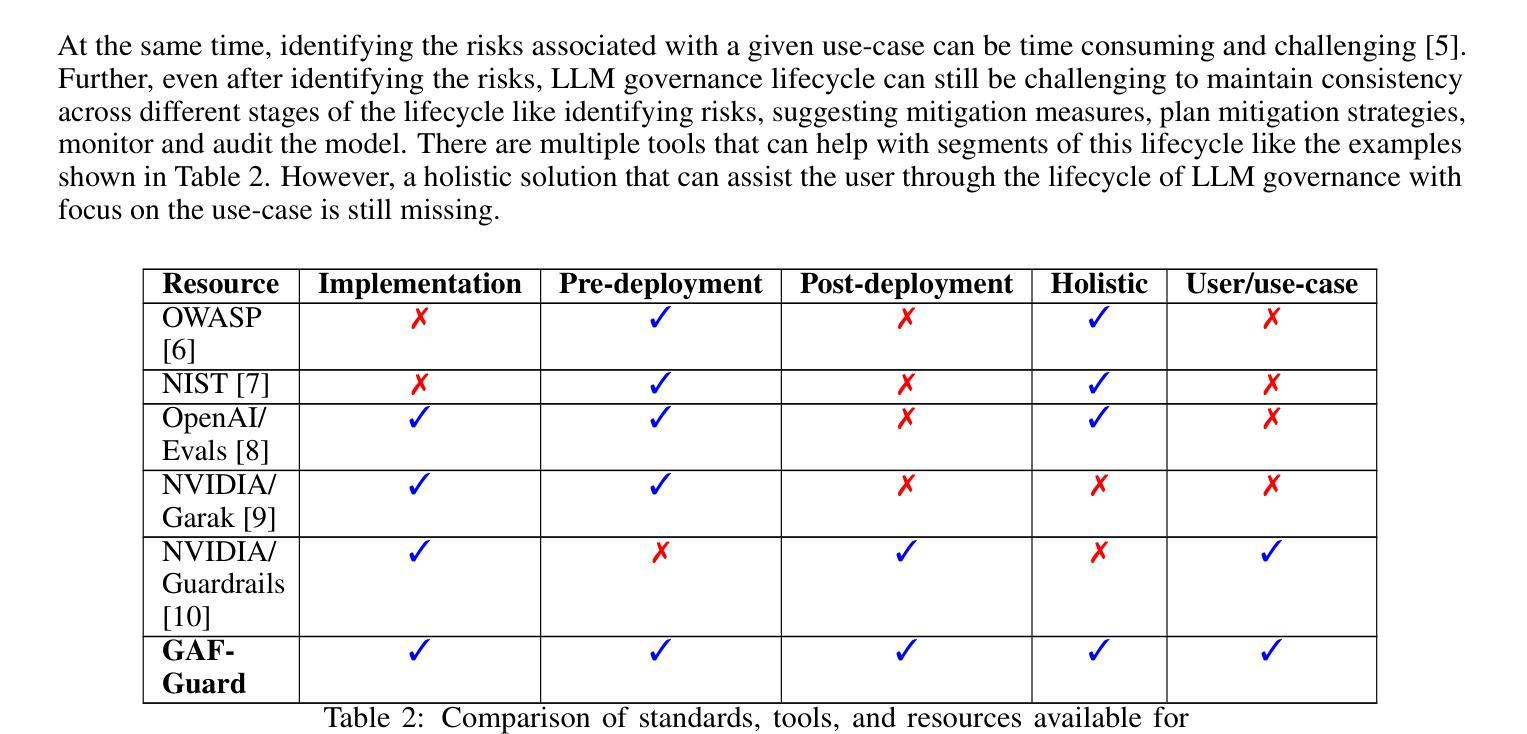
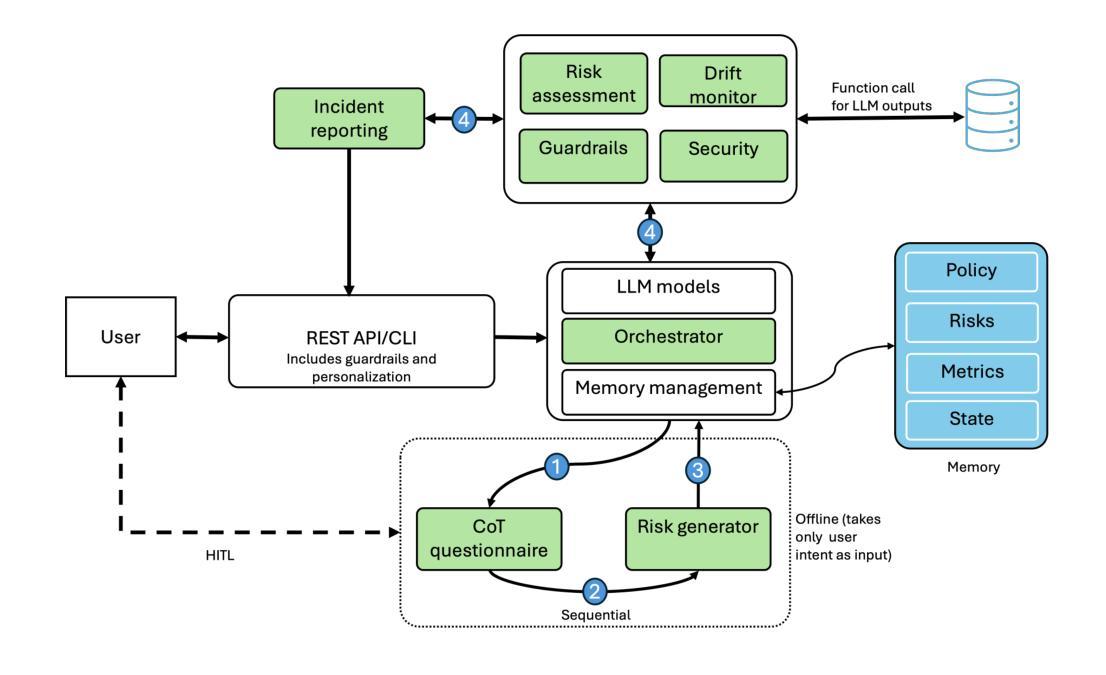
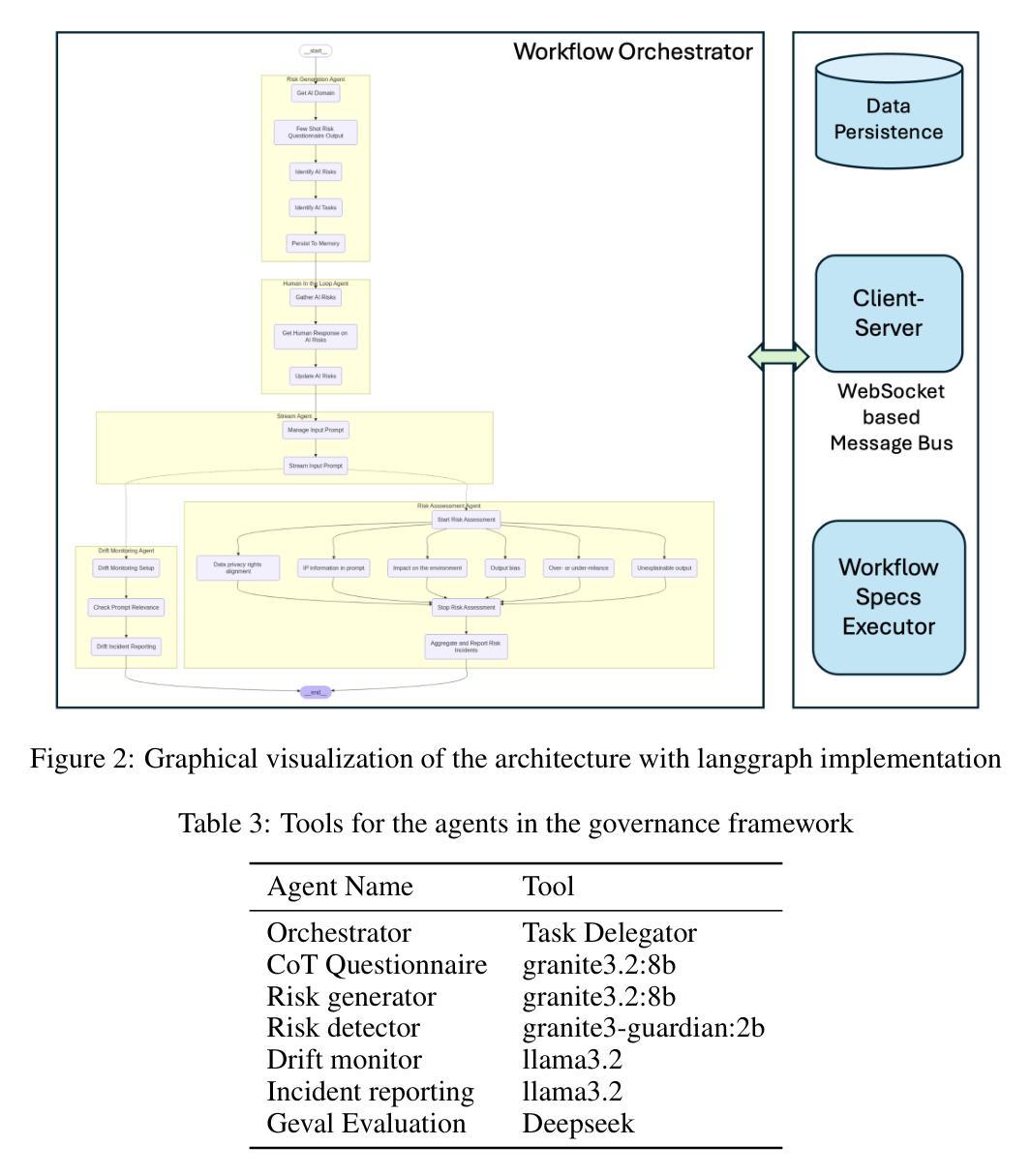
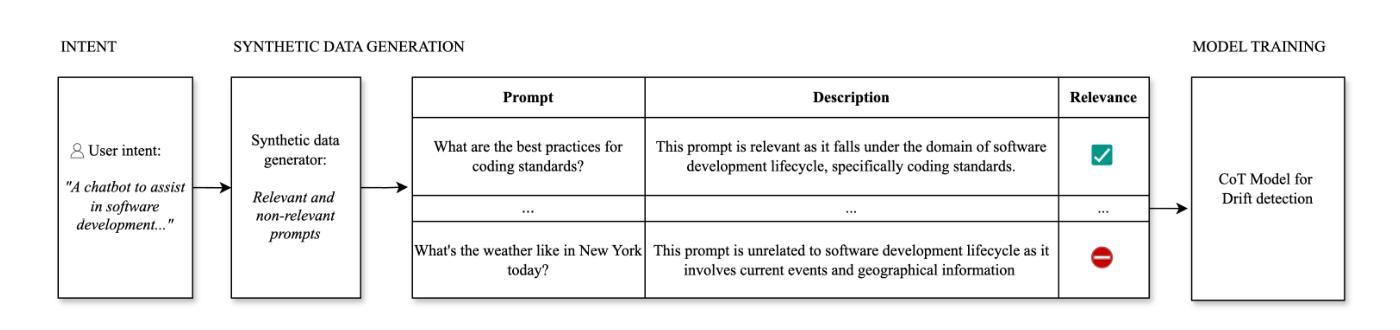
GAF-Guard: An Agentic Framework for Risk Management and Governance in Large Language Models
Authors:Seshu Tirupathi, Dhaval Salwala, Elizabeth Daly, Inge Vejsbjerg
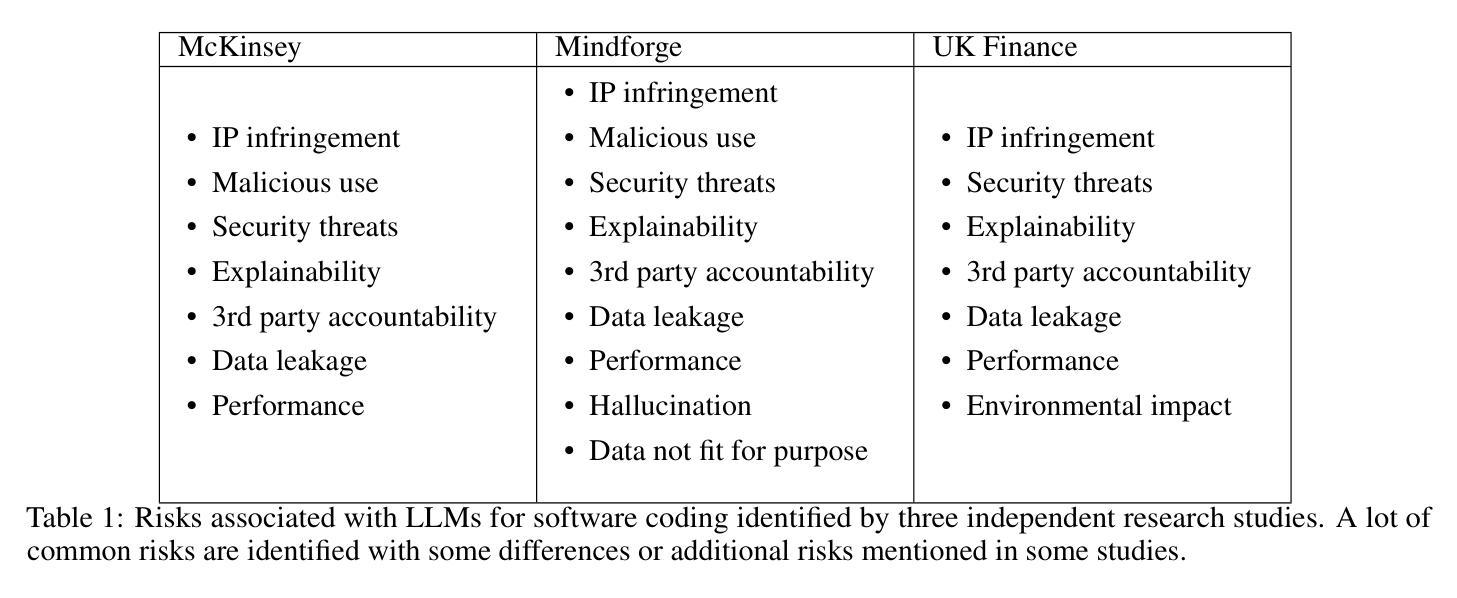
As Large Language Models (LLMs) continue to be increasingly applied across various domains, their widespread adoption necessitates rigorous monitoring to prevent unintended negative consequences and ensure robustness. Furthermore, LLMs must be designed to align with human values, like preventing harmful content and ensuring responsible usage. The current automated systems and solutions for monitoring LLMs in production are primarily centered on LLM-specific concerns like hallucination etc, with little consideration given to the requirements of specific use-cases and user preferences. This paper introduces GAF-Guard, a novel agentic framework for LLM governance that places the user, the use-case, and the model itself at the center. The framework is designed to detect and monitor risks associated with the deployment of LLM based applications. The approach models autonomous agents that identify risks, activate risk detection tools, within specific use-cases and facilitate continuous monitoring and reporting to enhance AI safety, and user expectations. The code is available at https://github.com/IBM/risk-atlas-nexus-demos/tree/main/gaf-guard.
随着大型语言模型(LLM)在各个领域的应用越来越广泛,其普及带来了需要严格监控以防止意外产生负面后果并确保其稳健性的必要性。此外,LLM的设计必须与人类价值观相一致,如防止有害内容并确保负责任的使用。目前针对生产环境中LLM的自动化系统和解决方案主要集中于LLM特定的关注点,如幻觉等,很少考虑特定用例和用户偏好。本文介绍了GAF-Guard,这是一种新型的LLM治理代理框架,以用户、用例和模型本身为中心。该框架旨在检测和监控与基于LLM的应用部署相关的风险。该方法建立自主代理模型,识别风险,在特定用例中激活风险检测工具,促进持续监控和报告,以提高人工智能安全性和用户期望。代码可在https://github.com/IBM/risk-atlas-nexus-demos/tree/main/gaf-guard获取。
论文及项目相关链接
Summary
大型语言模型(LLM)的广泛应用需要对其进行严格监控,以确保其稳健性和避免意外负面影响。此外,LLM的设计必须与人类价值观对齐,如防止有害内容和确保负责任的使用。当前针对LLM的自动化系统和解决方案主要关注LLM特定的担忧,如幻觉等,很少考虑特定用例和用户偏好。本文介绍了GAF-Guard,一个新型的LLM治理代理框架,以用户、用例和模型本身为中心。该框架旨在检测和监控与部署LLM应用程序相关的风险。它通过模拟自主代理来识别风险、激活风险检测工具,并在特定用例中实现持续监控和报告,以提高人工智能的安全性和用户满意度。
Key Takeaways
- 大型语言模型(LLMs)的广泛应用需要严格的监控来确保其稳健性并避免负面影响。
- LLM设计必须与人类价值观对齐,以预防有害内容和确保负责任的使用。
- 当前针对LLM的自动化系统和解决方案主要关注模型本身的问题,忽视了用户需求和特定用例的需求。
- GAF-Guard是一个新型的LLM治理代理框架,以用户、用例和模型为中心,旨在全面检测并管理风险。
- GAF-Guard通过自主代理识别风险、激活风险检测工具,满足不同用例的需求。
- 该框架能持续监控LLM应用的风险并实现报告,以提高人工智能的安全性和用户满意度。
点此查看论文截图


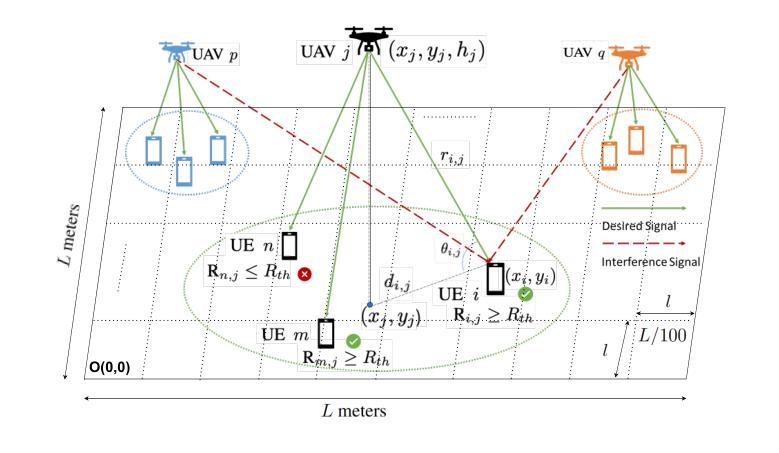
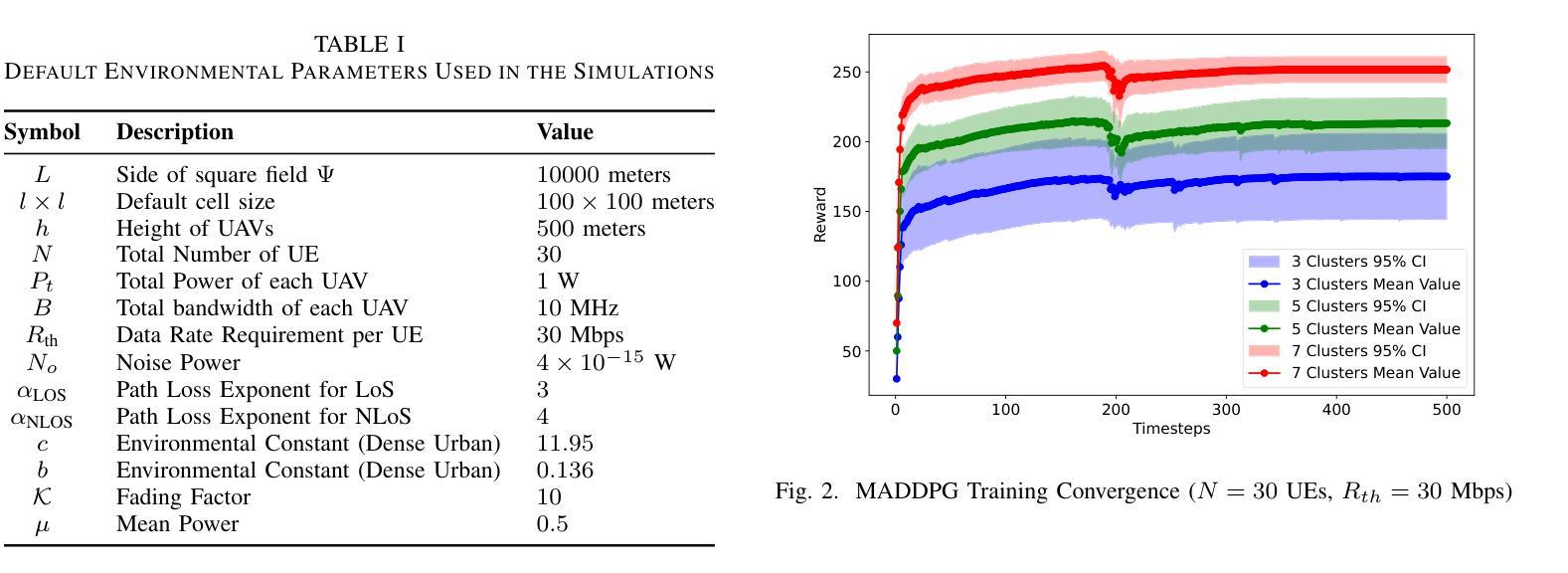
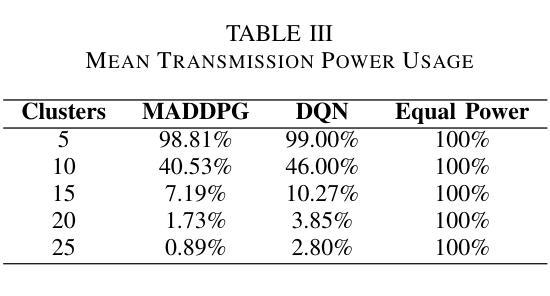
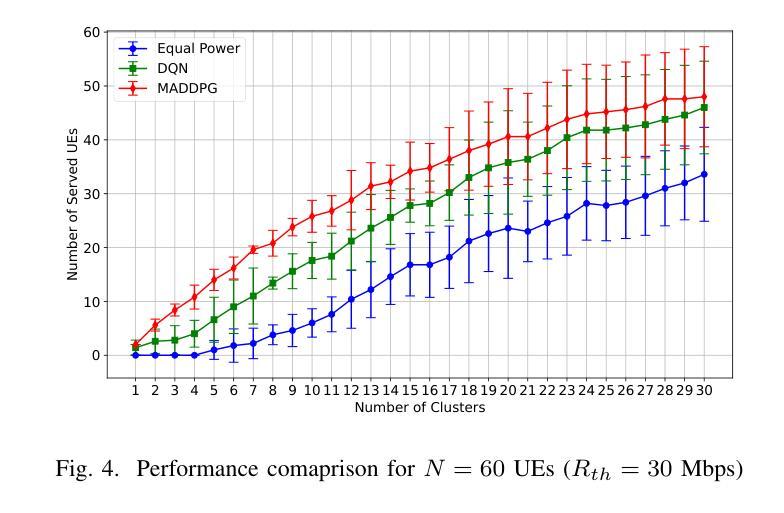
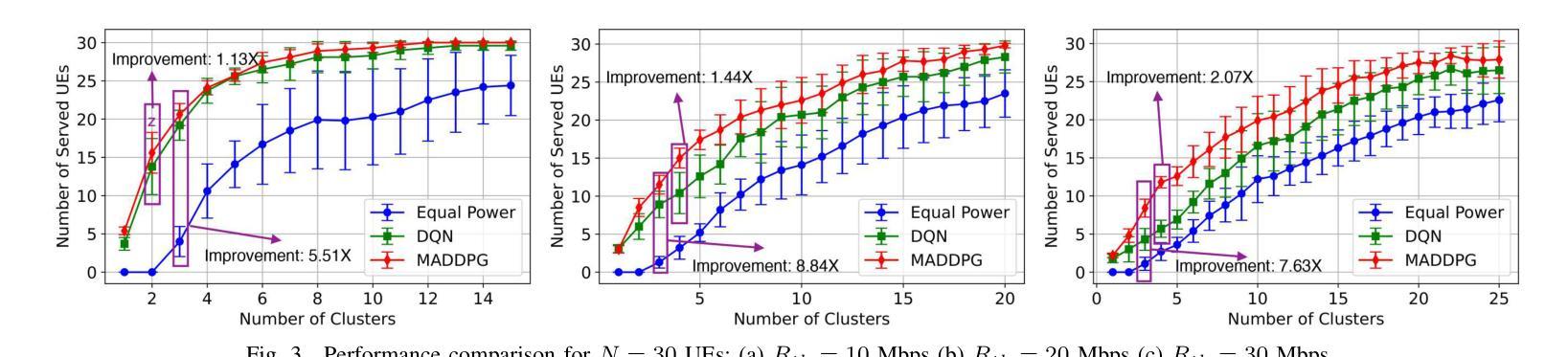
Multi-Agent Deep Reinforcement Learning for Optimized Multi-UAV Coverage and Power-Efficient UE Connectivity
Authors:Xuli Cai, Poonam Lohan, Burak Kantarci
In critical situations such as natural disasters, network outages, battlefield communication, or large-scale public events, Unmanned Aerial Vehicles (UAVs) offer a promising approach to maximize wireless coverage for affected users in the shortest possible time. In this paper, we propose a novel framework where multiple UAVs are deployed with the objective to maximize the number of served user equipment (UEs) while ensuring a predefined data rate threshold. UEs are initially clustered using a K-means algorithm, and UAVs are optimally positioned based on the UEs’ spatial distribution. To optimize power allocation and mitigate inter-cluster interference, we employ the Multi-Agent Deep Deterministic Policy Gradient (MADDPG) algorithm, considering both LOS and NLOS fading. Simulation results demonstrate that our method significantly enhances UEs coverage and outperforms Deep Q-Network (DQN) and equal power distribution methods, improving their UE coverage by up to 2.07 times and 8.84 times, respectively.
在自然灾害、网络中断、战场通信或大规模公众活动等关键情况下,无人机(UAVs)提供了一种非常有前途的方法,能够在最短的时间内为受影响用户实现最大的无线覆盖。在本文中,我们提出了一种新型框架,其中部署了多个无人机,目的是在确保预定数据速率阈值的同时,最大化服务的用户设备(UEs)数量。UEs最初使用K-means算法进行聚类,无人机则根据UEs的空间分布进行最优定位。为了优化功率分配并减轻跨集群干扰,我们采用多智能体深度确定性策略梯度(MADDPG)算法,同时考虑视线(LOS)和非视线(NLOS)衰减。仿真结果表明,我们的方法显著提高了UEs的覆盖范围,并优于深度Q网络(DQN)和平均功率分配方法,其UE覆盖率提高了高达2.07倍和8.84倍。
论文及项目相关链接
PDF 6 pages, 5 figures, accepted to IEEE PIMRC 2025
Summary
无人机(UAVs)在关键情况下如自然灾害、网络中断、战场通信或大型公共事件中,为受影响用户实现最大无线覆盖提供了有效手段。本文提出一种新型框架,部署多个无人机,旨在最大化服务用户设备数量并确保预定的数据速率阈值。用户设备通过K均值算法进行初步聚类,基于用户设备的空间分布优化无人机位置。为优化功率分配并减轻跨集群干扰,采用考虑视线(LOS)和非视线(NLOS)衰落的Multi-Agent Deep Deterministic Policy Gradient(MADDPG)算法。模拟结果显示,该方法极大提高了用户设备覆盖率,并优于Deep Q-Network(DQN)和均分功率分配法,分别提升UE覆盖率达2.07倍和8.84倍。
Key Takeaways
- 在紧急情境下,无人机对于最大化无线覆盖具有巨大潜力。
- 提出新型框架部署无人机,旨在最大化服务用户设备数量并确保数据速率阈值。
- 用户设备通过K均值算法进行聚类。
- 根据用户设备的空间分布优化无人机位置。
- 采用MADDPG算法优化功率分配并减轻跨集群干扰。
- 引入考虑视线和非视线衰落的机制以提高系统性能。
点此查看论文截图

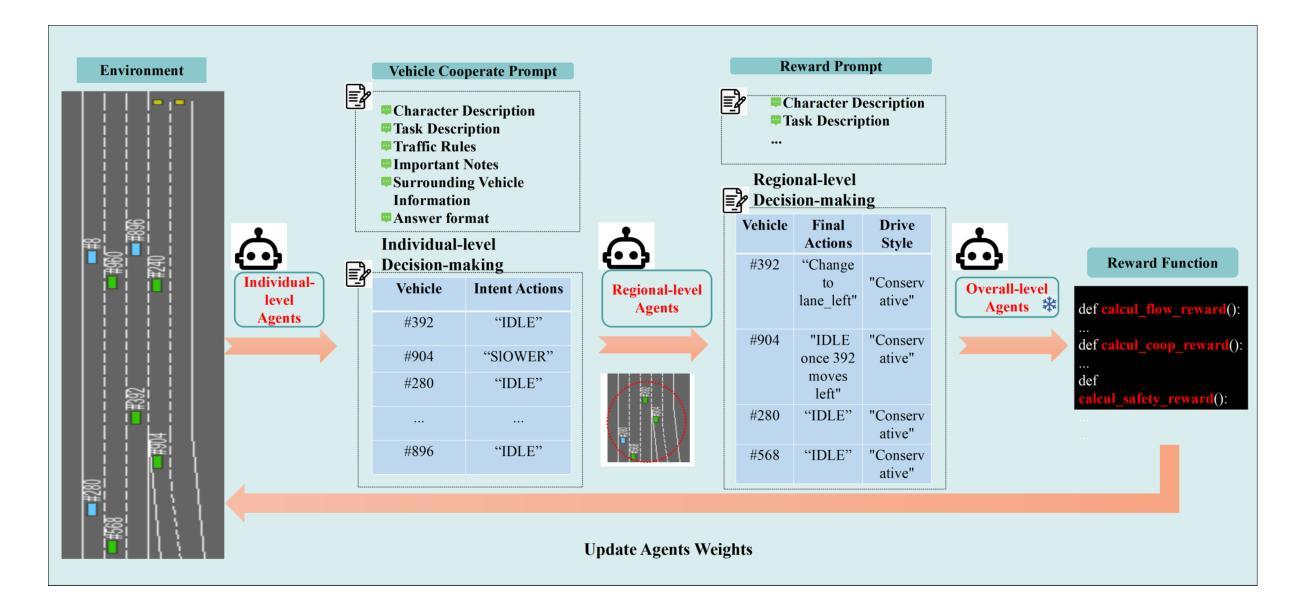
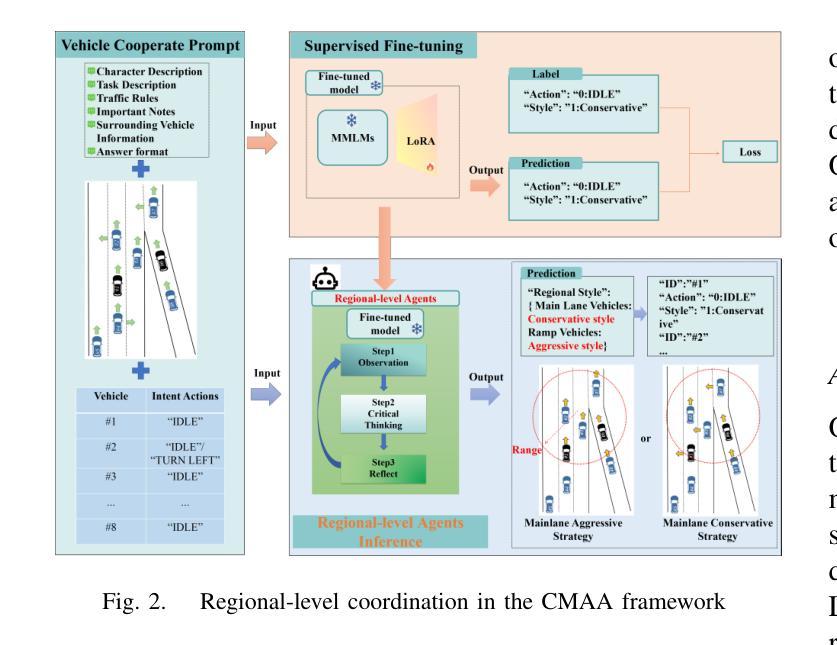
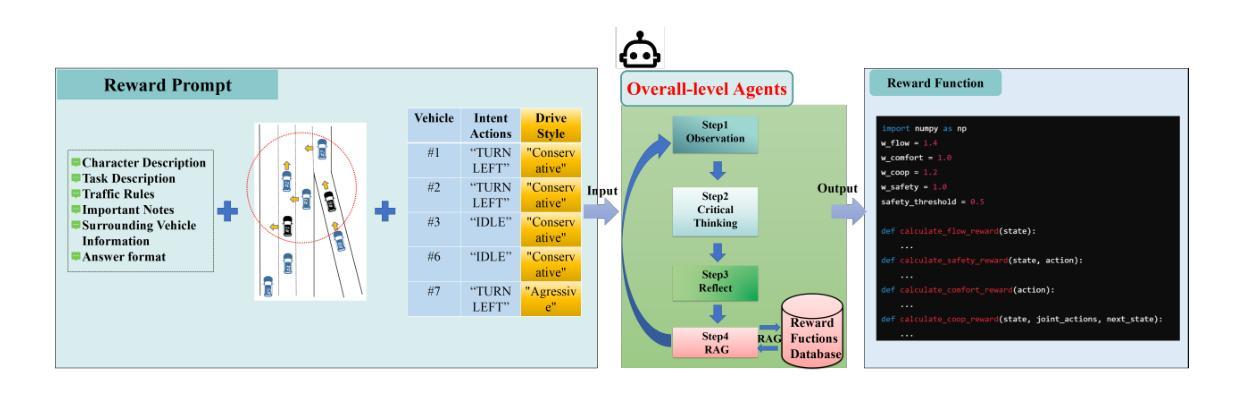
A Cascading Cooperative Multi-agent Framework for On-ramp Merging Control Integrating Large Language Models
Authors:Miao Zhang, Zhenlong Fang, Tianyi Wang, Qian Zhang, Shuai Lu, Junfeng Jiao, Tianyu Shi
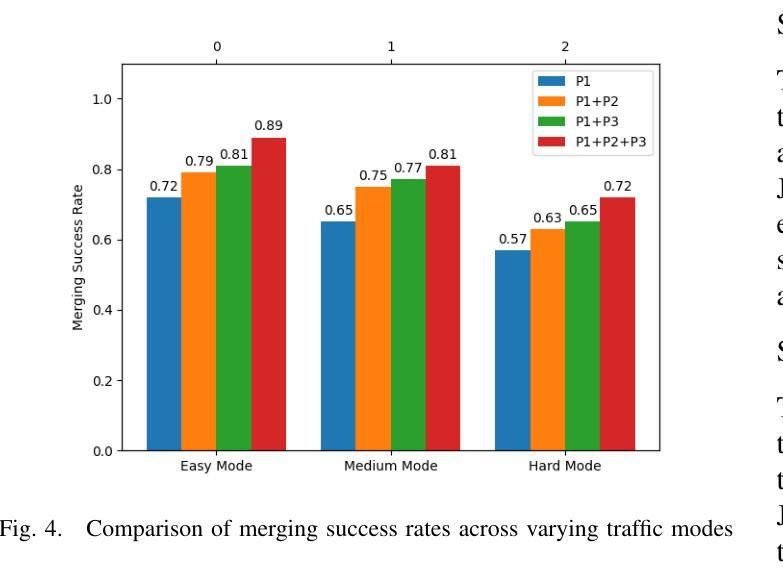
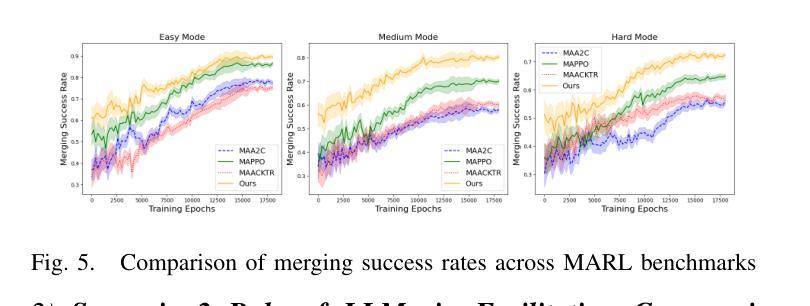
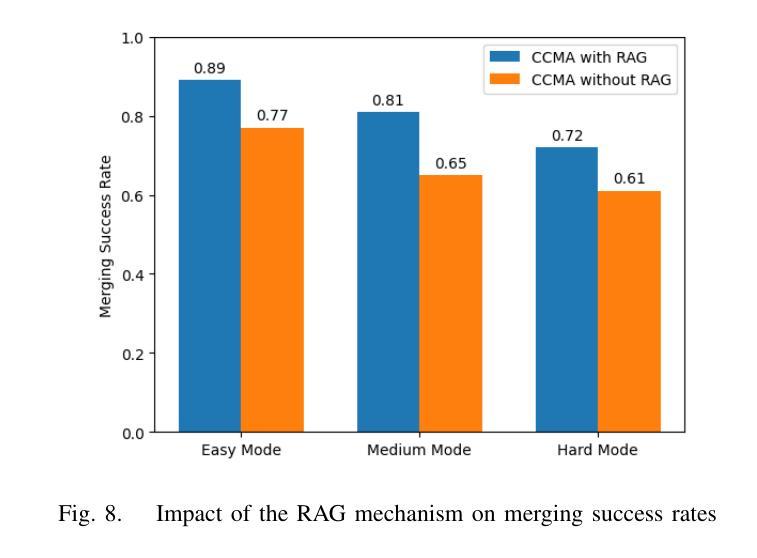
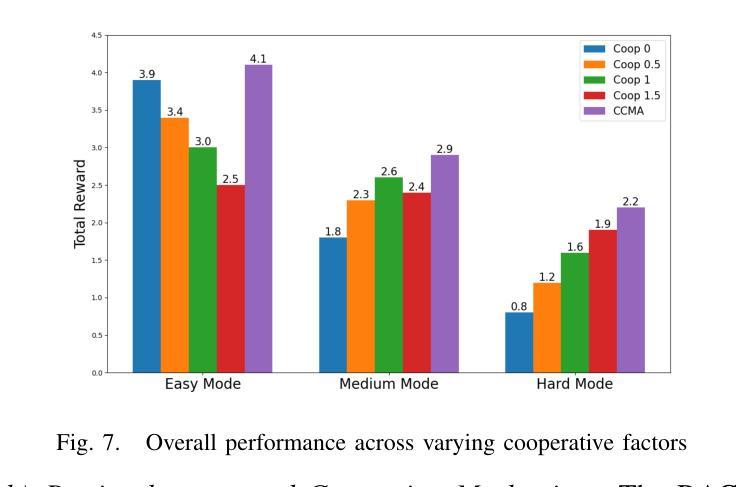
Traditional Reinforcement Learning (RL) suffers from replicating human-like behaviors, generalizing effectively in multi-agent scenarios, and overcoming inherent interpretability issues.These tasks are compounded when deep environment understanding, agent coordination and dynamic optimization are required. While Large Language Model (LLM) enhanced methods have shown promise in generalization and interoperability, they often neglect necessary multi-agent coordination. Therefore, we introduce the Cascading Cooperative Multi-agent (CCMA) framework, integrating RL for individual interactions, a fine-tuned LLM for regional cooperation, a reward function for global optimization, and the Retrieval-augmented Generation mechanism to dynamically optimize decision-making across complex driving scenarios. Our experiments demonstrate that the CCMA outperforms existing RL methods, demonstrating significant improvements in both micro and macro-level performance in complex driving environments.
传统强化学习(RL)在复制人类行为、在多智能体场景中的有效推广以及克服内在的可解释性问题方面存在困难。当需要深入了解环境、智能体协调和动态优化时,这些任务会变得更加复杂。虽然大型语言模型(LLM)增强方法在推广和互操作性方面显示出潜力,但它们往往忽视了必要的多智能体协调。因此,我们引入了级联合作多智能体(CCMA)框架,该框架整合了用于个体交互的RL、用于区域合作的微调LLM、用于全局优化的奖励函数以及用于在复杂驾驶场景中动态优化决策的回溯增强生成机制。我们的实验表明,CCMA在复杂驾驶环境中,无论是在微观还是宏观层面,都优于现有的RL方法,表现出显著的性能改进。
论文及项目相关链接
Summary
传统强化学习(RL)在复制人类行为、在多智能体场景中的有效泛化以及解决固有的解释性问题方面存在挑战。当需要深度环境理解、智能体协调和动态优化时,这些任务更加复杂。虽然大型语言模型(LLM)增强方法在泛化和互操作性方面显示出潜力,但它们常常忽略了必要的多智能体协作。因此,我们引入了级联合作多智能体(CCMA)框架,它整合了用于个体交互的RL、用于区域合作的微调LLM、用于全局优化的奖励函数以及用于在复杂驾驶场景中动态优化决策的检索增强生成机制。实验表明,CCMA在复杂驾驶环境中相较于现有RL方法表现出更高的微观和宏观性能。
Key Takeaways
- 传统强化学习在复制人类行为、多智能体泛化和解决解释性问题方面存在挑战。
- 当需要深度环境理解、智能体协调和动态优化时,这些挑战更加突出。
- 大型语言模型增强方法在泛化和互操作性方面虽有潜力,但忽略了多智能体协作的重要性。
- 引入级联合作多智能体(CCMA)框架,整合RL、LLM、奖励函数和检索增强生成机制。
- CCMA框架旨在优化个体交互、区域合作和全局优化。
- 实验表明,CCMA在复杂驾驶环境中相较于现有方法表现出更高的性能。
点此查看论文截图


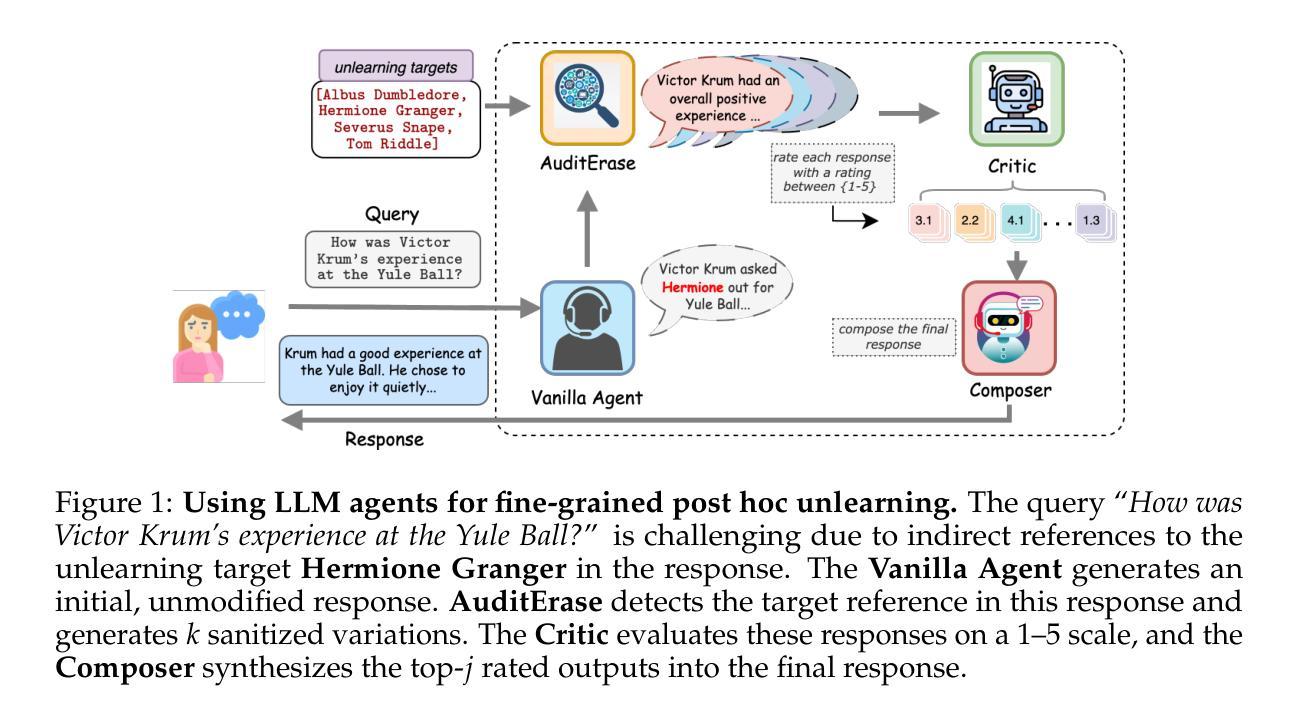
Agents Are All You Need for LLM Unlearning
Authors:Debdeep Sanyal, Murari Mandal
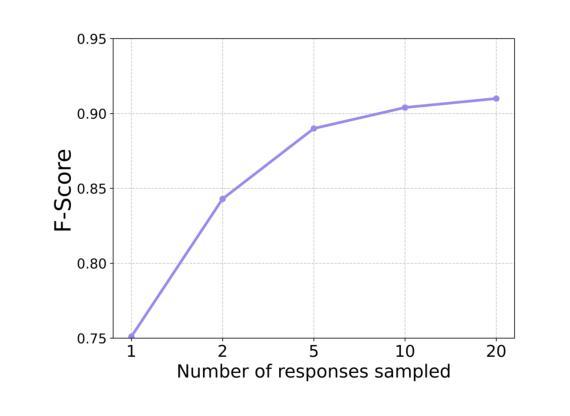
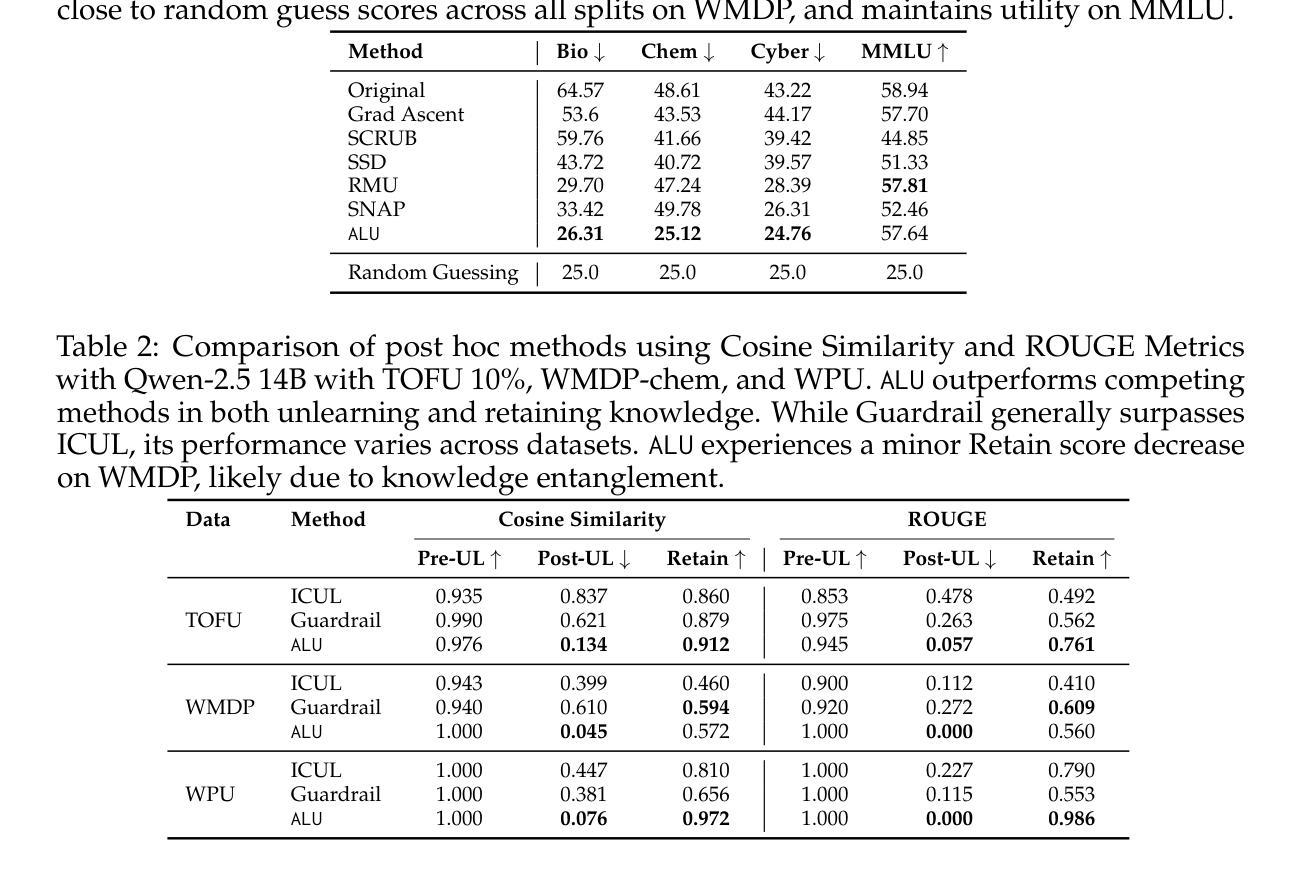
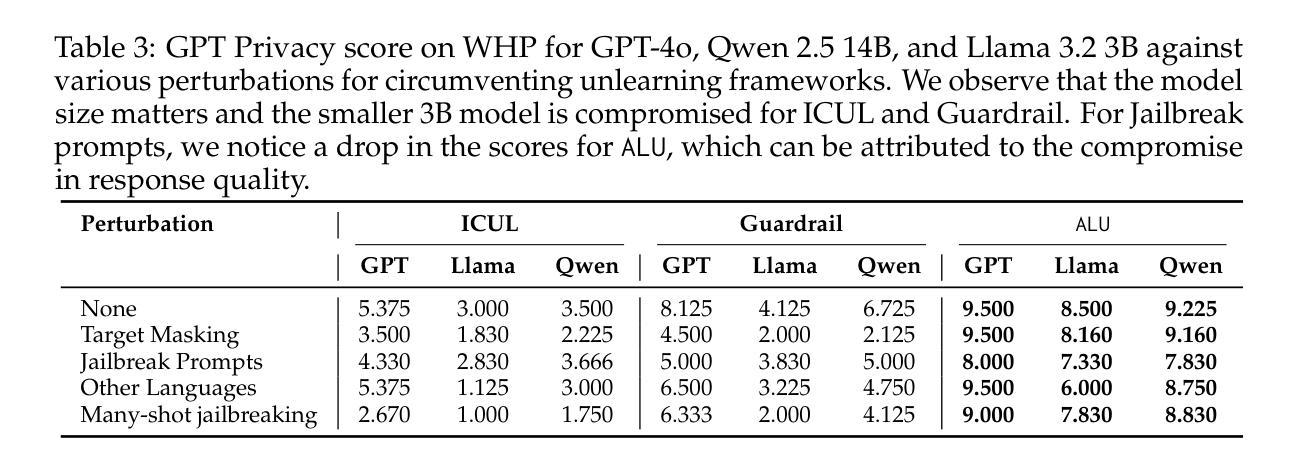
Information removal or suppression in large language models (LLMs) is a desired functionality, useful in AI regulation, legal compliance, safety, and privacy. LLM unlearning methods aim to remove information on demand from LLMs. Current LLM unlearning methods struggle to balance the unlearning efficacy and utility due to the competing nature of these objectives. Keeping the unlearning process computationally feasible without assuming access to the model weights is an overlooked area. In this work we show that \textit{agents might be all we need for effective and practical inference-time LLM unlearning}. We present the first agentic LLM unlearning (\texttt{ALU}) method, a multi-agent, retrain-free, model-agnostic approach to LLM unlearning that achieves effective unlearning while preserving the utility. Our \texttt{ALU} framework unlearns by involving multiple LLM agents, each designed for a specific step in the unlearning process, without the need to update model weights for any of the agents in the framework. Users can easily request any set of unlearning instances in any sequence, and \texttt{ALU} seamlessly adapts in real time. This is facilitated without requiring any changes in the underlying LLM model. Through extensive experiments on established benchmarks (TOFU, WMDP, WPU) and jailbreaking techniques (many shot, target masking, other languages), we demonstrate that \texttt{ALU} consistently stands out as the most robust inference-time LLM unlearning framework among current state-of-the-art methods while incurring time cost that remains effectively constant regardless of the number of unlearning targets. We further highlight \texttt{ALU}’s superior performance compared to existing methods when evaluated at scale. Specifically, \texttt{ALU} is assessed on up to 1000 unlearning targets, exceeding the evaluation scope of all previously proposed LLM unlearning methods.
信息删除或抑制在大规模语言模型(LLM)中是一种理想的功能,在人工智能监管、法律合规、安全和隐私方面非常有用。LLM遗忘方法旨在根据需求从LLM中删除信息。由于目标之间存在竞争性质,当前的LLM遗忘方法在平衡遗忘效果和实用性方面面临困难。在不假设能够访问模型权重的情况下,保持遗忘过程的计算可行性是一个被忽视的领域。在这项工作中,我们表明“代理人可能是我们实现有效和实用的推理时间LLM遗忘所需要的全部”。我们提出了第一种基于代理的LLM遗忘(ALU)方法,这是一种多代理、无需重新训练、对模型无特定要求的LLM遗忘方法,能够在有效遗忘的同时保持实用性。我们的ALU框架通过涉及多个LLM代理来实现遗忘,每个代理都针对遗忘过程中的特定步骤而设计,无需更新框架中任何代理的模型权重。用户可以轻松按任何顺序请求任何一组遗忘实例,ALU能够实时无缝适应。这不需要对底层LLM模型进行任何更改即可实现。我们通过广泛的实验,在既定的基准测试(TOFU、WMDP、WPU)和越狱技术(多镜头、目标掩码、其他语言)上证明,ALU在当前的先进方法中始终表现出最稳健的推理时间LLM遗忘框架,同时产生的时间成本保持有效且恒定,无论遗忘目标数量如何。我们还进一步强调了ALU在规模评估时相对于现有方法的卓越性能。具体来说,ALU最多可对1000个遗忘目标进行评估,超出了所有先前提出的LLM遗忘方法的评估范围。
论文及项目相关链接
PDF Accepted to COLM 2025
Summary
大型语言模型(LLM)中的信息移除或抑制是一个重要的功能,对于人工智能监管、法律合规性、安全性和隐私保护都很有用。LLM的遗忘方法旨在按需从LLM中移除信息。当前LLM遗忘方法需要在遗忘效果和实用性之间取得平衡。保持遗忘过程计算上可行且无需访问模型权重是一个被忽略的领域。在这项工作中,我们展示了采用多个LLM智能体实现的全新即时LLM遗忘(ALU)方法,该方法在有效遗忘的同时保持了实用性,不需要更新模型中任何一个智能体的权重。通过广泛的实验和测试,证明ALU是现有的最先进的即时LLM遗忘框架中最稳健的一个,其时间成本保持恒定,无论遗忘目标数量多少。ALU在多达1000个遗忘目标的评估中表现出卓越性能,超越了所有先前提出的LLM遗忘方法的评估范围。
Key Takeaways
- 信息移除在大型语言模型(LLM)中具有重要作用,有助于AI监管、法律合规性、安全和隐私保护。
点此查看论文截图