⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-10 更新
DS@GT at CheckThat! 2025: Ensemble Methods for Detection of Scientific Discourse on Social Media
Authors:Ayush Parikh, Hoang Thanh Thanh Truong, Jeanette Schofield, Maximilian Heil
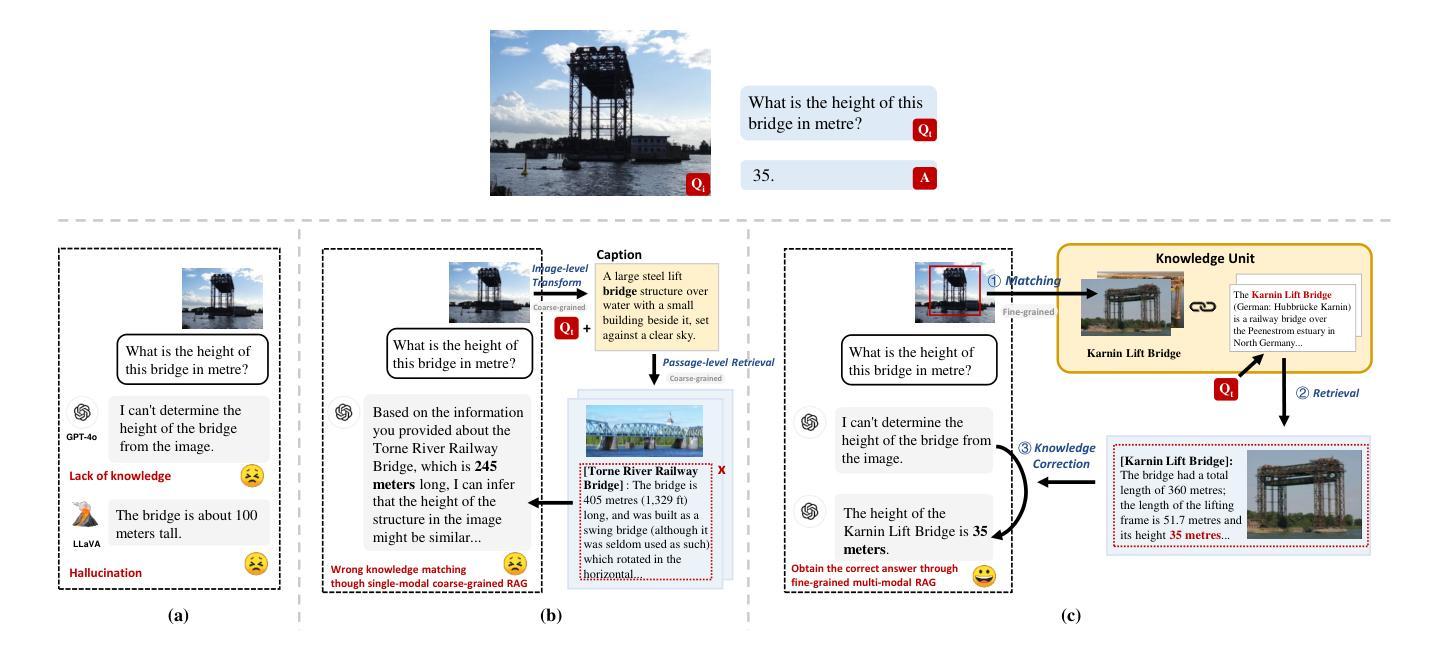
In this paper, we, as the DS@GT team for CLEF 2025 CheckThat! Task 4a Scientific Web Discourse Detection, present the methods we explored for this task. For this multiclass classification task, we determined if a tweet contained a scientific claim, a reference to a scientific study or publication, and/or mentions of scientific entities, such as a university or a scientist. We present 3 modeling approaches for this task: transformer finetuning, few-shot prompting of LLMs, and a combined ensemble model whose design was informed by earlier experiments. Our team placed 7th in the competition, achieving a macro-averaged F1 score of 0.8611, an improvement over the DeBERTaV3 baseline of 0.8375. Our code is available on Github at https://github.com/dsgt-arc/checkthat-2025-swd/tree/main/subtask-4a.
在这篇论文中,我们作为CLEF 2025 CheckThat!任务4a科学网络话语检测的DS@GT团队,介绍了我们为这项任务所探索的方法。针对这项多类分类任务,我们确定了推特中是否包含科学主张、对科学研究或出版的引用,以及是否提及科学实体,如大学或科学家。我们为这项任务提出了三种建模方法:变压器微调、大型语言模型的少量提示,以及根据早期实验设计的组合集成模型。我们的团队在比赛中排名第7,取得了宏观平均F1分数为0.8611的成绩,相较于DeBERTaV3基准模型的0.8375有所提升。我们的代码可在Github上获取:链接。
论文及项目相关链接
Summary
本文介绍了DS@GT团队在CLEF 2025 CheckThat!任务4a科学网络话语检测中所探索的方法。针对多类分类任务,我们确定推特中是否包含科学声明、对科学研究的引用、以及提及科学实体(如大学或科学家)。我们为此任务提出了三种建模方法:微调转换器、LLM的少样本提示和结合早期实验的集成模型设计。我们的团队在比赛中获得第七名,宏观平均F1分数为0.8611,较DeBERTaV3基准的0.8375有所提高。代码可在Github上找到。
Key Takeaways
- 介绍了团队在检测科学网络话语的多类分类任务中所采用的方法。
- 确定了推特中是否包含科学声明、对科学研究的引用以及提及的科学实体。
- 提出了三种建模方法:微调转换器、LLM的少样本提示和集成模型设计。
- 团队在比赛中获得第七名,宏观平均F1分数为0.8611。
- 与DeBERTaV3基准相比,取得了F1分数的改进。
- 代码已在Github上公开。
点此查看论文截图

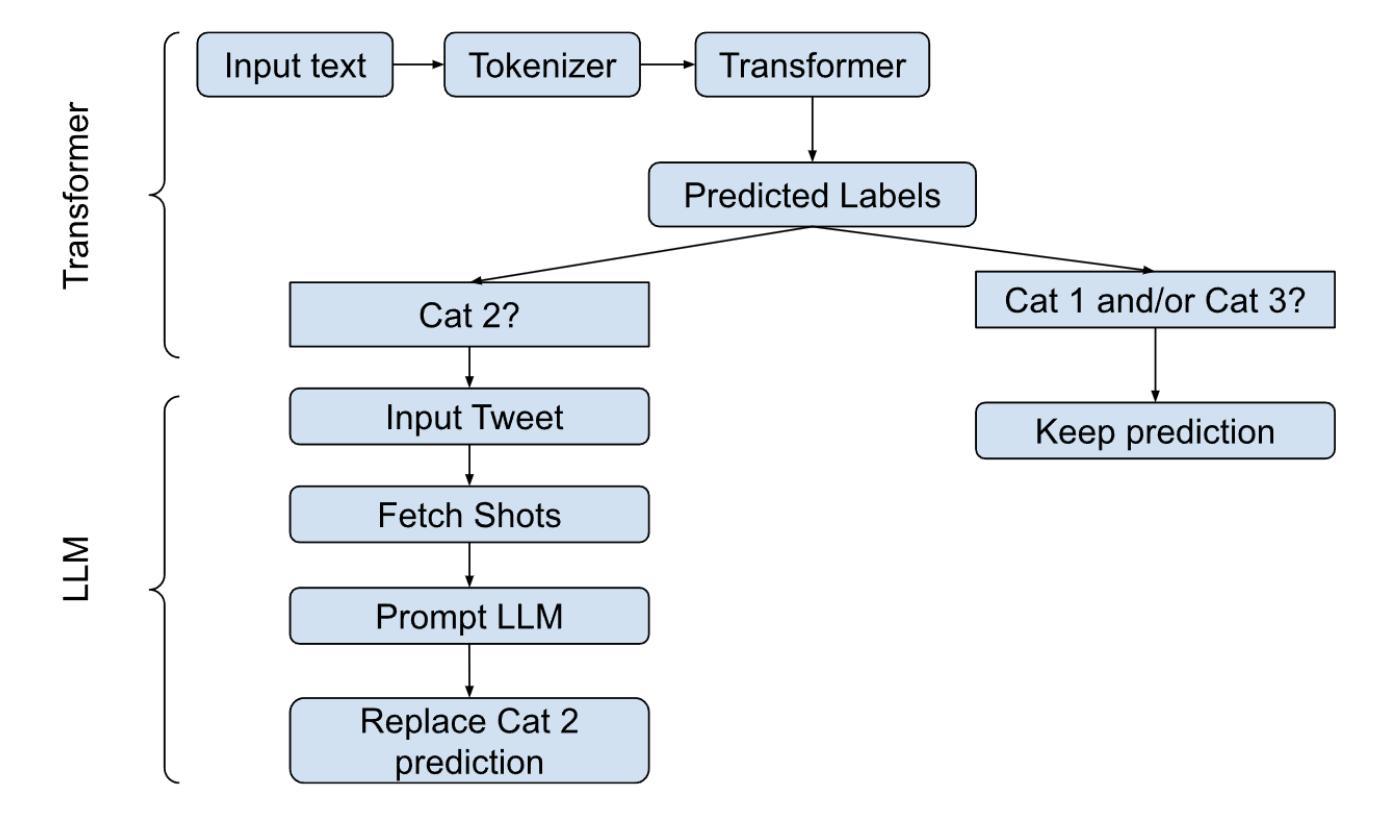
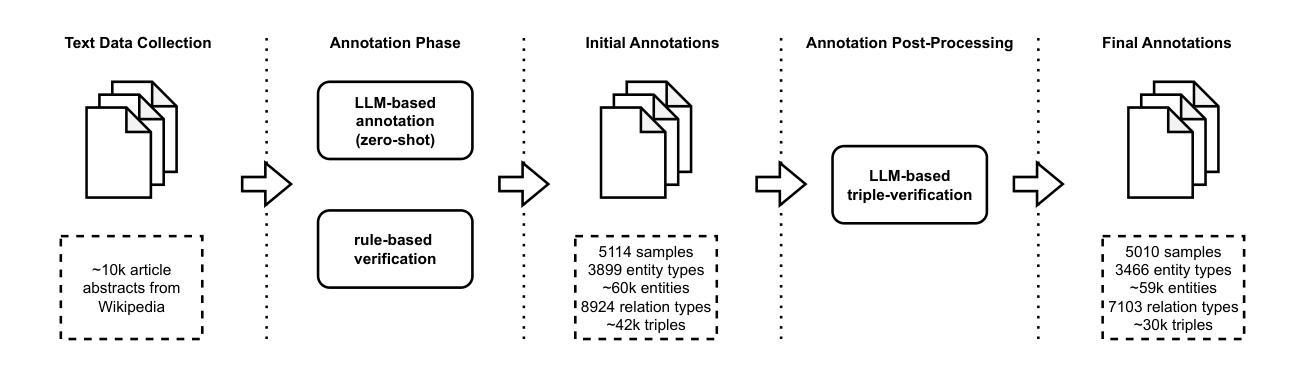
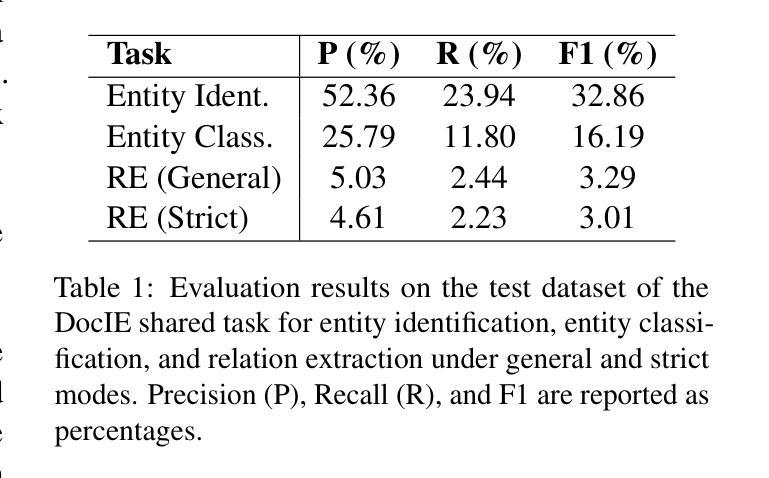
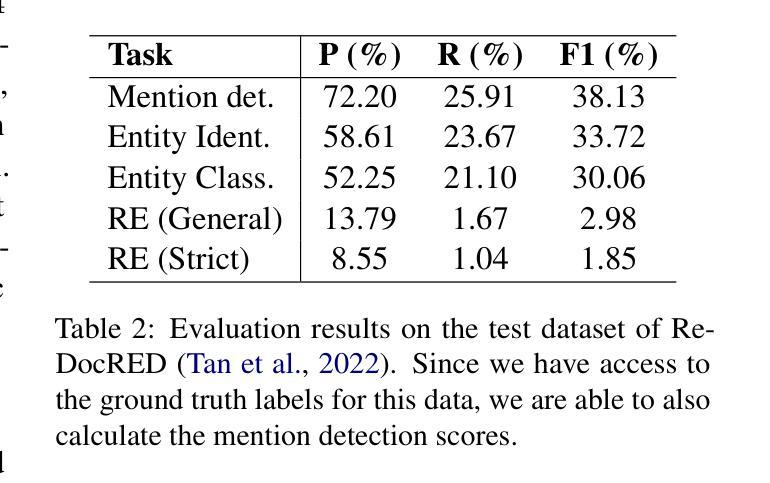
DocIE@XLLM25: In-Context Learning for Information Extraction using Fully Synthetic Demonstrations
Authors:Nicholas Popovič, Ashish Kangen, Tim Schopf, Michael Färber
Large, high-quality annotated corpora remain scarce in document-level entity and relation extraction in zero-shot or few-shot settings. In this paper, we present a fully automatic, LLM-based pipeline for synthetic data generation and in-context learning for document-level entity and relation extraction. In contrast to existing approaches that rely on manually annotated demonstrations or direct zero-shot inference, our method combines synthetic data generation with retrieval-based in-context learning, using a reasoning-optimized language model. This allows us to build a high-quality demonstration database without manual annotation and to dynamically retrieve relevant examples at inference time. Based on our approach we produce a synthetic dataset of over $5k$ Wikipedia abstracts with approximately $59k$ entities and $30k$ relation triples. Finally, we evaluate in-context learning performance on the DocIE shared task, extracting entities and relations from long documents in a zero-shot setting. We find that in-context joint entity and relation extraction at document-level remains a challenging task, even for state-of-the-art large language models.
在零样本或少样本环境下,文档级别的实体和关系抽取仍然缺乏大规模的高质量标注语料库。在本文中,我们提出了一种基于大型语言模型的全自动合成数据生成和上下文学习管道,用于文档级别的实体和关系抽取。与依赖手动标注演示或直接零样本推理的现有方法不同,我们的方法结合了合成数据生成和基于检索的上下文学习,并使用优化推理的语言模型。这使我们能够建立无需手动注释的高质量演示数据库,并在推理时动态检索相关示例。基于我们的方法,我们生成了一个包含超过5k个维基百科摘要的合成数据集,其中包含大约5.9万个实体和3万个关系三元组。最后,我们在DocIE共享任务上评估了上下文学习效果,该任务是在零样本设置下从长文档中抽取实体和关系。我们发现即使在最先进的大型语言模型面前,文档级别的上下文联合实体和关系抽取仍然是一项具有挑战性的任务。
论文及项目相关链接
Summary
本文介绍了一种全自动的、基于大型语言模型(LLM)的合成数据生成和上下文学习管道,用于文档级别的实体和关系提取。该方法结合了合成数据生成和基于检索的上下文学习,无需手动注释即可构建高质量的演示数据库,并在推理时动态检索相关示例。基于该方法,我们制作了一个包含超过5k篇Wikipedia摘要的合成数据集,其中包含约59k个实体和30k个关系三元组。最后,我们在DocIE共享任务上评估了上下文学习的性能,该任务是在零样本设置下从长文档中提取实体和关系。我们发现,即使在最先进的大型语言模型面前,文档级别的联合实体和关系提取仍然是一项具有挑战性的任务。
Key Takeaways
- 介绍了全自动、基于LLM的合成数据生成和上下文学习管道,用于文档级别的实体和关系提取。
- 结合了合成数据生成和基于检索的上下文学习,以构建高质量的演示数据库,并在推理时动态检索相关示例。
- 制作了一个包含超过5k篇Wikipedia摘要的合成数据集,包含约59k个实体和30k个关系三元组。
- 在DocIE共享任务上评估了上下文学习的性能,发现文档级别的联合实体和关系提取具有挑战性。
- 该方法允许在没有手动注释的情况下构建演示数据库。
- 所提出的方法在零样本设置下具有良好的性能。
点此查看论文截图

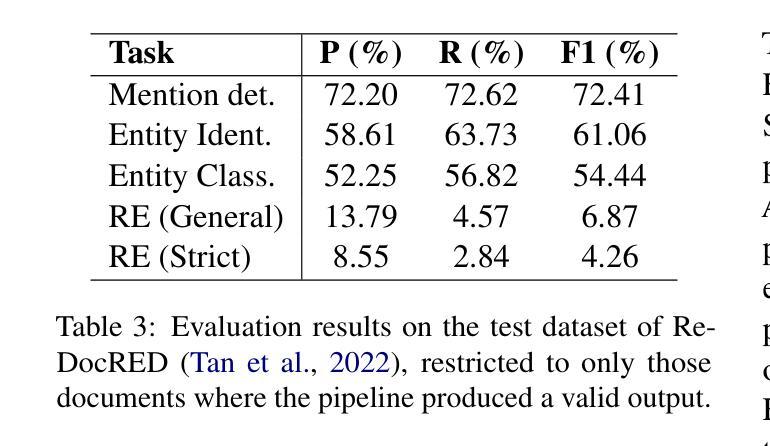
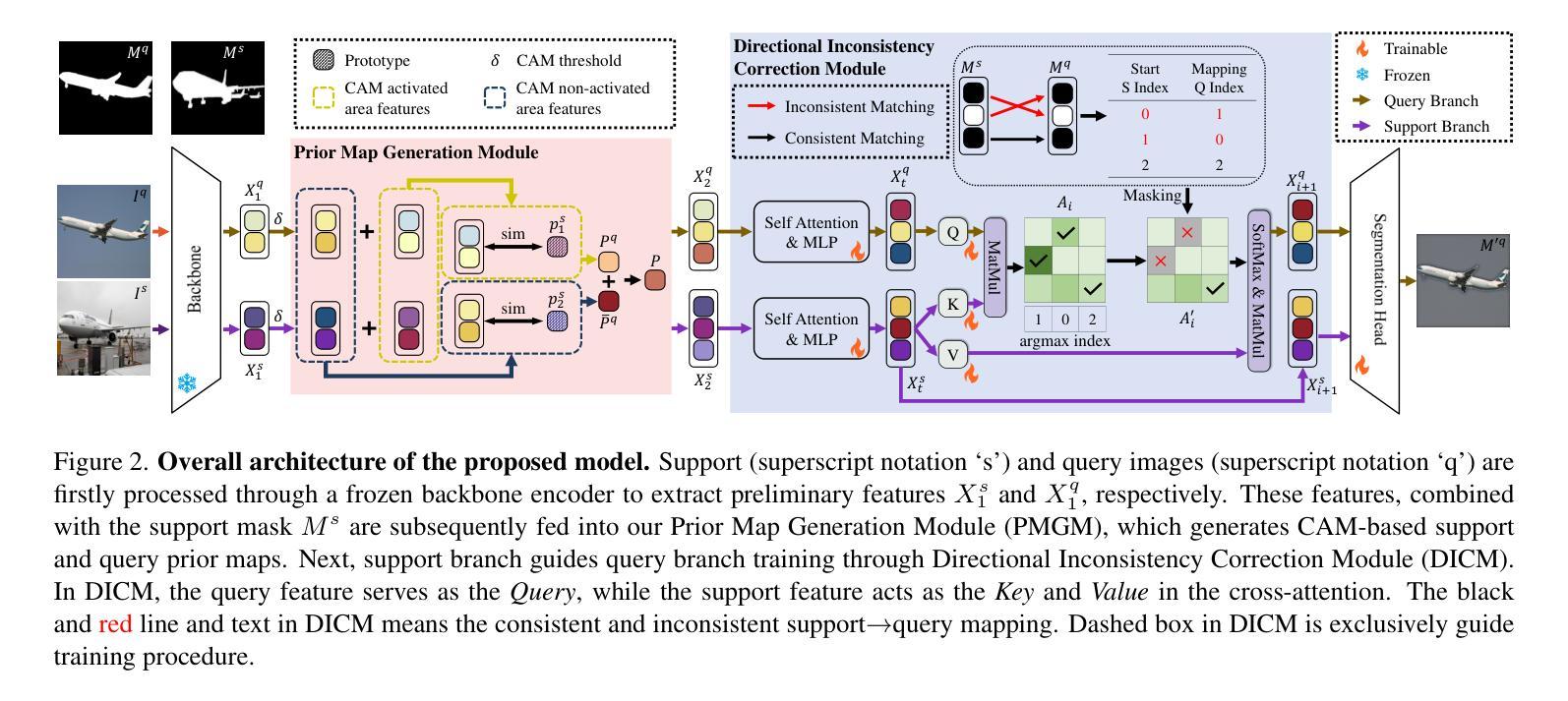
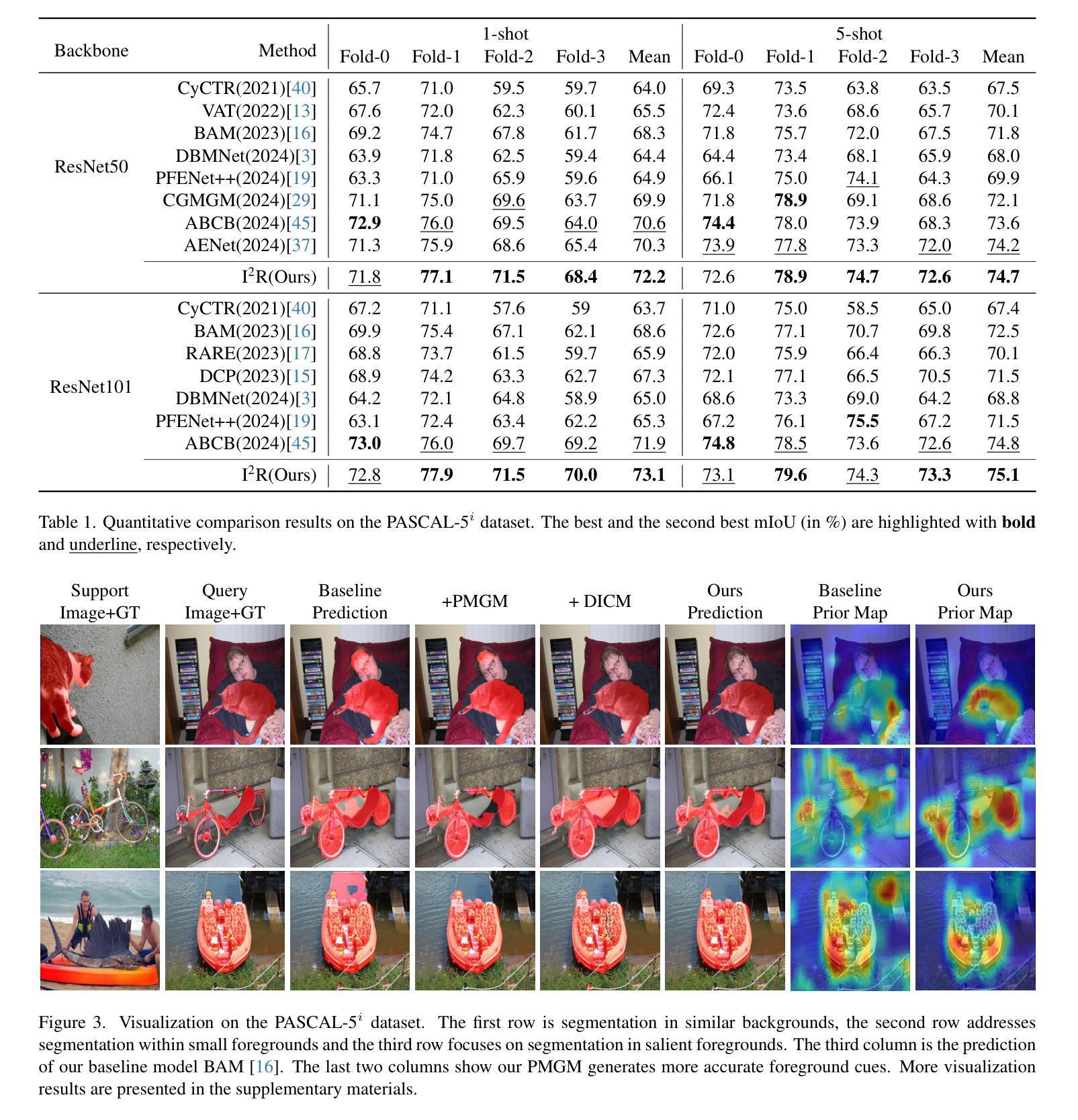
I$^2$R: Inter and Intra-image Refinement in Few Shot Segmentation
Authors:Ourui Fu, Hangzhou He, Xinliang Zhang, Lei Zhu, Shuang Zeng, ZhaoHeng Xie, Yanye Lu
The annotation bottleneck in semantic segmentation has driven significant interest in few-shot segmentation, which aims to develop segmentation models capable of generalizing rapidly to novel classes using minimal exemplars. Conventional training paradigms typically generate query prior maps by extracting masked-area features from support images, followed by making predictions guided by these prior maps. However, current approaches remain constrained by two critical limitations stemming from inter- and intra-image discrepancies, both of which significantly degrade segmentation performance: 1) The semantic gap between support and query images results in mismatched features and inaccurate prior maps; 2) Visually similar yet semantically distinct regions within support or query images lead to false negative or false positive predictions. We propose a novel FSS method called \textbf{I$^2$R}: 1) Using category-specific high level representations which aggregate global semantic cues from support and query images, enabling more precise inter-image region localization and address the first limitation. 2) Directional masking strategy that suppresses inconsistent support-query pixel pairs, which exhibit high feature similarity but conflicting mask, to mitigate the second issue. Experiments demonstrate that our method outperforms state-of-the-art approaches, achieving improvements of 1.9% and 2.1% in mIoU under the 1-shot setting on PASCAL-5$^i$ and COCO-20$^i$ benchmarks, respectively.
语义分割中的标注瓶颈引发了少量拍摄分割(few-shot segmentation)的极大兴趣。少量拍摄分割的目标是开发能够利用少量样本快速推广到新的类别的分割模型。传统的训练范式通常通过从支持图像中提取掩盖区域特征来生成查询先验图,然后通过这些先验图进行预测。然而,当前的方法仍然受到两个关键限制的影响,这些限制源于图像内部和图像之间的差异性,两者都会显著影响分割性能:(1)支持图像和查询图像之间的语义差距导致特征不匹配和不准确的先验图;(2)在支持图像或查询图像中视觉上相似但语义上不同的区域导致假阴性或假阳性预测。我们提出了一种新的FSS方法,称为I$^2$R:通过利用特定类别的高级表示形式来聚合来自支持图像和查询图像的全局语义线索,从而实现更精确的区域间定位并解决第一个限制。通过采用定向掩蔽策略来抑制不一致的支持-查询像素对(这些像素对表现出较高的特征相似性但存在冲突的掩蔽),从而缓解第二个问题。实验表明,我们的方法在PASCAL-5$^i$和COCO-20$^i$基准测试下的单镜头设置中,相较于最新方法提高了mIoU指标,分别提高了1.9%和2.1%。
论文及项目相关链接
Summary
本文介绍了少样本语义分割(Few-Shot Segmentation)领域的问题和挑战。针对现有方法的两个关键局限性——跨图像语义差距和图像内视觉相似但语义不同的区域,提出了一种新的方法I$^2$R。该方法利用类别特定的高级表示和方向性掩模策略来分别解决这两个问题,实现了更精确的跨图像区域定位和减少误判。实验结果表明,该方法在PASCAL-5$^i$和COCO-20$^i$基准测试中,相对于现有方法提高了1.9%和2.1%的mIoU。
Key Takeaways
- 现有方法在语义分割的标注瓶颈上促使了对少样本分割(Few-Shot Segmentation)的关注,目标是使用少量样本快速推广到新的类别。
- 传统训练模式通过从支持图像中提取掩码区域特征生成查询先验图,但在实际应用中存在两个关键局限性。
- 第一个局限性是跨图像语义差距导致的特征不匹配和不准确的先验图。本文提出了使用类别特定的高级表示来解决这个问题。
- 第二个局限性是图像内视觉上相似但语义不同的区域导致误判。为此,本文引入了方向性掩模策略来减少不一致的支持-查询像素对的干扰。
- 该方法名为I$^2$R,在PASCAL-5$^i$和COCO-20$^i$基准测试中表现优异,相对于现有方法提升了mIoU得分。
- I$^2$R方法通过更精确的跨图像区域定位和减少误判,解决了传统方法的局限性。
点此查看论文截图

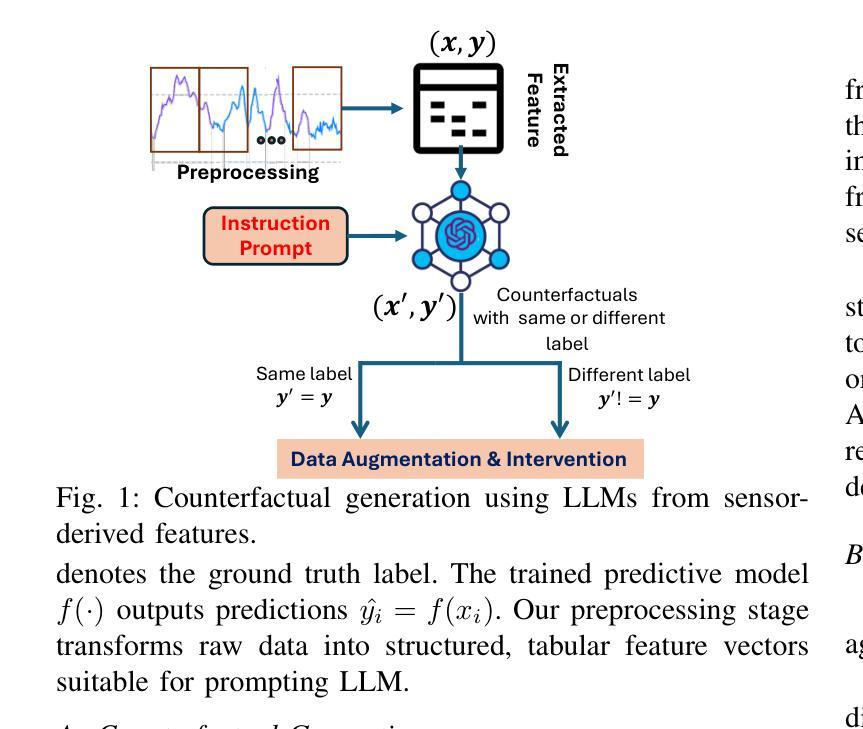
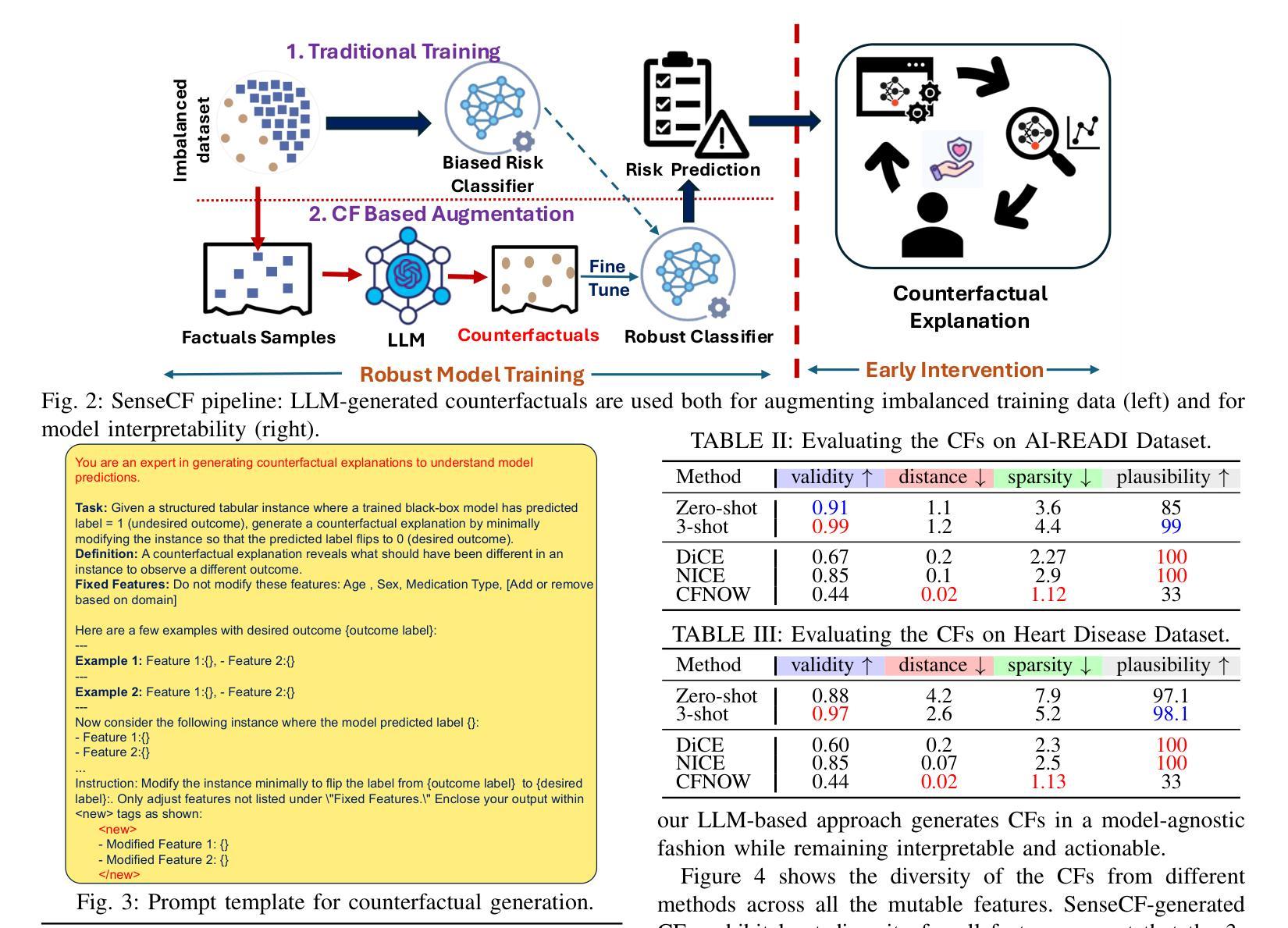
SenseCF: LLM-Prompted Counterfactuals for Intervention and Sensor Data Augmentation
Authors:Shovito Barua Soumma, Asiful Arefeen, Stephanie M. Carpenter, Melanie Hingle, Hassan Ghasemzadeh
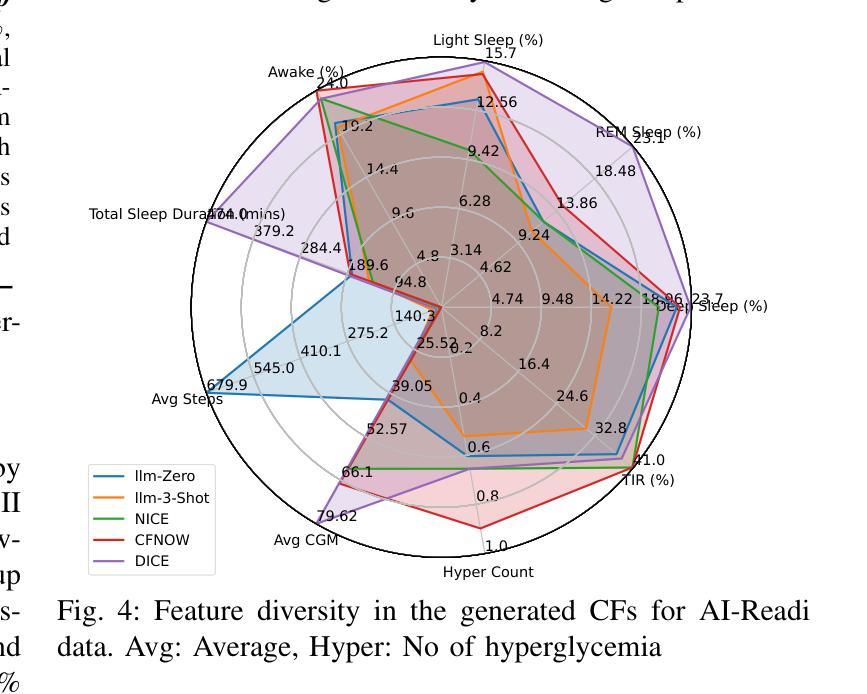
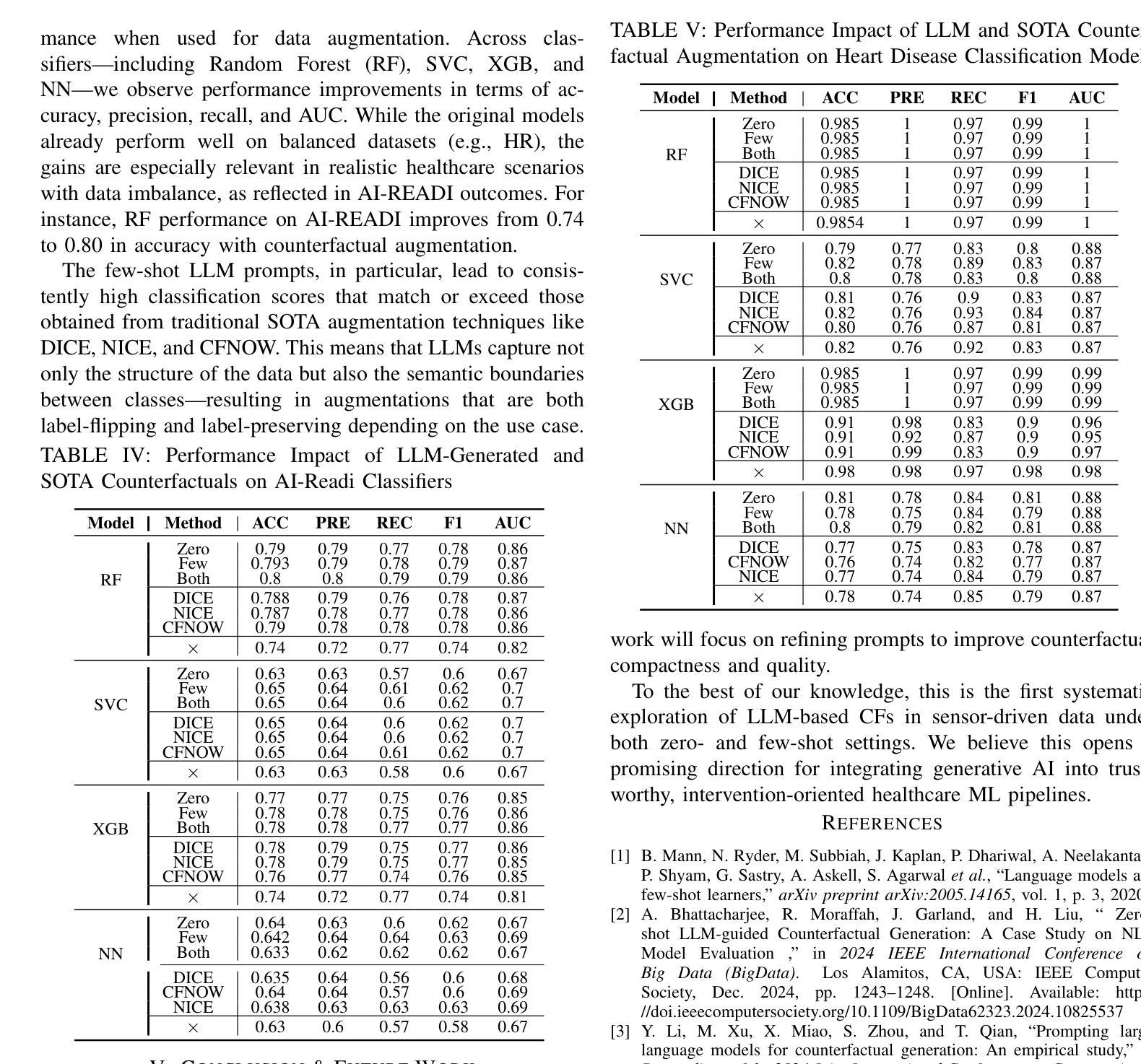
Counterfactual explanations (CFs) offer human-centric insights into machine learning predictions by highlighting minimal changes required to alter an outcome. Therefore, CFs can be used as (i) interventions for abnormality prevention and (ii) augmented data for training robust models. In this work, we explore large language models (LLMs), specifically GPT-4o-mini, for generating CFs in a zero-shot and three-shot setting. We evaluate our approach on two datasets: the AI-Readi flagship dataset for stress prediction and a public dataset for heart disease detection. Compared to traditional methods such as DiCE, CFNOW, and NICE, our few-shot LLM-based approach achieves high plausibility (up to 99%), strong validity (up to 0.99), and competitive sparsity. Moreover, using LLM-generated CFs as augmented samples improves downstream classifier performance (an average accuracy gain of 5%), especially in low-data regimes. This demonstrates the potential of prompt-based generative techniques to enhance explainability and robustness in clinical and physiological prediction tasks. Code base: github.com/anonymous/SenseCF.
因果解释(CFs)通过强调改变结果所需的最小变化,为机器学习预测提供了以人类为中心的见解。因此,因果解释可用于(i)异常预防干预和(ii)增强数据以训练稳健模型。在这项工作中,我们探索了大规模语言模型(LLM),特别是GPT-4o-mini,在零击和三次射击环境中生成因果解释。我们在两个数据集上评估了我们的方法:用于压力预测的AI-Readi旗舰数据集和用于心脏病检测公开数据集。与传统的DiCE、CFNOW和NICE等方法相比,我们基于少量数据的LLM方法实现了高达99%的可信度和高达0.99的强烈有效性,并且稀疏性具有竞争力。此外,使用LLM生成的因果解释作为增强样本提高了下游分类器的性能(平均准确率提高5%),特别是在数据较少的情况下。这证明了基于提示的生成技术增强临床和生理预测任务的可解释性和稳健性的潜力。代码库:github.com/anonymous/SenseCF。
论文及项目相关链接
PDF In review
Summary
基于文本描述,该研究探讨了使用大型语言模型(LLMs)生成反事实解释(CFs)的方法,用于提升机器学习的预测解释性和模型的稳健性。研究通过GPT-4o-mini模型在零样本和三样本环境下生成CFs,并在两个数据集上评估了方法的性能。与传统方法相比,该研究的方法实现了高可信度、有效性和竞争力强的稀疏性。此外,使用LLM生成的CFs作为增强样本能够提高下游分类器的性能,特别是在数据较少的情况下。这显示了提示生成技术在临床和生理预测任务中增强解释性和稳健性的潜力。
Key Takeaways
- 反事实解释(CFs)能够通过强调改变结果所需的最小变化来提供关于机器学习预测的人性化见解。
- CFs可以用作(i)异常预防的干预措施和(ii)训练稳健模型时的增强数据。
- 研究采用大型语言模型(LLMs)生成CFs,并在零样本和三样本环境下进行尝试。
- 在两个数据集上评估了该方法,实现了高可信度、有效性和竞争力强的稀疏性。
- 与传统方法相比,LLM生成CFs的方法表现出优势。
- 使用LLM生成的CFs作为增强样本能够提高下游分类器的性能,尤其在数据较少时效果更显著。
点此查看论文截图

pFedMMA: Personalized Federated Fine-Tuning with Multi-Modal Adapter for Vision-Language Models
Authors:Sajjad Ghiasvand, Mahnoosh Alizadeh, Ramtin Pedarsani
Vision-Language Models (VLMs) like CLIP have demonstrated remarkable generalization in zero- and few-shot settings, but adapting them efficiently to decentralized, heterogeneous data remains a challenge. While prompt tuning has emerged as a popular parameter-efficient approach in personalized federated learning, existing methods often sacrifice generalization in favor of personalization, struggling particularly on unseen classes or domains. In this work, we propose pFedMMA, the first personalized federated learning framework that leverages multi-modal adapters for vision-language tasks. Each adapter contains modality-specific up- and down-projection layers alongside a globally shared projection that aligns cross-modal features. Our asymmetric optimization strategy allows clients to locally adapt to personalized data distributions while collaboratively training the shared projection to improve global generalization. This design is also communication-efficient, as only the shared component is exchanged during rounds. Through extensive experiments across eleven datasets, including domain- and label-shift scenarios, we show that pFedMMA achieves state-of-the-art trade-offs between personalization and generalization, outperforming recent federated prompt tuning methods. The code is available at https://github.com/sajjad-ucsb/pFedMMA.
视觉语言模型(如CLIP)在零样本和少样本设置下已经展现出显著的泛化能力,但在分布式、异构数据上有效地适应它们仍然是一个挑战。虽然提示调整已成为个性化联邦学习中的参数高效方法的热门选择,但现有方法往往牺牲泛化性以换取个性化,尤其是在未见类别或领域上表现挣扎。在这项工作中,我们提出了pFedMMA,这是第一个利用多模态适配器的个性化联邦学习框架,用于视觉语言任务。每个适配器包含模态特定的上下投影层以及全局共享投影,以对齐跨模态特征。我们的不对称优化策略允许客户端本地适应个性化数据分布,同时协作训练共享投影以提高全局泛化能力。这种设计还具有通信效率,因为仅在几轮中交换共享组件。通过包括领域和标签偏移场景在内的十一个数据集的广泛实验,我们证明了pFedMMA在个性化和泛化之间达到了最先进的权衡,并超越了最近的联邦提示调整方法。代码可在https://github.com/sajjad-ucsb/pFedMMA找到。
论文及项目相关链接
Summary
VLMs如CLIP在零样本和少样本设置下展现出卓越的泛化能力,但在去中心化、异质数据的适应效率上仍面临挑战。现有方法常牺牲泛化能力以换取个性化,特别是在未见类别或领域上表现欠佳。本文提出pFedMMA,首个针对视觉语言任务利用多模态适配器的个性化联邦学习框架。pFedMMA设计有模态特定上下投影层及全局共享投影以对齐跨模态特征。不对称优化策略使客户端可适应个性化数据分布,同时训练共享投影以提高全局泛化。框架在11个数据集上的实验证明,pFedMMA在个性化与泛化间达到最优平衡,超越现有联邦提示调整方法。代码已公开。
Key Takeaways
- VLMs(如CLIP)在零样本和少样本环境下具有良好的泛化性能。
- 适应去中心化和异质数据对VLMs仍是挑战。
- 现有方法牺牲泛化能力以实现个性化,特别是在未见类别或领域上。
- pFedMMA是首个结合多模态适配器的个性化联邦学习框架。
- pFedMMA包含模态特定上下投影层及全局共享投影设计。
- pFedMMA采用不对称优化策略,实现个性化数据适应和全局泛化的平衡。
- pFedMMA在多个数据集上实现个性化与泛化的最佳平衡,代码已公开。
点此查看论文截图

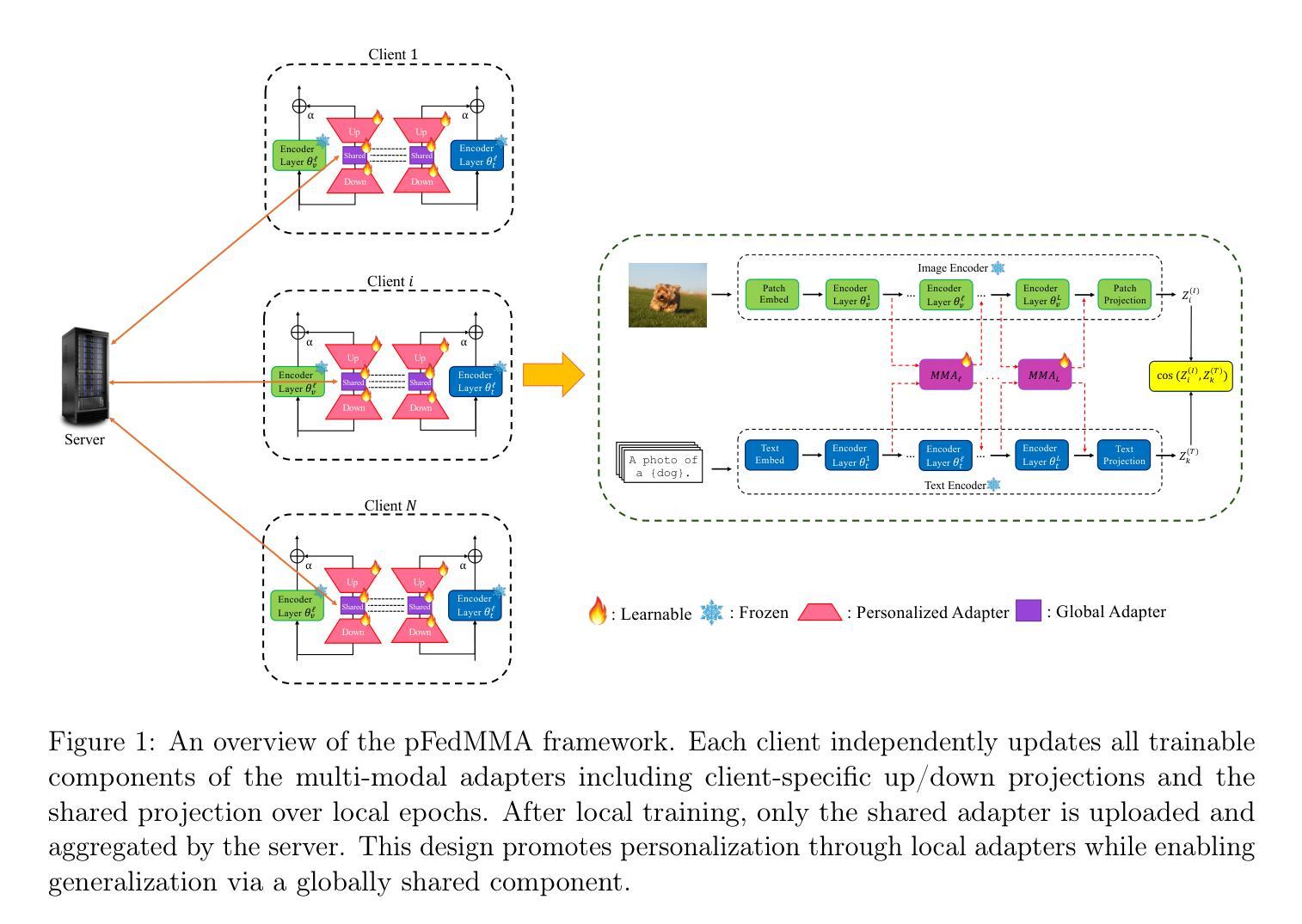
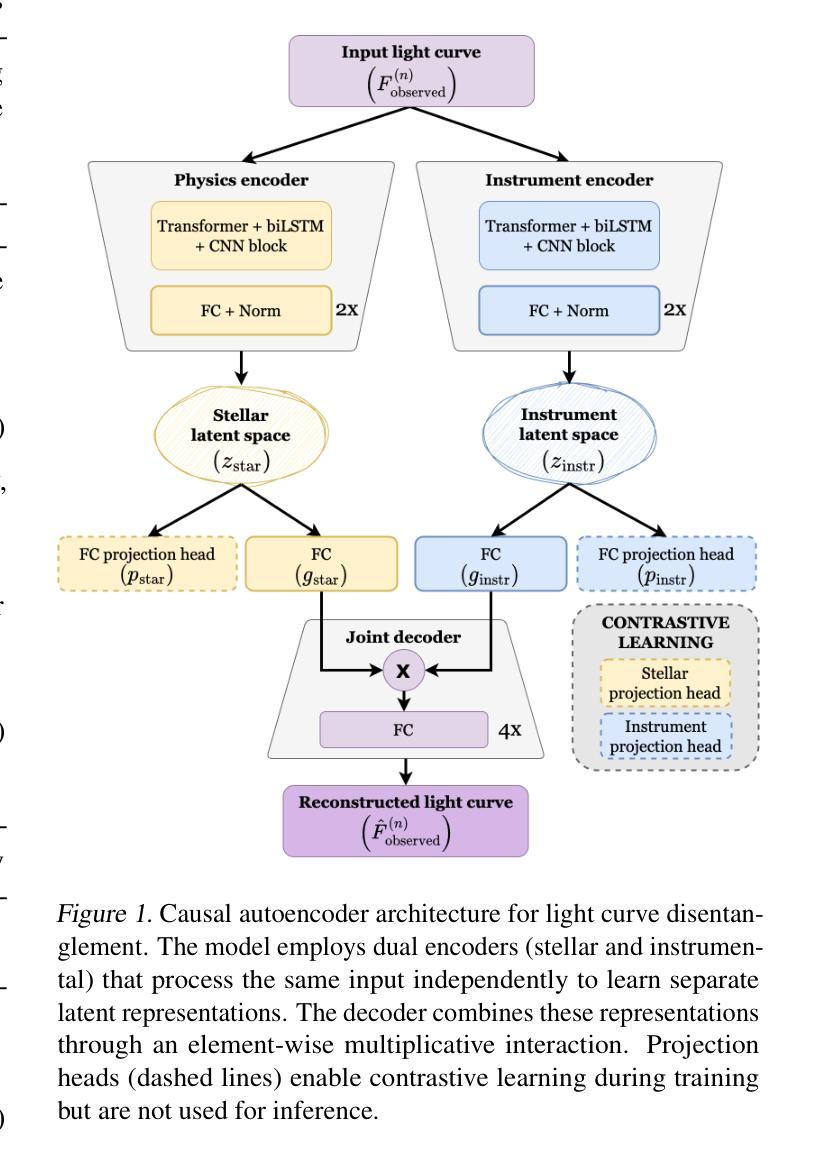
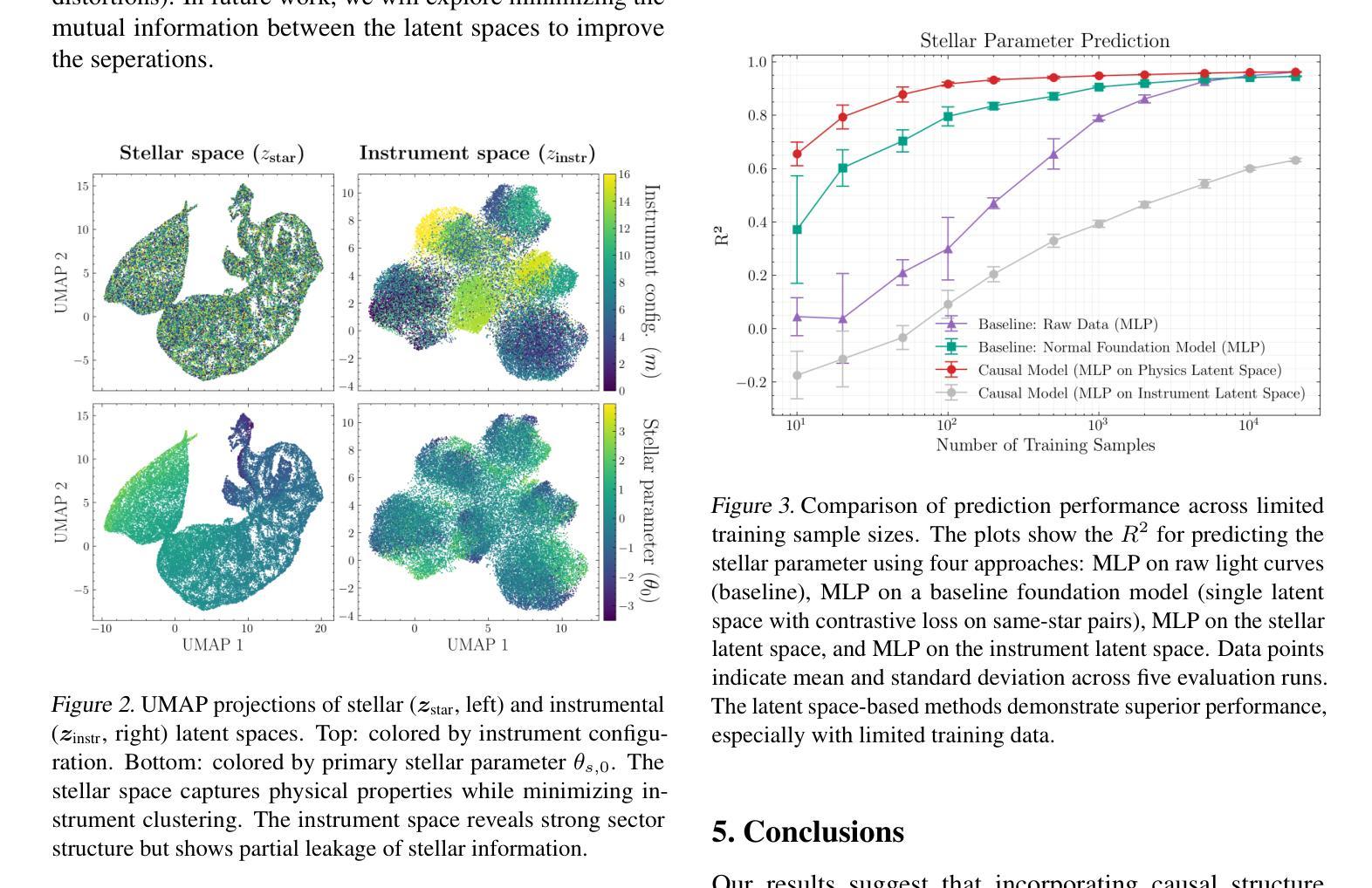
Causal Foundation Models: Disentangling Physics from Instrument Properties
Authors:Jeroen Audenaert, Daniel Muthukrishna, Paul F. Gregory, David W. Hogg, V. Ashley Villar
Foundation models for structured time series data must contend with a fundamental challenge: observations often conflate the true underlying physical phenomena with systematic distortions introduced by measurement instruments. This entanglement limits model generalization, especially in heterogeneous or multi-instrument settings. We present a causally-motivated foundation model that explicitly disentangles physical and instrumental factors using a dual-encoder architecture trained with structured contrastive learning. Leveraging naturally occurring observational triplets (i.e., where the same target is measured under varying conditions, and distinct targets are measured under shared conditions) our model learns separate latent representations for the underlying physical signal and instrument effects. Evaluated on simulated astronomical time series designed to resemble the complexity of variable stars observed by missions like NASA’s Transiting Exoplanet Survey Satellite (TESS), our method significantly outperforms traditional single-latent space foundation models on downstream prediction tasks, particularly in low-data regimes. These results demonstrate that our model supports key capabilities of foundation models, including few-shot generalization and efficient adaptation, and highlight the importance of encoding causal structure into representation learning for structured data.
结构时间序列数据的基础模型面临一个基本挑战:观测结果往往将真正的底层物理现象与测量仪器引入的系统扭曲混淆在一起。这种纠缠限制了模型的泛化能力,特别是在异构或多仪器环境中。我们提出了一种因果驱动的基础模型,该模型使用双编码器架构进行明确的结构对比学习,以分离物理和仪器因素。通过利用自然发生的观测三元组(即在变化条件下对同一目标进行测量,以及在共享条件下对不同目标进行测量),我们的模型学会了对底层物理信号和仪器效果的单独潜在表示。在模拟的天文时间序列上进行了评估,该模拟设计旨在模仿由美国宇航局的凌星外行星勘测卫星(TESS)等任务观察到的变星的复杂性,我们的方法在下游预测任务上显著优于传统的单一潜在空间基础模型,特别是在数据稀缺的情况下。这些结果证明了我们的模型支持基础模型的关键功能,包括少量样本的泛化和高效适应,并强调了将因果结构编码到结构化数据表示学习中的重要性。
论文及项目相关链接
PDF 8 pages, 5 figures. Accepted to the ICML 2025 Foundation Models for Structured Data Workshop and accepted to the Machine Learning for Astrophysics Workshop 2025
Summary
本文提出一种因果驱动的基础模型,用于显式地解开结构化时间序列数据中物理和仪器因素之间的纠缠。该模型采用双编码器架构,并利用结构化对比学习进行训练。通过利用自然观测的三元组,模型能够学习底层物理信号和仪器效应的单独潜在表示。在模拟的天文时间序列数据上的评估表明,该方法在下游预测任务上显著优于传统单潜在空间基础模型,特别是在数据稀缺的情况下。
Key Takeaways
- 现有基础模型在处理结构化时间序列数据时面临挑战,因为观测结果通常将底层物理现象与仪器引入的系统性扭曲混淆在一起。
- 提出的因果驱动基础模型使用双编码器架构,能够显式地解开物理和仪器因素,从而提高模型的泛化能力。
- 该模型利用结构化对比学习进行训练,通过自然观测的三元组学习底层物理信号和仪器效应的单独潜在表示。
- 模型在模拟的天文时间序列数据上的表现优于传统模型,特别是在数据稀缺的情况下。
- 该研究强调了因果结构在结构化数据表示学习中的重要性。
- 模型的应用潜力不仅限于天文学领域,还可应用于其他需要处理复杂时间序列数据的领域。
点此查看论文截图

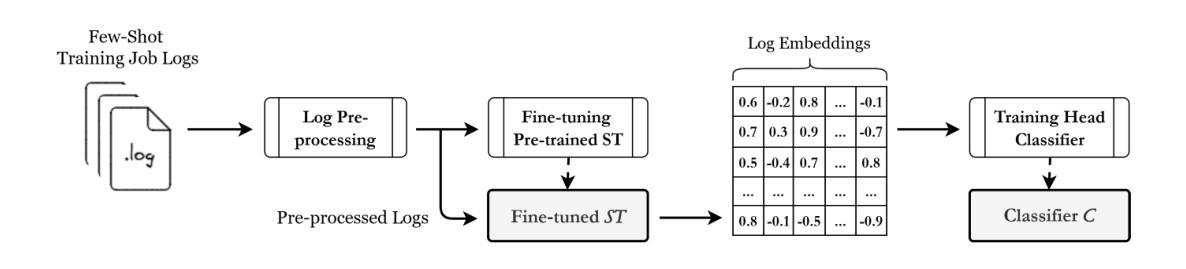
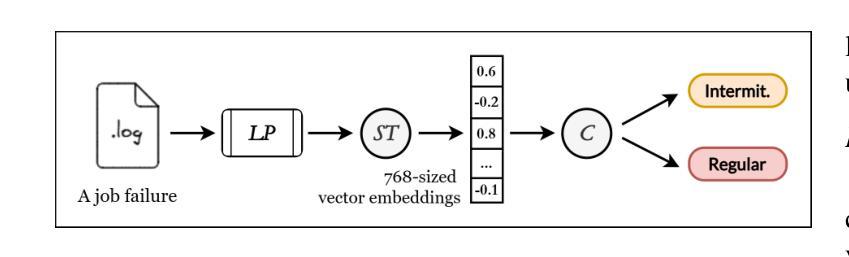
Efficient Detection of Intermittent Job Failures Using Few-Shot Learning
Authors:Henri Aïdasso, Francis Bordeleau, Ali Tizghadam
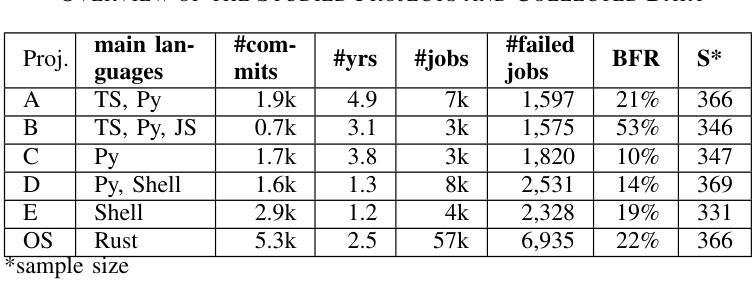
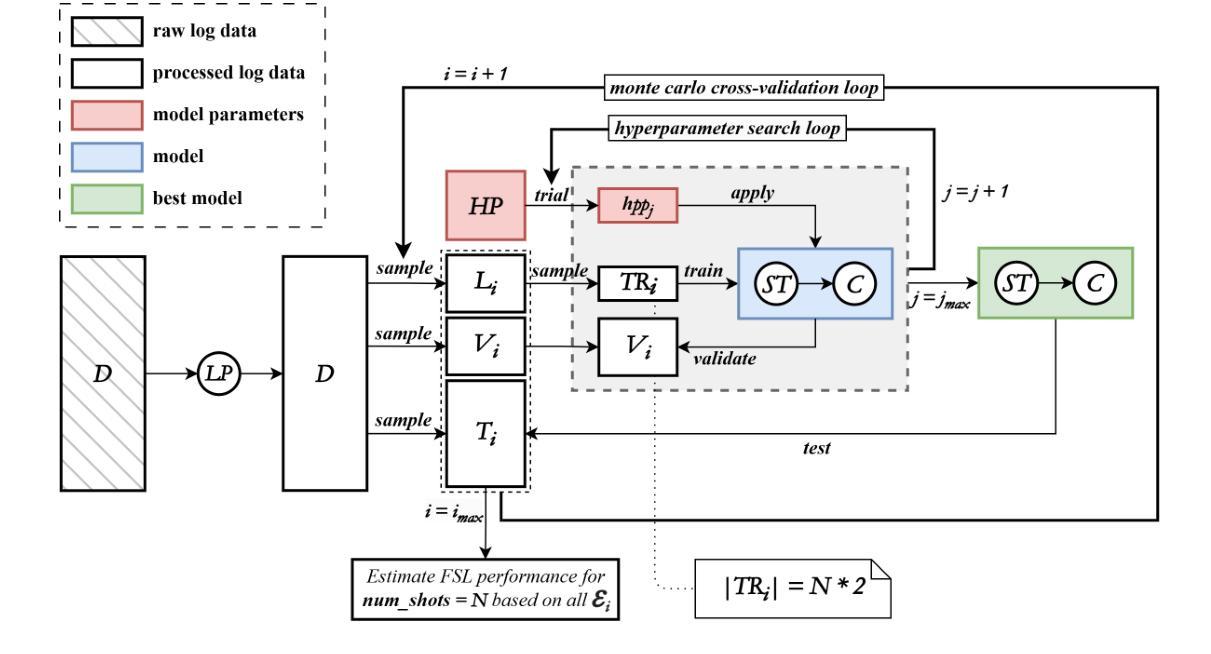
One of the main challenges developers face in the use of continuous integration (CI) and deployment pipelines is the occurrence of intermittent job failures, which result from unexpected non-deterministic issues (e.g., flaky tests or infrastructure problems) rather than regular code-related errors such as bugs. Prior studies developed machine learning (ML) models trained on large datasets of job logs to classify job failures as either intermittent or regular. As an alternative to costly manual labeling of large datasets, the state-of-the-art (SOTA) approach leveraged a heuristic based on non-deterministic job reruns. However, this method mislabels intermittent job failures as regular in contexts where rerunning suspicious job failures is not an explicit policy, and therefore limits the SOTA’s performance in practice. In fact, our manual analysis of 2,125 job failures from 5 industrial and 1 open-source projects reveals that, on average, 32% of intermittent job failures are mislabeled as regular. To address these limitations, this paper introduces a novel approach to intermittent job failure detection using few-shot learning (FSL). Specifically, we fine-tune a small language model using a few number of manually labeled log examples to generate rich embeddings, which are then used to train an ML classifier. Our FSL-based approach achieves 70-88% F1-score with only 12 shots in all projects, outperforming the SOTA, which proved ineffective (34-52% F1-score) in 4 projects. Overall, this study underlines the importance of data quality over quantity and provides a more efficient and practical framework for the detection of intermittent job failures in organizations.
开发者在使用持续集成(CI)和部署管道时面临的主要挑战之一是间歇性作业失败的发生。这些失败是由于意外的非确定性问题(例如,测试不稳定或基础设施问题)导致的,而不是常规的代码相关错误,如错误。早期的研究已经开发出了基于大型作业日志数据集训练的机器学习(ML)模型,用于将作业失败分类为间歇性失败或常规失败。作为对大型数据集昂贵手动标签的替代方案,最新方法利用基于非确定性作业重跑的启发式方法。然而,在重试可疑作业失败不是明确策略的情况下,这种方法会将间歇性作业失败误判为常规情况,因此在实际应用中限制了最新方法的性能。实际上,我们对来自五个工业项目和一开源项目的 2,125 次作业失败进行的手动分析显示,平均而言,有 32% 的间歇性作业失败被误判为常规情况。为了解决这些局限性,本文引入了一种新的间歇性作业故障检测法——基于少量学习的学习方法(FSL)。具体来说,我们使用少量手动标记的日志示例微调小型语言模型来生成丰富的嵌入表示,然后使用这些嵌入表示训练 ML 分类器。基于我们的少量学习的FSL方法在所有项目中仅使用 12 个样本就达到了 70-88% 的 F1 分数,优于先前技术状态的最优方法(在四个项目中 F1 分数仅为 34-52%),证明了其有效性。总体而言,该研究强调了数据质量而非数量在间歇性作业故障检测中的重要性,并提供了一个更有效率且实用的框架用于组织中的间歇性作业故障检测。
论文及项目相关链接
PDF Accepted at the 41st International Conference on Software Maintenance and Evolution - ICSME 2025 (Industry Track); 12 pages; typos corrected
Summary
该文本介绍了在连续集成和部署管道的使用中,开发者面临的一个主要挑战是偶发性作业失败的问题。针对这一问题,研究者引入了基于少量标注日志样本的少数学习(FSL)新方法来进行偶发性作业失败的检测。该方法通过微调小型语言模型生成丰富的嵌入,然后用于训练机器学习分类器。实验结果显示,该方法在所有项目中的F1分数达到70-88%,仅使用12个样本,优于现有方法。总体而言,该研究强调了数据质量比数量更重要,并为组织中的偶发性作业失败检测提供了更高效、更实用的框架。
Key Takeaways
- 偶发性作业失败是连续集成和部署管道中的一大挑战,源于非确定性问题,如测试不稳定或基础设施问题。
- 现有方法使用基于大型作业日志数据集训练的机器学习模型来分类作业失败类型。
- 最新方法引入基于少数学习的偶发性作业失败检测,仅使用少量手动标注的日志样本进行微调。
- 该方法生成丰富的嵌入,用于训练机器学习分类器,实现高F1分数(70-88%)。
- 与现有方法相比,该方法在多个项目中表现更优,突显数据质量的重要性。
- 研究结果提供了一种更实用、高效的框架来检测组织中的偶发性作业失败。
点此查看论文截图