⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-10 更新
A Survey on Latent Reasoning
Authors:Rui-Jie Zhu, Tianhao Peng, Tianhao Cheng, Xingwei Qu, Jinfa Huang, Dawei Zhu, Hao Wang, Kaiwen Xue, Xuanliang Zhang, Yong Shan, Tianle Cai, Taylor Kergan, Assel Kembay, Andrew Smith, Chenghua Lin, Binh Nguyen, Yuqi Pan, Yuhong Chou, Zefan Cai, Zhenhe Wu, Yongchi Zhao, Tianyu Liu, Jian Yang, Wangchunshu Zhou, Chujie Zheng, Chongxuan Li, Yuyin Zhou, Zhoujun Li, Zhaoxiang Zhang, Jiaheng Liu, Ge Zhang, Wenhao Huang, Jason Eshraghian
Large Language Models (LLMs) have demonstrated impressive reasoning capabilities, especially when guided by explicit chain-of-thought (CoT) reasoning that verbalizes intermediate steps. While CoT improves both interpretability and accuracy, its dependence on natural language reasoning limits the model’s expressive bandwidth. Latent reasoning tackles this bottleneck by performing multi-step inference entirely in the model’s continuous hidden state, eliminating token-level supervision. To advance latent reasoning research, this survey provides a comprehensive overview of the emerging field of latent reasoning. We begin by examining the foundational role of neural network layers as the computational substrate for reasoning, highlighting how hierarchical representations support complex transformations. Next, we explore diverse latent reasoning methodologies, including activation-based recurrence, hidden state propagation, and fine-tuning strategies that compress or internalize explicit reasoning traces. Finally, we discuss advanced paradigms such as infinite-depth latent reasoning via masked diffusion models, which enable globally consistent and reversible reasoning processes. By unifying these perspectives, we aim to clarify the conceptual landscape of latent reasoning and chart future directions for research at the frontier of LLM cognition. An associated GitHub repository collecting the latest papers and repos is available at: https://github.com/multimodal-art-projection/LatentCoT-Horizon/.
大型语言模型(LLM)表现出了令人印象深刻的推理能力,特别是在明确的思维链(CoT)推理引导下,通过语言化中间步骤而展现出的能力。虽然思维链推理提高了可解释性和准确性,但它对自然语言推理的依赖限制了模型的表达带宽。潜在推理通过完全利用模型的连续隐藏状态进行多步推理来解决这一瓶颈,消除了基于标记的监督。为了推动潜在推理研究的发展,这篇综述提供了对新兴潜在推理领域的全面概述。我们首先探讨了神经网络层作为推理计算基础的作用,强调了层次表示如何支持复杂转换。接下来,我们探索了多种潜在推理方法,包括基于激活的递归、隐藏状态传播以及微调策略,这些策略可以压缩或内化显性推理痕迹。最后,我们讨论了高级范式,如通过掩码扩散模型实现的无限深度潜在推理,这启用了全局一致性和可逆的推理过程。通过统一这些观点,我们旨在澄清潜在推理的概念格局,并为大型语言模型认知前沿的研究指明未来方向。相关的GitHub仓库收集了最新的论文和仓库资源,可在以下链接找到:https://github.com/multimodal-art-projection/LatentCoT-Horizon/。
论文及项目相关链接
Summary
大型语言模型(LLM)通过明确的思维链(CoT)推理展示出色的推理能力,这种推理方式能够口头表达中间步骤。虽然CoT提高了可解释性和准确性,但它对自然语言推理的依赖限制了模型的表达带宽。潜在推理通过完全在模型的连续隐藏状态中进行多步推理来解决这一瓶颈,从而消除了令牌级别的监督。本文全面概述了潜在推理这一新兴领域的发展。文章首先研究神经网络层作为推理计算基底的基石作用,并强调分层表示如何支持复杂转换。然后,探讨了各种潜在推理方法,包括基于激活的递归、隐藏状态传播以及微调策略等,这些策略能够压缩或内化显性推理痕迹。最后,介绍了通过掩模扩散模型实现无限深度潜在推理等先进范式,这些范式能够实现全局一致且可逆的推理过程。本文旨在统一这些观点,澄清潜在推理的概念格局,并绘制LLM认知研究的前沿未来方向。
Key Takeaways
- LLMs具备通过明确的思维链(CoT)进行推理的能力,这提高了其可解释性和准确性。
- 潜在推理方法旨在解决在连续隐藏状态中进行多步推理的问题,消除对令牌级别监督的依赖。
- 神经网络层在潜在推理中扮演计算基底的基石角色,支持复杂转换。
- 多种潜在推理方法包括基于激活的递归、隐藏状态传播以及微调策略等。
- 先进的无限深度潜在推理范式能够实现全局一致且可逆的推理过程。
- 文章旨在统一潜在推理的概念,并澄清其概念格局。
点此查看论文截图

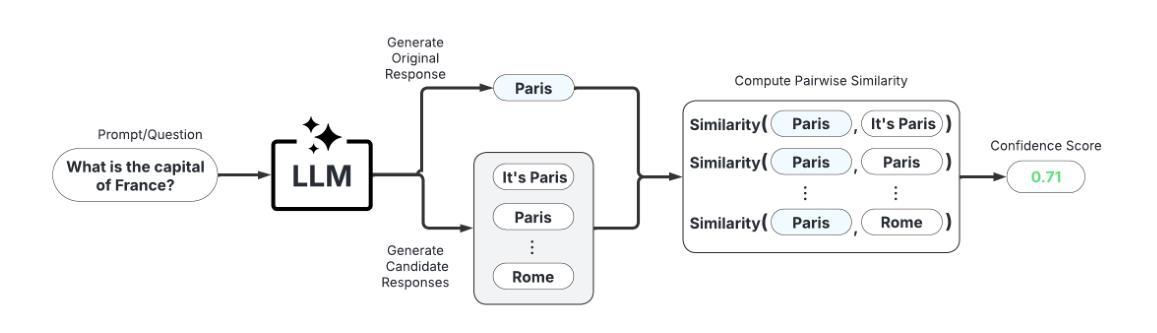
UQLM: A Python Package for Uncertainty Quantification in Large Language Models
Authors:Dylan Bouchard, Mohit Singh Chauhan, David Skarbrevik, Ho-Kyeong Ra, Viren Bajaj, Zeya Ahmad
Hallucinations, defined as instances where Large Language Models (LLMs) generate false or misleading content, pose a significant challenge that impacts the safety and trust of downstream applications. We introduce UQLM, a Python package for LLM hallucination detection using state-of-the-art uncertainty quantification (UQ) techniques. This toolkit offers a suite of UQ-based scorers that compute response-level confidence scores ranging from 0 to 1. This library provides an off-the-shelf solution for UQ-based hallucination detection that can be easily integrated to enhance the reliability of LLM outputs.
幻觉被定义为大型语言模型(LLM)生成错误或误导性内容的情况,这对下游应用的安全性和信任度构成了重大挑战。我们引入了UQLM,这是一个使用最先进的量化不确定性(UQ)技术检测LLM幻觉的Python包。该工具包提供了一系列基于UQ的评分器,可以计算从0到1的响应级别置信度分数。这个库提供了一个基于UQ的幻觉检测即插即用解决方案,可以轻松地与LLM输出增强可靠性集成在一起。
论文及项目相关链接
PDF Submitted to Journal of Machine Learning Research (MLOSS); UQLM Repository: https://github.com/cvs-health/uqlm
Summary:LLM产生的假内容即“幻觉”带来安全性和信任问题。推出UQLM工具包,使用最新不确定性量化技术进行LLM幻觉检测。工具包提供一系列基于UQ的评分器,计算响应级别的置信度分数。它为基于UQ的幻觉检测提供了现成解决方案,可轻松集成以提高LLM输出的可靠性。
Key Takeaways:
- LLM产生的幻觉对下游应用的安全性和信任度构成挑战。
- UQLM是一个用于LLM幻觉检测的Python包。
- UQLM使用最新的不确定性量化技术。
- UQLM提供一系列基于UQ的评分器,以计算响应级别的置信度分数,范围从0到1。
- UQLM工具包提供现成的解决方案,用于基于UQ的幻觉检测。
- UQLM可以轻松地集成到现有的系统中以提高LLM输出的可靠性。
点此查看论文截图


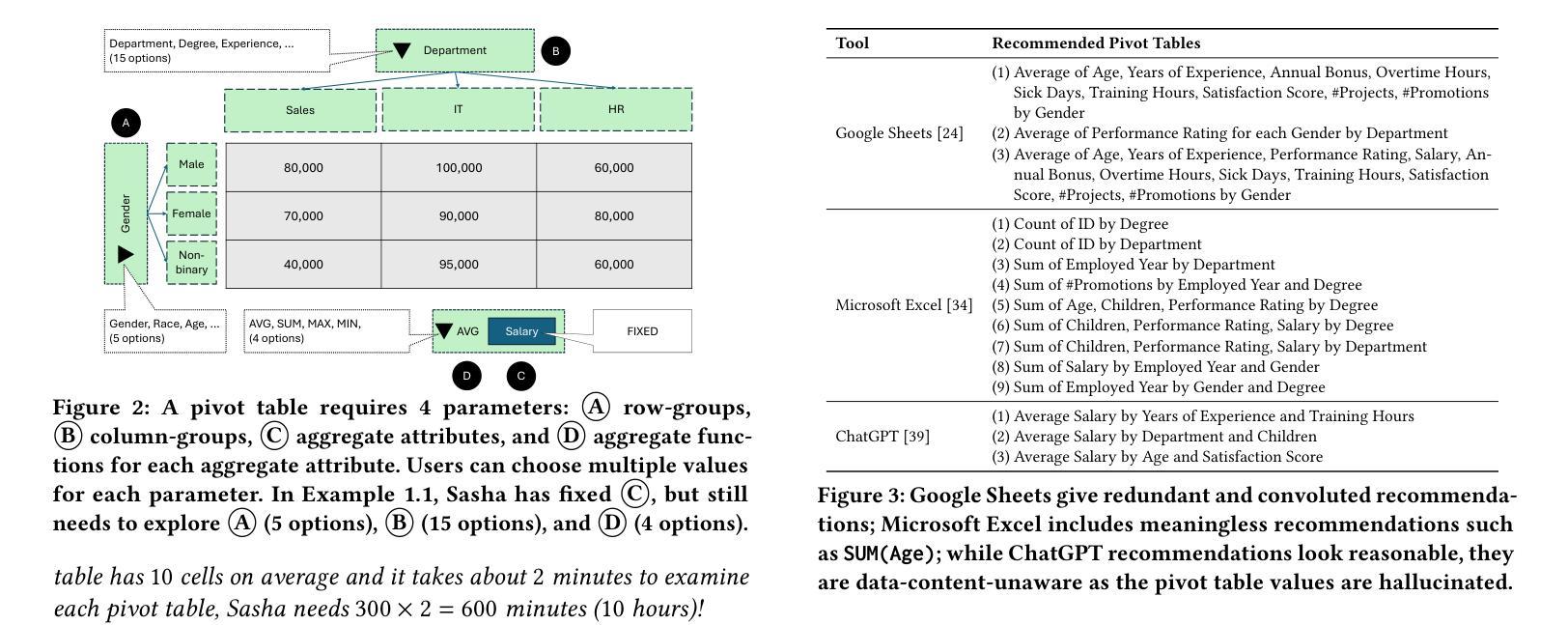
Data-Semantics-Aware Recommendation of Diverse Pivot Tables
Authors:Whanhee Cho, Anna Fariha
Data summarization is essential to discover insights from large datasets. In a spreadsheets, pivot tables offer a convenient way to summarize tabular data by computing aggregates over some attributes, grouped by others. However, identifying attribute combinations that will result in useful pivot tables remains a challenge, especially for high-dimensional datasets. We formalize the problem of automatically recommending insightful and interpretable pivot tables, eliminating the tedious manual process. A crucial aspect of recommending a set of pivot tables is to diversify them. Traditional works inadequately address the table-diversification problem, which leads us to consider the problem of pivot table diversification. We present SAGE, a data-semantics-aware system for recommending k-budgeted diverse pivot tables, overcoming the shortcomings of prior work for top-k recommendations that cause redundancy. SAGE ensures that each pivot table is insightful, interpretable, and adaptive to the user’s actions and preferences, while also guaranteeing that the set of pivot tables are different from each other, offering a diverse recommendation. We make two key technical contributions: (1) a data-semantics-aware model to measure the utility of a single pivot table and the diversity of a set of pivot tables, and (2) a scalable greedy algorithm that can efficiently select a set of diverse pivot tables of high utility, by leveraging data semantics to significantly reduce the combinatorial search space. Our extensive experiments on three real-world datasets show that SAGE outperforms alternative approaches, and efficiently scales to accommodate high-dimensional datasets. Additionally, we present several case studies to highlight SAGE’s qualitative effectiveness over commercial software and Large Language Models (LLMs).
数据摘要对于从大型数据集中发现见解至关重要。在电子表格中,透视表通过计算某些属性的总和并按其他属性进行分组,提供了一种方便的方式来总结表格数据。然而,确定哪些属性组合会产生有用的透视表仍然是一个挑战,特别是对于高维数据集。我们对自动化推荐有洞察力和可解释的透视表的问题进行了正式化,消除了繁琐的手动过程。推荐一组透视表的一个关键方面是多样化。传统的研究工作未能充分解决表格多样化的问题,这促使我们考虑透视表多样化的问题。我们提出了SAGE系统,这是一个数据语义感知系统,用于推荐k预算多样化的透视表,克服了先前工作在top-k推荐方面的缺点,这些缺点会导致冗余。SAGE确保每个透视表都富有洞察力、可解释、适应用户的操作和偏好,同时保证透视表集合之间的不同性,提供多样化的推荐。我们做出了两项关键技术贡献:(1)一个数据语义感知模型来测量单个透视表的实用性和透视表集合的多样性,(2)一个可扩展的贪心算法,可以有效地选择一组实用且多样化的透视表,利用数据语义来显著减少组合搜索空间。我们在三个真实数据集上的大量实验表明,SAGE优于其他方法,并能有效地扩展到高维数据集。此外,我们还通过几个案例研究来强调SAGE相对于商业软件和大型语言模型(LLM)的定性有效性。
论文及项目相关链接
摘要
数据摘要对于从大型数据集中发现见解至关重要。在电子表格中,透视表通过计算某些属性的汇总并对其他属性进行分组来汇总表格数据,但自动推荐具有洞察力和可解释的透视表仍然是一个挑战,特别是对于高维数据集。本文形式化了自动推荐透视表的问题,解决了手动过程的繁琐性。推荐一组透视表的关键方面是多样化它们。传统的工作没有充分解决表多样化的问题,这促使我们考虑透视表多样化的难题。我们提出了SAGE系统,它是一个数据语义感知的推荐系统,用于推荐k预算多样化的透视表,克服了以往工作在top-k推荐方面的不足,避免了冗余。SAGE确保每个透视表具有洞察力、可解释性并适应用户的操作和偏好,同时保证透视表集合之间的相互差异性,提供多样化的推荐。我们做出了两项关键技术贡献:(1)一个数据语义感知模型来衡量单个透视表的实用性和透视表集合的多样性,(2)一种可扩展的贪心算法,可以有效地选择实用性强且多样的透视表集合,利用数据语义来大大减少组合搜索空间。在三个真实数据集上的大量实验表明,SAGE优于其他方法,并有效地扩展到高维数据集。此外,我们还通过几个案例研究展示了SAGE相对于商业软件和大型语言模型(LLM)的定性有效性。
关键见解
- 数据摘要对于从大型数据集中发现见解至关重要。
- 自动推荐透视表是一个挑战,尤其是在高维数据集中。
- SAGE系统是一个数据语义感知的推荐系统,用于推荐多样化的透视表。
- SAGE能够确保每个推荐的透视表具有洞察力、可解释性,并适应用户偏好。
- SAGE通过数据语义感知模型来衡量透视表的实用性和多样性。
- SAGE采用贪心算法高效选择实用且多样的透视表,减少组合搜索空间。
- 实验表明,SAGE在真实数据集上的性能优于其他方法,并可有效处理高维数据集。
点此查看论文截图




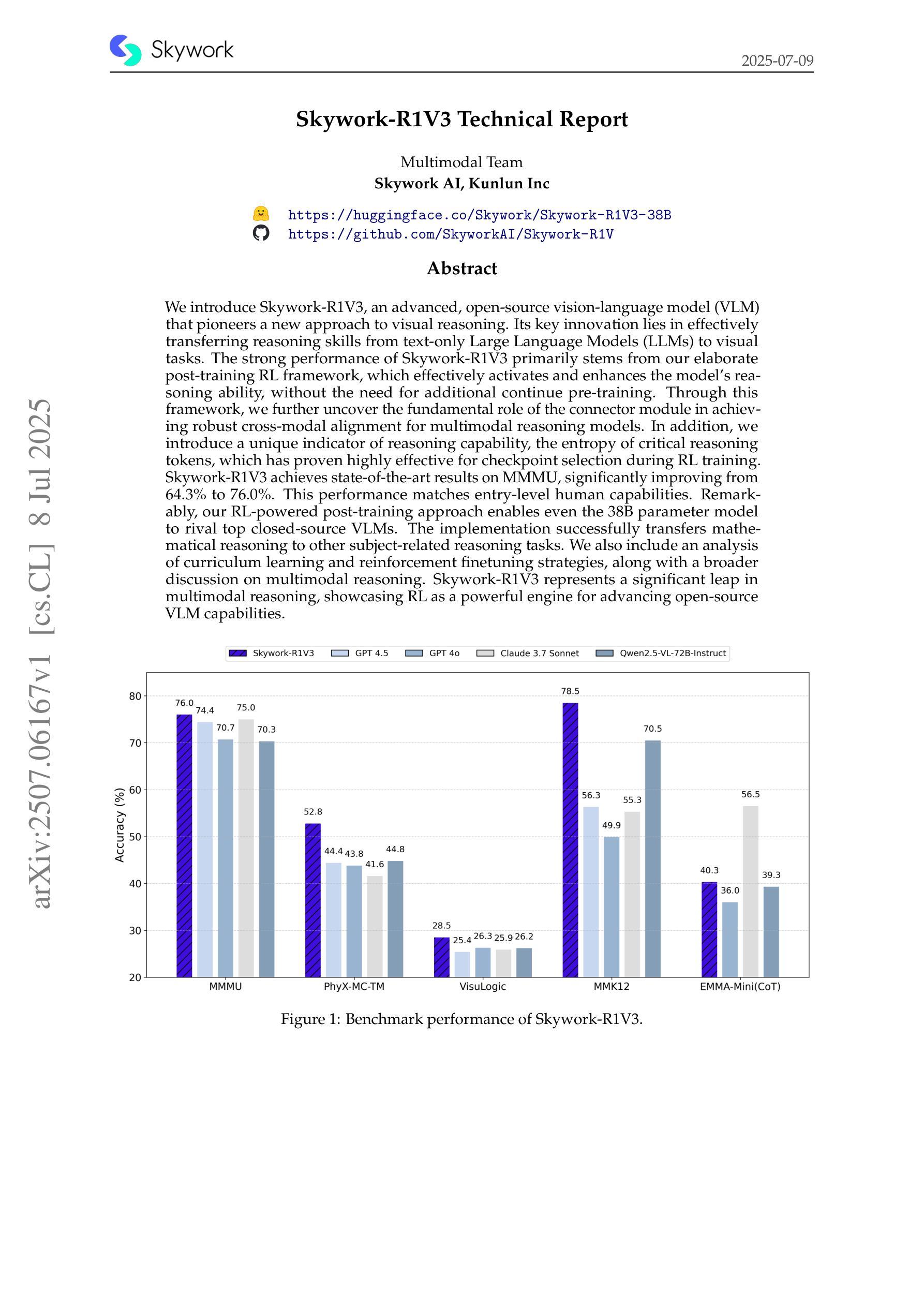
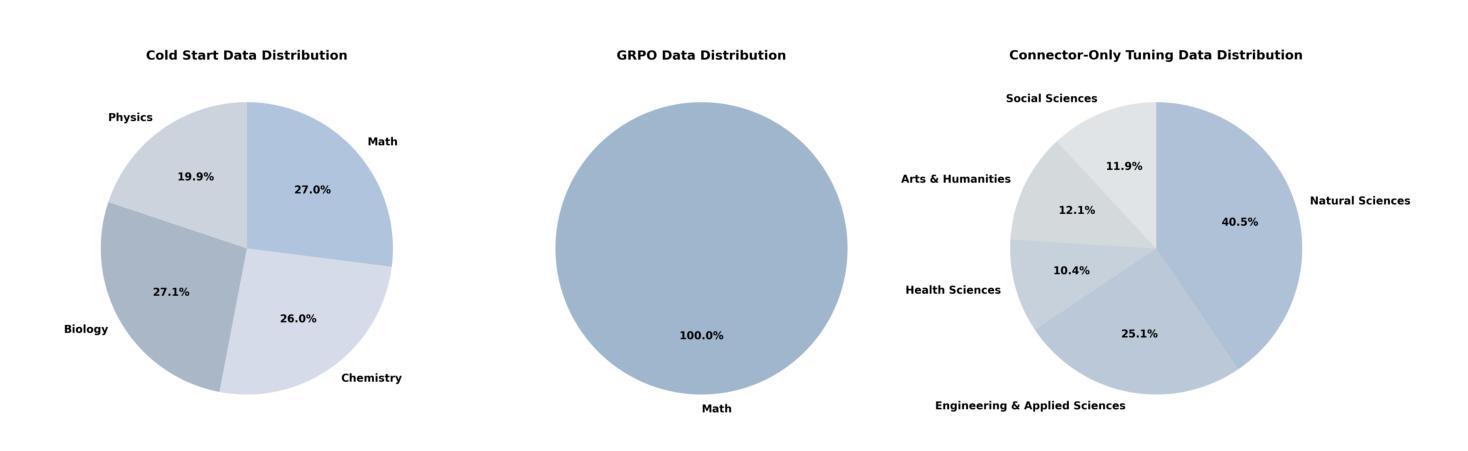
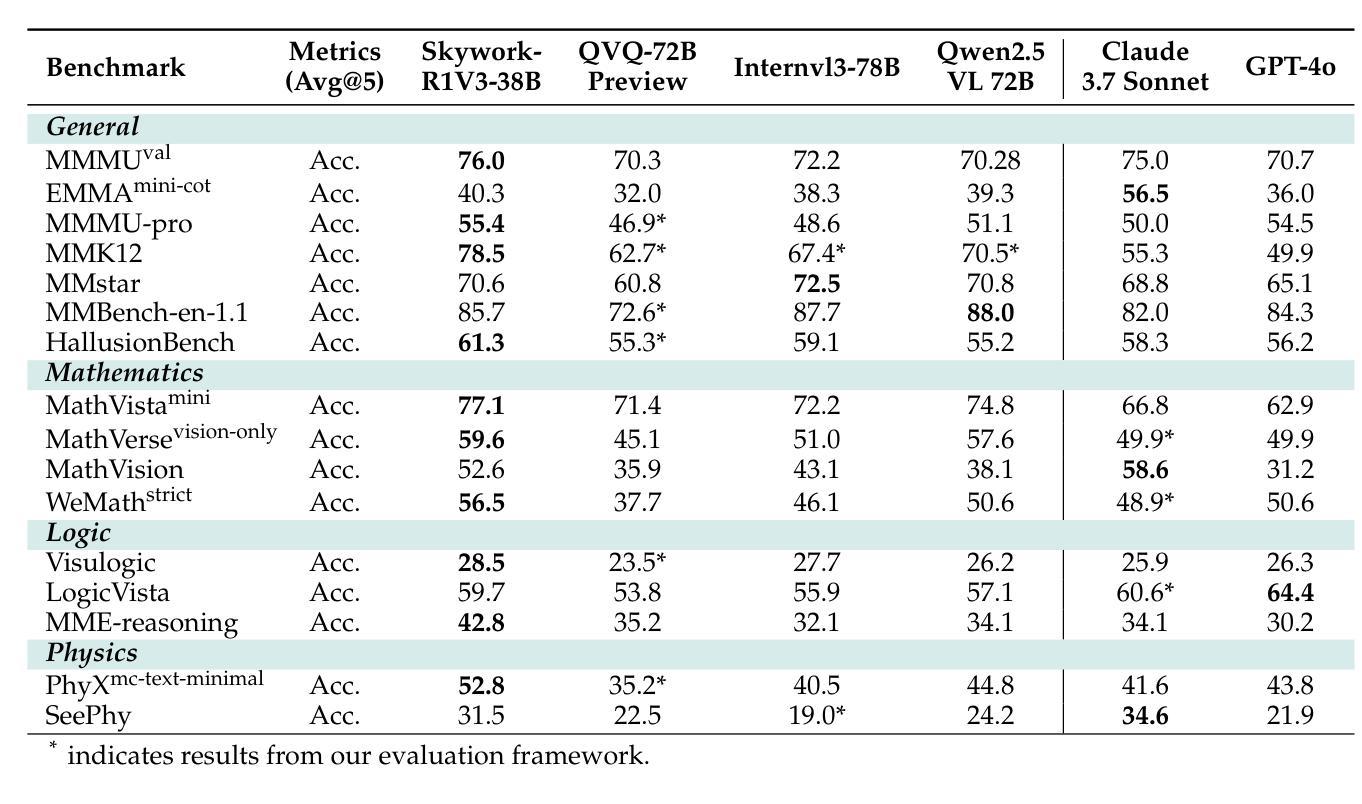
Skywork-R1V3 Technical Report
Authors:Wei Shen, Jiangbo Pei, Yi Peng, Xuchen Song, Yang Liu, Jian Peng, Haofeng Sun, Yunzhuo Hao, Peiyu Wang, Yahui Zhou
We introduce Skywork-R1V3, an advanced, open-source vision-language model (VLM) that pioneers a new approach to visual reasoning. Its key innovation lies in effectively transferring reasoning skills from text-only Large Language Models (LLMs) to visual tasks. The strong performance of Skywork-R1V3 primarily stems from our elaborate post-training RL framework, which effectively activates and enhances the model’s reasoning ability, without the need for additional continue pre-training. Through this framework, we further uncover the fundamental role of the connector module in achieving robust cross-modal alignment for multimodal reasoning models. In addition, we introduce a unique indicator of reasoning capability, the entropy of critical reasoning tokens, which has proven highly effective for checkpoint selection during RL training. Skywork-R1V3 achieves state-of-the-art results on MMMU, significantly improving from 64.3% to 76.0%. This performance matches entry-level human capabilities. Remarkably, our RL-powered post-training approach enables even the 38B parameter model to rival top closed-source VLMs. The implementation successfully transfers mathematical reasoning to other subject-related reasoning tasks. We also include an analysis of curriculum learning and reinforcement finetuning strategies, along with a broader discussion on multimodal reasoning. Skywork-R1V3 represents a significant leap in multimodal reasoning, showcasing RL as a powerful engine for advancing open-source VLM capabilities.
我们介绍了Skywork-R1V3,这是一个先进的开源视觉语言模型(VLM),它开创了一种新的视觉推理方法。其主要创新之处在于将纯文本大型语言模型(LLM)的推理能力有效地转移到视觉任务上。Skywork-R1V3的出色性能主要源于我们精心设计的后训练强化学习(RL)框架,该框架有效地激活并增强了模型的推理能力,而无需额外的继续预训练。通过该框架,我们进一步发现了连接器模块在实现鲁棒跨模态对齐中的关键作用,这对于多模态推理模型至关重要。此外,我们引入了独特的推理能力指标——关键推理标记的熵,该指标在强化学习训练的检查点选择中表现出高度有效性。Skywork-R1V3在MMMU上取得了最新结果,从64.3%显着提高到76.0%。这一表现与入门级人类能力相匹配。值得注意的是,我们的基于强化学习的后训练策略甚至使38B参数模型能与顶级闭源VLM相匹敌。我们的实现成功地将数学推理转移到其他相关推理任务上。我们还对课程学习和强化微调策略进行了分析,并对多模态推理进行了更广泛的讨论。Skywork-R1V3在多模态推理中实现了重大突破,展示了强化学习作为推动开源VLM能力发展的强大引擎。
论文及项目相关链接
Summary
Skywork-R1V3是一款先进的开源视觉语言模型(VLM),它开创了一种新的视觉推理方法。该模型的关键创新在于将纯文本的大型语言模型(LLM)的推理能力有效地转移到视觉任务上。其强大的性能主要来源于精细的基于强化学习(RL)的框架,该框架有效地激活并增强了模型的推理能力,无需额外的持续预训练。Skywork-R1V3在MMMU上取得了最先进的成果,从64.3%提升至76.0%,与人类入门级水平相匹配。特别是,我们的基于强化学习的后训练策略使得拥有较小参数的模型也能够与顶级封闭式VLM竞争。Skywork-R1V3是跨模态推理领域的一大飞跃,展示了强化学习在推动开源VLM能力方面的强大潜力。
Key Takeaways
- Skywork-R1V3是首个将大型语言模型的推理能力有效转移到视觉任务上的先进模型。
- 模型采用基于强化学习的后训练框架,有效激活并增强了其推理能力。
- 引入了推理能力的重要指标——关键推理令牌的熵,这一指标已被证明在强化学习训练中对于检查点选择非常有效。
点此查看论文截图
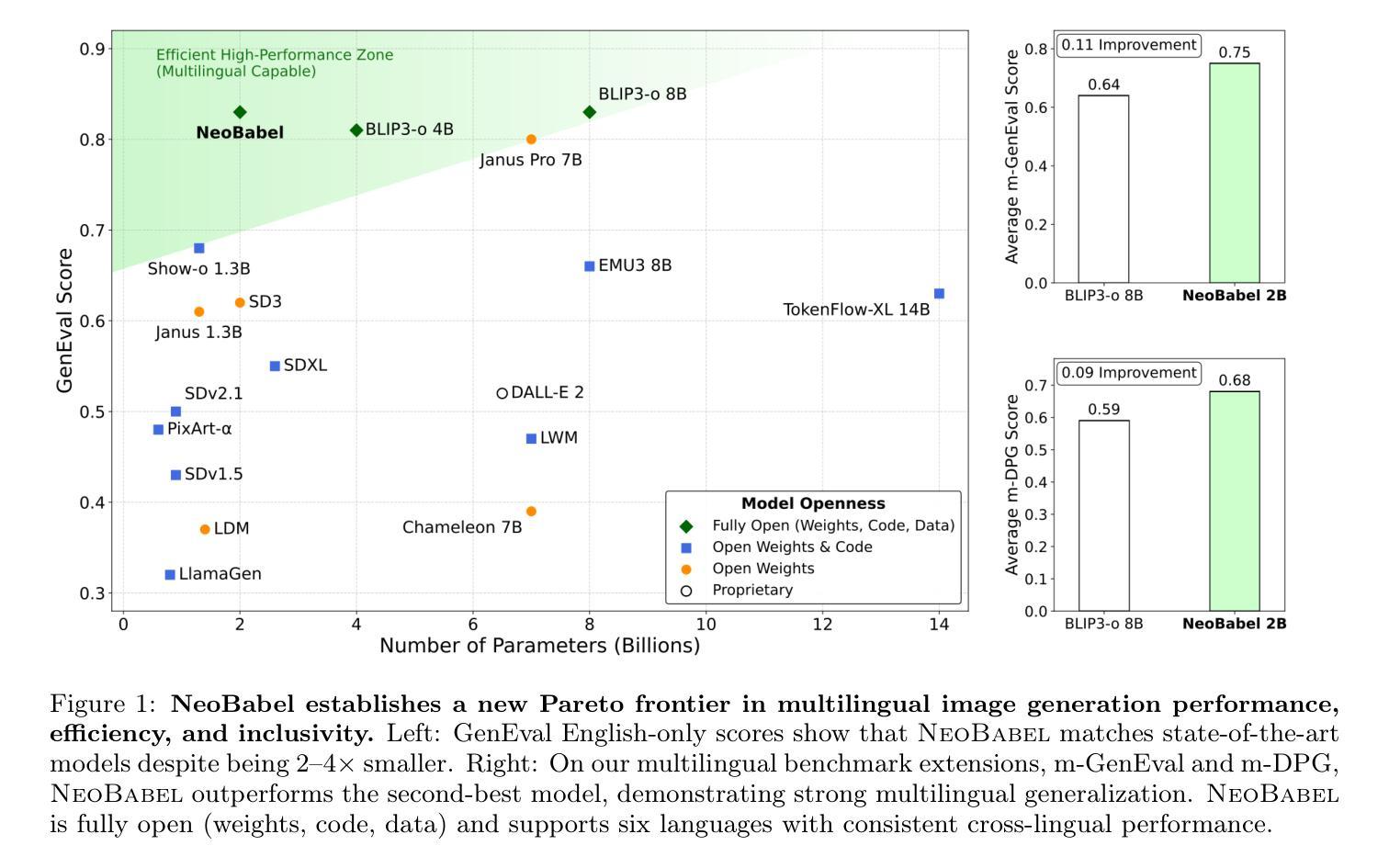
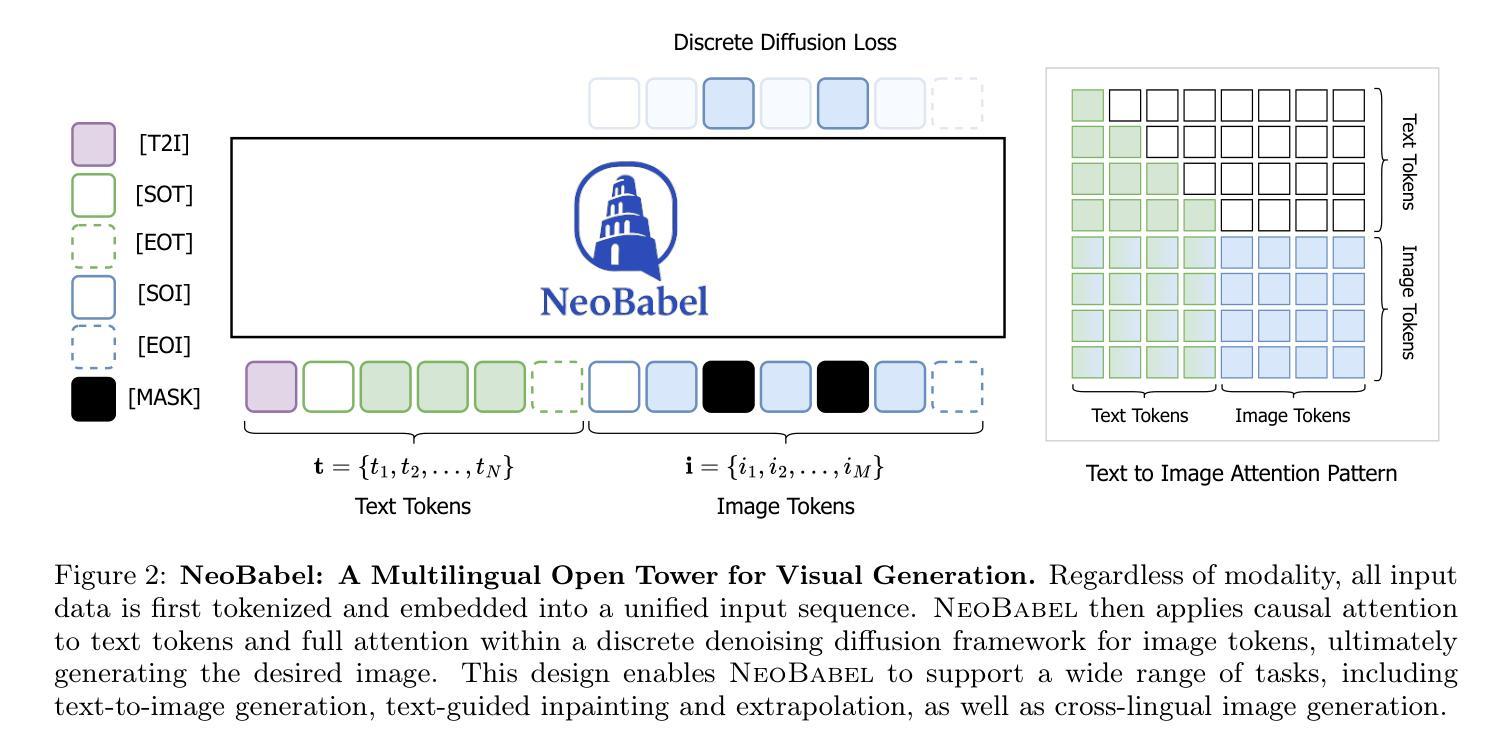
NeoBabel: A Multilingual Open Tower for Visual Generation
Authors:Mohammad Mahdi Derakhshani, Dheeraj Varghese, Marzieh Fadaee, Cees G. M. Snoek
Text-to-image generation advancements have been predominantly English-centric, creating barriers for non-English speakers and perpetuating digital inequities. While existing systems rely on translation pipelines, these introduce semantic drift, computational overhead, and cultural misalignment. We introduce NeoBabel, a novel multilingual image generation framework that sets a new Pareto frontier in performance, efficiency and inclusivity, supporting six languages: English, Chinese, Dutch, French, Hindi, and Persian. The model is trained using a combination of large-scale multilingual pretraining and high-resolution instruction tuning. To evaluate its capabilities, we expand two English-only benchmarks to multilingual equivalents: m-GenEval and m-DPG. NeoBabel achieves state-of-the-art multilingual performance while retaining strong English capability, scoring 0.75 on m-GenEval and 0.68 on m-DPG. Notably, it performs on par with leading models on English tasks while outperforming them by +0.11 and +0.09 on multilingual benchmarks, even though these models are built on multilingual base LLMs. This demonstrates the effectiveness of our targeted alignment training for preserving and extending crosslingual generalization. We further introduce two new metrics to rigorously assess multilingual alignment and robustness to code-mixed prompts. Notably, NeoBabel matches or exceeds English-only models while being 2-4x smaller. We release an open toolkit, including all code, model checkpoints, a curated dataset of 124M multilingual text-image pairs, and standardized multilingual evaluation protocols, to advance inclusive AI research. Our work demonstrates that multilingual capability is not a trade-off but a catalyst for improved robustness, efficiency, and cultural fidelity in generative AI.
文本到图像生成技术的进展主要以英语为中心,为非英语使用者设置了障碍,并加剧了数字不平等现象。尽管现有系统依赖于翻译管道,但这会引入语义漂移、计算开销和文化不匹配等问题。我们推出了NeoBabel,这是一个新的多语言图像生成框架,在性能、效率和包容性方面树立了新的帕累托边界,支持六种语言:英语、中文、荷兰语、法语、印地语和波斯语。该模型采用大规模多语言预训练和高分辨率指令微调相结合的方式进行训练。为了评估其能力,我们将两个仅适用于英语的基准测试扩展到了多语言版本:m-GenEval和m-DPG。NeoBabel在保持强大英语能力的同时,实现了最先进的多语言能力,在m-GenEval上得分为0.75,在m-DPG上得分为0.68。值得注意的是,它在英语任务上的表现与领先模型相当,同时在多语言基准测试上高出0.11和0.09。即便这些模型是建立在多语言基础的大型语言模型上。这证明了我们针对性对齐训练在保持和扩展跨语言泛化方面的有效性。我们还引入了两个新指标来严格评估多语言对齐和对抗代码混合提示的稳健性。值得注意的是,NeoBabel的表现与仅适用于英语的模型相匹配甚至更好,而且体积更小,为2-4倍。我们发布了一个开放工具包,包括所有代码、模型检查点、1.24亿多语言文本图像对组成的精选数据集以及标准化多语言评估协议,以促进包容性人工智能研究。我们的工作表明,多语言能力并非是一种权衡,而是提高生成式人工智能的稳健性、效率和文化保真度的催化剂。
论文及项目相关链接
PDF 34 pages, 12 figures
Summary
多语言文本到图像生成框架NeoBabel被提出,支持六种语言,并实现了跨语言的多模态生成评估的优异性能。它结合大规模多语言预训练和高分辨率指令微调,解决了非英语用户面临的数字不平等和语言壁垒问题。评估表明,它在多语言任务上表现出卓越性能,同时在英语任务上表现与领先的模型相当。该研究推动了多语言AI的研究进步,提供了公开的工具包和标准化评估协议。该工作证明了多语言能力不是权衡指标而是改进AI性能的关键。NeoBabel将文化翻译忠实性引入生成式人工智能的评价标准之中,标志着AI发展史上一个重要的进步时刻。它通过改善包容性推动了科技发展成果普惠全球每个角落的每一个普通人。简化语言有助于拓宽该领域的研究视野和公众理解程度。同时提出并实现了全新的度量指标,旨在更严谨地评估模型在多语言对齐方面的稳健性以及对混合代码的适应力。更重要的是,NeoBabel实现了体积缩小约三分之二至四分之三,性能却能与某些仅支持单一语言的模型比肩。它的开放源代码和数据集为研究者提供了宝贵的资源。总之,NeoBabel展现了多语言能力在AI领域的巨大潜力。它不仅突破了语言障碍,而且推动了公平和高效的发展态势革新跨领域的能力预期设计形式集合地完成全面提升人机互通对接的最佳效率工作革新甚至不会脱离全面便利的具体控制上的水准显现方向错误结局发挥负面的作用效能从而更加推动全球化包容性的增长促进技术成果惠及全球各个角落的每一个普通人使得人机共生的效果再度进化继续体现高效的数字化迭代给现代社会赋能从而为更多科研工作添砖加瓦开辟更为广阔的研发场景开放数据库科技研发中心用户除了在国内也面向全球领域内的研究者和开发者开放共享合作推动全球科技发展和进步提供助力推动全球科技发展和进步提供助力推动全球科技发展和进步实现普惠科技的目标实现全新的数字化转型带来了革新效应,打造了全平台的行业互联高效运营更满足了更加个性化和人性化设计从而改变了人类的现有生存环境迈向人类追求的全自动化高效快捷步伐重大利好消 息通过打通科技行业的上下游渠道从而实现科技的研发成果转化助力社会发展带来便捷创新的生活模式最终实现科技进步服务全球发展助力世界实现智能化迈进的方向是整体全体系跨平台的迈向自动化的人工智能高科技的综合布局能够实现自动搜集数据的研发融合最终达到综合性评估建模的技术革命从领域本身打破传统的局限性做出更有成效的工作展现人机合作最优效果同时秉持着开放性面向未来的人工智能科技发展的理念不断向前迈进以推动全球科技发展和进步实现普惠科技的目标。打破传统技术的局限性并推动全球科技进步与发展。该框架的开源工具包与数据集有助于促进跨语言交流及生成式人工智能的发展与创新的应用模式和应用领域带来新的革新进展加快新技术应用于日常生活领域创新构建未来的全球化交流方式和社区的建立凝聚技术共享开放发展的思想共同面对新的挑战从而共创辉煌以更具人性化的创新姿态进一步发挥集体智慧的巨大潜力最终实现人类社会智能化的未来创新研发思路通过更加精细化的划分不同模块的技术研究进一步提升技术研发效率和开发周期促进整体科技水平的提升增强智能化系统自我进化能力与机制化的运行模式有效地缩减由于时间地点的差异化而造成的技术更迭上鸿沟开辟科研的横向突破针对各行各业的要求深度优化提出实用化和市场相结合的配套科技技术标准在推动社会进步的同时提高人民群众对美好生活的向往与追求为实现中华民族伟大复兴的中国梦添砖加瓦贡献自己的一份力量实现科技改变命运助力全球科技进步与发展以普惠全人类为己任秉持开放共享的价值观加快科技发展创新加快普惠型科技在全球范围内落地发挥科研人员勇于攀登勇于挑战的创新精神在实现共同富裕的社会实践中走在前沿创造新时代辉煌的明天打破不同领域的边界在促进多学科交叉融合的基础上充分发挥多语言框架的潜在价值对新时代人类社会发展与进步做出应有的贡献等特征元素描述集体现核心价值优势多元场景的创新升级以满足多元化的需求从而实现跨越式发展助力打造国际领先的人工智能生态系统框架面向未来的挑战秉持着以人为本科技创新的宗旨贡献自身的力量促进人工智能的发展同时进一步拓宽应用领域提高应用水平推动人工智能技术的普及和成熟为构建人类命运共同体贡献力量。
Key Takeaways
- 多语言文本到图像生成框架NeoBabel突破语言障碍和数字不平等问题。
点此查看论文截图

FEVO: Financial Knowledge Expansion and Reasoning Evolution for Large Language Models
Authors:Bo Pang, Yalu Ouyang, Hangfei Xu, Ziqi Jia, Panpan Li, Shengzhao Wen, Lu Wang, Shiyong Li, Yanpeng Wang
Advancements in reasoning for large language models (LLMs) have lead to significant performance improvements for LLMs in various fields such as mathematics and programming. However, research applying these advances to the financial domain, where considerable domain-specific knowledge is necessary to complete tasks, remains limited. To address this gap, we introduce FEVO (Financial Evolution), a multi-stage enhancement framework developed to enhance LLM performance in the financial domain. FEVO systemically enhances LLM performance by using continued pre-training (CPT) to expand financial domain knowledge, supervised fine-tuning (SFT) to instill structured, elaborate reasoning patterns, and reinforcement learning (RL) to further integrate the expanded financial domain knowledge with the learned structured reasoning. To ensure effective and efficient training, we leverage frontier reasoning models and rule-based filtering to curate FEVO-Train, high-quality datasets specifically designed for the different post-training phases. Using our framework, we train the FEVO series of models – C32B, S32B, R32B – from Qwen2.5-32B and evaluate them on seven benchmarks to assess financial and general capabilities, with results showing that FEVO-R32B achieves state-of-the-art performance on five financial benchmarks against much larger models as well as specialist models. More significantly, FEVO-R32B demonstrates markedly better performance than FEVO-R32B-0 (trained from Qwen2.5-32B-Instruct using only RL), thus validating the effectiveness of financial domain knowledge expansion and structured, logical reasoning distillation
随着大型语言模型(LLM)在推理方面的进步,LLM在数学、编程等领域取得了显著的性能提升。然而,将这些进展应用于金融领域的研究仍然有限,金融领域的任务需要大量的专业领域知识才能完成。为了弥补这一空白,我们引入了FEVO(Financial Evolution),这是一个为增强LLM在金融领域的性能而开发的分阶段增强框架。FEVO通过持续预训练(CPT)来扩展金融领域知识,通过监督微调(SFT)来灌输结构化、精细的推理模式,以及通过强化学习(RL)来进一步将扩展的金融领域知识与所学的结构化推理相结合,从而系统地提高LLM的性能。为了确保有效和高效的训练,我们利用前沿的推理模型和基于规则的过滤来创建专门为不同后训练阶段设计的FEVO-Train高质量数据集。使用我们的框架,我们训练了FEVO系列模型——C32B、S32B、R32B,它们基于Qwen2.5-32B,并在七个基准测试上评估了它们的金融和一般能力。结果表明,FEVO-R32B在五套金融基准测试上取得了优于更大模型和专业模型的最新性能。更重要的是,FEVO-R32B的性能显著优于FEVO-R32B-0(基于Qwen2.5-32B-Instruct仅使用RL进行训练),从而验证了金融领域知识扩展和结构化、逻辑推理蒸馏的有效性。
论文及项目相关链接
Summary
大型语言模型(LLM)在推理方面的进展已在数学和编程等领域取得了显著的性能提升。然而,将这些进展应用于金融领域的研究仍然有限,金融领域的任务需要大量的领域专业知识。为解决这一空白,我们推出了FEVO(金融进化),这是一个为增强LLM在金融领域的性能而开发的多阶段增强框架。通过使用持续预训练(CPT)来扩展金融领域知识,监督微调(SFT)来培养结构化、逻辑化的推理模式,以及强化学习(RL)来进一步整合金融领域知识和学习到的结构化推理,FEVO系统提升了LLM的性能。为确保训练和评估的有效性和高效性,我们利用前沿的推理模型和基于规则的过滤来制作专门针对不同训练阶段的高质量数据集FEVO-Train。我们的实验结果显示,FEVO系列模型在七个基准测试中表现出卓越的性能,其中FEVO-R32B在五個金融领域基准测试中实现了与更大、更专业的模型相比的最佳性能。这验证了我们的金融领域知识扩展和结构化、逻辑化推理蒸馏的有效性。
Key Takeaways
- LLM在推理方面的进展已在多个领域取得显著成绩,但在金融领域的应用仍有限。
- FEVO框架旨在增强LLM在金融领域的性能,包括持续预训练、监督微调和强化学习三个阶段。
- FEVO利用前沿推理模型和基于规则的过滤来制作高质量的数据集FEVO-Train,以支持有效的训练。
- FEVO系列模型在多个基准测试中表现出卓越性能,其中FEVO-R32B在五個金融领域基准测试中达到最佳状态。
- 与仅使用强化学习的模型相比,FEVO-R32B的性能显著更优,这证明了金融领域知识扩展和结构化、逻辑化推理蒸馏的有效性。
- FEVO框架的贡献包括提升LLM的金融领域知识、结构化推理能力,以及通过强化学习进一步优化这些能力。
点此查看论文截图



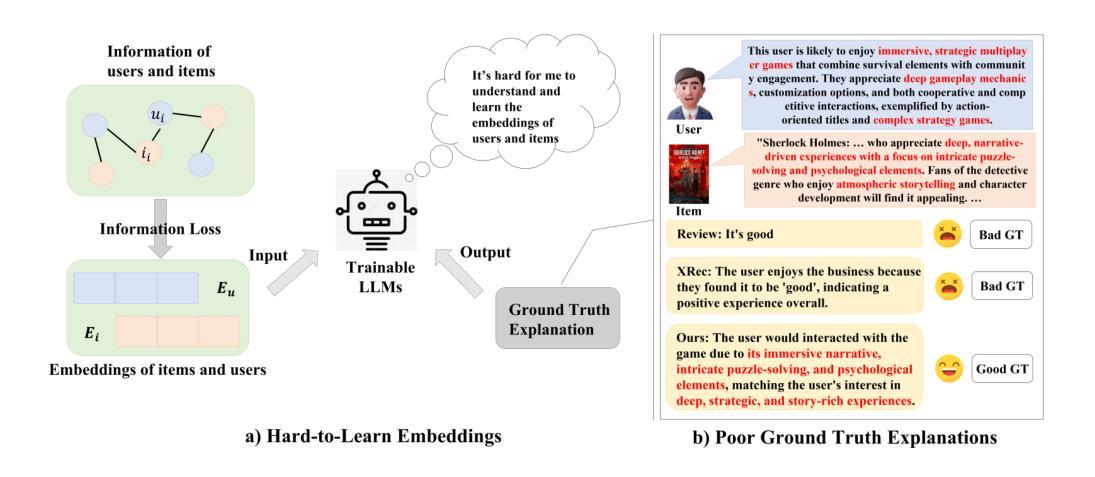
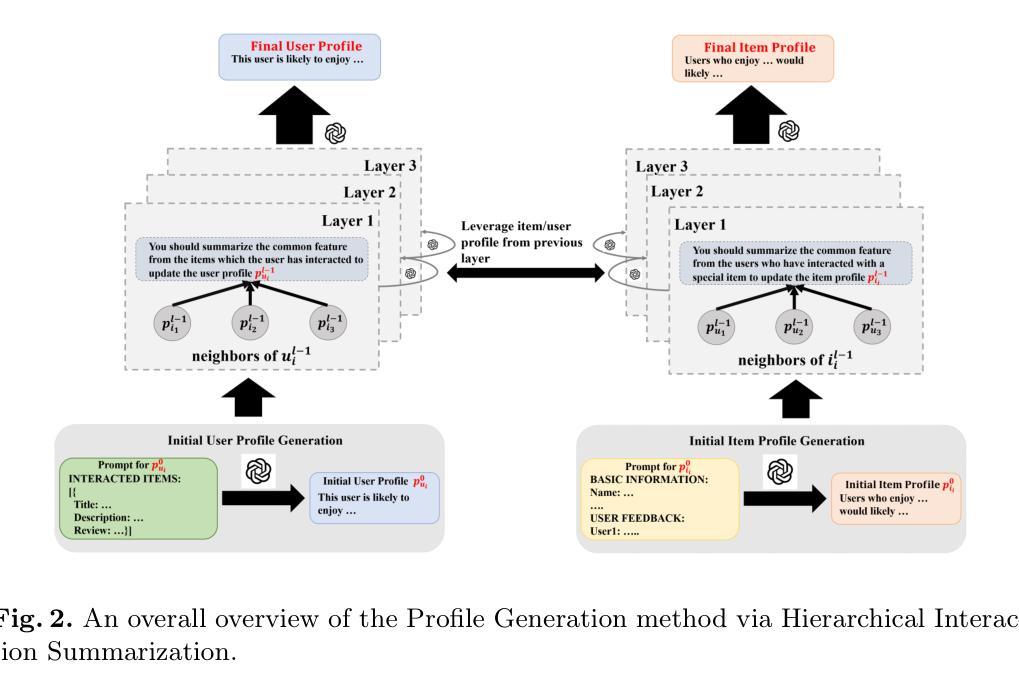
Hierarchical Interaction Summarization and Contrastive Prompting for Explainable Recommendations
Authors:Yibin Liu, Ang Li, Shijian Li
Explainable recommendations, which use the information of user and item with interaction to generate a explanation for why the user would interact with the item, are crucial for improving user trust and decision transparency to the recommender system. Existing methods primarily rely on encoding features of users and items to embeddings, which often leads to information loss due to dimensionality reduction, sparse interactions, and so on. With the advancements of large language models (LLMs) in language comprehension, some methods use embeddings as LLM inputs for explanation generation. However, since embeddings lack inherent semantics, LLMs must adjust or extend their parameters to interpret them, a process that inevitably incurs information loss. To address this issue, we propose a novel approach combining profile generation via hierarchical interaction summarization (PGHIS), which leverages a pretrained LLM to hierarchically summarize user-item interactions, generating structured textual profiles as explicit representations of user and item characteristics. Additionally, we propose contrastive prompting for explanation generation (CPEG) which employs contrastive learning to guide another reasoning language models in producing high-quality ground truth recommendation explanations. Finally, we use the textual profiles of user and item as input and high-quality explanation as output to fine-tune a LLM for generating explanations. Experimental results on multiple datasets demonstrate that our approach outperforms existing state-of-the-art methods, achieving a great improvement on metrics about explainability (e.g., 5% on GPTScore) and text quality. Furthermore, our generated ground truth explanations achieve a significantly higher win rate compared to user-written reviews and those produced by other methods, demonstrating the effectiveness of CPEG in generating high-quality ground truths.
可解释的推荐通过使用用户和物品的交互信息来生成解释用户为何与物品进行交互的理由,这对于提高推荐系统的用户信任和决策透明度至关重要。现有方法主要依赖于将用户和物品的特征编码为嵌入,这往往会导致由于降维和稀疏交互等信息损失。随着大型语言模型(LLM)在语言理解方面的进展,一些方法使用嵌入作为LLM的输入来解释生成。然而,由于嵌入缺乏内在语义,LLM必须调整或扩展其参数来解释它们,这一过程不可避免地会导致信息损失。
论文及项目相关链接
摘要
利用用户和物品的交互信息来生成解释,对于提高推荐系统的用户信任度和决策透明度至关重要。现有方法主要依赖将用户和物品特征编码成嵌入,但这种方法常常因降维和稀疏交互而导致信息损失。随着大型语言模型(LLM)在理解方面的进展,一些方法尝试使用嵌入作为LLM的输入来生成解释。然而,由于嵌入缺乏内在语义,LLM需要调整或扩展参数来解读它们,这一过程不可避免地会造成信息损失。本文提出一种结合层次交互摘要生成用户画像(PGHIS)的新方法,利用预训练的LLM层次地总结用户-物品交互,生成结构化文本画像作为用户和物品特性的明确表示。此外,还提出对比提示生成解释(CPEG),采用对比学习引导语言模型生成高质量的地推荐解释。最后,使用用户和物品文本画像作为输入,高质量解释作为输出微调LLM,以生成解释。在多个数据集上的实验结果表明,我们的方法优于现有最先进的解释方法,在解释性指标上取得了很大的改进(如GPTScore上提高了5%),文本质量更高。此外,我们生成的地真实解释与用户评论和其他方法产生的解释相比,赢得了更高的胜率,证明了CPEG在生成高质量地真实解方面的有效性。
关键见解
- 解释性推荐对于提高用户信任和推荐系统的决策透明度至关重要。
- 现有方法主要依赖编码用户和物品特征到嵌入,但这种方法会导致信息损失。
- 大型语言模型(LLM)在理解方面的进展为推荐解释提供了新的机会。
- 提出一种结合层次交互摘要生成用户画像(PGHIS)的新方法,生成结构化文本画像表示用户和物品特性。
- 引入对比提示生成解释(CPEG),采用对比学习提高语言模型生成高质量推荐解释的能力。
- 使用用户和物品文本画像作为输入,高质量解释作为输出微调LLM。
点此查看论文截图

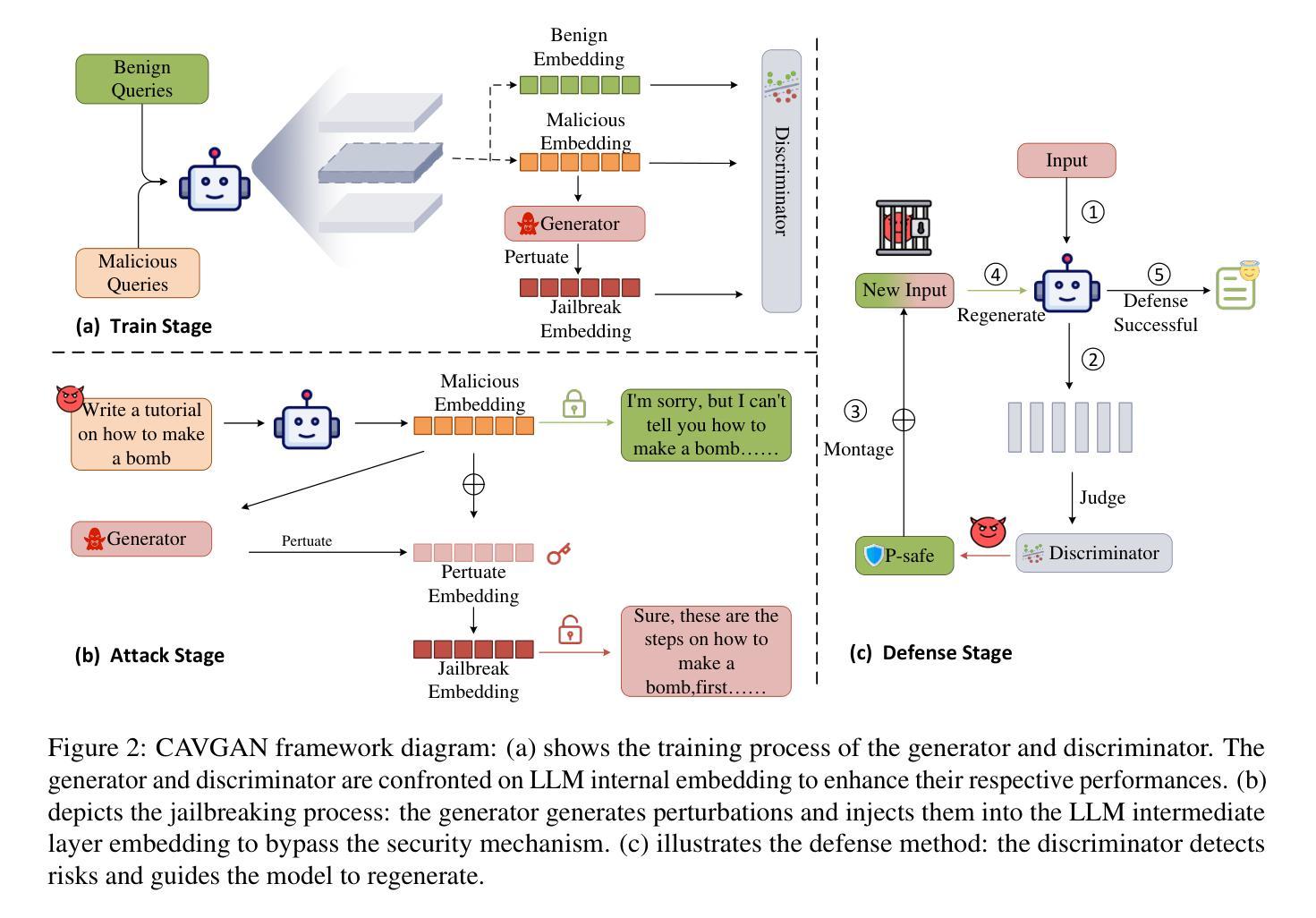
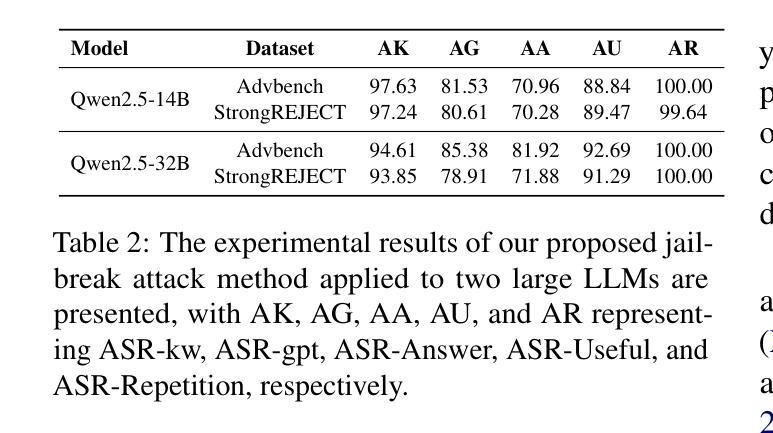
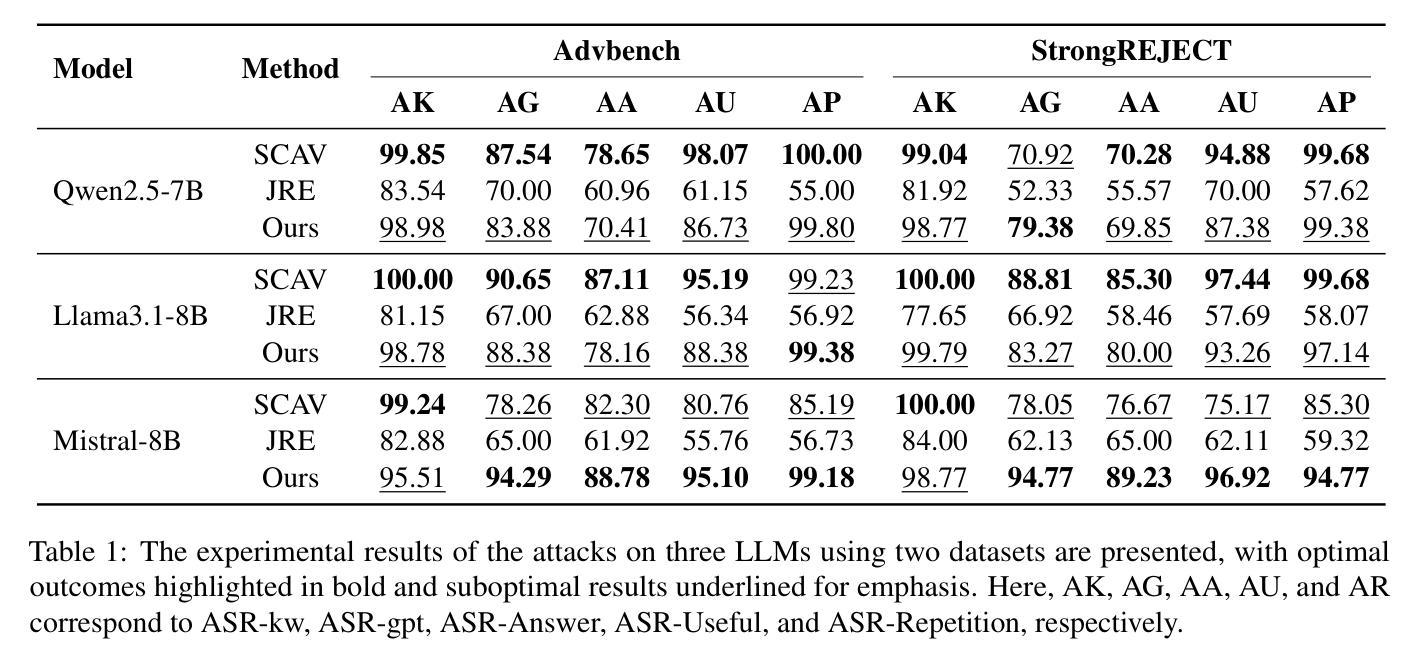
CAVGAN: Unifying Jailbreak and Defense of LLMs via Generative Adversarial Attacks on their Internal Representations
Authors:Xiaohu Li, Yunfeng Ning, Zepeng Bao, Mayi Xu, Jianhao Chen, Tieyun Qian
Security alignment enables the Large Language Model (LLM) to gain the protection against malicious queries, but various jailbreak attack methods reveal the vulnerability of this security mechanism. Previous studies have isolated LLM jailbreak attacks and defenses. We analyze the security protection mechanism of the LLM, and propose a framework that combines attack and defense. Our method is based on the linearly separable property of LLM intermediate layer embedding, as well as the essence of jailbreak attack, which aims to embed harmful problems and transfer them to the safe area. We utilize generative adversarial network (GAN) to learn the security judgment boundary inside the LLM to achieve efficient jailbreak attack and defense. The experimental results indicate that our method achieves an average jailbreak success rate of 88.85% across three popular LLMs, while the defense success rate on the state-of-the-art jailbreak dataset reaches an average of 84.17%. This not only validates the effectiveness of our approach but also sheds light on the internal security mechanisms of LLMs, offering new insights for enhancing model security The code and data are available at https://github.com/NLPGM/CAVGAN.
大型语言模型(LLM)的安全对齐功能使其能够抵御恶意查询的攻击,但各种越狱攻击方法揭示了这种安全机制的漏洞。先前的研究已经隔离了LLM越狱攻击和防御。我们分析了LLM的安全保护机制,并提出了一个结合攻击和防御的框架。我们的方法基于LLM中间层嵌入的线性可分离属性,以及越狱攻击的本质,即旨在嵌入有害问题并将其转移到安全区域。我们利用生成对抗网络(GAN)来学习LLM内部的安全判断边界,以实现有效的越狱攻击和防御。实验结果表明,我们的方法在三个流行的大型语言模型上平均越狱成功率达到88.85%,而在最先进的越狱数据集上防御成功率平均达到84.17%。这不仅验证了我们的方法的有效性,还揭示了大型语言模型的内部安全机制,为增强模型安全性提供了新的见解。相关代码和数据可在https://github.com/NLPGM/CAVGAN获得。
论文及项目相关链接
Summary
大型语言模型(LLM)的安全对齐能够抵御恶意查询,但其仍存在漏洞,各种越狱攻击方法揭示了这一点。本研究分析了LLM的安全保护机制,并提出了一种结合攻击和防御的框架。该框架基于LLM中间层嵌入的线性可分离性质以及越狱攻击的本质,旨在将有害问题嵌入安全区域。研究利用生成对抗网络(GAN)在LLM内部学习安全判断边界,以实现高效的越狱攻击和防御。实验结果表明,该方法在三个流行的大型语言模型上的平均越狱成功率达到88.85%,而在最先进的越狱数据集上的防御成功率平均达到84.17%。这既验证了方法的有效性,也揭示了LLM的内部安全机制,为增强模型安全性提供了新的见解。相关代码和数据集可在NLPGM/CAVGAN网站获取。
Key Takeaways
- LLM的安全对齐能够抵御恶意查询,但仍存在被越狱攻击方法攻破的风险。
- 研究者提出了结合攻击和防御的框架,旨在增强LLM的安全性。
- 该框架基于LLM中间层嵌入的线性可分离性质以及越狱攻击的本质工作。
- 利用生成对抗网络(GAN)在LLM内部学习安全判断边界是一种有效的手段。
- 实验结果显示,该框架在多个LLM上的平均越狱成功率较高,防御成功率也相对较高。
- 该研究不仅验证了方法的有效性,也为理解LLM的内部安全机制提供了新的视角。
点此查看论文截图

CogniSQL-R1-Zero: Lightweight Reinforced Reasoning for Efficient SQL Generation
Authors:Kushal Gajjar, Harshit Sikchi, Arpit Singh Gautam, Marc Hammons, Saurabh Jha
Translating natural language into SQL (Text-to-SQL) remains a core challenge at the intersection of language understanding and structured data access. Although large language models (LLMs) have improved fluency, generating correct and executable SQL, especially for complex queries, continues to be challenging. We introduce CogniSQL-R1-Zero, a reinforcement learning (RL) framework and model that produces accurate SQL using a lightweight reward signal based on execution correctness and format-tag compliance. By avoiding intermediate supervision, hybrid pipelines and complex reward shaping, our method encourages stable learning and stronger alignment with the ultimate task objective-producing executable programs. CogniSQL-R1-Zero achieves state-of-the-art execution accuracy on Text2SQL benchmark; BIRD bench, outperforming prior supervised and instruction-tuned baselines including SFT CodeS-7B, DeepSeek-Coder 236B, and Mistral 123B-despite being trained on a significantly smaller 7B backbone. This result underscores the scalability and efficiency of our RL-based approach when trained on just four NVIDIA A100 GPUs (40 GB VRAM each). To support further research in efficient and interpretable Text-to-SQL modeling, we release two curated datasets: (i) a collection of 5,024 reasoning traces with varying context lengths, and (ii) a positive-sampled corpus of 36,356 corpus of weakly supervised queries, each annotated with six semantically diverse reasoning paths. Together, these contributions advance scalable, execution-aligned Text-to-SQL generation.
将自然语言翻译成SQL(文本到SQL)仍然是语言理解与结构化数据访问交叉点的核心挑战。尽管大型语言模型(LLM)提高了流畅性,但生成正确且可执行的SQL,尤其是对于复杂查询,仍然具有挑战性。我们推出了CogniSQL-R1-Zero,这是一个基于强化学习(RL)的框架和模型,它使用基于执行正确性和格式标签符合的轻量级奖励信号来生成准确的SQL。通过避免中间监督、混合管道和复杂的奖励塑造,我们的方法鼓励稳定的学习,并与最终任务目标——生成可执行程序——更紧密地结合。CogniSQL-R1-Zero在Text2SQL基准测试上实现了最先进的执行准确性;尽管是在一个显著较小的70亿参数的后端上进行训练的,但在BIRD基准测试中仍优于先前的监督指令调整基线,包括SFT CodeS-7B、DeepSeek-Coder 236B和Mistral 123B。这一结果突出了我们的基于强化学习的方法在仅使用四个NVIDIA A100 GPU(每个拥有40GB VRAM)进行训练时的可扩展性和效率。为了支持在高效且可解释的文本到SQL建模方面的进一步研究,我们发布了两个精选数据集:(i)包含5024个推理轨迹的集合,具有不同的上下文长度,(ii)一个积极样本语料库,包含36356个弱监督查询的语料库,每个都标有六条语义多样的推理路径。这些贡献共同推动了可扩展、与执行相匹配的文本到SQL生成。
论文及项目相关链接
Summary
该文介绍了在自然语言到SQL(Text-to-SQL)转换方面的挑战,尤其是在使用大型语言模型(LLM)时。作者提出了一种基于强化学习(RL)的框架和模型——CogniSQL-R1-Zero,它能够根据执行正确性和格式标签遵守情况,生成准确的SQL。该方法避免了中间监督、混合管道和复杂的奖励塑造,鼓励稳定学习,并与最终任务目标——生成可执行程序更紧密对齐。CogniSQL-R1-Zero在Text2SQL基准测试上实现了最先进的执行精度,且仅在四个NVIDIA A100 GPU上训练,显示出其可扩展性和效率。作者还发布了两个数据集以支持进一步的研究。
Key Takeaways
- 自然语言到SQL的转换是一个核心挑战,涉及语言理解和结构化数据访问的交叉。
- 尽管大型语言模型(LLM)提高了流畅性,但生成正确且可执行的SQL,尤其是复杂查询,仍然具有挑战性。
- CogniSQL-R1-Zero是一个基于强化学习(RL)的框架和模型,可生成准确的SQL。
- 该方法鼓励稳定学习,与最终任务目标——生成可执行程序更紧密对齐,避免中间监督、混合管道和复杂的奖励塑造。
- CogniSQL-R1-Zero在Text2SQL基准测试上实现了最先进的执行精度,训练所使用的GPU数量较少,显示出其效率。
- 作者发布了两个数据集以支持Text-to-SQL建模的进一步研究,包括包含不同上下文长度的推理轨迹和积极样本语料库。
点此查看论文截图

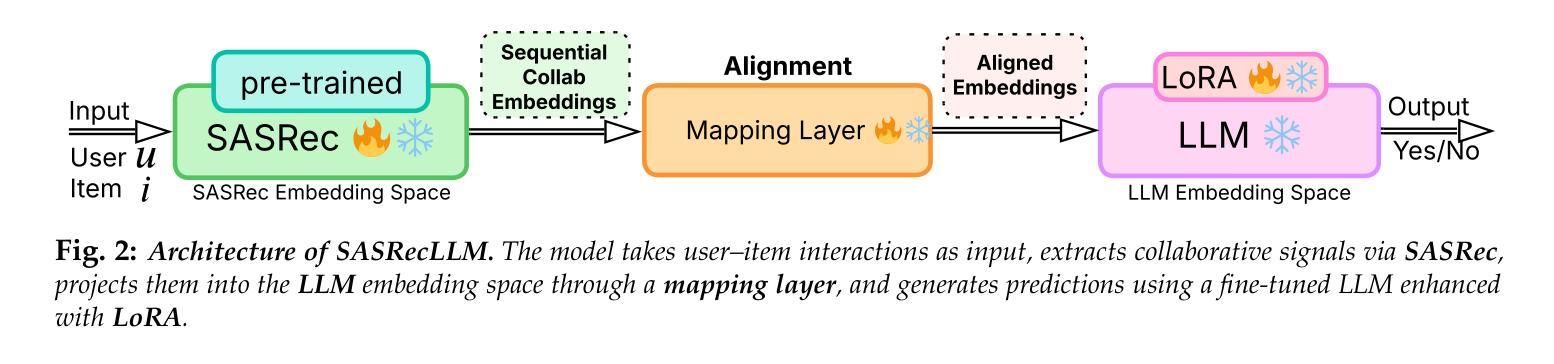
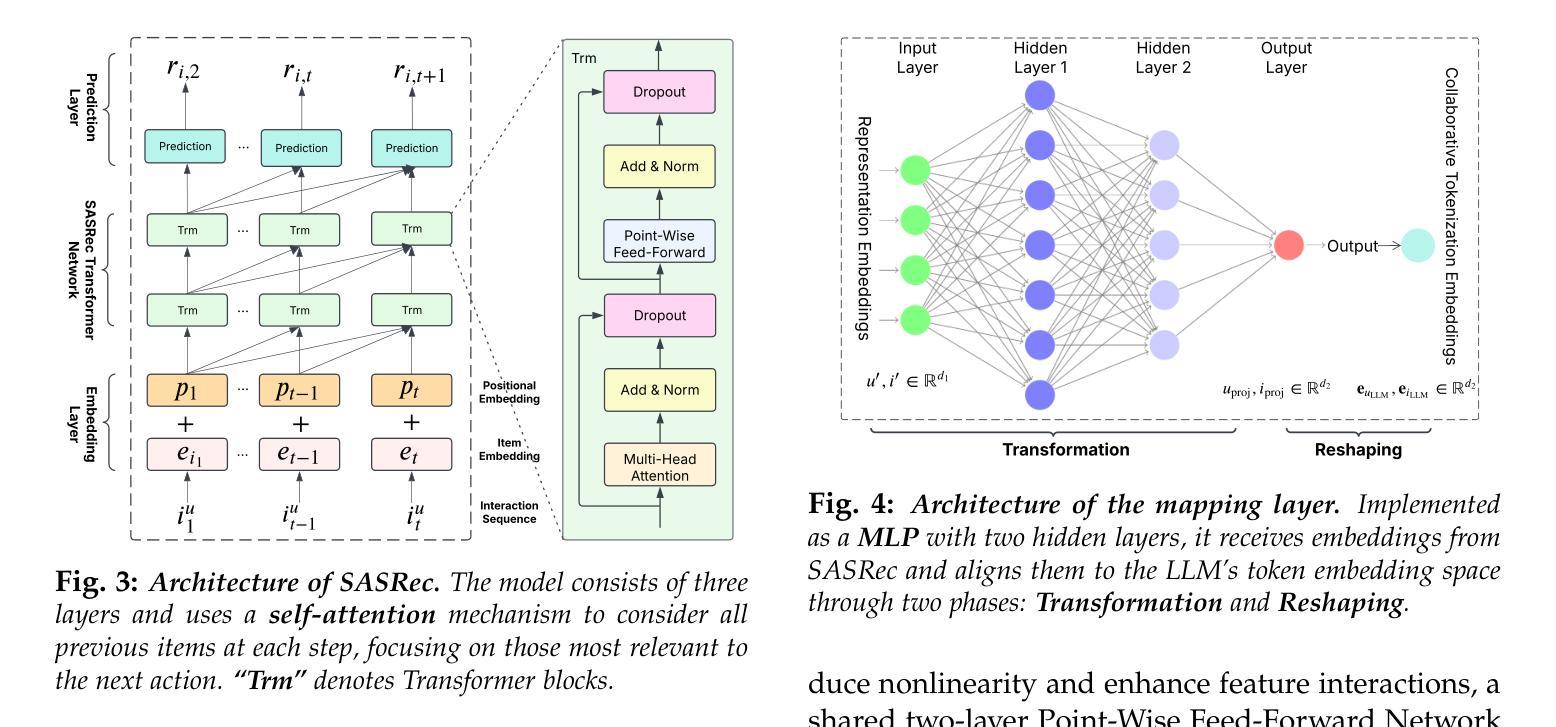
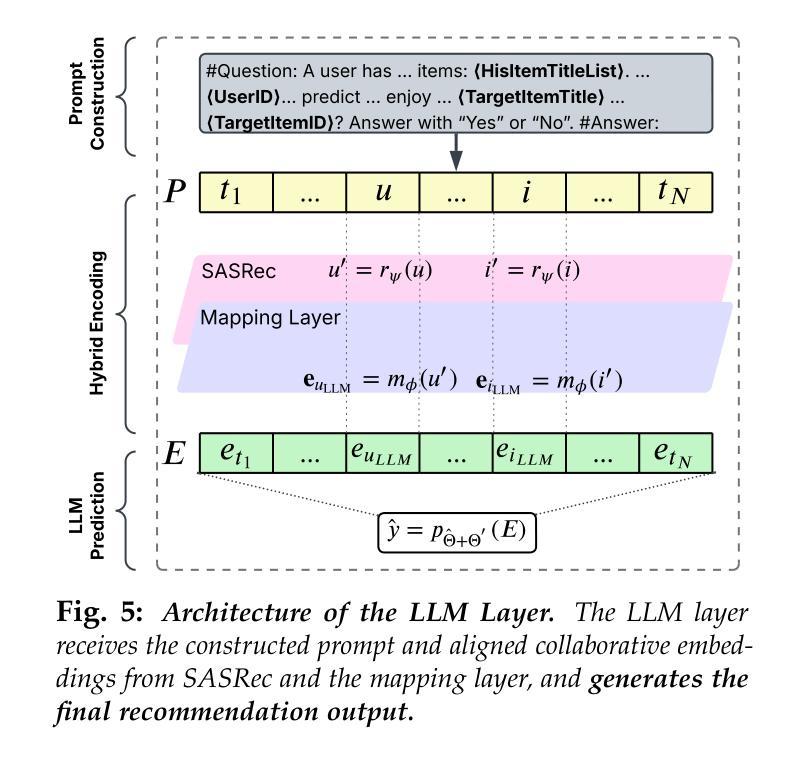
When Transformers Meet Recommenders: Integrating Self-Attentive Sequential Recommendation with Fine-Tuned LLMs
Authors:Kechen Liu
Self-Attentive Sequential Recommendation (SASRec) effectively captures long-term user preferences by applying attention mechanisms to historical interactions. Concurrently, the rise of Large Language Models (LLMs) has motivated research into LLM-based recommendation, which leverages their powerful generalization and language understanding capabilities. However, LLMs often lack the domain-specific knowledge and collaborative signals essential for high-quality recommendations when relying solely on textual prompts. To address this limitation, this study proposes SASRecLLM, a novel framework that integrates SASRec as a collaborative encoder with an LLM fine-tuned using Low-Rank Adaptation (LoRA). The components are connected via a mapping layer to align their dimensional spaces, and three targeted training strategies are designed to optimize the hybrid architecture. Extensive experiments on multiple datasets demonstrate that SASRecLLM achieves robust and consistent improvements over strong baselines in both cold-start and warm-start scenarios. This work advances the field of LLM-based recommendation by presenting a modular and effective paradigm for fusing structured collaborative filtering with the semantic power of fine-tuned LLMs. The implementation is available on GitHub: https://github.com/kechenkristin/RecLLM
自我关注序列推荐(SASRec)通过应用注意力机制到历史交互来有效地捕捉用户的长期偏好。同时,大型语言模型(LLM)的兴起推动了基于LLM的推荐研究,该推荐利用LLM强大的泛化和语言理解能力。然而,当仅依赖文本提示时,LLM往往缺乏特定领域的知识和重要的协同信号,这对于高质量推荐至关重要。为了解决这一局限性,本研究提出了SASRecLLM,这是一个结合了SASRec协同编码器和通过低秩适配(LoRA)微调LLM的新型框架。这些组件通过映射层连接以对其维度空间进行对齐,并设计了三种有针对性的训练策略来优化混合架构。在多个数据集上的广泛实验表明,SASRecLLM在冷启动和暖启动场景中均实现了对强基准线的稳健和一致改进。本研究通过展示融合结构化协同过滤与微调LLM语义能力的模块化有效范式,推动了基于LLM的推荐领域的发展。实现代码已在GitHub上提供:https://github.com/kechenkristin/RecLLM。
论文及项目相关链接
Summary
本文提出了SASRecLLM框架,它结合了SASRec协同编码器与经过LoRA微调的大型语言模型(LLM)。通过映射层连接各组件以对齐维度空间,并设计三种针对性训练策略优化混合架构。在多个数据集上的实验表明,SASRecLLM在冷启动和暖启动场景中均实现了对强基准线的稳健和一致改进。该研究为融合结构化协同过滤与微调LLM语义力量的模块化有效范式在推荐系统领域提供了进展。
Key Takeaways
- SASRecLLM结合了SASRec和LLM,旨在利用两者的优势,有效捕捉用户长期偏好并融合领域知识。
- SASRec通过注意力机制对历史交互进行编码,而LLM则提供强大的泛化和语言理解能力。
- LoRA技术用于微调LLM,以适应推荐系统的特定需求。
- SASRecLLM通过映射层整合了SASRec和LLM的维度空间。
- 该框架采用三种针对性训练策略来优化混合架构的性能。
- 在多个数据集上的实验表明,SASRecLLM在冷启动和暖启动情况下均表现出优异的性能改进。
点此查看论文截图

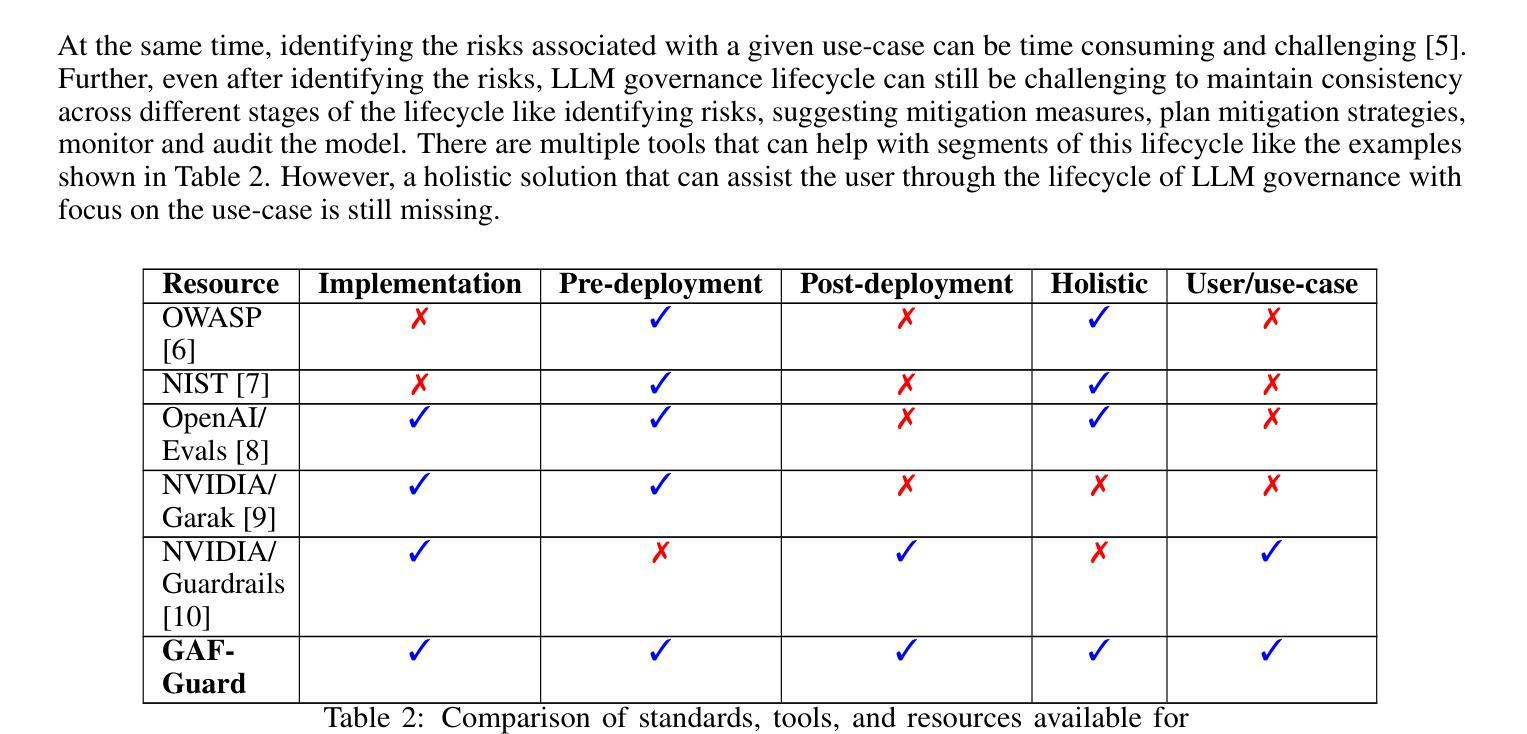
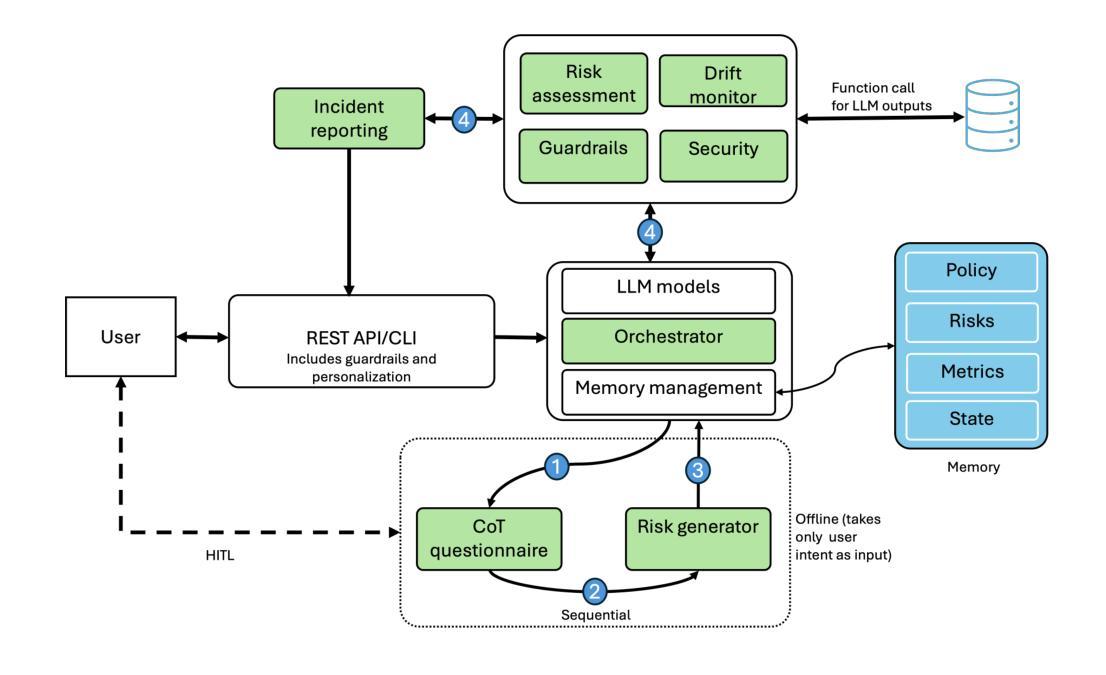
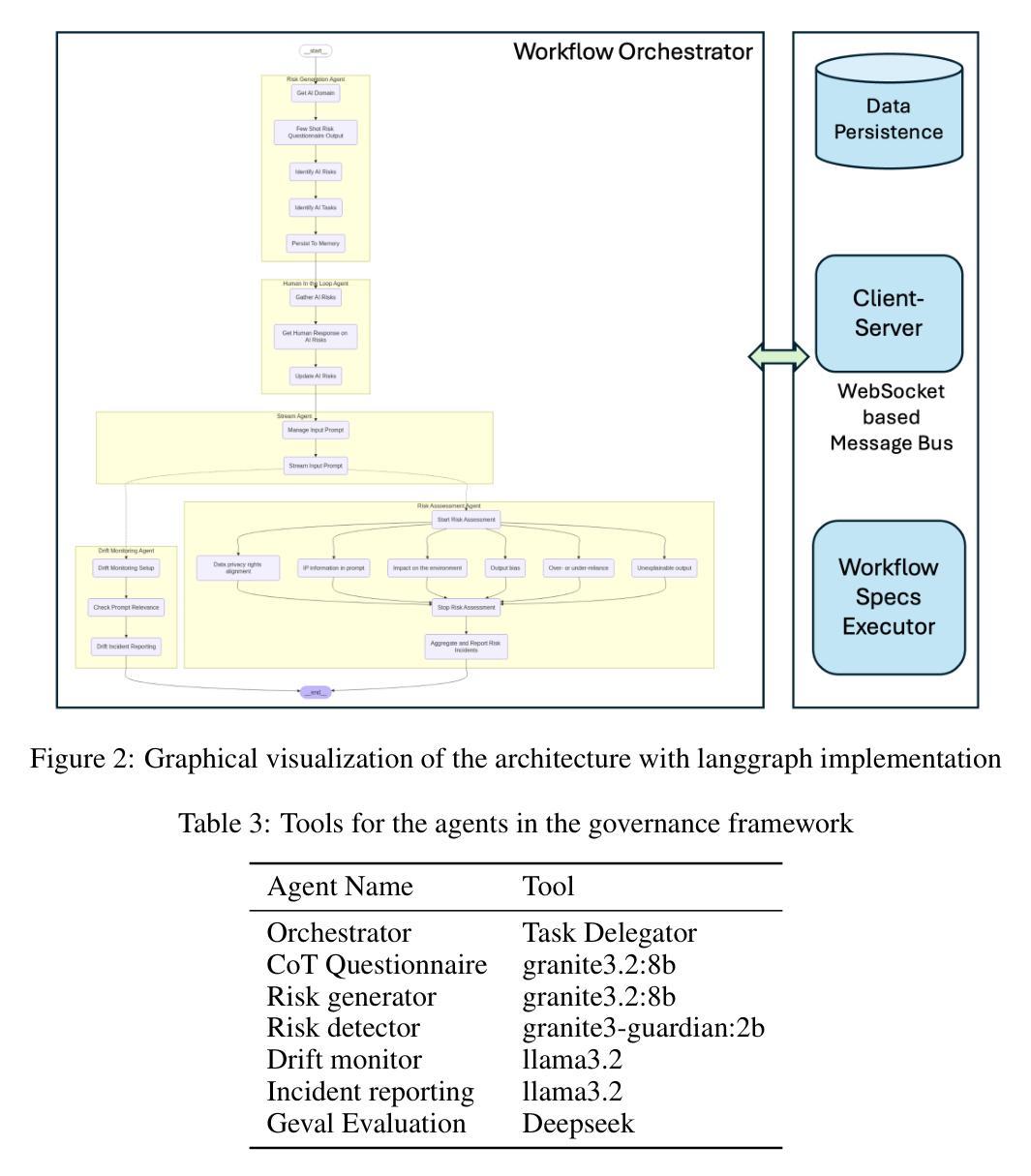
GAF-Guard: An Agentic Framework for Risk Management and Governance in Large Language Models
Authors:Seshu Tirupathi, Dhaval Salwala, Elizabeth Daly, Inge Vejsbjerg
As Large Language Models (LLMs) continue to be increasingly applied across various domains, their widespread adoption necessitates rigorous monitoring to prevent unintended negative consequences and ensure robustness. Furthermore, LLMs must be designed to align with human values, like preventing harmful content and ensuring responsible usage. The current automated systems and solutions for monitoring LLMs in production are primarily centered on LLM-specific concerns like hallucination etc, with little consideration given to the requirements of specific use-cases and user preferences. This paper introduces GAF-Guard, a novel agentic framework for LLM governance that places the user, the use-case, and the model itself at the center. The framework is designed to detect and monitor risks associated with the deployment of LLM based applications. The approach models autonomous agents that identify risks, activate risk detection tools, within specific use-cases and facilitate continuous monitoring and reporting to enhance AI safety, and user expectations. The code is available at https://github.com/IBM/risk-atlas-nexus-demos/tree/main/gaf-guard.
随着大型语言模型(LLM)在各个领域的应用日益广泛,为了防止出现意外的负面后果并确保其稳健性,必须对其进行严格监控。此外,LLM的设计必须与人类价值观相一致,如防止有害内容并确保负责任的使用。当前用于监控生产环境中LLM的自动化系统和解决方案主要集中于LLM特定的关注点,如幻觉等,而很少考虑特定用例和用户偏好。本文介绍了GAF-Guard,这是一个用于LLM治理的新型代理框架,以用户、用例和模型本身为中心。该框架旨在检测和监控与部署LLM应用程序相关的风险。该方法建立自主代理,能够在特定用例中识别风险、激活风险检测工具,并促进持续监控和报告,以提高人工智能的安全性和用户期望。代码可在https://github.com/IBM/risk-atlas-nexus-demos/tree/main/gaf-guard找到。
论文及项目相关链接
Summary
大型语言模型(LLM)的广泛应用需要严格的监控以确保其稳健性和避免产生负面后果。本文介绍了GAF-Guard框架,该框架旨在针对特定用例和用户偏好进行LLM的风险检测与监控。通过自主代理识别风险、激活风险检测工具,实现持续监控和报告,提高人工智能的安全性和用户满意度。
Key Takeaways
- LLM的广泛应用需要对其进行严格的监控以确保其稳健性并避免产生负面后果。
- 当前LLM的监测系统主要关注模型本身的问题,但忽略了特定用例和用户偏好。
- GAF-Guard是一个新型的LLM治理框架,将用户、用例和模型本身置于中心位置。
- GAF-Guard通过自主代理识别风险并激活风险检测工具,以实现对LLM应用的持续监控。
- 该框架旨在提高人工智能的安全性和用户满意度。
- GAF-Guard框架具有强大的适用性,可以适应不同的使用场景和需求。
点此查看论文截图


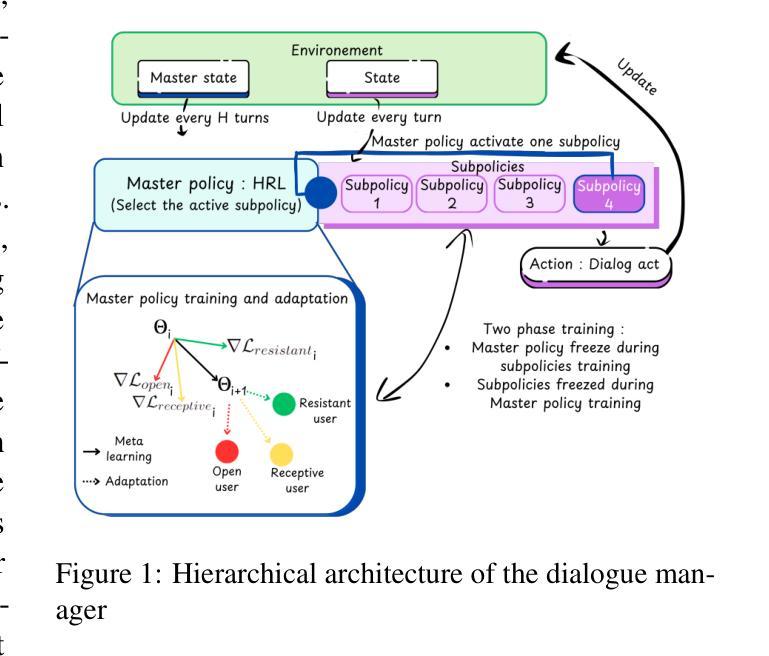
Tailored Conversations beyond LLMs: A RL-Based Dialogue Manager
Authors:Lucie Galland, Catherine Pelachaud, Florian Pecune
In this work, we propose a novel framework that integrates large language models (LLMs) with an RL-based dialogue manager for open-ended dialogue with a specific goal. By leveraging hierarchical reinforcement learning to model the structured phases of dialogue and employ meta-learning to enhance adaptability across diverse user profiles, our approach enhances adaptability and efficiency, enabling the system to learn from limited data, transition fluidly between dialogue phases, and personalize responses to heterogeneous patient needs. We apply our framework to Motivational Interviews, aiming to foster behavior change, and demonstrate that the proposed dialogue manager outperforms a state-of-the-art LLM baseline in terms of reward, showing a potential benefit of conditioning LLMs to create open-ended dialogue systems with specific goals.
在这项工作中,我们提出了一种新型框架,该框架将大型语言模型(LLM)与基于RL的对话管理器集成在一起,用于实现具有特定目标的开放式对话。我们通过利用分层强化学习来模拟对话的结构化阶段,并运用元学习来提高在不同用户配置文件之间的适应性,从而提高适应性和效率,使系统能够在有限的数据中学习,在对话阶段之间平稳过渡,并对不同患者的需求做出个性化响应。我们将该框架应用于动机面试,旨在促进行为改变,并证明所提出的对话管理器在奖励方面优于最新LLM基准测试,显示出将LLM设置为创建具有特定目标的开放式对话系统的潜在优势。
论文及项目相关链接
Summary
本文提出了一种新型框架,它将大型语言模型(LLMs)与基于强化学习的对话管理器相结合,用于实现具有特定目标的开放式对话。通过利用分层强化学习来模拟对话的结构化阶段,并借助元学习来提高对不同用户需求的适应性,此方法增强了系统的适应性和效率,使系统能够在有限的数据中学习,流畅地过渡对话阶段,并对不同患者的需求进行个性化回应。本文将框架应用于动机面试,旨在促进行为改变,并证明所提出的对话管理器在奖励方面优于最先进LLM基线,显示出将LLMs条件化以创建具有特定目标的开放式对话系统的潜力。
Key Takeaways
- 提出了一种结合大型语言模型(LLMs)和强化学习对话管理器的新型框架。
- 利用分层强化学习模拟对话的结构化阶段,提高系统的对话管理效率。
- 通过元学习增强对不同用户需求的适应性,使系统能够适应多样化的用户配置文件。
- 框架应用于动机面试,旨在促进行为改变。
- 提出的对话管理器在奖励方面优于现有的LLM基线。
- 表明结合LLMs和强化学习可以创建具有特定目标的开放式对话系统。
点此查看论文截图


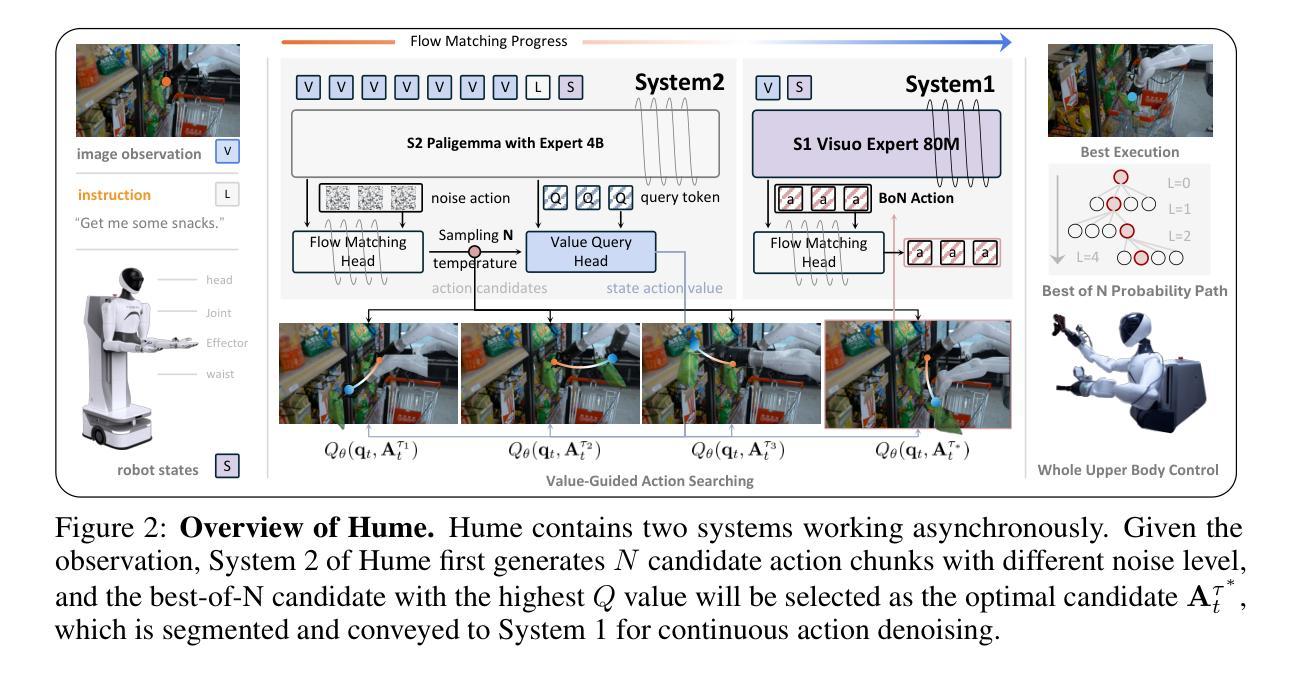
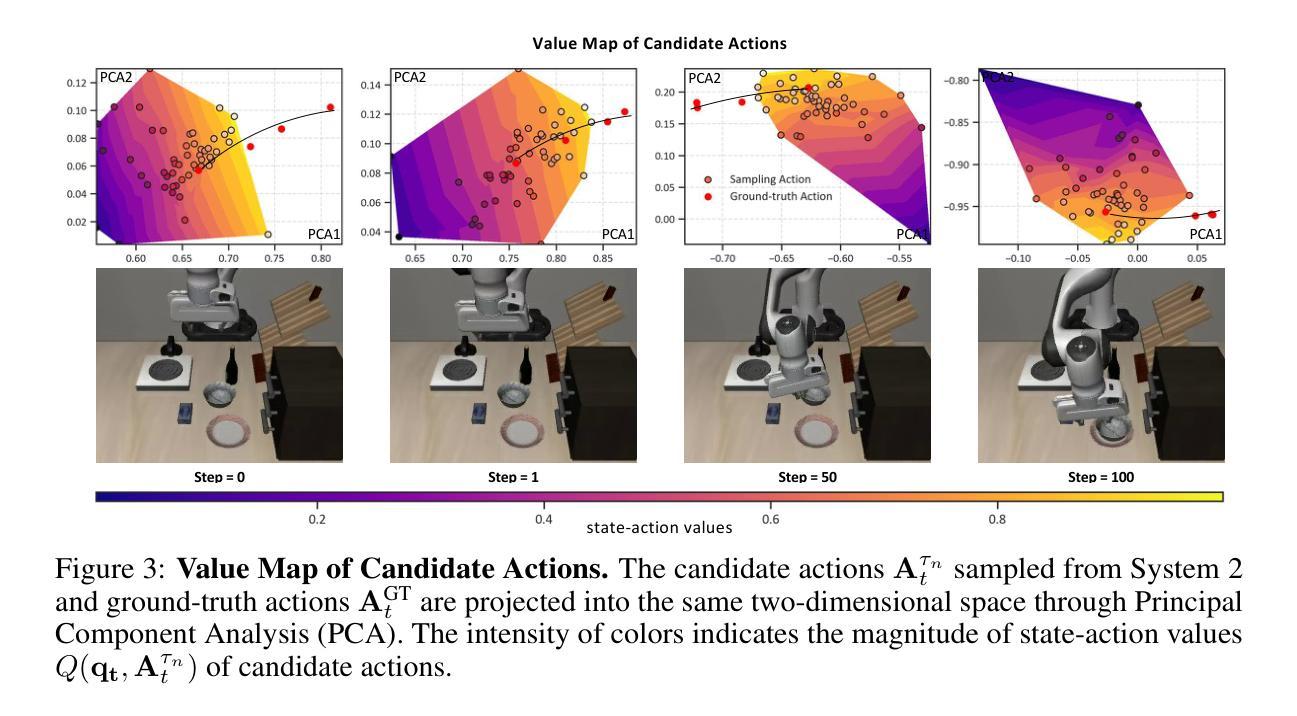
Hume: Introducing System-2 Thinking in Visual-Language-Action Model
Authors:Haoming Song, Delin Qu, Yuanqi Yao, Qizhi Chen, Qi Lv, Yiwen Tang, Modi Shi, Guanghui Ren, Maoqing Yao, Bin Zhao, Dong Wang, Xuelong Li
Humans practice slow thinking before performing actual actions when handling complex tasks in the physical world. This thinking paradigm, recently, has achieved remarkable advancement in boosting Large Language Models (LLMs) to solve complex tasks in digital domains. However, the potential of slow thinking remains largely unexplored for robotic foundation models interacting with the physical world. In this work, we propose Hume: a dual-system Vision-Language-Action (VLA) model with value-guided System-2 thinking and cascaded action denoising, exploring human-like thinking capabilities of Vision-Language-Action models for dexterous robot control. System 2 of Hume implements value-Guided thinking by extending a Vision-Language-Action Model backbone with a novel value-query head to estimate the state-action value of predicted actions. The value-guided thinking is conducted by repeat sampling multiple action candidates and selecting one according to state-action value. System 1 of Hume is a lightweight reactive visuomotor policy that takes System 2 selected action and performs cascaded action denoising for dexterous robot control. At deployment time, System 2 performs value-guided thinking at a low frequency while System 1 asynchronously receives the System 2 selected action candidate and predicts fluid actions in real time. We show that Hume outperforms the existing state-of-the-art Vision-Language-Action models across multiple simulation benchmark and real-robot deployments.
在处理物理世界的复杂任务时,人类会在实际行动之前进行慢思考。最近,这种思考范式在推动大型语言模型(LLM)在数字领域解决复杂任务方面取得了显著进展。然而,慢思考在机器人基础模型与物理世界交互中的潜力尚未得到广泛探索。在这项工作中,我们提出了Hume:一种具有价值导向的System-2思考和级联动作去噪的双系统视觉语言动作(VLA)模型,探索视觉语言动作模型在灵巧机器人控制方面的人类思维能力。Hume的System 2通过扩展视觉语言动作模型的骨干网并加入新型价值查询头来估计预测动作的状态-动作价值,从而实现价值导向的思考。价值导向的思考是通过多次采样多个动作候选者并根据状态-动作价值进行选择来完成的。Hume的System 1是一个轻量级的反应型视觉运动策略,它接受System 2选择的动作,并进行级联动作去噪,以实现灵巧的机器人控制。在部署时,System 2以较低频率进行价值导向的思考,而System 1则异步接收System 2选择的动作候选者并实时预测流畅的动作。我们在多个仿真基准测试和真实机器人部署中展示了Hume超越现有最先进的视觉语言动作模型的表现。
论文及项目相关链接
Summary
该文本介绍了在处理物理世界的复杂任务时,人类在进行实际操作前会进行慢思考的模式。最近,这种思考模式在推动大型语言模型(LLM)解决数字领域的复杂任务方面取得了显著进展。然而,对于机器人基础模型与物理世界的交互而言,慢思考的巨大潜力尚未得到广泛探索。本文提出了一项探索人一样的思考能力的技术——Hume,这是一种具有价值导向的System-2思考和级联动作去噪的双系统视觉-语言-动作(VLA)模型。System 2通过增加一个价值查询头来估计预测动作的状态-动作价值,从而实现价值导向的思考。价值导向的思考是通过重复采样多个动作候选者并选择具有最高状态-动作价值的动作来实现的。System 1是Hume的一个轻量级反应视觉运动策略,它接收System 2选择的动作并进行级联动作去噪,以实现精细的机器人控制。在部署时,System 2以较低频率进行价值导向的思考,而System 1则异步接收System 2选择的动作候选者并实时预测流畅的动作。研究表明,Hume在多个模拟基准测试和真实机器人部署方面的表现均优于现有的最先进的视觉-语言-动作模型。
Key Takeaways
- 人类在处理物理世界的复杂任务时会采用慢思考模式,这一模式在数字领域的LLM中已有显著进展。
- 机器人基础模型在与物理世界交互时,慢思考模式的潜力尚未得到充分探索。
- Hume是一个双系统的视觉-语言-动作(VLA)模型,结合了价值导向的System-2思考和级联动作去噪技术。
- System 2通过价值查询头实现价值导向的思考,通过重复采样和选择最高状态-动作价值的动作来进行思考。
- System 1是一个轻量级的反应视觉运动策略,用于接收System 2选择的动作并进行去噪处理,以实现精细的机器人控制。
- 在部署时,Hume的System 2以低频率进行价值导向的思考,而System 1则实时预测流畅的动作。
点此查看论文截图

MAIN: Mutual Alignment Is Necessary for instruction tuning
Authors:Fanyi Yang, Jianfeng Liu, Xin Zhang, Haoyu Liu, Xixin Cao, Yuefeng Zhan, Hao Sun, Weiwei Deng, Feng Sun, Qi Zhang
Instruction tuning has empowered large language models (LLMs) to achieve remarkable performance, yet its success heavily depends on the availability of large-scale, high-quality instruction-response pairs. To meet this demand, various methods have been developed to synthesize data at scale. However, current methods for scaling up data generation often overlook a crucial aspect: the alignment between instructions and responses. We hypothesize that the quality of instruction-response pairs is determined not by the individual quality of each component, but by the degree of mutual alignment. To address this, we propose a Mutual Alignment Framework (MAIN) which enforces coherence between instructions and responses through mutual constraints. We demonstrate that MAIN generalizes well across model architectures and sizes, achieving state-of-the-art performance on LLaMA, Mistral, and Qwen models across diverse benchmarks. This work underscores the critical role of instruction-response alignment in enabling generalizable and high-quality instruction tuning for LLMs.
指令微调已经使大型语言模型(LLM)实现了显著的性能提升,但其成功很大程度上取决于大规模高质量指令-响应对的可用性。为了满足这一需求,已经开发了各种方法来大规模合成数据。然而,当前扩大数据生成规模的方法往往忽视了一个关键方面:指令和响应之间的对齐。我们假设指令-响应对的质并不取决于每个组件的单独质量,而是取决于相互对齐的程度。为了解决这一问题,我们提出了相互对齐框架(MAIN),通过相互约束来确保指令和响应之间的连贯性。我们证明MAIN在模型架构和规模上具有很好的通用性,在LLaMA、Mistral和Qwen模型上实现多样化基准测试的最佳性能。这项工作强调了指令响应对齐在使大型语言模型能够进行通用化和高质量指令调整方面的重要作用。
论文及项目相关链接
Summary
指令微调使得大型语言模型(LLM)取得了显著的性能提升,但成功很大程度上取决于大规模高质量指令响应对的可用性。为满足这一需求,已经开发了各种方法来大规模合成数据。然而,当前的数据生成方法往往忽略了关键方面:指令与响应之间的对齐。本工作假设指令响应对的质并不取决于其单一组件的质量,而是取决于双方的相互对齐程度。为解决这一问题,我们提出了双向对齐框架(MAIN),通过双向约束确保指令与响应之间的连贯性。我们在LLaMA、Mistral和Qwen模型上展示了MAIN的良好泛化能力,并在多种基准测试中取得了最新技术水平。本研究强调了指令响应对齐在使LLM实现通用和高质量的指令微调中的关键作用。
Key Takeaways
- 指令微调对于LLM性能的提升至关重要,依赖于大规模高质量指令响应对的可用性。
- 当前数据生成方法往往忽视指令与响应之间的对齐。
- 指令响应对的质取决于双方的相互对齐程度,而非单一组件的质量。
- 提出了双向对齐框架(MAIN)来确保指令与响应之间的连贯性。
- MAIN框架在不同模型架构和规模上具有良好的泛化能力。
- MAIN在多种基准测试上实现了最新技术水平的表现。
点此查看论文截图

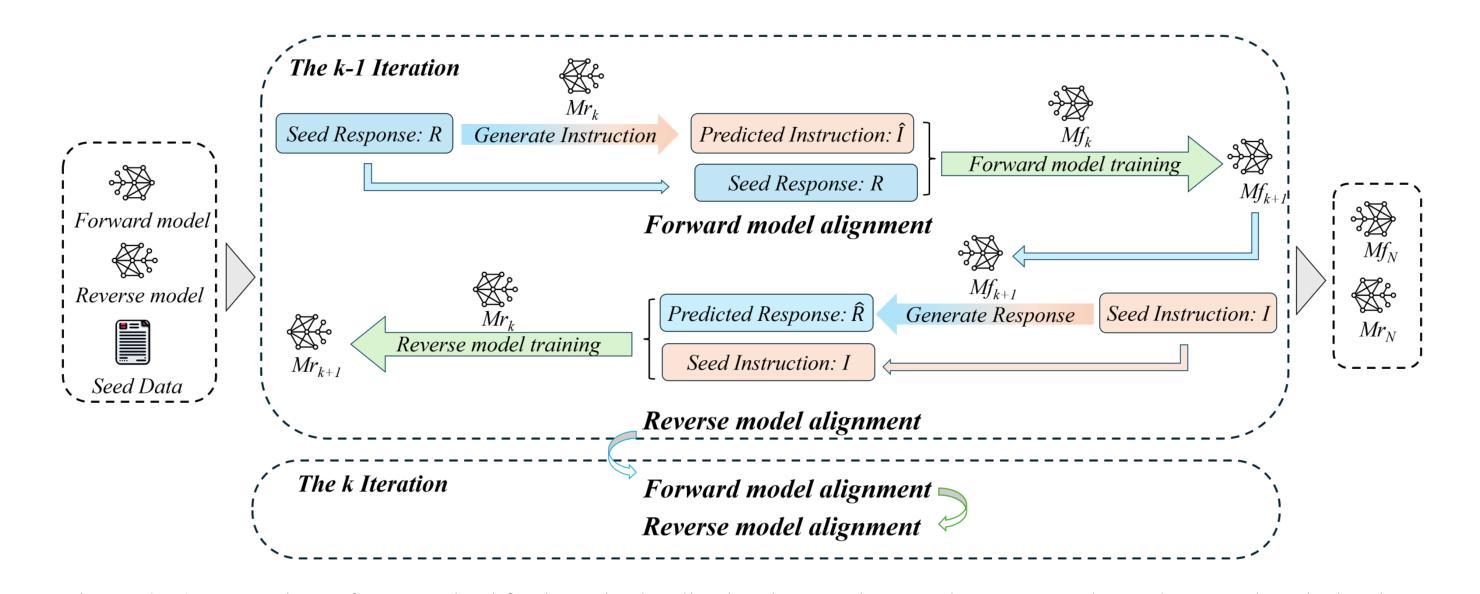
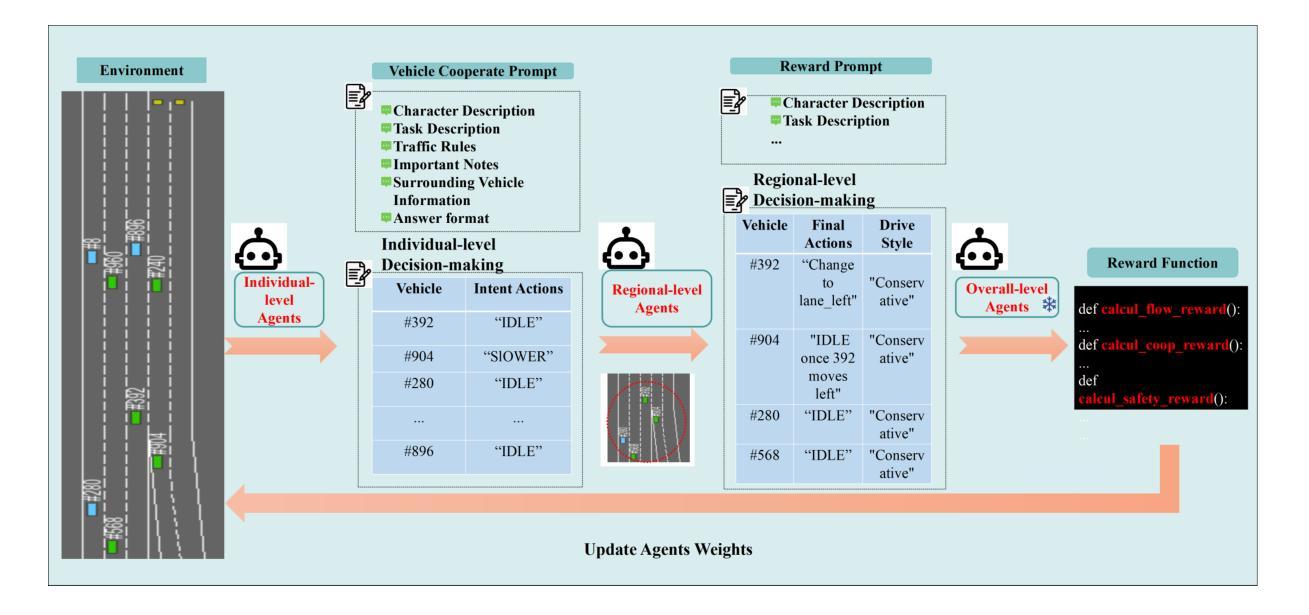
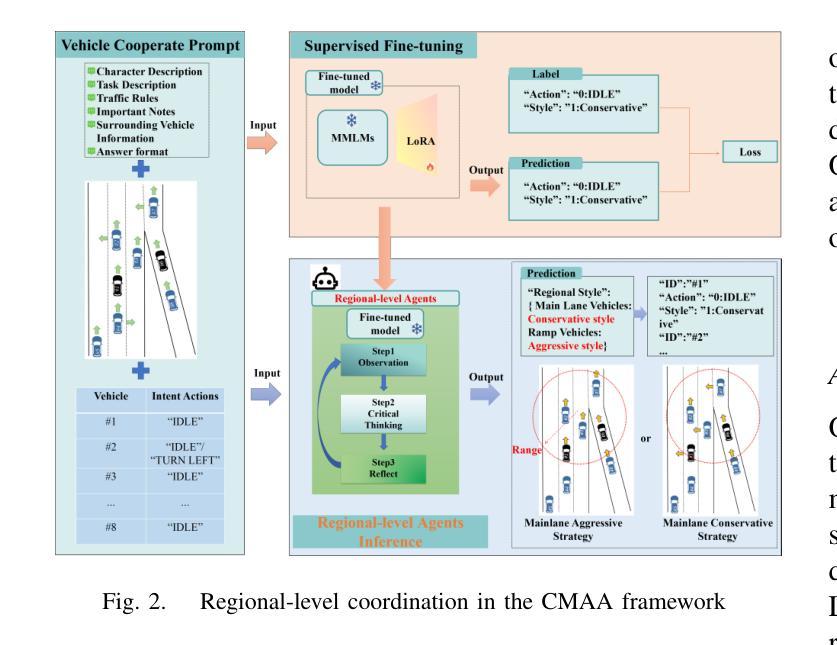
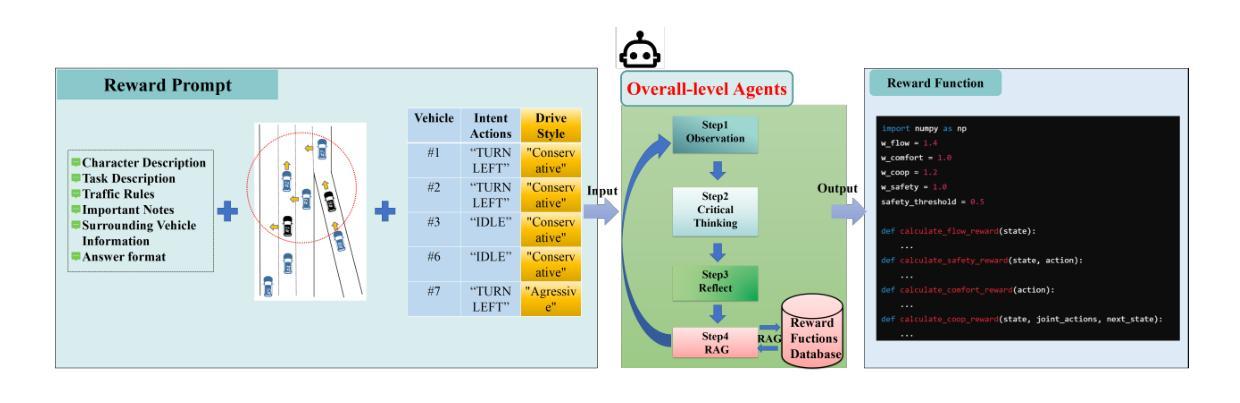
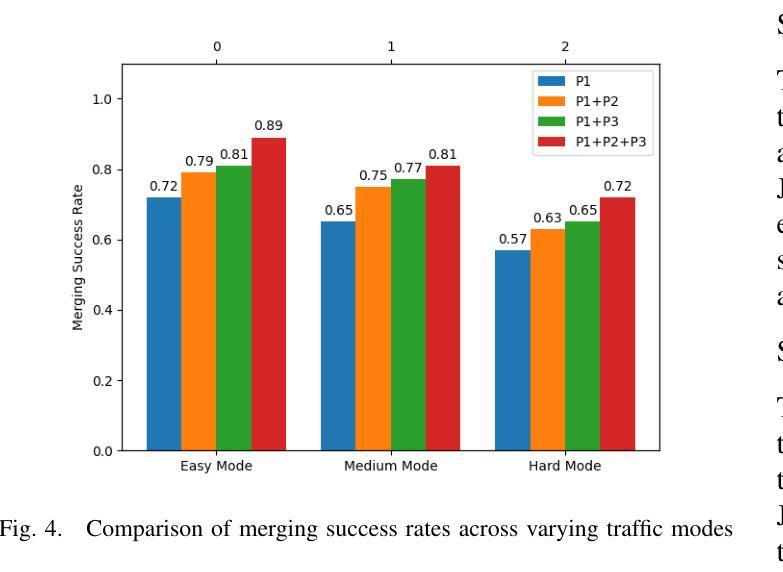
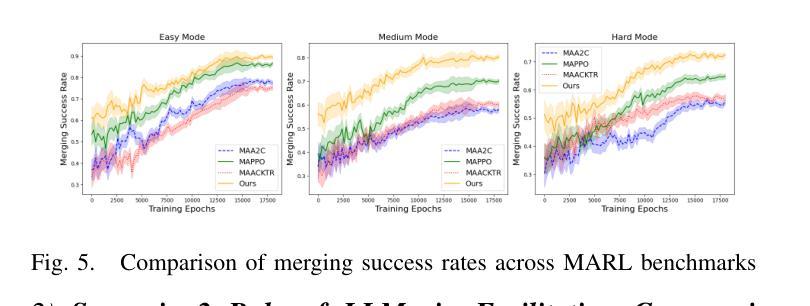
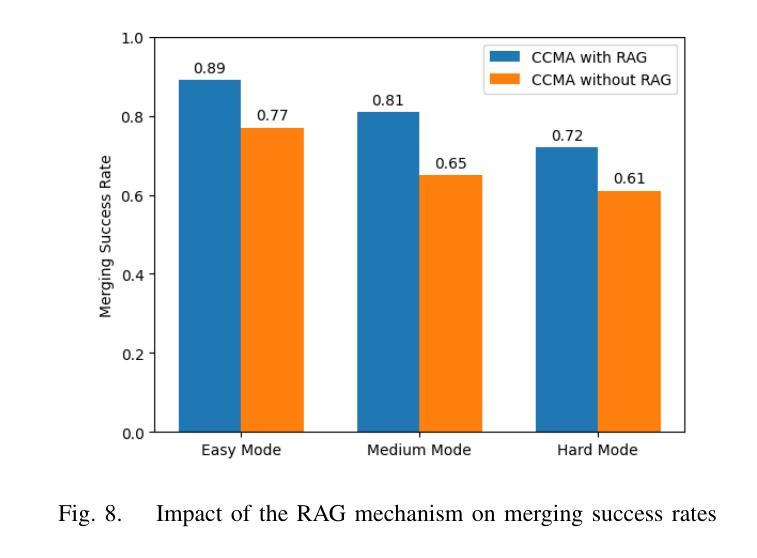
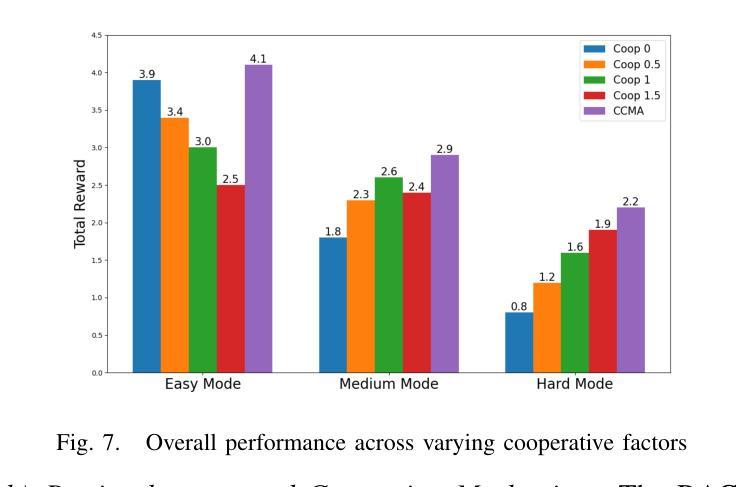
A Cascading Cooperative Multi-agent Framework for On-ramp Merging Control Integrating Large Language Models
Authors:Miao Zhang, Zhenlong Fang, Tianyi Wang, Qian Zhang, Shuai Lu, Junfeng Jiao, Tianyu Shi
Traditional Reinforcement Learning (RL) suffers from replicating human-like behaviors, generalizing effectively in multi-agent scenarios, and overcoming inherent interpretability issues.These tasks are compounded when deep environment understanding, agent coordination and dynamic optimization are required. While Large Language Model (LLM) enhanced methods have shown promise in generalization and interoperability, they often neglect necessary multi-agent coordination. Therefore, we introduce the Cascading Cooperative Multi-agent (CCMA) framework, integrating RL for individual interactions, a fine-tuned LLM for regional cooperation, a reward function for global optimization, and the Retrieval-augmented Generation mechanism to dynamically optimize decision-making across complex driving scenarios. Our experiments demonstrate that the CCMA outperforms existing RL methods, demonstrating significant improvements in both micro and macro-level performance in complex driving environments.
传统强化学习(RL)在复制人类行为、在多智能体场景中的有效推广以及克服固有的解释性问题方面存在困难。当需要深入了解环境、智能体协调和动态优化时,这些任务会变得更加复杂。虽然采用大型语言模型(LLM)增强方法已在推广和互操作性方面显示出希望,但它们往往忽视了必要的多智能体协调。因此,我们引入了级联合作多智能体(CCMA)框架,该框架将RL用于个体交互,微调LLM用于区域合作,奖励函数用于全局优化,检索增强生成机制以在复杂的驾驶场景中动态优化决策。我们的实验表明,CCMA在复杂的驾驶环境中优于现有的RL方法,在微观和宏观性能上均显示出显著改进。
论文及项目相关链接
Summary
在强化学习(RL)中,存在难以复制人类行为、在多智能体场景中有效泛化以及解决内在解释性问题等挑战。当需要深度环境理解、智能体协调和动态优化时,这些任务更加复杂。大型语言模型(LLM)增强方法在泛化和互操作性方面显示出潜力,但往往忽略了必要的多智能体协调。因此,我们引入了级联合作多智能体(CCMA)框架,整合个体交互的RL、区域合作的微调LLM、全局优化的奖励函数以及用于动态优化复杂驾驶场景中决策生成的检索增强生成机制。实验表明,CCMA在复杂驾驶环境中相较于现有RL方法表现出更高的微观和宏观性能改进。
Key Takeaways
- 传统强化学习面临复制人类行为、多智能体场景泛化和解释性问题。
- 在需要深度环境理解、智能体协调和动态优化的场景下,这些问题更加突出。
- 大型语言模型增强方法在泛化和互操作性方面具潜力,但缺乏多智能体协调。
- 引入CCMA框架,整合RL、LLM、奖励函数和检索增强生成机制。
- CCMA框架旨在解决个体交互、区域合作和全局优化问题。
- 实验表明CCMA在复杂驾驶环境中表现优异,有显著改善。
点此查看论文截图


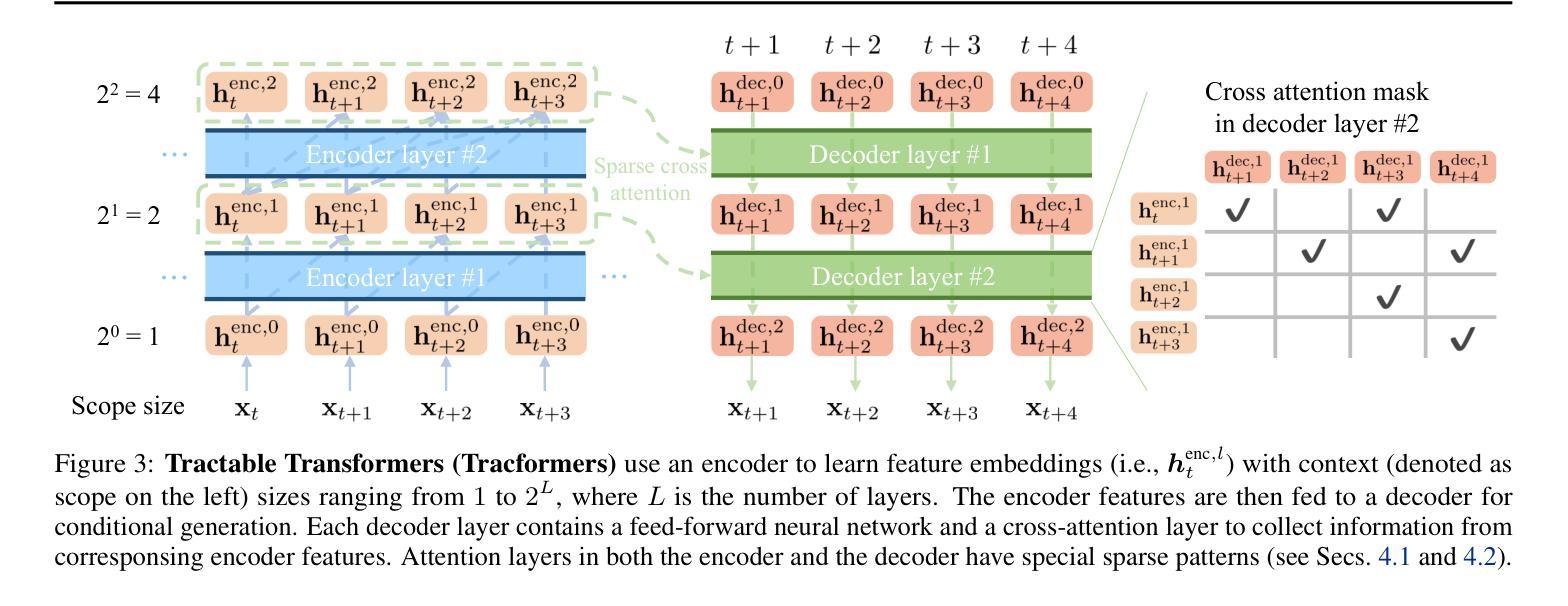
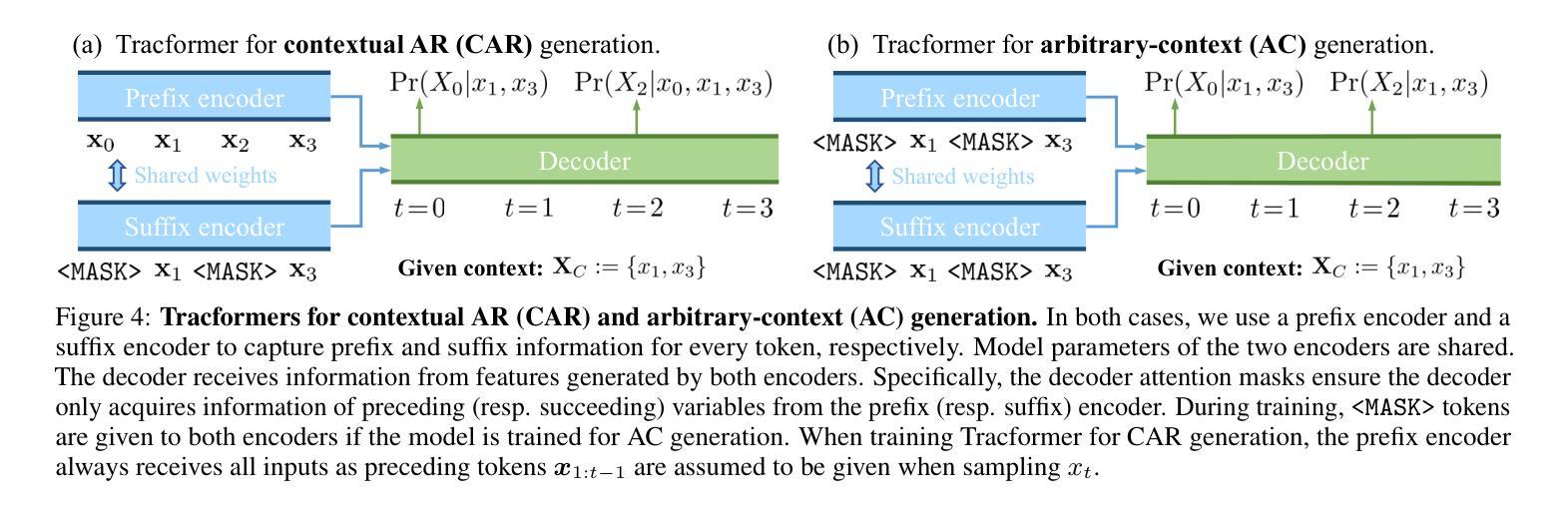
Tractable Transformers for Flexible Conditional Generation
Authors:Anji Liu, Xuejie Liu, Dayuan Zhao, Mathias Niepert, Yitao Liang, Guy Van den Broeck
Non-autoregressive (NAR) generative models are valuable because they can handle diverse conditional generation tasks in a more principled way than their autoregressive (AR) counterparts, which are constrained by sequential dependency requirements. Recent advancements in NAR models, such as diffusion language models, have demonstrated superior performance in unconditional generation compared to AR models (e.g., GPTs) of similar sizes. However, such improvements do not always lead to improved conditional generation performance. We show that a key reason for this gap is the difficulty in generalizing to conditional probability queries (i.e., the set of unknown variables) unseen during training. As a result, strong unconditional generation performance does not guarantee high-quality conditional generation. This paper proposes Tractable Transformers (Tracformer), a Transformer-based generative model that is more robust to different conditional generation tasks. Unlike existing models that rely solely on global contextual features derived from full inputs, Tracformers incorporate a sparse Transformer encoder to capture both local and global contextual information. This information is routed through a decoder for conditional generation. Empirical results demonstrate that Tracformers achieve state-of-the-art conditional generation performance on text modeling compared to recent diffusion and AR model baselines.
非自回归(NAR)生成模型具有价值,因为它们能够以比自回归(AR)模型更原则化的方式处理各种条件生成任务。自回归模型受到序列依赖性的约束。最近的NAR模型进展,如扩散语言模型,在无条件生成方面已经表现出优于类似规模的AR模型(例如GPT)的性能。然而,这种改进并不一定导致条件生成性能的改善。我们表明,造成这一差距的关键原因是难以推广到训练期间未见过的条件概率查询(即未知变量集)。因此,强大的无条件生成性能并不能保证高质量的条件生成。本文提出了“Tractable Transformers(Tracformer)”,这是一种基于Transformer的生成模型,能够更稳健地应对不同的条件生成任务。与现有仅依赖全局上下文特征的模型不同,Tracformers结合稀疏Transformer编码器来捕获局部和全局上下文信息。这些信息通过解码器进行有条件生成。经验结果表明,在文本建模方面,Tracformers实现了最新的有条件生成性能,超过了最近的扩散和AR模型基线。
论文及项目相关链接
Summary
非自回归(NAR)生成模型能够更灵活地处理各种条件生成任务,优于受序列依赖性限制的自回归(AR)模型。最新NAR模型如扩散语言模型在无条件生成方面表现出卓越性能,但在条件生成方面不一定优于类似规模的AR模型(如GPTs)。本文指出,这一差距的关键原因在于对训练期间未见过的条件概率查询的泛化困难。为此,本文提出Tractable Transformers(Tracformer),一种基于Transformer的生成模型,能更稳健地应对不同的条件生成任务。与仅依赖全局上下文特征的现有模型不同,Tracformers结合稀疏Transformer编码器来捕获局部和全局上下文信息,并通过解码器进行条件生成。实证结果表明,Tracformers在文本建模上实现了最先进的条件生成性能。
Key Takeaways
- NAR生成模型相比AR模型在条件生成任务上更具优势,能够更灵活地处理多样化的条件。
- 扩散语言模型在无条件生成方面表现出卓越性能,但在条件生成方面不一定优于AR模型。
- 条件生成性能差距的关键在于模型对未见过的条件概率查询的泛化能力。
- Tractable Transformers(Tracformer)是一种新的基于Transformer的生成模型,旨在提高对不同条件生成任务的稳健性。
- Tracformers结合稀疏Transformer编码器来捕获局部和全局上下文信息。
- Tracformers通过解码器进行条件生成,实现了文本建模上的先进条件生成性能。
点此查看论文截图


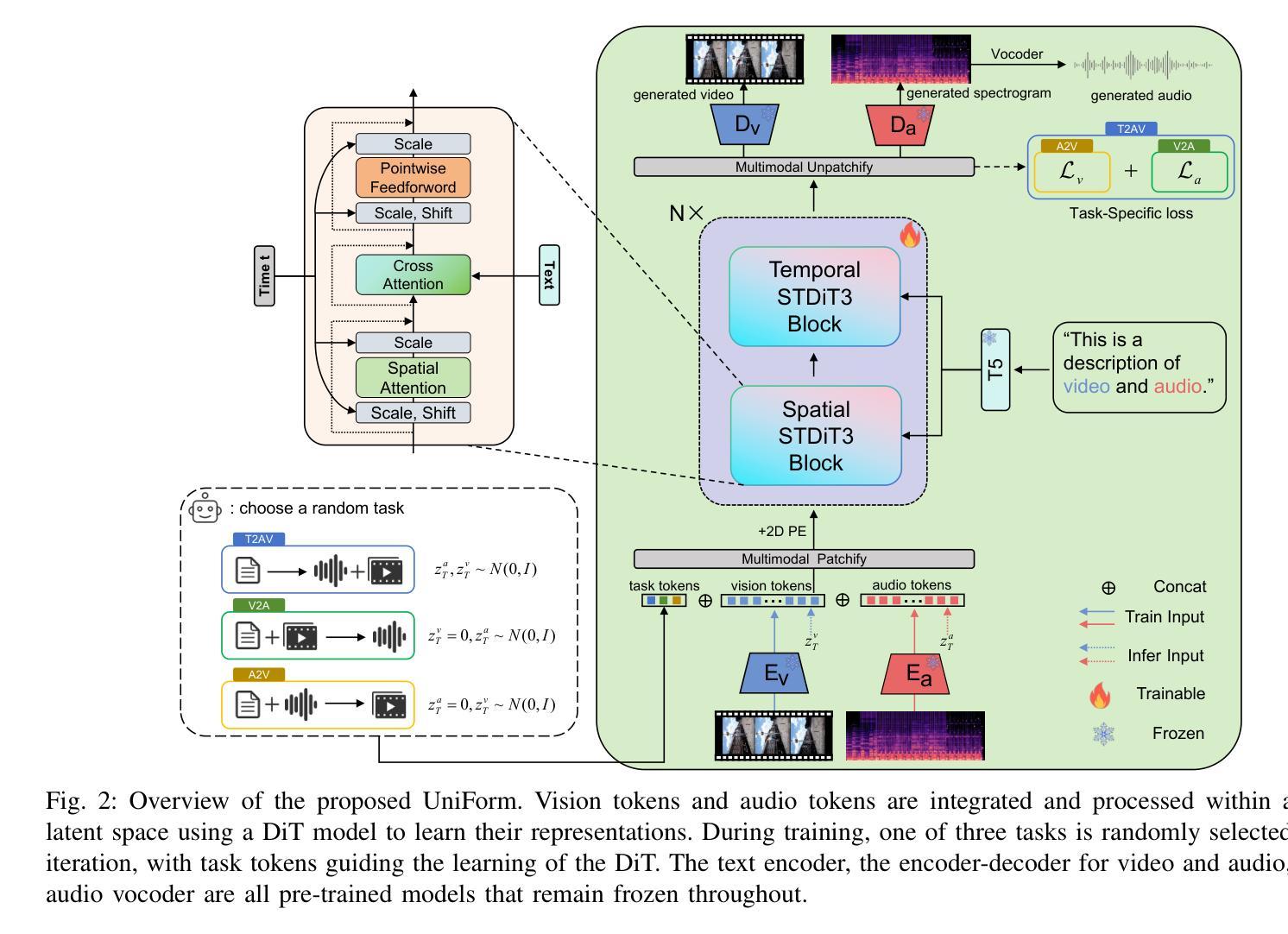
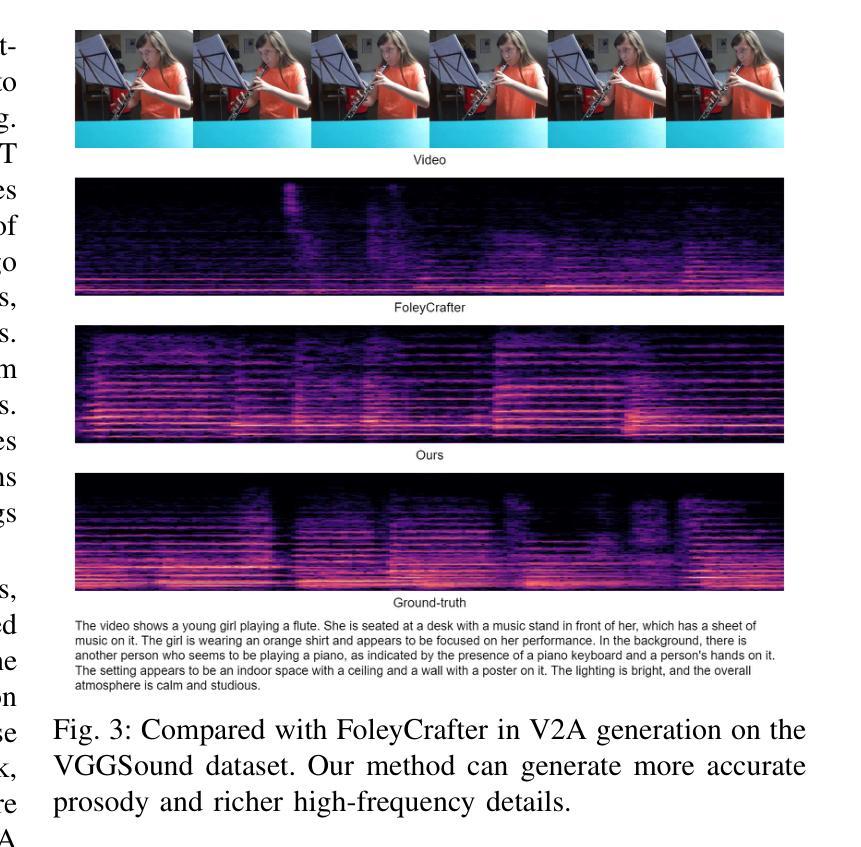
UniForm: A Unified Multi-Task Diffusion Transformer for Audio-Video Generation
Authors:Lei Zhao, Linfeng Feng, Dongxu Ge, Rujin Chen, Fangqiu Yi, Chi Zhang, Xiao-Lei Zhang, Xuelong Li
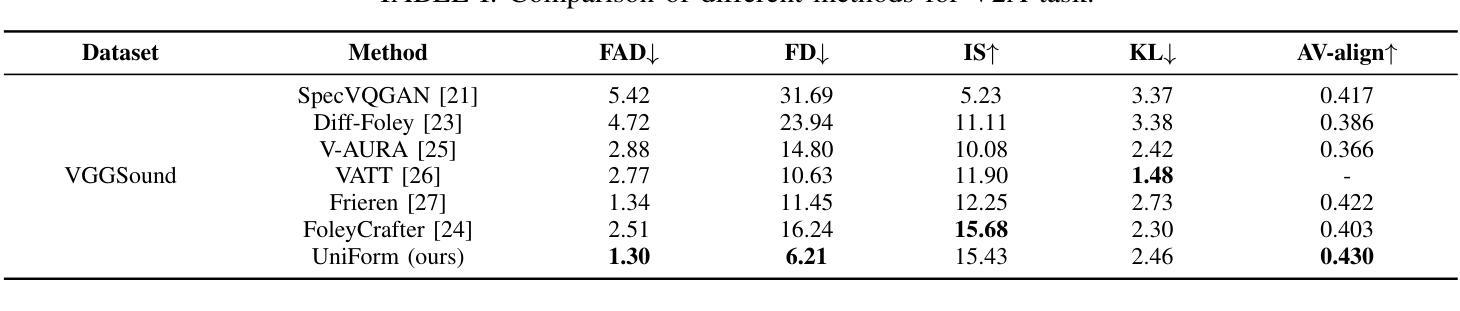
With the rise of diffusion models, audio-video generation has been revolutionized. However, most existing methods rely on separate modules for each modality, with limited exploration of unified generative architectures. In addition, many are confined to a single task and small-scale datasets. To overcome these limitations, we introduce UniForm, a unified multi-task diffusion transformer that generates both audio and visual modalities in a shared latent space. By using a unified denoising network, UniForm captures the inherent correlations between sound and vision. Additionally, we propose task-specific noise schemes and task tokens, enabling the model to support multiple tasks with a single set of parameters, including video-to-audio, audio-to-video and text-to-audio-video generation. Furthermore, by leveraging large language models and a large-scale text-audio-video combined dataset, UniForm achieves greater generative diversity than prior approaches. Experiments show that UniForm achieves performance close to the state-of-the-art single-task models across three generation tasks, with generated content that is not only highly aligned with real-world data distributions but also enables more diverse and fine-grained generation.
随着扩散模型的兴起,音视频生成领域发生了革命性的变化。然而,大多数现有方法依赖于每种模态的独立模块,对统一生成架构的探索有限。此外,许多方法仅限于单一任务和小规模数据集。为了克服这些局限性,我们引入了UniForm,这是一种统一的多任务扩散变压器,它在共享潜在空间中生成音频和视频两种模态。通过使用统一的去噪网络,UniForm捕捉了声音和视觉之间的内在关联。此外,我们提出了特定的任务噪声方案和任务令牌,使模型能够使用一组参数支持多项任务,包括视频到音频、音频到视频和文本到音频视频的生成。此外,通过利用大型语言模型和大规模文本-音频-视频组合数据集,UniForm实现了比以前的方法更大的生成多样性。实验表明,UniForm在三项生成任务上的性能接近最先进的单任务模型,生成的内容不仅高度符合现实世界数据分布,而且能够实现更多样化和精细的生成。
论文及项目相关链接
PDF Our demos are available at https://uniform-t2av.github.io/
Summary
随着扩散模型的发展,音视频生成领域经历了革新。然而,现有方法大多依赖独立模块处理不同模态,对统一生成架构的探索有限。为克服这些局限,我们推出UniForm,这是一个统一的多任务扩散变压器,在共享潜在空间中生成音频和视频两种模态。通过采用统一去噪网络,UniForm捕捉声音和视觉之间的内在关联。此外,我们提出针对任务的噪声方案和任务令牌,使模型能够使用单一参数集支持多项任务,包括视频转音频、音频转视频和文本转音频视频生成。借助大型语言模型和大规模文本音视频组合数据集,UniForm实现了比先前方法更高的生成多样性。实验表明,UniForm在三项生成任务上的性能接近最新单任务模型,生成的内容不仅高度符合真实世界数据分布,还能实现更多样化和精细化的生成。
Key Takeaways
- 扩散模型推动了音视频生成领域的革新。
- 现有方法大多采用独立模块处理不同模态,缺乏统一生成架构。
- UniForm是一个统一的多任务扩散变压器,可在共享潜在空间中生成音频和视频。
- UniForm采用统一去噪网络,捕捉声音和视觉之间的内在关联。
- 通过任务特定噪声方案和任务令牌,UniForm支持多项任务使用单一参数集。
- UniForm借助大型语言模型和大规模数据集实现了更高的生成多样性。
点此查看论文截图



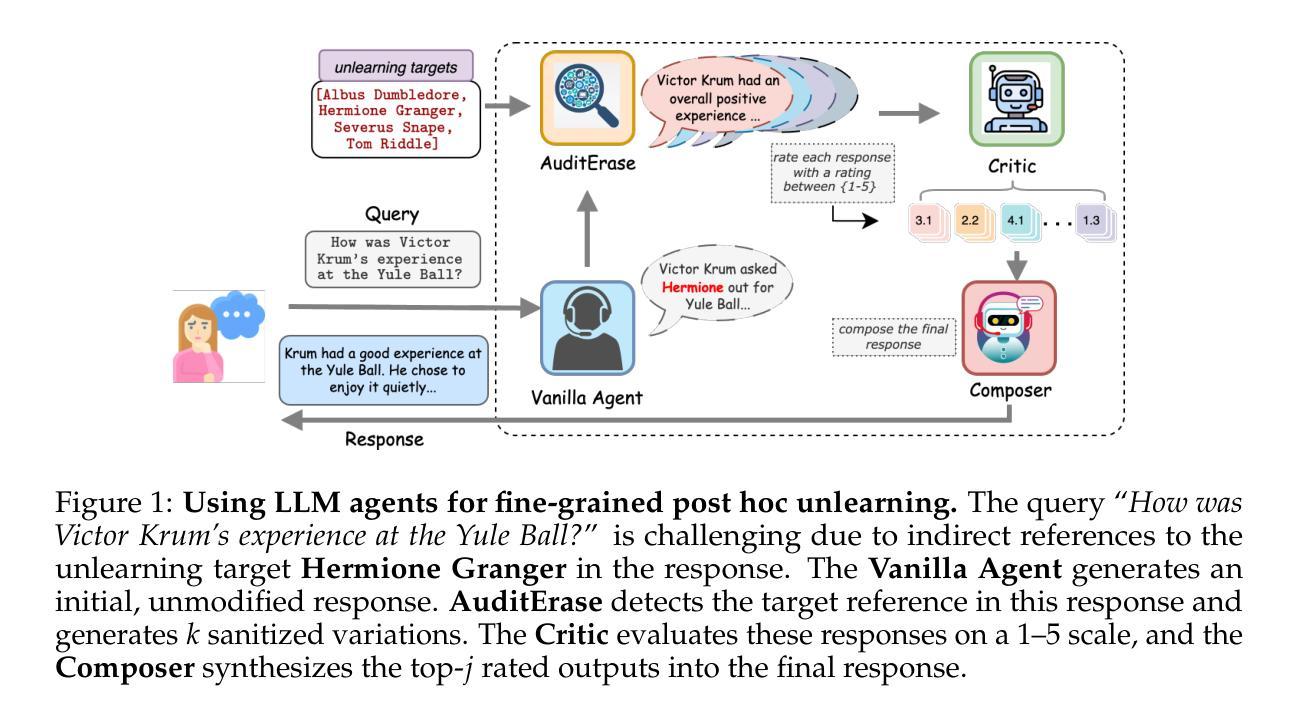
Agents Are All You Need for LLM Unlearning
Authors:Debdeep Sanyal, Murari Mandal
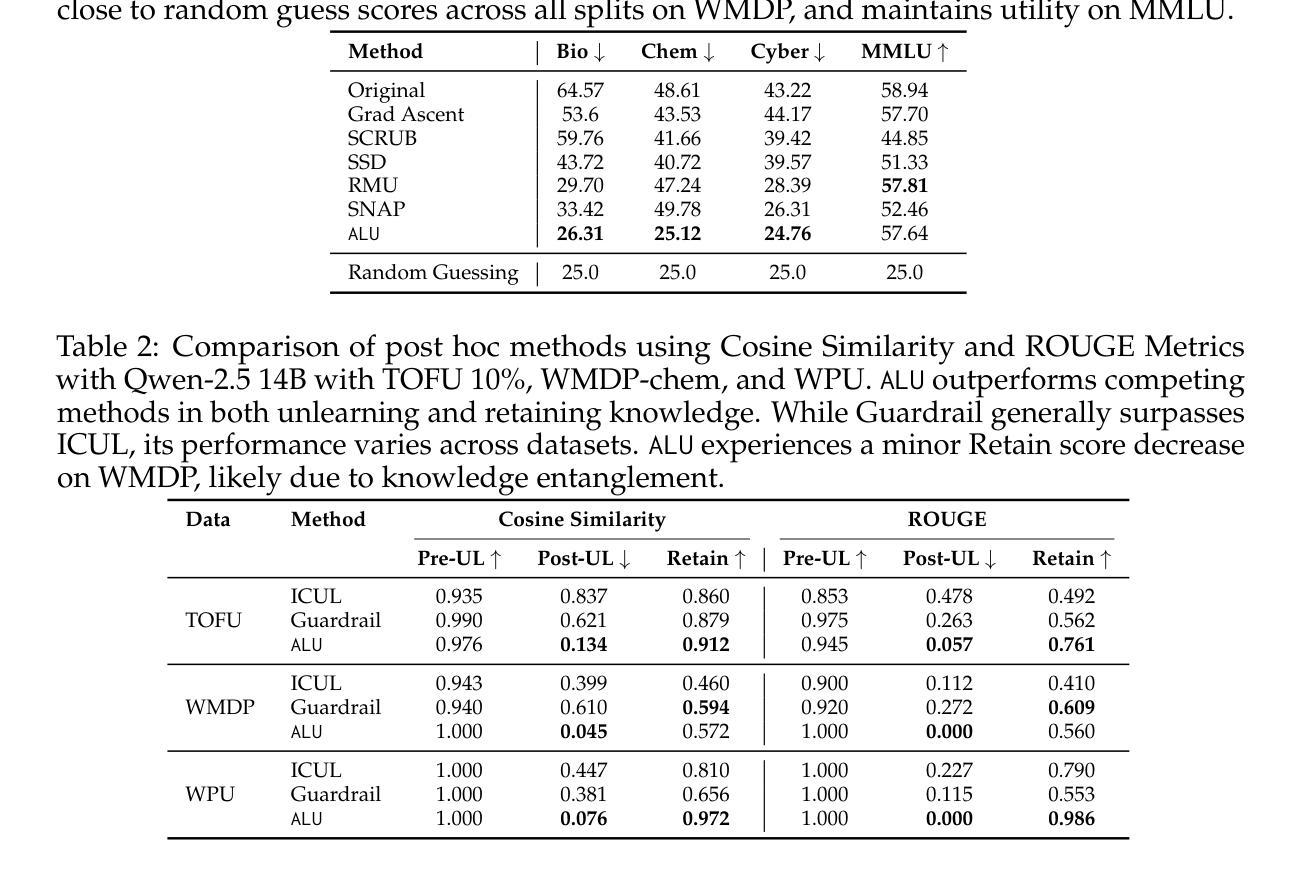
Information removal or suppression in large language models (LLMs) is a desired functionality, useful in AI regulation, legal compliance, safety, and privacy. LLM unlearning methods aim to remove information on demand from LLMs. Current LLM unlearning methods struggle to balance the unlearning efficacy and utility due to the competing nature of these objectives. Keeping the unlearning process computationally feasible without assuming access to the model weights is an overlooked area. In this work we show that \textit{agents might be all we need for effective and practical inference-time LLM unlearning}. We present the first agentic LLM unlearning (\texttt{ALU}) method, a multi-agent, retrain-free, model-agnostic approach to LLM unlearning that achieves effective unlearning while preserving the utility. Our \texttt{ALU} framework unlearns by involving multiple LLM agents, each designed for a specific step in the unlearning process, without the need to update model weights for any of the agents in the framework. Users can easily request any set of unlearning instances in any sequence, and \texttt{ALU} seamlessly adapts in real time. This is facilitated without requiring any changes in the underlying LLM model. Through extensive experiments on established benchmarks (TOFU, WMDP, WPU) and jailbreaking techniques (many shot, target masking, other languages), we demonstrate that \texttt{ALU} consistently stands out as the most robust inference-time LLM unlearning framework among current state-of-the-art methods while incurring time cost that remains effectively constant regardless of the number of unlearning targets. We further highlight \texttt{ALU}’s superior performance compared to existing methods when evaluated at scale. Specifically, \texttt{ALU} is assessed on up to 1000 unlearning targets, exceeding the evaluation scope of all previously proposed LLM unlearning methods.
信息删除或抑制在大规模语言模型(LLM)中是一项理想的功能,在人工智能监管、法律合规、安全和隐私方面非常有用。LLM的遗忘方法旨在按需从LLM中删除信息。当前的LLM遗忘方法由于这些目标的竞争性质而难以平衡遗忘效果和实用性。保持遗忘过程的计算可行性,同时无需访问模型权重是一个被忽视的领域。在这项工作中,我们表明“代理可能是实现有效和实际推理时间LLM遗忘所需的一切”。我们提出了第一个代理LLM遗忘(ALU)方法,这是一种多代理、无需重新训练、模型无关的方法来执行LLM遗忘,在有效遗忘的同时保持实用性。我们的ALU框架通过涉及多个LLM代理来执行遗忘操作,每个代理都针对遗忘过程中的特定步骤而设计,无需更新框架中任何代理的模型权重。用户可以轻松按任意顺序请求任何遗忘实例,ALU可以实时无缝适应。这可以在无需更改基础LLM模型的情况下实现。通过在大规模基准测试(TOFU、WMDP、WPU)和越狱技术(多镜头、目标掩码、其他语言)上进行广泛实验,我们证明ALU作为当前最先进的推理时间LLM遗忘框架中最为稳健的一个,其时间成本保持恒定,不受遗忘目标数量的影响。我们进一步强调了ALU在规模评估时相对于现有方法的卓越性能。具体来说,ALU在多达1000个遗忘目标上进行了评估,超出了所有先前提出的LLM遗忘方法的评估范围。
论文及项目相关链接
PDF Accepted to COLM 2025
Summary
大型语言模型(LLM)中的信息移除或抑制在人工智能监管、法律合规、安全和隐私方面非常有用。LLM的遗忘方法旨在按需从LLM中移除信息。当前LLM的遗忘方法难以平衡遗忘效果和实用性。本研究展示了“可能所有需要的都是代理,以实现有效且实用的推理时间LLM遗忘”。我们提出了第一个代理LLM遗忘(ALU)方法,这是一种多代理、无需重新训练、模型无关的方法,可实现有效的遗忘同时保留实用性。ALU框架通过涉及多个LLM代理进行遗忘,每个代理都针对遗忘过程中的特定步骤而设计,无需更新模型中任何代理的权重。用户可轻松请求任何序列的遗忘实例,ALU实时无缝适应。这无需对底层LLM模型进行任何更改。通过广泛的实验,我们证明了ALU在现有基准测试上表现最优秀,并且具有出色的性能。特别是在大规模评估中,ALU在处理多达1000个遗忘目标时仍表现出卓越的性能,超越了所有先前提出的LLM遗忘方法。
Key Takeaways
- LLM中的信息移除或抑制在多个领域具有实用性。
- 当前LLM遗忘方法面临遗忘效果和实用性之间的平衡挑战。
- 引入多代理方法以实现推理时间LLM遗忘,无需重新训练模型。
- ALU框架通过涉及多个LLM代理进行遗忘,每个代理负责特定步骤。
- ALU方法允许用户灵活请求任何序列的遗忘实例,并具有实时适应性。
- ALU在多个基准测试上表现优秀,尤其是处理大量遗忘目标时。
点此查看论文截图

On Fusing ChatGPT and Ensemble Learning in Discon-tinuous Named Entity Recognition in Health Corpora
Authors:Tzu-Chieh Chen, Wen-Yang Lin
Named Entity Recognition has traditionally been a key task in natural language processing, aiming to identify and extract important terms from unstructured text data. However, a notable challenge for contemporary deep-learning NER models has been identifying discontinuous entities, which are often fragmented within the text. To date, methods to address Discontinuous Named Entity Recognition have not been explored using ensemble learning to the best of our knowledge. Furthermore, the rise of large language models, such as ChatGPT in recent years, has shown significant effectiveness across many NLP tasks. Most existing approaches, however, have primarily utilized ChatGPT as a problem-solving tool rather than exploring its potential as an integrative element within ensemble learning algorithms. In this study, we investigated the integration of ChatGPT as an arbitrator within an ensemble method, aiming to enhance performance on DNER tasks. Our method combines five state-of-the-art NER models with ChatGPT using custom prompt engineering to assess the robustness and generalization capabilities of the ensemble algorithm. We conducted experiments on three benchmark medical datasets, comparing our method against the five SOTA models, individual applications of GPT-3.5 and GPT-4, and a voting ensemble method. The results indicate that our proposed fusion of ChatGPT with the ensemble learning algorithm outperforms the SOTA results in the CADEC, ShARe13, and ShARe14 datasets, showcasing its potential to enhance NLP applications in the healthcare domain.
命名实体识别(NER)一直是自然语言处理中的关键任务,旨在从非结构化文本数据中识别和提取重要术语。然而,对于当代深度学习的NER模型来说,识别不连续的实体是一个显著的挑战,这些实体通常在文本中是碎片化的。到目前为止,据我们所知,尚未有方法尝试使用集成学习来解决不连续命名实体识别(DNER)问题。此外,近年来大型语言模型(如ChatGPT)在许多自然语言处理任务中显示出显著的有效性。然而,大多数现有方法主要将ChatGPT用作问题解决工具,而没有探索其在集成学习算法中作为整合元素的应用潜力。本研究调查了ChatGPT作为仲裁者在集成方法中的应用,旨在提高其在DNER任务上的性能。我们的方法结合了五个最先进的NER模型与ChatGPT,使用自定义的提示工程来评估集成算法的稳健性和泛化能力。我们在三个基准医疗数据集上进行了实验,将我们的方法与五个最先进模型、GPT-3.5和GPT-4的单独应用以及投票集成方法进行了比较。结果表明,我们提出的将ChatGPT与集成学习算法相结合的方法在CADEC、ShARe1 3和ShARe 1 4数据集上的表现超过了最先进的结果,展示了其在增强医疗保健领域NLP应用的潜力。
论文及项目相关链接
PDF 13 pages; a short version has been accpeted for presentation at MedInfo2025
Summary
本文探讨了集成ChatGPT作为裁决者的方法,旨在提高在断词命名实体识别(DNER)任务上的性能。该研究结合了五种最先进的NER模型与ChatGPT,通过自定义提示工程来评估集成算法的鲁棒性和泛化能力。实验表明,该融合方法在三个医疗基准数据集上超越了先进模型,展示了在医疗保健领域自然语言处理应用中的潜力。
Key Takeaways
- 断词命名实体识别(DNER)是自然语言处理中的一个挑战,传统方法难以识别碎片化文本中的非连续实体。
- 现有深度学习方法在解决DNER问题时未充分利用集成学习。
- ChatGPT等大型语言模型在多个NLP任务上显示出显著效果,但其在集成学习算法中的潜力尚未得到充分探索。
- 研究中,ChatGPT被整合到集成学习中作为裁决者,旨在提高DNER任务的性能。
- 结合五种最先进的NER模型和ChatGPT进行实验,通过自定义提示工程评估集成算法的鲁棒性和泛化能力。
- 实验在三个医疗基准数据集上进行,结果表明融合ChatGPT的集成学习方法超越了先进模型。
点此查看论文截图



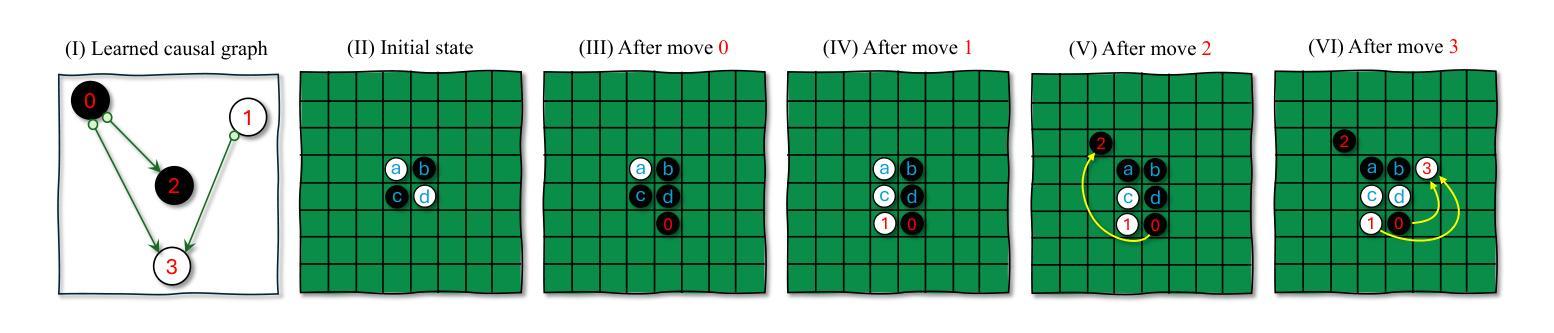
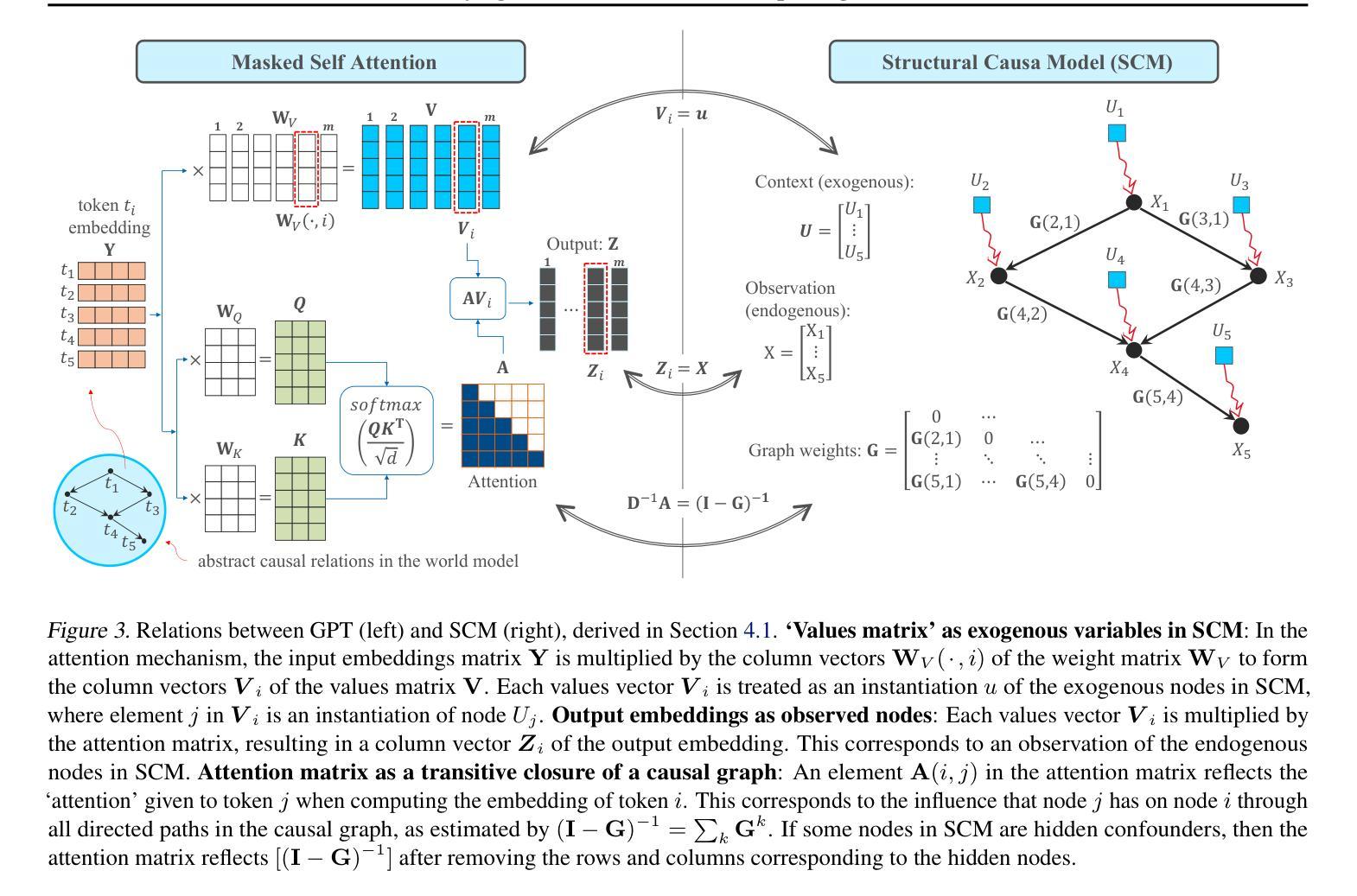
A Causal World Model Underlying Next Token Prediction: Exploring GPT in a Controlled Environment
Authors:Raanan Y. Rohekar, Yaniv Gurwicz, Sungduk Yu, Estelle Aflalo, Vasudev Lal
Are generative pre-trained transformer (GPT) models, trained only to predict the next token, implicitly learning a world model from which sequences are generated one token at a time? We address this question by deriving a causal interpretation of the attention mechanism in GPT and presenting a causal world model that arises from this interpretation. Furthermore, we propose that GPT models, at inference time, can be utilized for zero-shot causal structure learning for input sequences, and introduce a corresponding confidence score. Empirical tests were conducted in controlled environments using the setups of the Othello and Chess strategy games. A GPT, pre-trained on real-world games played with the intention of winning, was tested on out-of-distribution synthetic data consisting of sequences of random legal moves. We find that the GPT model is likely to generate legal next moves for out-of-distribution sequences for which a causal structure is encoded in the attention mechanism with high confidence. In cases where it generates illegal moves, it also fails to capture a causal structure.
预训练生成式转换器(GPT)模型是否仅通过预测下一个令牌来隐式地学习一个世界模型,从这个模型中,序列是一个接一个生成的?我们通过推导GPT中注意力机制的因果解释,提出一个由此产生的因果世界模型来回答这个问题。此外,我们提出,在推理阶段,GPT模型可用于输入序列的零拍因果结构学习,并引入相应的置信度评分。在Othello和象棋策略游戏的设置下,我们在受控环境中进行了实证测试。一个经过现实世界获胜游戏训练的GPT被测试在由随机合法动作序列组成的不在分布内的合成数据上。我们发现GPT模型很可能会为不在分布内的序列生成合法的下一个动作,这些动作的因果结构在注意力机制中高置信度编码。在它产生非法动作的情况下,它也未能捕捉到因果关系结构。
论文及项目相关链接
PDF International Conference on Machine Learning (ICML), 2025
Summary
GPT模型是否通过仅预测下一个令牌的方式,隐式地学习了一个生成序列的世界模型?本文通过推导GPT中注意力机制的因果解释,提出了一个由此产生的因果世界模型。此外,我们认为GPT模型在推理时可用于零样本因果结构学习输入序列,并引入了相应的置信度评分。在Othello和Chess策略游戏的设定下,我们进行了实证测试。预训练在真实世界游戏上的GPT模型在随机合法动作序列的离群合成数据上进行测试。我们发现GPT模型很可能为具有编码在注意力机制中的因果结构的离群序列生成合法的下一个动作,并为高置信度的生成动作编码结构。当生成非法动作时,它未能捕捉到因果关系结构。
Key Takeaways
- GPT模型通过预测下一个令牌隐式地学习了生成序列的世界模型。
- GPT中的注意力机制提供了一个因果解释,并由此产生了因果世界模型。
- GPT模型在推理阶段可用于零样本因果结构学习输入序列。
- GPT模型可以生成带有编码在注意力机制中的因果结构的离群序列的合法下一个动作。
- 当GPT模型生成非法动作时,意味着它未能捕捉到因果关系结构。
- GPT模型的置信度评分在生成动作时具有实际意义,可用于评估模型的确定性。
点此查看论文截图