⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-10 更新
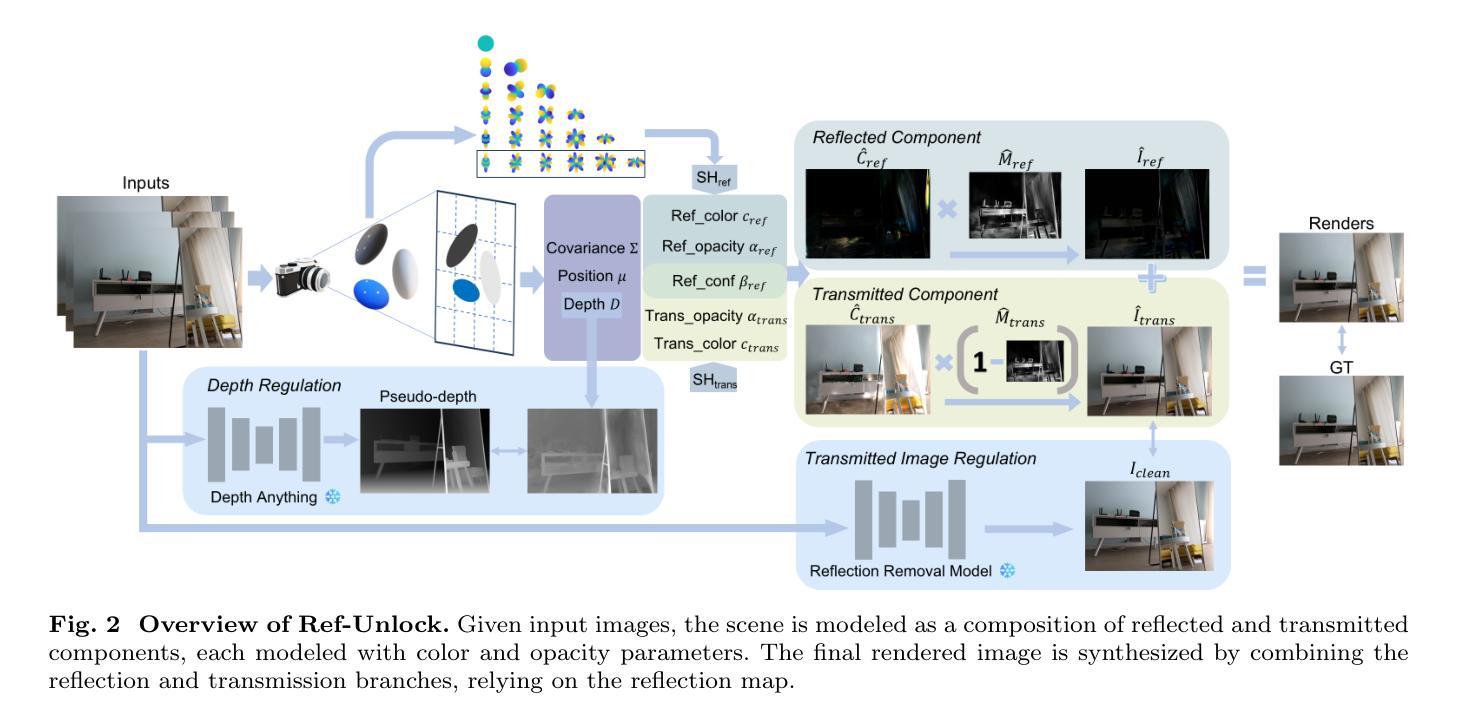
Reflections Unlock: Geometry-Aware Reflection Disentanglement in 3D Gaussian Splatting for Photorealistic Scenes Rendering
Authors:Jiayi Song, Zihan Ye, Qingyuan Zhou, Weidong Yang, Ben Fei, Jingyi Xu, Ying He, Wanli Ouyang
Accurately rendering scenes with reflective surfaces remains a significant challenge in novel view synthesis, as existing methods like Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) often misinterpret reflections as physical geometry, resulting in degraded reconstructions. Previous methods rely on incomplete and non-generalizable geometric constraints, leading to misalignment between the positions of Gaussian splats and the actual scene geometry. When dealing with real-world scenes containing complex geometry, the accumulation of Gaussians further exacerbates surface artifacts and results in blurred reconstructions. To address these limitations, in this work, we propose Ref-Unlock, a novel geometry-aware reflection modeling framework based on 3D Gaussian Splatting, which explicitly disentangles transmitted and reflected components to better capture complex reflections and enhance geometric consistency in real-world scenes. Our approach employs a dual-branch representation with high-order spherical harmonics to capture high-frequency reflective details, alongside a reflection removal module providing pseudo reflection-free supervision to guide clean decomposition. Additionally, we incorporate pseudo-depth maps and a geometry-aware bilateral smoothness constraint to enhance 3D geometric consistency and stability in decomposition. Extensive experiments demonstrate that Ref-Unlock significantly outperforms classical GS-based reflection methods and achieves competitive results with NeRF-based models, while enabling flexible vision foundation models (VFMs) driven reflection editing. Our method thus offers an efficient and generalizable solution for realistic rendering of reflective scenes. Our code is available at https://ref-unlock.github.io/.
准确渲染具有反射表面的场景在新型视图合成中仍然是一个重大挑战,因为现有的方法,如神经网络辐射场(NeRF)和3D高斯喷涂(3DGS),通常会将反射误解为物理几何,从而导致重建效果降低。之前的方法依赖于不完整且不可概括的几何约束,导致高斯喷涂的位置与实际场景几何之间的不对齐。在处理包含复杂几何的真实世界场景时,高斯累积会进一步加剧表面伪影,导致模糊的重建结果。
论文及项目相关链接
Summary
本文提出一种基于三维高斯体素化的反射建模框架Ref-Unlock,解决了现有方法在处理反射场景时的局限性。该方法能够明确区分传输和反射成分,更好地捕捉复杂反射,增强真实场景中的几何一致性。通过采用双分支表示法、高阶球面谐波、伪反射去除模块以及伪深度图和几何感知双边平滑约束等技术,提高了反射场景的渲染效果。实验表明,Ref-Unlock在经典GS反射方法和NeRF模型之间取得了显著的平衡,并实现了灵活的视觉基础模型驱动的反射编辑。
Key Takeaways
- Ref-Unlock是一种新型的反射建模框架,基于三维高斯体素化,解决了现有方法在渲染反射场景时的不足。
- 该方法能够明确区分传输和反射成分,以更好地捕捉复杂反射和增强几何一致性。
- 采用双分支表示法和高阶球面谐波技术,提高反射场景的渲染质量。
- 伪反射去除模块以及伪深度图和几何感知双边平滑约束的应用,进一步增强了渲染效果。
- Ref-Unlock在经典GS反射方法和NeRF模型之间取得了平衡,表现出优异的性能。
- 该方法实现了灵活的视觉基础模型驱动的反射编辑,具有广泛的应用潜力。
点此查看论文截图


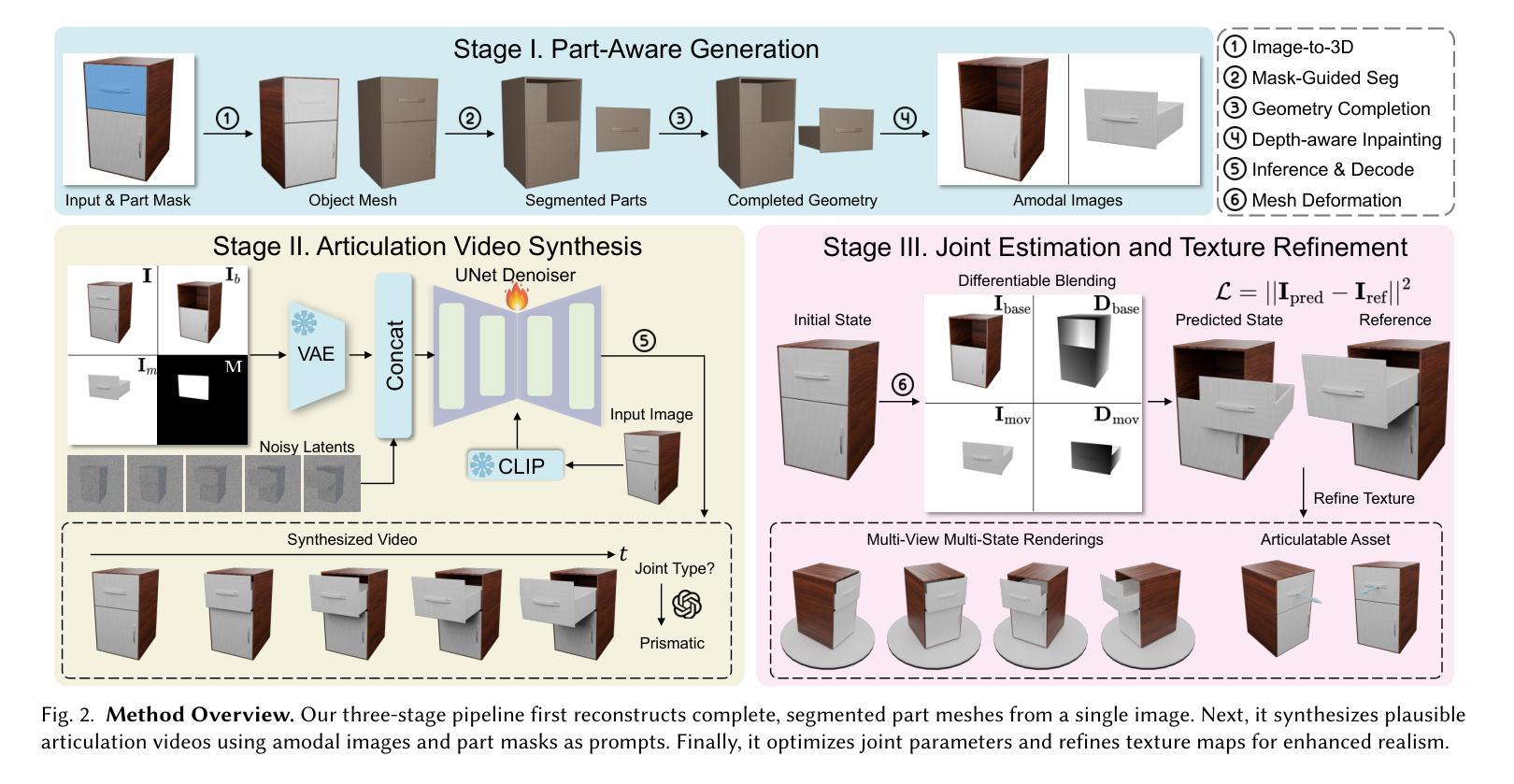
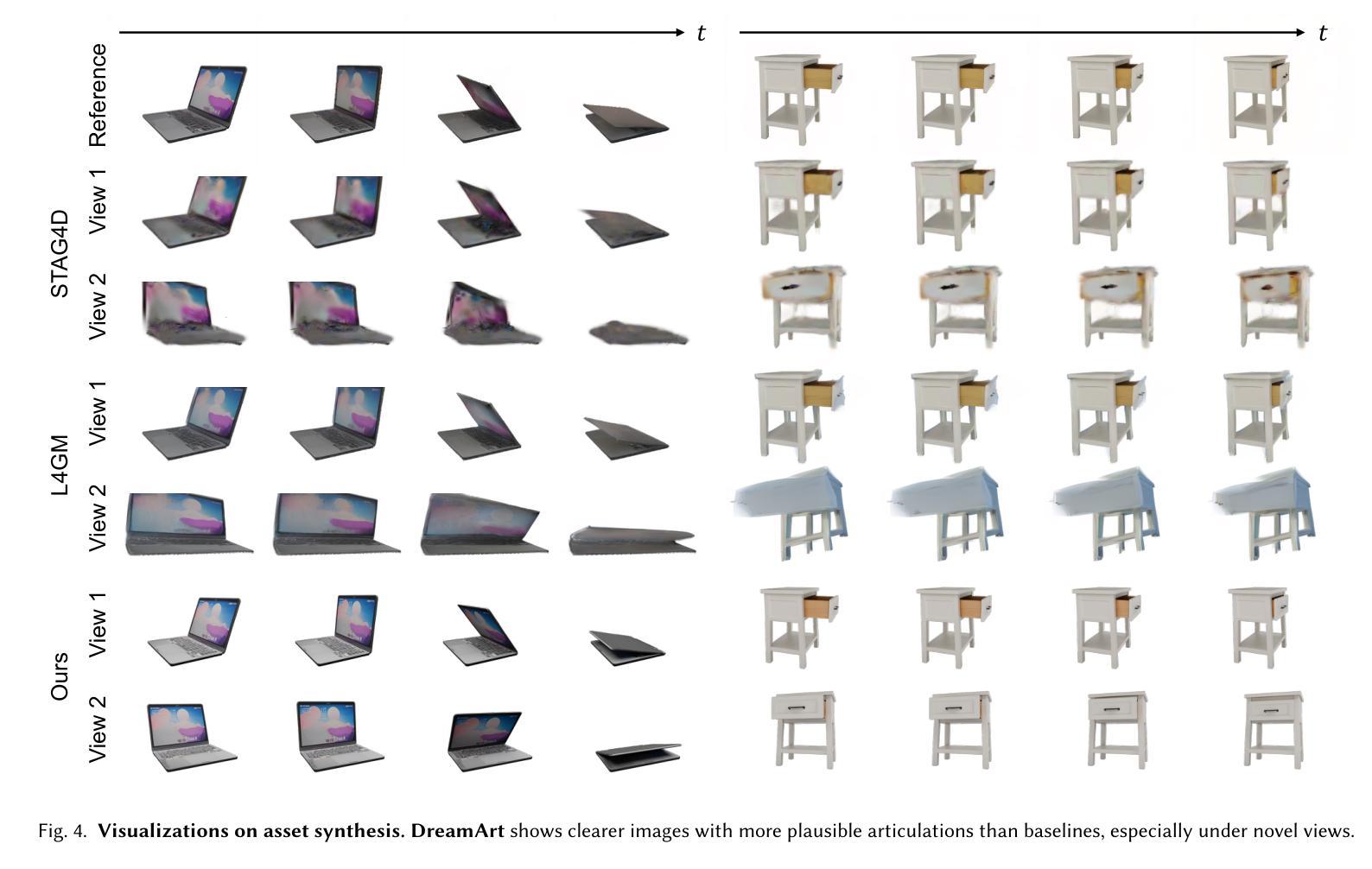
DreamArt: Generating Interactable Articulated Objects from a Single Image
Authors:Ruijie Lu, Yu Liu, Jiaxiang Tang, Junfeng Ni, Yuxiang Wang, Diwen Wan, Gang Zeng, Yixin Chen, Siyuan Huang
Generating articulated objects, such as laptops and microwaves, is a crucial yet challenging task with extensive applications in Embodied AI and AR/VR. Current image-to-3D methods primarily focus on surface geometry and texture, neglecting part decomposition and articulation modeling. Meanwhile, neural reconstruction approaches (e.g., NeRF or Gaussian Splatting) rely on dense multi-view or interaction data, limiting their scalability. In this paper, we introduce DreamArt, a novel framework for generating high-fidelity, interactable articulated assets from single-view images. DreamArt employs a three-stage pipeline: firstly, it reconstructs part-segmented and complete 3D object meshes through a combination of image-to-3D generation, mask-prompted 3D segmentation, and part amodal completion. Second, we fine-tune a video diffusion model to capture part-level articulation priors, leveraging movable part masks as prompt and amodal images to mitigate ambiguities caused by occlusion. Finally, DreamArt optimizes the articulation motion, represented by a dual quaternion, and conducts global texture refinement and repainting to ensure coherent, high-quality textures across all parts. Experimental results demonstrate that DreamArt effectively generates high-quality articulated objects, possessing accurate part shape, high appearance fidelity, and plausible articulation, thereby providing a scalable solution for articulated asset generation. Our project page is available at https://dream-art-0.github.io/DreamArt/.
生成具有关节的对象(如笔记本电脑和微波炉)在嵌入式人工智能和增强现实/虚拟现实中有广泛的应用,是一项至关重要的且具有挑战性的任务。当前从图像到3D的转换方法主要关注表面几何和纹理,忽视了部件分解和关节建模。同时,神经重建方法(例如NeRF或高斯平铺)依赖于密集的多视图或交互数据,这限制了其可扩展性。在本文中,我们介绍了DreamArt,这是一个从单视图图像生成高保真、可交互的关节资产的新框架。DreamArt采用了一个三阶段的流程:首先,它结合图像到3D的生成、基于掩膜的3D分割和部分无模态完成,重建了部件分割和完整的3D对象网格。其次,我们微调了视频扩散模型,以捕获部件级别的关节先验知识,利用可移动部件掩膜作为提示和无模态图像来缓解遮挡引起的歧义。最后,DreamArt优化了由双四元数表示的关节运动,并进行了全局纹理精化和重绘,以确保所有部件的纹理连贯且高质量。实验结果表明,DreamArt能够有效地生成高质量且具有关节的对象,具有准确的部件形状、高外观保真度和逼真的关节运动,从而为关节资产生成提供了可扩展的解决方案。我们的项目页面可在[https://dream-art-0.github.io/DreamArt/]访问。
论文及项目相关链接
PDF Technical Report
Summary
本文介绍了DreamArt框架,该框架能够从单视图图像生成高保真、可交互的关节式资产。通过三个阶段实现:重建部分分割的完整3D物体网格、利用视频扩散模型捕捉关节级别的运动先验,以及优化关节运动并进行全局纹理修复和重新上色。DreamArt有效生成高质量关节式物体,具有准确的部件形状、高外观保真度和合理的关节运动。
Key Takeaways
- DreamArt是一个从单视图图像生成关节式资产的框架,用于Embodied AI和AR/VR等领域。
- 该框架采用三阶段管道:重建3D物体网格、捕捉关节级别运动先验,以及优化关节运动和纹理。
- DreamArt通过结合图像到3D生成、掩膜引导的3D分割和部件模态完成技术,实现部件分割的完整3D物体网格重建。
- 利用可移动部件掩膜和模态图像,DreamArt解决了遮挡引起的模糊问题,并捕捉了部件级别的关节运动先验。
- 通过优化用双四元数表示的关节运动,DreamArt确保了各部分纹理的一致性和高质量。
- 实验结果表明,DreamArt能生成具有准确部件形状、高外观保真度和合理关节运动的高质量关节式物体。
点此查看论文截图