⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-11 更新
Dataset and Benchmark for Enhancing Critical Retained Foreign Object Detection
Authors:Yuli Wang, Victoria R. Shi, Liwei Zhou, Richard Chin, Yuwei Dai, Yuanyun Hu, Cheng-Yi Li, Haoyue Guan, Jiashu Cheng, Yu Sun, Cheng Ting Lin, Ihab Kamel, Premal Trivedi, Pamela Johnson, John Eng, Harrison Bai
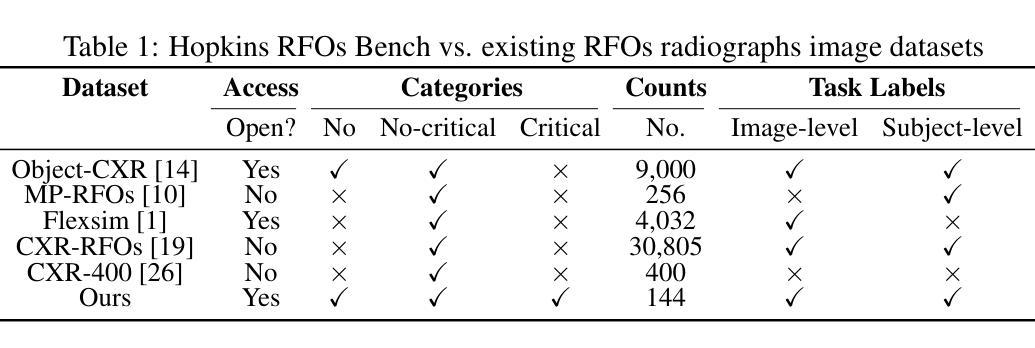
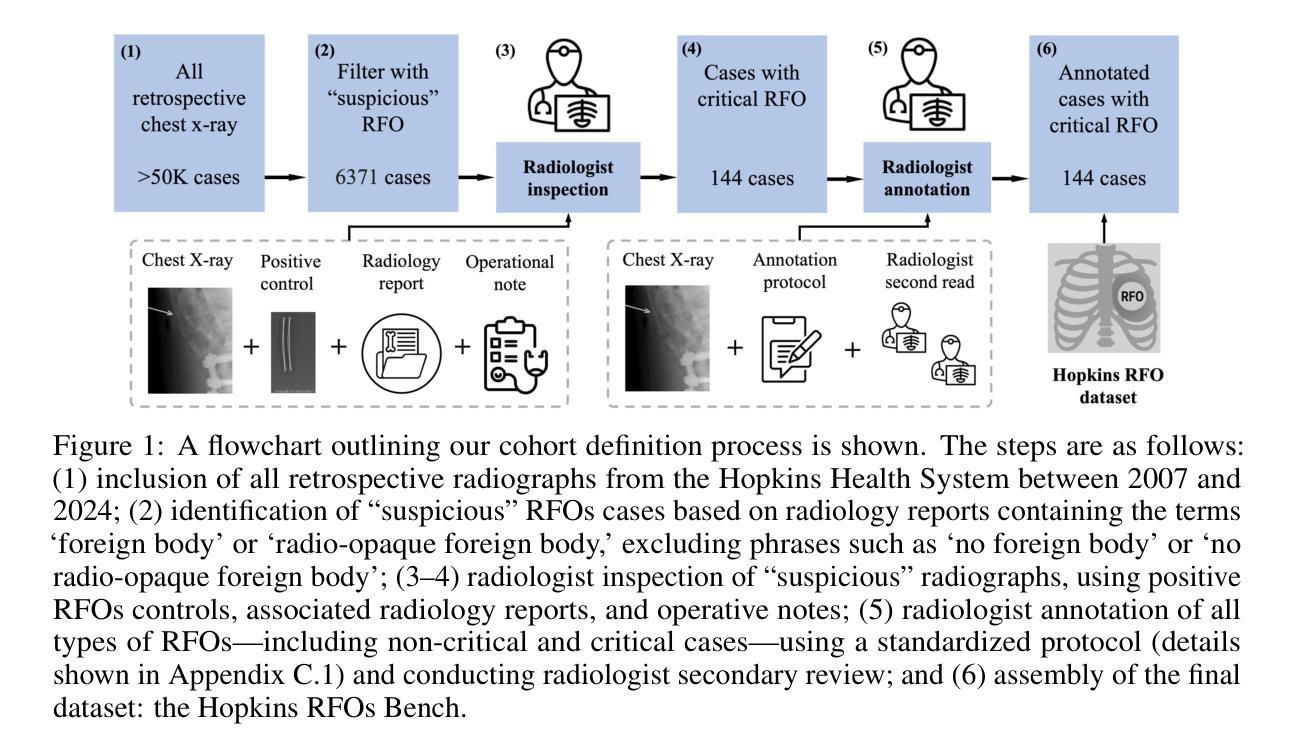
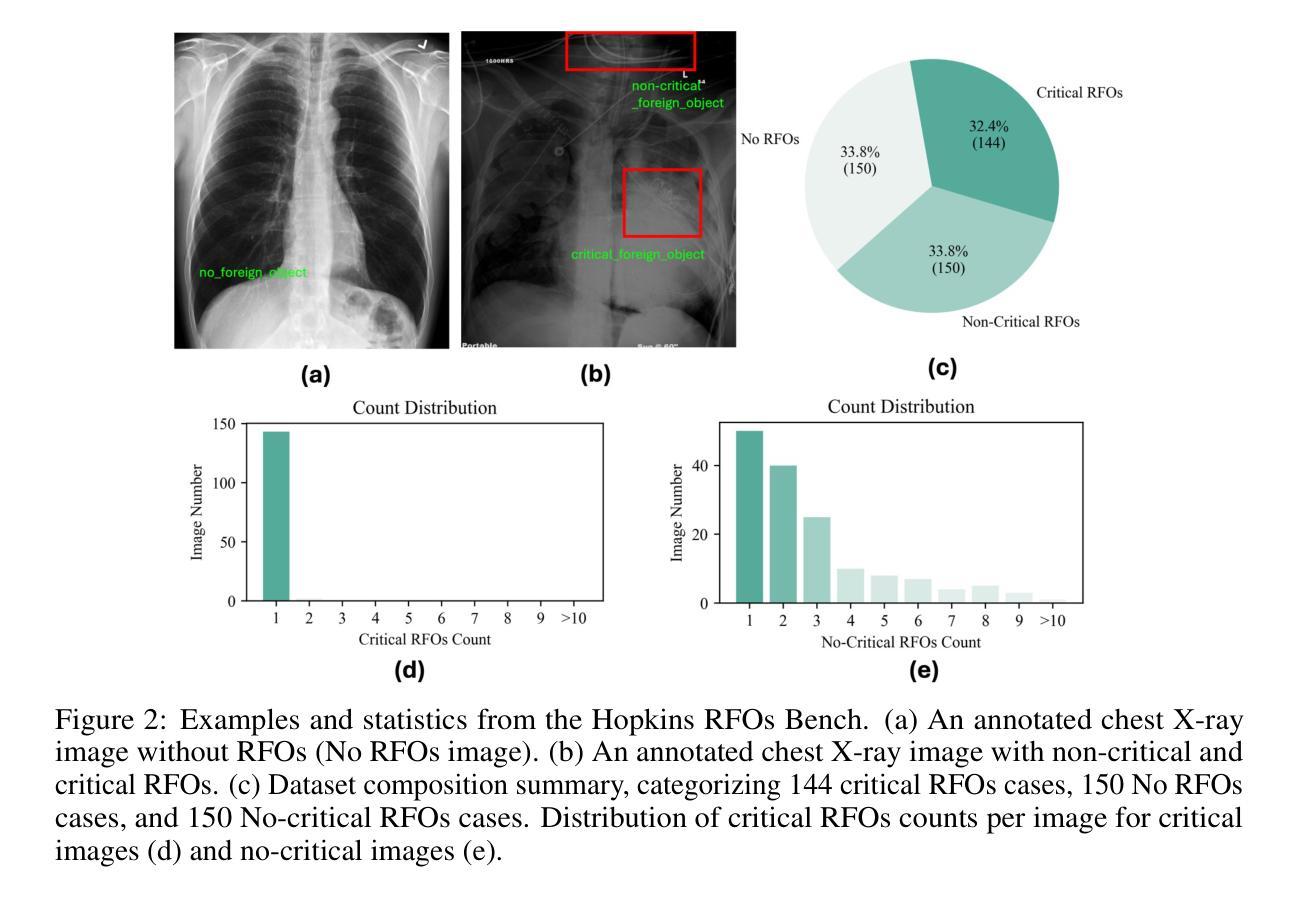
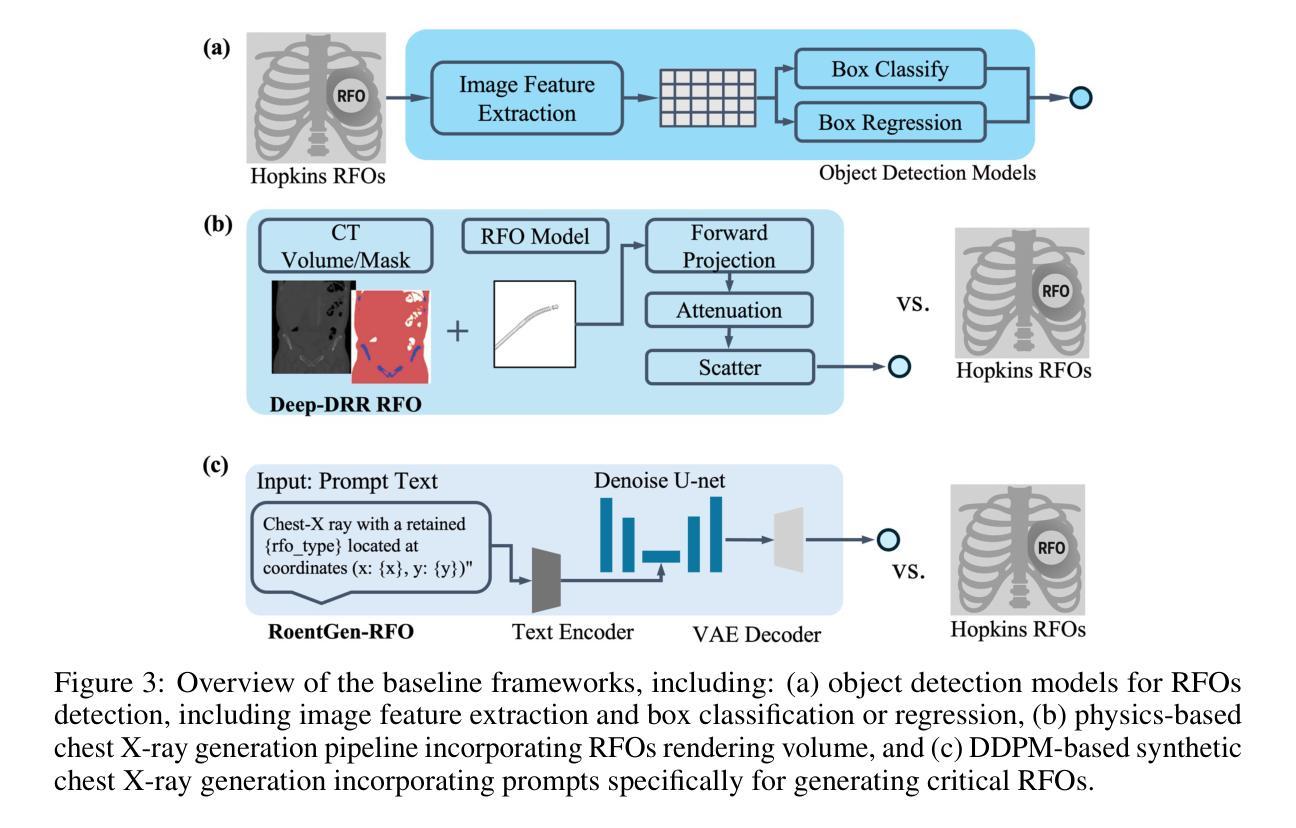
Critical retained foreign objects (RFOs), including surgical instruments like sponges and needles, pose serious patient safety risks and carry significant financial and legal implications for healthcare institutions. Detecting critical RFOs using artificial intelligence remains challenging due to their rarity and the limited availability of chest X-ray datasets that specifically feature critical RFOs cases. Existing datasets only contain non-critical RFOs, like necklace or zipper, further limiting their utility for developing clinically impactful detection algorithms. To address these limitations, we introduce “Hopkins RFOs Bench”, the first and largest dataset of its kind, containing 144 chest X-ray images of critical RFO cases collected over 18 years from the Johns Hopkins Health System. Using this dataset, we benchmark several state-of-the-art object detection models, highlighting the need for enhanced detection methodologies for critical RFO cases. Recognizing data scarcity challenges, we further explore image synthetic methods to bridge this gap. We evaluate two advanced synthetic image methods, DeepDRR-RFO, a physics-based method, and RoentGen-RFO, a diffusion-based method, for creating realistic radiographs featuring critical RFOs. Our comprehensive analysis identifies the strengths and limitations of each synthetic method, providing insights into effectively utilizing synthetic data to enhance model training. The Hopkins RFOs Bench and our findings significantly advance the development of reliable, generalizable AI-driven solutions for detecting critical RFOs in clinical chest X-rays.
关键遗留异物(RFOs),包括海绵、针等手术器械,对病人安全构成严重威胁,并为医疗机构带来重大经济和法律风险。使用人工智能检测关键的RFOs仍然是一个挑战,因为它们很少见,而且专门包含关键RFOs病例的胸部X射线数据集有限。现有数据集仅包含非关键的RFOs,如项链或拉链,这进一步限制了它们对开发具有临床影响力的检测算法的价值。为了解决这些局限性,我们推出了“霍普金斯RFOs基准测试集”,这是该领域首个也是最大的数据集,包含约144张胸部X射线图像的关键RFO病例,这些图像是在长达18年的时间里从约翰霍普金斯医疗系统收集的。使用这个数据集,我们对多个先进的物体检测模型进行了基准测试,强调了针对关键RFO病例需要改进的检测方法的必要性。我们认识到数据稀缺的挑战,进一步探索了图像合成方法来弥补这一差距。我们评估了两种先进的合成图像方法:基于物理的DeepDRR-RFO和基于扩散的RoentGen-RFO,用于创建具有真实感的放射图像。我们的综合分析确定了每种合成方法的优点和局限性,为有效利用合成数据提高模型训练提供了见解。“霍普金斯RFOs基准测试集”和我们的发现极大地推动了开发可靠、通用的AI驱动解决方案来检测临床胸部X射线中的关键RFOs的进程。
论文及项目相关链接
Summary:
本文介绍了关于医疗领域中的关键遗留异物(RFOs)检测的挑战及最新进展。针对关键RFOs检测的数据稀缺问题,创建了首个大规模的“Hopkins RFOs Bench”数据集,并对比评估了多种先进的物体检测模型。同时,为了弥补数据不足,探索了两种图像合成方法。研究对于推动可靠、可推广的AI解决方案在医疗临床中的实际应用具有重要意义。
Key Takeaways:
- 关键遗留异物(RFOs)对病人安全构成严重威胁,并给医疗机构带来经济和法律影响。
- 现有数据集主要关注非关键RFOs,限制了临床检测算法的发展。
- 引入了“Hopkins RFOs Bench”,包含144张关键RFO病例的胸部X光片,是此领域首个大规模数据集。
- 评估了多个先进物体检测模型,凸显了增强检测方法的必要性。
- 为解决数据稀缺问题,探索了两种图像合成方法:基于物理的DeepDRR-RFO和基于扩散的RoentGen-RFO。
- 综合分析了每种合成方法的长处和局限性。
点此查看论文截图

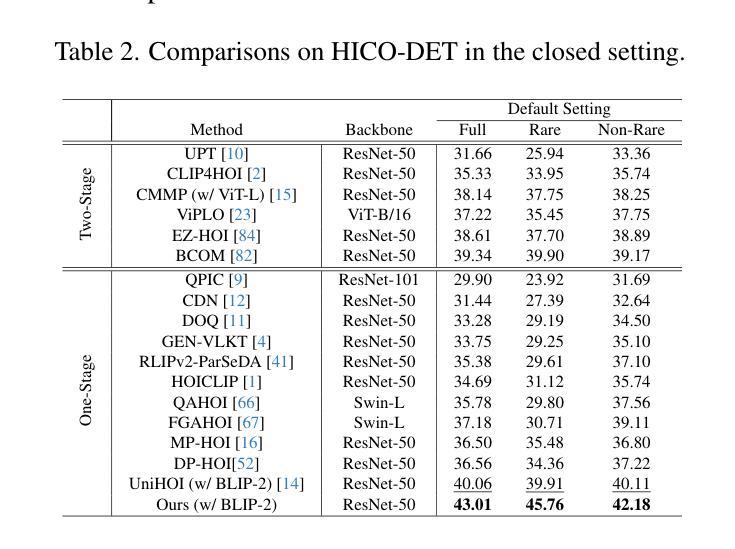
Bilateral Collaboration with Large Vision-Language Models for Open Vocabulary Human-Object Interaction Detection
Authors:Yupeng Hu, Changxing Ding, Chang Sun, Shaoli Huang, Xiangmin Xu
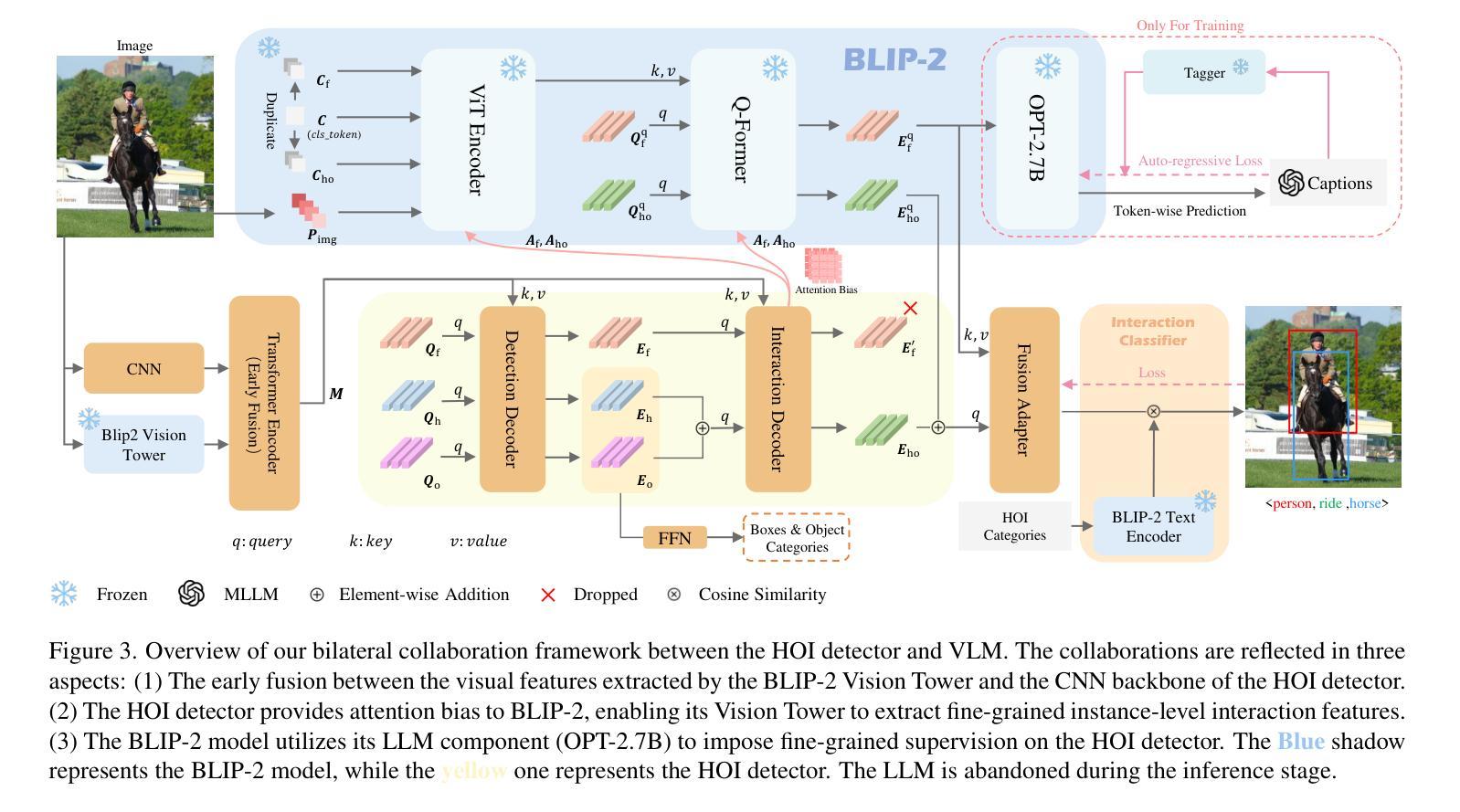
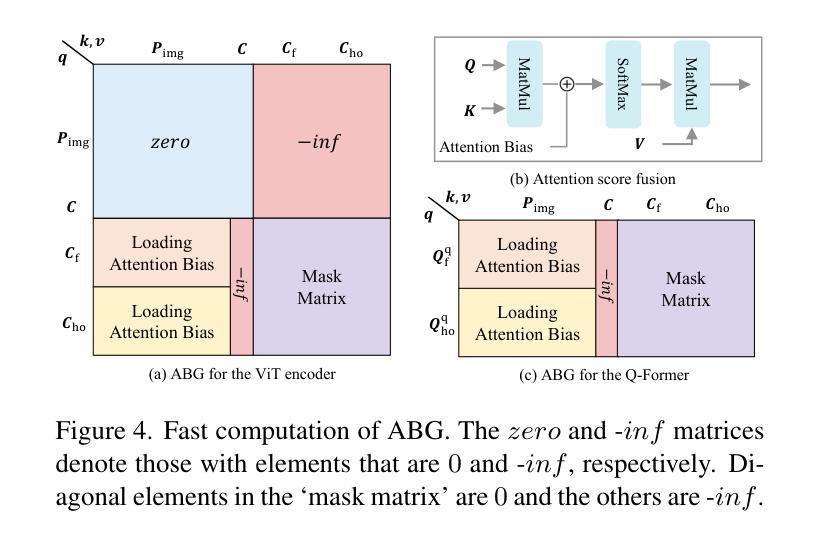
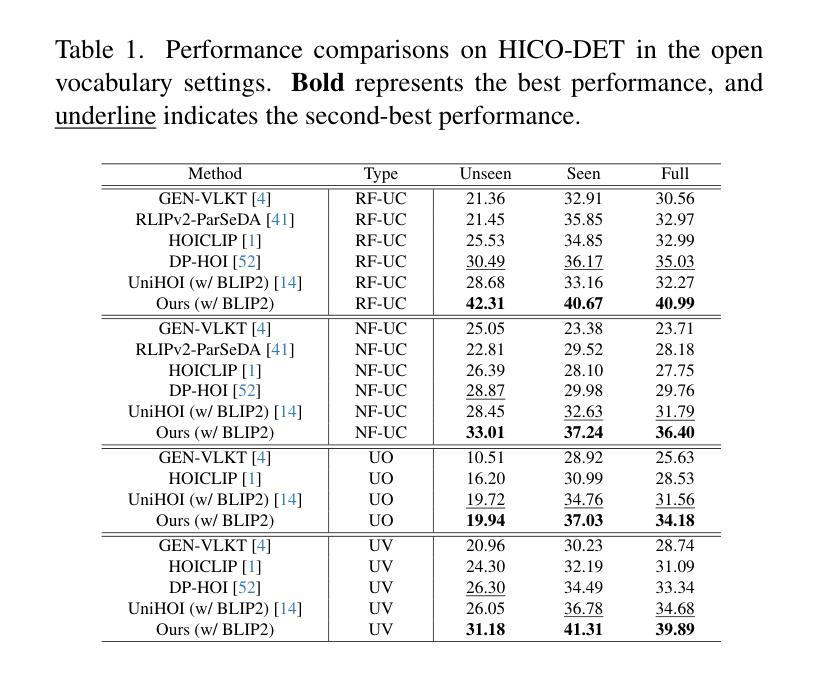
Open vocabulary Human-Object Interaction (HOI) detection is a challenging task that detects all <human, verb, object> triplets of interest in an image, even those that are not pre-defined in the training set. Existing approaches typically rely on output features generated by large Vision-Language Models (VLMs) to enhance the generalization ability of interaction representations. However, the visual features produced by VLMs are holistic and coarse-grained, which contradicts the nature of detection tasks. To address this issue, we propose a novel Bilateral Collaboration framework for open vocabulary HOI detection (BC-HOI). This framework includes an Attention Bias Guidance (ABG) component, which guides the VLM to produce fine-grained instance-level interaction features according to the attention bias provided by the HOI detector. It also includes a Large Language Model (LLM)-based Supervision Guidance (LSG) component, which provides fine-grained token-level supervision for the HOI detector by the LLM component of the VLM. LSG enhances the ability of ABG to generate high-quality attention bias. We conduct extensive experiments on two popular benchmarks: HICO-DET and V-COCO, consistently achieving superior performance in the open vocabulary and closed settings. The code will be released in Github.
开放词汇表的人机交互(HOI)检测是一项具有挑战性的任务,旨在检测图像中所有感兴趣的<人、动词、对象>三元组,即使是训练集中未预先定义的那些。现有方法通常依赖于大型视觉语言模型(VLM)生成的输出特征来提高交互表示的泛化能力。然而,VLM产生的视觉特征是整体的、粗粒度的,这与检测任务的本质相矛盾。为了解决这一问题,我们提出了一种用于开放词汇HOI检测的双边协作框架(BC-HOI)。该框架包括注意力偏差引导(ABG)组件,该组件根据HOI检测器提供的注意力偏差引导VLM生成精细的实例级交互特征。它还包括基于大型语言模型(LLM)的监督引导(LSG)组件,通过LLM组件为HOI检测器提供精细的令牌级监督。LSG增强了ABG生成高质量注意力偏差的能力。我们在两个流行的基准测试集HICO-DET和V-COCO上进行了广泛的实验,在开放词汇和封闭环境中均实现了卓越的性能。代码将在Github上发布。
论文及项目相关链接
PDF ICCV 2025
Summary
开放词汇表的Human-Object Interaction(HOI)检测任务具有挑战性,它能检测图像中所有感兴趣的<人、动词、对象>三元组,包括那些在训练集中未预先定义的。现有方法通常依赖于大型视觉语言模型(VLM)生成的输出特征来提高交互表示的泛化能力。然而,VLM产生的视觉特征是整体且粗粒度的,这与检测任务的性质相矛盾。为解决这一问题,我们提出了双边协作框架BC-HOI用于开放词汇表的HOI检测。该框架包括注意力偏差引导(ABG)组件和大语言模型(LLM)监督引导(LSG)组件,分别引导VLM根据HOI检测器提供的注意力偏差产生精细的实例级交互特征和为HOI检测器提供精细的标记级监督。我们在两个流行的基准测试HICO-DET和V-COCO上进行了大量实验,在开放词汇表和封闭设置下均表现出卓越的性能。
Key Takeaways
- 开放词汇表的Human-Object Interaction(HOI)检测任务具有挑战性,旨在检测图像中所有感兴趣的三元组。
- 当前方法依赖大型视觉语言模型(VLM)来提高交互表示的泛化能力,但存在局限性。
- BC-HOI框架通过引入注意力偏差引导(ABG)来解决现有问题,指导VLM产生更精细的实例级交互特征。
- BC-HOI还包括LLM监督引导(LSG)组件,为HOI检测器提供标记级监督,提高ABG生成高质量注意力偏差的能力。
- 在两个流行的基准测试HICO-DET和V-COCO上进行了大量实验,BC-HOI表现出卓越的性能。
- BC-HOI框架适用于开放词汇表和封闭设置下的HOI检测任务。
点此查看论文截图


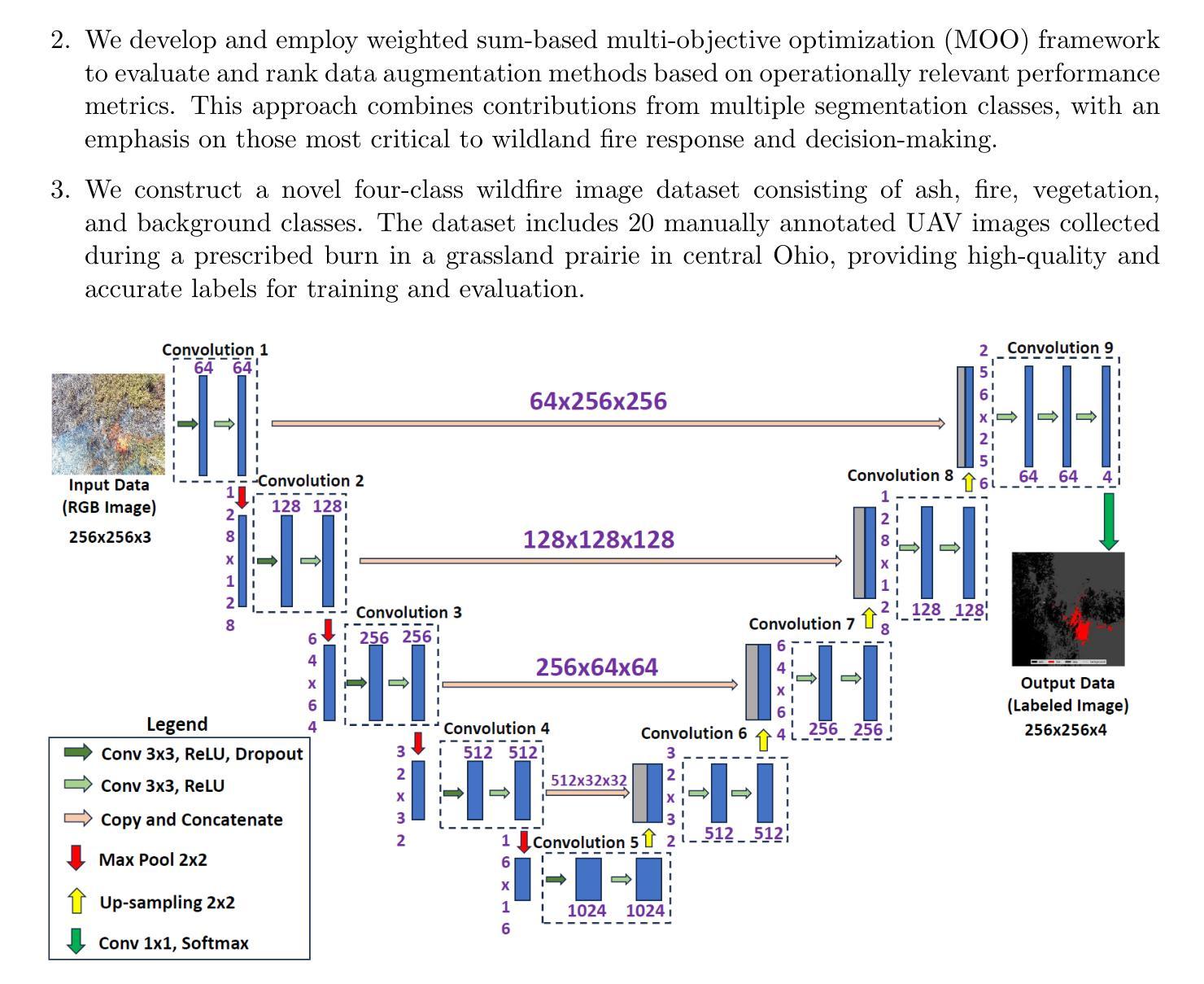
Centralized Copy-Paste: Enhanced Data Augmentation Strategy for Wildland Fire Semantic Segmentation
Authors:Joon Tai Kim, Tianle Chen, Ziyu Dong, Nishanth Kunchala, Alexander Guller, Daniel Ospina Acero, Roger Williams, Mrinal Kumar
Collecting and annotating images for the purpose of training segmentation models is often cost prohibitive. In the domain of wildland fire science, this challenge is further compounded by the scarcity of reliable public datasets with labeled ground truth. This paper presents the Centralized Copy-Paste Data Augmentation (CCPDA) method, for the purpose of assisting with the training of deep-learning multiclass segmentation models, with special focus on improving segmentation outcomes for the fire-class. CCPDA has three main steps: (i) identify fire clusters in the source image, (ii) apply a centralization technique to focus on the core of the fire area, and (iii) paste the refined fire clusters onto a target image. This method increases dataset diversity while preserving the essential characteristics of the fire class. The effectiveness of this augmentation technique is demonstrated via numerical analysis and comparison against various other augmentation methods using a weighted sum-based multi-objective optimization approach. This approach helps elevate segmentation performance metrics specific to the fire class, which carries significantly more operational significance than other classes (fuel, ash, or background). Numerical performance assessment validates the efficacy of the presented CCPDA method in alleviating the difficulties associated with small, manually labeled training datasets. It also illustrates that CCPDA outperforms other augmentation strategies in the application scenario considered, particularly in improving fire-class segmentation performance.
收集并标注图像以训练分割模型通常成本高昂。在野外火灾科学领域,由于缺乏可靠的公共带标签真实数据集,这一挑战进一步加剧。本文提出了集中式复制粘贴数据增强(CCPDA)方法,旨在帮助训练深度学习多类分割模型,特别侧重于提高火灾类别的分割效果。CCPDA主要有三个步骤:(i)在源图像中识别火灾集群,(ii)应用集中技术以关注火灾区域的核心,(iii)将优化后的火灾集群粘贴到目标图像上。此方法增加了数据集的多样性,同时保留了火灾类别的基本特征。该增强技术的有效性通过数值分析和与基于加权总和的多目标优化方法的其他增强方法的比较而得到证明。这种方法有助于提高针对火灾类别的分割性能指标,与燃料、灰烬或背景等其他类别相比,其操作意义更为重要。数值性能评估验证了所提出CCPDA方法在小规模手动标记训练数据集方面的有效性,并说明了在考虑的特定应用场景中,CCPDA在其他增强策略中的表现更佳,特别是在提高火灾类别分割性能方面。
论文及项目相关链接
PDF 21 pages, 5 figures, and under review for AIAA SciTech 2026
Summary
中央式复制粘贴数据增强法(CCPDA)能有效协助深度学习多类别分割模型的训练,尤其针对火情类别的分割效果提升显著。该方法通过识别源图像中的火情集群、实施中心化技术和将优化后的火情集群粘贴至目标图像三个主要步骤进行。此法能增加数据集多样性,同时保留火情类别的关键特征。通过数值分析和多目标优化方法的加权和比较,证明CCPDA在提升火情类别分割性能方面的有效性,且在考虑的应用场景中表现优于其他增强策略。
Key Takeaways
- 收集并标注图像以训练分割模型的成本通常较高,特别是在野外火灾科学领域,可靠公共数据集稀缺。
- 提出了中央式复制粘贴数据增强(CCPDA)方法,旨在协助深度学习多类别分割模型的训练。
- CCPDA包含三个主要步骤:识别源图像中的火情集群、实施中心化技术,以及将优化后的火情集群粘贴至目标图像。
- CCPDA能增加数据集多样性并保留火情类别的关键特征。
- 数值分析和多目标优化方法比较显示,CCPDA在提升火情类别分割性能方面表现出色。
- CCPDA在野外火灾科学领域的应用场景中,相较于其他数据增强策略具有优势。
点此查看论文截图



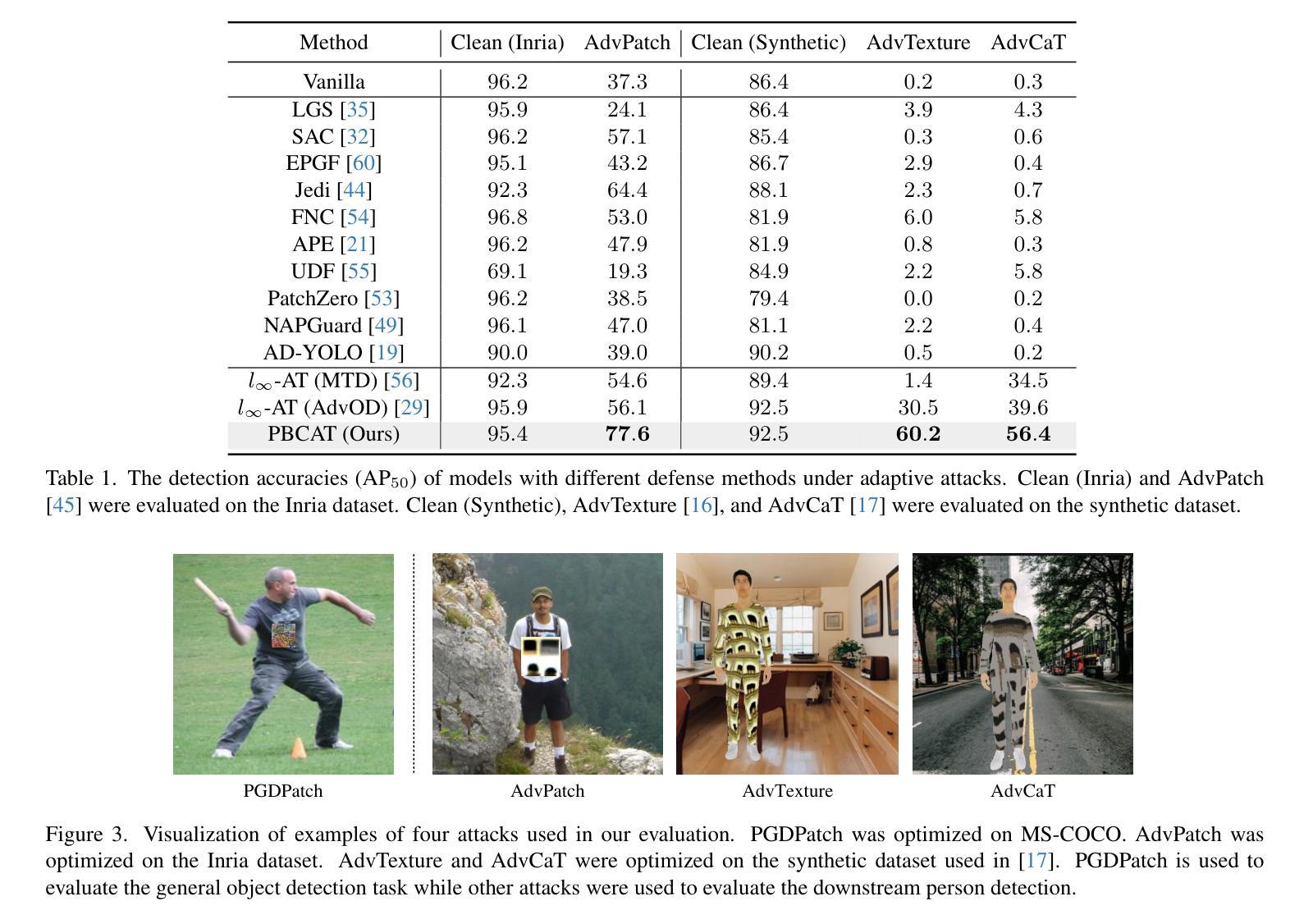
PBCAT: Patch-based composite adversarial training against physically realizable attacks on object detection
Authors:Xiao Li, Yiming Zhu, Yifan Huang, Wei Zhang, Yingzhe He, Jie Shi, Xiaolin Hu
Object detection plays a crucial role in many security-sensitive applications. However, several recent studies have shown that object detectors can be easily fooled by physically realizable attacks, \eg, adversarial patches and recent adversarial textures, which pose realistic and urgent threats. Adversarial Training (AT) has been recognized as the most effective defense against adversarial attacks. While AT has been extensively studied in the $l_\infty$ attack settings on classification models, AT against physically realizable attacks on object detectors has received limited exploration. Early attempts are only performed to defend against adversarial patches, leaving AT against a wider range of physically realizable attacks under-explored. In this work, we consider defending against various physically realizable attacks with a unified AT method. We propose PBCAT, a novel Patch-Based Composite Adversarial Training strategy. PBCAT optimizes the model by incorporating the combination of small-area gradient-guided adversarial patches and imperceptible global adversarial perturbations covering the entire image. With these designs, PBCAT has the potential to defend against not only adversarial patches but also unseen physically realizable attacks such as adversarial textures. Extensive experiments in multiple settings demonstrated that PBCAT significantly improved robustness against various physically realizable attacks over state-of-the-art defense methods. Notably, it improved the detection accuracy by 29.7% over previous defense methods under one recent adversarial texture attack.
对象检测在许多安全敏感应用中扮演着至关重要的角色。然而,最近的一些研究表明,对象检测器很容易受到物理可实现攻击(如对抗性补丁和最新的对抗性纹理)的欺骗,这些攻击带来了现实而紧迫的威胁。对抗性训练(AT)已被公认为对抗对抗性攻击的最有效防御手段。虽然AT在$l_\infty$攻击分类模型的设置中已经得到了广泛的研究,但针对对象检测器的物理可实现攻击的AT却受到了有限的探索。早期的尝试仅旨在防御对抗性补丁,针对更广泛的物理可实现攻击的AT尚未得到充分的探索。在这项工作中,我们考虑使用统一的AT方法来防御各种物理可实现攻击。我们提出了基于补丁的复合对抗训练策略(PBCAT)。PBCAT通过结合小区域梯度引导的对抗性补丁和覆盖整个图像的不明显的全局对抗性扰动来优化模型。通过这些设计,PBCAT不仅有望防御对抗性补丁,还能防御看不见的如对抗性纹理等物理可实现攻击。在多个设置中的大量实验表明,与最先进的防御方法相比,PBCAT在各种物理可实现攻击方面显著提高了鲁棒性。值得注意的是,它在最近的一次对抗性纹理攻击下,相比之前的防御方法提高了29.7%的检测准确率。
论文及项目相关链接
PDF Accepted by ICCV 2025
Summary
本文探讨了目标检测在安全性敏感应用中的挑战,指出对象检测器容易受到物理可实现攻击的影响,如对抗性补丁和对抗性纹理。文章提出一种新型的防御方法——基于补丁的复合对抗性训练(PBCAT),能够针对多种物理可实现攻击进行统一防御。实验证明,PBCAT在多种设置下显著提高了对抗物理可实现攻击的鲁棒性,相比现有防御方法具有显著优势。
Key Takeaways
- 目标检测在安全性敏感应用中面临挑战,易受到物理可实现攻击的影响。
- 对抗性训练(AT)是防御对抗性攻击的有效手段,但在对象检测器的物理可实现攻击方面的应用有限。
- PBCAT是一种新型的基于补丁的复合对抗性训练策略,能够统一防御多种物理可实现攻击。
- PBCAT通过结合小区域梯度引导对抗性补丁和覆盖整个图像的不易察觉的全局对抗性扰动来优化模型。
- PBCAT不仅能防御对抗性补丁,还能防御未知的物理可实现攻击,如对抗性纹理。
- 实验证明,PBCAT在多种设置下显著提高了对抗物理可实现攻击的鲁棒性,相比现有防御方法具有显著优势。
点此查看论文截图