⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-11 更新
Photometric Stereo using Gaussian Splatting and inverse rendering
Authors:Matéo Ducastel, David Tschumperlé, Yvain Quéau
Recent state-of-the-art algorithms in photometric stereo rely on neural networks and operate either through prior learning or inverse rendering optimization. Here, we revisit the problem of calibrated photometric stereo by leveraging recent advances in 3D inverse rendering using the Gaussian Splatting formalism. This allows us to parameterize the 3D scene to be reconstructed and optimize it in a more interpretable manner. Our approach incorporates a simplified model for light representation and demonstrates the potential of the Gaussian Splatting rendering engine for the photometric stereo problem.
近期最先进的光度立体算法依赖于神经网络,并通过先验学习或逆渲染优化进行操作。在这里,我们借助最近基于高斯点绘技术的三维逆渲染技术进展重新考虑校准光度立体问题。这使我们能够以更具解释性的方式对重建的三维场景进行参数化并对其进行优化。我们的方法采用了简化的光照表示模型,展示了高斯点绘渲染引擎在光度立体问题上的潜力。
论文及项目相关链接
PDF in French language. GRETSI 2025, Association GRETSI, Aug 2025, Strasbourg, France
Summary
最新先进的光度立体视觉算法依赖于神经网络,通过预先学习或逆向渲染优化来操作。本研究利用最新的三维逆向渲染高斯平铺形式的进展,重新审视了校准光度立体视觉问题。通过参数化待重建的三维场景,能以更易理解的方式进行优化。研究采用简化的光照表示模型,展示了高斯平铺渲染引擎在光度立体视觉问题中的潜力。
Key Takeaways
- 论文利用高斯平铺形式的最新三维逆向渲染技术来改进光度立体视觉问题。
- 该方法采用参数化方式重建三维场景,使优化过程更为直观。
- 通过简化光照表示模型,提升了算法的效率和准确性。
- 论文展示了高斯平铺渲染引擎在光度立体视觉中的潜力。
- 该方法主要依赖神经网络来解决问题,使用预先学习和逆向渲染优化两种方式操作。
- 该方法可能提高场景重建的精度和可靠性。
点此查看论文截图




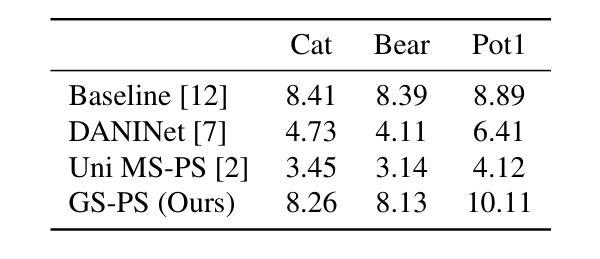
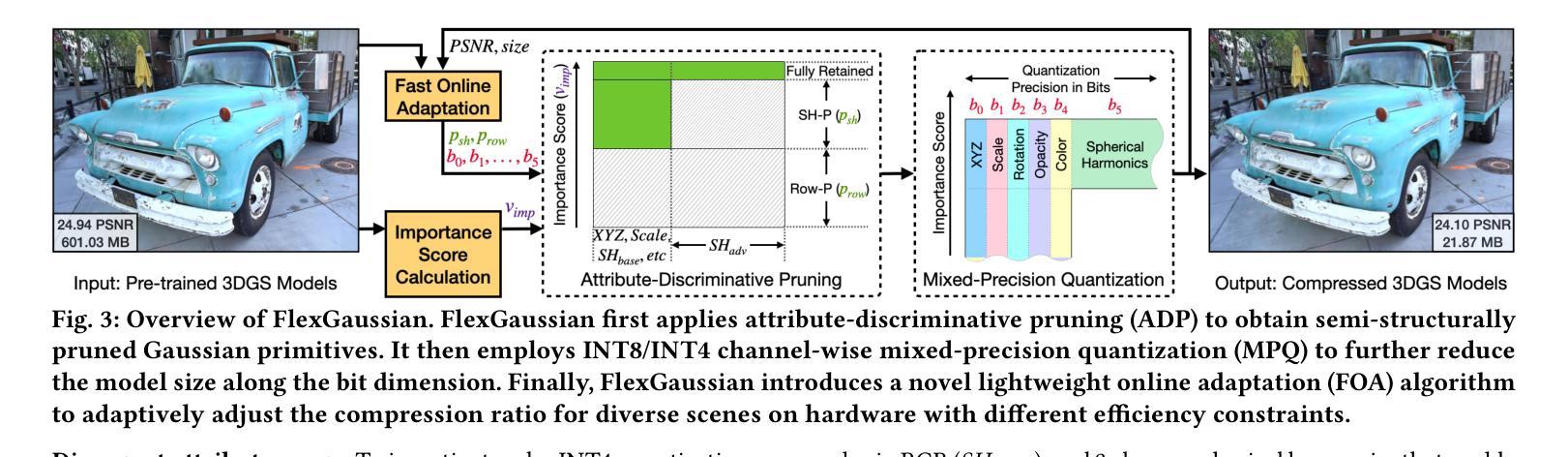
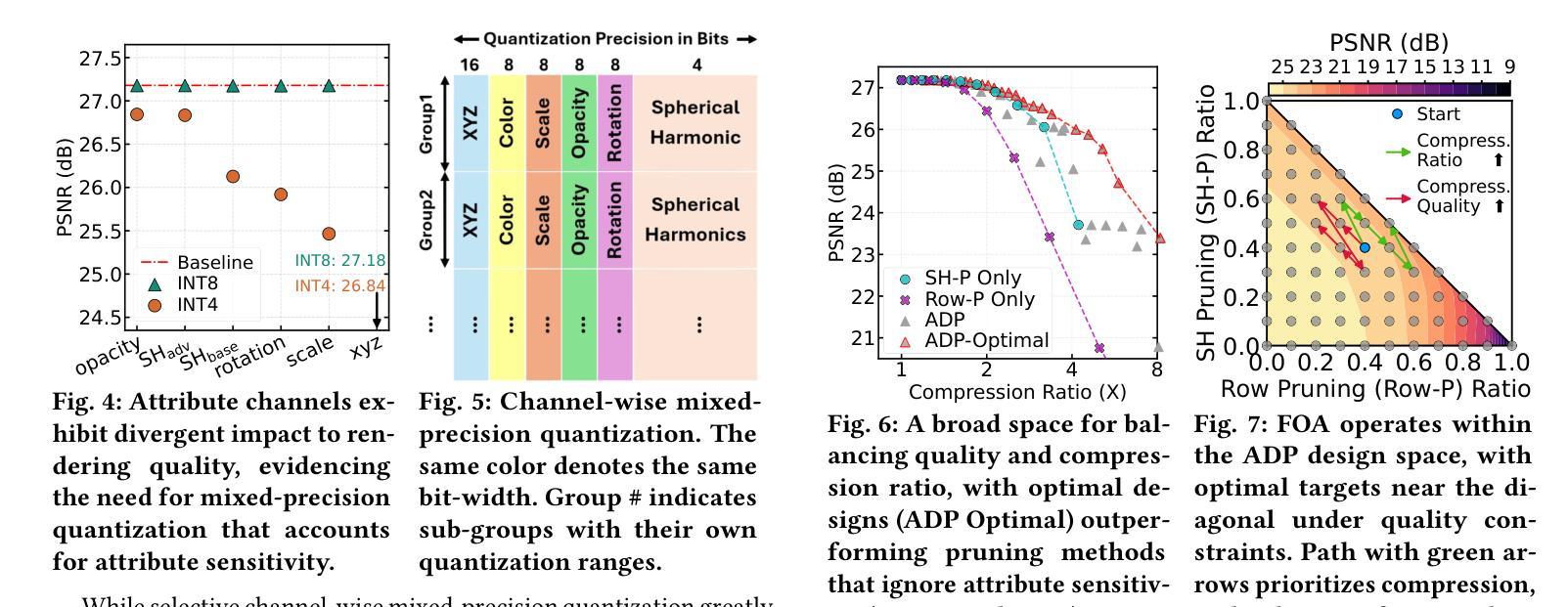
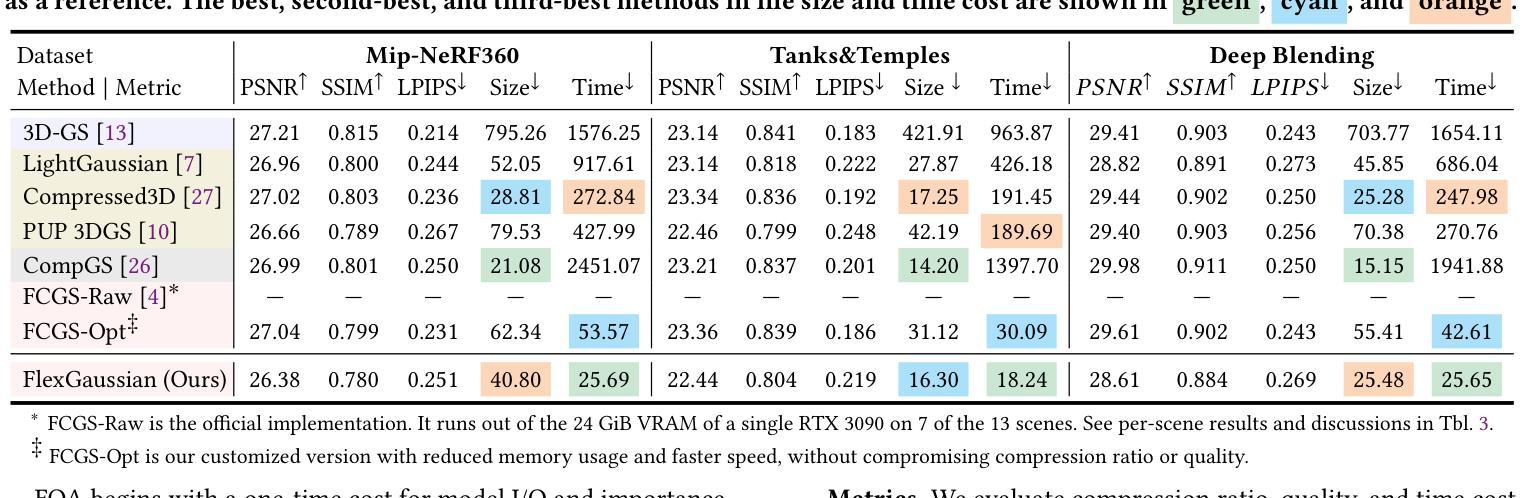
FlexGaussian: Flexible and Cost-Effective Training-Free Compression for 3D Gaussian Splatting
Authors:Boyuan Tian, Qizhe Gao, Siran Xianyu, Xiaotong Cui, Minjia Zhang
3D Gaussian splatting has become a prominent technique for representing and rendering complex 3D scenes, due to its high fidelity and speed advantages. However, the growing demand for large-scale models calls for effective compression to reduce memory and computation costs, especially on mobile and edge devices with limited resources. Existing compression methods effectively reduce 3D Gaussian parameters but often require extensive retraining or fine-tuning, lacking flexibility under varying compression constraints. In this paper, we introduce FlexGaussian, a flexible and cost-effective method that combines mixed-precision quantization with attribute-discriminative pruning for training-free 3D Gaussian compression. FlexGaussian eliminates the need for retraining and adapts easily to diverse compression targets. Evaluation results show that FlexGaussian achieves up to 96.4% compression while maintaining high rendering quality (<1 dB drop in PSNR), and is deployable on mobile devices. FlexGaussian delivers high compression ratios within seconds, being 1.7-2.1x faster than state-of-the-art training-free methods and 10-100x faster than training-involved approaches. The code is being prepared and will be released soon at: https://github.com/Supercomputing-System-AI-Lab/FlexGaussian
3D高斯贴图技术因其高保真和速度优势而成为表示和呈现复杂3D场景的重要技术。然而,对大规模模型日益增长的需求要求对内存和计算成本进行有效压缩,尤其是在资源和计算能力有限的移动和边缘设备上。现有压缩方法虽然可以有效地减少3D高斯参数,但通常需要大量的重新训练或微调,在不同的压缩约束下缺乏灵活性。在本文中,我们介绍了FlexGaussian,这是一种灵活且经济高效的压缩方法,结合了混合精度量化和属性判别修剪,无需训练即可进行3D高斯压缩。FlexGaussian无需重新训练,可轻松适应不同的压缩目标。评估结果表明,FlexGaussian在保持高渲染质量的同时(峰值信噪比下降小于1dB),实现了高达96.4%的压缩率,并可在移动设备上部署。FlexGaussian可在几秒内实现高压缩比,比最新的无训练方法快1.7-2.1倍,比涉及训练的方法快10-100倍。代码正在准备中,很快将在https://github.com/Supercomputing-System-AI-Lab/FlexGaussian发布。
论文及项目相关链接
PDF To appear at ACM MM 2025
Summary
3D高斯贴片技术因其高保真和速度优势而成为表示和呈现复杂3D场景的重要技术。随着对大规模模型的需求增长,需要在不损失性能的情况下有效压缩模型,特别是在资源有限的移动和边缘设备上。本文介绍了一种名为FlexGaussian的灵活且经济高效的方法,它结合了混合精度量化和属性判别剪枝,实现了无需训练的3D高斯压缩。FlexGaussian无需重新训练,可轻松适应不同的压缩目标,在保持高质量渲染的同时实现了高达96.4%的压缩率。此外,FlexGaussian部署在移动设备上的速度也很快。
Key Takeaways
- 3D高斯贴片技术因高保真和速度而受到青睐。
- 大规模模型需要有效的压缩方法以降低内存和计算成本。
- FlexGaussian结合了混合精度量化和属性判别剪枝,实现了无需训练的3D高斯压缩。
- FlexGaussian无需重新训练,可适应不同的压缩目标。
- FlexGaussian实现了高达96.4%的压缩率,同时保持高质量的渲染。
- FlexGaussian比现有的无训练压缩方法和涉及训练的方法更快。
点此查看论文截图

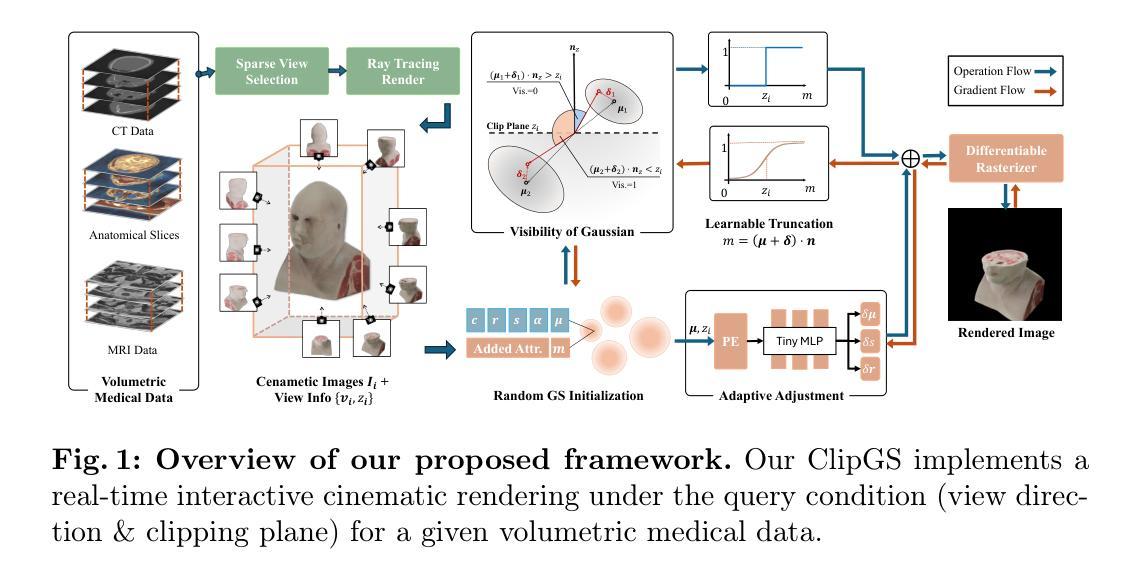
ClipGS: Clippable Gaussian Splatting for Interactive Cinematic Visualization of Volumetric Medical Data
Authors:Chengkun Li, Yuqi Tong, Kai Chen, Zhenya Yang, Ruiyang Li, Shi Qiu, Jason Ying-Kuen Chan, Pheng-Ann Heng, Qi Dou
The visualization of volumetric medical data is crucial for enhancing diagnostic accuracy and improving surgical planning and education. Cinematic rendering techniques significantly enrich this process by providing high-quality visualizations that convey intricate anatomical details, thereby facilitating better understanding and decision-making in medical contexts. However, the high computing cost and low rendering speed limit the requirement of interactive visualization in practical applications. In this paper, we introduce ClipGS, an innovative Gaussian splatting framework with the clipping plane supported, for interactive cinematic visualization of volumetric medical data. To address the challenges posed by dynamic interactions, we propose a learnable truncation scheme that automatically adjusts the visibility of Gaussian primitives in response to the clipping plane. Besides, we also design an adaptive adjustment model to dynamically adjust the deformation of Gaussians and refine the rendering performance. We validate our method on five volumetric medical data (including CT and anatomical slice data), and reach an average 36.635 PSNR rendering quality with 156 FPS and 16.1 MB model size, outperforming state-of-the-art methods in rendering quality and efficiency.
医学体积数据的可视化对于提高诊断准确性、改善手术规划和教育具有重要意义。电影渲染技术通过提供高质量的可视化效果,展现复杂的解剖细节,从而丰富这一过程,促进在医学环境中的理解和决策。然而,高昂的计算成本和较低的渲染速度限制了其在实际应用中的交互式可视化需求。在本文中,我们介绍了ClipGS,这是一种支持裁剪平面的创新高斯贴图框架,用于医学体积数据的交互式电影可视化。为了解决动态交互所带来的挑战,我们提出了一种可学习的截断方案,该方案可以自动根据裁剪平面调整高斯原始数据的可见性。此外,我们还设计了一个自适应调整模型,以动态调整高斯值的变形并优化渲染性能。我们在五种医学体积数据(包括CT和解剖切片数据)上验证了我们的方法,达到了平均36.635的峰值信噪比(PSNR)渲染质量,帧率为每秒156帧,模型大小为16.1MB,在渲染质量和效率方面均优于现有先进技术。
论文及项目相关链接
PDF Early accepted by MICCAI 2025. Project is available at: https://med-air.github.io/ClipGS
Summary
体积医疗数据的可视化对于提高诊断准确性、改善手术规划和教育至关重要。电影渲染技术通过提供高质量的可视化,展示复杂的解剖细节,丰富了这一过程。然而,高昂的计算成本和较低的渲染速度限制了其在实践中的互动可视化需求。本文介绍了一种创新的Gaussian splatting框架ClipGS,支持裁剪平面,用于体积医疗数据的交互式电影渲染。为解决动态交互带来的挑战,我们提出了一种可学习的截断方案,该方案可自动根据裁剪平面调整高斯原始数据的可见性。此外,我们还设计了一个自适应调整模型,以动态调整高斯变形并优化渲染性能。在五个体积医疗数据(包括CT和解剖切片数据)上的验证结果表明,我们的方法在渲染质量和效率方面均优于现有先进技术,平均PSNR渲染质量为36.635,帧速率为156 FPS,模型大小为16.1 MB。
Key Takeaways
- 体积医疗数据可视化对于诊断、手术规划和医学教育至关重要。
- 电影渲染技术能够提供高质量的医疗数据可视化,展示解剖细节。
- 现有可视化方法在计算成本和渲染速度上存在限制。
- 本文介绍了一种新的Gaussian splatting框架ClipGS,支持裁剪平面,用于体积医疗数据的交互式电影渲染。
- ClipGS通过可学习的截断方案和自适应调整模型,提高了渲染性能和视觉效果。
- 在多个体积医疗数据上的验证结果表明ClipGS在渲染质量和效率上均表现优异。
- ClipGS有望改善医疗领域的诊断、治疗和教育工作。
点此查看论文截图

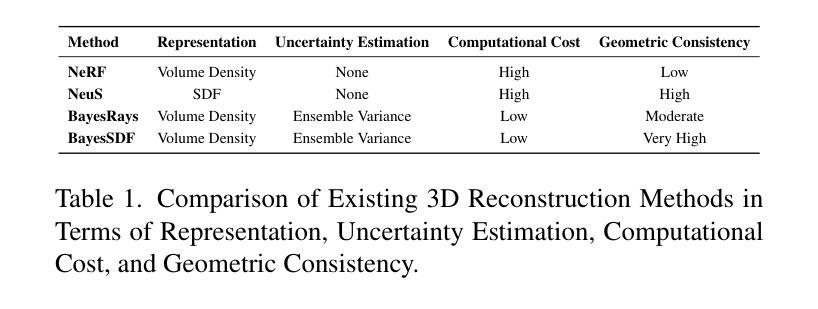
A Probabilistic Approach to Uncertainty Quantification Leveraging 3D Geometry
Authors:Rushil Desai, Frederik Warburg, Trevor Darrell, Marissa Ramirez de Chanlatte
Quantifying uncertainty in neural implicit 3D representations, particularly those utilizing Signed Distance Functions (SDFs), remains a substantial challenge due to computational inefficiencies, scalability issues, and geometric inconsistencies. Existing methods typically neglect direct geometric integration, leading to poorly calibrated uncertainty maps. We introduce BayesSDF, a novel probabilistic framework for uncertainty quantification in neural implicit SDF models, motivated by scientific simulation applications with 3D environments (e.g., forests) such as modeling fluid flow through forests, where precise surface geometry and awareness of fidelity surface geometric uncertainty are essential. Unlike radiance-based models such as NeRF or 3D Gaussian splatting, which lack explicit surface formulations, SDFs define continuous and differentiable geometry, making them better suited for physical modeling and analysis. BayesSDF leverages a Laplace approximation to quantify local surface instability via Hessian-based metrics, enabling computationally efficient, surface-aware uncertainty estimation. Our method shows that uncertainty predictions correspond closely with poorly reconstructed geometry, providing actionable confidence measures for downstream use. Extensive evaluations on synthetic and real-world datasets demonstrate that BayesSDF outperforms existing methods in both calibration and geometric consistency, establishing a strong foundation for uncertainty-aware 3D scene reconstruction, simulation, and robotic decision-making.
在神经隐式三维表示中量化不确定性,特别是那些使用带符号距离函数(SDFs)的表示,仍然是一个巨大的挑战,主要是由于计算效率低下、可扩展性问题以及几何不一致性。现有方法通常忽略直接几何集成,导致校准不良的不确定性地图。我们引入了BayesSDF,这是一种用于神经隐式SDF模型中的不确定性量化的新型概率框架,其灵感来源于具有三维环境(例如森林)的科学模拟应用程序,例如模拟森林中的水流,其中精确的曲面几何和对保真度曲面几何不确定性的认识是至关重要的。不同于基于辐射的模型(如NeRF或三维高斯平铺),缺乏明确的表面公式,SDF定义了连续且可微分的几何形状,使其更适合物理建模和分析。BayesSDF利用拉普拉斯近似来通过基于Hessian的指标量化局部表面不稳定性,从而实现计算效率高且具备表面感知的不确定性估计。我们的方法显示出不确定性预测与重建不良的几何形状紧密相关,为下游使用提供了可操作的可信措施。在合成和真实世界数据集上的广泛评估表明,在标定和几何一致性方面,BayesSDF优于现有方法,为具有不确定性的三维场景重建、模拟和机器人决策制定建立了坚实的基础。
论文及项目相关链接
PDF ICCV 2025 Workshops (8 Pages, 6 Figures, 2 Tables)
Summary
神经网络隐式三维表示中的不确定性量化,特别是使用符号距离函数(SDFs)的方法,面临计算效率低下、可扩展性差和几何不一致等挑战。现有方法通常忽视直接几何集成,导致不确定性映射校准不良。本文介绍了一种基于贝叶斯的新概率框架BayesSDF,用于神经隐式SDF模型的不确定性量化,其动机来源于需要精确表面几何和表面几何不确定性的三维环境模拟应用(如森林模型)。BayesSDF利用Laplace近似法通过Hessian度量计算局部表面不稳定度,实现了计算高效、具有表面感知的不确定性估计。该方法显示不确定性预测与重建不良的几何结构紧密对应,为下游应用提供了可操作的可信度量。在合成和真实数据集上的广泛评估表明,BayesSDF在校准和几何一致性方面优于现有方法,为不确定性感知的3D场景重建、模拟和机器人决策制定奠定了坚实基础。
Key Takeaways
- 神经网络隐式三维表示中的不确定性量化存在挑战,包括计算效率低下、可扩展性差和几何不一致。
- 现有方法忽视直接几何集成,导致不确定性映射校准不良。
- BayesSDF是一种新型概率框架,用于神经隐式SDF模型的不确定性量化。
- BayesSDF适用于需要精确表面几何和表面几何不确定性的三维环境模拟应用。
- BayesSDF利用Laplace近似法通过Hessian度量计算局部表面不稳定度,实现高效、具有表面感知的不确定性估计。
- BayesSDF能对应出预测结果与重建不良的几何结构之间的关系。
点此查看论文截图

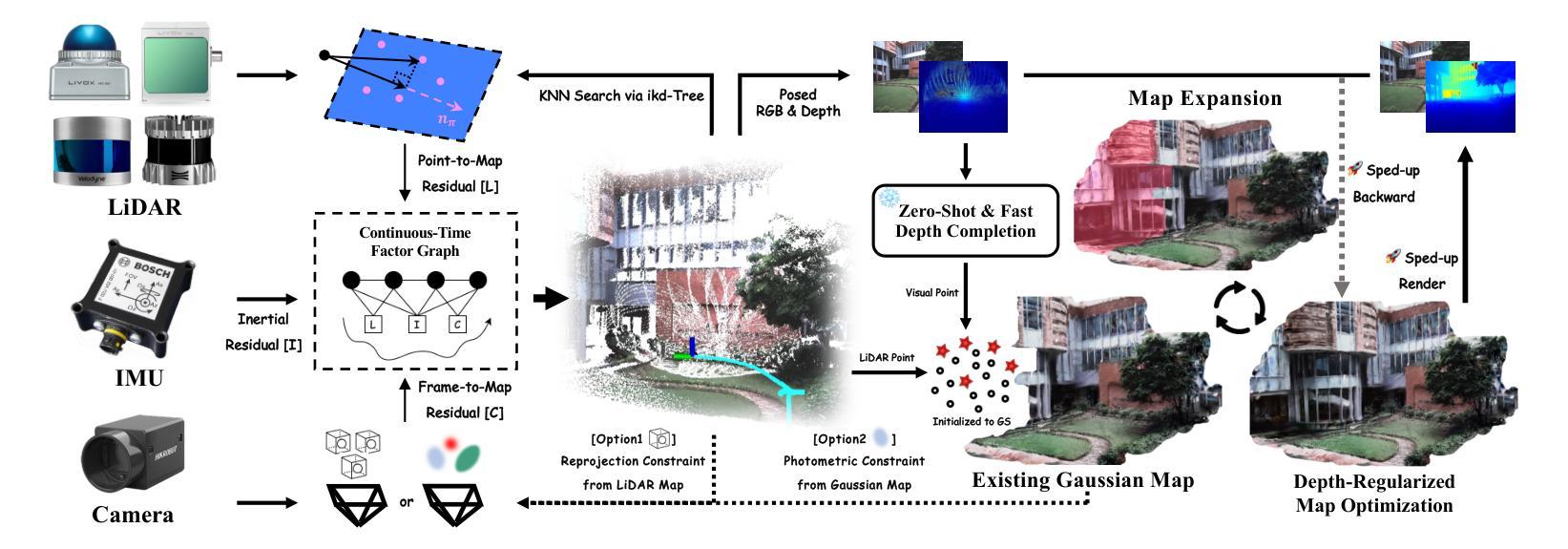
Gaussian-LIC2: LiDAR-Inertial-Camera Gaussian Splatting SLAM
Authors:Xiaolei Lang, Jiajun Lv, Kai Tang, Laijian Li, Jianxin Huang, Lina Liu, Yong Liu, Xingxing Zuo
This paper presents the first photo-realistic LiDAR-Inertial-Camera Gaussian Splatting SLAM system that simultaneously addresses visual quality, geometric accuracy, and real-time performance. The proposed method performs robust and accurate pose estimation within a continuous-time trajectory optimization framework, while incrementally reconstructing a 3D Gaussian map using camera and LiDAR data, all in real time. The resulting map enables high-quality, real-time novel view rendering of both RGB images and depth maps. To effectively address under-reconstruction in regions not covered by the LiDAR, we employ a lightweight zero-shot depth model that synergistically combines RGB appearance cues with sparse LiDAR measurements to generate dense depth maps. The depth completion enables reliable Gaussian initialization in LiDAR-blind areas, significantly improving system applicability for sparse LiDAR sensors. To enhance geometric accuracy, we use sparse but precise LiDAR depths to supervise Gaussian map optimization and accelerate it with carefully designed CUDA-accelerated strategies. Furthermore, we explore how the incrementally reconstructed Gaussian map can improve the robustness of odometry. By tightly incorporating photometric constraints from the Gaussian map into the continuous-time factor graph optimization, we demonstrate improved pose estimation under LiDAR degradation scenarios. We also showcase downstream applications via extending our elaborate system, including video frame interpolation and fast 3D mesh extraction. To support rigorous evaluation, we construct a dedicated LiDAR-Inertial-Camera dataset featuring ground-truth poses, depth maps, and extrapolated trajectories for assessing out-of-sequence novel view synthesis. Both the dataset and code will be made publicly available on project page https://xingxingzuo.github.io/gaussian_lic2.
本文介绍了首个逼真的激光雷达惯性相机高斯混合SLAM系统,该系统同时解决了视觉质量、几何精度和实时性能的问题。所提出的方法在连续时间轨迹优化框架内进行稳健而准确的姿态估计,同时实时地利用相机和激光雷达数据逐步重建一个三维高斯地图。所得的地图能够实现高质量、实时的RGB图像和深度图的新型视图渲染。为了有效解决激光雷达未覆盖区域的重建不足问题,我们采用了一种轻量级的零射击深度模型,该模型协同结合了RGB外观线索和稀疏的激光雷达测量数据,以生成密集的深度图。深度补全使得在激光雷达盲区实现可靠的高斯初始化,大大提高了系统对于稀疏激光雷达传感器的适用性。为了提高几何精度,我们使用稀疏但精确的激光雷达深度来监督高斯地图的优化,并借助精心设计的CUDA加速策略来加速优化过程。此外,我们还探讨了逐步重建的高斯地图如何增强里程计的稳健性。通过将高斯地图的光度约束紧密地融入连续时间因子图优化中,我们在激光雷达退化场景下展示了改进的姿态估计。我们还通过扩展我们精致的系统来展示下游应用,包括视频帧插值和快速三维网格提取。为了支持严格的评估,我们构建了一个专用的激光雷达惯性相机数据集,其中包含用于评估不按顺序的新型视图合成的真实姿态、深度图和推断轨迹。数据集和代码都将在项目页面上进行公开,网址为:https://xingxingzuo.github.io/gaussian_lic2。
论文及项目相关链接
摘要
本文提出了首个逼真的激光雷达惯性相机高斯模糊SLAM系统,该系统同时解决了视觉质量、几何精度和实时性能的问题。该方法在连续时间轨迹优化框架内进行稳健和准确的姿态估计,同时增量构建三维高斯地图,使用相机和激光雷达数据,均可在实时环境下完成。所得地图可实现高质量实时渲染RGB图像和深度图。为解决激光雷达未覆盖区域的重建不足问题,我们采用轻量级零射深度模型,结合RGB外观线索和稀疏激光雷达测量值生成密集深度图。深度完成功能可在激光雷达盲区实现可靠的高斯初始化,显著提高系统对稀疏激光雷达传感器的适用性。为提高几何精度,我们使用稀疏但精确的激光雷达深度值监督高斯地图优化,并采用精心设计CUDA加速策略进行加速。此外,我们探索了增量重建高斯地图如何提升里程计的稳健性。通过紧密地将高斯地图的光度约束纳入连续时间因子图优化,我们在激光雷达退化场景下展示了改进的姿态估计。我们还通过扩展我们精致的系统展示了下游应用,包括视频帧插值和快速三维网格提取。为支持严格评估,我们构建了一个专用的激光雷达惯性相机数据集,包含用于评估序列外新视图合成的真实姿态、深度图和轨迹外推。数据集和代码均将在项目页面公开,网址为https://xingxingzuo.github.io/gaussian_lic2。
要点
- 提出了首个结合视觉质量、几何精度和实时性能的光谱级激光雷达惯性相机高斯模糊SLAM系统。
- 在连续时间轨迹优化框架内进行稳健和准确的姿态估计,并增量构建三维高斯地图。
- 通过结合RGB外观线索和稀疏激光雷达测量值生成密集深度图,解决了激光雷达未覆盖区域的重建问题。
- 利用稀疏但精确的激光雷达深度值监督高斯地图优化,并加速优化过程。
- 高斯地图的引入提高了里程计的稳健性,尤其在激光雷达退化场景下。
- 系统下游应用包括视频帧插值和快速三维网格提取等。
点此查看论文截图

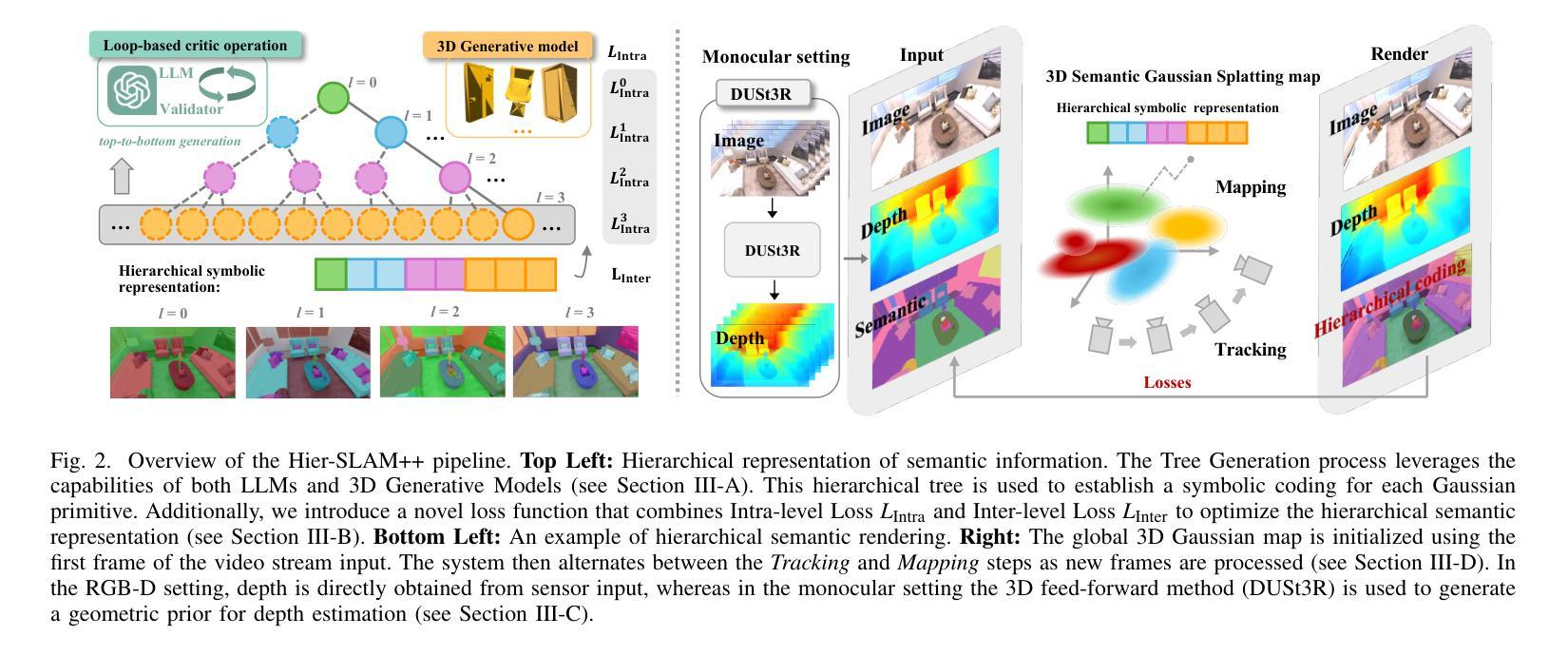
Hier-SLAM++: Neuro-Symbolic Semantic SLAM with a Hierarchically Categorical Gaussian Splatting
Authors:Boying Li, Vuong Chi Hao, Peter J. Stuckey, Ian Reid, Hamid Rezatofighi
We propose Hier-SLAM++, a comprehensive Neuro-Symbolic semantic 3D Gaussian Splatting SLAM method with both RGB-D and monocular input featuring an advanced hierarchical categorical representation, which enables accurate pose estimation as well as global 3D semantic mapping. The parameter usage in semantic SLAM systems increases significantly with the growing complexity of the environment, making scene understanding particularly challenging and costly. To address this problem, we introduce a novel hierarchical representation that encodes both semantic and geometric information in a compact form into 3D Gaussian Splatting, leveraging the capabilities of large language models (LLMs) as well as the 3D generative model. By utilizing the proposed hierarchical tree structure, semantic information is symbolically represented and learned in an end-to-end manner. We further introduce an advanced semantic loss designed to optimize hierarchical semantic information through both Intra-level and Inter-level optimizations. Additionally, we propose an improved SLAM system to support both RGB-D and monocular inputs using a feed-forward model. To the best of our knowledge, this is the first semantic monocular Gaussian Splatting SLAM system, significantly reducing sensor requirements for 3D semantic understanding and broadening the applicability of semantic Gaussian SLAM system. We conduct experiments on both synthetic and real-world datasets, demonstrating superior or on-par performance with state-of-the-art methods, while significantly reducing storage and training time requirements. Our project page is available at: https://hierslampp.github.io/
我们提出了Hier-SLAM++,这是一种全面的神经符号语义3D高斯混叠SLAM方法,支持RGB-D和单目输入,并带有高级分层类别表示。该方法能够实现精确的姿势估计和全局3D语义映射。随着环境复杂性的增加,语义SLAM系统中的参数使用量也显著增加,使得场景理解变得特别具有挑战性和成本高昂。为了解决这一问题,我们引入了一种新的分层表示方法,以紧凑的形式将语义和几何信息编码到3D高斯混洗中,利用大型语言模型和3D生成模型的能力。通过利用所提出的层次树结构,语义信息以符号方式表示并以端到端的方式进行学习。我们进一步引入了一种先进的语义损失,旨在通过跨级别优化来优化分层语义信息。此外,我们提出了一种改进的SLAM系统,该系统支持RGB-D和单目输入,并使用前馈模型。据我们所知,这是第一个语义单目高斯混洗SLAM系统,大大降低了对3D语义理解的传感器要求并扩大了语义高斯SLAM系统的应用范围。我们在合成数据集和真实世界数据集上进行了实验,展示了卓越或相当的性能,同时显著降低了存储和训练时间要求。我们的项目页面可在:https://hierslampp.github.io/(链接无法直接访问)。
论文及项目相关链接
PDF 18 pages. Under review
摘要
高效三维语义理解的新方法:基于Hierarchical语义表达和Neuro-Symbolic模型的三维高斯飞溅SLAM。使用先进的层次化分类表达,实现了精确的姿态估计和全局三维语义地图构建。引入新型层次化表达方法,将语义和几何信息以紧凑形式编码于三维高斯飞溅中,利用大型语言模型和三维生成模型的优势进行信息学习。创新地设计了层次化语义损失,用于优化内部和外部层次的语义信息。提出的改进型SLAM系统支持RGB-D和单目相机输入,实现了领先的性能,降低了对传感器的依赖,扩展了语义高斯SLAM系统的应用范围。在合成和真实数据集上的实验证明了该方法的优越性。更多信息可访问项目网页:https://hierslampp.github.io/。
关键发现点
一、Hierarchical语义表达和Neuro-Symbolic模型结合:此方法结合了层次化语义表达和Neuro-Symbolic模型的优势,实现了高效的三维语义理解。
二、紧凑的三维高斯飞溅表达:通过引入新型层次化表达方法,将语义和几何信息编码于三维高斯飞溅中,提高信息的存储和处理效率。
三、利用大型语言模型和三维生成模型:利用大型语言模型和三维生成模型的能力,增强系统的语义理解和三维重建能力。
四、层次化语义损失设计:创新的层次化语义损失设计能够优化内部和外部层次的语义信息,提高系统的准确性和鲁棒性。
五、支持RGB-D和单目相机输入:提出的改进型SLAM系统不仅支持RGB-D输入,还支持单目相机输入,降低了传感器要求,扩大了应用范围。
六、优越的性能表现:在合成和真实数据集上的实验证明了该方法具有领先的性能,与现有技术相比具有优势。
点此查看论文截图

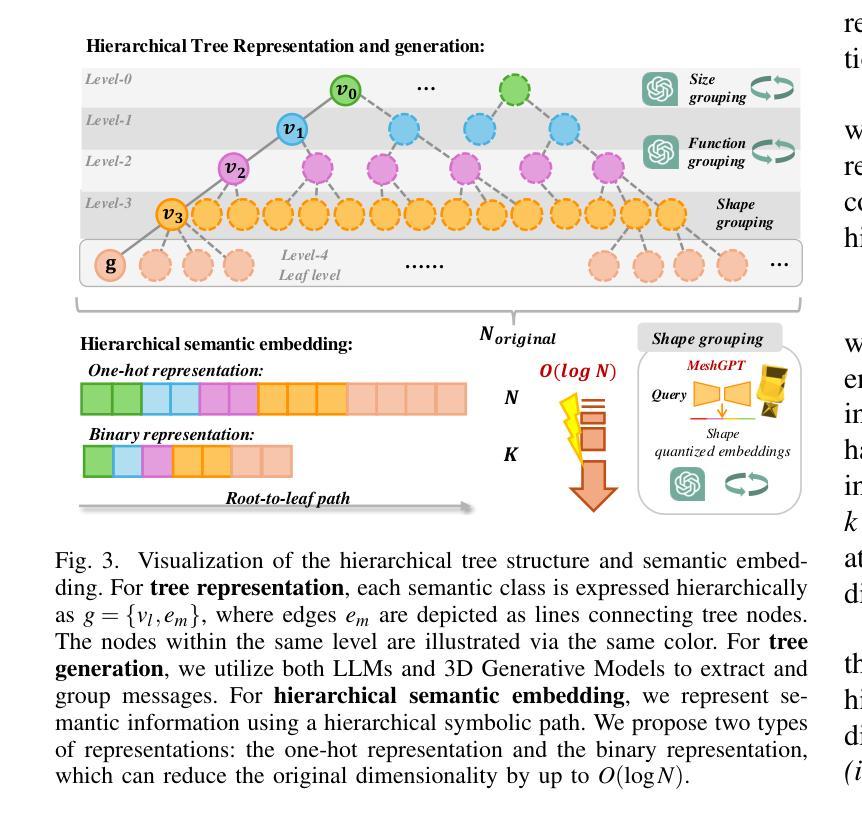
CULTURE3D: A Large-Scale and Diverse Dataset of Cultural Landmarks and Terrains for Gaussian-Based Scene Rendering
Authors:Xinyi Zheng, Steve Zhang, Weizhe Lin, Aaron Zhang, Walterio W. Mayol-Cuevas, Yunze Liu, Junxiao Shen
Current state-of-the-art 3D reconstruction models face limitations in building extra-large scale outdoor scenes, primarily due to the lack of sufficiently large-scale and detailed datasets. In this paper, we present a extra-large fine-grained dataset with 10 billion points composed of 41,006 drone-captured high-resolution aerial images, covering 20 diverse and culturally significant scenes from worldwide locations such as Cambridge Uni main buildings, the Pyramids, and the Forbidden City Palace. Compared to existing datasets, ours offers significantly larger scale and higher detail, uniquely suited for fine-grained 3D applications. Each scene contains an accurate spatial layout and comprehensive structural information, supporting detailed 3D reconstruction tasks. By reconstructing environments using these detailed images, our dataset supports multiple applications, including outputs in the widely adopted COLMAP format, establishing a novel benchmark for evaluating state-of-the-art large-scale Gaussian Splatting methods.The dataset’s flexibility encourages innovations and supports model plug-ins, paving the way for future 3D breakthroughs. All datasets and code will be open-sourced for community use.
当前最先进的3D重建模型在构建超大规模户外场景时面临局限,这主要是由于缺乏足够大规模和详细的数据库。在本文中,我们介绍了一个超大规模精细粒度的数据集,由包含一亿点以上的高度精细化高分辨率图像构成,含有世界各地独特、多元、高价值的场景共计高达四万零六百零六张无人机拍摄的照片,包括剑桥大学的主要建筑、金字塔和紫禁城等。与现有数据集相比,我们的数据集规模更大,细节更丰富,更独特地适合用于精细粒度级的分析与应用场景重建任务中每个场景都有精准的空间布局和综合结构信息数据来支撑这些详细的三维重建任务。通过这些详尽图像进行环境重建我们的数据集可以支持多种应用,包括使用广泛支持的COLMAP格式输出文件;这为评估最新的大规模高斯延展法技术提供了全新基准线。数据集的灵活性有助于创新并可通过模型插件拓展应用范围铺平未来开展第三次数字建模科技革新的道路所有数据集及代码均将以开源形式供公众使用。
论文及项目相关链接
Summary
本文介绍了一个超大规模精细粒度的数据集,包含由无人机拍摄的高分辨率空中图像组成的10亿个点,涵盖全球20个多样且文化意义重大的场景,如剑桥大学主要建筑、金字塔和紫禁城。该数据集规模更大、细节更丰富,适用于精细粒度的3D应用。它支持详细的环境重建任务,并鼓励未来的创新模型开发。数据集以开源形式提供使用。
Key Takeaways
- 介绍了针对超大规模户外场景的3D重建模型面临的挑战。
- 提出了一种超大规模精细粒度的数据集,包含由无人机拍摄的高分辨率空中图像组成的10亿个点。
- 数据集涵盖全球多样化的文化场景,如剑桥大学主要建筑、金字塔和紫禁城等。
- 数据集规模更大、细节更丰富,适用于精细粒度的3D应用。
- 数据集支持详细的环境重建任务,包括采用广泛使用的COLMAP格式输出。
- 数据集的灵活性鼓励创新并支持模型插件,为未来3D技术的突破打下基础。
点此查看论文截图

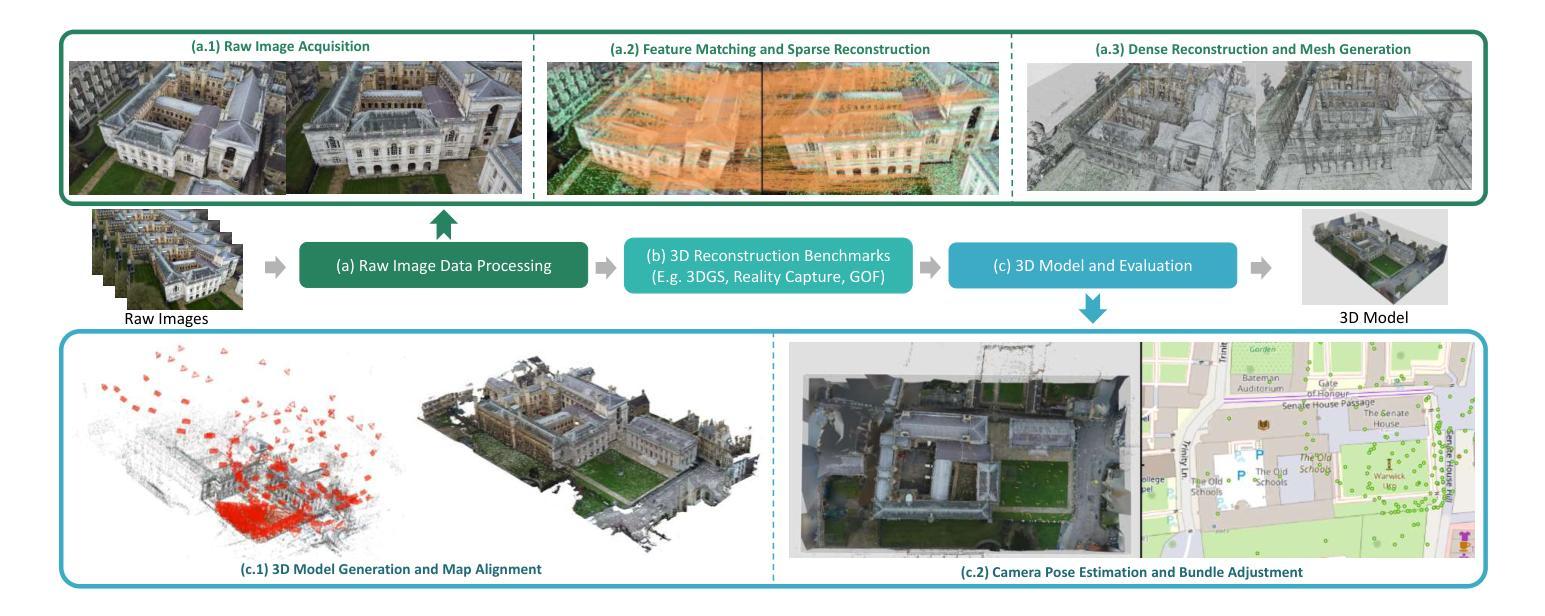

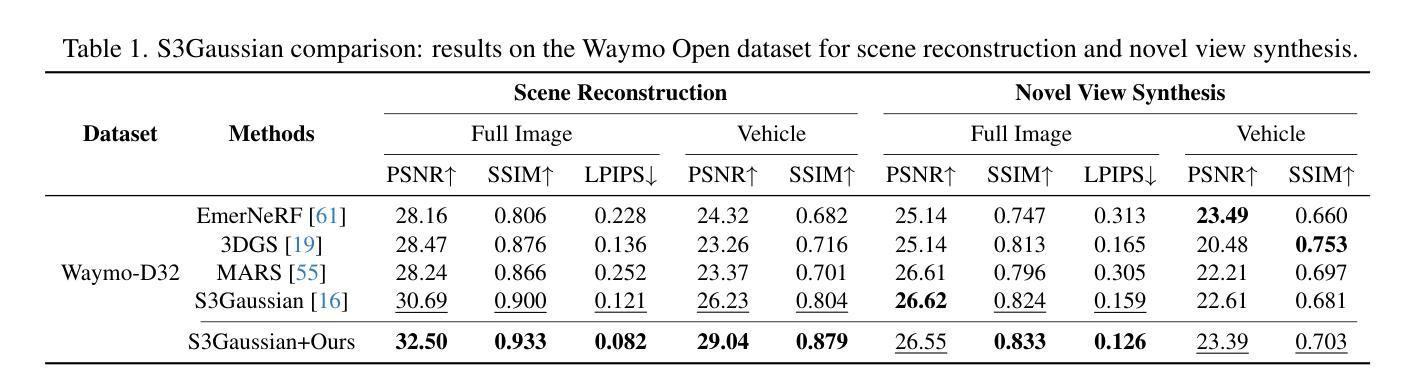
EMD: Explicit Motion Modeling for High-Quality Street Gaussian Splatting
Authors:Xiaobao Wei, Qingpo Wuwu, Zhongyu Zhao, Zhuangzhe Wu, Nan Huang, Ming Lu, Ningning MA, Shanghang Zhang
Photorealistic reconstruction of street scenes is essential for developing real-world simulators in autonomous driving. While recent methods based on 3D/4D Gaussian Splatting (GS) have demonstrated promising results, they still encounter challenges in complex street scenes due to the unpredictable motion of dynamic objects. Current methods typically decompose street scenes into static and dynamic objects, learning the Gaussians in either a supervised manner (e.g., w/ 3D bounding-box) or a self-supervised manner (e.g., w/o 3D bounding-box). However, these approaches do not effectively model the motions of dynamic objects (e.g., the motion speed of pedestrians is clearly different from that of vehicles), resulting in suboptimal scene decomposition. To address this, we propose Explicit Motion Decomposition (EMD), which models the motions of dynamic objects by introducing learnable motion embeddings to the Gaussians, enhancing the decomposition in street scenes. The proposed plug-and-play EMD module compensates for the lack of motion modeling in self-supervised street Gaussian splatting methods. We also introduce tailored training strategies to extend EMD to supervised approaches. Comprehensive experiments demonstrate the effectiveness of our method, achieving state-of-the-art novel view synthesis performance in self-supervised settings. The code is available at: https://qingpowuwu.github.io/emd.
街道场景的逼真重建对于开发自动驾驶现实世界模拟器至关重要。虽然最近基于3D/4D高斯拼贴(GS)的方法已经取得了有前景的结果,但由于动态对象的不可预测运动,它们在复杂的街道场景中仍然面临挑战。当前的方法通常将街道场景分解为静态和动态对象,以监督的方式(例如,使用3D边界框)或自监督的方式(例如,不使用3D边界框)学习高斯。然而,这些方法并不能有效地对动态对象(例如行人与车辆的运动速度明显不同)进行建模,导致场景分解不理想。为了解决这个问题,我们提出了显式运动分解(EMD),它通过向高斯引入可学习的运动嵌入来对动态对象的运动进行建模,增强了街道场景的分解。所提出的即插即用的EMD模块弥补了自监督街道高斯拼贴方法中运动建模的不足。我们还引入了定制的训练策略,将EMD扩展到监督方法。综合实验证明了我们方法的有效性,在自监督设置中实现了最先进的全新视图合成性能。代码可在:https://qingpowuwu.github.io/emd获取。
论文及项目相关链接
PDF Acccpeted by ICCV2025
Summary
针对自动驾驶中的真实街道场景重建,现有的基于3D/4D高斯散斑技术的方法虽表现出潜力,但在复杂场景中处理动态对象时仍面临挑战。新方法显式运动分解(EMD)通过引入可学习的运动嵌入到高斯中,对动态对象的运动进行建模,提高了街道场景的分解效果。该方法在自我监督的街道高斯散斑方法中弥补了运动建模的不足,并通过定制的训练策略扩展到监督方法。实验证明,该方法在自我监督设置下实现了新颖的视图合成性能的最佳效果。
Key Takeaways
- 真实街道场景的重建对于开发自动驾驶中的现实世界模拟器至关重要。
- 当前基于3D/4D高斯散斑的方法在复杂街道场景中处理动态对象时存在挑战。
- 现有方法通常将街道场景分解为静态和动态对象,但缺乏有效的动态对象运动建模。
- 显式运动分解(EMD)方法通过引入可学习的运动嵌入到高斯中,提高了街道场景分解的效果。
- EMD方法弥补了自我监督的街道高斯散斑方法中运动建模的不足。
- 定制的训练策略使EMD方法能够扩展到监督方法。
点此查看论文截图

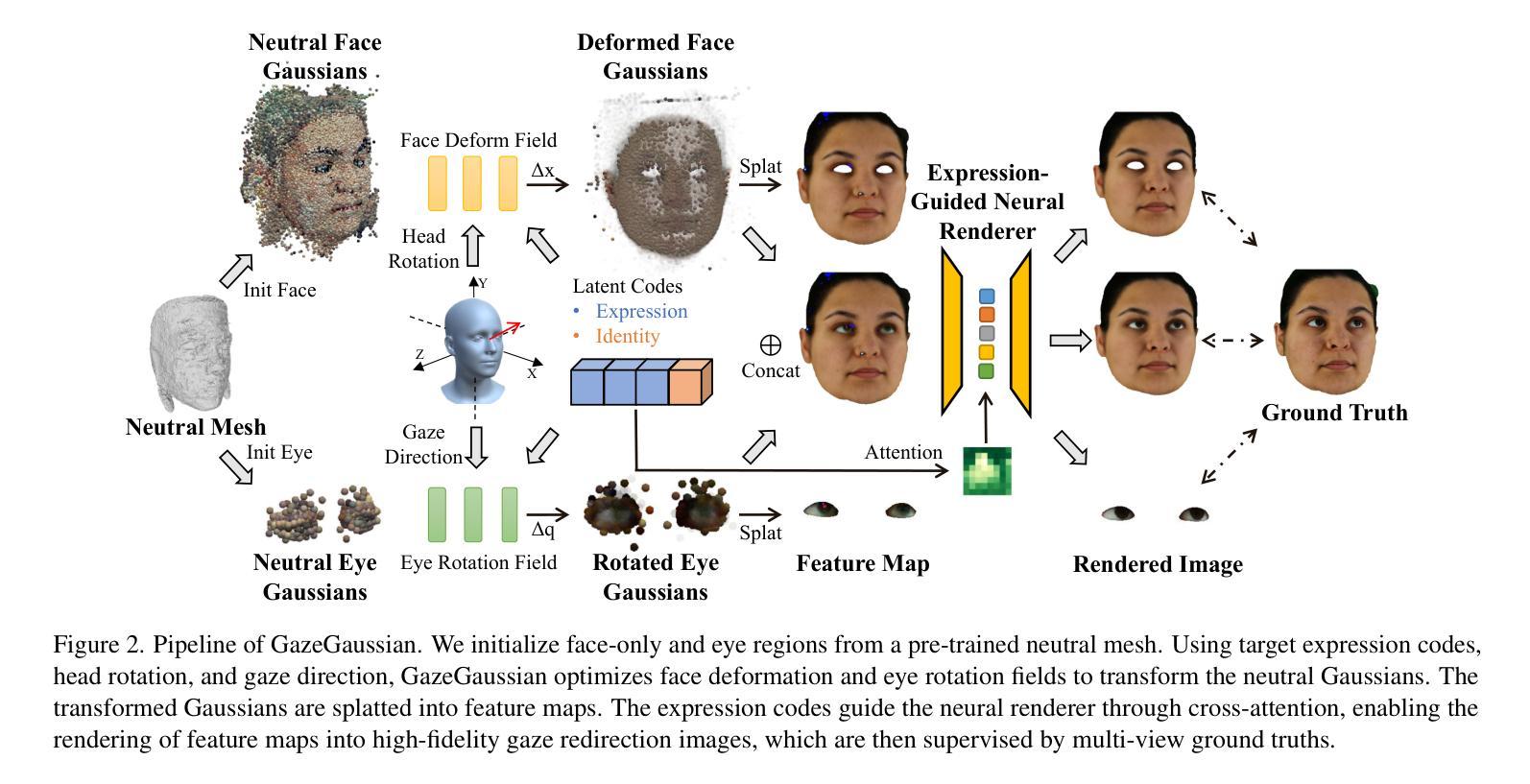
GazeGaussian: High-Fidelity Gaze Redirection with 3D Gaussian Splatting
Authors:Xiaobao Wei, Peng Chen, Guangyu Li, Ming Lu, Hui Chen, Feng Tian
Gaze estimation encounters generalization challenges when dealing with out-of-distribution data. To address this problem, recent methods use neural radiance fields (NeRF) to generate augmented data. However, existing methods based on NeRF are computationally expensive and lack facial details. 3D Gaussian Splatting (3DGS) has become the prevailing representation of neural fields. While 3DGS has been extensively examined in head avatars, it faces challenges with accurate gaze control and generalization across different subjects. In this work, we propose GazeGaussian, the first high-fidelity gaze redirection method that uses a two-stream 3DGS model to represent the face and eye regions separately. Leveraging the unstructured nature of 3DGS, we develop a novel representation of the eye for rigid eye rotation based on the target gaze direction. To enable synthesis generalization across various subjects, we integrate an expression-guided module to inject subject-specific information into the neural renderer. Comprehensive experiments show that GazeGaussian outperforms existing methods in rendering speed, gaze redirection accuracy, and facial synthesis across multiple datasets. The code is available at: https://ucwxb.github.io/GazeGaussian.
目光估计在处理离群分布数据时面临泛化挑战。为了解决这个问题,最近的方法使用神经辐射场(NeRF)来生成增强数据。然而,基于NeRF的现有方法计算量大且缺乏面部细节。3D高斯拼贴(3DGS)已成为神经场的流行表示方法。虽然3DGS在头像中得到了广泛的研究,但在准确的目光控制和不同主题的泛化方面仍面临挑战。在这项工作中,我们提出了GazeGaussian,这是第一个使用双流3DGS模型进行目光重定向的高保真方法,该模型能够分别表示面部和眼部区域。利用3DGS的无结构特性,我们开发了一种基于目标注视方向进行刚性眼球旋转的眼部表示新方法。为了实现跨各种主题的合成泛化,我们整合了一个表情引导模块,将主体特定信息注入到神经渲染器中。综合实验表明,GazeGaussian在渲染速度、目光重定向准确性和面部合成方面均优于现有方法,跨越多个数据集。代码可在以下网址找到:网站链接。
论文及项目相关链接
PDF Accepted by ICCV2025
Summary
本文提出一种基于神经辐射场的高保真眼神重定向方法——GazeGaussian。该方法采用双流3DGS模型分别表示面部和眼部区域,通过引入表情引导模块实现跨不同主题的合成泛化。相较于现有方法,GazeGaussian在渲染速度、眼神重定向精度和面部合成效果方面表现更佳。
Key Takeaways
- GazeGaussian使用双流3DGS模型,将面部和眼部区域分开表示,以提高眼神重定向的准确性。
- 通过利用3DGS的无结构特性,开发了一种基于目标眼神方向的新型眼睛表示方法,实现刚性眼球旋转。
- 为了实现跨不同主题的合成泛化,引入了表情引导模块,将主题特定信息注入到神经渲染器中。
- GazeGaussian具有快速渲染、准确的眼神重定向和优秀的面部合成效果。
- 该方法在多个数据集上的表现优于现有方法。
- GazeGaussian的代码已公开在相关网站上。
点此查看论文截图


Reconstructing Satellites in 3D from Amateur Telescope Images
Authors:Zhiming Chang, Boyang Liu, Yifei Xia, Youming Guo, Boxin Shi, He Sun
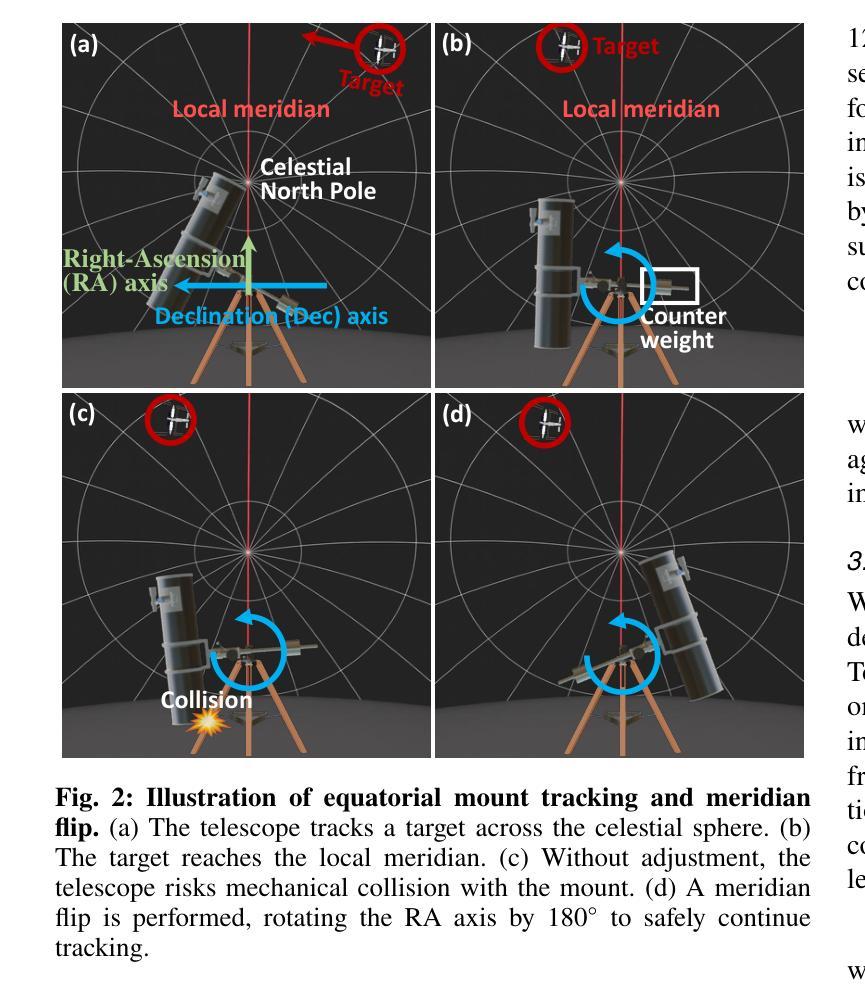
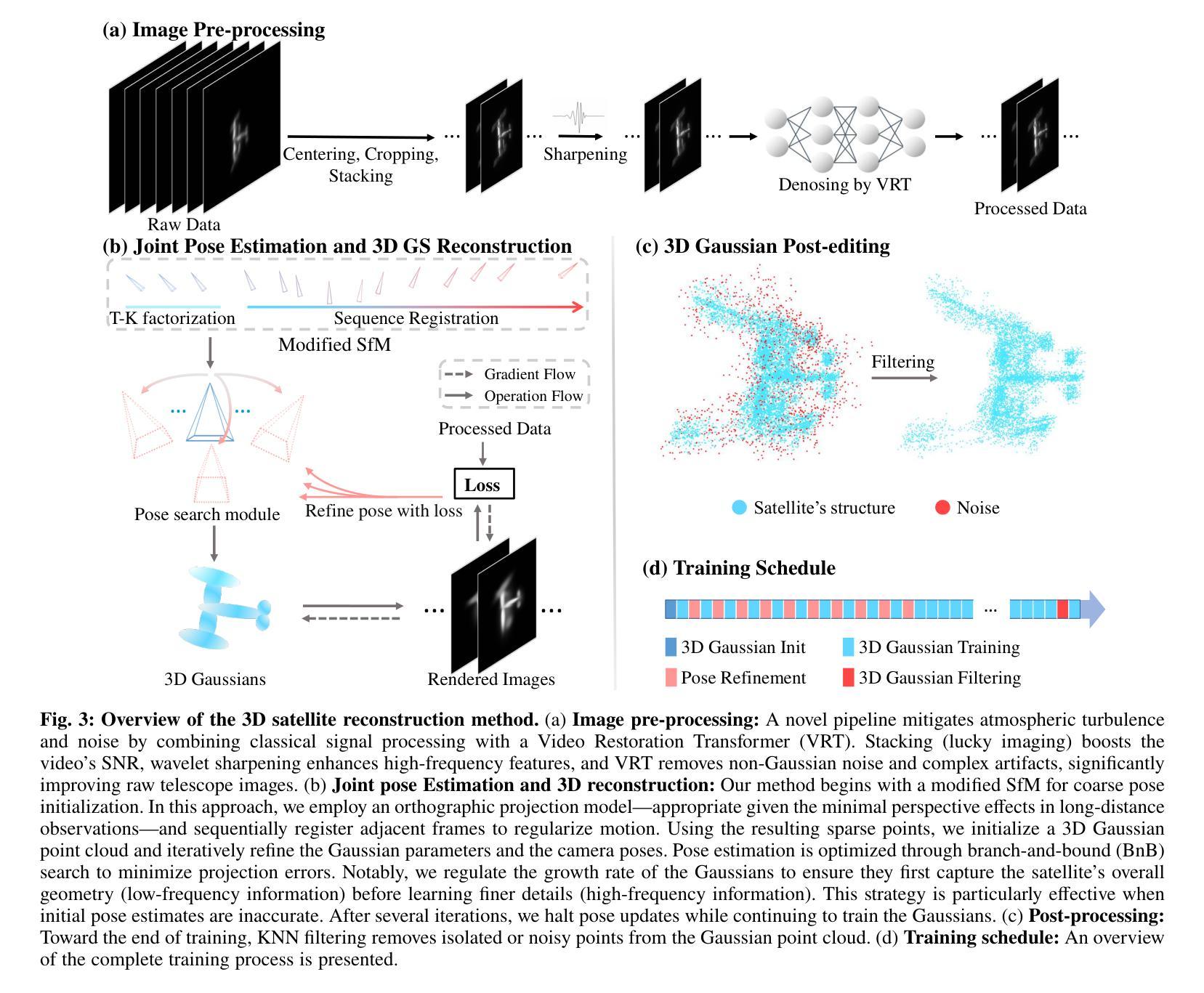
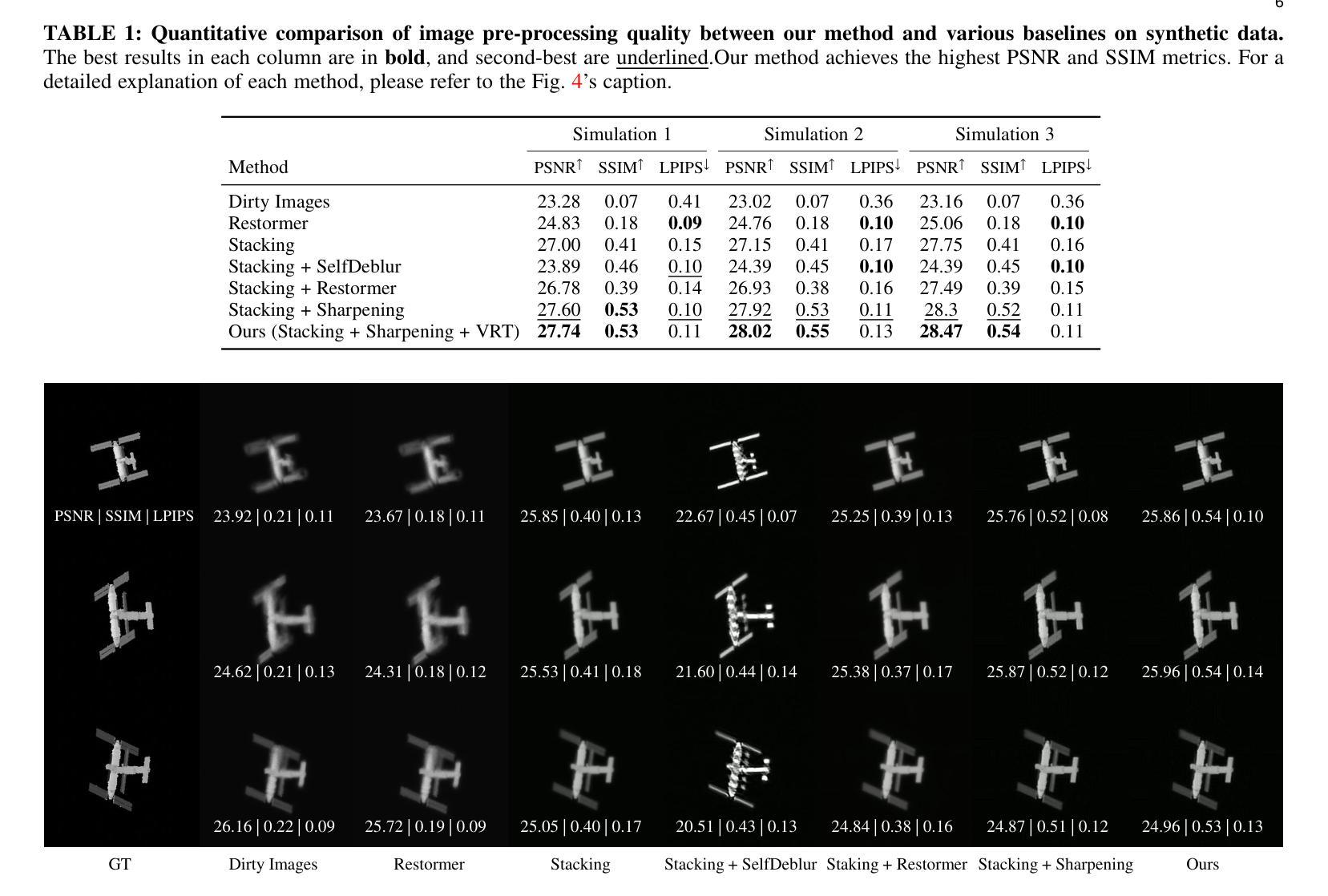
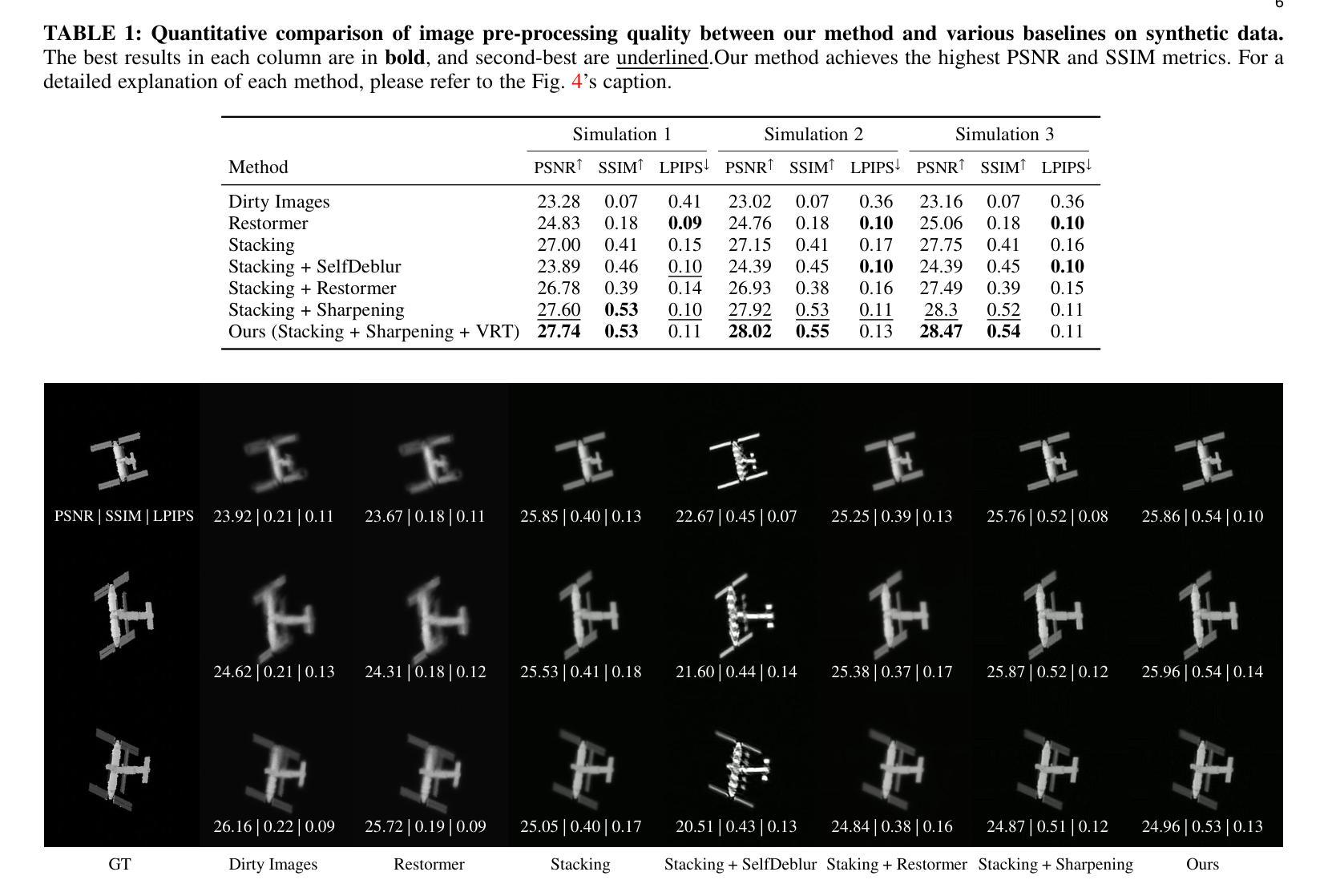
Monitoring space objects is crucial for space situational awareness, yet reconstructing 3D satellite models from ground-based telescope images is challenging due to atmospheric turbulence, long observation distances, limited viewpoints, and low signal-to-noise ratios. In this paper, we propose a novel computational imaging framework that overcomes these obstacles by integrating a hybrid image pre-processing pipeline with a joint pose estimation and 3D reconstruction module based on controlled Gaussian Splatting (GS) and Branch-and-Bound (BnB) search. We validate our approach on both synthetic satellite datasets and on-sky observations of China’s Tiangong Space Station and the International Space Station, achieving robust 3D reconstructions of low-Earth orbit satellites from ground-based data. Quantitative evaluations using SSIM, PSNR, LPIPS, and Chamfer Distance demonstrate that our method outperforms state-of-the-art NeRF-based approaches, and ablation studies confirm the critical role of each component. Our framework enables high-fidelity 3D satellite monitoring from Earth, offering a cost-effective alternative for space situational awareness. Project page: https://ai4scientificimaging.org/ReconstructingSatellites
对空间目标进行监测对于了解空间态势至关重要,然而从地面望远镜图像重建三维卫星模型是一个巨大的挑战,主要由于大气扰动、观测距离长、视角有限和信噪比低等原因。在本文中,我们提出了一种新颖的计算机成像框架,通过混合图像预处理管道与基于受控的高斯溅射(GS)和分形搜索(BnB)的联合姿态估计和三维重建模块相结合,克服了这些障碍。我们在合成卫星数据集和中国天宫空间站以及国际空间站的星空观测上验证了我们的方法,实现了从地面数据对低地球轨道卫星的稳健三维重建。使用结构相似性度量(SSIM)、峰值信噪比(PSNR)、局部感知图像相似性(LPIPS)和Chamfer距离进行的定量评估表明,我们的方法优于最新的基于NeRF的方法,消融研究证实了每个组件的关键作用。我们的框架实现了从地球进行的高保真三维卫星监测,为态势感知提供了一种经济高效的替代方案。项目页面:https://ai4scientificimaging.org/ReconstructingSatellites。
论文及项目相关链接
Summary
本文提出了一种新型的计算成像框架,通过混合图像预处理管道与基于受控高斯斑点和分支界定搜索的联合姿态估计和三维重建模块,克服了大气湍流、长观测距离、有限观测点和低信噪比等困难,实现了从地面望远镜图像重建三维卫星模型的难题。该研究不仅在合成卫星数据集上进行了验证,还对中国天宫空间站和国际空间站的在轨观测进行了实验,证明该方法能够从地面数据实现低地球轨道卫星的稳健三维重建。研究表明,该方法优于当前先进的NeRF方法,并具有成本低廉的优点。
Key Takeaways
- 该论文关注从地面望远镜图像重建三维卫星模型的问题。
- 提出的计算成像框架整合了混合图像预处理管道和联合姿态估计与三维重建模块。
- 框架克服了大气湍流、长观测距离、有限观测点和低信噪比等挑战。
- 在合成卫星数据集及实际在轨观测中进行了验证,实现了稳健的三维重建。
- 该方法优于现有的NeRF方法,并具备成本低廉的优势。
点此查看论文截图