⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-11 更新
Addressing Imbalanced Domain-Incremental Learning through Dual-Balance Collaborative Experts
Authors:Lan Li, Da-Wei Zhou, Han-Jia Ye, De-Chuan Zhan
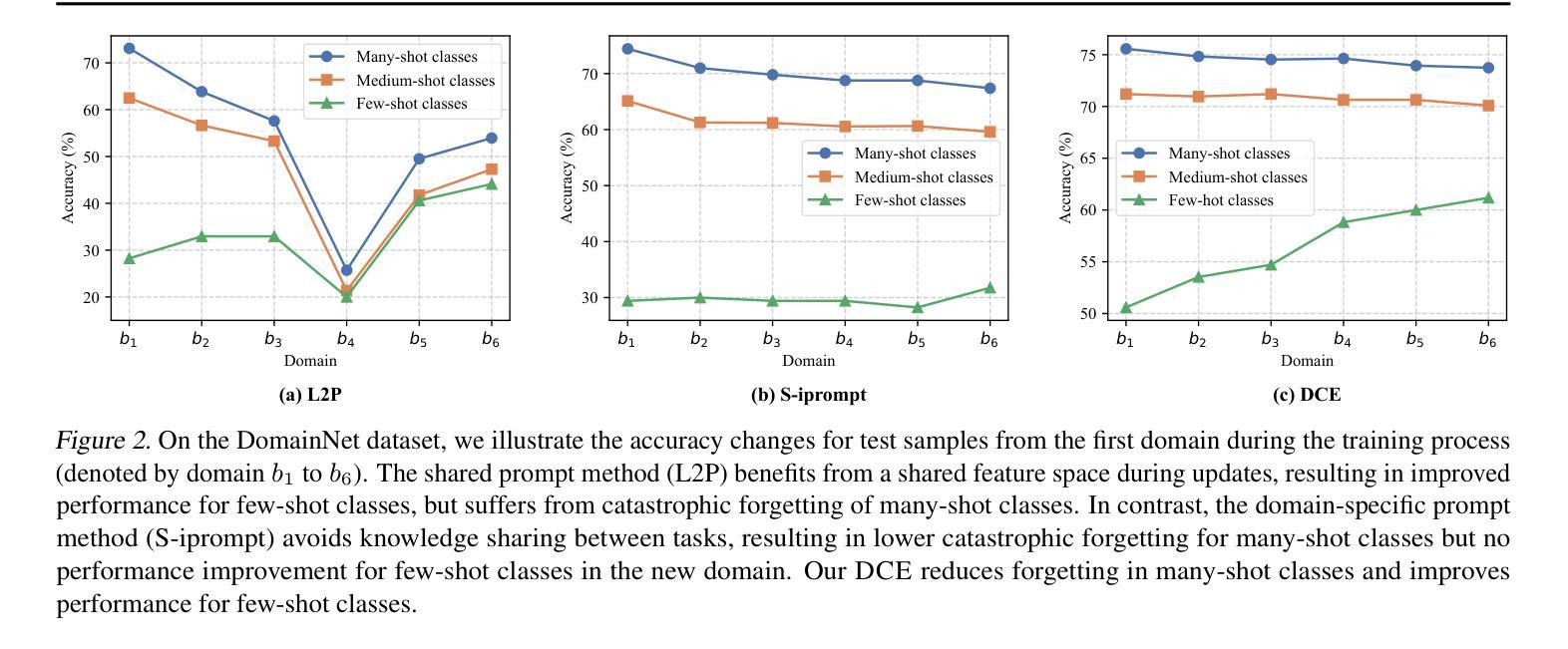
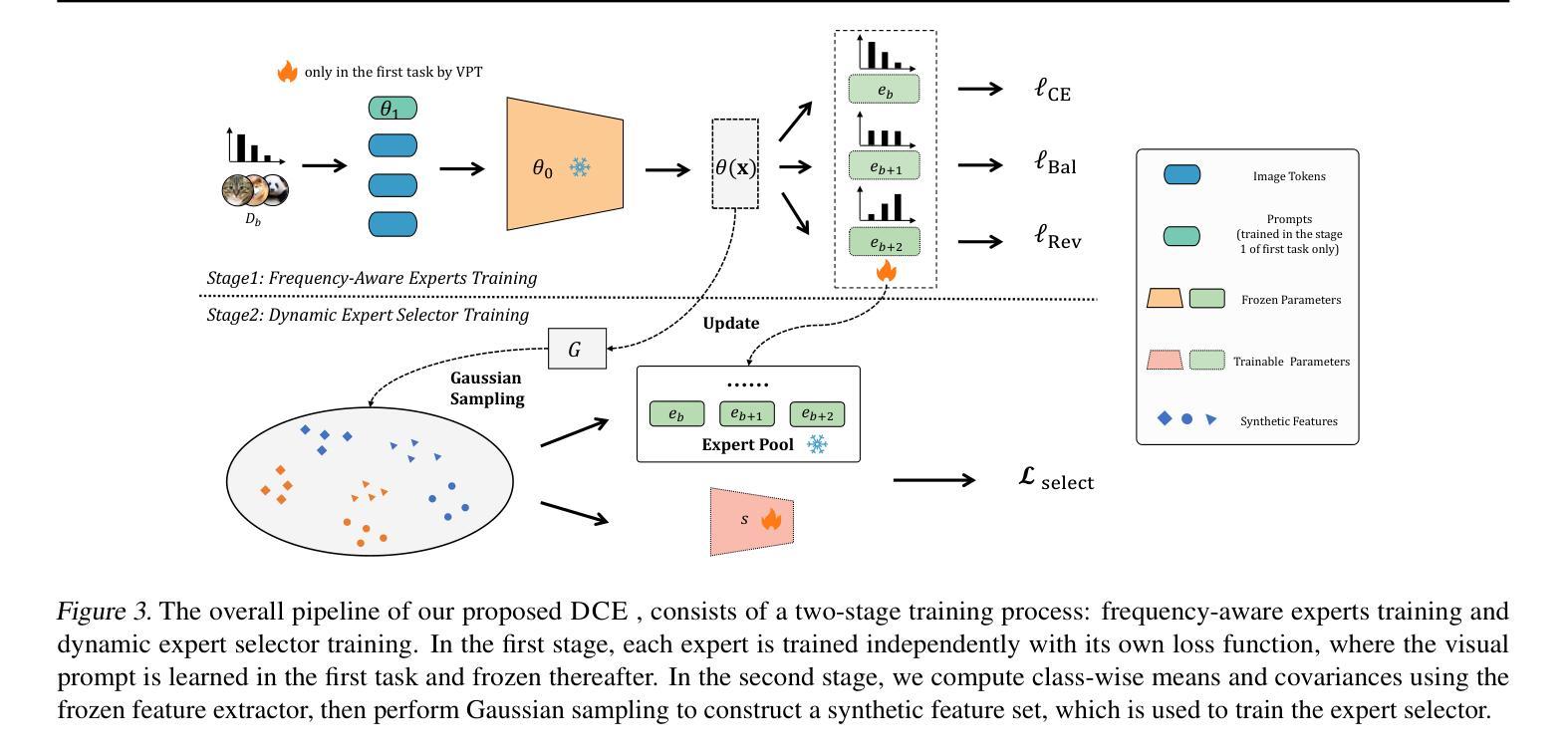
Domain-Incremental Learning (DIL) focuses on continual learning in non-stationary environments, requiring models to adjust to evolving domains while preserving historical knowledge. DIL faces two critical challenges in the context of imbalanced data: intra-domain class imbalance and cross-domain class distribution shifts. These challenges significantly hinder model performance, as intra-domain imbalance leads to underfitting of few-shot classes, while cross-domain shifts require maintaining well-learned many-shot classes and transferring knowledge to improve few-shot class performance in old domains. To overcome these challenges, we introduce the Dual-Balance Collaborative Experts (DCE) framework. DCE employs a frequency-aware expert group, where each expert is guided by specialized loss functions to learn features for specific frequency groups, effectively addressing intra-domain class imbalance. Subsequently, a dynamic expert selector is learned by synthesizing pseudo-features through balanced Gaussian sampling from historical class statistics. This mechanism navigates the trade-off between preserving many-shot knowledge of previous domains and leveraging new data to improve few-shot class performance in earlier tasks. Extensive experimental results on four benchmark datasets demonstrate DCE’s state-of-the-art performance.
领域增量学习(DIL)关注非静态环境中的持续学习,要求模型在适应不断演变的领域的同时保留历史知识。在数据不平衡的情境下,DIL面临两大挑战:域内类别不平衡和跨域类别分布转移。这些挑战极大地阻碍了模型性能,因为域内不平衡导致小样本类的欠拟合,而跨域转移则需要保持已学习的大量样本类的知识,并将知识转移以提高小样本类在旧域中的性能。为了克服这些挑战,我们引入了双平衡协作专家(DCE)框架。DCE采用频率感知专家组,每个专家由专门的损失函数引导,学习特定频率组的特征,有效解决域内类别不平衡问题。随后,通过从历史类别统计中通过平衡高斯采样合成伪特征来学习动态专家选择器。这种机制在保留之前领域的大量样本知识的同时,利用新数据提高早期任务中小样本类的性能,实现了两者的平衡。在四个基准数据集上的大量实验结果表明,DCE具有最先进的性能。
论文及项目相关链接
PDF Accepted by ICML 2025
Summary
本文介绍了领域增量学习(DIL)面临的挑战,特别是在非平衡数据的情况下。针对领域内类别不平衡和跨领域类别分布转移的问题,提出了双平衡协作专家(DCE)框架。DCE通过频率感知专家组和特殊损失函数来有效解决领域内类别不平衡问题,同时通过动态专家选择器,利用平衡高斯采样历史类别统计信息来权衡保留先前的知识并应用新数据来提高任务的性能。实验结果表明,DCE在四个基准数据集上表现优异。
Key Takeaways
- 领域增量学习(DIL)需要模型在非静态环境中持续学习,并适应不断变化的领域,同时保留历史知识。
- DIL面临两大挑战:领域内类别不平衡和跨领域类别分布转移。
- DCE框架通过频率感知专家组和特殊损失函数解决领域内类别不平衡问题。
- DCE利用平衡高斯采样历史类别统计信息来开发动态专家选择器。
- DCE框架能够在保留历史知识的同时利用新数据来提高性能。
- DCE在四个基准数据集上表现出卓越的性能。
点此查看论文截图

MADPOT: Medical Anomaly Detection with CLIP Adaptation and Partial Optimal Transport
Authors:Mahshid Shiri, Cigdem Beyan, Vittorio Murino
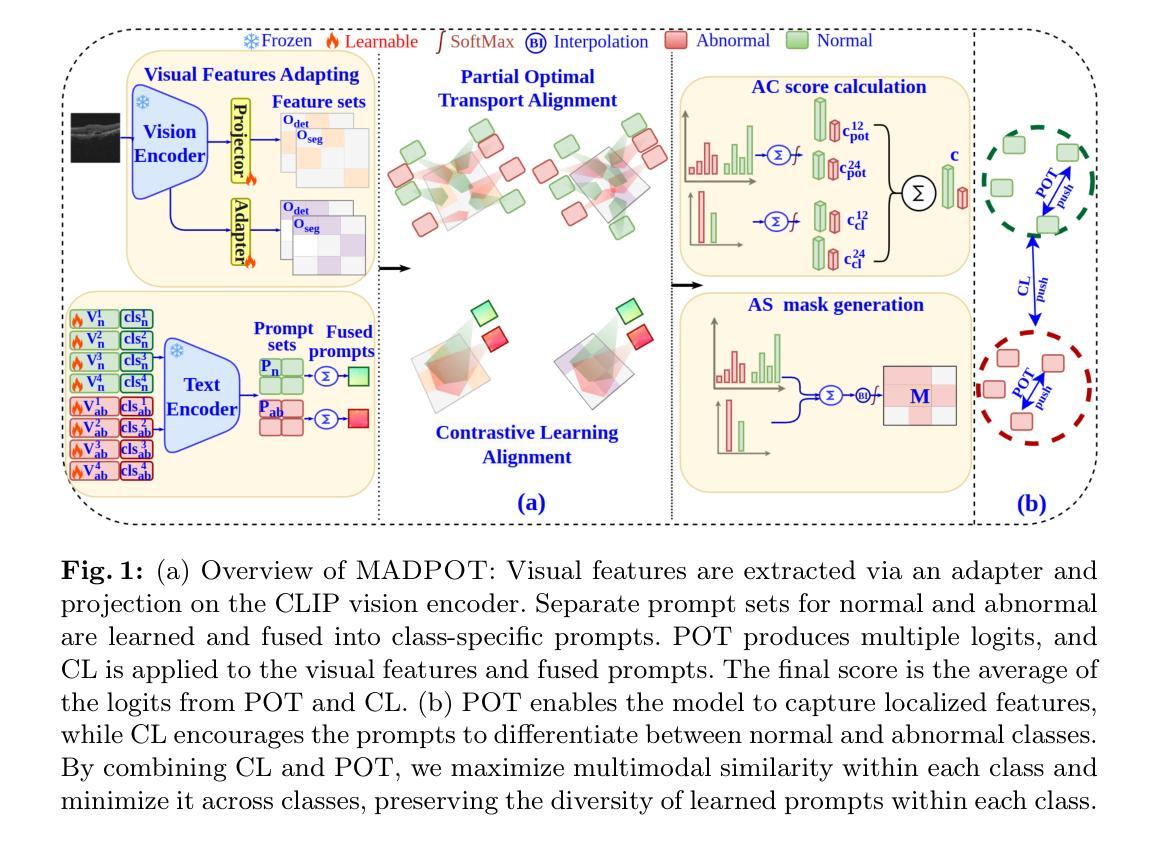
Medical anomaly detection (AD) is challenging due to diverse imaging modalities, anatomical variations, and limited labeled data. We propose a novel approach combining visual adapters and prompt learning with Partial Optimal Transport (POT) and contrastive learning (CL) to improve CLIP’s adaptability to medical images, particularly for AD. Unlike standard prompt learning, which often yields a single representation, our method employs multiple prompts aligned with local features via POT to capture subtle abnormalities. CL further enforces intra-class cohesion and inter-class separation. Our method achieves state-of-the-art results in few-shot, zero-shot, and cross-dataset scenarios without synthetic data or memory banks. The code is available at https://github.com/mahshid1998/MADPOT.
医疗异常检测(AD)由于多种成像模式、解剖结构差异和标记数据有限而具有挑战性。我们提出了一种新颖的方法,结合视觉适配器和提示学习,使用部分最优传输(POT)和对比学习(CL)来提高CLIP对医疗图像的适应性,尤其是用于AD。不同于通常产生单一表示的的标准提示学习,我们的方法通过POT使用与局部特征对齐的多个提示来捕捉细微的异常。CL进一步执行类内凝聚力和类间分离。我们的方法在少量、零量和跨数据集场景中实现了最佳结果,无需合成数据或内存库。代码可在https://github.com/mahshid1998/MADPOT找到。
论文及项目相关链接
PDF Accepted to ICIAP 2025 (this version is not peer-reviewed; it is the submitted version). ICIAP 2025 proceedings DOI will appear here
Summary:医学异常检测(AD)面临多种成像模式、解剖结构差异和标注数据有限的挑战。本研究提出一种新颖方法,结合视觉适配器和提示学习技术,辅以局部最优传输(POT)和对比学习(CL),以提高CLIP对医学图像尤其是AD场景下的适应性。与产生单一表征的传统提示学习方法不同,该方法使用多个与局部特征对齐的提示通过POT捕获细微异常。CL增强了同类内部联系和不同类别之间的区分。该法在少样本、零样本和跨数据集场景中表现均处于业界前沿水平,无需合成数据或内存库支持。相关代码可通过访问https://github.com/mahshid1998/MADPOT获取。
Key Takeaways:
- 医学异常检测面临多种成像模式、解剖结构差异和标注数据有限的挑战。
- 提出一种新颖方法结合视觉适配器、提示学习技术、局部最优传输和对比学习技术用于改进CLIP在医学图像中的适应性。
- 与传统提示学习方法不同,该方法使用多个与局部特征对齐的提示捕获细微异常。
- 对比学习增强了同类内部联系和不同类别之间的区分能力。
- 该方法在少样本、零样本和跨数据集场景下表现优异。
- 该方法无需合成数据或内存库支持。
点此查看论文截图

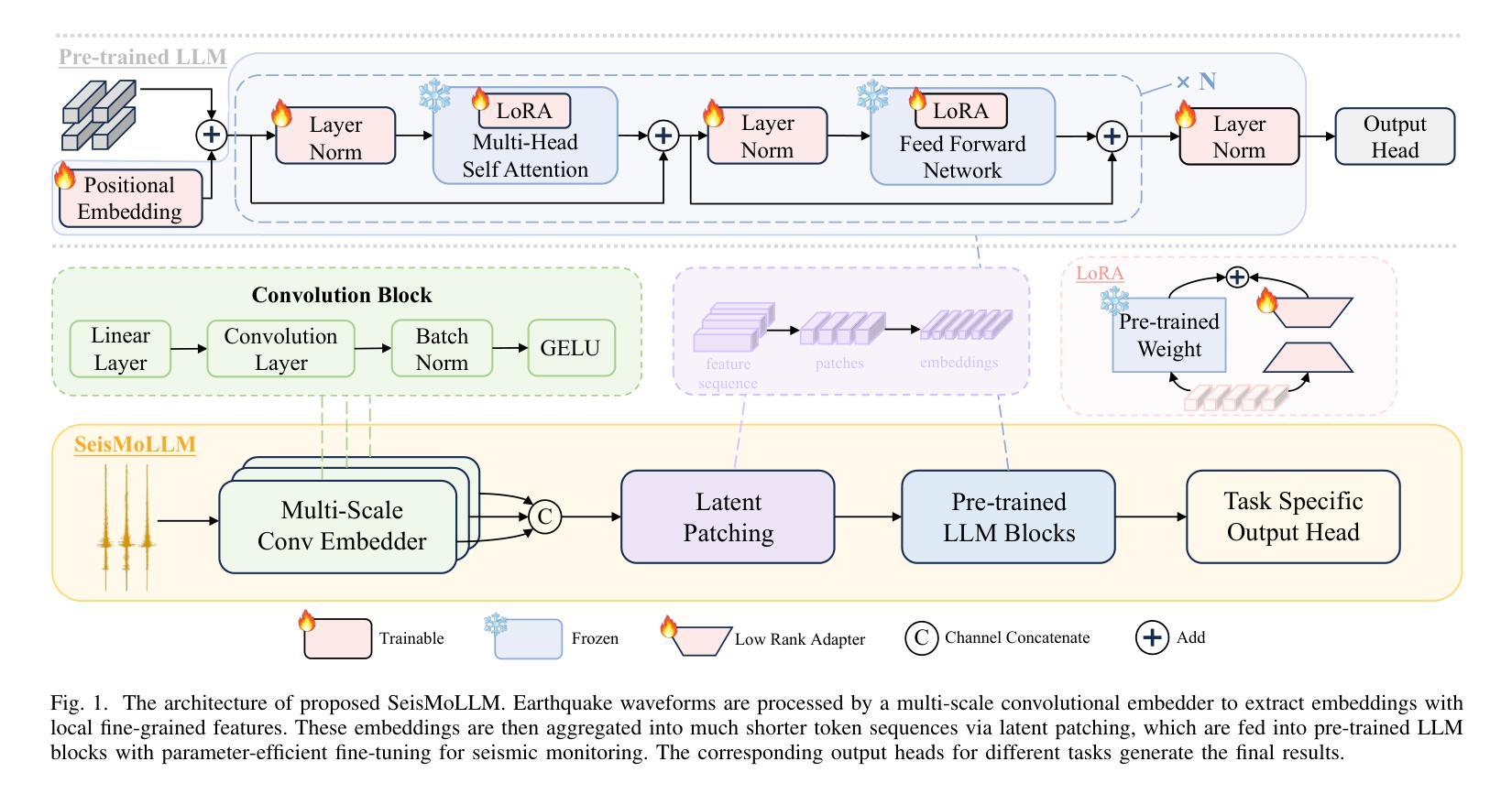
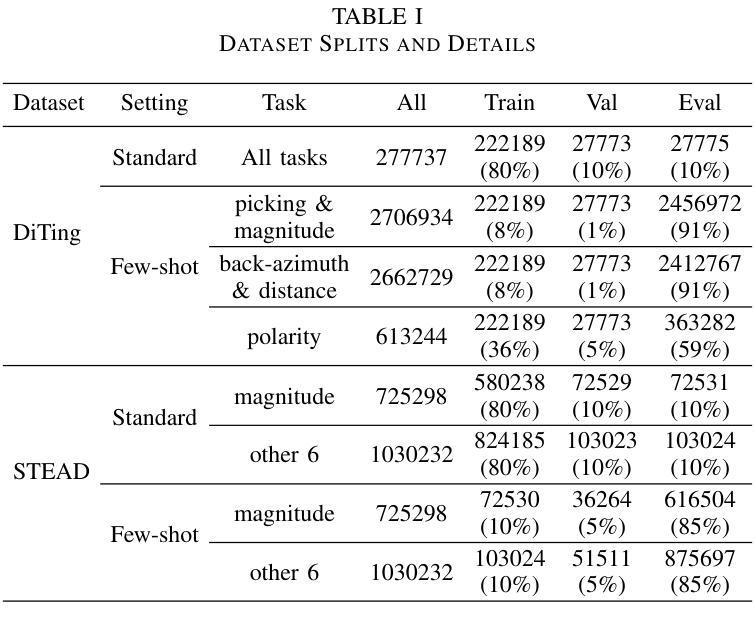
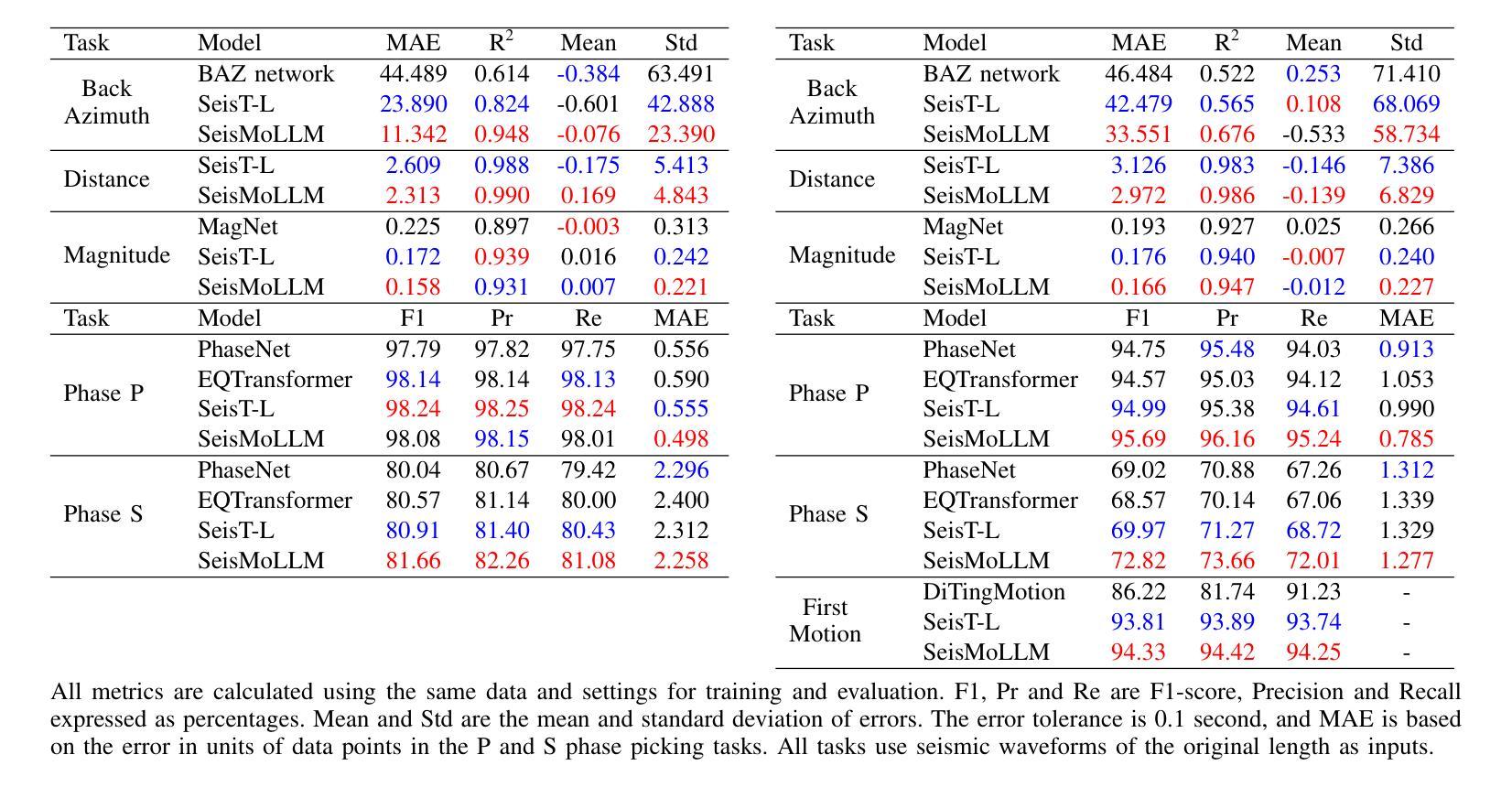
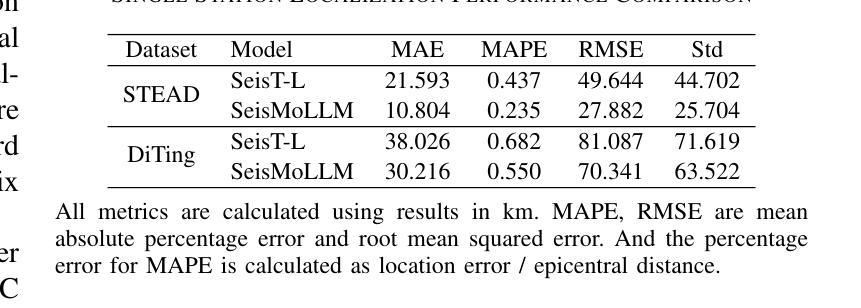
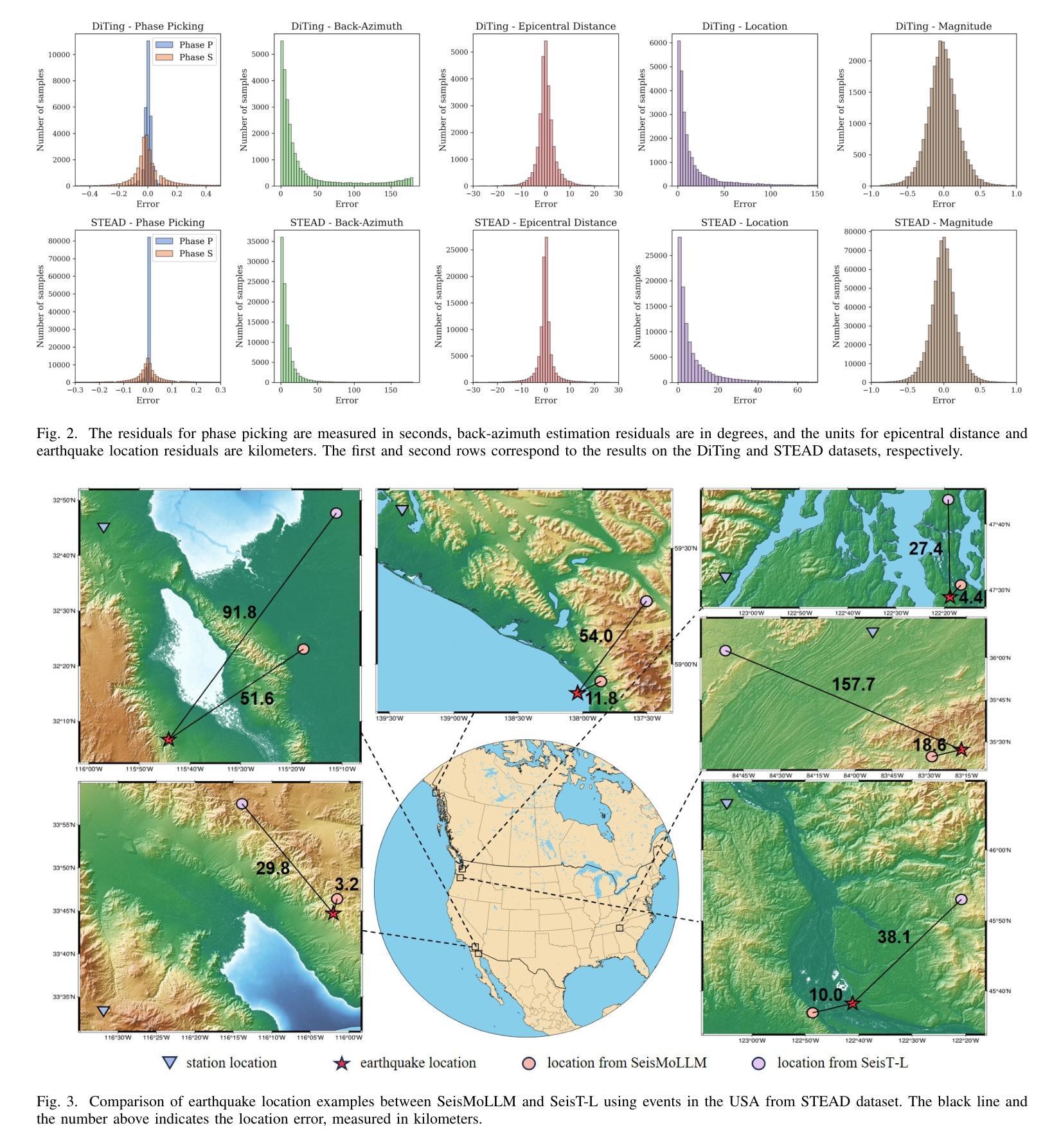
SeisMoLLM: Advancing Seismic Monitoring via Cross-modal Transfer with Pre-trained Large Language Model
Authors:Xinghao Wang, Feng Liu, Rui Su, Zhihui Wang, Lihua Fang, Lianqing Zhou, Lei Bai, Wanli Ouyang
Recent advances in deep learning have revolutionized seismic monitoring, yet developing a foundation model that performs well across multiple complex tasks remains challenging, particularly when dealing with degraded signals or data scarcity. This work presents SeisMoLLM, the first foundation model that utilizes cross-modal transfer for seismic monitoring, to unleash the power of large-scale pre-training from a large language model without requiring direct pre-training on seismic datasets. Through elaborate waveform tokenization and fine-tuning of pre-trained GPT-2 model, SeisMoLLM achieves state-of-the-art performance on the DiTing and STEAD datasets across five critical tasks: back-azimuth estimation, epicentral distance estimation, magnitude estimation, phase picking, and first-motion polarity classification. It attains 36 best results out of 43 task metrics and 12 top scores out of 16 few-shot generalization metrics, with many relative improvements ranging from 10% to 50%. In addition to its superior performance, SeisMoLLM maintains efficiency comparable to or even better than lightweight models in both training and inference. These findings establish SeisMoLLM as a promising foundation model for practical seismic monitoring and highlight cross-modal transfer as an exciting new direction for earthquake studies, showcasing the potential of advanced deep learning techniques to propel seismology research forward.
近期深度学习的发展为地震监测带来了革命性的变革,然而,开发一个能在多个复杂任务中表现良好的基础模型仍然具有挑战性,尤其是在处理退化信号或数据稀缺的情况下。本研究提出了SeisMoLLM,这是第一个利用跨模态迁移进行地震监测的基础模型,它充分发挥了大规模预训练语言模型的力量,而无需在地震数据集上进行直接预训练。通过精细的波形符号化和预训练的GPT-2模型的微调,SeisMoLLM在DiTing和STEAD数据集上完成了五个关键任务:后方角估计、震中距离估计、震级估计、相位拾取和初动极性分类,实现了最先进的性能。它在43个任务指标中获得了36个最佳结果,在16个少样本泛化指标中获得了12个最高分数,许多相对改进范围在10%到50%之间。除了卓越的性能外,SeisMoLLM在训练和推理方面的效率与轻型模型相当甚至更好。这些发现证明了SeisMoLLM作为实用地震监测的有前途的基础模型,并突出了跨模态迁移作为地震研究的一个令人兴奋的新方向,展示了先进深度学习技术推动地震学研究的潜力。
论文及项目相关链接
PDF Code is available at https://github.com/StarMoonWang/SeisMoLLM. v2 fixed errors in the location figures
Summary
SeisMoLLM是一个利用跨模态迁移进行地震监测的基础模型。它借助大规模预训练的语言模型,无需直接在地震数据集上进行预训练,即可实现卓越性能。通过精细的波形符号化和预训练的GPT-2模型的微调,SeisMoLLM在DiTing和STEAD数据集上的五项关键任务中达到最新技术水平,并在训练和推理方面保持了与轻量级模型相当的效率。这些发现证明了SeisMoLLM在实用地震监测中的潜力,并强调了跨模态迁移在地震学研究中的新方向。
Key Takeaways
- SeisMoLLM是首个利用跨模态迁移进行地震监测的基础模型。
- SeisMoLLM借助大规模预训练的语言模型实现性能,无需直接在地震数据集上预训练。
- 在DiTing和STEAD数据集上的五项关键任务中,SeisMoLLM达到了最新技术水平。
- SeisMoLLM在多项任务指标上取得了最佳结果,并在少量样本推广方面表现出色。
- SeisMoLLM的性能提升范围从10%到50%。
- SeisMoLLM在训练和推理方面的效率与轻量级模型相当或更好。
点此查看论文截图

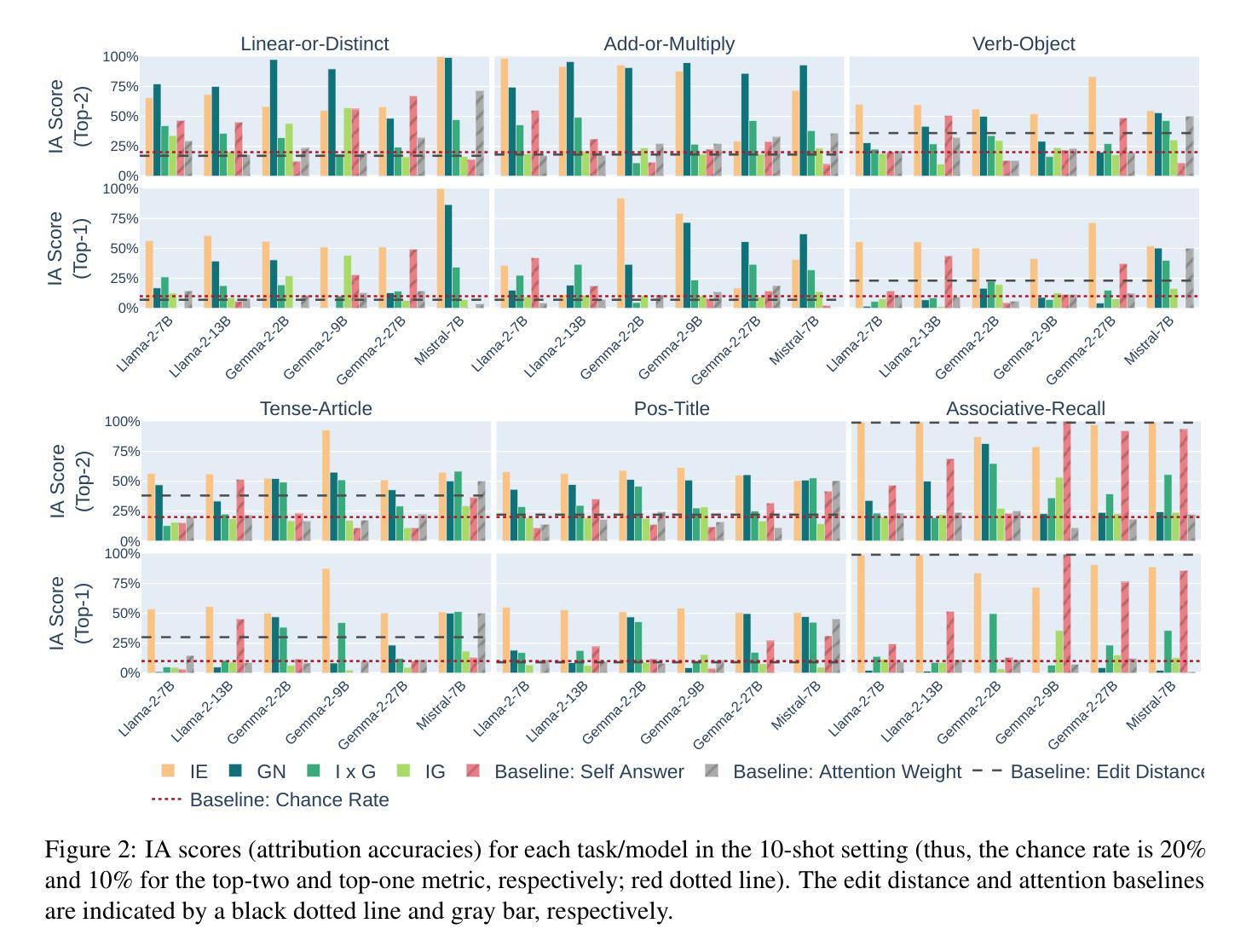
Can Input Attributions Explain Inductive Reasoning in In-Context Learning?
Authors:Mengyu Ye, Tatsuki Kuribayashi, Goro Kobayashi, Jun Suzuki
Interpreting the internal process of neural models has long been a challenge. This challenge remains relevant in the era of large language models (LLMs) and in-context learning (ICL); for example, ICL poses a new issue of interpreting which example in the few-shot examples contributed to identifying/solving the task. To this end, in this paper, we design synthetic diagnostic tasks of inductive reasoning, inspired by the generalization tests typically adopted in psycholinguistics. Here, most in-context examples are ambiguous w.r.t. their underlying rule, and one critical example disambiguates it. The question is whether conventional input attribution (IA) methods can track such a reasoning process, i.e., identify the influential example, in ICL. Our experiments provide several practical findings; for example, a certain simple IA method works the best, and the larger the model, the generally harder it is to interpret the ICL with gradient-based IA methods.
解释神经网络模型的内部过程一直是一个挑战。在大型语言模型(LLM)和上下文学习(ICL)的时代,这一挑战依然具有现实意义。例如,ICL提出了新的解释问题,即在少数案例中,哪个例子对识别或解决任务产生了贡献。为此,本文设计了基于归纳推理的合成诊断任务,该设计灵感来源于心理语言学中通常采用的推广测试。在这里,大多数上下文例子在基础规则方面是模糊的,而一个关键例子能够澄清模糊性。问题是常规输入归因(IA)方法是否能够追踪这样的推理过程,即在ICL中识别有影响力的例子。我们的实验提供了几个实际发现:例如,某种简单的IA方法效果最好,并且模型越大,通常使用基于梯度的IA方法来解释ICL就越困难。
论文及项目相关链接
PDF Findings of ACL 2025
Summary
本文探讨了大型语言模型(LLMs)和上下文学习(ICL)中的解释难题,特别是如何解释在少量示例中哪些例子对识别和解决任务有所贡献的问题。为此,设计了一种基于心理语言学中普遍采用的概括测试的合成诊断任务,以测试推理过程。实验发现,简单的输入归因方法效果最好,模型越大,使用基于梯度的输入归因方法来解释ICL的难度通常越大。
Key Takeaways
- 神经模型的内部过程解释一直是挑战。在大型语言模型和上下文学习时代,这一挑战仍然重要。
- 上下文学习带来了新的挑战,即解释哪些示例在少量示例中对任务识别和解决有贡献。
- 为应对这一挑战,设计了合成诊断任务以测试推理过程,这些任务灵感来源于心理语言学中的概括测试。
- 在实验中发现大多数上下文示例对其隐含规则存在歧义,关键示例有助于消除歧义。
- 实验探究了常规输入归因方法是否能追踪这一推理过程,实验结果表明简单的输入归因方法效果最佳。
- 模型大小对使用基于梯度的输入归因方法解释ICL的难度有影响,模型越大通常难度越大。
点此查看论文截图


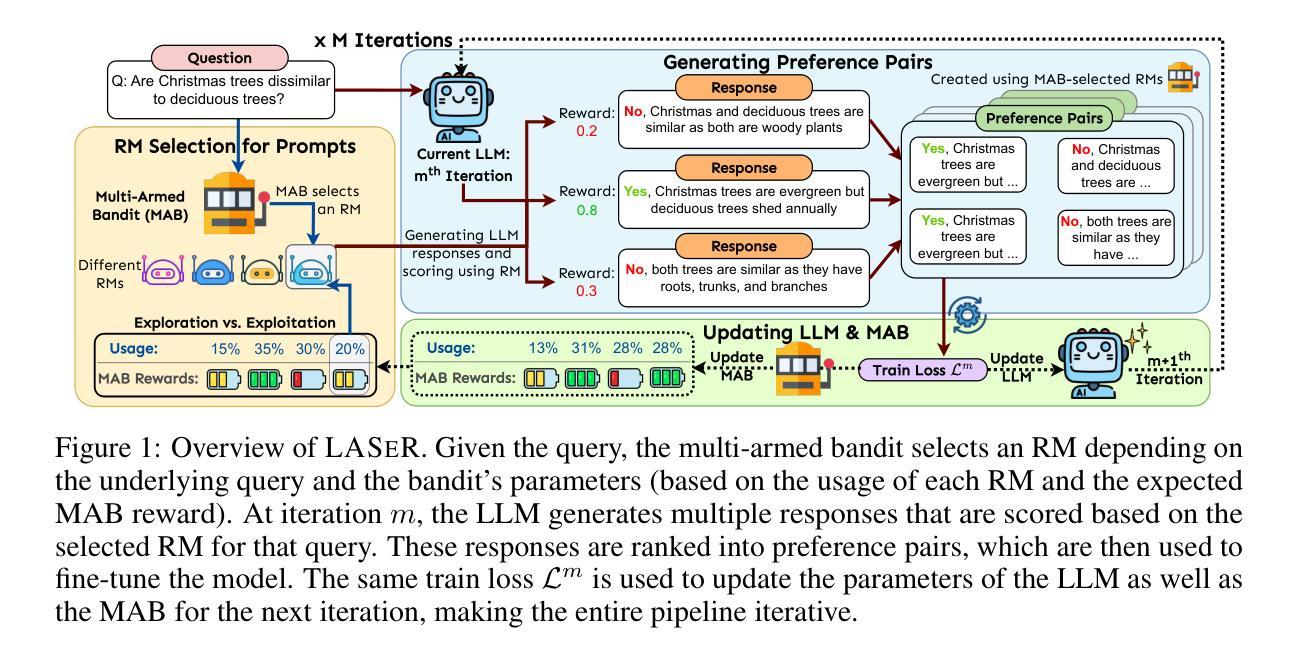
LASeR: Learning to Adaptively Select Reward Models with Multi-Armed Bandits
Authors:Duy Nguyen, Archiki Prasad, Elias Stengel-Eskin, Mohit Bansal
Reward Models (RMs) are crucial to aligning large language models (LLMs), but the degree to which an RM specialized to one task (e.g. writing) generalizes to new tasks (e.g. math) is often not known a priori, often making using only one fixed RM to train LLMs suboptimal. However, optimizing LLMs with multiple RMs simultaneously can incur a prohibitively high computational cost and lead to conflicting signals from different RMs that may degrade performance. To address these challenges, we introduce LASeR (Learning to Adaptively Select Rewards), which frames reward model selection as a multi-armed bandit problem, efficiently and iteratively training LLMs using multiple RMs by selecting the most well-suited RM for each instance. On commonsense and math reasoning tasks, we show that LASeR boosts iterative LLM training, improving the absolute average accuracy of Llama-3-8B over three datasets by 2.67% over an ensemble of RM scores while also showing superior efficiency (e.g., a 2x speedup). Moreover, on WildChat (open-ended instruction-following tasks), LASeR leads to a 72.69% AlpacaEval win rate over the RM score ensemble baseline. Extending to long-context generation, LASeR improves by 2.96 F1 points (avg.) on single-document QA tasks and 2.97 F1 points on few-shot learning over the RM score ensemble baseline with best-of-n sampling.
奖励模型(RM)对于对齐大型语言模型(LLM)至关重要,但对于针对某一任务(例如写作)的RM推广到新任务(例如数学)的程度往往事先并不清楚,因此通常使用单一固定RM来训练LLM并不理想。然而,同时使用多个RM优化LLM会产生过高的计算成本,并可能导致不同RM发出的冲突信号,从而可能降低性能。为了解决这些挑战,我们引入了LASeR(学习自适应选择奖励),它将奖励模型的选择构建为多臂赌博问题,通过为每个实例选择最合适的RM,以高效且迭代的方式使用多个RM训练LLM。在常识和数学推理任务中,我们展示了LASeR可以推动LLM的迭代训练,使用多个RM的评分集合,在三个数据集上,Llama-3-8B的绝对平均准确性提高了2.67%。同时,它还表现出卓越的效率(例如,速度提升2倍)。此外,在WildChat(开放式指令跟随任务)中,LASeR在RM评分集合基线的基础上,实现了72.69%的AlpacaEval胜率。扩展到长文本生成中,LASeR在单文档问答任务上的F1分数平均提高了2.96分,在少样本学习上的F1分数提高了2.97分,均优于RM评分集合基线的最好n采样结果。
论文及项目相关链接
PDF 28 pages; First two authors contributed equally. Code: https://github.com/duykhuongnguyen/LASeR-MAB
摘要
奖励模型(RM)在大型语言模型(LLM)的对齐中起到关键作用,但针对某一任务(如写作)的RM对全新任务(如数学)的通用性往往事先未知,因此仅使用一个固定RM来训练LLM往往不是最优选择。然而,同时使用多个RM优化LLM会带来计算成本高昂的问题,并可能导致不同RM发出的冲突信号,从而可能降低性能。为解决这些挑战,我们提出了LASeR(自适应选择奖励学习),它将奖励模型的选择作为多臂老虎机问题,有效且迭代地通过选择最适合每个实例的RM来训练LLM。在常识和数学推理任务上,我们证明了LASeR在迭代LLM训练中的提升作用,使用多个RM得分集合的LASeR在三个数据集上的平均准确度提高了2.67%,并且表现出更高的效率(例如,速度提升两倍)。此外,在开放指令遵循任务的WildChat上,LASeR在RM得分集合基线的基础上实现了72.69%的AlpacaEval胜率。在长文本生成方面,LASeR在单文档问答任务和少样本学习上的平均F1分数分别提高了2.96和2.97点。总的来说,LASeR为使用多个RM进行LLM训练提供了一个高效且性能优越的框架。
关键见解
- 奖励模型(RM)在大型语言模型(LLM)对齐中起到关键作用,但单一RM在跨任务通用性上存在局限。
- 同时使用多个RM进行优化会导致高计算成本和性能降低的风险。
- LASeR通过将奖励模型选择视为多臂老虎机问题来解决这一挑战。
- LASeR能够选择最适合每个实例的RM进行训练,从而提高LLM的性能。
- 在常识和数学推理任务上,LASeR显著提高了LLM的准确性和效率。
- 在开放指令遵循任务WildChat上,LASeR相对于RM得分集合基线取得了显著优势。
点此查看论文截图