⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-11 更新
Towards Multimodal Understanding via Stable Diffusion as a Task-Aware Feature Extractor
Authors:Vatsal Agarwal, Matthew Gwilliam, Gefen Kohavi, Eshan Verma, Daniel Ulbricht, Abhinav Shrivastava
Recent advances in multimodal large language models (MLLMs) have enabled image-based question-answering capabilities. However, a key limitation is the use of CLIP as the visual encoder; while it can capture coarse global information, it often can miss fine-grained details that are relevant to the input query. To address these shortcomings, this work studies whether pre-trained text-to-image diffusion models can serve as instruction-aware visual encoders. Through an analysis of their internal representations, we find diffusion features are both rich in semantics and can encode strong image-text alignment. Moreover, we find that we can leverage text conditioning to focus the model on regions relevant to the input question. We then investigate how to align these features with large language models and uncover a leakage phenomenon, where the LLM can inadvertently recover information from the original diffusion prompt. We analyze the causes of this leakage and propose a mitigation strategy. Based on these insights, we explore a simple fusion strategy that utilizes both CLIP and conditional diffusion features. We evaluate our approach on both general VQA and specialized MLLM benchmarks, demonstrating the promise of diffusion models for visual understanding, particularly in vision-centric tasks that require spatial and compositional reasoning. Our project page can be found https://vatsalag99.github.io/mustafar/.
近期多模态大型语言模型(MLLMs)的进步已经实现了基于图像的问答功能。然而,一个关键限制在于使用CLIP作为视觉编码器;虽然它可以捕捉粗糙的全局信息,但它往往会错过与输入查询相关的细微细节。为了解决这些缺点,这项工作研究了预训练的文本到图像扩散模型是否能作为指令感知的视觉编码器。通过对它们内部表示的分析,我们发现扩散特征既丰富语义,又能编码强大的图像文本对齐。此外,我们发现我们可以利用文本条件来使模型关注与输入问题相关的区域。然后,我们研究了如何将这些特征与大语言模型对齐,并发现了一个泄漏现象,即大型语言模型可能会无意中从原始的扩散提示中恢复信息。我们分析了这种泄漏的原因并提出了缓解策略。基于这些见解,我们探索了一种简单的融合策略,利用CLIP和条件扩散特征。我们在一般的VQA和专门的MLLM基准测试上评估了我们的方法,证明了扩散模型在视觉理解方面的潜力,特别是在需要空间和组合推理的以视觉为中心的任务中。我们的项目页面可访问于:https://vatsalag99.github.io/mustafar/。
论文及项目相关链接
PDF Website: see https://vatsalag99.github.io/mustafar/
Summary
本文研究了预训练的文本到图像扩散模型作为指令感知视觉编码器的潜力,用于改进基于图像的问答系统。通过分析扩散模型的内部表示,发现其语义丰富且图像与文本对齐能力强。研究还探讨了如何将这些特征与大型语言模型对齐,并揭示了信息泄漏现象及原因。为此提出了缓解策略,并通过融合CLIP和条件扩散特征简单策略进行评价,证明了扩散模型在视觉理解方面的潜力,特别是在需要空间和组合推理的以视觉为中心的任务中表现优异。
Key Takeaways
- 多模态大型语言模型(MLLMs)最近的进展已使基于图像的问答功能成为可能。
- 使用CLIP作为视觉编码器存在局限性,其可能错过与输入查询相关的细微细节。
- 预训练的文本到图像扩散模型语义丰富,图像与文本对齐能力强。
- 文本条件可以引导模型关注与输入问题相关的区域。
- 与大型语言模型对齐时会出现信息泄漏现象,研究分析了其原因并提出了缓解策略。
- 通过融合CLIP和条件扩散特征的评价,证明了扩散模型在视觉理解方面的潜力。
点此查看论文截图

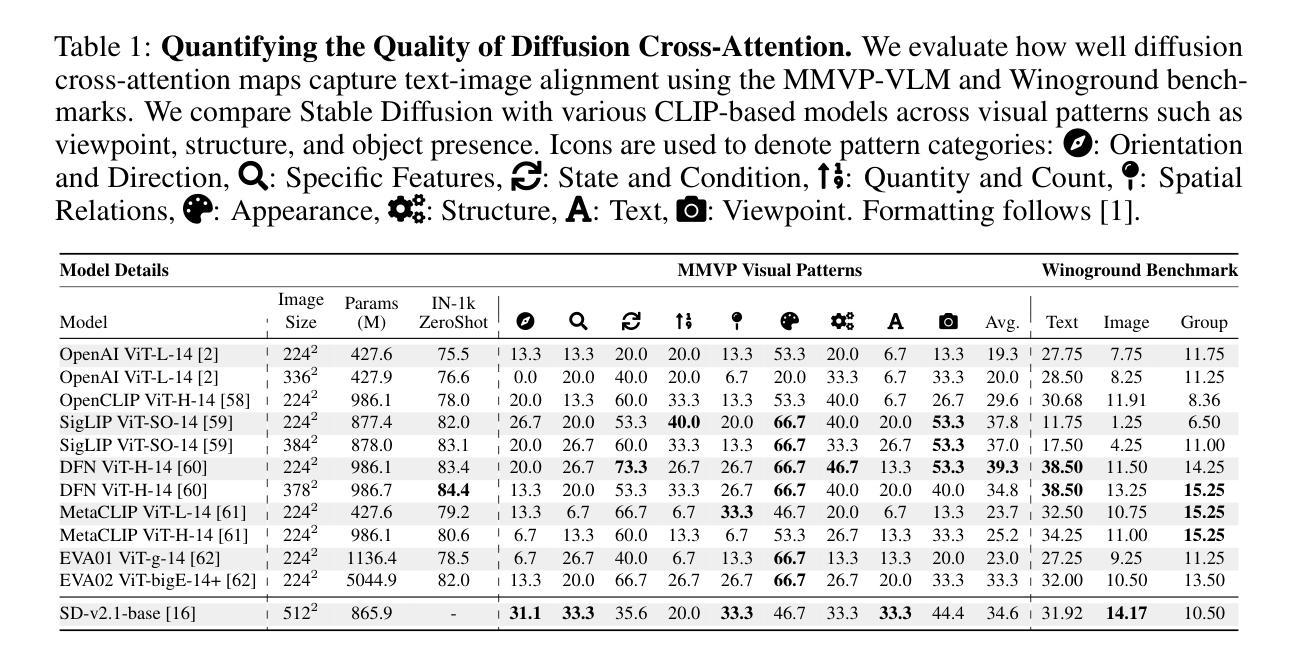
Vision-Language-Vision Auto-Encoder: Scalable Knowledge Distillation from Diffusion Models
Authors:Tiezheng Zhang, Yitong Li, Yu-cheng Chou, Jieneng Chen, Alan Yuille, Chen Wei, Junfei Xiao
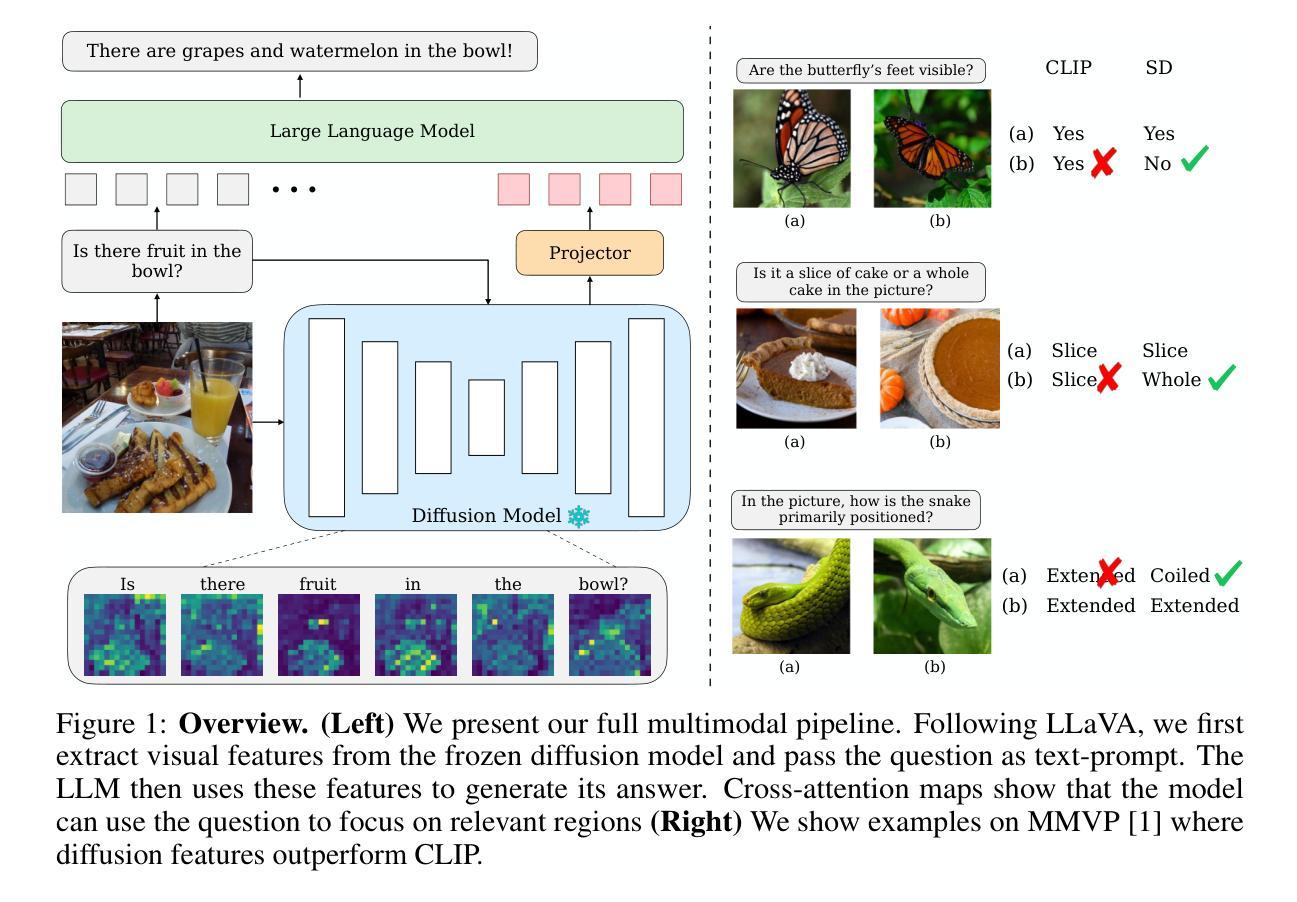
Building state-of-the-art Vision-Language Models (VLMs) with strong captioning capabilities typically necessitates training on billions of high-quality image-text pairs, requiring millions of GPU hours. This paper introduces the Vision-Language-Vision (VLV) auto-encoder framework, which strategically leverages key pretrained components: a vision encoder, the decoder of a Text-to-Image (T2I) diffusion model, and subsequently, a Large Language Model (LLM). Specifically, we establish an information bottleneck by regularizing the language representation space, achieved through freezing the pretrained T2I diffusion decoder. Our VLV pipeline effectively distills knowledge from the text-conditioned diffusion model using continuous embeddings, demonstrating comprehensive semantic understanding via high-quality reconstructions. Furthermore, by fine-tuning a pretrained LLM to decode the intermediate language representations into detailed descriptions, we construct a state-of-the-art (SoTA) captioner comparable to leading models like GPT-4o and Gemini 2.0 Flash. Our method demonstrates exceptional cost-efficiency and significantly reduces data requirements; by primarily utilizing single-modal images for training and maximizing the utility of existing pretrained models (image encoder, T2I diffusion model, and LLM), it circumvents the need for massive paired image-text datasets, keeping the total training expenditure under $1,000 USD.
构建具有强大描述功能的先进视觉语言模型(Vision-Language Models,简称VLM)通常需要训练数十亿高质量图像文本对,并需要数百万GPU小时。本文介绍了视觉语言视觉(Vision-Language-Vision,简称VLV)自动编码器框架,该框架策略性地利用了关键预训练组件:视觉编码器、文本到图像(Text-to-Image,简称T2I)扩散模型的解码器,然后是大型语言模型(Large Language Model,简称LLM)。具体来说,我们通过正则化语言表示空间来建立信息瓶颈,这是通过冻结预训练的T2I扩散解码器来实现的。我们的VLV管道有效地从文本条件扩散模型中蒸馏知识,使用连续嵌入来展示高质量重建的综合语义理解。此外,通过微调预训练的LLM以将中间语言表示解码为详细描述,我们构建了一个与GPT-4o和Gemini 2.0 Flash等领先模型相媲美的先进描述生成器。我们的方法证明了出色的成本效益并显著减少了数据需求;主要通过利用单模态图像进行训练并最大限度地利用现有预训练模型(图像编码器、T2I扩散模型和LLM),避免了需要大量配对图像文本数据集的需求,将总训练费用控制在1000美元以内。
论文及项目相关链接
总结
本论文提出了一种名为Vision-Language-Vision(VLV)的自动编码器框架,用于构建具有强大描述能力的视觉语言模型。该框架通过利用预训练的视觉编码器、文本到图像扩散模型的解码器以及大型语言模型,实现了高效的知识蒸馏。通过正则化语言表示空间建立信息瓶颈,利用文本条件扩散模型的连续嵌入进行高质量重建,并通过微调预训练的大型语言模型来解码中间语言表示以生成详细描述。该方法成本效益高,显著减少了数据需求,主要利用单模态图像进行训练,最大限度地利用现有预训练模型,无需大规模配对图像文本数据集,总训练费用控制在1000美元以内。
关键见解
- 论文提出了Vision-Language-Vision(VLV)自动编码器框架,结合了视觉语言模型的关键预训练组件。
- 通过建立信息瓶颈和正则化语言表示空间,实现了高效知识蒸馏。
- 利用文本条件扩散模型的连续嵌入进行高质量重建。
- 通过微调预训练的大型语言模型(LLM),提高了描述生成的质量。
- 该方法成本效益高,显著减少了数据需求,主要利用单模态图像进行训练。
- 最大化地利用了现有预训练模型(图像编码器、文本到图像扩散模型和LLM)。
- 该方法无需大规模配对图像文本数据集,总训练费用控制在1000美元以内。
点此查看论文截图

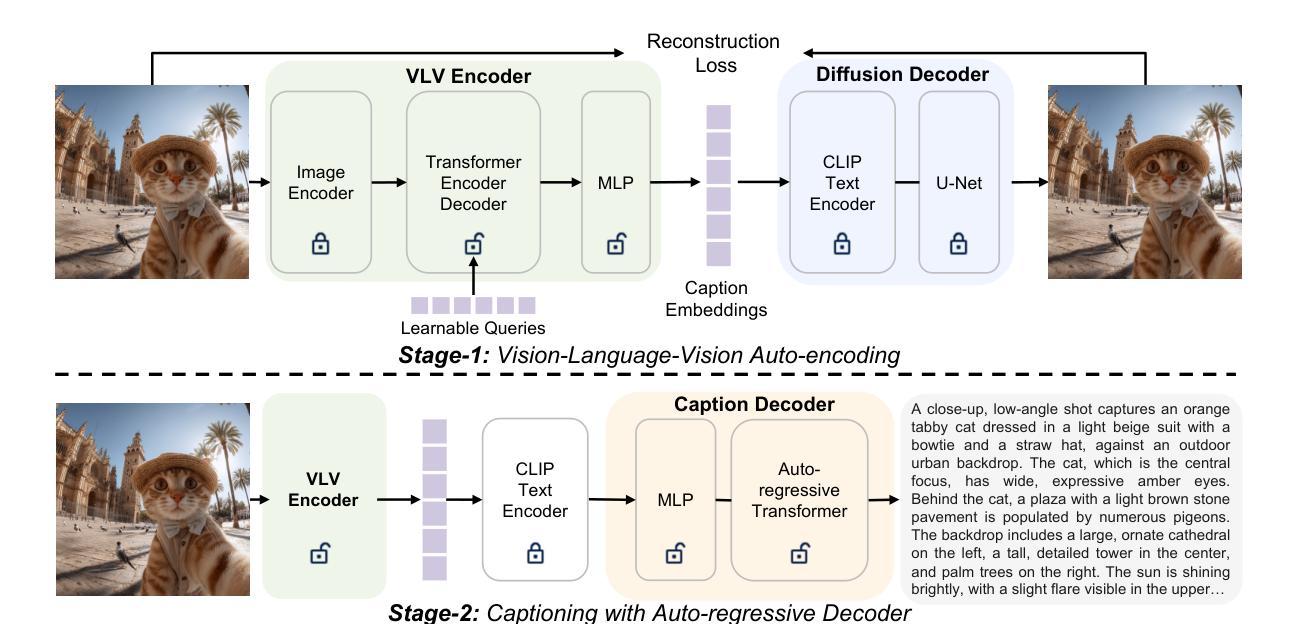

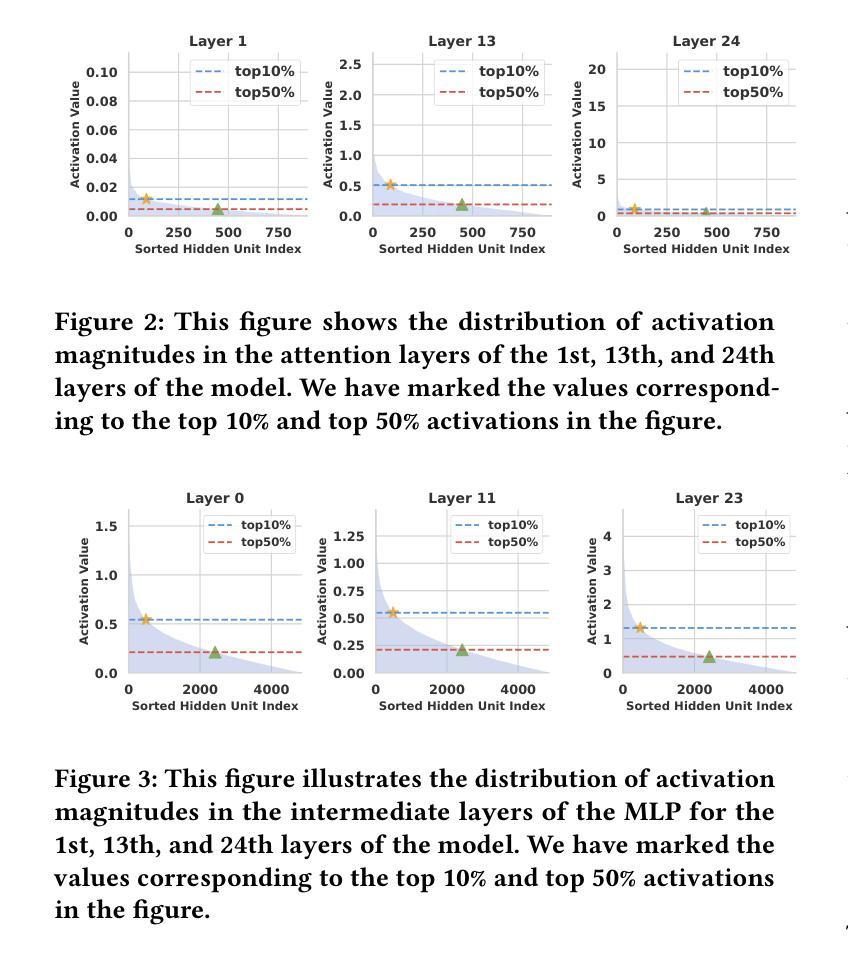
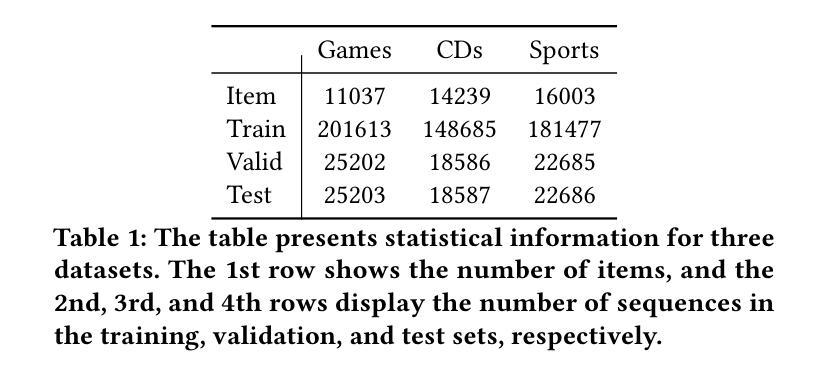
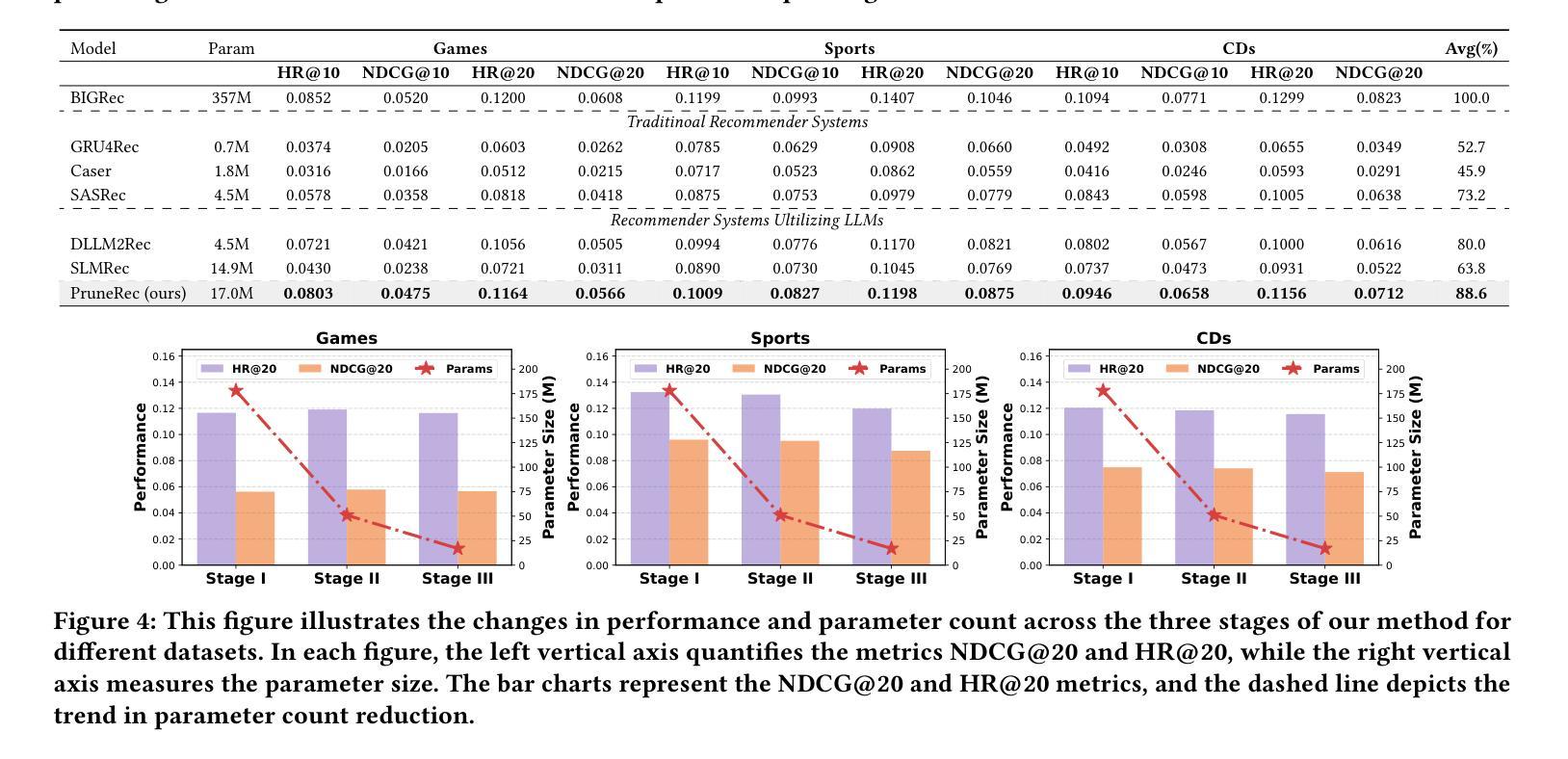
Boosting Parameter Efficiency in LLM-Based Recommendation through Sophisticated Pruning
Authors:Shanle Zheng, Keqin Bao, Jizhi Zhang, Yang Zhang, Fuli Feng, Xiangnan He
LLM-based recommender systems have made significant progress; however, the deployment cost associated with the large parameter volume of LLMs still hinders their real-world applications. This work explores parameter pruning to improve parameter efficiency while maintaining recommendation quality, thereby enabling easier deployment. Unlike existing approaches that focus primarily on inter-layer redundancy, we uncover intra-layer redundancy within components such as self-attention and MLP modules. Building on this analysis, we propose a more fine-grained pruning approach that integrates both intra-layer and layer-wise pruning. Specifically, we introduce a three-stage pruning strategy that progressively prunes parameters at different levels and parts of the model, moving from intra-layer to layer-wise pruning, or from width to depth. Each stage also includes a performance restoration step using distillation techniques, helping to strike a balance between performance and parameter efficiency. Empirical results demonstrate the effectiveness of our approach: across three datasets, our models achieve an average of 88% of the original model’s performance while pruning more than 95% of the non-embedding parameters. This underscores the potential of our method to significantly reduce resource requirements without greatly compromising recommendation quality. Our code will be available at: https://github.com/zheng-sl/PruneRec
基于LLM的推荐系统已经取得了显著的进步;然而,由于LLM的巨大参数体积所带来的部署成本仍然阻碍了它们在现实世界中的应用。本研究探索了参数修剪技术,以提高参数效率同时保持推荐质量,从而更容易进行部署。与主要关注层间冗余的现有方法不同,我们发现了组件(如自注意力机制和MLP模块)内的层内冗余。基于这一分析,我们提出了一种更精细的修剪方法,该方法结合了层内和层间修剪。具体来说,我们引入了一种三阶段修剪策略,该策略按不同级别和模型的不同部分逐步修剪参数,从层内修剪到层间修剪,或从宽度到深度。每个阶段还包括使用蒸馏技术的性能恢复步骤,有助于在性能和参数效率之间取得平衡。经验结果表明我们的方法有效:在三个数据集上,我们的模型在修剪超过95%的非嵌入参数的同时,平均达到原始模型性能的88%。这突出了我们的方法在显著降低资源要求的同时,不会过度牺牲推荐质量。我们的代码将在https://github.com/zheng-sl/PruneRec上提供。
论文及项目相关链接
Summary
LLM推荐系统虽有所进展,但部署成本高昂限制了其实际应用。本研究通过参数修剪提高参数效率,同时保持推荐质量,促进部署。研究不同层内冗余,提出精细修剪方法,结合层内和层间修剪。三阶段修剪策略逐步修剪模型不同层次和部分的参数,从层内到层间,从宽度到深度。使用蒸馏技术恢复性能,平衡性能与参数效率。在三个数据集上,模型修剪超过95%的非嵌入参数,仍能保持原始性能的88%,显著降低资源要求。
Key Takeaways
- LLM推荐系统虽有进展,但部署成本高昂限制了实际应用。
- 研究通过参数修剪提高LLM推荐系统的参数效率。
- 提出精细的修剪方法,结合层内和层间修剪策略。
- 采用三阶段修剪策略,从层内到层间,逐步修剪模型参数。
- 使用蒸馏技术恢复性能,保持推荐质量的同时降低资源需求。
- 在三个数据集上测试,修剪超过95%的非嵌入参数,仍能保持原始性能的88%。
- 代码将公开在GitHub上。
点此查看论文截图

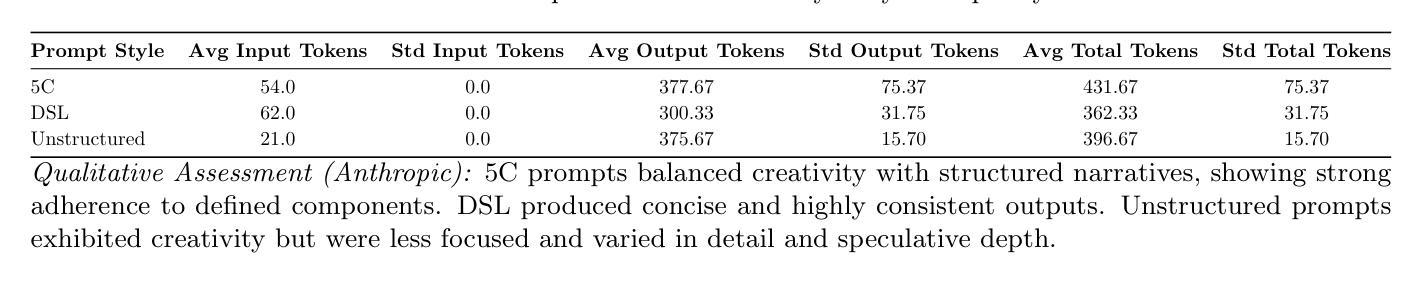
5C Prompt Contracts: A Minimalist, Creative-Friendly, Token-Efficient Design Framework for Individual and SME LLM Usage
Authors:Ugur Ari
The progression from traditional prompt engineering to a more rigorous discipline of prompt design marks a pivotal shift in human-LLM interaction. As Large Language Models (LLMs) become increasingly embedded in mission-critical applications, there emerges a pressing need for frameworks that are not only explicit and systematic but also minimal enough to remain practical and broadly accessible. While many existing approaches address prompt structuring through elaborate Domain-Specific Languages (DSLs) or multi-layered templates, such methods can impose significant token and cognitive overhead, potentially constraining the model’s creative capacity. In this context, we propose the 5C Prompt Contract, a framework that distills prompt design into five intuitive components: Character, Cause, Constraint, Contingency, and Calibration. This minimal cognitive schema explicitly integrates fallback and output optimization directives, fostering reliable, interpretable, and creatively flexible AI interactions. Experimental results demonstrate that the 5C framework consistently achieves superior input token efficiency while maintaining rich and consistent outputs across diverse LLM architectures (OpenAI, Anthropic, DeepSeek, and Gemini), making it particularly suited for individuals and Small-to-Medium Enterprises (SMEs) with limited AI engineering resources.
从传统提示工程到更严格的提示设计学科的转变,标志着人类与大型语言模型(LLM)交互中的关键性变革。随着大型语言模型在关键任务应用中越来越深入的嵌入,对于不仅是显性且系统化的、同时也足够精简以保持实用性和广泛可访问性的框架的需求日益迫切。虽然许多现有方法通过复杂的领域特定语言(DSL)或多层模板来解决提示结构问题,但此类方法可能会产生大量的标记和认知负担,从而可能限制模型的创造力。在此背景下,我们提出了5C提示合约(5C Prompt Contract)框架,它将提示设计提炼为五个直观组成部分:角色(Character)、原因(Cause)、约束(Constraint)、条件(Contingency)和校准(Calibration)。这一极简的认知模式显式地整合了后备和输出优化指令,促进了可靠、可解释和富有创造力的灵活人工智能交互。实验结果表明,5C框架在保持输出丰富且一致的同时,始终实现了出色的输入标记效率,适用于各种大型语言模型架构(OpenAI、Anthropic、DeepSeek和Gemini),特别适用于拥有有限人工智能工程资源的个人和中小型企业。
论文及项目相关链接
PDF 5 pages, 5 tables. Includes comparative experimental results across OpenAI, Anthropic, DeepSeek, and Gemini LLMs
Summary
传统提示工程向更严格的提示设计学科的转变标志着人类与大型语言模型(LLM)互动的重大变革。随着LLM在关键业务应用中的日益集成,出现了对不仅是明确和系统化的框架,而且是足够精简以保持实用和广泛可及性的迫切需求。提出的5C提示合约是一个将提示设计提炼为五个直观组成部分的框架:角色、原因、约束、连续性和校准。这个最小的认知模式显式地集成了后备和输出优化指令,促进了可靠、可解释和富有创造力的AI交互。实验结果表明,该框架在保持丰富和一致输出的同时,实现了较高的输入令牌效率,适用于资源有限的个人和中小企业。
Key Takeaways
- 大型语言模型(LLM)在关键业务应用中的集成不断增长,需要更明确的提示设计框架。
- 传统提示工程向提示设计学科的转变是LLM与人类互动的重要变革。
- 现有提示设计方法有较高的符号和认知开销,可能限制模型的创造力。
- 提出的5C提示合约是一个简洁、直观的框架,包括角色、原因、约束等五个元素。
- 5C框架结合了后备和输出优化指令,增强了AI交互的可靠性、可解释性和创造力。
- 实验证明,该框架在不同的大型语言模型架构中实现了高效的输入令牌效率和一致的输出表现。
点此查看论文截图


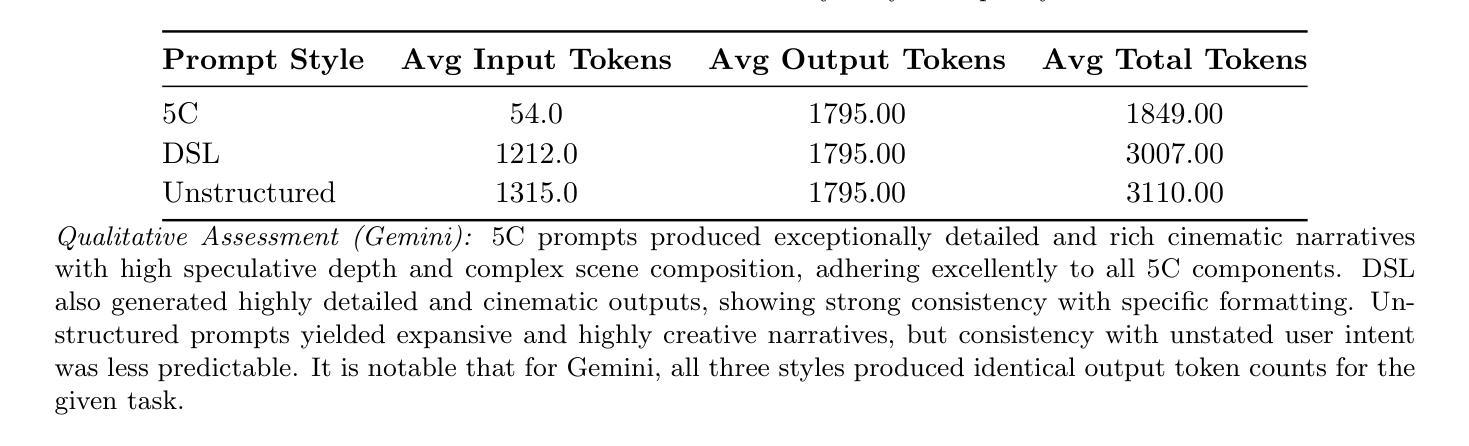
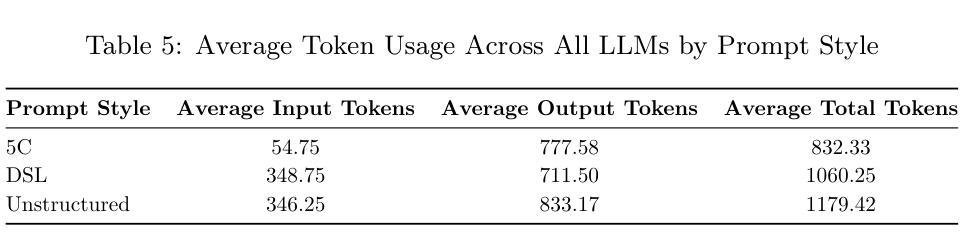
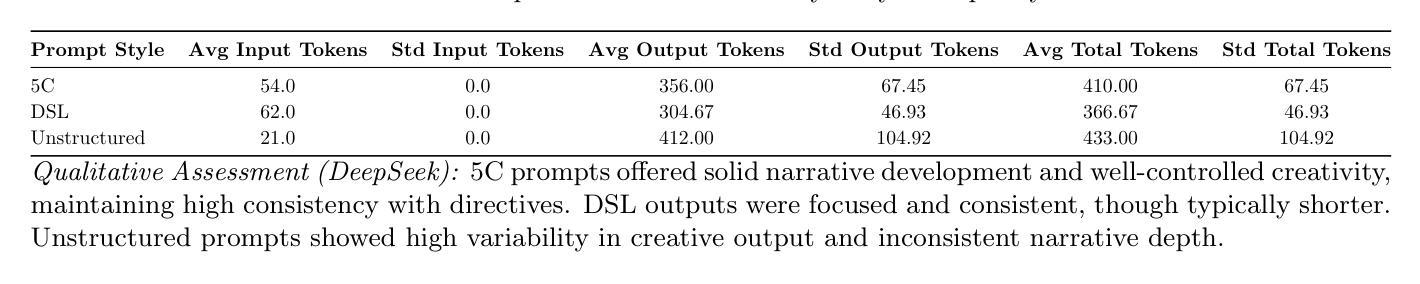
GNN-ViTCap: GNN-Enhanced Multiple Instance Learning with Vision Transformers for Whole Slide Image Classification and Captioning
Authors:S M Taslim Uddin Raju, Md. Milon Islam, Md Rezwanul Haque, Hamdi Altaheri, Fakhri Karray
Microscopic assessment of histopathology images is vital for accurate cancer diagnosis and treatment. Whole Slide Image (WSI) classification and captioning have become crucial tasks in computer-aided pathology. However, microscopic WSI face challenges such as redundant patches and unknown patch positions due to subjective pathologist captures. Moreover, generating automatic pathology captions remains a significant challenge. To address these issues, we introduce a novel GNN-ViTCap framework for classification and caption generation from histopathological microscopic images. First, a visual feature extractor generates patch embeddings. Redundant patches are then removed by dynamically clustering these embeddings using deep embedded clustering and selecting representative patches via a scalar dot attention mechanism. We build a graph by connecting each node to its nearest neighbors in the similarity matrix and apply a graph neural network to capture both local and global context. The aggregated image embeddings are projected into the language model’s input space through a linear layer and combined with caption tokens to fine-tune a large language model. We validate our method on the BreakHis and PatchGastric datasets. GNN-ViTCap achieves an F1 score of 0.934 and an AUC of 0.963 for classification, along with a BLEU-4 score of 0.811 and a METEOR score of 0.569 for captioning. Experimental results demonstrate that GNN-ViTCap outperforms state of the art approaches, offering a reliable and efficient solution for microscopy based patient diagnosis.
病理图像的微观评估对于准确的癌症诊断和治疗至关重要。全幻灯片图像(WSI)分类和标注已成为计算机辅助病理学中的关键任务。然而,微观WSI面临着由于主观病理学家捕获而导致的冗余斑块和未知斑块位置的挑战。此外,自动生成病理学标注仍然是一个巨大的挑战。为了解决这些问题,我们引入了一种新型的GNN-ViTCap框架,用于从病理显微图像中进行分类和生成标注。首先,视觉特征提取器生成斑块嵌入。然后,通过深度嵌入聚类动态地聚类这些嵌入,并通过标量点注意力机制选择代表性斑块,从而去除冗余斑块。我们通过将每个节点连接到相似度矩阵中的最近邻居来构建图,并应用图神经网络来捕获局部和全局上下文。聚合的图像嵌入通过线性层投射到语言模型的输入空间,并与标注令牌结合,以微调大型语言模型。我们在BreakHis和PatchGastric数据集上验证了我们的方法。GNN-ViTCap在分类方面达到了F1分数0.934和AUC分数0.963,在标注方面达到了BLEU-4分数0.811和METEOR分数0.569。实验结果表明,GNN-ViTCap优于现有方法,为基于显微镜的患者诊断提供了可靠高效的解决方案。
论文及项目相关链接
Summary
本文介绍了基于计算机辅助病理学的显微镜图像分析的重要性,特别是在癌症诊断和治疗中的应用。针对全显微镜图像(WSI)分类和描述面临的挑战,如冗余补丁和未知补丁位置等问题,提出了一种新型的GNN-ViTCap框架。该框架通过动态聚类去除冗余补丁,利用图神经网络捕捉局部和全局上下文信息,并结合语言模型进行图像分类和描述生成。实验结果表明,该框架在分类和描述方面均取得了优于现有方法的性能,为基于显微镜的患者诊断提供了可靠而高效的解决方案。
Key Takeaways
以下是文本的主要见解和关键点:
- 计算机辅助病理学中的显微镜图像分析对癌症诊断和治疗至关重要。
- 全显微镜图像(WSI)分类和描述是计算机辅助病理学中的关键任务。
- 现有的显微镜图像分析面临冗余补丁和未知补丁位置等挑战。
- 提出了一种新型的GNN-ViTCap框架来解决这些问题。
- GNN-ViTCap框架通过动态聚类去除冗余补丁,并利用图神经网络捕捉图像信息。
- GNN-ViTCap结合了语言模型进行图像分类和描述生成。
点此查看论文截图

Learning Deliberately, Acting Intuitively: Unlocking Test-Time Reasoning in Multimodal LLMs
Authors:Yahan Yu, Yuyang Dong, Masafumi Oyamada
Reasoning is a key capability for large language models (LLMs), particularly when applied to complex tasks such as mathematical problem solving. However, multimodal reasoning research still requires further exploration of modality alignment and training costs. Many of these approaches rely on additional data annotation and relevant rule-based rewards to enhance the understanding and reasoning ability, which significantly increases training costs and limits scalability. To address these challenges, we propose the Deliberate-to-Intuitive reasoning framework (D2I) that improves the understanding and reasoning ability of multimodal LLMs (MLLMs) without extra annotations and complex rewards. Specifically, our method sets deliberate reasoning strategies to enhance modality alignment only through the rule-based format reward during training. While evaluating, the reasoning style shifts to intuitive, which removes deliberate reasoning strategies during training and implicitly reflects the model’s acquired abilities in the response. D2I outperforms baselines across both in-domain and out-of-domain benchmarks. Our findings highlight the role of format reward in fostering transferable reasoning skills in MLLMs, and inspire directions for decoupling training-time reasoning depth from test-time response flexibility.
推理是大规模语言模型(LLM)的关键能力,特别是在应用于数学问题解决等复杂任务时。然而,多模态推理研究仍然需要进一步探索模态对齐和训练成本。许多这些方法依赖于额外的数据标注和相关基于规则的奖励来提高理解和推理能力,这显著增加了训练成本并限制了可扩展性。为了解决这些挑战,我们提出了Deliberate-to-Intuitive推理框架(D2I),该框架提高了多模态LLM(MLLM)的理解和推理能力,无需额外的注释和复杂的奖励。具体来说,我们的方法通过仅基于规则格式的奖励来设置深思熟虑的推理策略,以提高模态对齐的训练过程。在评估时,推理风格转变为直觉式,这在训练过程中消除了深思熟虑的推理策略,并在响应中隐含地反映了模型所获得的技能。D2I在域内和域外基准测试中均优于基线。我们的研究突出了格式奖励在促进多模态LLM中的可迁移推理技能方面的作用,并为从训练时的推理深度与测试时的响应灵活性之间找到平衡点提供了灵感。
论文及项目相关链接
PDF Work in progress
Summary
大型语言模型(LLM)在推理能力上至关重要,特别是在解决数学问题等复杂任务中。然而,多模态推理研究仍需要探索模态对齐和训练成本。为提高多模态LLM(MLLM)的理解和推理能力,我们提出了Deliberate-to-Intuitive推理框架(D2I),无需额外标注和复杂的奖励。该方法通过训练时设置刻意推理策略增强模态对齐,仅采用基于规则的格式奖励。评估时,推理风格转变为直觉式,反映模型的习得能力。D2I在域内和域外基准测试中都优于基线方法。研究发现,格式奖励在培养MLLM的可迁移推理技能中发挥作用,并为训练和测试时的推理深度与响应灵活性解耦提供了启示。
Key Takeaways
- 大型语言模型(LLM)在复杂任务如数学问题解决中需要强大的推理能力。
- 多模态推理研究面临模态对齐和训练成本的挑战。
- 现有的多模态LLM(MLLM)方法常依赖额外的数据标注和规则奖励来提升理解和推理能力,这增加了训练成本和限制了可扩展性。
- 提出的Deliberate-to-Intuitive推理框架(D2I)通过训练时的刻意推理策略和基于规则的格式奖励增强模态对齐。
- D2I在评估和测试时展现出优秀的性能,特别是在域内和域外基准测试中优于基线方法。
- 格式奖励在培养MLLM的可迁移推理技能中起到关键作用。
点此查看论文截图


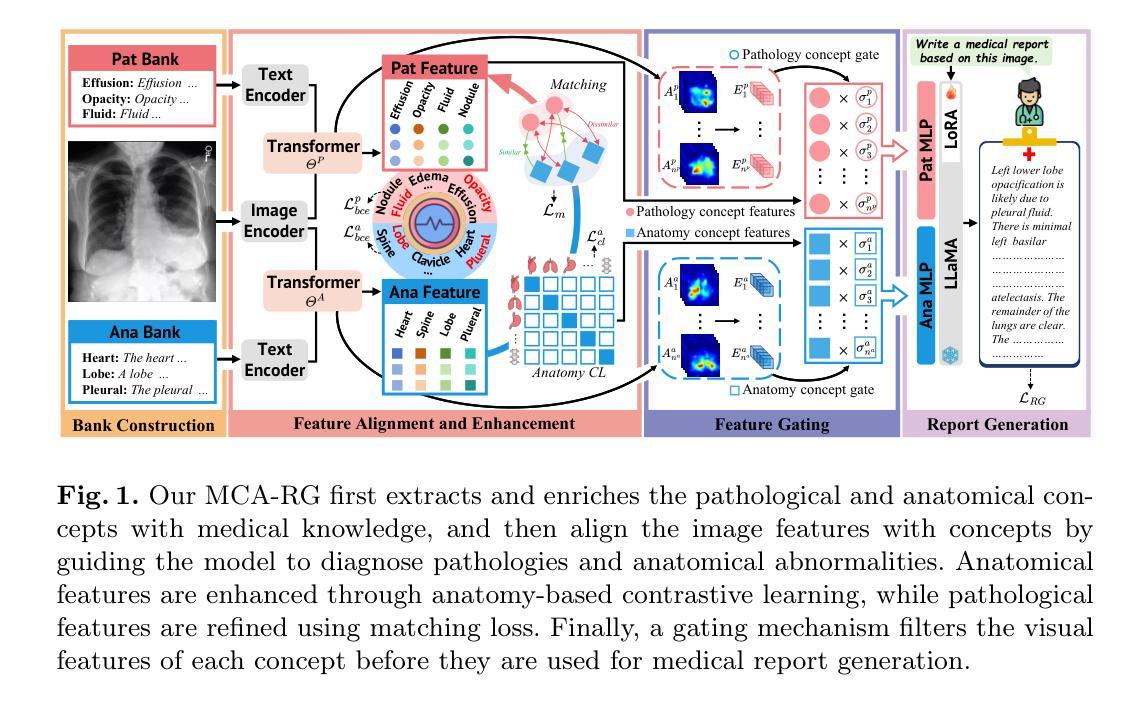
MCA-RG: Enhancing LLMs with Medical Concept Alignment for Radiology Report Generation
Authors:Qilong Xing, Zikai Song, Youjia Zhang, Na Feng, Junqing Yu, Wei Yang
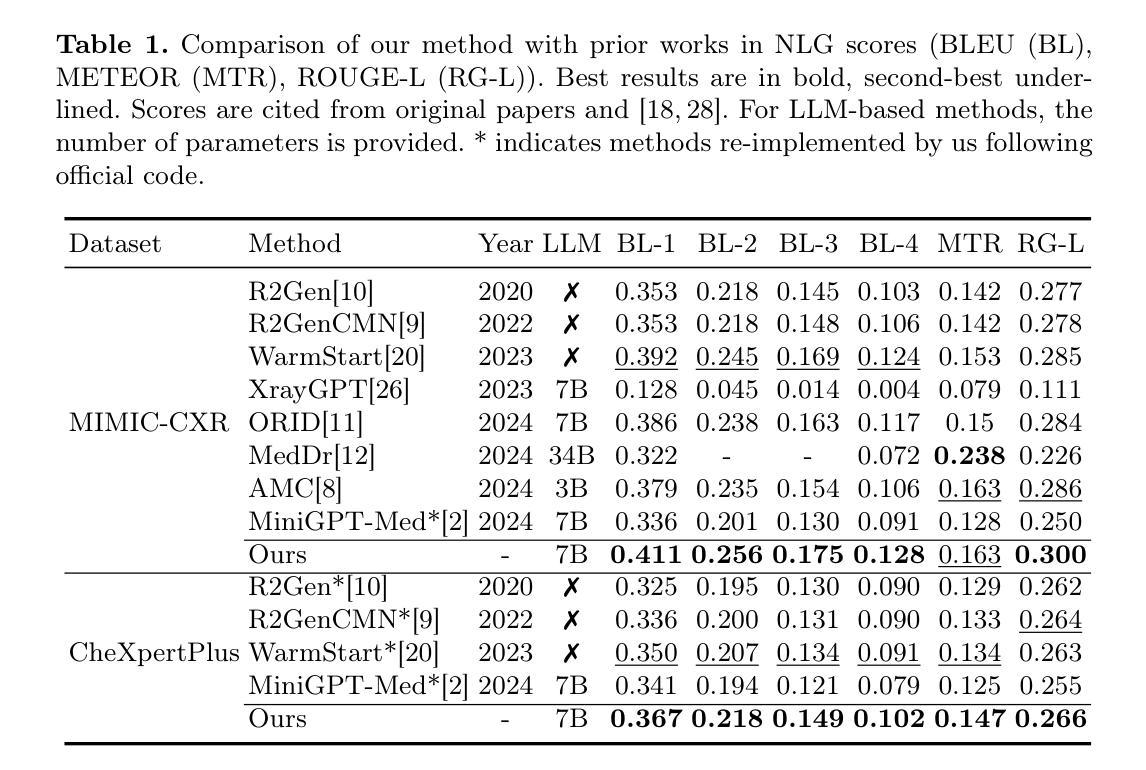
Despite significant advancements in adapting Large Language Models (LLMs) for radiology report generation (RRG), clinical adoption remains challenging due to difficulties in accurately mapping pathological and anatomical features to their corresponding text descriptions. Additionally, semantic agnostic feature extraction further hampers the generation of accurate diagnostic reports. To address these challenges, we introduce Medical Concept Aligned Radiology Report Generation (MCA-RG), a knowledge-driven framework that explicitly aligns visual features with distinct medical concepts to enhance the report generation process. MCA-RG utilizes two curated concept banks: a pathology bank containing lesion-related knowledge, and an anatomy bank with anatomical descriptions. The visual features are aligned with these medical concepts and undergo tailored enhancement. We further propose an anatomy-based contrastive learning procedure to improve the generalization of anatomical features, coupled with a matching loss for pathological features to prioritize clinically relevant regions. Additionally, a feature gating mechanism is employed to filter out low-quality concept features. Finally, the visual features are corresponding to individual medical concepts, and are leveraged to guide the report generation process. Experiments on two public benchmarks (MIMIC-CXR and CheXpert Plus) demonstrate that MCA-RG achieves superior performance, highlighting its effectiveness in radiology report generation.
尽管在将大型语言模型(LLM)适应于放射学报告生成(RRG)方面取得了重大进展,但由于将病理和解剖特征准确映射到其相应文本描述中的困难,临床采用仍具有挑战性。此外,语义无关的特征提取进一步阻碍了准确诊断报告的生成。为了解决这些挑战,我们引入了医学概念对齐放射学报告生成(MCA-RG),这是一个知识驱动框架,通过明确对齐视觉特征与不同的医学概念,以增强报告生成过程。MCA-RG利用两个定制的概念库:一个包含病变相关知识的病理库和一个包含解剖描述的解剖库。视觉特征与这些医学概念对齐,并进行有针对性的增强。我们进一步提出了一种基于解剖学的对比学习程序,以提高解剖特征的泛化能力,结合病理特征的匹配损失,以优先处理临床相关区域。此外,还采用特征门控机制来过滤掉低质量的概念特征。最终,视觉特征与个别医学概念相对应,并用于指导报告生成过程。在MIMIC-CXR和CheXpert Plus两个公共基准测试上的实验表明,MCA-RG取得了优越的性能,突显其在放射学报告生成中的有效性。
论文及项目相关链接
PDF MICCAI 2025
Summary
在适应大型语言模型(LLM)用于放射学报告生成(RRG)方面取得了显著进展,但临床采纳仍面临挑战,如难以将病理和解剖特征准确映射到相应的文本描述中。为应对这些挑战,提出医学概念对齐放射学报告生成(MCA-RG)知识驱动框架,该框架显式对齐视觉特征与不同的医学概念,以提升报告生成过程。实验结果表明,MCA-RG在放射学报告生成方面具有卓越性能。
Key Takeaways
- LLM在放射学报告生成方面的应用虽然已经取得进展,但仍面临临床采纳的挑战。
- 医学概念对齐放射学报告生成框架(MCA-RG)被提出来解决这些挑战。
- MCA-RG利用两个医学概念库:病理库包含病变相关知识,解剖库包含解剖描述。
- MCA-RG通过对齐视觉特征与医学概念来增强报告生成过程。
- 解剖学对比学习程序和匹配损失被用来改善解剖特征的泛化能力和优先处理临床相关区域。
- 特征门控机制被用来过滤掉低质量的医学概念特征。
点此查看论文截图

Exploring LLMs for Predicting Tutor Strategy and Student Outcomes in Dialogues
Authors:Fareya Ikram, Alexander Scarlatos, Andrew Lan
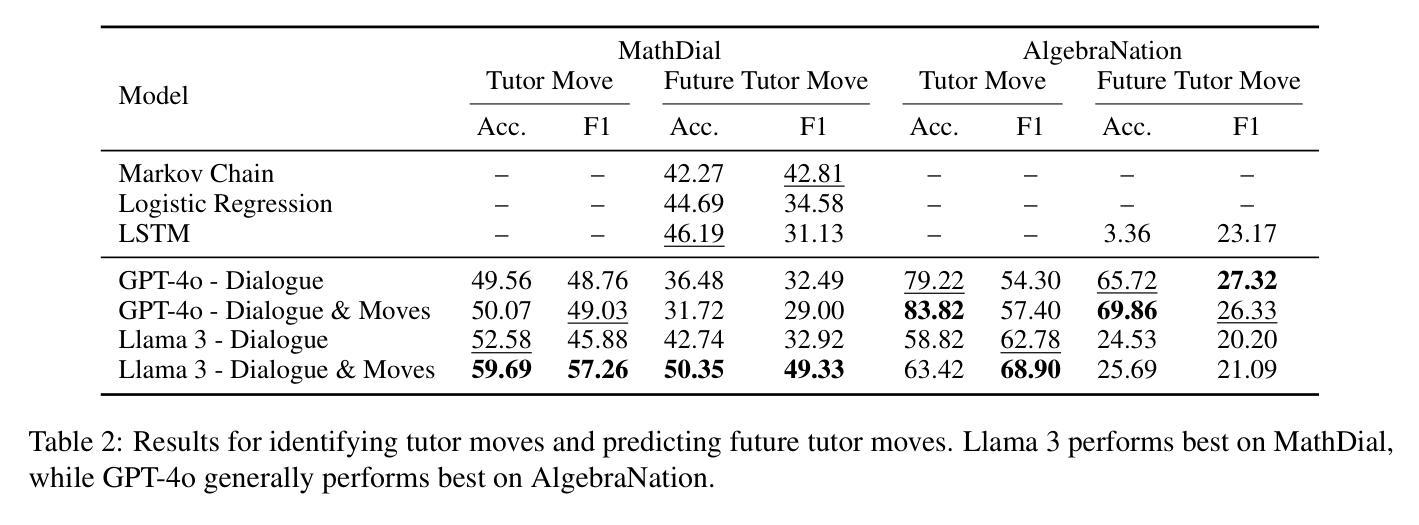
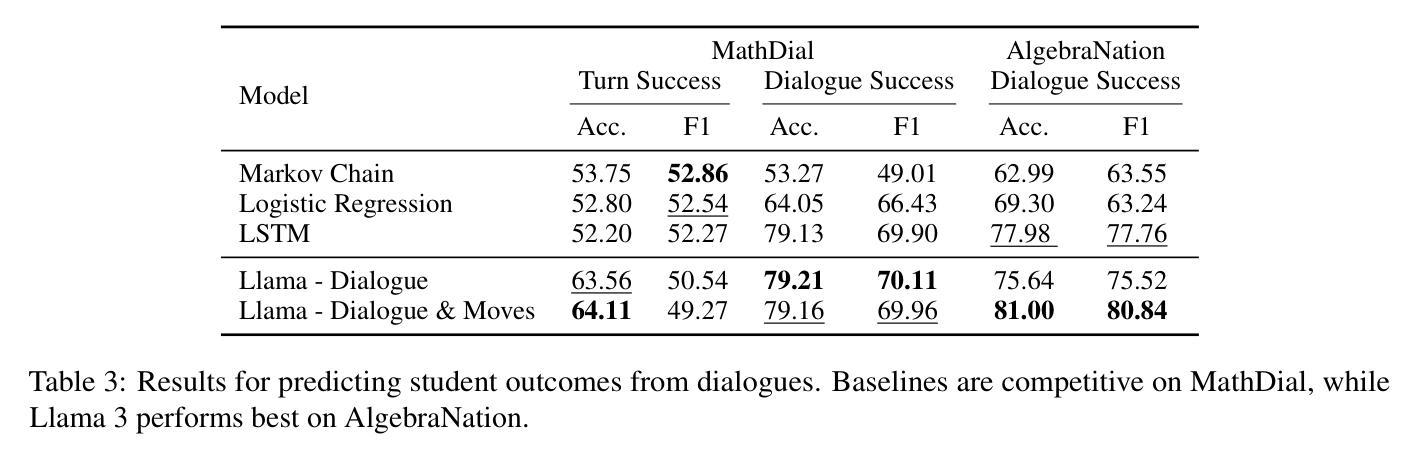
Tutoring dialogues have gained significant attention in recent years, given the prominence of online learning and the emerging tutoring abilities of artificial intelligence (AI) agents powered by large language models (LLMs). Recent studies have shown that the strategies used by tutors can have significant effects on student outcomes, necessitating methods to predict how tutors will behave and how their actions impact students. However, few works have studied predicting tutor strategy in dialogues. Therefore, in this work we investigate the ability of modern LLMs, particularly Llama 3 and GPT-4o, to predict both future tutor moves and student outcomes in dialogues, using two math tutoring dialogue datasets. We find that even state-of-the-art LLMs struggle to predict future tutor strategy while tutor strategy is highly indicative of student outcomes, outlining a need for more powerful methods to approach this task.
辅导对话近年来备受关注,特别是在线学习的普及以及由大型语言模型(LLM)驱动的人工智能(AI)代理的辅导能力的兴起。最近的研究表明,导师使用的策略对学生的成果有重大影响,因此需要方法预测导师的行为以及他们的行为如何影响学生。然而,很少有工作研究预测对话中的辅导策略。因此,在这项工作中,我们研究了现代LLM(特别是Llama 3和GPT-4o)在对话中预测未来导师的动作和学生成果的能力,使用了两个数学辅导对话数据集。我们发现,即使是最先进的LLM在预测未来辅导策略时也会遇到困难,而辅导策略非常能说明学生的成果,这突出了需要更强大的方法来应对这项任务。
论文及项目相关链接
PDF Published in BEA 2025: 20th Workshop on Innovative Use of NLP for Building Educational Applications
Summary:近年来,由于在线学习的普及以及由大型语言模型(LLM)驱动的人工智能(AI)代理的辅导能力突显,辅导对话已引起广泛关注。研究表明,导师的策略对学生成绩有重要影响,因此需要方法预测导师的行为及其对学生影响的程度。本研究调查了现代LLMs(特别是Llama 3和GPT-4o)在对话中预测未来导师动作和学生成绩的能力,使用两个数学辅导对话数据集。研究发现,即使是最先进的大型语言模型也很难预测未来的导师策略,而导师策略高度预示学生成绩,这突显了需要更强大的方法来应对这项任务。
Key Takeaways:
- 辅导对话近年来受到广泛关注,主要由于在线学习的普及和AI代理的辅导能力提高。
- 导师的策略对学生成绩有重要的影响。
- LLMs,如Llama 3和GPT-4o,被用于预测对话中的未来导师动作和学生成绩。
- 最先进的大型语言模型在预测未来导师策略方面面临挑战。
- 导师的策略高度预示学生成绩。
- 需要更强大的方法来预测导师的行为及其对学生影响。
点此查看论文截图

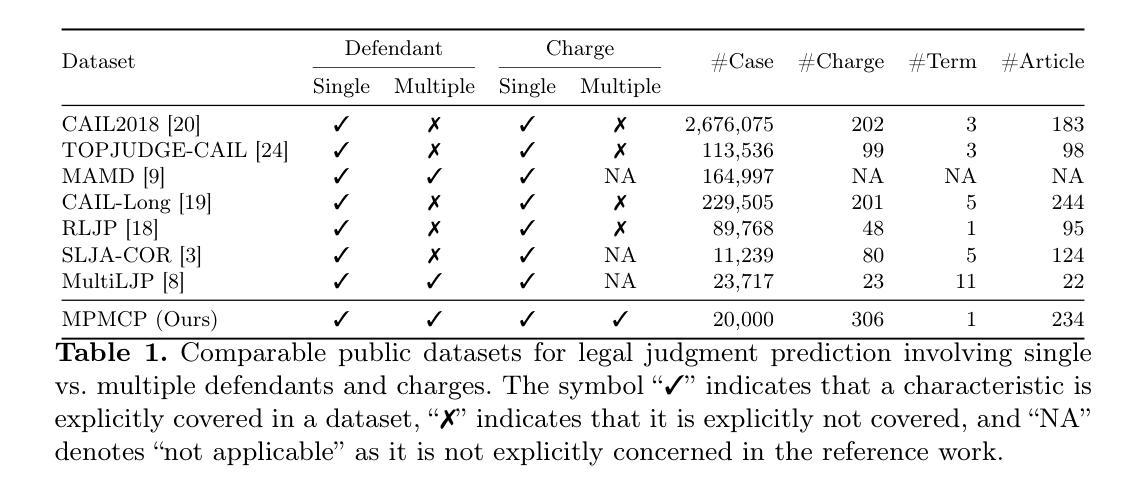
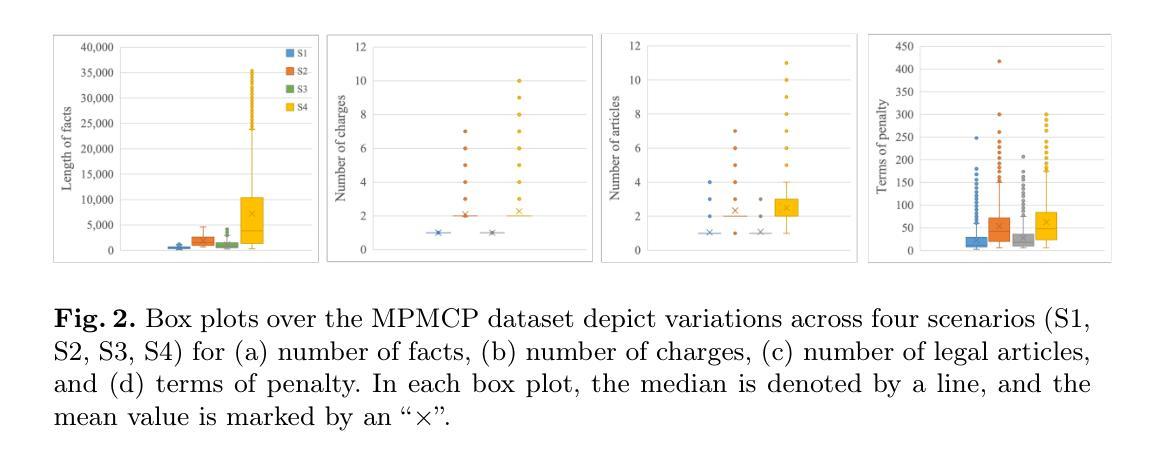
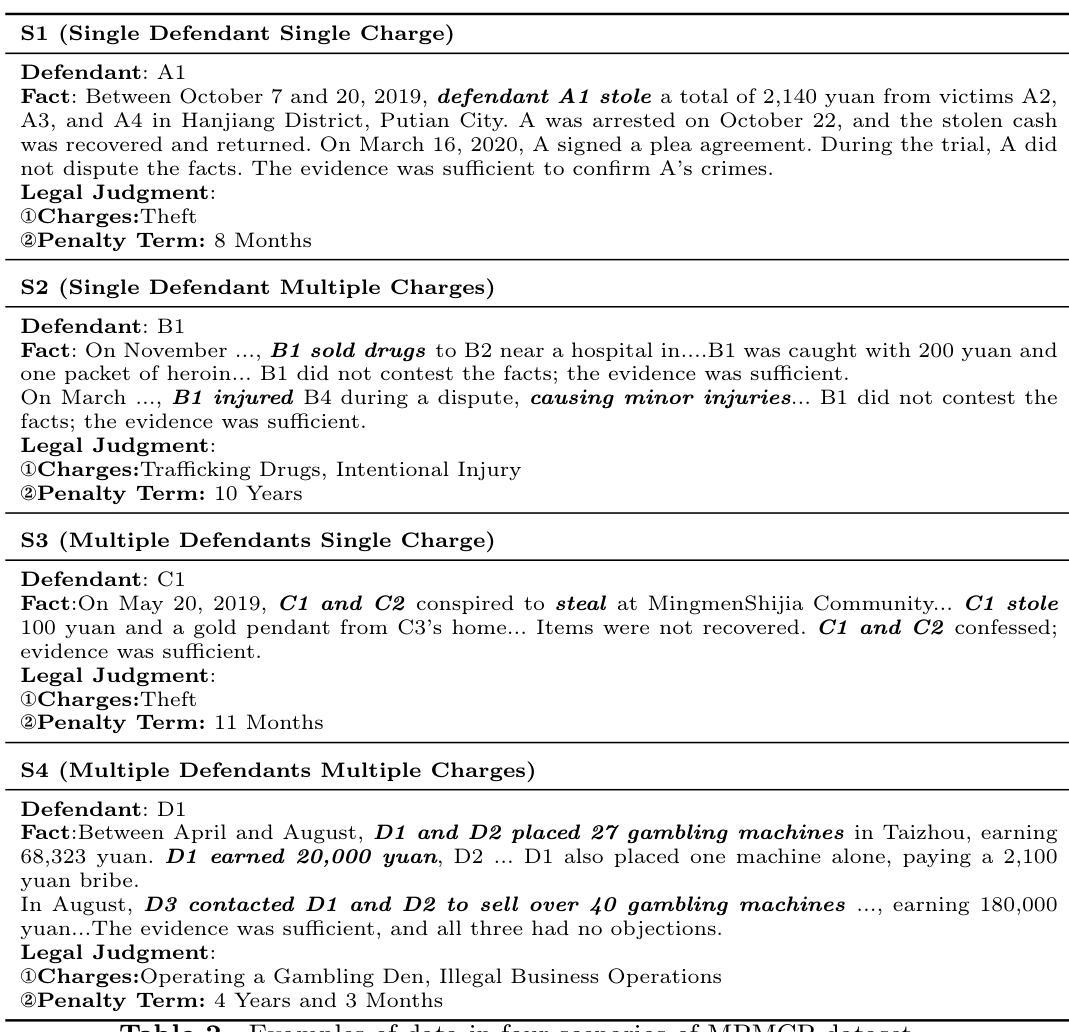
MultiJustice: A Chinese Dataset for Multi-Party, Multi-Charge Legal Prediction
Authors:Xiao Wang, Jiahuan Pei, Diancheng Shui, Zhiguang Han, Xin Sun, Dawei Zhu, Xiaoyu Shen
Legal judgment prediction offers a compelling method to aid legal practitioners and researchers. However, the research question remains relatively under-explored: Should multiple defendants and charges be treated separately in LJP? To address this, we introduce a new dataset namely multi-person multi-charge prediction (MPMCP), and seek the answer by evaluating the performance of several prevailing legal large language models (LLMs) on four practical legal judgment scenarios: (S1) single defendant with a single charge, (S2) single defendant with multiple charges, (S3) multiple defendants with a single charge, and (S4) multiple defendants with multiple charges. We evaluate the dataset across two LJP tasks, i.e., charge prediction and penalty term prediction. We have conducted extensive experiments and found that the scenario involving multiple defendants and multiple charges (S4) poses the greatest challenges, followed by S2, S3, and S1. The impact varies significantly depending on the model. For example, in S4 compared to S1, InternLM2 achieves approximately 4.5% lower F1-score and 2.8% higher LogD, while Lawformer demonstrates around 19.7% lower F1-score and 19.0% higher LogD. Our dataset and code are available at https://github.com/lololo-xiao/MultiJustice-MPMCP.
法律判决预测为法律从业者和研究人员提供了一种吸引人的辅助方法。然而,相关研究问题仍然相对被忽视:在法律判决预测中是否应该将多名被告和多项指控分别处理?为了解决这个问题,我们引入了一个新的数据集,即多人多指控预测(MPMCP),并通过评估几个流行的法律大型语言模型(LLM)在四种实际法律判决场景中的表现来寻找答案:(S1)单一被告单一指控,(S2)单一被告多项指控,(S3)多名被告单一指控,以及(S4)多名被告多项指控。我们对数据集进行了两项法律判决预测任务的评估,即罪名预测和处罚条款预测。我们进行了大量实验,发现涉及多名被告和多项指控的场景(S4)最具挑战性,其次是S2、S3和S1。影响程度因模型而异。例如,在S4与S1相比,InternLM2的F1分数降低了约4.5%,LogD增加了2.8%,而Lawformer的F1分数降低了约19.7%,LogD增加了19.0%。我们的数据集和代码可在https://github.com/lololo-xiao/MultiJustice-MPMCP找到。
论文及项目相关链接
PDF Accepted by NLPCC 2025
Summary:
针对法律判决预测中多被告人多指控情况的研究问题,引入多人物多指控预测(MPMCP)数据集,通过评估多种主流法律大型语言模型(LLM)在四种实际法律判决场景下的表现,探讨是否应将多被告人和多项指控分开处理。研究发现,涉及多被告人多指控的场景最具挑战性,不同模型的影响差异显著。数据集和代码已公开。
Key Takeaways:
- 法律判决预测是辅助法律从业者和研究人员的有力方法。
- 引入多人物多指控预测(MPMCP)数据集,针对多被告人和多项指控情况进行研究。
- 通过评估多种主流法律大型语言模型(LLM)在四种实际法律判决场景的表现来探讨研究问题。
- 涉及多被告人多指控的场景(S4)最具挑战性。
- 不同模型在处理不同场景时的表现存在差异。
- InternLM2和Lawformer在S4相比S1场景下的表现受到较大影响。
点此查看论文截图


SCoRE: Streamlined Corpus-based Relation Extraction using Multi-Label Contrastive Learning and Bayesian kNN
Authors:Luca Mariotti, Veronica Guidetti, Federica Mandreoli
The growing demand for efficient knowledge graph (KG) enrichment leveraging external corpora has intensified interest in relation extraction (RE), particularly under low-supervision settings. To address the need for adaptable and noise-resilient RE solutions that integrate seamlessly with pre-trained large language models (PLMs), we introduce SCoRE, a modular and cost-effective sentence-level RE system. SCoRE enables easy PLM switching, requires no finetuning, and adapts smoothly to diverse corpora and KGs. By combining supervised contrastive learning with a Bayesian k-Nearest Neighbors (kNN) classifier for multi-label classification, it delivers robust performance despite the noisy annotations of distantly supervised corpora. To improve RE evaluation, we propose two novel metrics: Correlation Structure Distance (CSD), measuring the alignment between learned relational patterns and KG structures, and Precision at R (P@R), assessing utility as a recommender system. We also release Wiki20d, a benchmark dataset replicating real-world RE conditions where only KG-derived annotations are available. Experiments on five benchmarks show that SCoRE matches or surpasses state-of-the-art methods while significantly reducing energy consumption. Further analyses reveal that increasing model complexity, as seen in prior work, degrades performance, highlighting the advantages of SCoRE’s minimal design. Combining efficiency, modularity, and scalability, SCoRE stands as an optimal choice for real-world RE applications.
对于利用外部语料库进行高效知识图谱(KG)增强的日益增长的需求,已经加剧了人们对关系抽取(RE)的兴趣,特别是在低监督设置下。为了解决需要与预训练的大型语言模型(PLM)无缝集成的可适应和噪声耐用的RE解决方案的问题,我们引入了SCoRE,这是一个模块化且经济实惠的句子级RE系统。SCoRE可以轻松切换PLM,无需微调,并可顺利适应各种语料库和知识图谱。它通过结合有监督的对比学习与贝叶斯k最近邻(kNN)分类器进行多标签分类,即使在远程监督语料库的噪声标注下也能实现稳健的性能。为了改善RE评估,我们提出了两个新指标:关联结构距离(CSD),用于衡量学习到的关系模式与知识图谱结构之间的对齐程度;以及精准度R(P@R),用于评估作为推荐系统的实用性。我们还发布了Wiki20d,这是一个复制现实RE条件的基准数据集,其中只有从知识图谱派生的注释可用。在五个基准测试上的实验表明,SCoRE的方法与最新技术相匹配或超越,同时大大降低了能耗。进一步的分析表明,如先前工作所见,增加模型复杂性会降低性能,从而突出了SCoRE设计的优势。通过结合效率、模块化和可扩展性,SCoRE成为适用于现实RE应用的最佳选择。
论文及项目相关链接
Summary
该文本介绍了一个名为SCoRE的模块化、低成本句子级关系抽取系统,用于满足利用外部语料库进行高效知识图谱富化的日益增长的需求。SCoRE系统易于与预训练的大型语言模型集成,无需微调,并能适应各种语料库和知识图谱。通过结合监督对比学习与贝叶斯k最近邻分类器进行多标签分类,SCoRE在噪声标注的远程监督语料库中实现了稳健的性能。此外,还提出了两种新的评估指标:用于衡量所学关系模式与知识图谱结构对齐程度的相关性结构距离(CSD)和用于评估推荐系统实用性的精确度R(P@R)。实验表明,SCoRE在五个基准测试中达到了或超越了最新技术水平,同时大大降低了能耗。进一步分析表明,与其他复杂模型相比,SCoRE的简洁设计带来了优势。该系统具有高效性、模块化以及可扩展性,是现实关系抽取应用的理想选择。
Key Takeaways
- SCoRE是一个模块化、低成本的关系抽取系统,适用于高效知识图谱富化。
- SCoRE易于与预训练的大型语言模型集成,且能适应不同的语料库和知识图谱。
- 结合监督对比学习与贝叶斯k最近邻分类器的多标签分类方法使得SCoRE在噪声标注的语料库中表现稳健。
- 提出了两种新的评估指标CSD和P@R来衡量关系抽取的效果。
- SCoRE在多个基准测试中表现优秀,同时降低了能耗。
- 与复杂模型相比,SCoRE的简洁设计具有优势。
点此查看论文截图

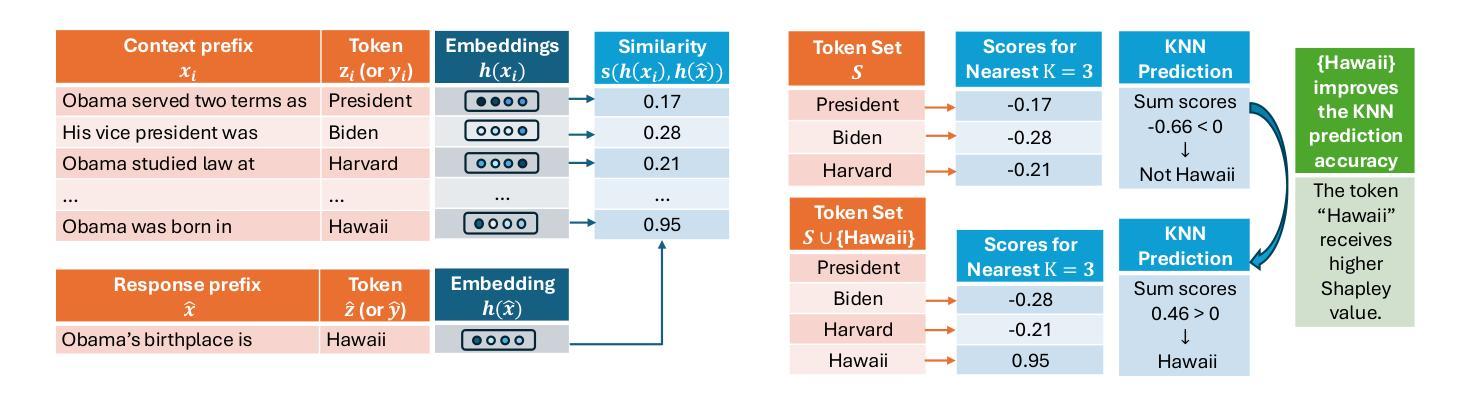
TokenShapley: Token Level Context Attribution with Shapley Value
Authors:Yingtai Xiao, Yuqing Zhu, Sirat Samyoun, Wanrong Zhang, Jiachen T. Wang, Jian Du
Large language models (LLMs) demonstrate strong capabilities in in-context learning, but verifying the correctness of their generated responses remains a challenge. Prior work has explored attribution at the sentence level, but these methods fall short when users seek attribution for specific keywords within the response, such as numbers, years, or names. To address this limitation, we propose TokenShapley, a novel token-level attribution method that combines Shapley value-based data attribution with KNN-based retrieval techniques inspired by recent advances in KNN-augmented LLMs. By leveraging a precomputed datastore for contextual retrieval and computing Shapley values to quantify token importance, TokenShapley provides a fine-grained data attribution approach. Extensive evaluations on four benchmarks show that TokenShapley outperforms state-of-the-art baselines in token-level attribution, achieving an 11-23% improvement in accuracy.
大型语言模型(LLM)在上下文学习方面表现出强大的能力,但验证其生成响应的正确性仍然是一个挑战。早期的工作已经探索了句子级别的归因,但当用户寻求对响应内特定关键词(如数字、年份或名称)的归因时,这些方法就显得不足。为了解决这一局限性,我们提出了TokenShapley,这是一种新型的词级归因方法,它结合了基于Shapley值的数据归因和受最近KNN增强LLMs技术启发的基于KNN的检索技术。通过利用预计算的数据存储进行上下文检索并计算Shapley值来量化令牌的重要性,TokenShapley提供了一种精细的数据归因方法。在四个基准测试上的广泛评估表明,TokenShapley在词级归因方面优于最新基线技术,准确率提高了11-23%。
论文及项目相关链接
Summary
LLM在上下文学习方面表现出强大的能力,但其生成响应的正确性验证仍然是一个挑战。现有方法主要集中在句子级别的归因上,但当用户需要针对响应中的特定关键词(如数字、年份或名称)进行归因时,这些方法就显得不足。为此,本文提出了TokenShapley,这是一种新的令牌级别归因方法,它结合了基于Shapley值的数据归因和基于KNN的检索技术。TokenShapley利用预先计算的数据存储进行上下文检索,并通过计算Shapley值来量化令牌的重要性,从而提供了一种精细化的数据归因方法。在四个基准测试上的广泛评估表明,TokenShapley在令牌级别归因方面优于最新基线技术,准确率提高了11-23%。
Key Takeaways
- LLM在上下文学习方面表现出强大的能力,但验证其生成响应的正确性仍然是一个挑战。
- 现有方法主要集中在句子级别的归因上,无法针对响应中的特定关键词进行归因。
- TokenShapley是一种新的令牌级别归因方法,结合了基于Shapley值的数据归因和基于KNN的检索技术。
- TokenShapley利用预先计算的数据存储进行上下文检索。
- TokenShapley通过计算Shapley值来量化令牌的重要性,提供精细化的数据归因。
- 在四个基准测试上的评估表明,TokenShapley在令牌级别归因方面优于现有方法。
点此查看论文截图


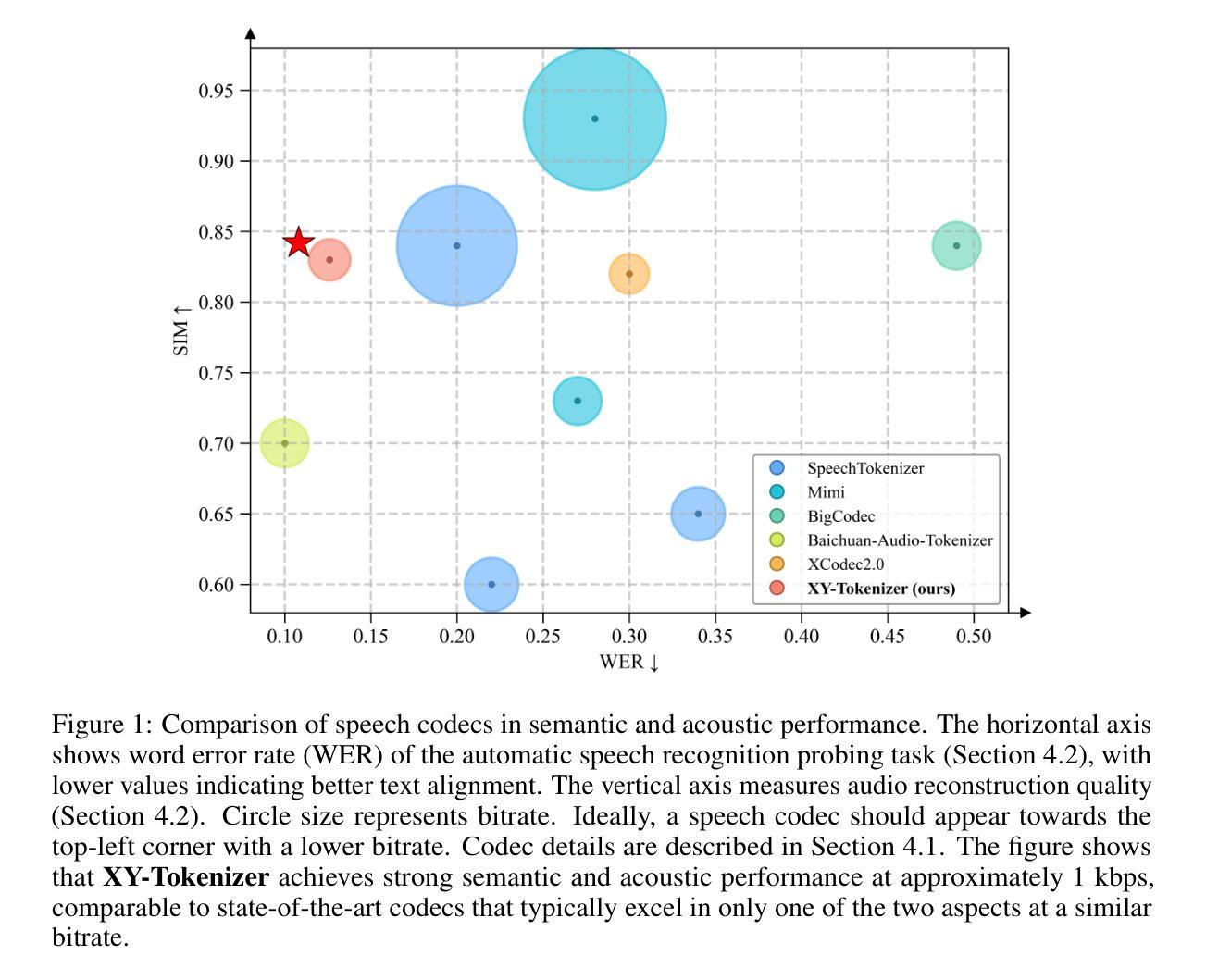
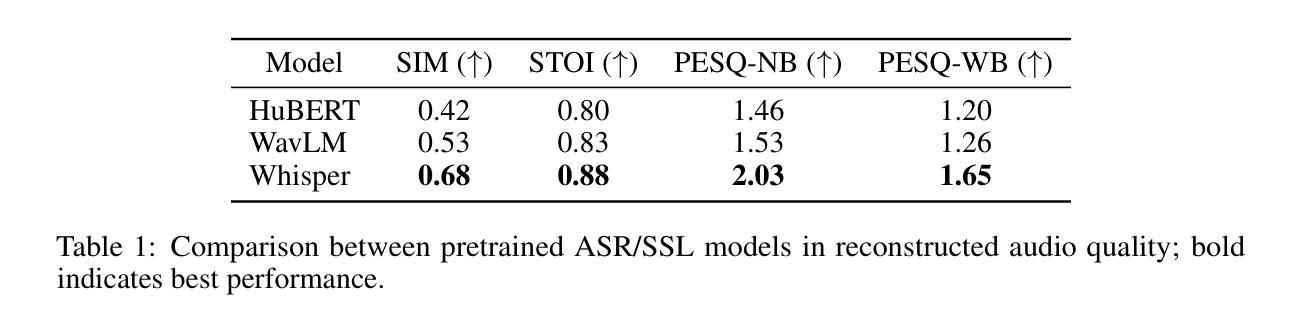
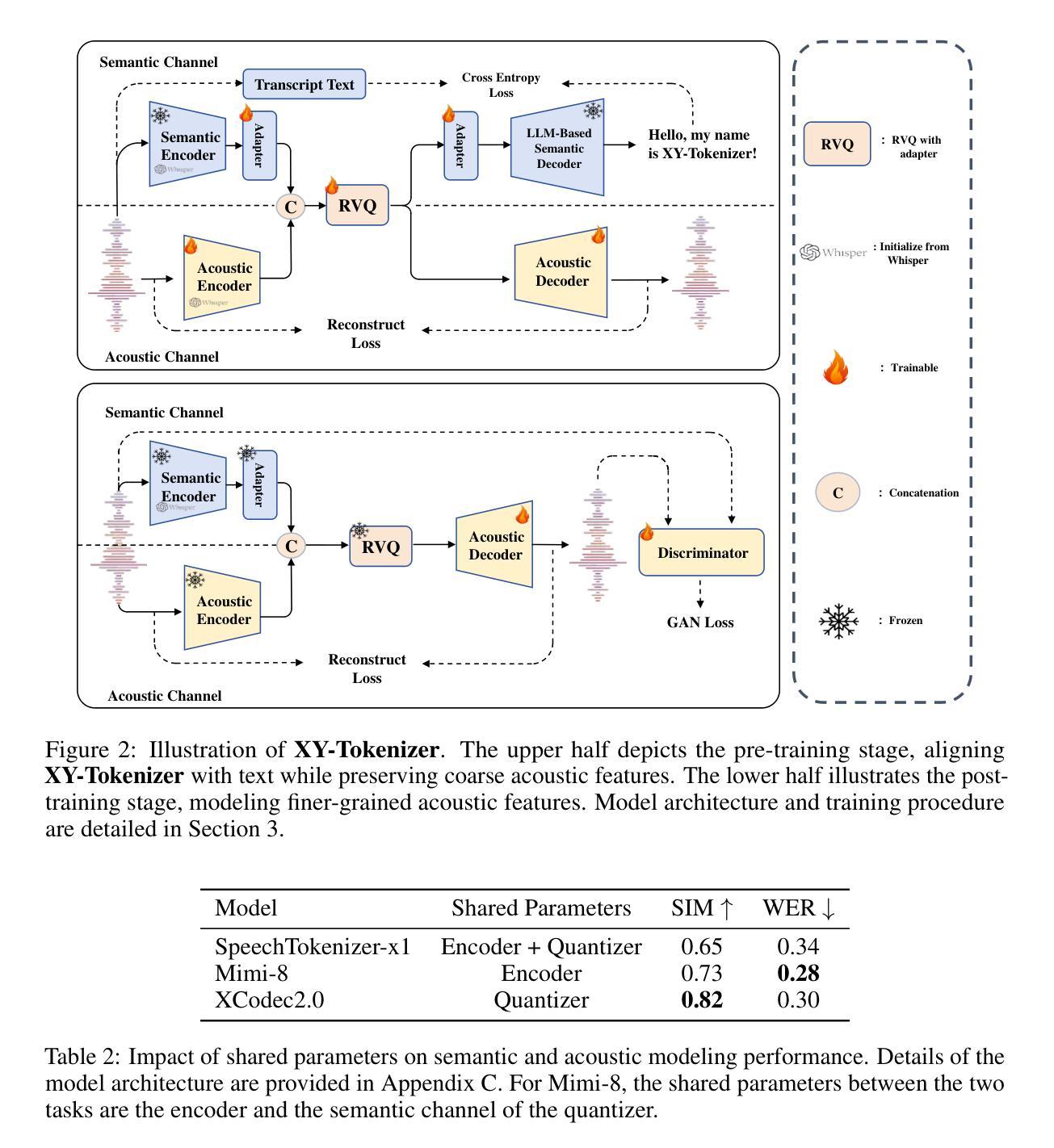
XY-Tokenizer: Mitigating the Semantic-Acoustic Conflict in Low-Bitrate Speech Codecs
Authors:Yitian Gong, Luozhijie Jin, Ruifan Deng, Dong Zhang, Xin Zhang, Qinyuan Cheng, Zhaoye Fei, Shimin Li, Xipeng Qiu
Speech codecs serve as bridges between speech signals and large language models. An ideal codec for speech language models should not only preserve acoustic information but also capture rich semantic information. However, existing speech codecs struggle to balance high-quality audio reconstruction with ease of modeling by language models. In this study, we analyze the limitations of previous codecs in balancing semantic richness and acoustic fidelity. We propose XY-Tokenizer, a novel codec that mitigates the conflict between semantic and acoustic capabilities through multi-stage, multi-task learning. Experimental results demonstrate that XY-Tokenizer achieves performance in both semantic and acoustic tasks comparable to that of state-of-the-art codecs operating at similar bitrates, even though those existing codecs typically excel in only one aspect. Specifically, XY-Tokenizer achieves strong text alignment, surpassing distillation-based semantic modeling methods such as SpeechTokenizer and Mimi, while maintaining a speaker similarity score of 0.83 between reconstructed and original audio. The reconstruction performance of XY-Tokenizer is comparable to that of BigCodec, the current state-of-the-art among acoustic-only codecs, which achieves a speaker similarity score of 0.84 at a similar bitrate. Code and models are available at https://github.com/gyt1145028706/XY-Tokenizer.
语音编解码器作为语音信号与大型语言模型之间的桥梁。对于语音语言模型而言,理想的编解码器不仅要保留声音信息,还要捕捉丰富的语义信息。然而,现有的语音编解码器在平衡高质量音频重建与语言模型的轻松建模方面存在困难。在这项研究中,我们分析了先前编解码器在平衡语义丰富度和声音保真度方面的局限性。我们提出了XY-Tokenizer这一新型编解码器,它通过多阶段多任务学习来缓解语义和声音能力之间的冲突。实验结果表明,XY-Tokenizer在语义和声音任务中的性能与类似比特率的先进编解码器相当,尽管这些现有编解码器通常只在一方面表现出色。具体来说,XY-Tokenizer实现了强大的文本对齐,超越了基于蒸馏的语义建模方法,如SpeechTokenizer和Mimi,同时保持重建音频与原始音频之间的说话人相似度为0.83。XY-Tokenizer的重建性能与当前先进的声音编解码器BigCodec相当,BigCodec在类似比特率下实现了说话人相似度得分为0.84。代码和模型可在https://github.com/gyt1145028706/XY-Tokenizer找到。
论文及项目相关链接
Summary
本文研究了语音编解码器在平衡语义丰富性和声音保真度方面的问题,并提出了一种新的编解码器XY-Tokenizer。通过多阶段多任务学习,XY-Tokenizer能够缓解语义和声音能力之间的冲突。实验结果表明,XY-Tokenizer在语义和声音任务上的性能与当前先进的编解码器相当,甚至在某些方面实现了超越。特别是在文本对齐方面,XY-Tokenizer超越了基于蒸馏的语义建模方法,如SpeechTokenizer和Mimi,同时保持了较高的声音相似性得分。该编解码器的代码和模型已在GitHub上公开。
Key Takeaways
- 现有语音编解码器在平衡语义丰富性和声音保真度方面存在挑战。
- XY-Tokenizer是一种新型编解码器,旨在缓解语义和声音能力之间的冲突。
- XY-Tokenizer通过多阶段多任务学习进行训练,提高了性能。
- XY-Tokenizer在语义和声音任务上的性能与当前先进的编解码器相当。
- XY-Tokenizer在文本对齐方面表现出色,超越了某些基于蒸馏的语义建模方法。
- XY-Tokenizer保持了较高的声音相似性得分,说明其音频重建性能良好。
点此查看论文截图

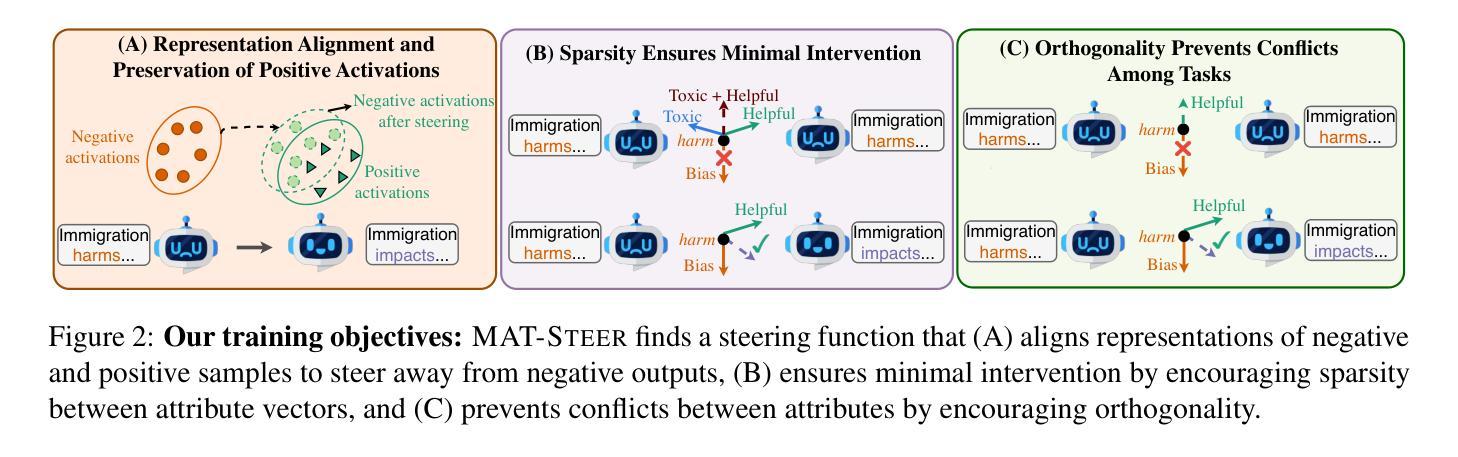
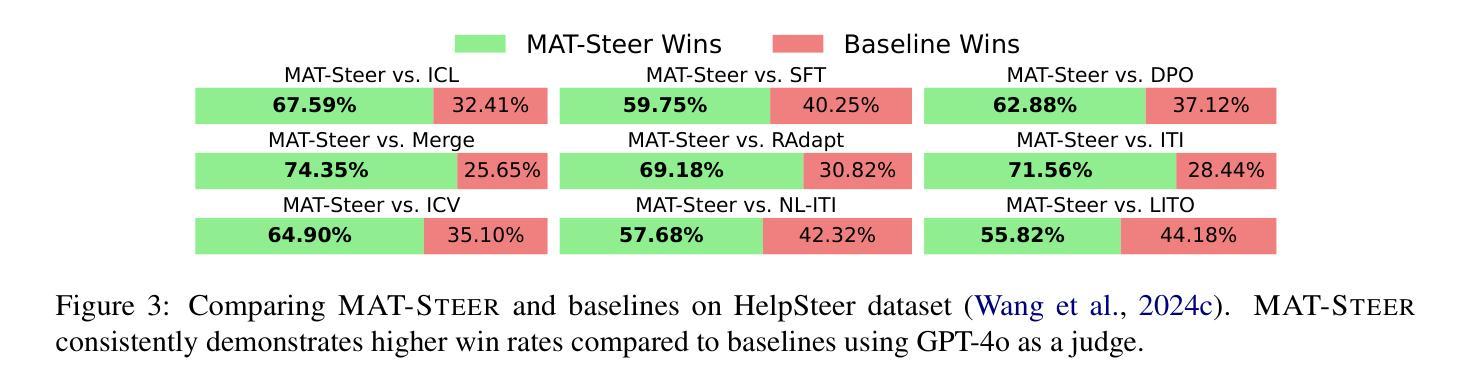
Multi-Attribute Steering of Language Models via Targeted Intervention
Authors:Duy Nguyen, Archiki Prasad, Elias Stengel-Eskin, Mohit Bansal
Inference-time intervention (ITI) has emerged as a promising method for steering large language model (LLM) behavior in a particular direction (e.g., improving helpfulness) by intervening on token representations without costly updates to the LLM’s parameters. However, existing ITI approaches fail to scale to multi-attribute settings with conflicts, such as enhancing helpfulness while also reducing toxicity. To address this, we introduce Multi-Attribute Targeted Steering (MAT-Steer), a novel steering framework designed for selective token-level intervention across multiple attributes. MAT-Steer learns steering vectors using an alignment objective that shifts the model’s internal representations of undesirable outputs closer to those of desirable ones while enforcing sparsity and orthogonality among vectors for different attributes, thereby reducing inter-attribute conflicts. We evaluate MAT-Steer in two distinct settings: (i) on question answering (QA) tasks where we balance attributes like truthfulness, bias, and toxicity; (ii) on generative tasks where we simultaneously improve attributes like helpfulness, correctness, and coherence. MAT-Steer outperforms existing ITI and parameter-efficient fine-tuning approaches across both task types (e.g., 3% average accuracy gain across QA tasks and 55.82% win rate against the best ITI baseline).
运行时干预(ITI)作为一种方法已经崭露头角,它通过干预令牌表示来引导大型语言模型(LLM)朝特定方向(例如,提高有用性)行为,而无需对LLM参数进行昂贵的更新。然而,现有的ITI方法无法扩展到具有冲突的多属性设置,例如增强有用性同时减少毒性。为解决这一问题,我们引入了多属性目标导向驾驶(MAT-Steer),这是一种新型驾驶框架,专为选择性令牌级干预多个属性而设计。MAT-Steer使用对齐目标学习驾驶向量,将模型对不良输出的内部表示转向良好输出的内部表示,同时在不同属性之间强制执行稀疏性和正交性,从而减少属性间的冲突。我们在两个独特的环境中评估了MAT-Steer:(i)问答(QA)任务中,我们平衡真实性、偏见和毒性等属性;(ii)生成任务中,我们同时提高有用性、正确性和连贯性等属性。MAT-Steer在两种任务类型中都优于现有的ITI和参数有效微调方法(例如,在QA任务中平均精度提高3%,对最佳ITI基准的胜率为55.82%)。
论文及项目相关链接
PDF ACL 2025 camera-ready, code link: https://github.com/duykhuongnguyen/MAT-Steer
Summary
大型语言模型(LLM)的行为可以通过干预令牌表示来进行引导,而无需昂贵的模型参数更新。现有方法难以处理多属性设置中的冲突问题,如同时提高有用性和降低毒性。我们提出了多属性目标引导(MAT-Steer)框架,用于选择性地对多个属性的令牌级别进行干预。MAT-Steer使用对齐目标来学习引导向量,将模型对不良输出的内部表示转向良好输出的表示,同时在不同属性之间强制执行稀疏性和正交性,从而减少属性间的冲突。在问答和生成任务上的评估表明,MAT-Steer在平衡真实性、偏见和毒性等属性以及同时提高有用性、正确性和连贯性等属性方面表现出色,优于现有方法。
Key Takeaways
- 现有大型语言模型(LLM)干预方法主要关注单一属性的干预。
- 多属性目标引导(MAT-Steer)框架被提出,用于处理多属性设置中的冲突问题。
- MAT-Steer使用对齐目标来学习引导向量,将不良输出向良好输出转移。
- MAT-Steer通过选择性令牌级别的干预来解决多个属性问题。
- 该框架通过强制执行稀疏性和正交性来减少不同属性之间的冲突。
- 在问答和生成任务上的评估显示,MAT-Steer在平衡多种属性方面表现出色。
点此查看论文截图

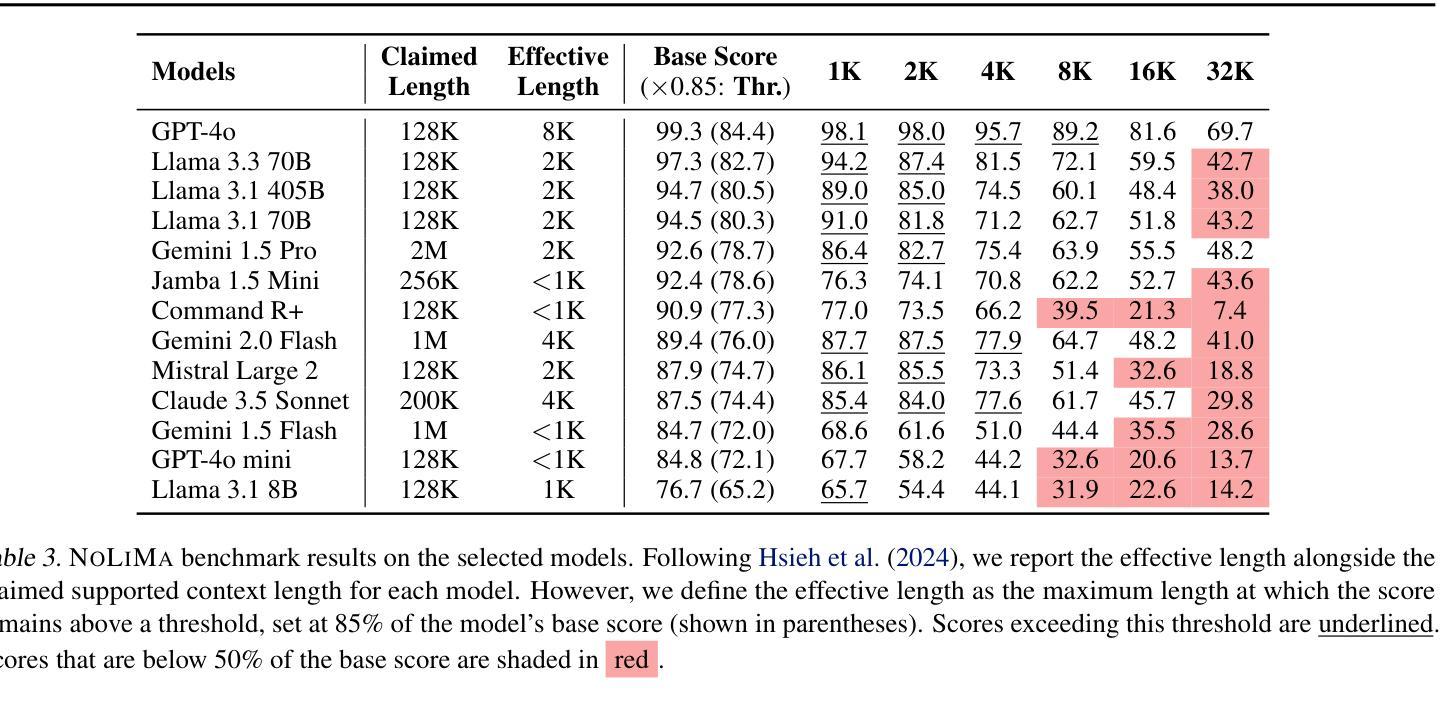
NoLiMa: Long-Context Evaluation Beyond Literal Matching
Authors:Ali Modarressi, Hanieh Deilamsalehy, Franck Dernoncourt, Trung Bui, Ryan A. Rossi, Seunghyun Yoon, Hinrich Schütze
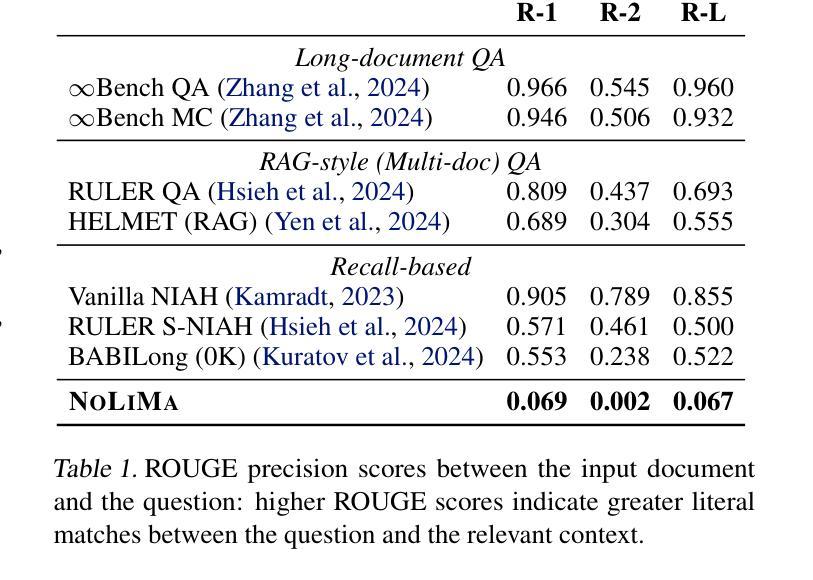
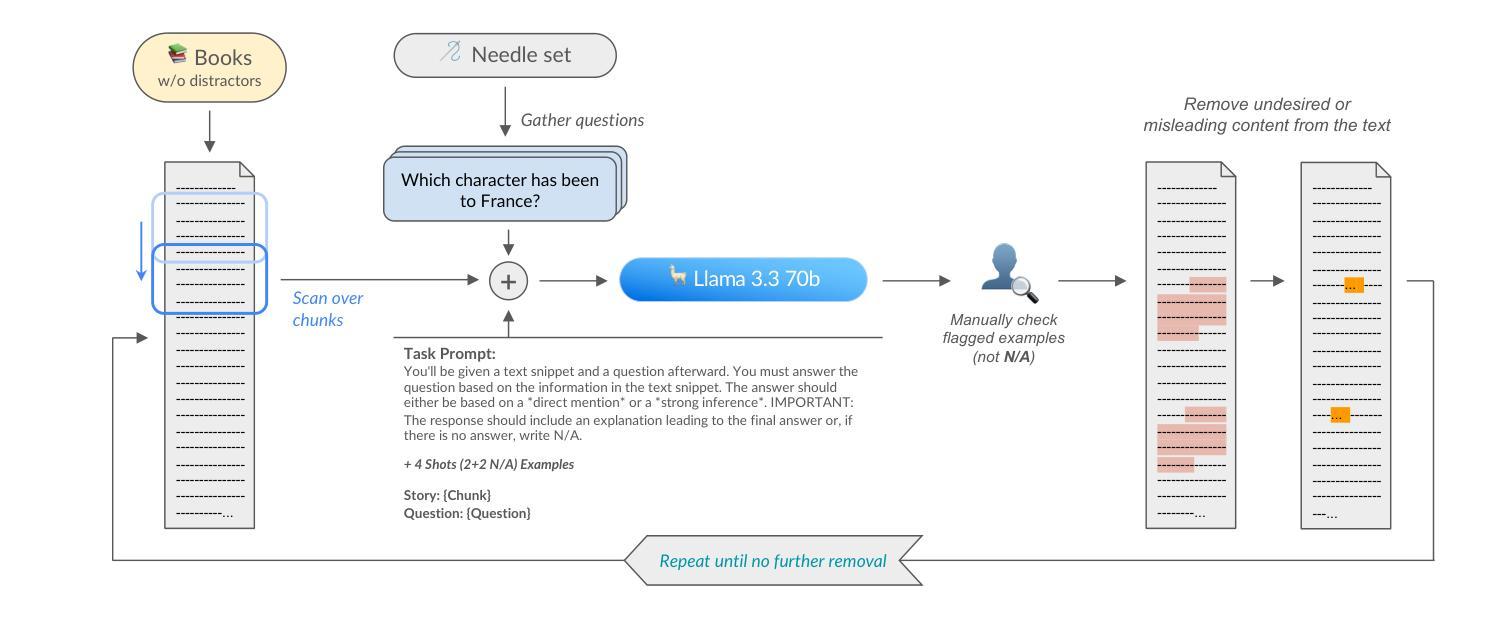
Recent large language models (LLMs) support long contexts ranging from 128K to 1M tokens. A popular method for evaluating these capabilities is the needle-in-a-haystack (NIAH) test, which involves retrieving a “needle” (relevant information) from a “haystack” (long irrelevant context). Extensions of this approach include increasing distractors, fact chaining, and in-context reasoning. However, in these benchmarks, models can exploit existing literal matches between the needle and haystack to simplify the task. To address this, we introduce NoLiMa, a benchmark extending NIAH with a carefully designed needle set, where questions and needles have minimal lexical overlap, requiring models to infer latent associations to locate the needle within the haystack. We evaluate 13 popular LLMs that claim to support contexts of at least 128K tokens. While they perform well in short contexts (<1K), performance degrades significantly as context length increases. At 32K, for instance, 11 models drop below 50% of their strong short-length baselines. Even GPT-4o, one of the top-performing exceptions, experiences a reduction from an almost-perfect baseline of 99.3% to 69.7%. Our analysis suggests these declines stem from the increased difficulty the attention mechanism faces in longer contexts when literal matches are absent, making it harder to retrieve relevant information. Even models enhanced with reasoning capabilities or CoT prompting struggle to maintain performance in long contexts. We publicly release the dataset and evaluation code at https://github.com/adobe-research/NoLiMa.
最近的大型语言模型(LLM)支持从128K到1M令牌的长上下文。评估这些能力的一种流行方法是“寻找大头针”(needle-in-a-haystack,NIAH)测试,该测试涉及从一堆无关的文本中找出相关的特定信息。这种方法的扩展包括增加干扰因素、事实链条和在情境中进行推理。然而,在这些基准测试中,模型可能会利用大头针和一堆文本之间的现有文字匹配来简化任务。为了解决这一问题,我们引入了NoLiMa基准测试,该测试在NIAH的基础上进行了扩展,提供了一个精心设计的大头针集,其中的问题和答案之间具有最小的词汇重叠,要求模型推断潜在关联以在大量文本中找到答案。我们评估了声称支持至少包含128K令牌上下文的13个流行的大型语言模型。它们在短上下文中的表现良好(<1K),但随着上下文长度的增加,性能会显著下降。例如,在32K的情况下,有11个模型的性能下降到其强大的短基线以下的一半。即使是表现最好的例外之一GPT-4o,也从近乎完美的基线(99.3%)下降到基线以下的正常水平(从学习到一些反常特性的提醒转变减少),面对模型的准确度较差也只能令其望尘莫及也远低于常理反应的快速确认回归指数问题随之成为现实中进一步努力的实践路。我们通过链接(https://github.com/adobe-research/NoLiMa)公开发布数据集和评估代码以面对较先进的输入评测此类方面科研公关的信心并保持公信诚免职责方的人员保持着预测自律和平面张进度公布的体验力争跟定的科学技术速度而且保证准确性并接受公众监督。我们的分析表明这些下降源于在较长上下文中当字面匹配缺失时注意力机制所面临的难度增加,这使得检索相关信息变得更加困难。即使在模型中增加了推理能力或使用复杂推理提示也无法在长期上下文中保持性能稳定。
论文及项目相关链接
PDF Accepted at ICML 2025
摘要
近期的大型语言模型(LLM)支持从128K到1M的长文本上下文。评估这些能力的一种流行方法是“众里寻针”(needle-in-a-haystack)测试,该测试旨在从大量的不相关文本(如海量的草堆中找到“针”,即相关的信息)。但在此基准测试中,模型会利用现有字面匹配简化任务。为解决此问题,我们推出了NoLiMa基准测试,它是NIAH的扩展版,其中包含精心设计的“针”集合,问题与“针”之间的词汇重叠最少,要求模型发现潜在的关联以在大量的草堆中找到那根“针”。我们评估了声称能支持至少128K令牌长度的13个流行LLM。它们在短文本中的表现良好,但随着上下文长度的增加,性能会显著下降。例如,在32K时,有11个模型的性能下降到其强大的短基线的一半以下。即使是表现最佳的GPT-4o模型,也从近乎完美的基线(99.3%)降至69.7%。分析表明,这些下降源于在没有字面匹配的情况下,长上下文中注意力机制所面临的难度增加,使得难以检索相关信息。即使使用推理能力增强或带有CoT提示的模型也很难维持长期性能。我们在https://github.com/adobe-research/NoLiMa公开发布数据集和评估代码。
要点归纳
- 大型语言模型(LLM)支持从长文本上下文中获取信息。
- “众里寻针”(NIAH)测试是评估LLM处理长文本能力的方法之一。
- 现有基准测试存在模型利用字面匹配的局限性。
- NoLiMa基准测试扩展了NIAH测试,要求模型发现潜在关联而非依赖字面匹配。
- 在处理长文本时,大多数LLM性能显著下降。
- 性能下降源于注意力机制在长文本中面临难度增加的问题。
点此查看论文截图


LCFO: Long Context and Long Form Output Dataset and Benchmarking
Authors:Marta R. Costa-jussà, Pierre Andrews, Mariano Coria Meglioli, Joy Chen, Joe Chuang, David Dale, Christophe Ropers, Alexandre Mourachko, Eduardo Sánchez, Holger Schwenk, Tuan Tran, Arina Turkatenko, Carleigh Wood
This paper presents the Long Context and Form Output (LCFO) benchmark, a novel evaluation framework for assessing gradual summarization and summary expansion capabilities across diverse domains. LCFO consists of long input documents (5k words average length), each of which comes with three summaries of different lengths (20%, 10%, and 5% of the input text), as well as approximately 15 questions and answers (QA) related to the input content. Notably, LCFO also provides alignments between specific QA pairs and corresponding summaries in 7 domains. The primary motivation behind providing summaries of different lengths is to establish a controllable framework for generating long texts from shorter inputs, i.e. summary expansion. To establish an evaluation metric framework for summarization and summary expansion, we provide human evaluation scores for human-generated outputs, as well as results from various state-of-the-art large language models (LLMs). GPT-4o-mini achieves best human scores among automatic systems in both summarization and summary expansion tasks (~ +10% and +20%, respectively). It even surpasses human output quality in the case of short summaries (~ +7%). Overall automatic metrics achieve low correlations with human evaluation scores (~ 0.4) but moderate correlation on specific evaluation aspects such as fluency and attribution (~ 0.6).
本文介绍了长语境与形式输出(LCFO)基准测试,这是一个新的评估框架,用于评估不同领域的渐进摘要和摘要扩展能力。LCFO包含长输入文档(平均长度5000字),每个文档都带有三个不同长度的摘要(分别为输入文本的20%、10%和5%),以及大约与输入内容相关的15个问题和答案(QA)。值得注意的是,LCFO还提供了7个领域中特定QA对和相应摘要之间的对齐。提供不同长度的摘要的主要动机是建立一个可控的框架,用于从较短的输入生成较长的文本,即摘要扩展。为了建立摘要和摘要扩展的评价指标框架,我们提供了人类生成输出的人类评价分数,以及来自各种最新先进的大型语言模型(LLM)的结果。GPT-4o-mini在摘要和摘要扩展任务中均获得最佳人类评分(分别提高了约10%和20%),甚至在短摘要的情况下超过了人类输出的质量(提高了约7%)。总体而言,自动度量与人类评价分数的相关性较低(约0.4),但在特定的评价方面(如流畅度和属性)达到中等相关性(约0.6)。
论文及项目相关链接
Summary:
本文提出了Long Context and Form Output(LCFO)基准测试,这是一个新的评估框架,用于评估跨不同领域的渐进摘要和摘要扩展能力。LCFO包含平均长度5000字的长期输入文档,每个文档都包含三个不同长度的摘要(分别占输入文本的20%、10%和5%),以及大约与输入内容相关的15个问题和答案。LCFO还提供7个领域中的特定问答对与相应摘要之间的对齐。该基准测试的主要动机是建立从较短的输入生成长文本的可控框架,即摘要扩展。为了建立摘要和摘要扩展的评价指标框架,我们提供了对人工生成输出的人类评价分数,以及来自各种最新大型语言模型(LLM)的结果。GPT-4o-mini在摘要和摘要扩展任务中的自动系统中表现最佳,分别提高了约10%和20%,甚至在短摘要的情况下超过了人类输出质量。总体而言,自动指标与人类评价分数的相关性较低(约0.4),但在特定评价方面如流畅度和归属度方面的相关性为中等(约0.6)。
Key Takeaways:
- LCFO基准测试包含长文档和多种长度的摘要,以及相关的问答对,用于评估摘要和摘要扩展的能力。
- 摘要不同长度的提供是为了建立从短输入生成长文本的可控框架。
- GPT-4o-mini在摘要和摘要扩展任务中表现最佳,超过了一些自动系统和其他LLM。
- 在短摘要的情况下,GPT-4o-mini甚至超过了人类输出质量。
- 自动评估指标与人类评价分数的总体相关性较低,但在特定方面如流畅度和归属度的相关性为中等。
- LCFO基准测试提供了人类评价分数,这有助于更准确地评估模型性能。
点此查看论文截图

A Runtime-Adaptive Transformer Neural Network Accelerator on FPGAs
Authors:Ehsan Kabir, Austin R. J. Downey, Jason D. Bakos, David Andrews, Miaoqing Huang
Transformer neural networks (TNN) excel in natural language processing (NLP), machine translation, and computer vision (CV) without relying on recurrent or convolutional layers. However, they have high computational and memory demands, particularly on resource-constrained devices like FPGAs. Moreover, transformer models vary in processing time across applications, requiring custom models with specific parameters. Designing custom accelerators for each model is complex and time-intensive. Some custom accelerators exist with no runtime adaptability, and they often rely on sparse matrices to reduce latency. However, hardware designs become more challenging due to the need for application-specific sparsity patterns. This paper introduces ADAPTOR, a runtime-adaptive accelerator for dense matrix computations in transformer encoders and decoders on FPGAs. ADAPTOR enhances the utilization of processing elements and on-chip memory, enhancing parallelism and reducing latency. It incorporates efficient matrix tiling to distribute resources across FPGA platforms and is fully quantized for computational efficiency and portability. Evaluations on Xilinx Alveo U55C data center cards and embedded platforms like VC707 and ZCU102 show that our design is 1.2$\times$ and 2.87$\times$ more power efficient than the NVIDIA K80 GPU and the i7-8700K CPU respectively. Additionally, it achieves a speedup of 1.7 to 2.25$\times$ compared to some state-of-the-art FPGA-based accelerators.
本文介绍了一种用于FPGA上变压器编码器解码器中密集矩阵运算的运行时自适应加速器ADAPTOR。变压器神经网络(TNN)在自然语言处理(NLP)、机器翻译和计算机视觉(CV)方面表现出色,无需依赖循环或卷积层。然而,它们对计算和内存的需求很高,特别是在FPGA等资源受限的设备上。此外,变压器模型在不同应用中的处理时间各不相同,需要具有特定参数的定制模型。设计每个模型的定制加速器是复杂且耗时的。虽然存在一些没有运行时适应性的定制加速器,但它们通常依赖于稀疏矩阵来减少延迟。然而,由于需要应用特定的稀疏模式,硬件设计变得更加具有挑战性。尽管有些挑战摆在面前,但该论文推出的ADAPTOR能有效提升处理单元和片上内存的利用率,强化并行处理并减少延迟。它采用高效的矩阵切片技术,能够在FPGA平台上分配资源,并为了计算效率和便携性进行全面量化。在Xilinx Alveo U55C数据中心卡和VC707及ZCU102等嵌入式平台上的评估表明,我们的设计相较于NVIDIA K80 GPU和i7-8700K CPU分别提高了1.2倍和2.87倍的能效。此外,相较于一些先进的FPGA加速器,它实现了1.7至2.25倍的速度提升。
论文及项目相关链接
PDF arXiv admin note: text overlap with arXiv:2409.14023
Summary
本文介绍了一种名为ADAPTOR的、能在FPGA上运行的、具有自适应性的加速器,用于提升Transformer神经网络中的密集矩阵运算效率。该加速器通过优化资源分配和提高并行性,增强了处理单元和片上内存的利用率,从而降低延迟。它在不同FPGA平台间采用矩阵分块技术以提高效率并保障可移植性。评估结果表明,相比于NVIDIA K80 GPU和i7-8700K CPU,ADAPTOR设计更加节能高效,同时与一些先进的FPGA加速器相比,其速度提升了1.7至2.25倍。
Key Takeaways
- ADAPTOR是一种针对FPGA的自适应加速器,用于提升Transformer神经网络中的密集矩阵运算效率。
- 该加速器通过优化资源分配和提高并行性,增强了处理单元和片上内存的利用率。
- ADAPTOR通过矩阵分块技术实现资源分配的优化,以适应不同的FPGA平台。
- 该设计具有高度的计算效率和可移植性。
- 与NVIDIA K80 GPU和i7-8700K CPU相比,ADAPTOR设计更加节能高效。
- 与一些先进的FPGA加速器相比,ADAPTOR实现了1.7至2.25倍的速度提升。
点此查看论文截图

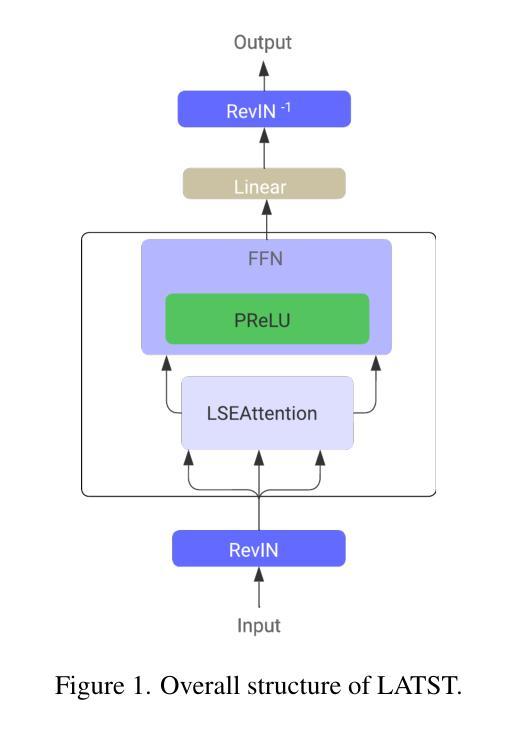
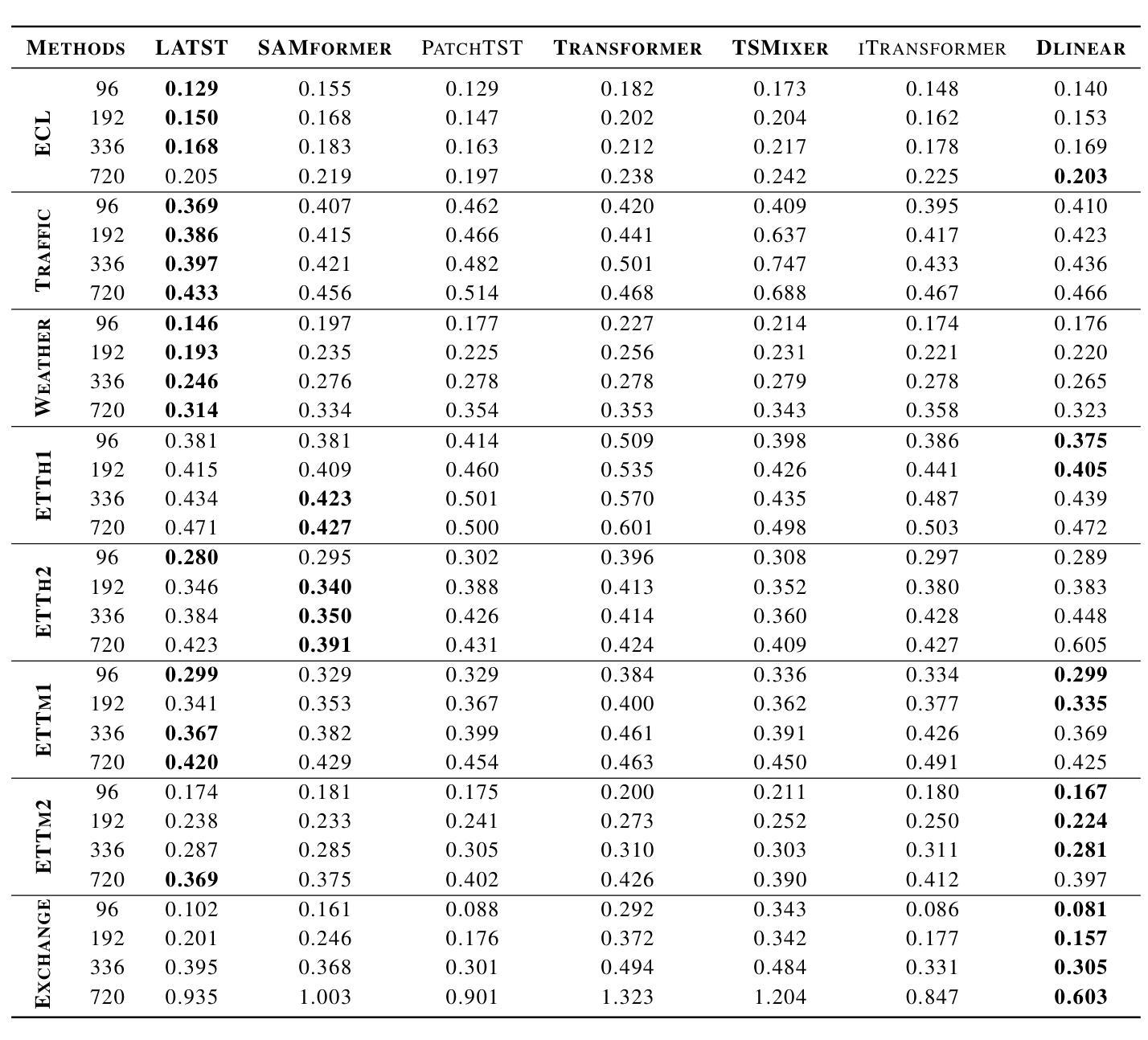
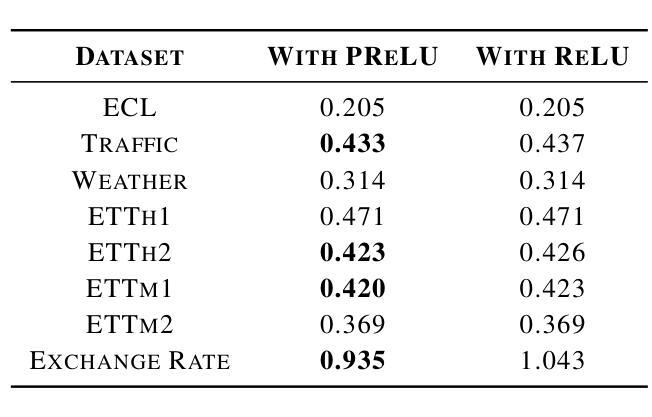
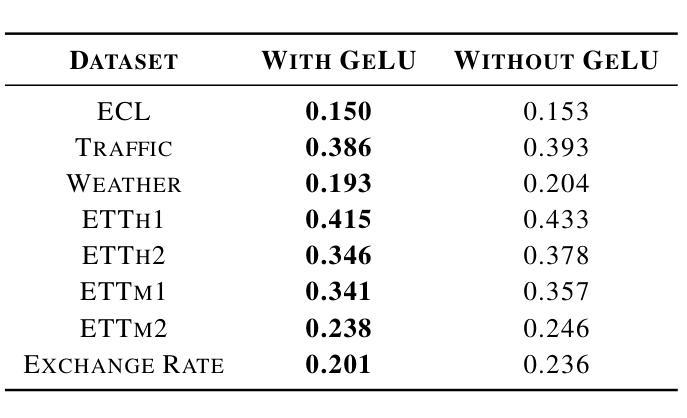
LATST: Are Transformers Necessarily Complex for Time-Series Forecasting
Authors:Dizhen Liang
Transformer-based architectures have achieved remarkable success in natural language processing and computer vision. However, their performance in multivariate long-term forecasting often falls short compared to simpler linear baselines. Previous research has identified the traditional attention mechanism as a key factor limiting their effectiveness in this domain. To bridge this gap, we introduce LATST, a novel approach designed to mitigate entropy collapse and training instability common challenges in Transformer-based time series forecasting. We rigorously evaluate LATST across multiple real-world multivariate time series datasets, demonstrating its ability to outperform existing state-of-the-art Transformer models. Notably, LATST manages to achieve competitive performance with fewer parameters than some linear models on certain datasets, highlighting its efficiency and effectiveness.
基于Transformer的架构在自然语言处理和计算机视觉领域取得了显著的成功。然而,它们在多元长期预测方面的性能往往不如简单的线性基线。之前的研究已经确定传统的注意力机制是限制其在该领域效力的关键因素。为了弥补这一差距,我们引入了LATST,这是一种旨在缓解基于Transformer的时间序列预测中常见的熵崩溃和训练不稳定问题的新型方法。我们在多个现实世界多元时间序列数据集上对LATST进行了严格评估,证明了其超越现有最先进的Transformer模型的能力。值得注意的是,LATST在某些数据集上用更少的参数实现了与某些线性模型相当的性能,这凸显了其高效性和有效性。
论文及项目相关链接
PDF 8 pages with referencing, 1 figure, 5 tables
Summary:Transformer架构在自然语言处理和计算机视觉领域取得了显著的成功,但在多元长期预测方面表现不佳。为了弥补这一缺陷,提出了名为LATST的新方法,解决了Transformer时间序列预测中的熵崩溃和训练不稳定问题。在多个真实世界的多元时间序列数据集上,LATST表现出卓越的性能,与一些线性模型相比参数更少,性能更优异。
Key Takeaways:
- Transformer架构在NLP和CV领域表现优秀,但在多元长期预测方面存在性能短板。
- 传统的注意力机制是限制Transformer在多元时间序列预测中效力的关键因素。
- LATST方法旨在解决Transformer面临的熵崩溃和训练不稳定问题。
- LATST在多个真实世界的多元时间序列数据集上表现出卓越性能。
- LATST在某些数据集上的性能与线性模型相当,但参数更少,体现了其高效性。
- LATST的引入为Transformer模型在多元时间序列预测方面的改进提供了新思路。
点此查看论文截图



Planning Anything with Rigor: General-Purpose Zero-Shot Planning with LLM-based Formalized Programming
Authors:Yilun Hao, Yang Zhang, Chuchu Fan
While large language models (LLMs) have recently demonstrated strong potential in solving planning problems, there is a trade-off between flexibility and complexity. LLMs, as zero-shot planners themselves, are still not capable of directly generating valid plans for complex planning problems such as multi-constraint or long-horizon tasks. On the other hand, many frameworks aiming to solve complex planning problems often rely on task-specific preparatory efforts, such as task-specific in-context examples and pre-defined critics/verifiers, which limits their cross-task generalization capability. In this paper, we tackle these challenges by observing that the core of many planning problems lies in optimization problems: searching for the optimal solution (best plan) with goals subject to constraints (preconditions and effects of decisions). With LLMs’ commonsense, reasoning, and programming capabilities, this opens up the possibilities of a universal LLM-based approach to planning problems. Inspired by this observation, we propose LLMFP, a general-purpose framework that leverages LLMs to capture key information from planning problems and formally formulate and solve them as optimization problems from scratch, with no task-specific examples needed. We apply LLMFP to 9 planning problems, ranging from multi-constraint decision making to multi-step planning problems, and demonstrate that LLMFP achieves on average 83.7% and 86.8% optimal rate across 9 tasks for GPT-4o and Claude 3.5 Sonnet, significantly outperforming the best baseline (direct planning with OpenAI o1-preview) with 37.6% and 40.7% improvements. We also validate components of LLMFP with ablation experiments and analyzed the underlying success and failure reasons. Project page: https://sites.google.com/view/llmfp.
虽然大型语言模型(LLM)最近在解决规划问题方面表现出了强大的潜力,但在灵活性和复杂性之间存在权衡。LLM作为零射击规划者本身,仍然无法为复杂的规划问题如多约束或长期任务直接生成有效的计划。另一方面,许多旨在解决复杂规划问题的框架通常依赖于特定的任务准备努力,如特定任务的上下文示例和预先定义的批评者/验证器,这限制了它们的跨任务泛化能力。
在本文中,我们通过观察许多规划问题的核心在于优化问题来解决这些挑战:在目标受约束(决策的先决条件和影响)的情况下,寻找最优解决方案(最佳计划)。利用LLM的常识、推理和编程能力,这为基于LLM的通用规划方法打开了可能性。
论文及项目相关链接
PDF 57 pages, 25 figures, 15 tables
Summary
大型语言模型(LLM)在解决规划问题上展现出巨大潜力,但在灵活性与复杂性之间存在权衡。LLM作为零样本规划器,尚无法直接为复杂规划问题生成有效方案,如多约束或长期任务。而许多旨在解决复杂规划问题的框架,需要依赖特定任务的准备性工作,如特定上下文示例和预先定义的批评者/验证器,这限制了其跨任务泛化能力。本文观察到规划问题的核心在于优化问题,即寻找受约束的目标下的最优解决方案。利用LLM的常识、推理和编程能力,为规划问题提出了一种基于LLM的通用方法。受此启发,本文提出了LLMFP框架,该框架利用LLM从规划问题中捕获关键信息,并将其正式制定为解决优化问题,无需特定任务示例。在多种规划问题上的实验表明,LLMFP框架在9项任务中平均达到83.7%和86.8%的最优率,显著优于最佳基线方法,分别提高了37.6%和40.7%。
Key Takeaways
- LLM在解决规划问题时面临灵活性与复杂性之间的权衡。
- LLM尚无法直接生成复杂规划问题的有效方案。
- 许多解决规划问题的框架因依赖特定任务准备而限制了其跨任务泛化能力。
- 规划问题的核心在于寻找受约束目标下的最优解决方案。
- LLMFP框架利用LLM的能力将规划问题制定为解决优化问题。
- LLMFP框架在多种规划问题上表现出显著效果,优于其他基线方法。
点此查看论文截图

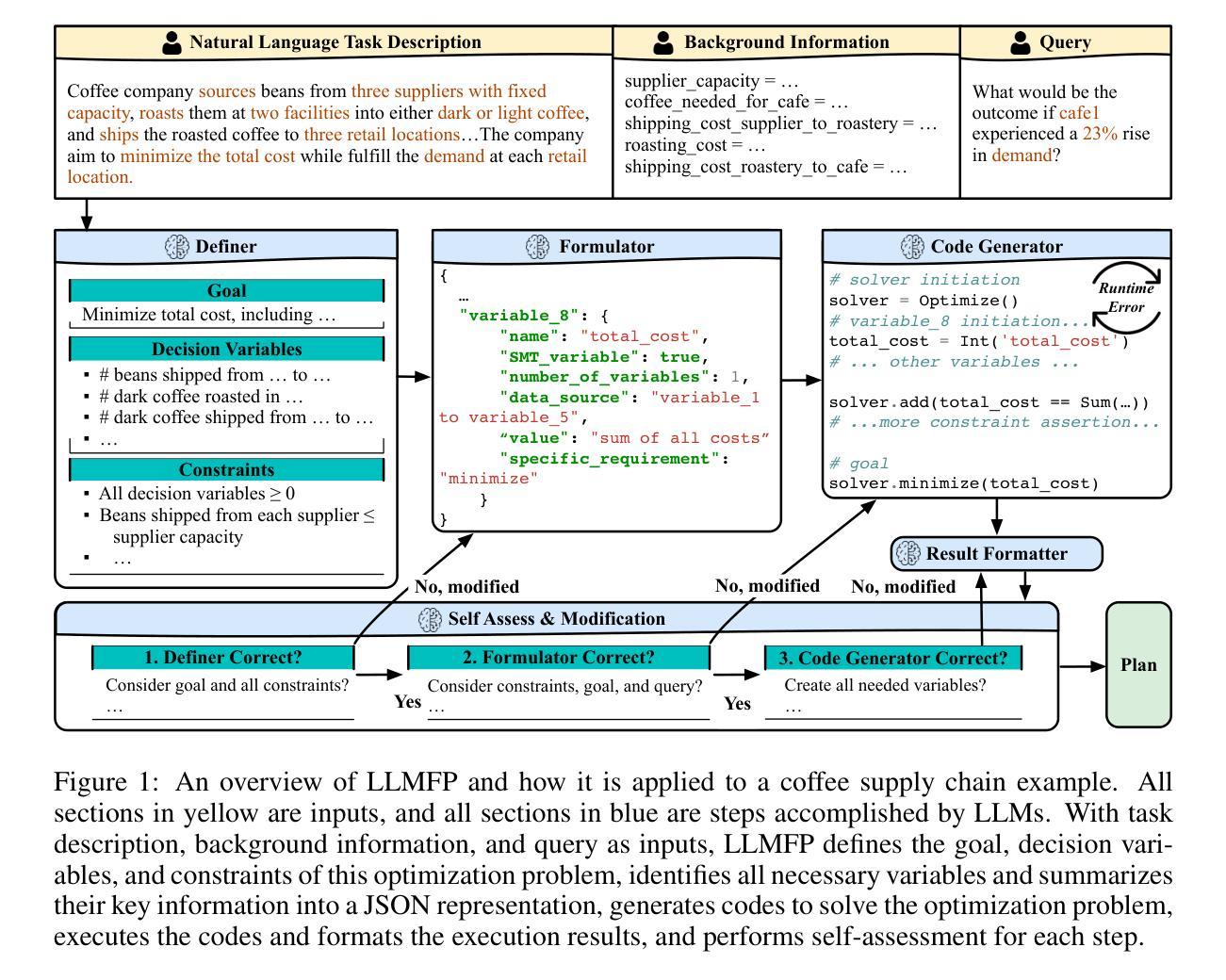

LASeR: Learning to Adaptively Select Reward Models with Multi-Armed Bandits
Authors:Duy Nguyen, Archiki Prasad, Elias Stengel-Eskin, Mohit Bansal
Reward Models (RMs) are crucial to aligning large language models (LLMs), but the degree to which an RM specialized to one task (e.g. writing) generalizes to new tasks (e.g. math) is often not known a priori, often making using only one fixed RM to train LLMs suboptimal. However, optimizing LLMs with multiple RMs simultaneously can incur a prohibitively high computational cost and lead to conflicting signals from different RMs that may degrade performance. To address these challenges, we introduce LASeR (Learning to Adaptively Select Rewards), which frames reward model selection as a multi-armed bandit problem, efficiently and iteratively training LLMs using multiple RMs by selecting the most well-suited RM for each instance. On commonsense and math reasoning tasks, we show that LASeR boosts iterative LLM training, improving the absolute average accuracy of Llama-3-8B over three datasets by 2.67% over an ensemble of RM scores while also showing superior efficiency (e.g., a 2x speedup). Moreover, on WildChat (open-ended instruction-following tasks), LASeR leads to a 72.69% AlpacaEval win rate over the RM score ensemble baseline. Extending to long-context generation, LASeR improves by 2.96 F1 points (avg.) on single-document QA tasks and 2.97 F1 points on few-shot learning over the RM score ensemble baseline with best-of-n sampling.
奖励模型(RM)对于对齐大型语言模型(LLM)至关重要,但对于针对某一任务(例如写作)专业化的RM推广到新任务(例如数学)的程度往往事先未知,因此通常使用单一固定RM来训练LLM并不理想。然而,同时使用多个RM优化LLM会带来过高的计算成本,并可能导致来自不同RM的相互冲突的信号,从而可能降低性能。为了解决这些挑战,我们引入了LASeR(自适应选择奖励学习),它将奖励模型的选择构造成一个多臂老虎机问题,通过为每个实例选择最合适的RM,有效地迭代训练LLM。在常识和数学推理任务中,我们证明了LASeR可以提升迭代LLM训练的效果,在三个数据集上,Llama-3-8B的绝对平均准确率相对于RM分数集合提高了2.67%,同时显示出更高的效率(例如,速度提高一倍)。此外,在WildChat(开放式指令遵循任务)上,LASeR的胜率高于RM分数集合基线,达到72.69%。在长文本生成方面,LASeR在单文档问答任务上的F1分数提高了2.96点(平均值),在few-shot学习上的F1分数提高了2.97点,优于RM分数集合基线并采用了最佳n采样策略。
论文及项目相关链接
PDF 28 pages; First two authors contributed equally. Code: https://github.com/duykhuongnguyen/LASeR-MAB
Summary
奖励模型(RM)对于对齐大型语言模型(LLM)至关重要,但针对特定任务(例如写作)的RM在新任务(例如数学)上的通用性往往未知,这使得仅使用一个固定RM来训练LLM通常不是最优的。然而,同时使用多个RM优化LLM会带来过高的计算成本,并且可能由于不同RM之间的冲突信号而降低性能。为解决这些挑战,我们提出了LASeR(学习自适应选择奖励),它将奖励模型的选择视为一个多臂老虎机问题,通过选择最适合每个实例的RM,有效地迭代训练LLM。在常识和数学推理任务上,LASeR提升了迭代LLM的训练效果,提高了Llama-3-8B模型在三个数据集上的平均准确率2.67%,同时显示出更高的效率(例如,速度提升2倍)。此外,在WildChat(开放式指令遵循任务)上,LASeR的胜率较RM分数集合基线提高了72.69%。在长期上下文生成任务中,LASeR在单文档问答任务和少样本学习上的F1分数分别提高了2.96和2.97。
Key Takeaways
- 奖励模型(RM)在大型语言模型(LLM)的对齐中起关键作用,但特定任务的RM在新任务上的通用性未知。
- 仅使用固定RM训练LLM通常不是最优的。
- 同时使用多个RM进行优化可能导致高计算成本和性能降低,因为不同RM之间可能存在冲突信号。
- LASeR通过选择最适合每个实例的RM,有效地迭代训练LLM。
- LASeR在常识和数学推理任务上提升了LLM的训练效果。
- LASeR在WildChat上的胜率较RM分数集合基线有显著提升。
点此查看论文截图

FAMOUS: Flexible Accelerator for the Attention Mechanism of Transformer on UltraScale+ FPGAs
Authors:Ehsan Kabir, Md. Arafat Kabir, Austin R. J. Downey, Jason D. Bakos, David Andrews, Miaoqing Huang
Transformer neural networks (TNNs) are being applied across a widening range of application domains, including natural language processing (NLP), machine translation, and computer vision (CV). Their popularity is largely attributed to the exceptional performance of their multi-head self-attention blocks when analyzing sequential data and extracting features. To date, there are limited hardware accelerators tailored for this mechanism, which is the first step before designing an accelerator for a complete model. This paper proposes \textit{FAMOUS}, a flexible hardware accelerator for dense multi-head attention (MHA) computation of TNNs on field-programmable gate arrays (FPGAs). It is optimized for high utilization of processing elements and on-chip memories to improve parallelism and reduce latency. An efficient tiling of large matrices has been employed to distribute memory and computing resources across different modules on various FPGA platforms. The design is evaluated on Xilinx Alveo U55C and U200 data center cards containing Ultrascale+ FPGAs. Experimental results are presented that show that it can attain a maximum throughput, number of parallel attention heads, embedding dimension and tile size of 328 (giga operations/second (GOPS)), 8, 768 and 64 respectively on the U55C. Furthermore, it is 3.28$\times$ and 2.6$\times$ faster than the Intel Xeon Gold 5220R CPU and NVIDIA V100 GPU respectively. It is also 1.3$\times$ faster than the fastest state-of-the-art FPGA-based accelerator.
Transformer神经网络(TNNs)正被广泛应用于包括自然语言处理(NLP)、机器翻译和计算机视觉(CV)在内的多个应用领域。它们的受欢迎程度主要归功于其多头自注意力块在分析序列数据和提取特征时的出色性能。迄今为止,针对这一机制的硬件加速器还很有限,这是设计完整的加速器之前的第一步。本文提出了面向FPGA的Transformer神经网络密集多头注意力(MHA)计算的灵活硬件加速器FAMOUS。它针对处理元件和片上内存的高利用率进行了优化,以提高并行性和降低延迟。采用大型矩阵的有效分块技术,将内存和计算资源分配给不同FPGA平台上的不同模块。该设计在Xilinx Alveo U55C和U200数据中心卡(包含Ultrascale+ FPGA)上进行了评估。实验结果表明,在U55C上,其最大吞吐量、并行注意力头数、嵌入维度和分块大小分别为328(吉操作/秒(GOPS))、8、768和64。此外,它比Intel Xeon Gold 5220R CPU和NVIDIA V100 GPU分别快3.28倍和2.6倍。它还比目前最先进的FPGA加速器快1.3倍。
论文及项目相关链接
PDF arXiv admin note: text overlap with arXiv:2409.13975
摘要
本文提出一种针对现场可编程门阵列(FPGA)上Transformer神经网络(TNN)密集多头注意力(MHA)计算的灵活硬件加速器FAMOUS。该设计优化处理元件和片上内存的利用率,以提高并行性并减少延迟。采用大型矩阵的有效分块,在不同FPGA平台上的各个模块间分配内存和计算资源。在Xilinx Alveo U55C和U200数据中心卡上评估设计,实验结果表明,其最大吞吐量、并行注意力头数、嵌入维度和分块大小分别为328GOPS、8、768和64。与Intel Xeon Gold 5220R CPU和NVIDIA V100 GPU相比,分别快3.28倍和2.6倍。与目前最先进的FPGA加速器相比,快1.3倍。
关键见解
- 本文介绍了一种针对Transformer神经网络(TNN)的多头注意力(MHA)计算的硬件加速器FAMOUS,特别适用于现场可编程门阵列(FPGA)。
- FAMOUS设计优化了处理元件和片上内存的利用率,以提高并行性和减少延迟。
- 通过矩阵分块,更有效地分配内存和计算资源。
- 在Xilinx Alveo U55C和U200平台上进行的实验评估表明,FAMOUS具有高性能表现。
- 与其他处理器相比,如Intel Xeon Gold 5220R CPU和NVIDIA V100 GPU,FAMOUS表现出更高的速度优势。
- FAMOUS的性能优于当前最先进的FPGA加速器。
- 此技术为针对TNNs的硬件加速器的进一步发展奠定了基础。
点此查看论文截图