⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-11 更新
Go to Zero: Towards Zero-shot Motion Generation with Million-scale Data
Authors:Ke Fan, Shunlin Lu, Minyue Dai, Runyi Yu, Lixing Xiao, Zhiyang Dou, Junting Dong, Lizhuang Ma, Jingbo Wang
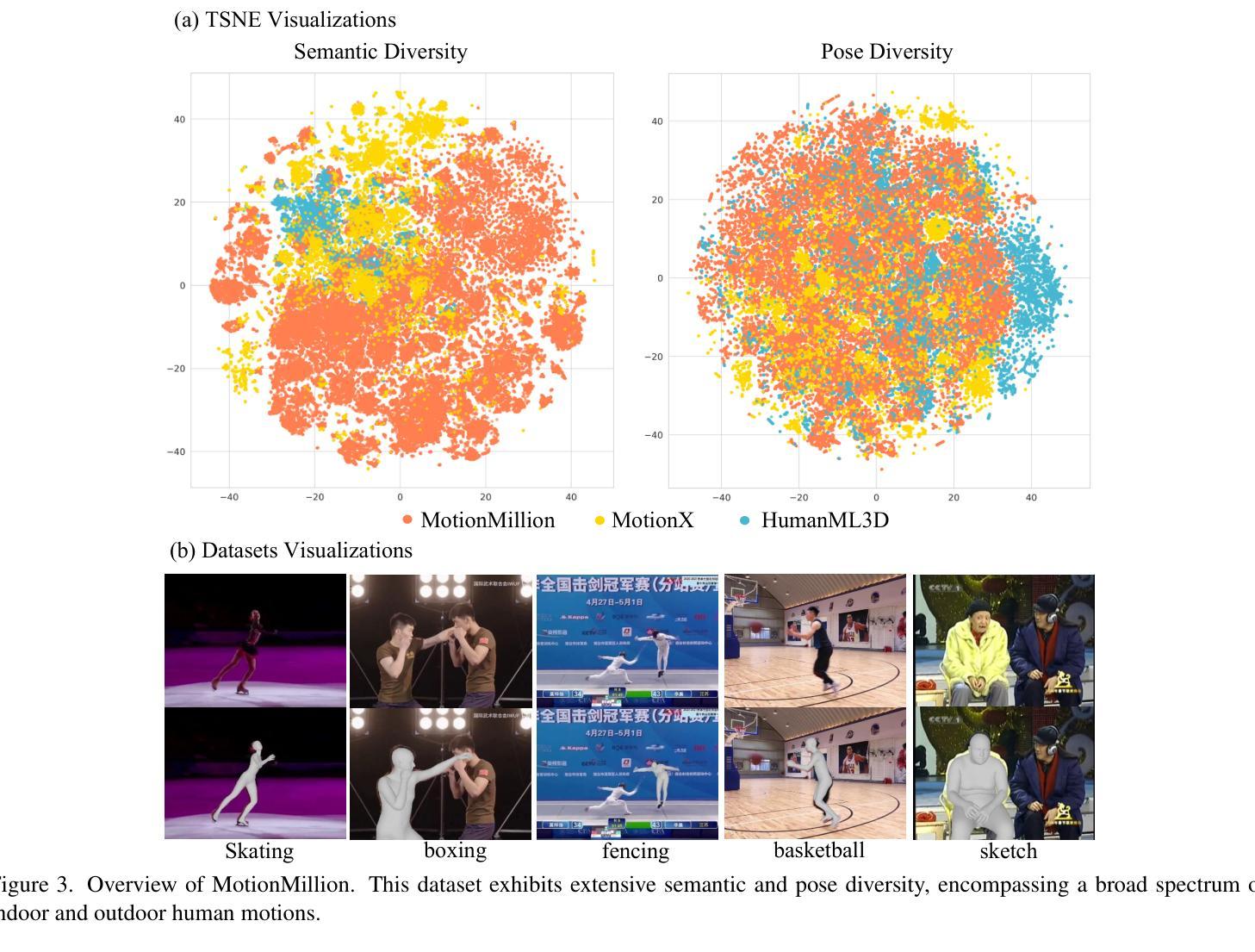
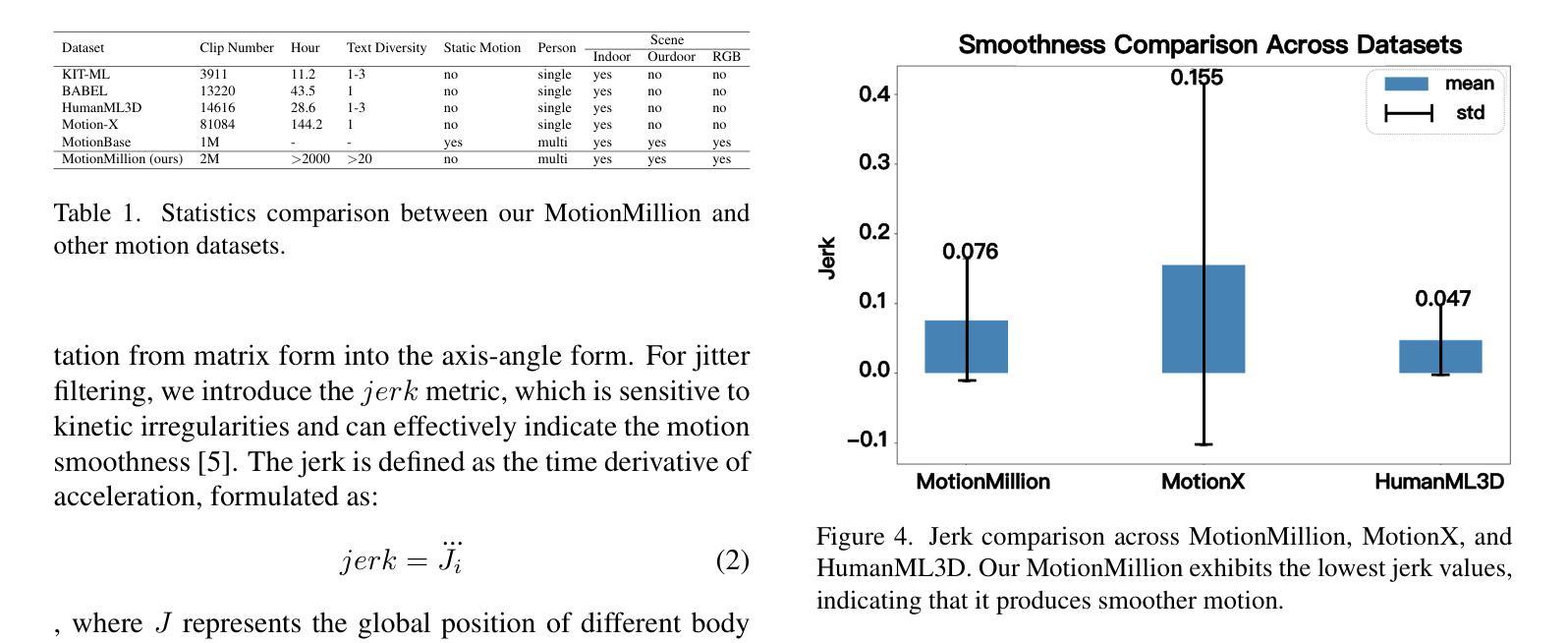
Generating diverse and natural human motion sequences based on textual descriptions constitutes a fundamental and challenging research area within the domains of computer vision, graphics, and robotics. Despite significant advancements in this field, current methodologies often face challenges regarding zero-shot generalization capabilities, largely attributable to the limited size of training datasets. Moreover, the lack of a comprehensive evaluation framework impedes the advancement of this task by failing to identify directions for improvement. In this work, we aim to push text-to-motion into a new era, that is, to achieve the generalization ability of zero-shot. To this end, firstly, we develop an efficient annotation pipeline and introduce MotionMillion-the largest human motion dataset to date, featuring over 2,000 hours and 2 million high-quality motion sequences. Additionally, we propose MotionMillion-Eval, the most comprehensive benchmark for evaluating zero-shot motion generation. Leveraging a scalable architecture, we scale our model to 7B parameters and validate its performance on MotionMillion-Eval. Our results demonstrate strong generalization to out-of-domain and complex compositional motions, marking a significant step toward zero-shot human motion generation. The code is available at https://github.com/VankouF/MotionMillion-Codes.
基于文本描述生成多样且自然的人类动作序列,是计算机视觉、图形学和机器人领域中的一个基本且具挑战性的研究方向。尽管该领域已取得了重大进展,但当前的方法常常面临零样本泛化能力的挑战,这主要归因于训练数据集的大小有限。此外,由于缺乏全面的评估框架,无法确定改进方向,阻碍了该任务的进展。在这项工作中,我们致力于将文本到运动的转换推向一个新的时代,即实现零样本的泛化能力。为此,我们首先开发了一个高效的注释管道,并引入了MotionMillion(迄今为止最大的人类运动数据集),包含超过2000小时和200万条高质量的运动序列。此外,我们还提出了MotionMillion-Eval,这是评估零样本运动生成的最全面的基准。利用可扩展的架构,我们将模型扩展到7亿参数,并在MotionMillion-Eval上验证了其性能。我们的结果表明,对于域外和复杂的组合动作具有很强的泛化能力,这是朝着零样本人类运动生成迈出的重要一步。代码可在https://github.com/VankouF/MotionMillion-Codes找到。
论文及项目相关链接
PDF Project Page: https://vankouf.github.io/MotionMillion/
Summary
文本描述了一个关于计算机视觉、图形学和机器人领域中基于文本描述生成多样化和自然的人类运动序列的研究领域。文章介绍了当前面临的挑战,如零样本泛化能力和评估框架的不足。为解决这些问题,研究团队开发了一个高效标注管道,并引入了迄今为止最大的人类运动数据集MotionMillion,包含超过2000小时和2百万高质量运动序列。此外,他们提出了最全面的评估基准MotionMillion-Eval,采用可扩展架构,将模型扩展到7亿参数,并在MotionMillion-Eval上验证了其性能。该研究成果在零样本人类运动生成方面取得了重要进展。
Key Takeaways
- 研究领域:文章涉及计算机视觉、图形学和机器人领域中基于文本描述生成人类运动序列的研究。
- 挑战:当前方法面临零样本泛化能力和缺乏全面评估框架的挑战。
- 数据集:引入迄今为止最大的人类运动数据集MotionMillion,包含2000多小时和2百万高质量运动序列。
- 评估基准:提出最全面的评估基准MotionMillion-Eval用于评估零样本运动生成。
- 模型性能:采用可扩展架构,模型扩展到7亿参数,并在MotionMillion-Eval上验证了性能。
- 成果:研究成果在零样本人类运动生成方面取得重要进展,具有强大的泛化能力,能够生成复杂组合运动。
- 可用资源:代码已公开在GitHub上。
点此查看论文截图

DeepRetro: Retrosynthetic Pathway Discovery using Iterative LLM Reasoning
Authors:Shreyas Vinaya Sathyanarayana, Rahil Shah, Sharanabasava D. Hiremath, Rishikesh Panda, Rahul Jana, Riya Singh, Rida Irfan, Ashwin Murali, Bharath Ramsundar
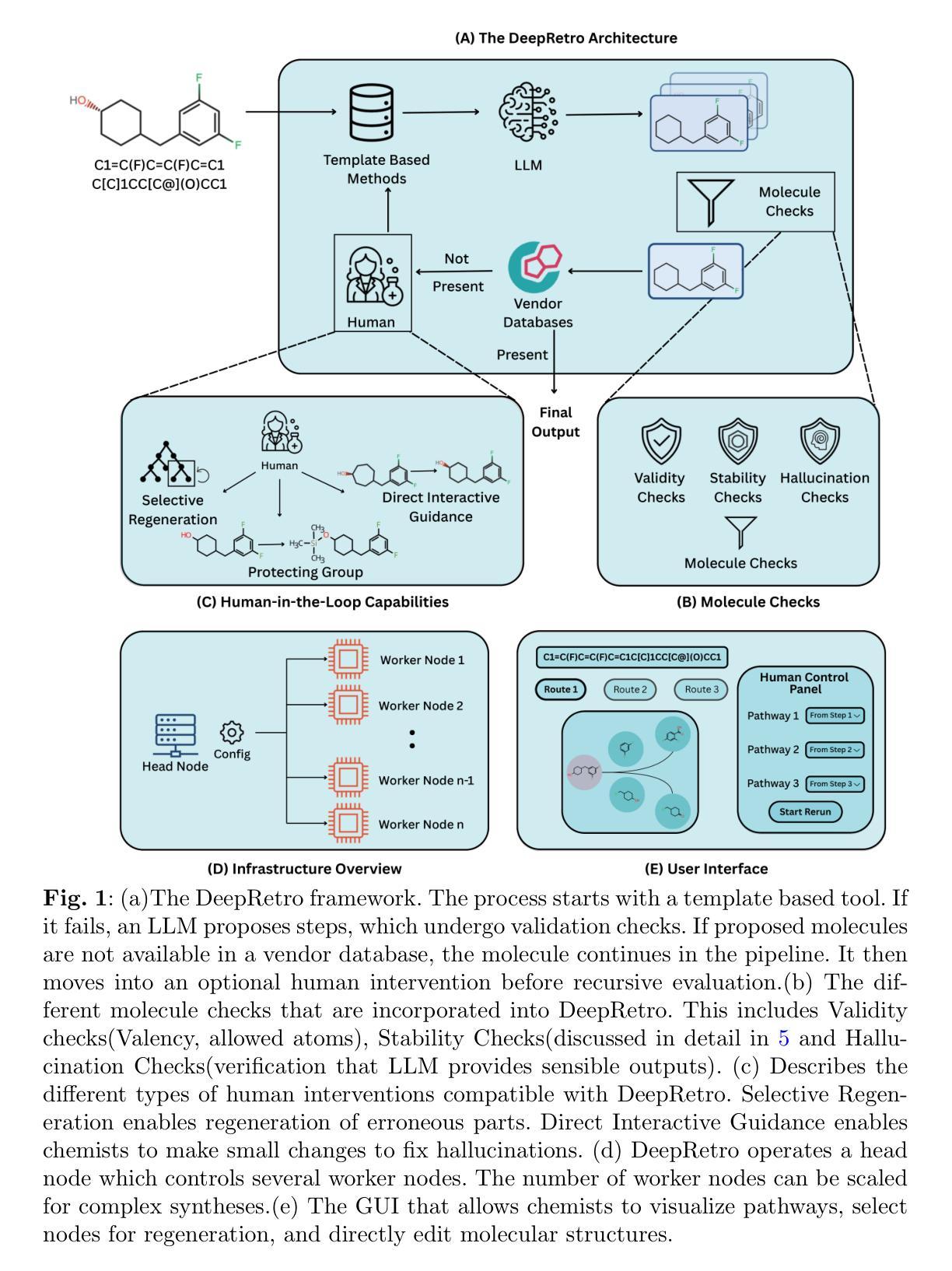
Retrosynthesis, the identification of precursor molecules for a target compound, is pivotal for synthesizing complex molecules, but faces challenges in discovering novel pathways beyond predefined templates. Recent large language model (LLM) approaches to retrosynthesis have shown promise but effectively harnessing LLM reasoning capabilities for effective multi-step planning remains an open question. To address this challenge, we introduce DeepRetro, an open-source, iterative, hybrid LLM-based retrosynthetic framework. Our approach integrates the strengths of conventional template-based/Monte Carlo tree search tools with the generative power of LLMs in a step-wise, feedback-driven loop. Initially, synthesis planning is attempted with a template-based engine. If this fails, the LLM subsequently proposes single-step retrosynthetic disconnections. Crucially, these suggestions undergo rigorous validity, stability, and hallucination checks before the resulting precursors are recursively fed back into the pipeline for further evaluation. This iterative refinement allows for dynamic pathway exploration and correction. We demonstrate the potential of this pipeline through benchmark evaluations and case studies, showcasing its ability to identify viable and potentially novel retrosynthetic routes. In particular, we develop an interactive graphical user interface that allows expert human chemists to provide human-in-the-loop feedback to the reasoning algorithm. This approach successfully generates novel pathways for complex natural product compounds, demonstrating the potential for iterative LLM reasoning to advance state-of-art in complex chemical syntheses.
回溯合成是识别目标化合物的前体分子,对于合成复杂分子至关重要,但在发现超出预定模板的新型途径时面临挑战。最近的用于回溯合成的大型语言模型(LLM)方法显示出了一定的潜力,但如何有效利用LLM的推理能力来进行有效的多步骤规划仍是一个悬而未决的问题。为了应对这一挑战,我们引入了DeepRetro,这是一个开源的、迭代的、基于LLM的回溯合成框架。我们的方法结合了基于模板/蒙特卡罗树搜索工具的传统优势与LLM的生成能力,采用逐步的、反馈驱动的回路。首先,尝试用基于模板的引擎进行合成规划。如果这失败了,LLM随后会提出单步回溯合成断裂。重要的是,这些建议在进行严格的有效性、稳定性和幻觉检查后,将产生的前体递归地反馈到管道中进行进一步评估。这种迭代细化允许动态路径探索和校正。我们通过基准评估和案例研究展示了该管道的潜力,展示了其发现可行且可能的新型回溯合成途径的能力。特别是,我们开发了一个交互式的图形用户界面,允许专业人类化学家向推理算法提供人类参与的反馈。这种方法成功地为复杂的天然产物化合物生成了新型途径,证明了迭代LLM推理在复杂化学合成中推动最新技术的潜力。
论文及项目相关链接
PDF 51 pages,
Summary:
深反合成(DeepRetro)是一个开源的、迭代的、基于大型语言模型(LLM)的逆合成框架,结合了传统模板化工具和LLM的优势。它通过逐步反馈环路进行合成规划,先尝试使用模板引擎,失败后则通过LLM提出单步逆合成断裂。框架经过严格的验证性、稳定性和虚构性检查,能够动态探索修正路径。评估结果表明其发现复杂天然产物化合物的逆合成路径的能力显著提高。
Key Takeaways:
- 深反合成(DeepRetro)是一个新型的逆合成框架,结合了模板工具和大型语言模型(LLM)的优势。
- 该框架采用逐步反馈环路进行合成规划,首先尝试模板引擎,失败后使用LLM提出单步断裂建议。
- DeepRetro具备严格的验证性、稳定性和虚构性检查机制,确保提出的路径可靠性。
- 通过基准评估和案例研究,展示了DeepRetro在发现复杂天然产物化合物的潜在逆合成路径上的能力。
点此查看论文截图

Learning Deliberately, Acting Intuitively: Unlocking Test-Time Reasoning in Multimodal LLMs
Authors:Yahan Yu, Yuyang Dong, Masafumi Oyamada
Reasoning is a key capability for large language models (LLMs), particularly when applied to complex tasks such as mathematical problem solving. However, multimodal reasoning research still requires further exploration of modality alignment and training costs. Many of these approaches rely on additional data annotation and relevant rule-based rewards to enhance the understanding and reasoning ability, which significantly increases training costs and limits scalability. To address these challenges, we propose the Deliberate-to-Intuitive reasoning framework (D2I) that improves the understanding and reasoning ability of multimodal LLMs (MLLMs) without extra annotations and complex rewards. Specifically, our method sets deliberate reasoning strategies to enhance modality alignment only through the rule-based format reward during training. While evaluating, the reasoning style shifts to intuitive, which removes deliberate reasoning strategies during training and implicitly reflects the model’s acquired abilities in the response. D2I outperforms baselines across both in-domain and out-of-domain benchmarks. Our findings highlight the role of format reward in fostering transferable reasoning skills in MLLMs, and inspire directions for decoupling training-time reasoning depth from test-time response flexibility.
推理是大型语言模型(LLM)的关键能力,特别是在应用于解决数学问题等复杂任务时。然而,多模态推理研究仍需要进一步探索模态对齐和训练成本。许多这些方法依赖于额外的数据标注和相关基于规则的奖励来提高理解和推理能力,这显著增加了训练成本并限制了可扩展性。为了解决这些挑战,我们提出了Deliberate-to-Intuitive推理框架(D2I),该框架能够在无需额外标注和复杂奖励的情况下,提高多模态LLM的理解和推理能力。具体来说,我们的方法通过设定有意识的推理策略来增强模态对齐,仅通过基于规则的格式奖励来进行训练。在评估时,推理风格转向直觉型,这在训练过程中消除了有意识的推理策略,并在响应中隐含地反映了模型所获得的能力。D2I在域内和跨域基准测试中均优于基线。我们的研究突出了格式奖励在促进多模态语言模型的可转移推理技能方面的作用,并为从训练时间的推理深度与测试时间的响应灵活性解耦提供了灵感。
论文及项目相关链接
PDF Work in progress
Summary
多媒体LLMs模型的推理研究已逐步开展,但其面对复杂的数学问题解决任务仍需进一步研究,其难度在于模态对齐和训练成本的问题。许多现有方法依赖额外的数据标注和基于规则的奖励来提高模型的推理能力,这增加了训练成本并限制了可扩展性。为解决这些问题,我们提出了Deliberate-to-Intuitive(D2I)推理框架,在不需要额外标注和复杂奖励的情况下,优化了多媒体LLMs的推理能力。我们通过训练时的刻意推理策略增强了模态对齐,只使用基于规则的格式奖励;评估时则转变为直觉推理风格,通过响应隐式反映模型习得的能力。D2I框架在领域内和跨领域基准测试中均表现出优于基线的效果。研究发现,格式奖励在促进MLLMs的可迁移推理技能方面发挥了作用,并为训练时的推理深度与测试时的响应灵活性之间的解耦提供了灵感。
Key Takeaways
- 多模态LLM在复杂任务如数学问题解决上的推理能力需要更多研究。
- 当前的方法主要依赖额外的数据标注和基于规则的奖励来提高模型的推理能力,这增加了训练成本和限制了可扩展性。
- Deliberate-to-Intuitive(D2I)推理框架优化了多媒体LLMs的推理能力,无需额外的标注和复杂的奖励机制。
- D2I通过训练时的刻意推理策略增强了模态对齐,并利用基于规则的格式奖励。
- 在评估阶段,模型展现出直觉推理风格,通过响应隐式反映模型习得的能力。
- D2I框架在多个基准测试中表现优异,证明了其有效性。
点此查看论文截图


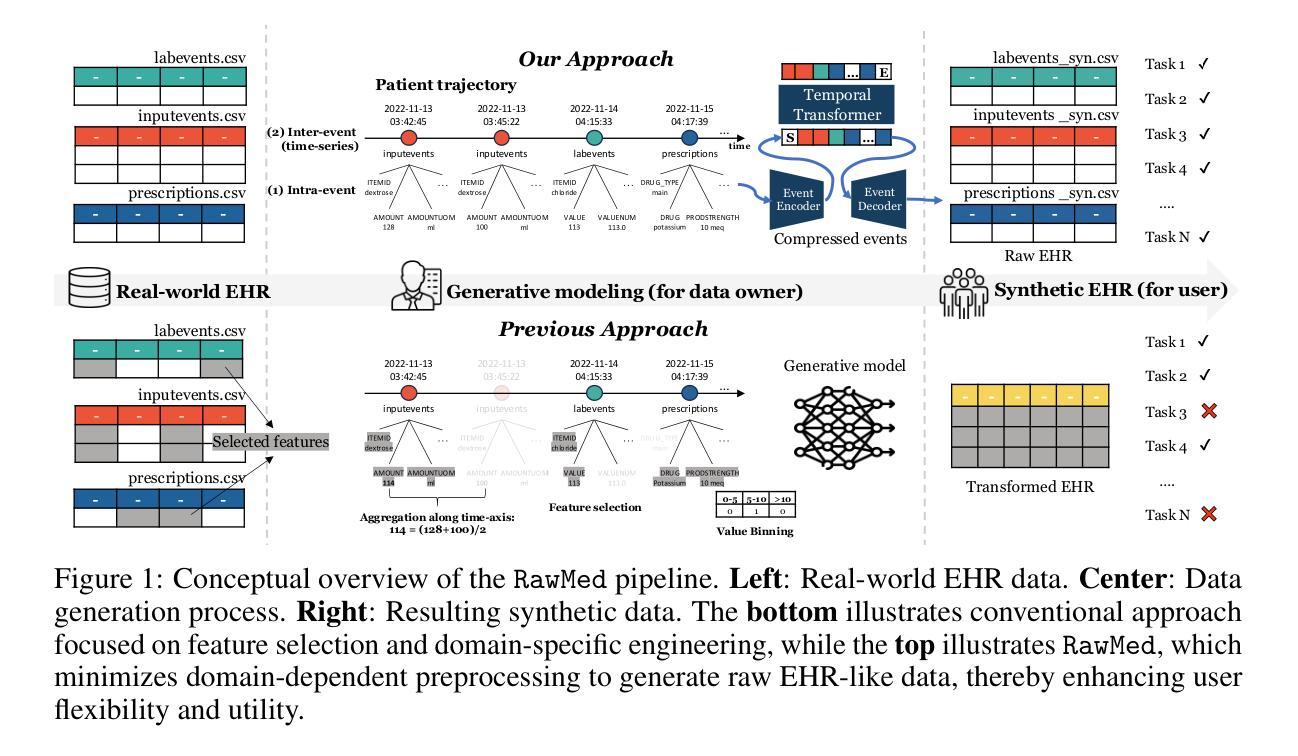
Generating Multi-Table Time Series EHR from Latent Space with Minimal Preprocessing
Authors:Eunbyeol Cho, Jiyoun Kim, Minjae Lee, Sungjin Park, Edward Choi
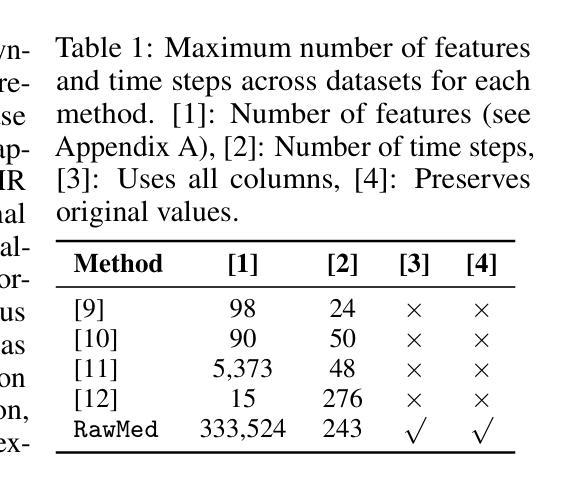
Electronic Health Records (EHR) are time-series relational databases that record patient interactions and medical events over time, serving as a critical resource for healthcare research and applications. However, privacy concerns and regulatory restrictions limit the sharing and utilization of such sensitive data, necessitating the generation of synthetic EHR datasets. Unlike previous EHR synthesis methods, which typically generate medical records consisting of expert-chosen features (e.g. a few vital signs or structured codes only), we introduce RawMed, the first framework to synthesize multi-table, time-series EHR data that closely resembles raw EHRs. Using text-based representation and compression techniques, RawMed captures complex structures and temporal dynamics with minimal preprocessing. We also propose a new evaluation framework for multi-table time-series synthetic EHRs, assessing distributional similarity, inter-table relationships, temporal dynamics, and privacy. Validated on two open-source EHR datasets, RawMed outperforms baseline models in fidelity and utility. The code is available at https://github.com/eunbyeol-cho/RawMed.
电子健康记录(EHR)是时间序列关系数据库,记录患者交互和医疗事件随时间变化的情况,是医疗护理研究与应用的关键资源。然而,隐私担忧和监管限制阻碍了这种敏感数据的共享和利用,因此需要生成合成EHR数据集。不同于通常只生成由专家选择特征构成的医疗记录的以往EHR合成方法(例如仅包含少数生命体征或结构化代码),我们推出了RawMed,这是第一个合成多表时间序列EHR数据的框架,它紧密模仿原始EHR。RawMed使用基于文本的表示和压缩技术,以最小的预处理捕获复杂结构和时间动态。我们还为多表时间序列合成EHR提出了一个新的评估框架,评估分布相似性、表间关系、时间动态和隐私。在两个开源EHR数据集上进行验证,RawMed在保真度和实用性方面优于基准模型。代码可在https://github.com/eunbyeol-cho/RawMed获得。
论文及项目相关链接
Summary:电子健康记录(EHR)是记录患者互动和医疗事件的时间序列关系型数据库,对医疗研究与应用至关重要。然而,隐私问题和监管限制阻碍了这类敏感数据的共享和利用,因此产生了合成EHR数据集的需求。本文介绍了RawMed框架,它能合成多表时间序列EHR数据,紧密模拟原始EHRs。使用基于文本的表示和压缩技术,RawMed能捕捉复杂结构和时间动态,而无需过多预处理。此外,本文还提出了针对多表时间序列合成EHR的新评估框架,评估其分布相似性、表间关系、时间动态和隐私。在两项开源EHR数据集上的验证显示,RawMed在保真度和实用性方面优于基准模型。
Key Takeaways:
- 电子健康记录(EHR)是医疗领域重要的时间序列关系型数据库,用于记录患者互动和医疗事件。
- 隐私和监管问题是EHR数据共享和利用的主要障碍,需要合成EHR数据集。
- RawMed是首个能合成多表时间序列EHR数据的框架,模拟原始EHRs。
- RawMed使用文本表示和压缩技术,能捕捉复杂结构和时间动态,减少预处理需求。
- 提出了新的评估框架,从分布相似性、表间关系、时间动态和隐私四个方面评估合成EHR数据。
- RawMed在两项开源EHR数据集上的表现优于其他模型,具有较高的保真度和实用性。
点此查看论文截图

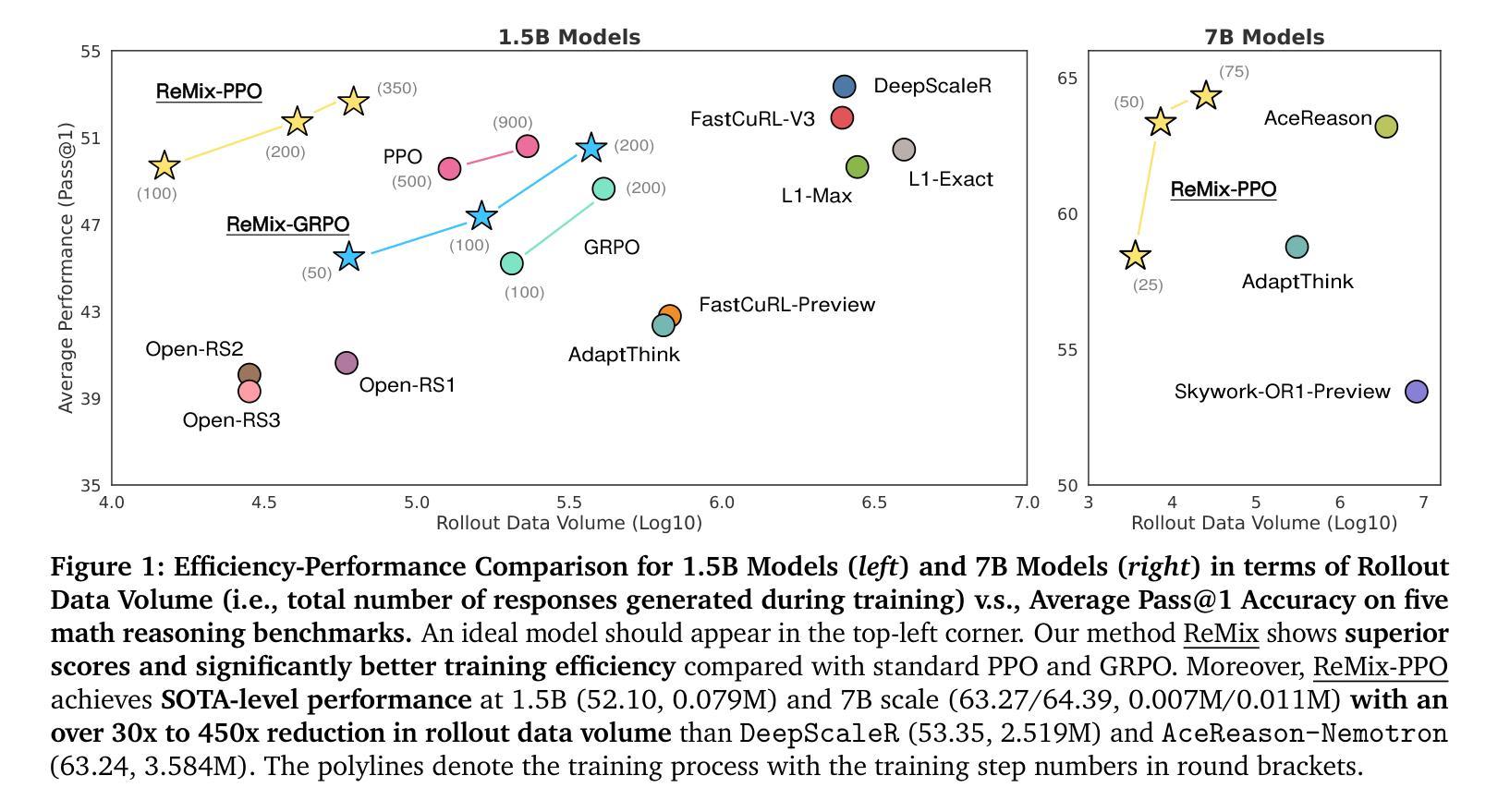
Squeeze the Soaked Sponge: Efficient Off-policy Reinforcement Finetuning for Large Language Model
Authors:Jing Liang, Hongyao Tang, Yi Ma, Jinyi Liu, Yan Zheng, Shuyue Hu, Lei Bai, Jianye Hao
Reinforcement Learning (RL) has demonstrated its potential to improve the reasoning ability of Large Language Models (LLMs). One major limitation of most existing Reinforcement Finetuning (RFT) methods is that they are on-policy RL in nature, i.e., data generated during the past learning process is not fully utilized. This inevitably comes at a significant cost of compute and time, posing a stringent bottleneck on continuing economic and efficient scaling. To this end, we launch the renaissance of off-policy RL and propose Reincarnating Mix-policy Proximal Policy Gradient (ReMix), a general approach to enable on-policy RFT methods like PPO and GRPO to leverage off-policy data. ReMix consists of three major components: (1) Mix-policy proximal policy gradient with an increased Update-To-Data (UTD) ratio for efficient training; (2) KL-Convex policy constraint to balance the trade-off between stability and flexibility; (3) Policy reincarnation to achieve a seamless transition from efficient early-stage learning to steady asymptotic improvement. In our experiments, we train a series of ReMix models upon PPO, GRPO and 1.5B, 7B base models. ReMix shows an average Pass@1 accuracy of 52.10% (for 1.5B model) with 0.079M response rollouts, 350 training steps and achieves 63.27%/64.39% (for 7B model) with 0.007M/0.011M response rollouts, 50/75 training steps, on five math reasoning benchmarks (i.e., AIME’24, AMC’23, Minerva, OlympiadBench, and MATH500). Compared with 15 recent advanced models, ReMix shows SOTA-level performance with an over 30x to 450x reduction in training cost in terms of rollout data volume. In addition, we reveal insightful findings via multifaceted analysis, including the implicit preference for shorter responses due to the Whipping Effect of off-policy discrepancy, the collapse mode of self-reflection behavior under the presence of severe off-policyness, etc.
强化学习(RL)已经显示出提高大型语言模型(LLM)推理能力的潜力。大多数现有强化微调(RFT)方法的一个主要局限性在于它们本质上是基于策略内强化学习(On-Policy RL),这意味着过去学习过程中生成的数据没有得到充分利用。这无疑会带来巨大的计算和时间成本,对持续的经济和高效扩展造成了严格的瓶颈。为此,我们发起了离策略强化学习(Off-Policy RL)的复兴,并提出了“再生混合策略近端策略梯度”(ReMix)方法,这是一种通用方法,使像PPO和GRPO这样的策略内微调方法能够利用离策略数据。ReMix主要包括三个组成部分:(1)通过增加数据更新比例(Update-To-Data, UTD)实现混合策略近端策略梯度以提高训练效率;(2)使用KL散度凸策略约束以平衡稳定性和灵活性之间的权衡;(3)策略重生,实现从高效早期学习到稳定渐进改善的无缝过渡。在我们的实验中,我们在PPO、GRPO以及基于1.5B和7B的模型上训练了一系列ReMix模型。ReMix在五个数学推理基准测试(即AIME’24、AMC’23、Minerva、OlympiadBench和MATH500)上,使用较少的响应滚动数据(对于1.5B模型为平均Pass@1准确率52.1%,使用0.079M响应滚动数据和350步训练;对于7B模型使用滚动数据0.007M或更多时需要经过的调整响应量和训练步骤更少),显示出卓越的性能表现。相较于其他近期的先进模型,ReMix在滚动数据量方面将训练成本减少了高达数百倍(最多达约四百五十倍)。此外,我们还通过多方面的分析揭示了深入的见解,包括由于离策略差异造成的鞭打效应导致的对较短答案的隐性偏好,以及在严重离策略情况下自我反思行为的崩溃模式等。
论文及项目相关链接
PDF Preliminary version. Project page: https://anitaleungxx.github.io/ReMix
Summary
强化学习(RL)能提高大型语言模型(LLM)的推理能力。现有大部分强化微调(RFT)方法都是基于策略的,限制了数据的充分利用并带来时间和成本的浪费。本文提出ReMix方法,结合混合策略近端策略梯度算法、KL散度凸策略约束和策略重生技术,使RFT方法能够利用非策略数据。实验结果显示,ReMix在不同规模的模型上表现优越,取得最佳表现,且在滚动数据量上减少训练成本达几十倍。同时,本文还通过多方面的分析揭示了一些有趣的发现。
Key Takeaways
- 强化学习在大型语言模型的推理能力方面具有巨大潜力。
- 现有的强化微调方法大多存在浪费计算和时间资源的瓶颈。
- ReMix是一个基于策略与非策略的混合学习技术,使得强化微调方法可以充分利用历史数据。
- ReMix通过结合混合策略近端策略梯度算法、KL散度凸策略约束和策略重生技术实现高效训练。
- ReMix在多个数学推理基准测试中表现优越,与先进模型相比大幅降低了训练成本。
- ReMix揭示了有趣的现象,例如非策略数据产生的鞭子效应导致对简短回应的隐性偏好。
点此查看论文截图

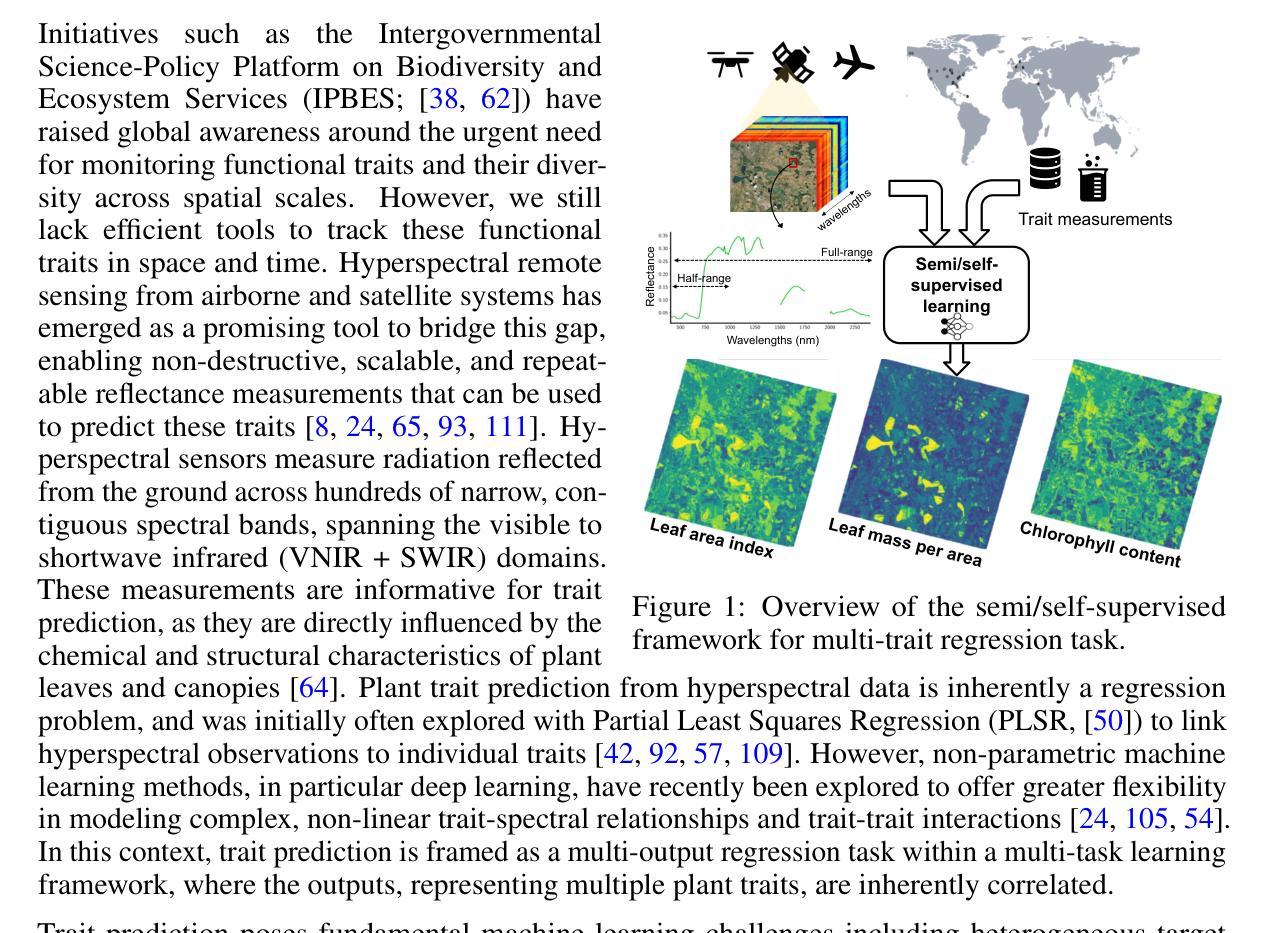
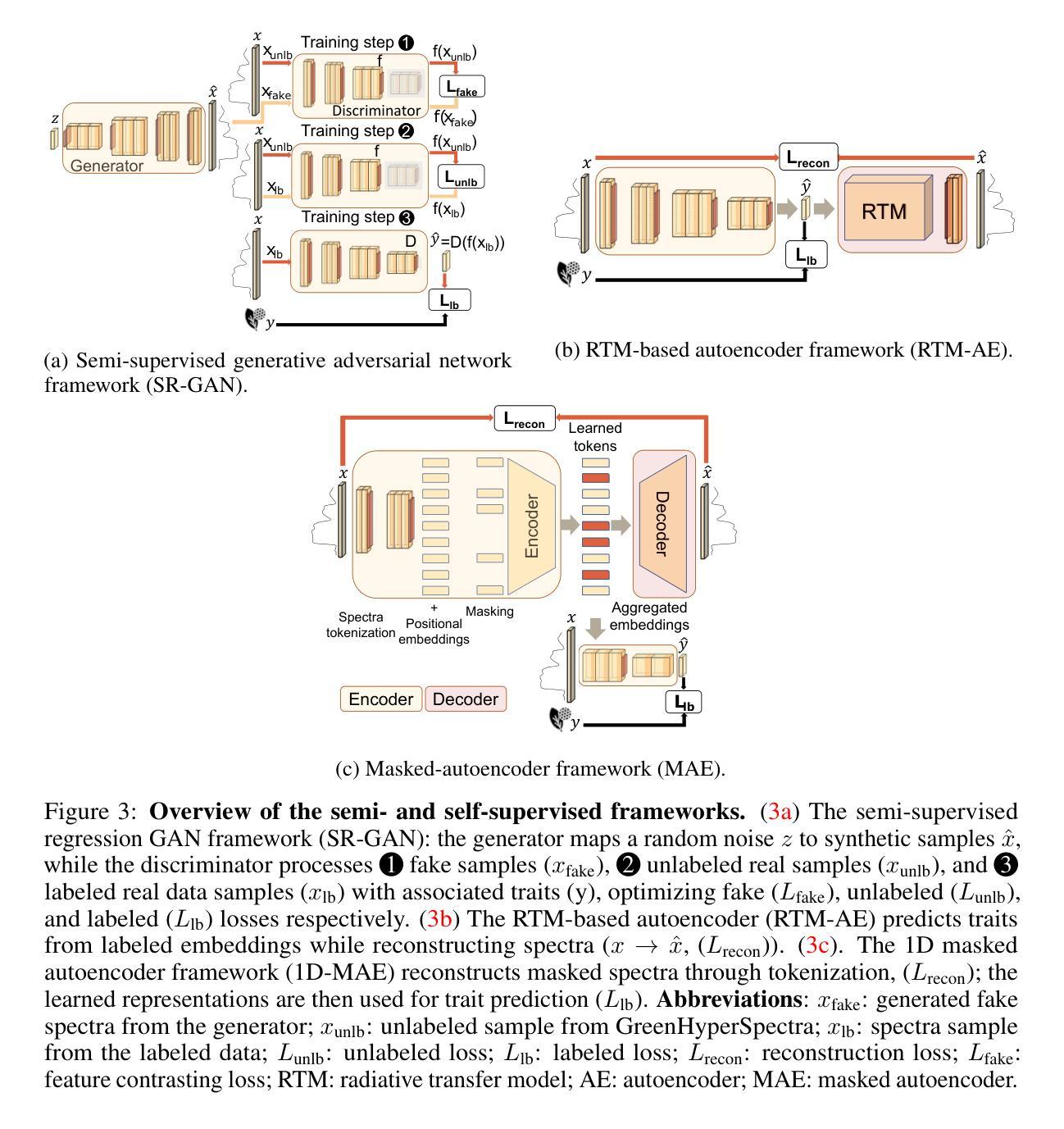
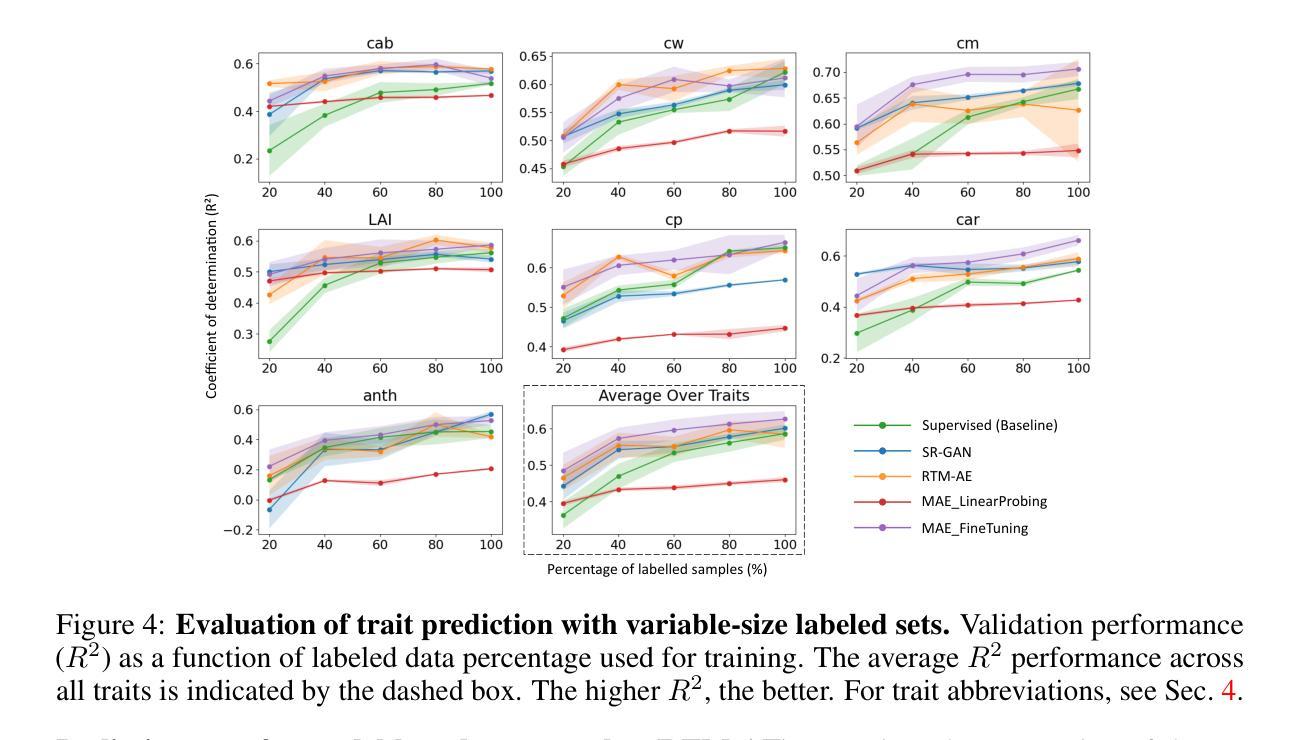
GreenHyperSpectra: A multi-source hyperspectral dataset for global vegetation trait prediction
Authors:Eya Cherif, Arthur Ouaknine, Luke A. Brown, Phuong D. Dao, Kyle R. Kovach, Bing Lu, Daniel Mederer, Hannes Feilhauer, Teja Kattenborn, David Rolnick
Plant traits such as leaf carbon content and leaf mass are essential variables in the study of biodiversity and climate change. However, conventional field sampling cannot feasibly cover trait variation at ecologically meaningful spatial scales. Machine learning represents a valuable solution for plant trait prediction across ecosystems, leveraging hyperspectral data from remote sensing. Nevertheless, trait prediction from hyperspectral data is challenged by label scarcity and substantial domain shifts (\eg across sensors, ecological distributions), requiring robust cross-domain methods. Here, we present GreenHyperSpectra, a pretraining dataset encompassing real-world cross-sensor and cross-ecosystem samples designed to benchmark trait prediction with semi- and self-supervised methods. We adopt an evaluation framework encompassing in-distribution and out-of-distribution scenarios. We successfully leverage GreenHyperSpectra to pretrain label-efficient multi-output regression models that outperform the state-of-the-art supervised baseline. Our empirical analyses demonstrate substantial improvements in learning spectral representations for trait prediction, establishing a comprehensive methodological framework to catalyze research at the intersection of representation learning and plant functional traits assessment. All code and data are available at: https://github.com/echerif18/HyspectraSSL.
植物特性,如叶片碳含量和叶片质量,在生物多样性和气候变化的研究中都是重要的变量。然而,传统的田间采样无法在实际生态空间尺度上覆盖特性的变异。机器学习在利用遥感超光谱数据进行生态系统间特性预测方面表现出宝贵的价值。然而,从超光谱数据进行特性预测面临着标签稀缺和显著领域转移(例如跨传感器、生态分布)的挑战,这需要稳健的跨域方法。在此,我们推出了GreenHyperSpectra数据集,这是一个包含现实世界跨传感器和跨生态系统样本的预训练数据集,旨在使用半监督和自监督方法对特性预测进行基准测试。我们采用了一个涵盖内部分布和外部分布场景的评价框架。我们成功地利用GreenHyperSpectra对标签高效的多输出回归模型进行了预训练,该模型优于最新的监督基线。我们的实证分析显示,在学习特性预测的谱表示方面取得了显著改进,建立了一个全面的方法论框架,以推动表征学习和植物功能特性评估交叉领域的研究。所有代码和数据均可在以下网址找到:https://github.com/echerif18/HyspectraSSL。
论文及项目相关链接
Summary
本文介绍了植物特性(如叶片碳含量和叶片质量)在生物多样性和气候变化研究中的重要性。传统采样方法无法覆盖生态上有意义的空间尺度的特性变化。机器学习利用遥感高光谱数据进行植物特性预测具有巨大潜力。然而,由于标签稀缺和领域差异显著(如不同传感器、生态分布),特性预测面临挑战。本文提出了GreenHyperSpectra数据集,包含真实跨传感器和跨生态系统样本,旨在通过半监督和自监督方法评估特性预测性能。通过采用涵盖内部和外部分布场景的评价框架,成功利用GreenHyperSpectra进行预训练标签高效的多输出回归模型,优于现有监督基线方法。实证分析显示,该方法在特性预测学习光谱表示方面取得了显著改进,为表征学习和植物功能特性评估研究提供了全面的方法论框架。
Key Takeaways
- 植物特性(如叶片碳含量和叶片质量)在生物多样性和气候变化研究中具有重要意义。
- 传统采样方法无法覆盖生态上有意义的空间尺度的特性变化。
- 机器学习利用遥感高光谱数据进行植物特性预测具有巨大潜力。
- 特性预测面临标签稀缺和领域差异显著的挑战。
- 提出GreenHyperSpectra数据集,用于跨传感器和跨生态系统的植物特性预测评估。
- 通过预训练标签高效的多输出回归模型,GreenHyperSpectra表现优于现有监督基线方法。
点此查看论文截图



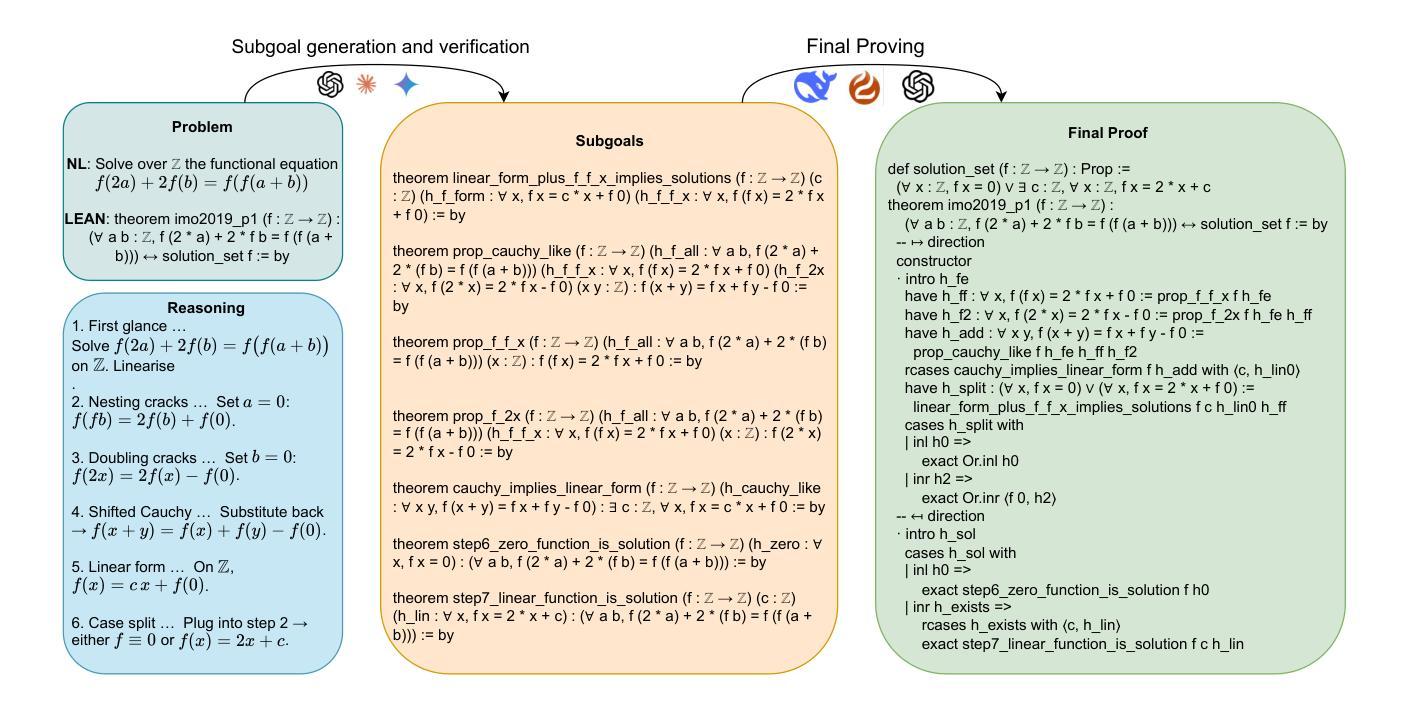
Towards Solving More Challenging IMO Problems via Decoupled Reasoning and Proving
Authors:Zhenwen Liang, Linfeng Song, Yang Li, Tao Yang, Feng Zhang, Haitao Mi, Dong Yu
Automated Theorem Proving (ATP) in formal languages is a foundational challenge for AI. While Large Language Models (LLMs) have driven remarkable progress, a significant gap remains between their powerful informal reasoning capabilities and their weak formal proving performance. Recent studies show that the informal accuracy exceeds 80% while formal success remains below 8% on benchmarks like PutnamBench. We argue this gap persists because current state-of-the-art provers, by tightly coupling reasoning and proving, are trained with paradigms that inadvertently punish deep reasoning in favor of shallow, tactic-based strategies. To bridge this fundamental gap, we propose a novel framework that decouples high-level reasoning from low-level proof generation. Our approach utilizes two distinct, specialized models: a powerful, general-purpose Reasoner to generate diverse, strategic subgoal lemmas, and an efficient Prover to rigorously verify them. This modular design liberates the model’s full reasoning potential and bypasses the pitfalls of end-to-end training. We evaluate our method on a challenging set of post-2000 IMO problems, a problem set on which no prior open-source prover has reported success. Our decoupled framework successfully solves 5 of these problems, demonstrating a significant step towards automated reasoning on exceptionally difficult mathematical challenges. To foster future research, we release our full dataset of generated and verified lemmas for a wide range of IMO problems, available at https://tencent-imo.github.io/ .
形式化语言中的自动化定理证明(ATP)是人工智能面临的一项基础挑战。尽管大型语言模型(LLM)取得了显著的进步,但在非正式推理能力和正式证明性能之间仍存在很大差距。最近的研究表明,在PutnamBench等基准测试上,非正式准确性超过80%,而正式成功率仍低于8%。我们认为这种差距持续存在,是因为当前最先进的证明器通过紧密耦合推理和证明,采用了一种范式,这种范式无意中惩罚了深度推理而偏向于浅层次的、基于策略的方法。为了弥合这一基本差距,我们提出了一种新型框架,它将高级推理与低级证明生成相分离。我们的方法利用两个截然不同的专业模型:一个功能强大、通用的推理机,用于生成多样化、策略性的子目标引理,以及一个高效的证明器,用于严格验证这些引理。这种模块化设计释放了模型的全部推理潜力,并避免了端到端培训的陷阱。我们在一组具有挑战性的2000年以后举办的国际数学奥林匹克竞赛问题上评估了我们的方法。在此问题上,尚无先前的开源证明器报告成功。我们的解耦框架成功解决了其中的五个问题,朝着在极其困难的数学挑战中实现自动化推理迈出了重要一步。为了促进未来研究,我们发布了一系列生成的已验证引理的全数据集,涵盖广泛的IMO问题,可在https://tencent-imo.github.io/获取。
论文及项目相关链接
PDF Work in progress
Summary:人工智能在形式语言中的自动定理证明(ATP)是一个基础挑战。虽然大型语言模型(LLM)取得了显著进展,但在诸如PutnamBench等基准测试中,它们在形式证明方面的表现仍然较弱,不到百分之八的正式证明成功率。研究者提出这种差距存在是因为目前顶尖的自动证明器在设计上过于紧密地耦合了推理和证明过程,训练范式无意中偏向于浅层次的战术策略而非深度推理。为了缩小这一基本差距,研究者提出了一种新型框架,该框架将高级推理与低级证明生成过程解耦。这一方法采用两个专门设计的模型:一个强大的通用推理器生成多种策略性子目标引理,一个高效的证明器则对其进行严格验证。这种模块化设计释放了模型的全部推理潜力,避免了端到端训练的局限性。评估显示,该框架在具有挑战性的后2000年IMO问题上取得了成功,解决了其中的五个问题。为了推动未来的研究,研究者发布了广泛的IMO问题生成的验证引理数据集。
Key Takeaways:
- 当前人工智能在自动定理证明领域存在从非正式到正式证明的巨大性能差距。
- 主流证明器在训练过程中偏向于战术性策略而非深度推理,这限制了它们的性能。
- 提出了一种新型框架,将高级推理与低级证明过程解耦,以提高证明性能。
- 采用模块化设计,包括一个推理器生成战略性子目标引理和一个证明器进行严格验证。
- 该方法在解决具有挑战性的后2000年IMO问题上取得了显著成效,成功解决了五个问题。
点此查看论文截图


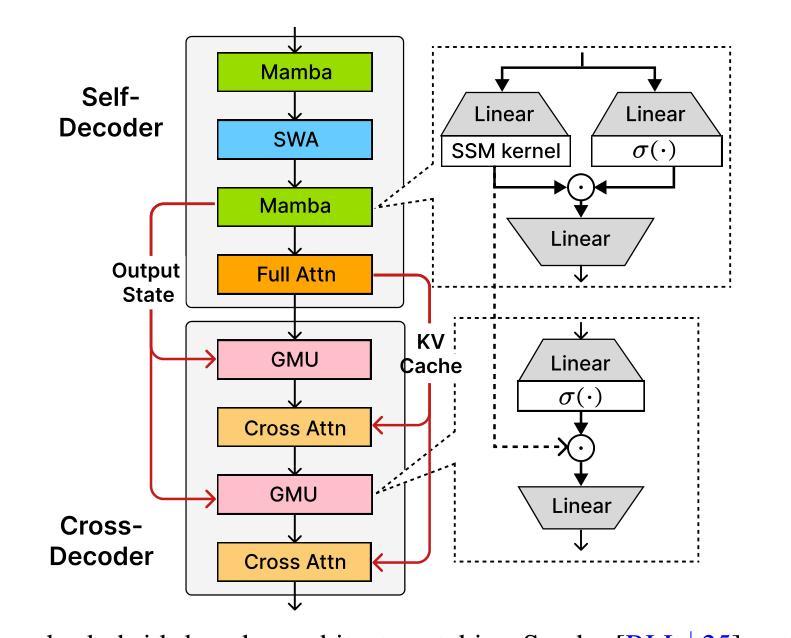
Decoder-Hybrid-Decoder Architecture for Efficient Reasoning with Long Generation
Authors:Liliang Ren, Congcong Chen, Haoran Xu, Young Jin Kim, Adam Atkinson, Zheng Zhan, Jiankai Sun, Baolin Peng, Liyuan Liu, Shuohang Wang, Hao Cheng, Jianfeng Gao, Weizhu Chen, Yelong Shen
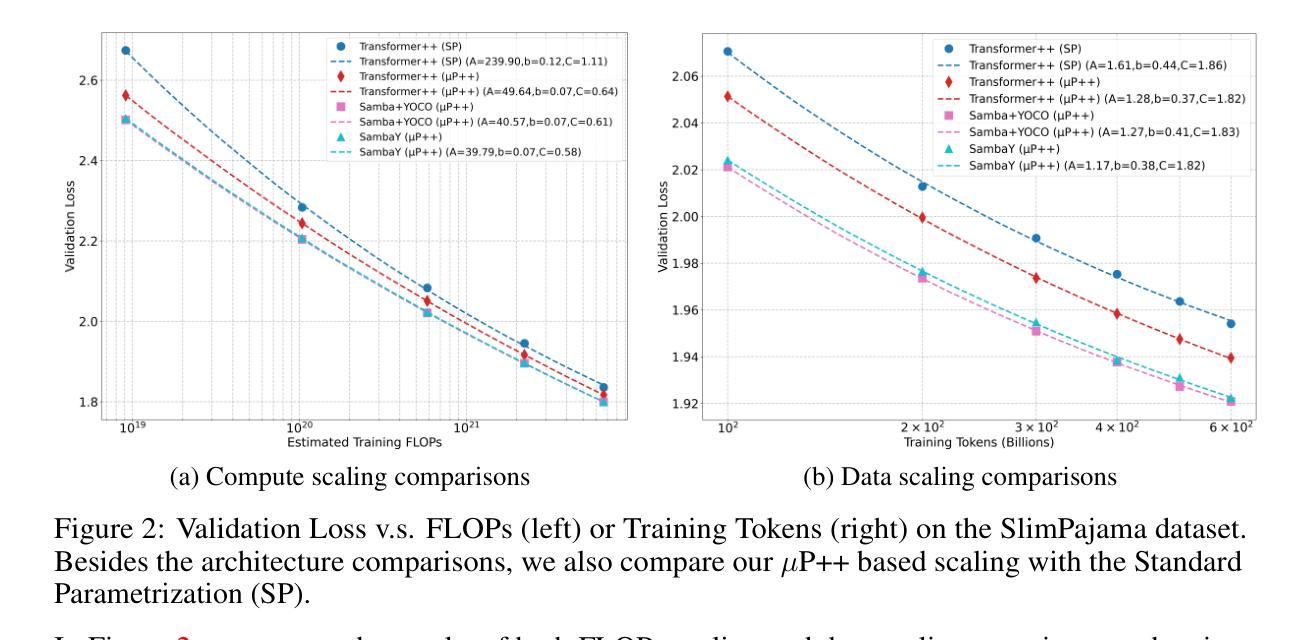
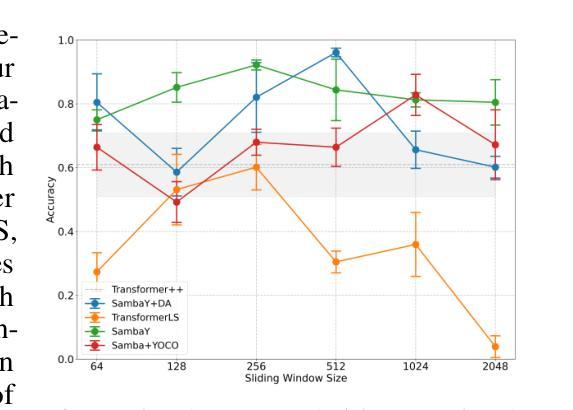
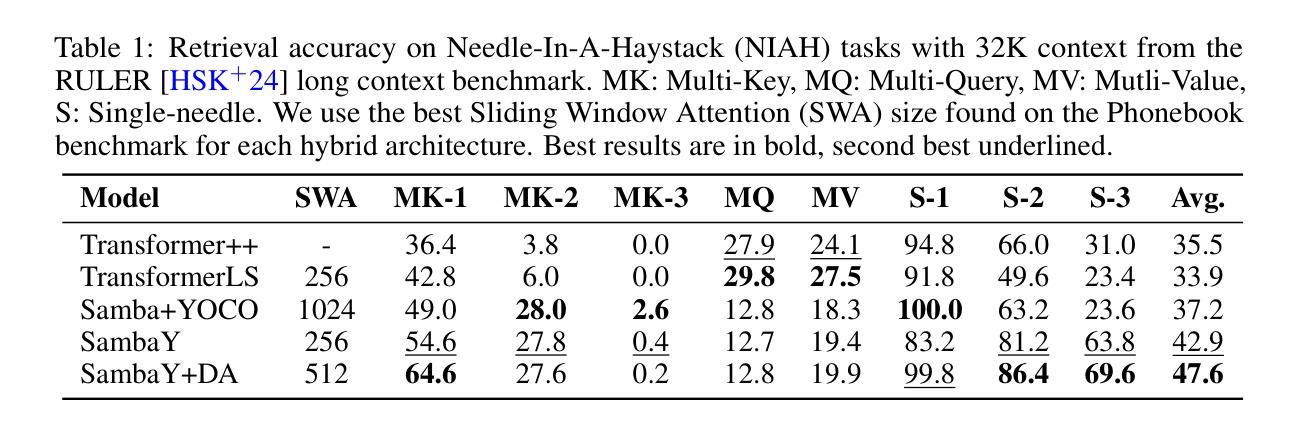
Recent advances in language modeling have demonstrated the effectiveness of State Space Models (SSMs) for efficient sequence modeling. While hybrid architectures such as Samba and the decoder-decoder architecture, YOCO, have shown promising performance gains over Transformers, prior works have not investigated the efficiency potential of representation sharing between SSM layers. In this paper, we introduce the Gated Memory Unit (GMU), a simple yet effective mechanism for efficient memory sharing across layers. We apply it to create SambaY, a decoder-hybrid-decoder architecture that incorporates GMUs in the cross-decoder to share memory readout states from a Samba-based self-decoder. SambaY significantly enhances decoding efficiency, preserves linear pre-filling time complexity, and boosts long-context performance, all while eliminating the need for explicit positional encoding. Through extensive scaling experiments, we demonstrate that our model exhibits a significantly lower irreducible loss compared to a strong YOCO baseline, indicating superior performance scalability under large-scale compute regimes. Our largest model enhanced with Differential Attention, Phi4-mini-Flash-Reasoning, achieves significantly better performance than Phi4-mini-Reasoning on reasoning tasks such as Math500, AIME24/25, and GPQA Diamond without any reinforcement learning, while delivering up to 10x higher decoding throughput on 2K-length prompts with 32K generation length under the vLLM inference framework. We release our training codebase on open-source data at https://github.com/microsoft/ArchScale.
最近的语言建模进展表明状态空间模型(SSMs)在高效序列建模中的有效性。虽然混合架构(如samba和编码器-解码器架构YOCO)在Transformer上显示出有前景的性能提升,但之前的研究尚未探讨SSM层之间表示共享的潜在效率。在本文中,我们引入了门控内存单元(GMU),这是一种简单而有效的跨层高效内存共享机制。我们将其应用于创建sambaY,这是一种结合了GMU的解码器混合解码器架构,可从基于samba的自我解码器中共享内存读取状态。sambaY在显著提高解码效率的同时,保留了线性预填充时间复杂度,并提高了长上下文性能,同时无需显式位置编码。通过广泛的规模实验,我们证明与强大的YOCO基线相比,我们的模型具有更低的不可约损失,这表明在大规模计算环境下具有卓越的性能可扩展性。我们采用差分注意力增强的最大模型,在Math500、AIME24/25和GPQA Diamond等推理任务上,相较于Phi4-mini-Reasoning取得了显著的优势,这一切都是在未使用强化学习的情况下实现的。此外,在vLLM推理框架下,对2K长度提示进行32K生成长度时,我们的模型解码吞吐量提高了高达10倍。我们在开源数据上发布我们的训练代码库:https://github.com/microsoft/ArchScale。
论文及项目相关链接
Summary
本文介绍了基于State Space Models(SSMs)的Gated Memory Unit(GMU)机制,这是一种简单的跨层内存共享方法。通过创建SambaY架构,将GMU应用于解码器混合架构中,实现了高效的内存共享。SambaY架构提高了解码效率,保持线性预填充时间复杂度,提高了长上下文性能,并消除了对显式位置编码的需求。同时展示的大规模计算实验表明,该模型相比基准模型YOCO具有显著的优势和更低的不可减少的损失。最终实现的模型在无需强化学习的情况下在多个推理任务上取得了优于其他模型的表现,同时在大规模生成场景下实现了更高的解码效率。该项目已经开源相关训练代码和数据集。
Key Takeaways
- 介绍了State Space Models(SSMs)的Gated Memory Unit(GMU)机制用于高效序列建模。
- 提出SambaY架构,将GMU应用于解码器混合架构中实现跨层内存高效共享。
- SambaY架构提高了解码效率,保持线性预填充时间复杂度,提升长上下文性能。
- 消除对显式位置编码的需求。
- 模型相比基准模型YOCO具有显著的优势和更低的不可减少的损失。
- 最终模型在多个推理任务上表现优异,无需强化学习。
点此查看论文截图

From Data-Centric to Sample-Centric: Enhancing LLM Reasoning via Progressive Optimization
Authors:Xinjie Chen, Minpeng Liao, Guoxin Chen, Chengxi Li, Biao Fu, Kai Fan, Xinggao Liu
Reinforcement learning with verifiable rewards (RLVR) has recently advanced the reasoning capabilities of large language models (LLMs). While prior work has emphasized algorithmic design, data curation, and reward shaping, we investigate RLVR from a sample-centric perspective and introduce LPPO (Learning-Progress and Prefix-guided Optimization), a framework of progressive optimization techniques. Our work addresses a critical question: how to best leverage a small set of trusted, high-quality demonstrations, rather than simply scaling up data volume. First, motivated by how hints aid human problem-solving, we propose prefix-guided sampling, an online data augmentation method that incorporates partial solution prefixes from expert demonstrations to guide the policy, particularly for challenging instances. Second, inspired by how humans focus on important questions aligned with their current capabilities, we introduce learning-progress weighting, a dynamic strategy that adjusts each training sample’s influence based on model progression. We estimate sample-level learning progress via an exponential moving average of per-sample pass rates, promoting samples that foster learning and de-emphasizing stagnant ones. Experiments on mathematical-reasoning benchmarks demonstrate that our methods outperform strong baselines, yielding faster convergence and a higher performance ceiling.
强化学习可验证奖励(RLVR)最近提升了大型语言模型(LLM)的推理能力。虽然以前的研究重点在算法设计、数据整理和奖励塑造上,但我们从样本中心的角度研究RLVR,并引入了LPPO(学习进度和前缀引导优化),这是一套渐进优化技术的框架。我们的工作解决了一个关键问题:如何最好地利用一小部分可信赖的高质量演示,而不是简单地扩大数据量。首先,受提示如何帮助人类解决问题的启发,我们提出了前缀引导采样,这是一种在线数据增强方法,它结合了专家演示中的部分解决方案前缀来引导策略,特别是在具有挑战性的情况下。其次,受人类如何关注与其当前能力相符的重要问题的启发,我们引入了学习进度加权,这是一种动态策略,根据模型的进展调整每个训练样本的影响。我们通过每个样本通过率的指数移动平均来估计样本级学习进度,以促进那些促进学习的样本并减少停滞的样本的重要性。在数学推理基准测试上的实验表明,我们的方法优于强大的基线,实现了更快的收敛和更高的性能上限。
论文及项目相关链接
PDF Work in progress
Summary
强化学习可验证奖励(RLVR)已提升大型语言模型(LLM)的推理能力。本研究从样本中心视角出发,引入LPPO(学习进度和前缀引导优化)框架,聚焦优化技术。研究重点在于如何有效利用少量可信赖的高质量演示,而非单纯扩大数据量。通过前缀引导采样和基于学习进度的加权策略,实现在线数据扩充和动态调整每个训练样本的影响。在数学推理基准测试上的实验表明,该方法优于强劲基准测试,实现更快收敛和更高性能上限。
Key Takeaways
- RLVR强化大型语言模型的推理能力。
- 从样本中心视角研究RLVR,引入LPPO框架。
- 有效利用少量高质量演示数据。
- 提出前缀引导采样,融合专家演示中的部分解决方案前缀,以指导策略,尤其针对挑战实例。
- 受人类关注与当前能力相符的重要问题的启发,引入基于学习进度的加权策略。
- 通过样本级别的学习进度估计,动态调整样本影响。
点此查看论文截图

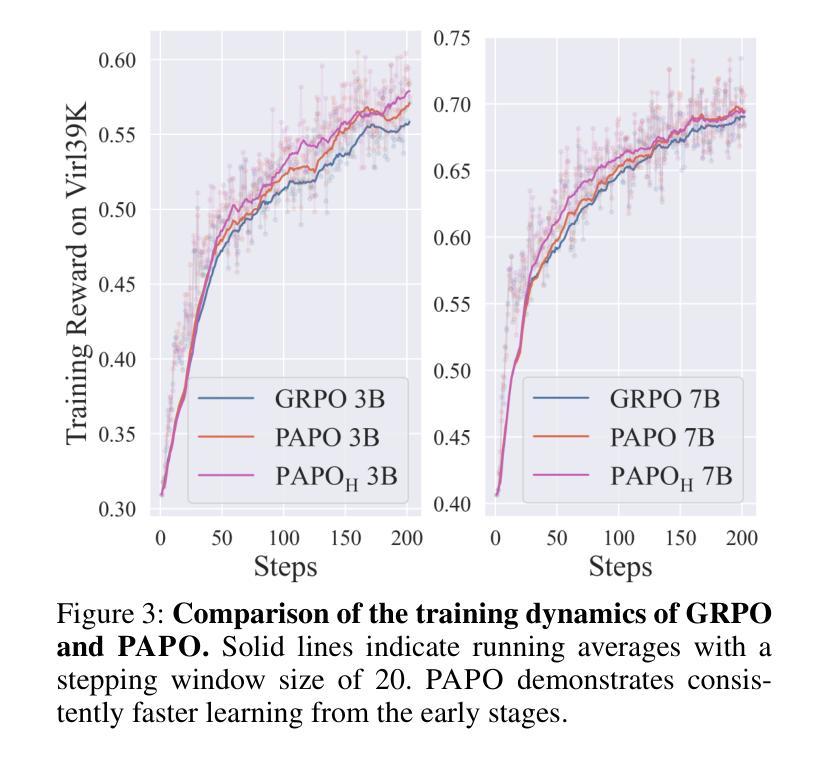
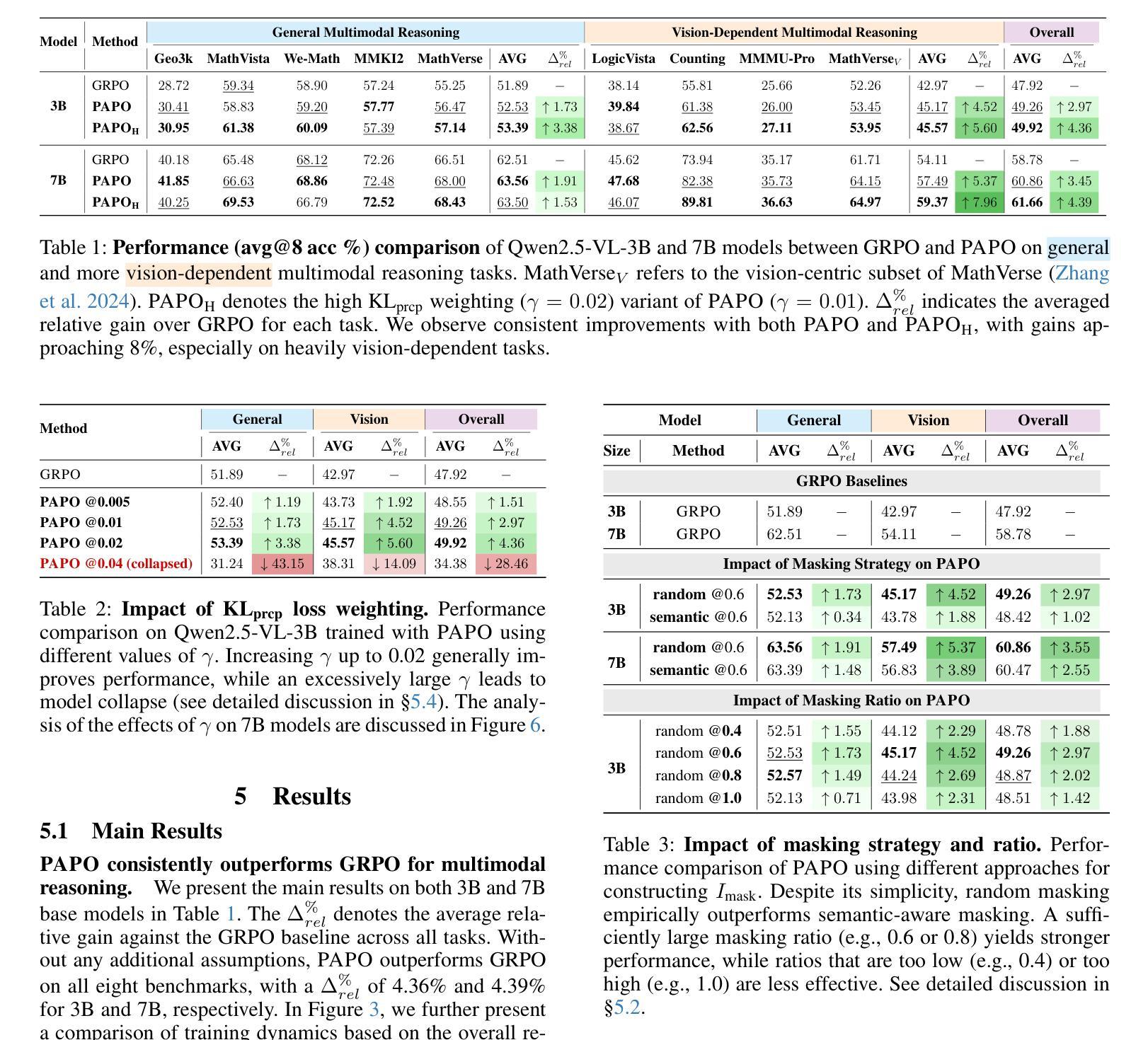
Perception-Aware Policy Optimization for Multimodal Reasoning
Authors:Zhenhailong Wang, Xuehang Guo, Sofia Stoica, Haiyang Xu, Hongru Wang, Hyeonjeong Ha, Xiusi Chen, Yangyi Chen, Ming Yan, Fei Huang, Heng Ji
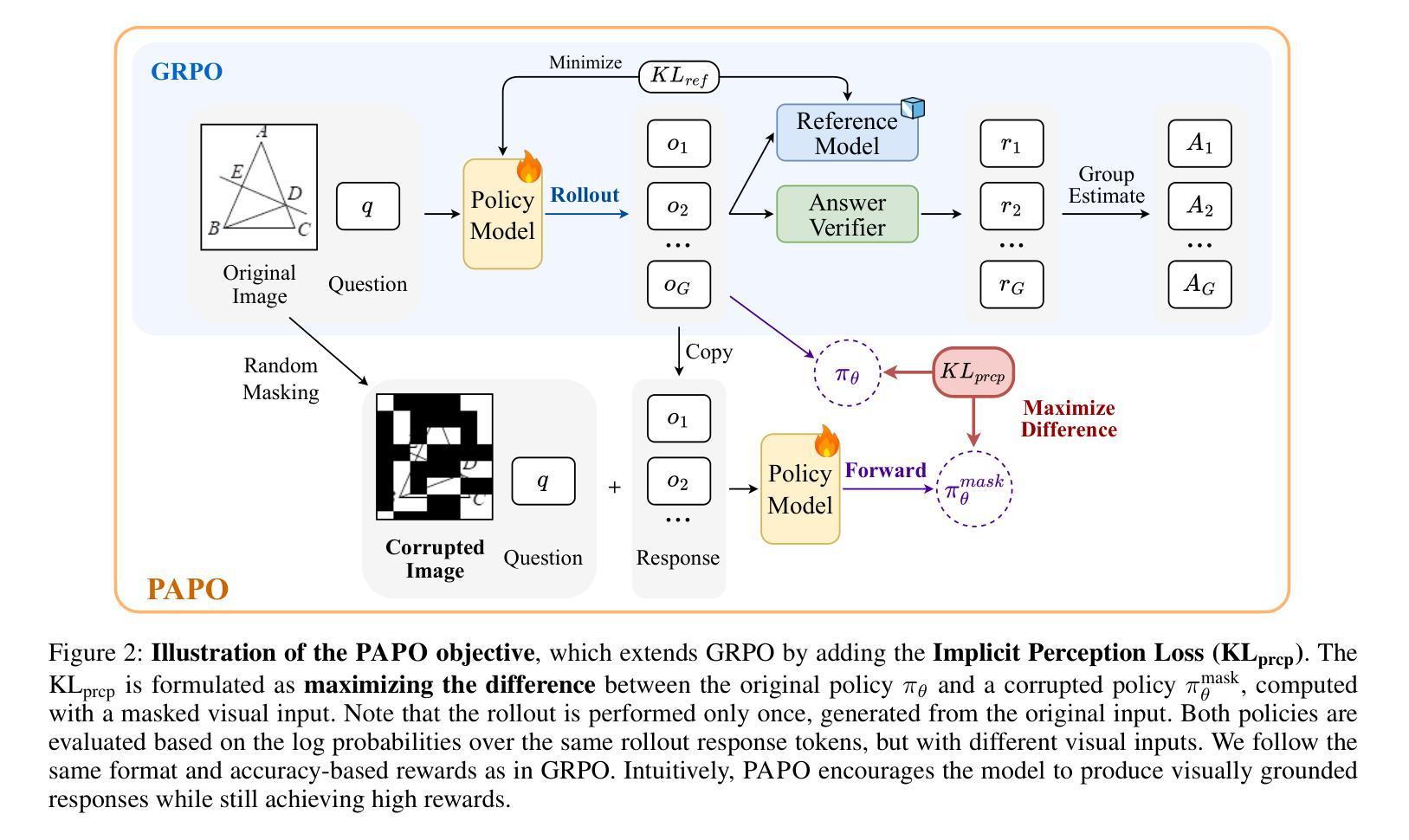
Reinforcement Learning with Verifiable Rewards (RLVR) has proven to be a highly effective strategy for endowing Large Language Models (LLMs) with robust multi-step reasoning abilities. However, its design and optimizations remain tailored to purely textual domains, resulting in suboptimal performance when applied to multimodal reasoning tasks. In particular, we observe that a major source of error in current multimodal reasoning lies in the perception of visual inputs. To address this bottleneck, we propose Perception-Aware Policy Optimization (PAPO), a simple yet effective extension of GRPO that encourages the model to learn to perceive while learning to reason, entirely from internal supervision signals. Notably, PAPO does not rely on additional data curation, external reward models, or proprietary models. Specifically, we introduce the Implicit Perception Loss in the form of a KL divergence term to the GRPO objective, which, despite its simplicity, yields significant overall improvements (4.4%) on diverse multimodal benchmarks. The improvements are more pronounced, approaching 8.0%, on tasks with high vision dependency. We also observe a substantial reduction (30.5%) in perception errors, indicating improved perceptual capabilities with PAPO. We conduct comprehensive analysis of PAPO and identify a unique loss hacking issue, which we rigorously analyze and mitigate through a Double Entropy Loss. Overall, our work introduces a deeper integration of perception-aware supervision into RLVR learning objectives and lays the groundwork for a new RL framework that encourages visually grounded reasoning. Project page: https://mikewangwzhl.github.io/PAPO.
强化学习与可验证奖励(RLVR)已被证明是赋予大型语言模型(LLM)强大的多步推理能力的一种高效策略。然而,其设计和优化仍然针对纯文本领域,导致在应用于多模态推理任务时的性能不佳。特别是,我们观察到当前多模态推理中的误差主要来源于视觉输入的感知。为了解决这一瓶颈,我们提出了感知感知策略优化(PAPO),这是GRPO的一个简单而有效的扩展,鼓励模型在学习推理的同时学习感知,完全基于内部监督信号。值得注意的是,PAPO不依赖于额外的数据整理、外部奖励模型或专有模型。具体地,我们在GRPO目标中引入了隐感知损失的形式为KL散度项,尽管其简单性,它在各种多模态基准测试上产生了显著的总体改进(4.4%)。在高度依赖视觉的任务上,改进更为显著,接近8.0%。我们还观察到感知错误的大幅减少(30.5%),这表明PAPO提高了感知能力。我们对PAPO进行了综合分析,并发现了一个独特的损失破解问题,我们进行了严格的分析,并通过双重熵损失减轻了该问题。总体而言,我们的工作将感知感知监督更深入地集成到RLVR学习目标中,并为鼓励视觉辅助推理的新RL框架奠定了基础。项目页面:https://mikewangwzhl.github.io/PAPO。
论文及项目相关链接
Summary
强化学习可通过赋予奖励证明奖励,具备对大型语言模型的稳健的多步推理能力。然而,设计优化仅限于纯文本领域,导致在多模态推理任务上表现不佳。为此,我们提出感知感知策略优化(PAPO),通过引入隐感知损失作为KL散度项,鼓励模型从内部监督信号中学习感知和推理能力。这种方法在不依赖额外数据、外部奖励模型或专有模型的情况下,在多样化多模态基准测试中实现了显著的性能提升。具体地,在视觉依赖性高的任务上,性能提升接近8%,感知错误减少了约三成。同时,我们还对PAPO进行了全面的分析,发现并解决了独特的损失问题,引入了双重熵损失以减轻该问题。本研究深入整合感知感知监督进入强化学习奖励证明的目标中,为后续鼓励视觉化推理的强化学习框架奠定基础。项目页面:链接。
Key Takeaways
- 强化学习通过奖励证明奖励策略有效增强大型语言模型的多步推理能力。
- 当前多模态推理的主要误差来源于视觉输入的感知问题。
- 提出感知感知策略优化(PAPO)方法,引入隐感知损失来解决上述问题。
- PAPO显著提升了多模态基准测试性能,在视觉依赖性高的任务上表现尤其明显。
- 通过双重熵损失解决独特的损失问题。
- PAPO方法提高了模型的感知能力,减少了感知错误。
点此查看论文截图

One task to rule them all: A closer look at traffic classification generalizability
Authors:Elham Akbari, Zihao Zhou, Mohammad Ali Salahuddin, Noura Limam, Raouf Boutaba, Bertrand Mathieu, Stephanie Moteau, Stephane Tuffin
Existing website fingerprinting and traffic classification solutions do not work well when the evaluation context changes, as their performances often heavily rely on context-specific assumptions. To clarify this problem, we take three prior solutions presented for different but similar traffic classification and website fingerprinting tasks, and apply each solution’s model to another solution’s dataset. We pinpoint dataset-specific and model-specific properties that lead each of them to overperform in their specific evaluation context. As a realistic evaluation context that takes practical labeling constraints into account, we design an evaluation framework using two recent real-world TLS traffic datasets from large-scale networks. The framework simulates a futuristic scenario in which SNIs are hidden in some networks but not in others, and the classifier’s goal is to predict destination services in one network’s traffic, having been trained on a labelled dataset collected from a different network. Our framework has the distinction of including real-world distribution shift, while excluding concept drift. We show that, even when abundant labeled data is available, the best solutions’ performances under distribution shift are between 30% and 40%, and a simple 1-Nearest Neighbor classifier’s performance is not far behind. We depict all performances measured on different models, not just the best ones, for a fair representation of traffic models in practice.
现有网站指纹和流量分类解决方案在评估上下文发生变化时效果不佳,因为它们的性能往往严重依赖于特定上下文的假设。为了澄清这个问题,我们选取了三个针对不同但相似的流量分类和网站指纹任务的先前解决方案,并将每个解决方案的模型应用到另一个解决方案的数据集上。我们指出了数据集特定和模型特定的属性,这些属性使它们在特定的评估上下文中表现出色。
论文及项目相关链接
Summary
网络流量分类和网站指纹识别方案在不同评估环境下表现不一,性能取决于特定的假设。为解决此问题,本文分析了三个不同但相似的任务中的解决方案,并使用各自模型处理其他方案的数据集。通过设计基于两个真实TLS流量数据集的评估框架,考虑了实际应用中的标签约束,模拟了SNI隐藏的场景,并评估了模型在不同网络环境中的性能差异。结果显示,即使在有足够标签数据的情况下,最佳解决方案的性能在分布转移下仍介于30%至40%之间,简单的1近邻分类器的性能与之不相上下。对所有模型进行了性能评估,而非仅限于最佳模型,以公平地展示实际应用中的流量模型。此研究解决了实际场景中可能出现的评估和迁移挑战问题。简言之,如何在复杂的网络环境改变中进行高效的网站指纹与流量识别依旧是一项值得深入研究的挑战。
Key Takeaways
- 网络流量分类和网站指纹识别方案在不同评估环境下表现不稳定,性能受特定假设影响。
- 对三个不同任务中的解决方案进行比较分析,显示各自在不同数据集和模型上的表现。
- 设计考虑实际应用中标签约束的评估框架,模拟SNI隐藏场景,突出实际网络环境复杂性对模型性能的影响。
- 在分布转移情况下,最佳解决方案的性能介于30%至40%,简单分类器性能与之相近。
- 评估不同模型的性能表现,不仅限于最佳模型,以反映实际应用中的真实情况。
- 研究解决了实际场景中可能出现的评估和迁移挑战问题。强调了在复杂网络环境下进行高效网站指纹与流量识别的挑战性和重要性。
点此查看论文截图

PERK: Long-Context Reasoning as Parameter-Efficient Test-Time Learning
Authors:Zeming Chen, Angelika Romanou, Gail Weiss, Antoine Bosselut
Long-context reasoning requires accurately identifying relevant information in extensive, noisy input contexts. Previous research shows that using test-time learning to encode context directly into model parameters can effectively enable reasoning over noisy information. However, meta-learning methods for enabling test-time learning are prohibitively memory-intensive, preventing their application to long context settings. In this work, we propose PERK (Parameter Efficient Reasoning over Knowledge), a scalable approach for learning to encode long input contexts using gradient updates to a lightweight model adapter at test time. Specifically, PERK employs two nested optimization loops in a meta-training phase. The inner loop rapidly encodes contexts into a low-rank adapter (LoRA) that serves as a parameter-efficient memory module for the base model. Concurrently, the outer loop learns to use the updated adapter to accurately recall and reason over relevant information from the encoded long context. Our evaluations on several long-context reasoning tasks show that PERK significantly outperforms the standard prompt-based long-context baseline, achieving average absolute performance gains of up to 90% for smaller models (GPT-2) and up to 27% for our largest evaluated model, Qwen-2.5-0.5B. In general, PERK is more robust to reasoning complexity, length extrapolation, and the locations of relevant information in contexts. Finally, we show that while PERK is memory-intensive during training, it scales more efficiently at inference time than prompt-based long-context inference.
长语境推理需要准确识别广泛、嘈杂输入语境中的相关信息。先前的研究表明,在测试时将语境直接编码到模型参数中,可以有效地对嘈杂信息进行推理。然而,实现测试时学习的元学习方法需要大量内存,阻碍了其在长语境设置中的应用。在这项工作中,我们提出了PERK(基于知识的参数高效推理),这是一种用于学习在测试时对长输入语境进行编码的可扩展方法,通过梯度更新对基础模型的轻量级模型适配器进行调整。具体来说,PERK在元训练阶段采用两个嵌套优化循环。内循环迅速将语境编码为低阶适配器(LoRA),作为基础模型的参数有效内存模块。同时,外循环学习使用更新的适配器来准确回忆和推理编码长语境中的相关信息。我们在几个长语境推理任务上的评估表明,PERK显著优于基于提示的长语境基线,对于较小的模型(GPT-2)平均绝对性能提升高达90%,对于我们评估的最大的模型Qwen-2.5-0.5B,提升高达27%。总的来说,PERK对于推理复杂性、长度扩展和语境中相关信息的位置更加稳健。最后,我们证明了虽然PERK在训练时内存密集,但在推理时间上的扩展效率比基于提示的长语境推理更高。
论文及项目相关链接
PDF 10 pages, 7 figures
Summary
本文提出了PERK(基于知识的参数有效推理)方法,用于在测试时学习编码长输入上下文。该方法通过梯度更新对基础模型的轻量级模型适配器进行编码,采用两层优化循环进行元训练。内循环快速将上下文编码为低阶适配器(LoRA),作为基础模型的参数有效内存模块。外循环学习使用更新的适配器来准确回忆和推理长上下文中的相关信息。在多个长上下文推理任务上的评估表明,PERK显著优于基于提示的长上下文基线,对小模型(GPT-2)的平均绝对性能提升高达90%,对最大评估模型(Qwen-2.5-0.5B)的提升约为27%。总体而言,PERK对推理复杂性、长度推断和上下文中相关信息的位置更具鲁棒性。同时,虽然PERK在训练期间内存密集,但在推理时比基于提示的长上下文推理更有效率。
Key Takeaways
- PERK是一种用于在测试时学习编码长输入上下文的方法。
- PERK采用两层优化循环进行元训练,内循环快速编码上下文信息,外循环学习准确回忆和推理相关信息。
- PERK通过梯度更新使用轻量级模型适配器进行编码,是一种参数有效的方法。
- 在多个长上下文推理任务上,PERK显著优于基于提示的方法。
- PERK对小模型的性能提升更大,同时也适用于较大模型。
- PERK对推理复杂性、长度推断和上下文中相关信息的位置具有鲁棒性。
点此查看论文截图



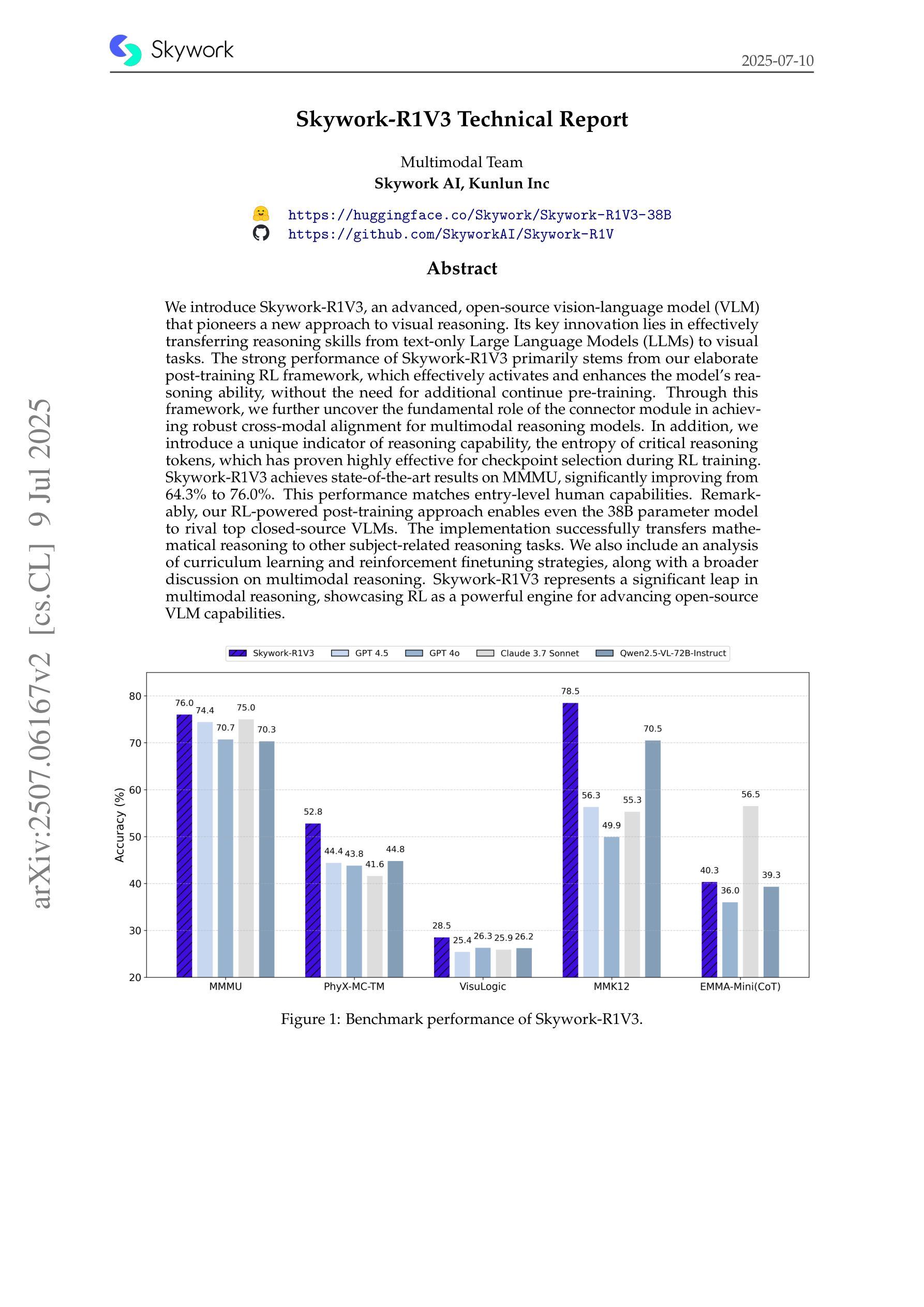
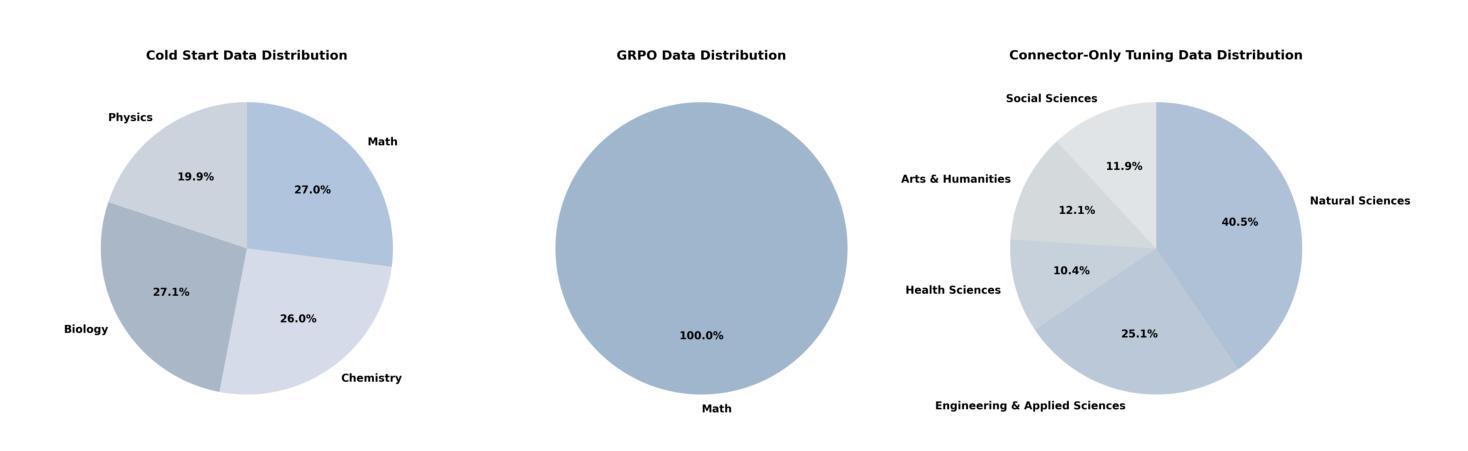
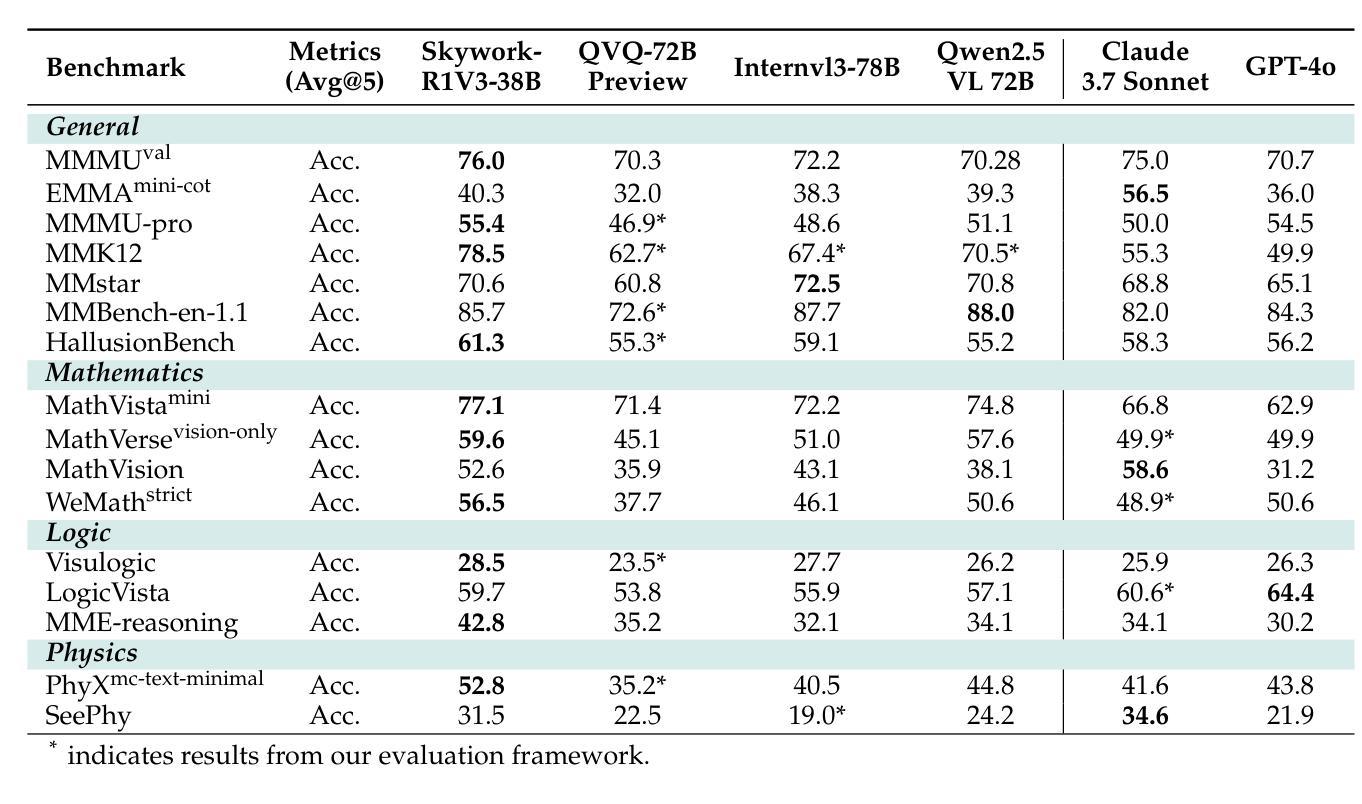
Skywork-R1V3 Technical Report
Authors:Wei Shen, Jiangbo Pei, Yi Peng, Xuchen Song, Yang Liu, Jian Peng, Haofeng Sun, Yunzhuo Hao, Peiyu Wang, Jianhao Zhang, Yahui Zhou
We introduce Skywork-R1V3, an advanced, open-source vision-language model (VLM) that pioneers a new approach to visual reasoning. Its key innovation lies in effectively transferring reasoning skills from text-only Large Language Models (LLMs) to visual tasks. The strong performance of Skywork-R1V3 primarily stems from our elaborate post-training RL framework, which effectively activates and enhances the model’s reasoning ability, without the need for additional continue pre-training. Through this framework, we further uncover the fundamental role of the connector module in achieving robust cross-modal alignment for multimodal reasoning models. In addition, we introduce a unique indicator of reasoning capability, the entropy of critical reasoning tokens, which has proven highly effective for checkpoint selection during RL training. Skywork-R1V3 achieves state-of-the-art results on MMMU, significantly improving from 64.3% to 76.0%. This performance matches entry-level human capabilities. Remarkably, our RL-powered post-training approach enables even the 38B parameter model to rival top closed-source VLMs. The implementation successfully transfers mathematical reasoning to other subject-related reasoning tasks. We also include an analysis of curriculum learning and reinforcement finetuning strategies, along with a broader discussion on multimodal reasoning. Skywork-R1V3 represents a significant leap in multimodal reasoning, showcasing RL as a powerful engine for advancing open-source VLM capabilities.
我们介绍了Skywork-R1V3,这是一个先进的开源视觉语言模型(VLM),它开创了一种新的视觉推理方法。其主要创新点在于有效地将从文本中获得的推理能力从大型语言模型(LLM)转移到视觉任务上。Skywork-R1V3的出色性能主要源于我们精心设计的后训练强化学习(RL)框架,该框架有效地激活并增强了模型的推理能力,而无需额外的继续预训练。通过这一框架,我们进一步发现了连接器模块在实现稳健的跨模态对齐的多模态推理模型中起着至关重要的作用。此外,我们引入了独特的推理能力指标——关键推理令牌的熵,该指标在强化学习训练过程中的检查点选择中被证明是非常有效的。Skywork-R1V3在MMMU上取得了最新结果,从64.3%显著提高至76.0%,与人类入门级能力相匹配。值得注意的是,我们的基于强化学习的后训练方法使得38B参数模型也能与顶级闭源VLM相竞争。我们的实现成功地将数学推理转移到其他相关推理任务中。我们还对课程学习和强化微调策略进行了分析,并对多模态推理进行了更广泛的讨论。Skywork-R1V3在多模态推理中实现了重大突破,展示了强化学习作为推动开源VLM能力进步的强大引擎。
论文及项目相关链接
Summary
Skywork-R1V3是一款先进的开源视觉语言模型(VLM),它开创了一种新的视觉推理方法。该模型的关键创新在于将纯文本的大型语言模型(LLM)的推理能力有效地转移到视觉任务上。其强大的性能主要来自于精细的基于强化学习(RL)的框架训练,该框架有效地激活并增强了模型的推理能力,无需额外的预训练。Skywork-R1V3实现了最先进的成绩,与基线相比有显著改善。
Key Takeaways
- Skywork-R1V3是一个先进的开源视觉语言模型,能够执行视觉推理任务。
- 该模型成功地将大型语言模型的推理能力转移到视觉任务上。
- Skywork-R1V3采用基于强化学习的框架进行训练,增强了模型的推理能力。
- 连接器模块在达成稳健的跨模态对齐中起到关键作用。
- 模型的性能达到了业界领先水平,特别是在MMMU测试中。
- 强化学习驱动的后训练策略使得较小的模型也能与顶级的闭源视觉语言模型相竞争。
点此查看论文截图
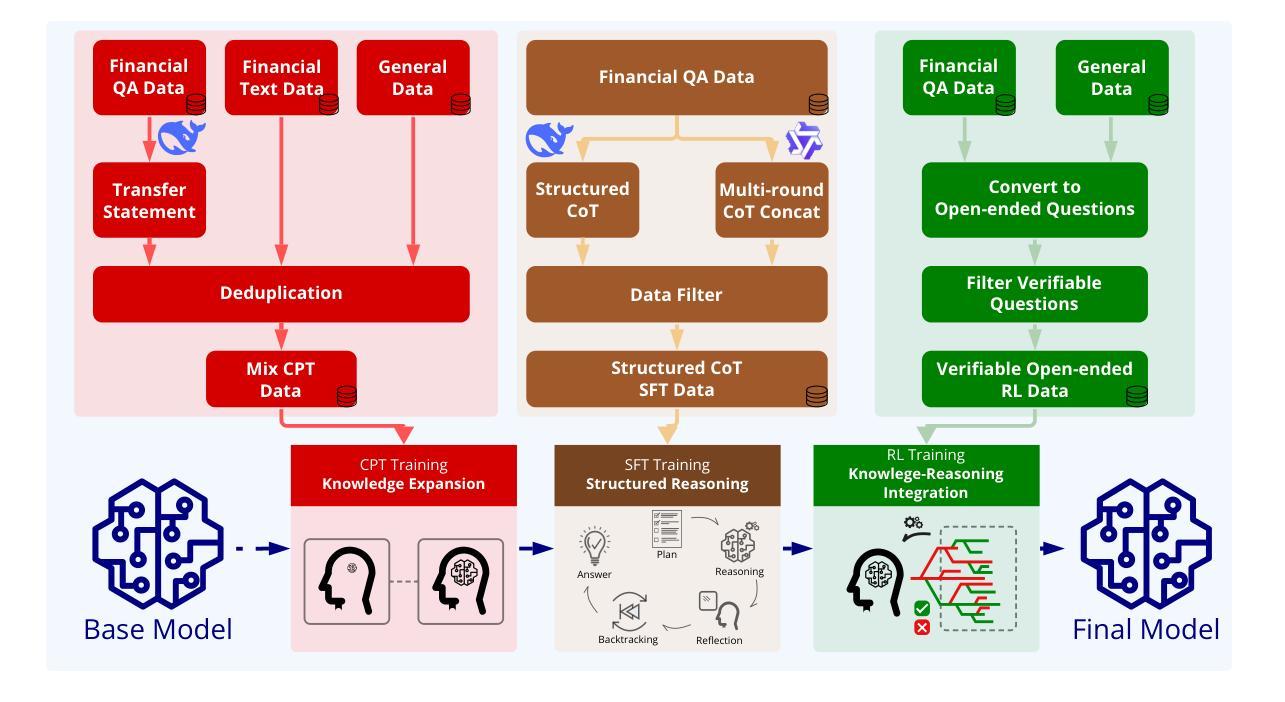
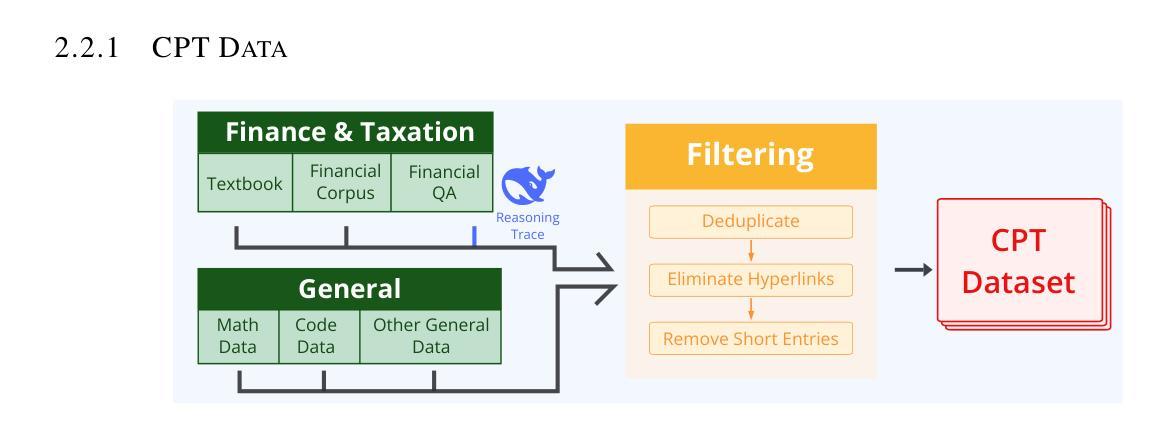
FEVO: Financial Knowledge Expansion and Reasoning Evolution for Large Language Models
Authors:Bo Pang, Yalu Ouyang, Hangfei Xu, Ziqi Jia, Panpan Li, Shengzhao Wen, Lu Wang, Shiyong Li, Yanpeng Wang
Advancements in reasoning for large language models (LLMs) have lead to significant performance improvements for LLMs in various fields such as mathematics and programming. However, research applying these advances to the financial domain, where considerable domain-specific knowledge is necessary to complete tasks, remains limited. To address this gap, we introduce FEVO (Financial Evolution), a multi-stage enhancement framework developed to enhance LLM performance in the financial domain. FEVO systemically enhances LLM performance by using continued pre-training (CPT) to expand financial domain knowledge, supervised fine-tuning (SFT) to instill structured, elaborate reasoning patterns, and reinforcement learning (RL) to further integrate the expanded financial domain knowledge with the learned structured reasoning. To ensure effective and efficient training, we leverage frontier reasoning models and rule-based filtering to curate FEVO-Train, high-quality datasets specifically designed for the different post-training phases. Using our framework, we train the FEVO series of models - C32B, S32B, R32B - from Qwen2.5-32B and evaluate them on seven benchmarks to assess financial and general capabilities, with results showing that FEVO-R32B achieves state-of-the-art performance on five financial benchmarks against much larger models as well as specialist models. More significantly, FEVO-R32B demonstrates markedly better performance than FEVO-R32B-0 (trained from Qwen2.5-32B-Instruct using only RL), thus validating the effectiveness of financial domain knowledge expansion and structured, logical reasoning distillation
随着大型语言模型(LLM)在推理方面的进步,LLM在数学、编程等领域取得了显著的性能提升。然而,将这些进展应用于金融领域的研究仍然有限,金融领域完成任务需要大量的特定领域知识。为了弥补这一空白,我们引入了FEVO(金融进化),这是一个为增强LLM在金融领域的性能而开发的多阶段增强框架。FEVO系统通过持续预训练(CPT)扩展金融领域知识,通过监督微调(SFT)培养结构化和逻辑化的推理模式,以及通过强化学习(RL)进一步将扩展的金融领域知识与学习的结构化推理相结合,从而增强LLM的性能。为确保有效和高效的训练,我们利用前沿的推理模型和基于规则的过滤来创建专门为不同训练后阶段设计的FEVO-Train高质量数据集。使用我们的框架,我们训练了FEVO系列模型 - C32B、S32B、R32B - 基于Qwen2.5-32B,并在七个基准测试上对它们进行评估,以评估其金融和一般能力。结果表明,FEVO-R32B在五项金融基准测试上达到了最先进的性能表现,相较于更大的模型和专业模型也有显著优势。更重要的是,FEVO-R32B的性能明显优于FEVO-R32B-0(仅使用RL从Qwen2.5-32B-Instruct进行训练),从而验证了金融领域知识扩展和结构化逻辑推理蒸馏的有效性。
论文及项目相关链接
Summary
LLM在多个领域表现出强大的性能,但在金融领域的应用仍然有限。为解决这一问题,研究团队推出了FEVO框架,通过持续预训练、监督微调及强化学习三个阶段增强LLM在金融领域的性能。FEVO系列模型在七个基准测试中表现出卓越性能,特别是在金融领域的五个基准测试中达到最新水平。研究表明,金融领域知识的扩展和结构逻辑推理蒸馏的结合有助于提升模型性能。
Key Takeaways
- LLM在金融领域的性能提升需求迫切,但仍面临挑战。
- FEVO框架旨在增强LLM在金融领域的性能,通过持续预训练、监督微调及强化学习三个阶段实现。
- FEVO系列模型在多个基准测试中表现优秀,特别是在金融领域的基准测试中达到最新水平。
- 金融领域知识的扩展对模型性能提升至关重要。
- 结构化、逻辑化的推理模式有助于提升模型在金融领域的推理能力。
- FEVO框架通过前沿的推理模型和规则过滤方法,为不同的训练阶段设计了高质量的数据集。
点此查看论文截图



MedGround-R1: Advancing Medical Image Grounding via Spatial-Semantic Rewarded Group Relative Policy Optimization
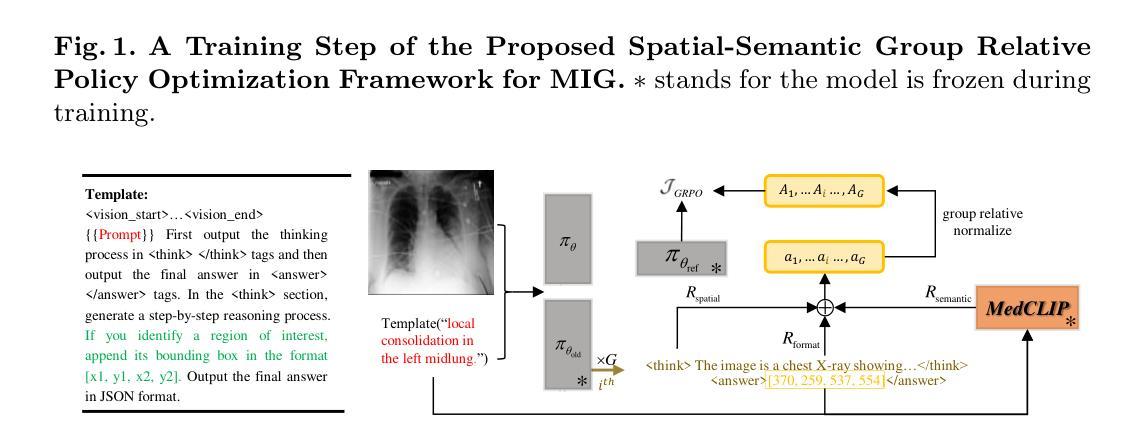
Authors:Huihui Xu, Yuanpeng Nie, Hualiang Wang, Ying Chen, Wei Li, Junzhi Ning, Lihao Liu, Hongqiu Wang, Lei Zhu, Jiyao Liu, Xiaomeng Li, Junjun He
Medical Image Grounding (MIG), which involves localizing specific regions in medical images based on textual descriptions, requires models to not only perceive regions but also deduce spatial relationships of these regions. Existing Vision-Language Models (VLMs) for MIG often rely on Supervised Fine-Tuning (SFT) with large amounts of Chain-of-Thought (CoT) reasoning annotations, which are expensive and time-consuming to acquire. Recently, DeepSeek-R1 demonstrated that Large Language Models (LLMs) can acquire reasoning abilities through Group Relative Policy Optimization (GRPO) without requiring CoT annotations. In this paper, we adapt the GRPO reinforcement learning framework to VLMs for Medical Image Grounding. We propose the Spatial-Semantic Rewarded Group Relative Policy Optimization to train the model without CoT reasoning annotations. Specifically, we introduce Spatial-Semantic Rewards, which combine spatial accuracy reward and semantic consistency reward to provide nuanced feedback for both spatially positive and negative completions. Additionally, we propose to use the Chain-of-Box template, which integrates visual information of referring bounding boxes into the
医疗图像定位(MIG)需要根据文本描述定位医学图像中的特定区域,这要求模型不仅要感知区域,还要推断这些区域的空间关系。现有的用于MIG的视觉语言模型(VLMs)通常依赖于大量思维链(CoT)推理注释的监督微调(SFT),这些注释的获取既昂贵又耗时。最近,DeepSeek-R1证明,大型语言模型(LLM)可以通过群体相对策略优化(GRPO)获得推理能力,而无需CoT注释。在本文中,我们将GRPO强化学习框架适应于用于医疗图像定位的视觉语言模型。我们提出空间语义奖励相对策略优化(Spatial-Semantic Rewarded Group Relative Policy Optimization),可在无需CoT推理注释的情况下训练模型。具体来说,我们引入了空间语义奖励,它将空间精度奖励和语义一致性奖励相结合,为正面和负面完成的空间提供细微的反馈。此外,我们提出使用“Chain-of-Box”模板,该模板将指代边界框的视觉信息整合到
推理过程中,使模型能够在中间步骤中明确推理空间区域。在MS-CXR、ChestX-ray8和M3D-RefSeg三个数据集上的实验表明,我们的方法在医疗图像定位方面达到了最新技术性能。消融研究进一步验证了我们的方法中每个组件的有效性。相关代码、检查点和数据集可通过https://github.com/bio-mlhui/MedGround-R1获取。
论文及项目相关链接
PDF MICCAI2025 Early Accept
Summary
本文介绍了针对医疗图像定位(MIG)任务的新的强化学习框架。该框架采用空间语义奖励强化组相对策略优化(Spatial-Semantic Rewarded Group Relative Policy Optimization),无需链式思维(CoT)推理注释即可训练模型。通过引入空间精度奖励和语义一致性奖励,该模型能够在空间上正向和负向完成中提供精细反馈。此外,还提出了使用链式框模板(Chain-of-Box template),将参照边界框的视觉信息融入推理过程中,使模型能够在中间步骤中明确推理空间区域。实验结果表明,该方法在医疗图像定位任务上取得了最新技术性能。
Key Takeaways
- 介绍了针对医疗图像定位的新强化学习框架,无需依赖大量昂贵的链式思维推理注释。
- 提出空间语义奖励,结合空间精度奖励和语义一致性奖励,为模型提供精细反馈。
- 采用链式框模板,将视觉信息融入推理过程,提高模型在空间区域的推理能力。
- 在三个数据集上的实验结果表明,该方法在医疗图像定位任务上取得了最新技术性能。
点此查看论文截图

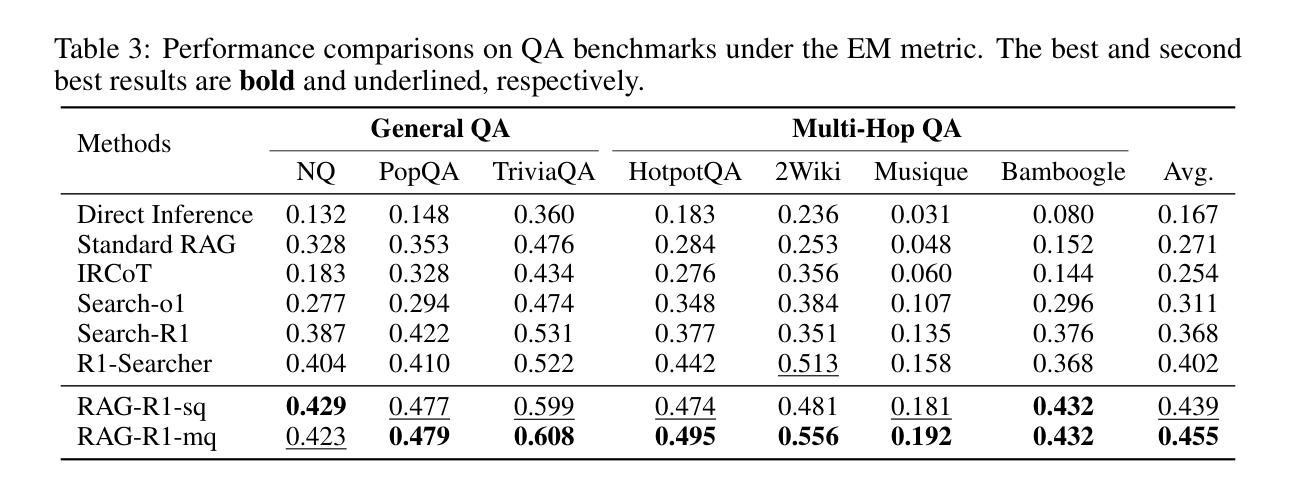
RAG-R1 : Incentivize the Search and Reasoning Capabilities of LLMs through Multi-query Parallelism
Authors:Zhiwen Tan, Jiaming Huang, Qintong Wu, Hongxuan Zhang, Chenyi Zhuang, Jinjie Gu
Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks, while they remain prone to generating hallucinated or outdated responses due to their static internal knowledge. Recent advancements in Retrieval-Augmented Generation (RAG) methods have explored enhancing models’ search and reasoning capabilities through reinforcement learning (RL). Although these methods demonstrate promising results, they face challenges in training stability and encounter issues such as substantial inference time and restricted capabilities due to the single-query mode. In this paper, we propose RAG-R1, a novel training framework designed to enable LLMs to adaptively leverage internal and external knowledge during the reasoning process. We further expand the generation and retrieval processes within the framework from single-query mode to multi-query parallelism, aimed at reducing inference time and enhancing the model’s capabilities. Extensive experiments on seven question-answering benchmarks demonstrate that our method outperforms the strongest baseline by up to 13.2% and decreases inference time by 11.1%.
大型语言模型(LLM)在各种任务中表现出了显著的能力,但由于其内部知识的静态性,它们容易产生虚构或过时的回应。最近,增强检索生成(RAG)方法的进步探索了通过强化学习(RL)增强模型的搜索和推理能力。尽管这些方法显示出有希望的结果,但它们面临着训练稳定性方面的挑战,并由于单查询模式而面临推理时间长和受限的能力等问题。在本文中,我们提出了RAG-R1,这是一种新型训练框架,旨在使LLM在推理过程中自适应地利用内部和外部知识。我们进一步将框架内的生成和检索过程从单查询模式扩展到多查询并行模式,旨在减少推理时间并提高模型的能力。在七个问答基准测试上的广泛实验表明,我们的方法比最强基线高出13.2%,并将推理时间减少了11.1%。
论文及项目相关链接
Summary
大型语言模型(LLMs)在各种任务中表现出卓越的能力,但它们容易产生虚构或过时回应,因为它们的内部知识是静态的。最近,检索增强生成(RAG)方法的进步通过强化学习(RL)提高了模型的搜索和推理能力。尽管这些方法显示出有希望的结果,但它们面临训练稳定性挑战,并遇到推理时间长和因单一查询模式导致的能力受限等问题。本文提出RAG-R1,一种新型训练框架,旨在使LLMs在推理过程中自适应地利用内部和外部知识。此外,我们在框架内将生成和检索过程从单一查询模式扩展到多查询并行模式,旨在减少推理时间并提高模型能力。在七个问答基准测试上的广泛实验表明,我们的方法比最强基线高出13.2%,并将推理时间减少11.1%。
Key Takeaways
- 大型语言模型(LLMs)虽然具有强大的能力,但容易产生虚构或过时回应,因为它们基于静态内部知识。
- 检索增强生成(RAG)方法通过强化学习(RL)提高了模型的搜索和推理能力。
- RAG方法虽然显示出有效结果,但仍面临训练稳定性挑战、推理时间长和因单一查询模式导致的能力受限等问题。
- 论文提出的RAG-R1是一种新型训练框架,旨在使LLMs在推理过程中自适应地利用内部和外部知识。
- RAG-R1框架将生成和检索过程从单一查询模式扩展到多查询并行模式,以提高效率和能力。
- 实验表明,RAG-R1在七个问答基准测试上的表现优于最强基线,性能提升高达13.2%,并减少推理时间11.1%。
- RAG-R1框架具有潜力改善LLMs的适应性和响应质量,同时提高效率和减少推理时间。
点此查看论文截图


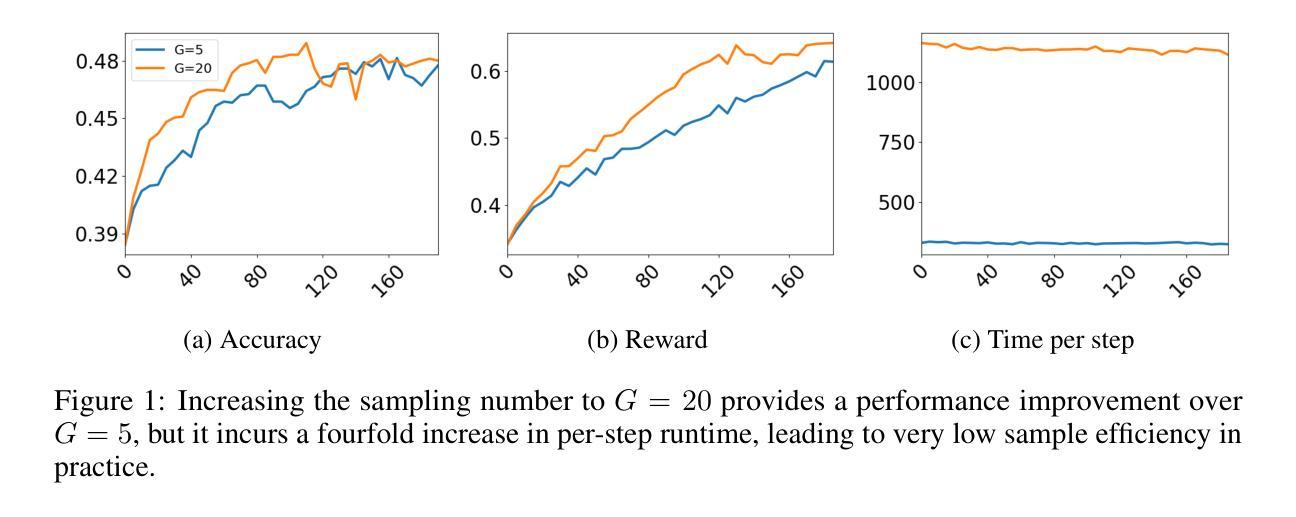
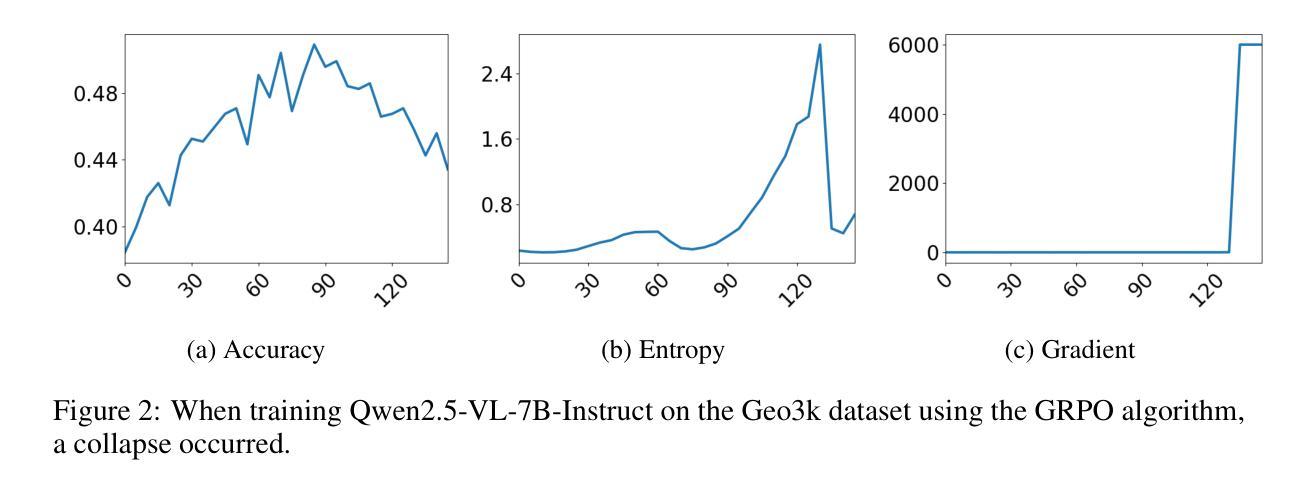
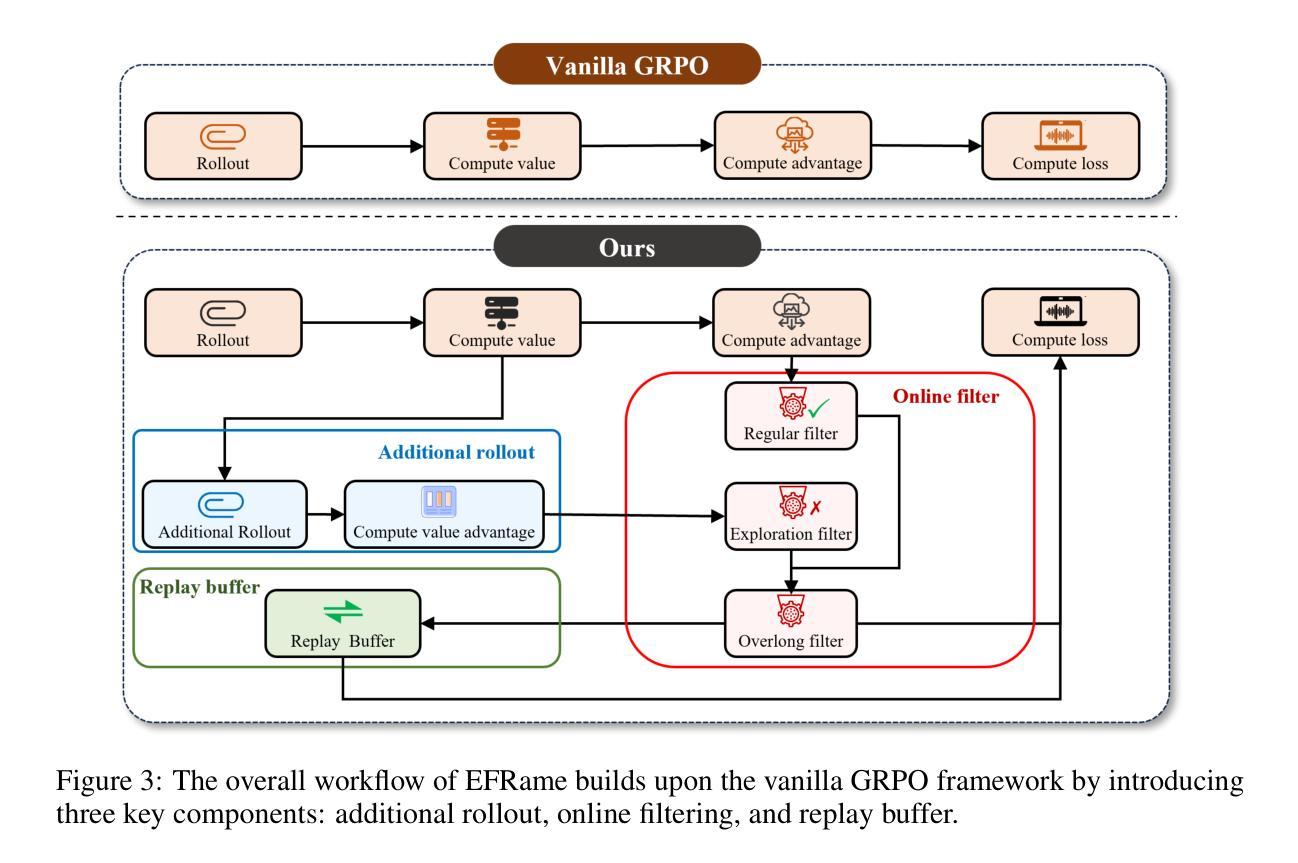
EFRame: Deeper Reasoning via Exploration-Filter-Replay Reinforcement Learning Framework
Authors:Chen Wang, Lai Wei, Yanzhi Zhang, Chenyang Shao, Zedong Dan, Weiran Huang, Yue Wang, Yuzhi Zhang
Recent advances in reinforcement learning (RL) have significantly enhanced the reasoning capabilities of large language models (LLMs). Group Relative Policy Optimization (GRPO), an efficient variant of PPO that lowers RL’s computational cost, still faces limited exploration, low sample efficiency and instability, constraining its performance on complex reasoning tasks. To address these limitations, we introduce EFRame, an Exploration-Filter-Replay framework that systematically augments GRPO along three critical dimensions. EFRame performs additional rollouts to explore high-quality trajectories, applies online filtering to eliminate low-quality samples that introduce noise and variance, and leverages experience replay to repeatedly exploit rare but informative samples. EFRame establishes a complete and stable learning cycle, guiding the model through a structured transition from exploration to convergence. Our experiments across a variety of reasoning benchmarks demonstrate that EFRame not only improves the robustness and efficiency of training, but also enables access to deeper reasoning capabilities that remain unattainable under vanilla GRPO. Furthermore, EFRame not only enables fine-grained categorization of training samples for deeper insight into their contributions, but also introduces an efficient and precise mechanism for entropy control, which is critical for balancing exploration and convergence in RL training. Our code is available at https://github.com/597358816/EFRame.
强化学习(RL)的最新进展极大地提高了大型语言模型(LLM)的推理能力。Group Relative Policy Optimization(GRPO)是PPO的一个有效变体,降低了RL的计算成本,但仍面临探索有限、样本效率较低和不稳定的问题,在复杂的推理任务上限制了其性能。为了解决这些局限性,我们引入了EFRame,这是一个探索-过滤-回放框架,系统地增强了GRPO的三个关键维度。EFRame执行额外的rollouts来探索高质量的轨迹,应用在线过滤来消除引入噪声和方差的低质量样本,并利用经验回放来反复利用稀有但具有信息量的样本。EFRame建立了一个完整稳定的学习周期,引导模型从探索到收敛的结构化过渡。我们在多种推理基准测试上的实验表明,EFRame不仅提高了训练的稳健性和效率,还实现了更深入的推理能力,这在普通GRPO下是无法达到的。此外,EFRame不仅能够对训练样本进行精细的分类,以深入了解其贡献,还引入了一种高效且精确的熵控制机制,这对于平衡强化学习训练中的探索和收敛至关重要。我们的代码可在https://github.com/597358816/EFRame找到。
论文及项目相关链接
Summary
强化学习(RL)的最新进展大大提高了大型语言模型(LLM)的推理能力。针对Group Relative Policy Optimization(GRPO)在复杂推理任务上的局限性,我们提出了EFRame框架,从探索、过滤和回放三个方面对GRPO进行了系统增强。实验表明,EFRame不仅提高了训练的稳健性和效率,还实现了更深入的推理能力。同时,EFRame还提供了一种精细的样本分类机制和有效的熵控制机制。
Key Takeaways
- 强化学习(RL)提高了大型语言模型(LLM)的推理能力。
- Group Relative Policy Optimization(GRPO)在复杂推理任务上存在局限性,如有限探索、低样本效率和不稳定。
- EFRame框架通过探索、过滤和回放三个关键方面增强GRPO。
- EFRame通过额外的rollout探索高质量的轨迹,在线过滤消除低质量样本的噪声和方差,并利用经验回放多次利用稀有但具有信息价值的样本。
- EFRame建立了一个完整稳定的学习周期,引导模型从探索到收敛的结构化过渡。
- 实验表明,EFRame提高了训练的稳健性和效率,并实现了更深入的推理能力。
点此查看论文截图

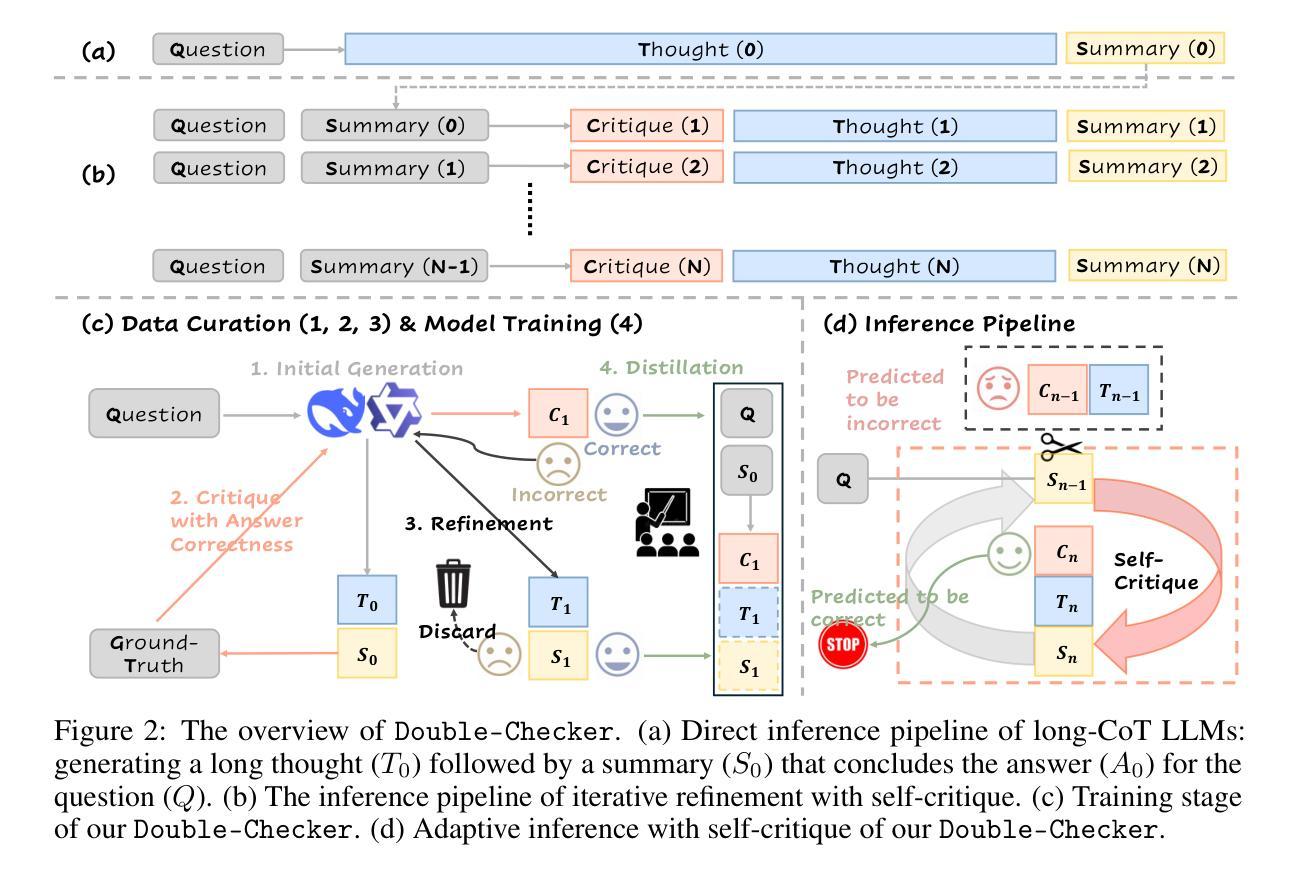
Double-Checker: Enhancing Reasoning of Slow-Thinking LLMs via Self-Critical Fine-Tuning
Authors:Xin Xu, Tianhao Chen, Fan Zhang, Wanlong Liu, Pengxiang Li, Ajay Kumar Jaiswal, Yuchen Yan, Jishan Hu, Yang Wang, Hao Chen, Shiwei Liu, Shizhe Diao, Can Yang, Lu Yin
While slow-thinking large language models (LLMs) exhibit reflection-like reasoning, commonly referred to as the “aha moment:, their ability to generate informative critiques and refine prior solutions remains limited. In this paper, we introduce Double-Checker, a principled framework designed to enhance the reasoning capabilities of slow-thinking LLMs by fostering explicit self-critique and iterative refinement of their previous solutions. By fine-tuning on our curated 1,730 self-critical instances, Double-Checker empowers long-CoT LLMs to iteratively critique and refine their outputs during inference until they evaluate their solutions as correct under self-generated critiques. We validate the efficacy of Double-Checker across a comprehensive suite of reasoning benchmarks, demonstrating that iterative self-critique significantly enhances the reasoning capabilities of long-CoT LLMs. Notably, our Double-Checker increases the pass@1 performance on challenging AIME benchmarks from 4.4% to 18.2% compared to the original long-CoT LLMs. These results highlight a promising direction for developing more trustworthy and effective LLMs capable of structured self-critique. Our codes and data are available at https://github.com/XinXU-USTC/DoubleChecker
虽然慢思考的大型语言模型(LLM)展现出类似反思的推理能力,通常被称为“顿悟时刻”,但它们生成有信息量的批判和精炼先前解决方案的能力仍然有限。在本文中,我们介绍了Double-Checker,这是一个旨在通过促进明确的自我批判和迭代完善其先前解决方案,增强慢思考型LLM推理能力的原则性框架。通过在我们精选的1730个自我批判实例上进行微调,Double-Checker赋予了长链推理LLM能力,在推理过程中迭代地批判和修正他们的输出,直到他们根据自我生成的批判评估自己的解决方案为正确。我们在一系列全面的推理基准测试上验证了Double-Checker的有效性,表明迭代的自我批判显著增强了长链推理LLM的推理能力。值得注意的是,我们的Double-Checker在具有挑战性的AIME基准测试上将前1名通过率从4.4%提高到18.2%,相较于原始的长链推理LLM。这些结果突显了一个有前景的方向,即开发更具可信度和有效性的LLM,能够进行自我批判。我们的代码和数据可在https://github.com/XinXU-USTC/DoubleChecker 找到。
论文及项目相关链接
PDF 10 pages
Summary:
本文介绍了Double-Checker框架,旨在通过促进明确的自我批判和迭代优化慢速思考的大型语言模型(LLMs)的推理能力。通过在我们的精选的1,730个自我批判实例上进行微调,Double-Checker赋能长认知链LLMs在推理过程中进行迭代批判和优化他们的输出,直到他们根据自我生成的批判评估自己的解决方案为正确。验证结果表明,迭代自我批判显著提高了长认知链LLMs的推理能力。我们的Double-Checker在具有挑战性的AIME基准测试中,将pass@1性能从4.4%提高到18.2%。这为开发能够进行结构化自我批判的更可靠、更有效的LLMs指明了有希望的方向。
Key Takeaways:
- Double-Checker框架旨在提高大型语言模型(LLMs)的推理能力,通过促进自我批判和迭代优化。
- Double-Checker赋能LLMs在推理过程中进行迭代批判和优化输出。
- 通过在精选的1,730个自我批判实例上进行微调,Double-Checker提高LLMs的推理性能。
- 验证结果表明,迭代自我批判对LLMs的推理能力有显著提高。
- Double-Checker在AIME基准测试中的表现显著,将pass@1性能从4.4%提高到18.2%。
- 开发的Double-Checker框架为开发更可靠、更有效的LLMs指明了方向。
点此查看论文截图


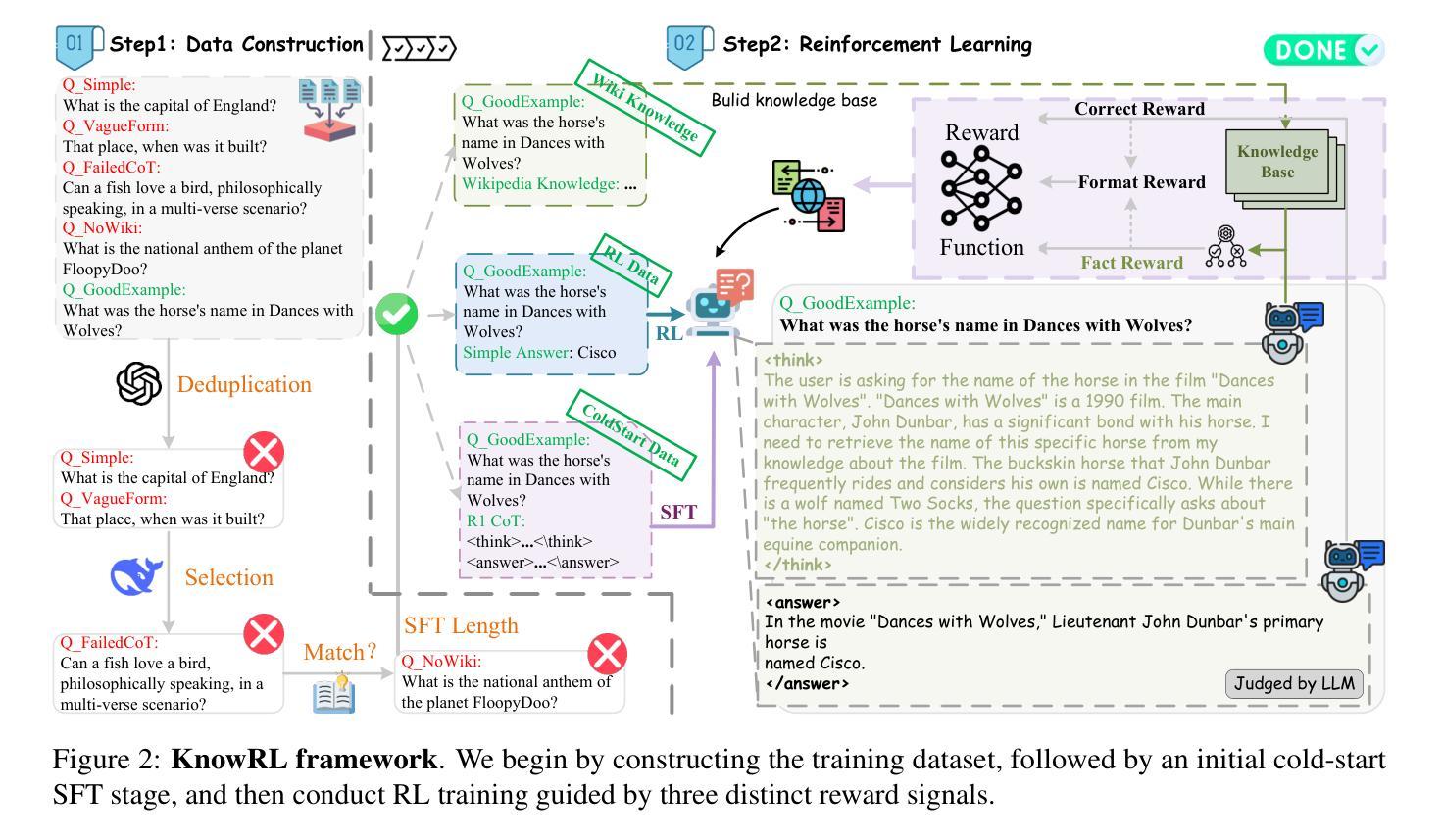
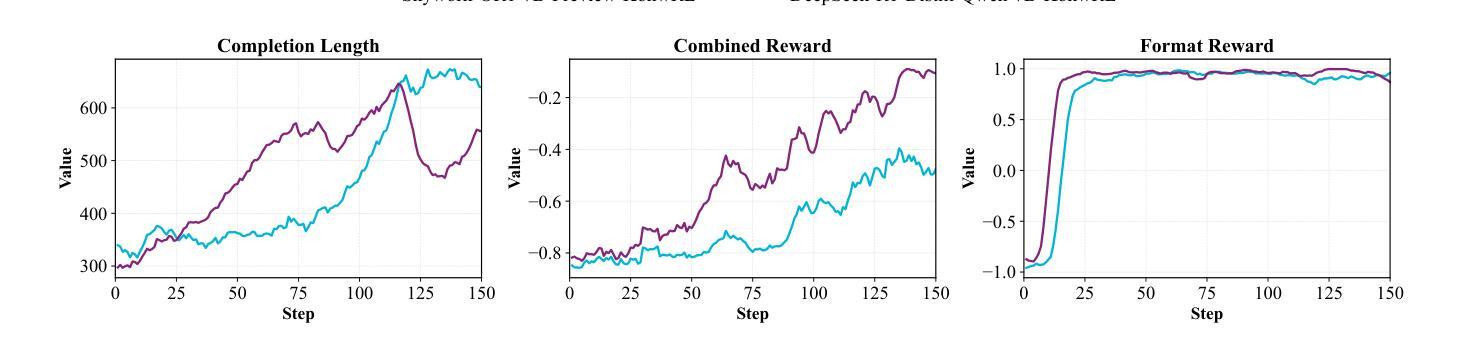
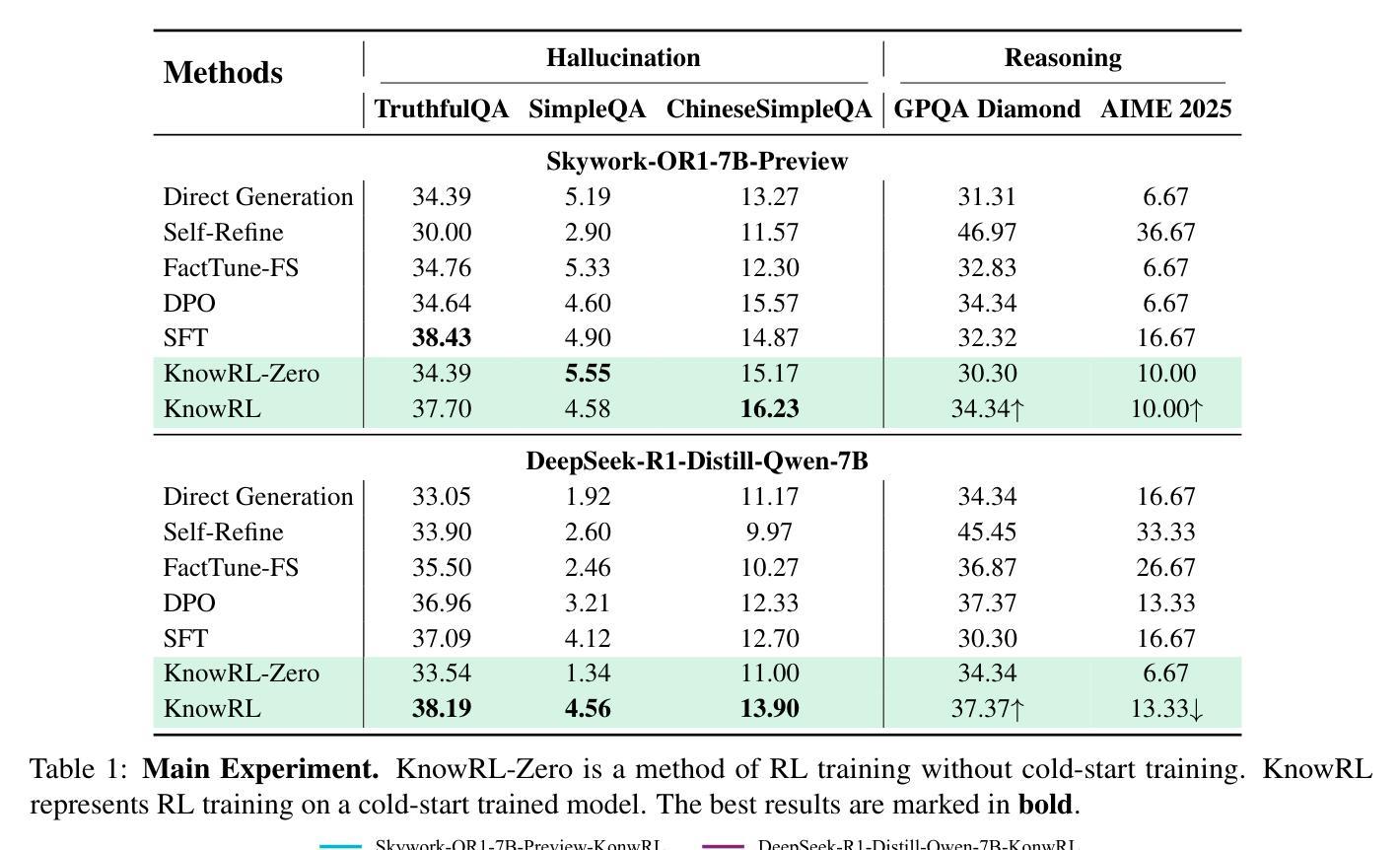
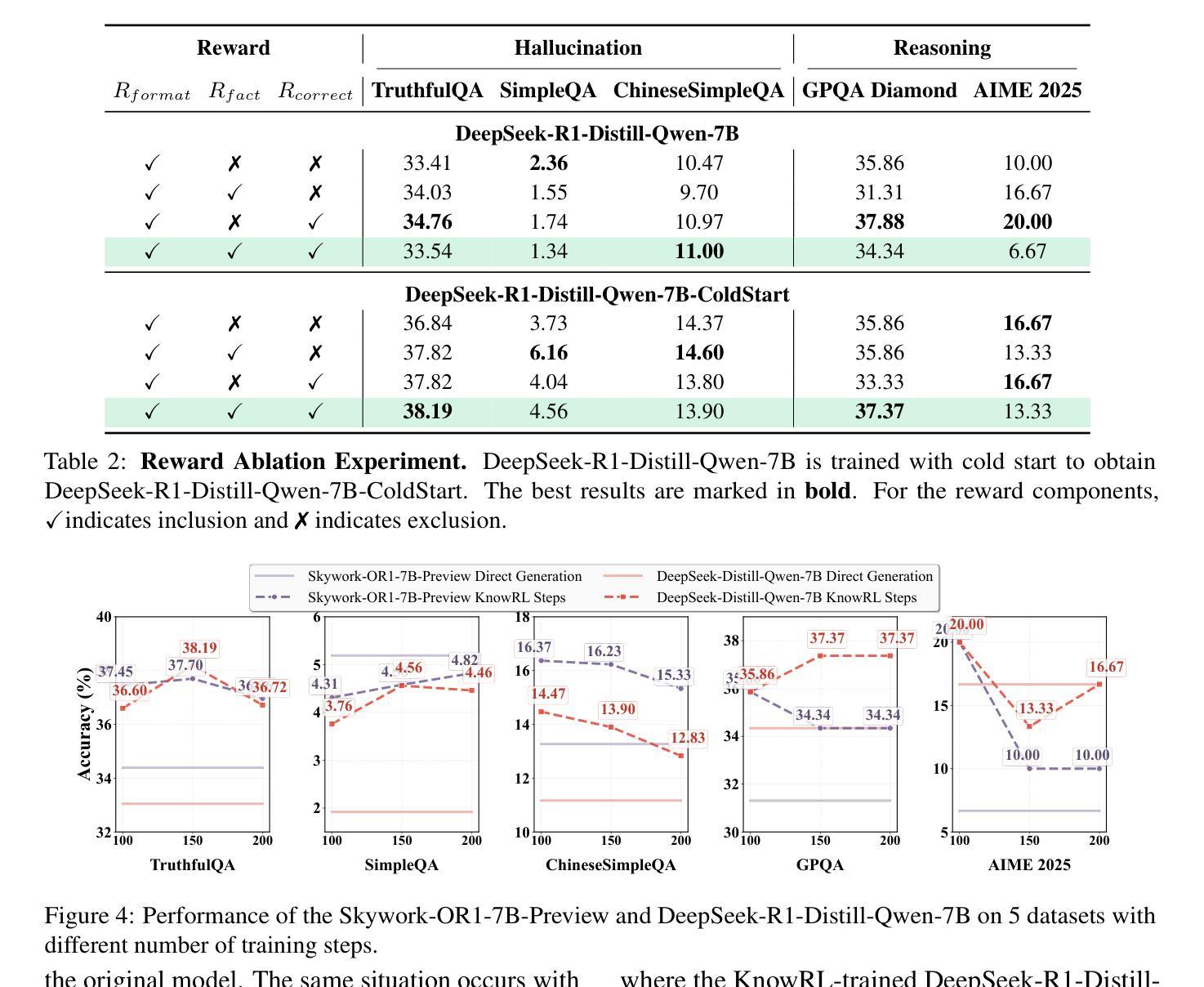
KnowRL: Exploring Knowledgeable Reinforcement Learning for Factuality
Authors:Baochang Ren, Shuofei Qiao, Wenhao Yu, Huajun Chen, Ningyu Zhang
Large Language Models (LLMs), particularly slow-thinking models, often exhibit severe hallucination, outputting incorrect content due to an inability to accurately recognize knowledge boundaries during reasoning. While Reinforcement Learning (RL) can enhance complex reasoning abilities, its outcome-oriented reward mechanism often lacks factual supervision over the thinking process, further exacerbating the hallucination problem. To address the high hallucination in slow-thinking models, we propose Knowledge-enhanced RL, KnowRL. KnowRL guides models to perform fact-based slow thinking by integrating a factuality reward, based on knowledge verification, into the RL training process, helping them recognize their knowledge boundaries. KnowRL guides models to perform fact-based slow thinking by integrating a factuality reward, based on knowledge verification, into the RL training process, helping them recognize their knowledge boundaries. This targeted factual input during RL training enables the model to learn and internalize fact-based reasoning strategies. By directly rewarding adherence to facts within the reasoning steps, KnowRL fosters a more reliable thinking process. Experimental results on three hallucination evaluation datasets and two reasoning evaluation datasets demonstrate that KnowRL effectively mitigates hallucinations in slow-thinking models while maintaining their original strong reasoning capabilities. Our code is available at https://github.com/zjunlp/KnowRL.
大型语言模型(LLM),尤其是慢思考模型,常常表现出严重的幻觉,由于推理过程中无法准确识别知识边界,从而输出错误内容。虽然强化学习(RL)可以增强复杂推理能力,但其以结果为导向的奖励机制往往缺乏对思考过程的真实监督,从而加剧了幻觉问题。为了解决慢思考模型中的高幻觉问题,我们提出了知识增强RL,即KnowRL。KnowRL通过将基于知识验证的真实性奖励融入RL训练过程,指导模型进行基于事实的慢思考,帮助它们识别知识边界。KnowRL的特殊设计旨在通过奖励模型在推理步骤中遵循事实,来培育一个更可靠的思考过程。在三份幻觉评估数据集和两份推理评估数据集上的实验结果表明,KnowRL在减轻慢思考模型的幻觉问题的同时,保持了其原有的强大推理能力。我们的代码可在[https://github.com/zjunlp/KnowRL获取。]
论文及项目相关链接
PDF Work in progress
Summary
大型语言模型(LLMs)在推理过程中存在知识边界识别困难的问题,导致严重的内容幻觉输出。强化学习(RL)虽然能提高复杂推理能力,但其结果导向的奖励机制缺乏思考过程的实际监督,加剧了幻觉问题。为解决这一问题,我们提出了结合知识验证的基于知识增强的强化学习(KnowRL)方法。通过集成基于知识验证的事实奖励来指导模型进行基于事实的慢速思考,帮助模型认识其知识边界。实验结果表明,KnowRL在减少慢思考模型的幻觉输出同时,保持了其原有的强大推理能力。代码已公开在GitHub上。
Key Takeaways
- 大型语言模型(LLMs)在推理时存在知识边界识别困难的问题,导致幻觉输出。
- 强化学习(RL)能提高模型的复杂推理能力,但奖励机制可能导致幻觉问题进一步加剧。
- KnowRL方法通过集成基于知识验证的事实奖励来指导模型进行基于事实的慢速思考。
- KnowRL帮助模型认识其知识边界,减少幻觉输出,同时保持原有的强大推理能力。
- KnowRL的实验结果已在三个幻觉评估数据集和两个推理评估数据集上得到验证。
点此查看论文截图

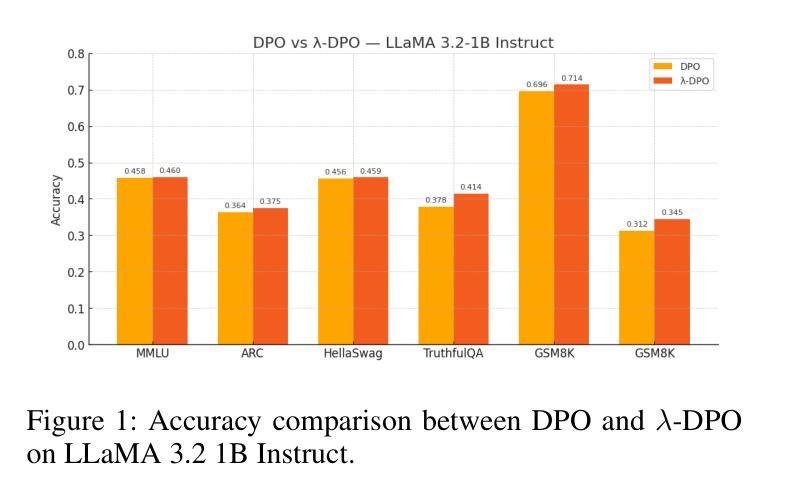
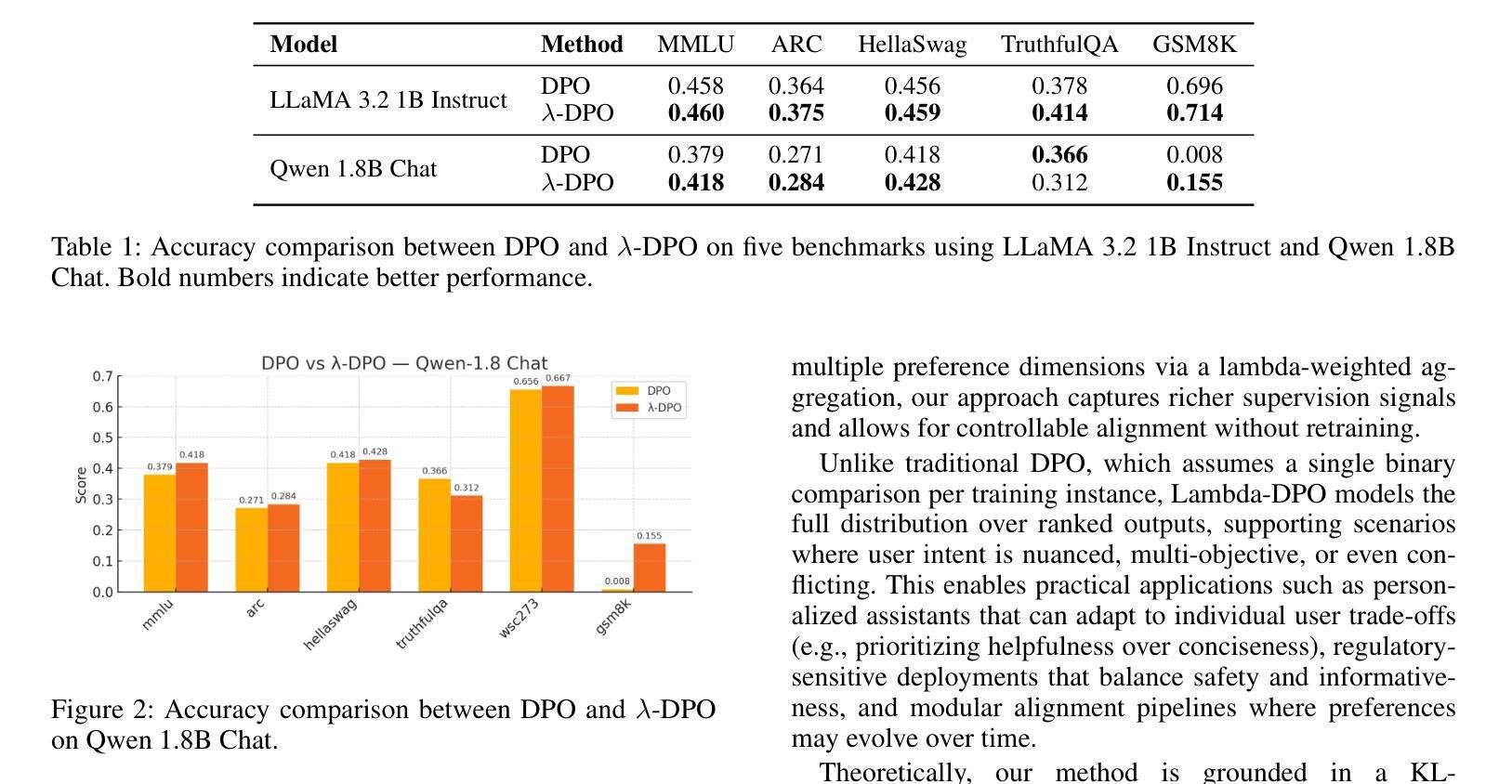
Multi-Preference Lambda-weighted Listwise DPO for Dynamic Preference Alignment
Authors:Yuhui Sun, Xiyao Wang, Zixi Li, Jinman Zhao
While large-scale unsupervised language models (LMs) capture broad world knowledge and reasoning capabilities, steering their behavior toward desired objectives remains challenging due to the lack of explicit supervision. Existing alignment techniques, such as reinforcement learning from human feedback (RLHF), rely on training a reward model and performing reinforcement learning to align with human preferences. However, RLHF is often computationally intensive, unstable, and sensitive to hyperparameters. To address these limitations, Direct Preference Optimization (DPO) was introduced as a lightweight and stable alternative, enabling direct alignment of language models with pairwise preference data via classification loss. However, DPO and its extensions generally assume a single static preference distribution, limiting flexibility in multi-objective or dynamic alignment settings. In this paper, we propose a novel framework: Multi-Preference Lambda-weighted Listwise DPO, which extends DPO to incorporate multiple human preference dimensions (e.g., helpfulness, harmlessness, informativeness) and enables dynamic interpolation through a controllable simplex-weighted formulation. Our method supports both listwise preference feedback and flexible alignment across varying user intents without re-training. Empirical and theoretical analysis demonstrates that our method is as effective as traditional DPO on static objectives while offering greater generality and adaptability for real-world deployment.
大规模无监督语言模型(LMs)虽然捕捉到了广泛的世界知识和推理能力,但由于缺乏明确的监督,将其行为导向既定目标仍然具有挑战性。现有的对齐技术,如强化学习从人类反馈(RLHF),依赖于训练奖励模型和进行强化学习以符合人类偏好。然而,RLHF通常计算量大、不稳定,对超参数敏感。为了解决这些局限性,引入了直接偏好优化(DPO)作为轻量级和稳定的替代方案,通过分类损失直接对齐语言模型与成对偏好数据。然而,DPO及其扩展通常假设单个静态偏好分布,这在多目标或动态对齐设置中限制了灵活性。在本文中,我们提出了一种新型框架:多偏好Lambda加权列表式DPO,它扩展了DPO以融入多种人类偏好维度(例如,有用性、无害性、信息量),并通过可控的单纯形加权公式实现动态插值。我们的方法支持列表式偏好反馈,并在不同的用户意图之间实现灵活对齐,而无需重新训练。实证和理论分析表明,我们的方法在静态目标上与传统DPO同样有效,同时提供了更大的通用性和适应性,适用于现实世界部署。
论文及项目相关链接
PDF 11 pages, 6 figures, appendix included. To appear in Proceedings of AAAI 2026. Code: https://github.com/yuhui15/Multi-Preference-Lambda-weighted-DPO
Summary
大型无监督语言模型捕捉广泛的世界知识和推理能力,但缺乏明确的监督导致难以控制其行为以达到期望目标。现有对齐技术如强化学习结合人类反馈(RLHF)依赖奖励模型的训练和强化学习以对齐人类偏好,但RLHF计算量大、不稳定且对超参数敏感。为解决这些问题,引入轻量级且稳定的直接偏好优化(DPO)。然而,DPO及其扩展假设单一静态偏好分布,限制了多目标或动态对齐设置的灵活性。本文提出新型框架:多偏好λ加权列表式DPO,它将DPO扩展到包含多重人类偏好维度(如帮助性、无害性和信息量),并通过可控的单纯加权公式实现动态插值。该方法支持列表式偏好反馈,并在无需重新训练的情况下灵活对齐不同用户意图。经验分析和理论证明显示,该方法在静态目标上与传统DPO同样有效,同时提供更大的通用性和适应性以适应现实世界的部署。
Key Takeaways
- 大型无监督语言模型面临如何控制行为以达到期望目标的问题。
- 现有对齐技术如RLHF存在计算量大、不稳定及对超参数敏感的问题。
- 直接偏好优化(DPO)作为一种轻量级、稳定的替代方法被引入。
- DPO及其扩展有单一静态偏好分布的局限性。
- 新型框架——多偏好λ加权列表式DPO扩展了DPO,纳入多重人类偏好维度。
- 该框架通过可控的单纯加权公式实现动态插值,支持列表式偏好反馈。
- 该方法在静态目标上与传统DPO效果相当,同时提供更大的通用性和适应性。
点此查看论文截图