⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-11 更新
KAConvText: Novel Approach to Burmese Sentence Classification using Kolmogorov-Arnold Convolution
Authors:Ye Kyaw Thu, Thura Aung, Thazin Myint Oo, Thepchai Supnithi
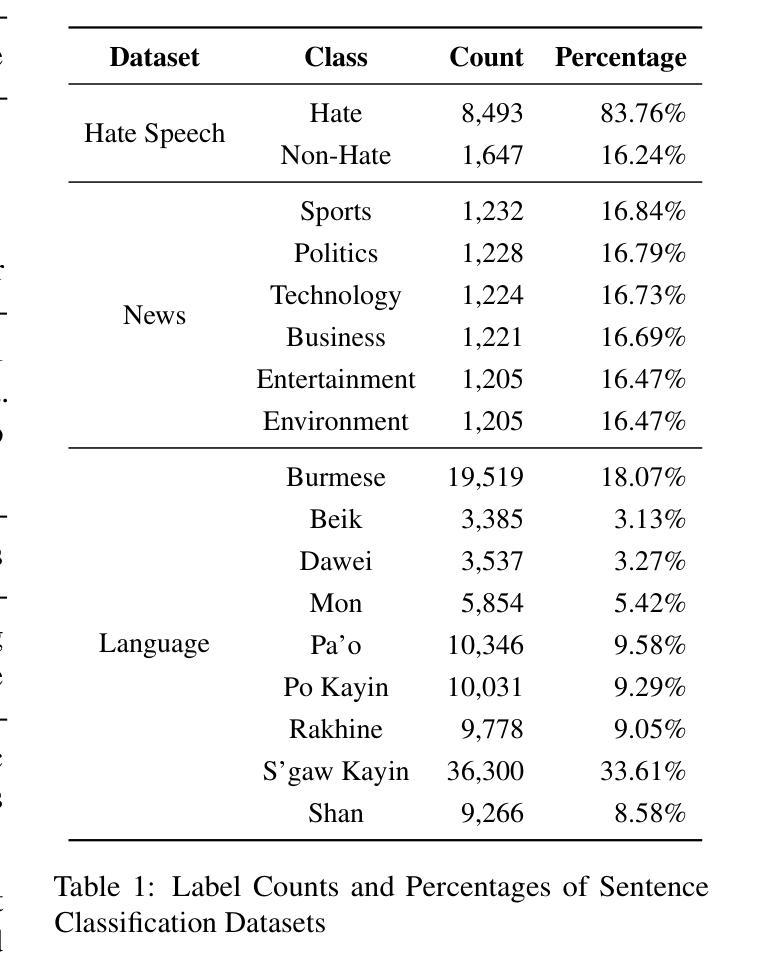
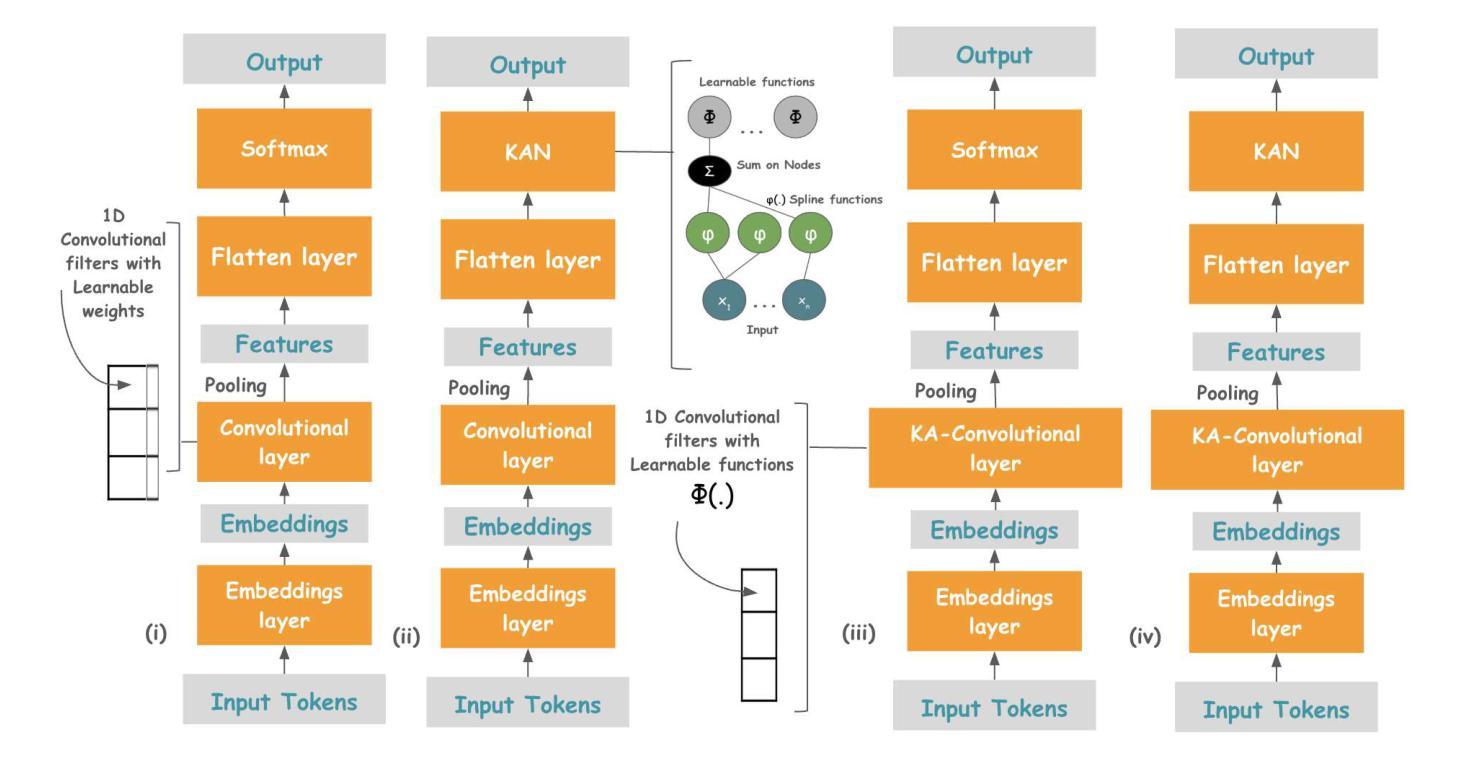
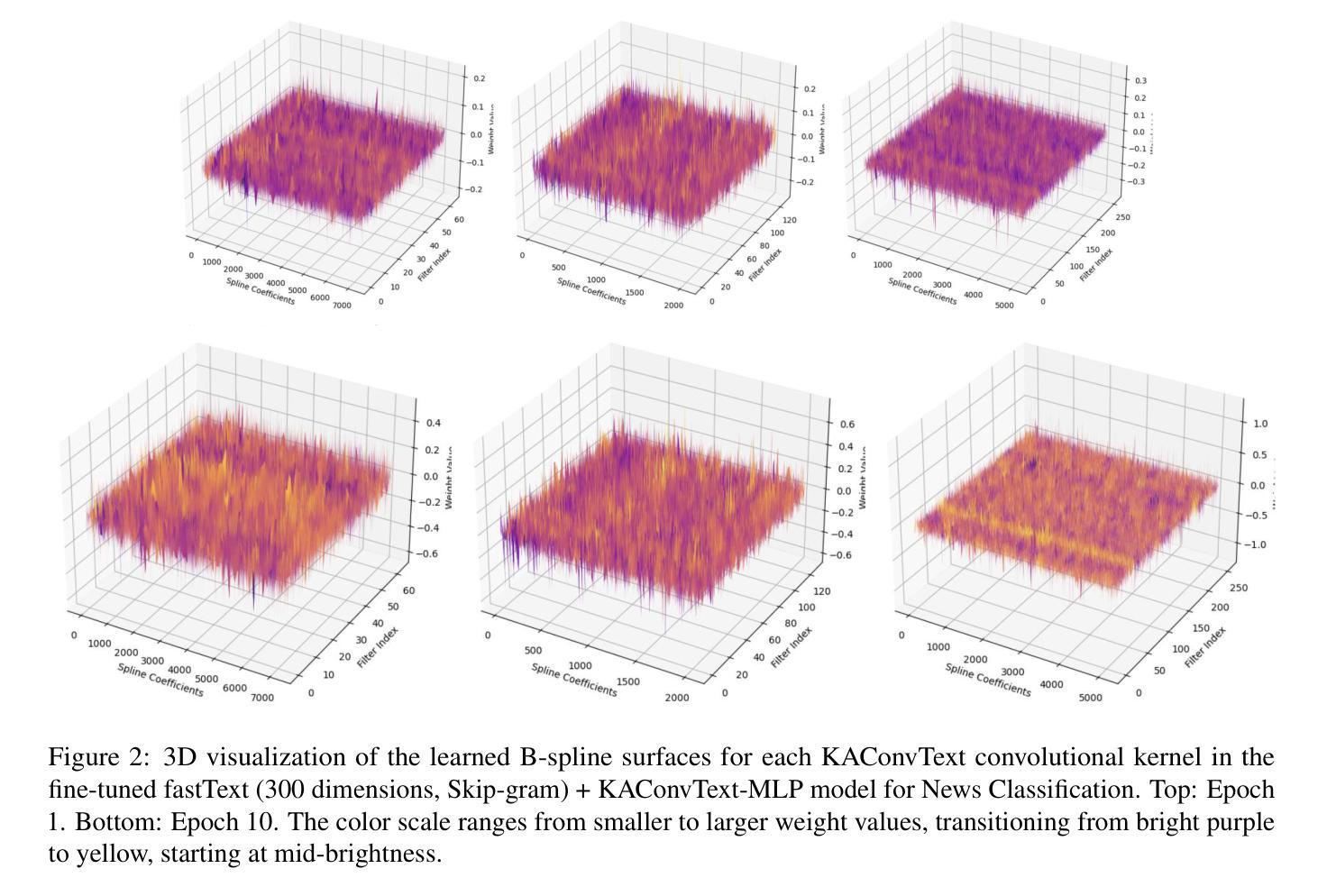
This paper presents the first application of Kolmogorov-Arnold Convolution for Text (KAConvText) in sentence classification, addressing three tasks: imbalanced binary hate speech detection, balanced multiclass news classification, and imbalanced multiclass ethnic language identification. We investigate various embedding configurations, comparing random to fastText embeddings in both static and fine-tuned settings, with embedding dimensions of 100 and 300 using CBOW and Skip-gram models. Baselines include standard CNNs and CNNs augmented with a Kolmogorov-Arnold Network (CNN-KAN). In addition, we investigated KAConvText with different classification heads - MLP and KAN, where using KAN head supports enhanced interpretability. Results show that KAConvText-MLP with fine-tuned fastText embeddings achieves the best performance of 91.23% accuracy (F1-score = 0.9109) for hate speech detection, 92.66% accuracy (F1-score = 0.9267) for news classification, and 99.82% accuracy (F1-score = 0.9982) for language identification.
本文首次将Kolmogorov-Arnold卷积应用于文本(KAConvText)应用于句子分类,涉及三个任务:不平衡二进制仇恨言论检测、平衡多类新闻分类和不平衡多类民族语言识别。我们研究了各种嵌入配置,比较了静态和微调设置中的随机到fastText嵌入,使用CBOW和Skip-gram模型,嵌入维度为100和300。基准线包括标准CNN和增强Kolmogorov-Arnold网络(CNN-KAN)的CNN。此外,我们还研究了不同分类头与KAConvText的结合,包括MLP和KAN,其中使用KAN头支持增强可解释性。结果表明,使用微调fastText嵌入的KAConvText-MLP在仇恨言论检测方面达到了91.23%的准确率(F1分数为0.9109),新闻分类方面的准确率为92.66%(F1分数为0.9267),语言识别方面的准确率为99.82%(F1分数为0.9982)。
论文及项目相关链接
PDF 10 pages, 3 figures, 4 tables
Summary
文本介绍了Kolmogorov-Arnold卷积在文本中的应用,重点研究了三项任务:平衡不平衡二元仇恨言论检测、平衡多元新闻分类和不平衡多元种族语言识别。通过对随机与fastText嵌入在静态和微调设置中的比较,采用CBOW和Skip-gram模型的嵌入维度为100和300的实验设置进行研究。初步工作包括使用CNN模型和标准CNNs,并提出了增强解释性的KAConvText模型。实验结果表明,使用fine-tuned fastText嵌入的KAConvText-MLP模型在仇恨言论检测方面取得了最佳性能,准确率为91.23%,F1分数为0.9109;在新闻分类方面准确率为92.66%,F1分数为0.9267;在语言识别方面准确率为99.82%,F1分数为0.9982。
Key Takeaways
- 该论文首次将Kolmogorov-Arnold卷积应用于文本中的句子分类任务。
- 研究涵盖了三种任务:仇恨言论检测、新闻分类和民族语言识别。
- 对比了随机嵌入与fastText嵌入在静态和微调状态下的性能差异。
- 初步研究包括标准CNN模型和结合Kolmogorov-Arnold网络的CNN模型(CNN-KAN)。
- 研究发现KAConvText使用不同的分类头(MLP和KAN)时表现出不同的性能,其中使用KAN头增强了模型的解释性。
点此查看论文截图

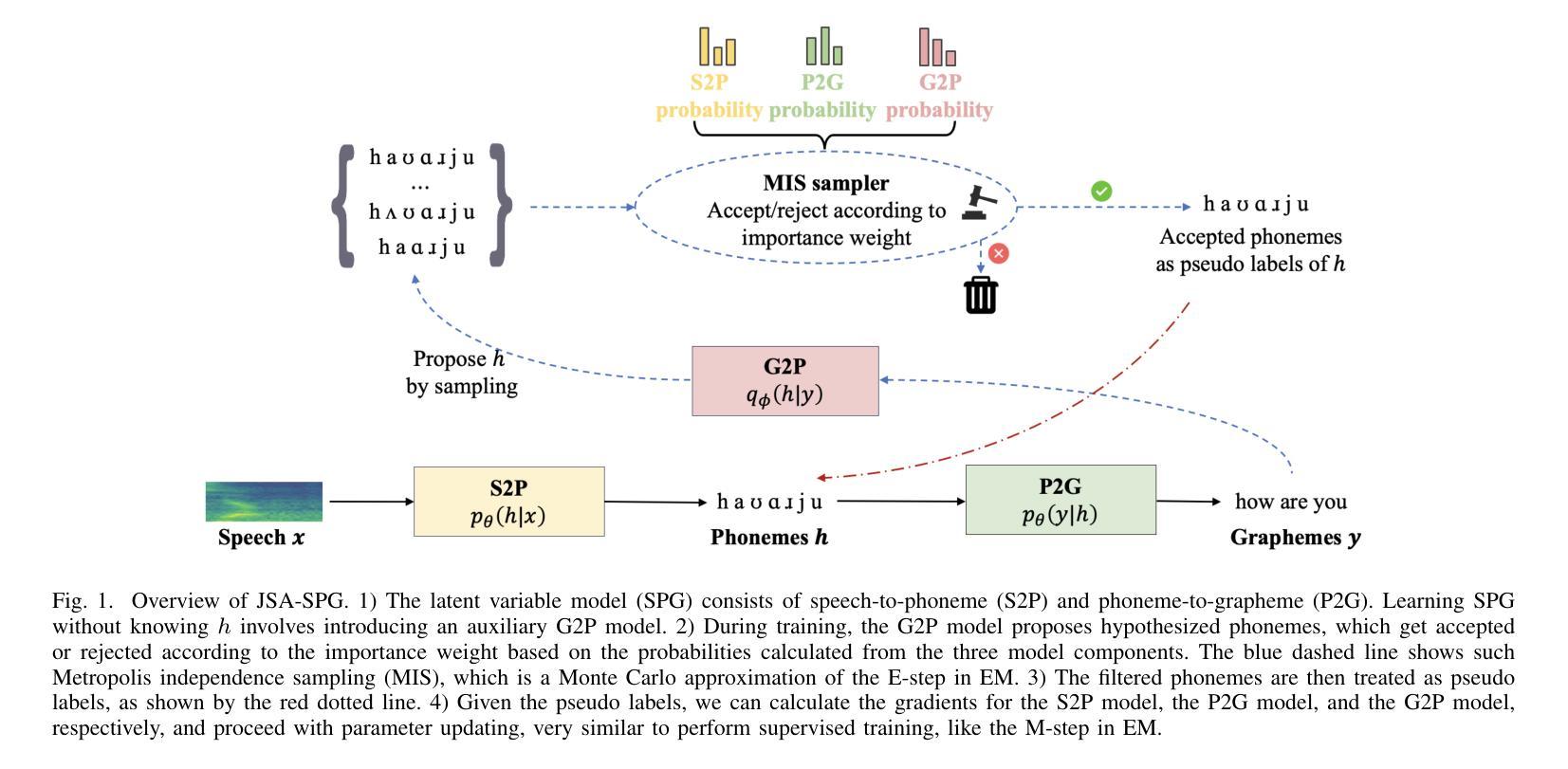
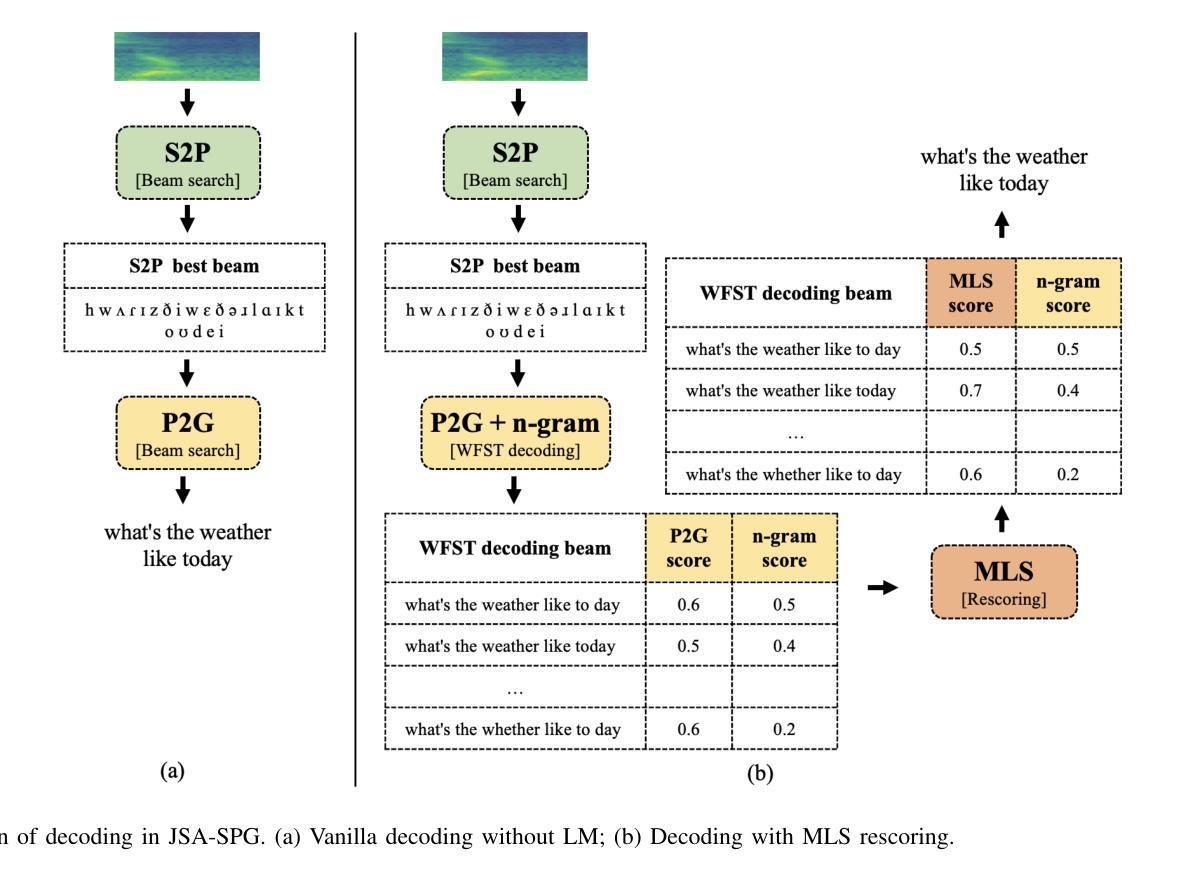
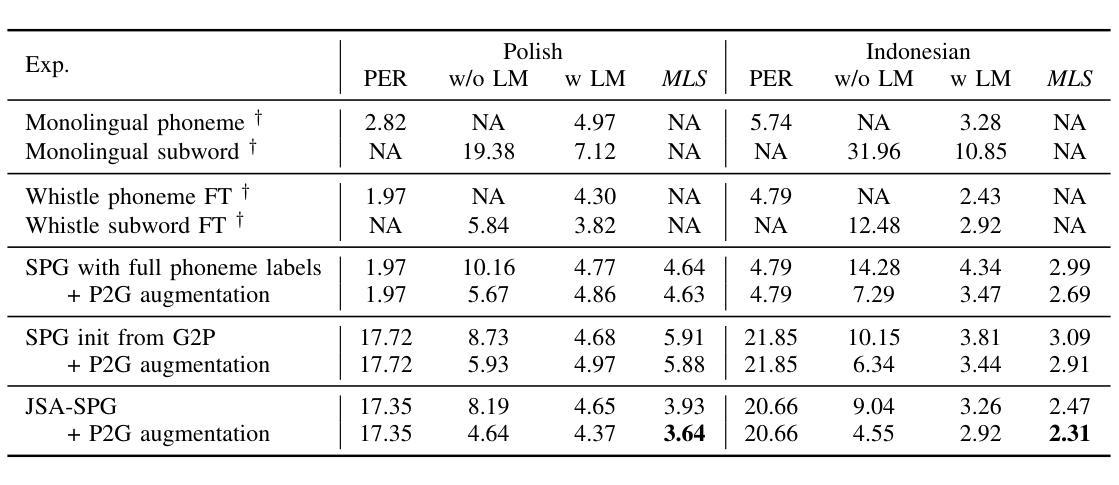
Pronunciation-Lexicon Free Training for Phoneme-based Crosslingual ASR via Joint Stochastic Approximation
Authors:Saierdaer Yusuyin, Te Ma, Hao Huang, Zhijian Ou
Recently, pre-trained models with phonetic supervision have demonstrated their advantages for crosslingual speech recognition in data efficiency and information sharing across languages. However, a limitation is that a pronunciation lexicon is needed for such phoneme-based crosslingual speech recognition. In this study, we aim to eliminate the need for pronunciation lexicons and propose a latent variable model based method, with phonemes being treated as discrete latent variables. The new method consists of a speech-to-phoneme (S2P) model and a phoneme-to-grapheme (P2G) model, and a grapheme-to-phoneme (G2P) model is introduced as an auxiliary inference model. To jointly train the three models, we utilize the joint stochastic approximation (JSA) algorithm, which is a stochastic extension of the EM (expectation-maximization) algorithm and has demonstrated superior performance particularly in estimating discrete latent variable models. Based on the Whistle multilingual pre-trained S2P model, crosslingual experiments are conducted in Polish (130 h) and Indonesian (20 h). With only 10 minutes of phoneme supervision, the new method, JSA-SPG, achieves 5% error rate reductions compared to the best crosslingual fine-tuning approach using subword or full phoneme supervision. Furthermore, it is found that in language domain adaptation (i.e., utilizing cross-domain text-only data), JSA-SPG outperforms the standard practice of language model fusion via the auxiliary support of the G2P model by 9% error rate reductions. To facilitate reproducibility and encourage further exploration in this field, we open-source the JSA-SPG training code and complete pipeline.
最近,带有语音监督的预训练模型在跨语言语音识别中显示出其在数据效率和跨语言信息共享方面的优势。然而,一个限制是需要一个发音词典来进行这种基于音素的跨语言语音识别。本研究旨在消除对发音词典的需求,并提出一种基于潜在变量模型的方法,其中音素被视为离散潜在变量。新方法包括语音到音素(S2P)模型和音素到字母(P2G)模型,并引入字母到音素(G2P)模型作为辅助推理模型。为了联合训练这三个模型,我们利用联合随机逼近(JSA)算法,它是EM(期望最大化)算法的随机扩展,在估计离散潜在变量模型方面表现出卓越的性能。基于Whistle多语言预训练S2P模型的波兰语(130小时)和印尼语(20小时)的跨语言实验表明,仅需10分钟的音素监督,新方法JSA-SPG与采用子词或全音素监督的最佳跨语言微调方法相比,实现了5%的错误率降低。此外,研究发现,在语言领域适应(即利用跨域文本数据),JSA-SPG通过G2P模型的辅助支持,实现了9%的错误率降低,优于语言模型融合的标准实践。为了促进该领域的可重复性和进一步探索,我们公开了JSA-SPG训练代码和完整流程。
论文及项目相关链接
PDF submitted to IEEE TASLP
摘要
基于Whistle多语言预训练S2P模型,本研究提出了一种无需语音字典的跨语言语音识别方法。该方法采用潜在变量模型,将语音作为离散潜在变量处理。通过联合训练语音到语音(S2P)、语音到字母(P2G)模型,并引入字母到语音(G2P)模型作为辅助推理模型,利用联合随机逼近(JSA)算法优化模型性能。在波兰语(130小时)和印尼语(20小时)的跨语言实验中,新方法JSA-SPG仅需10分钟的语音监督即可实现最佳跨语言微调方法的5%误差率降低。此外,在语言域适应(即利用跨域文本数据)方面,JSA-SPG通过G2P模型的辅助支持实现了9%的错误率降低。为便于复制和推动该领域的进一步探索,我们公开了JSA-SPG的训练代码和完整流程。
关键见解
- 跨语言语音识别中,无需语音字典的方法被提出,解决了依赖语音字典的问题。
- 采用潜在变量模型处理语音数据,其中语音被视为离散潜在变量。
- 联合训练了语音到语音(S2P)、语音到字母(P2G)模型,同时引入了字母到语音(G2P)模型作为辅助。
- 利用联合随机逼近(JSA)算法优化模型性能,特别是在估计离散潜在变量模型方面表现优越。
- 在波兰语和印尼语的跨语言实验中,新方法实现了显著的性能提升,与最佳跨语言微调方法相比,误差率降低了5%。
- 在语言域适应方面,新方法通过利用跨域文本数据实现了显著的性能改进,错误率降低了9%。
点此查看论文截图

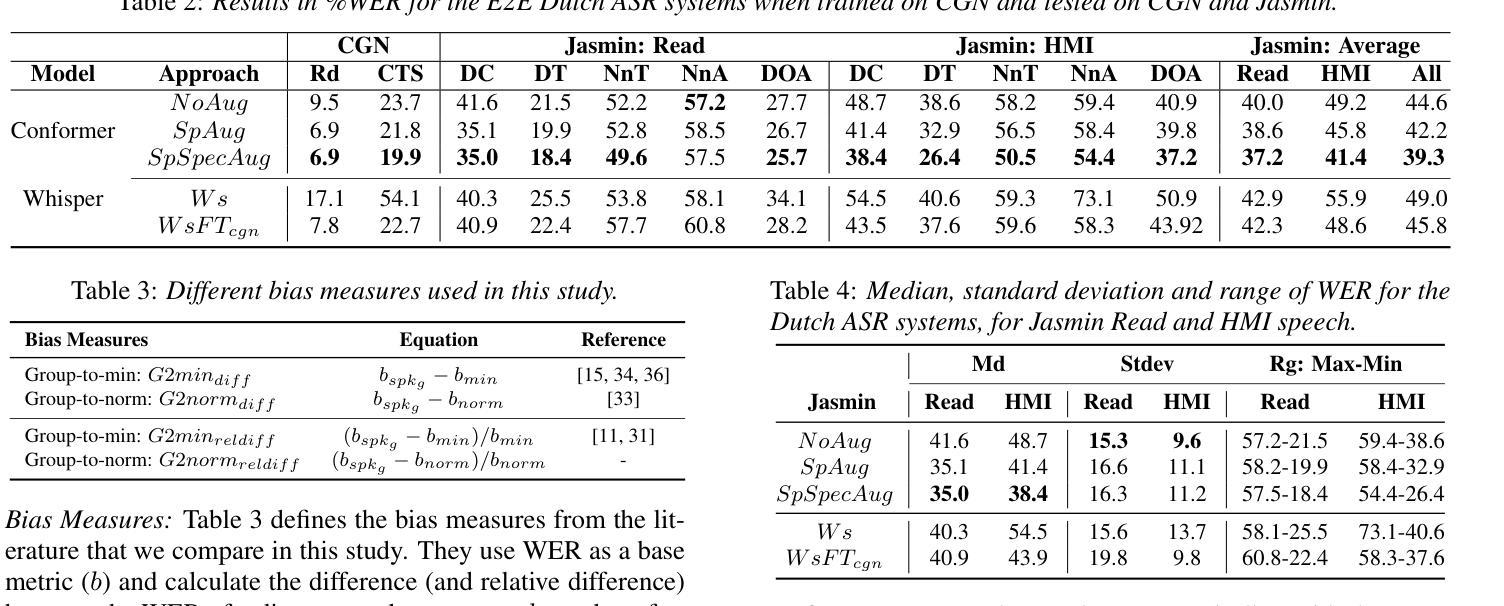
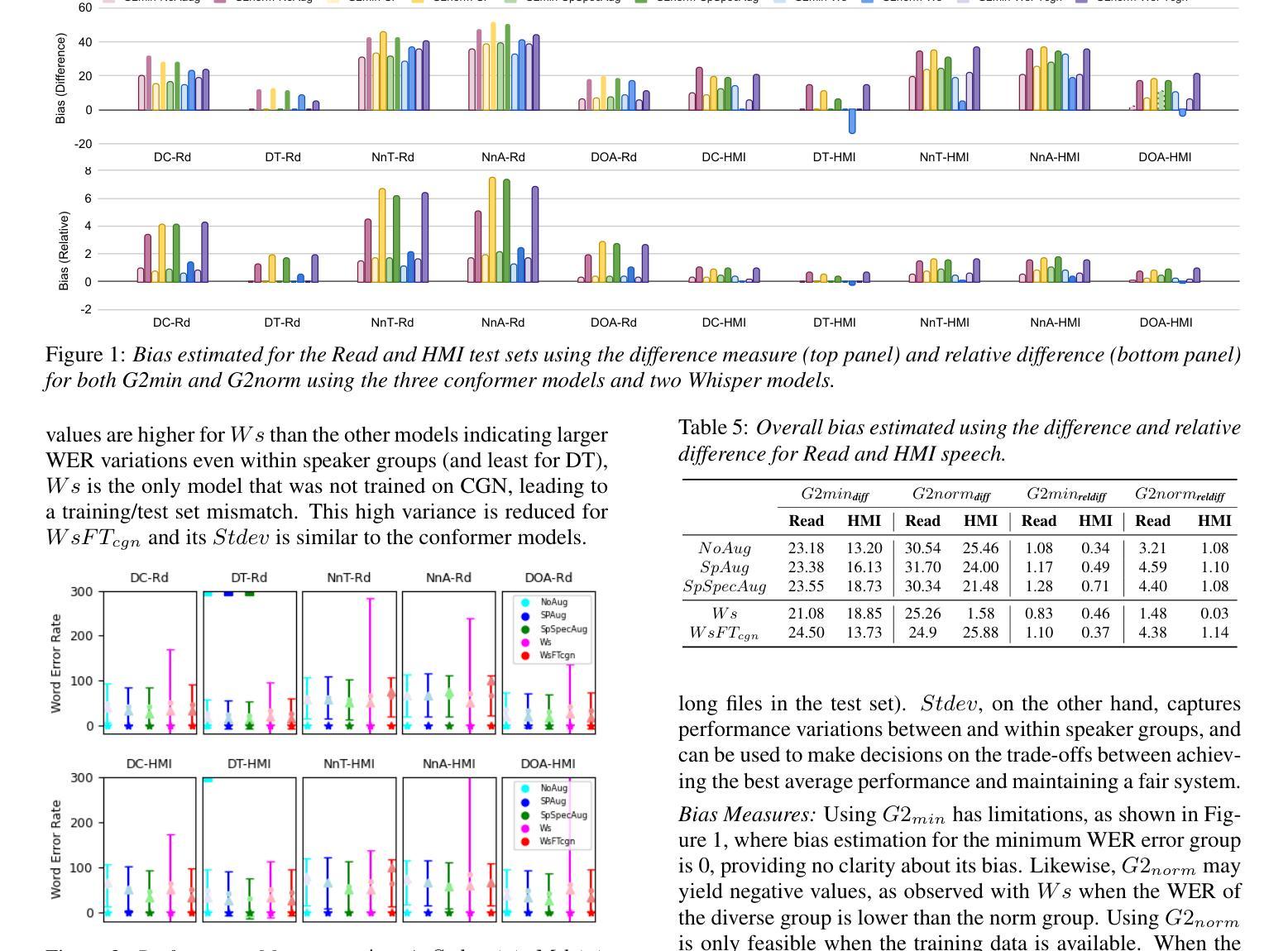
How to Evaluate Automatic Speech Recognition: Comparing Different Performance and Bias Measures
Authors:Tanvina Patel, Wiebke Hutiri, Aaron Yi Ding, Odette Scharenborg
There is increasingly more evidence that automatic speech recognition (ASR) systems are biased against different speakers and speaker groups, e.g., due to gender, age, or accent. Research on bias in ASR has so far primarily focused on detecting and quantifying bias, and developing mitigation approaches. Despite this progress, the open question is how to measure the performance and bias of a system. In this study, we compare different performance and bias measures, from literature and proposed, to evaluate state-of-the-art end-to-end ASR systems for Dutch. Our experiments use several bias mitigation strategies to address bias against different speaker groups. The findings reveal that averaged error rates, a standard in ASR research, alone is not sufficient and should be supplemented by other measures. The paper ends with recommendations for reporting ASR performance and bias to better represent a system’s performance for diverse speaker groups, and overall system bias.
自动语音识别(ASR)系统对不同说话者和说话者群体存在偏见,例如性别、年龄或口音等方面的偏见,这一证据越来越多。迄今为止,关于ASR偏见的研究主要集中在检测和量化偏见以及开发缓解方法上。尽管取得了进展,但开放的问题是如何衡量系统的性能和偏见。本研究中,我们比较了文献中提出的和自行提出的不同性能和偏见度量方法,以评估荷兰最先进的端到端ASR系统。我们的实验采用了多种偏见缓解策略,以解决针对不同说话者群体的偏见问题。研究结果表明,仅使用平均错误率(ASR研究中的标准)是不够的,应辅以其他度量方法。本文最后提出了报告ASR性能和偏见的建议,以更好地代表系统对不同说话者群体的性能以及整体的系统偏见。
论文及项目相关链接
Summary
本研究对比了不同性能与偏见衡量标准,以评估荷兰语端到端的自动语音识别系统。实验采用多种偏见缓解策略,以应对对不同说话群体的偏见问题。研究发现,仅使用平均错误率这一传统衡量标准并不足够,应辅以其他衡量手段。文章最后给出了关于报告自动语音识别性能和偏见的建议,以更好地代表系统对不同说话群体的性能以及整体的系统偏见。
Key Takeaways
- 自动语音识别(ASR)系统存在对不同说话者和说话群体(如性别、年龄或口音)的偏见。
- 目前的研究主要集中在检测、量化偏见和制定缓解方法上。
- 仅使用平均错误率作为衡量ASR系统性能和偏见的单一标准是不够的。
- 需要采用多种衡量手段来评估ASR系统的性能和偏见。
- 实验采用了多种偏见缓解策略来处理对不同说话群体的偏见问题。
- 推荐使用更全面的报告方式来展示ASR系统对不同说话群体的性能以及整体的系统偏见。
点此查看论文截图

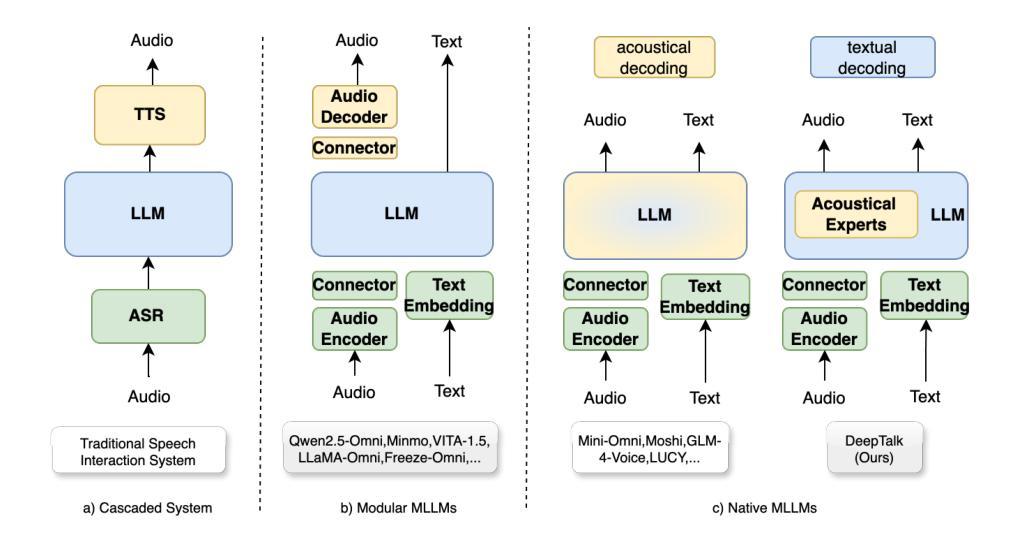
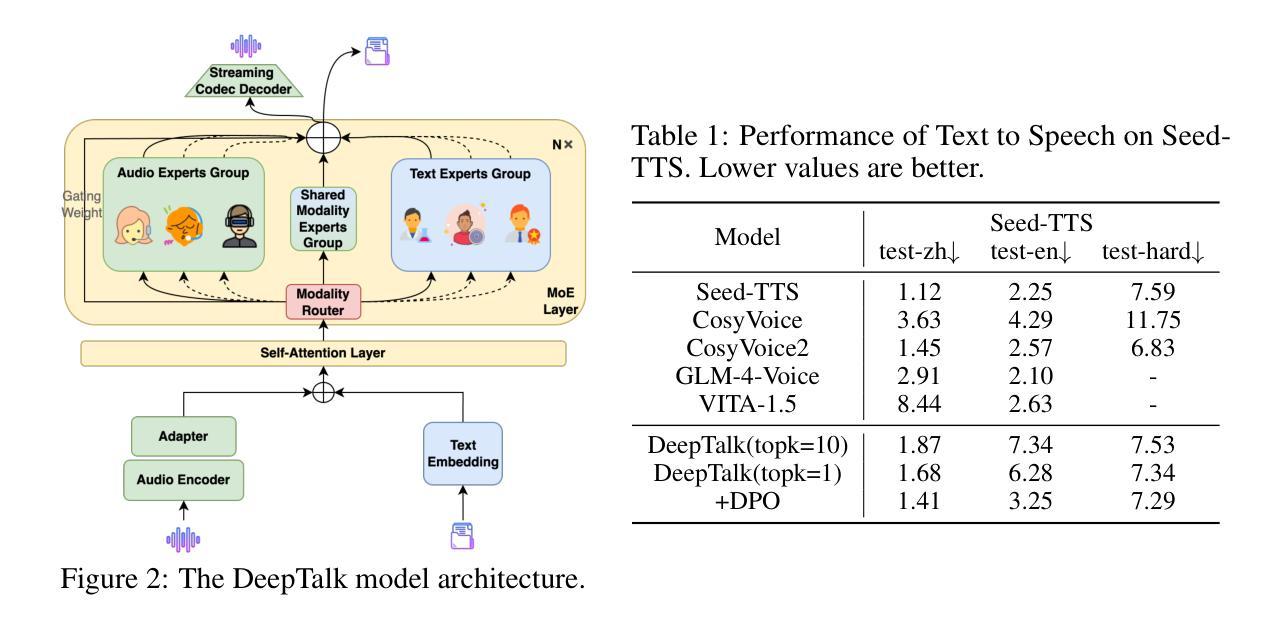
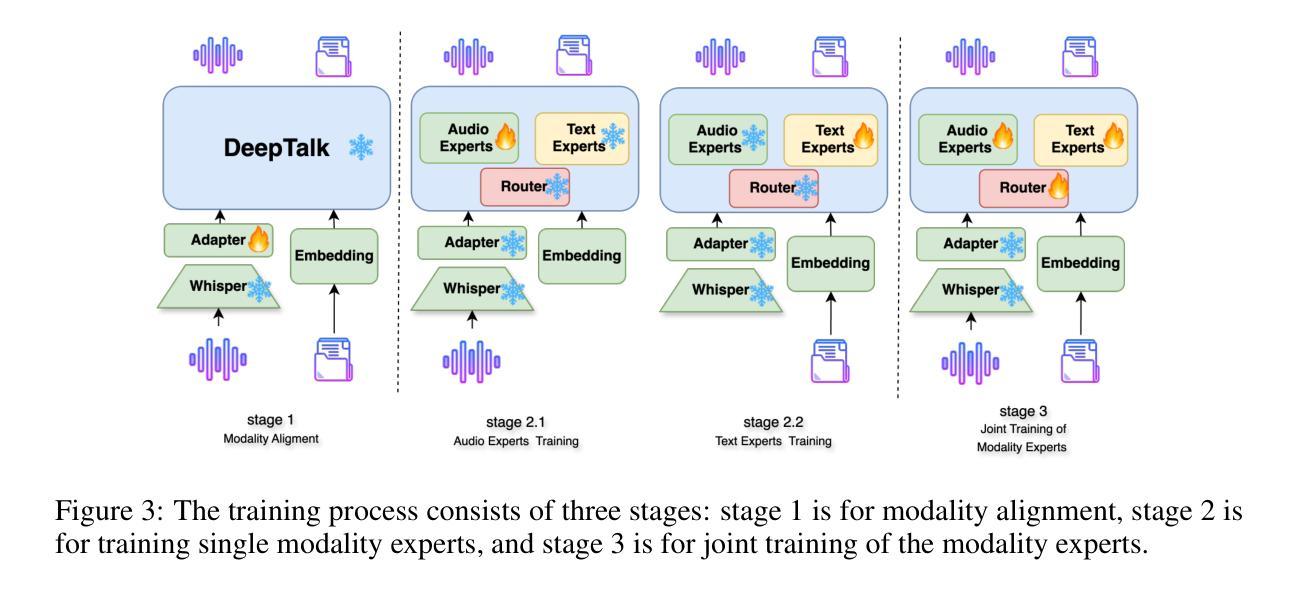
DeepTalk: Towards Seamless and Smart Speech Interaction with Adaptive Modality-Specific MoE
Authors:Hang Shao, Heting Gao, Yunhang Shen, Jiawei Chen, Lijiang Li, Zuwei Long, Bo Tong, Ke Li, Xing Sun
Native multimodal large language models (MLLMs) restructure a single large language model (LLM) into a spoken language model (SLM) capable of both speech and text generation. Compared to modular and aligned MLLMs, native MLLMs preserve richer paralinguistic features such as emotion and prosody, and generate speech responses directly within the backbone LLM rather than using a separate speech decoder. This integration also results in lower response latency and smoother interaction. However, native MLLMs suffer from catastrophic forgetting and performance degradation because the available paired speech-text data is insufficient to support the pretraining of MLLMs compared to the vast amount of text data required to pretrain text LLMs. To address this issue, we propose DeepTalk, a framework for adaptive modality expert learning based on a Mixture of Experts (MoE) architecture. DeepTalk first adaptively distinguishes modality experts according to their modality load within the LLM. Each modality expert then undergoes specialized single-modality training, followed by joint multimodal collaborative training. As a result, DeepTalk incurs only a 5.5% performance drop compared to the original LLM, which is significantly lower than the average performance drop of over 20% typically seen in native MLLMs (such as GLM-4-Voice), and is on par with modular MLLMs. Meanwhile, the end-to-end dialogue latency remains within 0.5 seconds, ensuring a seamless and intelligent speech interaction experience. Code and models are released at https://github.com/talkking/DeepTalk.
原生多模态大型语言模型(MLLMs)将单一的大型语言模型(LLM)重构为能够同时处理语音和文本生成的口语语言模型(SLM)。与模块化和对齐的MLLMs相比,原生MLLMs保留了更丰富的副语言特征,如情感和语调,并在主干LLM内直接生成语音响应,而不是使用单独的语音解码器。这种集成还带来了更低的响应延迟和更流畅的互动。然而,由于可用的配对语音-文本数据不足以支持MLLMs的预训练,与需要预训练文本LLM的大量文本数据相比,原生MLLMs遭受灾难性遗忘和性能下降的问题。为了解决这个问题,我们提出了DeepTalk,这是一个基于专家混合(MoE)架构的自适应模态专家学习框架。DeepTalk首先根据LLM内的模态负载自适应地区分模态专家。然后,每个模态专家接受专门的单模态训练,接着进行联合多模态协作训练。因此,DeepTalk的性能仅比原始LLM下降5.5%,远低于原生MLLMs通常出现的超过20%的平均性能下降,并与模块化MLLMs不相上下。同时,端到端对话延迟保持在0.5秒内,确保无缝、智能的语音交互体验。代码和模型已发布在https://github.com/talkking/DeepTalk。
论文及项目相关链接
PDF Under Review
Summary
本文介绍了原生多模态大型语言模型(MLLMs)的特点及其在语音和文本生成方面的优势。相较于模块化和对齐的MLLMs,原生MLLMs能保留更丰富的副语言特征,如情感和语调,并在主干LLM内直接生成语音响应。然而,由于可用的配对语音-文本数据不足以支持MLLMs的预训练,导致原生MLLMs容易出现灾难性遗忘和性能下降。为解决这一问题,本文提出了DeepTalk框架,采用基于混合专家(MoE)架构的自适应模态专家学习。DeepTalk首先根据LLM内的模态负载自适应地区分模态专家,随后进行专门的单模态训练和联合多模态协同训练。相较于原生LLM,DeepTalk的性能仅下降5.5%,远低于原生MLLMs通常出现的超过20%的性能下降,且与模块化MLLM相当。同时,端到端对话延迟保持在0.5秒内,确保流畅的智能语音交互体验。
Key Takeaways
- 原生多模态大型语言模型(MLLMs)能够同时处理语音和文本生成,保留丰富的副语言特征。
- 相较于模块化和对齐的MLLMs,原生MLLMs在交互方面具有更低的响应延迟和更流畅的体验。
- 原生MLLMs面临因数据不足导致的灾难性遗忘和性能下降问题。
- DeepTalk框架通过自适应模态专家学习来提高MLLMs的性能。
- DeepTalk仅导致5.5%的性能下降,远低于原生MLLMs通常的性能下降幅度。
- DeepTalk框架的性能与模块化MLLM相当。
- DeepTalk确保了流畅的智能语音交互体验,端到端对话延迟低于0.5秒。
点此查看论文截图

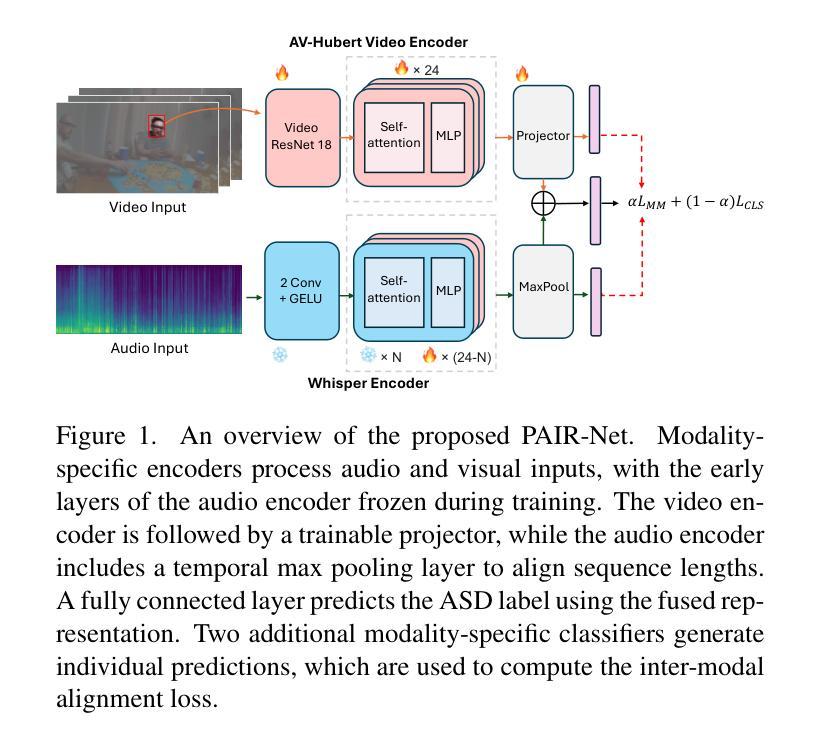
EgoVIS@CVPR: PAIR-Net: Enhancing Egocentric Speaker Detection via Pretrained Audio-Visual Fusion and Alignment Loss
Authors:Yu Wang, Juhyung Ha, David J. Crandall
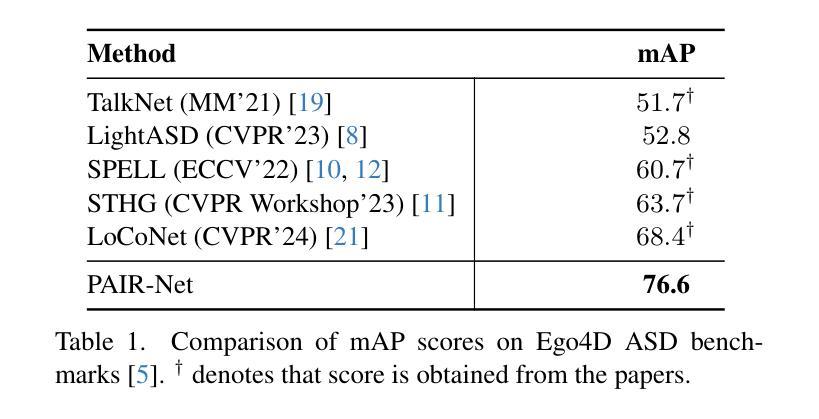
Active speaker detection (ASD) in egocentric videos presents unique challenges due to unstable viewpoints, motion blur, and off-screen speech sources - conditions under which traditional visual-centric methods degrade significantly. We introduce PAIR-Net (Pretrained Audio-Visual Integration with Regularization Network), an effective model that integrates a partially frozen Whisper audio encoder with a fine-tuned AV-HuBERT visual backbone to robustly fuse cross-modal cues. To counteract modality imbalance, we introduce an inter-modal alignment loss that synchronizes audio and visual representations, enabling more consistent convergence across modalities. Without relying on multi-speaker context or ideal frontal views, PAIR-Net achieves state-of-the-art performance on the Ego4D ASD benchmark with 76.6% mAP, surpassing LoCoNet and STHG by 8.2% and 12.9% mAP, respectively. Our results highlight the value of pretrained audio priors and alignment-based fusion for robust ASD under real-world egocentric conditions.
以自我为中心的视频中的主动说话人检测(ASD)面临着独特的挑战,如视角不稳定、运动模糊以及屏幕外的语音源等条件,这些条件下传统视觉中心的方法会显著退化。我们引入了PAIR-Net(具有正则化的预训练视听集成网络),这是一个有效的模型,它将部分冻结的Whisper音频编码器与微调后的AV-HuBERT视觉主干相结合,以稳健地融合跨模态线索。为了克服模态不平衡的问题,我们引入了一种跨模态对齐损失,以同步音频和视觉表示,从而实现跨模态的更一致收敛。在不依赖多说话人上下文或理想正面视角的情况下,PAIR-Net在Ego4D ASD基准测试上达到了最先进的性能,平均准确率为76.6%,分别比LoCoNet和STHG高出8.2%和12.9%的平均准确率。我们的结果突显了在现实世界的以自我为中心的环境下,预训练的音频先验和对齐融合的价值,为稳健的ASD提供了重要参考。
论文及项目相关链接
PDF 4 pages, 1 figure, and 1 table
Summary
预训练音频优先与正则化网络(PAIR-Net)能有效解决主动说话人检测(ASD)在自我中心视频中的挑战性问题。通过集成部分冻结的Whisper音频编码器与微调后的AV-HuBERT视觉主干,实现跨模态线索的稳健融合。引入跨模态对齐损失以对抗模态不平衡问题,同步音频和视觉表征,使各模态间收敛更一致。在不依赖多说话人语境或理想正面视角的情况下,PAIR-Net在Ego4D ASD基准测试中达到76.6%的mAP,较LoCoNet和STHG分别高出8.2%和12.9%的mAP。结果突显预训练音频先验和对齐融合在真实世界自我中心条件下的稳健ASD的价值。
Key Takeaways
- PAIR-Net模型解决了主动说话人检测在自我中心视频中的挑战,包括不稳定视角、运动模糊和离屏语音源等问题。
- PAIR-Net集成了预训练的Whisper音频编码器和AV-HuBERT视觉主干,实现跨模态信息的稳健融合。
- 引入跨模态对齐损失以对抗模态不平衡问题,确保音频和视觉表征的同步。
- PAIR-Net在Ego4D ASD基准测试中表现最佳,达到76.6%的mAP。
- 相较于其他模型,PAIR-Net在性能上有显著的提升。
- 预训练音频先验对于解决ASD问题具有重要价值。
点此查看论文截图

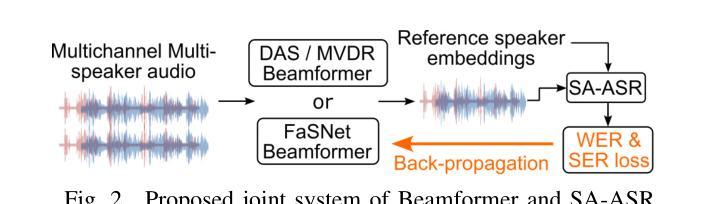
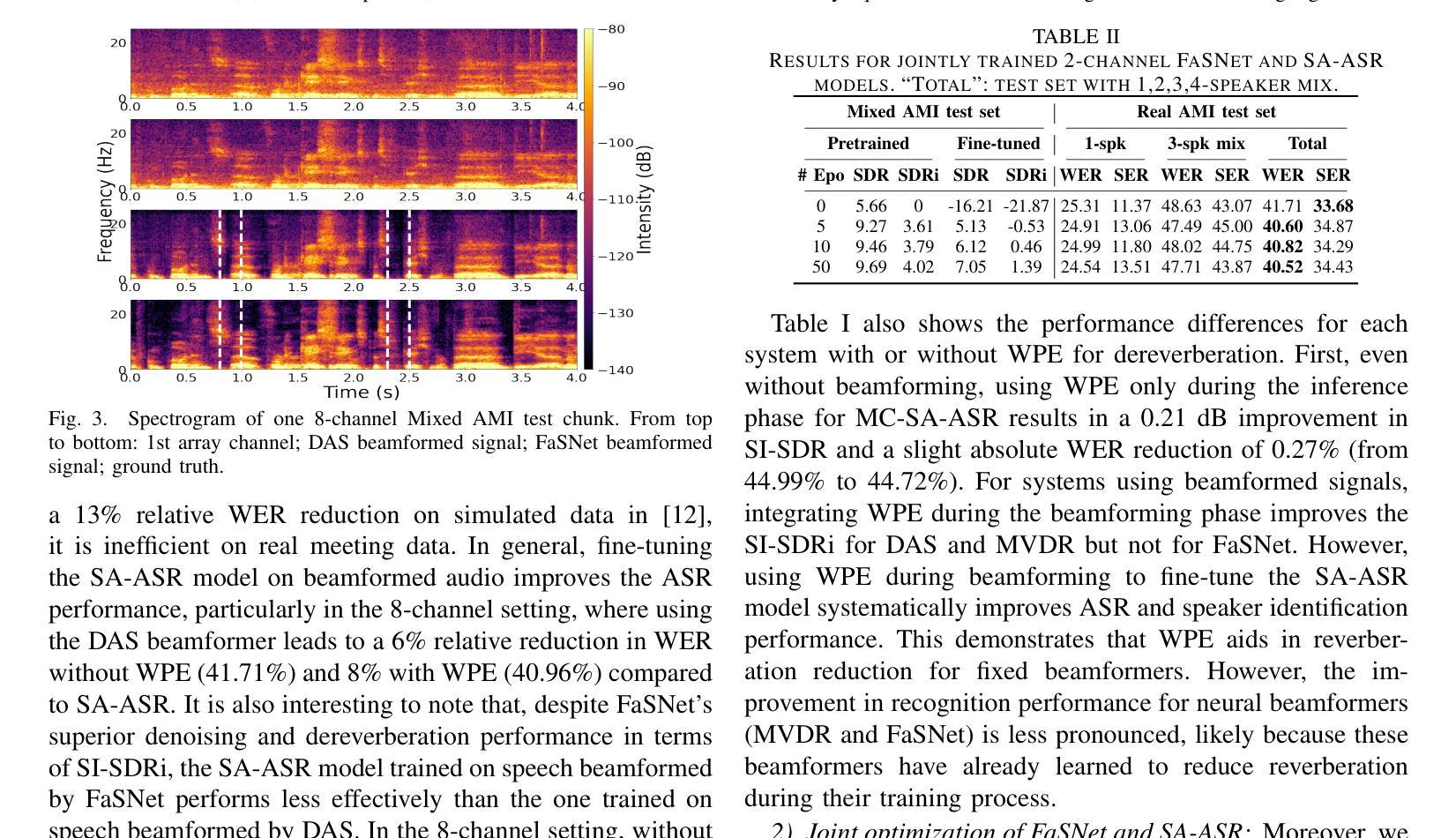
Joint Beamforming and Speaker-Attributed ASR for Real Distant-Microphone Meeting Transcription
Authors:Can Cui, Imran Ahamad Sheikh, Mostafa Sadeghi, Emmanuel Vincent
Distant-microphone meeting transcription is a challenging task. State-of-the-art end-to-end speaker-attributed automatic speech recognition (SA-ASR) architectures lack a multichannel noise and reverberation reduction front-end, which limits their performance. In this paper, we introduce a joint beamforming and SA-ASR approach for real meeting transcription. We first describe a data alignment and augmentation method to pretrain a neural beamformer on real meeting data. We then compare fixed, hybrid, and fully neural beamformers as front-ends to the SA-ASR model. Finally, we jointly optimize the fully neural beamformer and the SA-ASR model. Experiments on the real AMI corpus show that, while state-of-the-art multi-frame cross-channel attention based channel fusion fails to improve ASR performance, fine-tuning SA-ASR on the fixed beamformer’s output and jointly fine-tuning SA-ASR with the neural beamformer reduce the word error rate by 8% and 9% relative, respectively.
远程麦克风会议转录是一项具有挑战性的任务。当前最先进的端到端说话人属性自动语音识别(SA-ASR)架构缺乏多通道噪声和混响前端,这限制了其性能。在本文中,我们介绍了一种联合波束形成和SA-ASR的实时会议转录方法。首先,我们描述了一种数据对齐和增强方法,用于在真实会议数据上预训练神经波束形成器。然后,我们将固定、混合和完全神经波束形成器与SA-ASR模型进行比较。最后,我们对完全神经波束形成器和SA-ASR模型进行联合优化。在真实的AMI语料库上的实验表明,虽然基于多帧跨通道注意力的通道融合并未提高ASR性能,但在固定波束形成器的输出上对SA-ASR进行微调,以及将SA-ASR与神经波束形成器进行联合微调,分别将单词错误率降低了8%和9%。
论文及项目相关链接
Summary
本文提出一种联合波束形成和说话人属性自动语音识别(SA-ASR)的方法,用于远程麦克风会议转录。文章首先描述了一种用于预训练神经网络波束形成器的数据对齐和增强方法。随后对比了固定、混合和完全神经网络波束形成器作为SA-ASR模型的前端。最后,对完全神经网络波束形成器和SA-ASR模型进行联合优化。实验表明,虽然基于多帧跨通道注意力的通道融合未能提高语音识别性能,但使用固定波束形成器的输出对SA-ASR进行微调,以及联合微调SA-ASR与神经网络波束形成器,分别将词错误率降低了8%和9%。
Key Takeaways
- 远程麦克风会议转录是一项具有挑战性的任务。
- 当前先进的端到端说话人属性自动语音识别(SA-ASR)架构缺乏多通道噪声和混响减少的前端,限制了其性能。
- 文章介绍了一种联合波束形成和SA-ASR的方法,用于真实会议转录。
- 通过数据对齐和增强方法预训练神经网络波束形成器。
- 对比了固定、混合和完全神经网络波束形成器作为SA-ASR前端的效果。
- 实验表明,多帧跨通道注意力通道融合未提高语音识别性能。
点此查看论文截图