⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-11 更新
Differentiable Reward Optimization for LLM based TTS system
Authors:Changfeng Gao, Zhihao Du, Shiliang Zhang
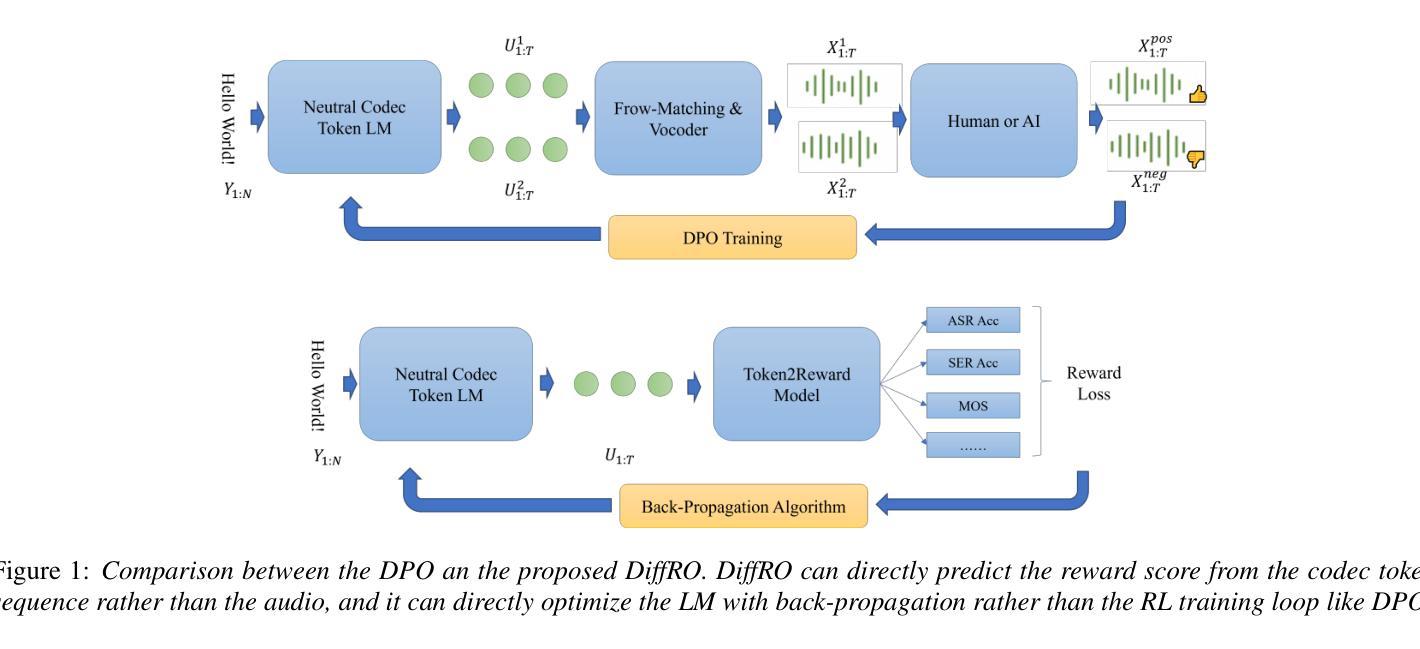
This paper proposes a novel Differentiable Reward Optimization (DiffRO) method aimed at enhancing the performance of neural codec language models based text-to-speech (TTS) systems. In contrast to conventional reinforcement learning from human feedback (RLHF) approaches applied to TTS, DiffRO directly compute the rewards based on neural codec tokens, rather than relying on synthesized audio. Furthermore, we employ the Gumbel-Softmax technique to render the reward function differentiable, thereby streamlining the RLHF training process. Additionally, we introduce a multi-task reward (MTR) model which can provide feedback from different perspectives and find that it can augment the system’s capability to follow instructions effectively.Experimental results indicate that DiffRO significantly improves the pronunciation accuracy of the TTS system, achieving state-of-the-art (SOTA) WER results on the seed-tts-eval benchmark. Moreover, with the integration of the MTR model, we demonstrate the ability to control emotional and quality attributes in a zero-shot manner.
本文提出了一种新型的可微分奖励优化(DiffRO)方法,旨在提高基于神经网络编解码器语言模型的文本-语音(TTS)系统的性能。与传统的应用于TTS的人反馈强化学习(RLHF)方法相比,DiffRO直接基于神经网络编解码器令牌计算奖励,而不是依赖于合成音频。此外,我们采用Gumbel-Softmax技术使奖励函数可微分,从而简化了RLHF训练过程。另外,我们引入了一个多任务奖励(MTR)模型,可以从不同的角度提供反馈,并发现它可以增强系统有效遵循指令的能力。实验结果表明,DiffRO显著提高了TTS系统的发音准确性,在seed-tts-eval基准测试中实现了最先进的WER结果。而且,通过MTR模型的集成,我们展示了零样本方式控制情感和品质属性的能力。
论文及项目相关链接
Summary
神经编码语言模型在文本转语音(TTS)系统中的应用得到了提升。本文提出了一种新的可微分奖励优化(DiffRO)方法,与传统的强化学习从人类反馈(RLHF)方法不同,DiffRO直接基于神经编码令牌计算奖励,而不是依赖于合成音频。此外,采用Gumbel-Softmax技术使奖励函数可微分,简化了RLHF训练过程。同时引入多任务奖励(MTR)模型,从不同角度提供反馈,提高了系统遵循指令的有效性。实验结果表明,DiffRO显著提高了TTS系统的发音准确性,并在seed-tts-eval基准测试中实现了最先进的词错误率(WER)。通过集成MTR模型,我们展示了零样本方式控制情感和品质属性的能力。
Key Takeaways
- DiffRO方法用于提升神经编码语言模型在TTS系统中的性能。
- DiffRO直接基于神经编码令牌计算奖励,区别于传统的基于合成音频的RLHF方法。
- 采用Gumbel-Softmax技术使奖励函数可微分,简化了训练过程。
- 引入多任务奖励(MTR)模型,提供不同角度的反馈。
- MTR模型提高了系统遵循指令的有效性。
- DiffRO显著提高TTS系统的发音准确性,达到先进的词错误率(WER)。
点此查看论文截图


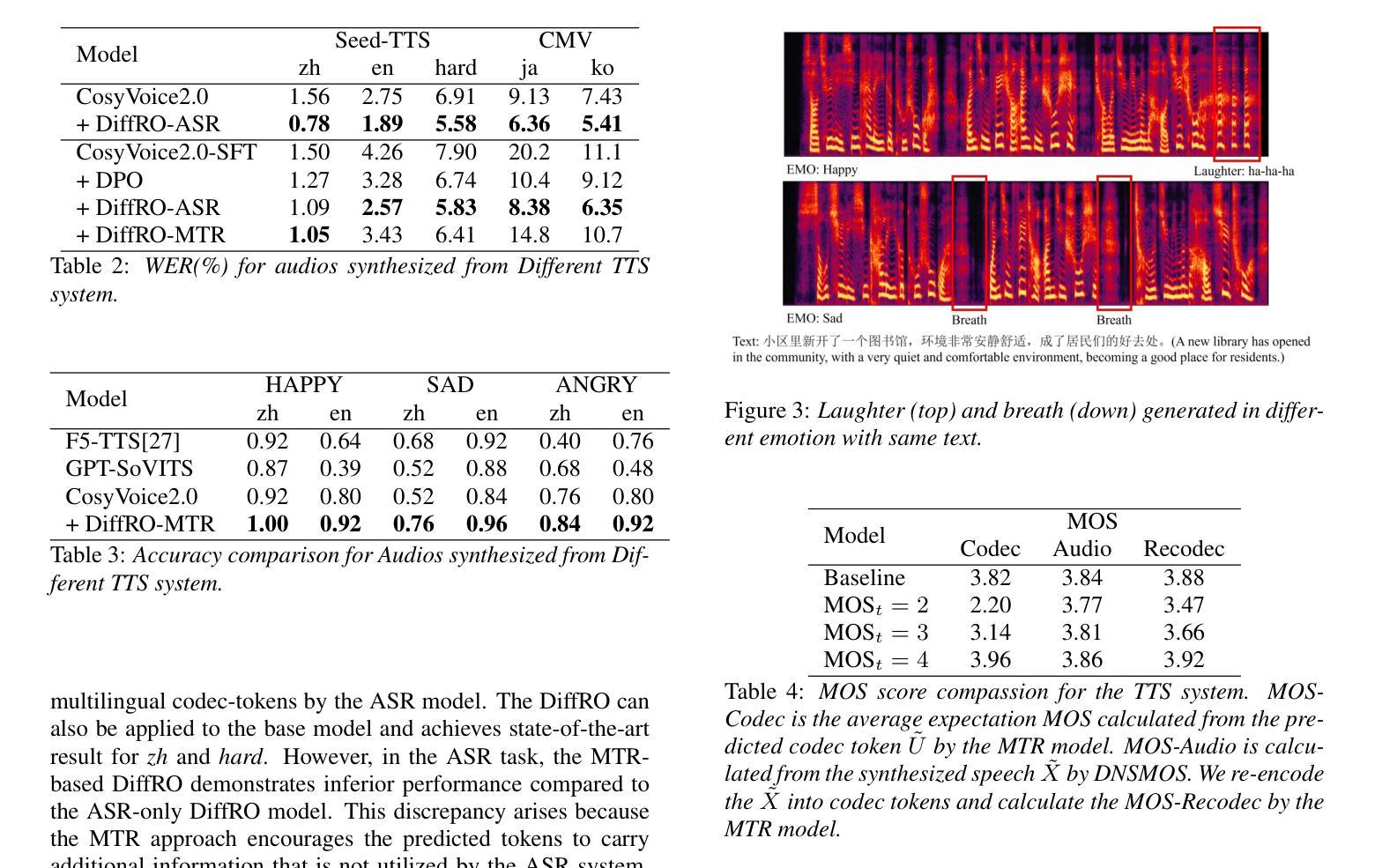
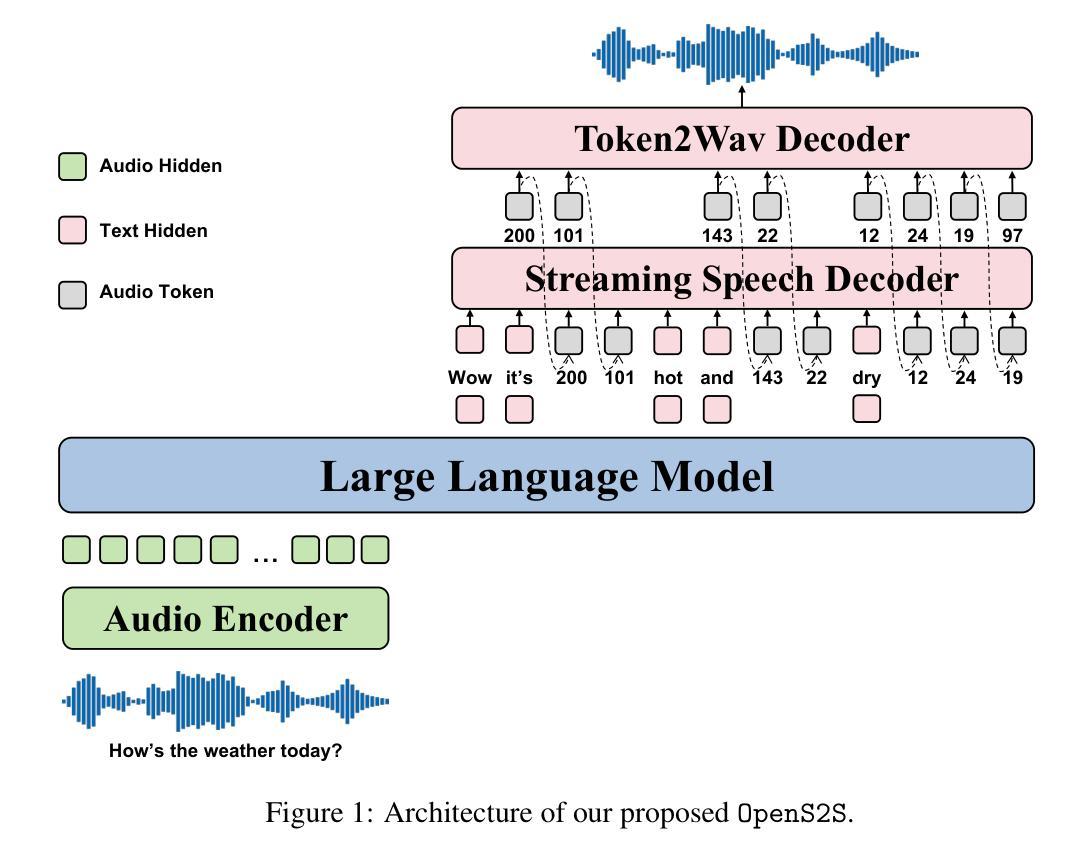
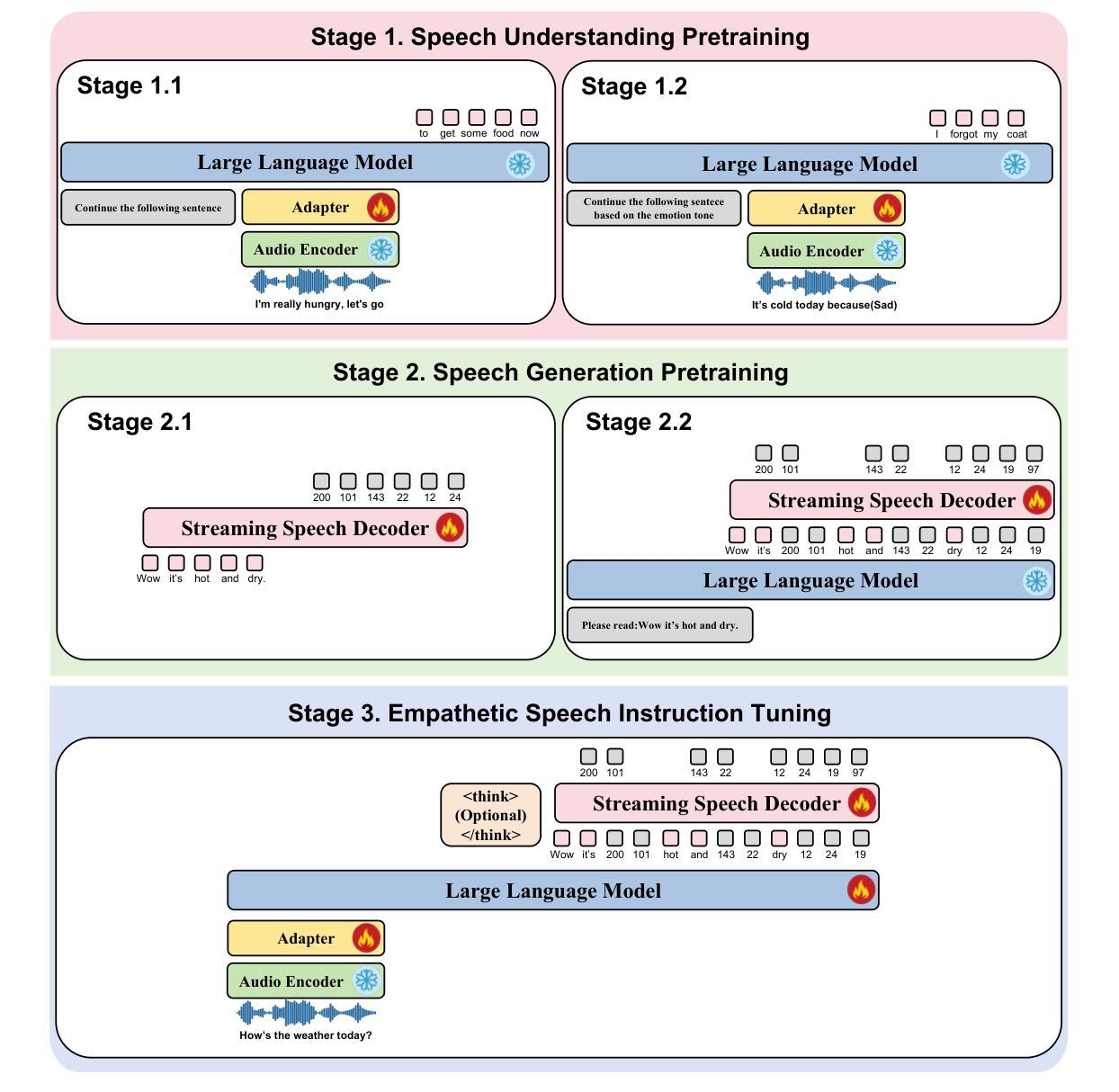
OpenS2S: Advancing Fully Open-Source End-to-End Empathetic Large Speech Language Model
Authors:Chen Wang, Tianyu Peng, Wen Yang, Yinan Bai, Guangfu Wang, Jun Lin, Lanpeng Jia, Lingxiang Wu, Jinqiao Wang, Chengqing Zong, Jiajun Zhang
Empathetic interaction is a cornerstone of human-machine communication, due to the need for understanding speech enriched with paralinguistic cues and generating emotional and expressive responses. However, the most powerful empathetic LSLMs are increasingly closed off, leaving the crucial details about the architecture, data and development opaque to researchers. Given the critical need for transparent research into the LSLMs and empathetic behavior, we present OpenS2S, a fully open-source, transparent and end-to-end LSLM designed to enable empathetic speech interactions. Based on our empathetic speech-to-text model BLSP-Emo, OpenS2S further employs a streaming interleaved decoding architecture to achieve low-latency speech generation. To facilitate end-to-end training, OpenS2S incorporates an automated data construction pipeline that synthesizes diverse, high-quality empathetic speech dialogues at low cost. By leveraging large language models to generate empathetic content and controllable text-to-speech systems to introduce speaker and emotional variation, we construct a scalable training corpus with rich paralinguistic diversity and minimal human supervision. We release the fully open-source OpenS2S model, including the dataset, model weights, pre-training and fine-tuning codes, to empower the broader research community and accelerate innovation in empathetic speech systems. The project webpage can be accessed at https://casia-lm.github.io/OpenS2S
共情交互是人与机器通信的基石,这主要是因为需要理解丰富语言副语言的语音并产生情感及表达性回应。然而,最强大的共情LSLM越来越封闭,使得关于架构、数据以及开发的关键细节对研究者来说模糊不清。考虑到对LSLM和共情行为透明研究的迫切需求,我们推出了OpenS2S,这是一个完全开源、透明、端到端的LSLM,旨在实现共情语音交互。基于我们的共情语音到文本模型BLSP-Emo,OpenS2S进一步采用流式交织解码架构来实现低延迟语音生成。为了促进端到端训练,OpenS2S引入了一个自动化数据构建管道,以低成本合成多样、高质量共情语音对话。通过利用大型语言模型来生成共情内容,并引入可控文本到语音系统来引入说话者和情感变化,我们构建了一个可扩展的训练语料库,具有丰富的副语言多样性和最小的人工监督。我们发布了完全开源的OpenS2S模型,包括数据集、模型权重、预训练和微调代码,以支持更广泛的研究群体并加速共情语音系统的创新。项目网页可通过https://casia-lm.github.io/OpenS2S访问。
论文及项目相关链接
PDF Technical Report
Summary
本文介绍了OpenS2S,一个用于支持人类与机器间富有同情心的语音交互的开源端到端LSLM模型。它基于BLSP-Emo的同情语音转文本模型,并采用流式交织解码架构实现低延迟语音生成。OpenS2S通过自动化数据构建管道进行端到端训练,合成多样、高质量的同情语音对话,同时引入大型语言模型生成同情内容和可控的文本转语音系统来引入发言人和情感变化,构建了一个可伸缩的训练语料库,具有丰富的副语言多样性和最小的人工监督。OpenS2S模型及其数据集、模型权重、预训练和微调代码均已完全开源。
Key Takeaways
- OpenS2S是一个支持富有同情心的语音交互的开源端到端LSLM模型。
- 它基于BLSP-Emo的同情语音转文本模型构建。
- 采用流式交织解码架构实现低延迟语音生成。
- 通过自动化数据构建管道进行端到端训练,合成多样、高质量的同情语音对话。
- 引入大型语言模型来生成富有同情心的内容,并引入可控的文本转语音系统来引入发言人和情感变化。
- 构建了丰富的副语言多样性和最小人工监督的可伸缩训练语料库。
- OpenS2S模型及其相关资源已完全开源,便于广大研究者使用并加速富有同情心的语音系统的创新。
点此查看论文截图


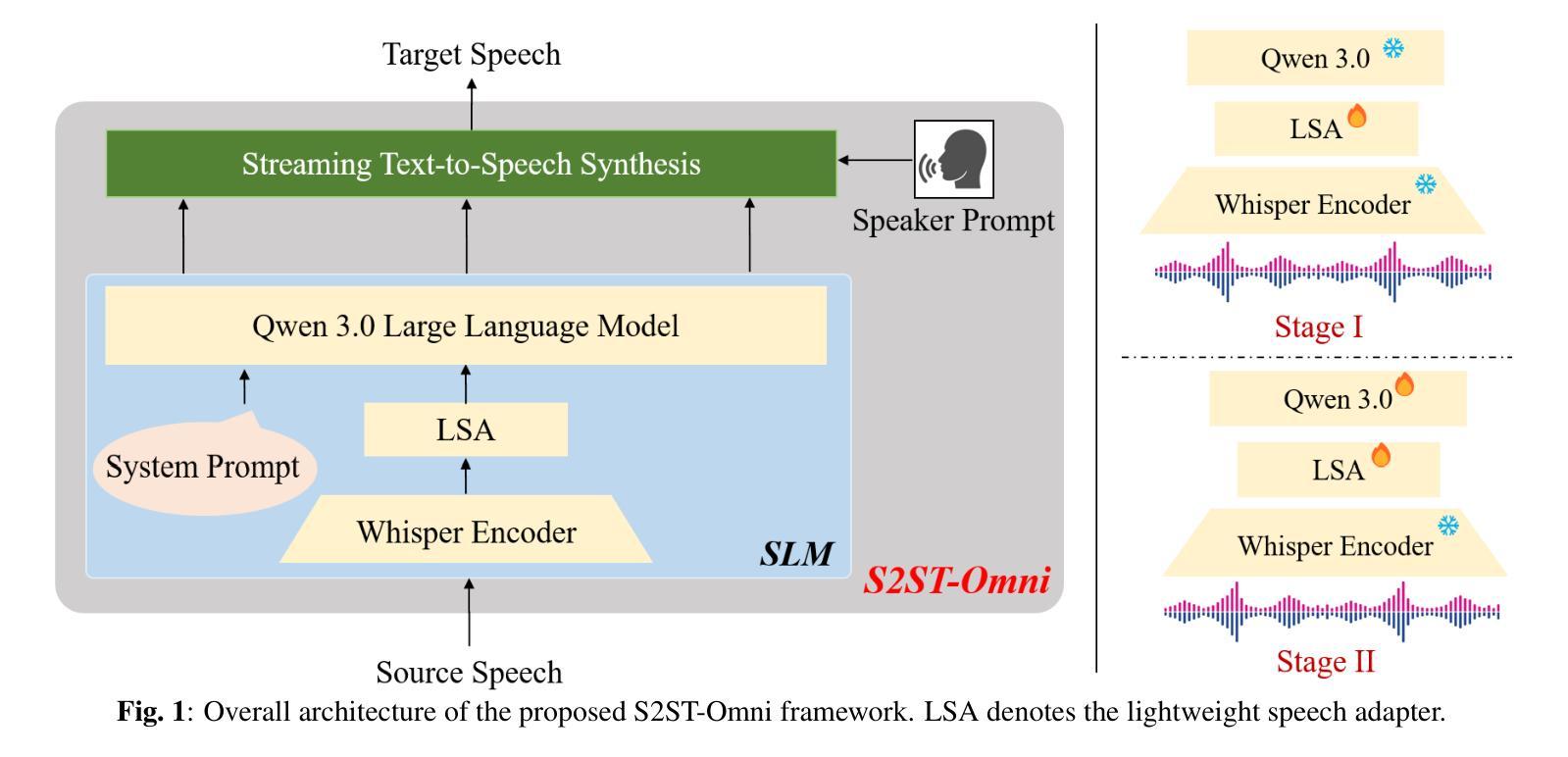
S2ST-Omni: An Efficient Multilingual Speech-to-Speech Translation Framework via Seamless Speech-Text Alignment and Progressive Fine-tuning
Authors:Yu Pan, Yuguang Yang, Yanni Hu, Jianhao Ye, Xiang Zhang, Hongbin Zhou, Lei Ma, Jianjun Zhao
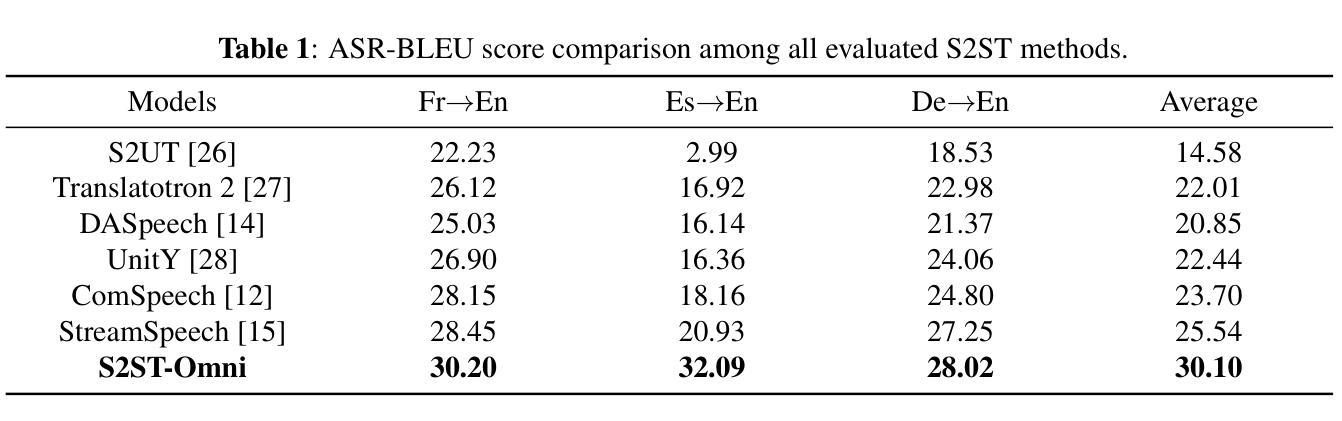
Despite recent advances in multilingual speech-to-speech translation (S2ST), several critical challenges persist: 1) achieving high-quality translation remains a major hurdle, and 2) most existing methods heavily rely on large-scale parallel speech corpora, which are costly and difficult to obtain. To address these issues, we propose \textit{S2ST-Omni}, an efficient and scalable framework for multilingual S2ST. Specifically, we decompose the S2ST task into speech-to-text translation (S2TT) and text-to-speech synthesis (TTS). For S2TT, we propose an effective speech language model that integrates the pretrained Whisper encoder for robust audio understanding and Qwen 3.0 for advanced text comprehension. A lightweight speech adapter is employed to bridge the modality gap between speech and text representations. To further facilitate the multimodal knowledge learning, a two-stage fine-tuning strategy is introduced. In the TTS stage, we adopt a streaming autoregressive generation approach to produce natural and fluent target speech. Experiments on the CVSS benchmark show that S2ST-Omni consistently outperforms existing state-of-the-art S2ST systems in translation quality, highlighting its effectiveness and superiority.
尽管多语言语音到语音翻译(S2ST)领域近期取得了进展,但仍存在几个关键挑战:1)实现高质量翻译仍是主要障碍;2)大多数现有方法严重依赖于大规模并行语音语料库,而这些语料库成本高昂且难以获取。为了解决这些问题,我们提出了名为“S2ST-Omni”的有效且可扩展的多语言S2ST框架。具体来说,我们将S2ST任务分解为语音到文本翻译(S2TT)和文本到语音合成(TTS)。对于S2TT,我们提出了有效的语音语言模型,该模型集成了预训练的Whisper编码器,用于稳健的音频理解,以及Qwen 3.0,用于高级文本理解。采用轻量级语音适配器来弥合语音和文本表示之间的模态差距。为了进一步促进多模态知识学习,引入了两阶段微调策略。在TTS阶段,我们采用流式自回归生成方法,以产生自然流畅的目标语音。在CVSS基准测试上的实验表明,S2ST-Omni在翻译质量方面始终优于现有最先进的S2ST系统,凸显了其有效性和优越性。
论文及项目相关链接
PDF Working in progress
Summary
本研究针对多语种语音到语音翻译存在的挑战,提出了高效的、可扩展的框架S2ST-Omni。通过分解为语音到文本翻译和文本到语音合成两个任务,利用预训练的Whisper编码器和Qwen 3.0技术,结合轻量级语音适配器与两阶段微调策略,实现了高质量的多语种语音翻译。在CVSS基准测试上,S2ST-Omni在翻译质量方面表现出卓越的效果和优势。
Key Takeaways
- 多语种语音到语音翻译(S2ST)仍存在高质量翻译和依赖大规模平行语料库的挑战。
- S2ST-Omni框架通过分解任务,针对语音到文本翻译(S2TT)和文本到语音合成(TTS)进行优化。
- S2TT采用有效的语音语言模型,结合预训练的Whisper编码器和Qwen 3.0技术,提高音频理解和文本综合能力。
- 轻量级语音适配器用于弥合语音和文本表示之间的模态差距。
- 为促进多模态知识学习,引入了两阶段微调策略。
- TTS阶段采用流式自回归生成方法,产生自然流畅的目标语音。
点此查看论文截图