⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-11 更新
Go to Zero: Towards Zero-shot Motion Generation with Million-scale Data
Authors:Ke Fan, Shunlin Lu, Minyue Dai, Runyi Yu, Lixing Xiao, Zhiyang Dou, Junting Dong, Lizhuang Ma, Jingbo Wang
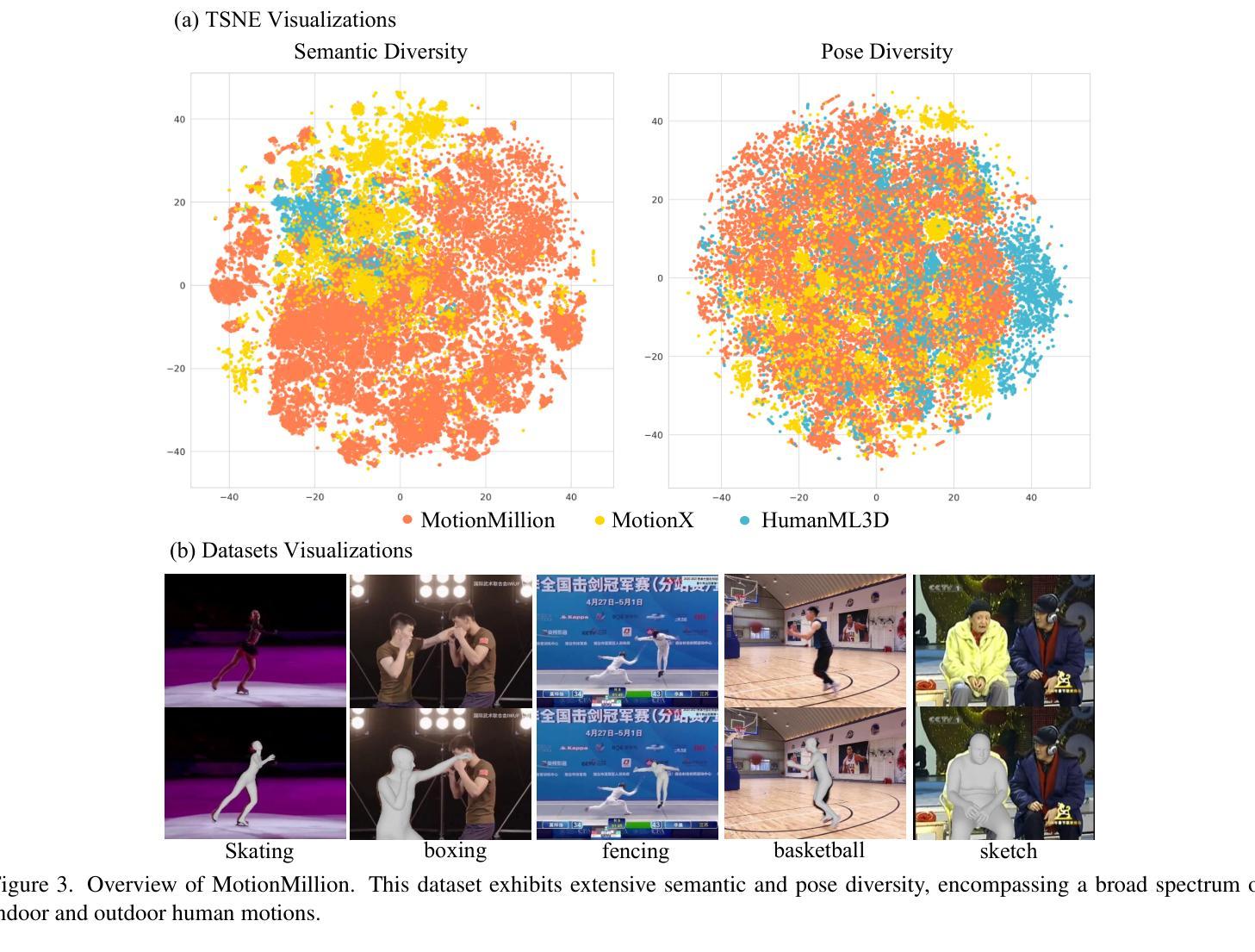
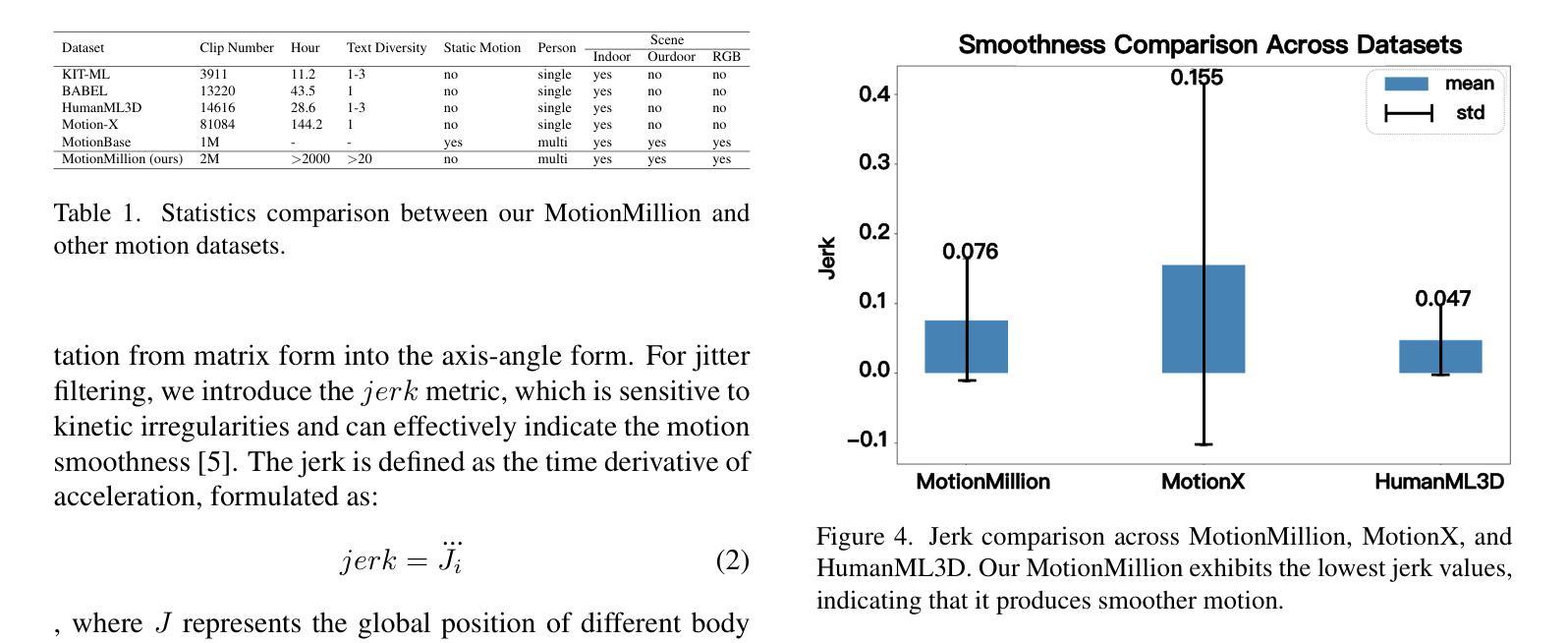
Generating diverse and natural human motion sequences based on textual descriptions constitutes a fundamental and challenging research area within the domains of computer vision, graphics, and robotics. Despite significant advancements in this field, current methodologies often face challenges regarding zero-shot generalization capabilities, largely attributable to the limited size of training datasets. Moreover, the lack of a comprehensive evaluation framework impedes the advancement of this task by failing to identify directions for improvement. In this work, we aim to push text-to-motion into a new era, that is, to achieve the generalization ability of zero-shot. To this end, firstly, we develop an efficient annotation pipeline and introduce MotionMillion-the largest human motion dataset to date, featuring over 2,000 hours and 2 million high-quality motion sequences. Additionally, we propose MotionMillion-Eval, the most comprehensive benchmark for evaluating zero-shot motion generation. Leveraging a scalable architecture, we scale our model to 7B parameters and validate its performance on MotionMillion-Eval. Our results demonstrate strong generalization to out-of-domain and complex compositional motions, marking a significant step toward zero-shot human motion generation. The code is available at https://github.com/VankouF/MotionMillion-Codes.
基于文本描述生成多样且自然的人类运动序列,是计算机视觉、图形学和机器人领域中的一个基本且具挑战性的研究方向。尽管该领域已取得显著进展,但当前的方法常常面临零样本泛化能力的挑战,这主要归因于训练数据集规模的限制。此外,由于缺乏全面的评估框架,无法确定改进方向,阻碍了该任务的进展。
在这项工作中,我们的目标是将文本到运动的转换推向一个新的时代,即实现零样本的泛化能力。为此,我们首先开发了一个高效的注释管道,并引入了迄今为止最大的人类运动数据集MotionMillion,包含超过2000小时和2百万条高质量运动序列。此外,我们还提出了MotionMillion-Eval,这是用于评估零样本运动生成的最全面的基准测试。利用可扩展的架构,我们将模型扩展到7亿个参数,并在MotionMillion-Eval上验证了其性能。
我们的结果表现出对域外和复杂组合运动的强大泛化能力,标志着零样本人类运动生成研究取得了重大进展。代码可在https://github.com/VankouF/MotionMillion-Codes获取。
论文及项目相关链接
PDF Project Page: https://vankouf.github.io/MotionMillion/
Summary
本文介绍了文本驱动的人类运动序列生成领域的研究进展和挑战。为了提升该任务的零样本泛化能力,研究团队开发了一个高效的标注流程,并推出了迄今为止最大的人类运动数据集MotionMillion,包含超过2000小时和2百万高质量运动序列。同时,团队还提出了全面的基准测试平台MotionMillion-Eval以评估零样本运动生成能力。该研究成功实现了模型在复杂组合运动上的泛化能力。有关代码可通过访问网站获得:https://github.com/VankouF/MotionMillion-Codes。
Key Takeaways
一、本文详细介绍了基于文本描述生成多样且自然的人类运动序列这一研究领域的挑战和进展。
二、当前的方法常常面临零样本泛化能力的挑战,这主要归因于训练数据集规模的限制。
三、为了提升该任务的泛化能力,研究团队开发了一个高效的标注流程并推出了迄今为止最大的人类运动数据集MotionMillion。
四、MotionMillion数据集包含超过2,000小时和2百万高质量运动序列,为相关研究提供了丰富的数据资源。
五、研究团队提出了全面的基准测试平台MotionMillion-Eval,用于评估零样本运动生成的能力。
六、该研究成功实现了模型在复杂组合运动上的泛化能力,这是零样本人类运动生成领域的一大突破。
点此查看论文截图

MOST: Motion Diffusion Model for Rare Text via Temporal Clip Banzhaf Interaction
Authors:Yin Wang, Mu li, Zhiying Leng, Frederick W. B. Li, Xiaohui Liang
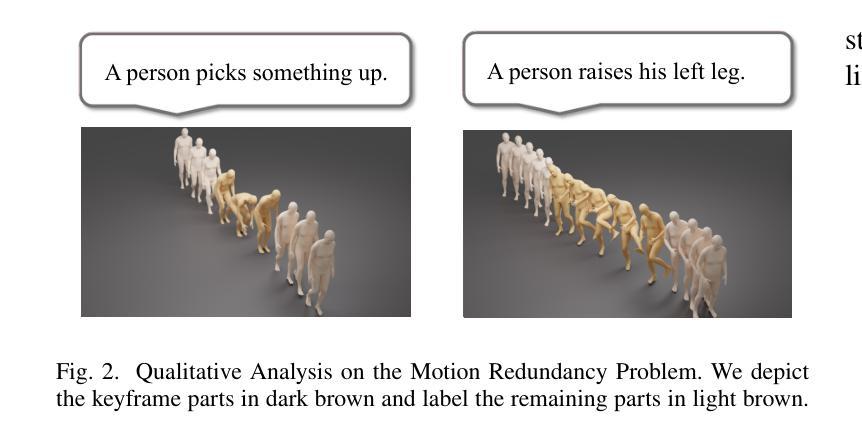
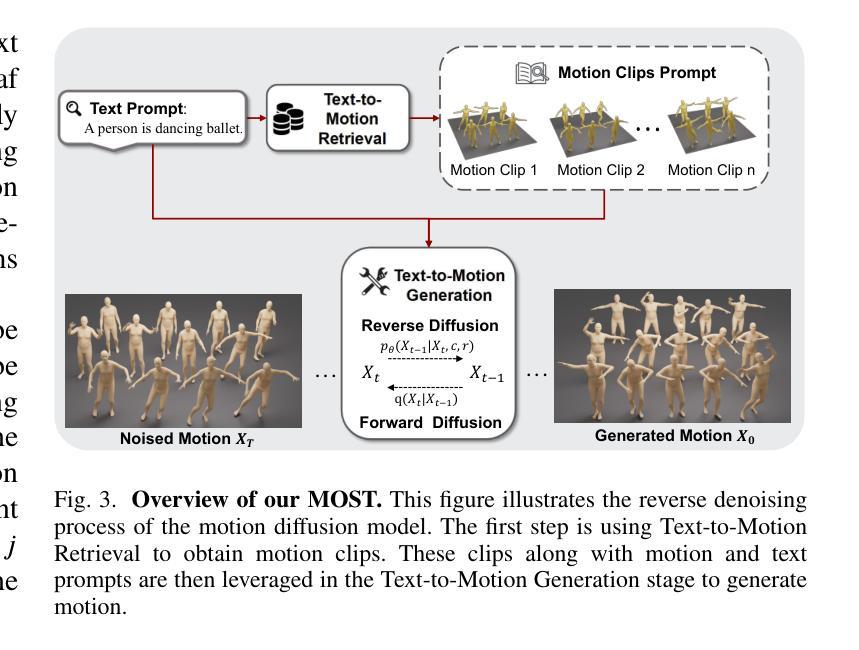
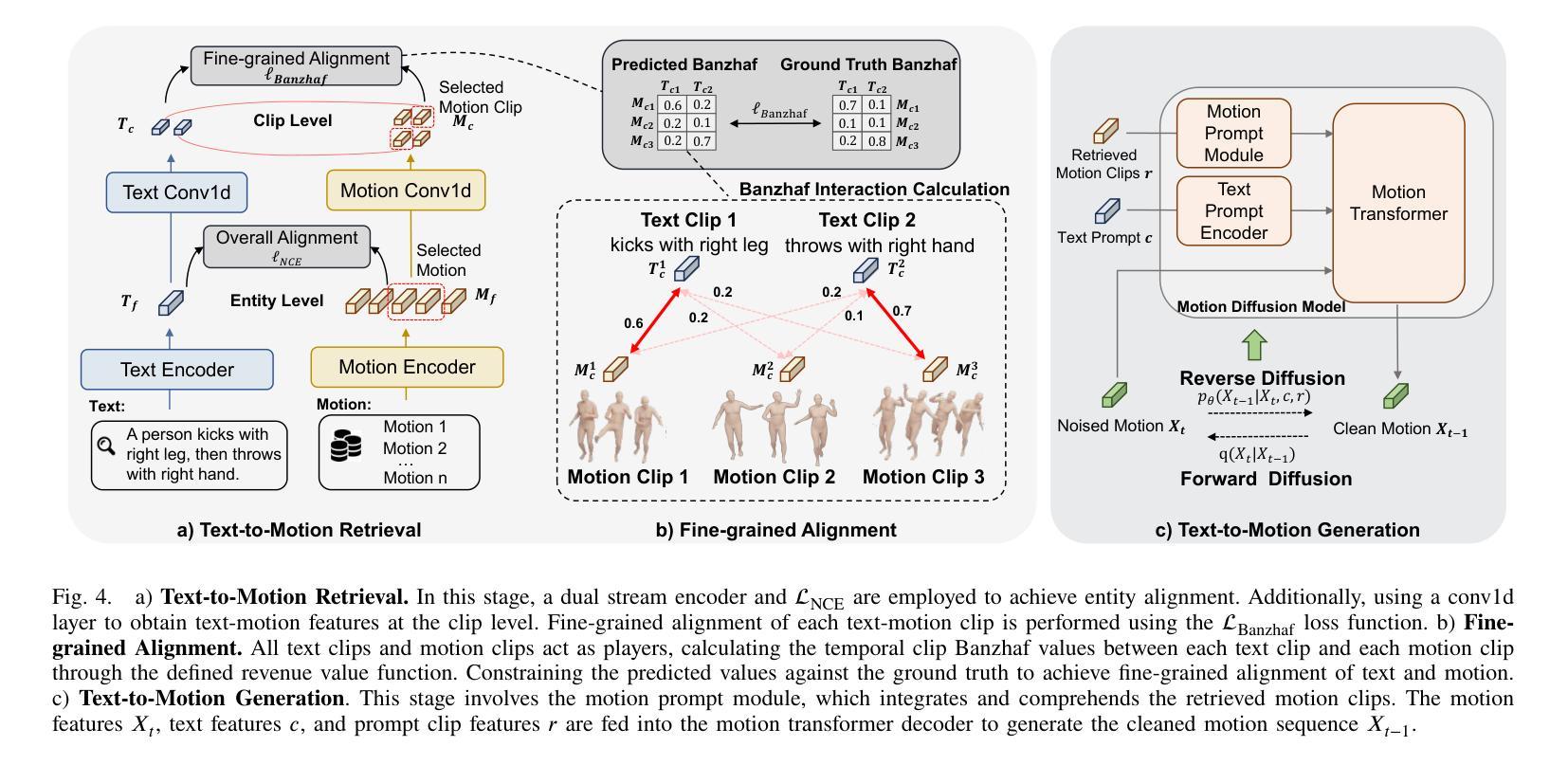
We introduce MOST, a novel motion diffusion model via temporal clip Banzhaf interaction, aimed at addressing the persistent challenge of generating human motion from rare language prompts. While previous approaches struggle with coarse-grained matching and overlook important semantic cues due to motion redundancy, our key insight lies in leveraging fine-grained clip relationships to mitigate these issues. MOST’s retrieval stage presents the first formulation of its kind - temporal clip Banzhaf interaction - which precisely quantifies textual-motion coherence at the clip level. This facilitates direct, fine-grained text-to-motion clip matching and eliminates prevalent redundancy. In the generation stage, a motion prompt module effectively utilizes retrieved motion clips to produce semantically consistent movements. Extensive evaluations confirm that MOST achieves state-of-the-art text-to-motion retrieval and generation performance by comprehensively addressing previous challenges, as demonstrated through quantitative and qualitative results highlighting its effectiveness, especially for rare prompts.
我们介绍了MOST,这是一种通过时间剪辑Banzhaf交互的新型运动扩散模型,旨在解决从罕见语言提示生成人类运动这一持久挑战。虽然以前的方法在粗粒度匹配方面苦苦挣扎,并由于运动冗余而忽略了重要的语义线索,但我们的关键见解在于利用精细的剪辑关系来缓解这些问题。MOST的检索阶段呈现了一种首创的时间剪辑Banzhaf交互,它精确量化了文本与剪辑之间的连贯性。这促进了直接、精细的文本到运动剪辑的匹配,消除了普遍的冗余。在生成阶段,运动提示模块有效利用检索到的运动片段来产生语义上连贯的动作。大量评估表明,MOST通过全面解决以前的问题,实现了最先进的文本到运动的检索和生成性能,定量和定性的结果都证明了其有效性,特别是在罕见提示方面。
论文及项目相关链接
Summary
文本介绍了一种名为MOST的新型运动扩散模型,通过时间剪辑Banzhaf交互,旨在解决从罕见语言提示生成人类运动这一持续挑战。该模型的关键在于利用精细剪辑关系来缓解之前方法中的粗粒度匹配和运动冗余问题。MOST的检索阶段首次提出了时间剪辑Banzhaf交互,精确量化文本与运动的剪辑级一致性,促进直接、精细的文本到运动剪辑匹配,消除普遍存在的冗余。生成阶段中的运动提示模块有效利用检索到的运动片段来产生语义上连贯的动作。评估表明,MOST在文本到运动的检索和生成性能上达到最佳状态,解决了之前的挑战。
Key Takeaways
- MOST模型是一种新的运动扩散模型,通过时间剪辑Banzhaf交互解决了从罕见语言提示生成人类运动的挑战。
- 该模型的关键在于利用精细剪辑关系来缓解之前方法中的粗粒度匹配和运动冗余问题。
- MOST的检索阶段首次提出了时间剪辑Banzhaf交互,以精确量化文本与运动的一致性。
- 该模型能实现直接、精细的文本到运动剪辑匹配,消除普遍存在的冗余。
- 生成阶段中的运动提示模块能有效利用检索到的运动片段。
- MOST在文本到运动的检索和生成性能上表现优异,达到最佳状态。
点此查看论文截图

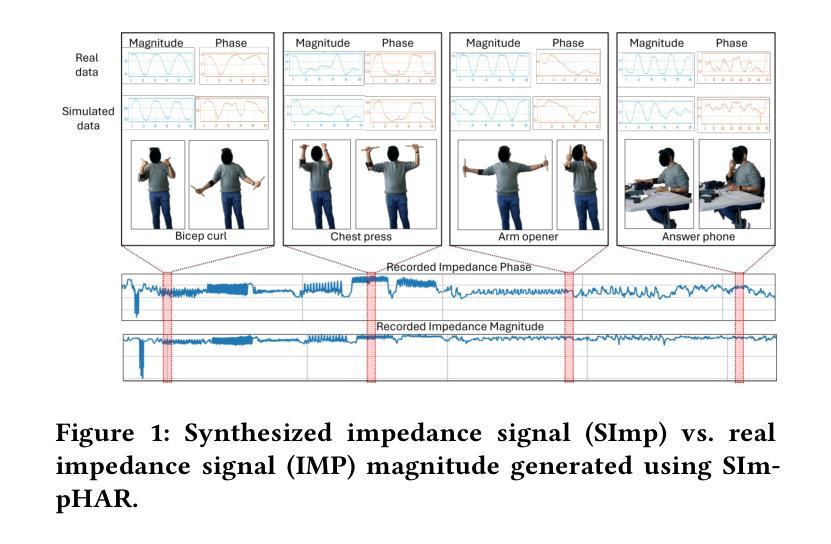
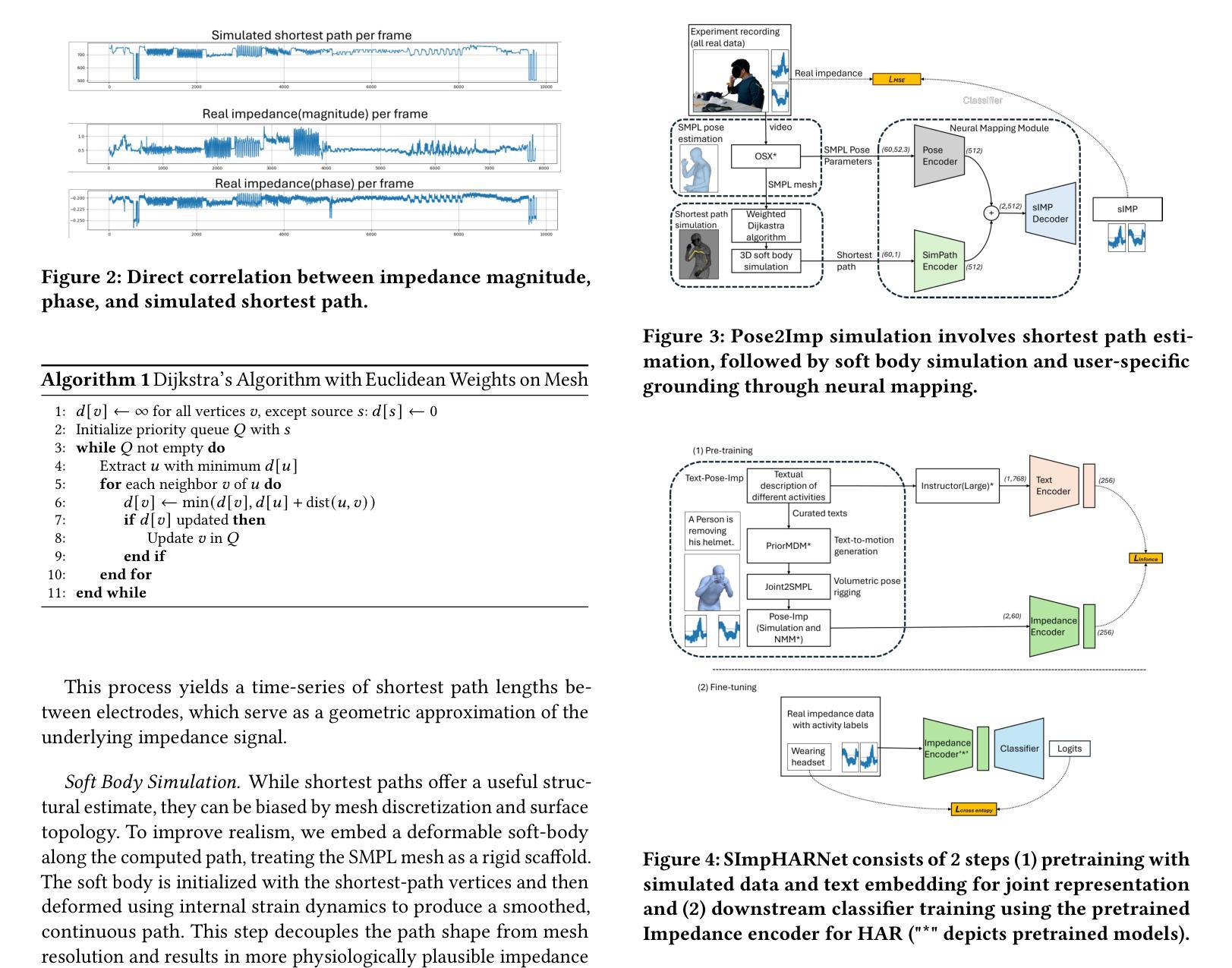
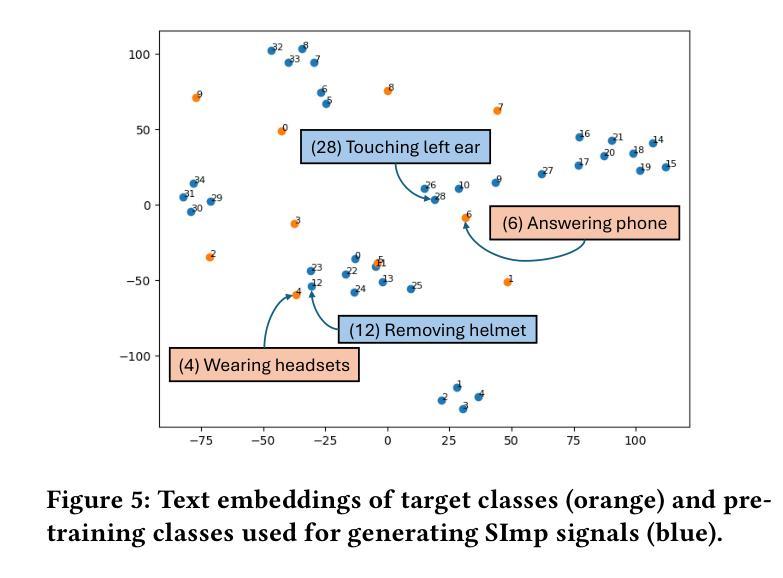
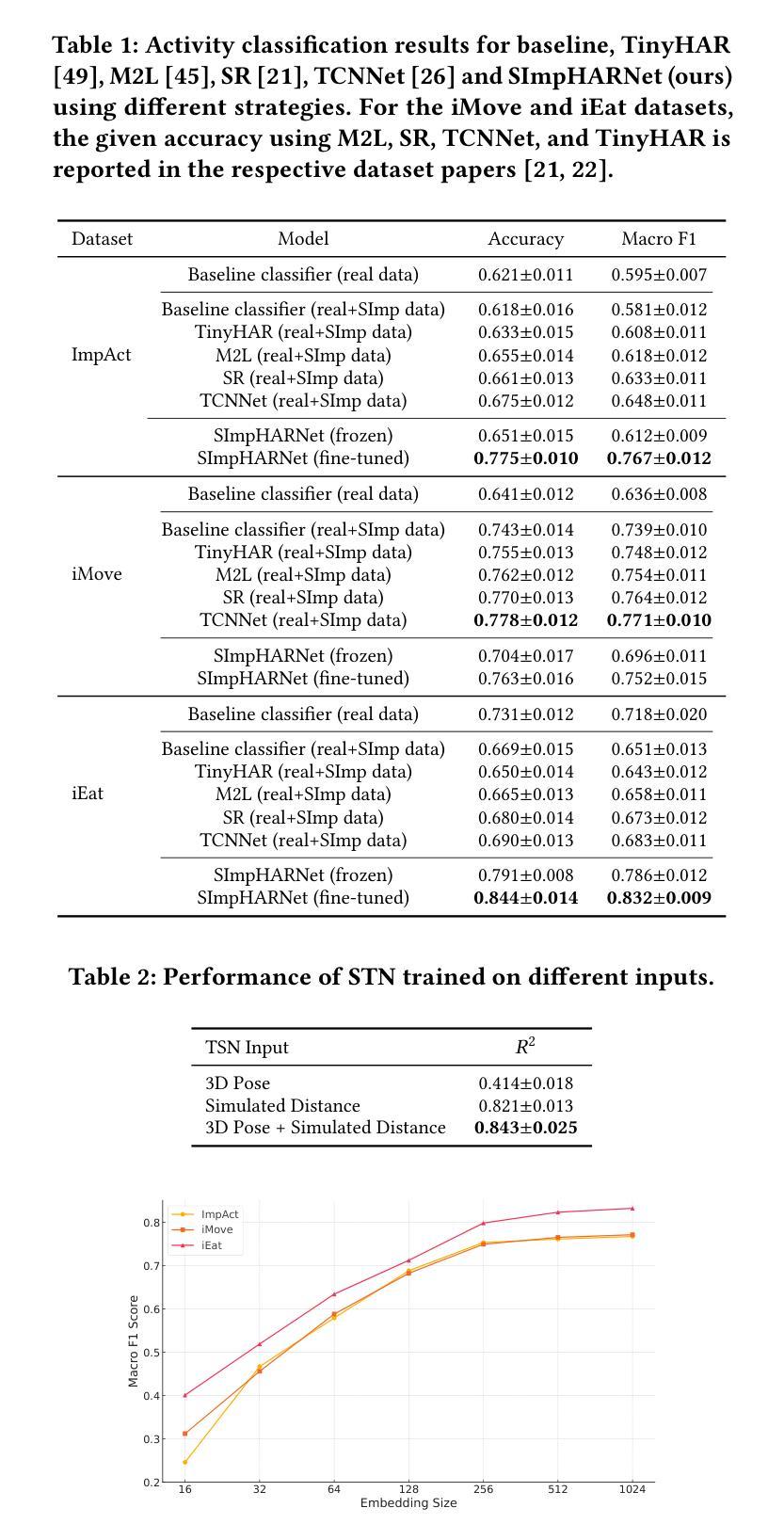
SImpHAR: Advancing impedance-based human activity recognition using 3D simulation and text-to-motion models
Authors:Lala Shakti Swarup Ray, Mengxi Liu, Deepika Gurung, Bo Zhou, Sungho Suh, Paul Lukowicz
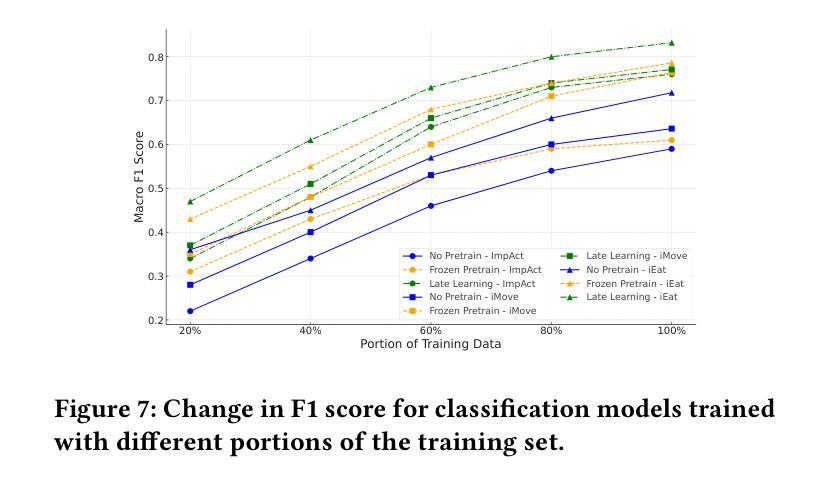
Human Activity Recognition (HAR) with wearable sensors is essential for applications in healthcare, fitness, and human-computer interaction. Bio-impedance sensing offers unique advantages for fine-grained motion capture but remains underutilized due to the scarcity of labeled data. We introduce SImpHAR, a novel framework addressing this limitation through two core contributions. First, we propose a simulation pipeline that generates realistic bio-impedance signals from 3D human meshes using shortest-path estimation, soft-body physics, and text-to-motion generation serving as a digital twin for data augmentation. Second, we design a two-stage training strategy with decoupled approach that enables broader activity coverage without requiring label-aligned synthetic data. We evaluate SImpHAR on our collected ImpAct dataset and two public benchmarks, showing consistent improvements over state-of-the-art methods, with gains of up to 22.3% and 21.8%, in terms of accuracy and macro F1 score, respectively. Our results highlight the promise of simulation-driven augmentation and modular training for impedance-based HAR.
人体活动识别(HAR)技术结合可穿戴传感器在医疗保健、健身和人机交互等领域具有广泛应用。生物阻抗传感在精细动作捕捉方面具有独特优势,但由于缺乏标记数据,其应用尚未得到充分利用。我们引入了SImpHAR这一新型框架,通过两个核心贡献来解决这一问题。首先,我们提出了一种仿真流程,使用最短路径估计、软体物理和文本到运动的生成技术,从3D人体网格生成逼真的生物阻抗信号,作为数据增强的数字双胞胎。其次,我们设计了一种两阶段训练策略,采用解耦方法,在不需要标签对齐合成数据的情况下实现更广泛的活动覆盖。我们在收集的ImpAct数据集和两个公共基准测试上对SImpHAR进行了评估,相较于最新技术,其在准确率和宏观F1分数方面分别提高了高达22.3%和21.8%。我们的结果突出了仿真驱动增强和模块化训练在阻抗式HAR中的潜力。
论文及项目相关链接
Summary
基于人体活动识别的需求,SImpHAR框架通过两项核心贡献解决了生物阻抗感知中缺乏标记数据的问题。首先,它提出了一种生成真实生物阻抗信号的仿真管道,该管道利用最短路径估计、软体物理和文本到运动的生成技术,从三维人体网格生成模拟信号。其次,设计了一种分阶段训练策略,通过解耦方式扩大活动覆盖范围,无需标签对齐的合成数据。在ImpAct数据集和两个公共基准测试上的评估结果表明,相较于最先进的方法,SImpHAR在准确度和宏观F1分数上分别提高了最多达22.3%和21.8%。这突显了模拟驱动增强和模块化训练在阻抗式人体活动识别中的潜力。
Key Takeaways
- SImpHAR框架解决了生物阻抗感知中因缺乏标记数据导致的问题。
- 通过仿真管道生成真实的生物阻抗信号,利用三维人体网格模拟信号。
- 设计了一种分阶段训练策略,通过解耦方式扩大活动覆盖范围。
- 不需要标签对齐的合成数据。
- 在ImpAct数据集及两个公共基准测试上的评估结果优于其他方法。
- 准确度和宏观F1分数均有显著提高。
- 突显了模拟驱动增强和模块化训练在阻抗式人体活动识别中的重要性。
点此查看论文截图