⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-12 更新
Doodle Your Keypoints: Sketch-Based Few-Shot Keypoint Detection
Authors:Subhajit Maity, Ayan Kumar Bhunia, Subhadeep Koley, Pinaki Nath Chowdhury, Aneeshan Sain, Yi-Zhe Song
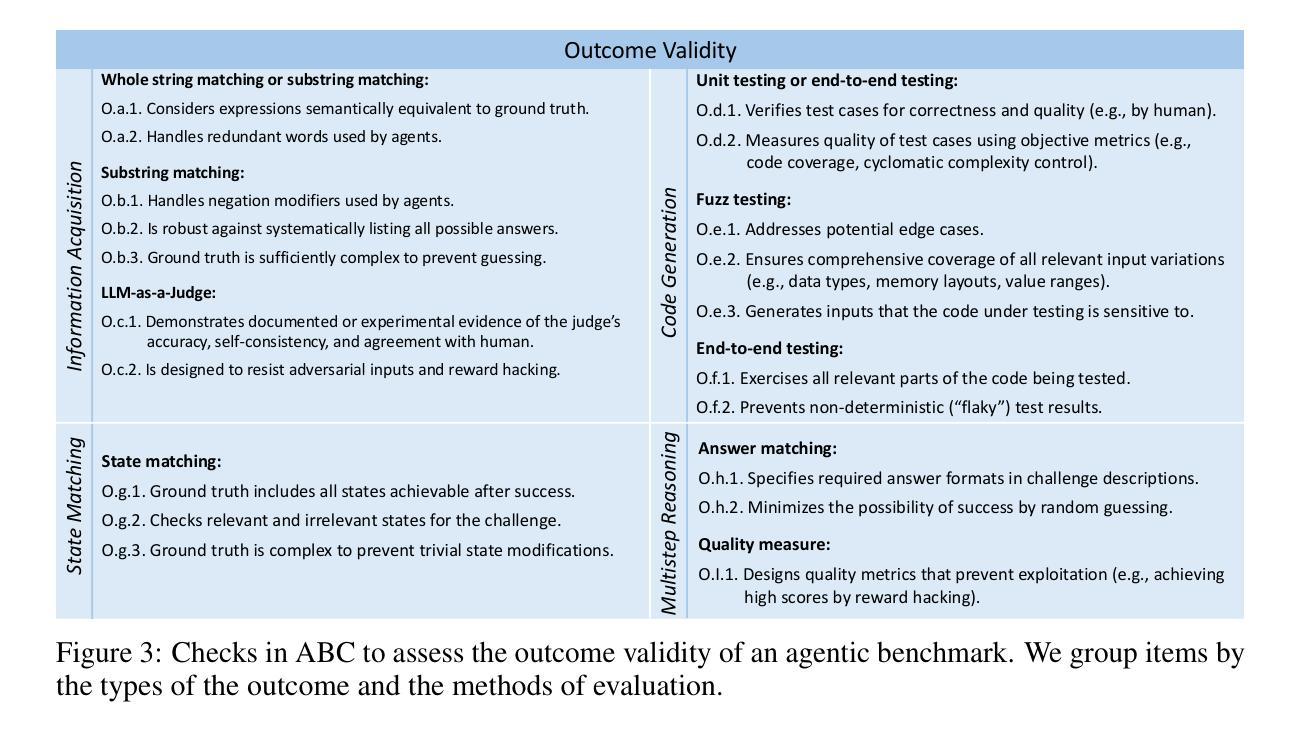
Keypoint detection, integral to modern machine perception, faces challenges in few-shot learning, particularly when source data from the same distribution as the query is unavailable. This gap is addressed by leveraging sketches, a popular form of human expression, providing a source-free alternative. However, challenges arise in mastering cross-modal embeddings and handling user-specific sketch styles. Our proposed framework overcomes these hurdles with a prototypical setup, combined with a grid-based locator and prototypical domain adaptation. We also demonstrate success in few-shot convergence across novel keypoints and classes through extensive experiments.
关键点检测是现代机器感知的核心,在少样本学习中面临挑战,尤其是在无法获取与查询数据相同分布的源数据时。为了解决这一空白,研究利用素描这种人类表达流行形式,为无资源情况提供替代方案。然而,掌握跨模态嵌入和应对用户特定素描风格时会出现挑战。我们提出的框架通过结合原型设置、基于网格的定位器和原型域适应,克服了这些障碍。此外,通过大量实验,我们在新型关键点和类别方面实现了少样本收敛的成功应用。
论文及项目相关链接
PDF Accepted at ICCV 2025. Project Page: https://subhajitmaity.me/DYKp
Summary:现代机器感知中的关键点检测在少样本学习中面临挑战,特别是在没有与查询相同分布的源数据的情况下。为解决此问题,可以利用人类表达的一种流行形式——草图作为源数据的替代方案。然而,掌握跨模态嵌入和处理用户特定的草图风格存在挑战。所提出的框架通过原型设置、网格定位器和原型域适应克服了这些障碍,并在新的关键点和类别上实现了少样本收敛。
Key Takeaways:
- 少样本学习在关键检测方面的挑战在于缺乏与查询相同的源数据分布。
- 草图作为人类表达的一种形式,可以作为源数据的替代方案。
- 掌握跨模态嵌入和处理用户特定的草图风格存在挑战。
- 所提出的框架利用原型设置来解决这些挑战。
- 网格定位器有助于在少样本场景下定位关键点。
- 原型域适应有助于适应不同的数据集和关键任务。
点此查看论文截图


NexViTAD: Few-shot Unsupervised Cross-Domain Defect Detection via Vision Foundation Models and Multi-Task Learning
Authors:Tianwei Mu, Feiyu Duan, Bo Zhou, Dan Xue, Manhong Huang
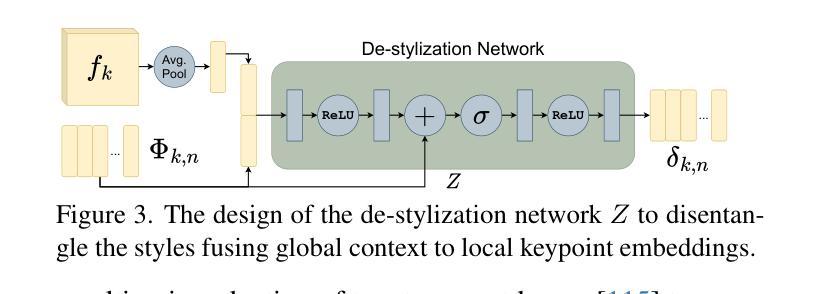
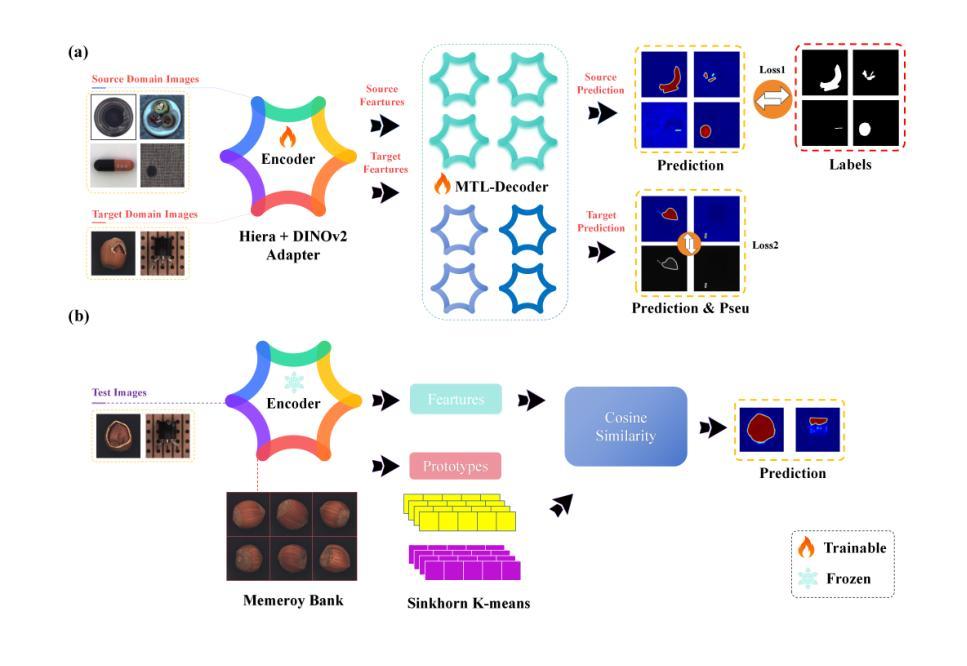
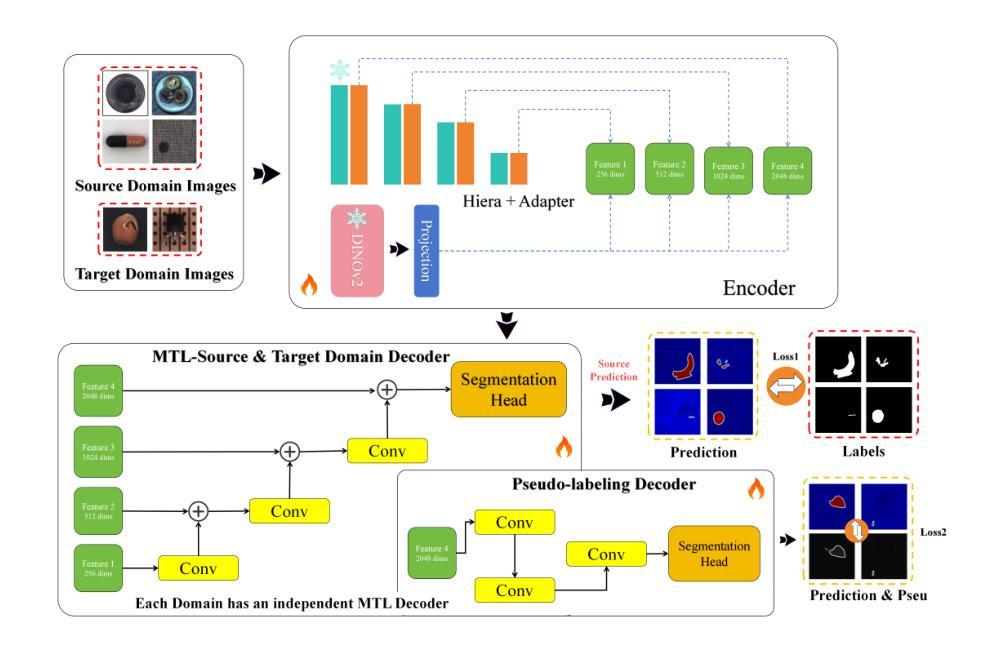
This paper presents a novel few-shot cross-domain anomaly detection framework, Nexus Vision Transformer for Anomaly Detection (NexViTAD), based on vision foundation models, which effectively addresses domain-shift challenges in industrial anomaly detection through innovative shared subspace projection mechanisms and multi-task learning (MTL) module. The main innovations include: (1) a hierarchical adapter module that adaptively fuses complementary features from Hiera and DINO-v2 pre-trained models, constructing more robust feature representations; (2) a shared subspace projection strategy that enables effective cross-domain knowledge transfer through bottleneck dimension constraints and skip connection mechanisms; (3) a MTL Decoder architecture supports simultaneous processing of multiple source domains, significantly enhancing model generalization capabilities; (4) an anomaly score inference method based on Sinkhorn-K-means clustering, combined with Gaussian filtering and adaptive threshold processing for precise pixel level. Valuated on the MVTec AD dataset, NexViTAD delivers state-of-the-art performance with an AUC of 97.5%, AP of 70.4%, and PRO of 95.2% in the target domains, surpassing other recent models, marking a transformative advance in cross-domain defect detection.
本文提出了一种基于视觉基础模型的新型小样本跨域异常检测框架——Nexus Vision Transformer for Anomaly Detection(NexViTAD)。它通过创新的共享子空间投影机制和多任务学习(MTL)模块,有效地解决了工业异常检测中的域迁移挑战。主要创新包括:(1)分层适配器模块,该模块自适应地融合来自Hiera和DINO-v2预训练模型的互补特征,构建更稳健的特征表示;(2)共享子空间投影策略,通过瓶颈维度约束和跳跃连接机制,实现有效的跨域知识转移;(3)多任务解码器架构支持同时处理多个源域,显著增强模型的泛化能力;(4)基于Sinkhorn-K-means聚类的异常分数推理方法,结合高斯滤波和自适应阈值处理,实现精确的像素级评估。在MVTec AD数据集上,NexViTAD以97.5%的AUC、70.4%的AP和95.2%的PRO在目标域中达到了最先进的性能,超越了其他最新模型,标志着跨域缺陷检测的重大突破。
论文及项目相关链接
Summary
基于视觉基础模型,本文提出了一种新颖的Few-Shot跨域异常检测框架Nexus Vision Transformer for Anomaly Detection(NexViTAD)。它通过创新的共享子空间投影机制和多任务学习(MTL)模块,有效解决了工业异常检测中的域偏移挑战。
Key Takeaways
- NexViTAD是一种基于视觉基础模型的few-shot跨域异常检测框架。
- 框架的主要创新包括:层次适配器模块、共享子空间投影策略、多任务学习解码器架构和异常分数推理方法。
- 层次适配器模块自适应融合Hiera和DINO-v2预训练模型的互补特征,构建更稳健的特征表示。
- 共享子空间投影策略通过瓶颈维度约束和跳跃连接机制,实现了有效的跨域知识转移。
- 多任务学习解码器架构支持同时处理多个源域,显著提高了模型的泛化能力。
- 异常分数推理方法基于Sinkhorn-K-means聚类,结合高斯滤波和自适应阈值处理,实现精确像素级异常检测。
- 在MVTec AD数据集上,NexViTAD实现了最先进的性能,AUC达到97.5%,AP达到70.4%,PRO达到95.2%,超越了其他最近模型,标志着跨域缺陷检测的变革性进展。
点此查看论文截图

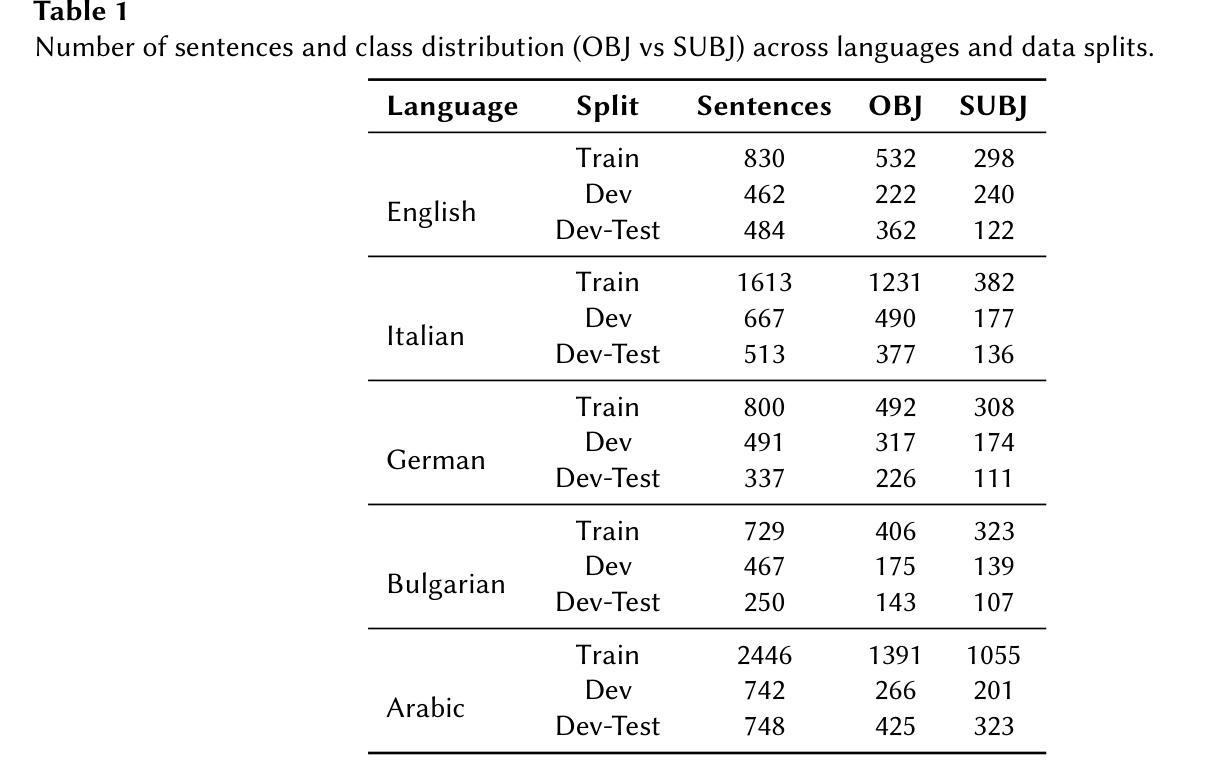
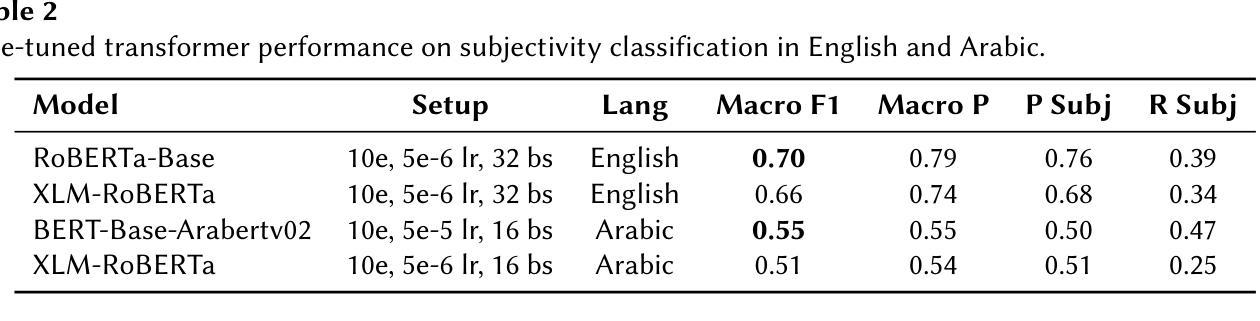
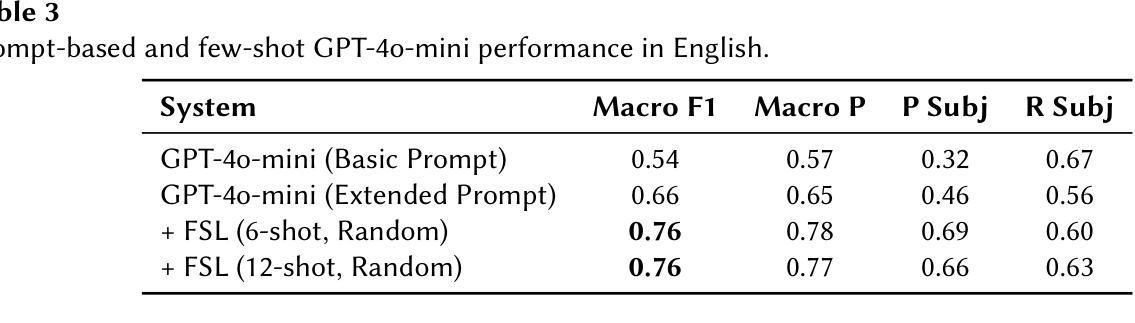
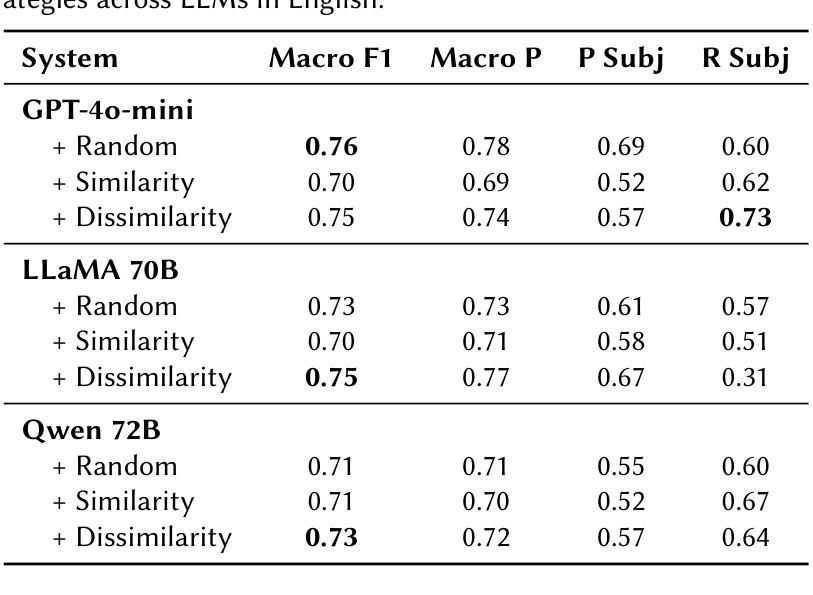
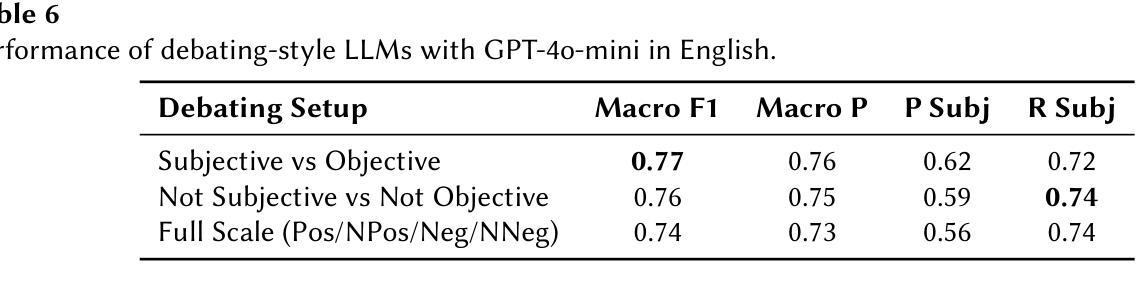
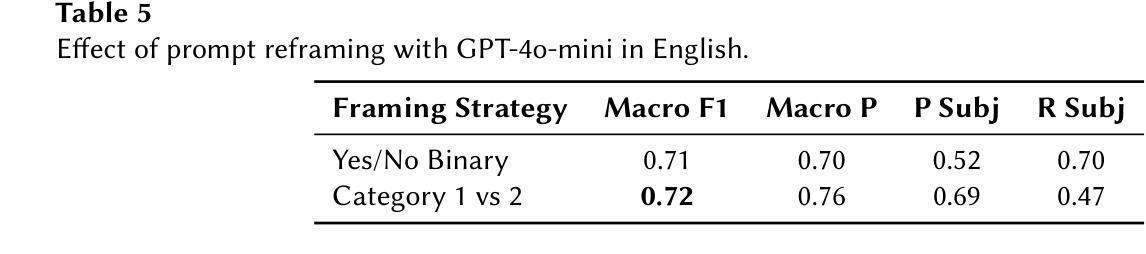
CEA-LIST at CheckThat! 2025: Evaluating LLMs as Detectors of Bias and Opinion in Text
Authors:Akram Elbouanani, Evan Dufraisse, Aboubacar Tuo, Adrian Popescu
This paper presents a competitive approach to multilingual subjectivity detection using large language models (LLMs) with few-shot prompting. We participated in Task 1: Subjectivity of the CheckThat! 2025 evaluation campaign. We show that LLMs, when paired with carefully designed prompts, can match or outperform fine-tuned smaller language models (SLMs), particularly in noisy or low-quality data settings. Despite experimenting with advanced prompt engineering techniques, such as debating LLMs and various example selection strategies, we found limited benefit beyond well-crafted standard few-shot prompts. Our system achieved top rankings across multiple languages in the CheckThat! 2025 subjectivity detection task, including first place in Arabic and Polish, and top-four finishes in Italian, English, German, and multilingual tracks. Notably, our method proved especially robust on the Arabic dataset, likely due to its resilience to annotation inconsistencies. These findings highlight the effectiveness and adaptability of LLM-based few-shot learning for multilingual sentiment tasks, offering a strong alternative to traditional fine-tuning, particularly when labeled data is scarce or inconsistent.
本文提出了一种利用大型语言模型(LLM)进行多语言主观性检测的竞争优势方法,并采用了小样本提示技术。我们参加了CheckThat! 2025评估活动的Task 1:主观性任务。研究表明,当大型语言模型与精心设计的小样本提示相结合时,它们可以在嘈杂或低质量数据环境中与经过精细调整的小型语言模型(SLM)相匹配或表现更好。尽管我们尝试了先进的提示工程技术,如辩论型LLM和各种示例选择策略,但发现除了精心制作的标准小样本提示外,其他提示的效益有限。我们的系统在CheckThat! 2025的多语言主观性检测任务中取得了多语言排名领先的成绩,包括在阿拉伯语和波兰语中获得第一名,并在意大利语、英语、德语和多语种赛道中进入前四名。值得注意的是,我们的方法在阿拉伯语数据集上表现得特别稳健,这可能是由于它对标注不一致具有较强的抗性。这些发现凸显了基于LLM的小样本学习在多语言情感任务中的有效性和适应性,为传统的微调方法提供了强有力的替代方案,尤其是在标记数据稀缺或不一致的情况下。
论文及项目相关链接
PDF Notebook for the CheckThat! Lab at CLEF 2025
Summary
利用大型语言模型(LLM)进行多语言主观性检测的竞赛方法。通过精心设计提示,LLM能在嘈杂或低质量数据环境中匹配或超越微调的小型语言模型(SLM)。在CheckThat! 2025主观性评价任务中,该系统在多语言领域取得了顶尖排名,特别是在阿拉伯语和波兰语中获得第一名,在英语、意大利语、德语和多语言赛道中也进入了前四名。该方法在阿拉伯语数据集上表现尤为稳健,这可能是由于其对标注不一致的抗性。研究凸显了基于LLM的少量学习在多语言情感任务中的有效性和适应性。
Key Takeaways
- LLMs配合精心设计提示,可在多语言主观性检测任务中表现优异。
- 在嘈杂或低质量数据环境中,LLMs能匹配或超越SLMs。
- 在CheckThat! 2025评价任务中,该系统取得多种语言顶尖排名。
- 阿拉伯语数据集上表现稳健,对标注不一致具有抗性。
- LLMs在少量学习情况下表现出强大的适应性和有效性。
- 先进的提示工程技术如辩论LLMs和各种示例选择策略,其额外效益有限。
点此查看论文截图

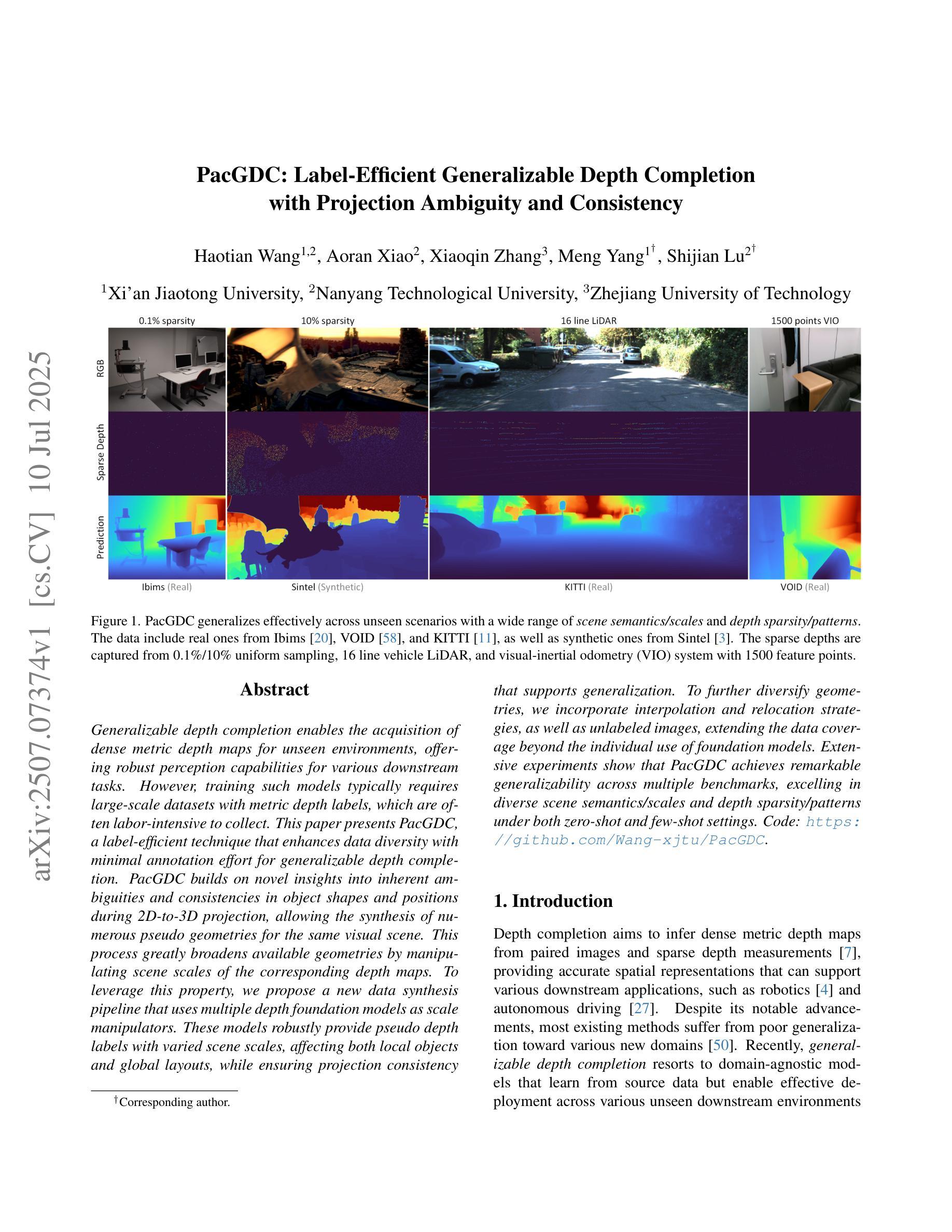
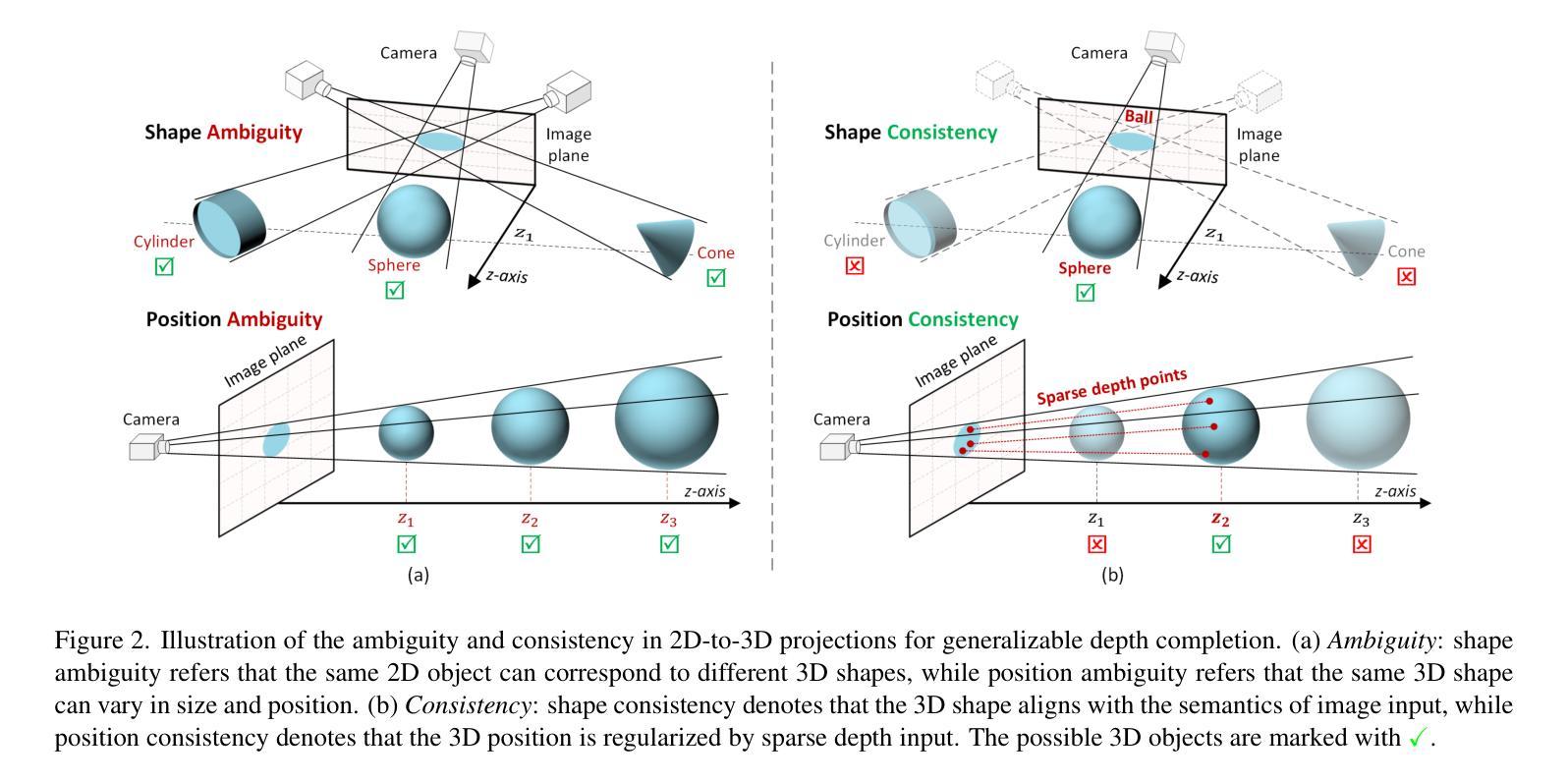
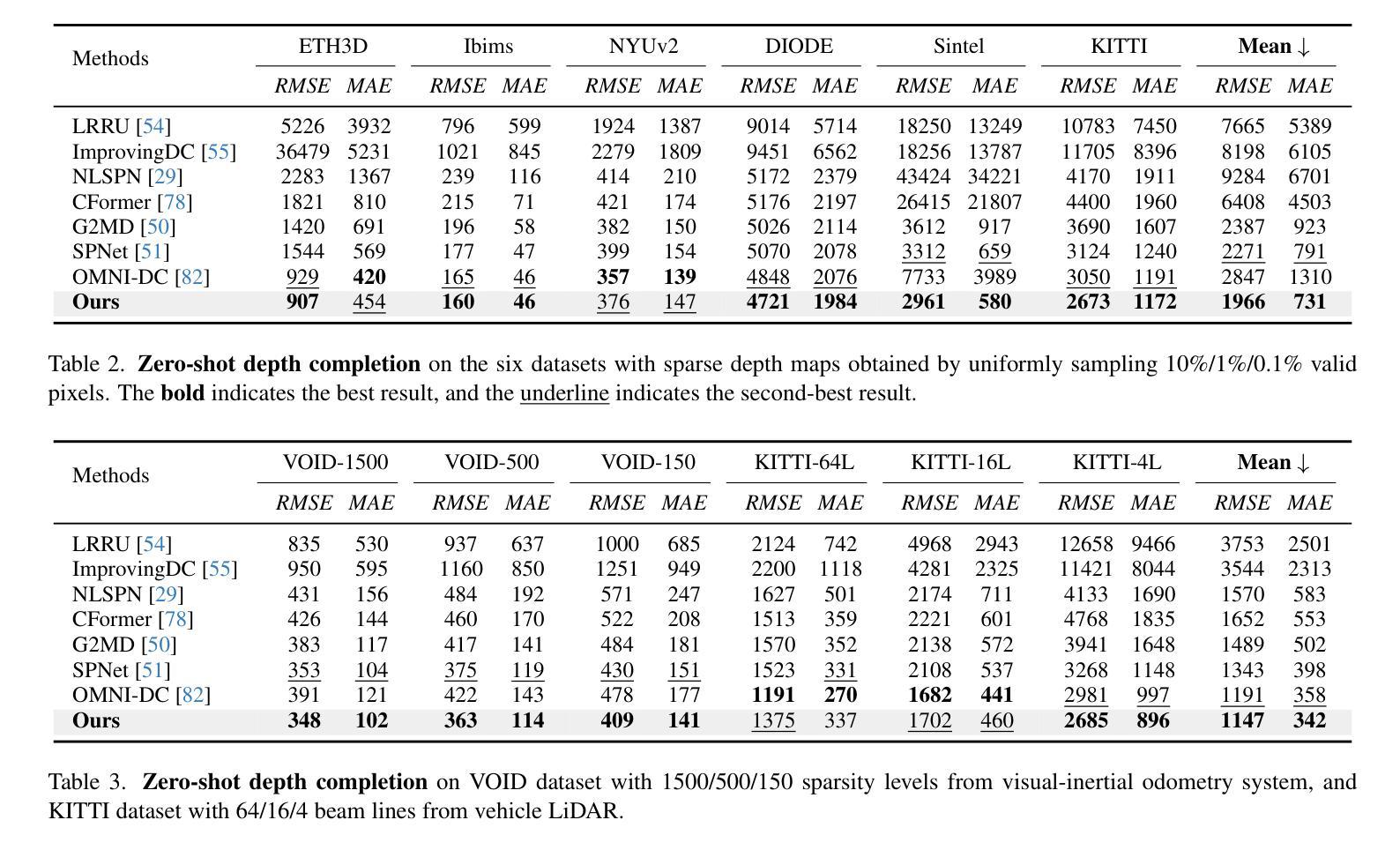
PacGDC: Label-Efficient Generalizable Depth Completion with Projection Ambiguity and Consistency
Authors:Haotian Wang, Aoran Xiao, Xiaoqin Zhang, Meng Yang, Shijian Lu
Generalizable depth completion enables the acquisition of dense metric depth maps for unseen environments, offering robust perception capabilities for various downstream tasks. However, training such models typically requires large-scale datasets with metric depth labels, which are often labor-intensive to collect. This paper presents PacGDC, a label-efficient technique that enhances data diversity with minimal annotation effort for generalizable depth completion. PacGDC builds on novel insights into inherent ambiguities and consistencies in object shapes and positions during 2D-to-3D projection, allowing the synthesis of numerous pseudo geometries for the same visual scene. This process greatly broadens available geometries by manipulating scene scales of the corresponding depth maps. To leverage this property, we propose a new data synthesis pipeline that uses multiple depth foundation models as scale manipulators. These models robustly provide pseudo depth labels with varied scene scales, affecting both local objects and global layouts, while ensuring projection consistency that supports generalization. To further diversify geometries, we incorporate interpolation and relocation strategies, as well as unlabeled images, extending the data coverage beyond the individual use of foundation models. Extensive experiments show that PacGDC achieves remarkable generalizability across multiple benchmarks, excelling in diverse scene semantics/scales and depth sparsity/patterns under both zero-shot and few-shot settings. Code: https://github.com/Wang-xjtu/PacGDC.
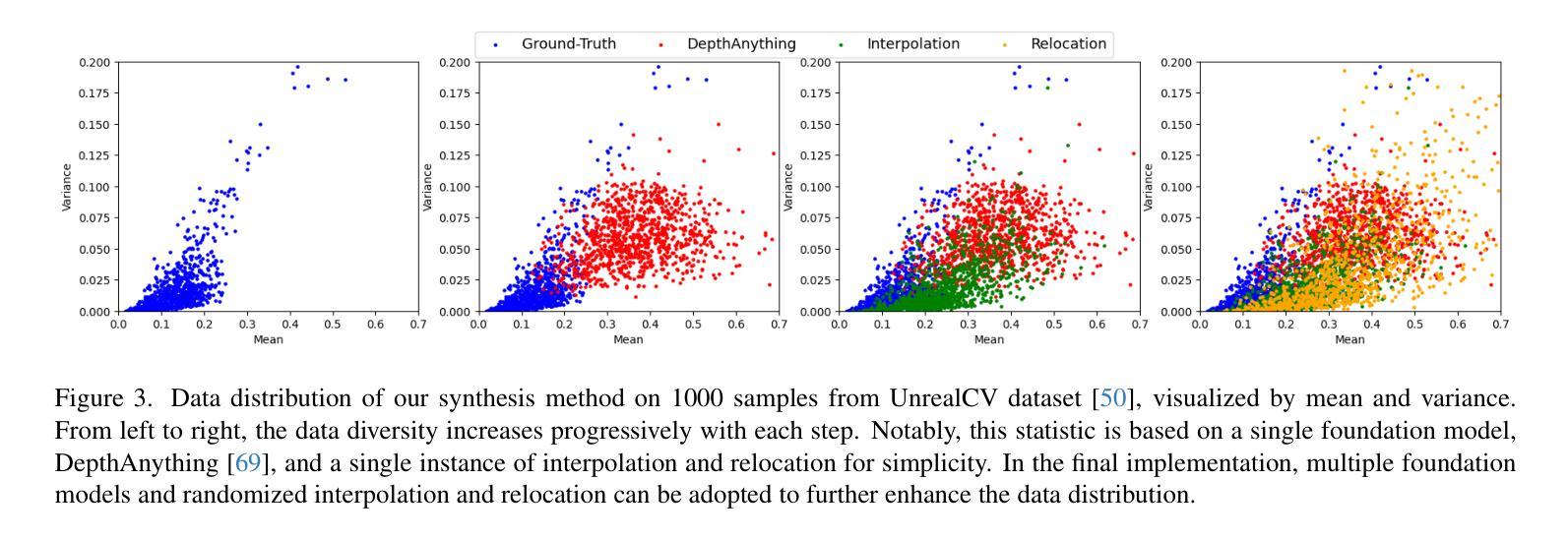
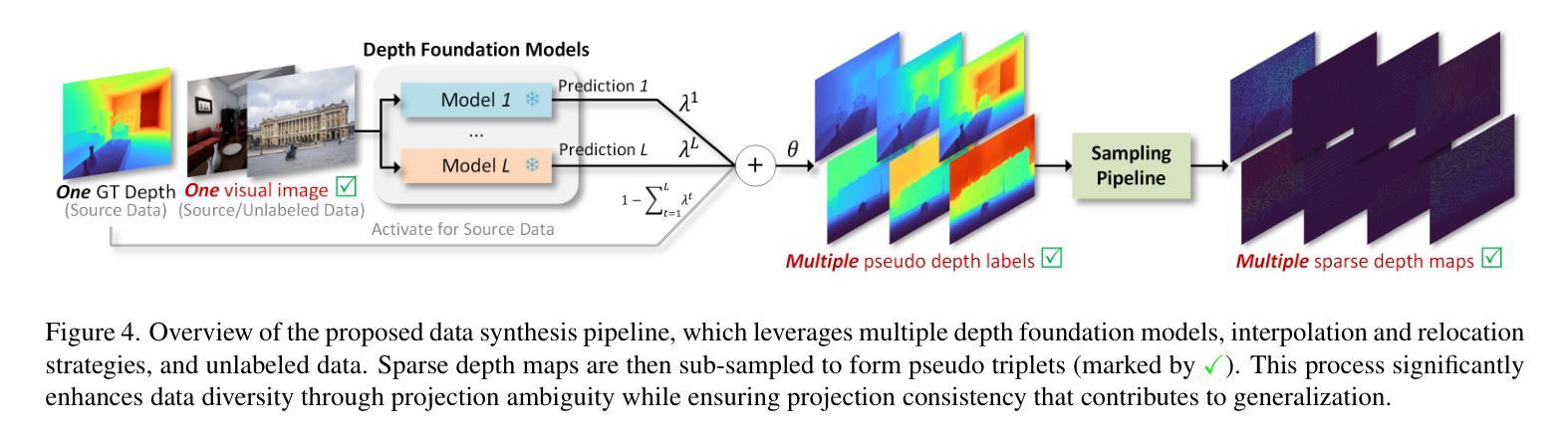
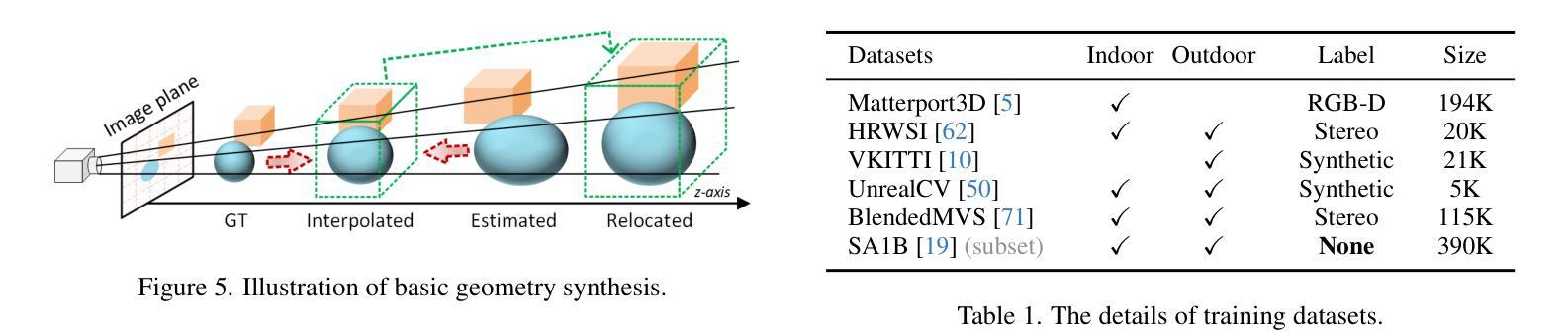
通用深度完成技术能够为未见过的环境获取密集的度量深度图,为各种下游任务提供稳健的感知能力。然而,训练此类模型通常需要带有度量深度标签的大规模数据集,这些数据集往往难以收集。本文提出了PacGDC,这是一种标签高效的技术,通过最小的标注工作量来提高数据多样性,以实现通用深度完成的可泛化性。PacGDC建立在从二维到三维投影过程中物体形状和位置固有模糊性和一致性的新见解上,允许对同一视觉场景合成大量伪几何结构。这一过程通过操作相应深度图的场景尺度,大大扩大了可用的几何结构。为了利用这一特性,我们提出了一种新的数据合成管道,使用多个深度基础模型作为尺度操纵器。这些模型能够稳健地提供具有不同场景尺度的伪深度标签,影响局部对象和全局布局,同时确保投影一致性以支持泛化能力。为了进一步优化几何结构的多样性,我们结合了插值和重新定位策略,以及未标记的图像,扩展了数据覆盖范围,而不仅仅是使用基础模型。大量实验表明,PacGDC在多个基准测试上实现了显著的可泛化性,在零样本和少样本设置下,擅长处理多样化的场景语义/尺度以及深度稀疏性/模式。代码:https://github.com/Wang-xjtu/PacGDC。
论文及项目相关链接
PDF Accepted to ICCV 2025
Summary
本文提出一种高效的深度完成方法PacGDC,通过利用数据合成管道和深度基础模型作为尺度操纵器,实现小规模标注下的数据多样性增强。此方法能够合成多种伪几何结构来模拟同一场景的不同深度分布,进而在多种深度基准测试中展现出色的泛化能力。
Key Takeaways
- PacGDC是一种高效的深度完成方法,旨在解决大规模数据集收集困难的问题。
- 利用对象形状和位置的固有模糊性和一致性,合成伪几何结构模拟同一场景的不同深度分布。
- 提出新的数据合成管道,使用多个深度基础模型作为尺度操纵器,提供不同场景的伪深度标签。
- 通过插值和重新定位策略以及未标记图像,进一步多样化几何结构,扩大数据覆盖范围。
- PacGDC通过模拟多种场景语义和尺度以及深度稀疏性和模式,实现了出色的泛化能力。
- 实验结果显示,PacGDC在零样本和少样本设置下均表现出色。
点此查看论文截图
Label-Efficient Chest X-ray Diagnosis via Partial CLIP Adaptation
Authors:Heet Nitinkumar Dalsania
Modern deep learning implementations for medical imaging usually rely on large labeled datasets. These datasets are often difficult to obtain due to privacy concerns, high costs, and even scarcity of cases. In this paper, a label-efficient strategy is proposed for chest X-ray diagnosis that seeks to reflect real-world hospital scenarios. The experiments use the NIH Chest X-ray14 dataset and a pre-trained CLIP ViT-B/32 model. The model is adapted via partial fine-tuning of its visual encoder and then evaluated using zero-shot and few-shot learning with 1-16 labeled examples per disease class. The tests demonstrate that CLIP’s pre-trained vision-language features can be effectively adapted to few-shot medical imaging tasks, achieving over 20% improvement in mean AUC score as compared to the zero-shot baseline. The key aspect of this work is to attempt to simulate internal hospital workflows, where image archives exist but annotations are sparse. This work evaluates a practical and scalable solution for both common and rare disease diagnosis. Additionally this research is intended for academic and experimental purposes only and has not been peer reviewed yet. All code is found at https://github.com/heet007-code/CLIP-disease-xray.
现代医学影像深度学习实现通常依赖于大量标注数据集。由于隐私担忧、高昂成本和案例稀缺等原因,这些数据集往往难以获取。本文提出了一种针对胸部X射线诊断的标签高效策略,旨在反映真实世界医院场景。实验使用NIH Chest X-ray14数据集和预训练的CLIP ViT-B/32模型。通过对其视觉编码器的部分微调,模型得以适应,然后使用每疾病类别1-16个标注样本进行零样本和少样本学习的评估。测试表明,CLIP的预训练视觉语言特征可以有效地适应少样本医学影像任务,与零样本基线相比,平均AUC得分提高了超过20%。这项工作的关键是尝试模拟医院内部工作流程,其中图像档案存在但注释稀疏。这项工作为常见和罕见疾病的诊断提供了实用且可扩展的解决方案。另外,本研究仅用于学术和实验目的,尚未经过同行评审。所有代码可在https://github.com/heet007-code/CLIP-disease-xray找到。
论文及项目相关链接
Summary
本文提出了一种针对胸部X射线诊断的标签效率策略,该策略适用于现实世界中医院场景。通过使用NIH Chest X-ray14数据集和预训练的CLIP ViT-B/32模型进行实验,通过部分微调视觉编码器并评估其在每个疾病类别仅有1-16个标记样本的零样本和少样本学习能力。实验结果表明,CLIP的预训练视觉语言特征可有效地适应少样本医学成像任务,平均AUC得分相比零样本基线提高了超过2.重要的一点是模拟内部医院工作流程,图像档案存在但注释稀疏。该研究为常见和罕见疾病的诊断提供了实用且可扩展的解决方案。请注意,该研究仅用于学术和实验目的,尚未经过同行评审。相关代码可在 https://github.com/heet007-code/CLIP-disease-xray 找到。
Key Takeaways
以下是关键见解的要点列表:
- 现代医疗成像的深度学习方法通常需要大量标注数据集,但由于隐私担忧、高昂成本和案例稀缺性而难以获得。本文提出一种适用于胸部X射线诊断的标签效率策略。
- 该策略旨在模拟现实世界中医院的场景,尤其是图像档案丰富但注释稀缺的情况。
- 使用NIH Chest X-ray14数据集和预训练的CLIP ViT-B/32模型进行实验验证。
- 通过部分微调视觉编码器,模型在少样本学习(每个疾病类别仅有1-16个标记样本)中表现出良好的性能。
- 与零样本学习相比,该策略在平均AUC得分上实现了超过20%的改进。
- 该研究为常见和罕见疾病的诊断提供了实用且可扩展的解决方案。此研究仅用于学术和实验目的,尚未经过同行评审。
点此查看论文截图

Judging from Support-set: A New Way to Utilize Few-Shot Segmentation for Segmentation Refinement Process
Authors:Seonghyeon Moon, Qingze, Liu, Haein Kong, Muhammad Haris Khan
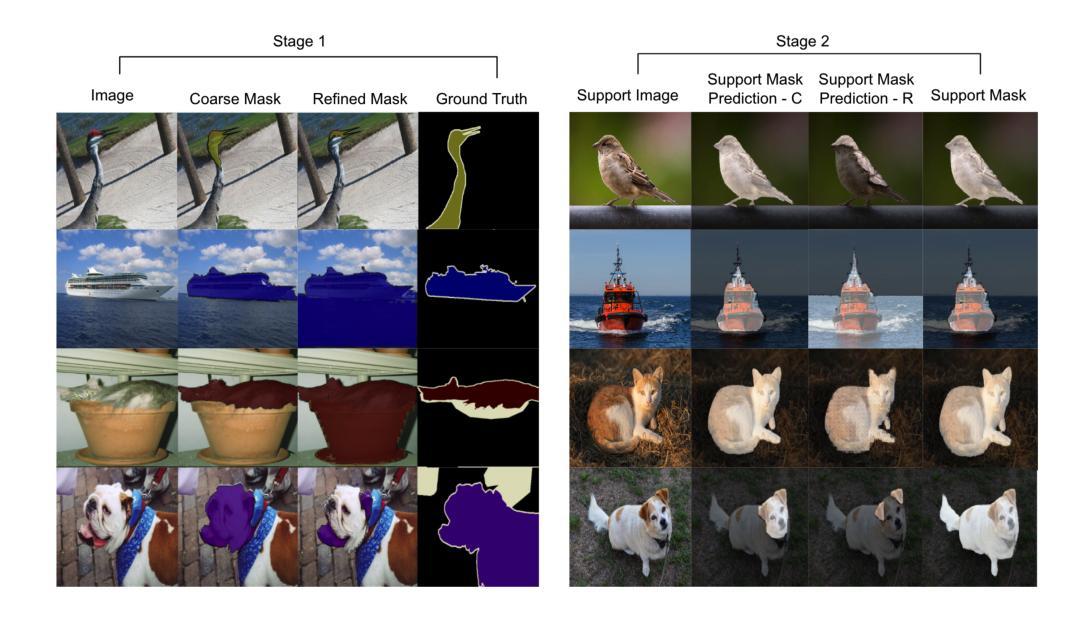
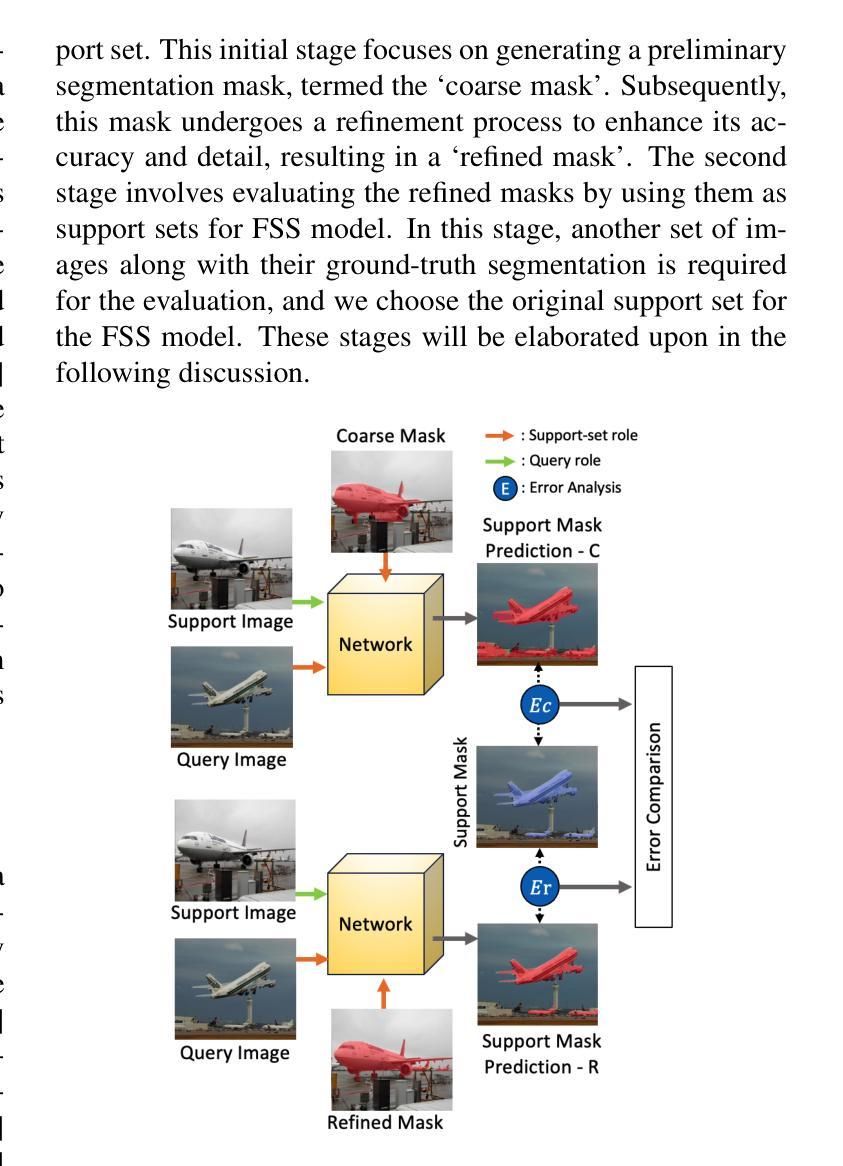
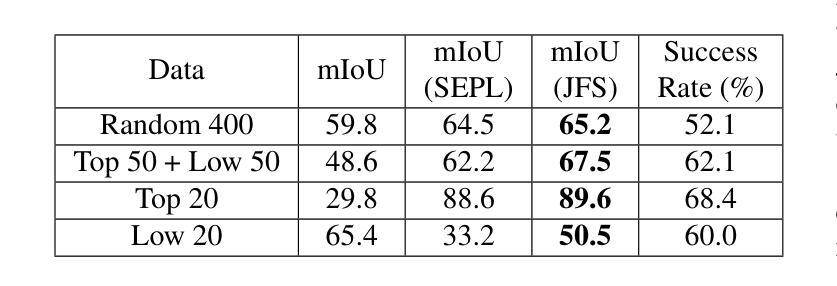
Segmentation refinement aims to enhance the initial coarse masks generated by segmentation algorithms. The refined masks are expected to capture more details and better contours of the target objects. Research on segmentation refinement has developed as a response to the need for high-quality image segmentations. However, to our knowledge, no method has been developed that can determine the success of segmentation refinement. Such a method could ensure the reliability of segmentation in applications where the outcome of the segmentation is important and fosters innovation in image processing technologies. To address this research gap, we propose Judging From Support-set (JFS), a method to judge the success of segmentation refinement leveraging an off-the-shelf few-shot segmentation (FSS) model. The traditional goal of the problem in FSS is to find a target object in a query image utilizing target information given by a support set. However, we propose a novel application of the FSS model in our evaluation pipeline for segmentation refinement methods. Given a coarse mask as input, segmentation refinement methods produce a refined mask; these two masks become new support masks for the FSS model. The existing support mask then serves as the test set for the FSS model to evaluate the quality of the refined segmentation by the segmentation refinement methods. We demonstrate the effectiveness of our proposed JFS framework by evaluating the SAM Enhanced Pseudo-Labels (SEPL) using SegGPT as the choice of FSS model on the PASCAL dataset. The results showed that JFS has the potential to determine whether the segmentation refinement process is successful.
分割优化旨在提高分割算法生成的初始粗略掩膜的质量。优化后的掩膜能够捕获更多的细节和更精确的目标对象轮廓。分割优化的研究是为了满足对高质量图像分割的需求而发展起来的。但是,据我们所知,还没有开发出一种方法来确定分割优化的成功与否。这样的方法可以保证分割结果在重要应用中的可靠性,并促进图像处理技术的创新。为了解决这一研究空白,我们提出了“从支持集判断”(JFS)的方法,这是一种利用现成的少样本分割(FSS)模型来判断分割优化是否成功的方法。FSS问题的传统目标是在查询图像中找到目标对象,这利用了支持集给出的目标信息。然而,我们提出了FSS模型在分割优化方法评估流程中的新颖应用。给定一个粗略的掩膜作为输入,分割优化方法会产生一个优化后的掩膜;这两个掩膜成为FSS模型的新支持集。现有的支持掩膜然后作为测试集,用于评估分割优化方法对优化分割质量的评估。我们通过使用SegGPT作为FSS模型在PASCAL数据集上评估SAM增强伪标签(SEPL),来证明我们提出的JFS框架的有效性。结果表明,JFS有潜力确定分割优化过程是否成功。
论文及项目相关链接
PDF ICIP 2025
Summary
本文提出了一个名为Judging From Support-set(JFS)的方法,用于评估分割细化方法的成功与否。该方法利用现成的少样本分割(FSS)模型,通过生成粗分割掩膜和细化后的分割掩膜作为新的支持掩膜来评估分割细化方法的质量。实验结果表明,JFS具有判断分割细化过程是否成功的潜力。
Key Takeaways
- 分割细化旨在提高分割算法生成的初始粗分割掩膜的质量,捕捉更多细节和目标对象的更好轮廓。
- 目前缺乏评估分割细化成功与否的方法,这影响了分割结果的重要性,并阻碍了图像处理技术的发展。
- 提出了一种新的方法Judging From Support-set(JFS),利用现成的少样本分割(FSS)模型来判断分割细化方法的成功与否。
- JFS通过将粗分割掩膜和细化后的分割掩膜作为新的支持掩膜,用于评估分割细化方法的质量。
- 实验在PASCAL数据集上,使用SegGPT作为FSS模型对SAM Enhanced Pseudo-Labels(SEPL)进行了评估,证明了JFS的潜力。
- JFS框架的引入为评估分割细化方法提供了新的思路和方法。
点此查看论文截图