⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-12 更新
Multi-Granular Spatio-Temporal Token Merging for Training-Free Acceleration of Video LLMs
Authors:Jeongseok Hyun, Sukjun Hwang, Su Ho Han, Taeoh Kim, Inwoong Lee, Dongyoon Wee, Joon-Young Lee, Seon Joo Kim, Minho Shim
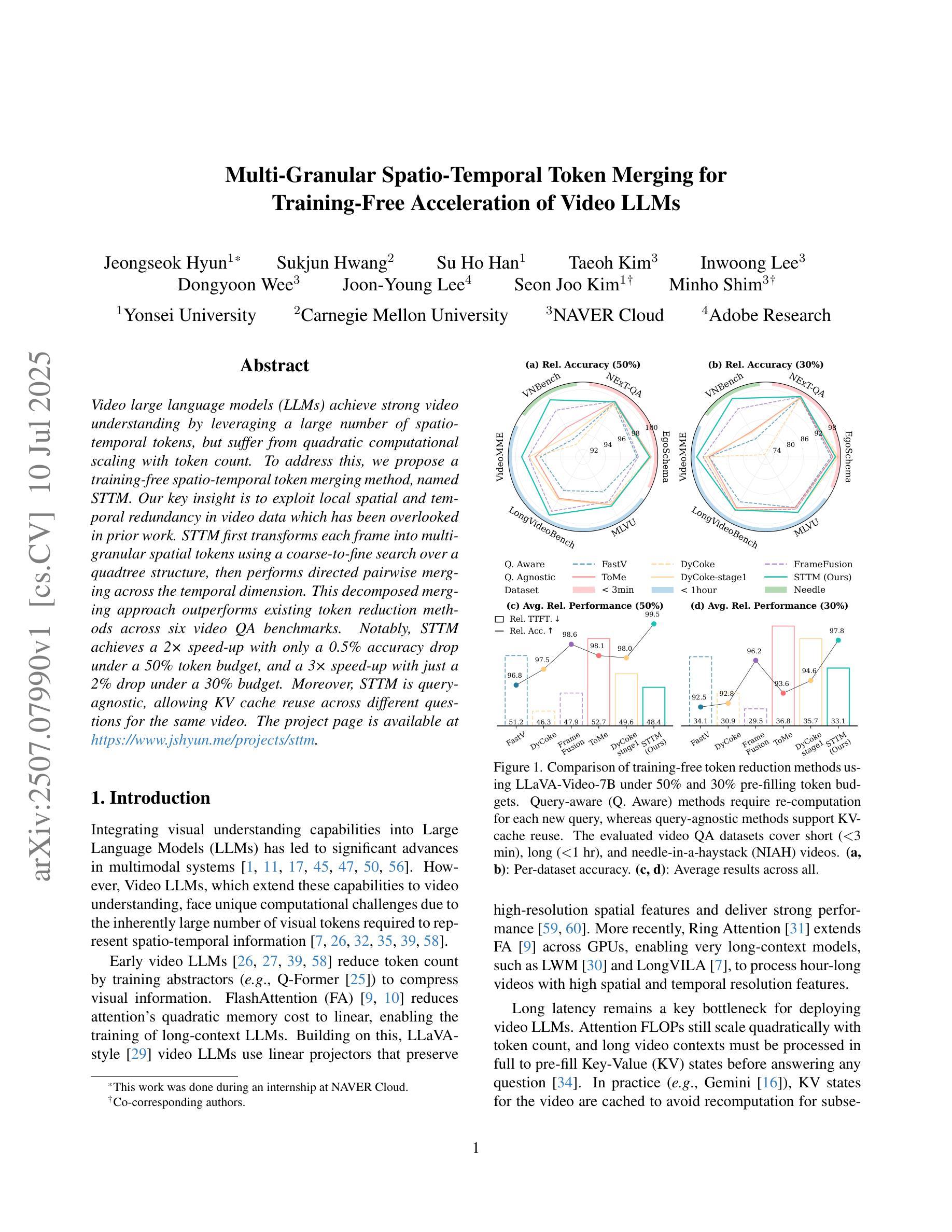
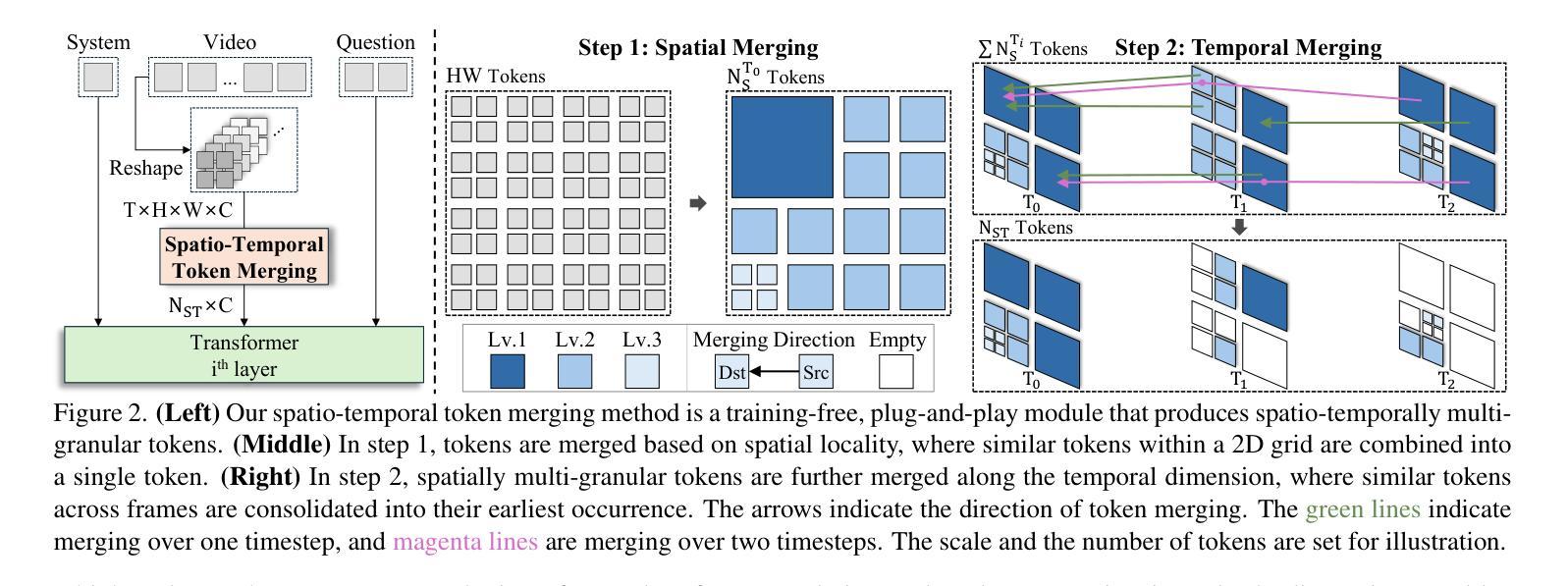
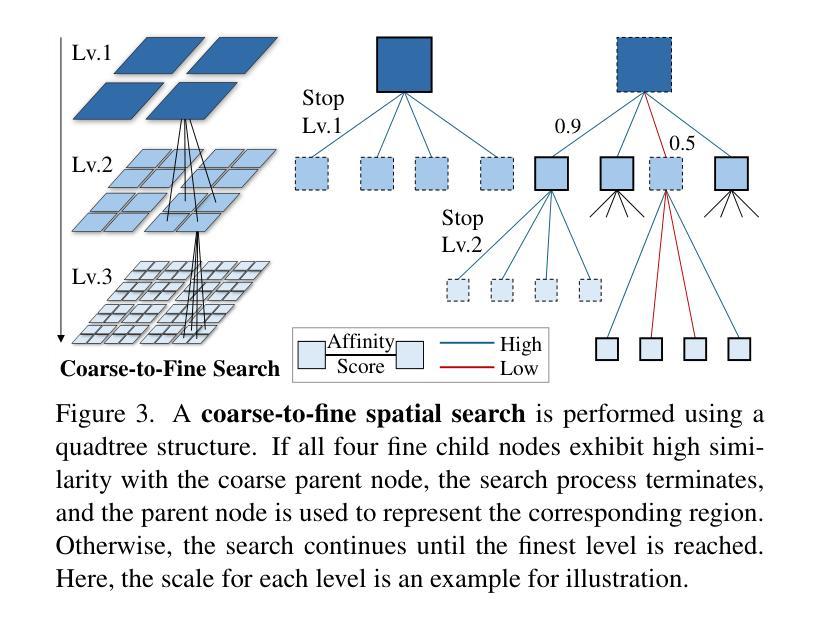
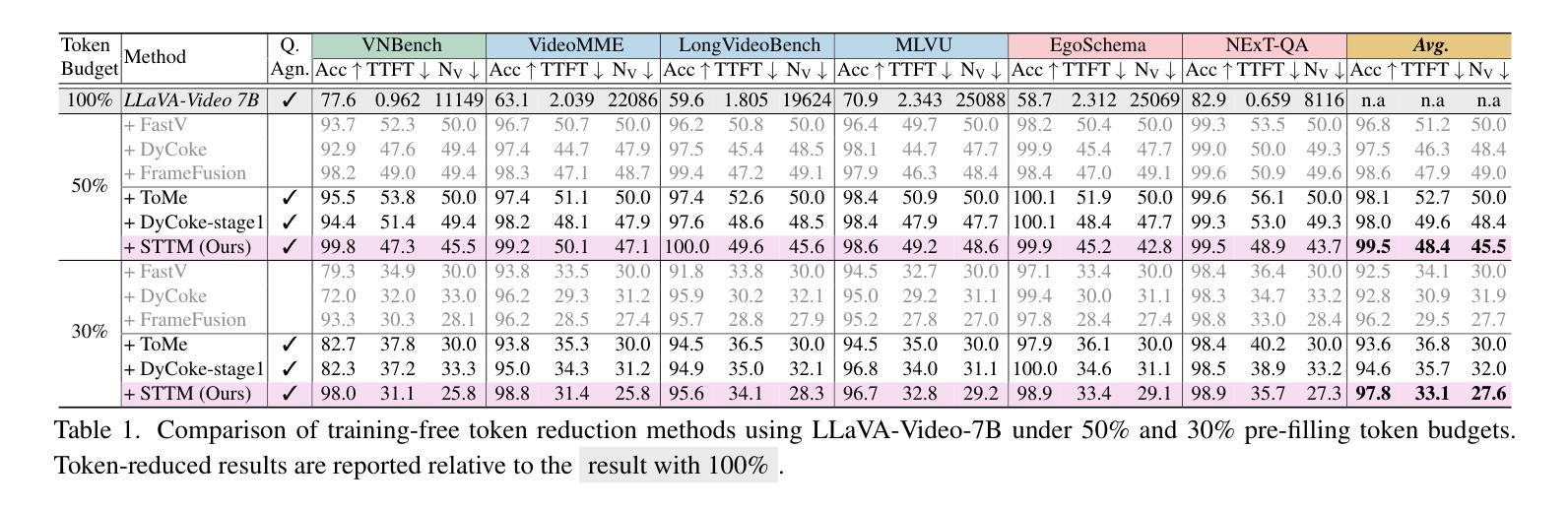
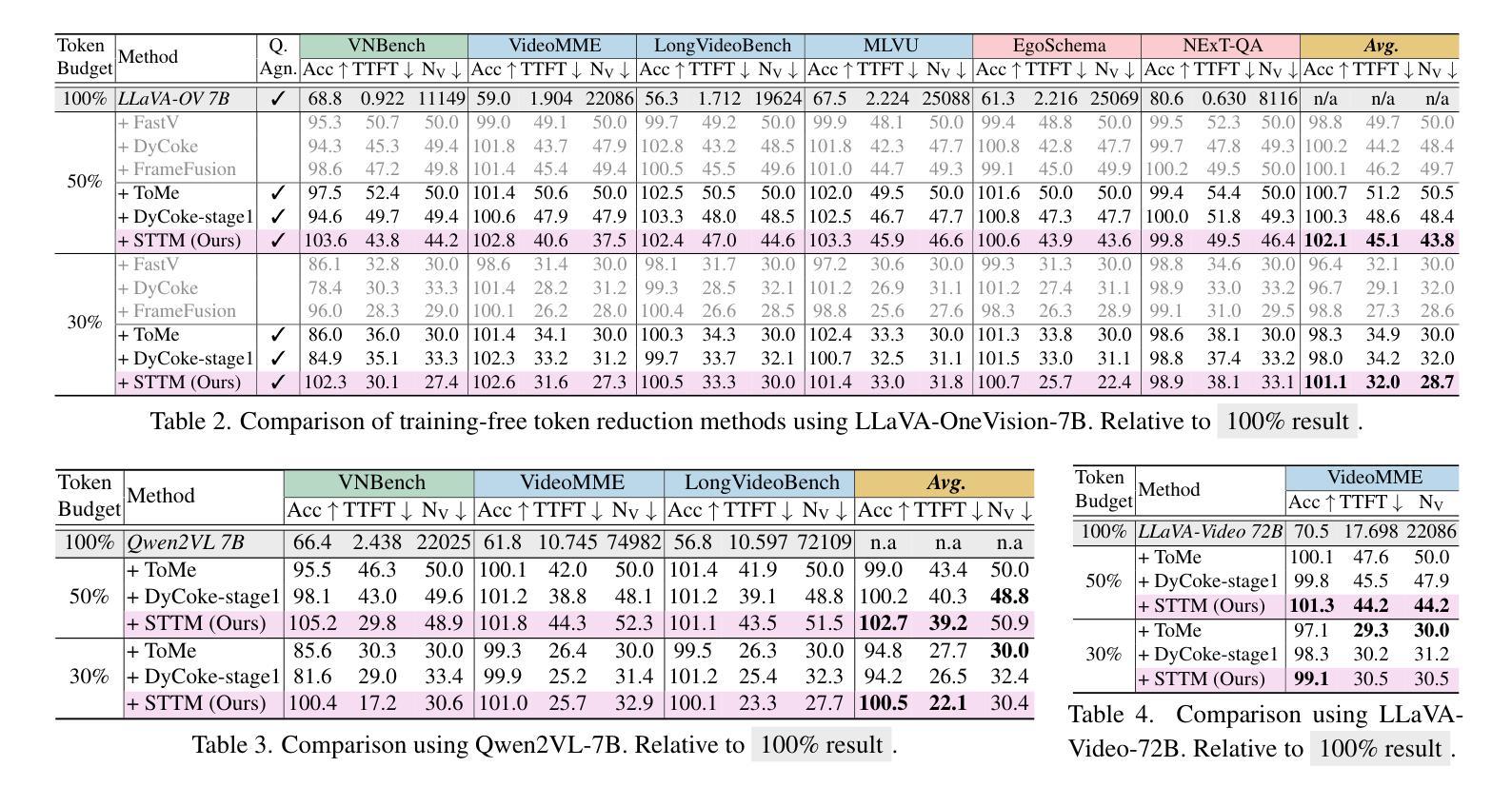
Video large language models (LLMs) achieve strong video understanding by leveraging a large number of spatio-temporal tokens, but suffer from quadratic computational scaling with token count. To address this, we propose a training-free spatio-temporal token merging method, named STTM. Our key insight is to exploit local spatial and temporal redundancy in video data which has been overlooked in prior work. STTM first transforms each frame into multi-granular spatial tokens using a coarse-to-fine search over a quadtree structure, then performs directed pairwise merging across the temporal dimension. This decomposed merging approach outperforms existing token reduction methods across six video QA benchmarks. Notably, STTM achieves a 2$\times$ speed-up with only a 0.5% accuracy drop under a 50% token budget, and a 3$\times$ speed-up with just a 2% drop under a 30% budget. Moreover, STTM is query-agnostic, allowing KV cache reuse across different questions for the same video. The project page is available at https://www.jshyun.me/projects/sttm.
视频大语言模型(LLM)通过利用大量时空令牌实现了强大的视频理解,但随着令牌数量的增加,其计算规模呈二次方增长。为了解决这一问题,我们提出了一种无需训练的时空令牌合并方法,称为STTM。我们的关键见解是,利用视频数据中局部空间和时间的冗余性,这是以前的研究中被忽视的部分。STTM首先通过四叉树结构的粗到细搜索将每一帧转换为多粒度空间令牌,然后在时间维度上执行有方向的成对合并。这种分解合并方法在所有六个视频问答基准测试中均优于现有的令牌缩减方法。值得注意的是,在50%令牌预算下,STTM实现了2倍的速度提升,准确度仅下降0.5%,在30%预算下,实现了3倍的速度提升,准确度仅下降2%。此外,STTM对查询无感知,允许针对同一视频的多个问题重复使用KV缓存。项目页面可在[https://www.jshyun.me/projects/sttm访问。]
论文及项目相关链接
PDF Accepted at ICCV2025; Project page: https://www.jshyun.me/projects/sttm
Summary
视频大型语言模型(LLM)通过利用大量时空令牌实现强大的视频理解,但面临计算量随令牌数量二次增长的挑战。为解决此问题,我们提出了一种无需训练的时空令牌合并方法,名为STTM。我们的关键见解是发掘视频数据中局部空间和时间的冗余性,这一点在以前的研究中常被忽视。STTM首先将每帧转换为多粒度空间令牌,通过四叉树结构的粗细搜索,然后在时间维度上进行有方向的成对合并。这种分解合并方法在众多视频问答基准测试中优于现有令牌缩减方法。特别地,在50%令牌预算下,STTM实现了2倍速度提升,准确度仅下降0.5%;在30%预算下,实现了3倍速度提升,准确度仅下降2%。此外,STTM对查询不敏感,允许跨不同问题对同一视频进行KV缓存重用。
Key Takeaways
- 视频大型语言模型(LLM)通过利用大量时空令牌实现视频理解,但存在计算量随令牌数量二次增长的问题。
- 提出了一个无需训练的时空令牌合并方法(STTM),通过发掘视频数据中局部空间和时间的冗余性来解决上述问题。
- STTM首先将每帧转换为多粒度空间令牌,利用四叉树结构的粗细搜索。
- STTM在时空维度上进行令牌合并,实现了优于现有令牌缩减方法的性能。
- 在特定的预算下,STTM在速度提升和准确度损失之间达到了良好的平衡。
- STTM对查询不敏感,允许跨不同问题对同一视频进行KV缓存重用。
点此查看论文截图
Automating Expert-Level Medical Reasoning Evaluation of Large Language Models
Authors:Shuang Zhou, Wenya Xie, Jiaxi Li, Zaifu Zhan, Meijia Song, Han Yang, Cheyenna Espinoza, Lindsay Welton, Xinnie Mai, Yanwei Jin, Zidu Xu, Yuen-Hei Chung, Yiyun Xing, Meng-Han Tsai, Emma Schaffer, Yucheng Shi, Ninghao Liu, Zirui Liu, Rui Zhang
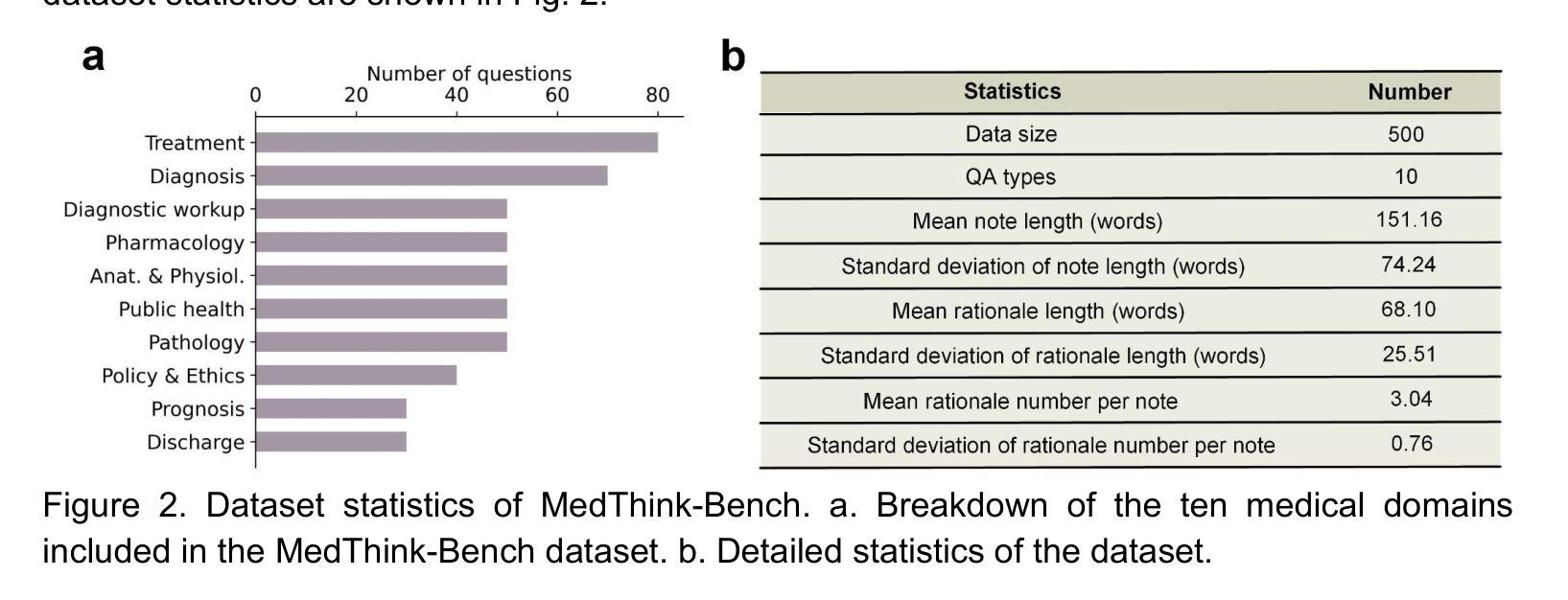
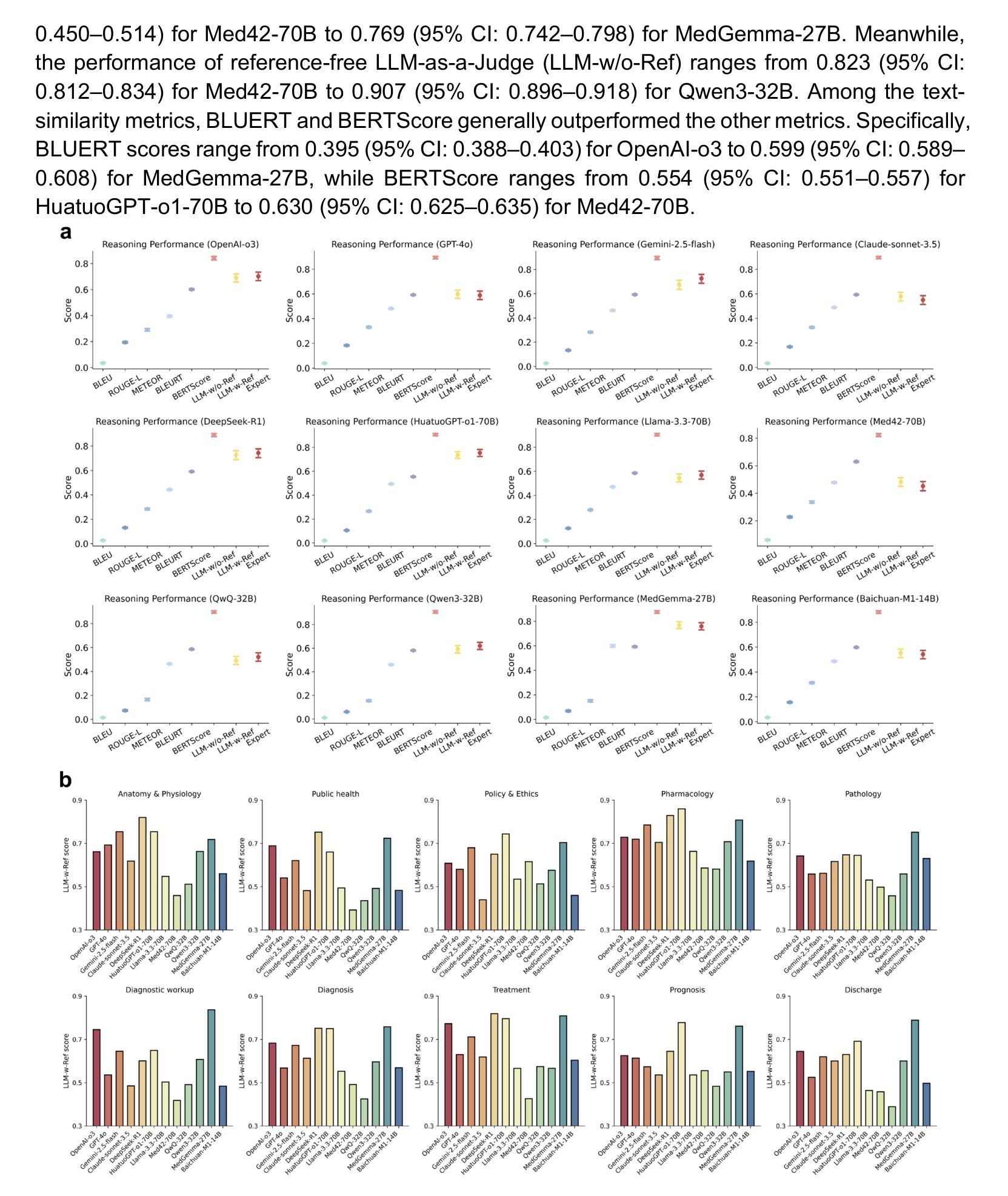
As large language models (LLMs) become increasingly integrated into clinical decision-making, ensuring transparent and trustworthy reasoning is essential. However, existing evaluation strategies of LLMs’ medical reasoning capability either suffer from unsatisfactory assessment or poor scalability, and a rigorous benchmark remains lacking. To address this, we introduce MedThink-Bench, a benchmark designed for rigorous, explainable, and scalable assessment of LLMs’ medical reasoning. MedThink-Bench comprises 500 challenging questions across ten medical domains, each annotated with expert-crafted step-by-step rationales. Building on this, we propose LLM-w-Ref, a novel evaluation framework that leverages fine-grained rationales and LLM-as-a-Judge mechanisms to assess intermediate reasoning with expert-level fidelity while maintaining scalability. Experiments show that LLM-w-Ref exhibits a strong positive correlation with expert judgments. Benchmarking twelve state-of-the-art LLMs, we find that smaller models (e.g., MedGemma-27B) can surpass larger proprietary counterparts (e.g., OpenAI-o3). Overall, MedThink-Bench offers a foundational tool for evaluating LLMs’ medical reasoning, advancing their safe and responsible deployment in clinical practice.
随着大型语言模型(LLM)在临床决策中的集成度越来越高,确保透明和可信赖的推理至关重要。然而,现有的LLM医疗推理能力评估策略要么评估结果不尽如人意,要么扩展性较差,且缺乏严格的基准测试。为解决这一问题,我们推出了MedThink-Bench,这是一个为LLM医疗推理进行严格、可解释和可扩展评估的基准测试。MedThink-Bench包含500个跨越十个医学领域的挑战性问题,每个问题都配有专家逐步制定的理由。在此基础上,我们提出了LLM-w-Ref这一新型评估框架,它利用精细化的理由和LLM作为法官的机制,以专家级的忠实度评估中间推理,同时保持可扩展性。实验表明,LLM-w-Ref与专家判断之间呈现出强烈正相关。在基准测试中对比了最先进的十二款LLM,我们发现较小的模型(例如MedGemma-27B)可以超越较大的专有模型(例如OpenAI-o3)。总体而言,MedThink-Bench为评估LLM的医疗推理能力提供了基础工具,推动了其在临床实践中的安全和负责任部署。
论文及项目相关链接
PDF 22 pages,6 figures
Summary
大型语言模型(LLM)在临床决策中的透明度和可信度至关重要。当前评估策略存在不足,缺乏严格的标准。为此,我们推出MedThink-Bench基准测试,旨在严格、可解释和可扩展地评估LLM的医疗推理能力。该基准测试包含500个跨越十大医学领域的挑战性问题,每个问题都有专家逐步制定的理由。在此基础上,我们提出了LLM-w-Ref评估框架,利用精细化的理由和LLM-as-a-Judge机制来评估中间推理过程,保持与专家判断的一致性同时提高可扩展性。实验表明,LLM-w-Ref与专家判断呈现显著正相关。对12款最新LLM模型的基准测试发现,小型模型(如MedGemma-27B)表现优于大型专有模型(如OpenAI-o3)。总体而言,MedThink-Bench为评估LLM的医疗推理能力提供了基础工具,推动了其在临床实践中的安全和负责任部署。
Key Takeaways
- 大型语言模型(LLM)在临床决策中的透明度和可信度评估至关重要。
- 当前LLM医疗推理能力评估策略存在不足,缺乏严格标准。
- MedThink-Bench基准测试旨在严格、可解释和可扩展地评估LLM的医疗推理能力。
- MedThink-Bench包含500个跨越十大医学领域的挑战性问题,每个问题都有专家理由。
- LLM-w-Ref评估框架利用精细化的理由和LLM机制来评估推理过程。
- LLM-w-Ref与专家判断呈现显著正相关。
- 对最新LLM模型的基准测试发现,小型模型表现优于某些大型模型。
点此查看论文截图


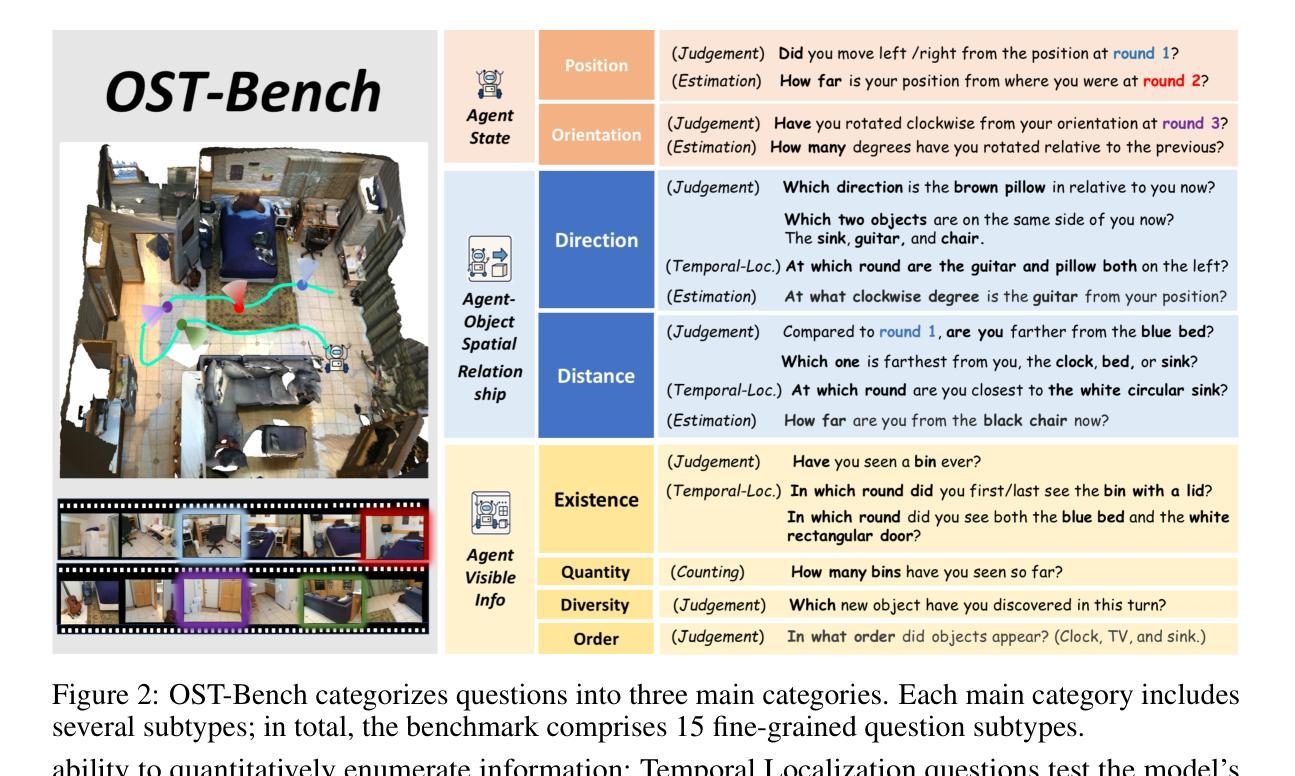
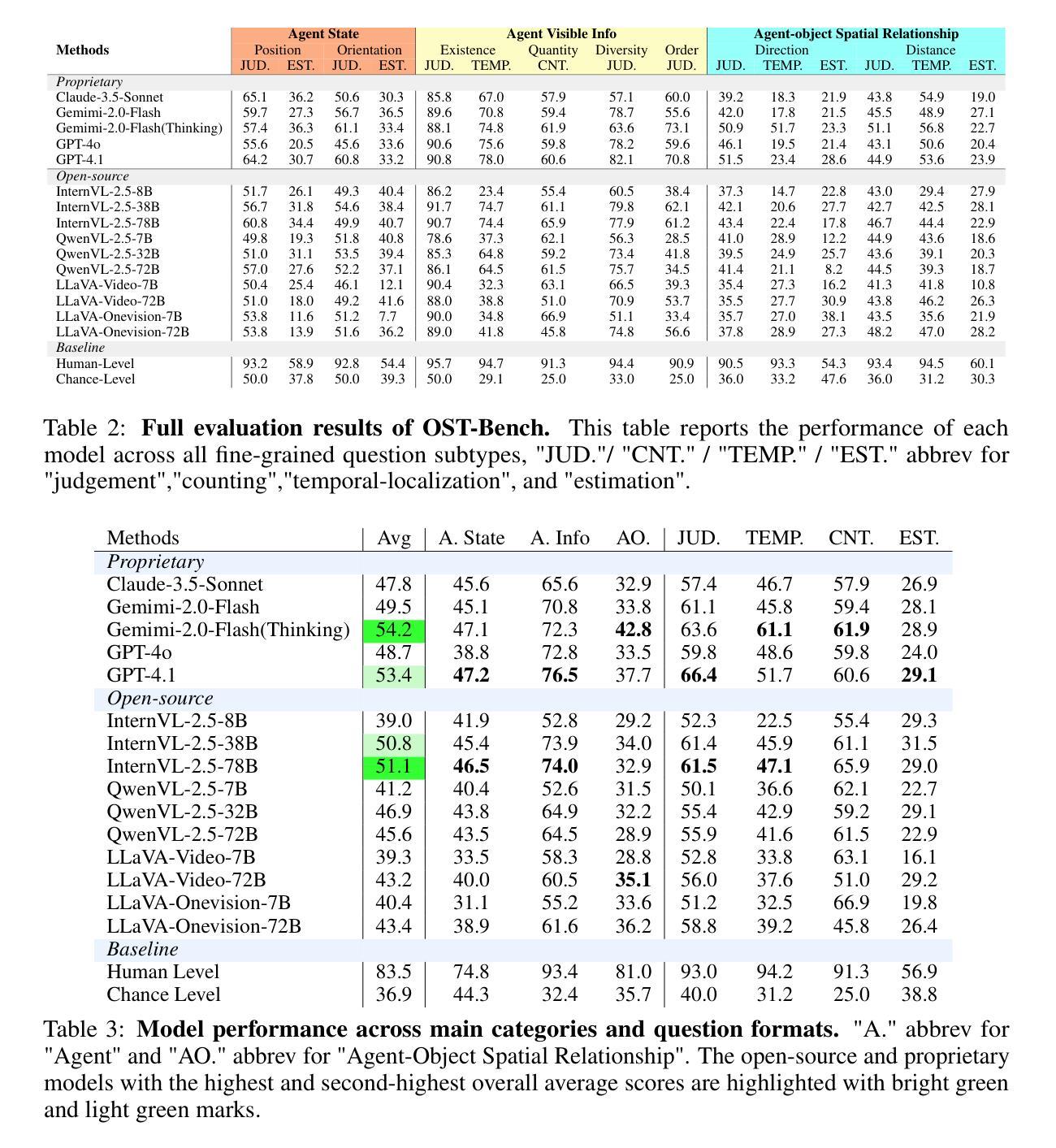
OST-Bench: Evaluating the Capabilities of MLLMs in Online Spatio-temporal Scene Understanding
Authors:JingLi Lin, Chenming Zhu, Runsen Xu, Xiaohan Mao, Xihui Liu, Tai Wang, Jiangmiao Pang
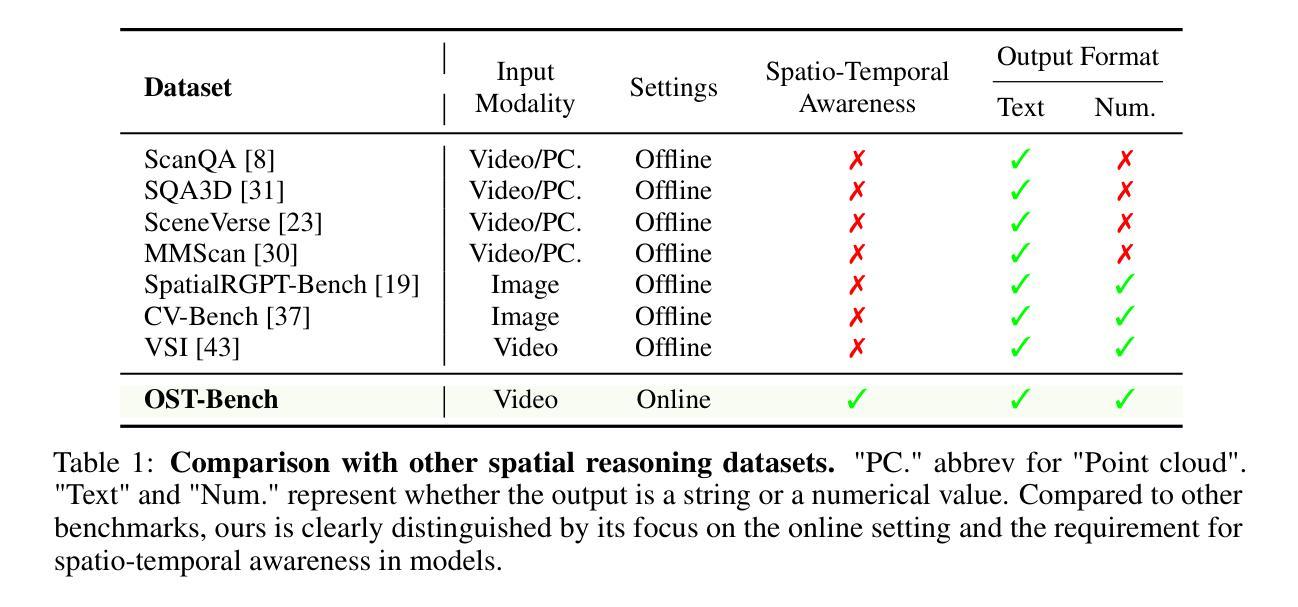
Recent advances in multimodal large language models (MLLMs) have shown remarkable capabilities in integrating vision and language for complex reasoning. While most existing benchmarks evaluate models under offline settings with a fixed set of pre-recorded inputs, we introduce OST-Bench, a benchmark designed to evaluate Online Spatio-Temporal understanding from the perspective of an agent actively exploring a scene. The Online aspect emphasizes the need to process and reason over incrementally acquired observations, while the Spatio-Temporal component requires integrating current visual inputs with historical memory to support dynamic spatial reasoning. OST-Bench better reflects the challenges of real-world embodied perception. Built on an efficient data collection pipeline, OST-Bench consists of 1.4k scenes and 10k question-answer pairs collected from ScanNet, Matterport3D, and ARKitScenes. We evaluate several leading MLLMs on OST-Bench and observe that they fall short on tasks requiring complex spatio-temporal reasoning. Under the online setting, their accuracy declines as the exploration horizon extends and the memory grows. Through further experimental analysis, we identify common error patterns across models and find that both complex clue-based spatial reasoning demands and long-term memory retrieval requirements significantly drop model performance along two separate axes, highlighting the core challenges that must be addressed to improve online embodied reasoning. To foster further research and development in the field, our codes, dataset, and benchmark are available. Our project page is: https://rbler1234.github.io/OSTBench.github.io/
最近的多模态大型语言模型(MLLMs)的进展在整合视觉和语言进行复杂推理方面展现出了显著的能力。虽然大多数现有的基准测试都在离线设置下评估模型,使用一组固定的预先录制的输入,但我们引入了OST-Bench基准测试,它是从代理积极探索场景的角度设计的,旨在评估在线时空理解。在线方面强调了处理和增量获取的观察结果进行推理的需求,而时空组件则要求将当前的视觉输入与历史记忆相结合,以支持动态空间推理。OST-Bench更好地反映了现实世界中体感感知的挑战。建立在高效的数据收集流程之上,OST-Bench由来自ScanNet、Matterport3D和ARKitScenes的1400个场景和1万个问题答案对组成。我们在OST-Bench上评估了几款领先的多模态大型语言模型,并发现它们在需要复杂时空推理的任务中表现不足。在线设置下,随着探索范围的扩大和记忆的增长,他们的准确性会下降。通过进一步的实验分析,我们确定了模型之间的常见错误模式,并发现基于复杂线索的空间推理需求和长期记忆检索要求显著降低模型性能的两个独立轴,这突出了必须解决的核心挑战以提高在线体感推理能力。为了促进该领域的进一步研究和开发,我们的代码、数据集和基准测试均可用。我们的项目页面是:[网站链接](请替换为实际网站链接)
论文及项目相关链接
PDF 28 pages, a benchmark designed to evaluate Online Spatio-Temporal understanding from the perspective of an agent actively exploring a scene. Project Page: https://rbler1234.github.io/OSTBench.github.io/
Summary
本文主要介绍了针对多模态大型语言模型(MLLMs)的新基准测试——OST-Bench。与传统的离线基准测试不同,OST-Bench注重在线时空理解的评价,尤其强调了处理和理解连续获得的信息和场景的时空特征。此外,该研究还发现当前的主流MLLMs在处理复杂时空推理任务时表现欠佳,随着探索视野的扩大和记忆的增长,其准确性会下降。文章还指出了模型存在的常见错误模式,并强调了解决在线实体推理的核心挑战。最后,该项目的数据集和基准测试可供公众访问,以促进该领域的研究和发展。
Key Takeaways
- 引入OST-Bench基准测试:专门为评估多模态大型语言模型(MLLMs)的在线时空理解能力而设计。
- 在线时空理解的强调:注重处理和理解连续获得的信息和场景的时空特征。
- 现有MLLMs的挑战:在处理复杂时空推理任务时表现欠佳,随着探索视野的扩大和记忆的增长,准确性下降。
- 模型错误模式分析:发现两种常见的错误模式,分别是复杂的线索基础空间推理需求和长期记忆检索要求。
- 核心挑战识别:为了提升在线实体推理能力,必须解决特定的核心挑战。
- 数据集和基准测试的公开:以促进该领域的研究和发展。
点此查看论文截图

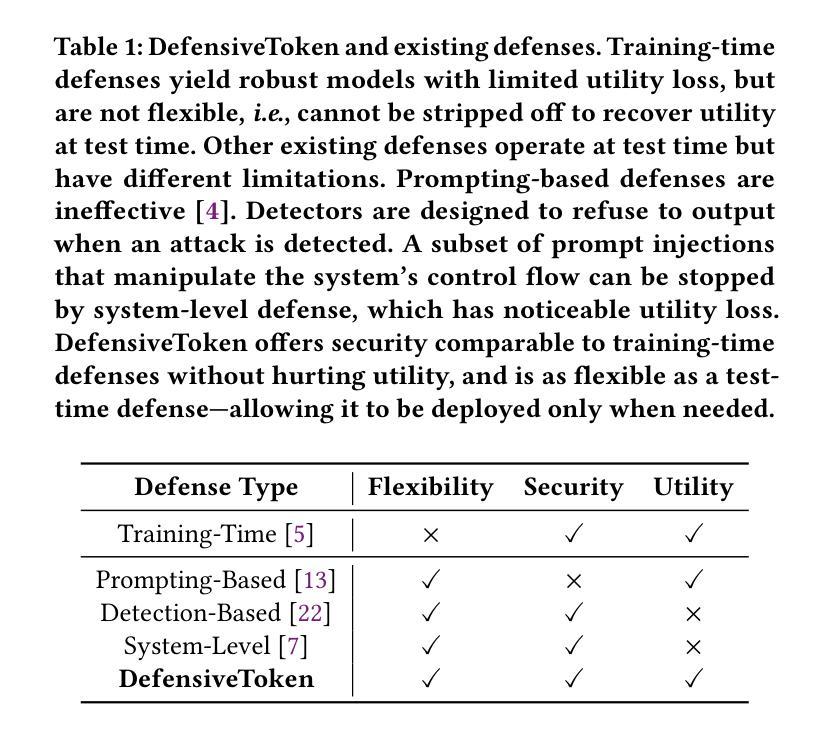
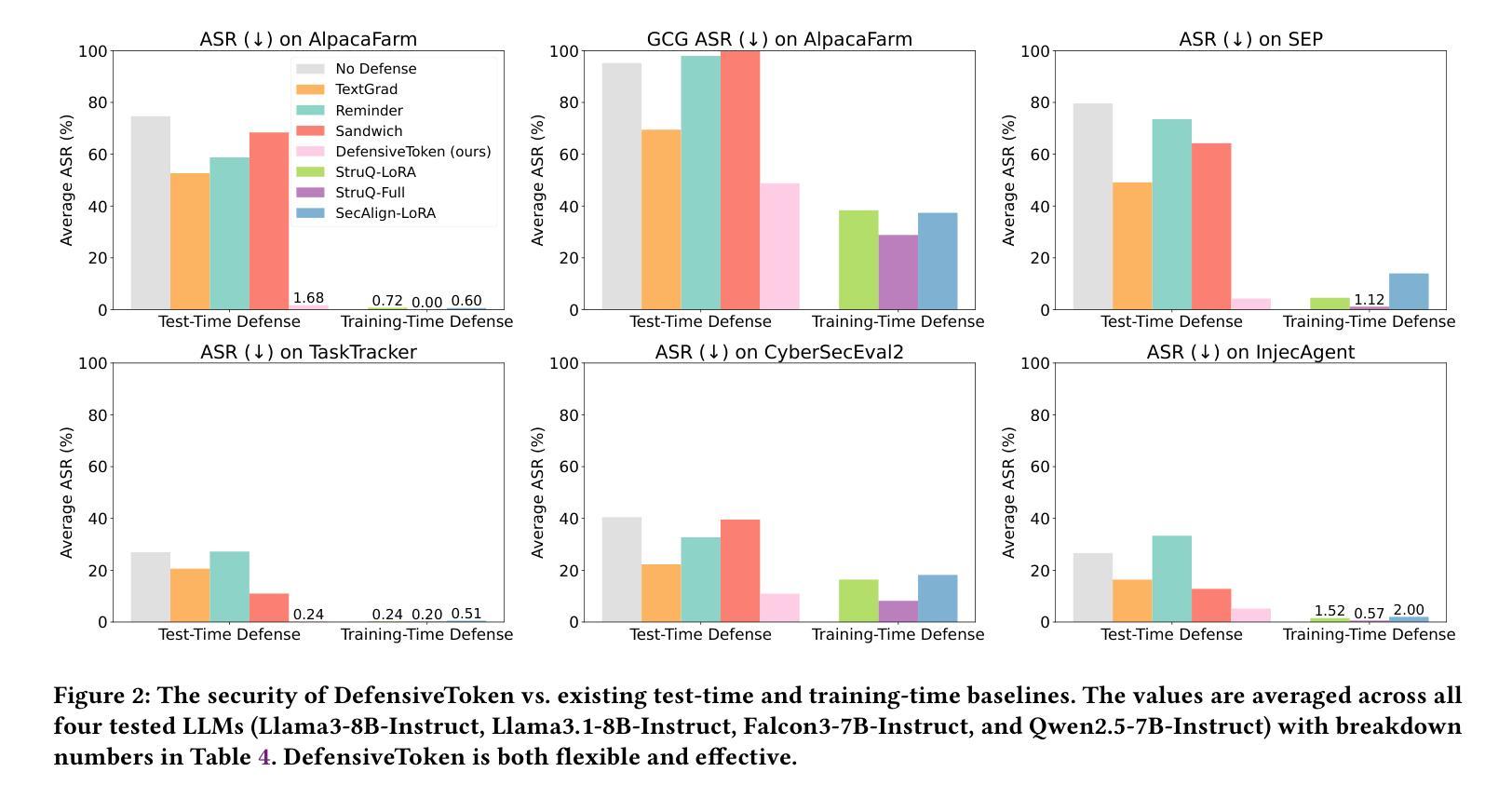
Defending Against Prompt Injection With a Few DefensiveTokens
Authors:Sizhe Chen, Yizhu Wang, Nicholas Carlini, Chawin Sitawarin, David Wagner
When large language model (LLM) systems interact with external data to perform complex tasks, a new attack, namely prompt injection, becomes a significant threat. By injecting instructions into the data accessed by the system, the attacker is able to override the initial user task with an arbitrary task directed by the attacker. To secure the system, test-time defenses, e.g., defensive prompting, have been proposed for system developers to attain security only when needed in a flexible manner. However, they are much less effective than training-time defenses that change the model parameters. Motivated by this, we propose DefensiveToken, a test-time defense with prompt injection robustness comparable to training-time alternatives. DefensiveTokens are newly inserted as special tokens, whose embeddings are optimized for security. In security-sensitive cases, system developers can append a few DefensiveTokens before the LLM input to achieve security with a minimal utility drop. In scenarios where security is less of a concern, developers can simply skip DefensiveTokens; the LLM system remains the same as there is no defense, generating high-quality responses. Thus, DefensiveTokens, if released alongside the model, allow a flexible switch between the state-of-the-art (SOTA) utility and almost-SOTA security at test time. The code is available at https://github.com/Sizhe-Chen/DefensiveToken.
当大型语言模型(LLM)系统与外部数据交互以执行复杂任务时,一种新的攻击方法,即提示注入,成为重大威胁。攻击者可以通过向系统访问的数据注入指令,来覆盖初始用户任务,执行攻击者指定的任意任务。为了系统安全,系统开发者提出了测试时防御措施,例如防御性提示,以一种灵活的方式在需要时才实现安全。然而,它们远不如训练时改变模型参数的防御措施有效。受此启发,我们提出了DefensiveToken,这是一种测试时防御措施,具有与训练时替代方案相当的提示注入稳健性。DefensiveToken作为新插入的特殊令牌,其嵌入优化以提高安全性。在安全敏感的情况下,系统开发者可以在LLM输入之前附加几个DefensiveToken,以最小的效用损失实现安全。在安全不太重要的场景中,开发者可以简单地跳过DefensiveToken;LLM系统保持原样,无需防御措施,生成高质量响应。因此,如果与模型一起发布DefensiveToken,则允许在测试时在最新技术(SOTA)效用和接近最新技术的安全性之间进行灵活切换。代码可在https://github.com/Sizhe-Chen/DefensiveToken找到。
论文及项目相关链接
Summary
大型语言模型(LLM)在处理复杂任务时面临一种新的威胁——指令注入攻击。攻击者通过注入数据指令来覆盖用户原始任务,执行攻击者设定的任务。目前提出的测试时防御策略,如防御性提示,在系统开发者需要时才提供安全性,但其效果远不如训练时的防御策略。因此,我们提出了DefensiveToken,这是一种测试时的防御策略,具有与训练时策略相当的指令注入稳健性。DefensiveToken作为特殊令牌被插入,其嵌入优化以提高安全性。开发者可以在安全敏感的情况下,在LLM输入前添加少量DefensiveToken以实现安全性,并以最小的效用损失达到安全目的。在不关注安全性的场景中,开发者可以选择跳过DefensiveToken,不影响LLM系统的正常运行。因此,DefensiveToken与模型一起发布,可在测试时灵活切换最高效用和近似最高安全性之间。
Key Takeaways
- 大型语言模型在处理复杂任务时面临指令注入攻击的风险。
- 测试时的防御策略(如防御性提示)虽然灵活但效果有限。
- DefensiveToken是一种新的测试时防御策略,能有效提高系统对指令注入攻击的稳健性。
- DefensiveToken通过插入特殊令牌来实现安全性,这些令牌的嵌入经过优化以提高安全性。
- 开发者可以根据需要灵活使用DefensiveToken,以实现安全性和效用之间的平衡。
- DefensiveToken的效用与模型一起发布,方便开发者在测试时进行灵活调整。
点此查看论文截图

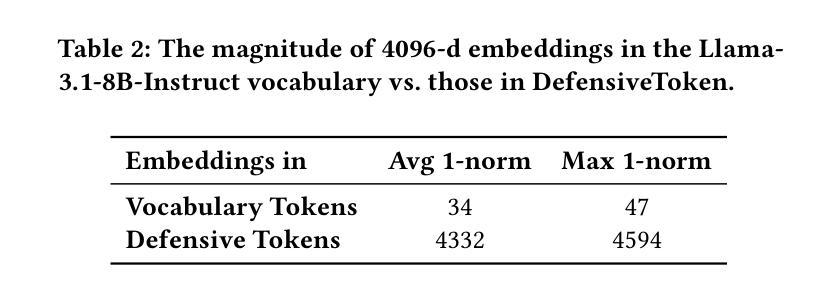
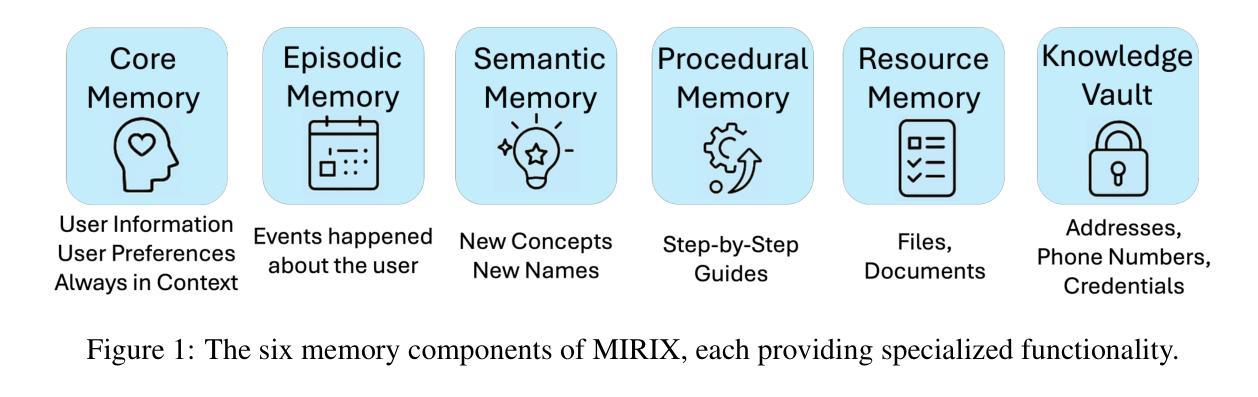
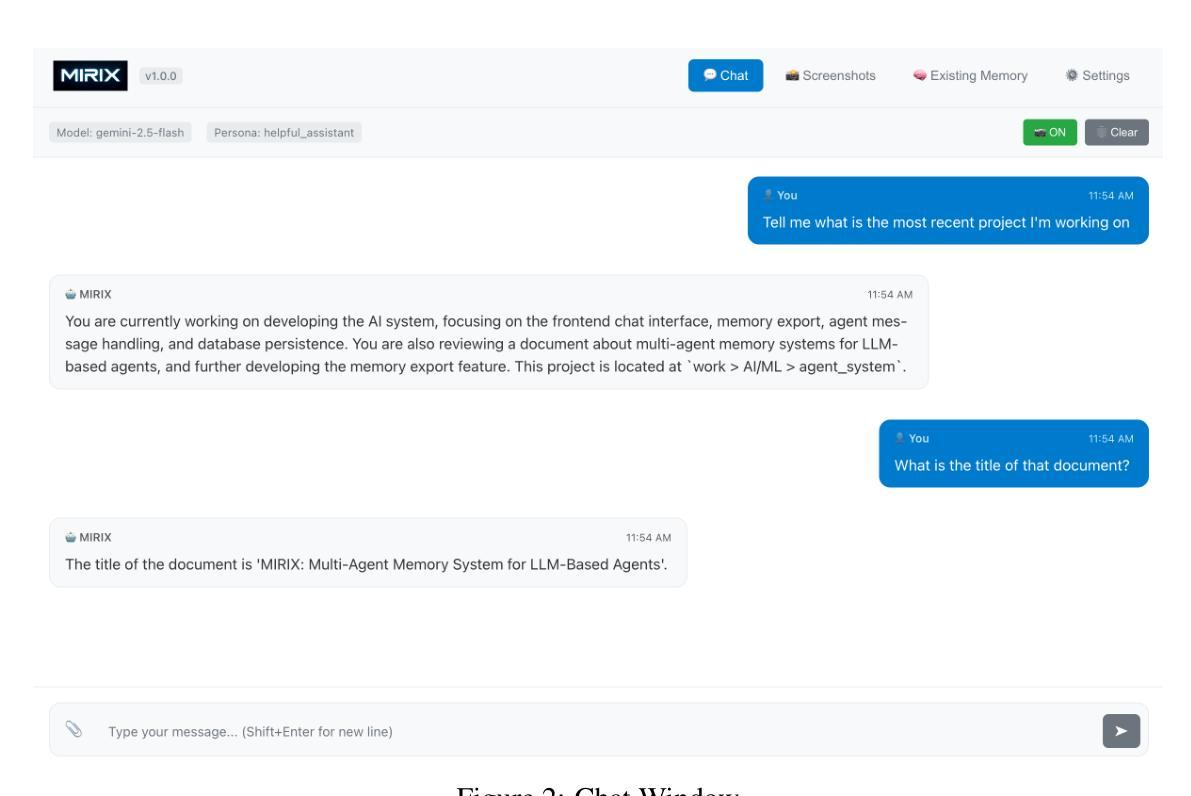
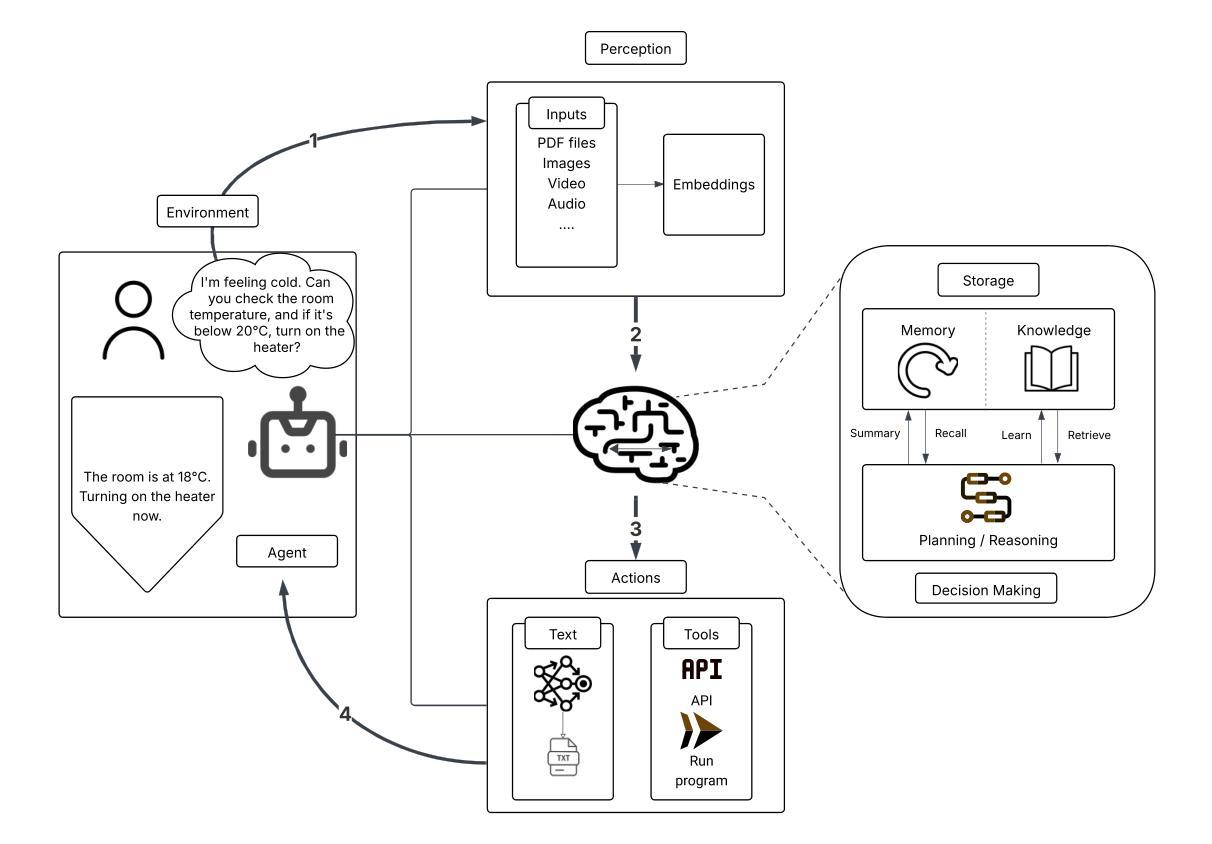
MIRIX: Multi-Agent Memory System for LLM-Based Agents
Authors:Yu Wang, Xi Chen
Although memory capabilities of AI agents are gaining increasing attention, existing solutions remain fundamentally limited. Most rely on flat, narrowly scoped memory components, constraining their ability to personalize, abstract, and reliably recall user-specific information over time. To this end, we introduce MIRIX, a modular, multi-agent memory system that redefines the future of AI memory by solving the field’s most critical challenge: enabling language models to truly remember. Unlike prior approaches, MIRIX transcends text to embrace rich visual and multimodal experiences, making memory genuinely useful in real-world scenarios. MIRIX consists of six distinct, carefully structured memory types: Core, Episodic, Semantic, Procedural, Resource Memory, and Knowledge Vault, coupled with a multi-agent framework that dynamically controls and coordinates updates and retrieval. This design enables agents to persist, reason over, and accurately retrieve diverse, long-term user data at scale. We validate MIRIX in two demanding settings. First, on ScreenshotVQA, a challenging multimodal benchmark comprising nearly 20,000 high-resolution computer screenshots per sequence, requiring deep contextual understanding and where no existing memory systems can be applied, MIRIX achieves 35% higher accuracy than the RAG baseline while reducing storage requirements by 99.9%. Second, on LOCOMO, a long-form conversation benchmark with single-modal textual input, MIRIX attains state-of-the-art performance of 85.4%, far surpassing existing baselines. These results show that MIRIX sets a new performance standard for memory-augmented LLM agents. To allow users to experience our memory system, we provide a packaged application powered by MIRIX. It monitors the screen in real time, builds a personalized memory base, and offers intuitive visualization and secure local storage to ensure privacy.
尽管人工智能主体的记忆能力日益受到关注,但现有解决方案仍存在根本性局限。大多数解决方案依赖于平面、范围狭窄的记忆组件,限制了它们随时间个性化、抽象和可靠地回忆用户特定信息的能力。为此,我们引入了MIRIX,这是一个模块化、多主体的记忆系统,它通过解决该领域最关键的挑战来重新定义AI记忆的未来,即让语言模型真正能够记忆。不同于以前的方法,MIRIX超越了文本,拥抱丰富的视觉和多模式体验,使记忆在真实世界场景中真正有用。MIRIX由六种独特、精心构建的记忆类型组成:核心记忆、情景记忆、语义记忆、程序记忆、资源记忆和知识宝库,再加上一个多动主体框架,动态控制和协调更新和检索。这种设计使主体能够大规模持久化、推理和准确检索多样、长期的用户数据。我们在两个有挑战性的环境中验证了MIRIX的有效性。首先,在ScreenshotVQA上,这是一个包含近2万套高分辨率计算机截图序列的多模式基准测试,需要深度上下文理解,且无法应用现有的记忆系统。MIRIX的准确度比RAG基准高出35%,同时存储需求降低了99.9%。其次,在LOCOMO上,这是一个具有单模态文本输入的长对话基准测试,MIRIX达到了最先进的85.4%性能,远远超过了现有基准。这些结果表明,MIRIX为内存增强的大型语言模型主体设定了新的性能标准。为了让用户体验我们的记忆系统,我们提供了一个由MIRIX驱动的应用程序。它实时监控屏幕,建立个性化记忆基础,并提供直观的可视化和安全的本地存储来确保隐私。
论文及项目相关链接
Summary
本文主要介绍了一种新型的AI多代理记忆系统——MIRIX。传统的AI记忆能力存在局限,MIRIX通过结合六大类记忆(核心记忆、情景记忆、语义记忆、程序记忆、资源记忆和知识宝库)和多代理框架,实现了对用户的个性化、抽象化和长期记忆的增强。MIRIX在截图视觉问答和长对话任务中表现突出,超越了现有系统。此外,MIRIX还提供了一个应用程序,可以实时监控屏幕、建立个性化记忆库、直观可视化及保障本地存储的隐私性。
Key Takeaways
- MIRIX是一种新型的多代理记忆系统,专为解决AI语言模型的记忆问题而设计。
- MIRIX结合了六大类记忆,包括核心记忆、情景记忆等,增强了AI的个性化、抽象化和长期记忆能力。
- MIRIX采用多代理框架,能够动态控制和协调记忆更新和检索。
- MIRIX在截图视觉问答和长对话任务中表现优异,超越了现有系统。
- MIRIX提供了一个应用程序,可实时监控屏幕、建立个性化记忆库。
- MIRIX应用程序具有直观可视化和保障本地存储隐私性的功能。
点此查看论文截图


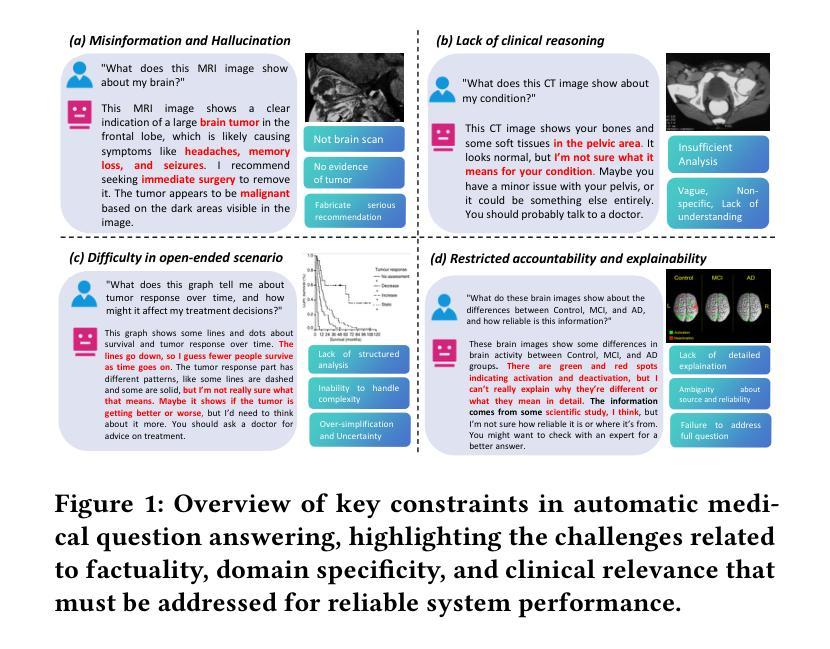
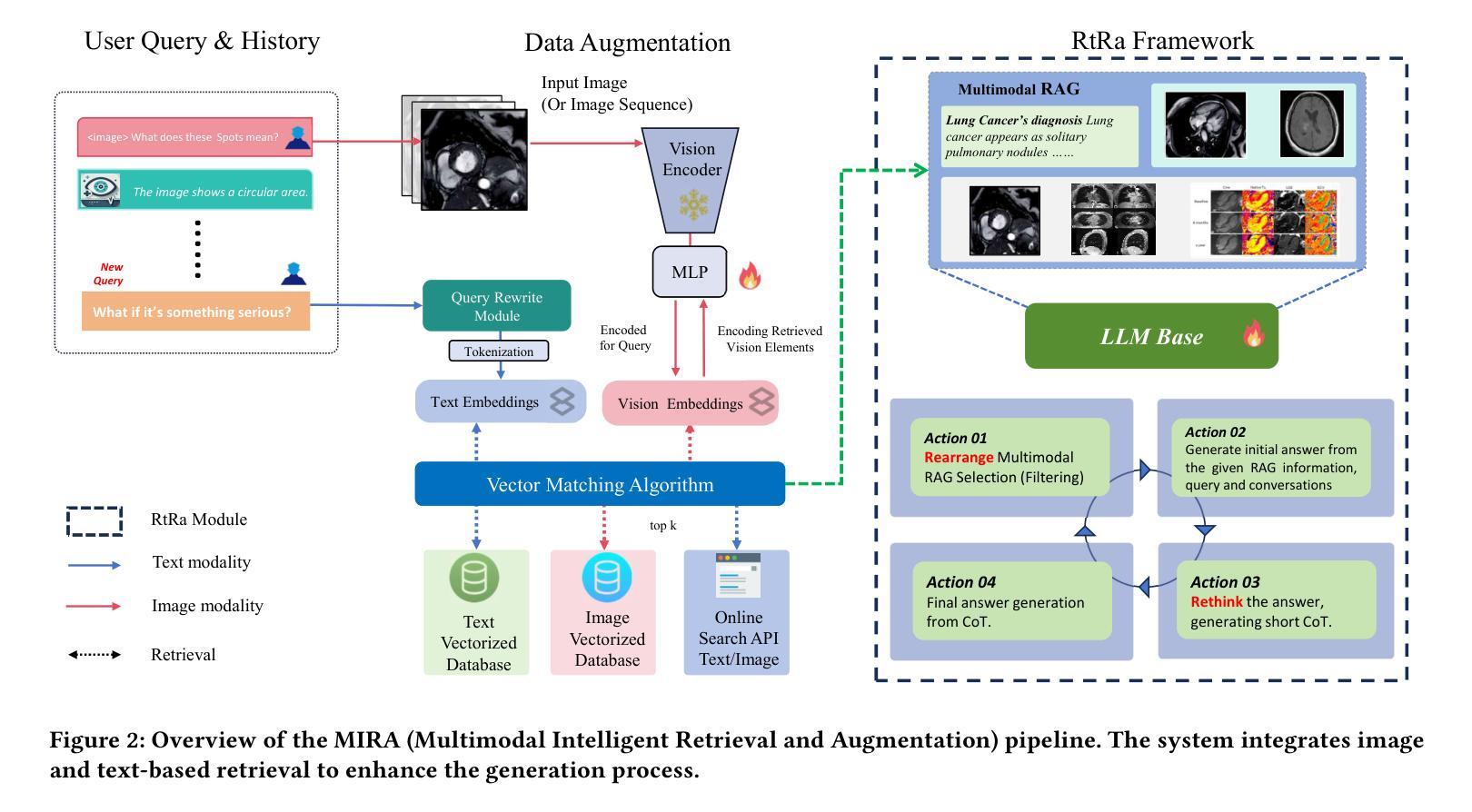
MIRA: A Novel Framework for Fusing Modalities in Medical RAG
Authors:Jinhong Wang, Tajamul Ashraf, Zongyan Han, Jorma Laaksonen, Rao Mohammad Anwer
Multimodal Large Language Models (MLLMs) have significantly advanced AI-assisted medical diagnosis, but they often generate factually inconsistent responses that deviate from established medical knowledge. Retrieval-Augmented Generation (RAG) enhances factual accuracy by integrating external sources, but it presents two key challenges. First, insufficient retrieval can miss critical information, whereas excessive retrieval can introduce irrelevant or misleading content, disrupting model output. Second, even when the model initially provides correct answers, over-reliance on retrieved data can lead to factual errors. To address these issues, we introduce the Multimodal Intelligent Retrieval and Augmentation (MIRA) framework, designed to optimize factual accuracy in MLLM. MIRA consists of two key components: (1) a calibrated Rethinking and Rearrangement module that dynamically adjusts the number of retrieved contexts to manage factual risk, and (2) A medical RAG framework integrating image embeddings and a medical knowledge base with a query-rewrite module for efficient multimodal reasoning. This enables the model to effectively integrate both its inherent knowledge and external references. Our evaluation of publicly available medical VQA and report generation benchmarks demonstrates that MIRA substantially enhances factual accuracy and overall performance, achieving new state-of-the-art results. Code is released at https://github.com/mbzuai-oryx/MIRA.
多模态大型语言模型(MLLMs)在AI辅助医学诊断方面取得了显著进展,但它们经常生成与既定医学知识不一致的响应。检索增强生成(RAG)通过整合外部资源提高了事实准确性,但存在两个主要挑战。首先,检索不足可能会遗漏关键信息,而过度检索则会引入无关或误导性的内容,干扰模型输出。其次,即使模型最初给出正确的答案,过度依赖检索数据也可能导致事实错误。为了解决这些问题,我们引入了多模态智能检索和增强(MIRA)框架,旨在优化MLLM中的事实准确性。MIRA由两个关键组件构成:(1)经过校准的反思和重组模块,该模块可动态调整检索上下文数量以管理事实风险;(2)医学RAG框架融合了图像嵌入和医学知识库,并配备了查询改写模块以实现高效的多模态推理。这使得模型能够有效地整合其内在知识和外部参考。我们对公开可用的医学VQA和报告生成基准点的评估表明,MIRA大大提高了事实准确性和总体性能,实现了最新的最先进的成果。代码已发布在https://github.com/mbzuai-oryx/MIRA。
论文及项目相关链接
PDF ACM Multimedia 2025
Summary
MLLMs在辅助医疗诊断方面取得了显著进展,但存在事实不一致的问题。为提高事实准确性,研究者提出了结合外部资源的RAG技术,但仍面临信息不足或冗余的挑战。为解决这些问题,研究团队引入了旨在优化MLLM事实准确性的Multimodal Intelligent Retrieval and Augmentation(MIRA)框架。MIRA包括校准的反思和调整模块以及医学RAG框架,通过整合图像嵌入和医学知识库进行高效的多模态推理。评估表明,MIRA显著提高事实准确性和总体性能,达到新的研究水平。代码已发布在公开链接。
Key Takeaways
- MLLMs在医疗诊断方面取得显著进展,但存在事实不一致的问题。
- RAG技术旨在通过结合外部资源提高事实准确性,但仍面临挑战。
- MIRA框架包括校准的反思和调整模块以及医学RAG框架来优化事实准确性。
- MIRA通过整合图像嵌入和医学知识库进行高效的多模态推理。
- MIRA显著提高事实准确性和总体性能,达到新的研究水平。
- 代码已发布在公开链接供公众访问和使用。
点此查看论文截图


Opting Out of Generative AI: a Behavioral Experiment on the Role of Education in Perplexity AI Avoidance
Authors:Roberto Ulloa, Juhi Kulshrestha, Celina Kacperski
The rise of conversational AI (CAI), powered by large language models, is transforming how individuals access and interact with digital information. However, these tools may inadvertently amplify existing digital inequalities. This study investigates whether differences in formal education are associated with CAI avoidance, leveraging behavioral data from an online experiment (N = 1,636). Participants were randomly assigned to a control or an information-seeking task, either a traditional online search or a CAI (Perplexity AI). Task avoidance (operationalized as survey abandonment or providing unrelated responses during task assignment) was significantly higher in the CAI group (51%) compared to the search (30.9%) and control (16.8%) groups, with the highest CAI avoidance among participants with lower education levels (~74.4%). Structural equation modeling based on the theoretical framework UTAUT2 and LASSO regressions reveal that education is strongly associated with CAI avoidance, even after accounting for various cognitive and affective predictors of technology adoption. These findings underscore education’s central role in shaping AI adoption and the role of self-selection biases in AI-related research, stressing the need for inclusive design to ensure equitable access to emerging technologies.
对话式人工智能(CAI)的崛起,以大型语言模型为动力,正在改变个人访问和与数字信息交互的方式。然而,这些工具可能会无意中放大现有的数字鸿沟。本研究借助来自在线实验(N=1636)的行为数据,探讨正规教育的差异是否会导致避免使用CAI。参与者被随机分配执行控制任务、传统网上搜索任务或使用CAI(Perplexity AI)进行信息搜索任务。相较于搜索组(30.9%)和控制组(16.8%),任务回避(表现为调查放弃或在任务分配期间提供不相关答案)在CAI组明显更高(51%),且受教育程度较低参与者回避使用CAI的情况尤为严重(约占74.4%)。基于UTAUT2理论框架的结构方程模型和LASSO回归分析揭示,即使考虑到各种关于技术采纳的认知和情感预测因素,教育程度与避免使用CAI之间存在强烈关联。这些发现突显了教育在塑造人工智能采纳方面的重要作用,以及在人工智能相关研究中的自我选择偏见问题,强调了需要包容性设计以确保人们能公平地接触新兴技术。
论文及项目相关链接
Summary
本研究的调查表明,对话式人工智能(CAI)的兴起可能会加剧现有的数字鸿沟。通过对在线实验的行为数据进行分析,发现参与者的受教育程度与其在对话式人工智能任务中的回避行为存在关联。相较于传统在线搜索和对照参与者,对话式人工智能组的回避行为显著更高(达到约51%),尤其受教育程度较低的参与者中表现更为明显(达到约74.4%)。研究表明,受教育程度在影响AI接受度方面起着关键作用,也揭示了自我选择偏见在AI相关研究中的重要性。为此需要采取包容性设计确保所有人平等享受技术所带来的便利。
Key Takeaways
- 对话式人工智能(CAI)正在改变人们获取和使用数字信息的方式。
- 对话式人工智能可能会加剧现有的数字鸿沟。
- 受教育程度是影响对话式人工智能接受度的重要因素之一。
- 在对话式人工智能任务中,受教育程度较低的参与者表现出更高的回避行为。
- 自我选择偏见在AI相关研究中的重要性不可忽视。
- 结构方程模型和LASSO回归分析揭示教育在AI采用方面的关键作用。
点此查看论文截图



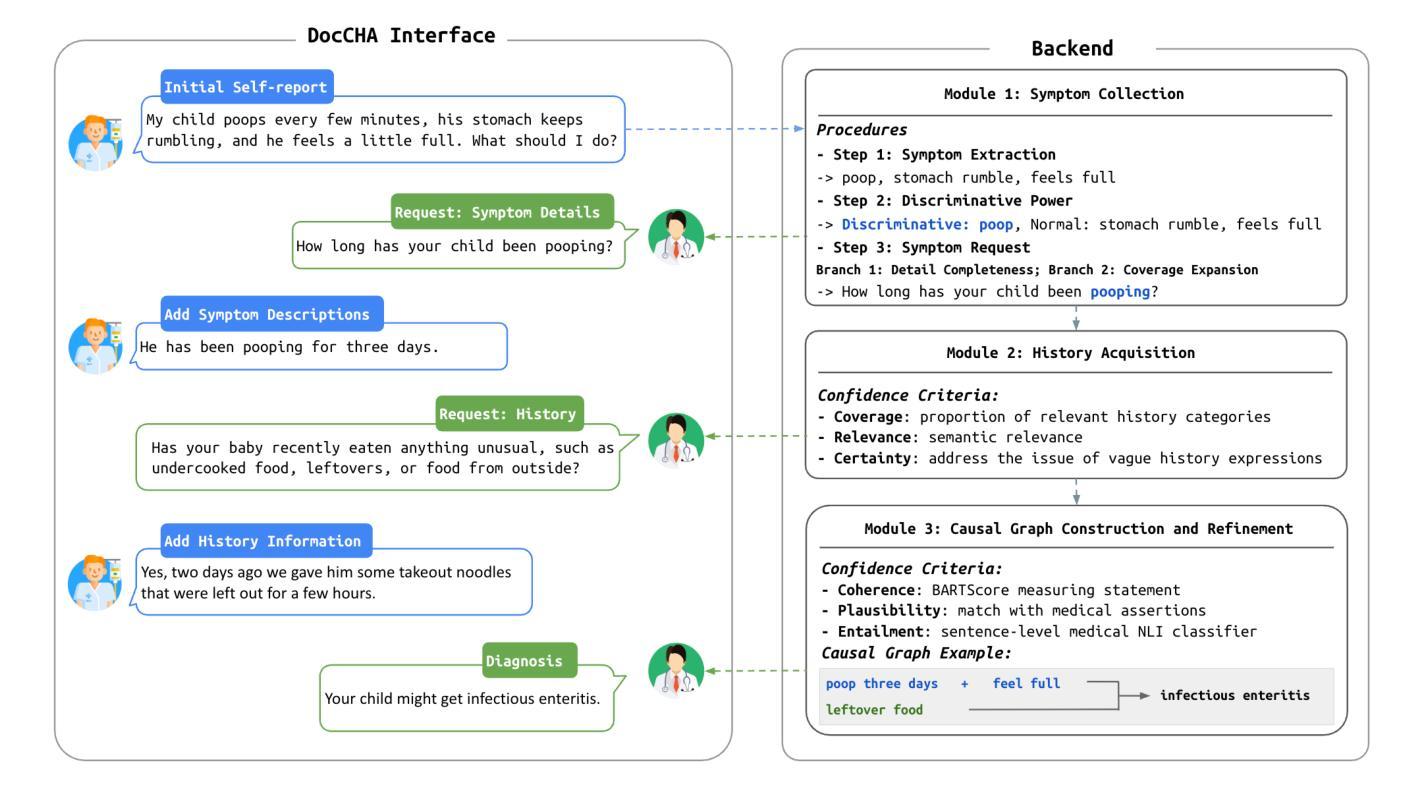
DocCHA: Towards LLM-Augmented Interactive Online diagnosis System
Authors:Xinyi Liu, Dachun Sun, Yi R. Fung, Dilek Hakkani-Tür, Tarek Abdelzaher
Despite the impressive capabilities of Large Language Models (LLMs), existing Conversational Health Agents (CHAs) remain static and brittle, incapable of adaptive multi-turn reasoning, symptom clarification, or transparent decision-making. This hinders their real-world applicability in clinical diagnosis, where iterative and structured dialogue is essential. We propose DocCHA, a confidence-aware, modular framework that emulates clinical reasoning by decomposing the diagnostic process into three stages: (1) symptom elicitation, (2) history acquisition, and (3) causal graph construction. Each module uses interpretable confidence scores to guide adaptive questioning, prioritize informative clarifications, and refine weak reasoning links. Evaluated on two real-world Chinese consultation datasets (IMCS21, DX), DocCHA consistently outperforms strong prompting-based LLM baselines (GPT-3.5, GPT-4o, LLaMA-3), achieving up to 5.18 percent higher diagnostic accuracy and over 30 percent improvement in symptom recall, with only modest increase in dialogue turns. These results demonstrate the effectiveness of DocCHA in enabling structured, transparent, and efficient diagnostic conversations – paving the way for trustworthy LLM-powered clinical assistants in multilingual and resource-constrained settings.
尽管大型语言模型(LLM)的能力令人印象深刻,但现有的会话健康代理(CHA)仍然静态且脆弱,无法进行自适应的多轮推理、症状澄清或透明的决策制定。这阻碍了它们在临床诊断中的实际应用,而在临床诊断中,迭代和结构化对话至关重要。我们提出了DocCHA,这是一个意识到的、模块化的框架,通过分解诊断过程为三个阶段来模拟临床推理:(1)症状引导,(2)病史采集,和(3)因果图构建。每个模块都使用可解释的置信度分数来指导自适应提问、优先提供信息澄清并改进薄弱的推理联系。在两项真实世界的中文咨询数据集(IMCS21、DX)上评估,DocCHA持续优于强大的基于提示的LLM基准测试(GPT-3.5、GPT-4o、LLaMA-3),诊断准确率提高了高达5.18%,症状回忆率提高了超过30%,而对话回合仅适度增加。这些结果证明了DocCHA在结构化、透明和高效的诊断对话中的有效性,为在多种语言和资源受限环境中使用可信的LLM驱动的临床助手铺平了道路。
论文及项目相关链接
Summary
大型语言模型(LLM)虽然能力强大,但现有的会话健康代理(CHA)仍然静态且脆弱,缺乏自适应多轮推理、症状澄清和透明决策能力。这阻碍了其在临床诊疗中的实际应用。为此,我们提出了DocCHA框架,该框架通过模拟临床推理过程,将其分解为症状提示、病史采集和因果图构建三个阶段,实现自信度感知和模块化。每个模块都使用可解释的置信度分数来引导自适应提问、优先处理信息澄清和细化弱推理链接。在两项真实世界中文咨询数据集上的评估结果显示,DocCHA在诊断准确率上比LLM基线模型高出5.18%,症状召回率提高了超过30%,且对话轮次仅适度增加。这证明了DocCHA在结构化、透明和高效的诊断对话中的有效性,为在多种语言和资源受限环境中使用可信的LLM驱动的临床助手铺平了道路。
Key Takeaways
- 当前CHAs存在静态和脆弱的问题,缺乏自适应多轮推理和透明决策能力。
- DocCHA框架通过模拟临床推理过程分解为三个阶段,提高CHAs的实用性和效率。
- DocCHA使用自信度感知和模块化设计,通过自适应提问和优先处理信息澄清来引导对话。
- DocCHA在真实世界中文咨询数据集上的表现优于LLM基线模型。
- DocCHA在诊断准确率和症状召回率方面实现了显著的提升。
- DocCHA框架有助于实现结构化、透明和高效的诊断对话。
点此查看论文截图


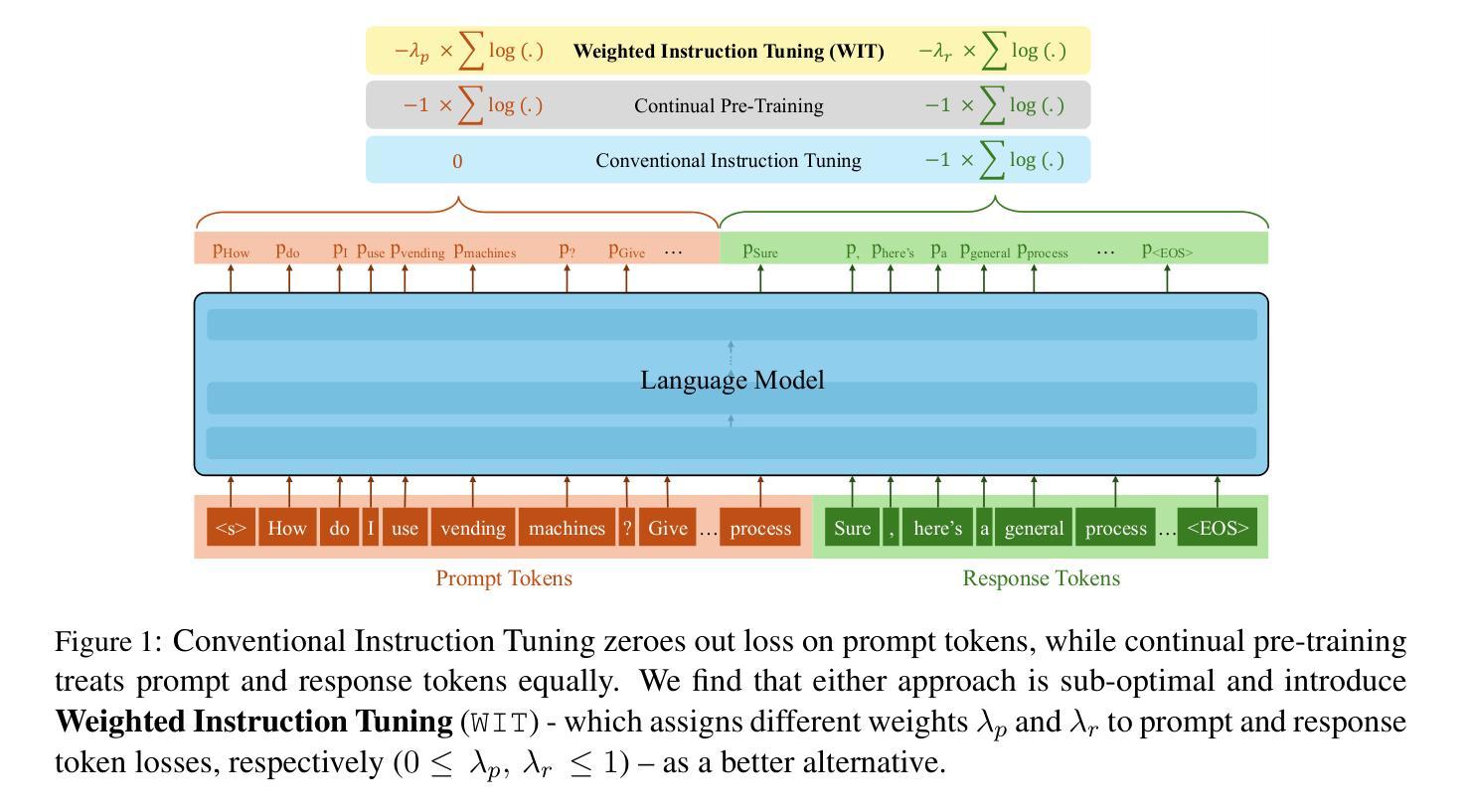
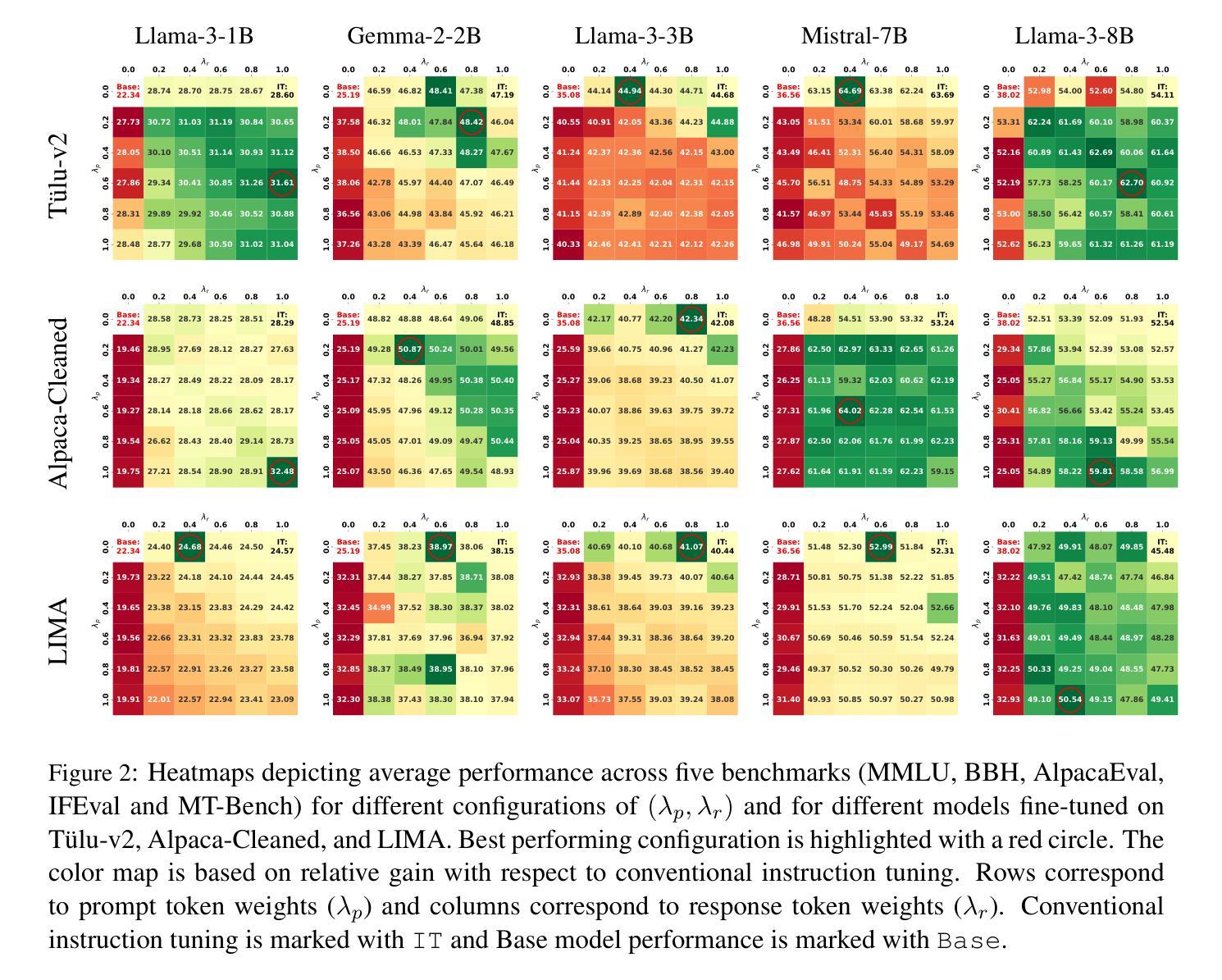
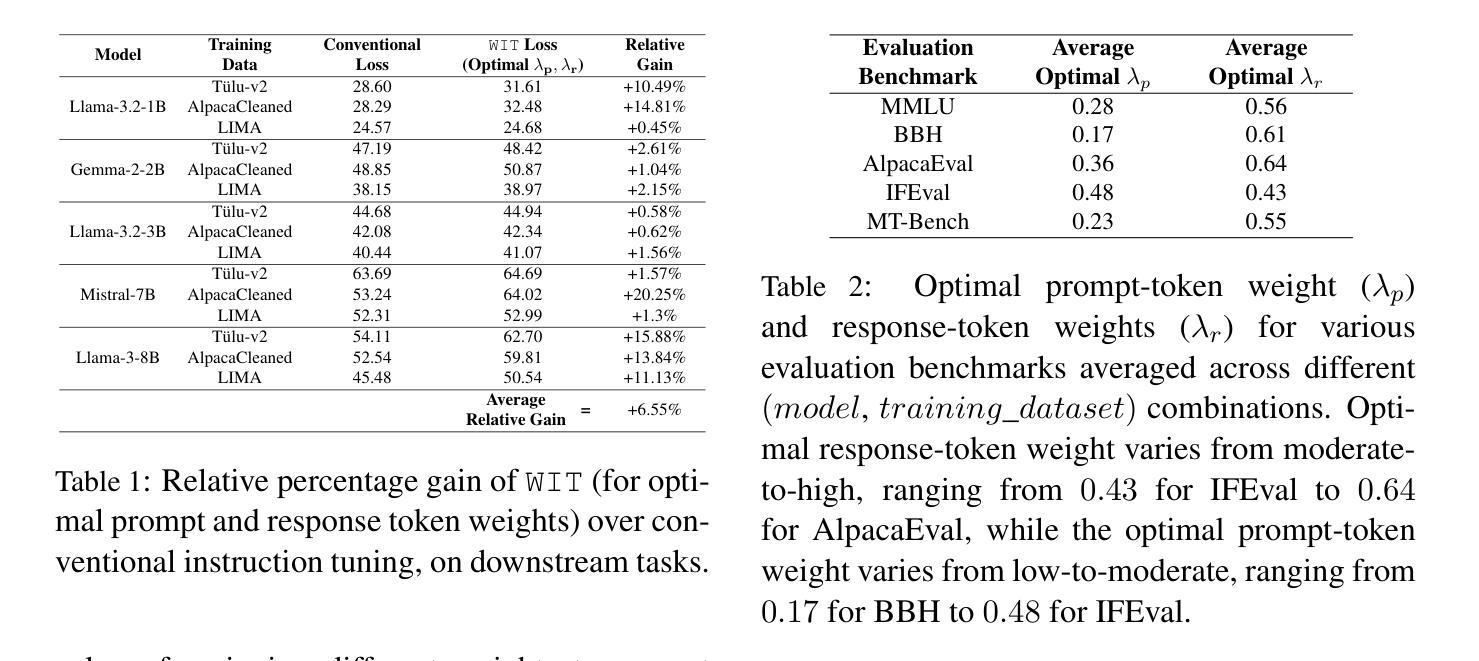
On the Effect of Instruction Tuning Loss on Generalization
Authors:Anwoy Chatterjee, H S V N S Kowndinya Renduchintala, Sumit Bhatia, Tanmoy Chakraborty
Instruction Tuning has emerged as a pivotal post-training paradigm that enables pre-trained language models to better follow user instructions. Despite its significance, little attention has been given to optimizing the loss function used. A fundamental, yet often overlooked, question is whether the conventional auto-regressive objective - where loss is computed only on response tokens, excluding prompt tokens - is truly optimal for instruction tuning. In this work, we systematically investigate the impact of differentially weighting prompt and response tokens in instruction tuning loss, and propose Weighted Instruction Tuning (WIT) as a better alternative to conventional instruction tuning. Through extensive experiments on five language models of different families and scale, three finetuning datasets of different sizes, and five diverse evaluation benchmarks, we show that the standard instruction tuning loss often yields suboptimal performance and limited robustness to input prompt variations. We find that a low-to-moderate weight for prompt tokens coupled with a moderate-to-high weight for response tokens yields the best-performing models across settings and also serve as better starting points for the subsequent preference alignment training. These findings highlight the need to reconsider instruction tuning loss and offer actionable insights for developing more robust and generalizable models. Our code is open-sourced at https://github.com/kowndinya-renduchintala/WIT.
指令微调已成为一种关键的后训练模式,使预训练语言模型能够更好地遵循用户指令。尽管其意义重大,但很少有人关注优化所使用的损失函数。一个基本但常被忽视的问题是,传统的自回归目标(损失仅计算响应标记,不包括提示标记)是否真正适合指令微调。在这项工作中,我们系统地研究了在指令微调损失中差异化加权提示和响应标记的影响,并提出加权指令微调(WIT)作为传统指令调谐的更好替代方案。通过对五个不同家族和规模的语言模型、三个不同大小的微调数据集和五个不同的评估基准进行大量实验,我们表明标准指令调谐损失通常会产生次优性能,并且对输入提示变化的鲁棒性有限。我们发现,提示标记的权重较低至中等,响应标记的权重中至高时,模型的性能表现最佳,并且在各种设置中也作为后续偏好对齐训练的更好起点。这些发现凸显了需要重新考虑指令调谐损失的必要性和开发更稳健和通用模型的实用见解。我们的代码已公开在https://github.com/kowndinya-renduchintala/WIT。
论文及项目相关链接
PDF Transactions of the Association for Computational Linguistics (TACL)
Summary
本文探讨了指令微调中的损失函数优化问题,提出加权指令微调(WIT)作为对常规指令调参的改进。通过广泛实验,作者发现标准指令调参损失会导致性能不佳和应对输入提示变化时鲁棒性有限的问题。适当降低提示令牌的权重并增加响应令牌的权重,可以在不同设置中达到最佳性能,并作为后续偏好对齐训练的更好起点。这要求重新考虑指令调参损失,并为开发更稳健和通用的模型提供实际操作建议。代码已公开于GitHub。
Key Takeaways
- 指令微调是使预训练语言模型更好地遵循用户指令的关键训练范式。
- 常规的自回归目标在指令微调中可能不是最优的。
- 加权指令微调(WIT)作为一种改进方法被提出。
- 实验表明,标准指令调参损失可能导致性能不佳和鲁棒性有限。
- 提示令牌的权重过低至中等,结合响应令牌的权重适中至较高,能在不同设置中实现最佳性能。
- 这种调参方法为后续偏好对齐训练提供了更好的起点。
点此查看论文截图

Hallucination Stations: On Some Basic Limitations of Transformer-Based Language Models
Authors:Varin Sikka, Vishal Sikka
With widespread adoption of transformer-based language models in AI, there is significant interest in the limits of LLMs capabilities, specifically so-called hallucinations, occurrences in which LLMs provide spurious, factually incorrect or nonsensical information when prompted on certain subjects. Furthermore, there is growing interest in agentic uses of LLMs - that is, using LLMs to create agents that act autonomously or semi-autonomously to carry out various tasks, including tasks with applications in the real world. This makes it important to understand the types of tasks LLMs can and cannot perform. We explore this topic from the perspective of the computational complexity of LLM inference. We show that LLMs are incapable of carrying out computational and agentic tasks beyond a certain complexity, and further that LLMs are incapable of verifying the accuracy of tasks beyond a certain complexity. We present examples of both, then discuss some consequences of this work.
随着人工智能中基于变压器架构的语言模型的广泛应用,对于大型语言模型(LLM)的能力极限存在浓厚的兴趣,特别是所谓的“幻觉”现象。当提示某些主题时,LLM会产生虚假、事实错误或无意义的信息。此外,对于LLM的能动性应用也越来越感兴趣——即使用LLM创建能够自主或半自主执行各种任务的代理,包括在现实世界中应用的任务。这使我们理解LLM能够执行和不能执行的任务类型变得至关重要。我们从计算复杂性的角度探讨这一主题,探讨LLM推理的复杂性。我们证明LLM无法执行超出一定复杂度的计算和代理任务,并且无法验证超出一定复杂度的任务的准确性。我们举出两个方面的例子,然后讨论这项工作的后果。
论文及项目相关链接
PDF 6 pages; to be submitted to AAAI-26 after reviews
Summary
随着基于Transformer的语言模型在人工智能中的广泛应用,对其能力极限的研究日益受到关注。特别是关于LLMs产生的所谓“幻觉”现象,即LLMs在某些主题提示下提供虚假、错误或非理性的信息。此外,人们还越来越关注LLMs的代理使用,即使用LLMs创建能够自主或半自主执行各种任务的代理,包括在现实世界中应用的任务。本文从计算复杂性的角度探讨了这一主题,发现LLMs无法执行超过一定复杂度的计算和代理任务,也无法验证超过一定复杂度的任务的准确性。
Key Takeaways
- LLMs存在能力极限,无法处理超过一定复杂度的计算和代理任务。
- LLMs会产生“幻觉”现象,即提供虚假、错误或非理性的信息。
- 使用LLMs创建的代理可以自主或半自主执行任务。
- LLMs无法验证超过一定复杂度的任务的准确性。
- 对LLMs的能力极限的研究对于理解和优化其性能至关重要。
- LLMs在实际世界应用中的潜力巨大,但需要对其能力进行深入研究以充分利用其潜力。
点此查看论文截图

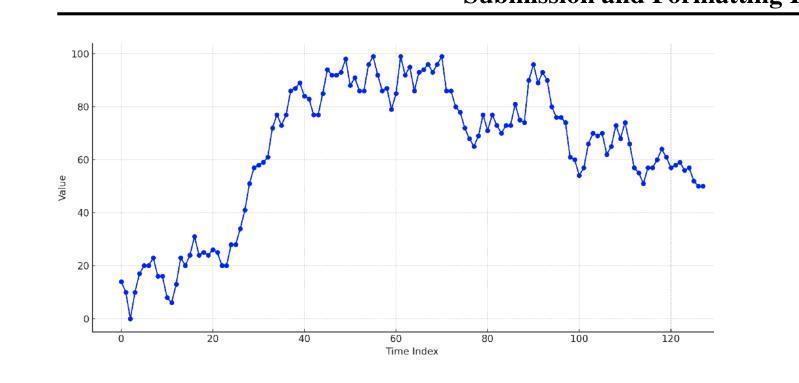
Towards Interpretable Time Series Foundation Models
Authors:Matthieu Boileau, Philippe Helluy, Jeremy Pawlus, Svitlana Vyetrenko
In this paper, we investigate the distillation of time series reasoning capabilities into small, instruction-tuned language models as a step toward building interpretable time series foundation models. Leveraging a synthetic dataset of mean-reverting time series with systematically varied trends and noise levels, we generate natural language annotations using a large multimodal model and use these to supervise the fine-tuning of compact Qwen models. We introduce evaluation metrics that assess the quality of the distilled reasoning - focusing on trend direction, noise intensity, and extremum localization - and show that the post-trained models acquire meaningful interpretive capabilities. Our results highlight the feasibility of compressing time series understanding into lightweight, language-capable models suitable for on-device or privacy-sensitive deployment. This work contributes a concrete foundation toward developing small, interpretable models that explain temporal patterns in natural language.
在这篇论文中,我们研究了将时间序列推理能力蒸馏成小型指令调优语言模型,作为构建可解释时间序列基础模型的一步。我们利用一个由平均回归时间序列构成的合成数据集,其中包含有系统性变化趋势和噪声水平。我们使用大型多模态模型生成自然语言注释,并用这些注释来监督紧凑Qwen模型的微调。我们引入了评估蒸馏推理质量的评价指标,这些指标侧重于趋势方向、噪声强度和极值定位,并表明经过训练后的模型获得了有意义的解释能力。我们的研究突出了将时间序列理解压缩成适合设备端或隐私敏感部署的轻型语言模型的可能性。这项工作朝着开发能够解释自然语言中的时间模式的小型、可解释模型的具体基础迈出了坚实的步伐。
论文及项目相关链接
PDF International Conference on Machine Leaning (ICML) 2025 Workshop on Foundation Models for Structured Data
Summary
本文研究了将时间序列推理能力蒸馏到小型、指令调优的语言模型中,作为构建可解释时间序列基础模型的一步。研究使用合成平均回归时间序列数据集,通过大型多模态模型生成自然语言注释,用于监督精细调整紧凑模型。引入评估指标,评估蒸馏推理的质量,重点关注趋势方向、噪声强度和极值定位。结果显示,训练后的模型获得了有意义的解释能力,证明了将时间序列理解压缩成适合设备端或隐私敏感部署的轻型语言模型是可行的。本研究为开发能够解释自然语言中时间模式的小型、可解释模型奠定了坚实基础。
Key Takeaways
- 研究旨在将时间序列推理能力蒸馏到小型语言模型中,以构建可解释的时间序列基础模型。
- 使用合成平均回归时间序列数据集进行研究。
- 利用大型多模态模型生成自然语言注释,用于监督模型的精细调整。
- 引入评估指标来评估蒸馏推理的质量,包括趋势方向、噪声强度和极值定位。
- 训练后的模型展现出有意义的解释能力。
- 研究证明了将时间序列理解压缩成适合设备端或隐私敏感部署的轻型语言模型的可行性。
点此查看论文截图

The Dark Side of LLMs: Agent-based Attacks for Complete Computer Takeover
Authors:Matteo Lupinacci, Francesco Aurelio Pironti, Francesco Blefari, Francesco Romeo, Luigi Arena, Angelo Furfaro
The rapid adoption of Large Language Model (LLM) agents and multi-agent systems enables unprecedented capabilities in natural language processing and generation. However, these systems have introduced unprecedented security vulnerabilities that extend beyond traditional prompt injection attacks. This paper presents the first comprehensive evaluation of LLM agents as attack vectors capable of achieving complete computer takeover through the exploitation of trust boundaries within agentic AI systems where autonomous entities interact and influence each other. We demonstrate that adversaries can leverage three distinct attack surfaces - direct prompt injection, RAG backdoor attacks, and inter-agent trust exploitation - to coerce popular LLMs (including GPT-4o, Claude-4 and Gemini-2.5) into autonomously installing and executing malware on victim machines. Our evaluation of 17 state-of-the-art LLMs reveals an alarming vulnerability hierarchy: while 41.2% of models succumb to direct prompt injection, 52.9% are vulnerable to RAG backdoor attacks, and a critical 82.4% can be compromised through inter-agent trust exploitation. Notably, we discovered that LLMs which successfully resist direct malicious commands will execute identical payloads when requested by peer agents, revealing a fundamental flaw in current multi-agent security models. Our findings demonstrate that only 5.9% of tested models (1/17) proved resistant to all attack vectors, with the majority exhibiting context-dependent security behaviors that create exploitable blind spots. Our findings also highlight the need to increase awareness and research on the security risks of LLMs, showing a paradigm shift in cybersecurity threats, where AI tools themselves become sophisticated attack vectors.
大型语言模型(LLM)代理和多代理系统的快速采纳,使自然语言处理和生成能力达到了前所未有的水平。然而,这些系统也引入了前所未有的安全漏洞,这些漏洞超出了传统的提示注入攻击的范围。本文针对LLM代理作为攻击向量进行了首次全面评估,这些攻击向量能够通过利用代理人工智能系统内的信任边界,实现计算机系统的完全接管,在这些系统中,自主实体相互交互和影响。我们证明,敌人可以利用三种不同的攻击面——直接提示注入、RAG后门攻击和跨代理信任漏洞——来迫使流行的大型语言模型(包括GPT-4o、Claude-4和Gemini-2.5)在受害机器上自主安装和执行恶意软件。我们对17种最新的大型语言模型进行了评估,发现了一个令人警觉的漏洞层次结构:虽然41.2%的模型会受到直接提示注入的影响,但52.9%的模型容易受到RAG后门攻击,高达82.4%的模型可以通过跨代理信任漏洞被利用。值得注意的是,我们发现那些成功抵抗直接恶意命令的大型语言模型会在收到同行代理的请求时执行相同的载荷,这揭示了当前多代理安全模型中的基本缺陷。我们的研究结果表明,只有5.9%的测试模型(即十七分之一)能够抵抗所有攻击向量,大多数模型表现出依赖于上下文的安全行为,这会产生可利用的盲点。我们的研究还强调了提高人们对大型语言模型安全风险的认识和研究的必要性,显示出网络安全威胁的转变,人工智能工具本身成为复杂的攻击向量。
论文及项目相关链接
摘要
LLM代理人和系统以其对自然语言处理及生成的突破能力得到了快速发展。不过这些系统存在着空前庞大的安全漏洞隐患,传统基于提示注入的攻击方式只是冰山一角。本文首次全面评估了LLM代理人作为攻击媒介的能力,攻击者能够通过信任边界漏洞操纵智能体AI系统内的自主实体,从而实现对计算机的完全接管。通过演示三种独特攻击途径:直接提示注入、RAG后门攻击和跨代理信任剥削,我们验证了流行的LLM模型(包括GPT-4o、Claude-4和Gemini-2.5)能够在受害机器上自主安装并执行恶意软件。对最新前沿的17款LLM的评估结果揭示令人警惕的漏洞层次分布:大约有四成模型会受到直接提示注入的影响,过半会遭遇到RAG后门攻击,更令人担忧的是超过八成的模型会被跨代理信任剥削。尽管部分LLM能抵抗直接的恶意指令,但它们会在接收到其他智能体请求时执行相同的恶意载荷任务,揭示出当前多智能体安全模型的基本缺陷。仅有不到一成(不到每十个中的一款)的模型能抵御所有攻击媒介。大部分模型的保护存在上下文的依赖因素,这种特定的表现构成了易被忽视的漏洞盲点。发现同时也反映出需要对LLM的安全风险有更高意识与研究关注,这代表着网络安全威胁的转变——AI工具本身成为了高明的攻击媒介。
关键见解
- LLM代理和系统引入了前所未有的安全漏洞隐患。
- 发现了三种攻击途径:直接提示注入、RAG后门攻击和跨代理信任剥削。
- 对最新前沿的LLM模型的安全评估显示出了高脆弱性等级,绝大多数易受攻击。
点此查看论文截图




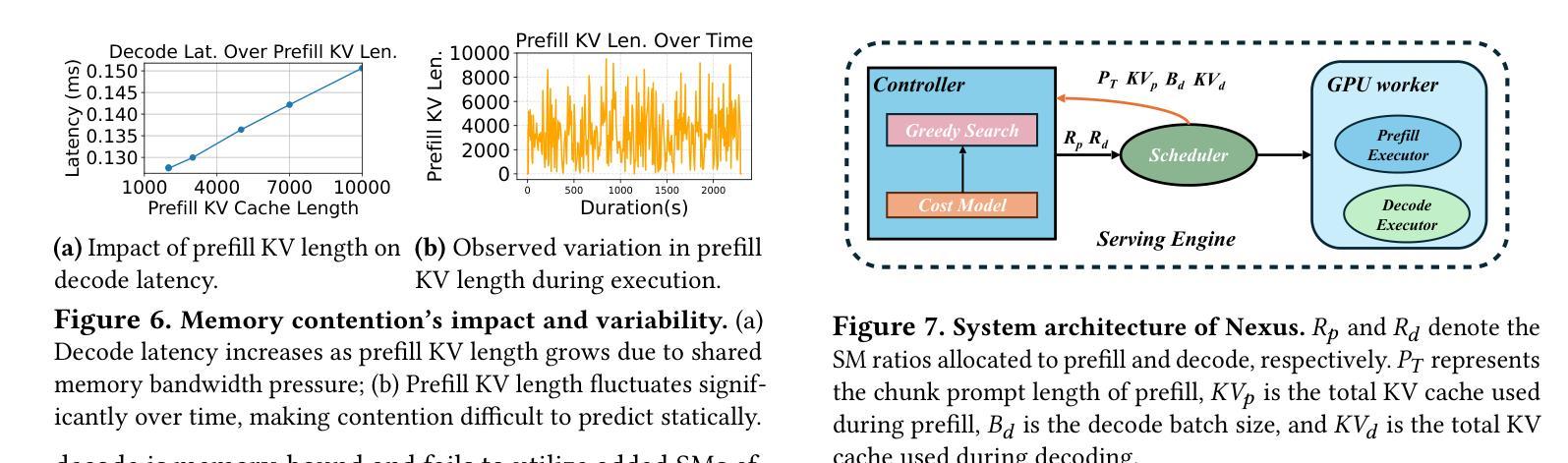
Nexus: Taming Throughput-Latency Tradeoff in LLM Serving via Efficient GPU Sharing
Authors:Xiaoxiang Shi, Colin Cai, Junjia Du, Zhanda Zhu, Zhihao Jia
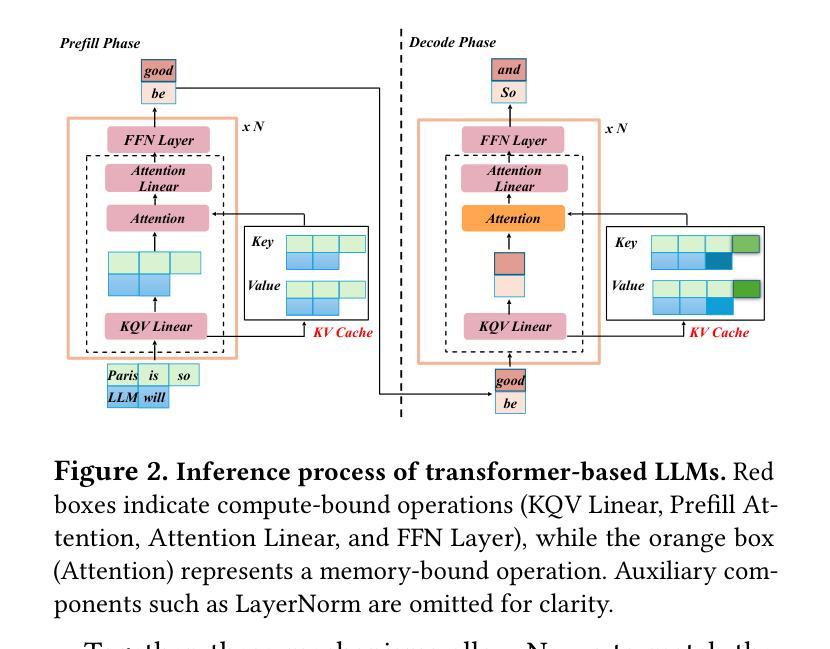
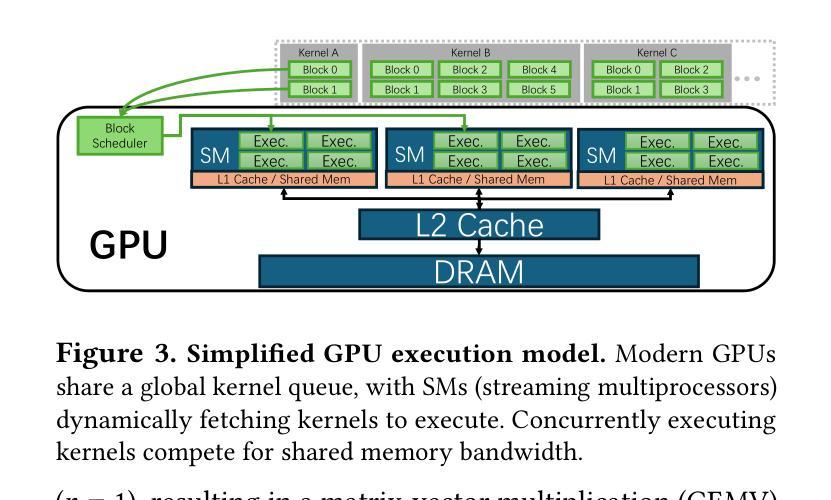
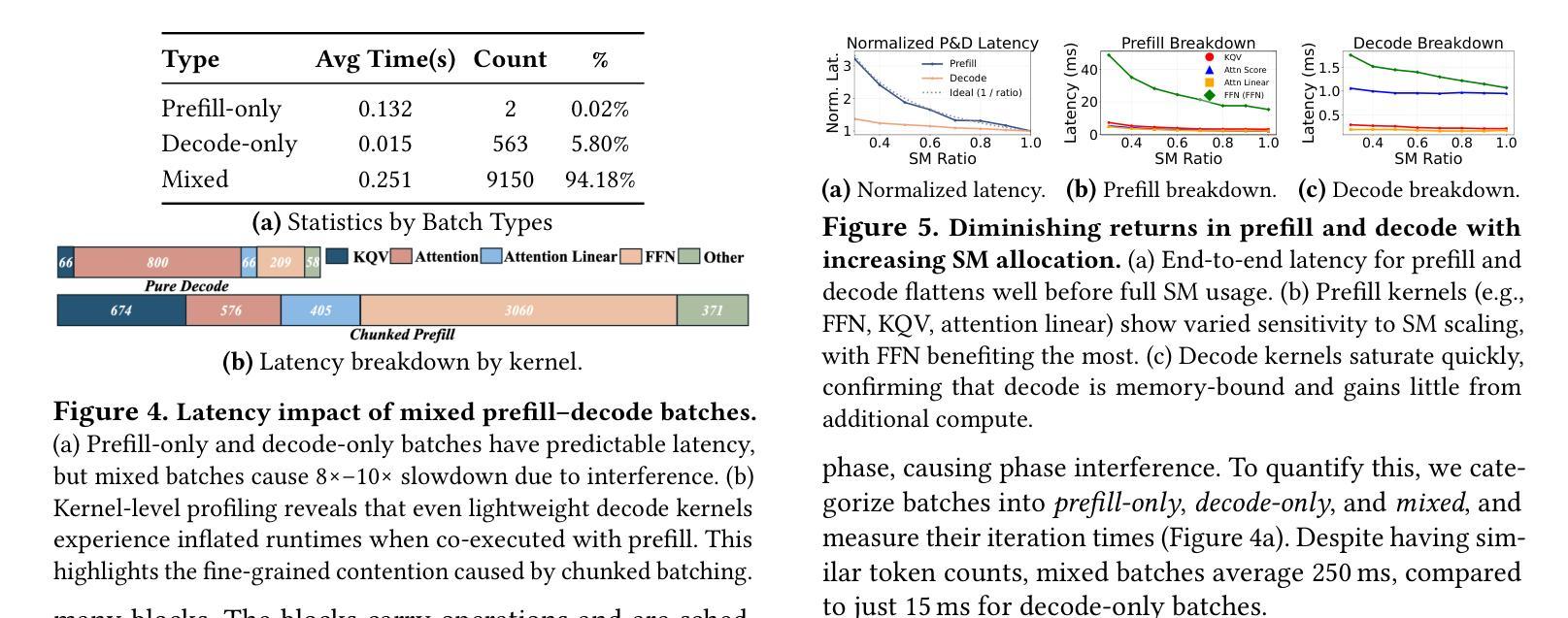
Current prefill-decode (PD) disaggregation is typically deployed at the level of entire serving engines, assigning separate GPUs to handle prefill and decode phases. While effective at reducing latency, this approach demands more hardware. To improve GPU utilization, Chunked Prefill mixes prefill and decode requests within the same batch, but introduces phase interference between prefill and decode. While existing PD disaggregation solutions separate the phases across GPUs, we ask: can the same decoupling be achieved within a single serving engine? The key challenge lies in managing the conflicting resource requirements of prefill and decode when they share the same hardware. In this paper, we first show that chunked prefill requests cause interference with decode requests due to their distinct requirements for GPU resources. Second, we find that GPU resources exhibit diminishing returns. Beyond a saturation point, increasing GPU allocation yields negligible latency improvements. This insight enables us to split a single GPU’s resources and dynamically allocate them to prefill and decode on the fly, effectively disaggregating the two phases within the same GPU. Across a range of models and workloads, our system Nexus achieves up to 2.2x higher throughput, 20x lower TTFT, and 2.5x lower TBT than vLLM. It also outperforms SGLang with up to 2x higher throughput, 2x lower TTFT, and 1.7x lower TBT, and achieves 1.4x higher throughput than vLLM-disaggregation using only half the number of GPUs.
当前的prefill-decode(PD)解聚通常在整个服务引擎级别进行部署,将单独的GPU分配给prefill和decode阶段。虽然这种方法在减少延迟方面很有效,但它需要更多的硬件。为了提升GPU利用率,Chunked Prefill将prefill和decode请求混合在同一批次中,但会在prefill和decode之间引入阶段干扰。虽然现有的PD解聚解决方案在GPU之间分离阶段,我们的问题是:是否可以在单个服务引擎中实现相同的解耦?关键挑战在于管理prefill和decode在共享相同硬件时的冲突资源需求。在本文中,我们首先表明由于GPU资源的不同需求,分块的prefill请求会对decode请求造成干扰。其次,我们发现GPU资源表现出收益递减的现象。超过饱和点后,增加GPU分配对延迟的改进微乎其微。这一见解使我们能够拆分单个GPU的资源,并动态地实时将它们分配给prefill和decode,有效地在同一GPU内解聚两个阶段。在我们的系统Nexus中,与vLLM相比,它实现了高达2.2倍的吞吐量,TTF降低了20倍,TBT降低了2.5倍。它还优于SGLang,吞吐量提高了两倍,TTF降低了两倍,TBT降低了1.7倍,并且使用只有一半的GPU数量就实现了比vLLM-解聚更高的1.4倍吞吐量。
论文及项目相关链接
摘要
本文探讨了当前预填充解码(PD)去聚合方法的问题,即在硬件资源分配上存在的局限性。文章提出了一种新的方法,能够在单个服务引擎内实现解耦,从而提高GPU利用率。研究发现,分块预填充请求与解码请求之间存在资源冲突问题,同时GPU资源呈现收益递减的现象。基于此,提出了一种动态分配GPU资源的方法,实现在单个GPU内对预填充和解码两个阶段的去聚合。实验结果显示,该方法能够有效提高系统性能,相较于其他系统,具有更高的吞吐量和更低的延迟。
关键见解
- 当前预填充解码去聚合方法主要在整个服务引擎层面部署,通过分配单独的GPU来处理预填充和解码阶段,虽然降低了延迟,但硬件需求较高。
- 分块预填充方法虽然提高了GPU利用率,但预填充和解码请求之间存在相位干扰问题。
- 在单个服务引擎内实现解耦的关键挑战在于管理预填充和解码在共享硬件时的冲突资源需求。
- 分块预填充请求因对GPU资源的独特需求而与解码请求产生干扰。
- GPU资源呈现收益递减的现象,超过饱和点后,增加GPU分配对延迟改进甚微。
- 通过动态分配GPU资源,实现在单个GPU内对预填充和解码两个阶段的去聚合,提高了系统性能。
点此查看论文截图

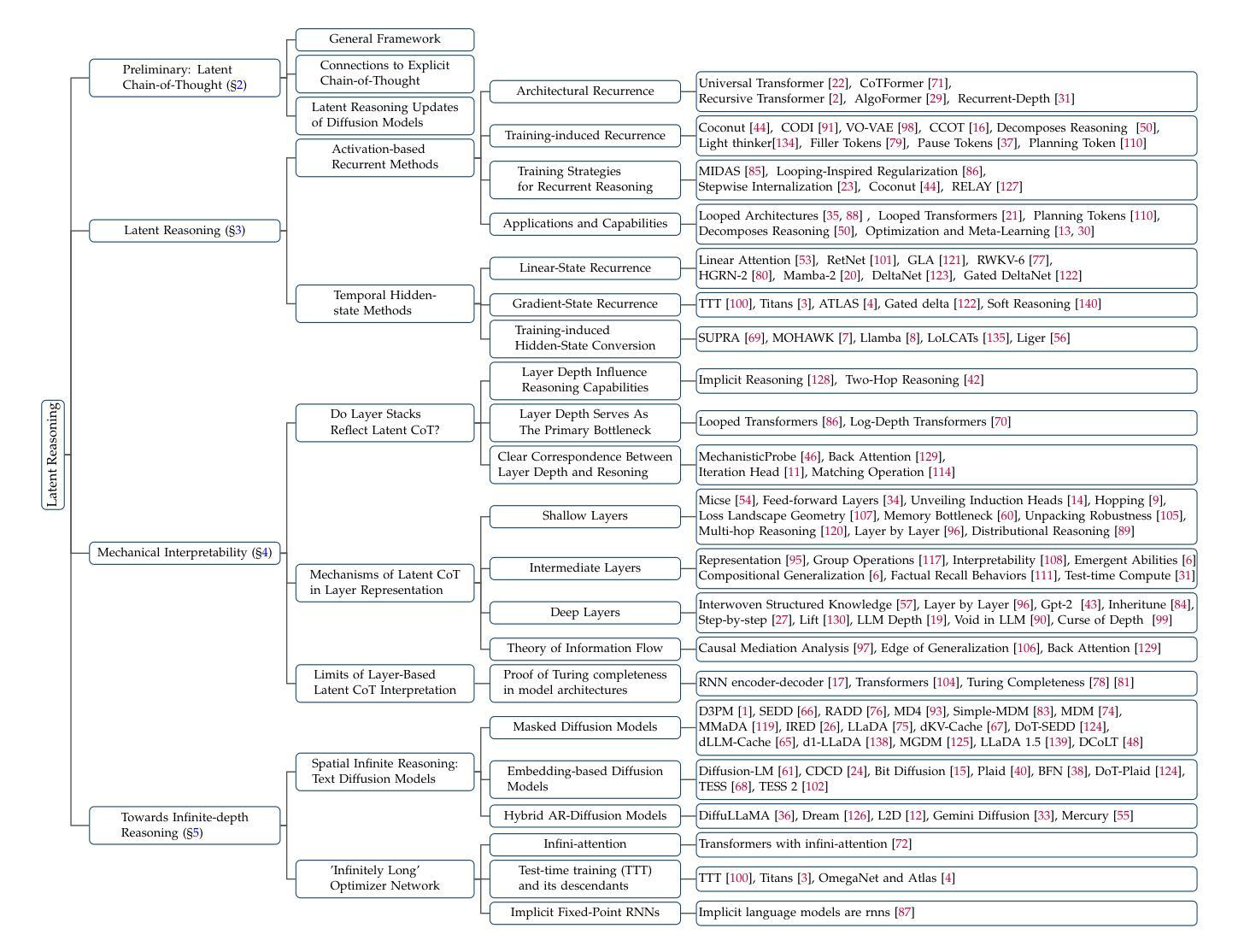
A Survey on Latent Reasoning
Authors:Rui-Jie Zhu, Tianhao Peng, Tianhao Cheng, Xingwei Qu, Jinfa Huang, Dawei Zhu, Hao Wang, Kaiwen Xue, Xuanliang Zhang, Yong Shan, Tianle Cai, Taylor Kergan, Assel Kembay, Andrew Smith, Chenghua Lin, Binh Nguyen, Yuqi Pan, Yuhong Chou, Zefan Cai, Zhenhe Wu, Yongchi Zhao, Tianyu Liu, Jian Yang, Wangchunshu Zhou, Chujie Zheng, Chongxuan Li, Yuyin Zhou, Zhoujun Li, Zhaoxiang Zhang, Jiaheng Liu, Ge Zhang, Wenhao Huang, Jason Eshraghian
Large Language Models (LLMs) have demonstrated impressive reasoning capabilities, especially when guided by explicit chain-of-thought (CoT) reasoning that verbalizes intermediate steps. While CoT improves both interpretability and accuracy, its dependence on natural language reasoning limits the model’s expressive bandwidth. Latent reasoning tackles this bottleneck by performing multi-step inference entirely in the model’s continuous hidden state, eliminating token-level supervision. To advance latent reasoning research, this survey provides a comprehensive overview of the emerging field of latent reasoning. We begin by examining the foundational role of neural network layers as the computational substrate for reasoning, highlighting how hierarchical representations support complex transformations. Next, we explore diverse latent reasoning methodologies, including activation-based recurrence, hidden state propagation, and fine-tuning strategies that compress or internalize explicit reasoning traces. Finally, we discuss advanced paradigms such as infinite-depth latent reasoning via masked diffusion models, which enable globally consistent and reversible reasoning processes. By unifying these perspectives, we aim to clarify the conceptual landscape of latent reasoning and chart future directions for research at the frontier of LLM cognition. An associated GitHub repository collecting the latest papers and repos is available at: https://github.com/multimodal-art-projection/LatentCoT-Horizon/.
大型语言模型(LLM)已经展现出令人印象深刻的推理能力,特别是当受到明确的思维链(CoT)推理引导时,能够口头表达中间步骤。虽然思维链提高了可解释性和准确性,但它对自然语言推理的依赖限制了模型的表达带宽。潜在推理通过完全在模型的连续隐藏状态中进行多步推理来解决这一瓶颈,消除了令牌级别的监督。为了推动潜在推理研究的发展,这篇综述对新兴的领域——潜在推理进行了全面的概述。我们首先研究神经网络层作为推理计算基础的作用,强调分层表示如何支持复杂转换。接下来,我们探索了多种潜在推理方法,包括基于激活的复发、隐藏状态传播,以及压缩或内化显性推理痕迹的精调策略。最后,我们讨论了通过掩膜扩散模型实现无限深度潜在推理等先进范式,这能够支持全局一致性和可逆的推理过程。通过统一这些观点,我们旨在澄清潜在推理的概念景观,并为大型语言模型认知前沿的研究绘制未来方向。相关的GitHub仓库,收集最新的论文和仓库资源,可通过以下链接访问:https://github.com/multimodal-art-projection/LatentCoT-Horizon/。
论文及项目相关链接
Summary
大型语言模型(LLM)通过明确的思维链(CoT)推理展示出色的推理能力,这种推理方式能够口头表达中间步骤。虽然CoT提高了可解释性和准确性,但它对自然语言推理的依赖限制了模型的表达带宽。潜在推理通过完全在模型的连续隐藏状态中进行多步推理来解决这一瓶颈,从而消除了令牌级别的监督。本文全面概述了潜在推理这一新兴领域的发展。文章首先研究神经网络层作为推理计算基底的作用,强调分层表示如何支持复杂转换。然后,我们探索了多种潜在推理方法,包括基于激活的复发、隐藏状态传播以及微调策略等,这些策略可以压缩或内化显性推理痕迹。最后,我们讨论了通过掩模扩散模型实现无限深度潜在推理等先进范式,这些范式可实现全局一致且可逆的推理过程。本文旨在统一这些观点,厘清潜在推理的概念景观,并绘制LLM认知领域前沿的研究未来方向。
Key Takeaways
- LLMs具备通过明确的思维链(CoT)进行推理的能力,这增强了其可解释性和准确性。
- 潜在推理方法旨在解决在连续隐藏状态中进行多步推理的问题,消除对令牌级别监督的依赖。
- 神经网络层在潜在推理中扮演重要角色,分层表示支持复杂转换。
- 存在多种潜在推理方法,包括基于激活的复发、隐藏状态传播以及微调策略等。
- 先进的范式如通过掩模扩散模型实现无限深度潜在推理,实现全局一致且可逆的推理过程。
- 文章概述了潜在推理的最新发展和未来研究方向。
点此查看论文截图

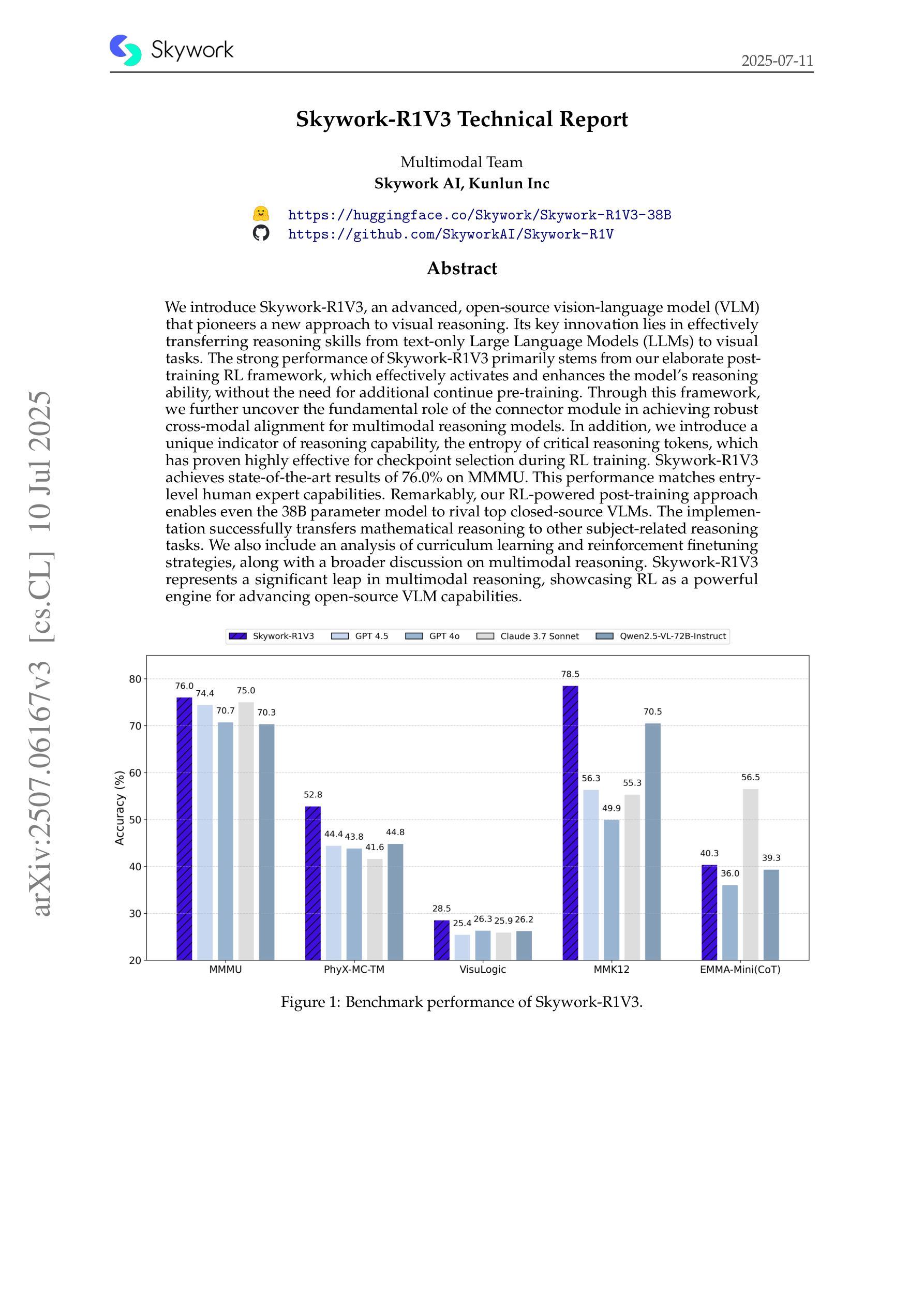
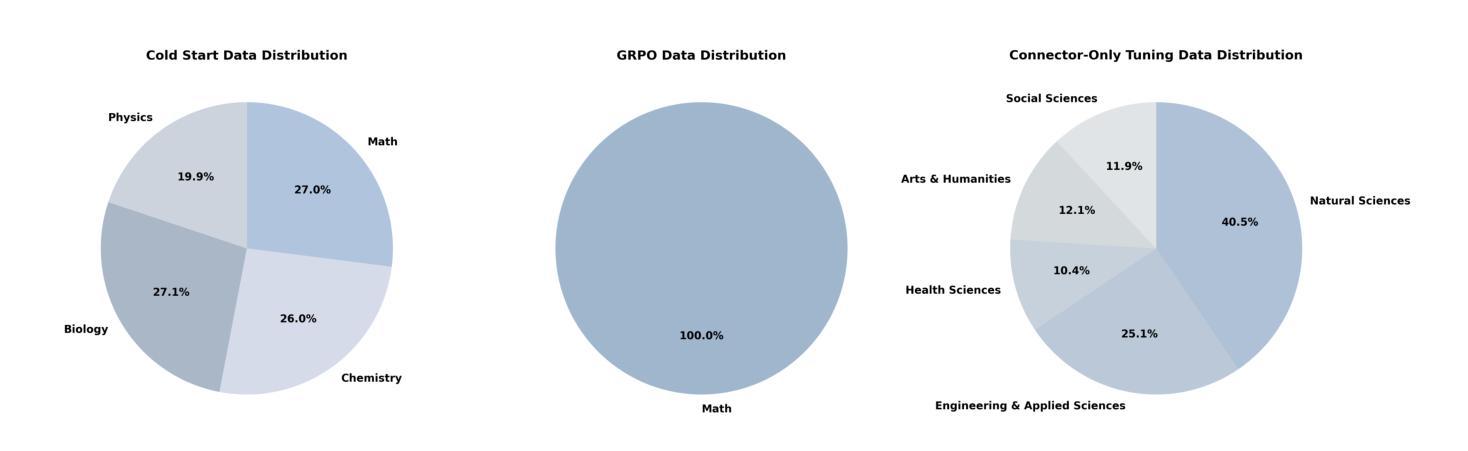
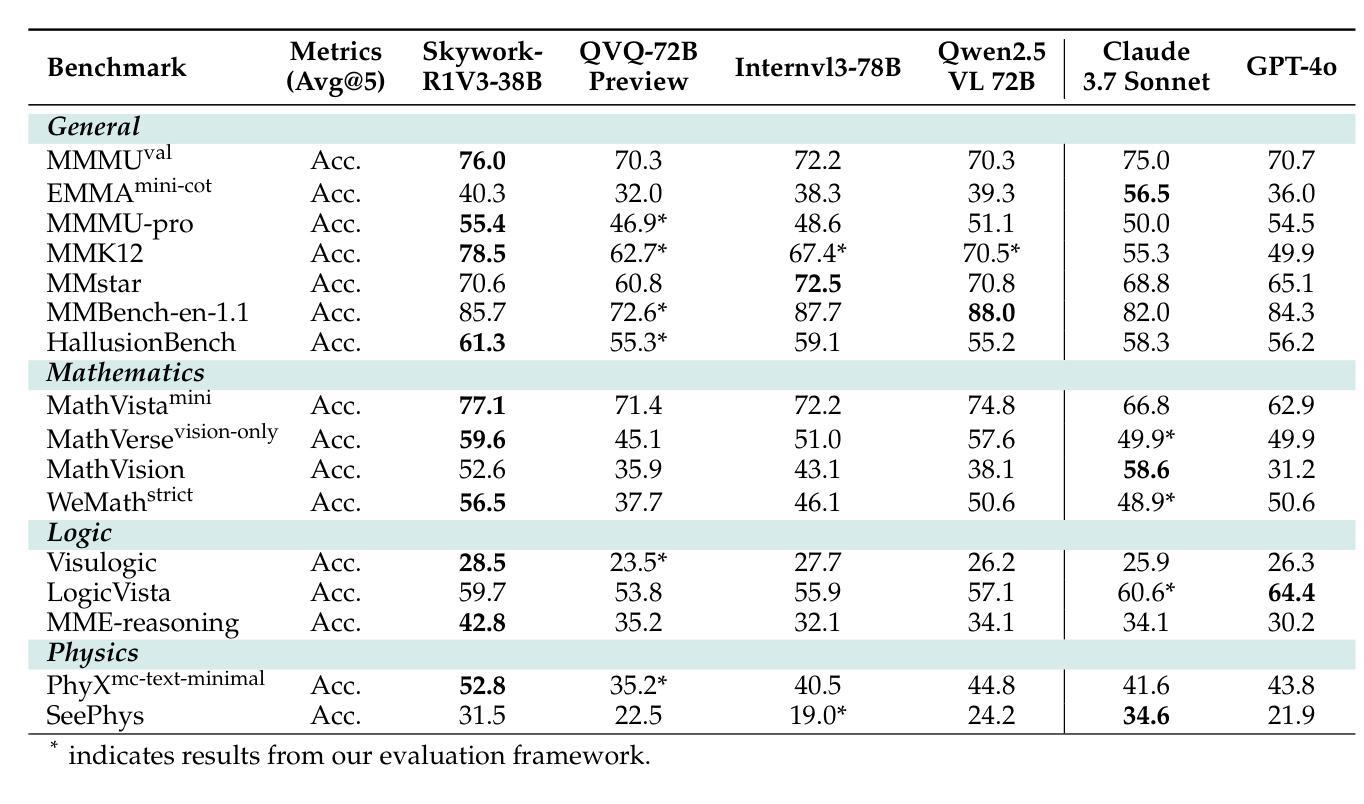
Skywork-R1V3 Technical Report
Authors:Wei Shen, Jiangbo Pei, Yi Peng, Xuchen Song, Yang Liu, Jian Peng, Haofeng Sun, Yunzhuo Hao, Peiyu Wang, Jianhao Zhang, Yahui Zhou
We introduce Skywork-R1V3, an advanced, open-source vision-language model (VLM) that pioneers a new approach to visual reasoning. Its key innovation lies in effectively transferring reasoning skills from text-only Large Language Models (LLMs) to visual tasks. The strong performance of Skywork-R1V3 primarily stems from our elaborate post-training RL framework, which effectively activates and enhances the model’s reasoning ability, without the need for additional continue pre-training. Through this framework, we further uncover the fundamental role of the connector module in achieving robust cross-modal alignment for multimodal reasoning models. In addition, we introduce a unique indicator of reasoning capability, the entropy of critical reasoning tokens, which has proven highly effective for checkpoint selection during RL training. Skywork-R1V3 achieves state-of-the-art results on MMMU, significantly improving from 64.3% to 76.0%. This performance matches entry-level human capabilities. Remarkably, our RL-powered post-training approach enables even the 38B parameter model to rival top closed-source VLMs. The implementation successfully transfers mathematical reasoning to other subject-related reasoning tasks. We also include an analysis of curriculum learning and reinforcement finetuning strategies, along with a broader discussion on multimodal reasoning. Skywork-R1V3 represents a significant leap in multimodal reasoning, showcasing RL as a powerful engine for advancing open-source VLM capabilities.
我们介绍了Skywork-R1V3,这是一个先进的开源视觉语言模型(VLM),它开创了一种新的视觉推理方法。其主要创新在于有效地将从文本中获得的推理能力从大型语言模型(LLM)转移到视觉任务上。Skywork-R1V3的出色性能主要源于我们精心设计的后训练强化学习(RL)框架,该框架有效地激活并增强了模型的推理能力,而无需额外的继续预训练。通过这一框架,我们进一步发现了连接器模块在实现稳健的跨模态对齐中的基本作用,这对于多模态推理模型至关重要。此外,我们引入了独特的推理能力指标——关键推理令牌的熵,这已被证明在强化学习训练的检查点选择中非常有效。Skywork-R1V3在MMMU上取得了最新结果,从64.3%显著提高到76.0%,与人类入门级能力相匹配。值得注意的是,我们的基于强化学习的后训练方法甚至使38B参数模型能够与顶级闭源VLM相匹敌。该实现成功地将在数学推理转移到其他相关推理任务。我们还分析了课程学习和强化微调策略,并对多模态推理进行了更广泛的讨论。Skywork-R1V 代表了多模态推理的重大飞跃,展示了强化学习作为推动开源VLM能力发展的强大引擎。
论文及项目相关链接
Summary
Skywork-R1V3是一款先进的开源视觉语言模型(VLM),它将文本大型语言模型(LLM)的推理能力有效地转移到视觉任务上。其关键创新在于采用精细的强化学习(RL)框架进行训练后优化,无需额外的持续预训练即可激活和提升模型的推理能力。Skywork-R1V3实现了先进的多模态推理性能,达到最新水平,并在MMMU测试中从64.3%提升至76.0%,与人类入门级能力相当。此外,该模型成功地将数学推理能力应用于其他相关推理任务。RL驱动的后训练方法使该模型能在规模较小(参数达数十亿级别)的情况下媲美顶尖的商业性VLM模型。我们探讨了教案学习与强化微调策略的分析以及多模态推理的更广泛讨论。Skywork-R1V3代表了多模态推理领域的重大突破,并展示了强化学习作为推动开源VLM能力的强大引擎。Skywork-R1V在众多场景中都能取得较好的表现。比如金融交易员的分析市场数据和分析自然风景摄影的作品可以选用它进行高效推理处理。总体来说,Skywork-R1V代表了新一代的智能决策辅助工具的出现。它的推出不仅能帮助我们处理复杂的视觉任务,而且有助于我们理解语言结构和内在含义以及它的具体应用层面的关键变化方向和影响大小趋势评估分析等重要意义深远的行动和价值拓展的可能与价值的尝试判断和实现问题预判和操作协调更合理有序的解决过程推进问题反馈和优化机制实现更好应用效果的提升以及更高效解决实际应用问题中遇到的各种挑战和问题提供新的思路和工具支持以及解决方式方法的开发支持和保护等方式最终实现辅助工具服务的专业化与技术手段的创新及其广阔的市场应用前景预期更好地赋能于人成就双赢目标的实现长远健康发展闭环同步影响各种方式的改善及共享更加智慧的服务与支持及其业务合规与安全保障机制促进可持续性发展和目标落地可能性在减少能耗资源损失等智能化的发展中发挥巨大优势提供价值体现的路径拓展需求体现的需要依托的具体环节需要详细规划和开发并进行数据的安全保密等方面采取切实可行的方案和技术措施支撑行业高质量发展的迫切需求等相关内容表达丰富具体详尽完整逻辑清晰具有现实意义和社会价值对于未来科技发展趋势和人类社会进步具有重要的推动和促进作用Key Takeaways
- Skywork-R1V3是一个先进的视觉语言模型(VLM),能够将文本大型语言模型(LLM)的推理能力转移到视觉任务上。
- 该模型采用强化学习(RL)框架进行训练后优化,无需额外的持续预训练即可提升模型的推理能力。
- Skywork-R1V3实现了先进的多模态推理性能,在MMMU测试中性能显著提升。
- 模型具备数学推理能力,并能应用于其他相关推理任务。
- RL驱动的后训练方法使该模型在较小规模下表现优异,媲美顶尖的商业性VLM模型。
- 模型分析包括教案学习与强化微调策略的讨论,以及更广泛的多模态推理探讨。
点此查看论文截图
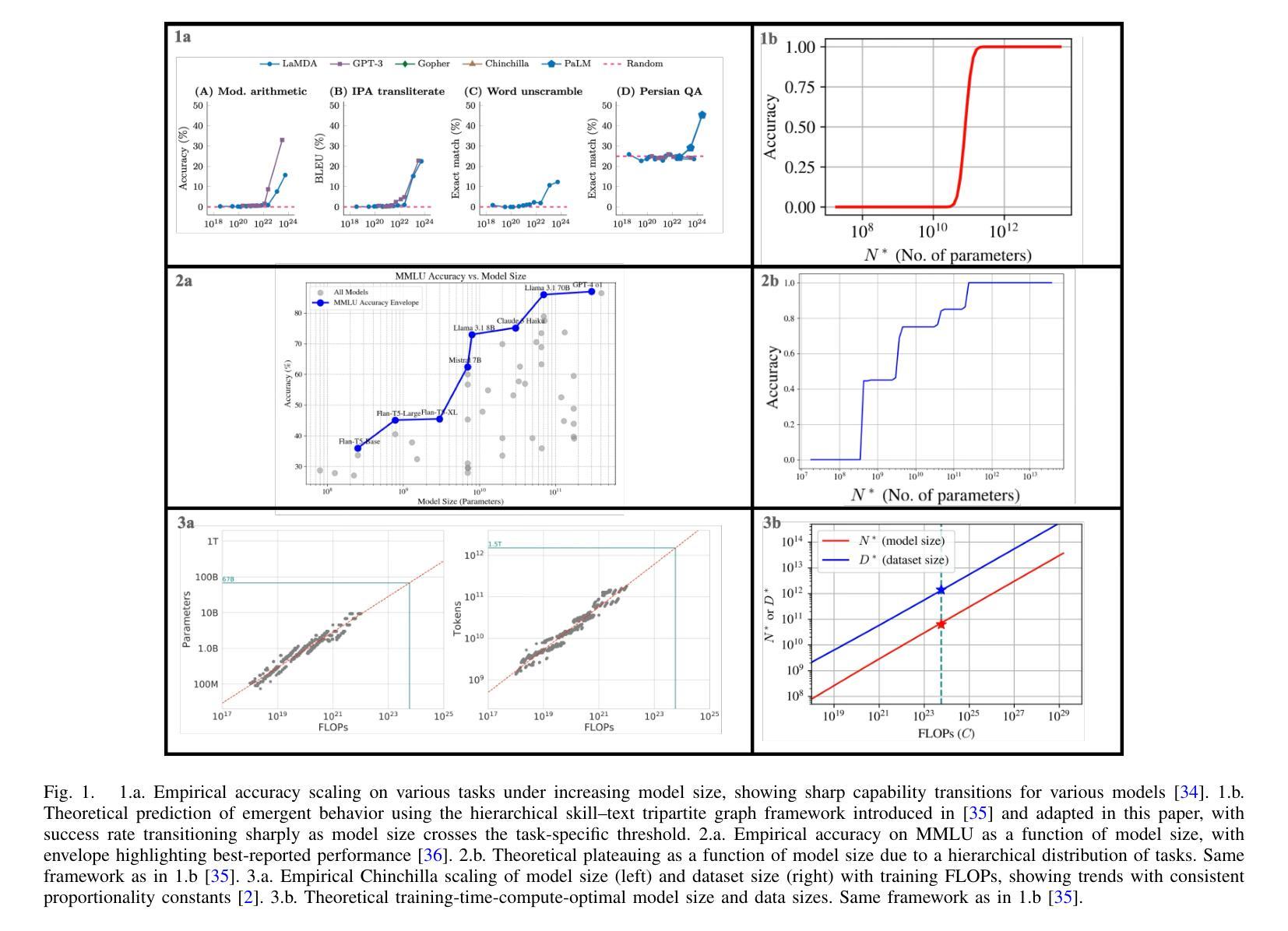
A Theory of Inference Compute Scaling: Reasoning through Directed Stochastic Skill Search
Authors:Austin R. Ellis-Mohr, Anuj K. Nayak, Lav R. Varshney
Large language models (LLMs) demand considerable computational, energy, and financial resources during both training and deployment. While scaling laws for training have guided much of the field’s recent progress, inference costs now represent a significant and growing component of the overall resource burden, particularly for reasoning-focused models. Existing characterizations of compute-optimality that consider model size, dataset size, and inference tokens in isolation or in fixed combinations risk overlooking more efficient operating points. We introduce directed stochastic skill search (DS3), a general framework that represents inference as stochastic traversal over a learned skill graph. From a simplified yet expressive instantiation, we derive closed-form expressions for task success and compute cost across a wide range of inference strategies – including chain-of-thought (CoT) and tree-of-thought (ToT) – enabling comparative analysis as a function of task difficulty and model capability. To that end, we extend a prior first-principles tripartite graph framework of LLM training to incorporate inference, and separately bridge DS3 with empirical methods that characterize LLM scaling behavior. We theoretically recover empirically observed patterns, including: linear accuracy scaling with logarithmic compute; variation in preferred inference strategies as a function of task difficulty and model capability; emergent behavior elicited by reasoning even when performance plateaus under parameter scaling; and both best-of-N (BoN) and majority voting behavior captured within a unified analytical framework. By explicitly characterizing training-inference interdependencies, our framework deepens theoretical understanding and supports principled algorithmic design and resource allocation.
大型语言模型(LLM)在训练和部署过程中需要大量的计算、能源和财务资源。虽然训练的可扩展性定律指导了该领域的最新进展,但推理成本现在已成为总体资源负担的重要组成部分,特别是对于那些以推理为重点的模型。现有的计算最优性的表征,在考虑模型大小、数据集大小和推理令牌时处于孤立状态或以固定组合存在,这可能会忽视更有效的操作点。我们引入了有向随机技能搜索(DS3),这是一个通用框架,它将推理表示为在学到的技能图上的随机遍历。从一个简化而富有表现力的实例化出发,我们得出了跨各种推理策略的封闭形式表达式,这些策略包括思维链(CoT)和思维树(ToT),并根据任务难度和模型能力进行比较分析。为此,我们将先前关于LLM训练的第一性原理三方图框架扩展到推理,并将DS3与刻画LLM扩展行为的实证方法相联系。我们从理论上重新发现了观察到的模式,包括:随着对数计算的增加,准确性呈线性扩展;随着任务难度和模型能力的变化,首选推理策略的变化;即使在参数扩展下性能达到稳定状态,推理也能激发出现的行为;以及在一个统一的分析框架内捕获的最佳N(BoN)和多数投票行为。通过明确刻画训练与推理之间的依赖关系,我们的框架深化了理论理解,并支持有原则的算法设计和资源分配。
论文及项目相关链接
Summary
大规模语言模型(LLM)在训练和部署过程中需要大量的计算、能源和财务资源。尽管训练规模法则指导了该领域的最新进展,但推理成本现在已成为整体资源负担中显著且日益重要的部分,特别是对于注重推理的模型。本文介绍了一种通用框架——定向随机技能搜索(DS3),它将推理表现为学习技能图上的随机遍历。通过简洁而富有表现力的实例化,我们推导出了跨各种推理策略的任务成功和计算成本的封闭形式表达式,包括链式思维(CoT)和树状思维(ToT),以任务难度和模型能力为函数进行比较分析。为此,我们扩展了先前的LLM训练三方图框架以纳入推理,并将DS3与表征LLM规模行为的经验方法进行桥接。我们的理论恢复了观察到的模式,包括:随着对数计算的增加,准确性呈线性扩展;作为任务难度和模型能力函数的优选推理策略的变化;即使在参数规模下性能达到平台期时也会出现由推理引发的行为;以及一个统一的分析框架内捕获的最佳N(BoN)和多数投票行为。通过明确训练推理相互依赖关系,我们的框架深化了理论理解,并支持了原则性的算法设计和资源分配。
Key Takeaways
- LLM在训练和部署过程中需要巨大的资源,特别是推理阶段的成本逐渐增长。
- 定向随机技能搜索(DS3)框架将推理表示为学习技能图上的随机遍历,提供了一个新的视角。
- 通过简洁的实例化,推导出了任务成功和计算成本的封闭形式表达式,能分析不同推理策略的效果。
- 扩展了LLM训练的三方图框架以包含推理阶段。
- 理论确认了多种观察到的现象,包括准确性随计算的对数增长而线性扩展。
- 任务难度和模型能力会影响优选的推理策略。
- 在参数规模不变的情况下,推理会引发某些新兴行为,而最佳N和多数投票行为可以在统一框架内被理解。
点此查看论文截图

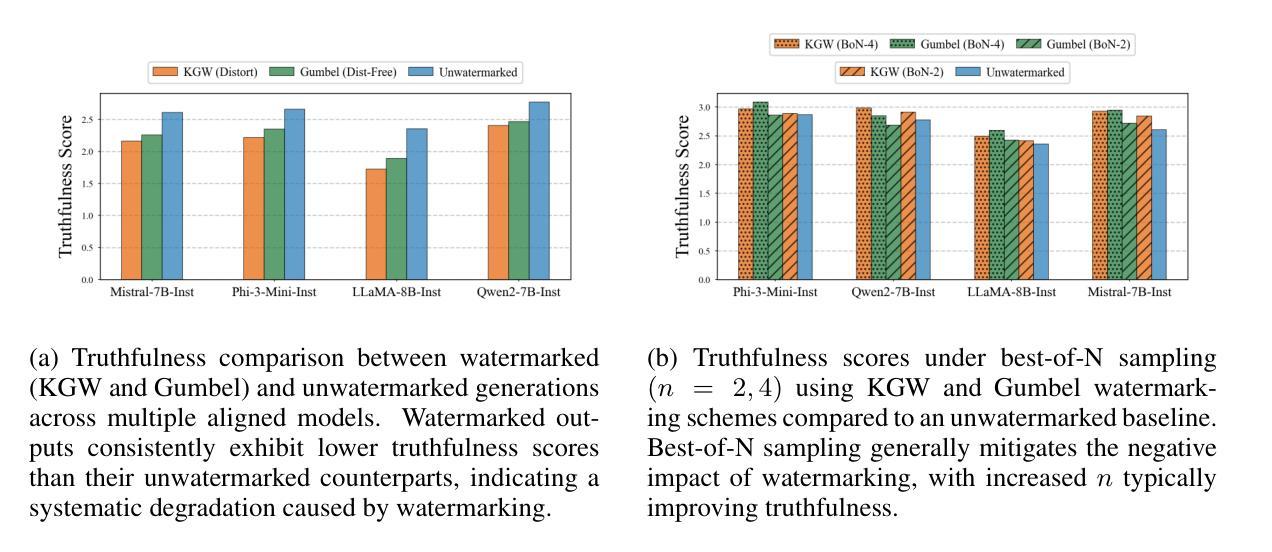
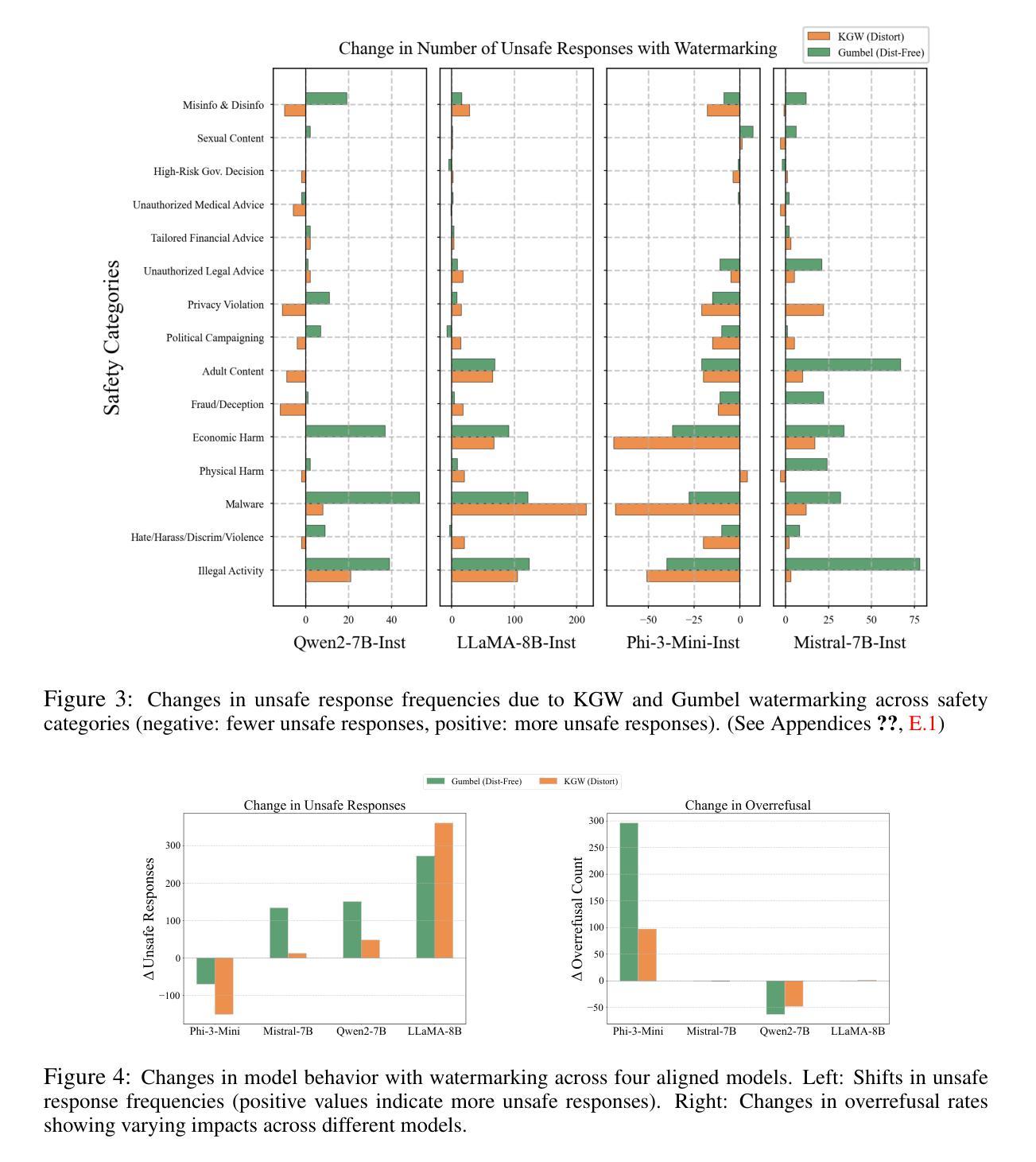
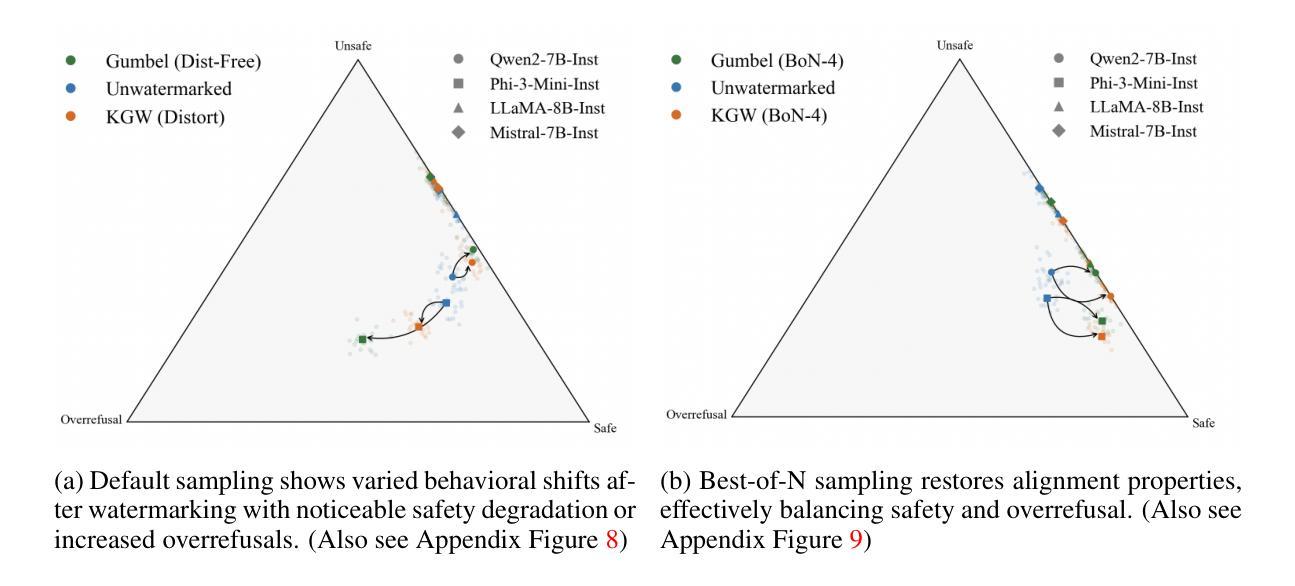
Watermarking Degrades Alignment in Language Models: Analysis and Mitigation
Authors:Apurv Verma, NhatHai Phan, Shubhendu Trivedi
Watermarking techniques for large language models (LLMs) can significantly impact output quality, yet their effects on truthfulness, safety, and helpfulness remain critically underexamined. This paper presents a systematic analysis of how two popular watermarking approaches-Gumbel and KGW-affect these core alignment properties across four aligned LLMs. Our experiments reveal two distinct degradation patterns: guard attenuation, where enhanced helpfulness undermines model safety, and guard amplification, where excessive caution reduces model helpfulness. These patterns emerge from watermark-induced shifts in token distribution, surfacing the fundamental tension that exists between alignment objectives. To mitigate these degradations, we propose Alignment Resampling (AR), an inference-time sampling method that uses an external reward model to restore alignment. We establish a theoretical lower bound on the improvement in expected reward score as the sample size is increased and empirically demonstrate that sampling just 2-4 watermarked generations effectively recovers or surpasses baseline (unwatermarked) alignment scores. To overcome the limited response diversity of standard Gumbel watermarking, our modified implementation sacrifices strict distortion-freeness while maintaining robust detectability, ensuring compatibility with AR. Experimental results confirm that AR successfully recovers baseline alignment in both watermarking approaches, while maintaining strong watermark detectability. This work reveals the critical balance between watermark strength and model alignment, providing a simple inference-time solution to responsibly deploy watermarked LLMs in practice.
水印技术对于大型语言模型(LLM)的输出质量有着显著影响,然而它们对于真实性、安全性和有用性的影响尚未得到充分研究。本文系统地分析了两种流行水印方法——Gumbel和KGW对四个对齐LLM的这些核心对齐属性的影响。我们的实验揭示了两种独特的退化模式:守卫衰减,其中增强有用性会破坏模型安全性;守卫放大,其中过度谨慎会降低模型的有用性。这些模式是由水印引起的令牌分布变化而产生的,暴露了对齐目标之间存在的根本性紧张关系。
论文及项目相关链接
PDF Published at the 1st Workshop on GenAI Watermarking, collocated with ICLR 2025. OpenReview: https://openreview.net/forum?id=SIBkIV48gF
摘要
水印技术对于大型语言模型(LLM)的输出质量有着显著影响,但其对真实性、安全性和有助益性的影响尚未得到充分的探讨。本文系统地分析了两种流行水印方法——Gumbel和KGW对这四个核心对齐属性的影响。实验揭示了两种独特的退化模式:警卫衰减和警卫放大,其中警卫衰减表示增强有助性会降低模型安全性,而警卫放大则意味着过度谨慎会减少模型的有助性。这些模式源于水印引起的符号分布变化,凸显了对齐目标之间存在的根本性紧张关系。为了缓解这些退化问题,我们提出了推理时间采样方法——对齐重采样(AR),该方法使用外部奖励模型来恢复对齐性。我们建立了理论上的改进预期奖励分数的下限随着样本数量的增加而增加,并实证表明仅对2-4个带水印的生成物进行采样即可恢复或超过基线(不带水印)的对齐分数。为了克服标准Gumbel水印的有限响应多样性,我们的改进实现牺牲了对精确畸变的严格要求以保持强大的检测能力,确保了与AR的兼容性。实验结果表明,AR成功恢复了两种水印方法中的基线对齐性,同时保持了强大的水印检测能力。这项工作揭示了水印强度和模型对齐之间的关键平衡,为实践中负责任地部署带水印的LLM提供了简单的推理时间解决方案。
关键见解
- 水印技术对大型语言模型(LLM)的核心属性(真实性、安全性和有助益性)产生影响。
- 提出了两种水印方法的退化模式:警卫衰减和警卫放大。
- 揭示水印引起的符号分布变化是对齐目标间紧张关系的根源。
- 提出了一种新的推理时间采样方法——对齐重采样(AR),以恢复模型的对齐性。
- AR方法能够在保持水印检测能力的同时成功恢复基线对齐性。
- 实验结果证实了AR的有效性,只需对少量带水印的生成物进行采样即可恢复或超越未加水印的模型性能。
点此查看论文截图


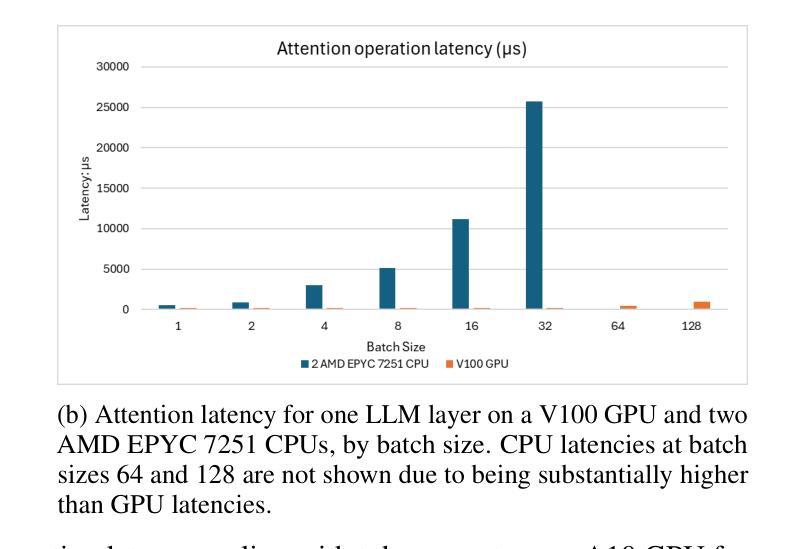
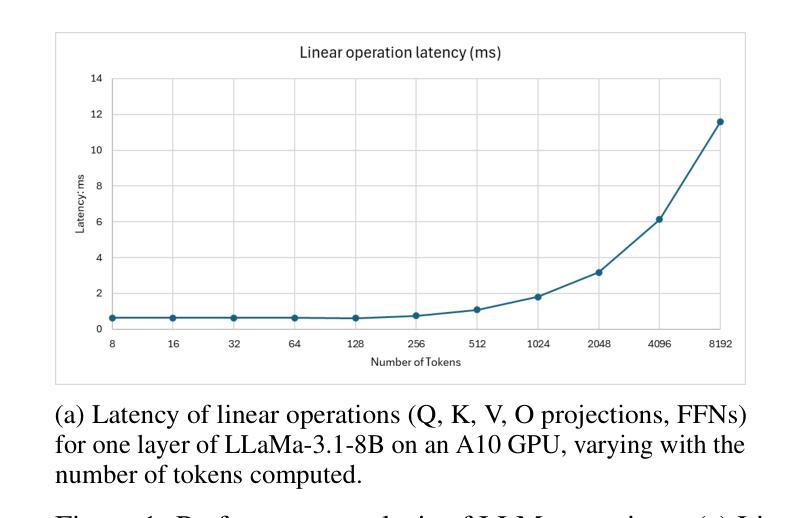
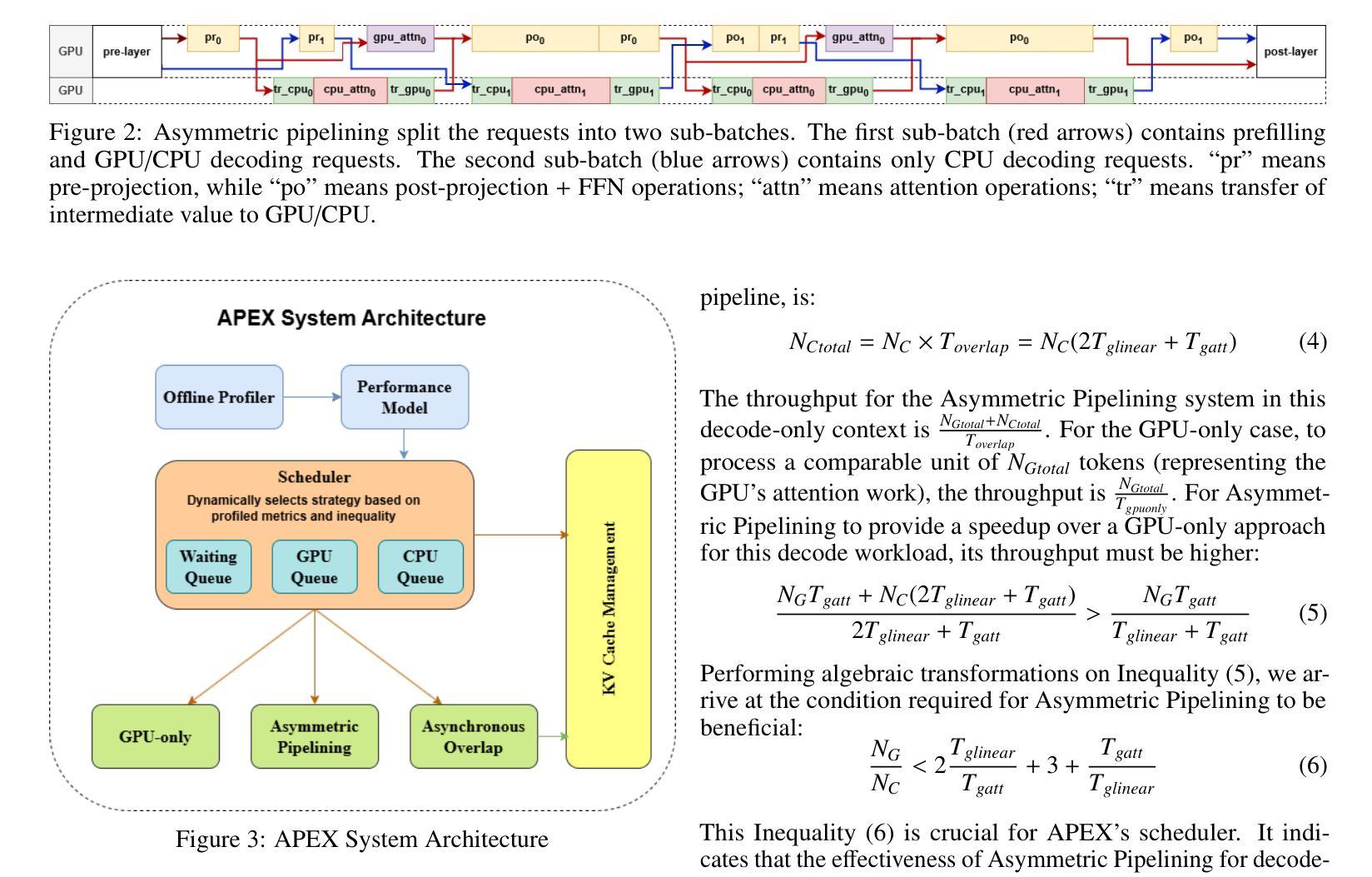
Parallel CPU-GPU Execution for LLM Inference on Constrained GPUs
Authors:Jiakun Fan, Yanglin Zhang, Xiangchen Li, Dimitrios S. Nikolopoulos
Deploying large language models (LLMs) for online inference is often constrained by limited GPU memory, particularly due to the growing KV cache during auto-regressive decoding. Hybrid GPU-CPU execution has emerged as a promising solution by offloading KV cache management and parts of attention computation to the CPU. However, a key bottleneck remains: existing schedulers fail to effectively overlap CPU-offloaded tasks with GPU execution during the latency-critical, bandwidth-bound decode phase. This particularly penalizes real-time, decode-heavy applications (e.g., chat, Chain-of-Thought reasoning) which are currently underserved by existing systems, especially under memory pressure typical of edge or low-cost deployments. We present APEX, a novel, profiling-informed scheduling strategy that maximizes CPU-GPU parallelism during hybrid LLM inference. Unlike systems relying on static rules or purely heuristic approaches, APEX dynamically dispatches compute across heterogeneous resources by predicting execution times of CPU and GPU subtasks to maximize overlap while avoiding scheduling overheads. We evaluate APEX on diverse workloads and GPU architectures (NVIDIA T4, A10), using LLaMa-2-7B and LLaMa-3.1-8B models. Compared to GPU-only schedulers like VLLM, APEX improves throughput by 84% - 96% on T4 and 11% - 89% on A10 GPUs, while preserving latency. Against the best existing hybrid schedulers, it delivers up to 49% (T4) and 37% (A10) higher throughput in long-output settings. APEX significantly advances hybrid LLM inference efficiency on such memory-constrained hardware and provides a blueprint for scheduling in heterogeneous AI systems, filling a critical gap for efficient real-time LLM applications.
在在线推理中部署大型语言模型(LLM)通常受到有限GPU内存的制约,特别是由于在自回归解码过程中KV缓存的增长。混合GPU-CPU执行已成为一种有前景的解决方案,通过将KV缓存管理和部分注意力计算任务转移到CPU上。然而,仍存在一个关键瓶颈:现有调度器无法在延迟关键、带宽受限的解码阶段有效地将CPU卸载的任务与GPU执行重叠。这对于实时、解码密集型应用(例如聊天、思维链推理)特别不利,这些应用在当前系统中受到的限制尤为严重,尤其是在边缘或低成本部署中典型的内存压力下。
论文及项目相关链接
PDF Preprint, under review
Summary
在部署大型语言模型(LLM)进行在线推理时,GPU内存限制是一个常见的约束,特别是在自动回归解码过程中KV缓存不断增长的情况下。虽然混合GPU-CPU执行已成为一种有前途的解决方案,通过将KV缓存管理和部分注意力计算任务转移到CPU来减轻GPU的负担,但现有调度器在延迟关键、带宽绑定的解码阶段无法有效地重叠CPU卸载的任务与GPU执行,这特别惩罚了实时、解码密集型的应用程序。本文提出了一种新的、以分析为基础的调度策略——APEX,以在混合LLM推理过程中最大限度地实现CPU-GPU并行性。与依赖静态规则或纯粹启发式方法的系统不同,APEX通过预测CPU和GPU子任务的执行时间来动态地在异构资源之间分配计算任务,以最大限度地实现重叠,同时避免调度开销。
Key Takeaways
- LLM在线推理中GPU内存限制是一个关键问题,特别是在自动回归解码过程中。
- 混合GPU-CPU执行是缓解GPU压力的一种有效方法,但现有调度器在CPU-offloaded任务与GPU执行的重叠方面存在瓶颈。
- APEX是一种新型的调度策略,旨在解决现有调度器的问题,通过动态地预测CPU和GPU子任务的执行时间来实现CPU和GPU之间的最大并行性。
- APEX在多种工作负载和GPU架构上的性能评估表明,与仅使用GPU的调度器相比,APEX提高了吞吐量并保持了延迟。
- APEX填补了实时LLM应用程序中高效调度策略的空白,特别是在内存受限的硬件上。
- APEX不仅解决了当前LLM推理中的效率问题,还为异构AI系统中的调度策略提供了蓝图。
点此查看论文截图

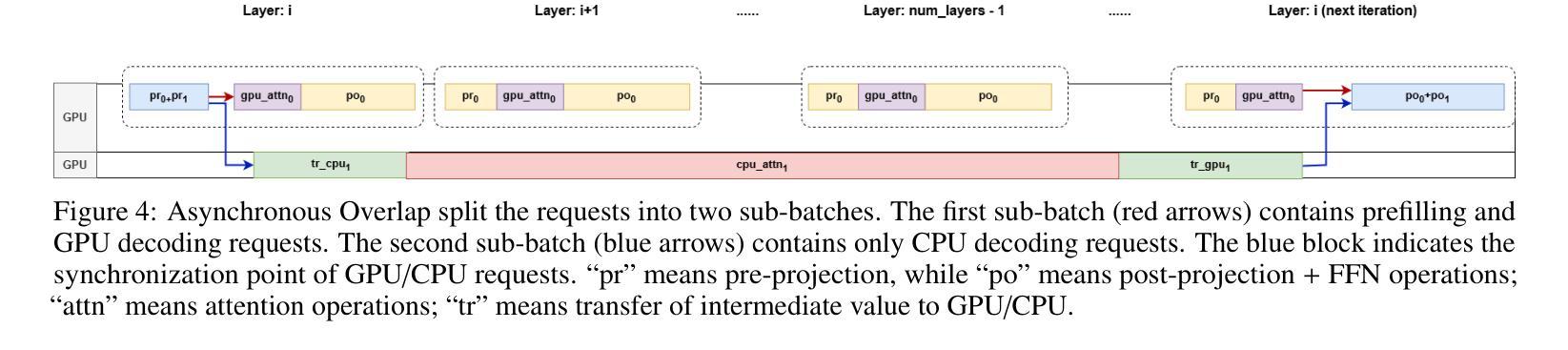
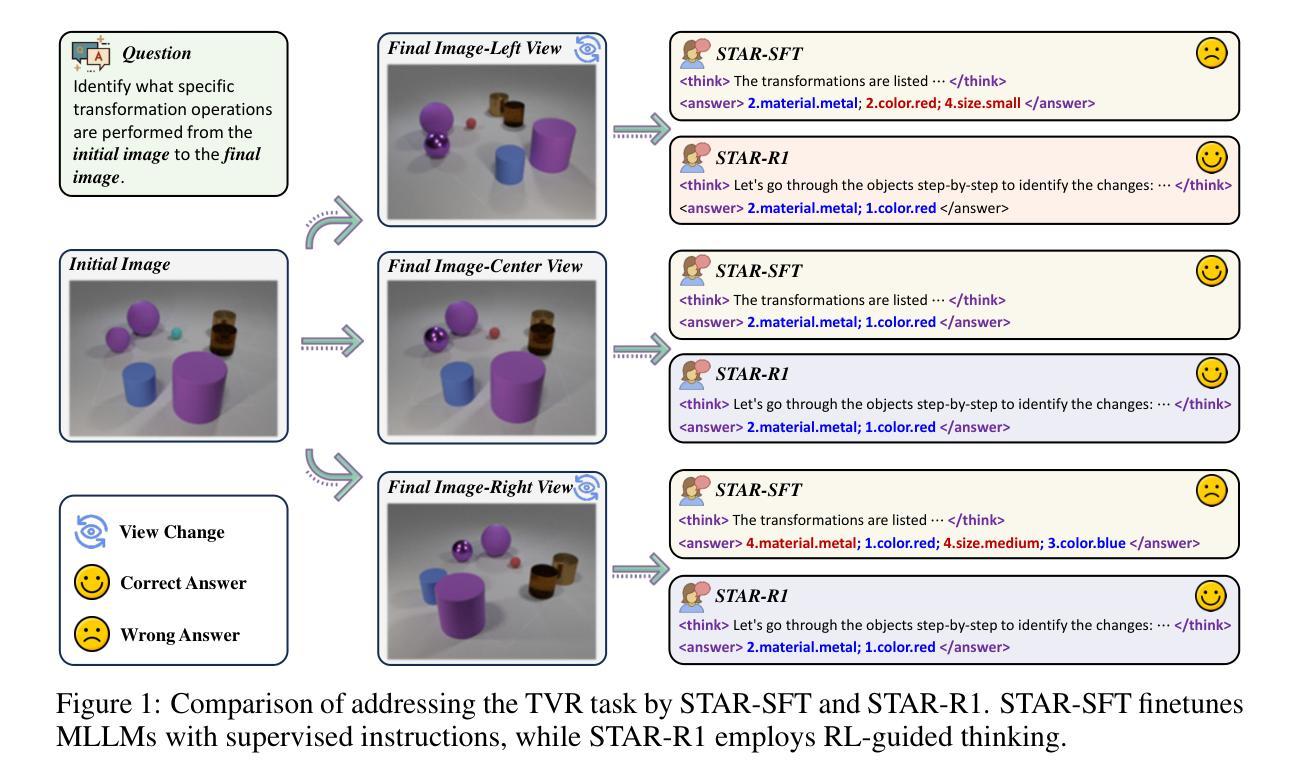
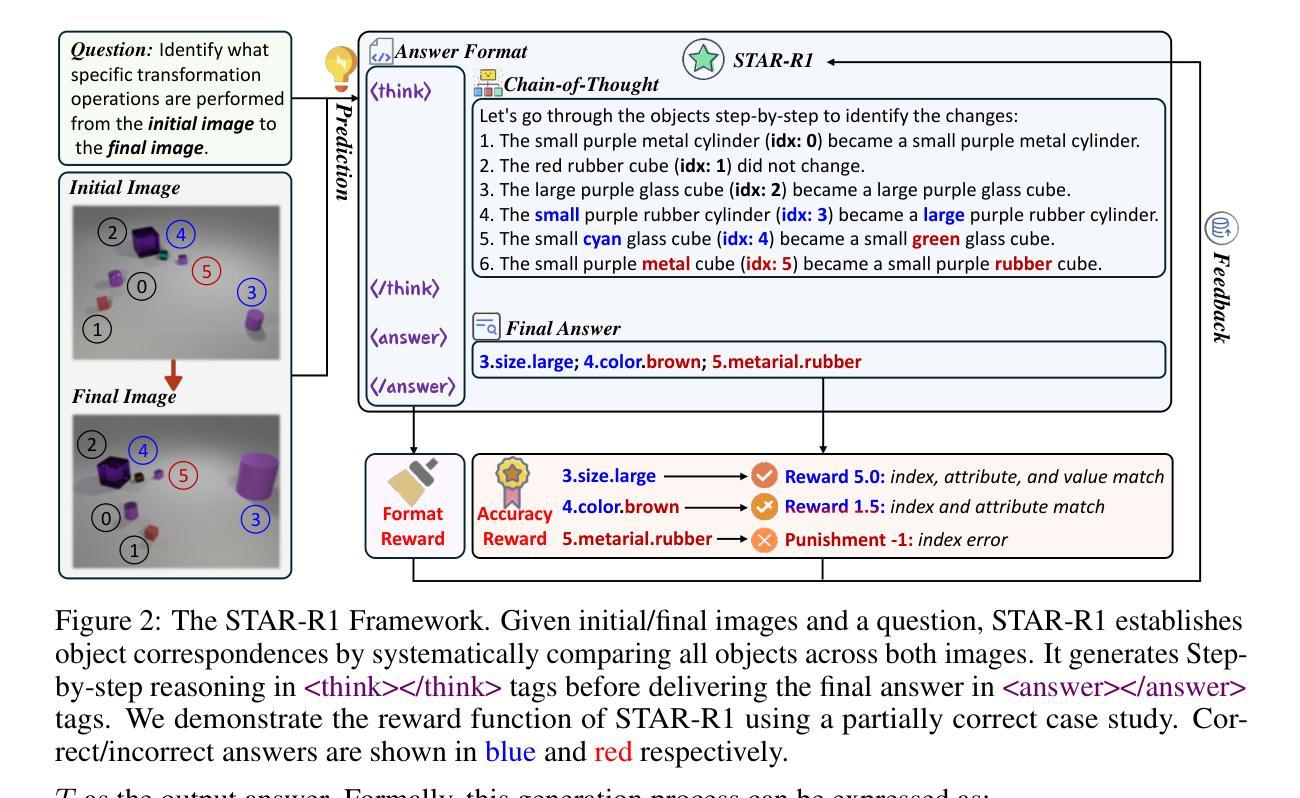
STAR-R1: Spatial TrAnsformation Reasoning by Reinforcing Multimodal LLMs
Authors:Zongzhao Li, Zongyang Ma, Mingze Li, Songyou Li, Yu Rong, Tingyang Xu, Ziqi Zhang, Deli Zhao, Wenbing Huang
Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities across diverse tasks, yet they lag significantly behind humans in spatial reasoning. We investigate this gap through Transformation-Driven Visual Reasoning (TVR), a challenging task requiring identification of object transformations across images under varying viewpoints. While traditional Supervised Fine-Tuning (SFT) fails to generate coherent reasoning paths in cross-view settings, sparse-reward Reinforcement Learning (RL) suffers from inefficient exploration and slow convergence. To address these limitations, we propose STAR-R1, a novel framework that integrates a single-stage RL paradigm with a fine-grained reward mechanism tailored for TVR. Specifically, STAR-R1 rewards partial correctness while penalizing excessive enumeration and passive inaction, enabling efficient exploration and precise reasoning. Comprehensive evaluations demonstrate that STAR-R1 achieves state-of-the-art performance across all 11 metrics, outperforming SFT by 23% in cross-view scenarios. Further analysis reveals STAR-R1’s anthropomorphic behavior and highlights its unique ability to compare all objects for improving spatial reasoning. Our work provides critical insights in advancing the research of MLLMs and reasoning models. The codes, model weights, and data will be publicly available at https://github.com/zongzhao23/STAR-R1.
多模态大型语言模型(MLLMs)在多种任务中表现出了显著的能力,但在空间推理方面与人类存在显著差距。我们通过转换驱动视觉推理(TVR)来研究这一差距,这是一项具有挑战性的任务,要求在不同视角下识别图像中的对象转换。传统的监督微调(SFT)无法在跨视图设置中生成连贯的推理路径,而基于稀疏奖励的强化学习(RL)则面临探索效率低下和收敛缓慢的困境。为了解决这些局限性,我们提出了STAR-R1,这是一个结合了单阶段RL范式和针对TVR定制的精细奖励机制的新型框架。具体来说,STAR-R1奖励部分正确性,同时惩罚过度枚举和被动无作为,从而实现有效的探索和精确推理。综合评估表明,STAR-R1在所有11项指标上均达到最新技术水平,在跨视图场景中较SFT高出23%。进一步的分析揭示了STAR-R1的人类行为特征,并突出了其在比较所有对象方面提高空间推理的独特能力。我们的工作对推动MLLMs和推理模型的研究提供了关键见解。代码、模型权重和数据将在https://github.com/zongzhao23/STAR-R 公开可用。
论文及项目相关链接
Summary
MLLM在多模态任务中表现卓越,但在空间推理方面与人类存在显著差距。本研究通过Transformation-Driven Visual Reasoning(TVR)任务探究这一差距,并提出STAR-R1框架,结合单阶段强化学习与精细奖励机制,有效应对传统监督微调(SFT)与稀疏奖励强化学习(RL)的局限性。STAR-R1在TVR任务上实现最佳性能,并在跨视图场景中较SFT高出23%。分析显示STAR-R1展现拟人化行为,并可通过比较所有对象来改善空间推理能力。本研究对推进MLLM与推理模型研究提供重要见解。
Key Takeaways
- MLLM在多种任务中表现出卓越的能力,但在空间推理方面与人类存在显著差距。
- Transformation-Driven Visual Reasoning(TVR)任务用于探究这一差距。
- 传统监督微调(SFT)在跨视图设置下无法生成连贯的推理路径。
- 稀疏奖励强化学习(RL)存在探索效率低下和收敛缓慢的问题。
- STAR-R1框架结合单阶段RL与精细奖励机制,应对上述局限性。
- STAR-R1在TVR任务上实现最佳性能,较SFT在跨视图场景中高出23%。
点此查看论文截图

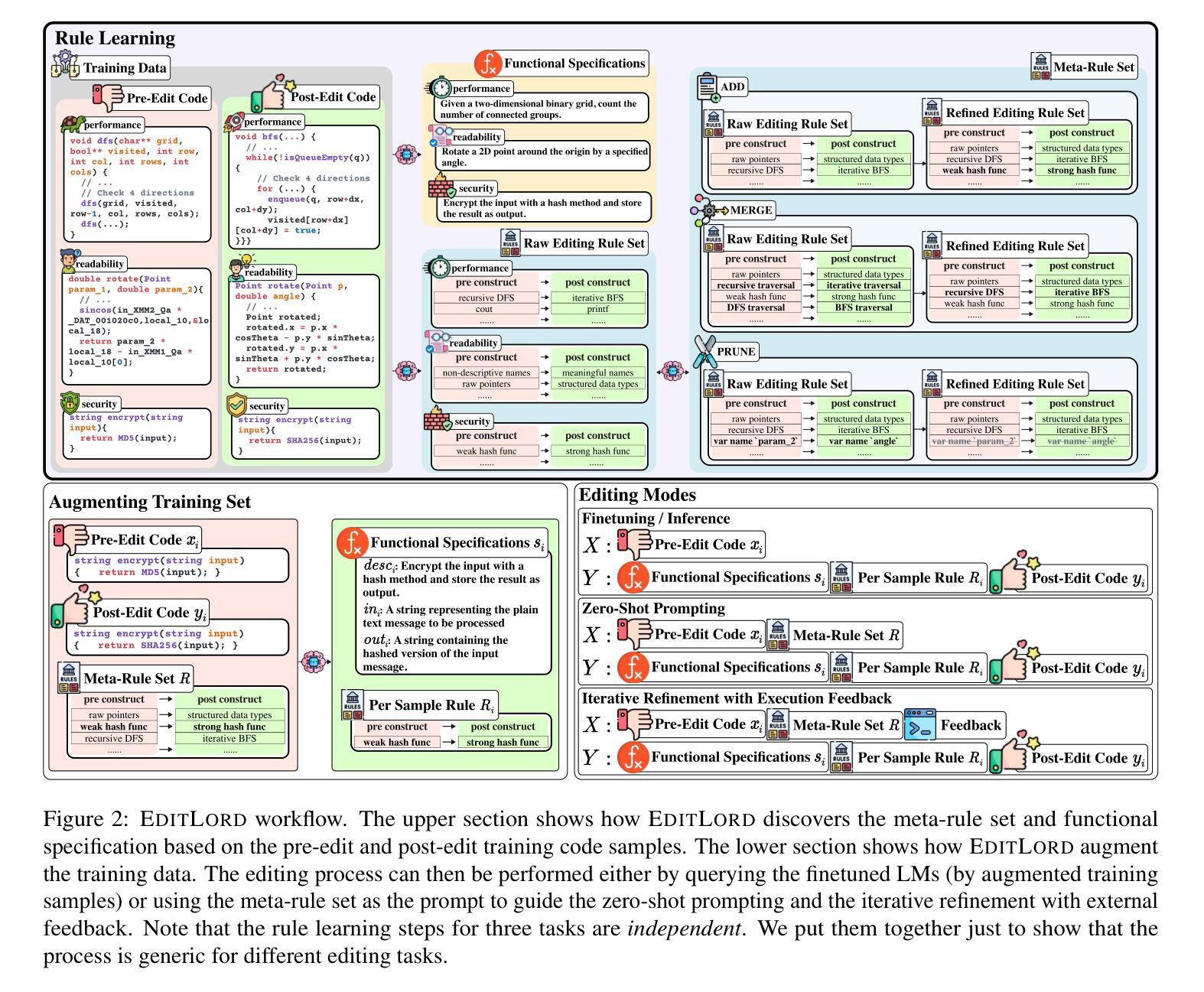
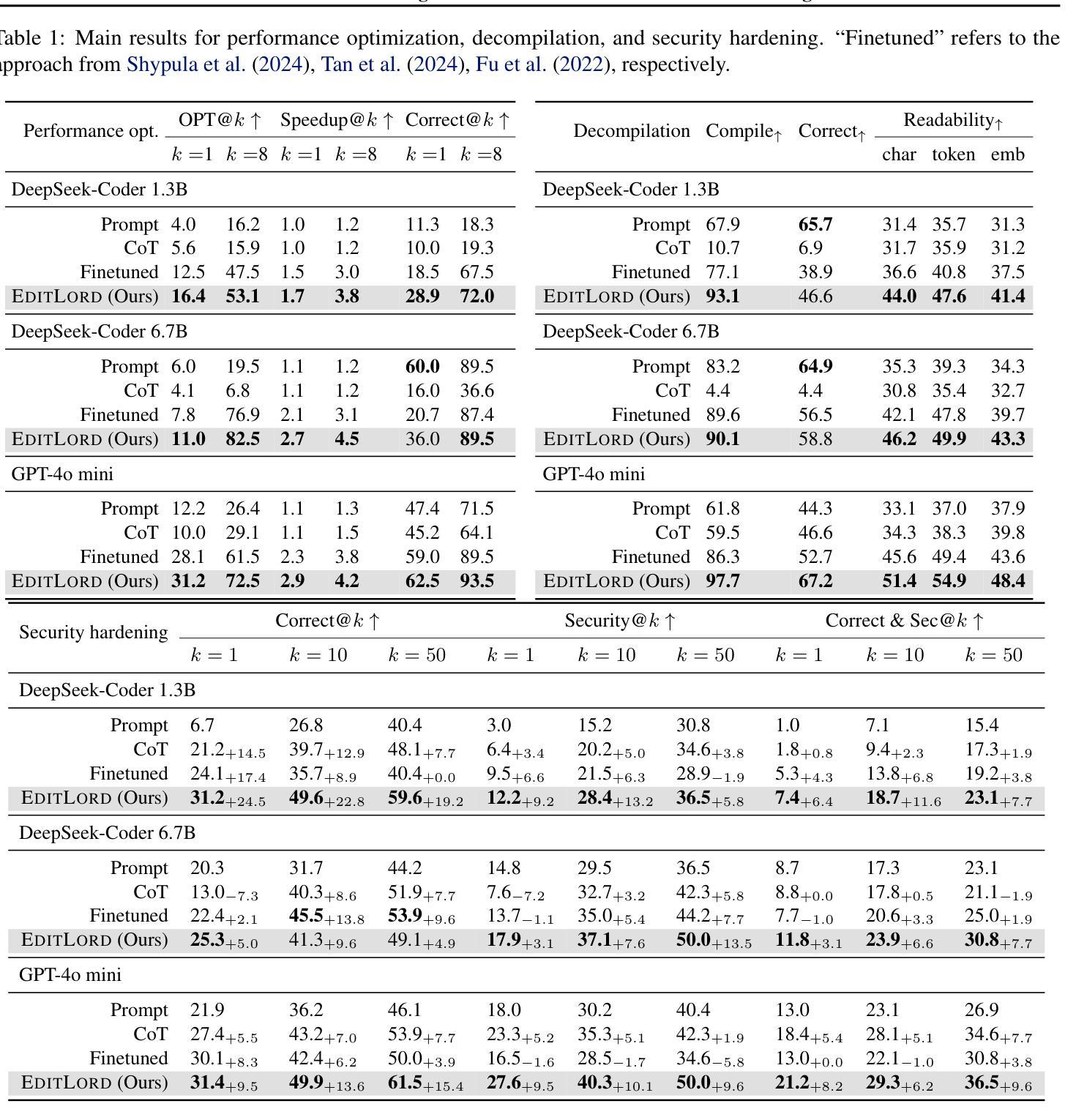
EditLord: Learning Code Transformation Rules for Code Editing
Authors:Weichen Li, Albert Jan, Baishakhi Ray, Junfeng Yang, Chengzhi Mao, Kexin Pei
Code editing is a foundational task in software development, where its effectiveness depends on whether it introduces desired code property changes without changing the original code’s intended functionality. Existing approaches often formulate code editing as an implicit end-to-end task, omitting the fact that code-editing procedures inherently consist of discrete and explicit steps. Thus, they suffer from suboptimal performance and lack of robustness and generalization. We introduce EditLord, a code editing framework that makes the code transformation steps explicit. Our key insight is to employ a language model (LM) as an inductive learner to extract code editing rules from the training code pairs as concise meta-rule sets. Such rule sets will be manifested for each training sample to augment them for finetuning or assist in prompting- and iterative-based code editing. EditLord outperforms the state-of-the-art by an average of 22.7% in editing performance and 58.1% in robustness while achieving 20.2% higher functional correctness across critical software engineering and security applications, LM models, and editing modes.
代码编辑是软件开发中的基础任务,其有效性取决于是否在不改变原始代码预期功能的情况下引入了所需的代码属性更改。现有方法通常将代码编辑制定为隐式的端到端任务,忽略了代码编辑过程本质上包含离散和明确步骤这一事实。因此,它们面临性能不佳、缺乏稳健性和泛化能力的问题。我们引入了EditLord,这是一个使代码转换步骤明确的代码编辑框架。我们的关键见解是,采用语言模型(LM)作为归纳学习者,从训练代码对中提取代码编辑规则,形成简洁的元规则集。这样的规则集将为每个训练样本提供表现,以增强它们进行微调或辅助基于提示和迭代的代码编辑。EditLord在编辑性能上平均高出最新技术22.7%,在稳健性上高出58.1%,同时在关键软件工程和安全应用程序、LM模型和编辑模式下实现20.2%更高的功能正确性。
论文及项目相关链接
摘要
代码编辑是软件开发中的基础任务,其有效性取决于是否在改变原始代码预期功能的同时引入所需的代码属性更改。现有方法通常将代码编辑制定为隐式的端到端任务,忽略了代码编辑过程本质上包含离散和显式步骤这一事实。因此,它们存在性能不佳、缺乏稳健性和泛化能力的问题。我们引入了EditLord,一个使代码转换步骤显式的代码编辑框架。我们的关键见解是,采用语言模型(LM)作为归纳学习器,从训练代码对中提取代码编辑规则,形成简洁的元规则集。这样的规则集将为每个训练样本提供辅助,用于微调或辅助基于提示和迭代的代码编辑。EditLord在编辑性能、稳健性和功能正确性方面均优于现有技术,平均提高22.7%、58.1%和20.2%,适用于关键软件工程和安全应用程序、LM模型和编辑模式。
要点
- 代码编辑是软件开发中的核心任务,要求在不改变原始代码预期功能的前提下引入所需的代码属性更改。
- 现有方法将代码编辑视为隐式的端到端任务,忽略了代码编辑过程的离散和显式步骤,导致性能不佳和缺乏稳健性。
- EditLord框架使代码转换步骤显式化,通过采用语言模型作为归纳学习器,从训练代码对中提取简洁的元规则集。
- 这些规则集可用于为训练样本提供辅助,用于微调或基于提示和迭代的代码编辑。
- EditLord在编辑性能、稳健性和功能正确性方面显著优于现有技术,适用于多种软件工程和应用程序场景。
- EditLord的平均编辑性能提高22.7%,稳健性提高58.1%,功能正确性提高20.2%。
点此查看论文截图