⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-12 更新
MUVOD: A Novel Multi-view Video Object Segmentation Dataset and A Benchmark for 3D Segmentation
Authors:Bangning Wei, Joshua Maraval, Meriem Outtas, Kidiyo Kpalma, Nicolas Ramin, Lu Zhang
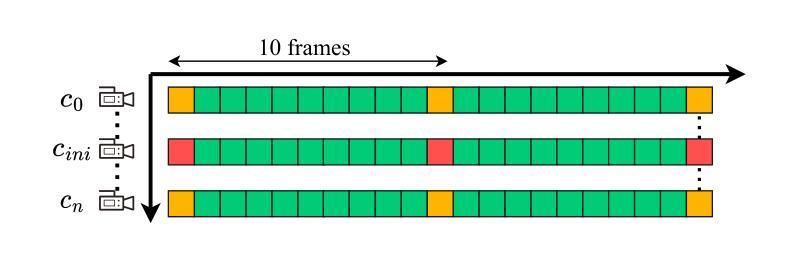
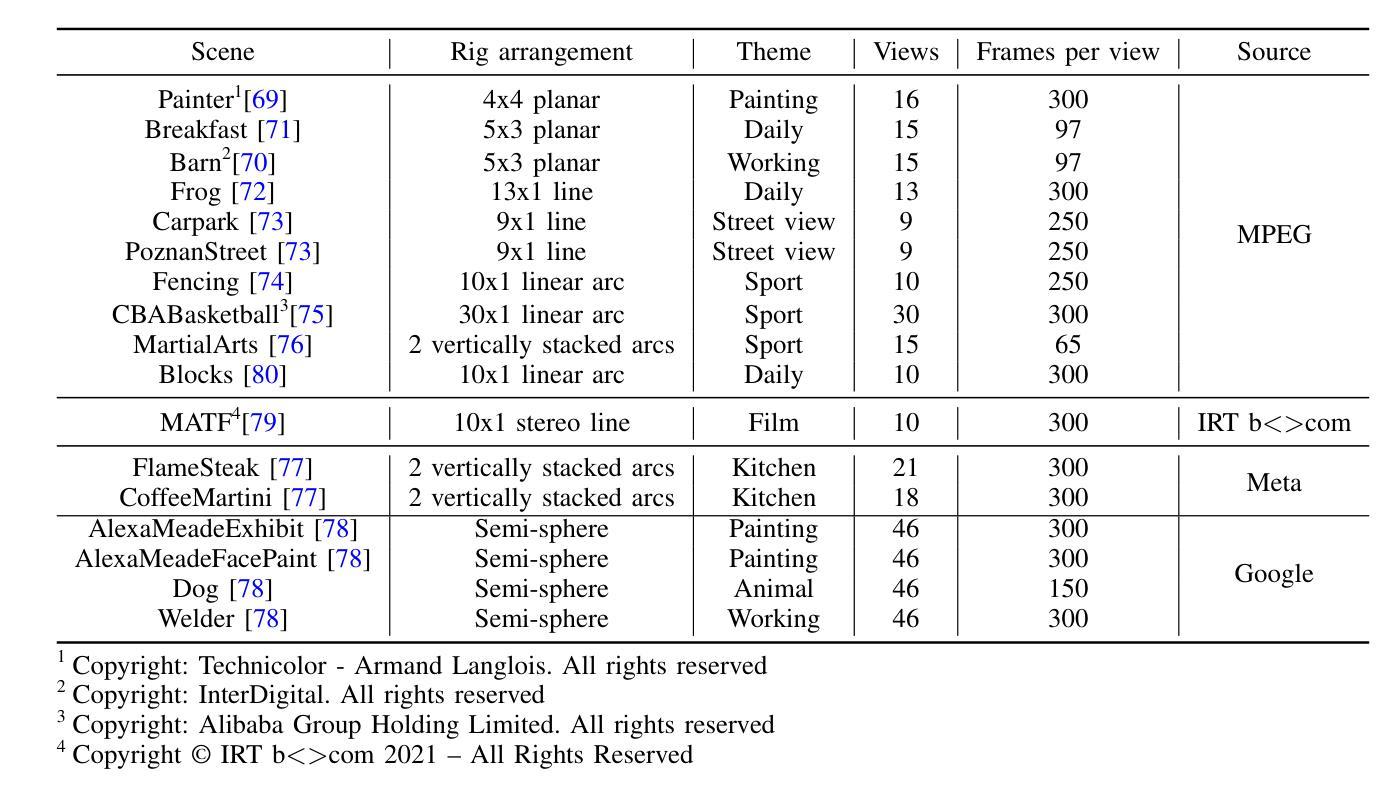
The application of methods based on Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3D GS) have steadily gained popularity in the field of 3D object segmentation in static scenes. These approaches demonstrate efficacy in a range of 3D scene understanding and editing tasks. Nevertheless, the 4D object segmentation of dynamic scenes remains an underexplored field due to the absence of a sufficiently extensive and accurately labelled multi-view video dataset. In this paper, we present MUVOD, a new multi-view video dataset for training and evaluating object segmentation in reconstructed real-world scenarios. The 17 selected scenes, describing various indoor or outdoor activities, are collected from different sources of datasets originating from various types of camera rigs. Each scene contains a minimum of 9 views and a maximum of 46 views. We provide 7830 RGB images (30 frames per video) with their corresponding segmentation mask in 4D motion, meaning that any object of interest in the scene could be tracked across temporal frames of a given view or across different views belonging to the same camera rig. This dataset, which contains 459 instances of 73 categories, is intended as a basic benchmark for the evaluation of multi-view video segmentation methods. We also present an evaluation metric and a baseline segmentation approach to encourage and evaluate progress in this evolving field. Additionally, we propose a new benchmark for 3D object segmentation task with a subset of annotated multi-view images selected from our MUVOD dataset. This subset contains 50 objects of different conditions in different scenarios, providing a more comprehensive analysis of state-of-the-art 3D object segmentation methods. Our proposed MUVOD dataset is available at https://volumetric-repository.labs.b-com.com/#/muvod.
基于神经网络辐射场(NeRF)和3D高斯拼贴(3D GS)的方法在静态场景的3D对象分割领域逐渐流行起来。这些方法在多种3D场景理解和编辑任务中表现出有效性。然而,由于缺少足够广泛且精确标注的多视角视频数据集,动态场景的4D对象分割仍然是一个未被充分研究的领域。在本文中,我们介绍了MUVOD,这是一个用于训练和评估重建现实场景中的对象分割的多视角视频数据集。所选择的17个场景描述了各种室内或室外活动,它们是从不同来源的数据集中收集的,这些数据集来源于各种类型的摄像机装置。每个场景包含最少9个视角和最多46个视角。我们提供了7830张RGB图像(每段视频30帧)及其相应的4D运动分割掩膜,这意味着场景中的任何感兴趣对象都可以在给定视角的时间帧内或在同一摄像机装置的不同视角中被追踪。这个数据集包含73个类别的459个实例,旨在作为多视角视频分割方法评估的基本基准。我们还介绍了一种评估指标和一种基线分割方法,以鼓励并评估这一不断发展领域的进展。此外,我们还针对从我们的MUVOD数据集中选取的带注释的多视角图像子集,提出了一个新的3D对象分割任务的基准。这个子集包含了不同场景下50个不同条件下的对象,为最先进的3D对象分割方法提供了更全面的分析。我们提出的MUVOD数据集可在https://volumetric-repository.labs.b-com.com/#/muvod上获得。
论文及项目相关链接
摘要
基于Neural Radiance Fields(NeRF)和3D Gaussian Splatting(3D GS)的方法在静态场景的3D对象分割领域已逐渐受到关注。本文提出一个新的多视角视频数据集MUVOD,用于训练和评估重建现实场景中的对象分割。数据集包含17个描述各种室内或室外活动的场景,来源于不同的相机设备。每个场景包含至少9个视角,最多达46个视角。提供了带有相应分割掩码的7830张RGB图像(每视频30帧),以呈现对象在四维运动中的分割情况。该数据集包含73类的459个实例,旨在作为多视角视频分割方法的基准评估数据集。此外,本文还提出了一个评估指标和基准分割方法,以鼓励并评估这一领域的进步。同时,我们还提出了一个新的3D对象分割任务的基准数据集,从我们的MUVOD数据集中选择了注释的多视角图像子集。这个子集在不同场景中包含了不同条件下的50个对象,为现有的先进3D对象分割方法提供了更全面的分析。MUVOD数据集可在链接获取。
关键见解
- 提出了一种新的多视角视频数据集MUVOD,用于训练和评估重建现实场景中的对象分割。
- 数据集包含至少包含九个视角、最多包含四十六个视角的十七个场景,涵盖了各种室内和室外活动。
- 数据集提供了四维运动中对象的RGB图像及其对应的分割掩码,可用于追踪场景中的任何感兴趣对象。
- 数据集包含属于七十三个类别的四百五十九个实例,作为多视角视频分割方法的基准评估数据集。
- 为了鼓励在该领域的进步,提出了一种新的评估指标和基准分割方法。
- 提出一个新的基于MUVOD数据集的子集作为新的基准数据集,用于评估先进的三维对象分割方法。这个子集包含不同条件下的五十个对象。
点此查看论文截图