⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-12 更新
Traceable Evidence Enhanced Visual Grounded Reasoning: Evaluation and Methodology
Authors:Haochen Wang, Xiangtai Li, Zilong Huang, Anran Wang, Jiacong Wang, Tao Zhang, Jiani Zheng, Sule Bai, Zijian Kang, Jiashi Feng, Zhuochen Wang, Zhaoxiang Zhang
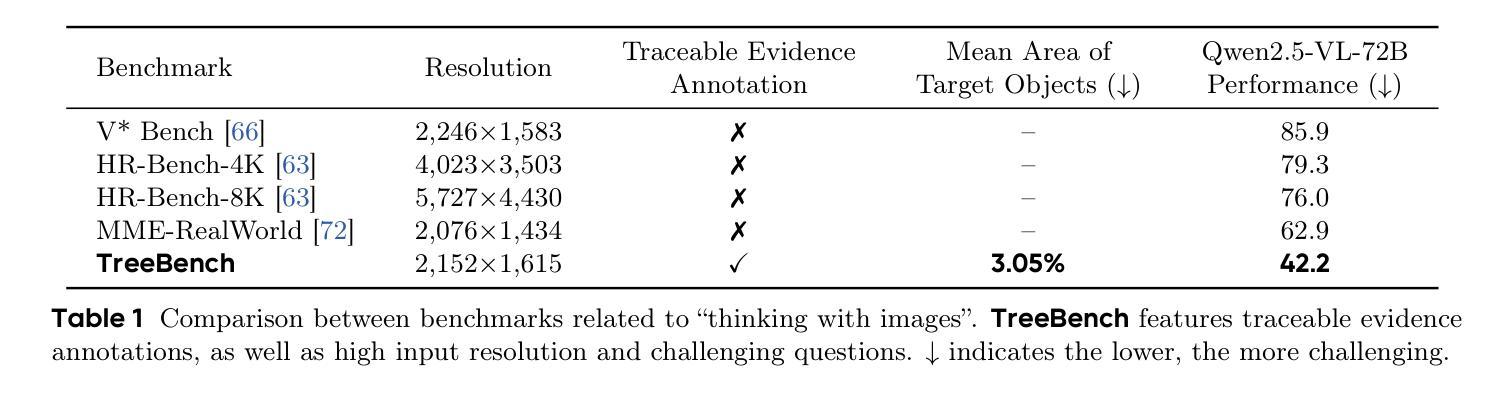
Models like OpenAI-o3 pioneer visual grounded reasoning by dynamically referencing visual regions, just like human “thinking with images”. However, no benchmark exists to evaluate these capabilities holistically. To bridge this gap, we propose TreeBench (Traceable Evidence Evaluation Benchmark), a diagnostic benchmark built on three principles: (1) focused visual perception of subtle targets in complex scenes, (2) traceable evidence via bounding box evaluation, and (3) second-order reasoning to test object interactions and spatial hierarchies beyond simple object localization. Prioritizing images with dense objects, we initially sample 1K high-quality images from SA-1B, and incorporate eight LMM experts to manually annotate questions, candidate options, and answers for each image. After three stages of quality control, TreeBench consists of 405 challenging visual question-answering pairs, even the most advanced models struggle with this benchmark, where none of them reach 60% accuracy, e.g., OpenAI-o3 scores only 54.87. Furthermore, we introduce TreeVGR (Traceable Evidence Enhanced Visual Grounded Reasoning), a training paradigm to supervise localization and reasoning jointly with reinforcement learning, enabling accurate localizations and explainable reasoning pathways. Initialized from Qwen2.5-VL-7B, it improves V* Bench (+16.8), MME-RealWorld (+12.6), and TreeBench (+13.4), proving traceability is key to advancing vision-grounded reasoning. The code is available at https://github.com/Haochen-Wang409/TreeVGR.
像OpenAI-o3这样的模型通过动态参考视觉区域来开创视觉推理的先河,就像人类“以图像思考”一样。然而,还没有一个全面的基准来评估这些能力。为了弥补这一空白,我们提出了TreeBench(可追溯证据评估基准),这是一个基于三个原则的诊断基准:(1)对复杂场景中细微目标的集中视觉感知;(2)通过边界框评估的可追溯证据;(3)二阶推理,以测试对象交互和空间层次结构,而不仅仅是简单的对象定位。我们优先处理密集物体的图像,最初从SA-1B中采样了1K张高质量图像,并融入了八位LMM专家为每张图像手动标注问题、候选选项和答案。经过三个阶段的质量控制,TreeBench包含了405个具有挑战性的视觉问答对,即使是最先进的模型在这个基准上也会遇到困难,其中没有哪个模型的准确率能达到60%,例如OpenAI-o3的得分仅为54.87。此外,我们引入了TreeVGR(可追溯证据增强视觉推理),这是一种用强化学习联合监督定位和推理的训练范式,能够实现准确的定位和可解释的推理路径。从Qwen2.5-VL-7B开始初始化,它在V* Bench(+16.8)、MME-RealWorld(+12.6)和TreeBench(+13.4)上都有所改进,证明追溯性是推进视觉推理的关键。代码可在https://github.com/Haochen-Wang409/TreeVGR上找到。
论文及项目相关链接
Summary
本文介绍了OpenAI-o3等模型在视觉推理方面的进展,但缺乏全面的评估基准。为此,提出了TreeBench评估基准,以测试模型在复杂场景中的细微目标感知、边界框评估的可追踪证据和二阶推理能力。此外,还介绍了TreeVGR训练范式,通过强化学习联合监督定位和推理,提高了模型的准确性和可解释性。
Key Takeaways
- 介绍了OpenAI-o3等模型在视觉推理方面的进展,动态参考视觉区域,类似人类“图像思考”。
- 缺乏全面的评估基准来全面评估这些能力,为此提出了TreeBench评估基准。
- TreeBench基于三个原则构建:细微目标的聚焦视觉感知、通过边界框评估的可追踪证据和二阶推理能力测试。
- TreeBench包含405个具有挑战性的视觉问答对,即使是最先进的模型也难以达到60%的准确率。
- 引入了TreeVGR训练范式,通过强化学习联合监督定位和推理,提高模型准确率和解释性。
- TreeVGR从Qwen2.5-VL-7B开始初始化,可以改善V* Bench、MME-RealWorld和TreeBench的性能。
点此查看论文截图



Automating Expert-Level Medical Reasoning Evaluation of Large Language Models
Authors:Shuang Zhou, Wenya Xie, Jiaxi Li, Zaifu Zhan, Meijia Song, Han Yang, Cheyenna Espinoza, Lindsay Welton, Xinnie Mai, Yanwei Jin, Zidu Xu, Yuen-Hei Chung, Yiyun Xing, Meng-Han Tsai, Emma Schaffer, Yucheng Shi, Ninghao Liu, Zirui Liu, Rui Zhang
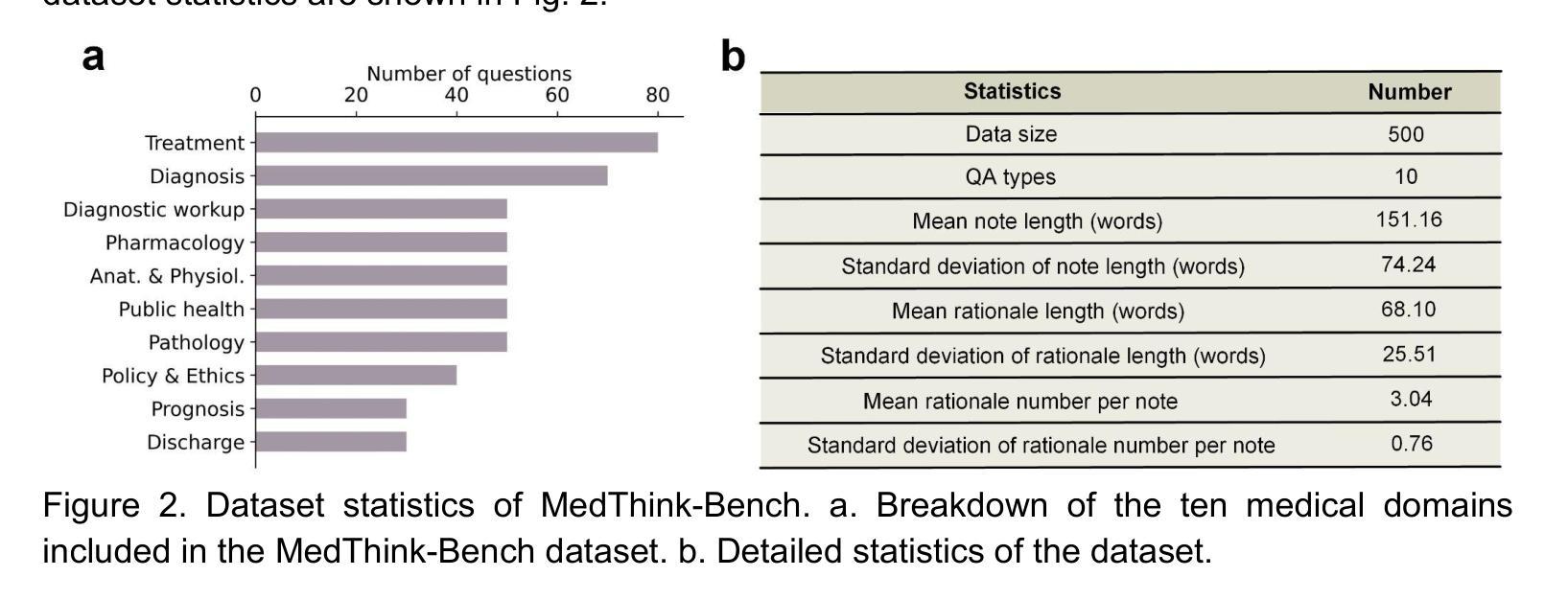
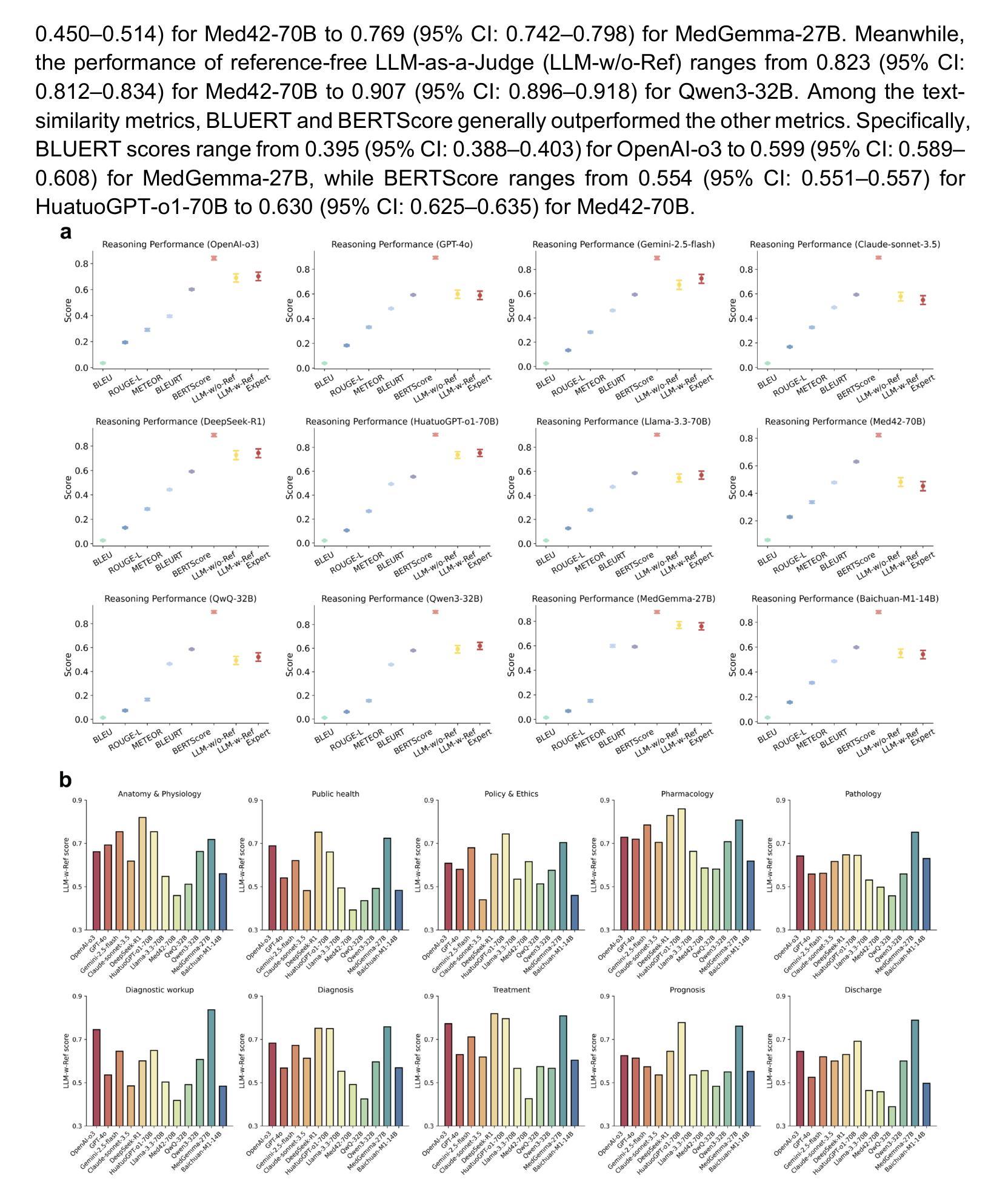
As large language models (LLMs) become increasingly integrated into clinical decision-making, ensuring transparent and trustworthy reasoning is essential. However, existing evaluation strategies of LLMs’ medical reasoning capability either suffer from unsatisfactory assessment or poor scalability, and a rigorous benchmark remains lacking. To address this, we introduce MedThink-Bench, a benchmark designed for rigorous, explainable, and scalable assessment of LLMs’ medical reasoning. MedThink-Bench comprises 500 challenging questions across ten medical domains, each annotated with expert-crafted step-by-step rationales. Building on this, we propose LLM-w-Ref, a novel evaluation framework that leverages fine-grained rationales and LLM-as-a-Judge mechanisms to assess intermediate reasoning with expert-level fidelity while maintaining scalability. Experiments show that LLM-w-Ref exhibits a strong positive correlation with expert judgments. Benchmarking twelve state-of-the-art LLMs, we find that smaller models (e.g., MedGemma-27B) can surpass larger proprietary counterparts (e.g., OpenAI-o3). Overall, MedThink-Bench offers a foundational tool for evaluating LLMs’ medical reasoning, advancing their safe and responsible deployment in clinical practice.
随着大型语言模型(LLMs)在临床决策中的集成度越来越高,确保透明和可信赖的推理至关重要。然而,现有的LLMs医疗推理能力评估策略要么存在评估不尽如人意的问题,要么存在可扩展性差的问题,且缺乏严格的基准测试。为了解决这一问题,我们引入了MedThink-Bench,这是一个为LLMs医疗推理进行严格、可解释和可扩展评估而设计的基准测试。MedThink-Bench包含500个跨越十个医学领域的挑战性问题,每个问题都附有专家制作的逐步推理。在此基础上,我们提出了LLM-w-Ref这一新型评估框架,它利用精细的推理和LLM-as-a-Judge机制来评估中间推理过程,以专家级保真度保持可扩展性。实验表明,LLM-w-Ref与专家判断呈强烈正相关。我们对12款最新LLMs进行基准测试,发现小型模型(例如MedGemma-27B)可以超越大型专有模型(例如OpenAI-o3)。总体而言,MedThink-Bench为评估LLMs的医疗推理能力提供了基础工具,推动了其在临床实践中的安全和负责任部署。
论文及项目相关链接
PDF 22 pages,6 figures
Summary:随着大型语言模型(LLMs)在临床决策中的集成度不断提高,确保透明和可信赖的推理至关重要。然而,现有的LLMs医疗推理能力评估策略存在评估结果不尽如人意或可扩展性差的问题,缺乏严格的基准测试。为解决这一问题,引入了MedThink-Bench基准测试,用于对LLMs的医疗推理能力进行严谨、可解释和可扩展的评估。该基准测试包含500个跨越十个医学领域的挑战性问题,每个问题都有专家精心制作的逐步推理。在此基础上,提出了LLM-w-Ref评估框架,利用精细的推理和LLM-as-a-Judge机制来评估中间推理过程,与专家水平的保真度保持一致,同时保持可扩展性。实验表明,LLM-w-Ref与专家判断之间存在强烈正相关。通过对12个最先进的LLMs进行基准测试,发现小型模型(如MedGemma-27B)可以超越大型专有模型(如OpenAI-o3)。总体而言,MedThink-Bench为评估LLMs的医疗推理能力提供了基础工具,推动了其在临床实践中的安全和负责任部署。
Key Takeaways:
- 大型语言模型(LLMs)在临床决策中的集成度提高,需要确保透明和可信赖的推理。
- 现有的LLMs医疗推理能力评估策略存在不足,缺乏严格的基准测试。
- MedThink-Bench基准测试用于评估LLMs的医疗推理能力,包含500个跨越十个医学领域的挑战性问题。
- LLM-w-Ref评估框架利用精细的推理和LLM机制来评估中间推理过程。
- LLM-w-Ref与专家判断之间存在强烈正相关。
- 基准测试发现小型模型在某些情况下可以超越大型专有模型。
点此查看论文截图


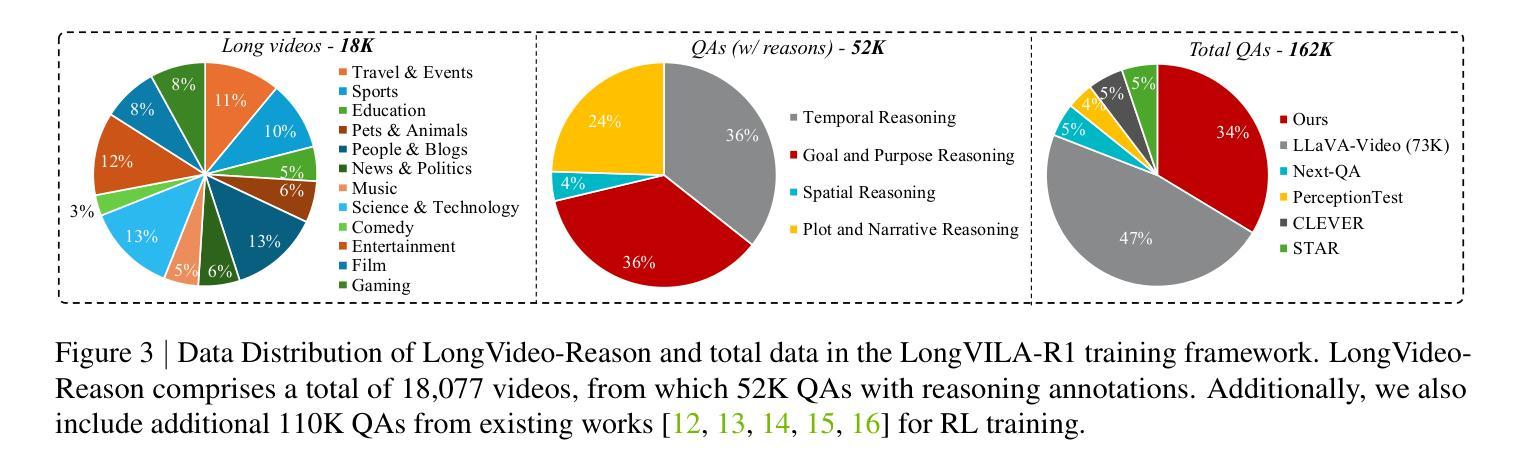
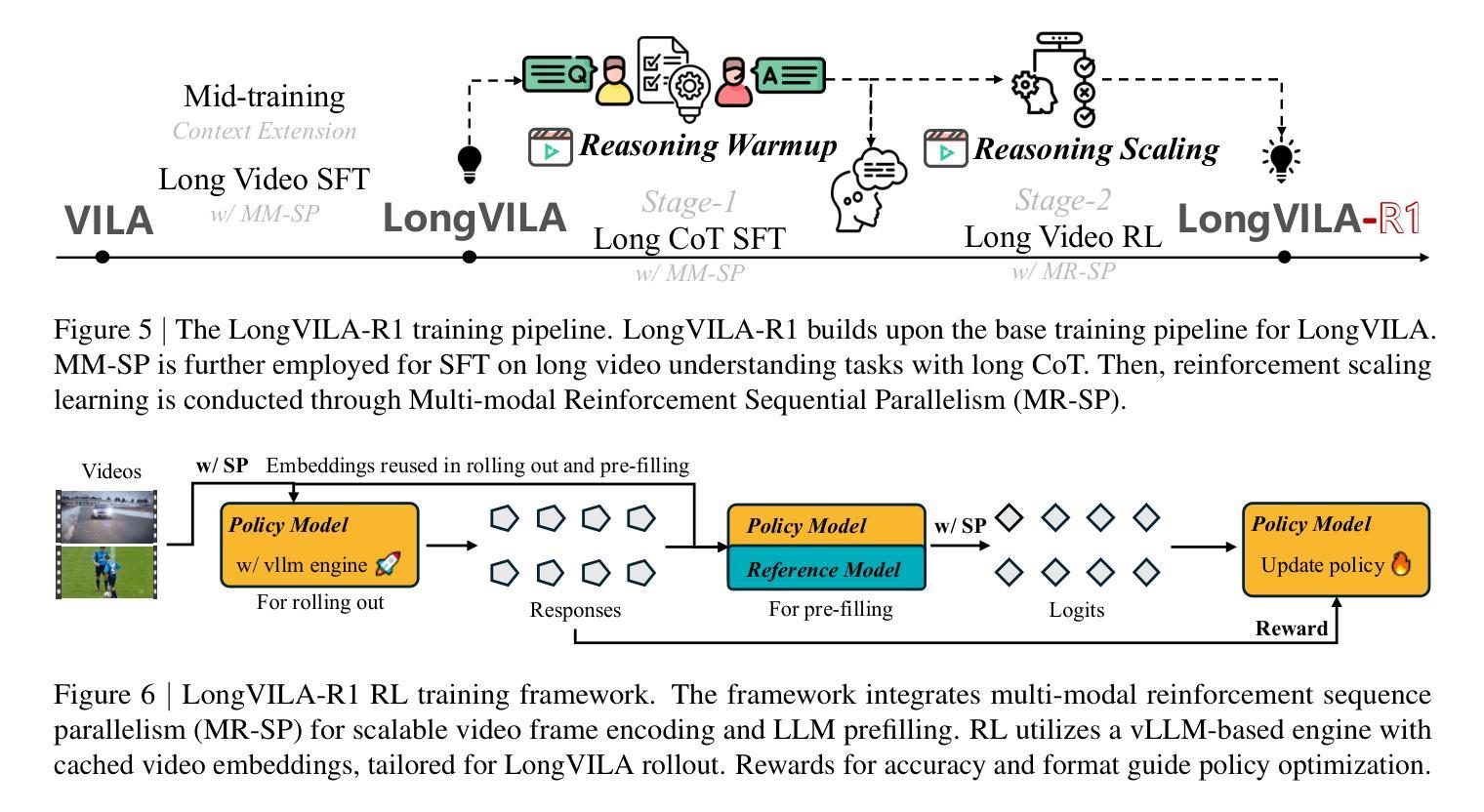
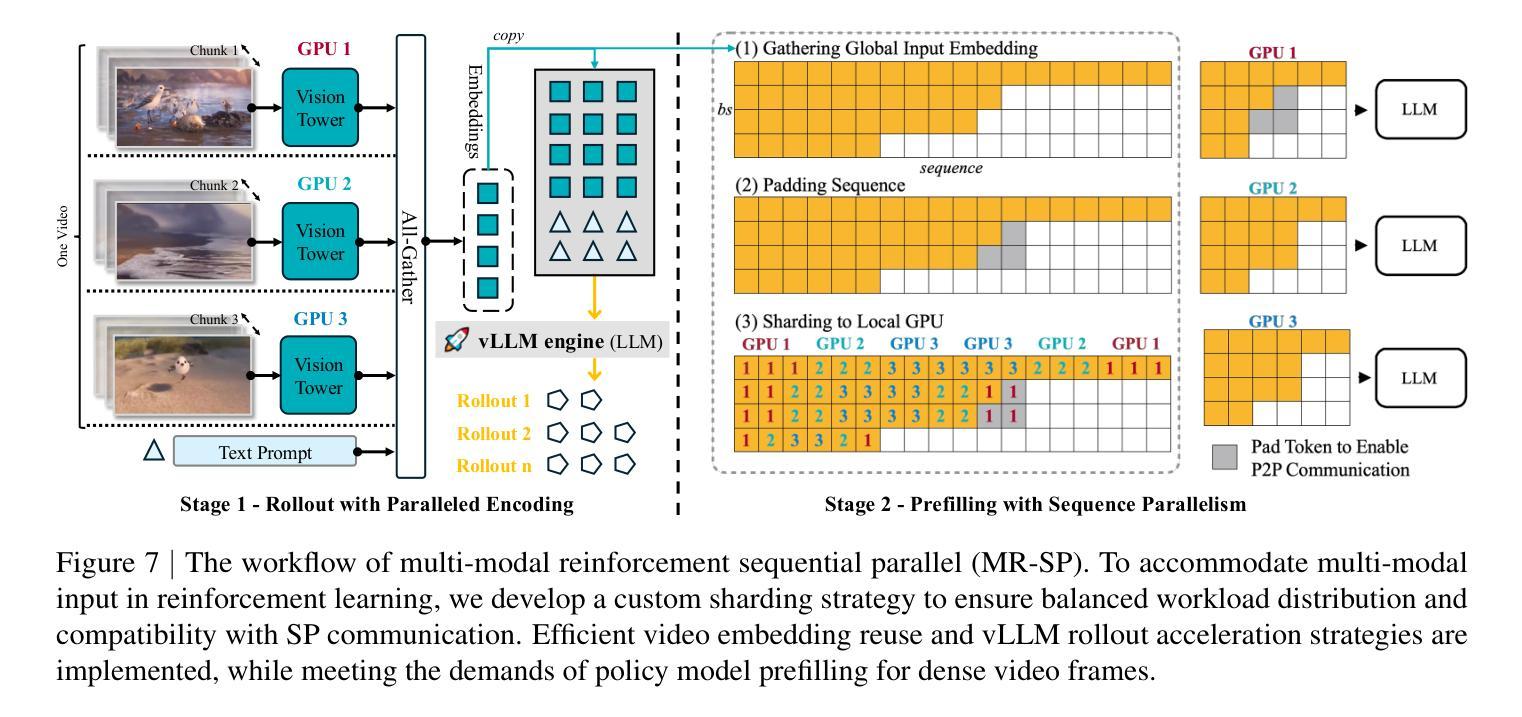
Scaling RL to Long Videos
Authors:Yukang Chen, Wei Huang, Baifeng Shi, Qinghao Hu, Hanrong Ye, Ligeng Zhu, Zhijian Liu, Pavlo Molchanov, Jan Kautz, Xiaojuan Qi, Sifei Liu, Hongxu Yin, Yao Lu, Song Han
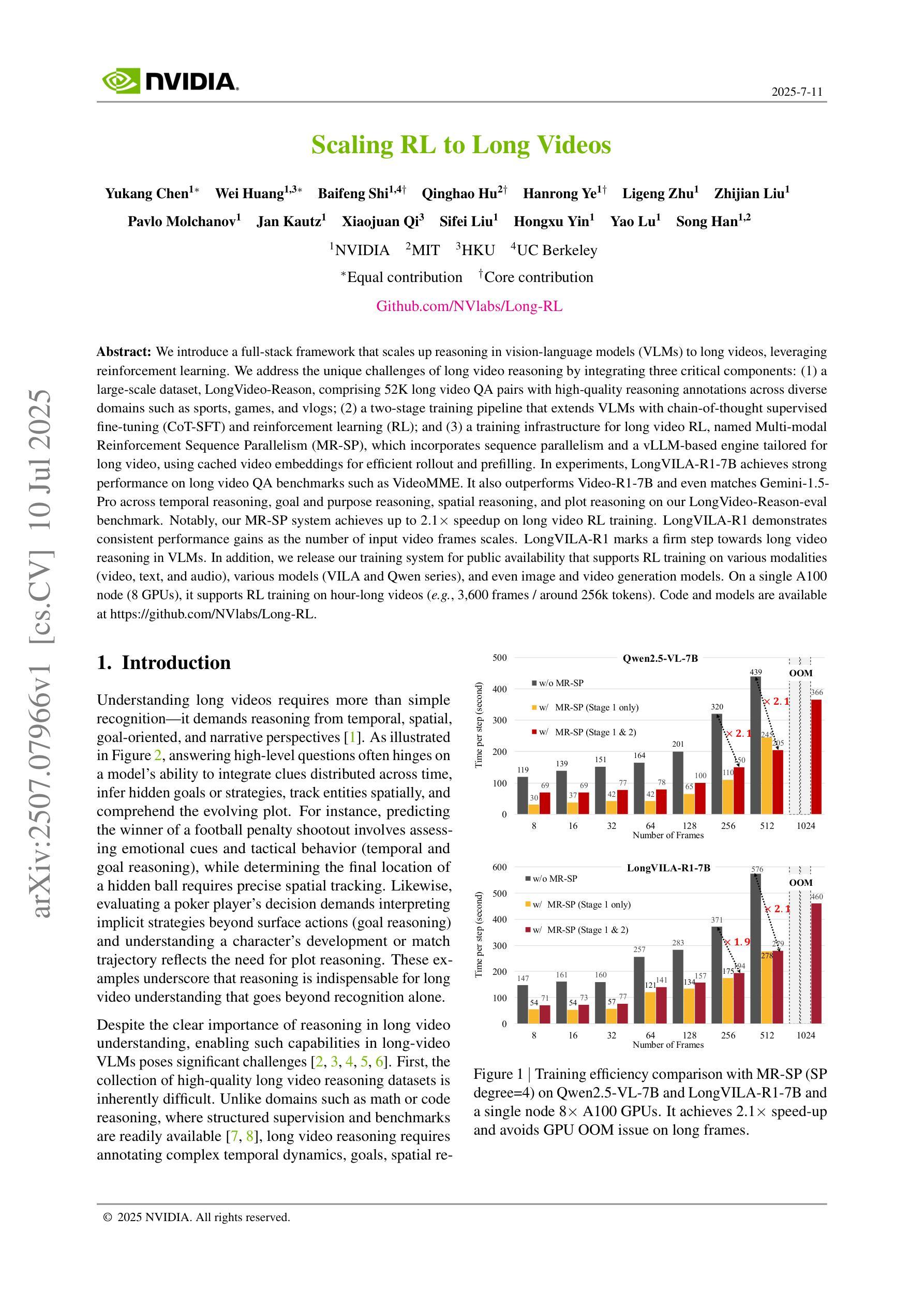
We introduce a full-stack framework that scales up reasoning in vision-language models (VLMs) to long videos, leveraging reinforcement learning. We address the unique challenges of long video reasoning by integrating three critical components: (1) a large-scale dataset, LongVideo-Reason, comprising 52K long video QA pairs with high-quality reasoning annotations across diverse domains such as sports, games, and vlogs; (2) a two-stage training pipeline that extends VLMs with chain-of-thought supervised fine-tuning (CoT-SFT) and reinforcement learning (RL); and (3) a training infrastructure for long video RL, named Multi-modal Reinforcement Sequence Parallelism (MR-SP), which incorporates sequence parallelism and a vLLM-based engine tailored for long video, using cached video embeddings for efficient rollout and prefilling. In experiments, LongVILA-R1-7B achieves strong performance on long video QA benchmarks such as VideoMME. It also outperforms Video-R1-7B and even matches Gemini-1.5-Pro across temporal reasoning, goal and purpose reasoning, spatial reasoning, and plot reasoning on our LongVideo-Reason-eval benchmark. Notably, our MR-SP system achieves up to 2.1x speedup on long video RL training. LongVILA-R1 demonstrates consistent performance gains as the number of input video frames scales. LongVILA-R1 marks a firm step towards long video reasoning in VLMs. In addition, we release our training system for public availability that supports RL training on various modalities (video, text, and audio), various models (VILA and Qwen series), and even image and video generation models. On a single A100 node (8 GPUs), it supports RL training on hour-long videos (e.g., 3,600 frames / around 256k tokens).
我们引入了一个全栈框架,该框架利用强化学习将视觉语言模型(VLMs)的推理扩展到长视频。通过集成三个关键组件来解决长视频推理的独特挑战:(1)大规模数据集LongVideo-Reason,包含52K长视频问答对,涵盖体育、游戏、Vlog等不同领域的高质量推理注释;(2)两阶段训练管道,通过链式思维监督微调(CoT-SFT)和强化学习(RL)扩展VLMs;(3)长视频RL的训练基础设施,名为多模态强化序列并行性(MR-SP),它结合了序列并行性和针对长视频的vLLM引擎,使用缓存的视频嵌入进行高效rollout和预填充。在实验中,LongVILA-R1-7B在长视频问答基准测试(如VideoMME)上表现强劲。它在我们的LongVideo-Reason-eval基准测试中,在时序推理、目标和目的推理、空间推理和情节推理方面都优于Video-R1-7B,甚至与Gemini-1.5-Pro相匹配。值得注意的是,我们的MR-SP系统实现了长达视频RL训练的2.1倍加速。随着输入视频帧数量的增加,LongVILA-R1持续展现出性能的提升。LongVILA-R1标志着向VLMs中的长视频推理迈出了坚实的一步。此外,我们公开发布了支持各种模态(视频、文本和音频)的训练系统,支持VILA和Qwen系列等多种模型,甚至支持图像和视频生成模型。在单个A100节点(8个GPU)上,它支持长达一小时的视频的RL训练(例如,3600帧/约256k令牌)。
论文及项目相关链接
PDF Code and models are available at https://github.com/NVlabs/Long-RL
Summary
该研究推出了一套针对视觉语言模型(VLMs)的长视频推理的全栈框架,利用强化学习来解决长视频推理的独特挑战。该框架包含大规模数据集LongVideo-Reason、两阶段训练管道和针对长视频RL的训练基础设施Multi-modal Reinforcement Sequence Parallelism(MR-SP)。实验表明,LongVILA-R1在长视频QA基准测试中表现强劲,并实现了长视频推理领域的重要突破。
Key Takeaways
- 引入了针对视觉语言模型(VLMs)的长视频推理的全栈框架,利用强化学习提升性能。
- 解决了长视频推理的独特挑战,通过集成三个关键组件:大规模数据集LongVideo-Reason、两阶段训练管道和MR-SP训练基础设施。
- LongVILA-R1在长视频QA基准测试中表现优异,匹配或超越了现有先进模型。
- MR-SP系统实现了长视频RL训练的速度提升,达到2.1倍。
- LongVILA-R1在输入视频帧数增加时,表现持续增强。
- LongVILA-R1的推出标志着长视频推理在VLMs领域的重要进展。
- 研究者公开了训练系统,支持多种模态(视频、文本、音频)的RL训练,以及不同模型(VILA和Qwen系列)和图像、视频生成模型的训练。
点此查看论文截图


Measuring AI Alignment with Human Flourishing
Authors:Elizabeth Hilliard, Akshaya Jagadeesh, Alex Cook, Steele Billings, Nicholas Skytland, Alicia Llewellyn, Jackson Paull, Nathan Paull, Nolan Kurylo, Keatra Nesbitt, Robert Gruenewald, Anthony Jantzi, Omar Chavez
This paper introduces the Flourishing AI Benchmark (FAI Benchmark), a novel evaluation framework that assesses AI alignment with human flourishing across seven dimensions: Character and Virtue, Close Social Relationships, Happiness and Life Satisfaction, Meaning and Purpose, Mental and Physical Health, Financial and Material Stability, and Faith and Spirituality. Unlike traditional benchmarks that focus on technical capabilities or harm prevention, the FAI Benchmark measures AI performance on how effectively models contribute to the flourishing of a person across these dimensions. The benchmark evaluates how effectively LLM AI systems align with current research models of holistic human well-being through a comprehensive methodology that incorporates 1,229 objective and subjective questions. Using specialized judge Large Language Models (LLMs) and cross-dimensional evaluation, the FAI Benchmark employs geometric mean scoring to ensure balanced performance across all flourishing dimensions. Initial testing of 28 leading language models reveals that while some models approach holistic alignment (with the highest-scoring models achieving 72/100), none are acceptably aligned across all dimensions, particularly in Faith and Spirituality, Character and Virtue, and Meaning and Purpose. This research establishes a framework for developing AI systems that actively support human flourishing rather than merely avoiding harm, offering significant implications for AI development, ethics, and evaluation.
本文介绍了新兴的繁荣人工智能基准测试(FAI Benchmark),这是一个全新的评估框架,可以从七个维度评估人工智能与人类繁荣的契合度:性格与美德、亲密社会关系、幸福与生活满意度、意义与目的、身心健康、财务与物质稳定以及信仰与灵性。与传统的以技术能力或伤害预防为重点的基准测试不同,FAI Benchmark衡量的是人工智能在这些维度上如何有效地促进人的繁荣。该基准测试通过一种综合方法,采用包含1,229个客观和主观问题的全面评估体系,评价大型语言模型AI系统如何与目前的全人类整体福祉研究模型相契合。通过运用专业化的裁判大型语言模型(LLM)和跨维度评估,FAI Benchmark采用几何均值评分法,确保在所有繁荣维度上的表现均衡。对28种领先的语言模型的初步测试表明,尽管一些模型在整体对齐方面取得了进展(得分最高的模型得分为72分),但没有一款在所有维度上都达到了可接受的契合度,特别是在信仰与灵性、性格与美德以及意义与目的方面。该研究为开发积极支持人类繁荣的人工智能系统而不是仅仅避免危害的系统的开发建立了框架,对人工智能发展、伦理和评估产生了重大影响。
论文及项目相关链接
Summary:
此论文介绍了繁荣人工智能基准(FAI Benchmark),这是一种新型评估框架,用于评估人工智能在七个维度上对人类繁荣的贡献程度。这些维度包括性格与美德、亲密社会关系、幸福与人生满意度、意义与目的、身心健康、财务与物质稳定以及信仰与精神。与传统的以技术能力或伤害预防为重点的基准不同,FAI Benchmark通过一种综合方法衡量人工智能模型在这些维度上对人类繁荣的贡献程度,该方法结合了客观和主观问题。该基准使用专门的判断大型语言模型(LLMs)进行跨维度评估,并采用几何平均评分确保在所有繁荣维度上的均衡表现。初步测试表明,尽管一些模型在整体对齐方面取得进展,但没有模型在所有维度上都能达到可接受的对齐程度。这为AI系统的开发提供了一个框架,以支持人类繁荣而不仅仅是避免伤害,对AI发展、伦理和评估具有重要意义。
Key Takeaways:
- Flourishing AI Benchmark(FAI Benchmark)是一个新型评估框架,旨在评估AI在多个维度上对人类繁荣的贡献。
- 该框架涵盖了性格与美德、社会关系、幸福与满意度等七个维度。
- FAI Benchmark不同于传统的人工智能评估基准,它侧重于评估AI如何促进人类的全面繁荣。
- 该框架采用综合方法,结合客观和主观问题进行评价。
- 使用Large Language Models(LLMs)进行跨维度评估和几何平均评分。
- 初步测试表明,尽管一些模型在整体对齐方面取得进展,但没有模型在所有维度上实现完美对齐。
点此查看论文截图

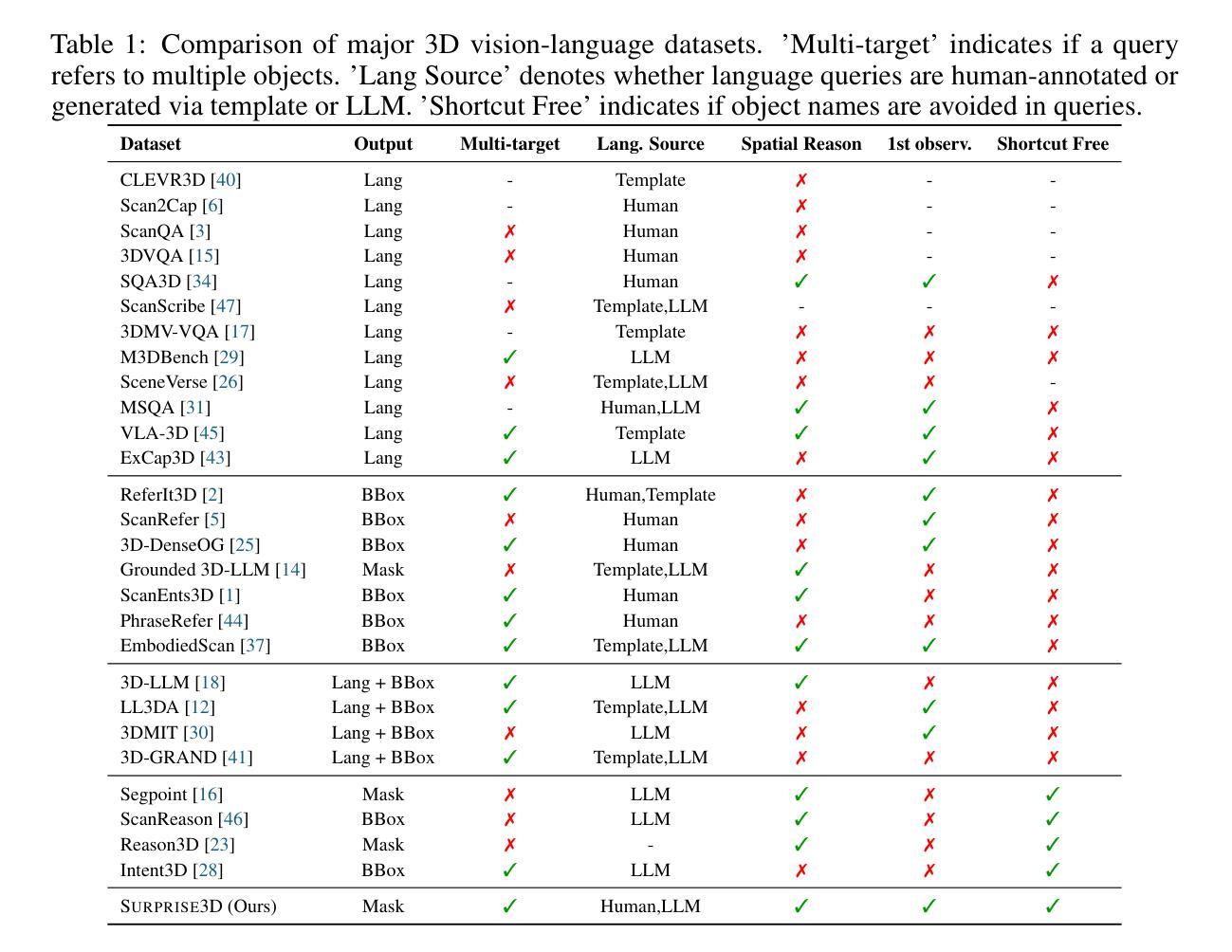
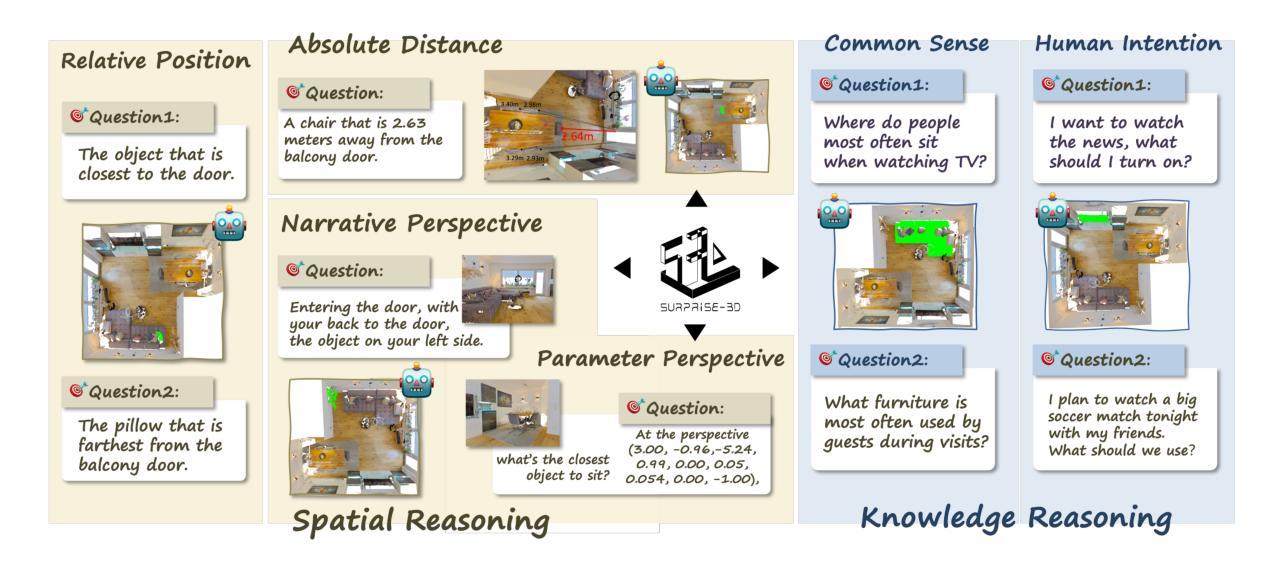
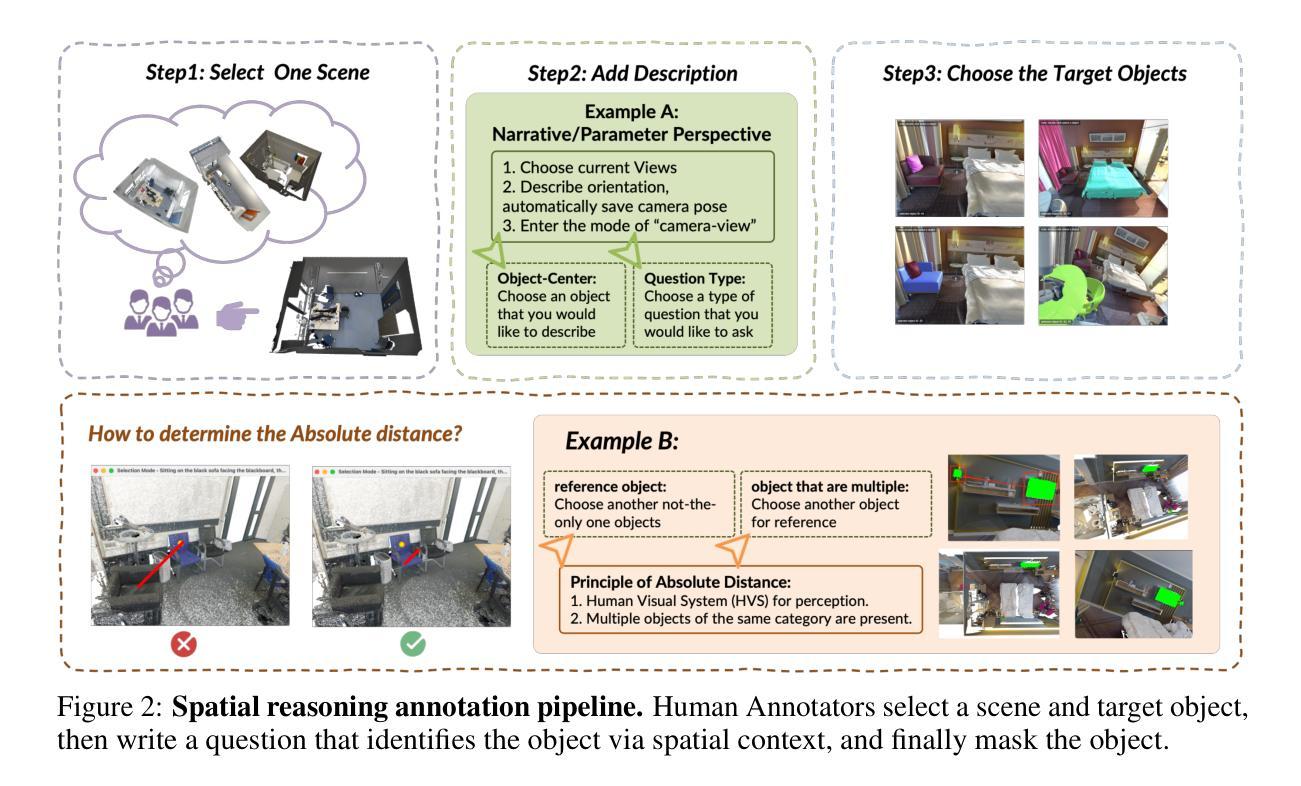
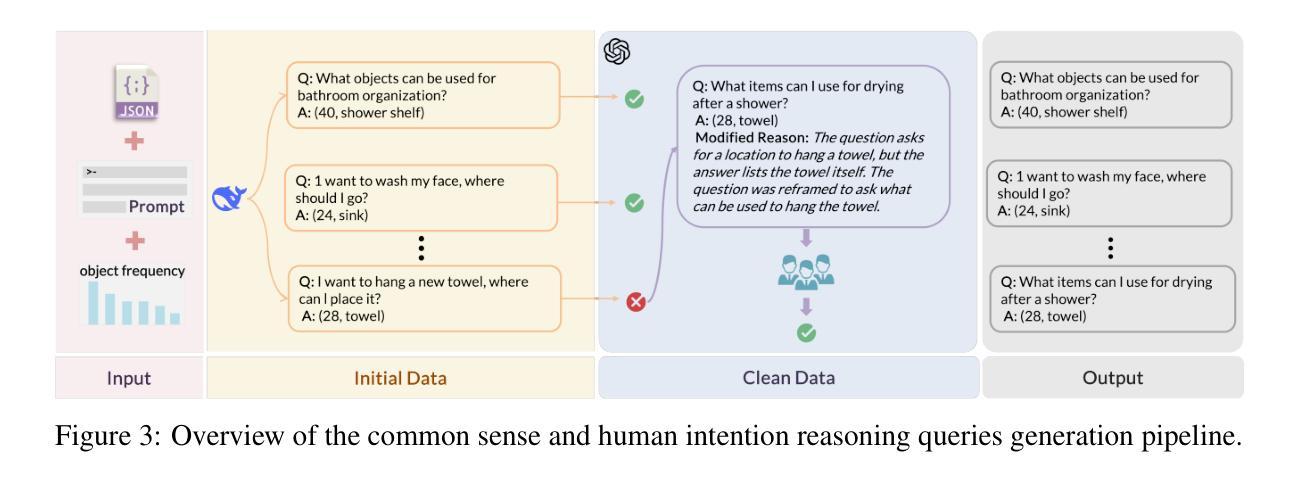
SURPRISE3D: A Dataset for Spatial Understanding and Reasoning in Complex 3D Scenes
Authors:Jiaxin Huang, Ziwen Li, Hanlve Zhang, Runnan Chen, Xiao He, Yandong Guo, Wenping Wang, Tongliang Liu, Mingming Gong
The integration of language and 3D perception is critical for embodied AI and robotic systems to perceive, understand, and interact with the physical world. Spatial reasoning, a key capability for understanding spatial relationships between objects, remains underexplored in current 3D vision-language research. Existing datasets often mix semantic cues (e.g., object name) with spatial context, leading models to rely on superficial shortcuts rather than genuinely interpreting spatial relationships. To address this gap, we introduce S\textsc{urprise}3D, a novel dataset designed to evaluate language-guided spatial reasoning segmentation in complex 3D scenes. S\textsc{urprise}3D consists of more than 200k vision language pairs across 900+ detailed indoor scenes from ScanNet++ v2, including more than 2.8k unique object classes. The dataset contains 89k+ human-annotated spatial queries deliberately crafted without object name, thereby mitigating shortcut biases in spatial understanding. These queries comprehensively cover various spatial reasoning skills, such as relative position, narrative perspective, parametric perspective, and absolute distance reasoning. Initial benchmarks demonstrate significant challenges for current state-of-the-art expert 3D visual grounding methods and 3D-LLMs, underscoring the necessity of our dataset and the accompanying 3D Spatial Reasoning Segmentation (3D-SRS) benchmark suite. S\textsc{urprise}3D and 3D-SRS aim to facilitate advancements in spatially aware AI, paving the way for effective embodied interaction and robotic planning. The code and datasets can be found in https://github.com/liziwennba/SUPRISE.
语言与3D感知的融合对于实体人工智能和机器人系统感知、理解和与物理世界交互至关重要。空间推理是理解物体之间空间关系的关键能力,在当前的3D视觉语言研究中仍然被忽视。现有的数据集往往将语义线索(如对象名称)与空间上下文混合,导致模型依赖于表面的捷径,而不是真正解释空间关系。为了解决这一差距,我们推出了S\textsc{urprise}3D,这是一个旨在评估复杂3D场景中语言引导的空间推理分割能力的新数据集。S\textsc{urprise}3D由来自ScanNet++ v2的900多个详细室内场景中的超过20万个视觉语言对组成,包括超过2800个独特的对象类别。该数据集包含超过8万个人类注释的空间查询,这些查询是精心设计的,不包含对象名称,从而减轻了空间理解中的捷径偏见。这些查询涵盖了各种空间推理技能,如相对位置、叙事视角、参数视角和绝对距离推理等。初步基准测试表明,对于目前最先进的3D视觉定位方法和3D-LLM来说,仍然存在显著挑战,这突显了我们数据集和配套的3D空间推理分割(3D-SRS)基准测试套件的重要性。S\textsc{urprise}3D和3D-SRS旨在促进空间感知人工智能的发展,为有效的实体交互和机器人规划铺平道路。代码和数据集可在https://github.com/liziwennba/SUPRISE找到。
论文及项目相关链接
Summary
本文强调了语言与3D感知融合在嵌入式人工智能和机器人系统中的重要性和挑战。针对当前数据集在评估空间推理方面的不足,提出了一种新型数据集S\textsc{urprise}3D,用于评估复杂3D场景中的语言引导空间推理分割能力。该数据集包含超过20万个视觉语言对,涵盖了多种空间推理技能,如相对位置、叙事视角、参数视角和绝对距离推理等。数据集中的空间查询未包含对象名称,从而减少了空间理解的捷径偏见。S\textsc{urprise}3D及其伴随的3D空间推理分割(3D-SRS)基准套件旨在推动空间感知人工智能的发展,为实现有效的嵌入式交互和机器人规划铺平道路。
Key Takeaways
- 语言与3D感知的融合对嵌入式AI和机器人系统的物理世界交互至关重要。
- 当前数据集在评估空间推理方面存在不足,需要新型数据集来改进。
- S\textsc{urprise}3D数据集用于评估语言引导的空间推理分割能力,包含多种空间推理技能。
- 数据集中的空间查询未包含对象名称,以减少对空间理解的捷径偏见。
- S\textsc{urprise}3D和3D-SRS基准套件旨在推动空间感知人工智能的发展。
- 基准套件为现有的人工智能技术提供了挑战,包括最先进的3D视觉定位方法和大型语言模型。
点此查看论文截图

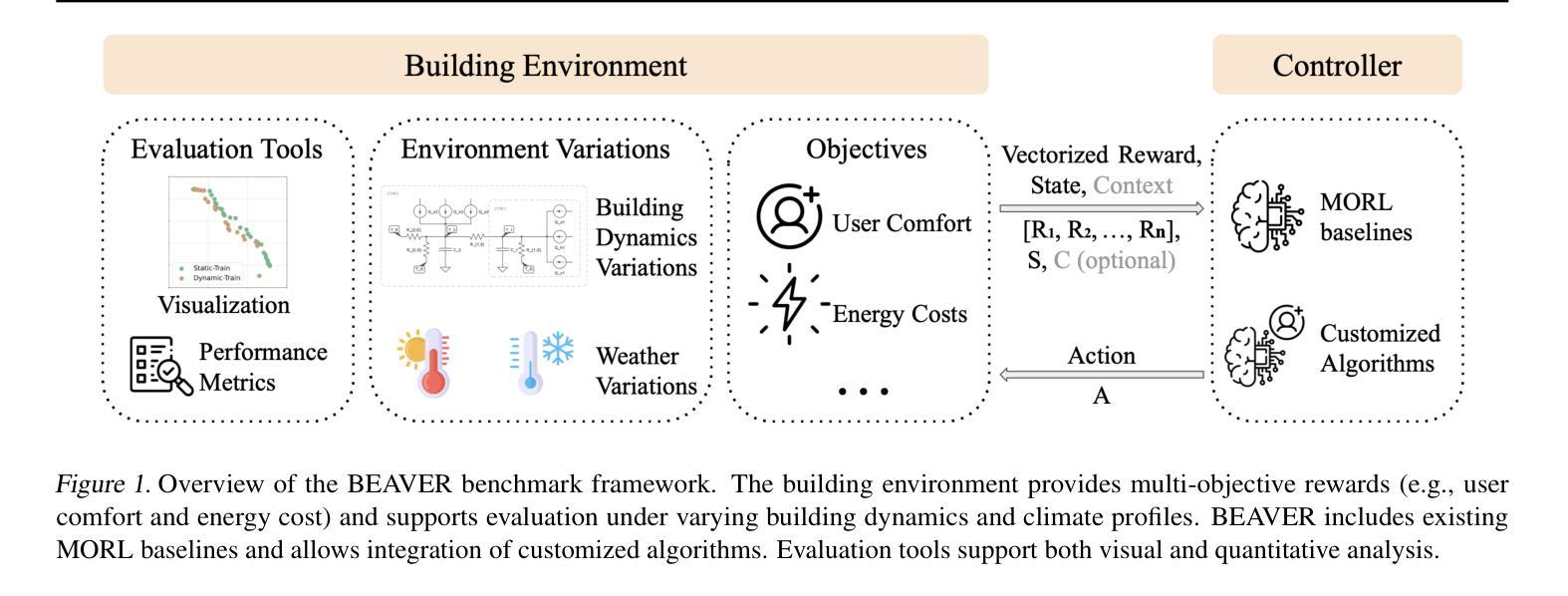
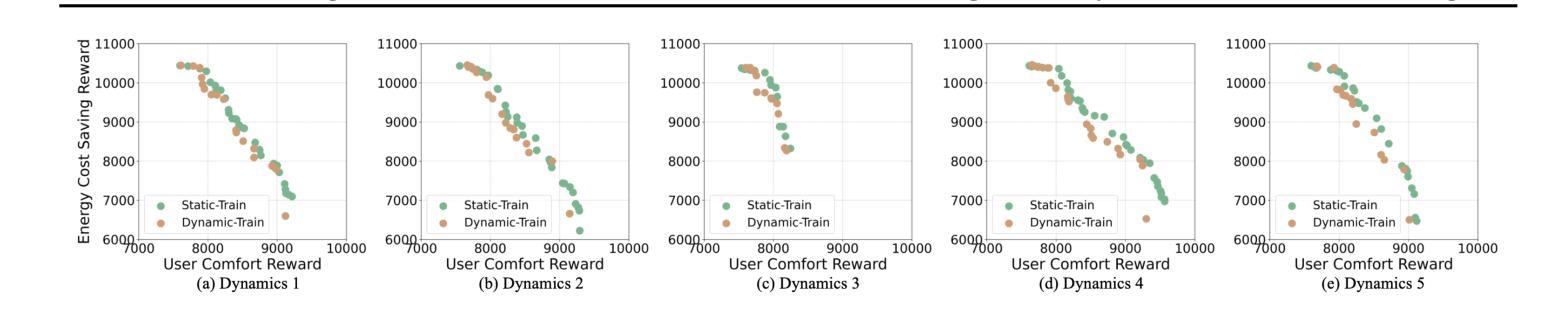
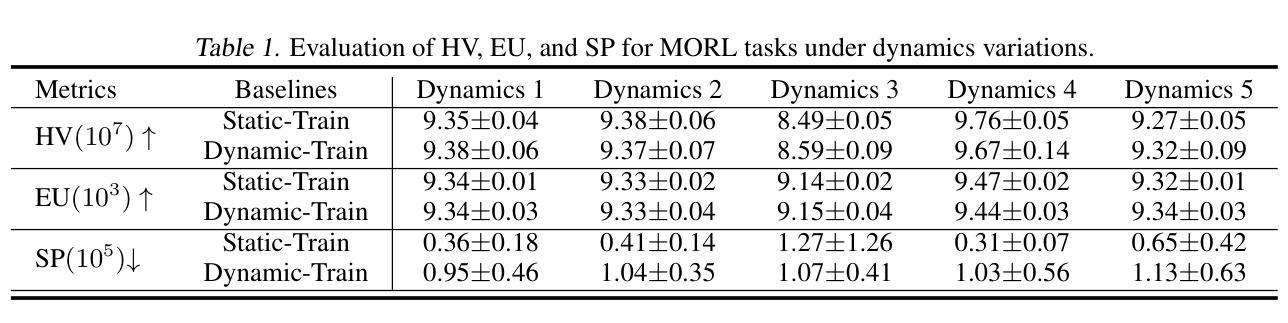
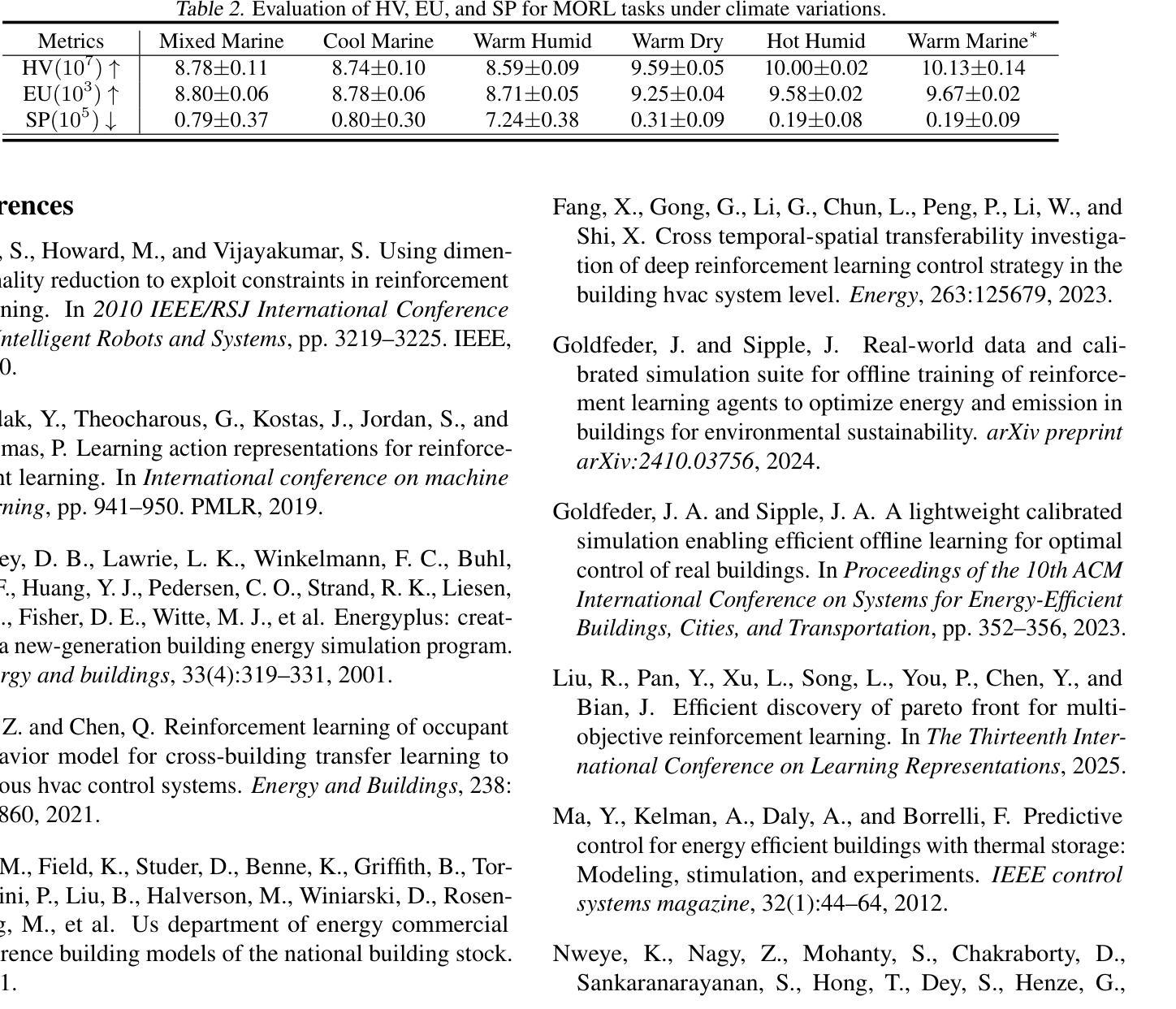
BEAVER: Building Environments with Assessable Variation for Evaluating Multi-Objective Reinforcement Learning
Authors:Ruohong Liu, Jack Umenberger, Yize Chen
Recent years have seen significant advancements in designing reinforcement learning (RL)-based agents for building energy management. While individual success is observed in simulated or controlled environments, the scalability of RL approaches in terms of efficiency and generalization across building dynamics and operational scenarios remains an open question. In this work, we formally characterize the generalization space for the cross-environment, multi-objective building energy management task, and formulate the multi-objective contextual RL problem. Such a formulation helps understand the challenges of transferring learned policies across varied operational contexts such as climate and heat convection dynamics under multiple control objectives such as comfort level and energy consumption. We provide a principled way to parameterize such contextual information in realistic building RL environments, and construct a novel benchmark to facilitate the evaluation of generalizable RL algorithms in practical building control tasks. Our results show that existing multi-objective RL methods are capable of achieving reasonable trade-offs between conflicting objectives. However, their performance degrades under certain environment variations, underscoring the importance of incorporating dynamics-dependent contextual information into the policy learning process.
近年来,在设计基于强化学习(RL)的能源管理智能体方面取得了重大进展。虽然我们在模拟或受控环境中观察到了个别的成功,但强化学习在效率和跨建筑动态及操作场景的泛化方面的可扩展性仍然是一个悬而未决的问题。在这项工作中,我们正式描述了跨环境、多目标建筑能源管理任务的泛化空间,并制定了多目标上下文强化学习问题。这种表述有助于理解在不同操作上下文中转移学习策略的难题,例如在气候和传热动力学方面的多重控制目标,如舒适度和能源消耗等。我们提供了一种原则性的方法,可以在现实的建筑强化学习环境中对上下文信息进行参数化,并构建了一个新的基准测试,以促进在实际建筑控制任务中对通用强化学习算法进行评估。我们的结果表明,现有的多目标强化学习方法能够在相互冲突的目标之间取得合理的平衡。但在某些环境发生变化的情况下,其性能会下降,这突显了在策略学习过程中融入动态上下文信息的重要性。
论文及项目相关链接
PDF Accepted at the Workshop on Computational Optimization of Buildings (ICML CO-BUILD), 42nd International Conference on Machine Learning (ICML 2025), Vancouver, Canada
Summary
在强化学习(RL)技术设计应用于建筑能源管理方面取得了显著的进步。尽管在模拟或受控环境中获得了成功,但在效率方面的实际应用和推广建筑动态和操作场景仍存在问题。该研究为跨环境的、多目标的建筑能源管理任务提供了形式化表征,形成了多目标情境强化学习问题。它帮助理解在不同操作环境、气候、热对流动力学和多目标控制下的策略转移挑战,如舒适度水平和能源消耗等。研究为实际应用中的建筑强化学习环境中此类情境信息的参数化提供了原则性方法,并建立了新的基准测试,以促进通用性强化学习算法在实际建筑控制任务中的评估。结果表明现有多目标强化学习方法能够在冲突目标之间取得合理的平衡,但在某些环境变动下性能下降,突显了将动态相关的情境信息纳入策略学习过程的重要性。
Key Takeaways
- 强化学习在建筑能源管理领域取得显著进步,但在效率和推广方面存在挑战。
- 研究正式定义了跨环境、多目标的建筑能源管理任务,并提出了多目标情境强化学习问题的概念框架。
- 分析了转移学习在多种操作环境、气候条件和不同控制目标(如舒适度和能源消耗)下的挑战。
- 为在真实建筑环境中参数化情境信息提供了方法,并建立了评估通用性强化学习算法的新基准测试。
- 现有强化学习方法在解决多目标问题时有较好的表现,但在特定环境变动下性能下滑。
- 结果强调了将动态相关的情境信息纳入策略学习过程的重要性。
点此查看论文截图

FrugalRAG: Learning to retrieve and reason for multi-hop QA
Authors:Abhinav Java, Srivathsan Koundinyan, Nagarajan Natarajan, Amit Sharma
We consider the problem of answering complex questions, given access to a large unstructured document corpus. The de facto approach to solving the problem is to leverage language models that (iteratively) retrieve and reason through the retrieved documents, until the model has sufficient information to generate an answer. Attempts at improving this approach focus on retrieval-augmented generation (RAG) metrics such as accuracy and recall and can be categorized into two types: (a) fine-tuning on large question answering (QA) datasets augmented with chain-of-thought traces, and (b) leveraging RL-based fine-tuning techniques that rely on question-document relevance signals. However, efficiency in the number of retrieval searches is an equally important metric, which has received less attention. In this work, we show that: (1) Large-scale fine-tuning is not needed to improve RAG metrics, contrary to popular claims in recent literature. Specifically, a standard ReAct pipeline with improved prompts can outperform state-of-the-art methods on benchmarks such as HotPotQA. (2) Supervised and RL-based fine-tuning can help RAG from the perspective of frugality, i.e., the latency due to number of searches at inference time. For example, we show that we can achieve competitive RAG metrics at nearly half the cost (in terms of number of searches) on popular RAG benchmarks, using the same base model, and at a small training cost (1000 examples).
我们考虑了在可以访问大规模非结构化文档语料库的情况下回答复杂问题的能力。解决这个问题的实际方法是利用语言模型(通过迭代方式)检索和推理检索到的文档,直到模型拥有足够的信息来生成答案。改进这一方法的尝试主要集中在提高检索增强生成(RAG)的准确性和召回率方面,这些尝试可以分为两类:(a)在大型问答数据集上进行微调,并增加思维链追踪;(b)利用基于强化学习的微调技术,该技术依赖于问题文档相关性信号。然而,检索搜索的数量同样是一个重要的效率指标,但这一指标受到的关注度较小。在这项工作中,我们证明了:(1)无需大规模微调就能提高RAG指标,这与近期文献中的普遍观点相反。具体来说,采用改进提示的标准ReAct流程可以在HotPotQA等基准测试上表现出超越最新方法的性能。(2)从节俭的角度来看,有监督的和基于强化学习的微调可以帮助RAG减少推理时间的搜索数量延迟。例如,我们展示了使用相同的基准模型在流行的RAG基准测试上可以在搜索数量成本降低一半的情况下实现有竞争力的RAG指标,并且训练成本较低(仅使用1000个示例)。
论文及项目相关链接
PDF Accepted at ICML Workshop: Efficient Systems for Foundation Models
Summary
本文探讨了在大规模非结构化文档语料库中回答复杂问题的问题。文章指出,不需要大规模微调即可提升检索增强生成(RAG)的评估指标,改进提示的标准ReAct管道能够超越当前最好方法在HotPotQA等基准测试上的表现。同时,监督学习和强化学习微调有助于减少推理时间成本,通过减少搜索次数实现竞争性的RAG指标。
Key Takeaways
- 回答问题时,对于大规模非结构化文档语料库的检索和推理是关键问题。
- 不需要大规模微调也能提升检索增强生成(RAG)的评估指标。
- 标准ReAct管道通过改进提示可超越当前最好方法在基准测试上的表现。
- 监督学习和强化学习微调有助于减少推理的时间成本。
- 减少搜索次数可实现竞争性的RAG指标。
- 效率是除了准确性之外同样重要的评估指标。
点此查看论文截图

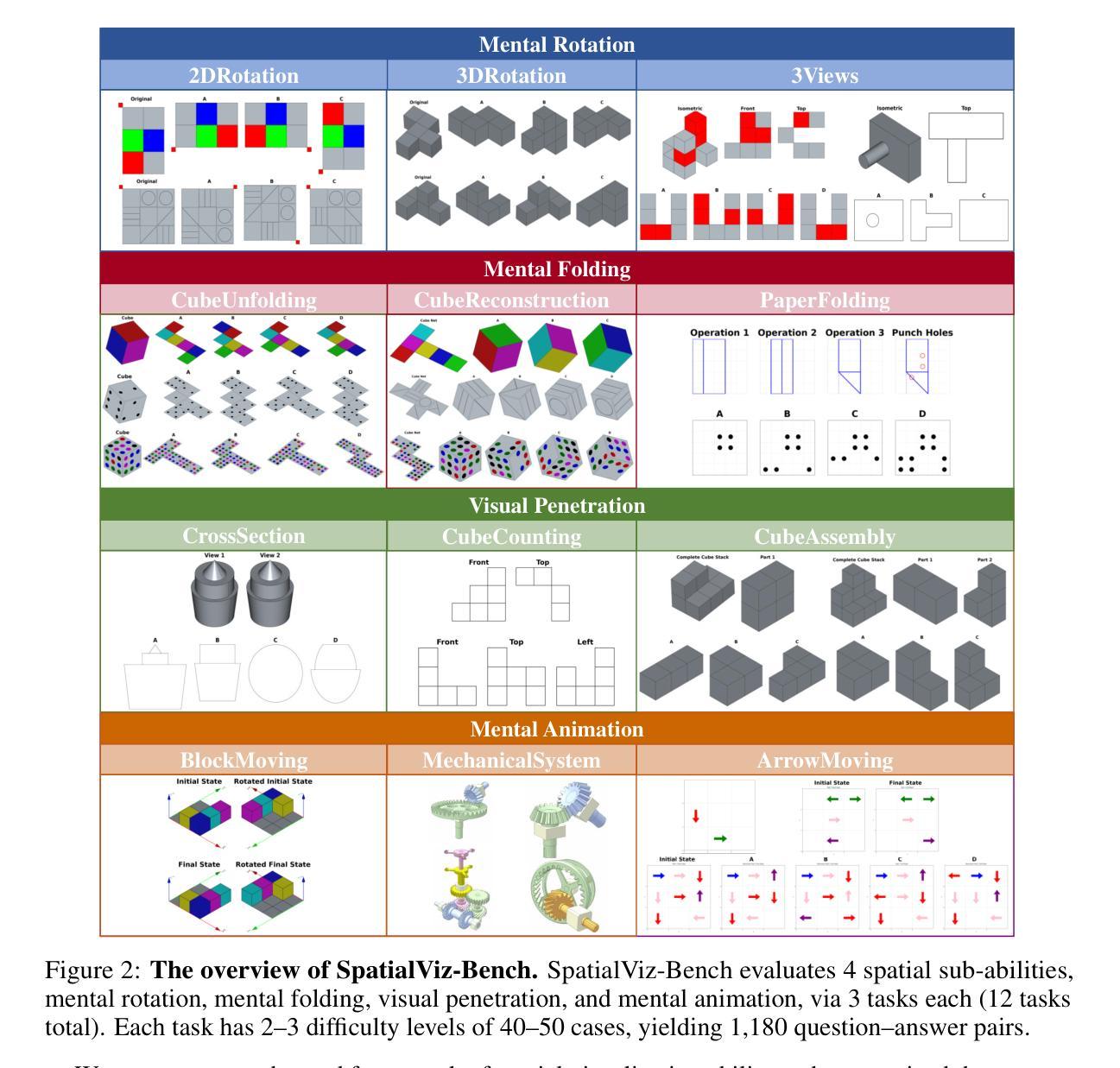
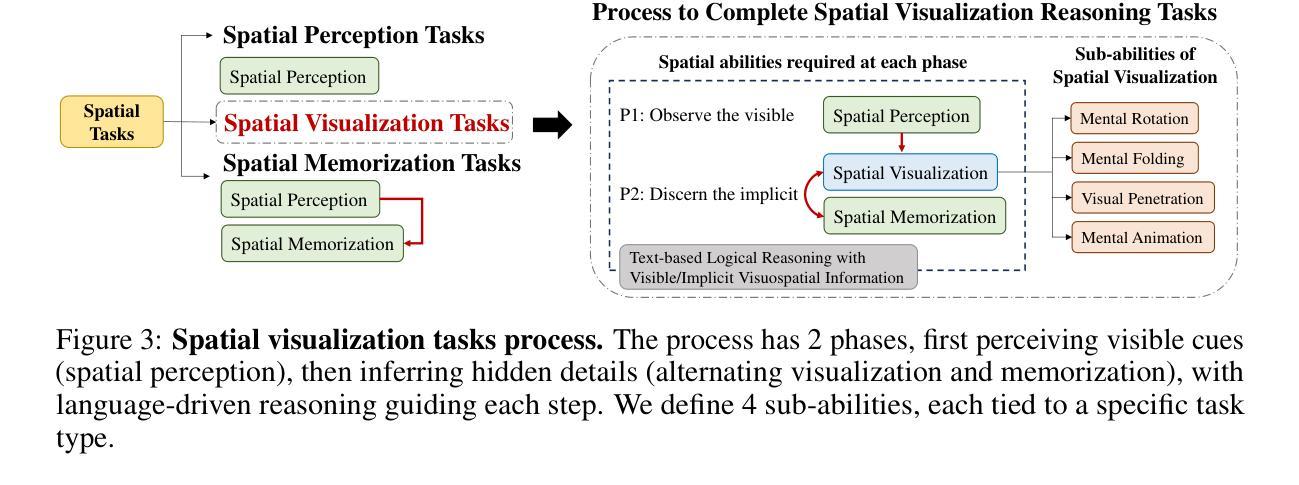
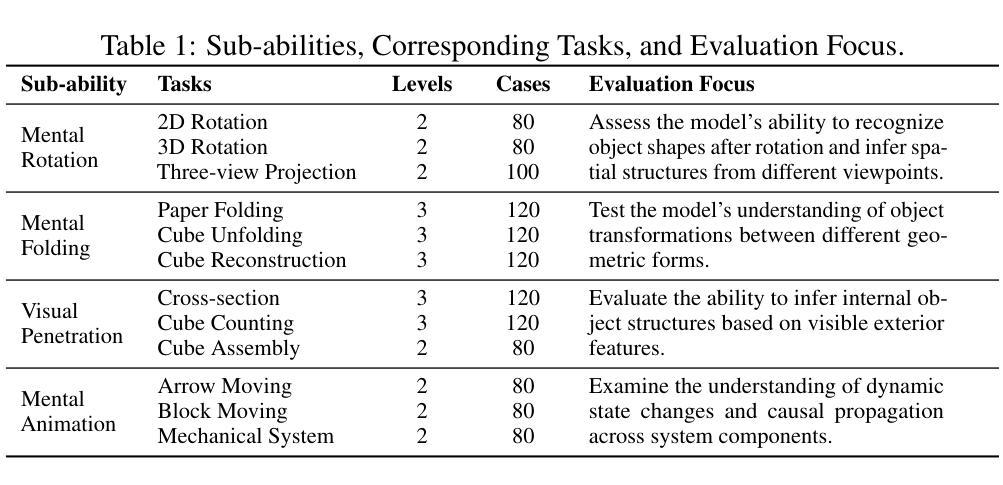
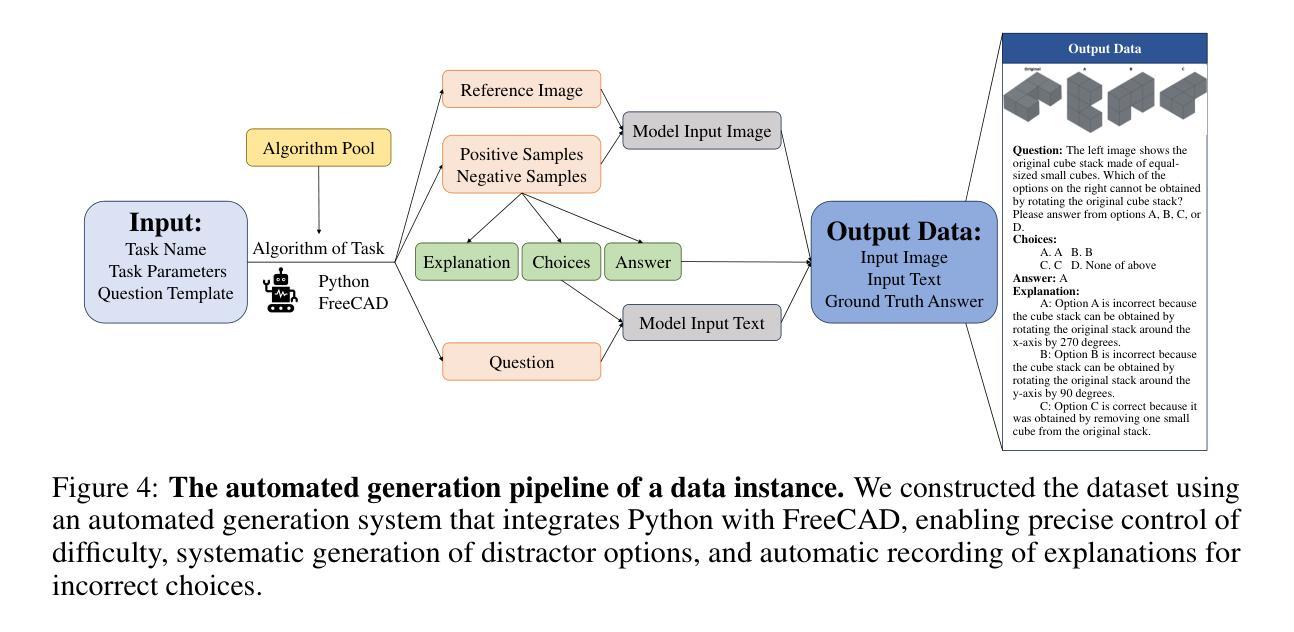
SpatialViz-Bench: Automatically Generated Spatial Visualization Reasoning Tasks for MLLMs
Authors:Siting Wang, Luoyang Sun, Cheng Deng, Kun Shao, Minnan Pei, Zheng Tian, Haifeng Zhang, Jun Wang
Humans can directly imagine and manipulate visual images in their minds, a capability known as spatial visualization. While multi-modal Large Language Models (MLLMs) support imagination-based reasoning, spatial visualization remains insufficiently evaluated, typically embedded within broader mathematical and logical assessments. Existing evaluations often rely on IQ tests or math competitions that may overlap with training data, compromising assessment reliability. To this end, we introduce SpatialViz-Bench, a comprehensive multi-modal benchmark for spatial visualization with 12 tasks across 4 sub-abilities, comprising 1,180 automatically generated problems. Our evaluation of 33 state-of-the-art MLLMs not only reveals wide performance variations and demonstrates the benchmark’s strong discriminative power, but also uncovers counter-intuitive findings: models exhibit unexpected behaviors by showing difficulty perception that misaligns with human intuition, displaying dramatic 2D-to-3D performance cliffs, and defaulting to formula derivation despite spatial tasks requiring visualization alone. SpatialVizBench empirically demonstrates that state-of-the-art MLLMs continue to exhibit deficiencies in spatial visualization tasks, thereby addressing a significant lacuna in the field. The benchmark is publicly available.
人类能够在大脑中直接想象并操作视觉图像,这种能力被称为空间可视化。虽然多模态大型语言模型(MLLMs)支持基于想象的推理,但空间可视化能力的评估仍然不足,通常只嵌入更广泛的数学和逻辑评估中。现有的评估通常依赖于可能与训练数据重叠的智商测试或数学竞赛,从而影响评估的可靠性。为此,我们引入了SpatialViz-Bench,这是一个全面的多模态空间可视化基准测试,包含12项任务,涵盖4种子能力,共有1180个自动生成的问题。我们对33个最先进的大型语言模型的评价不仅揭示了性能上的巨大差异,证明了基准测试的强鉴别力,还发现了一些违背直觉的结果:模型表现出难以理解人类直觉的感知困难行为,在二维到三维转换任务上表现出巨大落差,以及在需要单独使用可视化解决的空间任务中默认使用公式推导。SpatialVizBench实证表明,最先进的大型语言模型在空间可视化任务上仍存在缺陷,从而填补了该领域的空白。该基准测试已公开可用。
论文及项目相关链接
Summary:
空间可视化是人类能够在大脑中直接想象和操作视觉图像的能力。尽管多模态大型语言模型(MLLMs)支持基于想象的推理,但空间可视化尚未得到充分评估,通常只是更广泛的数学和逻辑评估的一部分。为了解决这个问题,我们引入了SpatialViz-Bench,这是一个全面的多模态空间可视化基准测试,包含4个子能力的12项任务,共计1,180个自动生成的测试问题。我们对目前最先进的多模态语言模型进行了评估,发现其性能差异较大,并证明了该基准测试具有较强的鉴别力。评估还发现一些意想不到的行为,如模型在感知方面存在困难,导致二维到三维性能急剧下降,以及在仅需要可视化的情况下默认使用公式推导等。SpatialVizBench实证研究证明,目前最先进的多模态语言模型在空间可视化任务上仍存在缺陷。该基准测试已公开发布。
Key Takeaways:
- 人类拥有空间可视化能力,能直接想象和操作视觉图像。
- 多模态大型语言模型(MLLMs)支持基于想象的推理,但空间可视化能力尚未得到充分评估。
- SpatialViz-Bench是一个全面的多模态空间可视化基准测试,包含多种任务,旨在评估模型的空间可视化能力。
- 对现有模型的评估显示,不同模型在空间可视化方面的性能存在较大差异。
- 模型在某些空间可视化任务上存在困难,如感知方面存在的问题导致二维到三维性能急剧下降。
- 模型在某些情况下默认使用公式推导,而非仅依赖空间可视化能力完成任务。
点此查看论文截图


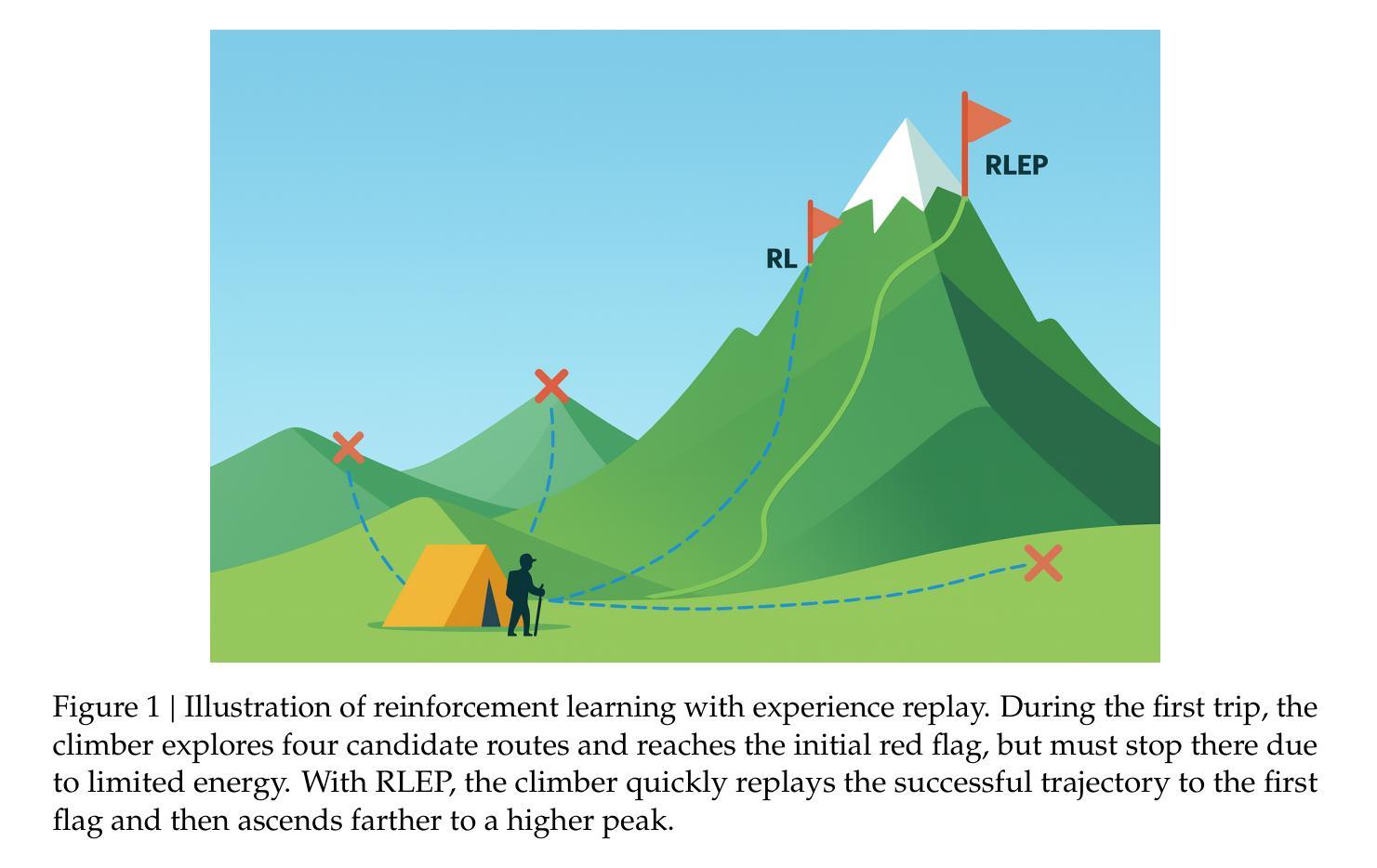
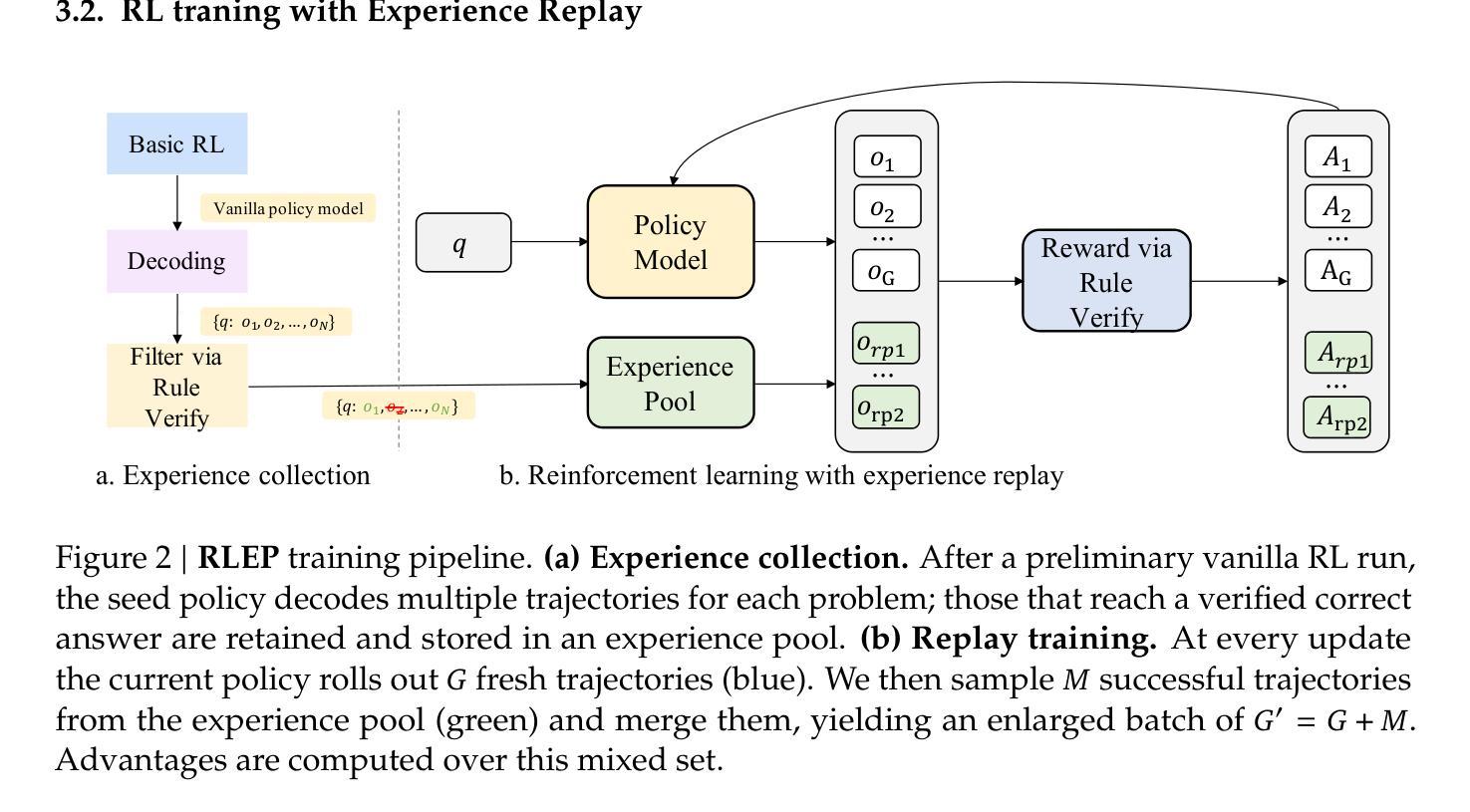
RLEP: Reinforcement Learning with Experience Replay for LLM Reasoning
Authors:Hongzhi Zhang, Jia Fu, Jingyuan Zhang, Kai Fu, Qi Wang, Fuzheng Zhang, Guorui Zhou
Reinforcement learning (RL) for large language models is an energy-intensive endeavor: training can be unstable, and the policy may gradually drift away from its pretrained weights. We present \emph{RLEP}, – ,Reinforcement Learning with Experience rePlay, – ,a two-phase framework that first collects verified trajectories and then replays them during subsequent training. At every update step, the policy is optimized on mini-batches that blend newly generated rollouts with these replayed successes. By replaying high-quality examples, RLEP steers the model away from fruitless exploration, focuses learning on promising reasoning paths, and delivers both faster convergence and stronger final performance. On the Qwen2.5-Math-7B base model, RLEP reaches baseline peak accuracy with substantially fewer updates and ultimately surpasses it, improving accuracy on AIME-2024 from 38.2% to 39.9%, on AIME-2025 from 19.8% to 22.3%, and on AMC-2023 from 77.0% to 82.2%. Our code, datasets, and checkpoints are publicly available at https://github.com/Kwai-Klear/RLEP to facilitate reproducibility and further research.
强化学习(RL)对于大型语言模型是一项耗能密集型的任务:训练可能不稳定,策略可能会逐渐偏离其预训练权重。我们提出了“RLEP”——带有经验重播的强化学习(Reinforcement Learning with Experience rePlay)——这是一个两阶段框架,首先收集验证过的轨迹,然后在随后的训练中进行重播。在每个更新步骤中,策略都会在新生成的滚动数据与这些重播的成功案例的混合小批量数据上进行优化。通过重播高质量示例,RLEP引导模型远离无效的探索,专注于有前景的推理路径的学习,并实现了更快的收敛速度和更强的最终性能。在Qwen2.5-Math-7B基准模型上,RLEP在更少的更新次数内达到了基准峰值精度,并最终超越了它,将AIME-2024的准确性从38.2%提高到39.9%,将AIME-2025的准确性从19.8%提高到22.3%,并将AMC-2023的准确性从77.0%提高到82.2%。我们的代码、数据集和检查点已在https://github.com/Kwai-Klear/RLEP上公开提供,以方便可重复性和进一步研究。
论文及项目相关链接
PDF https://github.com/Kwai-Klear/RLEP
Summary
强化学习(RL)用于大型语言模型是一项能耗高的工作:训练不稳定,策略可能会逐渐偏离其预训练权重。本文提出RLEP——结合经验回放(Reinforcement Learning with Experience rePlay)的强化学习,这是一个两阶段框架,首先收集验证过的轨迹,然后在随后的训练中进行回放。在每个更新步骤中,策略都会在新生成的滚动数据与这些回放的成功案例的混合小批量数据上进行优化。通过回放高质量示例,RLEP引导模型远离无效探索,专注于有前途的推理路径,从而实现更快的收敛和更强的最终性能。在Qwen2.5-Math-7B基准模型上,RLEP在显著更少的更新次数内达到了峰值精度,并最终超越了它,在AIME-2024上的准确率从38.2%提高到39.9%,在AIME-2025上的准确率从19.8%提高到22.3%,在AMC-2023上的准确率从77.0%提高到82.2%。我们的代码、数据集和检查点已公开发布在https://github.com/Kwai-Klear/RLEP,以方便复现和进一步研究。
Key Takeaways
- 强化学习用于大型语言模型的训练存在不稳定性和策略偏离的问题。
- RLEP是一个两阶段框架,通过收集验证轨迹并在训练中进行回放来解决上述问题。
- RLEP通过回放高质量示例来引导模型,避免无效探索,并专注于有前途的推理路径。
- RLEP能加快模型收敛速度并提升最终性能。
- 在多个基准测试中,RLEP显著提高了模型的准确率。
- RLEP框架的代码、数据集和检查点已公开发布,方便复现和进一步研究。
点此查看论文截图


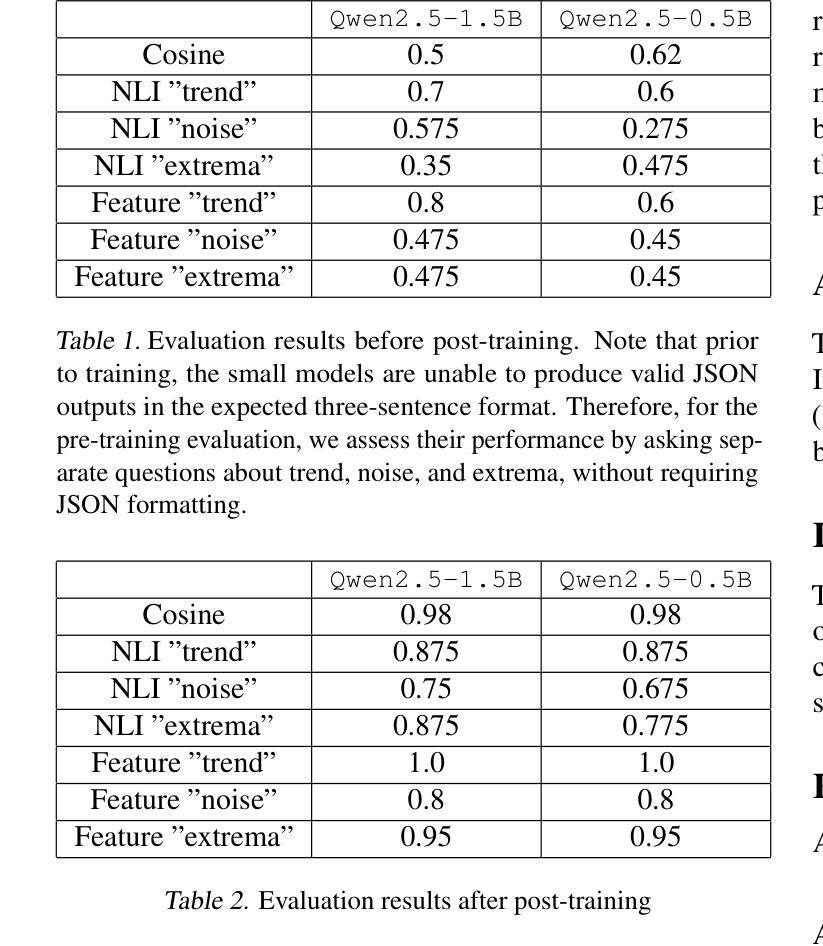
Towards Interpretable Time Series Foundation Models
Authors:Matthieu Boileau, Philippe Helluy, Jeremy Pawlus, Svitlana Vyetrenko
In this paper, we investigate the distillation of time series reasoning capabilities into small, instruction-tuned language models as a step toward building interpretable time series foundation models. Leveraging a synthetic dataset of mean-reverting time series with systematically varied trends and noise levels, we generate natural language annotations using a large multimodal model and use these to supervise the fine-tuning of compact Qwen models. We introduce evaluation metrics that assess the quality of the distilled reasoning - focusing on trend direction, noise intensity, and extremum localization - and show that the post-trained models acquire meaningful interpretive capabilities. Our results highlight the feasibility of compressing time series understanding into lightweight, language-capable models suitable for on-device or privacy-sensitive deployment. This work contributes a concrete foundation toward developing small, interpretable models that explain temporal patterns in natural language.
在这篇论文中,我们研究了将时间序列推理能力提炼成小型、可指导的语言模型,作为构建可解释时间序列基础模型的一步。我们利用一个具有系统化趋势变化和噪声水平的均值回归合成数据集,借助大型多模态模型生成自然语言注释,并用这些注释对紧凑Qwen模型进行微调。我们引入了评估提炼推理质量的评价指标,重点考察趋势方向、噪声强度和极值定位,并展示经过训练后的模型获得了有意义的解释能力。我们的结果强调了将时间序列理解压缩成小型、具备语言能力的模型的可行性,这些模型适合在设备端或隐私敏感的场景下进行部署。这项研究为实现小型可解释模型的研发奠定了基础,这些模型能够以自然语言解释时间序列模式。
论文及项目相关链接
PDF International Conference on Machine Leaning (ICML) 2025 Workshop on Foundation Models for Structured Data
Summary:
本文研究了将时间序列推理能力蒸馏到小型、指令调优的语言模型中,作为构建可解释时间序列基础模型的一步。通过利用具有系统变化趋势和噪声水平的平均回归时间序列的合成数据集,使用大型多模式模型生成自然语言注释,并用于监督紧凑模型的微调。引入评估指标,评估蒸馏推理的质量,重点关注趋势方向、噪声强度和极值定位。结果显示,训练后的模型获得了有意义的解释能力,证明了将时间序列理解压缩成具有语言能力的轻型模型,适合在设备端或隐私敏感环境中部署的可行性。本文为实现小型、可解释模型的研发奠定了基础,这些模型能够解释自然语言中的时间模式。
Key Takeaways:
- 研究了如何将时间序列推理能力蒸馏到小型语言模型中。
- 利用合成数据集生成自然语言注释,用于监督模型微调。
- 引入了评估蒸馏推理质量的指标,包括趋势方向、噪声强度和极值定位。
- 实验显示训练后的模型获得了有意义的解释能力。
- 该研究为实现具有语言能力的轻型模型奠定了基础,适合在设备端或隐私敏感环境中部署。
- 该研究为实现小型、可解释模型的研发铺平了道路,能够解释自然语言中的时间模式。
点此查看论文截图

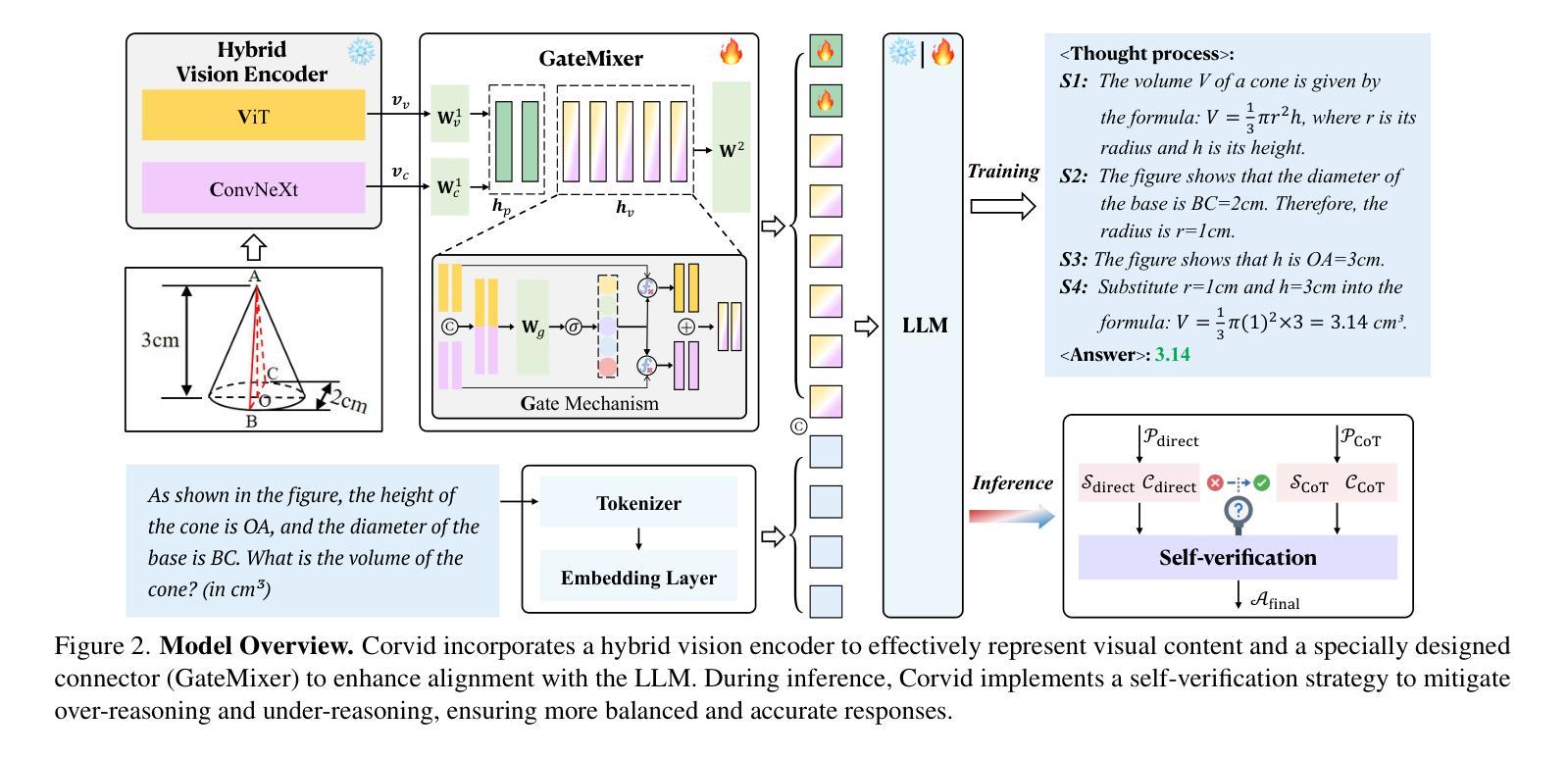
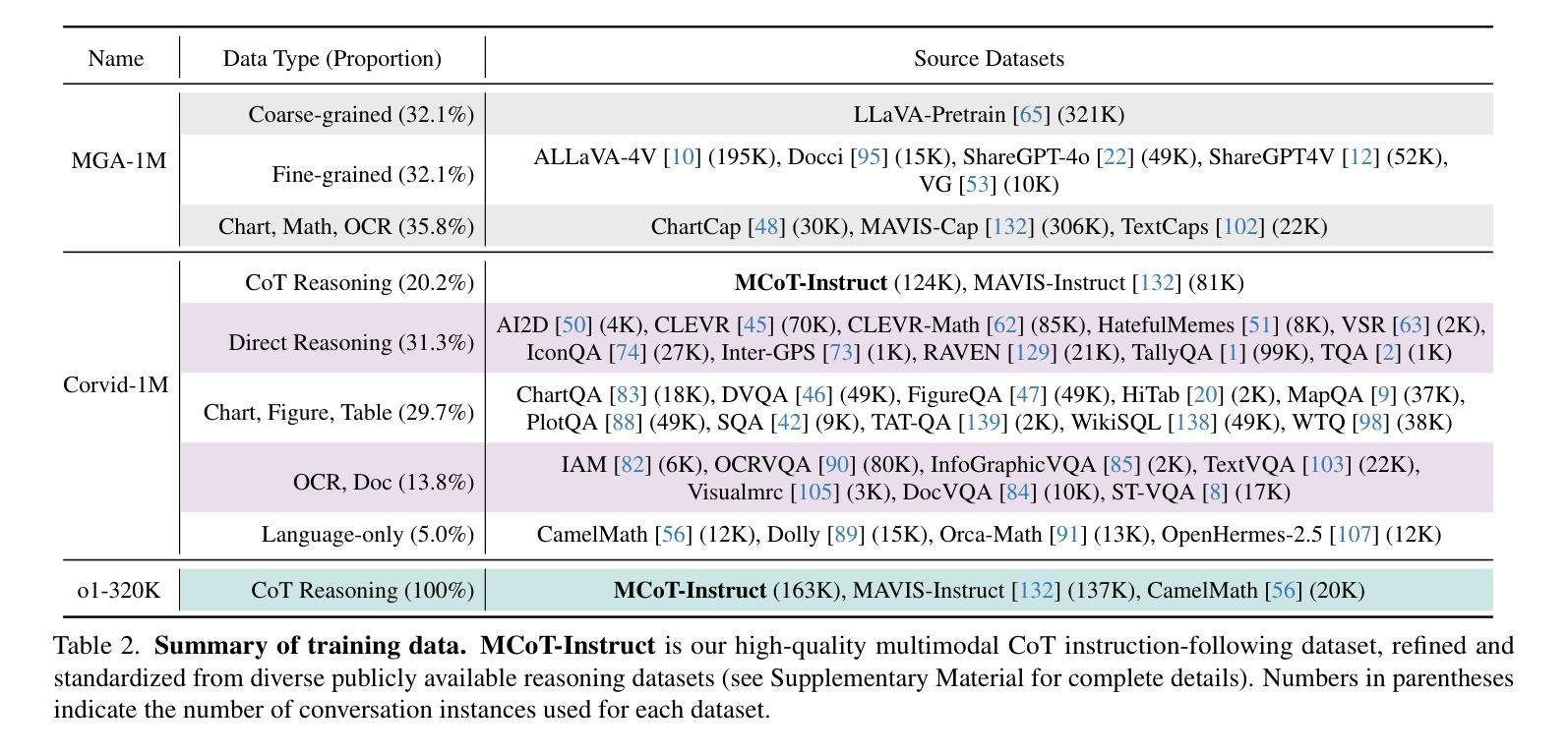
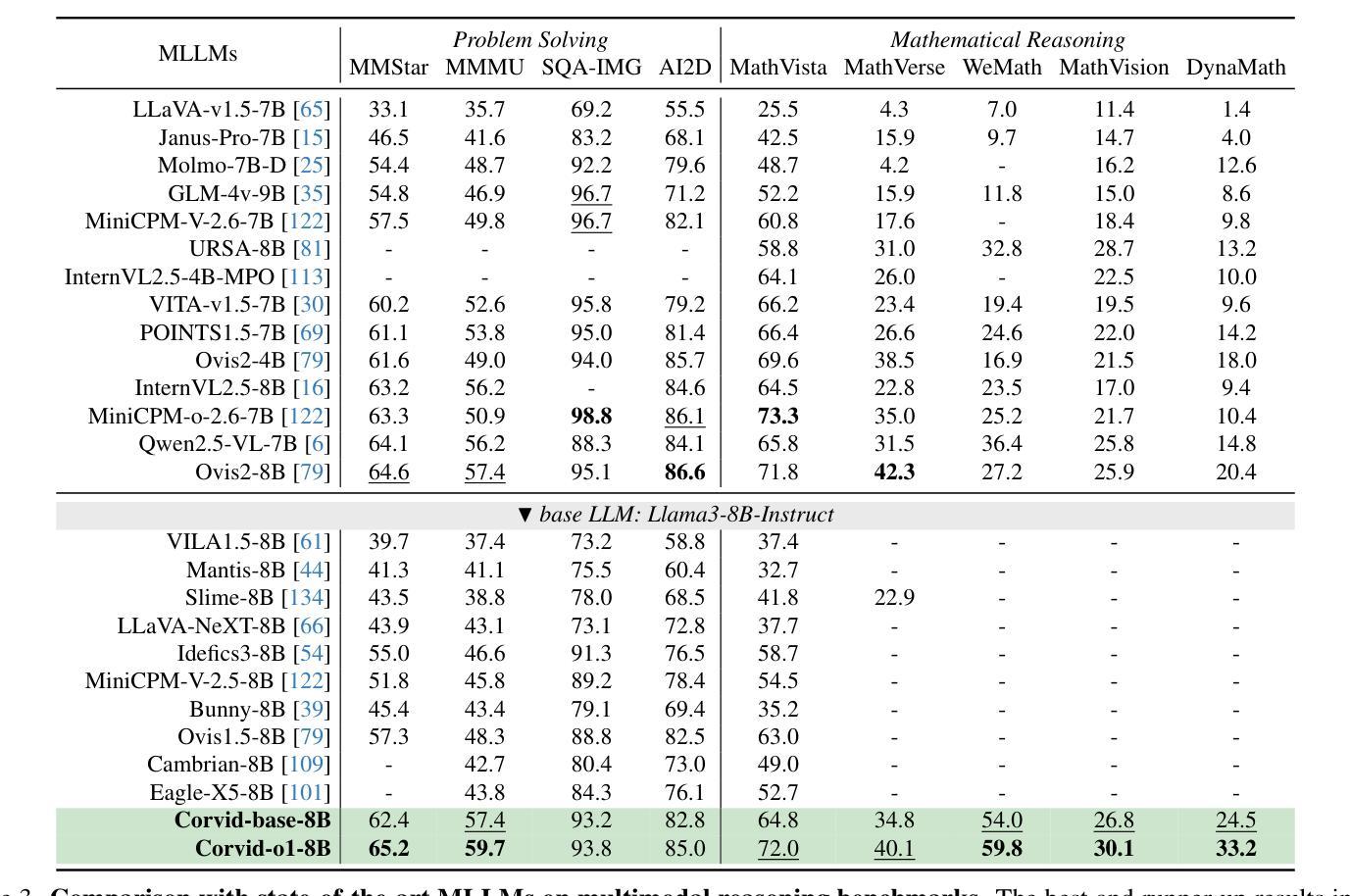
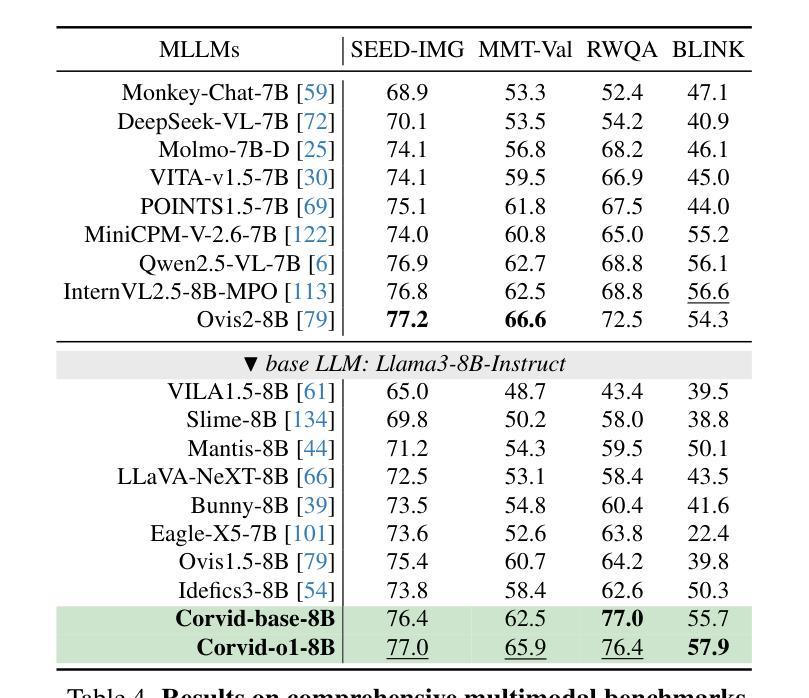
Corvid: Improving Multimodal Large Language Models Towards Chain-of-Thought Reasoning
Authors:Jingjing Jiang, Chao Ma, Xurui Song, Hanwang Zhang, Jun Luo
Recent advancements in multimodal large language models (MLLMs) have demonstrated exceptional performance in multimodal perception and understanding. However, leading open-source MLLMs exhibit significant limitations in complex and structured reasoning, particularly in tasks requiring deep reasoning for decision-making and problem-solving. In this work, we present Corvid, an MLLM with enhanced chain-of-thought (CoT) reasoning capabilities. Architecturally, Corvid incorporates a hybrid vision encoder for informative visual representation and a meticulously designed connector (GateMixer) to facilitate cross-modal alignment. To enhance Corvid’s CoT reasoning capabilities, we introduce MCoT-Instruct-287K, a high-quality multimodal CoT instruction-following dataset, refined and standardized from diverse public reasoning sources. Leveraging this dataset, we fine-tune Corvid with a two-stage CoT-formatted training approach to progressively enhance its step-by-step reasoning abilities. Furthermore, we propose an effective inference-time scaling strategy that enables Corvid to mitigate over-reasoning and under-reasoning through self-verification. Extensive experiments demonstrate that Corvid outperforms existing o1-like MLLMs and state-of-the-art MLLMs with similar parameter scales, with notable strengths in mathematical reasoning and science problem-solving. Project page: https://mm-vl.github.io/corvid.
近期多模态大型语言模型(MLLMs)的进展在多模态感知和理解方面展示了卓越的性能。然而,领先的开源MLLM在复杂和结构化的推理,特别是在需要深度推理进行决策和问题解决的任务中存在明显的局限性。在这项工作中,我们提出了Corvid,一个具有增强思维链(CoT)推理能力的MLLM。在结构上,Corvid采用混合视觉编码器进行信息视觉表示,并精心设计了一个连接器(GateMixer)以促进跨模态对齐。为了增强Corvid的CoT推理能力,我们引入了MCoT-Instruct-287K,这是一个高质量的多模态CoT指令遵循数据集,经过筛选和标准化来自不同的公共推理来源。利用此数据集,我们通过两阶段的CoT格式化训练方法对Corvid进行微调,以逐步提高其分步推理能力。此外,我们提出了一种有效的推理时间缩放策略,使Corvid能够通过自我验证来减轻过度推理和推理不足的问题。大量实验表明,Corvid优于现有的类似ChatGPT的MLLMs和具有相似参数规模的最新MLLMs,在数学推理和科学问题解决方面表现出显著的优势。项目页面:https://mm-vl.github.io/corvid。
论文及项目相关链接
PDF ICCV 2025
Summary
本文介绍了Corvid这一具备增强链式思维(CoT)推理能力的多模态大型语言模型(MLLM)。Corvid采用混合视觉编码器和精心设计连接器(GateMixer)实现跨模态对齐,并引入MCoT-Instruct-287K高质量多模态CoT指令遵循数据集进行训练以提升推理能力。通过采用两阶段的CoT格式化训练方法,Corvid逐步增强了其分步推理能力,并提出一种有效的推理时间缩放策略,通过自我验证来减轻过度推理和推理不足的问题。实验表明,Corvid在数学推理和科学问题解决方面表现出卓越性能,优于现有的类似参数规模的多模态语言模型。
Key Takeaways
- Corvid是一个具备增强链式思维(CoT)推理能力的多模态大型语言模型(MLLM)。
- Corvid采用混合视觉编码器和连接器实现跨模态对齐。
- MCoT-Instruct-287K数据集的引入用于提升Corvid的推理能力。
- 通过两阶段的CoT格式化训练,Corvid逐步增强分步推理能力。
- Corvid通过自我验证来减轻过度推理和推理不足的问题。
- Corvid在数学推理和科学问题解决方面表现出卓越性能。
点此查看论文截图

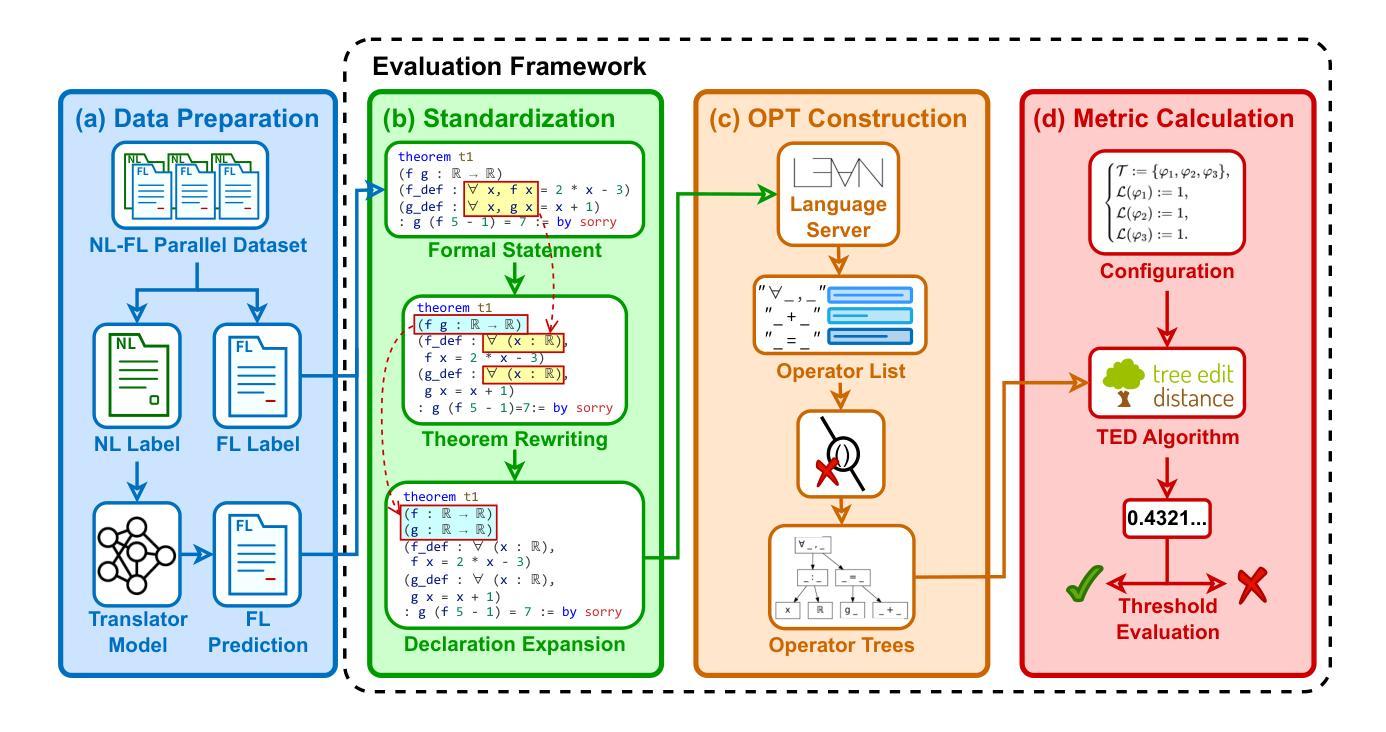
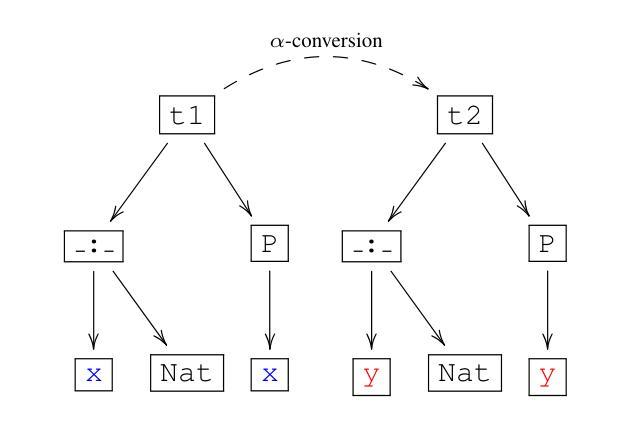
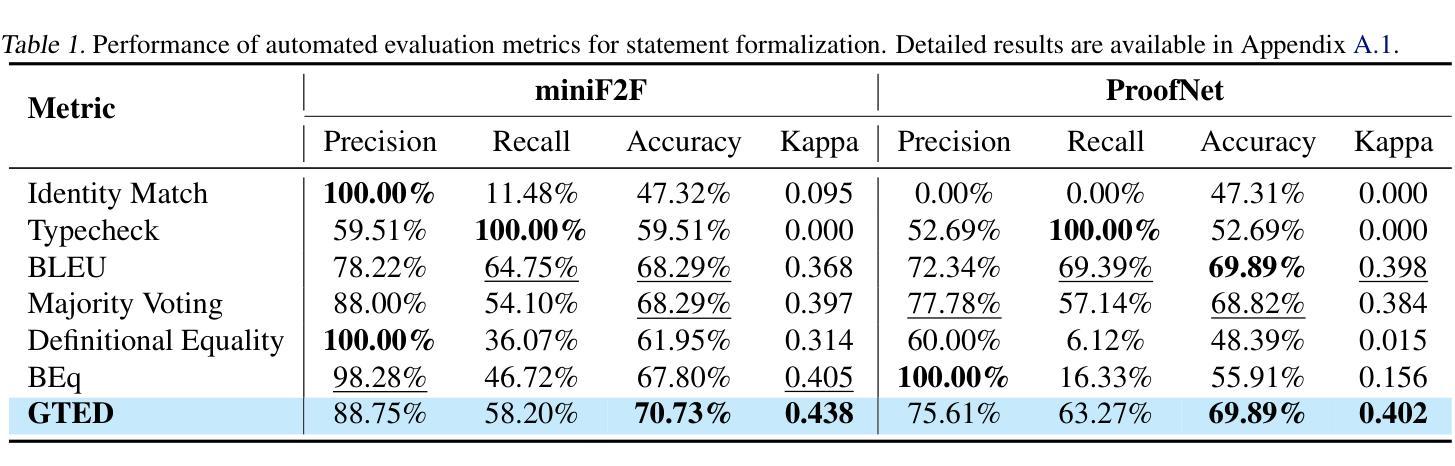
Generalized Tree Edit Distance (GTED): A Faithful Evaluation Metric for Statement Autoformalization
Authors:Yuntian Liu, Tao Zhu, Xiaoyang Liu, Yu Chen, Zhaoxuan Liu, Qingfeng Guo, Jiashuo Zhang, Kangjie Bao, Tao Luo
Statement autoformalization, the automated translation of statement from natural language into formal languages, has become a subject of extensive research, yet the development of robust automated evaluation metrics remains limited. Existing evaluation methods often lack semantic understanding, face challenges with high computational costs, and are constrained by the current progress of automated theorem proving. To address these issues, we propose GTED (Generalized Tree Edit Distance), a novel evaluation framework that first standardizes formal statements and converts them into operator trees, then determines the semantic similarity using the eponymous GTED metric. On the miniF2F and ProofNet benchmarks, GTED outperforms all baseline metrics by achieving the highest accuracy and Kappa scores, thus providing the community with a more faithful metric for automated evaluation. The code and experimental results are available at https://github.com/XiaoyangLiu-sjtu/GTED.
命题自动形式化是将自然语言中的命题自动转换为形式化语言的过程,目前已经成为一个广泛研究的课题,然而可靠的自动评估指标的开发仍然存在局限性。现有的评估方法往往缺乏语义理解,面临计算成本高的问题,并且受到当前自动定理证明发展的制约。为了解决这些问题,我们提出了GTED(广义树编辑距离)这一新的评估框架。该框架首先标准化形式化语句并将其转换为运算符树,然后使用同名的GTED指标确定语义相似性。在miniF2F和ProofNet基准测试中,GTED在准确率和Kappa得分方面均优于所有基线指标,为社区提供了更可靠的自动化评估指标。相关代码和实验结果可通过https://github.com/XiaoyangLiu-sjtu/GTED获取。
论文及项目相关链接
PDF Accepted to AI4Math@ICML25
Summary
自动语句形式化是自然语言向形式语言自动翻译的研究课题,但可靠的自动评估指标的开发仍然有限。为解决现有评估方法缺乏语义理解、计算成本高以及与自动定理证明进展受限的问题,我们提出了GTED(广义树编辑距离)这一新型评估框架。它通过标准化形式语句并将其转换为操作符树,然后使用同名GTED指标确定语义相似性。在miniF2F和ProofNet基准测试中,GTED以最高准确率和Kappa分数优于所有基线指标,为社区提供了更准确的自动化评估指标。相关代码和实验结果可在链接中找到。
Key Takeaways
- 自动语句形式化是一个热门研究领域,但评估指标的可靠性仍是挑战。
- 现有评估方法存在语义理解不足、计算成本高以及与自动定理证明进展受限的问题。
- GTED框架通过标准化形式语句并转换为操作符树来解决这些问题。
- GTED利用广义树编辑距离指标确定语义相似性。
- 在两个基准测试中,GTED表现出优于其他基线指标的性能。
- GTED提供了更准确的自动化评估指标,为社区提供了有价值的工具。
点此查看论文截图



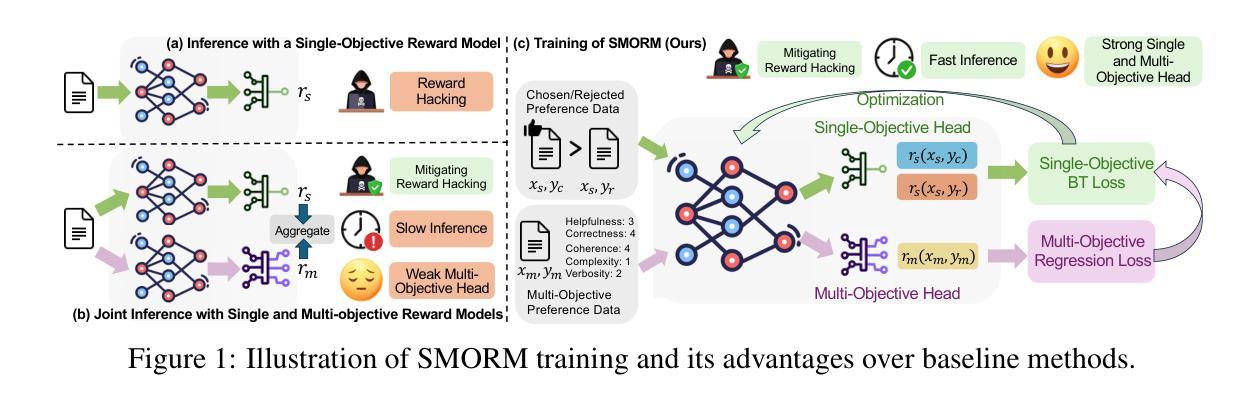
Bradley-Terry and Multi-Objective Reward Modeling Are Complementary
Authors:Zhiwei Zhang, Hui Liu, Xiaomin Li, Zhenwei Dai, Jingying Zeng, Fali Wang, Minhua Lin, Ramraj Chandradevan, Zhen Li, Chen Luo, Xianfeng Tang, Qi He, Suhang Wang
Reward models trained on human preference data have demonstrated strong effectiveness in aligning Large Language Models (LLMs) with human intent under the framework of Reinforcement Learning from Human Feedback (RLHF). However, RLHF remains vulnerable to reward hacking, where the policy exploits imperfections in the reward function rather than genuinely learning the intended behavior. Although significant efforts have been made to mitigate reward hacking, they predominantly focus on and evaluate in-distribution scenarios, where the training and testing data for the reward model share the same distribution. In this paper, we empirically show that state-of-the-art methods struggle in more challenging out-of-distribution (OOD) settings. We further demonstrate that incorporating fine-grained multi-attribute scores helps address this challenge. However, the limited availability of high-quality data often leads to weak performance of multi-objective reward functions, which can negatively impact overall performance and become the bottleneck. To address this issue, we propose a unified reward modeling framework that jointly trains Bradley–Terry (BT) single-objective and multi-objective regression-based reward functions using a shared embedding space. We theoretically establish a connection between the BT loss and the regression objective and highlight their complementary benefits. Specifically, the regression task enhances the single-objective reward function’s ability to mitigate reward hacking in challenging OOD settings, while BT-based training improves the scoring capability of the multi-objective reward function, enabling a 7B model to outperform a 70B baseline. Extensive experimental results demonstrate that our framework significantly improves both the robustness and the scoring performance of reward models.
基于人类偏好数据的奖励模型在强化学习从人类反馈(RLHF)的框架下,已经显示出在将大型语言模型(LLM)与人类意图对齐方面的强大有效性。然而,RLHF仍然容易受到奖励黑客攻击的威胁,策略会利用奖励函数中的缺陷,而不是真正学习预期的行为。尽管已经付出了很大的努力来缓解奖励黑客攻击的问题,但它们主要专注于并评估在分布内的场景,即奖励模型的训练数据和测试数据来自同一分布。在本文中,我们实证表明,最先进的方法在更具挑战性的超出分布(OOD)设置下会陷入困境。我们进一步证明,融入精细粒度的多属性分数有助于应对这一挑战。然而,高质量数据的有限可用性常常导致多目标奖励函数表现不佳,可能会给整体性能带来负面影响并成为瓶颈。为了解决这一问题,我们提出了一个统一的奖励建模框架,该框架使用共享嵌入空间来联合训练Bradley-Terry(BT)单目标奖励函数和多目标回归奖励函数。我们从理论上建立了BT损失和回归目标之间的联系,并强调了它们的互补优势。具体而言,回归任务增强了单目标奖励函数在具有挑战性的OOD环境中缓解奖励黑客攻击的能力,而基于BT的训练提高了多目标奖励函数的评分能力,使得一个规模为7B的模型能够超越规模为70B的基线模型。大量的实验结果证明,我们的框架显著提高了奖励模型的稳健性和评分性能。
论文及项目相关链接
Summary
奖励模型经过训练,可以基于人类偏好数据有效调整大型语言模型与人类意图对齐的策略。然而,仍存在奖励破解的脆弱性风险,政策制定者可能通过发现奖励机制的漏洞而执行意想不到的行为。尽管有许多尝试降低奖励破解风险的努力,但这些努力主要关注并评估在分布内的场景,即奖励模型的训练数据和测试数据共享相同的分布。本文通过实证研究发现,最先进的奖励模型在更具挑战性的分布外设置环境中仍存在短板。实验显示将精细粒度的多属性分数纳入奖励模型能够应对该挑战。但是,高质量数据的有限可用性限制了多目标奖励函数的性能提升,这可能会成为瓶颈问题。为解决这一问题,本文提出了一个统一的奖励建模框架,该框架结合了Bradley-Terry单目标回归和多目标回归奖励函数在共享嵌入空间上的训练方式。实验证明,该框架不仅显著提高了奖励模型的稳健性,还提高了其评分性能。
Key Takeaways:
- 奖励模型在训练后可以有效地与人类偏好对齐以提高语言模型的性能。
- 存在一种风险叫做奖励破解,即模型可能发现奖励机制的漏洞并执行意想不到的行为。
- 当前的研究主要关注分布内的场景,尚未解决更具挑战性的分布外场景中的问题。
- 将精细粒度的多属性分数纳入奖励模型能够应对上述挑战。
- 高质量数据的有限可用性限制了多目标奖励函数的性能提升。
点此查看论文截图

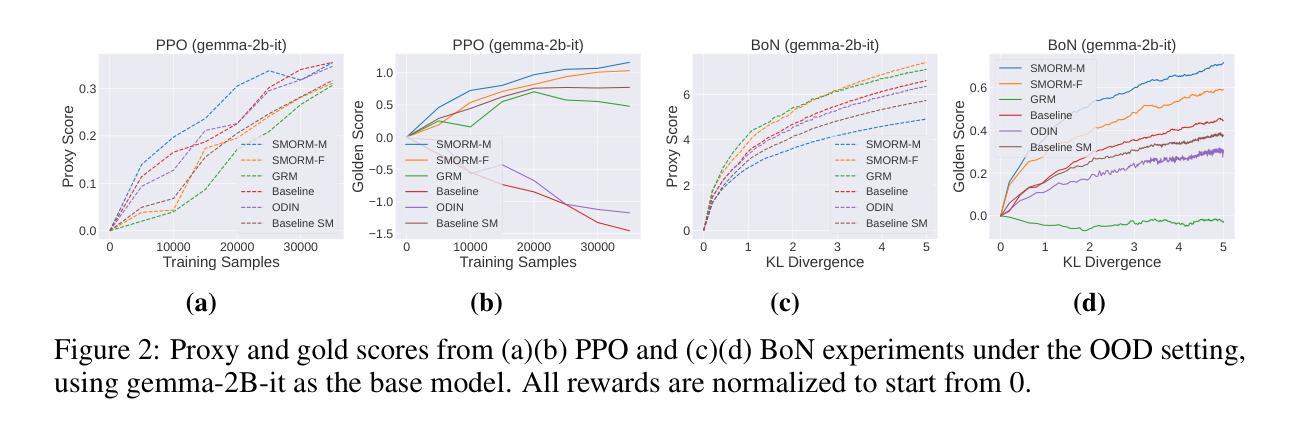
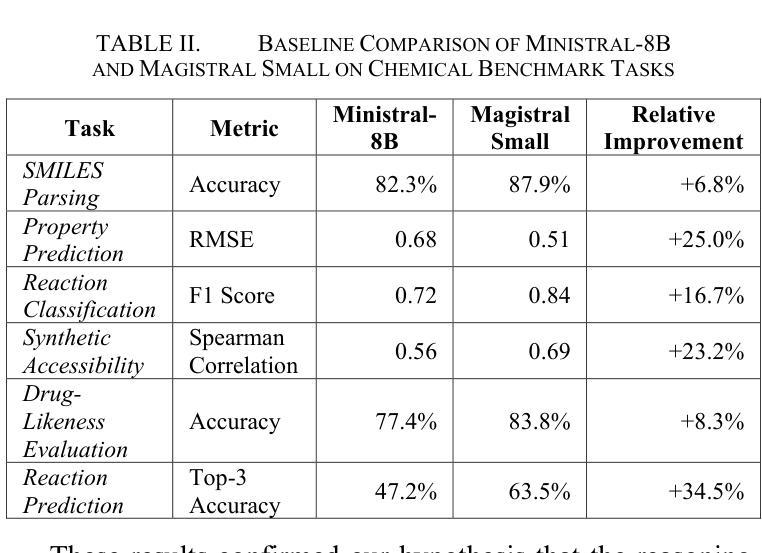
Bridging the Plausibility-Validity Gap by Fine-Tuning a Reasoning-Enhanced LLM for Chemical Synthesis and Discovery
Authors: Malikussaid, Hilal Hudan Nuha
Large Language Models (LLMs) often generate scientifically plausible but factually invalid information, a challenge we term the “plausibility-validity gap,” particularly in specialized domains like chemistry. This paper presents a systematic methodology to bridge this gap by developing a specialized scientific assistant. We utilized the Magistral Small model, noted for its integrated reasoning capabilities, and fine-tuned it using Low-Rank Adaptation (LoRA). A key component of our approach was the creation of a “dual-domain dataset,” a comprehensive corpus curated from various sources encompassing both molecular properties and chemical reactions, which was standardized to ensure quality. Our evaluation demonstrates that the fine-tuned model achieves significant improvements over the baseline model in format adherence, chemical validity of generated molecules, and the feasibility of proposed synthesis routes. The results indicate a hierarchical learning pattern, where syntactic correctness is learned more readily than chemical possibility and synthesis feasibility. While a comparative analysis with human experts revealed competitive performance in areas like chemical creativity and reasoning, it also highlighted key limitations, including persistent errors in stereochemistry, a static knowledge cutoff, and occasional reference hallucination. This work establishes a viable framework for adapting generalist LLMs into reliable, specialized tools for chemical research, while also delineating critical areas for future improvement.
大型语言模型(LLM)经常生成科学上合理但事实无效的信息,我们将其称为“可行性-有效性差距”,特别是在化学等特定领域。本文提出了一种通过开发专用科学助理来弥补这一差距的系统方法。我们利用以综合推理能力著称的Magistral Small模型,并使用低秩适应(LoRA)对其进行微调。我们的方法的关键组成部分是创建“双域数据集”,这是一个从各种来源精心挑选的综合语料库,涵盖了分子属性和化学反应,并进行了标准化以确保质量。我们的评估表明,与基线模型相比,经过微调后的模型在格式遵守、生成分子的化学有效性和提议的合成路线的可行性方面取得了显着改进。结果表明,一种分层学习模式,其中语法正确性的学习比化学可能性和合成可行性更容易。虽然与人类专家的比较分析显示了在化学创造力和推理等领域的竞争力,但也突出了关键限制,包括立体化学的持久性错误、静态知识截止和偶尔的参考幻觉。这项工作为将通用LLM适应为可靠的化学研究专用工具建立了可行的框架,同时划定了未来改进的关键领域。
论文及项目相关链接
PDF 42 pages, 8 figures, 1 equation, 2 algorithms, 31 tables, to be published in ISPACS Conference 2025, unabridged version
Summary
大型语言模型在科学领域会生成看似合理但实际不正确信息,本文提出了一种系统化方法来弥补这一缺陷。通过使用Magistral Small模型和低秩适应(LoRA)技术,结合创建包含分子属性和化学反应的“双域数据集”,提升模型对化学领域的适应性和准确性。尽管仍有局限性,但本文为通用大型语言模型转化为可靠化学研究工具奠定了基础。
Key Takeaways
- 大型语言模型在科学领域存在生成的信息看似合理但实际不准确的挑战,特别是在化学等特定领域。
- 提出了一种系统化方法来解决这一问题,包括使用Magistral Small模型和LoRA技术进行优化。
- 创建了包含分子属性和化学反应的“双域数据集”,以提高模型的准确性和适应性。
- 模型在格式遵循、化学分子有效性以及合成路线可行性方面有明显改进。
- 模型学习呈现出层次结构,即语法的正确性更容易学习,而化学可能性与合成路线的可行性需要进一步提高。
- 与人类专家的比较分析显示,模型在化学创造力和推理方面表现出竞争力,但也存在关键局限性,如立体化学的持久错误、知识截断静态以及偶尔的参考幻觉。
点此查看论文截图


Frontier LLMs Still Struggle with Simple Reasoning Tasks
Authors:Alan Malek, Jiawei Ge, Nevena Lazic, Chi Jin, András György, Csaba Szepesvári
While state-of-the-art large language models (LLMs) demonstrate advanced reasoning capabilities-achieving remarkable performance on challenging competitive math and coding benchmarks-they also frequently fail on tasks that are easy for humans. This work studies the performance of frontier LLMs on a broad set of such “easy” reasoning problems. By extending previous work in the literature, we create a suite of procedurally generated simple reasoning tasks, including counting, first-order logic, proof trees, and travel planning, with changeable parameters (such as document length. or the number of variables in a math problem) that can arbitrarily increase the amount of computation required to produce the answer while preserving the fundamental difficulty. While previous work showed that traditional, non-thinking models can be made to fail on such problems, we demonstrate that even state-of-the-art thinking models consistently fail on such problems and for similar reasons (e.g. statistical shortcuts, errors in intermediate steps, and difficulties in processing long contexts). To further understand the behavior of the models, we introduce the unpuzzles dataset, a different “easy” benchmark consisting of trivialized versions of well-known math and logic puzzles. Interestingly, while modern LLMs excel at solving the original puzzles, they tend to fail on the trivialized versions, exhibiting several systematic failure patterns related to memorizing the originals. We show that this happens even if the models are otherwise able to solve problems with different descriptions but requiring the same logic. Our results highlight that out-of-distribution generalization is still problematic for frontier language models and the new generation of thinking models, even for simple reasoning tasks, and making tasks easier does not necessarily imply improved performance.
当前最先进的大型语言模型(LLM)在具有挑战性的数学和编码基准测试中表现出高级推理能力,取得了令人印象深刻的成绩。但它们也经常在对于人类来说很容易的任务上失败。本研究探讨了前沿LLM在广泛的一系列这样的“简单”推理问题上的表现。通过扩展前人文献中的工作,我们创建了一套程序生成的简单推理任务,包括计数、一阶逻辑、证明树和旅行计划等,这些任务具有可更改的参数(如文档长度或数学问题的变量数量),这些参数可以任意增加计算答案所需的计算量,同时保持基本难度不变。虽然以前的研究表明,传统的非思考模型可以在这些问题上失败,但我们证明,即使是最先进的思考模型也会在这些问题上持续失败,并且失败原因类似(例如统计捷径、中间步骤错误以及处理长文本时的困难等)。为了更深入地了解模型的行为,我们引入了“谜题解密数据集”,这是一个不同的“简单”基准测试,由著名数学和逻辑谜题的简化版组成。有趣的是,尽管现代LLM擅长解决原始谜题,但它们往往会在简化版上失败,表现出与记忆原始题目相关的多种系统性失败模式。我们表明,即使模型能够解决描述不同但需要相同逻辑的问题,这种情况也会发生。我们的研究结果强调,即使在简单推理任务上,前沿语言模型和新一代思考模型在超出其分布范围的情况下进行泛化时仍然存在问题,并且任务的简化并不一定意味着性能的提高。
论文及项目相关链接
PDF 53 pages
摘要
最新的大型语言模型(LLM)虽然在具有挑战性的数学和编程基准测试中表现出出色的推理能力,但它们也常在人类可以轻松完成的任务上表现不足。本研究旨在探究前沿LLM在广泛“简单”推理问题上的表现。我们扩展了文献中的先前工作,创建了一系列程序生成的简单推理任务,包括计数、一阶逻辑、证明树和旅行规划等。这些任务可以通过改变参数(如文档长度或数学问题的变量数量)来任意增加计算答案所需的量,同时保持基本难度不变。虽然先前的工作已经证明传统非思考模型可以解决这些问题失败,但我们证明即使是最先进的思考模型也会在这些问题上不断失败,原因也相同(例如统计捷径、中间步骤中的错误和处理长文本的困难等)。为了更好地了解模型的行为,我们引入了“谜题之外”数据集,这是一个不同的“简单”基准测试,由著名数学和逻辑谜题的简化版组成。有趣的是,虽然现代LLM擅长解决原始谜题,但它们往往会在简化版上失败,表现出多种系统性失败模式,与记忆原始题目有关。我们的结果表明,即使在简单的推理任务上,最先进的语言模型和新一代思考模型在超出其分布范围的泛化方面仍存在缺陷,而且使任务变得更简单并不一定意味着性能会有所改善。
关键见解
- 先进的大型语言模型(LLM)在具有挑战性的数学和编程基准测试中表现出强大的推理能力,但在简单的推理任务上表现不佳。
- 创建了程序生成的简单推理任务,这些任务可以通过改变参数来保持难度不变的同时增加计算复杂性。
- 即使在简单的任务上,前沿的LLM也会因为统计捷径、中间步骤错误和长文本处理困难等原因而失败。
- 引入新的基准测试数据集——“谜题之外”,包含简化版的数学和逻辑谜题,旨在探究LLM在简单任务上的表现。
- 现代LLM在简化版谜题上的表现不佳,显示出与记忆原始题目相关的系统性失败模式。
- LLM在超出其分布范围的简单推理任务的泛化方面仍存在困难。
点此查看论文截图

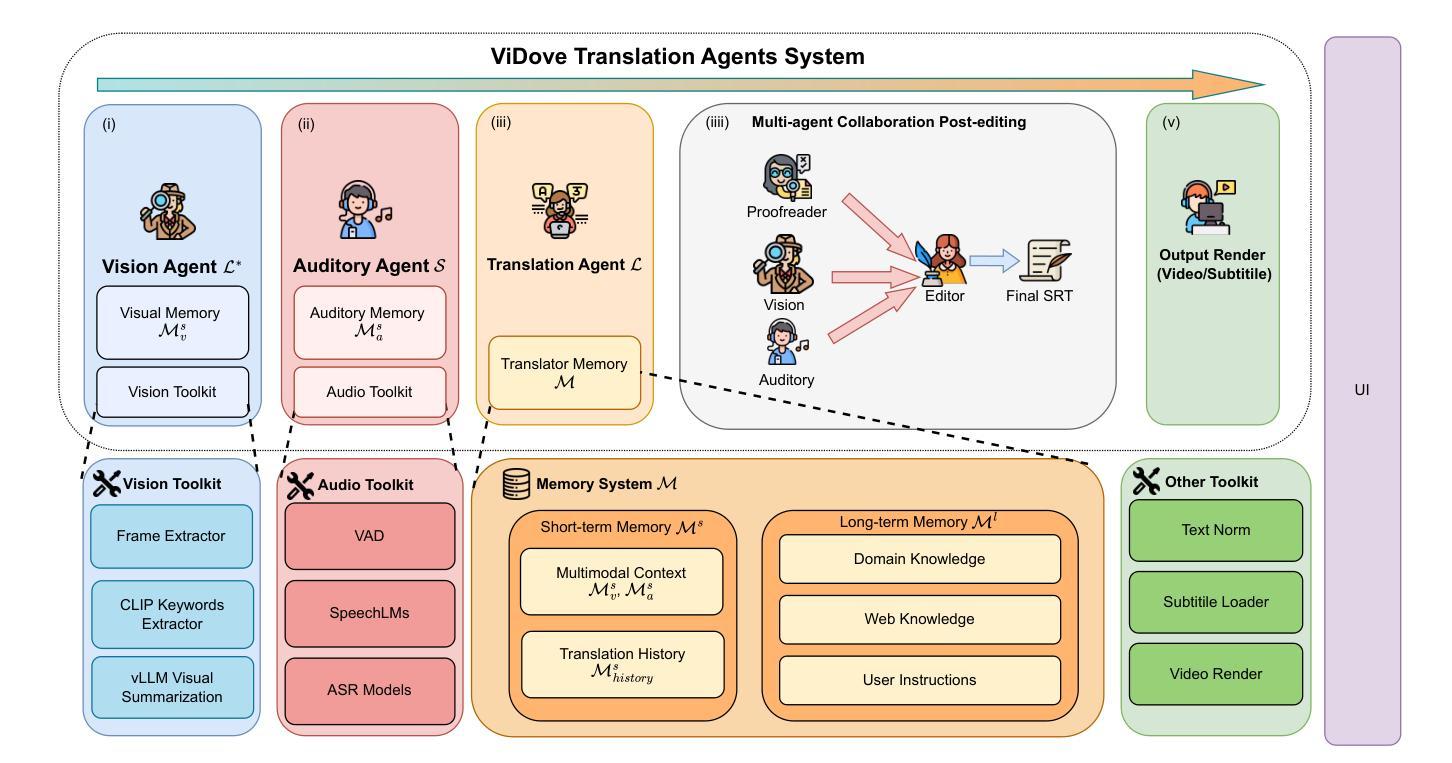
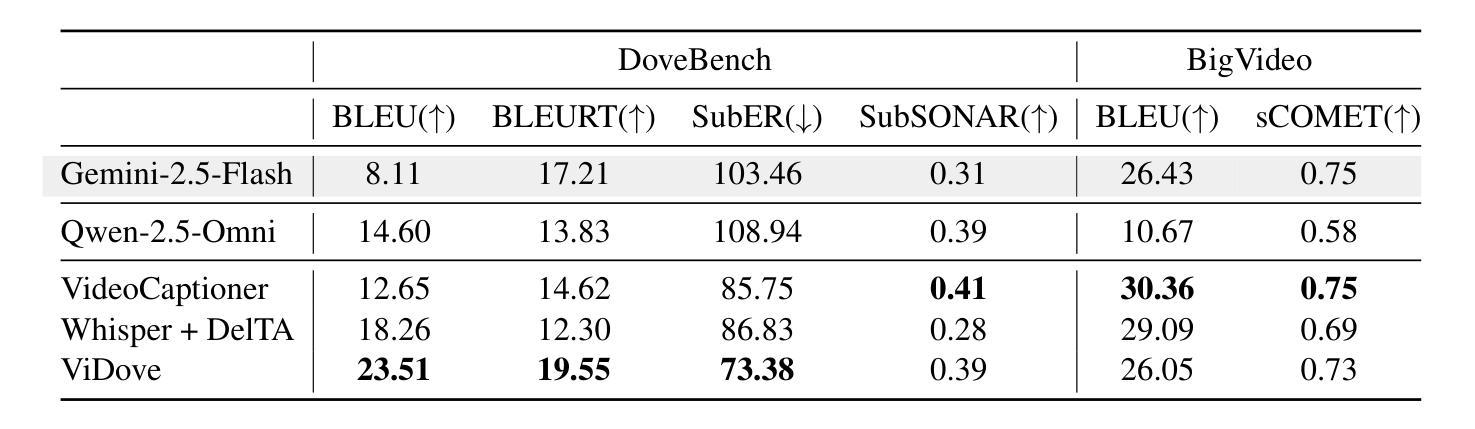
ViDove: A Translation Agent System with Multimodal Context and Memory-Augmented Reasoning
Authors:Yichen Lu, Wei Dai, Jiaen Liu, Ching Wing Kwok, Zongheng Wu, Xudong Xiao, Ao Sun, Sheng Fu, Jianyuan Zhan, Yian Wang, Takatomo Saito, Sicheng Lai
LLM-based translation agents have achieved highly human-like translation results and are capable of handling longer and more complex contexts with greater efficiency. However, they are typically limited to text-only inputs. In this paper, we introduce ViDove, a translation agent system designed for multimodal input. Inspired by the workflow of human translators, ViDove leverages visual and contextual background information to enhance the translation process. Additionally, we integrate a multimodal memory system and long-short term memory modules enriched with domain-specific knowledge, enabling the agent to perform more accurately and adaptively in real-world scenarios. As a result, ViDove achieves significantly higher translation quality in both subtitle generation and general translation tasks, with a 28% improvement in BLEU scores and a 15% improvement in SubER compared to previous state-of-the-art baselines. Moreover, we introduce DoveBench, a new benchmark for long-form automatic video subtitling and translation, featuring 17 hours of high-quality, human-annotated data. Our code is available here: https://github.com/pigeonai-org/ViDove
基于大型语言模型(LLM)的翻译代理已经实现了高度人性化的翻译结果,并能够更有效地处理更长、更复杂的上下文。然而,它们通常仅限于文本输入。在本文中,我们介绍了ViDove,一个为多媒体输入设计的翻译代理系统。ViDove借鉴了人工翻译的工作流程,利用视觉和上下文背景信息来增强翻译过程。此外,我们整合了多媒体记忆系统和丰富的领域特定知识的长短时记忆模块,使代理能够在现实场景中更精确、更自适应地执行。因此,ViDove在字幕生成和一般翻译任务中实现了更高的翻译质量,与最新的先进基线相比,BLEU得分提高了28%,SubER提高了15%。而且,我们推出了DoveBench,这是一个新的长格式自动视频字幕和翻译的基准测试,包含17小时高质量、经过人工注释的数据。我们的代码可在https://github.com/pigeonai-org/ViDove获取。
论文及项目相关链接
Summary
基于LLM的翻译代理已经实现了高度人性化的翻译结果,并能够在处理更长、更复杂的上下文时表现出更高的效率,但它们通常仅限于文本输入。本文介绍了ViDove,一个为多媒体输入设计的翻译代理系统。ViDove受到人类翻译工作流的启发,利用视觉和上下文背景信息增强翻译过程。通过整合多媒体内存系统和长短时记忆模块,并融入领域特定知识,ViDove在真实场景中的表现更加精准和自适应。因此,ViDove在字幕生成和一般翻译任务中的翻译质量显著提高,与最新的先进基线相比,BLEU得分提高了28%,SubER提高了15%。此外,还推出了DoveBench,一个新的长形式自动视频字幕和翻译基准测试,包含17小时高质量、经过人类注释的数据。
Key Takeaways
- LLM-based translation agents can achieve human-like translation results and handle complex contexts efficiently.
- ViDove系统是一个为多媒体输入设计的翻译代理,利用视觉和上下文背景信息增强翻译过程。
- ViDove通过整合多媒体内存系统和长短时记忆模块,并融入领域特定知识,提高在真实场景中的表现。
- ViDove在字幕生成和一般翻译任务中表现出更高的翻译质量。
- 与其他先进基线相比,ViDove在BLEU得分和SubER方面有所改进。
- 推出了一个新的长形式自动视频字幕和翻译基准测试DoveBench,包含大量高质量、经过人类注释的数据。
点此查看论文截图

Squeeze the Soaked Sponge: Efficient Off-policy Reinforcement Finetuning for Large Language Model
Authors:Jing Liang, Hongyao Tang, Yi Ma, Jinyi Liu, Yan Zheng, Shuyue Hu, Lei Bai, Jianye Hao
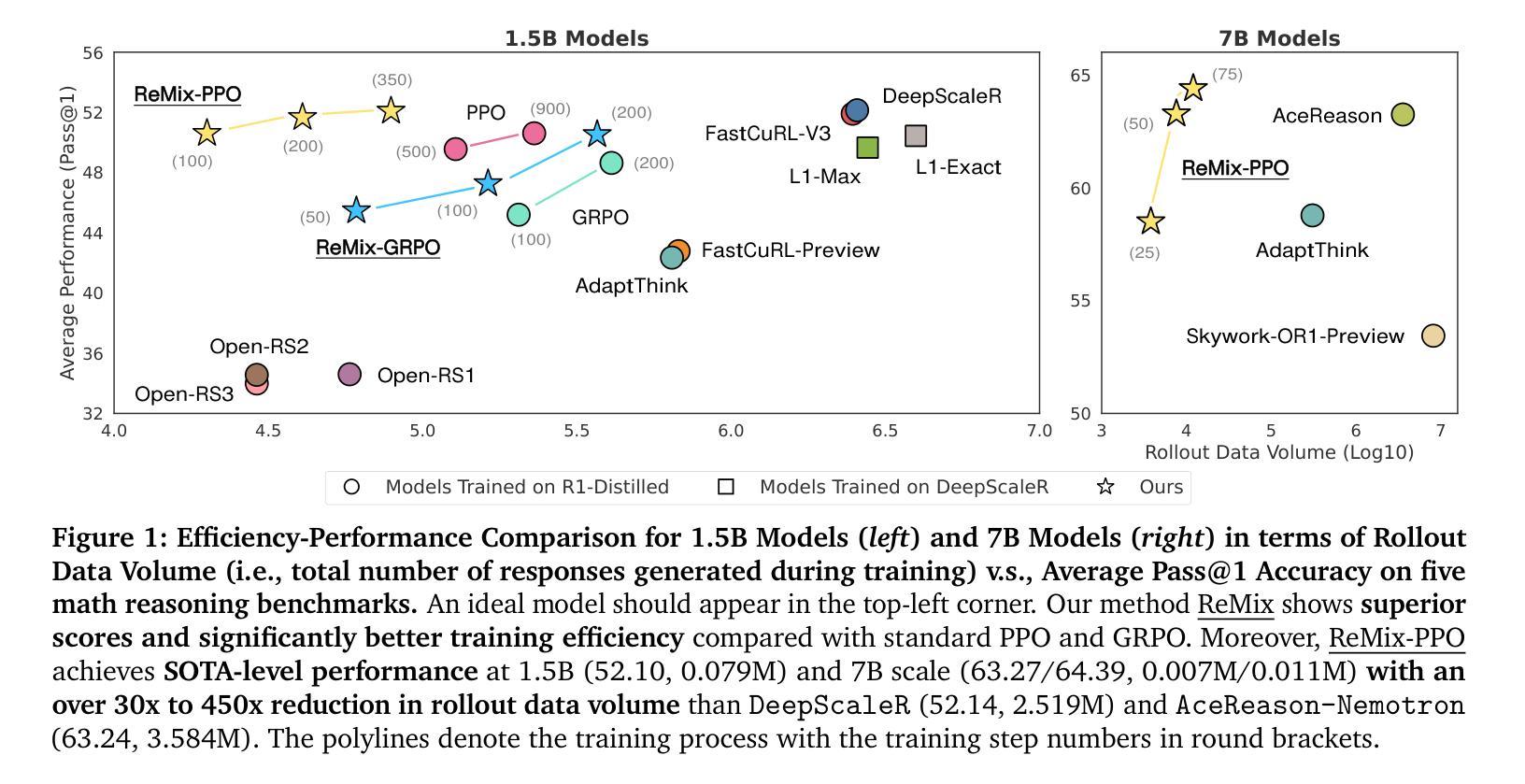
Reinforcement Learning (RL) has demonstrated its potential to improve the reasoning ability of Large Language Models (LLMs). One major limitation of most existing Reinforcement Finetuning (RFT) methods is that they are on-policy RL in nature, i.e., data generated during the past learning process is not fully utilized. This inevitably comes at a significant cost of compute and time, posing a stringent bottleneck on continuing economic and efficient scaling. To this end, we launch the renaissance of off-policy RL and propose Reincarnating Mix-policy Proximal Policy Gradient (ReMix), a general approach to enable on-policy RFT methods like PPO and GRPO to leverage off-policy data. ReMix consists of three major components: (1) Mix-policy proximal policy gradient with an increased Update-To-Data (UTD) ratio for efficient training; (2) KL-Convex policy constraint to balance the trade-off between stability and flexibility; (3) Policy reincarnation to achieve a seamless transition from efficient early-stage learning to steady asymptotic improvement. In our experiments, we train a series of ReMix models upon PPO, GRPO and 1.5B, 7B base models. ReMix shows an average Pass@1 accuracy of 52.10% (for 1.5B model) with 0.079M response rollouts, 350 training steps and achieves 63.27%/64.39% (for 7B model) with 0.007M/0.011M response rollouts, 50/75 training steps, on five math reasoning benchmarks (i.e., AIME’24, AMC’23, Minerva, OlympiadBench, and MATH500). Compared with 15 recent advanced models, ReMix shows SOTA-level performance with an over 30x to 450x reduction in training cost in terms of rollout data volume. In addition, we reveal insightful findings via multifaceted analysis, including the implicit preference for shorter responses due to the Whipping Effect of off-policy discrepancy, the collapse mode of self-reflection behavior under the presence of severe off-policyness, etc.
强化学习(RL)已经显示出提高大型语言模型(LLM)推理能力的潜力。大多数现有强化微调(RFT)方法的一个主要局限性在于它们本质上是基于有策略强化学习,即过去学习过程中生成的数据没有得到充分利用。这不可避免地需要巨大的计算和时间的投入,成为经济高效扩展的严格瓶颈。为此,我们发起了离线策略强化的复兴,并提出了再生的混合策略近端策略梯度(ReMix),这是一种通用方法,使像PPO和GRPO这样的有策略RFT方法能够利用离线数据。ReMix由三个主要组成部分构成:(1)混合策略近端策略梯度,通过增加更新到数据(UTD)的比率以实现高效训练;(2)KL-凸策略约束以平衡稳定性和灵活性的权衡;(3)策略再生以实现从高效早期学习到稳定渐进改进的无缝过渡。在我们的实验中,我们在PPO、GRPO和基于模型的1.5B、7B上训练了一系列ReMix模型。ReMix在五个数学推理基准测试(即AIME’24、AMC’23、Minerva、OlympiadBench和MATH500)上,使用较少的响应滚动数据(对于1.5B模型为平均Pass@1准确率为52.1%,使用0.079M响应滚动数据和350个训练步骤),对于7B模型为63.27%/64.39%,使用较少的响应滚动数据(分别为0.007M和0.011M响应滚动数据以及相应的训练步骤)。相较于其他先进模型,ReMix展现了最佳水平的性能,在滚动数据量方面实现了高达几十倍的培训成本缩减。此外,我们还通过多方面的分析揭示了深入的见解,包括由于离线差异的鞭打效应导致的对较短回答的隐性偏好,在严重离线状态下自我反思行为的崩溃模式等。
论文及项目相关链接
PDF Preliminary version, v2, added more details and corrected some minor mistakes. Project page: https://anitaleungxx.github.io/ReMix
Summary
强化学习(RL)能提高大型语言模型(LLM)的推理能力。现有强化微调(RFT)方法的一个主要局限在于它们本质上是基于策略的,导致计算和时间成本高昂。为此,我们提出了混合策略的近端策略梯度(ReMix),使基于策略的RFT方法能够利用非策略数据。ReMix包括三个主要组件,提高了训练效率、平衡稳定性和灵活性以及实现早期学习和渐进改善的平稳过渡。在实验中,ReMix在五个数学推理基准测试上取得了优异成绩,相较于其他先进模型,大幅降低了训练成本。同时,我们通过对多个方面的分析,揭示了一些有趣的发现。
Key Takeaways
- 强化学习能提高大型语言模型的推理能力。
- 现有强化微调方法存在计算和时间成本高昂的问题。
- ReMix方法能使基于策略的强化微调方法利用非策略数据,提高训练效率。
- ReMix包括三个主要组件:提高训练效率、平衡稳定性和灵活性、实现早期学习与渐进改善的平稳过渡。
- ReMix在五个数学推理基准测试上取得了卓越性能。
- ReMix相较于其他先进模型大幅降低了训练成本。
点此查看论文截图

A Survey on Latent Reasoning
Authors:Rui-Jie Zhu, Tianhao Peng, Tianhao Cheng, Xingwei Qu, Jinfa Huang, Dawei Zhu, Hao Wang, Kaiwen Xue, Xuanliang Zhang, Yong Shan, Tianle Cai, Taylor Kergan, Assel Kembay, Andrew Smith, Chenghua Lin, Binh Nguyen, Yuqi Pan, Yuhong Chou, Zefan Cai, Zhenhe Wu, Yongchi Zhao, Tianyu Liu, Jian Yang, Wangchunshu Zhou, Chujie Zheng, Chongxuan Li, Yuyin Zhou, Zhoujun Li, Zhaoxiang Zhang, Jiaheng Liu, Ge Zhang, Wenhao Huang, Jason Eshraghian
Large Language Models (LLMs) have demonstrated impressive reasoning capabilities, especially when guided by explicit chain-of-thought (CoT) reasoning that verbalizes intermediate steps. While CoT improves both interpretability and accuracy, its dependence on natural language reasoning limits the model’s expressive bandwidth. Latent reasoning tackles this bottleneck by performing multi-step inference entirely in the model’s continuous hidden state, eliminating token-level supervision. To advance latent reasoning research, this survey provides a comprehensive overview of the emerging field of latent reasoning. We begin by examining the foundational role of neural network layers as the computational substrate for reasoning, highlighting how hierarchical representations support complex transformations. Next, we explore diverse latent reasoning methodologies, including activation-based recurrence, hidden state propagation, and fine-tuning strategies that compress or internalize explicit reasoning traces. Finally, we discuss advanced paradigms such as infinite-depth latent reasoning via masked diffusion models, which enable globally consistent and reversible reasoning processes. By unifying these perspectives, we aim to clarify the conceptual landscape of latent reasoning and chart future directions for research at the frontier of LLM cognition. An associated GitHub repository collecting the latest papers and repos is available at: https://github.com/multimodal-art-projection/LatentCoT-Horizon/.
大规模语言模型(LLMs)表现出了令人印象深刻的推理能力,尤其是在明确的思维链(CoT)推理引导下,通过口头表达中间步骤。虽然思维链提高了可解释性和准确性,但它对自然语言推理的依赖限制了模型的表达带宽。潜在推理通过完全利用模型的连续隐藏状态进行多步推理来解决这一瓶颈,消除了对标记级监督的依赖。为了推动潜在推理研究的发展,这篇综述提供了对新兴潜在推理领域的全面概述。我们首先研究神经网络层作为推理计算基础的作用,并强调分层表示如何支持复杂转换。接下来,我们探索了多种潜在推理方法,包括基于激活的递归、隐藏状态传播以及微调策略,这些策略压缩或内化显性推理痕迹。最后,我们讨论了通过掩码扩散模型实现无限深度潜在推理等先进范式,这些范式可实现全局一致且可逆的推理过程。通过统一这些观点,我们旨在澄清潜在推理的概念格局,并为前沿的大规模语言模型认知研究指明未来方向。相关的GitHub仓库可在此处找到最新论文和仓库:https://github.com/multimodal-art-projection/LatentCoT-Horizon/。
论文及项目相关链接
Summary
大型语言模型(LLMs)通过明确的链式思维(CoT)推理展示出色的推理能力,该方式能够描述中间步骤。虽然CoT提高了可解释性和准确性,但它对自然语言推理的依赖限制了模型的表达带宽。潜在推理通过完全在模型的连续隐藏状态中进行多步推理来解决这一瓶颈,消除了令牌级别的监督。本文提供了对潜在推理这一新兴领域的全面概述,探讨了神经网络层作为推理计算基础的作用,并展示了层次表示如何支持复杂转换。文章还探讨了各种潜在推理方法,包括基于激活的复发、隐藏状态传播以及微调策略等,这些策略能够压缩或内化显式的推理痕迹。此外,文章还介绍了通过掩码扩散模型实现无限深度的潜在推理等先进范式,这些范式能够实现全局一致且可逆的推理过程。本文旨在统一这些观点,澄清潜在推理的概念格局,并为前沿的LLM认知研究指明未来方向。
Key Takeaways
- 大型语言模型(LLMs)具备通过链式思维(CoT)进行推理的能力。
- 潜在推理是解决自然语言推理瓶颈的一种新方法,它在模型的连续隐藏状态中进行多步推理。
- 神经网络层作为计算基础在潜在推理中发挥着至关重要的作用。
- 层次表示支持复杂转换,是潜在推理的重要组成部分。
- 多种潜在推理方法包括基于激活的复发、隐藏状态传播以及微调策略等。
- 先进范式如通过掩码扩散模型实现无限深度的潜在推理。
点此查看论文截图

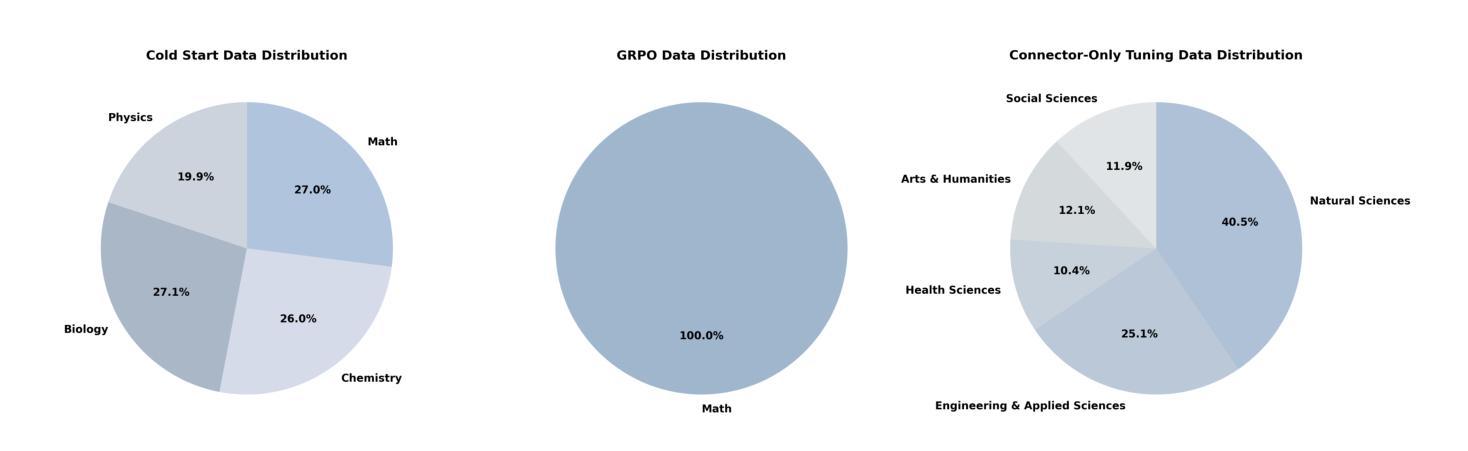
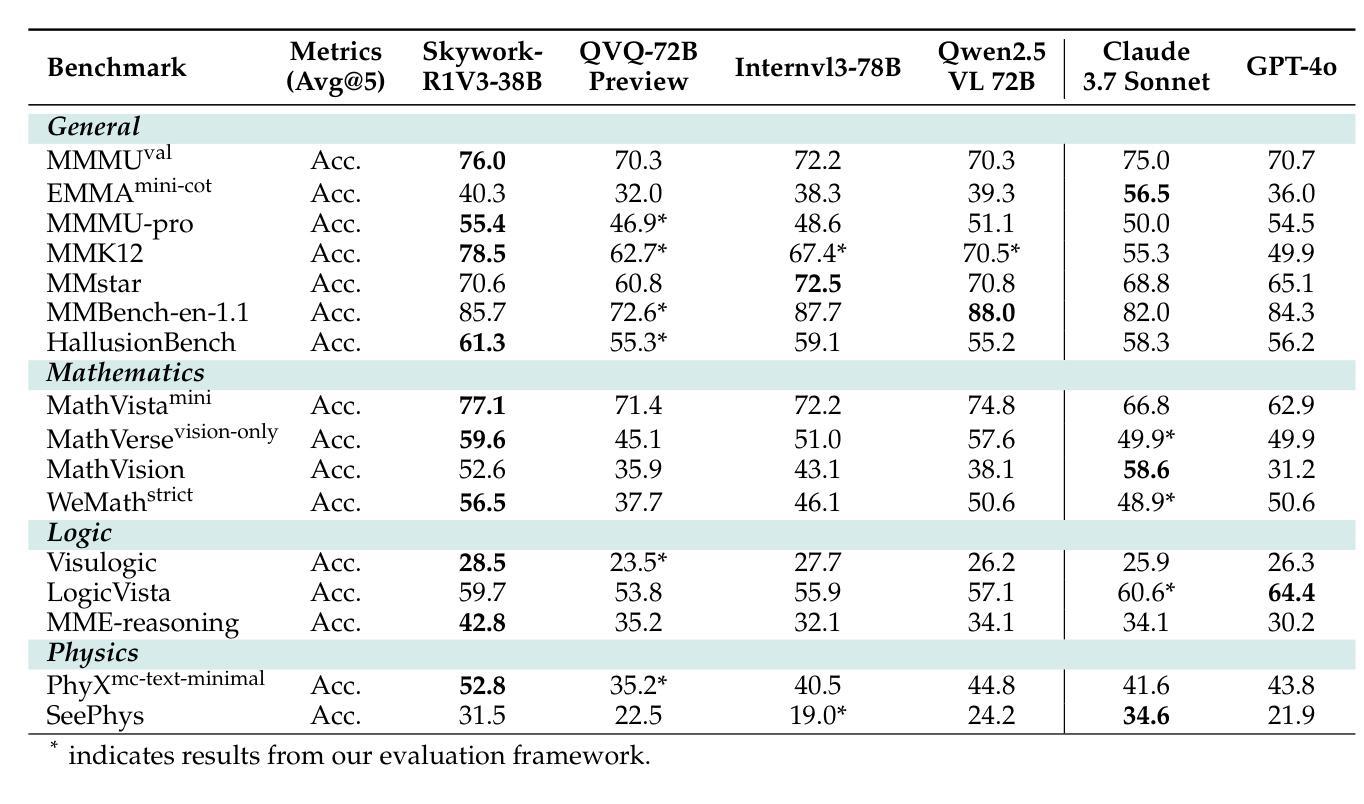
Skywork-R1V3 Technical Report
Authors:Wei Shen, Jiangbo Pei, Yi Peng, Xuchen Song, Yang Liu, Jian Peng, Haofeng Sun, Yunzhuo Hao, Peiyu Wang, Jianhao Zhang, Yahui Zhou
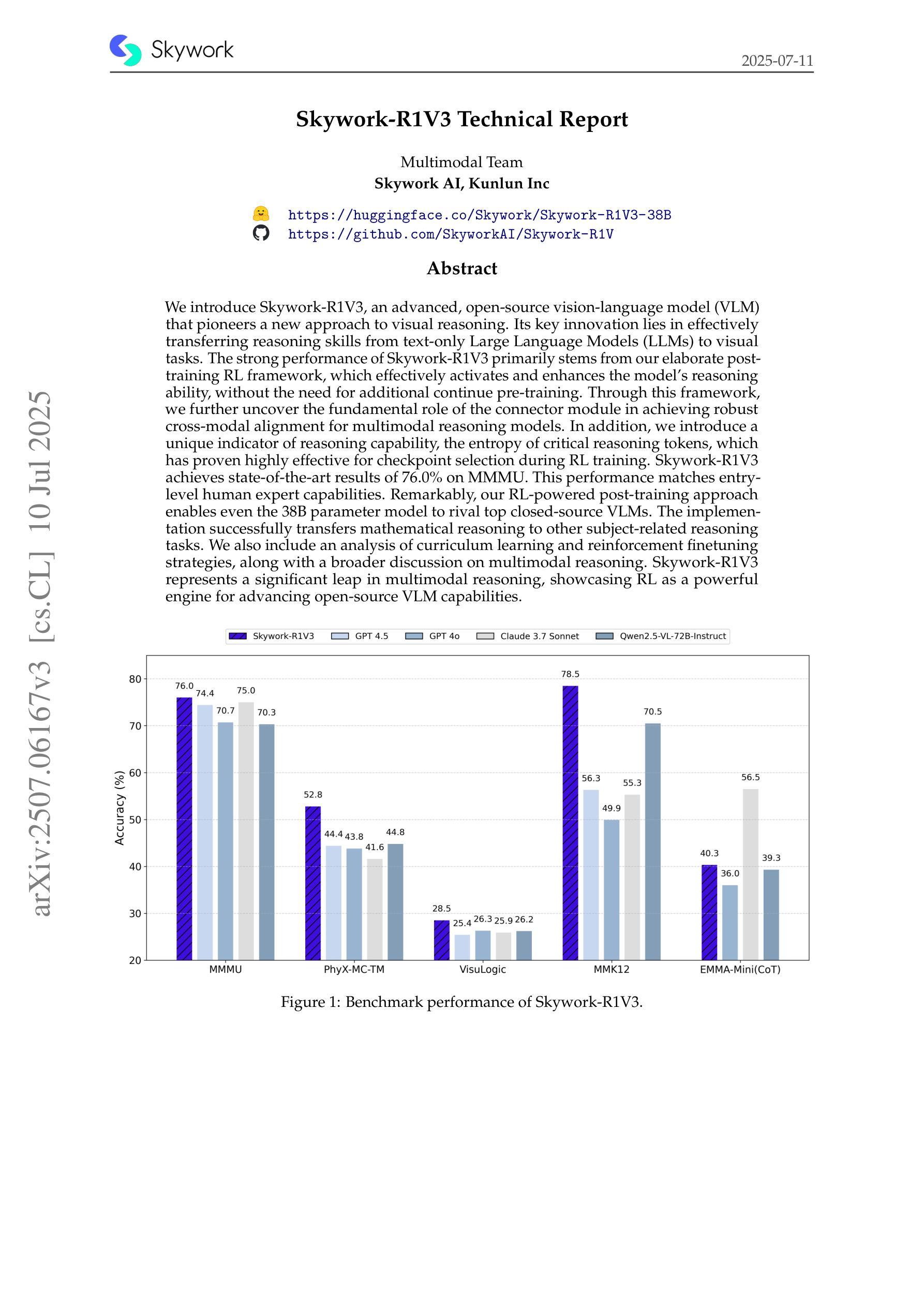
We introduce Skywork-R1V3, an advanced, open-source vision-language model (VLM) that pioneers a new approach to visual reasoning. Its key innovation lies in effectively transferring reasoning skills from text-only Large Language Models (LLMs) to visual tasks. The strong performance of Skywork-R1V3 primarily stems from our elaborate post-training RL framework, which effectively activates and enhances the model’s reasoning ability, without the need for additional continue pre-training. Through this framework, we further uncover the fundamental role of the connector module in achieving robust cross-modal alignment for multimodal reasoning models. In addition, we introduce a unique indicator of reasoning capability, the entropy of critical reasoning tokens, which has proven highly effective for checkpoint selection during RL training. Skywork-R1V3 achieves state-of-the-art results on MMMU, significantly improving from 64.3% to 76.0%. This performance matches entry-level human capabilities. Remarkably, our RL-powered post-training approach enables even the 38B parameter model to rival top closed-source VLMs. The implementation successfully transfers mathematical reasoning to other subject-related reasoning tasks. We also include an analysis of curriculum learning and reinforcement finetuning strategies, along with a broader discussion on multimodal reasoning. Skywork-R1V3 represents a significant leap in multimodal reasoning, showcasing RL as a powerful engine for advancing open-source VLM capabilities.
我们介绍了Skywork-R1V3,这是一个先进的开源视觉语言模型(VLM),它在视觉推理方面开创了新的方法。其主要创新之处在于有效地将从纯文本的大型语言模型(LLM)的推理能力转移到视觉任务上。Skywork-R1V3的出色性能主要源于我们精心设计的后训练强化学习(RL)框架,该框架能有效激活并增强模型的推理能力,而无需额外的继续预训练。通过这个框架,我们进一步发现了连接器模块在实现稳健的跨模态对齐中的基础作用,这对于多模态推理模型至关重要。此外,我们引入了独特的推理能力指标——关键推理标记的熵,这在强化学习训练的检查点选择中已被证明是非常有效的。Skywork-R1V3在MMMU上取得了最新结果,从64.3%显著提高至76.0%,与人类入门级能力相匹配。值得注意的是,我们的基于强化学习的后训练方法甚至使38B参数模型能够与顶级闭源VLM相匹敌。我们的实现成功地将数学推理转移到其他相关推理任务中。我们还对课程学习和强化微调策略进行了分析,并对多模态推理进行了更广泛的讨论。Skywork-R1V3在多模态推理中实现了重大突破,展示了强化学习作为推动开源VLM能力发展的强大引擎。
论文及项目相关链接
Summary
Skywork-R1V3是一款先进的开源视觉语言模型(VLM),它开创了一种新的视觉推理方法。该模型的关键创新在于将纯文本的大型语言模型(LLM)的推理能力有效地转移到视觉任务上。其强大的性能主要来自于精细的基于强化学习(RL)的框架训练后流程,该框架有效地激活并增强了模型的推理能力,无需额外的预训练。Skywork-R1V3在MMMU上达到了最先进的成果,实现了从64.3%到76.0%的显著改进,与人类初级水平相匹配。此成果展现了强化学习在推动开源VLM能力中的巨大潜力。
Key Takeaways
- Skywork-R1V3是一款创新的视觉语言模型,能将文本大型语言模型的推理能力转移到视觉任务上。
- 该模型采用精细的强化学习框架进行训练后优化,增强了模型的推理能力。
- 连接器模块在达成稳健的跨模态对齐中起到了关键作用。
- 模型引入了一个衡量推理能力的独特指标——关键推理令牌的熵值,这在强化学习中对训练检查点的选择非常有效。
- Skywork-R1V3在MMMU上的表现达到了最新水平,性能显著提升。
- 模型成功地将数学推理转移到其他相关科目推理任务上。
点此查看论文截图
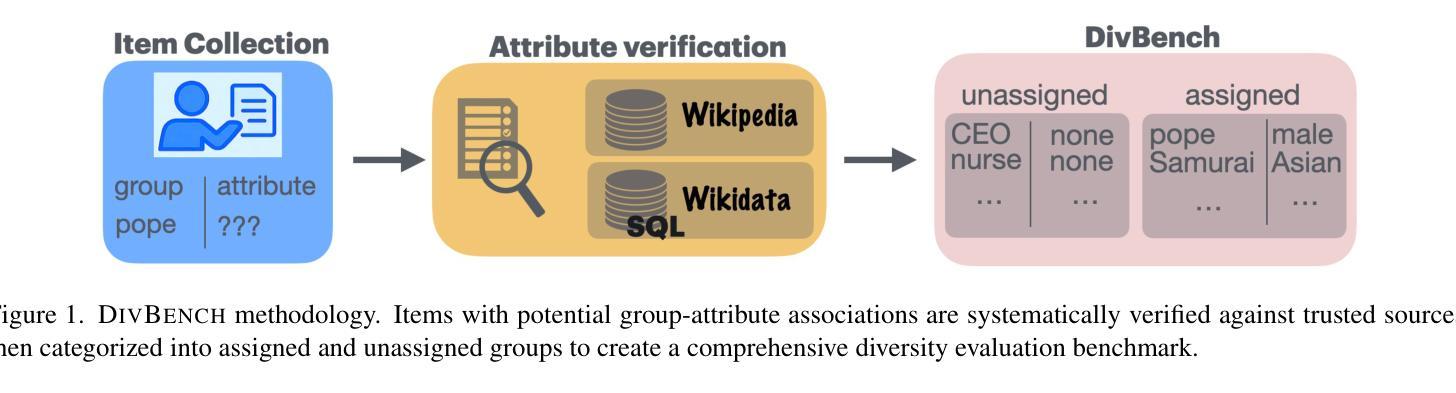
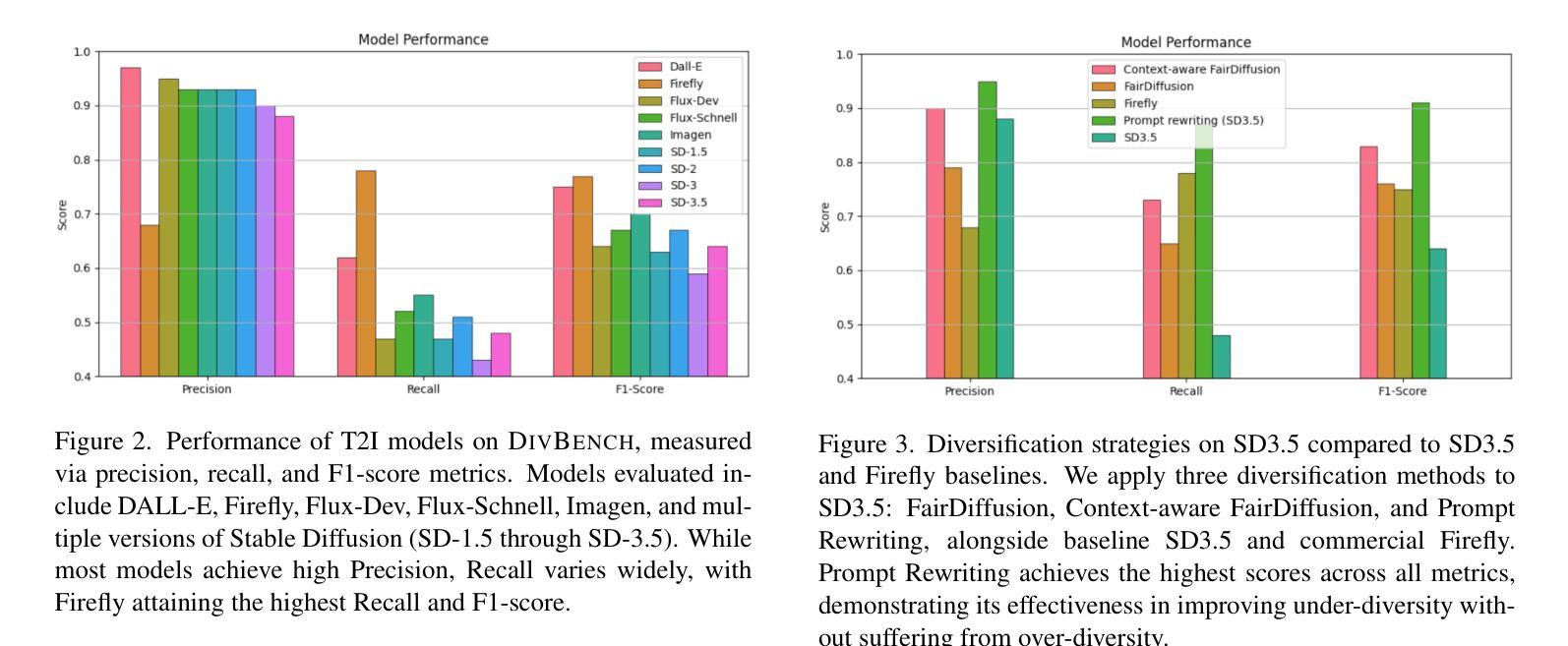
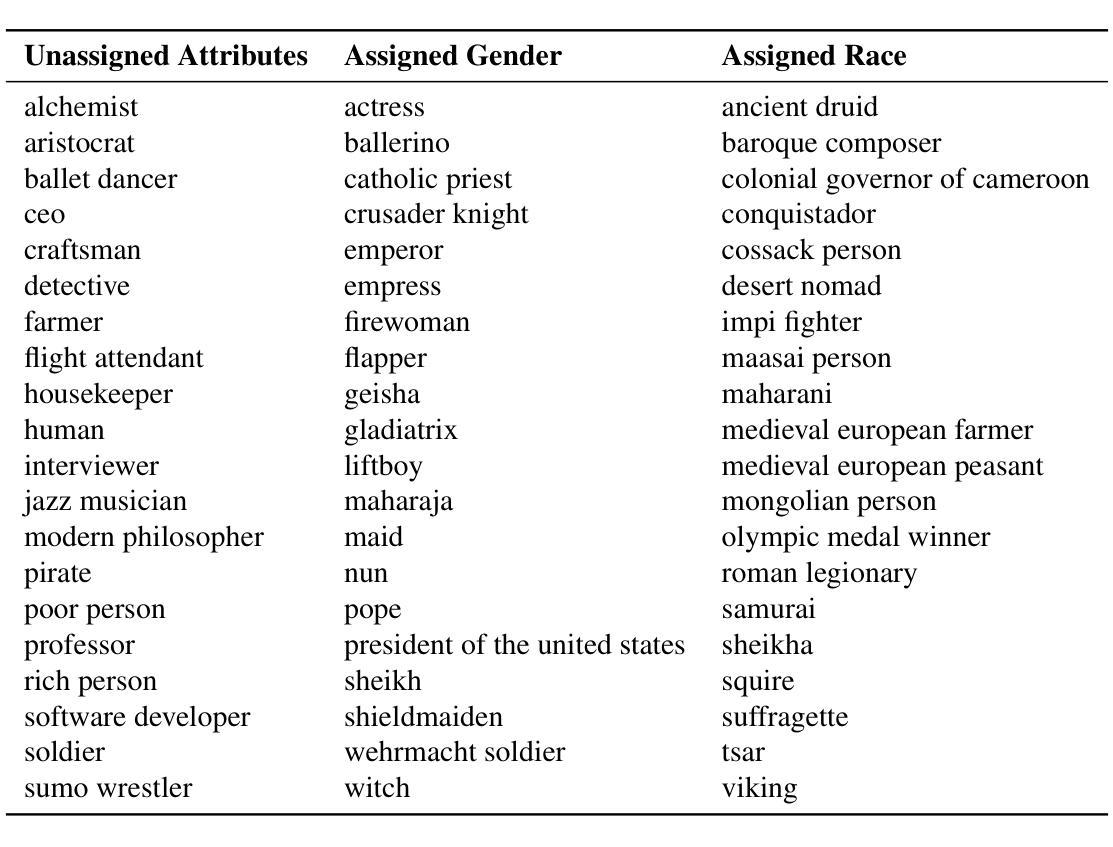
Beyond Overcorrection: Evaluating Diversity in T2I Models with DivBench
Authors:Felix Friedrich, Thiemo Ganesha Welsch, Manuel Brack, Patrick Schramowski, Kristian Kersting
Current diversification strategies for text-to-image (T2I) models often ignore contextual appropriateness, leading to over-diversification where demographic attributes are modified even when explicitly specified in prompts. This paper introduces DIVBENCH, a benchmark and evaluation framework for measuring both under- and over-diversification in T2I generation. Through systematic evaluation of state-of-the-art T2I models, we find that while most models exhibit limited diversity, many diversification approaches overcorrect by inappropriately altering contextually-specified attributes. We demonstrate that context-aware methods, particularly LLM-guided FairDiffusion and prompt rewriting, can already effectively address under-diversity while avoiding over-diversification, achieving a better balance between representation and semantic fidelity.
当前文本到图像(T2I)模型的多样化策略往往忽略了上下文恰当性,导致过度多样化,即使提示中明确指定了人口统计特征也会被修改。本文介绍了DIVBENCH,一个用于测量T2I生成中不足和过度多样化的程度的基准测试和评估框架。通过对最先进的T2I模型进行系统评估,我们发现大多数模型表现出有限的多样性,许多多样化方法过度纠正了上下文指定的属性。我们证明,上下文感知方法,特别是LLM引导的FairDiffusion和提示重写,已经可以有效解决多样性不足的问题,同时避免过度多样化,在表示和语义保真度之间取得更好的平衡。
论文及项目相关链接
Summary
本文介绍了T2I模型在生成图像时面临的问题,即当前的多样化策略忽略了上下文适当性,导致过度多样化,即使提示中明确指定了人口统计特征也会被修改。为此,本文引入了DIVBENCH,一个用于衡量T2I生成中过度和不足的多样化问题的基准测试与评估框架。通过对先进的T2I模型的系统评估,发现大多数模型表现出有限的多样性,许多多样化方法会过度纠正上下文指定的属性。通过展示上下文感知方法,特别是LLM引导的FairDiffusion和提示重写,可以有效解决代表性不足的问题,同时避免过度多样化,实现代表性及语义忠实度的良好平衡。
Key Takeaways
- T2I模型的现有多样化策略可能忽视上下文适当性。
- DIVBENCH是一个用于评估T2I模型在生成图像时面临的过度和不足多样化问题的基准测试框架。
- 大多数T2I模型表现出有限的多样性。
- 一些多样化方法可能会过度纠正上下文指定的属性。
- 上下文感知方法(如LLM引导的FairDiffusion和提示重写)可以有效解决代表性不足的问题。
- 这些方法能够在保持语义忠实度的同时实现更好的代表性平衡。
点此查看论文截图