⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-12 更新
Edge-ASR: Towards Low-Bit Quantization of Automatic Speech Recognition Models
Authors:Chen Feng, Yicheng Lin, Shaojie Zhuo, Chenzheng Su, Ramchalam Kinattinkara Ramakrishnan, Zhaocong Yuan, Xiaopeng Zhang
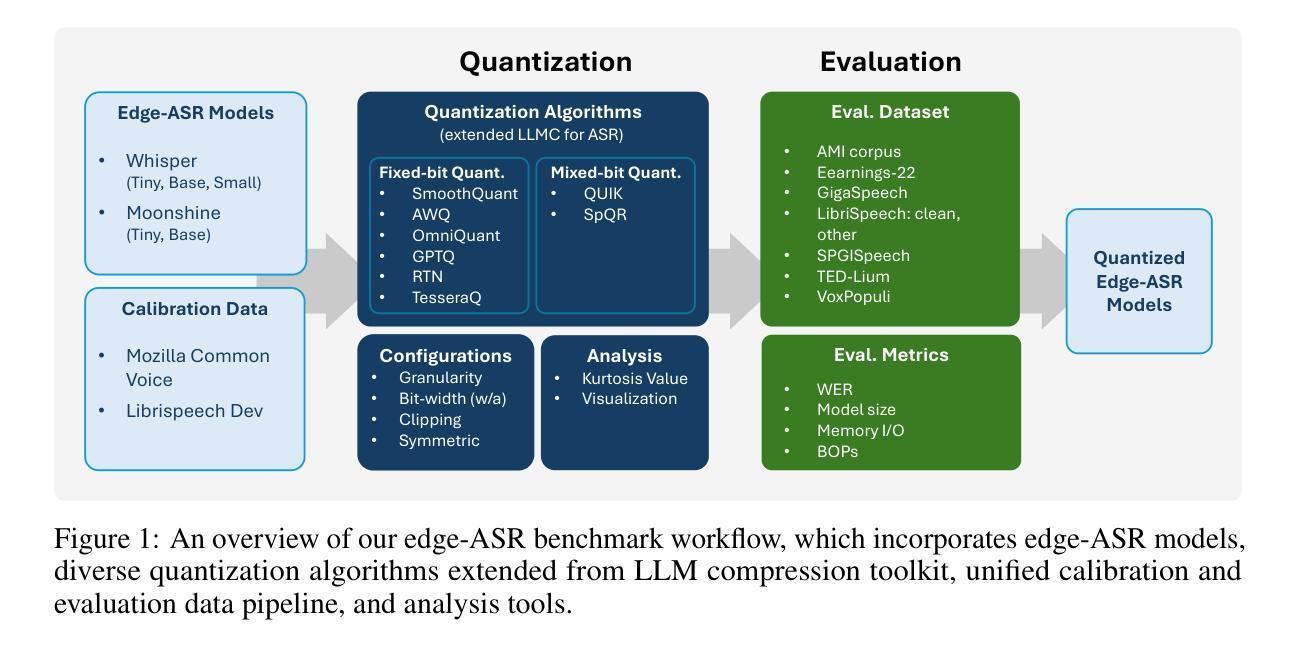
Recent advances in Automatic Speech Recognition (ASR) have demonstrated remarkable accuracy and robustness in diverse audio applications, such as live transcription and voice command processing. However, deploying these models on resource constrained edge devices (e.g., IoT device, wearables) still presents substantial challenges due to strict limits on memory, compute and power. Quantization, particularly Post-Training Quantization (PTQ), offers an effective way to reduce model size and inference cost without retraining. Despite its importance, the performance implications of various advanced quantization methods and bit-width configurations on ASR models remain unclear. In this work, we present a comprehensive benchmark of eight state-of-the-art (SOTA) PTQ methods applied to two leading edge-ASR model families, Whisper and Moonshine. We systematically evaluate model performances (i.e., accuracy, memory I/O and bit operations) across seven diverse datasets from the open ASR leaderboard, analyzing the impact of quantization and various configurations on both weights and activations. Built on an extension of the LLM compression toolkit, our framework integrates edge-ASR models, diverse advanced quantization algorithms, a unified calibration and evaluation data pipeline, and detailed analysis tools. Our results characterize the trade-offs between efficiency and accuracy, demonstrating that even 3-bit quantization can succeed on high capacity models when using advanced PTQ techniques. These findings provide valuable insights for optimizing ASR models on low-power, always-on edge devices.
最近,自动语音识别(ASR)技术的进展在各种音频应用(如实时转录和语音命令处理)中表现出了令人印象深刻的准确性和稳健性。然而,将这些模型部署在资源受限的边缘设备(例如物联网设备和可穿戴设备)上仍然面临巨大挑战,这主要是因为内存、计算和电源方面的严格限制。量化,尤其是训练后量化(PTQ),提供了一种有效的方式来减少模型大小和推理成本而无需重新训练。尽管其重要性不言而喻,但各种先进的量化方法和位宽配置对ASR模型性能的影响仍不清楚。在这项工作中,我们对应用于两个前沿边缘ASR模型家族Whisper和Moonshine的八种最先进的PTQ方法进行了全面基准测试。我们系统地评估了模型在七个公开ASR排行榜数据集上的性能(即准确性、内存输入/输出和位操作),分析了量化和各种配置对权重和激活的影响。我们的框架基于LLM压缩工具包的扩展,集成了边缘ASR模型、各种先进量化算法、统一的校准和评价数据管道以及详细的分析工具。我们的结果描述了效率和准确性之间的权衡,表明在使用先进的PTQ技术时,即使3位量化也可以在高性能模型中取得成功。这些发现对于在低功耗、始终开启的边缘设备上优化ASR模型提供了宝贵的见解。
论文及项目相关链接
Summary
本文研究了自动语音识别(ASR)模型在边缘设备上的部署挑战,特别是资源受限的设备。文章对两种领先的边缘ASR模型家族——Whisper和Moonshine,应用了八种最先进的PTQ(后训练量化)方法,并在七个公开ASR排行榜数据集上进行了系统评估。研究结果表明,使用先进的PTQ技术,甚至3位量化也可在高容量模型上取得成功。这为在低功耗、始终开启的边缘设备上优化ASR模型提供了宝贵见解。
Key Takeaways
- 最近ASR技术的进展在各种音频应用中表现出惊人的准确性和稳健性。
- 在资源受限的边缘设备上部署ASR模型仍存在挑战,如内存、计算和电力限制。
- 后训练量化(PTQ)是减少模型大小和推理成本的有效方法。
- 文章对两种边缘ASR模型家族应用了八种最先进的PTQ方法,并在七个数据集上进行了评估。
- 研究发现,使用先进的PTQ技术,甚至3位量化也可在高容量模型上实现良好性能。
- 文章提供了一个框架,整合了边缘ASR模型、各种先进量化算法、统一的校准和评价数据管道以及详细的分析工具。
点此查看论文截图


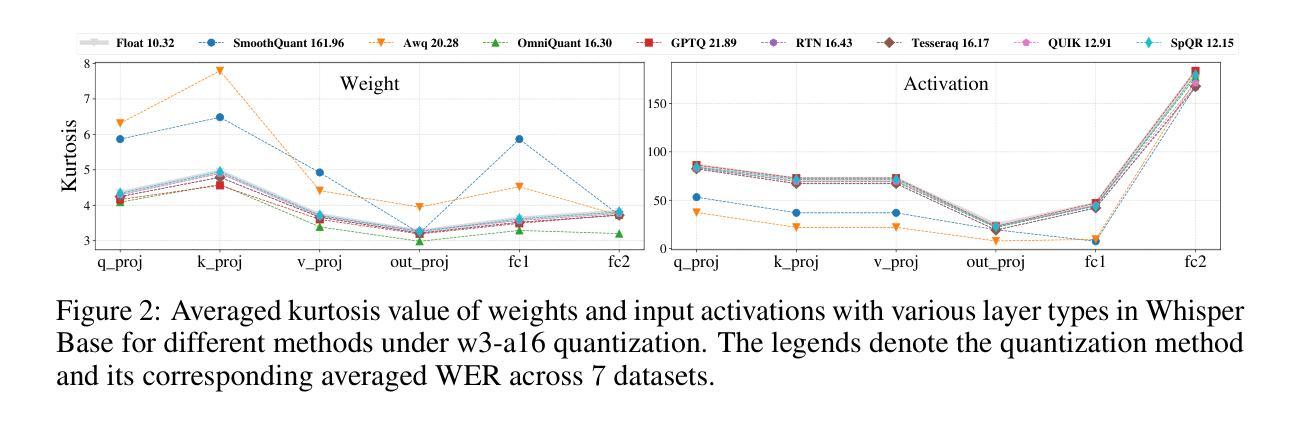
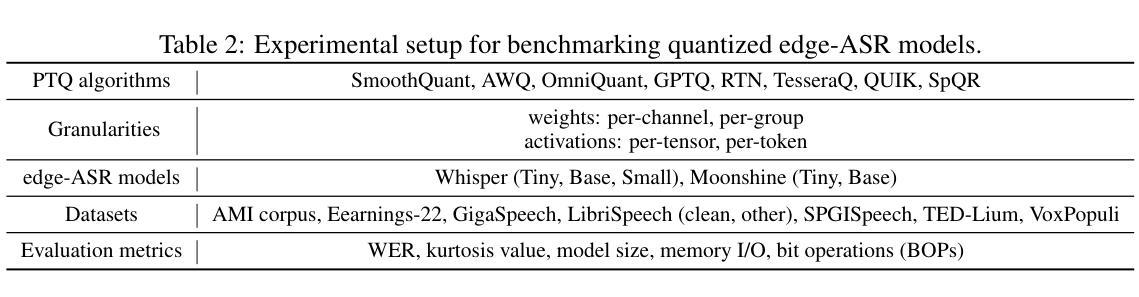
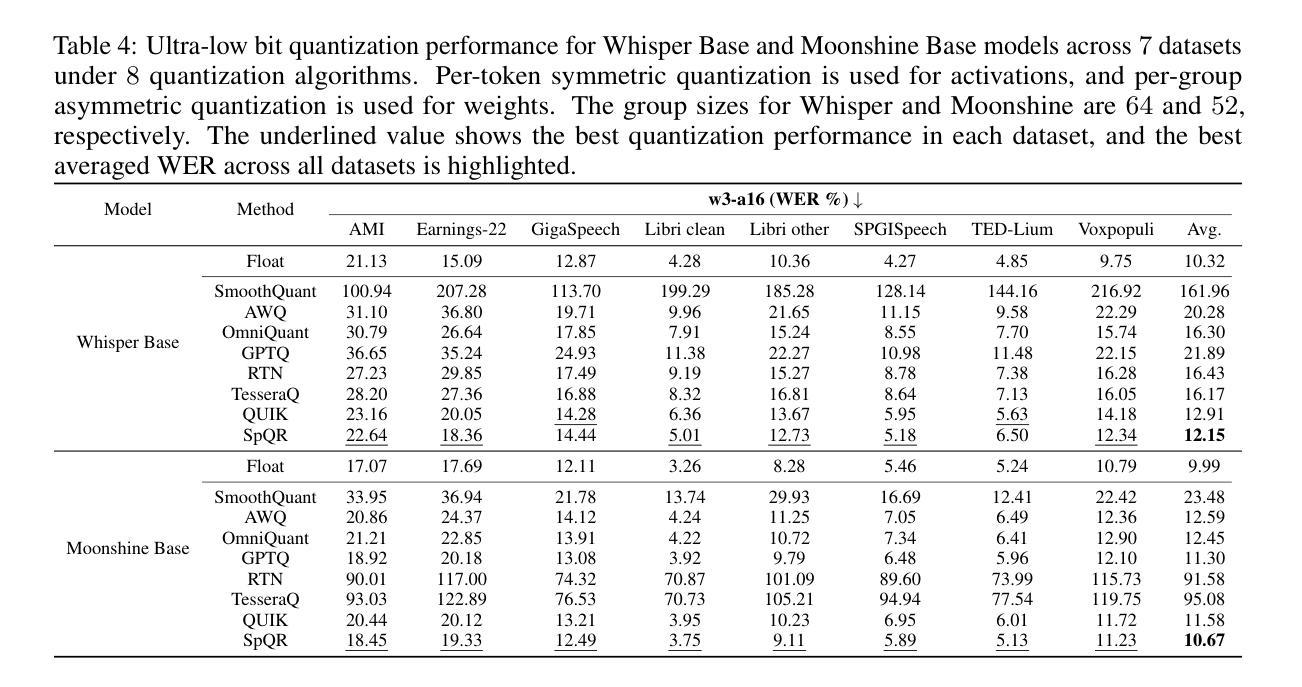
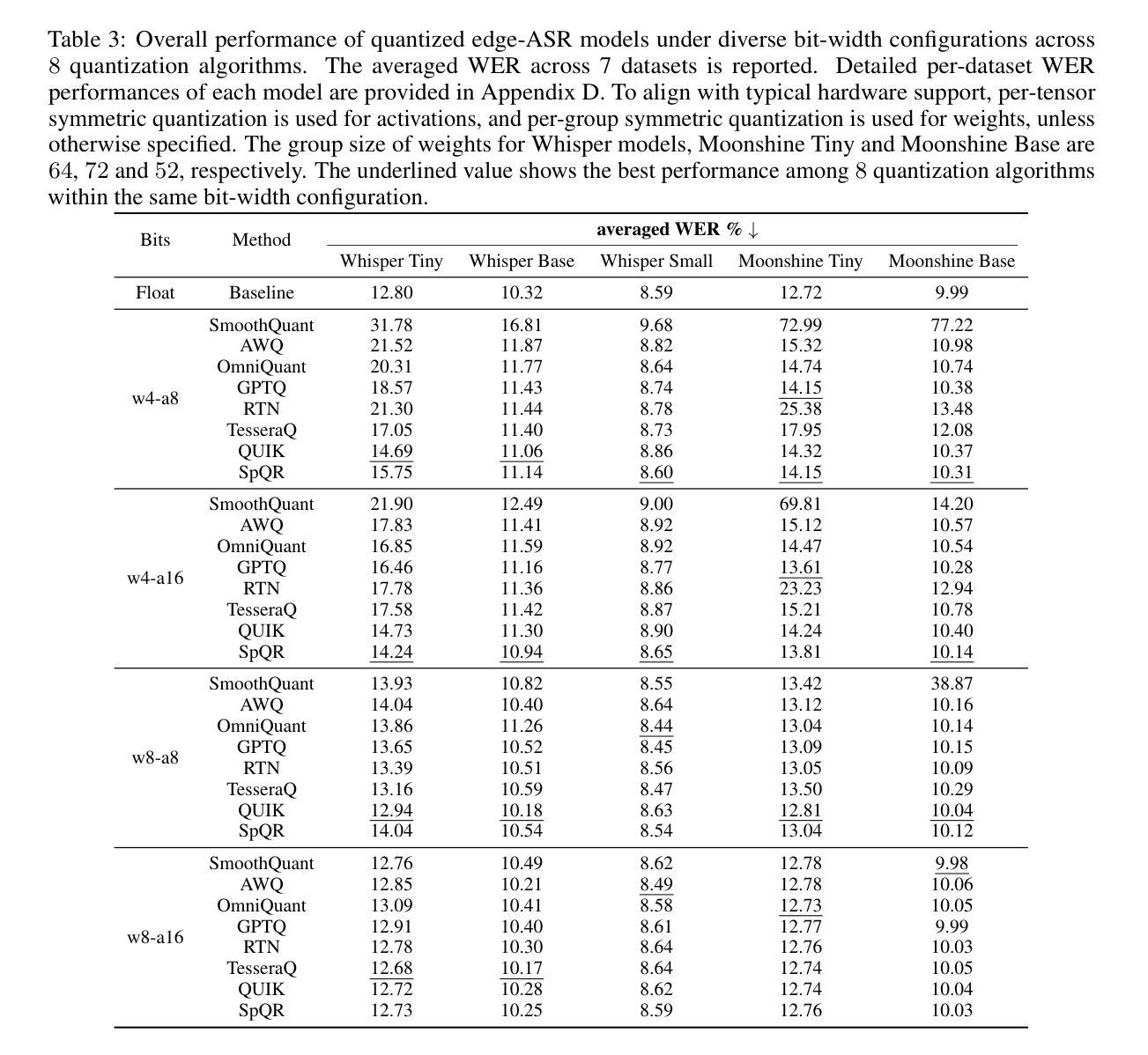
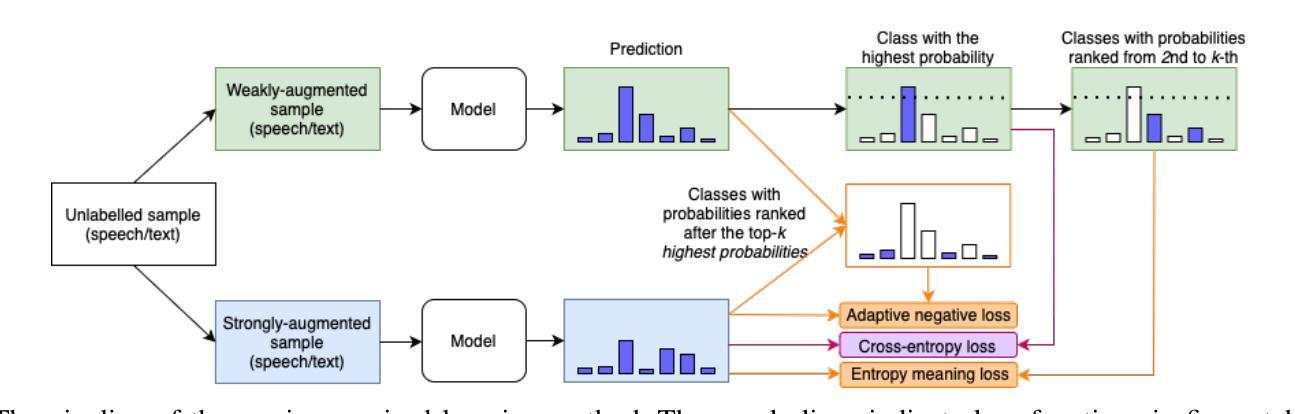
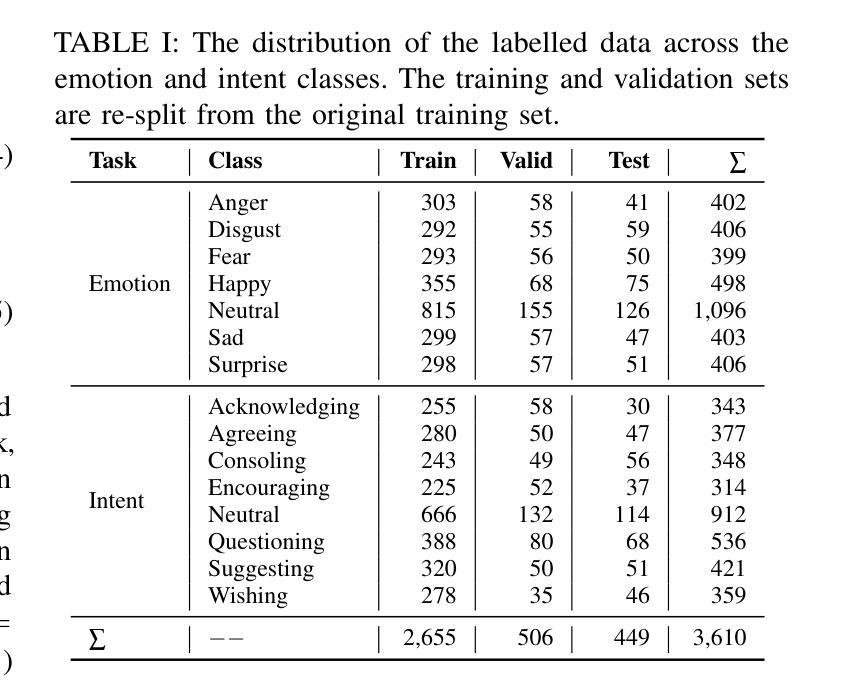
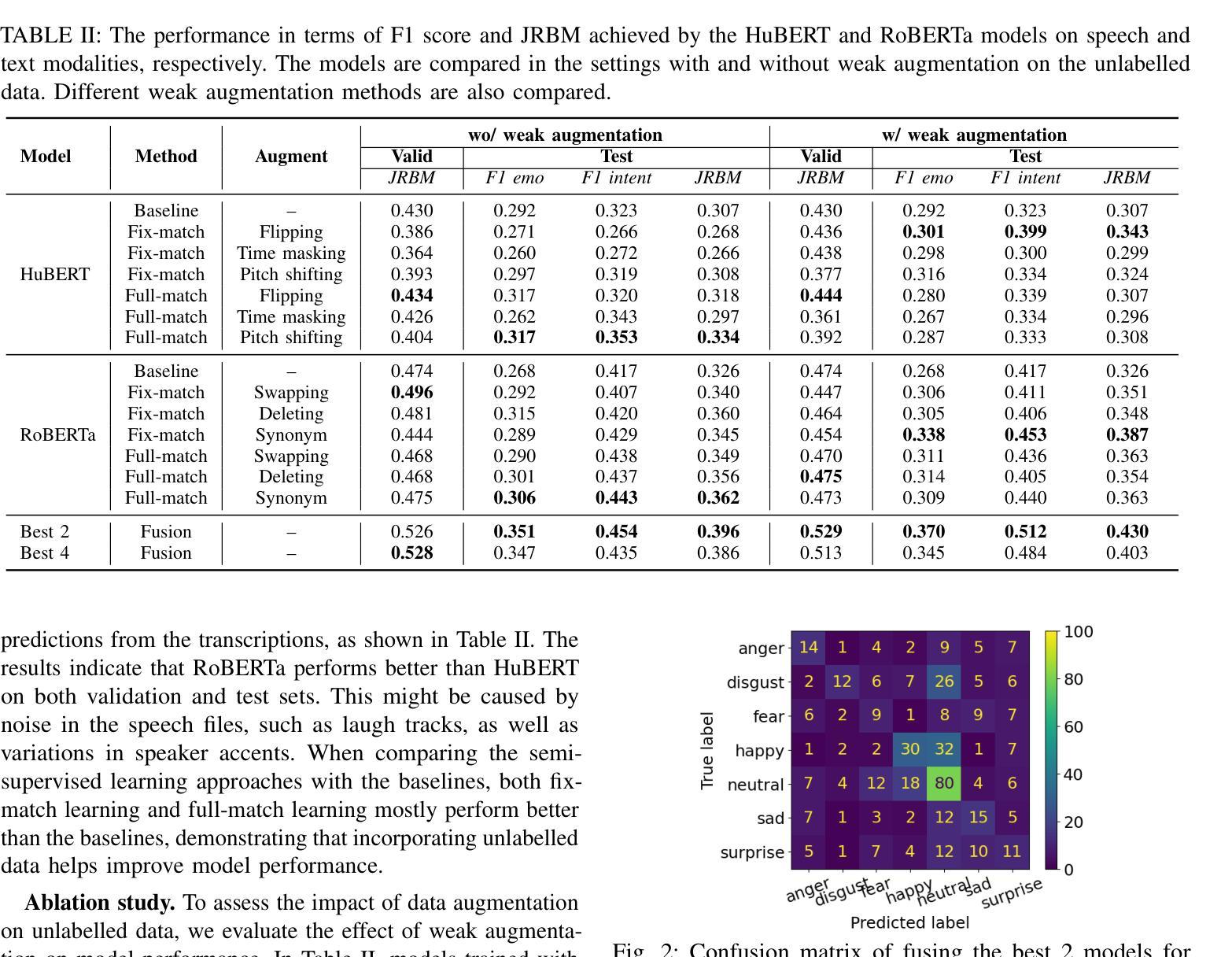
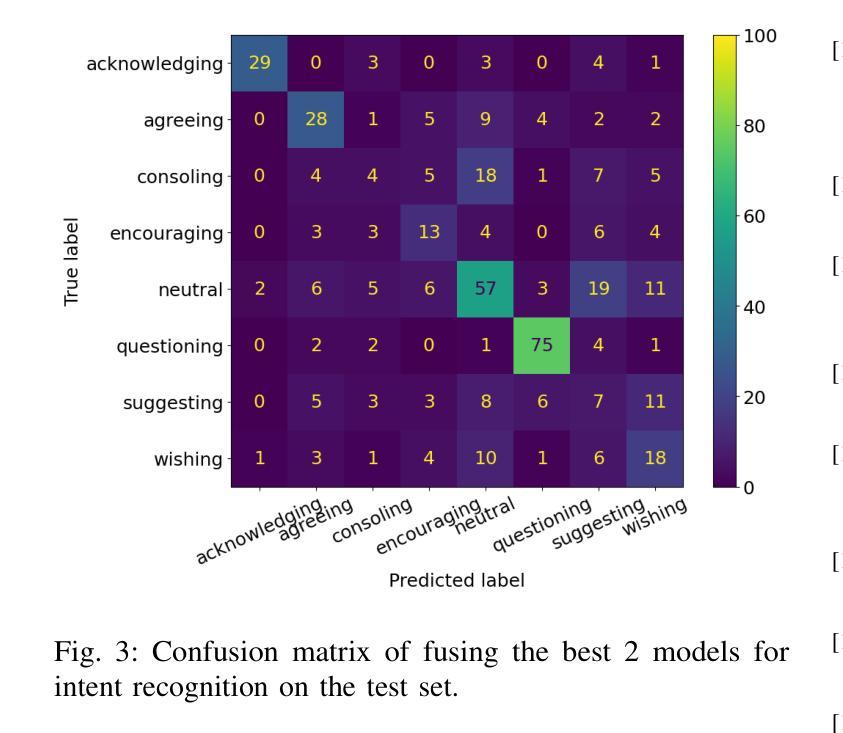
End-to-end Acoustic-linguistic Emotion and Intent Recognition Enhanced by Semi-supervised Learning
Authors:Zhao Ren, Rathi Adarshi Rammohan, Kevin Scheck, Sheng Li, Tanja Schultz
Emotion and intent recognition from speech is essential and has been widely investigated in human-computer interaction. The rapid development of social media platforms, chatbots, and other technologies has led to a large volume of speech data streaming from users. Nevertheless, annotating such data manually is expensive, making it challenging to train machine learning models for recognition purposes. To this end, we propose applying semi-supervised learning to incorporate a large scale of unlabelled data alongside a relatively smaller set of labelled data. We train end-to-end acoustic and linguistic models, each employing multi-task learning for emotion and intent recognition. Two semi-supervised learning approaches, including fix-match learning and full-match learning, are compared. The experimental results demonstrate that the semi-supervised learning approaches improve model performance in speech emotion and intent recognition from both acoustic and text data. The late fusion of the best models outperforms the acoustic and text baselines by joint recognition balance metrics of 12.3% and 10.4%, respectively.
语音中的情感和意图识别对于人机交互至关重要,并已得到广泛研究。社交媒体平台、聊天机器人等技术的快速发展导致了大量用户语音数据的流。然而,手动标注这些数据成本高昂,为训练用于识别目的的机器学习模型带来了挑战。为此,我们提出了应用半监督学习,将大规模未标记数据与相对较小的标记数据集合结合起来。我们训练端到端的声学模型和语言学模型,每个模型都采用多任务学习进行情感和意图识别。对比了包括固定匹配学习和全匹配学习在内的两种半监督学习方法。实验结果表明,半监督学习方法在语音情感和意图识别方面提高了模型性能,既适用于音频数据也适用于文本数据。最佳模型的后期融合通过联合识别平衡指标分别高出音频和文本基线12.3%和10.4%。
论文及项目相关链接
PDF Accepted by EMBC 2025
摘要
随着社交媒体平台、聊天机器人等技术的快速发展,用户产生的语音数据量大幅增加。手动标注这些数据非常昂贵,因此训练用于识别目的机器学习模型具有挑战性。为此,本文提出应用半监督学习,结合大规模未标注数据和相对较小的标注数据集。本文训练端到端的声学模型和语言学模型,两者均采用多任务学习进行情感和意图识别。比较了固定匹配学习和完全匹配学习两种半监督学习方法。实验结果表明,半监督学习方法可以提高语音情感和意图识别的模型性能,无论是从音频还是文本数据中。最佳模型的后期融合在识别平衡指标上优于声学模型和文本基线,分别提高了12.3%和10.4%。
要点掌握
- 情感和意图识别在人机交互中至关重要,面临大量语音数据的标注挑战。
- 提出应用半监督学习结合大量未标注数据和较少标注数据。
- 训练了端到端的声学模型和语言学模型,采用多任务学习进行情感和意图识别。
- 比较了固定匹配学习和完全匹配学习两种半监督方法。
- 实验表明半监督学习方法能提高语音情感和意图识别的模型性能。
- 最佳模型的后期融合在识别效果上显著提升。
点此查看论文截图

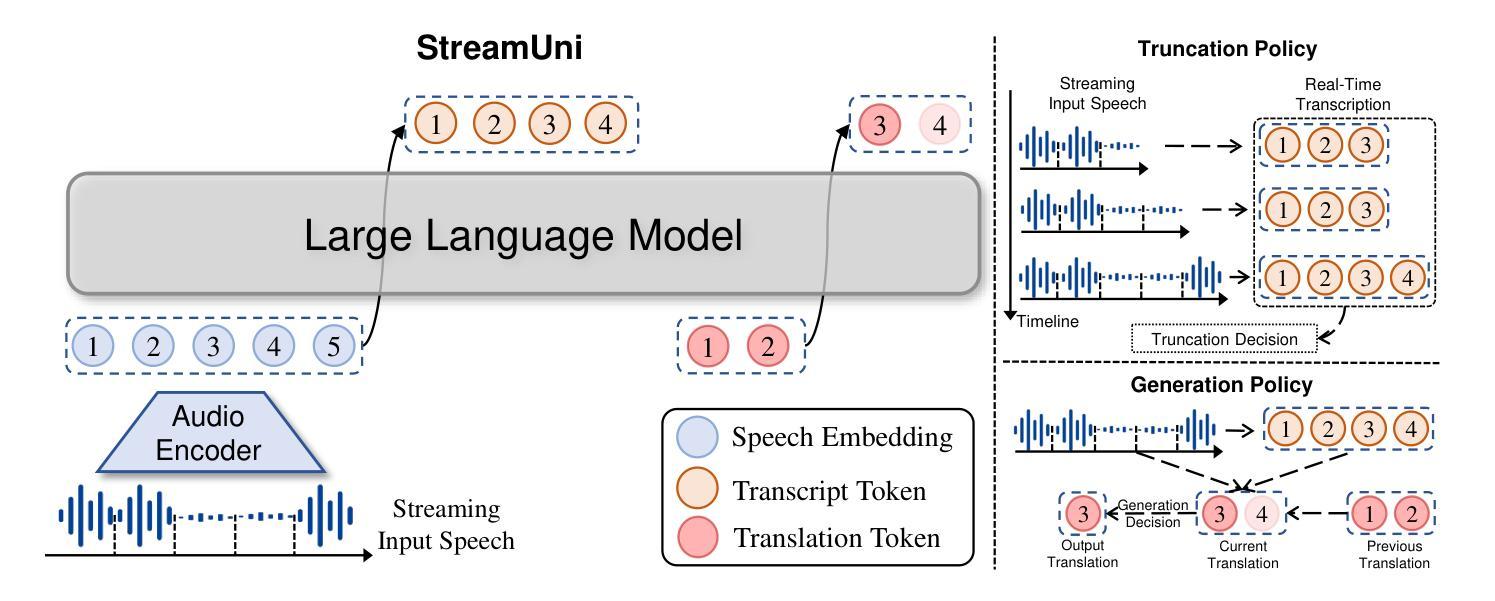
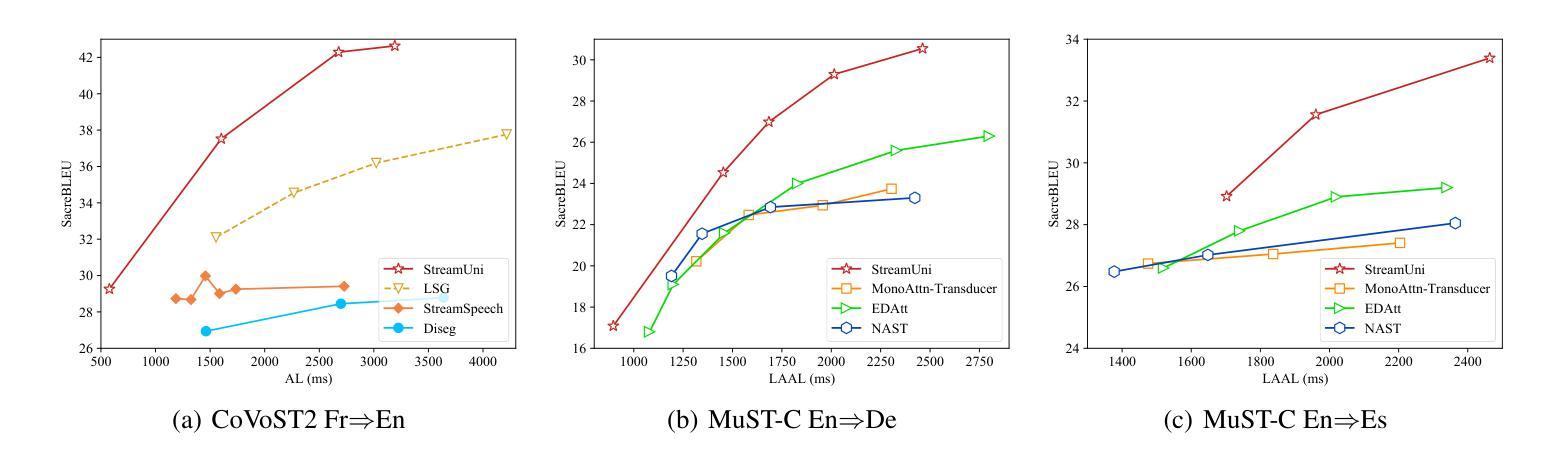
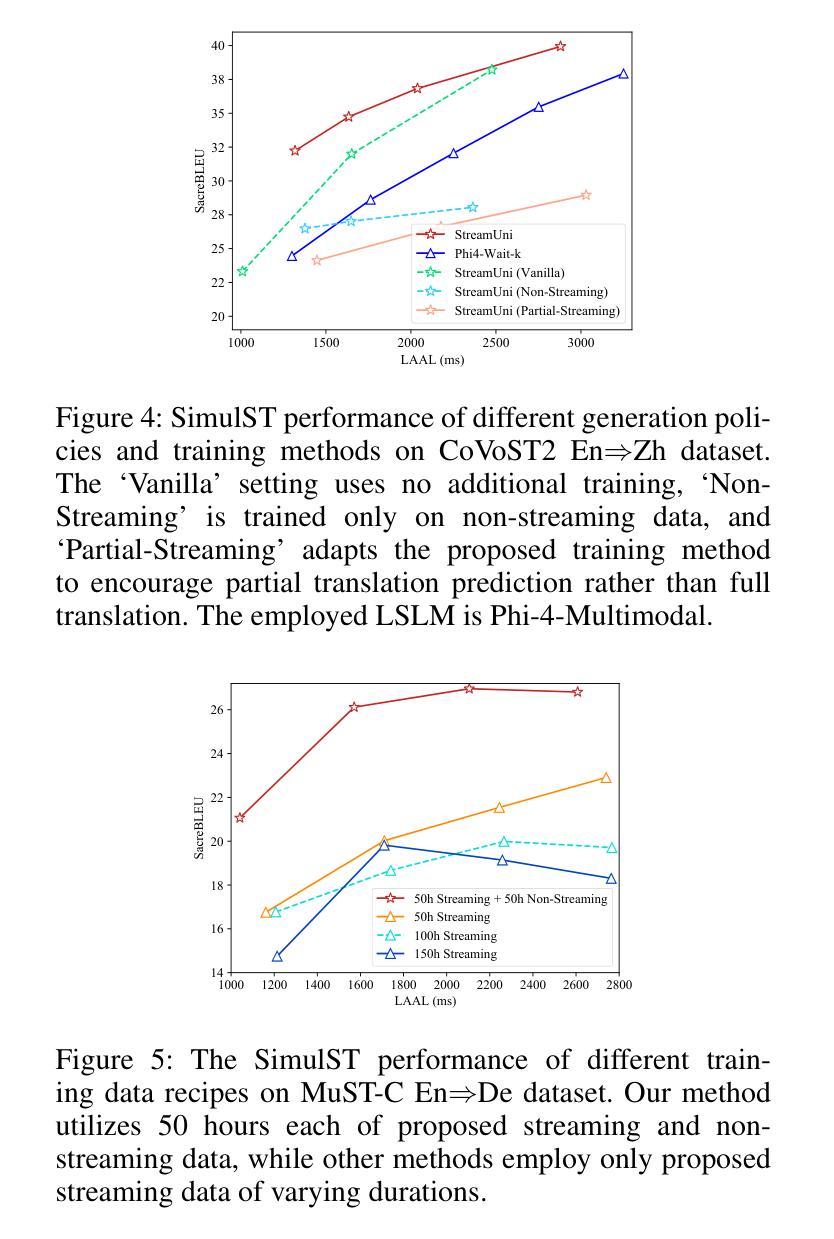
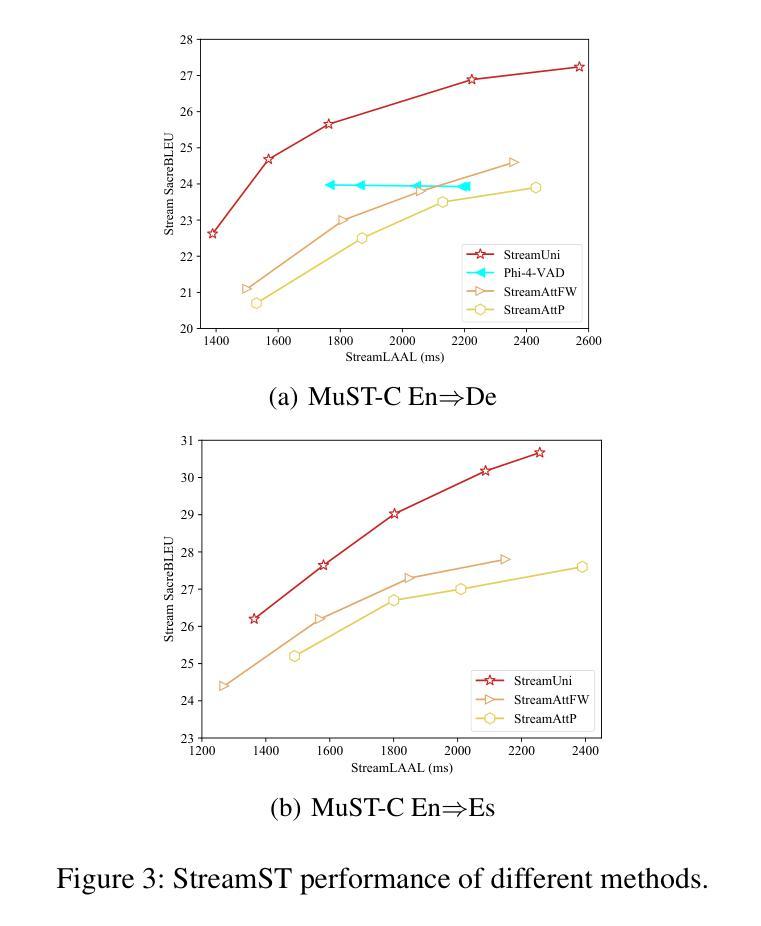
StreamUni: Achieving Streaming Speech Translation with a Unified Large Speech-Language Model
Authors:Shoutao Guo, Xiang Li, Shaolei Zhang, Mengge Liu, Wei Chen, Yang Feng
Streaming speech translation (StreamST) requires determining appropriate timing, known as policy, to generate translations while continuously receiving source speech inputs, balancing low latency with high translation quality. However, existing StreamST methods typically operate on sentence-level speech segments, referred to as simultaneous speech translation (SimulST). In practice, they require collaboration with segmentation models to accomplish StreamST, where the truncated speech segments constrain SimulST models to make policy decisions and generate translations based on limited contextual information. Moreover, SimulST models struggle to learn effective policies due to the complexity of speech inputs and cross-lingual generation. To address these challenges, we propose StreamUni, which achieves StreamST through a unified Large Speech-Language Model (LSLM). Specifically, StreamUni incorporates speech Chain-of-Thought (CoT) in guiding the LSLM to generate multi-stage outputs. Leveraging these multi-stage outputs, StreamUni simultaneously accomplishes speech segmentation, policy decision, and translation generation, completing StreamST without requiring massive policy-specific training. Additionally, we propose a streaming CoT training method that enhances low-latency policy decisions and generation capabilities using limited CoT data. Experiments demonstrate that our approach achieves state-of-the-art performance on StreamST tasks.
流式语音翻译(StreamST)要求在连续接收源语音输入的过程中确定适当的翻译生成时机,即策略,以在低延迟和高翻译质量之间取得平衡。然而,现有的StreamST方法通常运行在句子级别的语音段上,称为同步语音翻译(SimulST)。在实践中,它们需要与分割模型协作来完成StreamST,被截断的语音段限制SimulST模型基于有限的上下文信息做出策略决策和生成翻译。而且,由于语音输入的复杂性和跨语言生成,SimulST模型在学习有效策略方面感到困难。为了解决这些挑战,我们提出了StreamUni,它通过统一的大型语音语言模型(LSLM)实现了StreamST。具体来说,StreamUni在引导LSLM生成多阶段输出时纳入了语音思维链(CoT)。利用这些多阶段输出,StreamUni可以同时完成语音分割、策略决策和翻译生成,无需大量的特定策略训练即可完成StreamST。此外,我们提出了一种流式CoT训练方法,使用有限的CoT数据增强低延迟的策略决策和生成能力。实验表明,我们的方法在StreamST任务上达到了最新技术水平。
论文及项目相关链接
PDF The code is at https://github.com/ictnlp/StreamUni; The model is at https://huggingface.co/ICTNLP/StreamUni-Phi4
Summary
本文主要介绍了流式语音识别翻译(StreamST)面临的挑战及解决方案。现有的方法通常基于句子级别的语音段进行翻译,称为同步语音识别翻译(SimulST)。然而,SimulST模型需要在有限的上下文信息下做出策略决策和生成翻译,导致性能受限。为此,本文提出了StreamUni方法,通过统一的大型语音识别语言模型(LSLM)实现StreamST。StreamUni结合了语音链思维(CoT)来指导生成多阶段输出,从而同时完成语音分割、策略决策和翻译生成。此外,还提出了一种流式CoT训练方法,以提高在低延迟策略决策和生成能力方面的表现。实验证明,该方法在StreamST任务上达到了领先水平。
Key Takeaways
- 流式语音识别翻译(StreamST)需要在低延迟和高翻译质量之间找到适当的平衡。
- 现有的同步语音识别翻译(SimulST)方法依赖于句子级别的语音段,需要配合分割模型完成翻译任务。
- SimulST模型受限于上下文信息,难以做出有效的策略决策和生成高质量的翻译。
- StreamUni方法通过统一的Large Speech-Language Model(LSLM)实现StreamST,无需大规模的策略特定训练。
- StreamUni结合了语音链思维(CoT)来生成多阶段输出,实现语音分割、策略决策和翻译生成的同时完成。
- 流式CoT训练方法可以提高低延迟策略决策和生成能力。
点此查看论文截图

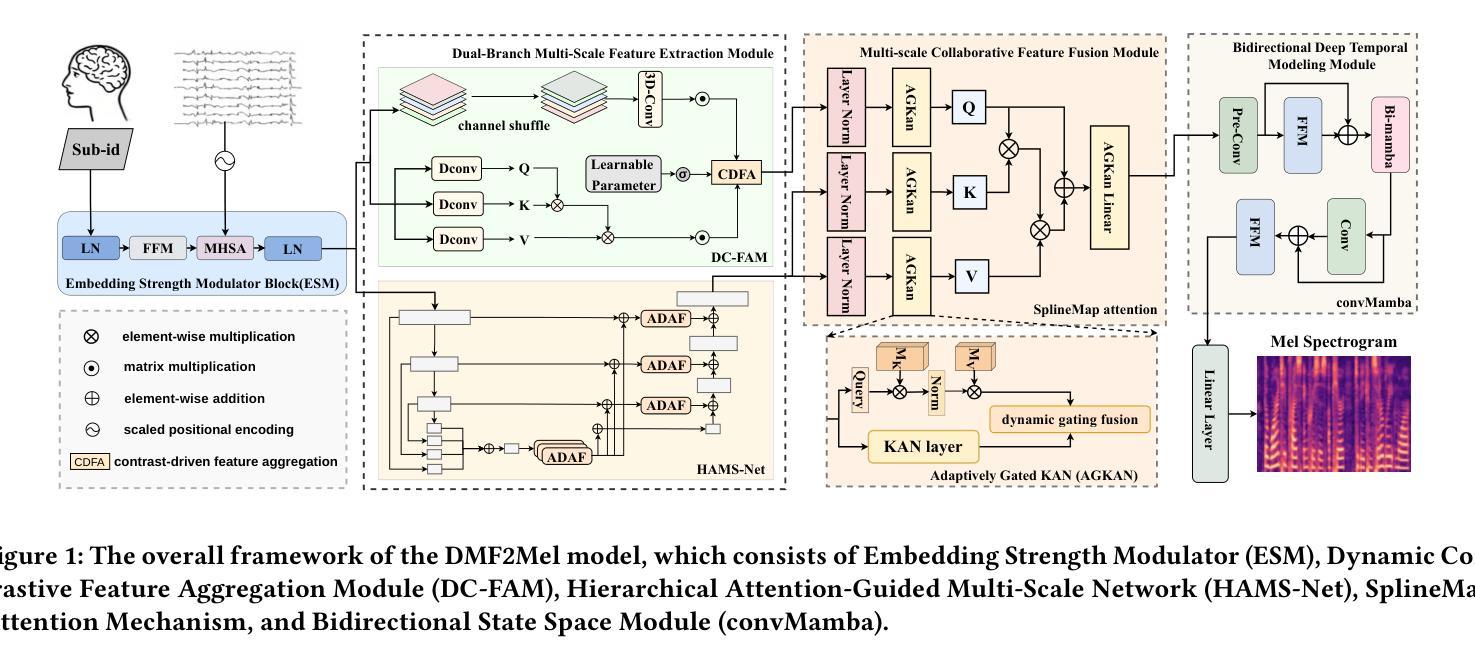
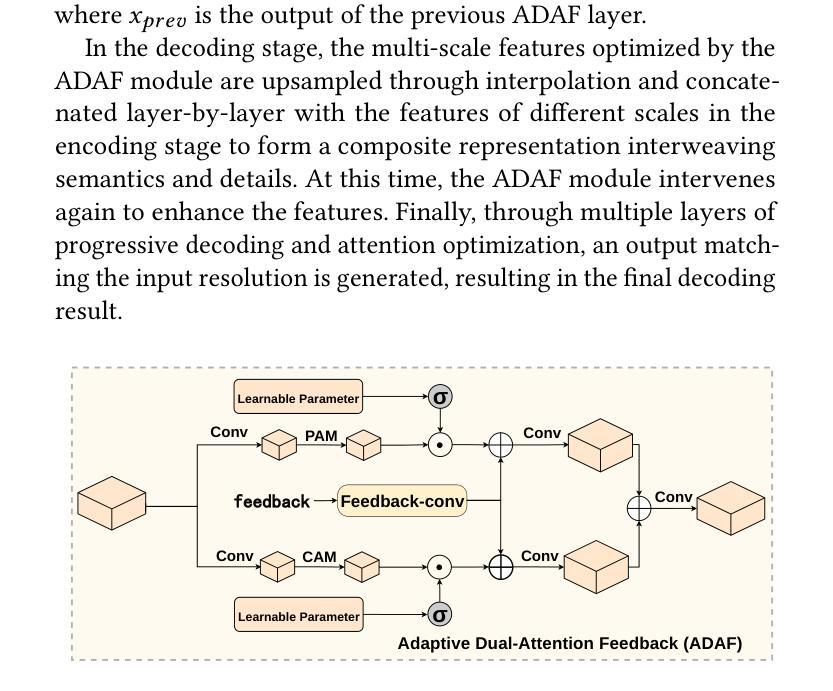
DMF2Mel: A Dynamic Multiscale Fusion Network for EEG-Driven Mel Spectrogram Reconstruction
Authors:Cunhang Fan, Sheng Zhang, Jingjing Zhang, Enrui Liu, Xinhui Li, Minggang Zhao, Zhao Lv
Decoding speech from brain signals is a challenging research problem. Although existing technologies have made progress in reconstructing the mel spectrograms of auditory stimuli at the word or letter level, there remain core challenges in the precise reconstruction of minute-level continuous imagined speech: traditional models struggle to balance the efficiency of temporal dependency modeling and information retention in long-sequence decoding. To address this issue, this paper proposes the Dynamic Multiscale Fusion Network (DMF2Mel), which consists of four core components: the Dynamic Contrastive Feature Aggregation Module (DC-FAM), the Hierarchical Attention-Guided Multi-Scale Network (HAMS-Net), the SplineMap attention mechanism, and the bidirectional state space module (convMamba). Specifically, the DC-FAM separates speech-related “foreground features” from noisy “background features” through local convolution and global attention mechanisms, effectively suppressing interference and enhancing the representation of transient signals. HAMS-Net, based on the U-Net framework,achieves cross-scale fusion of high-level semantics and low-level details. The SplineMap attention mechanism integrates the Adaptive Gated Kolmogorov-Arnold Network (AGKAN) to combine global context modeling with spline-based local fitting. The convMamba captures long-range temporal dependencies with linear complexity and enhances nonlinear dynamic modeling capabilities. Results on the SparrKULee dataset show that DMF2Mel achieves a Pearson correlation coefficient of 0.074 in mel spectrogram reconstruction for known subjects (a 48% improvement over the baseline) and 0.048 for unknown subjects (a 35% improvement over the baseline).Code is available at: https://github.com/fchest/DMF2Mel.
从脑电波解码语音是一个具有挑战性的研究课题。尽管现有技术已在重建听觉刺激的梅尔频谱图(如单词或字母级别)方面取得了进展,但在精确重建分钟级别的连续想象中的语音方面仍存在核心挑战:传统模型在平衡时间序列依赖建模的效率和长序列解码中的信息保留方面遇到困难。针对这一问题,本文提出了动态多尺度融合网络(DMF2Mel),它包含四个核心组件:动态对比特征聚合模块(DC-FAM)、分层注意力引导多尺度网络(HAMS-Net)、SplineMap注意力机制和双向状态空间模块(convMamba)。具体来说,DC-FAM通过局部卷积和全局注意力机制,将语音相关的“前景特征”从嘈杂的“背景特征”中分离出来,有效地抑制了干扰并增强了瞬态信号的表示。HAMS-Net基于U-Net框架,实现了高级语义和低级细节的跨尺度融合。SplineMap注意力机制结合了自适应门控Kolmogorov-Arnold网络(AGKAN),将全局上下文建模与基于样条的局部拟合相结合。convMamba以线性复杂度捕获长期时间依赖关系,并增强了非线性动态建模能力。在SparrKULee数据集上的结果表明,DMF2Mel在已知主题的梅尔频谱图重建中实现了0.074的皮尔逊相关系数(比基线提高了48%),在未知主题上实现了0.048(比基线提高了35%)。代码可访问于:https://github.com/fchest/DMF2Mel。
论文及项目相关链接
PDF Accepted by ACM MM 2025
摘要
解码大脑信号中的语音是一个充满挑战的研究问题。现有技术在重建听觉刺激的梅尔频谱图方面已取得进展,但仍面临精确重建分钟级连续想象语音的核心挑战。传统模型在平衡时间序列依赖性建模的效率和长期序列解码的信息保留方面存在困难。为解决此问题,本文提出了动态多尺度融合网络(DMF2Mel),包括四个核心组件:动态对比特征聚合模块(DC-FAM)、分层注意力引导多尺度网络(HAMS-Net)、SplineMap注意力机制和双向状态空间模块(convMamba)。特别是DC-FAM通过局部卷积和全局注意力机制,有效分离语音相关的“前景特征”和噪声“背景特征”,抑制干扰并增强瞬态信号的表示。HAMS-Net基于U-Net框架实现高级语义和低级细节的跨尺度融合。SplineMap注意力机制结合了自适应门控Kolmogorov-Arnold网络(AGKAN)进行全局上下文建模和基于样条的局部拟合。convMamba以线性复杂度捕获长期时间依赖性,并增强非线性动态建模能力。在SparrKULee数据集上的结果表明,DMF2Mel在已知主题的梅尔频谱图重建中实现了0.074的皮尔逊相关系数(较基线提高了48%),在未知主题上实现了0.048(较基线提高了35%)。代码可用https://github.com/fchest/DMF2Mel访问。
关键见解
- 解码大脑信号中的语音是一个挑战性问题,尤其是精确重建分钟级连续想象语音。
- 传统模型在平衡时间序列依赖性建模的效率和长期序列解码的信息保留方面遇到困难。
- DMF2Mel网络由四个核心组件构成,旨在解决这一难题。
- DC-FAM能够分离语音相关的关键特征,抑制干扰并增强瞬态信号的表示。
- HAMS-Net结合高级语义和低级细节进行跨尺度融合。
- SplineMap注意力机制和AGKAN结合进行全局和局部建模。
点此查看论文截图

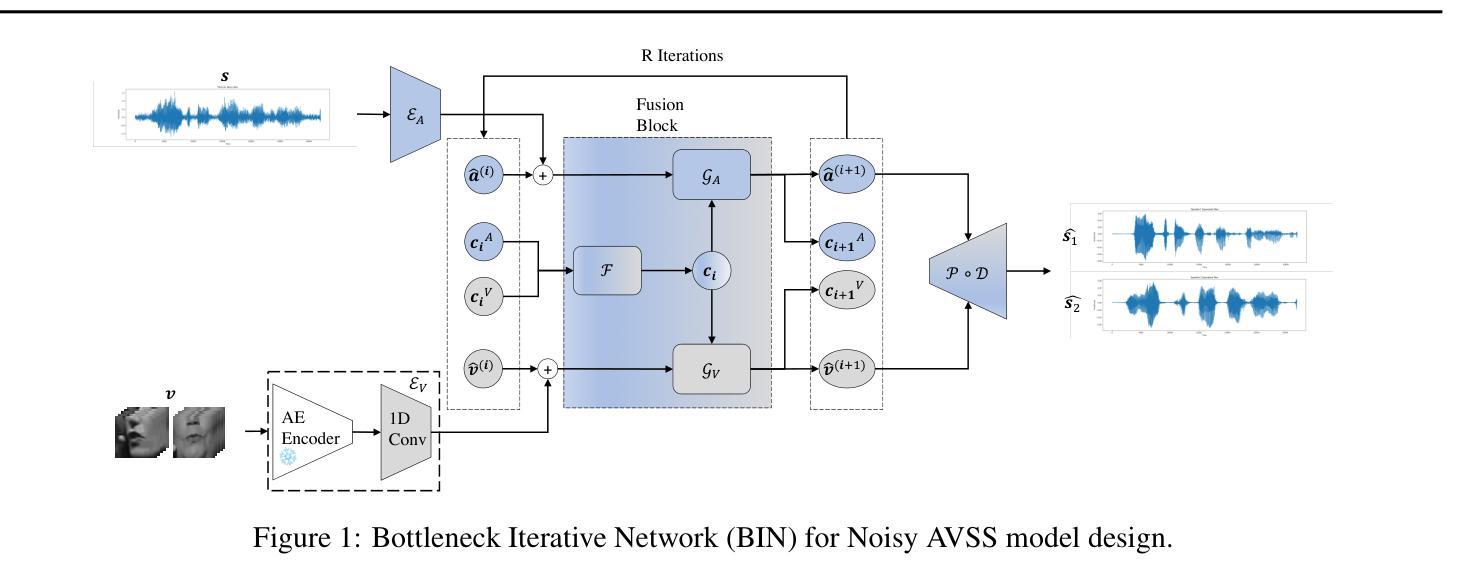
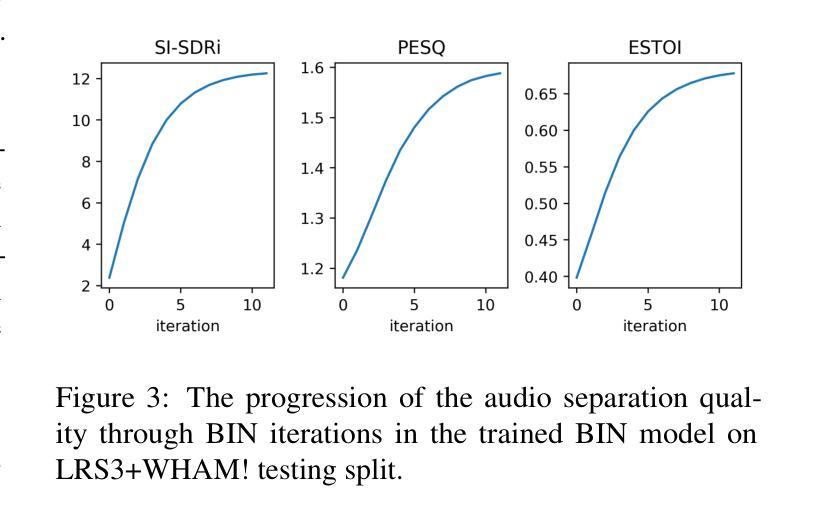
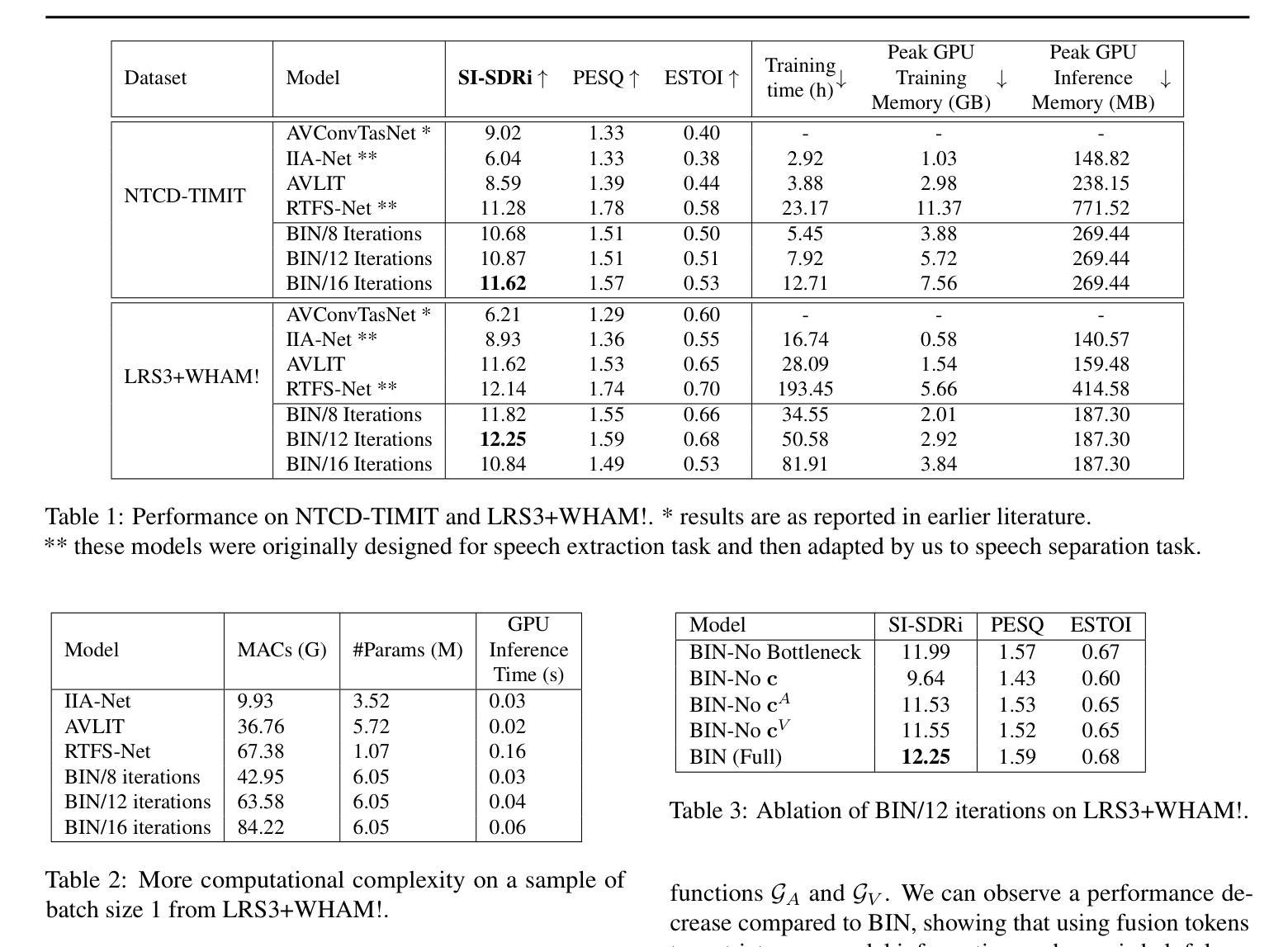
Audio-Visual Speech Separation via Bottleneck Iterative Network
Authors:Sidong Zhang, Shiv Shankar, Trang Nguyen, Andrea Fanelli, Madalina Fiterau
Integration of information from non-auditory cues can significantly improve the performance of speech-separation models. Often such models use deep modality-specific networks to obtain unimodal features, and risk being too costly or lightweight but lacking capacity. In this work, we present an iterative representation refinement approach called Bottleneck Iterative Network (BIN), a technique that repeatedly progresses through a lightweight fusion block, while bottlenecking fusion representations by fusion tokens. This helps improve the capacity of the model, while avoiding major increase in model size and balancing between the model performance and training cost. We test BIN on challenging noisy audio-visual speech separation tasks, and show that our approach consistently outperforms state-of-the-art benchmark models with respect to SI-SDRi on NTCD-TIMIT and LRS3+WHAM! datasets, while simultaneously achieving a reduction of more than 50% in training and GPU inference time across nearly all settings.
从非听觉线索中整合信息可以显著改善语音分离模型的性能。通常,此类模型使用深度模态特定网络来获取单模态特征,但这样做可能成本太高或过于简单缺乏能力。在这项工作中,我们提出了一种称为瓶颈迭代网络(BIN)的迭代表示细化方法,这是一种通过融合块进行反复迭代的技术,同时通过融合令牌对融合表示进行瓶颈处理。这有助于提高模型的容量,同时避免模型大小的重大增加,并在模型性能和训练成本之间取得平衡。我们在具有挑战性的嘈杂音频-视觉语音分离任务上测试了BIN,结果表明我们的方法在NTCD-TIMIT和LRS3+WHAM!数据集上的SI-SDRi方面始终优于最新基准模型,同时在所有设置下训练和GPU推理时间减少超过50%。
论文及项目相关链接
PDF Accepted to the 42nd International Conference on Machine Learning Workshop on Machine Learning for Audio
Summary
本文提出了一种基于非听觉线索信息的融合方法,可显著提高语音分离模型的性能。通过使用瓶颈迭代网络(BIN)的迭代表示优化技术,该模型能够在轻量级融合块中不断进步,并通过融合令牌进行瓶颈融合表示,提高了模型的容量,同时避免了模型尺寸的大幅增加,并平衡了模型性能和训练成本。在具有挑战性的噪声音频视觉语音分离任务上测试BIN,结果表明该方法在NTCD-TIMIT和LRS3+WHAM!数据集上的SI-SDRi表现始终优于最新基准模型,同时在所有设置下训练和GPU推理时间减少超过50%。
Key Takeaways
- 非听觉线索信息的融合能显著提升语音分离模型的性能。
- 瓶颈迭代网络(BIN)是一种迭代表示优化技术,适用于语音分离任务。
- BIN通过轻量级融合块实现模型性能的进步。
- 融合令牌用于瓶颈融合表示,提高模型容量。
- BIN在噪声音频视觉语音分离任务上表现优异。
- 与最新基准模型相比,BIN在SI-SDRi表现上更优秀。
点此查看论文截图


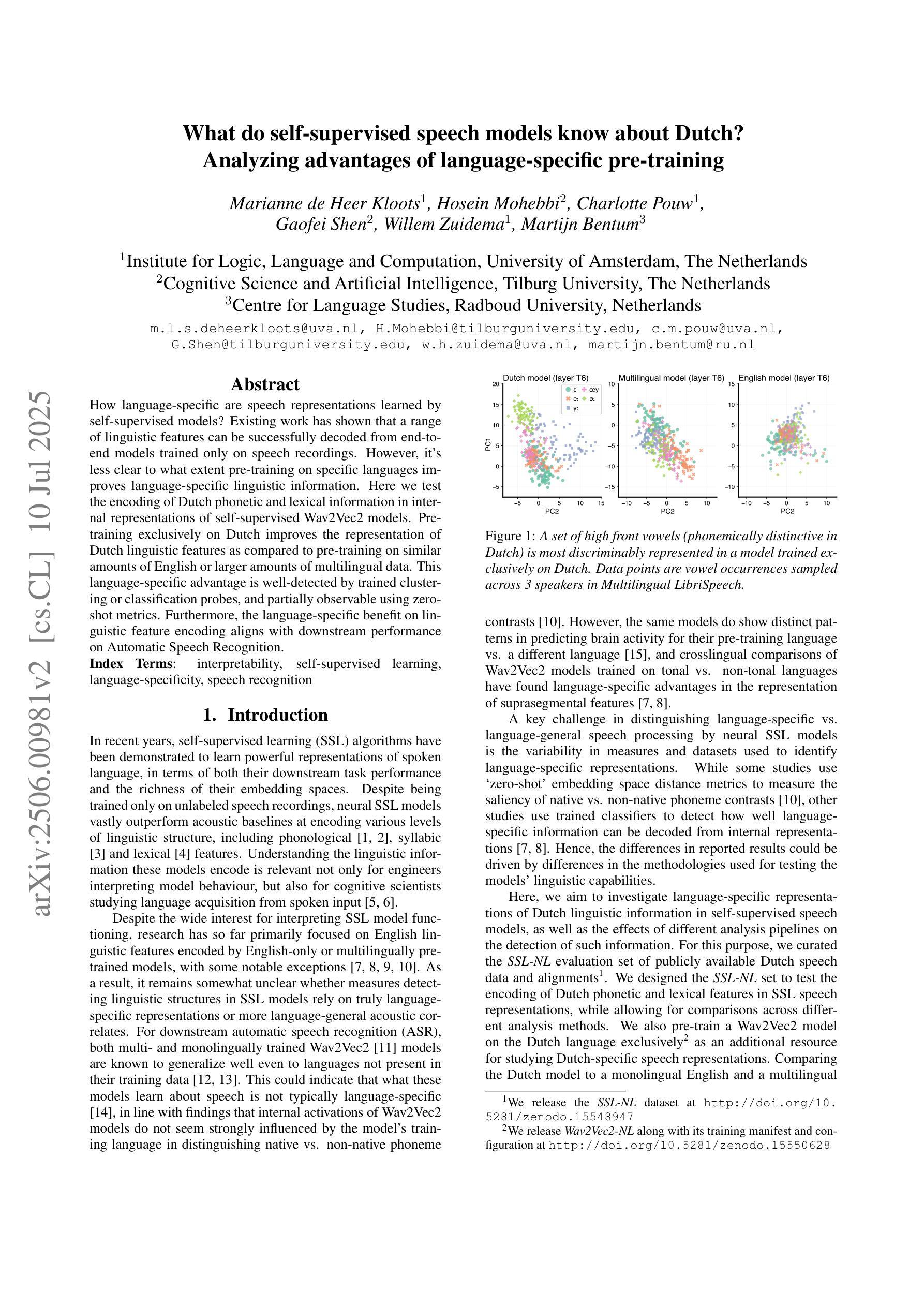
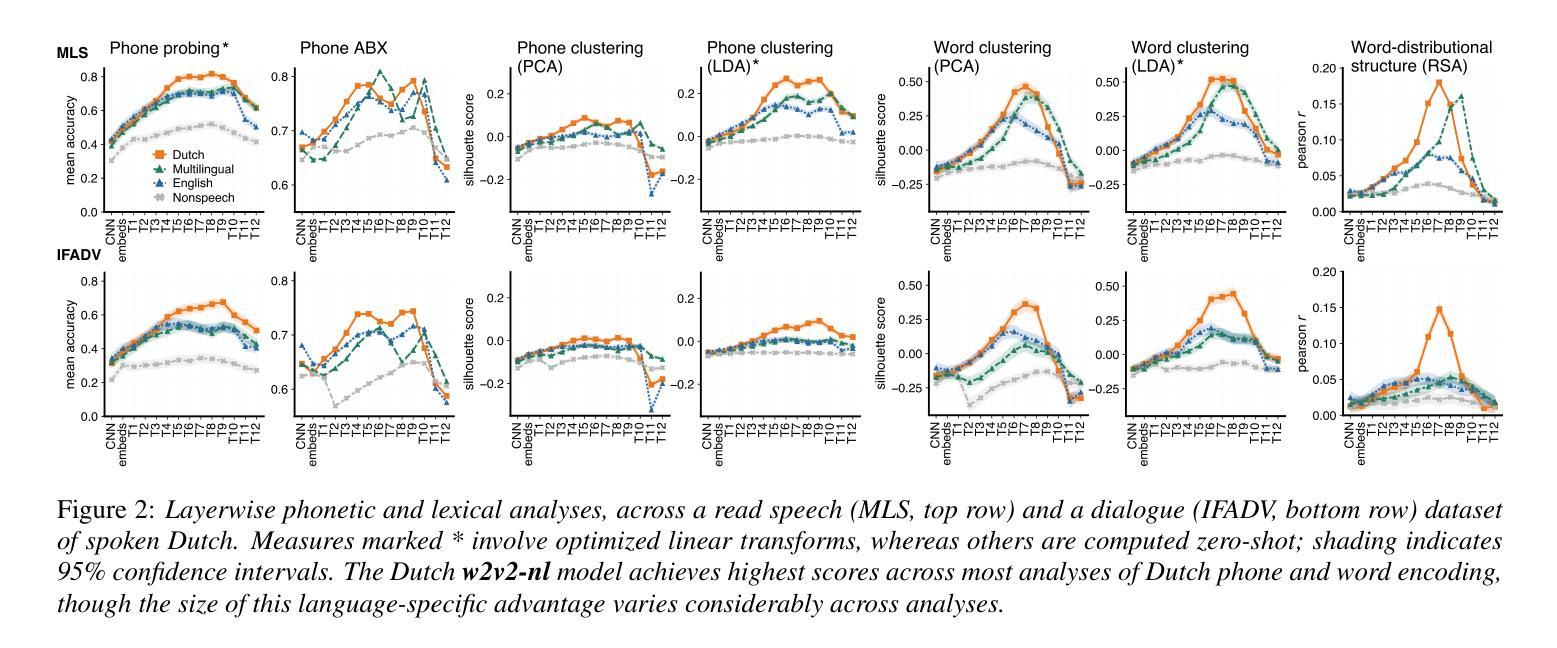
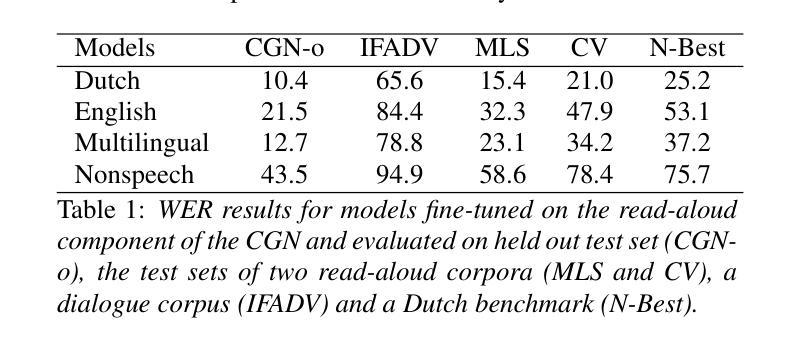
What do self-supervised speech models know about Dutch? Analyzing advantages of language-specific pre-training
Authors:Marianne de Heer Kloots, Hosein Mohebbi, Charlotte Pouw, Gaofei Shen, Willem Zuidema, Martijn Bentum
How language-specific are speech representations learned by self-supervised models? Existing work has shown that a range of linguistic features can be successfully decoded from end-to-end models trained only on speech recordings. However, it’s less clear to what extent pre-training on specific languages improves language-specific linguistic information. Here we test the encoding of Dutch phonetic and lexical information in internal representations of self-supervised Wav2Vec2 models. Pre-training exclusively on Dutch improves the representation of Dutch linguistic features as compared to pre-training on similar amounts of English or larger amounts of multilingual data. This language-specific advantage is well-detected by trained clustering or classification probes, and partially observable using zero-shot metrics. Furthermore, the language-specific benefit on linguistic feature encoding aligns with downstream performance on Automatic Speech Recognition.
通过自我监督模型学到的语音表示具有多大的语言特异性?现有工作已经表明,仅通过语音录音训练端到端模型,可以成功解码一系列语言特征。但是,预训练特定语言能在多大程度上提高语言特定的语言信息尚不清楚。在这里,我们测试了自我监督的Wav2Vec2模型中荷兰语音和词汇信息的编码。仅对荷兰语进行预训练,提高了荷兰语语言特征的表示,与预训练英语或大量多语言数据相比。这种语言特定的优势被训练过的聚类或分类探针很好地检测出来,使用零样本指标也可以部分观察到。此外,语言特征编码上的语言特异性优势与自动语音识别任务的下游性能表现一致。
论文及项目相关链接
PDF Accepted to Interspeech 2025. For model, code, and materials, see https://github.com/mdhk/SSL-NL-eval
Summary:
自监督模型学习的语音表示具有语言特异性。对荷兰语语音进行预训练可以提高模型对荷兰语语言特征表示的编码质量,相较于预训练英语或多语言数据,这种优势可通过训练聚类或分类探针检测。此外,这种语言特异性对语音编码的益处与自动语音识别下游性能表现一致。
Key Takeaways:
- 自监督模型学习的语音表示具有语言特异性。
- 预训练荷兰语能提高模型对荷兰语语言特征的编码质量。
- 与预训练英语或多语言数据相比,预训练荷兰语的优势可通过分类或聚类探针检测。
- 语言特异性对语音编码的益处与自动语音识别(ASR)的下游性能表现一致。
- 研究强调了语言特异性在语音表示学习中的重要性。
- 预训练特定语言的模型可能有助于提高其在实际语言任务中的表现。
点此查看论文截图
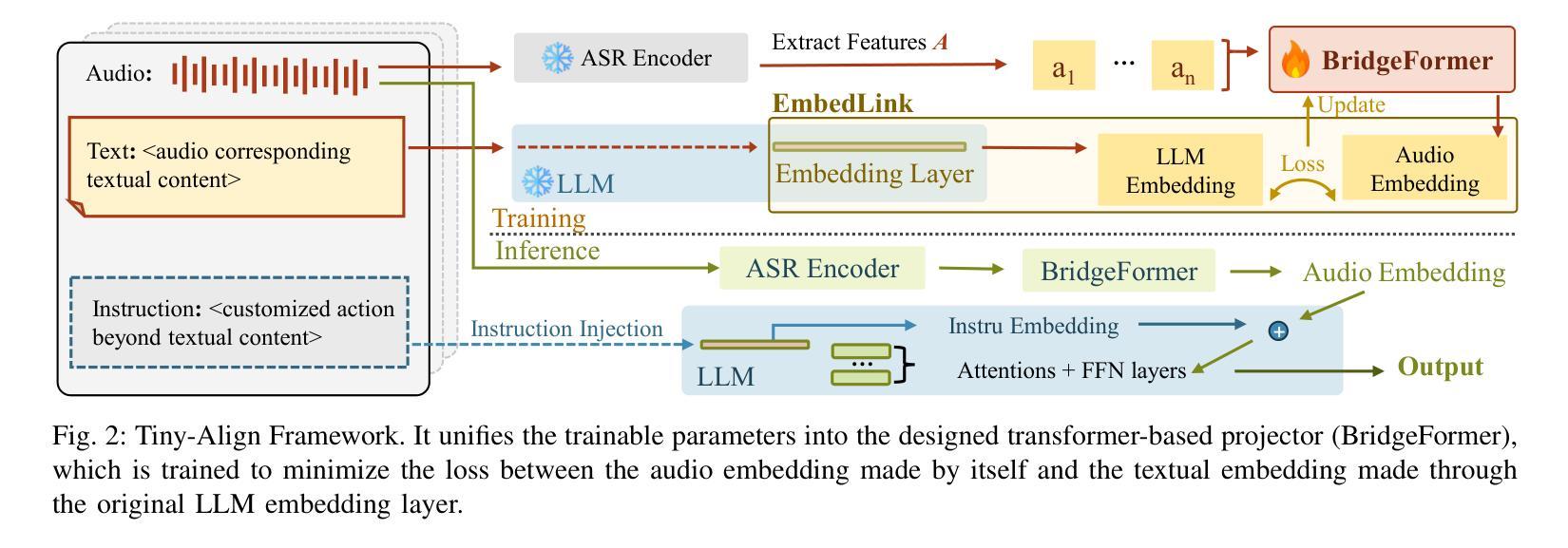
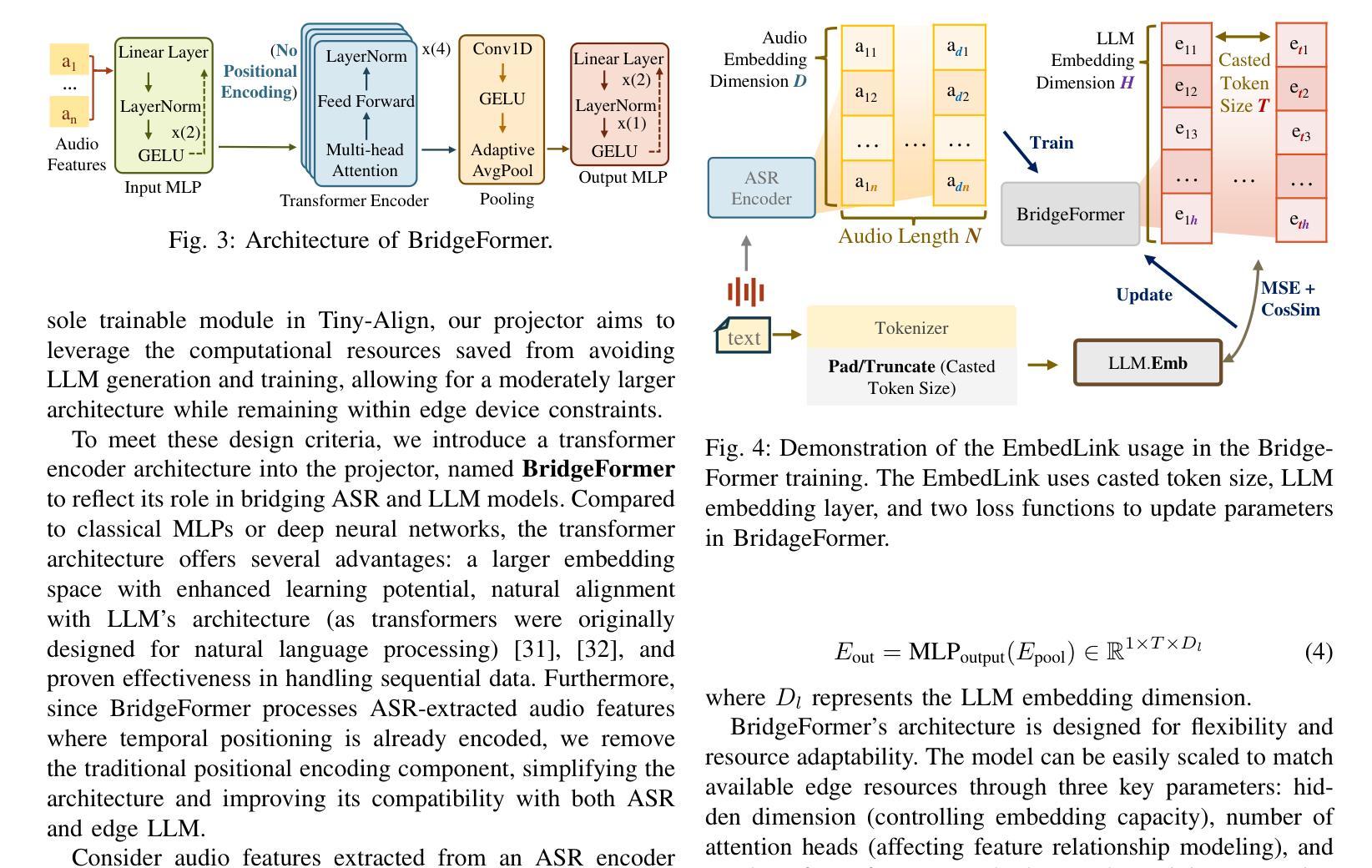
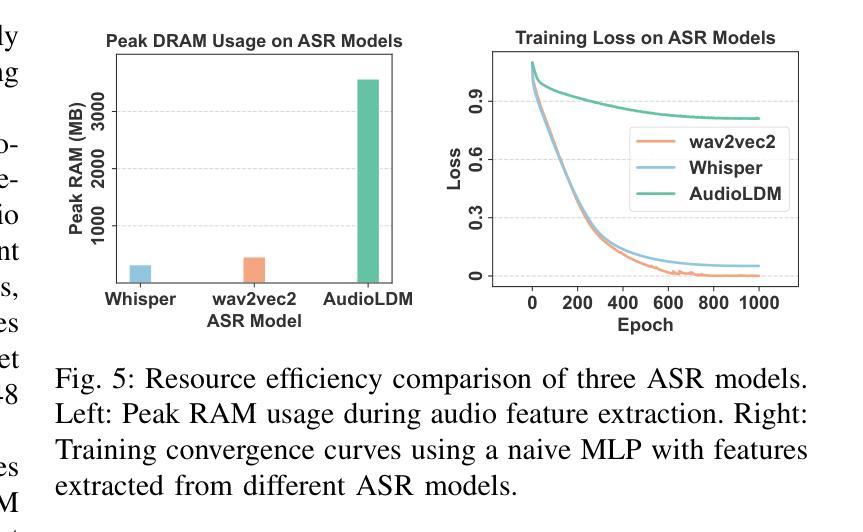
Tiny-Align: Bridging Automatic Speech Recognition and Large Language Model on the Edge
Authors:Ruiyang Qin, Dancheng Liu, Gelei Xu, Zheyu Yan, Chenhui Xu, Yuting Hu, X. Sharon Hu, Jinjun Xiong, Yiyu Shi
The combination of Large Language Models (LLM) and Automatic Speech Recognition (ASR), when deployed on edge devices (called edge ASR-LLM), can serve as a powerful personalized assistant to enable audio-based interaction for users. Compared to text-based interaction, edge ASR-LLM allows accessible and natural audio interactions. Unfortunately, existing ASR-LLM models are mainly trained in high-performance computing environments and produce substantial model weights, making them difficult to deploy on edge devices. More importantly, to better serve users’ personalized needs, the ASR-LLM must be able to learn from each distinct user, given that audio input often contains highly personalized characteristics that necessitate personalized on-device training. Since individually fine-tuning the ASR or LLM often leads to suboptimal results due to modality-specific limitations, end-to-end training ensures seamless integration of audio features and language understanding (cross-modal alignment), ultimately enabling a more personalized and efficient adaptation on edge devices. However, due to the complex training requirements and substantial computational demands of existing approaches, cross-modal alignment between ASR audio and LLM can be challenging on edge devices. In this work, we propose a resource-efficient cross-modal alignment framework that bridges ASR and LLMs on edge devices to handle personalized audio input. Our framework enables efficient ASR-LLM alignment on resource-constrained devices like NVIDIA Jetson Orin (8GB RAM), achieving 50x training time speedup while improving the alignment quality by more than 50%. To the best of our knowledge, this is the first work to study efficient ASR-LLM alignment on resource-constrained edge devices.
大型语言模型(LLM)与自动语音识别(ASR)的结合,在边缘设备上部署(称为边缘ASR-LLM)时,可作为强大的个性化助手,使用户能够基于音频进行交互。与基于文本的交互相比,边缘ASR-LLM允许可访问和自然的音频交互。然而,现有的ASR-LLM模型主要在高性能计算环境中进行训练,产生大量的模型权重,这使得它们难以在边缘设备上部署。更重要的是,为了更好地满足用户的个性化需求,ASR-LLM必须能够从每个不同的用户身上进行学习,鉴于音频输入通常包含高度个性化的特征,需要进行个性化的设备端训练。由于单独微调ASR或LLM往往会导致次优结果,端到端训练确保音频特征和语言理解的无缝集成(跨模态对齐),最终实现在边缘设备上更个性化和有效的适应。然而,由于现有方法的复杂训练要求和巨大的计算需求,ASR音频和LLM之间的跨模态对齐在边缘设备上可能具有挑战性。在这项工作中,我们提出了一个资源高效的跨模态对齐框架,该框架能够在边缘设备上桥接ASR和LLM,处理个性化的音频输入。我们的框架能够在资源受限的设备上实现高效的ASR-LLM对齐,如NVIDIA Jetson Orin(8GB RAM),实现50倍的培训时间加速,同时提高对齐质量超过50%。据我们所知,这是第一项在资源受限的边缘设备上研究高效ASR-LLM对齐的工作。
论文及项目相关链接
PDF Accepted by ICCAD’25
摘要
在边缘设备上部署大型语言模型(LLM)和自动语音识别(ASR)的组合(称为边缘ASR-LLM),可作为强大的个性化助手,实现基于音频的用户交互。相比文本交互,边缘ASR-LLM支持便捷的自然音频交互。然而,现有ASR-LLM模型主要在高性能计算环境中训练,模型体积庞大,难以部署在边缘设备上。为了更好服务用户的个性化需求,ASR-LLM需要从每个用户身上学习,因为音频输入通常包含高度个性化的特征,需要进行个性化设备端训练。由于单独微调ASR或LLM往往因模态特定限制而导致结果不佳,端到端训练可确保音频特征与语言理解无缝集成(跨模态对齐),最终在边缘设备上实现更个性化和高效的适应。然而,由于现有方法的复杂训练要求和巨大的计算需求,在边缘设备上实现ASR音频和LLM之间的跨模态对齐具有挑战性。本研究提出了一种资源高效的跨模态对齐框架,该框架可在边缘设备上实现ASR和LLM的桥梁作用,处理个性化音频输入。我们的框架可在资源受限的设备上实现高效的ASR-LLM对齐,如NVIDIA Jetson Orin(8GB RAM),实现50倍的训练时间加速,同时提高对齐质量超过50%。据我们所知,这是第一项在资源受限的边缘设备上研究高效ASR-LLM对齐的工作。
关键见解
- 大型语言模型(LLM)和自动语音识别(ASR)的结合,在边缘设备上作为个性化助手具有巨大潜力,可实现自然音频交互。
- 现有ASR-LLM模型主要在高性能计算环境中训练,难以部署在资源有限的边缘设备上。
- 个性化音频输入需要个性化设备端训练,因为音频输入包含高度个性化的特征。
- 单独的ASR或LLM微调因模态特定限制可能效果不佳,端到端训练可实现跨模态对齐,提高适应性和个性化程度。
- 跨模态对齐在边缘设备上具有挑战性,因为现有方法需要复杂的训练和大量的计算资源。
- 研究提出了一种资源高效的跨模态对齐框架,可在资源受限的边缘设备上实现ASR和LLM的有效对齐。
点此查看论文截图