⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-13 更新
PWD: Prior-Guided and Wavelet-Enhanced Diffusion Model for Limited-Angle CT
Authors:Yi Liu, Yiyang Wen, Zekun Zhou, Junqi Ma, Linghang Wang, Yucheng Yao, Liu Shi, Qiegen Liu
Generative diffusion models have received increasing attention in medical imaging, particularly in limited-angle computed tomography (LACT). Standard diffusion models achieve high-quality image reconstruction but require a large number of sampling steps during inference, resulting in substantial computational overhead. Although skip-sampling strategies have been proposed to improve efficiency, they often lead to loss of fine structural details. To address this issue, we propose a prior information embedding and wavelet feature fusion fast sampling diffusion model for LACT reconstruction. The PWD enables efficient sampling while preserving reconstruction fidelity in LACT, and effectively mitigates the degradation typically introduced by skip-sampling. Specifically, during the training phase, PWD maps the distribution of LACT images to that of fully sampled target images, enabling the model to learn structural correspondences between them. During inference, the LACT image serves as an explicit prior to guide the sampling trajectory, allowing for high-quality reconstruction with significantly fewer steps. In addition, PWD performs multi-scale feature fusion in the wavelet domain, effectively enhancing the reconstruction of fine details by leveraging both low-frequency and high-frequency information. Quantitative and qualitative evaluations on clinical dental arch CBCT and periapical datasets demonstrate that PWD outperforms existing methods under the same sampling condition. Using only 50 sampling steps, PWD achieves at least 1.7 dB improvement in PSNR and 10% gain in SSIM.
在医学成像领域,尤其是有限角度计算机断层扫描(LACT)中,生成式扩散模型已引起越来越多的关注。标准扩散模型虽然能够实现高质量图像重建,但在推理过程中需要大量采样步骤,导致计算开销很大。虽然有人提出了跳过采样策略来提高效率,但它们往往会导致精细结构细节的丢失。针对这一问题,我们提出了一种基于先验信息嵌入和小波特征融合的快速采样扩散模型,用于LACT重建。PWD(Prior Wavelet Diffusion)能够在LACT中实现高效采样,同时保持重建保真度,并有效地减轻了跳过采样通常引起的降解。具体而言,在训练阶段,PWD将LACT图像的分布映射到完全采样目标图像的分布,使模型能够学习两者之间的结构对应关系。在推理阶段,LACT图像作为明确的先验来引导采样轨迹,允许以更少的步骤实现高质量重建。此外,PWD在小波域执行多尺度特征融合,通过利用低频和高频信息有效地提高了精细细节的重建效果。在临床牙弓CBCT和根尖周数据集上的定量和定性评估表明,在相同的采样条件下,PWD的性能优于现有方法。仅使用50个采样步骤,PWD的PSNR提高了至少1.7dB,SSIM提高了10%。
论文及项目相关链接
Summary
本文提出了一种基于先验信息嵌入和小波特征融合的快速采样扩散模型,用于有限角度计算机断层扫描(LACT)重建。该模型在训练阶段将LACT图像分布映射到完全采样的目标图像分布,学习两者之间的结构对应关系。在推理阶段,利用LACT图像作为显式先验来指导采样轨迹,实现高质量重建并大大减少采样步骤。同时,该模型在小波域进行多尺度特征融合,利用高低频信息有效增强细节重建。实验结果表明,PWD在相同采样条件下优于现有方法,使用仅50个采样步骤时,PWD的峰值信噪比(PSNR)提高了至少1.7 dB,结构相似性(SSIM)提高了10%。
Key Takeaways
- 生成性扩散模型在医学成像中受到关注,特别是在有限角度计算机断层扫描(LACT)领域。
- 标准扩散模型虽然能实现高质量图像重建,但在推理过程中需要大量采样步骤,导致计算开销大。
- 提出的PWD模型通过先验信息嵌入和小波特征融合实现快速采样扩散。
- PWD在训练阶段学习LACT图像与完全采样目标图像之间的结构对应关系。
- 推理阶段利用LACT图像作为显式先验,实现高质量重建并减少采样步骤。
- PWD在小波域进行多尺度特征融合,利用高低频信息增强细节重建。
点此查看论文截图

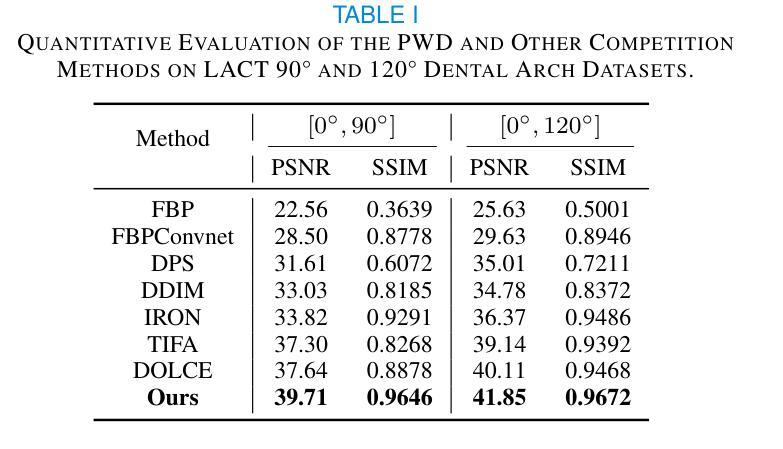
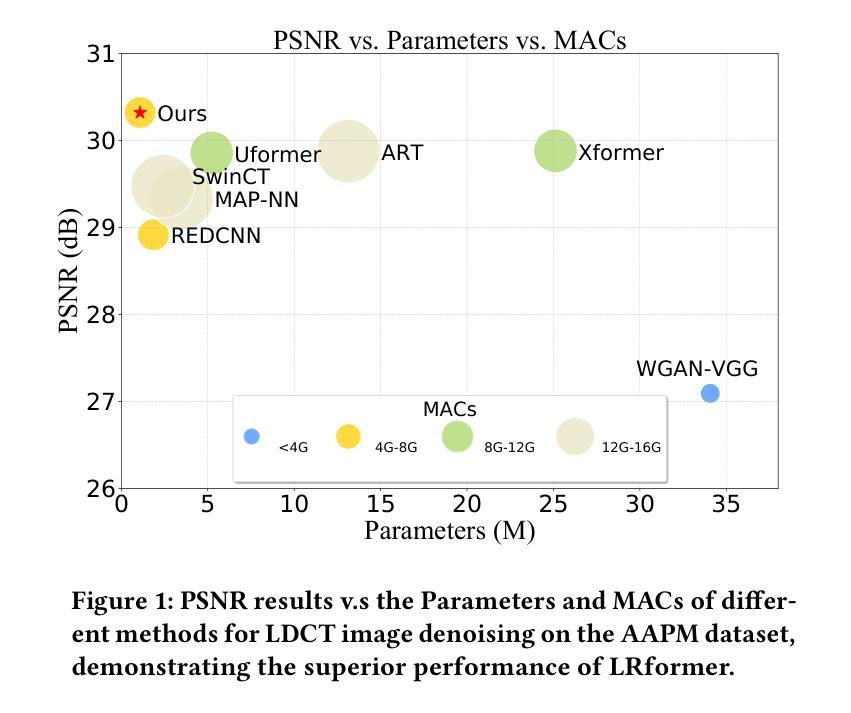
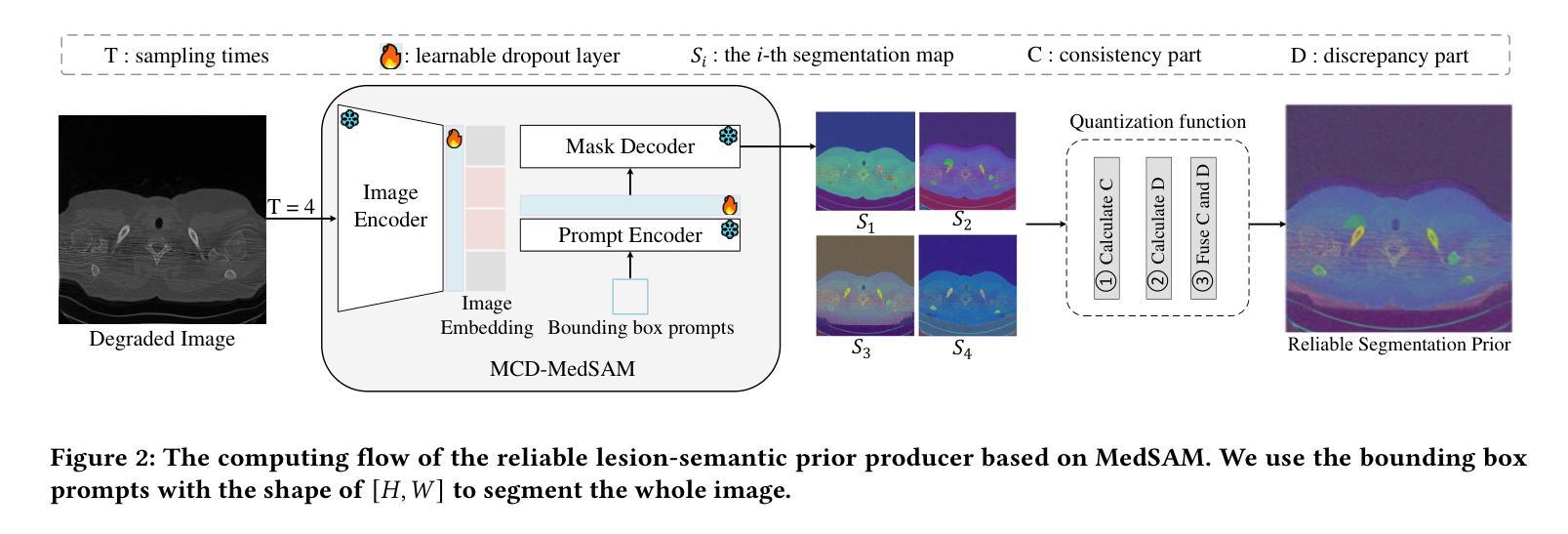
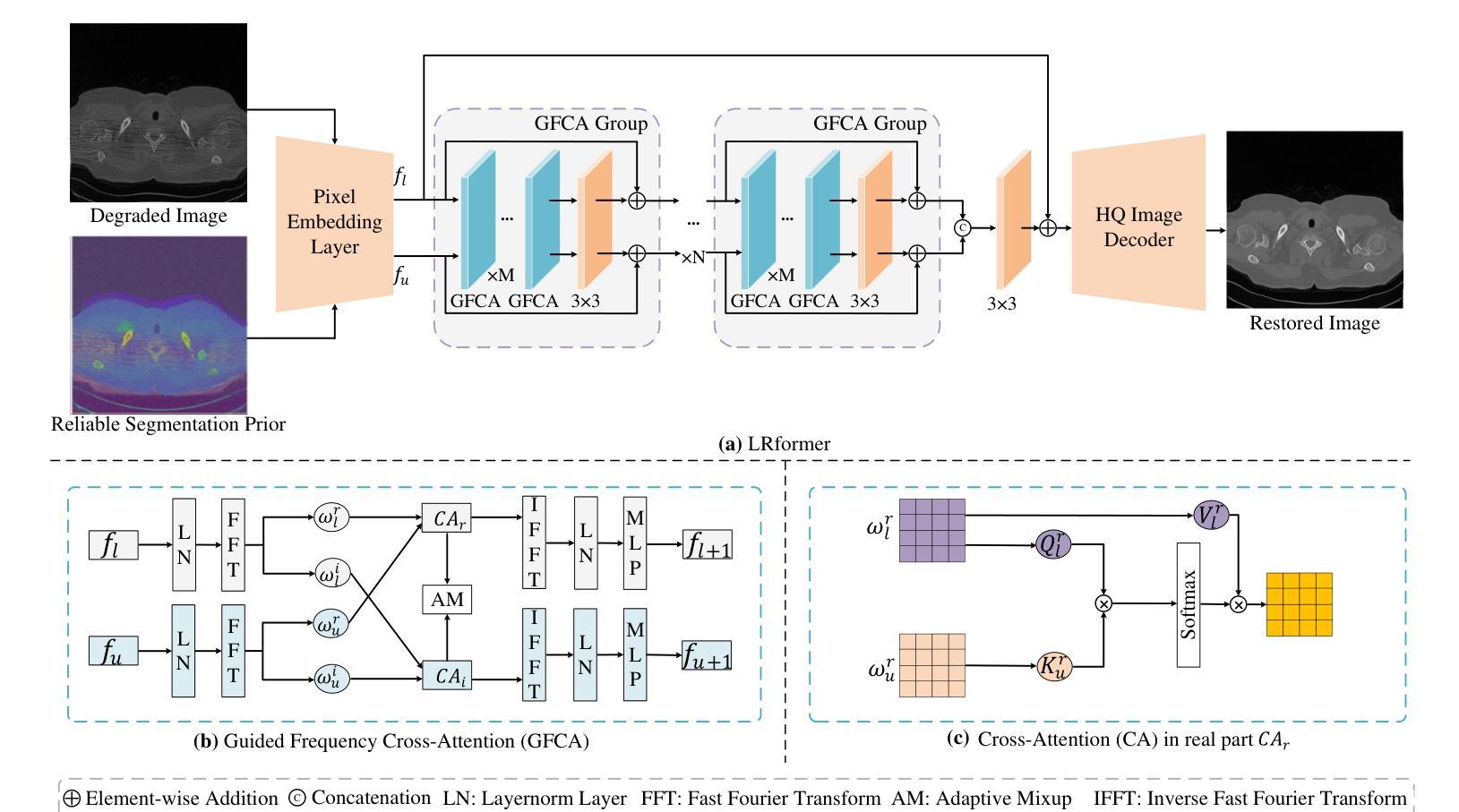
Lightweight Medical Image Restoration via Integrating Reliable Lesion-Semantic Driven Prior
Authors:Pengcheng Zheng, Kecheng Chen, Jiaxin Huang, Bohao Chen, Ju Liu, Yazhou Ren, Xiaorong Pu
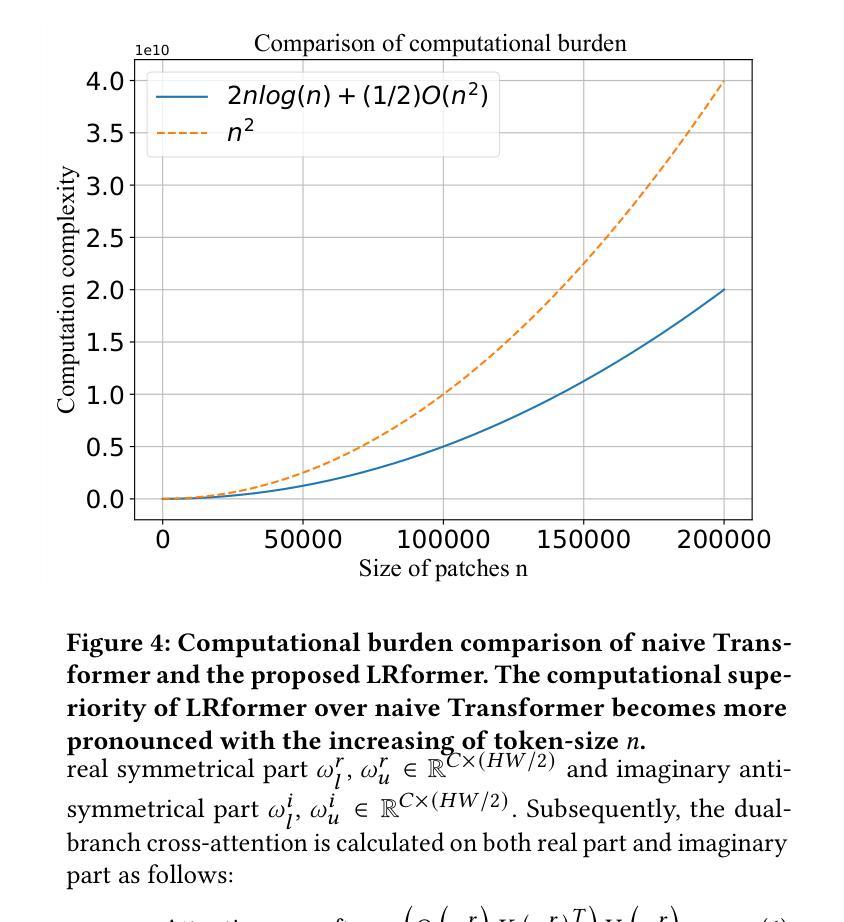
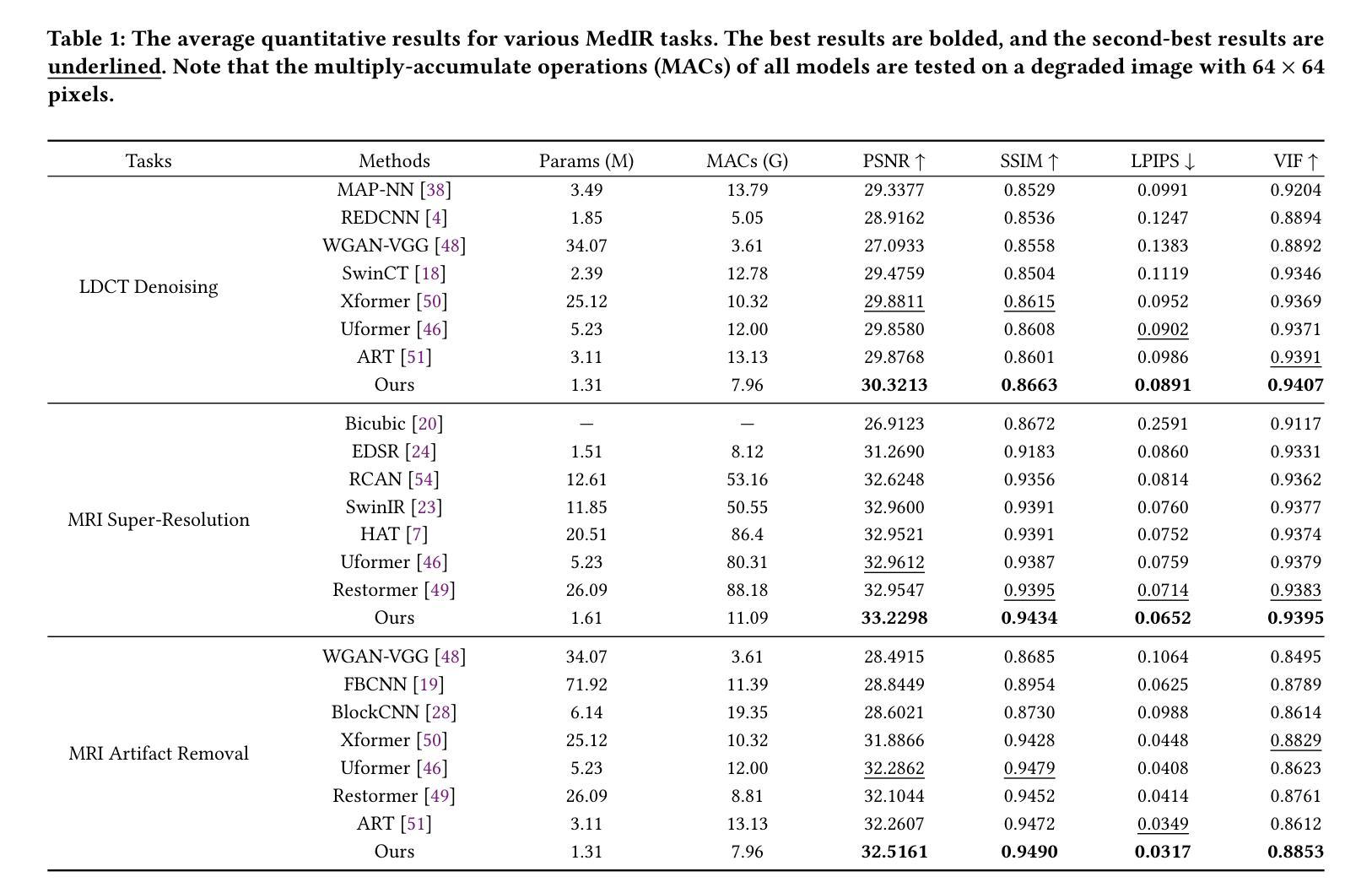
Medical image restoration tasks aim to recover high-quality images from degraded observations, exhibiting emergent desires in many clinical scenarios, such as low-dose CT image denoising, MRI super-resolution, and MRI artifact removal. Despite the success achieved by existing deep learning-based restoration methods with sophisticated modules, they struggle with rendering computationally-efficient reconstruction results. Moreover, they usually ignore the reliability of the restoration results, which is much more urgent in medical systems. To alleviate these issues, we present LRformer, a Lightweight Transformer-based method via Reliability-guided learning in the frequency domain. Specifically, inspired by the uncertainty quantification in Bayesian neural networks (BNNs), we develop a Reliable Lesion-Semantic Prior Producer (RLPP). RLPP leverages Monte Carlo (MC) estimators with stochastic sampling operations to generate sufficiently-reliable priors by performing multiple inferences on the foundational medical image segmentation model, MedSAM. Additionally, instead of directly incorporating the priors in the spatial domain, we decompose the cross-attention (CA) mechanism into real symmetric and imaginary anti-symmetric parts via fast Fourier transform (FFT), resulting in the design of the Guided Frequency Cross-Attention (GFCA) solver. By leveraging the conjugated symmetric property of FFT, GFCA reduces the computational complexity of naive CA by nearly half. Extensive experimental results in various tasks demonstrate the superiority of the proposed LRformer in both effectiveness and efficiency.
医学图像恢复任务旨在从退化的观察中恢复高质量图像,这在许多临床场景中展现出了迫切的需求,例如低剂量CT图像去噪、MRI超分辨率和MRI伪影去除。尽管现有的基于深度学习的恢复方法使用复杂的模块取得了成功,但它们在呈现计算高效的重建结果方面遇到了困难。此外,它们通常忽略了医疗系统中恢复结果的可靠性,这一点更为紧迫。为了缓解这些问题,我们提出了LRformer,这是一种基于轻量级Transformer的可靠性引导频率域学习方法。具体而言,我们受到贝叶斯神经网络(BNNs)中的不确定性量化的启发,开发了一种可靠的病灶语义先验生产者(RLPP)。RLPP利用蒙特卡洛(MC)估计器和随机采样操作,通过对基础医学图像分割模型MedSAM进行多次推理,生成足够可靠的先验。此外,我们没有直接在空间域中融入这些先验知识,而是利用快速傅里叶变换(FFT)将交叉注意(CA)机制分解为实对称和虚反对称部分,从而设计出引导频率交叉注意(GFCA)求解器。通过利用FFT的共轭对称属性,GFCA将朴素CA的计算复杂度降低了近一半。在各项任务中的广泛实验结果证明了所提出的LRformer在有效性和效率方面的优越性。
论文及项目相关链接
Summary
本文主要介绍了针对医学图像恢复任务的一种新型方法——LRformer。该方法结合了轻量级Transformer和可靠性引导学习,旨在解决现有深度学习恢复方法在效率和可靠性方面的问题。通过引入可靠的病灶语义先验生成器(RLPP)和导向频率交叉注意(GFCA)求解器,LRformer在各种医学图像恢复任务中展现出优越的效果和效率。
Key Takeaways
- LRformer是一种基于轻量级Transformer的医学图像恢复方法,旨在解决现有方法的计算效率与结果可靠性问题。
- RLPP利用贝叶斯神经网络(BNNs)的不确定性量化,通过Monte Carlo(MC)估计器和随机采样操作生成可靠的先验信息。
- GFCA求解器通过快速傅里叶变换(FFT)将交叉注意(CA)机制分解为实对称和虚反对称两部分,降低了计算复杂度。
- LRformer在多种医学图像恢复任务中进行了广泛实验,证明了其优越性和有效性。
- LRformer对于低剂量CT图像去噪、MRI超分辨率和MRI伪影去除等临床场景具有潜在应用价值。
- RLPP和GFCA的结合使得LRformer能够在保证恢复质量的同时,提高计算效率和结果可靠性。
点此查看论文截图

RL4Med-DDPO: Reinforcement Learning for Controlled Guidance Towards Diverse Medical Image Generation using Vision-Language Foundation Models
Authors:Parham Saremi, Amar Kumar, Mohamed Mohamed, Zahra TehraniNasab, Tal Arbel
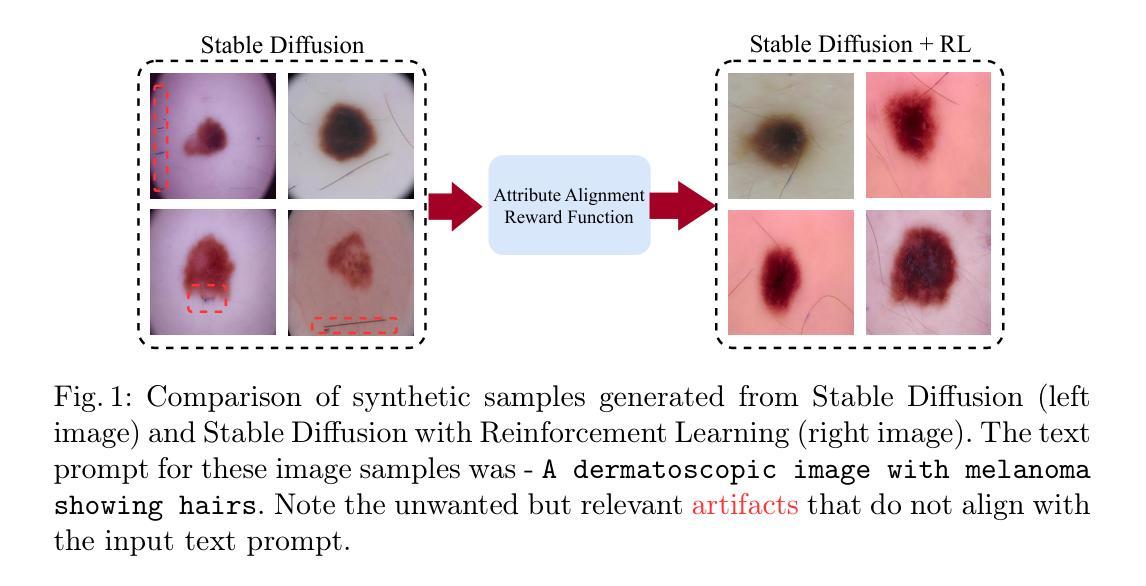
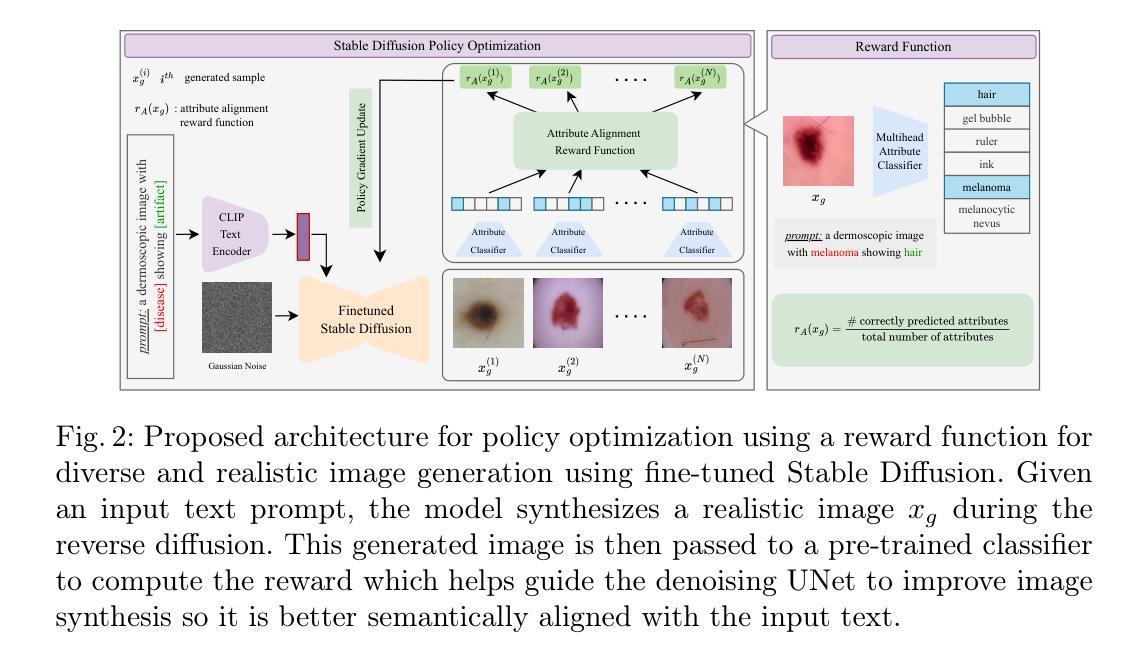
Vision-Language Foundation Models (VLFM) have shown a tremendous increase in performance in terms of generating high-resolution, photorealistic natural images. While VLFMs show a rich understanding of semantic content across modalities, they often struggle with fine-grained alignment tasks that require precise correspondence between image regions and textual descriptions, a limitation in medical imaging, where accurate localization and detection of clinical features are essential for diagnosis and analysis. To address this issue, we propose a multi-stage architecture where a pre-trained VLFM (e.g. Stable Diffusion) provides a cursory semantic understanding, while a reinforcement learning (RL) algorithm refines the alignment through an iterative process that optimizes for understanding semantic context. The reward signal is designed to align the semantic information of the text with synthesized images. Experiments on the public ISIC2019 skin lesion dataset demonstrate that the proposed method improves (a) the quality of the generated images, and (b) the alignment with the text prompt over the original fine-tuned Stable Diffusion baseline. We also show that the synthesized samples could be used to improve disease classifier performance for underrepresented subgroups through augmentation. Our code is accessible through the project website: https://parhamsaremi.github.io/rl4med-ddpo
视觉语言基础模型(VLFM)在生成高分辨率、逼真自然图像方面的性能表现显著提高。虽然VLFM在跨模态的语义内容理解方面表现出丰富的能力,但在需要图像区域和文本描述之间精确对应的精细对齐任务上常常遇到困难。在医学成像领域,这是诊断和分析中准确定位和检测临床特征的关键限制。为了解决这个问题,我们提出了一种多阶段架构,其中预训练的VLFM(如Stable Diffusion)提供粗略的语义理解,而强化学习(RL)算法通过优化理解语义上下文来完善对齐。奖励信号被设计为将文本中的语义信息与合成图像对齐。在公开的ISIC2019皮肤病变数据集上的实验表明,所提出的方法改进了(a)生成的图像质量,(b)与文本提示的对齐程度,优于原始微调后的Stable Diffusion基线。我们还证明了合成的样本可以通过数据增强来提高代表性不足的疾病分类器的性能。我们的代码可通过项目网站访问:https://parhamsaremi.github.io/rl4med-ddpo。
论文及项目相关链接
Summary
医学图像领域,预训练视觉语言融合模型(VLFM)虽能生成高质量的自然图像,但对精细对齐任务理解不足,尤其在医学成像中需准确定位和分析临床特征时受限。提出一种多阶段架构,采用预训练VLFM提供语义理解,并用强化学习算法迭代优化对齐精度。奖励信号用于使文本与合成图像语义信息对齐。在公开皮肤病变数据集上的实验表明,该方法提高了图像质量和文本对齐度,合成的样本可用于增强对代表性不足的疾病分类器的性能。
Key Takeaways
- 预训练视觉语言融合模型(VLFM)在医学图像生成中具有巨大的潜力。
- VLFM面临精细对齐任务挑战,即在医学成像中需要准确对应图像区域和文本描述。
- 提出一种多阶段架构,结合预训练VLFM和强化学习算法解决上述问题。
- 强化学习通过迭代优化过程提高语义上下文的理解和对齐精度。
- 奖励信号设计旨在使文本与合成图像的语义信息对齐。
- 在公开皮肤病变数据集上的实验验证了该方法的有效性,提高了图像质量和文本对齐度。
点此查看论文截图

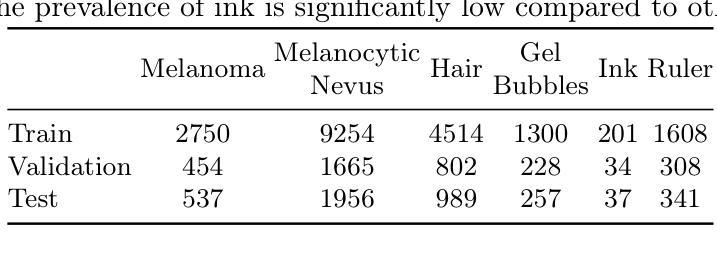
Physics-Driven Autoregressive State Space Models for Medical Image Reconstruction
Authors:Bilal Kabas, Fuat Arslan, Valiyeh A. Nezhad, Saban Ozturk, Emine U. Saritas, Tolga Çukur
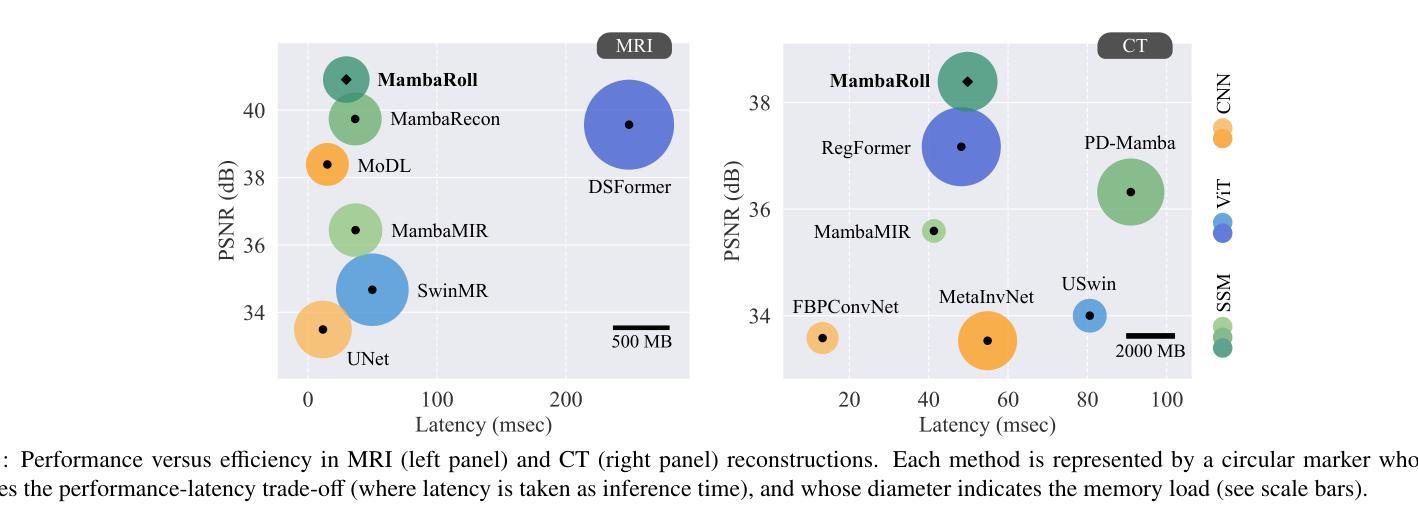
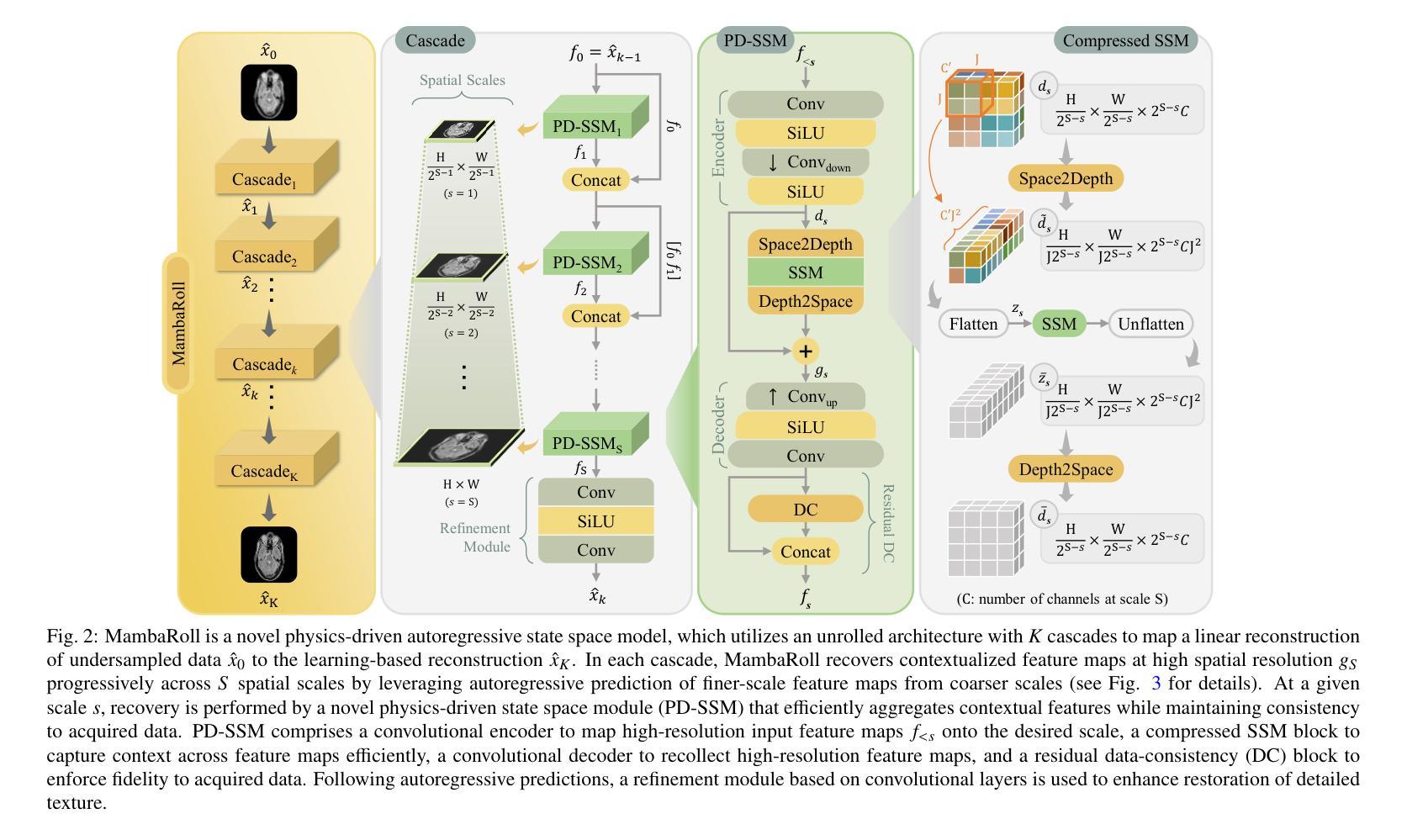
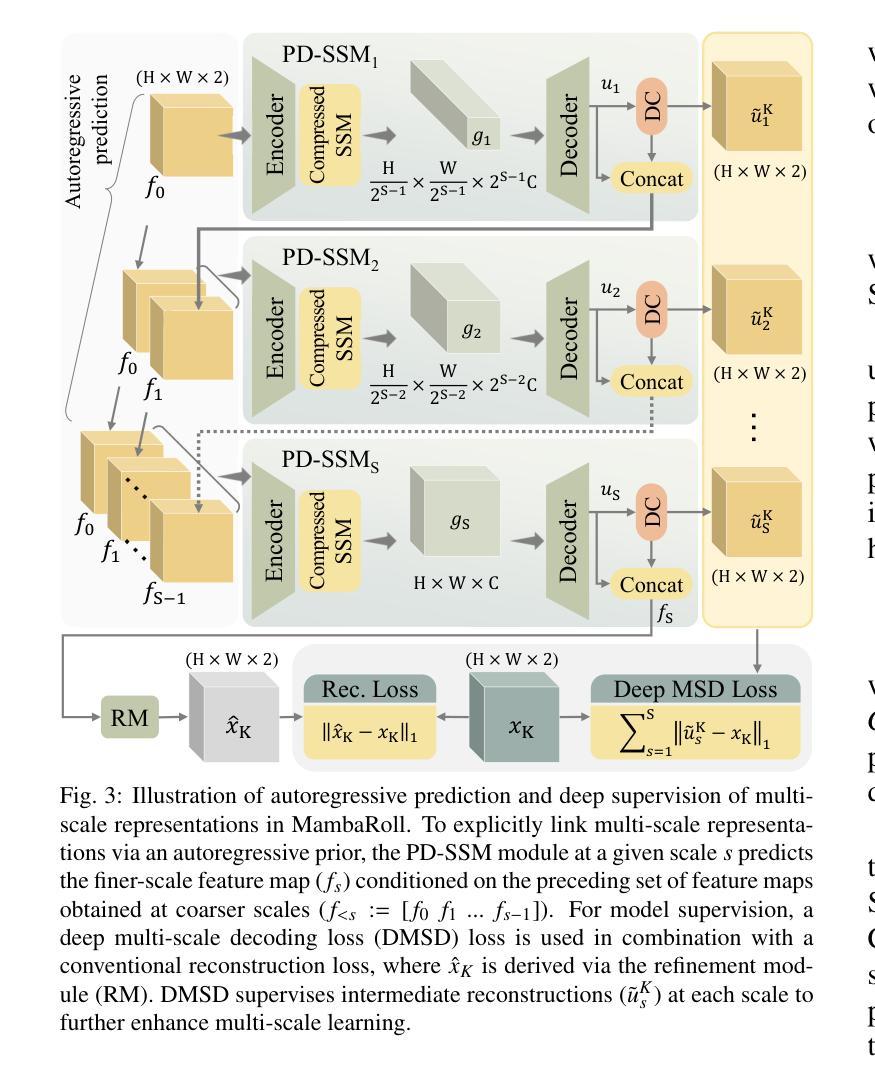
Medical image reconstruction from undersampled acquisitions is an ill-posed problem involving inversion of the imaging operator linking measurement and image domains. Physics-driven (PD) models have gained prominence in reconstruction tasks due to their desirable performance and generalization. These models jointly promote data fidelity and artifact suppression, typically by combining data-consistency mechanisms with learned network modules. Artifact suppression depends on the network’s ability to disentangle artifacts from true tissue signals, both of which can exhibit contextual structure across diverse spatial scales. Convolutional neural networks (CNNs) are strong in capturing local correlations, albeit relatively insensitive to non-local context. While transformers promise to alleviate this limitation, practical implementations frequently involve design compromises to reduce computational cost by balancing local and non-local sensitivity, occasionally resulting in performance comparable to or trailing that of CNNs. To enhance contextual sensitivity without incurring high complexity, we introduce a novel physics-driven autoregressive state-space model (MambaRoll) for medical image reconstruction. In each cascade of its unrolled architecture, MambaRoll employs a physics-driven state-space module (PD-SSM) to aggregate contextual features efficiently at a given spatial scale, and autoregressively predicts finer-scale feature maps conditioned on coarser-scale features to capture multi-scale context. Learning across scales is further enhanced via a deep multi-scale decoding (DMSD) loss tailored to the autoregressive prediction task. Demonstrations on accelerated MRI and sparse-view CT reconstructions show that MambaRoll consistently outperforms state-of-the-art data-driven and physics-driven methods based on CNN, transformer, and SSM backbones.
从欠采样采集中进行医学图像重建是一个不适定问题,涉及到连接测量和图像域之间的成像算子的反转。由于其在重建任务中的出色性能和泛化能力,物理驱动(PD)模型已经变得突出。这些模型通过结合数据一致性机制和学习的网络模块,同时促进数据保真和伪影抑制。伪影抑制依赖于网络从真实组织信号中分离伪影的能力,这两者在不同的空间尺度上都可以表现出上下文结构。卷积神经网络(CNN)擅长捕捉局部相关性,尽管对非局部上下文的敏感度相对较低。虽然变压器有望缓解这一局限性,但实际应用中经常需要在平衡局部和非局部敏感度的情况下做出设计上的妥协,以降低计算成本,这有时会使得性能与CNN相当或落后。为了在不增加高复杂度的情况下提高上下文敏感度,我们引入了一种新型物理驱动自回归状态空间模型(MambaRoll)用于医学图像重建。MambaRoll的展开架构中的每个级联都使用一个物理驱动状态空间模块(PD-SSM)来有效地聚合给定空间尺度的上下文特征,并自回归地预测更精细尺度的特征图,这些预测基于较粗糙尺度的特征,以捕获多尺度上下文。通过针对自回归预测任务设计的深度多尺度解码(DMSD)损失,进一步增强了跨尺度的学习。在加速MRI和稀疏视图CT重建上的演示表明,MambaRoll始终优于基于CNN、变压器和SSM的最新数据驱动和物理驱动方法。
论文及项目相关链接
PDF 14 pages, 11 figures
摘要
本文介绍了一种新型的医学图像重建方法——基于物理驱动的自回归状态空间模型(MambaRoll)。该方法旨在解决从欠采样采集中进行医学图像重建的逆问题。MambaRoll模型通过引入物理驱动的状态空间模块(PD-SSM),有效聚合了特定空间尺度上的上下文特征,并通过自回归方式预测更精细尺度的特征图,从而捕获多尺度上下文信息。此外,该模型还采用了一种针对自回归预测任务的深度多尺度解码(DMSD)损失,以进一步提高跨尺度学习能力。在加速MRI和稀疏视图CT重建的演示中,MambaRoll表现优异,超越了基于CNN、Transformer和SSM等先进数据驱动和物理驱动的方法。
关键见解
- 医学图像重建是从欠采样采集数据中恢复完整图像的过程,是一个不适定问题。
- 物理驱动(PD)模型在医学图像重建任务中因其性能优异而备受关注,它们通过结合数据一致性和学习网络模块来促进数据保真和伪影抑制。
- 卷积神经网络(CNNs)擅长捕捉局部相关性,但对非局部上下文相对不敏感。
- 虽然Transformer有潜力缓解这一局限性,但在实践中,为了降低计算成本而进行的平衡设计往往导致性能与CNN相当或落后。
- 提出了新型的基于物理驱动的自回归状态空间模型(MambaRoll)用于医学图像重建。
- MambaRoll通过物理驱动的状态空间模块(PD-SSM)在给定空间尺度上有效地聚合上下文特征。
- MambaRoll在加速MRI和稀疏视图CT重建任务中表现出卓越性能,超过了现有先进方法。
点此查看论文截图

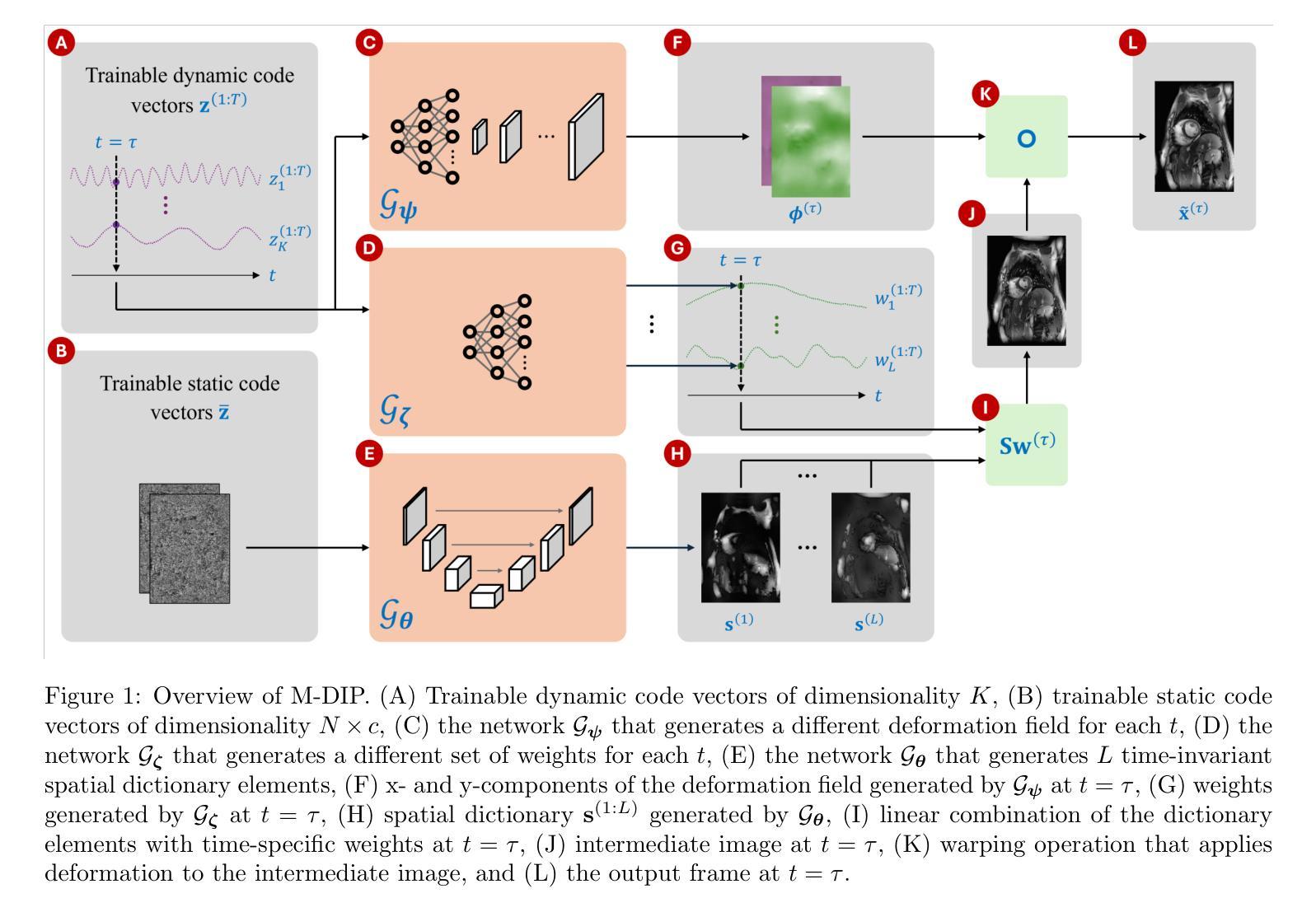
Multi-dynamic deep image prior for cardiac MRI
Authors:Marc Vornehm, Chong Chen, Muhammad Ahmad Sultan, Syed Murtaza Arshad, Yuchi Han, Florian Knoll, Rizwan Ahmad
Cardiovascular magnetic resonance imaging is a powerful diagnostic tool for assessing cardiac structure and function. However, traditional breath-held imaging protocols pose challenges for patients with arrhythmias or limited breath-holding capacity. This work aims to overcome these limitations by developing a reconstruction framework that enables high-quality imaging in free-breathing conditions for various dynamic cardiac MRI protocols. Multi-Dynamic Deep Image Prior (M-DIP), a novel unsupervised reconstruction framework for accelerated real-time cardiac MRI, is introduced. To capture contrast or content variation, M-DIP first employs a spatial dictionary to synthesize a time-dependent intermediate image. Then, this intermediate image is further refined using time-dependent deformation fields that model cardiac and respiratory motion. Unlike prior DIP-based methods, M-DIP simultaneously captures physiological motion and frame-to-frame content variations, making it applicable to a wide range of dynamic applications. We validate M-DIP using simulated MRXCAT cine phantom data as well as free-breathing real-time cine, single-shot late gadolinium enhancement (LGE), and first-pass perfusion data from clinical patients. Comparative analyses against state-of-the-art supervised and unsupervised approaches demonstrate M-DIP’s performance and versatility. M-DIP achieved better image quality metrics on phantom data, higher reader scores on in-vivo cine and LGE data, and comparable scores on in-vivo perfusion data relative to another DIP-based approach. M-DIP enables high-quality reconstructions of real-time free-breathing cardiac MRI without requiring external training data. Its ability to model physiological motion and content variations makes it a promising approach for various dynamic imaging applications.
心血管磁共振成像是一种评估心脏结构和功能的强大诊断工具。然而,传统的屏气成像协议对于心律失常或屏气能力有限的患者来说提出了挑战。这项工作旨在通过开发一个重建框架来克服这些限制,该框架能够在各种动态心脏MRI协议中实现自由呼吸条件下的高质量成像。介绍了一种用于加速实时心脏MRI的新型无监督重建框架——多动态深度图像先验(M-DIP)。为了捕捉对比度或内容的变化,M-DIP首先使用空间字典合成时间相关的中间图像。然后,这个中间图像进一步使用时间相关的变形场进行精细化处理,以模拟心脏和呼吸运动。与之前的DIP方法不同,M-DIP可以同时捕捉生理运动和帧间内容变化,使其适用于广泛的动态应用。我们使用模拟的MRXCAT电影幻影数据以及来自临床患者的自由呼吸实时电影、单次拍摄晚期钆增强(LGE)和首过灌注数据验证了M-DIP。与最新先进的有监督和无监督方法的对比分析证明了M-DIP的性能和通用性。M-DIP在幻影数据上实现了更好的图像质量指标,在体内电影和LGE数据上获得了更高的读者评分,与另一种基于DIP的方法相比,在体内灌注数据上的得分相当。M-DIP实现了自由呼吸状态下实时心脏MRI的高质量重建,而无需外部训练数据。其模拟生理运动和内容变化的能力使其成为各种动态成像应用的有前途的方法。
论文及项目相关链接
Summary
基于这篇文章的摘要指出,传统的心血管磁共振成像面临呼吸限制等问题,不利于心脏疾病的诊断。为应对这一挑战,研究人员提出一种名为M-DIP的新颖无监督重建框架,实现了高质量、实时的无呼吸限制心血管磁共振成像。该方法使用空间词典和变形场模型心脏运动和呼吸运动的时间依赖性,使各种动态心脏MRI成为可能。对比现有的监督和非监督方法显示,M-DIP表现优异,能够重建高质量的无呼吸限制实时心血管MRI图像。它有望在多种动态成像应用中展现出巨大的潜力。
Key Takeaways
- M-DIP是一种新颖的重建框架,用于解决传统心血管磁共振成像在呼吸受限情况下的挑战。
- M-DIP结合了空间词典和变形场模型心脏和呼吸运动的时间依赖性。
- M-DIP在各种动态心脏MRI协议中实现了高质量成像,包括实时、单镜头延迟增强和首过灌注数据。
- 对比现有方法,M-DIP在图像质量指标、读者评分方面表现优越。
- M-DIP无需外部训练数据即可实现高质量重建。
点此查看论文截图

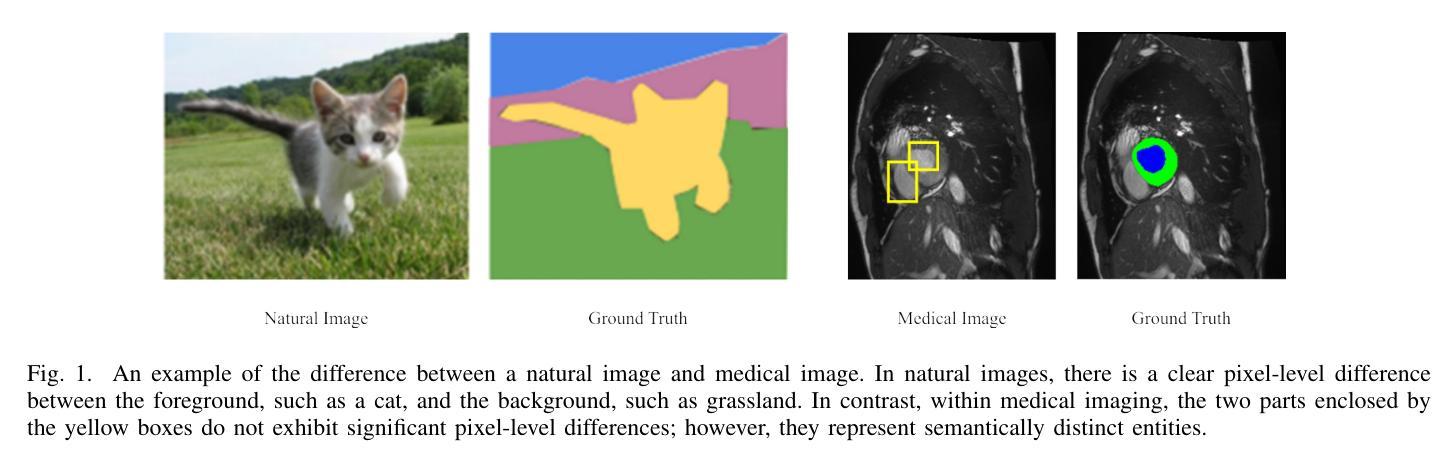
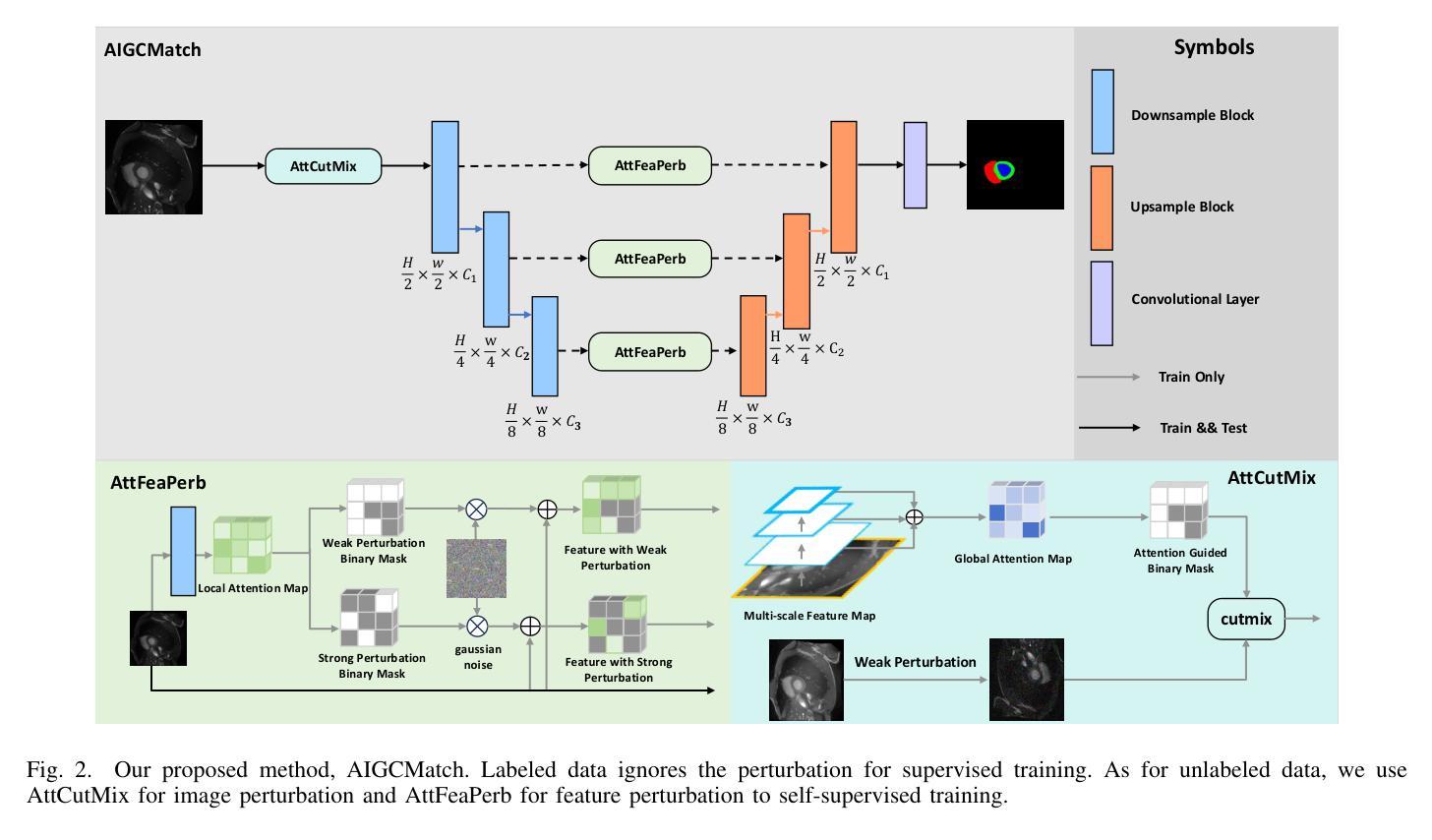
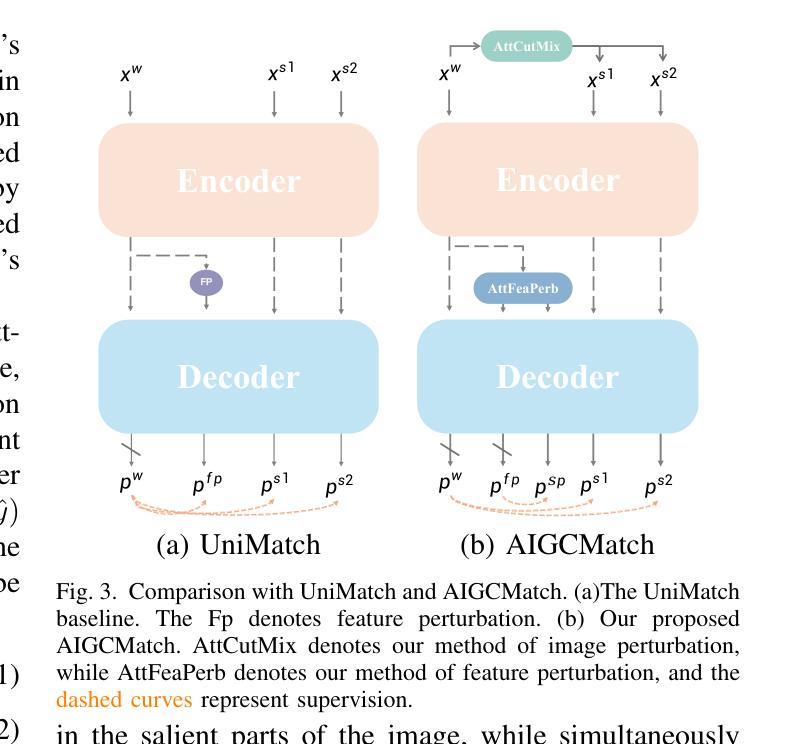
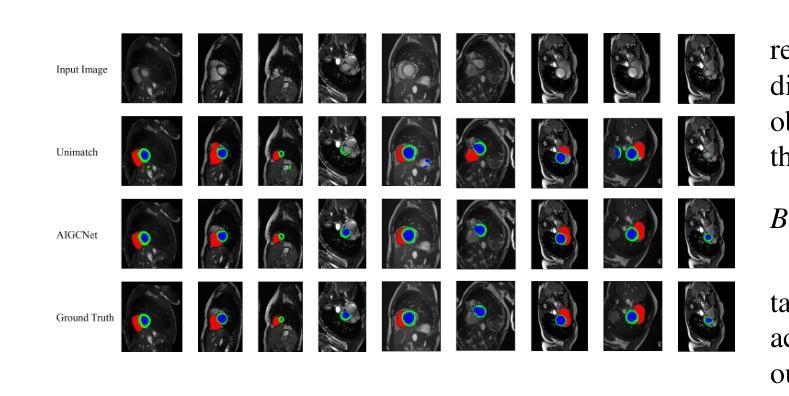
Mind the Context: Attention-Guided Weak-to-Strong Consistency for Enhanced Semi-Supervised Medical Image Segmentation
Authors:Yuxuan Cheng, Chenxi Shao, Jie Ma, Yunfei Xie, Guoliang Li
Medical image segmentation is a pivotal step in diagnostic and therapeutic processes, relying on high-quality annotated data that is often challenging and costly to obtain. Semi-supervised learning offers a promising approach to enhance model performance by leveraging unlabeled data. Although weak-to-strong consistency is a prevalent method in semi-supervised image segmentation, there is a scarcity of research on perturbation strategies specifically tailored for semi-supervised medical image segmentation tasks. To address this challenge, this paper introduces a simple yet efficient semi-supervised learning framework named Attention-Guided weak-to-strong Consistency Match (AIGCMatch). The AIGCMatch framework incorporates attention-guided perturbation strategies at both the image and feature levels to achieve weak-to-strong consistency regularization. This method not only preserves the structural information of medical images but also enhances the model’s ability to process complex semantic information. Extensive experiments conducted on the ACDC and ISIC-2017 datasets have validated the effectiveness of AIGCMatch. Our method achieved a 90.4% Dice score in the 7-case scenario on the ACDC dataset, surpassing the state-of-the-art methods and demonstrating its potential and efficacy in clinical settings.
医学图像分割是诊断和治疗过程中的关键步骤,依赖于高质量标注数据,而这些数据的获取往往具有挑战性和成本高昂。半监督学习通过利用未标注数据,为提高模型性能提供了一种有前途的方法。尽管弱到强的一致性是半监督图像分割中的流行方法,但针对半监督医学图像分割任务的扰动策略的研究却很匮乏。针对这一挑战,本文提出了一种简单而高效的半监督学习框架,名为注意力引导弱到强一致性匹配(AIGCMatch)。AIGCMatch框架在图像和特征层面结合了注意力引导扰动策略,实现了弱到强的一致性正则化。这种方法不仅保留了医学图像的结构信息,还提高了模型处理复杂语义信息的能力。在ACDC和ISIC-2017数据集上进行的广泛实验验证了AIGCMatch的有效性。我们的方法在ACDC数据集上的7个案例场景中实现了90.4%的Dice得分,超越了最先进的方法,证明了其在临床环境中的潜力和有效性。
论文及项目相关链接
Summary
医学图像分割在诊断和治疗过程中至关重要,需要大量高质量标注数据,但获取这些数据往往具有挑战性和成本高昂。半监督学习通过利用未标注数据来提高模型性能。尽管弱到强一致性是半监督图像分割中的常见方法,但针对半监督医学图像分割任务的扰动策略研究较少。针对这一挑战,本文提出了一种简单高效的半监督学习框架,名为注意力引导弱到强一致性匹配(AIGCMatch)。AIGCMatch框架在图像和特征层面采用注意力引导扰动策略,实现弱到强一致性正则化。此方法不仅保留了医学图像的结构信息,还提高了模型处理复杂语义信息的能力。在ACDC和ISIC-2017数据集上进行的广泛实验验证了AIGCMatch的有效性。在ACDC数据集上的7例场景中,我们的方法实现了90.4%的Dice得分,超越了最先进的方法,证明了其在临床环境中的潜力和有效性。
Key Takeaways
- 医学图像分割是医疗诊断与治疗的关键环节,对数据的标注质量和数量有较高要求。
- 获取高质量标注数据具有挑战性和高成本。
- 半监督学习能提高模型性能,利用未标注数据。
- 现有的半监督医学图像分割中的弱到强一致性方法需要结合更有效的扰动策略。
- 本文提出一种名为AIGCMatch的半监督学习框架,结合注意力引导的扰动策略实现弱到强一致性正则化。
- AIGCMatch能保留医学图像的结构信息,并提高模型处理复杂语义信息的能力。
点此查看论文截图

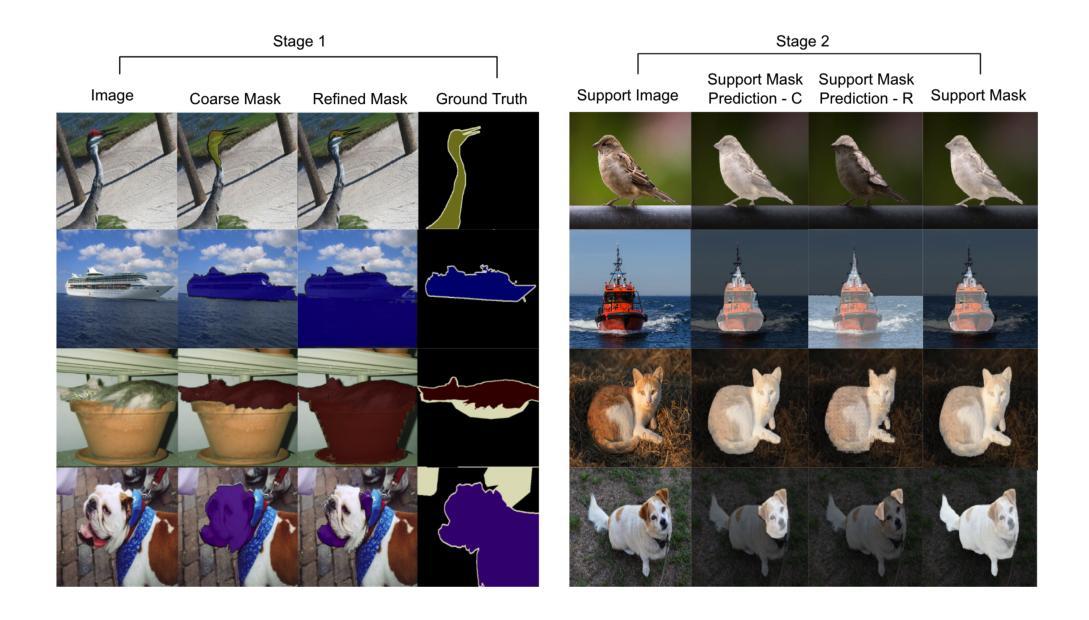
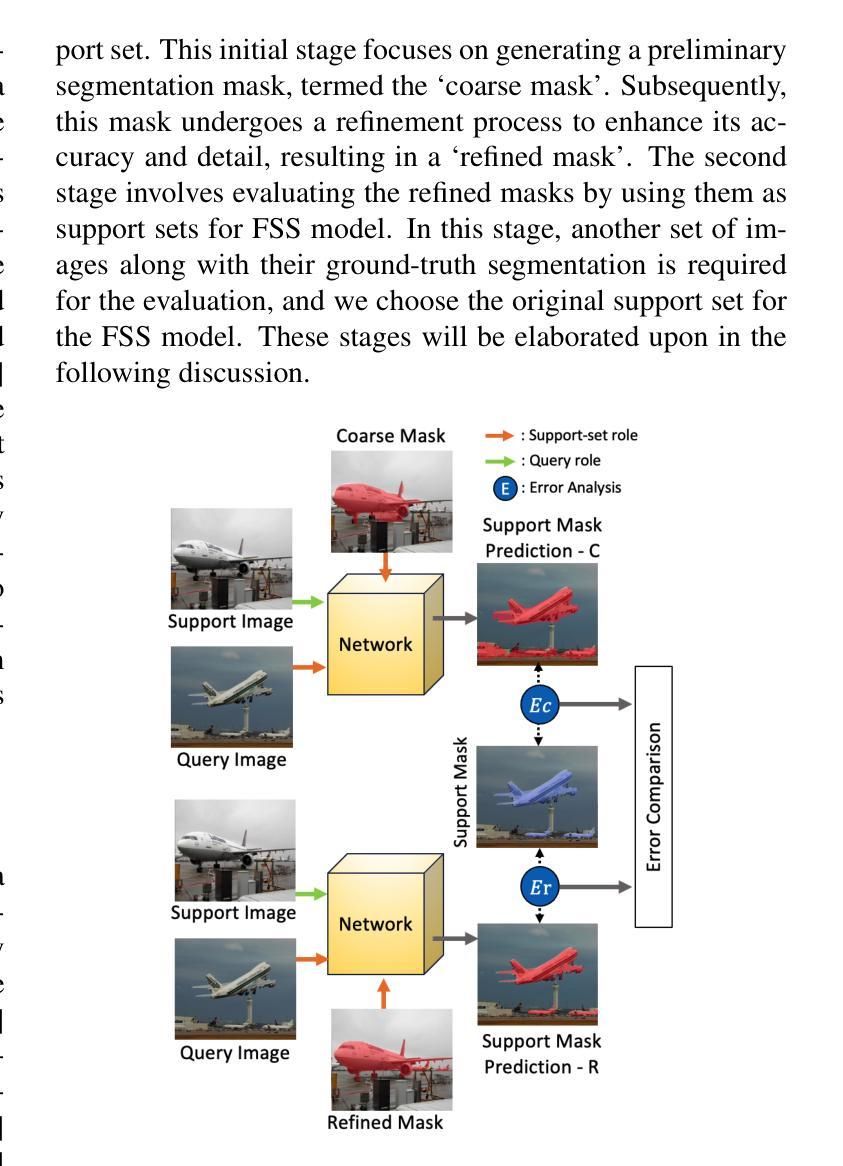
Judging from Support-set: A New Way to Utilize Few-Shot Segmentation for Segmentation Refinement Process
Authors:Seonghyeon Moon, Qingze, Liu, Haein Kong, Muhammad Haris Khan
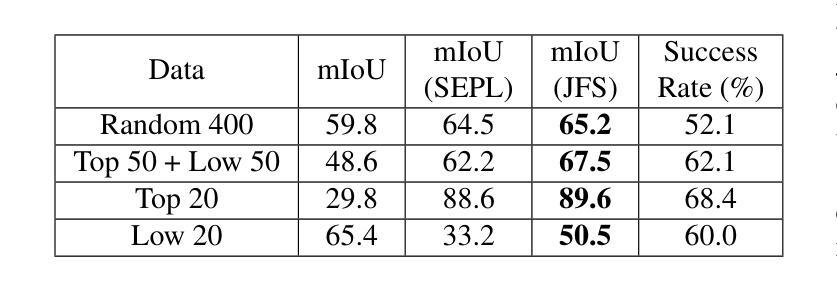
Segmentation refinement aims to enhance the initial coarse masks generated by segmentation algorithms. The refined masks are expected to capture more details and better contours of the target objects. Research on segmentation refinement has developed as a response to the need for high-quality image segmentations. However, to our knowledge, no method has been developed that can determine the success of segmentation refinement. Such a method could ensure the reliability of segmentation in applications where the outcome of the segmentation is important and fosters innovation in image processing technologies. To address this research gap, we propose Judging From Support-set (JFS), a method to judge the success of segmentation refinement leveraging an off-the-shelf few-shot segmentation (FSS) model. The traditional goal of the problem in FSS is to find a target object in a query image utilizing target information given by a support set. However, we propose a novel application of the FSS model in our evaluation pipeline for segmentation refinement methods. Given a coarse mask as input, segmentation refinement methods produce a refined mask; these two masks become new support masks for the FSS model. The existing support mask then serves as the test set for the FSS model to evaluate the quality of the refined segmentation by the segmentation refinement methods. We demonstrate the effectiveness of our proposed JFS framework by evaluating the SAM Enhanced Pseudo-Labels (SEPL) using SegGPT as the choice of FSS model on the PASCAL dataset. The results showed that JFS has the potential to determine whether the segmentation refinement process is successful.
分割细化旨在提高分割算法生成的初始粗糙掩模的质量。细化后的掩模能够捕捉更多细节和目标对象更好的轮廓。分割细化的研究是为了满足对高质量图像分割的需求而发展起来的。然而,据我们所知,还没有方法可以判断分割细化的成功与否。这样的方法可以保证分割在结果重要的应用中的可靠性,并促进图像处理技术的创新。为了弥补这一研究空白,我们提出了“从支持集判断”(JFS)的方法,这是一种利用现成的少样本分割(FSS)模型来判断分割细化成功与否的方法。FSS问题的传统目标是利用支持集给出的目标信息在查询图像中找到目标对象。然而,我们提出了FSS模型在分割细化方法评估管道中的新颖应用。给定一个粗略的掩模作为输入,分割细化方法会产生一个精细的掩模;这两个掩模成为FSS模型的新支持掩模。现有的支持掩模然后作为FSS模型的测试集,以评估分割细化方法所得到的精细分割的质量。我们通过使用SegGPT作为FSS模型在PASCAL数据集上评估SAM增强伪标签(SEPL)来展示我们所提出的JFS框架的有效性。结果表明,JFS具有判断分割细化过程是否成功的潜力。
论文及项目相关链接
PDF ICIP 2025
Summary
本文提出一种基于支持集(Support-set)的评判方法(JFS),用于评估图像分割精细化的效果。此方法借助现成的少量样本分割(FSS)模型,利用粗分割掩膜和精细化后的掩膜作为新的支持集,通过支持集对精细化分割方法进行测试集评估,从而判断分割精细化的成功与否。实验结果表明,JFS框架具有评估分割精细化过程是否成功的潜力。
Key Takeaways
- 分割细化旨在改进由分割算法生成的初始粗略掩膜,期望获得更多细节和更精确的目标物体轮廓。
- 目前尚未有方法能够确定分割细化的成功与否,这影响了分割结果重要的应用并限制了图像处理技术的创新。
- 提出了一种基于支持集(Support-set)的评判方法(JFS),用于评估分割细化的效果。
- JFS利用现成的少量样本分割(FSS)模型,将粗分割掩膜和精细化后的掩膜作为新的支持集。
- 通过支持集对精细化分割方法进行测试集评估,以判断分割精细化的成功与否。
点此查看论文截图