⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-13 更新
None of the Others: a General Technique to Distinguish Reasoning from Memorization in Multiple-Choice LLM Evaluation Benchmarks
Authors:Eva Sánchez Salido, Julio Gonzalo, Guillermo Marco
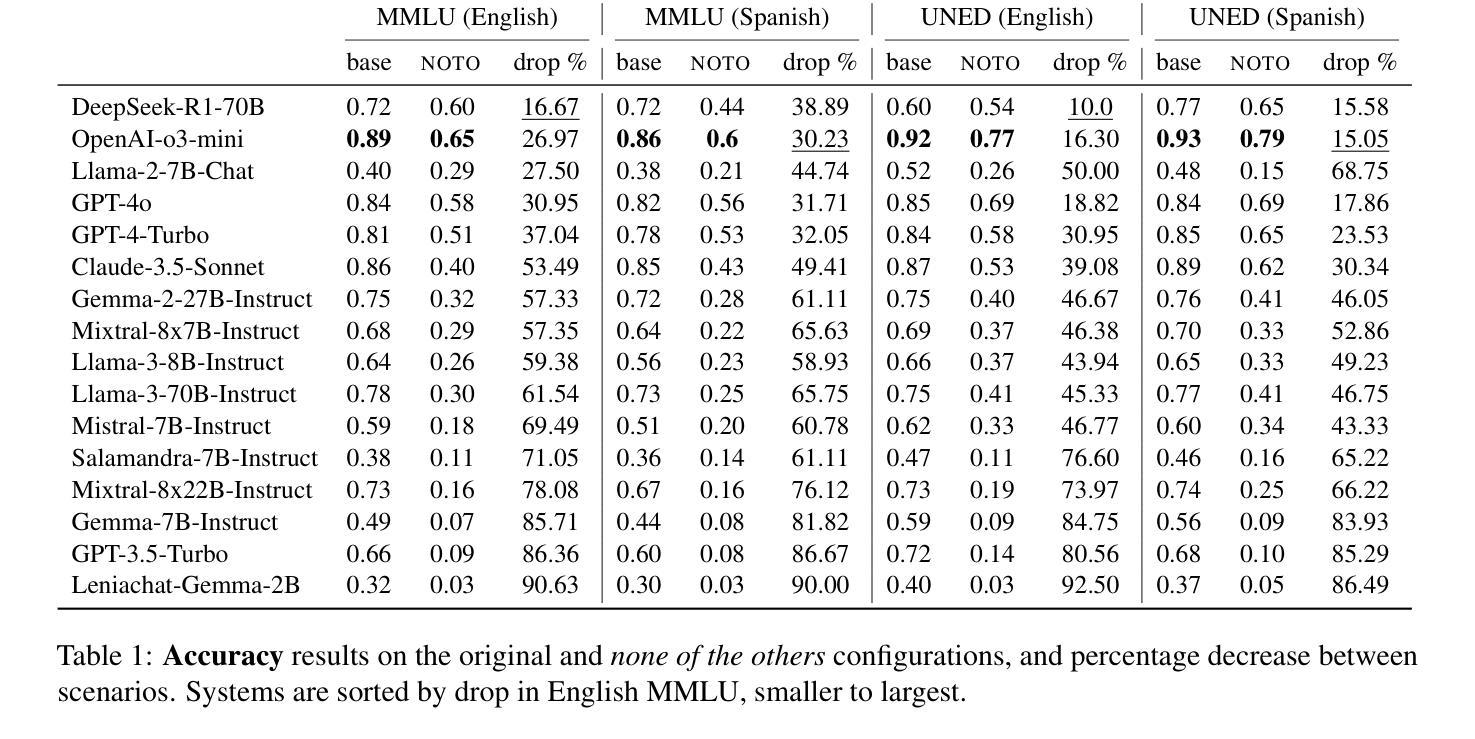
In LLM evaluations, reasoning is often distinguished from recall/memorization by performing numerical variations to math-oriented questions. Here we introduce a general variation method for multiple-choice questions that completely dissociates the correct answer from previously seen tokens or concepts, requiring LLMs to understand and reason (rather than memorizing) in order to answer correctly. Using this method, we evaluate state-of-the-art proprietary and open-source LLMs on two datasets available in English and Spanish: the public MMLU benchmark and the private UNED-Access 2024 dataset. Results show that all models experience remarkable accuracy drops under our proposed variation, with an average loss of 57% on MMLU and 50% on UNED-Access 2024, ranging from 10% to 93% across models. Notably, the most accurate model in our experimentation (OpenAI-o3-mini) is not the most robust (DeepSeek-R1-70B), suggesting that the best models in standard evaluations may not be the ones with better reasoning capabilities. Also, we see larger accuracy drops in public (vs private) datasets and questions posed in their original language (vs a manual translation), which are signs of contamination and also point to a relevant role of recall/memorization in current LLMs’ answers.
在LLM评估中,通常通过执行数学问题的数值变化来区分推理和回忆/记忆。在这里,我们介绍了一种多选题的一般变化方法,该方法完全将正确答案与先前见过的符号或概念区分开,要求LLM理解和推理(而不是记忆)以正确回答问题。使用这种方法,我们在两个英文和西班牙文数据集上评估了最先进的专业和开源LLM:公开的MMLU基准测试和私有的UNED-Access 2024数据集。结果显示,在我们提出的变体中,所有模型的准确率都出现了显著下降,在MMLU上的平均损失为57%,在UNED-Access 2024上的平均损失为5to;在不同模型之间的损失从10%到93%不等。值得注意的是,在我们实验中表现最准确的模型(OpenAI-o3-mini)并非最稳健(DeepSeek-R1-70B),这表明在标准评估中表现最佳的模型可能并不具备最好的推理能力。此外,我们还观察到公开数据集(与私有数据集相比)以及原始语言提出的问题(与手动翻译相比)的准确率下降幅度更大,这是污染的迹象,也表明回忆和记忆在当前LLM的答案中发挥了重要作用。
论文及项目相关链接
Summary
本文介绍了在LLM评估中,通过设计特殊的多项选择题评估方法,对LLM的理解推理能力进行评估,而非依赖其记忆能力。该方法将正确答案与先前接触过的符号或概念完全区分开。在公开数据集MMLU和私有数据集UNED-Access 2024上的实验结果显示,所有模型在此新评估方法下的准确度都有显著下降,平均损失达到MMLU的57%和UNED-Access 2024的5he比原始数据更清晰的实体为背景的情景图片带来显著提升的结果揭示。,更多资源优化的设备相对于准确度方面有着更高的效率,因此更加复杂的数据集更有可能对LLM推理能力产生积极影响。这一评估方法揭示了在标准评估中表现最佳的模型并不一定具有最佳的推理能力。此外,公开数据集的准确度下降幅度大于私有数据集,且使用原始语言的问题比人工翻译的问题更具挑战性,这表明当前LLM的答案中可能存在记忆污染问题。总的来说,该评估方法强调了当前LLM在理解和推理方面的挑战。
Key Takeaways
- 介绍了一种新的评估LLM的方法,该方法通过设计特殊的多项选择题来评估LLM的理解推理能力,而非依赖其记忆能力。
- 在公开数据集MMLU和私有数据集UNED-Access 2024上的实验结果显示,所有模型在新评估方法下的准确度都有显著下降。
- 最准确的模型在标准评估中并不一定是最具备推理能力的模型。这说明单纯的准确度评价并不足以衡量模型的推理能力。这意味着即便在某些标准的评价体系下被评定为先进的模型也可能存在推理能力的短板。这一发现强调了我们需要更全面的评估方法来衡量LLM的性能。
点此查看论文截图

Investigating Context-Faithfulness in Large Language Models: The Roles of Memory Strength and Evidence Style
Authors:Yuepei Li, Kang Zhou, Qiao Qiao, Bach Nguyen, Qing Wang, Qi Li
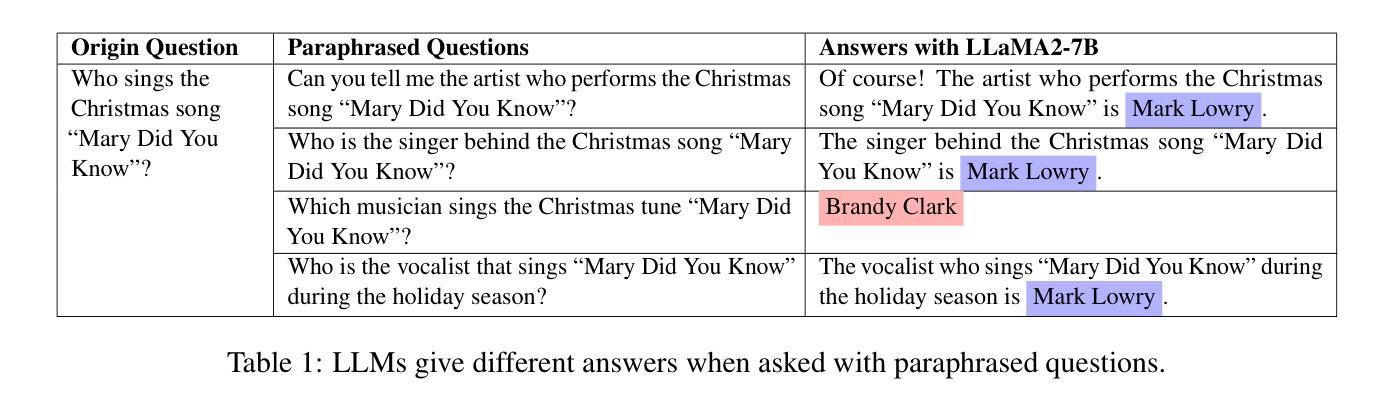
Retrieval-augmented generation (RAG) improves Large Language Models (LLMs) by incorporating external information into the response generation process. However, how context-faithful LLMs are and what factors influence LLMs’ context faithfulness remain largely unexplored. In this study, we investigate the impact of memory strength and evidence presentation on LLMs’ receptiveness to external evidence. We quantify the memory strength of LLMs by measuring the divergence in LLMs’ responses to different paraphrases of the same question, which is not considered by previous works. We also generate evidence in various styles to examine LLMs’ behavior. Our results show that for questions with high memory strength, LLMs are more likely to rely on internal memory. Furthermore, presenting paraphrased evidence significantly increases LLMs’ receptiveness compared to simple repetition or adding details. These findings provide key insights for improving retrieval-augmented generation and context-aware LLMs. Our code is available at https://github.com/liyp0095/ContextFaithful.
检索增强生成(RAG)通过将外部信息融入响应生成过程,改进了大语言模型(LLM)。然而,LLM的上下文忠实性及其影响因素仍未得到广泛探索。在这项研究中,我们探讨了记忆强度和证据呈现对LLM接受外部证据的影响。我们通过测量LLM对不同问题同义改写回答的差异性来衡量其记忆强度,这是以前的研究所没有考虑的。我们还以不同的风格生成证据来检验LLM的行为。我们的结果表明,对于高记忆强度的问题,LLM更可能依赖内部记忆。此外,与简单重复或添加细节相比,呈现同义改写证据能显著提高LLM的接受度。这些发现对于改进检索增强生成和上下文感知LLM提供了关键见解。我们的代码可在https://github.com/liyp0095/ContextFaithful找到。
论文及项目相关链接
PDF This work is published at ACL 2025
Summary
本摘要研究了大型语言模型(LLM)在检索增强生成(RAG)中的改进,并探讨了外部信息如何融入响应生成过程。文章主要探讨了LLM的语境忠实度及其影响因素,特别是记忆强度和证据呈现方式对其的影响。研究发现,记忆强度高的LLM更依赖内部记忆回应问题;呈现同义证据相较于简单重复或增加细节更能提升LLM对外部证据的接纳性。这些发现对改进检索增强生成和语境感知LLM具有关键意义。代码可通过相关链接获取。
Key Takeaways
以下是该文本的关键要点,以要点形式列出:
- 大型语言模型(LLM)可通过融入外部信息(检索增强生成)提高表现。
- 语境忠实度及其影响因素是LLM的一个重要研究方向。
- 研究量化分析了LLM对记忆的强度响应能力,主要通过测量其对同一问题的不同表述的反应差异来进行。
- 研究发现记忆强度高的LLM更依赖内部记忆回应问题。
- 同义证据呈现方式能有效提升LLM对外部证据的接纳性,优于简单重复或增加细节的方式。
点此查看论文截图

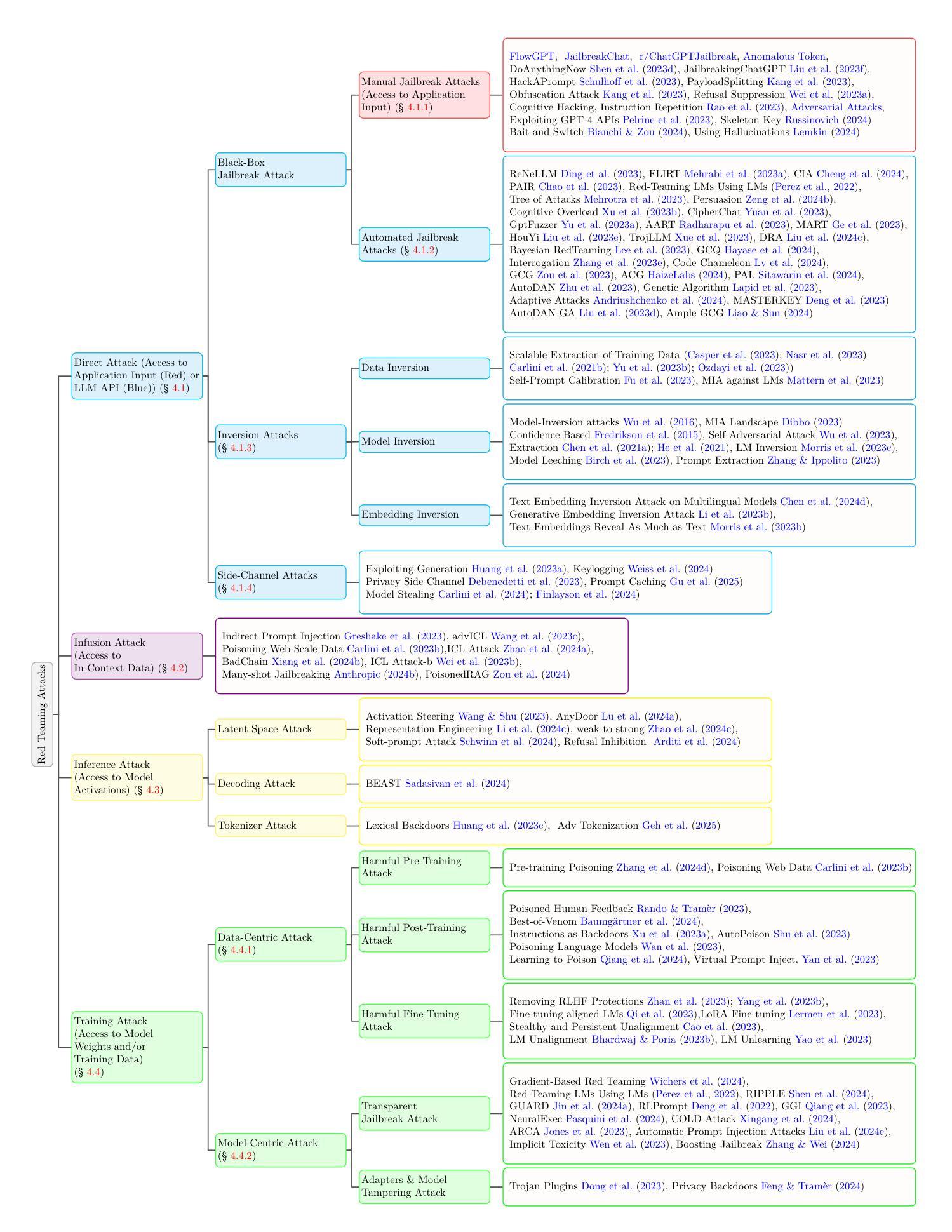
Operationalizing a Threat Model for Red-Teaming Large Language Models (LLMs)
Authors:Apurv Verma, Satyapriya Krishna, Sebastian Gehrmann, Madhavan Seshadri, Anu Pradhan, Tom Ault, Leslie Barrett, David Rabinowitz, John Doucette, NhatHai Phan
Creating secure and resilient applications with large language models (LLM) requires anticipating, adjusting to, and countering unforeseen threats. Red-teaming has emerged as a critical technique for identifying vulnerabilities in real-world LLM implementations. This paper presents a detailed threat model and provides a systematization of knowledge (SoK) of red-teaming attacks on LLMs. We develop a taxonomy of attacks based on the stages of the LLM development and deployment process and extract various insights from previous research. In addition, we compile methods for defense and practical red-teaming strategies for practitioners. By delineating prominent attack motifs and shedding light on various entry points, this paper provides a framework for improving the security and robustness of LLM-based systems.
使用大语言模型(LLM)创建安全和具有恢复能力的应用程序需要预见、适应和应对不可预见到的威胁。红队攻击已成为识别现实世界LLM实现中漏洞的关键技术。本文提出了详细的威胁模型,并提供了针对LLM的红队攻击的知识系统化(SoK)。我们基于LLM开发和部署的各个阶段开发了攻击分类,并从以前的研究中提取了各种见解。此外,我们还整理了防御方法和实用的红队攻击策略,供从业者参考。通过描绘突出的攻击动机并揭示各种切入点,本文为改进基于LLM的系统的安全性和稳健性提供了框架。
论文及项目相关链接
PDF Transactions of Machine Learning Research (TMLR)
Summary
使用大语言模型(LLM)构建安全和可靠的应用程序需要预测、适应和应对未知威胁。本文呈现了一个详细的威胁模型,并对LLM上的红队攻击进行了系统化知识(SoK)的梳理。文章基于LLM发展和部署的阶段建立攻击分类,从先前的研究中提取各种见解,并编制防御方法和实践红队策略以供从业者参考。通过描绘突出的攻击动机并揭示各种入口点,本文提供了一个改进LLM系统安全和稳健性的框架。
Key Takeaways
- LLM应用安全需预测、适应和应对未知威胁。
- 论文提供了LLM上的红队攻击系统化知识(SoK)的梳理。
- 基于LLM发展和部署阶段建立了攻击分类。
- 从先前研究中提取关于LLM攻击和防御的见解。
- 论文提供了防御方法和实践红队策略。
- 文章描绘了突出的攻击动机。
- 论文揭示了改进LLM系统安全和稳健性的途径。
点此查看论文截图

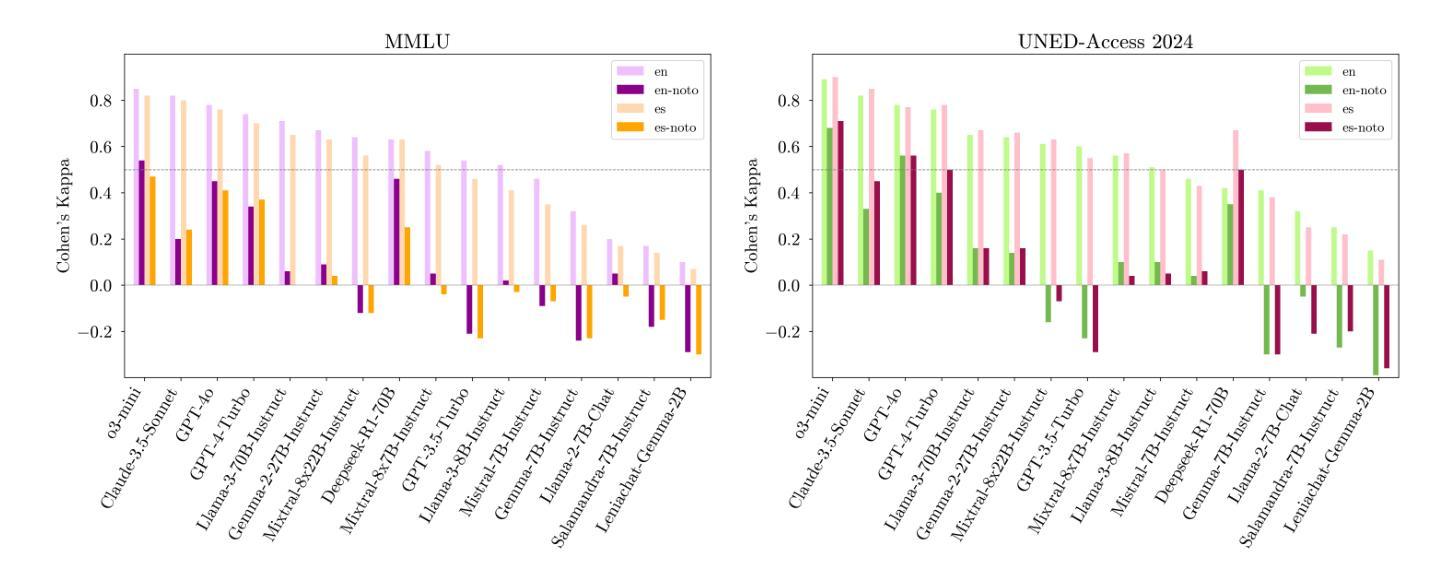
Truth-value judgment in language models: ‘truth directions’ are context sensitive
Authors:Stefan F. Schouten, Peter Bloem, Ilia Markov, Piek Vossen
Recent work has demonstrated that the latent spaces of large language models (LLMs) contain directions predictive of the truth of sentences. Multiple methods recover such directions and build probes that are described as uncovering a model’s “knowledge” or “beliefs”. We investigate this phenomenon, looking closely at the impact of context on the probes. Our experiments establish where in the LLM the probe’s predictions are (most) sensitive to the presence of related sentences, and how to best characterize this kind of sensitivity. We do so by measuring different types of consistency errors that occur after probing an LLM whose inputs consist of hypotheses preceded by (negated) supporting and contradicting sentences. We also perform a causal intervention experiment, investigating whether moving the representation of a premise along these truth-value directions influences the position of an entailed or contradicted sentence along that same direction. We find that the probes we test are generally context sensitive, but that contexts which should not affect the truth often still impact the probe outputs. Our experiments show that the type of errors depend on the layer, the model, and the kind of data. Finally, our results suggest that truth-value directions are causal mediators in the inference process that incorporates in-context information.
最近的研究表明,大型语言模型(LLM)的潜在空间包含预测句子真实性的方向。多种方法恢复了这些方向,并构建了探针,这些探针被描述为揭示了模型的“知识”或“信念”。我们研究这种现象,仔细观察上下文对探针的影响。我们的实验确定了探针预测在LLM中的敏感位置,这些位置最敏感于相关句子的存在,以及最好如何描述这种敏感性。我们通过测量在LLM探测后发生的各种一致性错误来实现这一点,LLM的输入由假设和前面的(否定)支持和矛盾句子组成。我们还进行了因果干预实验,研究沿这些真值方向移动前提的表示是否会影响沿着同一方向的相关句子或矛盾句子的位置。我们发现我们测试的探针通常是上下文敏感的,但那些本不应影响真实性的上下文仍然会影响探针输出。我们的实验表明,错误类型取决于层、模型和数据的种类。最后,我们的结果表明,真值方向是融入上下文信息的推理过程中的因果中介。
论文及项目相关链接
PDF COLM 2025
Summary
大型语言模型(LLM)的潜在空间包含预测句子真实性的方向。本文研究了这一现象,重点关注上下文对探针的影响。实验表明,探针预测对包含相关句子的位置非常敏感,并探讨了如何最好地描述这种敏感性。通过测量不同类型的一致性错误,我们发现探针通常对上下文敏感,但某些不应影响真实性的上下文仍会影响探针输出。实验结果表明,错误类型取决于层、模型和数据的种类。总之,真实值方向是融入上下文信息的推理过程中的因果中介。
Key Takeaways
- 大型语言模型(LLM)的潜在空间存在预测句子真实性的方向。
- 上下文对LLM的探针预测有重要影响。
- 探针预测对包含相关句子的位置非常敏感。
- 上下文敏感性可能导致不同类型的一致性错误。
- 某些不应影响真实性的上下文仍会影响探针输出。
- 错误类型取决于模型层、模型和数据的种类。
点此查看论文截图



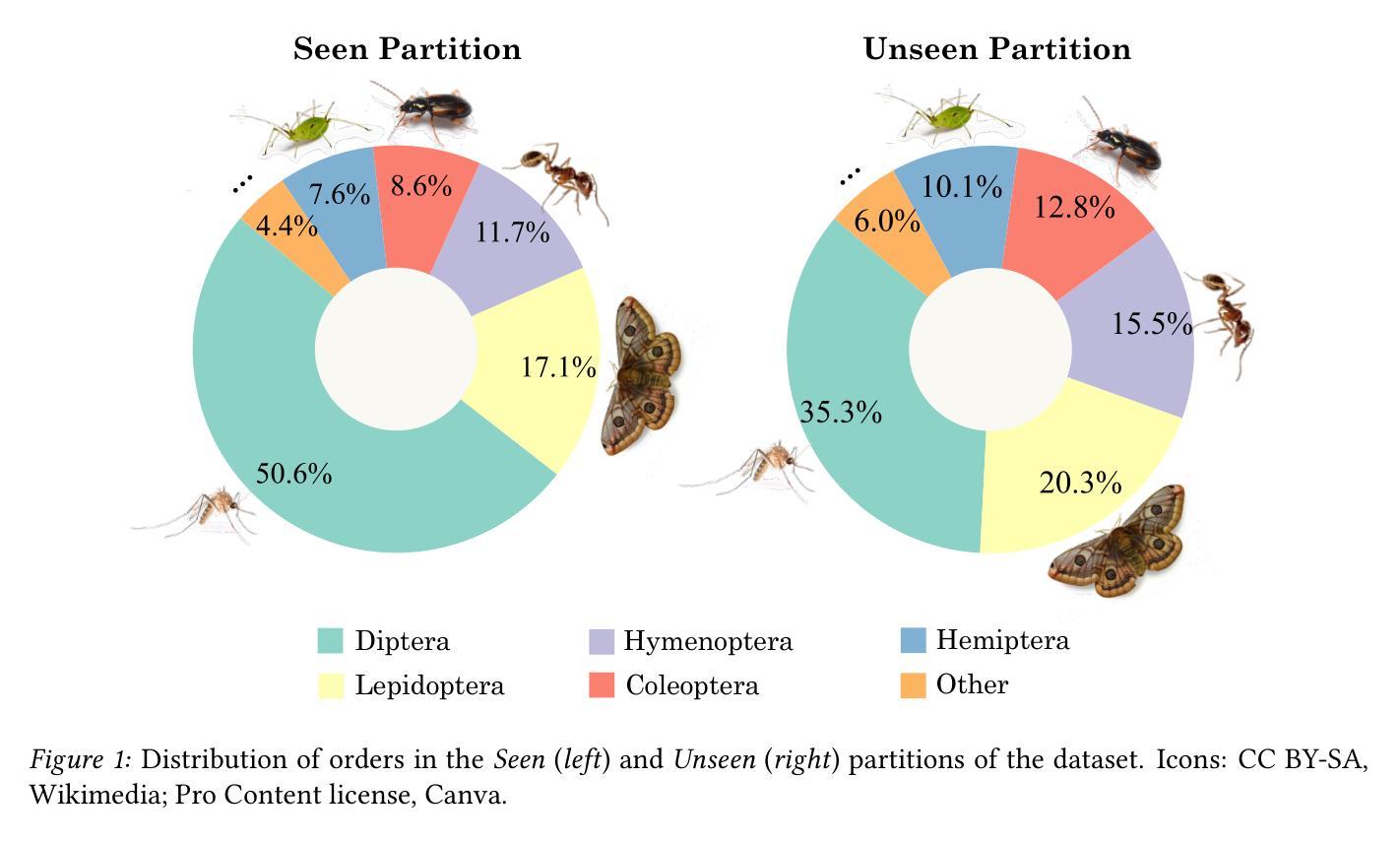
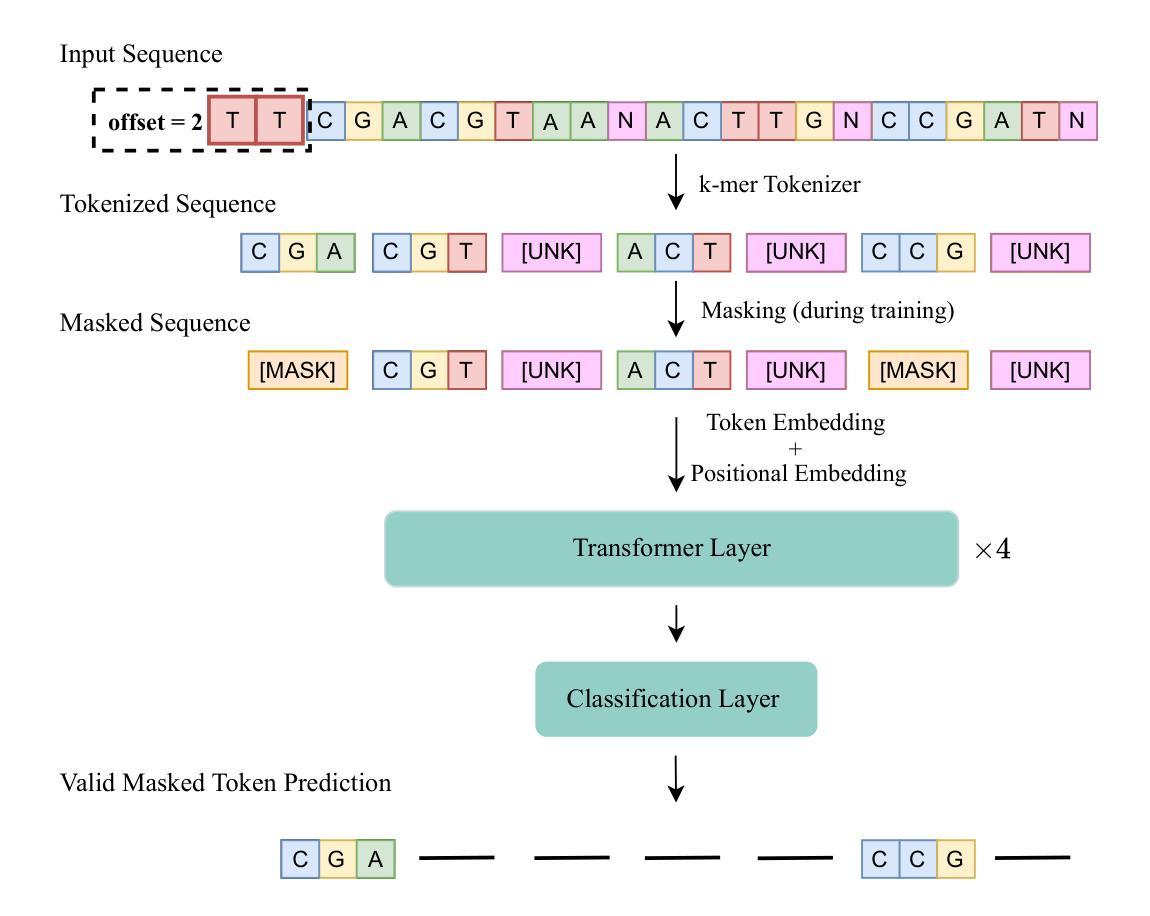
BarcodeBERT: Transformers for Biodiversity Analysis
Authors:Pablo Millan Arias, Niousha Sadjadi, Monireh Safari, ZeMing Gong, Austin T. Wang, Joakim Bruslund Haurum, Iuliia Zarubiieva, Dirk Steinke, Lila Kari, Angel X. Chang, Scott C. Lowe, Graham W. Taylor
In the global challenge of understanding and characterizing biodiversity, short species-specific genomic sequences known as DNA barcodes play a critical role, enabling fine-grained comparisons among organisms within the same kingdom of life. Although machine learning algorithms specifically designed for the analysis of DNA barcodes are becoming more popular, most existing methodologies rely on generic supervised training algorithms. We introduce BarcodeBERT, a family of models tailored to biodiversity analysis and trained exclusively on data from a reference library of 1.5M invertebrate DNA barcodes. We compared the performance of BarcodeBERT on taxonomic identification tasks against a spectrum of machine learning approaches including supervised training of classical neural architectures and fine-tuning of general DNA foundation models. Our self-supervised pretraining strategies on domain-specific data outperform fine-tuned foundation models, especially in identification tasks involving lower taxa such as genera and species. We also compared BarcodeBERT with BLAST, one of the most widely used bioinformatics tools for sequence searching, and found that our method matched BLAST’s performance in species-level classification while being 55 times faster. Our analysis of masking and tokenization strategies also provides practical guidance for building customized DNA language models, emphasizing the importance of aligning model training strategies with dataset characteristics and domain knowledge. The code repository is available at https://github.com/bioscan-ml/BarcodeBERT.
在全球理解和表征生物多样性的挑战中,被称为DNA条形码的特定物种的短基因组序列起到了至关重要的作用,使得在同一生命王国中的生物之间可以进行精细的比较。尽管针对DNA条形码分析而专门设计的机器学习算法越来越受欢迎,但大多数现有方法仍依赖于通用监督训练算法。我们介绍了BarcodeBERT,这是一系列针对生物多样性分析量身定制的模型,仅使用来自包含150万无脊椎动物DNA条形码的参考库的数据进行训练。我们将BarcodeBERT在分类鉴定任务上的性能与一系列机器学习进行了比较,包括经典神经架构的监督训练和通用DNA基础模型的微调。我们在特定域数据上的自监督预训练策略在鉴定任务上,尤其是在涉及较低分类群(如属和种)的鉴定任务上,表现优于经过微调的基础模型。我们还比较了BarcodeBERT与BLAST(一种广泛用于序列搜索的生物信息学工具),发现我们的方法在物种水平的分类中与BLAST的性能相匹配,同时运行速度为BLAST的55倍。我们对掩码和令牌化策略的分析还为构建定制的DNA语言模型提供了实际指导,强调模型训练策略必须与数据集特征和领域知识相一致。代码仓库可在https://github.com/bioscan-ml/BarcodeBERT获取。
论文及项目相关链接
PDF Main text: 14 pages, Total: 23 pages, 10 figures, formerly accepted at the 4th Workshop on Self-Supervised Learning: Theory and Practice (NeurIPS 2023)
Summary:针对全球生物多样性的理解和特征描述挑战,DNA条形码在物种间精细比较中起到关键作用。研究中引入专门用于生物多样性分析的BarcodeBERT模型家族,并在150万无脊椎动物DNA条形码参考库数据上进行训练。对比多种机器学习方法和现有的DNA基础模型预训练方法,发现BarcodeBERT在属和物种级分类任务上具有优越性能,且与广泛使用的BLAST工具在物种级别分类上性能相当但速度更快。同时,该研究还分析了构建定制化DNA语言模型时的掩码和分词策略重要性。
Key Takeaways:
- DNA条形码在生物多样性的精细比较中起到关键作用。
- BarcodeBERT是专门用于生物多样性分析的模型家族。
- BarcodeBERT在属和物种级分类任务上表现优越。
- BarcodeBERT与BLAST在物种级别分类上性能相当但速度更快。
- BarcodeBERT通过自我监督预训练策略在特定领域数据上进行训练。
- 掩码和分词策略对于构建定制化DNA语言模型至关重要。
点此查看论文截图