⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-13 更新
A Theory of Inference Compute Scaling: Reasoning through Directed Stochastic Skill Search
Authors:Austin R. Ellis-Mohr, Anuj K. Nayak, Lav R. Varshney
Large language models (LLMs) demand considerable computational, energy, and financial resources during both training and deployment. While scaling laws for training have guided much of the field’s recent progress, inference costs now represent a significant and growing component of the overall resource burden, particularly for reasoning-focused models. Existing characterizations of compute-optimality that consider model size, dataset size, and inference tokens in isolation or in fixed combinations risk overlooking more efficient operating points. We introduce directed stochastic skill search (DS3), a general framework that represents inference as stochastic traversal over a learned skill graph. From a simplified yet expressive instantiation, we derive closed-form expressions for task success and compute cost across a wide range of inference strategies – including chain-of-thought (CoT) and tree-of-thought (ToT) – enabling comparative analysis as a function of task difficulty and model capability. To that end, we extend a prior first-principles tripartite graph framework of LLM training to incorporate inference, and separately bridge DS3 with empirical methods that characterize LLM scaling behavior. We theoretically recover empirically observed patterns, including: linear accuracy scaling with logarithmic compute; variation in preferred inference strategies as a function of task difficulty and model capability; emergent behavior elicited by reasoning even when performance plateaus under parameter scaling; and both best-of-N (BoN) and majority voting behavior captured within a unified analytical framework. By explicitly characterizing training-inference interdependencies, our framework deepens theoretical understanding and supports principled algorithmic design and resource allocation.
大型语言模型(LLM)在训练和部署过程中需要大量的计算、能源和财务资源。虽然训练的可扩展性定律指导了该领域的最新进展,但推理成本现在已成为总体资源负担的重要组成部分,特别是针对以推理为重点的模型。现有的计算最优性的表征,孤立地或固定组合地考虑模型大小、数据集大小和推理令牌,可能会错过更有效的操作点。我们引入了有向随机技能搜索(DS3),这是一个将推理表示为在学习的技能图上进行随机遍历的一般框架。从一个简化而富有表现力的实例出发,我们推导出了一系列推理策略下任务成功和计算成本的封闭形式表达式,这些策略包括思维链(CoT)和思维树(ToT),从而能够根据任务难度和模型能力进行比较分析。为此,我们将先前的大型语言模型训练的第一原理三元组图框架扩展到推理,并将DS3与刻画大型语言模型扩展行为的实证方法联系起来。我们从理论上恢复了观察到的模式,包括:随着对数计算的线性精度扩展;随着任务难度和模型能力的变化,首选推理策略的变化;即使在参数扩展下性能达到平稳状态,推理也会引发的突发行为;以及在一个统一的分析框架内捕获的最佳N选(BoN)和多数投票行为。通过明确刻画训练-推理的相互依赖性,我们的框架深化了理论理解,并支持了原则性的算法设计和资源分配。
论文及项目相关链接
Summary
大型语言模型(LLMs)在训练和部署过程中需要大量的计算、能源和资金。尽管训练中的扩展定律为该领域最近的进展提供了指导,但推理成本现在已成为整体资源负担中的一个重要且不断增长的组成部分,特别是对于注重推理的模型。我们引入定向随机技能搜索(DS3),这是一个通用框架,它将推理表示为在学到的技能图上的随机遍历。通过简洁而富有表现力的实例化,我们得出了跨各种推理策略的任务成功和计算成本的封闭形式表达式,包括链思维(CoT)和树思维(ToT),从而可以根据任务难度和模型能力进行比较分析。为此,我们扩展了LLM训练的前期三方图框架以纳入推理,并单独地将DS3与描述LLM扩展行为的实证方法联系起来。我们的理论恢复了观察到的模式,包括:随着计算的增加线性精度提高;任务难度和模型能力变化时首选推理策略的变化;即使在参数扩展下性能达到平台期时,推理引发的行为也会出现新兴情况;以及一个统一的分析框架能够捕捉到最佳选择和多数投票行为。通过明确训练推理之间的依赖关系,我们的框架深化了理论理解并支持有原则性的算法设计和资源分配。
Key Takeaways
- 大型语言模型(LLMs)在训练和部署过程中需要巨大的资源,推理成本是其中重要的增长因素。
- 定向随机技能搜索(DS3)框架能够表达模型推理过程中的随机性,比较不同推理策略的效果。
- 任务难度和模型能力会影响首选的推理策略。
- LLM性能达到平台期时,会出现由推理引发的新兴行为。
- 通过统一的DS3框架可以捕捉最佳选择和多数投票行为。
- 训练与推理之间存在明确的依赖关系,这深化了理论理解并有助于算法设计和资源分配。
点此查看论文截图

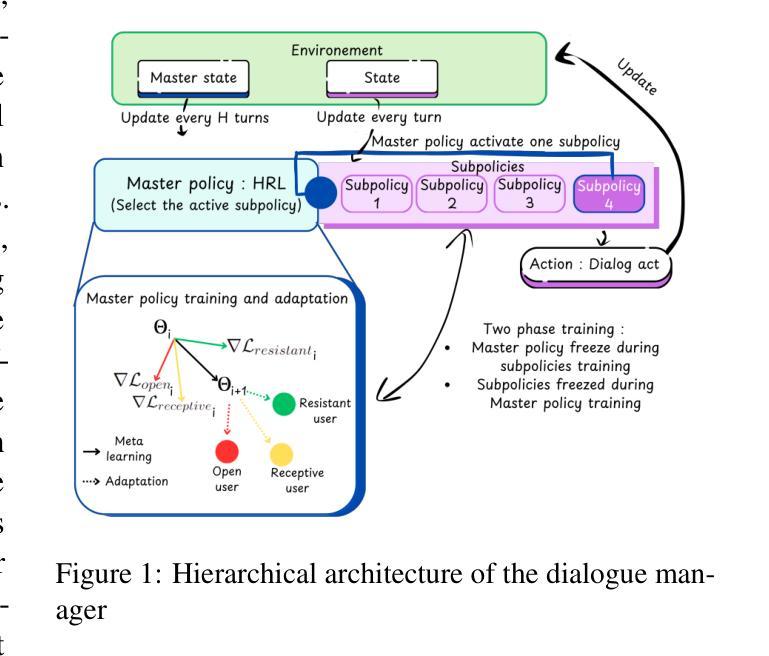
Tailored Conversations beyond LLMs: A RL-Based Dialogue Manager
Authors:Lucie Galland, Catherine Pelachaud, Florian Pecune
In this work, we propose a novel framework that integrates large language models (LLMs) with an RL-based dialogue manager for open-ended dialogue with a specific goal. By leveraging hierarchical reinforcement learning to model the structured phases of dialogue and employ meta-learning to enhance adaptability across diverse user profiles, our approach enhances adaptability and efficiency, enabling the system to learn from limited data, transition fluidly between dialogue phases, and personalize responses to heterogeneous patient needs. We apply our framework to Motivational Interviews, aiming to foster behavior change, and demonstrate that the proposed dialogue manager outperforms a state-of-the-art LLM baseline in terms of reward, showing a potential benefit of conditioning LLMs to create open-ended dialogue systems with specific goals.
在这项工作中,我们提出了一种新型框架,该框架将大型语言模型(LLM)与基于RL的对话管理器相结合,用于实现具有特定目标的开放对话。我们借助分层强化学习来模拟对话的结构化阶段,并应用元学习来提高不同用户之间的适应性。我们的方法提高了适应性和效率,使系统能够在有限的数据中学习,在对话阶段之间平稳过渡,并对不同的患者需求做出个性化的反应。我们将框架应用于动机面试,旨在促进行为改变,并证明所提出的对话管理器在奖励方面优于最新的LLM基线,显示出将LLM用于创建具有特定目标的开放对话系统的潜在优势。
论文及项目相关链接
Summary:
本文提出了一种新型框架,它将大型语言模型(LLMs)与基于强化学习(RL)的对话管理器相结合,用于实现具有特定目标的开放对话。通过利用分层强化学习对对话的结构阶段进行建模,并应用元学习来提高对不同用户配置的适应性,该方法增强了系统的适应性和效率,使系统能够从有限的数据中学习,在对话阶段之间流畅过渡,并对不同患者的需求做出个性化响应。本文将框架应用于动机面试,旨在促进行为改变,并证明所提出的对话管理器在奖励方面优于最先进的大型语言模型基线,显示出将大型语言模型应用于创建具有特定目标的开放对话系统的潜在优势。
Key Takeaways:
- 提出了一种结合大型语言模型和强化学习对话管理器的新型框架,用于实现具有特定目标的开放对话。
- 利用分层强化学习对对话的结构阶段进行建模。
- 应用元学习提高对不同用户配置的适应性。
- 系统能够从有限的数据中学习,并在对话阶段之间流畅过渡。
- 能够个性化响应不同患者的需求。
- 将框架应用于动机面试,旨在促进行为改变。
- 提出的对话管理器在奖励方面优于最先进的大型语言模型基线。
点此查看论文截图


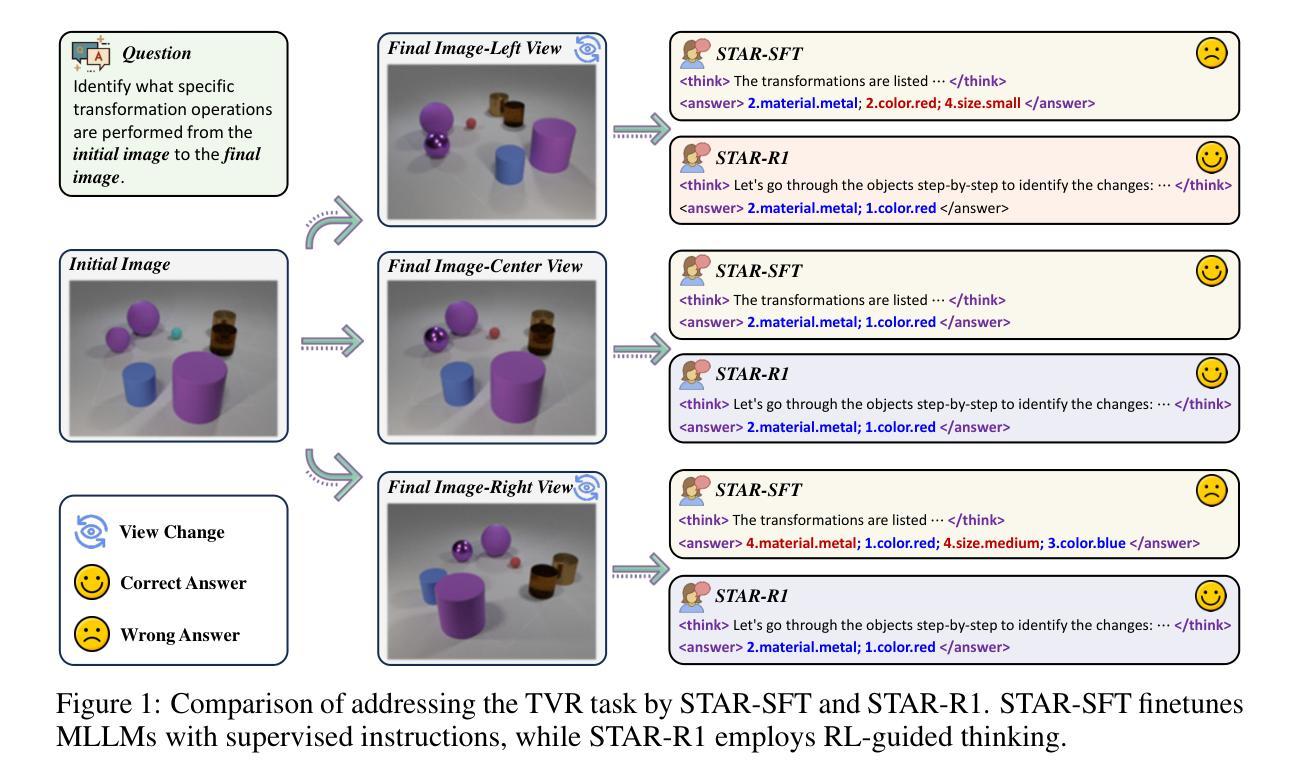
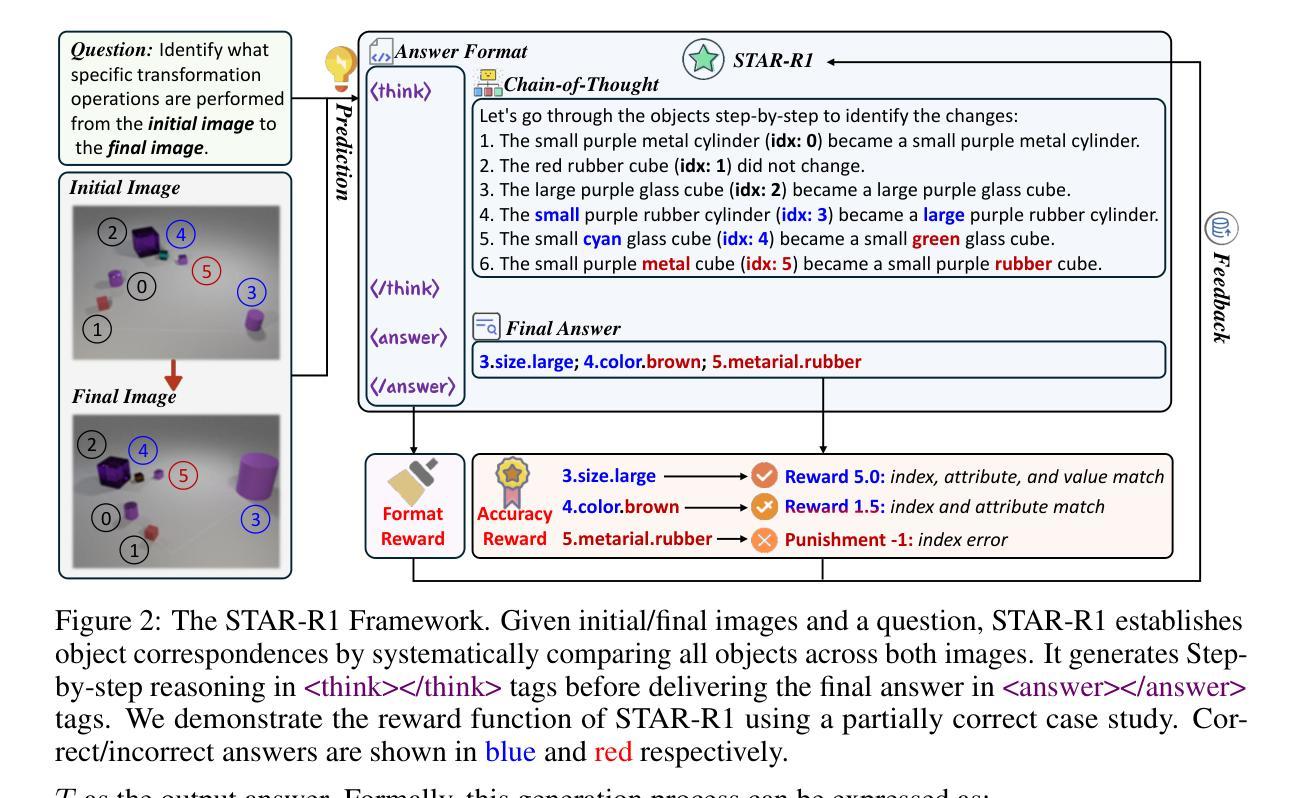
STAR-R1: Spatial TrAnsformation Reasoning by Reinforcing Multimodal LLMs
Authors:Zongzhao Li, Zongyang Ma, Mingze Li, Songyou Li, Yu Rong, Tingyang Xu, Ziqi Zhang, Deli Zhao, Wenbing Huang
Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities across diverse tasks, yet they lag significantly behind humans in spatial reasoning. We investigate this gap through Transformation-Driven Visual Reasoning (TVR), a challenging task requiring identification of object transformations across images under varying viewpoints. While traditional Supervised Fine-Tuning (SFT) fails to generate coherent reasoning paths in cross-view settings, sparse-reward Reinforcement Learning (RL) suffers from inefficient exploration and slow convergence. To address these limitations, we propose STAR-R1, a novel framework that integrates a single-stage RL paradigm with a fine-grained reward mechanism tailored for TVR. Specifically, STAR-R1 rewards partial correctness while penalizing excessive enumeration and passive inaction, enabling efficient exploration and precise reasoning. Comprehensive evaluations demonstrate that STAR-R1 achieves state-of-the-art performance across all 11 metrics, outperforming SFT by 23% in cross-view scenarios. Further analysis reveals STAR-R1’s anthropomorphic behavior and highlights its unique ability to compare all objects for improving spatial reasoning. Our work provides critical insights in advancing the research of MLLMs and reasoning models. The codes, model weights, and data will be publicly available at https://github.com/zongzhao23/STAR-R1.
多模态大型语言模型(MLLMs)在不同任务中展现了显著的能力,但在空间推理方面却远远落后于人类。我们通过转换驱动视觉推理(TVR)来研究这一差距,这是一项具有挑战性的任务,要求在不同视角的图像中识别对象转换。传统的监督微调(SFT)在跨视图设置中无法生成连贯的推理路径,而基于稀疏奖励的强化学习(RL)则面临探索效率低下和收敛速度慢的问题。为了解决这些局限性,我们提出了STAR-R1,这是一个结合了单阶段RL范式和针对TVR定制的精细奖励机制的全新框架。具体来说,STAR-R1奖励部分正确性,同时惩罚过度枚举和被动无作为,从而实现高效探索和精确推理。综合评估表明,STAR-R1在所有11项指标上均达到最新性能水平,在跨视图场景中较SFT高出23%。进一步的分析揭示了STAR-R1的人类行为特征,并突出了其在提高空间推理能力方面的独特能力——比较所有对象。我们的工作为多模态大型语言模型和推理模型的研究提供了关键见解。代码、模型权重和数据将在https://github.com/zongzhao23/STAR-R1上公开可用。
论文及项目相关链接
Summary
本文探讨了多模态大型语言模型在跨视角图像中的空间推理能力差距。通过提出一种名为STAR-R1的新型框架,结合单阶段强化学习与针对转换驱动视觉推理的精细奖励机制,实现了在跨视角场景中的高效探索和精确推理。评价显示,STAR-R1在所有11项指标上均达到最新水平,在跨视角场景中较传统监督微调技术提高了23%。这为推进多模态语言模型和推理模型的研究提供了重要见解。
Key Takeaways
- 多模态大型语言模型在空间推理方面与人类存在显著差距。
- 提出了一种名为STAR-R1的新型框架,结合了单阶段强化学习与精细奖励机制,以改善跨视角场景中的推理能力。
- STAR-R1通过奖励部分正确性和惩罚过度枚举与被动行为,实现了高效探索和精确推理。
- 综合评估显示,STAR-R1在所有11项指标上均达到最新水平,且在跨视角场景中较传统监督微调技术提高了23%。
- STAR-R1表现出类人行为,并具备改进空间推理的独特能力,能比较所有对象。
- 公开可用代码、模型权重和数据将推动进一步的研究和发展。
点此查看论文截图

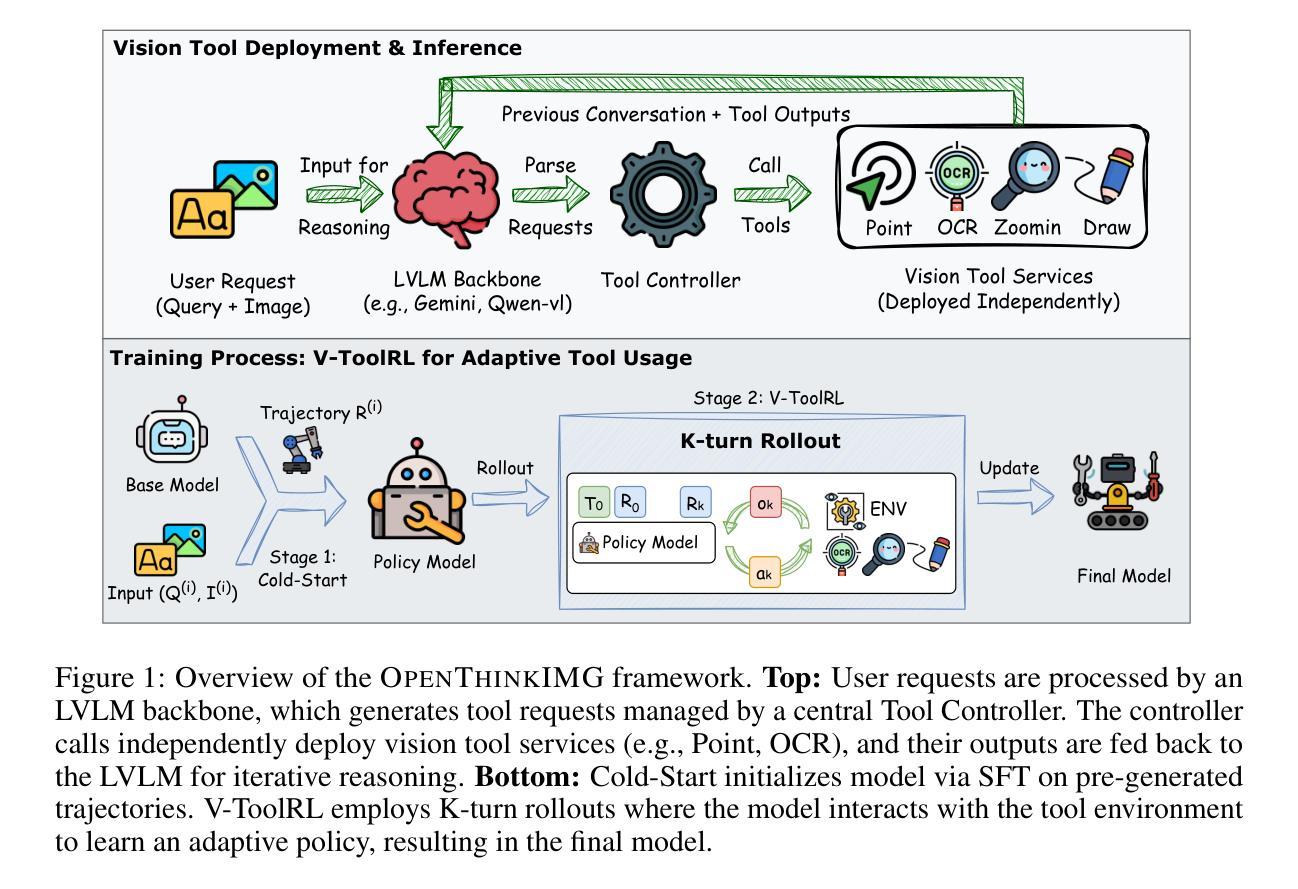
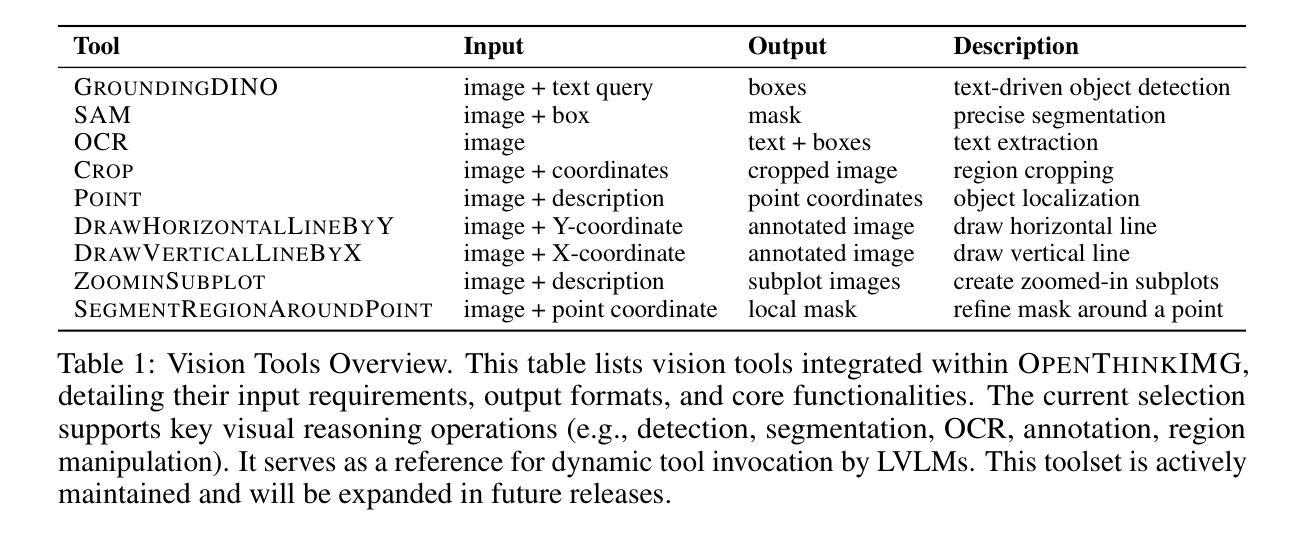
OpenThinkIMG: Learning to Think with Images via Visual Tool Reinforcement Learning
Authors:Zhaochen Su, Linjie Li, Mingyang Song, Yunzhuo Hao, Zhengyuan Yang, Jun Zhang, Guanjie Chen, Jiawei Gu, Juntao Li, Xiaoye Qu, Yu Cheng
While humans can flexibly leverage interactive visual cognition for complex problem-solving, enabling Large Vision-Language Models (LVLMs) to learn similarly adaptive behaviors with visual tools remains challenging. A significant hurdle is the current lack of standardized infrastructure, which hinders integrating diverse tools, generating rich interaction data, and training robust agents effectively. To address these gaps, we introduce OpenThinkIMG, the first open-source, comprehensive end-to-end framework for tool-augmented LVLMs. It features standardized vision tool interfaces, scalable trajectory generation for policy initialization, and a flexible training environment. Furthermore, considering supervised fine-tuning (SFT) on static demonstrations offers limited policy generalization for dynamic tool invocation, we propose a novel reinforcement learning (RL) framework V-ToolRL to train LVLMs to learn adaptive policies for invoking external vision tools. V-ToolRL enables LVLMs to autonomously discover optimal tool-usage strategies by directly optimizing for task success using feedback from tool interactions. We empirically validate V-ToolRL on challenging chart reasoning tasks. Our RL-trained agent, built upon a Qwen2-VL-2B, significantly outperforms its SFT-initialized counterpart (+28.83 points) and surpasses established supervised tool-learning baselines like Taco and CogCom by an average of +12.7 points. Notably, it also surpasses prominent closed-source models like GPT-4.1 by +8.68 accuracy points. We hope OpenThinkIMG can serve as a foundational framework for advancing dynamic, tool-augmented visual reasoning, helping the community develop AI agents that can genuinely “think with images”.
虽然人类可以灵活地利用交互视觉认知来解决复杂问题,但如何让大型视觉语言模型(LVLMs)学会类似自适应行为并使用视觉工具仍然具有挑战性。一个主要的障碍是目前缺乏标准化基础设施,这阻碍了整合各种工具、生成丰富的交互数据以及有效地训练稳健的代理。为了解决这些差距,我们推出了OpenThinkIMG,这是第一个开源的、全面的端到端框架,用于工具增强的大型视觉语言模型。它具备标准化视觉工具接口、可扩展的轨迹生成用于策略初始化以及灵活的训练环境。此外,考虑到对静态演示的监督微调(SFT)对于动态工具调用的策略泛化能力有限,我们提出了一种新的强化学习(RL)框架V-ToolRL,用于训练LVLMs学习自适应策略,以调用外部视觉工具。V-ToolRL使LVLMs能够通过直接优化任务成功度并利用工具交互的反馈来自主发现最佳的工具使用策略。我们在具有挑战性的图表推理任务上实证验证了V-ToolRL的有效性。我们的RL训练代理,基于Qwen2-VL-2B,显著优于其SFT初始化的对应物(+28.83点),并超越了如Taco和CogCom等既定的监督工具学习基准线,平均提高+12.7点。值得注意的是,它还超越了如GPT-4.1等知名的闭源模型,提高了+8.68的准确率。我们希望OpenThinkIMG可以作为推进动态、工具增强的视觉推理的基础框架,帮助社区开发能够真正“以图像思考”的AI代理。
论文及项目相关链接
PDF Work in progress
Summary
本文介绍了OpenThinkIMG框架,它是首个针对大型视觉语言模型(LVLMs)的工具增强型端到端框架。该框架解决了缺乏标准化基础设施的问题,并引入了V-ToolRL强化学习框架,使LVLMs能够学习自适应地调用外部视觉工具的策略。在图表推理任务上的实验表明,基于Qwen2-VL-2B的RL训练代理显著优于监督微调初始化的代理,并超越了其他工具学习方法的基线。
Key Takeaways
- 大型视觉语言模型(LVLMs)在利用视觉工具进行自适应行为学习方面存在挑战。
- 当前缺乏标准化基础设施是整合多样工具、生成丰富交互数据和有效训练智能代理的主要障碍。
- OpenThinkIMG框架是一个开放源代码、全面的端到端框架,用于工具增强的LVLMs,具有标准化视觉工具接口、可扩展轨迹生成和灵活的训练环境。
- 监督微调(SFT)在动态工具调用方面的策略泛化能力有限,因此提出了V-ToolRL强化学习框架。
- V-ToolRL使LVLMs能够自主发现最优的工具使用策略,通过直接优化任务成功反馈来进行工具交互。
- 在挑战性图表推理任务上的实验表明,RL训练的代理显著优于监督微调初始化的代理和其他基线方法,包括Taco和CogCom。
点此查看论文截图