⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-15 更新
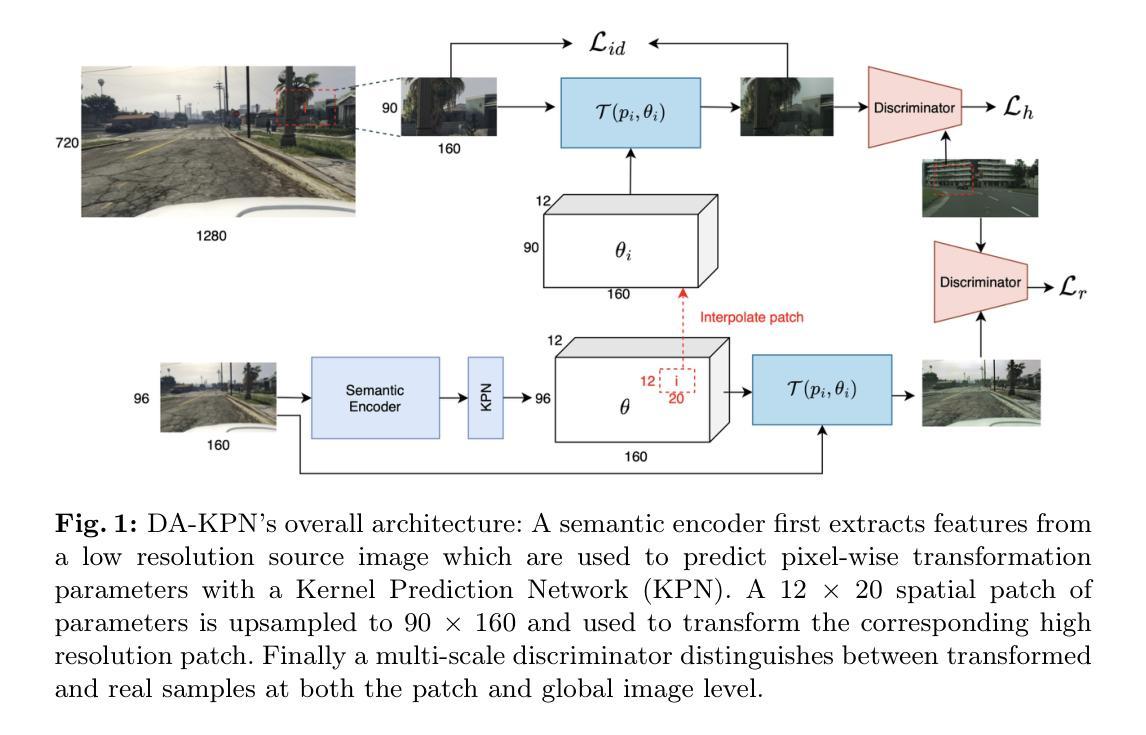
Image Translation with Kernel Prediction Networks for Semantic Segmentation
Authors:Cristina Mata, Michael S. Ryoo, Henrik Turbell
Semantic segmentation relies on many dense pixel-wise annotations to achieve the best performance, but owing to the difficulty of obtaining accurate annotations for real world data, practitioners train on large-scale synthetic datasets. Unpaired image translation is one method used to address the ensuing domain gap by generating more realistic training data in low-data regimes. Current methods for unpaired image translation train generative adversarial networks (GANs) to perform the translation and enforce pixel-level semantic matching through cycle consistency. These methods do not guarantee that the semantic matching holds, posing a problem for semantic segmentation where performance is sensitive to noisy pixel labels. We propose a novel image translation method, Domain Adversarial Kernel Prediction Network (DA-KPN), that guarantees semantic matching between the synthetic label and translation. DA-KPN estimates pixel-wise input transformation parameters of a lightweight and simple translation function. To ensure the pixel-wise transformation is realistic, DA-KPN uses multi-scale discriminators to distinguish between translated and target samples. We show DA-KPN outperforms previous GAN-based methods on syn2real benchmarks for semantic segmentation with limited access to real image labels and achieves comparable performance on face parsing.
语义分割依赖于大量的密集像素级标注来实现最佳性能,但由于现实世界数据获取准确标注的困难,实践者会在大规模合成数据集上进行训练。无配对图像翻译是一种在低数据情况下生成更现实的训练数据,从而解决由此产生的领域差异的方法。当前的无配对图像翻译方法训练生成对抗网络(GANs)执行翻译,并通过循环一致性强制像素级别的语义匹配。这些方法不能保证语义匹配,对于对噪声像素标签敏感的语义分割构成问题。我们提出了一种新的图像翻译方法——域对抗内核预测网络(DA-KPN),它保证了合成标签和翻译之间的语义匹配。DA-KPN估计轻量级简单翻译函数的像素级输入变换参数。为了确保像素级变换是现实的,DA-KPN使用多尺度鉴别器来区分翻译样本和目标样本。我们在有限的真实图像标签访问权限的语义分割syn2real基准测试上展示了DA-KPN优于之前的基于GAN的方法,并在面部解析上实现了相当的性能。
论文及项目相关链接
PDF OOD-CV Workshop at ECCV 2024
Summary
本文介绍了语义分割对密集像素级标注的依赖以及现实数据准确标注的困难。为解决低数据环境下的领域差距问题,研究人员采用无配对图像翻译方法生成更真实的训练数据。本文提出了一种新的图像翻译方法——领域对抗核预测网络(DA-KPN),它能保证合成标签和翻译之间的语义匹配。DA-KPN估计轻量级简单翻译函数的像素级输入变换参数,并使用多尺度鉴别器确保像素级变换的真实性。在有限的真实图像标签访问下,DA-KPN在语义分割的syn2real基准测试中优于之前的GAN方法,并在面部解析上实现了相当的性能。
Key Takeaways
- 语义分割依赖密集像素级标注,但现实数据准确标注困难。
- 无配对图像翻译是解决低数据环境下领域差距的方法之一。
- 当前的无配对图像翻译方法使用生成对抗网络(GANs)进行翻译,并通过循环一致性强制像素级语义匹配。
- 语义分割对噪声像素标签敏感,现有方法不能保证语义匹配。
- 提出的DA-KPN方法能保证合成标签和翻译之间的语义匹配。
- DA-KPN估计像素级输入变换参数,使用轻量级简单翻译函数。
点此查看论文截图


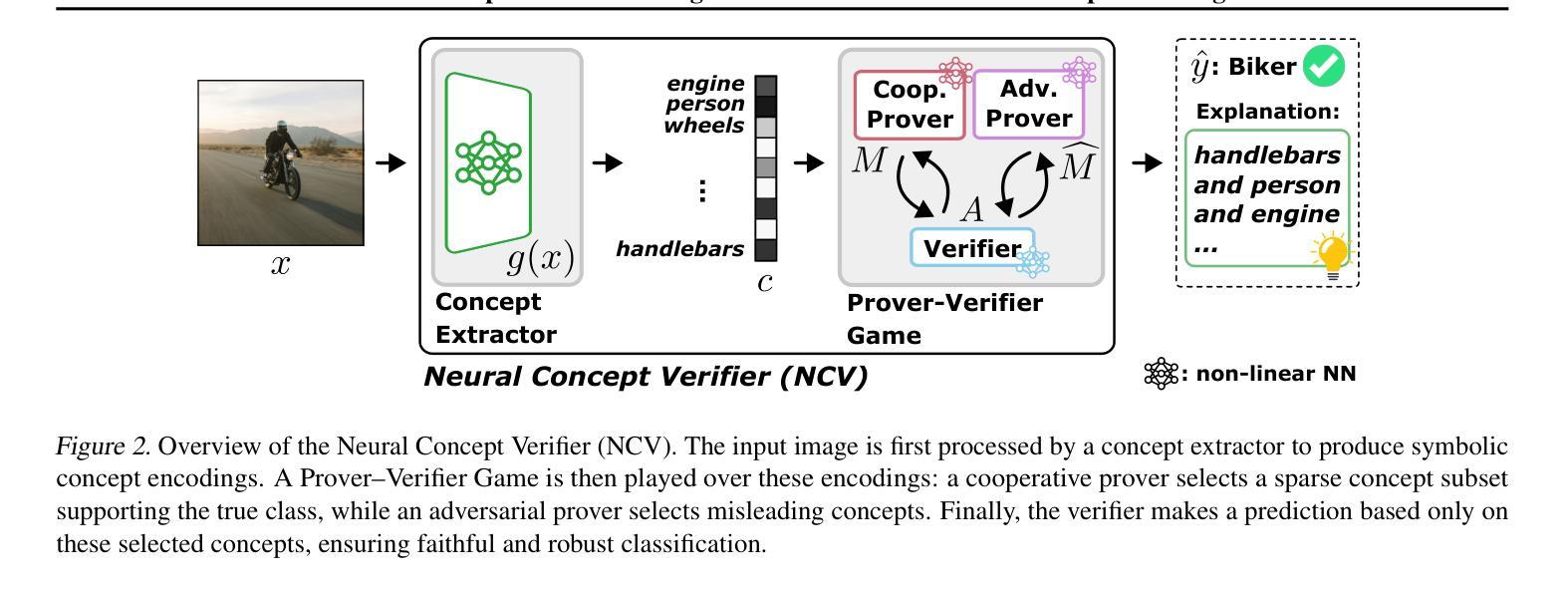
Neural Concept Verifier: Scaling Prover-Verifier Games via Concept Encodings
Authors:Berkant Turan, Suhrab Asadulla, David Steinmann, Wolfgang Stammer, Sebastian Pokutta
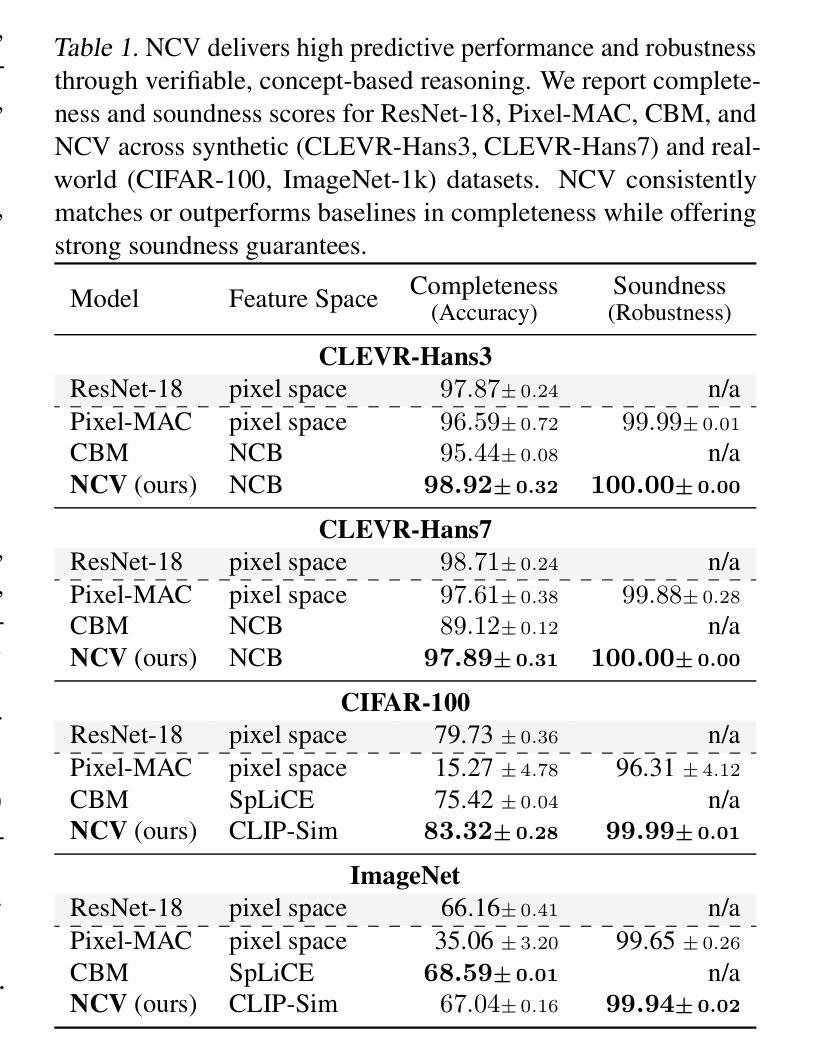
While Prover-Verifier Games (PVGs) offer a promising path toward verifiability in nonlinear classification models, they have not yet been applied to complex inputs such as high-dimensional images. Conversely, Concept Bottleneck Models (CBMs) effectively translate such data into interpretable concepts but are limited by their reliance on low-capacity linear predictors. In this work, we introduce the Neural Concept Verifier (NCV), a unified framework combining PVGs with concept encodings for interpretable, nonlinear classification in high-dimensional settings. NCV achieves this by utilizing recent minimally supervised concept discovery models to extract structured concept encodings from raw inputs. A prover then selects a subset of these encodings, which a verifier – implemented as a nonlinear predictor – uses exclusively for decision-making. Our evaluations show that NCV outperforms CBM and pixel-based PVG classifier baselines on high-dimensional, logically complex datasets and also helps mitigate shortcut behavior. Overall, we demonstrate NCV as a promising step toward performative, verifiable AI.
证明者验证者游戏(PVGs)为非线分类模型的可验证性提供了前景光明的路径,但它们尚未应用于复杂输入,如高维图像。相反,概念瓶颈模型(CBMs)能够有效地将此类数据转换为可解释的概念,但其受限于对低容量线性预测器的依赖。在这项工作中,我们引入了神经概念验证器(NCV),这是一个结合了PVGs和概念编码的统一框架,用于在高维设置中进行可解释的非线性分类。NCV通过利用最新的最小监督概念发现模型从原始输入中提取结构化概念编码来实现这一点。然后证明者从这些编码中选择一个子集,验证者使用这些子集作为非线性预测器进行决策。我们的评估表明,在高维、逻辑复杂的数据集上,NCV的性能优于CBM和基于像素的PVG分类器基线,并有助于缓解捷径行为。总的来说,我们证明了NCV是朝着高性能、可验证的人工智能迈出的有前途的一步。
论文及项目相关链接
PDF 16 pages, 4 figures, 8 tables, revised references
Summary
神经网络概念验证器(NCV)结合了证明者验证游戏(PVGs)和概念编码,在高维设置中实现可解释的、非线性分类。它通过利用最新最少的监督概念发现模型从原始输入中提取结构化概念编码,然后证明者选择一部分编码,验证器使用这些编码进行决策。在逻辑复杂的数据集上,NCV在高维数据上表现出优于CBM和像素级PVG分类器的性能,并有助于缓解捷径行为。总体而言,NCV是实现高性能、可验证人工智能的有前途的一步。
Key Takeaways
- 神经网络概念验证器(NCV)结合了证明者-验证者游戏(PVGs)和概念瓶颈模型(CBMs)的优势。
- NCV利用最少监督的概念发现模型从原始输入中提取结构化概念编码。
- 证明者选择概念编码的子集,验证器使用这些编码进行决策。
- NCV在高维、逻辑复杂的数据集上表现出优异的性能,优于传统的CBM和像素级PVG分类器。
- NCV有助于缓解机器学习模型中的“捷径行为”。
- NCV提供了一种可解释的、非线性分类的方法,增强了模型的可解释性和透明度。
点此查看论文截图

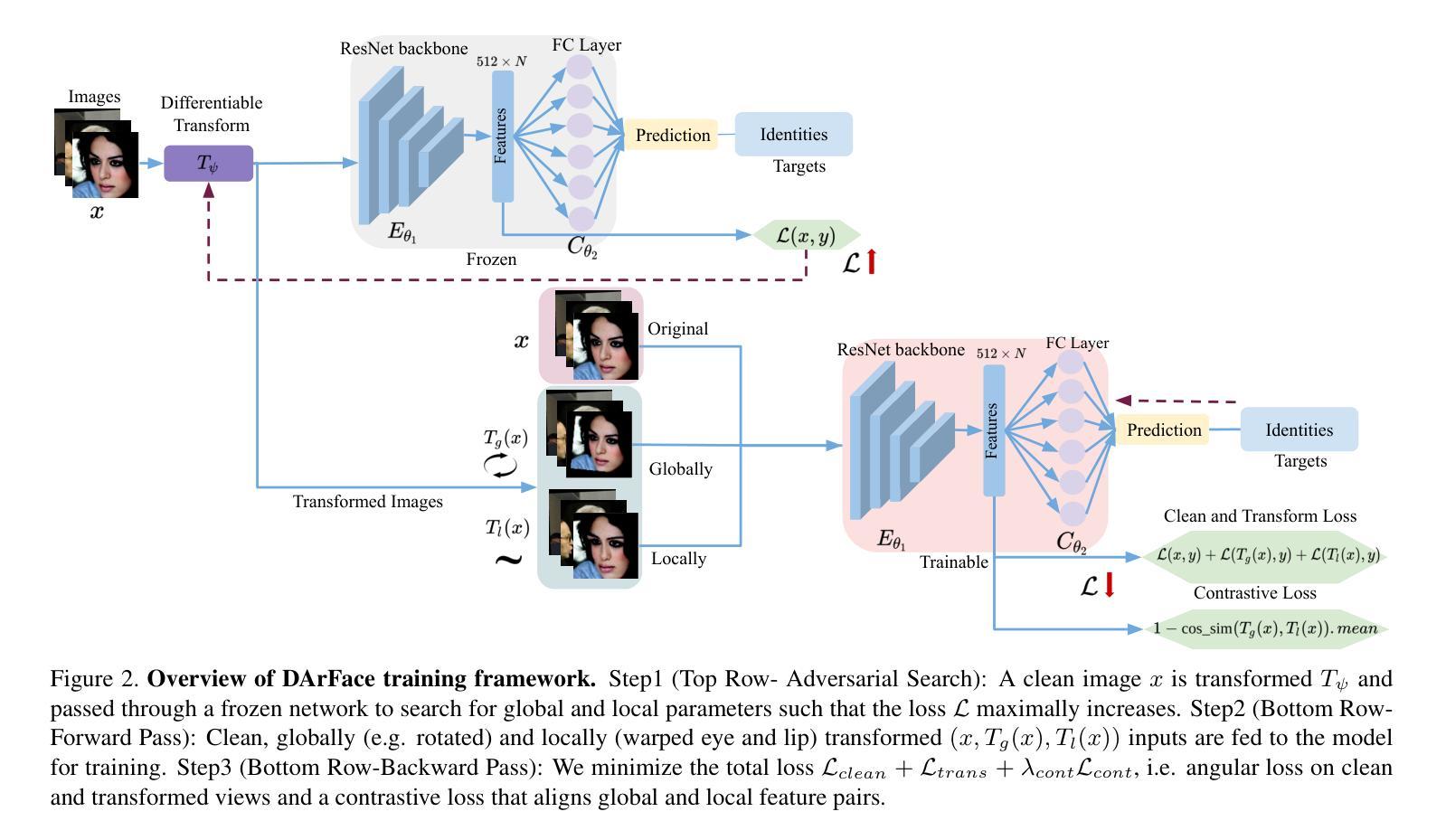
DArFace: Deformation Aware Robustness for Low Quality Face Recognition
Authors:Sadaf Gulshad, Abdullah Aldahlawi Thakaa
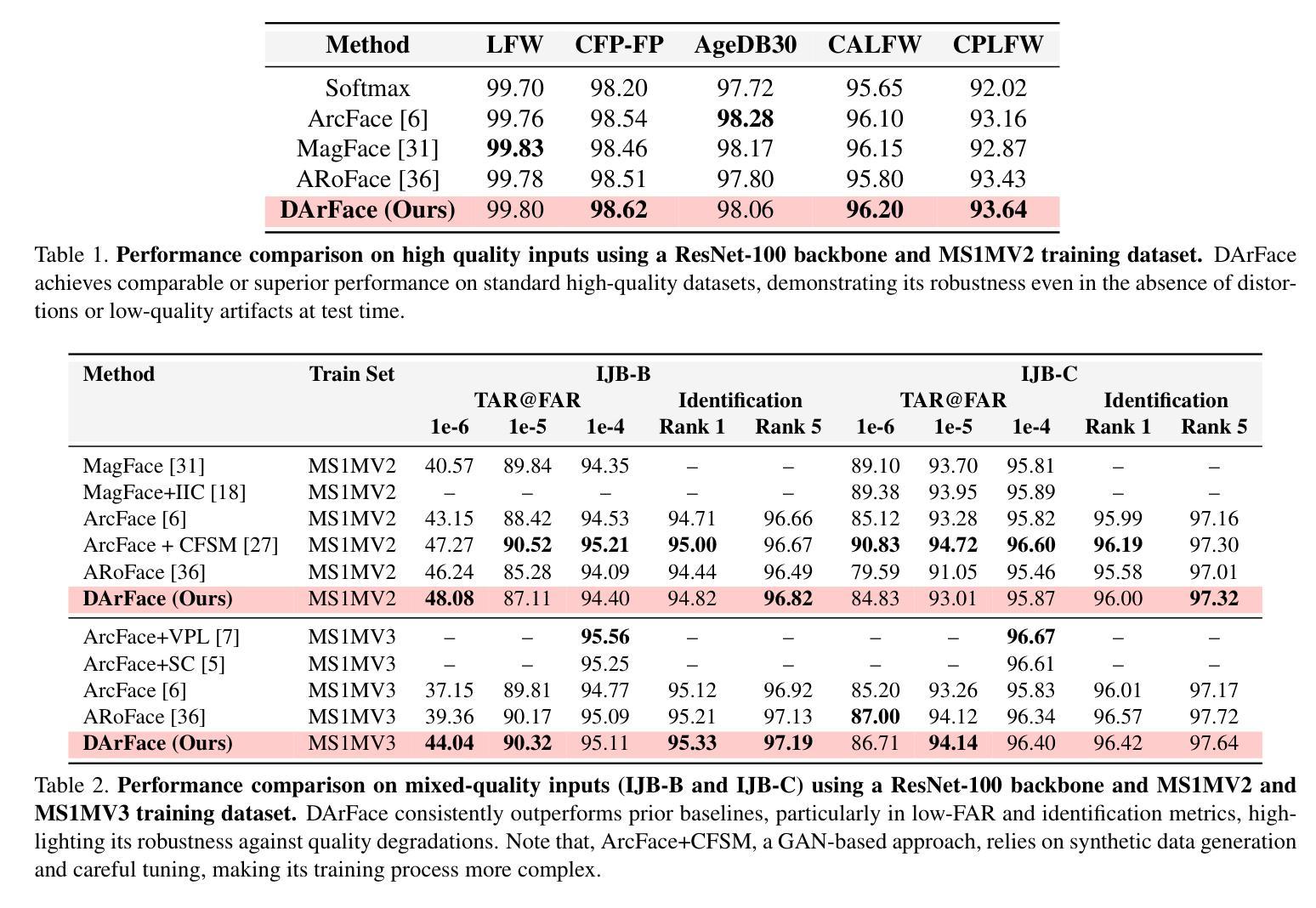
Facial recognition systems have achieved remarkable success by leveraging deep neural networks, advanced loss functions, and large-scale datasets. However, their performance often deteriorates in real-world scenarios involving low-quality facial images. Such degradations, common in surveillance footage or standoff imaging include low resolution, motion blur, and various distortions, resulting in a substantial domain gap from the high-quality data typically used during training. While existing approaches attempt to address robustness by modifying network architectures or modeling global spatial transformations, they frequently overlook local, non-rigid deformations that are inherently present in real-world settings. In this work, we introduce \textbf{DArFace}, a \textbf{D}eformation-\textbf{A}ware \textbf{r}obust \textbf{Face} recognition framework that enhances robustness to such degradations without requiring paired high- and low-quality training samples. Our method adversarially integrates both global transformations (e.g., rotation, translation) and local elastic deformations during training to simulate realistic low-quality conditions. Moreover, we introduce a contrastive objective to enforce identity consistency across different deformed views. Extensive evaluations on low-quality benchmarks including TinyFace, IJB-B, and IJB-C demonstrate that DArFace surpasses state-of-the-art methods, with significant gains attributed to the inclusion of local deformation modeling.
利用深度神经网络、先进的损失函数和大规模数据集,人脸识别系统已经取得了显著的成就。然而,它们在涉及低质量人脸图像的现实世界场景中性能往往会下降。这种退化在监控录像或远距离成像中很常见,包括低分辨率、运动模糊和各种失真,与训练期间通常使用的高质量数据之间存在很大的领域差距。虽然现有方法通过修改网络架构或建模全局空间变换来尝试解决稳健性问题,但它们经常忽略真实环境中固有的局部非刚性变形。在这项工作中,我们介绍了DArFace,这是一个变型感知稳健人脸识别框架,它提高了对这种退化的稳健性,而无需配对的高质量低质量训练样本。我们的方法通过在训练过程中对抗性地集成全局变换(例如旋转、平移)和局部弹性变形,来模拟现实的低质量条件。此外,我们引入了一个对比目标,以强制不同变形视图之间的身份一致性。在包括TinyFace、IJB-B和IJB-C的低质量基准测试上的广泛评估表明,DArFace超越了最先进的方法,其显著增益归功于局部变形建模的引入。
论文及项目相关链接
Summary
本文介绍了一种基于深度神经网络、先进的损失函数的大型数据集的人脸识别系统。但在实际应用中,特别是在监控录像或远距离成像等场景中,面对低质量的人脸图像,其性能往往下降。为了提升对这类降质的鲁棒性,本文提出了一种名为DArFace的框架,通过模拟真实低质量条件进行训练,并引入对比目标来强化身份一致性。实验证明,DArFace在多种低质量基准测试中表现超越现有方法。
Key Takeaways
- 人脸识别系统在实际应用中面临低质量图像挑战,如低分辨率、运动模糊和各种失真。
- 现有方法主要通过修改网络架构或建模全局空间转换来提升鲁棒性,但忽略了真实场景中的局部非刚性变形。
- DArFace框架旨在增强对这类降质的鲁棒性,无需配对高低质量训练样本。
- DArFace通过模拟真实低质量条件进行训练,整合全局转换和局部弹性变形,并引入对比目标来强化身份一致性。
- 在多个低质量基准测试上,DArFace表现超越现有方法。
- 显著的提升得益于局部变形建模的引入。
点此查看论文截图

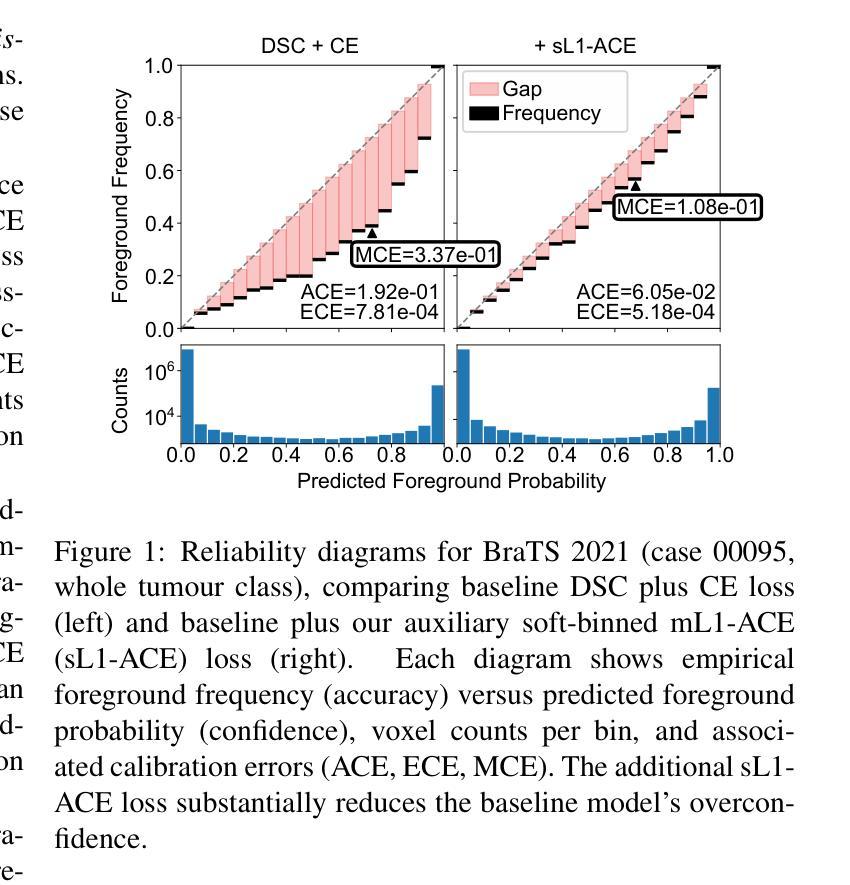
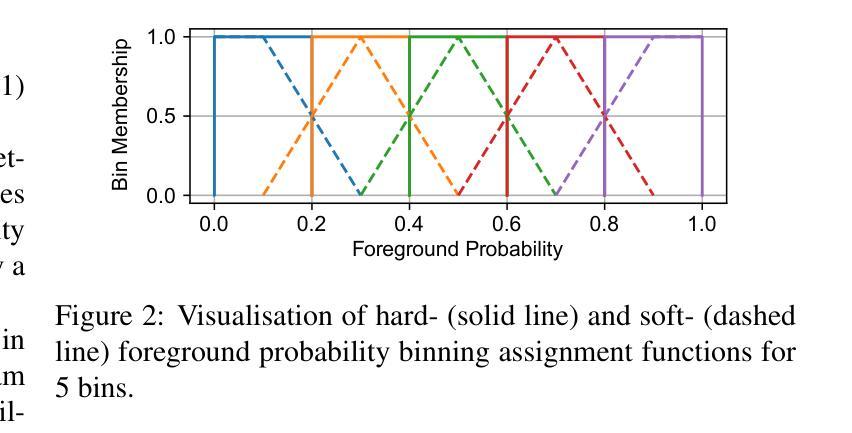
Average Calibration Error: A Differentiable Loss for Improved Reliability in Image Segmentation
Authors:Theodore Barfoot, Luis Garcia-Peraza-Herrera, Ben Glocker, Tom Vercauteren
Deep neural networks for medical image segmentation often produce overconfident results misaligned with empirical observations. Such miscalibration, challenges their clinical translation. We propose to use marginal L1 average calibration error (mL1-ACE) as a novel auxiliary loss function to improve pixel-wise calibration without compromising segmentation quality. We show that this loss, despite using hard binning, is directly differentiable, bypassing the need for approximate but differentiable surrogate or soft binning approaches. Our work also introduces the concept of dataset reliability histograms which generalises standard reliability diagrams for refined visual assessment of calibration in semantic segmentation aggregated at the dataset level. Using mL1-ACE, we reduce average and maximum calibration error by 45% and 55% respectively, maintaining a Dice score of 87% on the BraTS 2021 dataset. We share our code here: https://github.com/cai4cai/ACE-DLIRIS
针对医学图像分割的深度神经网络常常产生过于自信的结果,与实际观测结果不符。这种误校准对其临床翻译应用带来了挑战。我们建议使用边际L1平均校准误差(mL1-ACE)作为一种新型辅助损失函数,以提高像素级别的校准,同时不损害分割质量。我们证明,尽管使用了硬分箱,但该损失是可直接微分的,从而避免了需要使用近似但可微分的替代或软分箱方法。我们的工作还引入了数据集可靠性直方图的概念,它推广了标准可靠性图,用于在数据集层面进行校准的语义分割的精细化视觉评估。通过使用mL1-ACE,我们在BraTS 2021数据集上将平均和最大校准误差分别降低了45%和55%,同时保持Dice得分为87%。我们在此分享我们的代码:https://github.com/cai4cai/ACE-DLIRIS。
论文及项目相关链接
PDF accidental replacement intended for arXiv:2506.03942
Summary
神经网络在医学图像分割中常常出现过度自信的结果,与现实观察不符。本文提出使用边际L1平均校准误差(mL1-ACE)作为新的辅助损失函数,以提高像素级别的校准度而不影响分割质量。此方法虽然采用硬分箱,但可直接微分,无需使用近似但可微分的替代或软分箱方法。此外,本文还引入了数据集可靠性直方图的概念,用于更精细地可视化评估数据集级别的语义分割校准情况。使用mL1-ACE,我们在BraTS 2021数据集上将平均和最大校准误差分别降低了45%和55%,同时维持Dice分数为87%。
Key Takeaways
- 神经网络在医学图像分割中常出现过度自信的问题。
- 提出使用边际L1平均校准误差(mL1-ACE)作为新的辅助损失函数,提高像素级别校准。
- mL1-ACE可直接微分,无需使用近似替代方法。
- 引入数据集可靠性直方图,用于可视化评估数据集的语义分割校准情况。
- 使用mL1-ACE在BraTS 2021数据集上降低了校准误差,同时维持了较高的Dice分数。
点此查看论文截图