⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-15 更新
A Third Paradigm for LLM Evaluation: Dialogue Game-Based Evaluation using clembench
Authors:David Schlangen, Sherzod Hakimov, Jonathan Jordan, Philipp Sadler
There are currently two main paradigms for evaluating large language models (LLMs), reference-based evaluation and preference-based evaluation. The first, carried over from the evaluation of machine learning models in general, relies on pre-defined task instances, for which reference task executions are available. The second, best exemplified by the LM-arena, relies on (often self-selected) users bringing their own intents to a site that routes these to several models in parallel, among whose responses the user then selects their most preferred one. The former paradigm hence excels at control over what is tested, while the latter comes with higher ecological validity, testing actual use cases interactively. Recently, a third complementary paradigm has emerged that combines some of the strengths of these approaches, offering control over multi-turn, reference-free, repeatable interactions, while stressing goal-directedness: dialogue game based evaluation. While the utility of this approach has been shown by several projects, its adoption has been held back by the lack of a mature, easily re-usable implementation. In this paper, we present clembench, which has been in continuous development since 2023 and has in its latest release been optimized for ease of general use. We describe how it can be used to benchmark one’s own models (using a provided set of benchmark game instances in English), as well as how easily the benchmark itself can be extended with new, tailor-made targeted tests.
目前评估大型语言模型(LLM)主要有两种范式:基于参考的评估和基于偏好的评估。第一种范式沿袭了机器学习模型的一般评估方法,它依赖于预定义的任务实例,这些任务实例有相应的参考任务执行。第二种范式以LM-arena为例,依赖于(通常是自我选择的)用户将他们的意图带到网站上,该网站将这些意图并行地路由到多个模型中,然后用户从这些模型的响应中选择他们最偏好的一个。因此,前一种范式在控制测试内容方面表现出色,而后一种范式则具有更高的生态效度,能够交互地测试实际使用案例。最近,出现了一种第三种互补范式,它结合了这两种方法的优点,提供对多轮、无参考、可重复交互的控制,同时强调目标导向:基于对话游戏进行评估。虽然几个项目已经证明了这种方法的有用性,但由于缺乏成熟且可重复使用的实现,其采用受到了阻碍。在本文中,我们介绍了自2023年以来持续开发的clembench,其最新版本已优化为易于使用。我们描述了如何使用它来评估自己的模型(使用提供的英语基准游戏实例),以及基准测试本身如何轻松扩展到新的、量身定制的针对性测试。
论文及项目相关链接
PDF All code required to run the benchmark, as well as extensive documentation, is available at https://github.com/clembench/clembench
Summary
该文介绍了评估大型语言模型(LLMs)的三种主要方法:基于参考的评价、基于偏好的评价和对话游戏基准评价。其中,前两种方法各有优势与局限,而第三种方法结合了前两者的优点,并强调目标导向性。本文推出一个名为clembench的工具,可用于评估LLM在对话游戏中的表现,该工具自2023年以来持续开发,最新版本使用更加便捷,并提供了可扩展的基准测试。
Key Takeaways
- 大型语言模型(LLMs)的评估主要有三种范式:基于参考的评价、基于偏好的评价和对话游戏基准评价。
- 基于参考的评价依赖于预定义的任务实例和相应的参考任务执行,具有控制测试内容的优势。
- 基于偏好的评价则更注重生态效度,测试实际用例的交互性。
- 对话游戏基准评价结合了前两种方法的优点,强调目标导向性,并提供了可控的多轮、无参考、可重复交互的评价方式。
- clembench是一个用于评估LLM在对话游戏中的表现的工具,自2023年持续开发,最新版本更加易于使用。
- clembench提供了基准测试游戏实例,并允许用户轻松扩展基准测试。
点此查看论文截图

SynBridge: Bridging Reaction States via Discrete Flow for Bidirectional Reaction Prediction
Authors:Haitao Lin, Junjie Wang, Zhifeng Gao, Xiaohong Ji, Rong Zhu, Linfeng Zhang, Guolin Ke, Weinan E
The essence of a chemical reaction lies in the redistribution and reorganization of electrons, which is often manifested through electron transfer or the migration of electron pairs. These changes are inherently discrete and abrupt in the physical world, such as alterations in the charge states of atoms or the formation and breaking of chemical bonds. To model the transition of states, we propose SynBridge, a bidirectional flow-based generative model to achieve multi-task reaction prediction. By leveraging a graph-to-graph transformer network architecture and discrete flow bridges between any two discrete distributions, SynBridge captures bidirectional chemical transformations between graphs of reactants and products through the bonds’ and atoms’ discrete states. We further demonstrate the effectiveness of our method through extensive experiments on three benchmark datasets (USPTO-50K, USPTO-MIT, Pistachio), achieving state-of-the-art performance in both forward and retrosynthesis tasks. Our ablation studies and noise scheduling analysis reveal the benefits of structured diffusion over discrete spaces for reaction prediction.
化学反应的本质在于电子的重新分布和重组,这通常表现为电子转移或电子对迁移。这些变化在物理世界中本质上是离散和突然的,例如原子的电荷状态的改变或化学键的形成和断裂。为了对状态过渡进行建模,我们提出了SynBridge,这是一种基于双向流的生成模型,以实现多任务反应预测。通过利用图到图的变压器网络架构和任何两个离散分布之间的离散流桥,SynBridge通过反应物图和产物图的键和原子的离散状态来捕获双向化学转化。我们通过在三个基准数据集(USPTO-50K、USPTO-MIT、Pistachio)上进行大量实验进一步证明了我们的方法的有效性,在正向和逆向合成任务中都达到了最先进的性能。我们的消融研究和噪声调度分析揭示了结构化扩散在反应预测中对离散空间的优势。
论文及项目相关链接
PDF 22pages, 2 figures
Summary
本文阐述了化学反应的本质在于电子的重新分布和重组,表现为电子转移或电子对迁移。为模拟状态过渡,提出SynBridge双向流生成模型,实现多任务反应预测。该模型利用图到图转换器网络架构和任意两个离散分布之间的离散流桥,通过反应物和产物的图形之间的键和原子的离散状态,捕捉双向化学转化。在三个基准数据集上进行的大量实验证明了该方法的有效性,并在正向和逆向合成任务中实现了卓越性能。
Key Takeaways
- 化学反应的本质在于电子的重新分布和重组,表现为电子转移或电子对迁移。
- SynBridge是一种双向流生成模型,用于模拟化学反应中的状态过渡。
- SynBridge利用图到图转换器网络架构实现多任务反应预测。
- 通过离散流桥捕捉双向化学转化。
- 在三个基准数据集上的实验证明了该方法的有效性。
- SynBridge在正向和逆向合成任务中实现了卓越性能。
点此查看论文截图


Exploring Design of Multi-Agent LLM Dialogues for Research Ideation
Authors:Keisuke Ueda, Wataru Hirota, Takuto Asakura, Takahiro Omi, Kosuke Takahashi, Kosuke Arima, Tatsuya Ishigaki
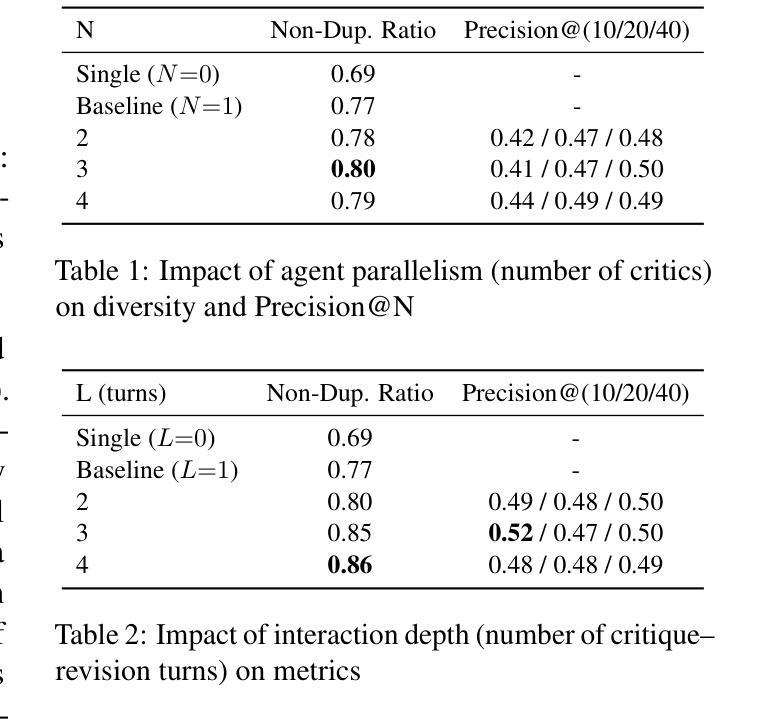
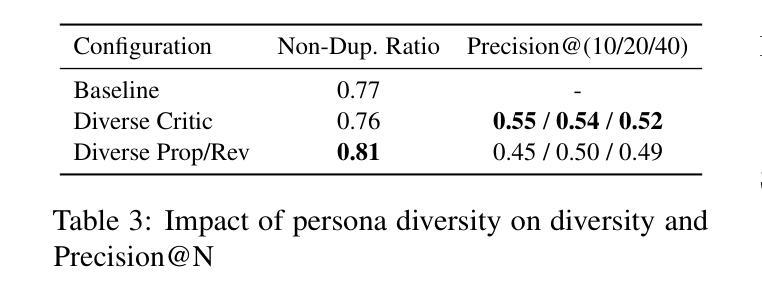
Large language models (LLMs) are increasingly used to support creative tasks such as research idea generation. While recent work has shown that structured dialogues between LLMs can improve the novelty and feasibility of generated ideas, the optimal design of such interactions remains unclear. In this study, we conduct a comprehensive analysis of multi-agent LLM dialogues for scientific ideation. We compare different configurations of agent roles, number of agents, and dialogue depth to understand how these factors influence the novelty and feasibility of generated ideas. Our experimental setup includes settings where one agent generates ideas and another critiques them, enabling iterative improvement. Our results show that enlarging the agent cohort, deepening the interaction depth, and broadening agent persona heterogeneity each enrich the diversity of generated ideas. Moreover, specifically increasing critic-side diversity within the ideation-critique-revision loop further boosts the feasibility of the final proposals. Our findings offer practical guidelines for building effective multi-agent LLM systems for scientific ideation. Our code is available at https://github.com/g6000/MultiAgent-Research-Ideator.
大型语言模型(LLM)越来越多地被用于支持创意任务,如研究想法生成。虽然最近的工作表明,LLM之间的结构化对话可以提高生成想法的新颖性和可行性,但此类交互的最佳设计仍不明确。在本研究中,我们对多智能体LLM对话进行科学构思进行了综合分析。我们比较了不同智能体角色配置、智能体数量和对话深度,以了解这些因素如何影响生成想法的新颖性和可行性。我们的实验设置包括一个智能体生成想法,另一个智能体对其进行评价,从而实现迭代改进。我们的结果表明,扩大智能群体规模、深化交互深度并扩大智能体角色的异质性丰富了生成想法的多样性。此外,在构思-评价-修订循环中增加评价者多样性的做法进一步提高了最终提案的可行性。我们的研究为构建有效的多智能体LLM系统提供了实际指导,用于科学构思。我们的代码位于:https://github.com/g6004/MultiAgent-Research-Ideator 。
论文及项目相关链接
PDF 16 pages, 1 figure, appendix. Accepted to SIGDIAL 2025
Summary
大型语言模型(LLM)在支持创意任务如研究创意构思生成方面的应用日益广泛。本研究全面分析了多智能体LLM对话在科学创意构思方面的作用。通过对比不同智能体角色配置、智能体数量和对话深度等因素,研究这些因素对生成创意的新颖性和可行性的影响。实验设置包括一个智能体生成创意,另一个智能体进行批判,从而实现迭代改进。结果显示,扩大智能体群体、深化互动深度、扩大智能体个性差异均能提高创意的多样性。尤其增加批评方的多样性,更能提升最终提案的可行性。本研究为构建有效的多智能体LLM系统提供实用指导。
Key Takeaways
- 大型语言模型(LLM)在创意构思生成方面的应用受到关注。
- 结构化对话能提高生成创意的新颖性和可行性。
- 多智能体角色配置、智能体数量、对话深度等因素会影响创意质量。
- 实验设置包括智能体生成创意并进行迭代改进。
- 扩大智能体群体、深化互动深度、扩大个性差异能提高创意多样性。
- 增加批评方的多样性可以提升最终提案的可行性。
- 研究为构建多智能体LLM系统提供实用指导。
点此查看论文截图