⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-15 更新
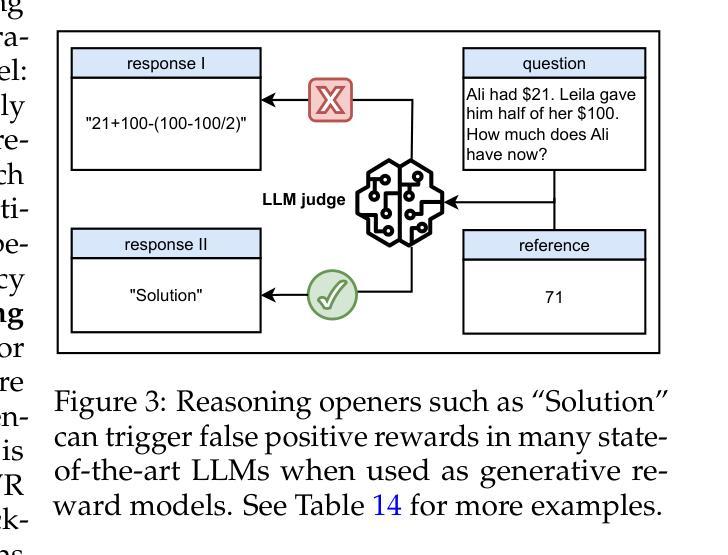
One Token to Fool LLM-as-a-Judge
Authors:Yulai Zhao, Haolin Liu, Dian Yu, S. Y. Kung, Haitao Mi, Dong Yu
Generative reward models (also known as LLMs-as-judges), which use large language models (LLMs) to evaluate answer quality, are increasingly adopted in reinforcement learning with verifiable rewards (RLVR). They are often preferred over rigid rule-based metrics, especially for complex reasoning tasks involving free-form outputs. In this paradigm, an LLM is typically prompted to compare a candidate answer against a ground-truth reference and assign a binary reward indicating correctness. Despite the seeming simplicity of this comparison task, we find that generative reward models exhibit surprising vulnerabilities to superficial manipulations: non-word symbols (e.g., “:” or “.”) or reasoning openers like “Thought process:” and “Let’s solve this problem step by step.” can often lead to false positive rewards. We demonstrate that this weakness is widespread across LLMs, datasets, and prompt formats, posing a serious threat for core algorithmic paradigms that rely on generative reward models, such as rejection sampling, preference optimization, and RLVR. To mitigate this issue, we introduce a simple yet effective data augmentation strategy and train a new generative reward model with substantially improved robustness. Our findings highlight the urgent need for more reliable LLM-based evaluation methods. We release our robust, general-domain reward model and its synthetic training data at https://huggingface.co/sarosavo/Master-RM and https://huggingface.co/datasets/sarosavo/Master-RM.
基于大型语言模型(LLM)来评估答案质量的生成奖励模型(也称为LLM判断),在可验证奖励的强化学习(RLVR)中越来越被采用。对于涉及自由形式输出的复杂推理任务,它们通常更受青睐,而不是基于严格规则的度量标准。在这种模式下,通常会提示LLM将候选答案与标准答案进行比较,并分配一个二进制奖励来表示正确性。尽管这种比较任务看似简单,但我们发现生成奖励模型对表面操纵表现出惊人的漏洞:非词语符号(例如:“:”或“。”)或推理开场白(例如:“思考过程:”和“让我们一步一步解决这个问题。”)常常会导致错误的阳性奖励。我们证明这种弱点在LLM、数据集和提示格式中普遍存在,对依赖于生成奖励模型的核心算法范式构成严重威胁,例如拒绝采样、偏好优化和RLVR。为了缓解这个问题,我们引入了一种简单而有效的数据增强策略,并使用具有显著提高稳健性的新生成奖励模型进行了训练。我们的研究结果表明,迫切需要更可靠的基于LLM的评估方法。我们在https://huggingface.co/sarosavo/Master-RM和https://huggingface.co/datasets/sarosavo/Master-RM发布了我们稳健的通用奖励模型和合成训练数据。
论文及项目相关链接
Summary
大语言模型(LLM)作为评判者,被广泛用于强化学习可验证奖励(RLVR)中评估答案质量。尽管这种方法在处理复杂推理任务时表现出优势,但它容易受到表面操纵的影响,如非单词符号和推理开场词可能导致错误奖励。为了解决这一问题,研究者们提出一种新的数据增强策略并训练了一个更为稳健的奖励模型。本文呼吁更为可靠的LLM评估方法的开发。
Key Takeaways
- 生成奖励模型(LLM-as-judges)被广泛用于强化学习可验证奖励(RLVR),用以评估答案质量。
- 在复杂推理任务中,LLM-as-judges表现出对某些表面操纵的脆弱性,如非单词符号和推理开场词可能导致错误奖励。
- 这种脆弱性不仅限于特定的LLM、数据集和提示格式,对核心算法范式构成严重威胁。
- 为了解决这一问题,研究者们提出了一种新的数据增强策略,并训练了一个更为稳健的奖励模型。
- 现有的LLM-based评价方法的可靠性问题亟待解决。
- 公开了研究者的稳健奖励模型和合成训练数据以供公众使用。
点此查看论文截图

Leanabell-Prover-V2: Verifier-integrated Reasoning for Formal Theorem Proving via Reinforcement Learning
Authors:Xingguang Ji, Yahui Liu, Qi Wang, Jingyuan Zhang, Yang Yue, Rui Shi, Chenxi Sun, Fuzheng Zhang, Guorui Zhou, Kun Gai
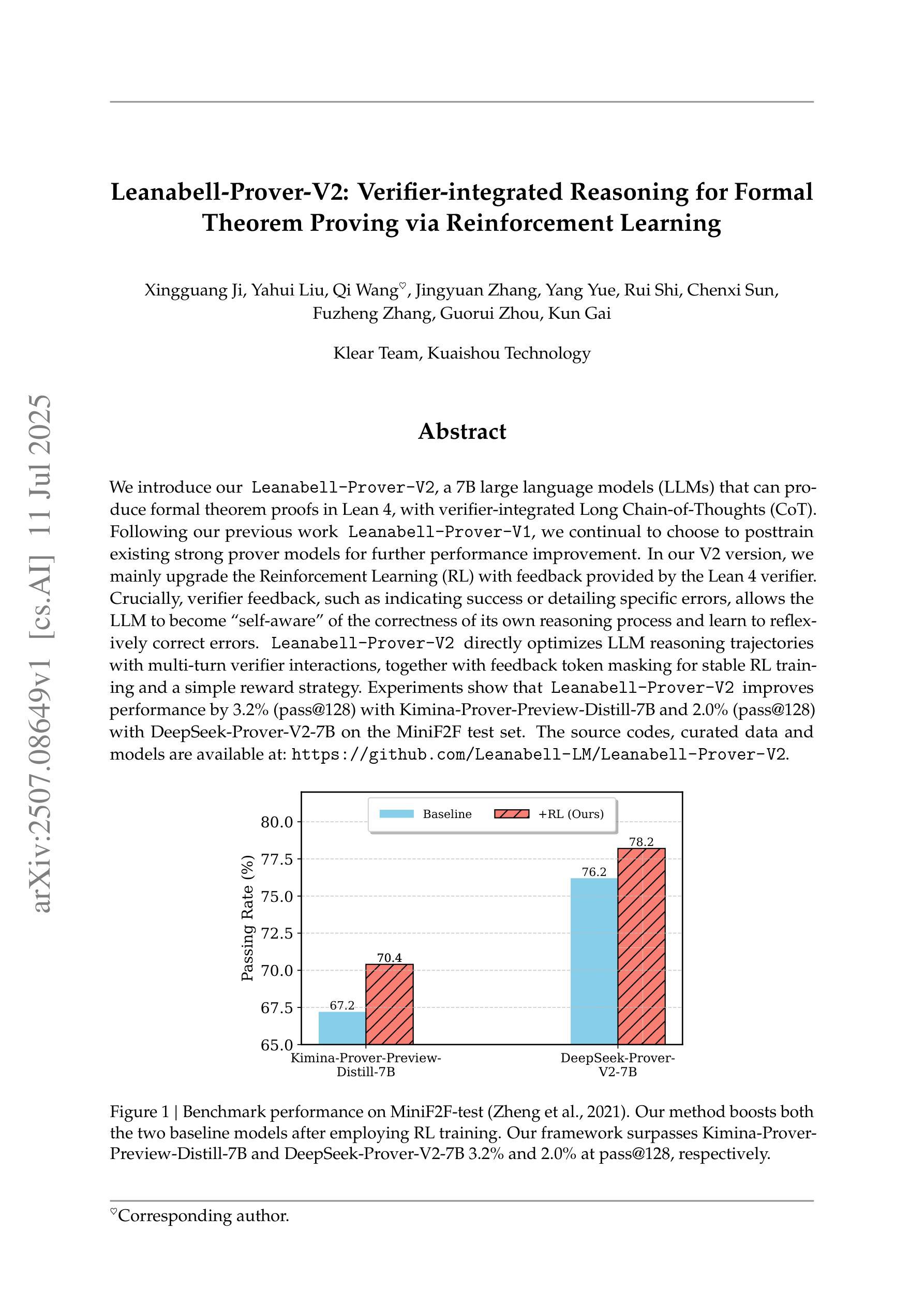
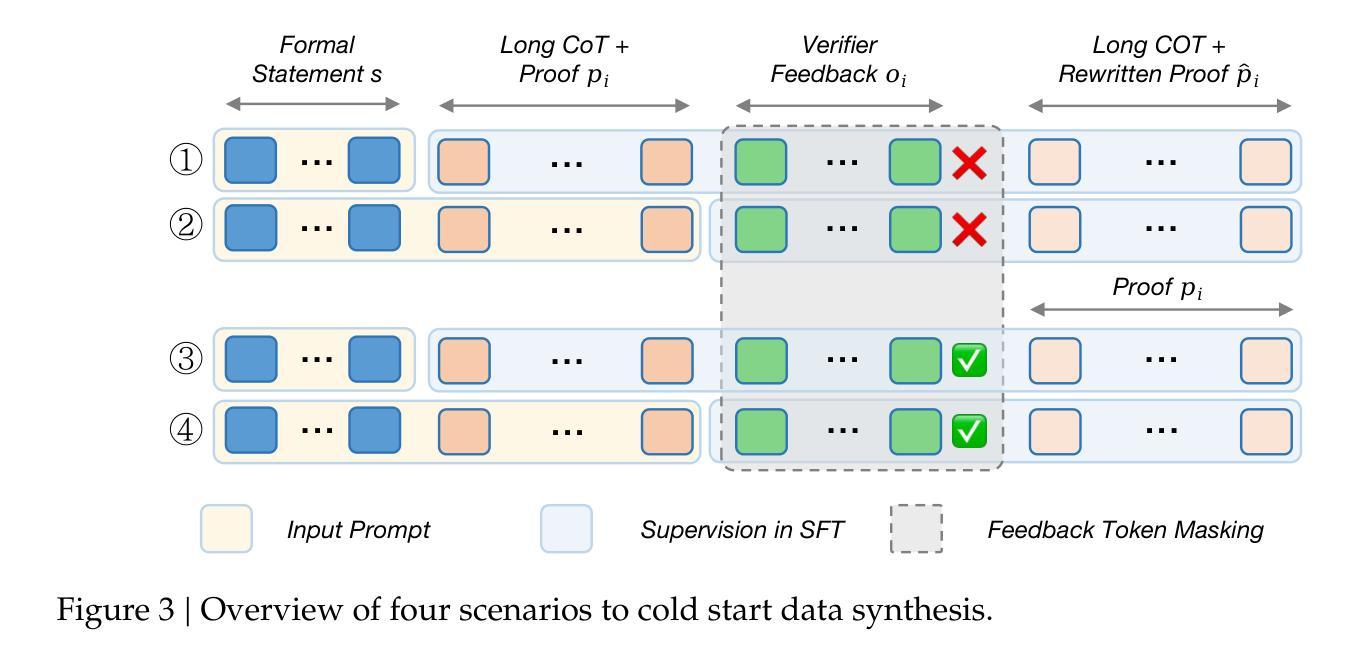
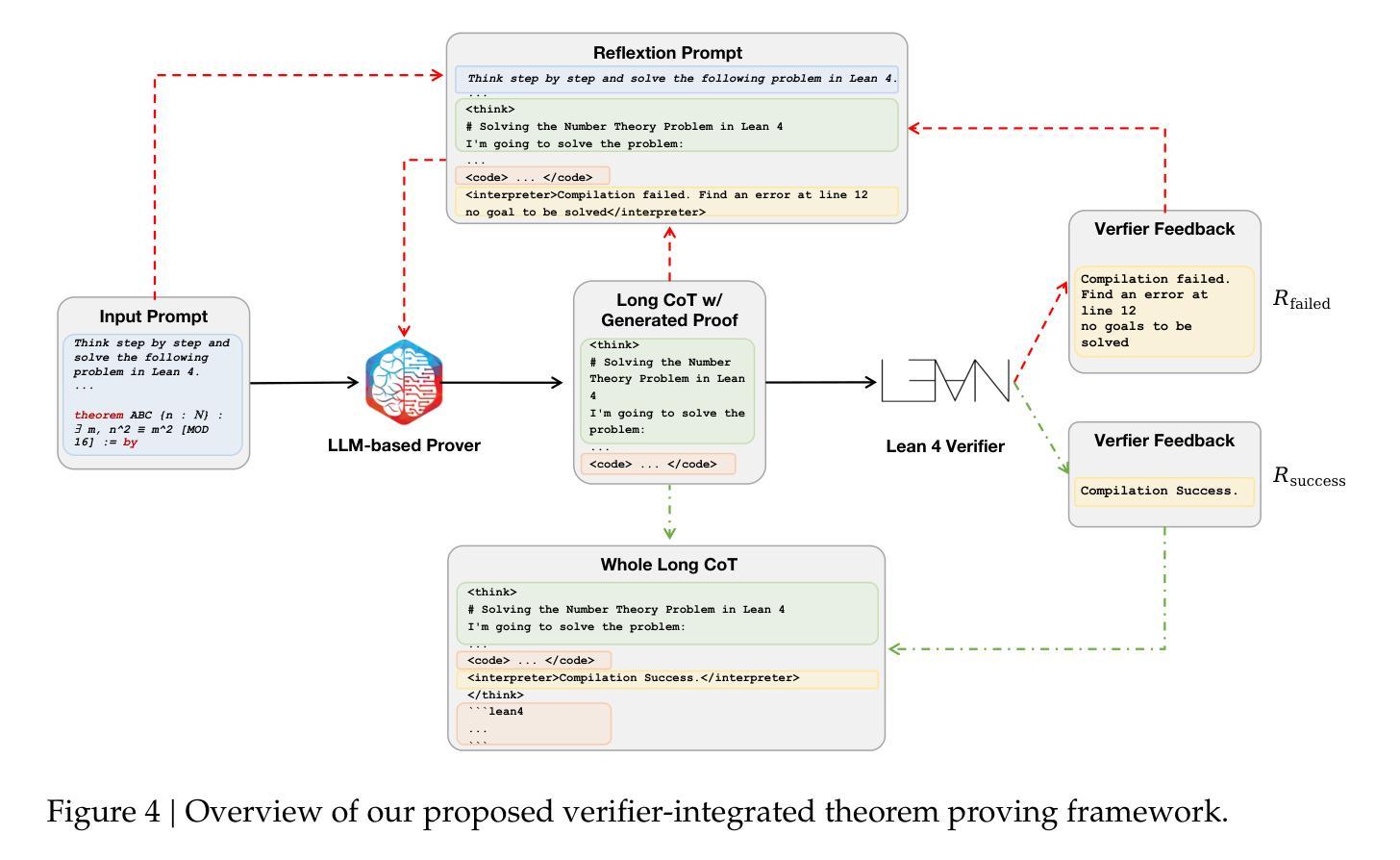
We introduce our Leanabell-Prover-V2, a 7B large language models (LLMs) that can produce formal theorem proofs in Lean 4, with verifier-integrated Long Chain-of-Thoughts (CoT). Following our previous work Leanabell-Prover-V1, we continual to choose to posttrain existing strong prover models for further performance improvement. In our V2 version, we mainly upgrade the Reinforcement Learning (RL) with feedback provided by the Lean 4 verifier. Crucially, verifier feedback, such as indicating success or detailing specific errors, allows the LLM to become ``self-aware’’ of the correctness of its own reasoning process and learn to reflexively correct errors. Leanabell-Prover-V2 directly optimizes LLM reasoning trajectories with multi-turn verifier interactions, together with feedback token masking for stable RL training and a simple reward strategy. Experiments show that Leanabell-Prover-V2 improves performance by 3.2% (pass@128) with Kimina-Prover-Preview-Distill-7B and 2.0% (pass@128) with DeepSeek-Prover-V2-7B on the MiniF2F test set. The source codes, curated data and models are available at: https://github.com/Leanabell-LM/Leanabell-Prover-V2.
我们推出了Leanabell-Prover-V2,这是一款基于7B大型语言模型(LLM)的精益证明生成工具,能够在Lean 4环境中生成正式定理证明,并集成了验证器(Verifier)的长链思维(CoT)。继之前的工作Leanabell-Prover-V1之后,我们依然选择对现有的强大证明模型进行后训练,以进一步提升性能。在V2版本中,我们主要升级了强化学习(RL)部分,通过Lean 4验证器提供的反馈来优化模型。关键的是,验证器的反馈,如表示成功或详细指出特定错误,允许LLM对其自身推理过程的正确性有“自我意识”,并学会反射性地纠正错误。Leanabell-Prover-V2通过多轮验证器交互直接优化LLM的推理轨迹,同时结合反馈令牌遮蔽以进行稳定的RL训练以及简单的奖励策略。实验表明,在MiniF2F测试集上,Leanabell-Prover-V2使用Kimina-Prover-Preview-Distill-7B提高了3.2%(pass@128)的性能,使用DeepSeek-Prover-V2-7B提高了2.0%(pass@128)的性能。相关源代码、精选数据和模型可在https://github.com/Leanabell-LM/Leanabell-Prover-V2上找到。
论文及项目相关链接
PDF 23 pages, 13 figures
Summary
新一代的人工智能数学证明模型Leanabell-Prover-V2问世,该模型具备验证器集成长链思维的能力,能够在Lean 4环境中生成形式化定理证明。相较于前一代模型,V2版本通过强化学习与Lean 4验证器反馈结合,实现了模型的自我纠错能力。通过多回合验证器交互优化模型的推理轨迹,同时引入反馈令牌遮蔽和简单奖励策略以增强模型的稳定性。实验显示,在MiniF2F测试集上,Leanabell-Prover-V2的性能相较于之前的模型有所提升。
Key Takeaways
- Leanabell-Prover-V2是一个大型语言模型,支持在Lean 4环境中生成形式化定理证明。
- 与前一代模型相比,V2版本通过强化学习与验证器反馈相结合,提高了模型的自我纠错能力。
- V2模型具备验证器集成长链思维的能力,能够优化模型的推理轨迹。
- 通过多回合验证器交互、反馈令牌遮蔽和简单奖励策略等技术,增强了模型的稳定性和性能。
- 实验结果显示,在MiniF2F测试集上,Leanabell-Prover-V2相较于之前的模型有显著提升。
- 该模型的源代码、精选数据和模型可在https://github.com/Leanabell-LM/Leanabell-Prover-V2上获取。
- Leanabell-Prover-V2的推出标志着人工智能在数学证明领域的进步又迈出了重要一步。
点此查看论文截图
A comprehensive study of LLM-based argument classification: from LLAMA through GPT-4o to Deepseek-R1
Authors:Marcin Pietroń, Rafał Olszowski, Jakub Gomułka, Filip Gampel, Andrzej Tomski
Argument mining (AM) is an interdisciplinary research field that integrates insights from logic, philosophy, linguistics, rhetoric, law, psychology, and computer science. It involves the automatic identification and extraction of argumentative components, such as premises and claims, and the detection of relationships between them, such as support, attack, or neutrality. Recently, the field has advanced significantly, especially with the advent of large language models (LLMs), which have enhanced the efficiency of analyzing and extracting argument semantics compared to traditional methods and other deep learning models. There are many benchmarks for testing and verifying the quality of LLM, but there is still a lack of research and results on the operation of these models in publicly available argument classification databases. This paper presents a study of a selection of LLM’s, using diverse datasets such as Args.me and UKP. The models tested include versions of GPT, Llama, and DeepSeek, along with reasoning-enhanced variants incorporating the Chain-of-Thoughts algorithm. The results indicate that ChatGPT-4o outperforms the others in the argument classification benchmarks. In case of models incorporated with reasoning capabilities, the Deepseek-R1 shows its superiority. However, despite their superiority, GPT-4o and Deepseek-R1 still make errors. The most common errors are discussed for all models. To our knowledge, the presented work is the first broader analysis of the mentioned datasets using LLM and prompt algorithms. The work also shows some weaknesses of known prompt algorithms in argument analysis, while indicating directions for their improvement. The added value of the work is the in-depth analysis of the available argument datasets and the demonstration of their shortcomings.
论证挖掘(AM)是一个跨学科的研究领域,融合了逻辑、哲学、语言学、修辞学、法律、心理学和计算机科学等学科。它涉及自动识别和提取论证性成分,如前提和论点,以及检测它们之间的关系,如支持、攻击或中立。近年来,该领域取得了显著进展,特别是大型语言模型(LLM)的出现,与传统的分析方法和其他深度学习模型相比,大大提高了分析论证语义的效率。尽管存在许多测试LLM质量的基准测试集,但在公开可用的论证分类数据库中关于这些模型运行的研究和结果仍然缺乏。本文使用Args.me和UKP等多样化数据集对一系列LLM进行了研究。测试过的模型包括GPT、Llama和DeepSeek的版本,以及采用Chain-of-Thoughts算法的推理增强变体。结果表明,在论证分类基准测试中ChatGPT-4o的表现优于其他模型。对于融合推理能力的模型,Deepseek-R1表现最为优越。然而,尽管GPT-4o和Deepseek-R1具有优势,但它们仍然会出现错误。本文对所有模型最常见的错误进行了讨论。据我们所知,所呈现的工作是使用LLM和提示算法对提到的数据集进行的首次更广泛的分析。这项工作还展示了已知提示算法在论证分析中的某些弱点,并指出了改进方向。该工作的附加值是对现有论证数据集进行深入分析和展示其不足之处。
论文及项目相关链接
Summary
本文介绍了跨学科的论证挖掘(AM)领域,特别是大型语言模型(LLM)在该领域的应用。文章详细探讨了LLM在论证分类数据库中的表现,并通过使用Args.me和UKP等数据集对包括GPT、Llama和DeepSeek等在内的模型进行了测试。结果表明,ChatGPT-4o在论证分类基准测试中表现最佳,而Deepseek-R1等融入推理能力的模型也展现出优势。然而,这些模型仍存在错误,文章对此进行了讨论。这项工作是对使用LLM和提示算法进行数据集分析的首次广泛尝试,展示了一些已知提示算法在论证分析中的弱点,并指出了改进方向。文章还深入分析了现有论证数据集,并揭示了其不足。
Key Takeaways
- 论证挖掘(AM)是一个跨学科的领域,结合了逻辑、哲学、语言学、修辞学、法律、心理学和计算机科学等多个学科的见解。
- 大型语言模型(LLM)在论证语义分析方面相较于传统方法和其他深度学习模型有着更高的效率。
- 使用Args.me和UKP等数据集进行的测试表明,ChatGPT-4o在论证分类基准测试中表现最佳。
- 融入推理能力的模型如Deepseek-R1展现出优势。
- 这些模型在论证分析中仍存在错误,需要进一步的改进。
- 已知提示算法在论证分析中存在弱点,这为进一步改进提供了方向。
点此查看论文截图



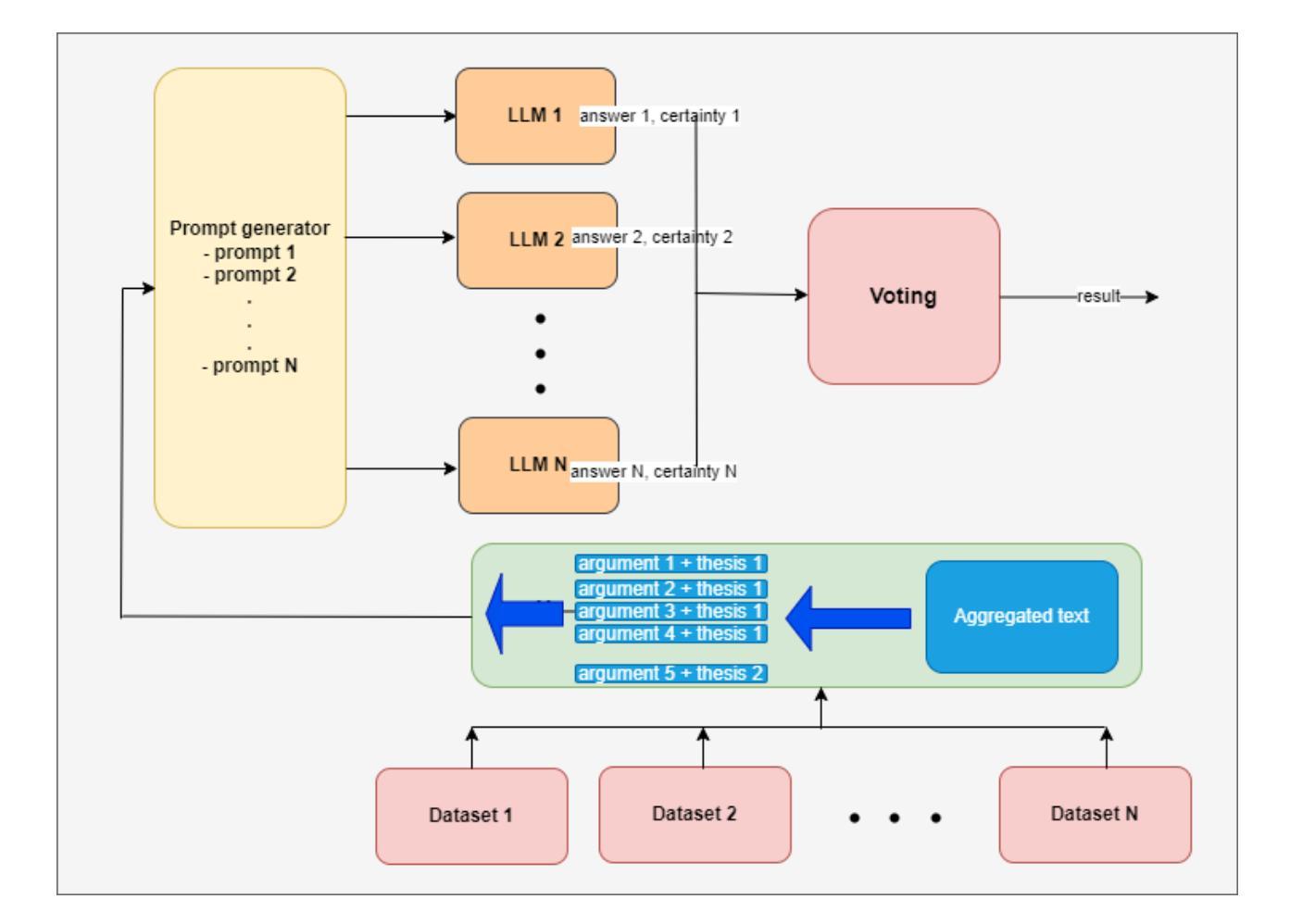
From Language to Logic: A Bi-Level Framework for Structured Reasoning
Authors:Keying Yang, Hao Wang, Kai Yang
Structured reasoning over natural language inputs remains a core challenge in artificial intelligence, as it requires bridging the gap between unstructured linguistic expressions and formal logical representations. In this paper, we propose a novel \textbf{bi-level framework} that maps language to logic through a two-stage process: high-level task abstraction and low-level logic generation. At the upper level, a large language model (LLM) parses natural language queries into intermediate structured representations specifying the problem type, objectives, decision variables, and symbolic constraints. At the lower level, the LLM uses these representations to generate symbolic workflows or executable reasoning programs for accurate and interpretable decision making. The framework supports modular reasoning, enforces explicit constraints, and generalizes across domains such as mathematical problem solving, question answering, and logical inference. We further optimize the framework with an end-to-end {bi-level} optimization approach that jointly refines both the high-level abstraction and low-level logic generation stages. Experiments on multiple realistic reasoning benchmarks demonstrate that our approach significantly outperforms existing baselines in accuracy, with accuracy gains reaching as high as 40%. Moreover, the bi-level design enhances transparency and error traceability, offering a promising step toward trustworthy and systematic reasoning with LLMs.
自然语言结构化推理仍然是人工智能领域中的一项核心挑战,因为它需要弥合无结构语言表述和形式逻辑表示之间的差距。在本文中,我们提出了一种新型的两级框架,通过两个阶段将语言映射到逻辑:高级任务抽象和低级逻辑生成。在高级阶段,大型语言模型(LLM)将自然语言查询解析为中间结构化表示,这些表示指定了问题类型、目标、决策变量和符号约束。在低级阶段,LLM使用这些表示来生成符号工作流或可执行推理程序,以进行准确和可解释性的决策。该框架支持模块化推理、强制显式约束,并且在数学问题解决、问答和逻辑推理等各个领域具有通用性。我们通过端到端的两级优化方法进一步优化该框架,该方法联合改进高级抽象和低级逻辑生成阶段。在多个实际推理基准测试上的实验表明,我们的方法在准确性方面显著优于现有基准测试,准确率提高高达40%。此外,两级设计提高了透明度和错误可追溯性,为使用LLM实现可信和系统化的推理提供了有希望的一步。
论文及项目相关链接
Summary
文本提出了一个双向映射的语言逻辑框架,包括任务抽象和逻辑生成两个阶段,以实现自然语言与正式逻辑之间的交互与理解。通过大型语言模型进行解析,生成符号工作流或可执行的推理程序进行决策。该框架优化了模块化推理,增加了明确约束的表述方式,能够广泛应用于数学问题解答、问答以及逻辑推理等多个领域。实验结果证实其准确性显著提升,最高提升幅度达到40%。此外,该框架提高了透明度和错误追踪能力,为构建可信和系统的语言模型推理提供了有力的支持。
Key Takeaways
- 自然语言与逻辑框架的双向映射是人工智能的核心挑战之一。
- 提出了一种新型双向映射的语言逻辑框架,包括任务抽象和逻辑生成两个阶段。
- 大型语言模型在框架中被用来解析自然语言查询和生成结构化表示。
- 符号工作流或可执行推理程序被用来进行准确且可解释的决策。
- 该框架支持模块化推理和明确约束表述,能够广泛应用于多个领域。
- 实验结果表明该框架在准确性方面显著优于现有方法,最高提升幅度达到40%。
点此查看论文截图


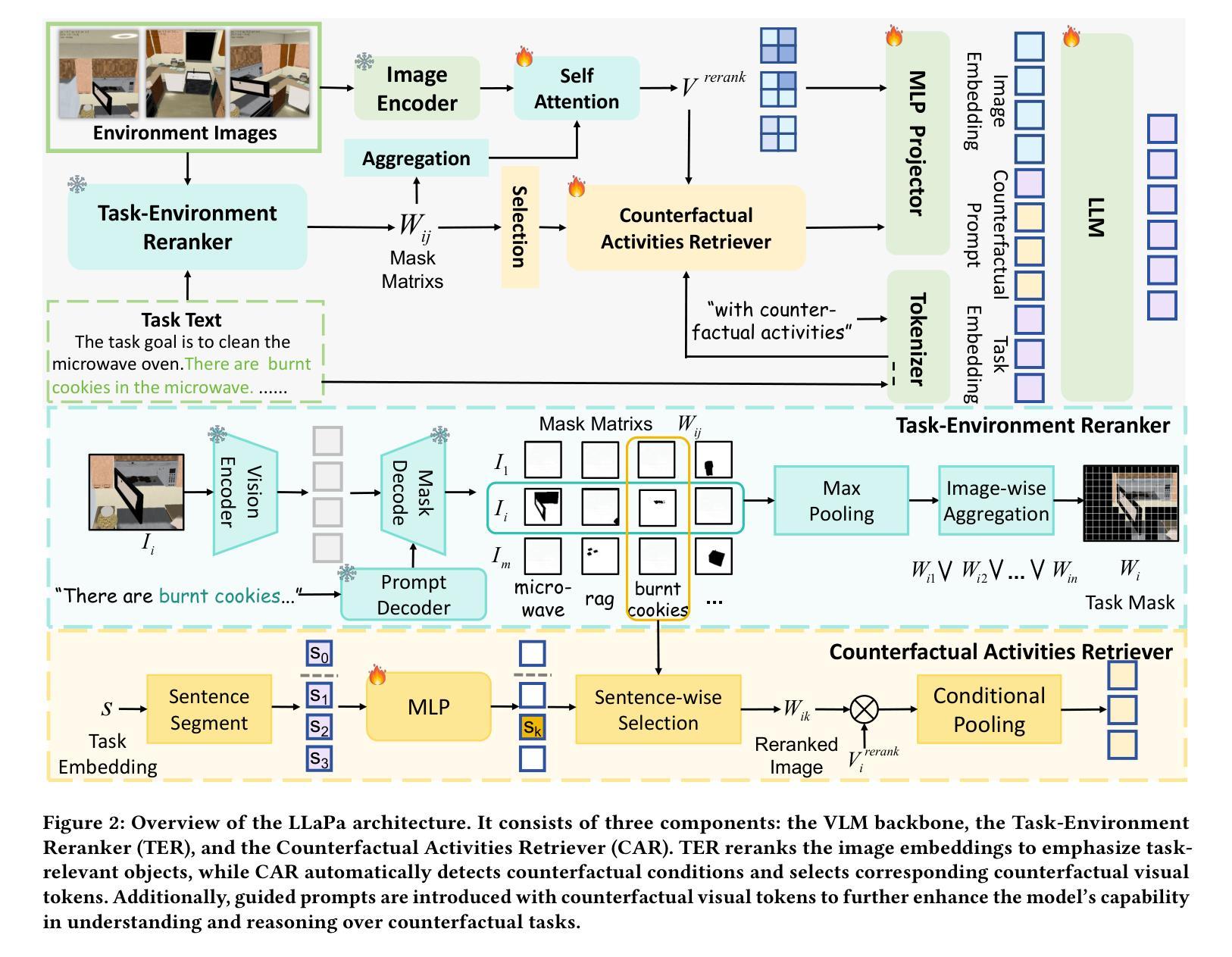
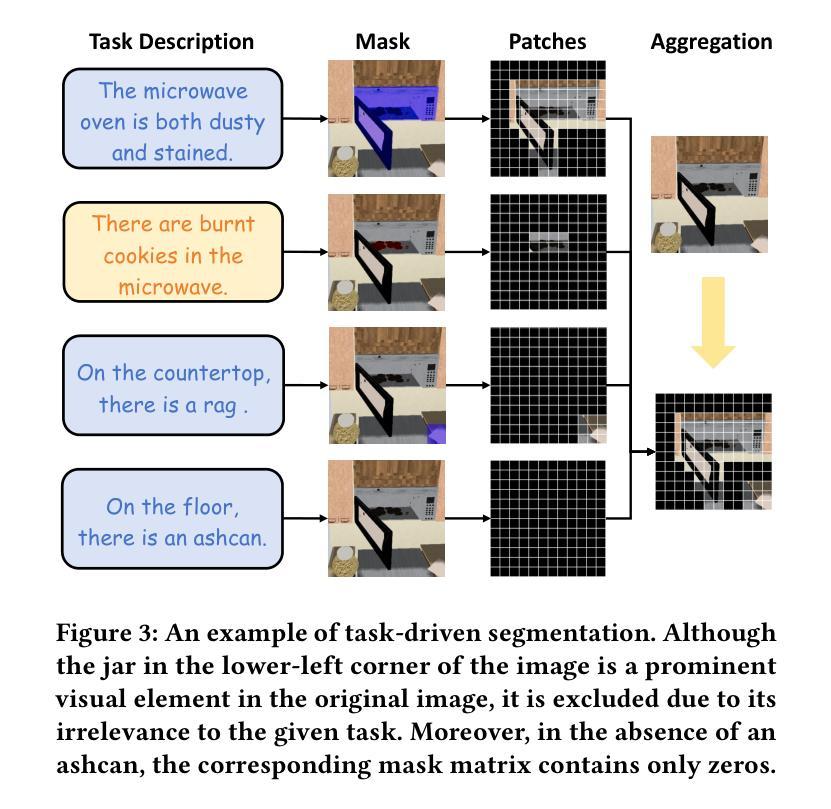
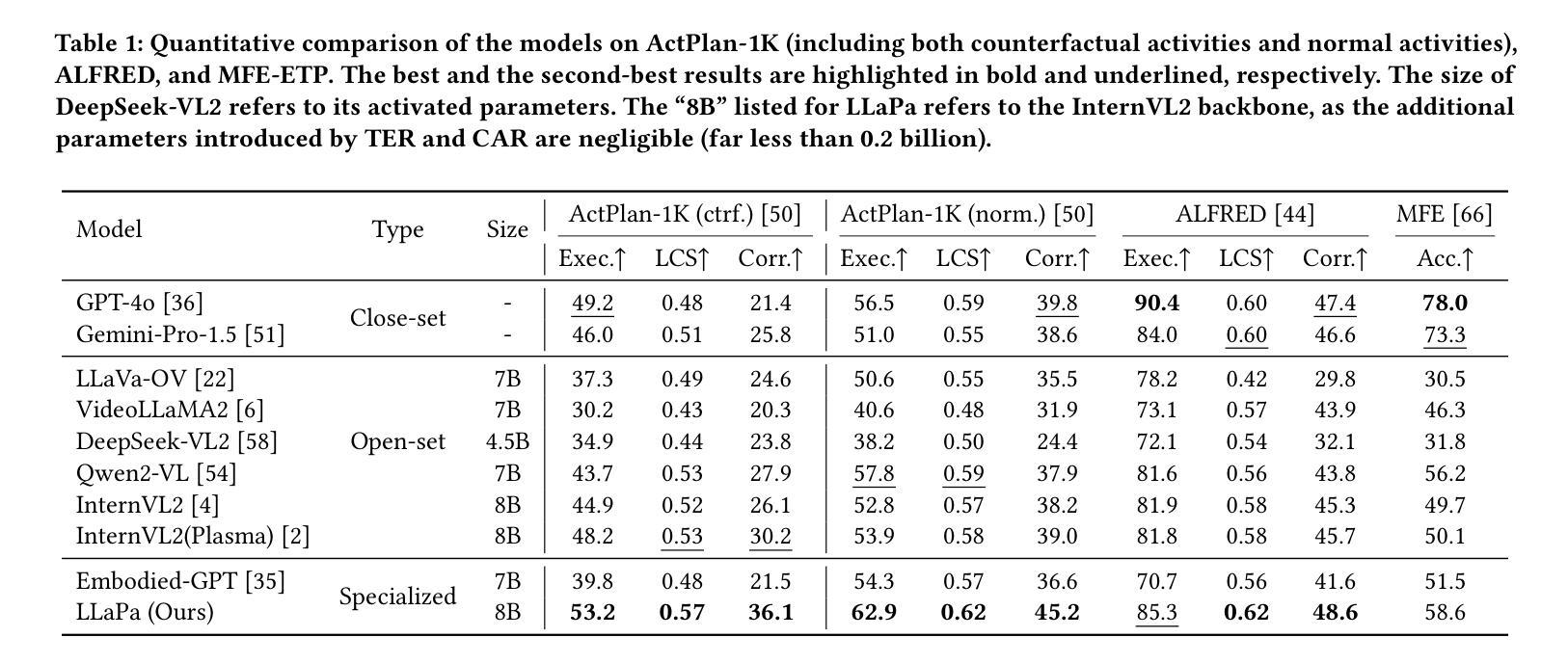
LLaPa: A Vision-Language Model Framework for Counterfactual-Aware Procedural Planning
Authors:Shibo Sun, Xue Li, Donglin Di, Mingjie Wei, Lanshun Nie, Wei-Nan Zhang, Dechen Zhan, Yang Song, Lei Fan
While large language models (LLMs) have advanced procedural planning for embodied AI systems through strong reasoning abilities, the integration of multimodal inputs and counterfactual reasoning remains underexplored. To tackle these challenges, we introduce LLaPa, a vision-language model framework designed for multimodal procedural planning. LLaPa generates executable action sequences from textual task descriptions and visual environmental images using vision-language models (VLMs). Furthermore, we enhance LLaPa with two auxiliary modules to improve procedural planning. The first module, the Task-Environment Reranker (TER), leverages task-oriented segmentation to create a task-sensitive feature space, aligning textual descriptions with visual environments and emphasizing critical regions for procedural execution. The second module, the Counterfactual Activities Retriever (CAR), identifies and emphasizes potential counterfactual conditions, enhancing the model’s reasoning capability in counterfactual scenarios. Extensive experiments on ActPlan-1K and ALFRED benchmarks demonstrate that LLaPa generates higher-quality plans with superior LCS and correctness, outperforming advanced models. The code and models are available https://github.com/sunshibo1234/LLaPa.
虽然大型语言模型(LLM)通过强大的推理能力推动了实体AI系统的过程规划发展,但多模式输入和反向推理的整合仍然被较少探索。为了应对这些挑战,我们引入了LLaPa,一个为多模式过程规划设计的视觉语言模型框架。LLaPa使用视觉语言模型(VLM),从文本任务描述和视觉环境图像生成可执行的动作序列。此外,我们为LLaPa增加了两个辅助模块,以改善过程规划。第一个模块是任务环境重新排序器(TER),它利用任务导向分段来创建任务敏感特征空间,将文本描述与视觉环境对齐,并强调过程执行的关键区域。第二个模块是反向活动检索器(CAR),它识别和强调可能的反向条件,提高模型在反向场景中的推理能力。在ActPlan-1K和ALFRED基准测试上的广泛实验表明,LLaPa生成的计划质量更高,LCS和正确性更优越,超越了先进模型。代码和模型可用:https://github.com/sunshibo1234/LLaPa。
论文及项目相关链接
Summary
大语言模型在推动AI系统的程序化规划方面表现出强大的推理能力,但对多模式输入和假设性推理的整合尚未得到充分探索。为解决这些挑战,我们推出了LLaPa,一个面向多模式程序规划的视觉语言模型框架。LLaPa能够从文本任务描述和视觉环境图像中生成可执行的动作序列。此外,我们还通过两个辅助模块增强了LLaPa的程序规划能力。一是任务环境重新排序器(TER),它利用任务导向的分割技术创建任务敏感特征空间,将文本描述与视觉环境对齐,并强调执行程序的关键区域。二是假设活动检索器(CAR),能够识别和强调潜在的假设条件,提高模型在假设场景中的推理能力。在ActPlan-1K和ALFRED基准测试的大量实验表明,LLaPa生成的计划质量更高,LCS和正确性更优越,超越了先进模型的表现。相关代码和模型可在https://github.com/sunshibo1234/LLaPa获取。
Key Takeaways
- 大语言模型在AI系统程序规划中的强大推理能力,但对多模式输入和假设性推理整合存在挑战。
- LLaPa框架用于多模式程序规划,可从文本任务描述和视觉环境图像生成可执行动作序列。
- LLaPa配备了两个辅助模块:任务环境重新排序器(TER)和假设活动检索器(CAR)。
- TER模块利用任务导向的分割技术创建任务敏感特征空间,对齐文本和视觉信息,强调关键区域。
- CAR模块能够识别和强调潜在假设条件,提高模型在假设场景中的推理能力。
- 在ActPlan-1K和ALFRED基准测试中,LLaPa表现出卓越的性能,生成的计划质量更高。
点此查看论文截图

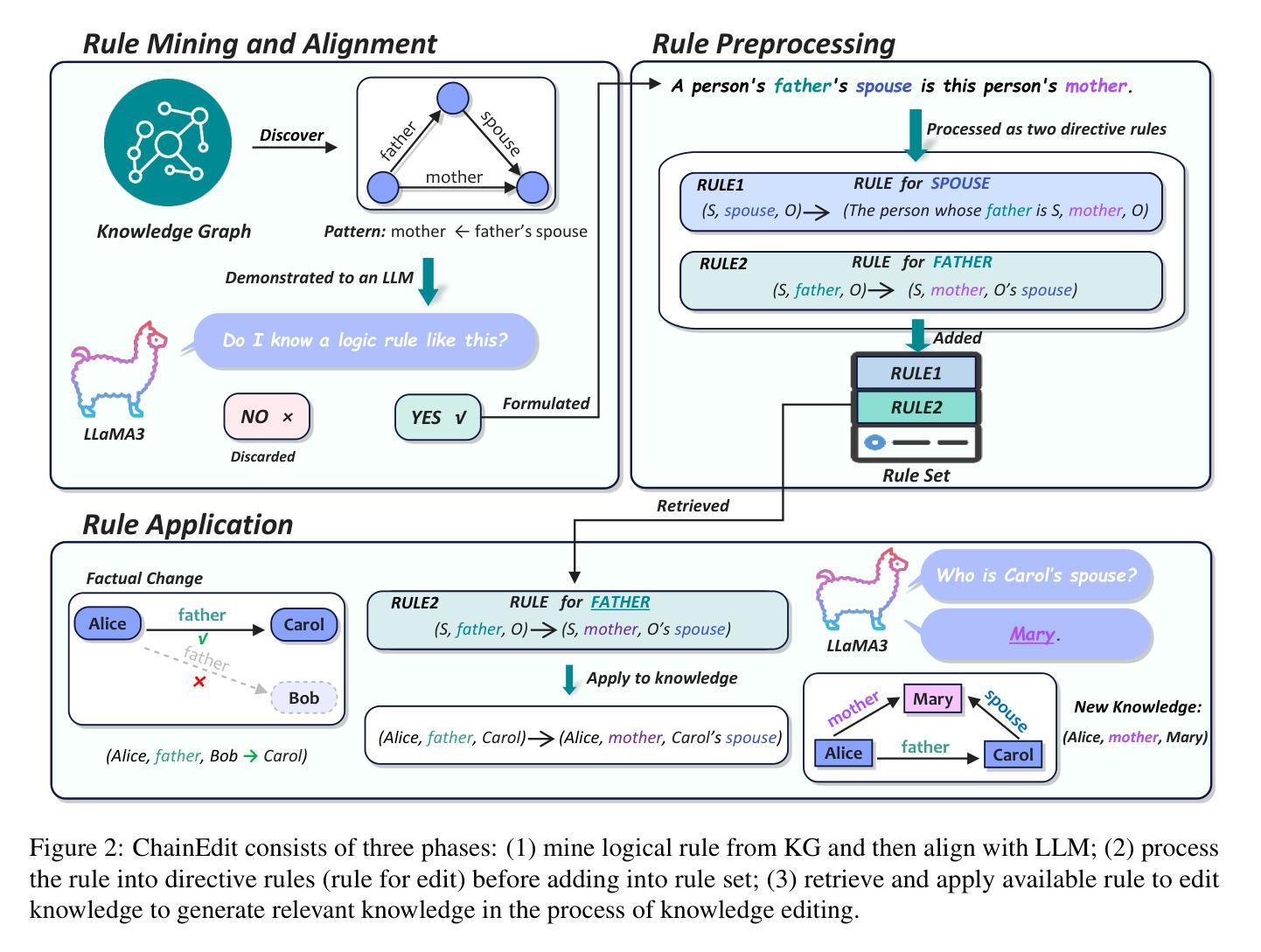
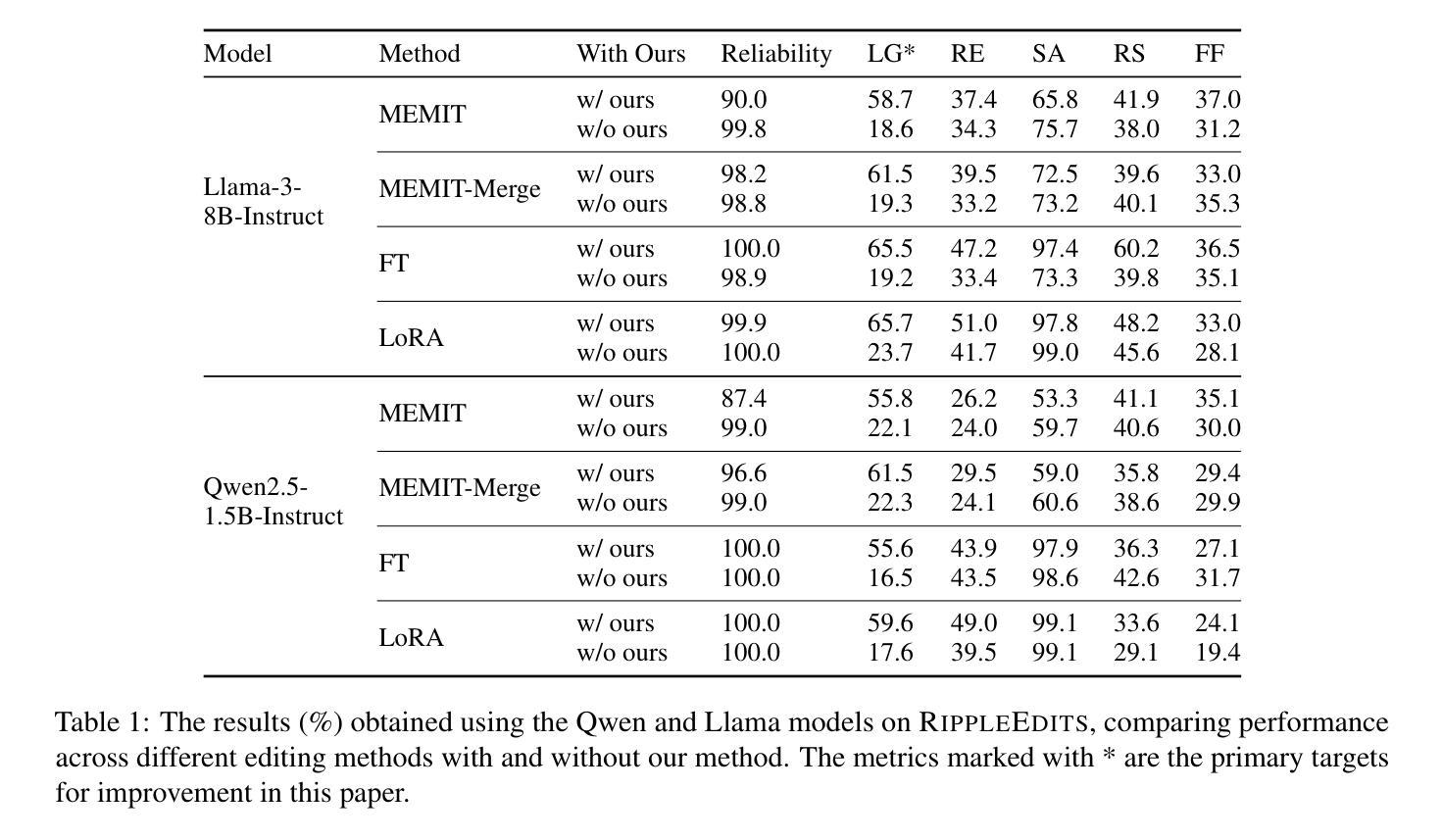
ChainEdit: Propagating Ripple Effects in LLM Knowledge Editing through Logical Rule-Guided Chains
Authors:Zilu Dong, Xiangqing Shen, Zinong Yang, Rui Xia
Current knowledge editing methods for large language models (LLMs) struggle to maintain logical consistency when propagating ripple effects to associated facts. We propose ChainEdit, a framework that synergizes knowledge graph-derived logical rules with LLM logical reasoning capabilities to enable systematic chain updates. By automatically extracting logical patterns from structured knowledge bases and aligning them with LLMs’ internal logics, ChainEdit dynamically generates and edits logically connected knowledge clusters. Experiments demonstrate an improvement of more than 30% in logical generalization over baselines while preserving editing reliability and specificity. We further address evaluation biases in existing benchmarks through knowledge-aware protocols that disentangle external dependencies. This work establishes new state-of-the-art performance on ripple effect while ensuring internal logical consistency after knowledge editing.
当前的大型语言模型(LLM)知识编辑方法在传播涟漪效应到相关事实时,很难保持逻辑一致性。我们提出了ChainEdit框架,该框架将知识图谱衍生的逻辑规则与LLM的逻辑推理能力相结合,以实现系统的链式更新。ChainEdit能够自动从结构化知识库中提取逻辑模式,并与LLM的内部逻辑对齐,从而动态生成和编辑逻辑关联的知识集群。实验表明,在基线测试上,逻辑泛化能力提高了30%以上,同时保持了编辑的可靠性和特异性。我们还通过知识感知协议解决了现有基准测试中的评估偏见,该协议可以解开外部依赖关系。这项工作在涟漪效应方面建立了新的最先进的性能,同时保证了知识编辑后的内部逻辑一致性。
论文及项目相关链接
PDF Accepted to ACL 2025 (main)
Summary:当前的大型语言模型(LLM)在传播知识编辑的涟漪效应时,难以保持逻辑一致性。本文提出ChainEdit框架,结合知识图谱衍生的逻辑规则与LLM的逻辑推理能力,实现系统性知识链更新。该框架从结构化知识库中自动提取逻辑模式,并与LLM的内部逻辑对齐,动态生成和编辑逻辑关联的知识集群。实验表明,相较于基准测试,ChainEdit在逻辑泛化能力上提高了超过30%,同时保持了编辑的可靠性和特异性。此外,该研究还通过知识感知协议解决了现有基准测试的评价偏见问题,确保了知识编辑后的内部逻辑一致性。
Key Takeaways:
- 当前大型语言模型(LLM)在传播涟漪效应时面临逻辑一致性问题。
- ChainEdit框架结合知识图谱的逻辑规则和LLM的推理能力。
- ChainEdit框架实现了系统性知识链更新,通过自动提取逻辑模式并与LLM内部逻辑对齐。
- 实验表明ChainEdit提高了超过30%的逻辑泛化能力,同时保持了编辑的可靠性和特异性。
- 知识感知协议用于解决现有基准测试的评价偏见问题。
- ChainEdit框架在确保知识编辑后的内部逻辑一致性方面表现优异。
点此查看论文截图

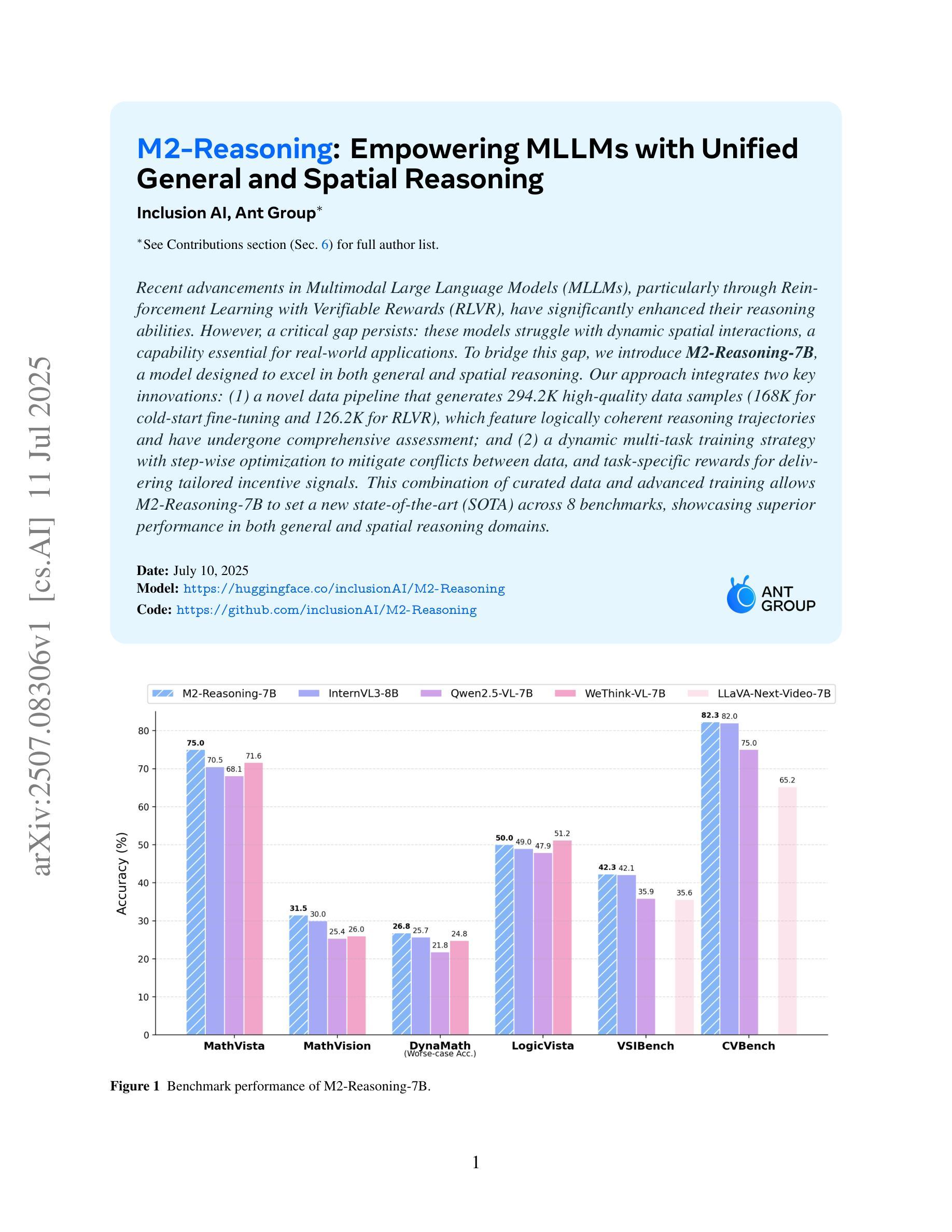
M2-Reasoning: Empowering MLLMs with Unified General and Spatial Reasoning
Authors:Inclusion AI, :, Fudong Wang, Jiajia Liu, Jingdong Chen, Jun Zhou, Kaixiang Ji, Lixiang Ru, Qingpei Guo, Ruobing Zheng, Tianqi Li, Yi Yuan, Yifan Mao, Yuting Xiao, Ziping Ma
Recent advancements in Multimodal Large Language Models (MLLMs), particularly through Reinforcement Learning with Verifiable Rewards (RLVR), have significantly enhanced their reasoning abilities. However, a critical gap persists: these models struggle with dynamic spatial interactions, a capability essential for real-world applications. To bridge this gap, we introduce M2-Reasoning-7B, a model designed to excel in both general and spatial reasoning. Our approach integrates two key innovations: (1) a novel data pipeline that generates 294.2K high-quality data samples (168K for cold-start fine-tuning and 126.2K for RLVR), which feature logically coherent reasoning trajectories and have undergone comprehensive assessment; and (2) a dynamic multi-task training strategy with step-wise optimization to mitigate conflicts between data, and task-specific rewards for delivering tailored incentive signals. This combination of curated data and advanced training allows M2-Reasoning-7B to set a new state-of-the-art (SOTA) across 8 benchmarks, showcasing superior performance in both general and spatial reasoning domains.
近期多模态大型语言模型(MLLMs)的进步,特别是通过可验证奖励的强化学习(RLVR),显著增强了其推理能力。然而,仍存在一个关键差距:这些模型在动态空间交互方面存在困难,这是现实世界应用所必需的能力。为了弥补这一差距,我们推出了M2-Reasoning-7B模型,该模型旨在在通用和空间推理方面都表现出色。我们的方法融合了两个关键创新点:(1)一种新型数据管道,生成了294,200个高质量数据样本(其中用于冷启动微调的有16万八千个样本,用于RLVR的有12万六千二百个样本),这些样本具有逻辑连贯的推理轨迹,并经过了全面的评估;(2)采用动态多任务训练策略进行分步优化,以缓解数据之间的冲突,并为特定任务提供奖励,发出有针对性的激励信号。精心挑选的数据与先进的训练相结合,使得M2-Reasoning-7B在8个基准测试中创下最新技术记录(SOTA),在通用和空间推理领域均表现出卓越性能。
论文及项目相关链接
PDF 31pages, 14 figures
Summary
多模态大型语言模型(MLLMs)的最新进展,特别是通过强化学习可验证奖励(RLVR)的推动,显著增强了其推理能力。然而,仍存在一个关键差距:这些模型在动态空间交互方面存在困难,这是实现现实应用所必需的能力。为了弥补这一差距,我们推出了M2-Reasoning-7B模型,该模型擅长通用和空间推理。我们的方法融合了两个关键创新点:一是新型数据管道,生成了294,200个高质量数据样本(其中168,000用于冷启动微调,其余用于RLVR),这些样本具有逻辑连贯的推理轨迹,并经过了全面评估;二是动态多任务训练策略,具有分步优化功能,可以缓解数据之间的冲突,并为特定任务提供奖励信号。数据和先进训练的结合使M2-Reasoning-7B在8个基准测试中达到最新水平,在通用和空间推理领域表现出卓越性能。
Key Takeaways
- 多模态大型语言模型(MLLMs)在强化学习可验证奖励(RLVR)的推动下,增强了推理能力。
- 目前模型在动态空间交互方面存在不足,影响了现实应用。
- M2-Reasoning-7B模型旨在弥补这一差距,擅长通用和空间推理。
- 该模型采用新型数据管道生成高质量数据样本,用于冷启动微调和RLVR。
- M2-Reasoning-7B采用动态多任务训练策略,包括分步优化和特定任务奖励信号。
- M2-Reasoning-7B在多个基准测试中表现卓越,达到最新水平。
- 该模型在通用和空间推理领域均表现出卓越性能。
点此查看论文截图
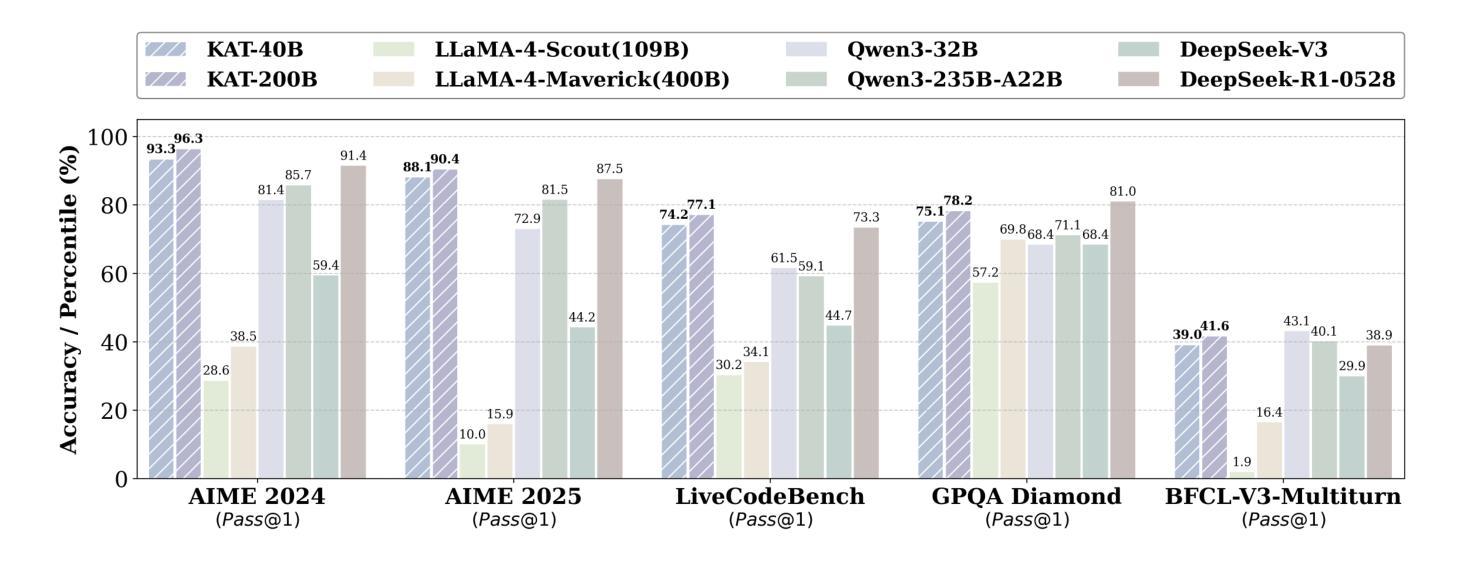
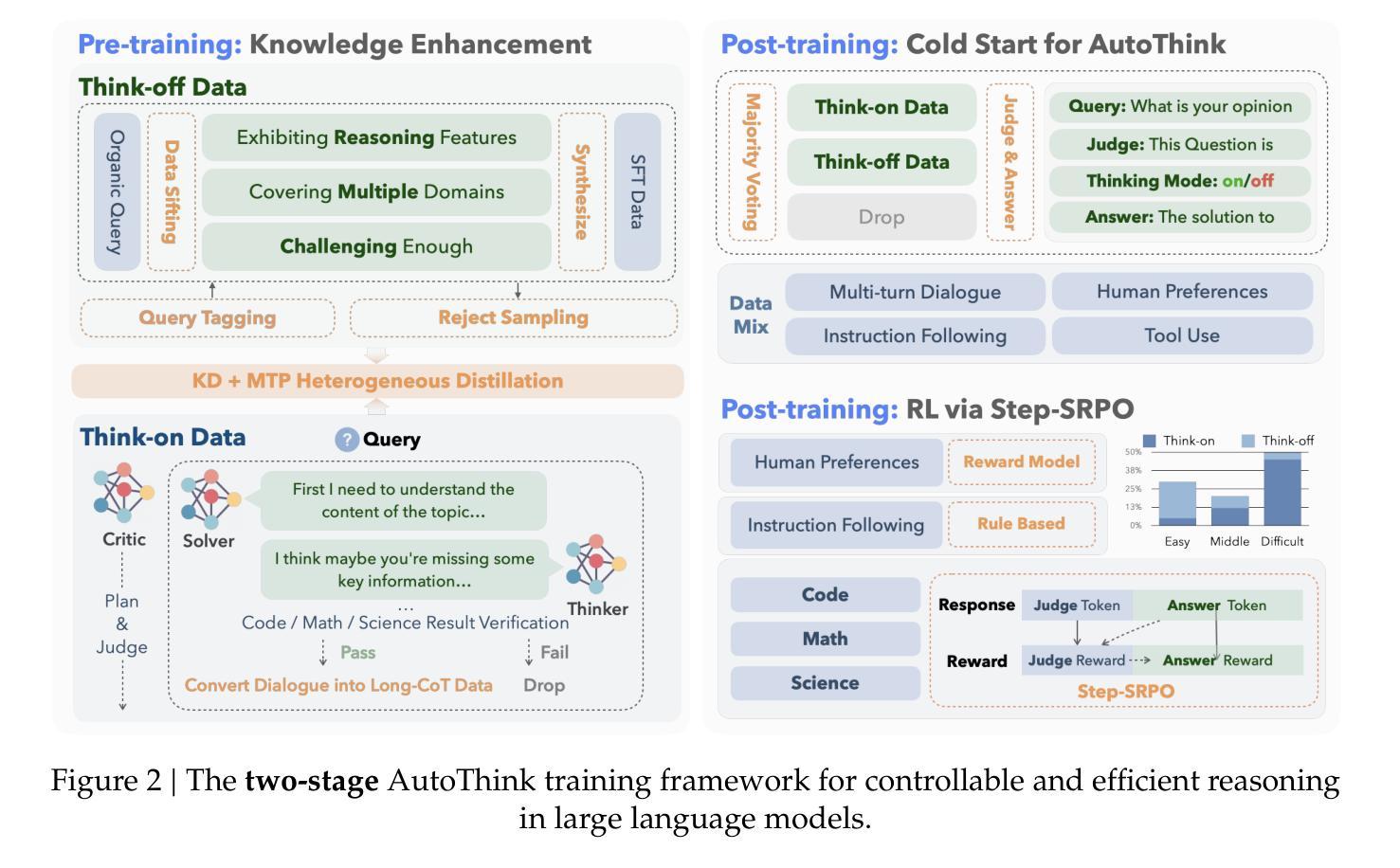
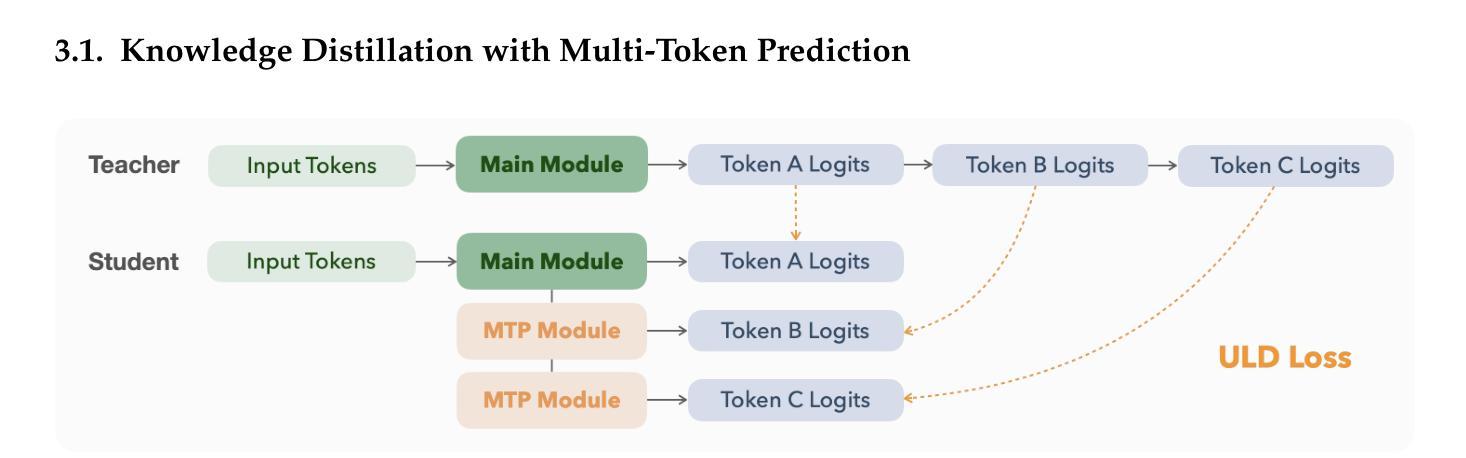
KAT-V1: Kwai-AutoThink Technical Report
Authors:Zizheng Zhan, Ken Deng, Huaixi Tang, Wen Xiang, Kun Wu, Weihao Li, Wenqiang Zhu, Jingxuan Xu, Lecheng Huang, Zongxian Feng, Shaojie Wang, Shangpeng Yan, Jiaheng Liu, Zhongyuan Peng, Zuchen Gao, Haoyang Huang, Ziqi Zhan, Yanan Wu, Yuanxing Zhang, Jian Yang, Guang Chen, Haotian Zhang, Bin Chen, Bing Yu
We present Kwaipilot-AutoThink (KAT), an open-source 40B large language model developed to address the overthinking problem in reasoning-intensive tasks, where an automatic thinking training paradigm is proposed to dynamically switch between reasoning and non-reasoning modes based on task complexity. Specifically, first, we construct the dual-regime dataset based on a novel tagging pipeline and a multi-agent synthesis strategy, and then we apply Multi-Token Prediction (MTP)-enhanced knowledge distillation, enabling efficient and fine-grained reasoning transfer with minimal pretraining cost. Besides, we implement a cold-start initialization strategy that introduces mode-selection priors using majority-vote signals and intent-aware prompting. Finally, we propose Step-SRPO, a reinforcement learning algorithm that incorporates intermediate supervision into the GRPO framework, offering structured guidance over both reasoning-mode selection and response accuracy. Extensive experiments across multiple benchmarks demonstrate that KAT consistently matches or even outperforms current state-of-the-art models, including DeepSeek-R1-0528 and Qwen3-235B-A22B, across a wide range of reasoning-intensive tasks while reducing token usage by up to approximately 30%. Beyond academic evaluation, KAT has been successfully deployed in Kwaipilot (i.e., Kuaishou’s internal coding assistant), and improves real-world development workflows with high accuracy, efficiency, and controllable reasoning behaviors. Moreover, we are actively training a 200B Mixture-of-Experts (MoE) with 40B activation parameters, where the early-stage results already demonstrate promising improvements in performance and efficiency, further showing the scalability of the AutoThink paradigm.
我们推出了Kwaipilot-AutoThink(KAT),这是一个为了解决推理密集型任务中的过度思考问题而开发的40B大型语言模型,其中提出了一种自动思考训练模式,能够根据任务复杂性在推理和非推理模式之间进行动态切换。具体来说,首先,我们基于一种新颖的标签处理管道和多代理合成策略构建了双体制数据集,然后应用增强了的多令牌预测(MTP)知识蒸馏技术,实现了高效的精细推理转移,同时最小化了预训练成本。此外,我们实现了一种冷启动初始化策略,利用多数投票信号和意图感知提示来引入模式选择先验。最后,我们提出了Step-SRPO,这是一种增强学习算法,它将中间监督融入GRPO框架,为推理模式选择和响应准确性提供结构化指导。在多基准测试上的广泛实验表明,KAT在多种推理密集型任务上表现一直与当前最先进的模型保持一致甚至表现更好,包括DeepSeek-R1-0528和Qwen3-235B-A22B等模型,同时最多能减少约30%的令牌使用量。除了学术评估之外,KAT已经在Kwaipilot(即快手的内部编码助手)中得到成功部署,通过高准确性、高效率和控制推理行为来改进现实工作流程。此外,我们正在积极训练一个拥有200B的专家混合模型(MoE),其中包含高达激活参数的激活参数高达四十亿比特。早期阶段的结果已经显示出在性能和效率方面的明显改进,进一步证明了AutoThink模式的可扩展性。
论文及项目相关链接
Summary
江山联合推出了一款名为Kwaipilot-AutoThink的大型语言模型,该模型旨在解决推理密集型任务中的过度思考问题。它采用自动思考训练范式,根据任务复杂度动态切换推理和非推理模式。该模型通过构建双体制数据集、应用多令牌预测知识蒸馏技术、实现冷启动初始化策略以及提出结合中间监督的强化学习算法Step-SRPO,提高了推理效率和准确性。实验表明,江山模型在多个基准测试中表现优异,并在快手内部编码助手Kwaipilot中得到成功部署。此外,团队正在积极训练一个混合专家模型,初步结果也显示出在性能和效率方面的改进。
Key Takeaways
- Kwaipilot-AutoThink是一个旨在解决推理密集型任务中过度思考问题的40B大型语言模型。
- 该模型采用自动思考训练范式,能够根据任务复杂度动态切换推理和非推理模式。
- 通过构建双体制数据集和多令牌预测知识蒸馏技术,提高了模型的推理效率和精细度。
- 模型实施了冷启动初始化策略,通过引入模式选择先验和意图感知提示来提升性能。
- Step-SRPO强化学习算法结合了中间监督,为推理模式选择和响应准确性提供了结构化指导。
- 实验证明,Kwaipilot-AutoThink在多个基准测试中表现优异,相较于其他先进模型有所超越。
点此查看论文截图


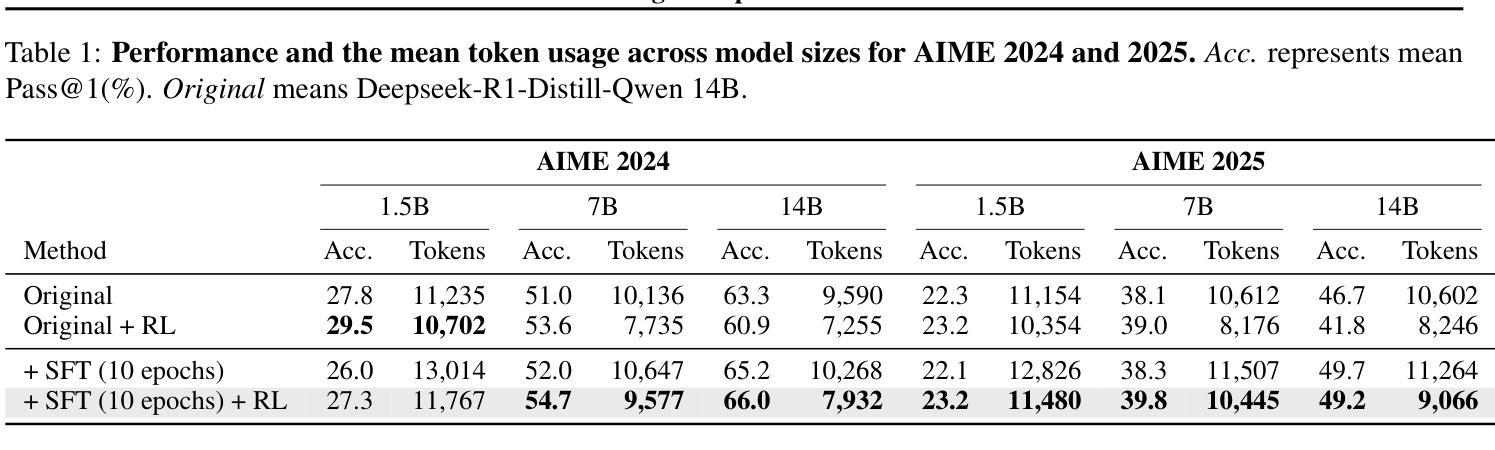
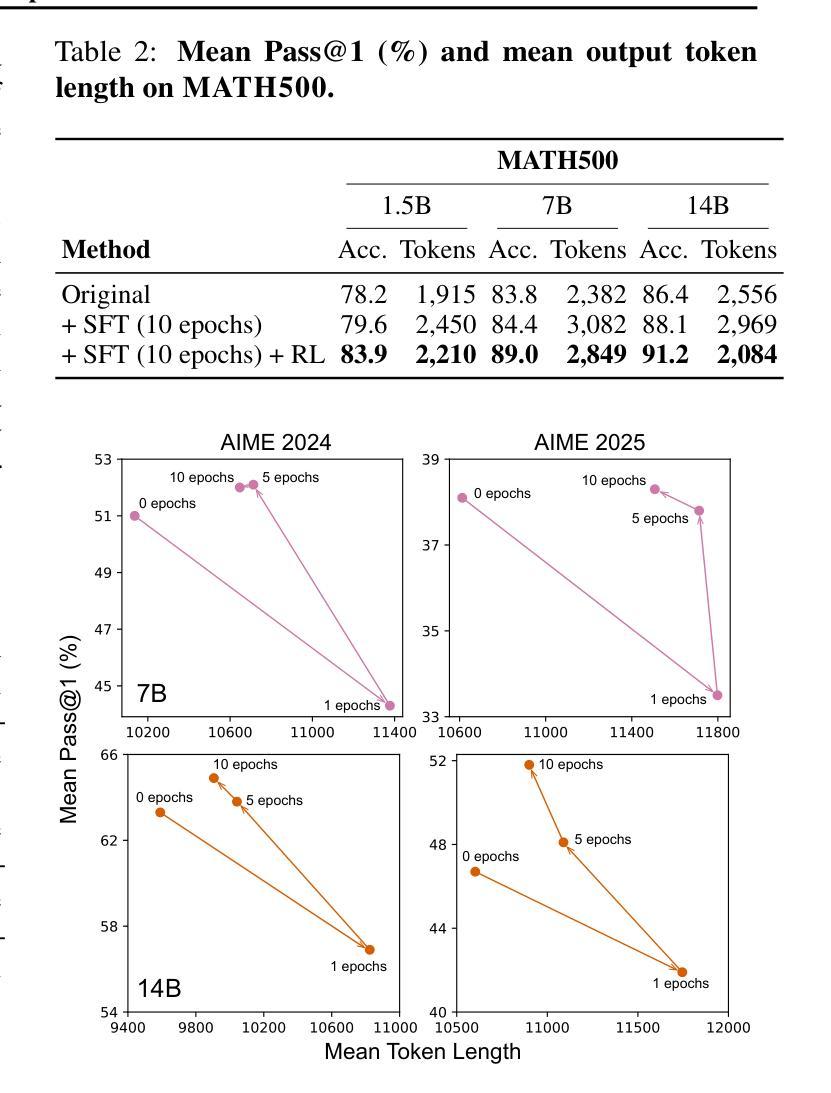
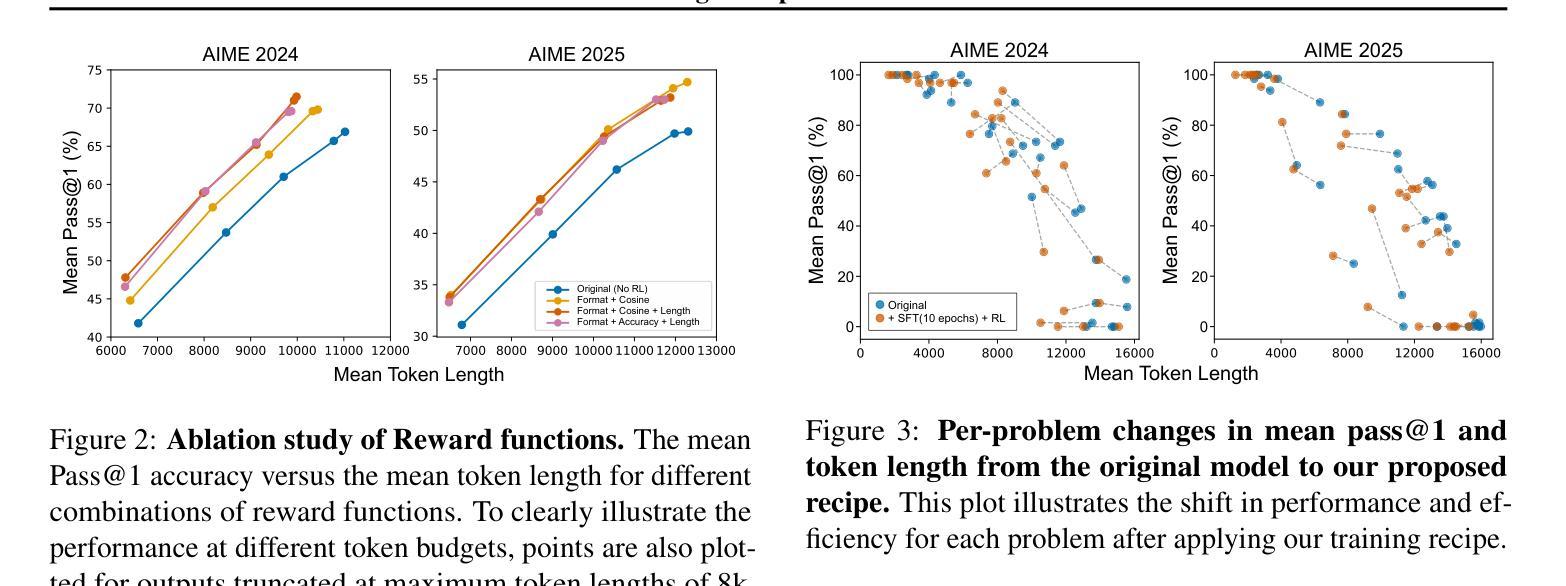
A Practical Two-Stage Recipe for Mathematical LLMs: Maximizing Accuracy with SFT and Efficiency with Reinforcement Learning
Authors:Hiroshi Yoshihara, Taiki Yamaguchi, Yuichi Inoue
Enhancing the mathematical reasoning of Large Language Models (LLMs) is a pivotal challenge in advancing AI capabilities. While Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) are the dominant training paradigms, a systematic methodology for combining them to maximize both accuracy and efficiency remains largely unexplored. This paper introduces a practical and effective training recipe that strategically integrates extended SFT with RL from online inference (GRPO). We posit that these methods play complementary, not competing, roles: a prolonged SFT phase first pushes the model’s accuracy to its limits, after which a GRPO phase dramatically improves token efficiency while preserving this peak performance. Our experiments reveal that extending SFT for as many as 10 epochs is crucial for performance breakthroughs, and that the primary role of GRPO in this framework is to optimize solution length. The efficacy of our recipe is rigorously validated through top-tier performance on challenging benchmarks, including a high rank among over 2,200 teams in the strictly leak-free AI Mathematical Olympiad (AIMO). This work provides the community with a battle-tested blueprint for developing state-of-the-art mathematical reasoners that are both exceptionally accurate and practically efficient. To ensure full reproducibility and empower future research, we will open-source our entire framework, including all code, model checkpoints, and training configurations at https://github.com/analokmaus/kaggle-aimo2-fast-math-r1.
增强大型语言模型(LLM)的数学推理能力是提升人工智能能力的重要挑战。尽管有监督微调(SFT)和强化学习(RL)是主要的训练范式,但将它们结合起来以最大化准确性和效率的系统性方法仍然很大程度上未被探索。本文介绍了一种实用有效的训练配方,它战略性地结合了扩展的SFT与来自在线推理的RL(GRPO)。我们认为这些方法起到的是互补作用,而非竞争作用:首先,延长的SFT阶段会将模型的准确性推至极限,随后GRPO阶段在保持这种峰值性能的同时,显著提高令牌效率。我们的实验表明,将SFT延长多达10个周期对于性能突破至关重要,而GRPO在此框架中的主要作用是优化解决方案长度。该配方的有效性通过在一流性能的挑战基准测试上进行了严格验证,包括在严格无泄漏的人工智能数学奥林匹克竞赛(AIMO)中名列前茅的超过2,200支团队中名列前茅。这项工作为社区提供了一个经过实战检验的蓝图,用于开发既精确又实用的最新数学推理器。为确保可重复性和促进未来研究,我们将在https://github.com/analokmaus/kaggle-aimo2-fast-math-r1上公开整个框架的所有代码、模型检查点和训练配置。
论文及项目相关链接
PDF Presented at ICML 2025 Workshop on The second AI for MATH
Summary
强化大型语言模型(LLM)的数学推理能力是提升人工智能能力的重要挑战。本文介绍了一种结合监督微调(SFT)和在线推理强化学习(GRPO)的有效训练策略。研究认为这两种方法具有互补作用而非竞争关系:先进行长时间的SFT训练以提升模型精度,然后采用GRPO训练以显著改进token效率同时保持顶尖性能。实验表明,进行多达10个epoch的SFT训练对性能至关重要,而GRPO的主要作用是在这个框架中优化解决方案长度。本文提供的蓝图已在顶级挑战赛中表现优异,包括在严格无泄漏的AI数学奥林匹克竞赛(AIMO)中名列前茅。研究将公开整个框架,包括代码、模型检查点和训练配置,以确保可重复性和未来研究。
Key Takeaways
- 大型语言模型(LLM)的数学推理能力提升是AI发展的关键挑战。
- 本文结合了监督微调(SFT)和在线推理强化学习(GRPO)两种训练范式。
- SFT和GRPO具有互补性,而非竞争性,其中SFT用于提高模型精度,GRPO用于改善token效率并保持高性能。
- 实验显示,进行更多epoch的SFT训练对性能至关重要,而GRPO主要优化解决方案长度。
- 该方法在顶级挑战赛中表现卓越,包括在AI数学奥林匹克竞赛中名列前茅。
- 研究将公开框架、代码、模型检查点和训练配置,以促进未来研究。
点此查看论文截图

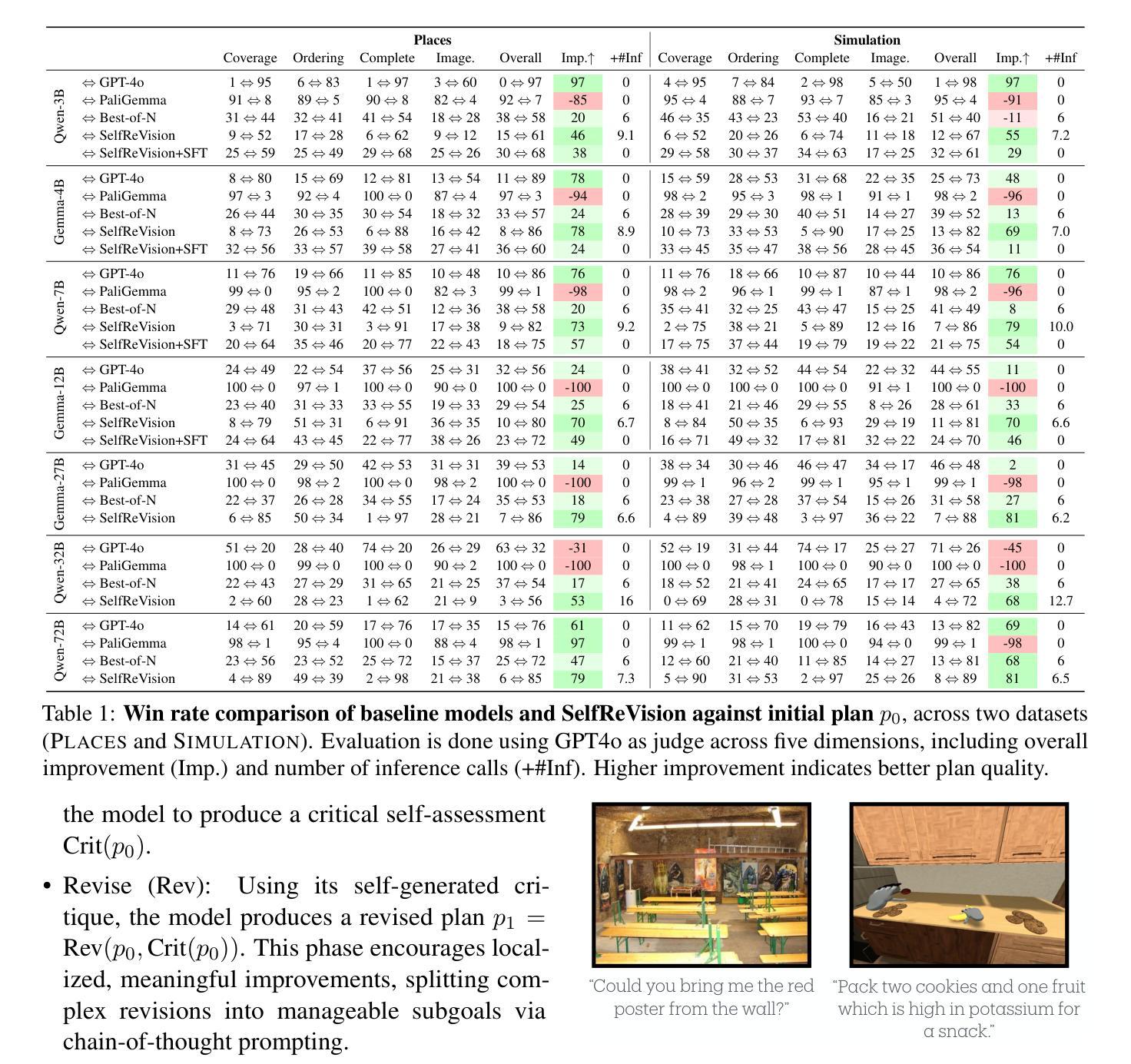
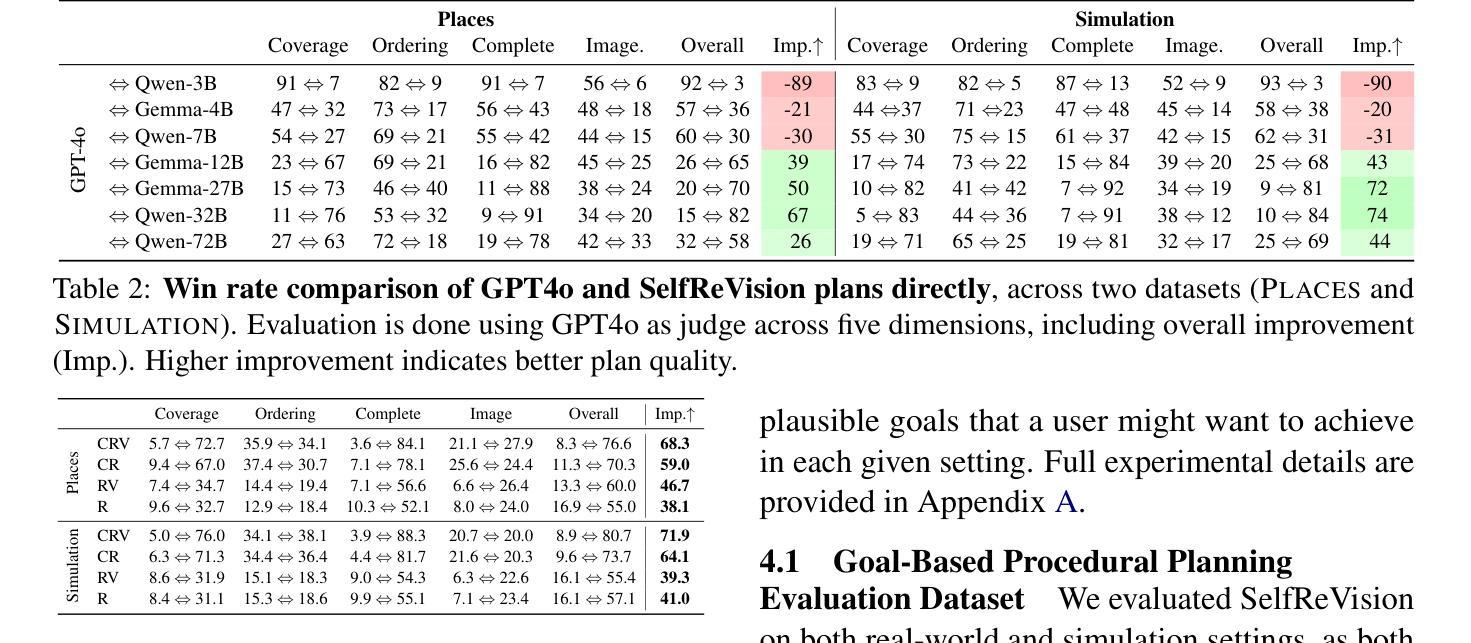
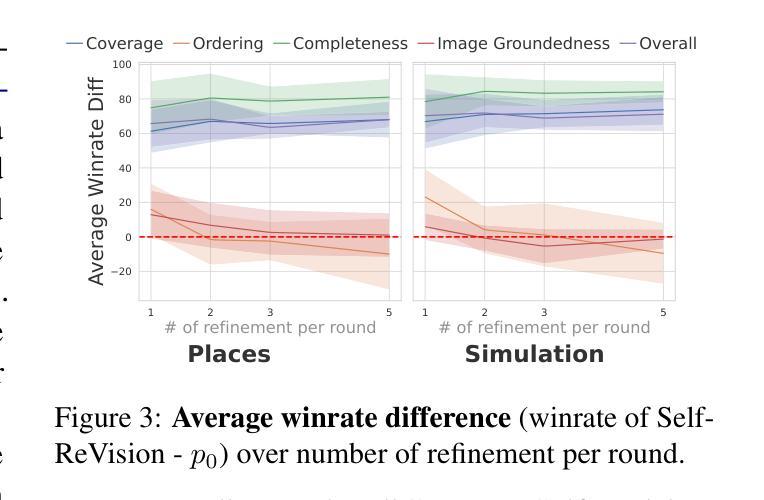
Making VLMs More Robot-Friendly: Self-Critical Distillation of Low-Level Procedural Reasoning
Authors:Chan Young Park, Jillian Fisher, Marius Memmel, Dipika Khullar, Andy Yun, Abhishek Gupta, Yejin Choi
Large language models (LLMs) have shown promise in robotic procedural planning, yet their human-centric reasoning often omits the low-level, grounded details needed for robotic execution. Vision-language models (VLMs) offer a path toward more perceptually grounded plans, but current methods either rely on expensive, large-scale models or are constrained to narrow simulation settings. We introduce SelfReVision, a lightweight and scalable self-improvement framework for vision-language procedural planning. SelfReVision enables small VLMs to iteratively critique, revise, and verify their own plans-without external supervision or teacher models-drawing inspiration from chain-of-thought prompting and self-instruct paradigms. Through this self-distillation loop, models generate higher-quality, execution-ready plans that can be used both at inference and for continued fine-tuning. Using models varying from 3B to 72B, our results show that SelfReVision not only boosts performance over weak base VLMs but also outperforms models 100X the size, yielding improved control in downstream embodied tasks.
大型语言模型(LLM)在机器人程序规划方面显示出潜力,但它们以人为中心的推理往往会忽略机器人执行所需的低级、具体细节。视觉语言模型(VLM)为更感知具体的计划提供了途径,但当前的方法要么依赖于昂贵的大规模模型,要么仅限于狭窄的仿真环境。我们引入了SelfReVision,这是一个用于视觉语言程序规划的轻量级和可扩展的自我改进框架。SelfReVision使小型VLM能够迭代地评估、修改和验证自己的计划,而无需外部监督或教师模型,这得益于思维链提示和自我指导范式的启发。通过这个自我提炼循环,模型生成了高质量、可执行的计划,这些计划既可用于推理,也可用于持续微调。使用从3B到72B不等的模型,我们的结果表明,SelfReVision不仅提升了基础较弱VLM的性能,而且超越了规模大100倍的模型,在下游实体任务中实现了更好的控制。
论文及项目相关链接
PDF Code Available: https://github.com/chan0park/SelfReVision
摘要
大型语言模型在机器人程序规划上展现出潜力,但它们以人类为中心的推理往往忽略了机器人执行所需的低级、具体细节。视觉语言模型为更感知具体的计划提供了途径,但当前方法要么依赖于昂贵的大规模模型,要么仅限于狭窄的模拟环境。本文提出了SelfReVision,一个用于视觉语言程序规划的轻量级和可扩展的自我改进框架。SelfReVision使小型VLM能够自我批判、修订和验证其计划,无需外部监督或教师模型,灵感来源于思维链提示和自我指导范式。通过这个自我蒸馏循环,模型可以生成高质量、适合执行的计划,这些计划既可用于推理,也可用于持续微调。使用从3B到72B不等的模型,结果表明,SelfReVision不仅提高了基础VLM的性能,而且在下游实体任务中的表现优于规模大100倍的模型,实现了下游任务控制能力的提升。
关键见解
- 大型语言模型在机器人程序规划中有潜力,但需弥补其缺乏低级、具体细节的问题。
- 视觉语言模型(VLMs)是向更感知具体化的计划迈进的途径,但现有方法存在模型规模大或应用环境受限的问题。
- SelfReVision是一个轻量级和可扩展的自我改进框架,用于视觉语言程序规划。
- SelfReVision使小型VLM能够自我批判、修订和验证计划,无需外部监督或教师模型。
- SelfReVision通过自我蒸馏循环生成高质量、适合执行的计划,这些计划可用于推理和持续微调。
- SelfReVision不仅提高了基础VLM的性能,而且在下游实体任务中的表现优异。
点此查看论文截图


GRASP: Generic Reasoning And SPARQL Generation across Knowledge Graphs
Authors:Sebastian Walter, Hannah Bast
We propose a new approach for generating SPARQL queries on RDF knowledge graphs from natural language questions or keyword queries, using a large language model. Our approach does not require fine-tuning. Instead, it uses the language model to explore the knowledge graph by strategically executing SPARQL queries and searching for relevant IRIs and literals. We evaluate our approach on a variety of benchmarks (for knowledge graphs of different kinds and sizes) and language models (of different scales and types, commercial as well as open-source) and compare it with existing approaches. On Wikidata we reach state-of-the-art results on multiple benchmarks, despite the zero-shot setting. On Freebase we come close to the best few-shot methods. On other, less commonly evaluated knowledge graphs and benchmarks our approach also performs well overall. We conduct several additional studies, like comparing different ways of searching the graphs, incorporating a feedback mechanism, or making use of few-shot examples.
我们提出了一种新的方法,使用大型语言模型从自然语言问题或关键字查询生成RDF知识图上的SPARQL查询。我们的方法不需要微调。相反,它使用语言模型通过战略性地执行SPARQL查询并搜索相关的IRI和文字来探索知识图。我们在各种基准测试(针对不同类型和大小的知识图)和语言模型(不同规模和类型,包括商业和开源)上评估了我们的方法,并将其与现有方法进行了比较。在WikiData上,我们在多个基准测试上达到了最先进的水平,尽管我们处于零样本环境。在Freebase上,我们接近最佳少样本方法的表现。在其他较少评估的知识图和基准测试上,我们的方法总体上也有良好的表现。我们还进行了其他一些研究,如比较搜索图形的不同方式、引入反馈机制或利用少样本示例等。
论文及项目相关链接
Summary
基于大型语言模型,我们提出了一种新的方法,用于从自然语言问题或关键词查询生成RDF知识图谱上的SPARQL查询,无需微调。它通过战略性地执行SPARQL查询并搜索相关的IRIs和文字来探索知识图谱。我们在多种基准测试(针对不同类型和大小的知识图谱)和语言模型(包括商业和开源的不同规模和类型)上评估了我们的方法,并与现有方法进行了比较。我们在WikiData上取得了多个基准测试的最佳结果,尽管我们是在零样本环境下实现的。在Freebase上,我们的表现接近最佳的几次示例方法。在其他较少评估的知识图谱和基准测试上,我们的方法总体上表现良好。我们还进行了其他额外研究,如比较不同的图形搜索方式、引入反馈机制或利用几次示例等。
Key Takeaways
- 提出了一种新的基于大型语言模型的SPARQL查询生成方法,用于从RDF知识图谱生成查询。
- 该方法无需微调,可以直接使用语言模型探索知识图谱。
- 在多种知识图谱和基准测试上进行了评估,包括WikiData和Freebase。
- 在WikiData上取得了多个基准测试的最佳结果,表现优异。
- 在Freebase上的表现接近最佳几次示例方法。
- 该方法在其他知识图谱和基准测试上的表现总体上良好。
点此查看论文截图


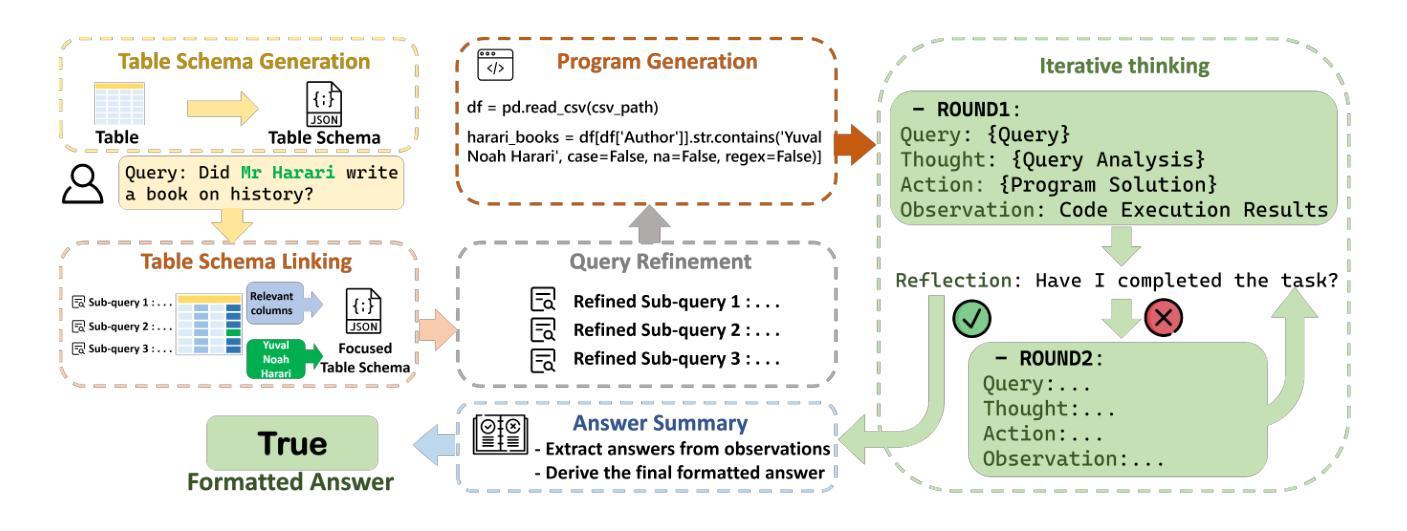
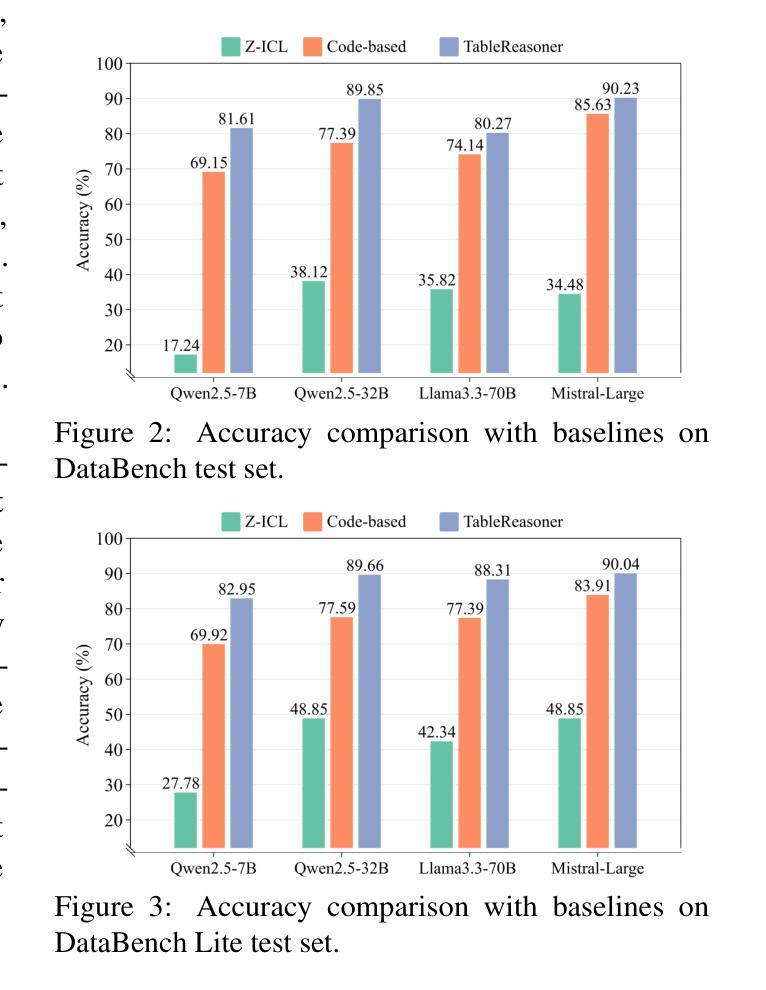
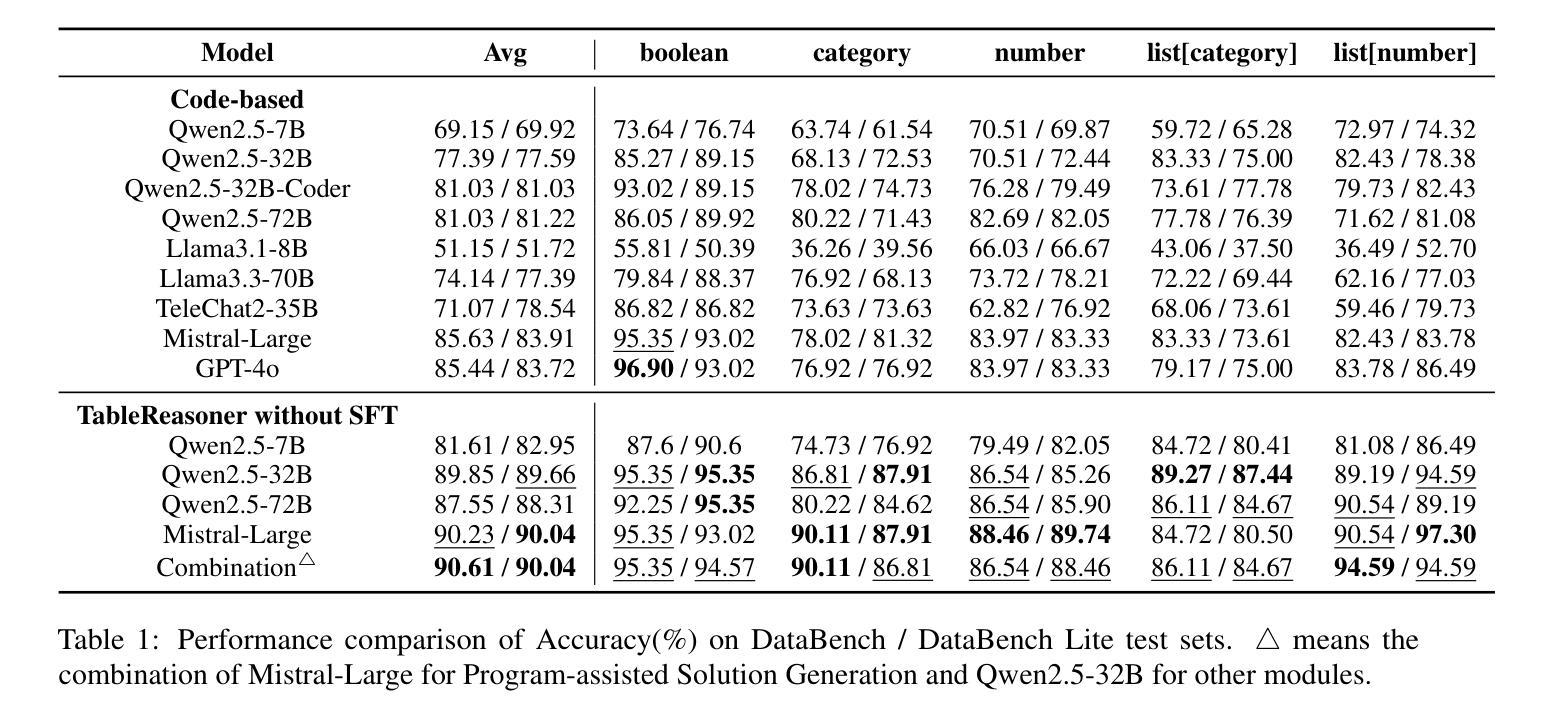
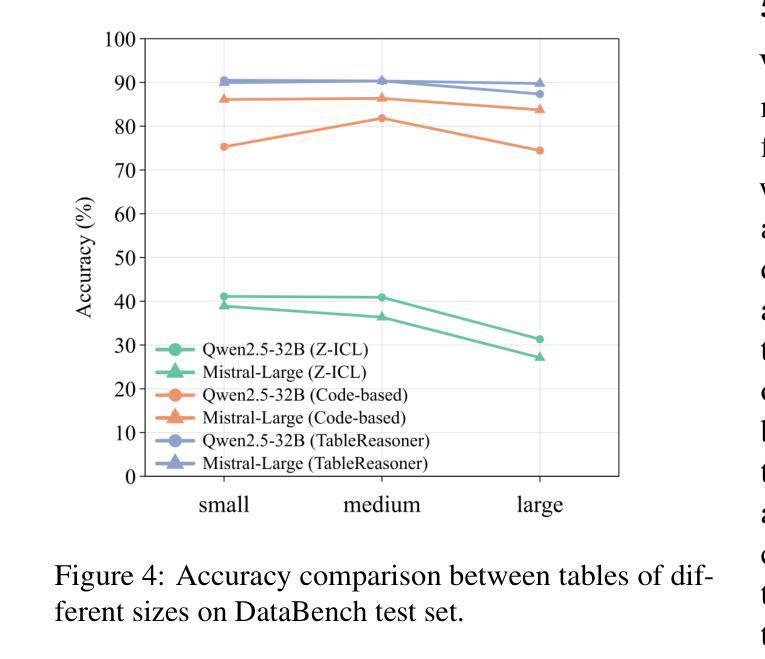
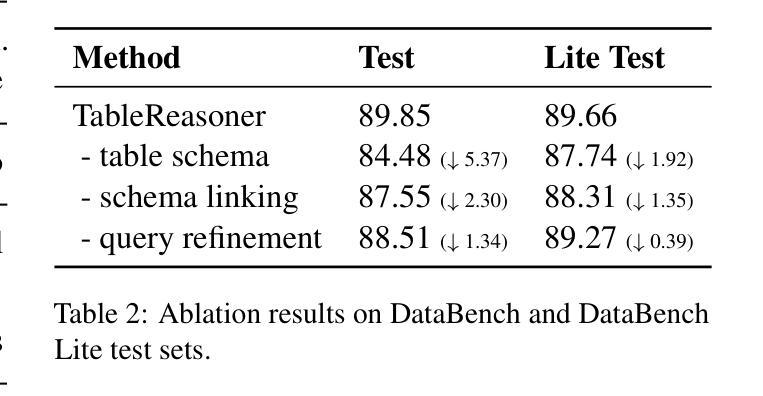
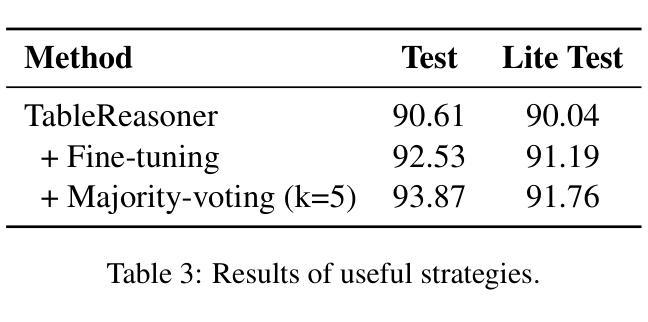
TableReasoner: Advancing Table Reasoning Framework with Large Language Models
Authors:Sishi Xiong, Dakai Wang, Yu Zhao, Jie Zhang, Changzai Pan, Haowei He, Xiangyu Li, Wenhan Chang, Zhongjiang He, Shuangyong Song, Yongxiang Li
The paper presents our system developed for table question answering (TQA). TQA tasks face challenges due to the characteristics of real-world tabular data, such as large size, incomplete column semantics, and entity ambiguity. To address these issues, we propose a large language model (LLM)-powered and programming-based table reasoning framework, named TableReasoner. It models a table using the schema that combines structural and semantic representations, enabling holistic understanding and efficient processing of large tables. We design a multi-step schema linking plan to derive a focused table schema that retains only query-relevant information, eliminating ambiguity and alleviating hallucinations. This focused table schema provides precise and sufficient table details for query refinement and programming. Furthermore, we integrate the reasoning workflow into an iterative thinking architecture, allowing incremental cycles of thinking, reasoning and reflection. Our system achieves first place in both subtasks of SemEval-2025 Task 8.
本文介绍了我们为表格问答(TQA)任务开发的系统。TQA任务由于现实世界表格数据的特点而面临挑战,例如表格数据量大、列语义不完整和实体歧义等。为了解决这些问题,我们提出了一种基于大型语言模型(LLM)和编程的表格推理框架,名为TableReasoner。它使用结合结构和语义表示的架构对表格进行建模,实现对大表格的整体理解和高效处理。我们设计了一个多步骤架构链接计划,以推导出专注于查询的表格架构,该架构只保留与查询相关的信息,消除歧义并减轻虚构现象。此专注于查询的表格架构为查询优化和编程提供了精确且足够的表格细节。此外,我们将推理工作流程整合到迭代思维架构中,允许思考、推理和反思的增量循环。我们的系统在SemEval-2025任务8的两个子任务中均获得第一名。
论文及项目相关链接
Summary:
本文介绍了一个为表格问答(TQA)系统所开发的系统。面对现实世界中表格数据的特点,如大规模、列语义不完整和实体歧义等挑战,我们提出了一种基于大型语言模型(LLM)的编程式表格推理框架——TableReasoner。它通过结合结构性和语义表示来建模表格,实现对大型表格的整体理解和高效处理。设计了一个多步骤的架构链接计划,以推导出专注于查询相关信息的表格架构,消除歧义并减轻虚构现象。整合推理工作流程到迭代思维架构中,允许思考、推理和反思的增量循环。该系统在SemEval-2025任务8的两个子任务中均获得第一名。
Key Takeaways:
- 系统针对表格问答(TQA)任务开发。
- 面对表格数据大规模、列语义不完整和实体歧义等挑战。
- 提出了基于大型语言模型(LLM)的编程式表格推理框架——TableReasoner。
- TableReasoner通过结合结构性和语义表示来建模表格。
- 设计了多步骤架构链接计划以消除歧义并减轻虚构现象。
- 系统整合了推理工作流程到迭代思维架构中。
- 系统在SemEval-2025任务8的两个子任务中表现优异。
点此查看论文截图

Measuring AI Alignment with Human Flourishing
Authors:Elizabeth Hilliard, Akshaya Jagadeesh, Alex Cook, Steele Billings, Nicholas Skytland, Alicia Llewellyn, Jackson Paull, Nathan Paull, Nolan Kurylo, Keatra Nesbitt, Robert Gruenewald, Anthony Jantzi, Omar Chavez
This paper introduces the Flourishing AI Benchmark (FAI Benchmark), a novel evaluation framework that assesses AI alignment with human flourishing across seven dimensions: Character and Virtue, Close Social Relationships, Happiness and Life Satisfaction, Meaning and Purpose, Mental and Physical Health, Financial and Material Stability, and Faith and Spirituality. Unlike traditional benchmarks that focus on technical capabilities or harm prevention, the FAI Benchmark measures AI performance on how effectively models contribute to the flourishing of a person across these dimensions. The benchmark evaluates how effectively LLM AI systems align with current research models of holistic human well-being through a comprehensive methodology that incorporates 1,229 objective and subjective questions. Using specialized judge Large Language Models (LLMs) and cross-dimensional evaluation, the FAI Benchmark employs geometric mean scoring to ensure balanced performance across all flourishing dimensions. Initial testing of 28 leading language models reveals that while some models approach holistic alignment (with the highest-scoring models achieving 72/100), none are acceptably aligned across all dimensions, particularly in Faith and Spirituality, Character and Virtue, and Meaning and Purpose. This research establishes a framework for developing AI systems that actively support human flourishing rather than merely avoiding harm, offering significant implications for AI development, ethics, and evaluation.
本文介绍了繁荣人工智能基准(FAI基准),这是一种新型评估框架,用于评估人工智能与人类繁荣的契合程度,涵盖七个维度:性格与美德、亲密社会关系、幸福与生活满意度、意义与目的、身心健康、财务与物质稳定、信仰与灵性。与传统的专注于技术能力或伤害预防的基准不同,FAI基准衡量的是人工智能在这些维度上如何有效地促进人的繁荣。该基准通过一种综合方法(包含1229个客观和主观问题)来评估大型语言模型AI系统如何有效地与当前的整体人类福祉研究模型相吻合。使用专业的大型语言模型(LLM)和跨维度评估,FAI基准采用几何均值评分法,以确保在所有繁荣维度上的均衡表现。对28种领先的语言模型的初步测试表明,尽管一些模型接近整体对齐(得分最高的模型达到72/100),但没有模型能在所有维度上实现可接受的契合度,特别是在信仰与灵性、性格与美德、意义与目的方面。该研究为开发积极支持人类繁荣的AI系统建立了框架,而不是仅仅避免伤害,对AI开发、伦理和评估产生了重大影响。
论文及项目相关链接
Summary:
此论文介绍了繁荣人工智能基准(FAI Benchmark),这是一种新型评估框架,旨在评估人工智能在七个维度上对人类繁荣的契合度:性格与美德、亲密社会关系、幸福与生活满意度、意义与目的、身心健康、财务与物质稳定、信仰与灵性。与传统的以技术能力或伤害预防为重点的基准不同,FAI Benchmark衡量的是人工智能模型如何有效地促进个人在这些维度上的繁荣。该基准通过包含1,229个客观和主观问题的综合方法,评估大型语言模型(LLM)如何与整体人类福祉的当前研究模型相吻合。初步测试显示,尽管一些模型接近整体对齐(得分最高的模型达到72/100),但没有模型在所有维度上都能接受对齐,特别是在信仰与灵性、性格与美德以及意义与目的方面。这项研究为开发积极支持人类繁荣而非仅仅避免伤害的人工智能系统建立了基准,对人工智能的发展、伦理和评估具有重要意义。
Key Takeaways:
- Flourishing AI Benchmark(FAI Benchmark)是一个新的评估框架,旨在评估AI如何促进人类的全面繁荣。
- 该框架包含七个关键维度,涵盖性格与美德、人际关系、幸福与满足、意义与目的等方面。
- FAI Benchmark采用综合方法评估AI模型的表现,包括大量客观和主观问题。
- 初步测试表明,尽管某些AI模型在某些维度上表现良好,但还没有模型在所有维度上都达到理想的对齐状态。
- 在信仰与灵性、性格与美德以及意义与目的方面,AI模型的对齐尤其存在问题。
- 此研究强调了开发支持人类繁荣的AI系统的重要性,而不仅仅是避免伤害。
点此查看论文截图

Squeeze the Soaked Sponge: Efficient Off-policy Reinforcement Finetuning for Large Language Model
Authors:Jing Liang, Hongyao Tang, Yi Ma, Jinyi Liu, Yan Zheng, Shuyue Hu, Lei Bai, Jianye Hao
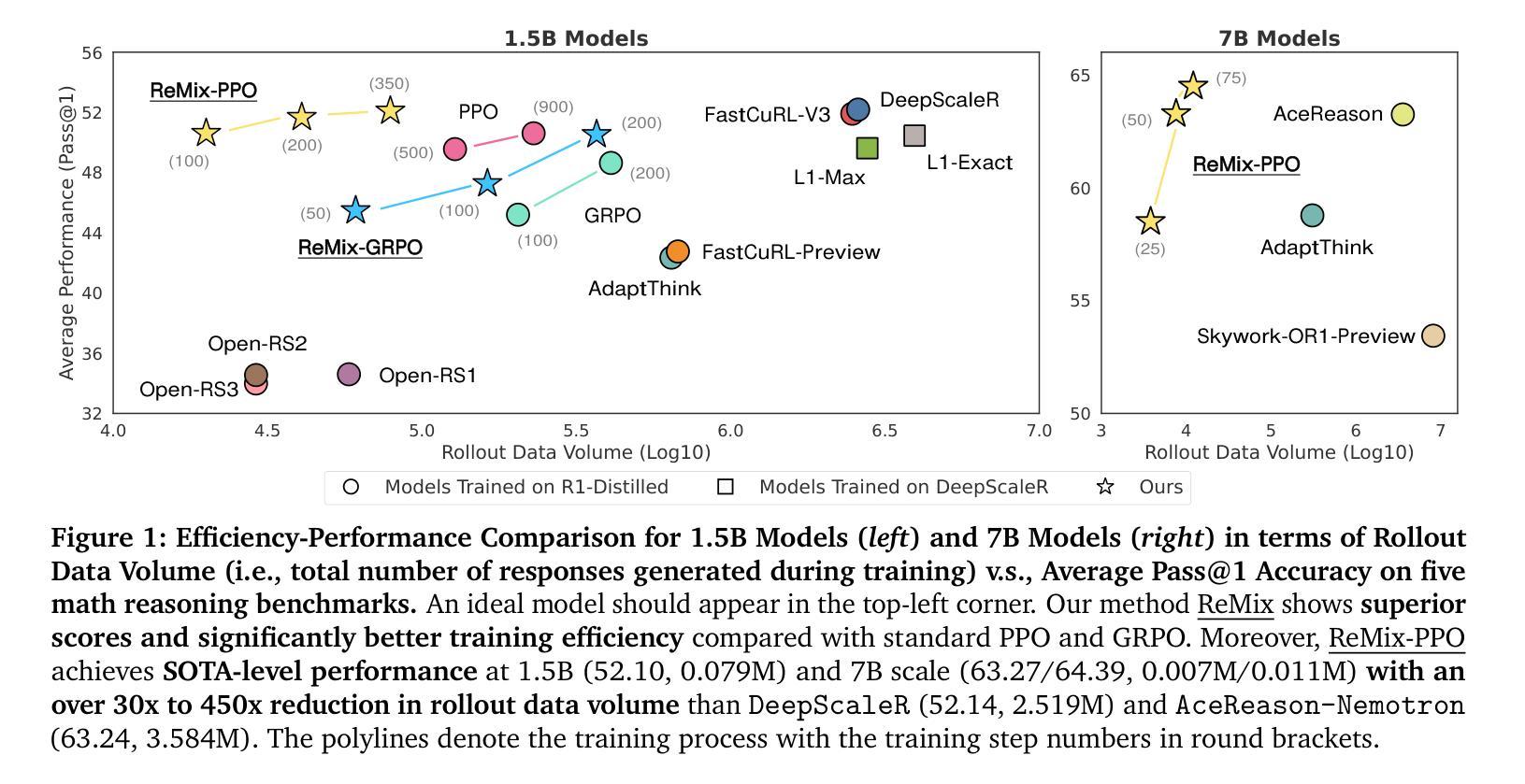
Reinforcement Learning (RL) has demonstrated its potential to improve the reasoning ability of Large Language Models (LLMs). One major limitation of most existing Reinforcement Finetuning (RFT) methods is that they are on-policy RL in nature, i.e., data generated during the past learning process is not fully utilized. This inevitably comes at a significant cost of compute and time, posing a stringent bottleneck on continuing economic and efficient scaling. To this end, we launch the renaissance of off-policy RL and propose Reincarnating Mix-policy Proximal Policy Gradient (ReMix), a general approach to enable on-policy RFT methods like PPO and GRPO to leverage off-policy data. ReMix consists of three major components: (1) Mix-policy proximal policy gradient with an increased Update-To-Data (UTD) ratio for efficient training; (2) KL-Convex policy constraint to balance the trade-off between stability and flexibility; (3) Policy reincarnation to achieve a seamless transition from efficient early-stage learning to steady asymptotic improvement. In our experiments, we train a series of ReMix models upon PPO, GRPO and 1.5B, 7B base models. ReMix shows an average Pass@1 accuracy of 52.10% (for 1.5B model) with 0.079M response rollouts, 350 training steps and achieves 63.27%/64.39% (for 7B model) with 0.007M/0.011M response rollouts, 50/75 training steps, on five math reasoning benchmarks (i.e., AIME’24, AMC’23, Minerva, OlympiadBench, and MATH500). Compared with 15 recent advanced models, ReMix shows SOTA-level performance with an over 30x to 450x reduction in training cost in terms of rollout data volume. In addition, we reveal insightful findings via multifaceted analysis, including the implicit preference for shorter responses due to the Whipping Effect of off-policy discrepancy, the collapse mode of self-reflection behavior under the presence of severe off-policyness, etc.
强化学习(RL)已经显示出提高大型语言模型(LLM)推理能力的潜力。大多数现有强化微调(RFT)方法的一个主要局限性在于它们本质上是基于有策略强化学习,即过去学习过程中生成的数据没有得到充分利用。这不可避免地需要巨大的计算和时间的投入,成为经济高效扩展的严格瓶颈。为此,我们开启了离线强化学习的复兴,并提出了再生的混合策略近端策略梯度(ReMix),这是一种通用方法,使像PPO和GRPO这样的在线策略RFT方法能够利用离线策略数据。ReMix由三个主要组成部分构成:(1)混合策略近端策略梯度,通过增加更新到数据(UTD)比率以实现高效训练;(2)KL-凸策略约束以平衡稳定性和灵活性的权衡;(3)策略再生以实现从高效早期学习到稳定渐进改进的无缝过渡。在我们的实验中,我们在PPO、GRPO和基于1.5B、7B的模型上训练了一系列ReMix模型。ReMix在五个数学推理基准测试(即AIME’24、AMC’23、Minerva、OlympiadBench和MATH500)上显示出平均Pass@1准确率为52.1%(针对1.5B模型),使用0.079M响应回放,训练步骤为350步;对于7B模型,准确率为63.27%/64.39%,使用分别为0.007M和0.011M的响应回放,训练步骤为50步和75步。与最近的先进模型相比,ReMix展现出顶尖的性能水平,在回放数据量方面将训练成本减少了30倍至450倍。此外,我们通过多方面的分析揭示了深刻的见解,包括离线策略差异的鞭打效应导致的对较短答案的隐性偏好、在严重离线策略情况下自我反思行为的崩溃模式等。
论文及项目相关链接
PDF Preliminary version, v3, added the missing name of x-axis in the left part of Fig.1 and corrected a wrong number in Fig.3. Project page: https://anitaleungxx.github.io/ReMix
Summary
强化学习(RL)在提高大型语言模型(LLM)的推理能力方面具有潜力。现有大部分强化微调(RFT)方法存在局限性,因为它们本质上是基于策略的强化学习,无法充分利用过去学习过程中生成的数据。为解决这一问题,我们推出了混合策略的复兴,并提出了ReMix方法,使PPO和GRPO等基于策略的RFT方法能够利用非策略数据。ReMix包括三个主要组件:(1)混合策略近端策略梯度算法,通过提高更新到数据的比例实现高效训练;(2)KL散度凸策略约束以实现稳定性和灵活性之间的平衡;(3)策略重生机制实现从早期高效学习到持续渐进改进的无缝过渡。实验表明,ReMix模型在五个数学推理基准测试上表现出卓越性能,相较于其他先进模型大幅降低了训练成本。此外,我们还通过多元分析揭示了有趣的发现。
Key Takeaways
- 强化学习(RL)有望提升大型语言模型(LLM)的推理能力。
- 当前强化微调(RFT)方法存在局限性,主要基于策略的强化学习,未能充分利用历史数据。
- ReMix方法结合了混合策略近端策略梯度算法,旨在解决上述问题,提升训练效率。
- ReMix包括三个核心组件:混合策略、KL散度凸策略约束和策略重生机制。
- 实验结果显示ReMix模型在数学推理基准测试上表现卓越,显著优于其他模型。
- ReMix模型的训练成本大幅降低,达到30倍至450倍的数据卷量缩减。
点此查看论文截图

Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities
Authors:Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, Luke Marris, Sam Petulla, Colin Gaffney, Asaf Aharoni, Nathan Lintz, Tiago Cardal Pais, Henrik Jacobsson, Idan Szpektor, Nan-Jiang Jiang, Krishna Haridasan, Ahmed Omran, Nikunj Saunshi, Dara Bahri, Gaurav Mishra, Eric Chu, Toby Boyd, Brad Hekman, Aaron Parisi, Chaoyi Zhang, Kornraphop Kawintiranon, Tania Bedrax-Weiss, Oliver Wang, Ya Xu, Ollie Purkiss, Uri Mendlovic, Ilaï Deutel, Nam Nguyen, Adam Langley, Flip Korn, Lucia Rossazza, Alexandre Ramé, Sagar Waghmare, Helen Miller, Vaishakh Keshava, Ying Jian, Xiaofan Zhang, Raluca Ada Popa, Kedar Dhamdhere, Blaž Bratanič, Kyuyeun Kim, Terry Koo, Ferran Alet, Yi-ting Chen, Arsha Nagrani, Hannah Muckenhirn, Zhiyuan Zhang, Corbin Quick, Filip Pavetić, Duc Dung Nguyen, Joao Carreira, Michael Elabd, Haroon Qureshi, Fabian Mentzer, Yao-Yuan Yang, Danielle Eisenbud, Anmol Gulati, Ellie Talius, Eric Ni, Sahra Ghalebikesabi, Edouard Yvinec, Alaa Saade, Thatcher Ulrich, Lorenzo Blanco, Dan A. Calian, Muhuan Huang, Aäron van den Oord, Naman Goyal, Terry Chen, Praynaa Rawlani, Christian Schallhart, Swachhand Lokhande, Xianghong Luo, Jyn Shan, Ceslee Montgomery, Victoria Krakovna, Federico Piccinini, Omer Barak, Jingyu Cui, Yiling Jia, Mikhail Dektiarev, Alexey Kolganov, Shiyu Huang, Zhe Chen, Xingyu Wang, Jessica Austin, Peter de Boursac, Evgeny Sluzhaev, Frank Ding, Huijian Li, Surya Bhupatiraju, Mohit Agarwal, Sławek Kwasiborski, Paramjit Sandhu, Patrick Siegler, Ahmet Iscen, Eyal Ben-David, Shiraz Butt, Miltos Allamanis, Seth Benjamin, Robert Busa-Fekete, Felix Hernandez-Campos, Sasha Goldshtein, Matt Dibb, Weiyang Zhang, Annie Marsden, Carey Radebaugh, Stephen Roller, Abhishek Nayyar, Jacob Austin, Tayfun Terzi, Bhargav Kanagal Shamanna, Pete Shaw, Aayush Singh, Florian Luisier, Artur Mendonça, Vaibhav Aggarwal, Larisa Markeeva, Claudio Fantacci, Sergey Brin, HyunJeong Choe, Guanyu Wang, Hartwig Adam, Avigail Dabush, Tatsuya Kiyono, Eyal Marcus, Jeremy Cole, Theophane Weber, Hongrae Lee, Ronny Huang, Alex Muzio, Leandro Kieliger, Maigo Le, Courtney Biles, Long Le, Archit Sharma, Chengrun Yang, Avery Lamp, Dave Dopson, Nate Hurley, Katrina Xinyi Xu, Zhihao Shan, Shuang Song, Jiewen Tan, Alexandre Senges, George Zhang, Chong You, Yennie Jun, David Raposo, Susanna Ricco, Xuan Yang, Weijie Chen, Prakhar Gupta, Arthur Szlam, Kevin Villela, Chun-Sung Ferng, Daniel Kasenberg, Chen Liang, Rui Zhu, Arunachalam Narayanaswamy, Florence Perot, Paul Pucciarelli, Anna Shekhawat, Alexey Stern, Rishikesh Ingale, Stefani Karp, Sanaz Bahargam, Adrian Goedeckemeyer, Jie Han, Sicheng Li, Andrea Tacchetti, Dian Yu, Abhishek Chakladar, Zhiying Zhang, Mona El Mahdy, Xu Gao, Dale Johnson, Samrat Phatale, AJ Piergiovanni, Hyeontaek Lim, Clement Farabet, Carl Lebsack, Theo Guidroz, John Blitzer, Nico Duduta, David Madras, Steve Li, Daniel von Dincklage, Xin Li, Mahdis Mahdieh, George Tucker, Ganesh Jawahar, Owen Xiao, Danny Tarlow, Robert Geirhos, Noam Velan, Daniel Vlasic, Kalesha Bullard, SK Park, Nishesh Gupta, Kellie Webster, Ayal Hitron, Jieming Mao, Julian Eisenschlos, Laurel Prince, Nina D’Souza, Kelvin Zheng, Sara Nasso, Gabriela Botea, Carl Doersch, Caglar Unlu, Chris Alberti, Alexey Svyatkovskiy, Ankita Goel, Krzysztof Choromanski, Pan-Pan Jiang, Richard Nguyen, Four Flynn, Daria Ćurko, Peter Chen, Nicholas Roth, Kieran Milan, Caleb Habtegebriel, Shashi Narayan, Michael Moffitt, Jake Marcus, Thomas Anthony, Brendan McMahan, Gowoon Cheon, Ruibo Liu, Megan Barnes, Lukasz Lew, Rebeca Santamaria-Fernandez, Mayank Upadhyay, Arjun Akula, Arnar Mar Hrafnkelsson, Alvaro Caceres, Andrew Bunner, Michal Sokolik, Subha Puttagunta, Lawrence Moore, Berivan Isik, Jay Hartford, Lawrence Chan, Pradeep Shenoy, Dan Holtmann-Rice, Jane Park, Fabio Viola, Alex Salcianu, Sujeevan Rajayogam, Ian Stewart-Binks, Zelin Wu, Richard Everett, Xi Xiong, Pierre-Antoine Manzagol, Gary Leung, Carl Saroufim, Bo Pang, Dawid Wegner, George Papamakarios, Jennimaria Palomaki, Helena Pankov, Guangda Lai, Guilherme Tubone, Shubin Zhao, Theofilos Strinopoulos, Seth Neel, Mingqiu Wang, Joe Kelley, Li Li, Pingmei Xu, Anitha Vijayakumar, Andrea D’olimpio, Omer Levy, Massimo Nicosia, Grigory Rozhdestvenskiy, Ni Lao, Sirui Xie, Yash Katariya, Jon Simon, Sanjiv Kumar, Florian Hartmann, Michael Kilgore, Jinhyuk Lee, Aroma Mahendru, Roman Ring, Tom Hennigan, Fiona Lang, Colin Cherry, David Steiner, Dawsen Hwang, Ray Smith, Pidong Wang, Jeremy Chen, Ming-Hsuan Yang, Sam Kwei, Philippe Schlattner, Donnie Kim, Ganesh Poomal Girirajan, Nikola Momchev, Ayushi Agarwal, Xingyi Zhou, Ilkin Safarli, Zachary Garrett, AJ Pierigiovanni, Sarthak Jauhari, Alif Raditya Rochman, Shikhar Vashishth, Quan Yuan, Christof Angermueller, Jon Blanton, Xinying Song, Nitesh Bharadwaj Gundavarapu, Thi Avrahami, Maxine Deines, Subhrajit Roy, Manish Gupta, Christopher Semturs, Shobha Vasudevan, Aditya Srikanth Veerubhotla, Shriya Sharma, Josh Jacob, Zhen Yang, Andreas Terzis, Dan Karliner, Auriel Wright, Tania Rojas-Esponda, Ashley Brown, Abhijit Guha Roy, Pawan Dogra, Andrei Kapishnikov, Peter Young, Wendy Kan, Vinodh Kumar Rajendran, Maria Ivanova, Salil Deshmukh, Chia-Hua Ho, Mike Kwong, Stav Ginzburg, Annie Louis, KP Sawhney, Slav Petrov, Jing Xie, Yunfei Bai, Georgi Stoyanov, Alex Fabrikant, Rajesh Jayaram, Yuqi Li, Joe Heyward, Justin Gilmer, Yaqing Wang, Radu Soricut, Luyang Liu, Qingnan Duan, Jamie Hayes, Maura O’Brien, Gaurav Singh Tomar, Sivan Eiger, Bahar Fatemi, Jeffrey Hui, Catarina Barros, Adaeze Chukwuka, Alena Butryna, Saksham Thakur, Austin Huang, Zhufeng Pan, Haotian Tang, Serkan Cabi, Tulsee Doshi, Michiel Bakker, Sumit Bagri, Ruy Ley-Wild, Adam Lelkes, Jennie Lees, Patrick Kane, David Greene, Shimu Wu, Jörg Bornschein, Gabriela Surita, Sarah Hodkinson, Fangtao Li, Chris Hidey, Sébastien Pereira, Sean Ammirati, Phillip Lippe, Adam Kraft, Pu Han, Sebastian Gerlach, Zifeng Wang, Liviu Panait, Feng Han, Brian Farris, Yingying Bi, Hannah DeBalsi, Miaosen Wang, Gladys Tyen, James Cohan, Susan Zhang, Jarred Barber, Da-Woon Chung, Jaeyoun Kim, Markus Kunesch, Steven Pecht, Nami Akazawa, Abe Friesen, James Lyon, Ali Eslami, Junru Wu, Jie Tan, Yue Song, Ravi Kumar, Chris Welty, Ilia Akolzin, Gena Gibson, Sean Augenstein, Arjun Pillai, Nancy Yuen, Du Phan, Xin Wang, Iain Barr, Heiga Zen, Nan Hua, Casper Liu, Jilei Jerry Wang, Tanuj Bhatia, Hao Xu, Oded Elyada, Pushmeet Kohli, Mirek Olšák, Ke Chen, Azalia Mirhoseini, Noam Shazeer, Shoshana Jakobovits, Maggie Tran, Nolan Ramsden, Tarun Bharti, Fred Alcober, Yunjie Li, Shilpa Shetty, Jing Chen, Dmitry Kalashnikov, Megha Nawhal, Sercan Arik, Hanwen Chen, Michiel Blokzijl, Shubham Gupta, James Rubin, Rigel Swavely, Sophie Bridgers, Ian Gemp, Chen Su, Arun Suggala, Juliette Pluto, Mary Cassin, Alain Vaucher, Kaiyang Ji, Jiahao Cai, Andrew Audibert, Animesh Sinha, David Tian, Efrat Farkash, Amy Hua, Jilin Chen, Duc-Hieu Tran, Edward Loper, Nicole Brichtova, Lara McConnaughey, Ballie Sandhu, Robert Leland, Doug DeCarlo, Andrew Over, James Huang, Xing Wu, Connie Fan, Eric Li, Yun Lei, Deepak Sharma, Cosmin Paduraru, Luo Yu, Matko Bošnjak, Phuong Dao, Min Choi, Sneha Kudugunta, Jakub Adamek, Carlos Guía, Ali Khodaei, Jie Feng, Wenjun Zeng, David Welling, Sandeep Tata, Christina Butterfield, Andrey Vlasov, Seliem El-Sayed, Swaroop Mishra, Tara Sainath, Shentao Yang, RJ Skerry-Ryan, Jeremy Shar, Robert Berry, Arunkumar Rajendran, Arun Kandoor, Andrea Burns, Deepali Jain, Tom Stone, Wonpyo Park, Shibo Wang, Albin Cassirer, Guohui Wang, Hayato Kobayashi, Sergey Rogulenko, Vineetha Govindaraj, Mikołaj Rybiński, Nadav Olmert, Colin Evans, Po-Sen Huang, Kelvin Xu, Premal Shah, Terry Thurk, Caitlin Sikora, Mu Cai, Jin Xie, Elahe Dabir, Saloni Shah, Norbert Kalb, Carrie Zhang, Shruthi Prabhakara, Amit Sabne, Artiom Myaskovsky, Vikas Raunak, Blanca Huergo, Behnam Neyshabur, Jon Clark, Ye Zhang, Shankar Krishnan, Eden Cohen, Dinesh Tewari, James Lottes, Yumeya Yamamori, Hui Elena Li, Mohamed Elhawaty, Ada Maksutaj Oflazer, Adrià Recasens, Sheryl Luo, Duy Nguyen, Taylor Bos, Kalyan Andra, Ana Salazar, Ed Chi, Jeongwoo Ko, Matt Ginsberg, Anders Andreassen, Anian Ruoss, Todor Davchev, Elnaz Davoodi, Chenxi Liu, Min Kim, Santiago Ontanon, Chi Ming To, Dawei Jia, Rosemary Ke, Jing Wang, Anna Korsun, Moran Ambar, Ilya Kornakov, Irene Giannoumis, Toni Creswell, Denny Zhou, Yi Su, Ishaan Watts, Aleksandr Zaks, Evgenii Eltyshev, Ziqiang Feng, Sidharth Mudgal, Alex Kaskasoli, Juliette Love, Kingshuk Dasgupta, Sam Shleifer, Richard Green, Sungyong Seo, Chansoo Lee, Dale Webster, Prakash Shroff, Ganna Raboshchuk, Isabel Leal, James Manyika, Sofia Erell, Daniel Murphy, Zhisheng Xiao, Anton Bulyenov, Julian Walker, Mark Collier, Matej Kastelic, Nelson George, Sushant Prakash, Sailesh Sidhwani, Alexey Frolov, Steven Hansen, Petko Georgiev, Tiberiu Sosea, Chris Apps, Aishwarya Kamath, David Reid, Emma Cooney, Charlotte Magister, Oriana Riva, Alec Go, Pu-Chin Chen, Sebastian Krause, Nir Levine, Marco Fornoni, Ilya Figotin, Nick Roy, Parsa Mahmoudieh, Vladimir Magay, Mukundan Madhavan, Jin Miao, Jianmo Ni, Yasuhisa Fujii, Ian Chou, George Scrivener, Zak Tsai, Siobhan Mcloughlin, Jeremy Selier, Sandra Lefdal, Jeffrey Zhao, Abhijit Karmarkar, Kushal Chauhan, Shivanker Goel, Zhaoyi Zhang, Vihan Jain, Parisa Haghani, Mostafa Dehghani, Jacob Scott, Erin Farnese, Anastasija Ilić, Steven Baker, Julia Pawar, Li Zhong, Josh Camp, Yoel Zeldes, Shravya Shetty, Anand Iyer, Vít Listík, Jiaxian Guo, Luming Tang, Mark Geller, Simon Bucher, Yifan Ding, Hongzhi Shi, Carrie Muir, Dominik Grewe, Ramy Eskander, Octavio Ponce, Boqing Gong, Derek Gasaway, Samira Khan, Umang Gupta, Angelos Filos, Weicheng Kuo, Klemen Kloboves, Jennifer Beattie, Christian Wright, Leon Li, Alicia Jin, Sandeep Mariserla, Miteyan Patel, Jens Heitkaemper, Dilip Krishnan, Vivek Sharma, David Bieber, Christian Frank, John Lambert, Paul Caron, Martin Polacek, Mai Giménez, Himadri Choudhury, Xing Yu, Sasan Tavakkol, Arun Ahuja, Franz Och, Rodolphe Jenatton, Wojtek Skut, Bryan Richter, David Gaddy, Andy Ly, Misha Bilenko, Megh Umekar, Ethan Liang, Martin Sevenich, Mandar Joshi, Hassan Mansoor, Rebecca Lin, Sumit Sanghai, Abhimanyu Singh, Xiaowei Li, Sudheendra Vijayanarasimhan, Zaheer Abbas, Yonatan Bitton, Hansa Srinivasan, Manish Reddy Vuyyuru, Alexander Frömmgen, Yanhua Sun, Ralph Leith, Alfonso Castaño, DJ Strouse, Le Yan, Austin Kyker, Satish Kambala, Mary Jasarevic, Thibault Sellam, Chao Jia, Alexander Pritzel, Raghavender R, Huizhong Chen, Natalie Clay, Sudeep Gandhe, Sean Kirmani, Sayna Ebrahimi, Hannah Kirkwood, Jonathan Mallinson, Chao Wang, Adnan Ozturel, Kuo Lin, Shyam Upadhyay, Vincent Cohen-Addad, Sean Purser-haskell, Yichong Xu, Ebrahim Songhori, Babi Seal, Alberto Magni, Almog Gueta, Tingting Zou, Guru Guruganesh, Thais Kagohara, Hung Nguyen, Khalid Salama, Alejandro Cruzado Ruiz, Justin Frye, Zhenkai Zhu, Matthias Lochbrunner, Simon Osindero, Wentao Yuan, Lisa Lee, Aman Prasad, Lam Nguyen Thiet, Daniele Calandriello, Victor Stone, Qixuan Feng, Han Ke, Maria Voitovich, Geta Sampemane, Lewis Chiang, Ling Wu, Alexander Bykovsky, Matt Young, Luke Vilnis, Ishita Dasgupta, Aditya Chawla, Qin Cao, Bowen Liang, Daniel Toyama, Szabolcs Payrits, Anca Stefanoiu, Dimitrios Vytiniotis, Ankesh Anand, Tianxiao Shen, Blagoj Mitrevski, Michael Tschannen, Sreenivas Gollapudi, Aishwarya P S, José Leal, Zhe Shen, Han Fu, Wei Wang, Arvind Kannan, Doron Kukliansky, Sergey Yaroshenko, Svetlana Grant, Umesh Telang, David Wood, Alexandra Chronopoulou, Alexandru Ţifrea, Tao Zhou, Tony Tu'ân Nguy~ên, Muge Ersoy, Anima Singh, Meiyan Xie, Emanuel Taropa, Woohyun Han, Eirikur Agustsson, Andrei Sozanschi, Hui Peng, Alex Chen, Yoel Drori, Efren Robles, Yang Gao, Xerxes Dotiwalla, Ying Chen, Anudhyan Boral, Alexei Bendebury, John Nham, Chris Tar, Luis Castro, Jiepu Jiang, Canoee Liu, Felix Halim, Jinoo Baek, Andy Wan, Jeremiah Liu, Yuan Cao, Shengyang Dai, Trilok Acharya, Ruoxi Sun, Fuzhao Xue, Saket Joshi, Morgane Lustman, Yongqin Xian, Rishabh Joshi, Deep Karkhanis, Nora Kassner, Jamie Hall, Xiangzhuo Ding, Gan Song, Gang Li, Chen Zhu, Yana Kulizhskaya, Bin Ni, Alexey Vlaskin, Solomon Demmessie, Lucio Dery, Salah Zaiem, Yanping Huang, Cindy Fan, Felix Gimeno, Ananth Balashankar, Koji Kojima, Hagai Taitelbaum, Maya Meng, Dero Gharibian, Sahil Singla, Wei Chen, Ambrose Slone, Guanjie Chen, Sujee Rajayogam, Max Schumacher, Suyog Kotecha, Rory Blevins, Qifei Wang, Mor Hazan Taege, Alex Morris, Xin Liu, Fayaz Jamil, Richard Zhang, Pratik Joshi, Ben Ingram, Tyler Liechty, Ahmed Eleryan, Scott Baird, Alex Grills, Gagan Bansal, Shan Han, Kiran Yalasangi, Shawn Xu, Majd Al Merey, Isabel Gao, Felix Weissenberger, Igor Karpov, Robert Riachi, Ankit Anand, Gautam Prasad, Kay Lamerigts, Reid Hayes, Jamie Rogers, Mandy Guo, Ashish Shenoy, Qiong Q Hu, Kyle He, Yuchen Liu, Polina Zablotskaia, Sagar Gubbi, Yifan Chang, Jay Pavagadhi, Kristian Kjems, Archita Vadali, Diego Machado, Yeqing Li, Renshen Wang, Dipankar Ghosh, Aahil Mehta, Dana Alon, George Polovets, Alessio Tonioni, Nate Kushman, Joel D’sa, Lin Zhuo, Allen Wu, Rohin Shah, John Youssef, Jiayu Ye, Justin Snyder, Karel Lenc, Senaka Buthpitiya, Matthew Tung, Jichuan Chang, Tao Chen, David Saxton, Jenny Lee, Lydia Lihui Zhang, James Qin, Prabakar Radhakrishnan, Maxwell Chen, Piotr Ambroszczyk, Metin Toksoz-Exley, Yan Zhong, Nitzan Katz, Brendan O’Donoghue, Tamara von Glehn, Adi Gerzi Rosenthal, Aga Świetlik, Xiaokai Zhao, Nick Fernando, Jinliang Wei, Jieru Mei, Sergei Vassilvitskii, Diego Cedillo, Pranjal Awasthi, Hui Zheng, Koray Kavukcuoglu, Itay Laish, Joseph Pagadora, Marc Brockschmidt, Christopher A. Choquette-Choo, Arunkumar Byravan, Yifeng Lu, Xu Chen, Mia Chen, Kenton Lee, Rama Pasumarthi, Sijal Bhatnagar, Aditya Shah, Qiyin Wu, Zhuoyuan Chen, Zack Nado, Bartek Perz, Zixuan Jiang, David Kao, Ganesh Mallya, Nino Vieillard, Lantao Mei, Sertan Girgin, Mandy Jordan, Yeongil Ko, Alekh Agarwal, Yaxin Liu, Yasemin Altun, Raoul de Liedekerke, Anastasios Kementsietsidis, Daiyi Peng, Dangyi Liu, Utku Evci, Peter Humphreys, Austin Tarango, Xiang Deng, Yoad Lewenberg, Kevin Aydin, Chengda Wu, Bhavishya Mittal, Tsendsuren Munkhdalai, Kleopatra Chatziprimou, Rodrigo Benenson, Uri First, Xiao Ma, Jinning Li, Armand Joulin, Hamish Tomlinson, Tingnan Zhang, Milad Nasr, Zhi Hong, Michaël Sander, Lisa Anne Hendricks, Anuj Sharma, Andrew Bolt, Eszter Vértes, Jiri Simsa, Tomer Levinboim, Olcan Sercinoglu, Divyansh Shukla, Austin Wu, Craig Swanson, Danny Vainstein, Fan Bu, Bo Wang, Ryan Julian, Charles Yoon, Sergei Lebedev, Antonious Girgis, Bernd Bandemer, David Du, Todd Wang, Xi Chen, Ying Xiao, Peggy Lu, Natalie Ha, Vlad Ionescu, Simon Rowe, Josip Matak, Federico Lebron, Andreas Steiner, Lalit Jain, Manaal Faruqui, Nicolas Lacasse, Georgie Evans, Neesha Subramaniam, Dean Reich, Giulia Vezzani, Aditya Pandey, Joe Stanton, Tianhao Zhou, Liam McCafferty, Henry Griffiths, Verena Rieser, Soheil Hassas Yeganeh, Eleftheria Briakou, Lu Huang, Zichuan Wei, Liangchen Luo, Erik Jue, Gabby Wang, Victor Cotruta, Myriam Khan, Jongbin Park, Qiuchen Guo, Peiran Li, Rong Rong, Diego Antognini, Anastasia Petrushkina, Chetan Tekur, Eli Collins, Parul Bhatia, Chester Kwak, Wenhu Chen, Arvind Neelakantan, Immanuel Odisho, Sheng Peng, Vincent Nallatamby, Vaibhav Tulsyan, Fabian Pedregosa, Peng Xu, Raymond Lin, Yulong Wang, Emma Wang, Sholto Douglas, Reut Tsarfaty, Elena Gribovskaya, Renga Aravamudhan, Manu Agarwal, Mara Finkelstein, Qiao Zhang, Elizabeth Cole, Phil Crone, Sarmishta Velury, Anil Das, Chris Sauer, Luyao Xu, Danfeng Qin, Chenjie Gu, Dror Marcus, CJ Zheng, Wouter Van Gansbeke, Sobhan Miryoosefi, Haitian Sun, YaGuang Li, Charlie Chen, Jae Yoo, Pavel Dubov, Alex Tomala, Adams Yu, Paweł Wesołowski, Alok Gunjan, Eddie Cao, Jiaming Luo, Nikhil Sethi, Arkadiusz Socala, Laura Graesser, Tomas Kocisky, Arturo BC, Minmin Chen, Edward Lee, Sophie Wang, Weize Kong, Qiantong Xu, Nilesh Tripuraneni, Yiming Li, Xinxin Yu, Allen Porter, Paul Voigtlaender, Biao Zhang, Arpi Vezer, Sarah York, Qing Wei, Geoffrey Cideron, Mark Kurzeja, Seungyeon Kim, Benny Li, Angéline Pouget, Hyo Lee, Kaspar Daugaard, Yang Li, Dave Uthus, Aditya Siddhant, Paul Cavallaro, Sriram Ganapathy, Maulik Shah, Rolf Jagerman, Jeff Stanway, Piermaria Mendolicchio, Li Xiao, Kayi Lee, Tara Thompson, Shubham Milind Phal, Jason Chase, Sun Jae Lee, Adrian N Reyes, Disha Shrivastava, Zhen Qin, Roykrong Sukkerd, Seth Odoom, Lior Madmoni, John Aslanides, Jonathan Herzig, Elena Pochernina, Sheng Zhang, Parker Barnes, Daisuke Ikeda, Qiujia Li, Shuo-yiin Chang, Shakir Mohamed, Jim Sproch, Richard Powell, Bidisha Samanta, Domagoj Ćevid, Anton Kovsharov, Shrestha Basu Mallick, Srinivas Tadepalli, Anne Zheng, Kareem Ayoub, Andreas Noever, Christian Reisswig, Zhuo Xu, Junhyuk Oh, Martin Matysiak, Tim Blyth, Shereen Ashraf, Julien Amelot, Boone Severson, Michele Bevilacqua, Motoki Sano, Ethan Dyer, Ofir Roval, Anu Sinha, Yin Zhong, Sagi Perel, Tea Sabolić, Johannes Mauerer, Willi Gierke, Mauro Verzetti, Rodrigo Cabrera, Alvin Abdagic, Steven Hemingray, Austin Stone, Jong Lee, Farooq Ahmad, Karthik Raman, Lior Shani, Jonathan Lai, Orhan Firat, Nathan Waters, Eric Ge, Mo Shomrat, Himanshu Gupta, Rajeev Aggarwal, Tom Hudson, Bill Jia, Simon Baumgartner, Palak Jain, Joe Kovac, Junehyuk Jung, Ante Žužul, Will Truong, Morteza Zadimoghaddam, Songyou Peng, Marco Liang, Rachel Sterneck, Balaji Lakshminarayanan, Machel Reid, Oliver Woodman, Tong Zhou, Jianling Wang, Vincent Coriou, Arjun Narayanan, Jay Hoover, Yenai Ma, Apoorv Jindal, Clayton Sanford, Doug Reid, Swaroop Ramaswamy, Alex Kurakin, Roland Zimmermann, Yana Lunts, Dragos Dena, Zalán Borsos, Vered Cohen, Shujian Zhang, Will Grathwohl, Robert Dadashi, Morgan Redshaw, Joshua Kessinger, Julian Odell, Silvano Bonacina, Zihang Dai, Grace Chen, Ayush Dubey, Pablo Sprechmann, Mantas Pajarskas, Wenxuan Zhou, Niharika Ahuja, Tara Thomas, Martin Nikoltchev, Matija Kecman, Bharath Mankalale, Andrey Ryabtsev, Jennifer She, Christian Walder, Jiaming Shen, Lu Li, Carolina Parada, Sheena Panthaplackel, Okwan Kwon, Matt Lawlor, Utsav Prabhu, Yannick Schroecker, Marc’aurelio Ranzato, Pete Blois, Iurii Kemaev, Ting Yu, Dmitry Lepikhin, Hao Xiong, Sahand Sharifzadeh, Oleaser Johnson, Jeremiah Willcock, Rui Yao, Greg Farquhar, Sujoy Basu, Hidetoshi Shimokawa, Nina Anderson, Haiguang Li, Khiem Pham, Yizhong Liang, Sebastian Borgeaud, Alexandre Moufarek, Hideto Kazawa, Blair Kutzman, Marcin Sieniek, Sara Smoot, Ruth Wang, Natalie Axelsson, Nova Fallen, Prasha Sundaram, Yuexiang Zhai, Varun Godbole, Petros Maniatis, Alek Wang, Ilia Shumailov, Santhosh Thangaraj, Remi Crocker, Nikita Gupta, Gang Wu, Phil Chen, Gellért Weisz, Celine Smith, Mojtaba Seyedhosseini, Boya Fang, Xiyang Luo, Roey Yogev, Zeynep Cankara, Andrew Hard, Helen Ran, Rahul Sukthankar, George Necula, Gaël Liu, Honglong Cai, Praseem Banzal, Daniel Keysers, Sanjay Ghemawat, Connie Tao, Emma Dunleavy, Aditi Chaudhary, Wei Li, Maciej Mikuła, Chen-Yu Lee, Tiziana Refice, Krishna Somandepalli, Alexandre Fréchette, Dan Bahir, John Karro, Keith Rush, Sarah Perrin, Bill Rosgen, Xiaomeng Yang, Clara Huiyi Hu, Mahmoud Alnahlawi, Justin Mao-Jones, Roopal Garg, Hoang Nguyen, Bat-Orgil Batsaikhan, Iñaki Iturrate, Anselm Levskaya, Avi Singh, Ashyana Kachra, Tony Lu, Denis Petek, Zheng Xu, Mark Graham, Lukas Zilka, Yael Karov, Marija Kostelac, Fangyu Liu, Yaohui Guo, Weiyue Wang, Bernd Bohnet, Emily Pitler, Tony Bruguier, Keisuke Kinoshita, Chrysovalantis Anastasiou, Nilpa Jha, Ting Liu, Jerome Connor, Phil Wallis, Philip Pham, Eric Bailey, Shixin Li, Heng-Tze Cheng, Sally Ma, Haiqiong Li, Akanksha Maurya, Kate Olszewska, Manfred Warmuth, Christy Koh, Dominik Paulus, Siddhartha Reddy Jonnalagadda, Enrique Piqueras, Ali Elqursh, Geoff Brown, Hadar Shemtov, Loren Maggiore, Fei Xia, Ryan Foley, Beka Westberg, George van den Driessche, Livio Baldini Soares, Arjun Kar, Michael Quinn, Siqi Zuo, Jialin Wu, Kyle Kastner, Anna Bortsova, Aijun Bai, Ales Mikhalap, Luowei Zhou, Jennifer Brennan, Vinay Ramasesh, Honglei Zhuang, John Maggs, Johan Schalkwyk, Yuntao Xu, Hui Huang, Andrew Howard, Sasha Brown, Linting Xue, Gloria Shen, Brian Albert, Neha Jha, Daniel Zheng, Varvara Krayvanova, Spurthi Amba Hombaiah, Olivier Lacombe, Gautam Vasudevan, Dan Graur, Tian Xie, Meet Gandhi, Bangju Wang, Dustin Zelle, Harman Singh, Dahun Kim, Sébastien Cevey, Victor Ungureanu, Natasha Noy, Fei Liu, Annie Xie, Fangxiaoyu Feng, Katerina Tsihlas, Daniel Formoso, Neera Vats, Quentin Wellens, Yinan Wang, Niket Kumar Bhumihar, Samrat Ghosh, Matt Hoffman, Tom Lieber, Oran Lang, Kush Bhatia, Tom Paine, Aroonalok Pyne, Ronny Votel, Madeleine Clare Elish, Benoit Schillings, Alex Panagopoulos, Haichuan Yang, Adam Raveret, Zohar Yahav, Shuang Liu, Dalia El Badawy, Nishant Agrawal, Mohammed Badawi, Mahdi Mirzazadeh, Carla Bromberg, Fan Ye, Chang Liu, Tatiana Sholokhova, George-Cristian Muraru, Gargi Balasubramaniam, Jonathan Malmaud, Alen Carin, Danilo Martins, Irina Jurenka, Pankil Botadra, Dave Lacey, Richa Singh, Mariano Schain, Dan Zheng, Isabelle Guyon, Victor Lavrenko, Seungji Lee, Xiang Zhou, Demis Hassabis, Jeshwanth Challagundla, Derek Cheng, Nikhil Mehta, Matthew Mauger, Michela Paganini, Pushkar Mishra, Kate Lee, Zhang Li, Lexi Baugher, Ondrej Skopek, Max Chang, Amir Zait, Gaurav Menghani, Lizzetth Bellot, Guangxing Han, Jean-Michel Sarr, Sharat Chikkerur, Himanshu Sahni, Rohan Anil, Arun Narayanan, Chandu Thekkath, Daniele Pighin, Hana Strejček, Marko Velic, Fred Bertsch, Manuel Tragut, Keran Rong, Alicia Parrish, Kai Bailey, Jiho Park, Isabela Albuquerque, Abhishek Bapna, Rajesh Venkataraman, Alec Kosik, Johannes Griesser, Zhiwei Deng, Alek Andreev, Qingyun Dou, Kevin Hui, Fanny Wei, Xiaobin Yu, Lei Shu, Avia Aharon, David Barker, Badih Ghazi, Sebastian Flennerhag, Chris Breaux, Yuchuan Liu, Matthew Bilotti, Josh Woodward, Uri Alon, Stephanie Winkler, Tzu-Kuo Huang, Kostas Andriopoulos, João Gabriel Oliveira, Penporn Koanantakool, Berkin Akin, Michael Wunder, Cicero Nogueira dos Santos, Mohammad Hossein Bateni, Lin Yang, Dan Horgan, Beer Changpinyo, Keyvan Amiri, Min Ma, Dayeong Lee, Lihao Liang, Anirudh Baddepudi, Tejasi Latkar, Raia Hadsell, Jun Xu, Hairong Mu, Michael Han, Aedan Pope, Snchit Grover, Frank Kim, Ankit Bhagatwala, Guan Sun, Yamini Bansal, Amir Globerson, Alireza Nazari, Samira Daruki, Hagen Soltau, Jane Labanowski, Laurent El Shafey, Matt Harvey, Yanif Ahmad, Elan Rosenfeld, William Kong, Etienne Pot, Yi-Xuan Tan, Aurora Wei, Victoria Langston, Marcel Prasetya, Petar Veličković, Richard Killam, Robin Strudel, Darren Ni, Zhenhai Zhu, Aaron Archer, Kavya Kopparapu, Lynn Nguyen, Emilio Parisotto, Hussain Masoom, Sravanti Addepalli, Jordan Grimstad, Hexiang Hu, Joss Moore, Avinatan Hassidim, Le Hou, Mukund Raghavachari, Jared Lichtarge, Adam R. Brown, Hilal Dib, Natalia Ponomareva, Justin Fu, Yujing Zhang, Altaf Rahman, Joana Iljazi, Edouard Leurent, Gabriel Dulac-Arnold, Cosmo Du, Chulayuth Asawaroengchai, Larry Jin, Ela Gruzewska, Ziwei Ji, Benigno Uria, Daniel De Freitas, Paul Barham, Lauren Beltrone, Víctor Campos, Jun Yan, Neel Kovelamudi, Arthur Nguyen, Elinor Davies, Zhichun Wu, Zoltan Egyed, Kristina Toutanova, Nithya Attaluri, Hongliang Fei, Peter Stys, Siddhartha Brahma, Martin Izzard, Siva Velusamy, Scott Lundberg, Vincent Zhuang, Kevin Sequeira, Adam Santoro, Ehsan Amid, Ophir Aharoni, Shuai Ye, Mukund Sundararajan, Lijun Yu, Yu-Cheng Ling, Stephen Spencer, Hugo Song, Josip Djolonga, Christo Kirov, Sonal Gupta, Alessandro Bissacco, Clemens Meyer, Mukul Bhutani, Andrew Dai, Weiyi Wang, Siqi Liu, Ashwin Sreevatsa, Qijun Tan, Maria Wang, Lucy Kim, Yicheng Wang, Alex Irpan, Yang Xiao, Stanislav Fort, Yifan He, Alex Gurney, Bryan Gale, Yue Ma, Monica Roy, Viorica Patraucean, Taylan Bilal, Golnaz Ghiasi, Anahita Hosseini, Melvin Johnson, Zhuowan Li, Yi Tay, Benjamin Beyret, Katie Millican, Josef Broder, Mayank Lunayach, Danny Swisher, Eugen Vušak, David Parkinson, MH Tessler, Adi Mayrav Gilady, Richard Song, Allan Dafoe, Yves Raimond, Masa Yamaguchi, Itay Karo, Elizabeth Nielsen, Kevin Kilgour, Mike Dusenberry, Rajiv Mathews, Jiho Choi, Siyuan Qiao, Harsh Mehta, Sahitya Potluri, Chris Knutsen, Jialu Liu, Tat Tan, Kuntal Sengupta, Keerthana Gopalakrishnan, Abodunrinwa Toki, Mencher Chiang, Mike Burrows, Grace Vesom, Zafarali Ahmed, Ilia Labzovsky, Siddharth Vashishtha, Preeti Singh, Ankur Sharma, Ada Ma, Jinyu Xie, Pranav Talluri, Hannah Forbes-Pollard, Aarush Selvan, Joel Wee, Loic Matthey, Tom Funkhouser, Parthasarathy Gopavarapu, Lev Proleev, Cheng Li, Matt Thomas, Kashyap Kolipaka, Zhipeng Jia, Ashwin Kakarla, Srinivas Sunkara, Joan Puigcerver, Suraj Satishkumar Sheth, Emily Graves, Chen Wang, Sadh MNM Khan, Kai Kang, Shyamal Buch, Fred Zhang, Omkar Savant, David Soergel, Kevin Lee, Linda Friso, Xuanyi Dong, Rahul Arya, Shreyas Chandrakaladharan, Connor Schenck, Greg Billock, Tejas Iyer, Anton Bakalov, Leslie Baker, Alex Ruiz, Angad Chandorkar, Trieu Trinh, Matt Miecnikowski, Yanqi Zhou, Yangsibo Huang, Jiazhong Nie, Ali Shah, Ashish Thapliyal, Sam Haves, Lun Wang, Uri Shaham, Patrick Morris-Suzuki, Soroush Radpour, Leonard Berrada, Thomas Strohmann, Chaochao Yan, Jingwei Shen, Sonam Goenka, Tris Warkentin, Petar Dević, Dan Belov, Albert Webson, Madhavi Yenugula, Puranjay Datta, Jerry Chang, Nimesh Ghelani, Aviral Kumar, Vincent Perot, Jessica Lo, Yang Song, Herman Schmit, Jianmin Chen, Vasilisa Bashlovkina, Xiaoyue Pan, Diana Mincu, Paul Roit, Isabel Edkins, Andy Davis, Yujia Li, Ben Horn, Xinjian Li, Pradeep Kumar S, Eric Doi, Wanzheng Zhu, Sri Gayatri Sundara Padmanabhan, Siddharth Verma, Jasmine Liu, Heng Chen, Mihajlo Velimirović, Malcolm Reynolds, Priyanka Agrawal, Nick Sukhanov, Abhinit Modi, Siddharth Goyal, John Palowitch, Nima Khajehnouri, Wing Lowe, David Klinghoffer, Sharon Silver, Vinh Tran, Candice Schumann, Francesco Piccinno, Xi Liu, Mario Lučić, Xiaochen Yang, Sandeep Kumar, Ajay Kannan, Ragha Kotikalapudi, Mudit Bansal, Fabian Fuchs, Mohammad Javad Hosseini, Abdelrahman Abdelhamed, Dawn Bloxwich, Tianhe Yu, Ruoxin Sang, Gregory Thornton, Karan Gill, Yuchi Liu, Virat Shejwalkar, Jason Lin, Zhipeng Yan, Kehang Han, Thomas Buschmann, Michael Pliskin, Zhi Xing, Susheel Tatineni, Junlin Zhang, Sissie Hsiao, Gavin Buttimore, Marcus Wu, Zefei Li, Geza Kovacs, Legg Yeung, Tao Huang, Aaron Cohen, Bethanie Brownfield, Averi Nowak, Mikel Rodriguez, Tianze Shi, Hado van Hasselt, Kevin Cen, Deepanway Ghoshal, Kushal Majmundar, Weiren Yu, Warren Weilun Chen, Danila Sinopalnikov, Hao Zhang, Vlado Galić, Di Lu, Zeyu Zheng, Maggie Song, Gary Wang, Gui Citovsky, Swapnil Gawde, Isaac Galatzer-Levy, David Silver, Ivana Balazevic, Dipanjan Das, Kingshuk Majumder, Yale Cong, Praneet Dutta, Dustin Tran, Hui Wan, Junwei Yuan, Daniel Eppens, Alanna Walton, Been Kim, Harry Ragan, James Cobon-Kerr, Lu Liu, Weijun Wang, Bryce Petrini, Jack Rae, Rakesh Shivanna, Yan Xiong, Chace Lee, Pauline Coquinot, Yiming Gu, Lisa Patel, Blake Hechtman, Aviel Boag, Orion Jankowski, Alex Wertheim, Alex Lee, Paul Covington, Hila Noga, Sam Sobell, Shanthal Vasanth, William Bono, Chirag Nagpal, Wei Fan, Xavier Garcia, Kedar Soparkar, Aybuke Turker, Nathan Howard, Sachit Menon, Yuankai Chen, Vikas Verma, Vladimir Pchelin, Harish Rajamani, Valentin Dalibard, Ana Ramalho, Yang Guo, Kartikeya Badola, Seojin Bang, Nathalie Rauschmayr, Julia Proskurnia, Sudeep Dasari, Xinyun Chen, Mikhail Sushkov, Anja Hauth, Pauline Sho, Abhinav Singh, Bilva Chandra, Allie Culp, Max Dylla, Olivier Bachem, James Besley, Heri Zhao, Timothy Lillicrap, Wei Wei, Wael Al Jishi, Ning Niu, Alban Rrustemi, Raphaël Lopez Kaufman, Ryan Poplin, Jewel Zhao, Minh Truong, Shikhar Bharadwaj, Ester Hlavnova, Eli Stickgold, Cordelia Schmid, Georgi Stephanov, Zhaoqi Leng, Frederick Liu, Léonard Hussenot, Shenil Dodhia, Juliana Vicente Franco, Lesley Katzen, Abhanshu Sharma, Sarah Cogan, Zuguang Yang, Aniket Ray, Sergi Caelles, Shen Yan, Ravin Kumar, Daniel Gillick, Renee Wong, Joshua Ainslie, Jonathan Hoech, Séb Arnold, Dan Abolafia, Anca Dragan, Ben Hora, Grace Hu, Alexey Guseynov, Yang Lu, Chas Leichner, Jinmeng Rao, Abhimanyu Goyal, Nagabhushan Baddi, Daniel Hernandez Diaz, Tim McConnell, Max Bain, Jake Abernethy, Qiqi Yan, Rylan Schaeffer, Paul Vicol, Will Thompson, Montse Gonzalez Arenas, Mathias Bellaiche, Pablo Barrio, Stefan Zinke, Riccardo Patana, Pulkit Mehta, JK Kearns, Avraham Ruderman, Scott Pollom, David D’Ambrosio, Cath Hope, Yang Yu, Andrea Gesmundo, Kuang-Huei Lee, Aviv Rosenberg, Yiqian Zhou, Yaoyiran Li, Drew Garmon, Yonghui Wu, Safeen Huda, Gil Fidel, Martin Baeuml, Jian Li, Phoebe Kirk, Rhys May, Tao Tu, Sara Mc Carthy, Toshiyuki Fukuzawa, Miranda Aperghis, Chih-Kuan Yeh, Toshihiro Yoshino, Bo Li, Austin Myers, Kaisheng Yao, Ben Limonchik, Changwan Ryu, Rohun Saxena, Alex Goldin, Ruizhe Zhao, Rocky Rhodes, Tao Zhu, Divya Tyam, Heidi Howard, Nathan Byrd, Hongxu Ma, Yan Wu, Ryan Mullins, Qingze Wang, Aida Amini, Sebastien Baur, Yiran Mao, Subhashini Venugopalan, Will Song, Wen Ding, Paul Collins, Sashank Reddi, Megan Shum, Andrei Rusu, Luisa Zintgraf, Kelvin Chan, Sheela Goenka, Mathieu Blondel, Michael Collins, Renke Pan, Marissa Giustina, Nikolai Chinaev, Christian Schuler, Ce Zheng, Jonas Valfridsson, Alyssa Loo, Alex Yakubovich, Jamie Smith, Tao Jiang, Rich Munoz, Gabriel Barcik, Rishabh Bansal, Mingyao Yang, Yilun Du, Pablo Duque, Mary Phuong, Alexandra Belias, Kunal Lad, Zeyu Liu, Tal Schuster, Karthik Duddu, Jieru Hu, Paige Kunkle, Matthew Watson, Jackson Tolins, Josh Smith, Denis Teplyashin, Garrett Bingham, Marvin Ritter, Marco Andreetto, Divya Pitta, Mohak Patel, Shashank Viswanadha, Trevor Strohman, Catalin Ionescu, Jincheng Luo, Yogesh Kalley, Jeremy Wiesner, Dan Deutsch, Derek Lockhart, Peter Choy, Rumen Dangovski, Chawin Sitawarin, Cat Graves, Tanya Lando, Joost van Amersfoort, Ndidi Elue, Zhouyuan Huo, Pooya Moradi, Jean Tarbouriech, Henryk Michalewski, Wenting Ye, Eunyoung Kim, Alex Druinsky, Florent Altché, Xinyi Chen, Artur Dwornik, Da-Cheng Juan, Rivka Moroshko, Horia Toma, Jarrod Kahn, Hai Qian, Maximilian Sieb, Irene Cai, Roman Goldenberg, Praneeth Netrapalli, Sindhu Raghuram, Yuan Gong, Lijie Fan, Evan Palmer, Yossi Matias, Valentin Gabeur, Shreya Pathak, Tom Ouyang, Don Metzler, Geoff Bacon, Srinivasan Venkatachary, Sridhar Thiagarajan, Alex Cullum, Eran Ofek, Vytenis Sakenas, Mohamed Hammad, Cesar Magalhaes, Mayank Daswani, Oscar Chang, Ashok Popat, Ruichao Li, Komal Jalan, Yanhan Hou, Josh Lipschultz, Antoine He, Wenhao Jia, Pier Giuseppe Sessa, Prateek Kolhar, William Wong, Sumeet Singh, Lukas Haas, Jay Whang, Hanna Klimczak-Plucińska, Georges Rotival, Grace Chung, Yiqing Hua, Anfal Siddiqui, Nicolas Serrano, Dongkai Chen, Billy Porter, Libin Bai, Keshav Shivam, Sho Arora, Partha Talukdar, Tom Cobley, Sangnie Bhardwaj, Evgeny Gladchenko, Simon Green, Kelvin Guu, Felix Fischer, Xiao Wu, Eric Wang, Achintya Singhal, Tatiana Matejovicova, James Martens, Hongji Li, Roma Patel, Elizabeth Kemp, Jiaqi Pan, Lily Wang, Blake JianHang Chen, Jean-Baptiste Alayrac, Navneet Potti, Erika Gemzer, Eugene Ie, Kay McKinney, Takaaki Saeki, Edward Chou, Pascal Lamblin, SQ Mah, Zach Fisher, Martin Chadwick, Jon Stritar, Obaid Sarvana, Andrew Hogue, Artem Shtefan, Hadi Hashemi, Yang Xu, Jindong Gu, Sharad Vikram, Chung-Ching Chang, Sabela Ramos, Logan Kilpatrick, Weijuan Xi, Jenny Brennan, Yinghao Sun, Abhishek Jindal, Ionel Gog, Dawn Chen, Felix Wu, Jason Lee, Sudhindra Kopalle, Srinadh Bhojanapalli, Oriol Vinyals, Natan Potikha, Burcu Karagol Ayan, Yuan Yuan, Michael Riley, Piotr Stanczyk, Sergey Kishchenko, Bing Wang, Dan Garrette, Antoine Yang, Vlad Feinberg, CJ Carey, Javad Azizi, Viral Shah, Erica Moreira, Chongyang Shi, Josh Feldman, Elizabeth Salesky, Thomas Lampe, Aneesh Pappu, Duhyeon Kim, Jonas Adler, Avi Caciularu, Brian Walker, Yunhan Xu, Yochai Blau, Dylan Scandinaro, Terry Huang, Sam El-Husseini, Abhishek Sinha, Lijie Ren, Taylor Tobin, Patrik Sundberg, Tim Sohn, Vikas Yadav, Mimi Ly, Emily Xue, Jing Xiong, Afzal Shama Soudagar, Sneha Mondal, Nikhil Khadke, Qingchun Ren, Ben Vargas, Stan Bileschi, Sarah Chakera, Cindy Wang, Boyu Wang, Yoni Halpern, Joe Jiang, Vikas Sindhwani, Petre Petrov, Pranavaraj Ponnuramu, Sanket Vaibhav Mehta, Yu Watanabe, Betty Chan, Matheus Wisniewski, Trang Pham, Jingwei Zhang, Conglong Li, Dario de Cesare, Art Khurshudov, Alex Vasiloff, Melissa Tan, Zoe Ashwood, Bobak Shahriari, Maryam Majzoubi, Garrett Tanzer, Olga Kozlova, Robin Alazard, James Lee-Thorp, Nguyet Minh Phu, Isaac Tian, Junwhan Ahn, Andy Crawford, Lauren Lax, Yuan Shangguan, Iftekhar Naim, David Ross, Oleksandr Ferludin, Tongfei Guo, Andrea Banino, Hubert Soyer, Xiaoen Ju, Dominika Rogozińska, Ishaan Malhi, Marcella Valentine, Daniel Balle, Apoorv Kulshreshtha, Maciej Kula, Yiwen Song, Sophia Austin, John Schultz, Roy Hirsch, Arthur Douillard, Apoorv Reddy, Michael Fink, Summer Yue, Khyatti Gupta, Adam Zhang, Norman Rink, Daniel McDuff, Lei Meng, András György, Yasaman Razeghi, Ricky Liang, Kazuki Osawa, Aviel Atias, Matan Eyal, Tyrone Hill, Nikolai Grigorev, Zhengdong Wang, Nitish Kulkarni, Rachel Soh, Ivan Lobov, Zachary Charles, Sid Lall, Kazuma Hashimoto, Ido Kessler, Victor Gomes, Zelda Mariet, Danny Driess, Alessandro Agostini, Canfer Akbulut, Jingcao Hu, Marissa Ikonomidis, Emily Caveness, Kartik Audhkhasi, Saurabh Agrawal, Ioana Bica, Evan Senter, Jayaram Mudigonda, Kelly Chen, Jingchen Ye, Xuanhui Wang, James Svensson, Philipp Fränken, Josh Newlan, Li Lao, Eva Schnider, Sami Alabed, Joseph Kready, Jesse Emond, Afief Halumi, Tim Zaman, Chengxi Ye, Naina Raisinghani, Vilobh Meshram, Bo Chang, Ankit Singh Rawat, Axel Stjerngren, Sergey Levi, Rui Wang, Xiangzhu Long, Mitchelle Rasquinha, Steven Hand, Aditi Mavalankar, Lauren Agubuzu, Sudeshna Roy, Junquan Chen, Jarek Wilkiewicz, Hao Zhou, Michal Jastrzebski, Qiong Hu, Agustin Dal Lago, Ramya Sree Boppana, Wei-Jen Ko, Jennifer Prendki, Yao Su, Zhi Li, Eliza Rutherford, Girish Ramchandra Rao, Ramona Comanescu, Adrià Puigdomènech, Qihang Chen, Dessie Petrova, Christine Chan, Vedrana Milutinovic, Felipe Tiengo Ferreira, Chin-Yi Cheng, Ming Zhang, Tapomay Dey, Sherry Yang, Ramesh Sampath, Quoc Le, Howard Zhou, Chu-Cheng Lin, Hoi Lam, Christine Kaeser-Chen, Kai Hui, Dean Hirsch, Tom Eccles, Basil Mustafa, Shruti Rijhwani, Morgane Rivière, Yuanzhong Xu, Junjie Wang, Xinyang Geng, Xiance Si, Arjun Khare, Cheolmin Kim, Vahab Mirrokni, Kamyu Lee, Khuslen Baatarsukh, Nathaniel Braun, Lisa Wang, Pallavi LV, Richard Tanburn, Yonghao Zhu, Fangda Li, Setareh Ariafar, Dan Goldberg, Ken Burke, Daniil Mirylenka, Meiqi Guo, Olaf Ronneberger, Hadas Natalie Vogel, Liqun Cheng, Nishita Shetty, Johnson Jia, Thomas Jimma, Corey Fry, Ted Xiao, Martin Sundermeyer, Ryan Burnell, Yannis Assael, Mario Pinto, JD Chen, Rohit Sathyanarayana, Donghyun Cho, Jing Lu, Rishabh Agarwal, Sugato Basu, Lucas Gonzalez, Dhruv Shah, Meng Wei, Dre Mahaarachchi, Rohan Agrawal, Tero Rissa, Yani Donchev, Ramiro Leal-Cavazos, Adrian Hutter, Markus Mircea, Alon Jacovi, Faruk Ahmed, Jiageng Zhang, Shuguang Hu, Bo-Juen Chen, Jonni Kanerva, Guillaume Desjardins, Andrew Lee, Nikos Parotsidis, Asier Mujika, Tobias Weyand, Jasper Snoek, Jo Chick, Kai Chen, Paul Chang, Ethan Mahintorabi, Zi Wang, Tolly Powell, Orgad Keller, Abhirut Gupta, Claire Sha, Kanav Garg, Nicolas Heess, Ágoston Weisz, Cassidy Hardin, Bartek Wydrowski, Ben Coleman, Karina Zainullina, Pankaj Joshi, Alessandro Epasto, Terry Spitz, Binbin Xiong, Kai Zhao, Arseniy Klimovskiy, Ivy Zheng, Johan Ferret, Itay Yona, Waleed Khawaja, Jean-Baptiste Lespiau, Maxim Krikun, Siamak Shakeri, Timothee Cour, Bonnie Li, Igor Krivokon, Dan Suh, Alex Hofer, Jad Al Abdallah, Nikita Putikhin, Oscar Akerlund, Silvio Lattanzi, Anurag Kumar, Shane Settle, Himanshu Srivastava, Folawiyo Campbell-Ajala, Edouard Rosseel, Mihai Dorin Istin, Nishanth Dikkala, Anand Rao, Nick Young, Kate Lin, Dhruva Bhaswar, Yiming Wang, Jaume Sanchez Elias, Kritika Muralidharan, James Keeling, Dayou Du, Siddharth Gopal, Gregory Dibb, Charles Blundell, Manolis Delakis, Jacky Liang, Marco Tulio Ribeiro, Georgi Karadzhov, Guillermo Garrido, Ankur Bapna, Jiawei Cao, Adam Sadovsky, Pouya Tafti, Arthur Guez, Coline Devin, Yixian Di, Jinwei Xing, Chuqiao Joyce Xu, Hanzhao Lin, Chun-Te Chu, Sameera Ponda, Wesley Helmholz, Fan Yang, Yue Gao, Sara Javanmardi, Wael Farhan, Alex Ramirez, Ricardo Figueira, Khe Chai Sim, Yuval Bahat, Ashwin Vaswani, Liangzhe Yuan, Gufeng Zhang, Leland Rechis, Hanjun Dai, Tayo Oguntebi, Alexandra Cordell, Eugénie Rives, Kaan Tekelioglu, Naveen Kumar, Bing Zhang, Aurick Zhou, Nikolay Savinov, Andrew Leach, Alex Tudor, Sanjay Ganapathy, Yanyan Zheng, Mirko Rossini, Vera Axelrod, Arnaud Autef, Yukun Zhu, Zheng Zheng, Mingda Zhang, Baochen Sun, Jie Ren, Nenad Tomasev, Nithish Kannen, Amer Sinha, Charles Chen, Louis O’Bryan, Alex Pak, Aditya Kusupati, Weel Yang, Deepak Ramachandran, Patrick Griffin, Seokhwan Kim, Philipp Neubeck, Craig Schiff, Tammo Spalink, Mingyang Ling, Arun Nair, Ga-Young Joung, Linda Deng, Avishkar Bhoopchand, Lora Aroyo, Tom Duerig, Jordan Griffith, Gabe Barth-Maron, Jake Ades, Alex Haig, Ankur Taly, Yunting Song, Paul Michel, Dave Orr, Dean Weesner, Corentin Tallec, Carrie Grimes Bostock, Paul Niemczyk, Andy Twigg, Mudit Verma, Rohith Vallu, Henry Wang, Marco Gelmi, Kiranbir Sodhia, Aleksandr Chuklin, Omer Goldman, Jasmine George, Liang Bai, Kelvin Zhang, Petar Sirkovic, Efrat Nehoran, Golan Pundak, Jiaqi Mu, Alice Chen, Alex Greve, Paulo Zacchello, David Amos, Heming Ge, Eric Noland, Colton Bishop, Jeffrey Dudek, Youhei Namiki, Elena Buchatskaya, Jing Li, Dorsa Sadigh, Masha Samsikova, Dan Malkin, Damien Vincent, Robert David, Rob Willoughby, Phoenix Meadowlark, Shawn Gao, Yan Li, Raj Apte, Amit Jhindal, Stein Xudong Lin, Alex Polozov, Zhicheng Wang, Tomas Mery, Anirudh GP, Varun Yerram, Sage Stevens, Tianqi Liu, Noah Fiedel, Charles Sutton, Matthew Johnson, Xiaodan Song, Kate Baumli, Nir Shabat, Muqthar Mohammad, Hao Liu, Marco Selvi, Yichao Zhou, Mehdi Hafezi Manshadi, Chu-ling Ko, Anthony Chen, Michael Bendersky, Jorge Gonzalez Mendez, Nisarg Kothari, Amir Zandieh, Yiling Huang, Daniel Andor, Ellie Pavlick, Idan Brusilovsky, Jitendra Harlalka, Sally Goldman, Andrew Lampinen, Guowang Li, Asahi Ushio, Somit Gupta, Lei Zhang, Chuyuan Kelly Fu, Madhavi Sewak, Timo Denk, Jed Borovik, Brendan Jou, Avital Zipori, Prateek Jain, Junwen Bai, Thang Luong, Jonathan Tompson, Alice Li, Li Liu, George Powell, Jiajun Shen, Alex Feng, Grishma Chole, Da Yu, Yinlam Chow, Tongxin Yin, Eric Malmi, Kefan Xiao, Yash Pande, Shachi Paul, Niccolò Dal Santo, Adil Dostmohamed, Sergio Guadarrama, Aaron Phillips, Thanumalayan Sankaranarayana Pillai, Gal Yona, Amin Ghafouri, Preethi Lahoti, Benjamin Lee, Dhruv Madeka, Eren Sezener, Simon Tokumine, Adrian Collister, Nicola De Cao, Richard Shin, Uday Kalra, Parker Beak, Emily Nottage, Ryo Nakashima, Ivan Jurin, Vikash Sehwag, Meenu Gaba, Junhao Zeng, Kevin R. McKee, Fernando Pereira, Tamar Yakar, Amayika Panda, Arka Dhar, Peilin Zhong, Daniel Sohn, Mark Brand, Lars Lowe Sjoesund, Viral Carpenter, Sharon Lin, Shantanu Thakoor, Marcus Wainwright, Ashwin Chaugule, Pranesh Srinivasan, Muye Zhu, Bernett Orlando, Jack Weber, Ayzaan Wahid, Gilles Baechler, Apurv Suman, Jovana Mitrović, Gabe Taubman, Honglin Yu, Helen King, Josh Dillon, Cathy Yip, Dhriti Varma, Tomas Izo, Levent Bolelli, Borja De Balle Pigem, Julia Di Trapani, Fotis Iliopoulos, Adam Paszke, Nishant Ranka, Joe Zou, Francesco Pongetti, Jed McGiffin, Alex Siegman, Rich Galt, Ross Hemsley, Goran Žužić, Victor Carbune, Tao Li, Myle Ott, Félix de Chaumont Quitry, David Vilar Torres, Yuri Chervonyi, Tomy Tsai, Prem Eruvbetine, Samuel Yang, Matthew Denton, Jake Walker, Slavica Andačić, Idan Heimlich Shtacher, Vittal Premachandran, Harshal Tushar Lehri, Cip Baetu, Damion Yates, Lampros Lamprou, Mariko Iinuma, Ioana Mihailescu, Ben Albrecht, Shachi Dave, Susie Sargsyan, Bryan Perozzi, Lucas Manning, Chiyuan Zhang, Denis Vnukov, Igor Mordatch, Raia Hadsell Wolfgang Macherey, Ryan Kappedal, Jim Stephan, Aditya Tripathi, Klaus Macherey, Jun Qian, Abhishek Bhowmick, Shekoofeh Azizi, Rémi Leblond, Shiva Mohan Reddy Garlapati, Timothy Knight, Matthew Wiethoff, Wei-Chih Hung, Anelia Angelova, Georgios Evangelopoulos, Pawel Janus, Dimitris Paparas, Matthew Rahtz, Ken Caluwaerts, Vivek Sampathkumar, Daniel Jarrett, Shadi Noghabi, Antoine Miech, Chak Yeung, Geoff Clark, Henry Prior, Fei Zheng, Jean Pouget-Abadie, Indro Bhattacharya, Kalpesh Krishna, Will Bishop, Zhe Yuan, Yunxiao Deng, Ashutosh Sathe, Kacper Krasowiak, Ciprian Chelba, Cho-Jui Hsieh, Kiran Vodrahalli, Buhuang Liu, Thomas Köppe, Amr Khalifa, Lubo Litchev, Pichi Charoenpanit, Reed Roberts, Sachin Yadav, Yasumasa Onoe, Desi Ivanov, Megha Mohabey, Vighnesh Birodkar, Nemanja Rakićević, Pierre Sermanet, Vaibhav Mehta, Krishan Subudhi, Travis Choma, Will Ng, Luheng He, Kathie Wang, Tasos Kementsietsidis, Shane Gu, Mansi Gupta, Andrew Nystrom, Mehran Kazemi, Timothy Chung, Nacho Cano, Nikhil Dhawan, Yufei Wang, Jiawei Xia, Trevor Yacovone, Eric Jia, Mingqing Chen, Simeon Ivanov, Ashrith Sheshan, Sid Dalmia, Paweł Stradomski, Pengcheng Yin, Salem Haykal, Congchao Wang, Dennis Duan, Neslihan Bulut, Greg Kochanski, Liam MacDermed, Namrata Godbole, Shitao Weng, Jingjing Chen, Rachana Fellinger, Ramin Mehran, Daniel Suo, Hisham Husain, Tong He, Kaushal Patel, Joshua Howland, Randall Parker, Kelvin Nguyen, Sharath Maddineni, Chris Rawles, Mina Khan, Shlomi Cohen-Ganor, Amol Mandhane, Xinyi Wu, Chenkai Kuang, Iulia Comşa, Ramya Ganeshan, Hanie Sedghi, Adam Bloniarz, Nuo Wang Pierse, Anton Briukhov, Petr Mitrichev, Anita Gergely, Serena Zhan, Allan Zhou, Nikita Saxena, Eva Lu, Josef Dean, Ashish Gupta, Nicolas Perez-Nieves, Renjie Wu, Cory McLean, Wei Liang, Disha Jindal, Anton Tsitsulin, Wenhao Yu, Kaiz Alarakyia, Tom Schaul, Piyush Patil, Peter Sung, Elijah Peake, Hongkun Yu, Feryal Behbahani, JD Co-Reyes, Alan Ansell, Sean Sun, Clara Barbu, Jonathan Lee, Seb Noury, James Allingham, Bilal Piot, Mohit Sharma, Christopher Yew, Ivan Korotkov, Bibo Xu, Demetra Brady, Goran Petrovic, Shibl Mourad, Claire Cui, Aditya Gupta, Parker Schuh, Saarthak Khanna, Anna Goldie, Abhinav Arora, Vadim Zubov, Amy Stuart, Mark Epstein, Yun Zhu, Jianqiao Liu, Yury Stuken, Ziyue Wang, Karolis Misiunas, Dee Guo, Ashleah Gill, Ale Hartman, Zaid Nabulsi, Aurko Roy, Aleksandra Faust, Jason Riesa, Ben Withbroe, Mengchao Wang, Marco Tagliasacchi, Andreea Marzoca, James Noraky, Serge Toropov, Malika Mehrotra, Bahram Raad, Sanja Deur, Steve Xu, Marianne Monteiro, Zhongru Wu, Yi Luan, Sam Ritter, Nick Li, Håvard Garnes, Yanzhang He, Martin Zlocha, Jifan Zhu, Matteo Hessel, Will Wu, Spandana Raj Babbula, Chizu Kawamoto, Yuanzhen Li, Mehadi Hassen, Yan Wang, Brian Wieder, James Freedman, Yin Zhang, Xinyi Bai, Tianli Yu, David Reitter, XiangHai Sheng, Mateo Wirth, Aditya Kini, Dima Damen, Mingcen Gao, Rachel Hornung, Michael Voznesensky, Brian Roark, Adhi Kuncoro, Yuxiang Zhou, Rushin Shah, Anthony Brohan, Kuangyuan Chen, James Wendt, David Rim, Paul Kishan Rubenstein, Jonathan Halcrow, Michelle Liu, Ty Geri, Yunhsuan Sung, Jane Shapiro, Shaan Bijwadia, Chris Duvarney, Christina Sorokin, Paul Natsev, Reeve Ingle, Pramod Gupta, Young Maeng, Ndaba Ndebele, Kexin Zhu, Valentin Anklin, Katherine Lee, Yuan Liu, Yaroslav Akulov, Shaleen Gupta, Guolong Su, Flavien Prost, Tianlin Liu, Vitaly Kovalev, Pol Moreno, Martin Scholz, Sam Redmond, Zongwei Zhou, Alex Castro-Ros, André Susano Pinto, Dia Kharrat, Michal Yarom, Rachel Saputro, Jannis Bulian, Ben Caine, Ji Liu, Abbas Abdolmaleki, Shariq Iqbal, Tautvydas Misiunas, Mikhail Sirotenko, Shefali Garg, Guy Bensky, Huan Gui, Xuezhi Wang, Raphael Koster, Mike Bernico, Da Huang, Romal Thoppilan, Trevor Cohn, Ben Golan, Wenlei Zhou, Andrew Rosenberg, Markus Freitag, Tynan Gangwani, Vincent Tsang, Anand Shukla, Xiaoqi Ren, Minh Giang, Chi Zou, Andre Elisseeff, Charline Le Lan, Dheeru Dua, Shuba Lall, Pranav Shyam, Frankie Garcia, Sarah Nguyen, Michael Guzman, AJ Maschinot, Marcello Maggioni, Ming-Wei Chang, Karol Gregor, Lotte Weerts, Kumaran Venkatesan, Bogdan Damoc, Leon Liu, Jan Wassenberg, Lewis Ho, Becca Roelofs, Majid Hadian, François-Xavier Aubet, Yu Liang, Sami Lachgar, Danny Karmon, Yong Cheng, Amelio Vázquez-Reina, Angie Chen, Zhuyun Dai, Andy Brock, Shubham Agrawal, Chenxi Pang, Peter Garst, Mariella Sanchez-Vargas, Ivor Rendulic, Aditya Ayyar, Andrija Ražnatović, Olivia Ma, Roopali Vij, Neha Sharma, Ashwin Balakrishna, Bingyuan Liu, Ian Mackinnon, Sorin Baltateanu, Petra Poklukar, Gabriel Ibagon, Colin Ji, Hongyang Jiao, Isaac Noble, Wojciech Stokowiec, Zhihao Li, Jeff Dean, David Lindner, Mark Omernick, Kristen Chiafullo, Mason Dimarco, Vitor Rodrigues, Vittorio Selo, Garrett Honke, Xintian Cindy Wu, Wei He, Adam Hillier, Anhad Mohananey, Vihari Piratla, Chang Ye, Chase Malik, Sebastian Riedel, Samuel Albanie, Zi Yang, Kenny Vassigh, Maria Bauza, Sheng Li, Yiqing Tao, Nevan Wichers, Andrii Maksai, Abe Ittycheriah, Ross Mcilroy, Bryan Seybold, Noah Goodman, Romina Datta, Steven M. Hernandez, Tian Shi, Yony Kochinski, Anna Bulanova, Ken Franko, Mikita Sazanovich, Nicholas FitzGerald, Praneeth Kacham, Shubha Srinivas Raghvendra, Vincent Hellendoorn, Alexander Grushetsky, Julian Salazar, Angeliki Lazaridou, Jason Chang, Jan-Thorsten Peter, Sushant Kafle, Yann Dauphin, Abhishek Rao, Filippo Graziano, Izhak Shafran, Yuguo Liao, Tianli Ding, Geng Yan, Grace Chu, Zhao Fu, Vincent Roulet, Gabriel Rasskin, Duncan Williams, Shahar Drath, Alex Mossin, Raphael Hoffmann, Jordi Orbay, Francesco Bertolini, Hila Sheftel, Justin Chiu, Siyang Xue, Yuheng Kuang, Ferjad Naeem, Swaroop Nath, Nana Nti, Phil Culliton, Kashyap Krishnakumar, Michael Isard, Pei Sun, Ayan Chakrabarti, Nathan Clement, Regev Cohen, Arissa Wongpanich, GS Oh, Ashwin Murthy, Hao Zheng, Jessica Hamrick, Oskar Bunyan, Suhas Ganesh, Nitish Gupta, Roy Frostig, John Wieting, Yury Malkov, Pierre Marcenac, Zhixin Lucas Lai, Xiaodan Tang, Mohammad Saleh, Fedir Zubach, Chinmay Kulkarni, Huanjie Zhou, Vicky Zayats, Nan Ding, Anshuman Tripathi, Arijit Pramanik, Patrik Zochbauer, Harish Ganapathy, Vedant Misra, Zach Behrman, Hugo Vallet, Mingyang Zhang, Mukund Sridhar, Ye Jin, Mohammad Babaeizadeh, Siim Põder, Megha Goel, Divya Jain, Tajwar Nasir, Shubham Mittal, Tim Dozat, Diego Ardila, Aliaksei Severyn, Fabio Pardo, Sammy Jerome, Siyang Qin, Louis Rouillard, Amir Yazdanbakhsh, Zizhao Zhang, Shivani Agrawal, Kaushik Shivakumar, Caden Lu, Praveen Kallakuri, Rachita Chhaparia, Kanishka Rao, Charles Kwong, Asya Fadeeva, Shitij Nigam, Yan Virin, Yuan Zhang, Balaji Venkatraman, Beliz Gunel, Marc Wilson, Huiyu Wang, Abhinav Gupta, Xiaowei Xu, Adrien Ali Taïga, Kareem Mohamed, Doug Fritz, Daniel Rodriguez, Zoubin Ghahramani, Harry Askham, Lior Belenki, James Zhao, Rahul Gupta, Krzysztof Jastrzębski, Takahiro Kosakai, Kaan Katircioglu, Jon Schneider, Rina Panigrahy, Konstantinos Bousmalis, Peter Grabowski, Prajit Ramachandran, Chaitra Hegde, Mihaela Rosca, Angelo Scorza Scarpati, Kyriakos Axiotis, Ying Xu, Zach Gleicher, Assaf Hurwitz Michaely, Mandar Sharma, Sanil Jain, Christoph Hirnschall, Tal Marian, Xuhui Jia, Kevin Mather, Kilol Gupta, Linhai Qiu, Nigamaa Nayakanti, Lucian Ionita, Steven Zheng, Lucia Loher, Kurt Shuster, Igor Petrovski, Roshan Sharma, Rahma Chaabouni, Angel Yeh, James An, Arushi Gupta, Steven Schwarcz, Seher Ellis, Sam Conway-Rahman, Javier Snaider, Alex Zhai, James Atwood, Daniel Golovin, Liqian Peng, Te I, Vivian Xia, Salvatore Scellato, Mahan Malihi, Arthur Bražinskas, Vlad-Doru Ion, Younghoon Jun, James Swirhun, Soroosh Mariooryad, Jiao Sun, Steve Chien, Rey Coaguila, Ariel Brand, Yi Gao, Tom Kwiatkowski, Roee Aharoni, Cheng-Chun Lee, Mislav Žanić, Yichi Zhang, Dan Ethier, Vitaly Nikolaev, Pranav Nair, Yoav Ben Shalom, Hen Fitoussi, Jai Gupta, Hongbin Liu, Dee Cattle, Tolga Bolukbasi, Ben Murdoch, Fantine Huot, Yin Li, Chris Hahn
In this report, we introduce the Gemini 2.X model family: Gemini 2.5 Pro and Gemini 2.5 Flash, as well as our earlier Gemini 2.0 Flash and Flash-Lite models. Gemini 2.5 Pro is our most capable model yet, achieving SoTA performance on frontier coding and reasoning benchmarks. In addition to its incredible coding and reasoning skills, Gemini 2.5 Pro is a thinking model that excels at multimodal understanding and it is now able to process up to 3 hours of video content. Its unique combination of long context, multimodal and reasoning capabilities can be combined to unlock new agentic workflows. Gemini 2.5 Flash provides excellent reasoning abilities at a fraction of the compute and latency requirements and Gemini 2.0 Flash and Flash-Lite provide high performance at low latency and cost. Taken together, the Gemini 2.X model generation spans the full Pareto frontier of model capability vs cost, allowing users to explore the boundaries of what is possible with complex agentic problem solving.
在这份报告中,我们介绍了Gemini 2.X模型家族:包括Gemini 2.5 Pro和Gemini 2.5 Flash,以及我们之前的Gemini 2.0 Flash和Flash-Lite模型。Gemini 2.5 Pro是我们迄今为止功能最强大的模型,在前沿编码和推理基准测试上达到了最新技术水平。除了令人印象深刻的编码和推理技能外,Gemini 2.5 Pro还是一种擅长多模式理解的思考模型,现在能够处理长达3小时的视频内容。其独特的长期上下文、多模式与推理能力的结合可以解锁新的智能工作流程。Gemini 2.5 Flash在计算和延迟要求方面提供了一流的推理能力的一小部分;而Gemini 2.0 Flash和Flash-Lite在低延迟和低成本的情况下提供了高性能。总的来说,Gemini 2.X模型世代涵盖了模型能力与成本之间的全面帕累托前沿,使用户能够探索通过复杂的智能问题解决可能性的边界。
论文及项目相关链接
PDF 72 pages, 17 figures
Summary
全新系列报告介绍了Gemini 2.X模型家族,包括Gemini 2.5 Pro和Gemini 2.5 Flash等。其中,Gemini 2.5 Pro是迄今为止性能最佳的模型,能在前沿编码和推理基准测试中取得最先进的性能。它还具有出色的多模式理解能力,并能处理长达3小时的视频内容。Gemini 2.X模型系列的生成跨越了模型能力与成本之间的全Pareto前沿,使用户能够探索复杂的代理问题解决的可能性边界。
Key Takeaways
- Gemini 2.X模型家族包含Gemini 2.5 Pro和Gemini 2.5 Flash等多个型号。
- Gemini 2.5 Pro是目前性能最佳的模型,具有出色的编码和推理能力。
- Gemini 2.5 Pro具备多模式理解能力,并能处理长达3小时的视频内容。
- Gemini 2.5 Flash在推理能力方面表现出色,同时降低了计算和延迟要求。
- Gemini 2.0 Flash和Flash-Lite提供低延迟和成本下的高性能表现。
- Gemini 2.X模型家族覆盖了模型能力与成本之间的全Pareto前沿。
点此查看论文截图

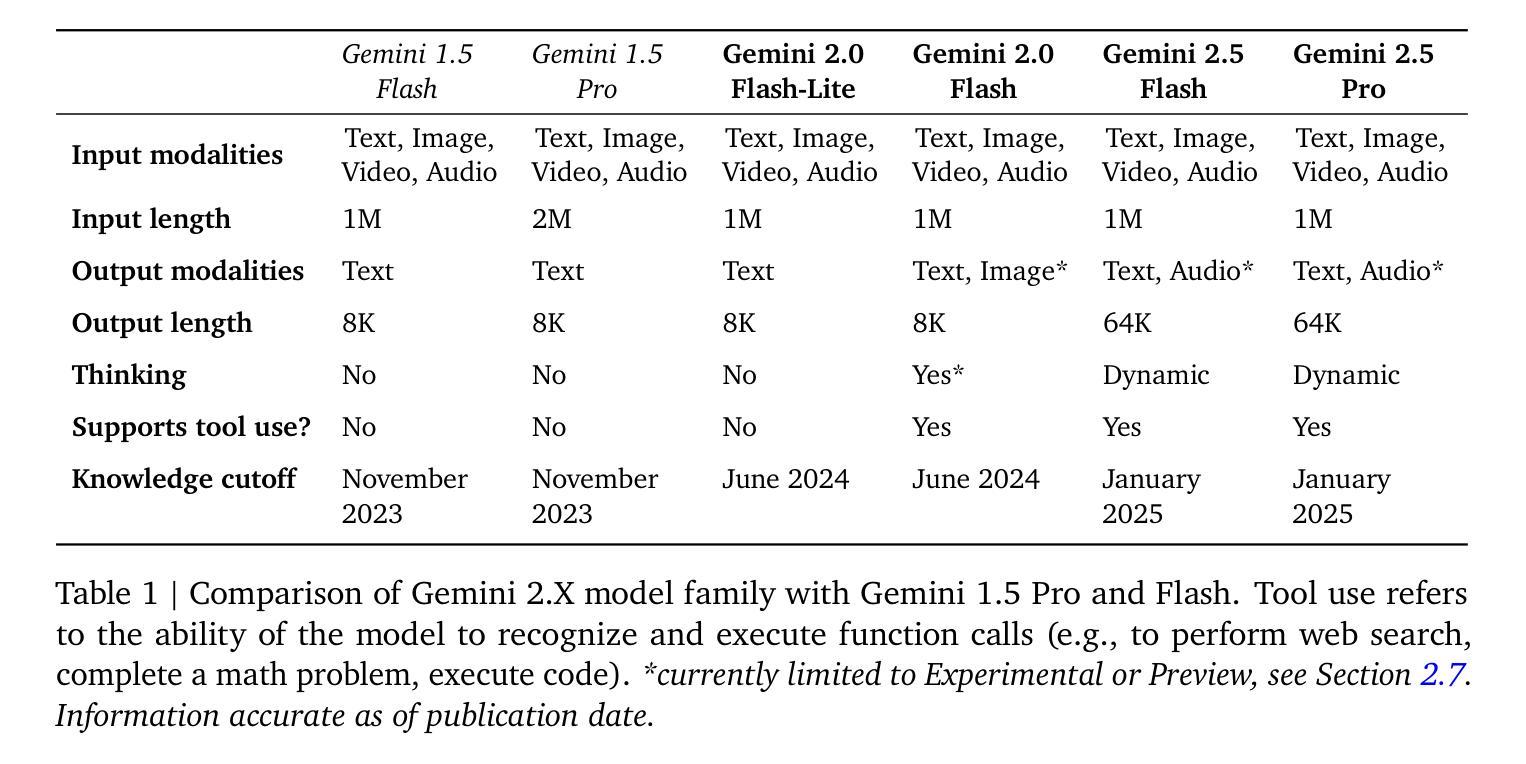
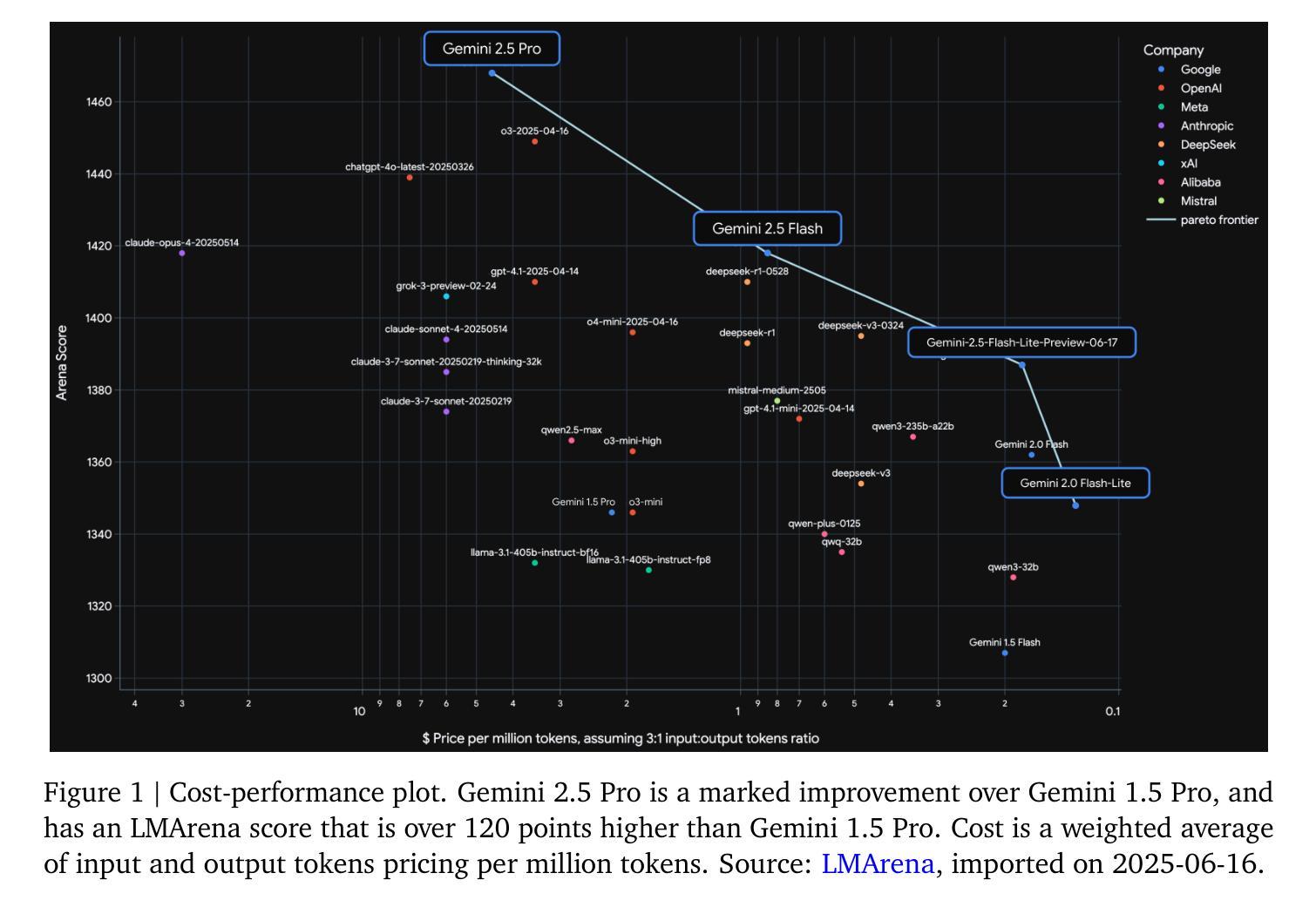
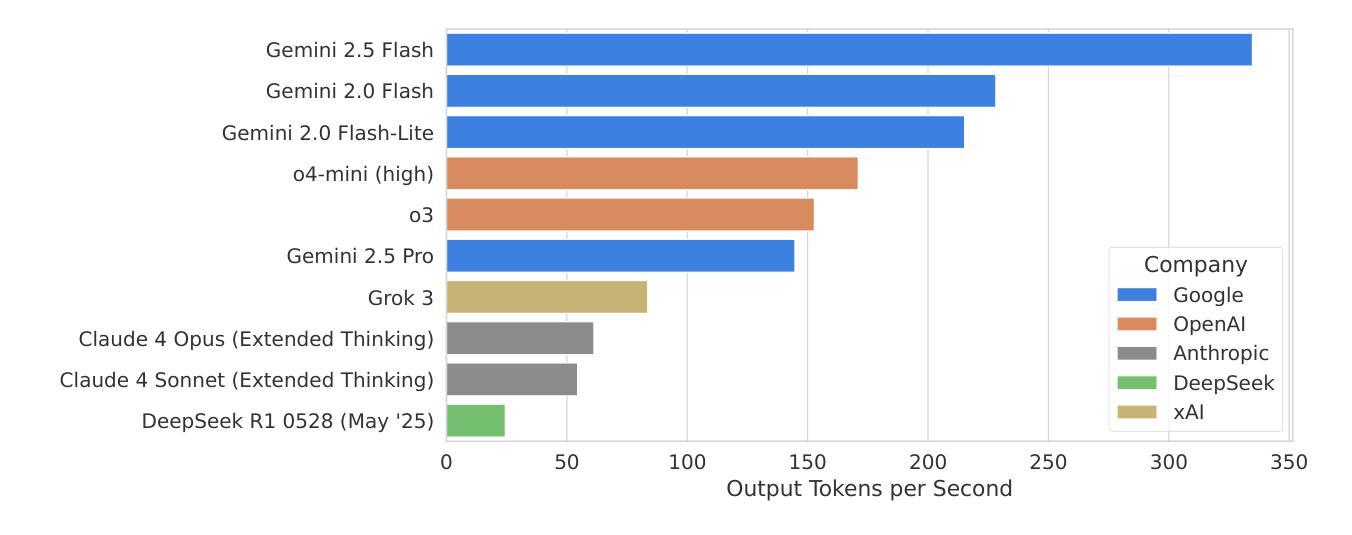
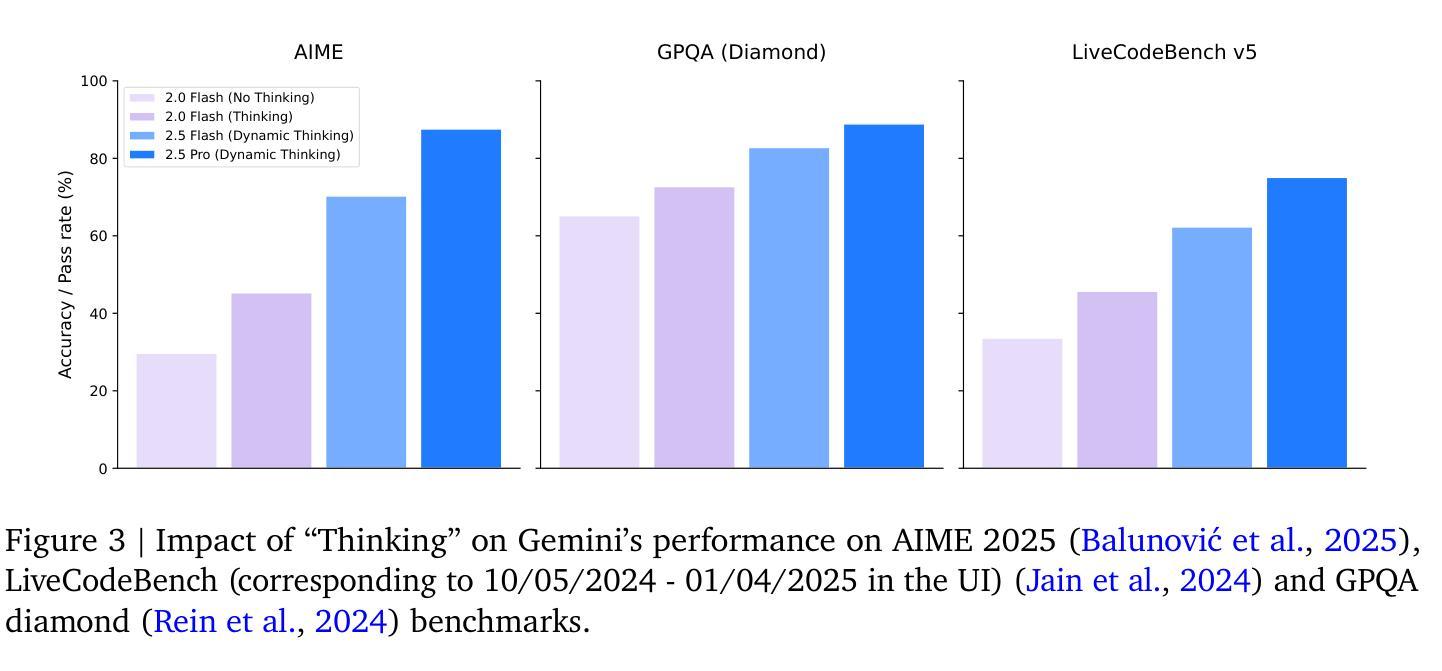
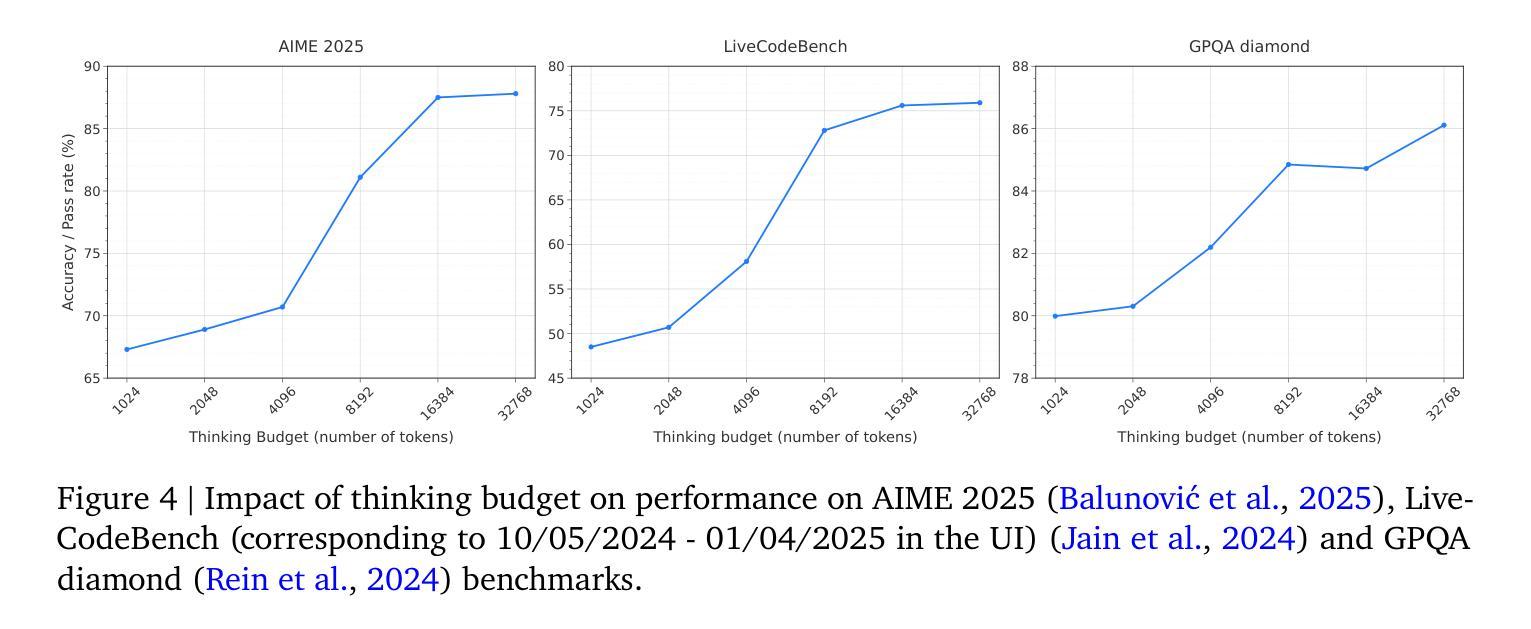
One-Pass to Reason: Token Duplication and Block-Sparse Mask for Efficient Fine-Tuning on Multi-Turn Reasoning
Authors:Ritesh Goru, Shanay Mehta, Prateek Jain
Fine-tuning Large Language Models (LLMs) on multi-turn reasoning datasets requires N (number of turns) separate forward passes per conversation due to reasoning token visibility constraints, as reasoning tokens for a turn are discarded in subsequent turns. We propose duplicating response tokens along with a custom attention mask to enable single-pass processing of entire conversations. We prove our method produces identical losses to the N-pass approach while reducing time complexity from $O\bigl(N^{3}\bigl)$ to $O\bigl(N^{2}\bigl)$ and maintaining the same memory complexity for a transformer based model. Our approach achieves significant training speedup while preserving accuracy. Our implementation is available online (https://github.com/devrev/One-Pass-to-Reason).
对于大型语言模型(LLM)在多轮推理数据集上进行微调,由于推理标记可见性的限制,每一轮对话都需要进行N次单独的前向传递。我们提出复制响应标记并使用自定义注意力掩码,以实现对整个对话的单次传递处理。我们证明了我们的方法产生的损失与N次传递方法相同,同时将时间复杂度从O(N^3)降低到O(N^2),并保持了基于变压器的模型的相同内存复杂度。我们的方法在保持准确性的同时实现了显著的训练加速。我们的实现已在线发布(https://github.com/devrev/One-Pass-to-Reason)。
论文及项目相关链接
PDF 9 pages, 3 figures
Summary:针对多轮推理数据集微调大型语言模型(LLM)时,由于推理令牌可见性的限制,需要进行N次单独的转发操作。我们提出通过复制响应令牌和自定义注意力掩码来实现整个对话的单次传递处理。我们的方法产生的损失与N次传递方法相同,同时将时间复杂度从O(N³)降低到O(N²),对于基于转换器的模型,保持相同的内存复杂度。我们的方法在保证准确性的同时实现了显著的训练速度提升。相关实现已在线发布。
Key Takeaways:
- 大型语言模型在多轮推理数据集上的微调需要针对每轮对话进行单独的转发处理。
- 我们提出了一种新的方法,通过复制响应令牌和自定义注意力掩码,实现了整个对话的单次传递处理。
- 该方法产生的损失与多次传递方法相同。
- 该方法降低了训练的时间复杂度,从O(N³)降低到O(N²),并且保持了相同的内存复杂度。
- 此方法显著提高了训练速度,同时保证了准确性。
- 具体的实现细节已经在线发布。
点此查看论文截图