⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-15 更新
MIDI-VALLE: Improving Expressive Piano Performance Synthesis Through Neural Codec Language Modelling
Authors:Jingjing Tang, Xin Wang, Zhe Zhang, Junichi Yamagishi, Geraint Wiggins, George Fazekas
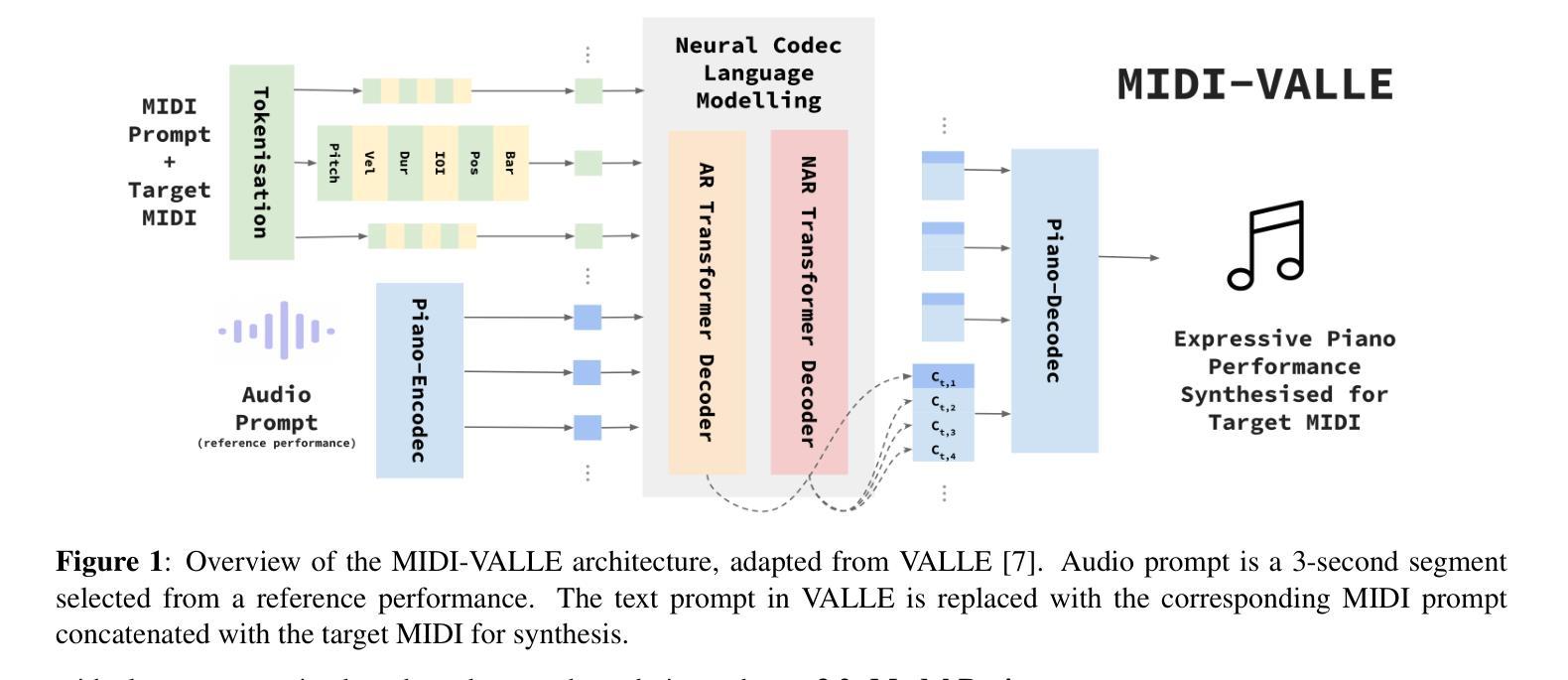
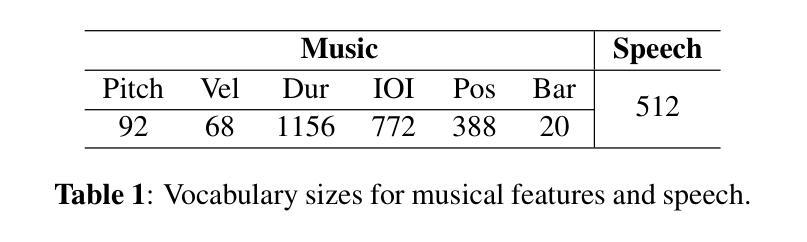
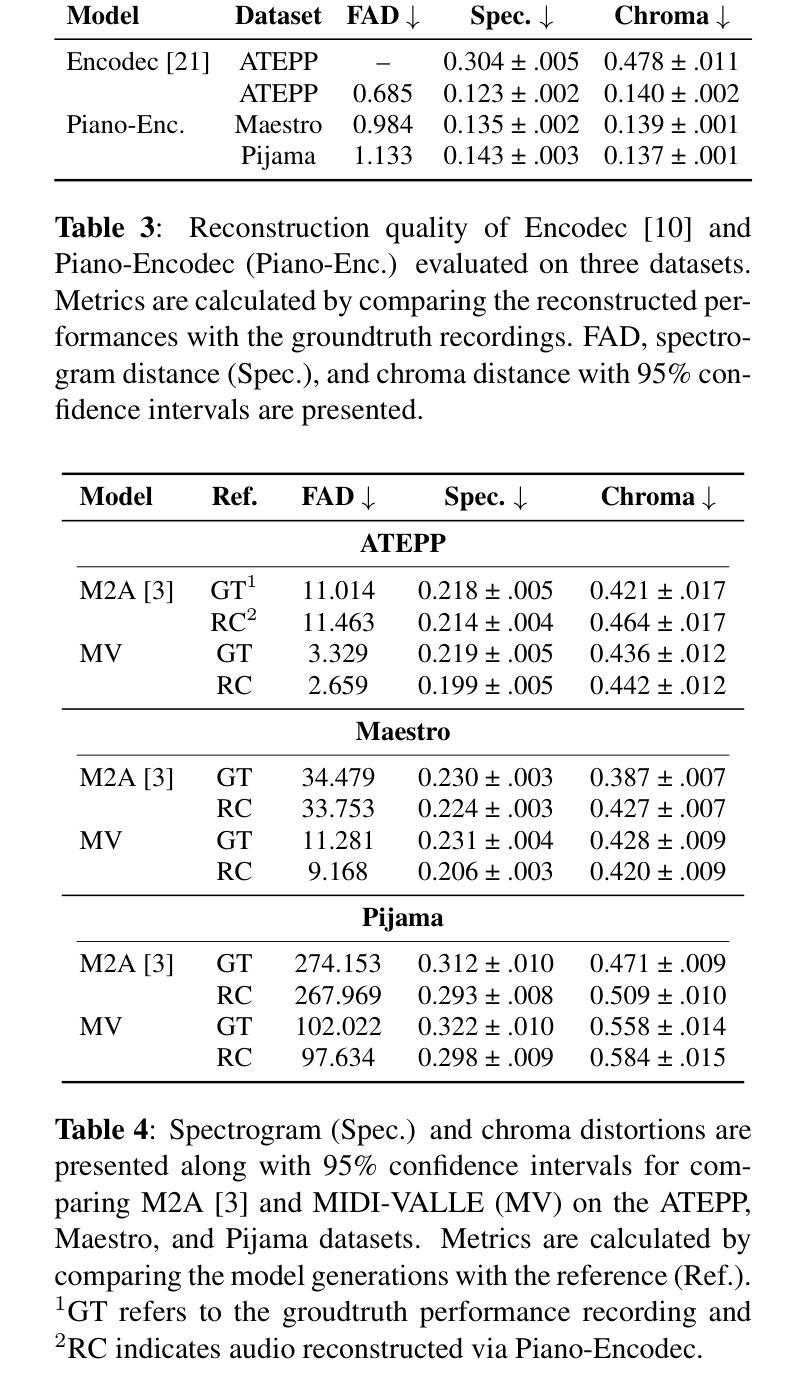
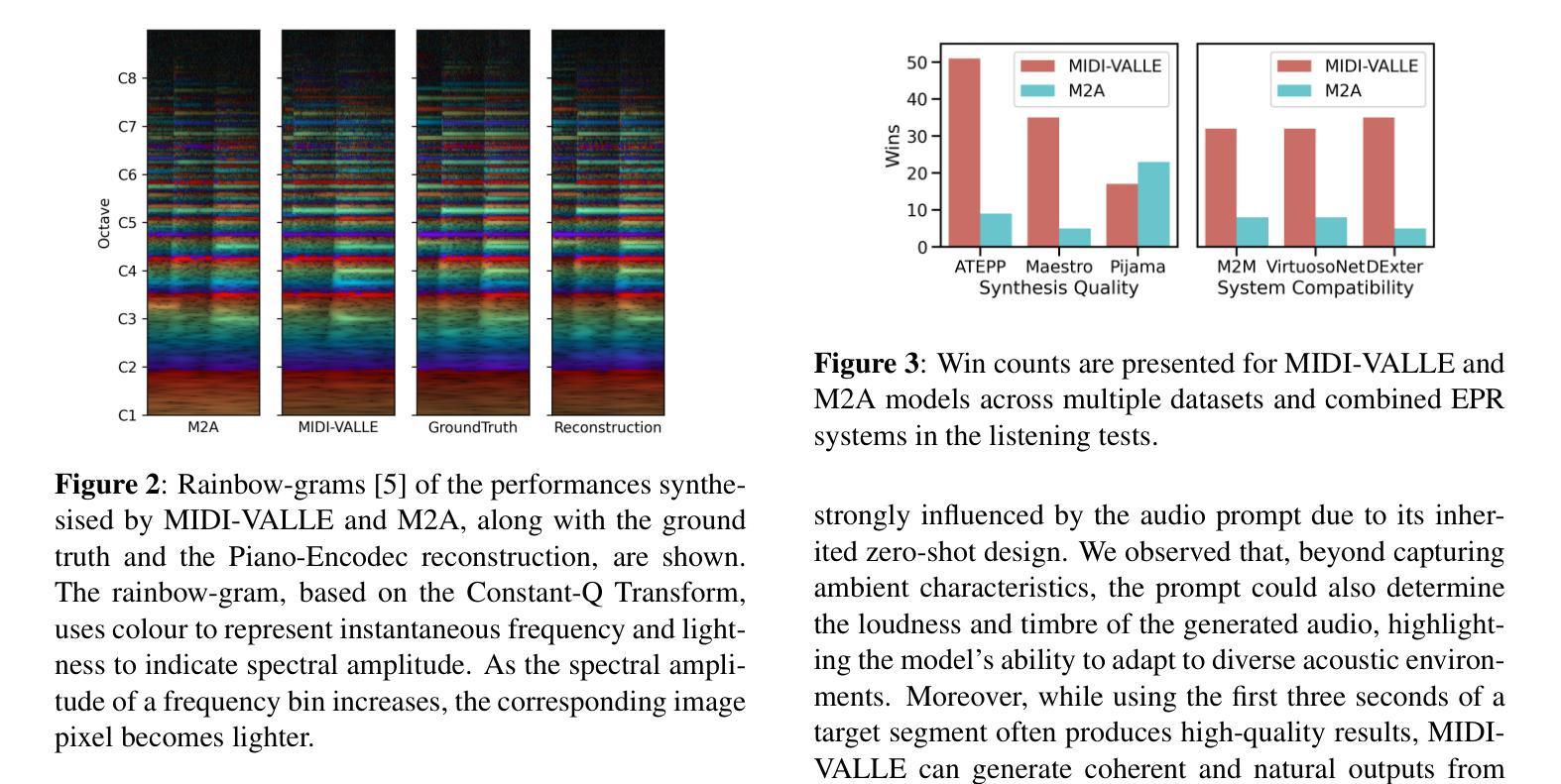
Generating expressive audio performances from music scores requires models to capture both instrument acoustics and human interpretation. Traditional music performance synthesis pipelines follow a two-stage approach, first generating expressive performance MIDI from a score, then synthesising the MIDI into audio. However, the synthesis models often struggle to generalise across diverse MIDI sources, musical styles, and recording environments. To address these challenges, we propose MIDI-VALLE, a neural codec language model adapted from the VALLE framework, which was originally designed for zero-shot personalised text-to-speech (TTS) synthesis. For performance MIDI-to-audio synthesis, we improve the architecture to condition on a reference audio performance and its corresponding MIDI. Unlike previous TTS-based systems that rely on piano rolls, MIDI-VALLE encodes both MIDI and audio as discrete tokens, facilitating a more consistent and robust modelling of piano performances. Furthermore, the model’s generalisation ability is enhanced by training on an extensive and diverse piano performance dataset. Evaluation results show that MIDI-VALLE significantly outperforms a state-of-the-art baseline, achieving over 75% lower Frechet Audio Distance on the ATEPP and Maestro datasets. In the listening test, MIDI-VALLE received 202 votes compared to 58 for the baseline, demonstrating improved synthesis quality and generalisation across diverse performance MIDI inputs.
从乐谱生成富有表现力的音频表演需要模型捕捉乐器的声学特性和人类解释。传统音乐表演合成管道遵循两阶段方法,首先根据乐谱生成富有表现力的性能MIDI,然后将MIDI合成音频。然而,合成模型往往难以在不同MIDI源、音乐风格和录音环境之间进行泛化。为了解决这些挑战,我们提出了MIDI-VALLE,这是一个基于VALLE框架的神经网络编解码器语言模型。VALLE框架最初是为零样本个性化文本到语音(TTS)合成而设计的。对于性能MIDI到音频合成,我们改进了架构,使其依赖于参考音频表演及其对应的MIDI。与之前的基于TTS的系统不同,MIDI-VALLE将MIDI和音频都编码为离散令牌,从而更一致、更稳健地建模钢琴演奏。此外,通过在广泛且多样的钢琴表演数据集上进行训练,增强了模型的泛化能力。评估结果表明,MIDI-VALLE显著优于最先进的基线模型,在ATEPP和Maestro数据集上的Frechet音频距离降低了75%以上。在聆听测试中,MIDI-VALLE获得了202票,而基线模型仅获得58票,这证明了其在合成质量和不同性能MIDI输入的泛化方面的改进。
论文及项目相关链接
PDF Accepted by ISMIR 2025
Summary:
提出了一种基于神经网络的语言模型MIDI-VALLE,用于从乐谱生成表达性音频表演。该模型适应于VALLE框架,并改进了架构以参考音频表演和其对应的MIDI。MIDI-VALLE在性能MIDI到音频合成方面表现出卓越的效果,通过编码MIDI和音频作为离散符号,实现了更一致和稳健的钢琴表演建模。模型在大量和多样化的钢琴表演数据集上进行训练,增强了其泛化能力。
Key Takeaways:
- MIDI-VALLE是一个基于神经网络的语言模型,用于从音乐乐谱生成表达性音频表演。
- 该模型采用VALLE框架,并进行了改进,以参考音频表演和其对应的MIDI。
- MIDI-VALLE通过将MIDI和音频编码为离散符号,实现了更一致和稳健的钢琴表演建模。
- 模型在广泛的多样化钢琴表演数据集上训练,增强了其泛化能力。
- MIDI-VALLE显著优于现有技术基线,在ATEPP和Maestro数据集上的Frechet Audio Distance降低了75%以上。
- 听觉测试表明,MIDI-VALLE的合成质量和泛化能力得到了显著提高,获得了202票相对于基线的58票。
点此查看论文截图


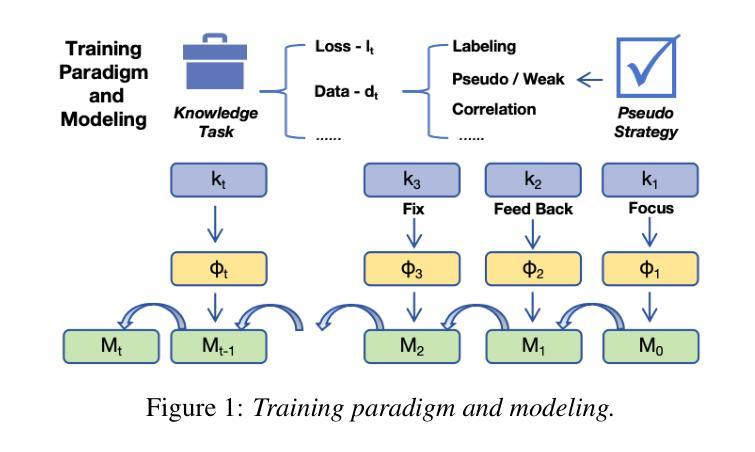
ILT-Iterative LoRA Training through Focus-Feedback-Fix for Multilingual Speech Recognition
Authors:Qingliang Meng, Hao Wu, Wei Liang, Wei Xu, Qing Zhao
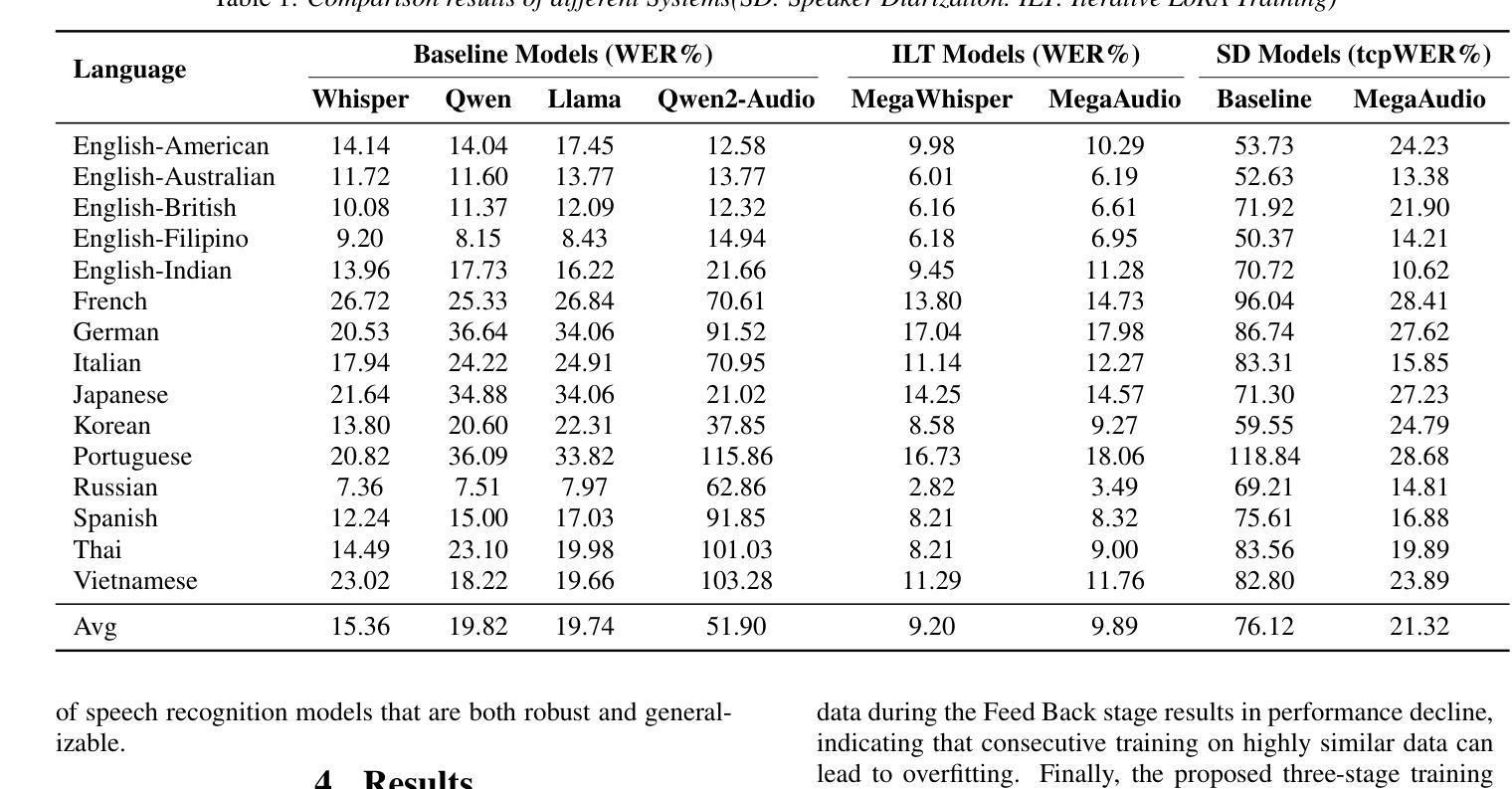
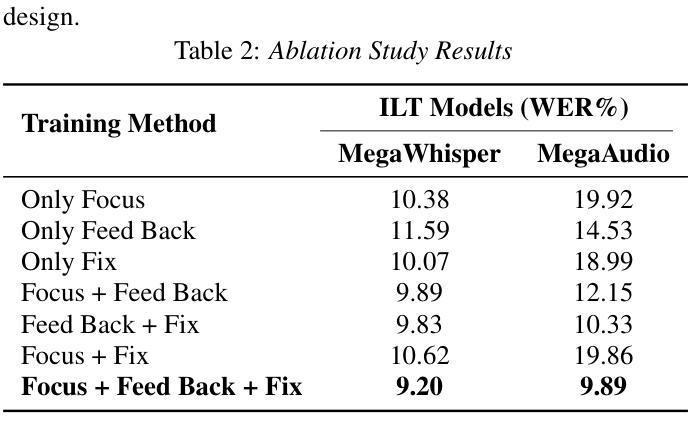
The deep integration of large language models and automatic speech recognition systems has become a promising research direction with high practical value. To address the overfitting issue commonly observed in Low-Rank Adaptation (LoRA) during the supervised fine-tuning (SFT) stage, this work proposes an innovative training paradigm Iterative LoRA Training (ILT) in combination with an Iterative Pseudo Labeling strategy, effectively enhancing the theoretical upper bound of model performance. Based on Whisper-large-v3 and Qwen2-Audio, we conduct systematic experiments using a three-stage training process: Focus Training, Feed Back Training, and Fix Training. Experimental results demonstrate the effectiveness of the proposed method. Furthermore, the MegaAIS research team applied this technique in the Interspeech 2025 Multilingual Conversational Speech Language Modeling Challenge (MLC-SLM), achieving 4th in Track 1 (Multilingual ASR Task) and 1st place in Track 2 (Speech Separation and Recognition Task), showcasing the practical feasibility and strong application potential of our approach.
大规模语言模型和自动语音识别系统的深度融合已成为具有极高实用价值的研究方向。针对低秩适配(LoRA)在监督微调(SFT)阶段经常出现的过拟合问题,本研究提出了一种创新的训练范式——迭代LoRA训练(ILT),并结合迭代伪标签策略,有效地提高了模型性能的理论上限。基于Whisper-large-v3和Qwen2-Audio,我们采用三阶段训练过程进行系统实验:专注训练、反馈训练和固定训练。实验结果证明了该方法的有效性。此外,MegaAIS研究团队在Interspeech 2025多语种对话语音语言建模挑战赛(MLC-SLM)中应用了这一技术,在赛道1(多语种ASR任务)中获得第4名,赛道2(语音分离与识别任务)中获得第1名,展示了我们方法的实际可行性和强大的应用潜力。
论文及项目相关链接
PDF Accepted By Interspeech 2025 MLC-SLM workshop as a Research Paper
Summary
大型语言模型与自动语音识别系统的深度整合已成为具有实际价值的研究方向。为解决低秩适配(LoRA)在监督微调(SFT)阶段常见的过拟合问题,本研究提出迭代低秩适配训练(ILT)结合迭代伪标签策略,有效提高了模型性能的理论上限。基于Whisper-large-v3和Qwen2-Audio,我们采用三阶段训练过程进行系统化实验:专注训练、反馈训练和固定训练。实验结果证明了该方法的有效性。此外,MegaAIS研究团队在Interspeech 2025多语言对话语音识别语言建模挑战赛(MLC-SLM)中应用此技术,分别在多语言ASR任务和语音分离与识别任务中取得第4名和第1名的成绩,展示了该方法的实际应用潜力和强大竞争力。
Key Takeaways
- 大型语言模型与自动语音识别系统的深度整合具有实际价值。
- 迭代低秩适配训练(ILT)结合迭代伪标签策略解决了低秩适配(LoRA)在监督微调阶段的过拟合问题。
- 三阶段训练过程包括专注训练、反馈训练和固定训练。
- 基于Whisper-large-v3和Qwen2-Audio的系统化实验证明了该方法的有效性。
- MegaAIS研究团队在MLC-SLM比赛中取得了显著成绩,展示了该方法的实际应用潜力。
- 该方法在多语言ASR任务中取得了第4名的成绩。
点此查看论文截图

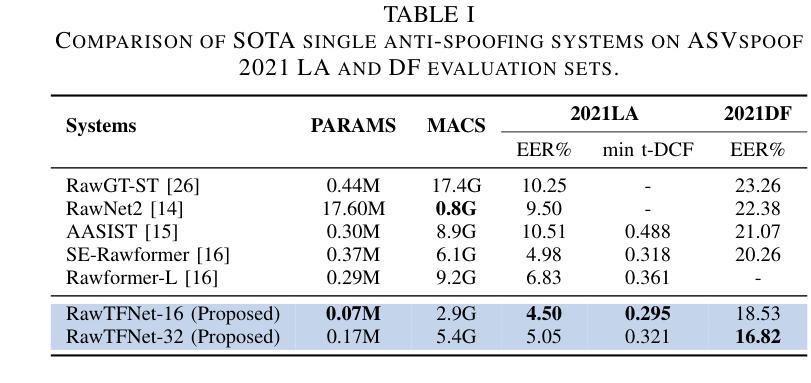
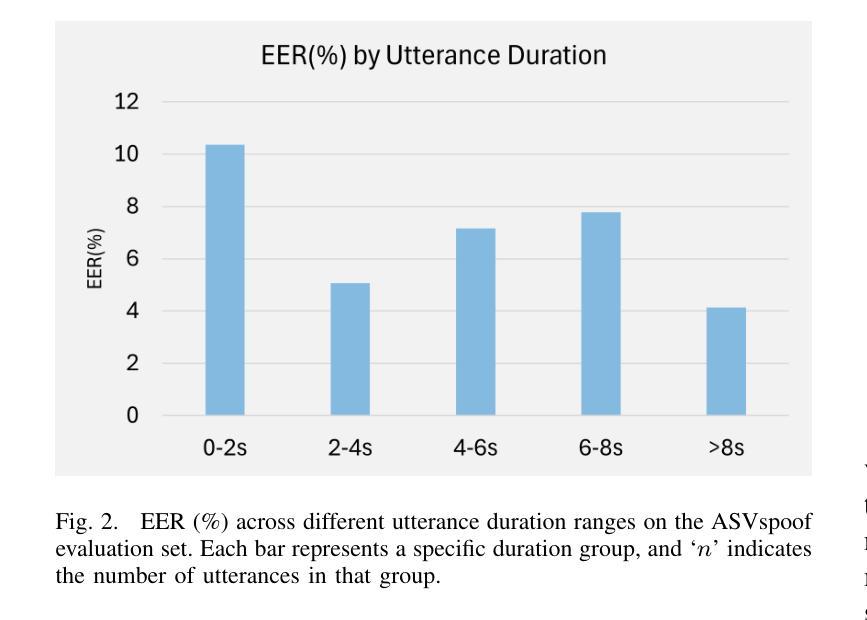
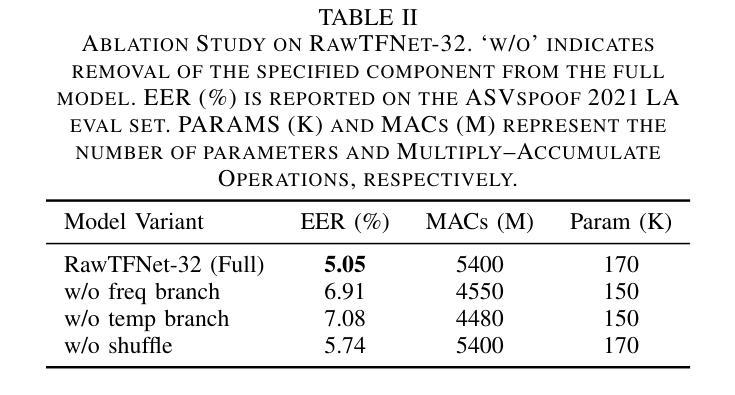
RawTFNet: A Lightweight CNN Architecture for Speech Anti-spoofing
Authors:Yang Xiao, Ting Dang, Rohan Kumar Das
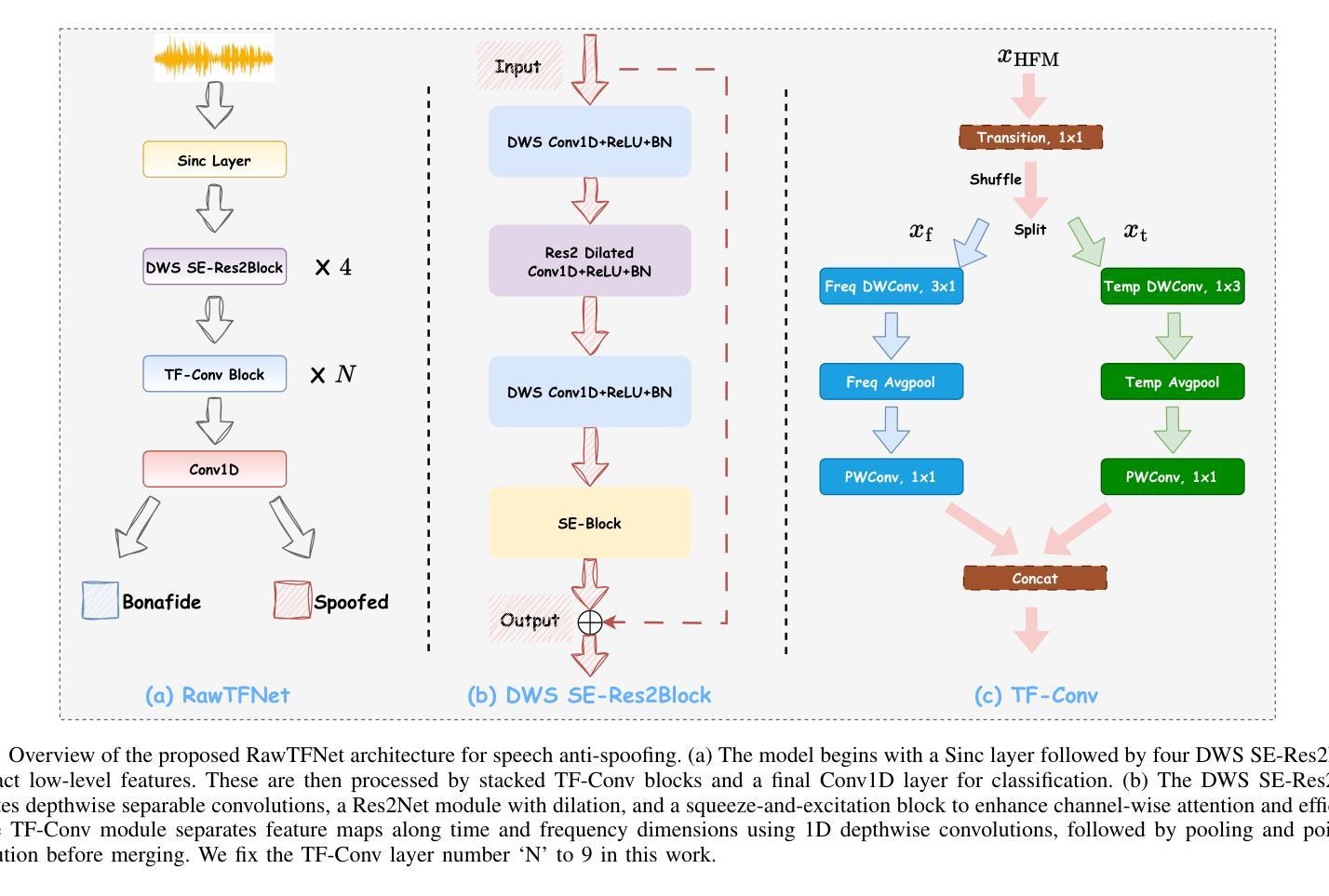
Automatic speaker verification (ASV) systems are often affected by spoofing attacks. Recent transformer-based models have improved anti-spoofing performance by learning strong feature representations. However, these models usually need high computing power. To address this, we introduce RawTFNet, a lightweight CNN model designed for audio signals. The RawTFNet separates feature processing along time and frequency dimensions, which helps to capture the fine-grained details of synthetic speech. We tested RawTFNet on the ASVspoof 2021 LA and DF evaluation datasets. The results show that RawTFNet reaches comparable performance to that of the state-of-the-art models, while also using fewer computing resources. The code and models will be made publicly available.
自动说话人验证(ASV)系统经常受到欺骗攻击的影响。最近基于Transformer的模型通过学习强大的特征表示,提高了防欺骗性能。然而,这些模型通常需要大量的计算能力。为了解决这一问题,我们引入了RawTFNet,这是一个为音频信号设计的轻量级CNN模型。RawTFNet在时间维度和频率维度上分离特征处理,有助于捕捉合成语音的精细细节。我们在ASVspoof 2021 LA和DF评估数据集上测试了RawTFNet。结果表明,RawTFNet的性能达到了最新模型的水平,同时使用的计算资源更少。代码和模型将公开发布。
论文及项目相关链接
PDF Submitted to APSIPA ASC 2025
Summary
本文介绍了自动说话人验证(ASV)系统面临的新型欺骗攻击问题。为了改善对欺骗行为的防御能力并减少计算需求,提出了一个名为RawTFNet的轻量级CNN模型。该模型能够沿时间和频率维度分离特征处理,以捕捉合成语音的精细细节。在ASVspoof 2021 LA和DF评估数据集上的测试显示,RawTFNet与最先进的模型相比表现相当,同时使用的计算资源更少。代码和模型将公开发布。
Key Takeaways
- 自动说话人验证(ASV)系统易受欺骗攻击的影响。
- 最新基于Transformer的模型通过强大的特征表示提高了抗欺骗性能。
- RawTFNet是一个轻量级的CNN模型,针对音频信号设计,旨在解决计算资源需求高的问题。
- RawTFNet能够沿时间和频率维度分离特征处理,以捕捉合成语音的精细细节。
- 在ASVspoof 2021 LA和DF评估数据集上的测试显示,RawTFNet性能与最先进的模型相当。
- RawTFNet使用较少的计算资源。
点此查看论文截图

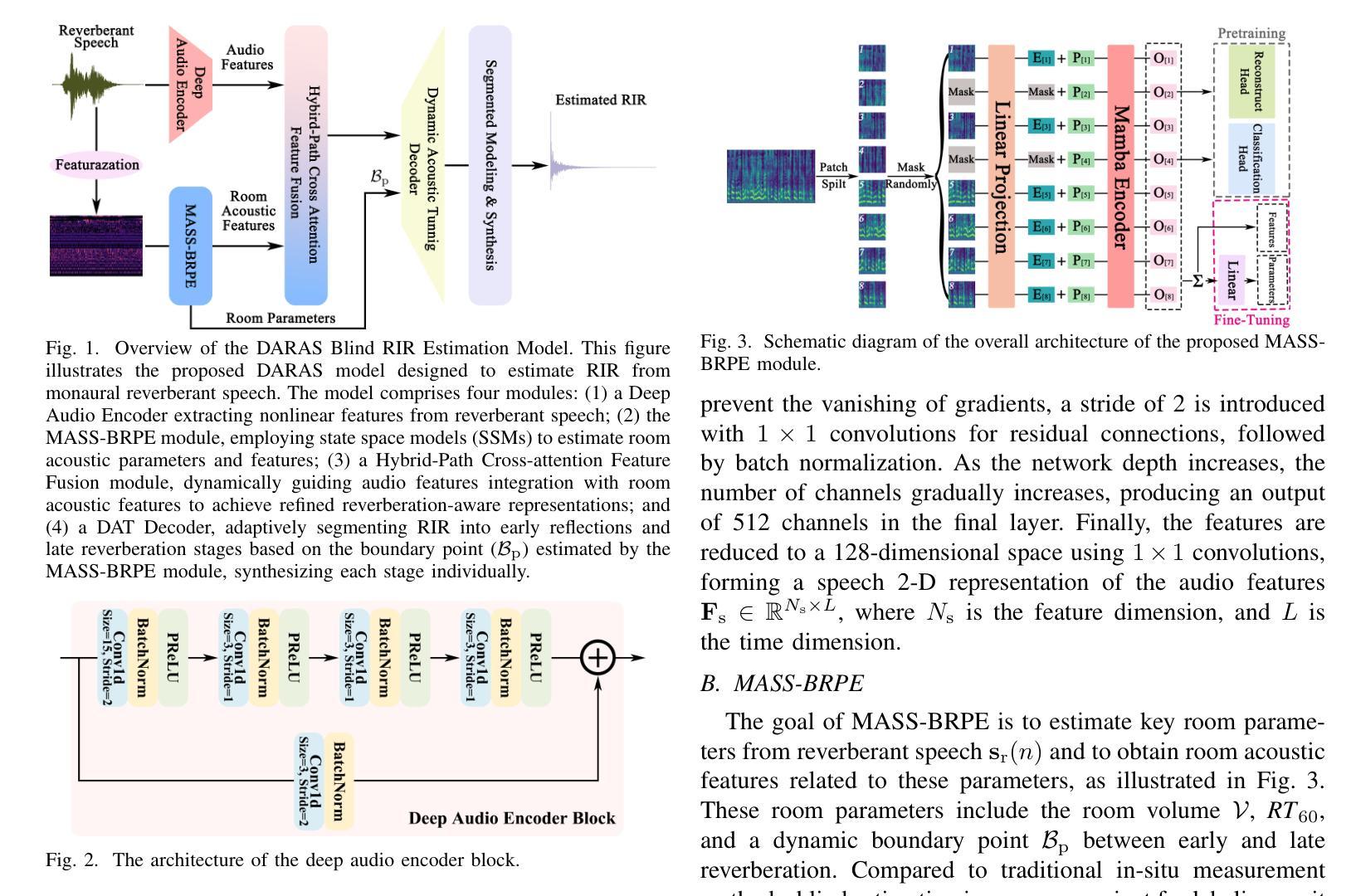
DARAS: Dynamic Audio-Room Acoustic Synthesis for Blind Room Impulse Response Estimation
Authors:Chunxi Wang, Maoshen Jia, Wenyu Jin
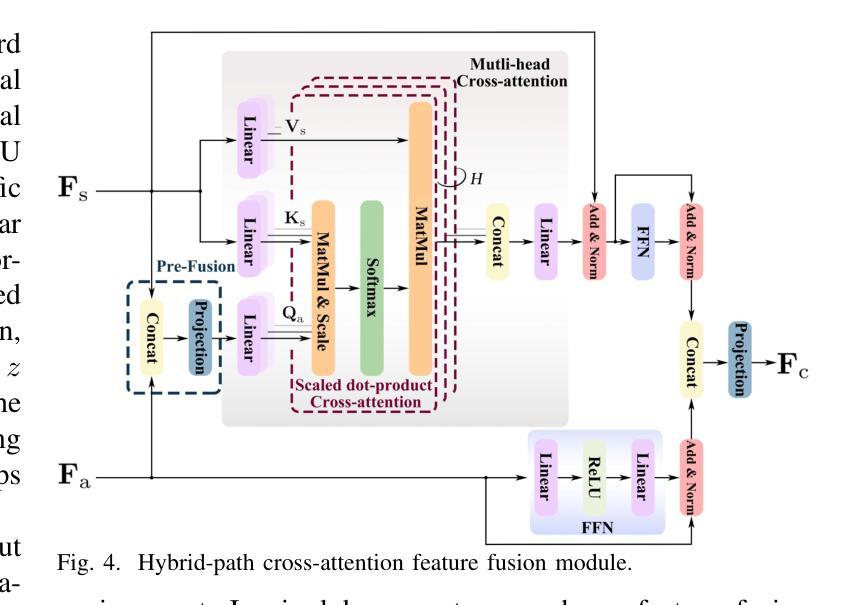
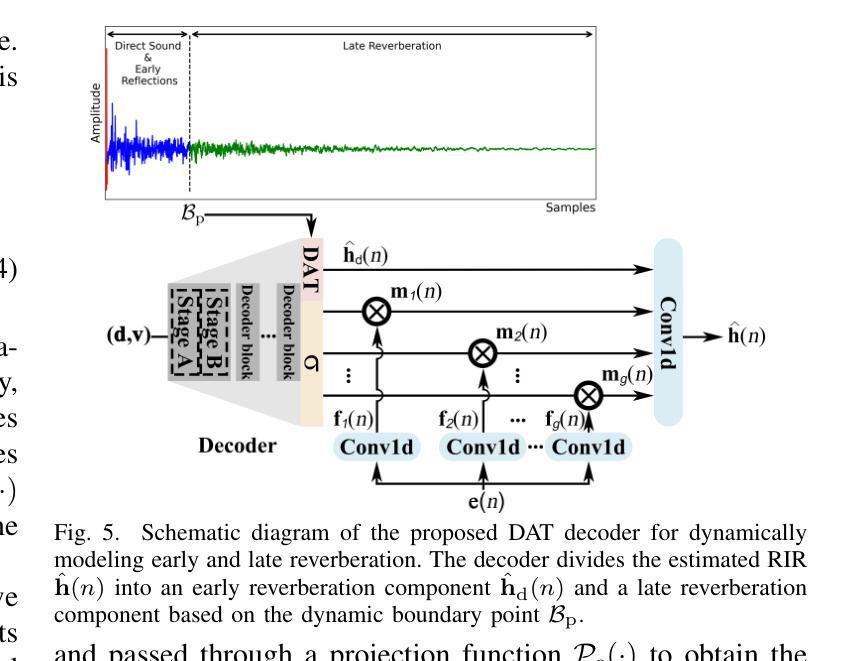
Room Impulse Responses (RIRs) accurately characterize acoustic properties of indoor environments and play a crucial role in applications such as speech enhancement, speech recognition, and audio rendering in augmented reality (AR) and virtual reality (VR). Existing blind estimation methods struggle to achieve practical accuracy. To overcome this challenge, we propose the dynamic audio-room acoustic synthesis (DARAS) model, a novel deep learning framework that is explicitly designed for blind RIR estimation from monaural reverberant speech signals. First, a dedicated deep audio encoder effectively extracts relevant nonlinear latent space features. Second, the Mamba-based self-supervised blind room parameter estimation (MASS-BRPE) module, utilizing the efficient Mamba state space model (SSM), accurately estimates key room acoustic parameters and features. Third, the system incorporates a hybrid-path cross-attention feature fusion module, enhancing deep integration between audio and room acoustic features. Finally, our proposed dynamic acoustic tuning (DAT) decoder adaptively segments early reflections and late reverberation to improve the realism of synthesized RIRs. Experimental results, including a MUSHRA-based subjective listening study, demonstrate that DARAS substantially outperforms existing baseline models, providing a robust and effective solution for practical blind RIR estimation in real-world acoustic environments.
室内环境的声学特性可以通过房间脉冲响应(RIRs)来准确表征,其在语音增强、语音识别以及增强现实(AR)和虚拟现实(VR)中的音频渲染等应用中发挥着至关重要的作用。现有的盲估计方法很难达到实用的准确度。为了应对这一挑战,我们提出了动态音频房间声学合成(DARAS)模型,这是一种专门为从单声道混响语音信号中盲估计RIRs而设计的新型深度学习框架。首先,专用的深度音频编码器有效地提取了相关的非线性潜在空间特征。其次,基于Mamba的自监督盲房间参数估计(MASS-BRPE)模块,利用高效的Mamba状态空间模型(SSM),准确估计了关键的房间声学参数和特征。第三,系统结合了一个混合路径交叉注意特征融合模块,增强了音频和房间声学特征之间的深度集成。最后,我们提出的动态声学调整(DAT)解码器自适应地分割早期反射和后期回响,提高了合成RIRs的真实性。包括基于MUSHRA的主观听觉研究在内的实验结果证明,DARAS在真实世界声学环境中显著优于现有基线模型,为实用盲RIR估计提供了稳健有效的解决方案。
论文及项目相关链接
PDF 14 pages, 9 figures, submitted to IEEE/ACM Transactions on Audio, Speech, and Language Processing
Summary
室内环境声音特性的精准描述对于语音增强、语音识别以及增强现实(AR)和虚拟现实(VR)中的音频渲染等应用至关重要。现有盲估计方法难以达到实用精度。为此,我们提出了动态音频房间声学合成(DARAS)模型,这是一种专门设计用于从单声道混响语音信号中盲估计RIR的深度学习框架。它通过深度音频编码器提取非线性潜在空间特征,利用基于Mamba的SSM模块估计房间声学参数,融合音频与房间声学特征,并通过动态声学调音解码器提高合成RIR的真实感。实验结果表明,DARAS在真实世界声学环境中显著优于现有基线模型。
Key Takeaways
- RIRs在室内环境声音特性表征中起关键作用,对语音增强和识别等应用至关重要。
- 现有盲估计方法存在实践中的准确性挑战。
- DARAS模型是一个深度学习框架,旨在从混响的语音信号中盲估计RIR。
- DARAS包含深度音频编码器、基于Mamba的SSM模块、特征融合模块和动态声学调音解码器。
- 深度音频编码器能有效提取非线性潜在空间特征。
- 基于Mamba的SSM模块用于准确估计关键房间声学参数。
点此查看论文截图

Modèle physique variationnel pour l’estimation de réponses impulsionnelles de salles
Authors:Louis Lalay, Mathieu Fontaine, Roland Badeau
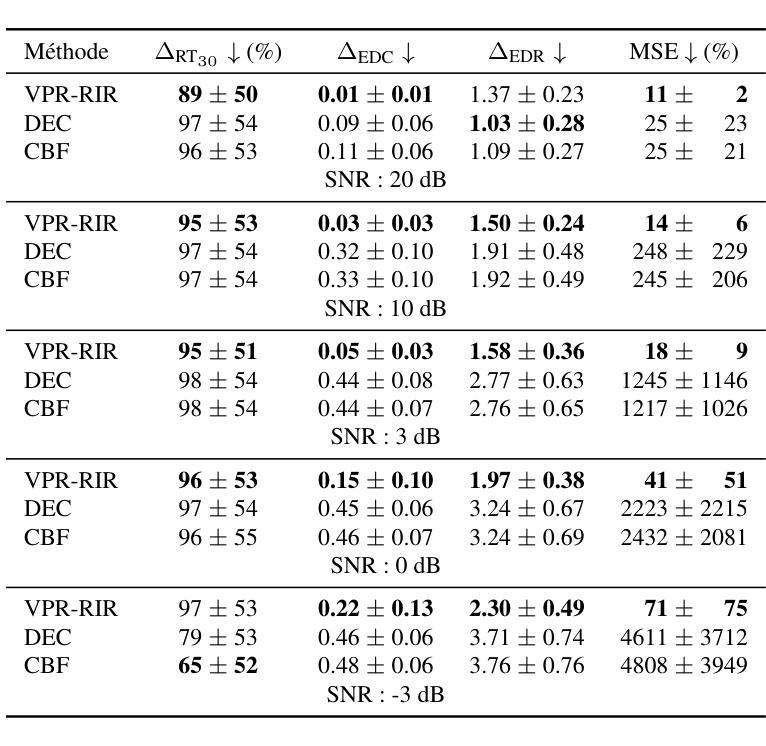
Room impulse response estimation is essential for tasks like speech dereverberation, which improves automatic speech recognition. Most existing methods rely on either statistical signal processing or deep neural networks designed to replicate signal processing principles. However, combining statistical and physical modeling for RIR estimation remains largely unexplored. This paper proposes a novel approach integrating both aspects through a theoretically grounded model. The RIR is decomposed into interpretable parameters: white Gaussian noise filtered by a frequency-dependent exponential decay (e.g. modeling wall absorption) and an autoregressive filter (e.g. modeling microphone response). A variational free-energy cost function enables practical parameter estimation. As a proof of concept, we show that given dry and reverberant speech signals, the proposed method outperforms classical deconvolution in noisy environments, as validated by objective metrics.
房间脉冲响应(Room Impulse Response,简称RIR)估计是语音去混响任务的关键,该任务能提高自动语音识别效果。现有的大多数方法依赖于统计信号处理或模拟信号处理原理的深度神经网络。然而,将统计和物理建模结合用于RIR估计仍然是一个未被充分研究的领域。本文提出了一个结合这两方面理论的新方法。RIR被分解为可解释的参数:经过频率相关指数衰减(如模拟墙壁吸收)和白高斯噪声滤波的以及一个自回归滤波器(如模拟麦克风响应)。一个变分自由能代价函数实现了实际的参数估计。作为概念验证,我们展示了给定干燥和混响语音信号的情况下,在噪声环境中,所提出的方法在客观指标上的表现优于经典的去卷积方法。
论文及项目相关链接
PDF in French language. GRETSI, Aug 2025, Strasbourg (67000), France
Summary
本文提出了一种结合统计和物理建模的房间脉冲响应(Room Impulse Response,RIR)估计新方法。该方法将RIR分解成可解释的参数,包括通过频率相关指数衰减模拟墙壁吸收和通过自回归滤波器模拟麦克风响应的白色高斯噪声。采用变分自由能成本函数实现参数估计。相较于经典去卷积方法,本文方法在噪声环境下表现更优。
Key Takeaways
- 本文强调了房间脉冲响应估计在语音去混响任务中的重要性,该任务能提高自动语音识别效果。
- 现有方法主要依赖统计信号处理或深度神经网络来模拟信号处理原理,但结合统计和物理建模的RIR估计尚未得到充分研究。
- 本文提出了一种结合统计和物理建模的新方法,将RIR分解成可解释的参数,包括模拟墙壁吸收和麦克风响应的模型。
- 采用变分自由能成本函数进行参数估计,实现理论支撑和实践应用的有效结合。
- 与经典去卷积方法相比,本文方法在噪声环境下的表现更优越。
- 本文不仅提供了一个理论框架,还有具体的实验结果,通过客观度量验证了其性能优势。
点此查看论文截图


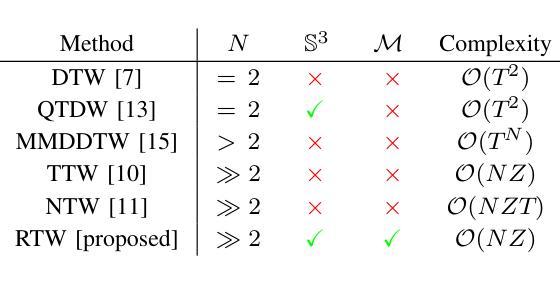
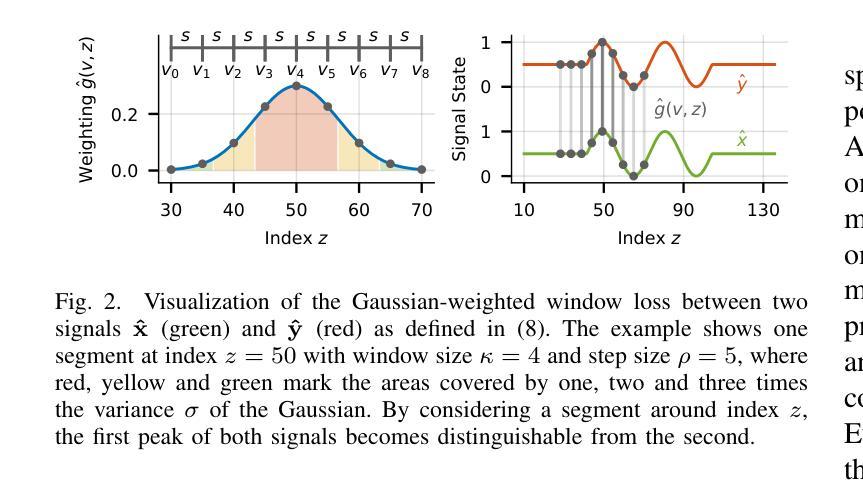
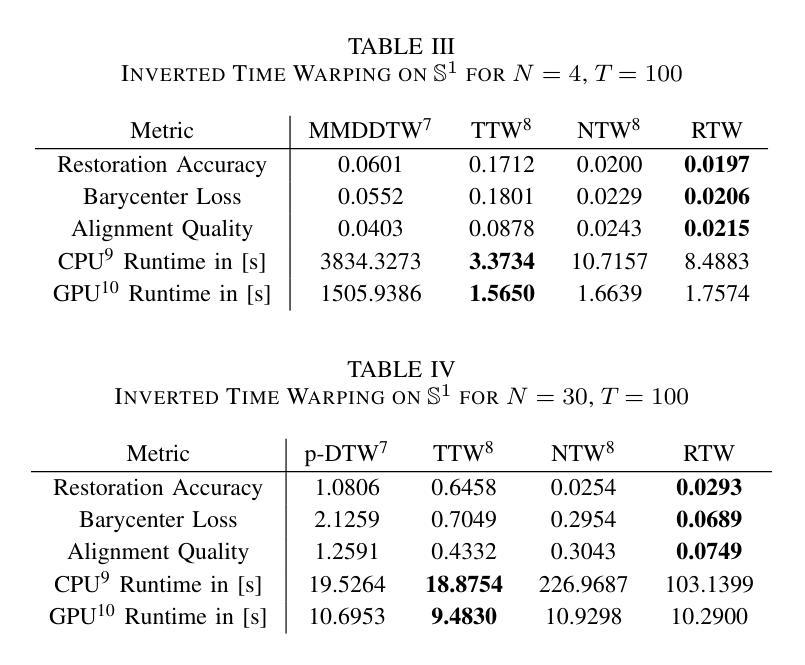
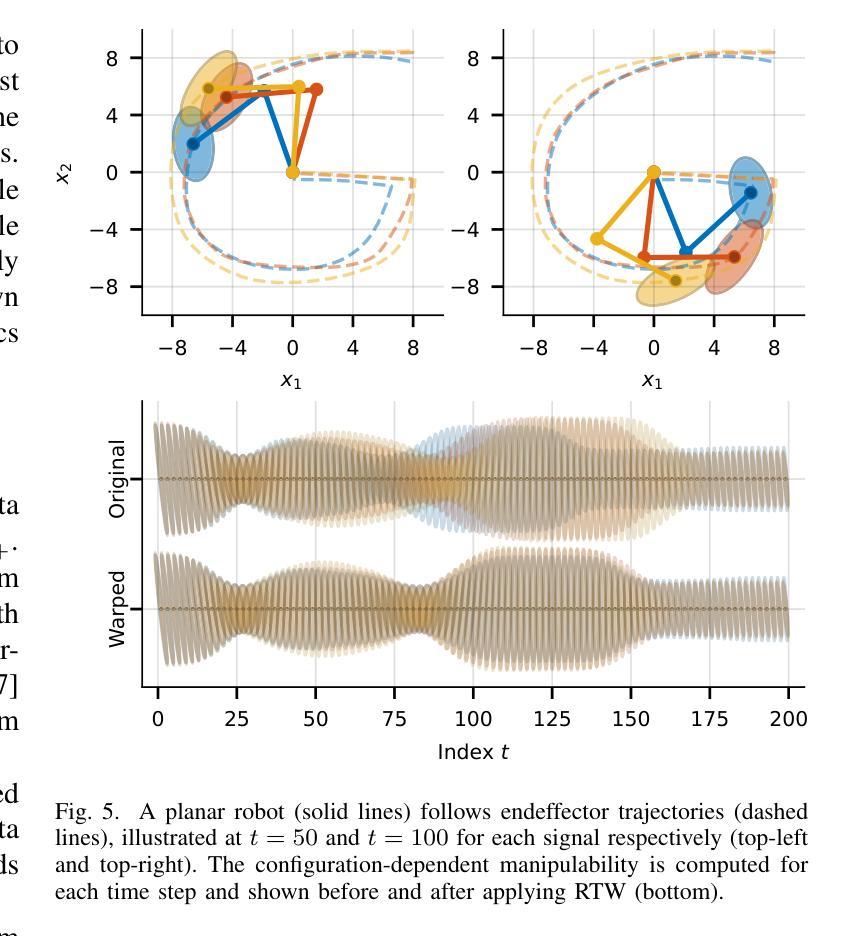
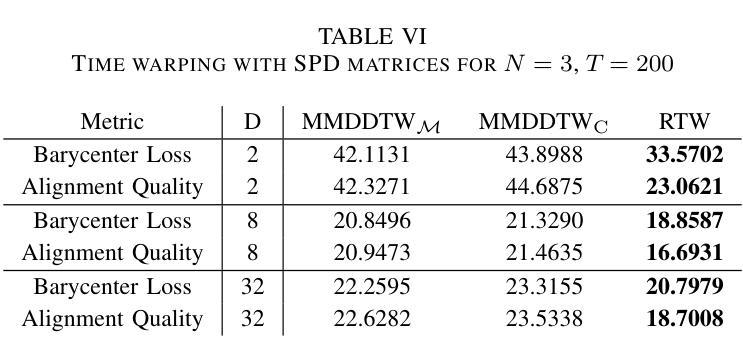
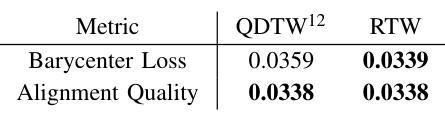
Riemannian Time Warping: Multiple Sequence Alignment in Curved Spaces
Authors:Julian Richter, Christopher Erdös, Christian Scheurer, Jochen J. Steil, Niels Dehio
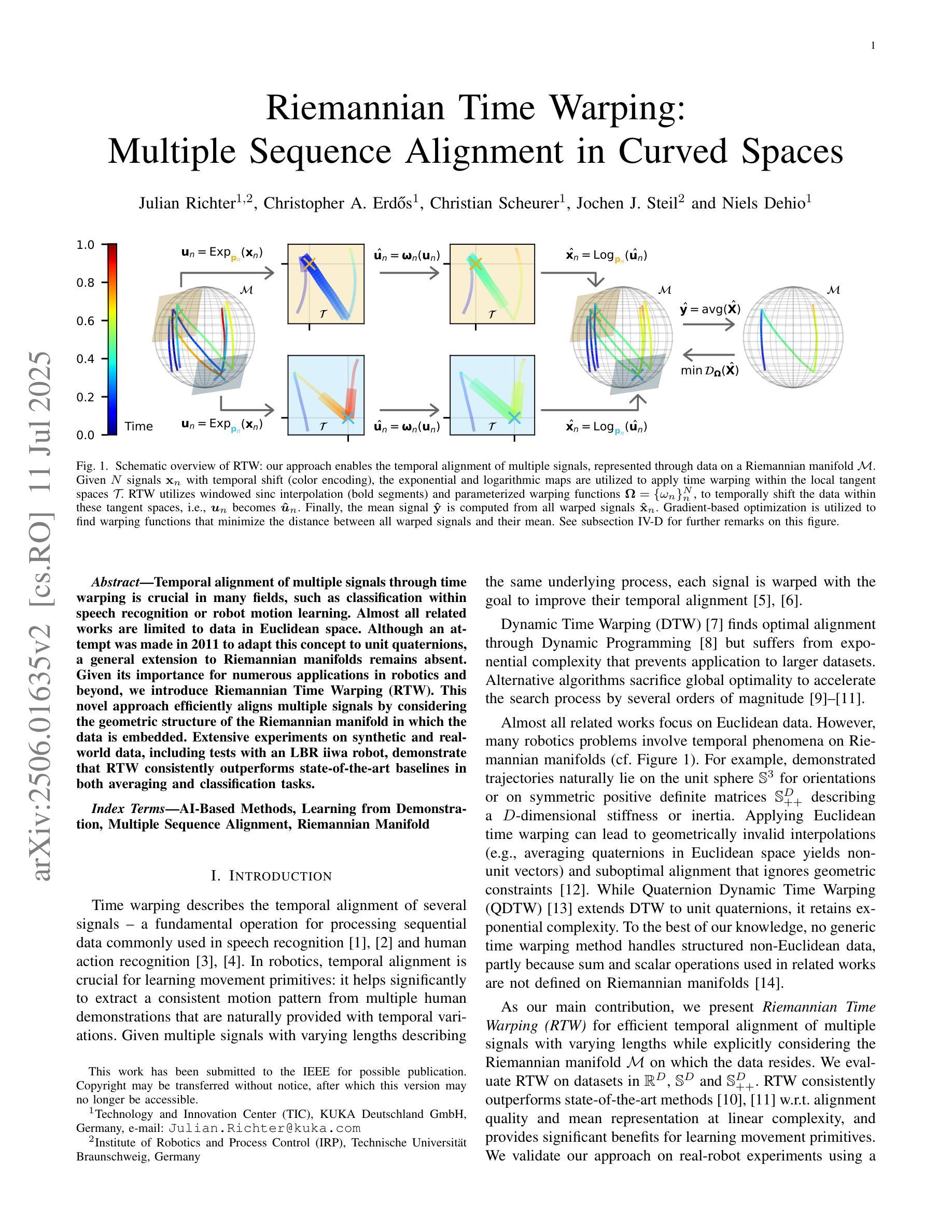
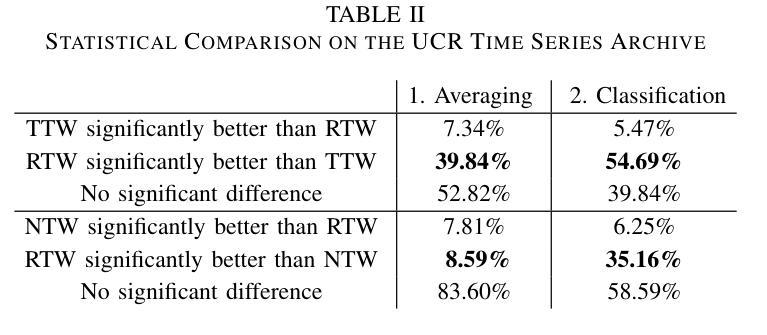
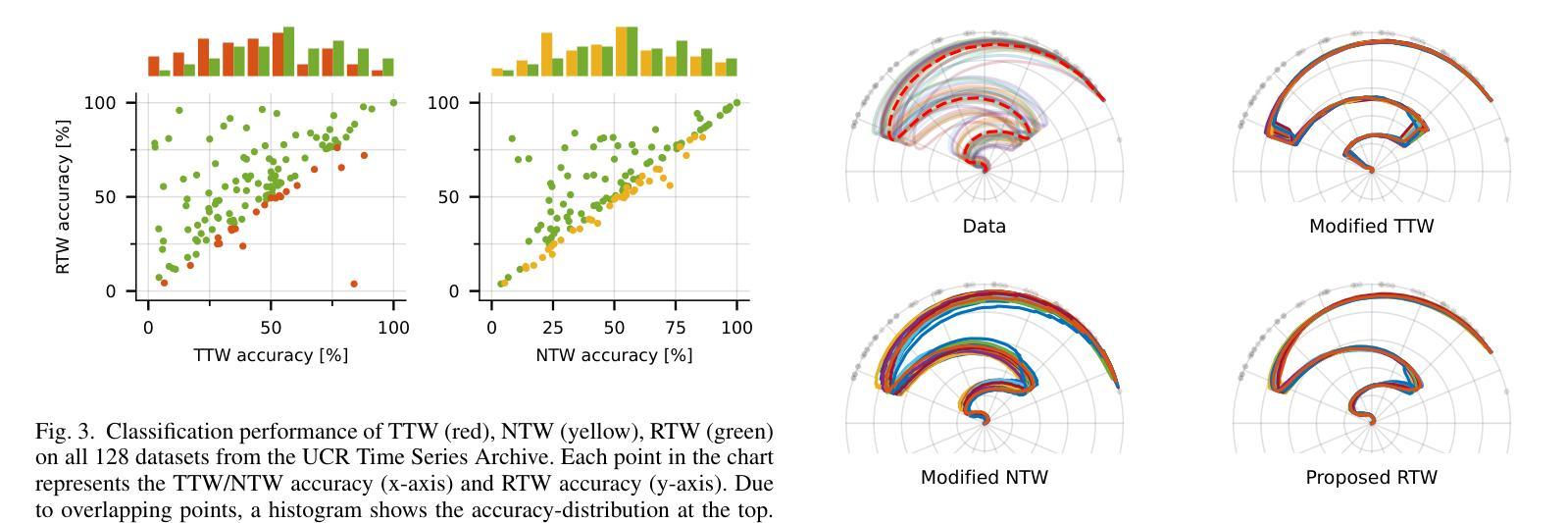
Temporal alignment of multiple signals through time warping is crucial in many fields, such as classification within speech recognition or robot motion learning. Almost all related works are limited to data in Euclidean space. Although an attempt was made in 2011 to adapt this concept to unit quaternions, a general extension to Riemannian manifolds remains absent. Given its importance for numerous applications in robotics and beyond, we introduce Riemannian Time Warping (RTW). This novel approach efficiently aligns multiple signals by considering the geometric structure of the Riemannian manifold in which the data is embedded. Extensive experiments on synthetic and real-world data, including tests with an LBR iiwa robot, demonstrate that RTW consistently outperforms state-of-the-art baselines in both averaging and classification tasks.
多信号的时间扭曲的时间对齐在多个领域(如语音识别或机器人运动学习中的分类)中至关重要。几乎所有相关工作都局限于欧几里得空间中的数据。尽管在2011年有人试图将此概念适应于单位四元数,但尚未将其推广到黎曼流形。考虑到其在机器人技术等多个领域的重要性,我们引入了黎曼时间扭曲(RTW)。这种方法通过考虑数据嵌入的黎曼流形的几何结构来有效地对齐多个信号。在合成数据和真实世界数据上的广泛实验以及对LBR iiwa机器人的测试表明,无论是在平均任务还是分类任务中,RTW始终优于最新的基准测试。
论文及项目相关链接
总结
本文主要介绍了针对黎曼流形上的时间序列数据的时间拉伸方法(Riemannian Time Warping,RTW)。考虑到数据内嵌的黎曼流形的几何结构,该方法有效地对齐多个信号,且在合成数据和真实世界数据上的大量实验以及对LBR iiwa机器人的测试均证明了其在平均和分类任务上的一致优秀表现。该方法的引入对机器人技术等领域具有重要意义。
要点提炼
- 时间拉伸技术在许多领域如语音识别或机器人运动学习中至关重要。
- 目前相关工作大多局限于欧几里得空间的数据处理。
- 虽然已有尝试将时间拉伸概念适应于单位四元数,但其在黎曼流形上的通用扩展仍然缺失。
- 引入的Riemannian Time Warping(RTW)方法考虑到数据内嵌的黎曼流形的几何结构,有效对齐多个信号。
- 实验证明,RTW在平均和分类任务上均表现出卓越性能,且表现稳定。
- RTW方法具有广泛的应用前景,特别是在机器人技术领域。
点此查看论文截图
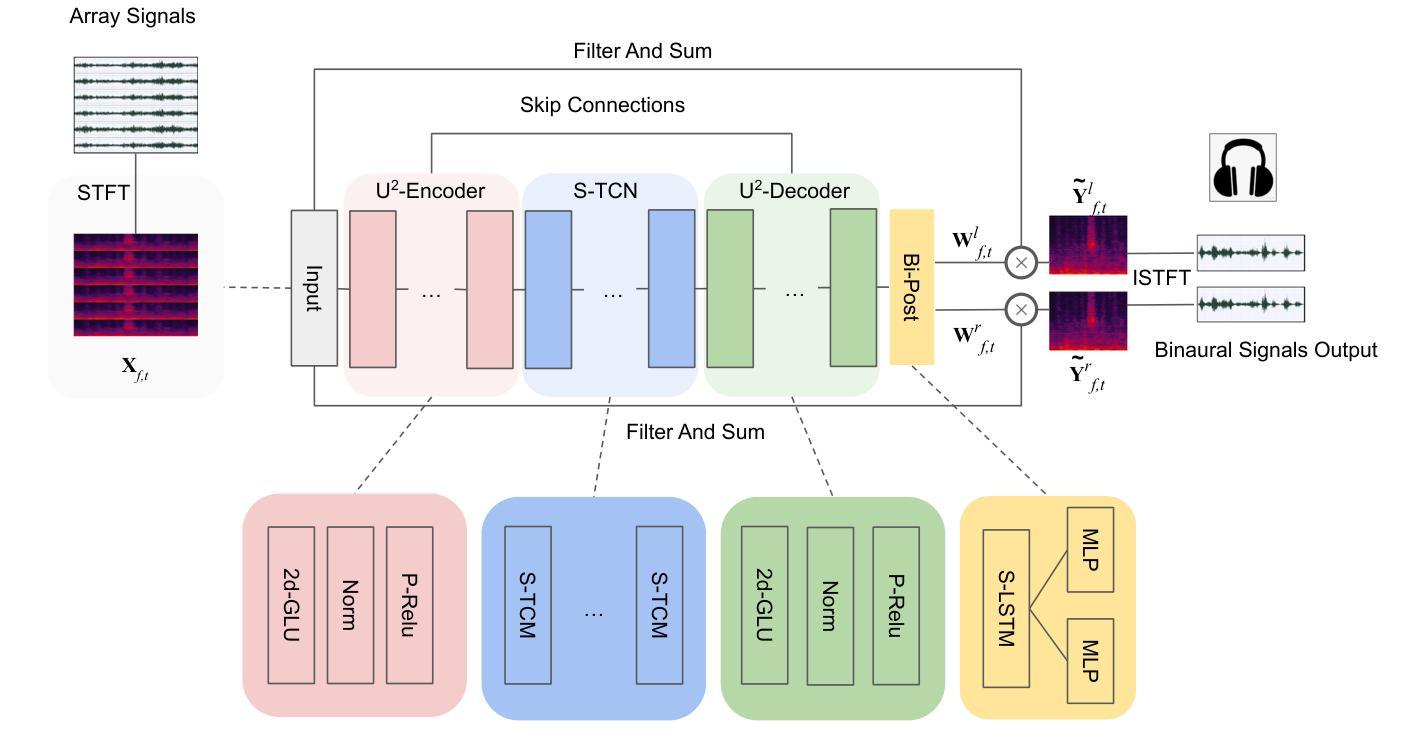
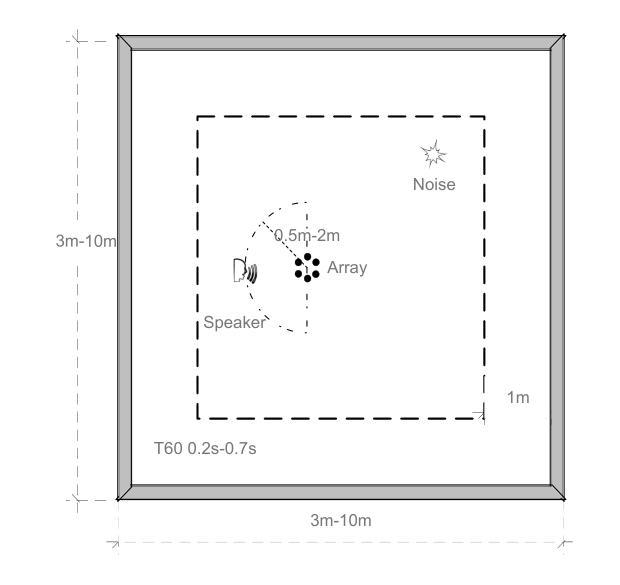
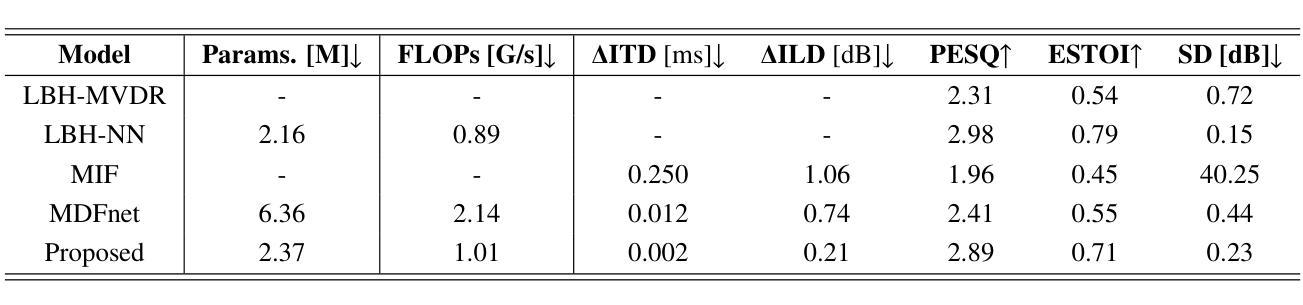
End-to-end multi-channel speaker extraction and binaural speech synthesis
Authors:Cheng Chi, Xiaoyu Li, Yuxuan Ke, Qunping Ni, Yao Ge, Xiaodong Li, Chengshi Zheng
Speech clarity and spatial audio immersion are the two most critical factors in enhancing remote conferencing experiences. Existing methods are often limited: either due to the lack of spatial information when using only one microphone, or because their performance is highly dependent on the accuracy of direction-of-arrival estimation when using microphone array. To overcome this issue, we introduce an end-to-end deep learning framework that has the capacity of mapping multi-channel noisy and reverberant signals to clean and spatialized binaural speech directly. This framework unifies source extraction, noise suppression, and binaural rendering into one network. In this framework, a novel magnitude-weighted interaural level difference loss function is proposed that aims to improve the accuracy of spatial rendering. Extensive evaluations show that our method outperforms established baselines in terms of both speech quality and spatial fidelity.
语音清晰度与空间音频沉浸感是提升远程会议体验的两个关键因素。现有方法往往存在局限性:有的因为只使用单个麦克风而缺乏空间信息;有的在面对噪音和使用回声信号时,其性能高度依赖于到达方向估计的准确性。为了克服这一问题,我们引入了一种端到端的深度学习框架,该框架具有将多通道噪音和回声信号直接映射为干净且空间化的双耳语音的能力。该框架将声源提取、降噪和双耳渲染集成到一个网络中。在该框架中,提出了一种新颖的幅度加权双耳水平差损失函数,旨在提高空间渲染的准确性。大量评估表明,我们的方法在语音质量和空间保真度方面都优于既定的基线方法。
论文及项目相关链接
Summary
本文提出一种端到端的深度学习框架,该框架能够将从多通道噪声和混响信号映射到干净且空间化的双耳语音。此框架融合了源提取、噪声抑制和双耳渲染,旨在提高远程会议体验的关键要素——语音清晰度和空间音频沉浸感。通过引入一种新的幅度加权耳间水平差损失函数,提高了空间渲染的准确性。实验评估表明,该方法在语音质量和空间保真度方面均优于现有基线。
Key Takeaways
- 语音清晰度和空间音频沉浸感是增强远程会议体验的两个关键因素。
- 现有方法因只使用单一麦克风缺乏空间信息,或因使用麦克风阵列时方向到达估计的准确性而受限。
- 提出一种端到端的深度学习框架,整合源提取、噪声抑制和双耳渲染。
- 引入新的幅度加权耳间水平差损失函数,以提高空间渲染的准确性。
- 该框架能提高语音质量和空间保真度。
- 相比现有基线,此框架在多个方面的性能表现更优。
点此查看论文截图