⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-15 更新
M2DAO-Talker: Harmonizing Multi-granular Motion Decoupling and Alternating Optimization for Talking-head Generation
Authors:Kui Jiang, Shiyu Liu, Junjun Jiang, Xin Yang, Hongxun Yang, Xiaopeng Fan
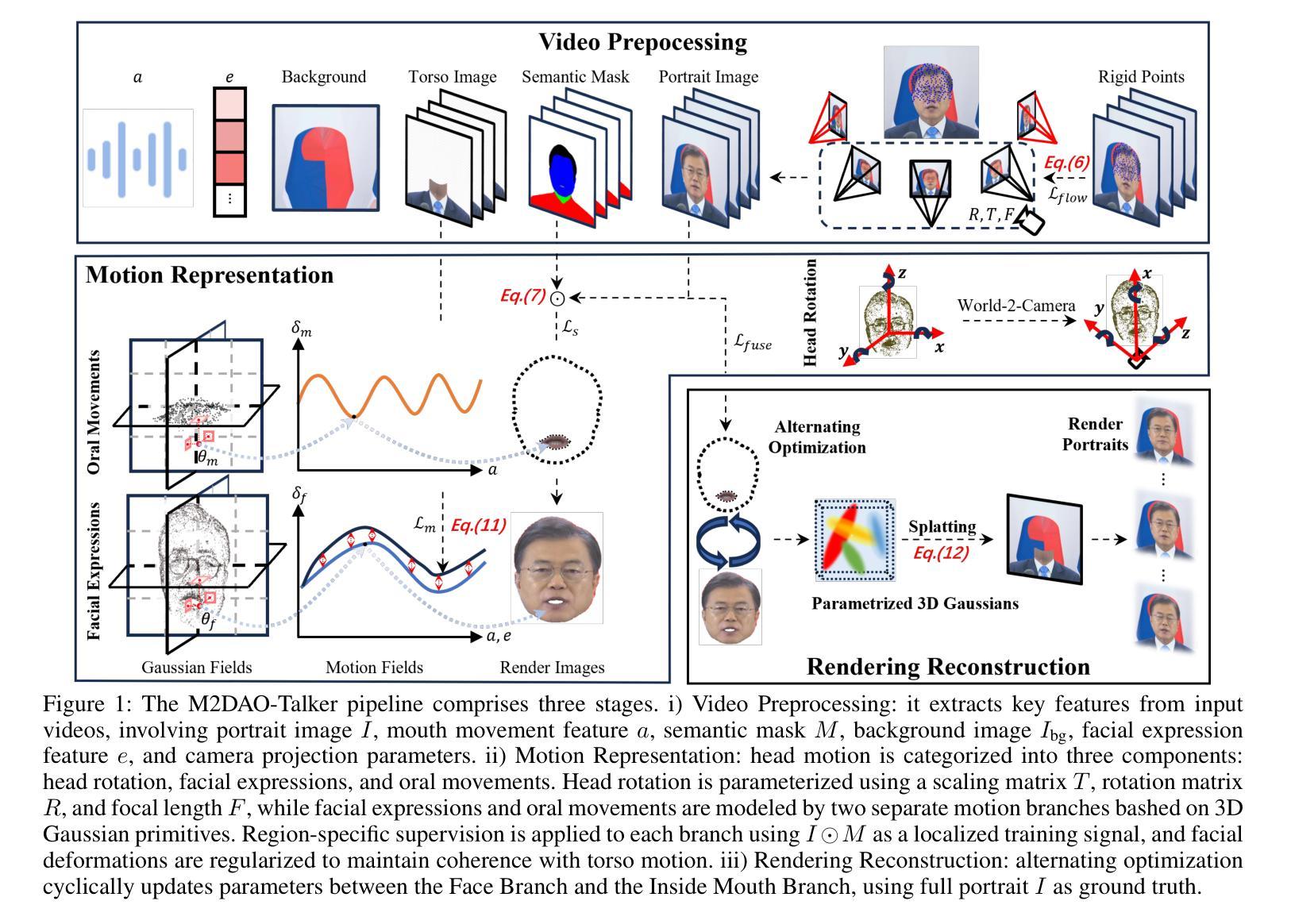
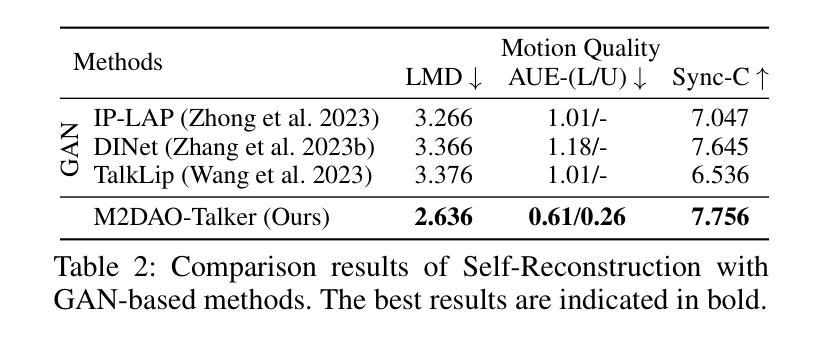
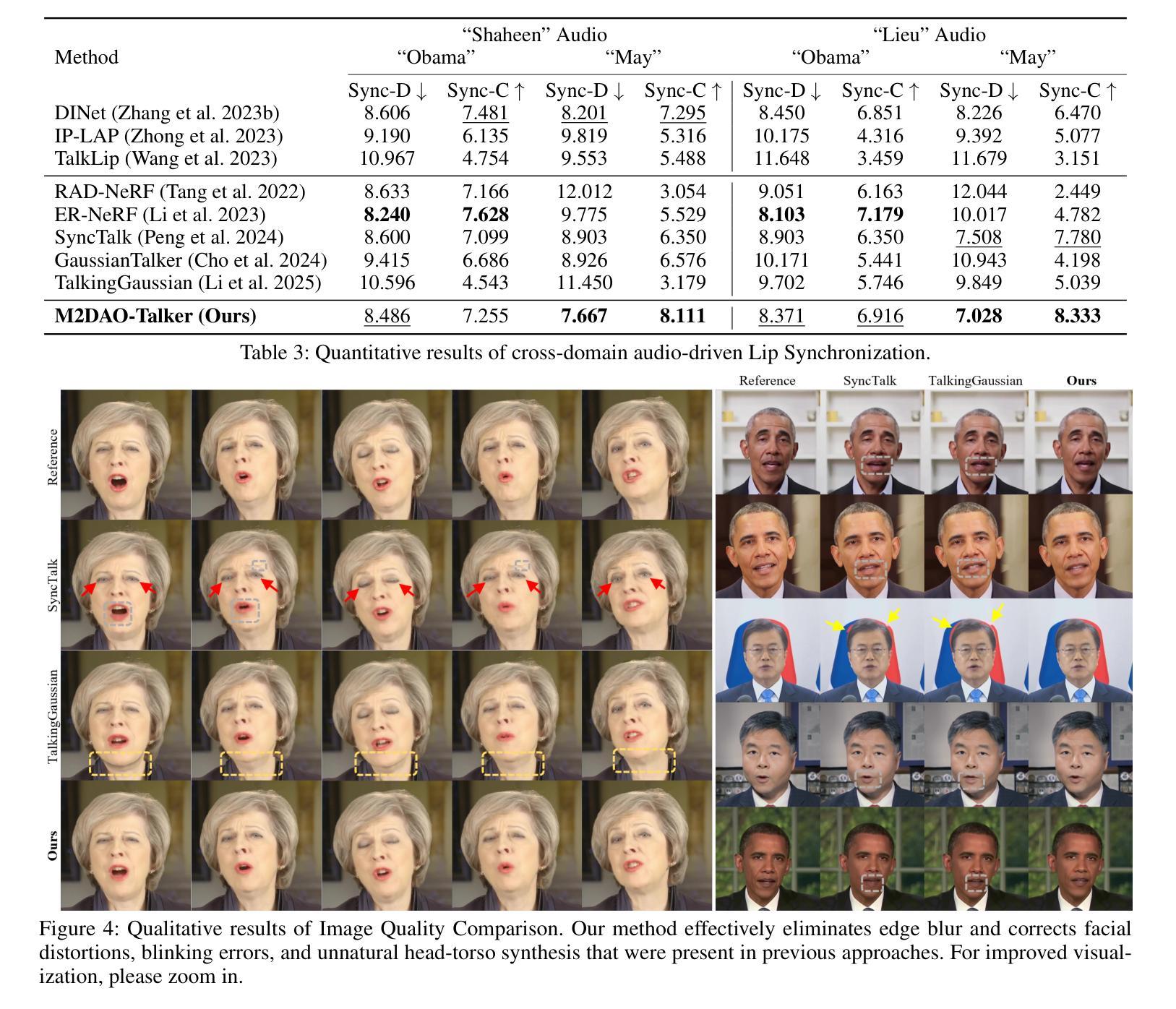
Audio-driven talking head generation holds significant potential for film production. While existing 3D methods have advanced motion modeling and content synthesis, they often produce rendering artifacts, such as motion blur, temporal jitter, and local penetration, due to limitations in representing stable, fine-grained motion fields. Through systematic analysis, we reformulate talking head generation into a unified framework comprising three steps: video preprocessing, motion representation, and rendering reconstruction. This framework underpins our proposed M2DAO-Talker, which addresses current limitations via multi-granular motion decoupling and alternating optimization.Specifically, we devise a novel 2D portrait preprocessing pipeline to extract frame-wise deformation control conditions (motion region segmentation masks, and camera parameters) to facilitate motion representation. To ameliorate motion modeling, we elaborate a multi-granular motion decoupling strategy, which independently models non-rigid (oral and facial) and rigid (head) motions for improved reconstruction accuracy.Meanwhile, a motion consistency constraint is developed to ensure head-torso kinematic consistency, thereby mitigating penetration artifacts caused by motion aliasing. In addition, an alternating optimization strategy is designed to iteratively refine facial and oral motion parameters, enabling more realistic video generation.Experiments across multiple datasets show that M2DAO-Talker achieves state-of-the-art performance, with the 2.43 dB PSNR improvement in generation quality and 0.64 gain in user-evaluated video realness versus TalkingGaussian while with 150 FPS inference speed. Our project homepage is https://m2dao-talker.github.io/M2DAO-Talk.github.io
音频驱动的谈话头生成技术对电影制作具有巨大潜力。尽管现有的3D方法在动作建模和内容合成方面有所进步,但由于在表示稳定、精细的动作场方面存在局限性,它们常常会产生渲染伪影,如运动模糊、时间抖动和局部穿透。通过系统分析,我们将谈话头生成重新制定为一个包含三个步骤的统一框架:视频预处理、动作表示和渲染重建。这个框架支撑了我们提出的M2DAO-Talker,它通过多粒度动作解耦和交替优化来解决当前限制。
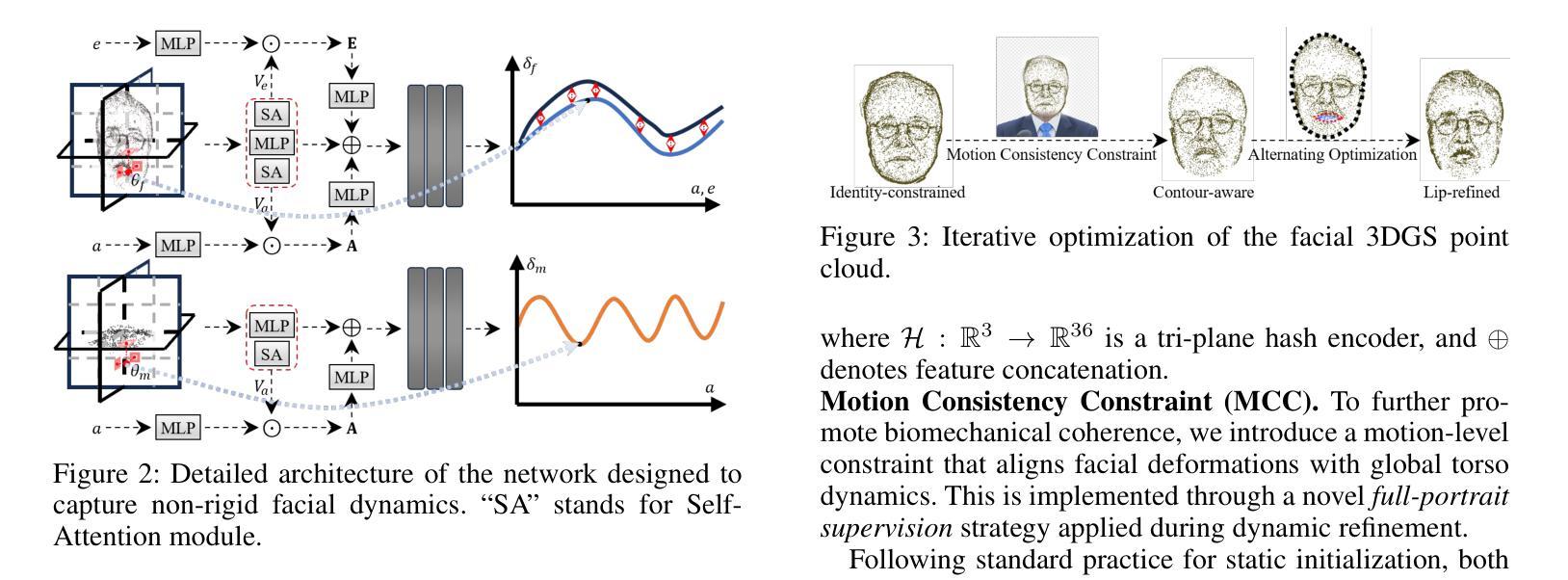
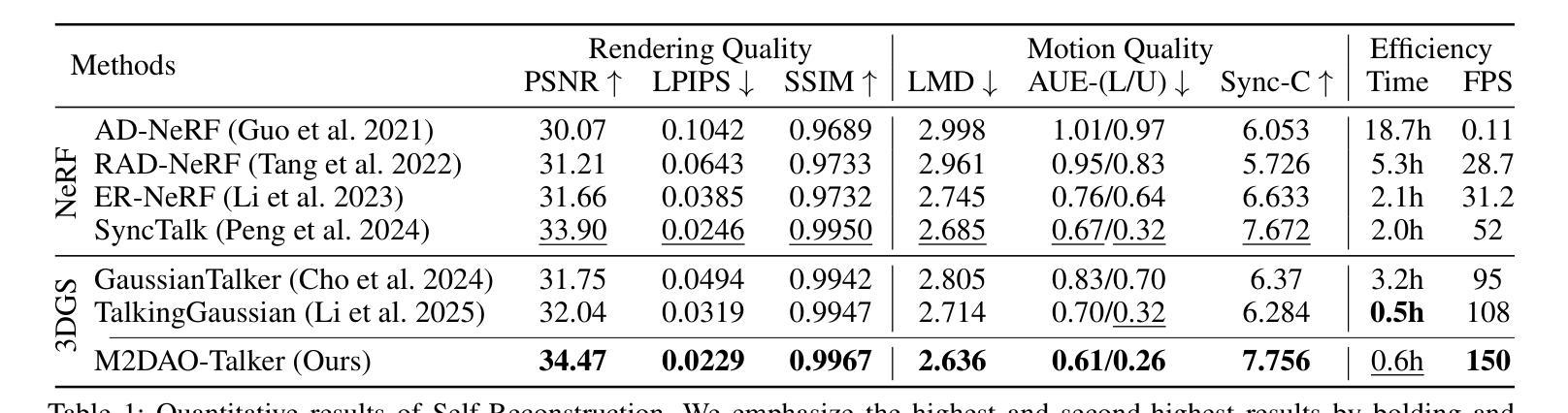
具体来说,我们设计了一种新颖的2D肖像预处理管道,用于提取帧级变形控制条件(运动区域分割掩膜和相机参数),以促进动作表示。为了改善动作建模,我们精心制定了一种多粒度动作解耦策略,该策略独立地对非刚性(口腔和面部)和刚性(头部)动作进行建模,以提高重建精度。同时,开发了一种运动一致性约束,以确保头部和躯干的运动学一致性,从而减轻由运动混淆引起的穿透伪影。此外,设计了一种交替优化策略,以迭代方式精细调整面部和口腔运动参数,从而实现更逼真的视频生成。
论文及项目相关链接
Summary
本文介绍了音频驱动的说话人头部生成技术在电影制作中的潜力。针对现有3D方法的不足,如运动模糊、时间抖动和局部穿透等问题,文章提出了一种统一的框架M2DAO-Talker,通过多粒度运动解耦和交替优化解决现有问题。该框架包括视频预处理、运动表示和渲染重建三个步骤,旨在提高重建精度和用户评价的视频真实性。
Key Takeaways
- 音频驱动的说话人头部生成在电影制作中有巨大潜力。
- 现有3D方法在说话人头部生成中存在运动模糊、时间抖动和局部穿透等问题。
- M2DAO-Talker框架包括视频预处理、运动表示和渲染重建三个步骤。
- M2DAO-Talker通过多粒度运动解耦策略独立建模非刚性(口腔和面部)和刚性(头部)运动,提高重建精度。
- 运动一致性约束确保头部和躯干的运动一致性,减少穿透伪影。
- 交替优化策略迭代优化面部和口腔运动参数,实现更真实的视频生成。
点此查看论文截图