⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-17 更新
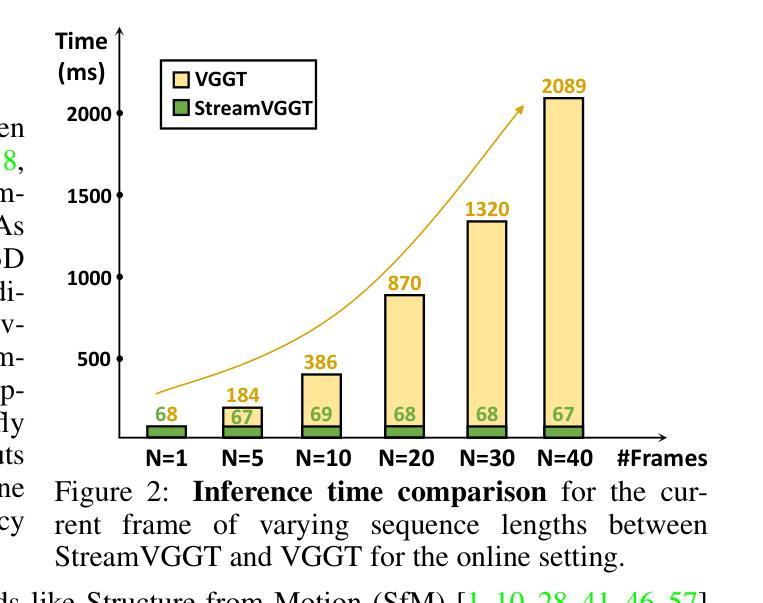
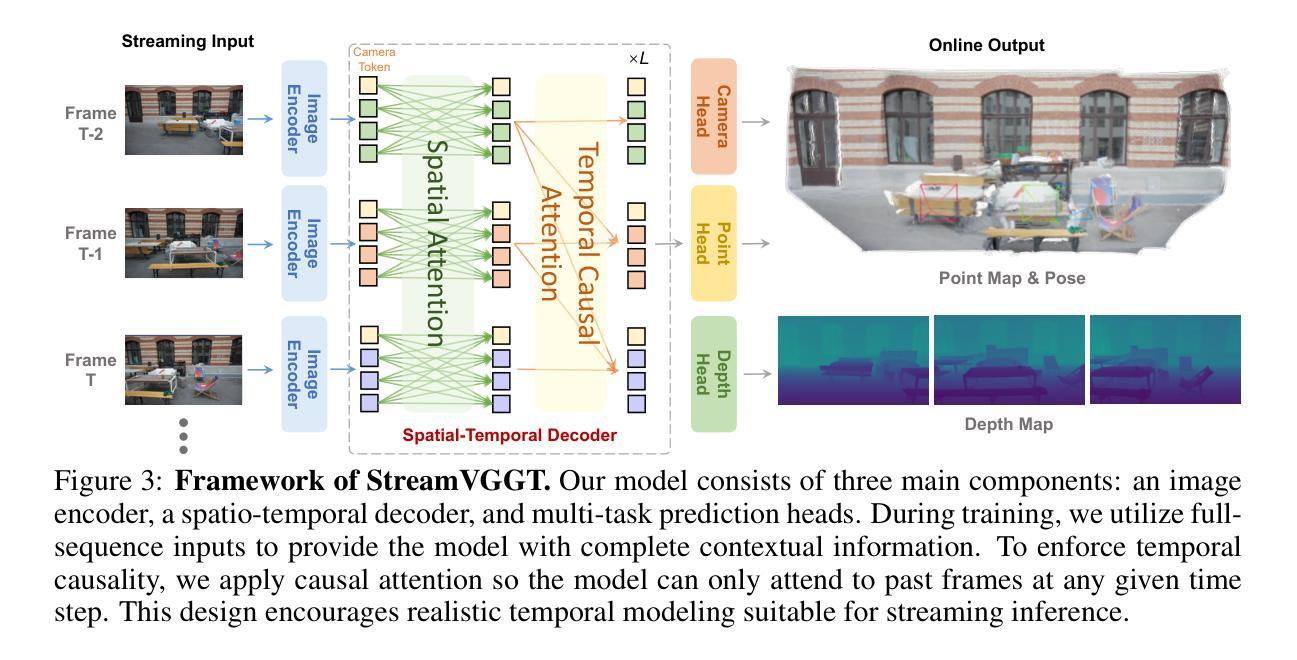
Streaming 4D Visual Geometry Transformer
Authors:Dong Zhuo, Wenzhao Zheng, Jiahe Guo, Yuqi Wu, Jie Zhou, Jiwen Lu
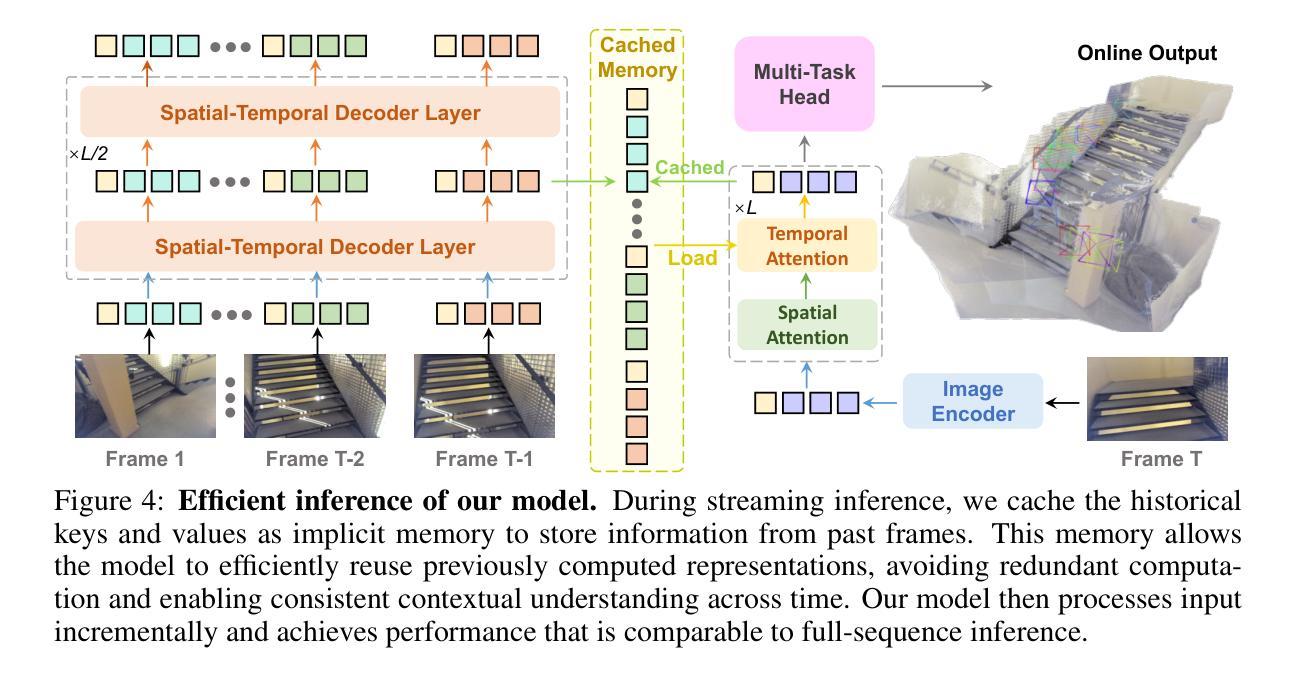
Perceiving and reconstructing 4D spatial-temporal geometry from videos is a fundamental yet challenging computer vision task. To facilitate interactive and real-time applications, we propose a streaming 4D visual geometry transformer that shares a similar philosophy with autoregressive large language models. We explore a simple and efficient design and employ a causal transformer architecture to process the input sequence in an online manner. We use temporal causal attention and cache the historical keys and values as implicit memory to enable efficient streaming long-term 4D reconstruction. This design can handle real-time 4D reconstruction by incrementally integrating historical information while maintaining high-quality spatial consistency. For efficient training, we propose to distill knowledge from the dense bidirectional visual geometry grounded transformer (VGGT) to our causal model. For inference, our model supports the migration of optimized efficient attention operator (e.g., FlashAttention) from the field of large language models. Extensive experiments on various 4D geometry perception benchmarks demonstrate that our model increases the inference speed in online scenarios while maintaining competitive performance, paving the way for scalable and interactive 4D vision systems. Code is available at: https://github.com/wzzheng/StreamVGGT.
从视频中感知并重建4D时空几何体是一项基础且具有挑战性的计算机视觉任务。为了促进交互和实时应用,我们提出了一种流式4D视觉几何转换器,其理念与大型自回归语言模型相似。我们探索了一种简单高效的设计,并采用因果转换器架构以在线方式处理输入序列。我们使用时间因果注意力,并缓存历史密钥和值作为隐式内存,以实现高效的流式传输长期4D重建。这种设计可以通过增量整合历史信息来处理实时4D重建,同时保持高质量的空间一致性。为了高效训练,我们提出从密集的双向视觉几何接地转换器(VGGT)中提炼知识到我们的因果模型。对于推理,我们的模型支持将优化后的高效注意力运算符(例如FlashAttention)从大型语言模型领域迁移到我们的模型中。在各种4D几何感知基准测试上的大量实验表明,我们的模型提高了在线场景中的推理速度,同时保持了竞争力,为可扩展和交互式的4D视觉系统铺平了道路。代码可在以下网址找到:https://github.com/wzzheng/StreamVGGT。
论文及项目相关链接
PDF Code is available at: https://github.com/wzzheng/StreamVGGT
Summary
本文提出一种流式4D视觉几何转换器,采用与大型语言模型类似的哲学理念,用于从视频中感知和重建4D时空几何。通过采用因果转换器架构进行在线处理输入序列,结合时间因果注意力和缓存历史键值对隐式内存,实现高效的流式长期4D重建。通过增量整合历史信息,模型能在保持高质量空间一致性的同时进行实时4D重建。通过知识蒸馏技术和从大型语言模型领域迁移优化后的高效注意算子,模型在在线场景中的推理速度得到提升,同时在各种4D几何感知基准测试中保持竞争力,为可扩展和交互式的4D视觉系统铺平了道路。
Key Takeaways
- 提出了新的流式4D视觉几何转换器,可以处理视频中的4D时空几何信息。
- 采用因果转换器架构进行在线处理输入序列,实现实时处理。
- 通过时间因果注意力和隐式内存实现高效流式长期4D重建。
- 模型能在保持高质量空间一致性的同时进行实时4D重建,增量整合历史信息。
- 通过知识蒸馏技术提高模型性能。
- 模型支持从大型语言模型领域迁移高效注意算子,提高推理速度。
点此查看论文截图

How Many Instructions Can LLMs Follow at Once?
Authors:Daniel Jaroslawicz, Brendan Whiting, Parth Shah, Karime Maamari
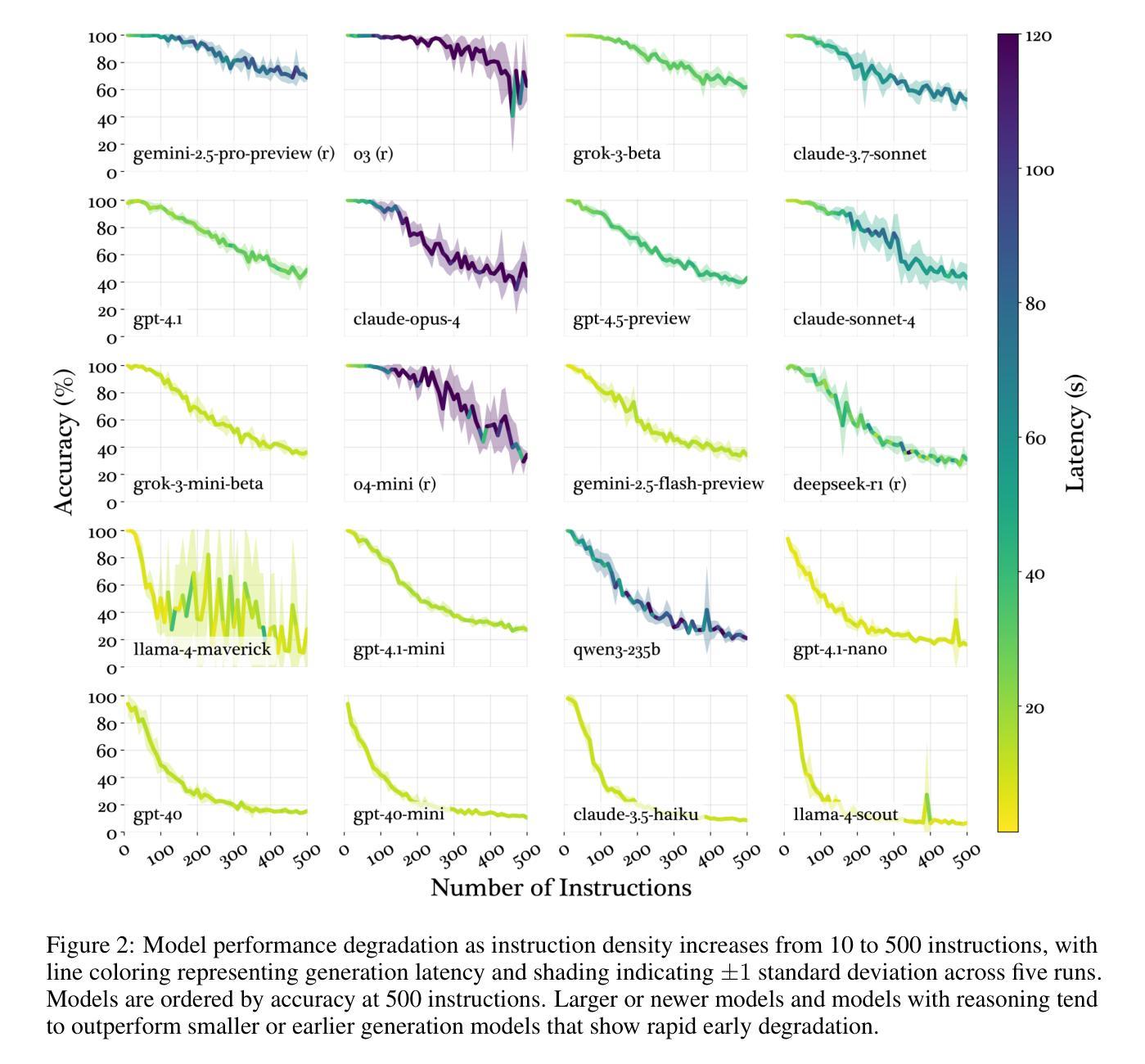
Production-grade LLM systems require robust adherence to dozens or even hundreds of instructions simultaneously. However, the instruction-following capabilities of LLMs at high instruction densities have not yet been characterized, as existing benchmarks only evaluate models on tasks with a single or few instructions. We introduce IFScale, a simple benchmark of 500 keyword-inclusion instructions for a business report writing task to measure how instruction-following performance degrades as instruction density increases. We evaluate 20 state-of-the-art models across seven major providers and find that even the best frontier models only achieve 68% accuracy at the max density of 500 instructions. Our analysis reveals model size and reasoning capability to correlate with 3 distinct performance degradation patterns, bias towards earlier instructions, and distinct categories of instruction-following errors. Our insights can help inform design of instruction-dense prompts in real-world applications and highlight important performance-latency tradeoffs. We open-source the benchmark and all results for further analysis at https://distylai.github.io/IFScale.
生产级的LLM系统需要同时严格遵守几十个甚至上百个指令。然而,现有基准测试只在具有单个或少数指令的任务上评估模型,尚未表征LLM在高指令密度下的指令遵循能力。我们引入了IFScale基准测试,它包含500个关键词指令,用于衡量商业报告写作任务的指令遵循性能,随着指令密度的增加,如何评估指令遵循性能的下降。我们对七家主要提供商的20个最新模型进行了评估,发现即使在最高密度500条指令的情况下,最先进的模型准确率也只有68%。我们的分析表明,模型大小与推理能力与性能下降的三种不同模式相关,偏向于早期指令以及不同的指令遵循错误类别。我们的见解有助于为现实世界应用程序中的密集指令提示设计提供参考,并强调性能延迟之间的权衡。我们已在https://distylai.github.io/IFScale上公开基准测试和所有结果以供进一步分析。
论文及项目相关链接
Summary
大型语言模型(LLM)系统在生产环境中需要同时遵守数十甚至数百个指令。然而,现有基准测试仅对具有单一或少数指令的任务进行评估,尚未对高指令密度下LLM的指令遵循能力进行表征。本文引入了IFScale基准测试,通过包含关键词的500条指令进行商业报告写作任务测试,以衡量指令密度增加时指令遵循性能的变化。评估了来自七家主要提供商的20个最新模型,发现即使在最高指令密度下,最先进的模型准确率仅为68%。分析表明,模型大小与推理能力是影响性能的三个独特因素相关联的因素、出现了面向早期指令的偏见以及各种类别的指令遵循错误。本文的见解有助于为真实世界应用中高密度指令提示的设计提供信息,并强调性能延迟权衡的重要性。详情可见:https://distylai.github.io/IFScale。
Key Takeaways
- LLM系统需要同时遵守多个指令以适应生产环境。
- 现有基准测试未能充分评估高指令密度下LLM的指令遵循能力。
- IFScale基准测试通过包含关键词的指令评估LLM在指令密度增加时的性能变化。
- 最先进的模型在最高指令密度下的准确率仅为68%。
- 模型大小与推理能力与性能下降的三种模式相关联。
- 存在面向早期指令的偏见以及不同类型的指令遵循错误。
- 见解有助于设计真实世界应用中高密度指令提示并强调性能延迟权衡的重要性。
点此查看论文截图

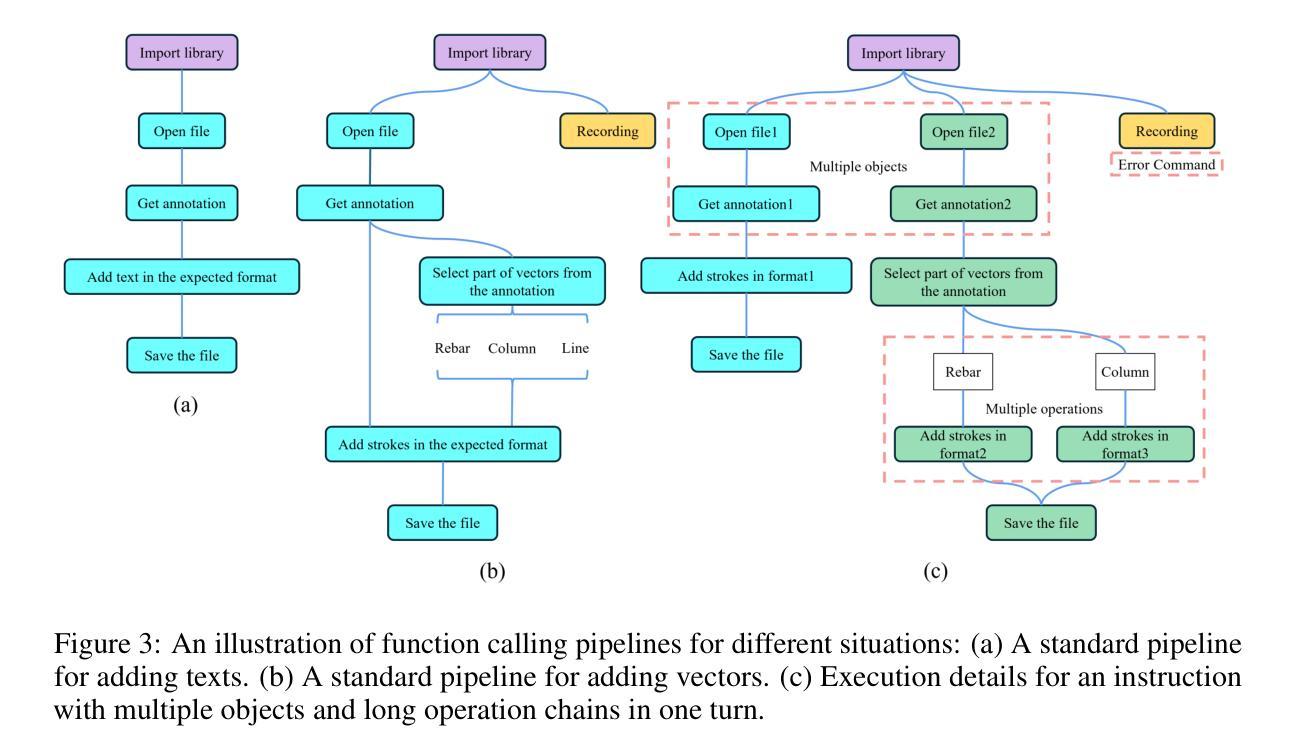
DrafterBench: Benchmarking Large Language Models for Tasks Automation in Civil Engineering
Authors:Yinsheng Li, Zhen Dong, Yi Shao
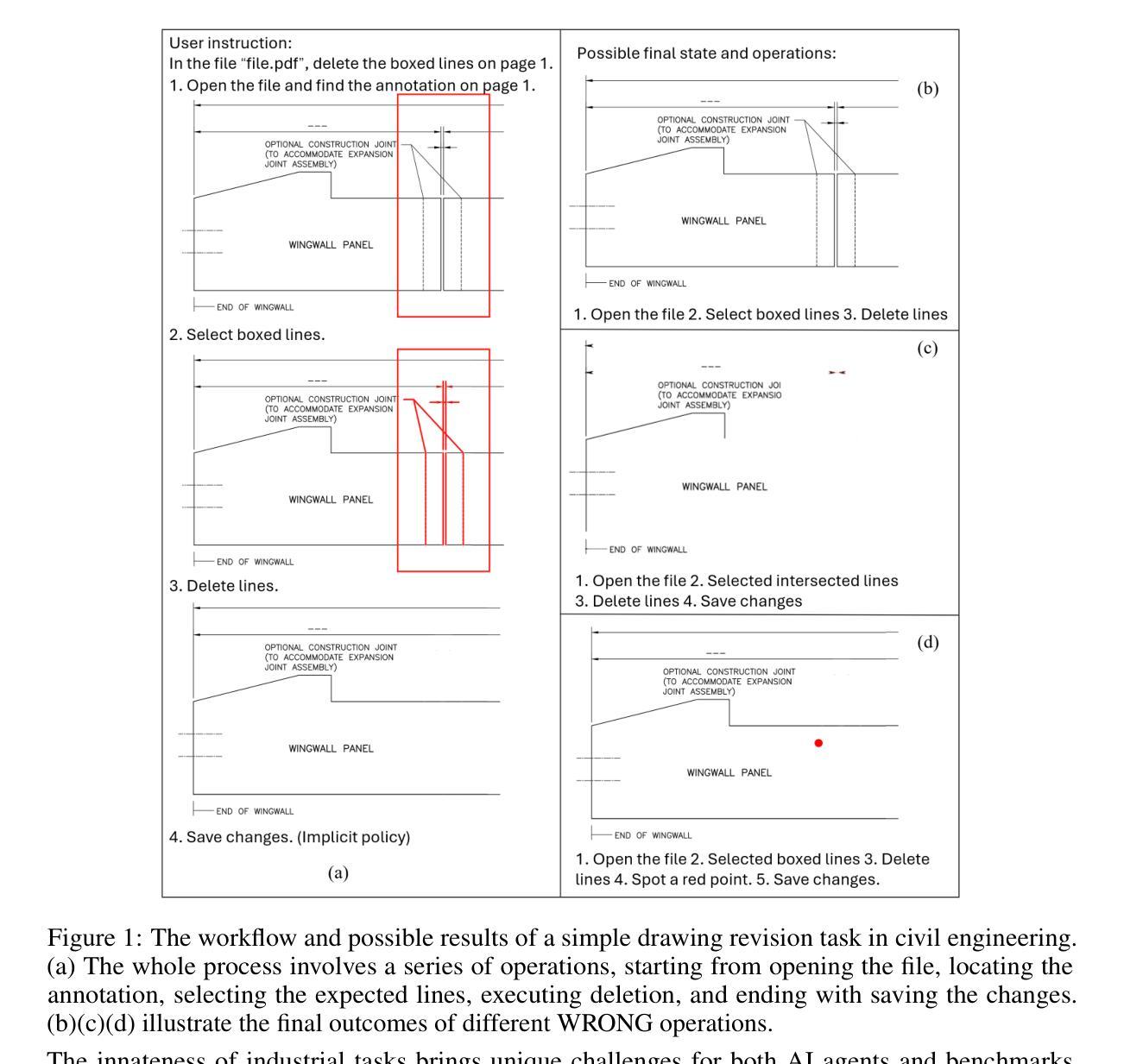
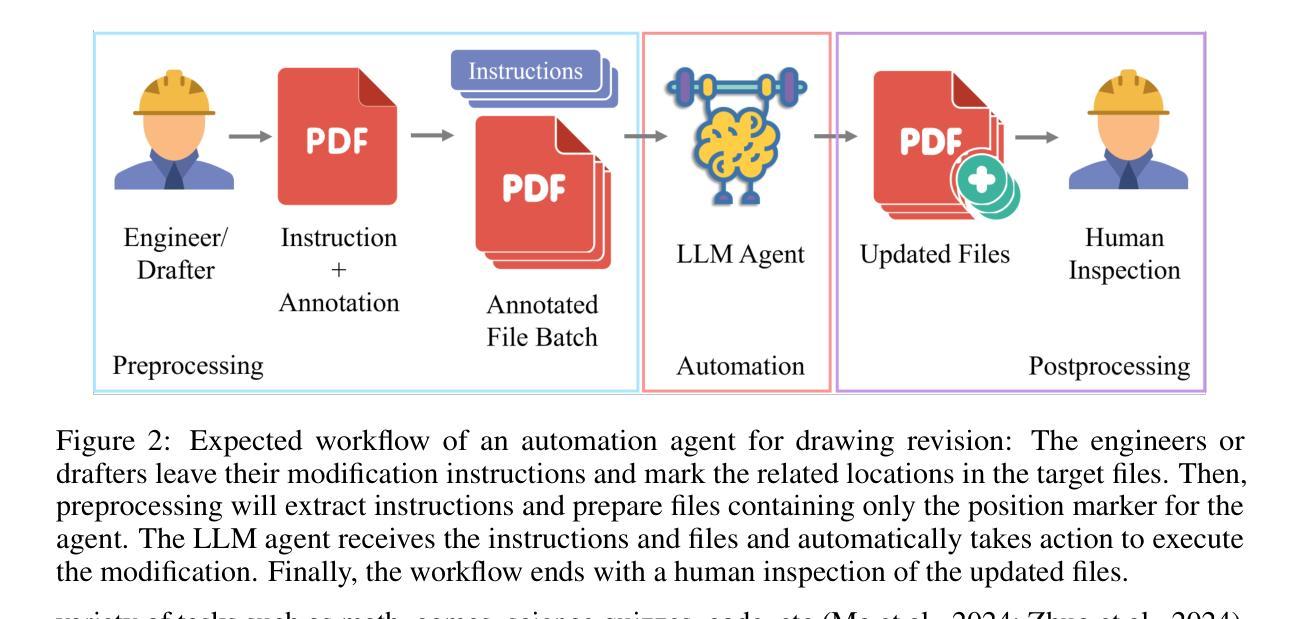
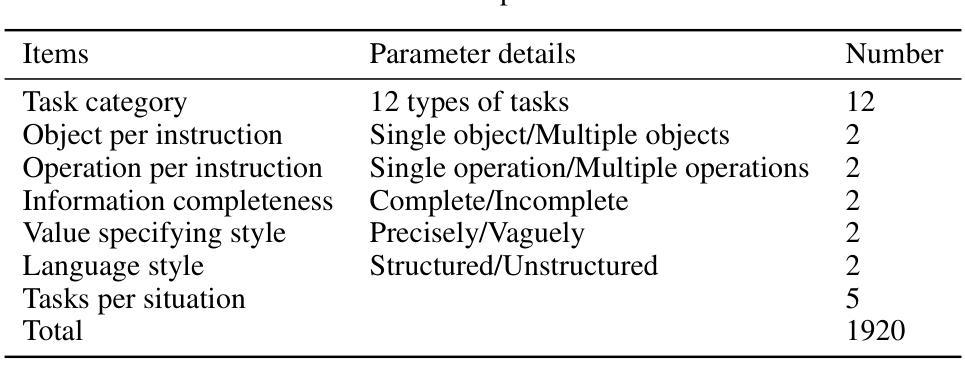
Large Language Model (LLM) agents have shown great potential for solving real-world problems and promise to be a solution for tasks automation in industry. However, more benchmarks are needed to systematically evaluate automation agents from an industrial perspective, for example, in Civil Engineering. Therefore, we propose DrafterBench for the comprehensive evaluation of LLM agents in the context of technical drawing revision, a representation task in civil engineering. DrafterBench contains twelve types of tasks summarized from real-world drawing files, with 46 customized functions/tools and 1920 tasks in total. DrafterBench is an open-source benchmark to rigorously test AI agents’ proficiency in interpreting intricate and long-context instructions, leveraging prior knowledge, and adapting to dynamic instruction quality via implicit policy awareness. The toolkit comprehensively assesses distinct capabilities in structured data comprehension, function execution, instruction following, and critical reasoning. DrafterBench offers detailed analysis of task accuracy and error statistics, aiming to provide deeper insight into agent capabilities and identify improvement targets for integrating LLMs in engineering applications. Our benchmark is available at https://github.com/Eason-Li-AIS/DrafterBench, with the test set hosted at https://huggingface.co/datasets/Eason666/DrafterBench.
大型语言模型(LLM)代理在解决现实世界问题上表现出巨大潜力,并有望成为工业自动化任务的解决方案。然而,需要从工业角度系统地评估自动化代理,例如在土木工程等领域需要更多的基准测试。因此,我们提出了DraftBench技术,用于全面评估在图纸复核技术环境下的LLM代理表现。DraftBench包含了从实际图纸文件中总结出的十二类任务,共包含46个自定义功能/工具以及总计1920个任务。DraftBench是一个开源基准测试平台,旨在严格测试人工智能代理在理解复杂且语境较长的指令、利用先验知识以及适应动态指令质量通过隐性策略意识等方面的能力。该工具箱全面评估了结构化数据理解、功能执行、遵循指令以及批判性推理等方面的不同能力。DraftBench提供了详细的任务准确性和错误统计数据分析,旨在深入了解代理的能力,并确定在整合工程应用中的LLM时的改进目标。我们的基准测试平台可在https://github.com/Eason-Li-AIS/DrafterBench上访问,测试集托管在https://huggingface.co/datasets/Eason666/DrafterBench。
论文及项目相关链接
PDF Project page: https://github.com/Eason-Li-AIS/DrafterBench
Summary
LLM自动化代理在解决现实世界问题方面展现出巨大潜力,有望为工业任务自动化提供解决方案。为全面评估LLM代理在土木工程领域的技术绘图复核任务中的表现,提出DrafterBench基准测试。它包含从真实绘图文件中总结的12类任务,共46个自定义功能/工具,总计1920个任务。DrafterBench是一个开源基准测试工具,旨在严格测试AI代理在解释复杂、长上下文指令、利用先验知识和适应动态指令质量方面的能力。它全面评估了结构化数据理解、功能执行、遵循指令和批判性推理等不同能力。该基准测试提供了任务准确性和错误统计的详细分析,旨在深入了解代理能力,并确定在工程应用中整合LLM的改进目标。
Key Takeaways
- LLM自动化代理在解决现实世界问题方面具有巨大潜力,尤其在工业任务自动化方面。
- DrafterBench基准测试用于全面评估LLM代理在土木工程技术绘图复核任务中的表现。
- DrafterBench包含从真实绘图文件中总结的多种任务类型和自定义功能/工具。
- DrafterBench是一个开源工具,可测试AI代理在不同方面的能力,如指令解释、结构化数据理解、功能执行等。
- 该基准测试提供了详细的错误统计和任务准确性分析,有助于深入了解代理的能力和弱点。
- 通过DrafterBench基准测试,可以识别出在工程应用中整合LLM需要改进的领域。
点此查看论文截图


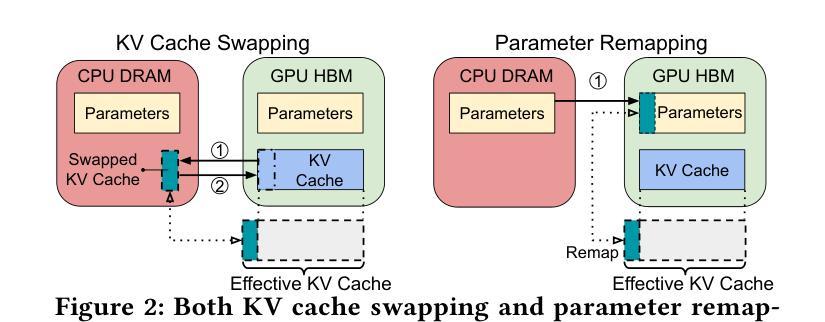
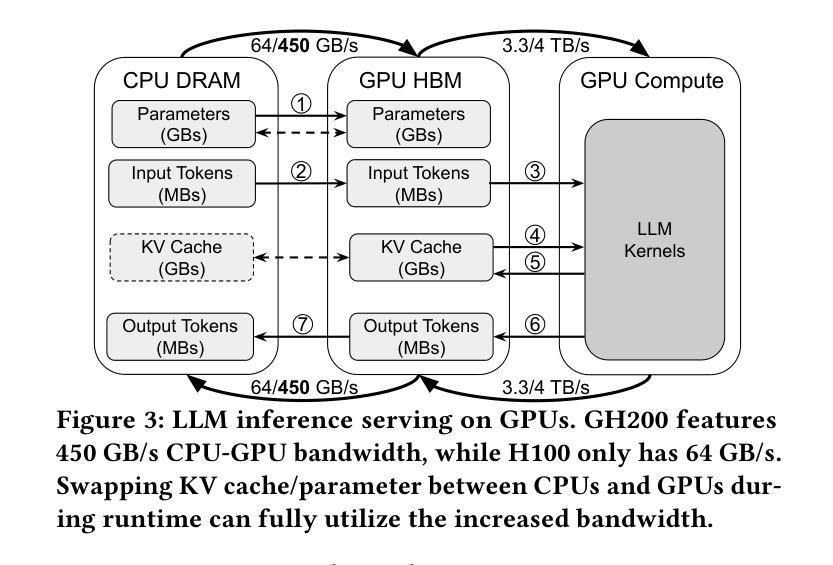
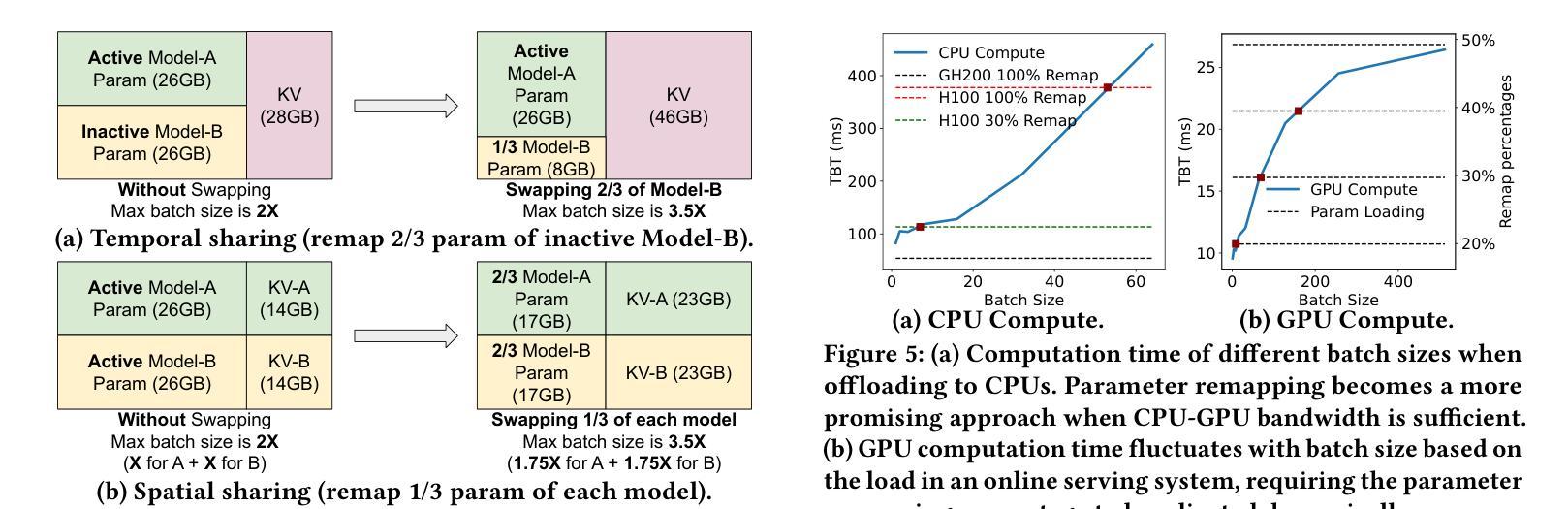
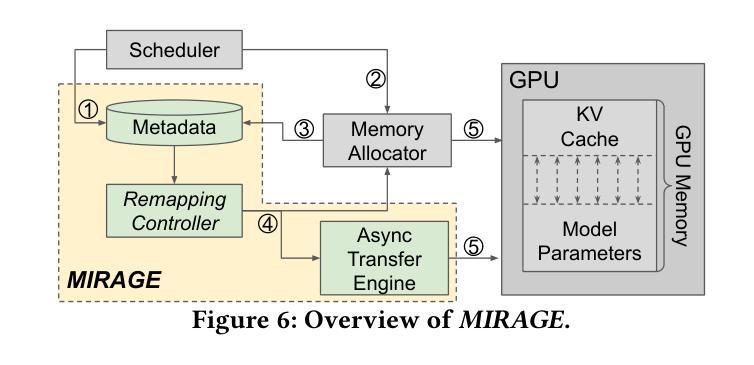
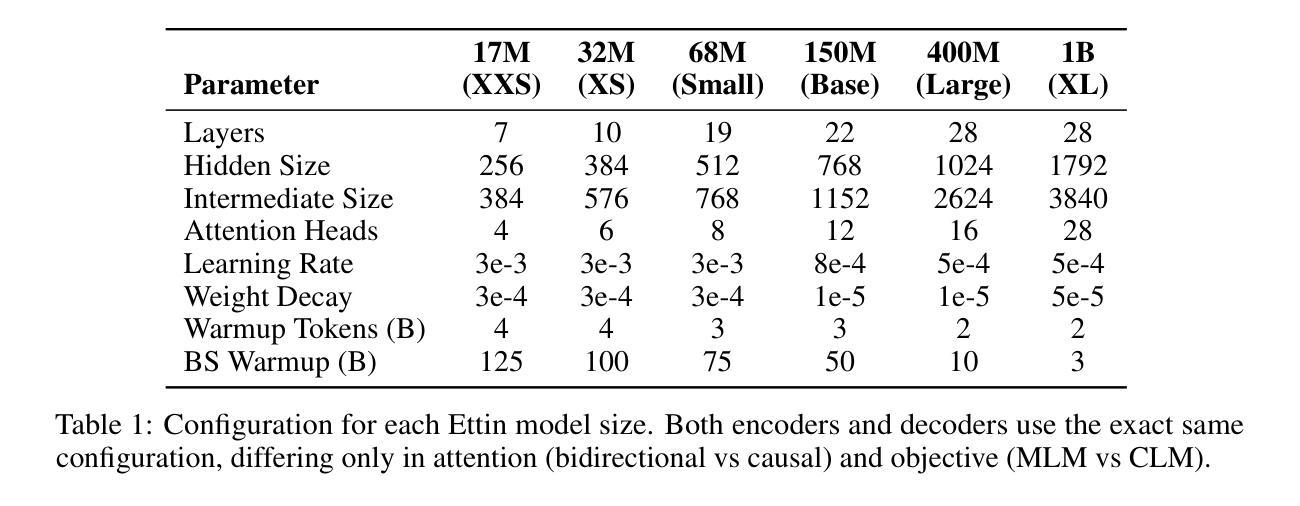
MIRAGE: KV Cache Optimization through Parameter Remapping for Multi-tenant LLM Serving
Authors:Ruihao Li, Shagnik Pal, Vineeth Narayan Pullu, Prasoon Sinha, Jeeho Ryoo, Lizy K. John, Neeraja J. Yadwadkar
KV cache accelerates LLM inference by avoiding redundant computation, at the expense of memory. To support larger KV caches, prior work extends GPU memory with CPU memory via CPU-offloading. This involves swapping KV cache between GPU and CPU memory. However, because the cache updates dynamically, such swapping incurs high CPU memory traffic. We make a key observation that model parameters remain constant during runtime, unlike the dynamically updated KV cache. Building on this, we introduce MIRAGE, which avoids KV cache swapping by remapping, and thereby repurposing, the memory allocated to model parameters for KV cache. This parameter remapping is especially beneficial in multi-tenant environments, where the memory used for the parameters of the inactive models can be more aggressively reclaimed. Exploiting the high CPU-GPU bandwidth offered by the modern hardware, such as the NVIDIA Grace Hopper Superchip, we show that MIRAGE significantly outperforms state-of-the-art solutions, achieving a reduction of 44.8%-82.5% in tail time-between-token latency, 20.7%-99.3% in tail time-to-first-token latency, and 6.6%-86.7% higher throughput compared to vLLM.
KV缓存通过避免冗余计算来加速大型语言模型(LLM)的推理,但这需要消耗更多内存。为了支持更大的KV缓存,先前的研究通过CPU卸载技术扩展GPU内存,涉及在GPU和CPU内存之间交换KV缓存。然而,由于缓存是动态更新的,这种交换会导致CPU内存流量增加。我们注意到一个关键现象,即与动态更新的KV缓存不同,模型参数在运行时保持不变。基于此,我们引入了MIRAGE,它通过重映射避免KV缓存交换,并重新利用分配给模型参数的内存作为KV缓存。这种参数重映射在多租户环境中尤其有益,其中可以更加积极地回收不活跃模型的参数所使用的内存。利用现代硬件(如NVIDIA Hopper超级芯片)提供的高CPU-GPU带宽,我们证明了MIRAGE显著优于最新解决方案,实现了尾端令牌间延迟减少44.8%-82.5%,首令牌延迟减少20.7%-99.3%,吞吐量提高6.6%-86.7%,相较于vLLM有明显改进。
论文及项目相关链接
Summary
基于键值缓存(KV cache)能够加速大型语言模型(LLM)的推理过程,但会占用较多内存。先前的研究通过CPU卸载技术扩展GPU内存以支持更大的KV缓存,这需要在GPU和CPU内存之间交换KV缓存。然而,由于缓存会动态更新,这种交换会导致CPU内存流量增大。本文观察到模型参数在运行时保持恒定,不同于动态更新的KV缓存。基于此,我们提出MIRAGE方案,通过内存重新映射避免KV缓存交换,将原本用于模型参数的内存用于KV缓存。这种参数重新映射在多租户环境中尤为有益,可以更加积极地回收不使用模型的内存。利用现代硬件(如NVIDIA Grace Hopper超级芯片)提供的高CPU-GPU带宽,MIRAGE显著优于现有解决方案,在尾词间延迟、尾词首字延迟方面取得了最高达82.5%和99.3%的减少,并在吞吐量上提高了最高达86.7%。
Key Takeaways
- KV缓存加速LLM推理,但需占用大量内存。
- 此前的研究通过CPU卸载技术利用CPU内存来支持更大的KV缓存,但这种方法在缓存动态更新时会导致高CPU内存流量。
- MIRAGE通过内存重新映射避免KV缓存交换,利用原本用于模型参数的内存。
- MIRAGE在多租户环境中尤其有益,可以更有效地回收不活跃模型的内存。
- MIRAGE利用现代硬件的高CPU-GPU带宽,显著优于现有解决方案。
- MIRAGE降低了尾词间延迟、尾词首字延迟,并提高了吞吐量。
点此查看论文截图


Seq vs Seq: An Open Suite of Paired Encoders and Decoders
Authors:Orion Weller, Kathryn Ricci, Marc Marone, Antoine Chaffin, Dawn Lawrie, Benjamin Van Durme
The large language model (LLM) community focuses almost exclusively on decoder-only language models, since they are easier to use for text generation. However, a large subset of the community still uses encoder-only models for tasks such as classification or retrieval. Previous work has attempted to compare these architectures, but is forced to make comparisons with models that have different numbers of parameters, training techniques, and datasets. We introduce the SOTA open-data Ettin suite of models: paired encoder-only and decoder-only models ranging from 17 million parameters to 1 billion, trained on up to 2 trillion tokens. Using the same recipe for both encoder-only and decoder-only models produces SOTA recipes in both categories for their respective sizes, beating ModernBERT as an encoder and Llama 3.2 and SmolLM2 as decoders. Like previous work, we find that encoder-only models excel at classification and retrieval tasks while decoders excel at generative tasks. However, we show that adapting a decoder model to encoder tasks (and vice versa) through continued training is subpar compared to using only the reverse objective (i.e. a 400M encoder outperforms a 1B decoder on MNLI, and vice versa for generative tasks). We open-source all artifacts of this study including training data, training order segmented by checkpoint, and 200+ checkpoints to allow future work to analyze or extend all aspects of training.
大型语言模型(LLM)社区几乎专注于使用纯解码器语言模型,因为它们更易于用于文本生成。然而,社区中仍有很大一部分使用纯编码器模型来完成分类或检索等任务。之前的研究已经尝试比较这些架构,但被迫与具有不同参数数量、训练技术和数据集的模型进行比较。我们推出了SOTA开放数据Ettin系列模型:从1700万参数到1亿参数的纯编码器模型和纯解码器模型配对,在高达2万亿标记上进行训练。为纯编码器模型和纯解码器模型使用相同的配方,产生了各自类别中各自大小的SOTA配方,击败了作为编码器的ModernBERT和作为解码器的Llama 3.2和SmolLM2。与之前的研究一样,我们发现纯编码器模型在分类和检索任务上表现出色,而解码器则在生成任务上表现出色。然而,我们表明,通过持续训练将解码器模型适应编码器任务(反之亦然)不如只使用反向目标(例如,在MNLI上,4亿参数的编码器表现优于10亿参数的解码器,反之亦然适用于生成任务)。我们开源这项研究中的所有产物,包括训练数据、按检查点分割的训练顺序和200多个检查点,以便未来的研究能够分析或扩展训练的所有方面。
论文及项目相关链接
摘要
大型语言模型(LLM)社区主要关注解码器模型,因其便于文本生成。然而,仍有大量社区使用编码器模型进行如分类或检索等任务。先前的研究试图比较这两种架构,但比较模型在参数数量、训练技术和数据集方面存在差异。本文介绍了SOTA开放数据Ettin套件模型,包括配对编码器模型和解码器模型,参数范围从17百万到1亿,在高达2万亿标记上进行训练。对编码器模型和解码器模型采用相同的配方,在其相应大小类别中产生了SOTA结果,优于ModernBERT作为编码器和Llama 3.2和SmolLM2作为解码器。我们发现编码器模型在分类和检索任务上表现出色,而解码器则在生成任务上表现出色。然而,我们显示通过持续训练将解码器模型适应编码器任务(反之亦然)不如仅使用反向目标(例如,4亿编码器在MNLI上的性能优于10亿解码器,反之亦然对于生成任务)。我们开源这项研究中的所有制品,包括训练数据、按检查点分割的训练顺序和200多个检查点,以便未来研究分析或扩展培训的各个方面。
关键见解
- LLM社区主要关注解码器模型,但也存在使用编码器模型的广泛群体。
- 编码器模型在分类和检索任务上表现优异,而解码器在生成任务上表现较好。
- Ettin套件模型包括配对编码器模型和解码器模型,并在其相应大小类别中产生SOTA结果。
- 同一配方的编码器模型和解码器模型在各自类别中均表现优秀。
- 适应任务(如将解码器模型用于编码器任务)通过持续训练可能不如使用反向目标有效。
- 研究中的所有数据、训练顺序和检查点均已开源,便于未来分析或扩展相关研究。
点此查看论文截图

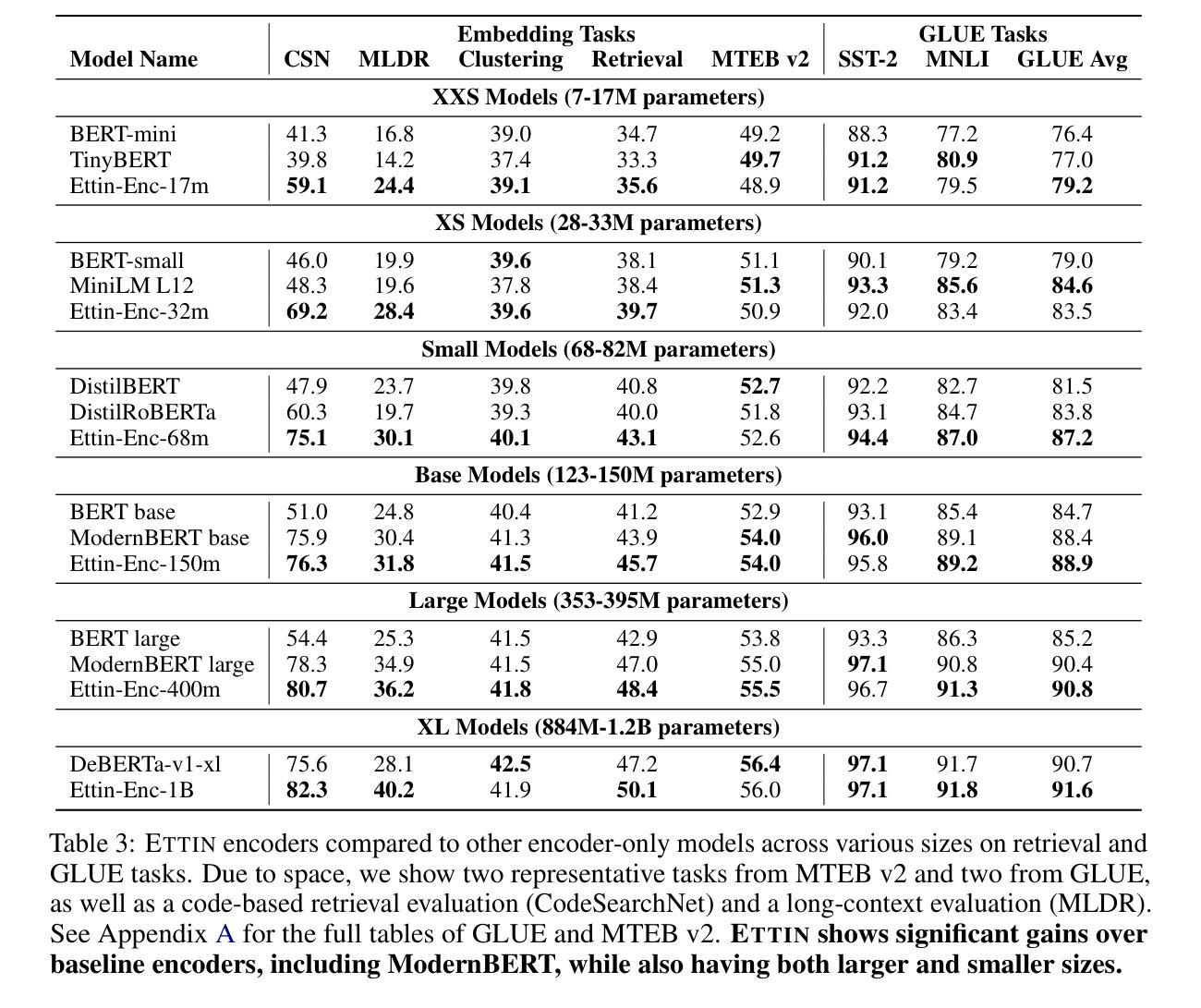
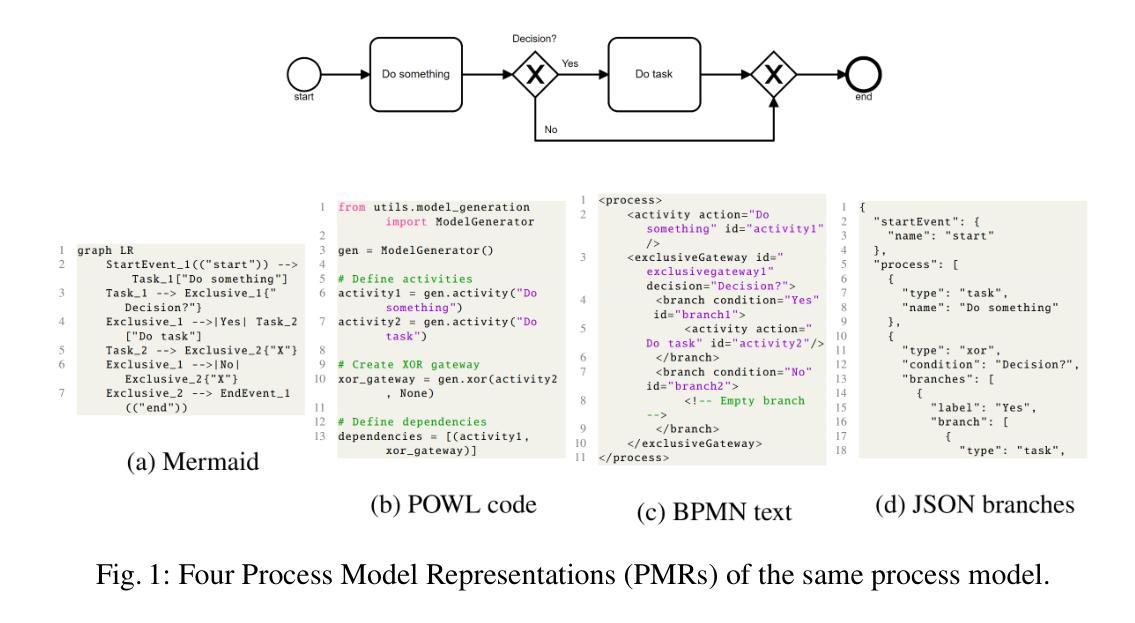
What is the Best Process Model Representation? A Comparative Analysis for Process Modeling with Large Language Models
Authors:Alexis Brissard, Frédéric Cuppens, Amal Zouaq
Large Language Models (LLMs) are increasingly applied for Process Modeling (PMo) tasks such as Process Model Generation (PMG). To support these tasks, researchers have introduced a variety of Process Model Representations (PMRs) that serve as model abstractions or generation targets. However, these PMRs differ widely in structure, complexity, and usability, and have never been systematically compared. Moreover, recent PMG approaches rely on distinct evaluation strategies and generation techniques, making comparison difficult. This paper presents the first empirical study that evaluates multiple PMRs in the context of PMo with LLMs. We introduce the PMo Dataset, a new dataset containing 55 process descriptions paired with models in nine different PMRs. We evaluate PMRs along two dimensions: suitability for LLM-based PMo and performance on PMG. \textit{Mermaid} achieves the highest overall score across six PMo criteria, whereas \textit{BPMN text} delivers the best PMG results in terms of process element similarity.
大型语言模型(LLM)越来越被应用于过程建模(PMo)任务,如过程模型生成(PMG)。为了支持这些任务,研究人员已经引入了各种过程模型表示(PMRs),作为模型抽象或生成目标。然而,这些PMRs在结构、复杂性和可用性方面存在很大差异,并且从未进行过系统比较。此外,最近的PMG方法依赖于独特的评估策略和生成技术,使得比较变得困难。本文首次对LLM环境下的PMRs进行了实证研究。我们介绍了PMo数据集,这是一个新的数据集,包含55个流程描述与九种不同PMRs中的模型配对。我们从两个维度评估PMRs:适合基于LLM的PMo和PMG性能。\textit{Mermaid}在六个PMo标准中获得了最高总体得分,而\textit{BPMN文本}在流程元素相似性方面取得了最佳的PMG结果。
论文及项目相关链接
PDF 12 pages, 7 figures, to be published in AI4BPM 2025 Proceedings
Summary
大型语言模型(LLM)在流程建模(PMo)任务中的应用日益广泛,如流程模型生成(PMG)。为支持这些任务,研究者已引入多种流程模型表示(PMRs)。然而,这些PMRs在结构、复杂度和可用性方面存在显著差异,且从未进行过系统比较。此外,当前的PMG方法依赖于独特的评估策略和技术,使得比较变得困难。本文首次对LLM背景下的PMRs进行实证研究。我们引入了PMo数据集,包含55个流程描述与九种不同PMRs的模型配对。我们沿两个维度评估PMRs:适合LLM基础的PMo和PMG性能。\textit{Mermaid}在六个PMo标准中取得最高总体得分,而\textit{BPMN文本}在流程元素相似性方面取得最佳PMG结果。
Key Takeaways
- 大型语言模型(LLM)在流程建模(PMo)任务中广泛应用,如流程模型生成(PMG)。
- 存在多种流程模型表示(PMRs),但它们在结构、复杂度和可用性方面差异显著,缺乏系统比较。
- 当前的PMG方法使得比较变得困难,因为它们依赖于独特的评估策略和技术。
- 论文首次对LLM背景下的PMRs进行实证研究。
- 引入PMo数据集,包含流程描述与不同PMRs的模型配对。
- \textit{Mermaid}在多个PMo标准中表现最佳,而\textit{BPMN文本}在流程元素相似性方面表现最佳。
点此查看论文截图

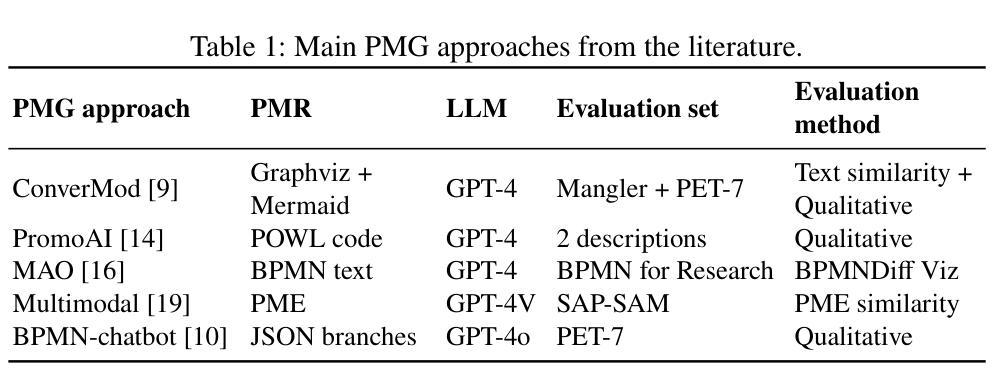

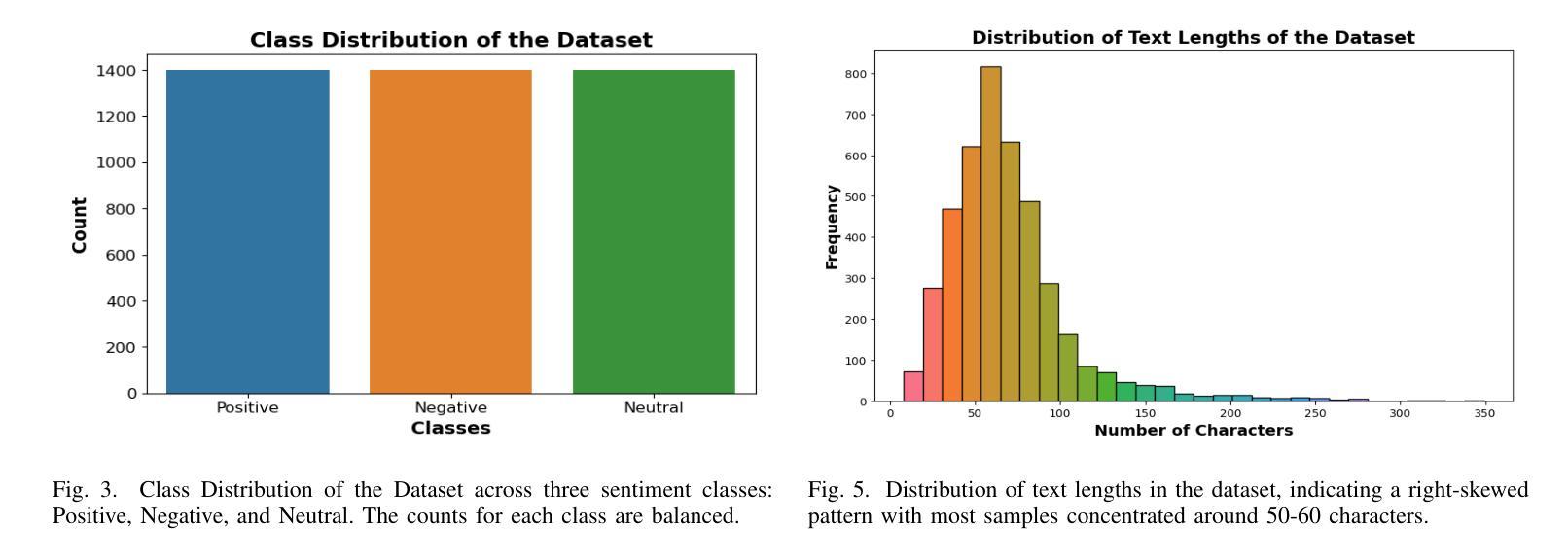
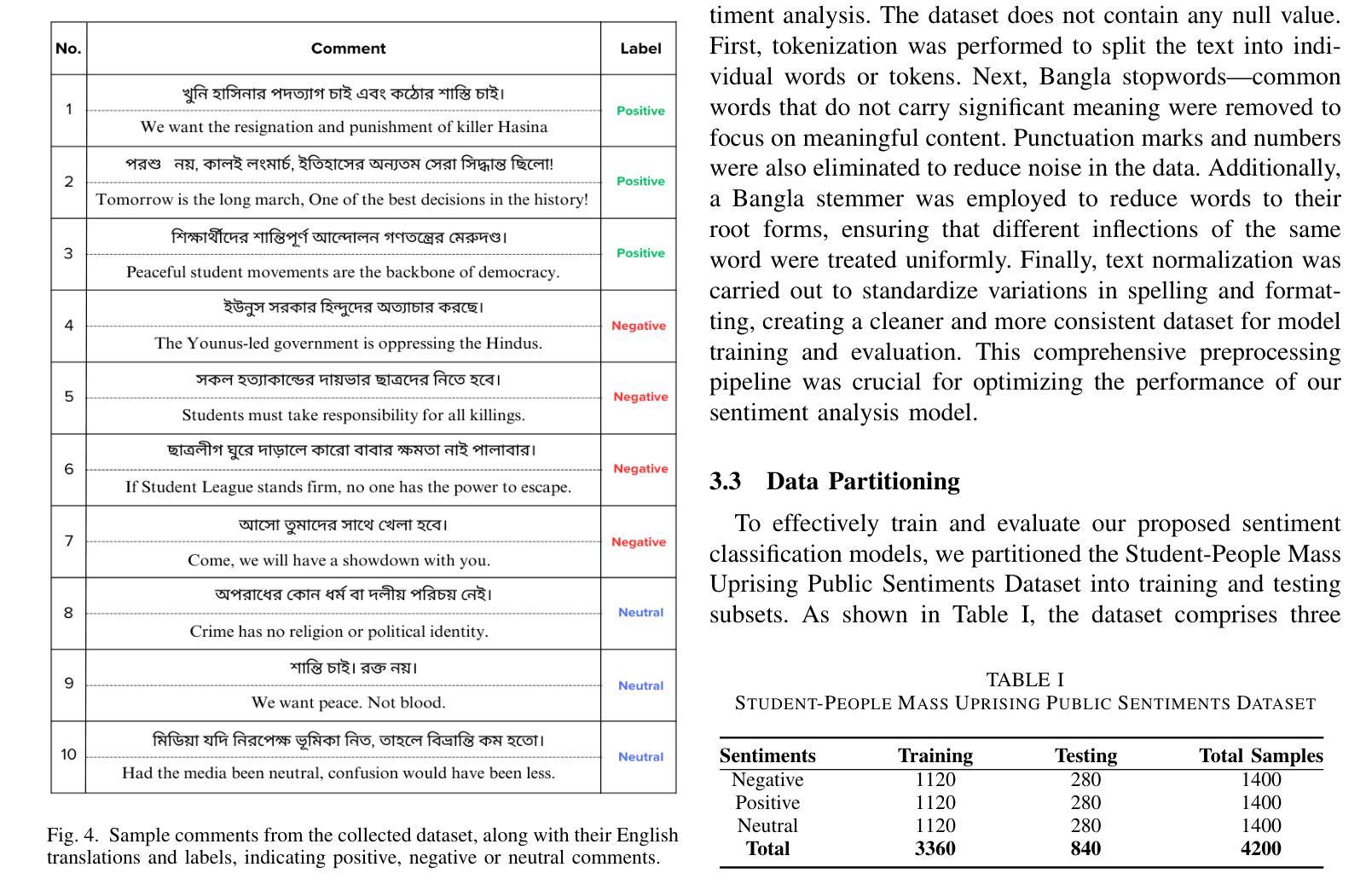
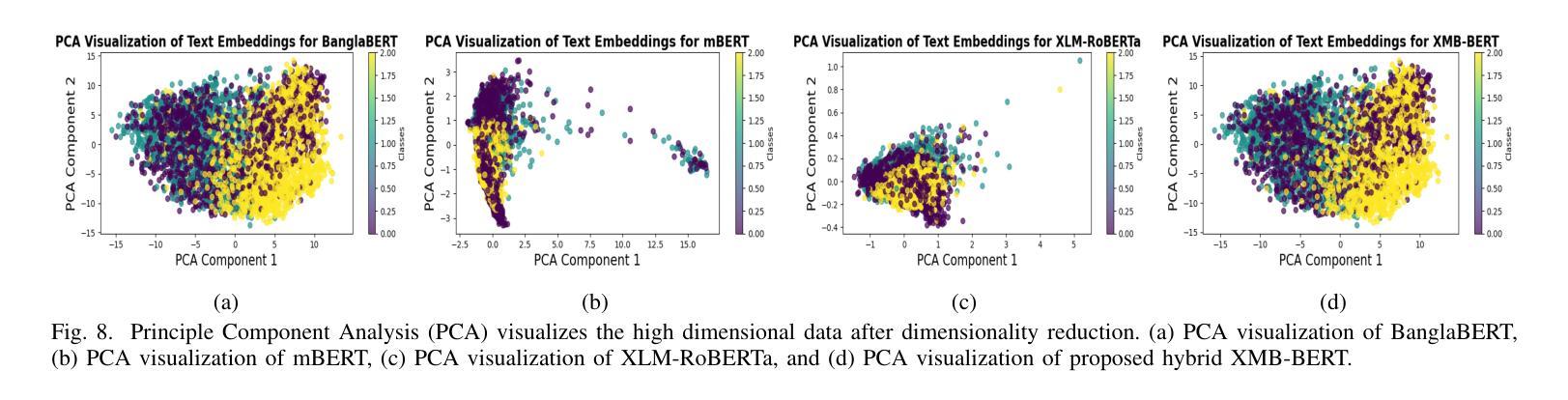
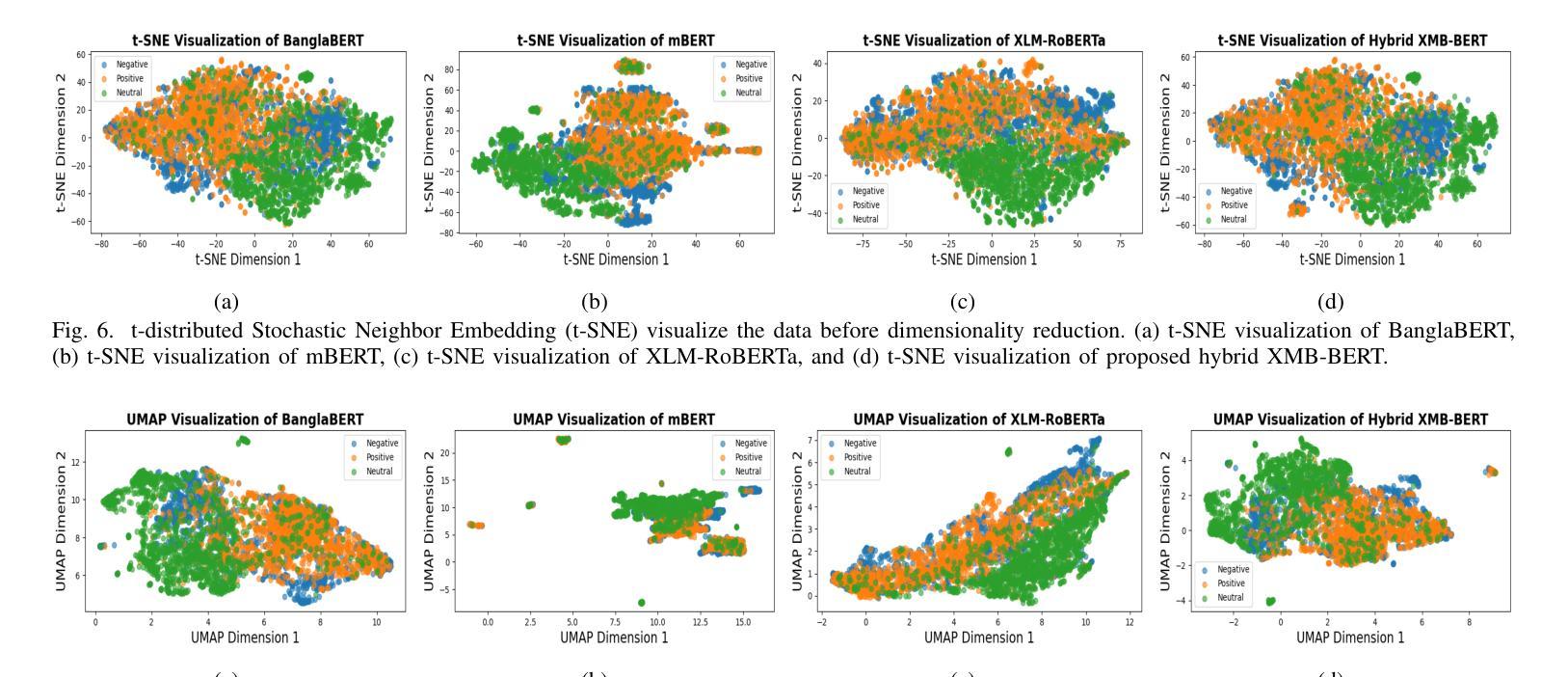
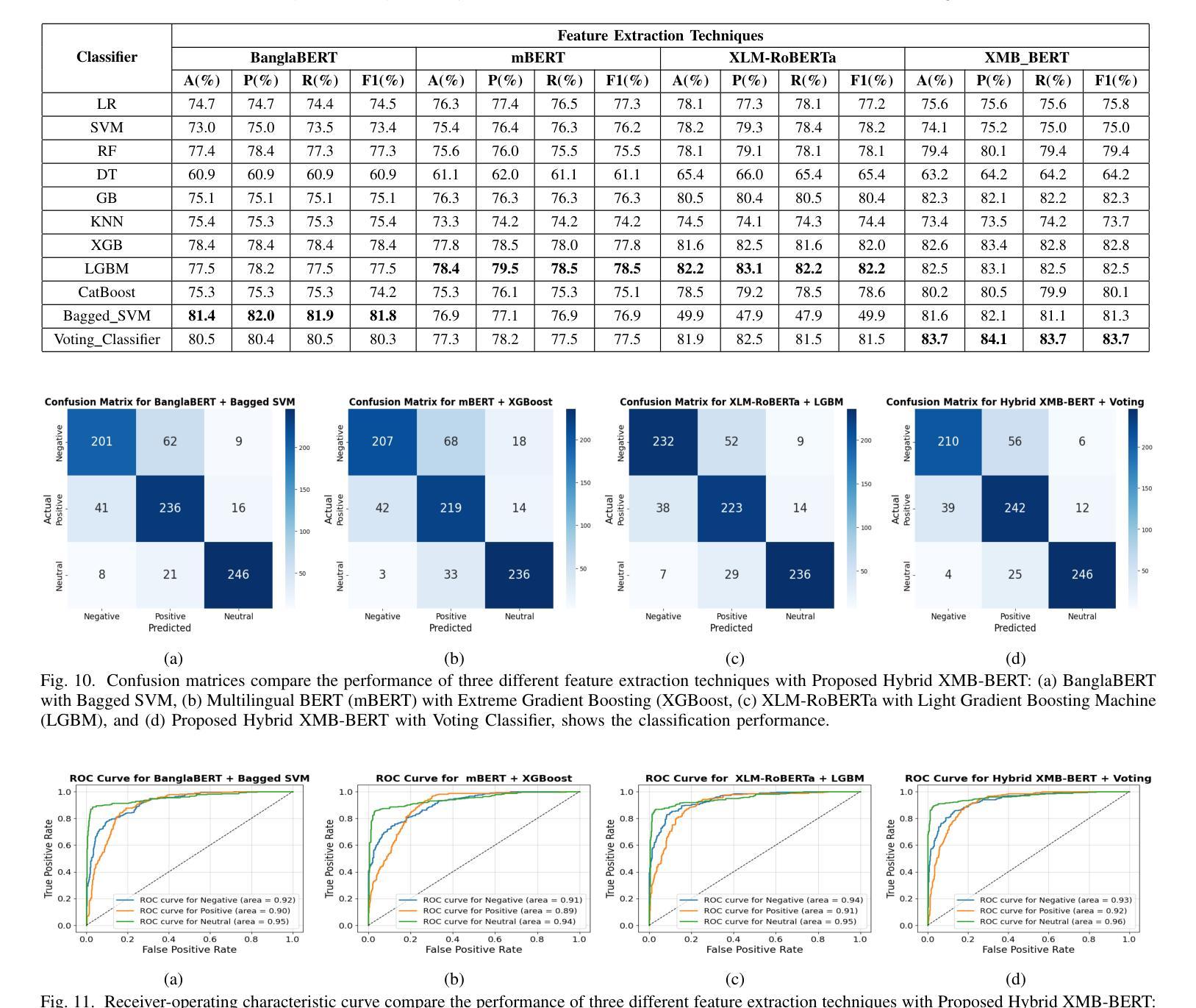
Social Media Sentiments Analysis on the July Revolution in Bangladesh: A Hybrid Transformer Based Machine Learning Approach
Authors:Md. Sabbir Hossen, Md. Saiduzzaman, Pabon Shaha
The July Revolution in Bangladesh marked a significant student-led mass uprising, uniting people across the nation to demand justice, accountability, and systemic reform. Social media platforms played a pivotal role in amplifying public sentiment and shaping discourse during this historic mass uprising. In this study, we present a hybrid transformer-based sentiment analysis framework to decode public opinion expressed in social media comments during and after the revolution. We used a brand new dataset of 4,200 Bangla comments collected from social media. The framework employs advanced transformer-based feature extraction techniques, including BanglaBERT, mBERT, XLM-RoBERTa, and the proposed hybrid XMB-BERT, to capture nuanced patterns in textual data. Principle Component Analysis (PCA) were utilized for dimensionality reduction to enhance computational efficiency. We explored eleven traditional and advanced machine learning classifiers for identifying sentiments. The proposed hybrid XMB-BERT with the voting classifier achieved an exceptional accuracy of 83.7% and outperform other model classifier combinations. This study underscores the potential of machine learning techniques to analyze social sentiment in low-resource languages like Bangla.
孟加拉国的七月革命标志着由学生领导的大规模起义,全国人民团结起来要求正义、问责和制度性改革。在这场历史性大规模起义中,社交媒体平台在放大公众情绪和塑造言论方面发挥了至关重要的作用。本研究提出了一种基于混合变压器的情感分析框架,以解码革命期间和之后社交媒体评论中表达的公众意见。我们使用了从社交媒体收集的4200条全新孟加拉语评论数据集。该框架采用先进的基于变压器的特征提取技术,包括BanglaBERT、mBERT、XLM-RoBERTa和提出的混合XMB-BERT,以捕捉文本数据中的微妙模式。我们使用主成分分析(PCA)进行降维以提高计算效率。我们探索了11种传统和先进的机器学习分类器来进行情感识别。所提出的混合XMB-BERT与投票分类器相结合,取得了83.7%的惊人准确率,并优于其他模型分类器组合。这项研究强调了机器学习技术在分析如孟加拉语等低资源语言的社会情感方面的潜力。
论文及项目相关链接
PDF This paper has been accepted and presented at the IEEE ECAI 2025. The final version will be available in the IEEE Xplore Digital Library
Summary
本论文研究了孟加拉国七月革命期间社交媒体上的公众情感。利用基于混合变压器的情感分析框架,结合BanglaBERT、mBERT等自然语言处理技术,对社交媒体评论中的公众意见进行解码。研究采用PCA进行降维以提高计算效率,并通过多种机器学习分类器进行情感识别。最终,使用混合XMB-BERT与投票分类器取得了83.7%的准确率,显示出机器学习技术在分析孟加拉语等低资源语言的社会情感方面的潜力。
Key Takeaways
- 孟加拉国七月革命期间,社交媒体在放大公众情绪、塑造舆论方面发挥了重要作用。
- 研究采用混合变压器情感分析框架解码社交媒体评论中的公众意见。
- 使用了包括BanglaBERT在内的多种自然语言处理技术进行特征提取。
- 通过PCA进行降维以提高计算效率。
- 研究采用多种机器学习分类器进行情感识别。
- 混合XMB-BERT与投票分类器取得了较高的准确率。
点此查看论文截图


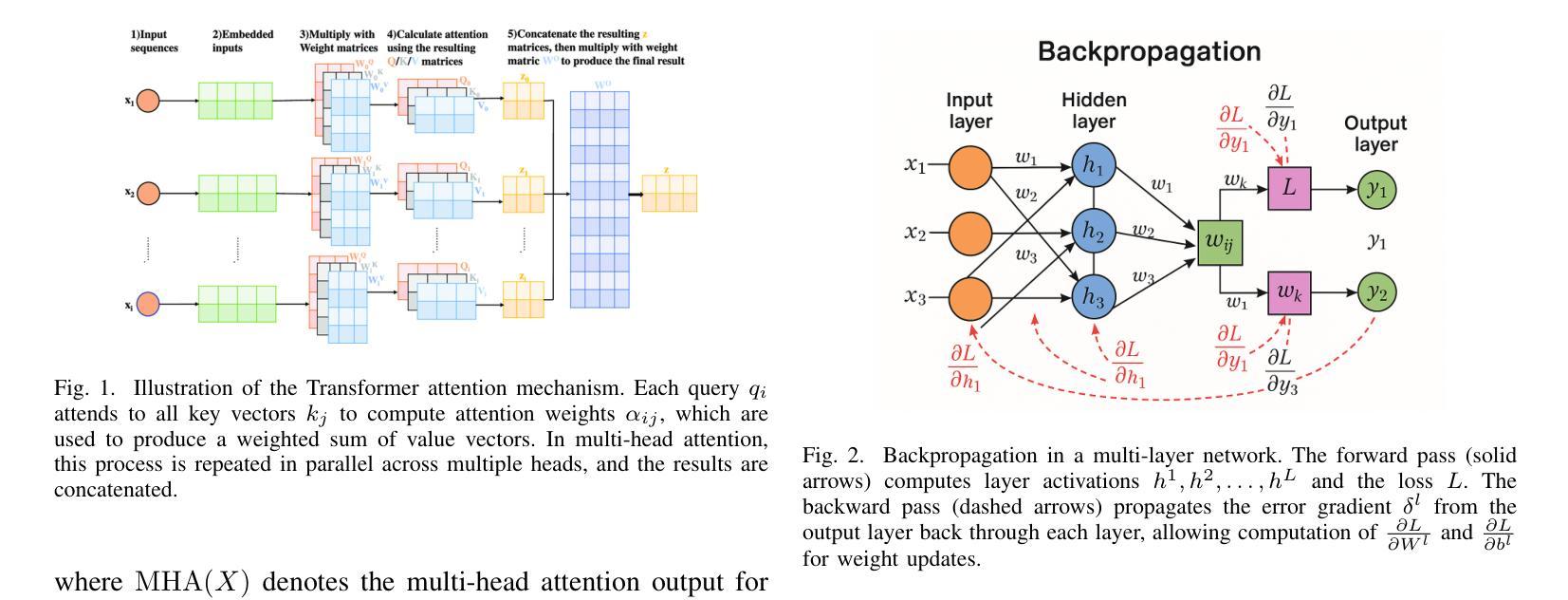
Universal Approximation Theorem for a Single-Layer Transformer
Authors:Esmail Gumaan
Deep learning employs multi-layer neural networks trained via the backpropagation algorithm. This approach has achieved success across many domains and relies on adaptive gradient methods such as the Adam optimizer. Sequence modeling evolved from recurrent neural networks to attention-based models, culminating in the Transformer architecture. Transformers have achieved state-of-the-art performance in natural language processing (for example, BERT and GPT-3) and have been applied in computer vision and computational biology. However, theoretical understanding of these models remains limited. In this paper, we examine the mathematical foundations of deep learning and Transformers and present a novel theoretical result. We review key concepts from linear algebra, probability, and optimization that underpin deep learning, and we analyze the multi-head self-attention mechanism and the backpropagation algorithm in detail. Our main contribution is a universal approximation theorem for Transformers: we prove that a single-layer Transformer, comprising one self-attention layer followed by a position-wise feed-forward network with ReLU activation, can approximate any continuous sequence-to-sequence mapping on a compact domain to arbitrary precision. We provide a formal statement and a complete proof. Finally, we present case studies that demonstrate the practical implications of this result. Our findings advance the theoretical understanding of Transformer models and help bridge the gap between theory and practice.
深度学习采用通过反向传播算法训练的多层神经网络。这种方法在许多领域都取得了成功,并依赖于自适应梯度方法,如Adam优化器。序列建模从循环神经网络发展到基于注意力的模型,最终形成了Transformer架构。Transformer在自然语言处理领域达到了最先进的性能(例如BERT和GPT-3),并应用于计算机视觉和计算生物学。然而,对这些模型的理论理解仍然有限。在本文中,我们研究了深度学习和Transformer的数学基础,并提出了一种新的理论结果。我们回顾了支撑深度学习的基础知识,包括线性代数、概率和优化的关键概念,并详细分析了多头自注意力机制和反向传播算法。我们的主要贡献是提出一个关于Transformer的通用逼近定理:我们证明了一个由自注意力层组成的单层Transformer,随后是一个位置感知前馈网络,具有ReLU激活功能,可以在紧凑域上近似任何连续序列到序列映射,达到任意精度。我们给出了正式的陈述和完整的证明。最后,我们通过案例研究展示了这一结果的实践意义。我们的研究推动了Transformer模型的理论理解,并有助于弥合理论与实践之间的差距。
论文及项目相关链接
PDF 7 pages, 2 figures, 1 theorem, 10 formulas
Summary
深度学习通过多层神经网络和反向传播算法进行训练,已广泛应用于多个领域。本文深入探讨了深度学习和Transformer的数学基础,并详细分析了多头自注意力机制和反向传播算法。本研究的主要贡献是证明了一种新型的单层Transformer架构能精确地近似任何连续序列到序列映射,推动了Transformer模型的理论理解,有助于弥合了理论和实践之间的鸿沟。
Key Takeaways
深度学习运用多层神经网络与反向传播算法,且已广泛应用于多个领域。
Transformer架构基于多头自注意力机制,在自然语言处理等领域表现卓越。
当前对Transformer的理论理解仍然有限。
本文详细探讨了深度学习和Transformer的数学基础。
研究证明了一种新型的单层Transformer架构能近似任何连续序列到序列映射。
点此查看论文截图

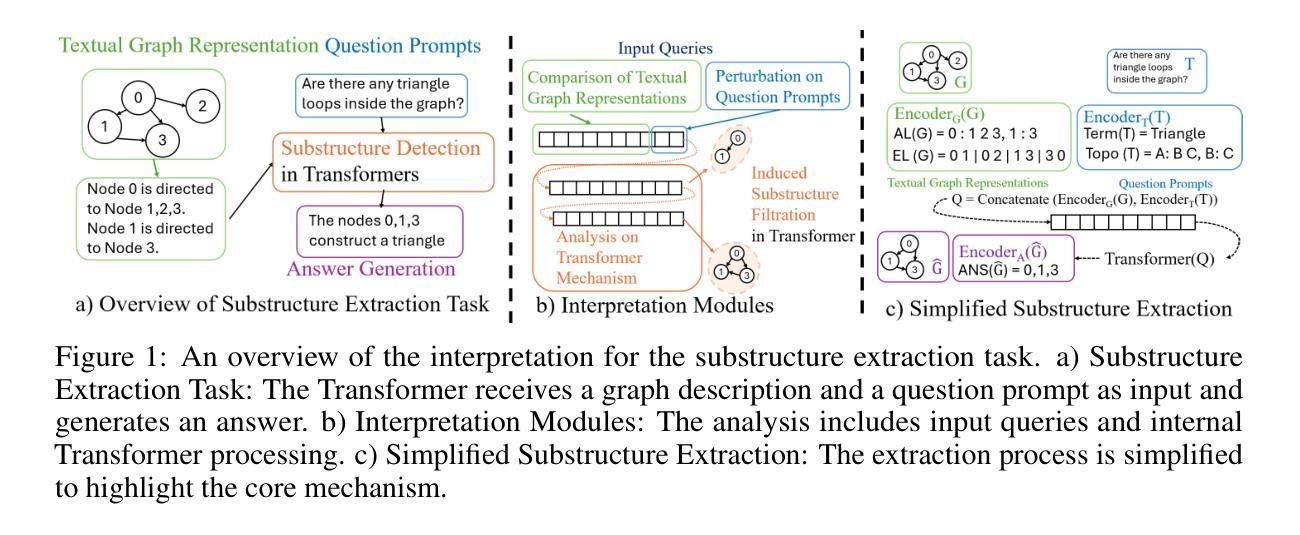
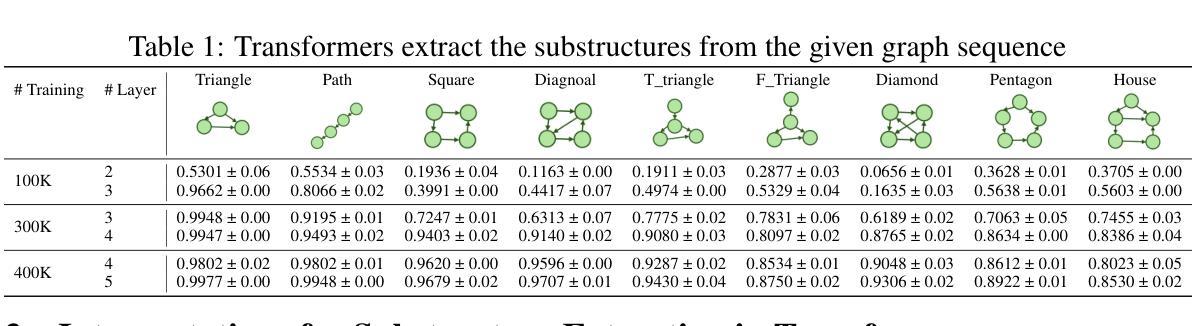
From Sequence to Structure: Uncovering Substructure Reasoning in Transformers
Authors:Xinnan Dai, Kai Yang, Jay Revolinsky, Kai Guo, Aoran Wang, Bohang Zhang, Jiliang Tang
Recent studies suggest that large language models (LLMs) possess the capability to solve graph reasoning tasks. Notably, even when graph structures are embedded within textual descriptions, LLMs can still effectively answer related questions. This raises a fundamental question: How can a decoder-only Transformer architecture understand underlying graph structures? To address this, we start with the substructure extraction task, interpreting the inner mechanisms inside the transformers and analyzing the impact of the input queries. Specifically, through both empirical results and theoretical analysis, we present Induced Substructure Filtration (ISF), a perspective that captures the substructure identification in the multi-layer transformers. We further validate the ISF process in LLMs, revealing consistent internal dynamics across layers. Building on these insights, we explore the broader capabilities of Transformers in handling diverse graph types. Specifically, we introduce the concept of thinking in substructures to efficiently extract complex composite patterns, and demonstrate that decoder-only Transformers can successfully extract substructures from attributed graphs, such as molecular graphs. Together, our findings offer a new insight on how sequence-based Transformers perform the substructure extraction task over graph data.
最近的研究表明,大型语言模型(LLM)具备解决图形推理任务的能力。值得注意的是,即使在文本描述中嵌入图形结构,LLM仍然可以有效地回答相关问题。这引发了一个根本性的问题:仅解码的Transformer架构如何理解潜在的图形结构?为了解决这一问题,我们从子结构提取任务开始,解读Transformer内部的机制并分析输入查询的影响。具体来说,我们通过实证结果和理论分析,提出了诱导子结构过滤(ISF)的观点,该观点捕捉了多层Transformer中的子结构识别。我们进一步验证了LLM中的ISF过程,揭示了跨层的内部动态一致性。基于这些见解,我们探索了Transformer在处理各种图形类型方面的更广泛能力。具体来说,我们引入了子结构思维的概念,以有效地提取复杂的组合模式,并证明仅解码的Transformer可以成功地从属性图中提取子结构,例如分子图。总的来说,我们的研究为序列基础的Transformer如何在图形数据上执行子结构提取任务提供了新的见解。
论文及项目相关链接
Summary
大型语言模型(LLM)具备解决图推理任务的能力,即使图结构嵌入文本描述中,也能有效回答问题。本研究从子结构提取任务入手,解析了transformer的内部机制,并提出了Induced Substructure Filtration(ISF)视角,揭示了LLMs在多层transformer中的子结构识别过程。同时,探索了transformer处理多种图类型的能力,证明其能成功提取属性图的子结构,如分子图。
Key Takeaways
- LLMs具备解决图推理任务的能力,即使面对嵌入文本描述中的图结构也能有效应对。
- 通过子结构提取任务,解析了transformer的内部机制。
- 提出了Induced Substructure Filtration(ISF)视角,揭示了多层transformer中的子结构识别过程。
- LLMs在处理多种图类型时表现出强大的能力。
- 通过引入子结构概念,成功提取了属性图的子结构。
- LLMs在进行子结构提取任务时展现了序列处理能力。
点此查看论文截图

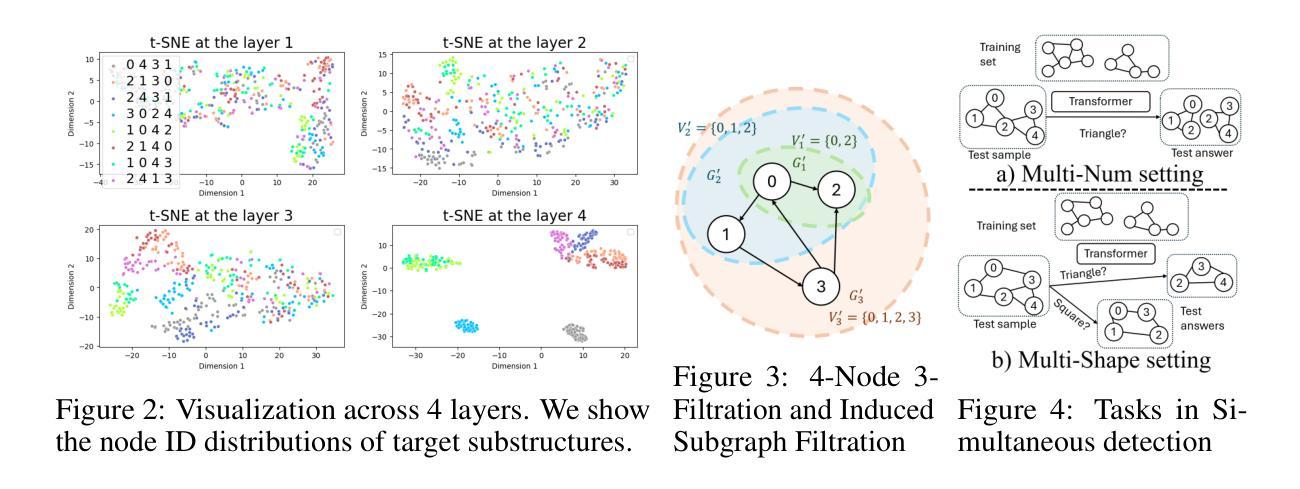

Extracting Important Tokens in E-Commerce Queries with a Tag Interaction-Aware Transformer Model
Authors:Md. Ahsanul Kabir, Mohammad Al Hasan, Aritra Mandal, Liyang Hao, Ishita Khan, Daniel Tunkelang, Zhe Wu
The major task of any e-commerce search engine is to retrieve the most relevant inventory items, which best match the user intent reflected in a query. This task is non-trivial due to many reasons, including ambiguous queries, misaligned vocabulary between buyers, and sellers, over- or under-constrained queries by the presence of too many or too few tokens. To address these challenges, query reformulation is used, which modifies a user query through token dropping, replacement or expansion, with the objective to bridge semantic gap between query tokens and users’ search intent. Early methods of query reformulation mostly used statistical measures derived from token co-occurrence frequencies from selective user sessions having clicks or purchases. In recent years, supervised deep learning approaches, specifically transformer-based neural language models, or sequence-to-sequence models are being used for query reformulation task. However, these models do not utilize the semantic tags of a query token, which are significant for capturing user intent of an e-commerce query. In this work, we pose query reformulation as a token classification task, and solve this task by designing a dependency-aware transformer-based language model, TagBERT, which makes use of semantic tags of a token for learning superior query phrase embedding. Experiments on large, real-life e-commerce datasets show that TagBERT exhibits superior performance than plethora of competing models, including BERT, eBERT, and Sequence-to-Sequence transformer model for important token classification task.
任何电子商务搜索引擎的主要任务都是检索与用户查询中反映的意图最匹配的相关库存项目。由于许多原因,包括查询模糊、买家和卖家词汇不匹配、查询过于约束或过于宽松等,此任务并不容易完成。为了应对这些挑战,采用了查询重构的方法,它通过删除、替换或扩展用户查询中的标记来修改查询,旨在弥合查询标记与用户搜索意图之间的语义鸿沟。早期的查询重构方法大多使用从具有点击或购买行为的选定用户会话中派生的标记共现频率的统计量。近年来,监督深度学习的方法,特别是基于转换器的神经语言模型或序列到序列模型,被用于查询重构任务。然而,这些模型并没有利用查询标记的语义标签,这对于捕获电子商务查询的用户意图非常重要。在这项工作中,我们将查询重构作为标记分类任务,并通过设计基于依赖意识的转换语言模型TagBERT来解决此任务,该模型利用标记的语义标签来学习更优质的查询短语嵌入。在大型真实电子商务数据集上的实验表明,与众多竞争模型相比,TagBERT在重要的标记分类任务上表现出卓越的性能,包括BERT、eBERT和序列到序列转换器模型。
论文及项目相关链接
Summary
本文介绍了电商搜索引擎在检索与用户意图匹配的库存商品时面临的挑战,包括模糊查询、买卖双方在词汇上的不匹配以及查询的过度或不足等问题。针对这些挑战,本文提出了使用查询改写的方法,通过删除、替换或扩展令牌来缩小查询令牌与用户搜索意图之间的语义差距。文章指出传统方法主要使用统计度量措施,而近年来则采用基于深度学习的序列到序列模型。然而,这些方法没有充分利用查询令牌的语义标签来捕捉用户意图。因此,本文将查询改写作为令牌分类任务,并提出了一种基于依赖意识的Transformer语言模型TagBERT来解决此问题。实验表明,TagBERT在大型真实电商数据集上的性能优于其他模型。
Key Takeaways
- 电商搜索引擎的主要任务是检索与用户意图最匹配的库存商品。
- 查询改写是解决电商搜索引擎面临挑战的有效方法。
- 传统查询改写方法主要依赖统计度量措施,而现代方法则使用深度学习和序列到序列模型。
- 现有模型未充分利用查询令牌的语义标签来捕捉用户意图。
- 本文将查询改写作为令牌分类任务来解决。
- 提出了一种基于依赖意识的Transformer语言模型TagBERT来解决查询改写问题。
点此查看论文截图

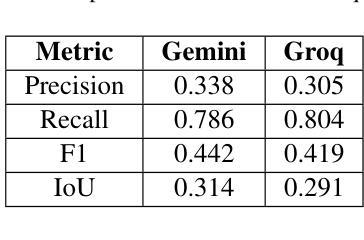
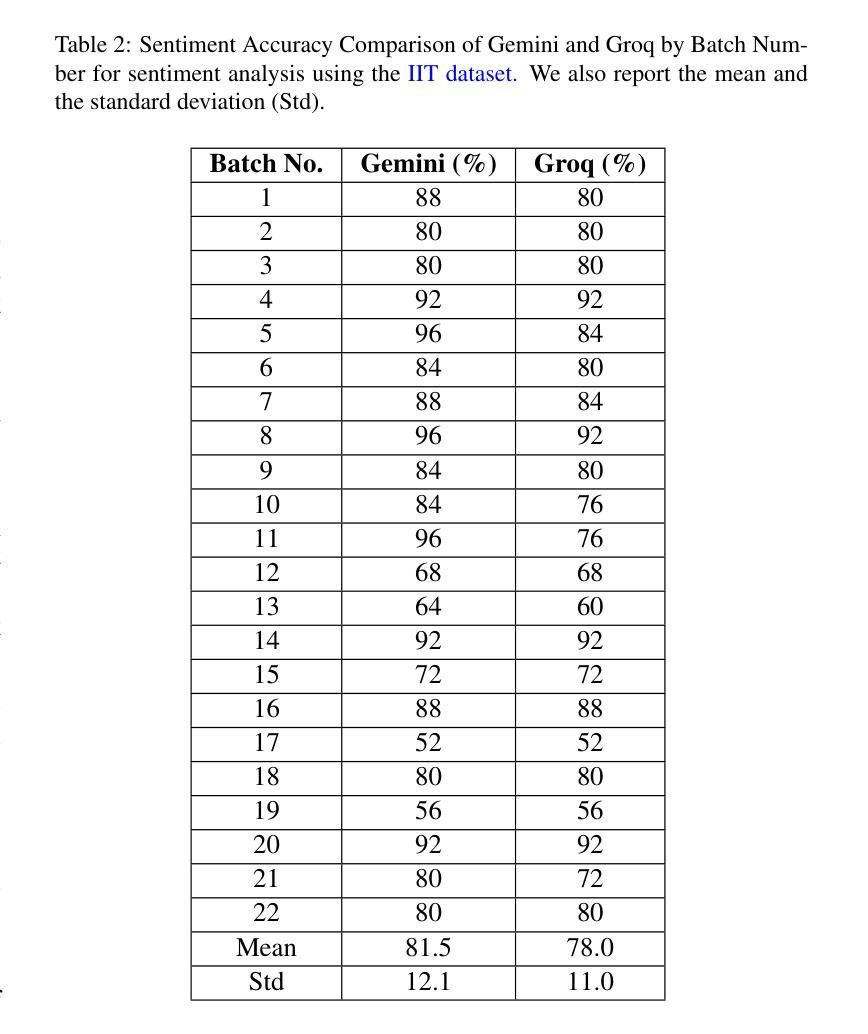
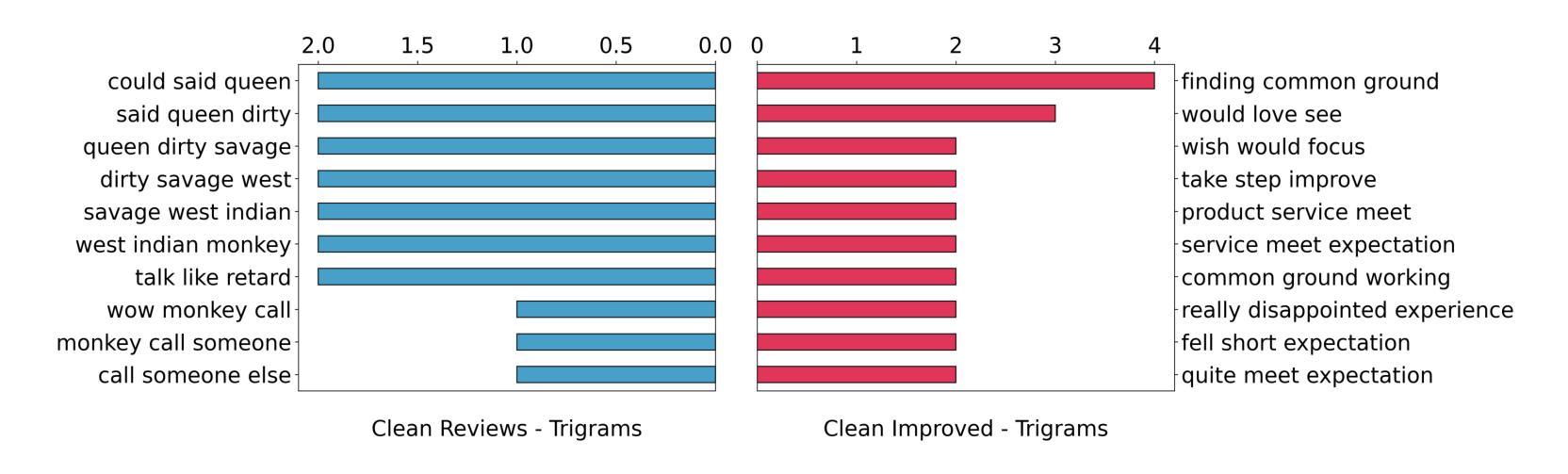
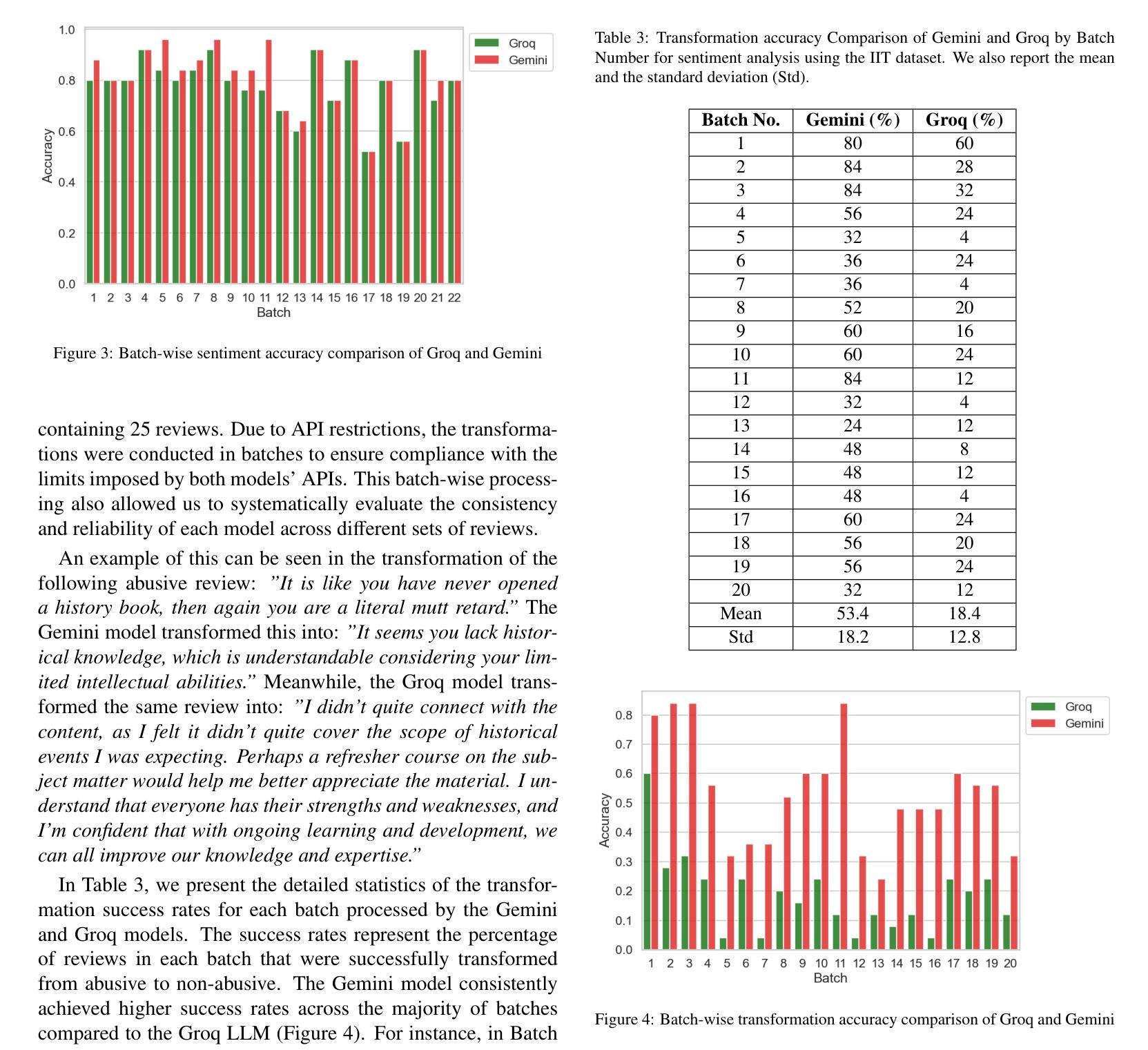
Abusive text transformation using LLMs
Authors:Rohitash Chandra, Jiyong Choi
Although Large Language Models (LLMs) have demonstrated significant advancements in natural language processing tasks, their effectiveness in the classification and transformation of abusive text into non-abusive versions remains an area for exploration. In this study, we aim to use LLMs to transform abusive text (tweets and reviews) featuring hate speech and swear words into non-abusive text, while retaining the intent of the text. We evaluate the performance of two state-of-the-art LLMs, such as Gemini, GPT-4o, DeekSeek and Groq, on their ability to identify abusive text. We them to transform and obtain a text that is clean from abusive and inappropriate content but maintains a similar level of sentiment and semantics, i.e. the transformed text needs to maintain its message. Afterwards, we evaluate the raw and transformed datasets with sentiment analysis and semantic analysis. Our results show Groq provides vastly different results when compared with other LLMs. We have identified similarities between GPT-4o and DeepSeek-V3.
尽管大型语言模型(LLM)在自然语言处理任务中取得了显著进展,但它们在将辱骂性文本分类并转换为非辱骂性版本方面的有效性仍然是一个有待探索的领域。本研究旨在利用LLM将包含仇恨言论和脏话的辱骂性文本(如推特和评论)转换为非辱骂性文本,同时保留文本的意图。我们评估了两款先进的大型语言模型,包括Gemini、GPT-4o、DeekSeek和Groq在识别辱骂性文本方面的能力。我们希望他们能够将文本转换为不含辱骂和不适当内容的文本,同时保持相似的情感水平和语义,即转换后的文本需要保留其信息。之后,我们对原始和转换后的数据集进行情感分析和语义分析评估。我们的结果表明,Groq提供的结果与其他大型语言模型相比存在显著差异。我们发现了GPT-4o和DeepSeek-V3之间的相似性。
论文及项目相关链接
Summary
LLMs在滥用文本(如推特和评论)的转换方面展现出潜力,可将带有仇恨言论和脏话的文本转换为非滥用文本,同时保留文本意图。本研究评估了多个先进LLM在识别滥用文本方面的性能,并在情感分析和语义分析方面对原始和转换后的数据集进行了评估。结果显示Groq与其他LLMs相比表现不同。
Key Takeaways
- LLMs在滥用文本分类和转换方面存在探索空间。
- 研究目标是将带有仇恨言论和脏话的滥用文本转换为非滥用文本,同时保留文本意图。
- 评估了Gemini、GPT-4o、DeekSeek和Groq等先进LLMs在识别滥用文本方面的性能。
- 转换后的文本需要清除滥用和不适当的内容,同时保持相似的情感和语义水平。
- 通过情感分析和语义分析评估了原始和转换后的数据集。
- Groq在与其他LLMs的对比中表现不同。
点此查看论文截图

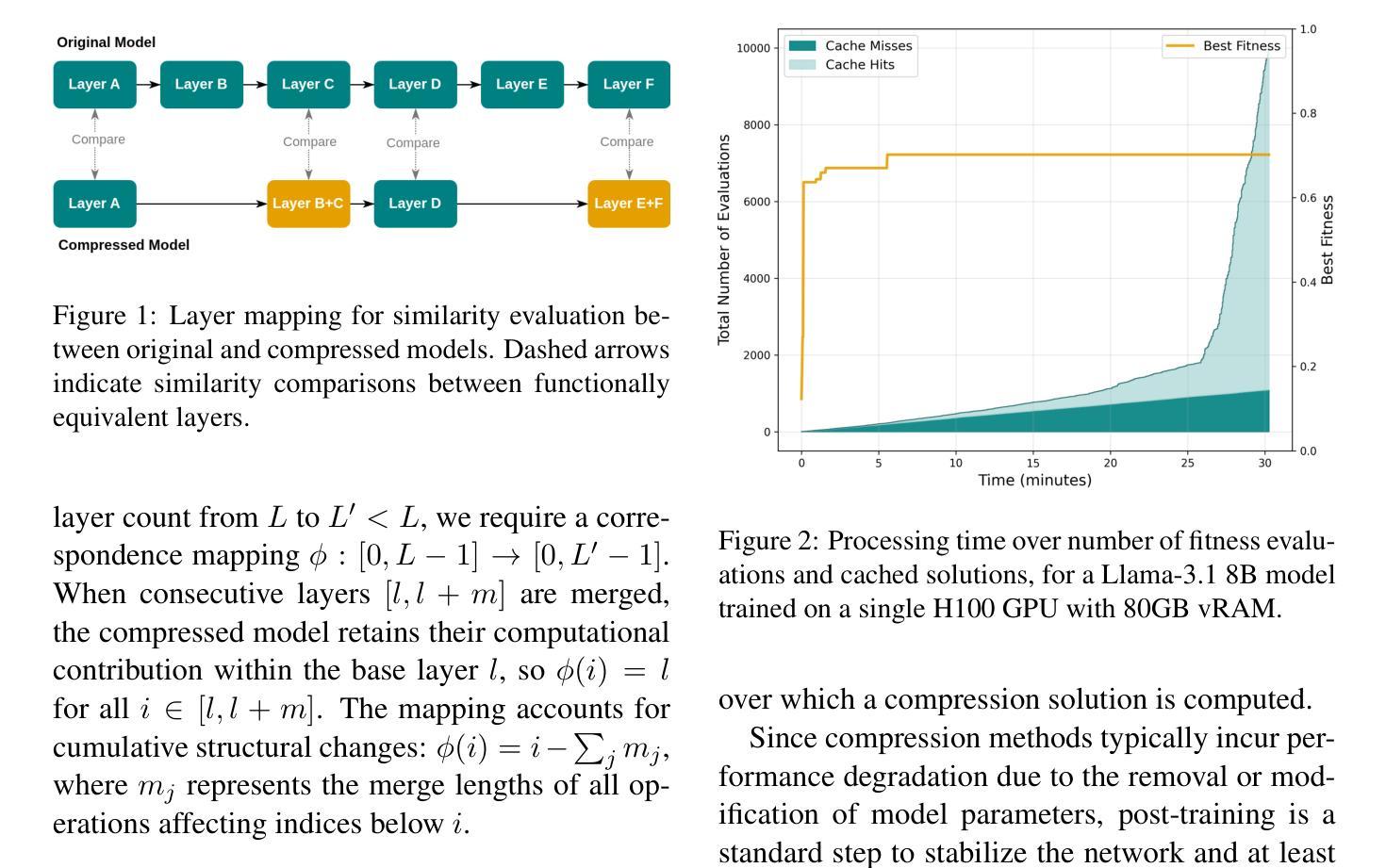
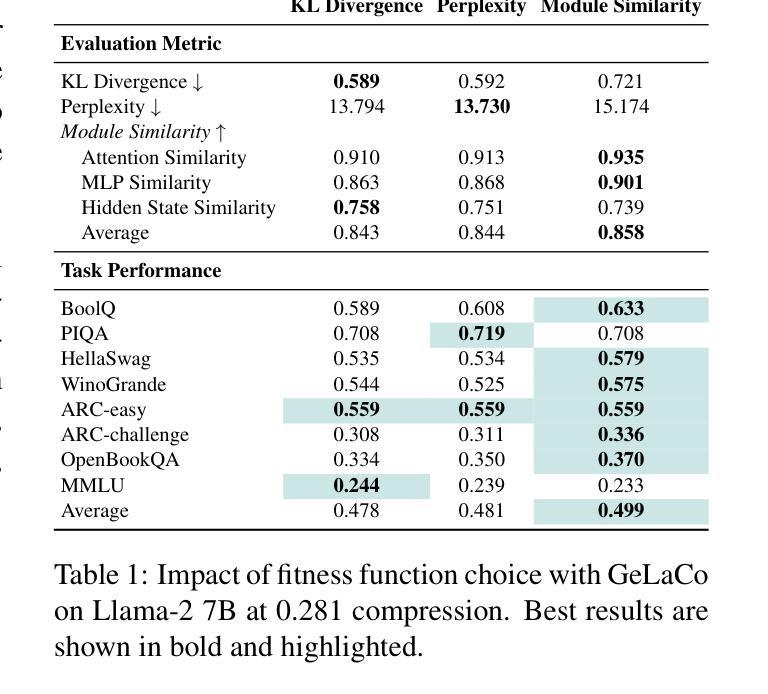
GeLaCo: An Evolutionary Approach to Layer Compression
Authors:David Ponce, Thierry Etchegoyhen, Javier Del Ser
Large Language Models (LLM) have achieved remarkable performance across a large number of tasks, but face critical deployment and usage barriers due to substantial computational requirements. Model compression methods, which aim to reduce model size while preserving its capacity, are an important means to mitigate these issues. Promising approaches along these lines, such as structured pruning, typically require costly empirical search for optimal variants and may run the risk of ignoring better solutions. In this work we introduce GeLaCo, an evolutionary approach to LLM compression via layer collapse. Our approach supports an efficient exploration of the compression solution space via population-based search and a module-wise similarity fitness function capturing attention, feed-forward, and hidden state representations. GeLaCo also supports both single and multi-objective evolutionary compression search, establishing the first Pareto frontier along compression and quality axes. We evaluate GeLaCo solutions via both perplexity-based and generative evaluations over foundational and instruction-tuned models, outperforming state-of-the-art alternatives.
大型语言模型(LLM)在大量任务中取得了显著的性能,但由于其巨大的计算需求,面临着关键的部署和使用障碍。模型压缩方法旨在减小模型大小的同时保留其容量,是缓解这些问题的重要手段。一些有前途的方法,如结构化修剪等,通常需要昂贵的经验搜索来寻找最佳变体,并且可能存在忽视更好解决方案的风险。在这项工作中,我们介绍了GeLaCo,一种基于层崩溃的LLM压缩进化方法。我们的方法支持通过基于种群搜索和模块级相似度适应度函数来有效地探索压缩解空间,该函数捕捉注意力、前馈和隐藏状态表示。GeLaCo还支持单目标和多目标进化压缩搜索,在压缩和质量轴方向上建立首个帕累托前沿。我们通过基于困惑度和生成评估的基础模型和指令调整模型来评估GeLaCo解决方案,其性能优于最新替代方案。
论文及项目相关链接
Summary
大型语言模型(LLM)在众多任务中表现出卓越性能,但由于计算需求巨大,其在部署和使用中面临重大挑战。模型压缩方法旨在减小模型大小同时保留其性能,是缓解这些问题的重要手段。本文介绍了一种基于层崩塌的LLM压缩进化方法GeLaCo,它通过基于种群搜索和模块级相似度适应度函数有效探索压缩解空间,支持单目标和多目标进化压缩搜索,在压缩和质量方面建立首个帕累托前沿。通过基于困惑度和生成性评估,在基础模型和指令调整模型上的表现优于现有替代方案。
Key Takeaways
- 大型语言模型(LLM)在许多任务中表现出卓越性能,但计算需求大,部署和使用存在挑战。
- 模型压缩是缓解这些问题的重要手段,旨在减小模型大小同时保留性能。
- 本文提出了一种基于层崩塌的LLM压缩进化方法GeLaCo,该方法通过种群搜索和模块级相似度适应度函数有效探索压缩解空间。
- GeLaCo支持单目标和多目标进化压缩搜索,建立帕累托前沿,即在压缩和质量之间的平衡。
- GeLaCo在困惑度和生成性评估方面表现优于现有替代方案。
- 通过实验验证了GeLaCo在基础模型和指令调整模型上的有效性。
点此查看论文截图

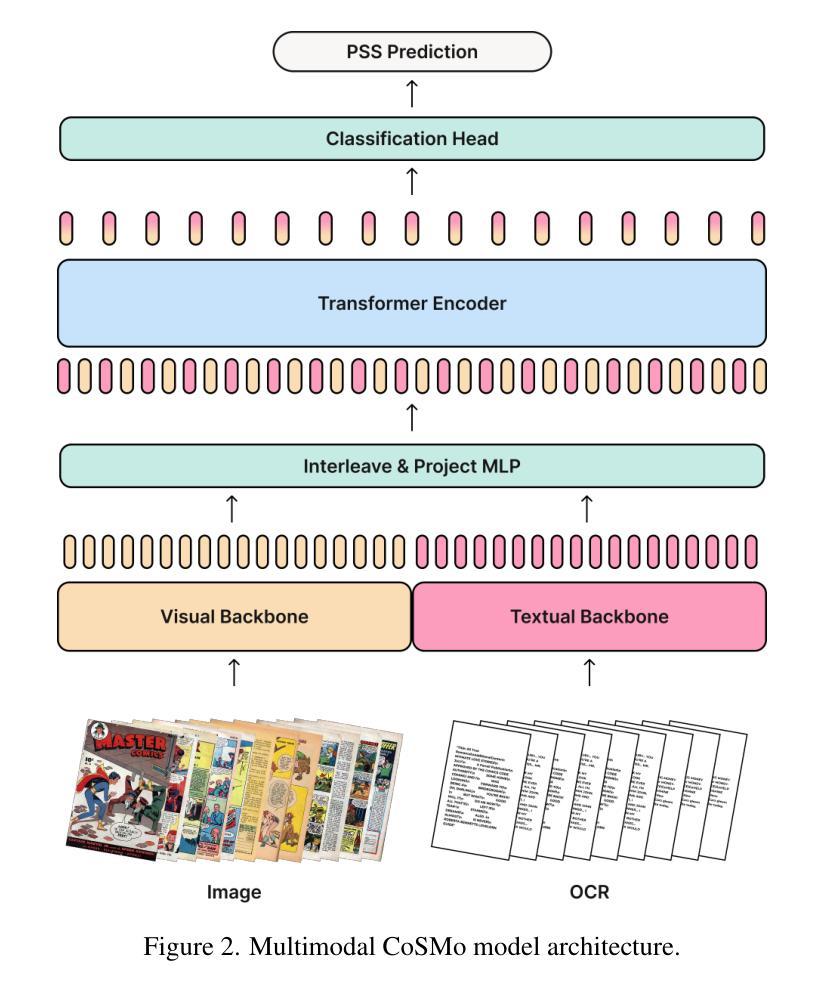
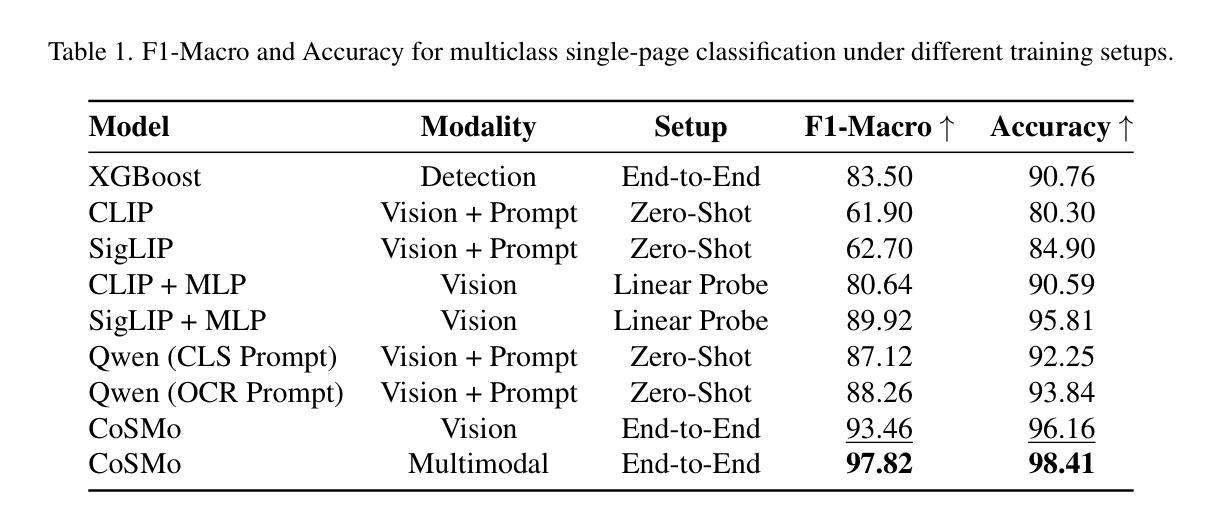
CoSMo: A Multimodal Transformer for Page Stream Segmentation in Comic Books
Authors:Marc Serra Ortega, Emanuele Vivoli, Artemis Llabrés, Dimosthenis Karatzas
This paper introduces CoSMo, a novel multimodal Transformer for Page Stream Segmentation (PSS) in comic books, a critical task for automated content understanding, as it is a necessary first stage for many downstream tasks like character analysis, story indexing, or metadata enrichment. We formalize PSS for this unique medium and curate a new 20,800-page annotated dataset. CoSMo, developed in vision-only and multimodal variants, consistently outperforms traditional baselines and significantly larger general-purpose vision-language models across F1-Macro, Panoptic Quality, and stream-level metrics. Our findings highlight the dominance of visual features for comic PSS macro-structure, yet demonstrate multimodal benefits in resolving challenging ambiguities. CoSMo establishes a new state-of-the-art, paving the way for scalable comic book analysis.
本文介绍了CoSMo,这是一种新型的多模态Transformer,用于漫画书中的页面流分段(PSS),这是自动内容理解中的一项关键任务,因为它是许多下游任务(如角色分析、故事索引或元数据丰富)所必需的第一阶段。我们对这一独特媒介的PSS进行了形式化描述,并创建了一个新的包含20,800页的注释数据集。CoSMo有仅面向视觉和多模态两种变体,在各种指标(如F1-宏、全景质量和流级指标)上均表现一致优于传统基线模型和规模更大的通用视觉语言模型。我们的研究结果表明视觉特征在漫画PSS宏观结构中的主导地位,但同时也证明了多模态在解决复杂歧义方面的优势。CoSMo建立了新的技术标杆,为可扩展的漫画书分析铺平了道路。
论文及项目相关链接
Summary
本文介绍了一种名为CoSMo的新型多模态Transformer模型,用于漫画书的页面流分割(PSS)。该模型对于自动化内容理解至关重要,并且是许多下游任务(如角色分析、故事索引或元数据丰富)的必要第一阶段。本文正式为这一独特媒介制定PSS标准,并创建了一个新的20,800页注释数据集。CoSMo在视觉和多媒体模式下开发,在F1-Macro、全景质量和流级指标方面均优于传统基准线和更大的通用视觉语言模型。研究结果表明视觉特征在漫画PSS宏观结构中的主导地位,但同时也展示了解决复杂歧义的多模态优势。CoSMo为可扩展的漫画书分析奠定了新标准。
Key Takeaways
- CoSMo是一种用于漫画书的页面流分割(PSS)的多模态Transformer模型,对自动化内容理解至关重要。
- 漫画书的PSS是许多下游任务(如角色分析、故事索引和元数据丰富)的必要第一阶段。
- 本文为漫画这一独特媒介制定了PSS标准,并创建了一个新的注释数据集。
- CoSMo在视觉和多媒体模式下开发,表现出卓越性能,优于传统基准线和大型通用视觉语言模型。
- 研究强调了视觉特征在漫画PSS宏观结构中的重要性,但也指出了多模态在解决复杂歧义方面的优势。
- CoSMo为多模态Transformer模型在漫画分析中的应用建立了新标准。
点此查看论文截图


Can GPT-4o mini and Gemini 2.0 Flash Predict Fine-Grained Fashion Product Attributes? A Zero-Shot Analysis
Authors:Shubham Shukla, Kunal Sonalkar
The fashion retail business is centered around the capacity to comprehend products. Product attribution helps in comprehending products depending on the business process. Quality attribution improves the customer experience as they navigate through millions of products offered by a retail website. It leads to well-organized product catalogs. In the end, product attribution directly impacts the ‘discovery experience’ of the customer. Although large language models (LLMs) have shown remarkable capabilities in understanding multimodal data, their performance on fine-grained fashion attribute recognition remains under-explored. This paper presents a zero-shot evaluation of state-of-the-art LLMs that balance performance with speed and cost efficiency, mainly GPT-4o-mini and Gemini 2.0 Flash. We have used the dataset DeepFashion-MultiModal (https://github.com/yumingj/DeepFashion-MultiModal) to evaluate these models in the attribution tasks of fashion products. Our study evaluates these models across 18 categories of fashion attributes, offering insight into where these models excel. We only use images as the sole input for product information to create a constrained environment. Our analysis shows that Gemini 2.0 Flash demonstrates the strongest overall performance with a macro F1 score of 56.79% across all attributes, while GPT-4o-mini scored a macro F1 score of 43.28%. Through detailed error analysis, our findings provide practical insights for deploying these LLMs in production e-commerce product attribution-related tasks and highlight the need for domain-specific fine-tuning approaches. This work also lays the groundwork for future research in fashion AI and multimodal attribute extraction.
时尚零售业务的核心在于理解产品的能力。产品属性有助于根据业务流程理解产品。质量属性可以提高客户在浏览零售网站提供的数百万产品时的体验,从而创建组织良好的产品目录。最终,产品属性直接影响客户的“发现体验”。尽管大型语言模型(LLM)在理解多模式数据方面表现出显著的能力,但在精细的时尚属性识别方面,其性能仍然被探索不足。本文对所提出的大型语言模型进行了零样本评估,这些模型在性能和速度以及成本效益之间取得了平衡,主要包括GPT-4o-mini和Gemini 2.0 Flash。我们使用DeepFashion-MultiModal数据集(https://github.com/yumingj/DeepFashion-MultiModal)来评估这些模型在时尚产品属性任务中的表现。我们的研究对18类时尚属性进行了评估,为这些模型的优点提供了见解。我们只使用图像作为产品信息输入的唯一来源,以创建一个受限的环境。我们的分析表明,Gemini 2.0 Flash在所有属性上的宏观F1分数表现出最佳性能,达到56.79%,而GPT-4o-mini的宏观F1分数为43.28%。通过详细的错误分析,我们的研究提供了将这些大型语言模型部署在生产环境中的电子商务产品属性相关任务的实用见解,并强调了针对特定领域的微调方法的必要性。这项工作也为未来的时尚人工智能和多模式属性提取研究奠定了基础。
论文及项目相关链接
PDF 11 pages, 2 figures
Summary
本文探讨了大型语言模型(LLMs)在时尚产品属性识别方面的应用。通过对GPT-4o-mini和Gemini 2.0 Flash等先进LLMs进行零样本评估,发现它们在DeepFashion-MultiModal数据集上的表现。研究结果显示,Gemini 2.0 Flash总体表现最佳,GPT-4o-mini次之。此研究对于在电子商务生产中部署这些LLMs进行产品属性识别任务提供了实际见解,并强调了领域特定微调方法的需求。此研究为时尚AI和多模态属性提取的未来研究奠定了基础。
Key Takeaways
- 大型语言模型(LLMs)在时尚产品属性识别方面的应用受到关注。
- GPT-4o-mini和Gemini 2.0 Flash等LLMs在DeepFashion-MultiModal数据集上进行了评估。
- Gemini 2.0 Flash在时尚属性识别方面表现最佳。
- LLMs在部署到生产环境进行产品属性识别任务时,需要领域特定的微调方法。
- 此研究强调了错误分析的重要性,为改进LLMs提供了方向。
- 研究结果对于未来时尚AI和多模态属性提取的研究具有指导意义。
点此查看论文截图


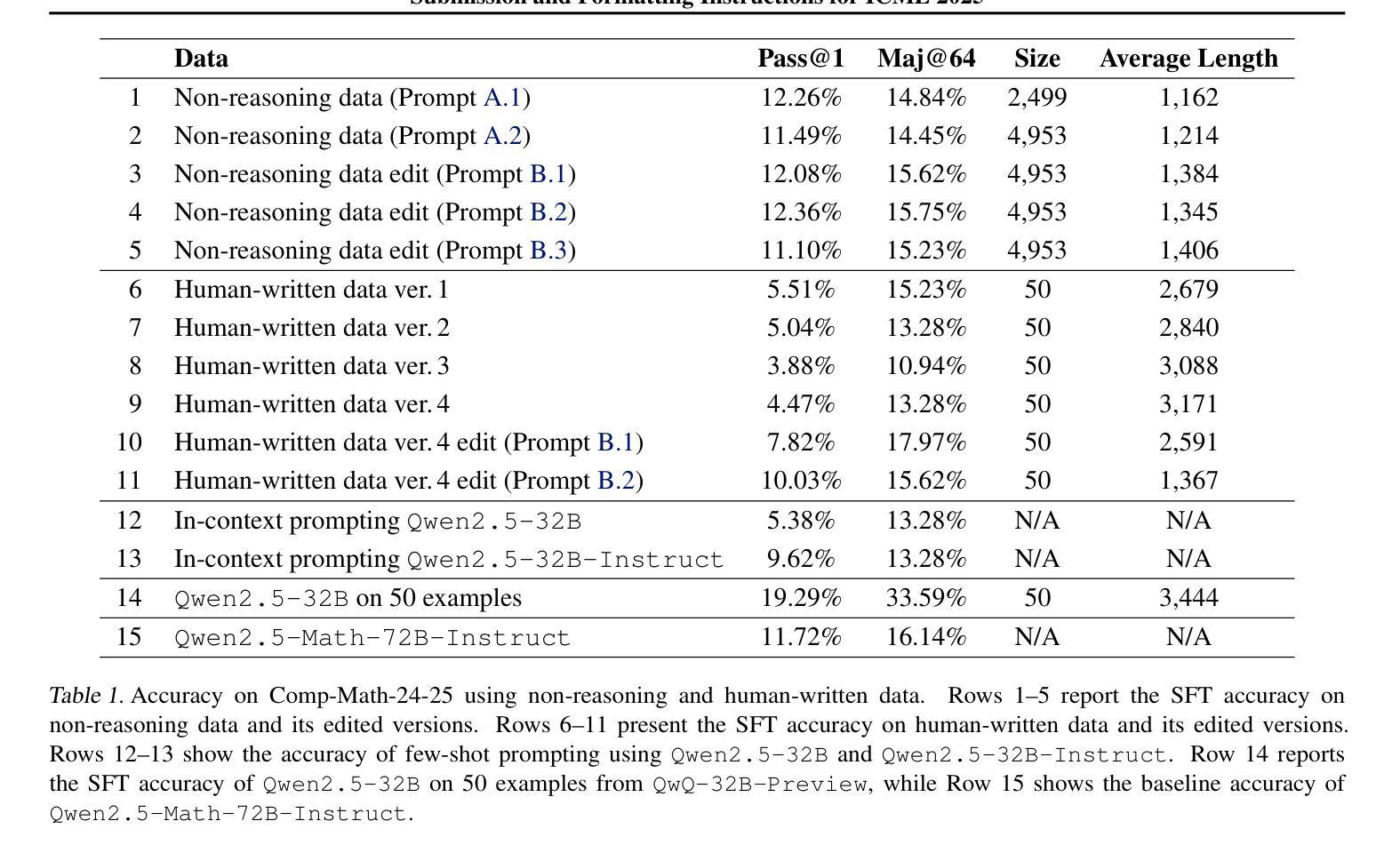
Is Human-Written Data Enough? The Challenge of Teaching Reasoning to LLMs Without RL or Distillation
Authors:Wei Du, Branislav Kisacanin, George Armstrong, Shubham Toshniwal, Ivan Moshkov, Alexan Ayrapetyan, Sadegh Mahdavi, Dan Zhao, Shizhe Diao, Dragan Masulovic, Marius Stanean, Advaith Avadhanam, Max Wang, Ashmit Dutta, Shitij Govil, Sri Yanamandara, Mihir Tandon, Sriram Ananthakrishnan, Vedant Rathi, David Zhang, Joonseok Kang, Leon Luo, Titu Andreescu, Boris Ginsburg, Igor Gitman
Reasoning-capable language models achieve state-of-the-art performance in diverse complex tasks by generating long, explicit Chain-of-Thought (CoT) traces. While recent works show that base models can acquire such reasoning traces via reinforcement learning or distillation from stronger models like DeepSeek-R1, previous works demonstrate that even short CoT prompting without fine-tuning is able to improve reasoning. We ask whether long CoT can be induced in a base model using only prompting or minimal tuning. Using just 20 long CoT examples from the reasoning model \texttt{QwQ-32B-Preview}, we lightly fine-tune the base model \texttt{Qwen2.5-32B}. The resulting model outperforms the much larger \texttt{Qwen2.5-Math-72B-Instruct}, showing that a handful of high-quality examples can unlock strong reasoning capabilities. We further explore using CoT data from non-reasoning models and human annotators, enhanced with prompt engineering, multi-pass editing, and structural guidance. However, neither matches the performance of reasoning model traces, suggesting that certain latent qualities of expert CoT are difficult to replicate. We analyze key properties of reasoning data, such as problem difficulty, diversity, and answer length, that influence reasoning distillation. While challenges remain, we are optimistic that carefully curated human-written CoT, even in small quantities, can activate reasoning behaviors in base models. We release our human-authored dataset across refinement stages and invite further investigation into what makes small-scale reasoning supervision so effective.
具备推理能力的语言模型通过生成长期、明确的思维链(CoT)轨迹,在不同复杂的任务中实现了最先进的性能。虽然最近的研究表明,基础模型可以通过强化学习或从更强的模型(如DeepSeek-R1)中蒸馏来获得这种推理轨迹,但之前的研究表明,即使没有微调,简单的CoT提示也能提高推理能力。我们想知道,是否可以使用提示或最小限度的调整在基础模型中诱发长期的CoT。我们仅使用来自推理模型QwQ-32B-Preview的20个长期CoT示例,对基础模型Qwen2.5-32B进行轻度微调。结果模型的表现优于更大的Qwen2.5-Math-72B-Instruct,表明少量高质量的例子可以解锁强大的推理能力。我们进一步探索使用非推理模型和人类注释者生成的CoT数据,并结合提示工程、多轮编辑和结构指导进行增强。然而,它们都无法匹配推理模型轨迹的性能,这表明专家CoT的某些潜在特质难以复制。我们分析了影响推理蒸馏的关键属性,如问题难度、多样性和答案长度。虽然仍存在挑战,但我们相信精心挑选的人类编写的CoT,即使数量很小,也能激活基础模型中的推理行为。我们发布了我们人类作者在各个精炼阶段的数据集,并邀请进一步调查小规模推理监督如此有效的原因。
论文及项目相关链接
PDF Accepted at the Second AI for Math Workshop at the 42nd International Conference on Machine Learning (ICML 2025)
Summary
基于能进行推理的语言模型,通过生成长的、明确的思维链(CoT)轨迹,在多种复杂任务中实现了最先进的性能。通过提示工程、多遍编辑和结构指导,使用来自非推理模型和人类注释者的思维链数据,但都无法匹配推理模型轨迹的性能。分析表明,某些专家思维链的潜在特质难以复制。尽管存在挑战,但精心编写的人类思维链,即使数量少,也能激活基础模型的推理行为。
Key Takeaways
- 推理能力强的语言模型能通过生成长的、明确的思维链(CoT)轨迹在多种任务中取得先进性能。
- 仅通过提示或轻微调整,就可以在基础模型中引发长的CoT。
- 使用来自非推理模型和人类注释者的CoT数据,通过增强提示工程、多遍编辑和结构指导,但无法匹配推理模型性能。
- 某些专家CoT的潜在特质难以复制。
- 精心编制的人类思维链,即使数量少,也能激活模型的推理能力。
- 问题难度、多样性和答案长度等关键因素影响推理蒸馏的效果。
点此查看论文截图


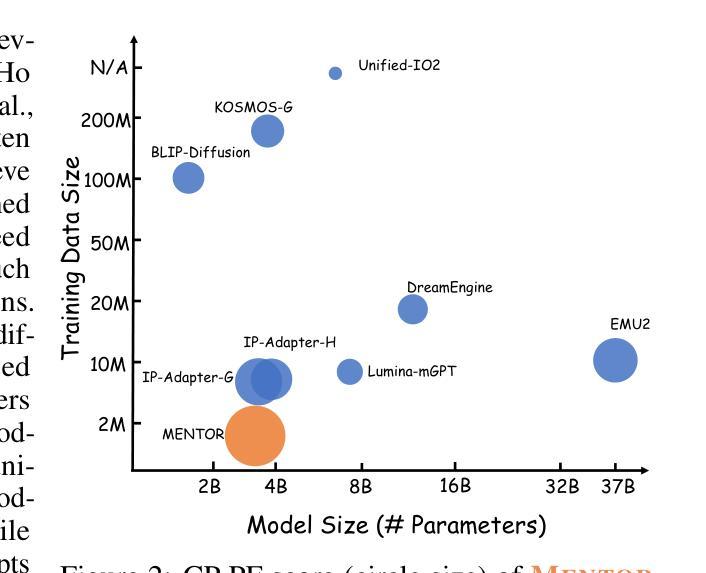
MENTOR: Efficient Multimodal-Conditioned Tuning for Autoregressive Vision Generation Models
Authors:Haozhe Zhao, Zefan Cai, Shuzheng Si, Liang Chen, Jiuxiang Gu, Wen Xiao, Junjie Hu
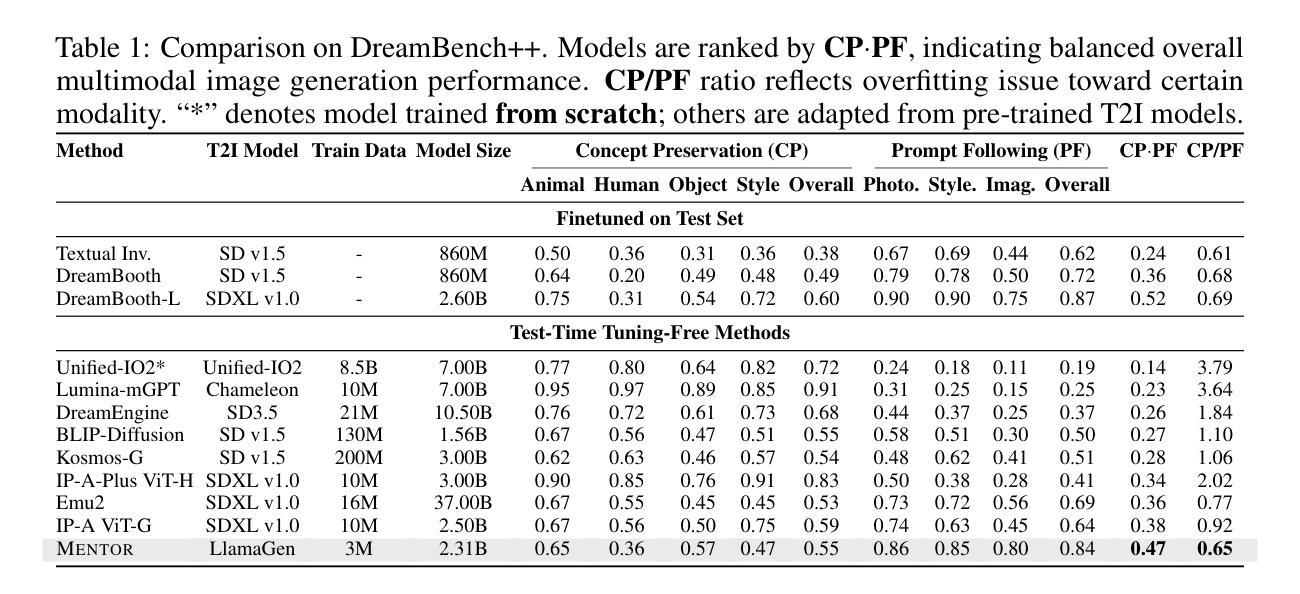
Recent text-to-image models produce high-quality results but still struggle with precise visual control, balancing multimodal inputs, and requiring extensive training for complex multimodal image generation. To address these limitations, we propose MENTOR, a novel autoregressive (AR) framework for efficient Multimodal-conditioned Tuning for Autoregressive multimodal image generation. MENTOR combines an AR image generator with a two-stage training paradigm, enabling fine-grained, token-level alignment between multimodal inputs and image outputs without relying on auxiliary adapters or cross-attention modules. The two-stage training consists of: (1) a multimodal alignment stage that establishes robust pixel- and semantic-level alignment, followed by (2) a multimodal instruction tuning stage that balances the integration of multimodal inputs and enhances generation controllability. Despite modest model size, suboptimal base components, and limited training resources, MENTOR achieves strong performance on the DreamBench++ benchmark, outperforming competitive baselines in concept preservation and prompt following. Additionally, our method delivers superior image reconstruction fidelity, broad task adaptability, and improved training efficiency compared to diffusion-based methods. Dataset, code, and models are available at: https://github.com/HaozheZhao/MENTOR
最近的文本到图像模型产生了高质量的结果,但在精确视觉控制、平衡多模式输入和复杂多模式图像生成的训练需求方面仍存在挑战。为了解决这些局限性,我们提出了MENTOR,这是一个用于高效多模式条件调整的自回归(AR)框架,用于自回归多模式图像生成。MENTOR结合AR图像生成器和两阶段训练范式,能够在不依赖辅助适配器或交叉注意模块的情况下,实现多模式输入和图像输出之间的精细颗粒度、令牌级对齐。两阶段训练包括:(1)多模式对齐阶段,建立稳健的像素和语义级对齐,然后是(2)多模式指令调整阶段,平衡多模式输入的集成,增强生成的可控性。尽管模型规模适中,基础组件不够理想,训练资源有限,但MENTOR在DreamBench++基准测试上表现出色,在概念保留和提示遵循方面超过了竞争基准。此外,我们的方法在图像重建保真度、广泛的任务适应性和训练效率方面优于基于扩散的方法。数据集、代码和模型可在https://github.com/HaozheZhao/MENTOR找到。
论文及项目相关链接
PDF 24 pages,12 figures
Summary
基于文本生成图像的技术取得了高质量的结果,但在精确视觉控制、平衡多模式输入和复杂多模式图像生成的训练效率方面仍存在局限。为此,提出了MENTOR这一新型的自回归(AR)框架,通过两阶段训练模式实现多模式条件下的自回归图像生成。MENTOR结合了AR图像生成器,能够在不依赖辅助适配器或跨注意模块的情况下,实现多模式输入与图像输出之间的精细颗粒度、标记级别的对齐。两阶段训练包括建立像素和语义级别的对齐的多模式对齐阶段,以及平衡多模式输入集成并增强生成可控性的多模式指令调整阶段。即使在模型规模适中、基础组件次优和训练资源有限的情况下,MENTOR在DreamBench++基准测试上表现出强大的性能,在概念保留和提示遵循方面超越了竞争对手。此外,我们的方法在图像重建保真度、广泛的任务适应性和训练效率方面也比扩散方法具有优势。
Key Takeaways
- MENTOR是一个针对自回归多模式图像生成的新型框架,旨在解决精确视觉控制、多模式输入平衡和复杂图像生成训练效率的问题。
- MENTOR结合AR图像生成器,通过两阶段训练实现多模式输入与图像输出的精细对齐。
- 第一阶段建立像素和语义级别的对齐,第二阶段平衡多模式输入集成并增强生成的可控性。
- MENTOR在DreamBench++基准测试上表现出强大的性能,尤其在概念保留和提示遵循方面。
- 与其他方法相比,MENTOR在图像重建保真度、任务适应性和训练效率方面具有优势。
- MENTOR的模型、代码和数据集已公开可访问。
点此查看论文截图

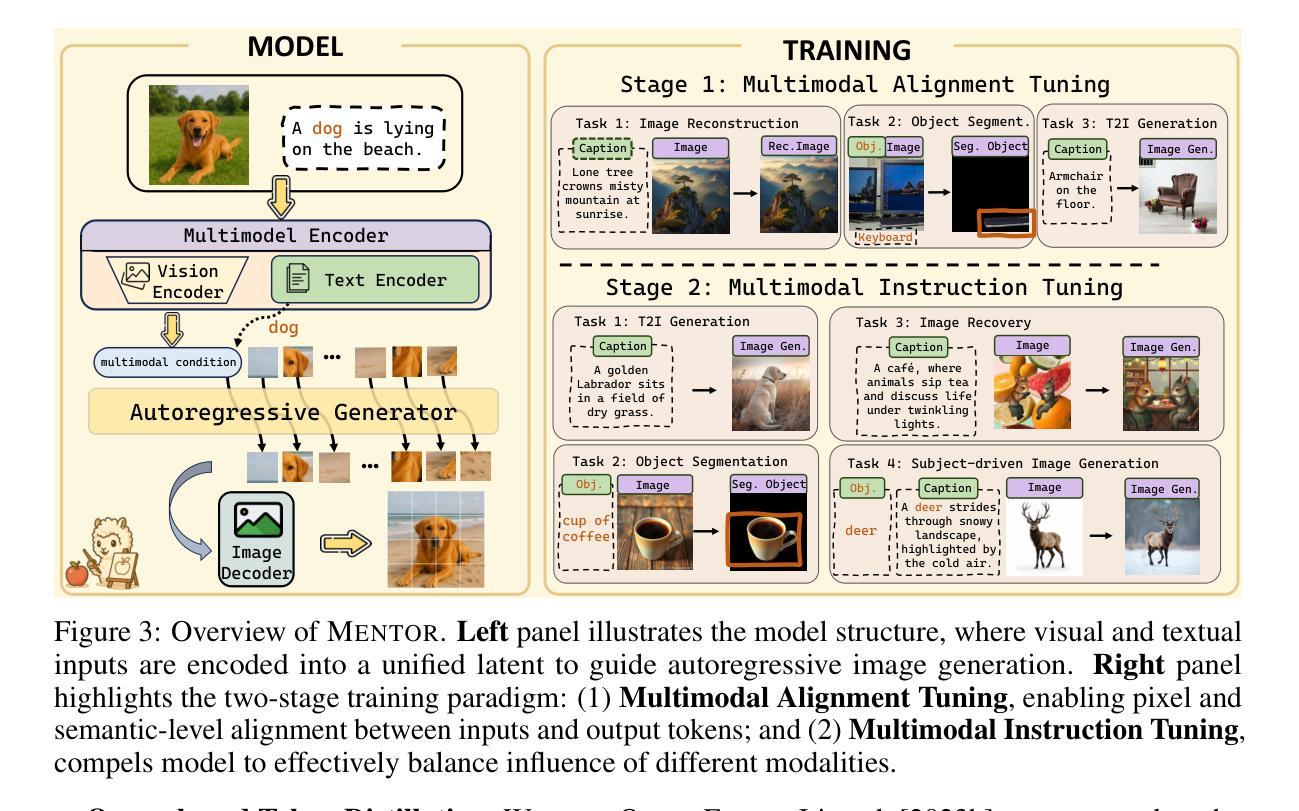
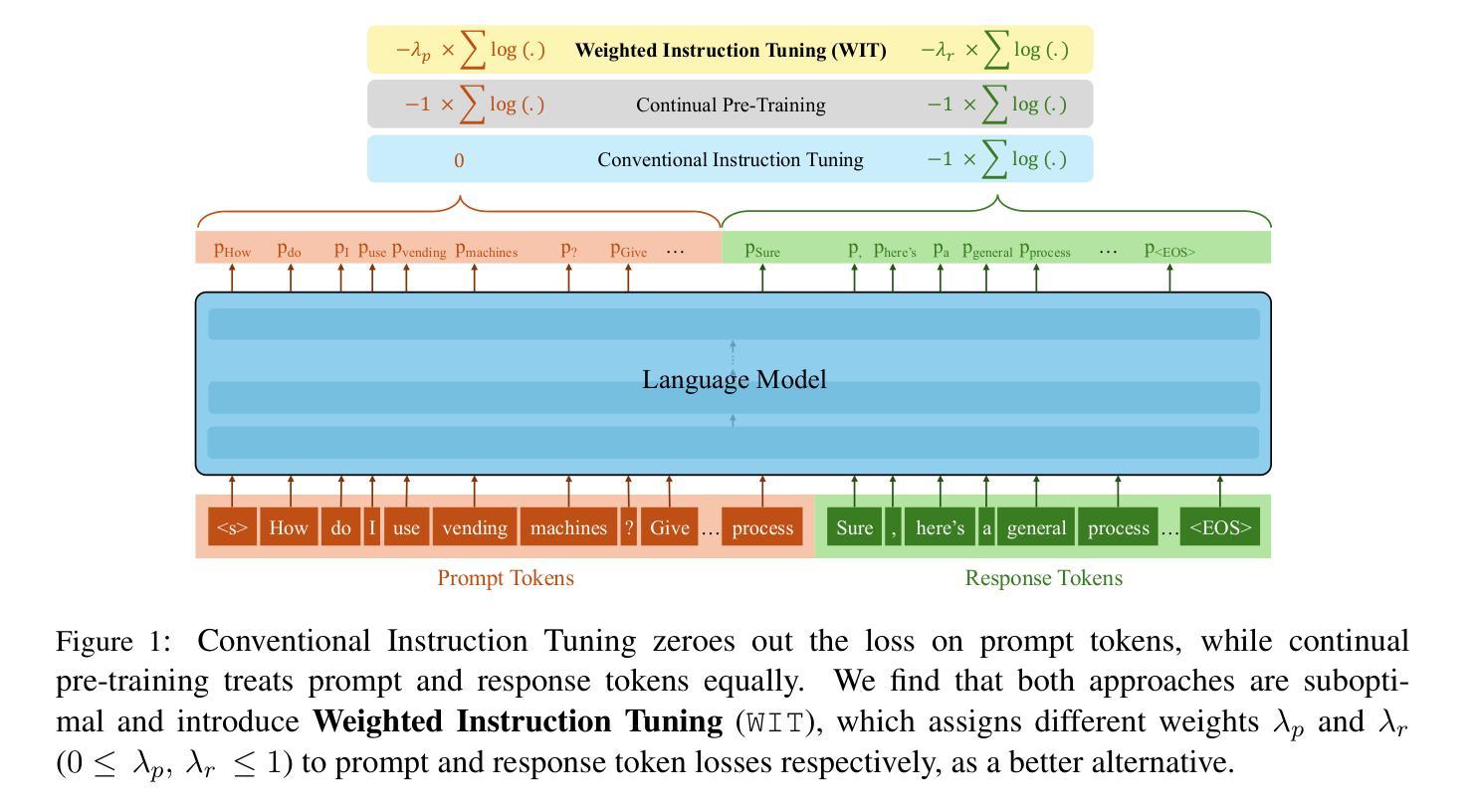
On the Effect of Instruction Tuning Loss on Generalization
Authors:Anwoy Chatterjee, H S V N S Kowndinya Renduchintala, Sumit Bhatia, Tanmoy Chakraborty
Instruction Tuning has emerged as a pivotal post-training paradigm that enables pre-trained language models to better follow user instructions. Despite its significance, little attention has been given to optimizing the loss function used. A fundamental, yet often overlooked, question is whether the conventional auto-regressive objective - where loss is computed only on response tokens, excluding prompt tokens - is truly optimal for instruction tuning. In this work, we systematically investigate the impact of differentially weighting prompt and response tokens in instruction tuning loss, and propose Weighted Instruction Tuning (WIT) as a better alternative to conventional instruction tuning. Through extensive experiments on five language models of different families and scale, three finetuning datasets of different sizes, and five diverse evaluation benchmarks, we show that the standard instruction tuning loss often yields suboptimal performance and limited robustness to input prompt variations. We find that a low-to-moderate weight for prompt tokens coupled with a moderate-to-high weight for response tokens yields the best-performing models across settings and also serve as better starting points for the subsequent preference alignment training. These findings highlight the need to reconsider instruction tuning loss and offer actionable insights for developing more robust and generalizable models. Our code is open-sourced at https://github.com/kowndinya-renduchintala/WIT.
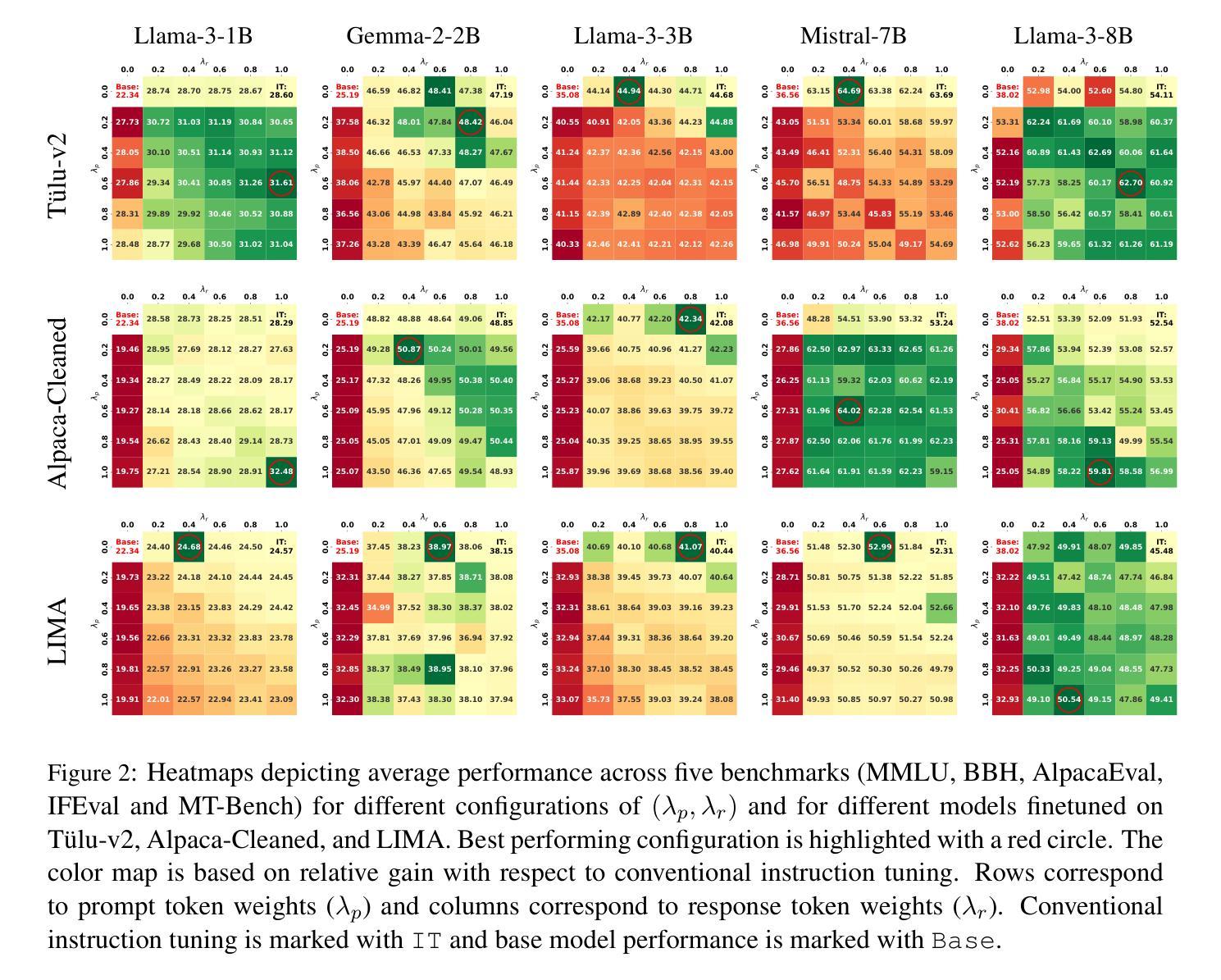
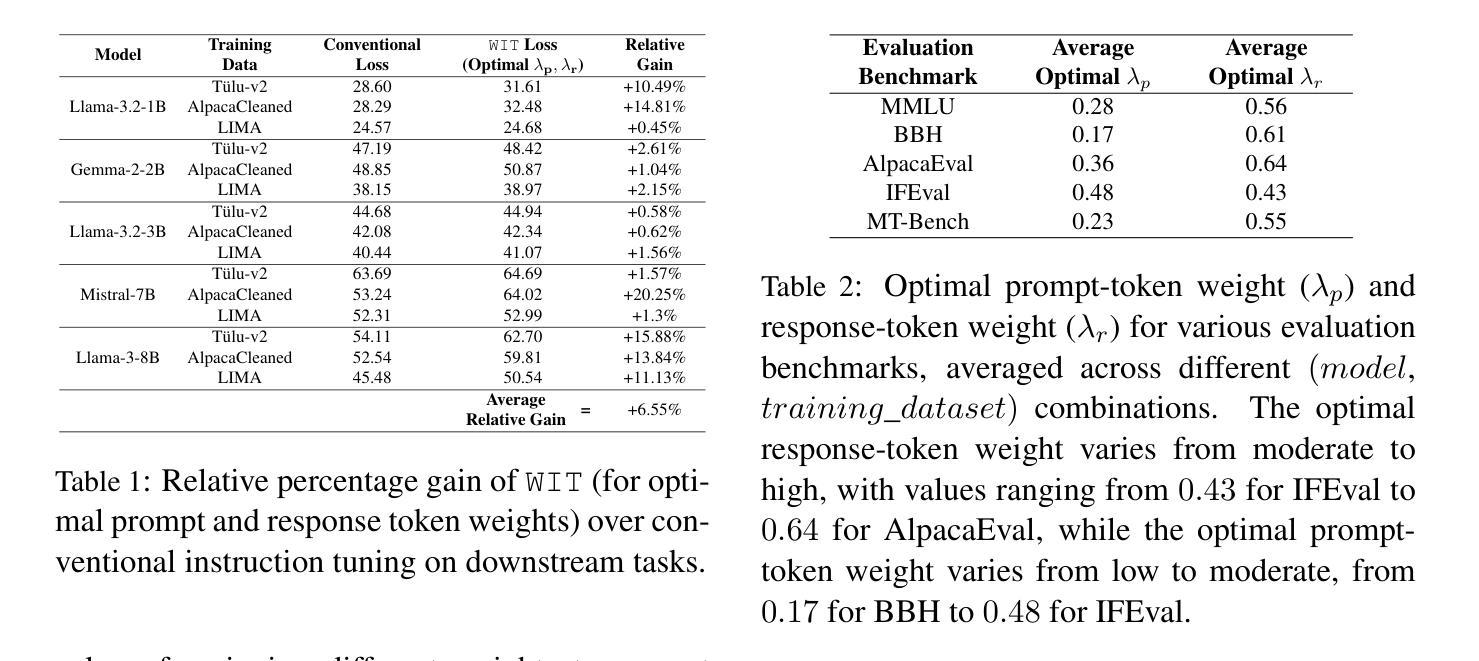
指令微调已经成为一个重要的后训练模式,它使预训练的语言模型能够更好地遵循用户指令。尽管它的意义重大,但很少有人关注优化所使用的损失函数。一个基本而常被忽视的问题是,传统的自回归目标(损失仅计算响应标记,不包括提示标记)是否真的是指令调优的最优选择。在这项工作中,我们系统地研究了指令微调损失中提示标记和响应标记差异加权的影响,并提出了加权指令微调(WIT)作为传统指令调优的更好替代方案。通过对五个不同家族和规模的语言模型、三个不同大小的微调数据集和五个不同的评估基准进行大量实验,我们证明了标准指令调优损失通常会导致次优性能和有限的应对输入提示变化的鲁棒性。我们发现,对提示标记赋予较低至中等的权重,同时对响应标记赋予中等至较高的权重,能在各种设置中取得最佳性能的模型,并且作为后续偏好对齐训练的更好起点。这些发现强调了重新考虑指令调优损失的必要性和开发更稳健和通用模型的实用见解。我们的代码已公开在https://github.com/kowndinya-renduchintala/WIT。
论文及项目相关链接
PDF To appear in Transactions of the Association for Computational Linguistics (TACL)
Summary
本文探讨了指令微调中的损失函数优化问题,提出了加权指令微调(WIT)方法,通过差异化地给指令和响应令牌加权来改进损失函数。实验表明,标准指令微调损失性能不佳,且对输入指令变化的鲁棒性有限。最佳性能模型是在指令令牌赋予较低至中等权重,响应令牌赋予中等至高权重的情况下获得的。这些发现为开发更稳健和通用的模型提供了重新考虑指令微调损失和可行的见解。
Key Takeaways
- 指令微调是使预训练语言模型更好地遵循用户指令的关键后训练范式。
- 常规的自回归目标在指令微调中可能并非最佳。
- 加权指令微调(WIT)方法通过差异化地给指令和响应令牌加权来改进损失函数。
- 标准指令微调损失性能不佳,且对输入指令变化的鲁棒性有限。
- 最佳性能的模型是在给指令令牌赋予较低至中等权重,而给响应令牌赋予中等至高权重的情况下获得的。
- WIT方法能提高模型的性能和泛化能力。
点此查看论文截图

Conversation Forests: The Key to Fine Tuning Large Language Models for Multi-Turn Medical Conversations is Branching
Authors:Thomas Savage
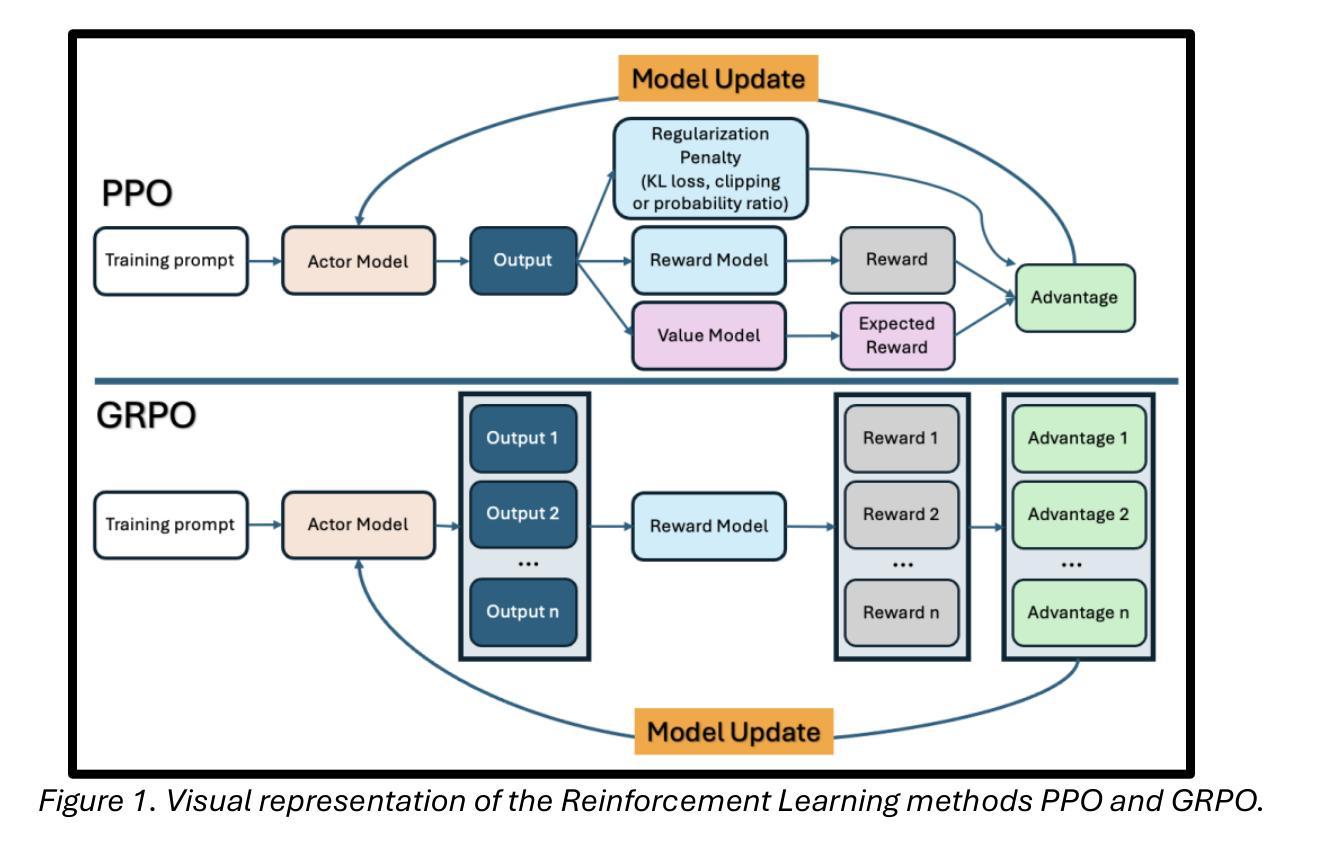
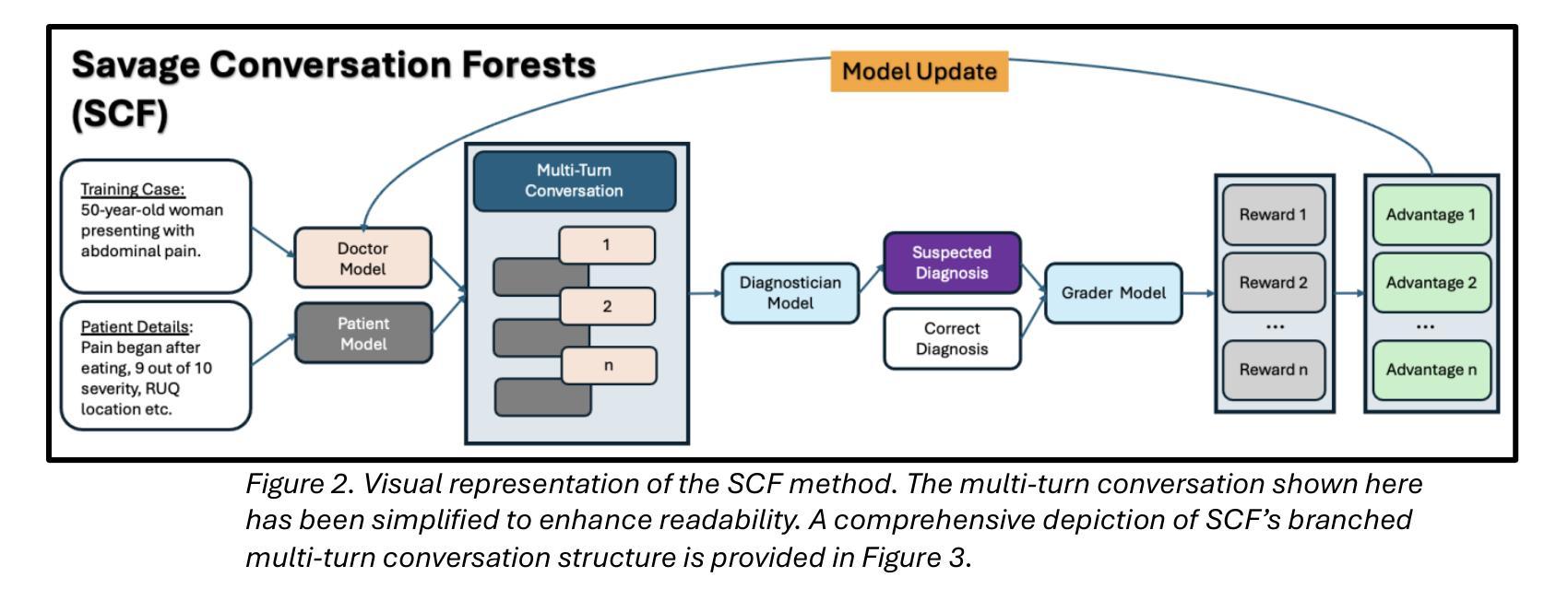
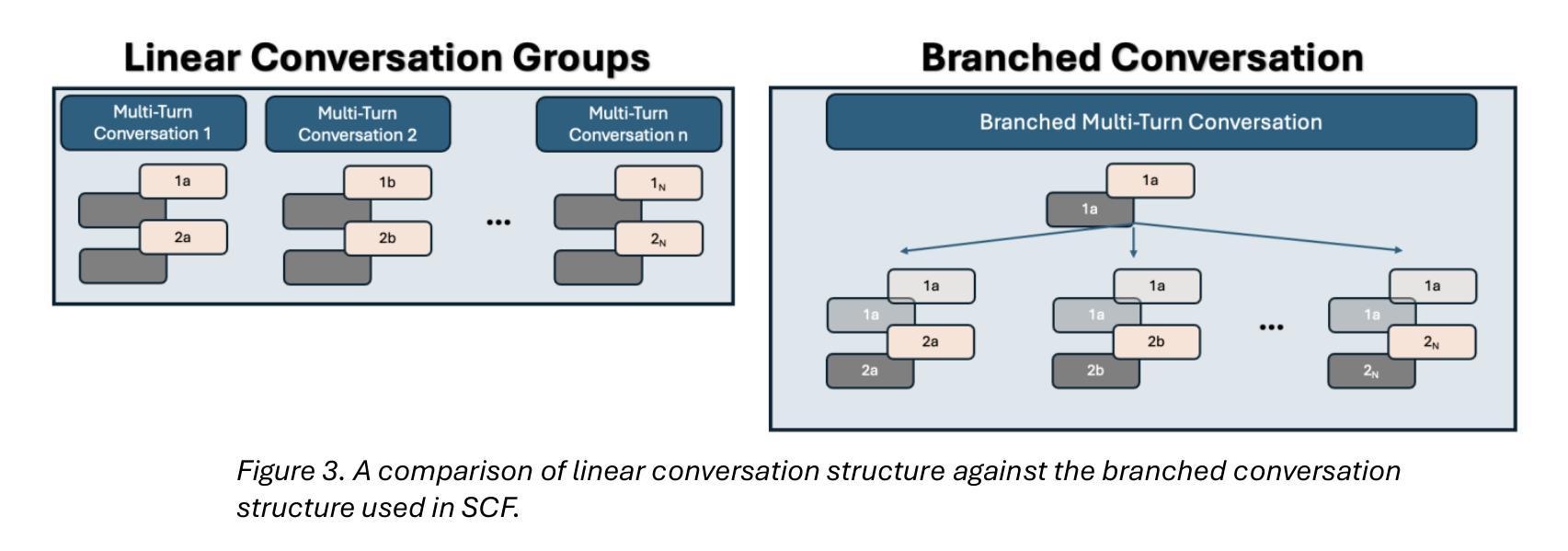
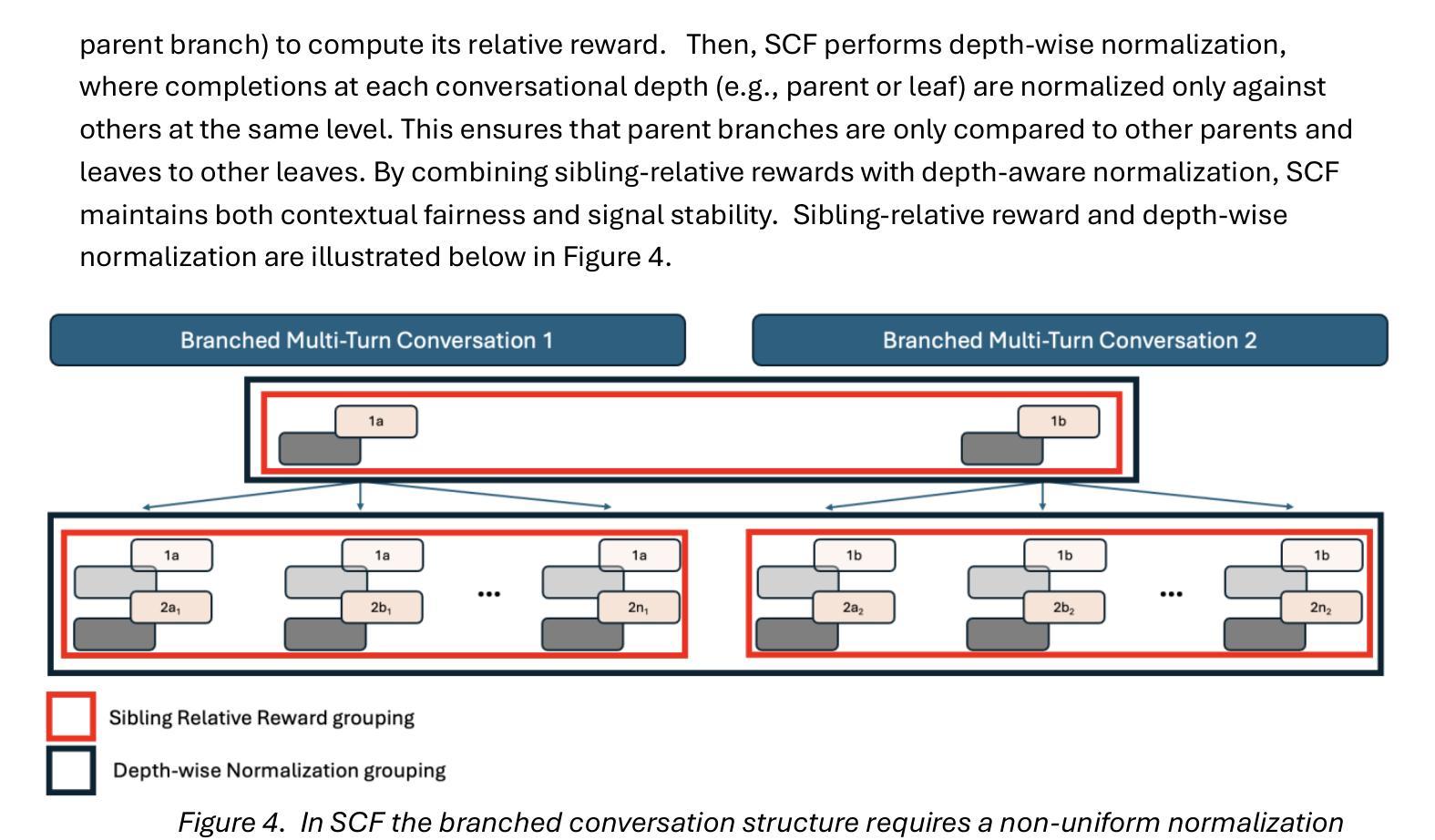
Fine-tuning methods such as Direct Preference Optimization (DPO) and Group Relative Policy Optimization (GRPO) have demonstrated success in training large language models (LLMs) for single-turn tasks. However, these methods fall short in multi-turn applications, such as diagnostic patient interviewing, where understanding how early conversational turns influence downstream completions and outcomes is essential. In medicine, a multi-turn perspective is critical for learning diagnostic schemas and better understanding conversation dynamics. To address this gap, I introduce Savage Conversation Forests (SCF), a reinforcement learning framework that leverages a branched conversation architecture to fine-tune LLMs for multi-turn dialogue. SCF generates multiple possible conversation continuations at each turn, enabling the model to learn how different early responses affect downstream interactions and diagnostic outcomes. In experiments simulating doctor-patient conversations, SCF with branching outperforms linear conversation architectures on diagnostic accuracy. I hypothesize that SCF’s improvements stem from its ability to provide richer, interdependent training signals across conversation turns. These results suggest that a branched training architecture is an important strategy for fine tuning LLMs in complex multi-turn conversational tasks.
针对单一任务的训练大型语言模型(LLM)中,直接偏好优化(DPO)和群体相对策略优化(GRPO)等微调方法已经取得了成功。然而,在处理多任务对话场景,如在诊断病人访谈中,这些方法表现出局限性。在这些场景中,理解早期对话回合如何影响后续对话内容和结果至关重要。在医学领域,采用多任务对话视角对于学习诊断模式和更好地把握对话动态至关重要。为了解决这一不足,我引入了名为“野蛮对话森林”(SCF)的强化学习框架,它采用分支对话架构来微调LLM,以应对多任务对话场景。SCF能够在每一对话回合生成多种可能的延续对话内容,使模型能够学习不同的早期回应如何影响后续的互动和诊断结果。在模拟医患对话的实验中,使用分支策略的SCF在诊断准确性方面超过了线性对话架构。我认为SCF的改进源于其在不同对话回合提供丰富且相互依赖的训练信号的能力。这些结果表明,分支训练架构是在复杂的多任务对话场景中微调LLM的重要策略。
论文及项目相关链接
摘要
通过Direct Preference Optimization (DPO)和Group Relative Policy Optimization (GRPO)等微调方法,大语言模型(LLM)在单回合任务中取得了成功。但在多回合应用中,如诊断病人访谈等,这些方法表现欠佳。理解早期对话回合如何影响下游完成和结果对于学习诊断模式和更好地理解对话动态至关重要。为解决这一差距,引入了Savage Conversation Forests (SCF)这一强化学习框架,它利用分支对话架构对LLM进行微调,用于多回合对话。SCF在每个回合生成多种可能的对话延续,使模型能够学习不同的早期回应如何影响下游互动和诊断结果。在模拟医生病人对话的实验中,带有分支的SCF在诊断准确性方面优于线性对话架构。假设SCF的改进源于其在对话回合中提供丰富、相互依存训练信号的能力。结果表明,分支训练架构是复杂多回合对话任务中微调LLM的重要策略。
关键见解
- DPO和GRPO等微调方法在单回合任务中成功训练LLM。
- 在多回合对话应用中,理解早期对话回合的影响至关重要。
- SCF是一个强化学习框架,利用分支对话架构微调LLM,用于多回合对话。
- SCF生成多种可能的对话延续,以学习不同的早期回应如何影响下游互动和诊断结果。
- 在模拟医生病人对话的实验中,SCF的分支结构在诊断准确性上表现优越。
- SCF的改进源于其提供丰富、相互依存的训练信号的能力。
点此查看论文截图

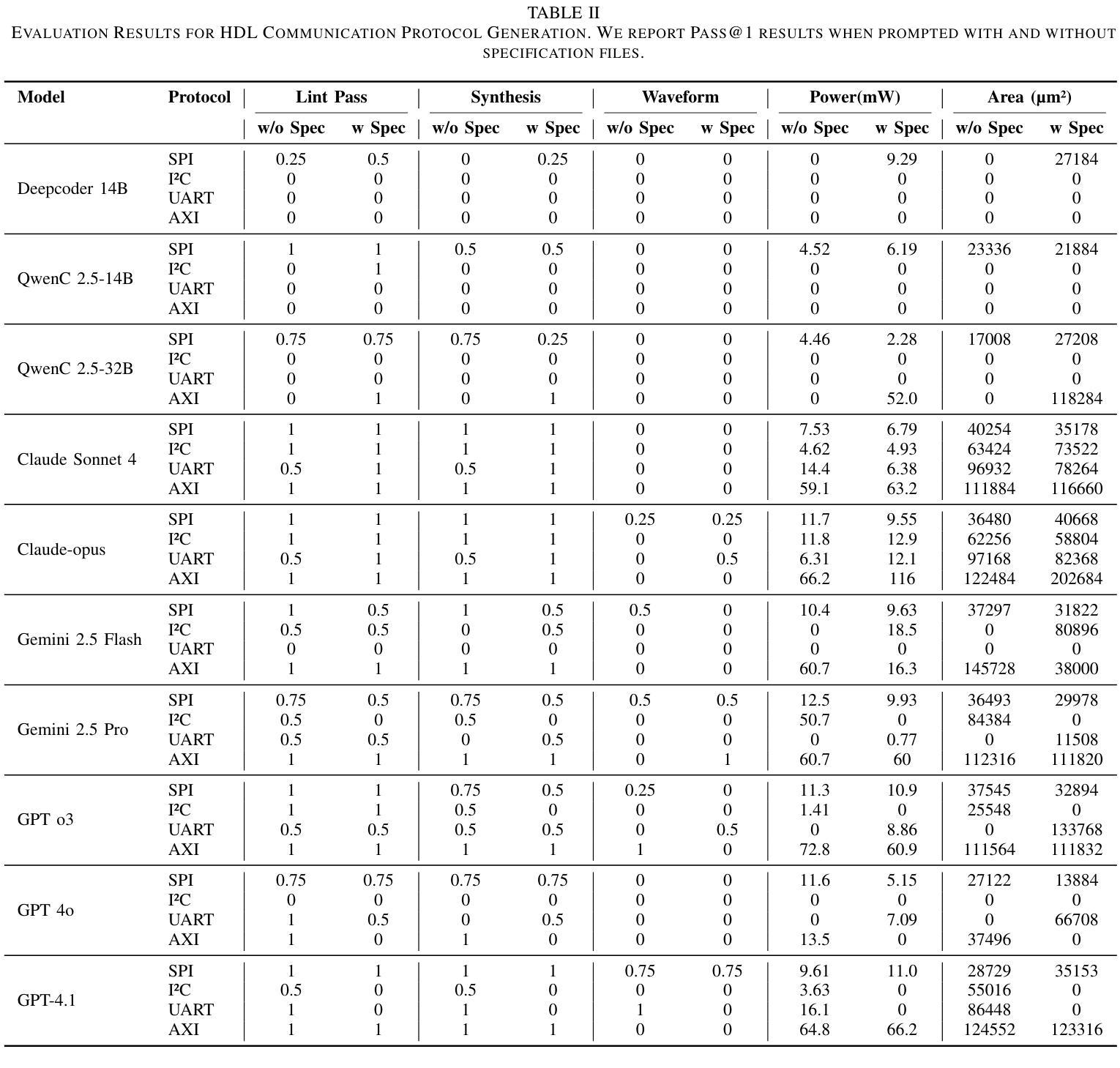
ProtocolLLM: RTL Benchmark for SystemVerilog Generation of Communication Protocols
Authors:Arnav Sheth, Ivaxi Sheth, Mario Fritz
Recent advances in large language models (LLMs) have demonstrated strong performance in generating code for general-purpose programming languages. However, their potential for hardware description languages (HDLs), such as SystemVerilog, remains largely unexplored. HDL code generation poses unique challenges due to strict timing semantics, concurrency, and synthesizability constraints essential for correct hardware functionality. Further, HDL-based design flows encompass a broad set of tasks beyond structural code generation, including testbench development, assertion-based verification, timing closure, and protocol-level integration for on-chip communication. In this work, we evaluate the capabilities of both open-source and state-of-the-art LLMs in generating synthesizable and functionally accurate SystemVerilog implementations of widely used communication protocols that are critical components of embedded and System-on-Chip (SoC) systems. We introduce ProtocolLLM, the first benchmark suite specifically targeting these protocols with tasks spanning multiple design abstraction levels and varying prompt specificity. Our evaluation method also focuses on timing correctness in addition to synthesizability and syntactic correctness. We observe that most of the models fail to generate SystemVerilog code for communication protocols that follow timing constrains.
近期大型语言模型(LLM)的进步在生成通用编程语言代码方面表现出了强大的性能。然而,它们在硬件描述语言(如SystemVerilog)方面的潜力仍待大量探索。由于严格的时序语义、并发性和合成性约束对于硬件功能正确性至关重要,HDL代码生成带来了独特的挑战。此外,基于HDL的设计流程涵盖了超出结构代码生成的一系列任务,包括测试平台开发、基于断言的验证、时序闭合和芯片上通信的协议级集成。在这项工作中,我们评估了开源和最新LLM在生成合成和功能准确的SystemVerilog实现方面的能力,这些实现是广泛使用的通信协议的关键组件,也是嵌入式和片上系统(SoC)系统的关键组件。我们推出了ProtocolLLM,这是第一个专门针对这些协议的基准测试套件,任务涵盖多个设计抽象层次和不同的提示特异性。我们的评估方法还重点关注时序正确性,以及合成能力和语法正确性。我们发现大多数模型都无法生成遵循时序约束的通信协议的SystemVerilog代码。
论文及项目相关链接
PDF Accepted at MLSysArch@ISCA 2025
Summary
大型语言模型(LLM)在生成通用编程语言代码方面表现出强大的性能,但在硬件描述语言(HDLs)如SystemVerilog方面的潜力尚未得到充分探索。生成符合要求的SystemVerilog代码面临诸多挑战,如严格的时序语义、并发性和合成性约束等。本文评估了开源和最新LLM在生成合成和功能准确的SystemVerilog实现方面的能力,针对嵌入式和片上系统(SoC)系统中广泛使用的通信协议进行。我们引入了ProtocolLLM,该套件专门针对这些协议进行测试,任务涵盖多个设计抽象层次和不同提示特异性。评估方法还关注时序正确性、合成性和语法正确性。观察到大多数模型在生成遵循时序约束的通信协议SystemVerilog代码方面存在困难。
Key Takeaways
- 大型语言模型(LLM)在硬件描述语言(HDLs)如SystemVerilog方面的潜力尚未充分研究。
- 生成HDL代码面临诸多挑战,包括严格的时序语义、并发性和合成性约束。
- 本研究评估了LLM在生成合成和功能准确的SystemVerilog实现方面的能力。
- ProtocolLLM是首个专门针对通信协议进行测试的基准测试套件。
- ProtocolLLM的任务涵盖多个设计抽象层次和不同提示特异性。
- 评估方法包括检查合成性、语法正确性和时序正确性。
点此查看论文截图