⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-17 更新
U-RWKV: Lightweight medical image segmentation with direction-adaptive RWKV
Authors:Hongbo Ye, Fenghe Tang, Peiang Zhao, Zhen Huang, Dexin Zhao, Minghao Bian, S. Kevin Zhou
Achieving equity in healthcare accessibility requires lightweight yet high-performance solutions for medical image segmentation, particularly in resource-limited settings. Existing methods like U-Net and its variants often suffer from limited global Effective Receptive Fields (ERFs), hindering their ability to capture long-range dependencies. To address this, we propose U-RWKV, a novel framework leveraging the Recurrent Weighted Key-Value(RWKV) architecture, which achieves efficient long-range modeling at O(N) computational cost. The framework introduces two key innovations: the Direction-Adaptive RWKV Module(DARM) and the Stage-Adaptive Squeeze-and-Excitation Module(SASE). DARM employs Dual-RWKV and QuadScan mechanisms to aggregate contextual cues across images, mitigating directional bias while preserving global context and maintaining high computational efficiency. SASE dynamically adapts its architecture to different feature extraction stages, balancing high-resolution detail preservation and semantic relationship capture. Experiments demonstrate that U-RWKV achieves state-of-the-art segmentation performance with high computational efficiency, offering a practical solution for democratizing advanced medical imaging technologies in resource-constrained environments. The code is available at https://github.com/hbyecoding/U-RWKV.
实现医疗护理可及性的公平需要针对医学图像分割提出轻便而高性能的解决方案,特别是在资源有限的环境中。现有的方法,如U-Net及其变体,常常受到全局有效感受野(ERFs)的限制,阻碍其捕捉长期依赖关系的能力。为了解决这一问题,我们提出了U-RWKV,一个利用循环加权键值(RWKV)架构的新型框架,以O(N)的计算成本实现高效的长程建模。该框架引入了两个关键的创新点:方向自适应RWKV模块(DARM)和阶段自适应挤压-激发模块(SASE)。DARM采用双RWKV和QuadScan机制来聚合图像间的上下文线索,减轻方向偏差,保留全局上下文,并保持较高的计算效率。SASE动态地适应其架构到不同的特征提取阶段,平衡高分辨率细节保留和语义关系捕捉。实验表明,U-RWKV以高计算效率实现了最先进的分割性能,为资源受限环境中先进医疗成像技术的普及提供了实际解决方案。代码可通过https://github.com/hbyecoding/U-RWKV获取。
论文及项目相关链接
PDF Accepted by MICCAI2025
Summary
医学图像分割是实现医疗资源公平分配的关键。为解决现有方法如U-Net等在处理全球有效感知场(ERFs)方面的局限性,提出U-RWKV框架,利用递归加权键值(RWKV)架构实现高效的长程建模。该框架包括方向自适应RWKV模块(DARM)和阶段自适应压缩激发模块(SASE)。实验证明,U-RWKV实现了高效且高性能的分割效果,特别适用于资源受限环境下的医学图像分割,有望推广先进的医疗成像技术在资源受限环境中的使用。
Key Takeaways
- 实现医疗资源公平分配需高效且高性能的医学图像分割解决方案。
- U-Net及其变体存在全球有效感知场(ERFs)的局限性,影响长程依赖捕捉能力。
- 提出U-RWKV框架,利用递归加权键值(RWKV)架构解决该问题。
- U-RWKV框架包括方向自适应RWKV模块(DARM)和阶段自适应压缩激发模块(SASE)。
- DARM采用Dual-RWKV和QuadScan机制来聚合图像上下文线索,减少方向偏差并维持高效计算。
- SASE可动态适应不同特征提取阶段,平衡高分辨率细节保留和语义关系捕捉。
- 实验显示U-RWKV实现高效且高性能的分割效果,适用于资源受限环境。
点此查看论文截图

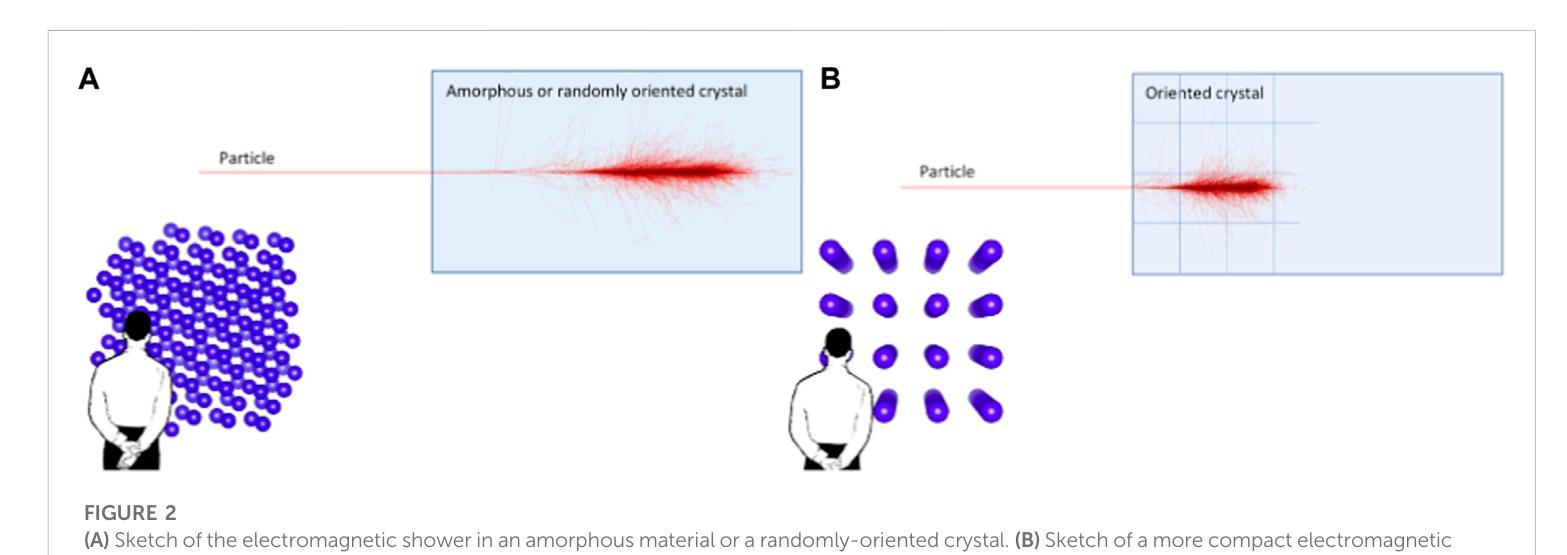
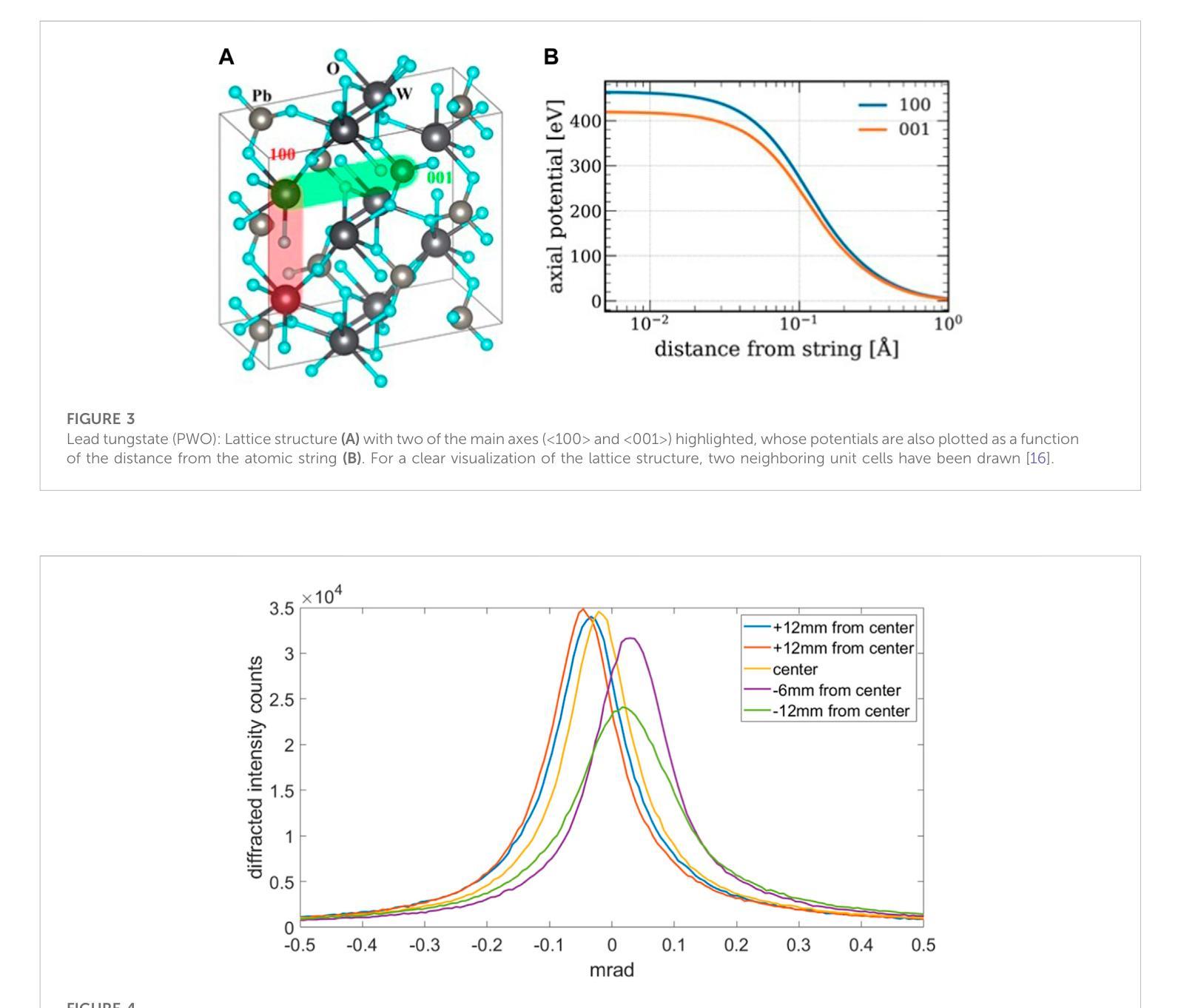
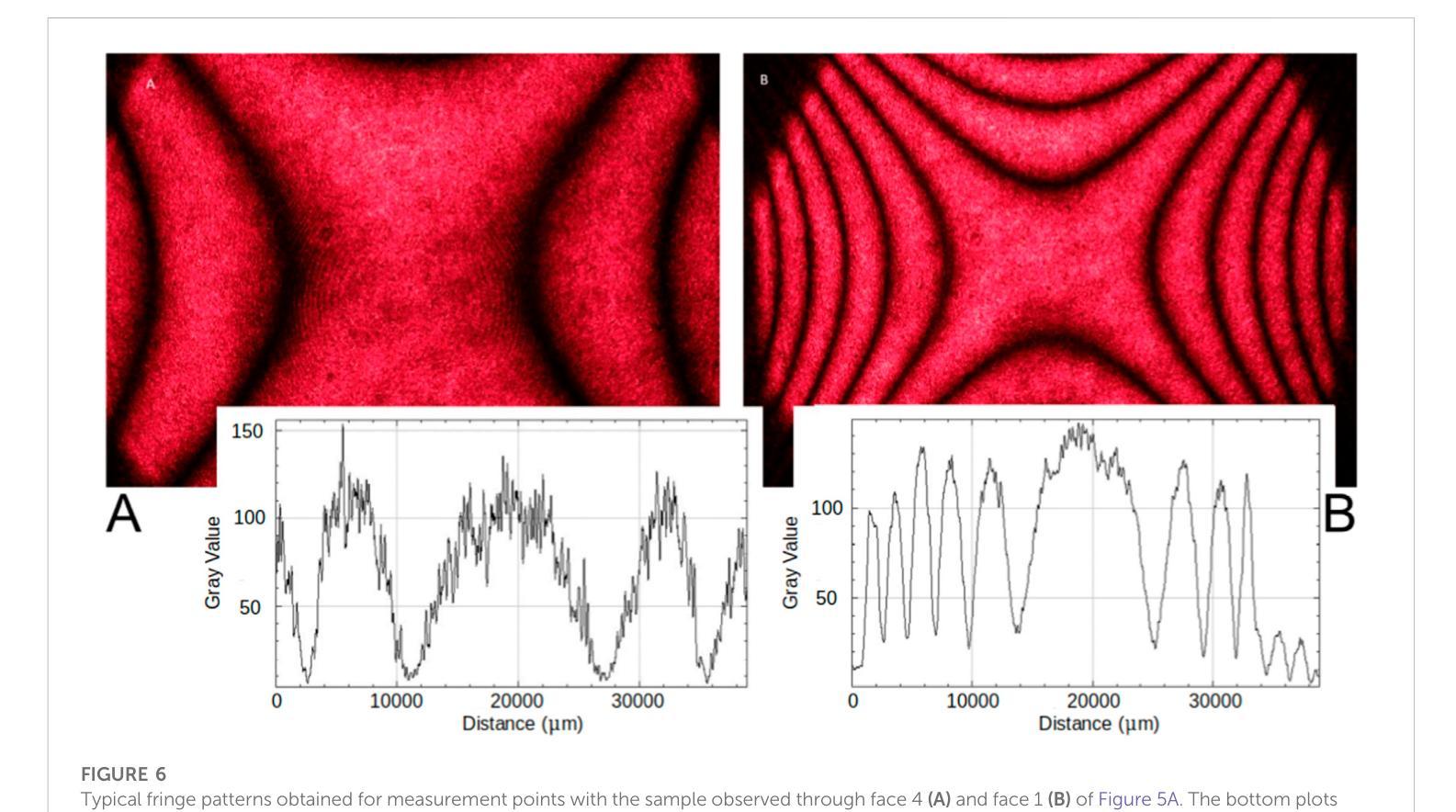
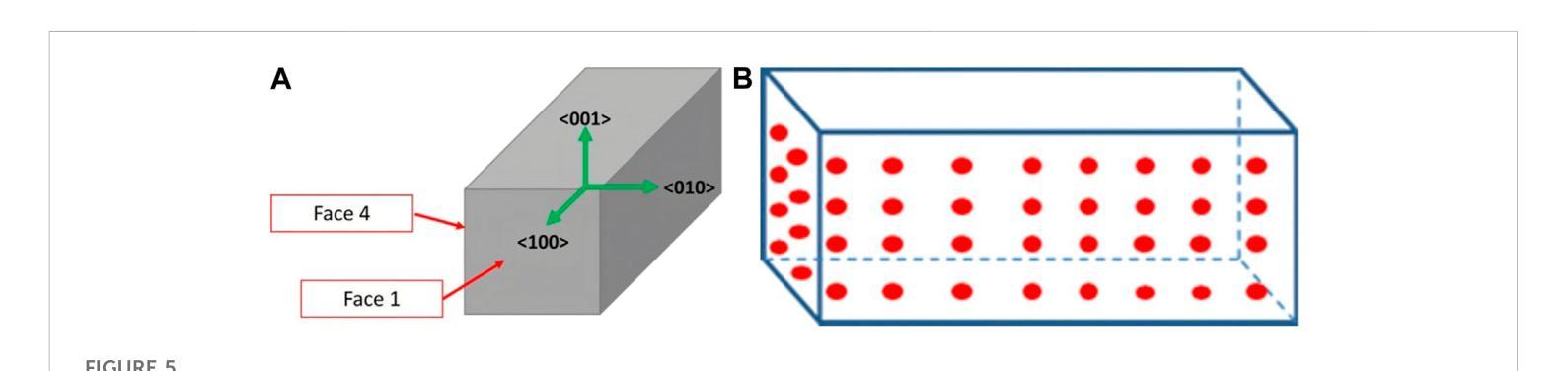
A highly-compact and ultra-fast homogeneous electromagnetic calorimeter based on oriented lead tungstate crystals
Authors:L. Bandiera, V. G. Baryshevsky, N. Canale, S. Carsi, S. Cutini, F. Davì, D. De Salvador, A. Gianoli, V. Guidi, V. Haurylavets, M. Korjik, A. S. Lobko, L. Malagutti, A. Mazzolari, L. Montalto, P. Monti Guarnieri, M. Moulson, R. Negrello, G. Paternò, M. Presti, D. Rinaldi, M. Romagnoni, A. Selmi, F. Sgarbossa, M. Soldani, A. Sytov, V. V. Tikhomirov, E. Vallazza
Progress in high-energy physics has been closely tied to the development of highperformance electromagnetic calorimeters. Recent experiments have demonstrated the possibility to significantly accelerate the development of electromagnetic showers inside scintillating crystals typically used in homogeneous calorimeters based on scintillating crystals when the incident beam is aligned with a crystallographic axis to within a few mrad. In particular, a reduction of the radiation length has been measured when ultrarelativistic electron and photon beams were incident on a high-Z scintillator crystal along one of its main axes. Here, we propose the possibility to exploit this physical effect for the design of a new type of compact e.m. calorimeter, based on oriented ultrafast lead tungstate (PWO-UF) crystals, with a significant reduction in the depth needed to contain electromagnetic showers produced by high-energy particles with respect to the state-of-the-art. We report results from tests of the crystallographic quality of PWO-UF samples via high-resolution X-ray diffraction and photoelastic analysis. We then describe a proof-of-concept calorimeter geometry defined with a Geant4 model including the shower development in oriented crystals. Finally, we discuss the experimental techniques needed for the realization of a matrix of scintillator crystals oriented along a specific crystallographic direction. Since the angular acceptance for e.m. shower acceleration depends little on the particle energy, while the decrease of the shower length remains pronounced at very high energy, an oriented crystal calorimeter will open the way for applications at the maximum energies achievable in current and future experiments. Such applications span from forward calorimeters, to compact beam dumps for the search for light dark matter, to source-pointing space-borne {\gamma}-ray telescopes.
高能物理的进展与高性能电磁量能器的发展密切相关。最近的实验表明,当入射束与晶体学轴对齐到几毫弧度(mrad)时,在通常用于基于闪烁晶体的均匀量能器中的闪烁晶体内部加速电磁簇射的发展是可能的。尤其是,当相对论超高速电子和光子束沿其主轴之一入射时,已经测量到辐射长度的减少。在这里,我们提出了一种利用这一物理效应设计新型紧凑电磁量能器的可能性,该量能器基于定向超快钨酸铅(PWO-UF)晶体。相较于当前主流技术,其深度大大减少了,能够容纳由高能粒子产生的电磁簇射。我们报告了通过高分辨率X射线衍射和光电分析测试PWO-UF样品晶体学质量的结果。然后,我们描述了一个概念验证的量能器几何结构,该结构由Geant4模型定义,包括定向晶体中的簇射发展。最后,我们讨论了实现沿特定晶体学方向定向的闪烁晶体矩阵所需的实验技术。由于电磁簇射加速的角接受度几乎不依赖于粒子能量,而簇射长度的减小在高能量时仍然很明显,因此定向晶体量能器将为当前和未来实验可达到的最大能量下的应用开辟道路。这些应用包括正向量能器、用于搜索轻暗物质的紧凑束流阻尼器以及源指向式太空γ射线望远镜。
论文及项目相关链接
Summary
本文介绍了高性能电磁量热计在高能物理研究中的重要性,提出利用定向超快铅钨酸盐(PWO-UF)晶体设计新型紧凑电磁量热计的构想。研究表明,当粒子束与晶体学轴对齐时,可以加速电磁簇的发展,从而显著降低所需的晶体深度。同时讨论了实现定向晶体矩阵的实验技术。定向晶体量热计的应用将涵盖当前和未来实验的最大能量范围,包括前向量热计、紧凑光束转储寻找轻暗物质以及源指向空间γ射线望远镜等。
Key Takeaways
- 高性能电磁量热计在高能物理研究中的作用突出。
- 通过定向超快铅钨酸盐(PWO-UF)晶体设计新型紧凑电磁量热计的构想被提出。
- 当粒子束与晶体学轴对齐时,可以加速电磁簇的发展。
- 定向晶体量热计所需的晶体深度显著降低。
- 实现定向晶体矩阵的实验技术被讨论。
- 定向晶体量热计的应用范围广泛,包括前向量热计、寻找轻暗物质的紧凑光束转储等。
点此查看论文截图


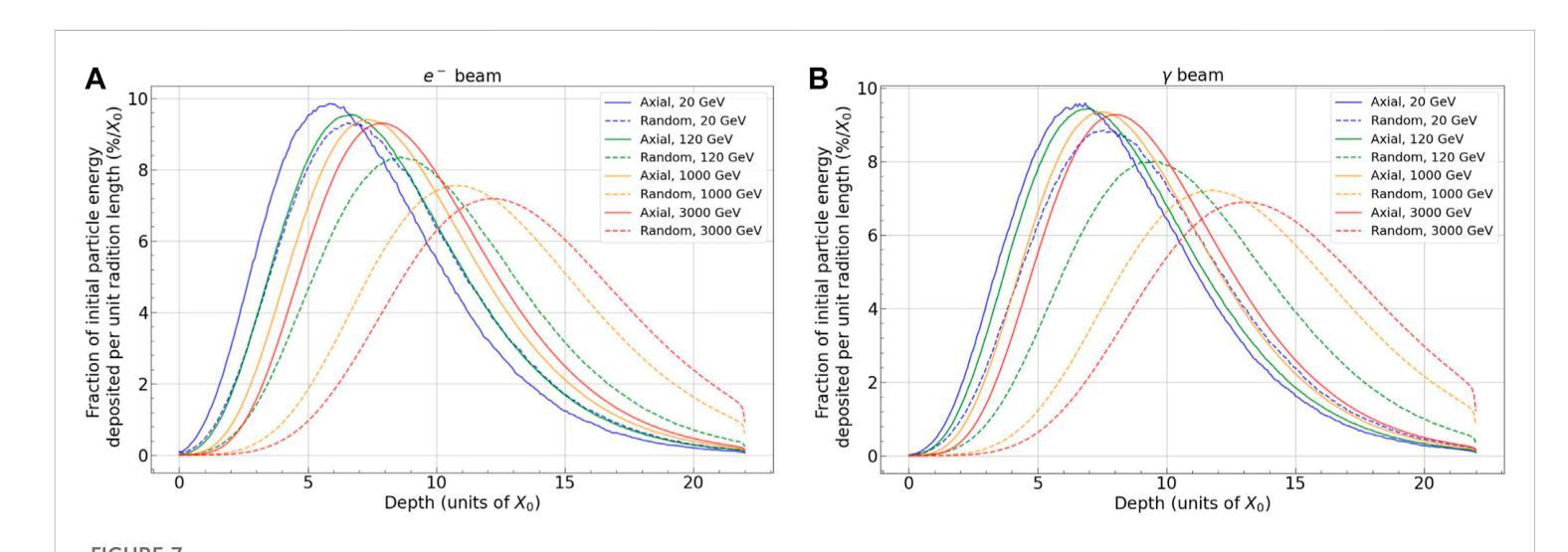
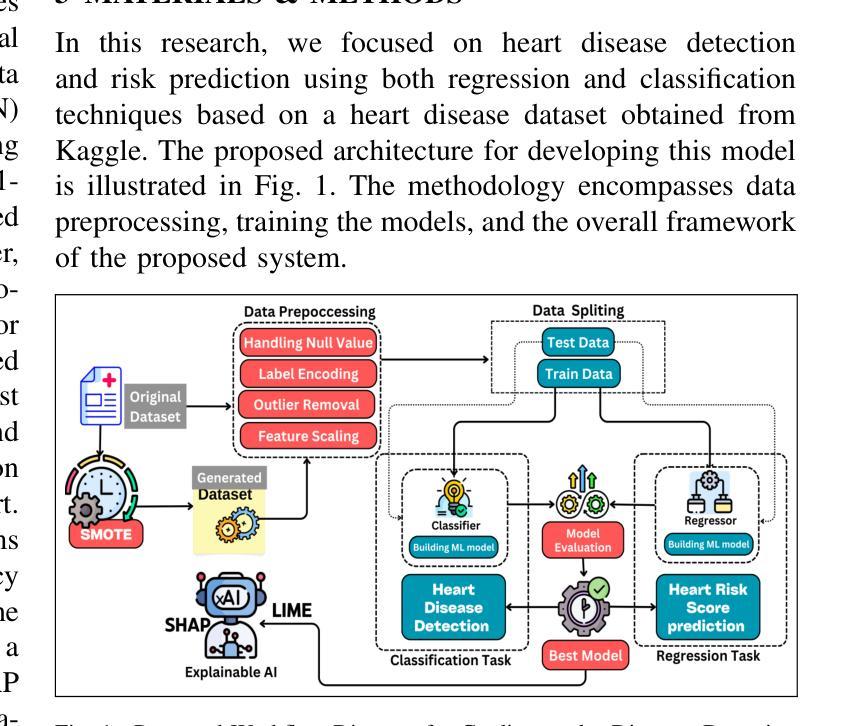
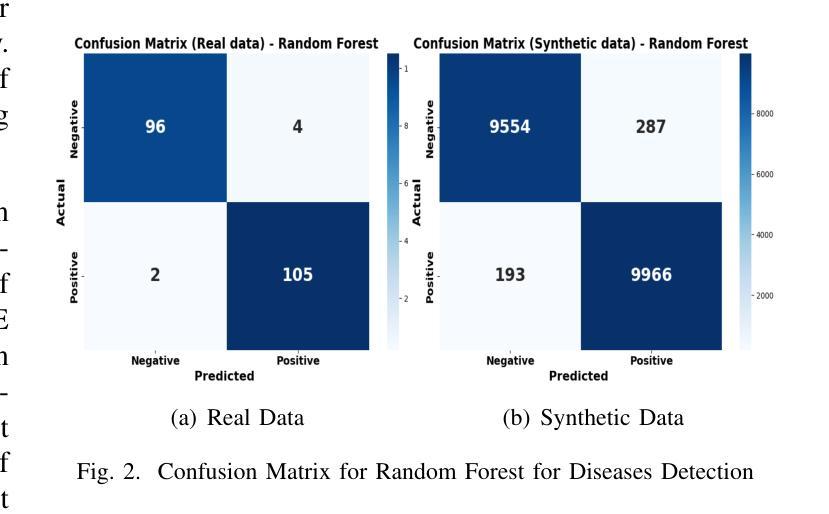
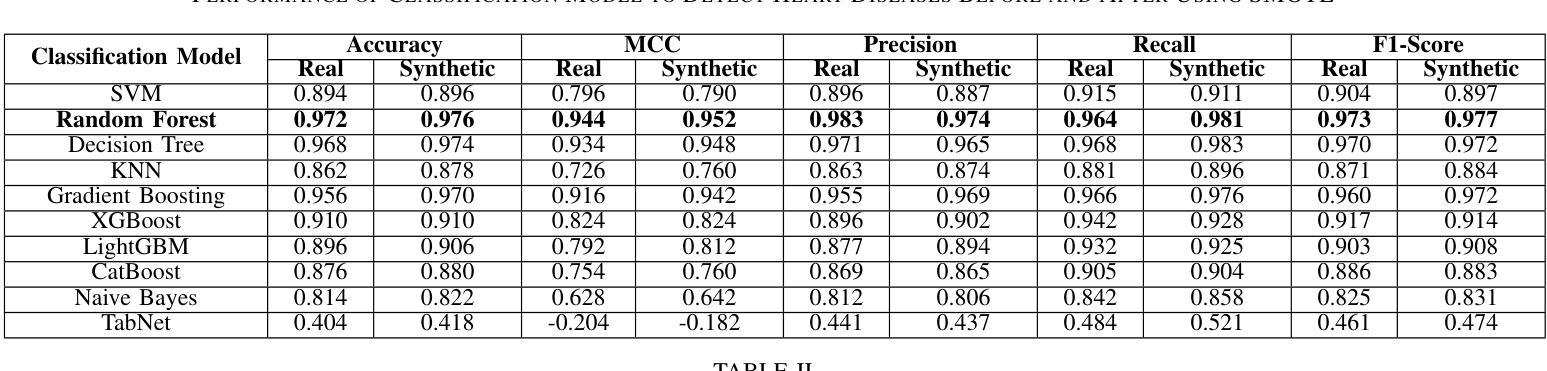
An Explainable AI-Enhanced Machine Learning Approach for Cardiovascular Disease Detection and Risk Assessment
Authors:Md. Emon Akter Sourov, Md. Sabbir Hossen, Pabon Shaha, Mohammad Minoar Hossain, Md Sadiq Iqbal
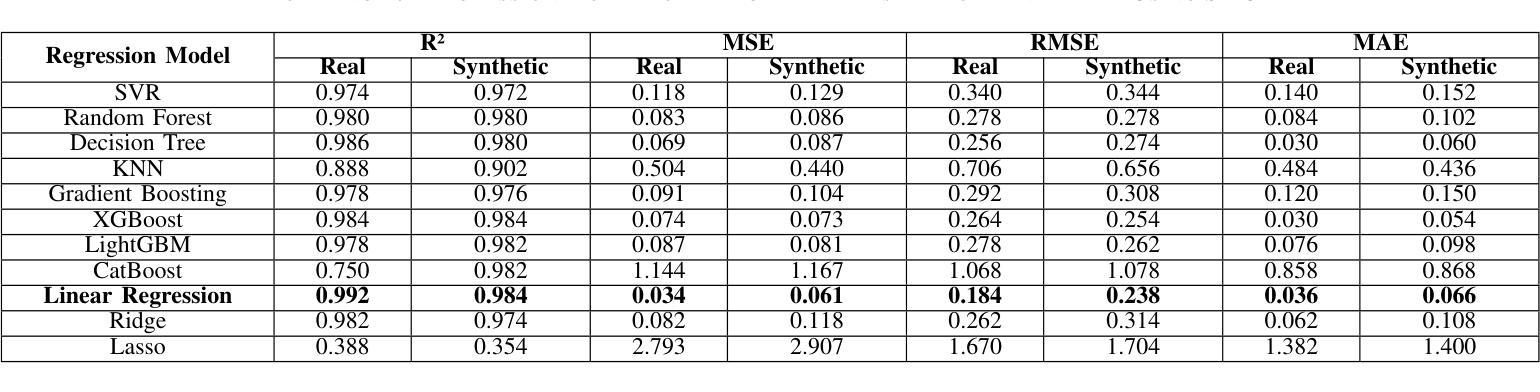
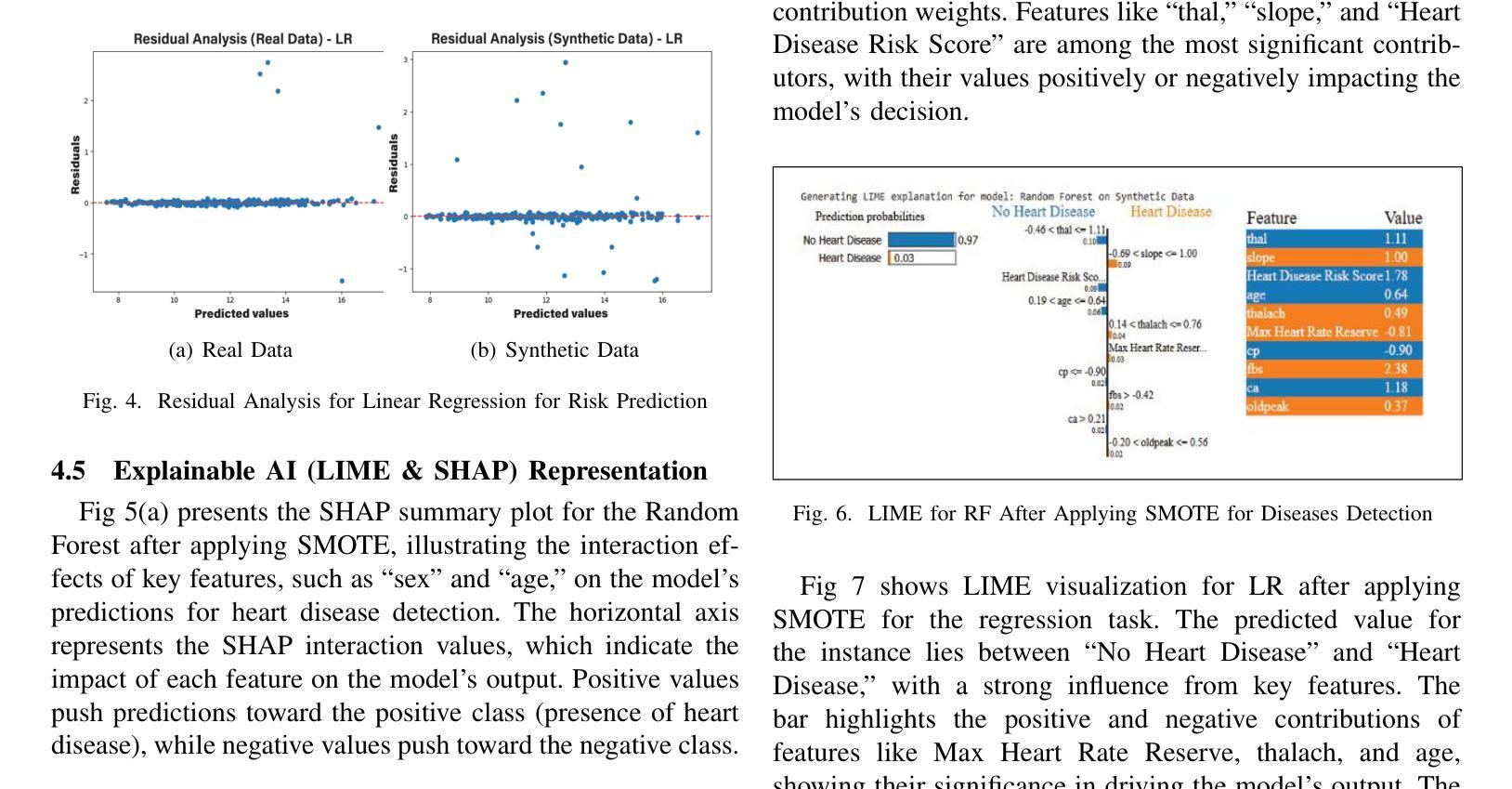
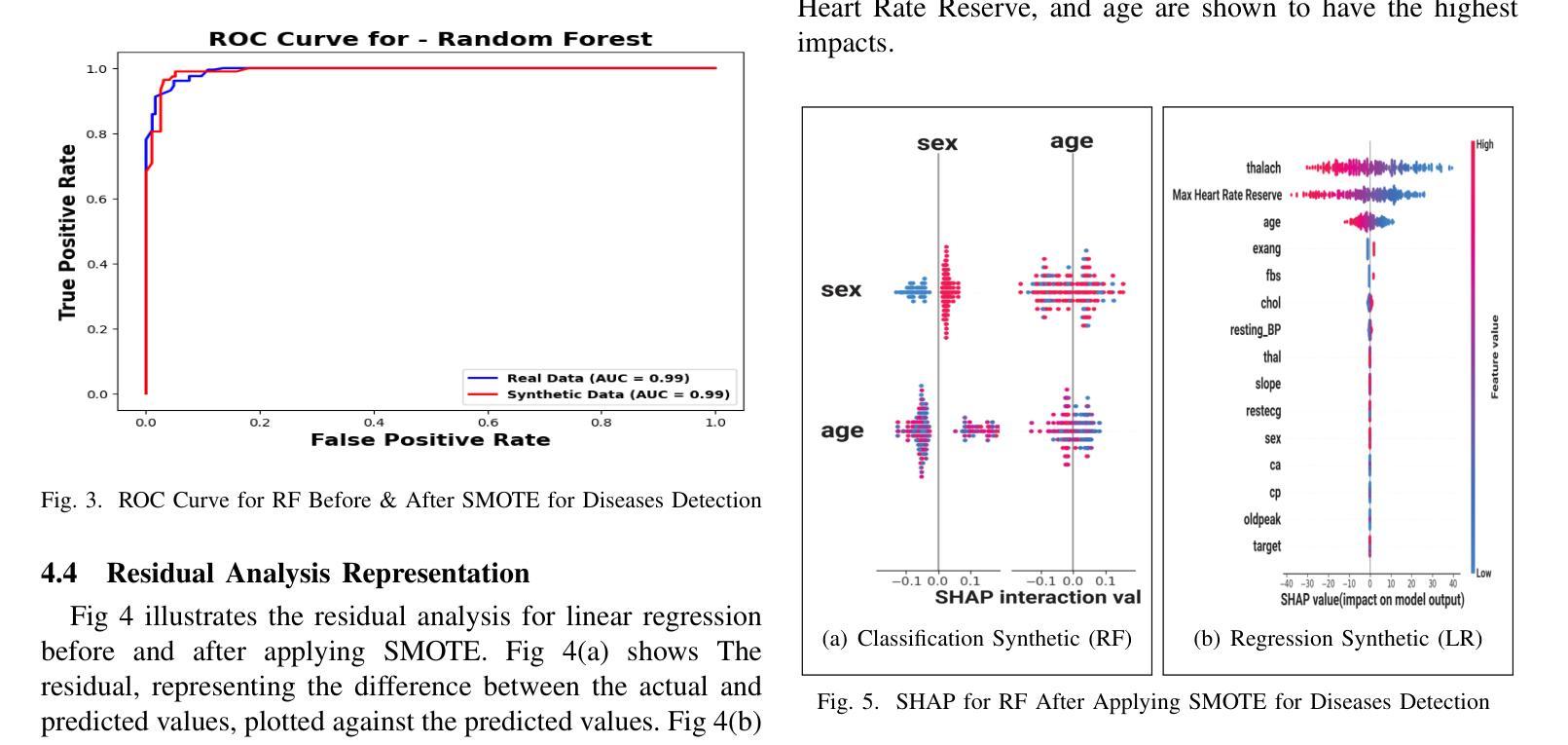
Heart disease remains a major global health concern, particularly in regions with limited access to medical resources and diagnostic facilities. Traditional diagnostic methods often fail to accurately identify and manage heart disease risks, leading to adverse outcomes. Machine learning has the potential to significantly enhance the accuracy, efficiency, and speed of heart disease diagnosis. In this study, we proposed a comprehensive framework that combines classification models for heart disease detection and regression models for risk prediction. We employed the Heart Disease dataset, which comprises 1,035 cases. To address the issue of class imbalance, the Synthetic Minority Oversampling Technique (SMOTE) was applied, resulting in the generation of an additional 100,000 synthetic data points. Performance metrics, including accuracy, precision, recall, F1-score, R2, MSE, RMSE, and MAE, were used to evaluate the model’s effectiveness. Among the classification models, Random Forest emerged as the standout performer, achieving an accuracy of 97.2% on real data and 97.6% on synthetic data. For regression tasks, Linear Regression demonstrated the highest R2 values of 0.992 and 0.984 on real and synthetic datasets, respectively, with the lowest error metrics. Additionally, Explainable AI techniques were employed to enhance the interpretability of the models. This study highlights the potential of machine learning to revolutionize heart disease diagnosis and risk prediction, thereby facilitating early intervention and enhancing clinical decision-making.
心脏病仍然是一个全球性的重大健康问题,特别是在医疗资源有限和诊断设施不足的地区。传统的诊断方法往往无法准确识别和管理心脏病风险,导致不良后果。机器学习有潜力显著提高心脏病诊断的准确性、效率和速度。在这项研究中,我们提出了一个全面的框架,该框架结合了用于心脏病检测的分类模型和用于风险预测的回归模型。我们采用了心脏病数据集,包含1035个病例。为了解决类别不平衡的问题,采用了合成少数过采样技术(SMOTE),生成了额外的10万个合成数据点。我们使用性能指标,包括准确性、精确度、召回率、F1分数、R平方、MSE、RMSE和MAE来评估模型的有效性。在分类模型中,随机森林表现出色,在真实数据上达到了97.2%的准确率,在合成数据上达到了97.6%的准确率。对于回归任务,线性回归在真实和合成数据集上分别获得了最高的R平方值0.992和0.984,并且具有最低的误差指标。此外,还采用了可解释的AI技术来提高模型的解释性。这项研究突出了机器学习在心脏病诊断和治疗中的潜力,有助于进行早期干预并增强临床决策能力。
论文及项目相关链接
PDF This paper has been accepted at the IEEE QPAIN 2025. The final version will be available in the IEEE Xplore Digital Library
Summary
该研究利用机器学习技术,提出一个综合框架用于心脏疾病的检测和风险预测。通过合成少数群体过采样技术(SMOTE)解决类别不平衡问题,并生成大量合成数据点以提高模型性能。研究结果显示,随机森林分类模型在真实和合成数据上的准确率分别达97.2%和97.6%,线性回归模型在回归任务中具有高R2值和低误差指标。此外,研究还利用可解释AI技术提高模型的解释性,有望为心脏疾病的早期诊断和预测提供革命性帮助。
Key Takeaways
- 心脏疾病仍然是一个全球性的健康问题,特别是在医疗资源诊断设施有限的地区。
- 传统诊断方法在准确识别和管理工作心脏疾病风险方面存在不足。
- 机器学习技术在心脏疾病诊断和治疗中具有巨大潜力,可以提高准确性、效率和速度。
- 研究中提出了一个综合框架,包括分类模型用于心脏疾病检测,回归模型用于风险预测。
- 采用合成少数群体过采样技术(SMOTE)解决类别不平衡问题,生成大量合成数据点以提高模型性能。
- 随机森林分类模型表现出优异的性能,在真实和合成数据上的准确率均超过97%。
点此查看论文截图


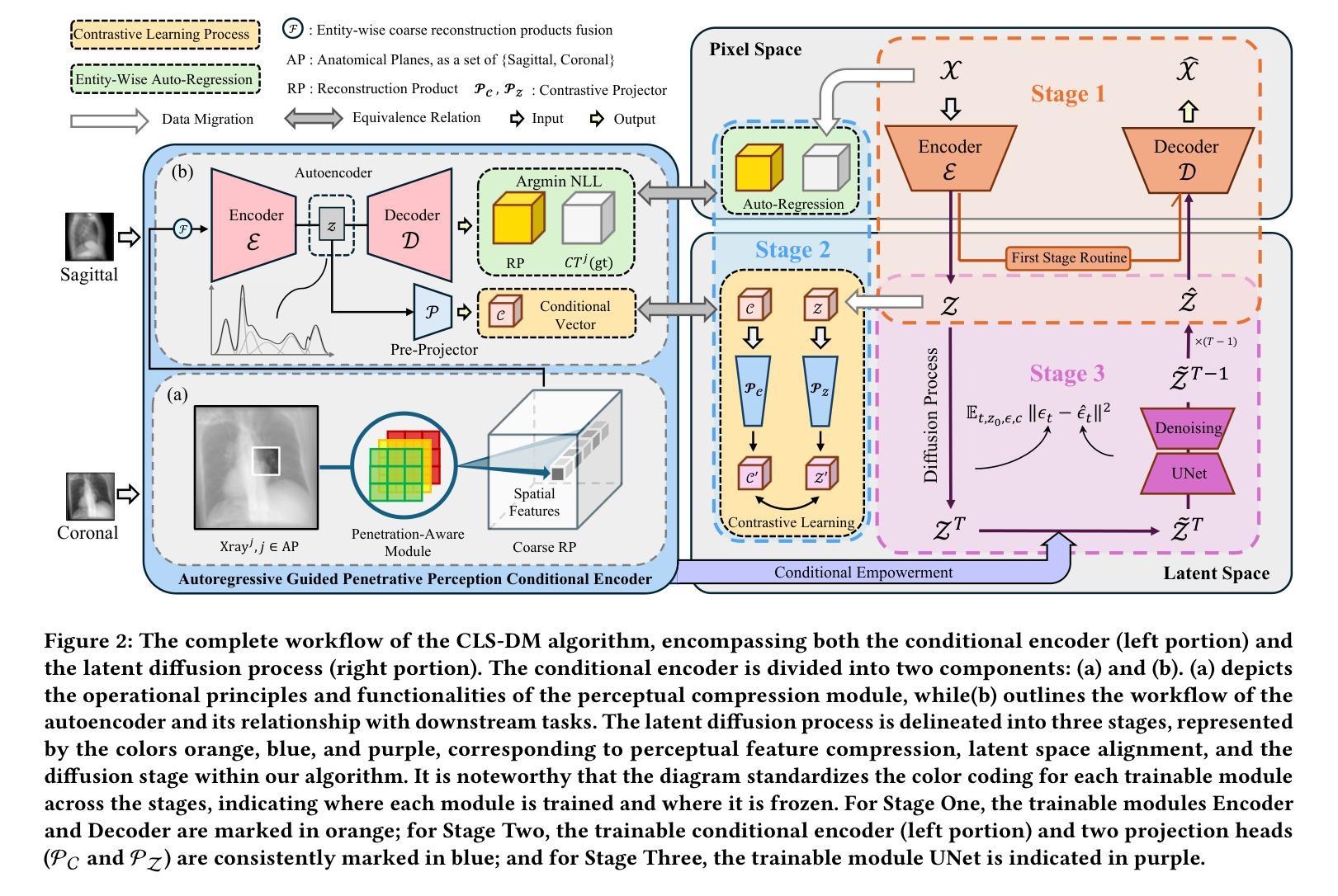
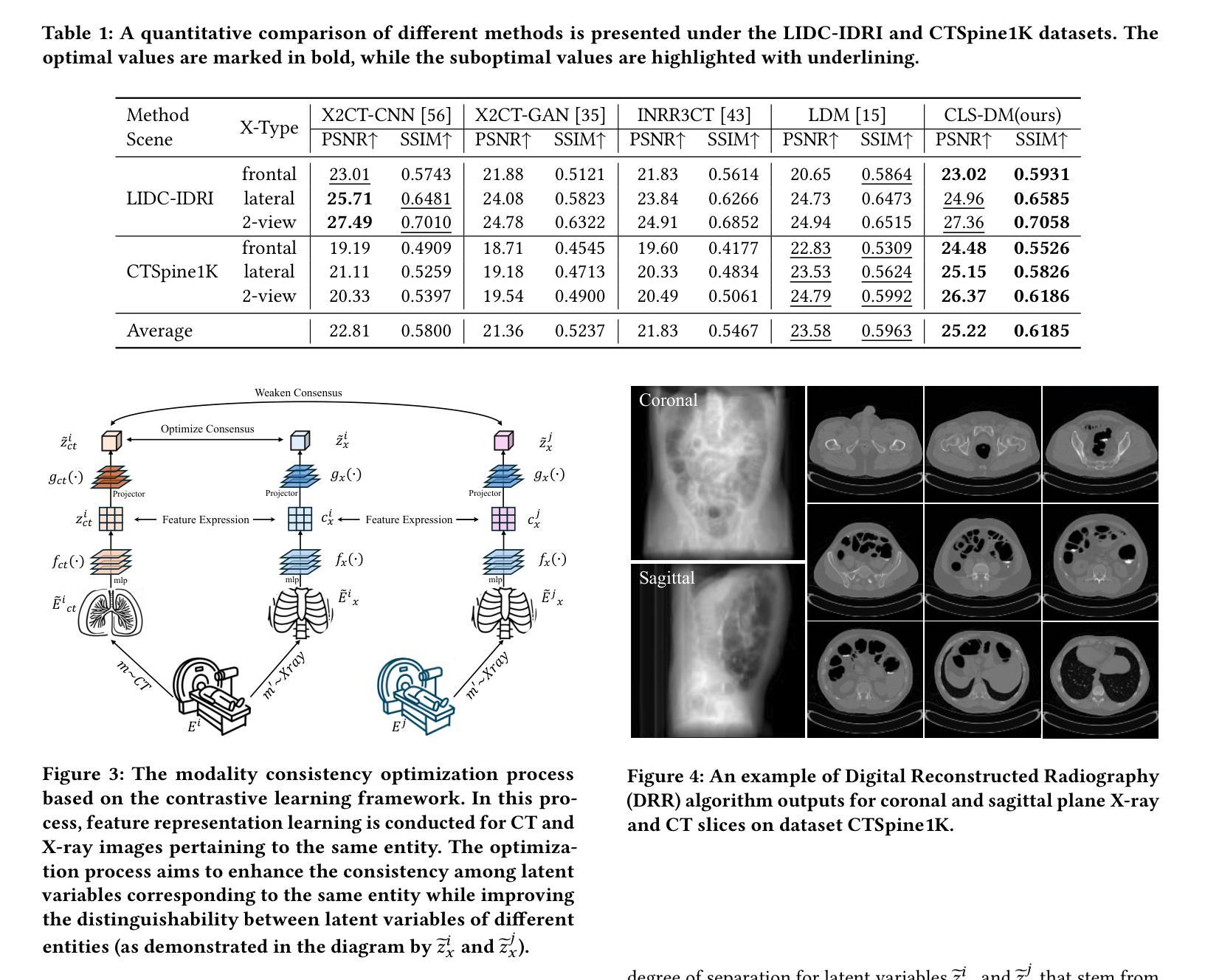
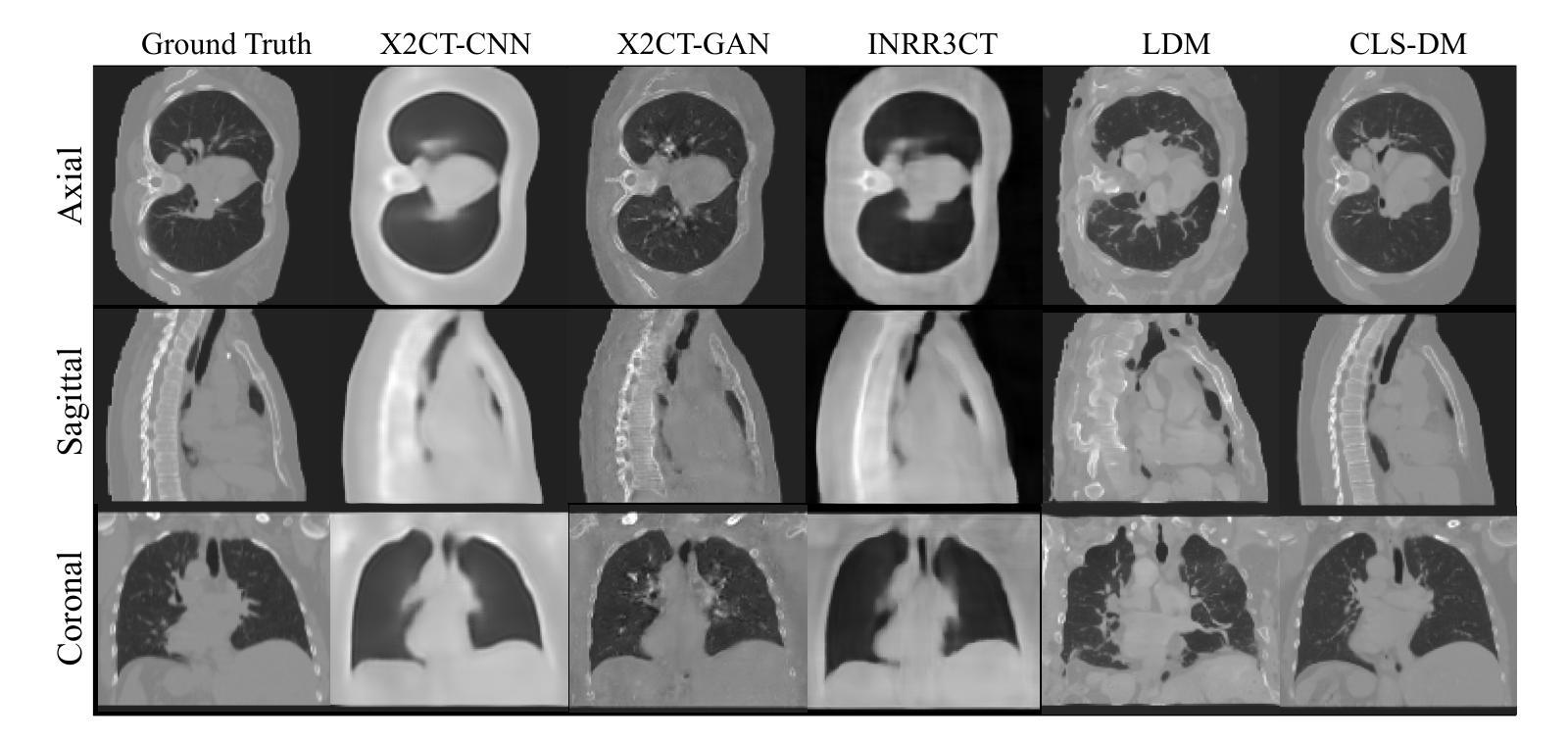
Latent Space Consistency for Sparse-View CT Reconstruction
Authors:Duoyou Chen, Yunqing Chen, Can Zhang, Zhou Wang, Cheng Chen, Ruoxiu Xiao
Computed Tomography (CT) is a widely utilized imaging modality in clinical settings. Using densely acquired rotational X-ray arrays, CT can capture 3D spatial features. However, it is confronted with challenged such as significant time consumption and high radiation exposure. CT reconstruction methods based on sparse-view X-ray images have garnered substantial attention from researchers as they present a means to mitigate costs and risks. In recent years, diffusion models, particularly the Latent Diffusion Model (LDM), have demonstrated promising potential in the domain of 3D CT reconstruction. Nonetheless, due to the substantial differences between the 2D latent representation of X-ray modalities and the 3D latent representation of CT modalities, the vanilla LDM is incapable of achieving effective alignment within the latent space. To address this issue, we propose the Consistent Latent Space Diffusion Model (CLS-DM), which incorporates cross-modal feature contrastive learning to efficiently extract latent 3D information from 2D X-ray images and achieve latent space alignment between modalities. Experimental results indicate that CLS-DM outperforms classical and state-of-the-art generative models in terms of standard voxel-level metrics (PSNR, SSIM) on the LIDC-IDRI and CTSpine1K datasets. This methodology not only aids in enhancing the effectiveness and economic viability of sparse X-ray reconstructed CT but can also be generalized to other cross-modal transformation tasks, such as text-to-image synthesis. We have made our code publicly available at https://anonymous.4open.science/r/CLS-DM-50D6/ to facilitate further research and applications in other domains.
计算机断层扫描(CT)是临床环境中广泛使用的成像技术。通过密集获取的旋转X射线阵列,CT可以捕捉三维空间特征。然而,它面临着时间消耗大、辐射暴露高等挑战。基于稀疏视角X射线图像的CT重建方法引起了研究人员的广泛关注,因为它们提供了一种降低成本和风险的方法。近年来,扩散模型,特别是潜在扩散模型(LDM)在三维CT重建领域显示出有前景的潜力。然而,由于X射线模态的二维潜在表示和CT模态的三维潜在表示之间存在很大差异,原始的LDM无法在潜在空间内进行有效对齐。为了解决这个问题,我们提出了统一的潜在空间扩散模型(CLS-DM),它结合了跨模态特征对比学习,可以有效地从二维X射线图像中提取潜在的三维信息,并在不同模态之间实现潜在空间对齐。实验结果表明,CLS-DM在LIDC-IDRI和CTSpine1K数据集上,在标准的体素级指标(PSNR,SSIM)方面优于经典和最新一代生成模型。这种方法不仅有助于提高稀疏X射线重建CT的有效性和经济可行性,还可以推广到其他跨模态转换任务,如文本到图像合成。我们的代码已公开在https://anonymous.4open.science/r/CLS-DM-50D6/,以便其他领域的研究和应用。
论文及项目相关链接
PDF ACMMM2025 Accepted
Summary
本文介绍了计算层析成像(CT)的广泛应用及其面临的挑战,如时间消耗和辐射暴露问题。研究者提出基于稀疏视图X射线图像的CT重建方法,以降低成本和风险。文章重点介绍了一种新型的扩散模型——一致潜在空间扩散模型(CLS-DM),该模型通过跨模态特征对比学习有效地从二维X射线图像中提取潜在的三维信息,并在不同模态之间实现潜在空间对齐。实验结果表明,CLS-DM在LIDC-IDRI和CTSpine1K数据集上优于经典和先进的生成模型,对于稀疏X射线重建CT的有效性和经济性有所提升,并可推广到其他跨模态转换任务,如文本到图像合成。
Key Takeaways
- CT是临床设置中广泛使用的成像方式,能捕捉三维空间特征,但面临时间消耗和辐射暴露的挑战。
- 基于稀疏视图X射线图像的CT重建方法受到关注,以降低成本和风险。
- 一致潜在空间扩散模型(CLS-DM)通过跨模态特征对比学习从二维X射线图像中提取潜在三维信息。
- CLS-DM实现了在不同模态之间的潜在空间对齐。
- CLS-DM在LIDC-IDRI和CTSpine1K数据集上的表现优于其他生成模型。
- CLS-DM提升了稀疏X射线重建CT的有效性和经济性。
点此查看论文截图

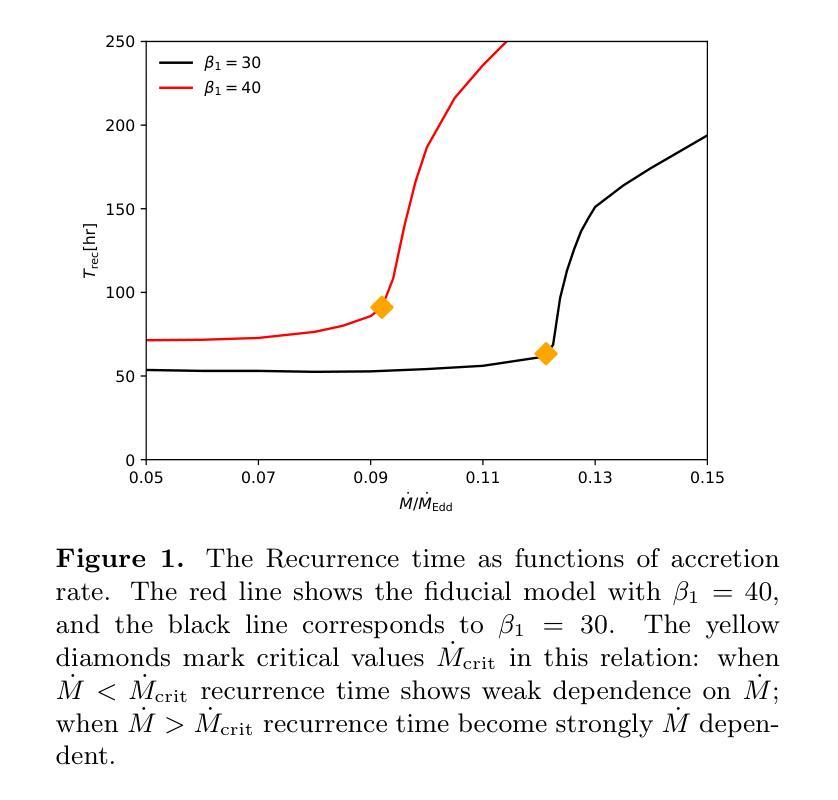
Disk Instability Model for Quasi-Periodic Eruptions: Investigating Period Dispersion and Peak Temperature
Authors:Xin Pan, Shuang-Liang Li, Xinwu Cao, Bifang Liu, Weimin Yuan
Quasi-periodic eruptions (QPEs) are a class of X-ray repeating burst phenomena discovered in recent years. Many models have been proposed to study this phenomenon, there remains significant debate regarding the physical origin of QPEs. In our previous work, we developed a disk instability model with a large-scale magnetic field and successfully reproduced the light curves and spectral characteristics of several QPE sources. We further investigate the model in this work, aiming to explain two key observational features: the dispersion in eruption periods and the peak temperatures during eruptions. The model reveals critical thresholds ($\dot{M}{\rm crit}$, $\beta{1,\rm crit}$) that separate systems into stable regimes with minimal period variations and unstable regimes where periods are highly sensitive to accretion rate and magnetic field parameter, while peak temperatures remain nearly constant across the parameter space. This framework successfully explains both the regular eruptions observed in sources like GSN 069 and the stochastic behavior in sources like eRO-QPE1, and simultaneously accounting for the observed temperature stability during long-term QPEs evolution.
准周期喷发(QPEs)是近年来发现的一类X射线重复爆发现象。尽管已经提出了许多模型来研究这一现象,但关于QPEs的物理起源仍存在重大争议。在我们之前的工作中,我们开发了一个具有大规模磁场的磁盘不稳定模型,并成功再现了多个QPE源的光变曲线和光谱特征。我们在这项工作中进一步研究了该模型,旨在解释两个关键的观测特征:喷发周期的分散和喷发期间的峰值温度。模型揭示了关键的阈值($\dot{M}{\rm crit}$,$\beta{1,\rm crit}$),这些阈值将系统划分为具有最小周期变化的稳定状态和高度敏感于吸积率和磁场参数的不稳定状态,而峰值温度在参数空间内几乎保持不变。这一框架成功解释了如GSN 069等源观察到的定期喷发和如eRO-QPE1等源的随机行为,同时说明了在长期QPEs演化过程中观察到的温度稳定性。
论文及项目相关链接
PDF 11 pages, 9 figures, Accepted for publication in the Astrophysical Journal
Summary
近期发现的一类X射线重复爆发现象称为准周期爆发(QPEs)。尽管有许多模型对其进行研究,但关于其物理起源仍存在争议。我们之前的工作开发了一个具有大尺度磁场的磁盘不稳定模型,并成功再现了多个QPE源的光变曲线和光谱特征。本次工作进一步探讨该模型,旨在解释两个关键观测特征:爆发周期的分散和爆发期间的峰值温度。模型揭示了将系统分为最小周期变化稳定的制度区域和高度敏感于增质率和磁场参数的不稳定区域的临界阈值($\dot{M}{\rm crit}$,$\beta{1,\rm crit}$)。同时,峰值温度在参数空间中保持近似恒定。该框架成功解释了如GSN 069等来源的常规爆发和如eRO-QPE1等来源的随机行为,同时解释了长期QPE演化期间观察到的温度稳定性。
Key Takeaways
- QPEs是一种X射线重复爆发现象,对其物理起源存在争议。
- 此前的工作提出了一个具有大尺度磁场的磁盘不稳定模型,成功模拟了QPE的光变曲线和光谱特征。
- 本次研究进一步探讨了该模型,旨在解释QPE的两个关键观测特征:爆发周期的分散和峰值温度的变化。
- 模型揭示了临界阈值($\dot{M}{\rm crit}$,$\beta{1,\rm crit}$),用于区分系统的稳定和不稳定的制度区域。
- 爆发周期的不稳定性与增质率和磁场参数的敏感性有关。
- 峰值温度在参数空间内保持相对稳定。
点此查看论文截图

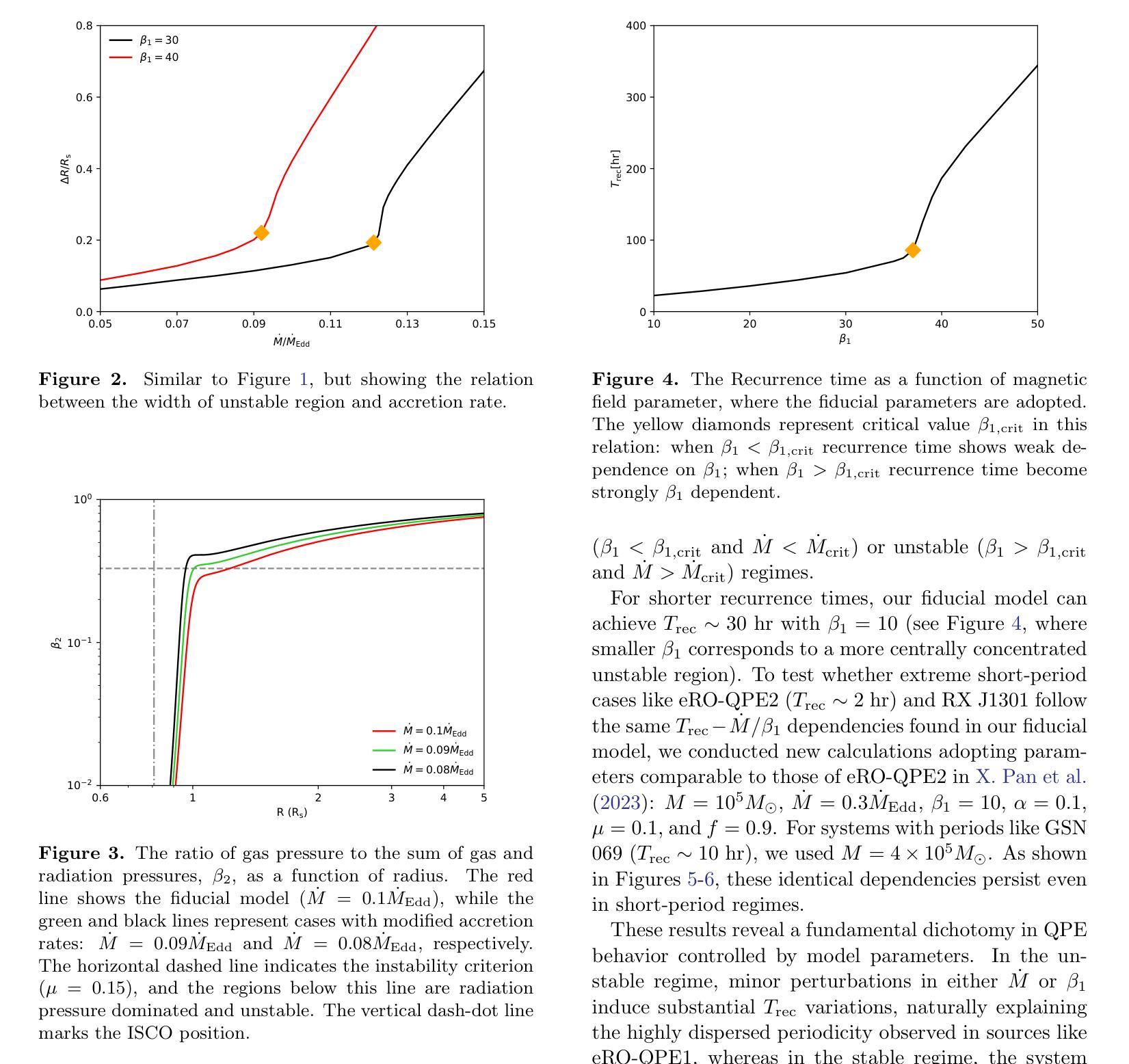
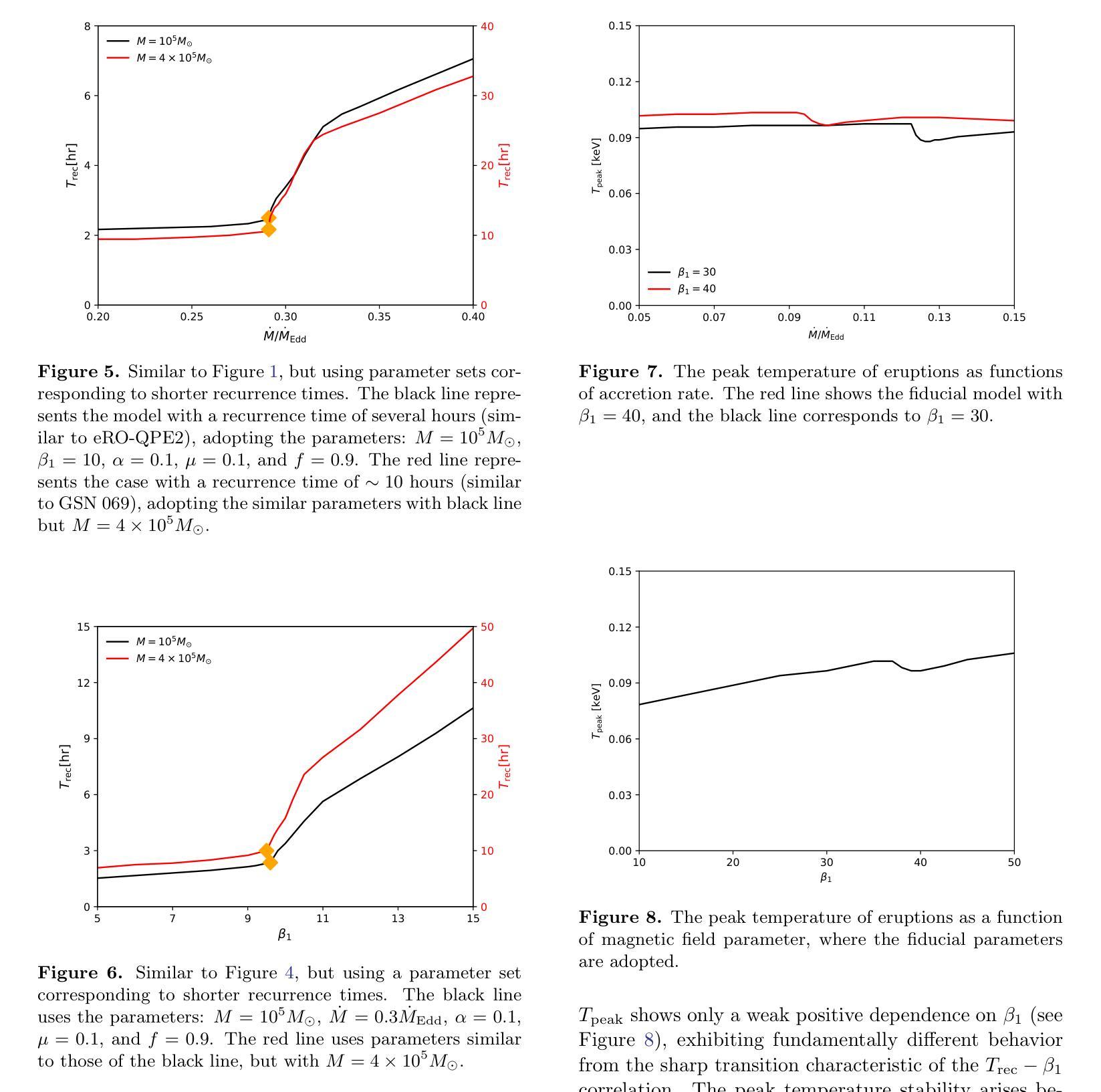
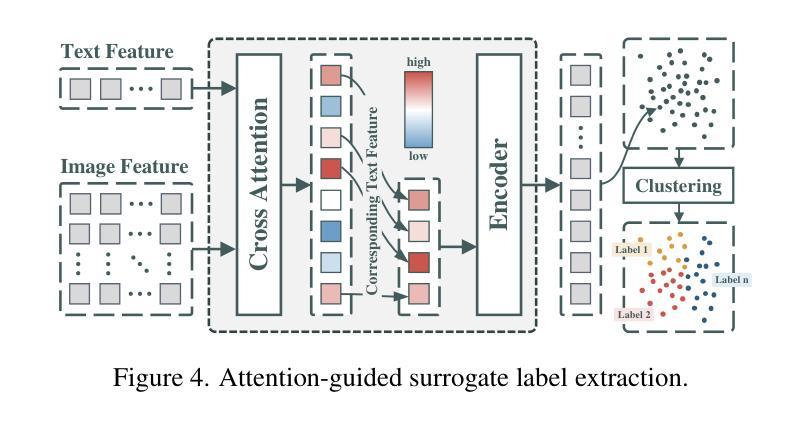
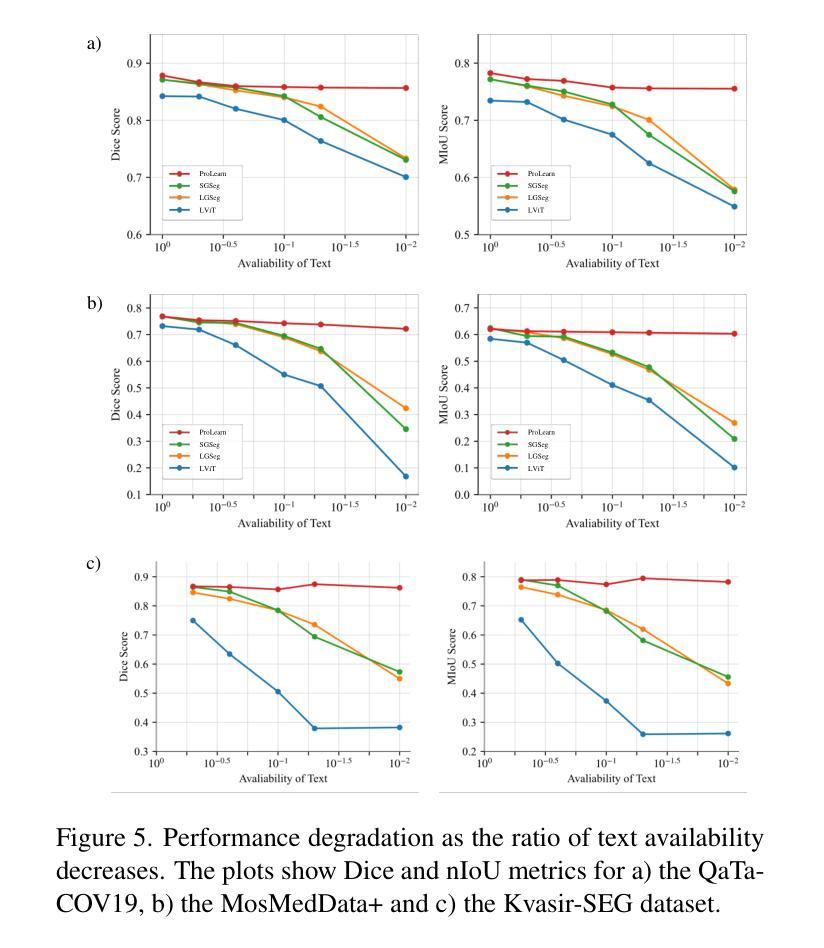
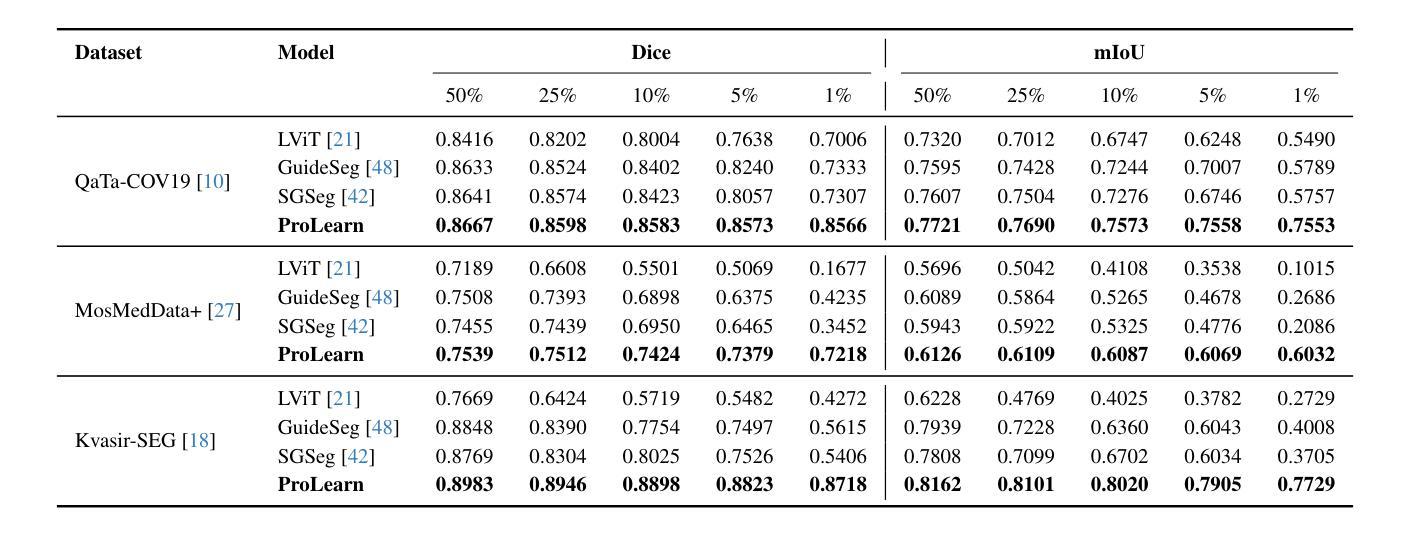
Alleviating Textual Reliance in Medical Language-guided Segmentation via Prototype-driven Semantic Approximation
Authors:Shuchang Ye, Usman Naseem, Mingyuan Meng, Jinman Kim
Medical language-guided segmentation, integrating textual clinical reports as auxiliary guidance to enhance image segmentation, has demonstrated significant improvements over unimodal approaches. However, its inherent reliance on paired image-text input, which we refer to as ``textual reliance”, presents two fundamental limitations: 1) many medical segmentation datasets lack paired reports, leaving a substantial portion of image-only data underutilized for training; and 2) inference is limited to retrospective analysis of cases with paired reports, limiting its applicability in most clinical scenarios where segmentation typically precedes reporting. To address these limitations, we propose ProLearn, the first Prototype-driven Learning framework for language-guided segmentation that fundamentally alleviates textual reliance. At its core, in ProLearn, we introduce a novel Prototype-driven Semantic Approximation (PSA) module to enable approximation of semantic guidance from textual input. PSA initializes a discrete and compact prototype space by distilling segmentation-relevant semantics from textual reports. Once initialized, it supports a query-and-respond mechanism which approximates semantic guidance for images without textual input, thereby alleviating textual reliance. Extensive experiments on QaTa-COV19, MosMedData+ and Kvasir-SEG demonstrate that ProLearn outperforms state-of-the-art language-guided methods when limited text is available.
医学语言引导分割技术通过将文本临床报告作为辅助指导来增强图像分割,证明其相对于单模态方法的显著改进。然而,其对配对图像文本输入的固有依赖(我们称之为“文本依赖”)存在两个基本局限:1)许多医学分割数据集缺少配对报告,导致大量仅包含图像的数据未能得到充分利用;2)推理仅限于具有配对报告的病例的回顾性分析,限制了其在大多数临床场景中的应用,因为在大多数情况下,分割是在报告之前进行的。为了解决这些局限,我们提出了ProLearn,即首个用于语言引导分割的原型驱动学习框架,从根本上减轻了文本依赖。在ProLearn的核心中,我们引入了一种新型的原型驱动语义近似(PSA)模块,以实现从文本输入进行语义指导的近似。PSA通过蒸馏来自文本报告的分割相关语义来初始化一个离散且紧凑的原型空间。初始化完成后,它支持查询和响应机制,可在没有文本输入的情况下近似语义指导,从而减轻对文本的依赖。在QaTa-COV19、MosMedData+和Kvasir-SEG上的大量实验表明,当可用文本有限时,ProLearn的表现优于最先进的语言引导方法。
论文及项目相关链接
PDF Accepted to ICCV 2025
Summary
医学语言引导分割技术结合文本临床报告作为辅助指导,提高了图像分割的精度。然而,其对配对图像文本输入的依赖存在两大局限:一是许多医学分割数据集缺乏配对报告,导致大量仅有图像的数据未能充分利用;二是推断仅限于有配对报告的病例回顾性分析,限制了其在临床场景中的应用。为解决这个问题,提出ProLearn——首个原型驱动的学习框架,用于语言引导分割,从根本上减轻了文本依赖。引入新型原型驱动语义逼近模块,实现从文本输入中近似语义指导。在QaTa-COV19、MosMedData+和Kvasir-SEG上的广泛实验表明,ProLearn在有限文本可用时,表现优于最先进的语言引导方法。
Key Takeaways
- 医学语言引导分割技术结合文本临床报告可以提高图像分割的精度。
- 医学分割数据集缺乏配对报告是一大挑战,导致数据利用率不高。
- 现有方法主要局限于有配对报告的病例回顾性分析。
- ProLearn是首个原型驱动的学习框架,用于语言引导分割。
- ProLearn引入原型驱动语义逼近模块,可近似实现无文本输入的语义指导。
- ProLearn在有限文本可用时表现优异,优于其他先进的语言引导方法。
点此查看论文截图

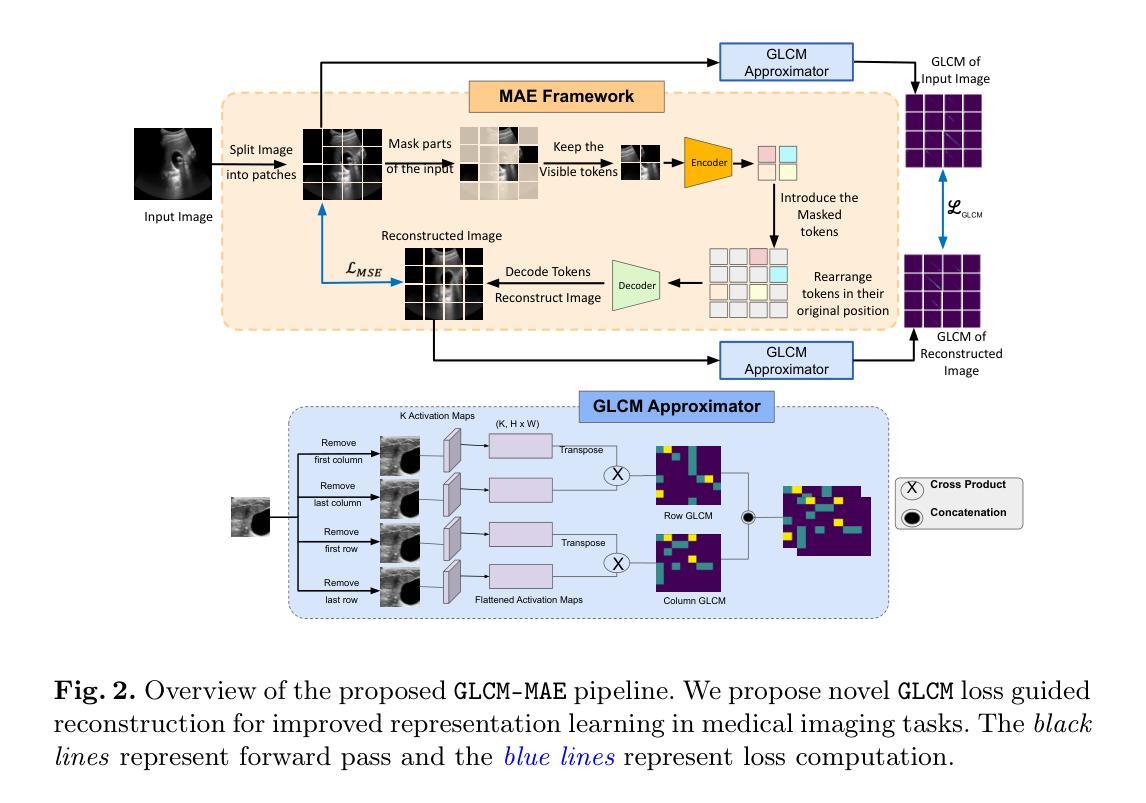
Focus on Texture: Rethinking Pre-training in Masked Autoencoders for Medical Image Classification
Authors:Chetan Madan, Aarjav Satia, Soumen Basu, Pankaj Gupta, Usha Dutta, Chetan Arora
Masked Autoencoders (MAEs) have emerged as a dominant strategy for self-supervised representation learning in natural images, where models are pre-trained to reconstruct masked patches with a pixel-wise mean squared error (MSE) between original and reconstructed RGB values as the loss. We observe that MSE encourages blurred image re-construction, but still works for natural images as it preserves dominant edges. However, in medical imaging, when the texture cues are more important for classification of a visual abnormality, the strategy fails. Taking inspiration from Gray Level Co-occurrence Matrix (GLCM) feature in Radiomics studies, we propose a novel MAE based pre-training framework, GLCM-MAE, using reconstruction loss based on matching GLCM. GLCM captures intensity and spatial relationships in an image, hence proposed loss helps preserve morphological features. Further, we propose a novel formulation to convert matching GLCM matrices into a differentiable loss function. We demonstrate that unsupervised pre-training on medical images with the proposed GLCM loss improves representations for downstream tasks. GLCM-MAE outperforms the current state-of-the-art across four tasks - gallbladder cancer detection from ultrasound images by 2.1%, breast cancer detection from ultrasound by 3.1%, pneumonia detection from x-rays by 0.5%, and COVID detection from CT by 0.6%. Source code and pre-trained models are available at: https://github.com/ChetanMadan/GLCM-MAE.
掩码自编码器(MAEs)已成为自然图像自监督表示学习的主流策略,其中模型经过预训练,以重建掩码区域,以原始和重建RGB值之间的像素级均方误差(MSE)作为损失函数。我们发现MSE鼓励模糊图像的重构,但在自然图像中仍然有效,因为它保留了主导边缘。然而,在医学成像中,当纹理线索对于视觉异常的分类更为重要时,该策略会失效。我们从放射学研究中灰阶共生矩阵(GLCM)特征中汲取灵感,提出了一种基于MAE的预训练框架GLCM-MAE,使用基于匹配GLCM的重构损失。GLCM捕捉图像中的强度和空间关系,因此所提出的损失有助于保留形态特征。此外,我们提出了一种新的公式,将匹配的GLCM矩阵转化为可微分的损失函数。我们证明,使用所提出的GLCM损失对医学图像进行无监督预训练,可以改善下游任务的表现。GLCM-MAE在四项任务上的性能超过了当前的最佳水平:超声图像胆囊癌检测提高2.1%,超声乳腺癌检测提高3.1%,X光肺炎检测提高0.5%,CT新冠肺炎检测提高0.6%。源代码和预训练模型可在https://github.com/ChetanMadan/GLCM-MAE找到。
论文及项目相关链接
PDF To appear at MICCAI 2025
Summary
本文介绍了基于灰度共生矩阵(GLCM)的Masked Autoencoders(MAEs)在医疗图像自我监督预训练中的使用。通过结合GLCM的特征与MAE的重建损失,形成新的预训练框架GLCM-MAE。此框架能够捕捉图像的强度和空间关系,有助于保留形态学特征。在四个任务上的实验表明,GLCM-MAE在医疗图像下游任务中的表现优于当前的最优方法。
Key Takeaways
- MAEs已成为自然图像自我监督表示学习的主要策略,但在医疗图像中,当纹理线索对视觉异常分类更重要时,基于MSE的策略会失效。
- 提出了基于灰度共生矩阵(GLCM)的MAE预训练框架GLCM-MAE。
- GLCM能够捕捉图像的强度和空间关系,通过匹配GLCM的重建损失有助于保留形态学特征。
- 将匹配GLCM矩阵转化为可微分的损失函数。
- 在四个任务上,GLCM-MAE均表现出超越当前最先进方法的效果,包括胆囊癌、乳腺癌检测的超声图像,肺炎检测的X光图像以及COVID检测的CT图像。
- 公开了源代码和预训练模型,便于他人使用和研究。
点此查看论文截图


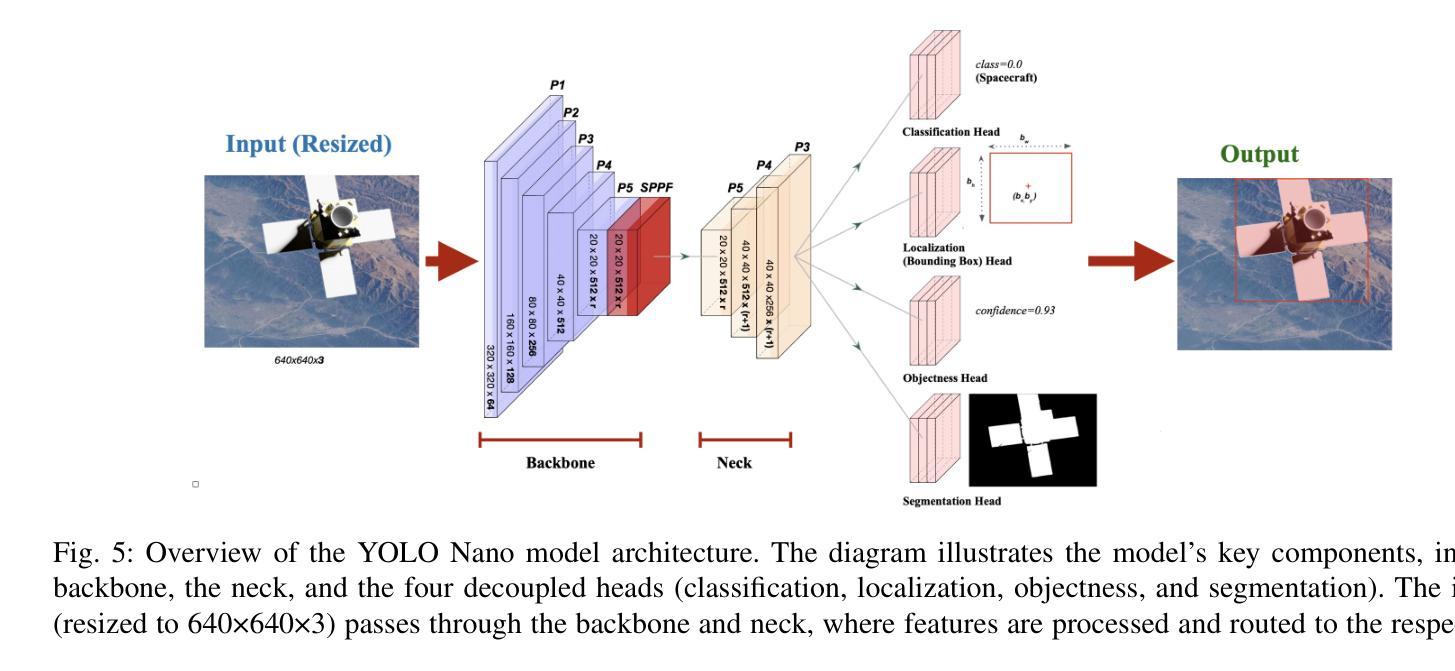
A New Dataset and Performance Benchmark for Real-time Spacecraft Segmentation in Onboard Flight Computers
Authors:Jeffrey Joan Sam, Janhavi Sathe, Nikhil Chigali, Naman Gupta, Radhey Ruparel, Yicheng Jiang, Janmajay Singh, James W. Berck, Arko Barman
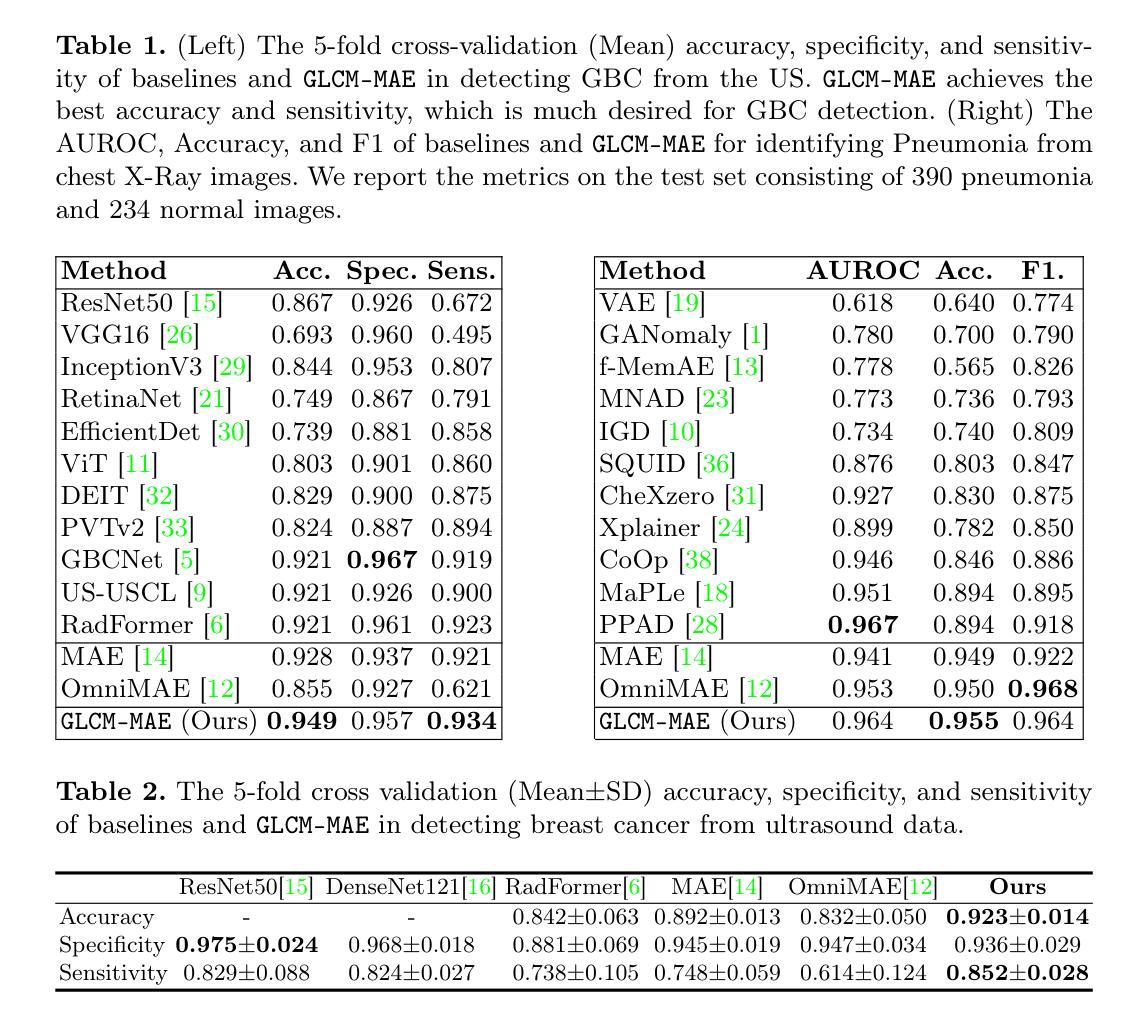
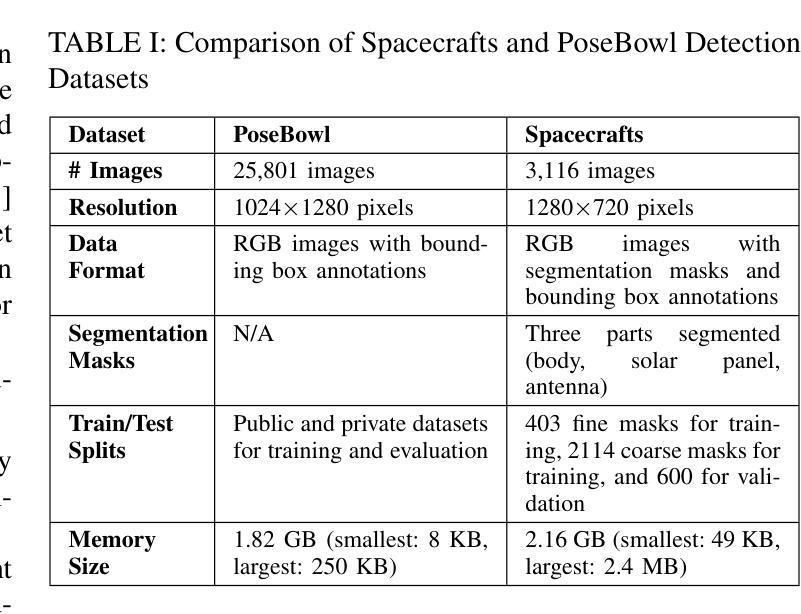
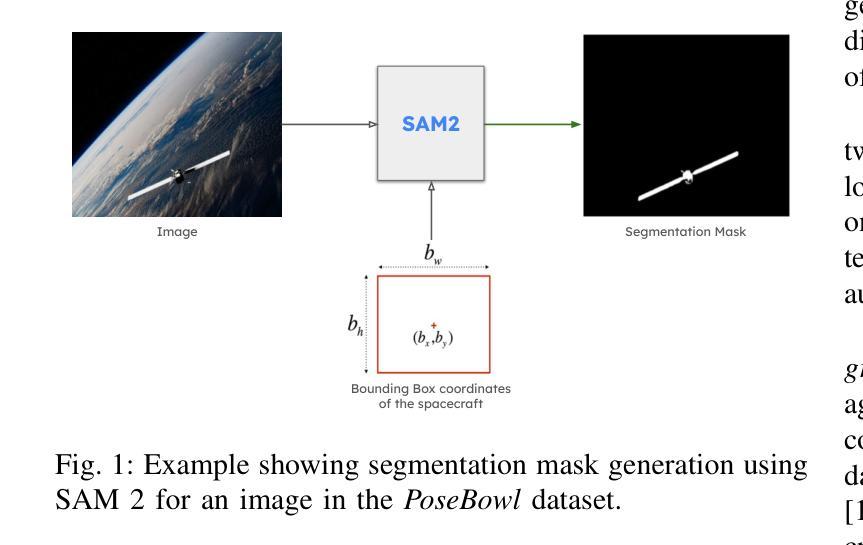
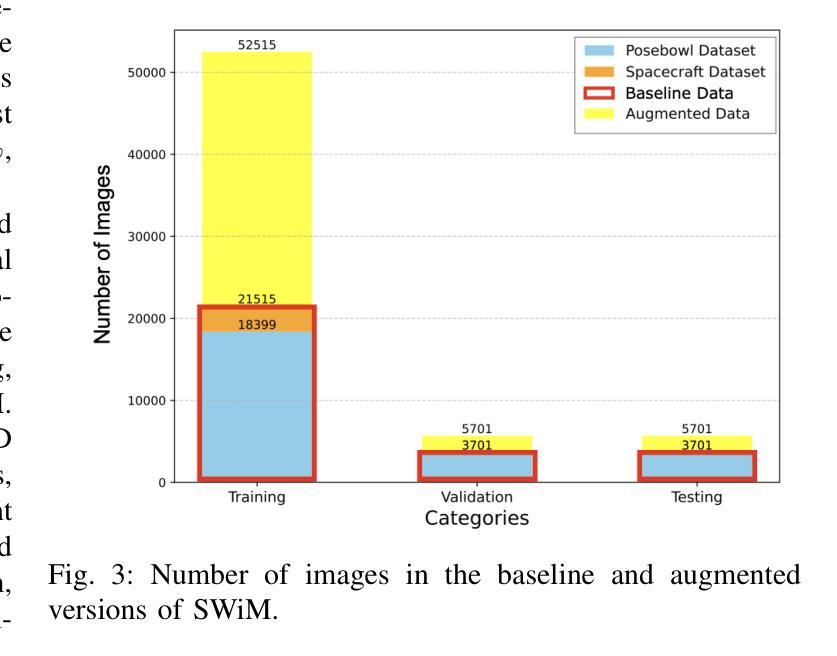
Spacecraft deployed in outer space are routinely subjected to various forms of damage due to exposure to hazardous environments. In addition, there are significant risks to the subsequent process of in-space repairs through human extravehicular activity or robotic manipulation, incurring substantial operational costs. Recent developments in image segmentation could enable the development of reliable and cost-effective autonomous inspection systems. While these models often require large amounts of training data to achieve satisfactory results, publicly available annotated spacecraft segmentation data are very scarce. Here, we present a new dataset of nearly 64k annotated spacecraft images that was created using real spacecraft models, superimposed on a mixture of real and synthetic backgrounds generated using NASA’s TTALOS pipeline. To mimic camera distortions and noise in real-world image acquisition, we also added different types of noise and distortion to the images. Finally, we finetuned YOLOv8 and YOLOv11 segmentation models to generate performance benchmarks for the dataset under well-defined hardware and inference time constraints to mimic real-world image segmentation challenges for real-time onboard applications in space on NASA’s inspector spacecraft. The resulting models, when tested under these constraints, achieved a Dice score of 0.92, Hausdorff distance of 0.69, and an inference time of about 0.5 second. The dataset and models for performance benchmark are available at https://github.com/RiceD2KLab/SWiM.
在太空部署的航天器经常暴露在危险环境中,因而受到各种形式的损害。此外,通过人类舱外活动或机器人操纵进行的太空修复过程存在重大风险,并产生大量操作成本。图像分割领域的最新发展可能会使可靠且经济的自主检查系统的开发成为可能。虽然这些模型通常需要大量的训练数据才能达到满意的结果,但公开可用的带注释的航天器分割数据非常稀缺。在这里,我们展示了一个新数据集,包含近6.4万张使用真实航天器模型制作的带注释的航天器图像。这些图像叠加在由NASA的TTALOS管道生成的真实和合成背景混合物上。为了模拟现实世界图像采集中的相机失真和噪声,我们还向图像中添加了不同类型的噪声和失真。最后,我们对YOLOv8和YOLOv11分割模型进行了微调,以生成针对该数据集的基准测试性能,这些测试在明确的硬件和推理时间约束下进行,以模拟NASA检查航天器上的实时机上应用的真实世界图像分割挑战。在这些约束条件下测试的模型取得了Dice系数为0.92、Hausdorff距离为0.69以及大约0.5秒的推理时间。数据集和性能基准模型可在https://github.com/RiceD2KLab/SWiM上找到。
论文及项目相关链接
Summary
本摘要提供了一种新型数据集,该数据集包含近6.4万张带有标注的航天器图像。数据集利用NASA的TTALOS管道生成真实和合成背景,并添加了不同类型的噪声和失真,以模拟太空环境中的相机失真和噪声。研究人员使用YOLOv8和YOLOv11分割模型进行微调,以在该数据集上生成性能基准测试,以模拟太空中的实时在线应用。模型在测试下取得了较高的性能表现。
Key Takeaways
- 新型数据集包含近6.4万张带有标注的航天器图像,用于自主检测系统的开发。
- 数据集结合了真实和合成背景,模拟太空环境。
- 添加了不同类型的噪声和失真,以模拟相机在真实世界中的失真和噪声问题。
- 使用YOLOv8和YOLOv11分割模型进行微调,以在该数据集上进行性能基准测试。
- 模型在模拟的太空环境中表现良好,达到了较高的性能指标。
- 模型的推理时间约为0.5秒,满足实时应用的需求。
点此查看论文截图



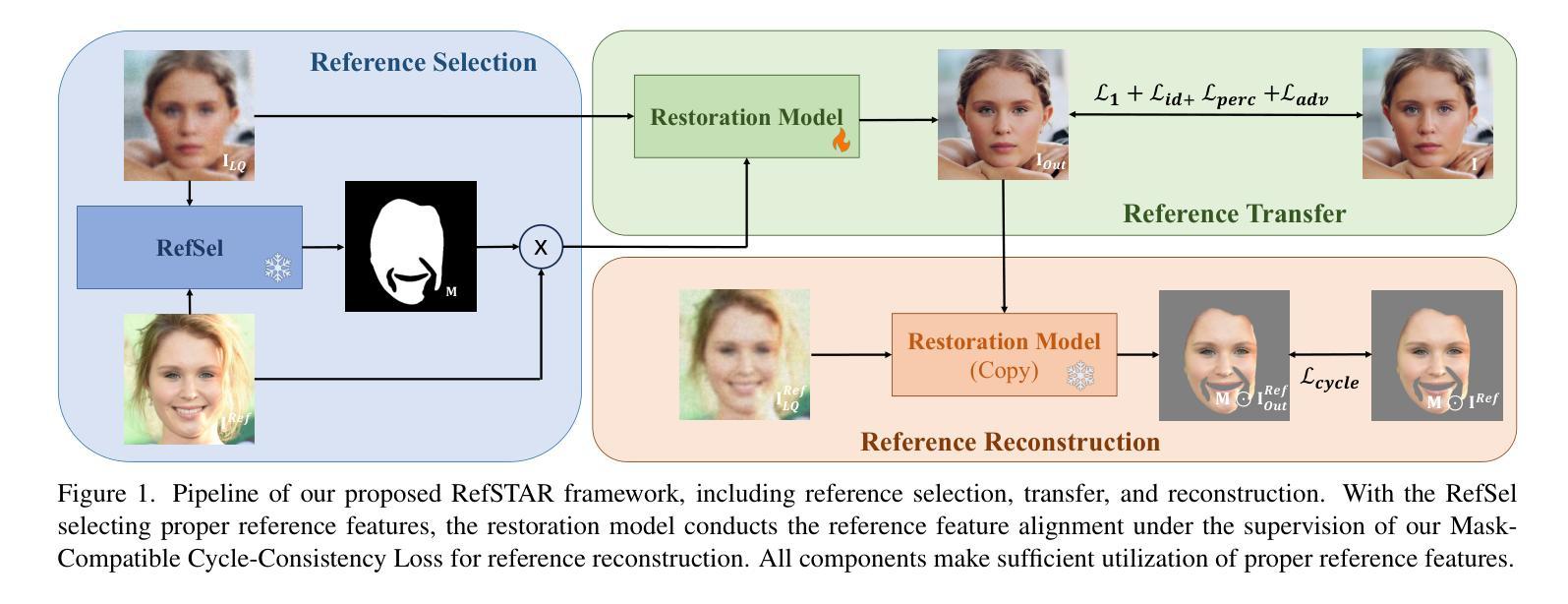
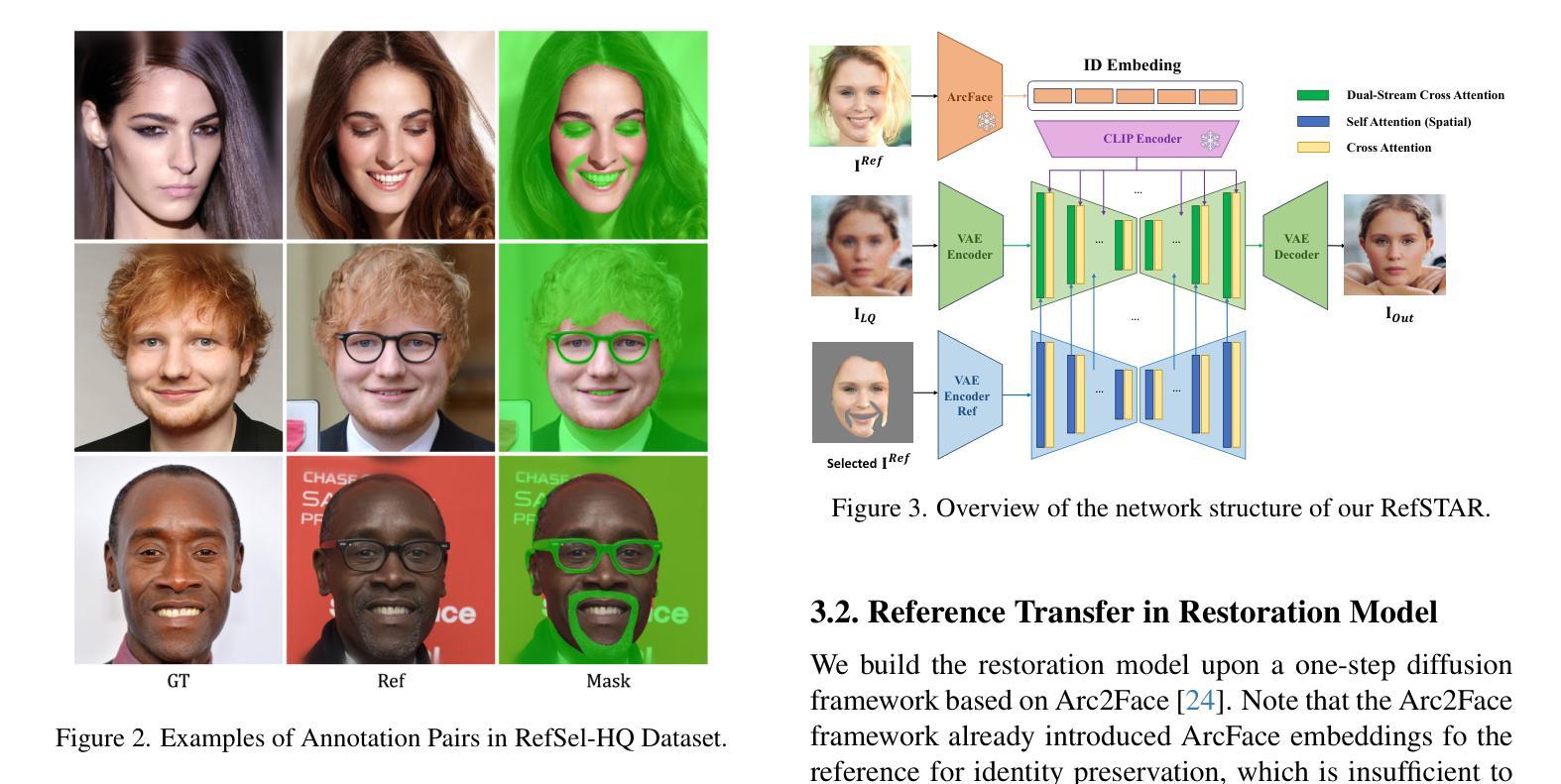
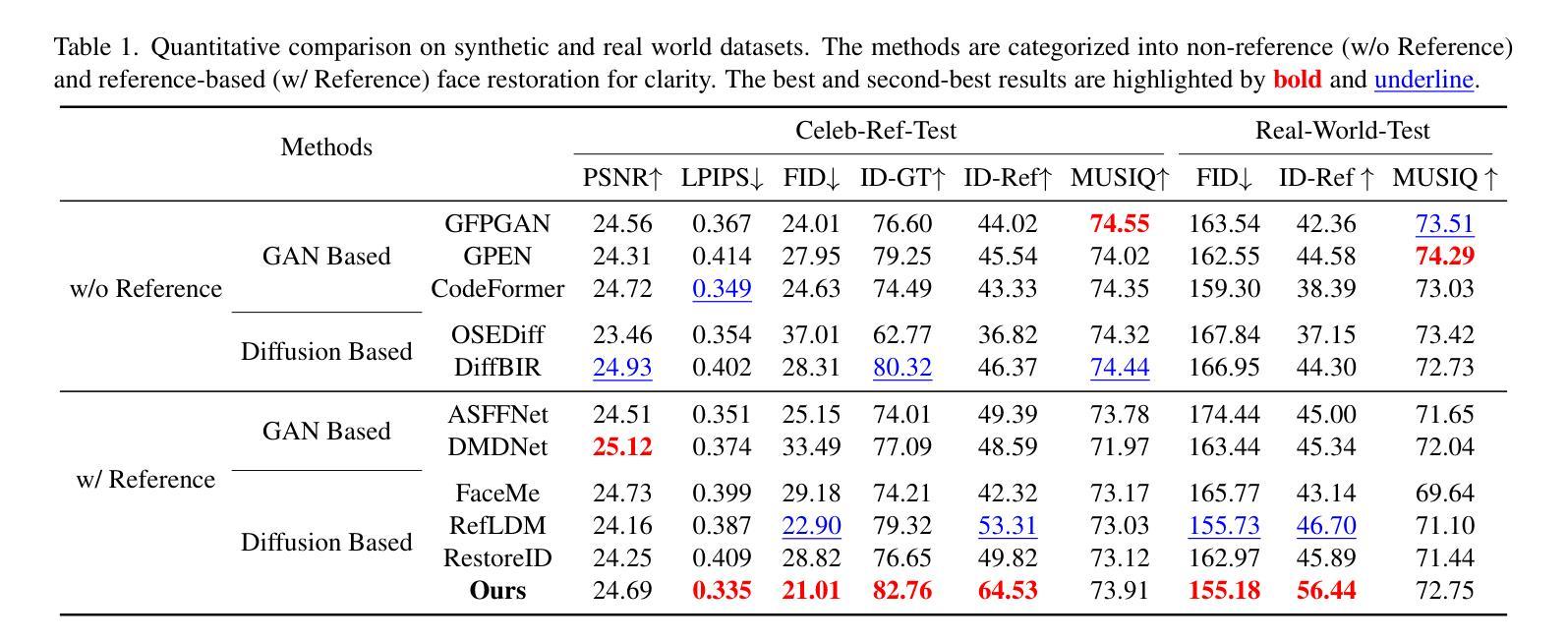
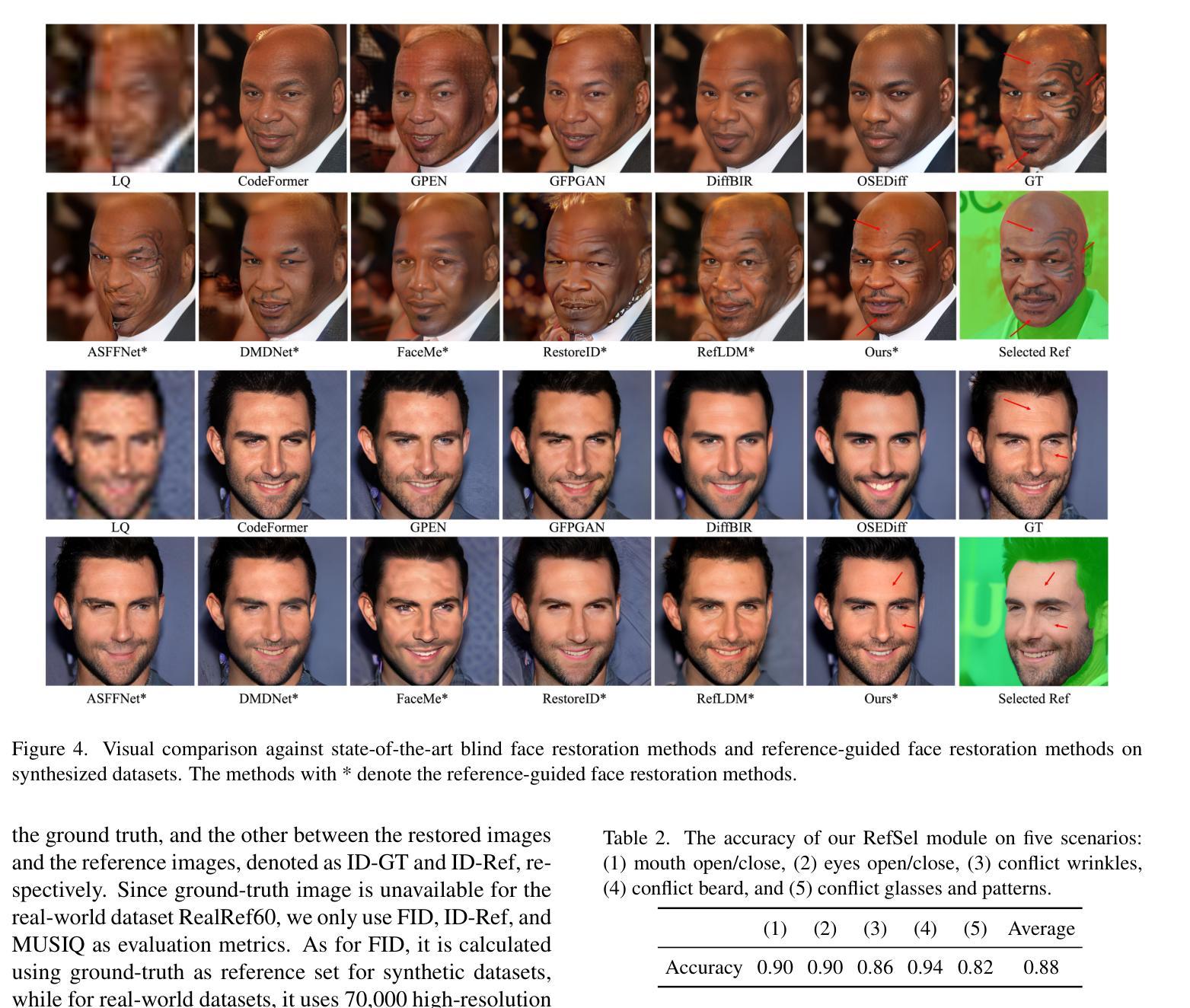
RefSTAR: Blind Facial Image Restoration with Reference Selection, Transfer, and Reconstruction
Authors:Zhicun Yin, Junjie Chen, Ming Liu, Zhixin Wang, Fan Li, Renjing Pei, Xiaoming Li, Rynson W. H. Lau, Wangmeng Zuo
Blind facial image restoration is highly challenging due to unknown complex degradations and the sensitivity of humans to faces. Although existing methods introduce auxiliary information from generative priors or high-quality reference images, they still struggle with identity preservation problems, mainly due to improper feature introduction on detailed textures. In this paper, we focus on effectively incorporating appropriate features from high-quality reference images, presenting a novel blind facial image restoration method that considers reference selection, transfer, and reconstruction (RefSTAR). In terms of selection, we construct a reference selection (RefSel) module. For training the RefSel module, we construct a RefSel-HQ dataset through a mask generation pipeline, which contains annotating masks for 10,000 ground truth-reference pairs. As for the transfer, due to the trivial solution in vanilla cross-attention operations, a feature fusion paradigm is designed to force the features from the reference to be integrated. Finally, we propose a reference image reconstruction mechanism that further ensures the presence of reference image features in the output image. The cycle consistency loss is also redesigned in conjunction with the mask. Extensive experiments on various backbone models demonstrate superior performance, showing better identity preservation ability and reference feature transfer quality. Source code, dataset, and pre-trained models are available at https://github.com/yinzhicun/RefSTAR.
面部图像的盲修复是一项极具挑战性的任务,这主要是因为未知的复杂退化和人类对面部的敏感性。尽管现有的方法引入了生成先验或高质量参考图像的辅助信息,但它们仍然面临着身份保留问题,这主要是因为细节纹理的不当特征引入。在本文中,我们专注于有效地融入高质量参考图像中的适当特征,提出了一种新型的面部图像盲修复方法,该方法考虑了参考选择、转移和重建(RefSTAR)。在参考选择方面,我们构建了参考选择(RefSel)模块。为了训练RefSel模块,我们通过掩模生成管道构建了RefSel-HQ数据集,其中包含10,000个真实参照对标注掩模。在转移方面,由于普通交叉注意操作存在平凡解,我们设计了一种特征融合范式来强制整合参考特征。最后,我们提出了一种参考图像重建机制,确保参考图像特征出现在输出图像中。循环一致性损失也与掩模重新设计。在不同主干模型上的大量实验表明,该方法具有卓越的性能,表现出更好的身份保留能力和参考特征转移质量。源代码、数据集和预训练模型可在https://github.com/yinzhicun/RefSTAR找到。
论文及项目相关链接
Summary
本文提出了一种新的盲面部图像恢复方法,通过有效融入高质量参考图像的特征,解决身份保留问题。该方法包括参考选择、转移和重建(RefSTAR),构建了参考选择(RefSel)模块,并通过RefSel-HQ数据集进行训练。设计特征融合范式,确保参考特征融入,并提出参考图像重建机制,确保输出图像包含参考图像特征。该方法在多种主干模型上表现优越,具有更好的身份保留能力和参考特征转移质量。
Key Takeaways
- 盲面部图像恢复面临未知复杂退化和人类对面部的敏感性挑战。
- 现有方法引入生成先验或高质量参考图像信息,但仍存在身份保留问题。
- 本文提出一种新盲面部图像恢复方法,通过融入高质量参考图像的特征解决身份保留问题。
- 构建参考选择(RefSel)模块,通过RefSel-HQ数据集进行训练。
- 设计特征融合范式,解决平凡交叉关注操作中的特征转移问题。
- 提出参考图像重建机制,确保输出图像包含参考图像特征。
点此查看论文截图

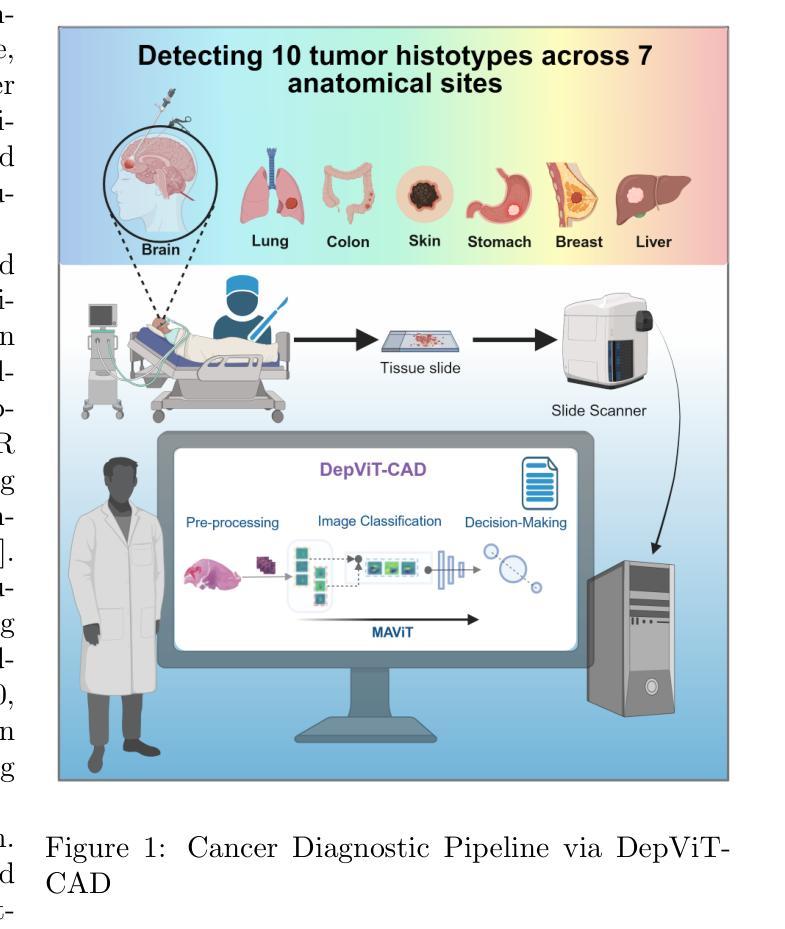
DepViT-CAD: Deployable Vision Transformer-Based Cancer Diagnosis in Histopathology
Authors:Ashkan Shakarami, Lorenzo Nicole, Rocco Cappellesso, Angelo Paolo Dei Tos, Stefano Ghidoni
Accurate and timely cancer diagnosis from histopathological slides is vital for effective clinical decision-making. This paper introduces DepViT-CAD, a deployable AI system for multi-class cancer diagnosis in histopathology. At its core is MAViT, a novel Multi-Attention Vision Transformer designed to capture fine-grained morphological patterns across diverse tumor types. MAViT was trained on expert-annotated patches from 1008 whole-slide images, covering 11 diagnostic categories, including 10 major cancers and non-tumor tissue. DepViT-CAD was validated on two independent cohorts: 275 WSIs from The Cancer Genome Atlas and 50 routine clinical cases from pathology labs, achieving diagnostic sensitivities of 94.11% and 92%, respectively. By combining state-of-the-art transformer architecture with large-scale real-world validation, DepViT-CAD offers a robust and scalable approach for AI-assisted cancer diagnostics. To support transparency and reproducibility, software and code will be made publicly available at GitHub.
准确及时的癌症诊断对于有效的临床决策至关重要。本文介绍了用于组织病理学多类癌症诊断的DepViT-CAD可部署AI系统。其核心是MAViT,这是一种新型的多注意力视觉转换器,旨在捕获多种肿瘤类型中的精细形态模式。MAViT是在来自1008张全切片图像的专家注释区域上进行训练的,涵盖包括10种主要癌症和非肿瘤组织在内的11个诊断类别。DepViT-CAD在两个独立队列中进行了验证:来自癌症基因组图谱的275个WSI和来自病理实验室的50例常规临床病例,诊断敏感性分别为94.11%和92%。通过将最先进的转换架构与大规模现实世界验证相结合,DepViT-CAD为AI辅助癌症诊断提供了稳健且可扩展的方法。为了支持透明度和可重复性,软件和代码将在GitHub上公开可用。
论文及项目相关链接
PDF 25 pages, 15 figures
Summary
医学图像领域的新研究介绍了一种名为DepViT-CAD的可部署人工智能系统,用于多类别癌症诊断。其核心是MAViT,一种新型的多注意力视觉转换器,能够捕捉不同肿瘤类型的精细形态模式。系统经过专家注释的补丁训练,可在全视野切片上识别十一种诊断类别,包括十种主要癌症和非肿瘤组织。在癌症基因组图谱的275张全视野切片图像和病理实验室的50例常规临床病例中进行验证,诊断敏感性分别为94.11%和92%。该系统结合了最先进的转换器架构和大规模现实世界验证,为人工智能辅助癌症诊断提供了稳健且可扩展的方法。
Key Takeaways
- DepViT-CAD是一个用于多类别癌症诊断的人工智能系统。
- MAViT是该系统的核心,是一种多注意力视觉转换器。
- MAViT能够捕捉各种肿瘤类型的精细形态模式。
- 系统经过专家注释的补丁训练,可识别十一种诊断类别。
- 在癌症基因组图谱和病理实验室的常规临床病例中进行验证,诊断敏感性高。
- 系统结合了最先进的转换器架构和大规模现实世界验证。
点此查看论文截图

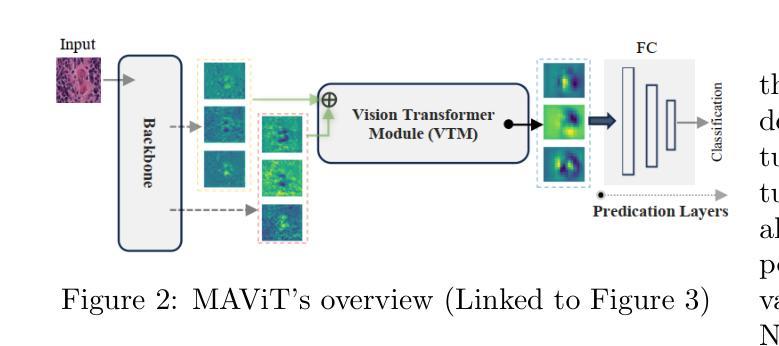
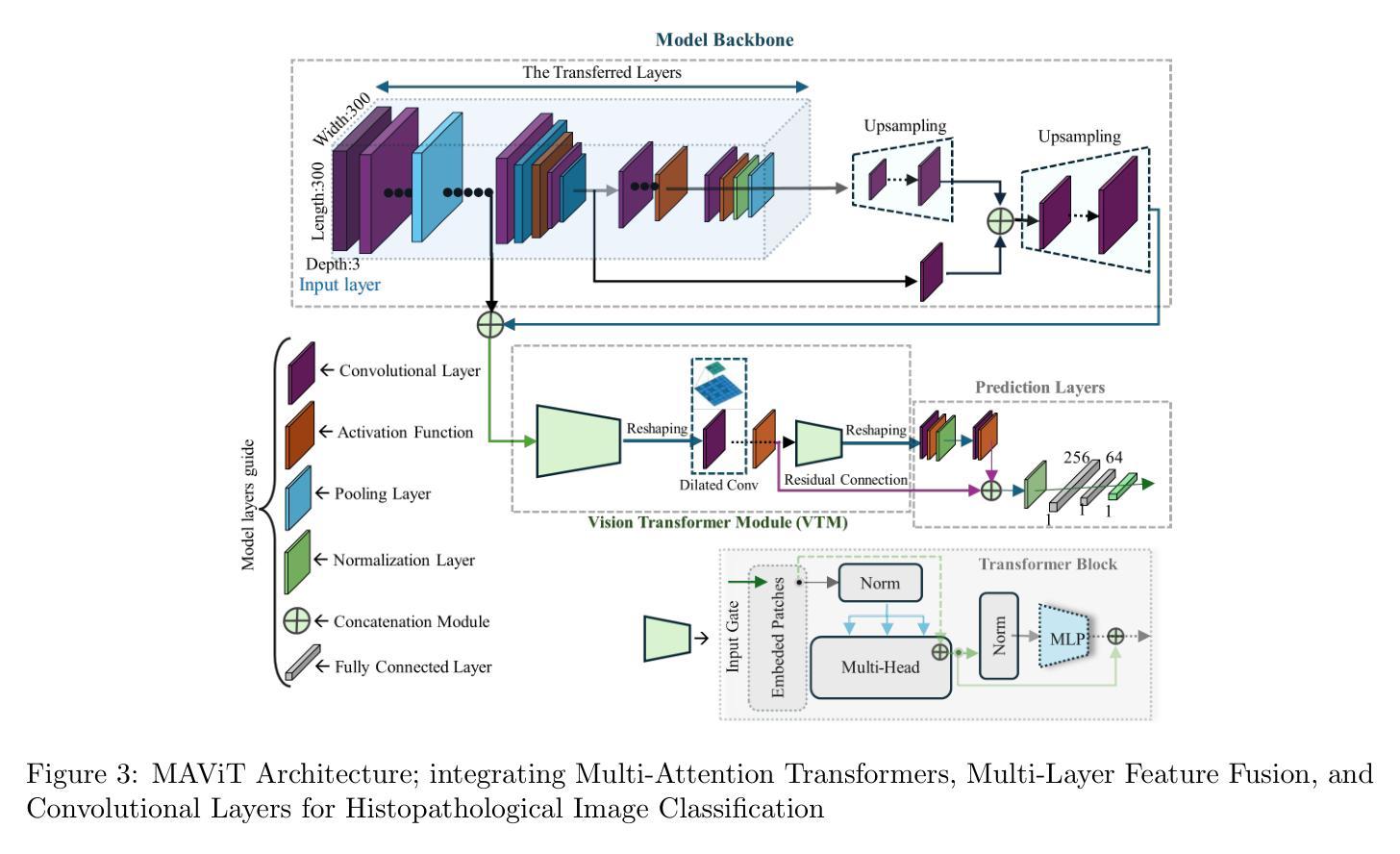
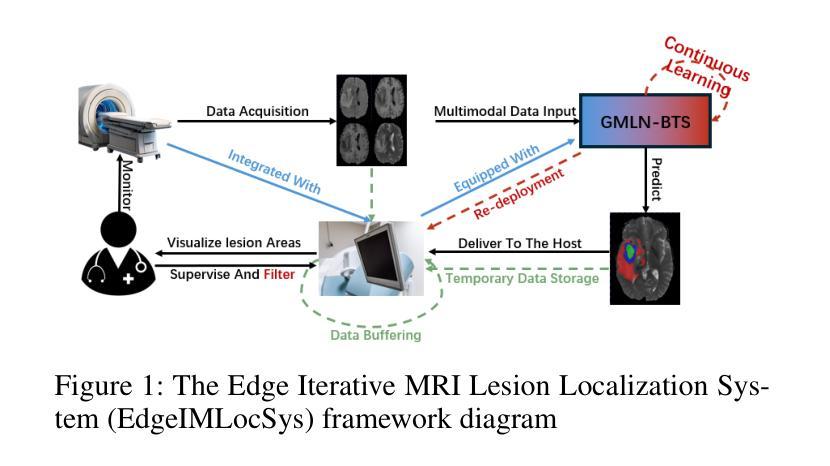
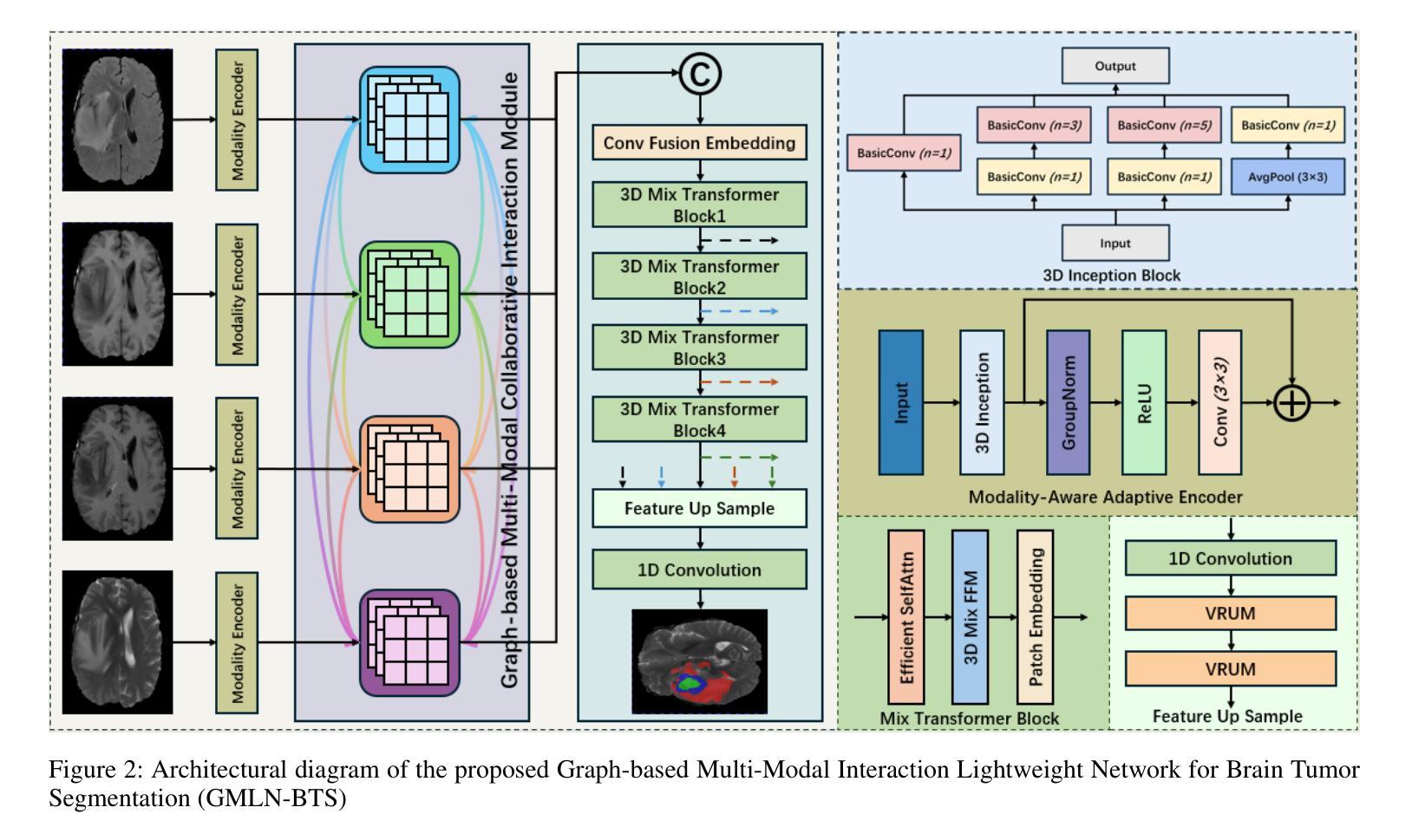
Graph-based Multi-Modal Interaction Lightweight Network for Brain Tumor Segmentation (GMLN-BTS) in Edge Iterative MRI Lesion Localization System (EdgeIMLocSys)
Authors:Guohao Huo, Ruiting Dai, Hao Tang
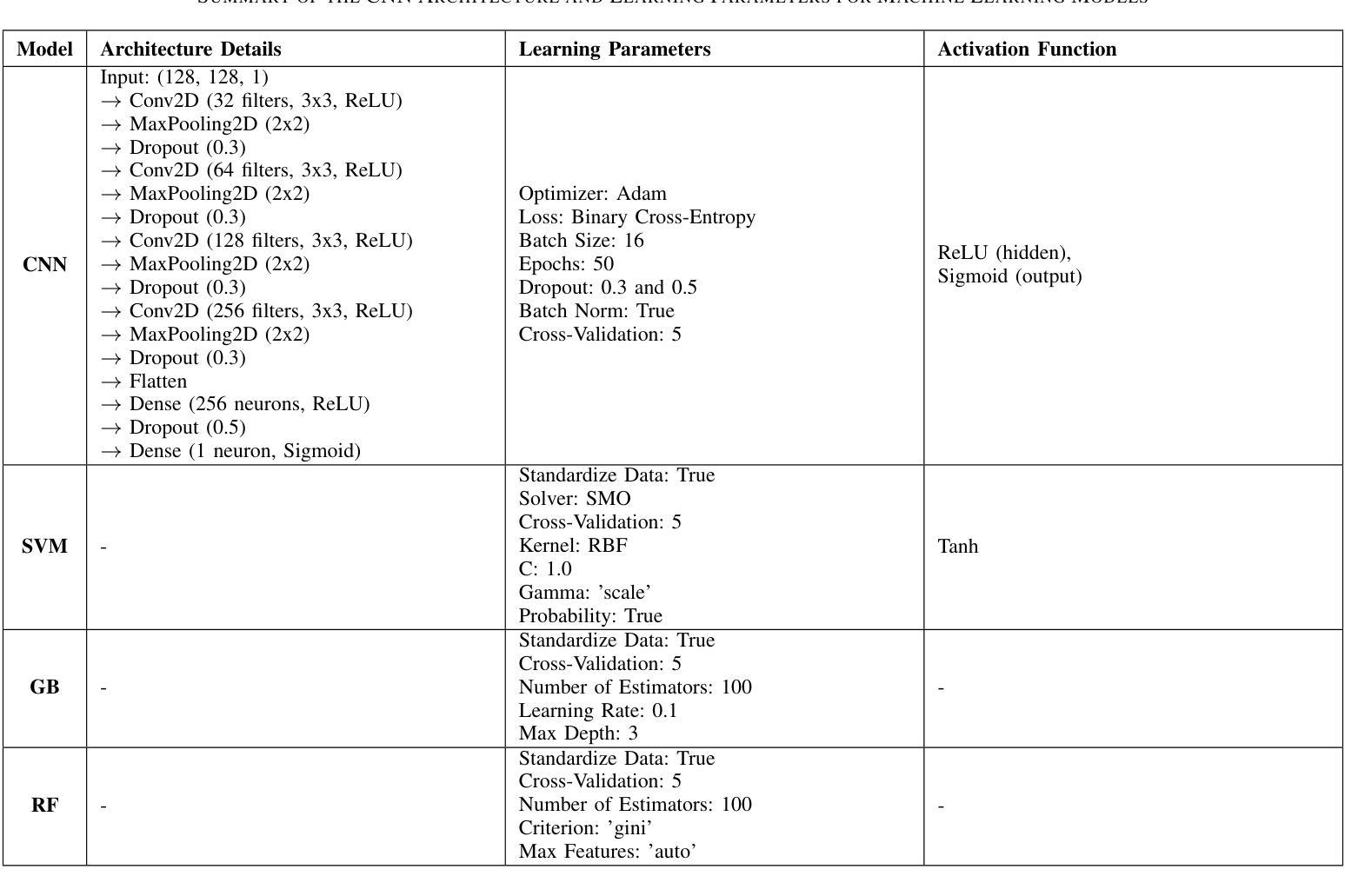
Brain tumor segmentation plays a critical role in clinical diagnosis and treatment planning, yet the variability in imaging quality across different MRI scanners presents significant challenges to model generalization. To address this, we propose the Edge Iterative MRI Lesion Localization System (EdgeIMLocSys), which integrates Continuous Learning from Human Feedback to adaptively fine-tune segmentation models based on clinician feedback, thereby enhancing robustness to scanner-specific imaging characteristics. Central to this system is the Graph-based Multi-Modal Interaction Lightweight Network for Brain Tumor Segmentation (GMLN-BTS), which employs a Modality-Aware Adaptive Encoder (M2AE) to extract multi-scale semantic features efficiently, and a Graph-based Multi-Modal Collaborative Interaction Module (G2MCIM) to model complementary cross-modal relationships via graph structures. Additionally, we introduce a novel Voxel Refinement UpSampling Module (VRUM) that synergistically combines linear interpolation and multi-scale transposed convolutions to suppress artifacts while preserving high-frequency details, improving segmentation boundary accuracy. Our proposed GMLN-BTS model achieves a Dice score of 85.1% on the BraTS2017 dataset with only 4.58 million parameters, representing a 98% reduction compared to mainstream 3D Transformer models, and significantly outperforms existing lightweight approaches. This work demonstrates a synergistic breakthrough in achieving high-accuracy, resource-efficient brain tumor segmentation suitable for deployment in resource-constrained clinical environments.
脑肿瘤分割在临床诊断和治疗计划制定中起着至关重要的作用,然而,不同MRI扫描仪成像质量的差异给模型通用化带来了重大挑战。为了解决这一问题,我们提出了边缘迭代MRI病变定位系统(EdgeIMLocSys),该系统通过整合人类反馈的连续学习来自适应微调分割模型,根据临床医生反馈提高系统对扫描仪特定成像特性的稳健性。该系统的核心是基于图的轻量级多模态交互网络脑肿瘤分割模型(GMLN-BTS),它采用模态感知自适应编码器(M2AE)高效提取多尺度语义特征,并利用基于图的跨模态协同交互模块(G2MCIM)通过图结构对互补跨模态关系进行建模。此外,我们还引入了一种新型的体素细化上采样模块(VRUM),该模块协同结合线性插值和多尺度转置卷积,在保留高频细节的同时抑制伪影,提高了分割边界的准确性。我们提出的GMLN-BTS模型在BraTS2017数据集上实现了85.1%的Dice得分,并且仅有458万个参数,相比主流的3D Transformer模型减少了98%,并且在轻量级方法中显著表现出优越性。这项工作证明了实现适合资源受限临床环境中的高精度、资源高效的脑肿瘤分割的协同突破。
论文及项目相关链接
Summary
针对MRI扫描仪之间成像质量差异对脑肿瘤分割模型通用化的挑战,提出EdgeIMLocSys系统。该系统通过整合人类反馈的持续学习,自适应微调分割模型,提高对不同扫描仪成像特性的稳健性。核心为GMLN-BTS网络,采用M2AE有效提取多尺度语义特征,并通过G2MCIM图结构模块进行跨模态协同交互。引入VRUM模块,结合线性插值和多尺度转置卷积,提高分割边界精度。GMLN-BTS模型在BraTS2017数据集上实现85.1%的Dice得分,参数仅4.58百万,显著优于现有轻量化方法。
Key Takeaways
- EdgeIMLocSys系统解决了不同MRI扫描仪成像质量差异对脑肿瘤分割模型通用化的挑战。
- 系统通过整合人类反馈的持续学习,提高模型的稳健性。
- GMLN-BTS网络是系统的核心,包含M2AE和G2MCIM两个关键模块。
- M2AE有效提取多尺度语义特征,G2MCIM则通过图结构进行跨模态协同交互。
- 引入VRUM模块,结合线性插值和转置卷积,提高分割边界精度。
- GMLN-BTS模型在BraTS2017数据集上表现优异,实现了高准确率。
点此查看论文截图

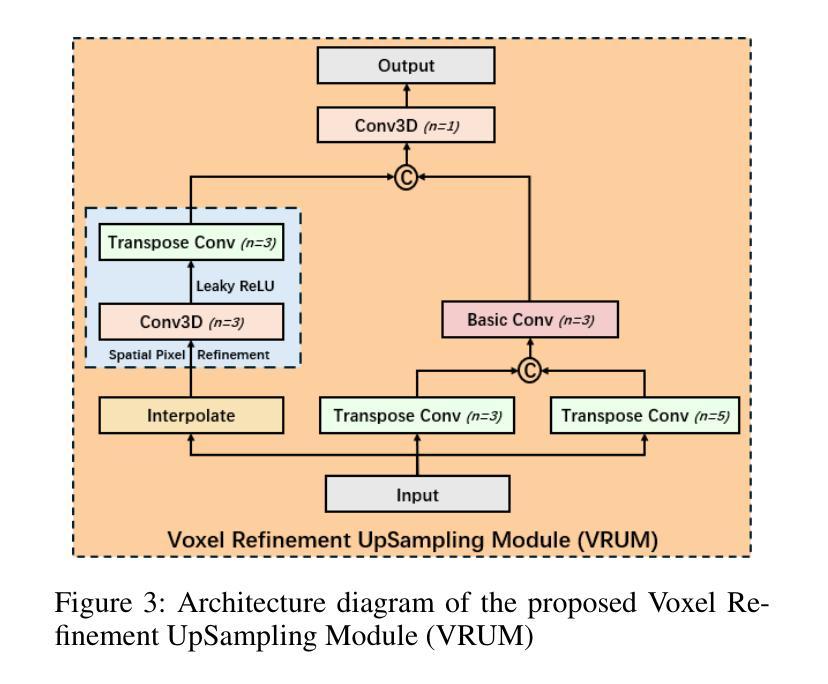
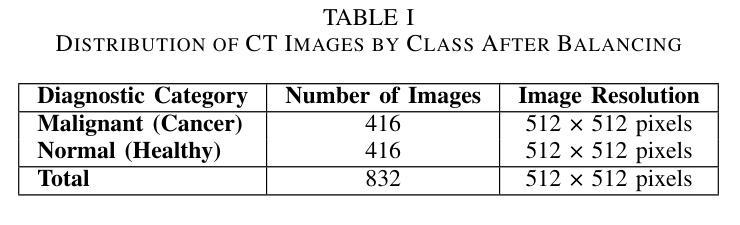
Advanced U-Net Architectures with CNN Backbones for Automated Lung Cancer Detection and Segmentation in Chest CT Images
Authors:Alireza Golkarieha, Kiana Kiashemshakib, Sajjad Rezvani Boroujenic, Nasibeh Asadi Isakand
This study investigates the effectiveness of U-Net architectures integrated with various convolutional neural network (CNN) backbones for automated lung cancer detection and segmentation in chest CT images, addressing the critical need for accurate diagnostic tools in clinical settings. A balanced dataset of 832 chest CT images (416 cancerous and 416 non-cancerous) was preprocessed using Contrast Limited Adaptive Histogram Equalization (CLAHE) and resized to 128x128 pixels. U-Net models were developed with three CNN backbones: ResNet50, VGG16, and Xception, to segment lung regions. After segmentation, CNN-based classifiers and hybrid models combining CNN feature extraction with traditional machine learning classifiers (Support Vector Machine, Random Forest, and Gradient Boosting) were evaluated using 5-fold cross-validation. Metrics included accuracy, precision, recall, F1-score, Dice coefficient, and ROC-AUC. U-Net with ResNet50 achieved the best performance for cancerous lungs (Dice: 0.9495, Accuracy: 0.9735), while U-Net with VGG16 performed best for non-cancerous segmentation (Dice: 0.9532, Accuracy: 0.9513). For classification, the CNN model using U-Net with Xception achieved 99.1 percent accuracy, 99.74 percent recall, and 99.42 percent F1-score. The hybrid CNN-SVM-Xception model achieved 96.7 percent accuracy and 97.88 percent F1-score. Compared to prior methods, our framework consistently outperformed existing models. In conclusion, combining U-Net with advanced CNN backbones provides a powerful method for both segmentation and classification of lung cancer in CT scans, supporting early diagnosis and clinical decision-making.
本研究探讨了结合不同卷积神经网络(CNN)骨干的U-Net架构在胸部CT图像中自动检测与分割肺癌的有效性,这解决了临床环境中对准确诊断工具的关键需求。使用对比限制自适应直方图均衡化(CLAHE)对包含832张胸部CT图像(其中416张为癌变,416张为非癌变)的平衡数据集进行预处理,并将其大小调整为128x128像素。本研究开发了三种使用ResNet50、VGG16和Xception作为骨干的U-Net模型来分割肺部区域。分割后,基于CNN的分类器以及结合CNN特征提取与传统机器学习分类器(支持向量机、随机森林和梯度增强)的混合模型,使用五折交叉验证进行评估。评价指标包括准确度、精确度、召回率、F1分数、Dice系数和ROC-AUC。使用ResNet50的U-Net在癌变肺部检测方面表现最佳(Dice:0.9495,准确度:0.9735),而使用VGG16的U-Net在非癌变分割方面表现最佳(Dice:0.9532,准确度:0.9513)。在分类方面,使用Xception的CNN模型实现了99.1%的准确度、99.74%的召回率和99.42%的F1分数。混合CNN-SVM-Xception模型实现了96.7%的准确度和97.88%的F1分数。与先前的方法相比,我们的框架始终优于现有模型。总之,将U-Net与先进的CNN骨干相结合,为CT扫描中的肺癌分割和分类提供了一种强大的方法,支持早期诊断和临床决策。
论文及项目相关链接
PDF This manuscript has 20 pages and 10 figures. It is submitted to the Journal ‘Scientific Reports’
Summary
本研究利用U-Net架构结合不同的卷积神经网络(CNN)主干网络,对胸部CT图像中的肺癌进行自动检测和分割。研究采用均衡数据集,对图像进行预处理并调整大小,使用ResNet50、VGG16和Xception作为U-Net的主干进行肺区域分割。评估指标包括准确度、精确度、召回率、F1分数、Dice系数和ROC-AUC。U-Net与ResNet50的结合在癌症肺部表现最佳,而U-Net与VGG16的结合在非癌症分割中表现最佳。分类任务中,使用U-Net与Xception的CNN模型表现突出。与先前方法相比,本研究框架始终优于现有模型,为肺癌的早期诊断和临床决策提供有力支持。
Key Takeaways
- 研究使用U-Net架构与多种CNN主干网络结合,用于自动检测与分割胸部CT图像中的肺癌。
- 采用均衡数据集并进行预处理,以适应模型训练。
- U-Net与ResNet50组合在癌症肺部分割中表现最佳,而U-Net与VGG16组合在非癌症分割中最佳。
- 在分类任务中,使用U-Net与Xception的CNN模型表现出高准确性。
- 提出的框架相较于先前的方法有优异表现。
- 结合U-Net与先进的CNN主干网络为肺癌的分割和分类提供了强大方法。
点此查看论文截图

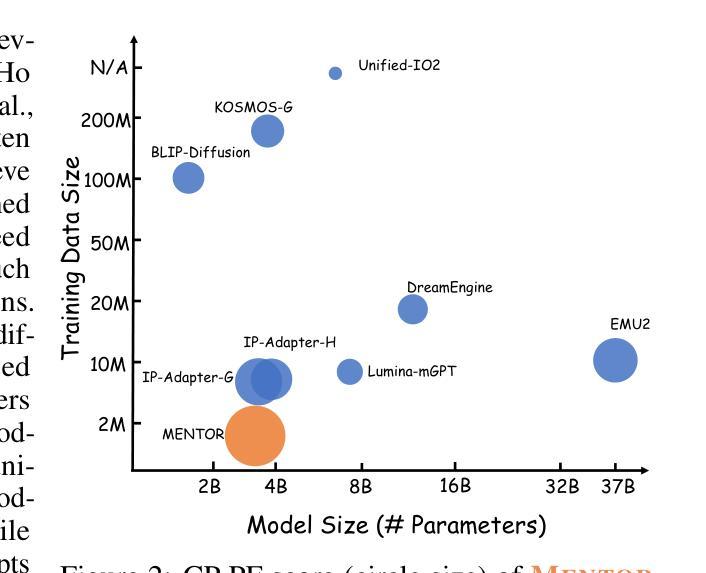
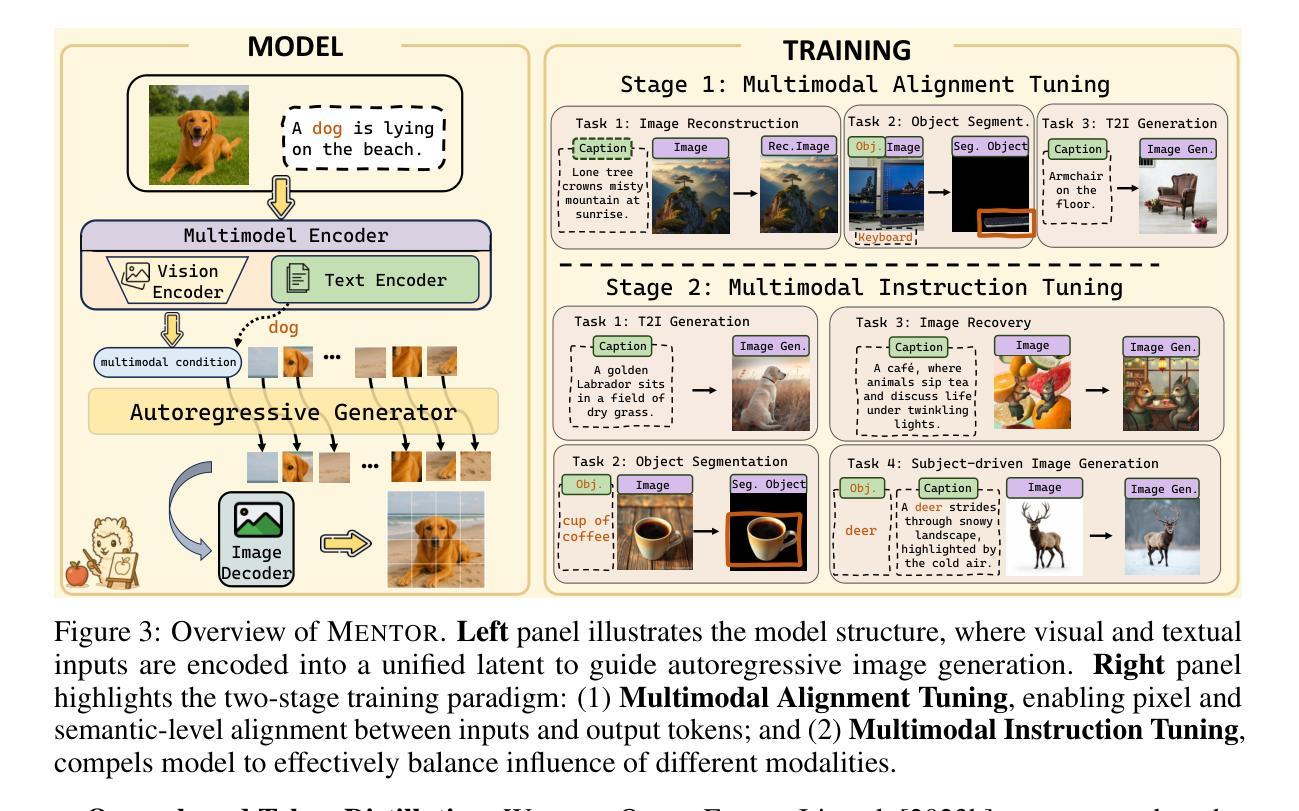
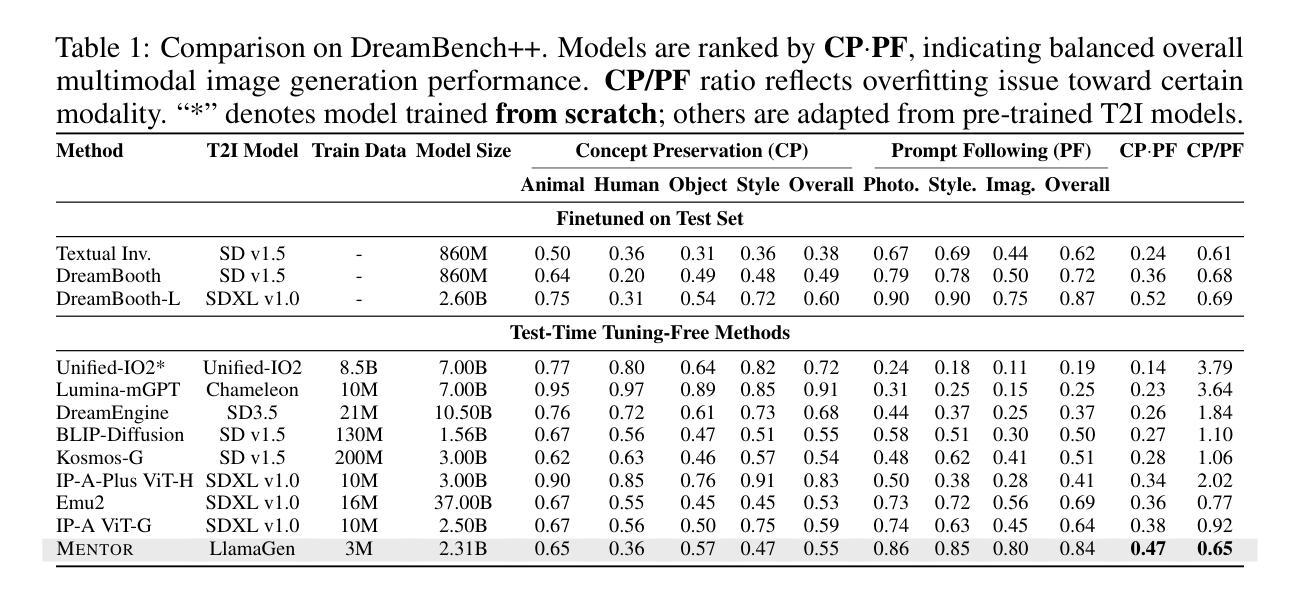
MENTOR: Efficient Multimodal-Conditioned Tuning for Autoregressive Vision Generation Models
Authors:Haozhe Zhao, Zefan Cai, Shuzheng Si, Liang Chen, Jiuxiang Gu, Wen Xiao, Junjie Hu
Recent text-to-image models produce high-quality results but still struggle with precise visual control, balancing multimodal inputs, and requiring extensive training for complex multimodal image generation. To address these limitations, we propose MENTOR, a novel autoregressive (AR) framework for efficient Multimodal-conditioned Tuning for Autoregressive multimodal image generation. MENTOR combines an AR image generator with a two-stage training paradigm, enabling fine-grained, token-level alignment between multimodal inputs and image outputs without relying on auxiliary adapters or cross-attention modules. The two-stage training consists of: (1) a multimodal alignment stage that establishes robust pixel- and semantic-level alignment, followed by (2) a multimodal instruction tuning stage that balances the integration of multimodal inputs and enhances generation controllability. Despite modest model size, suboptimal base components, and limited training resources, MENTOR achieves strong performance on the DreamBench++ benchmark, outperforming competitive baselines in concept preservation and prompt following. Additionally, our method delivers superior image reconstruction fidelity, broad task adaptability, and improved training efficiency compared to diffusion-based methods. Dataset, code, and models are available at: https://github.com/HaozheZhao/MENTOR
最近的文本到图像模型产生了高质量的结果,但在精确视觉控制、平衡多模式输入和复杂多模式图像生成的广泛训练方面仍存在困难。为了解决这些局限性,我们提出了MENTOR,这是一种用于高效多模式条件调整的自回归(AR)框架,用于自回归多模式图像生成。MENTOR结合AR图像生成器和两阶段训练范式,能够在不依赖辅助适配器或交叉注意模块的情况下,实现多模式输入和图像输出之间的细粒度、令牌级对齐。两阶段训练包括:(1)多模式对齐阶段,建立稳健的像素和语义级对齐,然后是(2)多模式指令调整阶段,平衡多模式输入的集成,增强生成的可控性。尽管模型规模适中,基础组件不够理想,且训练资源有限,但MENTOR在DreamBench++基准测试上表现出强大的性能,在概念保留和提示遵循方面超越了竞争基准。此外,我们的方法在图像重建保真度、广泛的任务适应性和训练效率方面优于基于扩散的方法。数据集、代码和模型可在https://github.com/HaozheZhao/MENTOR找到。
论文及项目相关链接
PDF 24 pages,12 figures
Summary
本文提出了一种名为MENTOR的新型自回归(AR)框架,用于高效的多模态条件调节自回归多模态图像生成。该框架结合了AR图像生成器和两阶段训练模式,能够在不使用辅助适配器或交叉注意力模块的情况下,实现多模态输入和图像输出之间的精细粒度、令牌级对齐。该框架解决了现有文本到图像模型在精确视觉控制、平衡多模态输入和复杂多模态图像生成的训练需求方面的问题。
Key Takeaways
- MENTOR是一个自回归(AR)框架,用于多模态图像生成。
- 它通过结合AR图像生成器和两阶段训练模式实现高效的多模态条件调节。
- MENTOR实现了多模态输入和图像输出之间的精细粒度、令牌级对齐。
- 该框架通过两阶段训练过程,包括多模态对齐阶段和多模态指令调整阶段。
- MENTOR在DreamBench++基准测试上表现出强大的性能,优于竞争对手基线,在概念保留和提示遵循方面。
- 该方法在图像重建保真度、广泛的任务适应性和训练效率方面均优于基于扩散的方法。
- 数据集、代码和模型可在https://github.com/HaozheZhao/MENTOR上获得。
点此查看论文截图

AlphaVAE: Unified End-to-End RGBA Image Reconstruction and Generation with Alpha-Aware Representation Learning
Authors:Zile Wang, Hao Yu, Jiabo Zhan, Chun Yuan
Recent advances in latent diffusion models have achieved remarkable results in high-fidelity RGB image synthesis by leveraging pretrained VAEs to compress and reconstruct pixel data at low computational cost. However, the generation of transparent or layered content (RGBA image) remains largely unexplored, due to the lack of large-scale benchmarks. In this work, we propose ALPHA, the first comprehensive RGBA benchmark that adapts standard RGB metrics to four-channel images via alpha blending over canonical backgrounds. We further introduce ALPHAVAE, a unified end-to-end RGBA VAE that extends a pretrained RGB VAE by incorporating a dedicated alpha channel. The model is trained with a composite objective that combines alpha-blended pixel reconstruction, patch-level fidelity, perceptual consistency, and dual KL divergence constraints to ensure latent fidelity across both RGB and alpha representations. Our RGBA VAE, trained on only 8K images in contrast to 1M used by prior methods, achieves a +4.9 dB improvement in PSNR and a +3.2% increase in SSIM over LayerDiffuse in reconstruction. It also enables superior transparent image generation when fine-tuned within a latent diffusion framework. Our code, data, and models are released on https://github.com/o0o0o00o0/AlphaVAE for reproducibility.
最近,潜在扩散模型(latent diffusion models)的进步在高保真RGB图像合成方面取得了显著成果,通过利用预训练的变分自编码器(VAEs)以较低的计算成本压缩和重建像素数据。然而,由于缺乏大规模基准测试,透明或分层内容(RGBA图像)的生成仍然未被充分探索。在这项工作中,我们提出了ALPHA,这是第一个适应标准RGB指标的全面RGBA基准测试,通过标准背景的alpha混合将其应用于四通道图像。我们还介绍了ALPHAVAE,这是一种统一的端到端RGBA变分自编码器(VAE),它通过引入专用的alpha通道扩展了预训练的RGB VAE。该模型采用组合目标进行训练,结合了alpha混合像素重建、补丁级别的保真度、感知一致性和双重KL散度约束,以确保RGB和alpha表示中的潜在保真度。我们的RGBA VAE仅使用8K图像进行训练,而先前的方法使用了1M图像。相比之下,它在PSNR上提高了4.9 dB,在SSIM上提高了3.2%。在潜在扩散框架内进行微调时,它还能够实现更出色的透明图像生成。我们的代码、数据和模型已在https://github.com/o0o0o00o0/AlphaVAE上发布,以确保可重复性。
论文及项目相关链接
Summary
本文介绍了利用潜在扩散模型在RGBA图像合成方面的最新进展。提出了一种新的RGBA基准测试ALPHA,以及一个统一的端到端RGBA VAE模型ALPHAVAE。该模型通过融入专门的alpha通道,扩展了预训练的RGB VAE。通过复合目标函数训练模型,实现了RGBA和alpha表示的潜在保真度。相较于先前的方法,仅在8K图像上训练的ALPHAVAE在重建任务上取得了显著的改进。
Key Takeaways
- 潜在扩散模型在RGBA图像合成方面取得了显著进展,利用预训练的VAE以低计算成本压缩和重建像素数据。
- 缺乏大规模基准测试是透明或分层内容生成(RGBA图像)的主要挑战。
- 提出了首个RGBA基准测试ALPHA,该测试通过alpha混合在标准背景上适应标准RGB指标。
- 介绍了ALPHAVAE,这是一个统一的端到端RGBA VAE模型,通过融入alpha通道扩展了预训练的RGB VAE。
- ALPHAVAE模型通过复合目标函数进行训练,包括alpha混合像素重建、补丁级别的保真度、感知一致性和双重KL散度约束。
- 在仅使用8K图像训练的ALPHAVAE在重建任务上较之前的方法有了显著改善,实现了PSNR的+4.9 dB提升和SSIM的+3.2%增长。
- ALPHAVAE在潜在扩散框架内进行微调后,能够实现更优质的透明图像生成。
点此查看论文截图


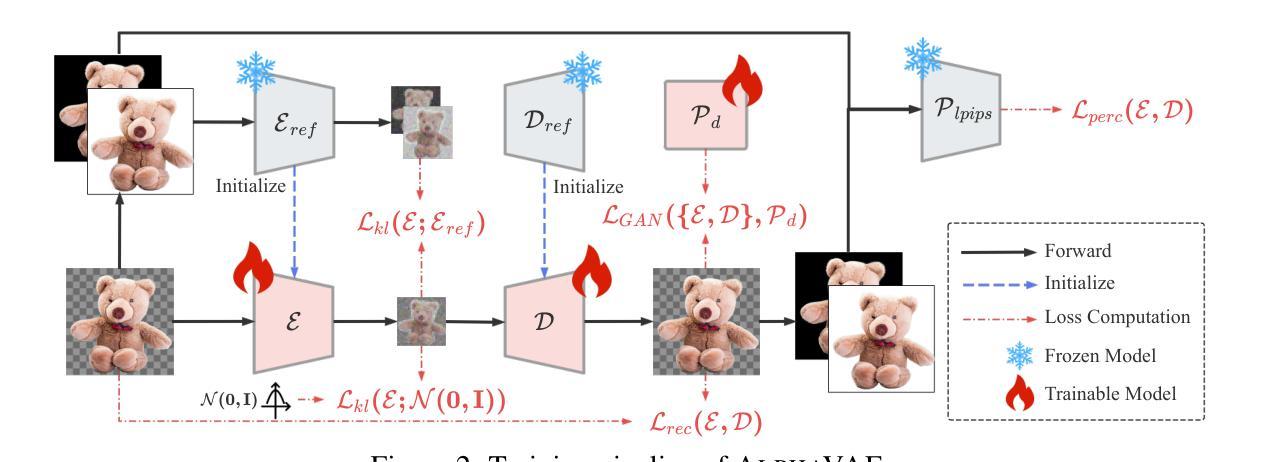
Calibrated and Robust Foundation Models for Vision-Language and Medical Image Tasks Under Distribution Shift
Authors:Behraj Khan, Tahir Syed
Foundation models like CLIP and SAM have transformed computer vision and medical imaging via low-shot transfer learning. However, deployment of these models hindered by two key challenges: \textit{distribution shift} between training and test data, and \textit{confidence misalignment} that leads to overconfident incorrect predictions. These issues manifest differently in vision-language classification and medical segmentation tasks, yet existing solutions remain domain-specific. We propose \textit{StaRFM}, a unified framework addressing both challenges. It introduces a Fisher information penalty (FIP), extended to 3D medical data via patch-wise regularization, to reduce covariate shift in CLIP and SAM embeddings. Additionally, a confidence misalignment penalty (CMP), reformulated for voxel-level predictions, calibrates uncertainty in segmentation tasks. We theoretically derive PAC-Bayes bounds showing FIP controls generalization via the Fisher-Rao norm, while CMP minimizes calibration error through Brier score optimization. StaRFM shows consistent performance like \texttt{+}3.5% accuracy and 28% lower ECE on 19 vision datasets (e.g., ImageNet, Office-Home), 84.7% DSC and 4.8mm HD95 in medical segmentation (e.g., BraTS, ATLAS), and 40% lower cross-domain performance gap compared to prior benchmarking methods. The framework is plug-and-play, requiring minimal architectural changes for seamless integration with foundation models. Code and models will be released at https://anonymous.4open.science/r/StaRFM-C0CD/README.md
类似CLIP和SAM的基石模型已通过小样本迁移学习转变了计算机视觉和医学影像领域。然而,这些模型的部署受到两个关键挑战的影响:训练数据和测试数据之间的分布偏移,以及导致过于自信的预测错误的置信度不匹配。这些问题在视觉语言分类和医学分割任务中表现出不同的形式,但现有解决方案仍然仅限于特定领域。我们提出了一个统一的框架StaRFM,旨在解决这两个挑战。它引入了一个Fisher信息惩罚(FIP),通过补丁级正则化扩展到3D医学数据,以减少CLIP和SAM嵌入中的协变量偏移。此外,针对体素级预测的置信度不匹配惩罚(CMP)校准了分割任务中的不确定性。我们从理论上推导了PAC-Bayes边界,显示FIP通过Fisher-Rao范数控制泛化,而CMP通过Brier得分优化最小化校准误差。StaRFM在19个视觉数据集(例如ImageNet、Office-Home)上表现出一致的性能,如提高+3.5%的准确性和降低28%的ECE,在医学分割(例如BraTS、ATLAS)方面,达到84.7%的DSC和4.8mm的HD95,与先前的基准方法相比,跨域性能差距降低了40%。该框架即插即用,无需对现有架构进行大量改动,即可无缝集成到基石模型中。代码和模型将在https://anonymous.4open.science/r/StaRFM-C0CD/README.md发布。
论文及项目相关链接
Summary
基于CLIP和SAM等基础模型,本文提出了StaRFM框架来解决计算机视觉和医学成像中遇到的两大挑战:训练与测试数据间的分布偏移和信心不匹配导致的过度自信错误预测。通过引入Fisher信息惩罚(FIP)和置信度不匹配惩罚(CMP),该框架有效减少了基础模型中的协变量偏移,并校准了分割任务中的不确定性。实验结果显示,StaRFM在视觉数据集和医学分割任务中均表现出卓越性能。
Key Takeaways
- 基础模型如CLIP和SAM已推动计算机视觉和医学成像的进步,但存在分布偏移和信心不匹配两大挑战。
- StaRFM框架旨在解决这两个问题,通过引入Fisher信息惩罚(FIP)减少协变量偏移,并用置信度不匹配惩罚(CMP)校准分割任务中的不确定性。
- FIP通过Fisher-Rao范数控制泛化,而CMP则通过Brier得分优化来最小化校准误差。
- StaRFM在多个视觉数据集和医学分割任务中表现出卓越性能,如提高准确率、降低过度自信预测等。
- 该框架具有即插即用特性,可无缝集成于基础模型,且对架构改动需求较小。
- 代码和模型将公开发布在指定链接。
点此查看论文截图

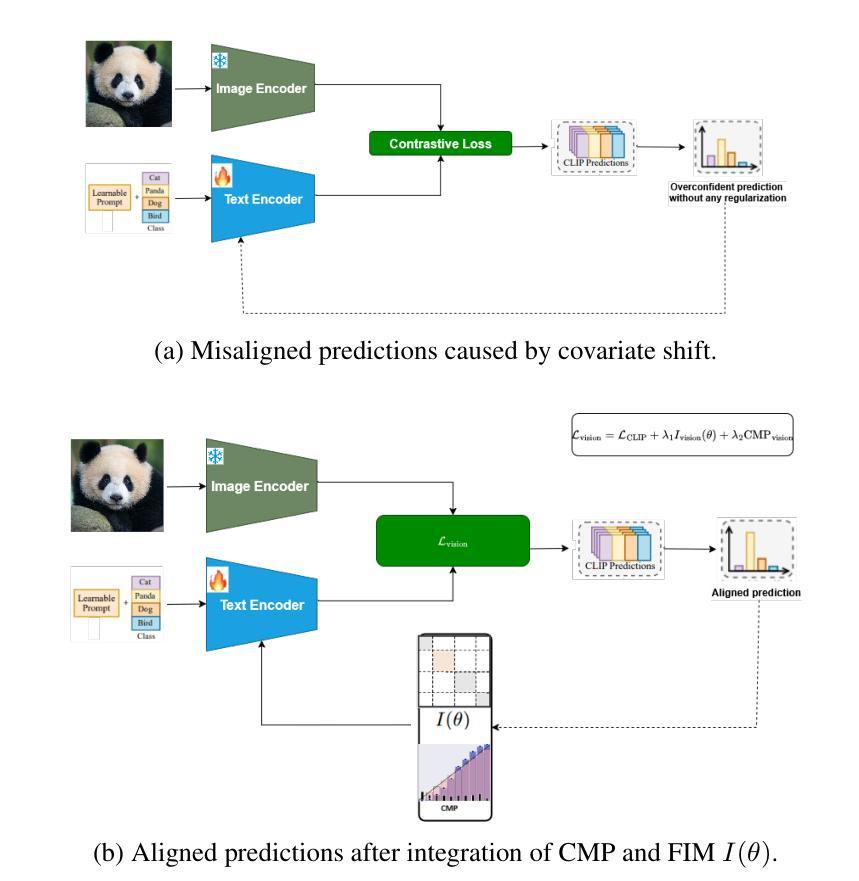
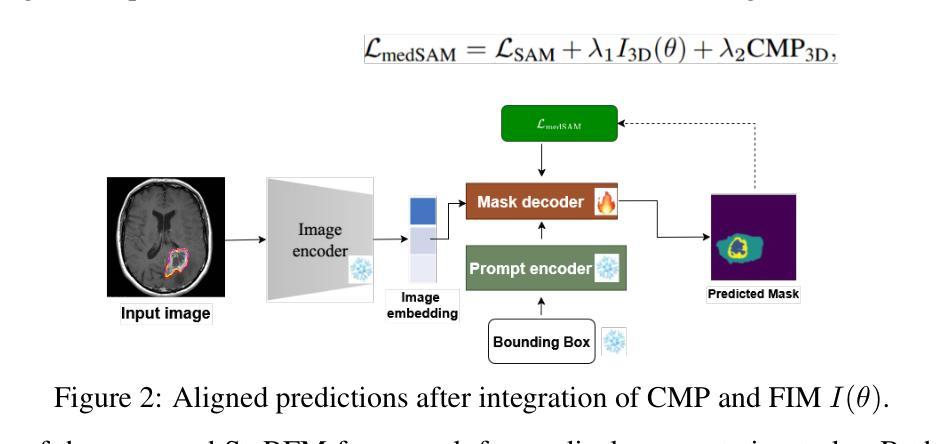

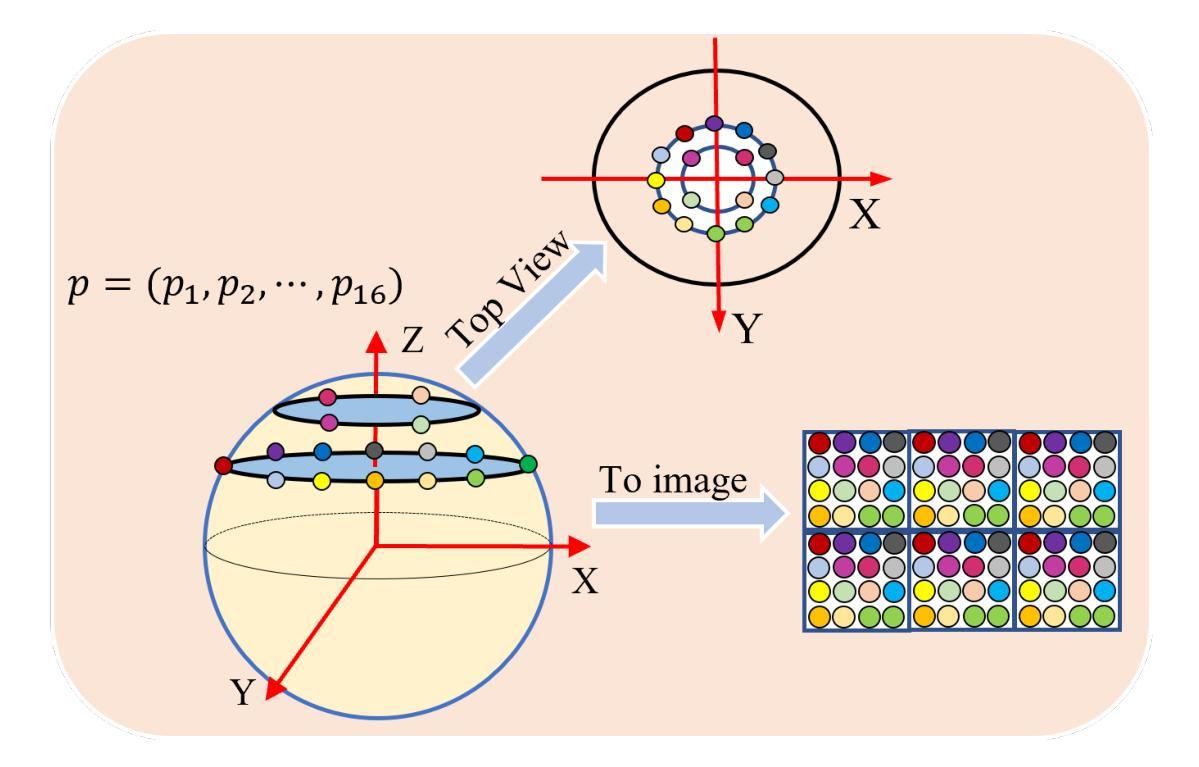
360-Degree Full-view Image Segmentation by Spherical Convolution compatible with Large-scale Planar Pre-trained Models
Authors:Jingguo Liu, Han Yu, Shigang Li, Jianfeng Li
Due to the current lack of large-scale datasets at the million-scale level, tasks involving panoramic images predominantly rely on existing two-dimensional pre-trained image benchmark models as backbone networks. However, these networks are not equipped to recognize the distortions and discontinuities inherent in panoramic images, which adversely affects their performance in such tasks. In this paper, we introduce a novel spherical sampling method for panoramic images that enables the direct utilization of existing pre-trained models developed for two-dimensional images. Our method employs spherical discrete sampling based on the weights of the pre-trained models, effectively mitigating distortions while achieving favorable initial training values. Additionally, we apply the proposed sampling method to panoramic image segmentation, utilizing features obtained from the spherical model as masks for specific channel attentions, which yields commendable results on commonly used indoor datasets, Stanford2D3D.
由于当前缺乏大规模百万级别的数据集,涉及全景图像的任务主要依赖于现有的二维预训练图像基准模型作为骨干网络。然而,这些网络并不具备识别全景图像固有的失真和断裂的能力,这对其在此类任务中的性能产生了不利影响。在本文中,我们为全景图像引入了一种新型球面采样方法,使得能够直接使用为二维图像开发的现有预训练模型。我们的方法基于预训练模型的权重采用球面离散采样,有效地缓解了失真问题,同时实现了良好的初始训练值。此外,我们将所提采样方法应用于全景图像分割,利用球面模型得到的特征作为特定通道注意力的掩膜,这在常用的室内数据集Stanford2D3D上取得了令人称赞的结果。
论文及项目相关链接
PDF This paper is accecpted by ICMEW 2025
Summary
针对全景图像任务缺乏大规模数据集的问题,本文提出一种新型球形采样方法,利用已有的二维预训练图像基准模型,通过球形离散采样和权重预处理,有效减轻全景图像的失真问题并实现较好的初始训练效果。此外,本文还将该采样方法应用于全景图像分割,利用球形模型特征作为特定通道注意力的掩膜,在常用的室内数据集Stanford2D3D上取得了良好效果。
Key Takeaways
- 全景图像任务缺乏大规模数据集,因此主要依赖现有的二维预训练图像基准模型。
- 现有的预训练模型无法识别全景图像的扭曲和不连续性,导致性能不佳。
- 本文提出了一种新型的球形采样方法,使现有预训练模型可直接应用于全景图像。
- 球形采样基于预训练模型的权重进行离散采样,有效减轻全景图像的失真问题。
- 本文方法在实现良好初始训练效果的同时,还应用于全景图像分割任务。
- 利用球形模型特征作为特定通道注意力的掩膜,提高了全景图像分割的效果。
点此查看论文截图


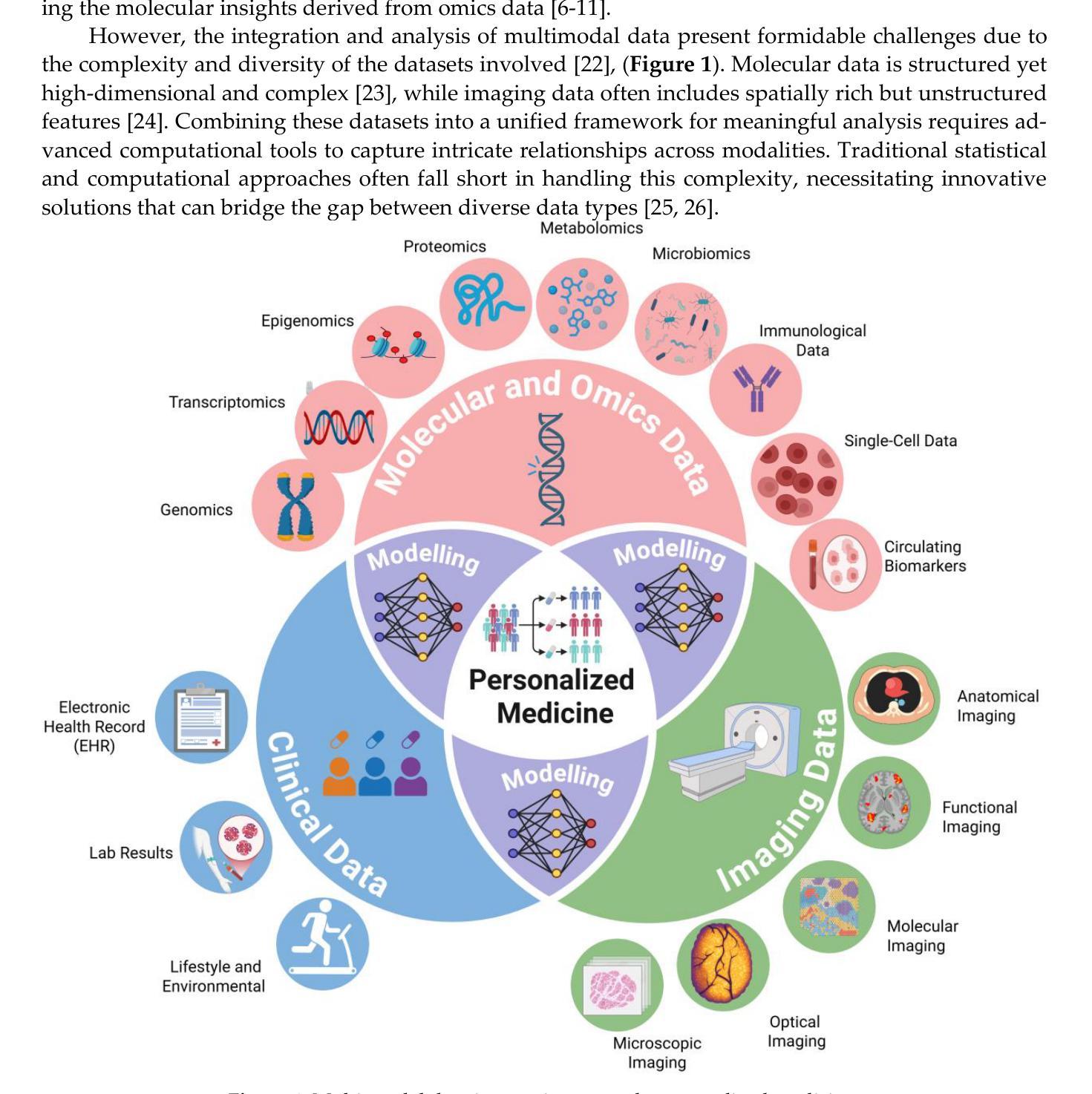
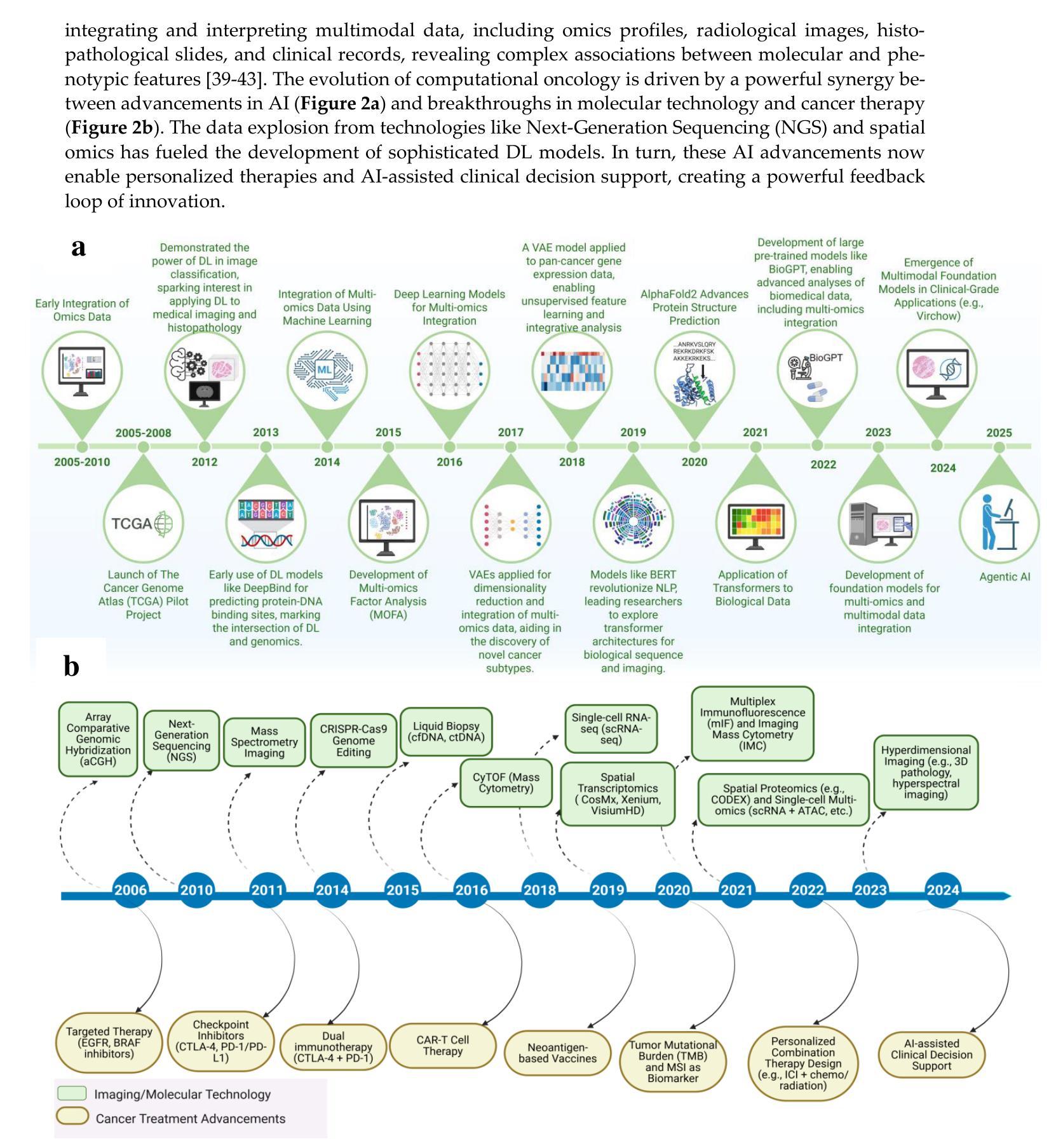
From Classical Machine Learning to Emerging Foundation Models: Review on Multimodal Data Integration for Cancer Research
Authors:Amgad Muneer, Muhammad Waqas, Maliazurina B Saad, Eman Showkatian, Rukhmini Bandyopadhyay, Hui Xu, Wentao Li, Joe Y Chang, Zhongxing Liao, Cara Haymaker, Luisa Solis Soto, Carol C Wu, Natalie I Vokes, Xiuning Le, Lauren A Byers, Don L Gibbons, John V Heymach, Jianjun Zhang, Jia Wu
Cancer research is increasingly driven by the integration of diverse data modalities, spanning from genomics and proteomics to imaging and clinical factors. However, extracting actionable insights from these vast and heterogeneous datasets remains a key challenge. The rise of foundation models (FMs) – large deep-learning models pretrained on extensive amounts of data serving as a backbone for a wide range of downstream tasks – offers new avenues for discovering biomarkers, improving diagnosis, and personalizing treatment. This paper presents a comprehensive review of widely adopted integration strategies of multimodal data to assist advance the computational approaches for data-driven discoveries in oncology. We examine emerging trends in machine learning (ML) and deep learning (DL), including methodological frameworks, validation protocols, and open-source resources targeting cancer subtype classification, biomarker discovery, treatment guidance, and outcome prediction. This study also comprehensively covers the shift from traditional ML to FMs for multimodal integration. We present a holistic view of recent FMs advancements and challenges faced during the integration of multi-omics with advanced imaging data. We identify the state-of-the-art FMs, publicly available multi-modal repositories, and advanced tools and methods for data integration. We argue that current state-of-the-art integrative methods provide the essential groundwork for developing the next generation of large-scale, pre-trained models poised to further revolutionize oncology. To the best of our knowledge, this is the first review to systematically map the transition from conventional ML to advanced FM for multimodal data integration in oncology, while also framing these developments as foundational for the forthcoming era of large-scale AI models in cancer research.
癌症研究正日益受到多种数据模态融合需求的推动,涵盖了基因组学、蛋白质组学、成像和临床因素等。然而,从大量且多样的数据集中提取可操作的见解仍然是一个关键挑战。随着预训练大规模数据的深度模型——基础模型(FMs)的兴起,它为发现生物标志物、改善诊断和个性化治疗提供了新的途径。本文全面回顾了广泛采用的多模态数据融合策略,旨在帮助推进肿瘤学数据驱动型发现的计算方法。我们研究了机器学习和深度学习的新兴趋势,包括方法论框架、验证协议以及针对癌症亚型分类、生物标志物发现、治疗指导和结果预测的开源资源。本文也全面概述了从传统的机器学习到FMs进行多模态融合的转变。我们提供了关于最近FMs发展和在多组学与高级成像数据融合过程中所面临的挑战的全面了解。我们确定了最先进的FMs、可公开访问的多模态存储库以及数据融合的高级工具和方法。我们认为,当前最先进的融合方法提供了开发下一代大型预训练模型的必要基础,有望进一步推动肿瘤学的革命。据我们所知,本文是对肿瘤学中从传统的机器学习到先进的FM用于多模态数据融合过渡的首次系统性回顾,同时将这些发展作为未来大规模癌症研究人工智能模型的基础。
论文及项目相关链接
PDF 6 figures, 3 tables
摘要
癌症研究正日益受到多模态数据整合的驱动,涵盖基因组学、蛋白质组学、成像和临床因素等多个领域。然而,从大量异质数据集中提取可操作的见解仍是关键挑战。随着预训练大量数据的深度学习模型——基础模型(FMs)的出现,为发现生物标志物、改进诊断和治疗个性化提供了新的途径。本文全面回顾了广泛采用的多模态数据整合策略,以协助推动肿瘤学数据驱动发现的计算方法。本文探讨了机器学习(ML)和深度学习(DL)的新兴趋势,包括方法论框架、验证协议和针对癌症亚型分类、生物标志物发现、治疗指导和结果预测的开源资源。本文还涵盖了从传统ML到FM的多模态整合转变。我们展示了最近的FM进展和面临的多组学与高级成像数据整合挑战。我们确定了最先进的FMs、可公开访问的多模式存储库以及数据整合的先进工具和方法。我们认为,当前最先进的整合方法为开发下一代大型预训练模型奠定了基础,这些模型将进一步推动肿瘤学的革命。据我们所知,这是第一篇系统回顾从传统的机器学习转向先进的FM用于肿瘤学多模态数据整合的论文,并将这些发展作为大规模AI模型在癌症研究中的新时代的基石。
关键见解
- 癌症研究正越来越多地依赖于多模态数据的整合,包括基因组学、蛋白质组学、成像和临床因素等。
- 从大量异质数据中提取可操作性的见解是当前的挑战之一。
- 基础模型(FMs)的出现为癌症研究中的生物标志物发现、诊断和治疗个性化提供了新的途径。
- 本文全面回顾了多模态数据整合的策略并探讨了机器学习(ML)和深度学习(DL)的新兴趋势。
- 文章强调了从传统ML到FM的转变,并展示了FM在癌症研究中的最新进展和挑战。
- 先进的FMs、多模态存储库以及数据整合的先进工具和方法的出现为未来的大规模AI模型在癌症研究中的应用奠定了基础。
- 当前的系统性回顾是首次对肿瘤学多模态数据整合中的机器学习转变进行梳理,为未来的研究提供了新的视角。
点此查看论文截图

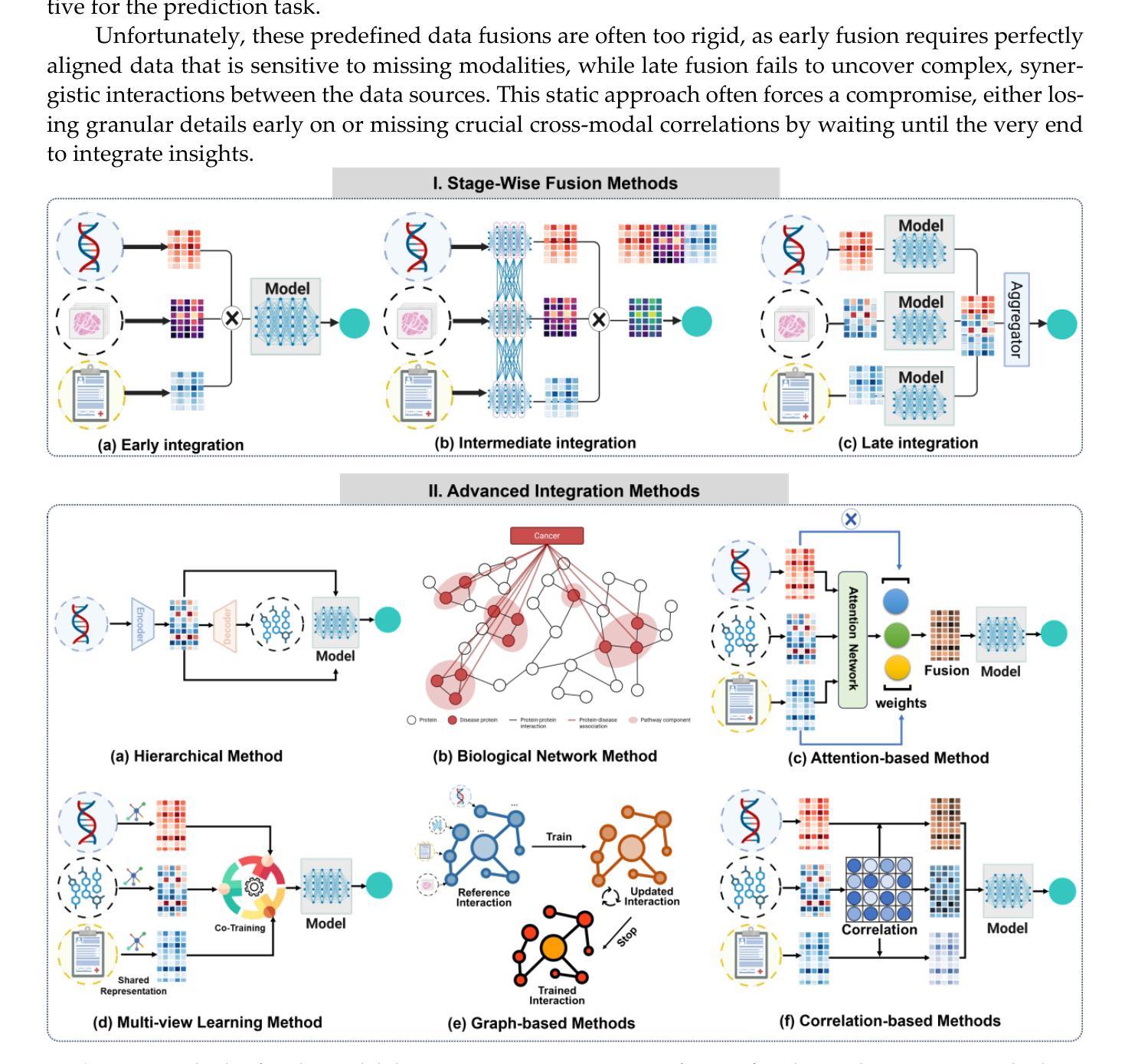
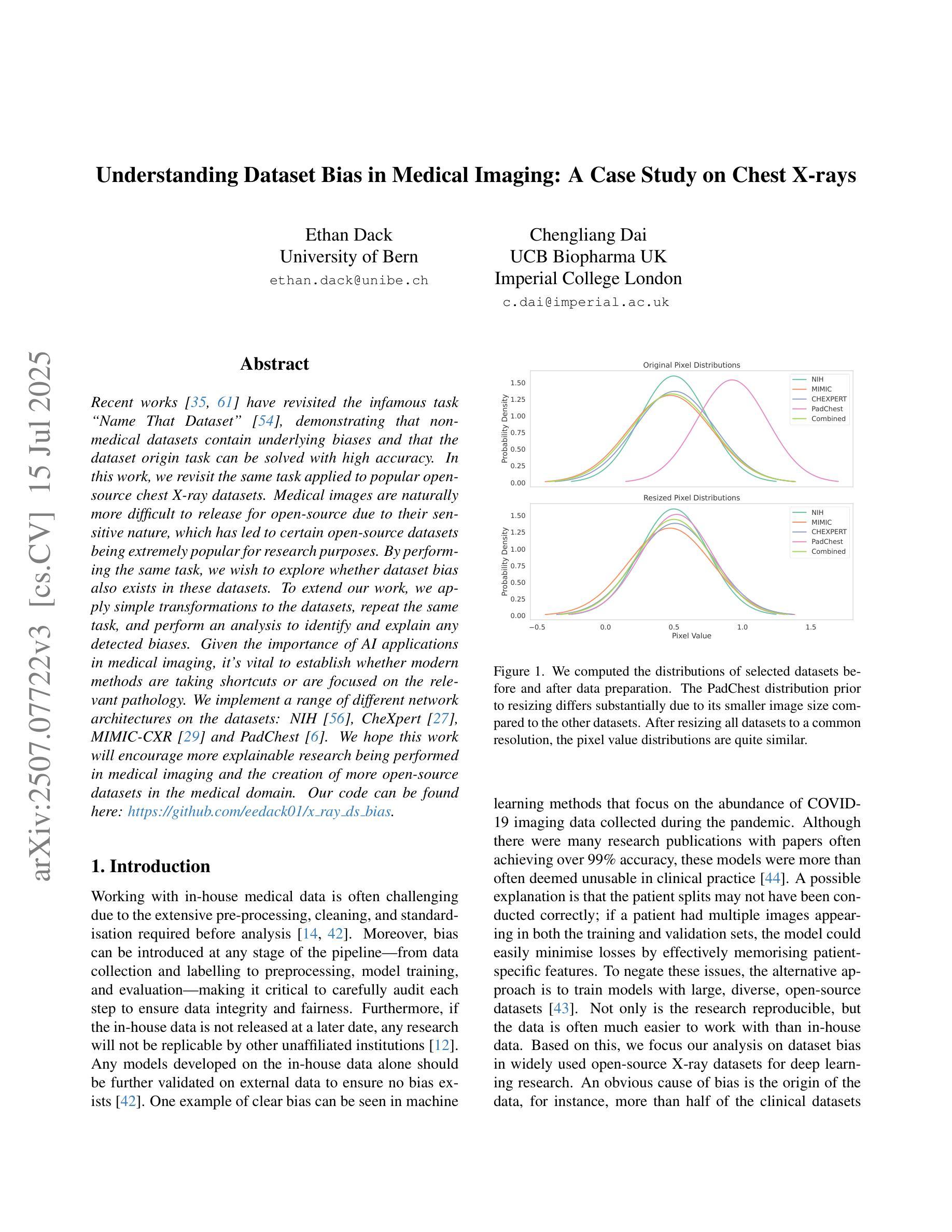
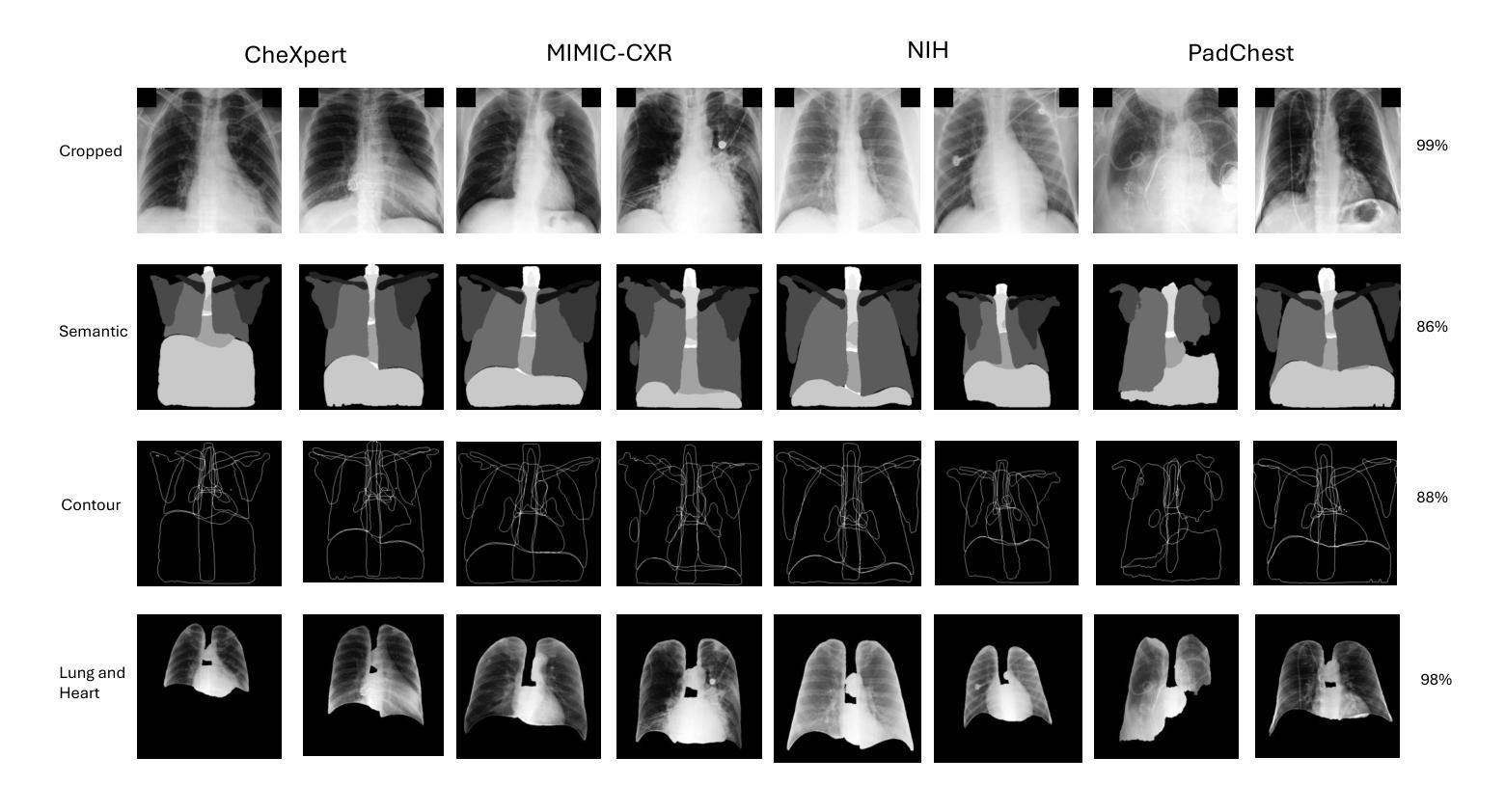
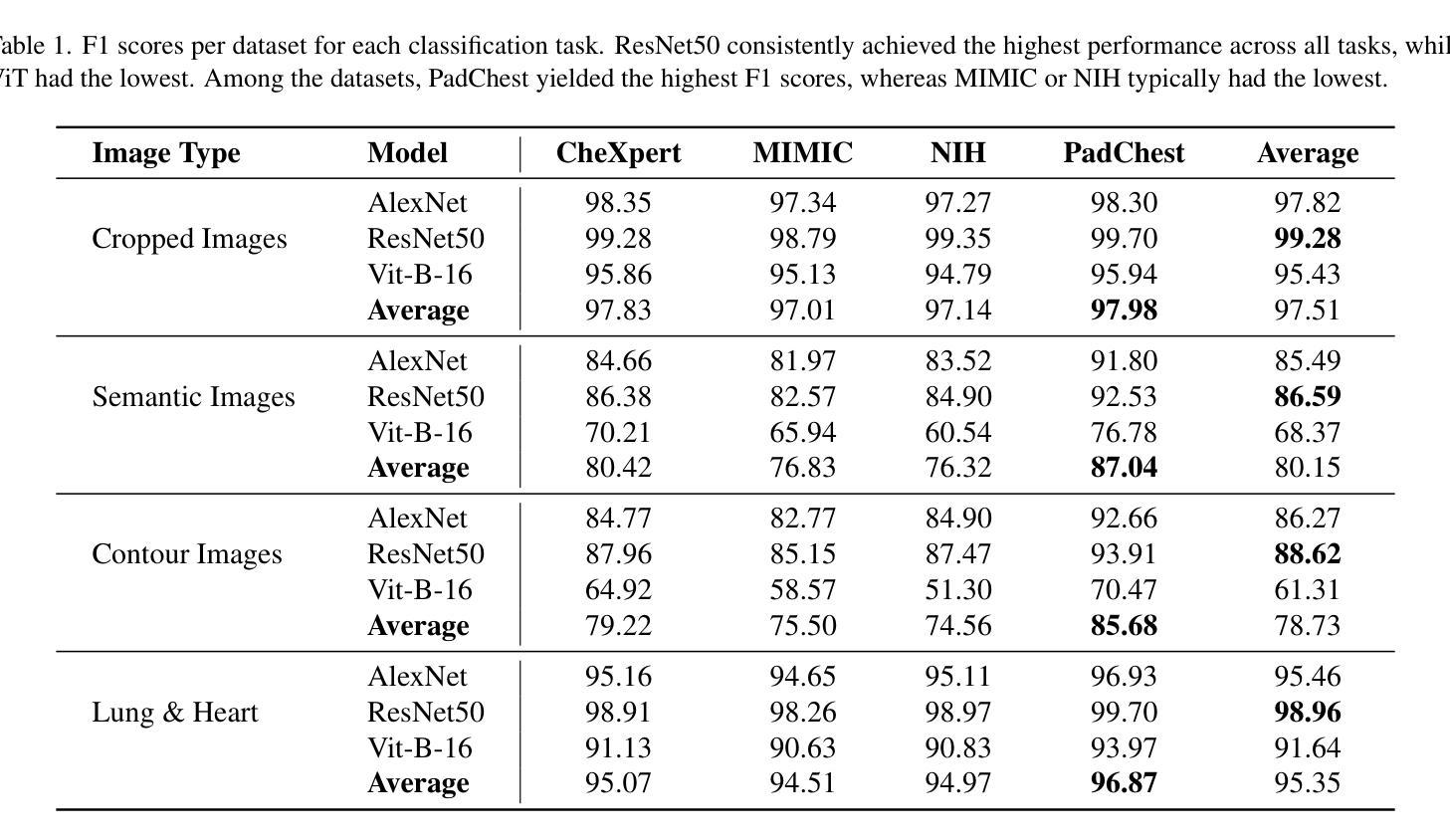
Understanding Dataset Bias in Medical Imaging: A Case Study on Chest X-rays
Authors:Ethan Dack, Chengliang Dai
Recent works have revisited the infamous task ``Name That Dataset’’, demonstrating that non-medical datasets contain underlying biases and that the dataset origin task can be solved with high accuracy. In this work, we revisit the same task applied to popular open-source chest X-ray datasets. Medical images are naturally more difficult to release for open-source due to their sensitive nature, which has led to certain open-source datasets being extremely popular for research purposes. By performing the same task, we wish to explore whether dataset bias also exists in these datasets. To extend our work, we apply simple transformations to the datasets, repeat the same task, and perform an analysis to identify and explain any detected biases. Given the importance of AI applications in medical imaging, it’s vital to establish whether modern methods are taking shortcuts or are focused on the relevant pathology. We implement a range of different network architectures on the datasets: NIH, CheXpert, MIMIC-CXR and PadChest. We hope this work will encourage more explainable research being performed in medical imaging and the creation of more open-source datasets in the medical domain. Our code can be found here: https://github.com/eedack01/x_ray_ds_bias.
近期的研究重新关注了“命名数据集”任务,表明非医学数据集存在潜在偏见,并且数据集起源任务可以高精度解决。在这项工作中,我们重新关注该任务,并应用于流行的开源胸部X射线数据集。由于医学图像由于其敏感性性质而天然更难以开源发布,这使得某些开源数据集成为研究用途的极受欢迎的资源。通过执行相同的任务,我们希望探索这些数据集是否存在数据集偏见。为了扩展我们的工作,我们对数据集应用了简单的转换,重复相同的任务,并进行分析以识别和解释任何检测到的偏见。鉴于人工智能在医学影像应用中的重要性,确定现代方法是否走捷径或专注于相关病理学至关重要。我们在NIH、CheXpert、MIMIC-CXR和PadChest等数据集上实现了多种不同的网络架构。我们希望这项工作将鼓励在医学影像领域进行更多可解释的研究,并在医学领域创建更多的开源数据集。我们的代码可以在这里找到:https://github.com/eedack01/x_ray_ds_bias 。
论文及项目相关链接
Summary
本文重新探讨了“Name That Dataset”任务在流行开源胸部X射线数据集上的应用,探索这些数集中是否存在数据集偏见。通过对数据集进行简单转换并重复任务,分析和解释检测到的偏见。文章指出AI在医学影像领域应用的重要性,提倡建立更多医学影像领域的开源数据集,并进行更具解释性的研究。代码可通过相关链接获取。
Key Takeaways
- 重新访问了“Name That Dataset”任务,并应用于流行的开源胸部X射线数据集。
- 探索了这些数据集是否存在数据集偏见。
- 通过简单转换数据集并重复任务来检测和分析偏见。
- 强调了AI在医学影像领域应用的重要性。
- 提倡建立更多医学影像领域的开源数据集。
- 提倡进行更具解释性的研究。
点此查看论文截图

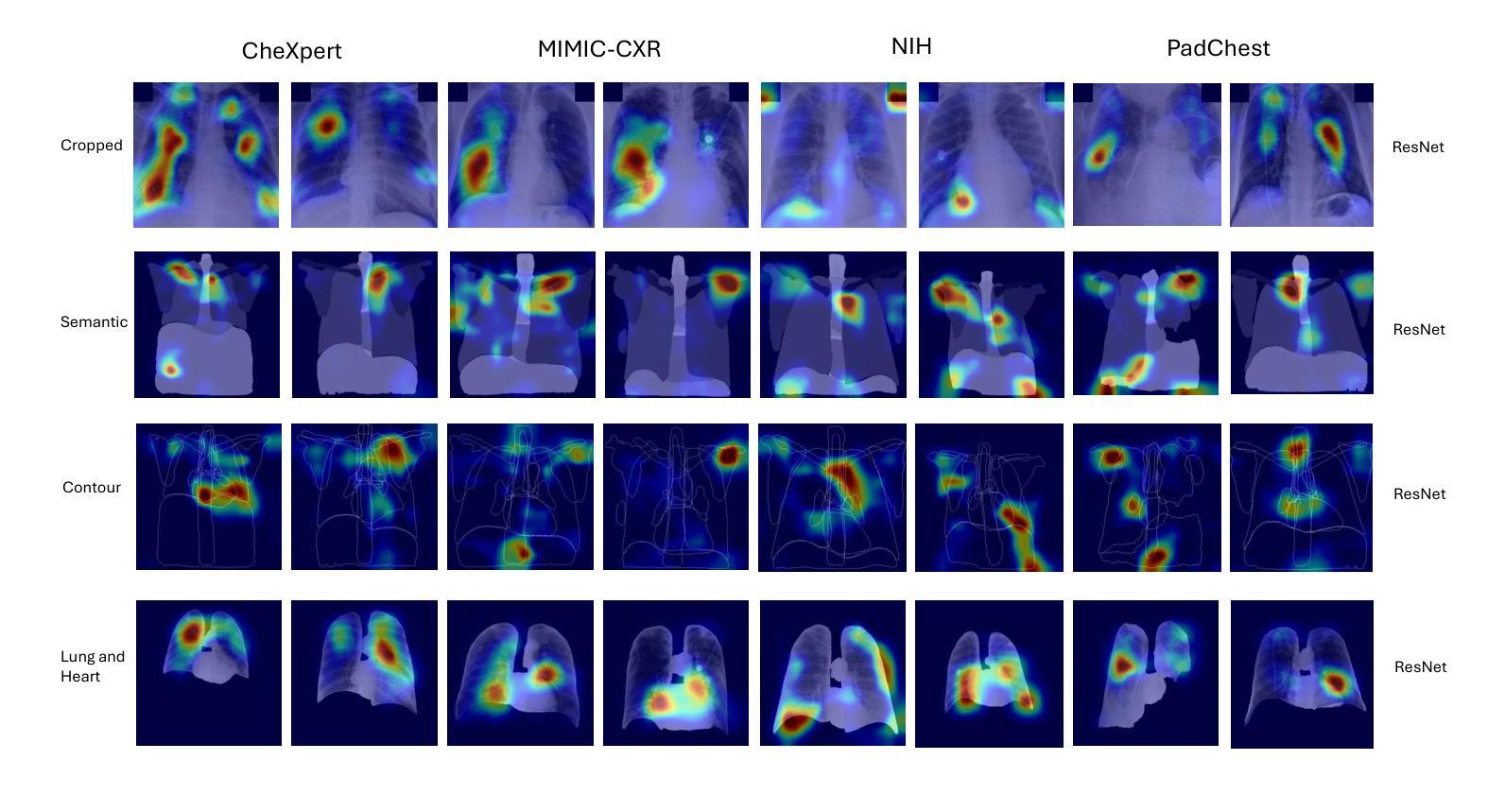
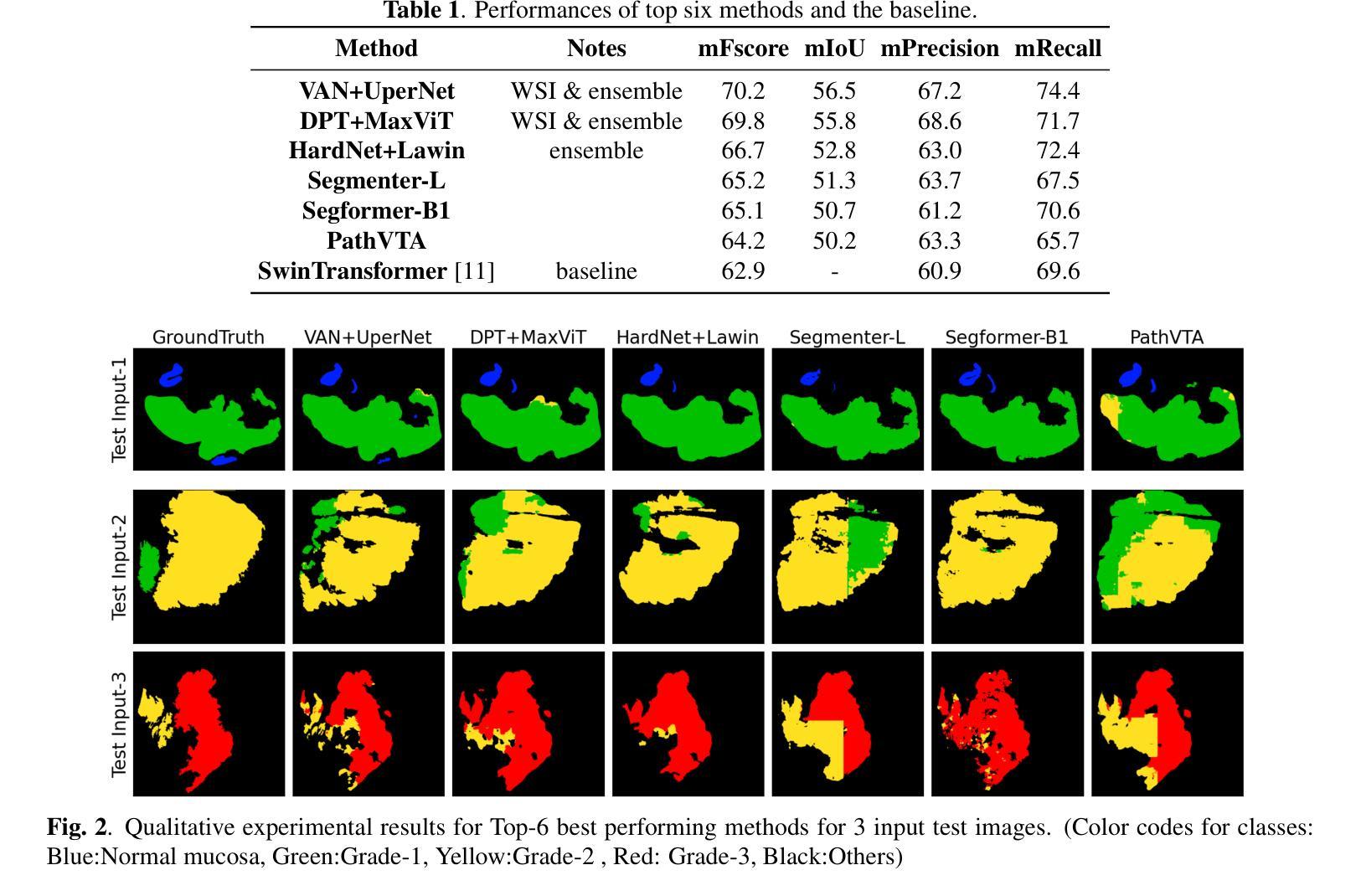
Colorectal Cancer Tumor Grade Segmentation in Digital Histopathology Images: From Giga to Mini Challenge
Authors:Alper Bahcekapili, Duygu Arslan, Umut Ozdemir, Berkay Ozkirli, Emre Akbas, Ahmet Acar, Gozde B. Akar, Bingdou He, Shuoyu Xu, Umit Mert Caglar, Alptekin Temizel, Guillaume Picaud, Marc Chaumont, Gérard Subsol, Luc Téot, Fahad Alsharekh, Shahad Alghannam, Hexiang Mao, Wenhua Zhang
Colorectal cancer (CRC) is the third most diagnosed cancer and the second leading cause of cancer-related death worldwide. Accurate histopathological grading of CRC is essential for prognosis and treatment planning but remains a subjective process prone to observer variability and limited by global shortages of trained pathologists. To promote automated and standardized solutions, we organized the ICIP Grand Challenge on Colorectal Cancer Tumor Grading and Segmentation using the publicly available METU CCTGS dataset. The dataset comprises 103 whole-slide images with expert pixel-level annotations for five tissue classes. Participants submitted segmentation masks via Codalab, evaluated using metrics such as macro F-score and mIoU. Among 39 participating teams, six outperformed the Swin Transformer baseline (62.92 F-score). This paper presents an overview of the challenge, dataset, and the top-performing methods
结直肠癌(CRC)是全球诊断率第三高的癌症,也是导致癌症相关死亡的第二大主要原因。CRC的准确组织病理学分级对预后和治疗计划至关重要,但仍是一个主观过程,容易受观察者变异性的影响,并受到全球训练有素病理学家短缺的限制。为了推广自动化和标准化的解决方案,我们使用了公开可用的METU CCTGS数据集,组织了国际图像病理挑战赛(ICIP Grand Challenge)结直肠癌肿瘤分级和分割挑战赛。该数据集包含103张全片图像,包括五种组织的专家像素级注释。参赛者通过Codalab提交分割掩膜,通过宏观F分数和mIoU等指标进行评价。在37支参赛队伍中,有六支队伍的表现超过了基线Swin Transformer(62.92 F分数)。本文介绍了挑战、数据集和表现最好的方法概况。
论文及项目相关链接
PDF Accepted Grand Challenge Paper ICIP 2025
Summary
结直肠癌(CRC)是全球诊断率第三高的癌症,也是导致癌症死亡的第二大原因。准确的病理分级对预后和治疗计划至关重要,但仍是一个主观过程,容易受观察者差异影响,并且全球病理学家短缺。为促进自动化和标准化解决方案,我们组织了基于公共可用METU CCTGS数据集的结直肠癌肿瘤分级和分割的ICIP Grand Challenge挑战。该数据集包含包含专家像素级注释的五个组织的全片图像共计103张。通过Codalab提交分割掩模,使用宏观F分数和mIoU等指标进行评估。在参与挑战的39支队伍中,有六支队伍的表现优于基线水平的Swin Transformer(62.92 F-score)。本文介绍了挑战概况、数据集及顶尖的表现方法。
Key Takeaways
- 结直肠癌是世界上诊断率和死亡率较高的癌症之一。
- 病理分级在结直肠癌的预后和治疗计划中起着至关重要的作用,但目前仍面临观察者差异和病理学家短缺的问题。
- 为解决上述问题,举办了ICIP Grand Challenge挑战,旨在促进结直肠癌肿瘤分级和分割的自动化和标准化解决方案。
- 该挑战使用了公开的METU CCTGS数据集,包含有专家像素级注释的五类组织的全片图像共计103张。
- 通过Codalab提交了参赛团队的分割掩模,通过宏观F分数和mIoU等指标评估参赛队伍的表现。
- 最终有六支队伍的表现超过了基线水平的Swin Transformer模型(F-score为62.92)。
点此查看论文截图

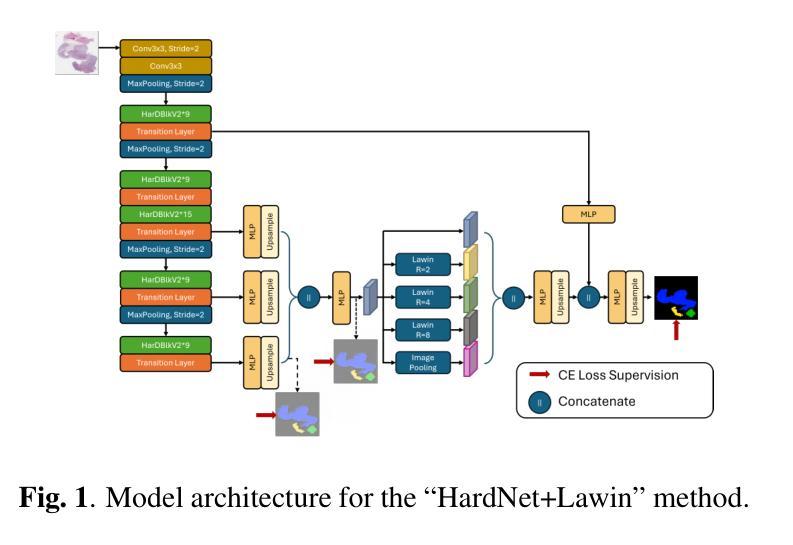
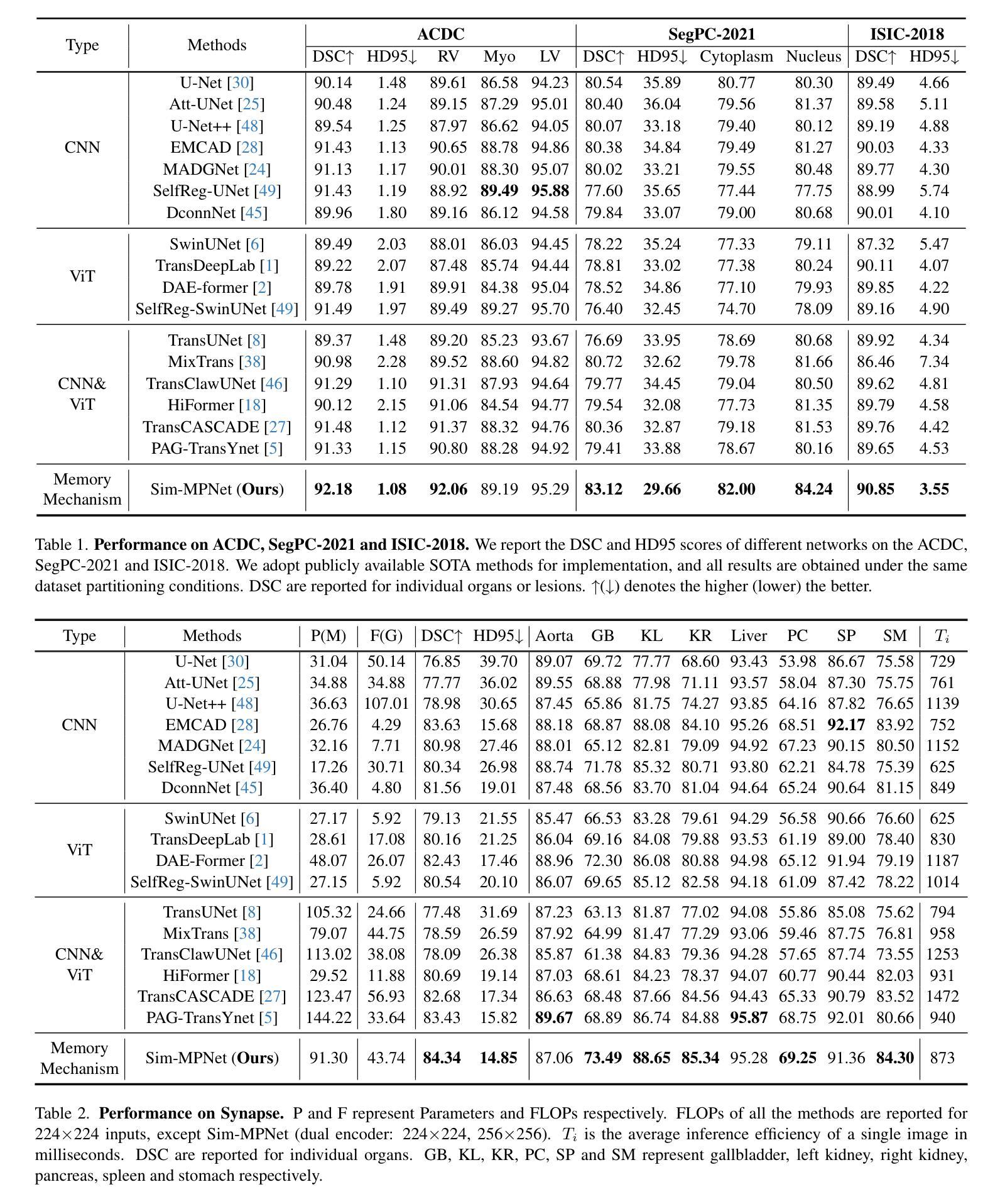
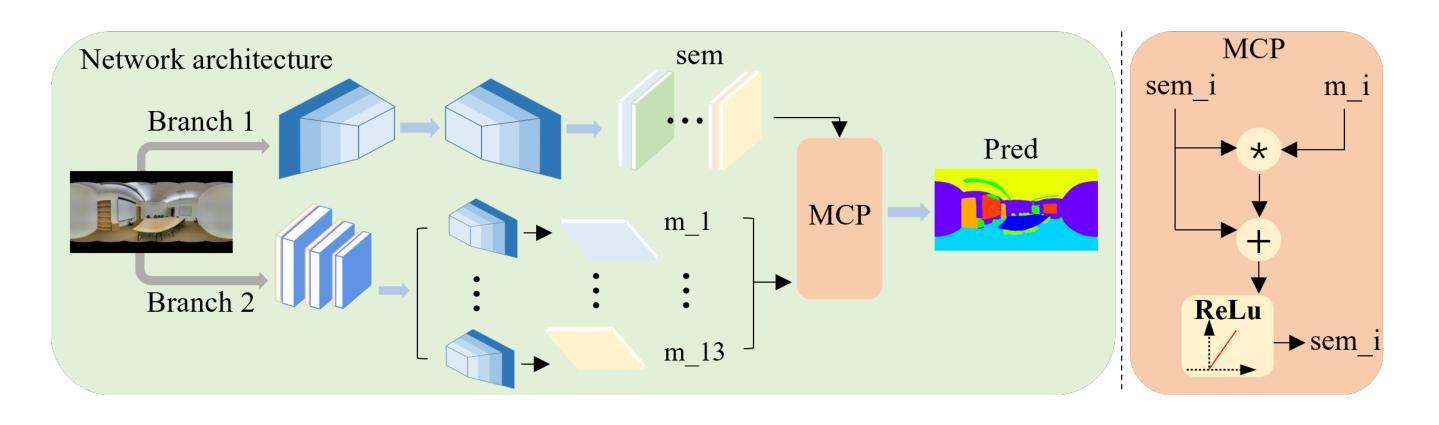
Similarity Memory Prior is All You Need for Medical Image Segmentation
Authors:Hao Tang, Zhiqing Guo, Liejun Wang, Chao Liu
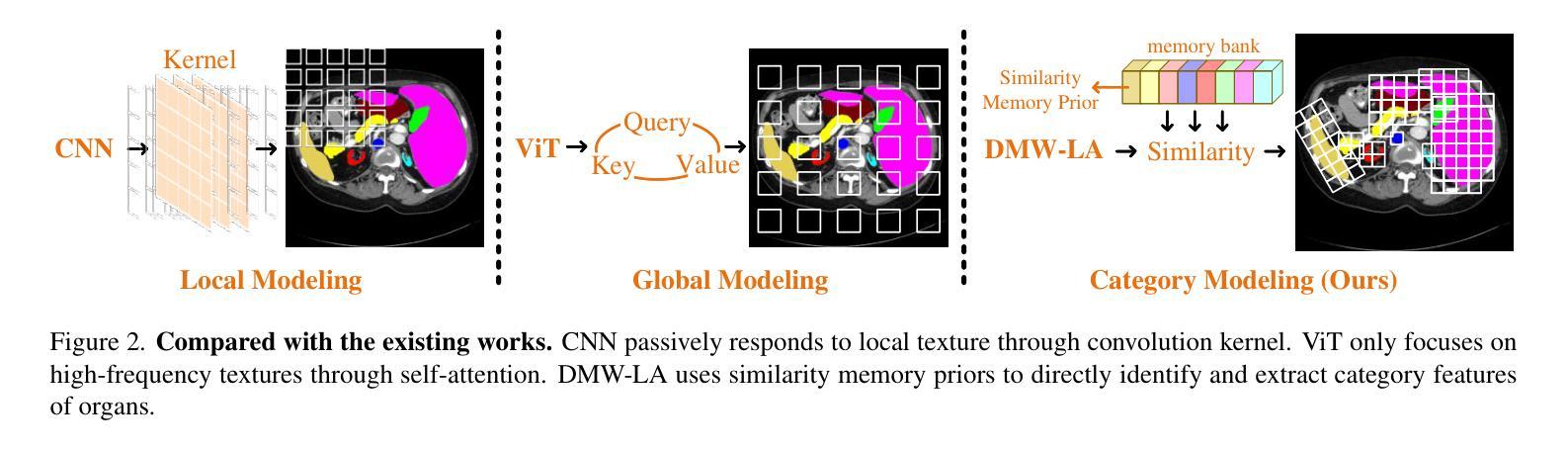
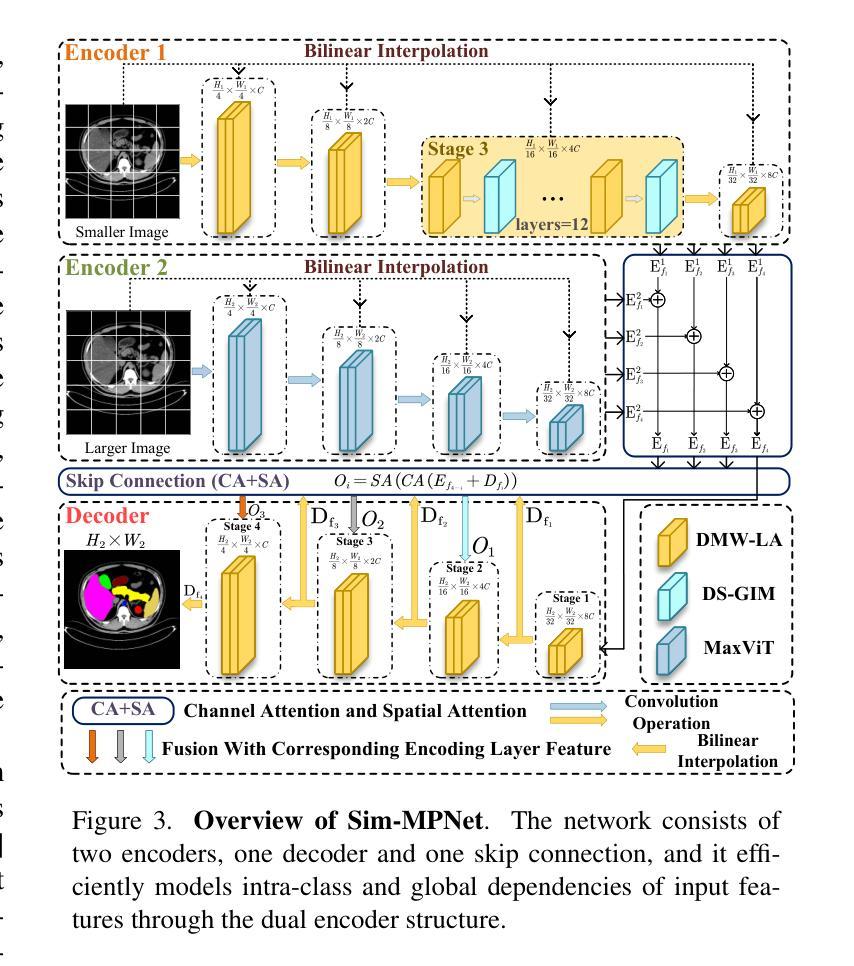
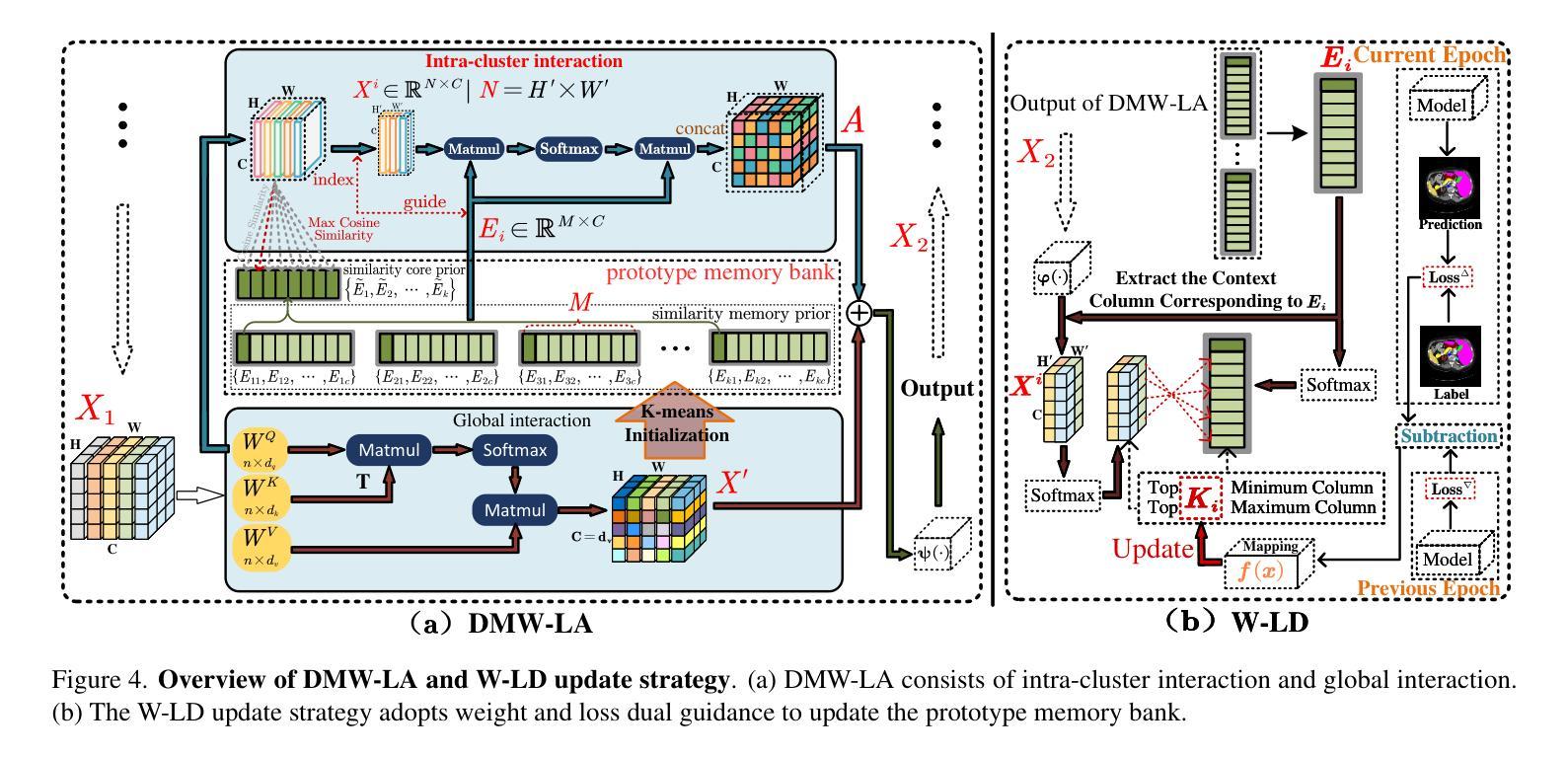
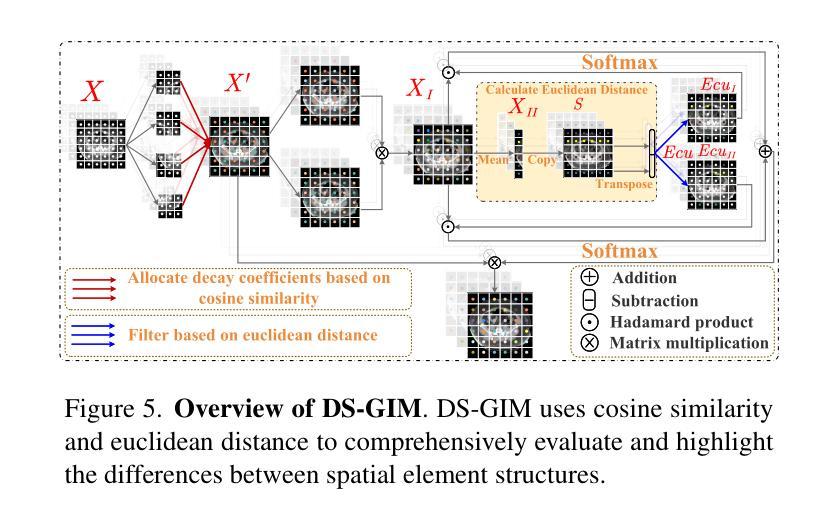
In recent years, it has been found that “grandmother cells” in the primary visual cortex (V1) of macaques can directly recognize visual input with complex shapes. This inspires us to examine the value of these cells in promoting the research of medical image segmentation. In this paper, we design a Similarity Memory Prior Network (Sim-MPNet) for medical image segmentation. Specifically, we propose a Dynamic Memory Weights-Loss Attention (DMW-LA), which matches and remembers the category features of specific lesions or organs in medical images through the similarity memory prior in the prototype memory bank, thus helping the network to learn subtle texture changes between categories. DMW-LA also dynamically updates the similarity memory prior in reverse through Weight-Loss Dynamic (W-LD) update strategy, effectively assisting the network directly extract category features. In addition, we propose the Double-Similarity Global Internal Enhancement Module (DS-GIM) to deeply explore the internal differences in the feature distribution of input data through cosine similarity and euclidean distance. Extensive experiments on four public datasets show that Sim-MPNet has better segmentation performance than other state-of-the-art methods. Our code is available on https://github.com/vpsg-research/Sim-MPNet.
近年来,研究发现猕猴初级视觉皮层(V1)中的“祖母细胞”能直接识别具有复杂形状的视觉输入,这激发了我们探索这些细胞在推动医学图像分割研究中的价值。在本文中,我们设计了一种用于医学图像分割的相似性记忆先验网络(Sim-MPNet)。具体来说,我们提出了一种动态记忆权重损失注意力(DMW-LA),它通过原型记忆库中的相似性记忆先验来匹配和记忆医学图像中特定病变或器官的分类特征,从而帮助网络学习类别之间的细微纹理变化。DMW-LA还通过重量损失动态(W-LD)更新策略反向动态更新相似性记忆先验,有效地帮助网络直接提取类别特征。此外,我们提出了双相似性全局内部增强模块(DS-GIM),通过余弦相似性和欧几里得距离深入探索输入数据特征分布的内部差异。在四个公共数据集上的大量实验表明,Sim-MPNet的分割性能优于其他最新方法。我们的代码可在https://github.com/vpsg-research/Sim-MPNet上找到。
论文及项目相关链接
Summary
本文研究了医学图像分割领域的新进展,提出了一种名为Sim-MPNet的神经网络模型。该模型利用动态记忆权重损失注意力机制(DMW-LA)和双重相似性全局内部增强模块(DS-GIM),通过匹配和记忆医学图像中特定病变或器官的特征类别,有效学习类别间的细微纹理变化,提升了医学图像分割的性能。
Key Takeaways
- “祖母细胞”在猕猴初级视觉皮层(V1)中的发现,为医学图像分割研究提供了新的启示。
- 提出了名为Sim-MPNet的神经网络模型,用于医学图像分割。
- Sim-MPNet中的DMW-LA机制能够匹配并记忆医学图像中特定病变或器官的特征类别。
- DMW-LA通过动态更新相似记忆优先权,有效辅助网络直接提取类别特征。
- DS-GIM模块深入探索了输入数据特征分布的内部差异,通过余弦相似度和欧几里得距离进行计算。
- Sim-MPNet在四个公共数据集上的实验表明,其分割性能优于其他最先进的方法。
点此查看论文截图