⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-17 更新
Alleviating Textual Reliance in Medical Language-guided Segmentation via Prototype-driven Semantic Approximation
Authors:Shuchang Ye, Usman Naseem, Mingyuan Meng, Jinman Kim
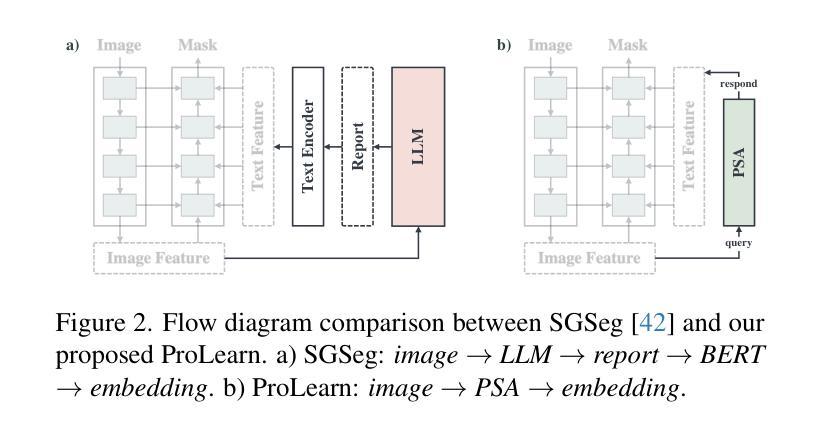
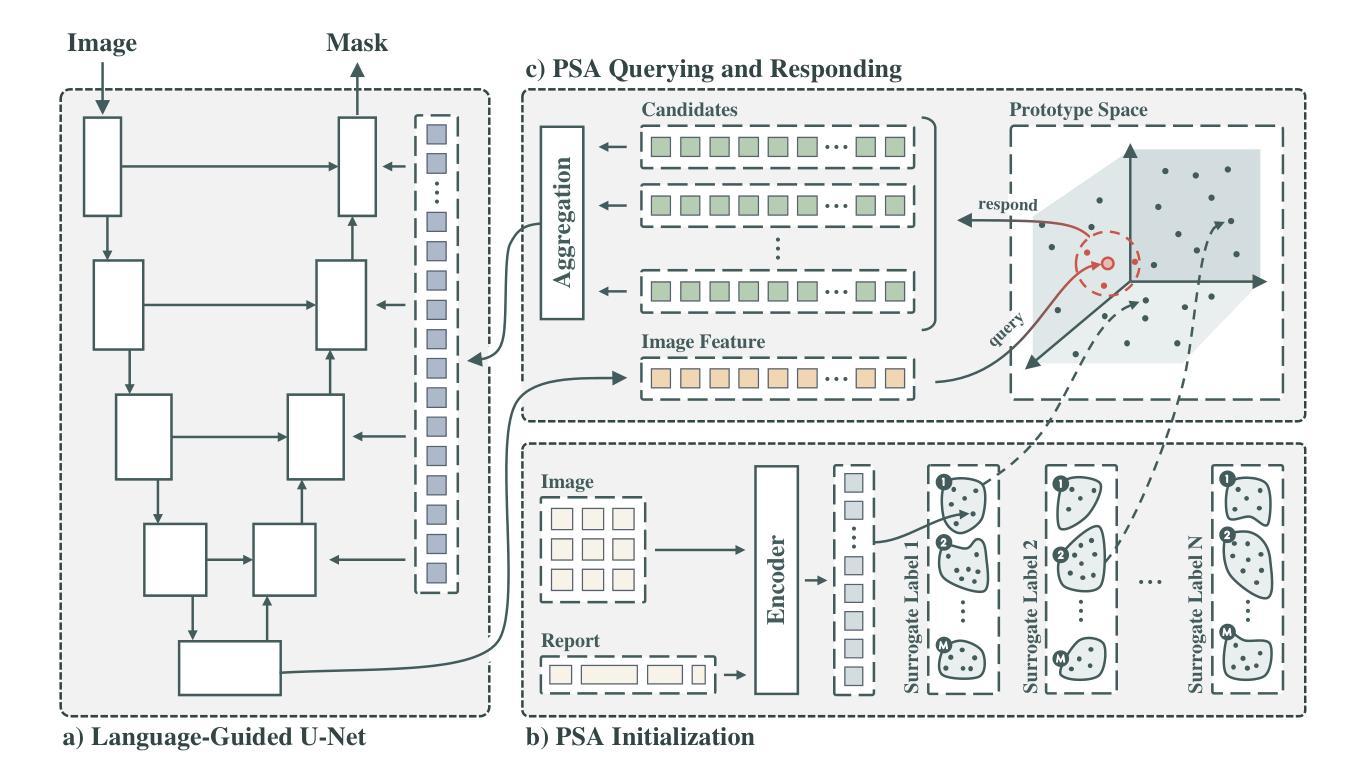
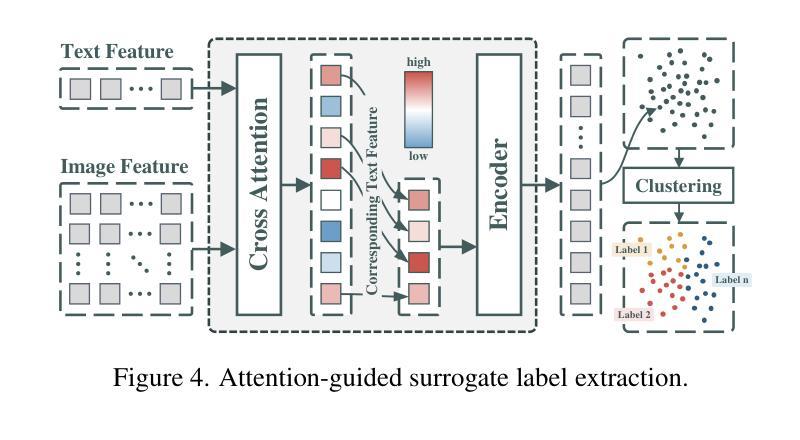
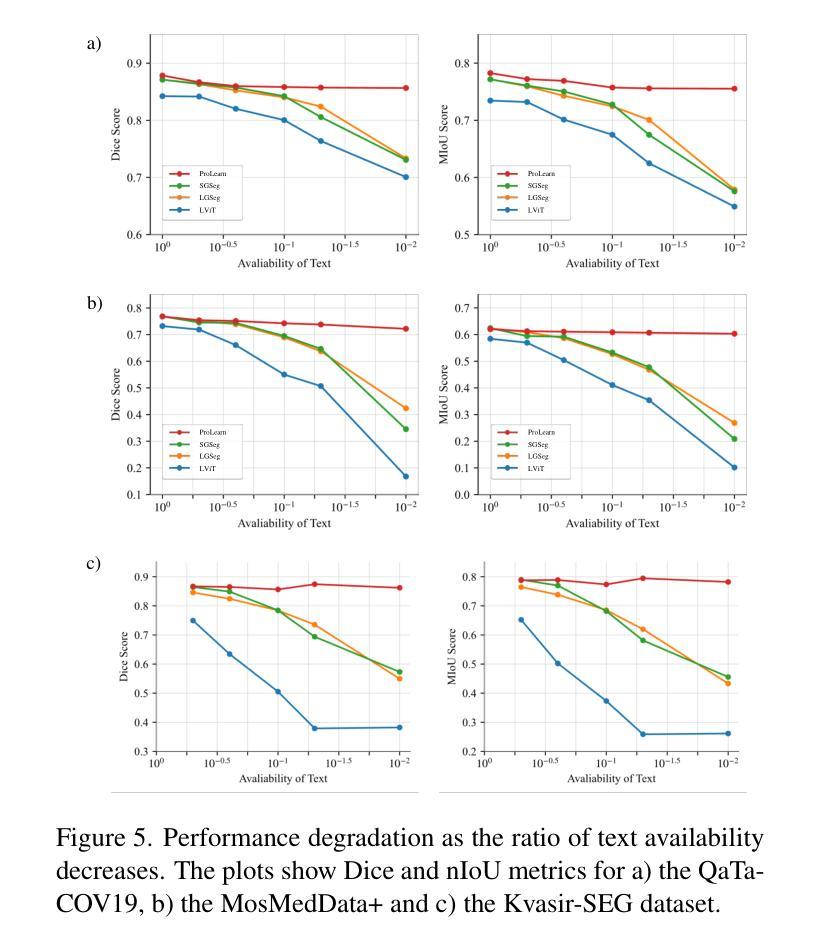
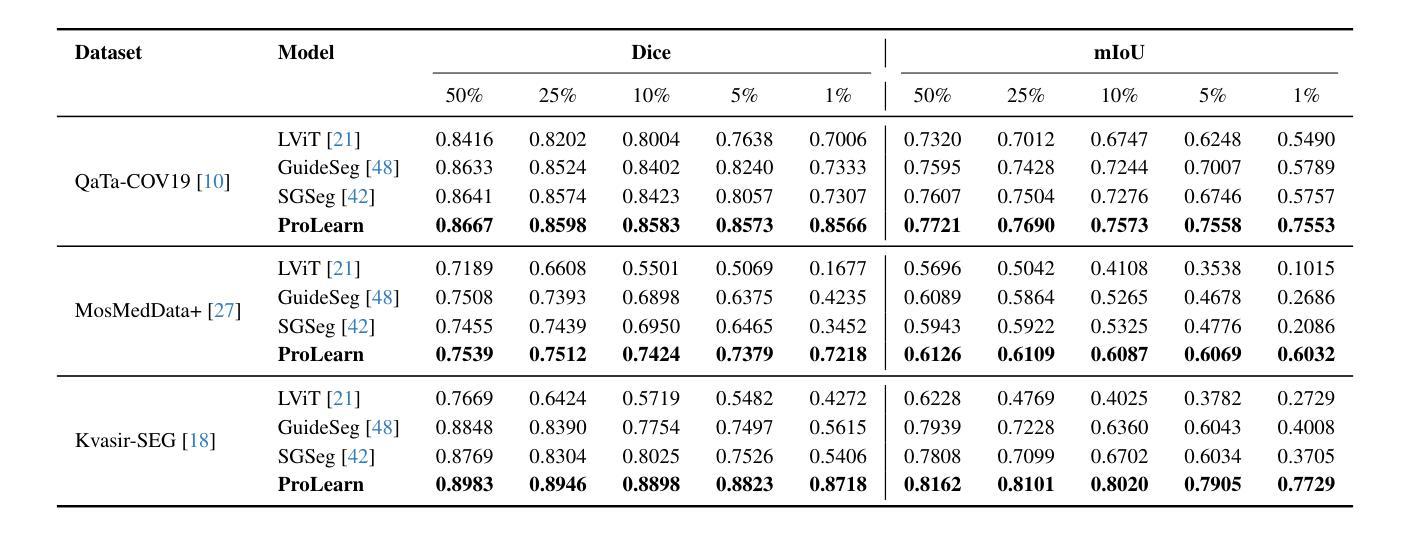
Medical language-guided segmentation, integrating textual clinical reports as auxiliary guidance to enhance image segmentation, has demonstrated significant improvements over unimodal approaches. However, its inherent reliance on paired image-text input, which we refer to as ``textual reliance”, presents two fundamental limitations: 1) many medical segmentation datasets lack paired reports, leaving a substantial portion of image-only data underutilized for training; and 2) inference is limited to retrospective analysis of cases with paired reports, limiting its applicability in most clinical scenarios where segmentation typically precedes reporting. To address these limitations, we propose ProLearn, the first Prototype-driven Learning framework for language-guided segmentation that fundamentally alleviates textual reliance. At its core, in ProLearn, we introduce a novel Prototype-driven Semantic Approximation (PSA) module to enable approximation of semantic guidance from textual input. PSA initializes a discrete and compact prototype space by distilling segmentation-relevant semantics from textual reports. Once initialized, it supports a query-and-respond mechanism which approximates semantic guidance for images without textual input, thereby alleviating textual reliance. Extensive experiments on QaTa-COV19, MosMedData+ and Kvasir-SEG demonstrate that ProLearn outperforms state-of-the-art language-guided methods when limited text is available.
医疗语言引导分割通过将文本临床报告作为辅助指导来增强图像分割,证明其在单模态方法上取得了显著改进。然而,其对配对图像文本输入的固有依赖(我们称之为“文本依赖”)存在两个基本局限:1)许多医疗分割数据集缺乏配对报告,导致大量仅包含图像的数据未能得到充分利用;2)推理仅限于具有配对报告的病例的回顾性分析,限制了其在大多数临床场景中的应用,因为在这些场景中,通常先进行分割再进行报告。为了解决这些局限性,我们提出了ProLearn,即首个用于语言引导分割的原型驱动学习框架,从根本上减轻了文本依赖。在ProLearn的核心中,我们引入了一种新颖的原型驱动语义近似(PSA)模块,以实现从文本输入中近似语义指导。PSA通过从文本报告中提炼出与分割相关的语义来初始化一个离散且紧凑的原型空间。初始化完成后,它支持一种查询和响应机制,可在没有文本输入的情况下为图像近似语义指导,从而减轻对文本的依赖。在QaTa-COV19、MosMedData+和Kvasir-SEG上的大量实验表明,当文本有限时,ProLearn的表现优于最先进的语言引导方法。
论文及项目相关链接
PDF Accepted to ICCV 2025
Summary:医学语言引导分割技术通过整合文本临床报告作为辅助指导,提高了图像分割的精度。然而,该技术依赖于配对图像文本输入,存在数据配对报告缺失和推理应用场景受限的问题。为解决这个问题,本文提出ProLearn原型驱动学习框架,通过引入原型驱动语义逼近模块实现语义指导的近似,降低对文本输入的依赖。实验证明,ProLearn在有限文本信息下表现优于现有语言引导方法。
Key Takeaways:
- 医学语言引导分割技术提高了图像分割的准确性,通过结合文本临床报告作为辅助指导。
- 现有技术依赖于配对图像文本输入,存在数据配对报告缺失的问题。
- ProLearn框架被提出以解决上述问题,通过引入原型驱动语义逼近模块实现语义指导的近似。
- ProLearn降低了对文本输入的依赖,使得在没有文本输入的情况下也能进行图像分割。
- 实验证明,在有限文本信息下,ProLearn的表现优于现有的语言引导方法。
- ProLearn具有更好的适用性和灵活性,能够适应大多数临床场景。
点此查看论文截图

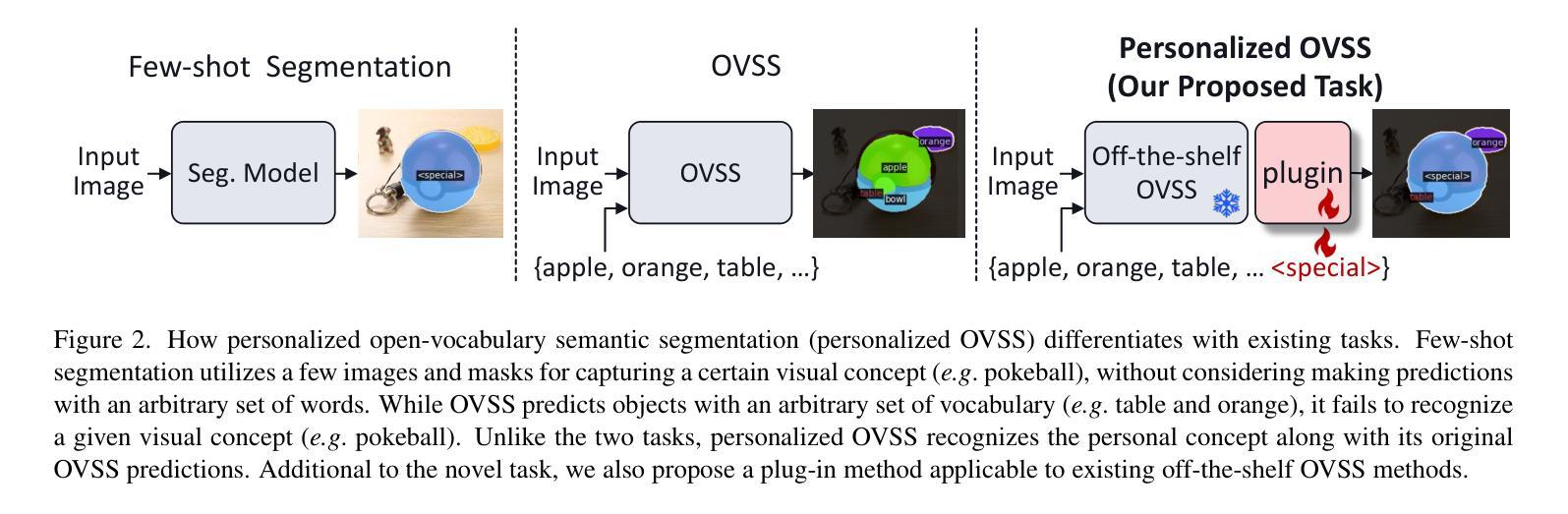
Personalized OVSS: Understanding Personal Concept in Open-Vocabulary Semantic Segmentation
Authors:Sunghyun Park, Jungsoo Lee, Shubhankar Borse, Munawar Hayat, Sungha Choi, Kyuwoong Hwang, Fatih Porikli
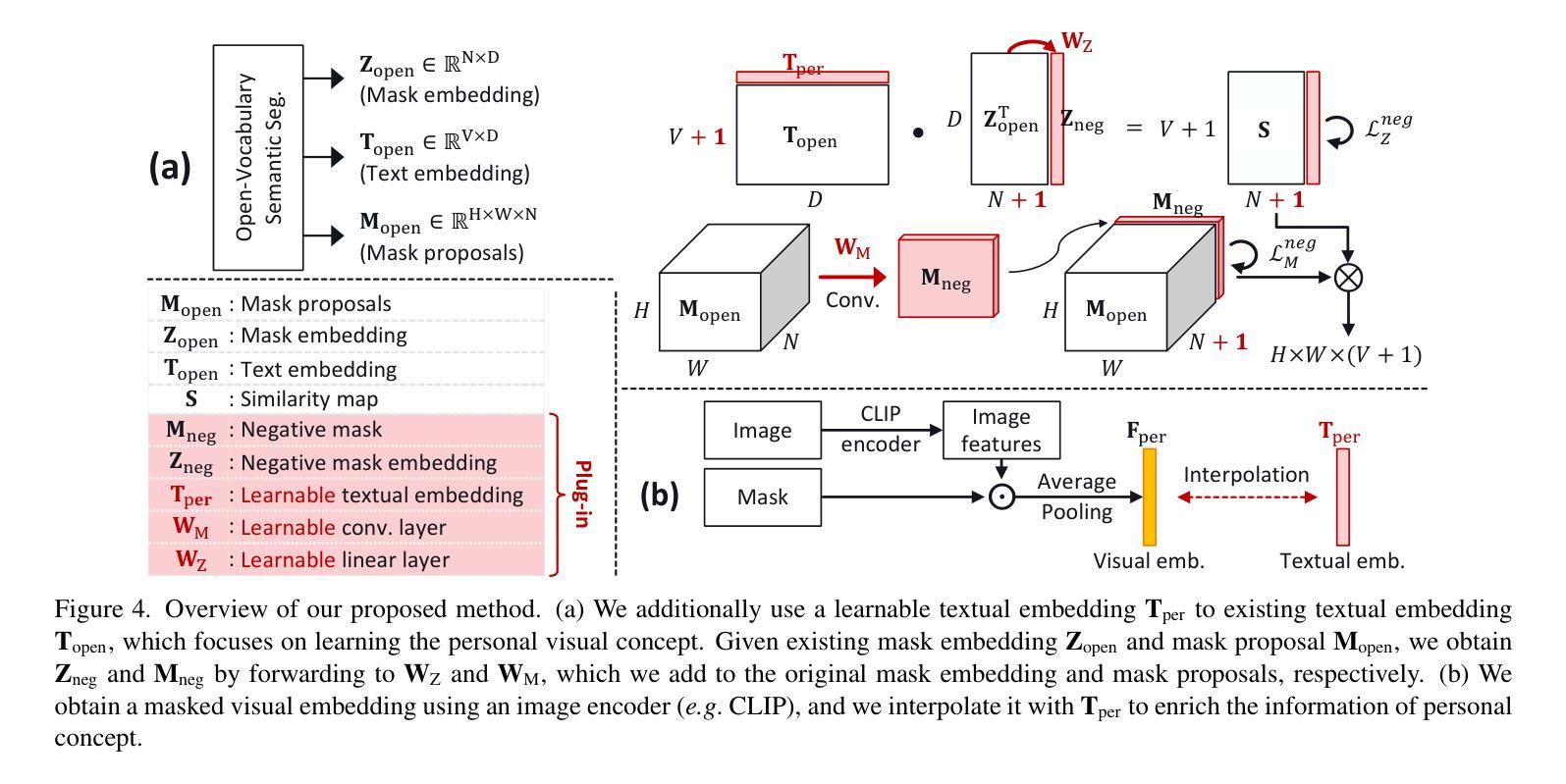
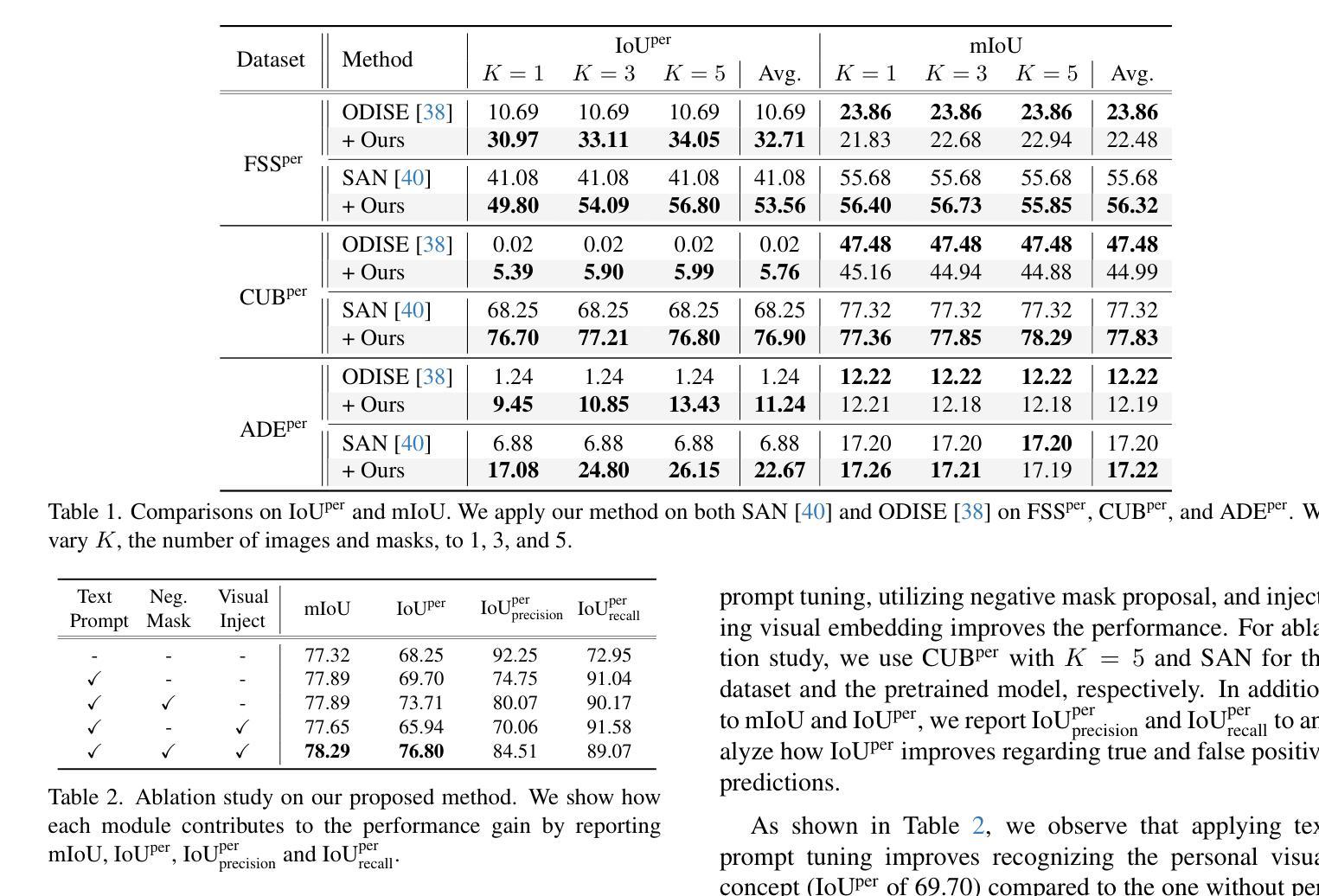
While open-vocabulary semantic segmentation (OVSS) can segment an image into semantic regions based on arbitrarily given text descriptions even for classes unseen during training, it fails to understand personal texts (e.g., my mug cup') for segmenting regions of specific interest to users. This paper addresses challenges like recognizing my mug cup’ among multiple mug cups'. To overcome this challenge, we introduce a novel task termed \textit{personalized open-vocabulary semantic segmentation} and propose a text prompt tuning-based plug-in method designed to recognize personal visual concepts using a few pairs of images and masks, while maintaining the performance of the original OVSS. Based on the observation that reducing false predictions is essential when applying text prompt tuning to this task, our proposed method employs negative mask proposal’ that captures visual concepts other than the personalized concept. We further improve the performance by enriching the representation of text prompts by injecting visual embeddings of the personal concept into them. This approach enhances personalized OVSS without compromising the original OVSS performance. We demonstrate the superiority of our method on our newly established benchmarks for this task, including FSS$^\text{per}$, CUB$^\text{per}$, and ADE$^\text{per}$.
开放词汇语义分割(OVSS)可以根据任意给定的文本描述将图像分割成语义区域,即使对于训练期间未见过的类别也是如此。然而,它无法理解个人文本(例如,“我的马克杯”),无法根据用户的特定兴趣分割区域。本文解决如从多个马克杯中识别出“我的马克杯”等挑战。为了克服这一挑战,我们引入了一项名为个性化开放词汇语义分割的新任务,并提出了一种基于文本提示调整的插件方法,旨在通过少量图像和遮罩对来识别个人视觉概念,同时保持原始OVSS的性能。基于将文本提示调整应用于此任务时减少错误预测至关重要的观察,我们提出的方法采用“负遮罩提议”,该提议捕捉除个性化概念以外的视觉概念。我们通过将个人概念的视觉嵌入注入文本提示中,丰富文本提示的表示,进一步提高性能。这种方法在不损害原始OVSS性能的情况下增强了个性化OVSS。我们在为此任务新建立的标准上展示了我们的方法优越性,包括FSS$^{\text{per}}$、CUB$^{\text{per}}$和ADE$^{\text{per}}$。
论文及项目相关链接
PDF Accepted to ICCV 2025; 15 pages
摘要
开放词汇语义分割(OVSS)能够根据任意给定的文本描述对图像进行语义分割,即使对于训练期间未见过的类别亦是如此。然而,它无法理解个人文本(例如,“我的马克杯”),无法根据用户的特定兴趣分割区域。本文解决在“多个马克杯”中识别“我的马克杯”等挑战。为了克服这一挑战,我们引入了一项名为个性化开放词汇语义分割的新任务,并提出了一种基于文本提示调整的插件方法,旨在通过少量图像和蒙版对来识别个性化视觉概念,同时保持原始OVSS的性能。我们发现减少错误预测在此任务中至关重要,因此我们的方法采用“负蒙版提议”,捕获除个性化概念之外的其他视觉概念。此外,通过向文本提示注入个性化概念的视觉嵌入来丰富其表示,进一步提高性能。这种方法在不损害原始OVSS性能的情况下提高了个性化OVSS的性能。我们在为此任务建立的新基准测试(包括FSS$^{per}$、CUB$^{per}$和ADE$^{per}$)上展示了我们的方法的优越性。
要点
- 开放词汇语义分割(OVSS)能够根据任意文本描述对图像进行语义分割,但无法理解个人文本。
- 引入个性化开放词汇语义分割新任务,旨在识别用户的特定兴趣区域。
- 提出基于文本提示调整的插件方法,通过少量图像和蒙版对来识别个性化视觉概念。
- 方法采用负蒙版提议,以捕获除个性化概念外的其他视觉概念,减少错误预测。
- 通过向文本提示注入个性化概念的视觉嵌入来丰富表示,进一步提高性能。
- 在新建立的基准测试上展示了方法优越性,包括FSS$^{per}$、CUB$^{per}$和ADE$^{per}$。
- 该方法在不损害原始OVSS性能的情况下增强了个性化OVSS的效果。
点此查看论文截图


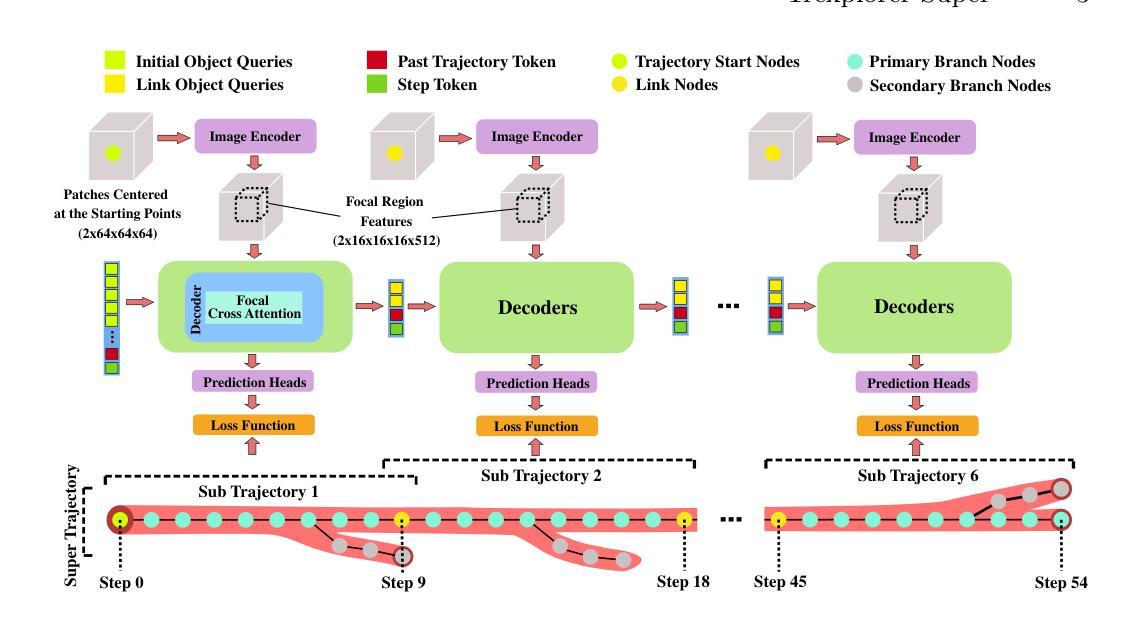
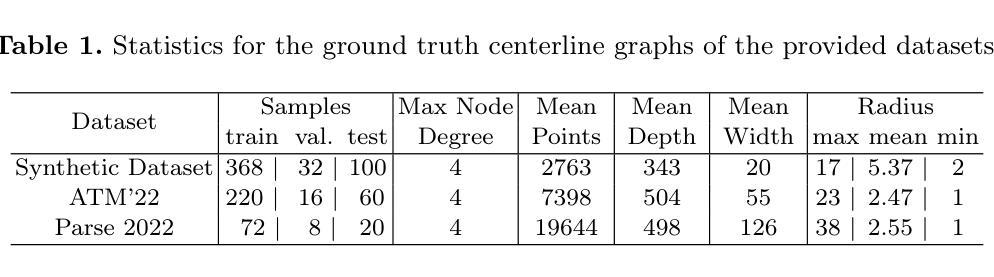
Trexplorer Super: Topologically Correct Centerline Tree Tracking of Tubular Objects in CT Volumes
Authors:Roman Naeem, David Hagerman, Jennifer Alvén, Lennart Svensson, Fredrik Kahl
Tubular tree structures, such as blood vessels and airways, are essential in human anatomy and accurately tracking them while preserving their topology is crucial for various downstream tasks. Trexplorer is a recurrent model designed for centerline tracking in 3D medical images but it struggles with predicting duplicate branches and terminating tracking prematurely. To address these issues, we present Trexplorer Super, an enhanced version that notably improves performance through novel advancements. However, evaluating centerline tracking models is challenging due to the lack of public datasets. To enable thorough evaluation, we develop three centerline datasets, one synthetic and two real, each with increasing difficulty. Using these datasets, we conduct a comprehensive evaluation of existing state-of-the-art (SOTA) models and compare them with our approach. Trexplorer Super outperforms previous SOTA models on every dataset. Our results also highlight that strong performance on synthetic data does not necessarily translate to real datasets. The code and datasets are available at https://github.com/RomStriker/Trexplorer-Super.
管状树状结构,如血管和气道,在人类解剖学中具有重要意义,而准确跟踪它们同时保持其拓扑结构对于各种下游任务至关重要。Trexplorer是一种为3D医学图像中的中心线跟踪设计的递归模型,但它面临着预测重复分支和过早终止跟踪的问题。为了解决这些问题,我们推出了Trexplorer Super,这是一个通过新颖的进步显著改进性能的提升版本。然而,由于缺少公共数据集,评估中心线跟踪模型具有挑战性。为了实现全面评估,我们开发了三个中心线数据集,一个合成数据集和两个真实数据集,每个数据集的难度都在增加。使用这些数据集,我们对现有的最先进的模型进行了全面评估,并将它们与我们的方法进行了比较。Trexplorer Super在每个数据集上的表现都超过了之前的最先进的模型。我们的结果还表明,在合成数据上的出色表现并不一定适用于真实数据集。代码和数据集可在https://github.com/RomStriker/Trexplorer-Super上找到。
论文及项目相关链接
PDF Submitted Version. Accepted at MICCAI 2025
Summary
Trexplorer Super是一款针对三维医学图像中心线跟踪的递归模型,解决了原有Trexplorer模型在预测重复分支和过早终止跟踪方面的问题。为全面评估模型性能,研究团队创建了三个中心线数据集,包括一个合成数据集和两个真实数据集,难度递增。评估现有最先进模型并与Trexplorer Super进行对比,发现该模型在所有数据集上均表现最佳。同时,研究发现在合成数据上的良好表现不一定能在真实数据集中得到体现。
Key Takeaways
- Tubular tree structures在人体解剖学中具有重要意义,准确的跟踪和拓扑保持对于各种下游任务至关重要。
- Trexplorer Super是专为三维医学图像中心线跟踪设计的递归模型,解决了原有模型的预测重复分支和过早终止跟踪问题。
- 为全面评估模型性能,创建了三个不同难度的中心线数据集,包括一个合成数据集和两个真实数据集。
- 对现有最先进模型进行了全面评估,并与Trexplorer Super进行了对比。
- Trexplorer Super在所有数据集上的表现均优于其他模型。
- 在合成数据上的良好表现不一定能在真实数据集中得到体现,这提示我们在实际应用中需考虑数据的真实性。
点此查看论文截图

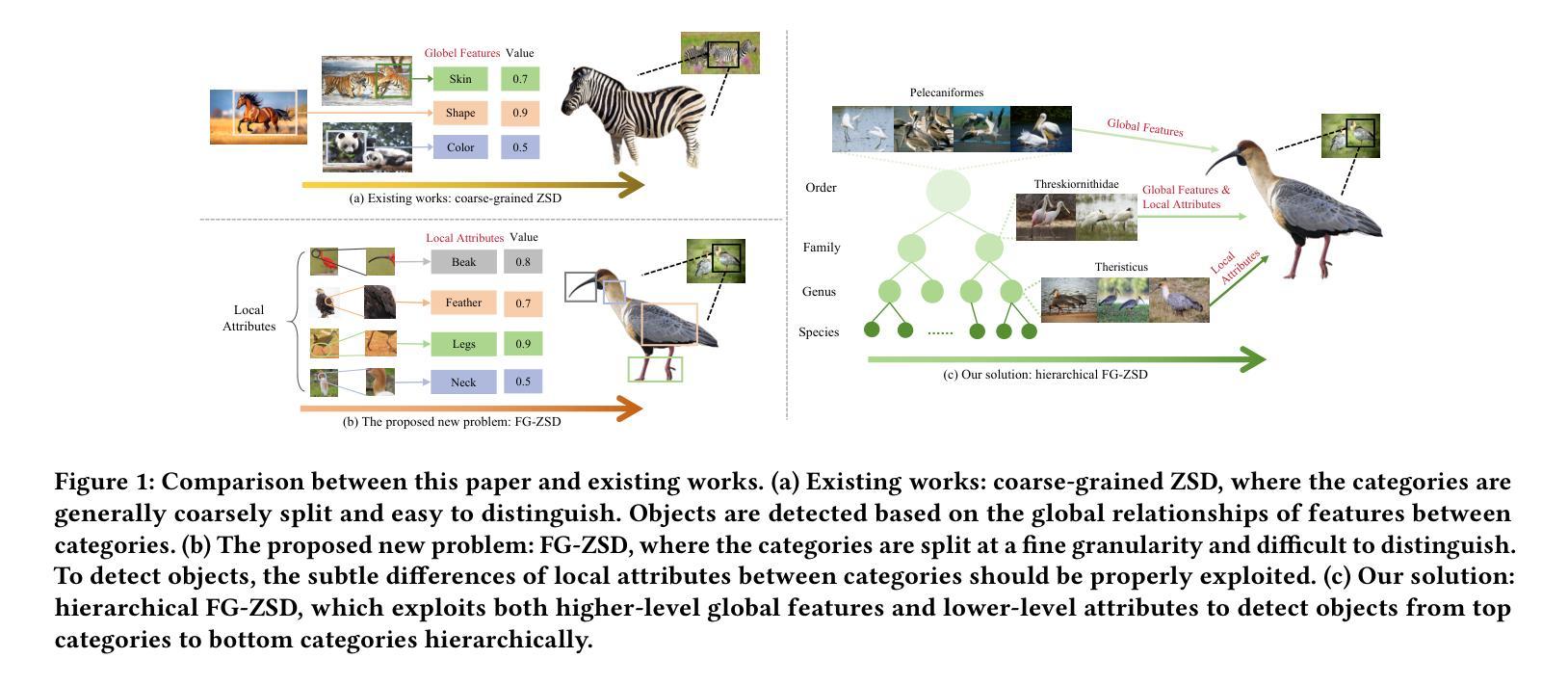
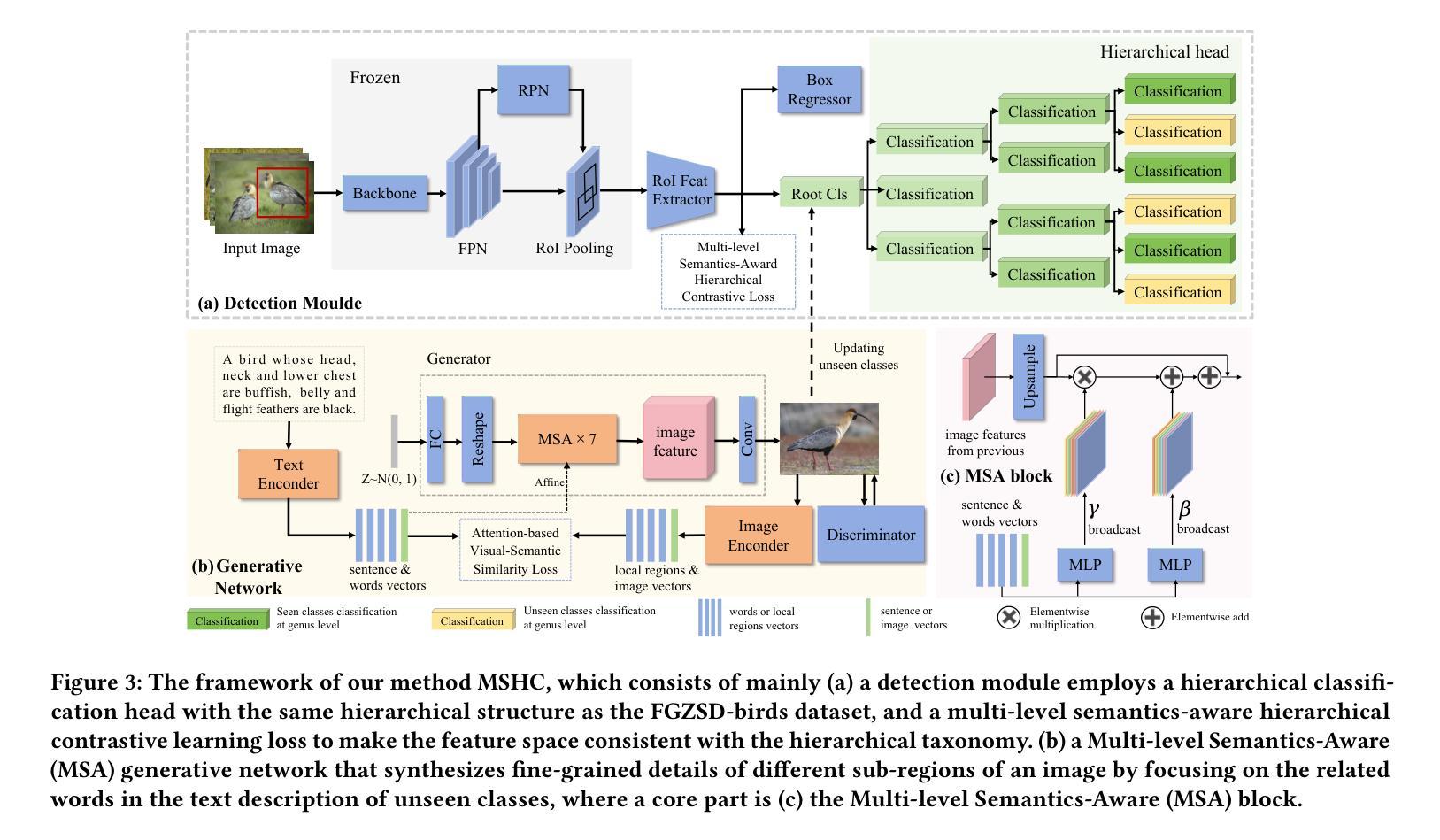
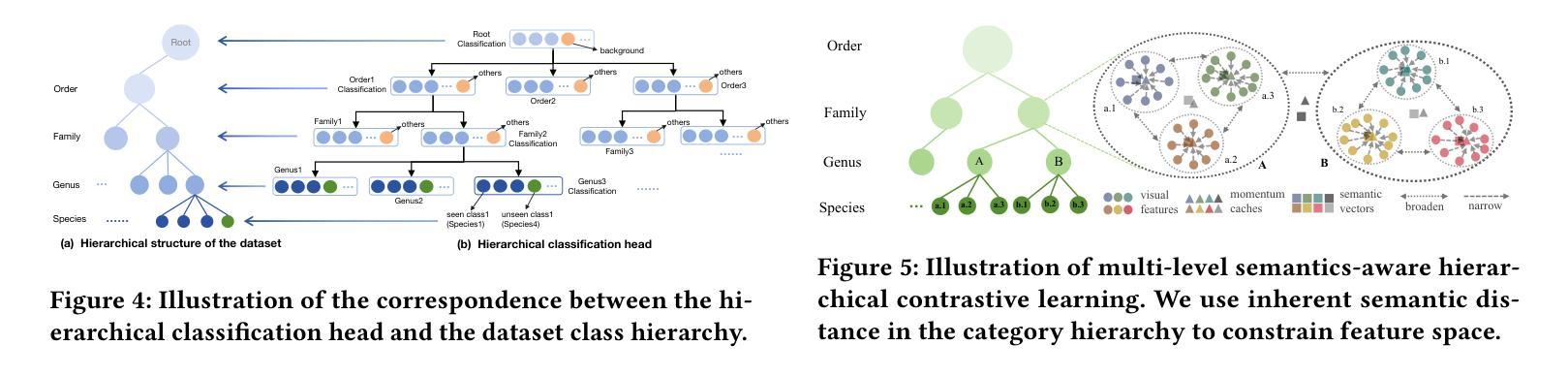
Fine-Grained Zero-Shot Object Detection
Authors:Hongxu Ma, Chenbo Zhang, Lu Zhang, Jiaogen Zhou, Jihong Guan, Shuigeng Zhou
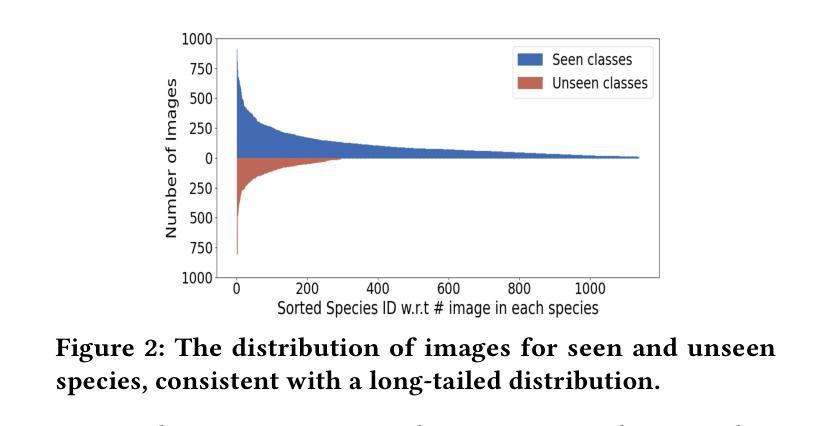
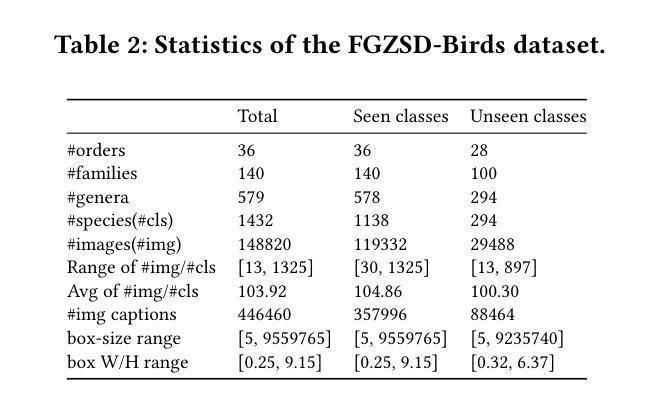
Zero-shot object detection (ZSD) aims to leverage semantic descriptions to localize and recognize objects of both seen and unseen classes. Existing ZSD works are mainly coarse-grained object detection, where the classes are visually quite different, thus are relatively easy to distinguish. However, in real life we often have to face fine-grained object detection scenarios, where the classes are too similar to be easily distinguished. For example, detecting different kinds of birds, fishes, and flowers. In this paper, we propose and solve a new problem called Fine-Grained Zero-Shot Object Detection (FG-ZSD for short), which aims to detect objects of different classes with minute differences in details under the ZSD paradigm. We develop an effective method called MSHC for the FG-ZSD task, which is based on an improved two-stage detector and employs a multi-level semantics-aware embedding alignment loss, ensuring tight coupling between the visual and semantic spaces. Considering that existing ZSD datasets are not suitable for the new FG-ZSD task, we build the first FG-ZSD benchmark dataset FGZSD-Birds, which contains 148,820 images falling into 36 orders, 140 families, 579 genera and 1432 species. Extensive experiments on FGZSD-Birds show that our method outperforms existing ZSD models.
零样本目标检测(ZSD)旨在利用语义描述来定位和识别已见和未见类别的目标。现有的ZSD工作主要集中在粗粒度目标检测上,这些类别的视觉差异很大,因此相对容易区分。然而,在现实生活中,我们经常面临细粒度目标检测的场景,这些类别的差异非常细微,难以区分。例如,检测不同种类的鸟类、鱼类和花卉。在本文中,我们提出并解决了一个新的问题,称为细粒度零样本目标检测(简称FG-ZSD),旨在在ZSD框架下检测具有细微差异的不同类别的目标。我们为FG-ZSD任务开发了一种有效的方法,称为MSHC,该方法基于改进的两阶段检测器,并采用多级语义感知嵌入对齐损失,确保视觉和语义空间之间的紧密耦合。考虑到现有的ZSD数据集不适合新的FG-ZSD任务,我们建立了第一个FG-ZSD基准数据集FGZSD-Birds,其中包含148820张图像,分为36个阶、140个家族、579个属和1432个物种。在FGZSD-Birds上的广泛实验表明,我们的方法优于现有的ZSD模型。
论文及项目相关链接
PDF Accepted by ACM MM’25
Summary
本文提出了精细粒度零样本目标检测(FG-ZSD)的新问题,旨在解决在零样本检测框架下不同类别目标之间的细微差异检测。为解决这一问题,提出了基于改进的两阶段检测器的方法,并采用多层次语义感知嵌入对齐损失,确保视觉和语义空间之间的紧密耦合。同时,建立了首个FG-ZSD基准数据集FGZSD-Birds,包含148,820张图像,涵盖36个阶、140个家族、579个属和1432个物种。实验表明,该方法优于现有ZSD模型。
Key Takeaways
- 引入精细粒度零样本目标检测(FG-ZSD)问题,关注类别间细微差异的检测。
- 提出基于改进两阶段检测器的方法,适用于FG-ZSD任务。
- 采用多层次语义感知嵌入对齐损失,实现视觉和语义空间的紧密耦合。
- 建立首个FG-ZSD基准数据集FGZSD-Birds,包含丰富的图像数据。
- 方法在FGZSD-Birds数据集上进行广泛实验验证。
- 提出的方法性能优于现有的零样本检测(ZSD)模型。
点此查看论文截图


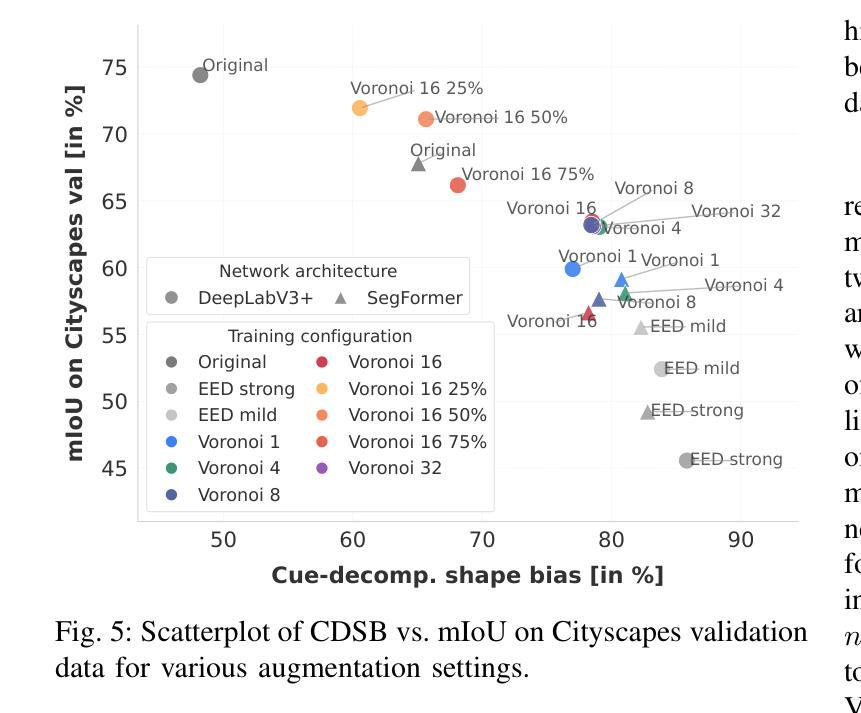
Transferring Styles for Reduced Texture Bias and Improved Robustness in Semantic Segmentation Networks
Authors:Ben Hamscher, Edgar Heinert, Annika Mütze, Kira Maag, Matthias Rottmann
Recent research has investigated the shape and texture biases of deep neural networks (DNNs) in image classification which influence their generalization capabilities and robustness. It has been shown that, in comparison to regular DNN training, training with stylized images reduces texture biases in image classification and improves robustness with respect to image corruptions. In an effort to advance this line of research, we examine whether style transfer can likewise deliver these two effects in semantic segmentation. To this end, we perform style transfer with style varying across artificial image areas. Those random areas are formed by a chosen number of Voronoi cells. The resulting style-transferred data is then used to train semantic segmentation DNNs with the objective of reducing their dependence on texture cues while enhancing their reliance on shape-based features. In our experiments, it turns out that in semantic segmentation, style transfer augmentation reduces texture bias and strongly increases robustness with respect to common image corruptions as well as adversarial attacks. These observations hold for convolutional neural networks and transformer architectures on the Cityscapes dataset as well as on PASCAL Context, showing the generality of the proposed method.
最近的研究已经探讨了深度神经网络(DNN)在图像分类中的形状和纹理偏见,这些偏见会影响其泛化能力和稳健性。研究表明,与常规DNN训练相比,使用风格化图像进行训练减少了图像分类中的纹理偏见,并提高了对图像腐蚀的稳健性。为了推进这一研究领域,我们研究了风格转换是否也能产生这两个效果在语义分割上。为此,我们在人工图像区域上执行了风格转换。这些随机区域由选择的Voronoi细胞形成。然后,使用得到的风格转换数据来训练语义分割DNN,目的是减少其对纹理线索的依赖,同时增强其对基于形状特征的依赖。在我们的实验中,事实证明,在语义分割中,风格转换增强减少了纹理偏见,并大大提高了对常见图像腐蚀以及对抗性攻击的稳健性。这些观察结果在城市景观数据集和PASCAL Context上的卷积神经网络和转换器架构中都得到了验证,显示了所提出方法的普遍性。
论文及项目相关链接
PDF accepted at ECAI 2025
Summary
近期研究表明,深度神经网络(DNN)在图像分类中的形状和纹理偏见影响其泛化能力和稳健性。通过采用风格化图像进行训练,可减少纹理偏见并提高图像失真鲁棒性。本研究将这种训练策略应用于语义分割领域,利用风格转移技术改变图像的部分区域,这些区域由一系列沃罗诺伊细胞组成。实验表明,风格转移增强训练可降低语义分割中的纹理偏见,并显著提高对常见图像失真以及对抗攻击的稳健性。这一观察结果适用于卷积神经网络和转换器架构,在Cityscapes和PASCAL Context数据集上都验证了该方法的通用性。
Key Takeaways
- 研究深入探讨了深度神经网络在图像分类中的形状和纹理偏见问题及其对泛化和稳健性的影响。
- 通过风格化图像进行训练,可有效减少纹理偏见并提高模型对图像失真的鲁棒性。
- 研究将风格转移技术应用于语义分割领域,通过改变图像的部分区域(由沃罗诺伊细胞组成)进行训练。
- 风格转移增强训练可降低语义分割中的纹理偏见。
- 该方法显著提高模型对常见图像失真以及对抗攻击的稳健性。
- 实验结果适用于卷积神经网络和转换器架构,验证了方法的通用性。
点此查看论文截图



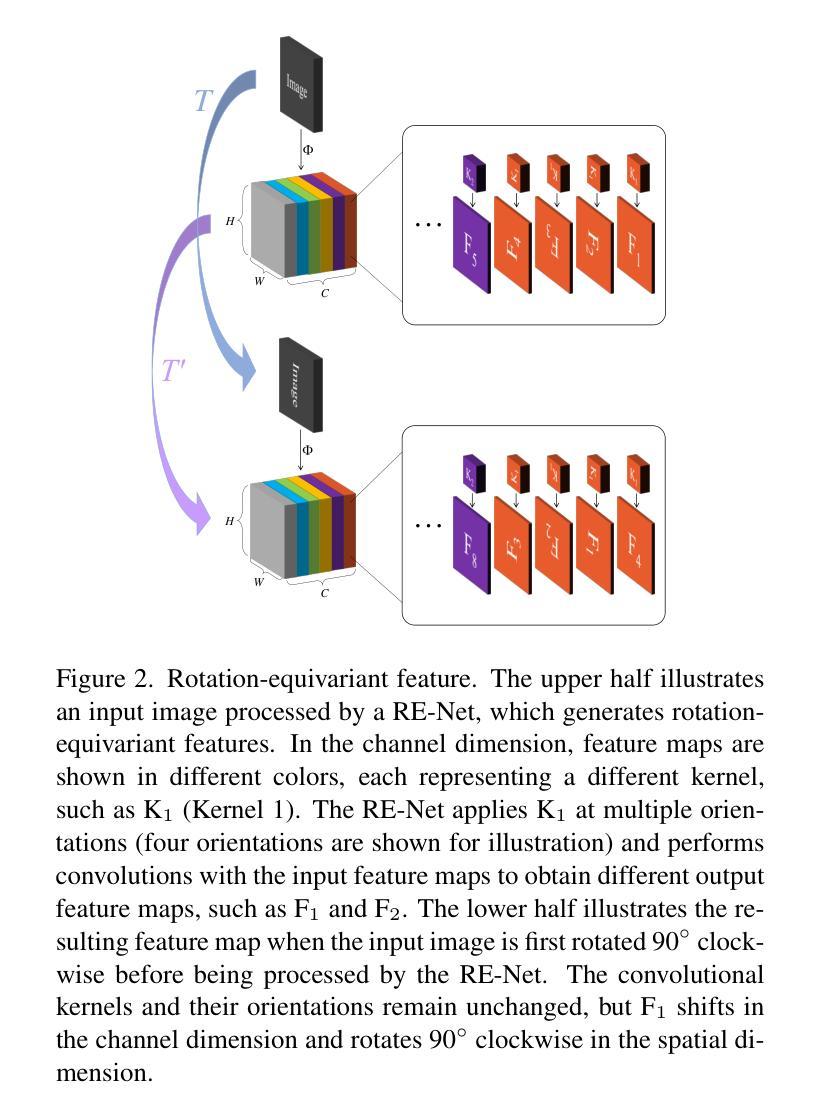
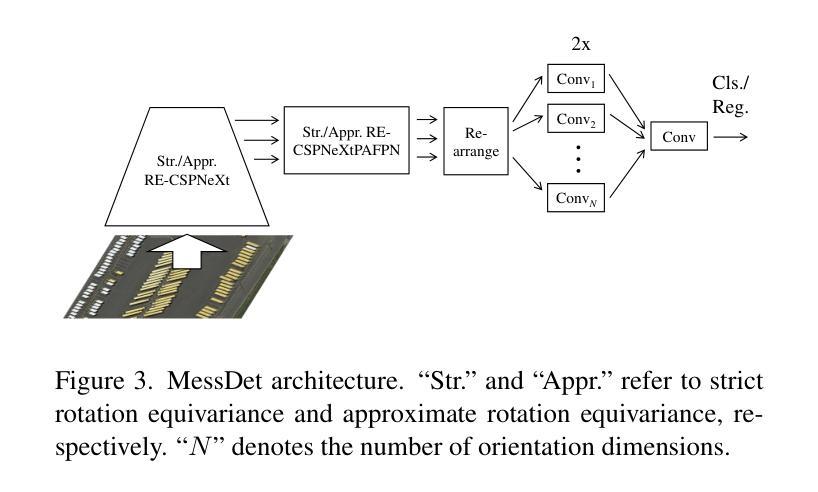
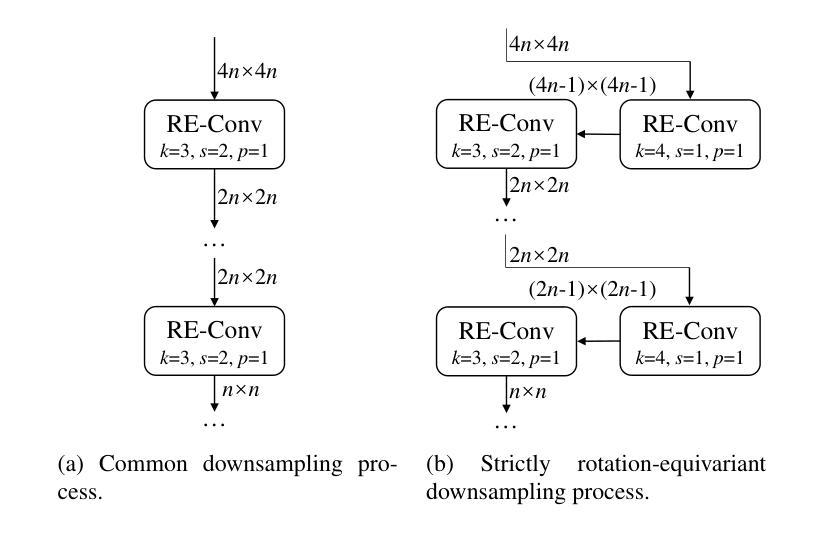
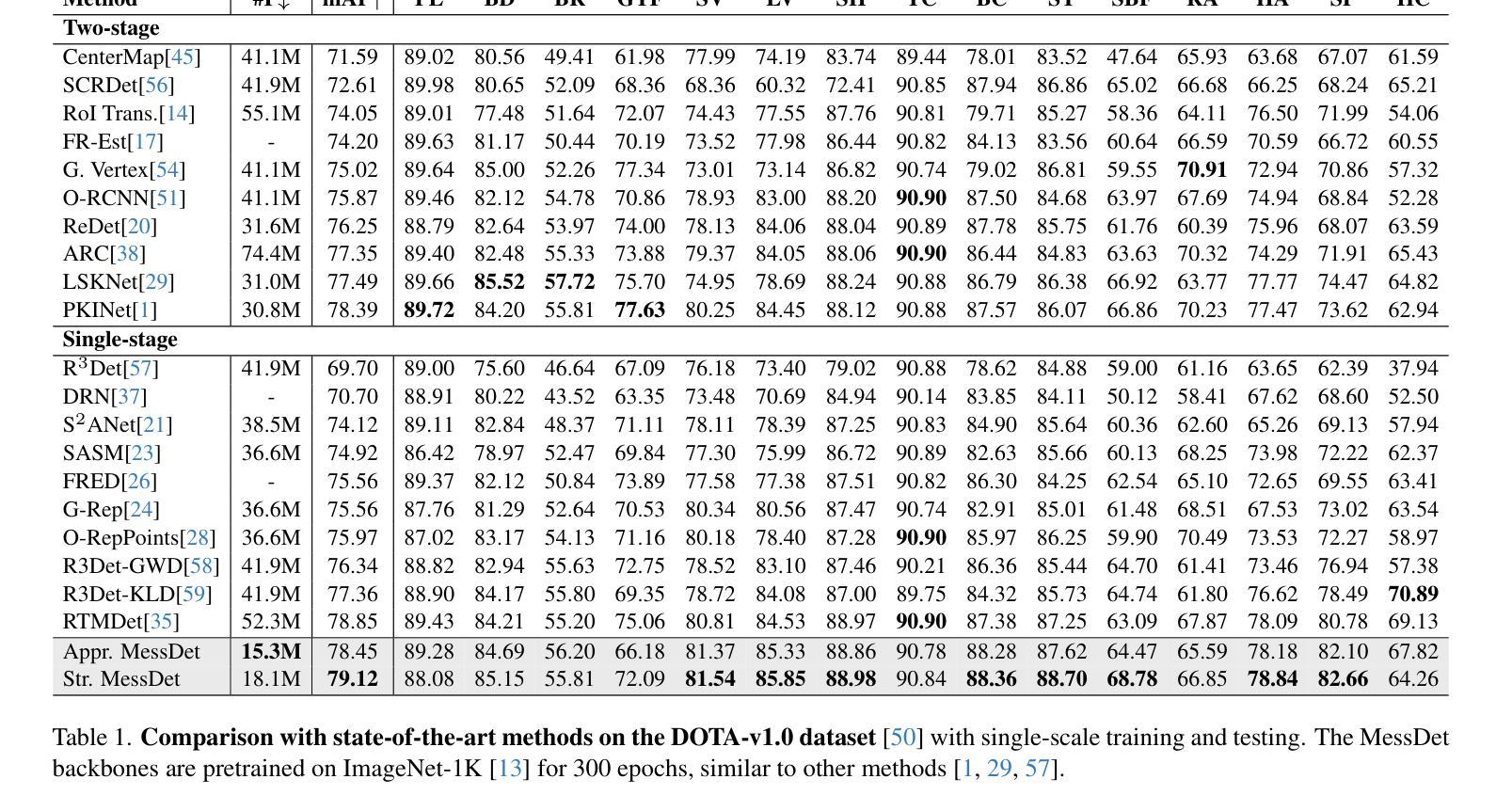
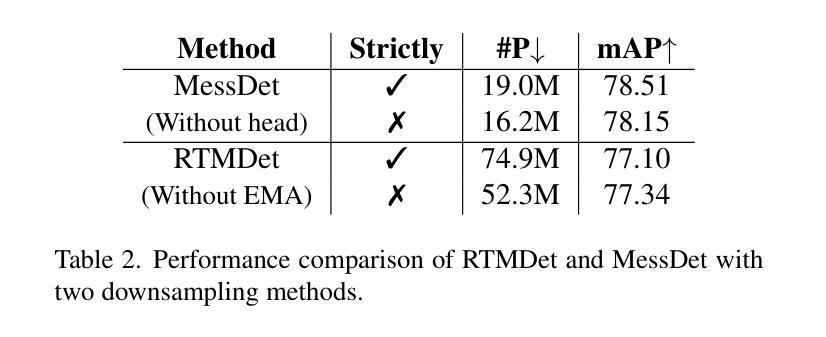
Measuring the Impact of Rotation Equivariance on Aerial Object Detection
Authors:Xiuyu Wu, Xinhao Wang, Xiubin Zhu, Lan Yang, Jiyuan Liu, Xingchen Hu
Due to the arbitrary orientation of objects in aerial images, rotation equivariance is a critical property for aerial object detectors. However, recent studies on rotation-equivariant aerial object detection remain scarce. Most detectors rely on data augmentation to enable models to learn approximately rotation-equivariant features. A few detectors have constructed rotation-equivariant networks, but due to the breaking of strict rotation equivariance by typical downsampling processes, these networks only achieve approximately rotation-equivariant backbones. Whether strict rotation equivariance is necessary for aerial image object detection remains an open question. In this paper, we implement a strictly rotation-equivariant backbone and neck network with a more advanced network structure and compare it with approximately rotation-equivariant networks to quantitatively measure the impact of rotation equivariance on the performance of aerial image detectors. Additionally, leveraging the inherently grouped nature of rotation-equivariant features, we propose a multi-branch head network that reduces the parameter count while improving detection accuracy. Based on the aforementioned improvements, this study proposes the Multi-branch head rotation-equivariant single-stage Detector (MessDet), which achieves state-of-the-art performance on the challenging aerial image datasets DOTA-v1.0, DOTA-v1.5 and DIOR-R with an exceptionally low parameter count.
由于空中图像中物体的任意方向性,旋转等变性对于空中物体检测器是一个关键属性。然而,关于旋转等变空中物体检测的研究仍然很少。大多数检测器依赖于数据增强来使模型学习近似旋转等变特征。一些检测器已经构建了旋转等变网络,但由于典型下采样过程破坏了严格的旋转等变性,这些网络仅实现了近似旋转等变骨干。对于空中图像目标检测而言,严格的旋转等变性是否必要仍然是一个悬而未决的问题。在本文中,我们实现了一个严格的旋转等变骨干和颈部网络,具有更先进的网络结构,并与近似旋转等变网络进行比较,以定量测量旋转等变性对空中图像检测器性能的影响。此外,利用旋转等变特征的固有分组特性,我们提出了一种多分支头网络,该网络在减少参数计数的同时提高了检测精度。基于上述改进,本研究提出了多分支头旋转等变单阶段检测器(MessDet),在具有挑战性的空中图像数据集DOTA-v1.0、DOTA-v1.5和DIOR-R上实现了最先进的性能,并且参数数量异常之低。
论文及项目相关链接
PDF Accepted by ICCV 2025
Summary
本文探讨了旋转等变性在面向航拍图像的目标检测中的重要性。文章实现了严格旋转等变的骨干网络和颈部网络,与近似旋转等变的网络相比,定量测量了旋转等变对航拍图像检测器性能的影响。此外,文章利用旋转等变特征的固有分组特性,提出了多分支头网络,降低了参数计数,提高了检测精度。基于此,本文提出了多分支头旋转等变单阶段检测器(MessDet),在具有挑战性的航拍图像数据集DOTA-v1.0、DOTA-v1.5和DIOR-R上实现了卓越的性能。
Key Takeaways
- 旋转等变性对于航拍图像中的对象检测至关重要,因为航拍图像中对象的朝向是任意的。
- 大多数检测器通过数据增强来使模型学习近似旋转等变特征,但严格旋转等变性仍有待研究。
- 文章实现了严格旋转等变的骨干网络和颈部网络。
- 与近似旋转等变的网络相比,严格旋转等变网络具有更好的性能。
- 利用旋转等变特征的固有分组特性,提出了多分支头网络,降低参数计数,提高检测精度。
- 基于上述改进,提出了多分支头旋转等变单阶段检测器(MessDet)。
点此查看论文截图

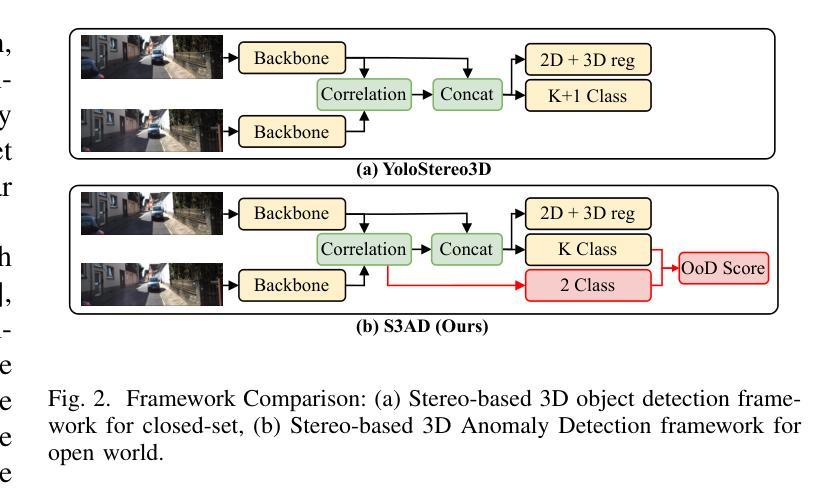
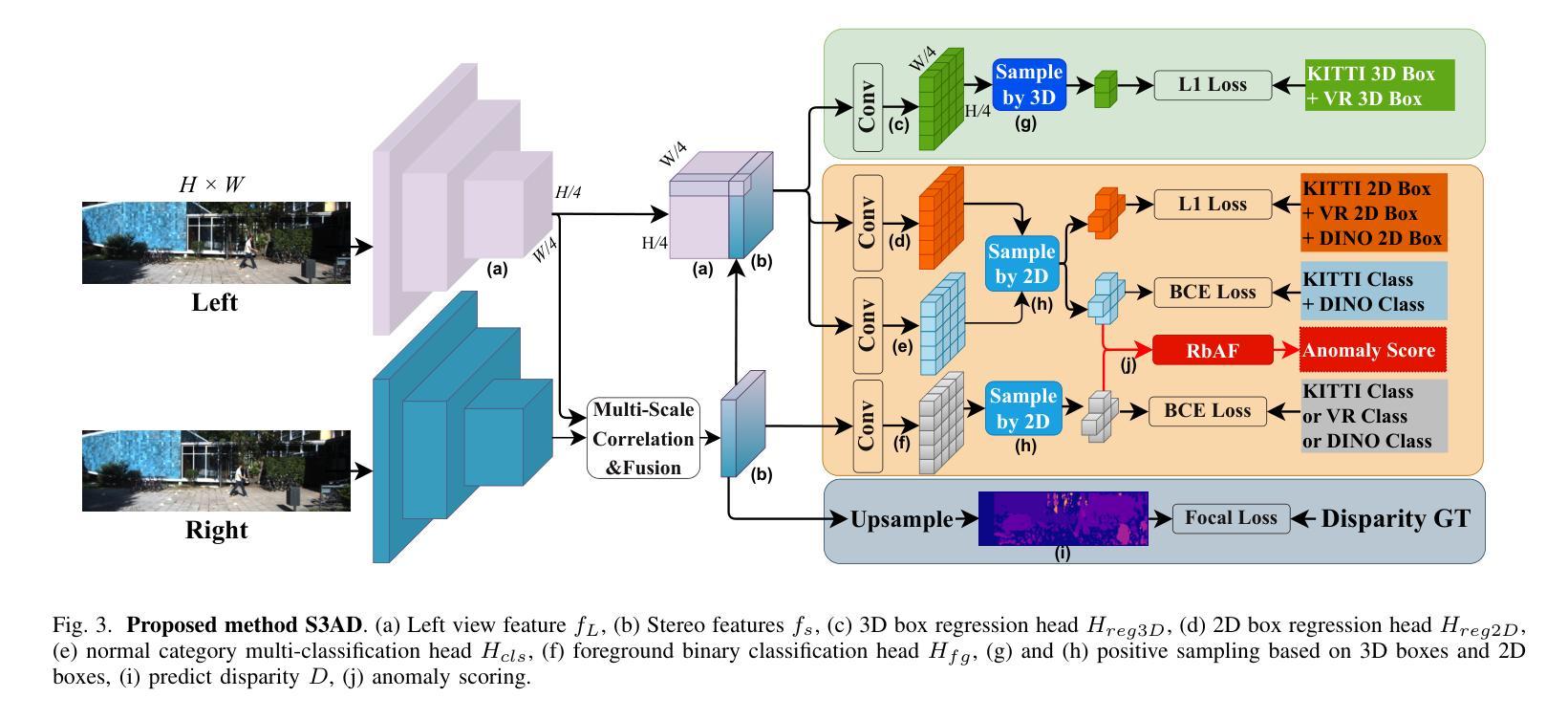
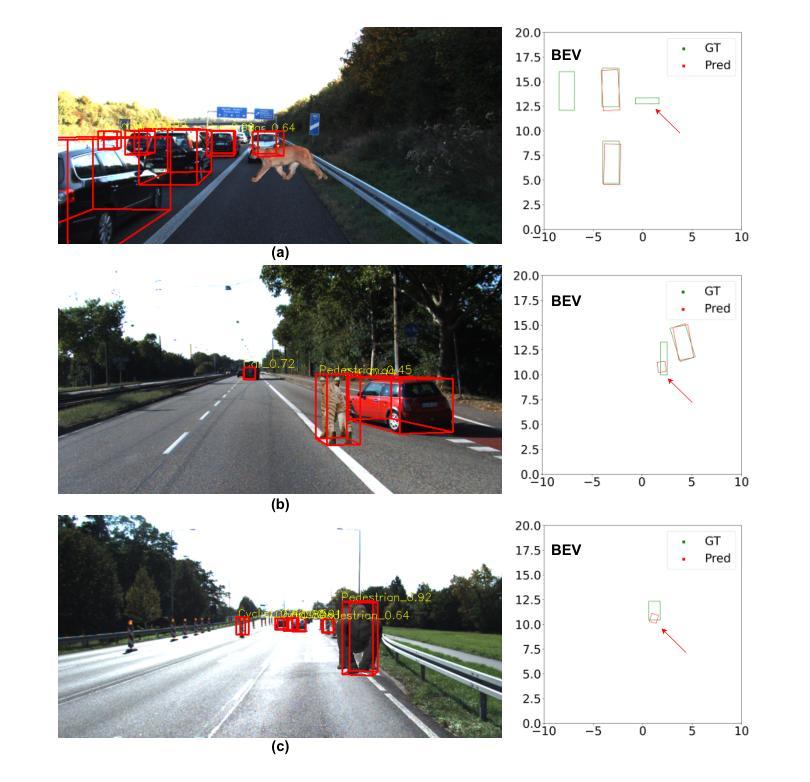
Stereo-based 3D Anomaly Object Detection for Autonomous Driving: A New Dataset and Baseline
Authors:Shiyi Mu, Zichong Gu, Hanqi Lyu, Yilin Gao, Shugong Xu
3D detection technology is widely used in the field of autonomous driving, with its application scenarios gradually expanding from enclosed highways to open conventional roads. For rare anomaly categories that appear on the road, 3D detection models trained on closed sets often misdetect or fail to detect anomaly objects. To address this risk, it is necessary to enhance the generalization ability of 3D detection models for targets of arbitrary shapes and to possess the capability to filter out anomalies. The generalization of 3D detection is limited by two factors: the coupled training of 2D and 3D, and the insufficient diversity in the scale distribution of training samples. This paper proposes a Stereo-based 3D Anomaly object Detection (S3AD) algorithm, which decouples the training strategy of 3D and 2D to release the generalization ability for arbitrary 3D foreground detection, and proposes an anomaly scoring algorithm based on foreground confidence prediction, achieving target-level anomaly scoring. In order to further verify and enhance the generalization of anomaly detection, we use a 3D rendering method to synthesize two augmented reality binocular stereo 3D detection datasets which named KITTI-AR. KITTI-AR extends upon KITTI by adding 97 new categories, totaling 6k pairs of stereo images. The KITTI-AR-ExD subset includes 39 common categories as extra training data to address the sparse sample distribution issue. Additionally, 58 rare categories form the KITTI-AR-OoD subset, which are not used in training to simulate zero-shot scenarios in real-world settings, solely for evaluating 3D anomaly detection. Finally, the performance of the algorithm and the dataset is verified in the experiments. (Code and dataset can be obtained at https://github.com/xxxx/xxx).
3D检测技术在自动驾驶领域有着广泛应用,其应用场景已从封闭的高速公路逐步扩展到开放的常规道路。对于道路上出现的稀有异常类别,在封闭集上训练的3D检测模型经常会发生误检或无法检测到异常物体。为了解决这一风险,必须提高3D检测模型对任意形状的目标的泛化能力,并需要具备过滤异常值的能力。3D检测的泛化受到两个因素的限制:2D和3D的耦合训练,以及训练样本尺度分布多样性不足。本文提出了一种基于立体视觉的3D异常物体检测(S3AD)算法,该算法解耦了3D和2D的训练策略,以释放对任意3D前景检测的泛化能力,并提出了一种基于前景置信度预测的异常评分算法,实现目标级别的异常评分。为了进一步验证和增强异常检测的泛化能力,我们采用了一种3D渲染方法来合成两个增强现实双目立体3D检测数据集,名为KITTI-AR。KITTI-AR在KITTI的基础上增加了97个新类别,总共包含6000对立体图像。KITTI-AR-ExD子集包含39个常见类别作为额外训练数据,以解决样本分布稀疏的问题。此外,58个罕见类别构成了KITTI-AR-OoD子集,这些类别不用于训练,以模拟现实世界中的零样本场景,仅用于评估3D异常检测。最后,通过实验验证了算法和数据集的性能。(代码和数据集可在https://github.com/xxxx/xxx获得。)
论文及项目相关链接
PDF under review
Summary
基于深度学习的三维检测技术在自动驾驶领域得到了广泛应用,但在面对开放道路上的罕见异常类别时存在误检或漏检的问题。本文提出了一种基于立体视觉的3D异常目标检测算法(S3AD),通过解耦二维和三维的训练策略提高模型的泛化能力,并基于前景置信度预测进行异常评分。为了验证和增强异常检测的泛化能力,利用三维渲染方法合成了两个增强现实双目立体三维检测数据集KITTI-AR。其中,KITTI-AR-ExD子集包含额外的训练数据以解决样本分布稀疏的问题,而KITTI-AR-OoD子集包含用于评估但不用于训练的罕见类别,以模拟现实世界中的零样本场景。实验验证了算法和数据集的性能。
Key Takeaways
- 3D检测技术在自动驾驶领域广泛应用,但面对开放道路上的罕见异常类别存在挑战。
- 本文提出了基于立体视觉的S3AD算法,通过解耦二维和三维训练提高模型泛化能力。
- 引入前景置信度预测进行异常评分,实现目标级别的异常检测。
- 采用了三维渲染方法合成KITTI-AR数据集,包含常见和罕见的类别,用于验证和增强异常检测的泛化能力。其中KITTI-AR-ExD解决样本分布稀疏问题,KITTI-AR-OoD模拟零样本场景。
点此查看论文截图

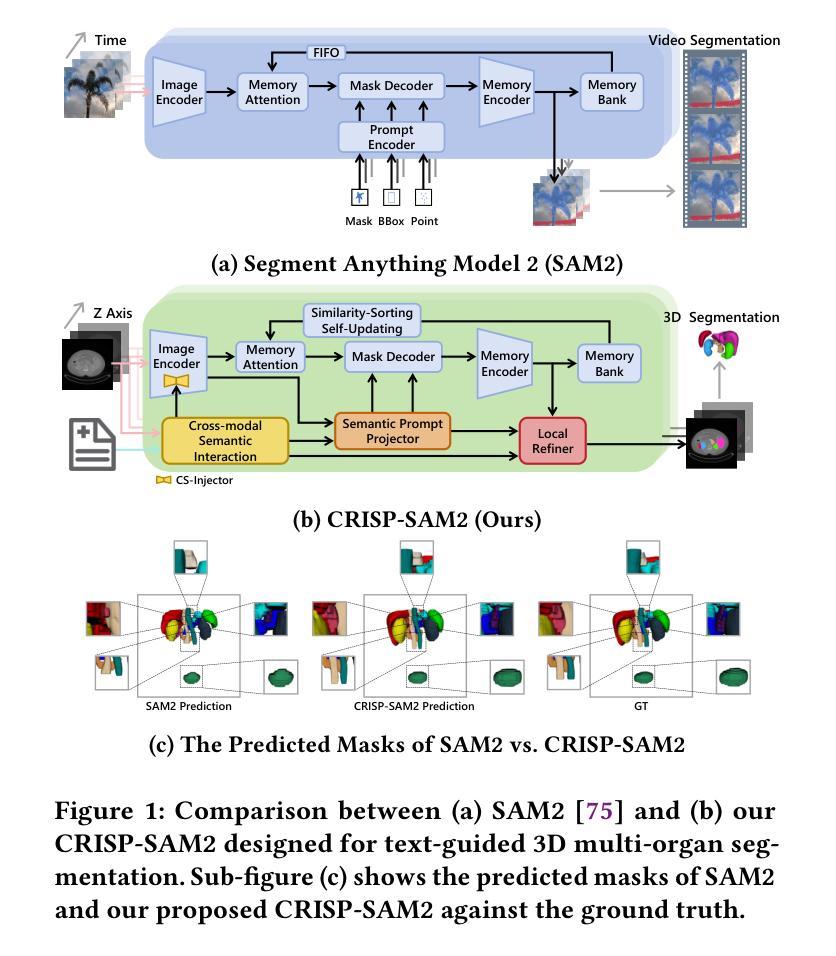
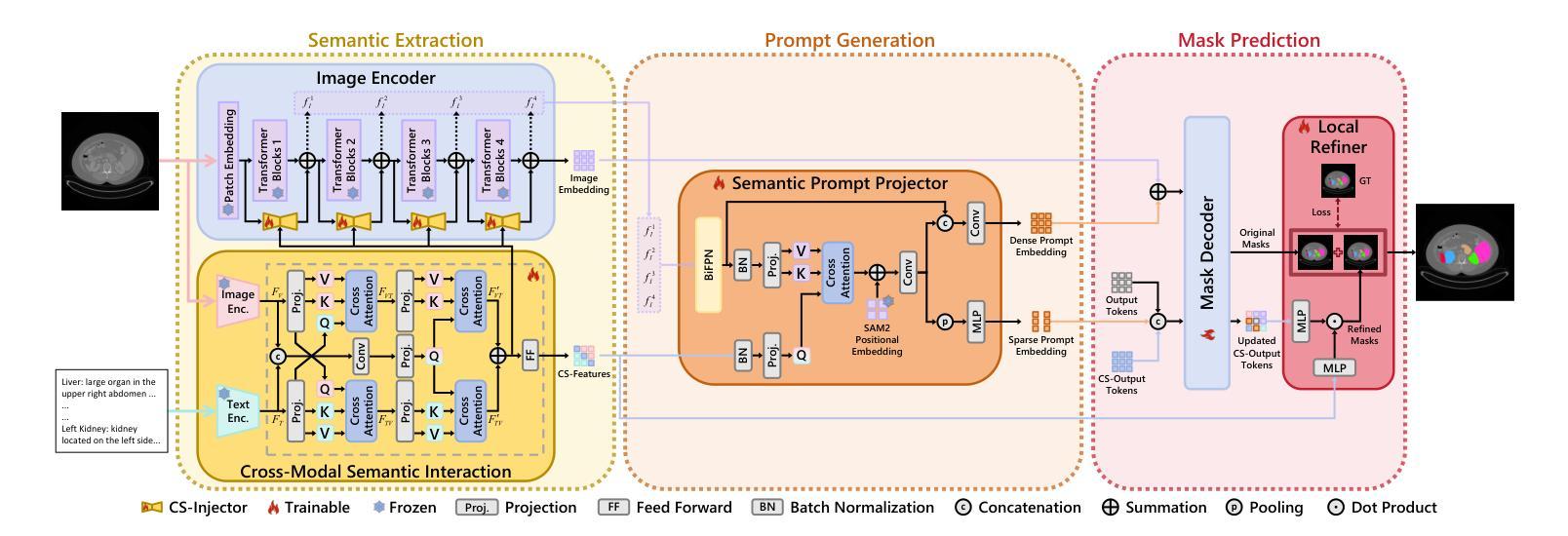
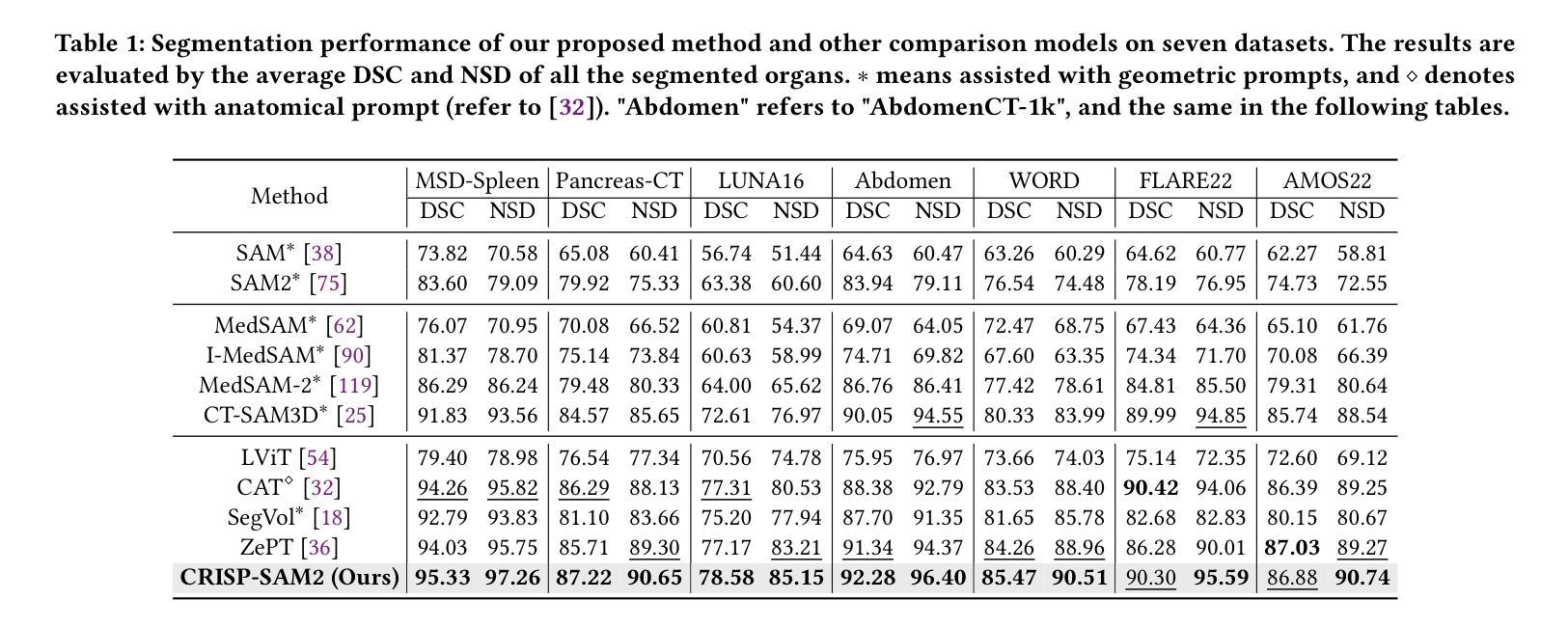
CRISP-SAM2: SAM2 with Cross-Modal Interaction and Semantic Prompting for Multi-Organ Segmentation
Authors:Xinlei Yu, Changmiao Wang, Hui Jin, Ahmed Elazab, Gangyong Jia, Xiang Wan, Changqing Zou, Ruiquan Ge
Multi-organ medical segmentation is a crucial component of medical image processing, essential for doctors to make accurate diagnoses and develop effective treatment plans. Despite significant progress in this field, current multi-organ segmentation models often suffer from inaccurate details, dependence on geometric prompts and loss of spatial information. Addressing these challenges, we introduce a novel model named CRISP-SAM2 with CRoss-modal Interaction and Semantic Prompting based on SAM2. This model represents a promising approach to multi-organ medical segmentation guided by textual descriptions of organs. Our method begins by converting visual and textual inputs into cross-modal contextualized semantics using a progressive cross-attention interaction mechanism. These semantics are then injected into the image encoder to enhance the detailed understanding of visual information. To eliminate reliance on geometric prompts, we use a semantic prompting strategy, replacing the original prompt encoder to sharpen the perception of challenging targets. In addition, a similarity-sorting self-updating strategy for memory and a mask-refining process is applied to further adapt to medical imaging and enhance localized details. Comparative experiments conducted on seven public datasets indicate that CRISP-SAM2 outperforms existing models. Extensive analysis also demonstrates the effectiveness of our method, thereby confirming its superior performance, especially in addressing the limitations mentioned earlier. Our code is available at: https://github.com/YU-deep/CRISP_SAM2.git.
医学多器官分割是医学图像处理的重要组成部分,对于医生进行准确的诊断和制定有效的治疗方案至关重要。尽管该领域取得了重大进展,但现有的多器官分割模型通常存在细节不准确、依赖几何提示和丢失空间信息等问题。为了解决这些挑战,我们引入了一种名为CRISP-SAM2的新模型,该模型基于SAM2具有跨模态交互和语义提示。该模型是一种很有前途的方法,可以通过器官的文本描述来指导多器官医学分割。我们的方法首先通过渐进的交叉注意力交互机制将视觉和文本输入转换为跨模态上下文语义。然后,这些语义被注入图像编码器,以提高对视觉信息的详细理解。为了减少对几何提示的依赖,我们采用了一种语义提示策略,以替代原始提示编码器,提高了对具有挑战性的目标的感知能力。此外,还采用了相似性排序的自更新策略进行内存管理和改进了掩膜过程,以进一步适应医学影像并增强局部细节。在七个公共数据集上进行的对比实验表明,CRISP-SAM2优于现有模型。广泛的分析也证明了我们的方法的有效性,从而证实了其卓越性能,特别是在解决上述限制方面。我们的代码可在:https://github.com/YU-deep/CRISP_SAM2.git上找到。
论文及项目相关链接
PDF Accepted By ACMMM25
Summary
一项重要研究提出了CRISP-SAM2模型,该模型通过跨模态交互和语义提示解决多器官医学分割面临的挑战。模型结合了视觉和文本输入,通过渐进的交叉注意力交互机制生成跨模态上下文语义,注入图像编码器以提高对视觉信息的详细理解。此外,采用语义提示策略减少对几何提示的依赖,并使用相似性排序的自更新策略和掩膜细化过程进一步适应医学成像并增强局部细节。在七个公共数据集上的对比实验表明,CRISP-SAM2模型表现优异,尤其是解决了先前存在的限制。
Key Takeaways
- 多器官医学分割是医疗图像处理中的关键部分,对医生做出准确诊断和治疗计划至关重要。
- 当前的多器官分割模型存在不准确、依赖几何提示和损失空间信息的问题。
- CRISP-SAM2模型通过跨模态交互和语义提示解决这些问题。
- 模型结合视觉和文本输入,生成跨模态上下文语义,提高视觉信息的详细理解。
- 采用语义提示策略减少几何提示的依赖,增强对挑战目标的感知。
- 相似性排序的自更新策略和掩膜细化过程进一步适应医学成像并增强局部细节。
点此查看论文截图

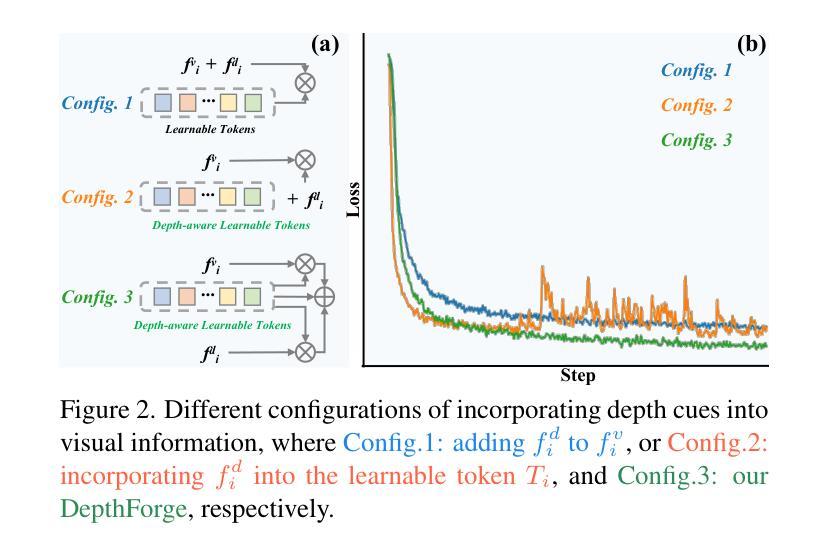
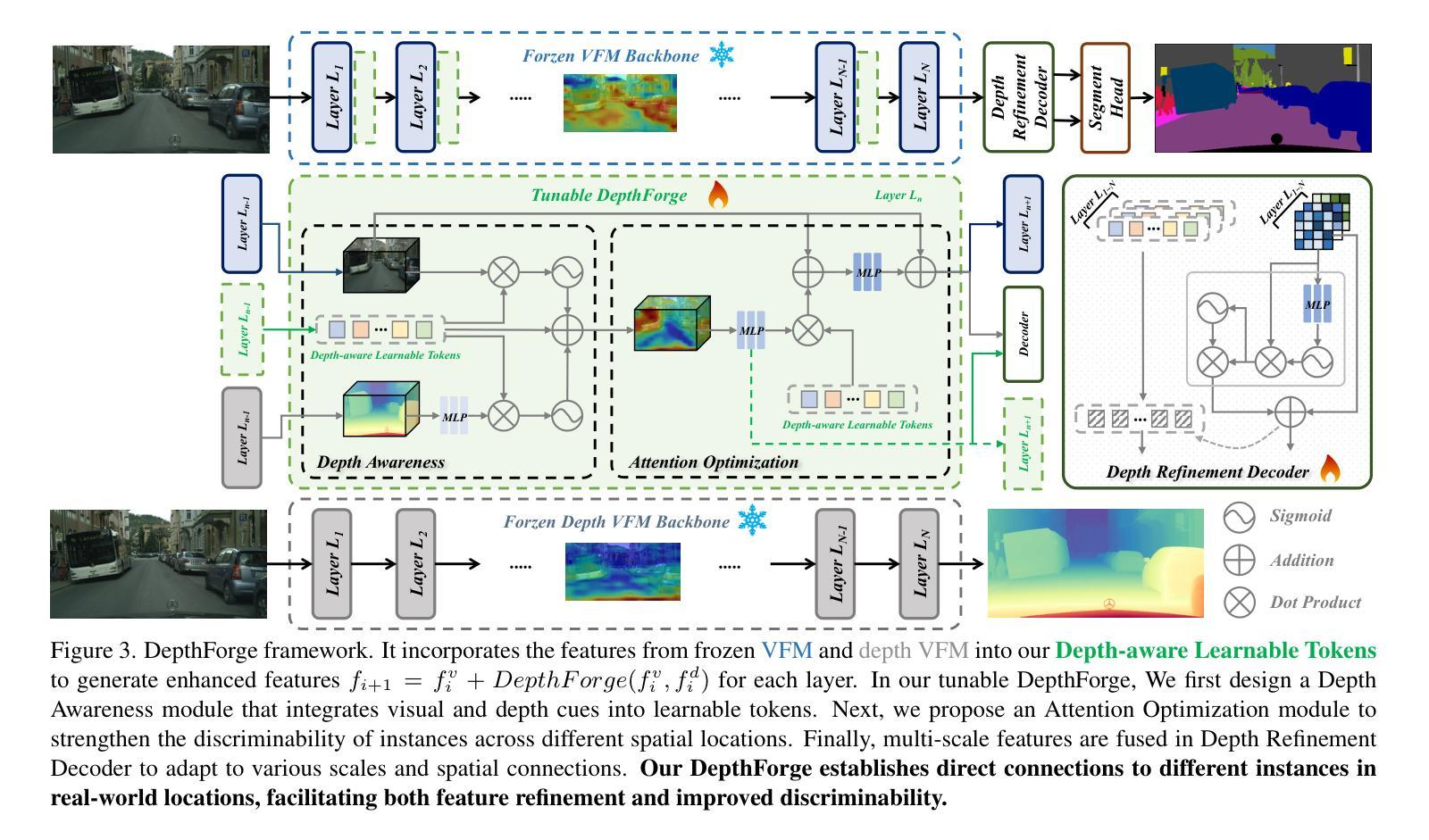
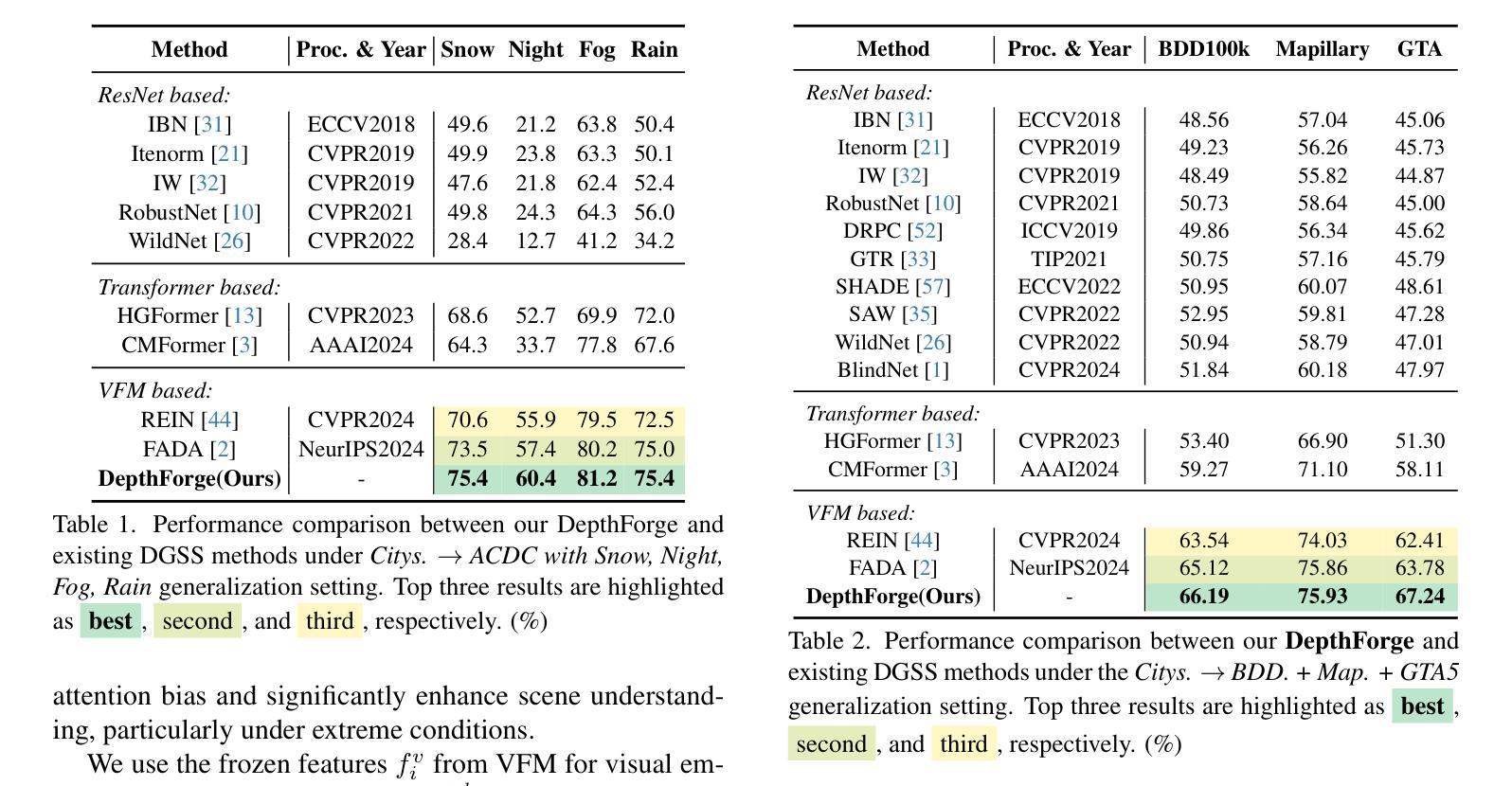
Stronger, Steadier & Superior: Geometric Consistency in Depth VFM Forges Domain Generalized Semantic Segmentation
Authors:Siyu Chen, Ting Han, Changshe Zhang, Xin Luo, Meiliu Wu, Guorong Cai, Jinhe Su
Vision Foundation Models (VFMs) have delivered remarkable performance in Domain Generalized Semantic Segmentation (DGSS). However, recent methods often overlook the fact that visual cues are susceptible, whereas the underlying geometry remains stable, rendering depth information more robust. In this paper, we investigate the potential of integrating depth information with features from VFMs, to improve the geometric consistency within an image and boost the generalization performance of VFMs. We propose a novel fine-tuning DGSS framework, named DepthForge, which integrates the visual cues from frozen DINOv2 or EVA02 and depth cues from frozen Depth Anything V2. In each layer of the VFMs, we incorporate depth-aware learnable tokens to continuously decouple domain-invariant visual and spatial information, thereby enhancing depth awareness and attention of the VFMs. Finally, we develop a depth refinement decoder and integrate it into the model architecture to adaptively refine multi-layer VFM features and depth-aware learnable tokens. Extensive experiments are conducted based on various DGSS settings and five different datsets as unseen target domains. The qualitative and quantitative results demonstrate that our method significantly outperforms alternative approaches with stronger performance, steadier visual-spatial attention, and superior generalization ability. In particular, DepthForge exhibits outstanding performance under extreme conditions (e.g., night and snow). Code is available at https://github.com/anonymouse-xzrptkvyqc/DepthForge.
视觉基础模型(VFMs)在域通用语义分割(DGSS)方面取得了显著的成绩。然而,最近的方法往往忽略了这样一个事实,即视觉线索是易变的,而基础几何结构是稳定的,这使得深度信息更加稳健。在本文中,我们探讨了将深度信息与VFMs的特征相结合,以提高图像内的几何一致性并提升VFMs的泛化性能。我们提出了一种新型的微调DGSS框架,名为DepthForge,它结合了来自冻结的DINOv2或EVA02的视觉线索和来自冻结的Depth Anything V2的深度线索。在VFMs的每一层中,我们引入了深度感知的可学习令牌,以连续地解耦域不变视觉和空间信息,从而提高VFMs的深度感知和注意力。最后,我们开发了一种深度细化解码器,并将其集成到模型架构中,以自适应地细化多层VFM特征和深度感知可学习令牌。基于各种DGSS设置和五个不同数据集作为未见过的目标域进行了广泛的实验。定性和定量结果表明,我们的方法显著优于其他方法,具有更强的性能、更稳定的视觉-空间注意力和更好的泛化能力。特别是,DepthForge在极端条件下(例如夜晚和雪地)表现出卓越的性能。代码可在https://github.com/anonymouse-xzrptkvyqc/DepthForge上找到。
论文及项目相关链接
PDF Accepted by ICCV 2025
Summary
本文探讨了将深度信息融入视觉基础模型(VFMs)以提升领域广义语义分割(DGSS)性能的方法。研究提出了一种名为DepthForge的新型微调DGSS框架,通过集成来自冻结的DINOv2或EVA02的视觉线索和来自冻结的Depth Anything V2的深度线索,以增强图像内的几何一致性和VFMs的泛化性能。通过在各层融入深度感知的可学习令牌,以持续解耦领域不变视觉和空间信息,从而提高深度感知和注意力。此外,开发了一个深度细化解码器,将其集成到模型架构中,以自适应地优化多层VFM特性和深度感知可学习令牌。实验结果表明,与替代方法相比,该方法具有更强的性能、更稳定的视觉空间注意力和更好的泛化能力,特别是在极端条件下表现出卓越性能。
Key Takeaways
- 本文强调了深度信息在领域广义语义分割(DGSS)中的重要作用,并提出了一种整合深度信息与视觉基础模型(VFMs)特征的方法。
- 提出了一种名为DepthForge的新型微调DGSS框架,融合了视觉线索和深度线索。
- DepthForge通过融入深度感知的可学习令牌,提高了VFMs的深度感知和注意力。
- 开发了一个深度细化解码器,以自适应地优化多层VFM特性和深度感知可学习令牌。
- 实验结果表明,DepthForge在多种DGSS设置和五个不同数据集上显著优于其他方法。
- DepthForge在极端条件下(如夜晚和雪地)表现出卓越性能。
点此查看论文截图



HA-RDet: Hybrid Anchor Rotation Detector for Oriented Object Detection
Authors:Phuc D. A. Nguyen
Oriented object detection in aerial images poses a significant challenge due to their varying sizes and orientations. Current state-of-the-art detectors typically rely on either two-stage or one-stage approaches, often employing Anchor-based strategies, which can result in computationally expensive operations due to the redundant number of generated anchors during training. In contrast, Anchor-free mechanisms offer faster processing but suffer from a reduction in the number of training samples, potentially impacting detection accuracy. To address these limitations, we propose the Hybrid-Anchor Rotation Detector (HA-RDet), which combines the advantages of both anchor-based and anchor-free schemes for oriented object detection. By utilizing only one preset anchor for each location on the feature maps and refining these anchors with our Orientation-Aware Convolution technique, HA-RDet achieves competitive accuracies, including 75.41 mAP on DOTA-v1, 65.3 mAP on DIOR-R, and 90.2 mAP on HRSC2016, against current anchor-based state-of-the-art methods, while significantly reducing computational resources.
针对航拍图像中的定向目标检测问题,由于其尺寸和方向的多样性,构成了一大挑战。当前最先进的检测器通常依赖于两阶段或一阶段的方法,经常采用基于锚点的策略。由于在训练过程中产生的锚点数量冗余,这可能导致计算成本较高的操作。相比之下,无锚点机制处理速度更快,但会降低训练样本的数量,从而可能影响检测精度。为了解决这些局限性,我们提出了混合锚点旋转检测器(HA-RDet),它将基于锚点和无锚点方案的优势结合起来,用于定向目标检测。通过在特征图的每个位置只使用一个预设锚点,并结合我们的方向感知卷积技术进行精细调整,HA-RDet实现了具有竞争力的精度,在DOTA-v1上达到75.41 mAP,在DIOR-R上达到65.3 mAP,在HRSC2016上达到90.2 mAP,与当前基于锚点的最先进方法相比,同时大大降低了计算资源。
论文及项目相关链接
PDF Bachelor thesis, Accepted to ICCV’25 SEA
Summary
基于空中图像的目标检测面临尺寸和方位多变的挑战。当前顶尖的检测器主要依赖两阶段或一阶段的检测方式,经常采用基于锚的策略,这会由于训练时生成的锚冗余而计算成本高。与此相对的是,无锚机制处理更快,但减少训练样本数量,可能影响检测精度。为了解决这些局限,我们提出了混合锚旋转检测器(HA-RDet),结合了基于锚和无锚方案的优势进行方位目标检测。通过在特征图的每个位置只使用一个预设锚,并使用我们的方向感知卷积技术进行精炼,HA-RDet在DOTA-v1达到75.41 mAP、DIOR-R达到65.3 mAP以及HRSC2016达到90.2 mAP,相较于当前的顶尖基于锚的方法具有竞争力,同时大幅减少计算资源。
Key Takeaways
- 空中图像的目标检测面临尺寸和方位多变的挑战。
- 当前顶尖检测器采用基于锚的策略会有计算成本高的缺点。
- 无锚机制处理更快,但可能影响检测精度。
- 混合锚旋转检测器(HA-RDet)结合了基于锚和无锚的优势。
- HA-RDet在每个特征图位置只使用一个预设锚。
- HA-RDet使用方向感知卷积技术精炼锚点。
点此查看论文截图




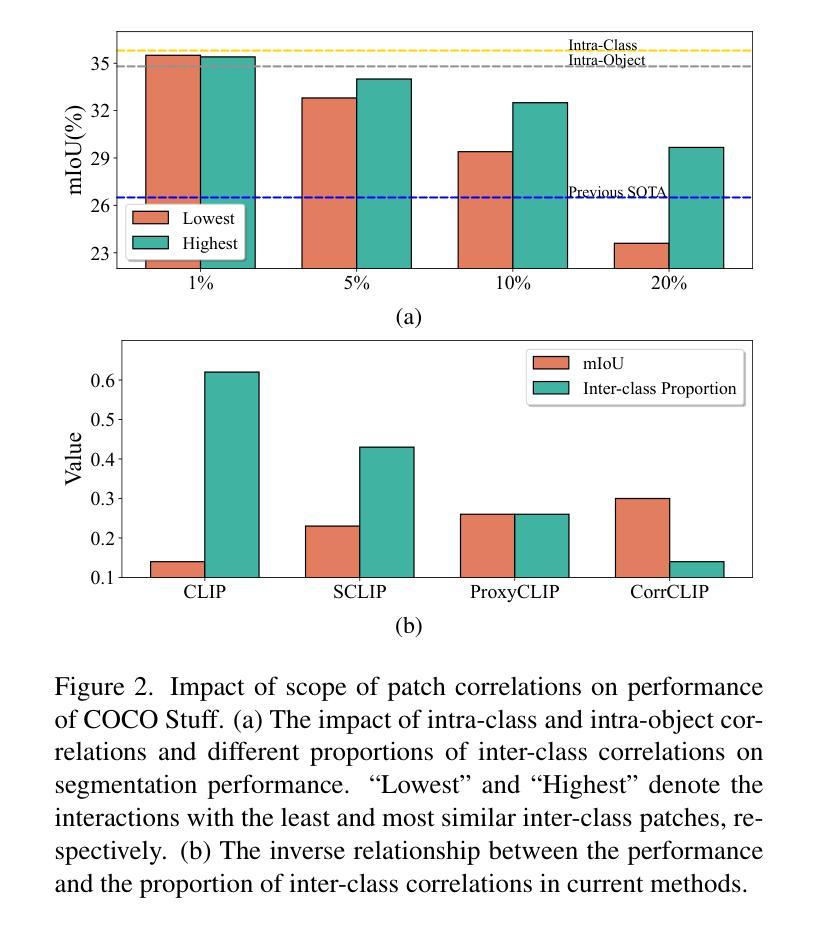
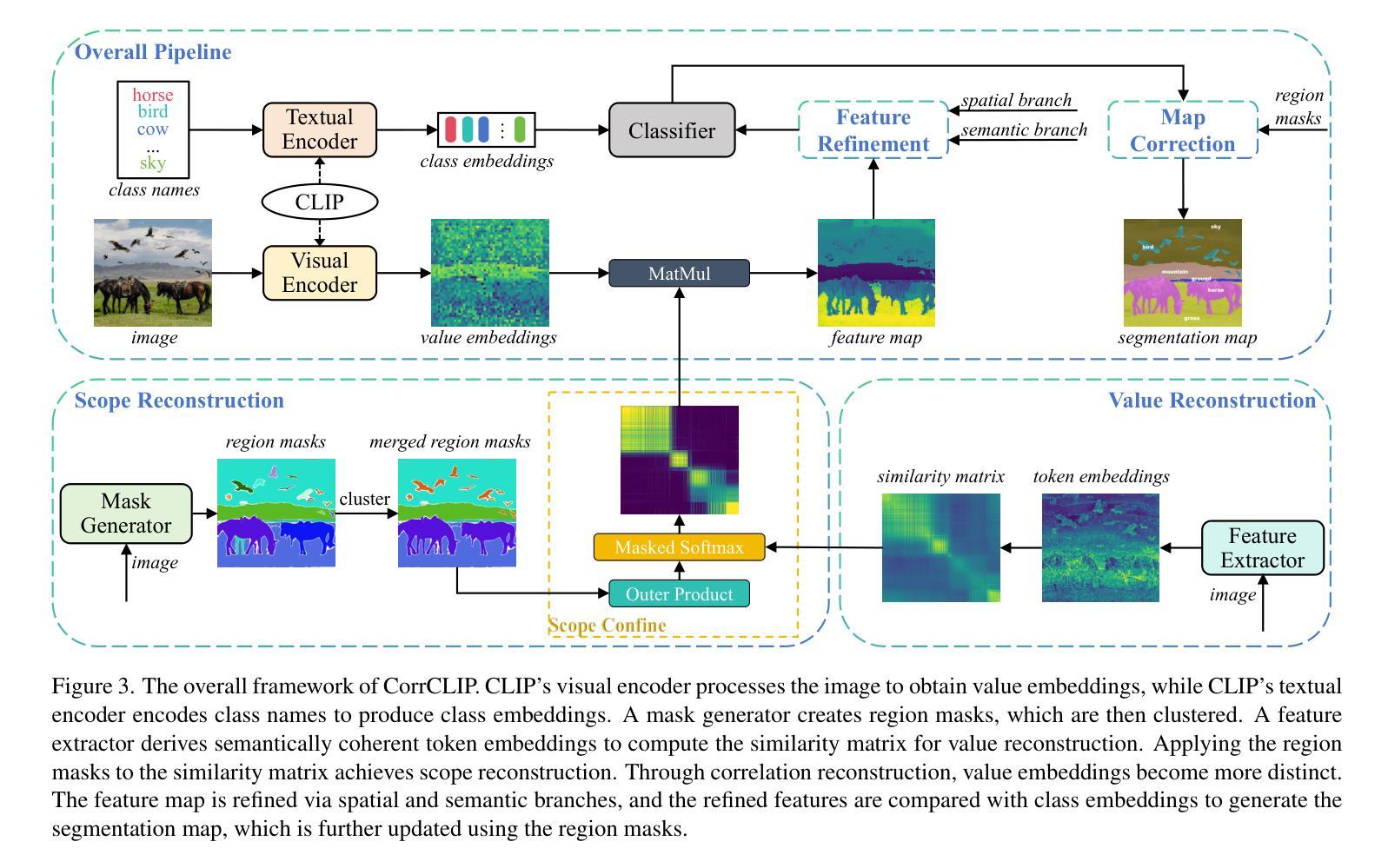
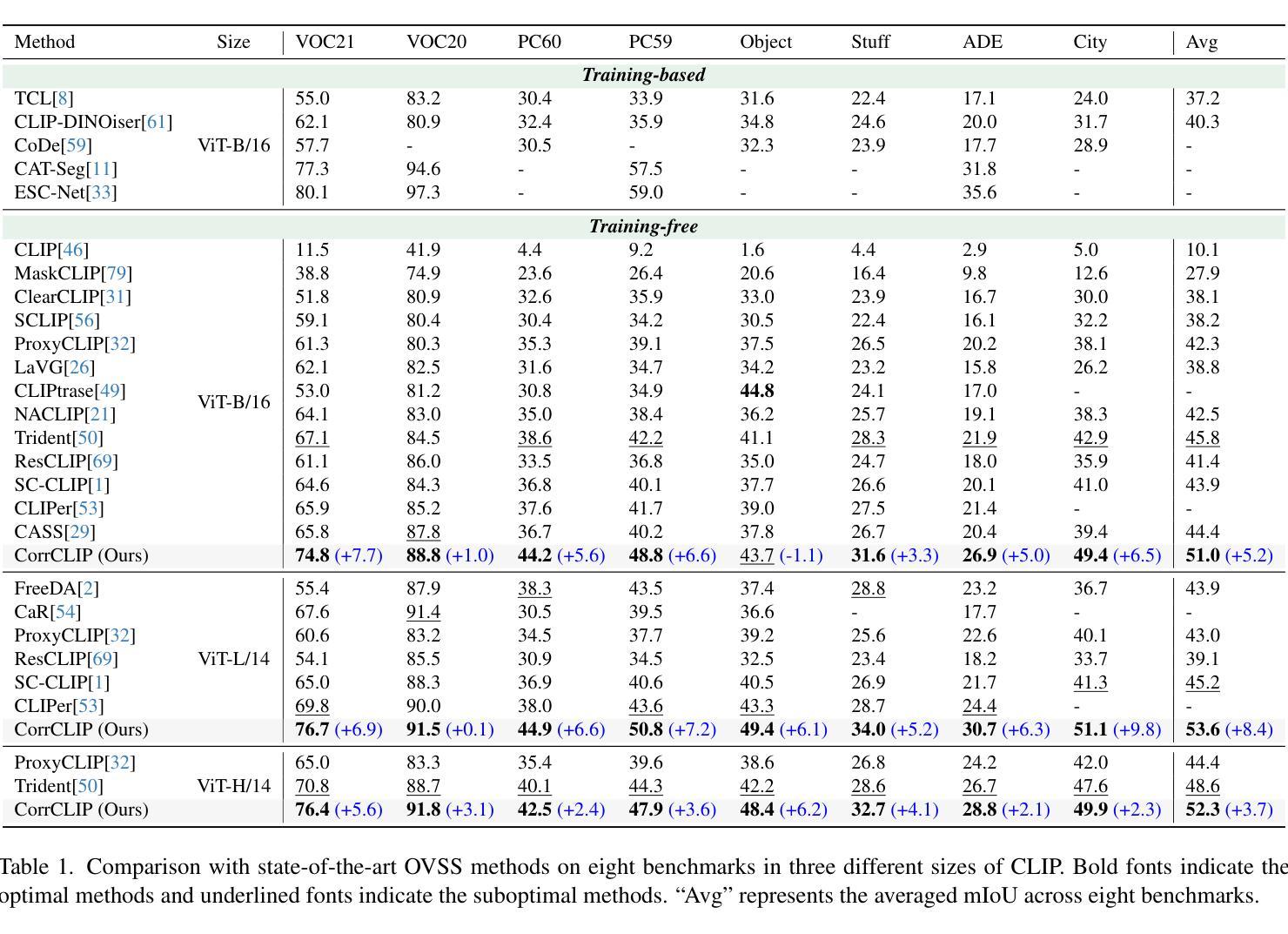
CorrCLIP: Reconstructing Patch Correlations in CLIP for Open-Vocabulary Semantic Segmentation
Authors:Dengke Zhang, Fagui Liu, Quan Tang
Open-vocabulary semantic segmentation aims to assign semantic labels to each pixel without being constrained by a predefined set of categories. While Contrastive Language-Image Pre-training (CLIP) excels in zero-shot classification, it struggles to align image patches with category embeddings because of its incoherent patch correlations. This study reveals that inter-class correlations are the main reason for impairing CLIP’s segmentation performance. Accordingly, we propose CorrCLIP, which reconstructs the scope and value of patch correlations. Specifically, CorrCLIP leverages the Segment Anything Model (SAM) to define the scope of patch interactions, reducing inter-class correlations. To mitigate the problem that SAM-generated masks may contain patches belonging to different classes, CorrCLIP incorporates self-supervised models to compute coherent similarity values, suppressing the weight of inter-class correlations. Additionally, we introduce two additional branches to strengthen patch features’ spatial details and semantic representation. Finally, we update segmentation maps with SAM-generated masks to improve spatial consistency. Based on the improvement across patch correlations, feature representations, and segmentation maps, CorrCLIP achieves superior performance across eight benchmarks. Codes are available at: https://github.com/zdk258/CorrCLIP.
开放词汇语义分割旨在为每个像素分配语义标签,而不受预设类别集的约束。虽然对比语言图像预训练(CLIP)在零样本分类方面表现出色,但由于其不连贯的补丁相关性,它很难将图像补丁与类别嵌入对齐。本研究表明,类间相关性是损害CLIP分割性能的主要原因。因此,我们提出了CorrCLIP,它重构了补丁相关性的范围和价值。具体来说,CorrCLIP利用万物可分割模型(SAM)定义补丁交互的范围,减少类间相关性。为了解决SAM生成的蒙版可能包含属于不同类别的补丁的问题,CorrCLIP结合了自监督模型来计算连贯的相似度值,抑制类间相关性的权重。此外,我们还引入了另外两个分支,以增强补丁特征的空间细节和语义表示。最后,我们用SAM生成的蒙版更新分割图,以提高空间一致性。基于补丁相关性、特征表示和分割图的改进,CorrCLIP在八个基准测试中实现了卓越的性能。代码可在以下网址找到:https://github.com/zdk258/CorrCLIP。
论文及项目相关链接
PDF Accepted to ICCV 2025
Summary
本文探讨了基于CLIP模型的语义分割问题,特别是其对于图像补丁与类别嵌入对齐的困难。研究发现,类间关联是制约CLIP分割性能的主要原因。为此,提出CorrCLIP模型,利用Segment Anything Model(SAM)定义补丁交互范围,降低类间关联。为解决SAM生成的掩膜可能包含不同类别补丁的问题,CorrCLIP结合自监督模型计算连贯的相似度值,抑制类间关联的权重。此外,增加两个分支以增强补丁特征的空间细节和语义表示。最后,使用SAM生成的掩膜更新分割图,提高空间一致性。CorrCLIP在八个基准测试中表现出卓越性能。
Key Takeaways
- 开放词汇语义分割旨在为每个像素分配语义标签,不受预定义类别集的约束。
- CLIP在零样本分类上表现出色,但在图像补丁与类别嵌入对齐方面存在困难。
- 类间关联是制约CLIP分割性能的主要原因。
- CorrCLIP模型利用Segment Anything Model(SAM)降低类间关联,提高分割性能。
- SAM生成的掩膜可能包含不同类别的补丁,CorrCLIP通过结合自监督模型计算相似度值来解决这一问题。
- CorrCLIP增加两个分支以增强补丁特征的空间细节和语义表示。
点此查看论文截图

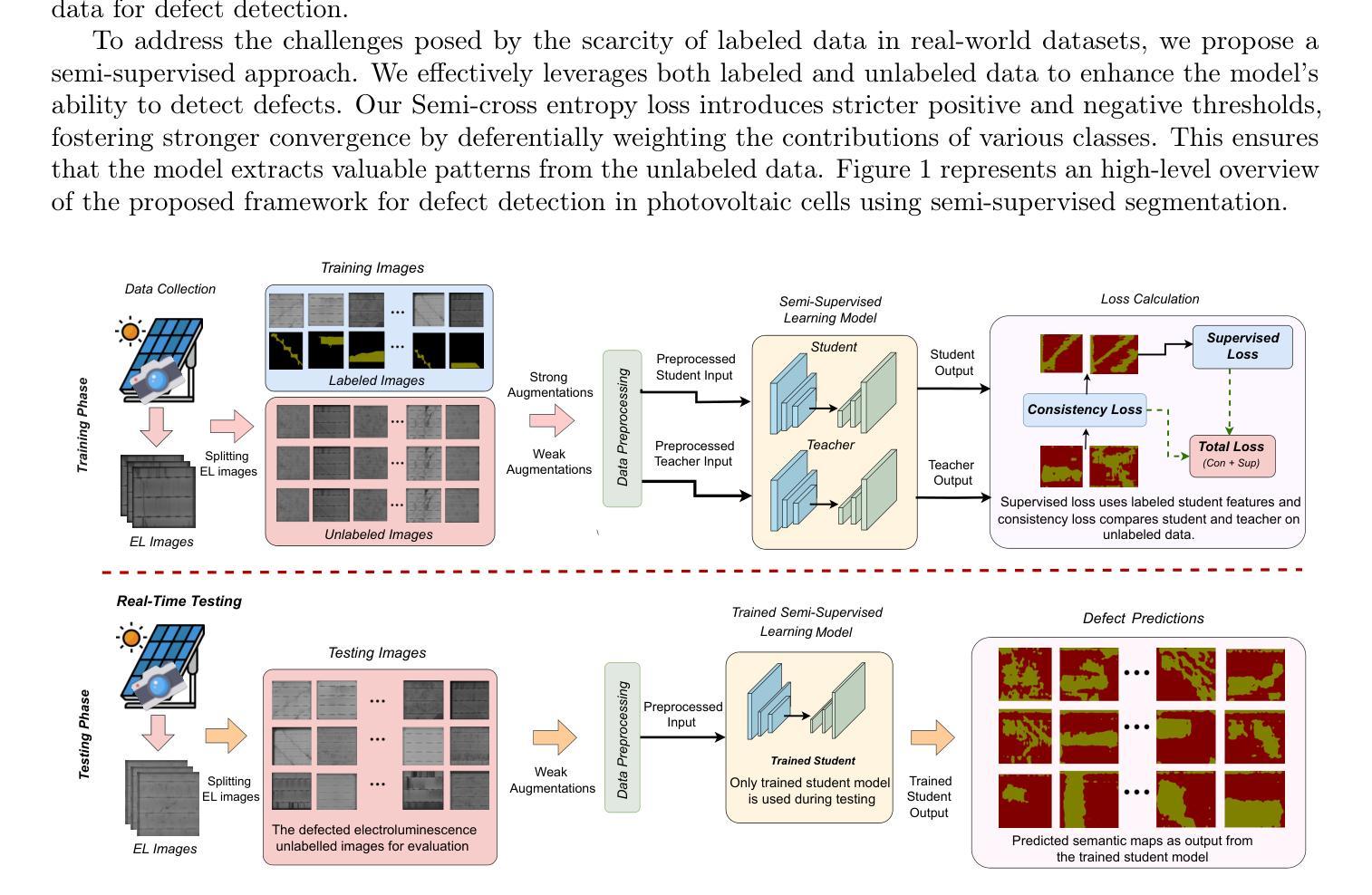
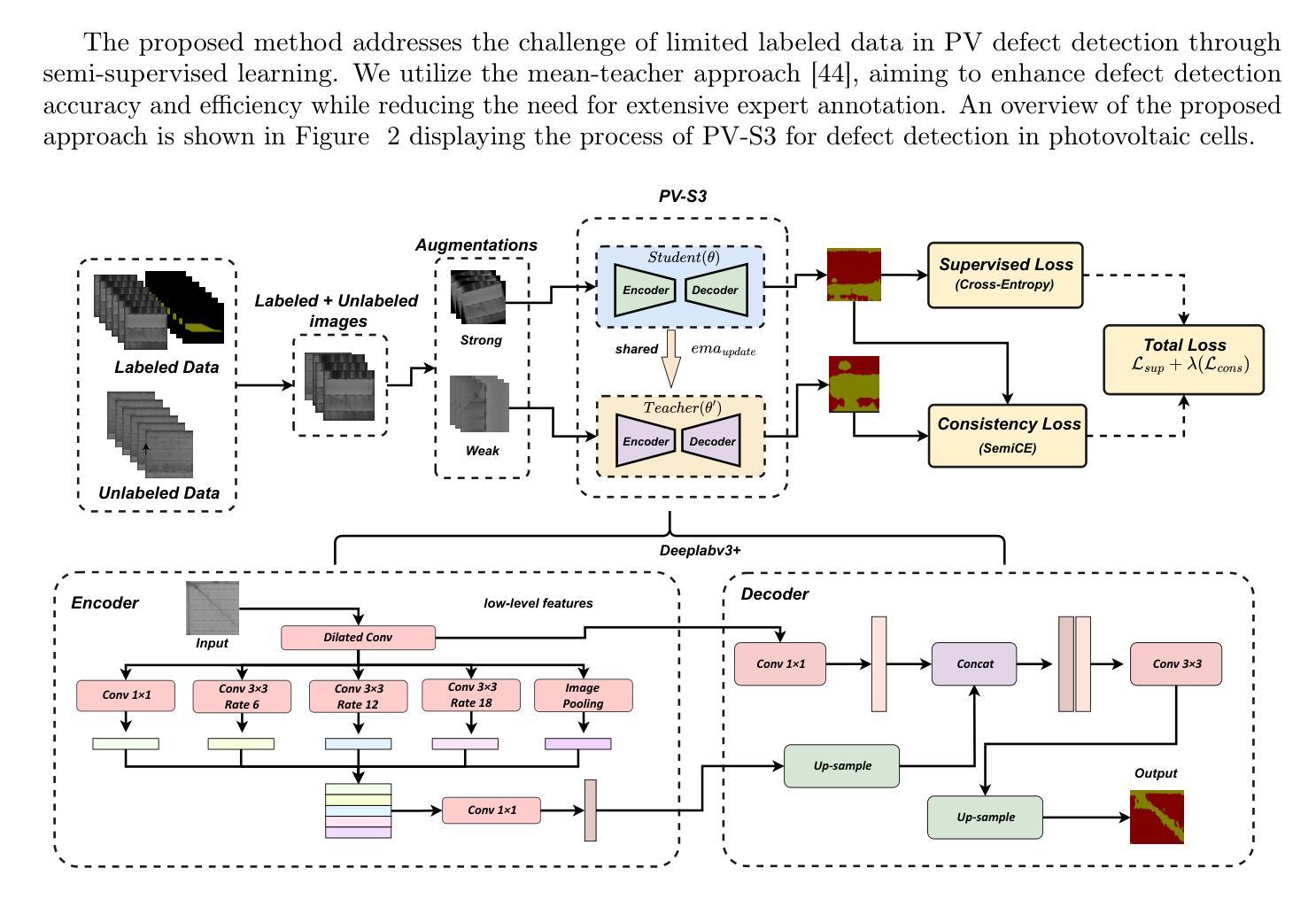
Advancing Automatic Photovoltaic Defect Detection using Semi-Supervised Semantic Segmentation of Electroluminescence Images
Authors:Abhishek Jha, Yogesh Rawat, Shruti Vyas
Photovoltaic (PV) systems allow us to tap into all abundant solar energy, however they require regular maintenance for high efficiency and to prevent degradation. Traditional manual health check, using Electroluminescence (EL) imaging, is expensive and logistically challenging which makes automated defect detection essential. Current automation approaches require extensive manual expert labeling, which is time-consuming, expensive, and prone to errors. We propose PV-S3 (Photovoltaic-Semi-supervised Semantic Segmentation), a Semi-Supervised Learning approach for semantic segmentation of defects in EL images that reduces reliance on extensive labeling. PV-S3 is an artificial intelligence (AI) model trained using a few labeled images along with numerous unlabeled images. We introduce a novel Semi Cross-Entropy loss function to deal with class imbalance. We evaluate PV-S3 on multiple datasets and demonstrate its effectiveness and adaptability. With merely 20% labeled samples, we achieve an absolute improvement of 9.7% in mean Intersection-over-Union (mIoU), 13.5% in Precision, 29.15% in Recall, and 20.42% in F1-Score over prior state-of-the-art supervised method (which uses 100% labeled samples) on University of Central Florida-Electroluminescence (UCF-EL) dataset (largest dataset available for semantic segmentation of EL images) showing improvement in performance while reducing the annotation costs by 80%. For more details, visit our GitHub repository: https://github.com/abj247/PV-S3.
光伏(PV)系统使我们能够利用所有丰富的太阳能,然而,为了获得高效率并防止性能退化,它们需要进行定期维护。传统的使用电致发光(EL)成像进行健康检查的方法成本高昂,在后勤方面也具有挑战性,这使得自动化缺陷检测至关重要。当前的自动化方法需要广泛的人工专家标记,这不仅耗时、成本高,而且容易出错。我们提出了PV-S3(光伏半监督语义分割),这是一种用于EL图像缺陷语义分割的半监督学习方法,减少对大量标记的依赖。PV-S3是一个人工智能(AI)模型,它使用少量标记图像和大量未标记图像进行训练。我们引入了一种新的半交叉熵损失函数来处理类别不平衡问题。我们在多个数据集上评估PV-S3,证明了其有效性和适应性。仅仅使用20%的标记样本,我们在佛罗里达大学电致发光(UCF-EL)数据集(可用于EL图像语义分割的最大数据集)上的平均交并比(mIoU)绝对提高了9.7%,精确度提高了13.5%,召回率提高了29.15%,F1分数提高了20.42%,超过了最新监督方法(使用100%标记样本)。更多详细信息,请访问我们的GitHub仓库:https://github.com/abj247/PV-S3。
论文及项目相关链接
PDF 19 pages, 10 figures
Summary:我们提出了一种利用半监督学习方法对太阳能电池板的缺陷进行语义分割的AI模型——PV-S3系统。与传统的依赖于大量手动标签的自动化缺陷检测方法相比,该系统仅需少量的标签图像即可进行训练。通过使用一种新型的半交叉熵损失函数来处理类别不平衡问题,PV-S3系统在多个数据集上的表现均优于先前的方法。在UCF-EL数据集上,仅使用20%的标签样本,性能提升显著,且标注成本降低了80%。详情请访问我们的GitHub仓库查看。
Key Takeaways:
- PV系统虽然可以充分利用太阳能,但需要定期维护以确保高效运行并防止性能下降。
- 传统的手动健康检查方法成本高昂且操作困难,因此自动化缺陷检测至关重要。
- 当前自动化方法过于依赖手动专家标签,既费时又容易出错。
- 提出了一种基于半监督学习的AI模型PV-S3,用于对EL图像中的缺陷进行语义分割。
- PV-S3通过使用少量标签图像和大量无标签图像进行训练,降低了对大量手动标签的依赖。
- 引入了一种新型的半交叉熵损失函数,以处理类别不平衡问题。
点此查看论文截图