⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-17 更新
SystolicAttention: Fusing FlashAttention within a Single Systolic Array
Authors:Jiawei Lin, Guokai Chen, Yuanlong Li, Thomas Bourgeat
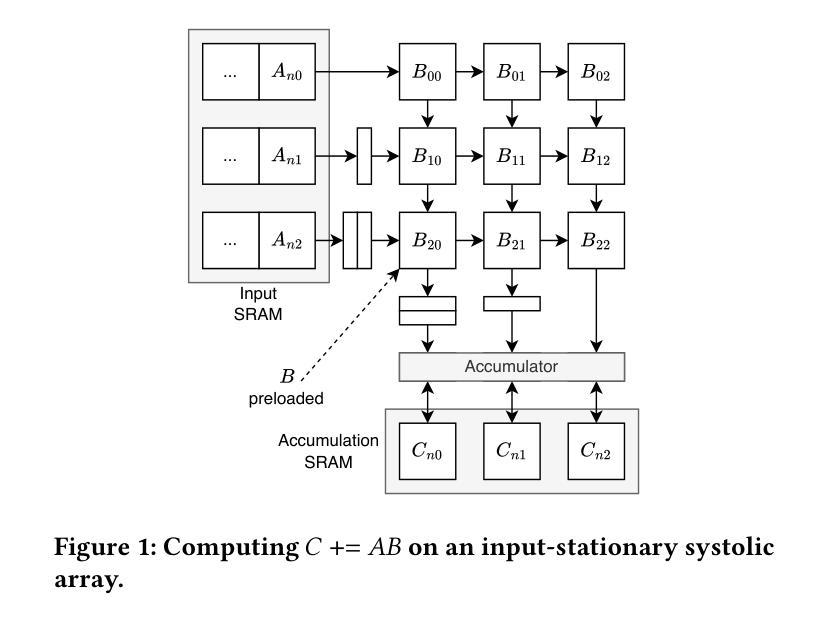
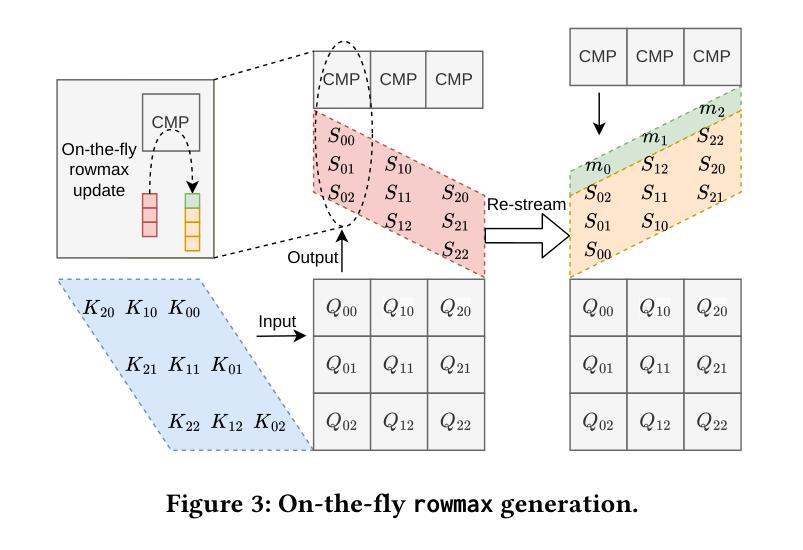
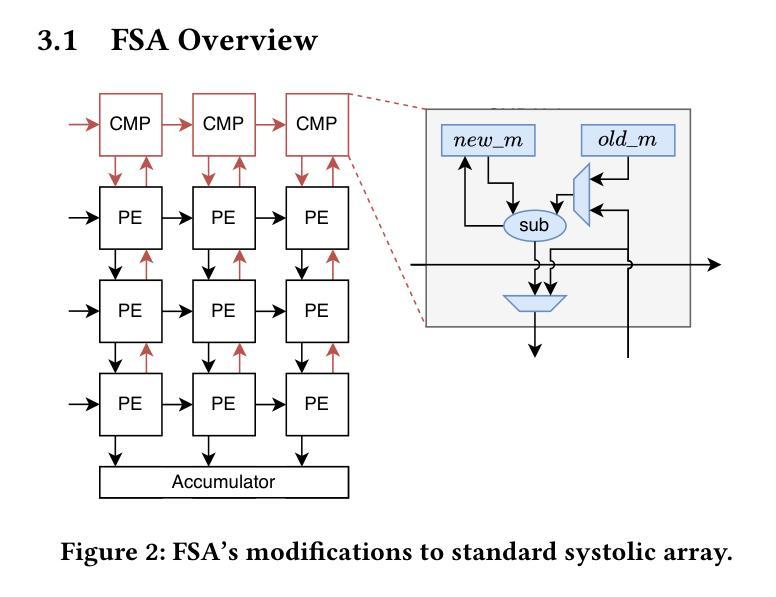
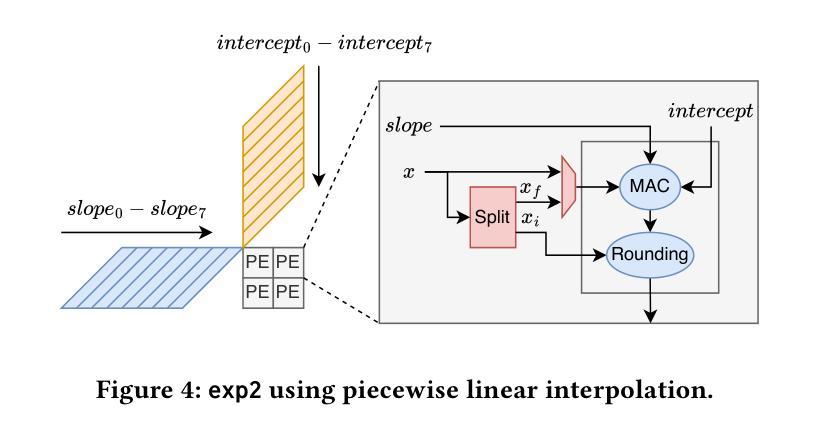
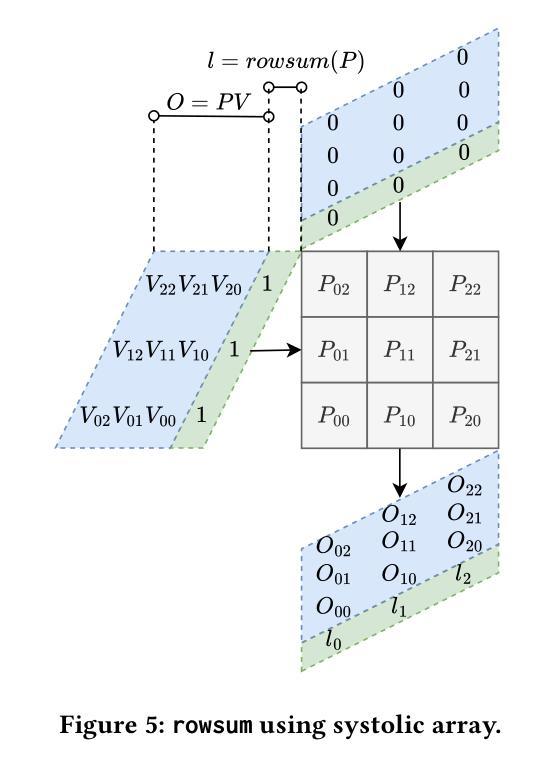
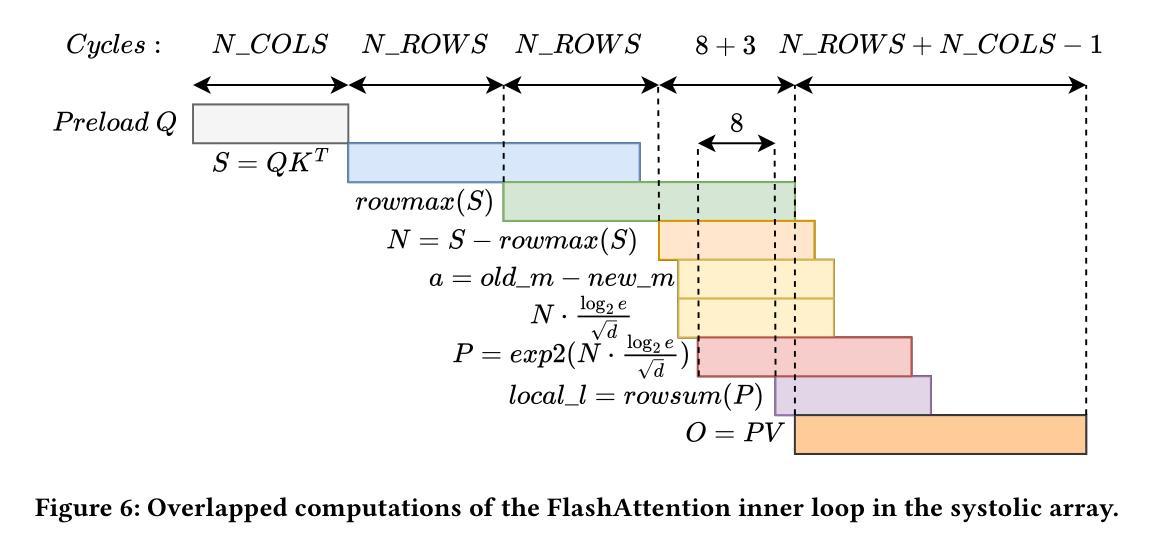
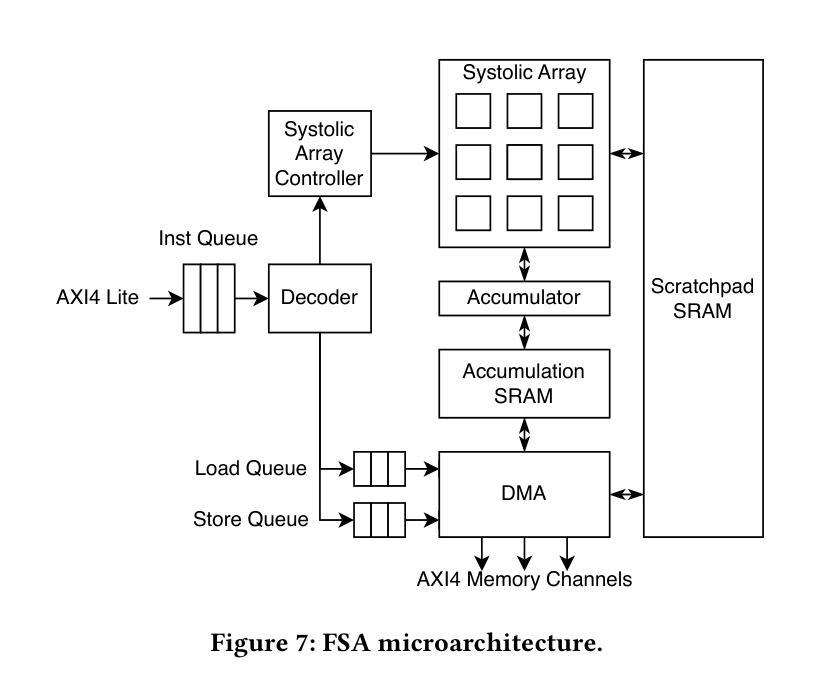
Transformer models rely heavily on scaled dot-product attention (SDPA), typically implemented using the FlashAttention algorithm. However, current systolic-array-based accelerators face significant challenges when executing FlashAttention. Systolic arrays can only achieve high utilization for consecutive and large matrix multiplications. In contrast, FlashAttention requires frequently interleaved matrix multiplications and softmax operations. The frequent data swaps between the systolic array and external vector units result in low systolic array utilization. This is further exacerbated by the fact that softmax involves numerous non-matrix operations, which are not well-suited for systolic arrays. Moreover, the concurrent execution of matrix multiplication on systolic arrays and softmax on vector units leads to register file and SRAM port contention, further degrading performance. To overcome these limitations, we propose FSA, an enhanced systolic array architecture that enables the entire FlashAttention algorithm to run entirely within a single systolic array, eliminating the need for external vector units. At the core of FSA is SystolicAttention, a novel scheduling algorithm that maps FlashAttention operations onto systolic arrays with fine-grained, element-wise overlap. This significantly improves array utilization while preserving the original floating-point operation order to maintain numerical stability. We implement FSA in synthesizable RTL and evaluate its performance against state-of-the-art commercial accelerators. Our results show that FSA achieves 1.77x and 4.83x higher attention FLOPs/s utilization compared to AWS NeuronCore-v2 and Google TPUv5e, respectively, with only about 10% area overhead.
Transformer模型在很大程度上依赖于缩放点积注意力(SDPA),通常使用FlashAttention算法来实现。然而,当前的基于系统阵列的加速器在执行FlashAttention时面临重大挑战。系统阵列只能对连续的较大矩阵乘法实现较高的利用率。相比之下,FlashAttention需要频繁交替的矩阵乘法和softmax操作。系统阵列与外部向量单元之间的频繁数据交换导致系统阵列利用率低。此外,softmax涉及大量非矩阵操作,不适合系统阵列。此外,在系统阵列上执行矩阵乘法的同时,在向量单元上执行softmax会导致寄存器文件和SRAM端口争用,进一步降低性能。为了克服这些限制,我们提出了FSA,这是一种增强的系统阵列架构,它能够使整个FlashAttention算法在一个单一的系统阵列中运行,无需外部向量单元。FSA的核心是SystolicAttention,这是一种新的调度算法,它以细粒度、元素级重叠的方式将FlashAttention操作映射到系统阵列上。这显著提高了阵列利用率,同时保持了原始的浮点操作顺序,以维持数值稳定性。我们在可综合的RTL中实现了FSA,并评估了其与最先进的商业加速器的性能。结果表明,FSA与AWS NeuronCore-v2和Google TPUv5e相比,注意力FLOPs/s利用率分别提高了1.77倍和4.83倍,而且只有大约10%的面积开销。
论文及项目相关链接
Summary:
本文介绍了Transformer模型在依赖缩放点积注意力(SDPA)时面临的挑战,特别是在使用FlashAttention算法时。由于Systolic阵列在处理FlashAttention时面临数据交换频繁的问题,本文提出了一种改进的Systolic阵列架构FSA,能够在单个Systolic阵列内运行整个FlashAttention算法,从而提高阵列利用率并维持数值稳定性。实验结果表明,FSA相较于AWS NeuronCore-v2和Google TPUv5e的注意力FLOPs/s利用率分别提高了1.77倍和4.83倍,且仅增加了约10%的面积开销。
Key Takeaways:
- Transformer模型依赖于缩放点积注意力(SDPA),通常通过FlashAttention算法实现。
- Systolic阵列在执行FlashAttention时面临数据交换频繁的挑战,导致利用率低下。
- FSA是一种改进的Systolic阵列架构,能够在单个Systolic阵列内运行整个FlashAttention算法。
- FSA采用SystolicAttention调度算法,通过精细粒度的元素级重叠来提高阵列利用率并保持数值稳定性。
- 实验结果表明,FSA相较于其他主流加速器具有更高的注意力FLOPs/s利用率。
- FSA在提高性能的同时,仅增加了约10%的面积开销。
点此查看论文截图


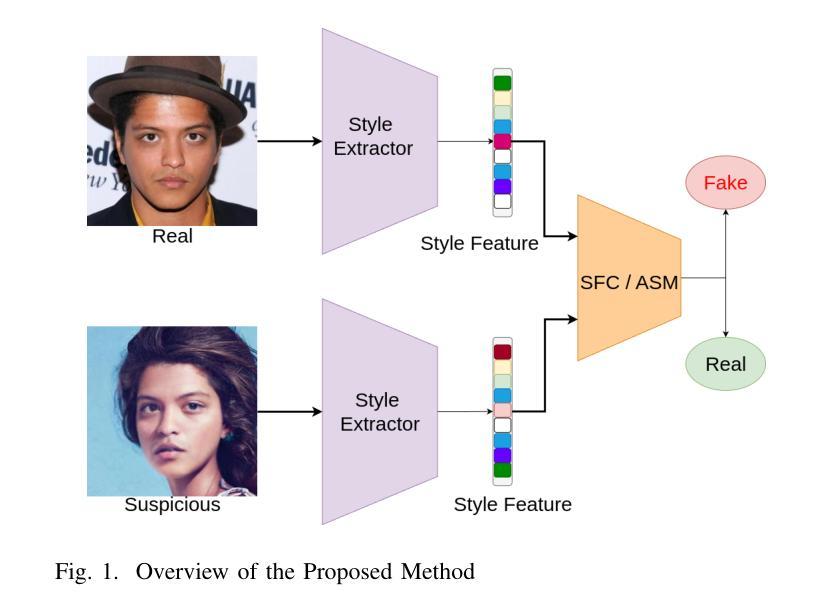
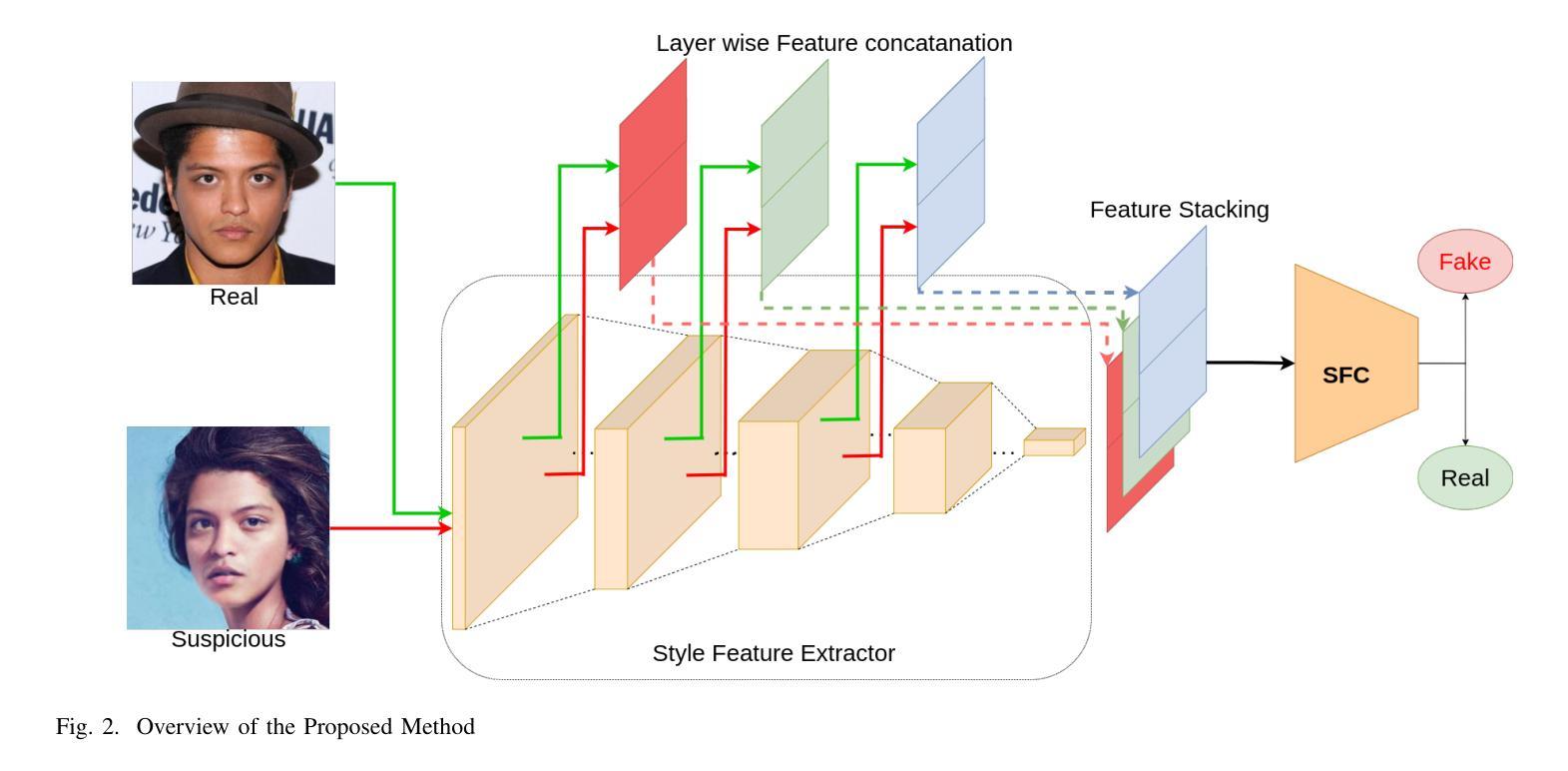
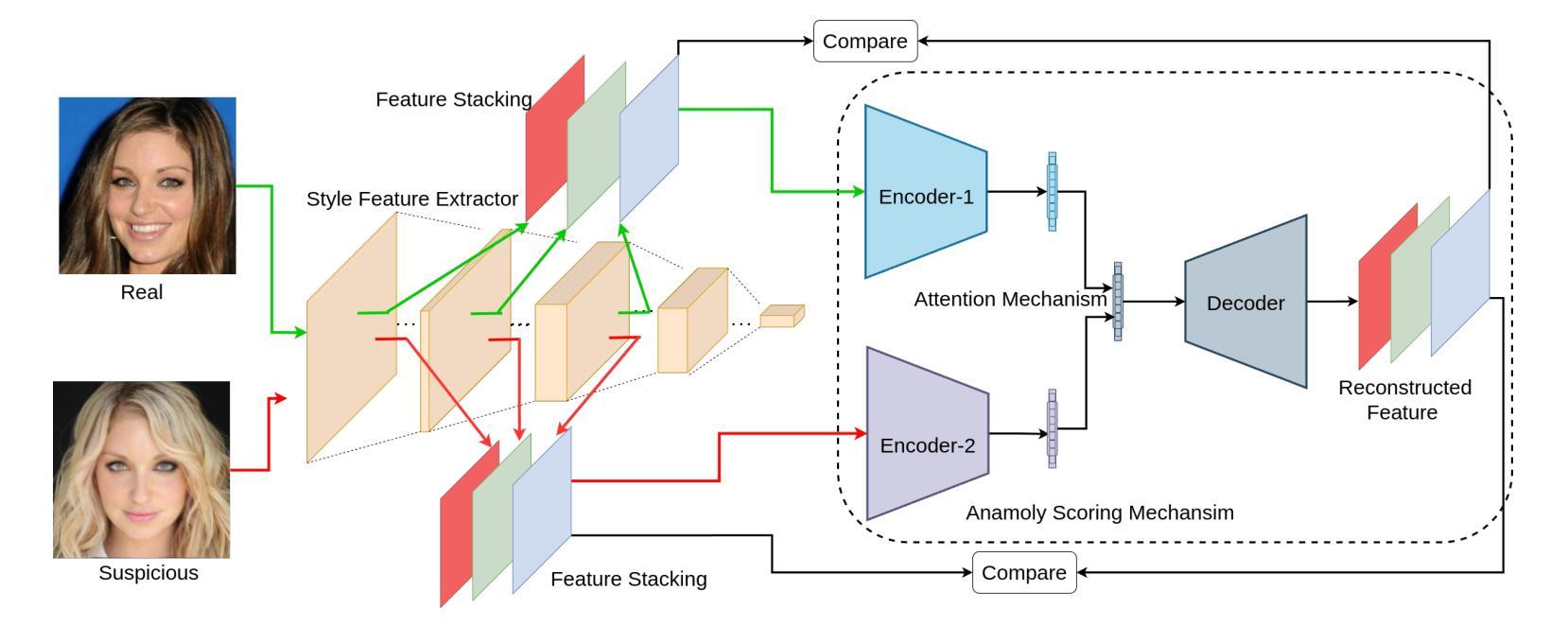
De-Fake: Style based Anomaly Deepfake Detection
Authors:Sudev Kumar Padhi, Harshit Kumar, Umesh Kashyap, Sk. Subidh Ali
Detecting deepfakes involving face-swaps presents a significant challenge, particularly in real-world scenarios where anyone can perform face-swapping with freely available tools and apps without any technical knowledge. Existing deepfake detection methods rely on facial landmarks or inconsistencies in pixel-level features and often struggle with face-swap deepfakes, where the source face is seamlessly blended into the target image or video. The prevalence of face-swap is evident in everyday life, where it is used to spread false information, damage reputations, manipulate political opinions, create non-consensual intimate deepfakes (NCID), and exploit children by enabling the creation of child sexual abuse material (CSAM). Even prominent public figures are not immune to its impact, with numerous deepfakes of them circulating widely across social media platforms. Another challenge faced by deepfake detection methods is the creation of datasets that encompass a wide range of variations, as training models require substantial amounts of data. This raises privacy concerns, particularly regarding the processing and storage of personal facial data, which could lead to unauthorized access or misuse. Our key idea is to identify these style discrepancies to detect face-swapped images effectively without accessing the real facial image. We perform comprehensive evaluations using multiple datasets and face-swapping methods, which showcases the effectiveness of SafeVision in detecting face-swap deepfakes across diverse scenarios. SafeVision offers a reliable and scalable solution for detecting face-swaps in a privacy preserving manner, making it particularly effective in challenging real-world applications. To the best of our knowledge, SafeVision is the first deepfake detection using style features while providing inherent privacy protection.
检测涉及面部交换的深度伪造(deepfakes)是一个巨大的挑战,特别是在任何人都可以利用免费工具和应用程序进行面部交换,而无需任何技术知识的现实场景中。现有的深度伪造检测手段依赖于面部特征点或像素级特征的不一致性,并且常常难以应对面部交换深度伪造,其中源面部无缝融合到目标图像或视频中。面部交换在日常生活中的普遍存在,被用于传播虚假信息、损害声誉、操纵政治舆论、创建非自愿亲密深度伪造(NCID),并通过创建儿童性虐待材料(CSAM)来剥削儿童。即使是著名的公众人物也难免受其影响,他们的深度伪造在社交媒体平台上广泛传播。深度伪造检测面临的另一个挑战是创建涵盖广泛变化的数据集,因为训练模型需要大量的数据。这引发了隐私担忧,特别是在处理和存储个人面部数据时,可能会导致未经授权的访问或滥用。我们的核心思想是识别这些风格差异,以有效检测面部交换图像,而无需访问真实面部图像。我们使用多个数据集和面部交换方法进行全面的评估,展示了SafeVision在检测面部交换深度伪造方面的有效性。SafeVision提供了一种可靠且可扩展的解决方案,以隐私保护的方式检测面部交换,使其在具有挑战性的现实世界应用中特别有效。据我们所知,SafeVision是首个利用风格特征进行深度伪造检测的同时提供内在隐私保护的系统。
论文及项目相关链接
摘要
人脸深度伪造技术给人们带来了一系列挑战,特别是在真实世界中。现有的检测方法难以准确识别被深度伪造技术替换的人脸,特别是在无需任何技术知识的免费工具和应用的广泛应用情况下。我们提出了一种利用风格特征来检测人脸交换的深度伪造技术的方法,无需访问真实面部图像即可有效识别。SafeVision通过跨多种数据集和人脸交换方法的综合评估,证明了其在不同场景下检测人脸交换深度伪造的可靠性和有效性。SafeVision提供了一种可靠且可扩展的解决方案,以隐私保护的方式检测人脸交换,使其特别适用于具有挑战性的真实世界应用。据我们所知,SafeVision是首个利用风格特征进行深度伪造检测的方法,同时提供了固有的隐私保护。
要点归纳
- 人脸深度伪造技术在现实世界中广泛存在,挑战现有检测方法的准确性。
- 现有方法主要依赖面部标志或像素级特征的不一致性检测,但对面部交换的深度伪造技术难以应对。
- SafeVision利用风格特征检测人脸交换的深度伪造技术,无需访问真实面部图像。
- SafeVision经过多种数据集和人脸交换方法的综合评估,证明其在不同场景下的有效性。
- SafeVision提供可靠且可扩展的解决方案,以隐私保护的方式检测人脸交换。
- 人脸交换深度伪造技术被用于传播虚假信息、损害声誉、操纵政治意见、创建非自愿亲密深度伪造和儿童性虐待材料。
- 创建涵盖广泛变化的数据集是深度伪造检测方法所面临的挑战之一,同时涉及个人隐私的担忧,特别是关于个人面部数据的处理和存储。
点此查看论文截图