⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-17 更新
Accurate generation of chemical reaction transition states by conditional flow matching
Authors:Ping Tuo, Jiale Chen, Ju Li
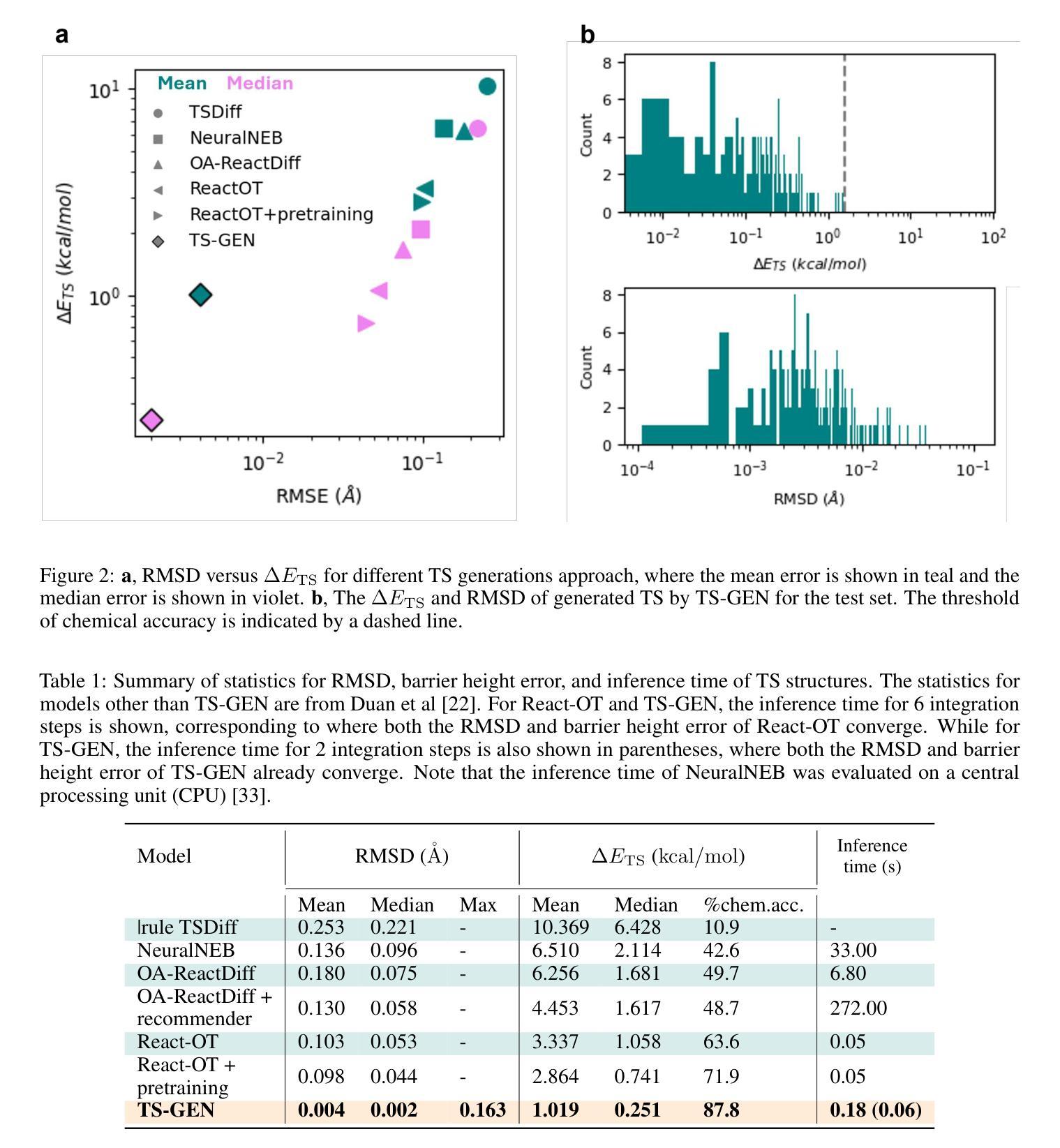
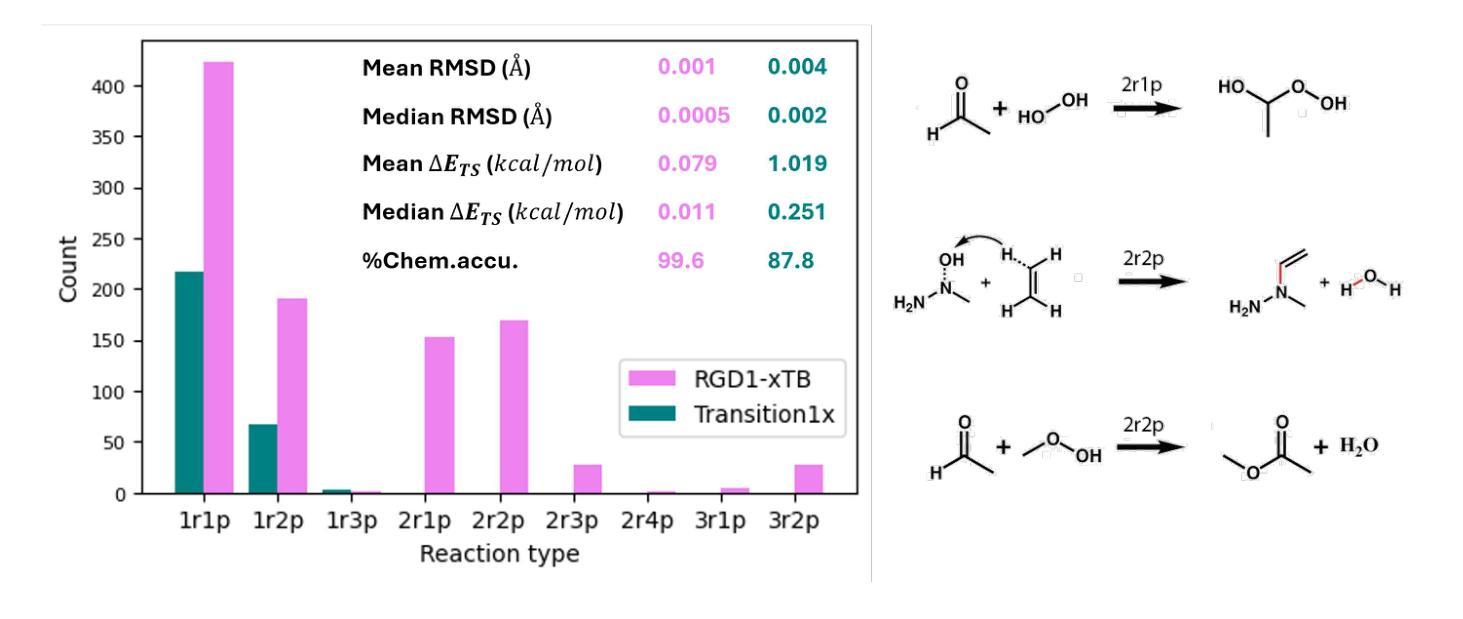
Transition state (TS) structures define the critical geometries and energy barriers underlying chemical reactivity, yet their fleeting nature renders them experimentally elusive and drives the reliance on costly, high-throughput density functional theory (DFT) calculations. Here, we introduce TS-GEN, a conditional flow-matching generative model that maps samples from a simple Gaussian prior directly to transition-state saddle-point geometries in a single, deterministic pass. By embedding both reactant and product conformations as conditioning information, TS-GEN learns to transport latent noise to true TS structures via an optimal-transport path, effectively replacing the iterative optimization common in nudged-elastic band or string-method algorithms. TS-GEN delivers unprecedented accuracy, achieving a root-mean-square deviation of $0.004\ \rm{\mathring{A}}$ (vs. $0.103\ \rm{\mathring{A}}$ for prior state-of-the-art) and a mean barrier-height error of $1.019\ {\rm kcal/mol}$ (vs. $2.864\ {\rm kcal/mol}$), while requiring only $0.06\ {\rm s}$ GPU time per inference. Over 87% of generated TSs meet chemical-accuracy criteria ($<1.58\ {\rm kcal/mol}$ error), substantially outpacing existing methods. TS-GEN also exhibits strong transferability to out-of-distribution reactions from a larger database. By uniting sub-angstrom precision, sub-second speed, and broad applicability, TS-GEN will be highly useful for high-throughput exploration of complex reaction networks, paving the way to the exploration of novel chemical reaction mechanisms.
过渡态(TS)结构定义了化学反应背后的关键几何结构和能量障碍,然而,由于其短暂的特性,实验很难对其进行捕捉,这促使人们依赖成本高昂的高通量密度泛函理论(DFT)计算。在这里,我们引入了TS-GEN,这是一种条件流匹配生成模型,它能够在一次确定性过程中直接将简单高斯先验的样本映射到过渡态鞍点几何结构。TS-GEN通过将反应物和产品构象作为条件信息嵌入,学习通过最优传输路径将潜在噪声传输到真正的TS结构,有效地替代了常见的基于弹性带或弦方法的迭代优化算法。TS-GEN提供了前所未有的准确性,均方根偏差达到$ 0.004 \text{Å}$(与先前最先进的$ 0.103 \text{Å}$相比),平均势垒高度误差为$ 1.019 \text{kcal/mol}$(与先前的$ 2.864 \text{kcal/mol}$相比),并且每次推理仅需$ 0.06 \text{s}$的GPU时间。超过87%的生成TS满足化学精度标准(误差小于$ 1.58 \text{kcal/mol}$),显著优于现有方法。TS-GEN还表现出对大型数据库中的分布外反应的强大迁移能力。通过结合亚埃精度、亚秒速度和广泛应用,TS-GEN将用于高通量复杂反应网络的探索,为探索新型化学反应机制铺平道路。
论文及项目相关链接
Summary
本文介绍了一种名为TS-GEN的新型条件流匹配生成模型,该模型可直接将简单高斯先验样本映射到过渡态鞍点几何结构上,以单一确定性过程完成。TS-GEN通过嵌入反应物与产物构象作为条件信息,学习将潜在噪声传输到真实的过渡态结构上,从而取代了常见的弹性带或弦方法的迭代优化过程。TS-GEN具有前所未有的准确性,实现了均方根偏差为$0.004\ \rm{\mathring{A}}$和平均势垒高度误差为$1.019\ {\rm kcal/mol}$的优异性能,同时每次推理仅需$0.06\ {\rm s}$的GPU时间。此外,TS-GEN对超出分布范围的反应也表现出强大的迁移能力,具有亚埃精度、亚秒速度和广泛应用性,将成为高通量探索复杂反应网络的有力工具,为探索新型化学反应机制铺平道路。
Key Takeaways
- TS-GEN是一种新型的过渡态结构生成模型。
- TS-GEN能够直接将简单高斯先验样本映射到过渡态鞍点几何结构。
- TS-GEN通过学习最优传输路径,实现潜在噪声到真实过渡态结构的转换。
- TS-GEN的准确率远超现有方法,具有亚埃精度和亚秒速度。
- TS-GEN对超出分布范围的反应也表现出强大的迁移能力。
- TS-GEN在化学准确性标准下生成的过渡态结构超过87%。
点此查看论文截图


SpeakerVid-5M: A Large-Scale High-Quality Dataset for Audio-Visual Dyadic Interactive Human Generation
Authors:Youliang Zhang, Zhaoyang Li, Duomin Wang, Jiahe Zhang, Deyu Zhou, Zixin Yin, Xili Dai, Gang Yu, Xiu Li
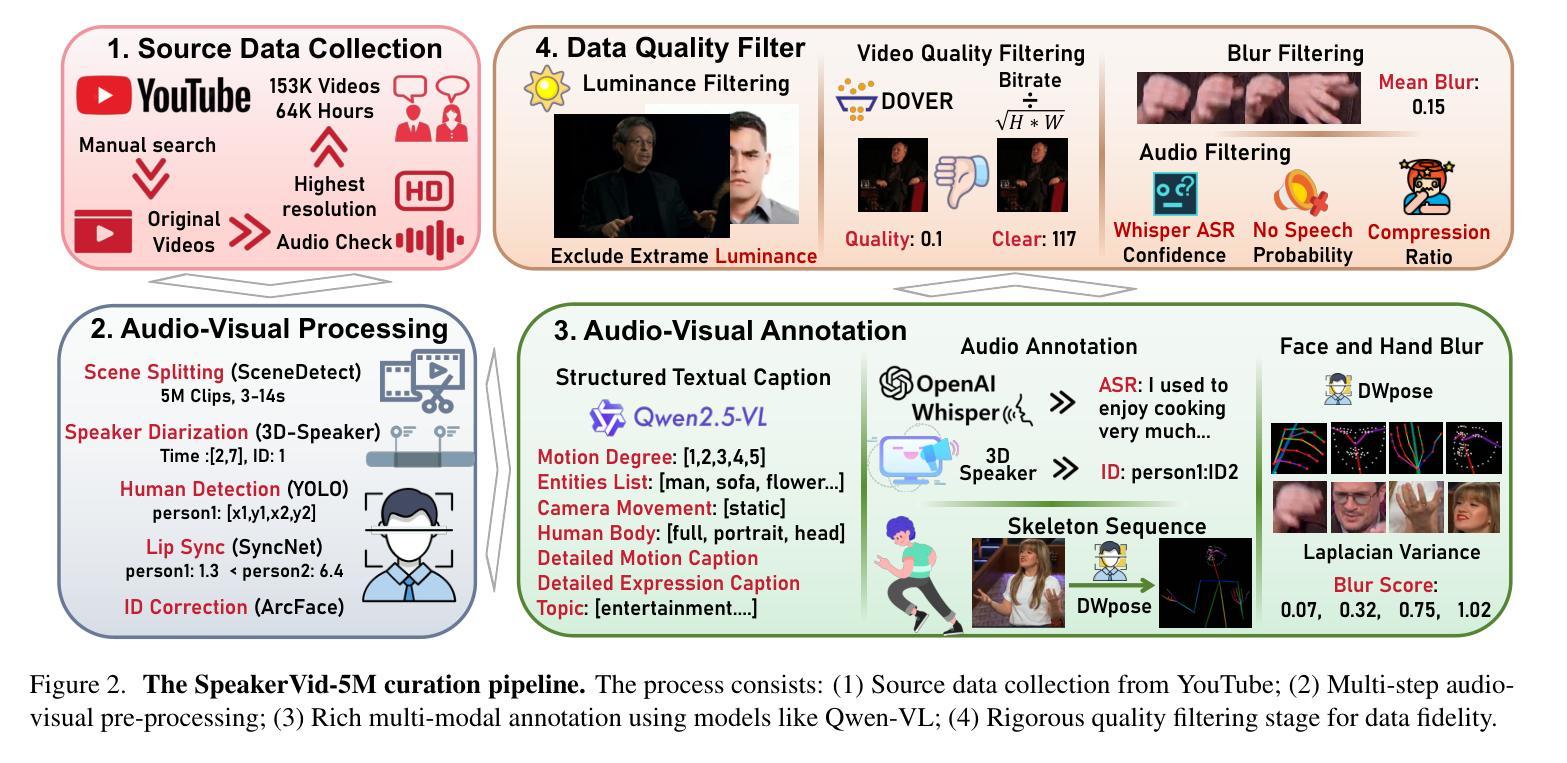
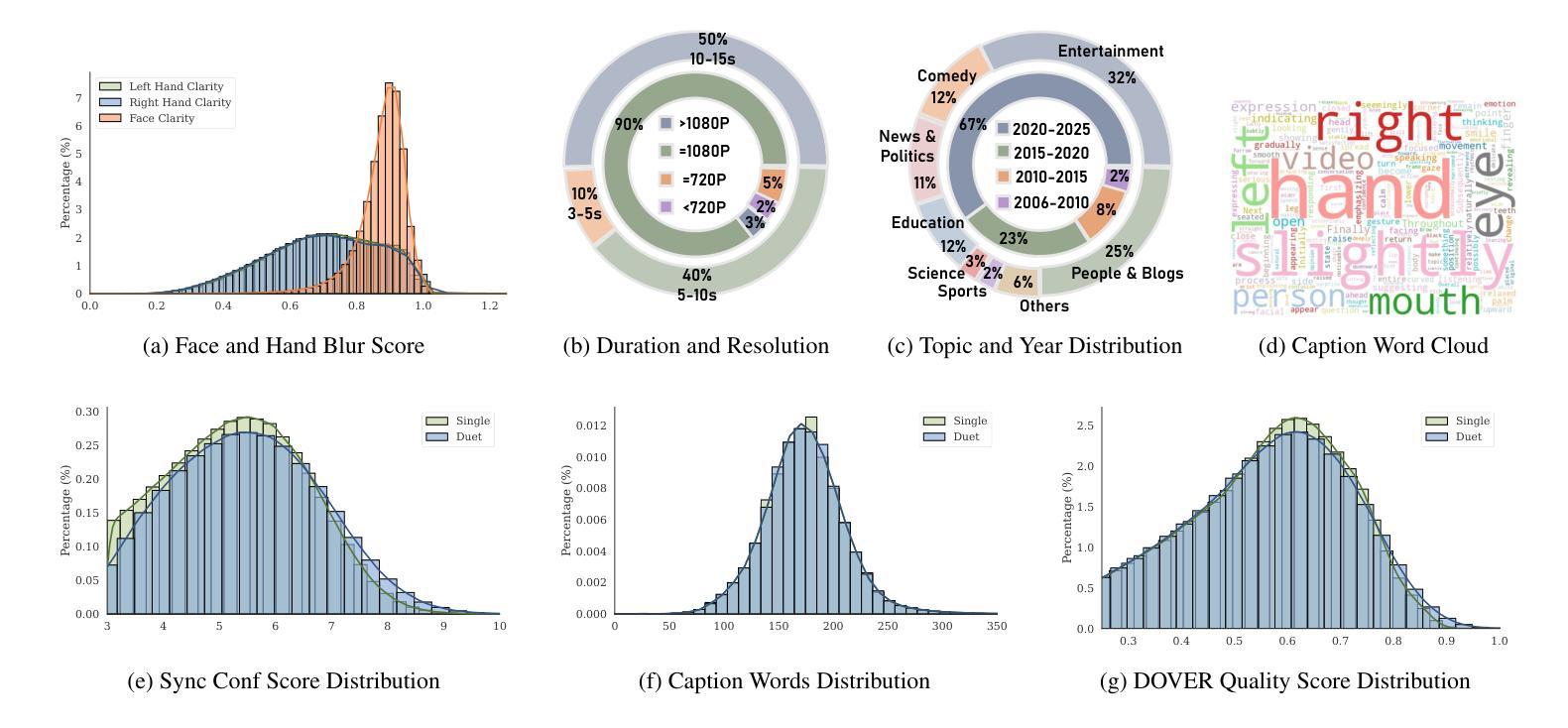
The rapid development of large-scale models has catalyzed significant breakthroughs in the digital human domain. These advanced methodologies offer high-fidelity solutions for avatar driving and rendering, leading academia to focus on the next major challenge: audio-visual dyadic interactive virtual human. To facilitate research in this emerging area, we present SpeakerVid-5M dataset, the first large-scale, high-quality dataset designed for audio-visual dyadic interactive virtual human generation. Totaling over 8,743 hours, SpeakerVid-5M contains more than 5.2 million video clips of human portraits. It covers diverse scales and interaction types, including monadic talking, listening, and dyadic conversations. Crucially, the dataset is structured along two key dimensions: interaction type and data quality. First, it is categorized into four types (dialogue branch, single branch, listening branch and multi-turn branch) based on the interaction scenario. Second, it is stratified into a large-scale pre-training subset and a curated, high-quality subset for Supervised Fine-Tuning (SFT). This dual structure accommodates a wide array of 2D virtual human tasks. In addition, we provide an autoregressive (AR)-based video chat baseline trained on this data, accompanied by a dedicated set of metrics and test data to serve as a benchmark VidChatBench for future work. Both the dataset and the corresponding data processing code will be publicly released. Project page: https://dorniwang.github.io/SpeakerVid-5M/
大规模模型的快速发展推动了数字人类领域的重大突破。这些先进的方法为化身驱动和渲染提供了高保真度的解决方案,使学术界专注于下一个重大挑战:视听二元交互虚拟人类。为了促进这一新兴领域的研究,我们推出了SpeakerVid-5M数据集,这是专门为视听二元交互虚拟人类生成的首个大规模、高质量数据集。总计超过8743小时,SpeakerVid-5M包含超过520万张人像视频剪辑。它涵盖了多种尺度和交互类型,包括独白、聆听和二元对话。重要的是,该数据集沿着两个关键维度构建:交互类型和数据质量。首先,它根据交互场景分为四种类型(对话分支、单一分支、聆听分支和多轮分支)。其次,它分为大规模预训练子集和精选的高质量子集,用于有监督微调(SFT)。这种双重结构可容纳多种2D虚拟人类任务。此外,我们提供了基于此数据的基于自回归(AR)的视频聊天基线,并配有专门的指标和测试数据,作为未来工作的基准VidChatBench。数据集和相应的数据处理代码将公开发布。项目页面:https://dorniwang.github.io/SpeakerVid-5M/
论文及项目相关链接
Summary
大规模模型技术的快速发展推动了数字人领域的显著突破。先进的方法为avatar驱动和渲染提供了高保真解决方案,学术界目前的重点挑战在于音频视觉二元交互虚拟人。为了促进这一新兴领域的研究,我们推出了SpeakerVid-5M数据集,这是为音频视觉二元交互虚拟人生成而设计的大型、高质量数据集。该数据集包含超过8743小时的视频剪辑,覆盖了多种尺度和交互类型。该数据集按两个关键维度进行结构化设计:交互类型和数据处理质量。此外,我们提供了一个基于AR的视频聊天基线系统作为基准的VidChatBench。数据集及相应的数据处理代码均已公开供用户使用。数据集和配套的代码集均为推进未来的研究和实际应用做出了重要的贡献。想要获取更多信息,请访问我们的项目页面链接。https://dorniwang.github.io/SpeakerVid-5M/。
Key Takeaways
点此查看论文截图

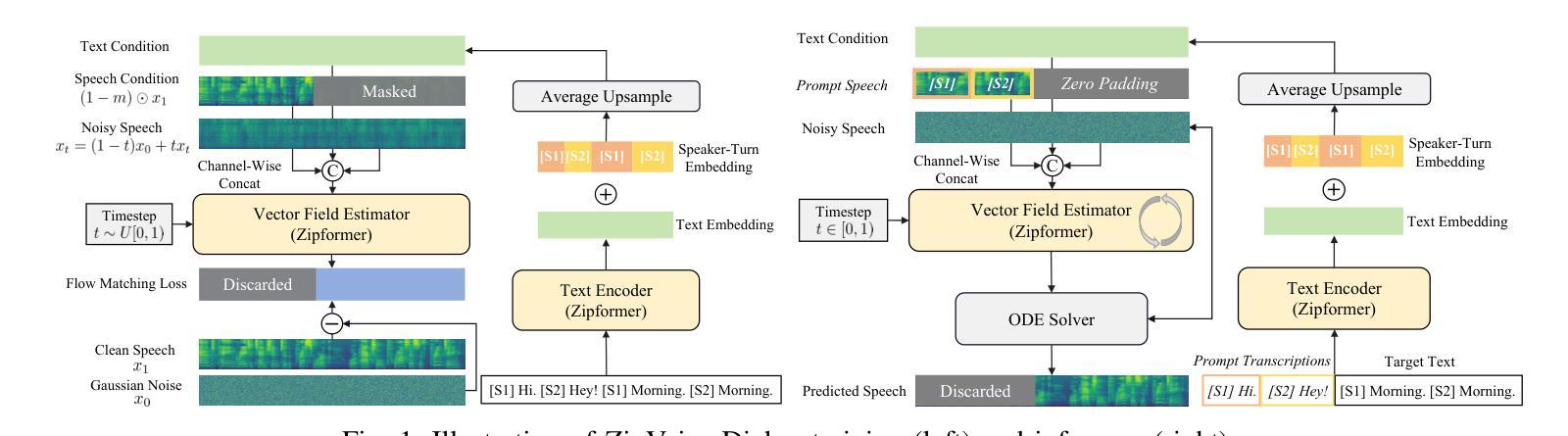
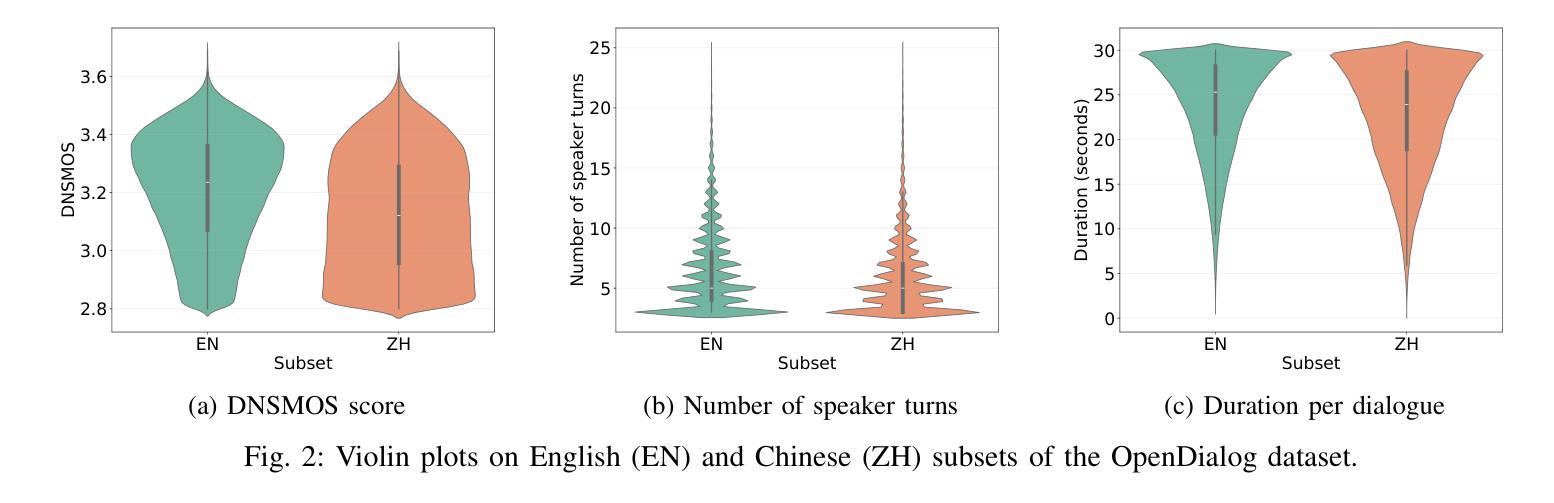
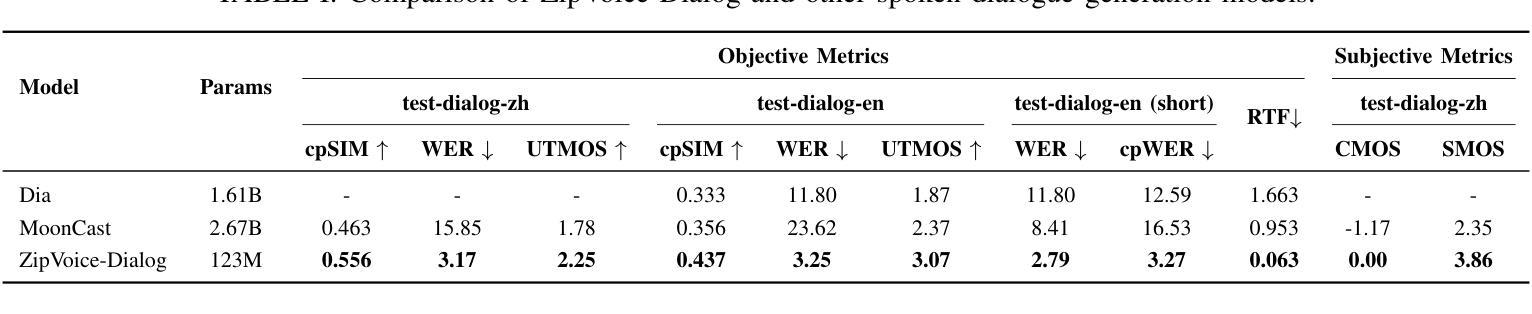
ZipVoice-Dialog: Non-Autoregressive Spoken Dialogue Generation with Flow Matching
Authors:Han Zhu, Wei Kang, Liyong Guo, Zengwei Yao, Fangjun Kuang, Weiji Zhuang, Zhaoqing Li, Zhifeng Han, Dong Zhang, Xin Zhang, Xingchen Song, Long Lin, Daniel Povey
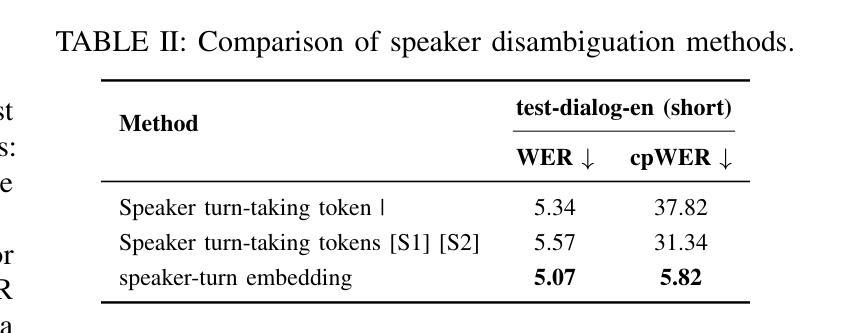
Generating spoken dialogue is more challenging than monologue text-to-speech (TTS) due to the need for realistic turn-taking and distinct speaker timbres. Existing spoken dialogue generation models, being auto-regressive, suffer from slow and unstable inference. To overcome these limitations, we introduce ZipVoice-Dialog, a non-autoregressive zero-shot spoken dialogue generation model built upon flow matching. Key designs include: 1) speaker-turn embeddings for precise speaker turn-taking; 2) a curriculum learning strategy for stable speech-text alignment; 3) specialized strategies to enable stereo dialogue generation. Additionally, recognizing the lack of open-source large-scale spoken dialogue datasets, we curated OpenDialog, a 6.8k-hour spoken dialogue dataset from in-the-wild speech data. Furthermore, we established a benchmark to comprehensively evaluate various models. Experimental results demonstrate that ZipVoice-Dialog achieves superior performance in intelligibility, speaker turn-taking accuracy, speaker similarity, and inference speed. Our codes, model checkpoints, demo samples, and the OpenDialog dataset are all publicly available at https://github.com/k2-fsa/ZipVoice.
生成对话语音相较于单语文本到语音(TTS)更具挑战性,因为对话需要更真实的轮替和不同的发音人音色。现有的对话语音生成模型采用自回归方式,存在推理速度慢和不稳定的缺陷。为了克服这些局限,我们推出了ZipVoice-Dialog,一个基于流匹配的非自回归零样本对话语音生成模型。关键设计包括:1)用于精确轮替的发言人轮替嵌入;2)用于稳定语音文本对齐的课程内容学习策略;3)实现立体声对话生成的专业策略。此外,我们认识到缺乏开源的大规模对话语音数据集,因此我们整理了OpenDialog数据集,该数据集包含来自野生语音数据的6.8千小时对话语音。此外,我们建立了一个基准测试来全面评估各种模型。实验结果表明,ZipVoice-Dialog在可理解性、发言人轮替准确性、发言人相似性和推理速度等方面均表现出卓越性能。我们的代码、模型检查点、演示样本以及OpenDialog数据集均可在https://github.com/k2-fsa/ZipVoice公开获取。
论文及项目相关链接
Summary
该文介绍了生成对话语音相较于单语文本到语音(TTS)所面临的挑战,包括需要真实的对话轮次和不同的说话人音色。现有对话生成模型采用自回归方式,存在推理速度慢且不稳定的问题。为解决这些问题,本文提出ZipVoice-Dialog非自回归零样本对话生成模型,通过引入说话人轮次嵌入、课程学习策略以及立体对话生成策略进行设计。同时,为解决缺乏大规模开源对话语音数据集的问题,本文整理了OpenDialog数据集,包含6.8k小时的真实对话语音数据。实验结果表明,ZipVoice-Dialog在可懂度、说话人轮次准确性、说话人相似性以及推理速度等方面表现出卓越性能。
Key Takeaways
- 生成对话语音相较于单语文本到语音(TTS)更具挑战性,需考虑真实的对话轮次和不同的说话人音色。
- 现有对话生成模型多采用自回归方式,存在推理速度慢且不稳定的问题。
- ZipVoice-Dialog是一种非自回归零样本对话生成模型,通过引入说话人轮次嵌入、课程学习策略及立体对话生成策略进行设计以解决上述问题。
- 说话人轮次嵌入用于实现精确的对说话人轮次管理。
- 课程学习策略有助于稳定语音与文本的对应关系。
- 特殊策略用于实现立体对话生成,以更好地模拟真实对话场景。
- 缺乏大规模开源对话语音数据集的问题通过整理OpenDialog数据集得到缓解,该数据集包含6.8k小时的真实对话语音数据。
点此查看论文截图

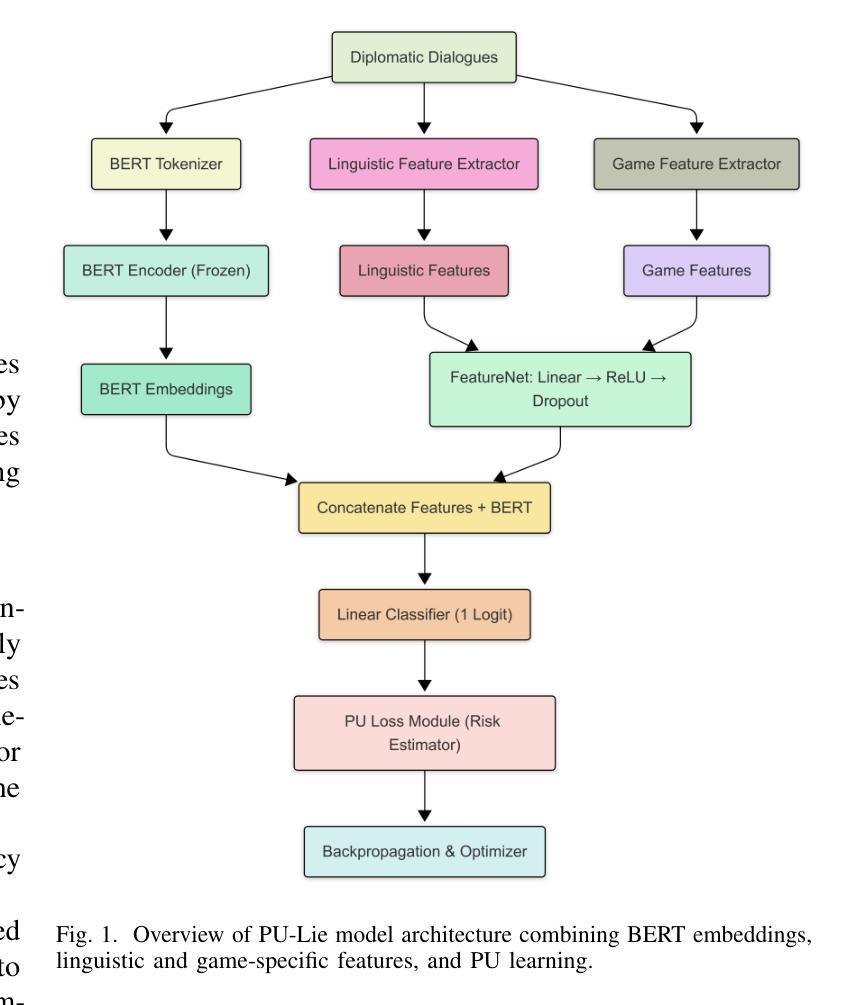
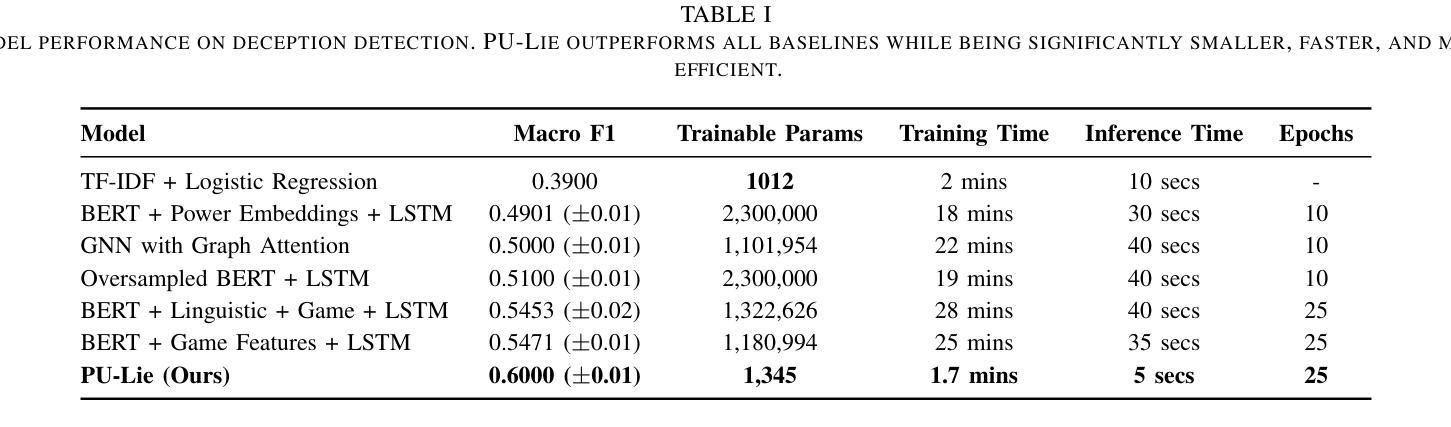
PU-Lie: Lightweight Deception Detection in Imbalanced Diplomatic Dialogues via Positive-Unlabeled Learning
Authors:Bhavinkumar Vinodbhai Kuwar, Bikrant Bikram Pratap Maurya, Priyanshu Gupta, Nitin Choudhury
Detecting deception in strategic dialogues is a complex and high-stakes task due to the subtlety of language and extreme class imbalance between deceptive and truthful communications. In this work, we revisit deception detection in the Diplomacy dataset, where less than 5% of messages are labeled deceptive. We introduce a lightweight yet effective model combining frozen BERT embeddings, interpretable linguistic and game-specific features, and a Positive-Unlabeled (PU) learning objective. Unlike traditional binary classifiers, PU-Lie is tailored for situations where only a small portion of deceptive messages are labeled, and the majority are unlabeled. Our model achieves a new best macro F1 of 0.60 while reducing trainable parameters by over 650x. Through comprehensive evaluations and ablation studies across seven models, we demonstrate the value of PU learning, linguistic interpretability, and speaker-aware representations. Notably, we emphasize that in this problem setting, accurately detecting deception is more critical than identifying truthful messages. This priority guides our choice of PU learning, which explicitly models the rare but vital deceptive class.
检测战略对话中的欺骗是一项复杂且高风险的任务,这主要是因为语言的细微差别以及欺骗和真实通信之间极端类别不平衡。在这项工作中,我们重新审视了外交数据集中的欺骗检测,其中只有不到5%的消息被标记为欺骗性。我们引入了一个轻便而有效的模型,该模型结合了冻结的BERT嵌入、可解释的语言和游戏特定特征,以及Positive-Unlabeled(PU)学习目标。与传统的二元分类器不同,PU-Lie是针对只有一小部分欺骗性消息被标记而大多数未被标记的情况量身定制的。我们的模型在减少可训练参数超过650倍的同时,实现了新的最佳宏观F1分数为0.60。通过对七个模型的全面评估和消融研究,我们证明了PU学习的价值、语言可解释性以及说话者感知表示。值得注意的是,我们强调,在这个问题设置中,准确检测欺骗比识别真实消息更重要。这一重点引导我们选择PU学习,它明确地对罕见的但至关重要的欺骗性类别进行建模。
论文及项目相关链接
Summary
本文介绍了在战略对话中检测欺骗的复杂性和挑战性,提出了一个轻量级但有效的模型PU-Lie,该模型结合了冻结的BERT嵌入、可解释的语言学和游戏特定特征,以及Positive-Unlabeled(PU)学习目标。该模型适用于只有一小部分欺骗性消息被标记,而大部分未标记的情况。通过全面的评估和七个模型的消融研究,证明了PU学习、语言学的可解释性和说话者感知表示的价值。本文强调在这个问题设置中,准确检测欺骗比识别真实消息更为重要。
Key Takeaways
- 战略对话中的欺骗检测因语言的细微差别和欺骗与真实通信之间的类不平衡而具有挑战。
- 本文在Diplomacy数据集上重新研究了欺骗检测问题,其中只有不到5%的消息被标记为欺骗性。
- 引入了一个轻量级但有效的模型PU-Lie,结合了BERT嵌入、语言学特征和游戏特定特征,以及Positive-Unlabeled(PU)学习目标。
- PU-Lie模型适用于标记的欺骗性消息较少的情况。
- 通过全面的评估和消融研究,证明了PU学习、语言学的可解释性和说话者感知表示的价值。
- 准确检测欺骗比识别真实消息更重要。
点此查看论文截图