⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-17 更新
FalseReject: A Resource for Improving Contextual Safety and Mitigating Over-Refusals in LLMs via Structured Reasoning
Authors:Zhehao Zhang, Weijie Xu, Fanyou Wu, Chandan K. Reddy
Safety alignment approaches in large language models (LLMs) often lead to the over-refusal of benign queries, significantly diminishing their utility in sensitive scenarios. To address this challenge, we introduce FalseReject, a comprehensive resource containing 16k seemingly toxic queries accompanied by structured responses across 44 safety-related categories. We propose a graph-informed adversarial multi-agent interaction framework to generate diverse and complex prompts, while structuring responses with explicit reasoning to aid models in accurately distinguishing safe from unsafe contexts. FalseReject includes training datasets tailored for both standard instruction-tuned models and reasoning-oriented models, as well as a human-annotated benchmark test set. Our extensive benchmarking on 29 state-of-the-art (SOTA) LLMs reveals persistent over-refusal challenges. Empirical results demonstrate that supervised finetuning with FalseReject substantially reduces unnecessary refusals without compromising overall safety or general language capabilities.
大型语言模型(LLM)的安全对齐方法通常会导致良性查询被拒绝的情况过多,这在敏感场景中显著降低了其效用。为了解决这一挑战,我们引入了FalseReject,这是一个包含16,000个看似有毒查询的综合资源,并配有44个安全相关类别的结构化响应。我们提出了一种基于图对抗的多智能体交互框架,以生成多样化和复杂的提示,同时利用结构化响应的明确推理来帮助模型准确区分安全和不安全的上下文。FalseReject包括针对标准指令调整模型和推理导向模型的训练数据集,以及一个人工注释的基准测试集。我们对29种最先进的LLM进行了广泛的基准测试,发现仍存在持续的过度拒绝挑战。经验结果表明,使用FalseReject进行有监督微调可以大大减少不必要的拒绝,同时不损害整体安全性或通用语言功能。
论文及项目相关链接
PDF Accepted at COLM 2025
Summary:大型语言模型(LLM)的安全对齐方法往往会导致良性查询被拒绝,降低了其在敏感场景中的实用性。为解决这一问题,我们推出FalseReject资源,包含看似有毒的查询和结构化响应。我们提出基于图对抗的多智能体交互框架来生成不同场景,响应结构化的理由能帮助模型区分安全和不安全环境。通过训练集,我们发现包括监督微调都能大幅减少不必要的拒绝拒绝而不影响总体安全或语言通用能力。对现状技术的全面基准测试证明依然存在持续存在的过度拒绝挑战。这个挑战利用FalseReject的用例明显减缓了很多不必要的情况,同时也能够保障总体的安全。此外,它还包含针对不同模型类型和任务类型的数据集,如标准指令训练模型和推理导向模型等。同时包含人类注释的基准测试集。我们的实验结果表明,使用FalseReject进行微调可以显著减少不必要的拒绝,同时不会损害模型的整体安全性或通用语言处理能力。
Key Takeaways:
- 大型语言模型(LLM)在敏感场景中面临过度拒绝良性查询的问题。
点此查看论文截图



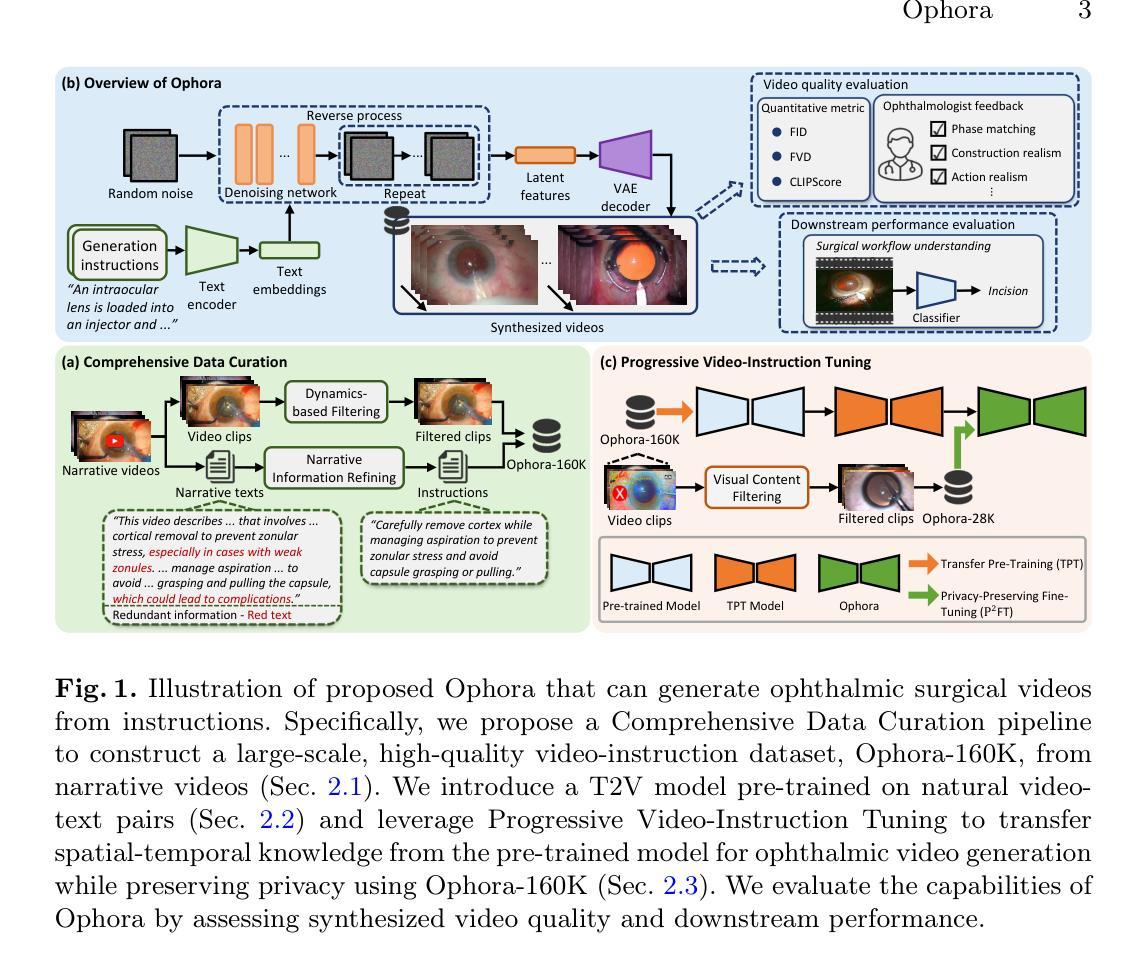
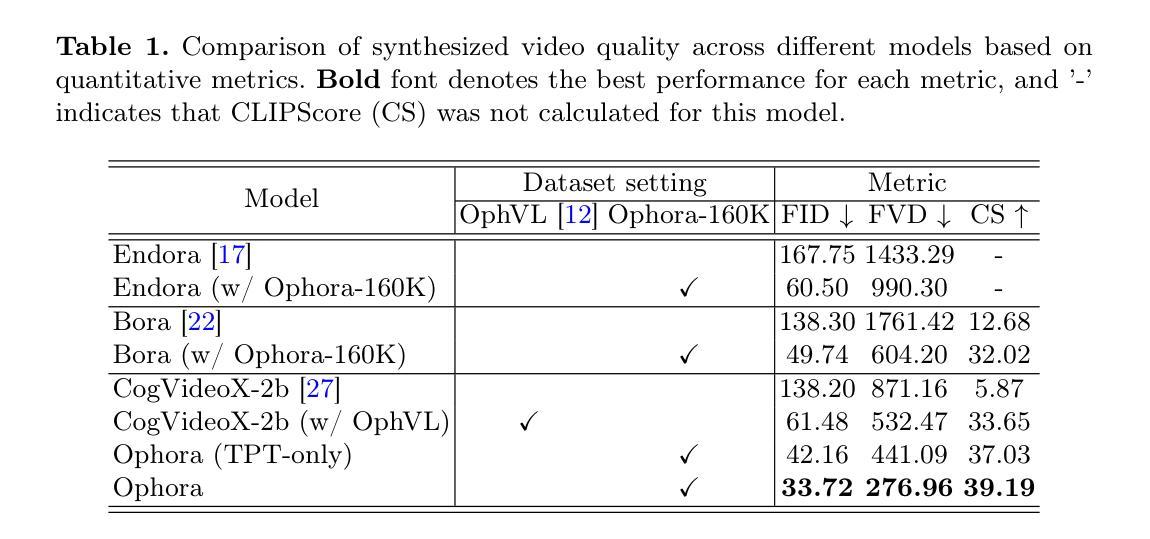
Ophora: A Large-Scale Data-Driven Text-Guided Ophthalmic Surgical Video Generation Model
Authors:Wei Li, Ming Hu, Guoan Wang, Lihao Liu, Kaijing Zhou, Junzhi Ning, Xin Guo, Zongyuan Ge, Lixu Gu, Junjun He
In ophthalmic surgery, developing an AI system capable of interpreting surgical videos and predicting subsequent operations requires numerous ophthalmic surgical videos with high-quality annotations, which are difficult to collect due to privacy concerns and labor consumption. Text-guided video generation (T2V) emerges as a promising solution to overcome this issue by generating ophthalmic surgical videos based on surgeon instructions. In this paper, we present Ophora, a pioneering model that can generate ophthalmic surgical videos following natural language instructions. To construct Ophora, we first propose a Comprehensive Data Curation pipeline to convert narrative ophthalmic surgical videos into a large-scale, high-quality dataset comprising over 160K video-instruction pairs, Ophora-160K. Then, we propose a Progressive Video-Instruction Tuning scheme to transfer rich spatial-temporal knowledge from a T2V model pre-trained on natural video-text datasets for privacy-preserved ophthalmic surgical video generation based on Ophora-160K. Experiments on video quality evaluation via quantitative analysis and ophthalmologist feedback demonstrate that Ophora can generate realistic and reliable ophthalmic surgical videos based on surgeon instructions. We also validate the capability of Ophora for empowering downstream tasks of ophthalmic surgical workflow understanding. Code is available at https://github.com/uni-medical/Ophora.
在眼科手术中,开发一个能够解读手术视频并预测后续操作的AI系统,需要大量的高质量标注眼科手术视频。由于隐私问题和劳动消耗,这些视频的收集非常困难。文本引导的视频生成(T2V)作为一种有前途的解决方案应运而生,它可以根据外科医生的指令生成眼科手术视频。在本文中,我们提出了Ophora,一个能够基于自然语言指令生成眼科手术视频的开创性模型。为了构建Ophora,我们首先提出了一个全面的数据整理管道,将叙述性眼科手术视频转化为大规模高质量数据集,包含超过16万对视频指令,称为Ophora-160K。然后,我们提出了一种渐进的视频指令调整方案,从在天然视频文本数据集上预训练的T2V模型中转移丰富的时空知识,用于基于Ophora-160K的隐私保护眼科手术视频生成。通过对视频质量的定量分析和眼科医生的反馈进行的实验表明,Ophora可以根据外科医生的指令生成现实和可靠的眼科手术视频。我们还验证了Ophora在眼科手术工作流程理解下游任务中的能力。代码可访问https://github.com/uni-medical/Ophora。
论文及项目相关链接
PDF Early accepted in MICCAI25
Summary
基于自然语言指令生成眼科手术视频是一个新兴的技术方向。本文提出了一种名为Ophora的模型,该模型可以通过大规模数据集和高质量注释生成眼科手术视频。通过数据清洗和逐步的视频指令调整策略,该模型能够基于自然语言指令生成真实可靠的眼科手术视频。此外,该模型还能支持眼科手术工作流程理解等下游任务。
Key Takeaways
1.Ophora是一个能够基于自然语言指令生成眼科手术视频的模型。
2.该模型使用大规模数据集和高质量注释来训练。
3.数据清洗和逐步的视频指令调整策略使得该模型能够生成真实可靠的眼科手术视频。
4.模型可以应用于眼科手术工作流程理解等下游任务。
5.模型具有隐私保护的功能,可以在保护患者隐私的前提下进行眼科手术视频的生成。
6.模型的代码已经开源,便于其他研究者进行研究和改进。
点此查看论文截图

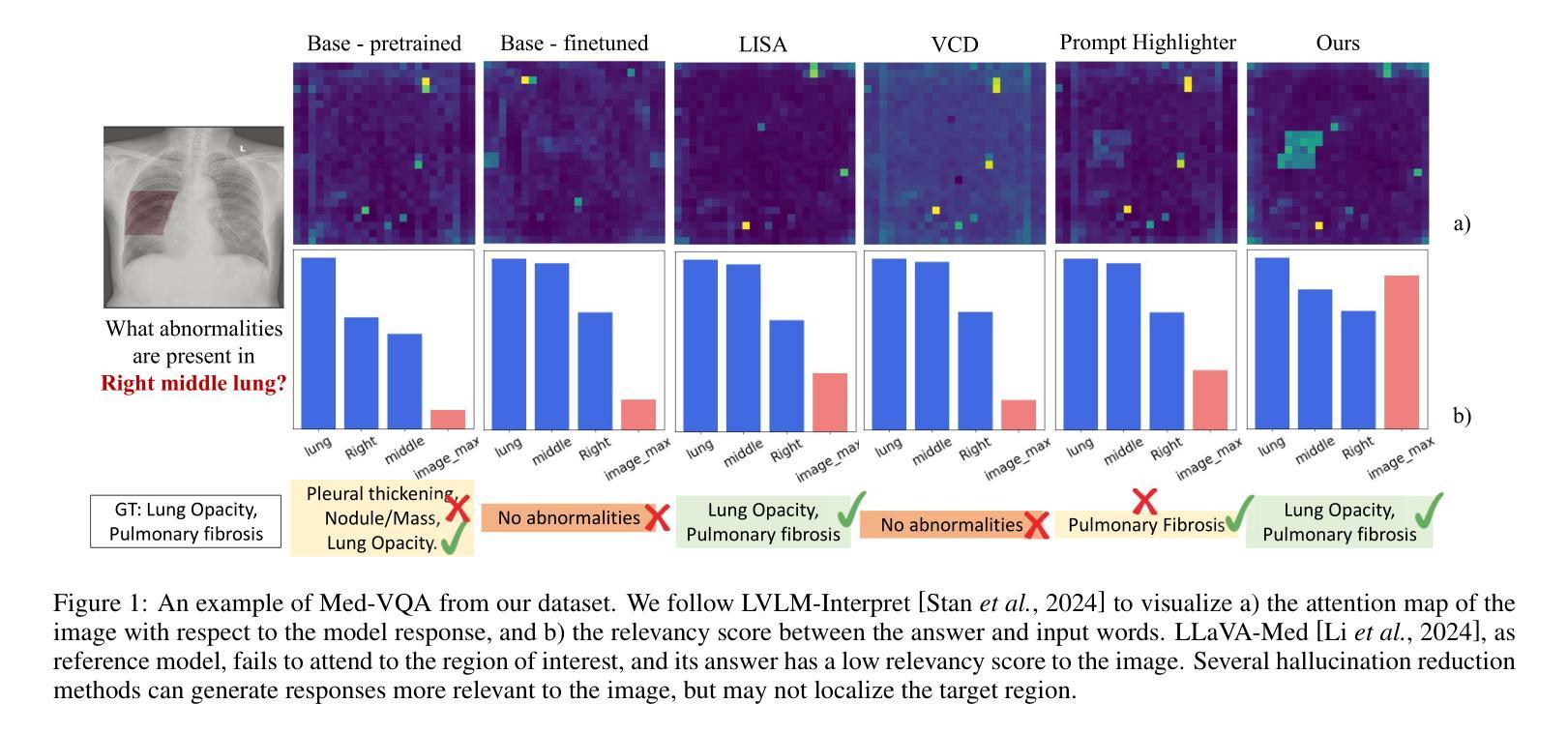
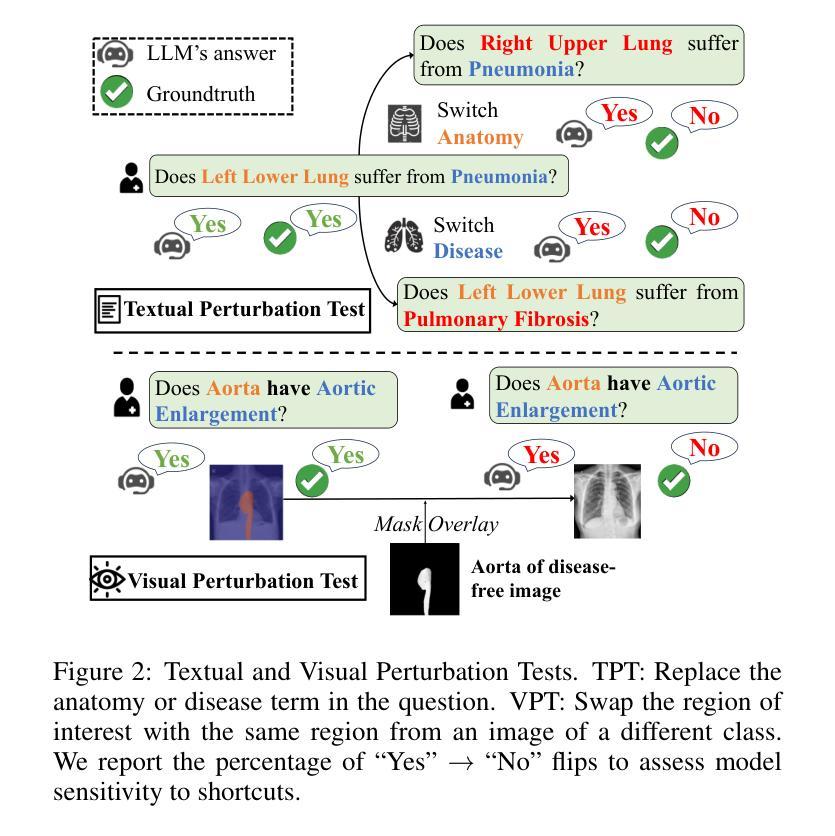
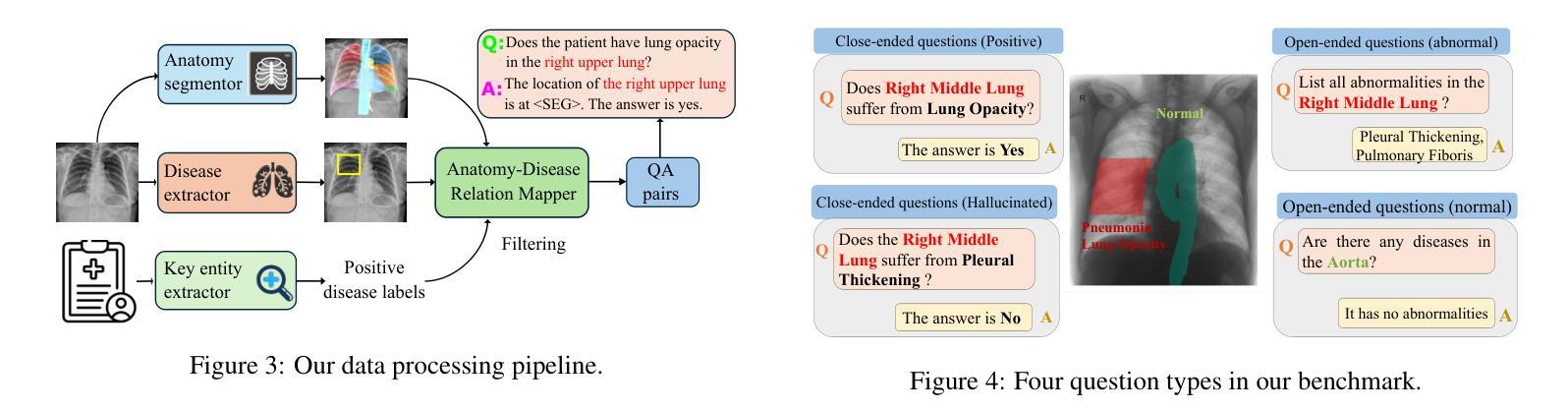
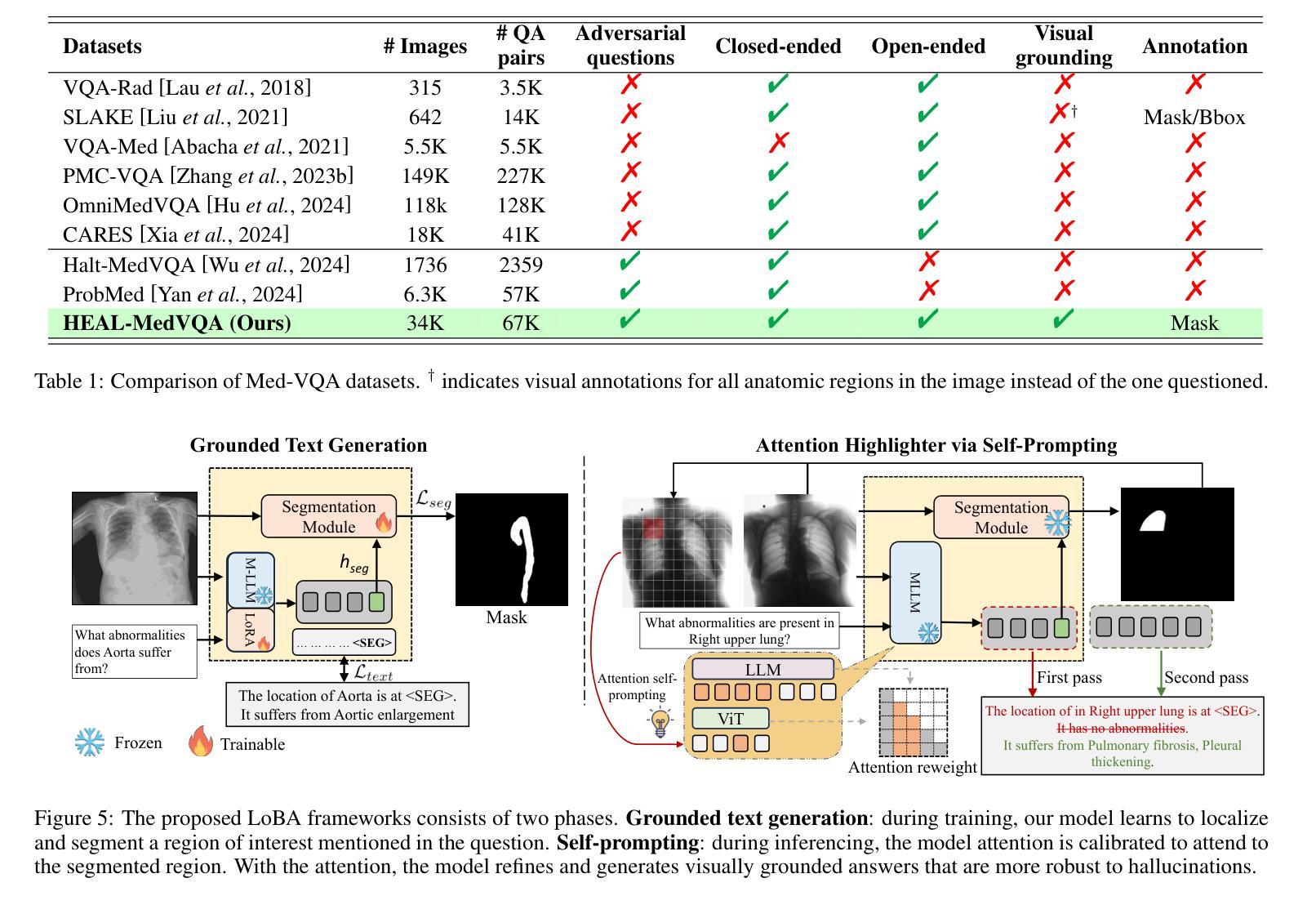
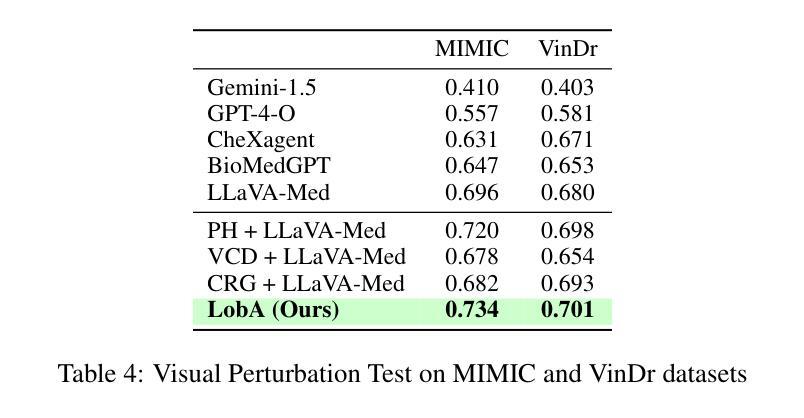
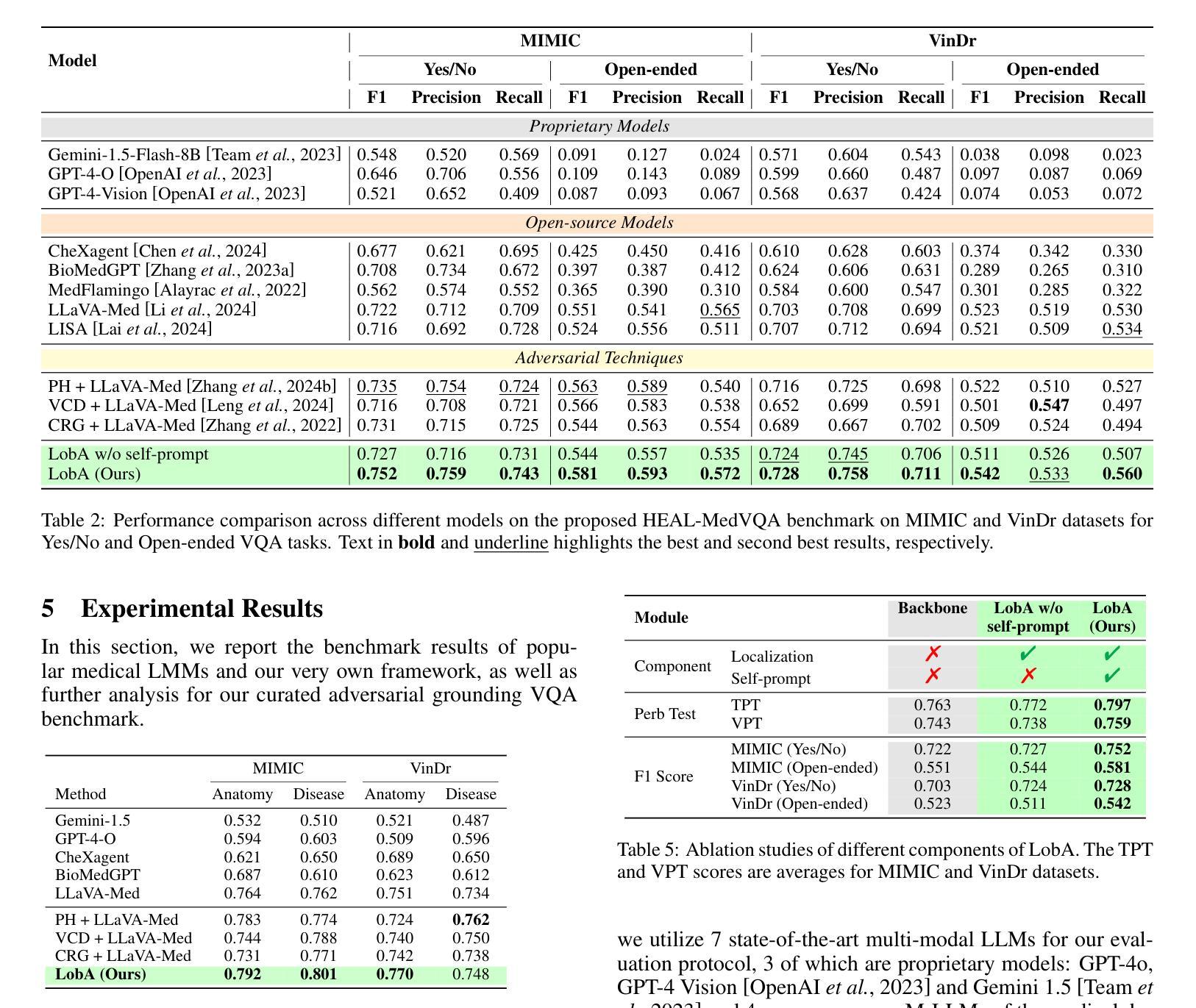
Localizing Before Answering: A Hallucination Evaluation Benchmark for Grounded Medical Multimodal LLMs
Authors:Dung Nguyen, Minh Khoi Ho, Huy Ta, Thanh Tam Nguyen, Qi Chen, Kumar Rav, Quy Duong Dang, Satwik Ramchandre, Son Lam Phung, Zhibin Liao, Minh-Son To, Johan Verjans, Phi Le Nguyen, Vu Minh Hieu Phan
Medical Large Multi-modal Models (LMMs) have demonstrated remarkable capabilities in medical data interpretation. However, these models frequently generate hallucinations contradicting source evidence, particularly due to inadequate localization reasoning. This work reveals a critical limitation in current medical LMMs: instead of analyzing relevant pathological regions, they often rely on linguistic patterns or attend to irrelevant image areas when responding to disease-related queries. To address this, we introduce HEAL-MedVQA (Hallucination Evaluation via Localization MedVQA), a comprehensive benchmark designed to evaluate LMMs’ localization abilities and hallucination robustness. HEAL-MedVQA features (i) two innovative evaluation protocols to assess visual and textual shortcut learning, and (ii) a dataset of 67K VQA pairs, with doctor-annotated anatomical segmentation masks for pathological regions. To improve visual reasoning, we propose the Localize-before-Answer (LobA) framework, which trains LMMs to localize target regions of interest and self-prompt to emphasize segmented pathological areas, generating grounded and reliable answers. Experimental results demonstrate that our approach significantly outperforms state-of-the-art biomedical LMMs on the challenging HEAL-MedVQA benchmark, advancing robustness in medical VQA.
医疗领域的大型多模态模型(LMMs)在医疗数据解读方面展现出了显著的能力。然而,这些模型经常产生与源证据相矛盾的幻觉,尤其是因为定位推理不足。这项工作揭示了当前医疗LMMs的一个关键局限:它们通常不是分析相关的病理区域,而是依赖于语言模式或关注与疾病相关查询不相关的图像区域来做出回应。为了解决这一问题,我们引入了HEAL-MedVQA(通过定位MedVQA评估幻觉),这是一个全面的基准测试,旨在评估LMMs的定位能力和幻觉稳健性。HEAL-MedVQA的特点包括:(i)两个创新的评估协议,用于评估视觉和文本捷径学习;(ii)包含67K个VQA对的数据集,每个问题都有医生注释的解剖分割掩膜来标记病理区域。为了提高视觉推理能力,我们提出了先定位再回答(LobA)框架,该框架训练LMMs定位感兴趣区域并进行自我提示以强调分割的病理区域,从而生成有根据且可靠的答案。实验结果表明,我们的方法在具有挑战性的HEAL-MedVQA基准测试上显著优于最先进的生物医学LMMs,提高了医疗VQA的稳健性。
论文及项目相关链接
PDF Accepted at Joint Conference on Artificial Intelligence (IJCAI) 2025
Summary
医疗领域的大型多模态模型(LMMs)在医疗数据解读方面展现出显著能力,但经常产生与源证据相矛盾的幻觉,尤其是因为缺乏定位推理。为解决此问题,本文揭示了当前医学LMMs的一个关键局限:它们往往不分析相关病理区域,而是依赖于语言模式或对疾病相关查询的无关图像区域进行回应。为此,我们引入了HEAL-MedVQA(通过定位评估幻觉的医萃问答)评估基准测试,旨在评估LMMs的定位能力和幻觉稳健性。HEAL-MedVQA包括两个创新评估协议来评估视觉和文本捷径学习,以及一个包含医生注释的解剖学分割掩膜数据集用于病理区域。为提高视觉推理能力,我们提出了先定位后回答(LobA)框架,训练LMMs定位感兴趣区域并自我提示强调分割的病理区域,生成可靠答案。实验结果表明,我们的方法在具有挑战性的HEAL-MedVQA基准测试中显著优于最新的生物医学LMMs,提升了医疗领域的视觉问答的稳健性。
Key Takeaways
- 医疗大型多模态模型(LMMs)在解读医疗数据上表现卓越,但存在生成与源证据矛盾的幻觉问题。
- LMMs的一个关键局限是缺乏定位推理,倾向于依赖语言模式或对非相关图像区域的回应。
- HEAL-MedVQA是一个新的评估基准,旨在评价LMMs的定位能力和幻觉稳健性。
- HEAL-MedVQA包括两个评估协议和包含医生注释的数据集用于评估病理区域。
- 先定位后回答(LobA)框架旨在提高LMMs的视觉推理能力,通过训练模型定位感兴趣区域并强调病理区域来生成可靠答案。
- 实验结果显示,LobA框架在HEAL-MedVQA基准测试中显著优于现有生物医学LMMs。
点此查看论文截图

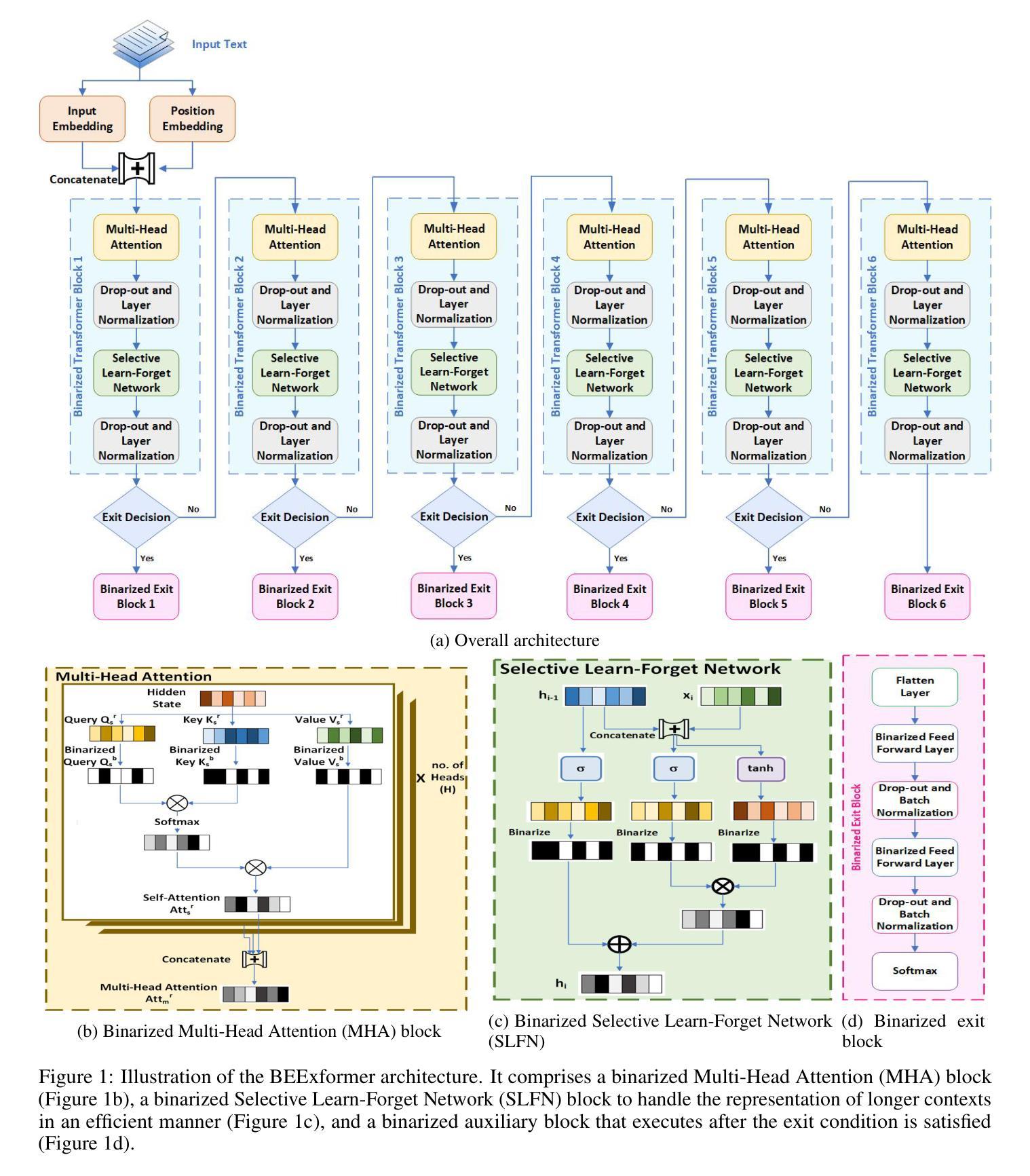
BEExformer: A Fast Inferencing Binarized Transformer with Early Exits
Authors:Wazib Ansar, Saptarsi Goswami, Amlan Chakrabarti
Large Language Models (LLMs) based on transformers achieve cutting-edge results on a variety of applications. However, their enormous size and processing requirements hinder deployment on constrained resources. To enhance efficiency, binarization and Early Exit (EE) have proved to be effective solutions. However, binarization may lead to performance loss as reduced precision affects gradient estimation and parameter updates. Besides, research on EE mechanisms is still in its early stages. To address these challenges, we introduce Binarized Early Exit Transformer (BEExformer), the first-ever selective learning-based transformer integrating Binarization-Aware Training (BAT) with EE for efficient and fast textual inference. Each transformer block has an integrated Selective-Learn Forget Network (SLFN) to enhance contextual retention while eliminating irrelevant information. The BAT employs a differentiable second-order approximation to the sign function, enabling gradient computation that captures both the sign and magnitude of the weights. This aids in 21.30 times reduction in model size. The EE mechanism hinges on fractional reduction in entropy among intermediate transformer blocks with soft-routing loss estimation. This accelerates inference by reducing FLOPs by 52.08% and even improves accuracy by 2.89% by resolving the “overthinking” problem inherent in deep networks. Extensive evaluation through comparison with the SOTA methods and various ablations across six datasets covering multiple NLP tasks demonstrates its Pareto-optimal performance-efficiency trade-off.
基于Transformer的大型语言模型(LLM)在各种应用上取得了尖端的结果。然而,它们庞大的规模和处理要求阻碍了其在有限资源上的部署。为了提高效率,二值化和提前退出(EE)已被证明是有效的解决方案。然而,二值化可能导致性能损失,因为精度降低会影响梯度估计和参数更新。此外,关于EE机制的研究仍处于早期阶段。
论文及项目相关链接
PDF This revised manuscript includes 18 pages, 17 figures, and 6 tables. Methodology and results sections have been improved for clarity and depth, incorporating additional comparisons, ablations, and a new evaluation dataset. A few relevant references were added, and overall organization refined for better readability
Summary
基于Transformer的大型语言模型(LLM)在各种应用上取得了尖端成果,但其庞大的规模和计算资源需求限制了其在资源受限环境中的应用。为提高效率,二进制化和提前退出(EE)被证明是有效的解决方案。然而,二进制化可能导致性能损失,影响梯度估计和参数更新。为解决这些挑战,我们推出Binarized Early Exit Transformer(BEExformer),首款结合二进制感知训练(BAT)和EE的选择性学习型变压器。每个变压器块都集成了选择性学习遗忘网络(SLFN),以增强上下文保留并消除无关信息。BAT使用符号函数的可微二阶近似进行梯度计算,有助于减小模型大小。EE机制依赖于中间变压器块之间熵的分数减少,以及软路由损失估计。这通过减少浮点运算次数(FLOPs)加速推理,并解决深度网络固有的“过度思考”问题,提高了准确率。在六个数据集上的大量评估表明其在性能效率上具有帕累托最优的权衡。
Key Takeaways
- 大型语言模型(LLM)在多种应用上表现卓越,但资源需求大,部署受限。
- 二进制化和提前退出(EE)是提高模型效率的有效方法。
- 二进制感知训练(BAT)结合选择性学习遗忘网络(SLFN)以增强模型的上下文保留能力并消除无关信息。
- BAT使用可微二阶近似进行梯度计算,有助于显著减小模型大小。
- EE机制通过减少中间变压器块的熵来加速推理,并解决“过度思考”问题,从而提高准确率。
- BEExformer在多个数据集上的评估表现出其帕累托最优的性能效率权衡。
点此查看论文截图

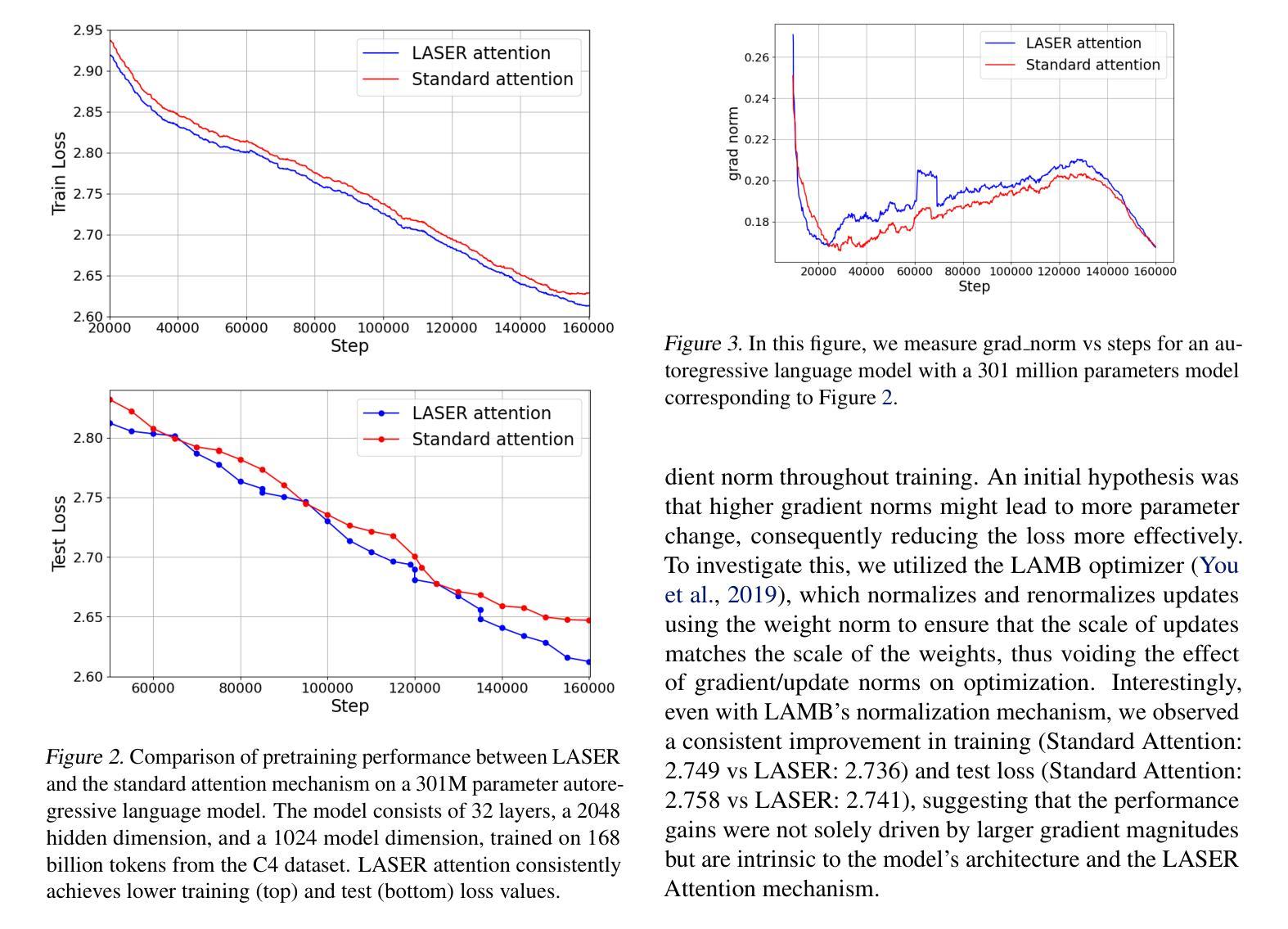
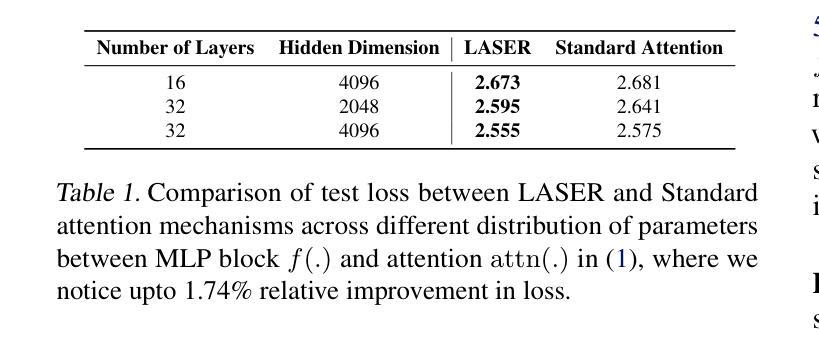
LASER: Attention with Exponential Transformation
Authors:Sai Surya Duvvuri, Inderjit S. Dhillon
Transformers have had tremendous impact for several sequence related tasks, largely due to their ability to retrieve from any part of the sequence via softmax based dot-product attention. This mechanism plays a crucial role in Transformer’s performance. We analyze the gradients backpropagated through the softmax operation in the attention mechanism and observe that these gradients can often be small. This poor gradient signal backpropagation can lead to inefficient learning of parameters preceeding the attention operations. To this end, we introduce a new attention mechanism called LASER, which we analytically show to admit a larger gradient signal. We show that LASER attention can be implemented by making small modifications to existing attention implementations. We conduct experiments on autoregressive large language models (LLMs) with upto 7.7 billion parameters with an average improvement of upto 1.44% over standard attention on downstream evaluations and 1.65% finetuning improvements. Additionally, LASER demonstrates generalization performance improvement across a variety of tasks (vision, text and speech):Vision Transformer (ViT) on Imagenet, Conformer on the Librispeech speech-to-text and BERT with 2.2 billion parameters.
Transformer对多个序列相关任务产生了巨大影响,这主要归功于其通过基于softmax的点积注意力从序列中检索信息的能力。这一机制在Transformer的性能中起着关键作用。我们分析了注意力机制中softmax操作反向传播的梯度,观察到这些梯度通常很小。这种不良的梯度信号反向传播可能导致注意力操作之前的参数学习效率低下。为此,我们引入了一种新的注意力机制,称为LASER。我们通过分析证明,LASER可以接纳更大的梯度信号。我们表明,通过对现有注意力实现进行微小修改,就可以实现LASER注意力。我们在具有高达7.7亿参数的自动回归大型语言模型(LLM)上进行了实验,在下游评估和标准注意力相比,平均改进了高达1.44%,微调改进了1.65%。此外,LASER在各种任务(视觉、文本和语音)上展示了泛化性能的提升:在Imagenet上的Vision Transformer(ViT)、Librispeech语音到文本的Conformer,以及具有22亿参数的BERT。
论文及项目相关链接
PDF ICML 2025
Summary
本文介绍了Transformer中的注意力机制对序列相关任务的影响,并分析了softmax操作中反向传播的梯度问题。针对这一问题,提出了一种新的注意力机制——LASER注意力,它可以实现更大的梯度信号,并通过对现有注意力实现的小修改实现。实验结果表明,在大型语言模型(LLM)中,LASER注意力在下游评估和微调方面均取得了显著改进。此外,LASER还在多种任务中展示了泛化性能的提升。
Key Takeaways
- Transformer的注意力机制对序列相关任务有巨大影响,得益于其通过softmax基于点积的注意力机制从序列中检索信息的能力。
- 分析发现,softmax操作中反向传播的梯度信号往往较小,可能导致注意力操作前参数的无效学习。
- 针对此问题,提出了名为LASER的新注意力机制,它可以实现更大的梯度信号,从而提高学习效率。
- LASER注意力可以通过对现有注意力实现的小修改来实现。
- 在大型语言模型(LLM)的下游评估和微调方面,LASER注意力取得了显著改进,平均改进率高达1.44%。
- LASER注意力在多种任务中展示了泛化性能的提升,包括图像分类(Vision Transformer on Imagenet)、语音识别(Conformer on Librispeech)和文本处理(BERT with 2.2 billion parameters)。
点此查看论文截图

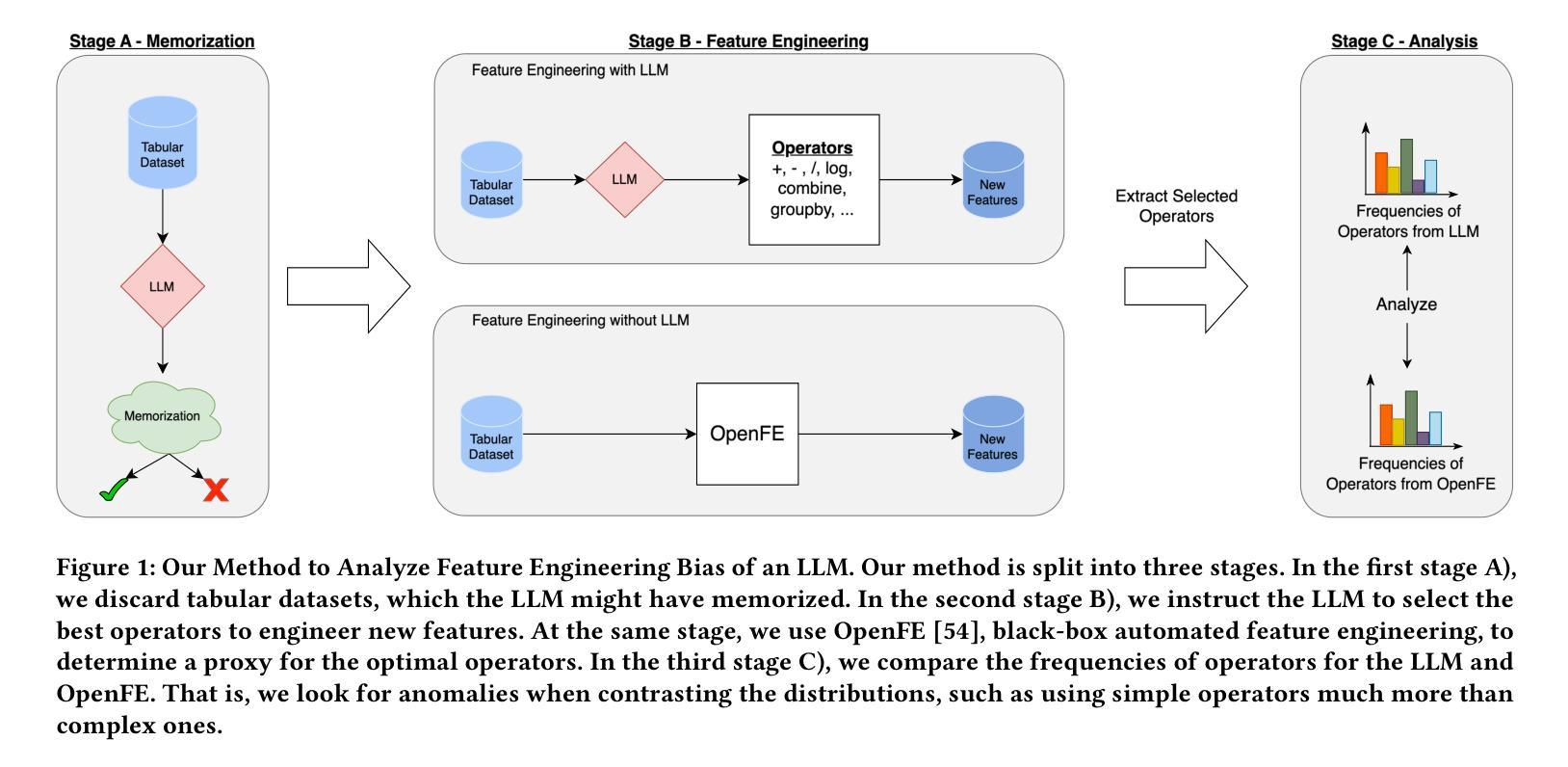
Large Language Models Engineer Too Many Simple Features For Tabular Data
Authors:Jaris Küken, Lennart Purucker, Frank Hutter
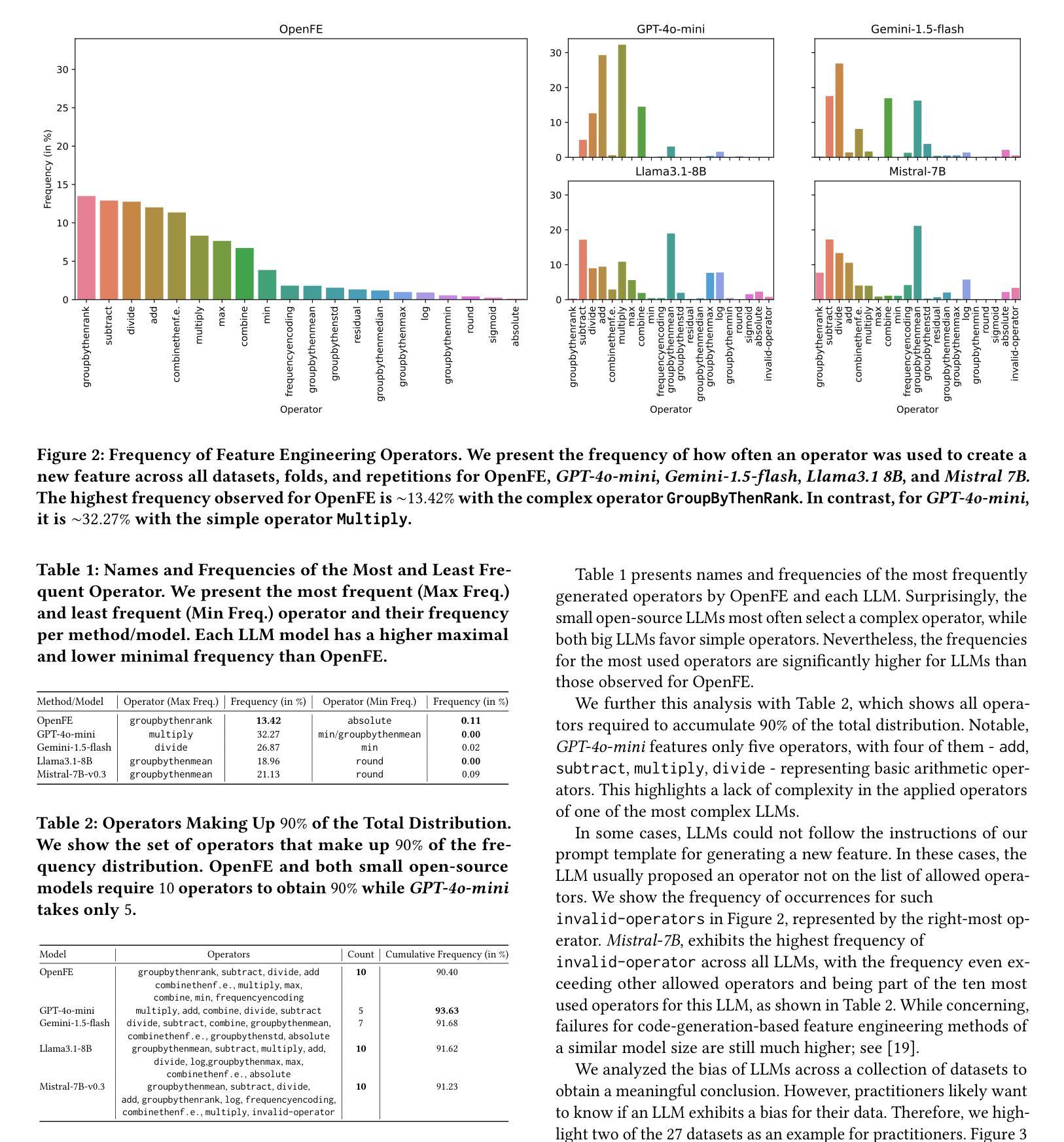
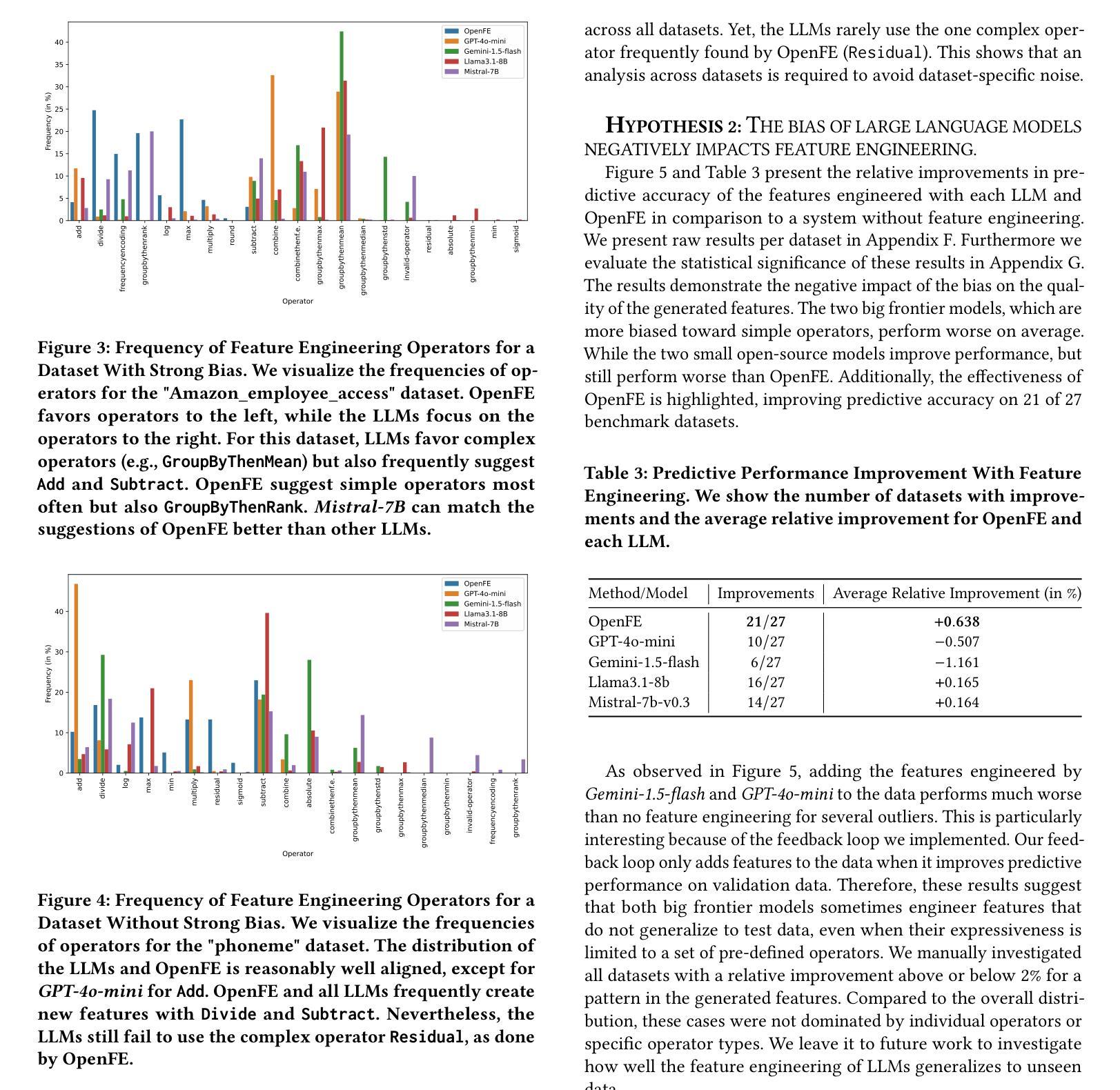
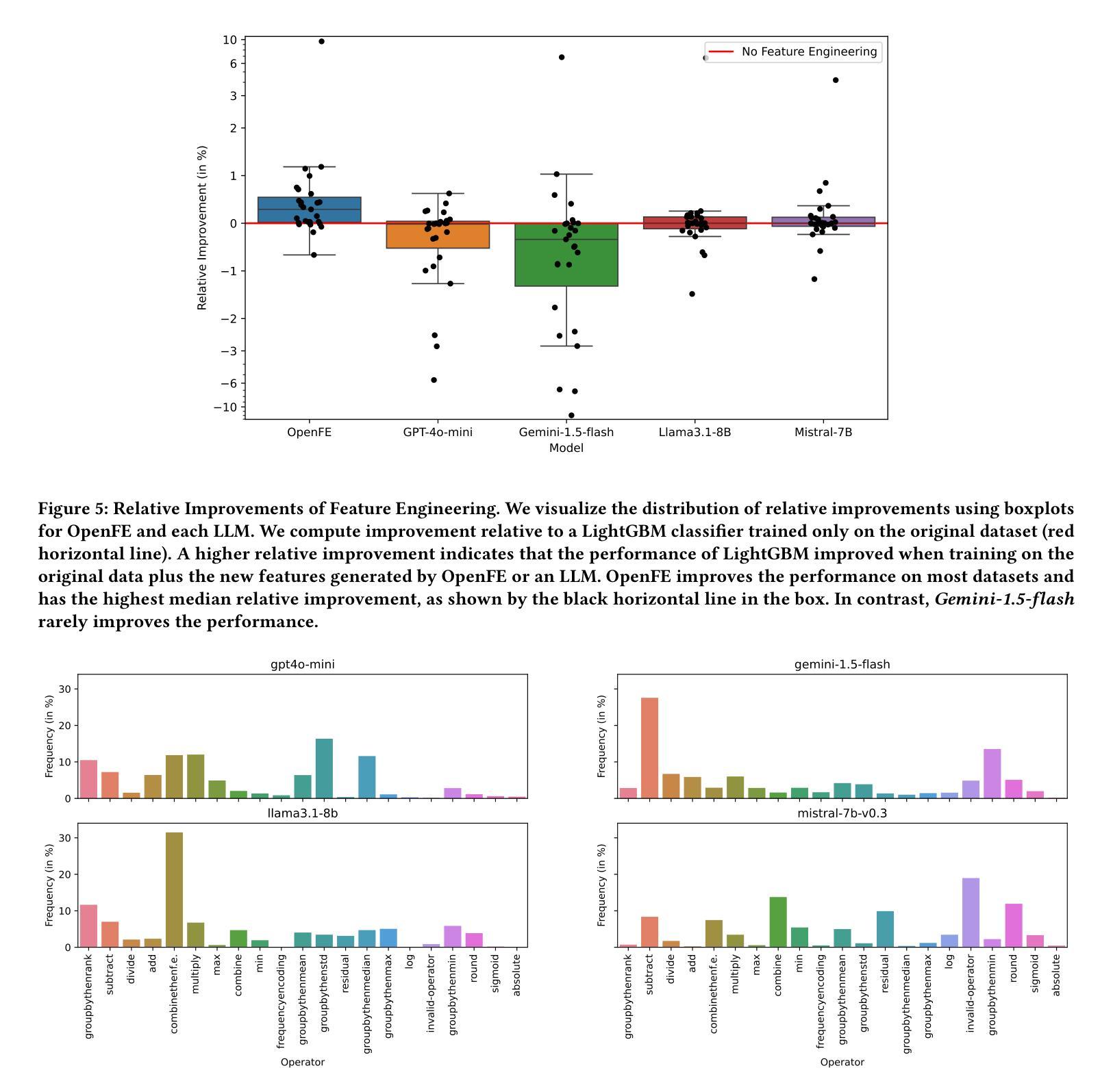
Tabular machine learning problems often require time-consuming and labor-intensive feature engineering. Recent efforts have focused on using large language models (LLMs) to capitalize on their potential domain knowledge. At the same time, researchers have observed ethically concerning negative biases in other LLM-related use cases, such as text generation. These developments motivated us to investigate whether LLMs exhibit a bias that negatively impacts the performance of feature engineering. While not ethically concerning, such a bias could hinder practitioners from fully utilizing LLMs for automated data science. Therefore, we propose a method to detect potential biases by detecting anomalies in the frequency of operators (e.g., adding two features) suggested by LLMs when engineering new features. Our experiments evaluate the bias of four LLMs, two big frontier and two small open-source models, across 27 tabular datasets. Our results indicate that LLMs are biased toward simple operators, such as addition, and can fail to utilize more complex operators, such as grouping followed by aggregations. Furthermore, the bias can negatively impact the predictive performance when using LLM-generated features. Our results call for mitigating bias when using LLMs for feature engineering.
表格型机器学习问题通常需要耗时且劳动密集型的特征工程。最近的努力集中在利用大型语言模型(LLM)发挥其潜在的领域知识优势上。与此同时,研究人员在其他与LLM相关的用例中观察到有悖伦理的负面偏见,例如文本生成。这些发展促使我们调查LLM是否表现出对特征工程性能产生负面影响的偏见。虽然并不违背伦理,但这种偏见可能会阻碍从业者充分利用LLM进行自动化数据科学。因此,我们提出了一种通过检测LLM在特征工程中建议的操作符频率异常来检测潜在偏见的方法(例如,添加两个特征)。我们的实验评估了四个LLM的偏见,包括两个大型前沿模型和两个小型的开源模型,跨越27个表格数据集。我们的结果表明,LLM偏向于简单的操作符,如加法,并且可能无法利用更复杂的操作符,如分组后的聚合。此外,这种偏见在使用LLM生成的特性进行预测时可能会产生负面影响。我们的研究结果呼吁在利用LLM进行特征工程时减轻偏见。
论文及项目相关链接
PDF Accepted at the 3rd Table Representation Learning Workshop @ NeurIPS 2024
Summary
大型语言模型(LLM)在特征工程应用中存在偏见。研究提出一种检测LLM偏见的方法,通过观察LLM建议的操作符频率来检测异常值。实验结果显示,LLM倾向于使用简单操作符,可能影响预测性能。
Key Takeaways
- 大型语言模型(LLM)在特征工程中具有潜力,但存在偏见问题。
- LLM倾向于使用简单操作符,如加法,可能忽视更复杂操作符。
- LLM的偏见可能影响预测性能。
- 提出一种通过检测LLM建议的操作符频率异常来检测潜在偏见的方法。
- 实验评估了四种LLM的偏见,包括两种大型前沿和两种小型开源模型。
- LLM在27个表格数据集上的表现存在偏见。
点此查看论文截图