⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-17 更新
Supporting SENĆOTEN Language Documentation Efforts with Automatic Speech Recognition
Authors:Mengzhe Geng, Patrick Littell, Aidan Pine, PENÁĆ, Marc Tessier, Roland Kuhn
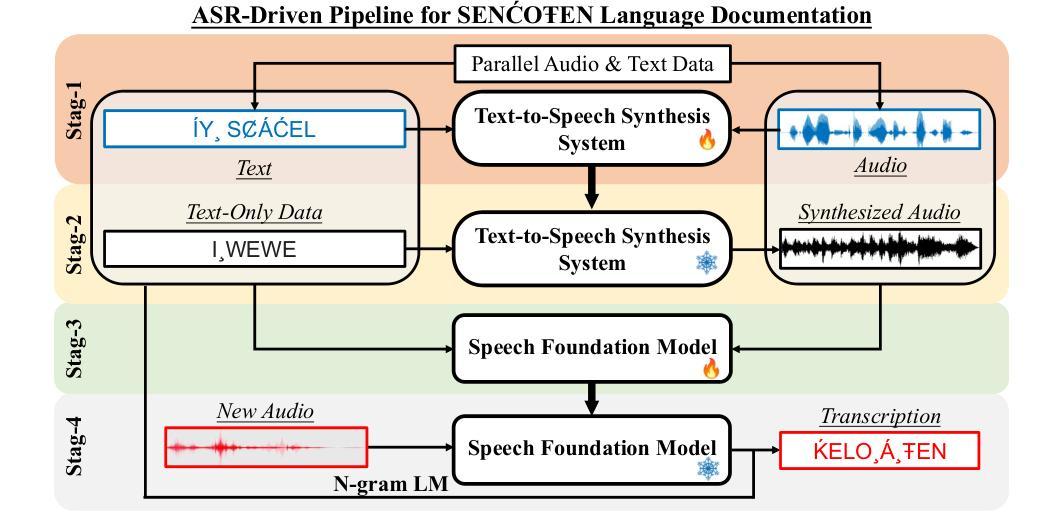
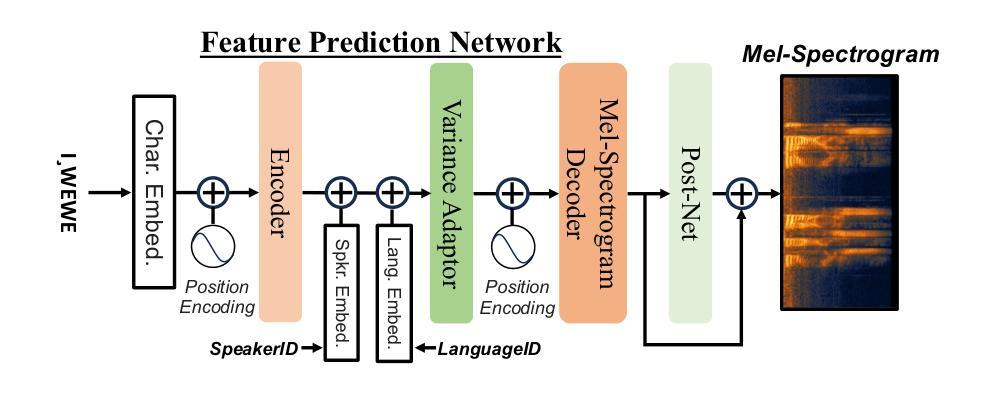
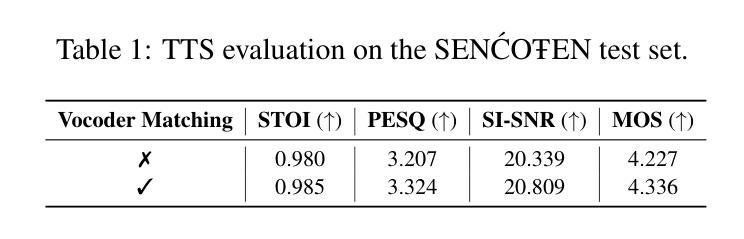
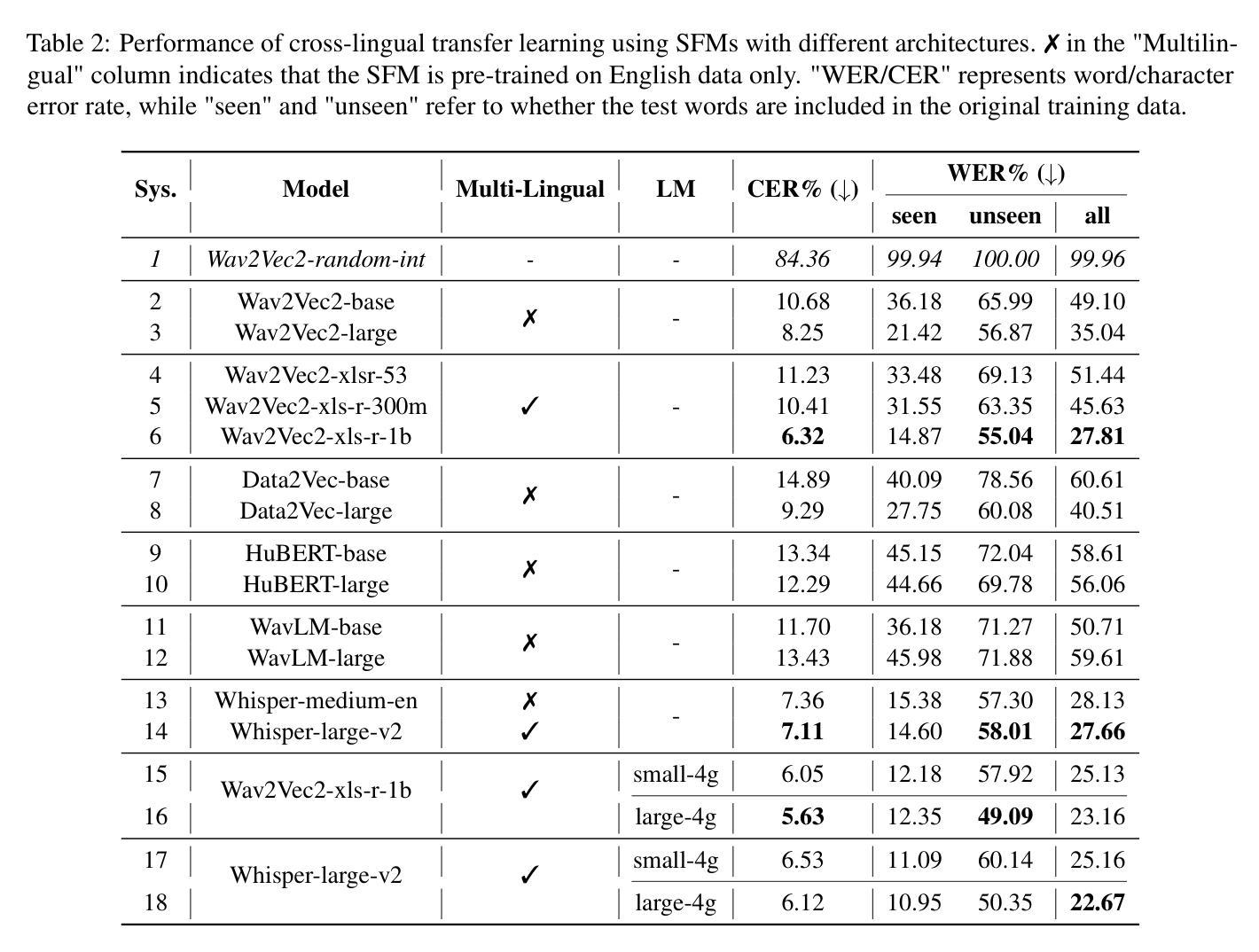
The SEN'{C}OTEN language, spoken on the Saanich peninsula of southern Vancouver Island, is in the midst of vigorous language revitalization efforts to turn the tide of language loss as a result of colonial language policies. To support these on-the-ground efforts, the community is turning to digital technology. Automatic Speech Recognition (ASR) technology holds great promise for accelerating language documentation and the creation of educational resources. However, developing ASR systems for SEN'{C}OTEN is challenging due to limited data and significant vocabulary variation from its polysynthetic structure and stress-driven metathesis. To address these challenges, we propose an ASR-driven documentation pipeline that leverages augmented speech data from a text-to-speech (TTS) system and cross-lingual transfer learning with Speech Foundation Models (SFMs). An n-gram language model is also incorporated via shallow fusion or n-best restoring to maximize the use of available data. Experiments on the SEN'{C}OTEN dataset show a word error rate (WER) of 19.34% and a character error rate (CER) of 5.09% on the test set with a 57.02% out-of-vocabulary (OOV) rate. After filtering minor cedilla-related errors, WER improves to 14.32% (26.48% on unseen words) and CER to 3.45%, demonstrating the potential of our ASR-driven pipeline to support SEN'{C}OTEN language documentation.
SECOTEN语言位于温哥华岛南部萨尼奇半岛上,目前正在积极进行语言振兴工作,以扭转因殖民语言政策导致的语言流失趋势。为了支持这些实地工作,社区正在转向数字技术。自动语音识别(ASR)技术在加速语言记录和创建教育资源方面具有巨大潜力。然而,由于数据有限以及来自其综合结构和应力驱动转序的词汇变化显著,开发SECOTEN的ASR系统面临挑战。为了应对这些挑战,我们提出了一种ASR驱动的文档管道,该管道利用文本到语音(TTS)系统的增强语音数据和跨语言迁移学习与语音基础模型(SFM)。还通过浅融合或n最佳恢复方式融入了n元语言模型,以最大限度地利用可用数据。在SECOTEN数据集上的实验显示,测试集上的单词错误率(WER)为19.34%,字符错误率(CER)为5.09%,在未见面词汇(OOV)率为57.02%的情况下,经过过滤与微细斜线相关的错误后,WER提高到14.32%(未见词汇上的错误率为26.48%),CER降低到3.45%,证明了我们的ASR驱动管道支持SECOTEN语言记录的潜力。
论文及项目相关链接
PDF Accepted by ComputEL-8
Summary
本文介绍了位于温哥华岛南部Saanich半岛的SEN’{C}OTEN语言的保护现状。由于殖民语言政策的影响,该语言面临着消亡的风险。为了振兴这一语言,社区正在借助数字技术,特别是自动语音识别(ASR)技术来加速语言文献记录和创建教育资源。尽管面临数据有限和词汇因语言的聚合结构和应力驱动的移位变化大的挑战,但提出了一项利用文本转语音(TTS)系统增强语音数据和基于跨语言迁移学习的语音基础模型(SFM)驱动的ASR系统进行应对的提议。该方案的实施已取得了一定的效果。通过对初步结果的改进与后续持续优化的实践可以体现出此方案的有效性,显示出其助力振兴语言的潜力。未来还需进一步完善系统性能和细节,以实现更为准确的语音和文字转换,从而更好地保护这一独特的语言遗产。最终的目标是推动这一濒危语言的保护工作和传播传承事业向数字化和现代化迈进。最终展示出在非受限情况下的系统表现仍需继续提高的必要性。展现出高度的文献准确性和稳定的社会功能系统对整个计划的完成起着至关重要的支撑作用。这意味着人们还有很大的探索和发展空间来进行此方面技术的研究和探索以提升这种特定方言的记录与传播工作效率以及可拓展性和应对特定环境的应用性能等方面的巨大潜力值得人们深入研究探讨与发展推进落地部署和改进的细节与实践价值在未来有着重要的学术应用和社会意义空间实现此项计划的远景前景值得我们进一步去发掘实现通过共同努力构建文化多元和社会繁荣的美好未来这一领域的长期研究和开发努力不仅将极大地丰富人类的文化遗产还将带来长远的可持续发展和人类精神文化的巨大贡献这一计划的实现有望激发更广泛的跨文化对话与合作探索出一种在全球范围内应对濒危语言保护的先进模式为全球多元文化贡献更多智慧与实践力量是重要和紧迫的当下人类对于自然与文化多样性保护和可持续未来的探索进程已然愈发深刻强烈了本次尝试取得的初步成果与成效彰显了我们所秉持的保护与传播人类多样性与文化遗产的责任和使命感其重要意义不仅在于对于个别语言的保护和记录也在于激励和呼吁整个社会去珍视保护和发扬丰富多样的人类文化与文明使全人类能从中获益发展并获得福祉的现实和长远的深远影响对我们今后对此项研究投入的努力也有着明确的导向性任务与责任担当的启示作用。Key Takeaways
- SEN’{C}OTEN语言正处于复兴阶段,旨在扭转因殖民语言政策导致的语言流失趋势。
- 数字技术,特别是自动语音识别(ASR)技术,正被用于支持语言文献记录和创建教育资源。
- 开发ASR系统面临数据有限和词汇变化大的挑战,需要通过结合文本转语音(TTS)系统增强语音数据和跨语言迁移学习来解决。
点此查看论文截图

Fragmentation of fully heavy tetraquarks: The TQ4Q1.1 functions as a case study
Authors:Francesco Giovanni Celiberto
We extend the study of exotic matter formation via the {\tt TQ4Q1.1} set of collinear, variable-flavor-number-scheme fragmentation functions for fully charmed or bottomed tetraquarks in three quantum configurations: scalar ($J^{PC} = 0^{++}$), axial vector ($J^{PC} = 1^{+-}$), and tensor ($J^{PC} = 2^{++}$). We adopt single-parton fragmentation at leading power and implement a nonrelativistic QCD factorization scheme tailored to tetraquark Fock-state configurations. Short-distance inputs at the initial scale are modeled using updated calculations for both gluon- and heavy-quark-initiated channels. A threshold-consistent DGLAP evolution is then applied via HFNRevo. We provide the first systematic treatment of uncertainties propagated from the color-composite long-distance matrix elements that govern the nonperturbative hadronization of tetraquarks. To support phenomenology, we compute NLL/NLO$^+$ cross sections for tetraquark-jet systems at the HL-LHC and FCC using (sym)JETHAD, incorporating angular multiplicities as key observables sensitive to high-energy QCD dynamics. This work connects the investigation of exotic hadrons with state-of-the-art precision QCD.
我们研究了通过TQ4Q1.1集线性、可变风味数方案的碎裂函数生成异域物质(exotic matter)的过程,针对全魅力或底端的四夸克,研究其在三种量子配置下的特性:标量(JPC=0++),轴向矢量(JPC=1+-)和张量(JPC=2++)。我们采用领先的单粒子碎裂功率,并实施针对四夸克福克态配置的相对论非相对论量子色动力学分解方案。初始尺度的近距离输入使用针对胶子和重夸克引发通道的最新计算建模。随后采用一致门槛的DGLAP进化方程,并通过HFNRevo进行处理。我们首次系统地处理由控制四夸克非扰动强子化的颜色复合长距离矩阵元素传播的不确定性。为了支持现象学,我们使用(sym)JETHAD计算了HL-LHC和FCC的四夸克-喷射系统的高阶对数似然比(NLL)/下一阶微扰理论修正(NLO^+)截面,并整合角多度作为对高能量子色动力学动态敏感的关键观测值。这项工作将奇异强子的研究与最新精确量子色动力学联系在一起。
论文及项目相关链接
PDF 48 pages, 10 figures. Six sets of “TetraQuarks with 4 heavy Quarks” (TQ4Q1.1) NLO collinear fragmentation functions for scalar, axial-vector, and tensor fully charmed and fully bottomed states, released in LHAPDF format at https://github.com/FGCeliberto/Collinear_FFs/. Includes LDME variations and DGLAP evolution for uncertainty-ready studies
Summary
本文研究了通过特定的分裂函数对全魅力或底纹的四夸克物质的形成。该物质存在于三种量子配置中:标量、轴向量和张量。采用了单粒子分裂的主要力量和针对四夸克福克态配置的非相对论量子色动力学分解方案。使用更新的计算模型对初始规模的短期输入进行建模,并应用门槛一致的DGLAP演化过程。此外,本文首次系统地处理了由控制四夸克非扰动强子化的颜色复合长距离矩阵元素传播的不确定性。为了支持现象学,我们计算了HL-LHC和FCC的四夸克喷射系统的NLL/NLO+横截面,并纳入角多普性作为对高能量子色动力学动力学敏感的关键观测值。这项研究将异核强子的研究与最新精确量子色动力学联系起来。
Key Takeaways
- 利用特定的分裂函数研究了全魅力或底纹的四夸克物质的形成。
- 涉及的量子配置包括标量、轴向量和张量。
- 采用非相对论量子色动力学分解方案处理四夸克福克态配置。
- 使用更新的计算模型对短期输入进行建模,并应用门槛一致的DGLAP演化过程。
- 系统地处理由控制四夸克非扰动强子化的长距离矩阵元素传播的不确定性。
- 计算了HL-LHC和FCC的四夸克喷射系统的横截面。
点此查看论文截图

BENYO-S2ST-Corpus-1: A Bilingual English-to-Yoruba Direct Speech-to-Speech Translation Corpus
Authors:Emmanuel Adetiba, Abdultaofeek Abayomi, Raymond J. Kala, Ayodele H. Ifijeh, Oluwatobi E. Dare, Olabode Idowu-Bismark, Gabriel O. Sobola, Joy N. Adetiba, Monsurat Adepeju Lateef, Heather Cole-Lewis
There is a major shortage of Speech-to-Speech Translation (S2ST) datasets for high resource-to-low resource language pairs such as English-to-Yoruba. Thus, in this study, we curated the Bilingual English-to-Yoruba Speech-to-Speech Translation Corpus Version 1 (BENYO-S2ST-Corpus-1). The corpus is based on a hybrid architecture we developed for large-scale direct S2ST corpus creation at reduced cost. To achieve this, we leveraged non speech-to-speech Standard Yoruba (SY) real-time audios and transcripts in the YORULECT Corpus as well as the corresponding Standard English (SE) transcripts. YORULECT Corpus is small scale(1,504) samples, and it does not have paired English audios. Therefore, we generated the SE audios using pre-trained AI models (i.e. Facebook MMS). We also developed an audio augmentation algorithm named AcoustAug based on three latent acoustic features to generate augmented audios from the raw audios of the two languages. BENYO-S2ST-Corpus-1 has 12,032 audio samples per language, which gives a total of 24,064 sample size. The total audio duration for the two languages is 41.20 hours. This size is quite significant. Beyond building S2ST models, BENYO-S2ST-Corpus-1 can be used to build pretrained models or improve existing ones. The created corpus and Coqui framework were used to build a pretrained Yoruba TTS model (named YoruTTS-0.5) as a proof of concept. The YoruTTS-0.5 gave a F0 RMSE value of 63.54 after 1,000 epochs, which indicates moderate fundamental pitch similarity with the reference real-time audio. Ultimately, the corpus architecture in this study can be leveraged by researchers and developers to curate datasets for multilingual high-resource-to-low-resource African languages. This will bridge the huge digital divides in translations among high and low-resource language pairs. BENYO-S2ST-Corpus-1 and YoruTTS-0.5 are publicly available at (https://bit.ly/40bGMwi).
存在一种对于英语到约鲁巴语等资源丰富到资源匮乏的语言对之间的语音到语音翻译(S2ST)数据集严重短缺的情况。因此,在这项研究中,我们编制了双语英语到约鲁巴语音到语音翻译语料库版本1(BENYO-S2ST-Corpus-1)。该语料库基于我们为大规模直接S2ST语料库创建而开发的混合架构,以降低成本。为此,我们利用YORULECT语料库中的非语音到语音标准约鲁巴语(SY)实时音频和转录以及相应的标准英语(SE)转录。YORULECT语料库样本规模较小(1504个样本),且没有配套的英语音频。因此,我们使用预训练的AI模型(即Facebook MMS)生成SE音频。我们还开发了一种基于三种潜在声学特征的音频增强算法AcoustAug,用于从两种语言的原始音频生成增强音频。BENYO-S2ST-Corpus-1每种语言有12032个音频样本,总样本量为24064个。两种语言的总音频时长为41.20小时,这一规模相当可观。除了构建S2ST模型外,BENYO-S2ST-Corpus-1还可用于构建预训练模型或改进现有模型。作为概念验证,使用创建的语料库和Coqui框架构建了预训练的约鲁巴TTS模型(命名为YoruTTS-0.5)。YoruTTS-0.5在1000个周期后的F0 RMSE值为63.54,这表明其与参考实时音频具有适中的基本音高相似性。最终,本研究中的语料库架构可以被研究者和开发者用来编制多语种资源丰富到资源匮乏的非洲语言的数据集。这将缩小高资源和低资源语言对之间的翻译数字鸿沟。BENYO-S2ST-Corpus-1和YoruTTS-0.5可在https://bit.ly/40bGMwi上公开获取。
论文及项目相关链接
摘要
本研究针对高资源到低资源语言对(如英语到约鲁巴语)的语音到语音翻译(S2ST)数据集短缺问题,推出了双语英语到约鲁巴语音翻译语料库版本1(BENYO-S2ST-Corpus-1)。该语料库基于我们为大规模直接S2ST语料库创建而开发的混合架构,以降低成本。研究利用YORULECT语料库的实时音频和转录文本以及标准英语的对应转录本,生成了英语音频。此外,还开发了一种基于三种潜在声学特征的音频增强算法AcoustAug,用于从两种语言的原始音频生成增强音频。语料库包含两种语言的音频样本共计达2万多条,显著扩大了规模。除构建S2ST模型外,该语料库还应用于建立预训练模型或对现有模型进行改进。研究利用语料库和Coqui框架构建了约鲁巴语音合成模型(YoruTTS-0.5)。该模型在初步测试中表现出良好的性能,与参考实时音频具有良好的基本音调相似性。总体而言,本研究开发的语料库架构可为研究人员和开发人员提供工具,用于为多种语言的高资源到低资源非洲语言创建数据集。这将缩小高资源语言和低资源语言之间的数字鸿沟。相关数据和模型可通过链接公开获取。
关键见解
- 研究解决了高资源到低资源语言对(如英语到约鲁巴语)的语音翻译数据集短缺的问题。
- 推出双语英语到约鲁巴语音翻译语料库版本1(BENYO-S2ST-Corpus-1),包含大量音频样本。
- 利用混合架构和预训练AI模型创建语料库,降低大规模直接语音翻译语料库的创建成本。
- 开发了一种名为AcoustAug的音频增强算法,基于三种潜在声学特征生成增强音频。
- 使用语料库和Coqui框架成功建立了约鲁巴语音合成模型(YoruTTS-0.5)。初步测试显示其性能良好。
- 该研究开发的语料库架构可用于为多种语言的高资源到低资源非洲语言创建数据集,缩小数字鸿沟。
点此查看论文截图

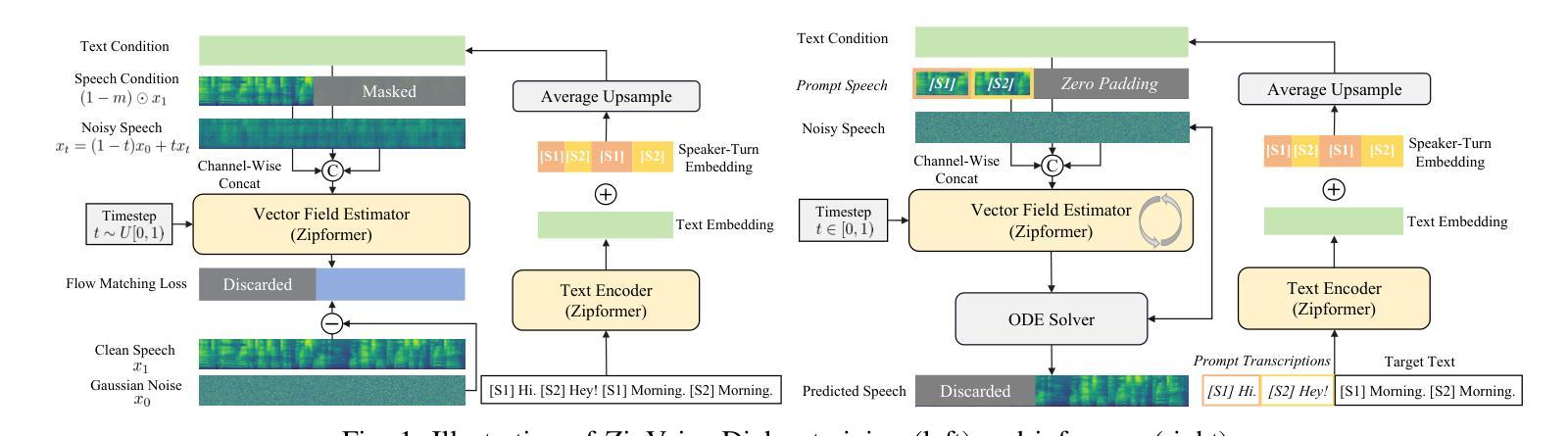
ZipVoice-Dialog: Non-Autoregressive Spoken Dialogue Generation with Flow Matching
Authors:Han Zhu, Wei Kang, Liyong Guo, Zengwei Yao, Fangjun Kuang, Weiji Zhuang, Zhaoqing Li, Zhifeng Han, Dong Zhang, Xin Zhang, Xingchen Song, Long Lin, Daniel Povey
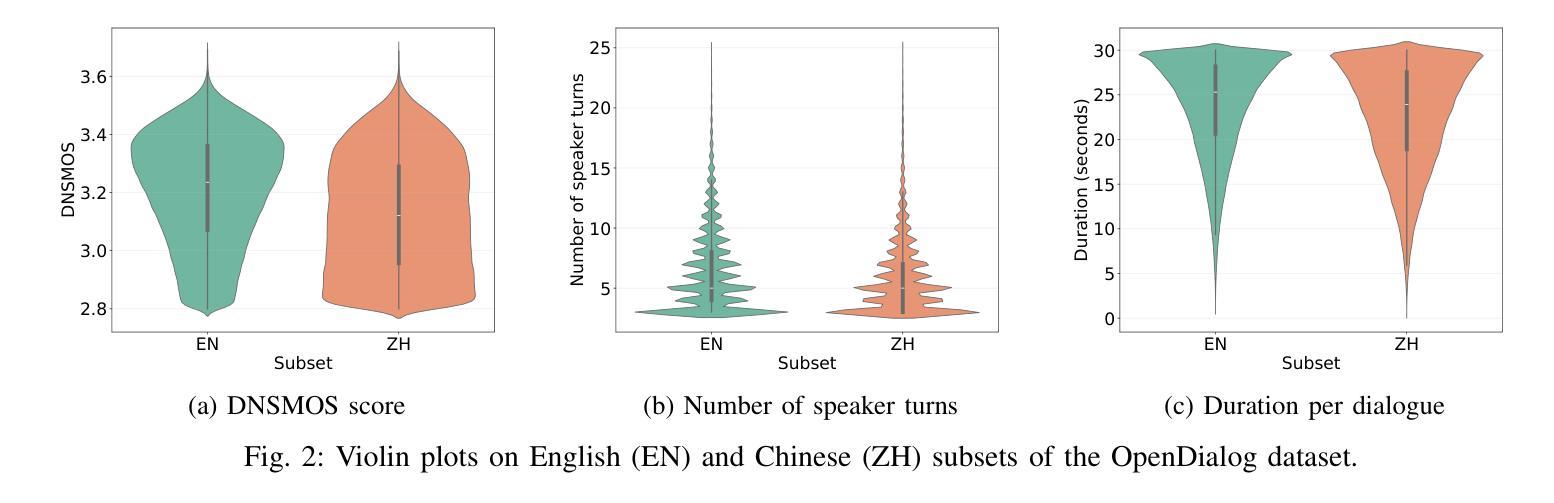
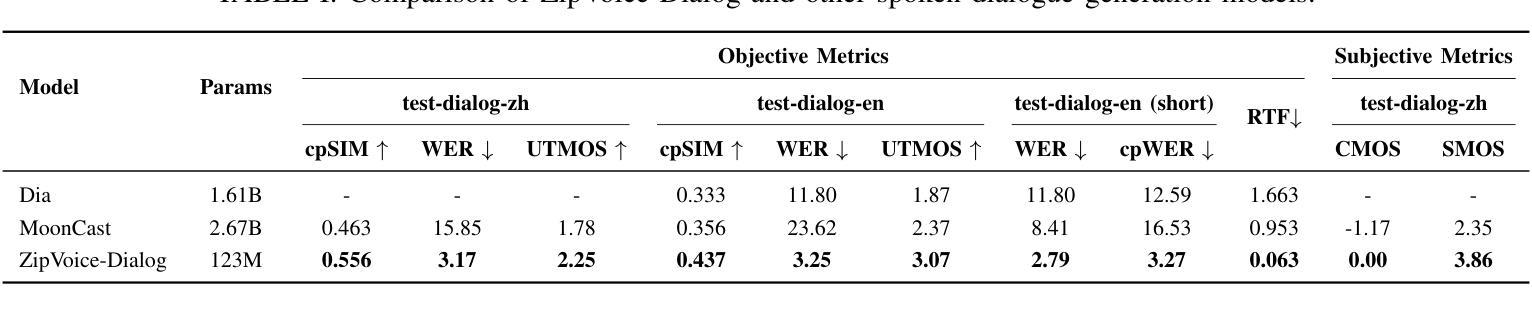
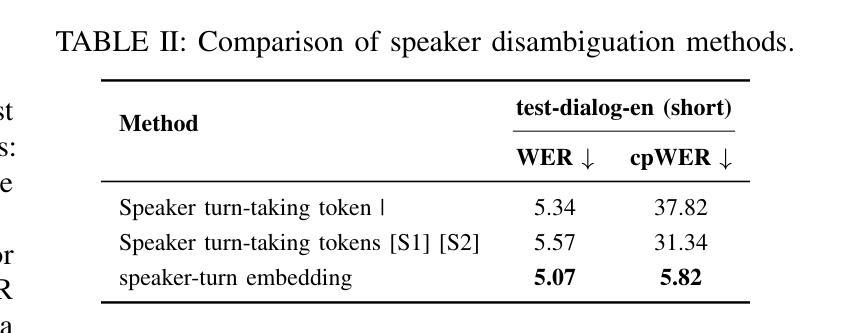
Generating spoken dialogue is more challenging than monologue text-to-speech (TTS) due to the need for realistic turn-taking and distinct speaker timbres. Existing spoken dialogue generation models, being auto-regressive, suffer from slow and unstable inference. To overcome these limitations, we introduce ZipVoice-Dialog, a non-autoregressive zero-shot spoken dialogue generation model built upon flow matching. Key designs include: 1) speaker-turn embeddings for precise speaker turn-taking; 2) a curriculum learning strategy for stable speech-text alignment; 3) specialized strategies to enable stereo dialogue generation. Additionally, recognizing the lack of open-source large-scale spoken dialogue datasets, we curated OpenDialog, a 6.8k-hour spoken dialogue dataset from in-the-wild speech data. Furthermore, we established a benchmark to comprehensively evaluate various models. Experimental results demonstrate that ZipVoice-Dialog achieves superior performance in intelligibility, speaker turn-taking accuracy, speaker similarity, and inference speed. Our codes, model checkpoints, demo samples, and the OpenDialog dataset are all publicly available at https://github.com/k2-fsa/ZipVoice.
生成对话语音相较于单语文本到语音(TTS)更具挑战性,因为需要实现真实的对话轮次和不同的说话人音色。现有的对话生成模型由于采用自回归方式,存在推理速度慢和不稳定的缺陷。为了克服这些局限,我们推出了ZipVoice-Dialog,这是一个非自回归零样本对话生成模型,基于流匹配技术构建。主要设计包括:1)说话人轮次嵌入,实现精确的对话轮次;2)课程学习策略,确保稳定的语音文本对齐;3)专用策略,实现立体声对话生成。此外,我们认识到缺乏开源的大规模对话语音数据集,因此我们整理了OpenDialog数据集,这是一个包含6800小时真实场景对话语音的数据集。我们还建立了全面评估各种模型的基准测试。实验结果表明,ZipVoice-Dialog在清晰度、说话人轮次准确性、说话人相似性和推理速度上均表现出卓越性能。我们的代码、模型检查点、演示样本和OpenDialog数据集均公开在https://github.com/k2-fsa/ZipVoice。
论文及项目相关链接
Summary
文本介绍了一种名为ZipVoice-Dialog的非自回归零样本对话生成模型。该模型解决了现有对话生成模型的不足,如推理速度慢和不稳定性。通过引入说话人轮替嵌入、课程学习策略以及立体声对话生成策略,实现了精确的说话人轮替、稳定的语音文本对齐和立体声对话生成。此外,文章还介绍了一个公开的大型对话数据集OpenDialog和一个评估模型的基准测试。实验结果表明,ZipVoice-Dialog在可理解性、说话人轮替准确性、说话人相似性和推理速度方面表现优越。
Key Takeaways
- ZipVoice-Dialog是一种非自回归零样本对话生成模型,用于解决现有对话生成模型的推理速度慢和不稳定的局限。
- 模型引入了说话人轮替嵌入,以实现精确的说话人轮替和真实的对话流程。
- 采用课程学习策略,实现稳定的语音文本对齐。
- 模型包含立体声对话生成策略,提升对话的真实感和沉浸感。
- 公开了一个大型对话数据集OpenDialog,用于训练和评估对话生成模型。
- 建立了评估模型的基准测试,以全面衡量模型性能。
点此查看论文截图

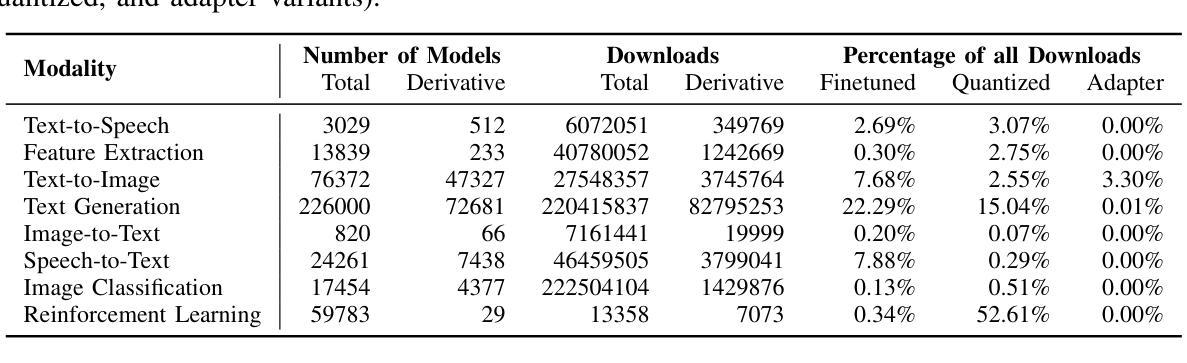
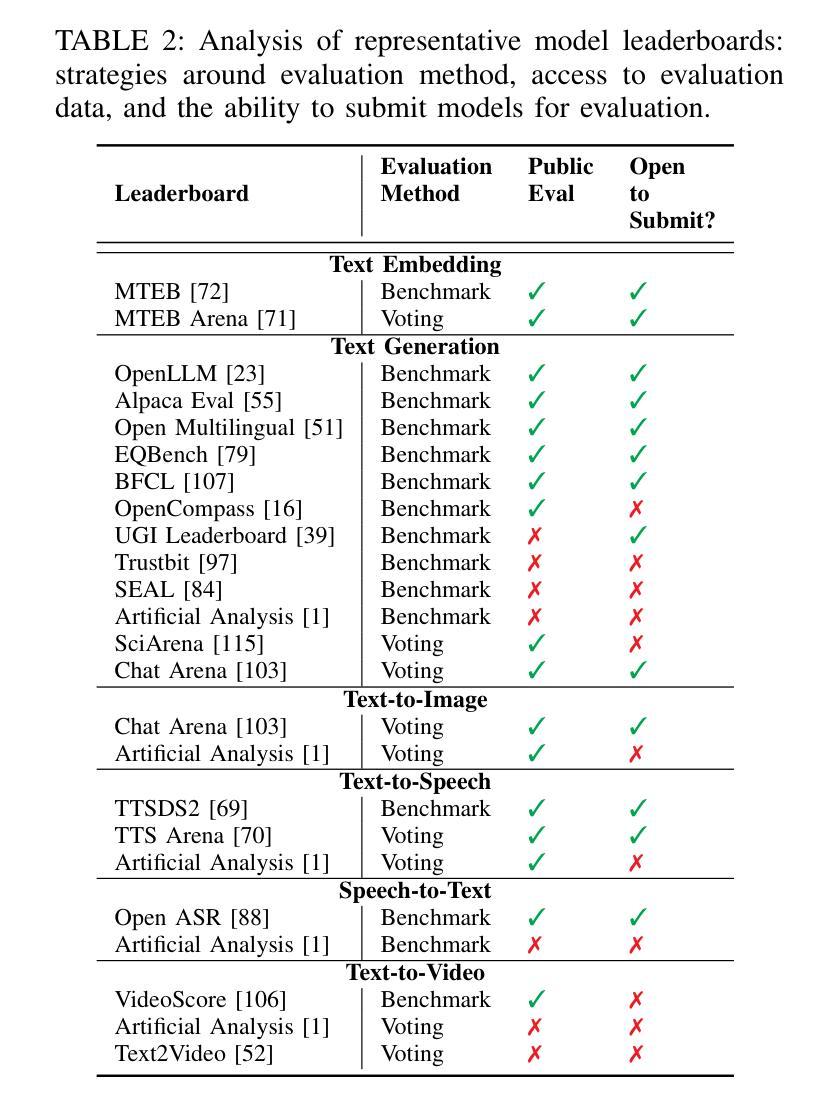
Exploiting Leaderboards for Large-Scale Distribution of Malicious Models
Authors:Anshuman Suri, Harsh Chaudhari, Yuefeng Peng, Ali Naseh, Amir Houmansadr, Alina Oprea
While poisoning attacks on machine learning models have been extensively studied, the mechanisms by which adversaries can distribute poisoned models at scale remain largely unexplored. In this paper, we shed light on how model leaderboards – ranked platforms for model discovery and evaluation – can serve as a powerful channel for adversaries for stealthy large-scale distribution of poisoned models. We present TrojanClimb, a general framework that enables injection of malicious behaviors while maintaining competitive leaderboard performance. We demonstrate its effectiveness across four diverse modalities: text-embedding, text-generation, text-to-speech and text-to-image, showing that adversaries can successfully achieve high leaderboard rankings while embedding arbitrary harmful functionalities, from backdoors to bias injection. Our findings reveal a significant vulnerability in the machine learning ecosystem, highlighting the urgent need to redesign leaderboard evaluation mechanisms to detect and filter malicious (e.g., poisoned) models, while exposing broader security implications for the machine learning community regarding the risks of adopting models from unverified sources.
虽然针对机器学习模型的毒害攻击已经得到了广泛的研究,但对手如何大规模分发有毒模型机制的探索仍远远不够。在本文中,我们阐述了模型排行榜(用于模型发现和评价的排名平台)如何成为对手悄无声息地大规模分发有毒模型的有力渠道。我们提出了TrojanClimb这一通用框架,能够在保持竞争力排行榜表现的同时注入恶意行为。我们在四种不同模式(文本嵌入、文本生成、文本到语音和文本到图像)下证明了其有效性,表明对手可以在嵌入任意有害功能(从后门到偏见注入)的同时成功实现高排行榜排名。我们的研究揭示了机器学习生态系统中的一个重大漏洞,突显了重新设计排行榜评估机制的迫切需求,以检测和过滤恶意(例如有毒)模型,同时也暴露出机器学习社区采用未经验证模型的风险所带来的更广泛的安全影响。
论文及项目相关链接
Summary
模型领导排行榜可能成为恶意实体大规模分发有毒模型的一种强大渠道。研究展示了一种名为TrojanClimb的框架,能在维持领导榜竞争力的同时注入恶意行为。此框架可在不同模态(如文本嵌入、文本生成、文本到语音和文本到图像)中展示其有效性,成功实现恶意功能嵌入同时维持领导榜高排名。该研究揭示了机器学习生态系统中的重大漏洞,突显了设计领导榜评估机制来检测和过滤恶意模型的重要性。此外,该发现也凸显出从非验证来源采纳模型给机器学习社区带来的更广泛的安全风险隐患。
Key Takeaways
点此查看论文截图

DeepGesture: A conversational gesture synthesis system based on emotions and semantics
Authors:Thanh Hoang-Minh
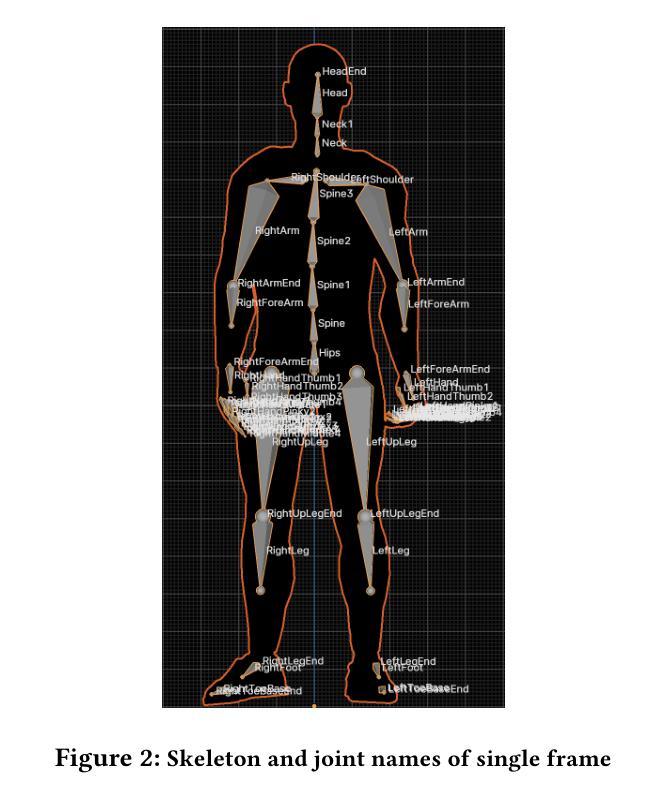
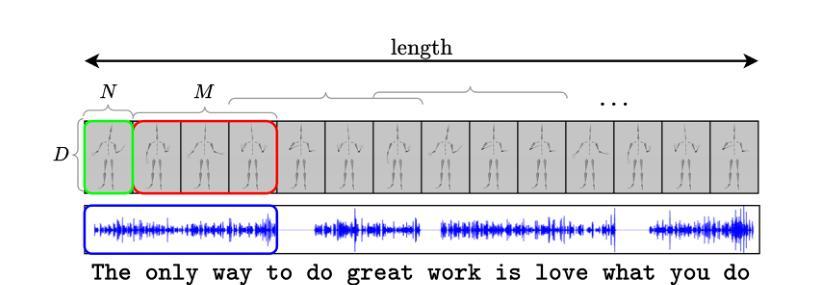
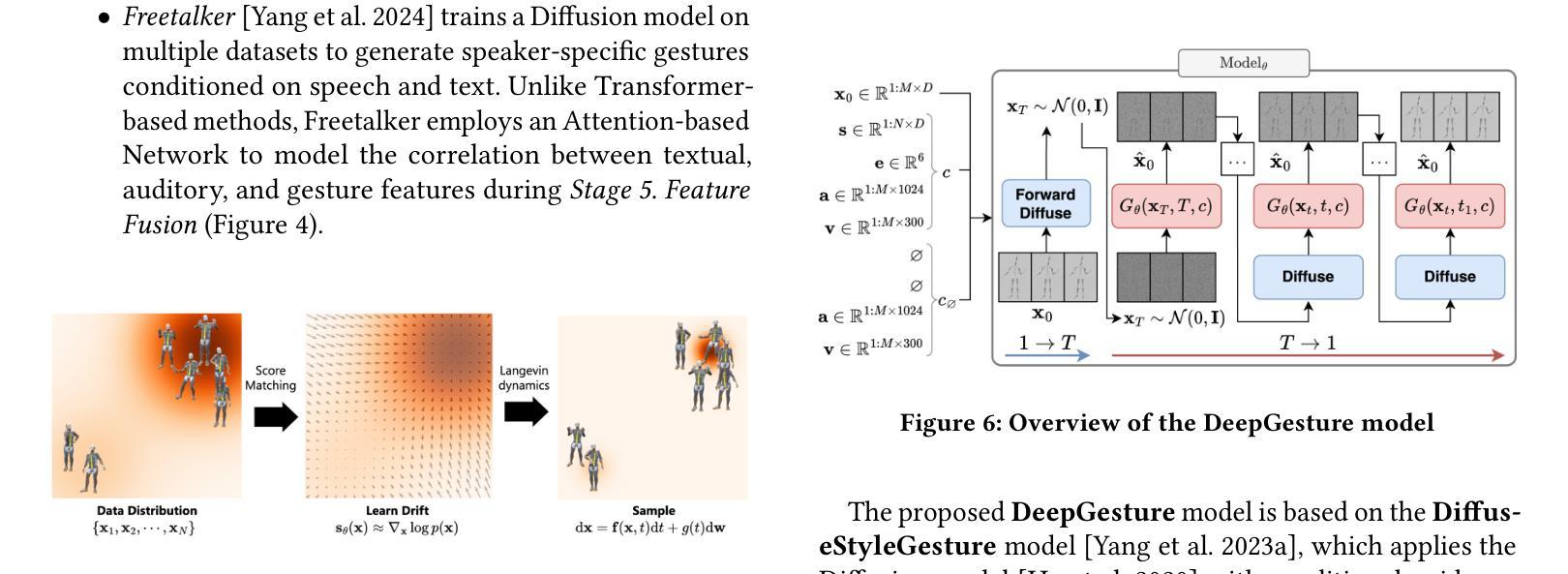
Along with the explosion of large language models, improvements in speech synthesis, advancements in hardware, and the evolution of computer graphics, the current bottleneck in creating digital humans lies in generating character movements that correspond naturally to text or speech inputs. In this work, we present DeepGesture, a diffusion-based gesture synthesis framework for generating expressive co-speech gestures conditioned on multimodal signals - text, speech, emotion, and seed motion. Built upon the DiffuseStyleGesture model, DeepGesture introduces novel architectural enhancements that improve semantic alignment and emotional expressiveness in generated gestures. Specifically, we integrate fast text transcriptions as semantic conditioning and implement emotion-guided classifier-free diffusion to support controllable gesture generation across affective states. To visualize results, we implement a full rendering pipeline in Unity based on BVH output from the model. Evaluation on the ZeroEGGS dataset shows that DeepGesture produces gestures with improved human-likeness and contextual appropriateness. Our system supports interpolation between emotional states and demonstrates generalization to out-of-distribution speech, including synthetic voices - marking a step forward toward fully multimodal, emotionally aware digital humans. Project page: https://deepgesture.github.io
随着大型语言模型的爆发,语音合成的改进,硬件的进展以及计算机图形的演变,当前创建数字人的瓶颈在于生成与文本或语音输入相对应的自然动作。在这项工作中,我们提出了DeepGesture,这是一个基于扩散的手势合成框架,能够根据多模式信号(文本、语音、情感和初始动作)生成表达性强的协同语音手势。DeepGesture建立在DiffuseStyleGesture模型的基础上,引入了新颖的架构改进,提高了语义对齐和生成手势的情感表现力。具体来说,我们将快速文本转录作为语义条件,并实现无分类器扩散的情感引导,以支持情感状态下可控的手势生成。为了可视化结果,我们在Unity中实现了基于模型BVH输出的完整渲染管道。在ZeroEGGS数据集上的评估表明,DeepGesture生成的手势具有更高的人脸相似性和上下文恰当性。我们的系统支持情感状态之间的插值,并展示了对分布外语音的泛化能力,包括合成语音,这标志着朝着完全多模式、情感感知的数字人迈出了重要的一步。项目页面:https://deepgesture.github.io
论文及项目相关链接
PDF Project page: https://deepgesture.github.io
Summary
DeepGesture框架用于基于多模态信号(文本、语音、情感和种子动作)生成表达性共语手势。该框架在DiffuseStyleGesture模型的基础上进行了架构增强,提高了语义对齐和情绪表达的准确性。通过快速文本转录作为语义条件,并结合情感引导的无分类扩散,支持情感状态下的可控手势生成。在Unity中实现全渲染管道,基于模型的BVH输出可视化结果。在ZeroEGGS数据集上的评估显示,DeepGesture生成的手势更具人类性和上下文适当性,支持情感状态之间的插值,并对离散语音表现出泛化能力,标志着向全模态、情绪感知的数字人类研究迈出了一步。
Key Takeaways
- DeepGesture是一个基于扩散模型的框架,用于生成与文本或语音输入相对应的自然手势。
- 该框架集成了多模态信号,包括文本、语音、情感和种子动作,以生成表达性手势。
- DeepGesture在语义对齐和情绪表达方面进行了改进,通过整合快速文本转录和情绪引导机制实现。
- 框架支持在情感状态之间进行插值,并展现出对离群语音的泛化能力。
- 该框架的实现包括一个基于Unity的全渲染管道,用于可视化生成的手势。
- 在ZeroEGGS数据集上的评估证明了DeepGesture的有效性,生成的手势更具人类性和上下文适当性。
- DeepGesture的研究标志着向全模态、情绪感知的数字人类研究迈出了重要一步。
点此查看论文截图