⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-17 更新
M2DAO-Talker: Harmonizing Multi-granular Motion Decoupling and Alternating Optimization for Talking-head Generation
Authors:Kui Jiang, Shiyu Liu, Junjun Jiang, Xin Yang, Hongxun Yao, Xiaopeng Fan
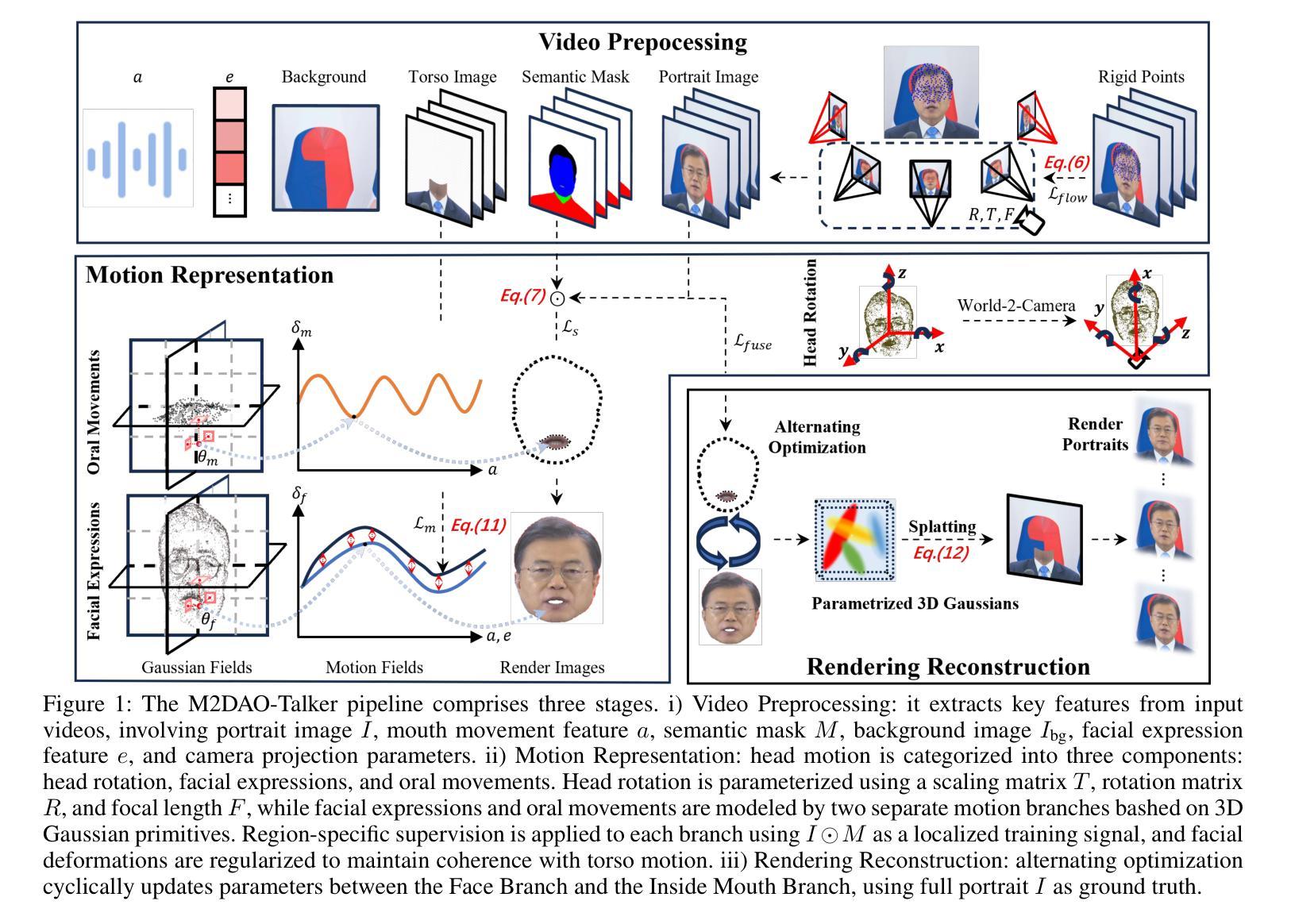
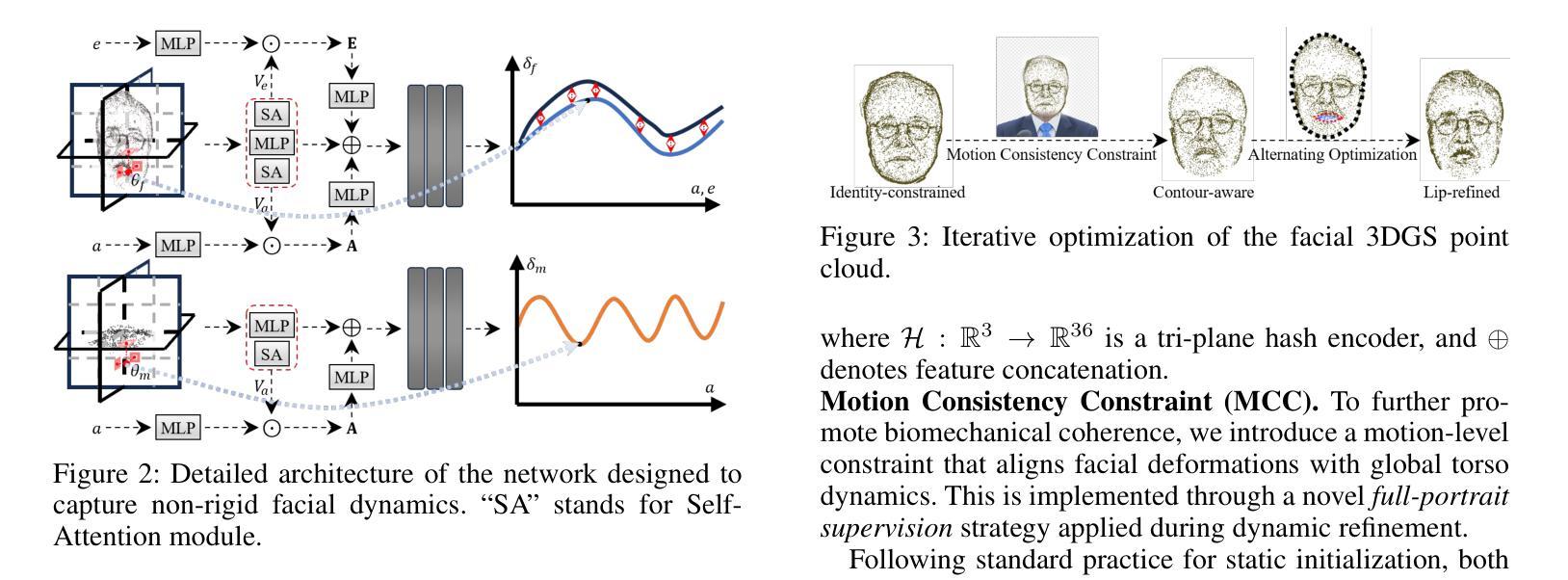
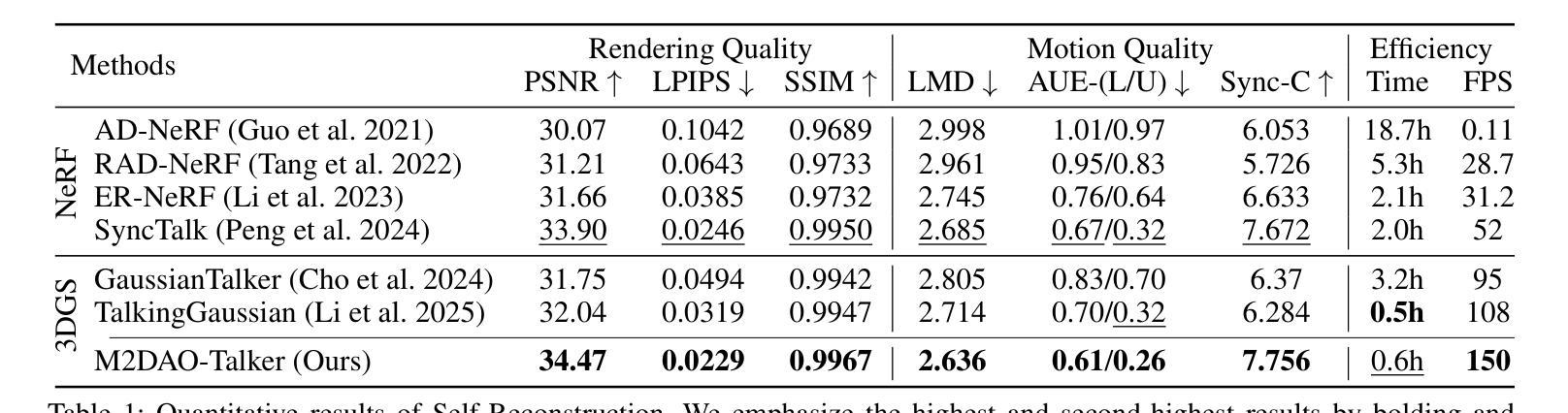
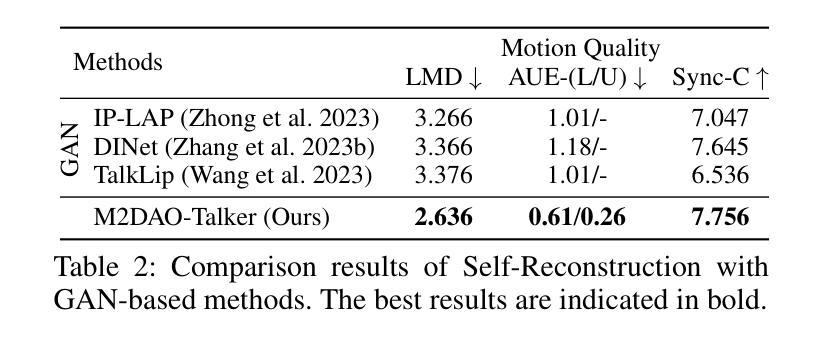
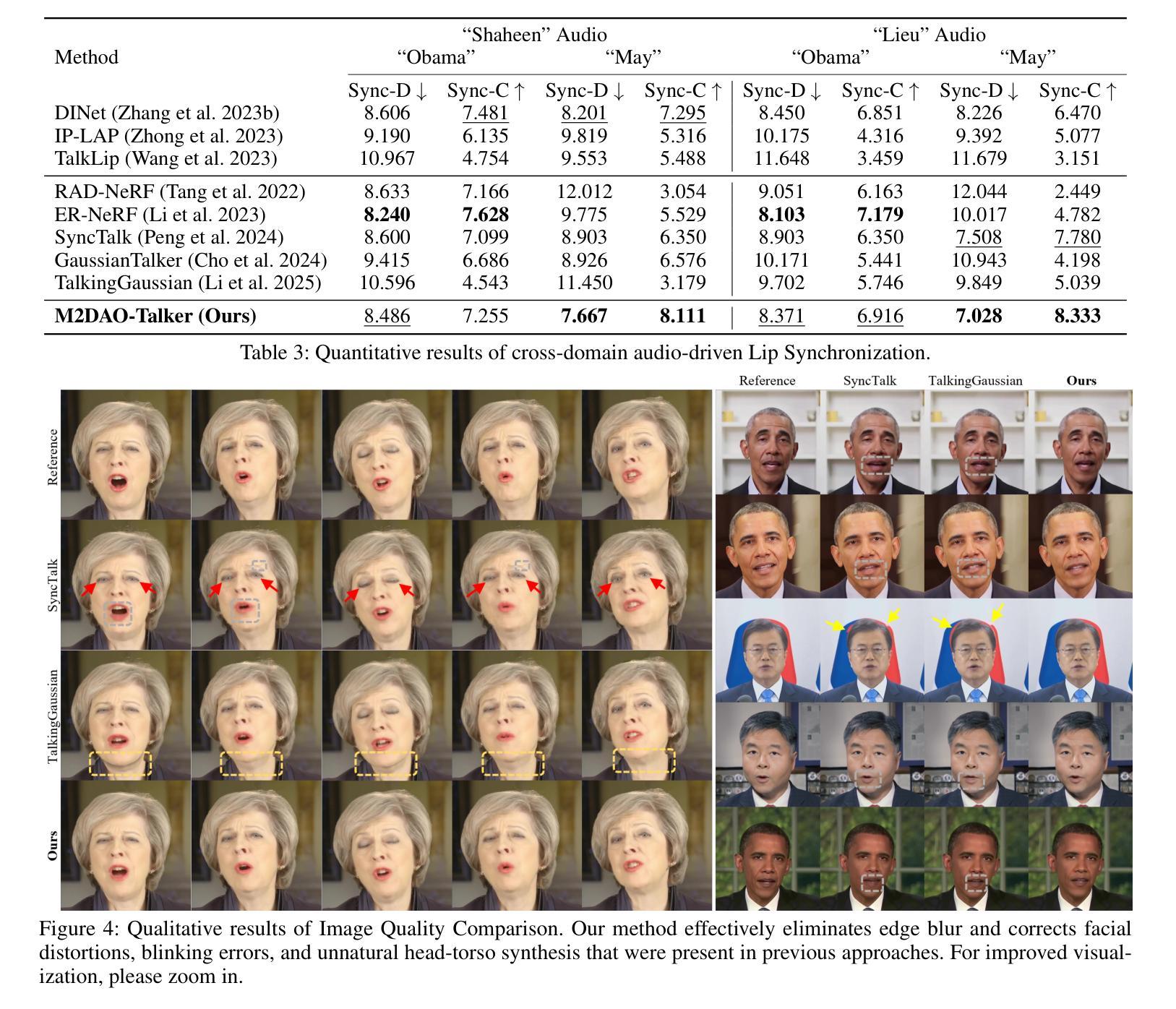
Audio-driven talking head generation holds significant potential for film production. While existing 3D methods have advanced motion modeling and content synthesis, they often produce rendering artifacts, such as motion blur, temporal jitter, and local penetration, due to limitations in representing stable, fine-grained motion fields. Through systematic analysis, we reformulate talking head generation into a unified framework comprising three steps: video preprocessing, motion representation, and rendering reconstruction. This framework underpins our proposed M2DAO-Talker, which addresses current limitations via multi-granular motion decoupling and alternating optimization. Specifically, we devise a novel 2D portrait preprocessing pipeline to extract frame-wise deformation control conditions (motion region segmentation masks, and camera parameters) to facilitate motion representation. To ameliorate motion modeling, we elaborate a multi-granular motion decoupling strategy, which independently models non-rigid (oral and facial) and rigid (head) motions for improved reconstruction accuracy. Meanwhile, a motion consistency constraint is developed to ensure head-torso kinematic consistency, thereby mitigating penetration artifacts caused by motion aliasing. In addition, an alternating optimization strategy is designed to iteratively refine facial and oral motion parameters, enabling more realistic video generation. Experiments across multiple datasets show that M2DAO-Talker achieves state-of-the-art performance, with the 2.43 dB PSNR improvement in generation quality and 0.64 gain in user-evaluated video realness versus TalkingGaussian while with 150 FPS inference speed. Our project homepage is https://m2dao-talker.github.io/M2DAO-Talk.github.io.
音频驱动的谈话头生成在电影制作中具有显著潜力。尽管现有的3D方法在动作建模和内容合成方面取得了进展,但由于在表示稳定、精细动作场方面的局限性,它们经常产生渲染伪影,如运动模糊、时间抖动和局部穿透。通过系统分析,我们将谈话头生成重新制定为一个包含三个步骤的统一框架:视频预处理、运动表示和渲染重建。这一框架支撑了我们提出的M2DAO-Talker,它通过多粒度运动解耦和交替优化解决当前限制。具体来说,我们设计了一种新型的2D肖像预处理管道,用于提取帧级变形控制条件(运动区域分割掩模和相机参数),以促进运动表示。为了改善运动建模,我们提出了一种多粒度运动解耦策略,该策略独立地对面部非刚性(口腔和面部)和刚性(头部)运动进行建模,以提高重建精度。同时,开发了一种运动一致性约束,以确保头部与躯干的运动学一致性,从而减轻由运动混叠引起的穿透伪影。此外,设计了一种交替优化策略,通过迭代优化面部和口腔运动参数,以实现更逼真的视频生成。在多个数据集上的实验表明,M2DAO-Talker达到了领先水平,生成质量的峰值信噪比(PSNR)提高了2.43 dB,用户评估的视频真实感增加了0.64,同时推理速度为每秒150帧。我们的项目主页是https://m2dao-talker.github.io/M2DAO-Talk.github.io。
论文及项目相关链接
Summary
本文探讨了音频驱动的说话人头部生成技术在电影制作中的潜力。针对现有3D方法在动作建模和内容合成方面的不足,提出一个统一的框架M2DAO-Talker,包括视频预处理、动作表示和渲染重建三个步骤。M2DAO-Talker通过多粒度动作解耦和交替优化解决现有问题,提出一种新型的2D肖像预处理管道,提取帧级变形控制条件,改善动作建模,并开发运动一致性约束以确保头部与躯干的运动协调性,减少穿透伪影。实验证明,M2DAO-Talker在多个数据集上实现最佳性能,生成质量提高2.43 dB PSNR,用户评价视频真实感增加0.64,同时推理速度达到150 FPS。
Key Takeaways
- 音频驱动的说话人头部生成技术在电影制作中具有显著潜力。
- 现有3D方法在动作建模和内容合成方面存在渲染伪影的问题。
- M2DAO-Talker是一个统一的框架,包括视频预处理、动作表示和渲染重建三个步骤。
- M2DAO-Talker通过多粒度动作解耦独立建模非刚性(口部和面部)和刚性(头部)动作,提高重建精度。
- 运动一致性约束确保头部与躯干的运动协调性,减少穿透伪影。
- 交替优化策略迭代优化面部和口部运动参数,实现更真实的视频生成。
点此查看论文截图

Model See Model Do: Speech-Driven Facial Animation with Style Control
Authors:Yifang Pan, Karan Singh, Luiz Gustavo Hafemann
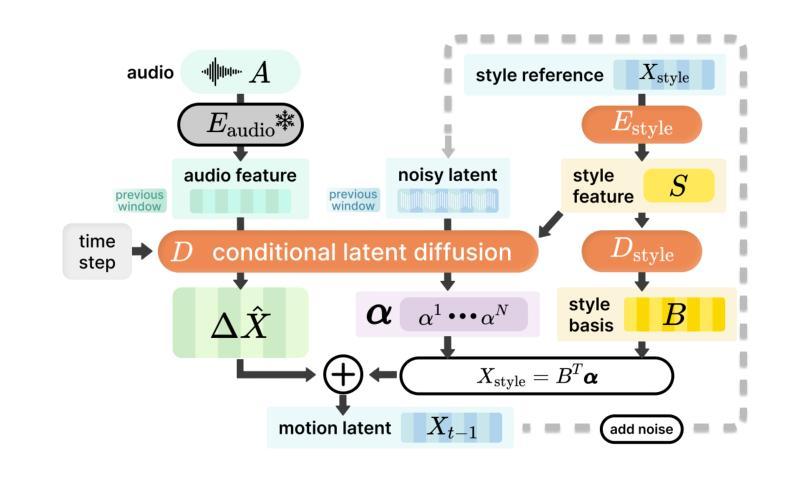
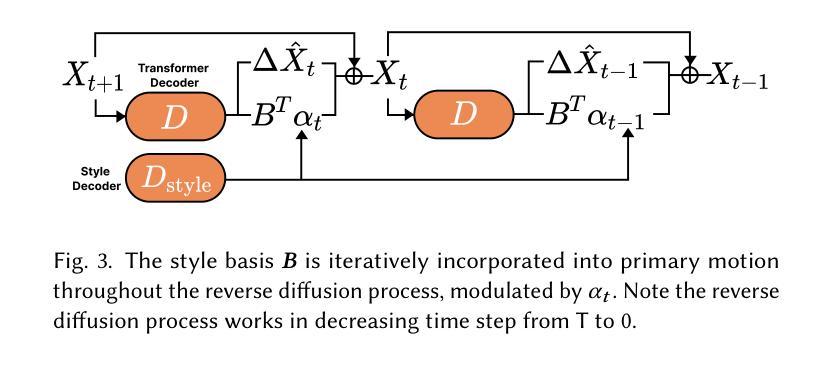
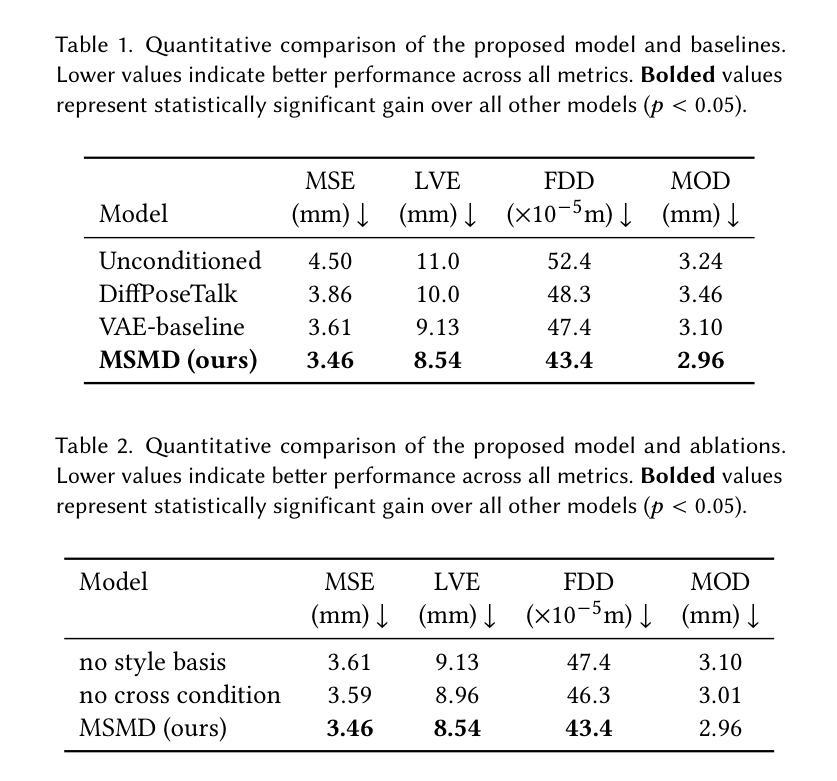
Speech-driven 3D facial animation plays a key role in applications such as virtual avatars, gaming, and digital content creation. While existing methods have made significant progress in achieving accurate lip synchronization and generating basic emotional expressions, they often struggle to capture and effectively transfer nuanced performance styles. We propose a novel example-based generation framework that conditions a latent diffusion model on a reference style clip to produce highly expressive and temporally coherent facial animations. To address the challenge of accurately adhering to the style reference, we introduce a novel conditioning mechanism called style basis, which extracts key poses from the reference and additively guides the diffusion generation process to fit the style without compromising lip synchronization quality. This approach enables the model to capture subtle stylistic cues while ensuring that the generated animations align closely with the input speech. Extensive qualitative, quantitative, and perceptual evaluations demonstrate the effectiveness of our method in faithfully reproducing the desired style while achieving superior lip synchronization across various speech scenarios.
语音驱动的3D面部动画在虚拟角色、游戏和数字内容创作等应用中发挥着关键作用。尽管现有方法在实现准确的唇同步和生成基本情感表达方面取得了显著进展,但它们往往难以捕捉并有效转移微妙的表演风格。我们提出了一种基于实例的生成框架,该框架以一个参考风格片段为条件,训练潜在扩散模型来生成高度表达且时间连贯的面部动画。为解决准确遵循风格参考的挑战,我们引入了一种新型调节机制,称为风格基础,它从参考中提取关键姿势,并增量式地指导扩散生成过程,以适应风格而不损害唇同步质量。这种方法使模型能够捕捉微妙的风格线索,同时确保生成的动画与输入语音紧密对齐。广泛的定性、定量和感知评估表明,我们的方法在忠实再现所需风格的同时,在各种语音场景中实现了卓越的唇同步效果。
论文及项目相关链接
PDF 10 pages, 7 figures, SIGGRAPH Conference Papers ‘25
摘要
基于语音驱动的3D面部动画在虚拟角色、游戏和数字内容创作等领域扮演着重要角色。现有方法在准确唇同步和基本情感表达方面取得了显著进展,但在捕捉和有效转移微妙的表演风格方面仍存在挑战。本研究提出了一种基于范例的生成框架,该框架以参考风格片段为条件,通过潜在扩散模型生成高度表达且时间连贯的面部动画。为解决准确遵循风格参考的挑战,我们引入了一种名为“风格基础”的新型调节机制,该机制从参考中提取关键姿势,并通过扩散生成过程进行附加指导,从而在不影响唇同步质量的情况下适应风格。这种方法使模型能够捕捉微妙的风格线索,同时确保生成的动画与输入语音紧密对齐。广泛的质量、数量和感知评估表明,我们的方法能够在各种语音场景中忠实再现所需风格,同时实现卓越的唇同步效果。
关键见解
- 现有方法在语音驱动的3D面部动画中虽然能实现准确的唇同步和基本情感表达,但在捕捉和转移微妙的表演风格方面存在挑战。
- 提出了一种基于范例的生成框架,通过潜在扩散模型以参考风格片段为条件,生成高度表达且时间连贯的面部动画。
- 引入了一种名为“风格基础”的新型调节机制,能从参考中提取关键姿势,并引导扩散生成过程以贴合风格,同时保持唇同步质量。
- 该方法能够捕捉微妙的风格线索,确保生成的动画与输入语音对齐。
- 通过质量、数量和感知评估,证明该方法在忠实再现所需风格和实现卓越唇同步效果方面的有效性。
- 该方法在多种语音场景中表现优越,如虚拟角色、游戏和数字内容创作等。
- 提出的框架和机制为创建更自然、更丰富的语音驱动3D面部动画提供了新的可能性。
点此查看论文截图

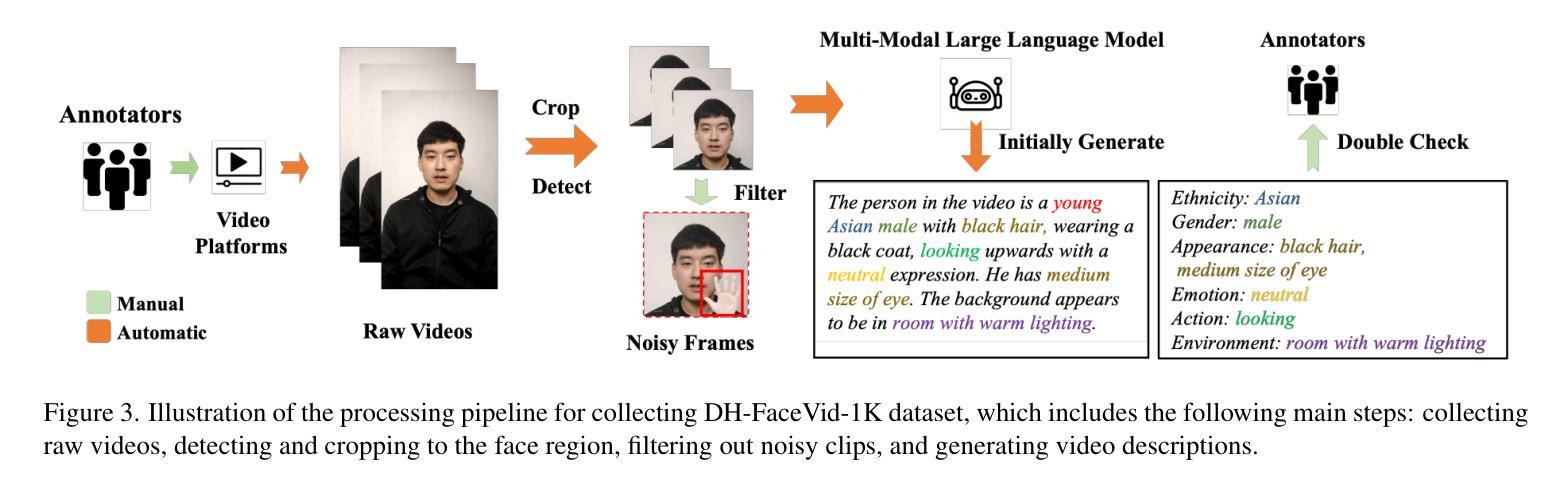
DH-FaceVid-1K: A Large-Scale High-Quality Dataset for Face Video Generation
Authors:Donglin Di, He Feng, Wenzhang Sun, Yongjia Ma, Hao Li, Wei Chen, Lei Fan, Tonghua Su, Xun Yang
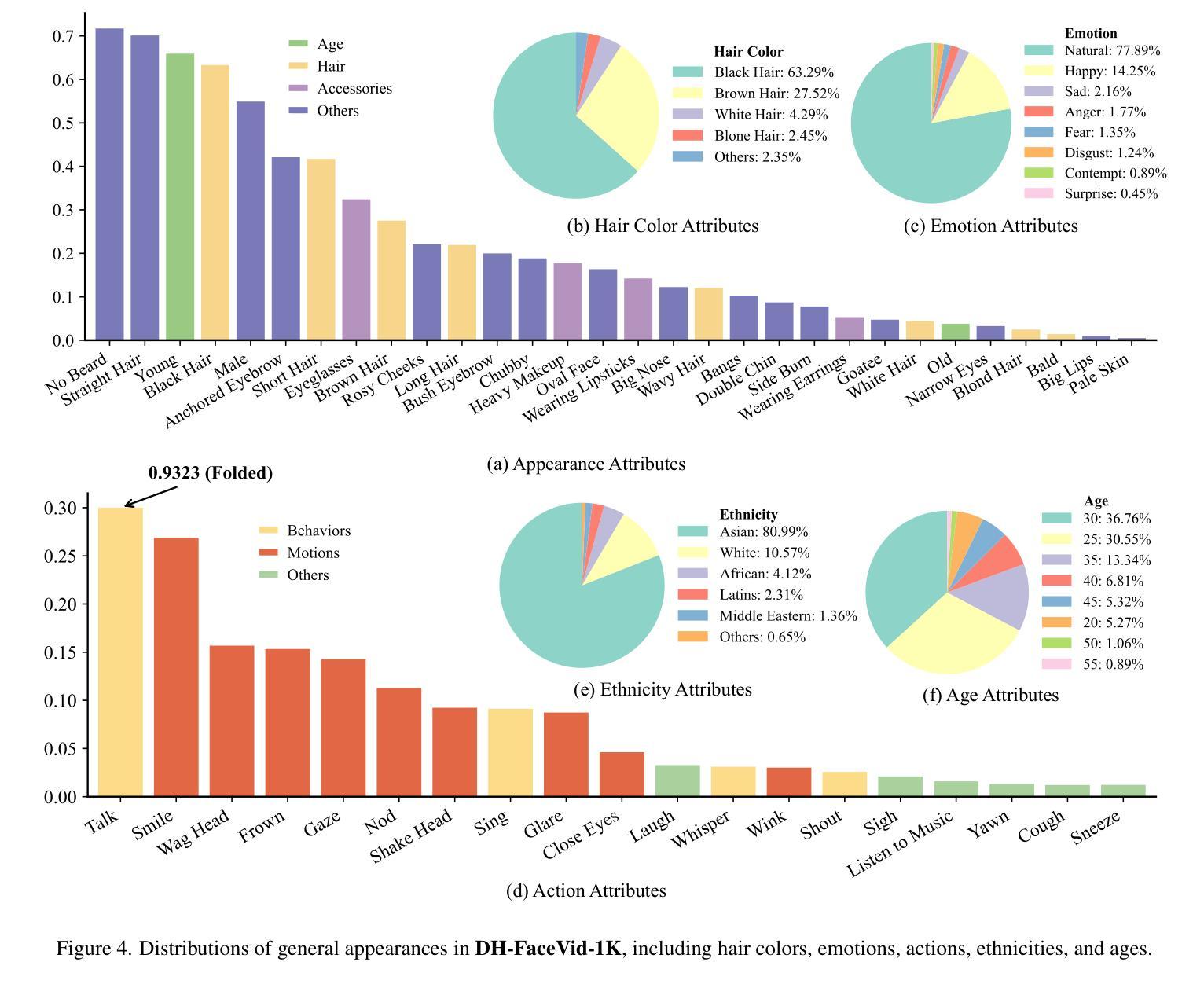
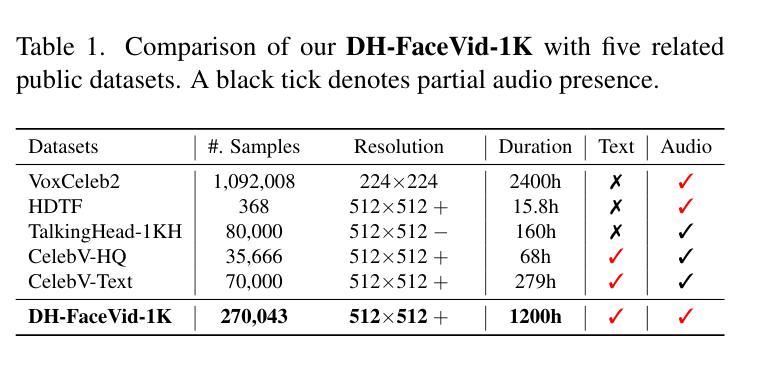
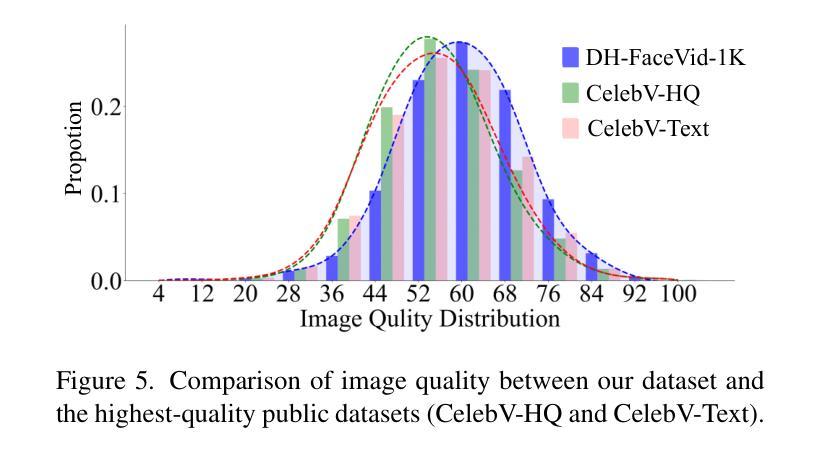
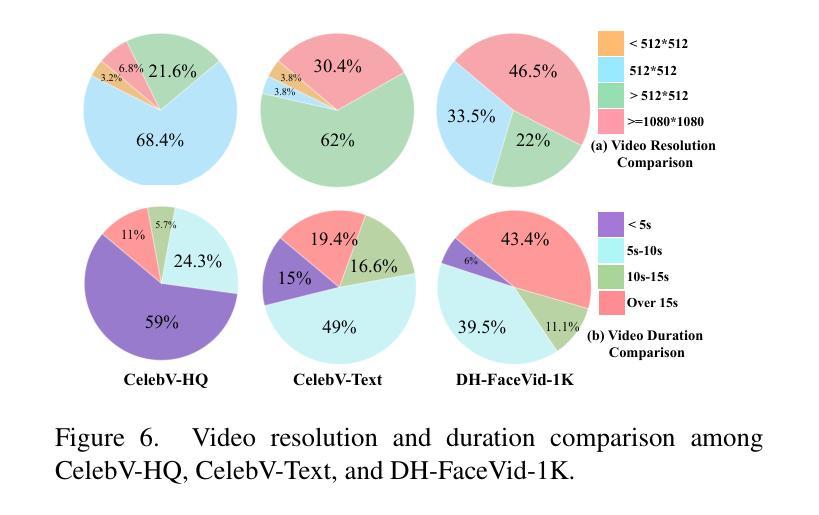
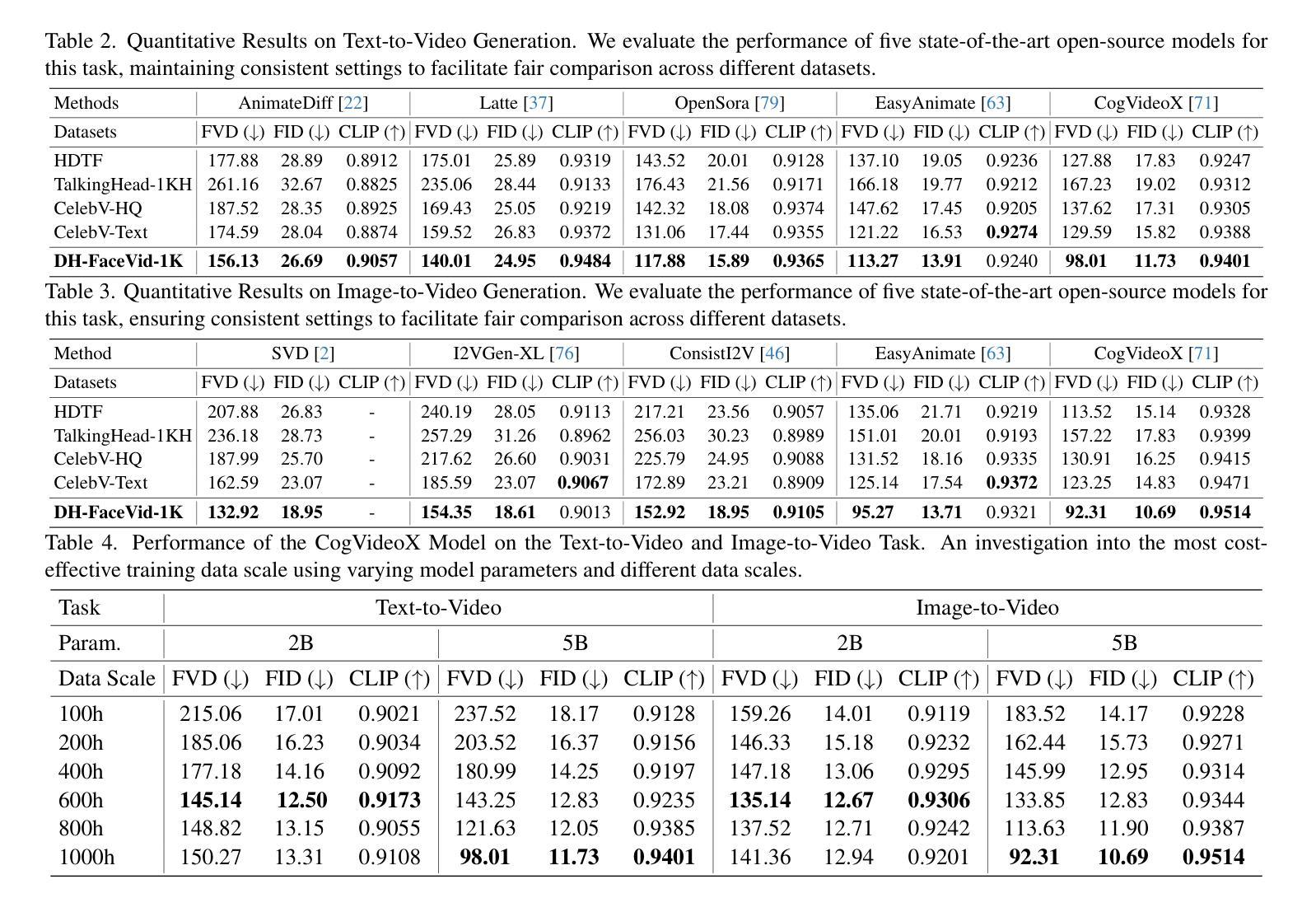
Human-centric generative models are becoming increasingly popular, giving rise to various innovative tools and applications, such as talking face videos conditioned on text or audio prompts. The core of these capabilities lies in powerful pre-trained foundation models, trained on large-scale, high-quality datasets. However, many advanced methods rely on in-house data subject to various constraints, and other current studies fail to generate high-resolution face videos, which is mainly attributed to the significant lack of large-scale, high-quality face video datasets. In this paper, we introduce a human face video dataset, \textbf{DH-FaceVid-1K}. Our collection spans 1,200 hours in total, encompassing 270,043 video clips from over 20,000 individuals. Each sample includes corresponding speech audio, facial keypoints, and text annotations. Compared to other publicly available datasets, ours distinguishes itself through its multi-ethnic coverage and high-quality, comprehensive individual attributes. We establish multiple face video generation models supporting tasks such as text-to-video and image-to-video generation. In addition, we develop comprehensive benchmarks to validate the scaling law when using different proportions of proposed dataset. Our primary aim is to contribute a face video dataset, particularly addressing the underrepresentation of Asian faces in existing curated datasets and thereby enriching the global spectrum of face-centric data and mitigating demographic biases. \textbf{Project Page:} https://luna-ai-lab.github.io/DH-FaceVid-1K/
以人类为中心的生成模型越来越受欢迎,催生了各种创新工具和应用,如根据文本或音频提示生成对话面部视频。这些功能的核心在于在大型高质量数据集上训练的强大预训练基础模型。然而,许多先进的方法依赖于受各种约束的内部数据,其他当前的研究无法生成高分辨率的面部视频,这主要归因于缺乏大规模高质量面部视频数据集。在本文中,我们介绍了一个人脸视频数据集“DH-FaceVid-1K”。我们的收藏品总共跨越1200小时,包含来自超过20000个人的270043个视频片段。每个样本包括相应的语音音频、面部关键点文本注释。与其他公开数据集相比,我们的数据集通过其多民族覆盖和高质量、全面的个人属性而与众不同。我们建立了支持文本到视频和图像到视频生成等任务的多个人脸视频生成模型。此外,我们开发了全面的基准测试,以验证使用不同比例所提议数据集时的规模定律。我们的主要目标是提供一个人脸视频数据集,特别是解决现有精选数据集中亚洲人脸的代表不足问题,从而丰富以面部为中心的数据的全球光谱并缓解人口统计偏见。项目页面:https://luna-ai-lab.github.io/DH-FaceVid-1K/
论文及项目相关链接
Summary
本文介绍了一种新型的人脸视频数据集DH-FaceVid-1K,包含超过2万人的27万多个视频剪辑,总时长1200小时。数据集包含对应的语音音频、面部关键点以及文本注释,具有多民族覆盖和高质量个体属性。文章建立了多个人脸视频生成模型,支持文本到视频和图像到视频生成等任务,并提供了使用不同比例数据集的基准测试。其主要目标是贡献一个人脸视频数据集,特别是解决现有数据集中亚洲人脸的代表不足问题,从而丰富全球人脸数据,缓解种族偏见。
Key Takeaways
- DH-FaceVid-1K是一个新型的人脸视频数据集,包含大量高质量视频剪辑。
- 数据集具备多民族覆盖和全面的个体属性。
- 数据集包含对应的语音音频、面部关键点以及文本注释。
- 文章建立了多个基于该数据集的人脸视频生成模型。
- 该数据集能解决现有数据集中亚洲人脸代表不足的问题。
- 数据集有助于丰富全球人脸数据并缓解种族偏见。
点此查看论文截图