⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-17 更新
SnapMoGen: Human Motion Generation from Expressive Texts
Authors:Chuan Guo, Inwoo Hwang, Jian Wang, Bing Zhou
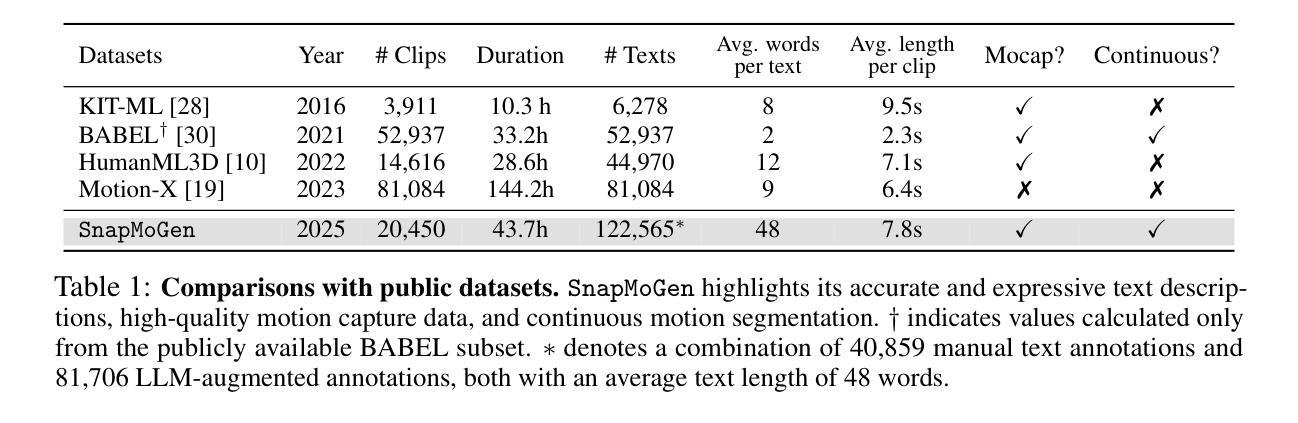
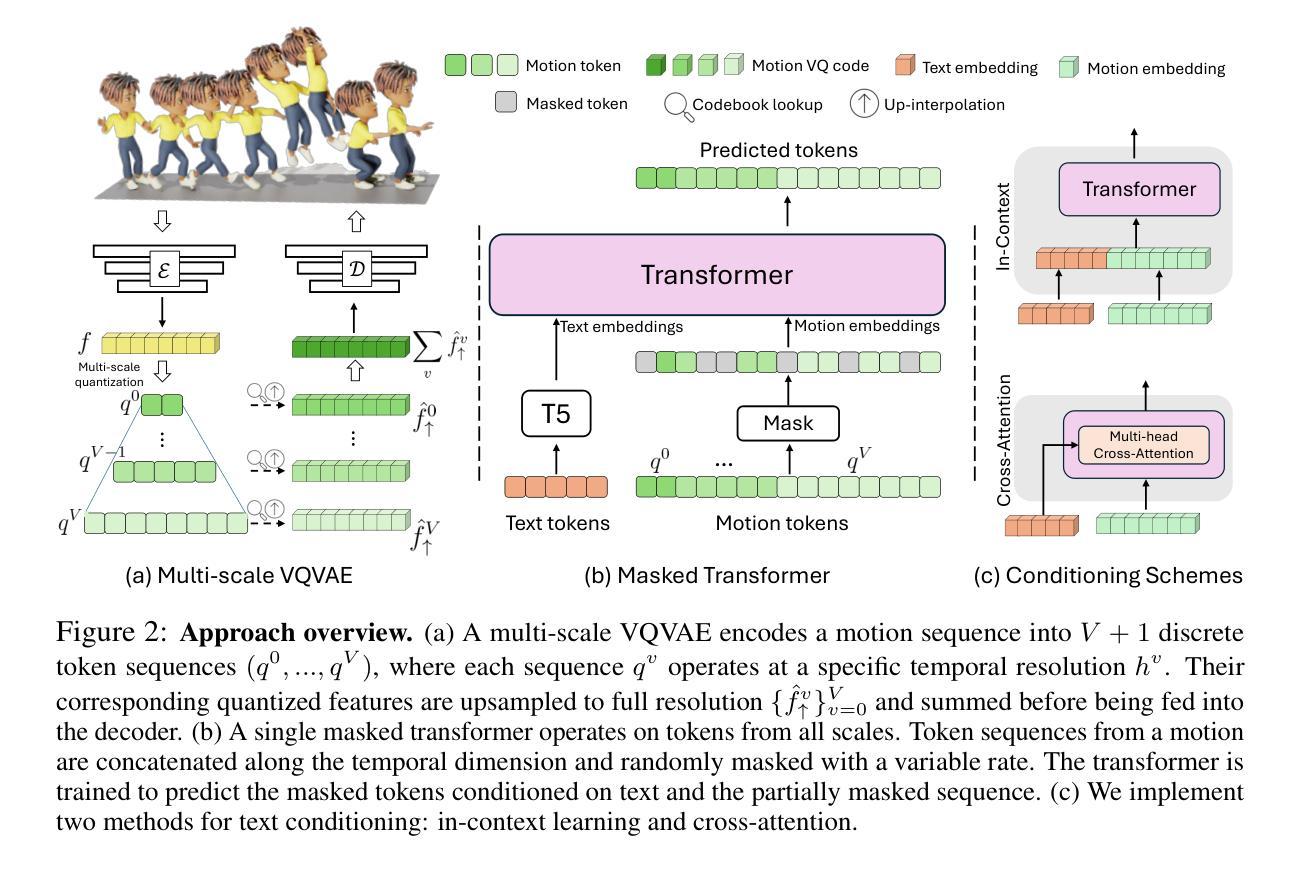
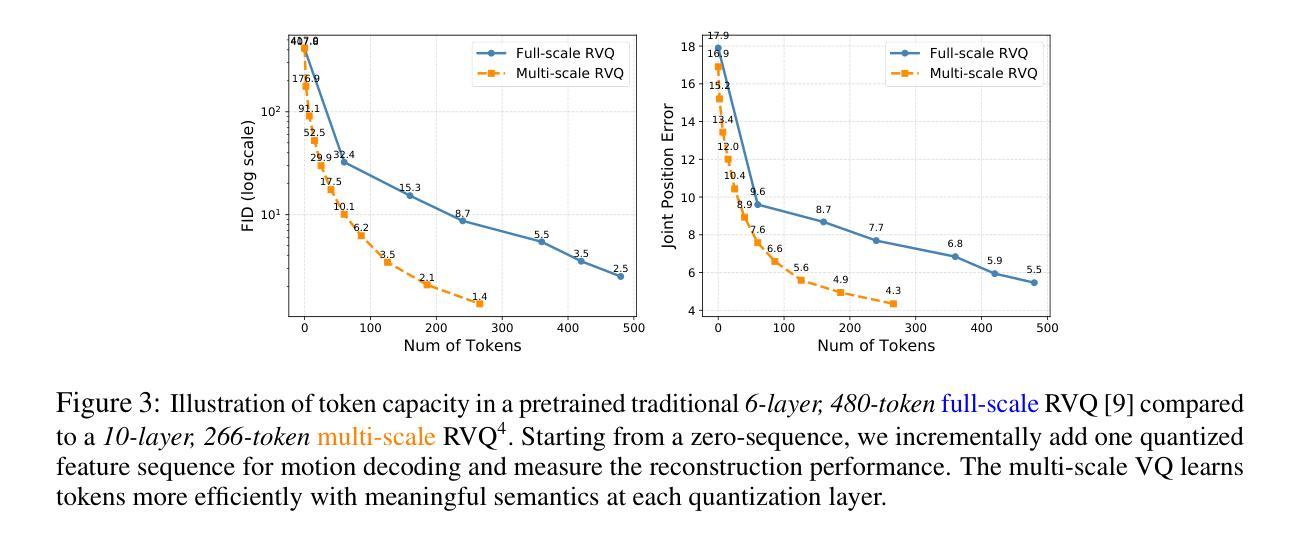
Text-to-motion generation has experienced remarkable progress in recent years. However, current approaches remain limited to synthesizing motion from short or general text prompts, primarily due to dataset constraints. This limitation undermines fine-grained controllability and generalization to unseen prompts. In this paper, we introduce SnapMoGen, a new text-motion dataset featuring high-quality motion capture data paired with accurate, expressive textual annotations. The dataset comprises 20K motion clips totaling 44 hours, accompanied by 122K detailed textual descriptions averaging 48 words per description (vs. 12 words of HumanML3D). Importantly, these motion clips preserve original temporal continuity as they were in long sequences, facilitating research in long-term motion generation and blending. We also improve upon previous generative masked modeling approaches. Our model, MoMask++, transforms motion into multi-scale token sequences that better exploit the token capacity, and learns to generate all tokens using a single generative masked transformer. MoMask++ achieves state-of-the-art performance on both HumanML3D and SnapMoGen benchmarks. Additionally, we demonstrate the ability to process casual user prompts by employing an LLM to reformat inputs to align with the expressivity and narration style of SnapMoGen. Project webpage: https://snap-research.github.io/SnapMoGen/
文本到动作生成技术在近年来取得了显著的进步。然而,当前的方法仍然局限于从简短或通用的文本提示中合成动作,这主要是因为数据集的限制。这种限制影响了对未见提示的精细控制和泛化能力。在本文中,我们介绍了SnapMoGen,一个全新的文本运动数据集,它拥有高质量的运动捕捉数据与准确、生动的文本注释相配对。该数据集包含20,000个运动片段,总时长为44小时,配有12.2万个详细的文本描述,每个描述平均包含48个词(相比之下HumanML3D只有12个词)。重要的是,这些运动片段保留了原始的时间连续性,因为它们来自长序列,有助于长期运动生成和混合的研究。我们还改进了之前的生成式掩模建模方法。我们的模型MoMask++将运动转换为多尺度令牌序列,更好地利用令牌容量,并学习使用单个生成式掩码变压器生成所有令牌。MoMask++在HumanML3D和SnapMoGen基准测试上均达到了最新水平。此外,我们展示了通过使用大型语言模型来处理用户即兴提示的能力,通过重新格式化输入来与SnapMoGen的表达能力和叙述风格保持一致。项目网页链接:https://snap-research.github.io/SnapMoGen/
论文及项目相关链接
PDF Project Webpage: https://snap-research.github.io/SnapMoGen/
Summary
本文介绍了SnapMoGen数据集,该数据集包含高质量的运动捕捉数据与精确、生动的文本注解相配对。数据集包含20K运动片段,总时长为44小时,拥有详细的文本描述,有利于研究长时运动生成和混合。此外,文章还改进了先前的生成式掩模建模方法,MoMask++模型能将运动转化为多尺度标记序列,更好地利用标记容量,并在HumanML3D和SnapMoGen基准测试中取得最佳性能。同时,该模型还能处理用户随机提示,通过大型语言模型将输入重新格式化,以符合SnapMoGen的表达和叙述风格。
Key Takeaways
- SnapMoGen数据集由高质量运动捕捉数据和准确生动的文本注解配对组成,包含详细的文本描述。
- 数据集包含长达44小时的运动片段,有助于研究长时运动生成和混合。
- MoMask++模型可以将运动转化为多尺度标记序列,并展示出色的性能。
- MoMask++模型能够处理用户的随机提示并将其融入生成的运动中。
- 通过大型语言模型对输入进行重新格式化,提高模型表达力并适应SnapMoGen的叙述风格。
- SnapMoGen数据集的公开访问网址为https://snap-research.github.io/SnapMoGen/。
点此查看论文截图