⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-07-17 更新
Comparative Analysis of Vision Transformers and Traditional Deep Learning Approaches for Automated Pneumonia Detection in Chest X-Rays
Authors:Gaurav Singh
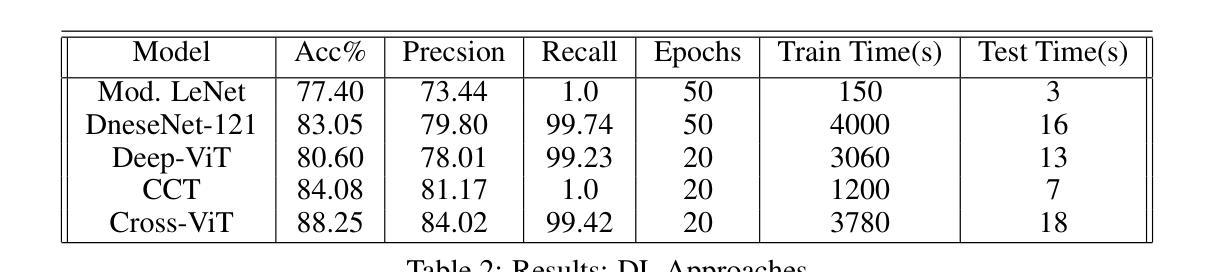
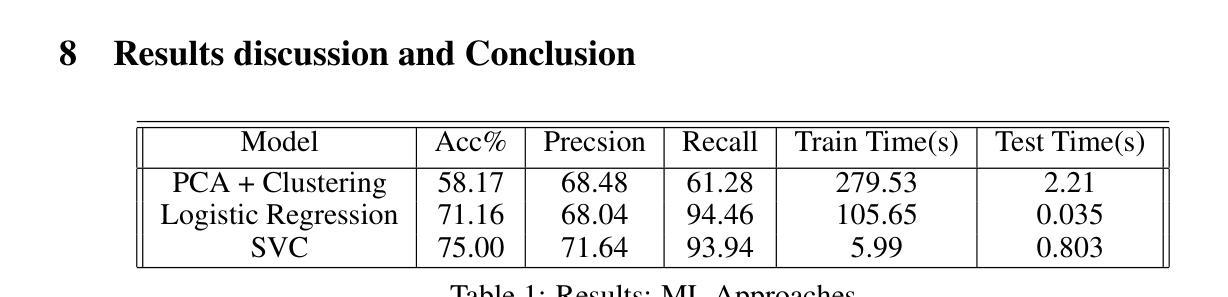
Pneumonia, particularly when induced by diseases like COVID-19, remains a critical global health challenge requiring rapid and accurate diagnosis. This study presents a comprehensive comparison of traditional machine learning and state-of-the-art deep learning approaches for automated pneumonia detection using chest X-rays (CXRs). We evaluate multiple methodologies, ranging from conventional machine learning techniques (PCA-based clustering, Logistic Regression, and Support Vector Classification) to advanced deep learning architectures including Convolutional Neural Networks (Modified LeNet, DenseNet-121) and various Vision Transformer (ViT) implementations (Deep-ViT, Compact Convolutional Transformer, and Cross-ViT). Using a dataset of 5,856 pediatric CXR images, we demonstrate that Vision Transformers, particularly the Cross-ViT architecture, achieve superior performance with 88.25% accuracy and 99.42% recall, surpassing traditional CNN approaches. Our analysis reveals that architectural choices impact performance more significantly than model size, with Cross-ViT’s 75M parameters outperforming larger models. The study also addresses practical considerations including computational efficiency, training requirements, and the critical balance between precision and recall in medical diagnostics. Our findings suggest that Vision Transformers offer a promising direction for automated pneumonia detection, potentially enabling more rapid and accurate diagnosis during health crises.
肺炎,特别是由COVID-19等疾病引发的肺炎,仍然是全球一个重要的健康挑战,需要快速而准确的诊断。本研究对传统机器学习和最新深度学习方法进行全面比较,使用胸部X射线(CXRs)进行自动肺炎检测。我们评估了多种方法,包括传统机器学习技术(基于PCA的聚类、逻辑回归和支持向量分类)和先进的深度学习架构,包括卷积神经网络(修改后的LeNet、DenseNet-121)和各种视觉变压器(ViT)实现(Deep-ViT、紧凑卷积变压器和Cross-ViT)。我们使用包含5856张儿童CXR图像的数据集证明,视觉变压器,尤其是Cross-ViT架构,具有卓越的性能,准确率为88.25%,召回率为99.42%,超越了传统的CNN方法。我们的分析表明,与模型大小相比,架构选择对性能的影响更为显著,Cross-ViT的75M参数表现优于较大的模型。该研究还涉及实际考量,包括计算效率、培训要求以及在医学诊断中精度和召回率之间的关键平衡。我们的研究结果表明,视觉变压器在自动肺炎检测方面提供了有前景的方向,可能在健康危机期间实现更快速和准确的诊断。
论文及项目相关链接
Summary
本文研究了传统机器学习与最新深度学习技术在基于胸部X光片的自动化肺炎检测方面的应用对比。研究涵盖了多种方法,包括传统机器学习和先进的深度神经网络架构以及多种视觉转换器(Vision Transformer,ViT)。研究表明,视觉转换器,特别是Cross-ViT架构,表现出卓越性能,准确率高达88.25%,召回率高达99.42%,超越了传统CNN方法。此外,研究还发现模型架构的选择对性能的影响远大于模型大小。这项研究对于实现医疗诊断中的精准和高效有着重要意义,尤其是视觉转换器展现了应对肺炎检测健康危机的潜力。
Key Takeaways
以下是文中涉及的几个关键观点或发现,用简化中文进行列举:
- 自动化肺炎检测是一个重要的全球健康挑战,特别是在COVID-19等疾病的背景下。
- 研究对比了传统机器学习和深度学习方法在基于胸部X光片的肺炎检测方面的表现。
- 视觉转换器(Vision Transformer)方法如Cross-ViT显示出优越性能,准确率较高。
- 模型架构的选择对性能的影响大于模型大小。
- Cross-ViT架构在较小的参数数量(75M)下表现出高性能,超过了较大的模型。
- 研究考虑了计算效率、训练要求等实际问题。
点此查看论文截图

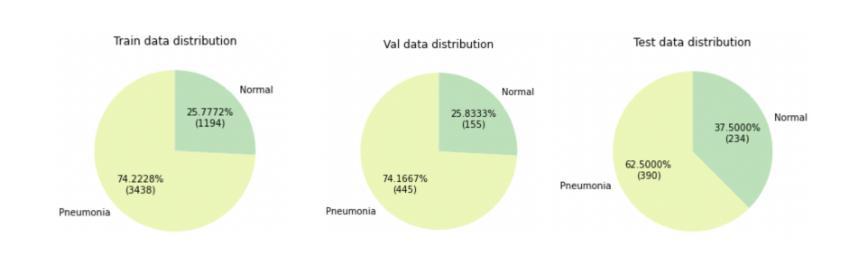
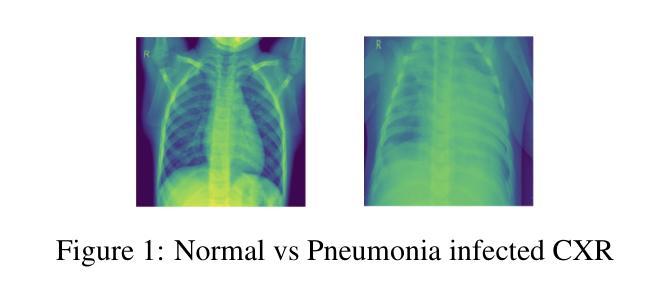
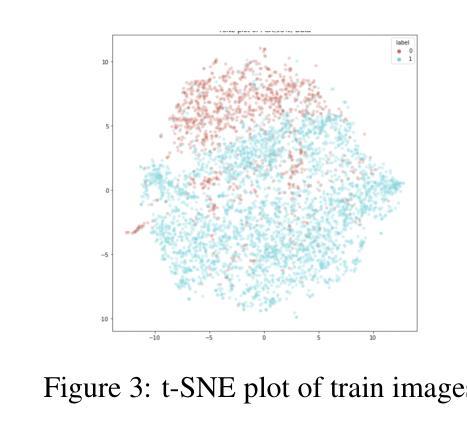

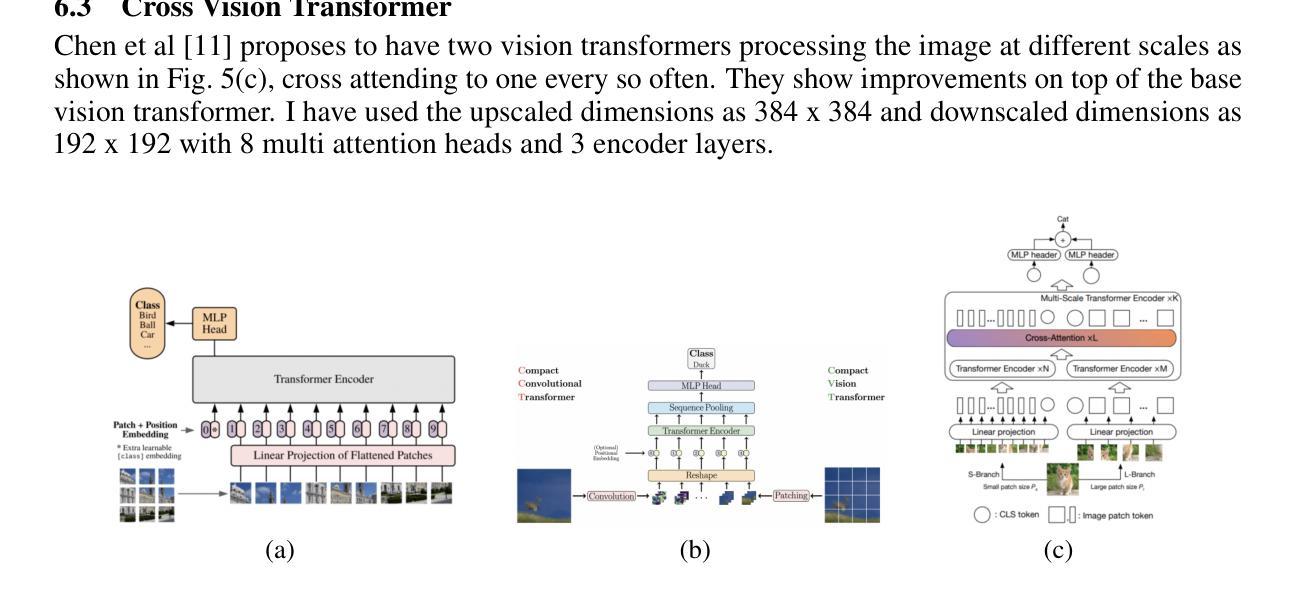
Mind the Gap: Aligning Vision Foundation Models to Image Feature Matching
Authors:Yuhan Liu, Jingwen Fu, Yang Wu, Kangyi Wu, Pengna Li, Jiayi Wu, Sanping Zhou, Jingmin Xin
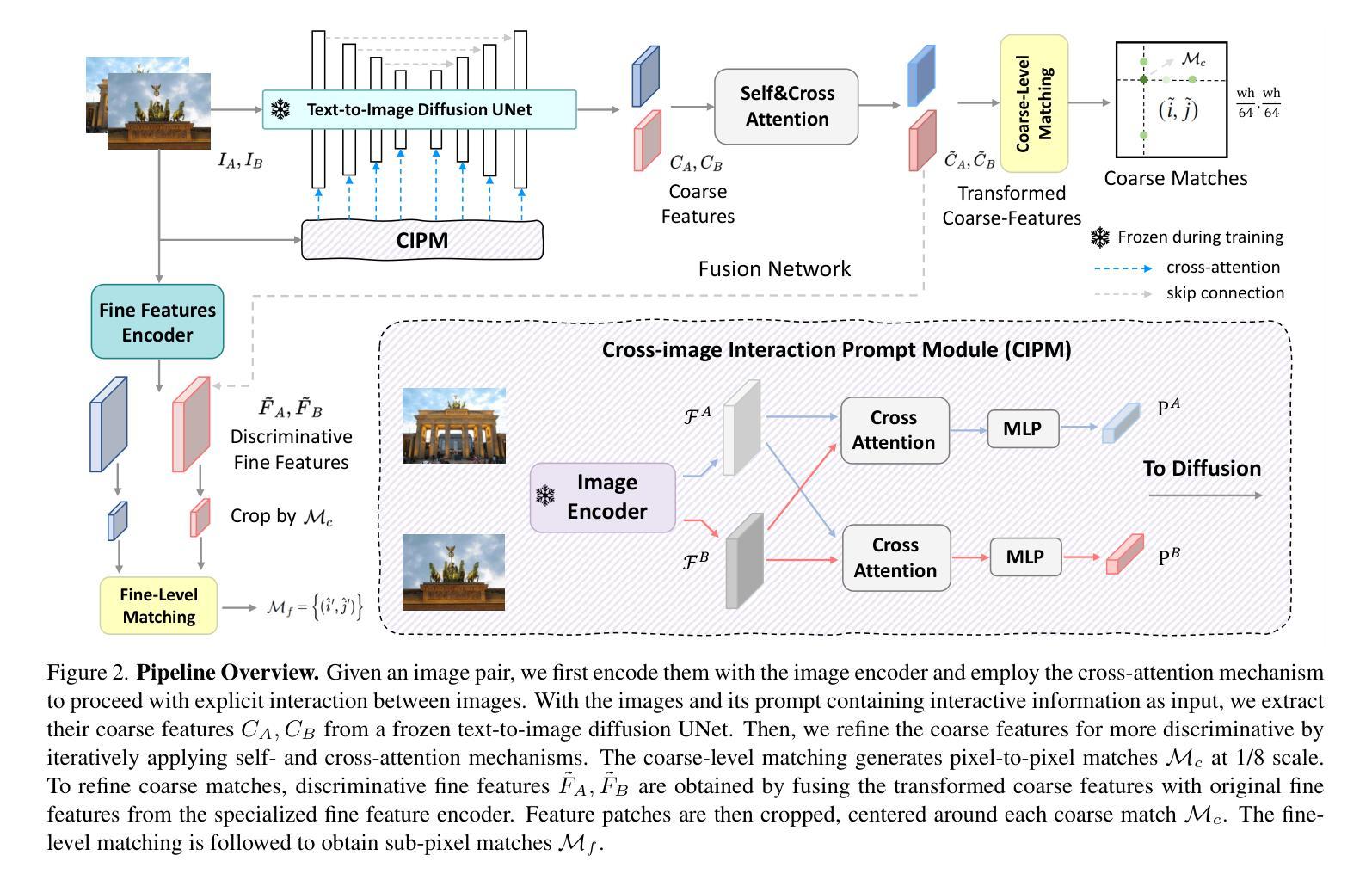
Leveraging the vision foundation models has emerged as a mainstream paradigm that improves the performance of image feature matching. However, previous works have ignored the misalignment when introducing the foundation models into feature matching. The misalignment arises from the discrepancy between the foundation models focusing on single-image understanding and the cross-image understanding requirement of feature matching. Specifically, 1) the embeddings derived from commonly used foundation models exhibit discrepancies with the optimal embeddings required for feature matching; 2) lacking an effective mechanism to leverage the single-image understanding ability into cross-image understanding. A significant consequence of the misalignment is they struggle when addressing multi-instance feature matching problems. To address this, we introduce a simple but effective framework, called IMD (Image feature Matching with a pre-trained Diffusion model) with two parts: 1) Unlike the dominant solutions employing contrastive-learning based foundation models that emphasize global semantics, we integrate the generative-based diffusion models to effectively capture instance-level details. 2) We leverage the prompt mechanism in generative model as a natural tunnel, propose a novel cross-image interaction prompting module to facilitate bidirectional information interaction between image pairs. To more accurately measure the misalignment, we propose a new benchmark called IMIM, which focuses on multi-instance scenarios. Our proposed IMD establishes a new state-of-the-art in commonly evaluated benchmarks, and the superior improvement 12% in IMIM indicates our method efficiently mitigates the misalignment.
利用视觉基础模型提高图像特征匹配的性能已成为主流范式。然而,先前的工作在将基础模型引入特征匹配时忽略了不匹配问题。这种不匹配源于基础模型对单图像理解的关注与特征匹配对跨图像理解的要求之间的差异。具体来说,1)常用基础模型产生的嵌入与用于特征匹配的最佳嵌入之间存在差异;2)缺乏一种有效的机制来利用单图像理解能力来实现跨图像理解。不匹配的一个显著后果是它们在解决多实例特征匹配问题时感到困难。为了解决这一问题,我们引入了一个简单有效的框架,称为IMD(带有预训练扩散模型的图像特征匹配),它包含两部分:1)与采用基于对比学习的基础模型的主流解决方案不同,这些基础模型强调全局语义,我们集成了基于生成扩散模型来有效捕获实例级细节。2)我们利用生成模型中的提示机制作为一个自然通道,提出了一种新型的跨图像交互提示模块,以促进图像对之间的双向信息交互。为了更准确地测量不匹配程度,我们提出了一个新的基准测试IMIM,它专注于多实例场景。我们提出的IMD在常用的基准测试中建立了新的最先进的水平,IMIM的12%的优越改进表明我们的方法有效地缓解了不匹配问题。
论文及项目相关链接
PDF Accepted by ICCV 2025
Summary
在这个文本中,作者介绍了利用预训练扩散模型进行图像特征匹配的新框架IMD。该框架解决了主流解决方案在处理多实例特征匹配问题时存在的局限性,通过引入生成型扩散模型,并结合跨图像交互提示模块,提高了图像特征匹配的准确性。同时,作者提出了一个新的基准测试IMIM,专注于多实例场景,以更准确地衡量不匹配的程度。IMD框架在常见的基准测试中建立了新的最高水平,并且在IMIM上的优异改进表明该方法有效地缓解了不匹配的问题。
Key Takeaways
- 利用预训练扩散模型进行图像特征匹配已成为主流范式。
- 现有方法在处理多实例特征匹配时存在不匹配问题。
- IMD框架通过引入生成型扩散模型解决此问题,强调实例级细节捕捉。
- IMD框架结合跨图像交互提示模块,促进图像对之间的双向信息交互。
- 提出新的基准测试IMIM,专注于多实例场景以衡量不匹配程度。
- IMD框架在基准测试中表现优异,并在IMIM上的改进表明其有效缓解不匹配问题。
点此查看论文截图
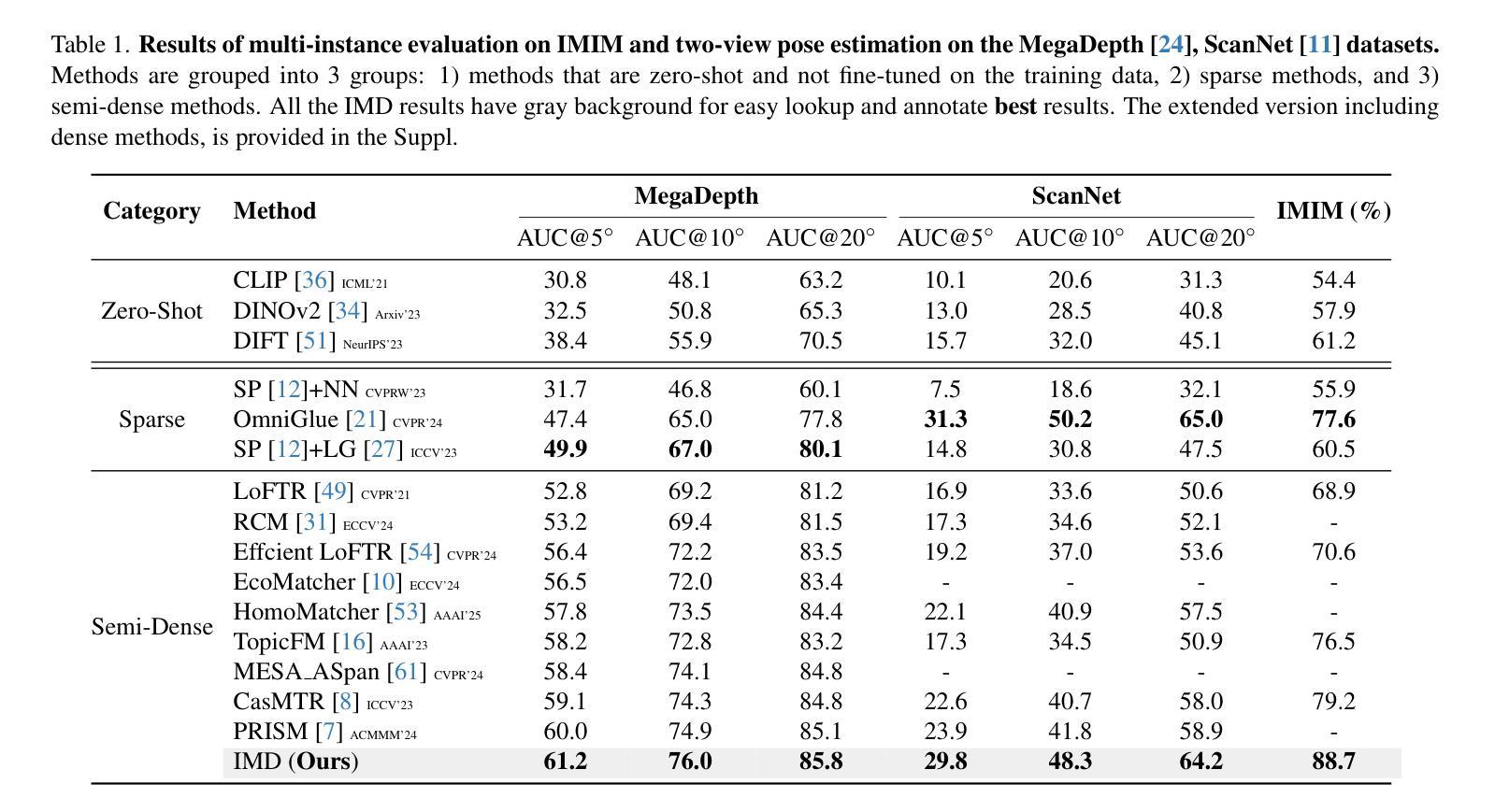
When Schrödinger Bridge Meets Real-World Image Dehazing with Unpaired Training
Authors:Yunwei Lan, Zhigao Cui, Xin Luo, Chang Liu, Nian Wang, Menglin Zhang, Yanzhao Su, Dong Liu
Recent advancements in unpaired dehazing, particularly those using GANs, show promising performance in processing real-world hazy images. However, these methods tend to face limitations due to the generator’s limited transport mapping capability, which hinders the full exploitation of their effectiveness in unpaired training paradigms. To address these challenges, we propose DehazeSB, a novel unpaired dehazing framework based on the Schr"odinger Bridge. By leveraging optimal transport (OT) theory, DehazeSB directly bridges the distributions between hazy and clear images. This enables optimal transport mappings from hazy to clear images in fewer steps, thereby generating high-quality results. To ensure the consistency of structural information and details in the restored images, we introduce detail-preserving regularization, which enforces pixel-level alignment between hazy inputs and dehazed outputs. Furthermore, we propose a novel prompt learning to leverage pre-trained CLIP models in distinguishing hazy images and clear ones, by learning a haze-aware vision-language alignment. Extensive experiments on multiple real-world datasets demonstrate our method’s superiority. Code: https://github.com/ywxjm/DehazeSB.
近期在无配对去雾技术的最新进展,特别是使用生成对抗网络(GANs)的方法,在处理真实世界中的雾霾图像时表现出良好的性能。然而,这些方法往往面临由于生成器的有限传输映射能力而导致的局限性,这阻碍了它们在无配对训练模式中的完全有效性。为了解决这些挑战,我们提出了基于Schrödinger Bridge的去雾SB(DehazeSB)新型无配对去雾框架。通过利用最优传输(OT)理论,DehazeSB直接连接雾霾图像和清晰图像之间的分布。这能够实现从雾霾图像到清晰图像的最优传输映射,并且步骤更少,从而生成高质量的结果。为了确保恢复图像的结构信息的一致性并保留细节,我们引入了细节保留正则化方法,该方法强制雾霾输入和去雾输出之间的像素级对齐。此外,我们提出了一种新型提示学习法,利用预训练的CLIP模型来区分雾霾图像和清晰的图像,通过学习对雾霾有感知的视语言对齐。在多个真实世界数据集上的广泛实验证明了我们方法的优越性。代码地址:https://github.com/ywxjm/DehazeSB。
论文及项目相关链接
PDF Accepted by ICCV2025
Summary
新一代基于GAN的无配对去雾技术取得显著进展,但仍面临生成器传输映射能力有限的挑战。我们提出一种基于Schrödinger Bridge的去雾框架DehazeSB,通过最优传输理论直接桥接雾天和晴朗图像分布,实现高质量去雾效果。此外,我们引入细节保留正则化和提示学习,提高结构信息的一致性和细节保留能力,并利用预训练CLIP模型进行图像清晰度判别。实验证明,该方法在真实数据集上具有优势。
Key Takeaways
- GAN在去雾技术中的应用展现了前景,但仍受生成器映射能力限制。
- DehazeSB框架基于Schrödinger Bridge和最优传输理论,实现雾天和晴朗图像分布的直接桥接。
- DehazeSB能在较少的步骤内完成从雾到晴朗图像的传输映射,生成高质量结果。
- 引入细节保留正则化,确保恢复图像的结构信息和细节一致性。
- 提出一种新的提示学习方法,利用预训练的CLIP模型进行图像清晰度判别。
- 该方法在多个真实数据集上的实验表现优越。
点此查看论文截图


ViT-ProtoNet for Few-Shot Image Classification: A Multi-Benchmark Evaluation
Authors:Abdulvahap Mutlu, Şengül Doğan, Türker Tuncer
The remarkable representational power of Vision Transformers (ViTs) remains underutilized in few-shot image classification. In this work, we introduce ViT-ProtoNet, which integrates a ViT-Small backbone into the Prototypical Network framework. By averaging class conditional token embeddings from a handful of support examples, ViT-ProtoNet constructs robust prototypes that generalize to novel categories under 5-shot settings. We conduct an extensive empirical evaluation on four standard benchmarks: Mini-ImageNet, FC100, CUB-200, and CIFAR-FS, including overlapped support variants to assess robustness. Across all splits, ViT-ProtoNet consistently outperforms CNN-based prototypical counterparts, achieving up to a 3.2% improvement in 5-shot accuracy and demonstrating superior feature separability in latent space. Furthermore, it outperforms or is competitive with transformer-based competitors using a more lightweight backbone. Comprehensive ablations examine the impact of transformer depth, patch size, and fine-tuning strategy. To foster reproducibility, we release code and pretrained weights. Our results establish ViT-ProtoNet as a powerful, flexible approach for few-shot classification and set a new baseline for transformer-based meta-learners.
视觉Transformer(ViT)的表示能力十分强大,但在小样本图像分类中的应用尚未得到充分利用。在此工作中,我们推出了ViT-ProtoNet,它将ViT-Small骨干网集成到原型网络框架中。通过平均少量支持例子的类别条件令牌嵌入,ViT-ProtoNet构建了在5种场景设置下能够推广到新型类别的稳健原型。我们在四个标准数据集上进行了广泛的实证评估:Mini-ImageNet、FC100、CUB-200和CIFAR-FS,包括重叠的支持变体以评估稳健性。在所有拆分中,ViT-ProtoNet始终优于基于CNN的原型对应物,在5次射击的准确度上提高了高达3.2%,并在潜在空间中显示出优越的特征可分离性。此外,使用更轻量级骨干网的基于transformer的竞争对手相比,它具有出色的表现或与之竞争。全面的消融研究检验了transformer深度、补丁大小和微调策略的影响。为了促进可重复性,我们发布了代码和预训练权重。我们的结果确立了ViT-ProtoNet作为小样本分类的强大、灵活的方法,并为基于transformer的元学习者设定了新的基准。
论文及项目相关链接
PDF All codes are available at https://github.com/abdulvahapmutlu/vit-protonet
Summary
ViT-ProtoNet将Vision Transformer(ViT)的强大表示能力与Prototypical Network框架相结合,用于少样本图像分类。通过平均少量支持样本的类别条件令牌嵌入,构建可在新型类别中通用的稳健原型。在多个标准基准测试上的广泛实证评估表明,ViT-ProtoNet在5种场景设置中始终优于基于CNN的原型网络,在准确性方面取得了高达3.2%的提升,并显示出强大的特征分离能力。该研究为基于Vision Transformer的少样本分类建立了强大的灵活方法,并为基于transformer的元学习者设定了新的基准。
Key Takeaways
- ViT-ProtoNet结合了Vision Transformer(ViT)和Prototypical Network框架,展示了强大的表示能力。
- 通过平均少量支持样本的类别条件令牌嵌入,构建了稳健的原型。
- 在多个标准基准测试上,ViT-ProtoNet在少样本图像分类方面表现出优异的性能。
- 与基于CNN的原型网络相比,ViT-ProtoNet在准确性方面有所提高,达到3.2%。
- ViT-ProtoNet在潜在空间中的特征分离能力强大。
- 研究提供了关于transformer深度、补丁大小和微调策略的综合分析。
点此查看论文截图

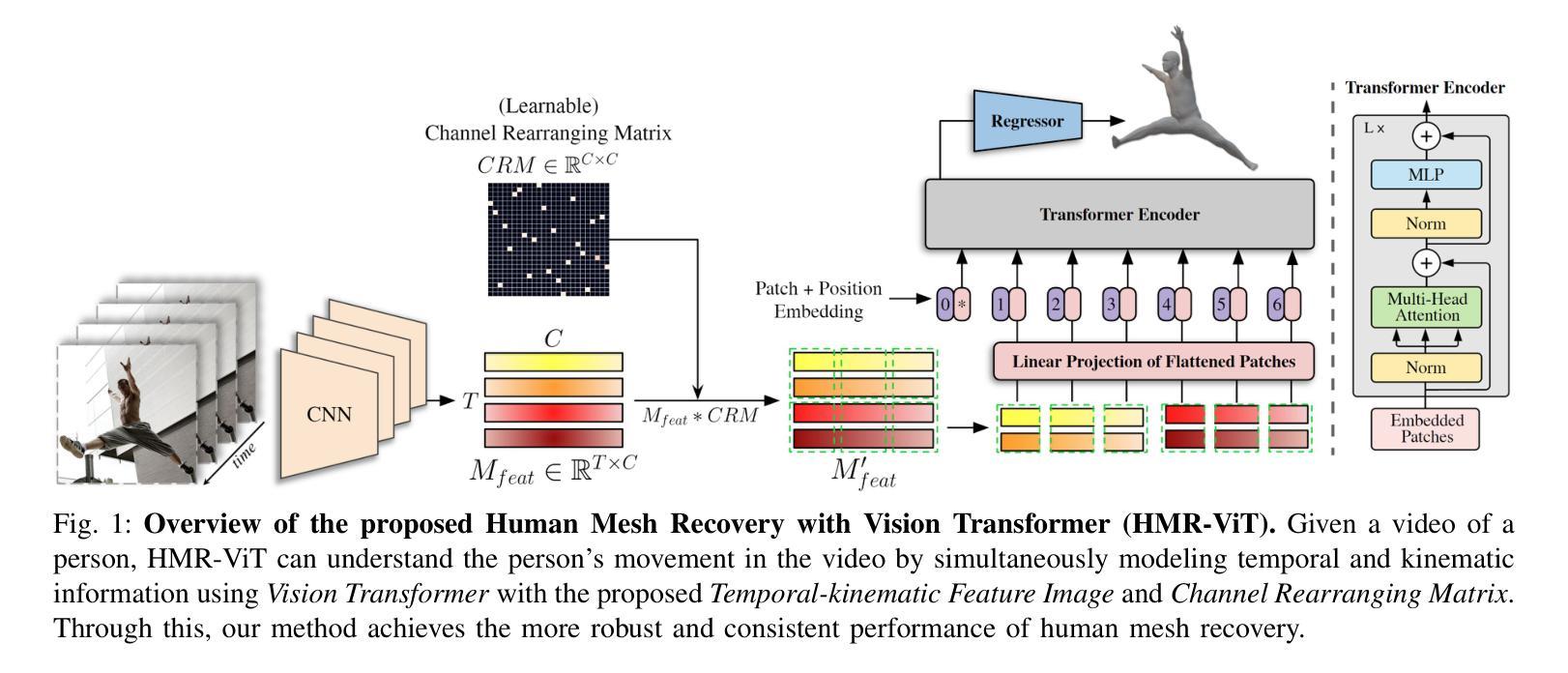
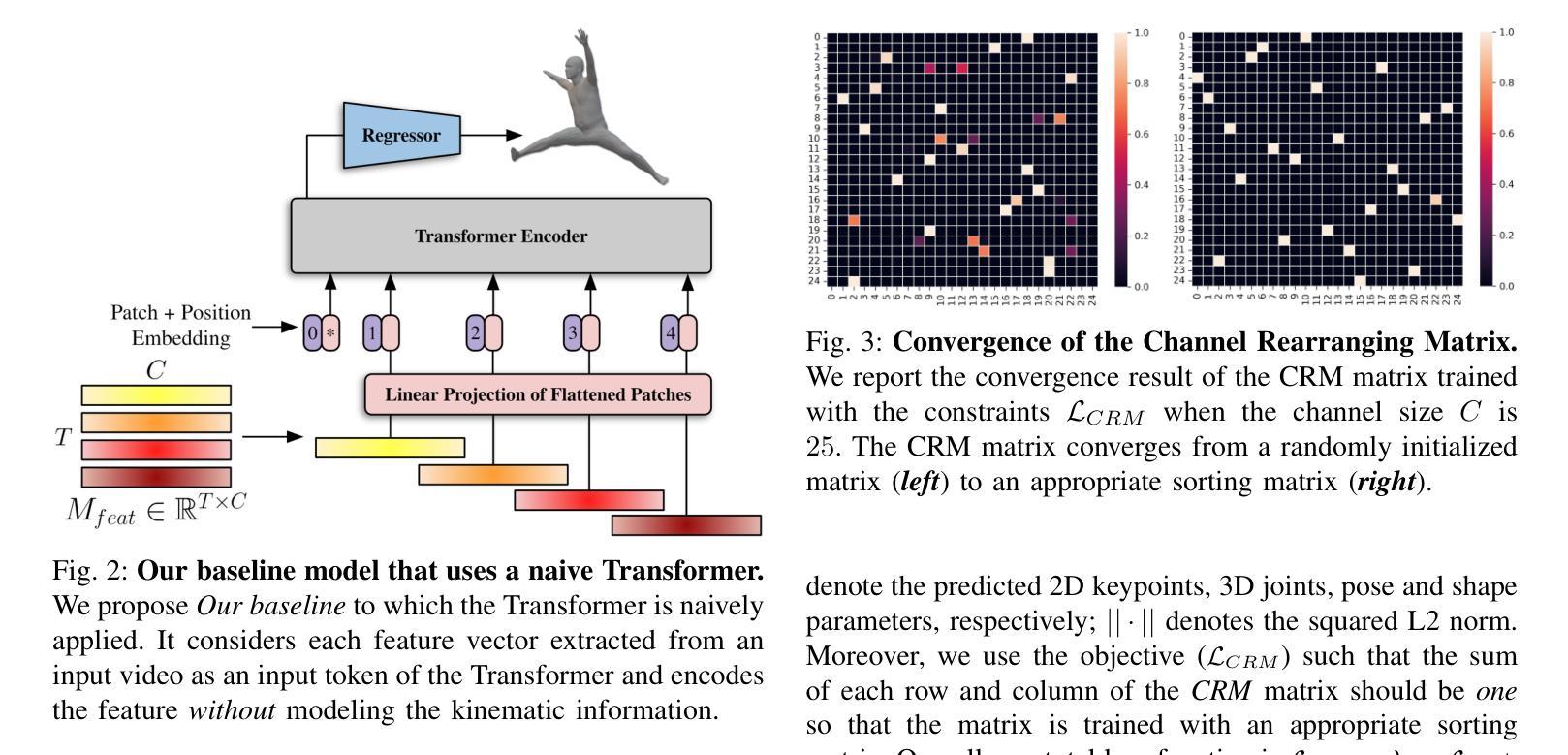
Video Inference for Human Mesh Recovery with Vision Transformer
Authors:Hanbyel Cho, Jaesung Ahn, Yooshin Cho, Junmo Kim
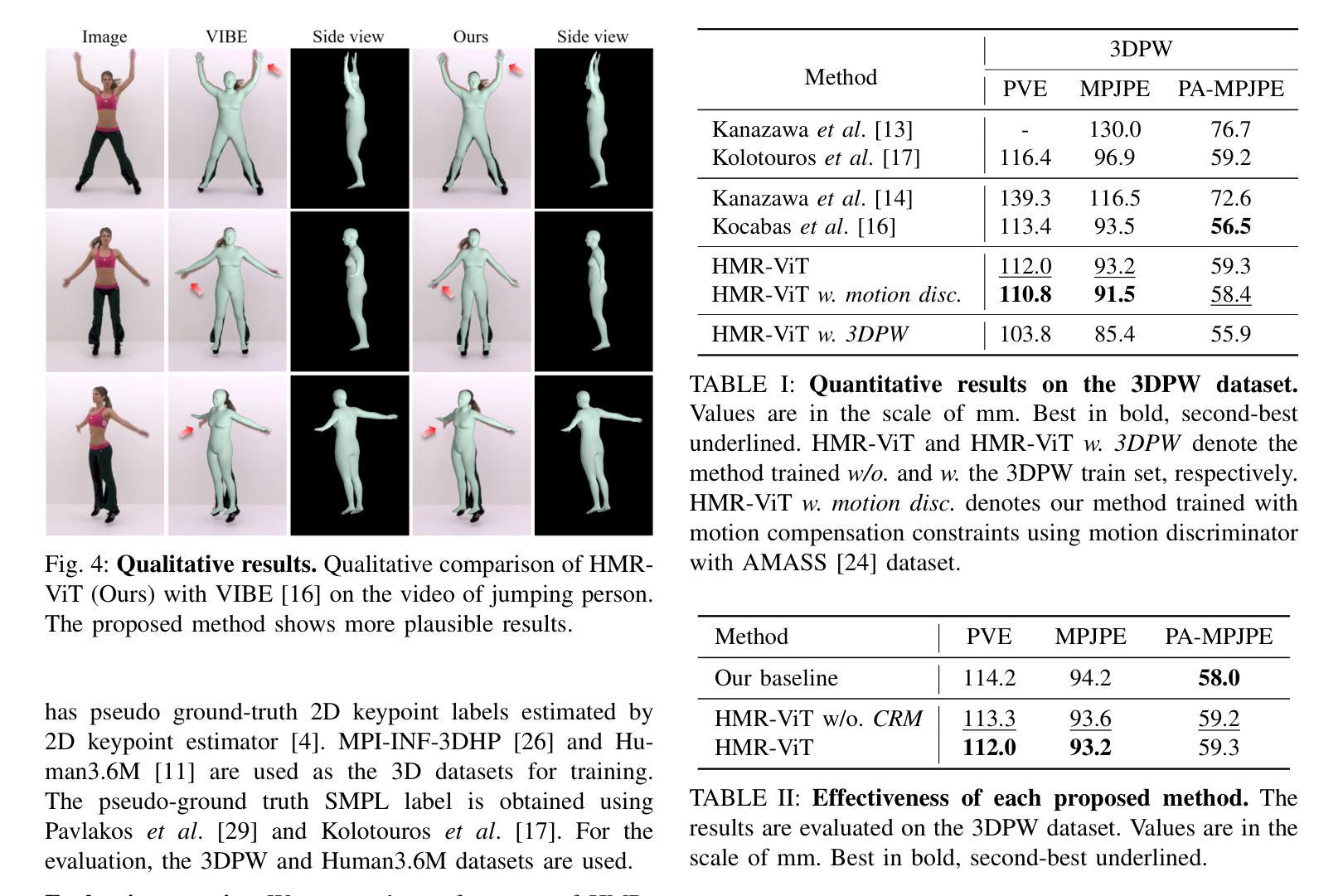
Human Mesh Recovery (HMR) from an image is a challenging problem because of the inherent ambiguity of the task. Existing HMR methods utilized either temporal information or kinematic relationships to achieve higher accuracy, but there is no method using both. Hence, we propose “Video Inference for Human Mesh Recovery with Vision Transformer (HMR-ViT)” that can take into account both temporal and kinematic information. In HMR-ViT, a Temporal-kinematic Feature Image is constructed using feature vectors obtained from video frames by an image encoder. When generating the feature image, we use a Channel Rearranging Matrix (CRM) so that similar kinematic features could be located spatially close together. The feature image is then further encoded using Vision Transformer, and the SMPL pose and shape parameters are finally inferred using a regression network. Extensive evaluation on the 3DPW and Human3.6M datasets indicates that our method achieves a competitive performance in HMR.
从图像中进行人体网格恢复(HMR)是一个具有挑战性的问题,因为该任务本身就存在固有的模糊性。现有的HMR方法利用时间信息或运动学关系来提高精度,但没有方法可以同时使用两者。因此,我们提出了“基于视频推理和视觉转换器的人体网格恢复(HMR-ViT)”,该方法可以考虑时间和运动学信息。在HMR-ViT中,使用来自视频帧的特征向量构建一个时间运动学特征图像,该图像由图像编码器生成。在生成特征图像时,我们使用通道重新排列矩阵(CRM),以便将相似的运动学特征在空间上紧密地定位在一起。然后,使用视觉转换器进一步对特征图像进行编码,并最终通过回归网络推断SMPL姿势和形状参数。在3DPW和Human3.6M数据集上的广泛评估表明,我们的方法在HMR中取得了具有竞争力的表现。
论文及项目相关链接
PDF Accepted to IEEE FG 2023
Summary
本文提出一种利用视频信息来进行人体网格恢复(HMR)的新方法,名为“基于视频信息的HMR-ViT人体网格恢复”。该方法结合了时间信息和运动学关系,构建了一个时间运动特征图像,并使用图像编码器和视觉转换器进行特征提取和编码。通过重新安排通道矩阵(CRM),使相似的运动学特征在空间上更接近。最后,使用回归网络推断SMPL姿势和形状参数。在3DPW和Human3.6M数据集上的评估表明,该方法在HMR中取得了具有竞争力的性能。
Key Takeaways
- HMR是一个具有挑战性的问题,因为任务本身就存在固有的模糊性。
- 目前大多数HMR方法只利用时间信息或运动学关系来提高精度。
- 本文提出一种新的方法HMR-ViT,能同时考虑时间和运动学信息。
- HMR-ViT构建了一个时间运动特征图像,通过图像编码器和视觉转换器进行特征提取和编码。
- 使用CRM来重新安排通道,使相似的运动学特征在空间上更接近。
- 通过回归网络推断SMPL姿势和形状参数。
- 在多个数据集上的评估表明,HMR-ViT在HMR任务中取得了具有竞争力的性能。
点此查看论文截图

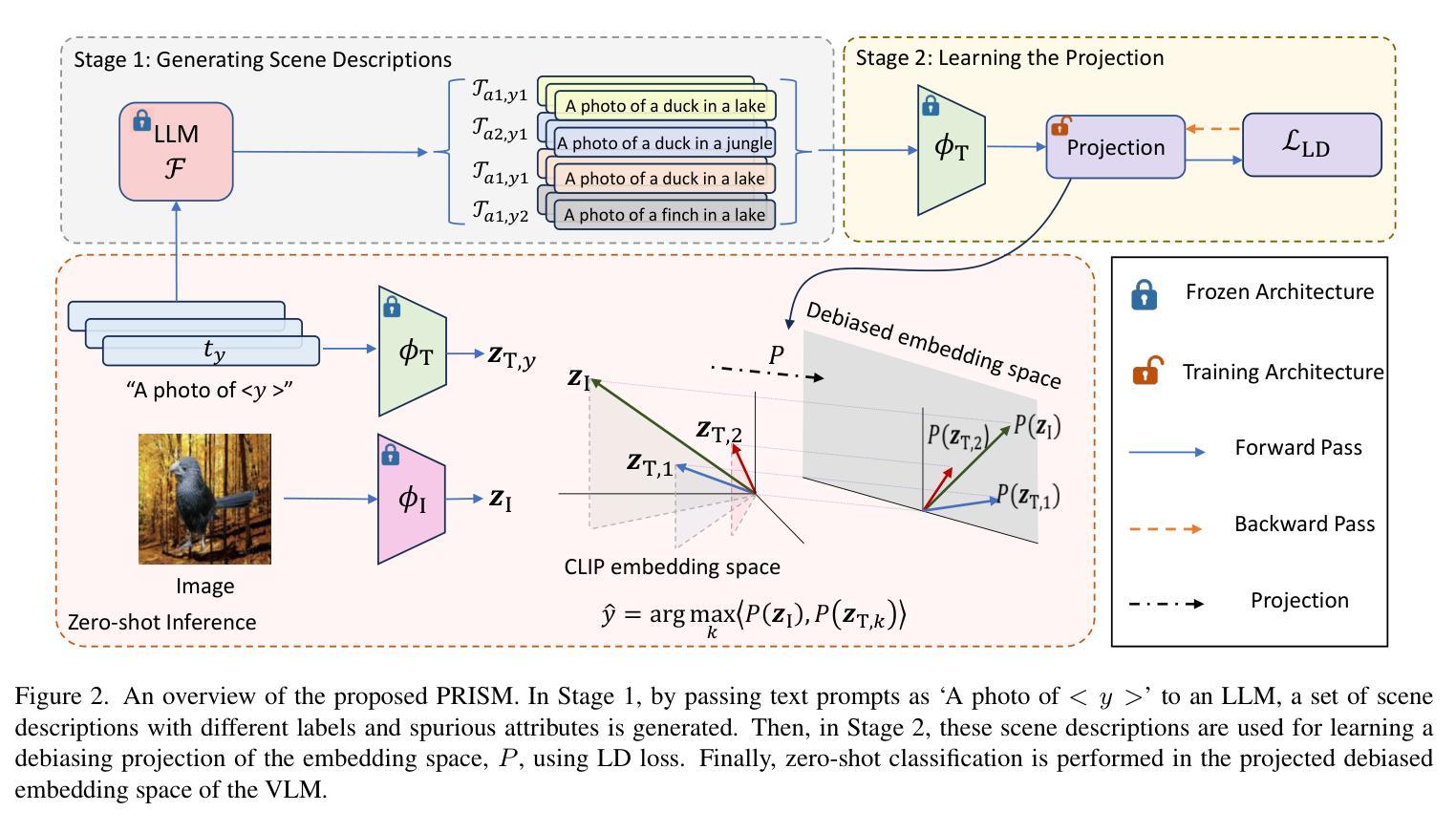
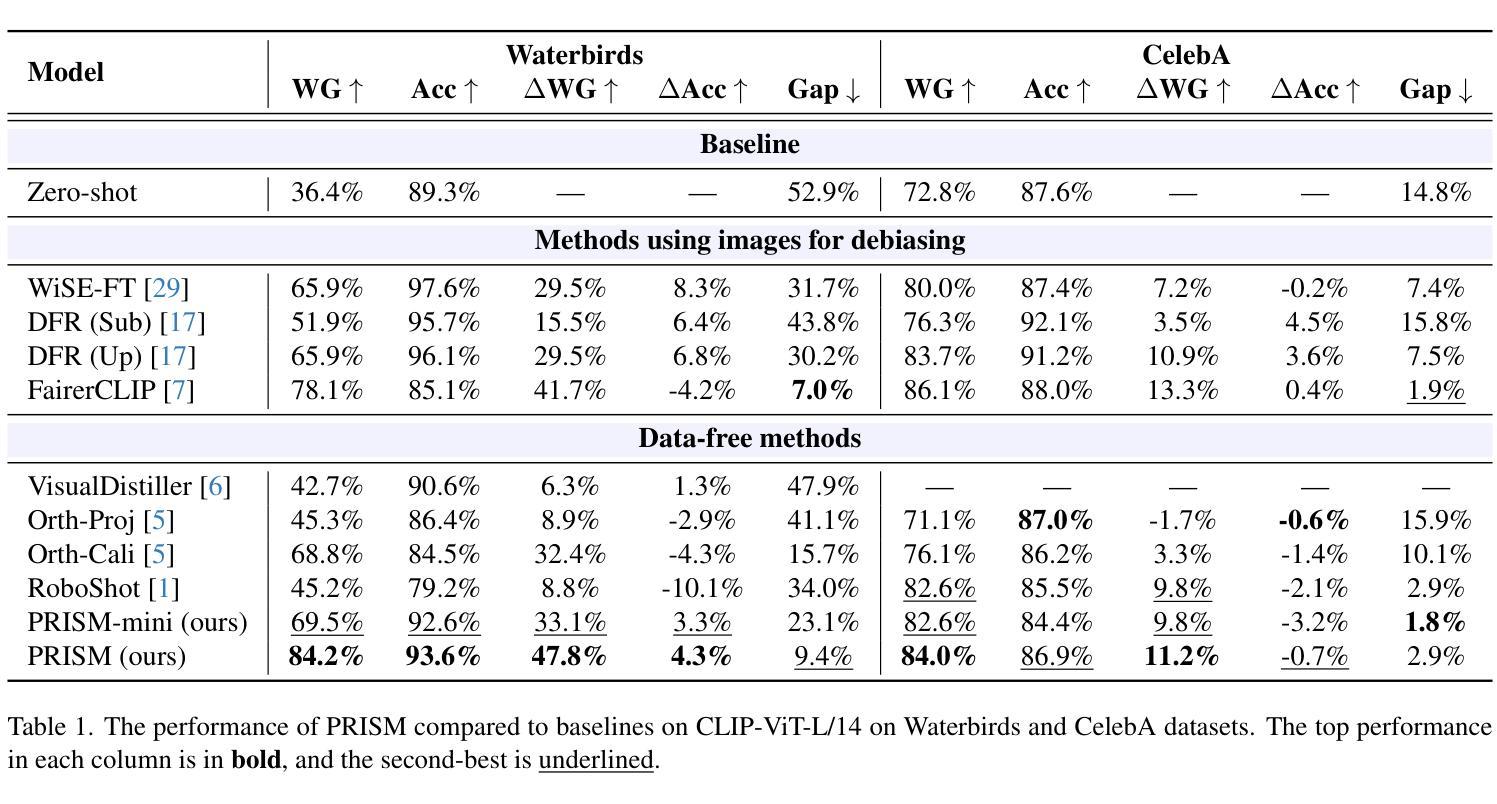
PRISM: Reducing Spurious Implicit Biases in Vision-Language Models with LLM-Guided Embedding Projection
Authors:Mahdiyar Molahasani, Azadeh Motamedi, Michael Greenspan, Il-Min Kim, Ali Etemad
We introduce Projection-based Reduction of Implicit Spurious bias in vision-language Models (PRISM), a new data-free and task-agnostic solution for bias mitigation in VLMs like CLIP. VLMs often inherit and amplify biases in their training data, leading to skewed predictions. PRISM is designed to debias VLMs without relying on predefined bias categories or additional external data. It operates in two stages: first, an LLM is prompted with simple class prompts to generate scene descriptions that contain spurious correlations. Next, PRISM uses our novel contrastive-style debiasing loss to learn a projection that maps the embeddings onto a latent space that minimizes spurious correlations while preserving the alignment between image and text embeddings.Extensive experiments demonstrate that PRISM outperforms current debiasing methods on the commonly used Waterbirds and CelebA datasets We make our code public at: https://github.com/MahdiyarMM/PRISM.
我们引入了基于投影的隐式偏见减少(PRISM),这是一种新的无数据和任务无关的解决偏见缓解问题的方法,适用于如CLIP这样的视觉语言模型(VLMs)。VLMs通常会继承并放大其训练数据中的偏见,导致预测结果出现偏差。PRISM旨在在不依赖预定义的偏见类别或额外的外部数据的情况下对VLMs进行去偏处理。它分为两个阶段:首先,使用简单的类别提示提示大型语言模型(LLM)生成包含错误关联的场景描述。接下来,PRISM使用我们新颖的对比式去偏损失来学习一种投影方法,将嵌入映射到一个潜在空间,该空间在最小化错误关联的同时,保留图像和文本嵌入之间的对齐。大量实验表明,PRISM在常用的Waterbirds和CelebA数据集上的去偏效果优于当前的去偏方法。我们在以下网站公开了我们的代码:https://github.com/MahdiyarMM/PRISM。
论文及项目相关链接
PDF Accepted to ICCV 2025
Summary
本文介绍了基于投影的隐式偏见减少方法(PRISM),这是一种针对视觉语言模型(如CLIP)偏见缓解的新数据免费和任务无关的解决方案。PRISM旨在不依赖预设偏见类别或额外外部数据对VLMs进行去偏处理。它通过两个阶段进行操作:首先,用简单的类别提示提示大型语言模型生成包含错误相关性的场景描述;接着,PRISM使用新型对比风格去偏损失来学习将嵌入映射到潜在空间中的投影,这个潜在空间最小化错误相关性,同时保留图像和文本嵌入之间的对齐。广泛实验表明,PRISM在常用的小鸟与名人脸部识别数据集(Waterbirds和CelebA)上的去偏效果优于当前方法。
Key Takeaways
- PRISM是一种针对视觉语言模型(VLMs)如CLIP的偏见缓解新方法。
- PRISM是数据免费和任务无关的解决方案,旨在解决VLMs中继承并放大的偏见问题。
- PRISM操作分为两个阶段:使用大型语言模型生成场景描述,并使用对比风格去偏损失进行投影映射。
- PRISM通过最小化错误相关性并保留图像和文本嵌入之间的对齐来实现去偏。
- PRISM在广泛实验中表现出良好的性能,特别是在Waterbirds和CelebA数据集上。
- PRISM方法具有公开可用的代码,便于其他研究者使用和改进。
- 该方法不依赖预设偏见类别或额外外部数据,具有通用性和灵活性。
点此查看论文截图

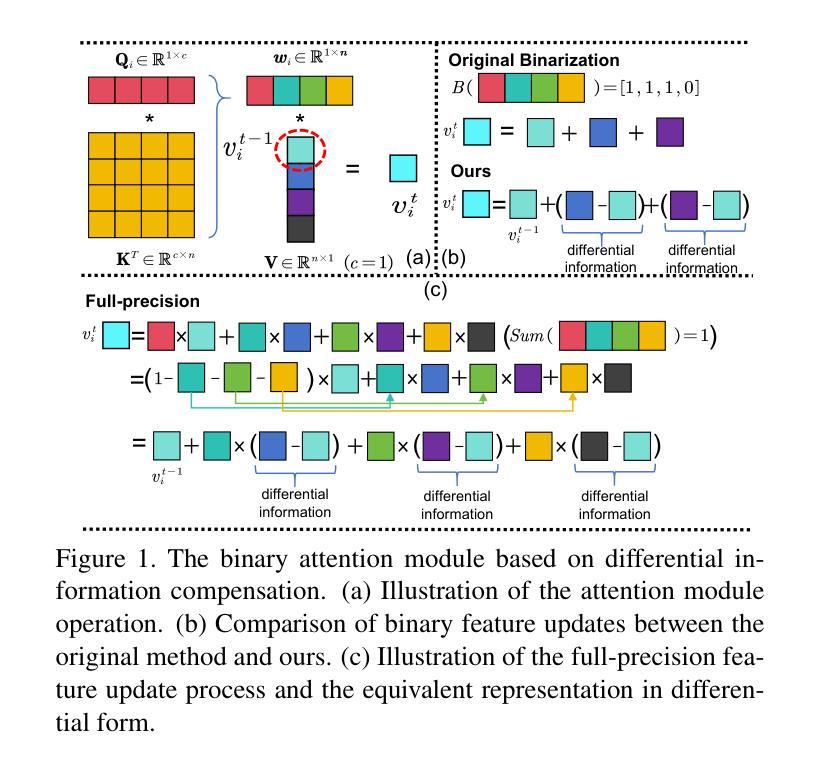
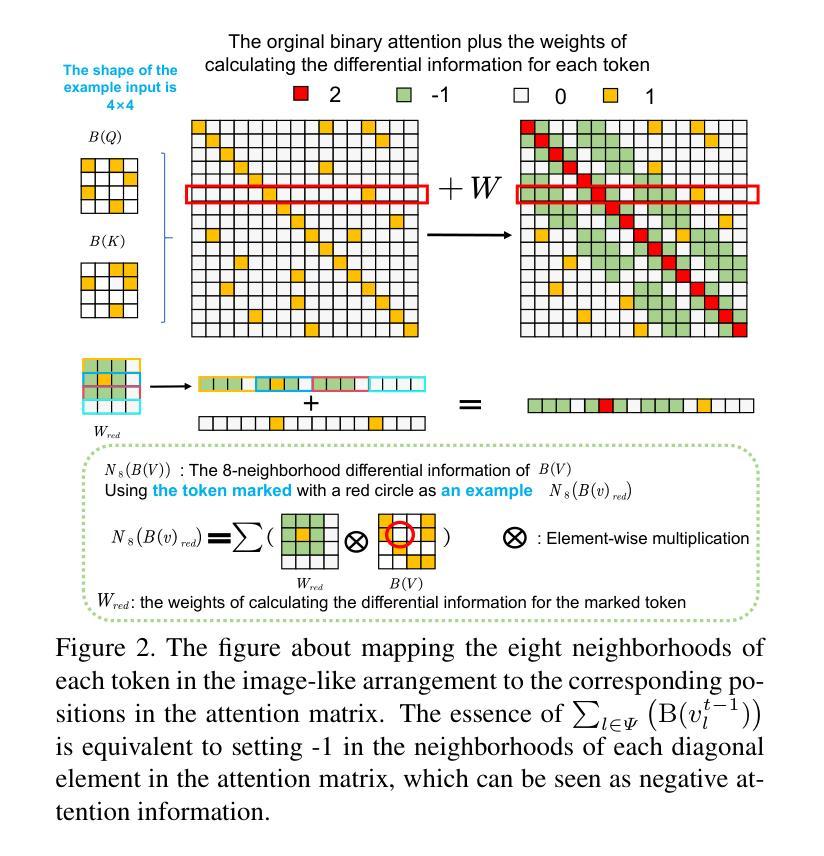
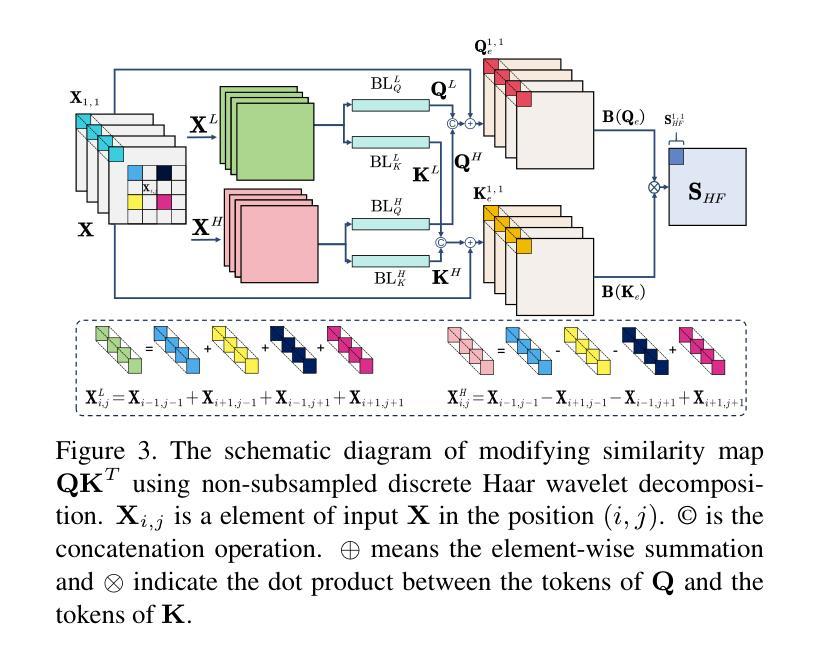
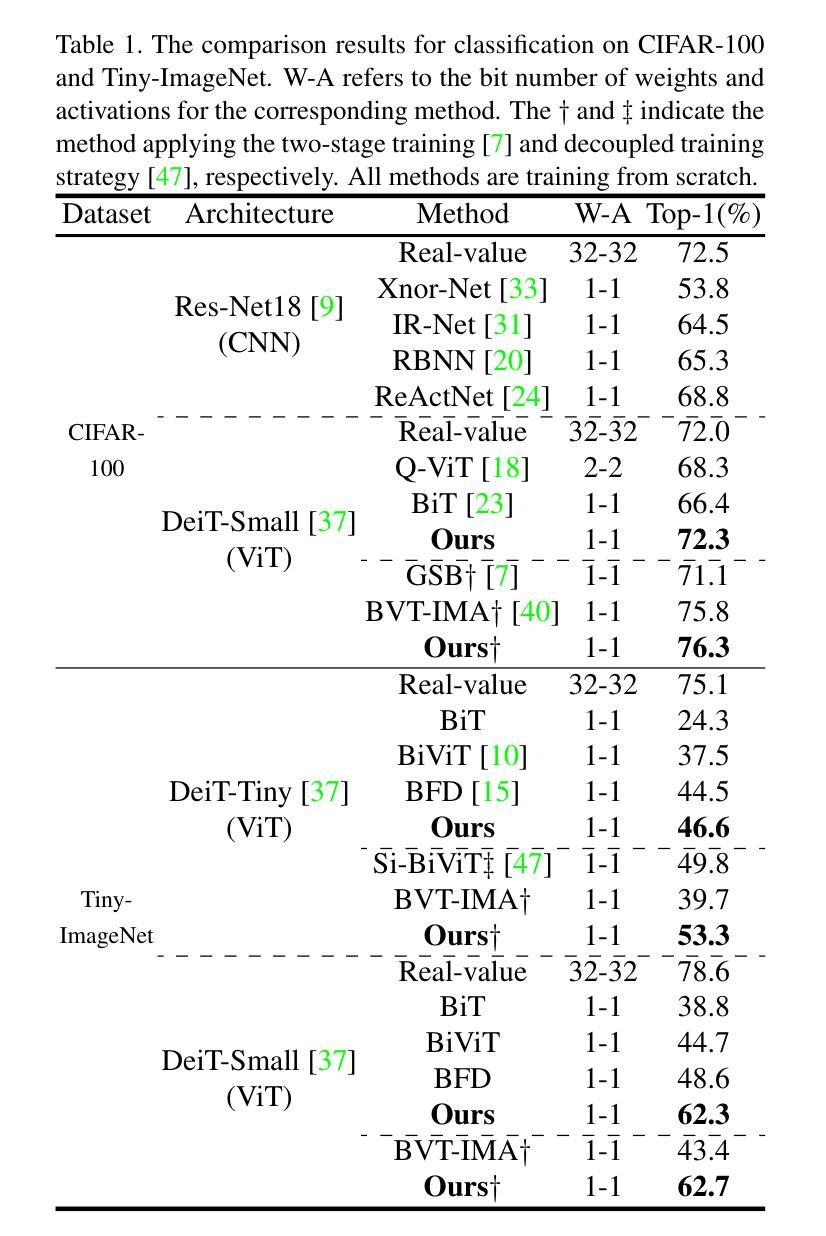
High-Fidelity Differential-information Driven Binary Vision Transformer
Authors:Tian Gao, Zhiyuan Zhang, Kaijie Yin, Xu-Cheng Zhong, Hui Kong
The binarization of vision transformers (ViTs) offers a promising approach to addressing the trade-off between high computational/storage demands and the constraints of edge-device deployment. However, existing binary ViT methods often suffer from severe performance degradation or rely heavily on full-precision modules. To address these issues, we propose DIDB-ViT, a novel binary ViT that is highly informative while maintaining the original ViT architecture and computational efficiency. Specifically, we design an informative attention module incorporating differential information to mitigate information loss caused by binarization and enhance high-frequency retention. To preserve the fidelity of the similarity calculations between binary Q and K tensors, we apply frequency decomposition using the discrete Haar wavelet and integrate similarities across different frequencies. Additionally, we introduce an improved RPReLU activation function to restructure the activation distribution, expanding the model’s representational capacity. Experimental results demonstrate that our DIDB-ViT significantly outperforms state-of-the-art network quantization methods in multiple ViT architectures, achieving superior image classification and segmentation performance.
视觉变压器的二值化(ViTs)为解决高计算/存储需求与边缘设备部署限制之间的权衡提供了有前景的方法。然而,现有的二进制ViT方法常常面临性能严重下降的问题,或者严重依赖于全精度模块。为了解决这些问题,我们提出了DIDB-ViT,这是一种新型的二值ViT,在保持原始ViT架构和计算效率的同时,具有很高的信息量。具体来说,我们设计了一个包含差异信息的有效注意力模块,以减轻二值化引起的信息损失并增强高频保留。为了保留二进制Q和K张量之间相似性计算的保真度,我们采用离散哈尔小波进行频率分解并整合不同频率的相似性。此外,我们引入了一种改进的RPReLU激活函数来重构激活分布,扩大模型的表示能力。实验结果表明,我们的DIDB-ViT在多种ViT架构中显著优于最新的网络量化方法,实现了出色的图像分类和分割性能。
论文及项目相关链接
Summary
本文提出了一个新型的二值化视觉转换器(DIDB-ViT),它在保持原始ViT架构和计算效率的同时,引入了具有差分信息的高度信息量的注意力模块来缓解二值化引起的信息损失并增强高频保留。同时采用离散小波变换进行频率分解,整合不同频率的相似性计算,改进RPReLU激活函数以重塑激活分布,扩大模型的表征能力。实验结果显示,DIDB-ViT在多个ViT架构上显著优于现有的网络量化方法,实现了出色的图像分类和分割性能。
Key Takeaways
- DIDB-ViT解决了现有二进制ViT方法面临的性能下降或依赖全精度模块的问题。
- 引入了一种新型的注意力模块,该模块结合了差分信息以减少二值化带来的信息损失。
- 使用离散Haar小波变换进行频率分解,用以优化相似度计算。
- 创新地结合了不同频率下的相似性,增强模型的性能。
- 提出改进的RPReLU激活函数以重塑激活分布,增强模型的表征能力。
- DIDB-ViT在多种ViT架构上实现了优于现有网络量化方法的性能。
点此查看论文截图

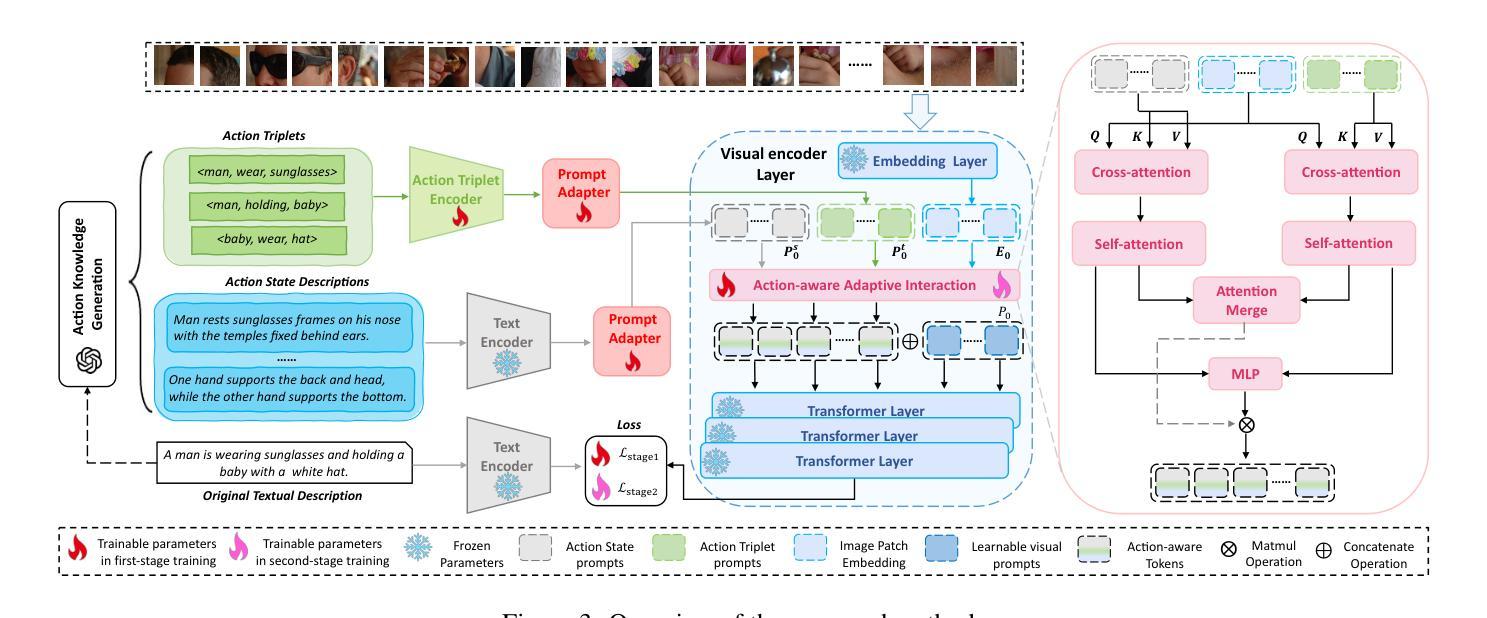
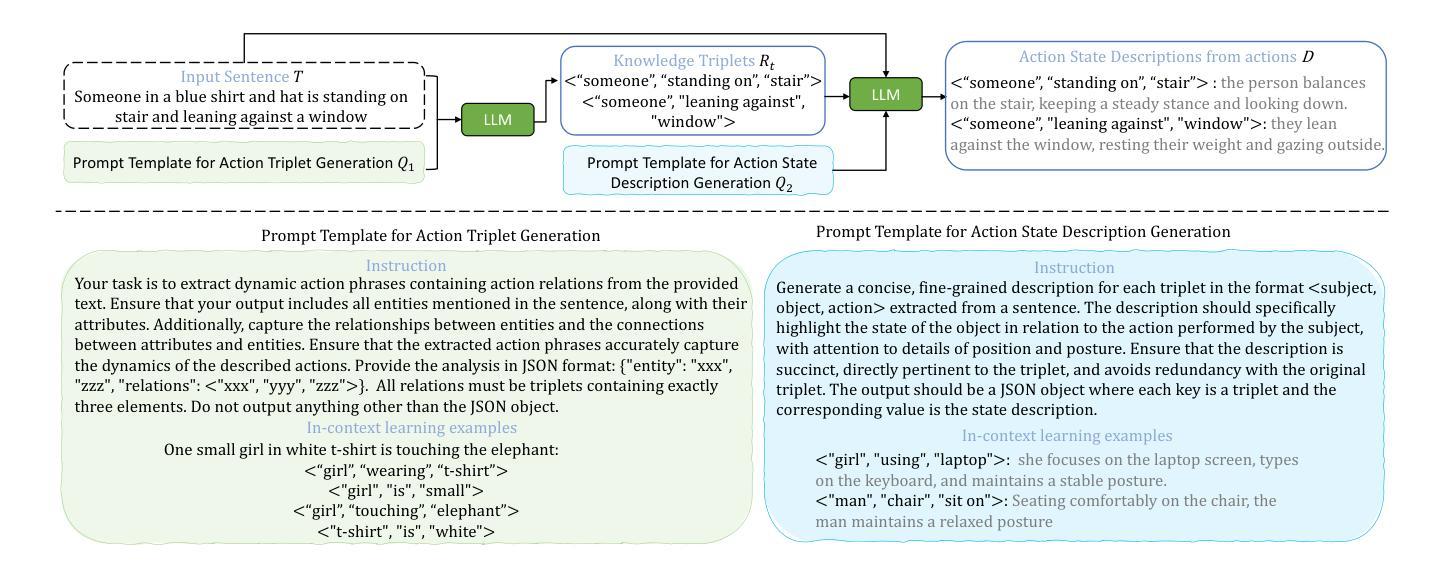
LLM-enhanced Action-aware Multi-modal Prompt Tuning for Image-Text Matching
Authors:Mengxiao Tian, Xinxiao Wu, Shuo Yang
Driven by large-scale contrastive vision-language pre-trained models such as CLIP, recent advancements in the image-text matching task have achieved remarkable success in representation learning. Due to image-level visual-language alignment, CLIP falls short in understanding fine-grained details such as object attributes and spatial relationships between objects. Recent efforts have attempted to compel CLIP to acquire structured visual representations by introducing prompt learning to achieve object-level alignment. While achieving promising results, they still lack the capability to perceive actions, which are crucial for describing the states or relationships between objects. Therefore, we propose to endow CLIP with fine-grained action-level understanding by introducing an LLM-enhanced action-aware multi-modal prompt-tuning method, incorporating the action-related external knowledge generated by large language models (LLMs). Specifically, we design an action triplet prompt and an action state prompt to exploit compositional semantic knowledge and state-related causal knowledge implicitly stored in LLMs. Subsequently, we propose an adaptive interaction module to aggregate attentive visual features conditioned on action-aware prompted knowledge for establishing discriminative and action-aware visual representations, which further improves the performance. Comprehensive experimental results on two benchmark datasets demonstrate the effectiveness of our method.
在大规模对比视觉语言预训练模型(如CLIP)的驱动下,图像文本匹配任务的最新进展在表示学习方面取得了显著的成功。然而,由于图像级别的视觉语言对齐,CLIP在理解精细的细节方面表现不足,如对象属性和对象之间的空间关系。最近的努力尝试通过引入提示学习来迫使CLIP获得结构化视觉表示,以实现对象级别的对齐。虽然取得了一定的成果,但它们仍然缺乏感知动作的能力,这对于描述对象的状态或关系至关重要。因此,我们提出了一种通过引入LLM增强的动作感知多模式提示调整方法,为CLIP赋予精细的动作级别理解,该方法结合了由大型语言模型(LLM)生成的动作相关外部知识。具体来说,我们设计了动作三元组提示和动作状态提示来利用LLM中隐含的组成语义知识和状态相关因果知识。然后,我们提出了一个自适应交互模块,该模块根据动作感知提示知识聚合注意力视觉特征,以建立具有鉴别力和动作感知的视觉表示,这进一步提高了性能。在两个基准数据集上的综合实验结果证明了我们的方法的有效性。
论文及项目相关链接
PDF accepted by ICCV 2025
Summary
基于CLIP的大型对比式视觉语言预训练模型在图像文本匹配任务中取得了显著成功,但在理解对象属性、对象间空间关系等细节方面存在不足。为弥补这一缺陷,近期研究尝试引入提示学习来引导CLIP获取结构化视觉表征,实现对象级别的对齐。然而,这些方法仍无法感知动作,对描述对象状态或关系至关重要。因此,我们提出一种结合大型语言模型(LLM)增强的动作感知多模式提示调整方法,引入动作相关的外部知识。通过设计动作三元组提示和动作状态提示来利用LLM中隐含的组成语义知识和状态相关因果知识,并提出自适应交互模块,根据动作感知提示知识聚合注意力视觉特征,建立有判别力和动作感知的视觉表征,进一步提高性能。
Key Takeaways
- 大型对比式视觉语言预训练模型(如CLIP)在图像文本匹配任务中取得显著进展。
- CLIP在理解图像细节(如对象属性、空间关系)方面存在局限。
- 为改进CLIP,引入提示学习以实现对象级别的对齐是一种有效方法。
- 现有方法缺乏动作感知能力,这是描述对象状态或关系的关键。
- 提出结合大型语言模型(LLM)增强的动作感知多模式提示调整方法。
- 通过设计动作三元组提示和动作状态提示,利用LLM中的组成语义和状态相关因果知识。
- 引入自适应交互模块,根据动作感知提示知识聚合注意力视觉特征,提高性能。
点此查看论文截图


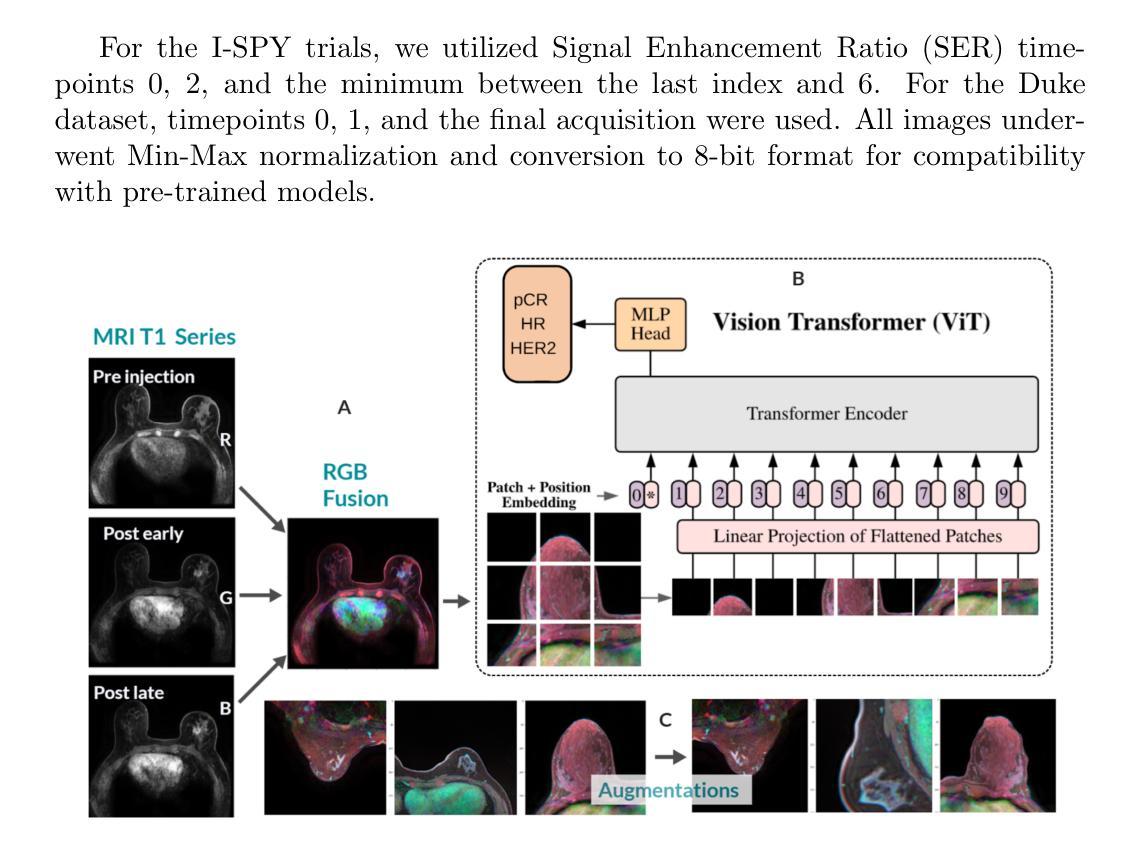
BreastDCEDL: A Comprehensive Breast Cancer DCE-MRI Dataset and Transformer Implementation for Treatment Response Prediction
Authors:Naomi Fridman, Bubby Solway, Tomer Fridman, Itamar Barnea, Anat Goldstein
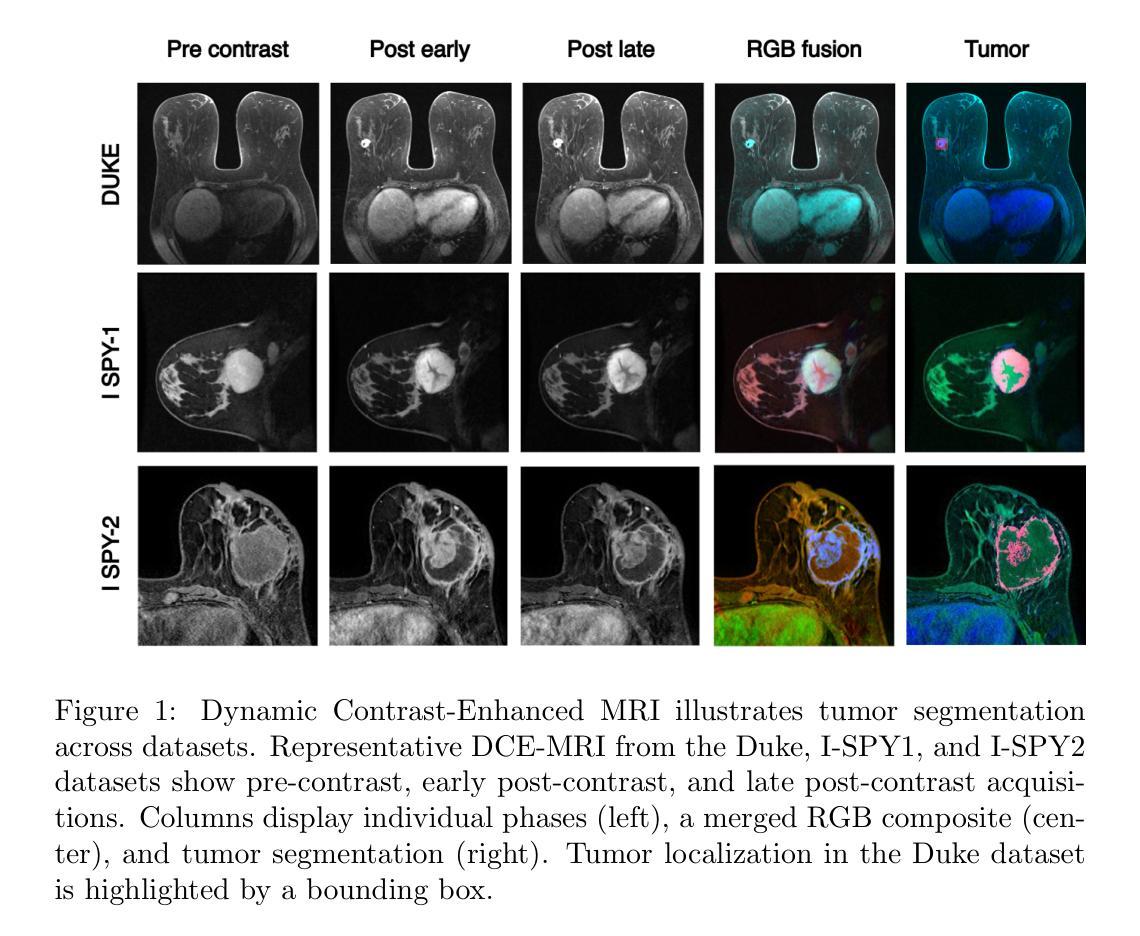
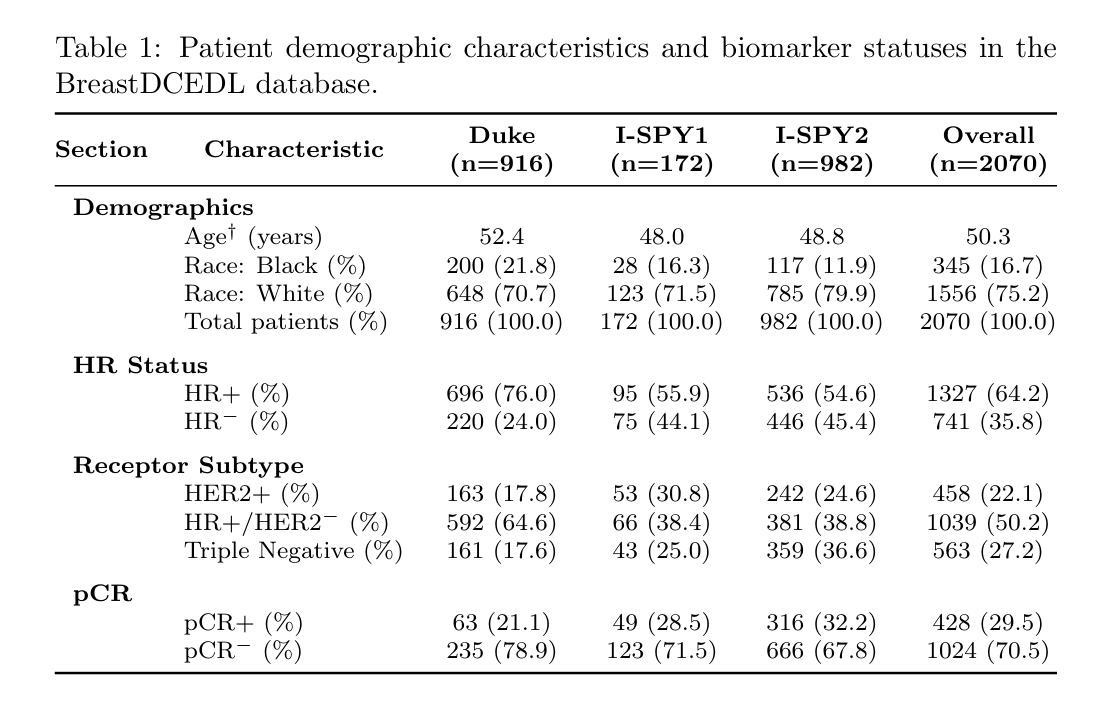
Breast cancer remains a leading cause of cancer-related mortality worldwide, making early detection and accurate treatment response monitoring critical priorities. We present BreastDCEDL, a curated, deep learning-ready dataset comprising pre-treatment 3D Dynamic Contrast-Enhanced MRI (DCE-MRI) scans from 2,070 breast cancer patients drawn from the I-SPY1, I-SPY2, and Duke cohorts, all sourced from The Cancer Imaging Archive. The raw DICOM imaging data were rigorously converted into standardized 3D NIfTI volumes with preserved signal integrity, accompanied by unified tumor annotations and harmonized clinical metadata including pathologic complete response (pCR), hormone receptor (HR), and HER2 status. Although DCE-MRI provides essential diagnostic information and deep learning offers tremendous potential for analyzing such complex data, progress has been limited by lack of accessible, public, multicenter datasets. BreastDCEDL addresses this gap by enabling development of advanced models, including state-of-the-art transformer architectures that require substantial training data. To demonstrate its capacity for robust modeling, we developed the first transformer-based model for breast DCE-MRI, leveraging Vision Transformer (ViT) architecture trained on RGB-fused images from three contrast phases (pre-contrast, early post-contrast, and late post-contrast). Our ViT model achieved state-of-the-art pCR prediction performance in HR+/HER2- patients (AUC 0.94, accuracy 0.93). BreastDCEDL includes predefined benchmark splits, offering a framework for reproducible research and enabling clinically meaningful modeling in breast cancer imaging.
乳腺癌仍然是全球癌症相关死亡的主要原因之一,因此早期检测和精确的治疗反应监测成为至关重要的优先事项。我们推出了BreastDCEDL,这是一个精心策划、为深度学习准备的数据集,包含来自I-SPY1、I-SPY2和Duke队列的2070例乳腺癌患者的治疗前3D动态增强MRI(DCE-MRI)扫描,所有数据均来自癌症成像档案。原始的DICOM成像数据被严格转换为标准化的3DNIfTI体积数据,同时保留了信号完整性,并附有统一的肿瘤注释和协调一致的临床元数据,包括病理完全反应(pCR)、激素受体(HR)和HER2状态。尽管DCE-MRI提供了重要的诊断信息,深度学习在分析此类复杂数据方面拥有巨大潜力,但由于缺乏可访问的公共多中心数据集,进展一直受到限制。BreastDCEDL通过支持开发先进模型来解决这一差距,包括需要大量训练数据的最新变压器架构。为了展示其稳健建模的能力,我们开发了基于变压器的首个乳腺癌DCE-MRI模型,该模型利用在三个对比阶段(预对比、早期后对比和晚期后对比)的RGB融合图像上训练的Vision Transformer(ViT)架构。我们的ViT模型在HR+/HER2-患者中实现了最先进的pCR预测性能(AUC 0.94,准确率0.93)。BreastDCEDL包括预定义的基准测试分割,为可重复的研究提供了一个框架,并在乳腺癌成像中实现了具有临床意义的建模。
论文及项目相关链接
Summary
乳腺癌仍是全球癌症死亡的主要原因之一,早期检测和准确的治疗反应监测是关键。我们推出BreastDCEDL数据集,包含来自I-SPY1、I-SPY2和Duke队列的2070例乳腺癌患者的预治疗3D动态增强MRI(DCE-MRI)扫描图像,源于癌症成像档案。数据集包含标准化的3DNIfTI体积数据、统一的肿瘤注释和协调的临床元数据,如病理完全反应、激素受体和HER2状态。BreastDCEDL解决了缺乏公共多中心数据集的问题,支持先进模型的开发,包括基于最新Transformer架构的模型。我们开发了基于Vision Transformer的乳腺DCE-MRI模型,在HR+/HER2-患者中实现了优异性能。BreastDCEDL包含预设的基准分割,为可重复的研究提供框架,并能在乳腺癌成像中进行临床意义建模。
Key Takeaways
- 乳腺癌仍是全球主要的癌症死亡原因之一,早期检测和精准治疗反应监测是关键挑战。
- BreastDCEDL是一个包含预治疗DCE-MRI扫描的深度学习就绪数据集,涵盖了大量患者数据并具备标准化处理的临床元数据。
- 数据集解决了缺乏公共多中心数据集的难题,为开发先进的模型提供了机会,包括基于Vision Transformer的模型。
- 首次展示了基于Vision Transformer的乳腺DCE-MRI模型,在特定患者群体中实现了高性能预测。
- BreastDCEDL包括预设的基准分割,有助于进行可重复的研究和临床意义建模。
- 数据集可用于开发预测病理完全反应的模型,对临床决策具有潜在价值。
点此查看论文截图

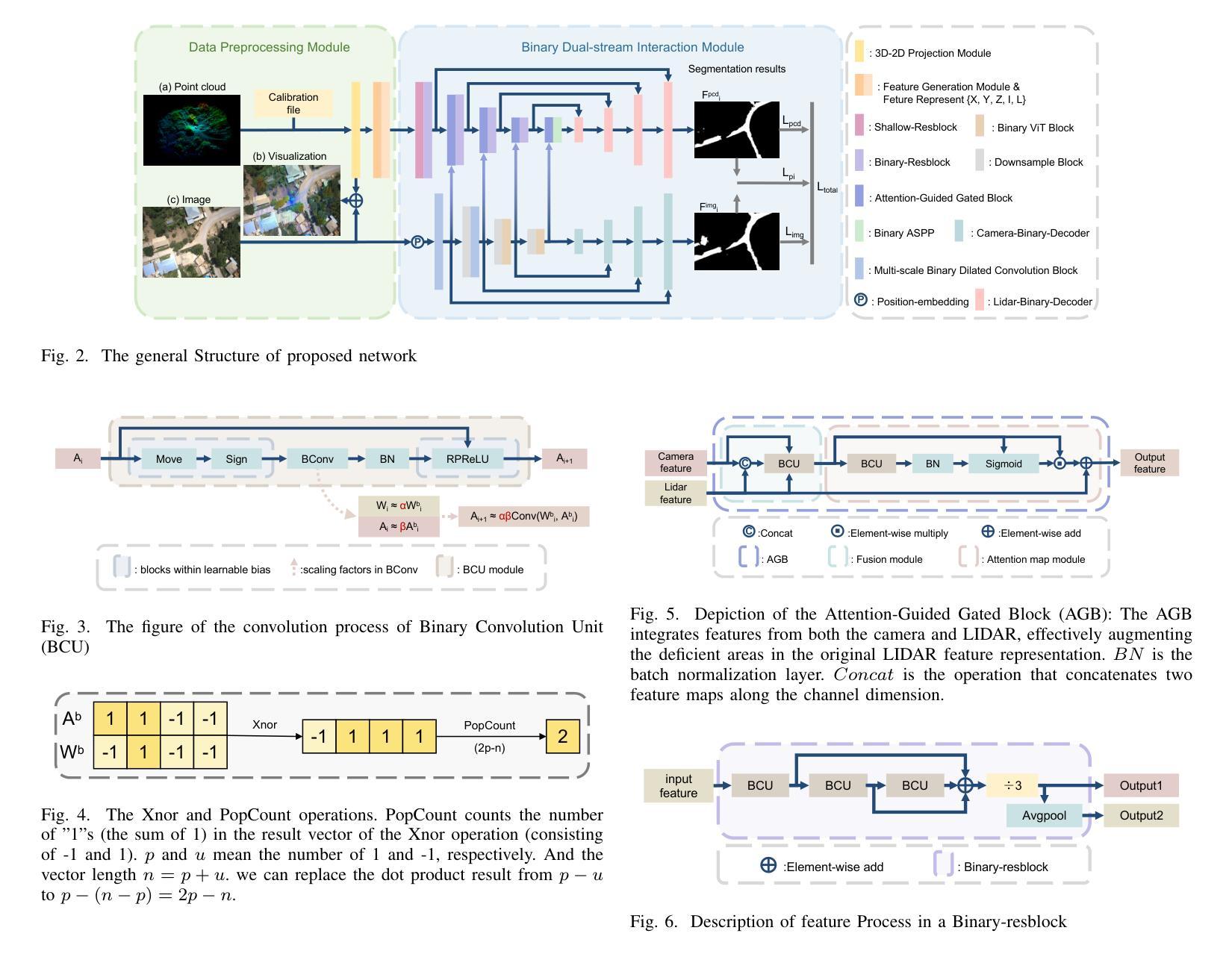
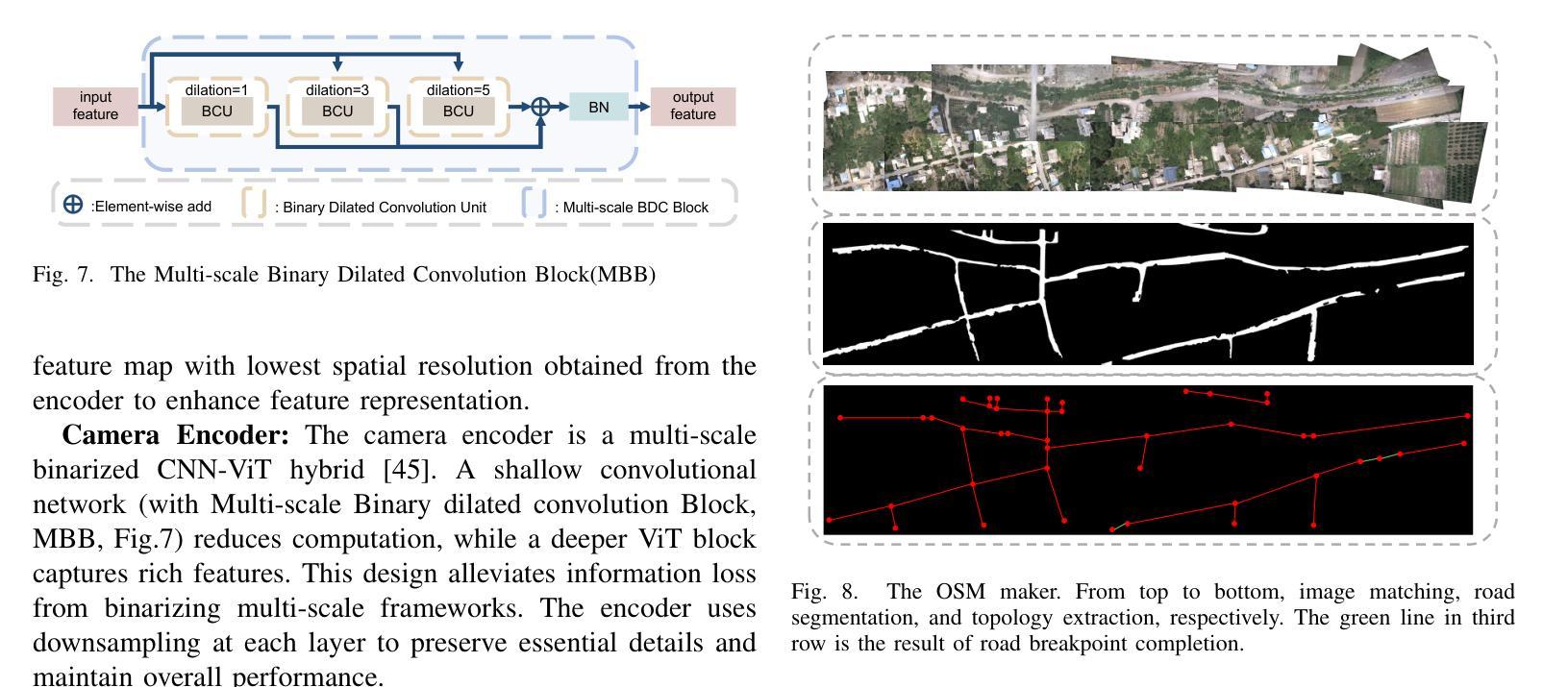
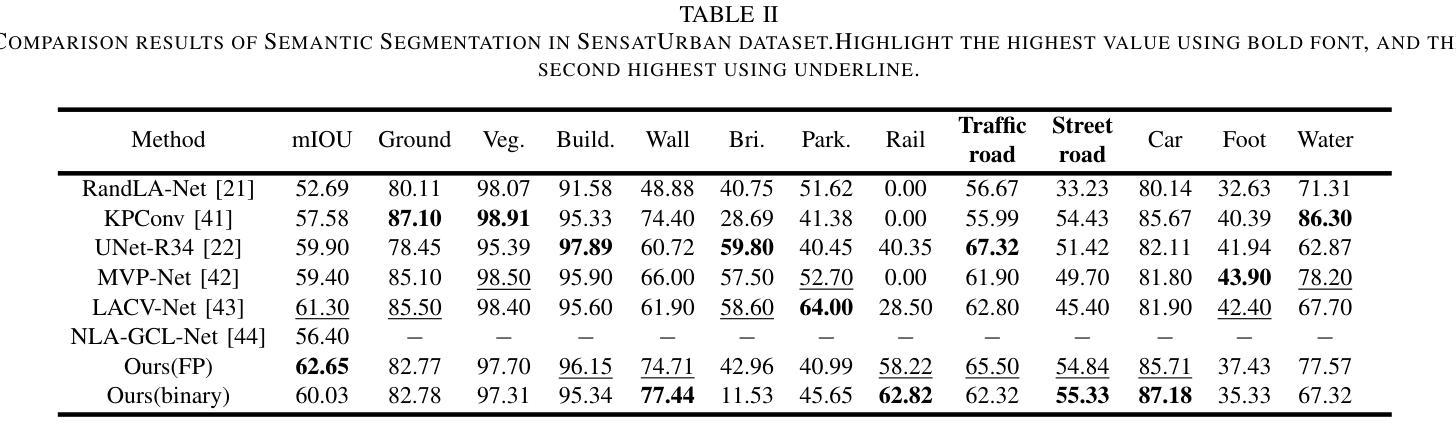
Pathfinder for Low-altitude Aircraft with Binary Neural Network
Authors:Kaijie Yin, Tian Gao, Hui Kong
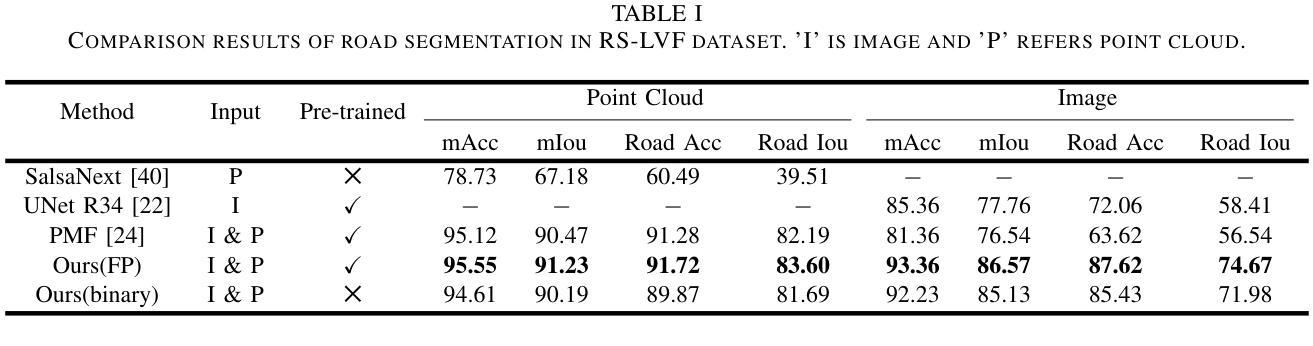
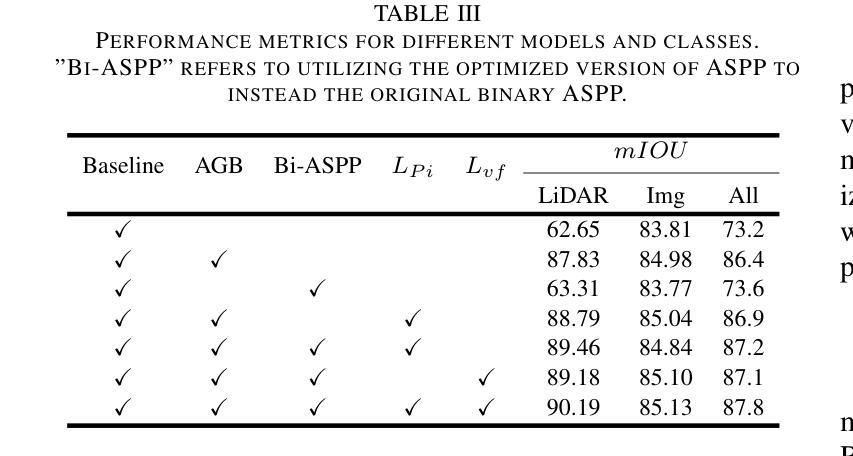
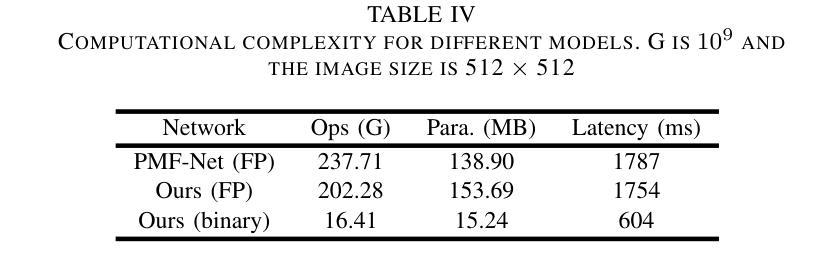
A prior global topological map (e.g., the OpenStreetMap, OSM) can boost the performance of autonomous mapping by a ground mobile robot. However, the prior map is usually incomplete due to lacking labeling in partial paths. To solve this problem, this paper proposes an OSM maker using airborne sensors carried by low-altitude aircraft, where the core of the OSM maker is a novel efficient pathfinder approach based on LiDAR and camera data, i.e., a binary dual-stream road segmentation model. Specifically, a multi-scale feature extraction based on the UNet architecture is implemented for images and point clouds. To reduce the effect caused by the sparsity of point cloud, an attention-guided gated block is designed to integrate image and point-cloud features. To optimize the model for edge deployment that significantly reduces storage footprint and computational demands, we propose a binarization streamline to each model component, including a variant of vision transformer (ViT) architecture as the encoder of the image branch, and new focal and perception losses to optimize the model training. The experimental results on two datasets demonstrate that our pathfinder method achieves SOTA accuracy with high efficiency in finding paths from the low-level airborne sensors, and we can create complete OSM prior maps based on the segmented road skeletons. Code and data are available at: \href{https://github.com/IMRL/Pathfinder}{https://github.com/IMRL/Pathfinder}.
先前的全局拓扑地图(例如,OpenStreetMap,OSM)可以通过地面移动机器人提升自主测绘的性能。然而,由于部分路径缺乏标注,先前的地图通常是不完整的。为了解决这一问题,本文提出了一种使用低空飞机携带的机载传感器的OSM制作方法。其中,OSM制作的核心是一种基于激光雷达和相机数据的新型高效路径查找方法,即二进制双流道路分割模型。具体来说,基于UNet架构实现了图像和点云的多尺度特征提取。为了减少点云稀疏造成的影响,设计了一种注意力引导的门控块来融合图像和点云特征。为了优化模型进行边缘部署,以显著降低存储空间和计算需求,我们对模型的每个组件都进行了二值化处理,包括使用变种视觉转换器(ViT)架构作为图像分支的编码器,以及新的焦点和感知损失来优化模型训练。在两个数据集上的实验结果表明,我们的路径查找方法以高效率达到了最先进水平的精度,可以从低级别机载传感器中找到路径,并且我们可以基于分割的道路骨架创建完整的OSM先前地图。代码和数据可在[https://github.com/IMRL/Pathfinder]找到。
论文及项目相关链接
摘要
利用先验全局拓扑地图(如OpenStreetMap,OSM)可以提高地面移动机器人的自主映射性能。然而,由于部分路径缺乏标注,先验地图通常是不完整的。为解决此问题,本文提出了一种利用低空飞机携带的机载传感器构建OSM的方法,其核心是一种基于激光雷达和相机数据的新型高效路径查找方法,即二进制双流道路分割模型。具体实现了基于UNet架构的多尺度特征提取,用于图像和点云。为解决点云稀疏引起的影响,设计了注意力引导门控块来整合图像和点云特征。为优化模型进行边缘部署,显著降低存储和计算需求,我们对模型各组件提出了一条二进制化流线,包括使用视觉变压器(ViT)架构作为图像分支的编码器,以及新的焦点和感知损失以优化模型训练。在两个数据集上的实验结果表明,我们的路径查找方法具有高精度和高效率地寻找来自低级别机载传感器的路径,并且我们可以基于分割的道路骨架创建完整的OSM先验地图。
关键见解
- 先验全局拓扑地图(如OpenStreetMap)能提高自主映射性能。
- 提出的OSM制作方法使用低空飞机的机载传感器。
- 路径查找方法的核心是二进制双流道路分割模型。
- 该模型使用基于UNet架构的多尺度特征提取处理图像和点云数据。
- 为应对点云的稀疏性,结合了图像和点云特征的注意力引导门控块。
- 为边缘部署优化了模型,包括使用视觉变压器架构和新的焦点及感知损失。
- 实验结果表明,该方法在寻找低级别机载传感器路径方面达到高精度和高效率,并能创建完整的OSM先验地图。
点此查看论文截图



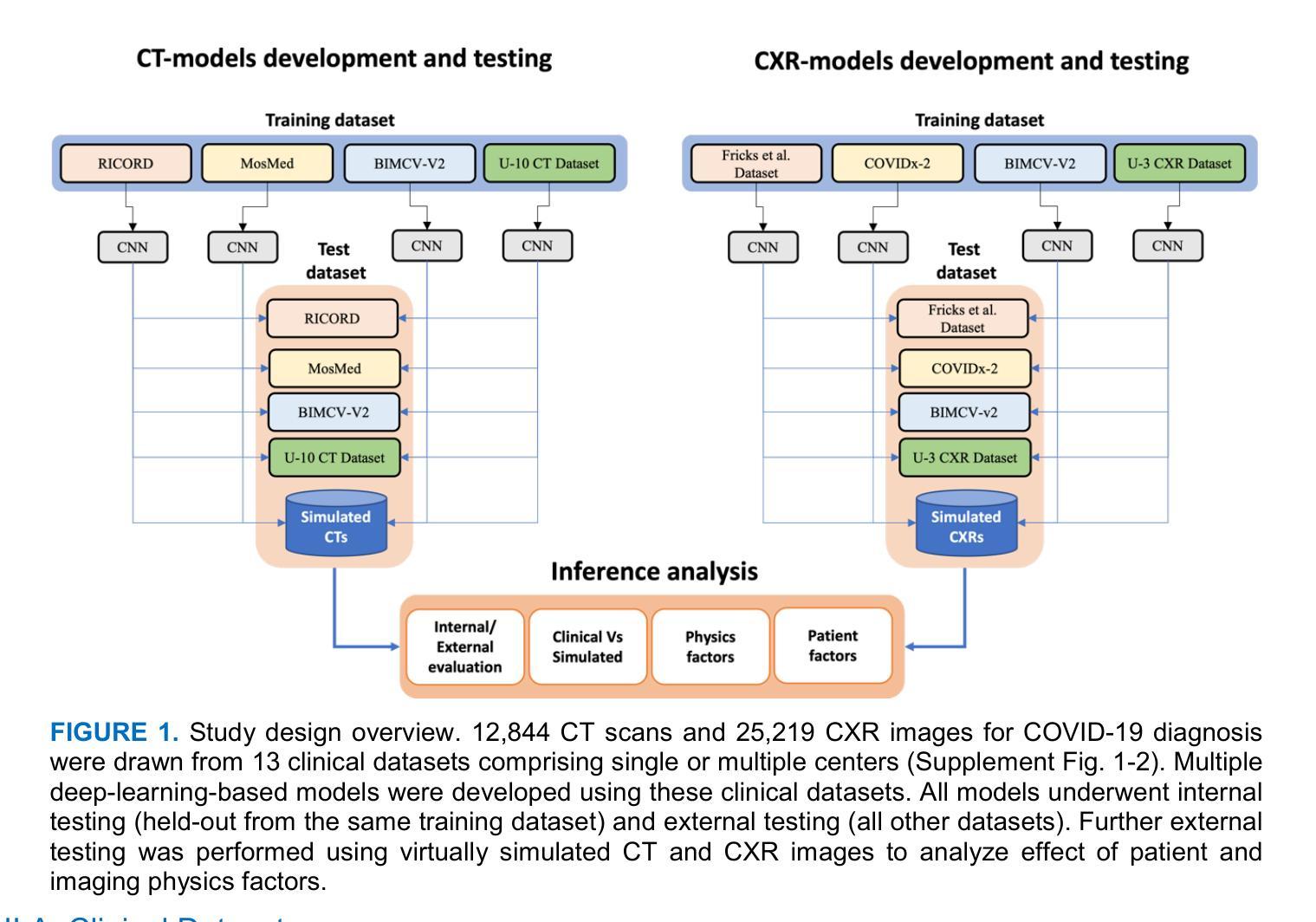
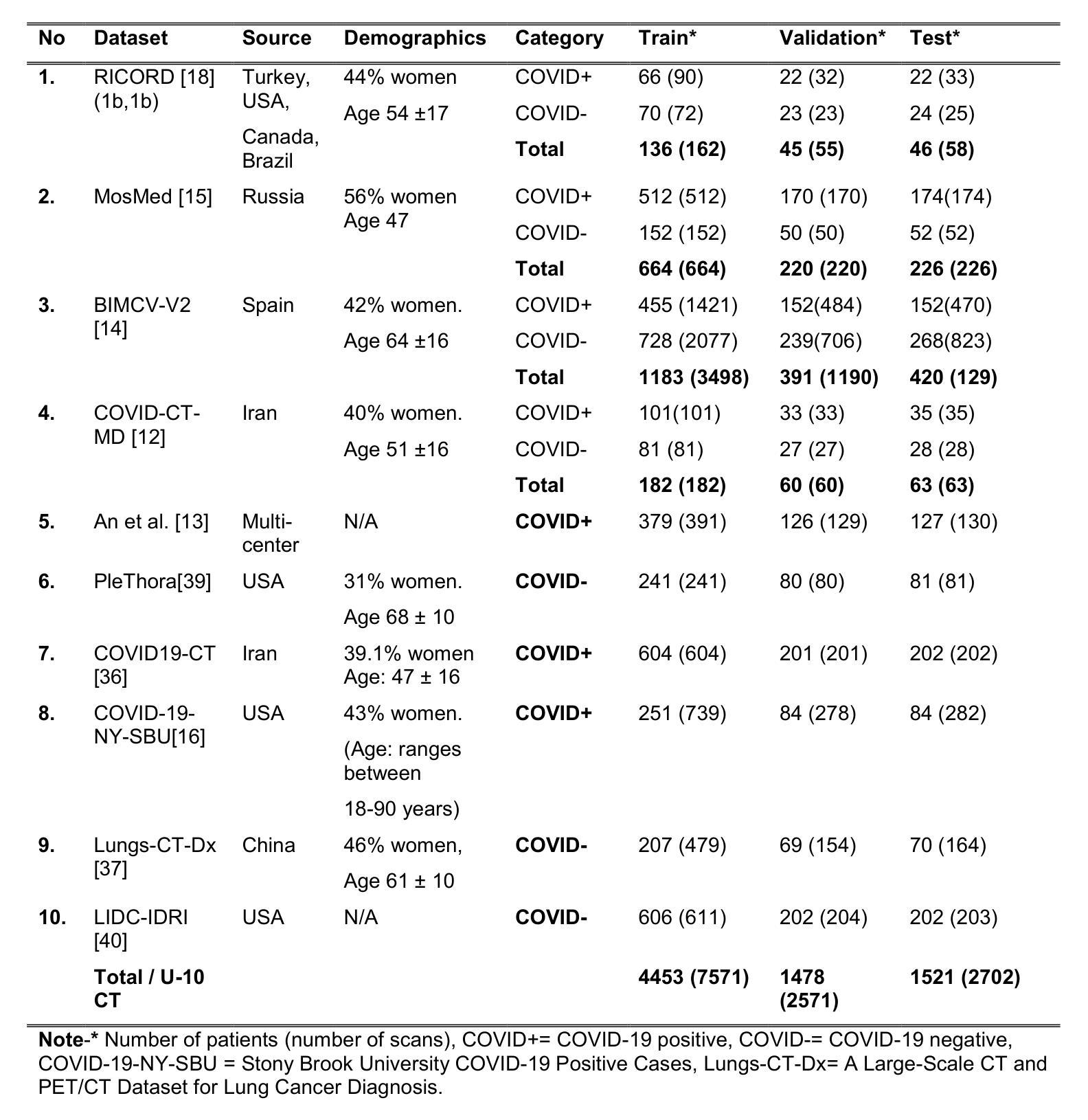
The Utility of the Virtual Imaging Trials Methodology for Objective Characterization of AI Systems and Training Data
Authors:Fakrul Islam Tushar, Lavsen Dahal, Saman Sotoudeh-Paima, Ehsan Abadi, W. Paul Segars, Ehsan Samei, Joseph Y. Lo
The credibility of Artificial Intelligence (AI) models for medical imaging continues to be a challenge, affected by the diversity of models, the data used to train the models, and applicability of their combination to produce reproducible results for new data. In this work we aimed to explore if the emerging Virtual Imaging Trials (VIT) methodologies can provide an objective resource to approach this challenge. The study was conducted for the case example of COVID-19 diagnosis using clinical and virtual computed tomography (CT) and chest radiography (CXR) processed with convolutional neural networks (CNNs). Multiple AI models were developed and tested using 3D ResNet-like and 2D EfficientNetv2 architectures across diverse datasets. The performance differences were evaluated in terms of the area under the curve (AUC) and the DeLong method for AUC confidence intervals. The models trained on the most diverse datasets showed the highest external testing performance, with AUC values ranging from 0.73 to 0.76 for CT and 0.70 to 0.73 for CXR. Internal testing yielded higher AUC values (0.77 to 0.85 for CT and 0.77 to 1.0 for CXR), highlighting a substantial drop in performance during external validation, which underscores the importance of diverse and comprehensive training and testing data. Most notably, the VIT approach provided objective assessment of the utility of diverse models and datasets while further providing insight into the influence of dataset characteristics, patient factors, and imaging physics on AI efficacy. The VIT approach can be used to enhance model transparency and reliability, offering nuanced insights into the factors driving AI performance and bridging the gap between experimental and clinical settings.
人工智能(AI)模型在医学影像领域的可信度仍然是一个挑战,受到模型多样性、用于训练模型的数据,以及它们组合应用于新数据产生可重复结果的影响。在这项工作中,我们旨在探索新兴的虚拟成像试验(VIT)方法是否可以为应对这一挑战提供客观资源。该研究是针对COVID-19诊断的案例分析,使用临床和虚拟计算机断层扫描(CT)以及经过卷积神经网络(CNN)处理的胸部X射线(CXR)。使用3D ResNet和2D EfficientNetv2架构开发并测试了多个AI模型,涉及不同的数据集。性能差异是根据曲线下面积(AUC)和AUC置信区间的DeLong方法进行评估的。在最具多样性的数据集上训练的模型在外部测试中的表现最佳,CT的AUC值范围从0.73到0.76,CXR的AUC值范围从0.70到0.73。内部测试的AUC值较高(CT的AUC值为0.77到0.85,CXR的AUC值为0.77到1.0),突显了外部验证中性能的大幅下降,这强调了多样性和全面的训练和测试数据的重要性。值得注意的是,VIT方法为不同的模型和数据集提供了客观评估,同时进一步深入了解数据集特性、患者因素和成像物理学对AI效力的影响。VIT方法可用于提高模型的透明度和可靠性,提供关于驱动AI性能因素的微妙见解,并弥合实验与临床环境之间的差距。
论文及项目相关链接
Summary
本文探讨了人工智能模型在医学影像领域的可信度问题,研究了虚拟成像试验(VIT)方法能否为解决此问题提供客观资源。以新冠肺炎诊断为例,研究使用临床和虚拟计算机断层扫描(CT)以及胸部放射摄影(CXR)处理的卷积神经网络(CNN)模型,并在多样数据集上进行训练和测试。研究结果表明,在多样数据集上训练的模型在外部测试中具有最高性能,而内部测试的性能较高,凸显了外部验证时性能的显著下降。虚拟成像试验(VIT)方法为评估不同模型和数据集提供了客观视角,并进一步深入探究了数据集特征、患者因素和成像物理对人工智能效能的影响。此研究方法可以提高模型的透明度和可靠性,并为弥合实验与临床之间的差距提供深刻见解。
Key Takeaways
- 人工智能模型在医学影像领域的可信度面临挑战,主要受模型多样性、训练数据多样性和对新数据产生可重复结果的能力影响。
- 虚拟成像试验(VIT)方法为评估模型性能提供了新的视角。
- 使用临床和虚拟计算机断层扫描(CT)以及胸部放射摄影(CXR)处理卷积神经网络(CNN)进行新冠肺炎诊断的模型测试表明多样数据集训练的模型具有最佳性能。
- 外部验证结果揭示了模型的性能下降,突显了训练和测试数据的多样性和全面性的重要性。
- VIT方法能客观地评估不同模型和数据集的性能,提供对AI效能影响因素的深刻见解,如数据集特性、患者因素和成像物理。
- VIT方法有助于增强模型的透明度和可靠性。
点此查看论文截图