⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-02 更新
MoGA: 3D Generative Avatar Prior for Monocular Gaussian Avatar Reconstruction
Authors:Zijian Dong, Longteng Duan, Jie Song, Michael J. Black, Andreas Geiger
We present MoGA, a novel method to reconstruct high-fidelity 3D Gaussian avatars from a single-view image. The main challenge lies in inferring unseen appearance and geometric details while ensuring 3D consistency and realism. Most previous methods rely on 2D diffusion models to synthesize unseen views; however, these generated views are sparse and inconsistent, resulting in unrealistic 3D artifacts and blurred appearance. To address these limitations, we leverage a generative avatar model, that can generate diverse 3D avatars by sampling deformed Gaussians from a learned prior distribution. Due to the limited amount of 3D training data such a 3D model alone cannot capture all image details of unseen identities. Consequently, we integrate it as a prior, ensuring 3D consistency by projecting input images into its latent space and enforcing additional 3D appearance and geometric constraints. Our novel approach formulates Gaussian avatar creation as a model inversion process by fitting the generative avatar to synthetic views from 2D diffusion models. The generative avatar provides a meaningful initialization for model fitting, enforces 3D regularization, and helps in refining pose estimation. Experiments show that our method surpasses state-of-the-art techniques and generalizes well to real-world scenarios. Our Gaussian avatars are also inherently animatable
我们提出了一种名为MoGA的新型方法,可以从单视图图像重建高保真3D高斯化身。主要挑战在于推断出看不见的外观和几何细节,同时确保3D的一致性和真实性。大多数之前的方法依赖于2D扩散模型来合成未见的视图;然而,这些生成的视图是稀疏且不一致的,导致3D出现不真实的伪影和模糊的外观。为了解决这些局限性,我们利用生成化身模型,通过从学习的先验分布中采样变形的高斯函数,可以生成多样化的3D化身。由于3D训练数据量有限,单一的3D模型无法捕获未见身份的所有图像细节。因此,我们将其整合为优先级,通过将输入图像投影到其潜在空间并施加额外的3D外观和几何约束,确保3D的一致性。我们的新方法将高斯化身的创建制定为一个模型反转过程,通过将生成的化身适应于来自2D扩散模型的合成视图。生成的化身为模型拟合提供了有意义的初始化,实施了3D正则化,并有助于改进姿态估计。实验表明,我们的方法超越了最先进的技术并在真实场景中具有很好的通用性。我们的高斯化身本质上是可动画的。
论文及项目相关链接
PDF ICCV 2025 (Highlight), Project Page: https://zj-dong.github.io/MoGA/
Summary
本文介绍了MoGA方法,这是一种从单视角图像重建高保真3D高斯虚拟形象的新技术。该方法主要挑战在于推断未见的外观和几何细节,同时确保3D一致性和真实性。针对现有方法的不足,该研究采用生成式虚拟形象模型,通过从学习到的先验分布中采样变形高斯来生成多样化的3D虚拟形象。同时,结合输入图像的投影和额外的3D外观及几何约束,确保3D一致性。该研究将高斯虚拟形象创建制定为模型反演过程,通过将生成式虚拟形象与来自二维扩散模型的合成视图相匹配来实现。
Key Takeaways
- MoGA是一种从单视角图像重建高保真3D高斯虚拟形象的方法。
- 该方法主要挑战在于推断未见的外观和几何细节,并确保3D一致性和真实性。
- 现有方法主要依赖2D扩散模型合成未见视图,但生成的视图稀疏且不一致,导致3D伪影和模糊外观。
- 研究采用生成式虚拟形象模型,通过采样变形高斯来生成多样化的3D虚拟形象。
- 结合输入图像的投影和额外的3D及几何约束,确保3D一致性。
- 高斯虚拟形象创建被制定为一个模型反演过程,通过匹配生成式虚拟形象和来自二维扩散模型的合成视图来实现。
点此查看论文截图


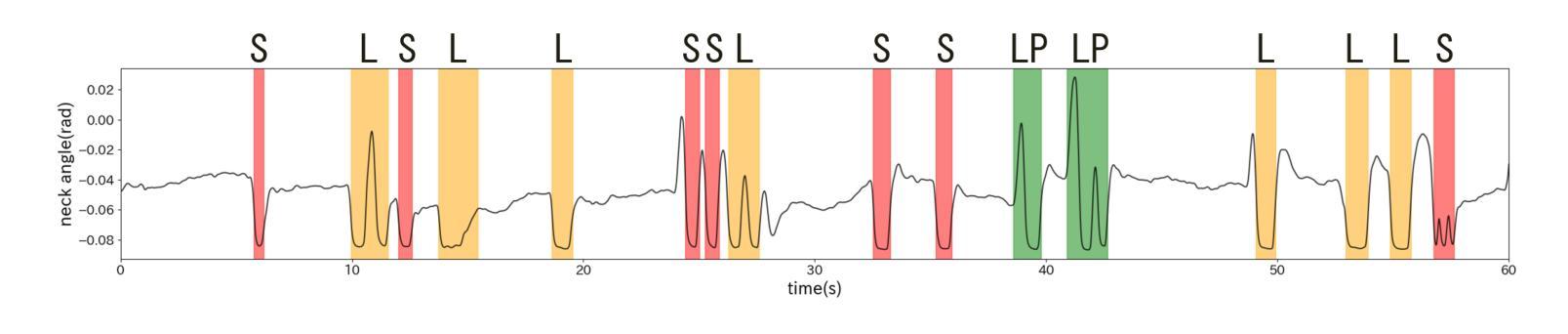
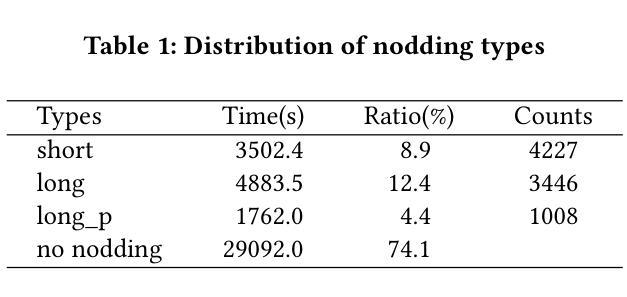
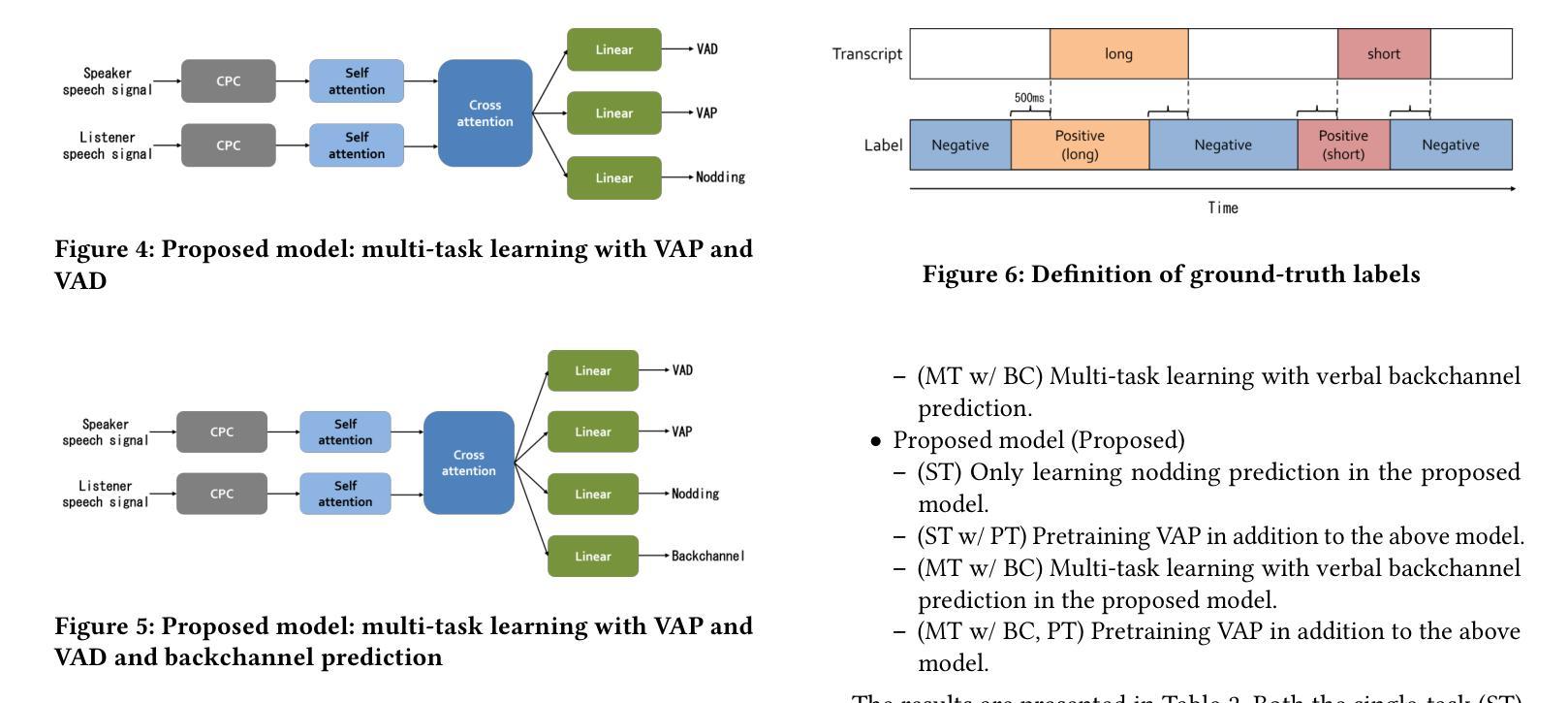
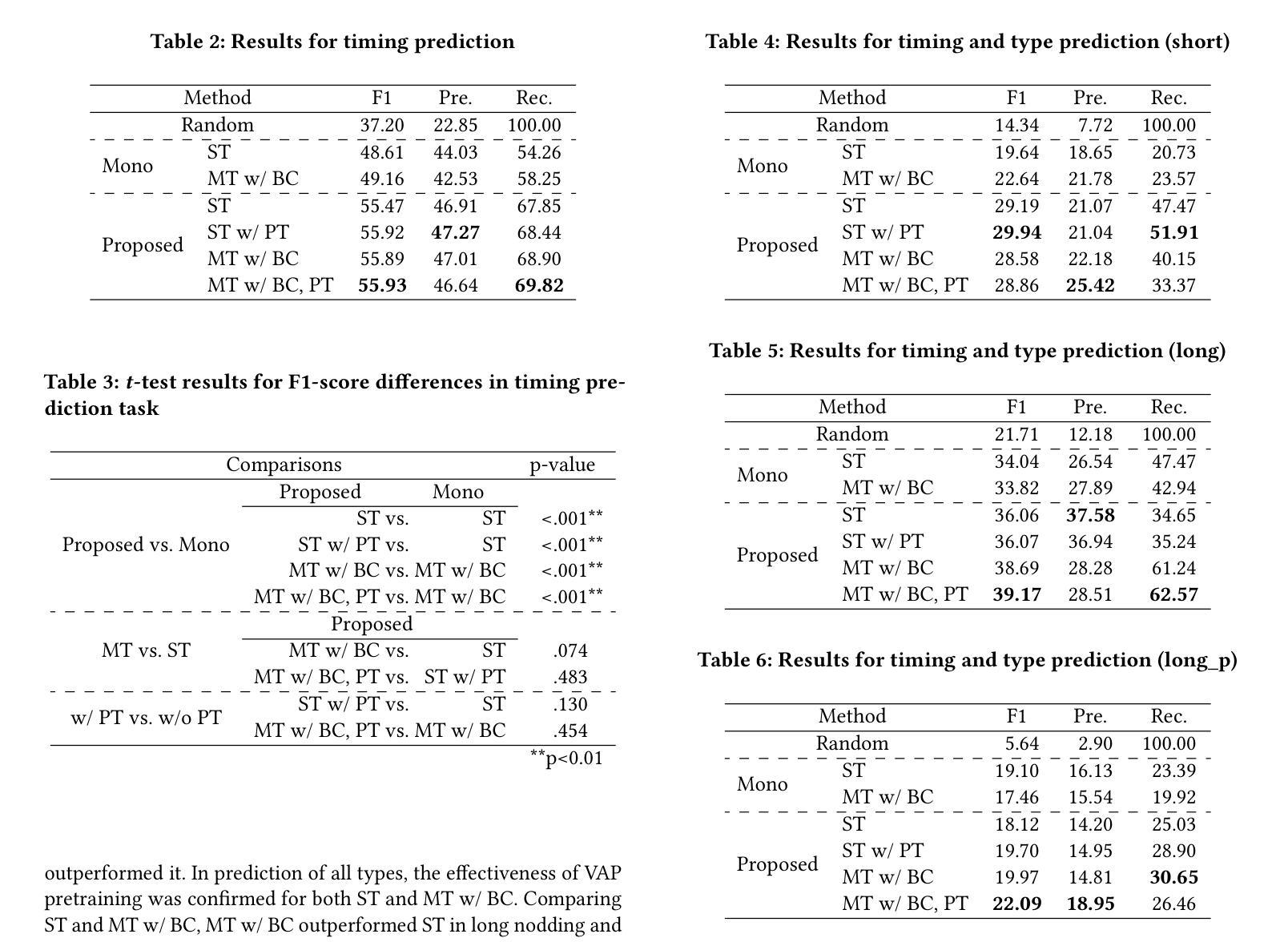
Real-time Generation of Various Types of Nodding for Avatar Attentive Listening System
Authors:Kazushi Kato, Koji Inoue, Divesh Lala, Keiko Ochi, Tatsuya Kawahara
In human dialogue, nonverbal information such as nodding and facial expressions is as crucial as verbal information, and spoken dialogue systems are also expected to express such nonverbal behaviors. We focus on nodding, which is critical in an attentive listening system, and propose a model that predicts both its timing and type in real time. The proposed model builds on the voice activity projection (VAP) model, which predicts voice activity from both listener and speaker audio. We extend it to prediction of various types of nodding in a continuous and real-time manner unlike conventional models. In addition, the proposed model incorporates multi-task learning with verbal backchannel prediction and pretraining on general dialogue data. In the timing and type prediction task, the effectiveness of multi-task learning was significantly demonstrated. We confirmed that reducing the processing rate enables real-time operation without a substantial drop in accuracy, and integrated the model into an avatar attentive listening system. Subjective evaluations showed that it outperformed the conventional method, which always does nodding in sync with verbal backchannel. The code and trained models are available at https://github.com/MaAI-Kyoto/MaAI.
在人类的对话中,非言语信息如点头和面部表情与言语信息一样重要,人们也期望对话系统能够表达这样的非言语行为。我们专注于点头,这在倾听系统中至关重要,并提出一个模型,该模型可以实时预测点头的时机和类型。所提出的模型基于语音活动投影(VAP)模型,该模型可以从听众和说话者的音频中预测语音活动。我们将其扩展到连续实时预测各种点头方式,不同于传统模型。此外,所提出的模型结合了多任务学习与言语反馈预测,并在一般对话数据上进行预训练。在预测时间和类型任务中,多任务学习的有效性得到了显著证明。我们确认降低处理速率可以在不显著降低准确率的情况下实现实时操作,并将该模型集成到虚拟角色倾听系统中。主观评估表明,它优于传统方法,后者总是与言语反馈同步点头。相关代码和训练好的模型可在https://github.com/MaAI-Kyoto/MaAI上找到。
论文及项目相关链接
PDF Accepted by 27th ACM International Conference on Multimodal Interaction (ICMI ‘25), Long paper
Summary
该研究关注人类对话中的点头行为,这是一种重要的非言语信息。研究团队提出了一种模型,能够实时预测点头的时机和类型。该模型基于语音活动预测模型,并进行了扩展,以连续实时的方式预测各种点头行为。此外,该模型还结合了语言回馈预测多任务学习和一般对话数据的预训练。实验证明,多任务学习在预测点头时机和类型方面效果显著。该模型被集成到一个虚拟人身的倾听系统中,主观评估表明,与传统的总是与语言回馈同步点头的方法相比,该模型表现更佳。
Key Takeaways
- 研究重视非言语信息,特别是点头行为在对话中的重要性。
- 提出一种模型,能实时预测点头的时机和类型。
- 模型基于语音活动预测模型进行扩展,以连续实时的方式预测各种点头行为。
- 模型采用多任务学习,结合语言回馈预测,并在一般对话数据上进行预训练。
- 多任务学习在预测点头时机和类型上效果显著。
- 模型被成功集成到虚拟人身的倾听系统中。
点此查看论文截图


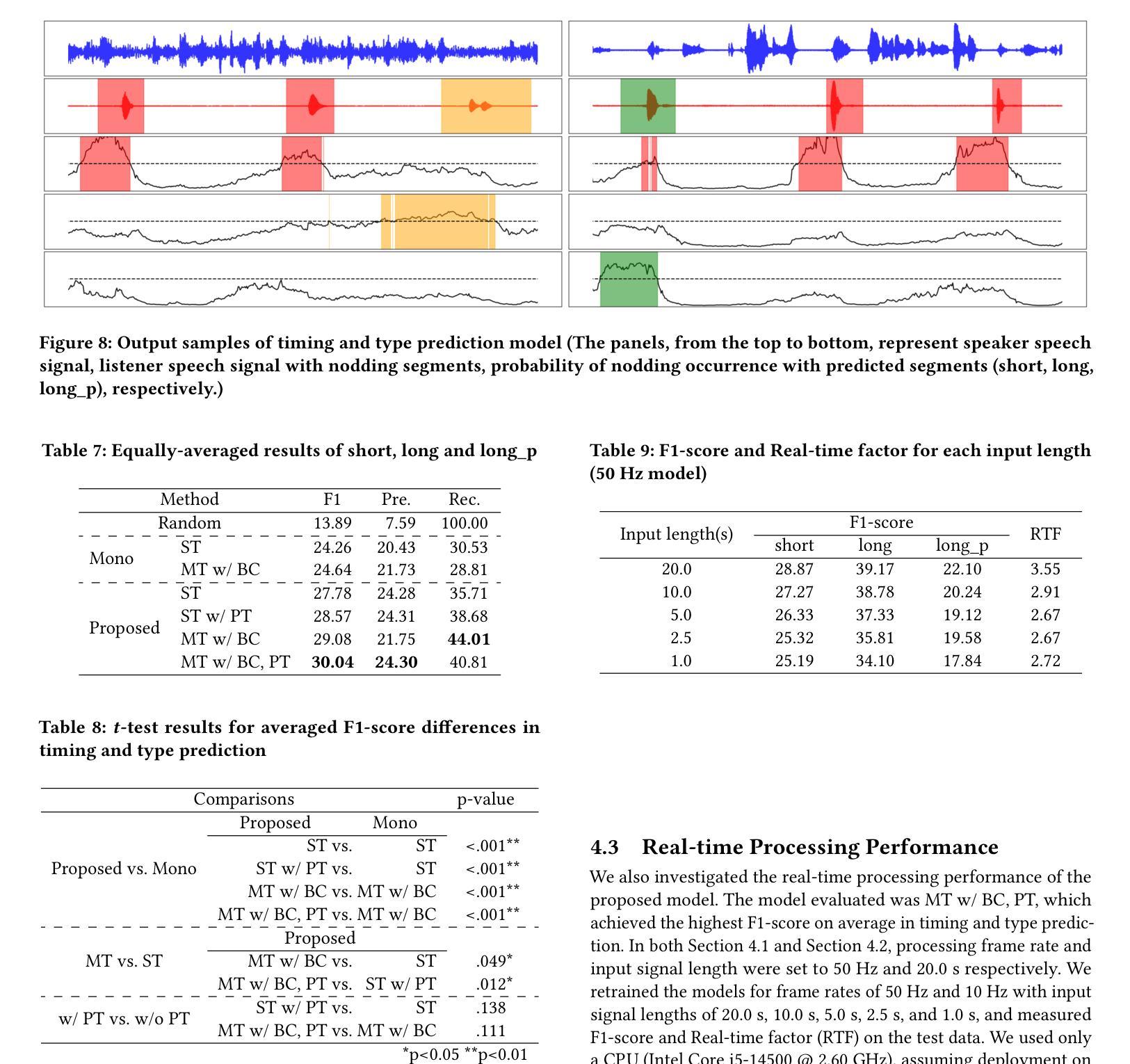
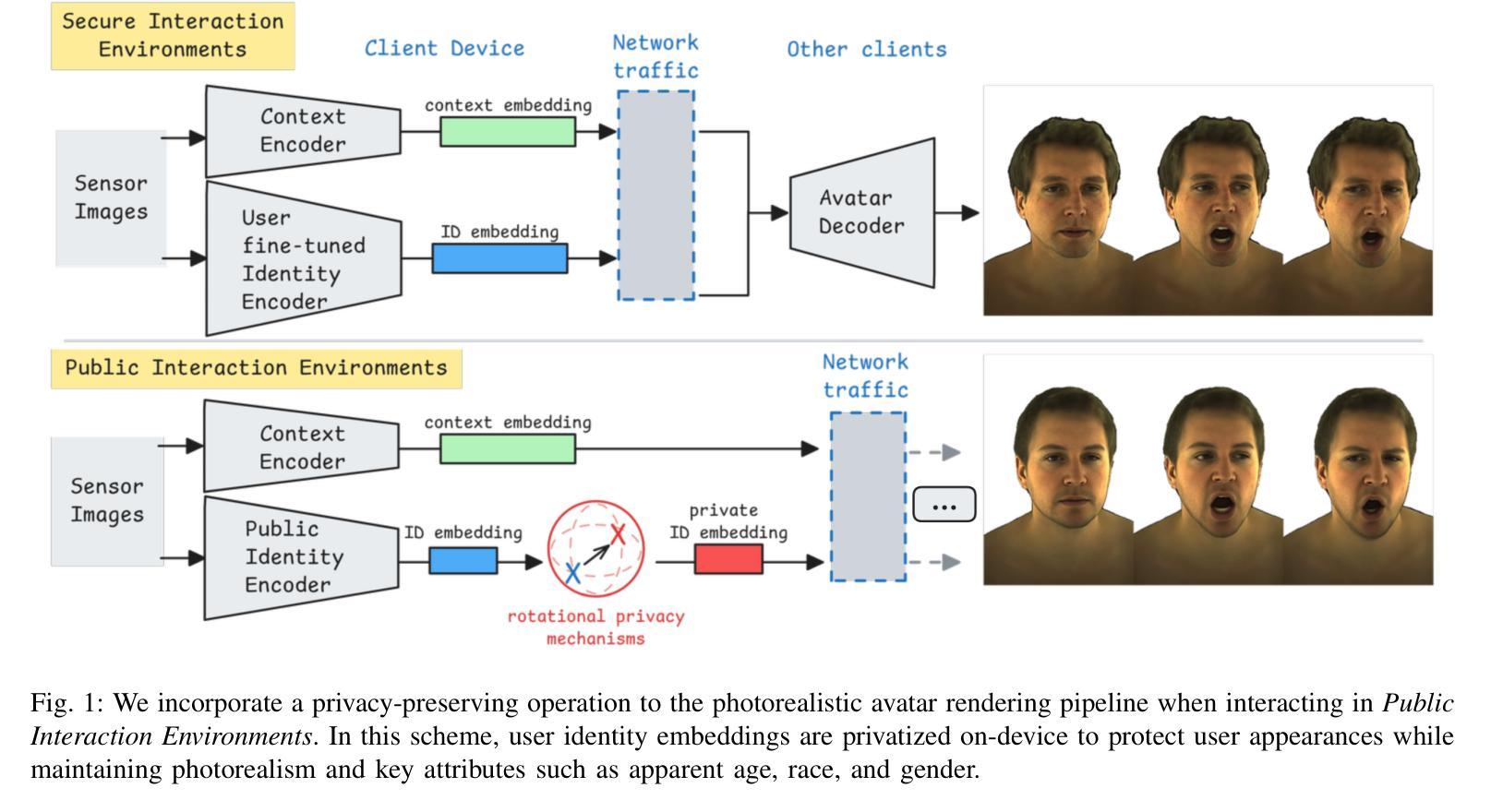
Towards Privacy-preserving Photorealistic Self-avatars in Mixed Reality
Authors:Ethan Wilson, Vincent Bindschaedler, Sophie Jörg, Sean Sheikholeslam, Kevin Butler, Eakta Jain
Photorealistic 3D avatar generation has rapidly improved in recent years, and realistic avatars that match a user’s true appearance are more feasible in Mixed Reality (MR) than ever before. Yet, there are known risks to sharing one’s likeness online, and photorealistic MR avatars could exacerbate these risks. If user likenesses were to be shared broadly, there are risks for cyber abuse or targeted fraud based on user appearances. We propose an alternate avatar rendering scheme for broader social MR – synthesizing realistic avatars that preserve a user’s demographic identity while being distinct enough from the individual user to protect facial biometric information. We introduce a methodology for privatizing appearance by isolating identity within the feature space of identity-encoding generative models. We develop two algorithms that then obfuscate identity: \epsmethod{} provides differential privacy guarantees and \thetamethod{} provides fine-grained control for the level of identity offset. These methods are shown to successfully generate de-identified virtual avatars across multiple generative architectures in 2D and 3D. With these techniques, it is possible to protect user privacy while largely preserving attributes related to sense of self. Employing these techniques in public settings could enable the use of photorealistic avatars broadly in MR, maintaining high realism and immersion without privacy risk.
近年来,逼真的三维化身生成技术已得到迅速改进,在混合现实(MR)中匹配用户真实外貌的逼真化身比以往任何时候都更加可行。然而,在线上分享自己的肖像存在已知风险,而逼真的MR化身可能会加剧这些风险。如果用户的肖像被广泛分享,那么根据用户的外貌特征进行网络欺凌或针对性欺诈的风险就会增加。我们提出了一种用于更广泛的社会MR的替代化身渲染方案——合成逼真的化身,保留用户的身份特征信息,同时足够个性化地保护面部生物识别信息。我们介绍了一种通过身份编码生成模型的特性空间来隔离身份从而保护外貌隐私的方法论。我们开发了两个模糊身份特征的算法:\epsmethod{}提供差分隐私保证,而\thetamethod{}提供精细的身份偏移控制级别。这些方法成功地在二维和三维的多个生成架构中生成了匿名虚拟化身。通过这些技术,可以在保护用户隐私的同时,保留与自我意识相关的属性。在公共场所采用这些技术,可以在保持高度现实感和沉浸感的同时,实现MR中逼真化身的广泛应用,而不存在隐私风险。
论文及项目相关链接
Summary
近期3D头像生成技术迅速发展,使得在混合现实(MR)中创建与用户真实外貌相匹配的逼真头像变得更为可行。然而,分享个人肖像存在风险,而逼真的MR头像可能加剧这些风险。若用户肖像被广泛分享,可能会遭受网络欺凌或针对个人外貌的欺诈。为此,我们提出了一种替代的头像渲染方案——合成逼真头像,保留用户的身份特征信息的同时,又能保护面部生物识别信息。通过身份编码生成模型的特性空间进行身份信息的隔离,我们提出了两种模糊身份的方法:提供差分隐私保证的ε方法(\epsmethod)和提供精细身份偏移控制的θ方法(\thetamethod)。这些方法成功地在多种二维和三维生成架构中生成了匿名虚拟头像。这些技术能够在保护用户隐私的同时,保留与自我认知相关的属性。在公共场合应用这些技术,可以在保持高真实感和沉浸感的同时,降低使用MR中的逼真头像的隐私风险。
Key Takeaways
- 3D头像生成技术迅速发展,使得在混合现实中创建与用户真实外貌匹配的头像更为可行。
- 分享个人肖像存在风险,逼真的MR头像可能加剧这些风险,如遭受网络欺凌或欺诈。
- 提出了一种合成逼真头像的方法,既保留用户身份特征信息,又保护面部生物识别信息。
- 通过身份编码生成模型的特性空间进行身份信息的隔离。
- 介绍了两种模糊身份的方法,提供了差分隐私保证和精细的身份偏移控制。
- 这些方法在多种生成架构中成功生成了匿名虚拟头像。
点此查看论文截图

JWB-DH-V1: Benchmark for Joint Whole-Body Talking Avatar and Speech Generation Version 1
Authors:Xinhan Di, Kristin Qi, Pengqian Yu
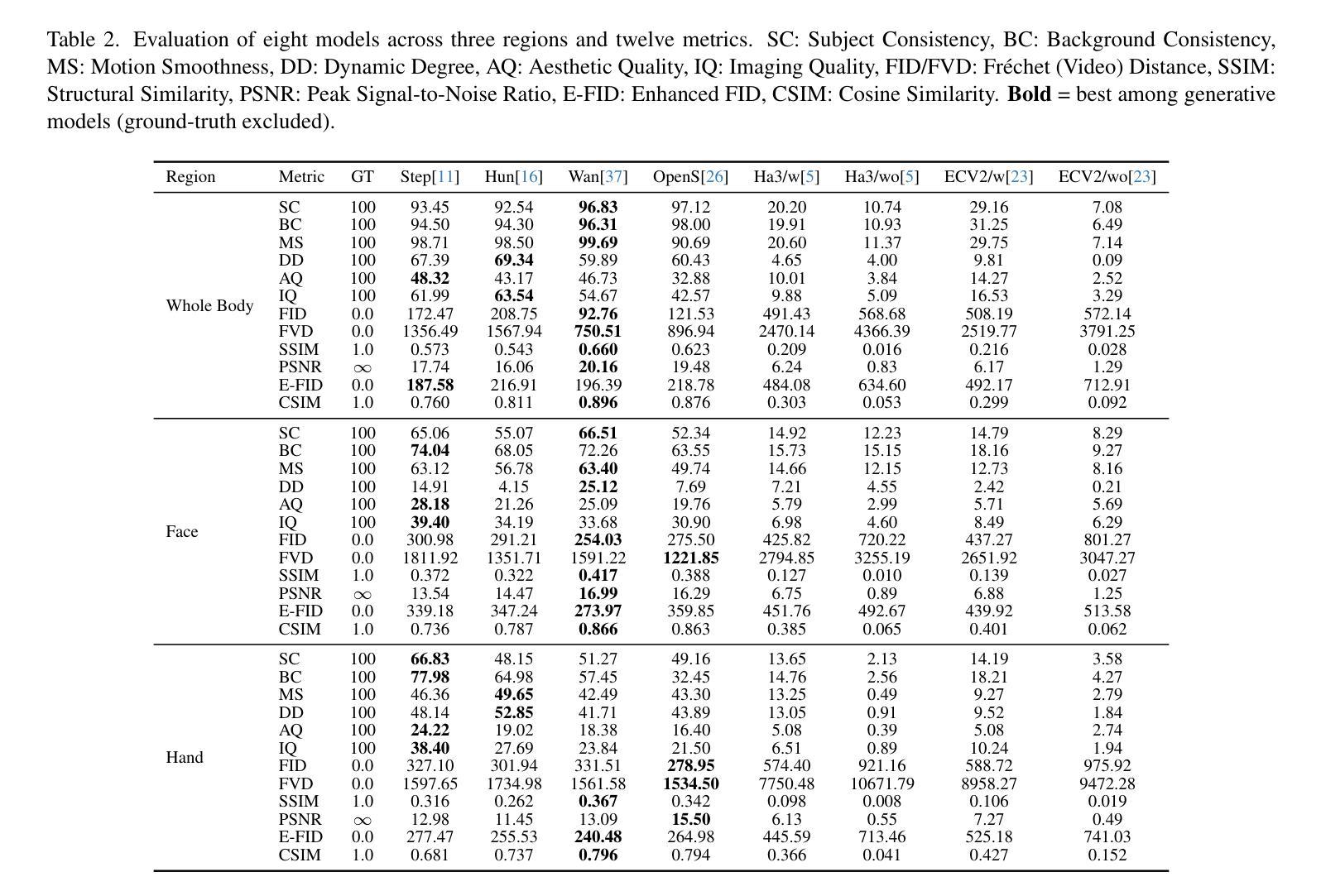
Recent advances in diffusion-based video generation have enabled photo-realistic short clips, but current methods still struggle to achieve multi-modal consistency when jointly generating whole-body motion and natural speech. Current approaches lack comprehensive evaluation frameworks that assess both visual and audio quality, and there are insufficient benchmarks for region-specific performance analysis. To address these gaps, we introduce the Joint Whole-Body Talking Avatar and Speech Generation Version I(JWB-DH-V1), comprising a large-scale multi-modal dataset with 10,000 unique identities across 2 million video samples, and an evaluation protocol for assessing joint audio-video generation of whole-body animatable avatars. Our evaluation of SOTA models reveals consistent performance disparities between face/hand-centric and whole-body performance, which incidates essential areas for future research. The dataset and evaluation tools are publicly available at https://github.com/deepreasonings/WholeBodyBenchmark.
近期扩散式视频生成技术的进展已经能够实现逼真的短片生成,但当前的方法在联合生成全身运动和自然语音时,仍难以实现多模式的一致性。现有方法缺乏综合评估框架,无法对视觉和音频质量进行评估,且针对特定区域的性能分析基准不足。为了弥补这些空白,我们推出了联合全身说话虚拟形象与语音生成版本I(JWB-DH-V1),其包括一个大规模多模式数据集,涵盖1万个唯一身份和超过2百万视频样本,以及一个用于评估全身可动画虚拟形象的联合音视频生成的评估协议。我们对最新模型的评估显示,面向面部/手部与全身性能之间存在持续的性能差异,这指明了未来研究的关键领域。数据集和评估工具可在 https://github.com/deepreasonings/WholeBodyBenchmark 公开获取。
论文及项目相关链接
PDF WiCV @ ICCV 2025
Summary
近期扩散技术进展为生成逼真的短片视频提供了可能,但在联合生成全身运动和自然语音时仍面临多模态一致性挑战。缺乏综合评估框架对视觉和音频质量进行评估,且区域特定性能分析的基准测试不足。为解决这些问题,我们推出联合全身说话半身像和语音生成版本一(JWB-DH-V1),包括大规模多模态数据集,涵盖10,000个唯一身份和超过2百万视频样本,以及评估全身可动画半身像联合音视频生成的评估协议。对最新模型的评估显示,面部/手部为中心与全身性能之间存在持续的性能差异,这为未来研究指明了关键方向。数据集和评估工具可在https://github.com/deepreasonings/WholeBodyBenchmark公开获取。
Key Takeaways
- 扩散技术已经实现了逼真视频的生成。
- 当前技术在联合生成全身运动和自然语音时面临多模态一致性挑战。
- 缺乏评估视觉和音频质量的综合评估框架。
- 需要更多的区域特定性能分析的基准测试。
- 推出JWB-DH-V1数据集,包含大规模多模态数据,旨在解决上述问题。
- 对现有模型的评估显示,全身性能与面部/手部为中心的模型之间存在性能差异。
点此查看论文截图


HairCUP: Hair Compositional Universal Prior for 3D Gaussian Avatars
Authors:Byungjun Kim, Shunsuke Saito, Giljoo Nam, Tomas Simon, Jason Saragih, Hanbyul Joo, Junxuan Li
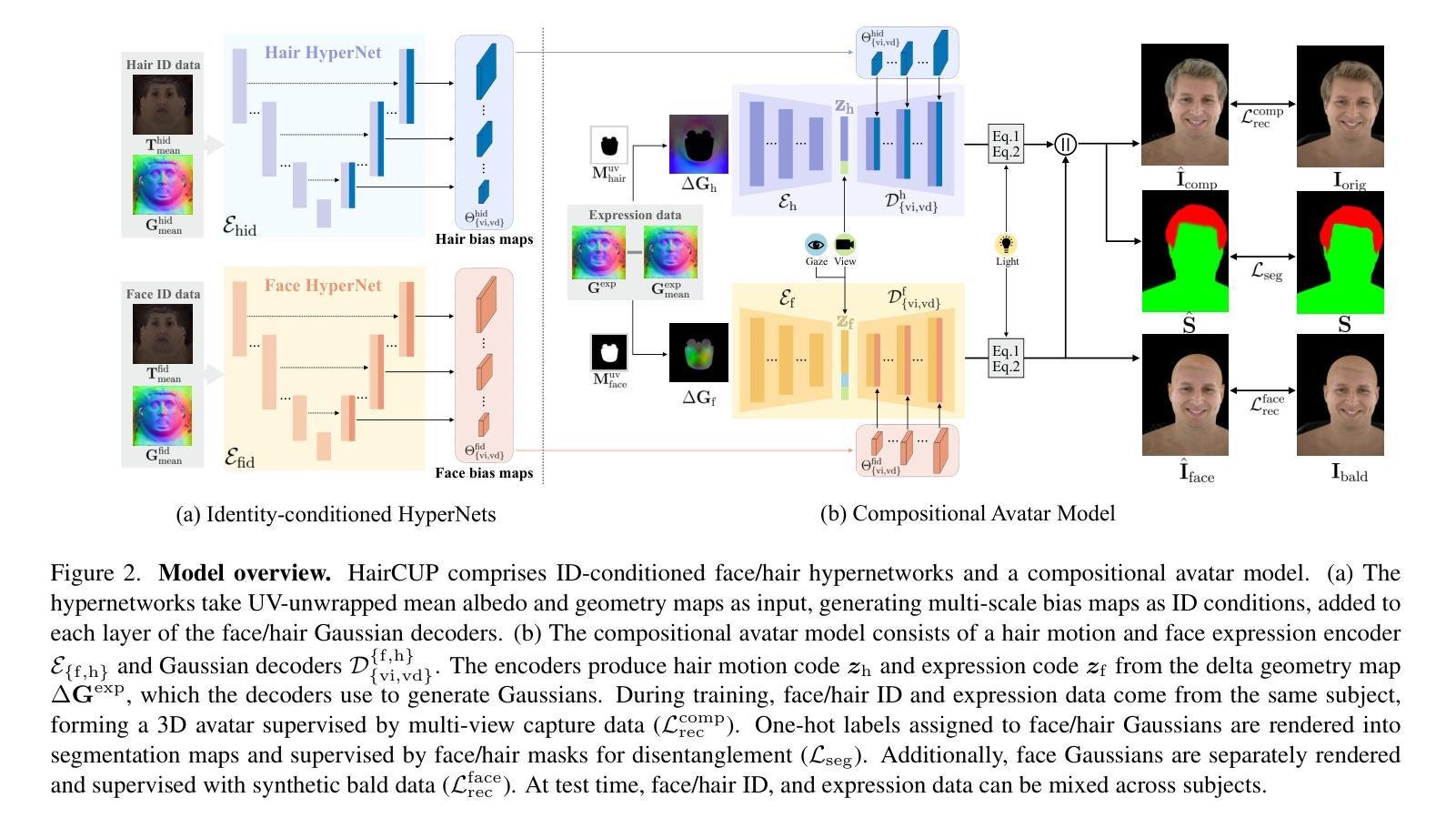
We present a universal prior model for 3D head avatars with explicit hair compositionality. Existing approaches to build generalizable priors for 3D head avatars often adopt a holistic modeling approach, treating the face and hair as an inseparable entity. This overlooks the inherent compositionality of the human head, making it difficult for the model to naturally disentangle face and hair representations, especially when the dataset is limited. Furthermore, such holistic models struggle to support applications like 3D face and hairstyle swapping in a flexible and controllable manner. To address these challenges, we introduce a prior model that explicitly accounts for the compositionality of face and hair, learning their latent spaces separately. A key enabler of this approach is our synthetic hairless data creation pipeline, which removes hair from studio-captured datasets using estimated hairless geometry and texture derived from a diffusion prior. By leveraging a paired dataset of hair and hairless captures, we train disentangled prior models for face and hair, incorporating compositionality as an inductive bias to facilitate effective separation. Our model’s inherent compositionality enables seamless transfer of face and hair components between avatars while preserving identity. Additionally, we demonstrate that our model can be fine-tuned in a few-shot manner using monocular captures to create high-fidelity, hair-compositional 3D head avatars for unseen subjects. These capabilities highlight the practical applicability of our approach in real-world scenarios, paving the way for flexible and expressive 3D avatar generation.
我们提出了一种具有明确头发组合性的3D头像通用先验模型。现有的为3D头像构建通用先验模型的方法通常采用整体建模方法,将脸和头发视为一个不可分割的实体。这忽略了人头的内在组合性,使得模型很难自然地分离面部和头发的表示,尤其是在数据集有限的情况下。此外,这种整体模型很难以灵活和可控的方式支持3D面部和发型交换等应用程序。为了应对这些挑战,我们引入了一种先验模型,该模型明确考虑了面部和头发的组合性,分别学习它们的潜在空间。此方法的关键是我们合成无发数据创建管道,该管道使用估计的无发几何和纹理从扩散先验中去除从工作室捕获的数据集中的头发。通过利用带有头发和无发捕获的配对数据集,我们对面部和头发进行了分离训练先验模型,将组合性作为归纳偏置,以促进有效的分离。我们模型的内在组合性使得头像之间的面部和头发组件无缝转移,同时保持身份。此外,我们证明我们的模型可以通过单目捕获进行微调,为未见过的主题创建高保真、具有头发组合的3D头像。这些功能突显了我们的方法在现实世界场景中的实际应用性,为灵活和富有表现力的3D头像生成铺平了道路。
论文及项目相关链接
PDF ICCV 2025. Project Page: https://bjkim95.github.io/haircup/
Summary
本文介绍了一种针对具有明确头发组合性的3D头部化身通用先验模型。现有方法在处理可推广的先验模型时常常采用整体建模方式,将面部和头发视为不可分割的实体,忽略了头部固有的组合性。本文方法通过明确考虑面部和头发的组合性,分别学习它们的潜在空间来解决这一问题。通过合成无发数据创建管道去除基于扩散先验估计的无发几何结构和纹理的捕获数据中的头发,并使用配对的数据集对脸和头发进行训练,融入组合性作为归纳偏置以促进有效分离。该模型的固有组合性能够实现化身之间的脸和头发组件无缝转移,同时保留身份。此外,该研究还展示了该模型可以通过少量单目捕获进行微调,为未见过的主体创建高保真、具有头发组合的3D头部化身,突显了其在现实场景中的实用应用价值。
Key Takeaways
- 现有3D头部化身通用先验模型常常采用整体建模方式,难以自然分离面部和头发表示。
- 本文提出了一种考虑面部和头发组合性的先验模型,分别学习它们的潜在空间。
- 通过合成无发数据创建管道去除头发,使用配对数据集进行训练。
- 模型的固有组合性可实现无缝转移脸和头发组件。
- 模型可少量单目捕获进行微调,创建高保真3D头部化身。
- 该方法为未见过的主体提供灵活的3D头像生成能力。
点此查看论文截图


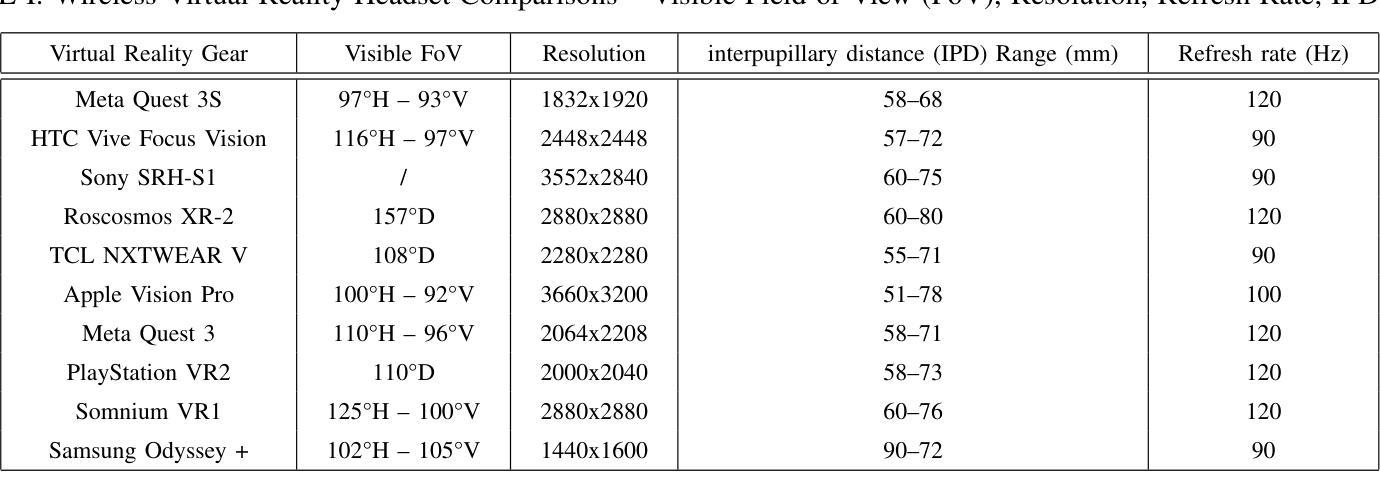
AI Enabled 6G for Semantic Metaverse: Prospects, Challenges and Solutions for Future Wireless VR
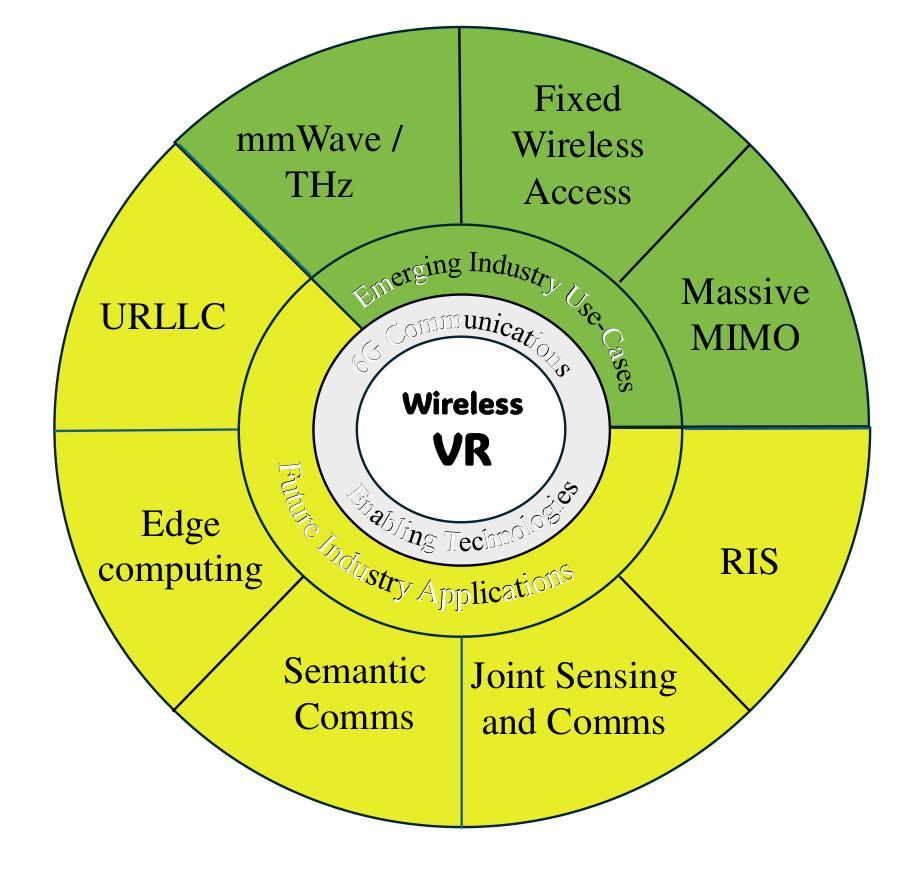
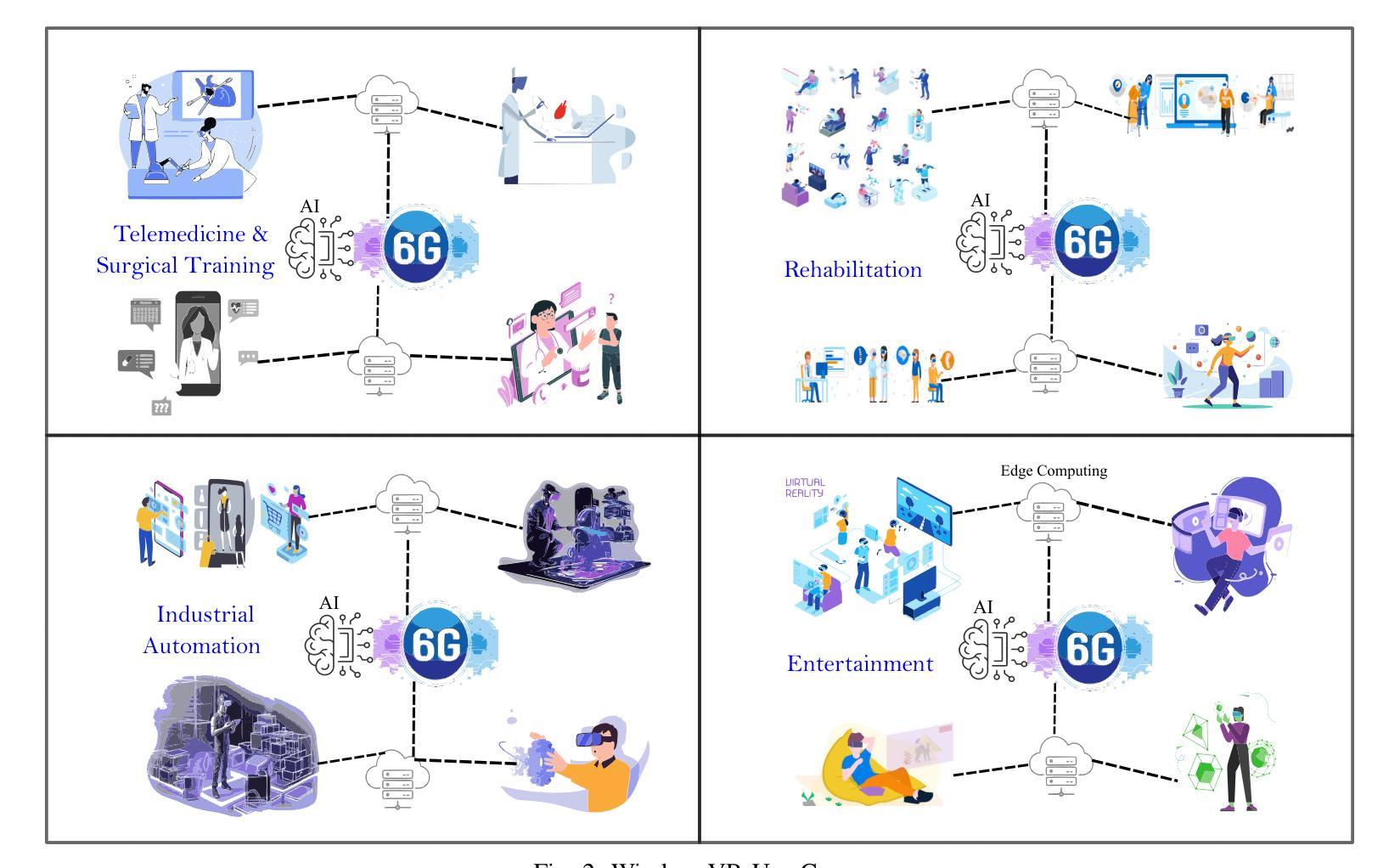
Authors:Muhammad Ahmed Mohsin, Sagnik Bhattacharya, Abhiram Gorle, Muhammad Ali Jamshed, John M. Cioffi
Wireless support of virtual reality (VR) has challenges when a network has multiple users, particularly for 3D VR gaming, digital AI avatars, and remote team collaboration. This work addresses these challenges through investigation of the low-rank channels that inevitably occur when there are more active users than there are degrees of spatial freedom, effectively often the number of antennas. The presented approach uses optimal nonlinear transceivers, equivalently generalized decision-feedback or successive cancellation for uplink and superposition or dirty-paper precoders for downlink. Additionally, a powerful optimization approach for the users’ energy allocation and decoding order appears to provide large improvements over existing methods, effectively nearing theoretical optima. As the latter optimization methods pose real-time challenges, approximations using deep reinforcement learning (DRL) are used to approximate best performance with much lower (5x at least) complexity. Experimental results show significantly larger sum rates and very large power savings to attain the data rates found necessary to support VR. Experimental results show the proposed algorithm outperforms current industry standards like orthogonal multiple access (OMA), non-orthogonal multiple access (NOMA), as well as the highly researched methods in multi-carrier NOMA (MC-NOMA), enhancing sum data rate by 39%, 28%, and 16%, respectively, at a given power level. For the same data rate, it achieves power savings of 75%, 45%, and 40%, making it ideal for VR applications. Additionally, a near-optimal deep reinforcement learning (DRL)-based resource allocation framework for real-time use by being 5x faster and reaching 83% of the global optimum is introduced.
无线技术在对虚拟环境(VR)提供支持时面临多个用户的挑战,尤其是在诸如多人参与的在线虚拟世界体验等3D虚拟现实游戏以及数字人工智能分身或远程团队合作的场合。该研究解决了上述问题,针对出现更多活跃用户相较于可用的空间自由度时所不可避免地产生的低秩通道进行了深入研究。这在许多场景下意味着面临用户天线数量不足的难题。文中使用了一种最优的非线性收发器,包括上行链路中的广义决策反馈或连续取消技术,以及下行链路中的叠加或脏纸编码技术。此外,对于用户能量分配和解码顺序的强大优化方法也带来了对已有技术的巨大改进,这种改进接近理论最优解。尽管后者提出的优化方法面临实时处理方面的挑战,但通过深度强化学习进行的近似算法能在大大降低计算复杂度(至少减少一半)的情况下实现近似最优性能。实验结果显示出新型算法支持显著更高的数据传输率及更低的能耗水平。实验结果表明,相较于正交多址接入(OMA)、非正交多址接入(NOMA)以及多载波非正交多址接入(MC-NOMA)等现有行业标准的协议表现优越。当处于相同的功率水平时,所提算法提高了各自行业标准的传输率分别达到惊人的近三分之一,且消耗的功率降低四分之一左右。这使其成为理想支持虚拟现实应用的通信技术。此外,我们还引入了一种基于深度强化学习的资源分配框架,能够在接近实时的环境中快速运行并达到全局最优解的八成左右。这是一种具有重大应用价值的近乎理想的优化策略,特别适合在未来基于多用户的无线通信网络中发挥作用以推动元宇宙技术的广泛运用及长足发展。
论文及项目相关链接
PDF IEEE Wireless Communications Magazine
Summary
针对虚拟现实(VR)的无线支持在多用户网络中面临挑战,特别是在3D VR游戏、数字AI化身和远程团队协作中。本研究通过探索低等级通道来解决这些问题,当活跃用户数量超过空间自由度时,这些通道不可避免地会出现。研究采用最优非线性收发器,并利用深度学习强化算法优化用户能量分配和解码顺序。实验结果显示,该方法优于当前行业标准,提高了数据速率并大幅节省能源。
Key Takeaways
- 虚拟现实(VR)的无线支持在多用户网络中具有挑战,特别是在3D VR游戏、数字AI化身和远程团队协作中。
- 研究通过探索低等级通道解决挑战,采用最优非线性收发器。
- 通过深度学习强化算法优化用户能量分配和解码顺序,以逼近理论最优性能。
- 实验结果显示该方法优于当前行业标准,如正交多址接入(OMA)、非正交多址接入(NOMA)和多载波NOMA(MC-NOMA)。
- 该方法在给定功率水平下提高了数据速率,并在相同数据速率下实现了显著的节能。
- 引入了一种基于深度学习强化算法的实时资源分配框架,运行速度快,接近全局最优解的83%。
点此查看论文截图

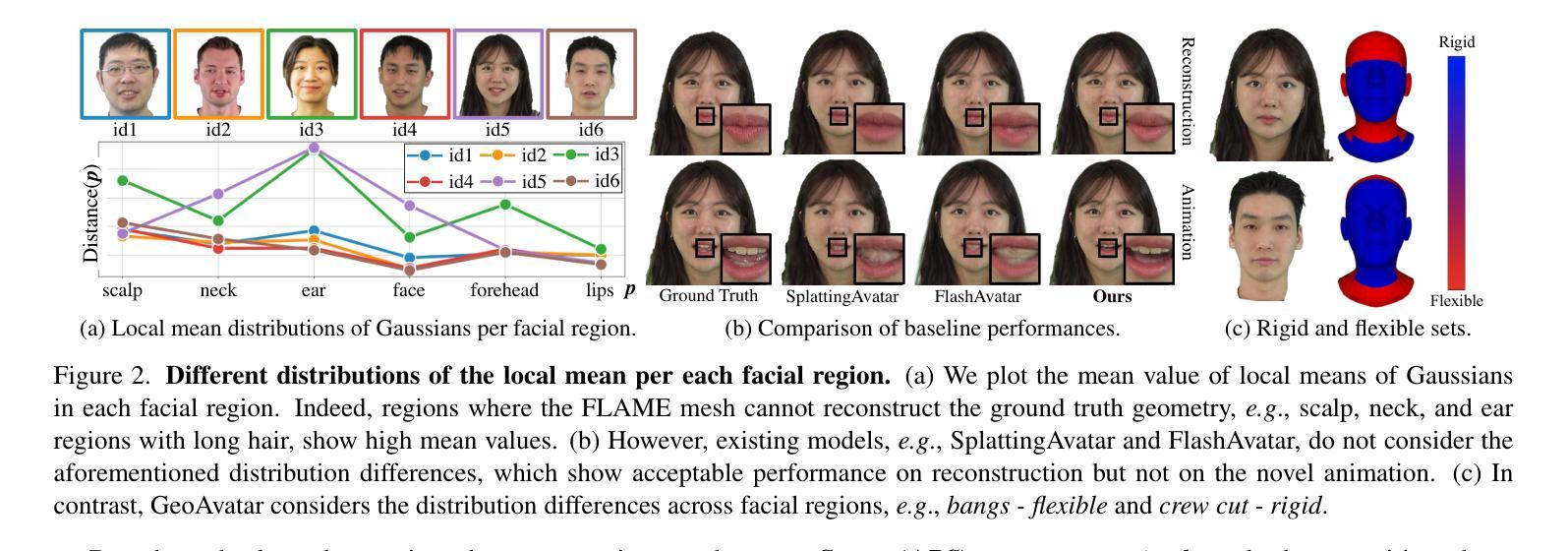
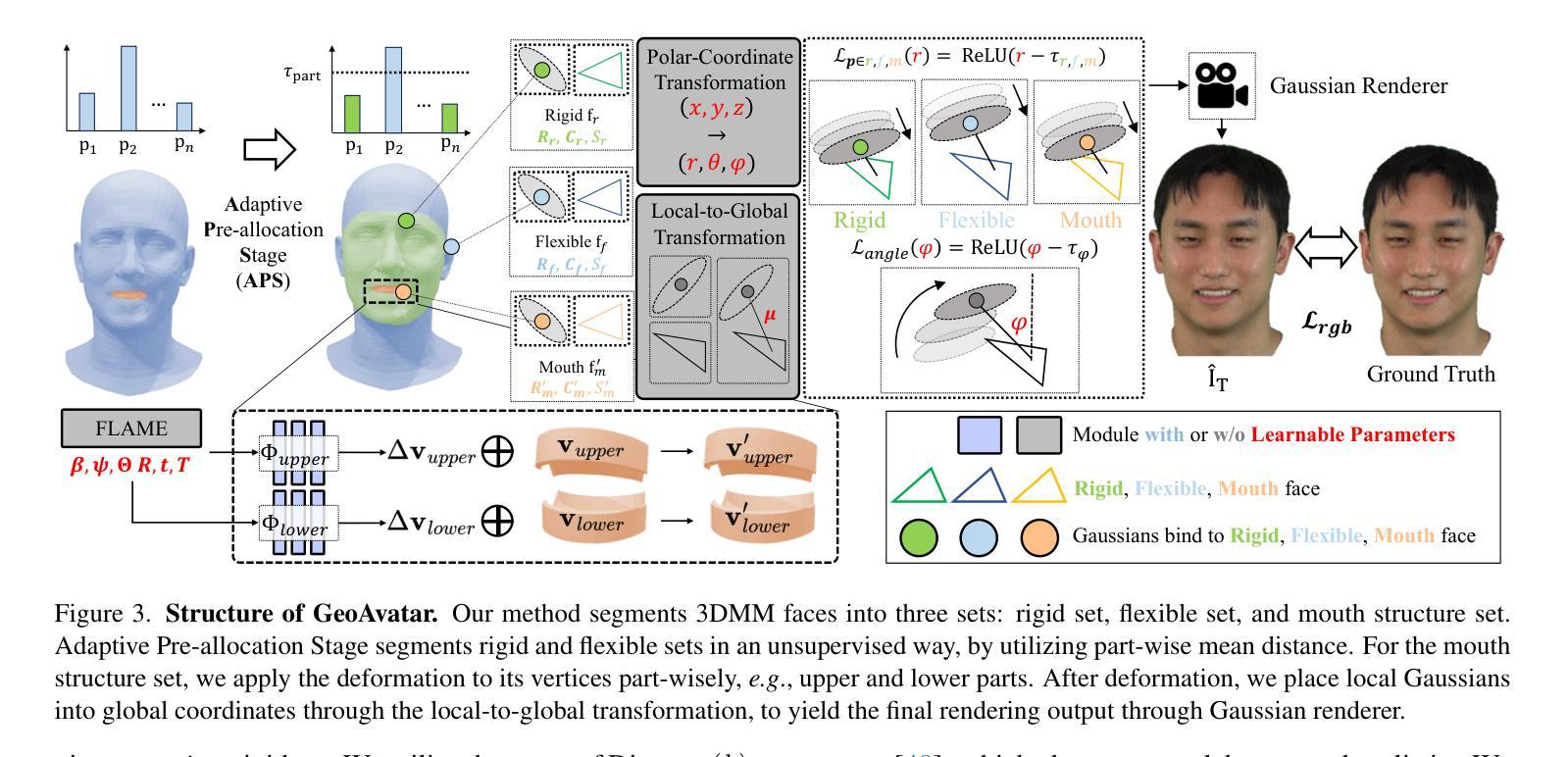
GeoAvatar: Adaptive Geometrical Gaussian Splatting for 3D Head Avatar
Authors:SeungJun Moon, Hah Min Lew, Seungeun Lee, Ji-Su Kang, Gyeong-Moon Park
Despite recent progress in 3D head avatar generation, balancing identity preservation, i.e., reconstruction, with novel poses and expressions, i.e., animation, remains a challenge. Existing methods struggle to adapt Gaussians to varying geometrical deviations across facial regions, resulting in suboptimal quality. To address this, we propose GeoAvatar, a framework for adaptive geometrical Gaussian Splatting. GeoAvatar leverages Adaptive Pre-allocation Stage (APS), an unsupervised method that segments Gaussians into rigid and flexible sets for adaptive offset regularization. Then, based on mouth anatomy and dynamics, we introduce a novel mouth structure and the part-wise deformation strategy to enhance the animation fidelity of the mouth. Finally, we propose a regularization loss for precise rigging between Gaussians and 3DMM faces. Moreover, we release DynamicFace, a video dataset with highly expressive facial motions. Extensive experiments show the superiority of GeoAvatar compared to state-of-the-art methods in reconstruction and novel animation scenarios.
尽管最近在3D头像生成方面取得了进展,但在平衡身份保留(即重建)与新颖姿势和表情(即动画)之间仍然存在挑战。现有方法难以将高斯适应面部各区域的几何偏差变化,导致质量不佳。为了解决这一问题,我们提出了GeoAvatar,一个自适应几何高斯拼贴框架。GeoAvatar利用自适应预分配阶段(APS),这是一种无监督方法,将高斯分为刚性和柔性集,用于自适应偏移正则化。然后,基于口腔结构和动态,我们引入了一种新的口腔结构和部分变形策略,以提高口腔动画的保真度。最后,我们提出了一种针对高斯和3DMM面部之间精确骨架的正则化损失。此外,我们发布了DynamicFace,这是一个高度表情丰富的面部动作视频数据集。大量实验表明,GeoAvatar在重建和新颖动画场景方面优于最新方法。
论文及项目相关链接
PDF ICCV 2025, Project page: https://hahminlew.github.io/geoavatar/
Summary
该文探讨了三维头像生成技术面临的挑战,尤其是在保持身份(重建)与新颖姿态和表情(动画)之间的平衡问题。为解决现有方法在处理面部几何偏差时面临的挑战,提出GeoAvatar框架,通过自适应几何高斯拼贴技术,提高了头像生成的品质。同时,引入了一种新的嘴巴结构和部分变形策略,增强了嘴巴动画的逼真度。此外,还提出了一种正则化损失方法,用于精确调整高斯与三维人脸模型之间的对应关系。实验表明,GeoAvatar相较于现有技术有明显优势。
Key Takeaways
- GeoAvatar框架旨在解决三维头像生成中的身份与动画平衡问题。
- 现有方法在面部几何偏差处理上存在挑战,导致生成质量不佳。
- GeoAvatar采用自适应几何高斯拼贴技术提高头像生成质量。
- 引入新的嘴巴结构和部分变形策略,增强嘴巴动画的逼真度。
- 提出一种正则化损失方法,精确调整高斯与三维人脸模型之间的对应关系。
- DynamicFace数据集用于实验验证,展示了GeoAvatar在重建和新颖动画场景中的优越性。
点此查看论文截图

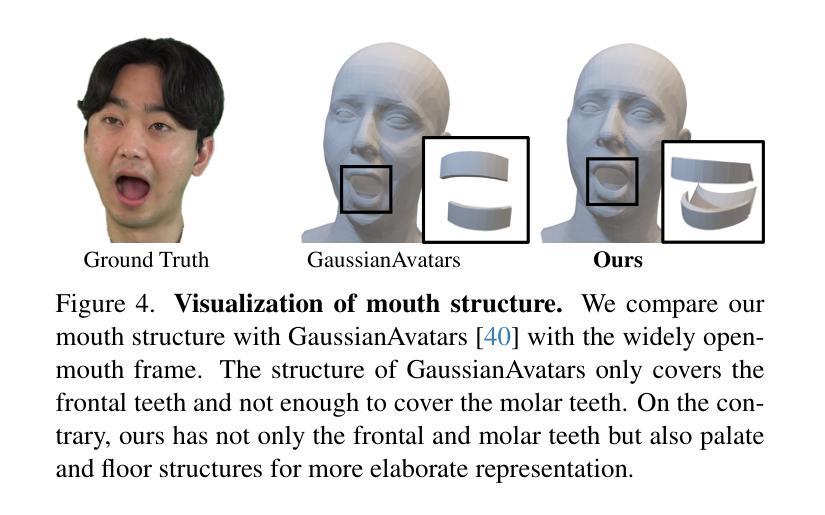
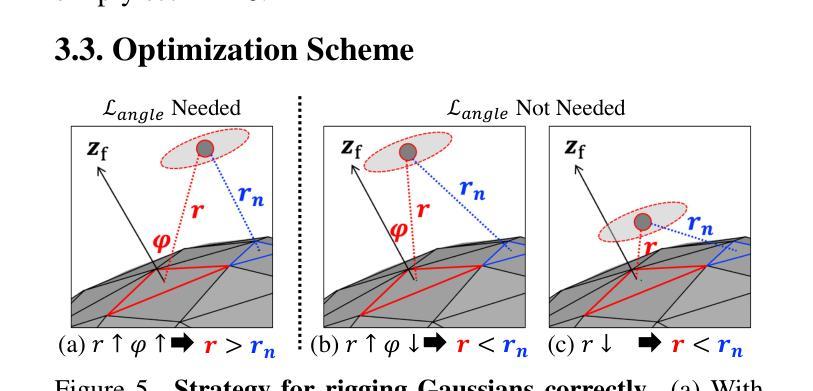

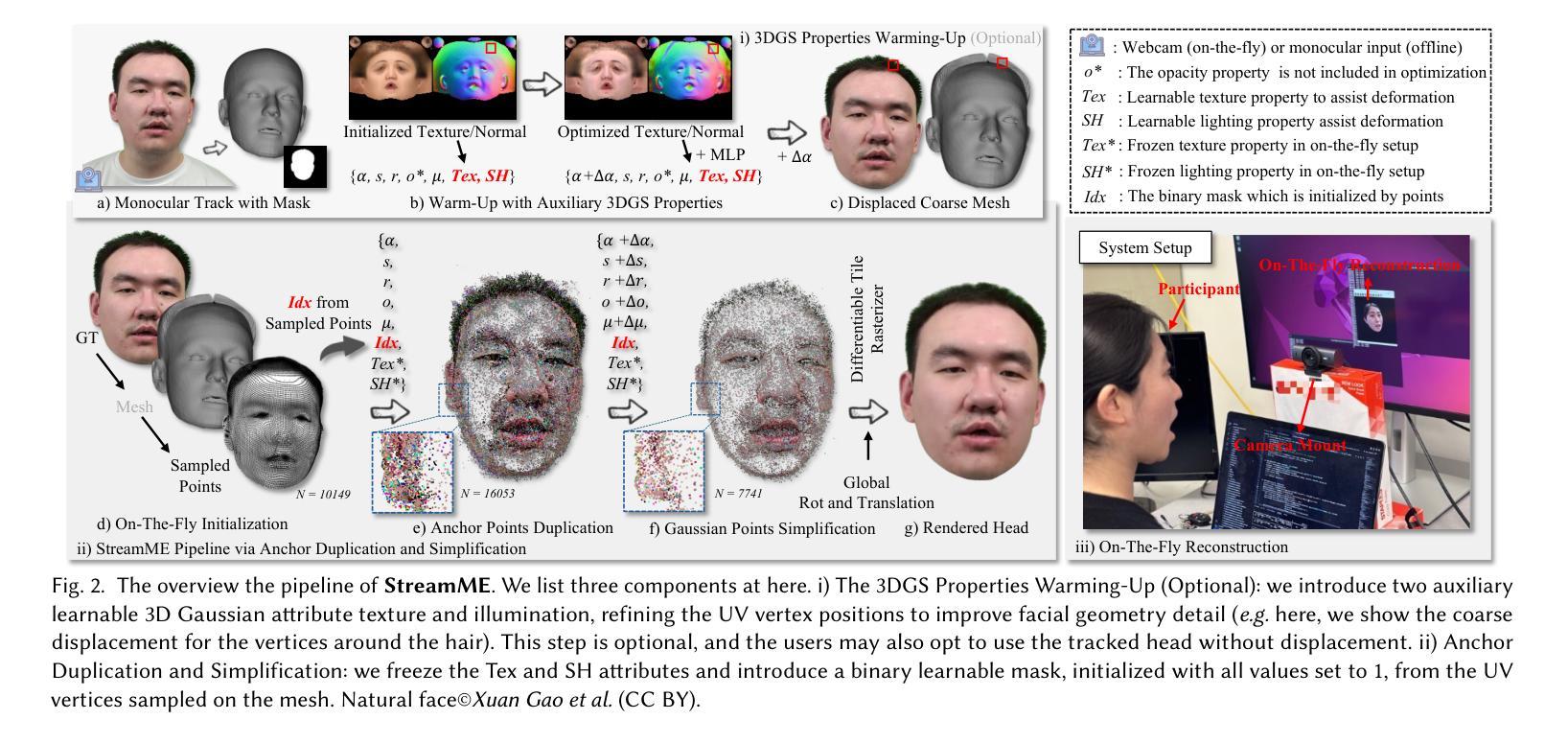
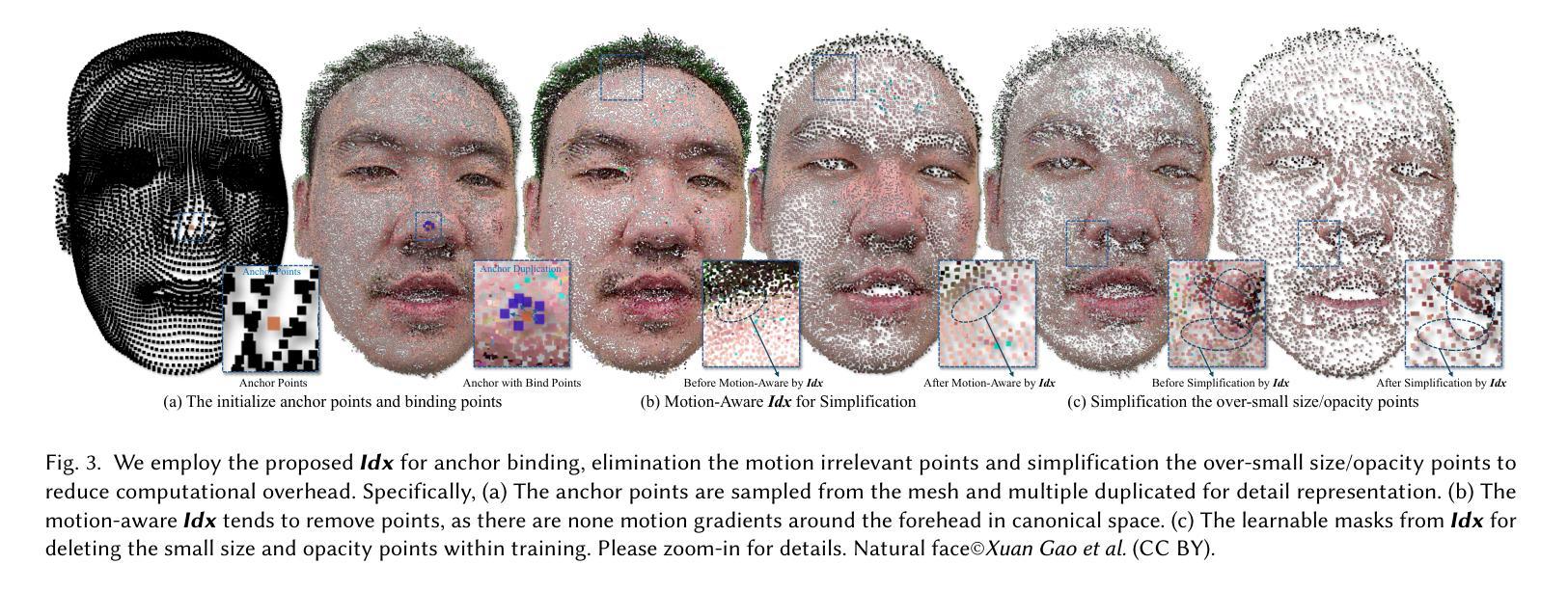
StreamME: Simplify 3D Gaussian Avatar within Live Stream
Authors:Luchuan Song, Yang Zhou, Zhan Xu, Yi Zhou, Deepali Aneja, Chenliang Xu
We propose StreamME, a method focuses on fast 3D avatar reconstruction. The StreamME synchronously records and reconstructs a head avatar from live video streams without any pre-cached data, enabling seamless integration of the reconstructed appearance into downstream applications. This exceptionally fast training strategy, which we refer to as on-the-fly training, is central to our approach. Our method is built upon 3D Gaussian Splatting (3DGS), eliminating the reliance on MLPs in deformable 3DGS and relying solely on geometry, which significantly improves the adaptation speed to facial expression. To further ensure high efficiency in on-the-fly training, we introduced a simplification strategy based on primary points, which distributes the point clouds more sparsely across the facial surface, optimizing points number while maintaining rendering quality. Leveraging the on-the-fly training capabilities, our method protects the facial privacy and reduces communication bandwidth in VR system or online conference. Additionally, it can be directly applied to downstream application such as animation, toonify, and relighting. Please refer to our project page for more details: https://songluchuan.github.io/StreamME/.
我们提出了StreamME方法,它专注于快速3D化身重建。StreamME同步记录并从实时视频流中重建头部化身,无需任何预先缓存的数据,使得重建的外观能够无缝地集成到下游应用中。我们称之为“即时训练”的这种极其快速的训练策略是我们的方法的核心。我们的方法建立在3D高斯平铺(3DGS)的基础上,消除了对可变形3DGS中多层感知器(MLPs)的依赖,只依赖于几何结构,这显著提高了对面部表情的适应速度。为了确保即时训练的高效率,我们引入了一种基于主要点的简化策略,该策略在面部表面更稀疏地分布点云,在保持渲染质量的同时优化了点的数量。利用即时训练功能,我们的方法保护了面部的隐私并降低了VR系统或在线会议中的通信带宽。此外,它可以直接应用于动画、卡通化和重新照明等下游应用。更多细节请参见我们的项目页面:https://songluchuan.github.io/StreamME/。
论文及项目相关链接
PDF 12 pages, 15 Figures
Summary
本文提出了StreamME方法,专注于快速3D头像重建。该方法可从实时视频流中同步录制并重建头像,无需预先缓存数据,使得重建的外观能够无缝融入下游应用。其核心是采用即时训练策略,建立在3D高斯飞溅技术之上,简化点云分布,提高渲染质量,同时保护面部隐私并降低VR系统或在线会议的通信带宽。可应用于动画、卡通化和重照明等下游应用。
Key Takeaways
- StreamME方法专注于快速3D头像重建,从实时视频流中同步录制并重建头像。
- 采用即时训练策略,无需预先缓存数据,可无缝融入下游应用。
- 方法建立在3D高斯飞溅技术之上,提高面部表达适应性。
- 通过简化点云分布优化渲染质量,同时保护面部隐私。
- 降低VR系统或在线会议的通信带宽。
- 可直接应用于动画、卡通化和重照明等下游应用。
点此查看论文截图


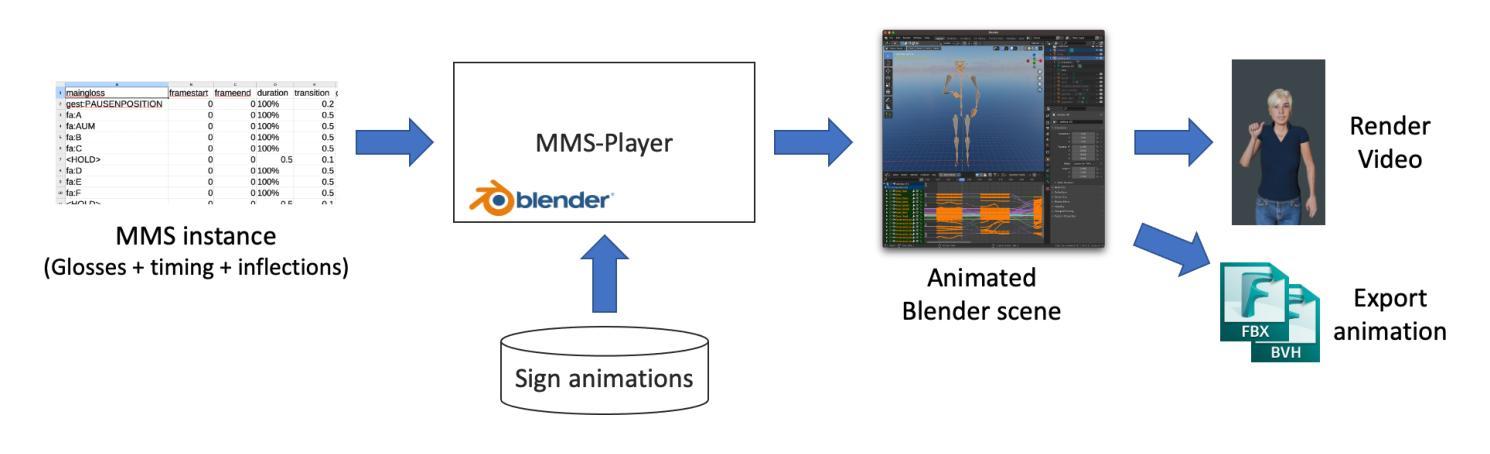
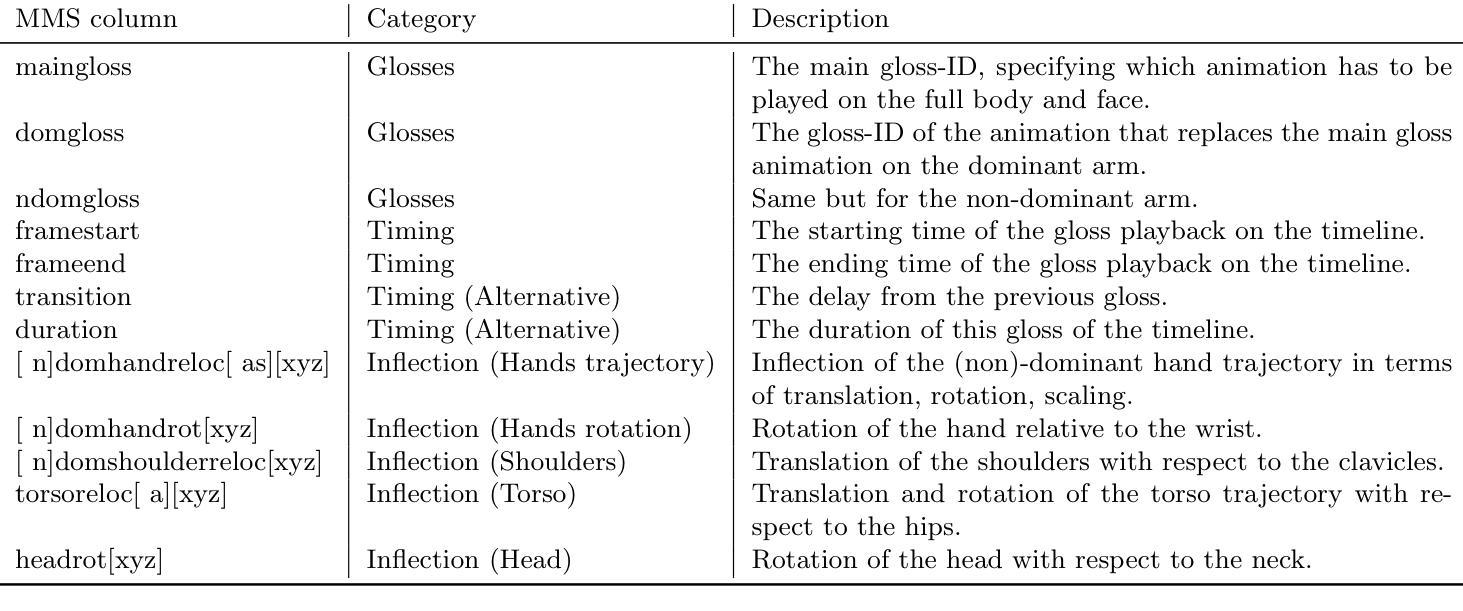
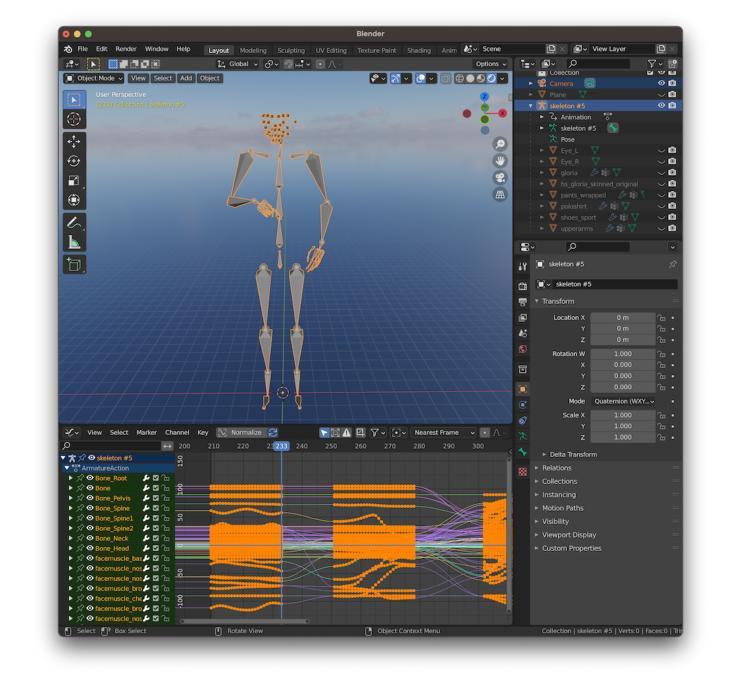
MMS Player: an open source software for parametric data-driven animation of Sign Language avatars
Authors:Fabrizio Nunnari, Shailesh Mishra, Patrick Gebhard
This paper describes the MMS-Player, an open source software able to synthesise sign language animations from a novel sign language representation format called MMS (MultiModal Signstream). The MMS enhances gloss-based representations by adding information on parallel execution of signs, timing, and inflections. The implementation consists of Python scripts for the popular Blender 3D authoring tool and can be invoked via command line or HTTP API. Animations can be rendered as videos or exported in other popular 3D animation exchange formats. The software is freely available under GPL-3.0 license at https://github.com/DFKI-SignLanguage/MMS-Player.
本文介绍了MMS-Player这一开源软件,它能够从未经处理的手语表示格式(称为MMS,即多模态手语流)合成手语动画。MMS通过增加关于手语并行执行、时间和语调的信息,增强了基于手语词汇的描述。该实现包含针对流行的Blender 3D创作工具的Python脚本,可以通过命令行或HTTP API进行调用。动画可以呈现为视频或以其他流行的3D动画交换格式导出。该软件可在GPL-3.0许可下免费访问:https://github.com/DFKI-SignLanguage/MMS-Player。
论文及项目相关链接
Summary:
本文介绍了一个名为MMS-Player的开源软件,该软件能够从一种新型的手势语言表示格式MMS(多模式手势流)中合成手势语言动画。MMS通过增加关于手势并行执行、时序和语调的信息,增强了基于光泽的表示。该软件使用Python脚本为流行的Blender 3D创作工具实现,可通过命令行或HTTP API进行调用。动画可以呈现为视频或以其他流行的3D动画交换格式导出。该软件在GPL-3.0许可下免费提供,可在https://github.com/DFKI-SignLanguage/MMS-Player获取。
Key Takeaways:
- MMS-Player是一款开源软件,可以从MMS(多模式手势流)格式中合成手势语言动画。
- MMS在原有手势语言表示基础上增加了并行执行、时序和语调的信息。
- 软件采用Python脚本实现,适用于Blender 3D创作工具。
- 可通过命令行或HTTP API调用软件。
- 动画可呈现为视频,也可导出为其他流行的3D动画交换格式。
- 软件在GPL-3.0许可下免费提供。
点此查看论文截图


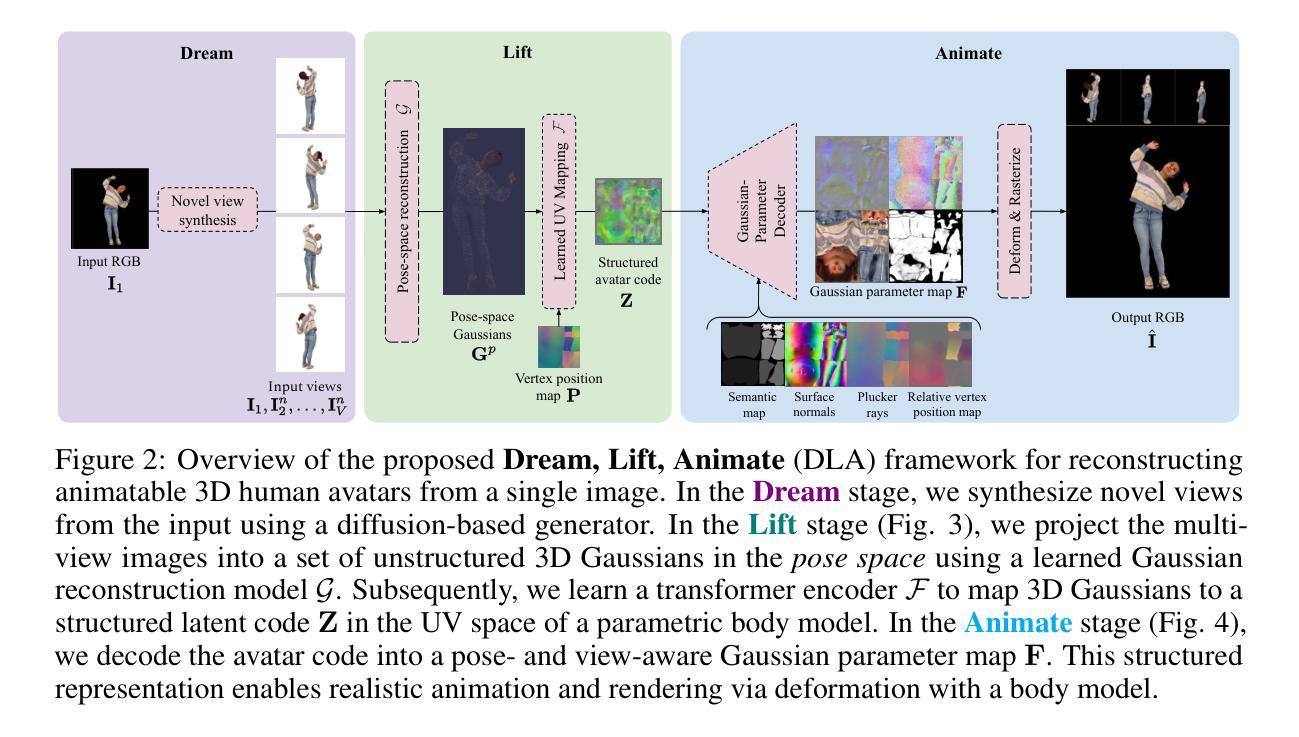
Dream, Lift, Animate: From Single Images to Animatable Gaussian Avatars
Authors:Marcel C. Bühler, Ye Yuan, Xueting Li, Yangyi Huang, Koki Nagano, Umar Iqbal
We introduce Dream, Lift, Animate (DLA), a novel framework that reconstructs animatable 3D human avatars from a single image. This is achieved by leveraging multi-view generation, 3D Gaussian lifting, and pose-aware UV-space mapping of 3D Gaussians. Given an image, we first dream plausible multi-views using a video diffusion model, capturing rich geometric and appearance details. These views are then lifted into unstructured 3D Gaussians. To enable animation, we propose a transformer-based encoder that models global spatial relationships and projects these Gaussians into a structured latent representation aligned with the UV space of a parametric body model. This latent code is decoded into UV-space Gaussians that can be animated via body-driven deformation and rendered conditioned on pose and viewpoint. By anchoring Gaussians to the UV manifold, our method ensures consistency during animation while preserving fine visual details. DLA enables real-time rendering and intuitive editing without requiring post-processing. Our method outperforms state-of-the-art approaches on ActorsHQ and 4D-Dress datasets in both perceptual quality and photometric accuracy. By combining the generative strengths of video diffusion models with a pose-aware UV-space Gaussian mapping, DLA bridges the gap between unstructured 3D representations and high-fidelity, animation-ready avatars.
我们介绍了Dream、Lift、Animate(DLA),这是一种从单张图像重建可动画的3D人类虚拟偶像的新型框架。这通过利用多视角生成、3D高斯提升和姿态感知的UV空间高斯映射来实现。给定一张图像,我们首先使用视频扩散模型梦想出合理的多视角,捕捉丰富的几何和外观细节。然后,这些视角被提升为无结构的3D高斯。为了实现动画效果,我们提出了一种基于变压器的编码器,该编码器对全局空间关系进行建模,并将这些高斯投影到与参数化身体模型的UV空间对齐的结构化潜在表示中。这个潜在代码被解码成UV空间的高斯,可以通过身体驱动的变形进行动画处理,并根据姿态和视点进行渲染。通过将高斯锚定到UV流形上,我们的方法确保了动画的一致性,同时保留了精细的视觉细节。DLA实现了实时渲染和直观编辑,无需后期处理。我们的方法在ActorsHQ和4D-Dress数据集上的感知质量和光度准确性方面都优于最先进的方法。通过将视频扩散模型的生成能力与姿态感知的UV空间高斯映射相结合,DLA在非结构化三维表示和高保真、动画准备的虚拟偶像之间架起了一座桥梁。
论文及项目相关链接
Summary:
DLA框架能够从单一图像重建可动画的3D人类角色。它利用多角度生成、3D高斯提升和姿态感知UV空间高斯映射等技术实现。给定图像,首先通过视频扩散模型生成多角度视图,然后提升到3D高斯空间,再通过基于变压器的编码器进行动画处理,将高斯映射到参数化身体模型的UV空间。这种方法可实现实时渲染和直观编辑,无需后期处理,且在ActorsHQ和4D-Dress数据集上的表现优于现有方法。
Key Takeaways:
- DLA框架能从单一图像重建可动画的3D人类角色。
- 利用视频扩散模型生成多角度视图,丰富几何和外观细节。
- 通过3D高斯提升技术将视图提升到3D空间。
- 采用基于变压器的编码器进行动画处理,将高斯映射到参数化身体模型的UV空间。
- 方法可实现实时渲染和直观编辑,无需后期处理。
- 在ActorsHQ和4D-Dress数据集上的表现优于现有方法。
点此查看论文截图

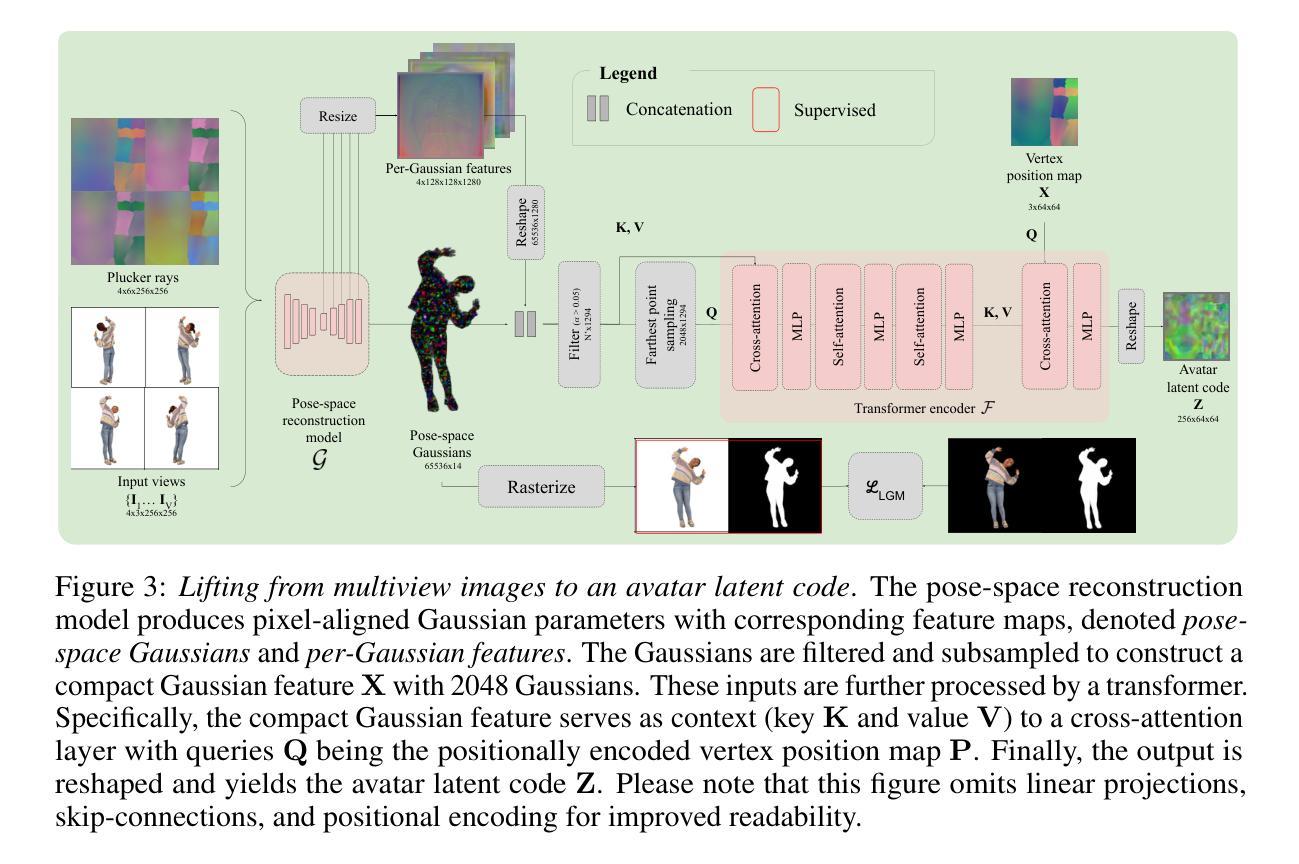
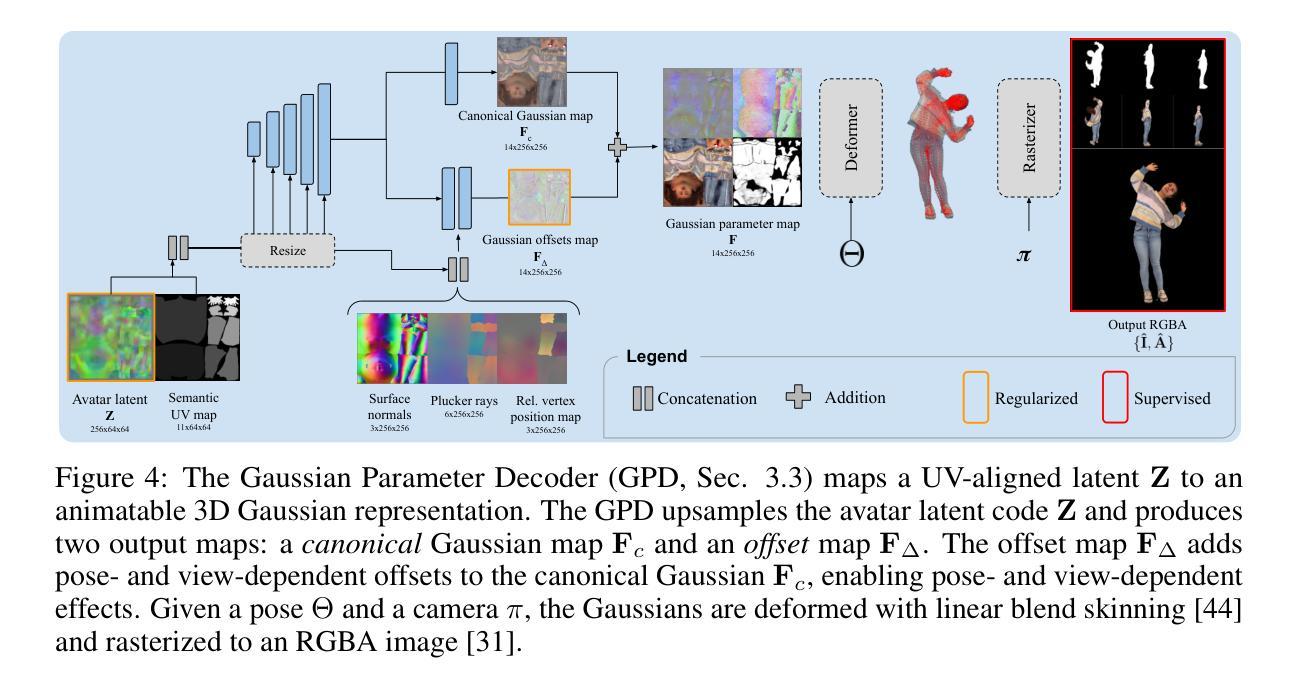
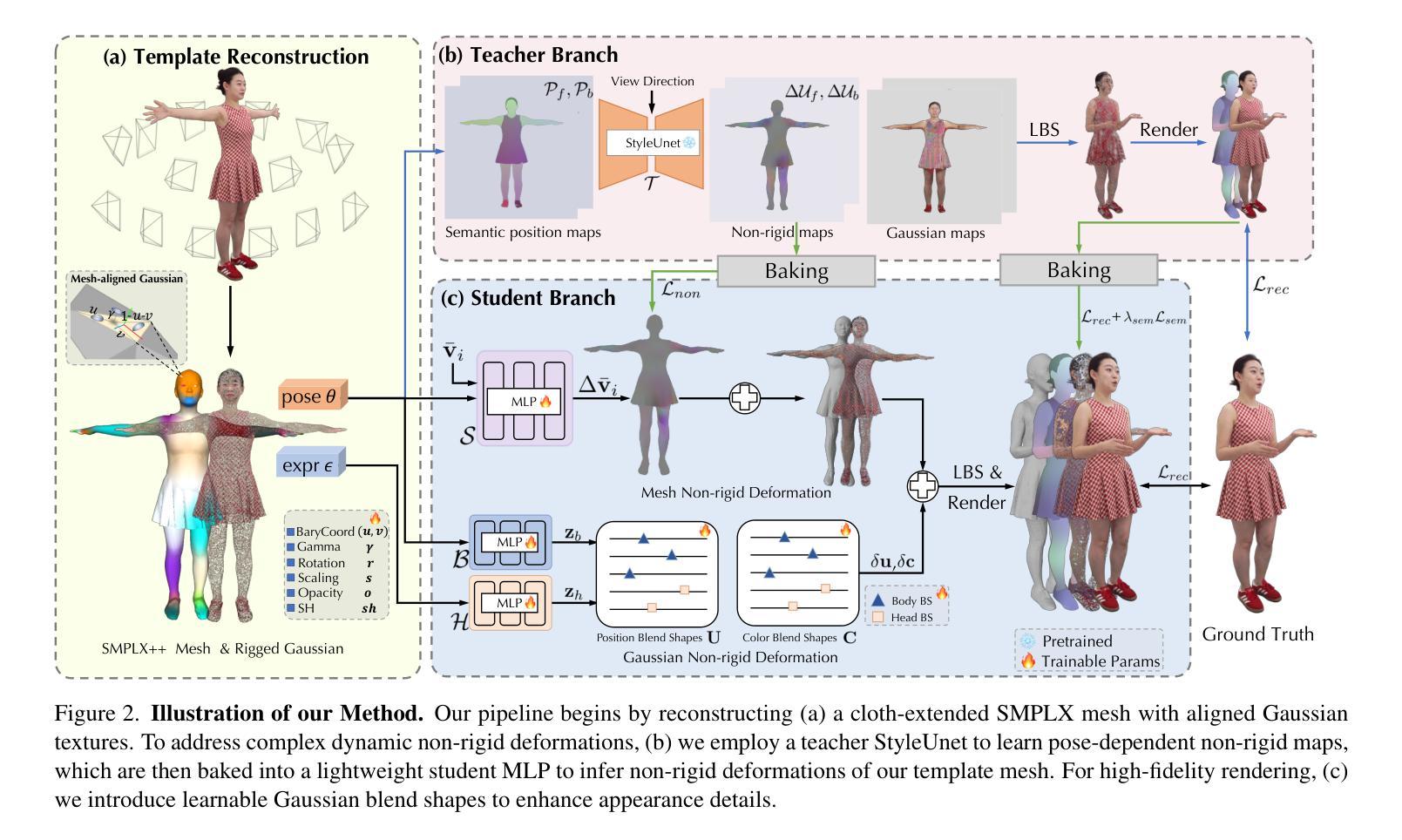
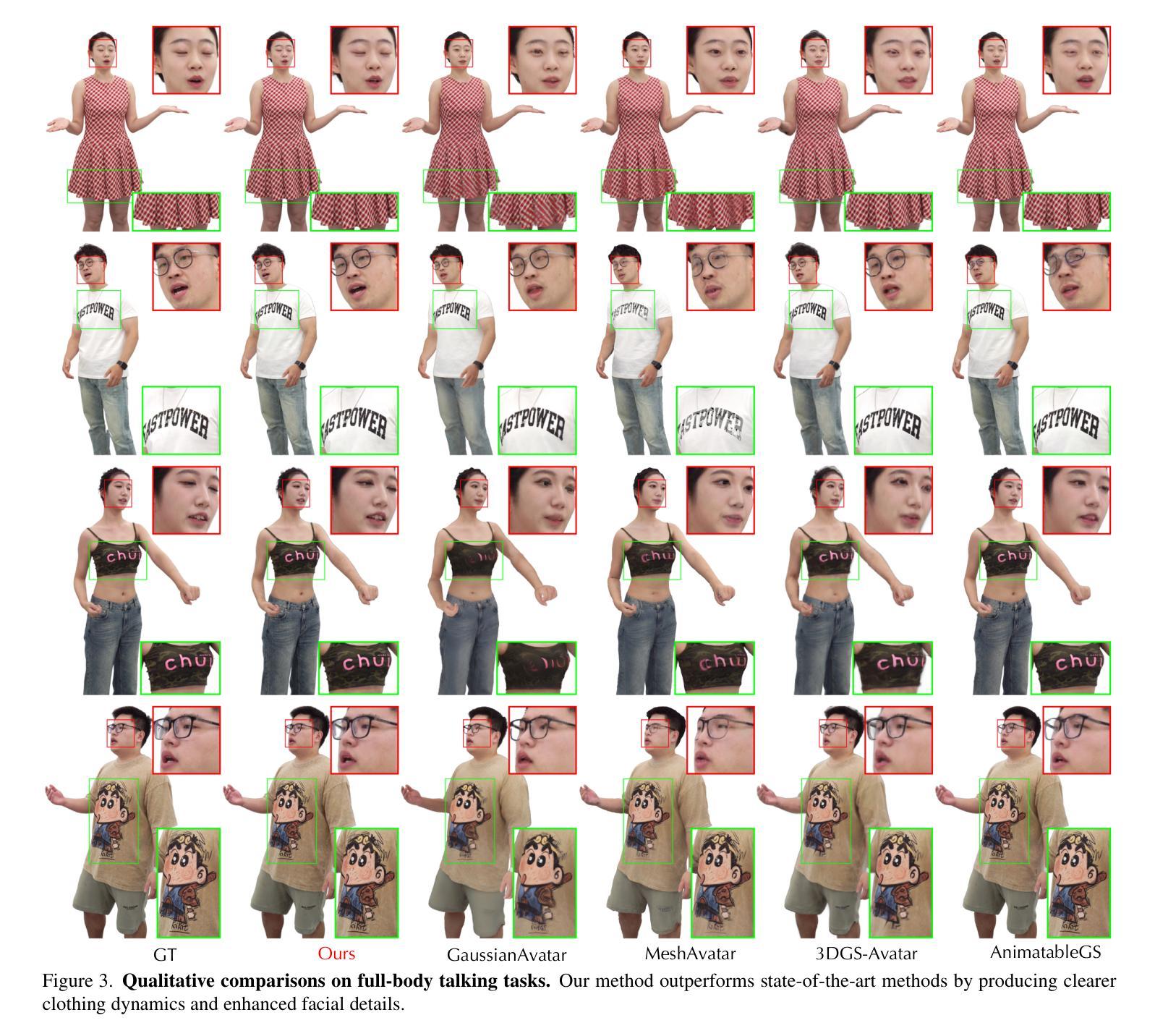
TaoAvatar: Real-Time Lifelike Full-Body Talking Avatars for Augmented Reality via 3D Gaussian Splatting
Authors:Jianchuan Chen, Jingchuan Hu, Gaige Wang, Zhonghua Jiang, Tiansong Zhou, Zhiwen Chen, Chengfei Lv
Realistic 3D full-body talking avatars hold great potential in AR, with applications ranging from e-commerce live streaming to holographic communication. Despite advances in 3D Gaussian Splatting (3DGS) for lifelike avatar creation, existing methods struggle with fine-grained control of facial expressions and body movements in full-body talking tasks. Additionally, they often lack sufficient details and cannot run in real-time on mobile devices. We present TaoAvatar, a high-fidelity, lightweight, 3DGS-based full-body talking avatar driven by various signals. Our approach starts by creating a personalized clothed human parametric template that binds Gaussians to represent appearances. We then pre-train a StyleUnet-based network to handle complex pose-dependent non-rigid deformation, which can capture high-frequency appearance details but is too resource-intensive for mobile devices. To overcome this, we “bake” the non-rigid deformations into a lightweight MLP-based network using a distillation technique and develop blend shapes to compensate for details. Extensive experiments show that TaoAvatar achieves state-of-the-art rendering quality while running in real-time across various devices, maintaining 90 FPS on high-definition stereo devices such as the Apple Vision Pro.
逼真的3D全身对话虚拟人在增强现实领域具有巨大的潜力,其应用范围从电子商务直播到全息通信。尽管在用于创建逼真虚拟人的3D高斯拼贴(3DGS)方面取得了进展,但现有方法在全身对话任务中的面部表情和躯体动作的精细控制方面仍面临挑战。此外,它们通常缺乏足够的细节,无法在移动设备上实时运行。我们推出了TaoAvatar,一个由各种信号驱动的高保真、轻量级的3DGS全身对话虚拟人。我们的方法首先是通过创建个性化的穿衣人类参数模板来绑定高斯值以表示外观。然后,我们基于StyleUnet网络进行预先训练,以处理复杂的姿势相关的非刚性变形,该网络能够捕捉高频外观细节,但对于移动设备来说资源过于密集。为了克服这一点,我们使用蒸馏技术将非刚性变形“烘焙”到一个基于MLP的轻量级网络中,并开发混合形状来补偿细节。大量实验表明,TaoAvatar在追求实时渲染的同时达到了业界领先的渲染质量,在各种设备上均能实时运行,在高分辨率立体声设备如Apple Vision Pro上保持90 FPS。
论文及项目相关链接
PDF Accepted by CVPR 2025 (Highlight), project page: https://PixelAI-Team.github.io/TaoAvatar
Summary:
面向增强现实应用的真实3D全身对话虚拟人具有巨大潜力,涵盖电商直播、全息通信等领域。针对现有方法在精细面部表情和全身动作控制上的不足,提出一种基于3D高斯拼贴技术的高保真、轻量级全身对话虚拟人TaoAvatar。通过创建个性化模板和预训练网络处理复杂姿势相关的非刚性变形,并采用蒸馏技术和混合形状技术实现高质量渲染和实时运行。TaoAvatar在Apple Vision Pro等高清立体设备上实现了每秒90帧的实时渲染性能。
Key Takeaways:
- 真实3D全身对话虚拟人在AR领域具有广泛的应用前景,包括电商直播和全息通信等。
- 现有方法在精细面部表情和全身动作控制上存在挑战。
- TaoAvatar基于3D高斯拼贴技术,旨在解决这些问题并实现高保真渲染。
- 创建个性化模板以表示外观,并预训练网络处理复杂姿势的非刚性变形。
- 采用蒸馏技术将非刚性变形“烘焙”到轻量级MLP网络中。
- 发展混合形状技术以补偿细节损失。
点此查看论文截图

StrandHead: Text to Hair-Disentangled 3D Head Avatars Using Human-Centric Priors
Authors:Xiaokun Sun, Zeyu Cai, Ying Tai, Jian Yang, Zhenyu Zhang
While haircut indicates distinct personality, existing avatar generation methods fail to model practical hair due to the data limitation or entangled representation. We propose StrandHead, a novel text-driven method capable of generating 3D hair strands and disentangled head avatars with strand-level attributes. Instead of using large-scale hair-text paired data for supervision, we demonstrate that realistic hair strands can be generated from prompts by distilling 2D generative models pre-trained on human mesh data. To this end, we propose a meshing approach guided by strand geometry to guarantee the gradient flow from the distillation objective to the neural strand representation. The optimization is then regularized by statistically significant haircut features, leading to stable updating of strands against unreasonable drifting. These employed 2D/3D human-centric priors contribute to text-aligned and realistic 3D strand generation. Extensive experiments show that StrandHead achieves the state-of-the-art performance on text to strand generation and disentangled 3D head avatar modeling. The generated 3D hair can be applied on avatars for strand-level editing, as well as implemented in the graphics engine for physical simulation or other applications. Project page: https://xiaokunsun.github.io/StrandHead.github.io/.
虽然发型可以显示个性,但现有的化身生成方法由于受数据限制或表示纠缠而无法模拟实际发型。我们提出一种名为StrandHead的新型文本驱动方法,能够生成3D发丝和没有纠缠的头化身,并具有发丝级别的属性。我们证明了不需要大规模的发型文本配对数据进行监督,通过蒸馏预先训练在人类网格数据上的2D生成模型,就可以从提示中生成逼真的发丝。为此,我们提出了一种由发丝几何形状引导的网格化方法,以保证从蒸馏目标到神经发丝表示的梯度流。然后,通过统计上显著的发型特征对优化进行正则化,防止发丝在不合理的方向上漂移,从而实现稳定的更新。这些所采用的2D/3D以人类为中心的先验知识有助于实现与文本对齐且逼真的3D发丝生成。大量实验表明,StrandHead在文本到发丝生成和去纠缠的3D头化身建模方面达到了最先进的性能。生成的3D发型可应用于化身发丝级别的编辑,并可在图形引擎中实现物理模拟或其他应用。项目页面:https://xiaokunsun.github.io/StrandHead.github.io/。
论文及项目相关链接
PDF Accepted by ICCV 2025
Summary
本文提出了一种名为StrandHead的新型文本驱动方法,能够生成3D发丝并能够解耦头部虚拟形象。该方法通过蒸馏预训练在人体网格数据上的2D生成模型,从提示中生成真实发丝。采用由发丝几何引导的网格方法,确保从蒸馏目标到神经发丝表示的梯度流。通过统计显著的发型特征进行正则化优化,使发丝更新稳定,避免不合理漂移。所采纳的2D/3D人体优先策略有助于实现文本对齐和真实的3D发丝生成。实验表明,StrandHead在文本到发丝生成和解耦3D头部虚拟形象建模方面达到最新技术水平。
Key Takeaways
- StrandHead是一种新型的文本驱动方法,能够生成3D发丝并解耦头部虚拟形象。
- 通过蒸馏预训练的2D生成模型,从提示中生成真实发丝。
- 采用由发丝几何引导的网格方法,确保从蒸馏目标的梯度流到神经发丝表示。
- 通过统计显著的发型特征进行正则化优化,稳定发丝更新。
- 采纳的2D/3D人体优先策略有助于实现文本对齐和真实的3D发丝生成。
- StrandHead在文本到发丝生成和解耦3D头部虚拟形象建模方面达到最新技术水平。
- 生成的3D发丝可用于虚拟形象的发丝级别编辑,并可应用于图形引擎进行物理模拟或其他应用。
点此查看论文截图