⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-02 更新
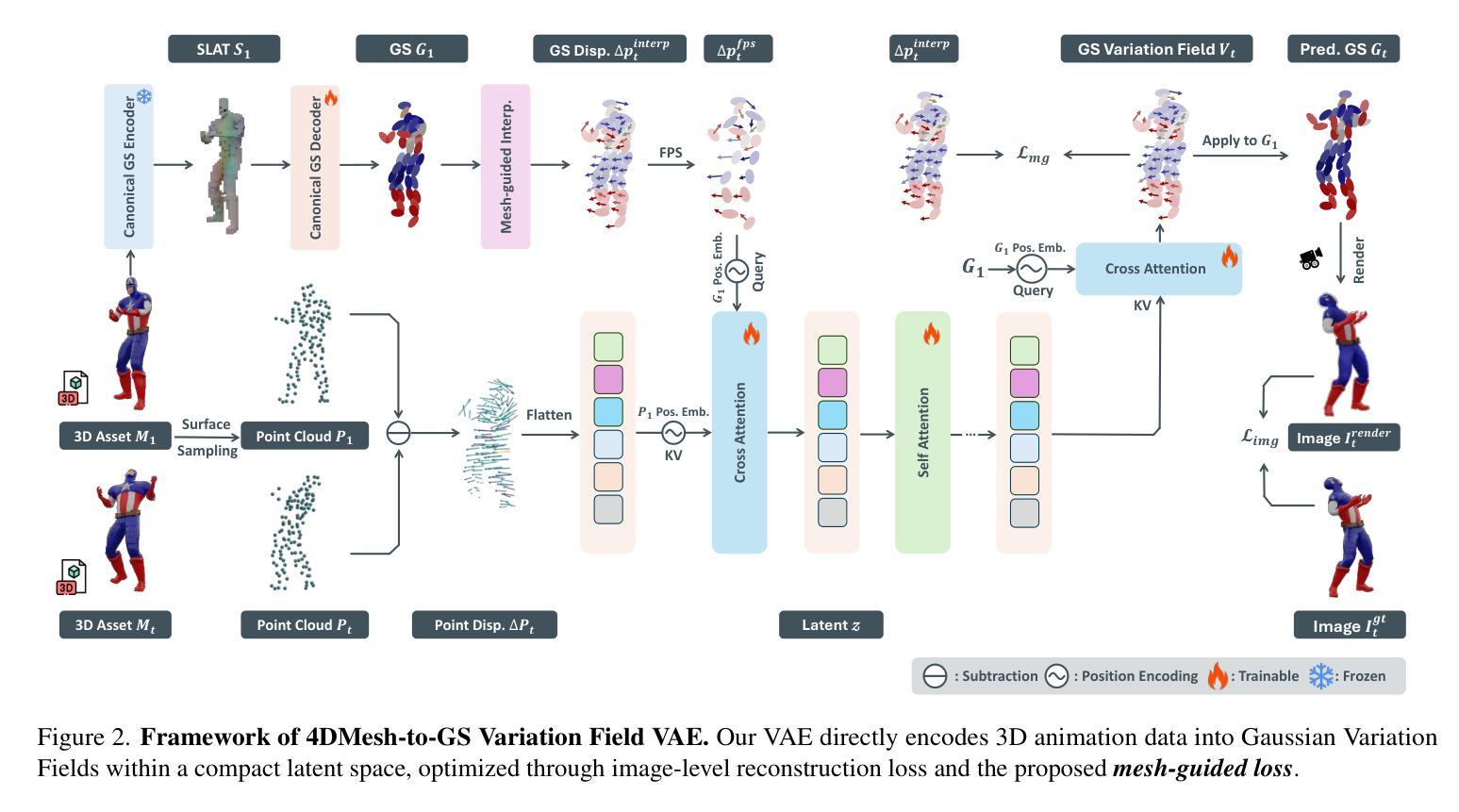
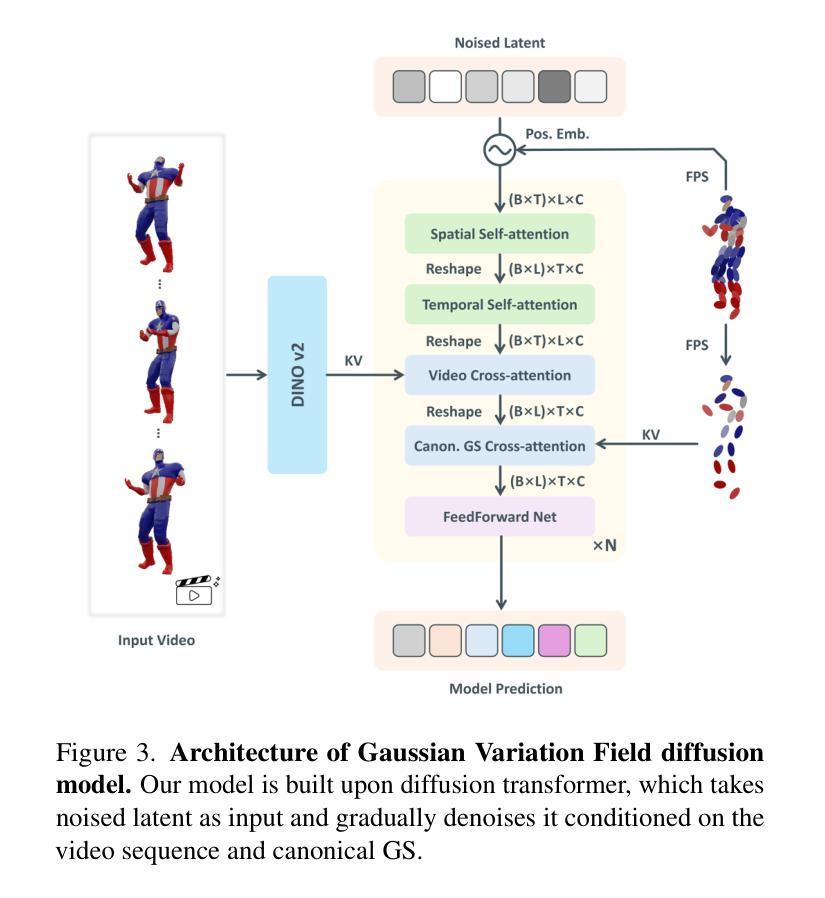
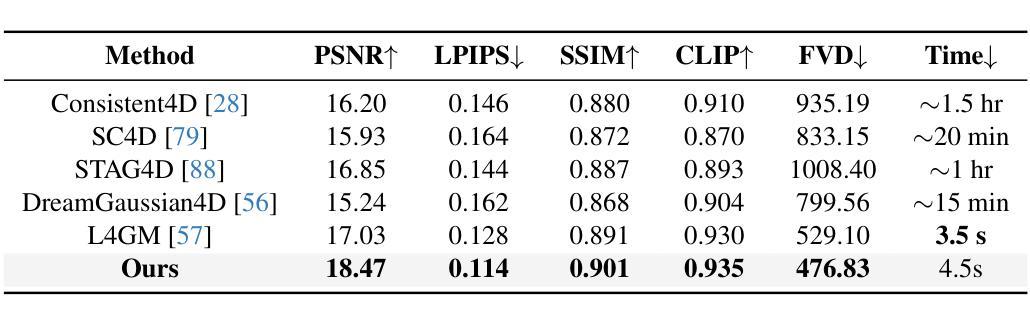
Gaussian Variation Field Diffusion for High-fidelity Video-to-4D Synthesis
Authors:Bowen Zhang, Sicheng Xu, Chuxin Wang, Jiaolong Yang, Feng Zhao, Dong Chen, Baining Guo
In this paper, we present a novel framework for video-to-4D generation that creates high-quality dynamic 3D content from single video inputs. Direct 4D diffusion modeling is extremely challenging due to costly data construction and the high-dimensional nature of jointly representing 3D shape, appearance, and motion. We address these challenges by introducing a Direct 4DMesh-to-GS Variation Field VAE that directly encodes canonical Gaussian Splats (GS) and their temporal variations from 3D animation data without per-instance fitting, and compresses high-dimensional animations into a compact latent space. Building upon this efficient representation, we train a Gaussian Variation Field diffusion model with temporal-aware Diffusion Transformer conditioned on input videos and canonical GS. Trained on carefully-curated animatable 3D objects from the Objaverse dataset, our model demonstrates superior generation quality compared to existing methods. It also exhibits remarkable generalization to in-the-wild video inputs despite being trained exclusively on synthetic data, paving the way for generating high-quality animated 3D content. Project page: https://gvfdiffusion.github.io/.
在本文中,我们提出了一个用于视频到4D生成的新型框架,该框架能够从单个视频输入中创建高质量动态3D内容。直接4D扩散建模由于数据构建成本高昂以及同时表示3D形状、外观和运动的维数过高而极具挑战性。我们通过引入Direct 4DMesh-to-GS变化场VAE来解决这些挑战,该VAE能够直接从3D动画数据对规范高斯Splats(GS)及其时间变化进行编码,而无需逐个实例进行拟合,并将高维动画压缩到紧凑的潜在空间中。在此基础上,我们训练了一个基于时间感知扩散Transformer的高斯变化场扩散模型,该模型根据输入视频和规范GS进行训练。该模型在精心挑选的来自Objaverse数据集的动画3D对象上进行训练,与现有方法相比,其生成质量更胜一筹。尽管该模型仅在合成数据上进行训练,但它对天然视频输入的泛化能力仍然十分显著,为生成高质量动画3D内容铺平了道路。项目页面:https://gvfdiffusion.github.io/。
论文及项目相关链接
PDF ICCV 2025. Project page: https://gvfdiffusion.github.io/
Summary
本文提出了一种新颖的框架,可从单个视频输入生成高质量动态3D内容。通过引入Direct 4DMesh-to-GS Variation Field VAE,直接对规范高斯Splats(GS)及其时间变化进行编码,无需对每个实例进行拟合,并将高维动画压缩到紧凑的潜在空间。在此基础上,训练了一个基于高斯变异场扩散模型的具有时间感知扩散变压器的模型,以输入视频和规范GS为条件。在Objaverse数据集的可动画3D对象上进行训练,与现有方法相比,该模型展现出更高的生成质量,并且对野生视频输入具有出色的泛化能力。
Key Takeaways
- 论文提出了一种新的视频到4D生成框架,可从单个视频创建高质量动态3D内容。
- 引入Direct 4DMesh-to-GS Variation Field VAE,有效表示和压缩3D动画数据。
- 采用高斯变异场扩散模型,结合时间感知扩散变压器进行训练。
- 模型在Objaverse数据集上进行训练,展现出优秀的生成质量。
- 模型具有良好的泛化能力,能处理来自野生环境的视频输入。
- 该模型能够直接处理规范高斯Splats(GS)及其时间变化,无需对每个实例进行拟合。
点此查看论文截图


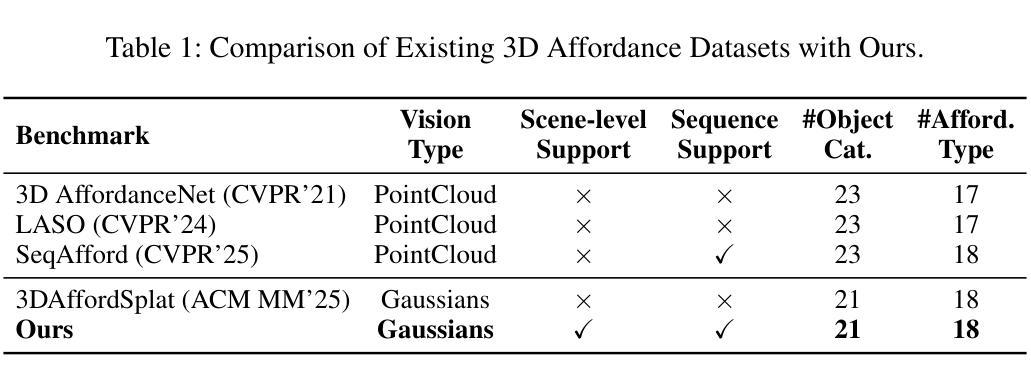
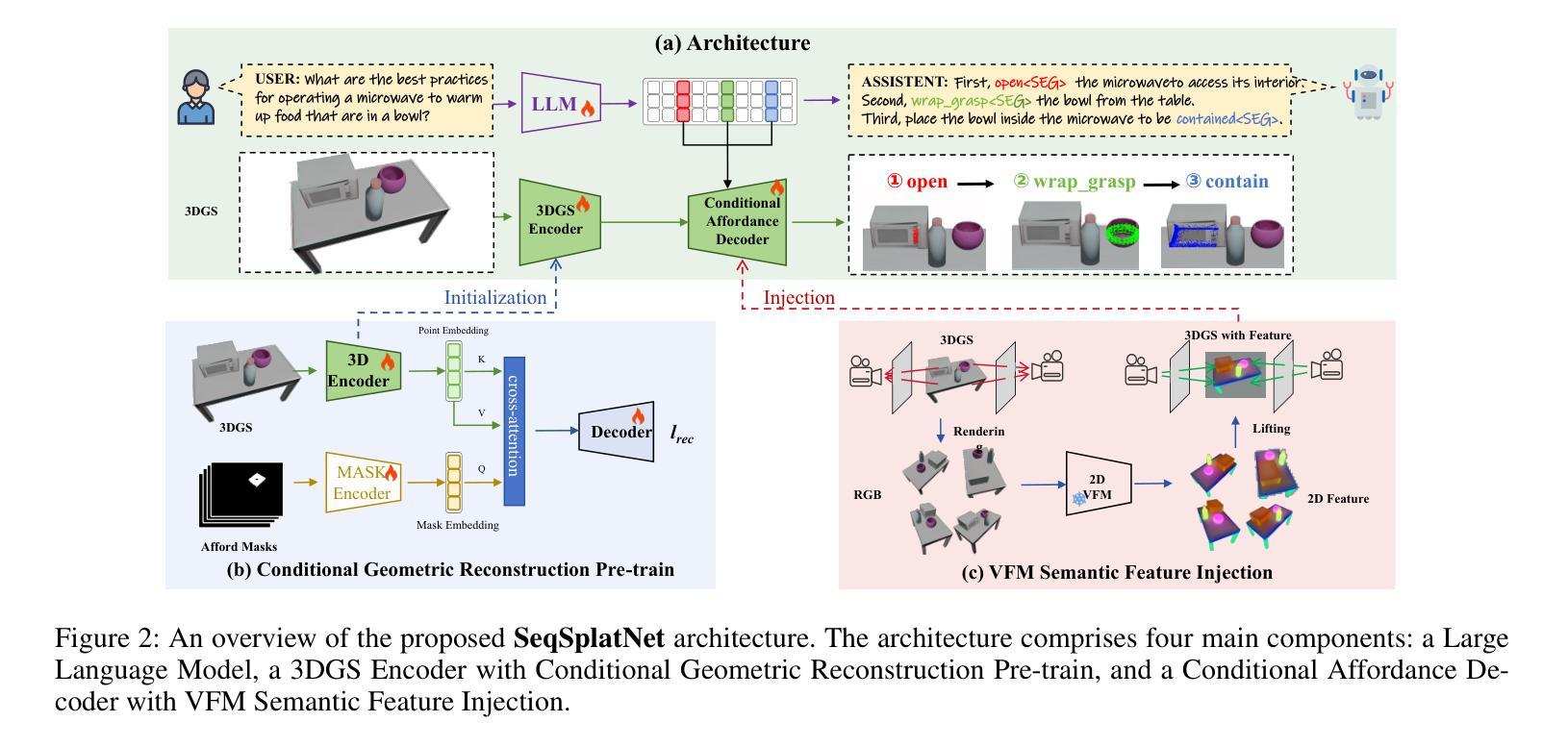
SeqAffordSplat: Scene-level Sequential Affordance Reasoning on 3D Gaussian Splatting
Authors:Di Li, Jie Feng, Jiahao Chen, Weisheng Dong, Guanbin Li, Yuhui Zheng, Mingtao Feng, Guangming Shi
3D affordance reasoning, the task of associating human instructions with the functional regions of 3D objects, is a critical capability for embodied agents. Current methods based on 3D Gaussian Splatting (3DGS) are fundamentally limited to single-object, single-step interactions, a paradigm that falls short of addressing the long-horizon, multi-object tasks required for complex real-world applications. To bridge this gap, we introduce the novel task of Sequential 3D Gaussian Affordance Reasoning and establish SeqAffordSplat, a large-scale benchmark featuring 1800+ scenes to support research on long-horizon affordance understanding in complex 3DGS environments. We then propose SeqSplatNet, an end-to-end framework that directly maps an instruction to a sequence of 3D affordance masks. SeqSplatNet employs a large language model that autoregressively generates text interleaved with special segmentation tokens, guiding a conditional decoder to produce the corresponding 3D mask. To handle complex scene geometry, we introduce a pre-training strategy, Conditional Geometric Reconstruction, where the model learns to reconstruct complete affordance region masks from known geometric observations, thereby building a robust geometric prior. Furthermore, to resolve semantic ambiguities, we design a feature injection mechanism that lifts rich semantic features from 2D Vision Foundation Models (VFM) and fuses them into the 3D decoder at multiple scales. Extensive experiments demonstrate that our method sets a new state-of-the-art on our challenging benchmark, effectively advancing affordance reasoning from single-step interactions to complex, sequential tasks at the scene level.
3D作用推理是一项将人类指令与3D对象的功能区域相关联的重要任务,对于实体代理而言是一项至关重要的能力。当前基于3D高斯泼溅(3DGS)的方法根本上仅限于单对象、单步骤交互的模式,这种模式无法应对复杂现实世界应用所需的长周期、多对象任务。为了弥补这一差距,我们引入了序列3D高斯作用推理这一新任务,并建立了SeqAffordSplat大规模基准测试,包含1800多个场景,以支持在复杂3DGS环境中对长周期作用理解的研究。然后,我们提出了SeqSplatNet端到端框架,该框架直接将指令映射到一系列3D作用掩膜。SeqSplatNet采用大型语言模型,通过自回归生成与特殊分割令牌交织的文本,指导条件解码器生成相应的3D掩膜。为了处理复杂的场景几何结构,我们引入了预训练策略,即条件几何重建,在该策略中,模型学习从已知的几何观测中重建完整的作用区域掩膜,从而建立稳健的几何先验。此外,为了解决语义歧义问题,我们设计了一种特征注入机制,从二维视觉基础模型(VFM)中提取丰富的语义特征,并将它们融合到多个尺度的三维解码器中。大量实验表明,我们的方法在我们的具有挑战性的基准测试上达到了最新水平,有效地将作用推理从单步骤交互推进到复杂的场景级序列任务。
论文及项目相关链接
摘要
本文介绍了三维高斯分割技术(3DGS)在智能体执行任务中的局限性,特别是在处理复杂现实世界中的长期多目标任务时的不足。为解决这一问题,本文提出了序列三维高斯功能推理(Sequential 3D Gaussian Affordance Reasoning)的新任务,并建立了SeqAffordSplat大规模基准测试平台,包含超过1800个场景。此外,本文还提出了一种名为SeqSplatNet的端到端框架,该框架可直接将指令映射到一系列三维功能掩膜。SeqSplatNet采用大型语言模型进行预训练,并通过条件解码器生成相应的三维掩膜。为解决场景几何复杂性和语义模糊性问题,本文引入了条件几何重建策略和特征注入机制。实验证明,SeqSplatNet在复杂场景级别的长期多目标任务上表现优异,将功能推理从单步交互推向了新的高度。
关键见解
- 当前基于三维高斯分割(3DGS)的方法在处理长期多目标任务时存在局限性。
- 引入了序列三维高斯功能推理的新任务,以应对复杂现实世界中的长期多目标任务。
- 建立了SeqAffordSplat大规模基准测试平台,包含多样化场景,支持长期功能理解的研究。
- 提出了SeqSplatNet框架,能直接处理指令并生成一系列三维功能掩膜。
- 采用大型语言模型进行预训练,解决场景几何复杂性问题。
- 引入条件几何重建策略,提升模型对完整功能区域的重建能力。
- 设计了特征注入机制,融合二维视觉基础模型的丰富语义特征,提高语义理解的准确性。
点此查看论文截图

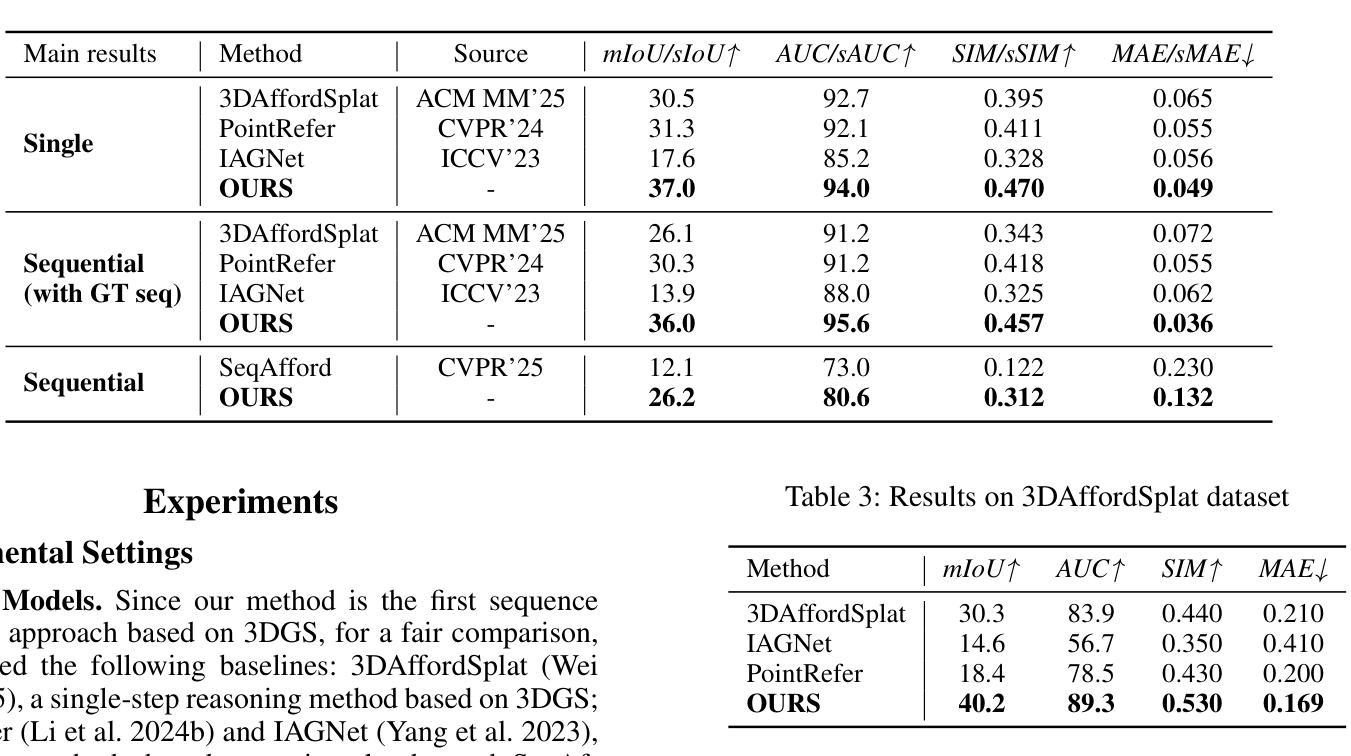
MoGA: 3D Generative Avatar Prior for Monocular Gaussian Avatar Reconstruction
Authors:Zijian Dong, Longteng Duan, Jie Song, Michael J. Black, Andreas Geiger
We present MoGA, a novel method to reconstruct high-fidelity 3D Gaussian avatars from a single-view image. The main challenge lies in inferring unseen appearance and geometric details while ensuring 3D consistency and realism. Most previous methods rely on 2D diffusion models to synthesize unseen views; however, these generated views are sparse and inconsistent, resulting in unrealistic 3D artifacts and blurred appearance. To address these limitations, we leverage a generative avatar model, that can generate diverse 3D avatars by sampling deformed Gaussians from a learned prior distribution. Due to the limited amount of 3D training data such a 3D model alone cannot capture all image details of unseen identities. Consequently, we integrate it as a prior, ensuring 3D consistency by projecting input images into its latent space and enforcing additional 3D appearance and geometric constraints. Our novel approach formulates Gaussian avatar creation as a model inversion process by fitting the generative avatar to synthetic views from 2D diffusion models. The generative avatar provides a meaningful initialization for model fitting, enforces 3D regularization, and helps in refining pose estimation. Experiments show that our method surpasses state-of-the-art techniques and generalizes well to real-world scenarios. Our Gaussian avatars are also inherently animatable
我们提出了MoGA,这是一种从单视图图像重建高保真3D高斯头像的新方法。主要挑战在于推断出看不见的外观和几何细节,同时确保3D的一致性和真实性。大多数之前的方法依赖于2D扩散模型来合成未见的视图;然而,这些生成的视图是稀疏且不一致的,导致3D人工制品不真实和外观模糊。为了解决这些局限性,我们利用生成头像模型,通过从学习的先验分布中采样变形高斯来生成各种3D头像。由于3D训练数据的数量有限,仅使用这样的3D模型无法捕获未见身份的所有图像细节。因此,我们将其整合为优先事项,通过将输入图像投影到其潜在空间并强制额外的3D外观和几何约束来确保3D一致性。我们的新方法将高斯头像创建公式化为一个模型反转过程,通过将生成的头像拟合到来自2D扩散模型的合成视图。生成的头像为模型拟合提供了一个有意义的初始化,强制进行3D正则化,并有助于改进姿势估计。实验表明,我们的方法超越了最新技术,并能很好地推广到现实世界场景。我们的高斯头像本质上是可动画的。
论文及项目相关链接
PDF ICCV 2025 (Highlight), Project Page: https://zj-dong.github.io/MoGA/
Summary
本文提出了MoGA,一种从单视角图像重建高保真3D高斯头像的新方法。主要挑战在于推断出隐藏的外观和几何细节,同时确保3D的一致性和真实性。通过结合生成头像模型和投影输入图像到潜在空间等技术,解决了以往方法生成的视图稀疏、不一致、导致3D效果不真实的问题。新方法将高斯头像创建表述为模型反演过程,通过拟合生成头像到来自二维扩散模型的合成视图。实验表明,该方法超越现有技术,并良好地推广至真实世界场景。
Key Takeaways
- 提出了一种新的方法MoGA,能够从单视角图像重建高保真3D高斯头像。
- 解决了以往方法生成的视图稀疏、不一致的问题,提高了3D头像的真实性和一致性。
- 通过结合生成头像模型,采用从学习到的先验分布中采样变形高斯的方式,生成多样的3D头像。
- 将生成头像模型作为先验,通过投影输入图像到潜在空间,加强3D一致性。
- 将高斯头像创建表述为模型反演过程,通过拟合生成头像到二维扩散模型的合成视图。
- MoGA方法超越了现有技术,并在真实世界场景中具有良好的推广性。
点此查看论文截图

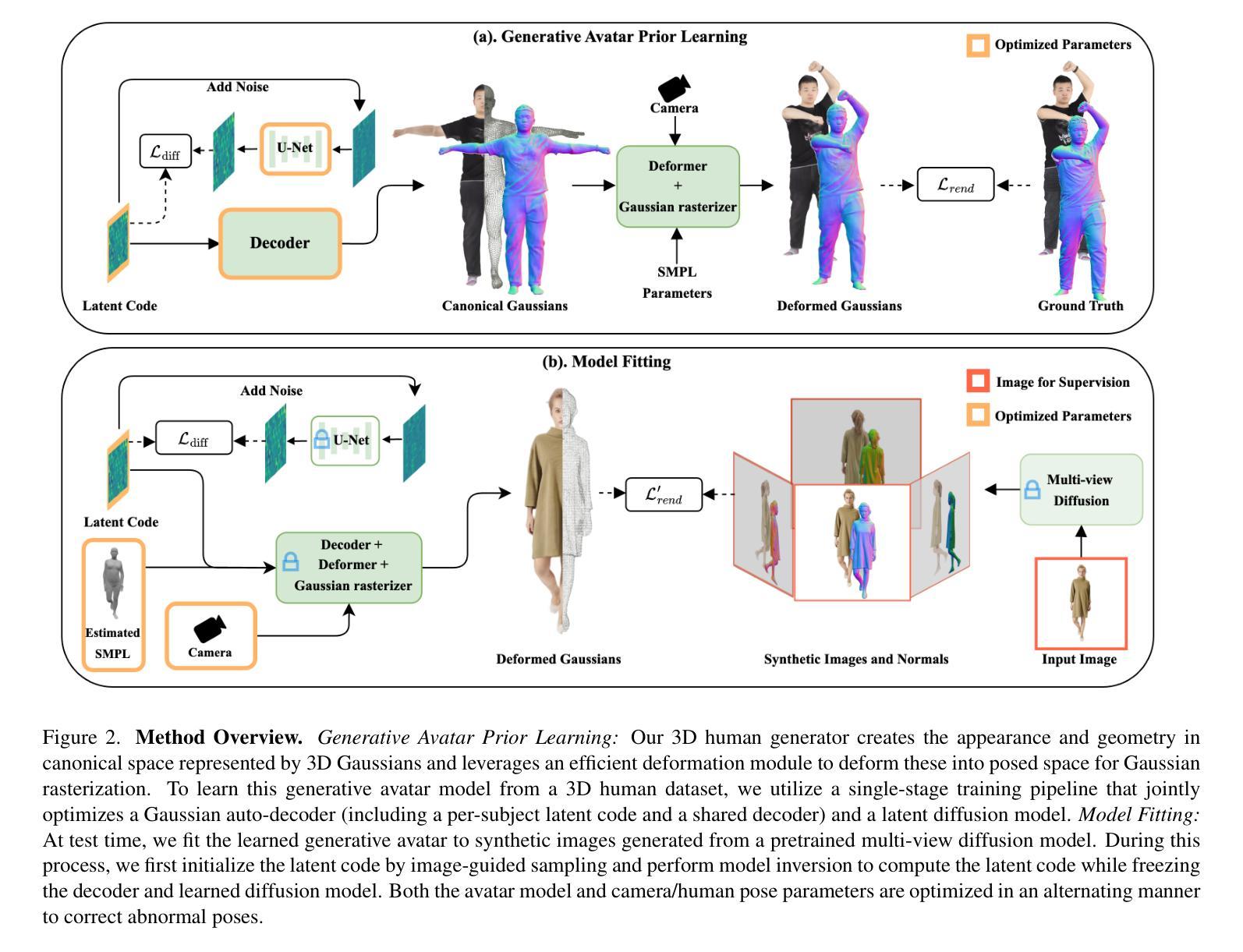

Gaussian Splatting Feature Fields for Privacy-Preserving Visual Localization
Authors:Maxime Pietrantoni, Gabriela Csurka, Torsten Sattler
Visual localization is the task of estimating a camera pose in a known environment. In this paper, we utilize 3D Gaussian Splatting (3DGS)-based representations for accurate and privacy-preserving visual localization. We propose Gaussian Splatting Feature Fields (GSFFs), a scene representation for visual localization that combines an explicit geometry model (3DGS) with an implicit feature field. We leverage the dense geometric information and differentiable rasterization algorithm from 3DGS to learn robust feature representations grounded in 3D. In particular, we align a 3D scale-aware feature field and a 2D feature encoder in a common embedding space through a contrastive framework. Using a 3D structure-informed clustering procedure, we further regularize the representation learning and seamlessly convert the features to segmentations, which can be used for privacy-preserving visual localization. Pose refinement, which involves aligning either feature maps or segmentations from a query image with those rendered from the GSFFs scene representation, is used to achieve localization. The resulting privacy- and non-privacy-preserving localization pipelines, evaluated on multiple real-world datasets, show state-of-the-art performances.
视觉定位是在已知环境中估计相机姿态的任务。在本文中,我们利用基于3D高斯拼贴(3DGS)的表示来进行精确且保护隐私的视觉定位。我们提出高斯拼贴特征场(GSFFs),这是一种视觉定位的场景表示,它将显式的几何模型(3DGS)与隐式的特征场相结合。我们利用3DGS的密集几何信息和可微栅格化算法,学习基于3D的稳健特征表示。特别是,我们通过对比框架在3D尺度感知特征场和2D特征编码器之间建立一个通用的嵌入空间。通过利用3D结构信息的聚类程序,我们进一步正则化表示学习,无缝地将特征转换为分割,这可用于保护隐私的视觉定位。姿态修正涉及将查询图像的特征图或分割与从GSFFs场景表示呈现的特征进行对齐,以实现定位。在多个真实世界数据集上评估的隐私和非隐私保护定位流程均显示出最新技术性能。
论文及项目相关链接
PDF CVPR 2025
Summary
本文利用基于三维高斯拼贴(3DGS)的表示方法进行精确且保护隐私的视觉定位。提出高斯拼贴特征场(GSFFs),结合显式几何模型(3DGS)和隐式特征场,用于视觉定位的场景表示。通过利用3DGS的密集几何信息和可微分栅格化算法,学习基于三维的稳健特征表示。通过对比框架,将三维尺度感知特征场和二维特征编码器对齐到公共嵌入空间。利用三维结构感知聚类程序,进一步规范表示学习,无缝转换特征为分段,可用于保护隐私的视觉定位。通过姿势微调,实现定位,即在查询图像的特征图或分段与GSFFs场景表示所呈现的特征图或分段之间进行对齐。在多个真实世界数据集上的评估结果证明了隐私和非隐私保护定位管道均达到最新技术水平。
Key Takeaways
- 利用三维高斯拼贴(3DGS)进行视觉定位,实现精确性并保护隐私。
- 提出高斯拼贴特征场(GSFFs),结合显式几何模型与隐式特征场。
- 利用3DGS的密集几何信息和可微分栅格化算法,学习稳健的三维特征表示。
- 通过对比框架对齐三维尺度感知特征场和二维特征编码器。
- 采用三维结构感知聚类程序,实现特征到分段的转换,用于隐私保护定位。
- 通过姿势微调实现定位,通过对齐查询图像的特征图或分段与场景表示的特征图或分段来完成。
点此查看论文截图

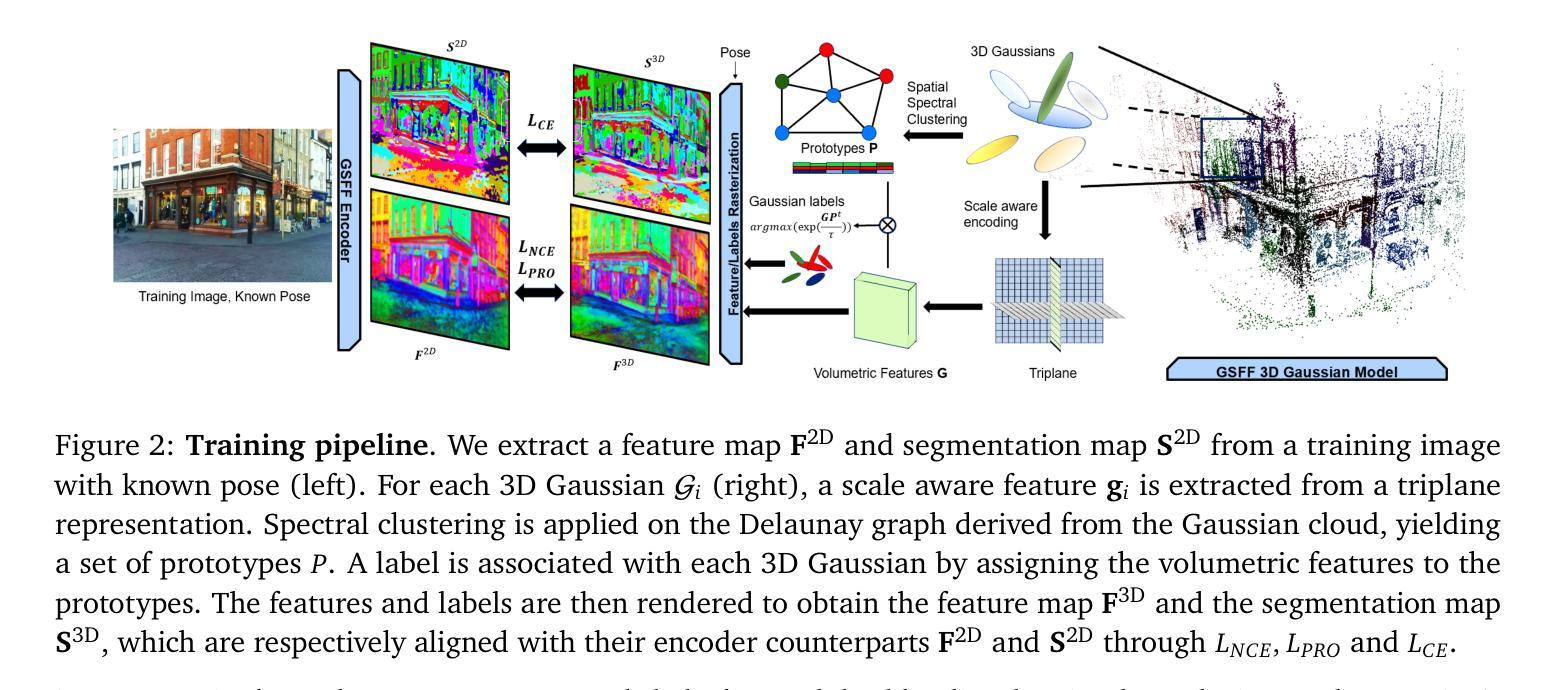

NeRF Is a Valuable Assistant for 3D Gaussian Splatting
Authors:Shuangkang Fang, I-Chao Shen, Takeo Igarashi, Yufeng Wang, ZeSheng Wang, Yi Yang, Wenrui Ding, Shuchang Zhou
We introduce NeRF-GS, a novel framework that jointly optimizes Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS). This framework leverages the inherent continuous spatial representation of NeRF to mitigate several limitations of 3DGS, including sensitivity to Gaussian initialization, limited spatial awareness, and weak inter-Gaussian correlations, thereby enhancing its performance. In NeRF-GS, we revisit the design of 3DGS and progressively align its spatial features with NeRF, enabling both representations to be optimized within the same scene through shared 3D spatial information. We further address the formal distinctions between the two approaches by optimizing residual vectors for both implicit features and Gaussian positions to enhance the personalized capabilities of 3DGS. Experimental results on benchmark datasets show that NeRF-GS surpasses existing methods and achieves state-of-the-art performance. This outcome confirms that NeRF and 3DGS are complementary rather than competing, offering new insights into hybrid approaches that combine 3DGS and NeRF for efficient 3D scene representation.
我们介绍了NeRF-GS,这是一个新型框架,它联合优化了神经辐射场(NeRF)和3D高斯拼贴(3DGS)。该框架利用NeRF的固有连续空间表示来减轻3DGS的几个局限性,包括高斯初始化的敏感性、空间感知的局限性以及高斯间关联较弱等问题,从而提高了其性能。在NeRF-GS中,我们重新设计了3DGS,并逐步将其空间特征与NeRF对齐,使两种表示形式能够通过共享的三维空间信息在同一场景中进行优化。我们进一步通过优化隐特征和高斯位置的残差向量来解决两种方法之间的形式差异,以增强3DGS的个性化能力。在基准数据集上的实验结果表明,NeRF-GS超越了现有方法,达到了最先进的性能。这一结果证实,NeRF和3DGS是互补的而不是竞争的,为结合3DGS和NeRF的高效3D场景表示提供了混合方法的全新见解。
论文及项目相关链接
PDF Accepted by ICCV
摘要
NeRF-GS是一种结合了神经辐射场(NeRF)和三维高斯拼贴(3DGS)的新型框架。它通过利用NeRF的内在连续空间表示来克服3DGS的几个局限性,包括高斯初始化的敏感性、空间感知的有限性以及高斯间关联性的微弱。在NeRF-GS中,重新设计了3DGS,逐步将其空间特征与NeRF对齐,使两种表示方法能够在同一场景中进行优化,通过共享三维空间信息来增强性能。通过优化隐式特征和高斯位置的残差向量,解决了两者之间的形式差异,提高了3DGS的个性化能力。在基准数据集上的实验结果表明,NeRF-GS超越了现有方法,达到了最先进的性能。这证明了NeRF和3DGS是互补的而不是竞争的,为结合3DGS和NeRF的有效三维场景表示提供了新见解。
要点
- NeRF-GS结合了神经辐射场(NeRF)和三维高斯拼贴(3DGS)的新型框架。
- NeRF-GS克服了3DGS的几个局限性,包括高斯初始化的敏感性、空间感知的有限性以及高斯间关联性的微弱。
- 通过共享三维空间信息,NeRF和3DGS在优化中可以相互补充。
- 重新设计了3DGS的空间特征,使其与NeRF对齐。
- 通过优化隐式特征和高斯位置的残差向量,解决了NeRF和3DGS之间的形式差异。
- 实验结果表明,NeRF-GS达到了最先进的性能,超越了现有方法。
点此查看论文截图

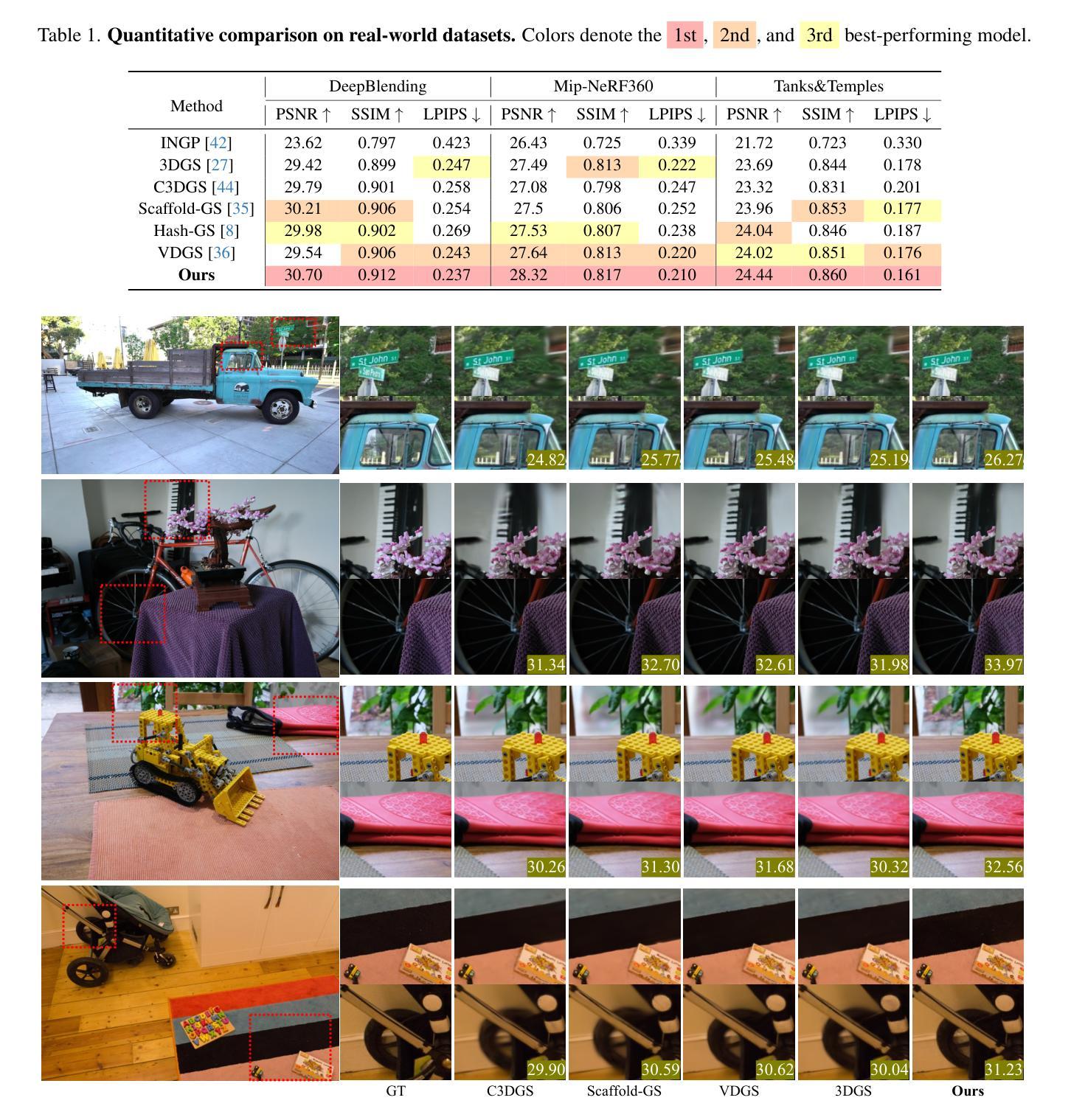
iLRM: An Iterative Large 3D Reconstruction Model
Authors:Gyeongjin Kang, Seungtae Nam, Xiangyu Sun, Sameh Khamis, Abdelrahman Mohamed, Eunbyung Park
Feed-forward 3D modeling has emerged as a promising approach for rapid and high-quality 3D reconstruction. In particular, directly generating explicit 3D representations, such as 3D Gaussian splatting, has attracted significant attention due to its fast and high-quality rendering, as well as numerous applications. However, many state-of-the-art methods, primarily based on transformer architectures, suffer from severe scalability issues because they rely on full attention across image tokens from multiple input views, resulting in prohibitive computational costs as the number of views or image resolution increases. Toward a scalable and efficient feed-forward 3D reconstruction, we introduce an iterative Large 3D Reconstruction Model (iLRM) that generates 3D Gaussian representations through an iterative refinement mechanism, guided by three core principles: (1) decoupling the scene representation from input-view images to enable compact 3D representations; (2) decomposing fully-attentional multi-view interactions into a two-stage attention scheme to reduce computational costs; and (3) injecting high-resolution information at every layer to achieve high-fidelity reconstruction. Experimental results on widely used datasets, such as RE10K and DL3DV, demonstrate that iLRM outperforms existing methods in both reconstruction quality and speed. Notably, iLRM exhibits superior scalability, delivering significantly higher reconstruction quality under comparable computational cost by efficiently leveraging a larger number of input views.
前馈3D建模已成为一种有前景的快速、高质量3D重建方法。特别是直接生成显式3D表示(如3D高斯散斑)引起了广泛关注,因其快速、高质量的渲染以及众多的应用。然而,许多最先进的方法主要基于transformer架构,存在严重的可扩展性问题,因为它们依赖于来自多个输入视图的图像标记的全注意力,随着视图数量或图像分辨率的增加,计算成本成为禁止性成本。为了实现可伸缩和高效的前馈3D重建,我们引入了一种迭代式大型3D重建模型(iLRM),该模型通过迭代细化机制生成3D高斯表示,由三个核心原则指导:(1)将场景表示与输入视图图像解耦,以实现紧凑的3D表示;(2)将全注意力多视图交互分解为两阶段注意力方案,以降低计算成本;(3)在每一层注入高分辨率信息,以实现高保真重建。在RE10K和DL3DV等常用数据集上的实验结果表明,iLRM在重建质量和速度方面均优于现有方法。值得注意的是,iLRM表现出卓越的可扩展性,通过有效利用更多的输入视图,在可比较的计算成本下实现更高的重建质量。
论文及项目相关链接
PDF Project page: https://gynjn.github.io/iLRM/
Summary
本文介绍了基于迭代的大型三维重建模型(iLRM)在三维重建中的应用。iLRM通过迭代优化机制生成三维高斯表示,采用三个核心原则实现高效的三维重建:解耦场景表示与输入视图图像,实现紧凑的三维表示;将全注意力多视图交互分解为两阶段注意力方案以降低计算成本;在每一层注入高分辨率信息以实现高保真重建。实验结果表明,iLRM在重建质量和速度方面均优于现有方法,展现出优越的扩展性。
Key Takeaways
- 文中提出利用迭代的大型三维重建模型(iLRM)实现高效的三维重建。该模型采用迭代优化机制生成三维高斯表示。
- iLRM通过三个核心原则实现紧凑的三维表示和高效计算:解耦场景表示与输入视图图像;采用两阶段注意力方案降低计算成本;注入高分辨率信息以提升重建质量。
点此查看论文截图

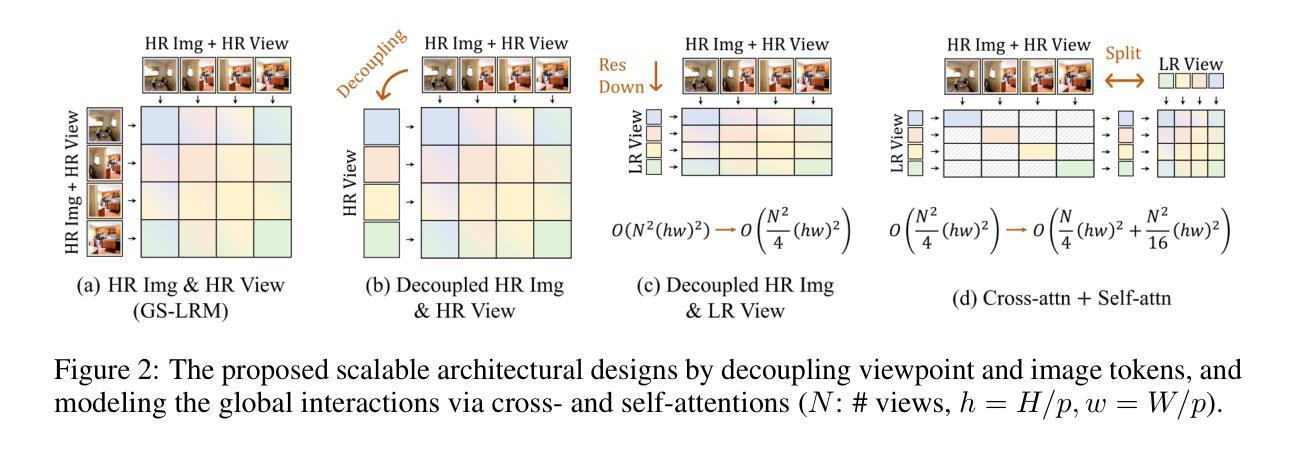
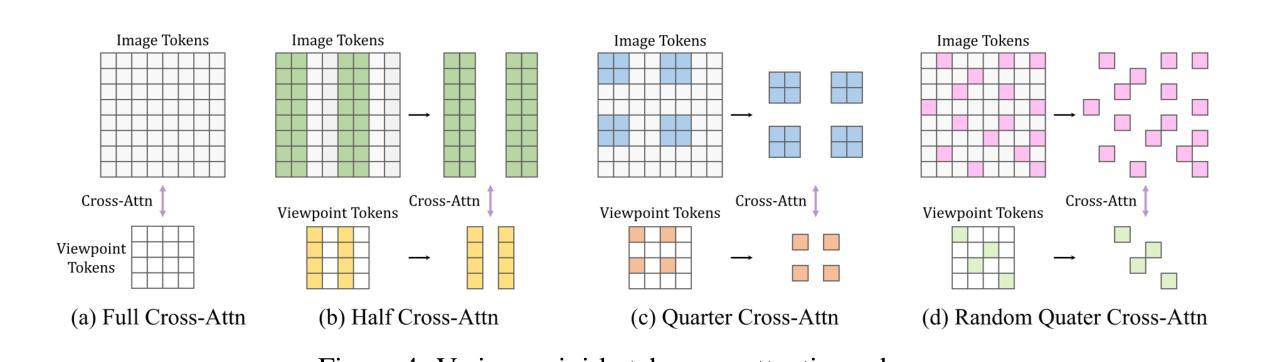
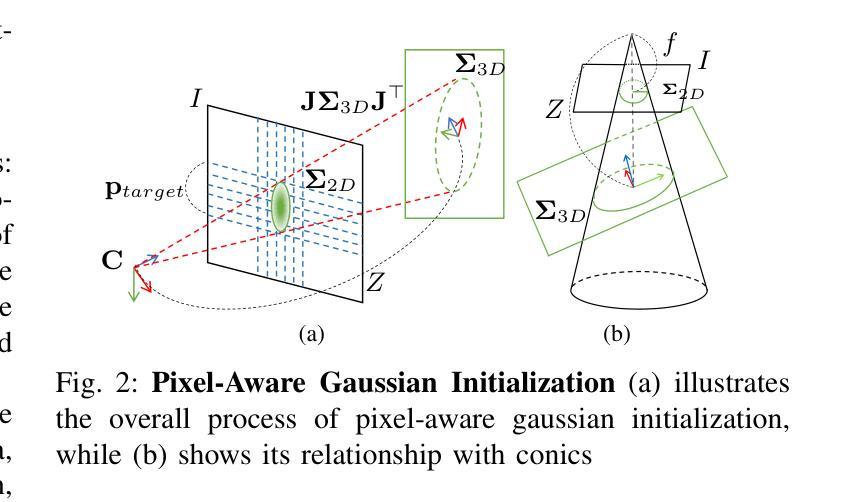
GSFusion:Globally Optimized LiDAR-Inertial-Visual Mapping for Gaussian Splatting
Authors:Jaeseok Park, Chanoh Park, Minsu Kim, Soohwan Kim
While 3D Gaussian Splatting (3DGS) has revolutionized photorealistic mapping, conventional approaches based on camera sensor, even RGB-D, suffer from fundamental limitations such as high computational load, failure in environments with poor texture or illumination, and short operational ranges. LiDAR emerges as a robust alternative, but its integration with 3DGS introduces new challenges, such as the need for exceptional global alignment for photorealistic quality and prolonged optimization times caused by sparse data. To address these challenges, we propose GSFusion, an online LiDAR-Inertial-Visual mapping system that ensures high-precision map consistency through a surfel-to-surfel constraint in the global pose-graph optimization. To handle sparse data, our system employs a pixel-aware Gaussian initialization strategy for efficient representation and a bounded sigmoid constraint to prevent uncontrolled Gaussian growth. Experiments on public and our datasets demonstrate our system outperforms existing 3DGS SLAM systems in terms of rendering quality and map-building efficiency.
虽然3D高斯延展(3DGS)已经实现了对真实感映射的革命性改变,但基于相机传感器的传统方法,甚至是RGB-D,仍然存在一些基本局限,如计算负载高、在纹理或照明不良的环境中失效以及操作范围短等。激光雷达作为一种稳健的替代方案而出现,但将其与3DGS集成带来了新的挑战,例如为了实现真实感质量而需要进行出色的全局对齐以及由于稀疏数据而导致的优化时间延长。为了解决这些挑战,我们提出了GSFusion,这是一种在线激光雷达惯性视觉映射系统,它通过全局姿态图优化中的surfel-to-surfel约束确保高精度地图一致性。为了处理稀疏数据,我们的系统采用像素感知高斯初始化策略进行高效表示,并使用有界sigmoid约束来防止高斯增长失控。在公共数据集和我们自己的数据集上的实验表明,我们的系统在渲染质量和地图构建效率方面超过了现有的3DGS SLAM系统。
论文及项目相关链接
Summary
本文介绍了基于LiDAR的在线三维映射系统GSFusion,该系统结合了LiDAR、惯性测量和视觉传感器技术,解决了传统方法在光照和纹理不佳环境下存在的问题,同时通过surfels全局姿态优化算法保证了高质量的三维重建精度和地图一致性。采用像素感知高斯初始化策略应对稀疏数据挑战,并在优化过程中应用边界sigmoid约束以避免高斯增长失控。实验证明,该系统在渲染质量和地图构建效率方面优于现有的基于3DGS的SLAM系统。
Key Takeaways
- 传统的基于相机传感器的RGB-D方法在光照和纹理不佳环境下存在局限性。
- LiDAR作为一种替代方法具有稳健性,但与3DGS集成带来全局对齐挑战和稀疏数据处理问题。
- GSFusion系统结合LiDAR、惯性测量和视觉传感器技术,实现了高精度地图一致性。
- GSFusion通过surfels全局姿态优化算法解决了精准性问题。
- 系统采用像素感知高斯初始化策略应对稀疏数据挑战。
- 采用边界sigmoid约束防止高斯增长失控。
点此查看论文截图

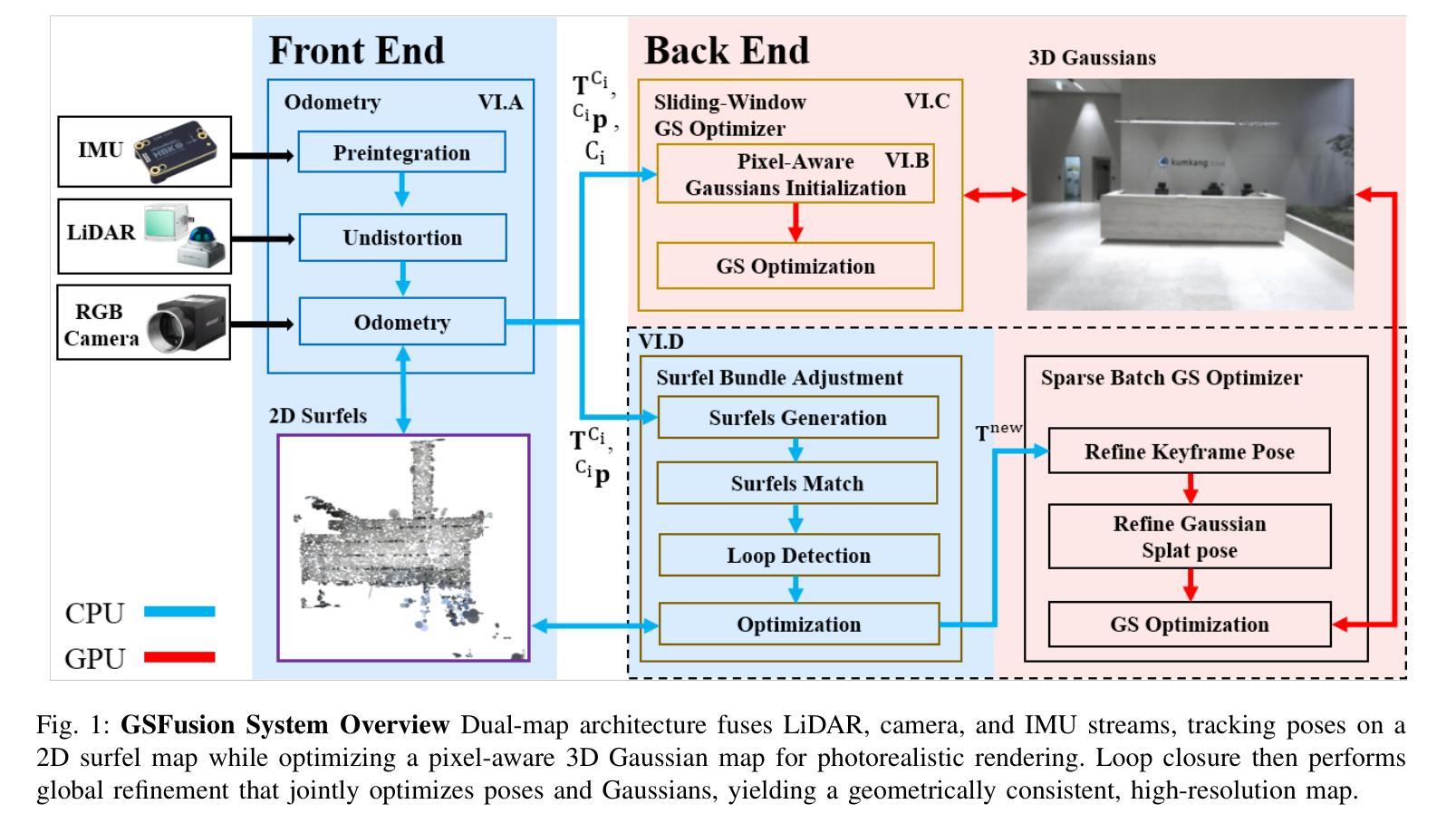


Robust and Efficient 3D Gaussian Splatting for Urban Scene Reconstruction
Authors:Zhensheng Yuan, Haozhi Huang, Zhen Xiong, Di Wang, Guanghua Yang
We present a framework that enables fast reconstruction and real-time rendering of urban-scale scenes while maintaining robustness against appearance variations across multi-view captures. Our approach begins with scene partitioning for parallel training, employing a visibility-based image selection strategy to optimize training efficiency. A controllable level-of-detail (LOD) strategy explicitly regulates Gaussian density under a user-defined budget, enabling efficient training and rendering while maintaining high visual fidelity. The appearance transformation module mitigates the negative effects of appearance inconsistencies across images while enabling flexible adjustments. Additionally, we utilize enhancement modules, such as depth regularization, scale regularization, and antialiasing, to improve reconstruction fidelity. Experimental results demonstrate that our method effectively reconstructs urban-scale scenes and outperforms previous approaches in both efficiency and quality. The source code is available at: https://yzslab.github.io/REUrbanGS.
我们提出了一种框架,能够在多视角捕获中快速重建和实时渲染城市场景,同时保持对各种外观变化的稳健性。我们的方法从场景分区并行训练开始,采用基于可见性的图像选择策略来优化训练效率。可控的层次细节(LOD)策略在用户定义的预算下明确调节高斯密度,能够在保持高视觉保真度的同时实现高效的训练和渲染。外观变换模块减轻了图像间外观不一致的负面影响,同时实现灵活调整。此外,我们还使用增强模块,如深度正则化、尺度正则化和抗锯齿,以提高重建的保真度。实验结果表明,我们的方法在重建城市场景方面非常有效,在效率和质量方面都优于以前的方法。源代码可在:https://yzslab.github.io/REUrbanGS。
论文及项目相关链接
Summary
该框架支持城市级场景的快速重建和实时渲染,能应对多视角捕捉中的外观变化。采用基于可见性的图像选择策略进行场景分区并行训练,优化训练效率。可控的细节层次(LOD)策略在用户定义预算下调控高斯密度,实现高效训练和渲染的同时保持高视觉保真度。外观变换模块减轻了图像间外观不一致的负面影响,并实现了灵活调整。此外,还使用深度正则化、尺度正则化和抗锯齿等增强模块,提高重建的保真度。实验结果证明,该方法在城市级场景的重建中表现优异,在效率和质量上均超过之前的方法。
Key Takeaways
- 框架支持城市级场景的快速重建和实时渲染。
- 采用场景分区并行训练和基于可见性的图像选择策略优化训练效率。
- 细节层次(LOD)策略调控高斯密度,实现高效训练和渲染。
- 外观变换模块应对多视角捕捉中的外观变化。
- 增强模块如深度正则化、尺度正则化和抗锯齿提高重建的保真度。
- 框架性能优越,在重建效率和质量上超越之前的方法。
点此查看论文截图


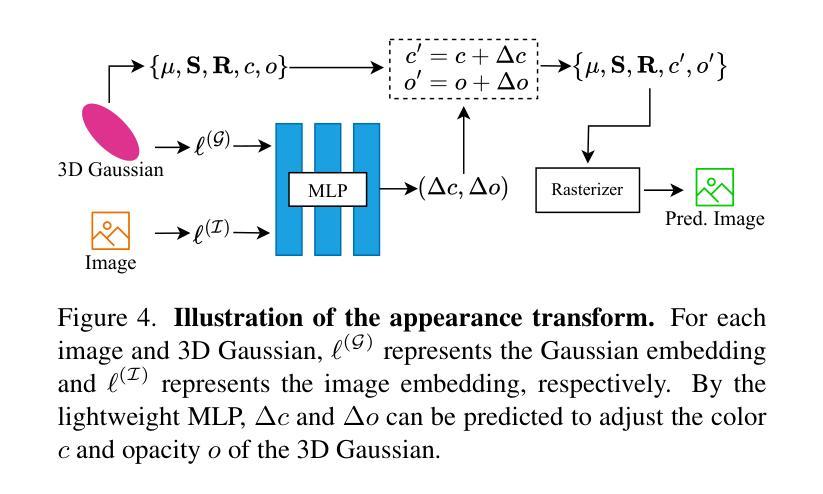
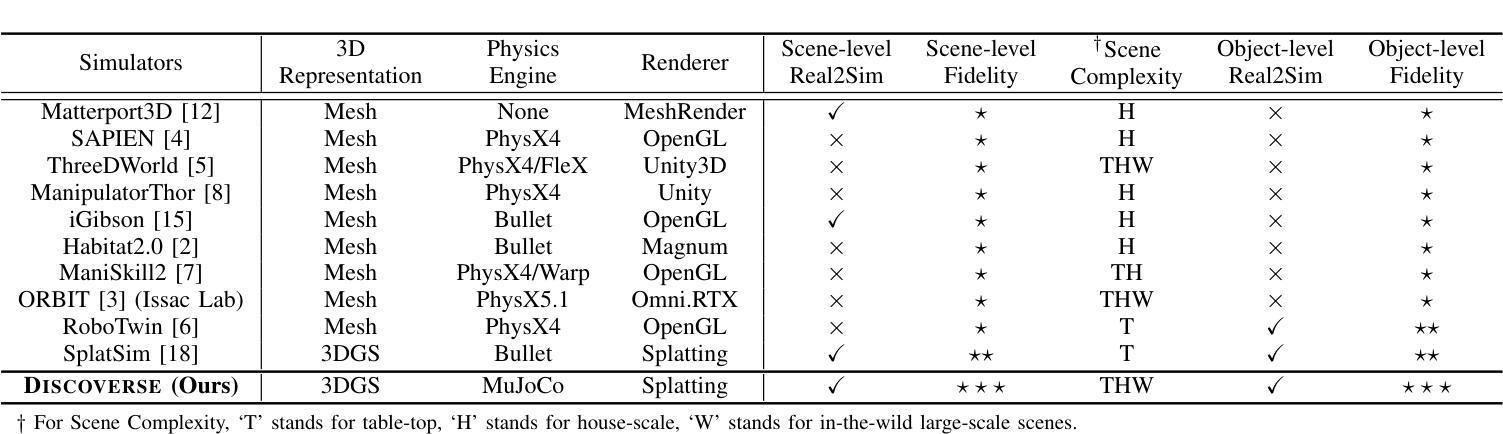
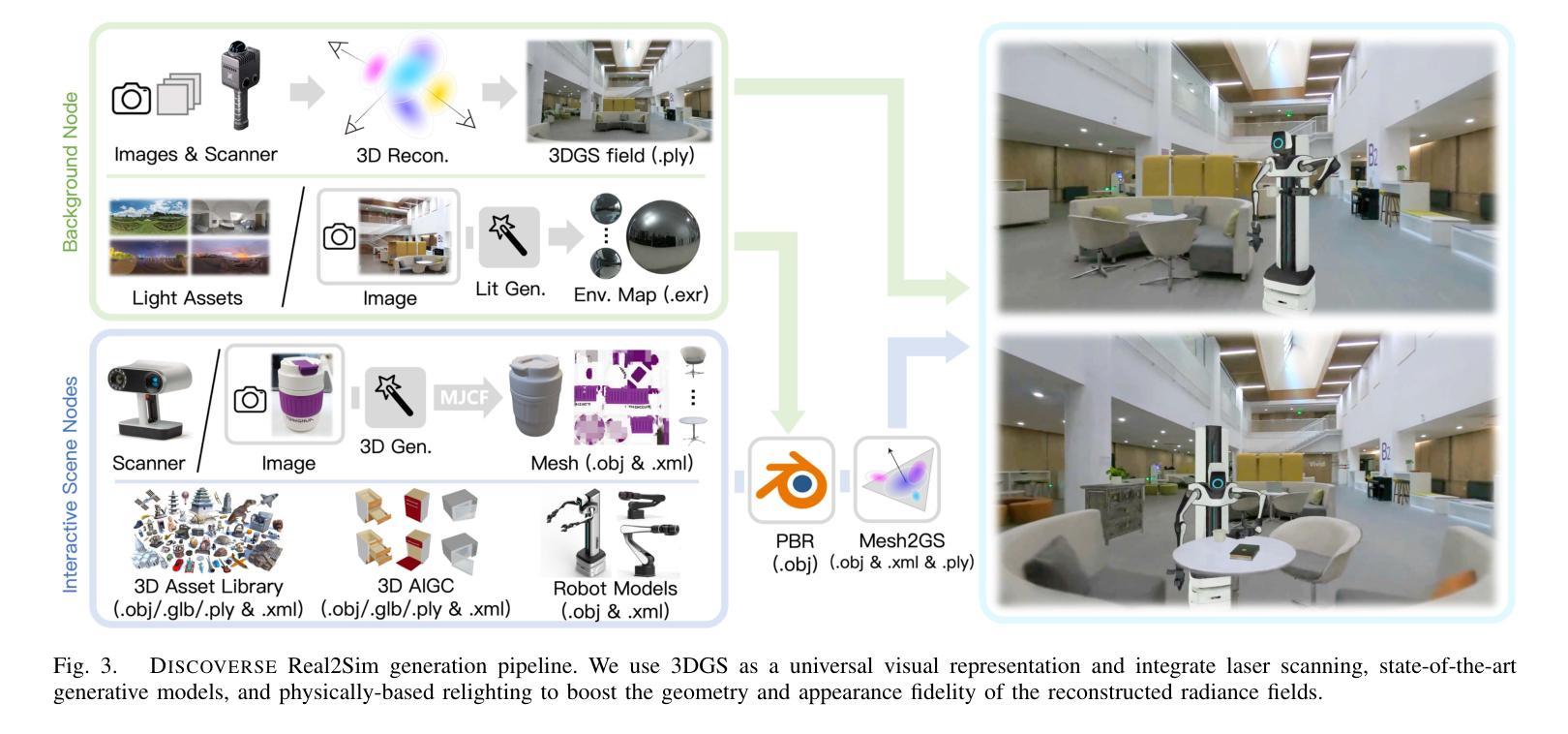
DISCOVERSE: Efficient Robot Simulation in Complex High-Fidelity Environments
Authors:Yufei Jia, Guangyu Wang, Yuhang Dong, Junzhe Wu, Yupei Zeng, Haonan Lin, Zifan Wang, Haizhou Ge, Weibin Gu, Kairui Ding, Zike Yan, Yunjie Cheng, Yue Li, Ziming Wang, Chuxuan Li, Wei Sui, Lu Shi, Guanzhong Tian, Ruqi Huang, Guyue Zhou
We present the first unified, modular, open-source 3DGS-based simulation framework for Real2Sim2Real robot learning. It features a holistic Real2Sim pipeline that synthesizes hyper-realistic geometry and appearance of complex real-world scenarios, paving the way for analyzing and bridging the Sim2Real gap. Powered by Gaussian Splatting and MuJoCo, Discoverse enables massively parallel simulation of multiple sensor modalities and accurate physics, with inclusive supports for existing 3D assets, robot models, and ROS plugins, empowering large-scale robot learning and complex robotic benchmarks. Through extensive experiments on imitation learning, Discoverse demonstrates state-of-the-art zero-shot Sim2Real transfer performance compared to existing simulators. For code and demos: https://air-discoverse.github.io/.
我们推出了首个统一、模块化、开源的基于3DGS的Real2Sim2Real机器人学习仿真框架。它具备全面的Real2Sim管道,能够合成超逼真的复杂现实世界场景的几何和外观,为分析和弥合Sim2Real差距铺平了道路。借助高斯Splatting和MuJoCo,Discoverse能够实现多种传感器模式的大规模并行仿真和精确的物理模拟,同时支持现有的3D资产、机器人模型和ROS插件,为大规模的机器人学习和复杂的机器人基准测试提供支持。通过模仿学习的广泛实验,Discoverse展现出与现有模拟器相比的卓越零射击Sim2Real传输性能。有关代码和演示,请访问:https://air-discoverse.github.io/。
论文及项目相关链接
PDF 8pages, IROS2025 (Camera Ready)
Summary
本文介绍了一个基于3DGS的统一、模块化、开源的仿真框架Discoverse,用于Real2Sim2Real机器人学习。该框架具备完整的Real2Sim管道,能合成复杂真实场景的超高仿真几何与外观,为分析并缩小Sim2Real差距铺平了道路。借助高斯拼贴和MuJoCo,Discoverse支持多种传感器模式的并行仿真和精确物理计算,并支持现有3D资产、机器人模型和ROS插件,为大规模机器人学习和复杂机器人基准测试提供了支持。通过模仿学习的广泛实验,Discoverse展现出相较于其他模拟器的卓越零射击Sim2Real转移性能。
Key Takeaways
- 基于3DGS的仿真框架:Discoverse为Real2Sim2Real机器人学习提供了首个统一、模块化、开源的仿真框架。
- Real2Sim管道:该框架具备完整的Real2Sim管道,能够合成高度逼真的几何和外观,有助于缩小Sim2Real差距。
- 支持多种传感器模式:Discoverse支持多种传感器模式的并行仿真。
- 精确物理计算:借助高斯拼贴和MuJoCo,Discoverse实现了精确的物理计算。
- 广泛的支持性:Discoverse支持现有3D资产、机器人模型和ROS插件,为大规模机器人学习和基准测试提供了支持。
- 卓越性能表现:在模仿学习实验中,Discoverse展现出卓越的性能表现,尤其是零射击Sim2Real转移性能。
点此查看论文截图




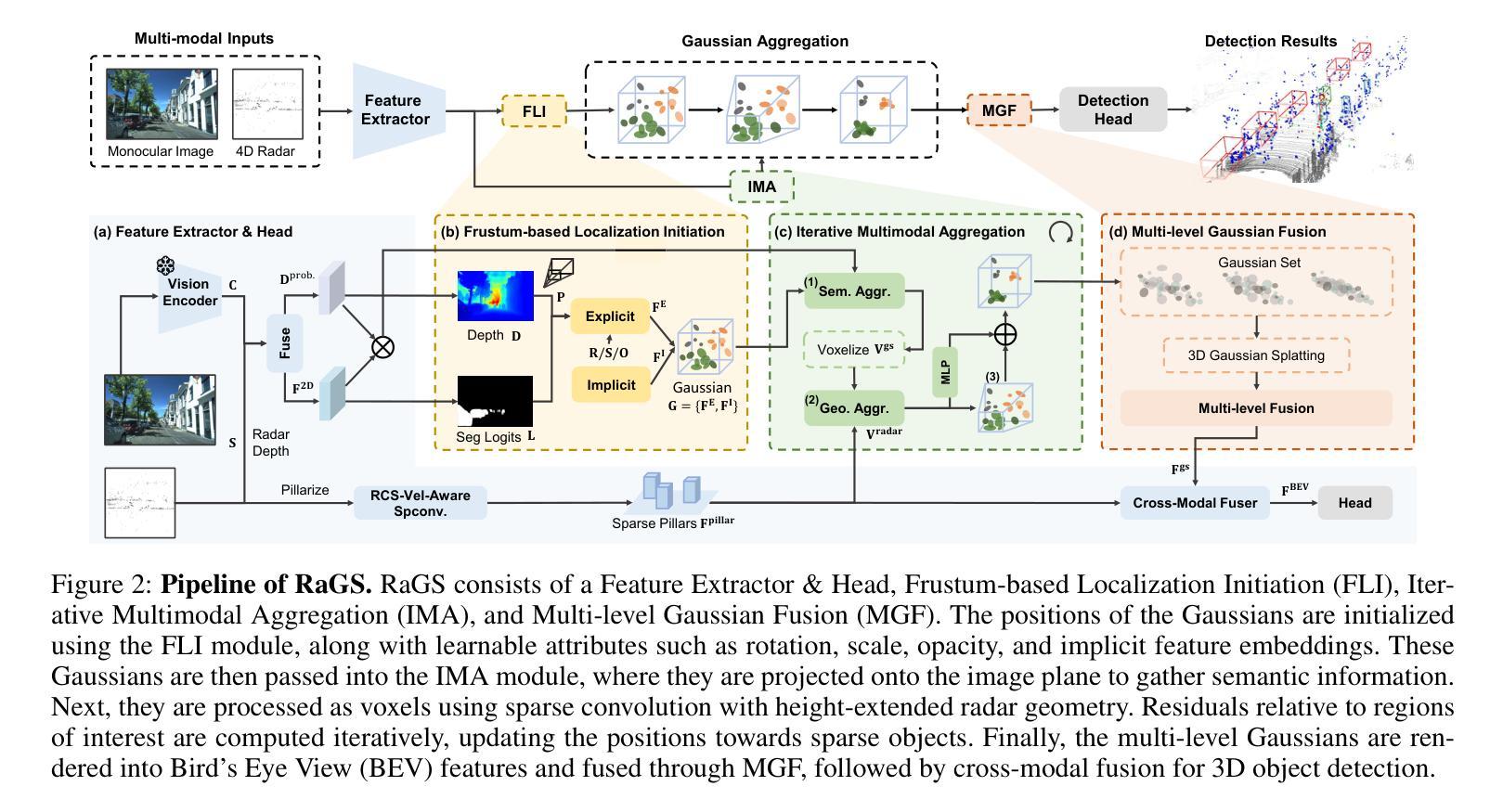
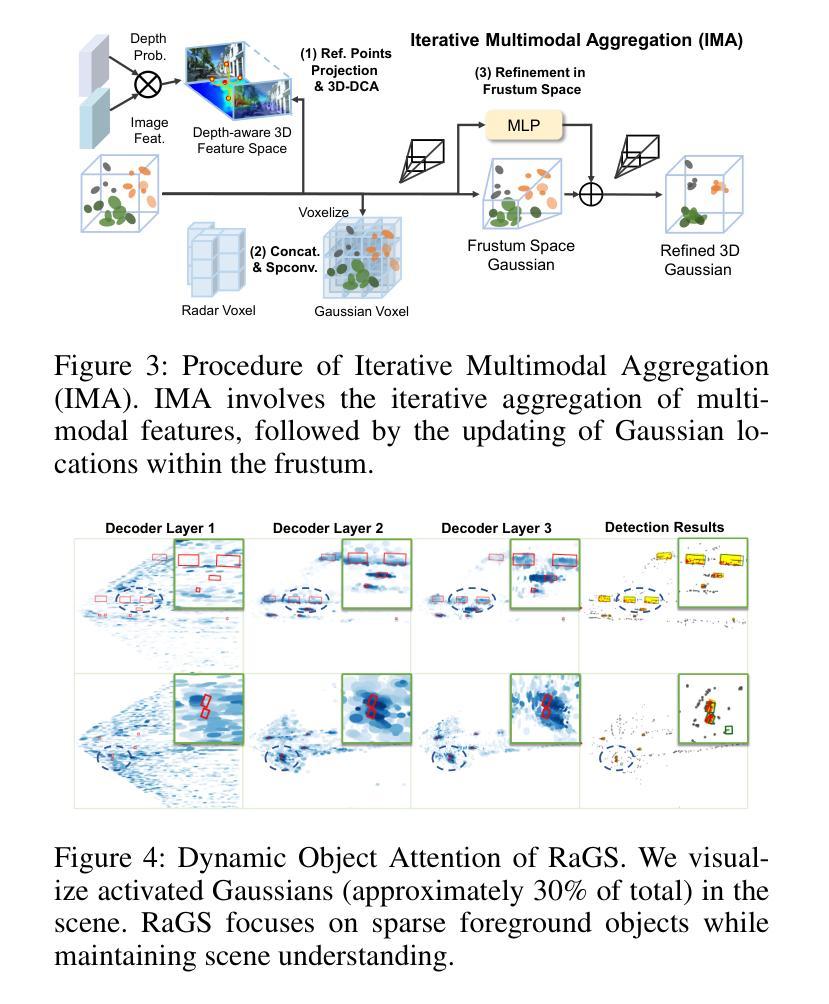
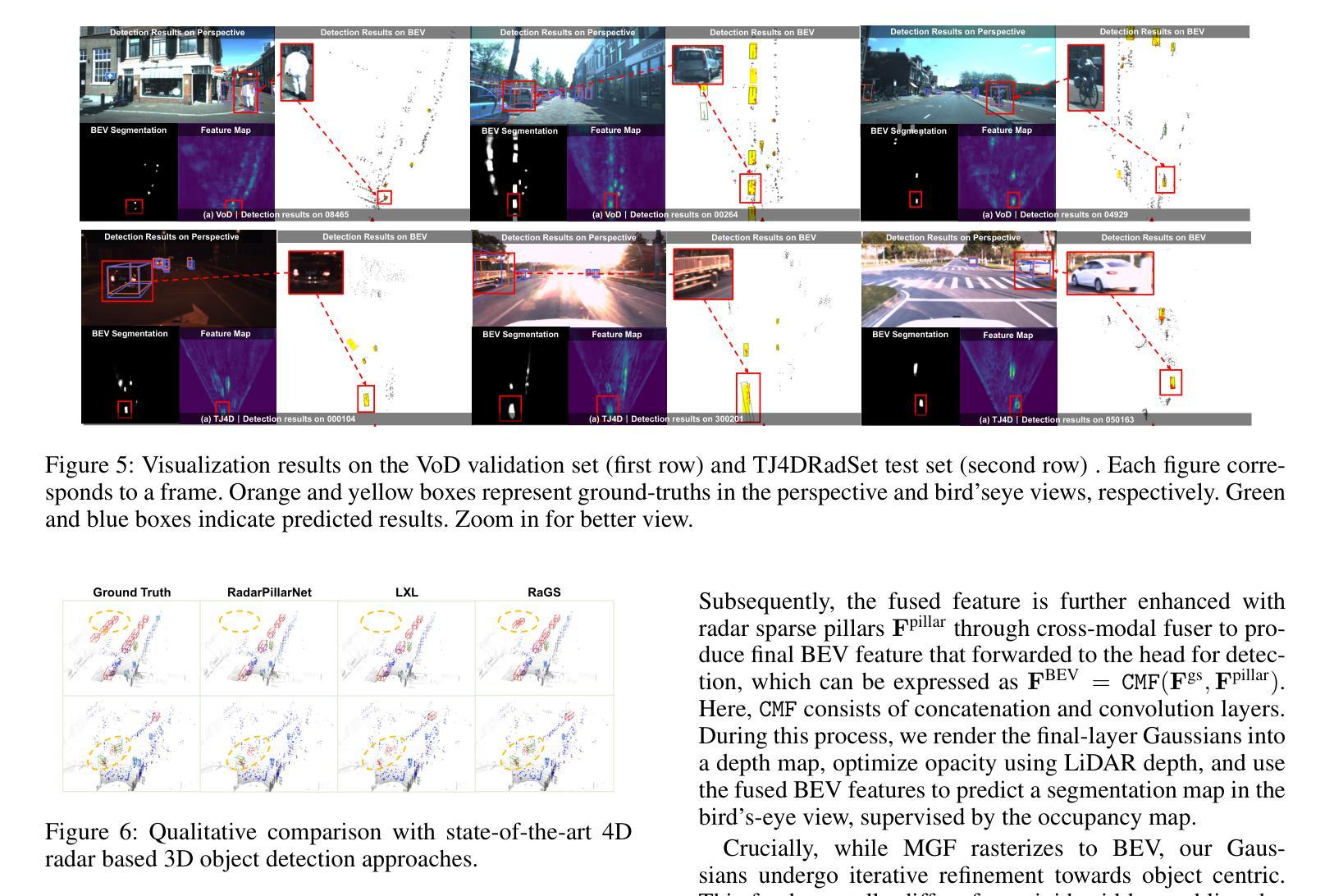
RaGS: Unleashing 3D Gaussian Splatting from 4D Radar and Monocular Cues for 3D Object Detection
Authors:Xiaokai Bai, Chenxu Zhou, Lianqing Zheng, Si-Yuan Cao, Jianan Liu, Xiaohan Zhang, Zhengzhuang Zhang, Hui-liang Shen
4D millimeter-wave radar has emerged as a promising sensor for autonomous driving, but effective 3D object detection from both 4D radar and monocular images remains a challenge. Existing fusion approaches typically rely on either instance-based proposals or dense BEV grids, which either lack holistic scene understanding or are limited by rigid grid structures. To address these, we propose RaGS, the first framework to leverage 3D Gaussian Splatting (GS) as representation for fusing 4D radar and monocular cues in 3D object detection. 3D GS naturally suits 3D object detection by modeling the scene as a field of Gaussians, dynamically allocating resources on foreground objects and providing a flexible, resource-efficient solution. RaGS uses a cascaded pipeline to construct and refine the Gaussian field. It starts with the Frustum-based Localization Initiation (FLI), which unprojects foreground pixels to initialize coarse 3D Gaussians positions. Then, the Iterative Multimodal Aggregation (IMA) fuses semantics and geometry, refining the limited Gaussians to the regions of interest. Finally, the Multi-level Gaussian Fusion (MGF) renders the Gaussians into multi-level BEV features for 3D object detection. By dynamically focusing on sparse objects within scenes, RaGS enable object concentrating while offering comprehensive scene perception. Extensive experiments on View-of-Delft, TJ4DRadSet, and OmniHD-Scenes benchmarks demonstrate its state-of-the-art performance. Code will be released.
随着自动驾驶的兴起,4D毫米波雷达已经成为了一个有前景的传感器,但如何从雷达的雷达数据和单目图像进行高效3D物体检测仍然是一个挑战。现有的融合方法大多依赖于实例化的提议或密集的BEV网格,它们要么缺乏全局场景理解,要么受限于刚性的网格结构。为了解决这些问题,我们提出了RaGS框架,首次使用三维高斯平铺(GS)作为融合四维雷达和单目视觉提示的代表,用于三维物体检测。三维高斯表示法自然地适合三维物体检测,它将场景建模为高斯场,动态分配资源于前景物体,并提供灵活、资源高效的解决方案。RaGS使用级联管道来构建和细化高斯场。它以基于视锥的定位初始化(FLI)开始,将前景像素反投影以初始化粗略的三维高斯位置。然后,迭代多模态聚合(IMA)融合语义和几何信息,将有限的高斯细分到感兴趣区域。最后,多级高斯融合(MGF)将高斯渲染成多级BEV特征用于三维物体检测。通过动态关注场景中的稀疏物体,RaGS能够在物体集中时提供全面的场景感知。在View-of-Delft、TJ4DRadSet和OmniHD-Scenes基准测试上的大量实验证明了其卓越的性能。代码将公开发布。
论文及项目相关链接
PDF 9 pages, 6 figures, conference
Summary
本文提出一种名为RaGS的新框架,用于在自主驾驶中的四维雷达和单目图像融合的三维对象检测。它通过采用三维高斯模板作为场景表示方法,并通过一系列模块来构建和优化高斯场实现精准的三维对象检测。RaGS的创新点在于其对前景对象进行动态资源分配并提供灵活、资源高效的解决方案,最终通过多层次高斯融合(MGF)实现先进性能。
Key Takeaways
- 4D雷达已成为自主驾驶中有前景的传感器,但融合雷达和图像实现三维物体检测仍然存在挑战。
- 目前融合方法主要依赖于实例提议或密集BEV网格,存在对场景理解不全面或受网格结构限制的问题。
- RaGS框架首次利用三维高斯模板(GS)作为表示方法,融合四维雷达和单目图像进行三维对象检测。
- 三维高斯模板自然适用于三维对象检测,通过动态资源分配对前景对象进行建模,提供灵活且资源高效的解决方案。
- RaGS使用级联管道构建和优化高斯场,包括基于视锥的定位启动(FLI)、迭代多模式聚合(IMA)和多层次高斯融合(MGF)。
- 通过聚焦场景中的稀疏对象,RaGS实现了对象集中并提供了全面的场景感知。
- 在多个基准测试中,RaGS表现出卓越性能。
点此查看论文截图

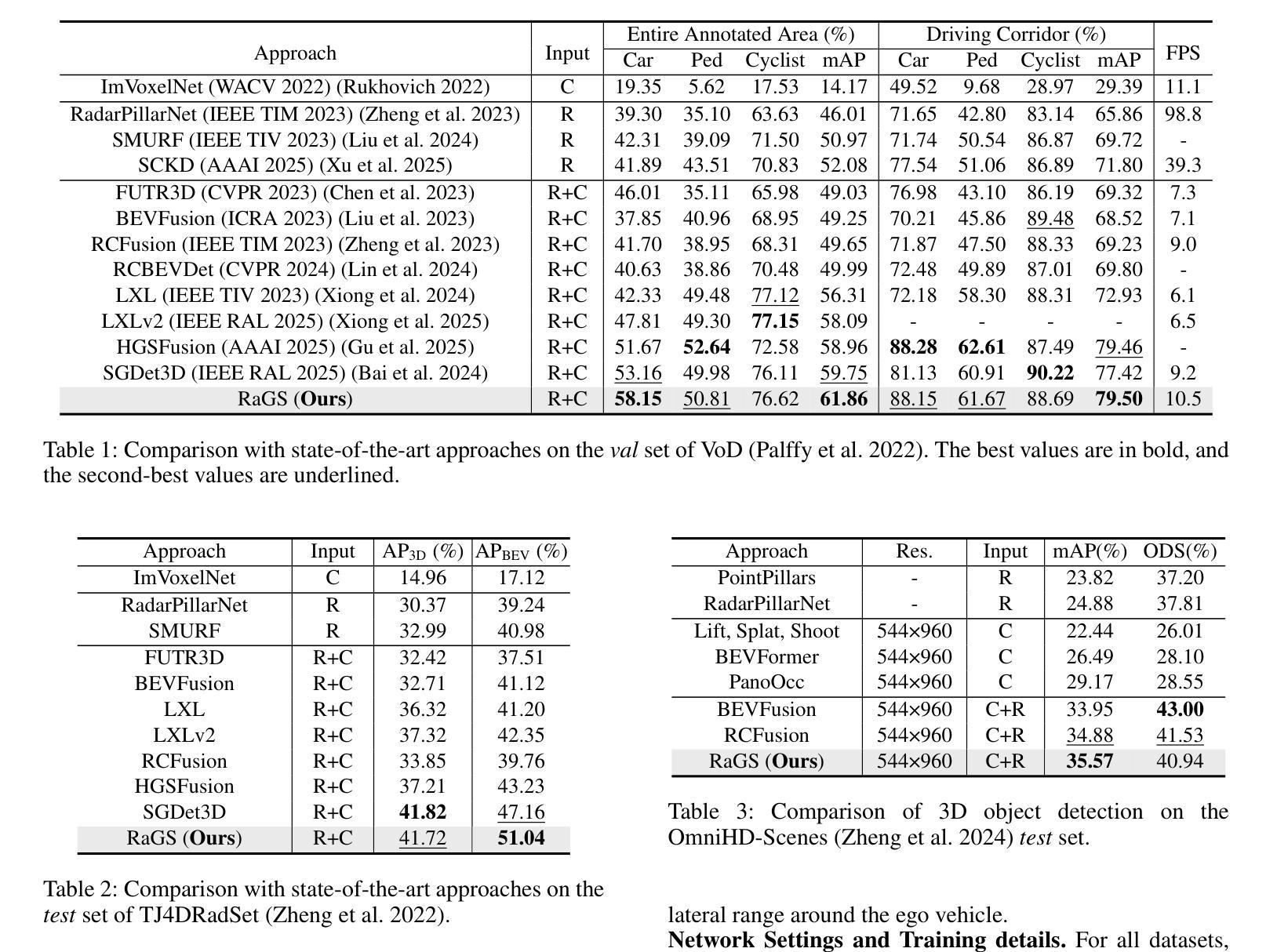
GS-Occ3D: Scaling Vision-only Occupancy Reconstruction for Autonomous Driving with Gaussian Splatting
Authors:Baijun Ye, Minghui Qin, Saining Zhang, Moonjun Gong, Shaoting Zhu, Zebang Shen, Luan Zhang, Lu Zhang, Hao Zhao, Hang Zhao
Occupancy is crucial for autonomous driving, providing essential geometric priors for perception and planning. However, existing methods predominantly rely on LiDAR-based occupancy annotations, which limits scalability and prevents leveraging vast amounts of potential crowdsourced data for auto-labeling. To address this, we propose GS-Occ3D, a scalable vision-only framework that directly reconstructs occupancy. Vision-only occupancy reconstruction poses significant challenges due to sparse viewpoints, dynamic scene elements, severe occlusions, and long-horizon motion. Existing vision-based methods primarily rely on mesh representation, which suffer from incomplete geometry and additional post-processing, limiting scalability. To overcome these issues, GS-Occ3D optimizes an explicit occupancy representation using an Octree-based Gaussian Surfel formulation, ensuring efficiency and scalability. Additionally, we decompose scenes into static background, ground, and dynamic objects, enabling tailored modeling strategies: (1) Ground is explicitly reconstructed as a dominant structural element, significantly improving large-area consistency; (2) Dynamic vehicles are separately modeled to better capture motion-related occupancy patterns. Extensive experiments on the Waymo dataset demonstrate that GS-Occ3D achieves state-of-the-art geometry reconstruction results. By curating vision-only binary occupancy labels from diverse urban scenes, we show their effectiveness for downstream occupancy models on Occ3D-Waymo and superior zero-shot generalization on Occ3D-nuScenes. It highlights the potential of large-scale vision-based occupancy reconstruction as a new paradigm for scalable auto-labeling. Project Page: https://gs-occ3d.github.io/
占用信息对于自动驾驶至关重要,它为感知和规划提供了必要的几何先验信息。然而,现有方法主要依赖于基于激光雷达的占用标注,这限制了可扩展性,并阻止了利用大量潜在的众包数据进行自动标注。为了解决这一问题,我们提出了GS-Occ3D,这是一个可扩展的仅视觉框架,可直接重建占用信息。仅使用视觉的占用信息重建由于稀疏的视点、动态场景元素、严重的遮挡和长距离运动而面临重大挑战。现有的基于视觉的方法主要依赖于网格表示,这导致了几何不完整性和额外的后处理,从而限制了可扩展性。为了克服这些问题,GS-Occ3D使用基于八叉树的高斯Surfel表示法优化明确的占用表示,确保效率和可扩展性。此外,我们将场景分解为静态背景、地面和动态物体,以实现定制建模策略:(1)地面被明确重建为一个主要结构元素,这显著提高了大面积的一致性;(2)动态车辆被单独建模,以更好地捕捉与运动相关的占用模式。在Waymo数据集上的广泛实验表明,GS-Occ3D实现了最先进的几何重建结果。我们通过从各种城市场景中整理仅使用视觉的二进制占用标签,展示了它们在Occ3D-Waymo上的下游占用模型的有效性,以及在Occ3D-nuScenes上的零样本泛化优势。它突出了大规模基于视觉的占用信息重建作为新的可扩展自动标注范式的潜力。项目页面:https://gs-occ3d.github.io/
论文及项目相关链接
PDF ICCV 2025. Project Page: https://gs-occ3d.github.io/
Summary
本文提出一种名为GS-Occ3D的仅视觉的占有率重建框架,用于直接重建自主驾驶中的占有率。该框架采用基于Octree的Gaussian Surfel公式进行明确的占有率表示,确保效率和可扩展性。通过分解场景为静态背景、地面和动态物体,实现有针对性的建模策略,并在Waymo数据集上达到最先进的几何重建结果。此外,从多样的城市场景中提取仅视觉的二元占有率标签,展示其在下游占有率模型中的有效性,并强调大规模视觉基础占有率重建作为可伸缩自动标注的新范式潜力。
Key Takeaways
- GS-Occ3D是一个仅视觉的占有率重建框架,可直接重建自主驾驶中的占有率。
- 该框架采用基于Octree的Gaussian Surfel公式,优化明确的占有率表示,确保效率和可扩展性。
- 场景被分解为静态背景、地面和动态物体,以实现有针对性的建模策略。
- 在Waymo数据集上,GS-Occ3D实现了最先进的几何重建结果。
- 从多样的城市场景中提取仅视觉的二元占有率标签,这些标签对于下游占有率模型非常有效。
- GS-Occ3D显示出大规模视觉基础占有率重建作为可伸缩自动标注新范式的潜力。
点此查看论文截图

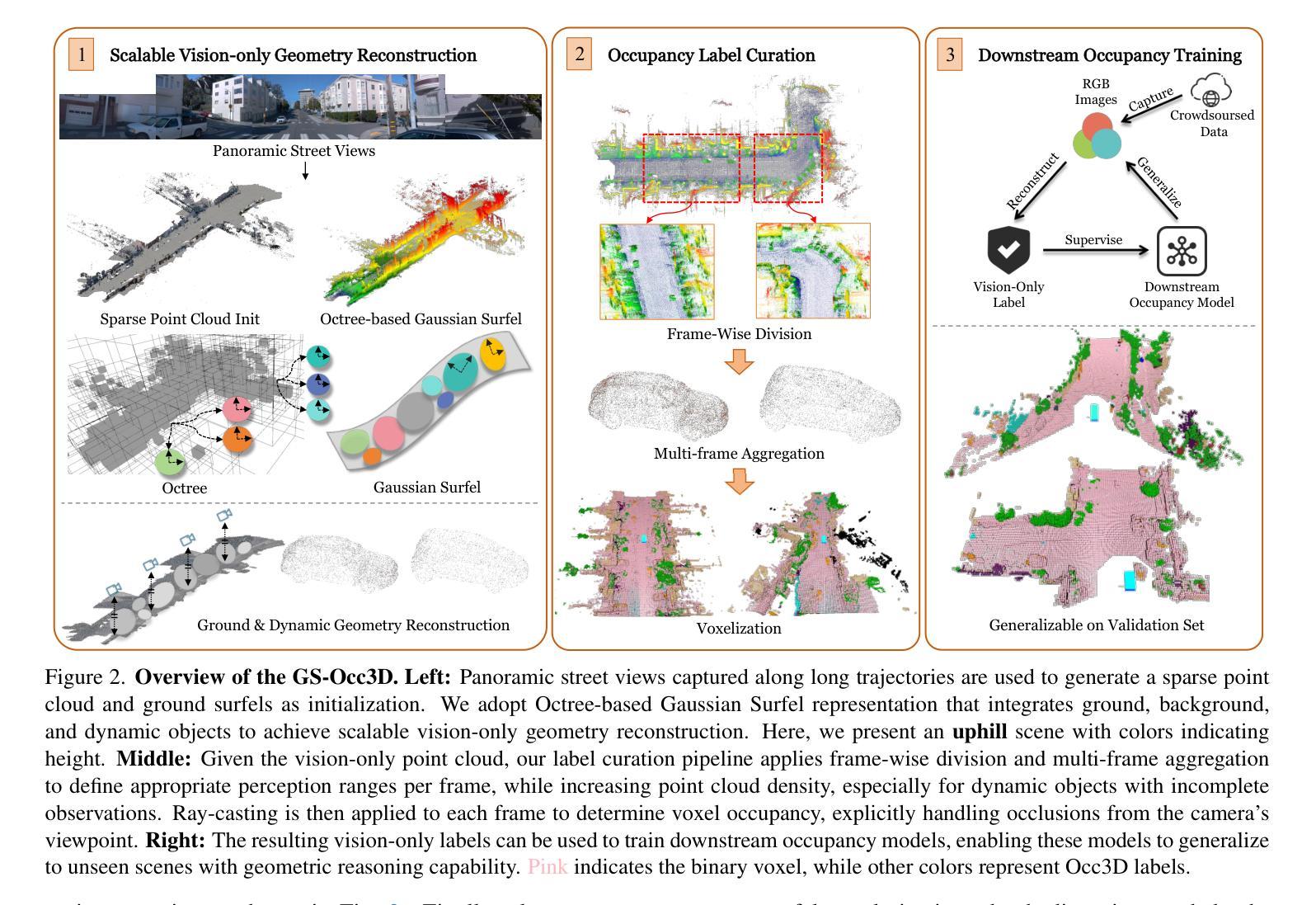

MVG4D: Image Matrix-Based Multi-View and Motion Generation for 4D Content Creation from a Single Image
Authors:DongFu Yin, Xiaotian Chen, Fei Richard Yu, Xuanchen Li, Xinhao Zhang
Advances in generative modeling have significantly enhanced digital content creation, extending from 2D images to complex 3D and 4D scenes. Despite substantial progress, producing high-fidelity and temporally consistent dynamic 4D content remains a challenge. In this paper, we propose MVG4D, a novel framework that generates dynamic 4D content from a single still image by combining multi-view synthesis with 4D Gaussian Splatting (4D GS). At its core, MVG4D employs an image matrix module that synthesizes temporally coherent and spatially diverse multi-view images, providing rich supervisory signals for downstream 3D and 4D reconstruction. These multi-view images are used to optimize a 3D Gaussian point cloud, which is further extended into the temporal domain via a lightweight deformation network. Our method effectively enhances temporal consistency, geometric fidelity, and visual realism, addressing key challenges in motion discontinuity and background degradation that affect prior 4D GS-based methods. Extensive experiments on the Objaverse dataset demonstrate that MVG4D outperforms state-of-the-art baselines in CLIP-I, PSNR, FVD, and time efficiency. Notably, it reduces flickering artifacts and sharpens structural details across views and time, enabling more immersive AR/VR experiences. MVG4D sets a new direction for efficient and controllable 4D generation from minimal inputs.
生成模型的进步极大推动了数字内容的创作,从二维图像扩展到复杂的三维甚至四维场景。尽管取得了很大进展,但生成高保真且时间一致的动态四维内容仍是一个挑战。本文提出了一种新型框架MVG4D,通过结合多视图合成与四维高斯斑点(4D GS),从单一静态图像生成动态四维内容。MVG4D的核心在于采用图像矩阵模块,合成时间连贯且空间多样的多视图图像,为下游的三维和四维重建提供丰富的监督信号。这些多视图图像用于优化三维高斯点云,通过轻量级变形网络进一步扩展到时间域。我们的方法有效地提高了时间一致性、几何保真度和视觉逼真度,解决了影响基于四维GS的方法的运动不连续和背景退化等关键挑战。在Objaverse数据集上的大量实验表明,MVG4D在CLIP-I、PSNR、FVD和时间效率方面优于最新基线。值得注意的是,它减少了闪烁伪影,提高了跨视图和时间的结构细节清晰度,为增强AR/VR体验提供了更多沉浸式体验。MVG4D为从最小输入实现高效可控的四维生成设置了新的方向。
论文及项目相关链接
Summary
本文提出MVG4D框架,通过结合多视角合成与四维高斯点云技术,从单一静态图像生成动态四维内容。该框架采用图像矩阵模块,合成时空连贯且视角多样的图像,为下游三维和四维重建提供丰富的监督信号。通过优化三维高斯点云,并在时间域进行轻量化变形网络扩展,有效提升了时序一致性、几何精度和视觉真实感。在Objaverse数据集上的实验表明,MVG4D在CLIP-I、PSNR、FVD和时间效率等方面优于现有基线,减少了闪烁伪影,提高了结构细节清晰度,为AR/VR体验提供更沉浸式体验。
Key Takeaways
- MVG4D框架结合了多视角合成与四维高斯点云技术,能够从单一静态图像生成动态四维内容。
- 图像矩阵模块用于合成时空连贯且视角多样的图像,为下游三维和四维重建提供丰富的监督信号。
- 通过优化三维高斯点云,并在时间域进行轻量化变形网络扩展,提升了时序一致性、几何精度和视觉真实感。
- MVG4D解决了基于四维高斯点云方法存在的运动不连续和背景退化等关键挑战。
- 在Objaverse数据集上的实验表明,MVG4D在多个指标上优于现有方法,包括CLIP-I、PSNR、FVD等。
- MVG4D减少了生成内容中的闪烁伪影,提高了结构细节的清晰度。
点此查看论文截图

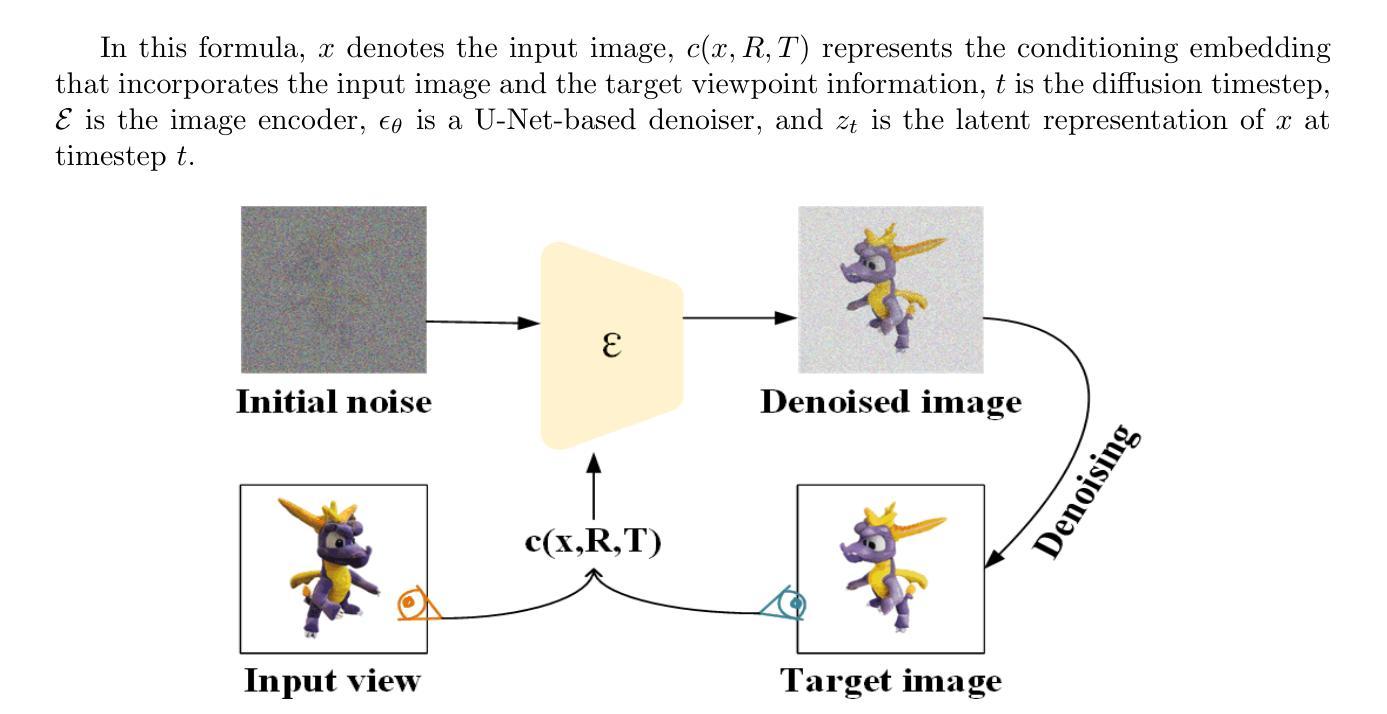
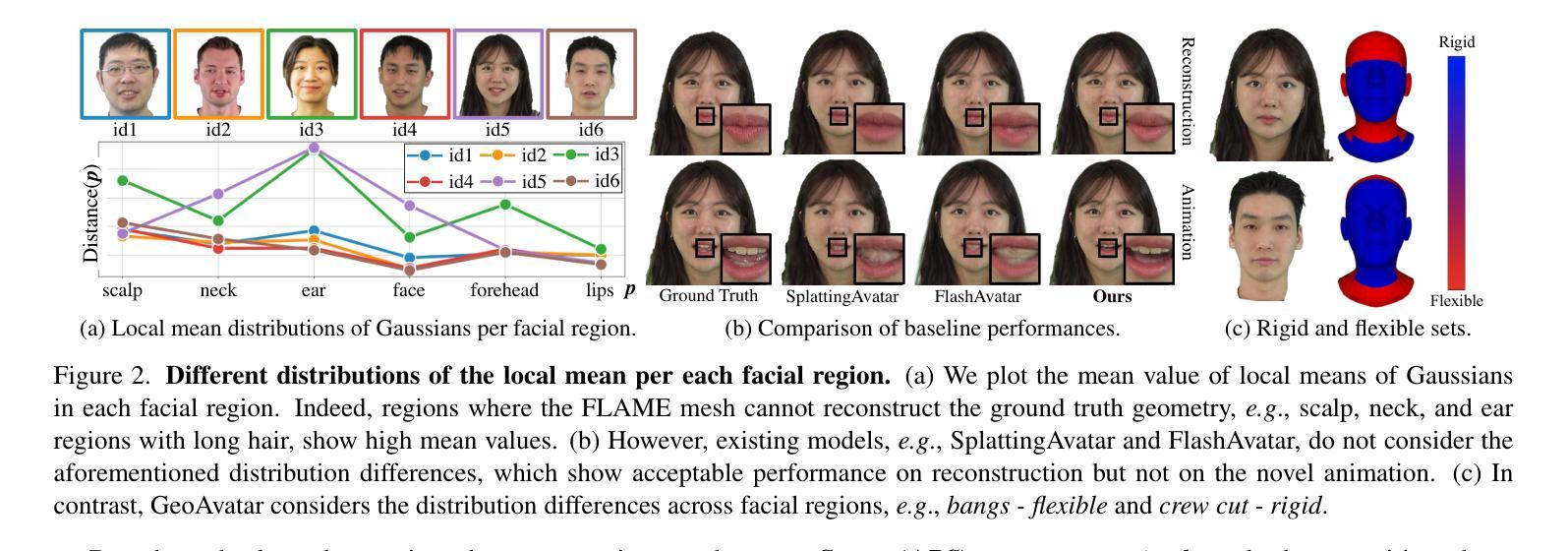
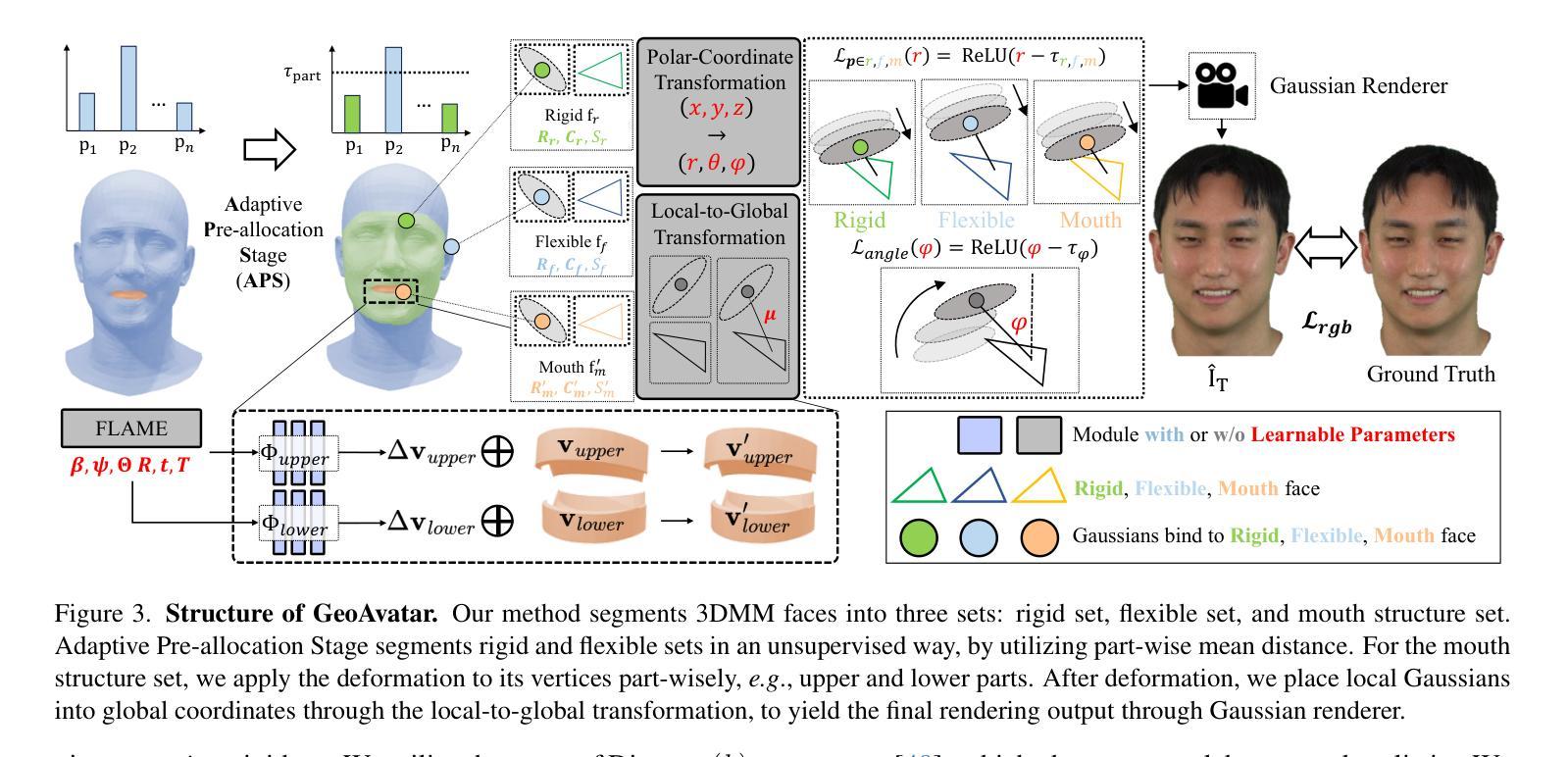
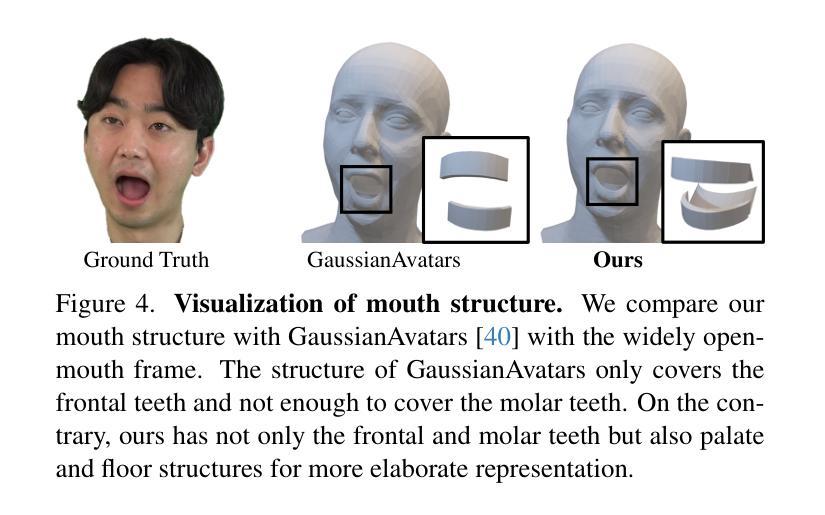
GeoAvatar: Adaptive Geometrical Gaussian Splatting for 3D Head Avatar
Authors:SeungJun Moon, Hah Min Lew, Seungeun Lee, Ji-Su Kang, Gyeong-Moon Park
Despite recent progress in 3D head avatar generation, balancing identity preservation, i.e., reconstruction, with novel poses and expressions, i.e., animation, remains a challenge. Existing methods struggle to adapt Gaussians to varying geometrical deviations across facial regions, resulting in suboptimal quality. To address this, we propose GeoAvatar, a framework for adaptive geometrical Gaussian Splatting. GeoAvatar leverages Adaptive Pre-allocation Stage (APS), an unsupervised method that segments Gaussians into rigid and flexible sets for adaptive offset regularization. Then, based on mouth anatomy and dynamics, we introduce a novel mouth structure and the part-wise deformation strategy to enhance the animation fidelity of the mouth. Finally, we propose a regularization loss for precise rigging between Gaussians and 3DMM faces. Moreover, we release DynamicFace, a video dataset with highly expressive facial motions. Extensive experiments show the superiority of GeoAvatar compared to state-of-the-art methods in reconstruction and novel animation scenarios.
尽管最近在3D头像生成方面取得了进展,但在平衡身份保留(即重建)与新颖姿势和表情(即动画)之间仍然存在挑战。现有方法难以适应面部各区域不同的几何偏差,导致质量不佳。为了解决这一问题,我们提出了GeoAvatar,一个自适应几何高斯拼贴框架。GeoAvatar利用自适应预分配阶段(APS),这是一种无监督方法,将高斯分割成刚性和柔性集合,用于自适应偏移正则化。然后,基于嘴巴结构和动态特性,我们引入了一种新的嘴巴结构和部分变形策略,以提高嘴巴的动画保真度。最后,我们提出了一种针对高斯和3DMM面孔之间的精确骨架的正则化损失。此外,我们发布了DynamicFace,这是一个具有高度表达性面部动作的视频数据集。大量实验表明,GeoAvatar在重建和新颖动画场景中相较于最先进的方法具有优越性。
论文及项目相关链接
PDF ICCV 2025, Project page: https://hahminlew.github.io/geoavatar/
Summary
该文探讨了在3D头像生成领域中的一项挑战,即如何在保持身份不变的同时实现新的姿态和表情。为解决现有方法在面部几何形变上的不足,提出GeoAvatar框架,利用自适应预分配阶段和基于嘴巴解剖结构和动态特性的创新技术,提升头像质量。此外,还引入了一种新的动态面部数据集DynamicFace。
Key Takeaways
- 3D头像生成中保持身份、重建和动画平衡仍是挑战。
- 现有方法难以适应面部几何形变,导致质量不佳。
- GeoAvatar框架通过自适应几何高斯点分布解决此问题。
- 利用自适应预分配阶段(APS)进行高斯分割,实现自适应偏移正则化。
- 基于嘴巴解剖结构和动态特性引入新型嘴巴结构和部分变形策略,提升动画逼真度。
- 引入正则化损失,精确调整高斯和3DMM面部之间的关联。
点此查看论文截图

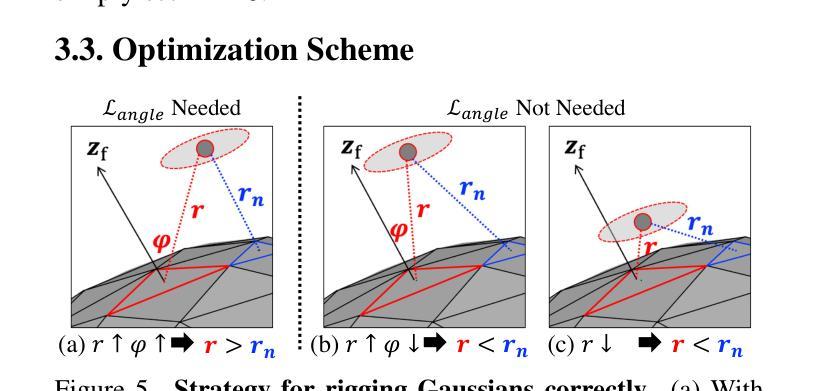

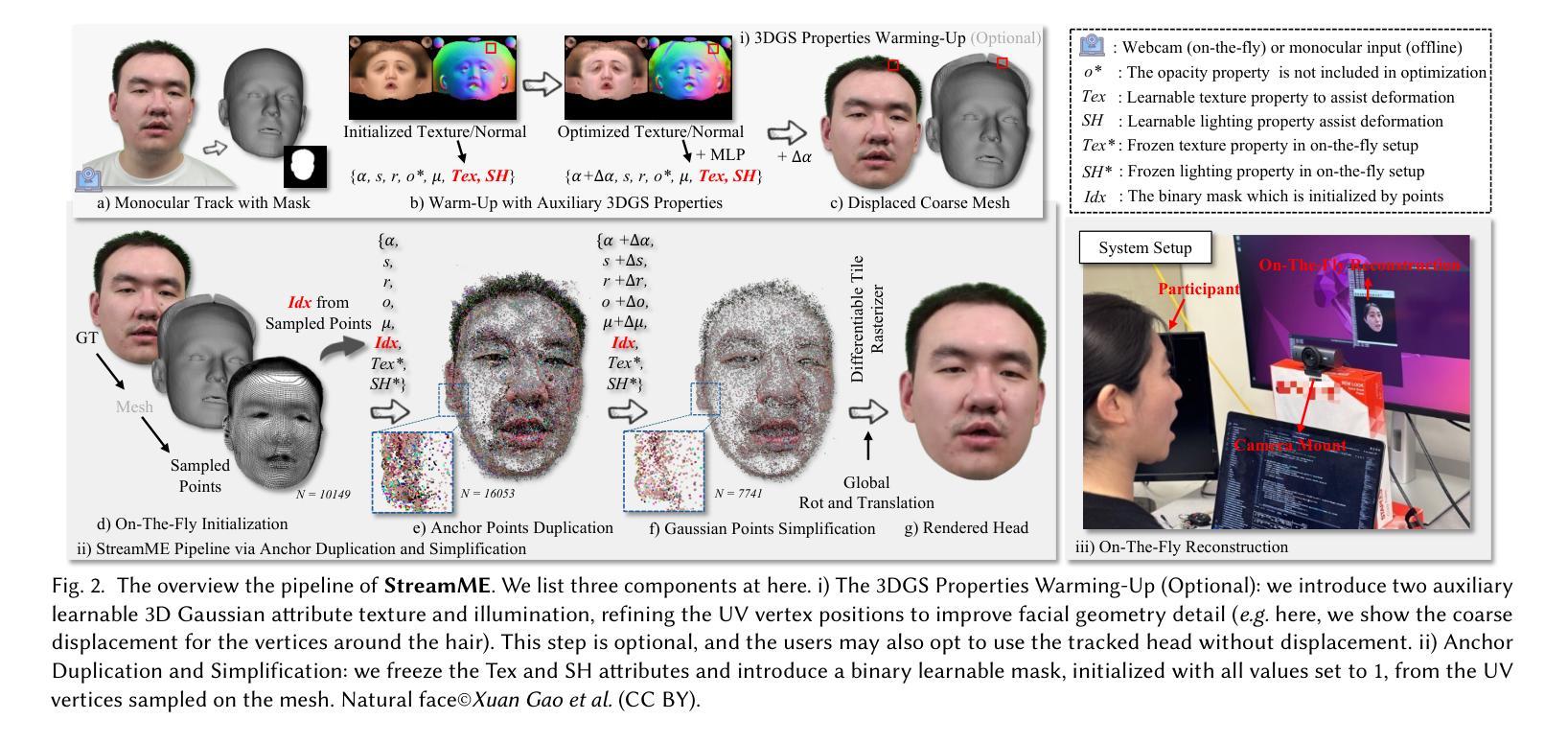
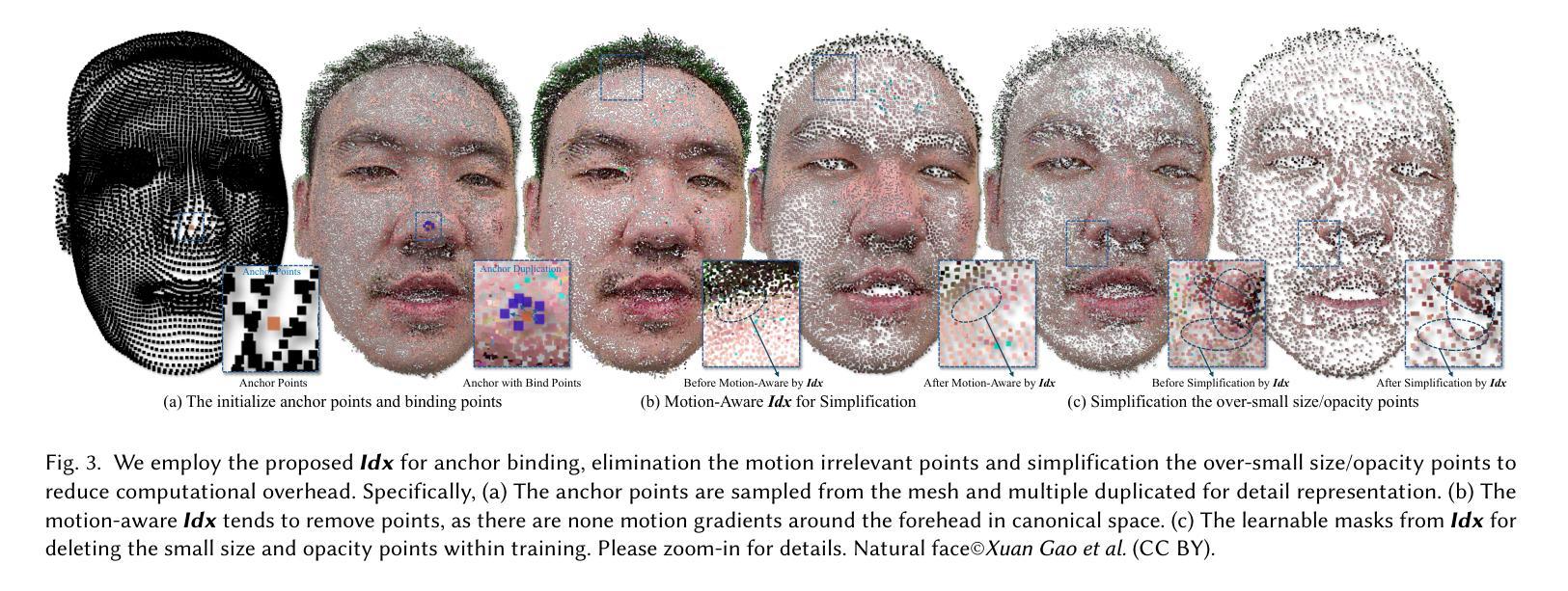
StreamME: Simplify 3D Gaussian Avatar within Live Stream
Authors:Luchuan Song, Yang Zhou, Zhan Xu, Yi Zhou, Deepali Aneja, Chenliang Xu
We propose StreamME, a method focuses on fast 3D avatar reconstruction. The StreamME synchronously records and reconstructs a head avatar from live video streams without any pre-cached data, enabling seamless integration of the reconstructed appearance into downstream applications. This exceptionally fast training strategy, which we refer to as on-the-fly training, is central to our approach. Our method is built upon 3D Gaussian Splatting (3DGS), eliminating the reliance on MLPs in deformable 3DGS and relying solely on geometry, which significantly improves the adaptation speed to facial expression. To further ensure high efficiency in on-the-fly training, we introduced a simplification strategy based on primary points, which distributes the point clouds more sparsely across the facial surface, optimizing points number while maintaining rendering quality. Leveraging the on-the-fly training capabilities, our method protects the facial privacy and reduces communication bandwidth in VR system or online conference. Additionally, it can be directly applied to downstream application such as animation, toonify, and relighting. Please refer to our project page for more details: https://songluchuan.github.io/StreamME/.
我们提出了StreamME方法,它专注于快速3D化身重建。StreamME同步记录并从实时视频流中重建头部化身,无需任何预先缓存的数据,使得重建的外观能够无缝地集成到下游应用中。我们称之为即时训练的超快训练策略是我们方法的核心。我们的方法基于3D高斯展开技术(3DGS),摒弃了可变形3DGS中对多层感知机(MLPs)的依赖,只依赖几何结构,这极大地提高了对面部表情的适应速度。为了确保即时训练的高效率,我们引入了一种基于主要点的简化策略,该策略在面部表面更稀疏地分布点云,在保持渲染质量的同时优化了点的数量。借助即时训练功能,我们的方法保护了面部的隐私并降低了VR系统或在线会议中的通信带宽。此外,它可以直接应用于动画、卡通化和重新照明等下游应用。想了解更多详情,请访问我们的项目页面:https://songluchuan.github.io/StreamME/。
论文及项目相关链接
PDF 12 pages, 15 Figures
Summary
本文提出一种名为StreamME的快速3D头像重建方法,它同步记录并从实时视频流中重建头像,无需预先缓存数据。该方法以实时训练为核心,建立于3D高斯展开技术之上,简化了点云分布,提高渲染效率,保护面部隐私并减少虚拟实境系统或在线会议中的通信带宽需求。可直接应用于动画、卡通渲染和重光照等下游应用。
Key Takeaways
- StreamME是一种快速3D头像重建方法,可从实时视频流中同步记录和重建头像。
- 该方法采用实时训练策略,摒弃了对多层感知机的依赖,仅依赖几何信息,提高了对面部表情的适应速度。
- StreamME基于主要点简化策略,优化了点云分布,在保持渲染质量的同时减少了点数。
- 该方法能提高渲染效率,保护面部隐私,降低虚拟实境系统或在线会议的通信带宽需求。
- StreamME可直接应用于动画、卡通渲染和重光照等下游应用。
- 文章提到的3D高斯展开技术是该方法的重要基础。
点此查看论文截图


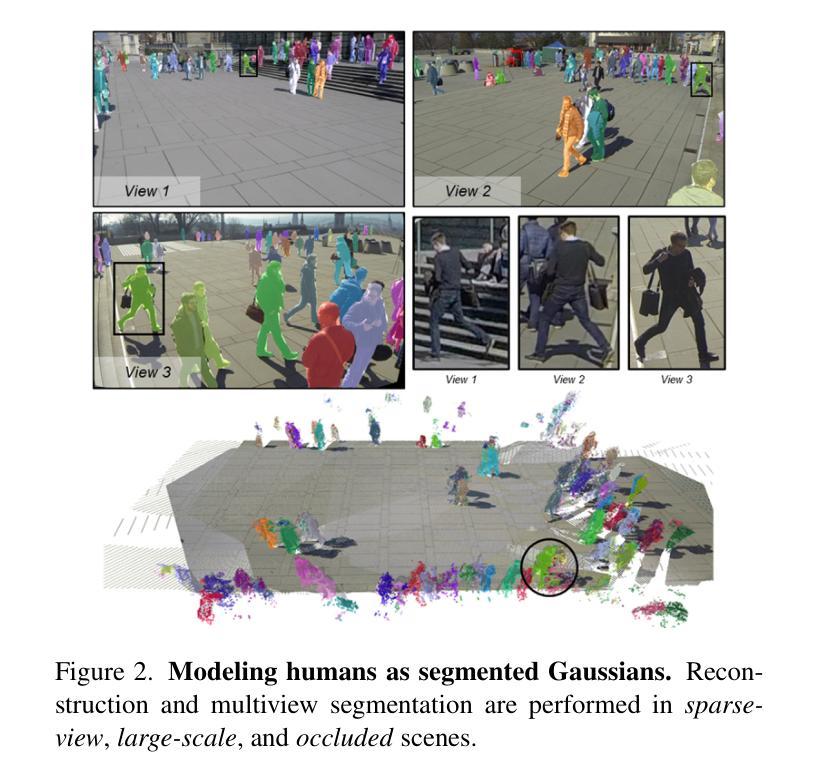
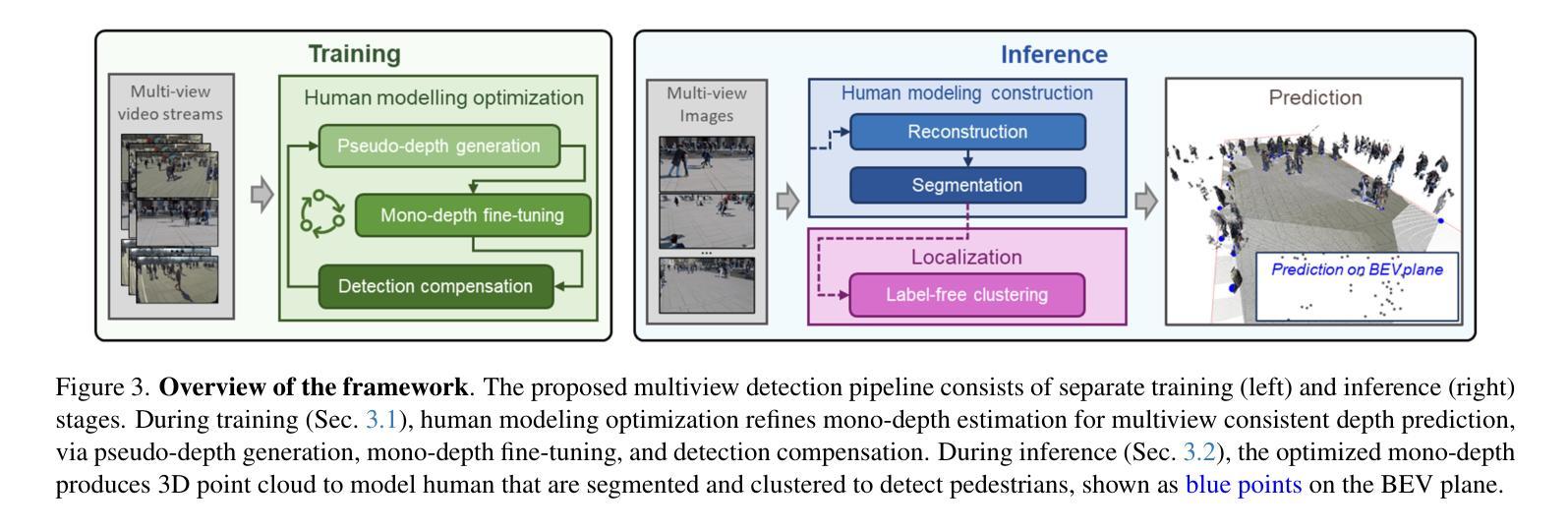
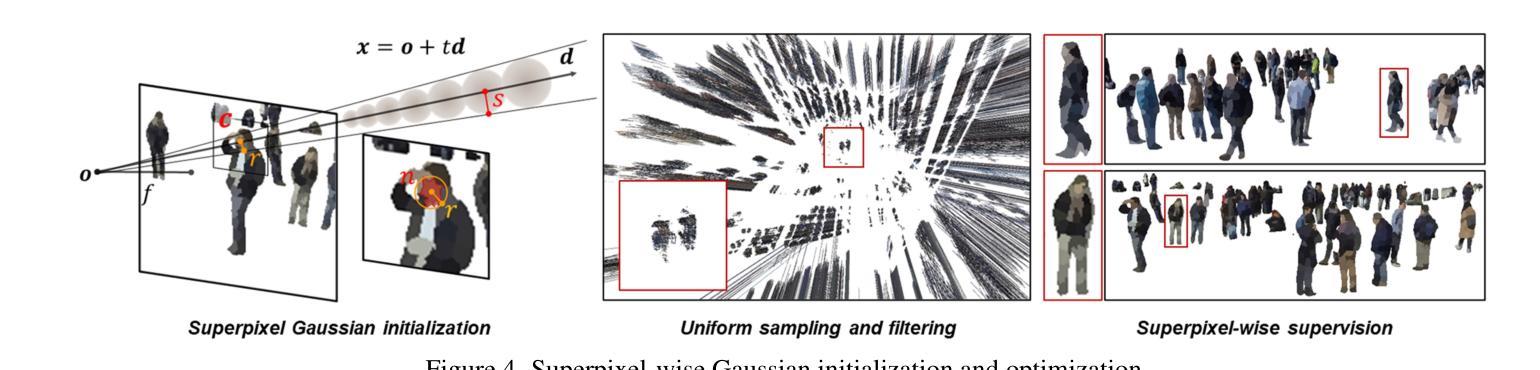
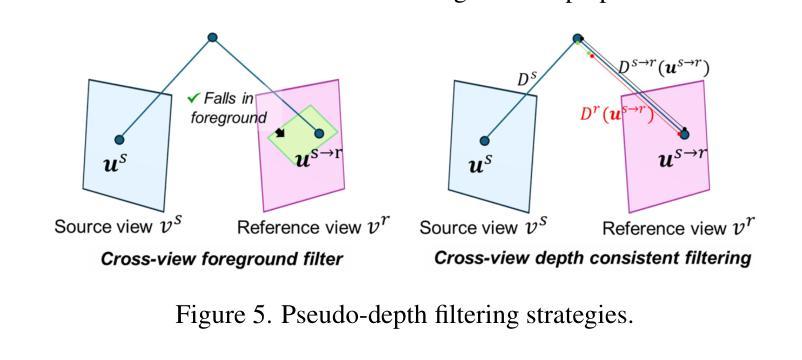
DCHM: Depth-Consistent Human Modeling for Multiview Detection
Authors:Jiahao Ma, Tianyu Wang, Miaomiao Liu, David Ahmedt-Aristizabal, Chuong Nguyen
Multiview pedestrian detection typically involves two stages: human modeling and pedestrian localization. Human modeling represents pedestrians in 3D space by fusing multiview information, making its quality crucial for detection accuracy. However, existing methods often introduce noise and have low precision. While some approaches reduce noise by fitting on costly multiview 3D annotations, they often struggle to generalize across diverse scenes. To eliminate reliance on human-labeled annotations and accurately model humans, we propose Depth-Consistent Human Modeling (DCHM), a framework designed for consistent depth estimation and multiview fusion in global coordinates. Specifically, our proposed pipeline with superpixel-wise Gaussian Splatting achieves multiview depth consistency in sparse-view, large-scaled, and crowded scenarios, producing precise point clouds for pedestrian localization. Extensive validations demonstrate that our method significantly reduces noise during human modeling, outperforming previous state-of-the-art baselines. Additionally, to our knowledge, DCHM is the first to reconstruct pedestrians and perform multiview segmentation in such a challenging setting. Code is available on the \href{https://jiahao-ma.github.io/DCHM/}{project page}.
多视角行人检测通常涉及两个阶段:人体建模和行人定位。人体建模通过融合多视角信息来在三维空间中表示行人,因此其质量对检测精度至关重要。然而,现有方法往往会引入噪声且精度较低。虽然一些方法通过适应成本高昂的多视角三维标注来减少噪声,但它们往往在跨不同场景时推广困难。为了消除对人类标注的依赖并实现精准的人体建模,我们提出了深度一致人体建模(DCHM),这是一个用于全局坐标系中的一致深度估计和多视角融合的框架。具体来说,我们提出的具有超像素级高斯平铺的管道在稀疏视角、大规模和拥挤的场景中实现了多视角深度一致性,为行人定位生成精确的点云。广泛的验证表明,我们的方法在人建建模过程中显著降低了噪声,优于最新的基线。此外,据我们所知,DCHM是在如此具有挑战性的环境中重建行人和进行多视角分割的第一种方法。代码可在项目页面找到:[https://jiahao-ma.github.io/DCHM/] 。
论文及项目相关链接
PDF multi-view detection, sparse-view reconstruction
Summary
三维多视角行人检测包括人体建模和行人定位两个阶段。现有的人体建模方法融合多视角信息表示行人,但引入噪声并降低精度。我们提出Depth-Consistent Human Modeling(DCHM)框架,旨在实现深度一致性多视角融合。通过超像素级的高斯延展技术,在稀疏视角、大规模和拥挤场景中实现深度一致性,为行人定位生成精确的点云。验证表明,我们的方法显著降低了人体建模中的噪声,优于现有技术。DCHM是首个在此类复杂环境中重建行人和进行多视角分割的方法。
Key Takeaways
- Multiview pedestrian detection涉及人体建模和行人定位两个阶段。
- 现有方法融合多视角信息表示行人,但存在引入噪声和精度低的问题。
- Depth-Consistent Human Modeling(DCHM)框架旨在实现深度一致性多视角融合。
- DCHM通过超像素级的高斯延展技术实现深度一致性。
- DCHM在稀疏视角、大规模和拥挤场景中表现优越。
- DCHM生成精确的点云,有助于行人定位。
- 与现有技术相比,DCHM在人体建模中显著降低噪声。
点此查看论文截图


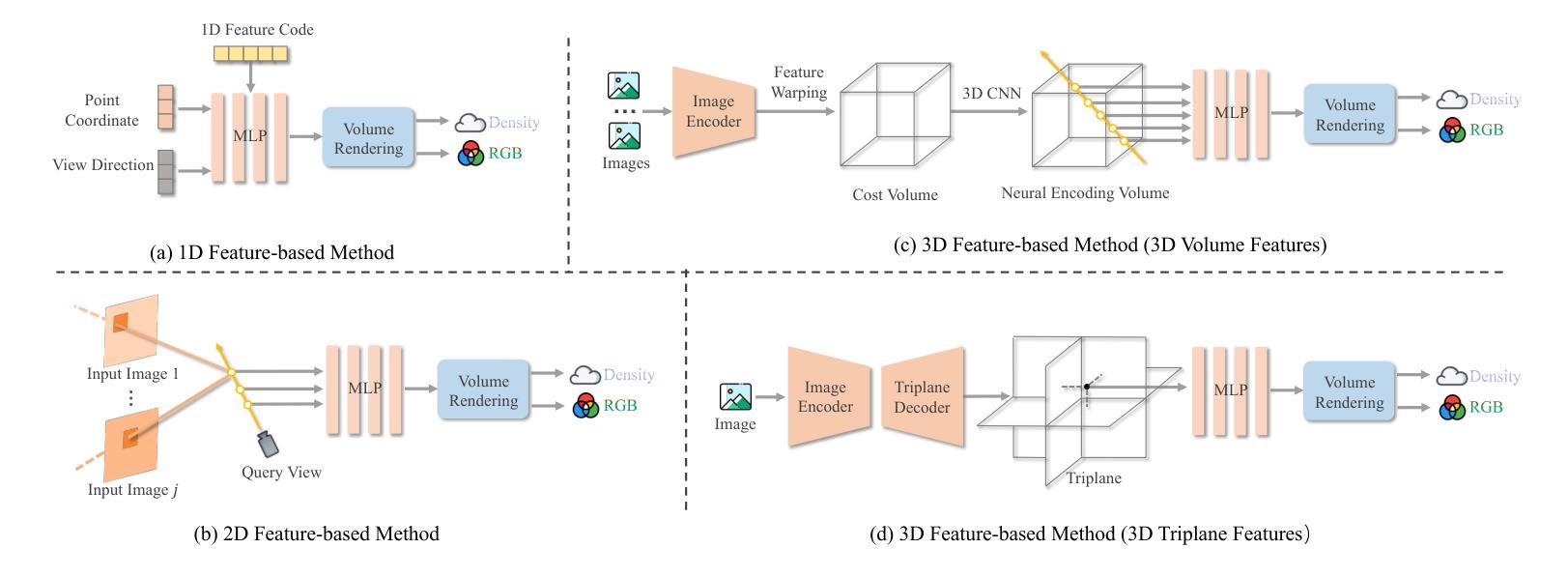
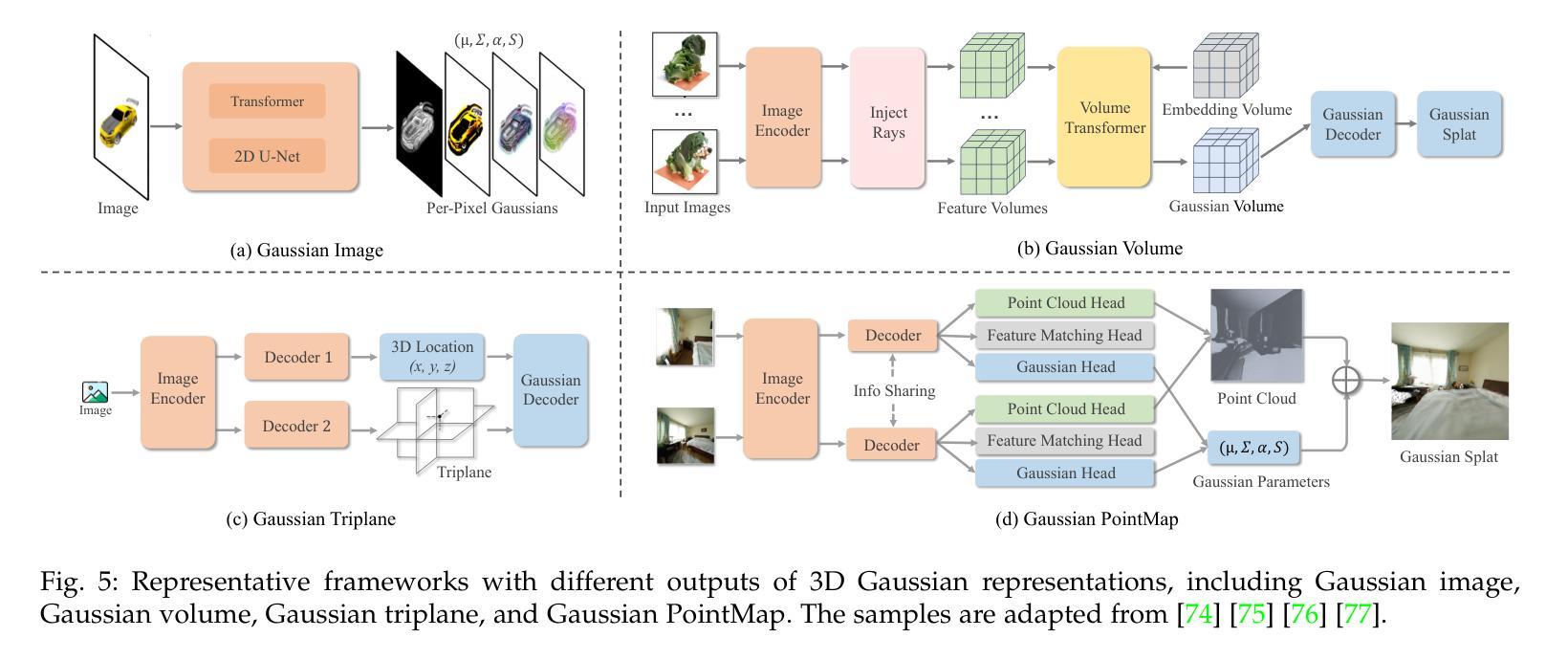
Advances in Feed-Forward 3D Reconstruction and View Synthesis: A Survey
Authors:Jiahui Zhang, Yuelei Li, Anpei Chen, Muyu Xu, Kunhao Liu, Jianyuan Wang, Xiao-Xiao Long, Hanxue Liang, Zexiang Xu, Hao Su, Christian Theobalt, Christian Rupprecht, Andrea Vedaldi, Hanspeter Pfister, Shijian Lu, Fangneng Zhan
3D reconstruction and view synthesis are foundational problems in computer vision, graphics, and immersive technologies such as augmented reality (AR), virtual reality (VR), and digital twins. Traditional methods rely on computationally intensive iterative optimization in a complex chain, limiting their applicability in real-world scenarios. Recent advances in feed-forward approaches, driven by deep learning, have revolutionized this field by enabling fast and generalizable 3D reconstruction and view synthesis. This survey offers a comprehensive review of feed-forward techniques for 3D reconstruction and view synthesis, with a taxonomy according to the underlying representation architectures including point cloud, 3D Gaussian Splatting (3DGS), Neural Radiance Fields (NeRF), etc. We examine key tasks such as pose-free reconstruction, dynamic 3D reconstruction, and 3D-aware image and video synthesis, highlighting their applications in digital humans, SLAM, robotics, and beyond. In addition, we review commonly used datasets with detailed statistics, along with evaluation protocols for various downstream tasks. We conclude by discussing open research challenges and promising directions for future work, emphasizing the potential of feed-forward approaches to advance the state of the art in 3D vision.
3D重建和视图合成是计算机视觉、图形学和沉浸式技术(如增强现实(AR)、虚拟现实(VR)和数字孪生)中的基础问题。传统方法依赖于复杂链中的计算密集型迭代优化,这在现实场景的应用中存在一定的局限性。最近,深度学习驱动的前馈方法的进步已经彻底改变了这一领域,实现了快速和通用的3D重建和视图合成。这篇综述全面介绍了前馈技术在3D重建和视图合成方面的应用,并根据底层表示架构进行了分类,包括点云、3D高斯溅射(3DGS)、神经辐射场(NeRF)等。我们研究了关键任务,如姿态自由重建、动态3D重建和3D感知图像和视频合成,突出了它们在数字人类、SLAM、机器人技术等领域的应用以及其他更广泛的应用。此外,我们还回顾了常用的数据集及其详细统计数据,以及各种下游任务的评估协议。最后,我们讨论了当前的研究挑战以及未来工作的有前途的方向,强调了前馈方法在推动3D视觉技术前沿的潜力。
论文及项目相关链接
PDF A project page associated with this survey is available at https://fnzhan.com/projects/Feed-Forward-3D
Summary
本文综述了基于深度学习的Feed-forward技术在三维重建和视图合成方面的应用,涵盖了各种底层架构,如点云、三维高斯渲染技术和神经网络辐射场等。本文详细讨论了三维重建中的关键任务,包括无姿态重建、动态三维重建和三维图像和视频合成等,并强调了这些技术在数字人、即时定位与地图构建(SLAM)、机器人等领域的应用。此外,本文还介绍了常用的数据集及其详细统计信息,以及各种下游任务的评估协议。最后,本文探讨了开放的研究挑战和未来研究的有前途的方向,强调了Feed-forward技术在推动三维视觉技术前沿的潜力。
Key Takeaways
- Feed-forward技术推动了三维重建和视图合成的革命性发展,使快速且通用的三维重建成为可能。
- 点云、三维高斯渲染技术和神经网络辐射场等是主要的底层架构。
- 无姿态重建、动态三维重建和三维图像和视频合成是三维重建中的关键任务。
- 这些技术在数字人、即时定位与地图构建(SLAM)、机器人等领域有广泛应用。
- 常用的数据集及其详细统计信息对于研究和应用至关重要。
- 评估协议对于各种下游任务非常重要,有助于衡量技术性能。
点此查看论文截图

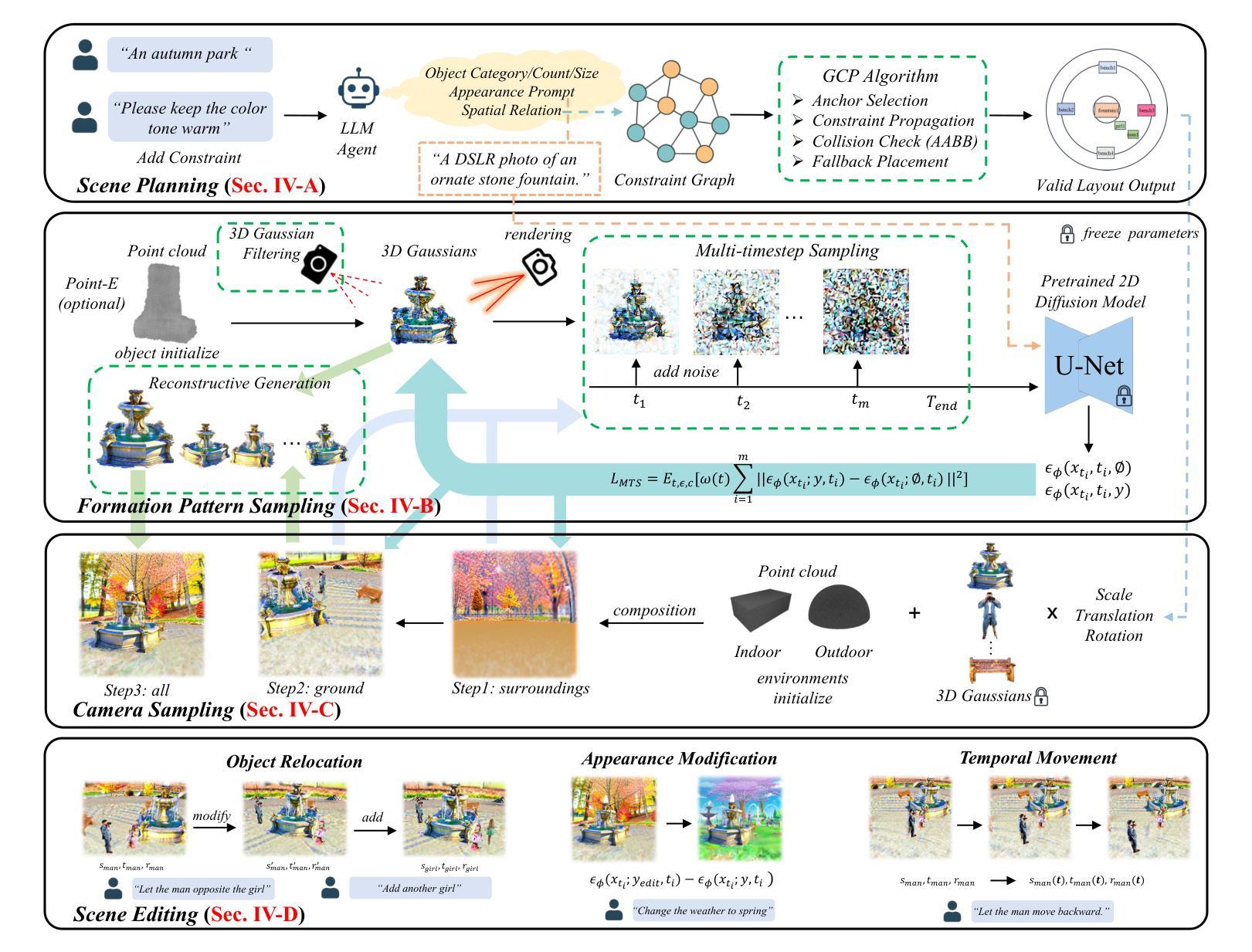
DreamScene: 3D Gaussian-based End-to-end Text-to-3D Scene Generation
Authors:Haoran Li, Yuli Tian, Kun Lan, Yong Liao, Lin Wang, Pan Hui, Peng Yuan Zhou
Generating 3D scenes from natural language holds great promise for applications in gaming, film, and design. However, existing methods struggle with automation, 3D consistency, and fine-grained control. We present DreamScene, an end-to-end framework for high-quality and editable 3D scene generation from text or dialogue. DreamScene begins with a scene planning module, where a GPT-4 agent infers object semantics and spatial constraints to construct a hybrid graph. A graph-based placement algorithm then produces a structured, collision-free layout. Based on this layout, Formation Pattern Sampling (FPS) generates object geometry using multi-timestep sampling and reconstructive optimization, enabling fast and realistic synthesis. To ensure global consistent, DreamScene employs a progressive camera sampling strategy tailored to both indoor and outdoor settings. Finally, the system supports fine-grained scene editing, including object movement, appearance changes, and 4D dynamic motion. Experiments demonstrate that DreamScene surpasses prior methods in quality, consistency, and flexibility, offering a practical solution for open-domain 3D content creation. Code and demos are available at https://jahnsonblack.github.io/DreamScene-Full/.
从自然语言生成3D场景在游戏、电影和设计等领域的应用具有巨大潜力。然而,现有方法在自动化、3D一致性和精细控制方面存在挑战。我们提出了DreamScene,一个从文本或对话中进行高质量和可编辑的3D场景生成的端到端框架。DreamScene从场景规划模块开始,GPT-4智能体会推断对象语义和空间约束来构建混合图。基于图的放置算法然后产生结构化的、无碰撞的布局。基于该布局,Formation Pattern Sampling(FPS)使用多时步采样和重建优化生成对象几何,实现快速和逼真的合成。为确保全局一致性,DreamScene采用针对室内和室外环境的渐进式相机采样策略。最后,该系统支持精细的场景编辑,包括对象移动、外观变化和4D动态运动。实验表明,DreamScene在质量、一致性和灵活性方面超越了之前的方法,为开放域3D内容创建提供了实用解决方案。代码和演示可在https://jahnsonblack.github.io/DreamScene-Full/找到。
论文及项目相关链接
PDF Extended version of ECCV 2024 paper “DreamScene”
Summary
文本描述了一个名为DreamScene的端到端框架,它能从文本或对话中生成高质量且可编辑的3D场景。该框架通过场景规划模块开始,使用GPT-4代理推断对象语义和空间约束来构建混合图。基于图的放置算法生成结构化的无碰撞布局,然后通过Formation Pattern Sampling生成对象几何结构。为确保全局一致性,DreamScene采用了面向室内和室外环境的渐进式摄像机采样策略。该系统支持精细的场景编辑,如对象移动、外观变化和四维动态运动。实验表明,DreamScene在质量、一致性和灵活性方面超越了以前的方法,为开放领域的3D内容创建提供了切实可行的解决方案。
Key Takeaways
- DreamScene是一个用于从文本生成高质量且可编辑的3D场景的端到端框架。
- 它使用GPT-4代理进行场景规划,通过推断对象语义和空间约束来构建混合图。
- 基于图的放置算法生成无碰撞的布局结构。
- Formation Pattern Sampling用于生成对象几何结构,确保快速且逼真的合成。
- DreamScene采用渐进式摄像机采样策略,确保全局一致性,适用于室内和室外环境。
- 该系统支持精细的场景编辑功能,如对象移动、外观变化和动态运动。
点此查看论文截图




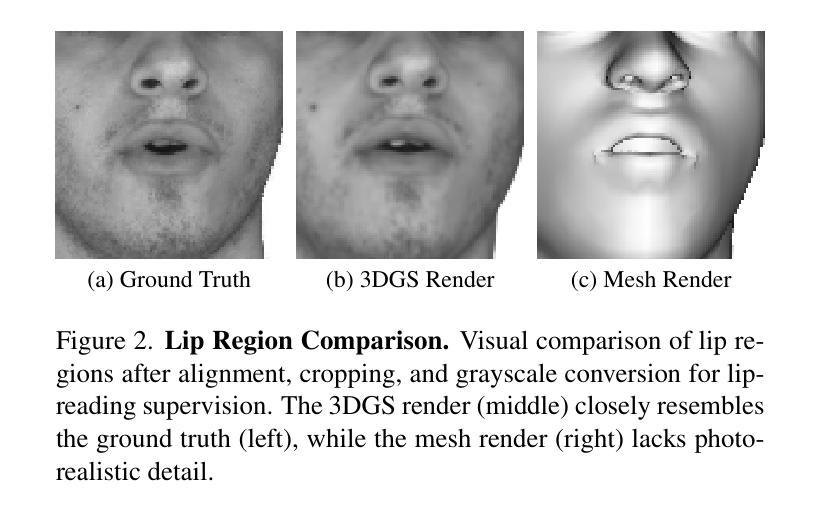
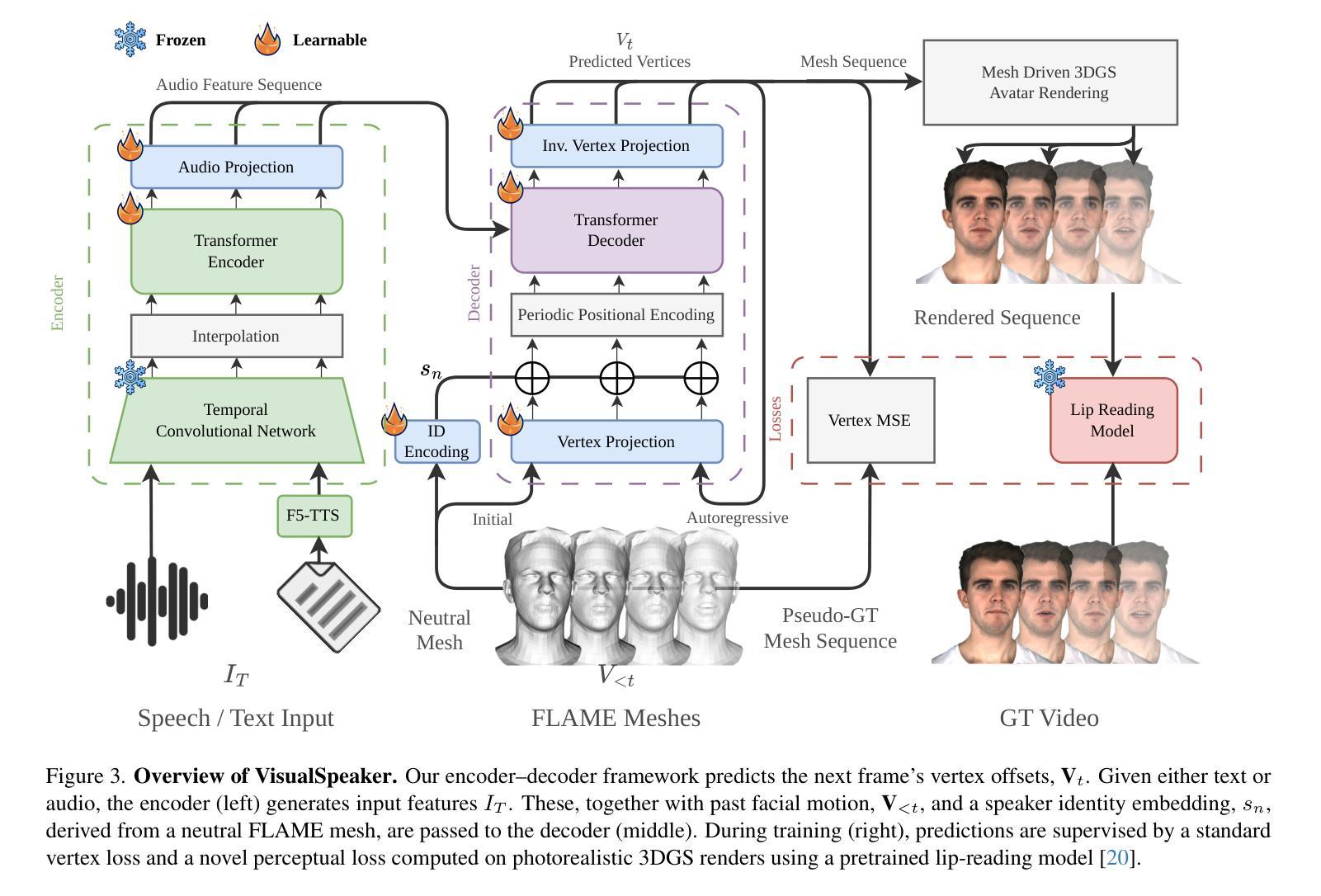
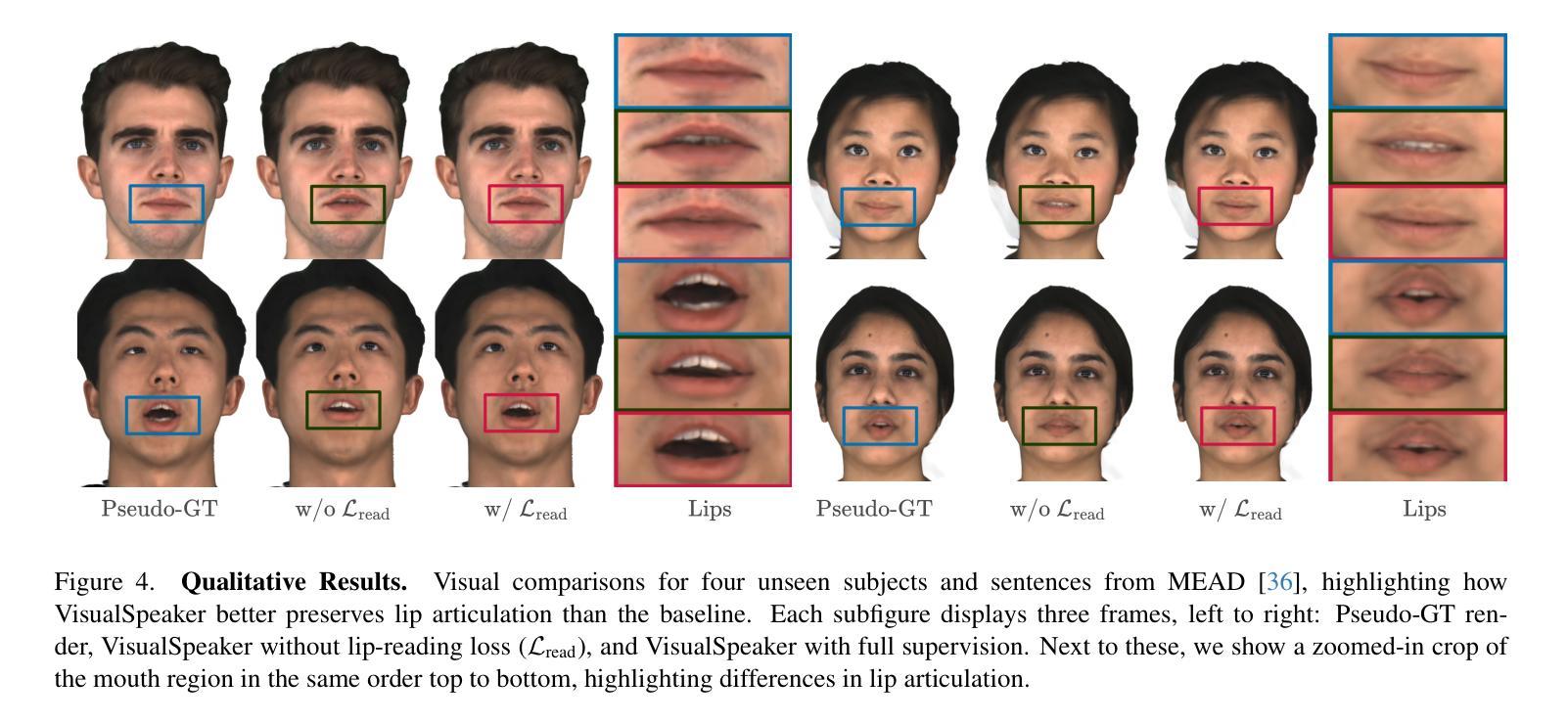
VisualSpeaker: Visually-Guided 3D Avatar Lip Synthesis
Authors:Alexandre Symeonidis-Herzig, Özge Mercanoğlu Sincan, Richard Bowden
Realistic, high-fidelity 3D facial animations are crucial for expressive avatar systems in human-computer interaction and accessibility. Although prior methods show promising quality, their reliance on the mesh domain limits their ability to fully leverage the rapid visual innovations seen in 2D computer vision and graphics. We propose VisualSpeaker, a novel method that bridges this gap using photorealistic differentiable rendering, supervised by visual speech recognition, for improved 3D facial animation. Our contribution is a perceptual lip-reading loss, derived by passing photorealistic 3D Gaussian Splatting avatar renders through a pre-trained Visual Automatic Speech Recognition model during training. Evaluation on the MEAD dataset demonstrates that VisualSpeaker improves both the standard Lip Vertex Error metric by 56.1% and the perceptual quality of the generated animations, while retaining the controllability of mesh-driven animation. This perceptual focus naturally supports accurate mouthings, essential cues that disambiguate similar manual signs in sign language avatars.
真实、高保真度的三维面部动画对于人机交互和可访问性中的表情符号系统至关重要。尽管先前的方法显示出有希望的品质,但它们对网格域的依赖限制了它们充分利用二维计算机视觉和图形中快速视觉创新的能力。我们提出了VisualSpeaker,这是一种新方法,通过真实可渲染的技术缩小这一差距,由视觉语音识别进行监督,以提高三维面部动画的质量。我们的贡献在于感知唇读损失,它是通过在训练过程中将通过预训练的视觉自动语音识别模型的真实三维高斯变形人脸渲染传递,从而派生出来的。在MEAD数据集上的评估表明,VisualSpeaker不仅将标准唇顶点误差度量提高了56.1%,而且提高了生成动画的感知质量,同时还保持了网格驱动动画的可控性。这种感知重点自然支持准确的嘴部动作,这是区分类似手动符号的手语表情符号的重要线索。
论文及项目相关链接
PDF Accepted in International Conference on Computer Vision (ICCV) Workshops
Summary
本文提出一种名为VisualSpeaker的新型方法,通过采用逼真的可微分渲染技术,结合视觉语音识别的监督,改进了3D面部动画。该方法使用感知唇读损失,通过在训练期间将通过逼真渲染的3D高斯喷溅人像呈现给预训练的视觉自动语音识别模型来得到。在MEAD数据集上的评估显示,VisualSpeaker改进了唇顶点误差指标,提高了动画生成的质量,同时保留了网格驱动的动画的可控性。这种方法为真实、高质量的3D面部动画提供了新的可能性,对人机交互和访问控制中的表情符号系统尤为重要。
Key Takeaways
- VisualSpeaker是一种改进3D面部动画的新型方法,结合了逼真的可微分渲染和视觉语音识别的监督。
- 该方法通过使用感知唇读损失来提高动画质量,该损失是通过将逼真的3D面部渲染呈现给预训练的视觉自动语音识别模型来计算的。
- VisualSpeaker在MEAD数据集上的表现优于传统方法,唇顶点误差指标改进了56.1%。
- 该方法提高了动画的感知质量,同时保留了网格驱动动画的可控性。
- VisualSpeaker对于人机交互和访问控制中的表情符号系统尤为重要。
- 该方法能够支持准确的嘴部动作,这对于区分手动符号语言中的相似手动标志至关重要。
点此查看论文截图


FOCI: Trajectory Optimization on Gaussian Splats
Authors:Mario Gomez Andreu, Maximum Wilder-Smith, Victor Klemm, Vaishakh Patil, Jesus Tordesillas, Marco Hutter
3D Gaussian Splatting (3DGS) has recently gained popularity as a faster alternative to Neural Radiance Fields (NeRFs) in 3D reconstruction and view synthesis methods. Leveraging the spatial information encoded in 3DGS, this work proposes FOCI (Field Overlap Collision Integral), an algorithm that is able to optimize trajectories directly on the Gaussians themselves. FOCI leverages a novel and interpretable collision formulation for 3DGS using the notion of the overlap integral between Gaussians. Contrary to other approaches, which represent the robot with conservative bounding boxes that underestimate the traversability of the environment, we propose to represent the environment and the robot as Gaussian Splats. This not only has desirable computational properties, but also allows for orientation-aware planning, allowing the robot to pass through very tight and narrow spaces. We extensively test our algorithm in both synthetic and real Gaussian Splats, showcasing that collision-free trajectories for the ANYmal legged robot that can be computed in a few seconds, even with hundreds of thousands of Gaussians making up the environment. The project page and code are available at https://rffr.leggedrobotics.com/works/foci/
三维高斯散斑法(3DGS)最近成为了在三维重建和视角合成方法中,神经网络辐射场(NeRFs)的一种更快替代方法而受到欢迎。利用三维高斯散斑法中的空间信息编码,这项工作提出了FOCI(高斯域碰撞积分),这是一种能在高斯函数本身上直接优化轨迹的算法。FOCI利用一个新颖的可解释的碰撞公式来描述三维高斯散斑法,采用高斯之间的重叠积分概念。与其他使用保守边界框表示机器人,从而低估环境通行性的方法不同,我们提出将环境和机器人表示为高斯散斑。这不仅具有理想的计算特性,还允许具有方向感知的规划,使机器人能够穿过非常狭窄的空间。我们在合成和真实的高斯散斑上都测试了我们的算法,展示了即使在由数十万高斯组成的环境中,也可以在几秒内计算出适合人马机器人且无碰撞的轨迹。项目页面和代码可以在 https://rffr.leggedrobotics.com/works/foci/ 找到。
论文及项目相关链接
PDF 8 pages, 8 figures, Mario Gomez Andreu and Maximum Wilder-Smith contributed equally
Summary
3D高斯混合(3DGS)在三维重建和视图合成方法中作为神经网络辐射场(NeRFs)的更快替代方案而受到关注。本研究提出FOCI(基于场重叠碰撞积分)算法,该算法能够在高斯分布本身上直接优化轨迹。FOCI利用高斯之间重叠积分的概念,采用一种新颖且可解释性强的碰撞公式用于优化机器人与环境之间的交互。与其他方法不同,FOCI将机器人和环境表示为高斯混合,这不仅具有理想的计算属性,还允许进行方向感知规划,使机器人能够穿过非常紧凑和狭窄的空间。我们的算法在合成和真实的高斯混合中都经过了广泛测试,展示了即使在由数十万高斯组成的环境中,也能在几秒钟内计算出ANYmal步行机器人的无碰撞轨迹。
Key Takeaways
- 3DGS作为NeRFs的替代方法,在三维重建和视图合成中受到关注。
- FOCI算法利用高斯之间的空间信息优化轨迹。
- FOCI采用新颖的碰撞公式,基于高斯之间的重叠积分。
- 与其他方法不同,FOCI将机器人和环境表示为高斯混合,提高了环境遍历能力的估计。
- 高斯混合表示允许方向感知规划,适用于狭窄空间。
- 在合成和真实环境中广泛测试了FOCI算法。
点此查看论文截图





Sparfels: Fast Reconstruction from Sparse Unposed Imagery
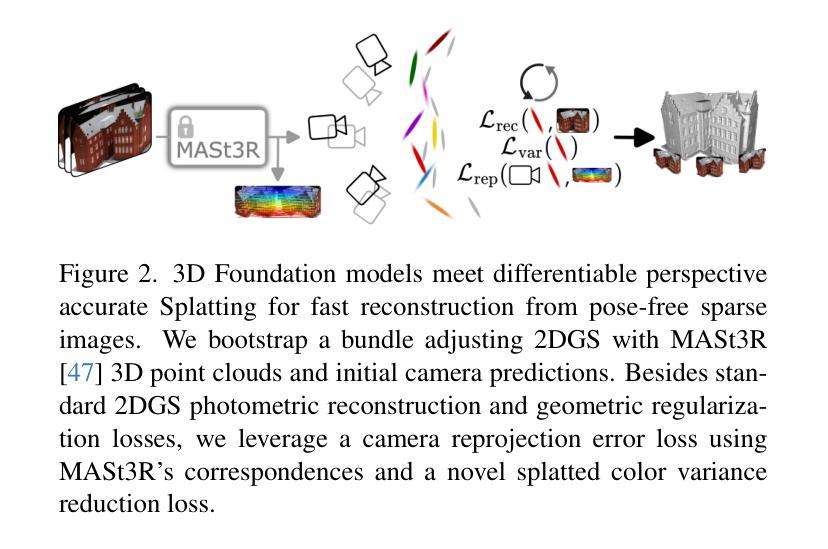
Authors:Shubhendu Jena, Amine Ouasfi, Mae Younes, Adnane Boukhayma
We present a method for Sparse view reconstruction with surface element splatting that runs within 3 minutes on a consumer grade GPU. While few methods address sparse radiance field learning from noisy or unposed sparse cameras, shape recovery remains relatively underexplored in this setting. Several radiance and shape learning test-time optimization methods address the sparse posed setting by learning data priors or using combinations of external monocular geometry priors. Differently, we propose an efficient and simple pipeline harnessing a single recent 3D foundation model. We leverage its various task heads, notably point maps and camera initializations to instantiate a bundle adjusting 2D Gaussian Splatting (2DGS) model, and image correspondences to guide camera optimization midst 2DGS training. Key to our contribution is a novel formulation of splatted color variance along rays, which can be computed efficiently. Reducing this moment in training leads to more accurate shape reconstructions. We demonstrate state-of-the-art performances in the sparse uncalibrated setting in reconstruction and novel view benchmarks based on established multi-view datasets.
我们提出了一种利用表面元素喷绘进行稀疏视角重建的方法,该方法在消费级GPU上运行时间不超过3分钟。尽管已有少数方法解决了从带噪声或无姿态的稀疏相机学习稀疏辐射场的问题,但在此环境中,形状恢复仍然相对研究不足。几种辐射和形状学习的测试时间优化方法通过数据先验或结合外部单眼几何先验来解决稀疏设定的姿态问题。与之不同,我们提出了一种高效且简单的流程,利用最新的单一3D基础模型。我们利用其各种任务头,特别是点图和相机初始化来实例化调整束的二维高斯喷绘(2DGS)模型,并利用图像对应关系来指导在二维GS训练过程中的相机优化。我们贡献的关键在于沿光线喷绘颜色方差的新公式,该公式可以高效计算。在训练中减少这一点会导致更准确的形状重建。我们在稀疏未校准环境中展示了最先进的重建和基于多视角数据集的新视角基准测试性能。
论文及项目相关链接
PDF ICCV 2025. Project page : https://shubhendu-jena.github.io/Sparfels-web/
摘要
本文提出了一种基于表面元素拼贴技术的稀疏视角重建方法,该方法在消费级GPU上运行时间不超过3分钟。尽管已有一些方法解决了稀疏辐射场学习的问题,但在噪声或无固定姿势的稀疏摄像机条件下,形状恢复仍是相对未被充分探索的领域。本文通过高效简洁的管道流程提出解决方案,该流程依赖于单个最新的三维基础模型。我们利用它的多个任务头部,特别是点图和相机初始化来建立束调整二维高斯拼贴模型,并利用图像对应关系来指导相机优化与二维GS训练。本文的关键贡献是沿射线拼贴颜色方差的新公式,该公式可以高效计算。在训练中减少这一时刻会导致更准确的形状重建。我们在稀疏未校准设置中重建和新颖视图基准上展示了最先进的性能表现,这些基准基于公认的多视角数据集。
要点摘要
一、提出了一种基于表面元素拼贴技术的稀疏视角重建方法,运行时间短。
二、在消费级GPU上实现。
三、在噪声或无固定姿势的稀疏摄像机条件下,解决了形状恢复的难题。
四、提出了一个高效且简洁的管道流程解决方案,依赖单个最新的三维基础模型。
五、利用点图和相机初始化等任务头部建立束调整二维高斯拼贴模型。
六、通过图像对应关系指导相机优化与二维GS训练。
点此查看论文截图