⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-01 更新
Rule2Text: Natural Language Explanation of Logical Rules in Knowledge Graphs
Authors:Nasim Shirvani-Mahdavi, Devin Wingfield, Amin Ghasemi, Chengkai Li
Knowledge graphs (KGs) often contain sufficient information to support the inference of new facts. Identifying logical rules not only improves the completeness of a knowledge graph but also enables the detection of potential errors, reveals subtle data patterns, and enhances the overall capacity for reasoning and interpretation. However, the complexity of such rules, combined with the unique labeling conventions of each KG, can make them difficult for humans to understand. In this paper, we explore the potential of large language models to generate natural language explanations for logical rules. Specifically, we extract logical rules using the AMIE 3.5.1 rule discovery algorithm from the benchmark dataset FB15k-237 and two large-scale datasets, FB-CVT-REV and FB+CVT-REV. We examine various prompting strategies, including zero- and few-shot prompting, including variable entity types, and chain-of-thought reasoning. We conduct a comprehensive human evaluation of the generated explanations based on correctness, clarity, and hallucination, and also assess the use of large language models as automatic judges. Our results demonstrate promising performance in terms of explanation correctness and clarity, although several challenges remain for future research. All scripts and data used in this study are publicly available at https://github.com/idirlab/KGRule2NL}{https://github.com/idirlab/KGRule2NL.
知识图谱(KG)通常包含支持新事实推断的充足信息。识别逻辑规则不仅提高了知识图谱的完整性,还能够检测潜在错误,揭示细微的数据模式,并提高了整体推理和解释能力。然而,这些规则的复杂性以及每个知识图谱独特的标签约定使得人类难以理解。在本文中,我们探索了大型语言模型为逻辑规则生成自然语言解释的能力。具体来说,我们使用AMIE 3.5.1规则发现算法从基准数据集FB1intablea范围内的新下载更新将我的数值保存在a myproject所在目录中更改现有目录下上传的数据模型b户脚本也已被迁移到mytest的新位置或该项目以及两个大规模数据集FB-CVT-REV和FB+CVT-REV中提取逻辑规则。我们研究了各种提示策略,包括零次和一次式提示策略、可变实体类型和思维链推理等。我们对生成的解释进行了基于正确性、清晰度和幻觉的综合人类评估,并对大型语言模型作为自动裁判的使用进行了评估。我们的研究结果在解释的准确性和清晰度方面表现出有前途的性能,尽管仍然存在一些挑战,未来需要进行进一步的研究。本研究所使用的所有脚本和数据均可在https://github.com/idirlab/KGRule2NL上公开访问。
论文及项目相关链接
摘要
本文探讨了大型语言模型在知识图谱逻辑规则解释中的潜力。研究利用AMIE 3.5.1规则发现算法从基准数据集FB15k-237和两个大规模数据集FB-CVT-REV和FB+CVT-REV中提取逻辑规则,并探索了不同的提示策略,包括零样本和少样本提示、可变实体类型和链式思维推理。研究对生成的解释进行了全面的人类评估,评估依据为正确性、清晰度和幻觉现象,同时评估了大型语言模型作为自动裁判的使用情况。研究结果表明,在解释的正确性和清晰度方面表现出有希望的性能,尽管仍存在一些挑战,需要未来进一步研究。
关键见解
- 知识图谱包含支持新事实推断的充足信息,逻辑规则的识别不仅提高了知识图谱的完整性,还有助于检测潜在错误、揭示微妙的数据模式并增强推理和解释的总体能力。
- 大型语言模型具有生成自然语言解释知识图谱逻辑规则的潜力。
- 研究使用了AMIE 3.5.1规则发现算法,从基准数据集FB15k-237以及两个大规模数据集FB-CVT-REV和FB+CVT-REV中提取逻辑规则。
- 研究探索了多种提示策略,包括零样本和少样本提示,考虑了可变实体类型和链式思维推理。
- 生成解释的人类评估考虑了正确性、清晰度和幻觉现象等方面。
- 大型语言模型在作为自动裁判方面的使用得到了评估。
- 尽管在解释的正确性和清晰度方面表现出有希望的结果,但仍存在一些挑战,需要未来的进一步研究。
点此查看论文截图

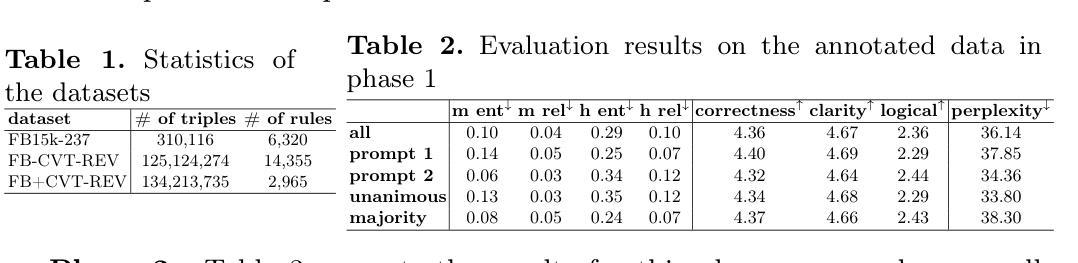
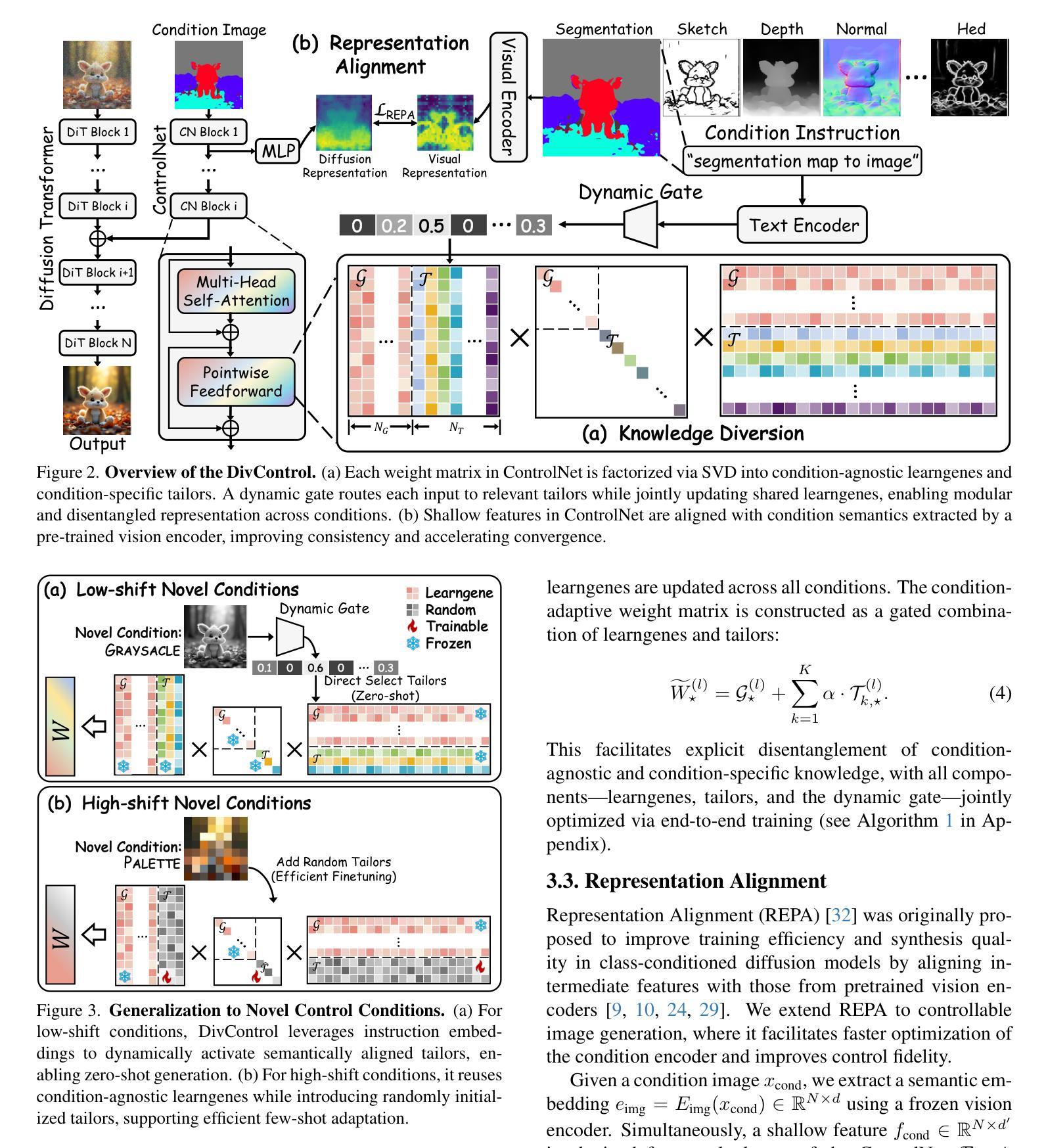
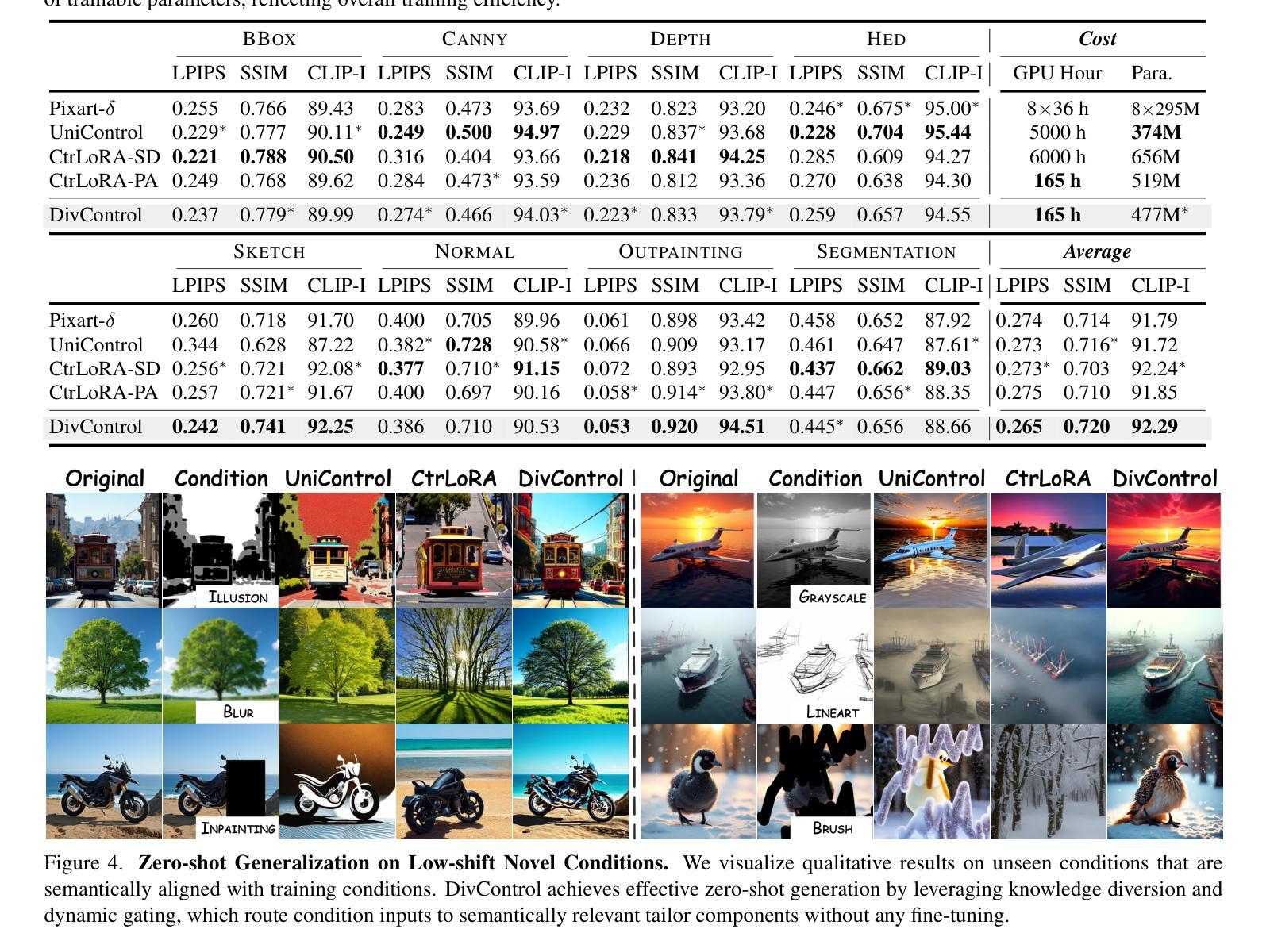
DivControl: Knowledge Diversion for Controllable Image Generation
Authors:Yucheng Xie, Fu Feng, Ruixiao Shi, Jing Wang, Yong Rui, Xin Geng
Diffusion models have advanced from text-to-image (T2I) to image-to-image (I2I) generation by incorporating structured inputs such as depth maps, enabling fine-grained spatial control. However, existing methods either train separate models for each condition or rely on unified architectures with entangled representations, resulting in poor generalization and high adaptation costs for novel conditions. To this end, we propose DivControl, a decomposable pretraining framework for unified controllable generation and efficient adaptation. DivControl factorizes ControlNet via SVD into basic components-pairs of singular vectors-which are disentangled into condition-agnostic learngenes and condition-specific tailors through knowledge diversion during multi-condition training. Knowledge diversion is implemented via a dynamic gate that performs soft routing over tailors based on the semantics of condition instructions, enabling zero-shot generalization and parameter-efficient adaptation to novel conditions. To further improve condition fidelity and training efficiency, we introduce a representation alignment loss that aligns condition embeddings with early diffusion features. Extensive experiments demonstrate that DivControl achieves state-of-the-art controllability with 36.4$\times$ less training cost, while simultaneously improving average performance on basic conditions. It also delivers strong zero-shot and few-shot performance on unseen conditions, demonstrating superior scalability, modularity, and transferability.
扩散模型已经通过结合结构化输入(例如深度图)从文本到图像(T2I)的生成发展到图像到图像(I2I)的生成,实现了精细的空间控制。然而,现有方法要么针对每种条件训练单独的模型,要么依赖于具有纠缠表示的统一架构,导致对新颖条件的泛化能力较差和较高的适应成本。为此,我们提出了DivControl,这是一个可分解的预训练框架,用于统一的可控生成和高效适应。DivControl通过SVD将ControlNet进行分解,得到基本组件——一对奇异向量,通过多任务训练中的知识分流将其分离为条件无关的学习基因和条件特定的裁缝。知识分流是通过动态门实现的,该门根据条件指令的语义对裁缝进行软路由选择,实现零样本泛化和对新颖条件的参数高效适应。为了进一步提高条件保真度和训练效率,我们引入了一种表示对齐损失,将条件嵌入与早期扩散特征对齐。大量实验表明,DivControl在减少36.4倍训练成本的同时,实现了最先进的可控性,同时提高了基本条件下的平均性能。它在未见过的条件上表现出强大的零样本和少样本性能,证明了其可扩展性、模块化和可迁移性。
论文及项目相关链接
Summary
扩散模型已从文本到图像(T2I)发展到图像到图像(I2I)生成,通过融入结构化输入如深度图,实现了精细的空间控制。然而,现有方法要么为每种条件训练单独模型,要么依赖于统一架构,导致表征纠缠,对新条件的泛化性能差和适应成本高。为此,我们提出DivControl,一种可分解的预训练框架,用于统一的可控生成和高效适应。DivControl通过SVD将ControlNet分解为基本组件——奇异向量对,并在多条件训练期间通过知识分流将其分解为条件无关的学习基因和条件特定的裁缝。知识分流通过动态门实现,根据条件指令的语义对裁缝进行软路由选择,实现零样本泛化和对新条件的参数高效适应。为提高条件保真度和训练效率,我们引入了表征对齐损失,使条件嵌入与早期扩散特征对齐。实验表明,DivControl实现了先进可控性,减少了36.4倍的训练成本,同时提高了基本条件下的平均性能,并在未见条件下表现出强大的零样本和少样本性能,展现出卓越的可扩展性、模块性和可迁移性。
Key Takeaways
- 扩散模型已从文本到图像生成扩展到图像到图像生成,融入结构化输入如深度图实现精细空间控制。
- 现有方法存在对新条件泛化性能差和适应成本高的问题。
- DivControl框架通过SVD分解ControlNet为基本组件,并通过知识分流实现条件无关的学习和条件特定的适应。
- 知识分流通过动态门实现软路由选择,提高零样本泛化和对新条件的参数效率。
- 引入表征对齐损失以提高条件保真度和训练效率。
- DivControl实现了先进可控性,并显著减少训练成本。
点此查看论文截图

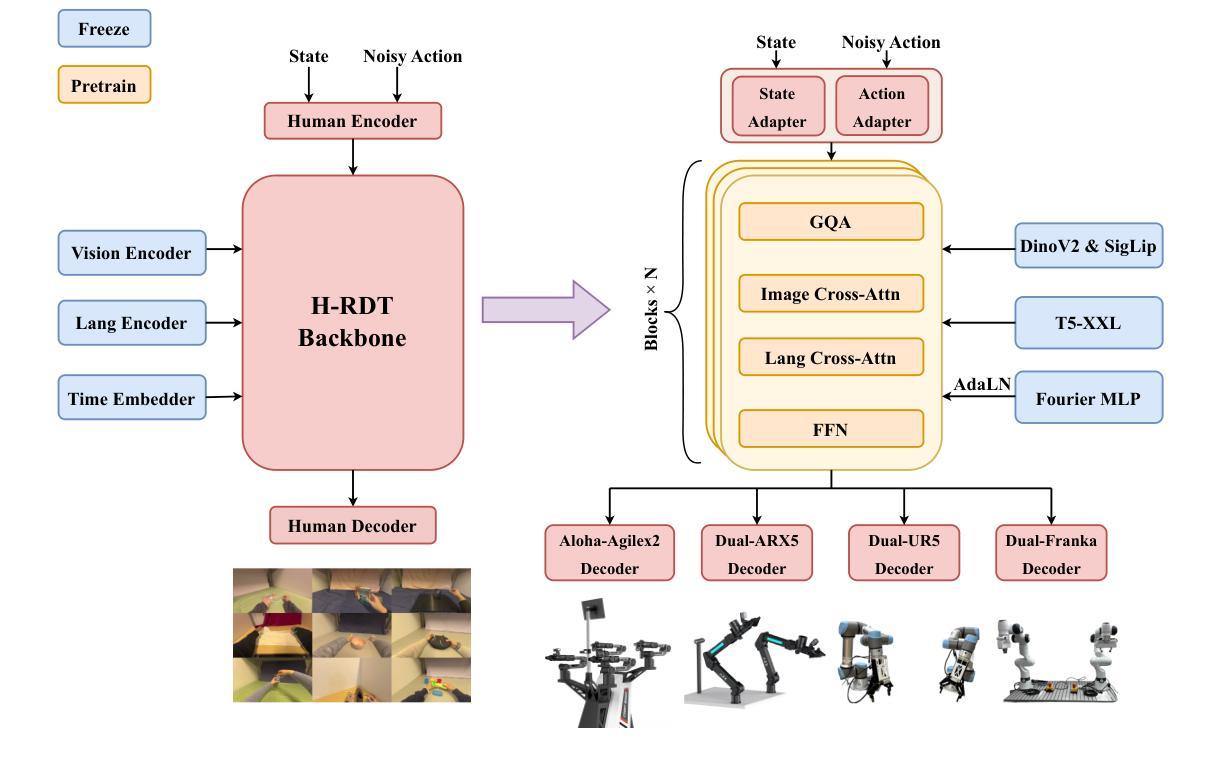
H-RDT: Human Manipulation Enhanced Bimanual Robotic Manipulation
Authors:Hongzhe Bi, Lingxuan Wu, Tianwei Lin, Hengkai Tan, Zhizhong Su, Hang Su, Jun Zhu
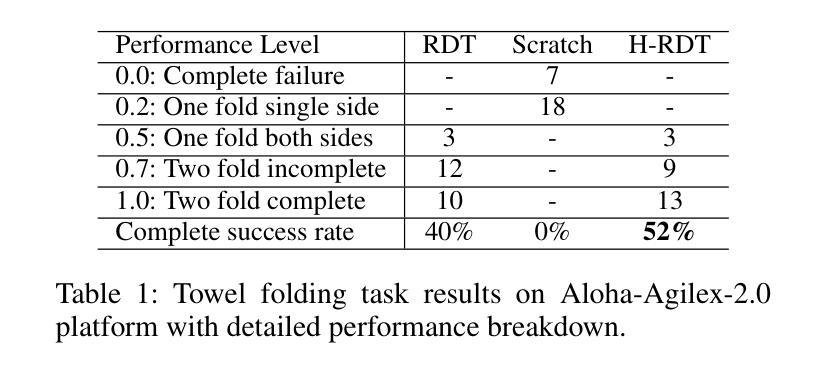
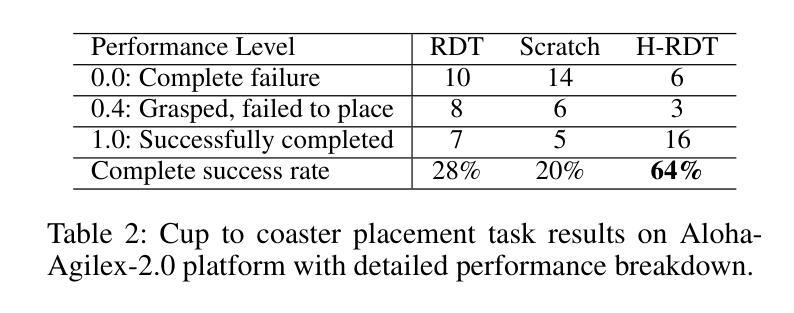
Imitation learning for robotic manipulation faces a fundamental challenge: the scarcity of large-scale, high-quality robot demonstration data. Recent robotic foundation models often pre-train on cross-embodiment robot datasets to increase data scale, while they face significant limitations as the diverse morphologies and action spaces across different robot embodiments make unified training challenging. In this paper, we present H-RDT (Human to Robotics Diffusion Transformer), a novel approach that leverages human manipulation data to enhance robot manipulation capabilities. Our key insight is that large-scale egocentric human manipulation videos with paired 3D hand pose annotations provide rich behavioral priors that capture natural manipulation strategies and can benefit robotic policy learning. We introduce a two-stage training paradigm: (1) pre-training on large-scale egocentric human manipulation data, and (2) cross-embodiment fine-tuning on robot-specific data with modular action encoders and decoders. Built on a diffusion transformer architecture with 2B parameters, H-RDT uses flow matching to model complex action distributions. Extensive evaluations encompassing both simulation and real-world experiments, single-task and multitask scenarios, as well as few-shot learning and robustness assessments, demonstrate that H-RDT outperforms training from scratch and existing state-of-the-art methods, including Pi0 and RDT, achieving significant improvements of 13.9% and 40.5% over training from scratch in simulation and real-world experiments, respectively. The results validate our core hypothesis that human manipulation data can serve as a powerful foundation for learning bimanual robotic manipulation policies.
机器人操纵模仿学习面临一个根本挑战:大规模高质量机器人演示数据的稀缺性。最近的机器人基础模型通常会在跨形态机器人数据集上进行预训练,以增加数据规模,然而,由于不同机器人形态之间的形态多样性和动作空间差异,统一训练面临重大挑战。在本文中,我们提出了H-RDT(人类到机器人的扩散转换器),这是一种利用人类操作数据增强机器人操作能力的新方法。我们的关键见解是,大规模的第一人称人类操作视频配上3D手部姿势注释,提供了丰富的行为先验,能够捕捉自然的操作策略,并有益于机器人策略学习。我们引入了一种两阶段训练模式:(1)在第一人称人类操作数据上进行大规模预训练;(2)使用模块化动作编码器和解码器,在机器人特定数据上进行跨形态微调。H-RDT建立在具有20亿参数的扩散转换器架构上,使用流程匹配来模拟复杂的动作分布。全面的评估包括模拟和真实世界的实验、单任务和多任务场景,以及小样本学习和稳健性评估,结果表明,H-RDT优于从头开始训练和现有的最先进的方法,包括Pi0和RDT,在模拟和真实世界实验中分别比从头开始训练提高了13.9%和40.5%。结果验证了我们的核心假设,即人类操作数据可以作为学习双手机器人操作策略的有力基础。
论文及项目相关链接
Summary
本文主要介绍了一种新型机器人操作方法H-RDT,该方法利用人类操作数据增强机器人操作能力。研究的关键见解是,大规模第一人称人类操作视频与配套的3D手势注释提供了丰富的行为先验,捕捉自然操作策略,有益于机器人政策学习。该方法采用两阶段训练模式,首先在大量第一人称人类操作数据上进行预训练,然后在特定机器人数据上进行跨体态微调,使用模块化动作编码器和解码器以及扩散转换器架构。实验结果表明,H-RDT在模拟和真实世界实验、单任务和多任务场景、小样本学习和稳健性评估等方面均优于从头开始训练和现有先进技术方法。
Key Takeaways
- H-RDT是一种新型机器人操作方法,利用人类操作数据增强机器人操作能力。
- 大规模第一人称人类操作视频与配套的3D手势注释提供了丰富的行为先验。
- H-RDT采用两阶段训练模式,包括预训练和跨体态微调。
- 模块化动作编码器和解码器以及扩散转换器架构是H-RDT的关键组成部分。
- H-RDT在模拟和真实世界实验中表现出优异性能,显著优于从头开始训练和现有技术方法。
- H-RDT在单任务和多任务场景、小样本学习等方面具有优势。
点此查看论文截图

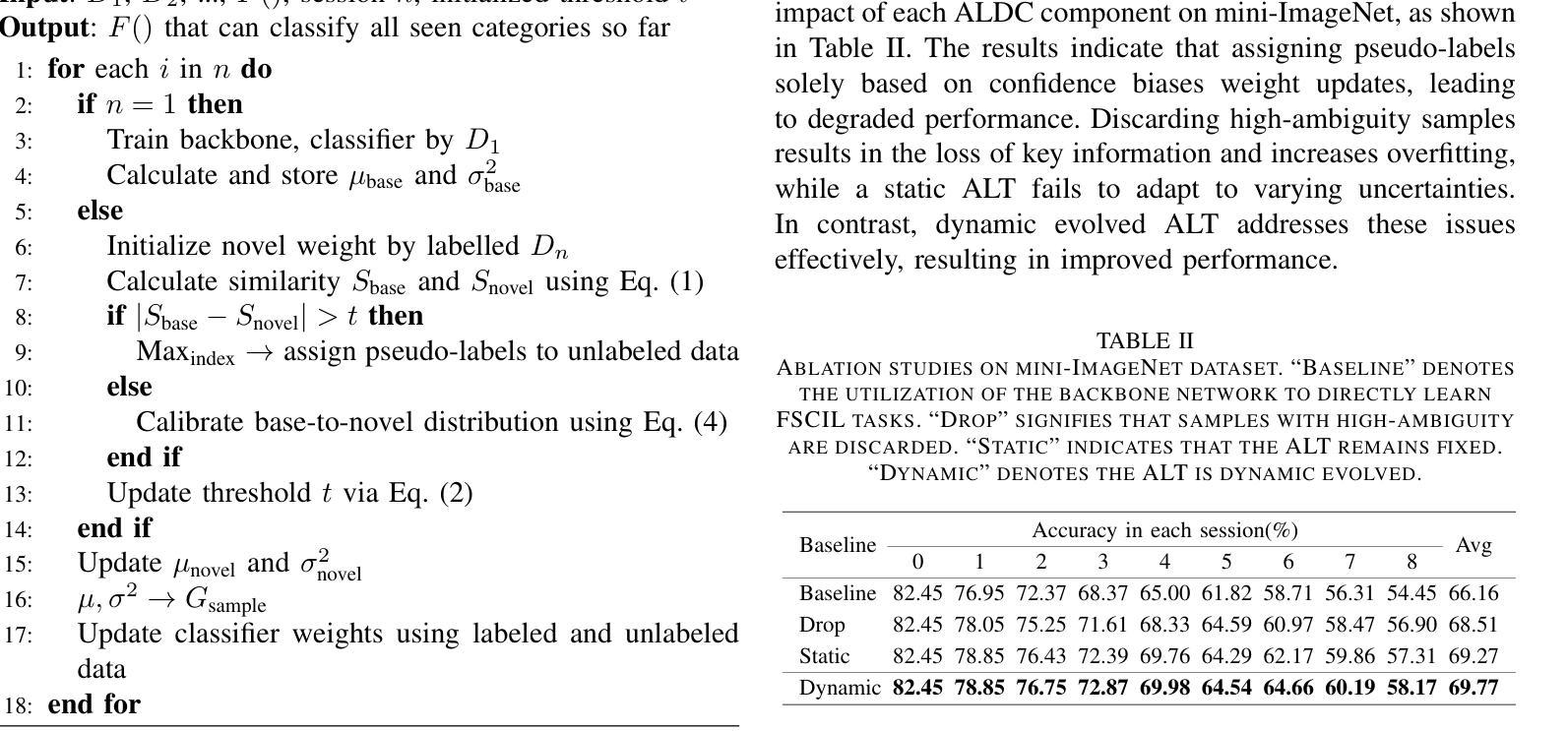
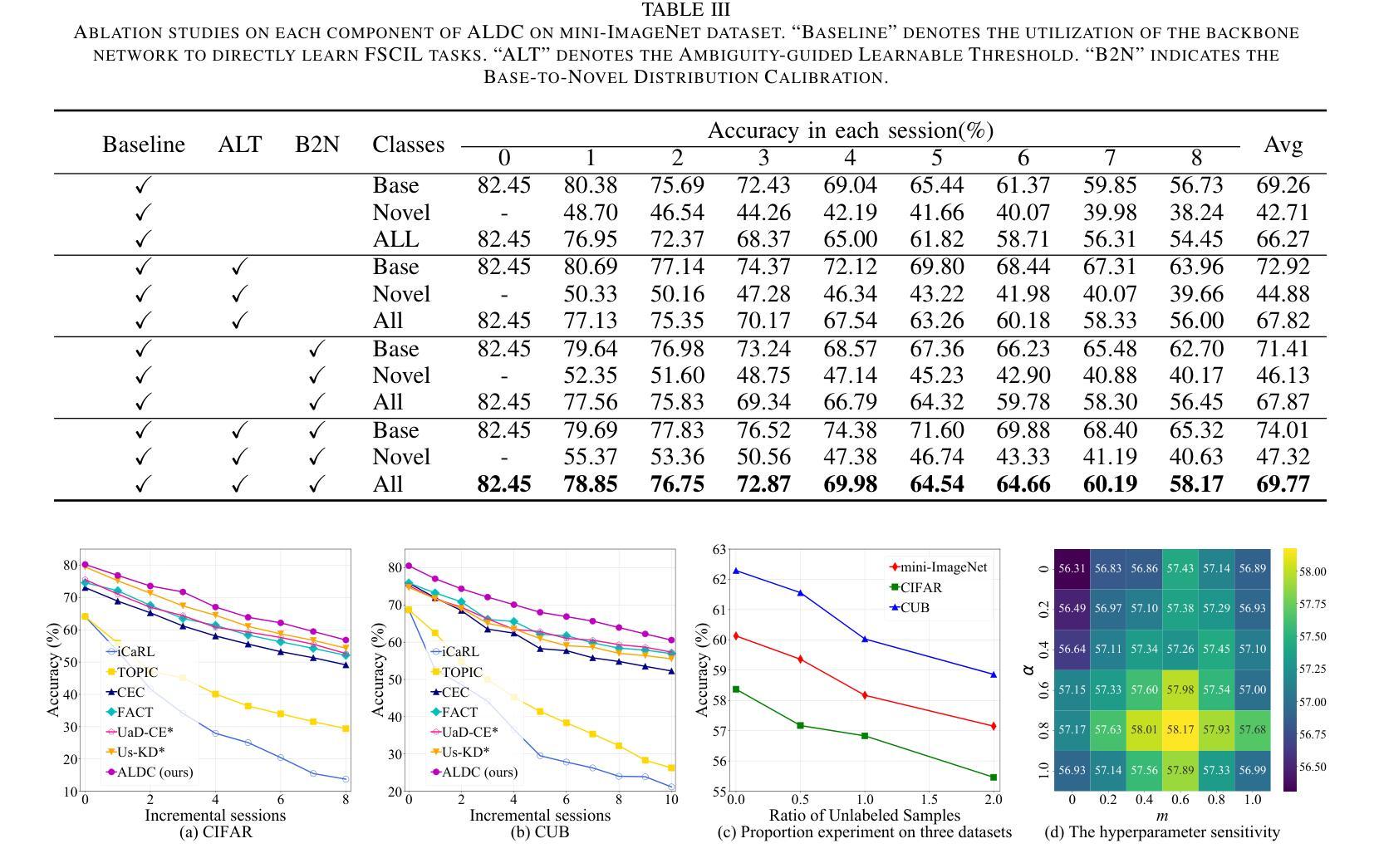
Ambiguity-Guided Learnable Distribution Calibration for Semi-Supervised Few-Shot Class-Incremental Learning
Authors:Fan Lyu, Linglan Zhao, Chengyan Liu, Yinying Mei, Zhang Zhang, Jian Zhang, Fuyuan Hu, Liang Wang
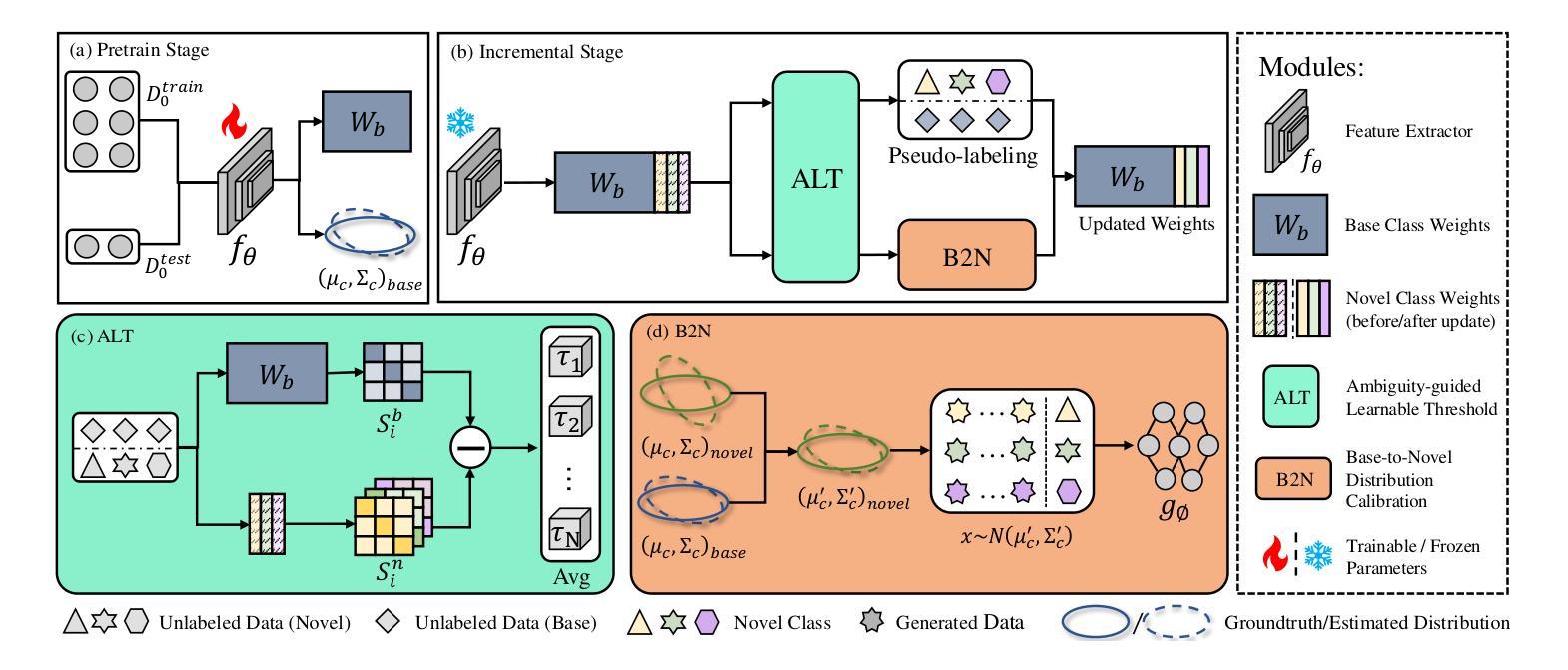
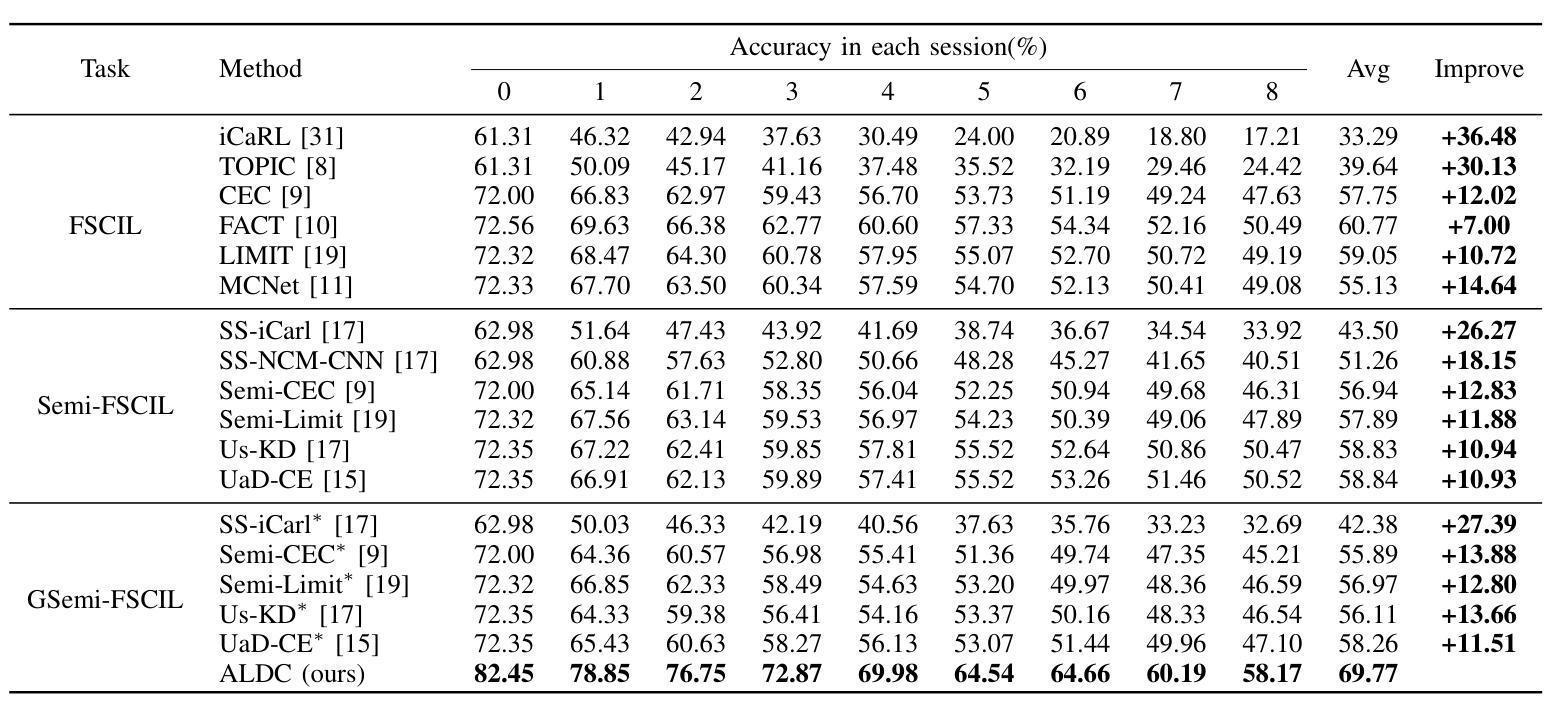
Few-Shot Class-Incremental Learning (FSCIL) focuses on models learning new concepts from limited data while retaining knowledge of previous classes. Recently, many studies have started to leverage unlabeled samples to assist models in learning from few-shot samples, giving rise to the field of Semi-supervised Few-shot Class-Incremental Learning (Semi-FSCIL). However, these studies often assume that the source of unlabeled data is only confined to novel classes of the current session, which presents a narrow perspective and cannot align well with practical scenarios. To better reflect real-world scenarios, we redefine Semi-FSCIL as Generalized Semi-FSCIL (GSemi-FSCIL) by incorporating both base and all the ever-seen novel classes in the unlabeled set. This change in the composition of unlabeled samples poses a new challenge for existing methods, as they struggle to distinguish between unlabeled samples from base and novel classes. To address this issue, we propose an Ambiguity-guided Learnable Distribution Calibration (ALDC) strategy. ALDC dynamically uses abundant base samples to correct biased feature distributions for few-shot novel classes. Experiments on three benchmark datasets show that our method outperforms existing works, setting new state-of-the-art results.
少量类别增量学习(FSCIL)关注模型从有限数据中学习新概念的同时,保留对之前类别的知识。最近,许多研究开始利用未标记的样本来帮助模型从少量样本中学习,从而出现了半监督少量类别增量学习(Semi-FSCIL)领域。然而,这些研究通常假设未标记数据的来源仅限于当前会话的新类别,这呈现了一种狭隘的视角,并不能很好地与实际应用场景相符。为了更好地反映真实世界场景,我们通过将基础类别和所有已见过的新类别纳入未标记集,将Semi-FSCIL重新定义为广义Semi-FSCIL(GSemi-FSCIL)。未标记样本组成的这种变化给现有方法带来了新的挑战,因为它们很难区分来自基础类别和新类别的未标记样本。为了解决这一问题,我们提出了一种模糊引导的可学习分布校准(ALDC)策略。ALDC动态使用大量的基础样本纠正少量新类别的特征分布偏差。在三个基准数据集上的实验表明,我们的方法优于现有工作,创下了新的最高性能记录。
论文及项目相关链接
PDF 6 pages, 5 figures
Summary
半监督小样本类增量学习(GSemi-FSCIL)重新定义了半监督场景下的少样本类增量学习问题,将基础类和所有已见过的新类的未标记样本纳入未标记集,对现有的方法提出了新的挑战。针对这一问题,提出了基于模糊度引导的可学习分布校准(ALDC)策略,利用丰富的基础样本对少数新类的特征分布进行校正。实验表明,该方法在三个基准数据集上取得了优于现有方法的结果。
Key Takeaways
- 半监督小样本类增量学习(GSemi-FSCIL)扩展了问题的定义,将基础类和所有已见过的新类的未标记样本纳入考虑。
- 现有方法在区分基础类和新类的未标记样本时面临挑战。
- 提出了一种基于模糊度引导的可学习分布校准(ALDC)策略来解决上述问题。
- ALDC策略利用丰富的基础样本对少数新类的特征分布进行校正。
- 该方法在三个基准数据集上进行了实验验证。
- 实验结果表明,该方法在性能上优于现有方法,达到了新的先进水平。
点此查看论文截图



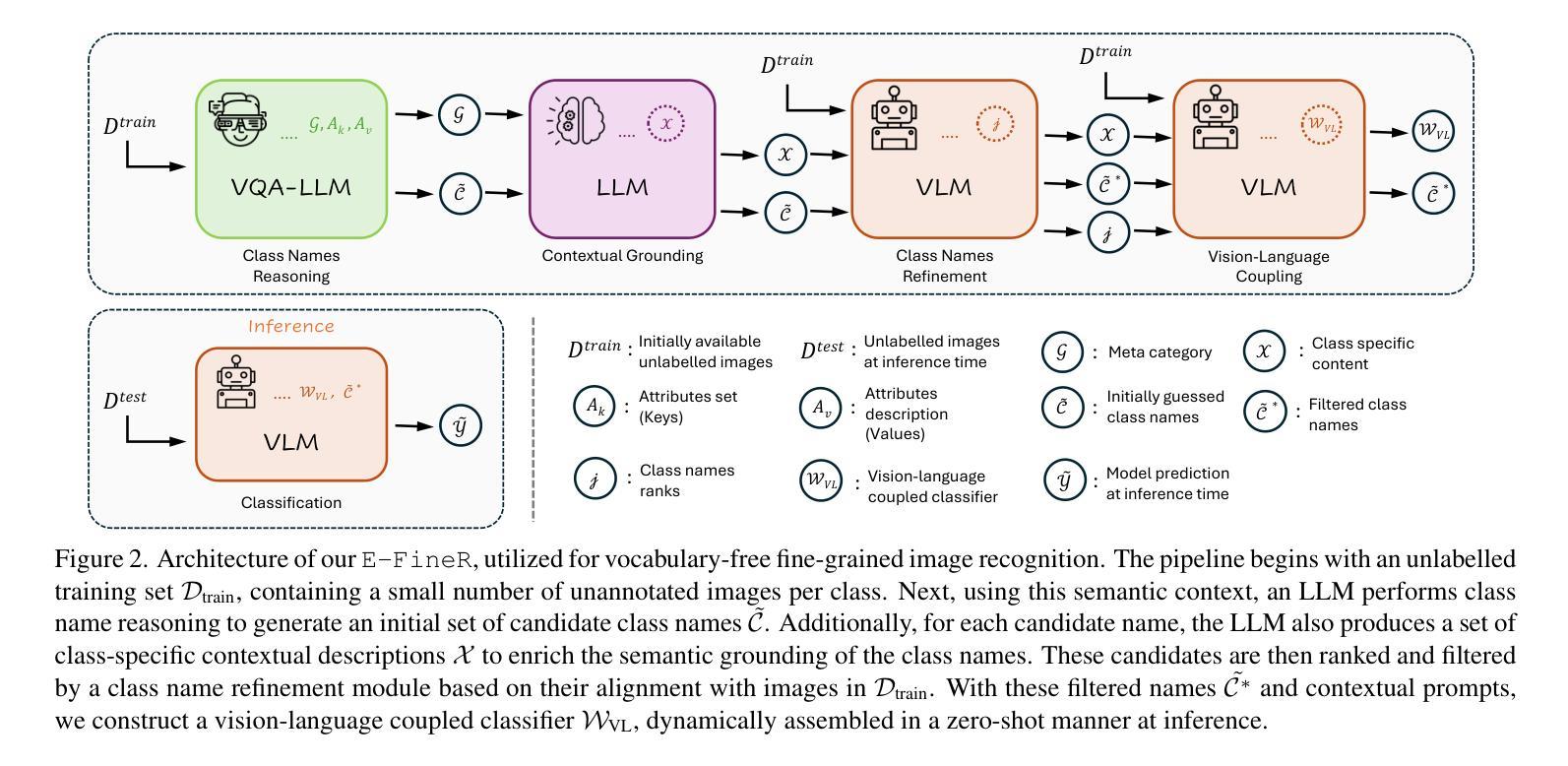
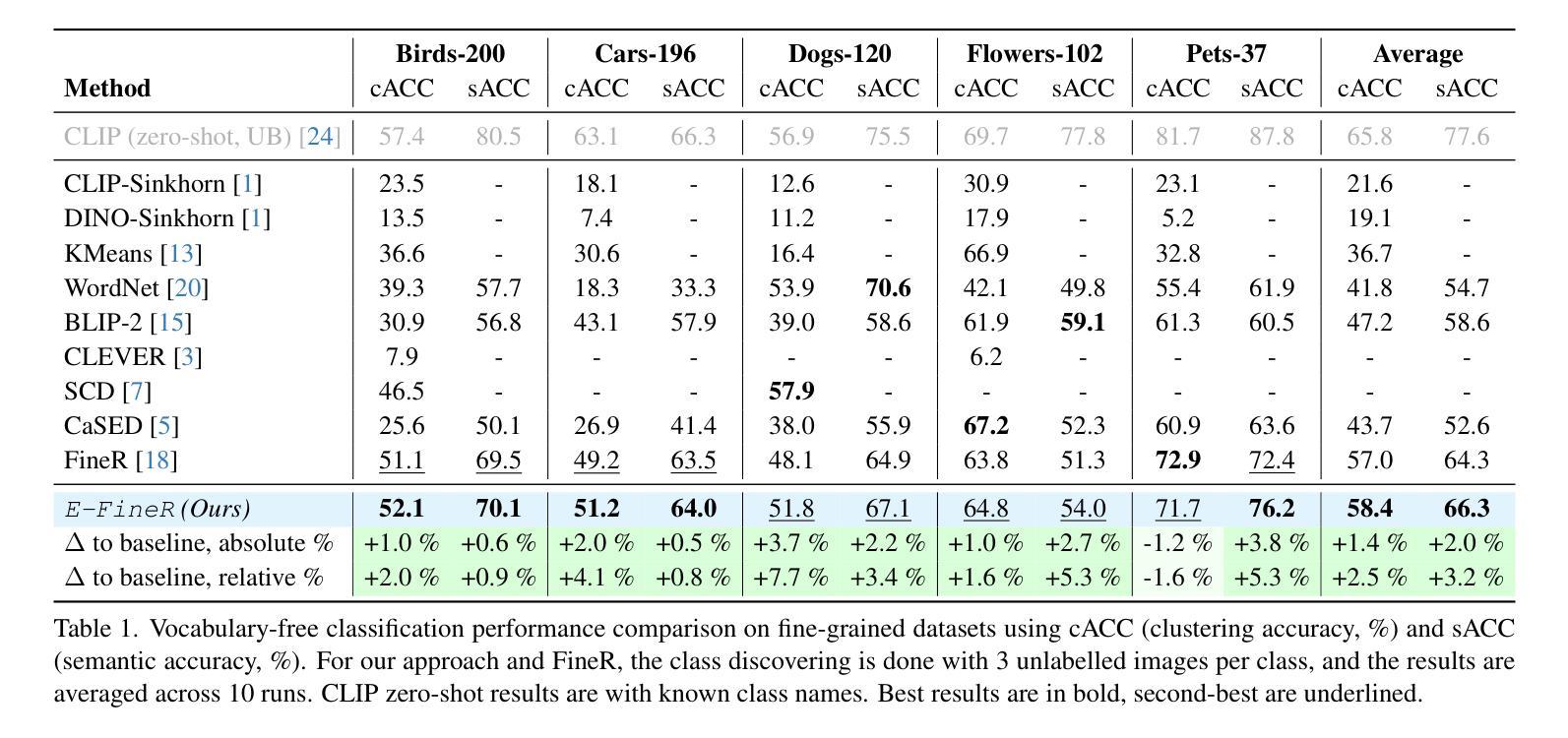
Vocabulary-free Fine-grained Visual Recognition via Enriched Contextually Grounded Vision-Language Model
Authors:Dmitry Demidov, Zaigham Zaheer, Omkar Thawakar, Salman Khan, Fahad Shahbaz Khan
Fine-grained image classification, the task of distinguishing between visually similar subcategories within a broader category (e.g., bird species, car models, flower types), is a challenging computer vision problem. Traditional approaches rely heavily on fixed vocabularies and closed-set classification paradigms, limiting their scalability and adaptability in real-world settings where novel classes frequently emerge. Recent research has demonstrated that combining large language models (LLMs) with vision-language models (VLMs) makes open-set recognition possible without the need for predefined class labels. However, the existing methods are often limited in harnessing the power of LLMs at the classification phase, and also rely heavily on the guessed class names provided by an LLM without thorough analysis and refinement. To address these bottlenecks, we propose our training-free method, Enriched-FineR (or E-FineR for short), which demonstrates state-of-the-art results in fine-grained visual recognition while also offering greater interpretability, highlighting its strong potential in real-world scenarios and new domains where expert annotations are difficult to obtain. Additionally, we demonstrate the application of our proposed approach to zero-shot and few-shot classification, where it demonstrated performance on par with the existing SOTA while being training-free and not requiring human interventions. Overall, our vocabulary-free framework supports the shift in image classification from rigid label prediction to flexible, language-driven understanding, enabling scalable and generalizable systems for real-world applications. Well-documented code is available on https://github.com/demidovd98/e-finer.
细粒度图像分类是在一个更广泛的类别中区分视觉上相似的子类别(例如鸟类、汽车型号、花卉类型)的任务,这是一个具有挑战性的计算机视觉问题。传统的方法严重依赖于固定的词汇表和封闭集分类范式,这在现实世界环境中存在局限性,因为新的类别经常会出现。最近的研究表明,将大型语言模型(LLMs)与视觉语言模型(VLMs)相结合,可以在无需预先定义的类别标签的情况下实现开放集识别。然而,现有方法往往无法充分利用LLMs在分类阶段的潜力,并且严重依赖于LLM提供的猜测类名,而没有进行深入的分析和细化。为了解决这些瓶颈,我们提出了无需训练的方法Enriched-FineR(或简称为E-FineR),该方法在细粒度视觉识别方面达到了最先进的技术成果,同时提供了更高的可解释性,突显了其在难以获得专家注释的现实场景和新领域中的强大潜力。此外,我们展示了所提出的方法在零样本和少样本分类中的应用,该方法在无需训练和人为干预的情况下达到了与现有技术相当的性能。总的来说,我们的无词汇表框架支持图像分类从僵化的标签预测转向灵活的语言驱动理解,为实际应用提供了可扩展和通用的系统。相关代码已详细记录在https://github.com/demidovd98/e-finer上。
论文及项目相关链接
PDF Accepted to ICCV 2025
Summary
本文探讨了细粒度图像分类中的挑战,包括如何区分广泛类别中的视觉相似子类(如鸟类物种、汽车型号和花卉类型)。传统的分类方法严重依赖于固定词汇表和封闭集分类模式,限制了其在现实世界中的可扩展性和适应性,因为现实世界经常出现新的类别。近期的研究通过将大型语言模型(LLMs)与视觉语言模型(VLMs)相结合,实现了开放式集识别,无需预先定义的类别标签。然而,现有方法往往无法充分利用LLMs在分类阶段的潜力,并严重依赖于LLMs提供的猜测类名,缺乏深入的分析和改进。针对这些瓶颈,本文提出了一种无需训练的Enriched-FineR方法(简称E-FineR),在细粒度视觉识别方面取得了最新成果,并提供了更高的可解释性,突显其在难以获得专家注释的现实世界场景和新领域中的强大潜力。此外,本文展示了该方法在零样本和少样本分类中的应用,其性能与现有技术相当,无需训练且无需人工干预。总体而言,本文的词汇表外框架支持图像分类从刚性标签预测向灵活的语言驱动理解的转变,为实现可扩展和通用的真实世界应用系统提供了可能。
Key Takeaways
- 细粒度图像分类是区分广泛类别中视觉相似子类的问题,具有挑战性。
- 传统方法依赖于固定词汇和封闭集分类模式,限制了其在现实世界的适应性。
- 结合大型语言模型和视觉语言模型可实现开放式集识别。
- 现有方法无法充分利用语言模型在分类阶段的潜力并依赖猜测类名。
- 提出的Enriched-FineR方法无需训练,在细粒度视觉识别方面取得最新成果。
- Enriched-FineR提供了更高的可解释性,适用于现实世界场景和新领域。
点此查看论文截图

Empirical Evaluation of Concept Drift in ML-Based Android Malware Detection
Authors:Ahmed Sabbah, Radi Jarrar, Samer Zein, David Mohaisen
Despite outstanding results, machine learning-based Android malware detection models struggle with concept drift, where rapidly evolving malware characteristics degrade model effectiveness. This study examines the impact of concept drift on Android malware detection, evaluating two datasets and nine machine learning and deep learning algorithms, as well as Large Language Models (LLMs). Various feature types–static, dynamic, hybrid, semantic, and image-based–were considered. The results showed that concept drift is widespread and significantly affects model performance. Factors influencing the drift include feature types, data environments, and detection methods. Balancing algorithms helped with class imbalance but did not fully address concept drift, which primarily stems from the dynamic nature of the malware landscape. No strong link was found between the type of algorithm used and concept drift, the impact was relatively minor compared to other variables since hyperparameters were not fine-tuned, and the default algorithm configurations were used. While LLMs using few-shot learning demonstrated promising detection performance, they did not fully mitigate concept drift, highlighting the need for further investigation.
尽管结果出色,但基于机器学习的Android恶意软件检测模型仍然受到概念漂移的困扰,其中快速演变的恶意软件特征会降低模型的有效性。本研究探讨了概念漂移对Android恶意软件检测的影响,评估了两个数据集和九个机器学习和深度学习算法以及大型语言模型(LLM)。考虑了各种特征类型,包括静态、动态、混合、语义和图像。结果表明,概念漂移普遍存在,严重影响模型性能。影响漂移的因素包括特征类型、数据环境和检测方法。平衡算法有助于解决类不平衡问题,但没有完全解决概念漂移问题,这主要源于恶意软件景观的动态性。没有发现所使用的算法类型与概念漂移之间存在强关联,由于未对超参数进行微调并使用默认算法配置,与其他变量相比,其影响相对较小。虽然使用少量样本学习的LLM显示出有希望的检测性能,但它们并没有完全缓解概念漂移问题,这凸显了需要进一步调查的需要。
论文及项目相关链接
PDF 18 pages, 12 tables, 14 figures, paper under review
Summary
本文研究了概念漂移对基于机器学习的Android恶意软件检测模型的影响。通过对两个数据集和九种机器学习与深度学习算法以及大型语言模型(LLMs)的评估发现,概念漂移普遍存在并严重影响模型性能。影响概念漂移的因素包括特征类型、数据环境和检测方法。虽然平衡算法有助于解决类别不平衡问题,但未能完全解决概念漂移问题,其主要源于恶意软件景观的动态性。LLMs的少数学习虽表现出良好的检测性能,但未完全缓解概念漂移问题,需要进一步研究。
Key Takeaways
- 概念漂移在Android恶意软件检测中是普遍存在的,且严重影响模型性能。
- 特征类型、数据环境和检测方法都是影响概念漂移的重要因素。
- 平衡算法有助于解决类别不平衡问题,但无法完全解决概念漂移。
- 概念漂移主要源于恶意软件景观的动态性。
- 使用的算法类型与概念漂移之间未发现有强烈联系。
- 大型语言模型(LLMs)的少数学习虽表现出检测潜力,但未能完全缓解概念漂移。
点此查看论文截图



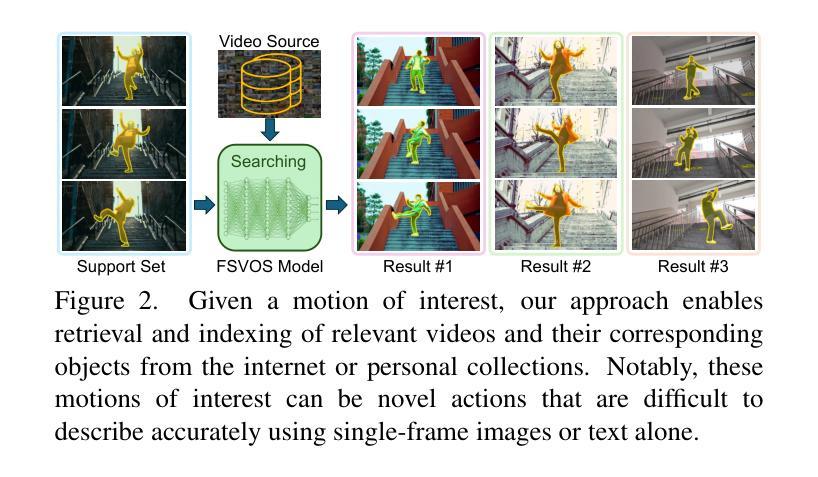
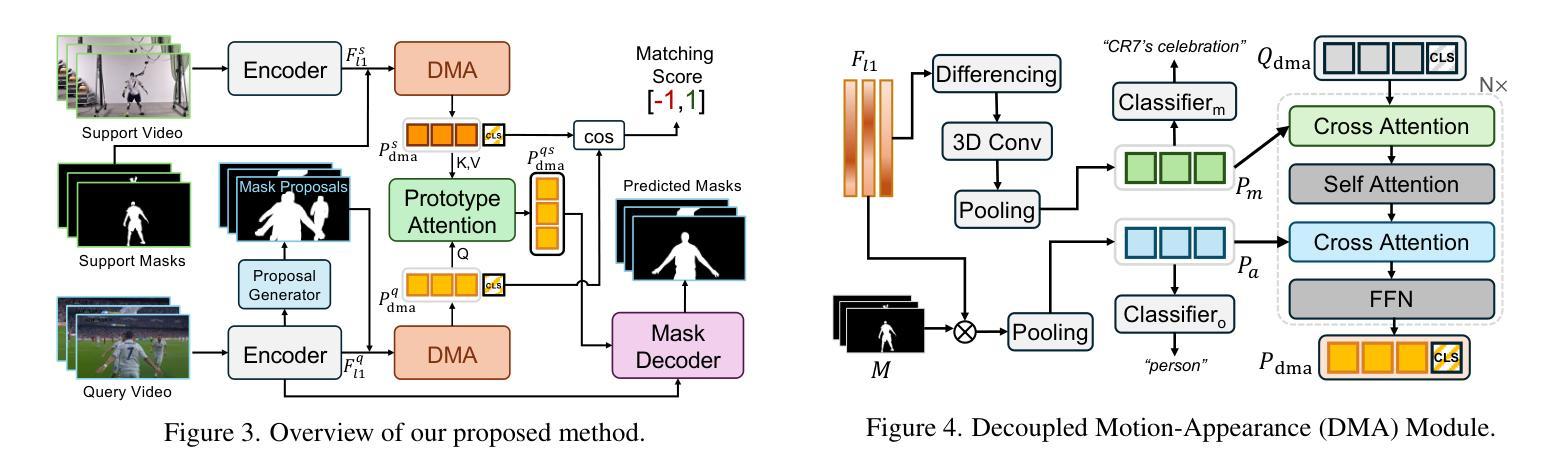
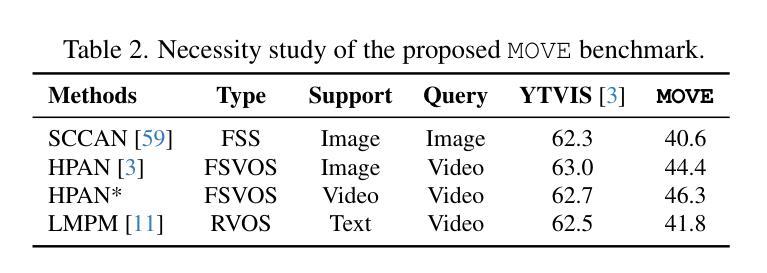
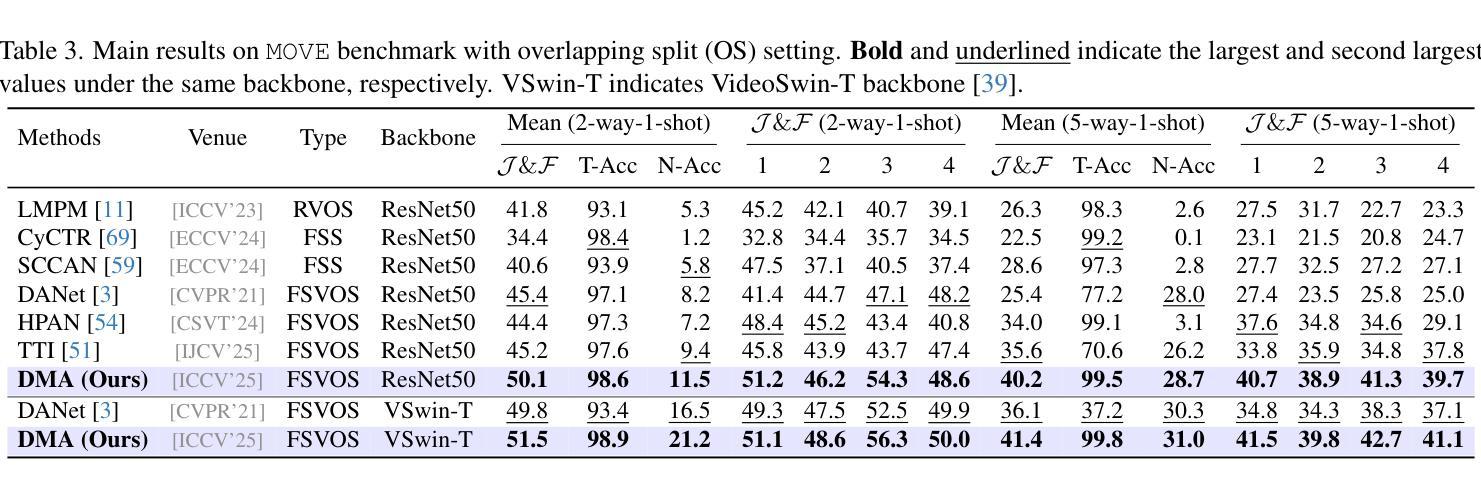
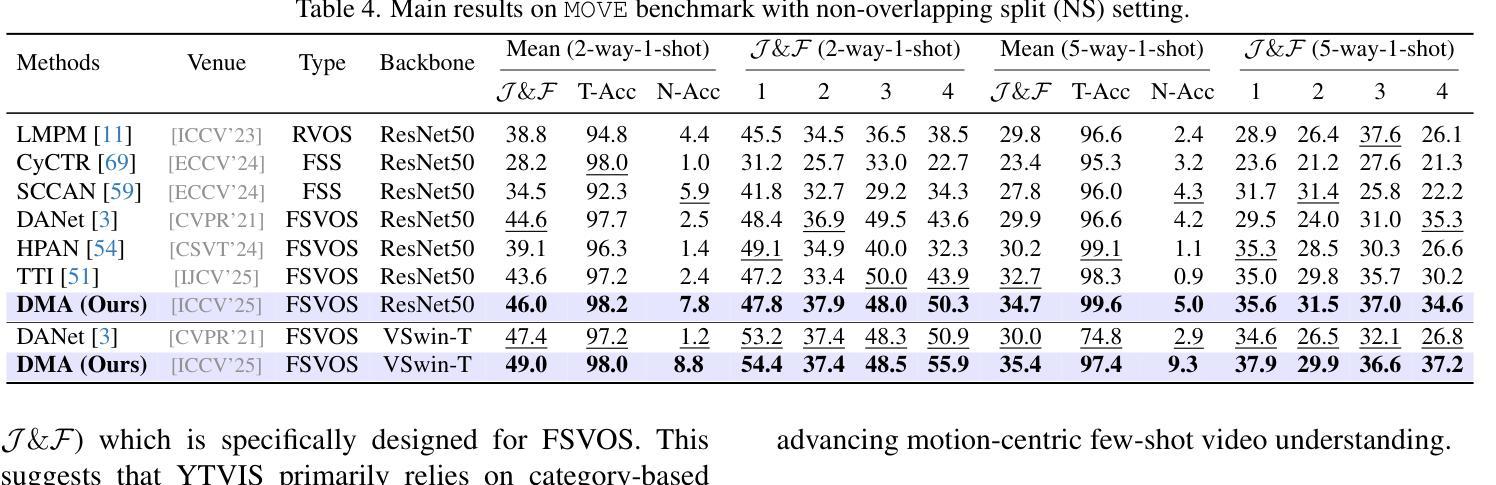
MOVE: Motion-Guided Few-Shot Video Object Segmentation
Authors:Kaining Ying, Hengrui Hu, Henghui Ding
This work addresses motion-guided few-shot video object segmentation (FSVOS), which aims to segment dynamic objects in videos based on a few annotated examples with the same motion patterns. Existing FSVOS datasets and methods typically focus on object categories, which are static attributes that ignore the rich temporal dynamics in videos, limiting their application in scenarios requiring motion understanding. To fill this gap, we introduce MOVE, a large-scale dataset specifically designed for motion-guided FSVOS. Based on MOVE, we comprehensively evaluate 6 state-of-the-art methods from 3 different related tasks across 2 experimental settings. Our results reveal that current methods struggle to address motion-guided FSVOS, prompting us to analyze the associated challenges and propose a baseline method, Decoupled Motion Appearance Network (DMA). Experiments demonstrate that our approach achieves superior performance in few shot motion understanding, establishing a solid foundation for future research in this direction.
本文涉及运动引导的小样本视频对象分割(FSVOS),旨在基于具有相同运动模式的少量注释示例来分割视频中的动态对象。现有的FSVOS数据集和方法通常关注对象类别,这些静态属性忽略了视频中的丰富时间动态,从而限制了它们在需要运动理解场景中的应用。为了填补这一空白,我们引入了专为运动引导FSVOS设计的大规模数据集MOVE。基于MOVE,我们在两个实验环境下全面评估了来自三个不同任务的6种最新方法。结果表明,当前方法难以解决运动引导FSVOS问题,促使我们分析相关挑战并提出基线方法,即解耦运动外观网络(DMA)。实验表明,我们的方法在少量运动理解中取得了卓越的性能,为未来在这一方向的研究奠定了坚实的基础。
论文及项目相关链接
PDF ICCV 2025, Project Page: https://henghuiding.com/MOVE/
Summary
视频中的动态物体可通过其运动模式进行识别分割,而现有的数据集和方法多侧重于静态属性的物体类别而忽视视频中的丰富时间动态。为此,我们引入了MOVE数据集并设计了用于运动引导下的少样本视频对象分割(FSVOS)任务。我们评估了多个先进方法和任务在MOVE数据集上的表现,发现现有方法在处理运动引导下的FSVOS时面临挑战。因此,我们提出了一个基线方法——解耦运动外观网络(DMA),在少量样本运动理解上取得了优异性能。
Key Takeaways
- 该研究针对运动引导下的少样本视频对象分割(FSVOS)任务展开研究。
- 现有FSVOS数据集和方法多侧重于静态属性的物体类别,忽视了视频中的丰富时间动态。
- 我们引入了MOVE数据集用于运动引导下的FSVOS任务,具有大规模特性。
- 对多种先进方法和任务在MOVE数据集上的表现进行了评估。
- 实验结果显示现有方法在处理运动引导下的FSVOS时存在挑战。
- 提出了一种基线方法——解耦运动外观网络(DMA)。
点此查看论文截图


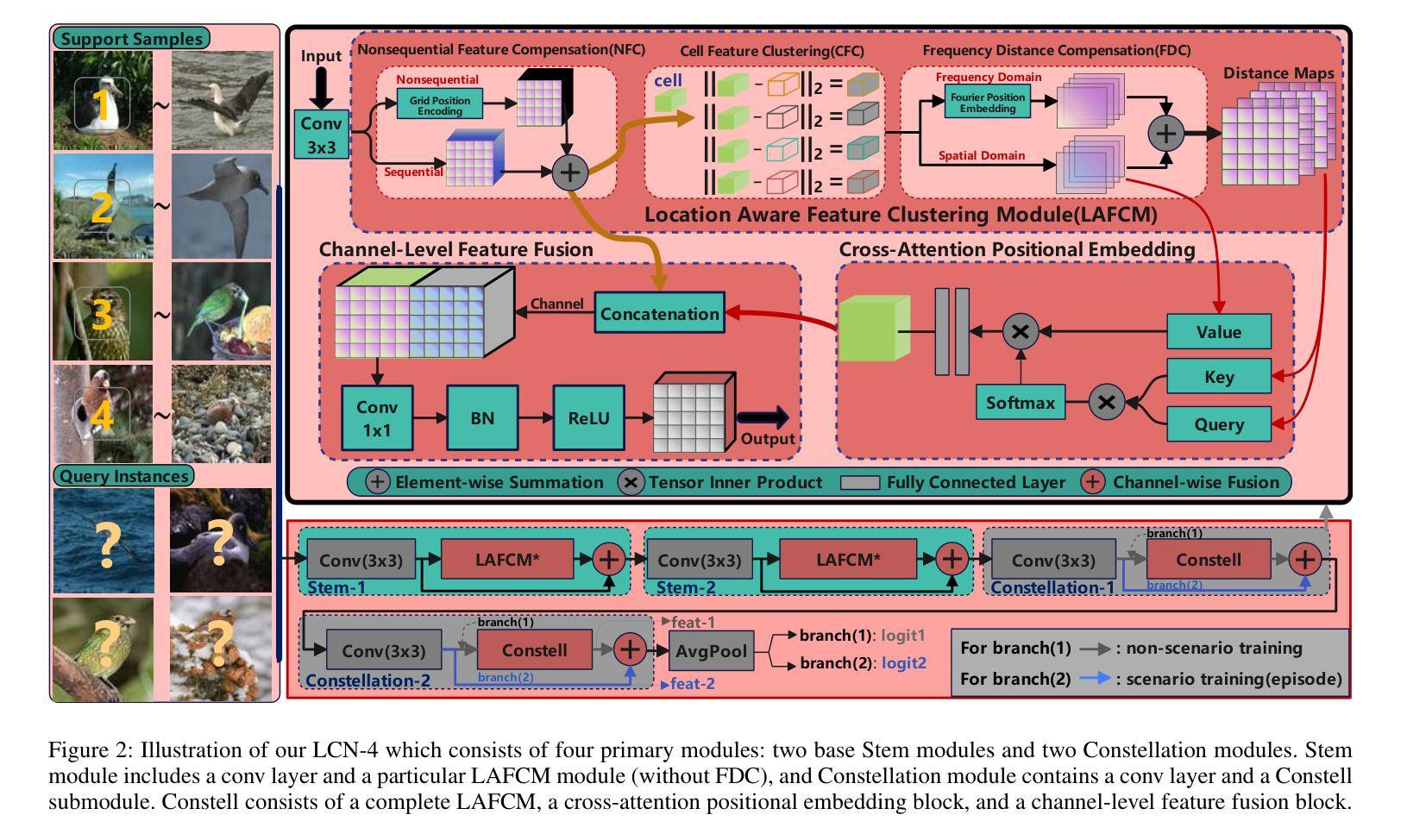
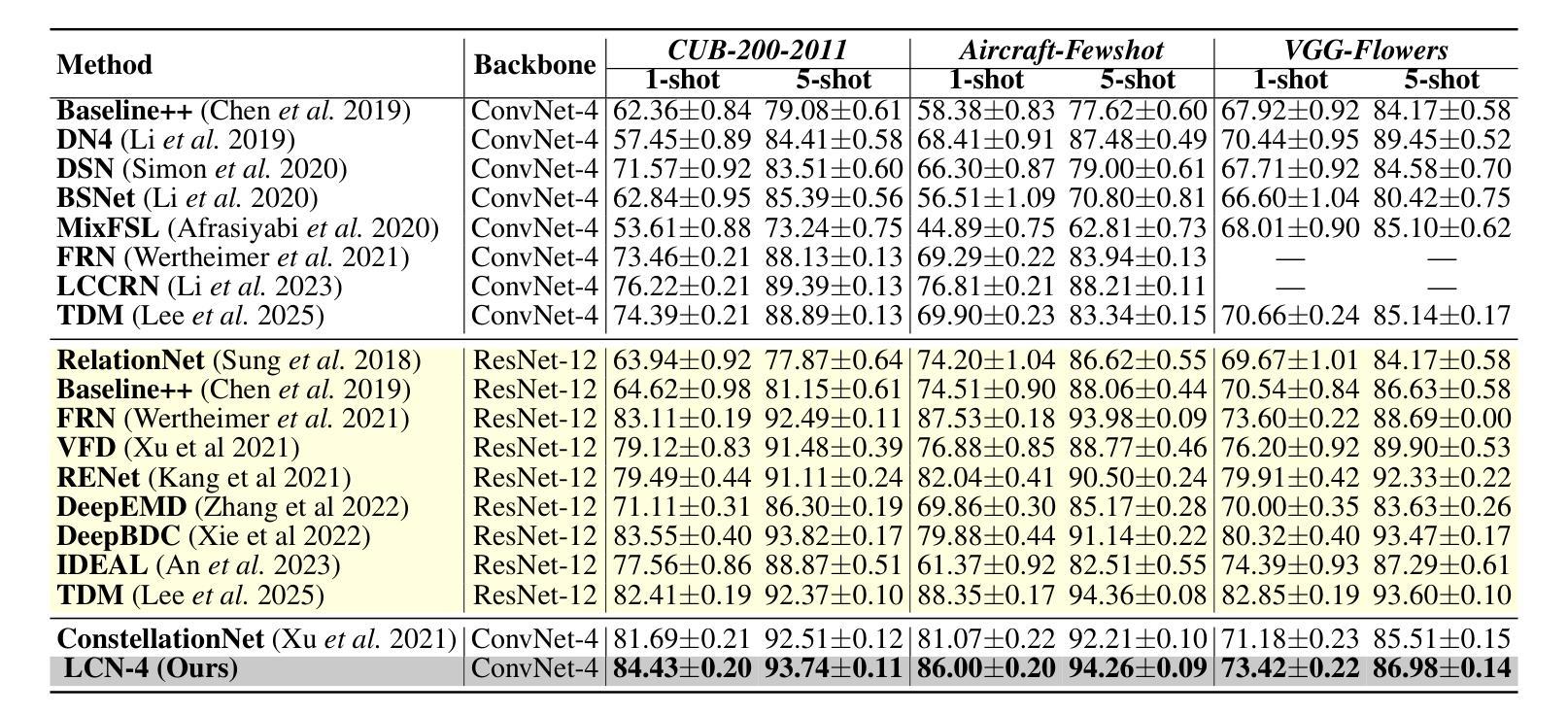
Shallow Deep Learning Can Still Excel in Fine-Grained Few-Shot Learning
Authors:Chaofei Qi, Chao Ye, Zhitai Liu, Weiyang Lin, Jianbin Qiu
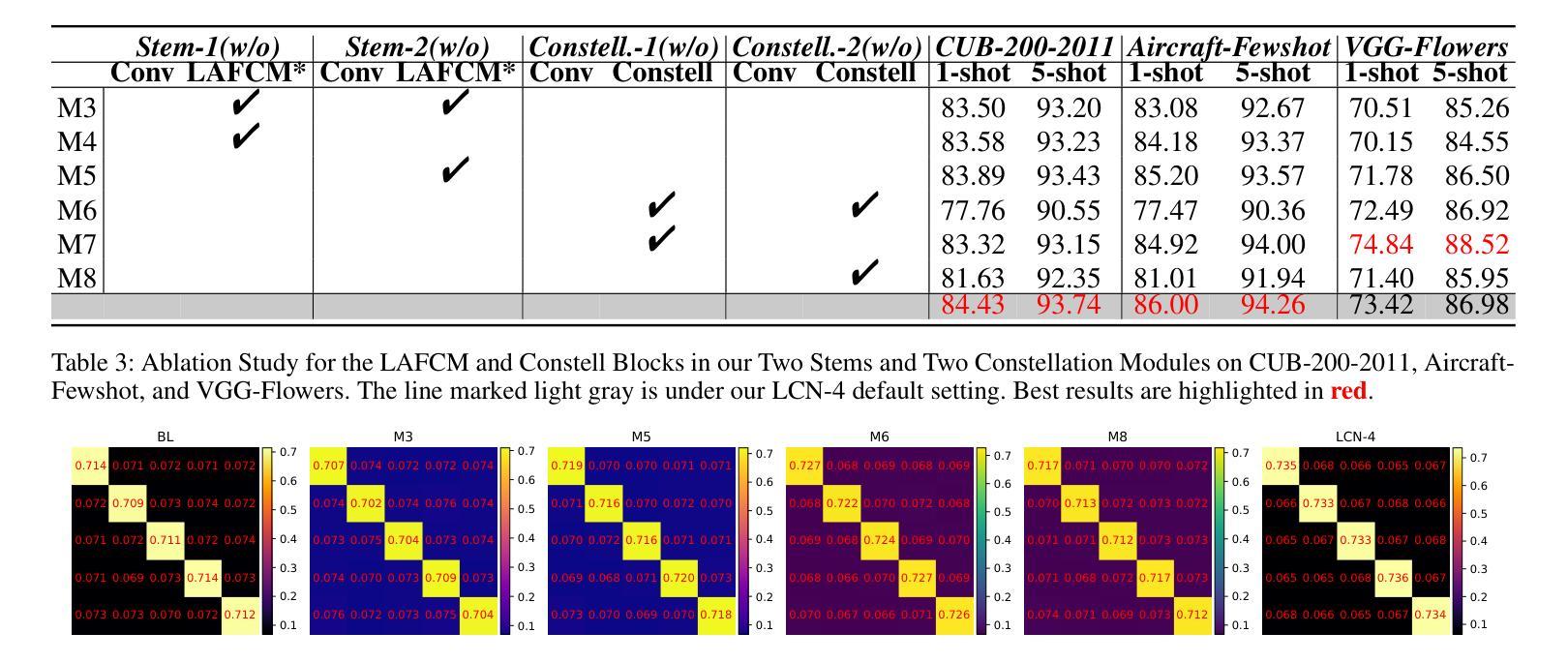
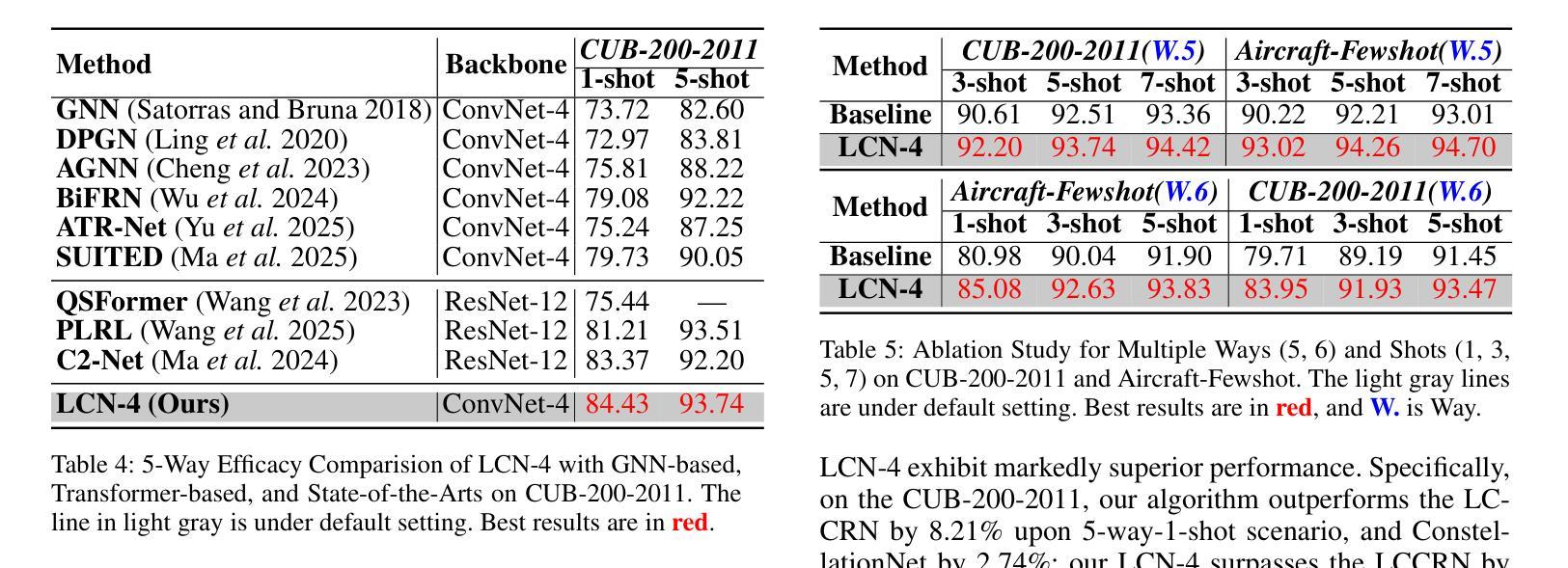
Deep learning has witnessed the extensive utilization across a wide spectrum of domains, including fine-grained few-shot learning (FGFSL) which heavily depends on deep backbones. Nonetheless, shallower deep backbones such as ConvNet-4, are not commonly preferred because they’re prone to extract a larger quantity of non-abstract visual attributes. In this paper, we initially re-evaluate the relationship between network depth and the ability to fully encode few-shot instances, and delve into whether shallow deep architecture could effectuate comparable or superior performance to mainstream deep backbone. Fueled by the inspiration from vanilla ConvNet-4, we introduce a location-aware constellation network (LCN-4), equipped with a cutting-edge location-aware feature clustering module. This module can proficiently encoder and integrate spatial feature fusion, feature clustering, and recessive feature location, thereby significantly minimizing the overall loss. Specifically, we innovatively put forward a general grid position encoding compensation to effectively address the issue of positional information missing during the feature extraction process of specific ordinary convolutions. Additionally, we further propose a general frequency domain location embedding technique to offset for the location loss in clustering features. We have carried out validation procedures on three representative fine-grained few-shot benchmarks. Relevant experiments have established that LCN-4 notably outperforms the ConvNet-4 based State-of-the-Arts and achieves performance that is on par with or superior to most ResNet12-based methods, confirming the correctness of our conjecture.
深度学习已在多个领域得到广泛应用,其中包括精细的少量学习(FGFSL),这严重依赖于深度骨干网络。然而,较浅的深度骨干网络(如ConvNet-4)通常不受欢迎,因为它们容易提取大量的非抽象视觉属性。在本文中,我们重新评估了网络深度与完全编码少量实例的能力之间的关系,并探讨了浅层深度架构是否能够实现与主流深度骨干网络相当或更好的性能。受普通ConvNet-4的启发,我们引入了一种位置感知星座网络(LCN-4),配备了一种尖端的位置感知特征聚类模块。该模块能够熟练地编码和集成空间特征融合、特征聚类和隐性特征位置,从而显著减少总体损失。具体来说,我们创新地提出了一种通用网格位置编码补偿,以有效解决普通卷积在特征提取过程中缺失位置信息的问题。此外,我们进一步提出了一种通用的频域位置嵌入技术,以补偿聚类特征中的位置损失。我们在三个代表性的精细少量基准测试上进行了验证程序。相关实验表明,LCN-4显著优于基于ConvNet-4的现有技术,并且性能与大多数基于ResNet12的方法相当或更好,这证实了我们的猜想。
论文及项目相关链接
Summary
本文探讨了深度学习在精细粒度小样本学习(FGFSL)中的应用,对网络深度与编码小样本实例能力之间的关系进行了重新评估。提出了一种基于位置感知的天秤网络(LCN-4),配备了先进的位置感知特征聚类模块,能有效编码和整合空间特征融合、特征聚类和隐性特征位置,从而显著减少总体损失。通过通用网格位置编码补偿和频率域位置嵌入技术,解决了普通卷积在特征提取过程中丢失位置信息的问题。在三个代表性的小样本精细粒度基准测试上进行了验证,表明LCN-4显著优于基于ConvNet-4的现有技术,性能与基于ResNet12的方法相当或更优。
Key Takeaways
- 探讨了网络深度在精细粒度小样本学习中的重要性。
- 重新评估了网络深度与编码小样本实例能力之间的关系。
- 介绍了位置感知的天秤网络(LCN-4),结合了先进的位置感知特征聚类模块。
- LCN-4能有效编码和整合空间特征融合、特征聚类和隐性特征位置。
- 通过通用网格位置编码补偿解决了普通卷积中位置信息丢失的问题。
- 提出了一种频率域位置嵌入技术,以弥补聚类特征中的位置损失。
点此查看论文截图


MSGCoOp: Multiple Semantic-Guided Context Optimization for Few-Shot Learning
Authors:Zhaolong Wang, Tongfeng Sun, Mingzheng Du, Yachao Huang
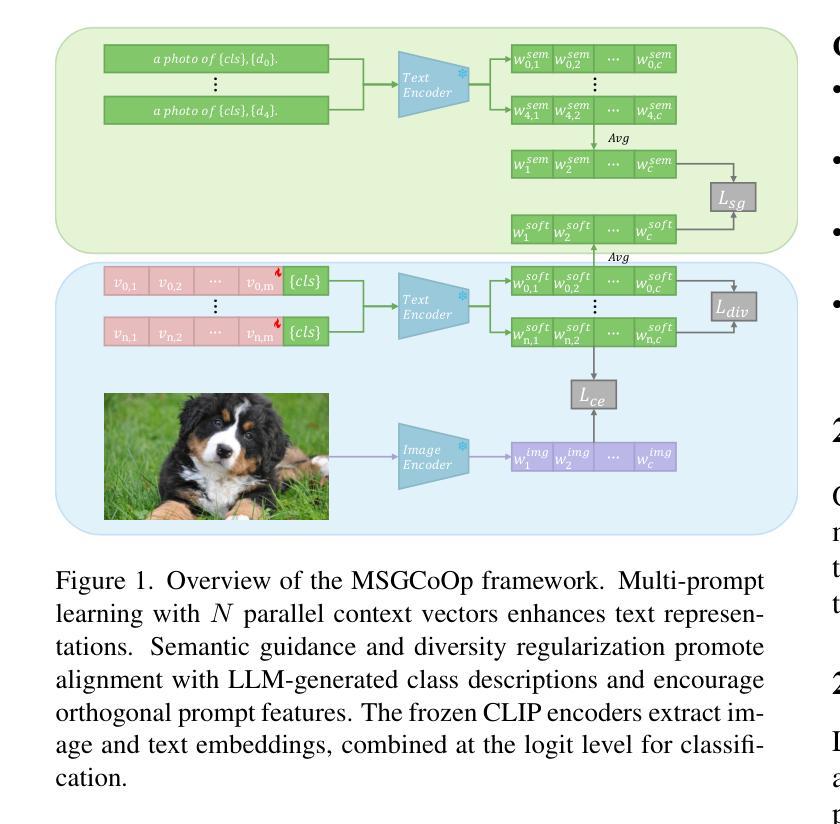
Vision-language pre-trained models (VLMs) such as CLIP have demonstrated remarkable zero-shot generalization, and prompt learning has emerged as an efficient alternative to full fine-tuning. However, existing methods often struggle with generalization to novel classes, a phenomenon attributed to overfitting on seen classes and forgetting general knowledge. Furthermore, recent approaches that improve generalization often introduce complex architectures or heavy computational overhead. In this paper, we propose a Multiple Semantic-Guided Context Optimization (MSGCoOp) framework to enhance few-shot generalization while maintaining computational efficiency. Our approach leverages an ensemble of parallel learnable context vectors to capture diverse semantic aspects. To enrich these prompts, we introduce a semantic guidance mechanism that aligns them with comprehensive class descriptions automatically generated by a Large Language Model (LLM). Furthermore, a diversity regularization loss encourages the prompts to learn complementary and orthogonal features, preventing them from collapsing into redundant representations. Extensive experiments on 11 benchmark datasets show that MSGCoOp significantly improves performance on base-to-novel generalization, achieving an average harmonic mean improvement of 1.10% over the strong KgCoOp baseline. Our method also demonstrates enhanced robustness in cross-domain generalization tasks. Our code is avaliable at: \href{https://github.com/Rain-Bus/MSGCoOp}{https://github.com/Rain-Bus/MSGCoOp}.
视觉语言预训练模型(如CLIP)已经展现出惊人的零样本泛化能力,而提示学习已经成为全微调的一个有效替代方案。然而,现有方法在泛化到新类别时往往表现不佳,这种现象被归因于对所见类别的过拟合以及遗忘通用知识。此外,最近一些提高泛化的方法往往引入复杂的架构或大量的计算开销。在本文中,我们提出了一个多重语义引导上下文优化(MSGCoOp)框架,旨在提高少样本泛化能力的同时保持计算效率。我们的方法利用一组并行可学习的上下文向量来捕捉各种语义方面。为了丰富这些提示,我们引入了一种语义引导机制,使其与大型语言模型(LLM)自动生成的全面类别描述相吻合。此外,多样性正则化损失鼓励提示学习互补和正交特征,防止它们陷入冗余表示。在11个基准数据集上的广泛实验表明,MSGCoOp在基础到新颖的泛化方面显著提高性能,相较于强大的KgCoOp基线,平均调和均值提高了1.10%。我们的方法在跨域泛化任务中也表现出增强的稳健性。我们的代码可用在:https://github.com/Rain-Bus/MSGCoOp。
论文及项目相关链接
Summary
本文提出了一种名为MSGCoOp的语义引导上下文优化框架,旨在提高小样本泛化能力同时保持计算效率。通过利用并行学习上下文向量的集合来捕捉多样化的语义方面,并引入语义引导机制使提示与大型语言模型自动生成的全面类别描述对齐。此外,通过多样性正则化损失鼓励提示学习互补和正交特征,防止其陷入冗余表示。在多个基准数据集上的实验表明,MSGCoOp在基础到新颖的泛化任务上取得了显著的性能提升,平均调和平均数较强大的KgCoOp基线提高了1.10%。此外,该方法在跨域泛化任务中也表现出增强的稳健性。
Key Takeaways
- MSGCoOp框架旨在提高小样本泛化能力并保持计算效率。
- 通过利用并行学习上下文向量的集合捕捉多样化的语义方面。
- 引入语义引导机制,使提示与大型语言模型自动生成的全面类别描述对齐。
- 多样性正则化损失鼓励提示学习互补和正交特征,避免冗余表示。
- MSGCoOp在基础到新颖的泛化任务上取得了显著性能提升。
- 平均调和平均数较强大的KgCoOp基线提高了1.10%。
- MSGCoOp方法在跨域泛化任务中表现出增强的稳健性。
点此查看论文截图



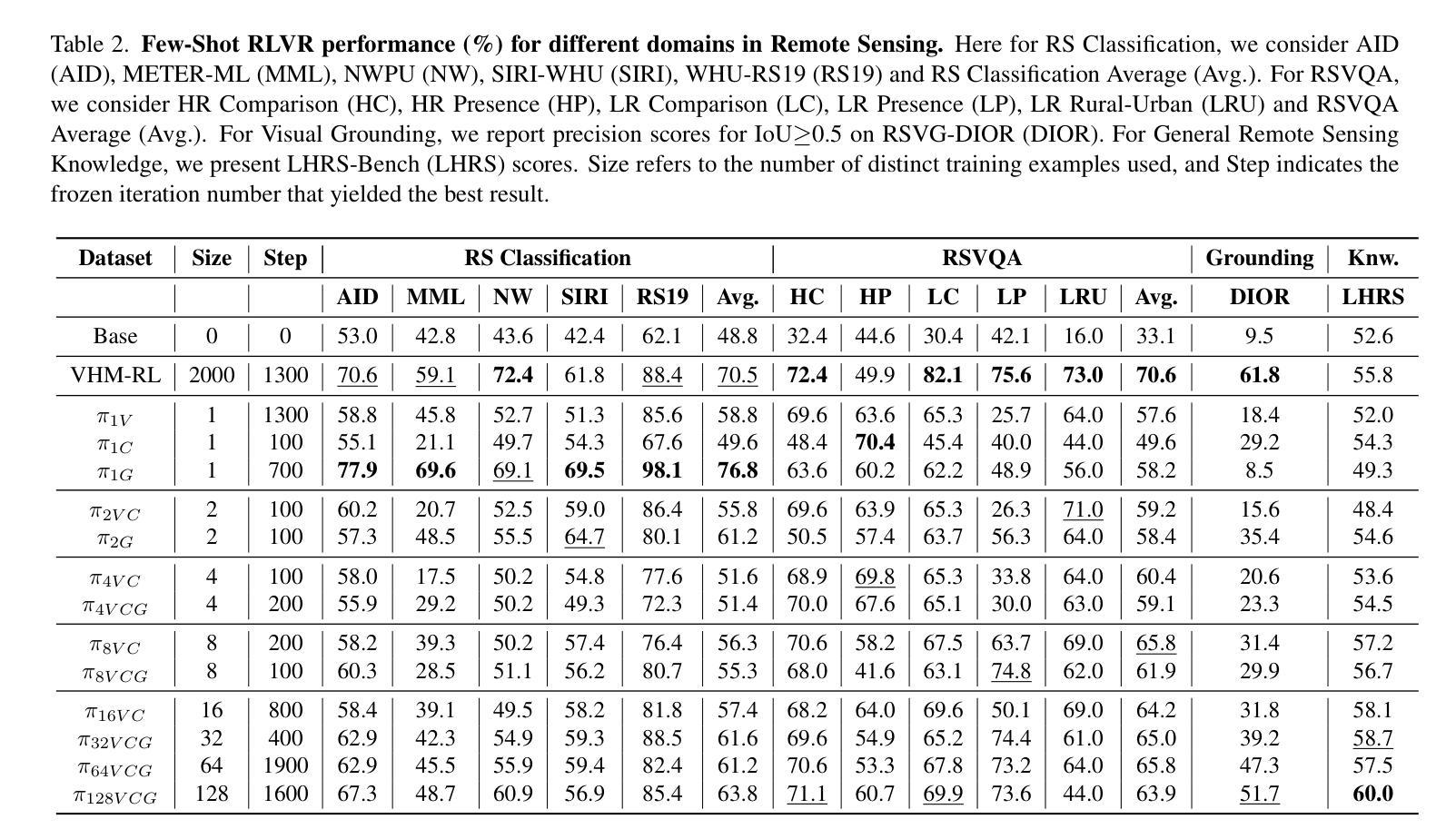
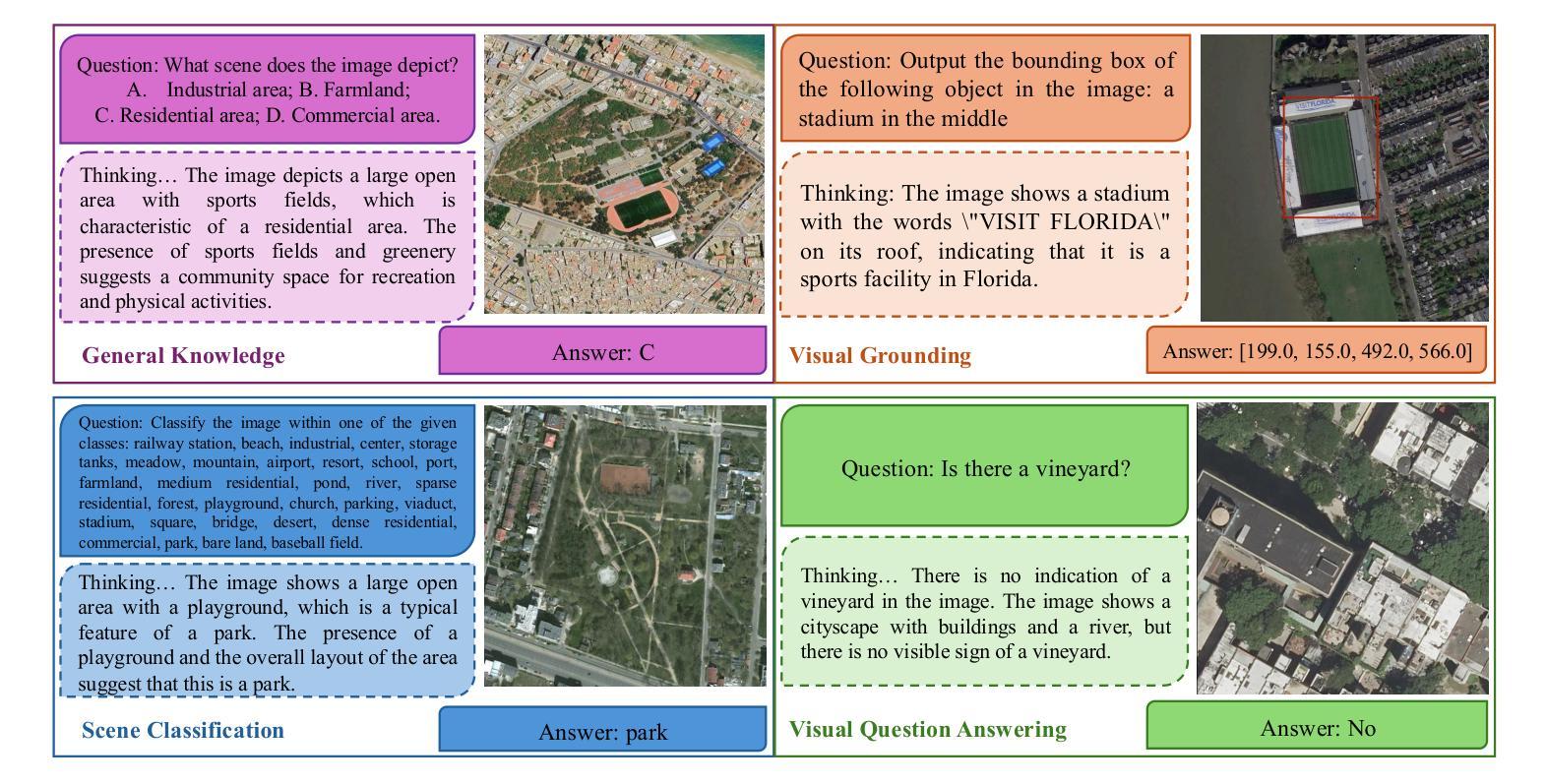
Few-Shot Vision-Language Reasoning for Satellite Imagery via Verifiable Rewards
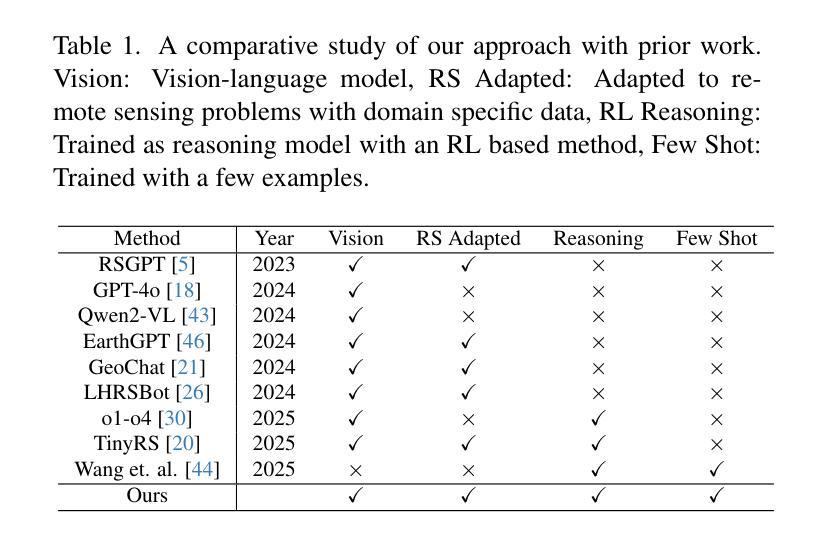
Authors:Aybora Koksal, A. Aydin Alatan
Recent advances in large language and vision-language models have enabled strong reasoning capabilities, yet they remain impractical for specialized domains like remote sensing, where annotated data is scarce and expensive. We present the first few-shot reinforcement learning with verifiable reward (RLVR) framework for satellite imagery that eliminates the need for caption supervision–relying solely on lightweight, rule-based binary or IoU-based rewards. Adapting the “1-shot RLVR” paradigm from language models to vision-language models, we employ policy-gradient optimization with as few as one curated example to align model outputs for satellite reasoning tasks. Comprehensive experiments across multiple remote sensing benchmarks–including classification, visual question answering, and grounding–show that even a single example yields substantial improvements over the base model. Scaling to 128 examples matches or exceeds models trained on thousands of annotated samples. While the extreme one-shot setting can induce mild, task-specific overfitting, our approach consistently demonstrates robust generalization and efficiency across diverse tasks. Further, we find that prompt design and loss weighting significantly influence training stability and final accuracy. Our method enables cost-effective and data-efficient development of domain-specialist vision-language reasoning models, offering a pragmatic recipe for data-scarce fields: start from a compact VLM, curate a handful of reward-checkable cases, and train via RLVR.
近期大型语言和视觉语言模型的进步赋予了强大的推理能力,但在遥感等特定领域仍不切实际,因为这些领域缺乏标注数据且价格昂贵。我们首次提出一种无需注释监督的基于可验证奖励的强化学习(RLVR)框架,该框架专门用于卫星图像,仅依赖于轻量级、基于规则的二元奖励或基于IoU的奖励。我们将语言模型的“一次强化学习(RLVR)”范式应用于视觉语言模型,采用策略梯度优化法,仅凭一个精选示例就能对卫星推理任务进行模型输出匹配。跨越多个遥感基准的综合性实验——包括分类、视觉问答和定位——表明,即使在单次学习中,相较于基础模型也有显著的改进。扩展到128个样本的性能与在数千个标注样本上训练的模型相匹配或更好。虽然极端的一次性学习设置可能会导致特定任务的轻微过拟合,但我们的方法在各种任务中始终展现出稳健的泛化能力和效率。此外,我们发现提示设计和损失权重对训练稳定性和最终精度有显著影响。我们的方法实现了领域特定视觉语言推理模型的低成本高效开发,为数据稀缺领域提供了一个务实方案:从紧凑的VLM开始,挑选一些可奖励验证的案例,然后通过RLVR进行训练。
论文及项目相关链接
PDF ICCV 2025 Workshop on Curated Data for Efficient Learning (CDEL). 10 pages, 3 figures, 6 tables. Our model, training code and dataset will be at https://github.com/aybora/FewShotReasoning
Summary
大型语言和视觉语言模型的最新进展赋予了强大的推理能力,但在遥感等特定领域仍不适用,缺乏标注数据且成本高昂。本研究提出了首个无需监督标注的少量强化学习验证奖励(RLVR)框架,用于卫星图像。该框架仅依赖于轻量级、基于规则的二元或IoU奖励,无需字幕监督。通过适应语言模型的“一次强化学习验证奖励”(RLVR)范式,采用基于策略的梯度优化,仅使用一个精选示例即可对齐卫星推理任务模型输出。实验表明,即使在单次示例下,该模型也实现了对基准模型的显著改进。扩展到128个示例与在数千个标注样本上训练的模型相匹配或表现更佳。虽然极端单次训练可能会引发特定任务的过度拟合,但该方法在多样化任务中始终表现出稳健的泛化能力和效率。此外,研究发现提示设计和损失权重对训练稳定性和最终精度有重大影响。该方法为数据稀缺领域提供了经济高效的数据驱动视觉语言推理模型开发实用方案:从紧凑的VLM开始,精选少量可验证奖励的案例,并通过RLVR进行训练。
Key Takeaways
- 提出了一种新的少量强化学习验证奖励(RLVR)框架,适用于卫星图像,无需字幕监督。
- 适应了语言模型的“一次强化学习验证奖励”(RLVR)范式,并将其应用于视觉语言模型。
- 通过策略梯度优化,仅使用一个精选示例即可对齐卫星推理任务的模型输出。
- 实验表明,该方法在多个遥感基准测试中实现了显著改进,即使使用少量示例。
- 方法的泛化能力和效率在多样化任务中得到了验证。
- 提示设计和损失权重对训练稳定性和最终精度有重要影响。
点此查看论文截图

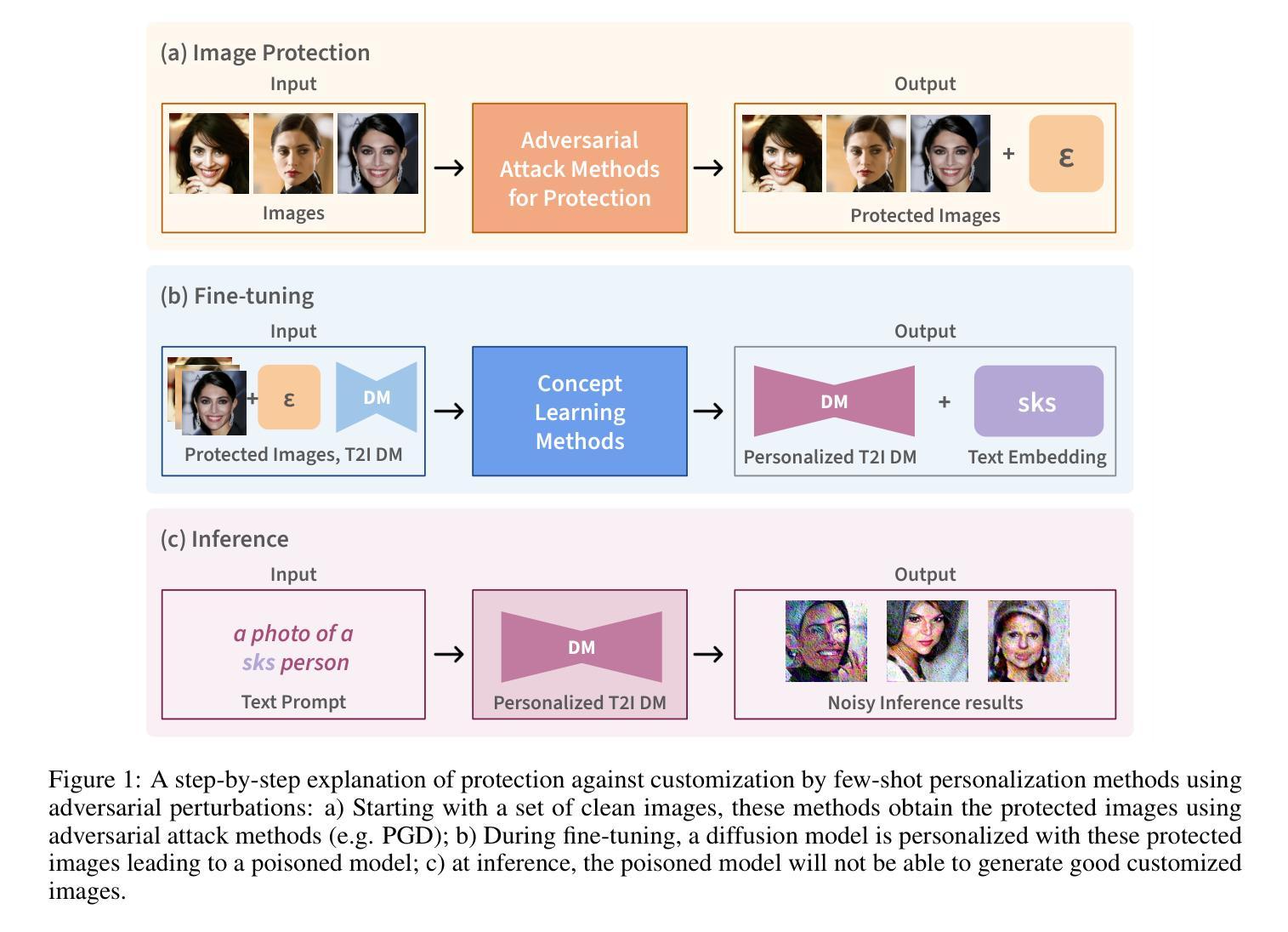
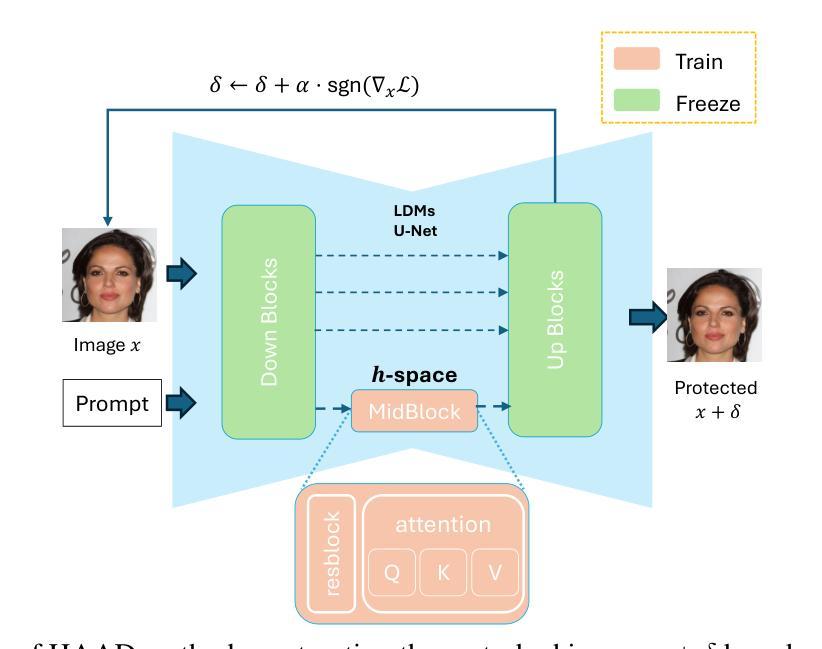
An h-space Based Adversarial Attack for Protection Against Few-shot Personalization
Authors:Xide Xu, Sandesh Kamath, Muhammad Atif Butt, Bogdan Raducanu
The versatility of diffusion models in generating customized images from few samples raises significant privacy concerns, particularly regarding unauthorized modifications of private content. This concerning issue has renewed the efforts in developing protection mechanisms based on adversarial attacks, which generate effective perturbations to poison diffusion models. Our work is motivated by the observation that these models exhibit a high degree of abstraction within their semantic latent space (`h-space’), which encodes critical high-level features for generating coherent and meaningful content. In this paper, we propose a novel anti-customization approach, called HAAD (h-space based Adversarial Attack for Diffusion models), that leverages adversarial attacks to craft perturbations based on the h-space that can efficiently degrade the image generation process. Building upon HAAD, we further introduce a more efficient variant, HAAD-KV, that constructs perturbations solely based on the KV parameters of the h-space. This strategy offers a stronger protection, that is computationally less expensive. Despite their simplicity, our methods outperform state-of-the-art adversarial attacks, highlighting their effectiveness.
扩散模型的通用性能够从少量样本中生成定制图像,这引发了关于未经授权的私人内容修改的严重隐私担忧。这一令人担忧的问题促使我们基于对抗性攻击发展保护机制,生成能有效干扰扩散模型的扰动。我们的工作受到观察启发,观察到这些模型在其语义潜在空间(h空间)内表现出高度抽象,该空间编码了生成连贯和有意义内容的关键高级特征。在本文中,我们提出了一种新的反定制方法,称为HAAD(基于h空间的扩散模型对抗性攻击),它利用对抗性攻击来基于h空间制造扰动,可以有效地破坏图像生成过程。基于HAAD,我们进一步介绍了一种更高效的变体,即仅基于h空间的KV参数构建扰动的HAAD-KV。该策略提供了更强大的保护,同时计算成本更低。尽管方法简单,但我们的方法优于最新先进的对抗性攻击方法,突出了其有效性。
论文及项目相关链接
PDF 32 pages, 15 figures. Accepted by ACM Multimedia 2025
Summary
扩散模型具备从少量样本生成定制化图像的能力,但其多功能性引发了关于未经授权的私人内容修改的重大隐私担忧。本研究受到观察启发,观察到这些模型在其语义潜在空间(h空间)内存在高度抽象,该空间编码了生成连贯和有意义内容的关键高级特征。本文提出了一种新型的反定制方法HAAD(基于h空间的扩散模型对抗攻击法),利用对抗性攻击制造基于h空间的扰动,可有效破坏图像生成过程。在HAAD的基础上,我们进一步引入了更高效的HAAD-KV变体,仅基于h空间的KV参数构建扰动。该方法在保护方面更强大且计算成本更低。尽管方法简单,但我们的方法在性能上优于最先进的对抗性攻击,突显其有效性。
Key Takeaways
- 扩散模型具备生成定制化图像的能力,引发关于未经授权修改内容的隐私担忧。
- 语义潜在空间(h空间)在扩散模型中起到关键作用,编码了生成连贯图像的高级特征。
- 提出了新型反定制方法HAAD,利用对抗性攻击制造基于h空间的扰动。
- HAAD的改进版本HAAD-KV更加高效,仅使用h空间的KV参数构建扰动。
- HAAD和HAAD-KV方法在计算效率和保护效果方面表现出优势。
- 与现有对抗性攻击相比,HAAD和HAAD-KV方法展现出更高的性能。
点此查看论文截图


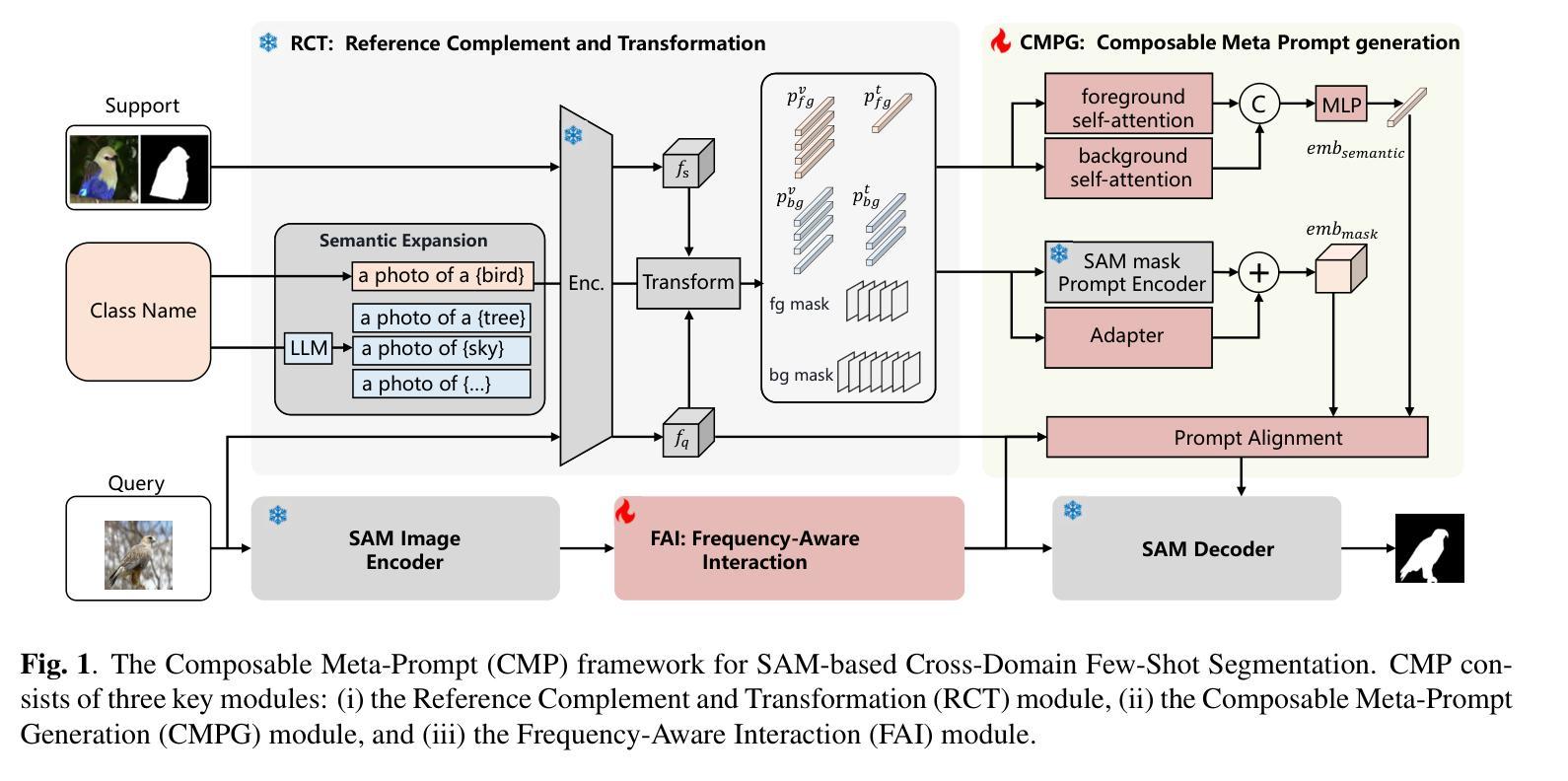
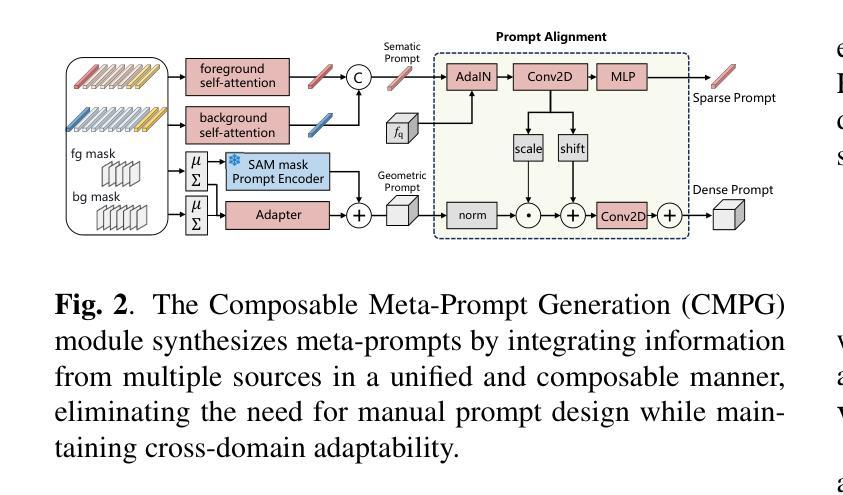
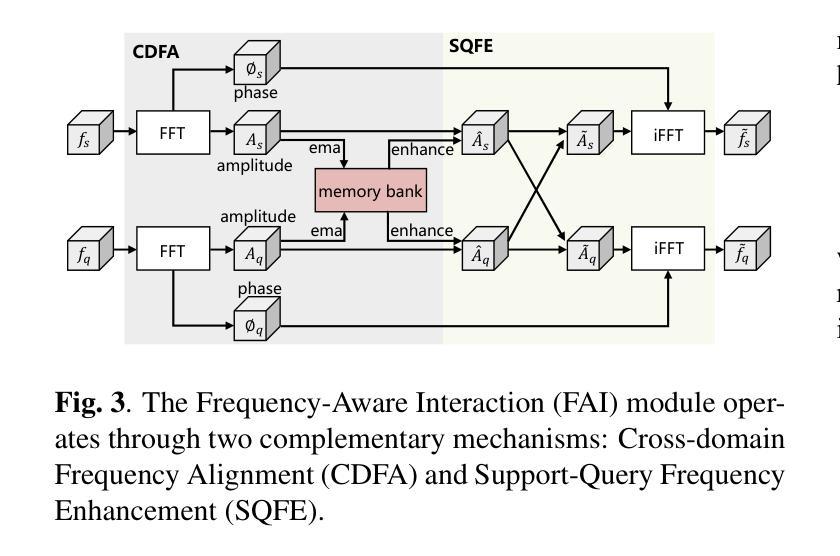
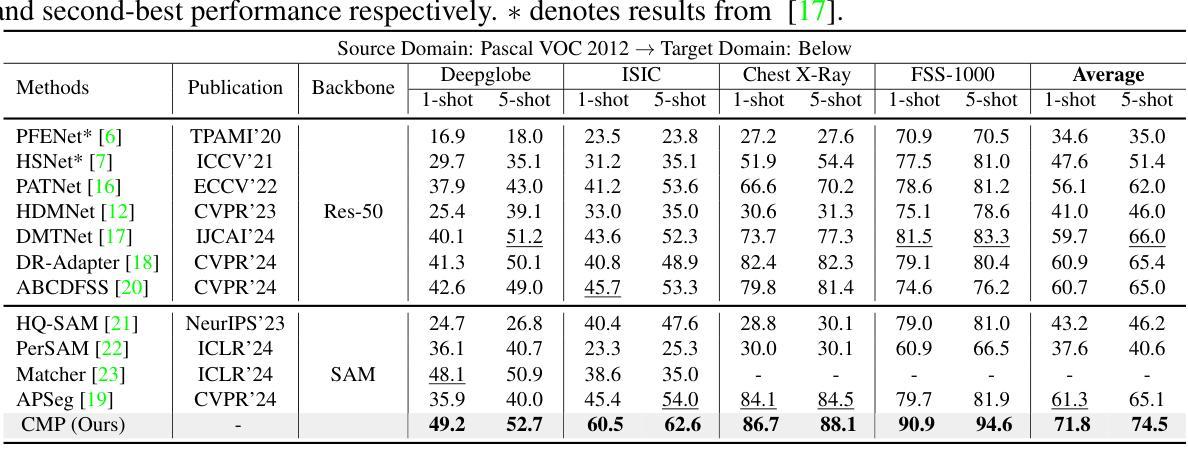
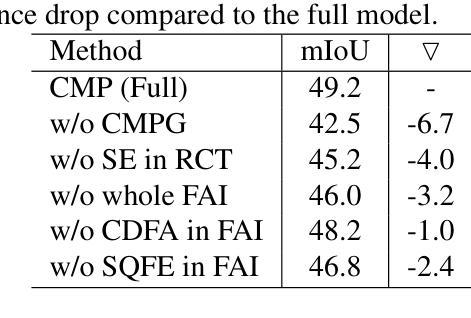
CMP: A Composable Meta Prompt for SAM-Based Cross-Domain Few-Shot Segmentation
Authors:Shuai Chen, Fanman Meng, Chunjin Yang, Haoran Wei, Chenhao Wu, Qingbo Wu, Hongliang Li
Cross-Domain Few-Shot Segmentation (CD-FSS) remains challenging due to limited data and domain shifts. Recent foundation models like the Segment Anything Model (SAM) have shown remarkable zero-shot generalization capability in general segmentation tasks, making it a promising solution for few-shot scenarios. However, adapting SAM to CD-FSS faces two critical challenges: reliance on manual prompt and limited cross-domain ability. Therefore, we propose the Composable Meta-Prompt (CMP) framework that introduces three key modules: (i) the Reference Complement and Transformation (RCT) module for semantic expansion, (ii) the Composable Meta-Prompt Generation (CMPG) module for automated meta-prompt synthesis, and (iii) the Frequency-Aware Interaction (FAI) module for domain discrepancy mitigation. Evaluations across four cross-domain datasets demonstrate CMP’s state-of-the-art performance, achieving 71.8% and 74.5% mIoU in 1-shot and 5-shot scenarios respectively.
跨域小样本分割(CD-FSS)由于数据有限和领域偏移而仍然具有挑战性。最近的基石模型,如分割任何模型(SAM),在一般分割任务中表现出了惊人的零样本泛化能力,使其成为小样本场景的很有前途的解决方案。然而,将SAM适应于CD-FSS面临两个关键挑战:依赖手动提示和有限的跨域能力。因此,我们提出了可组合元提示(CMP)框架,该框架引入了三个关键模块:(i)参考补全和转换(RCT)模块,用于语义扩展;(ii)可组合元提示生成(CMPG)模块,用于自动元提示合成;(iii)频率感知交互(FAI)模块,用于领域差异缓解。在四个跨域数据集上的评估证明了CMP的卓越性能,在1次和5次拍摄的场景中分别实现了71.8%和74.5%的mIoU。
论文及项目相关链接
PDF 3 figures
Summary
跨域小样本分割(CD-FSS)面临有限数据和域差异的挑战。最近的分割通用模型,如Segment Anything Model(SAM),在一般分割任务中显示出惊人的零样本泛化能力,对于小样本场景具有潜力。然而,将SAM适应于CD-FSS面临两个关键问题:依赖手动提示和有限的跨域能力。因此,我们提出了Composable Meta-Prompt(CMP)框架,引入三个关键模块:用于语义扩展的Reference Complement and Transformation(RCT)模块、用于自动元提示合成的Composable Meta-Prompt Generation(CMPG)模块、以及用于域差异缓解的频率感知交互(FAI)模块。在四个跨域数据集上的评估显示,CMP具有最先进的性能,在1-shot和5-shot场景下分别实现了71.8%和74.5%的mIoU。
Key Takeaways
- CD-FSS面临有限数据和域差异的挑战。
- SAM模型在一般分割任务中表现出零样本泛化能力。
- 将SAM适应于CD-FSS存在两个关键挑战:依赖手动提示和有限的跨域能力。
- 提出的CMP框架包含三个关键模块:RCT、CMPG和FAI。
- CMP框架旨在解决语义扩展、自动元提示合成和域差异缓解的问题。
- CMP框架在四个跨域数据集上的评估表现优异,达到最先进的性能。
点此查看论文截图

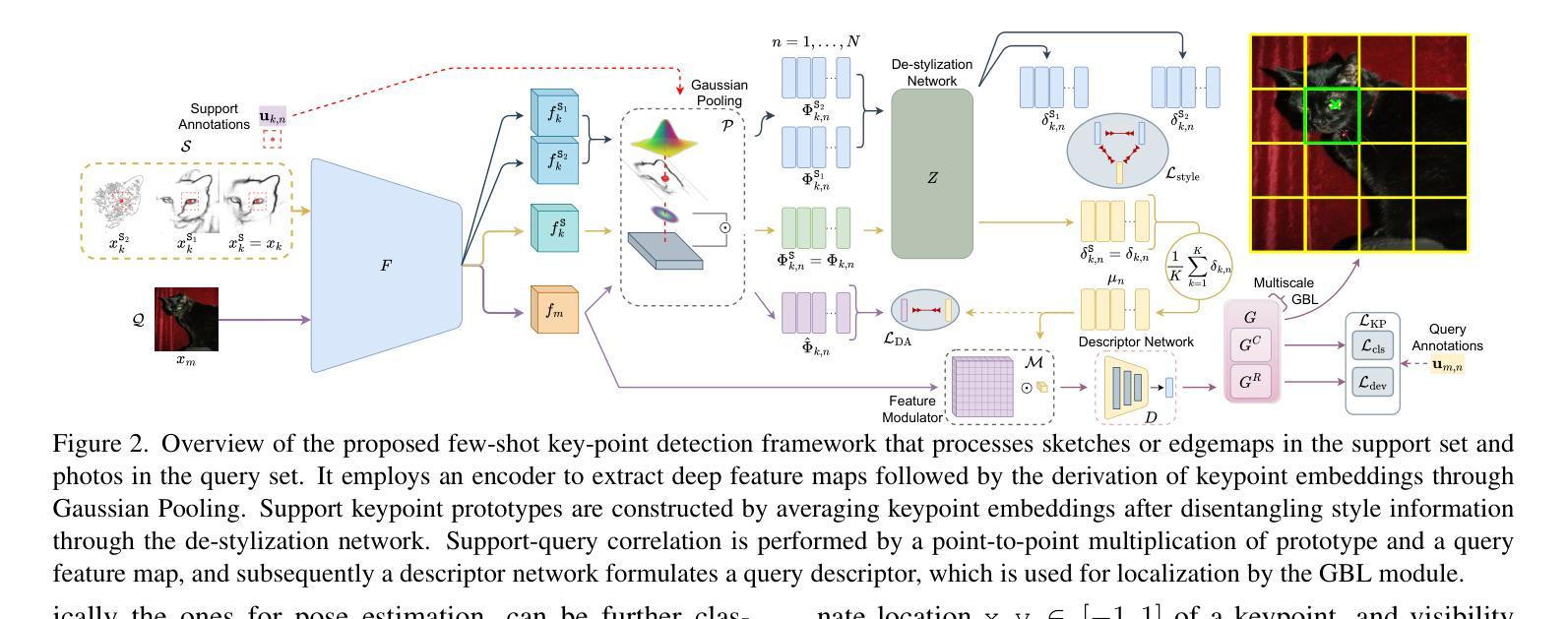
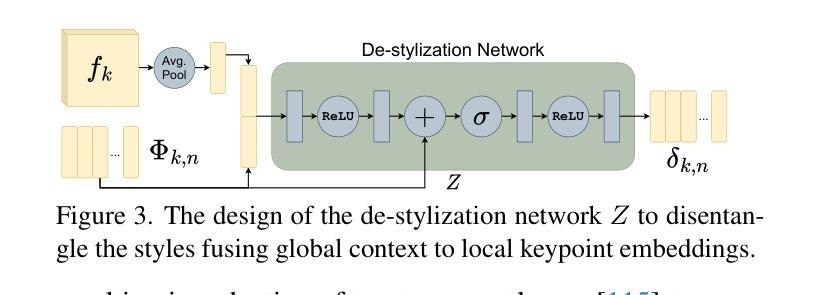
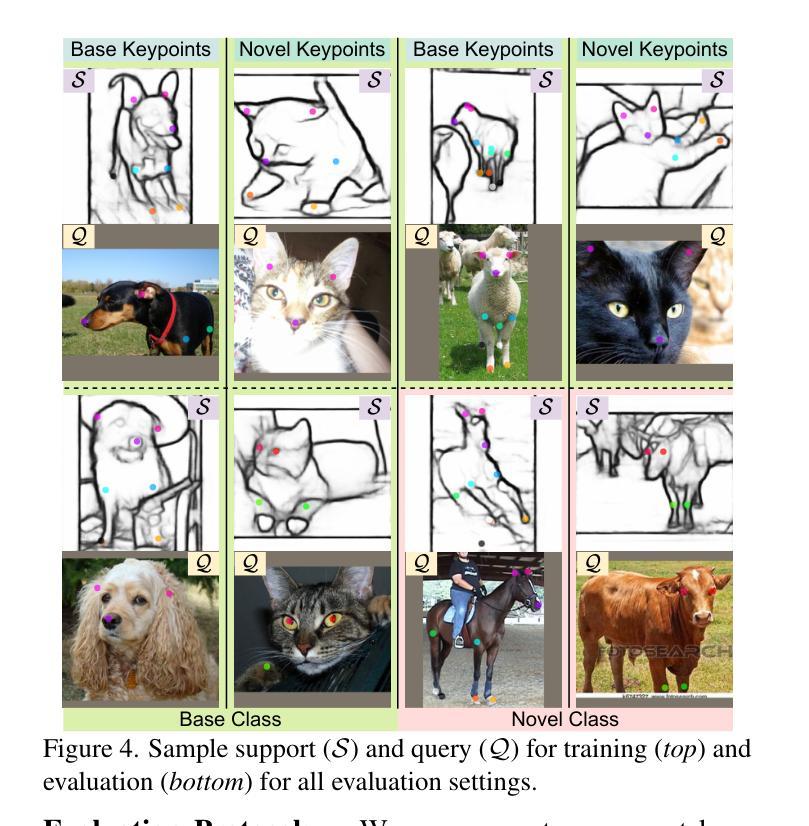
Doodle Your Keypoints: Sketch-Based Few-Shot Keypoint Detection
Authors:Subhajit Maity, Ayan Kumar Bhunia, Subhadeep Koley, Pinaki Nath Chowdhury, Aneeshan Sain, Yi-Zhe Song
Keypoint detection, integral to modern machine perception, faces challenges in few-shot learning, particularly when source data from the same distribution as the query is unavailable. This gap is addressed by leveraging sketches, a popular form of human expression, providing a source-free alternative. However, challenges arise in mastering cross-modal embeddings and handling user-specific sketch styles. Our proposed framework overcomes these hurdles with a prototypical setup, combined with a grid-based locator and prototypical domain adaptation. We also demonstrate success in few-shot convergence across novel keypoints and classes through extensive experiments.
关键点检测是现代机器感知的核心,在少样本学习中面临挑战,尤其是在无法获取与查询相同分布的源数据时。为解决这一空白,我们利用素描这一流行的人类表达方式,提供一种无需源数据的替代方案。然而,掌握跨模态嵌入和处理用户特定的素描风格却存在挑战。我们提出的框架通过结合原型设置、基于网格的定位器和原型域适应,克服了这些障碍。我们还通过大量实验证明了在新关键点和新类别上的少样本收敛的成功。
论文及项目相关链接
PDF Accepted at ICCV 2025. Project Page: https://subhajitmaity.me/DYKp
Summary:
现代机器感知中的关键点检测在少样本学习中面临挑战,特别是在没有与查询相同分布的源数据的情况下。通过利用人类表达的一种流行形式——草图作为源数据的替代方案来解决这一问题。然而,掌握跨模态嵌入和处理用户特定的草图风格仍存在挑战。提出的框架通过原型设置和基于网格的定位器以及原型域适应来克服这些障碍,并通过广泛的实验证明了在新型关键点和类别上的少样本收敛的成功。
Key Takeaways:
- 现代机器感知中的关键点检测在少样本学习环境下具有挑战。
- 当缺乏与查询相同的源数据分布时,利用草图作为替代方案来解决这一问题。
- 掌握跨模态嵌入和处理用户特定草图风格是面临的挑战。
- 提出的框架采用原型设置来解决这些挑战。
- 基于网格的定位器有助于处理草图数据。
- 通过原型域适应来提高模型的适应性。
点此查看论文截图