⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-01 更新
Explainable Image Classification with Reduced Overconfidence for Tissue Characterisation
Authors:Alfie Roddan, Chi Xu, Serine Ajlouni, Irini Kakaletri, Patra Charalampaki, Stamatia Giannarou
The deployment of Machine Learning models intraoperatively for tissue characterisation can assist decision making and guide safe tumour resections. For image classification models, pixel attribution methods are popular to infer explainability. However, overconfidence in deep learning model’s predictions translates to overconfidence in pixel attribution. In this paper, we propose the first approach which incorporates risk estimation into a pixel attribution method for improved image classification explainability. The proposed method iteratively applies a classification model with a pixel attribution method to create a volume of PA maps. This volume is used for the first time, to generate a pixel-wise distribution of PA values. We introduce a method to generate an enhanced PA map by estimating the expectation values of the pixel-wise distributions. In addition, the coefficient of variation (CV) is used to estimate pixel-wise risk of this enhanced PA map. Hence, the proposed method not only provides an improved PA map but also produces an estimation of risk on the output PA values. Performance evaluation on probe-based Confocal Laser Endomicroscopy (pCLE) data and ImageNet verifies that our improved explainability method outperforms the state-of-the-art.
在手术过程中部署机器学习模型进行组织特征分析,可协助决策并引导安全地进行肿瘤切除手术。对于图像分类模型,像素归因方法是推断解释性的流行方法。然而,对深度学习模型预测过度自信会转化为对像素归因的过度自信。在本文中,我们首次提出了一种方法,将风险估计纳入像素归因方法,以提高图像分类的解释性。所提出的方法迭代地将分类模型与像素归因方法相结合,以创建PA映射卷。该卷被首次用于生成像素级的PA值分布。我们介绍了一种通过估计像素级分布的期望值来生成增强型PA图的方法。此外,还使用变异系数来估计增强型PA图的像素级风险。因此,所提出的方法不仅提供了改进的PA图,而且还在输出PA值上产生了风险估计。基于探针的共焦激光内窥镜(pCLE)数据和ImageNet的性能评估证实,我们改进的解释方法优于当前最新技术。
论文及项目相关链接
Summary
机器学习模型在手术中对组织进行表征可辅助决策并引导安全肿瘤切除。图像分类模型通常采用像素归因方法推断解释性。然而,对深度学习模型预测的过度自信会导致像素归因的过度自信。本文首次将风险估计融入像素归因方法,以提高图像分类的解释性。该方法通过迭代应用分类模型和像素归因方法创建像素级归因地图卷积。首次使用此卷积生成像素级归因值分布,并引入一种方法生成增强型归因地图,通过估计期望值来评估像素级风险。因此,该方法不仅提供了增强的归因地图,还输出了归因值的预估风险。在基于探针的共焦激光显微内镜数据和ImageNet上的性能评估证明,改进的解释性方法优于现有技术。
Key Takeaways
- 机器学习模型在手术中用于组织表征可以提高决策效率和指导安全肿瘤切除。
- 像素归因方法是推断图像分类模型解释性的常用手段,但需避免过度自信。
- 本文首次结合风险估计与像素归因方法,提高图像分类解释性。
- 通过迭代应用分类模型和像素归因方法创建归因地图卷积,并利用此卷积生成像素级归因值分布。
- 引入一种方法生成增强型归因地图,通过估计期望值评估像素级风险。
- 所提方法不仅优化了解释性,还能对归因值的风险进行预估。
点此查看论文截图

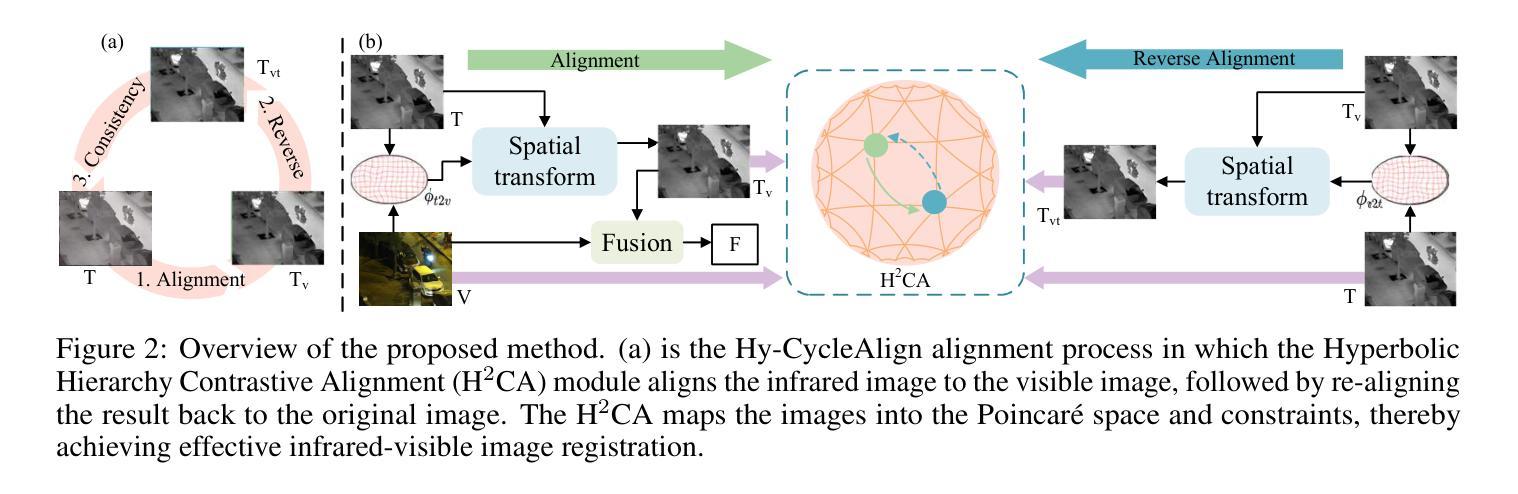
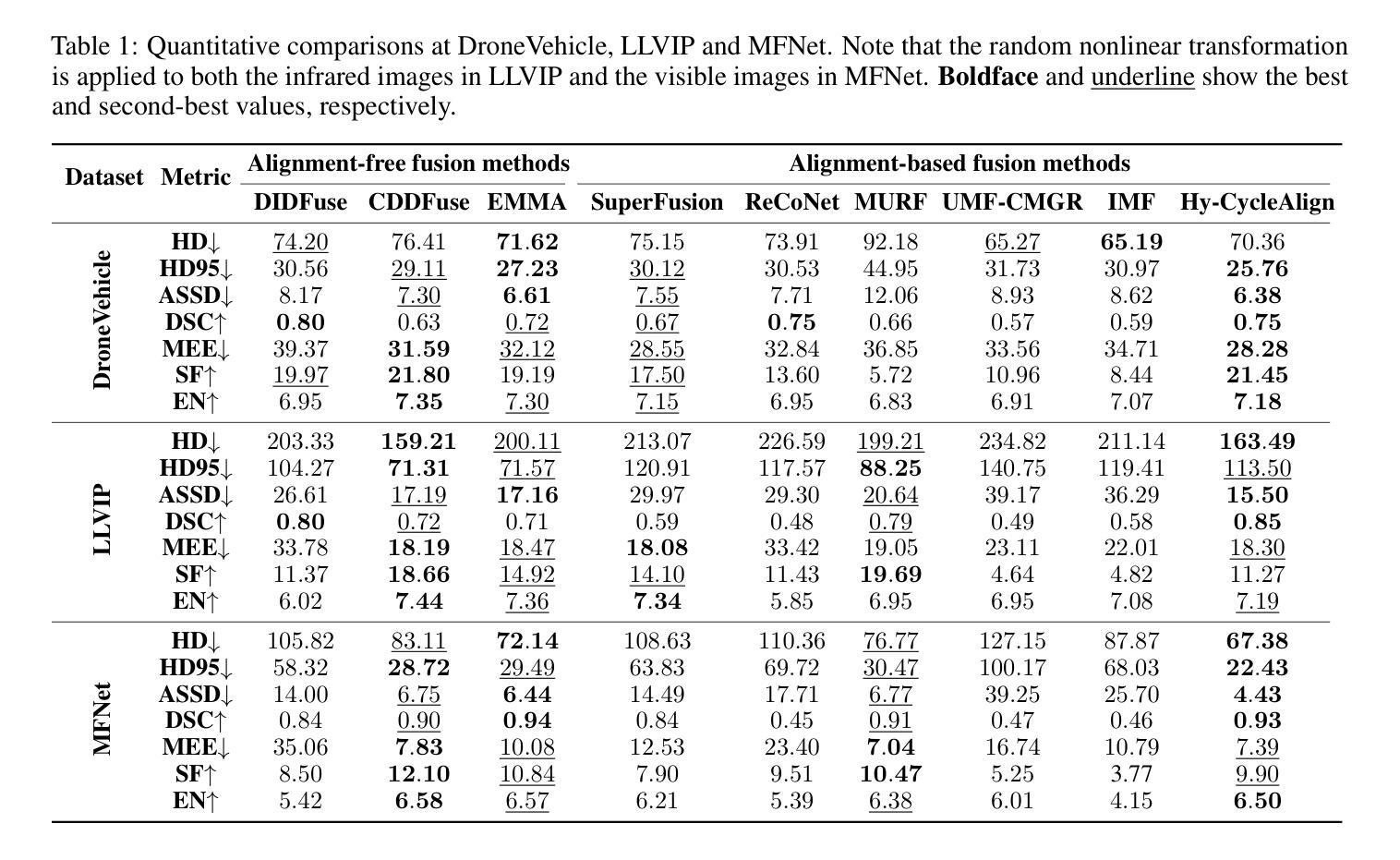
Hyperbolic Cycle Alignment for Infrared-Visible Image Fusion
Authors:Timing Li, Bing Cao, Jiahe Feng, Haifang Cao, Qinghau Hu, Pengfei Zhu
Image fusion synthesizes complementary information from multiple sources, mitigating the inherent limitations of unimodal imaging systems. Accurate image registration is essential for effective multi-source data fusion. However, existing registration methods, often based on image translation in Euclidean space, fail to handle cross-modal misalignment effectively, resulting in suboptimal alignment and fusion quality. To overcome this limitation, we explore image alignment in non-Euclidean space and propose a Hyperbolic Cycle Alignment Network (Hy-CycleAlign). To the best of our knowledge, Hy-CycleAlign is the first image registration method based on hyperbolic space. It introduces a dual-path cross-modal cyclic registration framework, in which a forward registration network aligns cross-modal inputs, while a backward registration network reconstructs the original image, forming a closed-loop registration structure with geometric consistency. Additionally, we design a Hyperbolic Hierarchy Contrastive Alignment (H$^{2}$CA) module, which maps images into hyperbolic space and imposes registration constraints, effectively reducing interference caused by modality discrepancies. We further analyze image registration in both Euclidean and hyperbolic spaces, demonstrating that hyperbolic space enables more sensitive and effective multi-modal image registration. Extensive experiments on misaligned multi-modal images demonstrate that our method significantly outperforms existing approaches in both image alignment and fusion. Our code will be publicly available.
图像融合通过综合来自多个源头的互补信息,缓解了单模态成像系统的固有局限性。准确的图像配准对于有效的多源数据融合至关重要。然而,现有的配准方法通常基于欧几里得空间的图像翻译,无法有效地处理跨模态的不对准问题,导致配准和融合质量不佳。为了克服这一局限性,我们探索了非欧几里得空间的图像配准,并提出了一种双曲循环配准网络(Hy-CycleAlign)。据我们所知,Hy-CycleAlign是基于双曲空间的第一个图像配准方法。它引入了一个双路径跨模态循环配准框架,其中前向配准网络对齐跨模态输入,而后向配准网络重建原始图像,形成一个具有几何一致性的闭环配准结构。此外,我们设计了一个双曲层次对比配准(H²CA)模块,它将图像映射到双曲空间并施加配准约束,有效减少了由模态差异引起的干扰。我们进一步分析了欧几里得空间和双曲空间中的图像配准,表明双曲空间能够实现更敏感和有效的多模态图像配准。在对错位多模态图像的大量实验中,我们的方法在图像配准和融合方面都显著优于现有方法。我们的代码将公开可用。
论文及项目相关链接
Summary
图像融合通过合成来自多个源头的互补信息,减轻了单模态成像系统的固有局限性。准确图像配准是实现多源数据有效融合的关键。然而,现有的配准方法通常基于欧几里得空间的图像翻译,无法有效地处理跨模态的误对齐问题,导致配准和融合效果不佳。为克服这一局限,我们探索了在非欧几里得空间中的图像对齐,并提出了一种双路径超循环对齐网络(Hy-CycleAlign)。据我们所知,Hy-CycleAlign是基于双曲空间的第一个图像配准方法。它引入了一个双路径跨模态循环配准框架,其中正向配准网络对齐跨模态输入,反向配准网络重建原始图像,形成一个具有几何一致性的闭环配准结构。此外,我们还设计了超层次对比对齐模块(H²CA),将图像映射到双曲空间并施加配准约束,有效降低由模态差异引起的干扰。我们进一步分析了欧几里得空间和双曲空间中的图像配准,表明双曲空间能够实现更敏感和有效的多模态图像配准。在误对齐的多模态图像上的大量实验表明,我们的方法在图像配准和融合方面都显著优于现有方法。我们的代码将公开可用。
Key Takeaways
- 图像融合旨在结合多源信息以克服单模态成像的局限性。
- 准确配准是实现多源数据有效融合的关键步骤。
- 现有基于欧几里得空间的配准方法在处理跨模态误对齐时表现有限。
- 提出了基于非欧几里得空间的图像配准方法——Hy-CycleAlign网络。
- Hy-CycleAlign网络采用双路径跨模态循环配准框架,包含正向和反向配准网络。
- H²CA模块用于将图像映射到双曲空间并施加配准约束。
点此查看论文截图


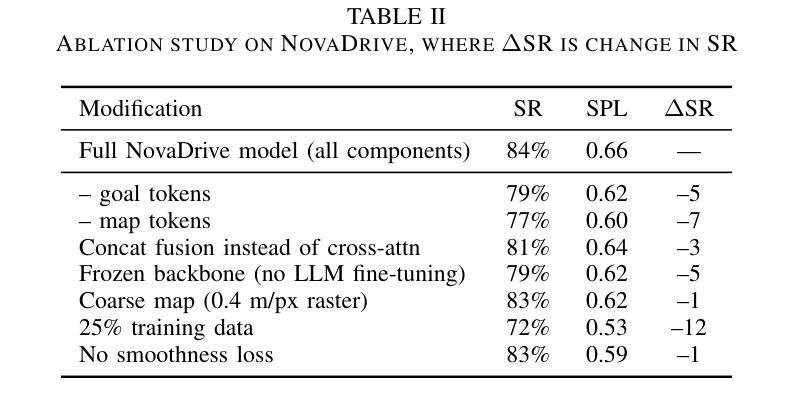
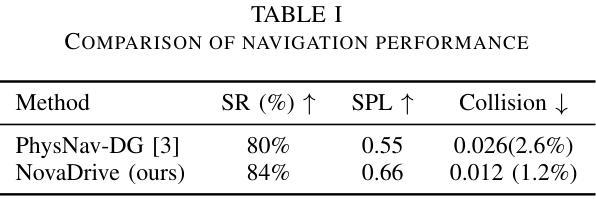
Early Goal-Guided Multi-Scale Fusion for Real-Time Vision-Language Driving
Authors:Santosh Patapati, Trisanth Srinivasan
Autonomous vehicles must react in milliseconds while reasoning about road geometry and traffic intent to navigate complex situations. We introduce NovaDrive, a single-branch vision-language architecture that processes front-camera images, HD-map tiles, LiDAR depth, and textual waypoints in a single branch. A lightweight, two-stage cross-attention block first aligns waypoint tokens with the HD map, then refines attention over fine-grained image and depth patches. Coupled with a novel smoothness loss that discourages abrupt steering and speed changes, this design eliminates the need for recurrent memory. We fine-tune the top 15 layers of an 11B LLaMA-3.2 vision-language backbone, enabling real-time inference. On the nuScenes / Waymo subset of the MD-NEX Outdoor benchmark, NovaDrive raises success rate to 84% (+4%), boosts path-efficiency (SPL) to 0.66 (+0.11), and reduces collision frequency from 2.6% to 1.2% (-1.4%) relative to the previous state-of-the-art. Our ablations confirm that waypoint tokens, partial VLM fine-tuning, and the cross-attention fusion each contribute the most to these gains. Beyond safety, NovaDrive’s shorter routes (resulting from the novel smoothness loss) translate to lower fuel or battery usage, pointing toward leaner, more easily updated driving stacks. NovaDrive can be extended to other embodied-AI domains as well.
我们推出了NovaDrive,这是一种单分支视觉语言架构,能够在单个分支中处理前置摄像头图像、高清地图瓦片、激光雷达深度和文本坐标点。其通过一个轻量级的两阶段交叉注意力模块,首先对齐坐标点与高清地图,然后精细调整图像和深度补丁的注意力。结合一种新型平滑损失,该设计可避免急剧转向和速度变化,从而无需使用循环内存。我们微调了规模为11B的LLaMA-3.2视觉语言主干的前15层,以实现实时推理。在MD-NEX室外基准的nuScenes/Waymo子集上,NovaDrive将成功率提升至84%(+4%),路径效率(SPL)提高到0.66(+0.11),与之前的最新技术相比,碰撞频率从2.6%降至1.2%(-1.4%)。我们的剖析研究证实,坐标点标记、部分VLM微调以及交叉注意力融合等都对这些增益贡献最大。除了提高安全性外,NovaDrive的较短路线(由新型平滑损失产生)转化为更低的燃油或电池使用率,指向更精简、更容易更新的驾驶堆栈。NovaDrive还可以扩展到其他实体AI领域。
论文及项目相关链接
PDF 6 pages
Summary
在自动驾驶过程中,处理视觉信息对于车辆应对复杂道路和交通环境至关重要。我们提出了NovaDrive系统,这是一种单一分支的视觉语言架构,可以处理前视摄像头图像、高清地图切片、激光雷达深度以及文本导航点等信息。该系统通过一种新颖的跨注意力机制实现了图像与导航点的精准对齐,并结合了一种新型的平滑损失函数,减少了车辆的急转弯和速度变化。NovaDrive在MD-NEX户外基准测试中的表现优于现有技术,成功率和路径效率均有所提高,碰撞频率降低。此外,NovaDrive还可以缩短行驶路线,降低燃油或电池消耗,并有望应用于其他智能体领域。
Key Takeaways
- NovaDrive系统是一个单一的视觉语言架构,可以处理多种驾驶相关信息的输入。
- 系统通过新颖的跨注意力机制实现图像与导航点的精准对齐。
- NovaDrive结合了新型的平滑损失函数,减少车辆的急转弯和速度变化。
- NovaDrive在基准测试中表现优异,成功率和路径效率提高,碰撞频率降低。
- NovaDrive可缩短行驶路线,降低燃油或电池消耗。
- NovaDrive系统具有广泛的应用潜力,可应用于其他智能体领域。
点此查看论文截图

Meta CLIP 2: A Worldwide Scaling Recipe
Authors:Yung-Sung Chuang, Yang Li, Dong Wang, Ching-Feng Yeh, Kehan Lyu, Ramya Raghavendra, James Glass, Lifei Huang, Jason Weston, Luke Zettlemoyer, Xinlei Chen, Zhuang Liu, Saining Xie, Wen-tau Yih, Shang-Wen Li, Hu Xu
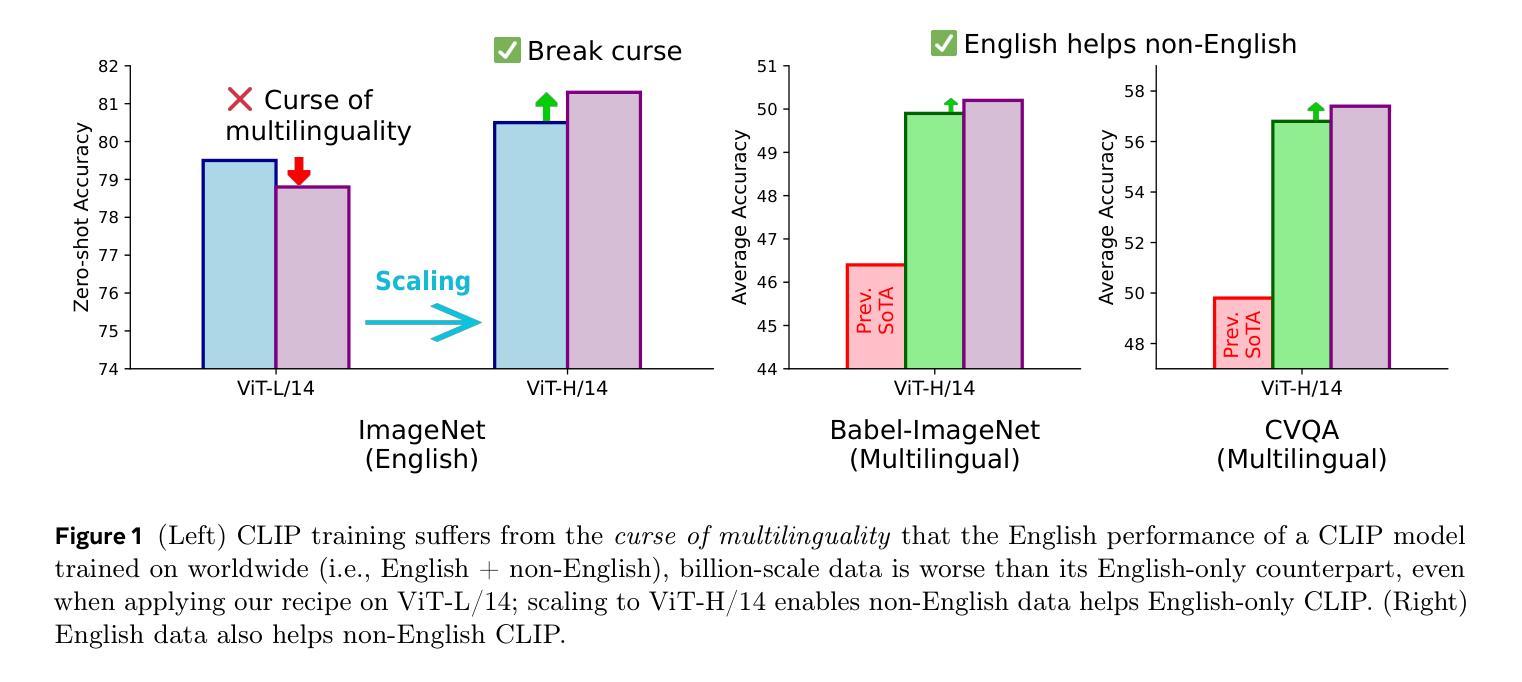
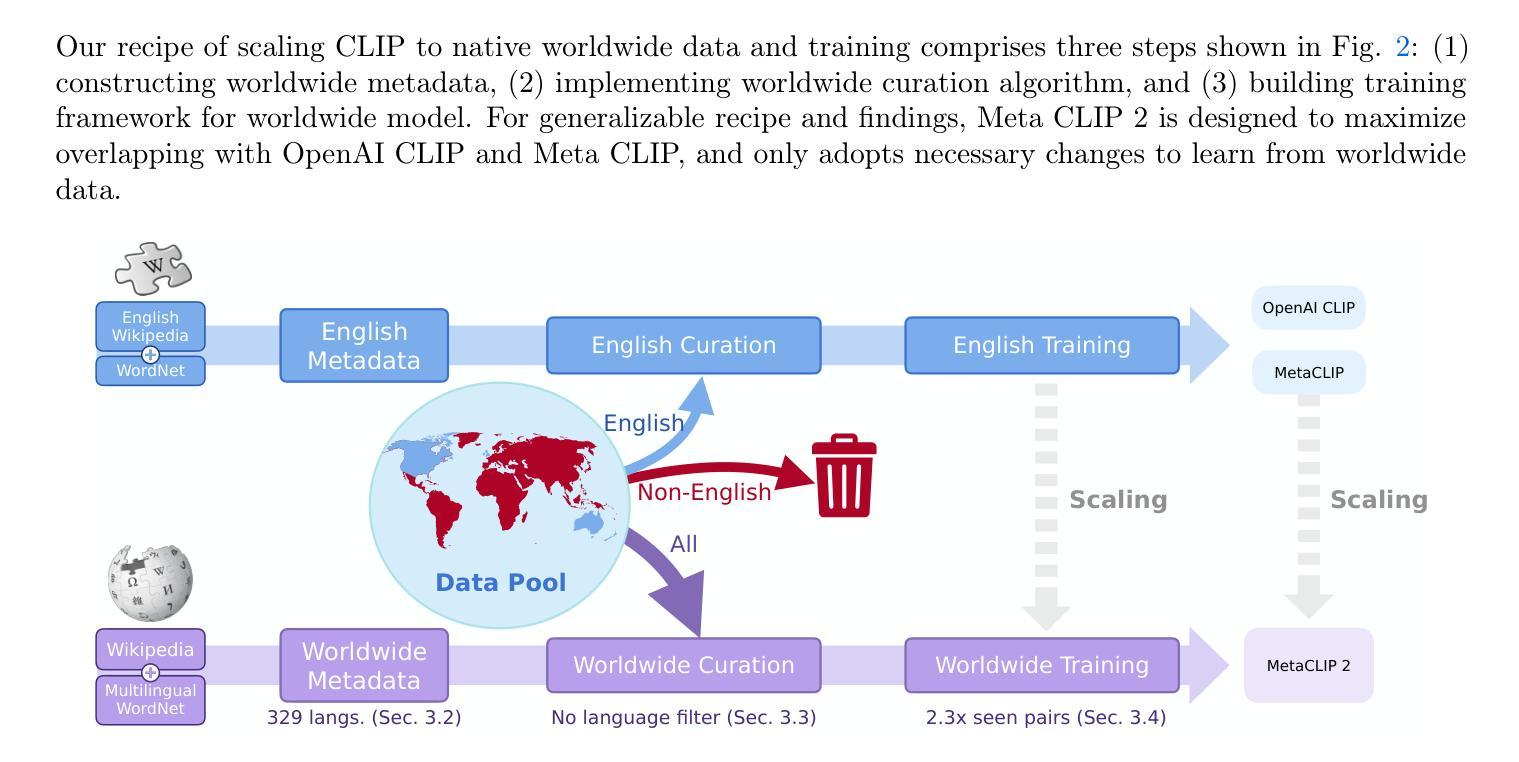
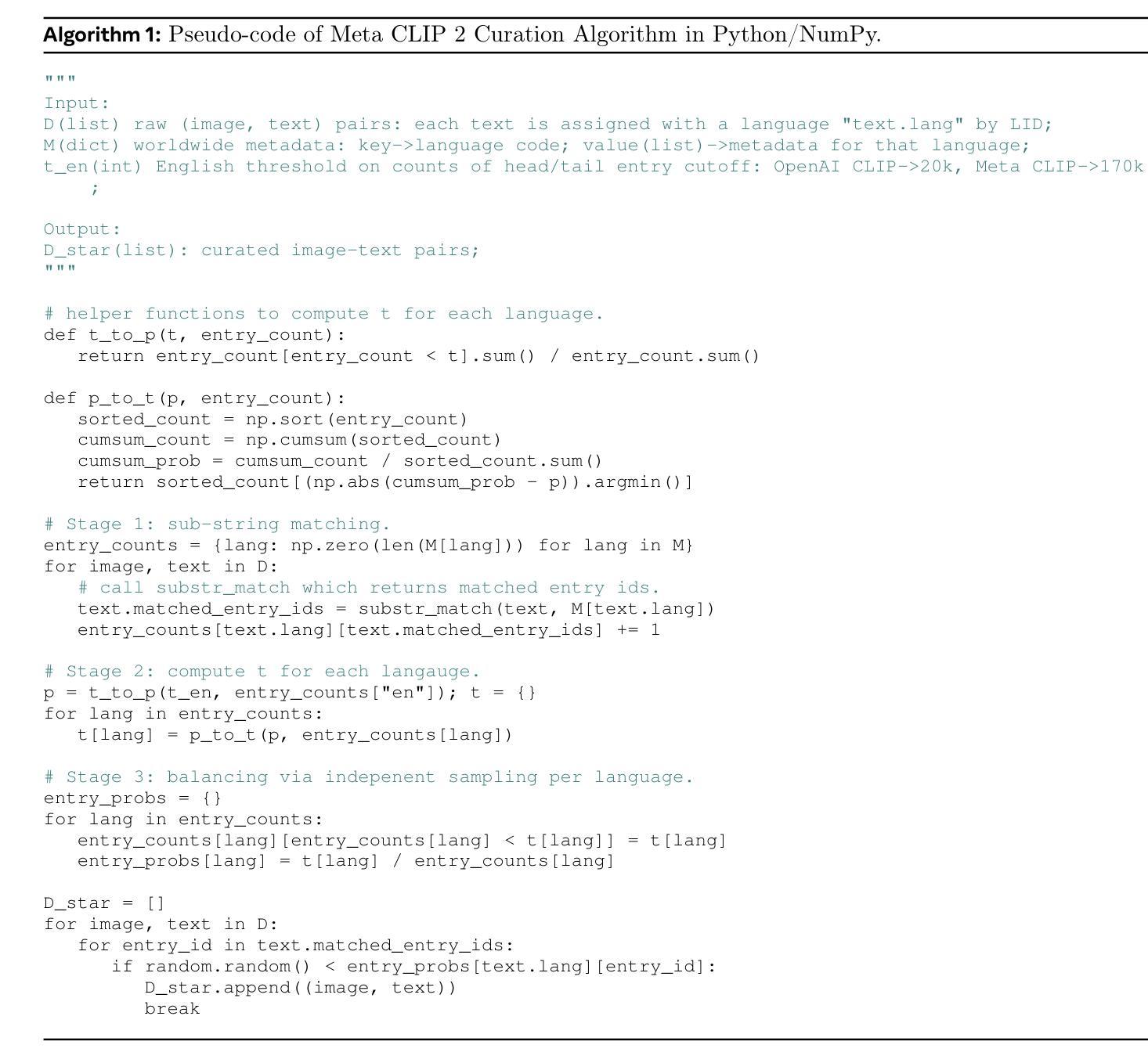
Contrastive Language-Image Pretraining (CLIP) is a popular foundation model, supporting from zero-shot classification, retrieval to encoders for multimodal large language models (MLLMs). Although CLIP is successfully trained on billion-scale image-text pairs from the English world, scaling CLIP’s training further to learning from the worldwide web data is still challenging: (1) no curation method is available to handle data points from non-English world; (2) the English performance from existing multilingual CLIP is worse than its English-only counterpart, i.e., “curse of multilinguality” that is common in LLMs. Here, we present Meta CLIP 2, the first recipe training CLIP from scratch on worldwide web-scale image-text pairs. To generalize our findings, we conduct rigorous ablations with minimal changes that are necessary to address the above challenges and present a recipe enabling mutual benefits from English and non-English world data. In zero-shot ImageNet classification, Meta CLIP 2 ViT-H/14 surpasses its English-only counterpart by 0.8% and mSigLIP by 0.7%, and surprisingly sets new state-of-the-art without system-level confounding factors (e.g., translation, bespoke architecture changes) on multilingual benchmarks, such as CVQA with 57.4%, Babel-ImageNet with 50.2% and XM3600 with 64.3% on image-to-text retrieval.
对比语言图像预训练(CLIP)是一种流行的基础模型,支持零次分类、检索和多模态大型语言模型(MLLMs)的编码器。尽管CLIP已成功地在英文世界的百亿级图像文本对上进行了训练,但进一步将CLIP的训练扩展到从全球网络数据上进行学习仍然具有挑战性:(1)没有处理方法可以用来处理非英语世界的数据点;(2)现有跨语言CLIP的英语性能表现不如其英语专属的对应模型,即常见的多语言大型模型中的“多语言诅咒”。在这里,我们提出了Meta CLIP 2,这是首次从头开始在全球网络规模的图像文本对上训练CLIP的方法。为了推广我们的发现,我们进行了严格的必要最小变化消融实验,以解决上述挑战,并提出了一种能从英语和非英语世界数据中实现互利共赢的配方。在零次ImageNet分类中,Meta CLIP 2 ViT-H/14的精度超过了其英语专属的对应模型0.8%,并超越了mSigLIP 0.7%,令人惊讶的是在多种多语言基准测试中,如CVQA达到57.4%,Babel-ImageNet达到50.2%,XM3600的图像到文本检索达到64.3%,并且没有任何系统级别的混淆因素(如翻译、专用架构更改)。
论文及项目相关链接
PDF 10 pages
Summary
本文介绍了Contrastive Language-Image Pretraining(CLIP)模型在全球化网络数据训练上的挑战,并推出了Meta CLIP 2模型。该模型可以在全球网页规模图像文本对上从零开始训练CLIP。研究通过严谨的消融实验,解决上述挑战并实现了英语和非英语世界数据的互利。在零样本ImageNet分类中,Meta CLIP 2超越了仅针对英语的CLIP模型和mSigLIP模型,并在跨语言基准测试中取得了最新成果。
Key Takeaways
- CLIP模型在全球化网络数据训练上存在挑战,缺乏处理非英语世界数据点的策略。
- Meta CLIP 2是首个从头开始在全球网页规模图像文本对上训练的CLIP模型。
- 研究通过必要的最小变化进行了严谨的消融实验,解决上述挑战并实现英语和非英语数据的互利。
- Meta CLIP 2在零样本ImageNet分类中性能卓越,超越了仅针对英语的CLIP模型和mSigLIP模型。
- 在跨语言基准测试中(如CVQA、Babel-ImageNet和XM3600),Meta CLIP 2实现了图像到文本的检索新水平。
点此查看论文截图

Semantic Segmentation of iPS Cells: Case Study on Model Complexity in Biomedical Imaging
Authors:Maoquan Zhang, Bisser Raytchev, Xiujuan Sun
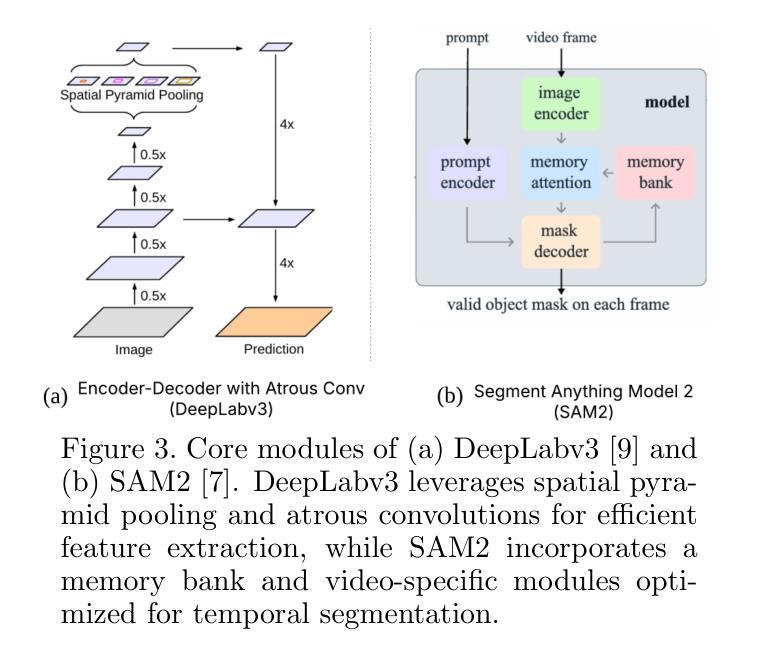
Medical image segmentation requires not only accuracy but also robustness under challenging imaging conditions. In this study, we show that a carefully configured DeepLabv3 model can achieve high performance in segmenting induced pluripotent stem (iPS) cell colonies, and, under our experimental conditions, outperforms large-scale foundation models such as SAM2 and its medical variant MedSAM2 without structural modifications. These results suggest that, for specialized tasks characterized by subtle, low-contrast boundaries, increased model complexity does not necessarily translate to better performance. Our work revisits the assumption that ever-larger and more generalized architectures are always preferable, and provides evidence that appropriately adapted, simpler models may offer strong accuracy and practical reliability in domain-specific biomedical applications. We also offer an open-source implementation that includes strategies for small datasets and domain-specific encoding, with the aim of supporting further advances in semantic segmentation for regenerative medicine and related fields.
医学图像分割不仅需要准确性,还需要在具有挑战性的成像条件下具有稳健性。在这项研究中,我们展示了精心配置的DeepLabv3模型在分割诱导多能干细胞(iPS)菌落方面的高性能,并且在我们的实验条件下,未经结构修改即优于大规模基础模型(如SAM2及其医学变体MedSAM2)。这些结果表明,对于特征表现为细微、低对比度边界的特定任务,增加模型复杂性并不一定意味着更好的性能。我们的工作重新考虑了假设更大的、更通用的架构总是可取的,并提供了证据支持适当简化并适应的模型在特定领域生物医学应用中具有强大的准确性和实用性。我们还提供了一个开源实现,包括针对小数据集和特定领域编码的策略,旨在支持再生医学和相关领域的语义分割的进一步发展。
论文及项目相关链接
PDF 19th International Conference on Machine Vision Applications MVA2025
摘要
本研究展示了精心配置的DeepLabv3模型在诱导多能干细胞(iPS)菌落分割方面的高性能表现。相较于大规模的基础模型如SAM2及其医学变体MedSAM2,该模型在特定实验条件下无需结构修改便展现出更佳性能。结果提示,对于特征为细微、低对比度边界的专项任务,增加模型复杂性并不一定意味着性能提升。本研究重新审视了“越大越广的基础架构总是更可取”的假设,并提供证据表明,适当简化并适应特定领域的模型可能在生物医学应用中提供强大的准确性和实际可靠性。我们还提供了包含小数据集策略和领域特定编码策略的开源实现,旨在支持再生医学和相关领域的语义分割的进一步发展。
要点
- DeepLabv3模型在iPS细胞菌落分割中表现出高性能。
- 在特定实验条件下,DeepLabv3性能优于大规模基础模型SAM2及其医学变体MedSAM2。
- 对于细微、低对比度边界的专项任务,增加模型复杂性并不一定意味着性能提升。
- 研究挑战了“越大越广的基础架构更可取”的假设。
- 适当简化并适应特定领域的模型在生物医学应用中可能更可靠。
- 提供包含小数据集策略和领域特定编码策略的开源实现。
点此查看论文截图


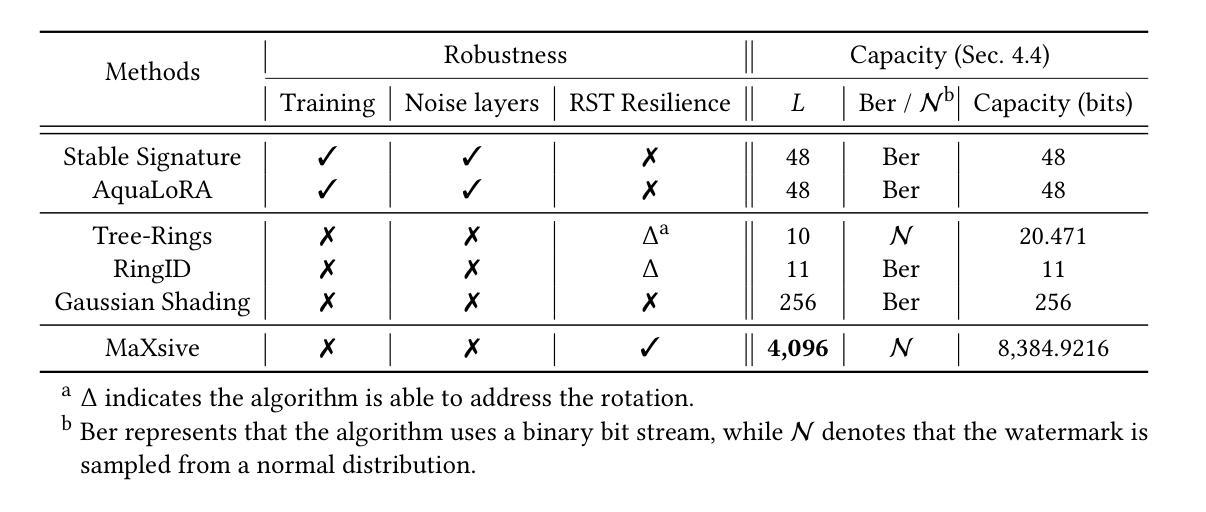
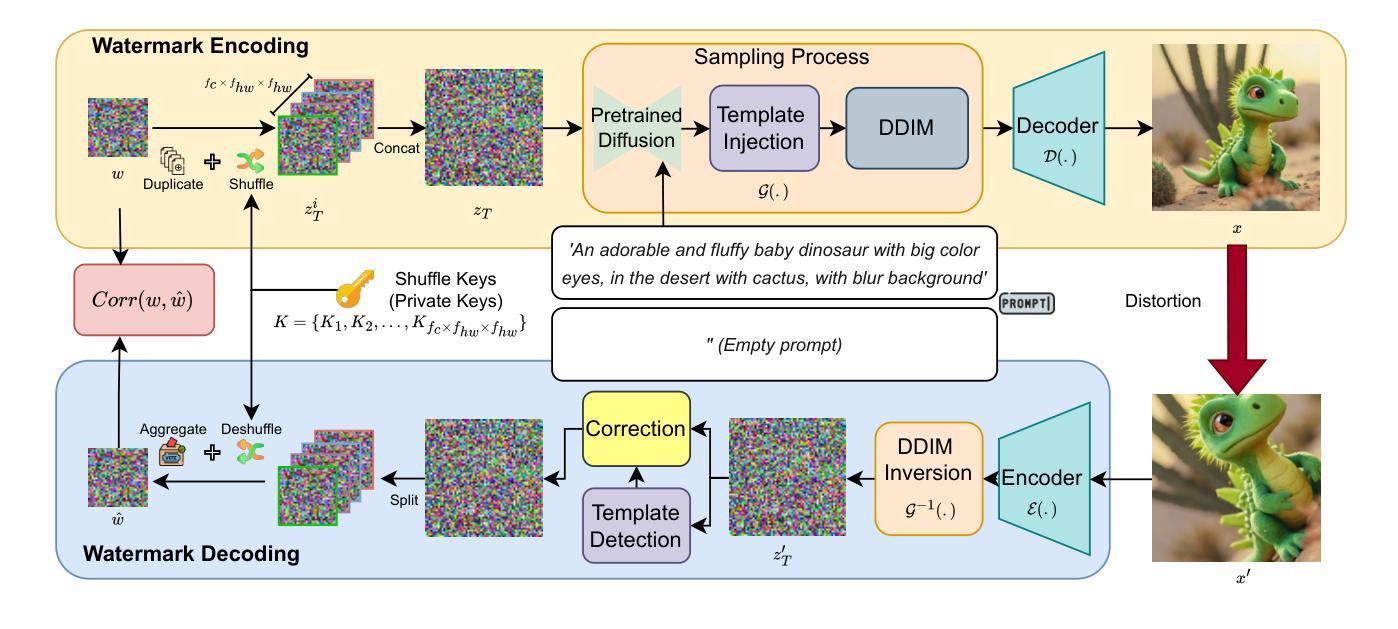
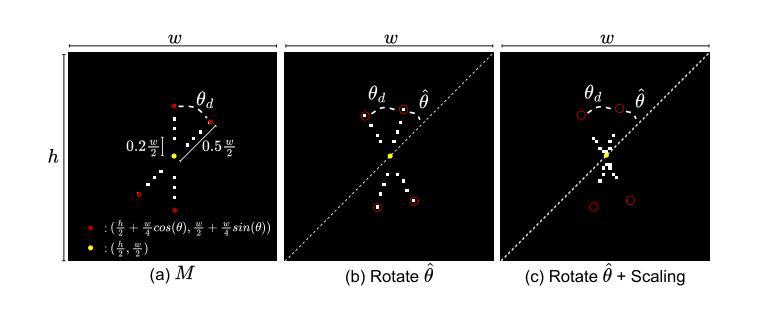
MaXsive: High-Capacity and Robust Training-Free Generative Image Watermarking in Diffusion Models
Authors:Po-Yuan Mao, Cheng-Chang Tsai, Chun-Shien Lu
The great success of the diffusion model in image synthesis led to the release of gigantic commercial models, raising the issue of copyright protection and inappropriate content generation. Training-free diffusion watermarking provides a low-cost solution for these issues. However, the prior works remain vulnerable to rotation, scaling, and translation (RST) attacks. Although some methods employ meticulously designed patterns to mitigate this issue, they often reduce watermark capacity, which can result in identity (ID) collusion. To address these problems, we propose MaXsive, a training-free diffusion model generative watermarking technique that has high capacity and robustness. MaXsive best utilizes the initial noise to watermark the diffusion model. Moreover, instead of using a meticulously repetitive ring pattern, we propose injecting the X-shape template to recover the RST distortions. This design significantly increases robustness without losing any capacity, making ID collusion less likely to happen. The effectiveness of MaXsive has been verified on two well-known watermarking benchmarks under the scenarios of verification and identification.
扩散模型在图像合成方面的巨大成功催生了庞大的商业模型,进而引发了版权保护和不当内容生成的问题。无训练扩散水印技术为这些问题提供了低成本解决方案。然而,先前的工作仍然容易受到旋转、缩放和平移(RST)攻击。尽管一些方法采用精心设计的模式来缓解这一问题,但它们往往会降低水印容量,从而导致身份(ID)碰撞。为了解决这些问题,我们提出了MaXsive,这是一种无训练扩散模型生成式水印技术,具有大容量和高鲁棒性。MaXsive充分利用初始噪声来为扩散模型添加水印。此外,我们没有使用精心设计的重复性环形图案,而是提出了注入X形模板来恢复RST失真。这种设计在不损失容量的前提下显著提高了鲁棒性,使身份碰撞的可能性大大降低。MaXsive的有效性已在两个著名的水印基准测试场景下通过验证和识别得到了证实。
论文及项目相关链接
Summary
扩散模型在图像合成领域的巨大成功引发了商用大型模型的涌现,随之带来版权保护与不当内容生成的问题。训练式扩散水印法为此提供了低成本解决方案,但以往的方法容易受到旋转、缩放和平移(RST)攻击。为解决这些问题,我们提出名为MaXsive的训练式扩散模型生成水印技术,该技术具有大容量和高鲁棒性。MaXsive充分利用初始噪声进行水印处理,并提出使用X形模板来恢复RST失真,而非采用精细重复的环形图案。这一设计在不损失容量的前提下大大提高了鲁棒性,降低了身份碰撞的可能性。MaXsive在两个著名的水印基准测试上得到了验证,证明了其在验证和识别场景下的有效性。
Key Takeaways
- 扩散模型成功推动商业大型模型的发展,但也带来了版权保护和不当内容生成的问题。
- 训练式扩散水印法为上述问题提供了低成本解决方案,但原有方法易受旋转、缩放和平移(RST)攻击。
- MaXsive技术通过利用初始噪声进行水印处理提高了水印技术的鲁棒性和容量。
- MaXsive使用X形模板恢复RST失真,避免了精细重复环形图案的使用。
- MaXsive设计在不损失容量的前提下增强了鲁棒性,降低了身份碰撞的风险。
- MaXsive在两个著名的水印基准测试上经过了验证,证明了其在验证和识别场景下的有效性。
- MaXsive技术对于保护版权和防止不当内容生成具有重要意义。
点此查看论文截图

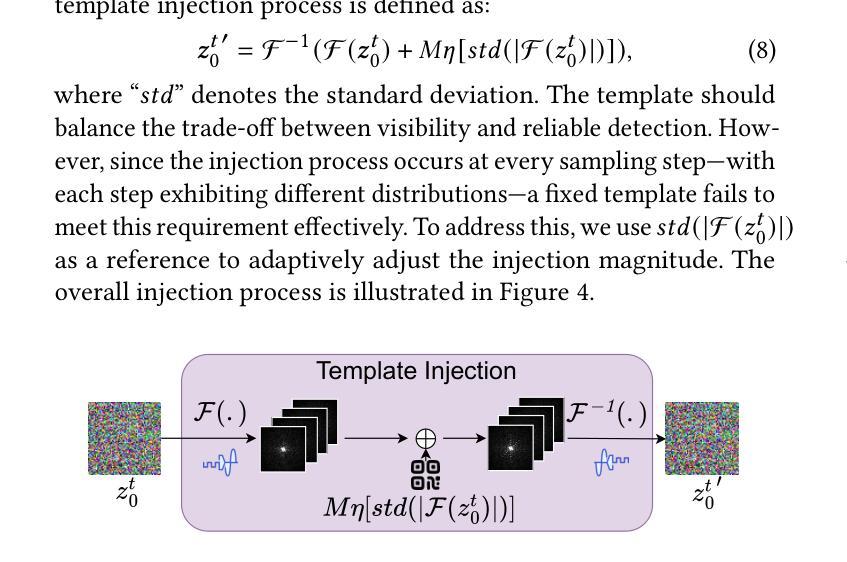
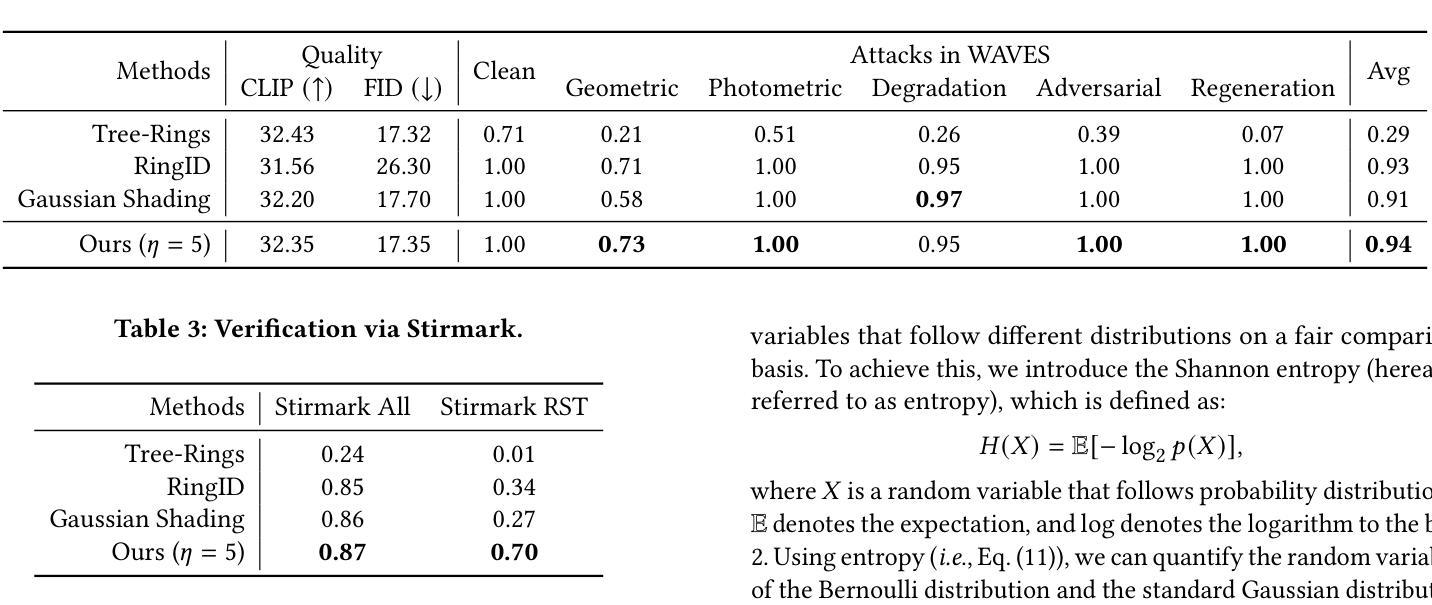
A Metabolic-Imaging Integrated Model for Prognostic Prediction in Colorectal Liver Metastases
Authors:Qinlong Li, Pu Sun, Guanlin Zhu, Tianjiao Liang, Honggang QI
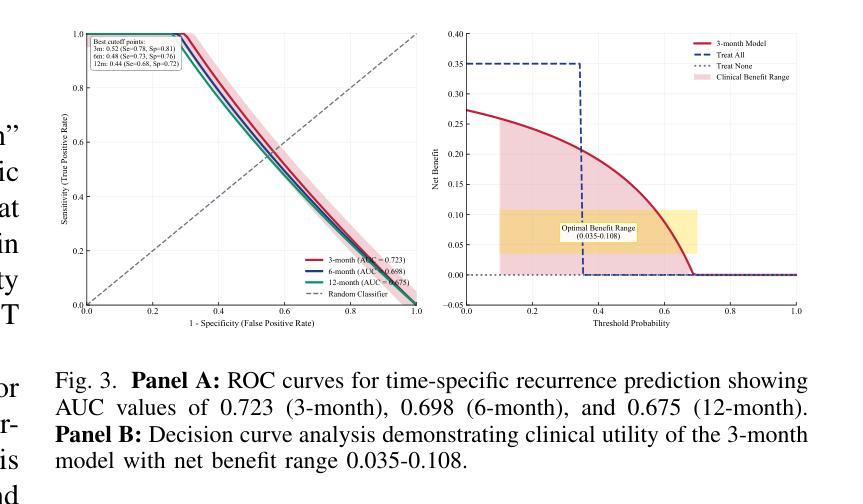
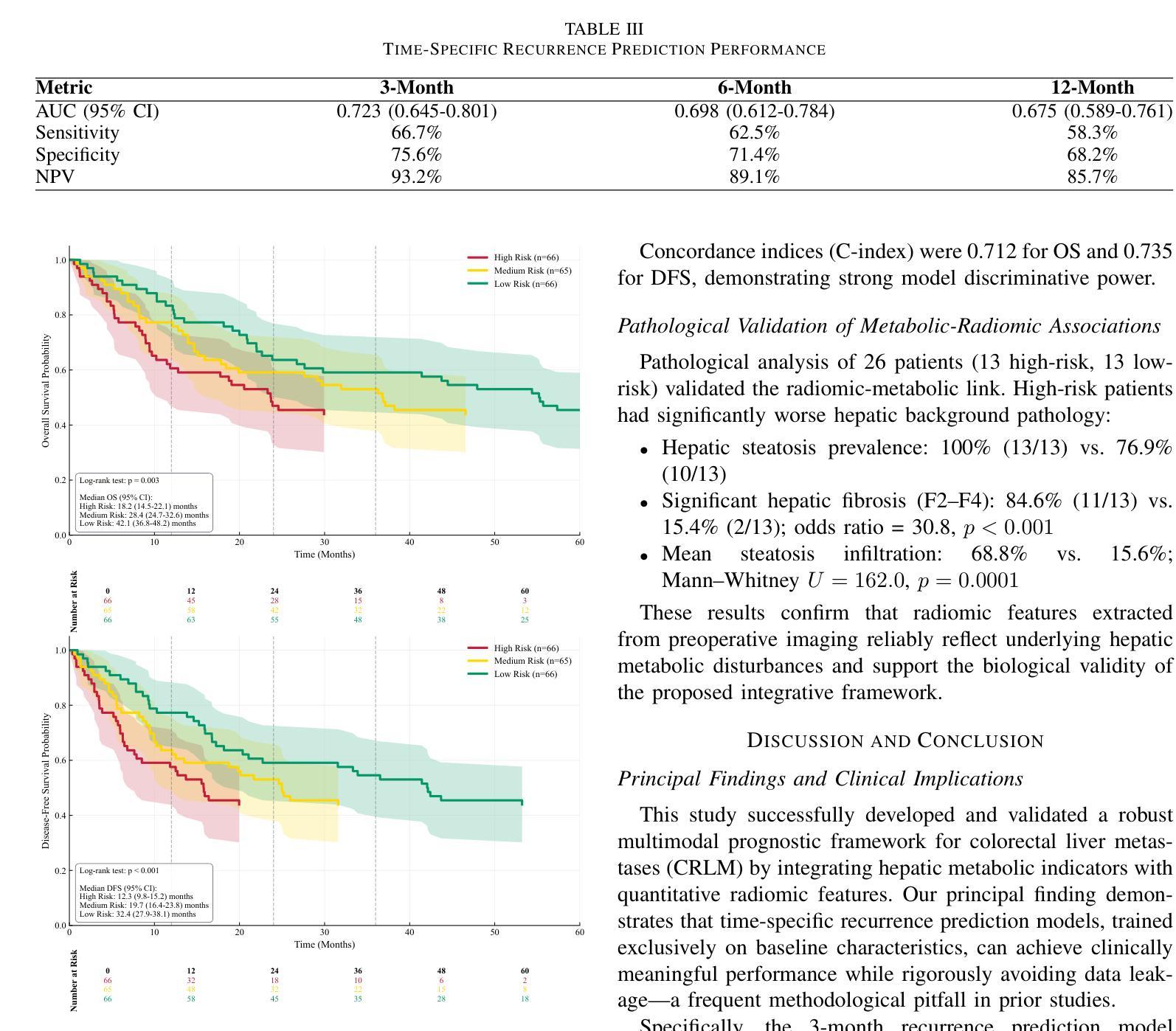
Prognostic evaluation in patients with colorectal liver metastases (CRLM) remains challenging due to suboptimal accuracy of conventional clinical models. This study developed and validated a robust machine learning model for predicting postoperative recurrence risk. Preliminary ensemble models achieved exceptionally high performance (AUC $>$ 0.98) but incorporated postoperative features, introducing data leakage risks. To enhance clinical applicability, we restricted input variables to preoperative baseline clinical parameters and radiomic features from contrast-enhanced CT imaging, specifically targeting recurrence prediction at 3, 6, and 12 months postoperatively. The 3-month recurrence prediction model demonstrated optimal performance with an AUC of 0.723 in cross-validation. Decision curve analysis revealed that across threshold probabilities of 0.55-0.95, the model consistently provided greater net benefit than “treat-all” or “treat-none” strategies, supporting its utility in postoperative surveillance and therapeutic decision-making. This study successfully developed a robust predictive model for early CRLM recurrence with confirmed clinical utility. Importantly, it highlights the critical risk of data leakage in clinical prognostic modeling and proposes a rigorous framework to mitigate this issue, enhancing model reliability and translational value in real-world settings.
在结直肠癌肝转移(CRLM)患者的预后评估中,由于传统临床模型的准确性不高,仍面临挑战。本研究开发并验证了一个稳健的机器学习任务学习模型来预测术后复发风险。初步集合模型表现异常出色(AUC大于0.98),但包含了术后特征,存在数据泄露风险。为了提高临床实用性,我们将输入变量限制为术前基线临床参数和增强CT成像的放射学特征,特别针对术后3个月、6个月和12个月的复发预测。3个月复发预测模型在交叉验证中表现出最佳性能,AUC为0.723。决策曲线分析表明,在阈概率0.55-0.95范围内,该模型提供的净效益始终大于“全部治疗”或“不治疗”策略,这支持其在术后监测和治疗决策中的实用性。本研究成功地为早期CRLM复发构建了一个稳健的预测模型,并证实了其在临床上的实用性。重要的是,它强调了临床预后模型中数据泄露的关键风险,并提出了一个严格的框架来减轻这个问题,提高了模型在真实世界环境中的可靠性和翻译价值。
论文及项目相关链接
PDF 8 pages,4 figues
Summary:
针对结直肠癌肝转移患者的预后评估仍面临挑战,因传统临床模型的准确度有待提高。本研究开发并验证了一种稳健的机器学模型以预测术后复发风险。研究初期集合模型表现出极高性能(AUC>0.98),但纳入术后特征,存在数据泄露风险。为提高临床实用性,研究使用术前基线临床参数和增强CT成像的放射组学特征作为输入变量,专门针对术后3个月、6个月和1年的复发预测建模。其中,术后3个月复发预测模型的交叉验证表现最佳,AUC为0.723。决策曲线分析表明,在阈概率0.55至0.95范围内,该模型提供的净效益高于“一律治疗”或“一律不治疗”的策略,证实了其在术后监测和治疗决策中的实用性。本研究成功开发了一个可靠的早期CRLM复发预测模型,并强调了临床预后建模中数据泄露的风险,提出了一个严格的框架来减轻这一问题,提高了模型在现实世界的可靠性和翻译价值。
Key Takeaways:
- 传统临床模型在预测结直肠癌肝转移(CRLM)患者预后时的准确性有待提高。
- 集合模型虽表现出极高性能,但存在数据泄露风险。
- 研究聚焦于使用术前临床参数和放射组学特征预测术后复发风险。
- 术后三个月复发预测模型性能最佳,交叉验证AUC为0.723。
- 决策曲线分析证实该模型在特定阈概率范围内优于其他治疗策略。
- 研究成功开发了一个可靠的早期CRLM复发预测模型,有助于术后监测和治疗决策。
点此查看论文截图


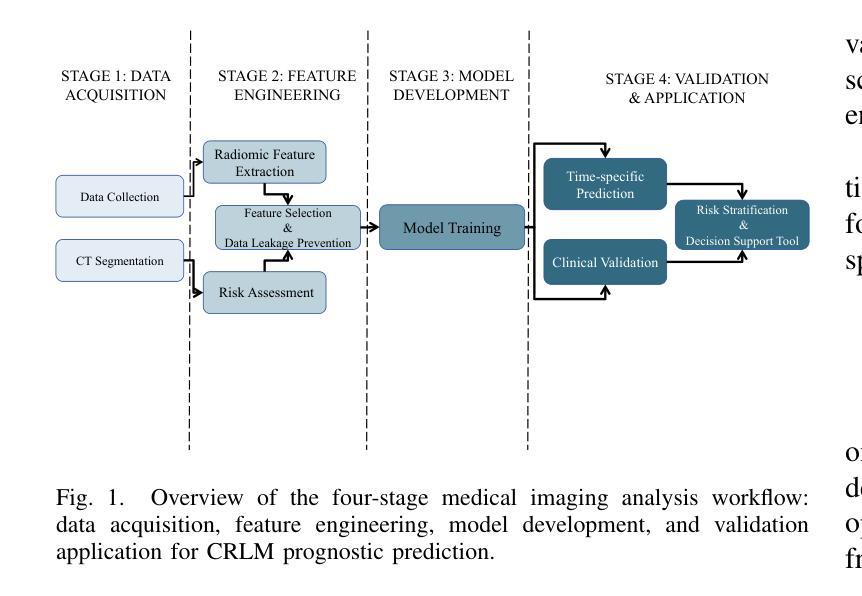
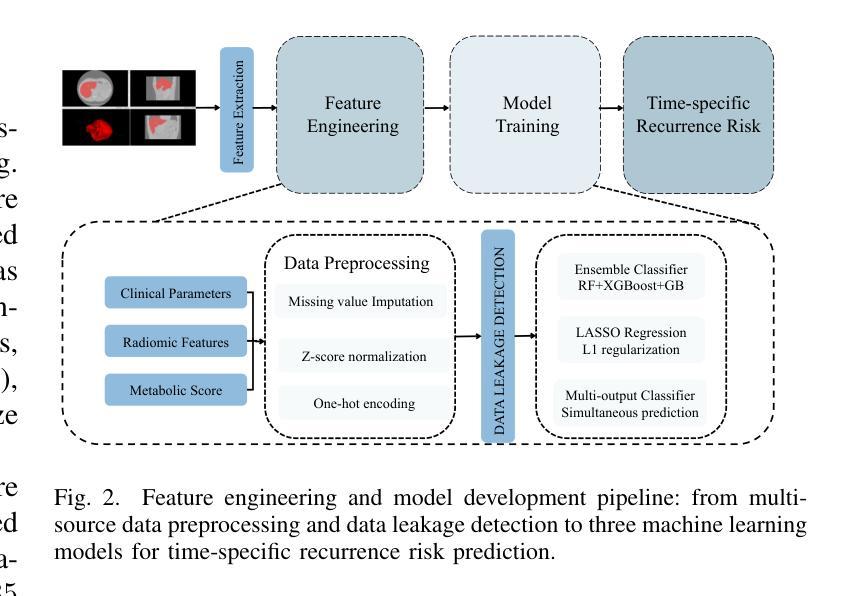
Continual Learning-Based Unified Model for Unpaired Image Restoration Tasks
Authors:Kotha Kartheek, Lingamaneni Gnanesh Chowdary, Snehasis Mukherjee
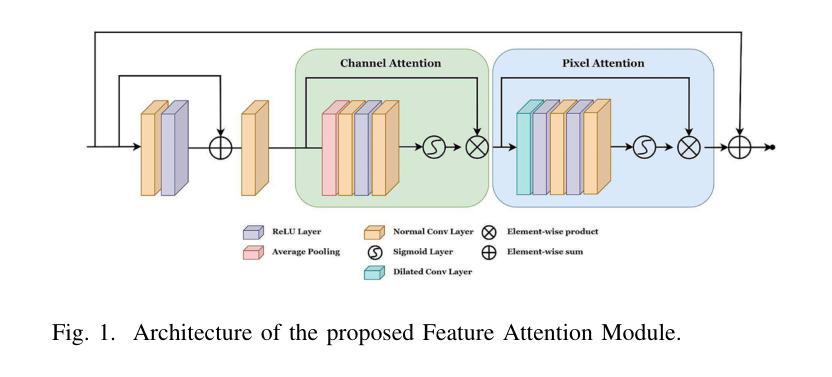
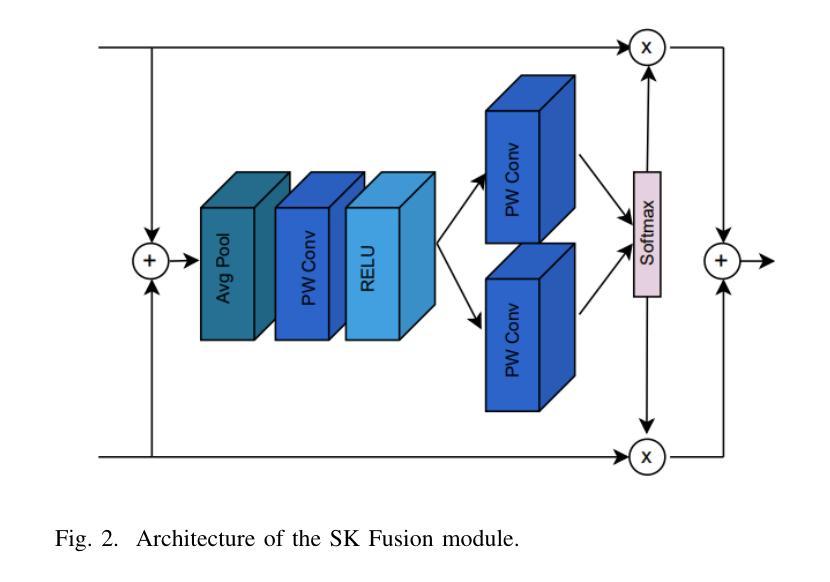
Restoration of images contaminated by different adverse weather conditions such as fog, snow, and rain is a challenging task due to the varying nature of the weather conditions. Most of the existing methods focus on any one particular weather conditions. However, for applications such as autonomous driving, a unified model is necessary to perform restoration of corrupted images due to different weather conditions. We propose a continual learning approach to propose a unified framework for image restoration. The proposed framework integrates three key innovations: (1) Selective Kernel Fusion layers that dynamically combine global and local features for robust adaptive feature selection; (2) Elastic Weight Consolidation (EWC) to enable continual learning and mitigate catastrophic forgetting across multiple restoration tasks; and (3) a novel Cycle-Contrastive Loss that enhances feature discrimination while preserving semantic consistency during domain translation. Further, we propose an unpaired image restoration approach to reduce the dependance of the proposed approach on the training data. Extensive experiments on standard benchmark datasets for dehazing, desnowing and deraining tasks demonstrate significant improvements in PSNR, SSIM, and perceptual quality over the state-of-the-art.
由于天气条件的多样性,由雾、雪和雨等不同恶劣天气条件污染的图片恢复是一项具有挑战性的任务。现有的大多数方法主要关注某一种特定的天气条件。然而,对于自动驾驶等应用,由于不同的天气条件导致图像退化,因此需要一种统一模型进行恢复。我们提出了一种持续学习的方法,以建立一个统一的图像恢复框架。该框架集成了三项关键创新:1)选择性核融合层,它能动态结合全局和局部特征,实现稳健的自适应特征选择;2)弹性权重巩固(EWC),以实现持续学习,并减轻多个恢复任务中的灾难性遗忘;3)一种新的循环对比损失,它提高了特征辨别力,同时在域转换过程中保留了语义一致性。此外,我们提出了一种无需配对的图像恢复方法,以减少所提出方法对训练数据的依赖。在除雾、消雪和去雨任务的标准基准数据集上进行的广泛实验表明,在峰值信号噪声比(PSNR)、结构相似性(SSIM)和感知质量方面均有显著改进,超过了最新技术水平。
论文及项目相关链接
PDF Under Review
Summary
针对恶劣天气条件(如雾、雪和雨)导致的图像污染恢复是一项具有挑战性的任务,因为天气条件的变化多样。现有方法大多专注于特定的天气条件,但在自动驾驶等应用中,需要一种统一模型来恢复因不同天气条件而损坏的图像。本文提出了一种持续学习的方法,建立一个统一的图像恢复框架,该框架集成了三大创新点:选择性核融合层可动态结合全局和局部特征进行稳健的自适应特征选择;弹性权重巩固(EWC)可实现持续学习并减轻多个恢复任务中的灾难性遗忘;以及新型的循环对比损失,可在域转换过程中增强特征鉴别力并保留语义一致性。此外,本文提出了一种无需配对的图像恢复方法,以降低该方案对训练数据的依赖性。在消雾、除雪和去雨的标准基准数据集上进行的广泛实验表明,与最新技术相比,它在峰值信噪比(PSNR)、结构相似性(SSIM)和感知质量方面都有显著提高。
Key Takeaways
- 恶劣天气条件下的图像恢复是一项挑战,因为天气条件的变化多样。
- 现有方法大多专注于特定天气条件,需要一种统一模型来处理多种天气条件下的图像恢复。
- 提出的统一框架集成了三大创新点:选择性核融合层、弹性权重巩固(EWC)和循环对比损失。
- 选择性核融合层能够动态结合全局和局部特征,进行稳健的自适应特征选择。
- 弹性权重巩固(EWC)有助于实现持续学习并减轻灾难性遗忘。
- 新型的循环对比损失可增强特征鉴别力,并在域转换过程中保留语义一致性。
- 该研究还提出了一种无需配对的图像恢复方法,以降低对训练数据的依赖性。
点此查看论文截图

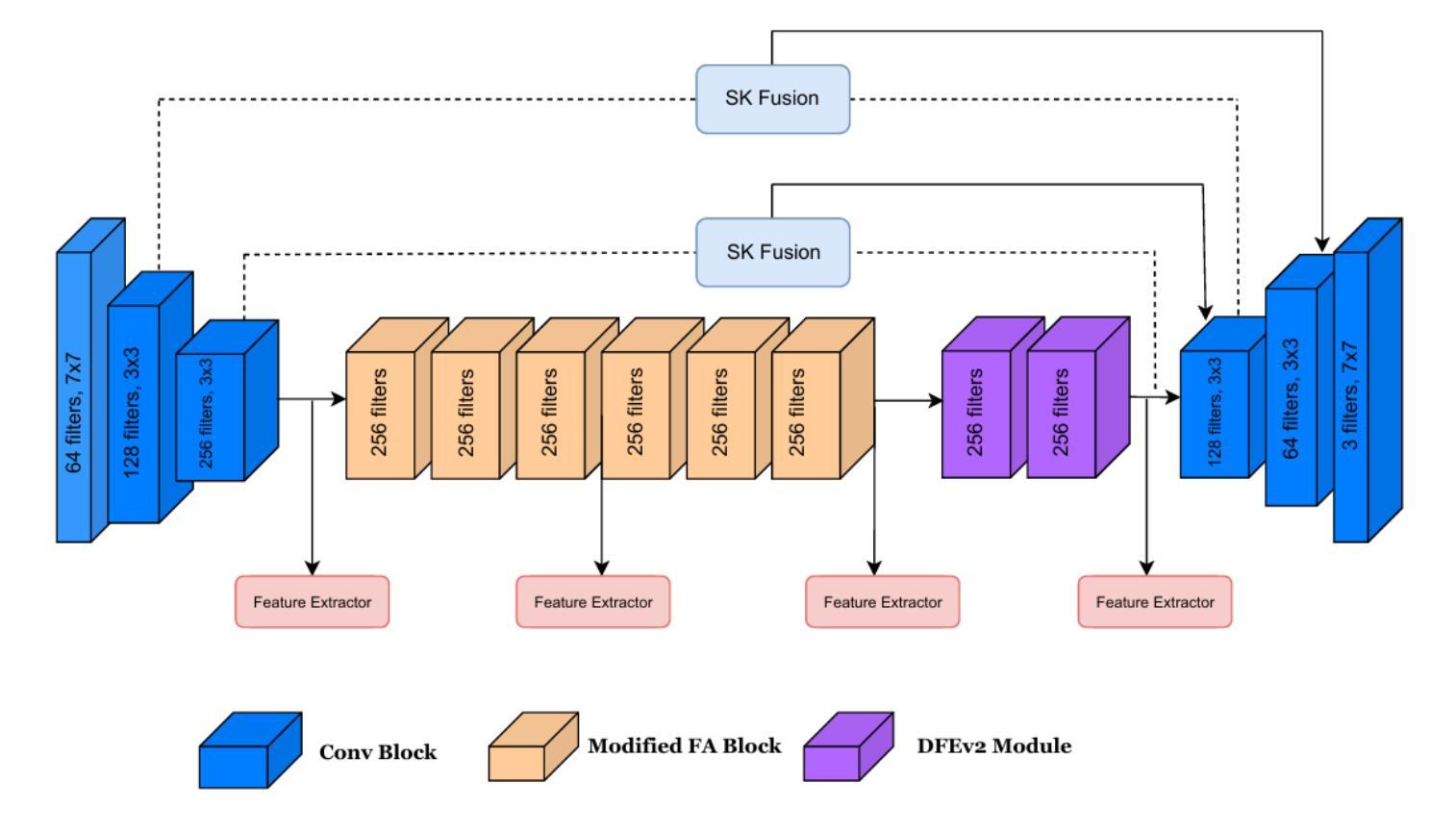
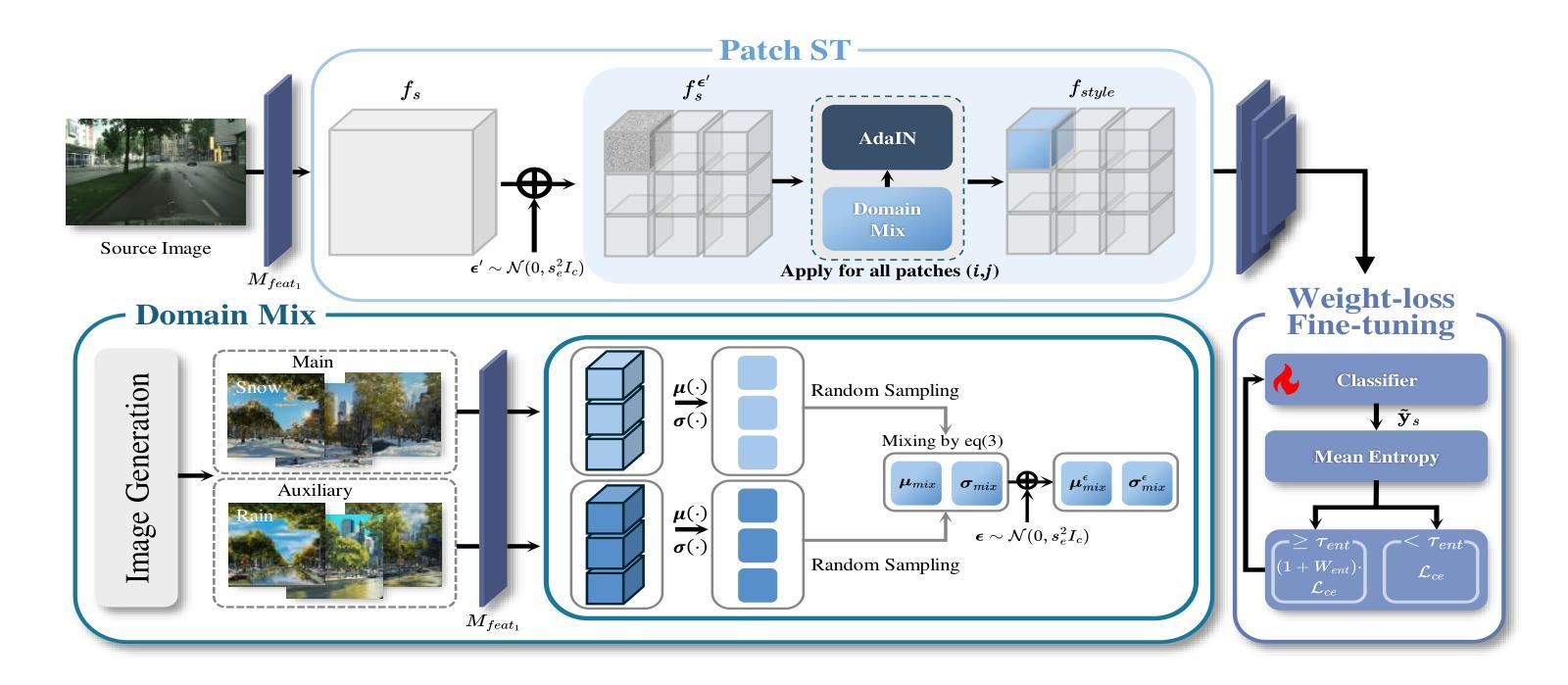
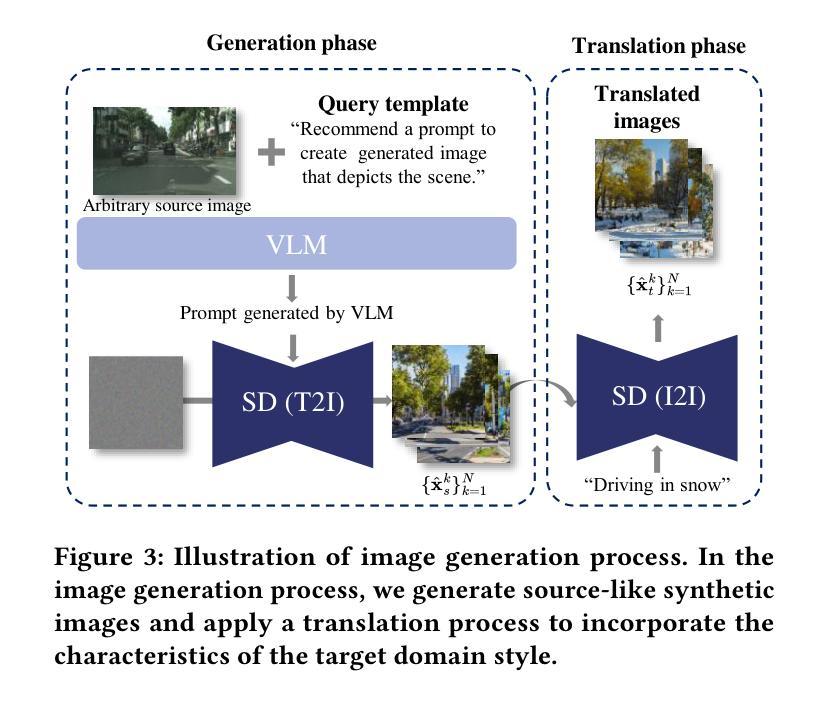
SIDA: Synthetic Image Driven Zero-shot Domain Adaptation
Authors:Ye-Chan Kim, SeungJu Cha, Si-Woo Kim, Taewhan Kim, Dong-Jin Kim
Zero-shot domain adaptation is a method for adapting a model to a target domain without utilizing target domain image data. To enable adaptation without target images, existing studies utilize CLIP’s embedding space and text description to simulate target-like style features. Despite the previous achievements in zero-shot domain adaptation, we observe that these text-driven methods struggle to capture complex real-world variations and significantly increase adaptation time due to their alignment process. Instead of relying on text descriptions, we explore solutions leveraging image data, which provides diverse and more fine-grained style cues. In this work, we propose SIDA, a novel and efficient zero-shot domain adaptation method leveraging synthetic images. To generate synthetic images, we first create detailed, source-like images and apply image translation to reflect the style of the target domain. We then utilize the style features of these synthetic images as a proxy for the target domain. Based on these features, we introduce Domain Mix and Patch Style Transfer modules, which enable effective modeling of real-world variations. In particular, Domain Mix blends multiple styles to expand the intra-domain representations, and Patch Style Transfer assigns different styles to individual patches. We demonstrate the effectiveness of our method by showing state-of-the-art performance in diverse zero-shot adaptation scenarios, particularly in challenging domains. Moreover, our approach achieves high efficiency by significantly reducing the overall adaptation time.
零样本域自适应是一种无需使用目标域图像数据即可使模型适应目标域的方法。为了在无需目标图像的情况下实现自适应,现有研究利用CLIP的嵌入空间和文本描述来模拟目标相似的风格特征。尽管在零样本域自适应方面取得了先前的成就,我们观察到这些文本驱动的方法在捕捉现实世界复杂变化方面遇到了困难,并且由于对齐过程而增加了大量的自适应时间。我们不再依赖文本描述,而是探索利用图像数据的解决方案,图像数据提供了多样且更精细的风格线索。在这项工作中,我们提出了一种新的高效零样本域自适应方法,即利用合成图像进行自适应(SIDA)。为了生成合成图像,我们首先创建详细的源域图像,并通过图像翻译来反映目标域的样式。然后,我们利用这些合成图像的样式特征作为目标域的代理。基于这些特征,我们引入了Domain Mix和Patch Style Transfer模块,它们可以有效地模拟现实世界的变化。特别是,Domain Mix通过混合多种风格来扩展域内表示,而Patch Style Transfer则为各个补丁分配不同的风格。我们在多种零样本自适应场景中展示了我们的方法的有效性,特别是在具有挑战性的领域里。此外,我们的方法通过大大减少了总体自适应时间而实现了高效率。
论文及项目相关链接
PDF Accepted to ACM MM 2025
Summary
本文提出了一种基于合成图像的高效零样本域自适应方法(SIDA)。该方法通过生成合成图像来模拟目标域的样式特征,进而实现模型对目标域的适应,而无需使用目标域的图像数据。通过混合多种风格并转移补丁风格,该方法能够更有效地模拟真实世界的变化。此外,该方法显著减少了自适应时间,提高了效率。
Key Takeaways
- 零样本域自适应方法无需使用目标域图像数据即可使模型适应目标域。
- 本文提出了一种基于合成图像的方法来实现零样本域自适应。
- 通过生成详细的源域图像并应用图像翻译来反映目标域的样式,进而模拟目标域的样式特征。
- 引入Domain Mix和Patch Style Transfer模块,以更有效地模拟真实世界的变化。
- Domain Mix通过混合多种风格来扩展域内表示。
- Patch Style Transfer将不同的风格分配给单独的补丁,以提高模型的表现力。
点此查看论文截图

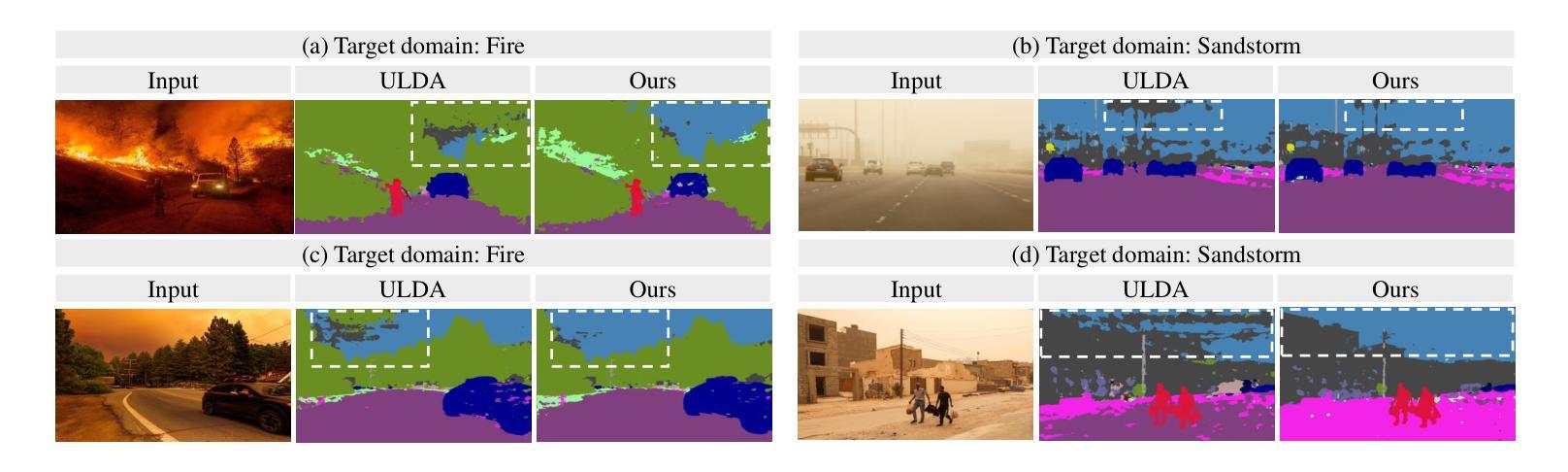

GIIFT: Graph-guided Inductive Image-free Multimodal Machine Translation
Authors:Jiafeng Xiong, Yuting Zhao
Multimodal Machine Translation (MMT) has demonstrated the significant help of visual information in machine translation. However, existing MMT methods face challenges in leveraging the modality gap by enforcing rigid visual-linguistic alignment whilst being confined to inference within their trained multimodal domains. In this work, we construct novel multimodal scene graphs to preserve and integrate modality-specific information and introduce GIIFT, a two-stage Graph-guided Inductive Image-Free MMT framework that uses a cross-modal Graph Attention Network adapter to learn multimodal knowledge in a unified fused space and inductively generalize it to broader image-free translation domains. Experimental results on the Multi30K dataset of English-to-French and English-to-German tasks demonstrate that our GIIFT surpasses existing approaches and achieves the state-of-the-art, even without images during inference. Results on the WMT benchmark show significant improvements over the image-free translation baselines, demonstrating the strength of GIIFT towards inductive image-free inference.
多模态机器翻译(MMT)已经证明了视觉信息在机器翻译中的巨大帮助。然而,现有的MMT方法在利用模态差距方面面临挑战,它们通过强制实施严格的视觉语言对齐,同时受限于其训练的多模态域内的推理。在这项工作中,我们构建了新型的多模态场景图,以保留和整合特定模态的信息,并引入了GIIFT,这是一个两阶段的图引导归纳无图多模态机器翻译框架,它使用跨模态图注意力网络适配器,在统一融合空间学习多模态知识,并归纳推广至更广泛的无图像翻译领域。在Multi30K英语到法语和英语到德语任务的实验结果表明,我们的GIIFT超越了现有方法,达到了最先进的水平,即使在推理过程中没有使用图像。在WMT基准测试上的结果也显著优于无图像翻译基线,证明了GIIFT在无图像推理方面的优势。
论文及项目相关链接
Summary:本研究通过构建新型的多模态场景图来融合多模态信息,提出了一种基于图注意力网络的图像自由机器翻译框架GIIFT。该框架能在统一的融合空间中学习多模态知识,并在没有图像的情况下推广到更广泛的翻译领域。在Multi30K数据集上的实验结果表明,GIIFT超越了现有方法,达到了图像自由翻译的最先进水平。在WMT基准测试上的结果也显著优于基线模型,证明了GIIFT在图像自由推理方面的优势。
Key Takeaways:
- 多模态机器翻译(MMT)借助视觉信息为机器翻译提供了重要帮助。
- 当前MMT方法面临模态间差距的挑战,需要更灵活的视觉语言对齐方式,并局限于已训练的多模态领域。
- 研究构建了新型的多模态场景图来保存和整合模态特定信息。
- 引入了GIIFT框架,这是一个两阶段的图引导图像自由MMT框架。
- GIIFT使用跨模态图注意力网络适配器,在统一的融合空间中学习多模态知识,并归纳推广到更广泛的图像自由翻译领域。
- 在Multi30K数据集上的实验结果表明,GIIFT达到了最先进的图像自由翻译水平,特别是在推理过程中无需图像。
点此查看论文截图

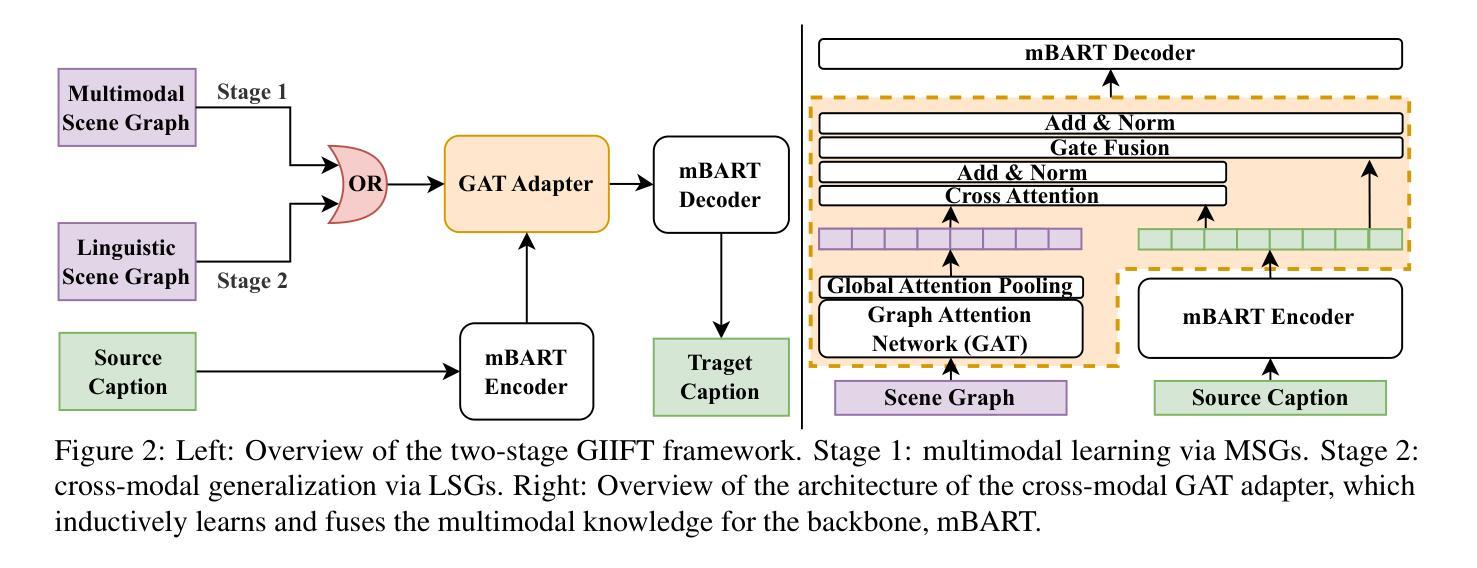
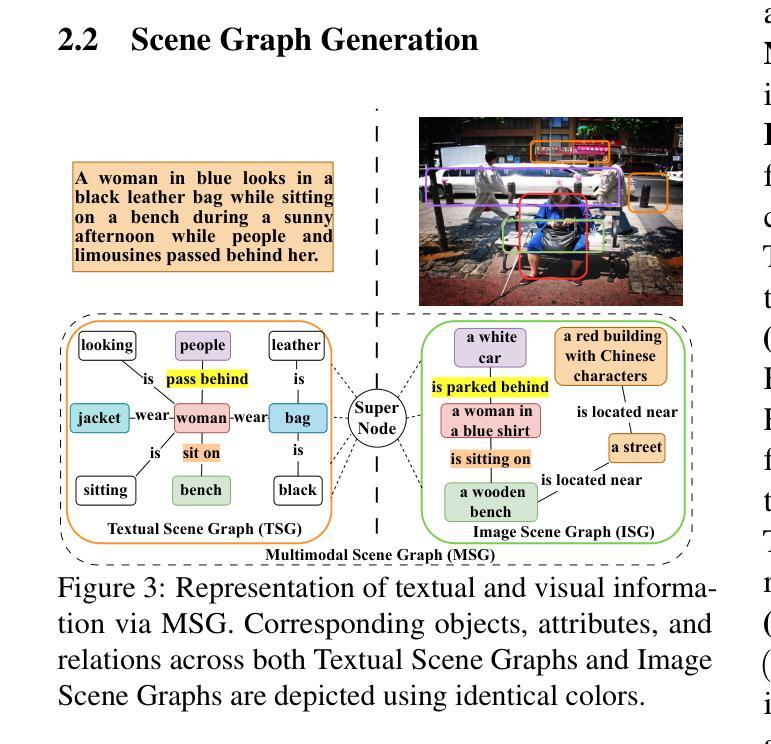
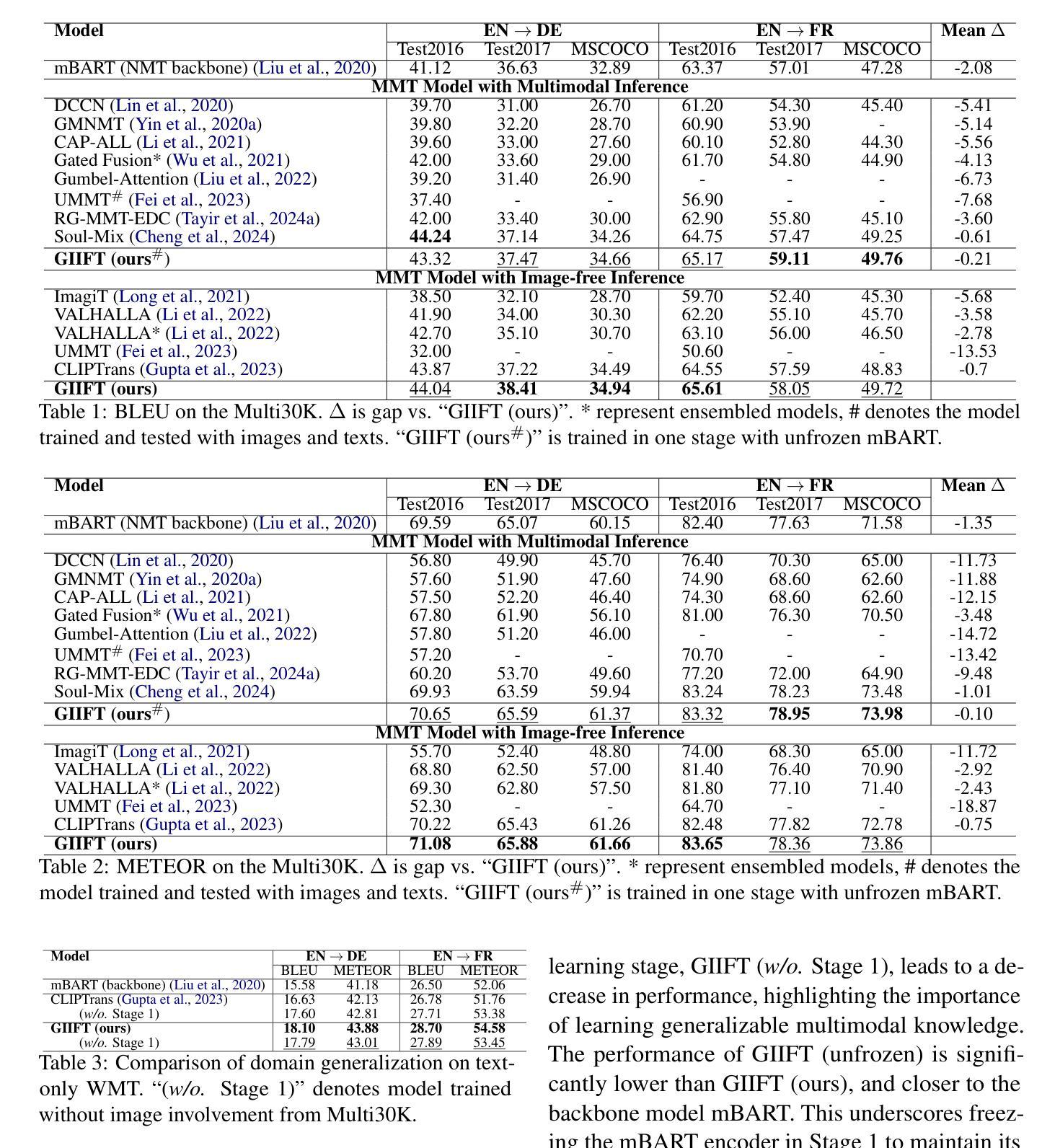
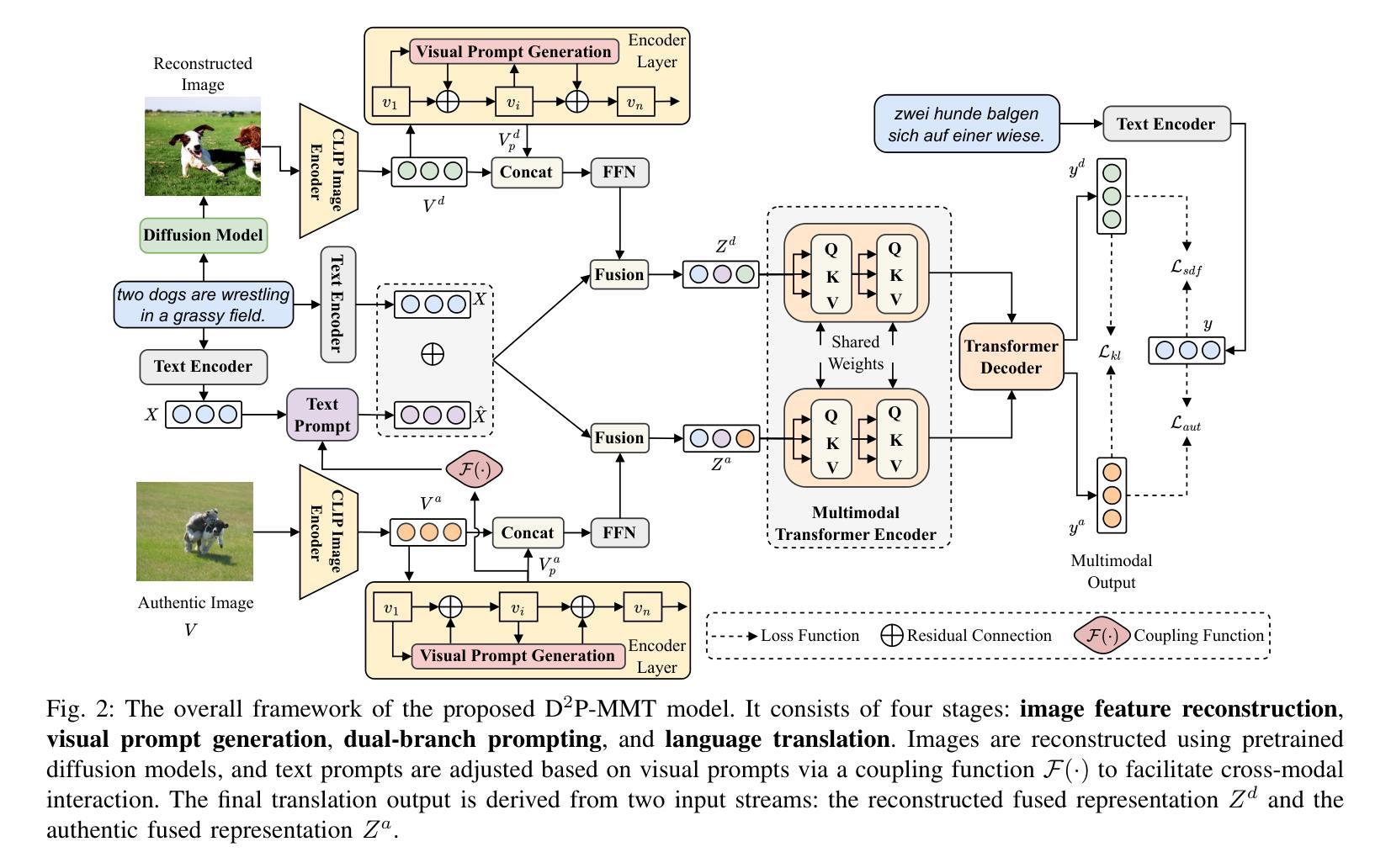
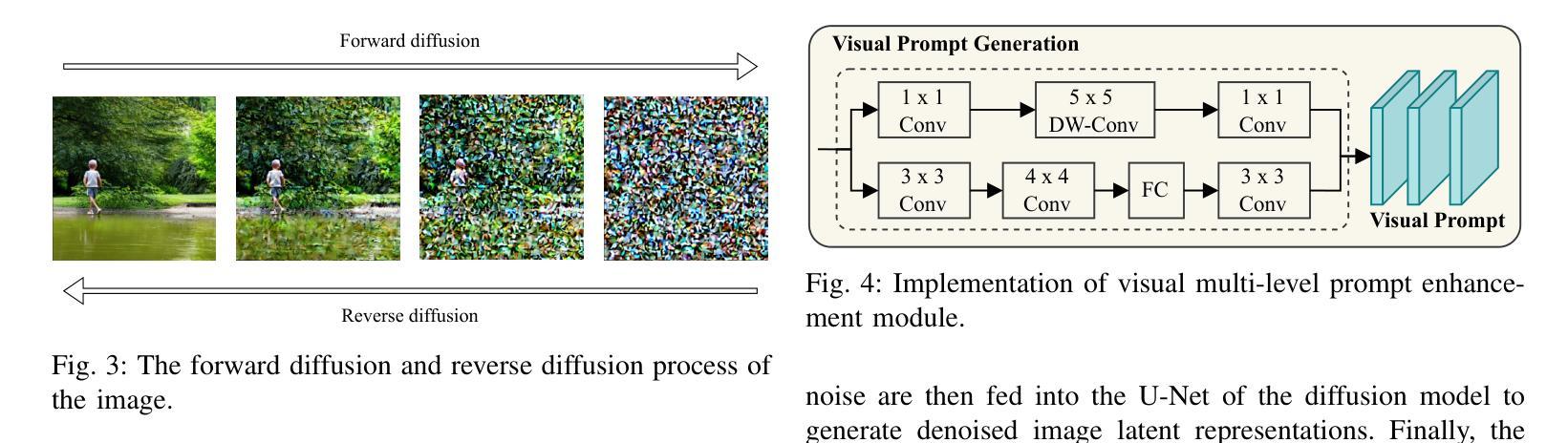
Dual-branch Prompting for Multimodal Machine Translation
Authors:Jie Wang, Zhendong Yang, Liansong Zong, Xiaobo Zhang, Dexian Wang, Ji Zhang
Multimodal Machine Translation (MMT) typically enhances text-only translation by incorporating aligned visual features. Despite the remarkable progress, state-of-the-art MMT approaches often rely on paired image-text inputs at inference and are sensitive to irrelevant visual noise, which limits their robustness and practical applicability. To address these issues, we propose D2P-MMT, a diffusion-based dual-branch prompting framework for robust vision-guided translation. Specifically, D2P-MMT requires only the source text and a reconstructed image generated by a pre-trained diffusion model, which naturally filters out distracting visual details while preserving semantic cues. During training, the model jointly learns from both authentic and reconstructed images using a dual-branch prompting strategy, encouraging rich cross-modal interactions. To bridge the modality gap and mitigate training-inference discrepancies, we introduce a distributional alignment loss that enforces consistency between the output distributions of the two branches. Extensive experiments on the Multi30K dataset demonstrate that D2P-MMT achieves superior translation performance compared to existing state-of-the-art approaches.
多模态机器翻译(MMT)通常通过融入对齐的视觉特征来增强纯文本翻译。尽管取得了显著的进步,但最新的MMT方法通常在推理阶段依赖于配对图像文本输入,并对不相关的视觉噪声敏感,这限制了其稳健性和实际应用能力。为了解决这些问题,我们提出了D2P-MMT,这是一种基于扩散模型的双分支提示框架,用于实现稳健的视觉引导翻译。具体而言,D2P-MMT仅需要源文本和一个由预训练扩散模型生成的重建图像,该模型能够自然地过滤掉令人分心的视觉细节,同时保留语义线索。在训练过程中,模型采用双分支提示策略,从真实和重建的图像中学习,鼓励丰富的跨模态交互。为了缩小模态差距并减轻训练与推理之间的差异,我们引入了一种分布对齐损失,以强制两个分支输出分布的一致性。在Multi30K数据集上的大量实验表明,与现有的最新方法相比,D2P-MMT实现了卓越的翻译性能。
论文及项目相关链接
Summary
多模态机器翻译(MMT)通过融入对齐的视觉特征增强了纯文本翻译。然而,当前先进技术的方法在推理时通常依赖于配对图像文本输入,并对无关的视觉噪声敏感,这限制了其稳健性和实际应用能力。为解决这些问题,我们提出了基于扩散模型的双分支提示框架D2P-MMT,用于稳健的视觉引导翻译。具体而言,D2P-MMT仅需要源文本和由预训练扩散模型生成的重建图像,该模型能够自然过滤掉令人分心的视觉细节,同时保留语义线索。在训练过程中,模型采用双分支提示策略,从真实和重建的图像中学习,促进跨模态的丰富交互。为缩小模态差距并减轻训练与推理之间的差异,我们引入了一种分布对齐损失,以确保两个分支输出分布的一致性。在Multi30K数据集上的广泛实验表明,D2P-MMT的翻译性能优于现有先进技术。
Key Takeaways
- 多模态机器翻译(MMT)通过结合视觉特征改进文本翻译。
- 当前MMT方法依赖于配对图像文本输入,对视觉噪声敏感。
- D2P-MMT框架提出一种基于扩散模型的解决方案,仅需要源文本和重建图像。
- 重建图像自然过滤掉干扰视觉细节,保留语义线索。
- 模型采用双分支提示策略进行训练,促进跨模态交互。
- 引入分布对齐损失以缩小模态差距和减少训练与推理差异。
- 在Multi30K数据集上,D2P-MMT表现出优于现有技术的翻译性能。
点此查看论文截图

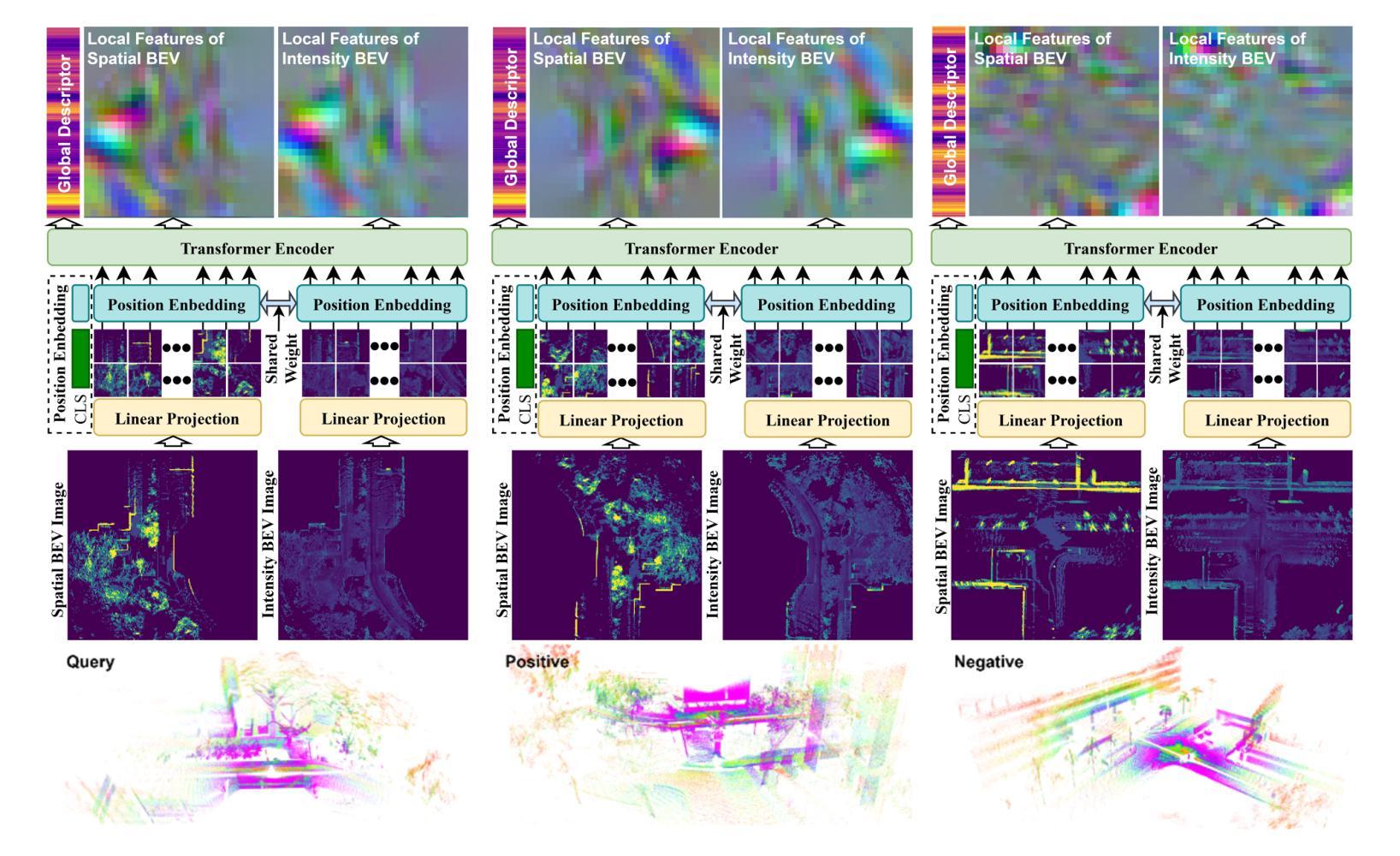
UniLGL: Learning Uniform Place Recognition for FOV-limited/Panoramic LiDAR Global Localization
Authors:Hongming Shen, Xun Chen, Yulin Hui, Zhenyu Wu, Wei Wang, Qiyang Lyu, Tianchen Deng, Danwei Wang
Existing LGL methods typically consider only partial information (e.g., geometric features) from LiDAR observations or are designed for homogeneous LiDAR sensors, overlooking the uniformity in LGL. In this work, a uniform LGL method is proposed, termed UniLGL, which simultaneously achieves spatial and material uniformity, as well as sensor-type uniformity. The key idea of the proposed method is to encode the complete point cloud, which contains both geometric and material information, into a pair of BEV images (i.e., a spatial BEV image and an intensity BEV image). An end-to-end multi-BEV fusion network is designed to extract uniform features, equipping UniLGL with spatial and material uniformity. To ensure robust LGL across heterogeneous LiDAR sensors, a viewpoint invariance hypothesis is introduced, which replaces the conventional translation equivariance assumption commonly used in existing LPR networks and supervises UniLGL to achieve sensor-type uniformity in both global descriptors and local feature representations. Finally, based on the mapping between local features on the 2D BEV image and the point cloud, a robust global pose estimator is derived that determines the global minimum of the global pose on SE(3) without requiring additional registration. To validate the effectiveness of the proposed uniform LGL, extensive benchmarks are conducted in real-world environments, and the results show that the proposed UniLGL is demonstratively competitive compared to other State-of-the-Art LGL methods. Furthermore, UniLGL has been deployed on diverse platforms, including full-size trucks and agile Micro Aerial Vehicles (MAVs), to enable high-precision localization and mapping as well as multi-MAV collaborative exploration in port and forest environments, demonstrating the applicability of UniLGL in industrial and field scenarios.
现有的LGL方法通常只考虑LiDAR观测的部分信息(例如几何特征),或者为均质的LiDAR传感器而设计,忽略了LGL中的均匀性。在此工作中,提出了一种统一的LGL方法,称为UniLGL,它同时实现了空间、材料以及传感器类型的均匀性。该方法的关键思想是将包含几何和材料信息的完整点云编码为一对BEV图像(即空间BEV图像和强度BEV图像)。设计了一个端到端的多BEV融合网络来提取均匀特征,使UniLGL具备空间和材料均匀性。为了确保跨不同LiDAR传感器的稳健LGL,引入了视点不变性假设,该假设取代了现有LPR网络中常用的平移等价假设,并促使UniLGL在全局描述符和局部特征表示上实现传感器类型均匀性。最后,基于二维BEV图像上的局部特征与点云之间的映射关系,导出了一个稳健的全局姿态估计器,该估计器可在SE(3)上确定全局姿态的全局最小值,无需额外的注册过程。为了验证所提统一LGL的有效性,在真实环境中进行了广泛的基准测试,结果表明与其他最新LGL方法相比,所提的UniLGL具有竞争力。此外,UniLGL已部署在多种平台上,包括全尺寸卡车和敏捷微型航空车辆(MAVs),以实现港口和森林环境中的高精度定位和映射以及多MAV协同探索,证明了UniLGL在工业和现场场景中的适用性。
论文及项目相关链接
Summary
本文提出了一种名为UniLGL的统一LGL方法,该方法实现了空间、材质和传感器类型的均匀性。通过将点云编码成一对BEV图像,并结合端到端的多BEV融合网络提取均匀特征,该方法具有空间和材质均匀性。为确保在不同激光雷达传感器之间的稳健性LGL,引入了视点不变假设,代替了现有LPR网络中常用的平移等价假设,并实现了传感器类型的统一。基于局部特征与点云之间的映射关系,推导出了稳健的全局姿态估计器。实验验证表明,与其他先进的LGL方法相比,UniLGL具有竞争力,并已部署在各种平台上进行实际应用。
Key Takeaways
- UniLGL方法考虑了激光雷达观测的完整性信息,并实现了空间、材质和传感器类型的均匀性。
- 通过将点云编码成BEV图像,并结合多BEV融合网络提取均匀特征。
- 引入视点不变假设以确保在不同激光雷达传感器之间的稳健性。
- UniLGL实现了全局和局部特征表示中的传感器类型统一。
- 基于局部特征与点云之间的映射关系,推导出了全局姿态估计器。
- 实验验证显示UniLGL与其他先进的LGL方法相比具有竞争力。
点此查看论文截图


Time-resolved dynamic CBCT reconstruction using prior-model-free spatiotemporal Gaussian representation (PMF-STGR)
Authors:Jiacheng Xie, Hua-Chieh Shao, You Zhang
Time-resolved CBCT imaging, which reconstructs a dynamic sequence of CBCTs reflecting intra-scan motion (one CBCT per x-ray projection without phase sorting or binning), is highly desired for regular and irregular motion characterization, patient setup, and motion-adapted radiotherapy. Representing patient anatomy and associated motion fields as 3D Gaussians, we developed a Gaussian representation-based framework (PMF-STGR) for fast and accurate dynamic CBCT reconstruction. PMF-STGR comprises three major components: a dense set of 3D Gaussians to reconstruct a reference-frame CBCT for the dynamic sequence; another 3D Gaussian set to capture three-level, coarse-to-fine motion-basis-components (MBCs) to model the intra-scan motion; and a CNN-based motion encoder to solve projection-specific temporal coefficients for the MBCs. Scaled by the temporal coefficients, the learned MBCs will combine into deformation vector fields to deform the reference CBCT into projection-specific, time-resolved CBCTs to capture the dynamic motion. Due to the strong representation power of 3D Gaussians, PMF-STGR can reconstruct dynamic CBCTs in a ‘one-shot’ training fashion from a standard 3D CBCT scan, without using any prior anatomical or motion model. We evaluated PMF-STGR using XCAT phantom simulations and real patient scans. Metrics including the image relative error, structural-similarity-index-measure, tumor center-of-mass-error, and landmark localization error were used to evaluate the accuracy of solved dynamic CBCTs and motion. PMF-STGR shows clear advantages over a state-of-the-art, INR-based approach, PMF-STINR. Compared with PMF-STINR, PMF-STGR reduces reconstruction time by 50% while reconstructing less blurred images with better motion accuracy. With improved efficiency and accuracy, PMF-STGR enhances the applicability of dynamic CBCT imaging for potential clinical translation.
时间解析CBCT成像重建了一连串反映扫描内运动的CBCT(每次X射线投影都有一个CBCT,无需相位排序或分箱),这在常规和运动不规则的运动表征、患者设置和适应性运动放疗中都非常受欢迎。我们用三维高斯表示患者解剖结构和相关运动场,开发了一个基于高斯表示的框架(PMF-STGR),用于快速准确的动态CBCT重建。PMF-STGR主要包括三个组成部分:一组密集的三维高斯用于重建动态序列的参考框架CBCT;另一组三维高斯用于捕捉三级粗到细的运动基础成分(MBCs),以模拟扫描内的运动;以及基于CNN的运动编码器,用于解决MBC的投影特定时间系数。根据时间系数,学习的MBC将组合成变形矢量场,以变形参考CBCT为投影特定的时间解析CBCT,以捕捉动态运动。由于三维高斯具有强大的表征能力,PMF-STGR可以从标准的3D CBCT扫描中进行“单次”训练方式重建动态CBCT,而无需使用任何先前的解剖或运动模型。我们使用XCAT幻影模拟和实际患者扫描对PMF-STGR进行了评估。使用图像相对误差、结构相似性指数度量、肿瘤质心误差和地标定位误差等指标来评估求解的动态CBCT和运动的准确性。与当前先进的INR方法PMF-STINR相比,PMF-STGR具有明显的优势。与PMF-STINR相比,PMF-STGR在重建时间减少50%的同时,重建的图像更清晰,运动精度更高。通过提高效率和准确性,PMF-STGR增强了动态CBCT成像的适用性,具有潜在的临床翻译价值。
论文及项目相关链接
PDF 25 pages, 5 figures
Summary
基于三维高斯表示的框架(PMF-STGR)实现了快速准确的动态CBC成像重建。它采用一套密集的三维高斯函数来重建参考帧CBC图像,用于动态序列;另一套三维高斯函数用于捕捉不同级别的运动基础分量(MBCs);采用CNN(卷积神经网络)基于运动编码器解决投影特定时间系数的问题。通过动态训练,PMF-STGR能够从标准的三维CBC扫描中重建动态CBC图像,无需使用任何先验解剖或运动模型。评估结果显示,与当前主流方法相比,PMF-STGR在重建时间和图像质量方面均表现出优势。
Key Takeaways
- 时间解析CBCT成像对于常规和不规则运动表征、患者设置和运动适应放疗具有重要意义。
- PMF-STGR框架利用三维高斯表示来快速准确地重建动态CBCT图像。
- PMF-STGR包含三个主要组件:用于重建参考帧CBCT的密集三维高斯集、捕捉运动基础分量(MBCs)的另一三维高斯集以及基于CNN的运动编码器。
- 通过结合学习的MBC和时间系数,PMF-STGR能够重建投影特定的时间解析CBCT图像。
- PMF-STGR具有强大的表示能力,可从标准的三维CBCT扫描中通过一次性训练重建动态CBCT图像,无需使用任何先验解剖或运动模型。
- 评估结果表明,与现有方法相比,PMF-STGR在图像质量、运动准确性和重建时间方面具有明显优势。
点此查看论文截图

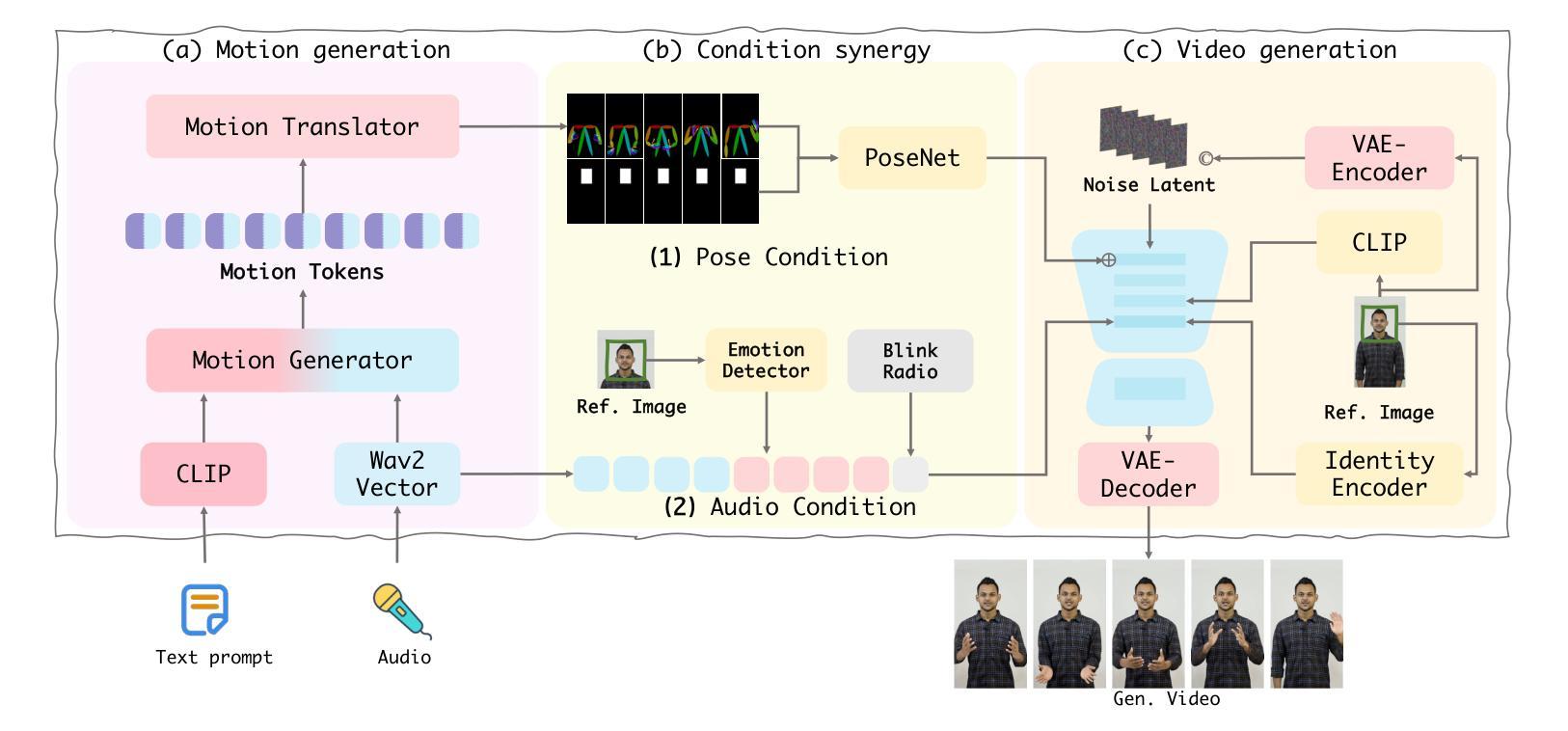
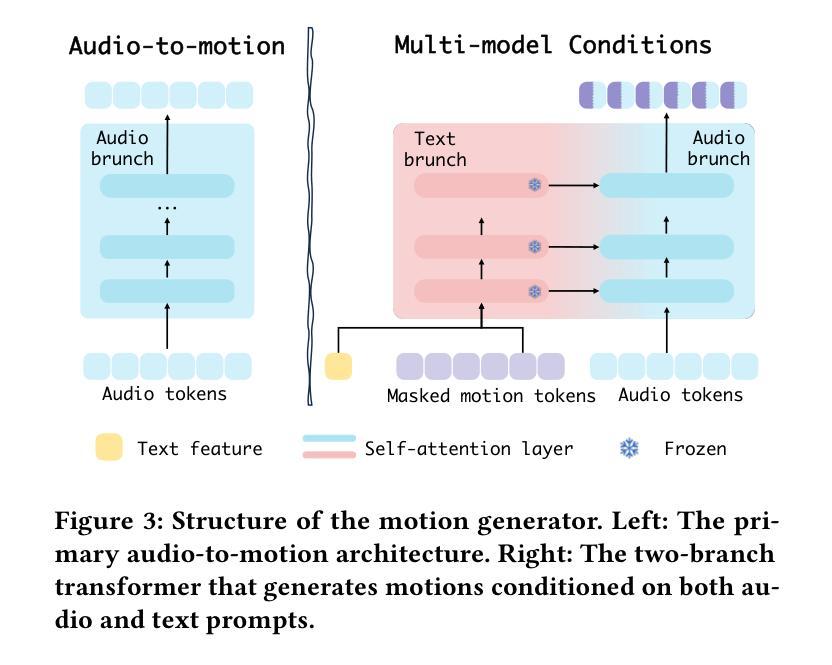
Versatile Multimodal Controls for Expressive Talking Human Animation
Authors:Zheng Qin, Ruobing Zheng, Yabing Wang, Tianqi Li, Zixin Zhu, Sanping Zhou, Ming Yang, Le Wang
In filmmaking, directors typically allow actors to perform freely based on the script before providing specific guidance on how to present key actions. AI-generated content faces similar requirements, where users not only need automatic generation of lip synchronization and basic gestures from audio input but also desire semantically accurate and expressive body movement that can be ``directly guided’’ through text descriptions. Therefore, we present VersaAnimator, a versatile framework that synthesizes expressive talking human videos from arbitrary portrait images. Specifically, we design a motion generator that produces basic rhythmic movements from audio input and supports text-prompt control for specific actions. The generated whole-body 3D motion tokens can animate portraits of various scales, producing talking heads, half-body gestures and even leg movements for whole-body images. Besides, we introduce a multi-modal controlled video diffusion that generates photorealistic videos, where speech signals govern lip synchronization, facial expressions, and head motions while body movements are guided by the 2D poses. Furthermore, we introduce a token2pose translator to smoothly map 3D motion tokens to 2D pose sequences. This design mitigates the stiffness resulting from direct 3D to 2D conversion and enhances the details of the generated body movements. Extensive experiments shows that VersaAnimator synthesizes lip-synced and identity-preserving videos while generating expressive and semantically meaningful whole-body motions.
在电影制作中,导演通常会让演员根据剧本自由发挥,然后再提供关于如何呈现关键动作的具体指导。人工智能生成的内容面临着类似的要求,用户不仅需要自动生成与音频输入同步的基本动作,还希望得到语义准确、富有表现力的身体动作,这些动作可以通过文字描述来“直接指导”。因此,我们推出了VersaAnimator,这是一个通用框架,可以从任意的肖像图中合成富有表现力的说话人类视频。具体来说,我们设计了一个动作生成器,它可以从音频输入中产生基本的有节奏的动作,并支持通过文字提示来控制特定动作。生成的全身3D动作令牌可以驱动各种规模的肖像图,产生说话头部、半身手势甚至全身图像的腿部动作。此外,我们引入了一种多模式控制视频扩散技术,生成逼真的视频,其中语音信号控制唇部同步、面部表情和头部动作,而身体动作则由二维姿势引导。而且,我们还推出了token2pose转换器,它能将3D动作令牌平稳地映射到2D姿势序列。这种设计减轻了直接3D到2D转换导致的僵硬感,并增强了生成的身体动作的细节。大量实验表明,VersaAnimator能合成唇音同步、身份保留的视频,同时生成富有表现力和语义的全身动作。
论文及项目相关链接
PDF Accepted by ACM MM2025
Summary
VersaAnimator框架可以生成基于任意肖像图像的表达式说话人类视频。该框架设计了一个动作生成器,可以从音频输入产生基本节奏动作并支持通过文本描述进行特定动作的直接指导。此框架能生成全身3D动作令牌,可以动画化不同规模的肖像,产生谈话头部、半身姿势甚至是全身图像腿部动作。此外,引入多模式控制视频扩散技术,生成真实感视频,语音信号控制唇部同步、面部表情和头部运动,而身体运动则由2D姿势引导。同时,引入token2pose翻译器,将3D动作令牌平滑映射到2D姿势序列,增强生成的身体运动细节。实验表明,VersaAnimator合成的视频具有唇部同步、身份保留的特点,同时能生成表达力强、语义明确的全身动作。
Key Takeaways
- VersaAnimator是一个通用框架,可以从任意肖像图像生成表达式说话人类视频。
- 该框架包含运动生成器,能根据音频输入产生基本节奏动作,并支持文本描述对特定动作的直接指导。
- 能生成全身3D动作令牌,适用于不同规模的肖像动画,包括谈话头部、半身姿势和全身图像腿部动作。
- 引入多模式控制视频扩散技术,结合语音信号和2D姿势,生成真实感视频。
- token2pose翻译器用于将3D动作令牌映射到2D姿势序列,增强身体运动细节的真实性。
- VersaAnimator合成的视频具有唇部同步、身份保留特点。
点此查看论文截图




Rapid and Reproducible Whole-Brain Multi-Pool CEST Imaging at 3T Using a Single-Shot True FISP Readout
Authors:Yupeng Wu, Siyuan Fang, Siyuan Wang, Caixia Fu, Jianqi Li
Purpose: To develop and validate a comprehensive, rapid, and reproducible solution for whole-brain, multi-pool CEST imaging at 3T, overcoming key barriers to clinical translation such as long acquisition times and inaccuracies from field inhomogeneities. Methods: This study integrated a single-shot 3D True FISP readout sequence for efficient whole-brain CEST data acquisition. A streamlined workflow was developed to acquire B0, B1, and T1 maps for correction. To overcome the time-consuming nature of traditional B1 correction, we implemented a machine learning-based method to perform rapid B1 correction using data from a single B1 power acquisition. Data were analyzed using a four-pool Lorentzian model to derive quantitative metrics, including MTRLD and the AREX. The method’s accuracy was validated in phantoms and its test-retest reproducibility was assessed in healthy volunteers across 96 brain regions. Results: The True FISP sequence acquired high-quality, whole-brain images free of major artifacts. The neural network accurately replicated the gold-standard three-point B1 correction, achieving excellent intraclass correlation (ICC > 0.97) in human subjects. The AREX metric successfully corrected for T1 and MT confounders, reducing the CV from 33.6% to 6.9% in phantoms. The complete pipeline, including Z-spectrum and correction maps, took approximately 9 minutes. The method demonstrated high region-level reproducibility, with the average CV for APT_AREX under 10% for most brain regions across test-retest scans. Conclusion: This study presents a validated, end-to-end solution for whole-brain, multi-pool CEST imaging. By combining an efficient sequence with a rapid, AI-driven correction pipeline and robust quantitative analysis, our method delivers high-fidelity, reproducible, and quantitative multi-parameter maps of brain metabolism in a clinically acceptable timeframe.
目的:旨在开发并验证一种全面、快速、可重复的针对全脑多池化学交换饱和转移成像(CEST成像)的解决方案,克服长期存在的临床翻译障碍,如采集时间过长以及由于磁场不均匀性导致的准确性问题。方法:本研究结合了单发三维真实FISP读出序列,用于高效全脑CEST数据采集。为了获取校正所需的B0、B1和T1图,开发了一个简化的工作流程。为了克服传统B1校正耗时的问题,我们实施了一种基于机器学习的方法进行快速B1校正,使用单次B1功率采集的数据。数据使用四池洛伦兹模型进行分析,以推导定量指标,包括MTRLD和AREX。该方法的准确性在模拟体模中得到了验证,并在健康志愿者的96个脑区中对测试重复再现性进行了评估。结果:True FISP序列获得的高质量全脑图像无主要伪影。神经网络准确复制了金标准三点B1校正,在人类受试者中达到了良好的组内相关系数(ICC> 0.97)。AREX指标成功地校正了T1和MT混淆因素,将模拟体模中的变异系数从33.6%减少到6.9%。完整的流程包括Z谱和校正图,大约需要9分钟。该方法显示出较高的区域水平可重复性,大多数脑区的APT_AREX测试再测试扫描的平均变异系数低于10%。结论:本研究提出了一种经过验证的端到端全脑多池CEST成像解决方案。通过结合高效的序列、快速的人工智能驱动校正管道和稳健的定量分析,我们的方法在可接受的临床时间内提供了高保真、可重复和定量的脑代谢多参数图。
论文及项目相关链接
PDF Keywords: CEST, whole-brain, multi-pool, true fast imaging with steady-state precession (True FISP), balanced steady state free precession (bSSFP)
Summary
本文旨在开发并验证一种全面、快速、可重复的针对全脑多池 CEST 成像的综合解决方案。该研究通过整合单发射 3D True FISP 读出序列,实现了高效的全脑 CEST 数据采集。通过开发标准化工作流程,用于获取 B0、B1 和 T1 图进行校正。为了克服传统 B1 校正的时间消耗,研究实施了基于机器学习的方法,利用单次 B1 功率采集数据进行快速 B1 校正。该研究在幻影中验证了方法的准确性,并在健康志愿者中对 96 个脑区进行了测试-再测试的可重复性评估。结果显示,True FISP 序列获取的全脑图像质量高且无主要伪影。神经网络准确复制了金标准三点 B1 校正,在人类受试者中达到了极高的组内相关系数(ICC > 0.97)。AREX 指标成功校正了 T1 和 MT 干扰因素,在幻影中将变异系数从 33.6% 降低到 6.9%。整个管道包括 Z 光谱和校正图,大约需要 9 分钟。该方法显示了高度区域可重复性,在测试-再测试扫描中,大多数脑区的 APT_AREX 平均变异系数低于 10%。本研究提出了一个经过验证的端到端解决方案,用于全脑多池 CEST 成像,该方法结合了高效的序列、快速的 AI 驱动校正管道和稳健的定量分析,提供高保真、可重复和量化的脑代谢多参数图,临床可接受时间范围内。
Key Takeaways
- 研究目标是开发并验证一种适用于全脑多池 CEST 成像的综合解决方案。
- 通过整合单发射 3D True FISP 读出序列实现了高效的全脑数据获取。
- 利用机器学习技术实现快速 B1 校正以缩短成像时间。
- 使用四池洛伦兹模型进行数据分析,以生成定量指标。
- 方法在幻影中的准确性和在人类受试者中的可重复性得到了验证。
- AREX 指标成功校正了 T1 和 MT 的干扰因素,提高了成像质量。
点此查看论文截图

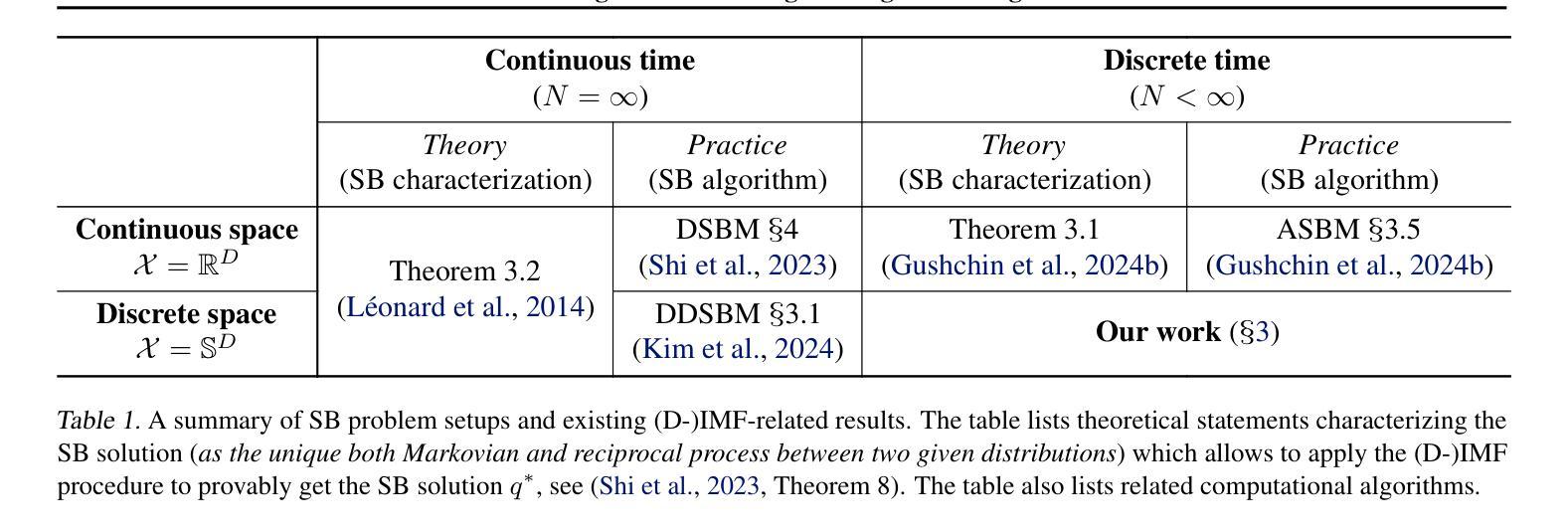
Categorical Schrödinger Bridge Matching
Authors:Grigoriy Ksenofontov, Alexander Korotin
The Schr"odinger Bridge (SB) is a powerful framework for solving generative modeling tasks such as unpaired domain translation. Most SB-related research focuses on continuous data space $\mathbb{R}^{D}$ and leaves open theoretical and algorithmic questions about applying SB methods to discrete data, e.g, on finite spaces $\mathbb{S}^{D}$. Notable examples of such sets $\mathbb{S}$ are codebooks of vector-quantized (VQ) representations of modern autoencoders, tokens in texts, categories of atoms in molecules, etc. In this paper, we provide a theoretical and algorithmic foundation for solving SB in discrete spaces using the recently introduced Iterative Markovian Fitting (IMF) procedure. Specifically, we theoretically justify the convergence of discrete-time IMF (D-IMF) to SB in discrete spaces. This enables us to develop a practical computational algorithm for SB, which we call Categorical Schr"odinger Bridge Matching (CSBM). We show the performance of CSBM via a series of experiments with synthetic data and VQ representations of images. The code of CSBM is available at https://github.com/gregkseno/csbm.
薛定谔桥(SB)是一个强大的框架,用于解决如非配对域翻译等生成建模任务。大多数与SB相关的研究都集中在连续数据空间$\mathbb{R}^{D}$上,而将SB方法应用于离散数据(例如有限空间$\mathbb{S}^{D}$)的理论和算法问题留待解决。集合$\mathbb{S}$的著名例子包括现代自动编码器的向量量化(VQ)表示的代码本、文本中的令牌、分子中的原子类别等。在本文中,我们利用最近提出的迭代马尔可夫拟合(IMF)程序,为解决离散空间中的SB提供了理论和算法基础。具体来说,我们从理论上证明了离散时间IMF(D-IMF)收敛到离散空间中的SB。这使我们能够为SB开发一种实用的计算算法,我们称之为分类薛定谔桥匹配(CSBM)。我们通过合成数据和VQ图像表示的一系列实验展示了CSBM的性能。CSBM的代码可在https://github.com/gregkseno/csbm找到。
论文及项目相关链接
Summary
本文介绍了Schrödinger Bridge(SB)在离散空间中的应用,通过使用最近引入的Iterative Markovian Fitting(IMF)程序解决SB在离散空间中的理论和方法基础。作者提出了一种实用的计算算法,称为Categorical Schrödinger Bridge Matching(CSBM),并通过合成数据和VQ图像表示的实验验证了其性能。
Key Takeaways
- Schrödinger Bridge (SB) 是一个强大的生成建模框架,用于解决如未配对领域翻译等任务。
- 现有研究大多关注连续数据空间中的SB,而对离散数据应用SB方法仍存在理论和算法问题。
- 文章提供了在离散空间中解决SB的理论和算法基础,使用新引入的Iterative Markovian Fitting (IMF) 程序。
- 离散时间IMF(D-IMF)收敛到SB的理论证明。
- 基于此,开发了一种实用的计算算法Categorical Schrödinger Bridge Matching (CSBM)。
- 通过合成数据和VQ图像表示的实验验证了CSBM的性能。
点此查看论文截图

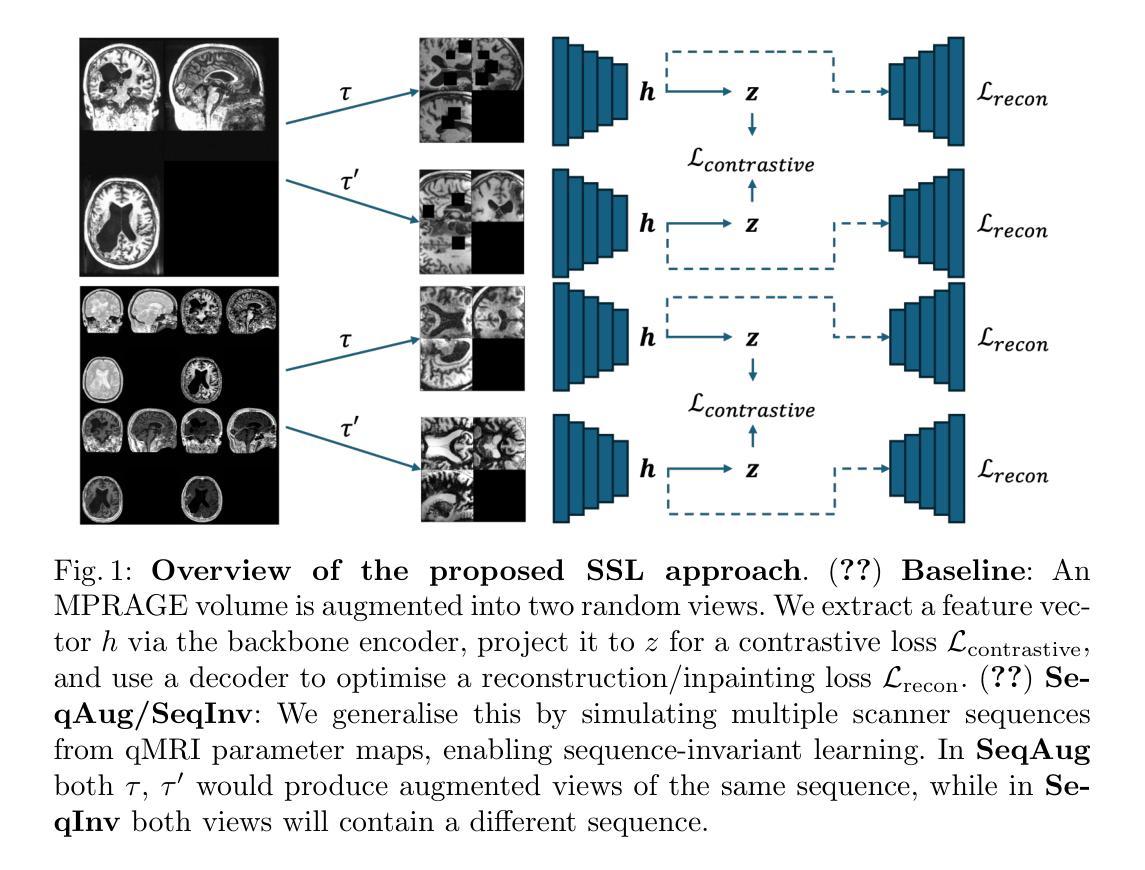
Unified 3D MRI Representations via Sequence-Invariant Contrastive Learning
Authors:Liam Chalcroft, Jenny Crinion, Cathy J. Price, John Ashburner
Self-supervised deep learning has accelerated 2D natural image analysis but remains difficult to translate into 3D MRI, where data are scarce and pre-trained 2D backbones cannot capture volumetric context. We present a \emph{sequence-invariant} self-supervised framework leveraging quantitative MRI (qMRI). By simulating multiple MRI contrasts from a single 3D qMRI scan and enforcing consistent representations across these contrasts, we learn anatomy-centric rather than sequence-specific features. The result is a single 3D encoder that excels across tasks and protocols. Experiments on healthy brain segmentation (IXI), stroke lesion segmentation (ARC), and MRI denoising show significant gains over baseline SSL approaches, especially in low-data settings (up to +8.3% Dice, +4.2 dB PSNR). It also generalises to unseen sites, supporting scalable clinical use. Code and trained models are publicly available at https://github.com/liamchalcroft/contrast-squared
自监督深度学习已加速2D自然图像分析,但转化为3D MRI仍然困难,3D MRI数据稀缺,预训练的2D骨干网无法捕捉体积上下文。我们提出了一种利用定量MRI(qMRI)的序列不变自监督框架。通过模拟单个3D qMRI扫描的多个MRI对比度,并强制这些对比度之间保持一致的表示,我们学习以解剖为中心的特征,而非特定序列的特征。结果是一个单一的3D编码器,它在各种任务和协议中都表现出色。在健康大脑分割(IXI)、中风病灶分割(ARC)和MRI降噪方面的实验显示,与传统的自监督学习方法相比,尤其是在数据较少的情况下(最高可提高+8.3%的Dice系数,+4.2分贝峰值信噪比),该方法取得了显著的优势。它还适用于未见过的站点,支持可扩展的临床使用。相关代码和训练模型已在https://github.com/liamchalcroft/contrast-squared公开可用。
论文及项目相关链接
Summary
基于定量MRI(qMRI)的序列不变自监督框架,通过模拟单个3DqMRI扫描的多个MRI对比度并强制这些对比度之间的一致性表示,学习以解剖为中心而非特定序列的特征。该框架使3D MRI分析受益于自监督深度学习,并克服了在低数据情况下应用困难的问题。该框架在各种任务和协议中表现出卓越性能,尤其在健康大脑分割(IXI)、中风病灶分割(ARC)和MRI去噪方面取得了显著进展。代码和训练模型已公开在GitHub上提供。
Key Takeaways
- 自监督深度学习在加速二维自然图像分析方面取得了进展,但难以应用于三维MRI数据。
- 三维MRI数据稀缺,且预训练的二维骨干网无法捕捉体积上下文信息,造成应用困难。
- 提出了一种利用定量MRI(qMRI)的序列不变自监督框架,模拟单个3DqMRI扫描的多个MRI对比度并强制其一致性表示。
- 学习以解剖为中心的特征而非特定序列的特征,解决MRI数据的独特挑战。
- 单一3D编码器在不同任务和协议中表现卓越,特别是在低数据设置下。
- 在健康大脑分割、中风病灶分割和MRI去噪方面取得了显著进展,相较于基线SSL方法有明显提升。
- 该框架具有在未见过的站点进行推广的能力,支持可扩展的临床应用。
点此查看论文截图

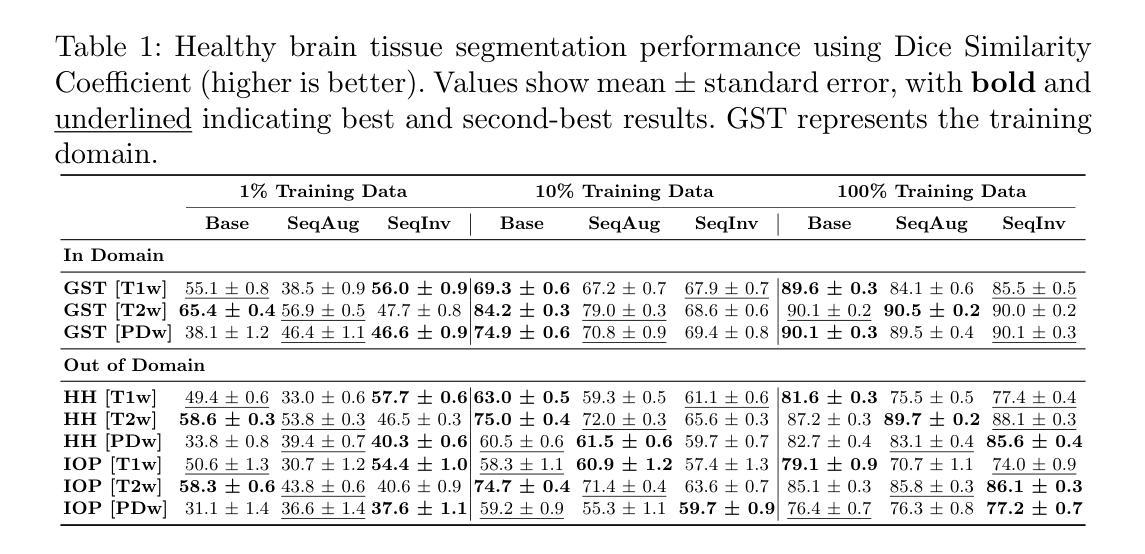
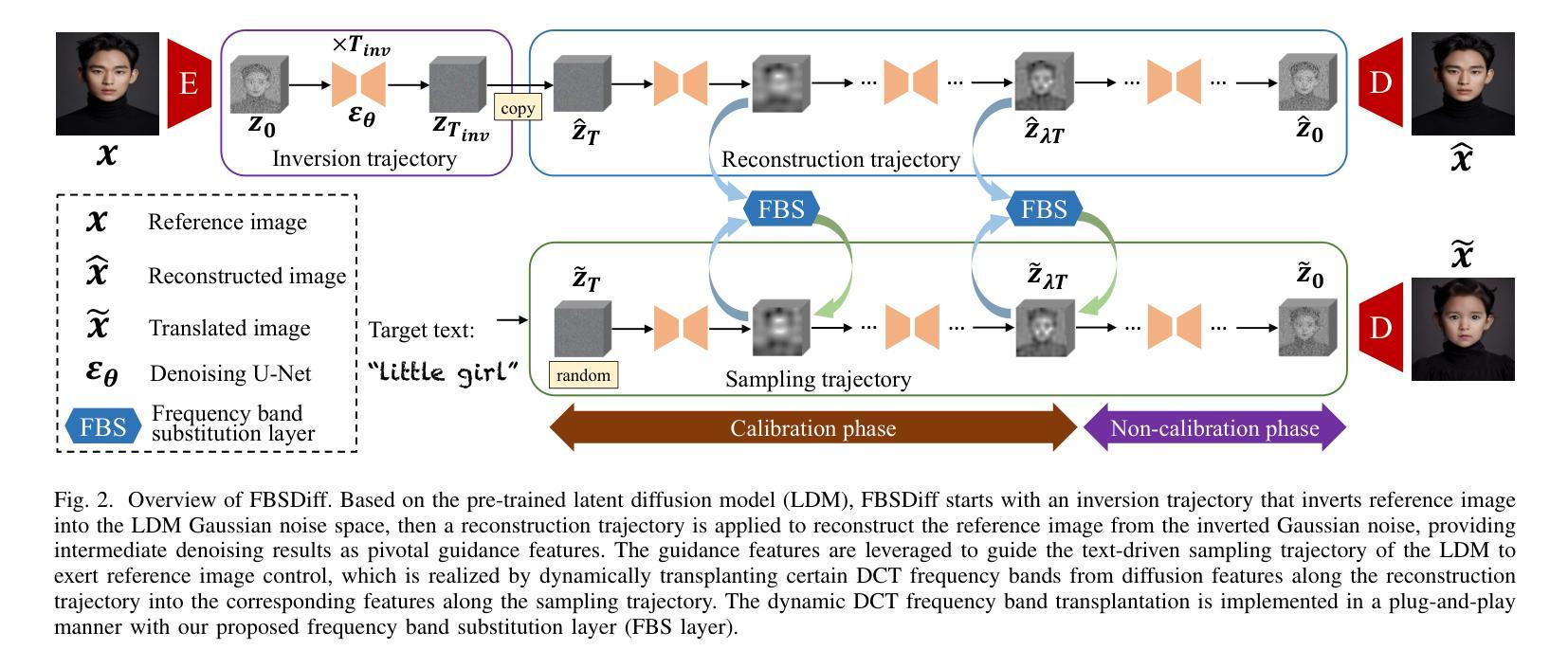
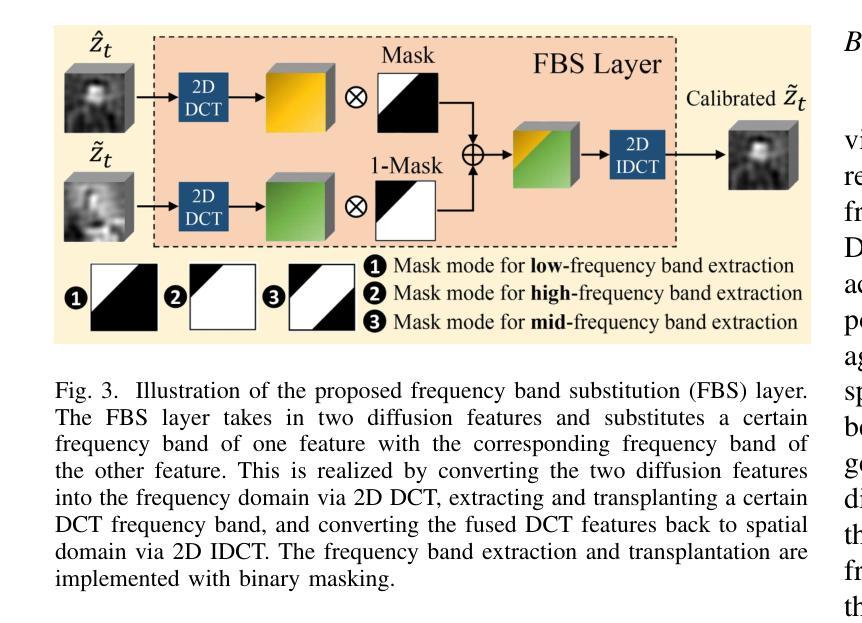
FBSDiff: Plug-and-Play Frequency Band Substitution of Diffusion Features for Highly Controllable Text-Driven Image Translation
Authors:Xiang Gao, Jiaying Liu
Large-scale text-to-image diffusion models have been a revolutionary milestone in the evolution of generative AI and multimodal technology, allowing wonderful image generation with natural-language text prompt. However, the issue of lacking controllability of such models restricts their practical applicability for real-life content creation. Thus, attention has been focused on leveraging a reference image to control text-to-image synthesis, which is also regarded as manipulating (or editing) a reference image as per a text prompt, namely, text-driven image-to-image translation. This paper contributes a novel, concise, and efficient approach that adapts pre-trained large-scale text-to-image (T2I) diffusion model to the image-to-image (I2I) paradigm in a plug-and-play manner, realizing high-quality and versatile text-driven I2I translation without any model training, model fine-tuning, or online optimization process. To guide T2I generation with a reference image, we propose to decompose diverse guiding factors with different frequency bands of diffusion features in the DCT spectral space, and accordingly devise a novel frequency band substitution layer which realizes dynamic control of the reference image to the T2I generation result in a plug-and-play manner. We demonstrate that our method allows flexible control over both guiding factor and guiding intensity of the reference image simply by tuning the type and bandwidth of the substituted frequency band, respectively. Extensive qualitative and quantitative experiments verify superiority of our approach over related methods in I2I translation visual quality, versatility, and controllability. The code is publicly available at: https://github.com/XiangGao1102/FBSDiff.
大规模文本到图像的扩散模型在生成式人工智能和多模态技术的演变中成为了一个革命性的里程碑。它能够通过自然语言文本提示来生成精彩的图像。然而,这类模型缺乏可控性的问题限制了它们在现实生活内容创建中的实际应用。因此,人们开始关注利用参考图像来控制文本到图像的合成,这被视为根据文本提示操作(或编辑)参考图像,即文本驱动的图像到图像翻译。本文贡献了一种新颖、简洁、高效的方法,该方法将预训练的大规模文本到图像(T2I)扩散模型适应到图像到图像(I2I)范式中,以即插即用方式,无需任何模型训练、模型微调或在线优化过程,即可实现高质量和多功能文本驱动的I2I翻译。为了用参考图像引导T2I生成,我们提出在DCT谱空间中分解具有不同频率带的扩散特征的多种指导因素,并相应地设计了一种新型频率带替换层,以即插即用方式动态控制参考图像对T2I生成结果的影响。我们证明,通过简单地调整替代的频率带的类型和带宽,我们的方法能够灵活地控制参考图像的指导因素和强度。大量的定性和定量实验验证了我们方法在图像到图像翻译的视觉质量、多样性和可控性方面的优越性。代码公开在:https://github.com/XiangGao1102/FBSDiff。
论文及项目相关链接
PDF Accepted conference paper of ACM MM 2024
Summary
文本介绍了大型文本到图像扩散模型在生成AI和多模态技术方面的革命性里程碑,但缺乏可控性限制了其实用性。因此,研究利用参考图像来控制文本到图像的合成,提出了一种新型的、简洁高效的方法,通过预训练的大型文本到图像扩散模型,以即插即用方式实现高质量的文本驱动图像到图像翻译,无需模型训练或微调。通过分解不同频率带的扩散特征,提出了频率带替代层,实现了对参考图像的动态控制。该方法通过调整替代的频率带类型和带宽,可以灵活控制指导因素和参考图像的指导强度。实验验证了在图像到图像翻译的视觉质量、通用性和可控性方面的优越性。
Key Takeaways
- 大型文本到图像扩散模型在生成AI和多模态技术领域具有革命性。
- 缺乏可控性是这些模型实际应用中的主要限制。
- 利用参考图像控制文本到图像的合成已成为研究焦点。
- 该论文提出了一种新型方法,通过预训练的文本到图像扩散模型实现即插即用的图像到图像翻译。
- 方法涉及在DCT谱空间中分解不同频率带的扩散特征。
- 频率带替代层可实现参考图像的动态控制。
- 该方法允许通过调整替代的频率带类型和带宽来灵活控制指导因素和参考图像的指导强度。
点此查看论文截图


X-ray2CTPA: Leveraging Diffusion Models to Enhance Pulmonary Embolism Classification
Authors:Noa Cahan, Eyal Klang, Galit Aviram, Yiftach Barash, Eli Konen, Raja Giryes, Hayit Greenspan
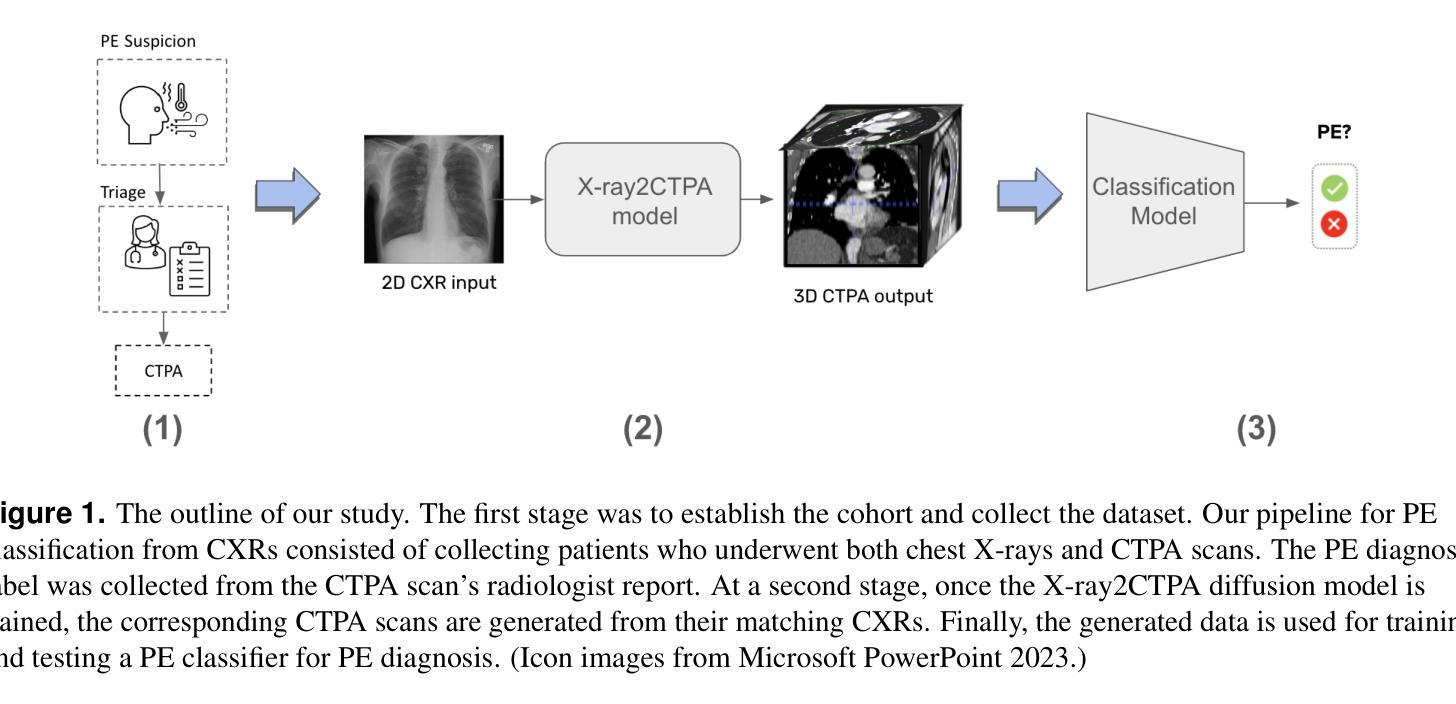
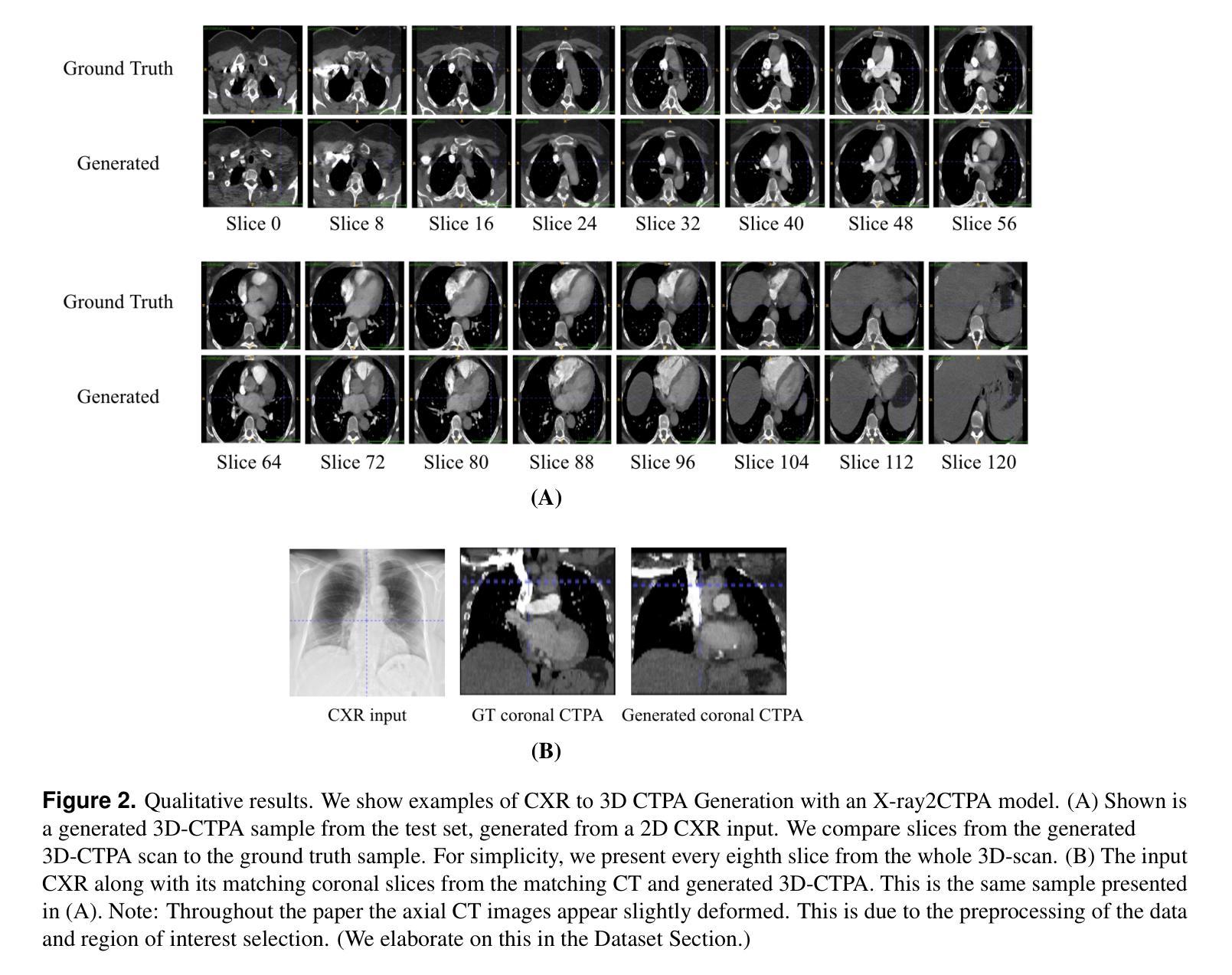
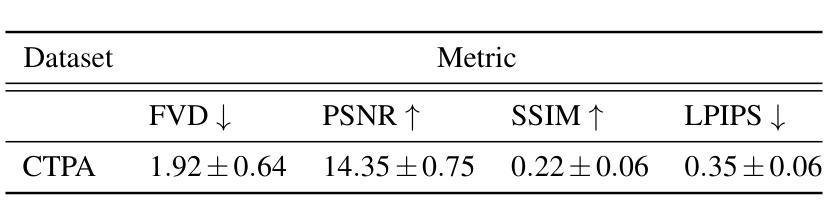
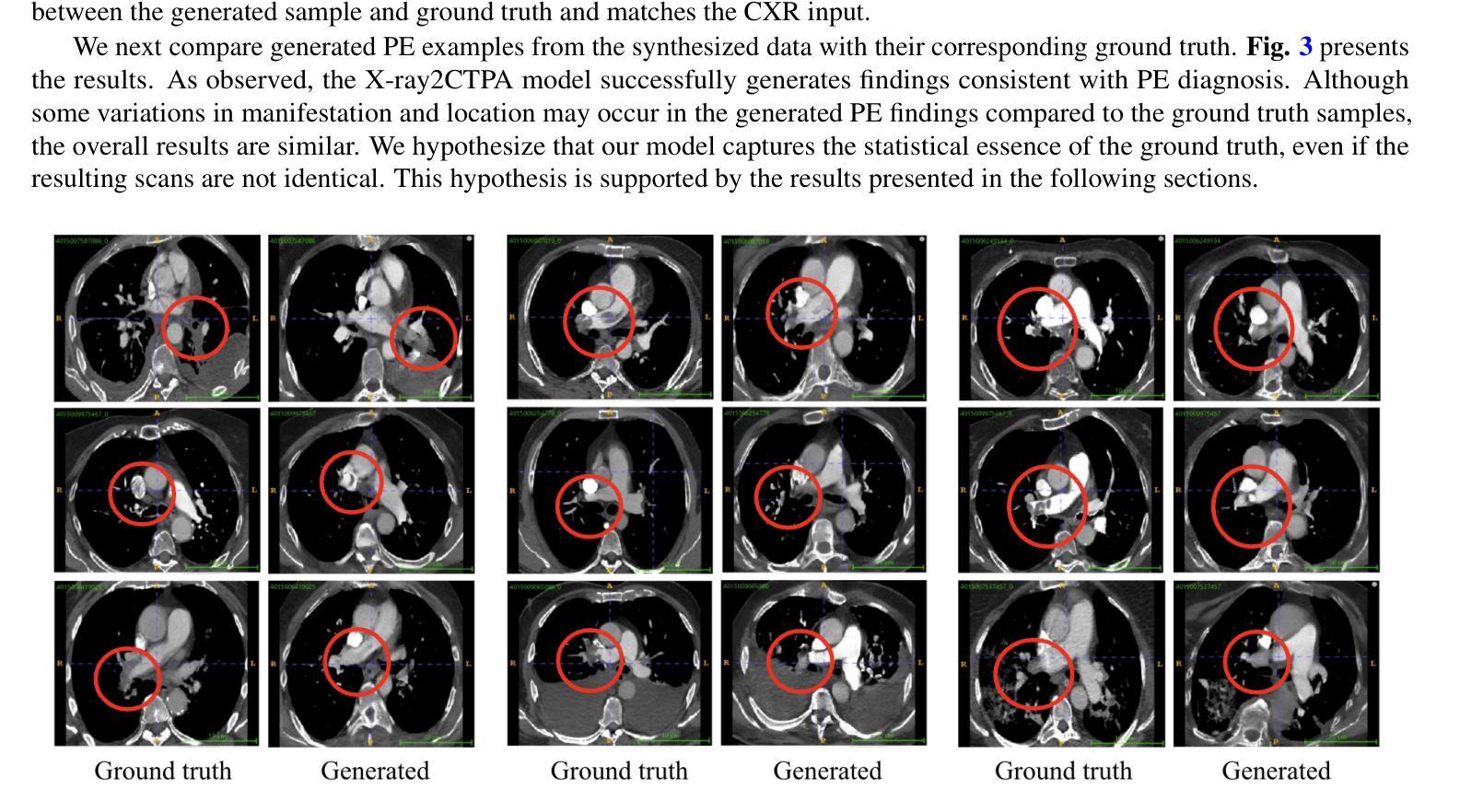
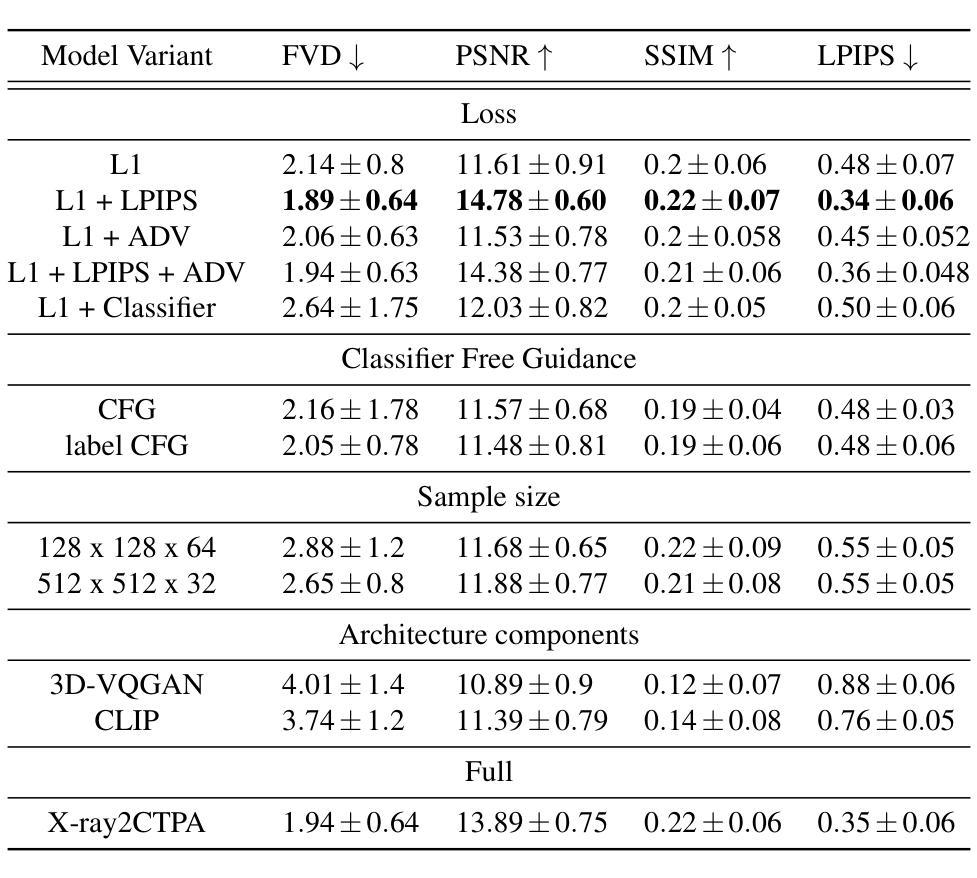
Chest X-rays or chest radiography (CXR), commonly used for medical diagnostics, typically enables limited imaging compared to computed tomography (CT) scans, which offer more detailed and accurate three-dimensional data, particularly contrast-enhanced scans like CT Pulmonary Angiography (CTPA). However, CT scans entail higher costs, greater radiation exposure, and are less accessible than CXRs. In this work we explore cross-modal translation from a 2D low contrast-resolution X-ray input to a 3D high contrast and spatial-resolution CTPA scan. Driven by recent advances in generative AI, we introduce a novel diffusion-based approach to this task. We evaluate the models performance using both quantitative metrics and qualitative feedback from radiologists, ensuring diagnostic relevance of the generated images. Furthermore, we employ the synthesized 3D images in a classification framework and show improved AUC in a PE categorization task, using the initial CXR input. The proposed method is generalizable and capable of performing additional cross-modality translations in medical imaging. It may pave the way for more accessible and cost-effective advanced diagnostic tools. The code for this project is available: https://github.com/NoaCahan/X-ray2CTPA .
胸部X射线或胸部放射摄影(CXR)是医学诊断中常用的方法,与计算机断层扫描(CT)相比,其成像通常较为有限。CT扫描可以提供更详细和准确的三维数据,特别是像CT肺动脉造影(CTPA)这样的增强扫描。然而,CT扫描的成本较高,辐射暴露量较大,且相对于CXRs来说不太容易获得。在这项工作中,我们探索了从低对比度的2D X射线输入到高对比度和空间分辨率的3DCTPA扫描的跨模态翻译。得益于生成人工智能的最新进展,我们针对此任务引入了一种新型的基于扩散的方法。我们利用定量指标和来自放射科医师的定性反馈来评估模型性能,以确保生成图像的诊断相关性。此外,我们在分类框架中使用了合成的3D图像,并在使用初始CXR输入的PE分类任务中显示出提高了AUC。所提出的方法具有通用性,能够执行其他医学成像的跨模态翻译。它可能为更便捷和成本效益更高的先进诊断工具铺平道路。该项目的代码可在以下网址找到:https://github.com/NoaCahan/X-ray2CTPA 。
论文及项目相关链接
PDF preprint, project code: https://github.com/NoaCahan/X-ray2CTPA
Summary
本文介绍了将二维低对比度分辨率的X光片转化为三维高对比度和高分辨率的CT肺动脉造影(CTPA)扫描的跨模态转换技术。利用生成式人工智能的最新进展,提出了一种基于扩散的方法来完成这一任务。经过定量评估和放射科医生定性反馈,生成的图像具有诊断意义。此外,合成的三维图像在分类框架中用于PE分类任务,使用初始的CXR输入提高了AUC值。该方法具有通用性,可应用于医学影像的其他跨模态转换,可能为更可访问和成本效益高的先进诊断工具铺平道路。相关代码已在GitHub上公开。
Key Takeaways
- 介绍了从二维低对比度分辨率的X光片到三维高对比度和高分辨率CT肺动脉造影(CTPA)扫描的跨模态转换技术。
- 利用生成式人工智能的最新进展,提出了一种基于扩散的方法来完成这一任务,保证图像转化的准确性。
- 通过定量评估和放射科医生的定性反馈验证了生成的图像具有诊断意义。
- 合成的三维图像在分类框架中用于PE分类任务,提高了AUC值,证明了其在临床应用中的潜力。
- 该方法具有通用性,可应用于医学影像的其他跨模态转换任务。
- 该技术可能为更可访问和成本效益高的先进诊断工具铺平道路,有助于降低医疗成本和提高诊断效率。
点此查看论文截图