⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-01 更新
iLSU-T: an Open Dataset for Uruguayan Sign Language Translation
Authors:Ariel E. Stassi, Yanina Boria, J. Matías Di Martino, Gregory Randall
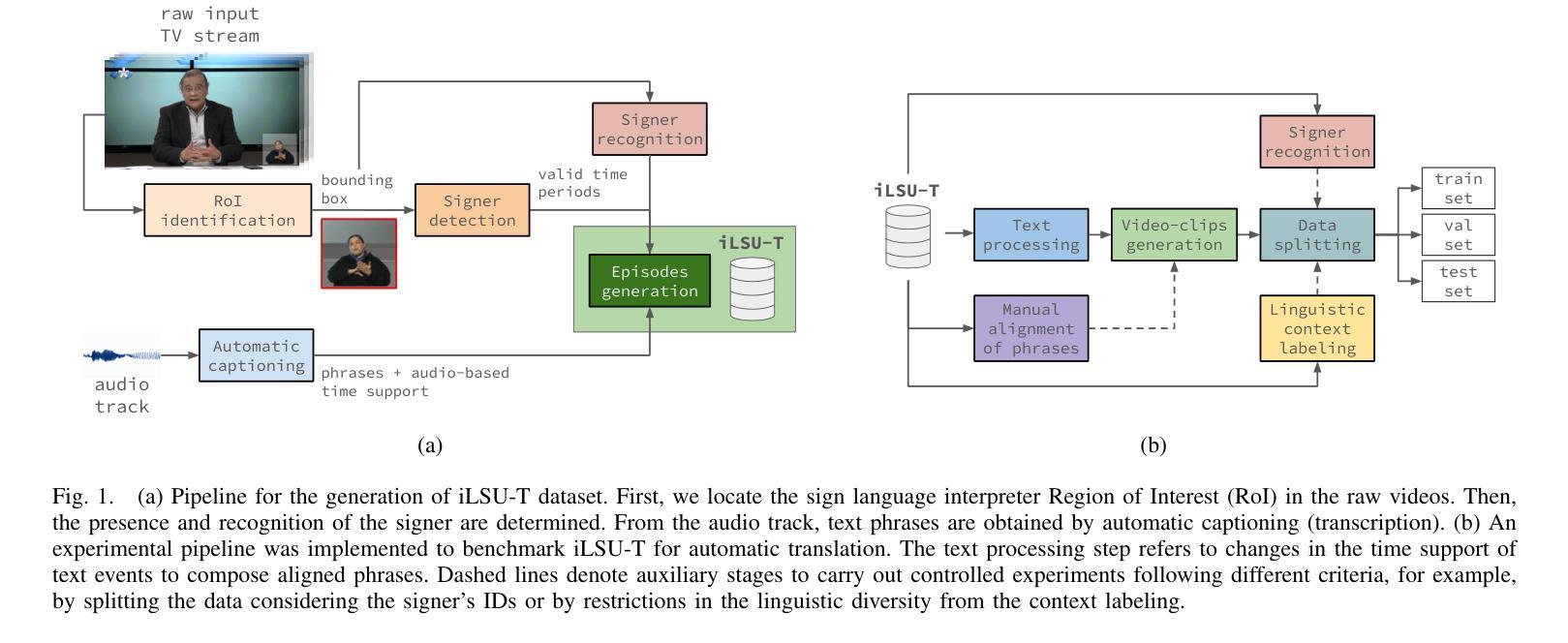
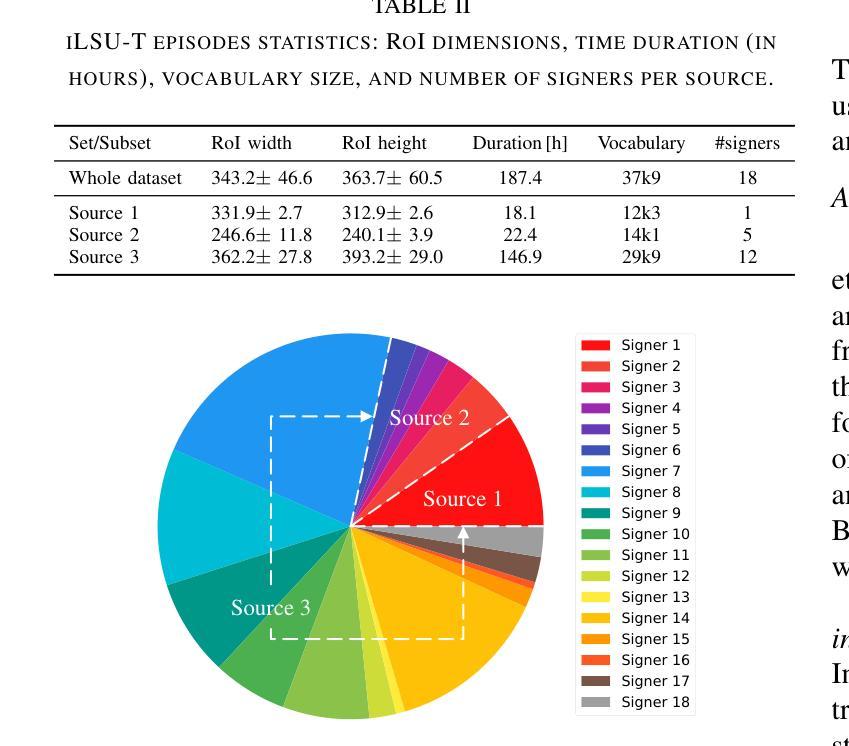
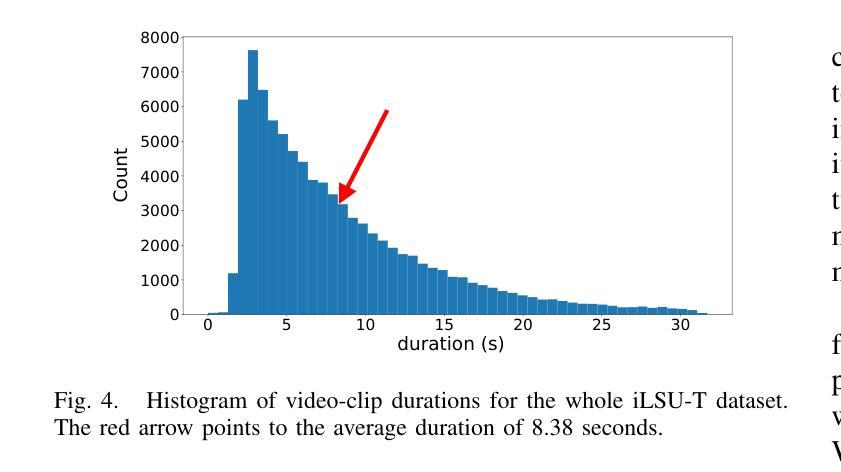
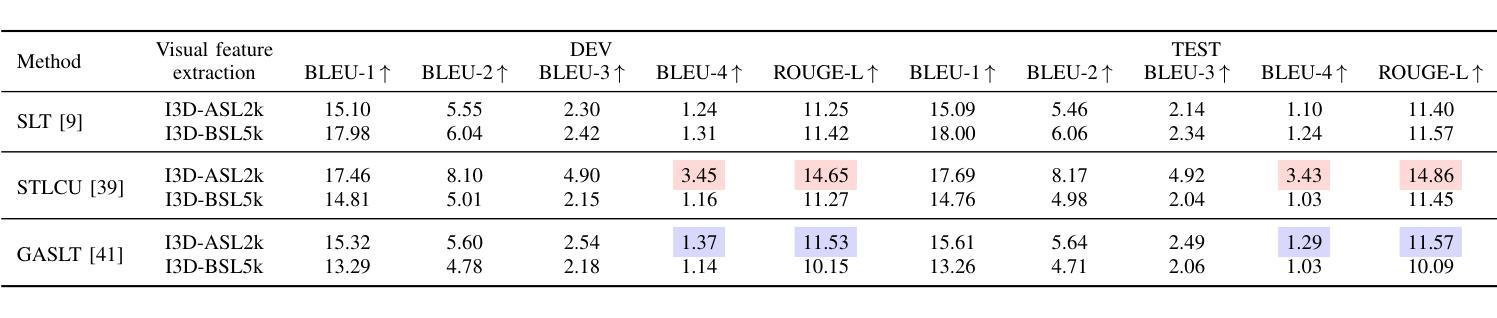
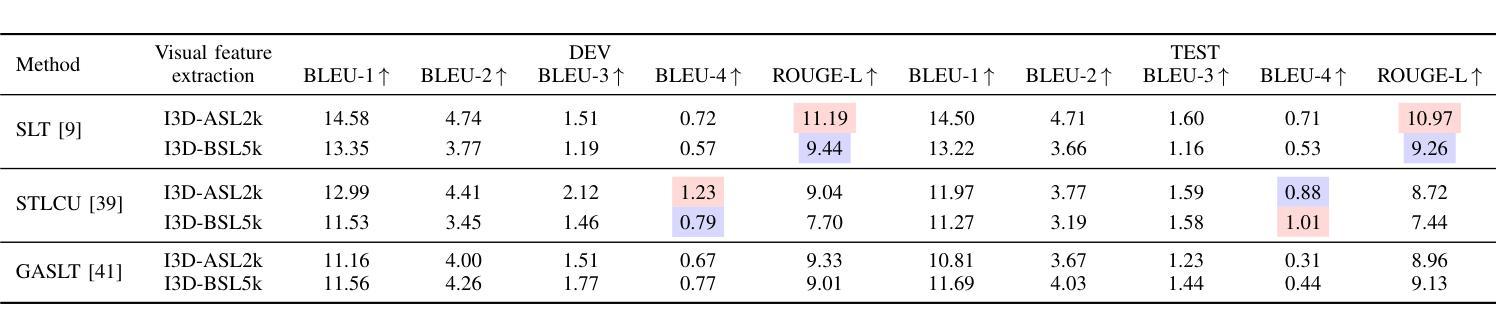
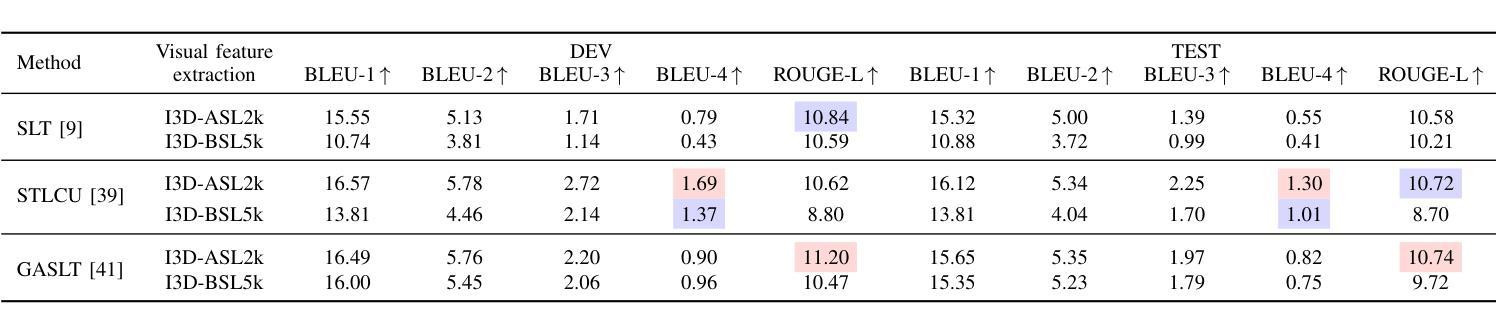
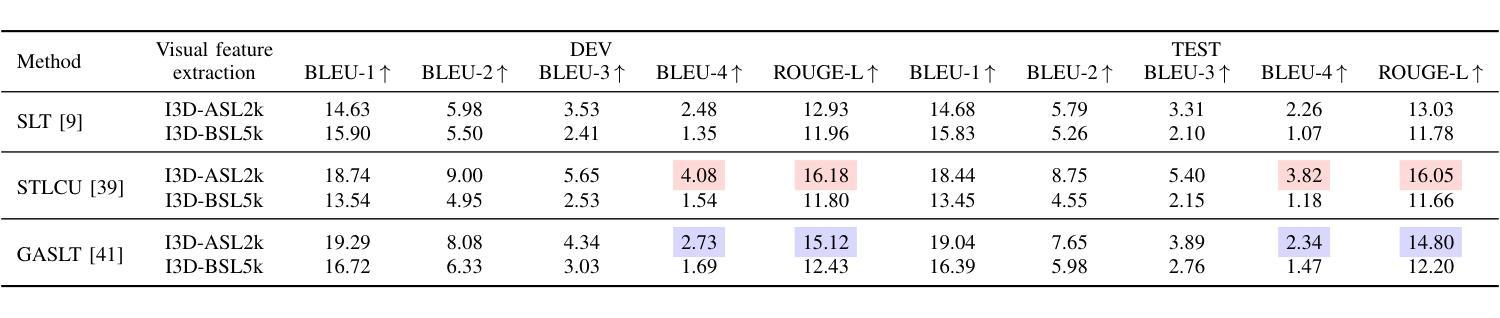
Automatic sign language translation has gained particular interest in the computer vision and computational linguistics communities in recent years. Given each sign language country particularities, machine translation requires local data to develop new techniques and adapt existing ones. This work presents iLSU T, an open dataset of interpreted Uruguayan Sign Language RGB videos with audio and text transcriptions. This type of multimodal and curated data is paramount for developing novel approaches to understand or generate tools for sign language processing. iLSU T comprises more than 185 hours of interpreted sign language videos from public TV broadcasting. It covers diverse topics and includes the participation of 18 professional interpreters of sign language. A series of experiments using three state of the art translation algorithms is presented. The aim is to establish a baseline for this dataset and evaluate its usefulness and the proposed pipeline for data processing. The experiments highlight the need for more localized datasets for sign language translation and understanding, which are critical for developing novel tools to improve accessibility and inclusion of all individuals. Our data and code can be accessed.
近年来,自动手语翻译在计算机视觉和计算语言学领域引起了特别的关注。考虑到每个手语国家的特殊性,机器翻译需要本地数据来开发新技术和适应现有技术。本文介绍了iLSU T,这是一个乌拉圭手语RGB视频开放数据集,包含音频和文字转录。这种多模态和精选数据对于开发理解手语处理或生成工具的新方法至关重要。iLSU T包含来自公共电视广播的超过185小时的翻译手语视频。它涵盖了各种主题,包括18名专业手语翻译人员的参与。本文介绍了一系列使用三种最先进的翻译算法的实验。其目的是为这个数据集建立基准线,并评估其实用性和提出的数据处理管道。实验突出了对更本地化手语翻译和理解数据集的需求,这对于开发新工具以提高所有个体的可访问性和包容性至关重要。我们的数据和代码都可以访问。
论文及项目相关链接
PDF 10 pages, 5 figures, 19th International Conference on Automatic Face and Gesture Recognition IEEE FG 2025
Summary
本文介绍了自动手语翻译领域的研究进展,特别是计算机视觉和计算语言学社区的关注点。针对每个国家的特有手语特性,机器翻译需要本地数据来开发新技术和调整现有技术。本文提出了一个乌拉圭手语RGB视频数据集iLSU T,该数据集包含音频和文字转录,是开发手语处理工具的关键。iLSU T包含超过185小时的公开电视广播手语视频。本文还进行了一系列使用三种前沿翻译算法的实验,旨在建立数据集基准并评估其实用性和数据处理流程。实验强调了对手语翻译和理解领域的本地化数据集的需求,这对于开发改善所有个体可访问性和包容性的工具至关重要。数据集和代码可供访问。
Key Takeaways
- 自动手语翻译在计算机视觉和计算语言学领域受到关注。
- 不同国家的手语特性使得机器翻译需要本地数据。
- iLSU T是一个包含音频和文字转录的乌拉圭手语RGB视频数据集,对于开发手语处理工具至关重要。
- iLSU T包含超过185小时的公开电视广播手语视频。
- 进行了一系列前沿翻译算法的实验以评估数据集和数据处理流程的实用性。
- 实验结果强调对手语翻译和理解领域的本地化数据集的需求。
点此查看论文截图


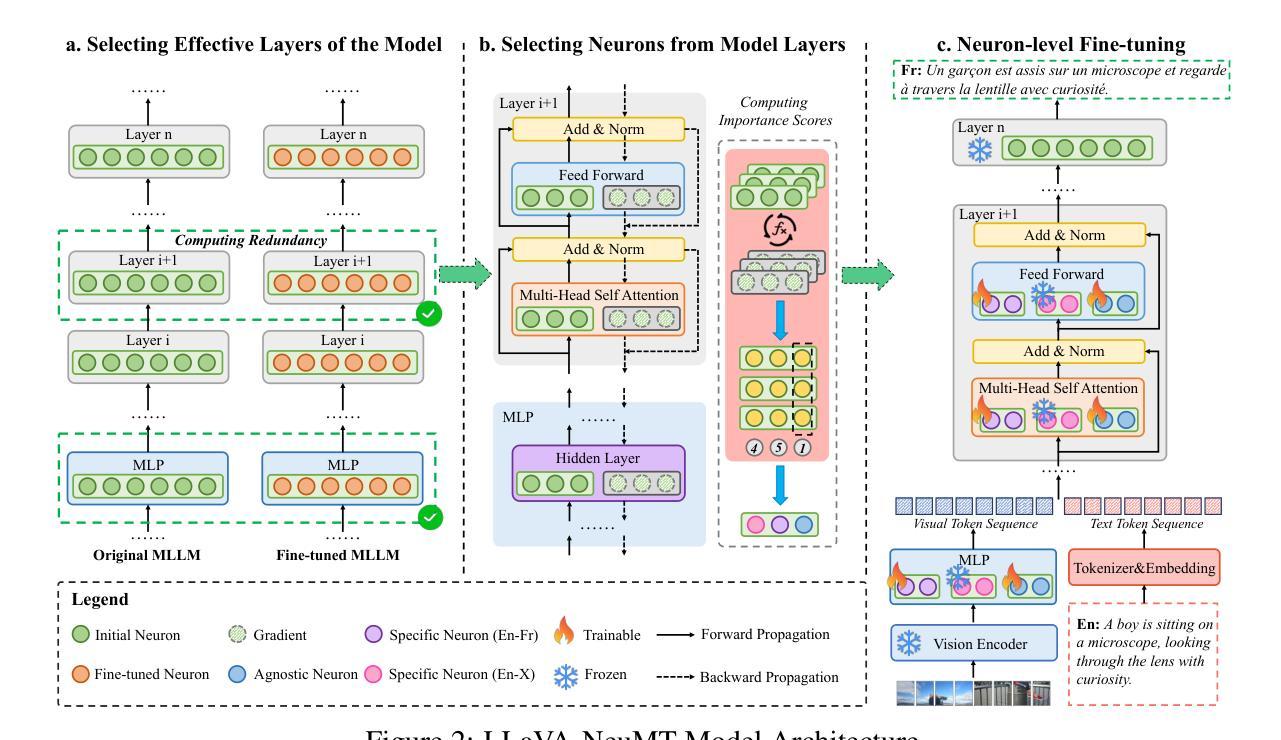
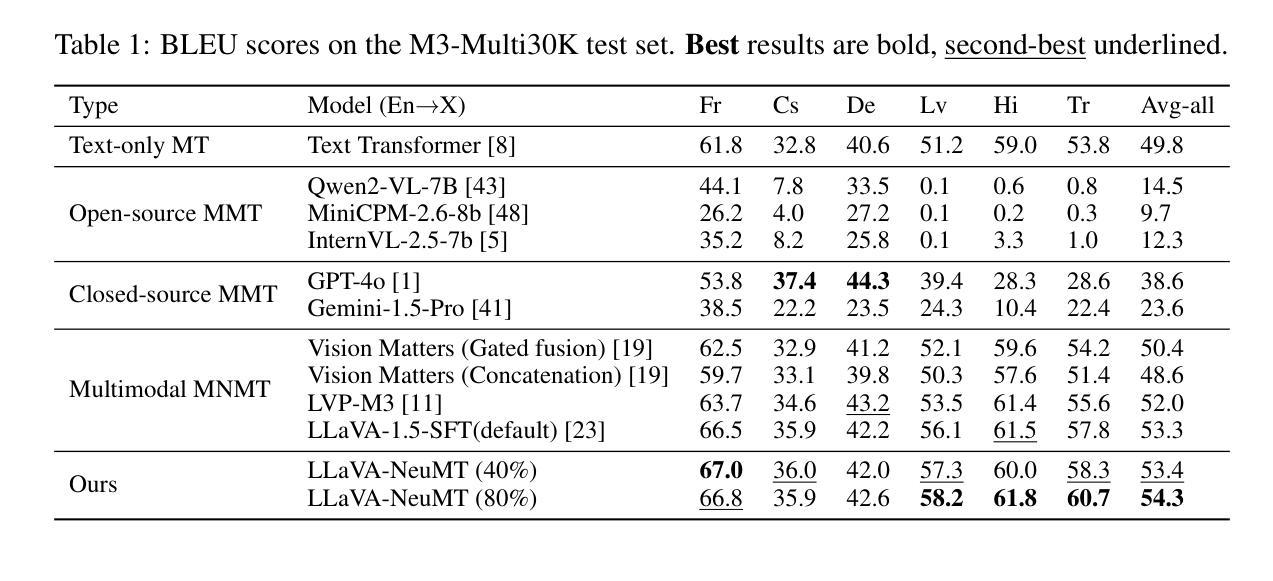
LLaVA-NeuMT: Selective Layer-Neuron Modulation for Efficient Multilingual Multimodal Translation
Authors:Jingxuan Wei, Caijun Jia, Qi Chen, Yujun Cai, Linzhuang Sun, Xiangxiang Zhang, Gaowei Wu, Bihui Yu
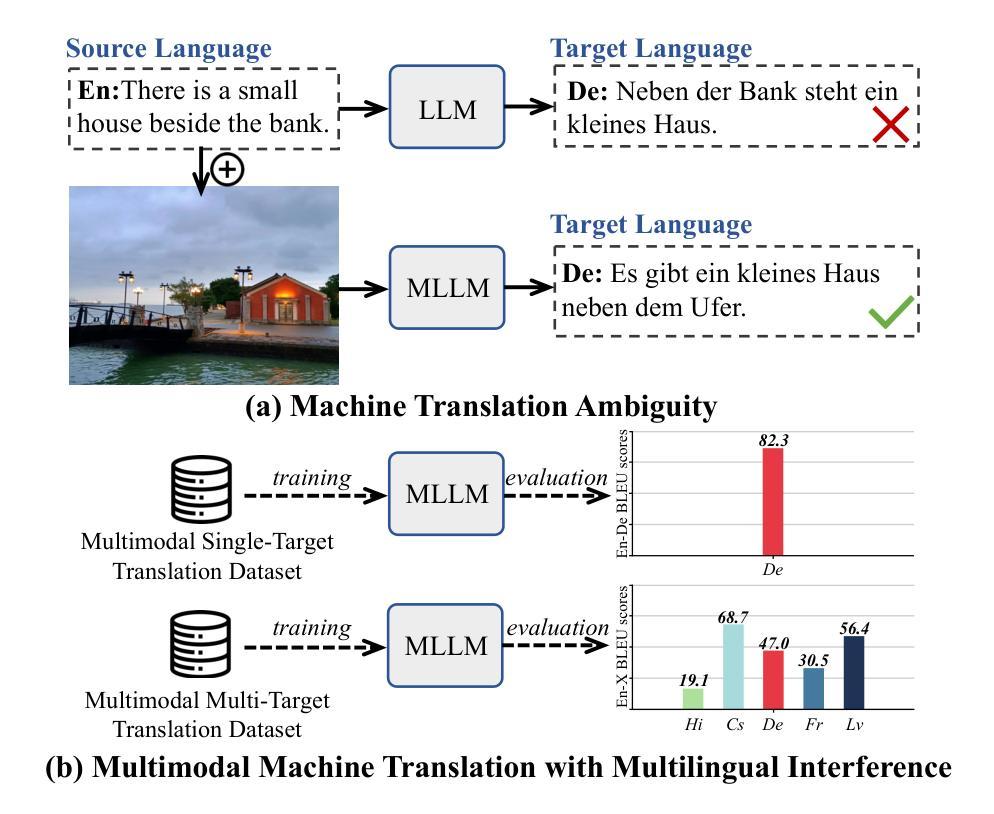
Multimodal Machine Translation (MMT) enhances translation quality by incorporating visual context, helping to resolve textual ambiguities. While existing MMT methods perform well in bilingual settings, extending them to multilingual translation remains challenging due to cross-lingual interference and ineffective parameter-sharing strategies. To address this, we propose LLaVA-NeuMT, a novel multimodal multilingual translation framework that explicitly models language-specific and language-agnostic representations to mitigate multilingual interference. Our approach consists of a layer selection mechanism that identifies the most informative layers for different language pairs and a neuron-level adaptation strategy that dynamically selects language-specific and agnostic neurons to improve translation quality while reducing redundancy. We conduct extensive experiments on the M3-Multi30K and M3-AmbigCaps datasets, demonstrating that LLaVA-NeuMT, while fine-tuning only 40% of the model parameters, surpasses full fine-tuning approaches and ultimately achieves SOTA results on both datasets. Our analysis further provides insights into the importance of selected layers and neurons in multimodal multilingual adaptation, offering an efficient and scalable solution to cross-lingual adaptation in multimodal translation.
多模态机器翻译(MMT)通过融入视觉上下文增强翻译质量,帮助解决文本歧义。虽然现有的MMT方法在双语环境中表现良好,但将其扩展到多语种翻译仍然具有挑战性,因为存在跨语种干扰和无效的参数共享策略。为了解决这个问题,我们提出了LLaVA-NeuMT这一新颖的多模态多语种翻译框架,它显式地建模语言特定和通用的表示,以减轻多语种干扰。我们的方法包括一个层选择机制,用于识别不同语言对的最具信息量的层,以及一个神经元级别的适应策略,动态选择语言特定和通用的神经元以提高翻译质量并减少冗余。我们在M3-Multi30K和M3-AmbigCaps数据集上进行了大量实验,结果表明LLaVA-NeuMT在仅微调模型参数的40%的情况下,超越了全微调方法,最终在这两个数据集上达到了最新水平的结果。我们的分析进一步深入了解了所选的层和神经元在多模态多语种适应中的重要性,为多模态翻译的跨语种适应提供了高效且可扩展的解决方案。
论文及项目相关链接
Summary
MMT通过融入视觉语境提高翻译质量,解决文本歧义问题。针对多语种翻译中遇到的跨语种干扰和参数共享策略失效的问题,提出LLaVA-NeuMT这一新颖的多模态多语种翻译框架。它通过建模语言特有和无关的表现层,减少多语种干扰。采用层选择机制和神经元级适应策略,动态筛选对不同语言对最具有信息量的层和神经元,提高翻译质量并降低冗余。在M3-Multi30K和M3-AmbigCaps数据集上的实验表明,LLaVA-NeuMT仅需微调模型参数的40%,即可超越全量微调方法,达到两个数据集的最好水平。同时,对所选层和神经元的分析为未来的多模态多语种适配提供了重要启示。
Key Takeaways
- MMT通过结合视觉上下文提高翻译质量。
- 处理多语种翻译时面临跨语种干扰和参数共享问题。
- LLaVA-NeuMT是一个处理多模态多语种翻译的新框架,通过建模语言特有和无关的表现层来减轻多语种干扰。
- LLaVA-NeuMT采用层选择机制,识别对不同语言对最具有信息量的层。
- 神经元级适应策略能动态筛选语言特定和无关的神经元,提高翻译质量并降低冗余。
- 在M3-Multi30K和M3-AmbigCaps数据集上的实验表明LLaVA-NeuMT效果显著。
点此查看论文截图

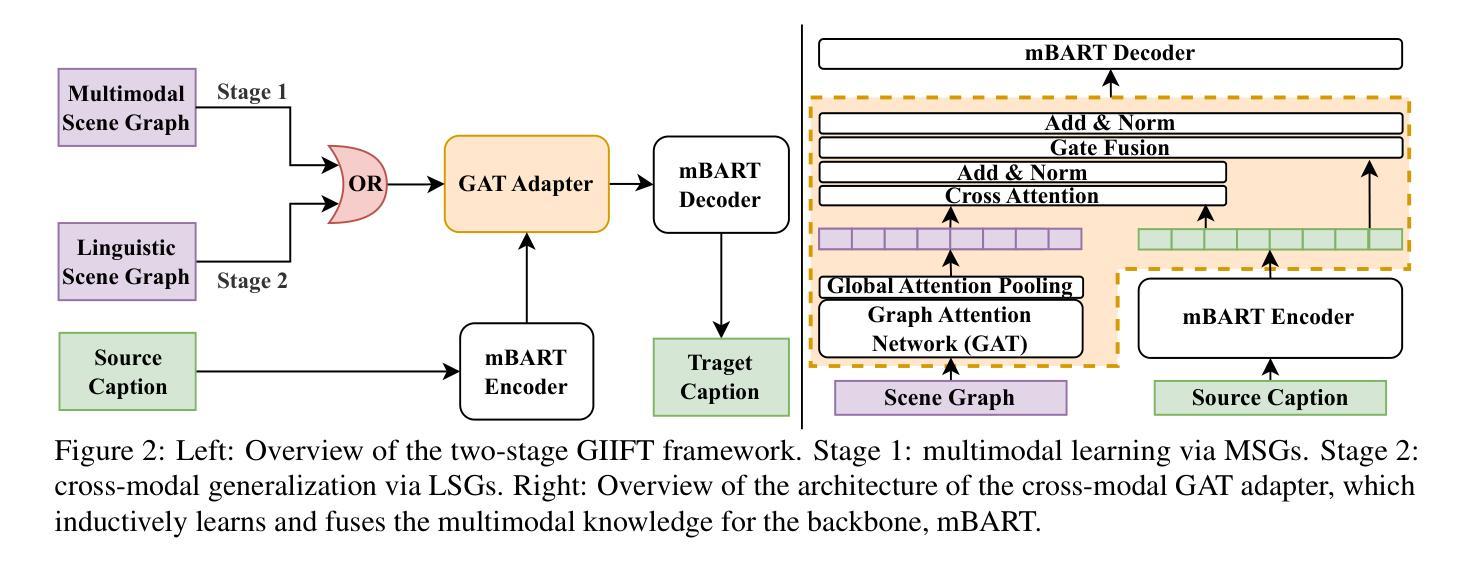
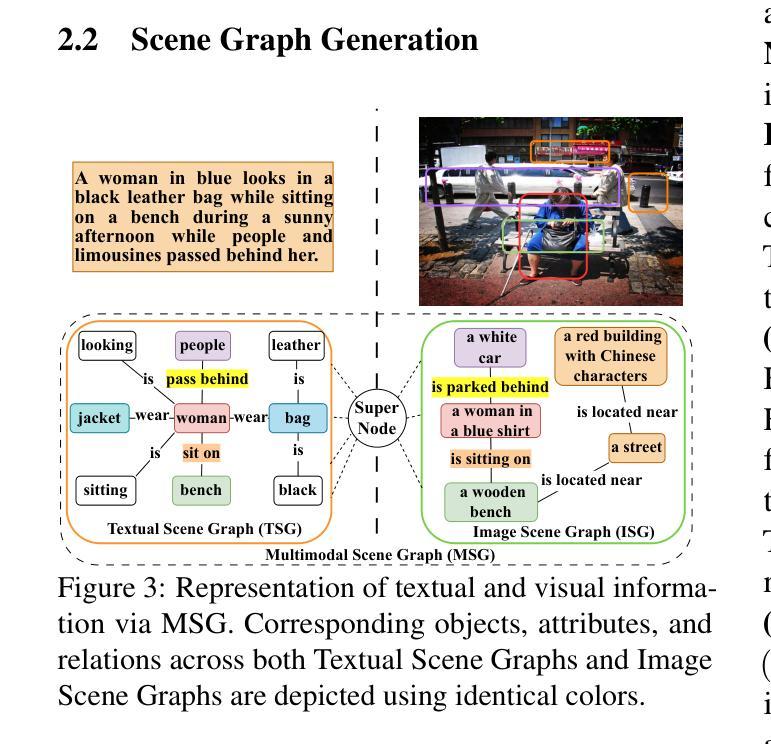
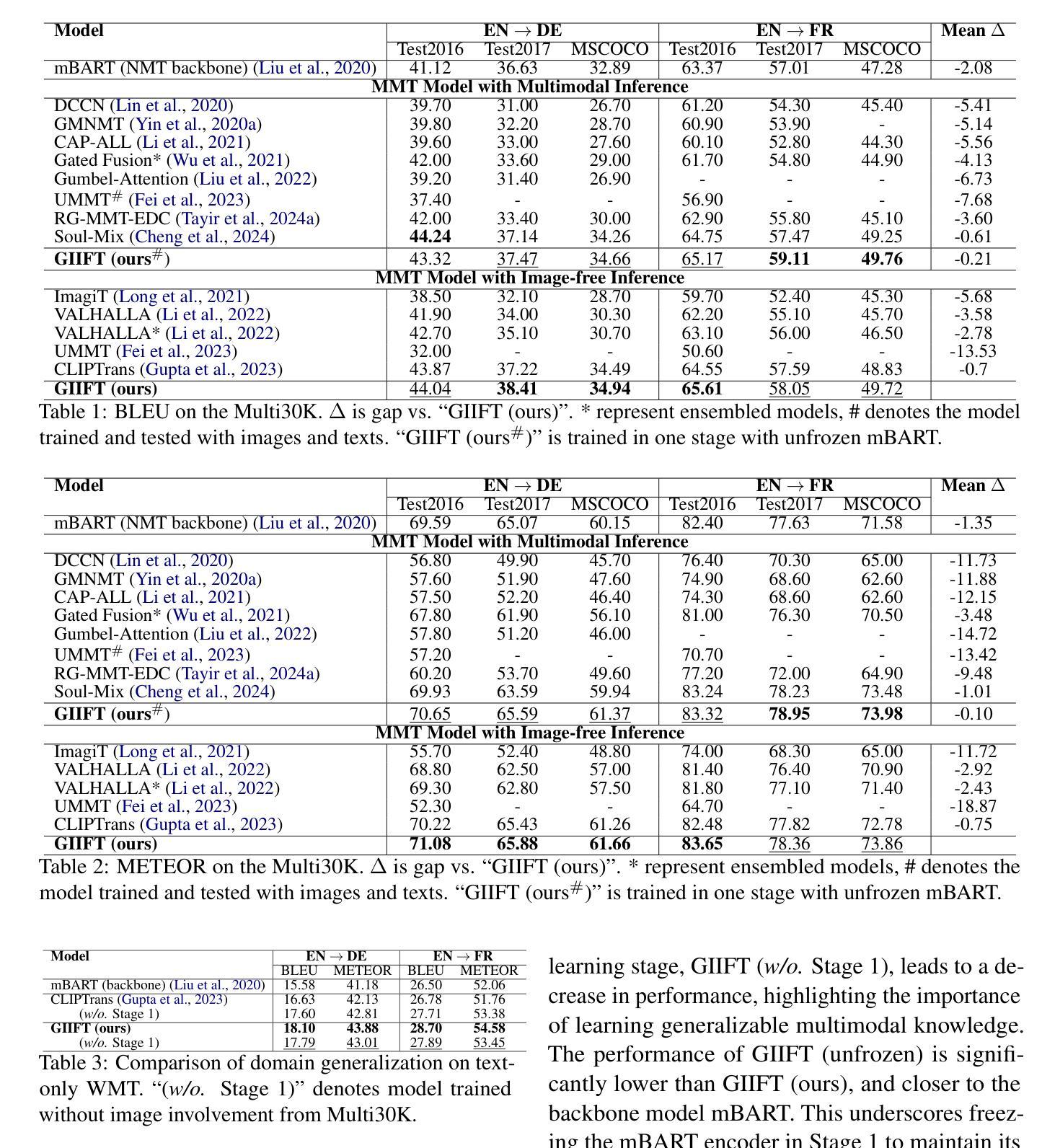
GIIFT: Graph-guided Inductive Image-free Multimodal Machine Translation
Authors:Jiafeng Xiong, Yuting Zhao
Multimodal Machine Translation (MMT) has demonstrated the significant help of visual information in machine translation. However, existing MMT methods face challenges in leveraging the modality gap by enforcing rigid visual-linguistic alignment whilst being confined to inference within their trained multimodal domains. In this work, we construct novel multimodal scene graphs to preserve and integrate modality-specific information and introduce GIIFT, a two-stage Graph-guided Inductive Image-Free MMT framework that uses a cross-modal Graph Attention Network adapter to learn multimodal knowledge in a unified fused space and inductively generalize it to broader image-free translation domains. Experimental results on the Multi30K dataset of English-to-French and English-to-German tasks demonstrate that our GIIFT surpasses existing approaches and achieves the state-of-the-art, even without images during inference. Results on the WMT benchmark show significant improvements over the image-free translation baselines, demonstrating the strength of GIIFT towards inductive image-free inference.
多模态机器翻译(MMT)已经证明了视觉信息在机器翻译中的巨大帮助。然而,现有的MMT方法在利用模态间隙方面面临挑战,它们通过强制视觉语言对齐而受到限制,同时受限于其训练的多模态域内的推理。在这项工作中,我们构建了新型的多模态场景图来保存和整合特定模态的信息,并引入了GIIFT,这是一个两阶段的图引导归纳无图多模态机器翻译框架,它使用跨模态图注意力网络适配器在统一融合空间中学习多模态知识,并将其归纳推广到更广泛的无图像翻译领域。在Multi30K英语到法语和英语到德语任务的实验结果表明,我们的GIIFT超越了现有方法并达到了最新水平,即使在推理过程中没有图像也是如此。在WMT基准测试上的结果证明,相较于无图像翻译基线,GIIFT取得了显著的提升,证明了其在归纳无图像推理方面的优势。
论文及项目相关链接
Summary
本文介绍了多模态机器翻译(MMT)中视觉信息的重要辅助作用,但现有MMT方法在利用模态间隙方面面临挑战。为应对这一挑战,本文构建了新型多模态场景图以保存和整合模态特定信息,并引入了GIIFT框架。该框架采用两阶段图引导的无图像MMT方式,利用跨模态图注意力网络适配器在统一融合空间学习多模态知识,并推广至更广泛的无需图像翻译领域。在Multi30K数据集上的英语至法语和英语至德语任务实验表明,GIIFT超越现有方法,达到最新水平,且推理过程中无需图像。在WMT基准测试上的结果也显著优于无图像翻译基线,证明了GIIFT在归纳无图像推理方面的优势。
Key Takeaways
- 多模态机器翻译(MMT)中视觉信息起到重要辅助作用。
- 现有MMT方法在利用模态间隙方面存在挑战,需要构建新型多模态场景图。
- 本文引入GIIFT框架,采用两阶段图引导的无图像MMT方式。
- GIIFT利用跨模态图注意力网络适配器在统一融合空间学习多模态知识。
- GIIFT能够推广至更广泛的无需图像的翻译领域。
- 在Multi30K数据集上的实验表明,GIIFT超越现有方法,达到最新翻译水平。
- 在WMT基准测试上,GIIFT表现优于无图像翻译基线,证明其在归纳无图像推理方面的优势。
点此查看论文截图

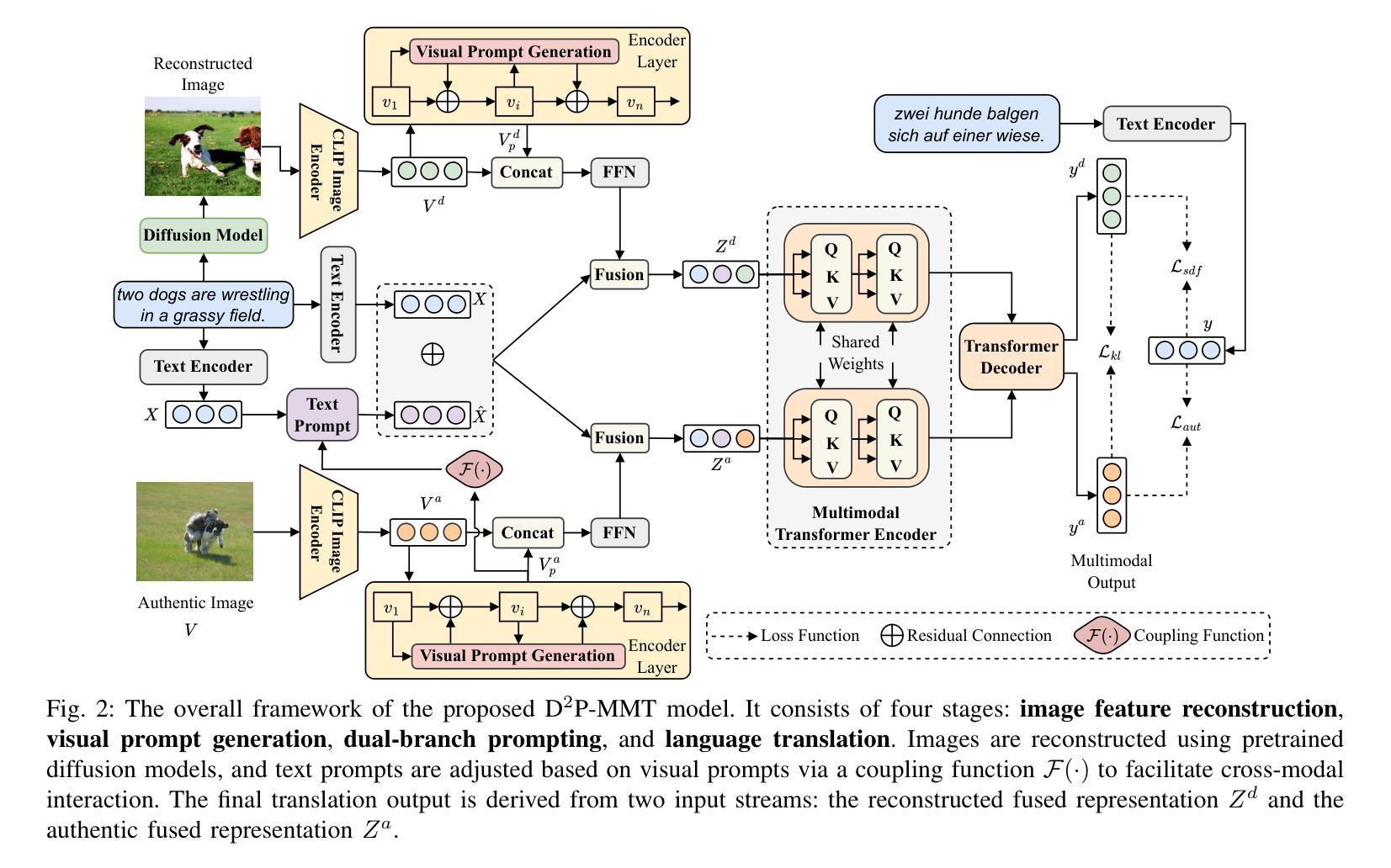
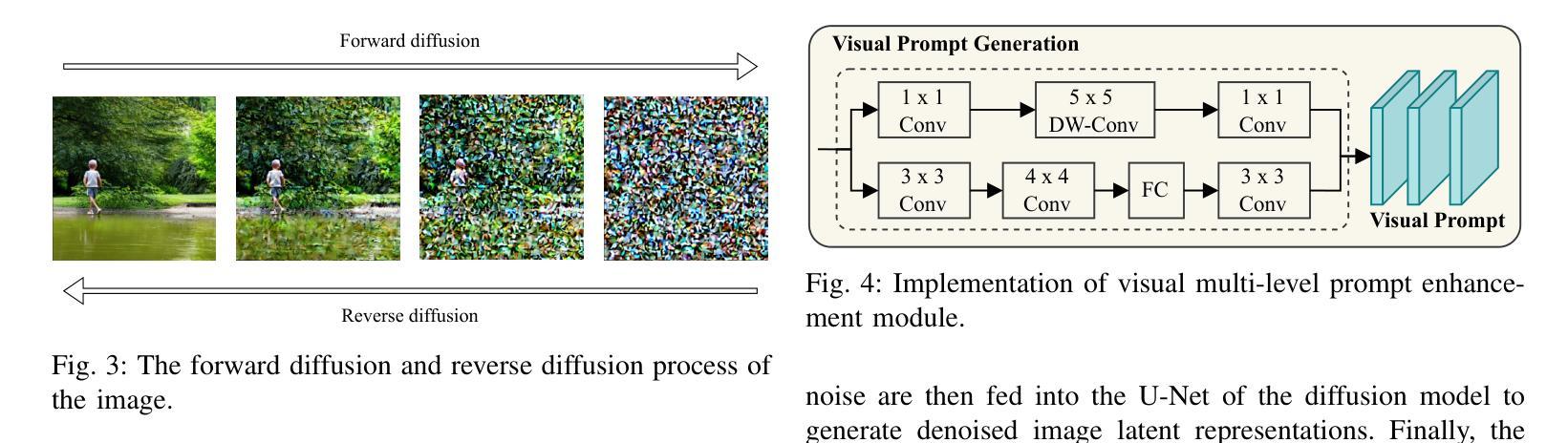
Dual-branch Prompting for Multimodal Machine Translation
Authors:Jie Wang, Zhendong Yang, Liansong Zong, Xiaobo Zhang, Dexian Wang, Ji Zhang
Multimodal Machine Translation (MMT) typically enhances text-only translation by incorporating aligned visual features. Despite the remarkable progress, state-of-the-art MMT approaches often rely on paired image-text inputs at inference and are sensitive to irrelevant visual noise, which limits their robustness and practical applicability. To address these issues, we propose D2P-MMT, a diffusion-based dual-branch prompting framework for robust vision-guided translation. Specifically, D2P-MMT requires only the source text and a reconstructed image generated by a pre-trained diffusion model, which naturally filters out distracting visual details while preserving semantic cues. During training, the model jointly learns from both authentic and reconstructed images using a dual-branch prompting strategy, encouraging rich cross-modal interactions. To bridge the modality gap and mitigate training-inference discrepancies, we introduce a distributional alignment loss that enforces consistency between the output distributions of the two branches. Extensive experiments on the Multi30K dataset demonstrate that D2P-MMT achieves superior translation performance compared to existing state-of-the-art approaches.
多模态机器翻译(MMT)通常通过集成对齐的视觉特征来增强纯文本翻译。尽管取得了显著的进步,但最新的MMT方法通常在推理过程中依赖于配对的图像文本输入,并对不相关的视觉噪声敏感,这限制了它们的稳健性和实际应用性。为了解决这些问题,我们提出了D2P-MMT,这是一个基于扩散的双分支提示框架,用于稳健的视觉引导翻译。具体来说,D2P-MMT仅需要源文本和一个由预训练扩散模型生成的重构图像,这可以自然地过滤掉令人分心的视觉细节,同时保留语义线索。在训练过程中,模型使用双分支提示策略从真实和重构的图像中学习,鼓励丰富的跨模态交互。为了缩小模态间隙并减轻训练与推理之间的差异,我们引入了一种分布对齐损失,以强制两个分支输出分布的一致性。在Multi30K数据集上的广泛实验表明,D2P-MMT实现了优于现有最新方法的翻译性能。
论文及项目相关链接
Summary
基于多模态机器翻译(MMT)的扩散模型技术在增强文本翻译中引入了对齐的视觉特征,虽然进展显著,但在推理阶段往往依赖配对图像文本输入并对无关的视觉噪声敏感,这限制了其稳健性和实际应用范围。为了解决这个问题,我们提出了基于扩散的双分支提示框架D2P-MMT,用于稳健的视觉引导翻译。它只需要源文本和由预训练扩散模型生成的重建图像,自然过滤掉干扰的视觉细节,同时保留语义线索。在训练过程中,模型通过双分支提示策略从真实和重建图像中学习,促进跨模态的丰富交互。为了缩小模态差距并减少训练和推理之间的差异,我们引入了一种分布对齐损失,强制两个分支输出分布的一致性。在Multi30K数据集上的大量实验表明,D2P-MMT相较于现有先进技术取得了优越的翻译性能。
Key Takeaways
- MMT通过引入视觉特征增强文本翻译。
- 当前MMT方法在推理阶段依赖配对图像文本输入。
- MMT对无关视觉噪声敏感,需提高稳健性。
- 提出基于扩散的双分支提示框架D2P-MMT,用于稳健的视觉引导翻译。
- D2P-MMT仅需要源文本和预训练扩散模型生成的重建图像。
- D2P-MMT通过双分支提示策略学习,促进跨模态交互。
点此查看论文截图