⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-02 更新
NeRF Is a Valuable Assistant for 3D Gaussian Splatting
Authors:Shuangkang Fang, I-Chao Shen, Takeo Igarashi, Yufeng Wang, ZeSheng Wang, Yi Yang, Wenrui Ding, Shuchang Zhou
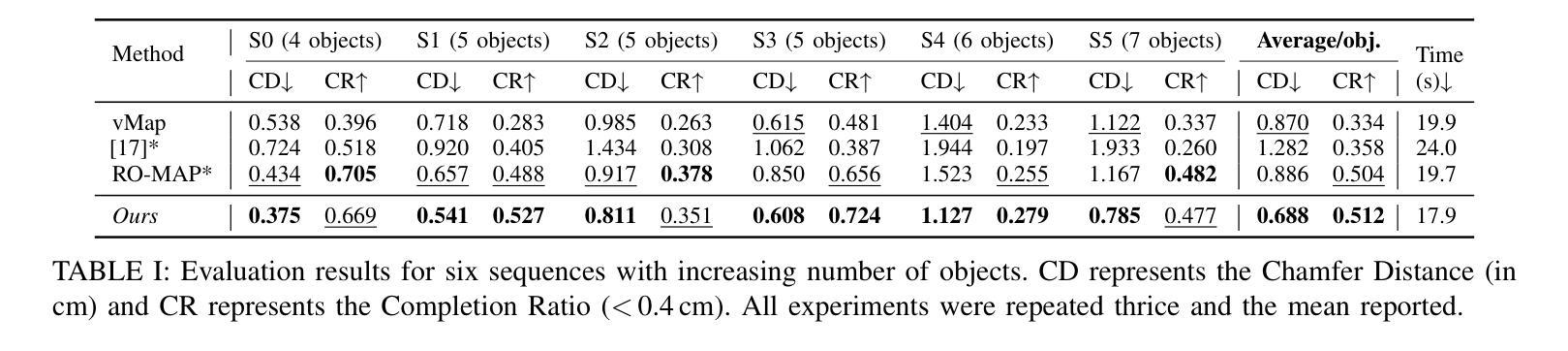
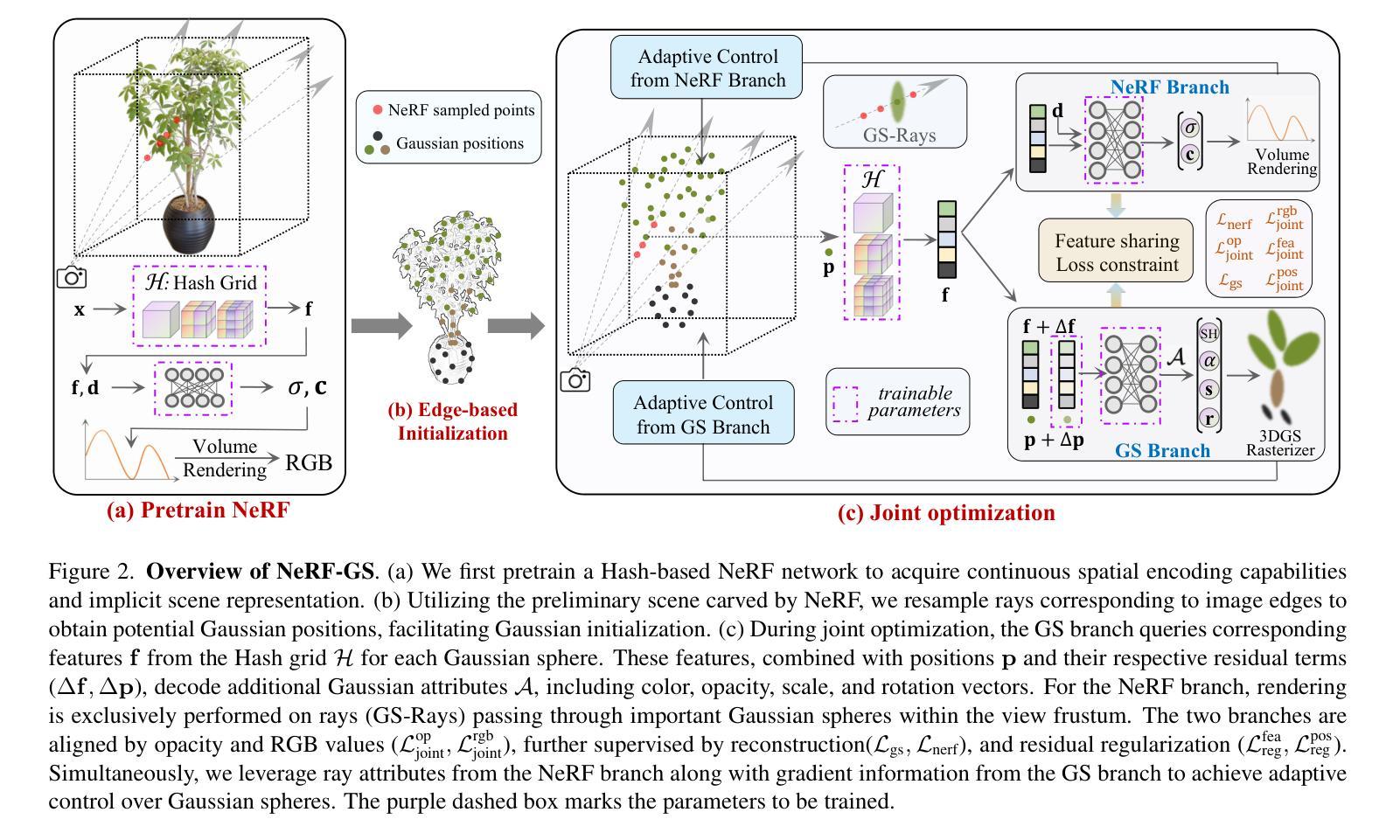
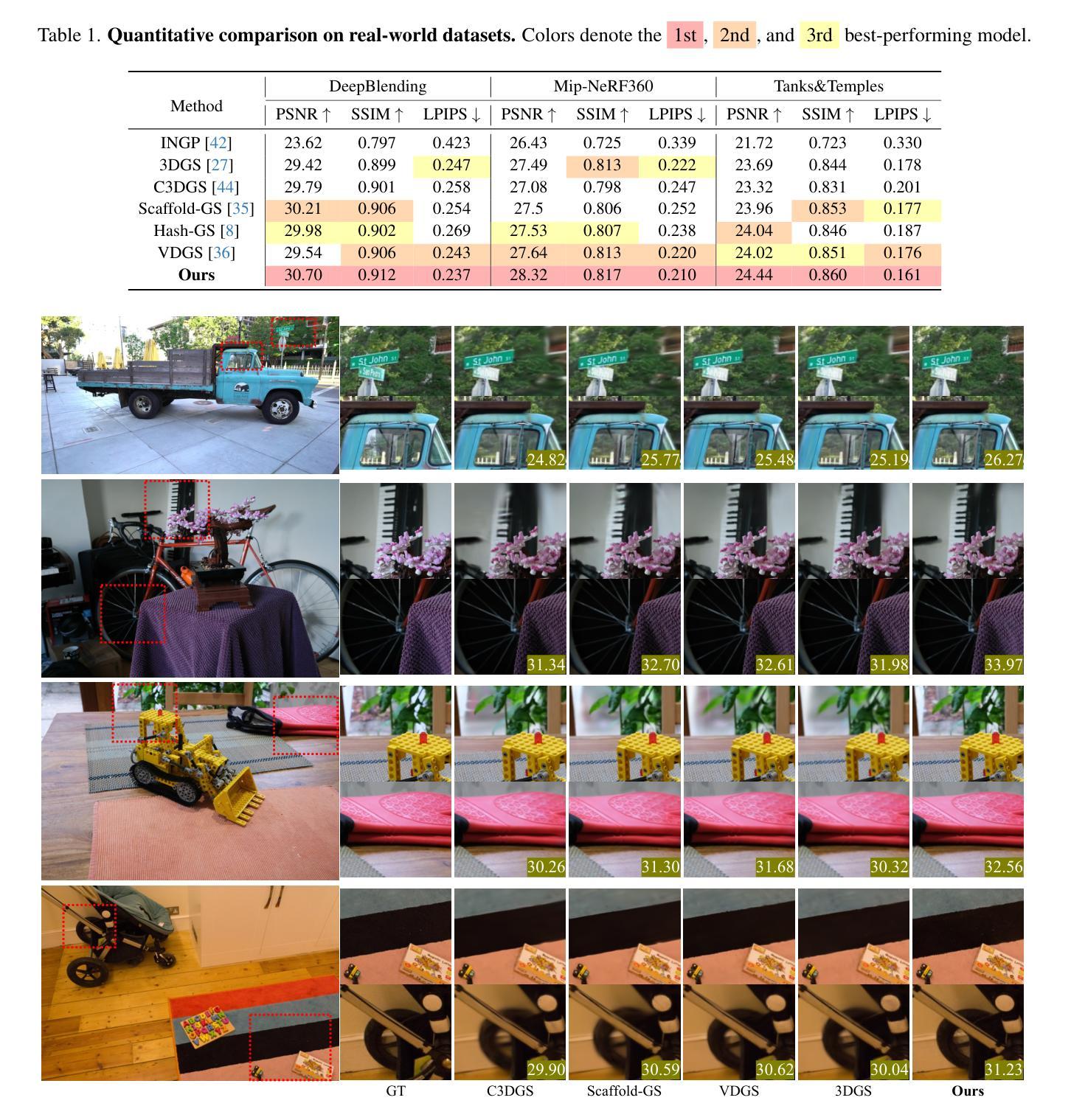
We introduce NeRF-GS, a novel framework that jointly optimizes Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS). This framework leverages the inherent continuous spatial representation of NeRF to mitigate several limitations of 3DGS, including sensitivity to Gaussian initialization, limited spatial awareness, and weak inter-Gaussian correlations, thereby enhancing its performance. In NeRF-GS, we revisit the design of 3DGS and progressively align its spatial features with NeRF, enabling both representations to be optimized within the same scene through shared 3D spatial information. We further address the formal distinctions between the two approaches by optimizing residual vectors for both implicit features and Gaussian positions to enhance the personalized capabilities of 3DGS. Experimental results on benchmark datasets show that NeRF-GS surpasses existing methods and achieves state-of-the-art performance. This outcome confirms that NeRF and 3DGS are complementary rather than competing, offering new insights into hybrid approaches that combine 3DGS and NeRF for efficient 3D scene representation.
我们介绍了NeRF-GS,这是一个新型框架,它联合优化了神经辐射场(NeRF)和3D高斯拼贴(3DGS)。该框架利用NeRF的固有连续空间表示来减轻3DGS的几个局限性,包括高斯初始化的敏感性、空间感知的有限性以及高斯之间的弱相关性,从而提高了其性能。在NeRF-GS中,我们重新审视了3DGS的设计,并逐一对齐其空间特征与NeRF,使这两种表示形式能够通过共享3D空间信息在同一场景中进行优化。我们进一步通过优化隐式特征和高斯位置的残差向量来解决两种方法之间的形式区别,以增强3DGS的个性化能力。在基准数据集上的实验结果表明,NeRF-GS超越了现有方法,达到了最先进的性能。这一结果证实,NeRF和3DGS是互补的而不是竞争的,为结合3DGS和NeRF的混合方法提供了新见解,以实现有效的3D场景表示。
论文及项目相关链接
PDF Accepted by ICCV
摘要
我们推出NeRF-GS,这是一个结合Neural Radiance Fields(NeRF)与3D Gaussian Splatting(3DGS)的新型框架。它通过NeRF的内在连续空间表示,减轻了3DGS的几个局限性,包括高斯初始化的敏感性、空间感知的有限性以及高斯间相关性较弱的问题,从而提高了其性能。在NeRF-GS中,我们重新审视了3DGS的设计,逐步将其空间特征与NeRF对齐,使两种表示形式能够通过共享的三维空间信息在同一场景中进行优化。我们通过优化隐式特征和高斯位置的残差向量,解决了两者之间的形式差异,增强了3DGS的个性化能力。在基准数据集上的实验结果表明,NeRF-GS超越了现有方法,达到了最先进的性能水平。这证明NeRF和3DGS是互补的而非竞争的,为结合3DGS和NeRF的高效3D场景表示提供了新见解。
要点
- NeRF-GS结合了NeRF与3DGS,形成了一种新型框架。
- NeRF的连续空间表示有助于解决3DGS的几个关键局限性。
- 在NeRF-GS中,3DGS的空间特征设计被重新检视,与NeRF逐步对齐。
- 通过共享三维空间信息,两种表示形式可以在同一场景中进行优化。
- 优化了隐式特征和高斯位置的残差向量,缩小了NeRF和3DGS之间的形式差异。
- 实验结果表明,NeRF-GS达到了最先进的性能水平,超越了现有方法。
- NeRF和3DGS是互补的,这为结合两者的混合方法提供了新见解。
点此查看论文截图

NeuroVoxel-LM: Language-Aligned 3D Perception via Dynamic Voxelization and Meta-Embedding
Authors:Shiyu Liu, Lianlei Shan
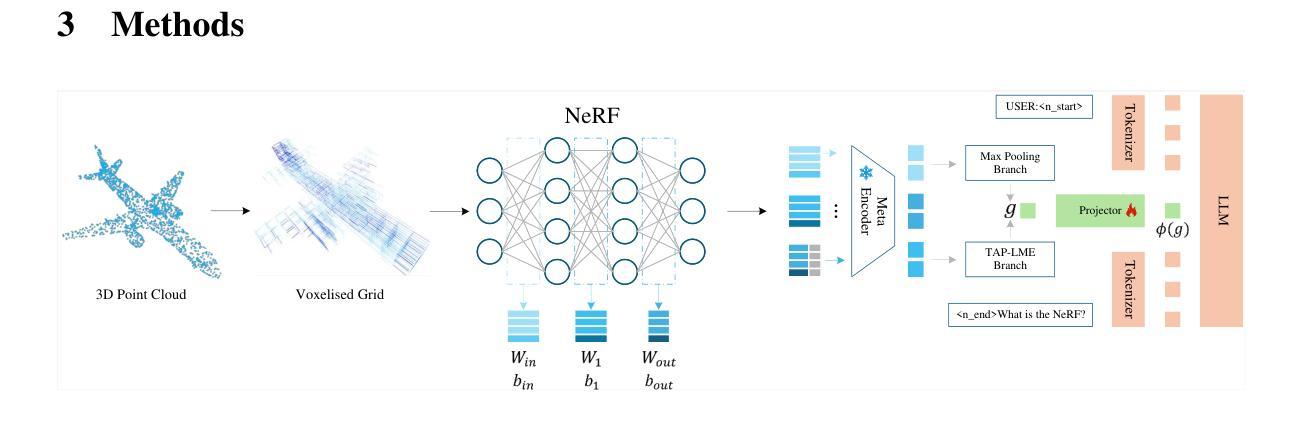
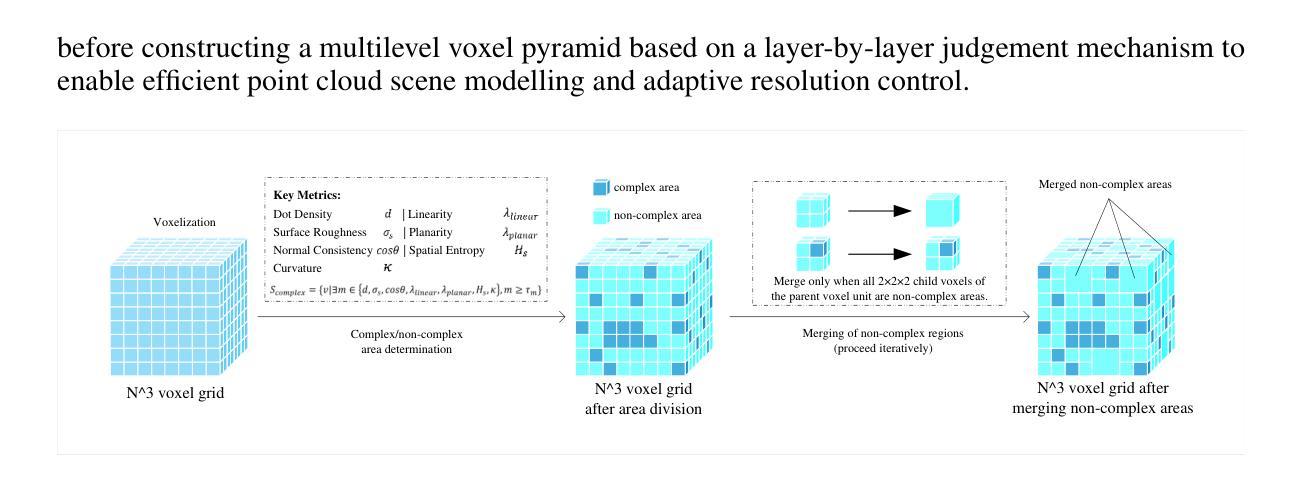
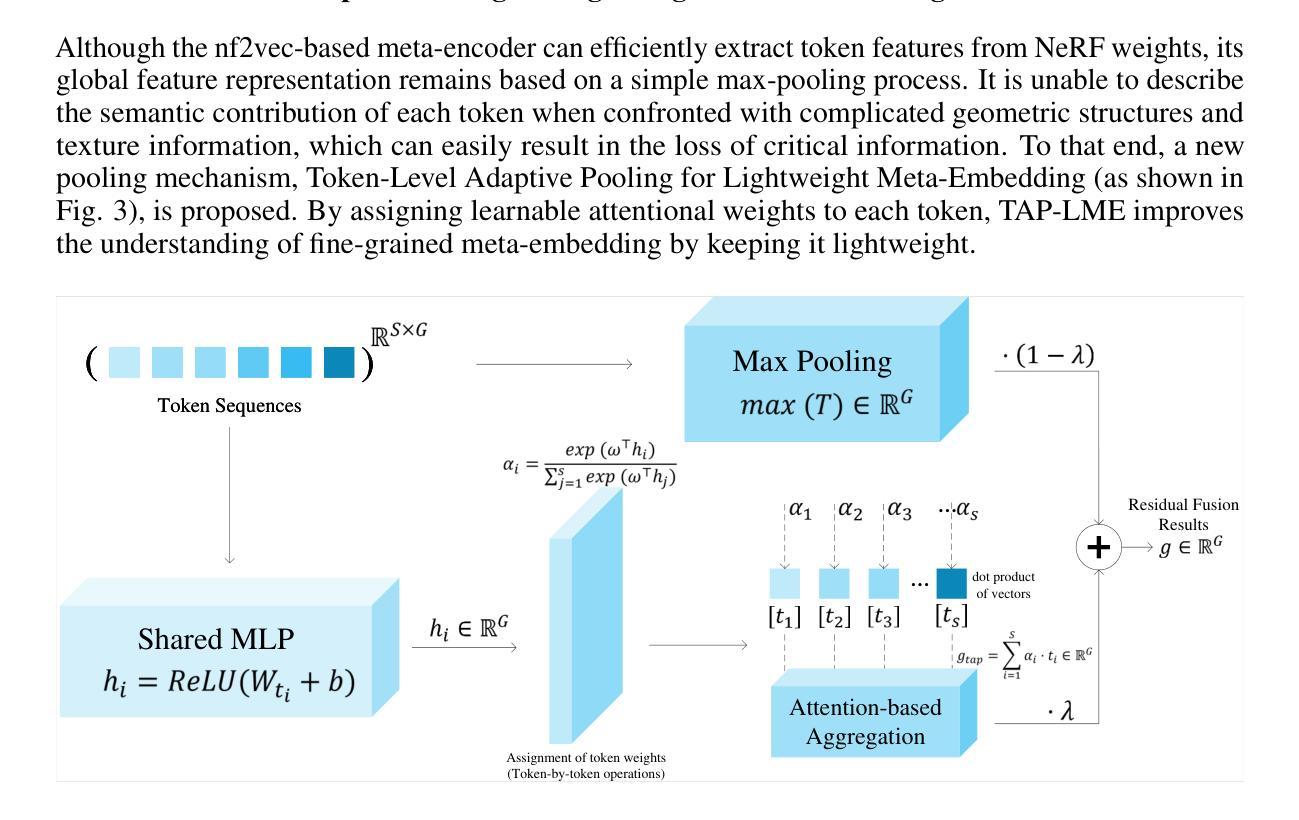
Recent breakthroughs in Visual Language Models (VLMs) and Multimodal Large Language Models (MLLMs) have significantly advanced 3D scene perception towards language-driven cognition. However, existing 3D language models struggle with sparse, large-scale point clouds due to slow feature extraction and limited representation accuracy. To address these challenges, we propose NeuroVoxel-LM, a novel framework that integrates Neural Radiance Fields (NeRF) with dynamic resolution voxelization and lightweight meta-embedding. Specifically, we introduce a Dynamic Resolution Multiscale Voxelization (DR-MSV) technique that adaptively adjusts voxel granularity based on geometric and structural complexity, reducing computational cost while preserving reconstruction fidelity. In addition, we propose the Token-level Adaptive Pooling for Lightweight Meta-Embedding (TAP-LME) mechanism, which enhances semantic representation through attention-based weighting and residual fusion. Experimental results demonstrate that DR-MSV significantly improves point cloud feature extraction efficiency and accuracy, while TAP-LME outperforms conventional max-pooling in capturing fine-grained semantics from NeRF weights.
最近的视觉语言模型(VLMs)和多模态大型语言模型(MLLMs)的突破,极大地推动了3D场景感知向语言驱动认知的发展。然而,由于特征提取速度慢和表示精度有限,现有的3D语言模型在处理稀疏的大规模点云时遇到了困难。为了解决这些挑战,我们提出了NeuroVoxel-LM这一新型框架,它将神经辐射场(NeRF)与动态分辨率体素化和轻量级元嵌入相结合。具体来说,我们引入了一种动态分辨率多尺度体素化(DR-MSV)技术,该技术可以根据几何和结构复杂性自适应地调整体素粒度,从而在降低计算成本的同时保持重建的保真度。此外,我们提出了用于轻量级元嵌入的标记级自适应池化(TAP-LME)机制,它通过基于注意力的加权和残差融合来增强语义表示。实验结果表明,DR-MSV能显著提高点云特征提取的效率和准确性,而TAP-LME在捕获NeRF权重的精细语义方面优于传统的最大池化。
论文及项目相关链接
PDF **14 pages, 3 figures, 2 tables
Summary
神经辐射场(NeRF)技术结合动态分辨率体素化和轻量级元嵌入的NeuroVoxel-LM框架,能有效解决现有3D语言模型在处理稀疏大规模点云时面临的特征提取慢和表示精度有限的问题。该框架通过动态分辨率多尺度体素化(DR-MSV)技术自适应调整体素粒度,基于几何和结构复杂度,降低计算成本的同时保持重建保真度。此外,还提出了用于轻量级元嵌入的标记级别自适应池化(TAP-LME)机制,通过注意力加权的残差融合增强语义表示。实验结果表明,DR-MSV能显著提高点云特征提取的效率和准确性,TAP-LME在捕获NeRF权重的精细语义方面优于传统的最大池化。
Key Takeaways
- NeuroVoxel-LM框架结合了NeRF技术、动态分辨率体素化和轻量级元嵌入,旨在解决现有3D语言模型在处理点云时的挑战。
- DR-MSV技术能够自适应调整体素粒度,基于几何和结构复杂度,以提高特征提取效率和重建保真度。
- TAP-LME机制通过注意力加权的残差融合增强语义表示,在捕获NeRF权重的精细语义方面表现优异。
- 框架解决了现有3D语言模型在处理大规模稀疏点云时的计算成本问题。
- 实验结果表明,NeuroVoxel-LM在点云特征提取和表示方面具有较高的准确性和效率。
- 该框架的应用前景广泛,可推动语言驱动的认知3D场景感知的发展。
点此查看论文截图

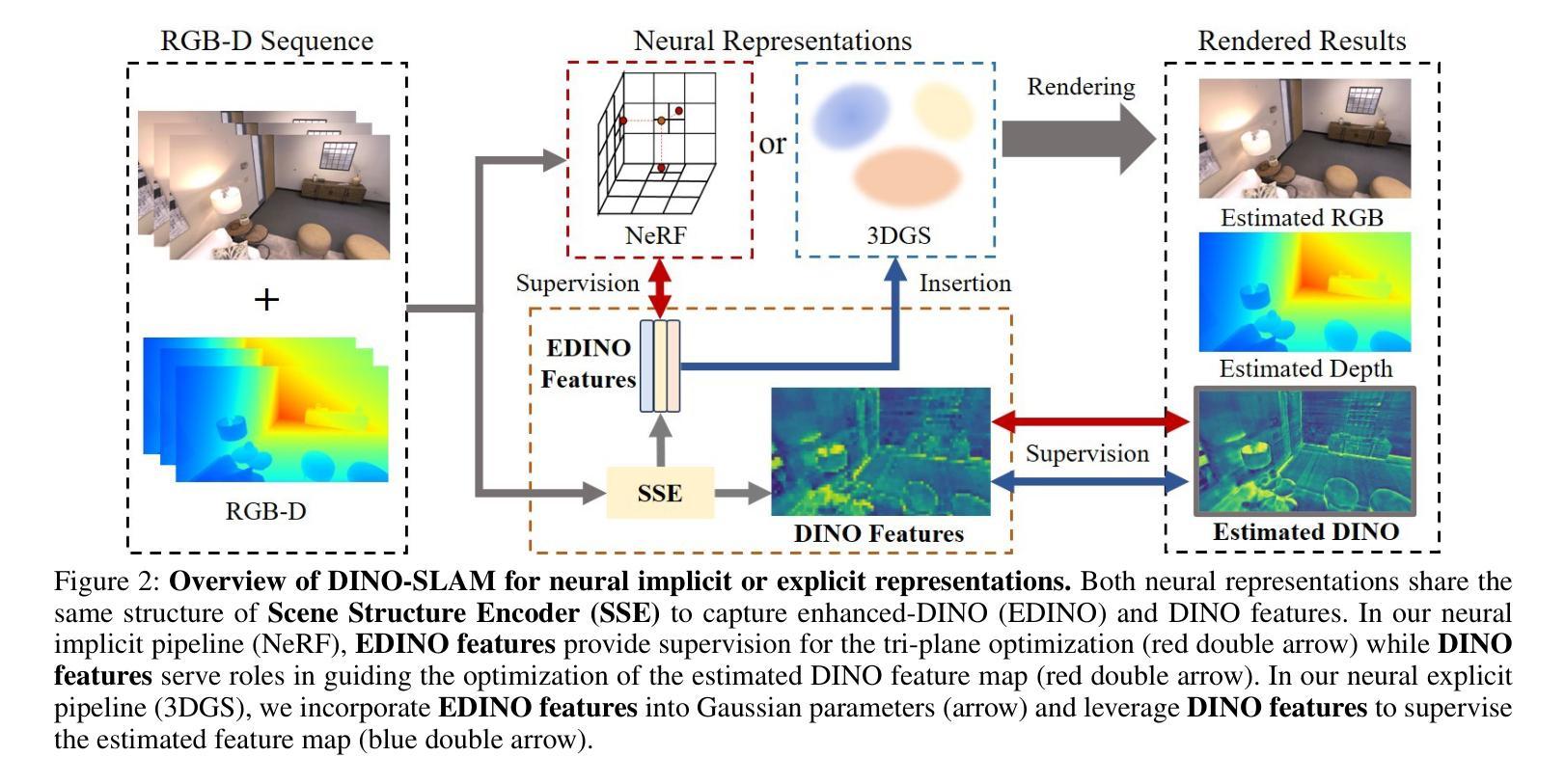
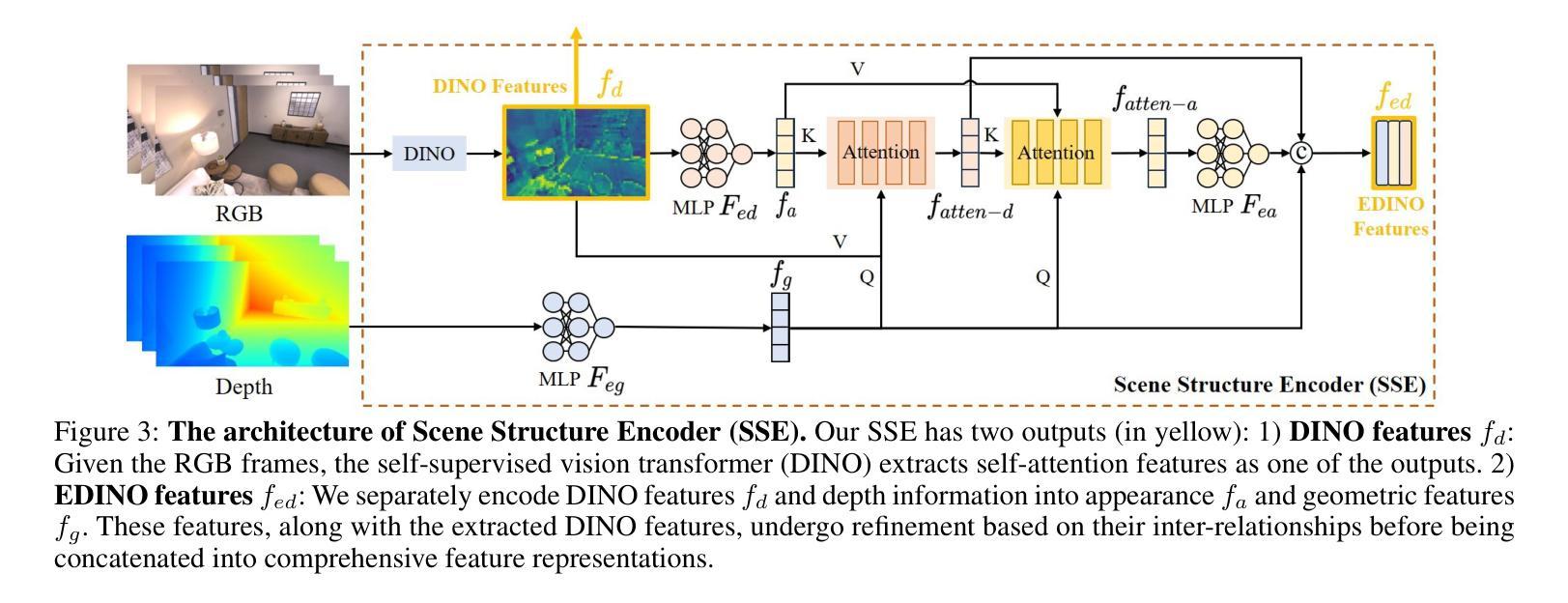
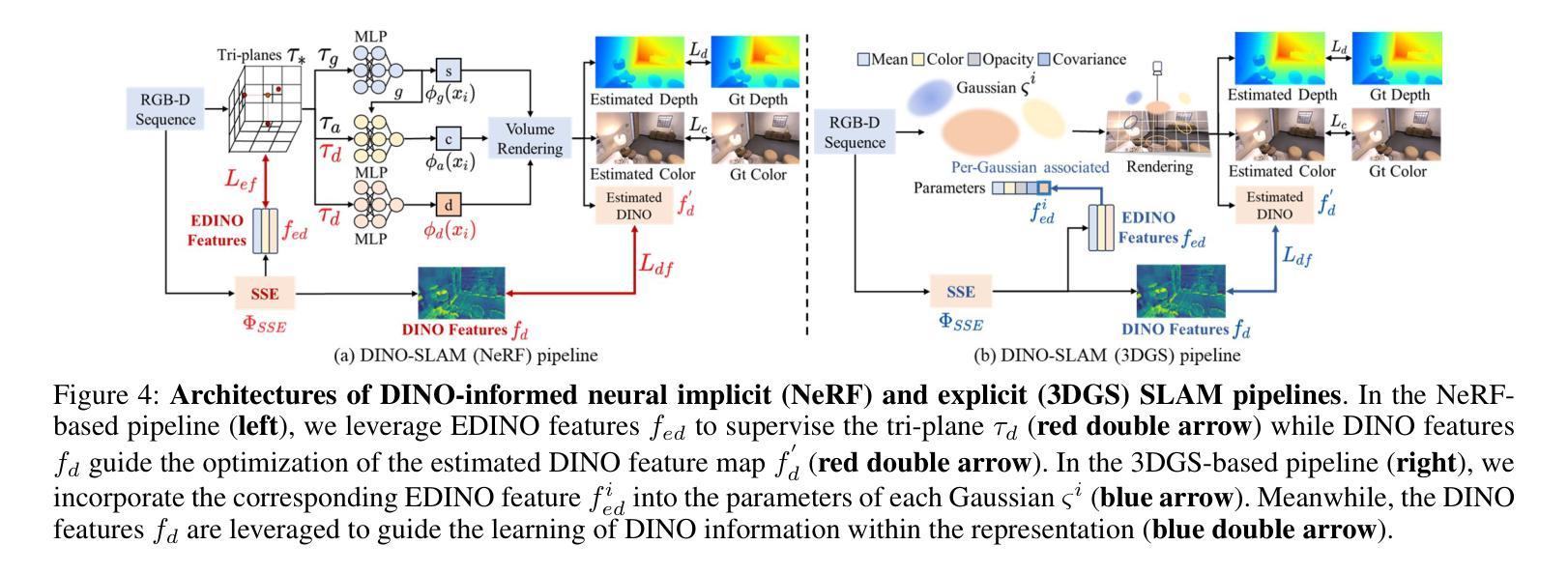
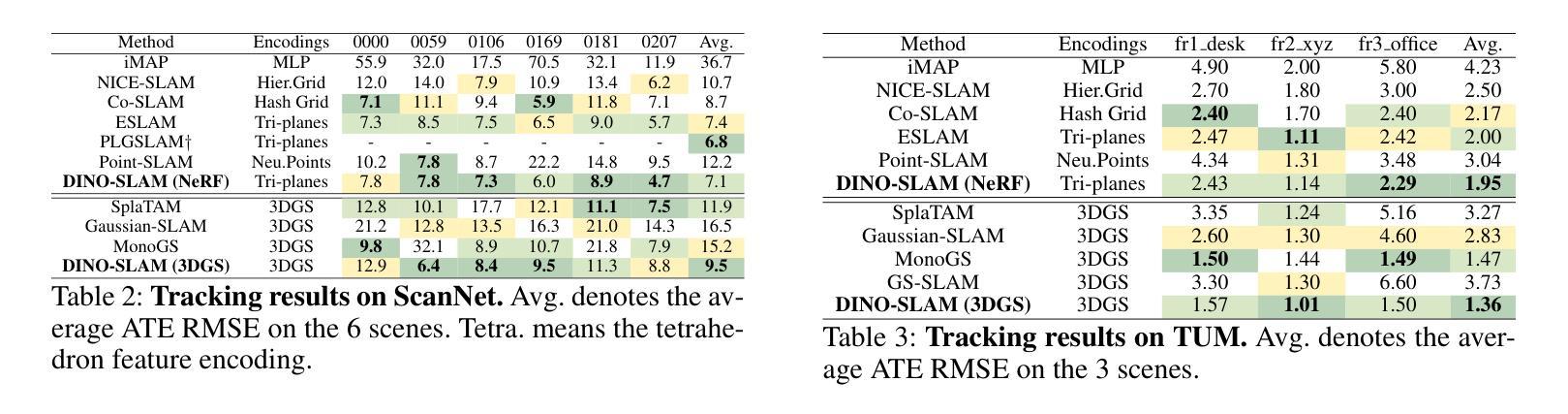
DINO-SLAM: DINO-informed RGB-D SLAM for Neural Implicit and Explicit Representations
Authors:Ziren Gong, Xiaohan Li, Fabio Tosi, Youmin Zhang, Stefano Mattoccia, Jun Wu, Matteo Poggi
This paper presents DINO-SLAM, a DINO-informed design strategy to enhance neural implicit (Neural Radiance Field – NeRF) and explicit representations (3D Gaussian Splatting – 3DGS) in SLAM systems through more comprehensive scene representations. Purposely, we rely on a Scene Structure Encoder (SSE) that enriches DINO features into Enhanced DINO ones (EDINO) to capture hierarchical scene elements and their structural relationships. Building upon it, we propose two foundational paradigms for NeRF and 3DGS SLAM systems integrating EDINO features. Our DINO-informed pipelines achieve superior performance on the Replica, ScanNet, and TUM compared to state-of-the-art methods.
本文介绍了DINO-SLAM,这是一种以DINO为指导的设计策略,通过更全面的场景表示,增强SLAM系统中的神经隐式(神经辐射场-NeRF)和显式表示(三维高斯拼贴-3DGS)。为此,我们依赖场景结构编码器(SSE),它将DINO特征丰富为增强型DINO特征(EDINO),以捕获分层场景元素及其结构关系。在此基础上,我们为NeRF和3DGS SLAM系统提出了两种融合EDINO特征的基础范式。我们的以DINO为指导的管道在Replica、ScanNet和TUM上与最先进的方法相比实现了卓越的性能。
论文及项目相关链接
Summary
本文介绍了DINO-SLAM,这是一种基于DINO技术的设计策略,旨在通过更全面的场景表示增强神经隐式(Neural Radiance Field - NeRF)和显式表示(3D Gaussian Splatting - 3DGS)在SLAM系统中的表现。该研究通过场景结构编码器(SSE)丰富DINO特征,形成增强型DINO特征(EDINO),以捕捉场景元素的层次结构和它们之间的结构关系。在此基础上,研究提出了两个针对NeRF和3DGS SLAM系统的基本范式,整合EDINO特征。在Replica、ScanNet和TUM上的实验表明,DINO-SLAM的性能优于现有方法。
Key Takeaways
- DINO-SLAM是基于DINO技术的设计策略,旨在增强神经隐式和显式表示在SLAM系统中的表现。
- 通过场景结构编码器(SSE)丰富DINO特征,形成增强型DINO特征(EDINO)。
- EDINO特征用于捕捉场景元素的层次结构和结构关系。
- 提出了两个针对NeRF和3DGS SLAM系统的基本范式,整合EDINO特征。
- DINO-SLAM在Replica、ScanNet和TUM等数据集上的性能优于现有方法。
- 该策略能够提供更加全面的场景表示。
点此查看论文截图


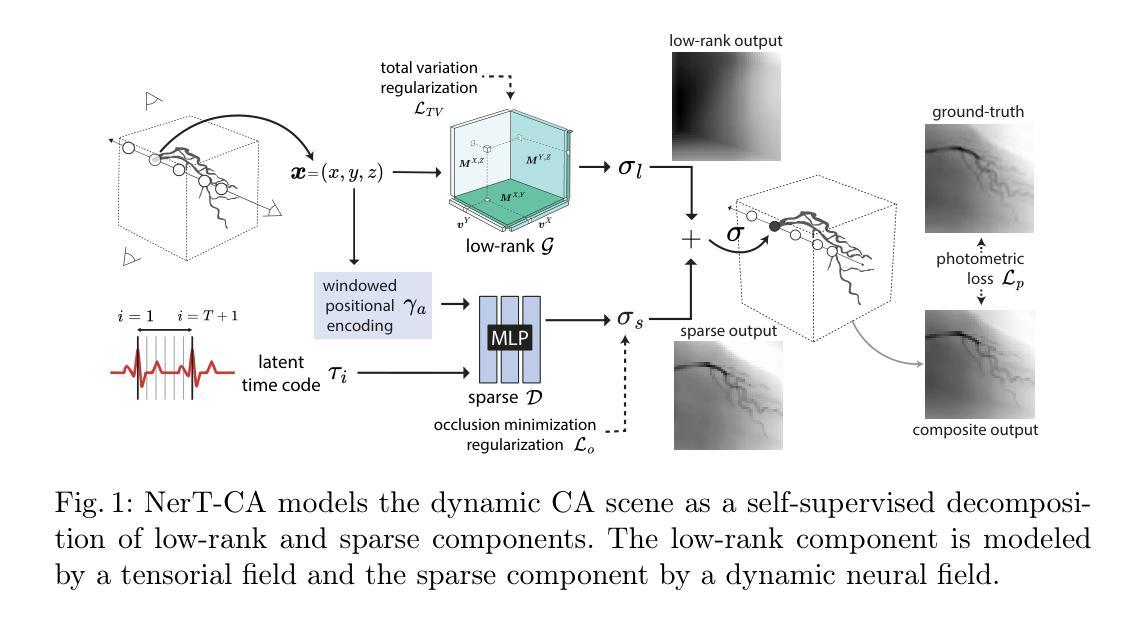
NerT-CA: Efficient Dynamic Reconstruction from Sparse-view X-ray Coronary Angiography
Authors:Kirsten W. H. Maas, Danny Ruijters, Nicola Pezzotti, Anna Vilanova
Three-dimensional (3D) and dynamic 3D+time (4D) reconstruction of coronary arteries from X-ray coronary angiography (CA) has the potential to improve clinical procedures. However, there are multiple challenges to be addressed, most notably, blood-vessel structure sparsity, poor background and blood vessel distinction, sparse-views, and intra-scan motion. State-of-the-art reconstruction approaches rely on time-consuming manual or error-prone automatic segmentations, limiting clinical usability. Recently, approaches based on Neural Radiance Fields (NeRF) have shown promise for automatic reconstructions in the sparse-view setting. However, they suffer from long training times due to their dependence on MLP-based representations. We propose NerT-CA, a hybrid approach of Neural and Tensorial representations for accelerated 4D reconstructions with sparse-view CA. Building on top of the previous NeRF-based work, we model the CA scene as a decomposition of low-rank and sparse components, utilizing fast tensorial fields for low-rank static reconstruction and neural fields for dynamic sparse reconstruction. Our approach outperforms previous works in both training time and reconstruction accuracy, yielding reasonable reconstructions from as few as three angiogram views. We validate our approach quantitatively and qualitatively on representative 4D phantom datasets.
从X射线冠状动脉造影(CA)进行冠状动脉的三维(3D)和动态3D+时间(4D)重建具有改善临床流程的潜力。然而,还存在许多待解决的问题,最显著的是血管结构稀疏、背景与血管区分度差、视角稀疏以及扫描内运动。最先进的重建方法依赖于耗时的人工或易出错的自动分割,这限制了其在临床上的可用性。最近,基于神经辐射场(NeRF)的方法在稀疏视角下的自动重建方面显示出希望。然而,它们由于依赖于MLP表示而具有较长的训练时间。我们提出了NerT-CA,这是一种用于加速稀疏视角CA的4D重建的神经和张量表征的混合方法。基于之前的NeRF相关工作,我们将CA场景建模为低阶和稀疏成分的分解,利用快速的张量场进行低阶静态重建和神经场进行动态稀疏重建。我们的方法在训练时间和重建精度上都优于以前的工作,从仅三个血管造影视角就能得到合理的重建结果。我们在典型的4D Phantom数据集上从数量和性质两个方面验证了我们的方法。
论文及项目相关链接
Summary
基于NeRF的冠状动脉三维(3D)及四维(动态3D+时间)重建方法面临多种挑战,如血管结构稀疏、背景与血管区分不清等。为加快训练速度和提升重建准确性,我们提出了一种基于神经网络与张量表示的混合方法NerT-CA。该方法利用快速张量场进行静态低秩重建,利用神经网络进行动态稀疏重建。在代表性四维幻影数据集上进行定量和定性验证,表明该方法在训练时间和重建准确性方面均优于以前的工作。
Key Takeaways
- 基于NeRF的冠状动脉重建方法具有潜力改善临床过程。
- 当前面临的挑战包括血管结构稀疏、背景与血管区分不清等。
- NerT-CA是一种基于神经网络与张量表示的混合方法,旨在解决这些问题。
- NerT-CA利用快速张量场进行静态低秩重建,神经网络进行动态稀疏重建。
- 该方法在训练时间和重建准确性方面均优于以前的工作。
- 该方法能够从极少的造影视角(如三个视角)进行合理重建。
点此查看论文截图

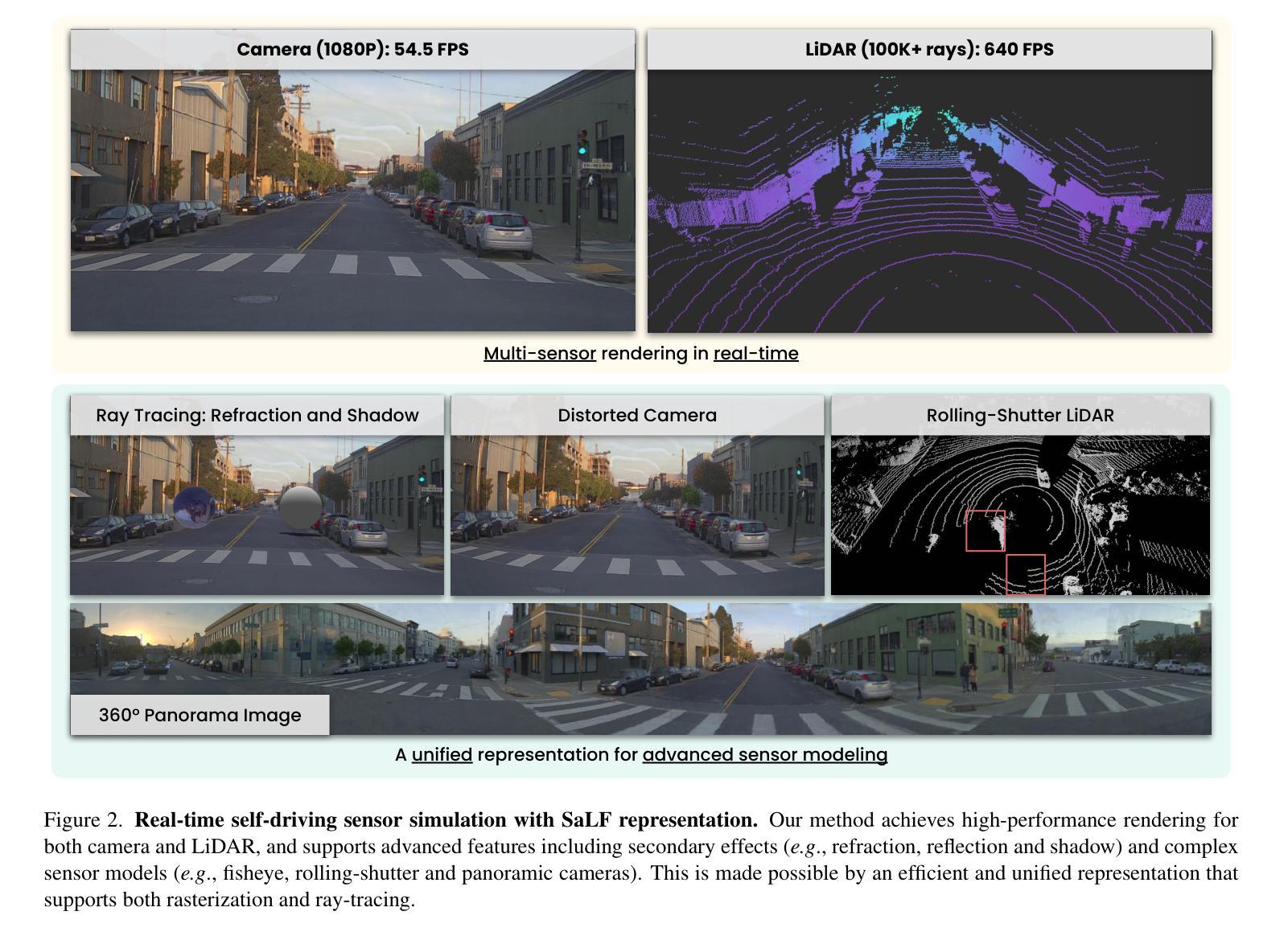
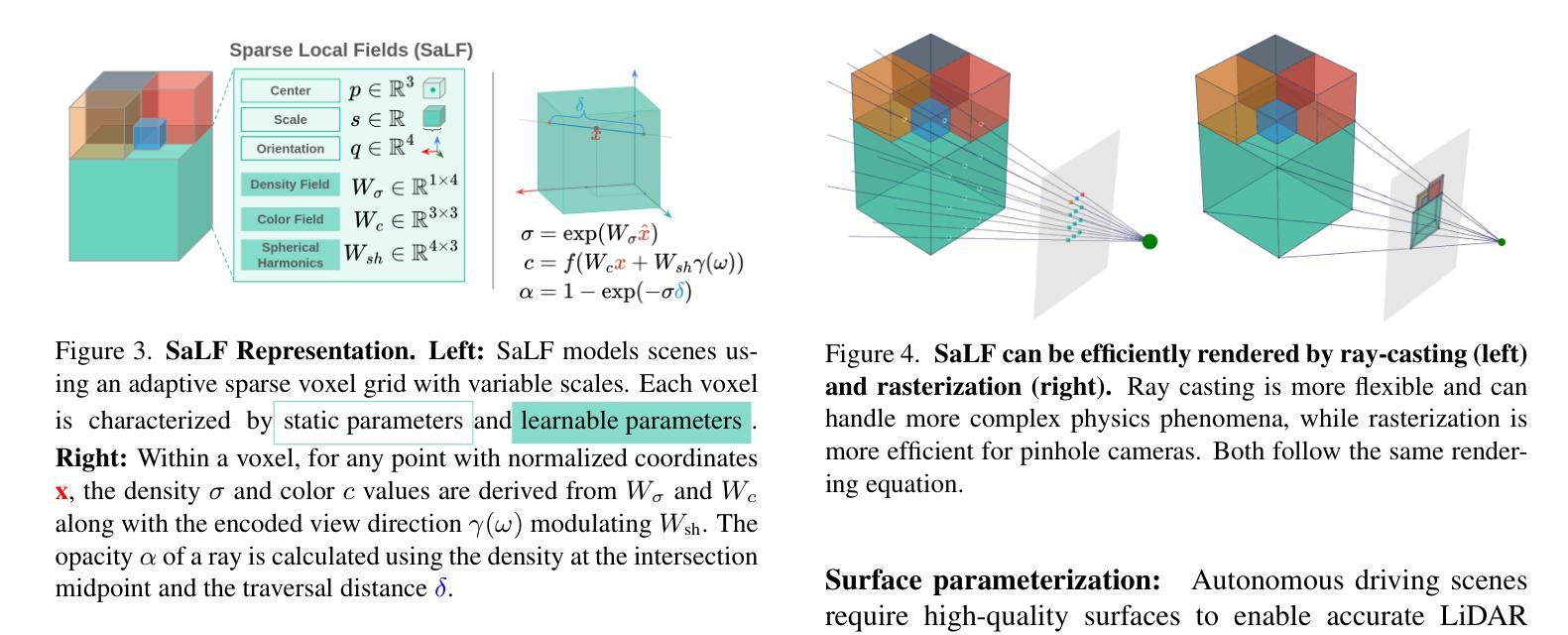
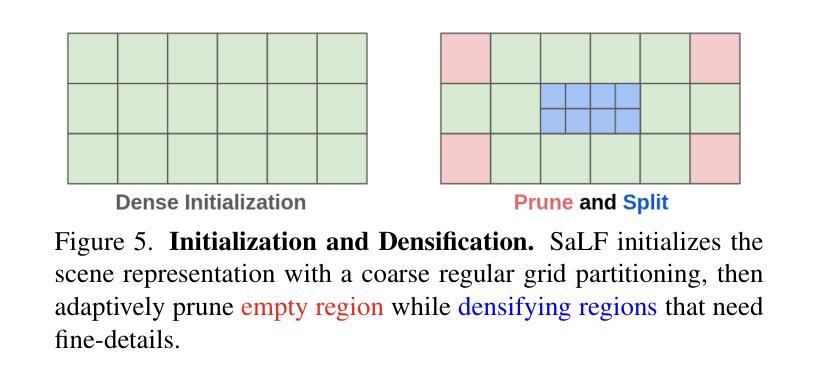
SaLF: Sparse Local Fields for Multi-Sensor Rendering in Real-Time
Authors:Yun Chen, Matthew Haines, Jingkang Wang, Krzysztof Baron-Lis, Sivabalan Manivasagam, Ze Yang, Raquel Urtasun
High-fidelity sensor simulation of light-based sensors such as cameras and LiDARs is critical for safe and accurate autonomy testing. Neural radiance field (NeRF)-based methods that reconstruct sensor observations via ray-casting of implicit representations have demonstrated accurate simulation of driving scenes, but are slow to train and render, hampering scale. 3D Gaussian Splatting (3DGS) has demonstrated faster training and rendering times through rasterization, but is primarily restricted to pinhole camera sensors, preventing usage for realistic multi-sensor autonomy evaluation. Moreover, both NeRF and 3DGS couple the representation with the rendering procedure (implicit networks for ray-based evaluation, particles for rasterization), preventing interoperability, which is key for general usage. In this work, we present Sparse Local Fields (SaLF), a novel volumetric representation that supports rasterization and raytracing. SaLF represents volumes as a sparse set of 3D voxel primitives, where each voxel is a local implicit field. SaLF has fast training (<30 min) and rendering capabilities (50+ FPS for camera and 600+ FPS LiDAR), has adaptive pruning and densification to easily handle large scenes, and can support non-pinhole cameras and spinning LiDARs. We demonstrate that SaLF has similar realism as existing self-driving sensor simulation methods while improving efficiency and enhancing capabilities, enabling more scalable simulation. https://waabi.ai/salf/
基于摄像头和激光雷达等光基传感器的高保真传感器模拟对于安全和准确的自主性测试至关重要。基于神经辐射场(NeRF)的方法通过光线投射隐式表示来重建传感器观测,已证明可以准确模拟驾驶场景,但训练和渲染速度较慢,影响了其扩展性。3D高斯喷涂(3DGS)通过栅格化实现了更快的训练和渲染时间,但主要局限于针孔相机传感器,无法用于现实的多传感器自主性评估。此外,NeRF和3DGS都将表示与渲染程序相结合(基于射线的隐式网络评估、粒子栅格化),妨碍了互操作性,这对于通用使用至关重要。在这项工作中,我们提出了稀疏局部场(SaLF),这是一种新的体积表示法,支持栅格化和光线追踪。SaLF将体积表示为一组稀疏的3D体素原语,其中每个体素都是一个局部隐式场。SaLF具有快速训练(<30分钟)和渲染能力(摄像头50+ FPS和激光雷达600+ FPS),具有自适应的修剪和细化,可轻松处理大场景,并且可以支持非针孔相机和旋转激光雷达。我们证明,SaLF具有与现有自动驾驶传感器模拟方法类似的逼真度,同时提高了效率和增强了功能,使模拟更加可扩展。详情请访问https://waabi.ai/salf/了解。
论文及项目相关链接
Summary
本文介绍了Sparse Local Fields(SaLF)这一新型体积表示法,它支持光线追踪和栅格化,可用于高保真传感器模拟。SaLF具有快速训练和渲染能力,能轻松处理大场景,并支持非针孔相机和旋转激光雷达。它提高了自动驾驶传感器模拟的效率并增强了其功能,同时保持与现实场景的逼真度。
Key Takeaways
- 高保真传感器模拟对安全和精确的自动驾驶测试至关重要。
- Neural Radiance Field(NeRF)方法能通过射线投射隐式表示重建传感器观察,但训练和渲染速度慢,限制了其规模应用。
- 3D Gaussian Splatting(3DGS)方法通过栅格化实现更快的训练和渲染时间,但主要局限于针孔相机传感器,无法用于现实的多传感器自动驾驶评估。
- 现有的方法将表示与渲染过程相结合,阻碍了互操作性,这是通用用途的关键。
- SaLF是一种新型体积表示法,支持栅格化和光线追踪,具有快速训练和渲染能力,并能处理大场景。
- SaLF可以支持非针孔相机和旋转激光雷达,提高了现实感并保持高效率。
点此查看论文截图

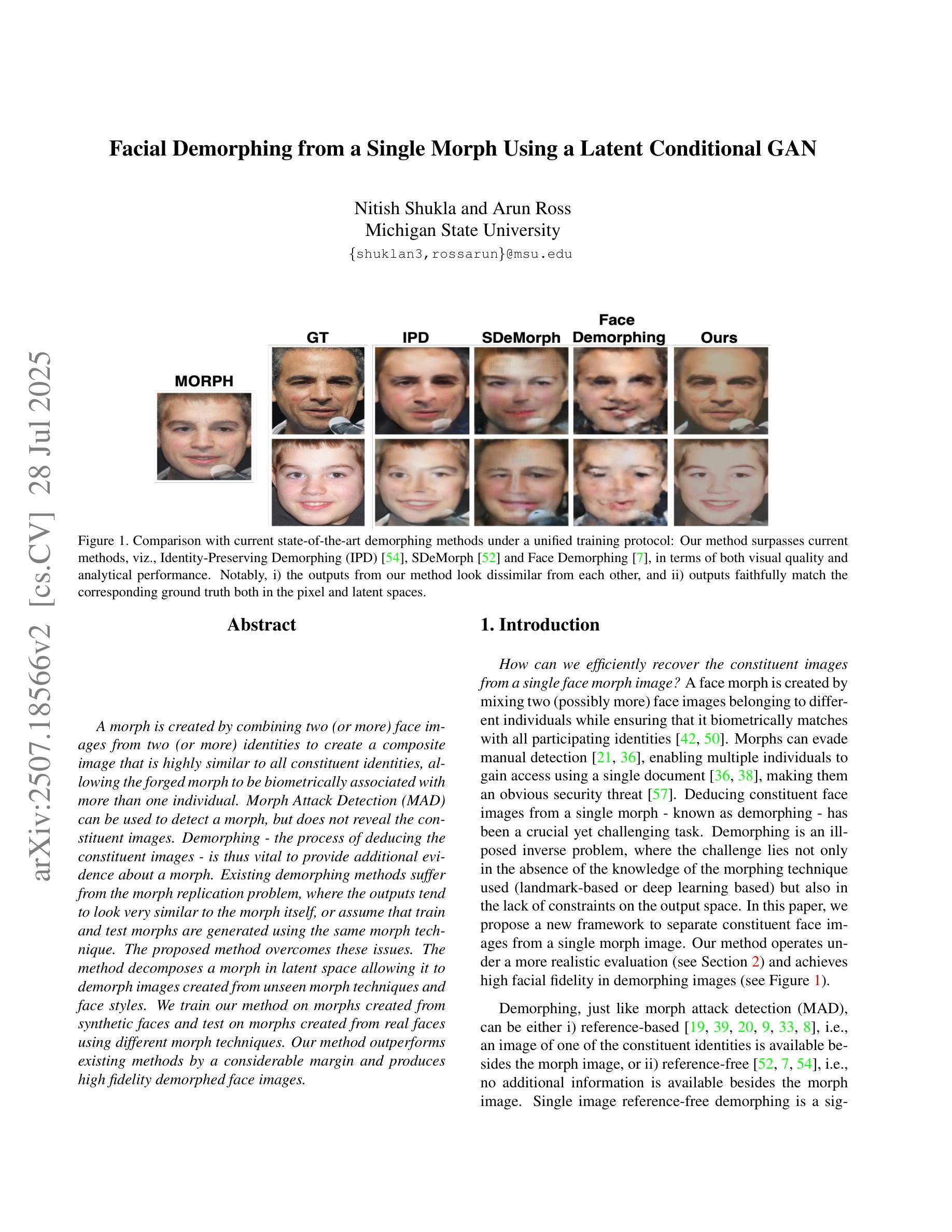
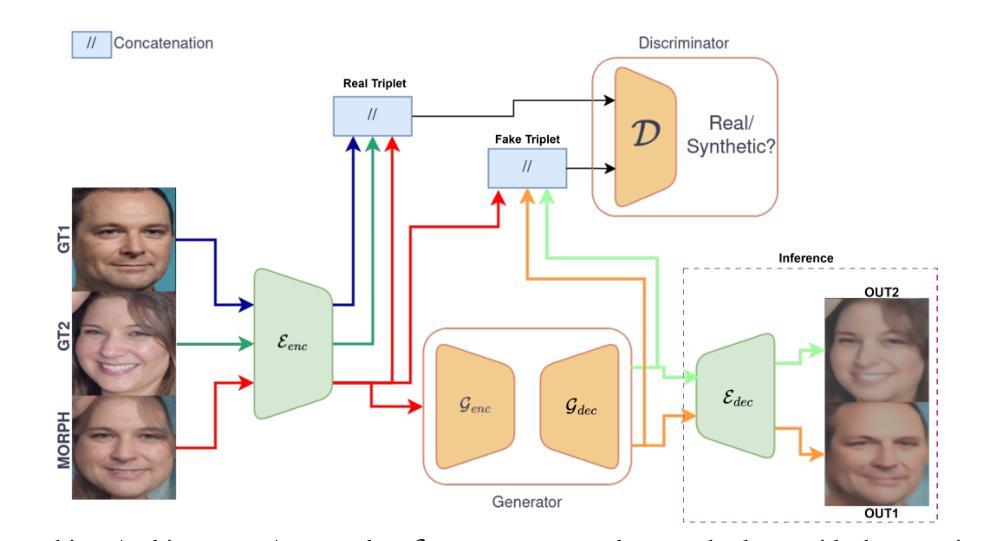
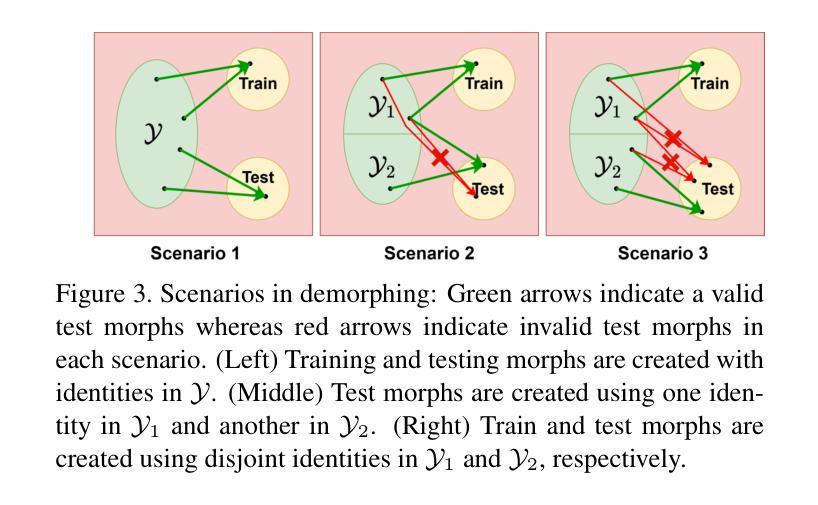
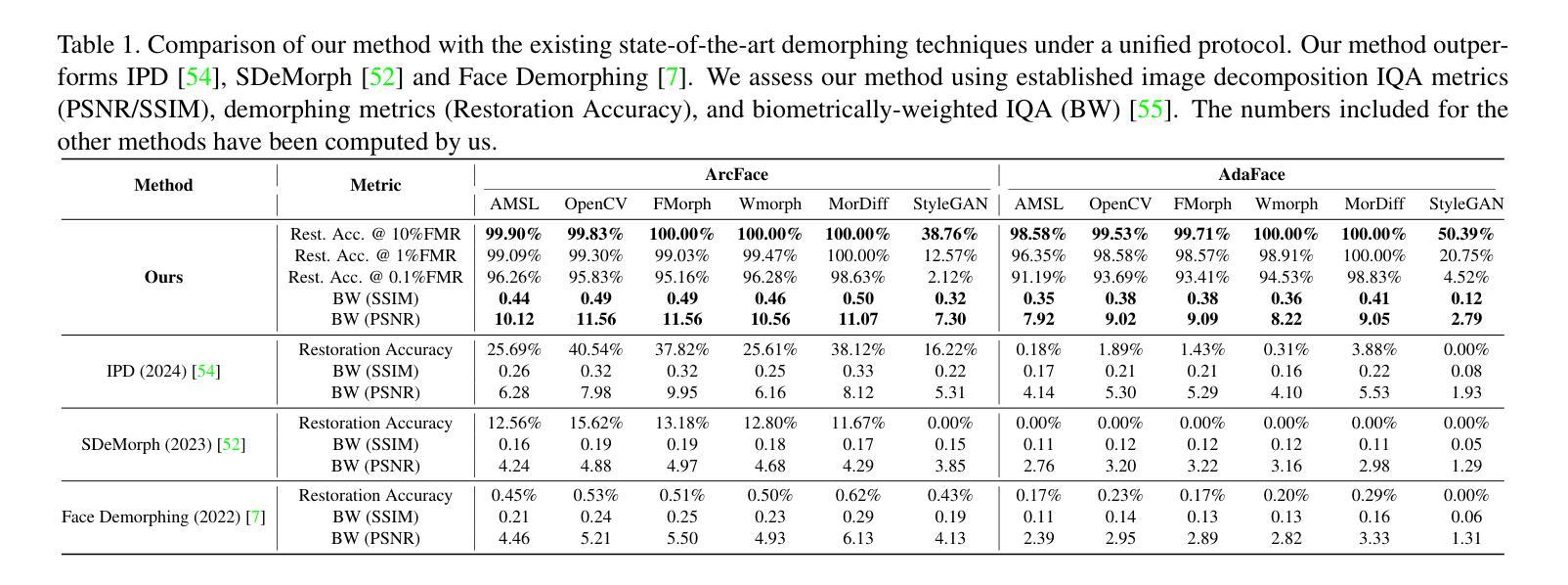
Facial Demorphing from a Single Morph Using a Latent Conditional GAN
Authors:Nitish Shukla, Arun Ross
A morph is created by combining two (or more) face images from two (or more) identities to create a composite image that is highly similar to all constituent identities, allowing the forged morph to be biometrically associated with more than one individual. Morph Attack Detection (MAD) can be used to detect a morph, but does not reveal the constituent images. Demorphing - the process of deducing the constituent images - is thus vital to provide additional evidence about a morph. Existing demorphing methods suffer from the morph replication problem, where the outputs tend to look very similar to the morph itself, or assume that train and test morphs are generated using the same morph technique. The proposed method overcomes these issues. The method decomposes a morph in latent space allowing it to demorph images created from unseen morph techniques and face styles. We train our method on morphs created from synthetic faces and test on morphs created from real faces using different morph techniques. Our method outperforms existing methods by a considerable margin and produces high fidelity demorphed face images.
通过结合两个(或更多)身份的两个(或更多)面部图像,创建一个形态,以创建一个与所有组成身份高度相似的合成图像,从而使伪造形态能够与多个个体进行生物特征关联。形态攻击检测(MAD)可用于检测形态,但不会显示组成图像。因此,形态推导(还原组成图像的过程)对于提供有关形态的额外证据至关重要。现有形态推导方法存在形态复制问题,输出的结果往往与形态本身非常相似,或者假设训练和测试形态是使用相同的形态技术生成的。所提出的方法克服了这些问题。该方法在潜在空间内对形态进行分解,使其能够还原由未见过的形态技术和面部风格所创建的图像。我们在由合成面部创建的形态上训练我们的方法,并在使用不同形态技术由真实面部创建的形态上进行测试。我们的方法在性能上大大超过了现有方法,并产生了高保真度的还原面部图像。
论文及项目相关链接
Summary
本文介绍了通过结合两个或多个身份的面像创建复合图像的技术,称为形态攻击(Morph Attack)。形态攻击检测(MAD)可以检测形态攻击,但不揭示构成图像。因此,去形态化(Demorphing)过程——推断构成图像的过程——对于提供形态攻击的额外证据至关重要。现有去形态化方法存在形态复制问题,输出的图像往往与原始形态相似或假设训练和测试形态使用相同的形态技术。而新方法克服了这些问题,它在潜在空间中分解形态,使其能够对由未见过的形态技术和面部风格创建的图像进行去形态化。经过在合成面部和真实面部上创建的不同形态技术的测试,该方法显著优于现有方法,并产生高保真度的去形态化面部图像。
Key Takeaways
- 形态攻击是通过结合多个身份的面像创建复合图像的技术。
- 形态攻击检测(MAD)能够检测形态攻击,但不揭示构成图像。
- 去形态化(Demorphing)是推断构成图像的过程,对于揭示形态攻击的证据至关重要。
- 现有去形态化方法存在形态复制问题,即输出图像与原始形态相似。
- 新方法能够在潜在空间中分解形态,克服现有问题。
- 该方法能够处理由未见过的形态技术和面部风格创建的图像。
点此查看论文截图

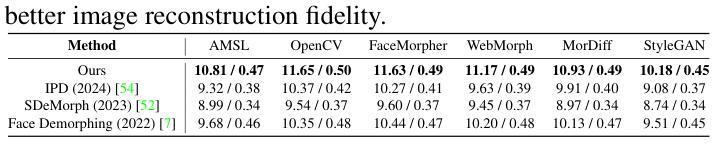
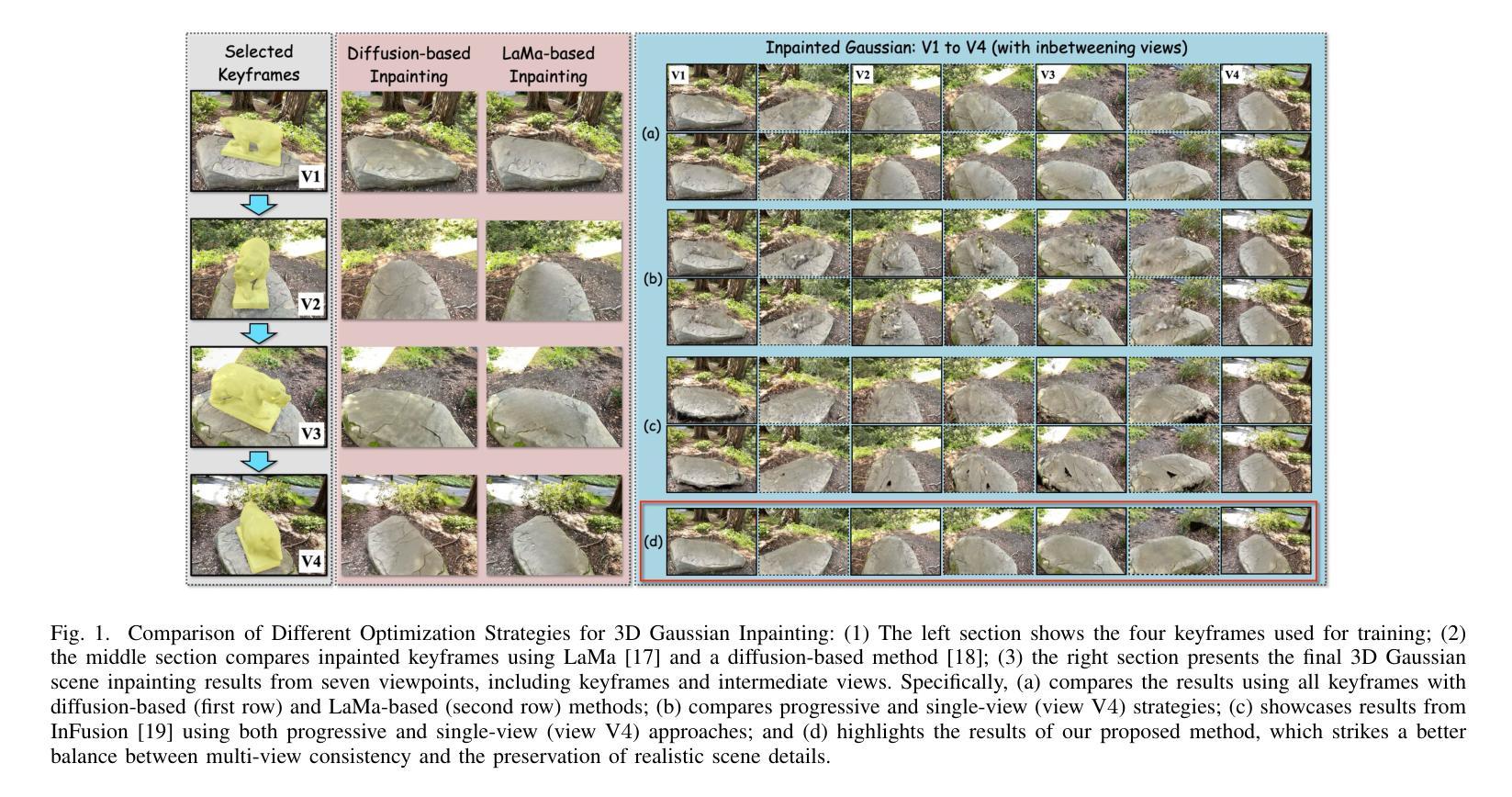
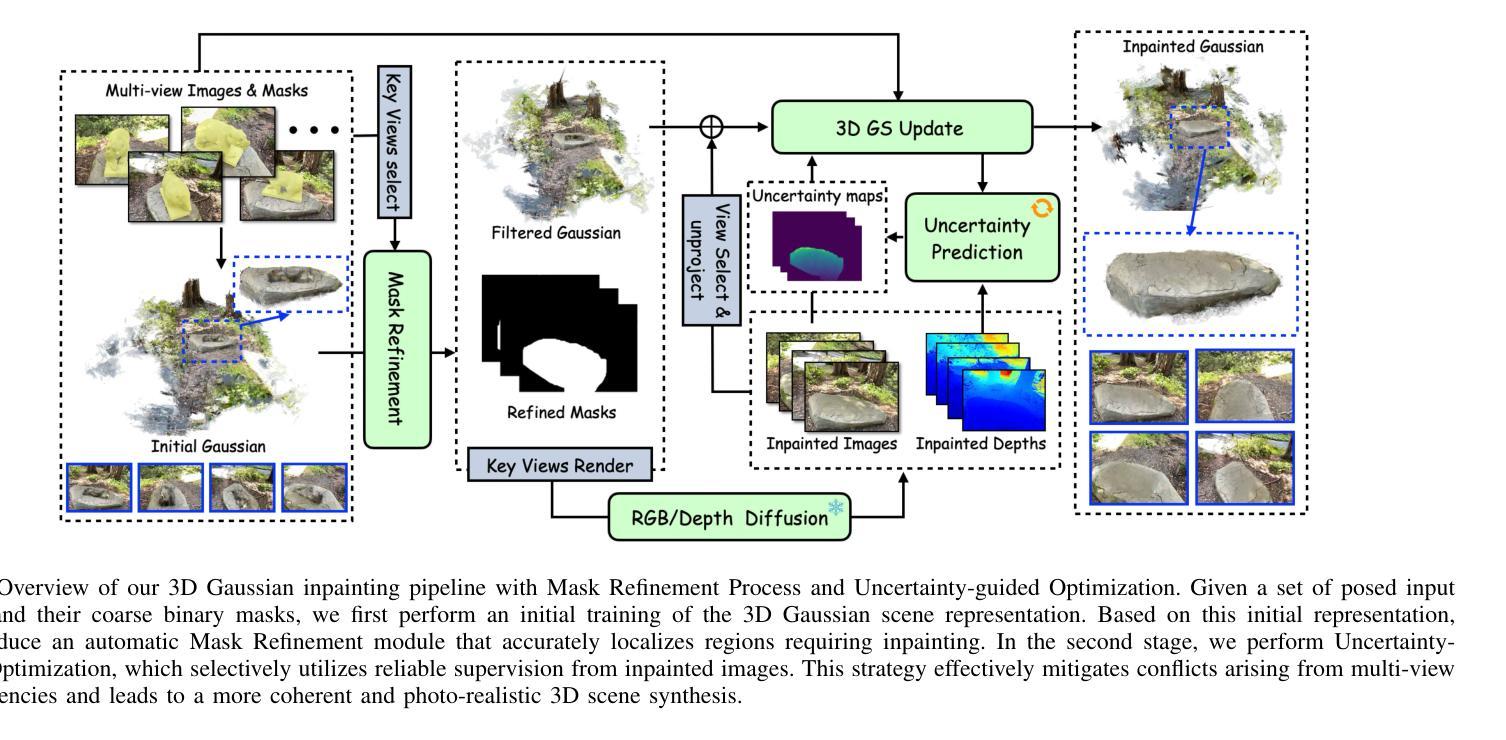
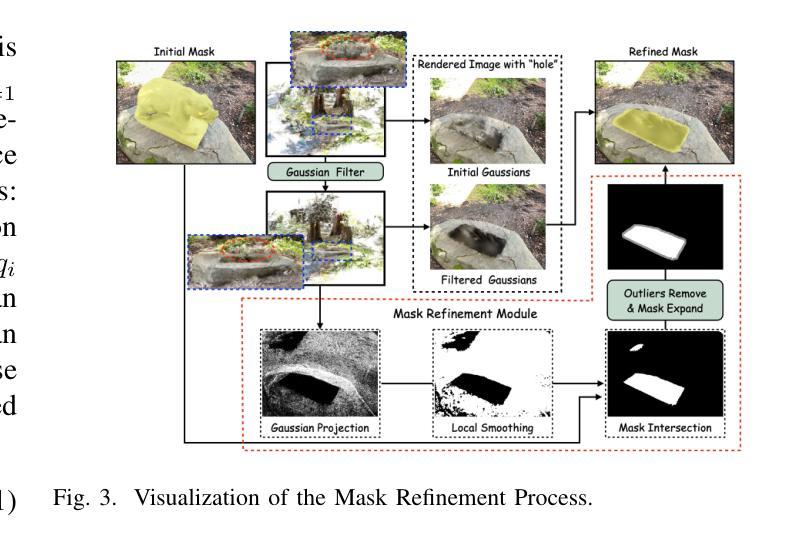
High-fidelity 3D Gaussian Inpainting: preserving multi-view consistency and photorealistic details
Authors:Jun Zhou, Dinghao Li, Nannan Li, Mingjie Wang
Recent advancements in multi-view 3D reconstruction and novel-view synthesis, particularly through Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS), have greatly enhanced the fidelity and efficiency of 3D content creation. However, inpainting 3D scenes remains a challenging task due to the inherent irregularity of 3D structures and the critical need for maintaining multi-view consistency. In this work, we propose a novel 3D Gaussian inpainting framework that reconstructs complete 3D scenes by leveraging sparse inpainted views. Our framework incorporates an automatic Mask Refinement Process and region-wise Uncertainty-guided Optimization. Specifically, we refine the inpainting mask using a series of operations, including Gaussian scene filtering and back-projection, enabling more accurate localization of occluded regions and realistic boundary restoration. Furthermore, our Uncertainty-guided Fine-grained Optimization strategy, which estimates the importance of each region across multi-view images during training, alleviates multi-view inconsistencies and enhances the fidelity of fine details in the inpainted results. Comprehensive experiments conducted on diverse datasets demonstrate that our approach outperforms existing state-of-the-art methods in both visual quality and view consistency.
近期多视角三维重建和新颖视角合成方面的进展,特别是通过神经辐射场(NeRF)和三维高斯拼贴(3DGS),极大地提高了三维内容创建的真实性和效率。然而,由于三维结构本身的不规则性和保持多视角一致性的关键需求,对三维场景的上色填充仍然是一项具有挑战性的任务。在这项工作中,我们提出了一种新的三维高斯填充框架,它利用稀疏填充视图重建完整的三维场景。我们的框架结合了自动蒙版细化过程和区域不确定性引导优化。具体来说,我们使用一系列操作来优化填充蒙版,包括高斯场景滤波器和反向投影,从而更准确地定位遮挡区域并实现逼真的边界恢复。此外,我们的不确定性引导精细优化策略在训练过程中估计多视角图像中每个区域的重要性,减轻了多视角的不一致性,提高了填充结果中细节的真实性。在多个数据集上进行的综合实验表明,我们的方法在视觉质量和视角一致性方面均优于现有最先进的方法。
论文及项目相关链接
摘要
近期多视角三维重建和新颖视角合成(尤其是通过神经辐射场和三维高斯拼贴技术)的进步大大提高了三维内容创作的保真度和效率。然而,对三维场景的补全依然是一个挑战,主要由于三维结构的不规则性和保持多视角一致性的关键需求。本研究提出了一种新型的三维高斯补全框架,通过利用稀疏的补全视角来重建完整的三维场景。此框架结合了自动掩膜细化过程和区域不确定性引导优化。具体来说,我们通过一系列操作如高斯场景过滤和反向投影来优化补全掩膜,可以更准确地定位遮挡区域并实现逼真的边界恢复。此外,我们的不确定性引导精细优化策略在训练过程中估计每个区域在多视角图像中的重要性,减轻了多视角的不一致性,提高了补全结果的细节保真度。在多个数据集上的综合实验表明,我们的方法在视觉质量和视角一致性方面均优于现有最先进的方法。
关键见解
- 利用多视角三维重建和新颖视角合成技术的最新进展,增强了三维内容创作的保真度和效率。
- 提出了一种新型的三维高斯补全框架,利用稀疏的补全视角重建完整三维场景。
- 框架包含自动掩膜细化过程,通过高斯场景过滤和反向投影等操作优化补全掩膜。
- 引入区域不确定性引导优化策略,估计每个区域在多视角图像中的重要性,减少多视角不一致性。
- 综合实验证明,该方法在视觉质量和视角一致性方面均优于现有方法。
- 该框架能有效处理三维结构的不规则性,实现更准确的遮挡区域定位和逼真的边界恢复。
点此查看论文截图



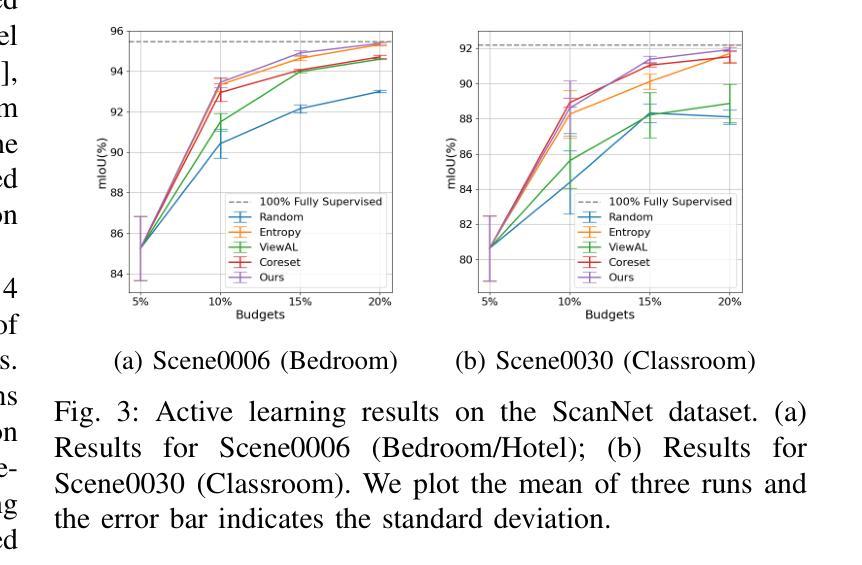
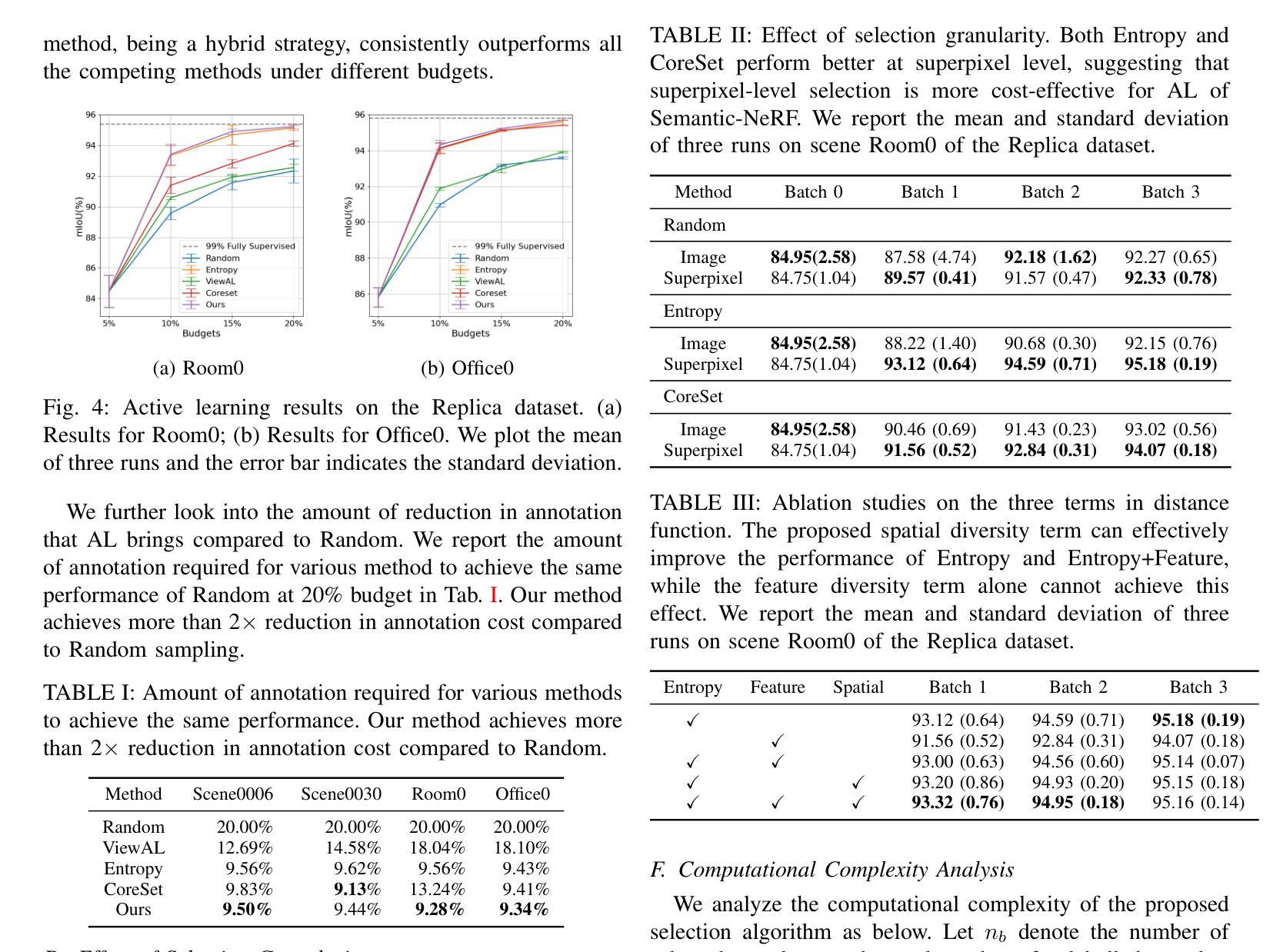
Exploring Active Learning for Label-Efficient Training of Semantic Neural Radiance Field
Authors:Yuzhe Zhu, Lile Cai, Kangkang Lu, Fayao Liu, Xulei Yang
Neural Radiance Field (NeRF) models are implicit neural scene representation methods that offer unprecedented capabilities in novel view synthesis. Semantically-aware NeRFs not only capture the shape and radiance of a scene, but also encode semantic information of the scene. The training of semantically-aware NeRFs typically requires pixel-level class labels, which can be prohibitively expensive to collect. In this work, we explore active learning as a potential solution to alleviate the annotation burden. We investigate various design choices for active learning of semantically-aware NeRF, including selection granularity and selection strategies. We further propose a novel active learning strategy that takes into account 3D geometric constraints in sample selection. Our experiments demonstrate that active learning can effectively reduce the annotation cost of training semantically-aware NeRF, achieving more than 2X reduction in annotation cost compared to random sampling.
神经辐射场(NeRF)模型是一种隐式神经场景表示方法,为新视角合成提供了前所未有的能力。语义感知NeRF不仅捕捉场景的形状和辐射度,还编码场景语义信息。语义感知NeRF的训练通常需要像素级类别标签,这些标签的收集可能非常昂贵。在这项工作中,我们探索了主动学习作为减轻标注负担的潜在解决方案。我们研究了语义感知NeRF主动学习的各种设计选择,包括选择粒度和选择策略。我们进一步提出了一种新的主动学习策略,该策略在样本选择时考虑了3D几何约束。我们的实验表明,主动学习可以有效地降低训练语义感知NeRF的标注成本,与随机采样相比,标注成本降低了两倍以上。
论文及项目相关链接
PDF Accepted to ICME 2025
Summary
本文探讨了Neural Radiance Field(NeRF)模型的语义化问题,介绍了一种结合主动学习方法减少语义感知NeRF训练中的标注成本的方式。研究通过设计不同选择粒度及策略来探讨主动学习的可行性,并提出了一个新的主动学习策略,即在样本选择时考虑到三维几何约束。实验表明,主动学习可以有效降低语义感知NeRF训练的标注成本,相较于随机采样,标注成本降低了两倍以上。
Key Takeaways
- NeRF模型是隐式神经网络场景表示方法,能进行前所未有的新视角合成。
- 语义感知NeRF不仅能捕捉场景的形状和辐射度,还能编码场景语义信息。
- 语义感知NeRF训练通常需要像素级别的类标签,这会导致标注成本过高。
- 主动学习是一种降低标注成本的有效方式。
- 研究通过设计不同选择粒度及策略来探讨主动学习的有效性。
- 提出了一种新的主动学习策略,考虑三维几何约束在样本选择中的作用。
点此查看论文截图


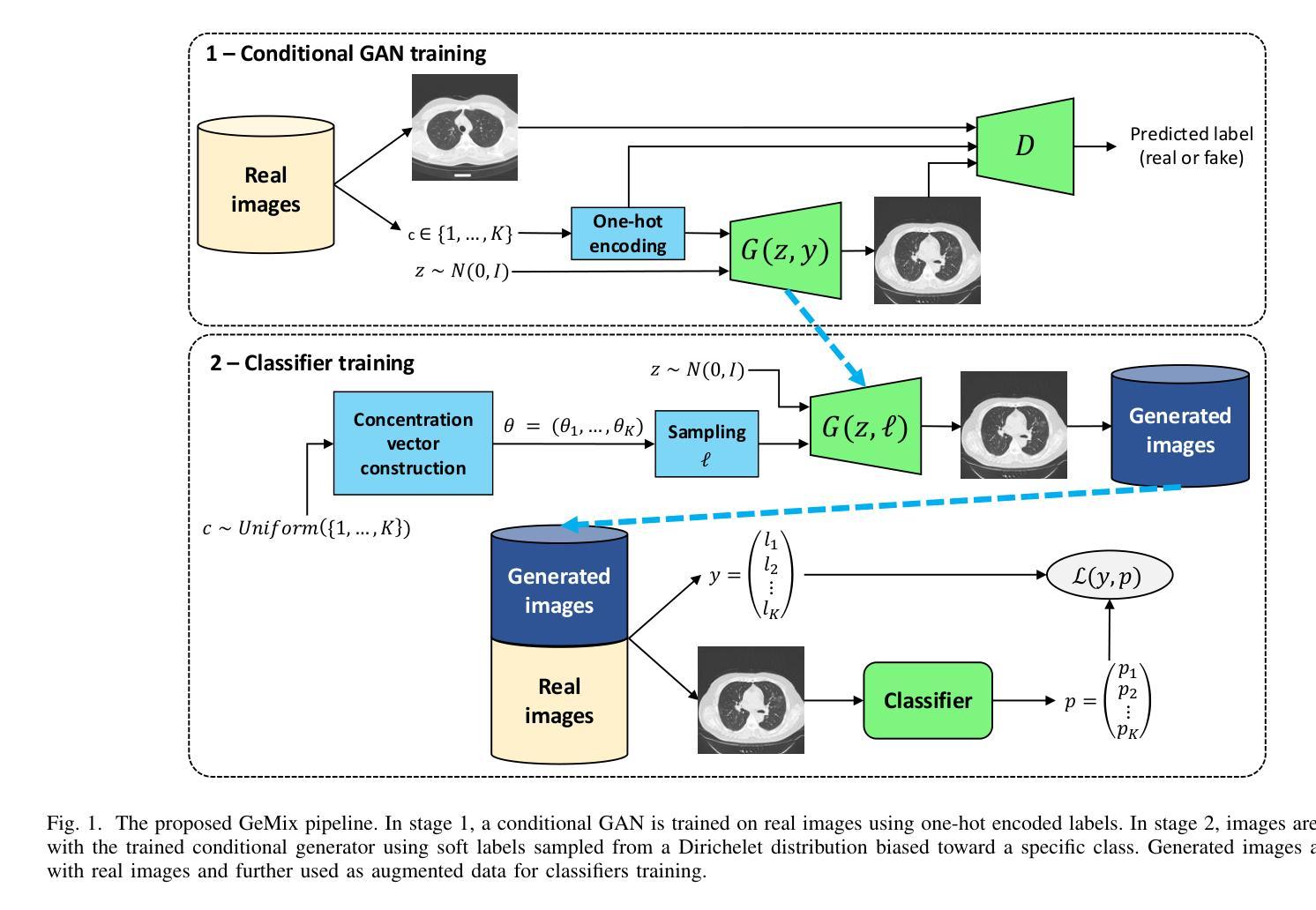
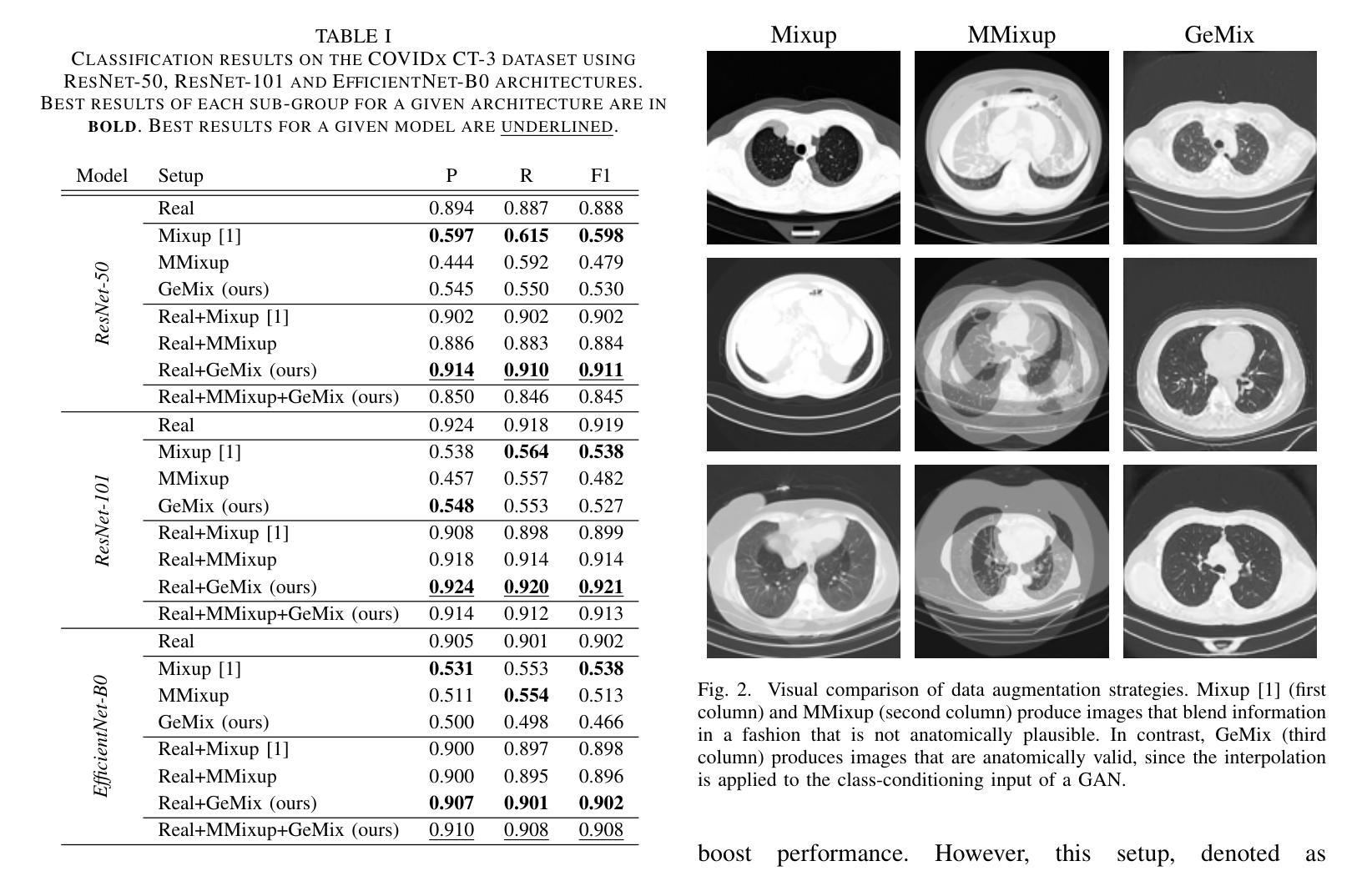
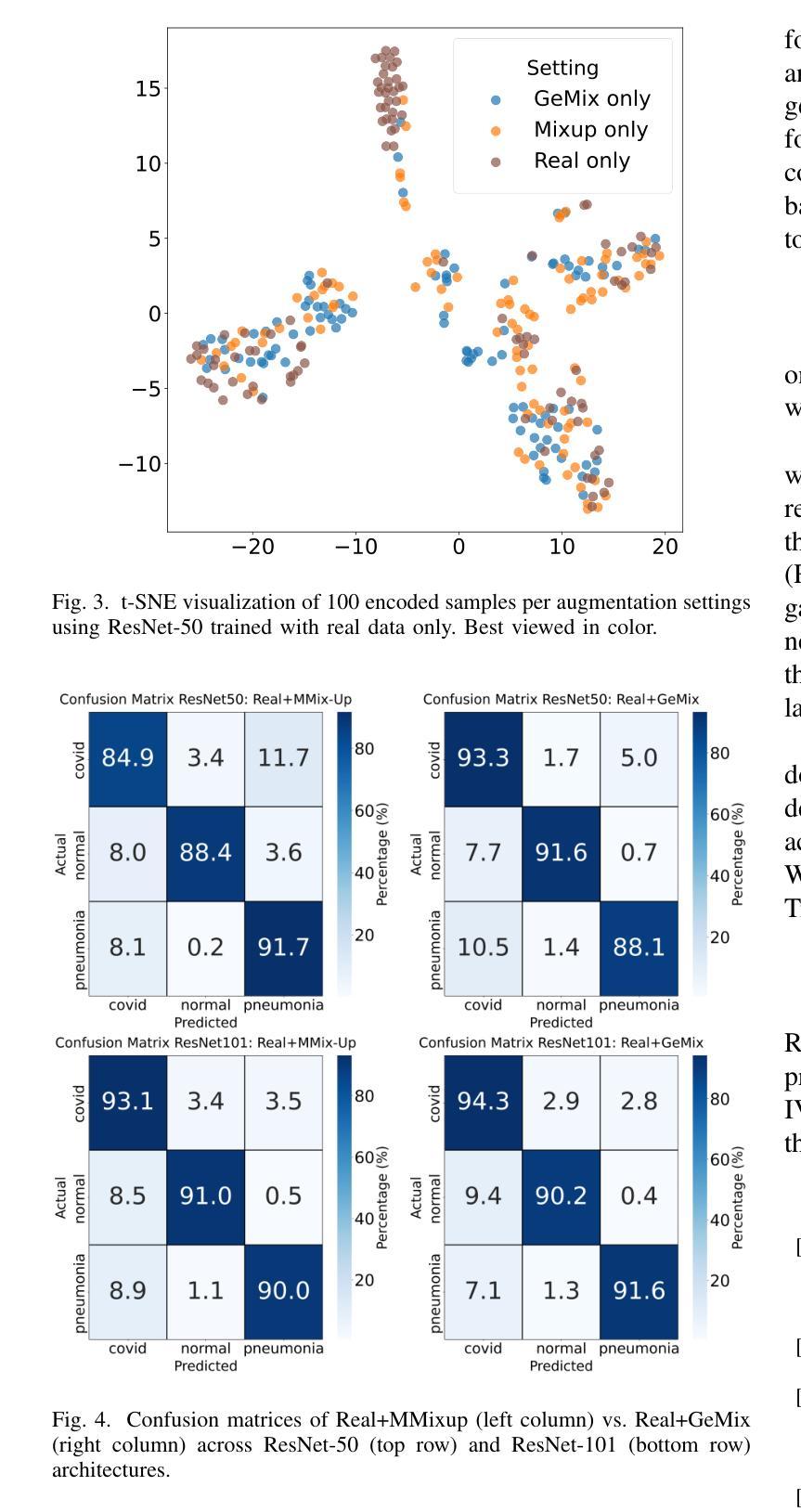
GeMix: Conditional GAN-Based Mixup for Improved Medical Image Augmentation
Authors:Hugo Carlesso, Maria Eliza Patulea, Moncef Garouani, Radu Tudor Ionescu, Josiane Mothe
Mixup has become a popular augmentation strategy for image classification, yet its naive pixel-wise interpolation often produces unrealistic images that can hinder learning, particularly in high-stakes medical applications. We propose GeMix, a two-stage framework that replaces heuristic blending with a learned, label-aware interpolation powered by class-conditional GANs. First, a StyleGAN2-ADA generator is trained on the target dataset. During augmentation, we sample two label vectors from Dirichlet priors biased toward different classes and blend them via a Beta-distributed coefficient. Then, we condition the generator on this soft label to synthesize visually coherent images that lie along a continuous class manifold. We benchmark GeMix on the large-scale COVIDx-CT-3 dataset using three backbones (ResNet-50, ResNet-101, EfficientNet-B0). When combined with real data, our method increases macro-F1 over traditional mixup for all backbones, reducing the false negative rate for COVID-19 detection. GeMix is thus a drop-in replacement for pixel-space mixup, delivering stronger regularization and greater semantic fidelity, without disrupting existing training pipelines. We publicly release our code at https://github.com/hugocarlesso/GeMix to foster reproducibility and further research.
数据增强策略Mixup在图像分类中受到广泛欢迎,但其简单的像素级插值经常生成不真实的图像,可能阻碍学习,特别是在高风险的医疗应用中。我们提出了GeMix,这是一个两阶段的框架,它用基于类别条件GAN的学习感知插值替换启发式混合。首先,我们在目标数据集上训练StyleGAN2-ADA生成器。在数据增强过程中,我们从偏向不同类别的Dirichlet先验中采样两个标签向量,并通过Beta分布系数将它们混合。然后,我们将生成器设置在这个软标签上,合成视觉上连贯的图像,这些图像位于连续的类别流形上。我们在大规模的COVIDx-CT-3数据集上使用三种骨干网络(ResNet-50、ResNet-101、EfficientNet-B0)对GeMix进行基准测试。当与真实数据结合时,我们的方法在所有骨干网络上相对于传统Mixup提高了宏观F1分数,降低了新冠肺炎检测的误报率。因此,GeMix可作为像素空间Mixup的替代品,提供更强的正则化和更高的语义保真度,而不会破坏现有的训练管道。我们公开发布我们的代码在https://github.com/hugocarlesso/GeMix上,以促进可重复性和进一步研究。
论文及项目相关链接
Summary
数据增强策略Mixup在图像分类中广泛应用,但在高风险的医疗应用中,其简单的像素级插值会产生不真实图像,影响学习效果。为此,本文提出GeMix,一个两阶段框架,用基于类别条件GAN的标记感知插值替换启发式混合。GeMix在COVIDx-CT-3数据集上表现优异,能提高宏观F1分数,降低COVID-19检测的误报率。GeMix可替代像素空间Mixup,提供更强大的正则化和更高的语义保真度,且不会干扰现有训练流程。
Key Takeaways
- Mixup作为一种数据增强策略在图像分类中广泛应用,但在医疗领域存在局限性。
- GeMix框架通过引入基于类别条件GAN的标记感知插值,改进了Mixup的局限性。
- GeMix使用StyleGAN2-ADA生成器生成视觉连贯的图像,这些图像位于连续的类别流形上。
- 在COVIDx-CT-3数据集上进行的实验表明,GeMix相较于传统Mixup提高了宏观F1分数,降低了误报率。
- GeMix可替代像素空间Mixup,提供更强大的正则化和更高的语义保真度。
- GeMix不会对现有训练流程造成干扰。
点此查看论文截图

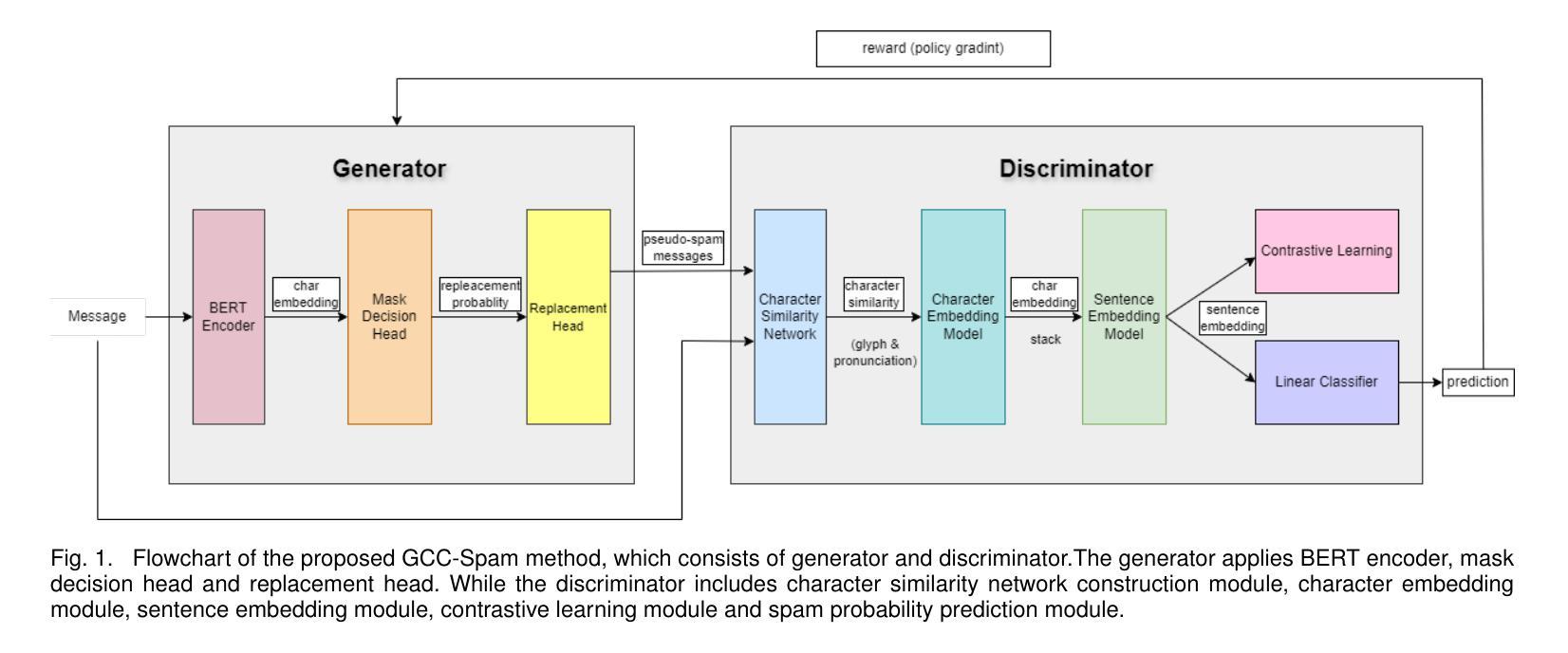
GCC-Spam: Spam Detection via GAN, Contrastive Learning, and Character Similarity Networks
Authors:Zhijie Wang, Zixin Xu, Zhiyuan Pan
The exponential growth of spam text on the Internet necessitates robust detection mechanisms to mitigate risks such as information leakage and social instability. This work addresses two principal challenges: adversarial strategies employed by spammers and the scarcity of labeled data. We propose a novel spam-text detection framework GCC-Spam, which integrates three core innovations. First, a character similarity network captures orthographic and phonetic features to counter character-obfuscation attacks and furthermore produces sentence embeddings for downstream classification. Second, contrastive learning enhances discriminability by optimizing the latent-space distance between spam and normal texts. Third, a Generative Adversarial Network (GAN) generates realistic pseudo-spam samples to alleviate data scarcity while improving model robustness and classification accuracy. Extensive experiments on real-world datasets demonstrate that our model outperforms baseline approaches, achieving higher detection rates with significantly fewer labeled examples.
随着互联网上垃圾文本呈指数级增长,为了减少信息泄露和社会不稳定等风险,需要强大的检测机制。这项工作解决了两个主要挑战:垃圾邮件发送者采用的对抗策略和标记数据的稀缺性。我们提出了一种新的垃圾文本检测框架GCC-Spam,它融合了三个核心创新点。首先,一个字符相似网络能够捕获正字和语音特征来对抗字符混淆攻击,并为下游分类产生句子嵌入。其次,对比学习通过优化垃圾文本和正常文本之间的潜在空间距离来提高鉴别力。最后,生成对抗网络(GAN)生成逼真的伪垃圾邮件样本,以缓解数据稀缺问题,同时提高模型的稳健性和分类准确性。在现实数据集上的大量实验表明,我们的模型优于基线方法,在更少的标记样本的情况下实现了更高的检测率。
论文及项目相关链接
Summary
互联网上的垃圾文本指数级增长,带来信息泄露和社会不稳定风险。针对此问题,本研究提出了GCC-Spam框架,整合三大创新策略:字符相似网络应对字符混淆攻击并生成句子嵌入;对比学习优化垃圾文本与正常文本的潜在空间距离;生成对抗网络生成逼真的伪垃圾文本样本以缓解数据短缺问题,同时提高模型稳健性和分类精度。实验证明该模型在真实数据集上的检测率高于基线方法。
Key Takeaways
- 互联网垃圾文本增长引发风险,需强化检测机制。
- GCC-Spam框架整合三大创新策略应对垃圾文本检测挑战。
- 字符相似网络应对字符混淆攻击并生成句子嵌入。
- 对比学习优化潜在空间距离,提高识别精度。
- 生成对抗网络生成伪垃圾文本样本,缓解数据短缺问题。
- GCC-Spam框架在真实数据集上的检测率高于基线方法。
点此查看论文截图

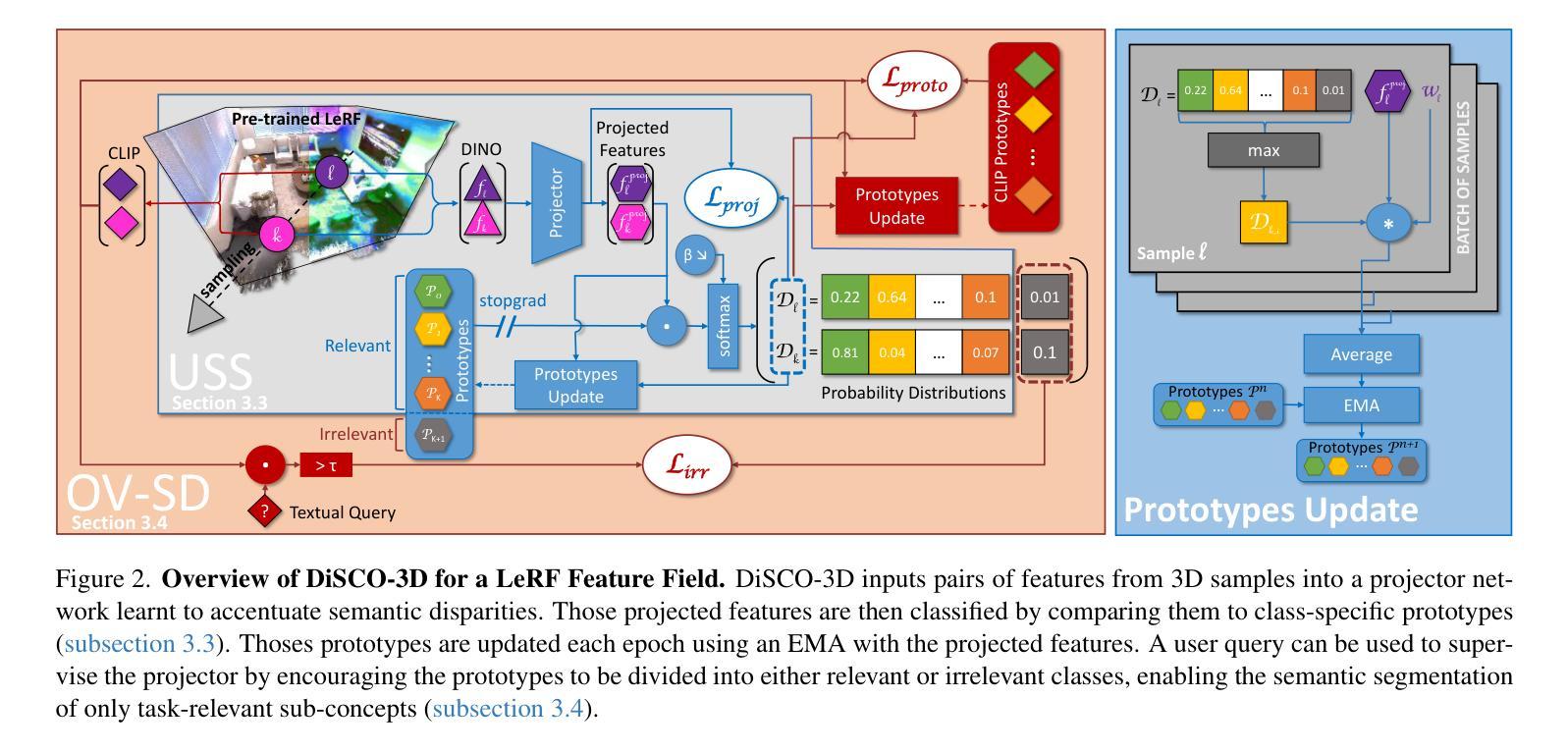
DiSCO-3D : Discovering and segmenting Sub-Concepts from Open-vocabulary queries in NeRF
Authors:Doriand Petit, Steve Bourgeois, Vincent Gay-Bellile, Florian Chabot, Loïc Barthe
3D semantic segmentation provides high-level scene understanding for applications in robotics, autonomous systems, \textit{etc}. Traditional methods adapt exclusively to either task-specific goals (open-vocabulary segmentation) or scene content (unsupervised semantic segmentation). We propose DiSCO-3D, the first method addressing the broader problem of 3D Open-Vocabulary Sub-concepts Discovery, which aims to provide a 3D semantic segmentation that adapts to both the scene and user queries. We build DiSCO-3D on Neural Fields representations, combining unsupervised segmentation with weak open-vocabulary guidance. Our evaluations demonstrate that DiSCO-3D achieves effective performance in Open-Vocabulary Sub-concepts Discovery and exhibits state-of-the-art results in the edge cases of both open-vocabulary and unsupervised segmentation.
3D语义分割为机器人技术、自主系统等领域的应用提供了高级场景理解。传统方法只适应于特定任务的特定目标(开放式词汇分割)或场景内容(无监督语义分割)。我们提出DiSCO-3D,这是第一个解决更广泛的开放式词汇子概念发现问题的三维方法,旨在提供一种适应场景和用户查询的三维语义分割。我们在神经场表示的基础上构建DiSCO-3D,将无监督分割与弱开放式词汇引导相结合。我们的评估表明,DiSCO-3D在开放式词汇子概念发现方面表现出强大的性能,同时在开放式词汇和无监督分割的极端情况下都处于一流水平。
论文及项目相关链接
PDF Published at ICCV’25
Summary
本文提出了DiSCO-3D方法,旨在解决3D开放词汇子概念发现这一更广泛的问题。该方法结合了无监督分割与弱开放词汇指导,旨在为场景和用户查询提供自适应的3D语义分割。评价显示,DiSCO-3D在开放词汇子概念发现中取得了有效性能,并在开放词汇和无监督分割的边缘情况下展现了最佳结果。
Key Takeaways
- 3D语义分割为机器人、自主系统等应用提供了高级场景理解。
- 传统方法主要适应于任务特定目标或场景内容。
- DiSCO-3D是首个解决3D开放词汇子概念发现问题的办法。
- DiSCO-3D旨在提供自适应于场景和用户查询的3D语义分割。
- DiSCO-3D基于神经场表示,结合了无监督分割与弱开放词汇指导。
- DiSCO-3D在开放词汇子概念发现中表现有效。
点此查看论文截图


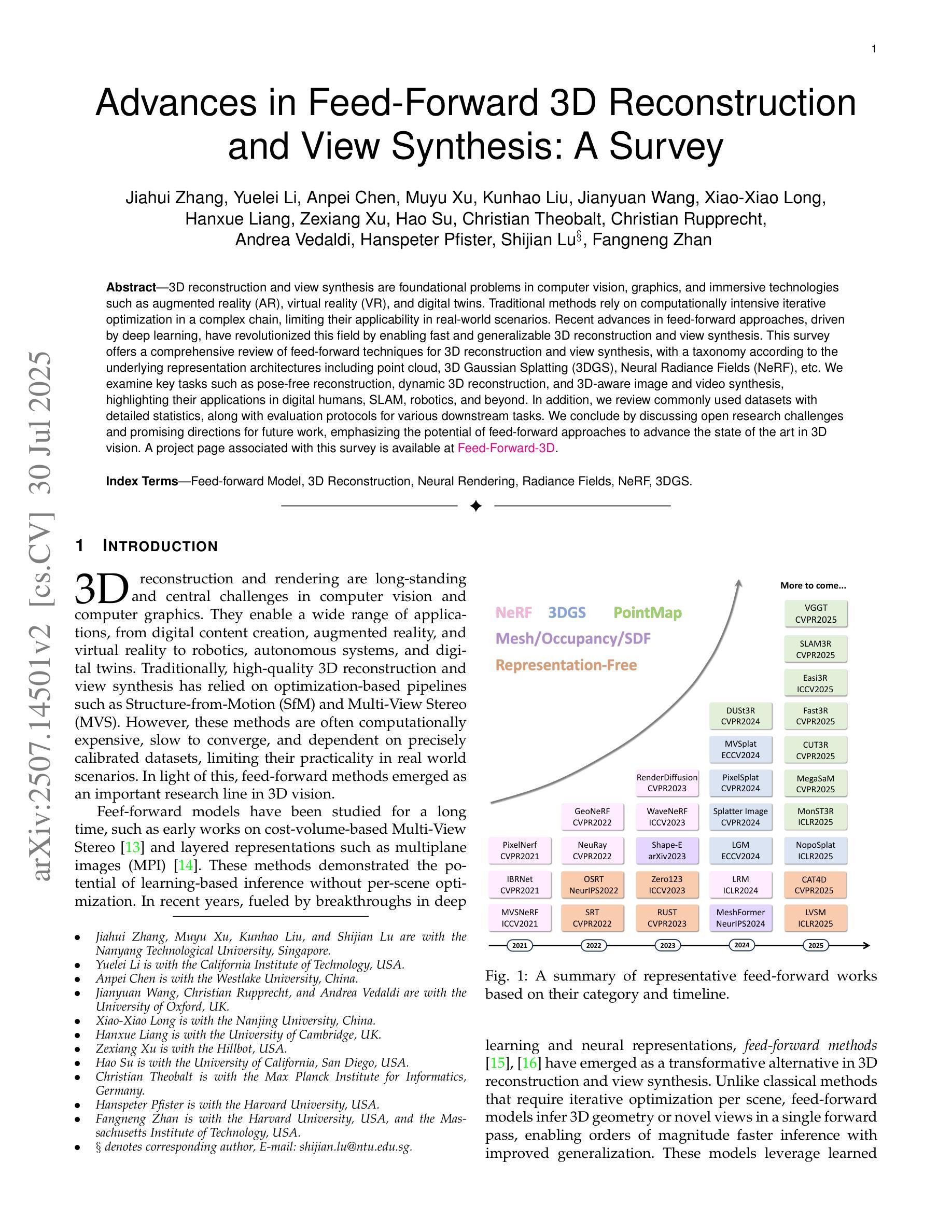
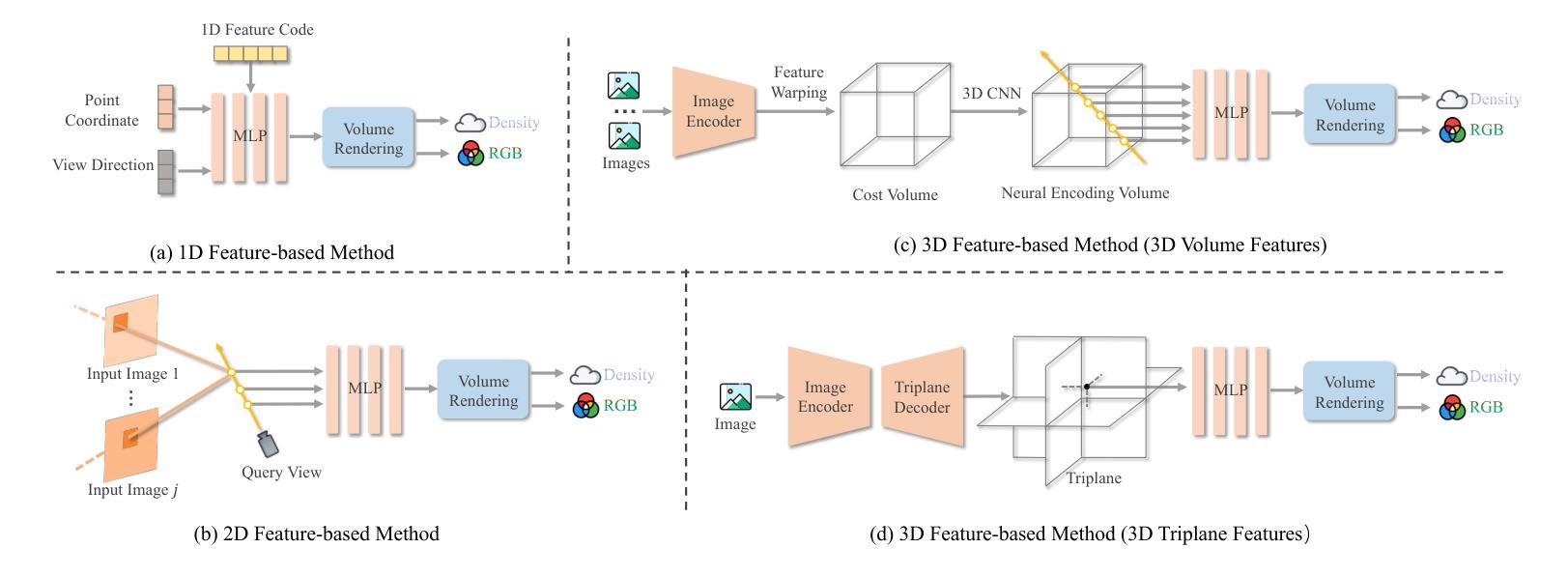
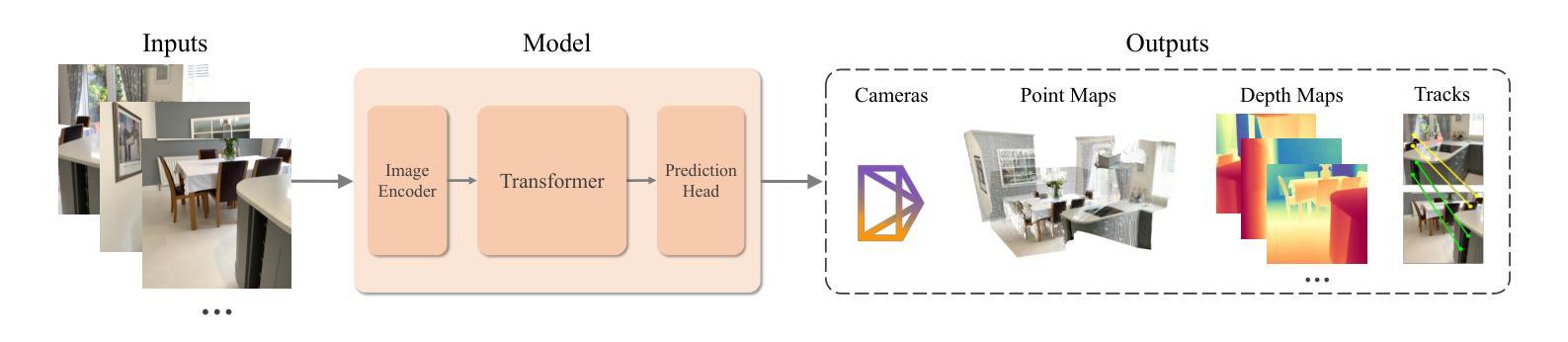
Advances in Feed-Forward 3D Reconstruction and View Synthesis: A Survey
Authors:Jiahui Zhang, Yuelei Li, Anpei Chen, Muyu Xu, Kunhao Liu, Jianyuan Wang, Xiao-Xiao Long, Hanxue Liang, Zexiang Xu, Hao Su, Christian Theobalt, Christian Rupprecht, Andrea Vedaldi, Hanspeter Pfister, Shijian Lu, Fangneng Zhan
3D reconstruction and view synthesis are foundational problems in computer vision, graphics, and immersive technologies such as augmented reality (AR), virtual reality (VR), and digital twins. Traditional methods rely on computationally intensive iterative optimization in a complex chain, limiting their applicability in real-world scenarios. Recent advances in feed-forward approaches, driven by deep learning, have revolutionized this field by enabling fast and generalizable 3D reconstruction and view synthesis. This survey offers a comprehensive review of feed-forward techniques for 3D reconstruction and view synthesis, with a taxonomy according to the underlying representation architectures including point cloud, 3D Gaussian Splatting (3DGS), Neural Radiance Fields (NeRF), etc. We examine key tasks such as pose-free reconstruction, dynamic 3D reconstruction, and 3D-aware image and video synthesis, highlighting their applications in digital humans, SLAM, robotics, and beyond. In addition, we review commonly used datasets with detailed statistics, along with evaluation protocols for various downstream tasks. We conclude by discussing open research challenges and promising directions for future work, emphasizing the potential of feed-forward approaches to advance the state of the art in 3D vision.
3D重建和视图合成是计算机视觉、图形学和沉浸式技术(如增强现实(AR)、虚拟现实(VR)和数字孪生)中的基础问题。传统方法依赖于复杂链中的计算密集型迭代优化,这在现实场景中的应用具有一定的局限性。最近,由深度学习驱动的前馈方法的最新进展已经彻底改变了这一领域,实现了快速和通用的3D重建和视图合成。这篇综述对前馈技术在3D重建和视图合成方面的应用进行了全面的回顾,并根据基础表示架构进行了分类,包括点云、3D高斯拼贴(3DGS)、神经辐射场(NeRF)等。我们研究了关键任务,如姿态自由重建、动态3D重建和3D感知图像和视频合成,重点介绍了它们在数字人类、SLAM、机器人技术等领域的应用。此外,我们还回顾了常用数据集及其详细统计数据,以及各种下游任务的评估协议。最后,我们讨论了当前的研究挑战以及未来工作的有前途的方向,强调了前馈方法在推动计算机视觉领域发展的潜力。
论文及项目相关链接
PDF A project page associated with this survey is available at https://fnzhan.com/projects/Feed-Forward-3D
Summary
神经网络辐射场(NeRF)在三维重建和视图合成中的综合研究。该文回顾了基于点云、三维高斯喷溅(NeRF)、深度学习等新兴技术的面向任务方法的演变及优劣点。强调应用包括动态三维重建和场景认知的视频图像合成等。同时,文章还讨论了数据集和评估协议,并展望了未来研究挑战和潜在方向。
Key Takeaways
- 介绍了基于深度学习的即时方法(feed-forward approaches)在三维重建和视图合成中的优势。与传统的复杂迭代优化方法相比,这些方法更为快速和普遍适用。
- 提供了一种对基于神经网络辐射场(NeRF)和其他技术(如点云和三维高斯喷溅)的分类方法,并对每种技术的特点进行了概述。
- 讨论了关键任务,如姿势无关重建、动态三维重建和三维感知图像和视频合成等,并展示了它们在数字人类、SLAM(即时定位和地图构建)、机器人等领域的应用。
- 分析了现有数据集并提供了详细的统计数据,同时探讨了用于各种下游任务的评估协议。
- 最后,文章总结了当前研究的开放挑战和未来研究方向,并强调了面向即时方法在推动三维视觉领域中的潜力。
点此查看论文截图

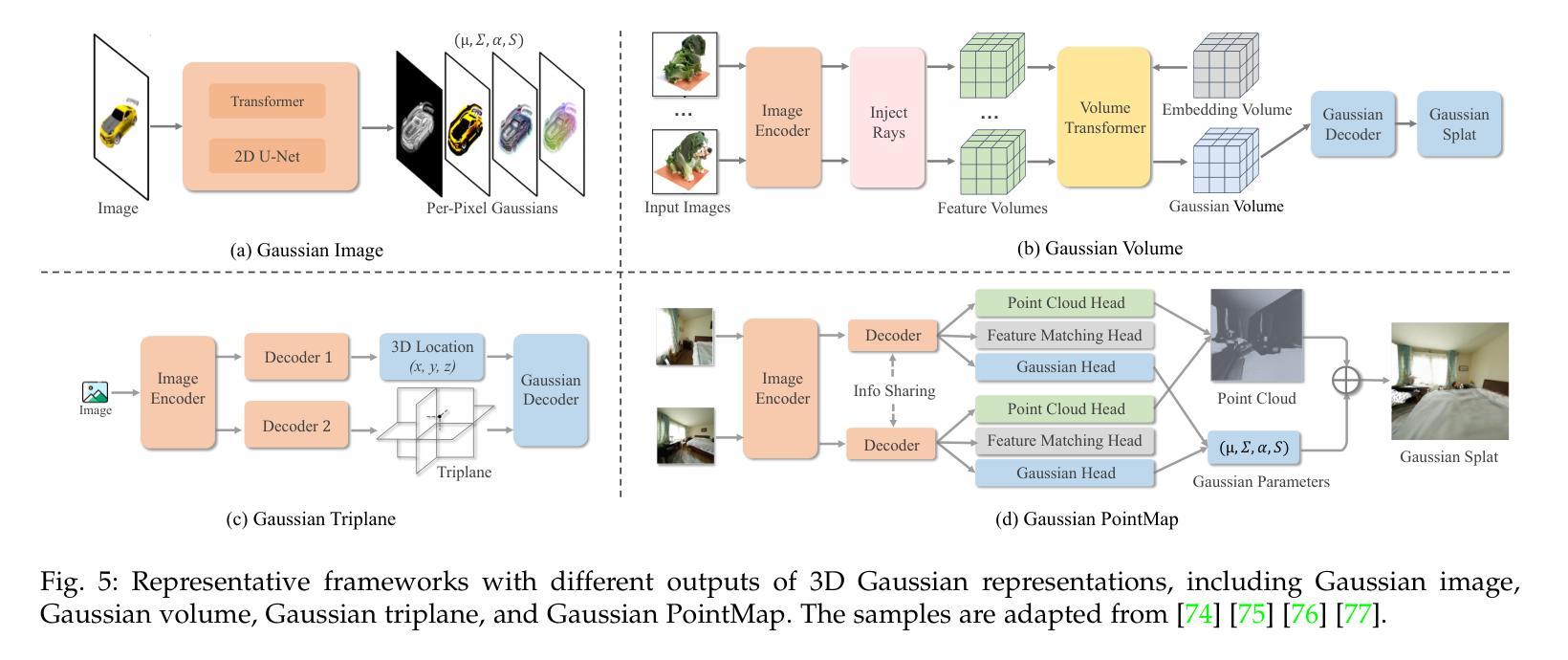
EPSilon: Efficient Point Sampling for Lightening of Hybrid-based 3D Avatar Generation
Authors:Seungjun Moon, Sangjoon Yu, Gyeong-Moon Park
The rapid advancement of neural radiance fields (NeRF) has paved the way to generate animatable human avatars from a monocular video. However, the sole usage of NeRF suffers from a lack of details, which results in the emergence of hybrid representation that utilizes SMPL-based mesh together with NeRF representation. While hybrid-based models show photo-realistic human avatar generation qualities, they suffer from extremely slow inference due to their deformation scheme: to be aligned with the mesh, hybrid-based models use the deformation based on SMPL skinning weights, which needs high computational costs on each sampled point. We observe that since most of the sampled points are located in empty space, they do not affect the generation quality but result in inference latency with deformation. In light of this observation, we propose EPSilon, a hybrid-based 3D avatar generation scheme with novel efficient point sampling strategies that boost both training and inference. In EPSilon, we propose two methods to omit empty points at rendering; empty ray omission (ERO) and empty interval omission (EIO). In ERO, we wipe out rays that progress through the empty space. Then, EIO narrows down the sampling interval on the ray, which wipes out the region not occupied by either clothes or mesh. The delicate sampling scheme of EPSilon enables not only great computational cost reduction during deformation but also the designation of the important regions to be sampled, which enables a single-stage NeRF structure without hierarchical sampling. Compared to existing methods, EPSilon maintains the generation quality while using only 3.9% of sampled points and achieves around 20 times faster inference, together with 4 times faster training convergence. We provide video results on https://github.com/seungjun-moon/epsilon.
神经辐射场(NeRF)的快速发展为实现从单目视频中生成可动画的人类化身铺平了道路。然而,仅仅使用NeRF会导致细节不足,这导致了利用基于SMPL的网格与NeRF表示相结合的混合表示的出现。虽然混合模型表现出逼真的人类化身生成质量,但由于其变形方案,它们遭受了极慢的推理过程:为了与网格对齐,混合模型使用基于SMPL蒙皮权重的变形,这在每个采样点上都需要很高的计算成本。我们观察到,由于大多数采样点位于空白空间中,它们并不影响生成质量,但却导致了具有变形的推理延迟。鉴于此观察,我们提出了EPSILON,这是一种基于混合的3D化身生成方案,具有新颖的高效点采样策略,可以加速训练和推理。在EPSILON中,我们提出了两种方法来省略渲染中的空白点:空白射线省略(ERO)和空白间隔省略(EIO)。ERO消除了穿过空白空间的射线。然后,EIO缩小了射线上的采样间隔,从而消除了未被衣服或网格占据的区域。EPSILON的精细采样方案不仅大大降低了变形过程中的计算成本,还能指定要采样的重要区域,从而实现无需分层采样的单阶段NeRF结构。与现有方法相比,EPSILON在保持生成质量的同时,仅使用3.9%的采样点,实现了约20倍的快速推理,以及4倍的训练收敛速度。视频结果可在https://github.com/seungjun-moon/epsilon上查看。
论文及项目相关链接
Summary
本文介绍了基于NeRF技术的动画人物生成方法。传统方法使用NeRF结合SMPL网格模型生成人物,但存在细节不足和计算效率低下的问题。为此,本文提出了一种名为EPSilon的混合模型,采用高效的点采样策略提升训练和推理速度,同时保持高质量的生成效果。EPSILON通过剔除无效采样点,实现了快速变形和单阶段NeRF结构,显著提高了计算效率。
Key Takeaways
- NeRF技术结合SMPL网格模型生成动画人物面临细节不足和计算效率低下的问题。
- EPSILON模型采用高效的点采样策略,剔除无效采样点以提高计算和训练效率。
- EPSILON实现了快速变形和单阶段NeRF结构,显著提高了性能。
- EPSILON在保持高质量生成效果的同时,实现了约20倍加速的推理速度和4倍加速的训练收敛速度。
- EPSILON模型在GitHub上提供了视频结果,供公众查看和参考。
- EPSILON模型的提出解决了传统方法中的一些问题,如采样点多、计算量大等。
点此查看论文截图

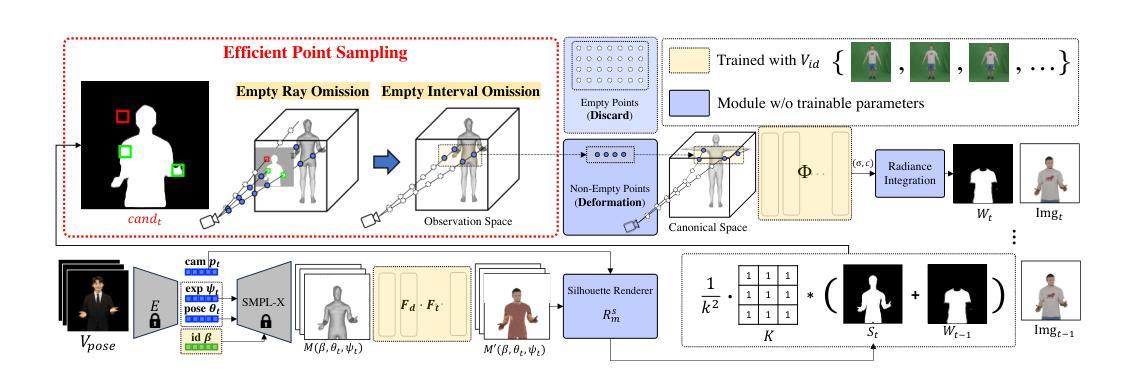
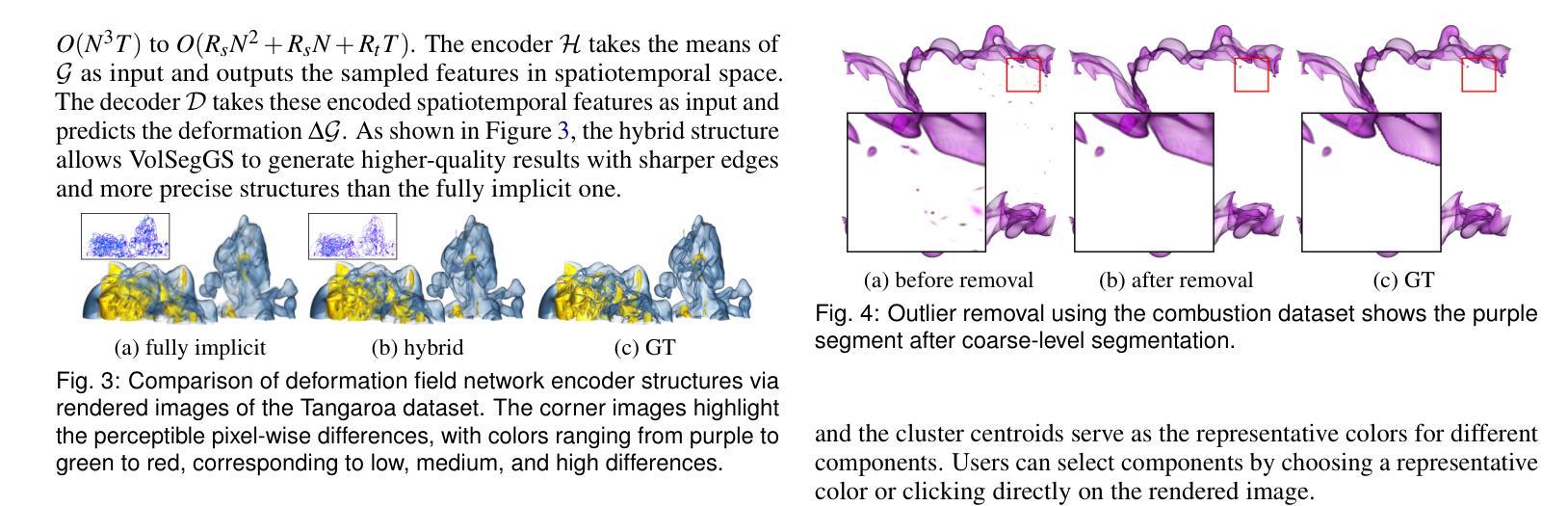
VolSegGS: Segmentation and Tracking in Dynamic Volumetric Scenes via Deformable 3D Gaussians
Authors:Siyuan Yao, Chaoli Wang
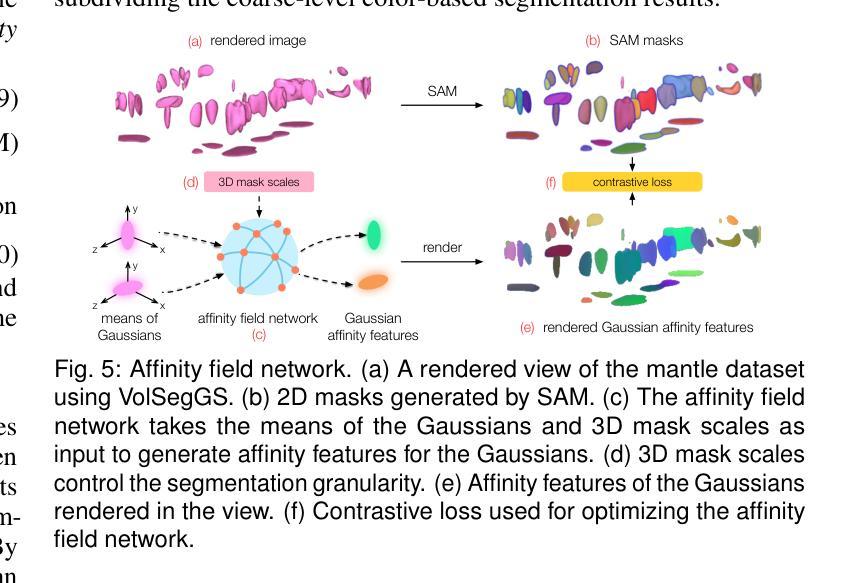
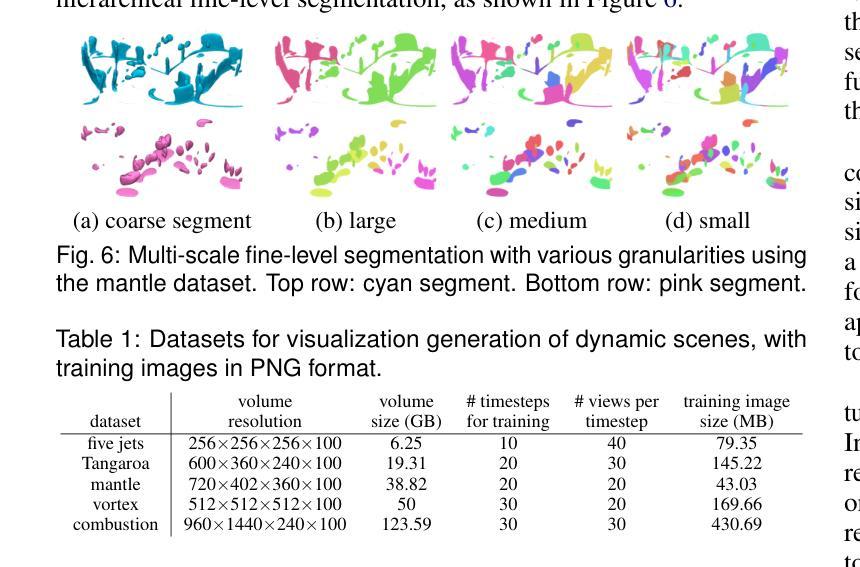
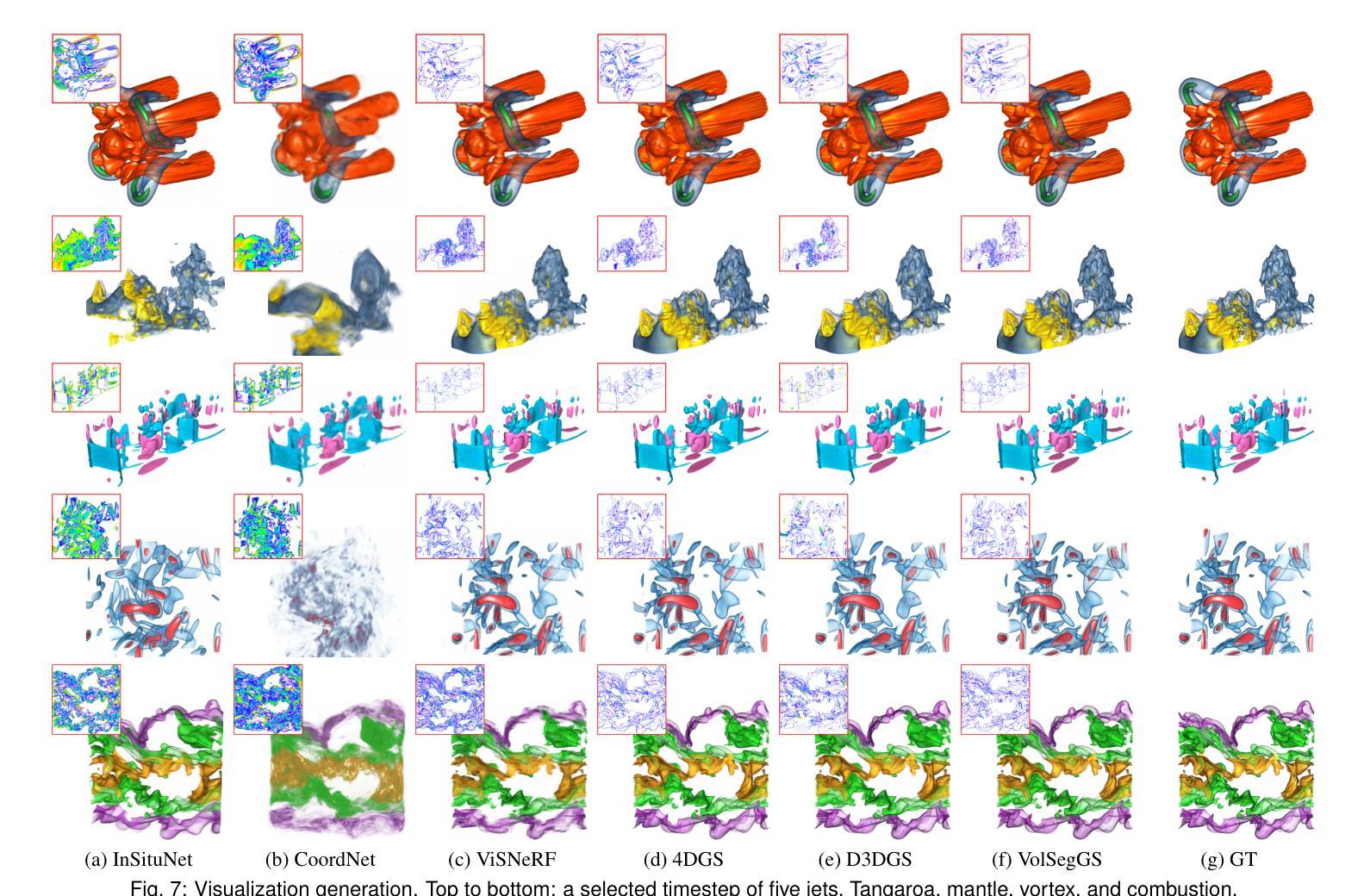
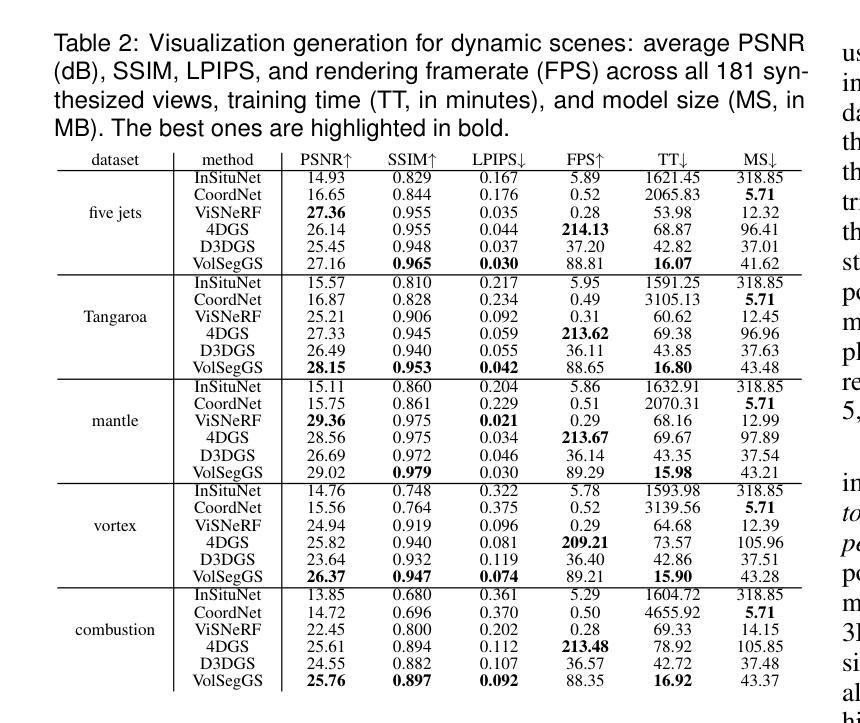
Visualization of large-scale time-dependent simulation data is crucial for domain scientists to analyze complex phenomena, but it demands significant I/O bandwidth, storage, and computational resources. To enable effective visualization on local, low-end machines, recent advances in view synthesis techniques, such as neural radiance fields, utilize neural networks to generate novel visualizations for volumetric scenes. However, these methods focus on reconstruction quality rather than facilitating interactive visualization exploration, such as feature extraction and tracking. We introduce VolSegGS, a novel Gaussian splatting framework that supports interactive segmentation and tracking in dynamic volumetric scenes for exploratory visualization and analysis. Our approach utilizes deformable 3D Gaussians to represent a dynamic volumetric scene, allowing for real-time novel view synthesis. For accurate segmentation, we leverage the view-independent colors of Gaussians for coarse-level segmentation and refine the results with an affinity field network for fine-level segmentation. Additionally, by embedding segmentation results within the Gaussians, we ensure that their deformation enables continuous tracking of segmented regions over time. We demonstrate the effectiveness of VolSegGS with several time-varying datasets and compare our solutions against state-of-the-art methods. With the ability to interact with a dynamic scene in real time and provide flexible segmentation and tracking capabilities, VolSegGS offers a powerful solution under low computational demands. This framework unlocks exciting new possibilities for time-varying volumetric data analysis and visualization.
大规模时变仿真数据的可视化对于领域科学家分析复杂现象至关重要,但这需要巨大的输入/输出带宽、存储和计算资源。为了在本地低端机器上实现有效的可视化,最近的视图合成技术(如神经辐射场)利用神经网络为体积场景生成新型可视化。然而,这些方法侧重于重建质量,而不是促进交互式可视化探索,如特征提取和跟踪。我们引入了VolSegGS,这是一种新的高斯喷涂框架,支持动态体积场景中的交互式分割和跟踪,用于探索性可视化和分析。我们的方法利用可变形的三维高斯来表示动态体积场景,从而实现实时的新型视图合成。为了获得准确的分割,我们利用高斯视图独立颜色进行粗略分割,并使用亲和场网络对结果进行细化。此外,通过将分割结果嵌入高斯中,我们确保它们的变形能够实时跟踪分割区域的连续变化。我们通过多个时变数据集展示了VolSegGS的有效性,并与最先进的解决方案进行了比较。VolSegGS能够在实时与动态场景进行交互,并提供灵活的分割和跟踪功能,它在低计算需求下提供了强大的解决方案。这一框架为时变体积数据分析和可视化开启了令人兴奋的新可能性。
论文及项目相关链接
Summary
本文介绍了针对大规模时变仿真数据可视化的一种新方法——VolSegGS。该方法采用高斯喷绘框架,支持动态体积场景中的交互式分割和跟踪,为探索性可视化和分析提供了强大的工具。通过利用可变形三维高斯数表示动态体积场景,实现实时新颖视图合成。该方法利用高斯视独立颜色进行粗略分割,并通过亲和场网络进行精细分割。通过将分割结果嵌入高斯数中,确保了分割区域的连续跟踪。VolSegGS为时间变化数据集的分析和可视化提供了实时交互、灵活分割和跟踪能力的强大解决方案。
Key Takeaways
- VolSegGS是一种基于高斯喷绘框架的方法,用于支持动态体积场景中的交互式分割和跟踪。
- 方法实现了实时新颖视图合成,通过利用可变形三维高斯数表示动态体积场景。
- 利用高斯视独立颜色进行粗略分割,并结合亲和场网络进行精细分割。
- 通过将分割结果嵌入高斯数中,确保了分割区域的连续跟踪。
- VolSegGS对于时间变化数据集的分析和可视化具有强大的实时交互能力。
- 该方法在满足低计算需求的同时,提供了灵活的分割和跟踪功能。
点此查看论文截图


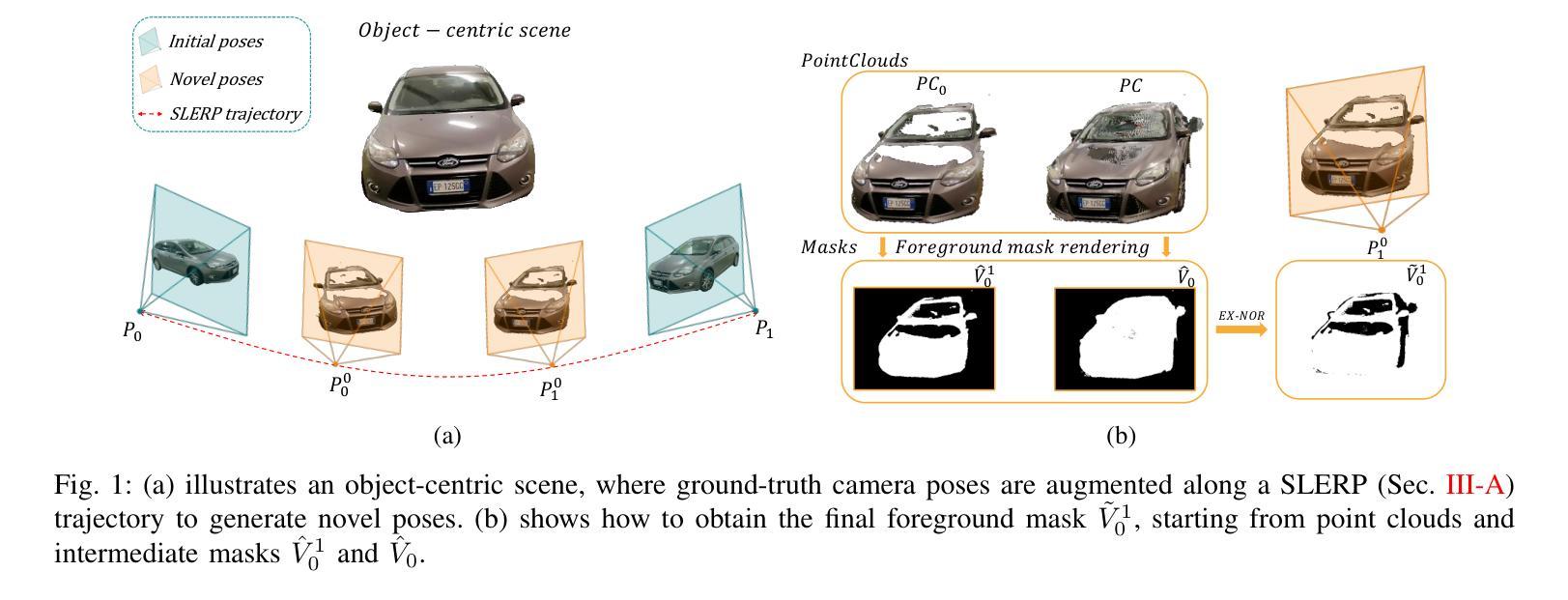
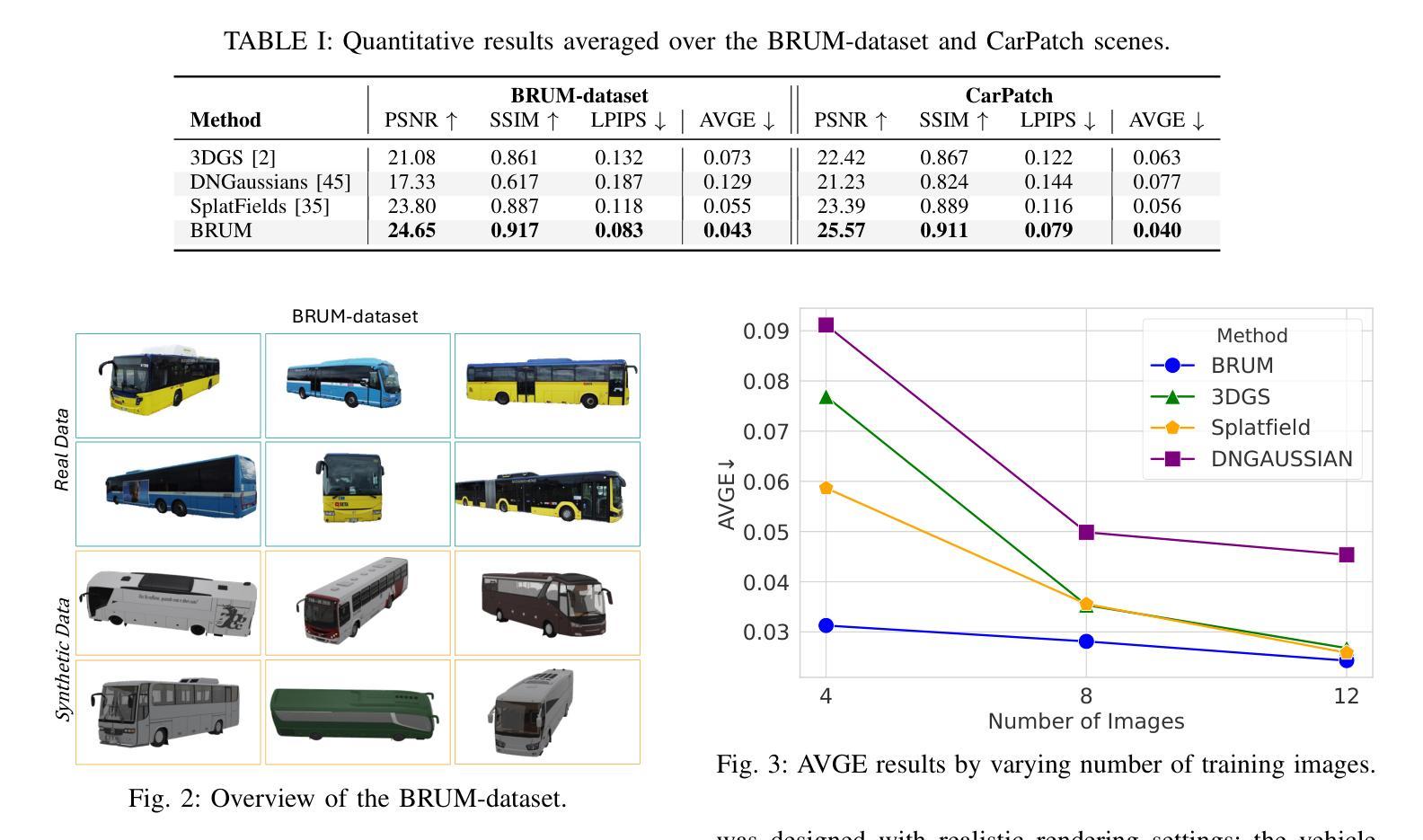
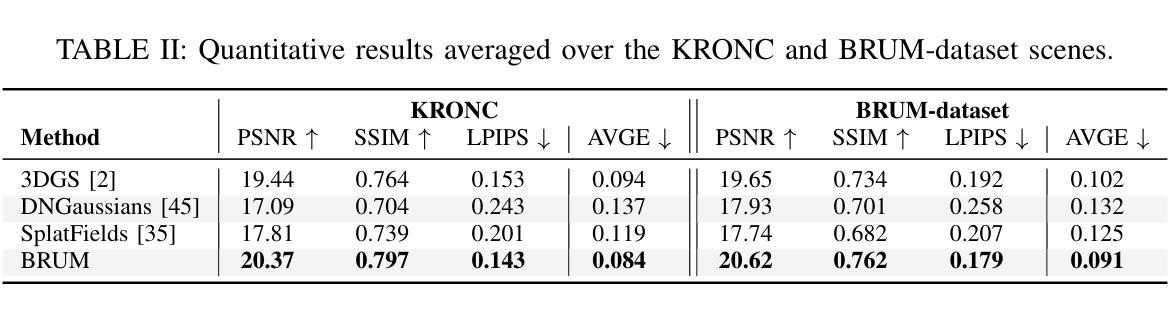
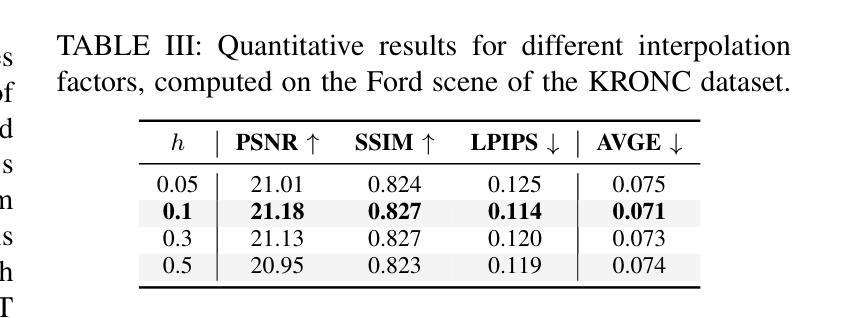
BRUM: Robust 3D Vehicle Reconstruction from 360 Sparse Images
Authors:Davide Di Nucci, Matteo Tomei, Guido Borghi, Luca Ciuffreda, Roberto Vezzani, Rita Cucchiara
Accurate 3D reconstruction of vehicles is vital for applications such as vehicle inspection, predictive maintenance, and urban planning. Existing methods like Neural Radiance Fields and Gaussian Splatting have shown impressive results but remain limited by their reliance on dense input views, which hinders real-world applicability. This paper addresses the challenge of reconstructing vehicles from sparse-view inputs, leveraging depth maps and a robust pose estimation architecture to synthesize novel views and augment training data. Specifically, we enhance Gaussian Splatting by integrating a selective photometric loss, applied only to high-confidence pixels, and replacing standard Structure-from-Motion pipelines with the DUSt3R architecture to improve camera pose estimation. Furthermore, we present a novel dataset featuring both synthetic and real-world public transportation vehicles, enabling extensive evaluation of our approach. Experimental results demonstrate state-of-the-art performance across multiple benchmarks, showcasing the method’s ability to achieve high-quality reconstructions even under constrained input conditions.
车辆的精确3D重建对于车辆检测、预测性维护和城市规划等应用至关重要。现有的方法,如神经网络辐射场和高斯拼贴法,已经取得了令人印象深刻的结果,但它们仍然受限于对密集输入视图的依赖,这阻碍了它们在现实世界中的应用。本文针对稀疏视图输入下的车辆重建问题,利用深度图和稳健的姿态估计架构来合成新视图并增强训练数据。具体来说,我们通过对高置信度像素仅应用选择性光度损失,改进了高斯拼贴法,并用DUSt3R架构取代了标准从运动恢复结构管道,以提高相机姿态估计。此外,我们推出了一个新型数据集,其中包含合成和真实世界的公共交通车辆,能够广泛评估我们的方法。实验结果表明,我们在多个基准测试上达到了最先进的性能,展示了该方法在受限输入条件下实现高质量重建的能力。
论文及项目相关链接
摘要
该论文聚焦于利用稀疏视图进行车辆重建的挑战,提出了一种改进的高斯渲染技术,该技术集成了选择性光度损失,只对高置信度像素应用损失。论文同时采用了深度地图和一个强大的姿态估计架构来合成新视角并扩充训练数据。实验结果在多个人造车辆数据集上展示了前沿性能,证明了即使在有限的输入条件下也能实现高质量重建的能力。此外,论文还提出了一种新型数据集,包含合成和真实公共交通车辆数据,为评估方法提供了更全面的视角。
关键见解
- 针对车辆的三维重建进行了深入研究,对实际应用如车辆检测、预测性维护和城市规划具有重要意义。
- 提出了一种改进的高斯渲染技术,解决了现有方法依赖密集输入视图的问题,增强了稀疏视图输入下的车辆重建能力。
- 通过深度地图和姿态估计架构的合成新视角技术,扩充了训练数据,提高了模型性能。
- 引入选择性光度损失,优化高置信度像素的重建质量。
- 替代了传统的结构从运动(SfM)管道,采用了DUSt3R架构进行相机姿态估计,提高了估计的准确性。
- 开发了一种新型数据集,包含合成和真实公共交通车辆数据,为评估车辆重建方法提供了更全面的视角。
点此查看论文截图

Tile and Slide : A New Framework for Scaling NeRF from Local to Global 3D Earth Observation
Authors:Camille Billouard, Dawa Derksen, Alexandre Constantin, Bruno Vallet
Neural Radiance Fields (NeRF) have recently emerged as a paradigm for 3D reconstruction from multiview satellite imagery. However, state-of-the-art NeRF methods are typically constrained to small scenes due to the memory footprint during training, which we study in this paper. Previous work on large-scale NeRFs palliate this by dividing the scene into NeRFs. This paper introduces Snake-NeRF, a framework that scales to large scenes. Our out-of-core method eliminates the need to load all images and networks simultaneously, and operates on a single device. We achieve this by dividing the region of interest into NeRFs that 3D tile without overlap. Importantly, we crop the images with overlap to ensure each NeRFs is trained with all the necessary pixels. We introduce a novel $2\times 2$ 3D tile progression strategy and segmented sampler, which together prevent 3D reconstruction errors along the tile edges. Our experiments conclude that large satellite images can effectively be processed with linear time complexity, on a single GPU, and without compromise in quality.
神经辐射场(NeRF)最近已成为从多视角卫星图像进行3D重建的一种范式。然而,最先进的NeRF方法通常受限于小场景,因为训练过程中的内存占用较大,我们在本文中对此进行了研究。之前关于大规模NeRF的工作通过将场景划分为NeRF来缓解这个问题。本文介绍了Snake-NeRF框架,该框架可扩展到大型场景。我们的外置存储方法无需同时加载所有图像和网络,可在单个设备上运行。我们通过将感兴趣区域划分为无重叠的NeRF来做到这一点,重要的是,我们裁剪了有重叠的图像,以确保每个NeRF都能使用所有必要的像素进行训练。我们引入了一种新颖的$ 2\times 2$ 3D瓦片递进策略和分段采样器,它们共同防止了瓦片边缘处的3D重建错误。我们的实验得出结论,可以在单个GPU上以线性时间复杂度有效地处理大型卫星图像,且不会降低质量。
论文及项目相关链接
PDF Accepted at ICCV 2025 Workshop 3D-VAST (From street to space: 3D Vision Across Altitudes). Our code will be made public after the conference at https://github.com/Ellimac0/Snake-NeRF
Summary
本文介绍了Neural Radiance Fields(NeRF)在大规模场景三维重建中的应用。针对NeRF在训练过程中的内存占用问题,本文提出了一种名为Snake-NeRF的框架,通过划分感兴趣区域为无重叠的NeRFs,实现了大规模场景下的NeRF重建。该框架采用了一种新颖的$2\times 2$三维平铺进展策略和分段采样器,有效避免了在平铺边缘出现三维重建错误。实验证明,可以在单个GPU上以线性时间复杂度处理大规模卫星图像,且不影响质量。
Key Takeaways
- NeRF被应用于大规模场景的三维重建。
- Snake-NeRF框架解决了NeRF在处理大规模场景时的内存占用问题。
- Snake-NeRF通过将感兴趣区域划分为无重叠的NeRFs来实现大规模场景下的NeRF重建。
- Snake-NeRF采用了一种新颖的$2\times 2$三维平铺进展策略,有效避免了在平铺边缘的三维重建错误。
- Snake-NeRF通过分段采样器提高了重建质量。
- 实验证明,Snake-NeRF可以在单个GPU上以线性时间复杂度处理大规模卫星图像。
点此查看论文截图





FOCI: Trajectory Optimization on Gaussian Splats
Authors:Mario Gomez Andreu, Maximum Wilder-Smith, Victor Klemm, Vaishakh Patil, Jesus Tordesillas, Marco Hutter
3D Gaussian Splatting (3DGS) has recently gained popularity as a faster alternative to Neural Radiance Fields (NeRFs) in 3D reconstruction and view synthesis methods. Leveraging the spatial information encoded in 3DGS, this work proposes FOCI (Field Overlap Collision Integral), an algorithm that is able to optimize trajectories directly on the Gaussians themselves. FOCI leverages a novel and interpretable collision formulation for 3DGS using the notion of the overlap integral between Gaussians. Contrary to other approaches, which represent the robot with conservative bounding boxes that underestimate the traversability of the environment, we propose to represent the environment and the robot as Gaussian Splats. This not only has desirable computational properties, but also allows for orientation-aware planning, allowing the robot to pass through very tight and narrow spaces. We extensively test our algorithm in both synthetic and real Gaussian Splats, showcasing that collision-free trajectories for the ANYmal legged robot that can be computed in a few seconds, even with hundreds of thousands of Gaussians making up the environment. The project page and code are available at https://rffr.leggedrobotics.com/works/foci/
近期,三维高斯扩展(3DGS)作为三维重建和视角合成方法中神经辐射场(NeRFs)的快速替代方案而备受关注。借助编码在三维高斯扩展中的空间信息,本研究提出了FOCI(基于场重叠碰撞积分算法),它能够直接在高斯函数本身上优化轨迹。FOCI利用高斯之间重叠积分的概念,为三维高斯扩展提出了一种新颖且可解释性的碰撞公式。与其他方法不同,这些方法使用保守的边界框来表示机器人,低估了环境的可通行性,我们提议将环境和机器人表示为高斯扩展。这不仅具有理想化的计算属性,而且允许根据方向进行规划,允许机器人在非常狭窄的空间中通过。我们在合成和真实的高斯扩展中都测试了我们的算法,展示了即使在由数十万高斯组成的环境中,也能在几秒钟内计算出ANYmal步行机器人的无碰撞轨迹。项目页面和代码可在https://rffr.leggedrobotics.com/works/foci/找到。
论文及项目相关链接
PDF 8 pages, 8 figures, Mario Gomez Andreu and Maximum Wilder-Smith contributed equally
Summary
本文介绍了基于三维高斯插值(3DGS)技术的FOCI算法,该算法优化了轨迹生成的效率,在三维重建和视图合成方法中成为一种快速替代神经网络辐射场(NeRF)的方法。FOCI利用新颖的碰撞公式对Gaussians进行重叠积分处理,相较于传统方法更精确地代表环境和机器人。此方法实现了快速、精确的环境感知和机器人轨迹规划,尤其适用于紧凑狭窄空间内的规划任务。在合成和真实的高斯插值环境中进行了广泛的测试,展示了算法的高效性。项目页面和代码可在https://rffr.leggedrobotics.com/works/foci/找到。
Key Takeaways
- FOCI算法基于三维高斯插值技术优化了轨迹生成。
- 利用新颖的碰撞公式进行高斯重叠积分处理。
- 将环境和机器人表示为高斯插值,而非保守的边界框,提高了环境感知的准确性。
- 实现快速、精确的环境感知和机器人轨迹规划。
- 适用于紧凑狭窄空间内的规划任务。
- 在合成和真实环境中进行了广泛的测试,验证了算法的高效性。
点此查看论文截图




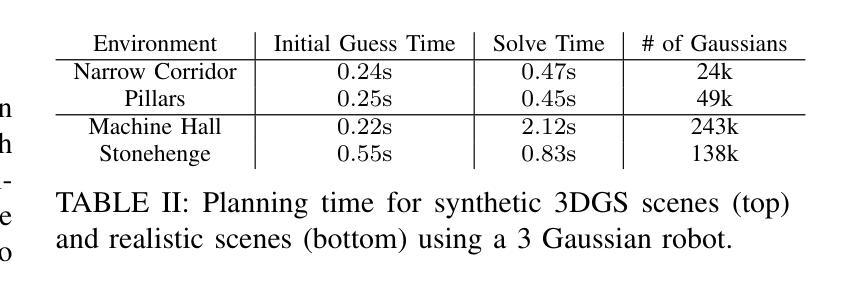

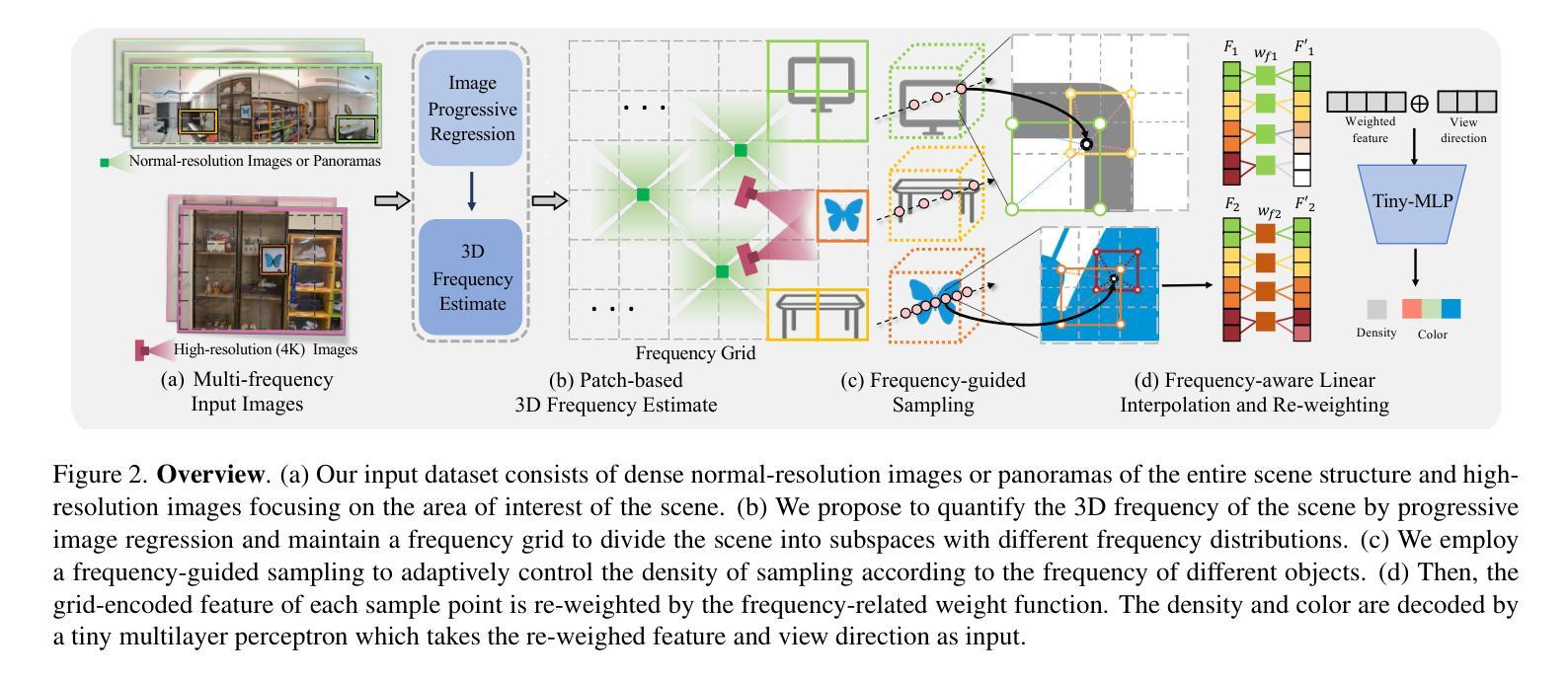
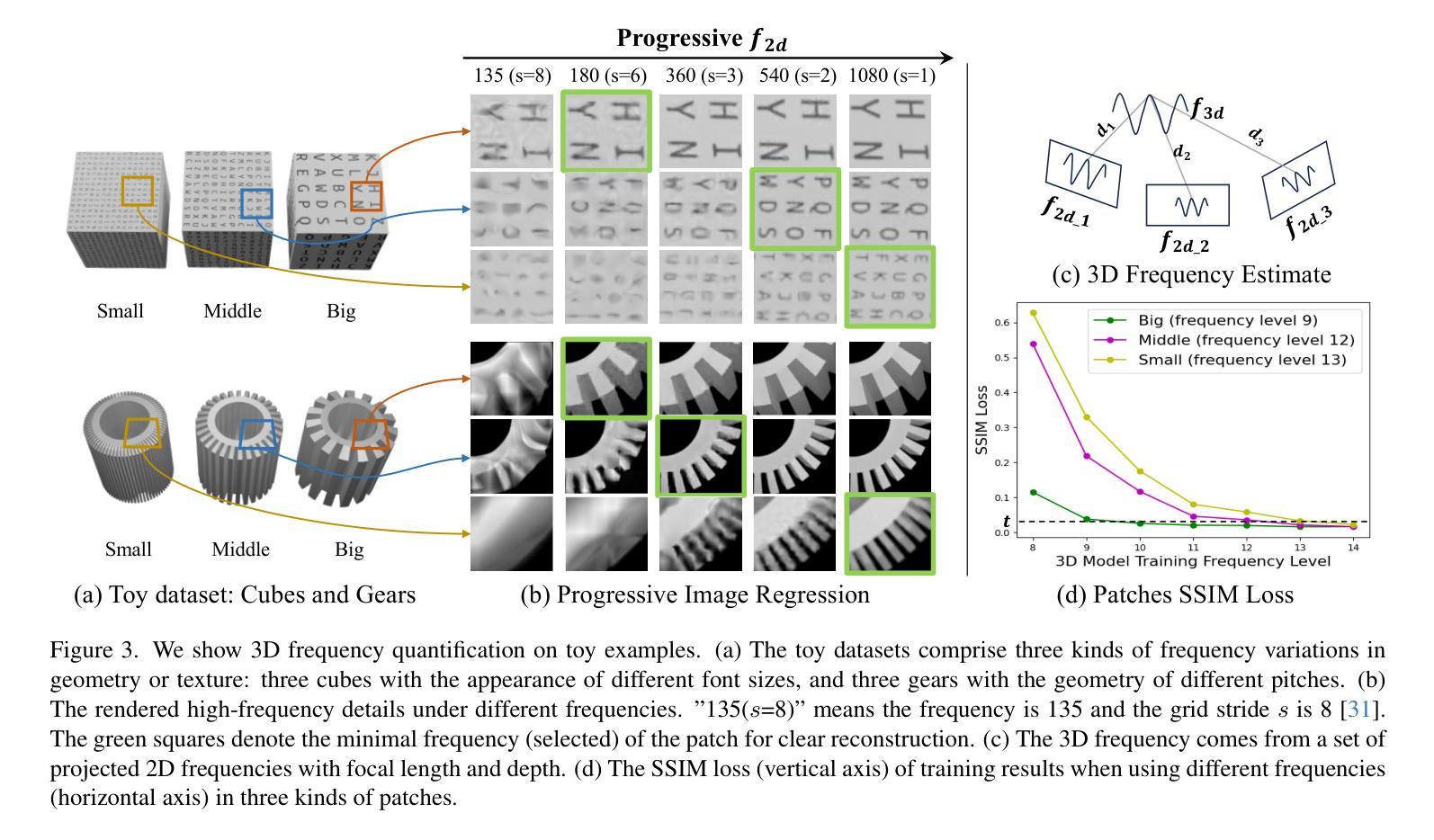
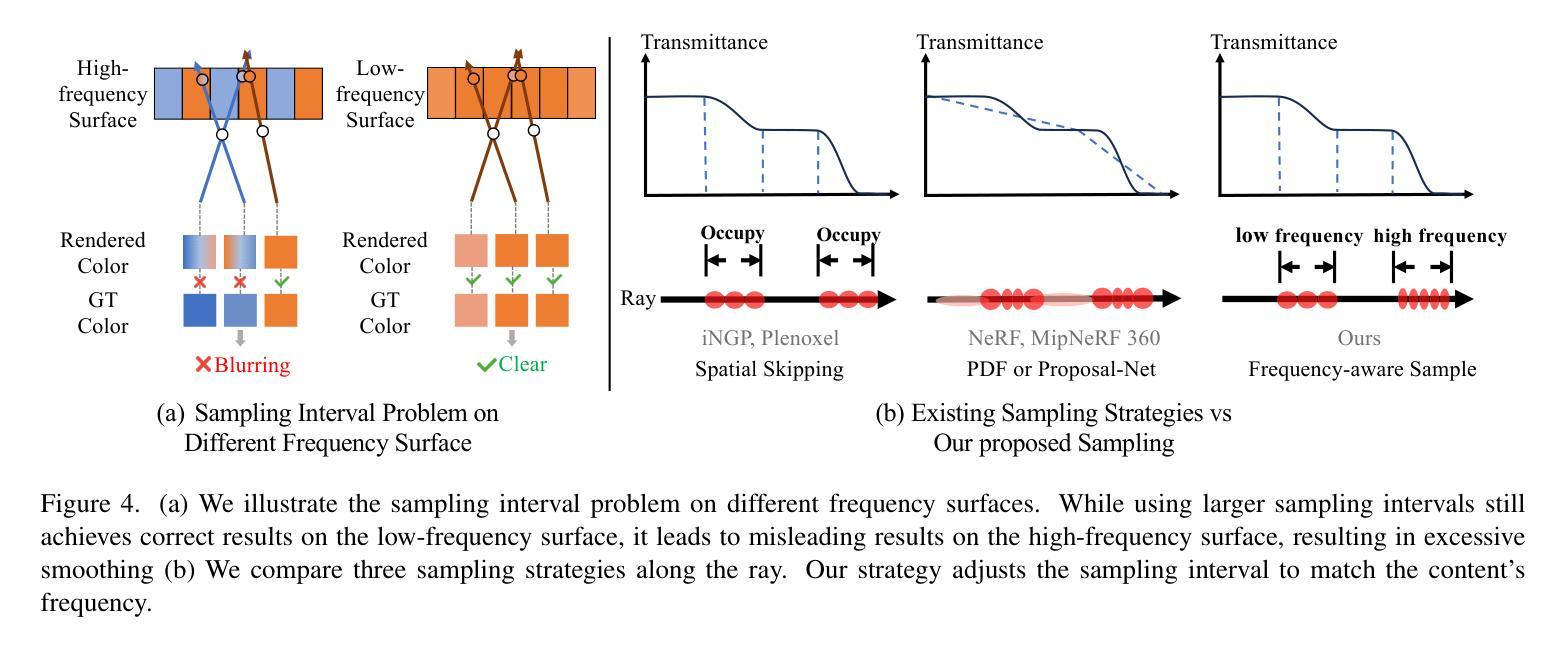
LookCloser: Frequency-aware Radiance Field for Tiny-Detail Scene
Authors:Xiaoyu Zhang, Weihong Pan, Chong Bao, Xiyu Zhang, Xiaojun Xiang, Hanqing Jiang, Hujun Bao
Humans perceive and comprehend their surroundings through information spanning multiple frequencies. In immersive scenes, people naturally scan their environment to grasp its overall structure while examining fine details of objects that capture their attention. However, current NeRF frameworks primarily focus on modeling either high-frequency local views or the broad structure of scenes with low-frequency information, which is limited to balancing both. We introduce FA-NeRF, a novel frequency-aware framework for view synthesis that simultaneously captures the overall scene structure and high-definition details within a single NeRF model. To achieve this, we propose a 3D frequency quantification method that analyzes the scene’s frequency distribution, enabling frequency-aware rendering. Our framework incorporates a frequency grid for fast convergence and querying, a frequency-aware feature re-weighting strategy to balance features across different frequency contents. Extensive experiments show that our method significantly outperforms existing approaches in modeling entire scenes while preserving fine details. Project page: https://coscatter.github.io/LookCloser/
人类通过跨越多个频率的信息来感知和理解周围环境。在沉浸式场景中,人们自然地会扫描环境,以把握其整体结构,同时关注吸引他们的物体的细节。然而,当前的NeRF框架主要侧重于对高频局部视图或场景广泛结构的建模,涉及低频信息,这在平衡两者时存在局限性。我们介绍了FA-NeRF,这是一种新型频率感知框架,用于视图合成,能够在单个NeRF模型中同时捕捉场景的整体结构和高清细节。为了实现这一点,我们提出了一种三维频率量化方法,分析场景的频率分布,实现频率感知渲染。我们的框架结合了频率网格以实现快速收敛和查询,以及频率感知特征重加权策略,以平衡不同频率内容的功能。大量实验表明,我们的方法在建模整个场景时显著优于现有方法,同时保留了细节。项目页面:https://coscatter.github.io/LookCloser/
论文及项目相关链接
PDF Accepted to CVPR 2025. Project page: https://coscatter.github.io/LookCloser
Summary
NeRF技术通常只能平衡对场景的整体结构和高频细节建模的关注,但我们提出了一个频率感知的NeRF框架,可同时捕捉场景的整体结构和高清细节。我们引入了一种新的频率量化方法,并采用了频率网格和特征重加权策略。实验证明,我们的方法显著优于现有技术,能更准确地建模整个场景并保留细节。
Key Takeaways
- 当前NeRF技术难以同时关注场景的整体结构和高频细节建模。
- 提出了一种频率感知的NeRF框架(FA-NeRF),可同时捕捉场景的整体结构和高清细节。
- 引入了一种新的频率量化方法,用于分析场景的频率分布并实现频率感知渲染。
- 采用频率网格实现快速收敛和查询。
- 采用特征重加权策略平衡不同频率内容之间的特征。
点此查看论文截图

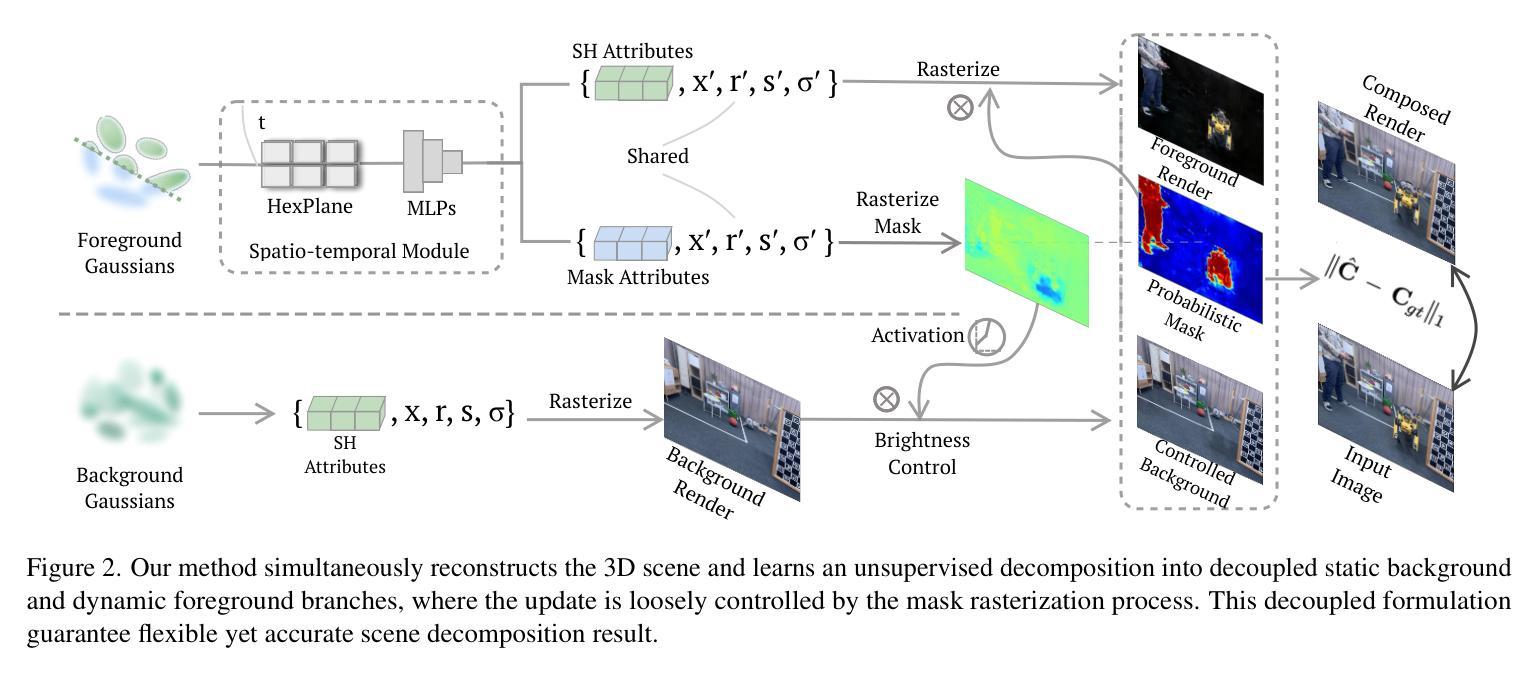
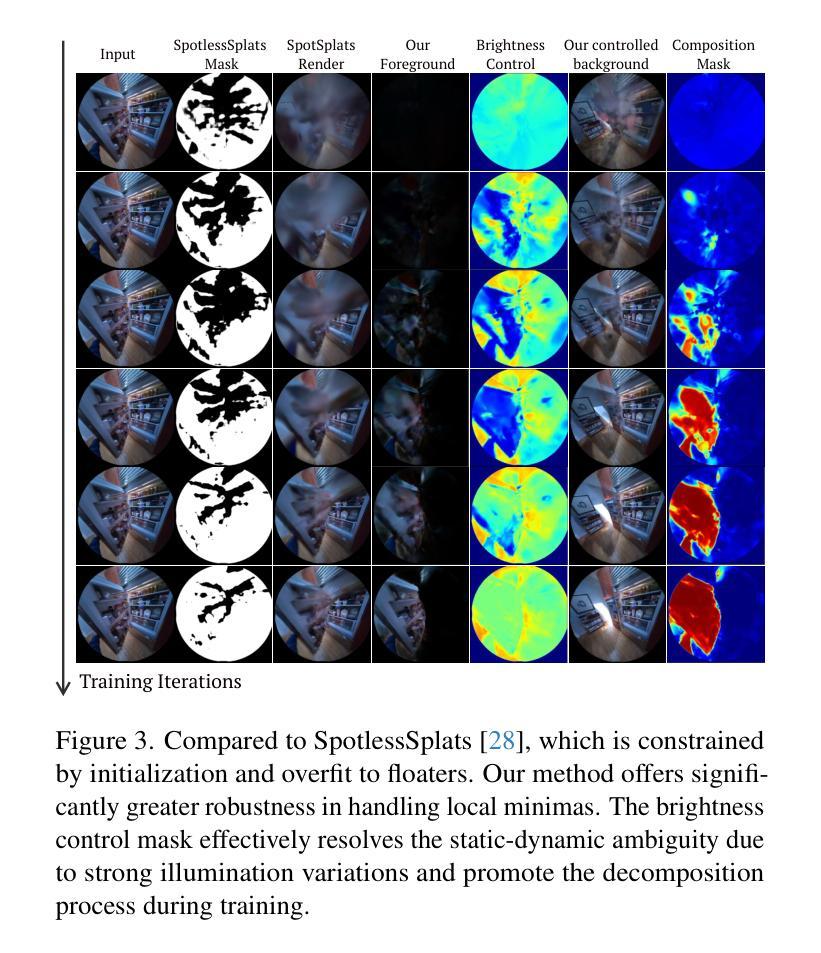
DeGauss: Dynamic-Static Decomposition with Gaussian Splatting for Distractor-free 3D Reconstruction
Authors:Rui Wang, Quentin Lohmeyer, Mirko Meboldt, Siyu Tang
Reconstructing clean, distractor-free 3D scenes from real-world captures remains a significant challenge, particularly in highly dynamic and cluttered settings such as egocentric videos. To tackle this problem, we introduce DeGauss, a simple and robust self-supervised framework for dynamic scene reconstruction based on a decoupled dynamic-static Gaussian Splatting design. DeGauss models dynamic elements with foreground Gaussians and static content with background Gaussians, using a probabilistic mask to coordinate their composition and enable independent yet complementary optimization. DeGauss generalizes robustly across a wide range of real-world scenarios, from casual image collections to long, dynamic egocentric videos, without relying on complex heuristics or extensive supervision. Experiments on benchmarks including NeRF-on-the-go, ADT, AEA, Hot3D, and EPIC-Fields demonstrate that DeGauss consistently outperforms existing methods, establishing a strong baseline for generalizable, distractor-free 3D reconstructionin highly dynamic, interaction-rich environments. Project page: https://batfacewayne.github.io/DeGauss.io/
从真实世界的捕捉中重建干净、无干扰物的3D场景仍然是一个巨大的挑战,特别是在高度动态和杂乱的环境中,如以自我为中心的视频。为了解决这个问题,我们引入了DeGauss,这是一个简单而稳健的自监督动态场景重建框架,基于解耦的动态静态高斯拼贴设计。DeGauss使用前景高斯对动态元素进行建模,使用背景高斯对静态内容进行建模,并使用概率掩膜来协调它们的组合,以实现独立但互补的优化。DeGauss在广泛的各种真实场景中表现稳健,从随意的图像集合到漫长的动态以自我为中心的视频,无需依赖复杂的启发式方法或广泛的监督。在包括NeRF-on-the-go、ADT、AEA、Hot3D和EPIC-Fields等多个基准测试上的实验表明,DeGauss始终优于现有方法,为高度动态、交互丰富的环境中的通用、无干扰物3D重建建立了强大的基线。项目页面:https://batfacewayne.github.io/DeGauss.io/
论文及项目相关链接
PDF Accepted by ICCV 2025
摘要
DeGauss是一种简单而稳健的自监督动态场景重建框架,适用于从真实世界捕捉的图像中重建干净、无干扰的3D场景。该框架采用解耦的动态静态高斯喷绘设计,用前景高斯建模动态元素,用背景高斯建模静态内容。通过概率掩码协调它们的组合,实现独立但互补的优化。DeGauss在多种真实场景,如日常图像集和动态第一人称视频中具有强大的泛化能力,无需依赖复杂的启发式方法或广泛的监督即可实现。在多个基准测试上的实验表明,DeGauss在高度动态、交互丰富的环境中始终优于现有方法,为无干扰的3D重建建立了强有力的基线。
要点解析
- DeGauss是一个针对真实世界捕捉图像的动态场景重建框架,旨在解决干净、无干扰的3D场景重建问题。
- 该框架采用动态静态解耦的高斯喷绘设计,以区分动态元素和静态内容。
- DeGauss利用概率掩码来协调前景高斯和背景高斯组合的构建。
- 该框架实现了独立但互补的优化,提高了场景重建的准确性和稳定性。
- DeGauss在各种真实场景中表现出强大的泛化能力,包括日常图像集和动态第一人称视频。
- 对比多个基准测试的实验结果表明,DeGauss在高度动态、交互丰富的环境中性能卓越,优于现有方法。
点此查看论文截图


Category-level Meta-learned NeRF Priors for Efficient Object Mapping
Authors:Saad Ejaz, Hriday Bavle, Laura Ribeiro, Holger Voos, Jose Luis Sanchez-Lopez
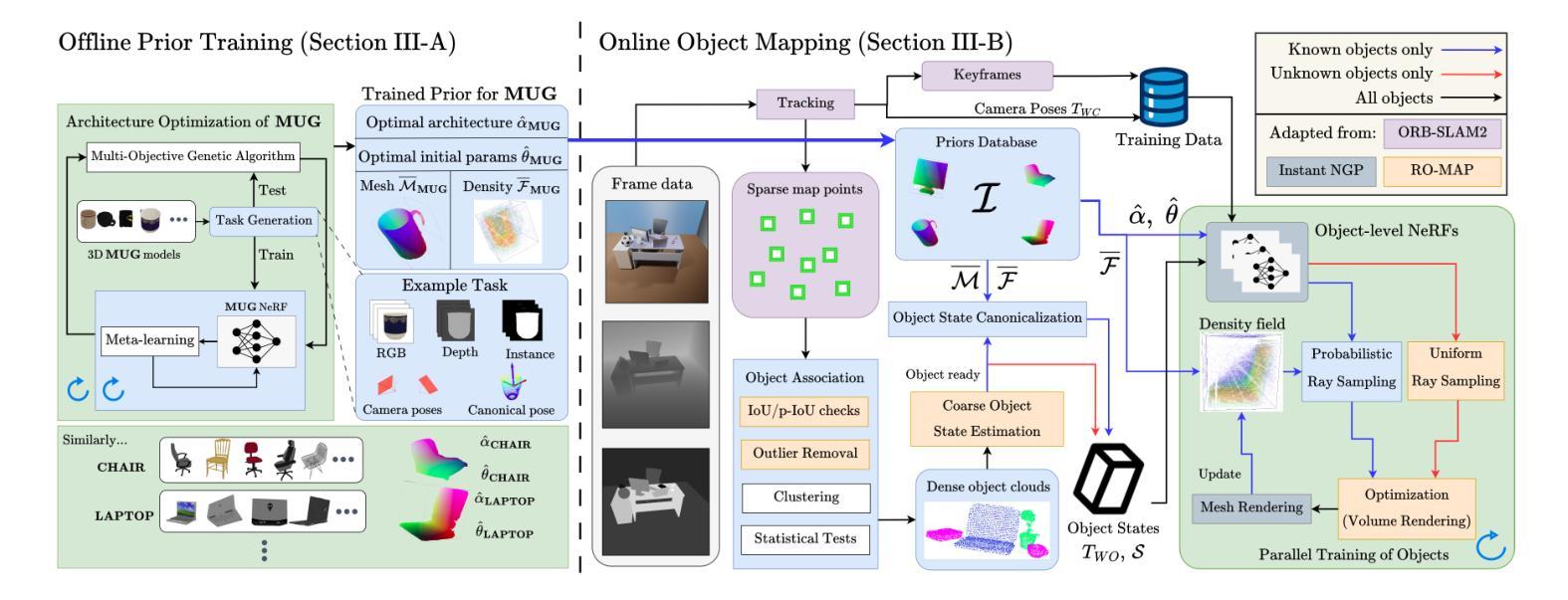
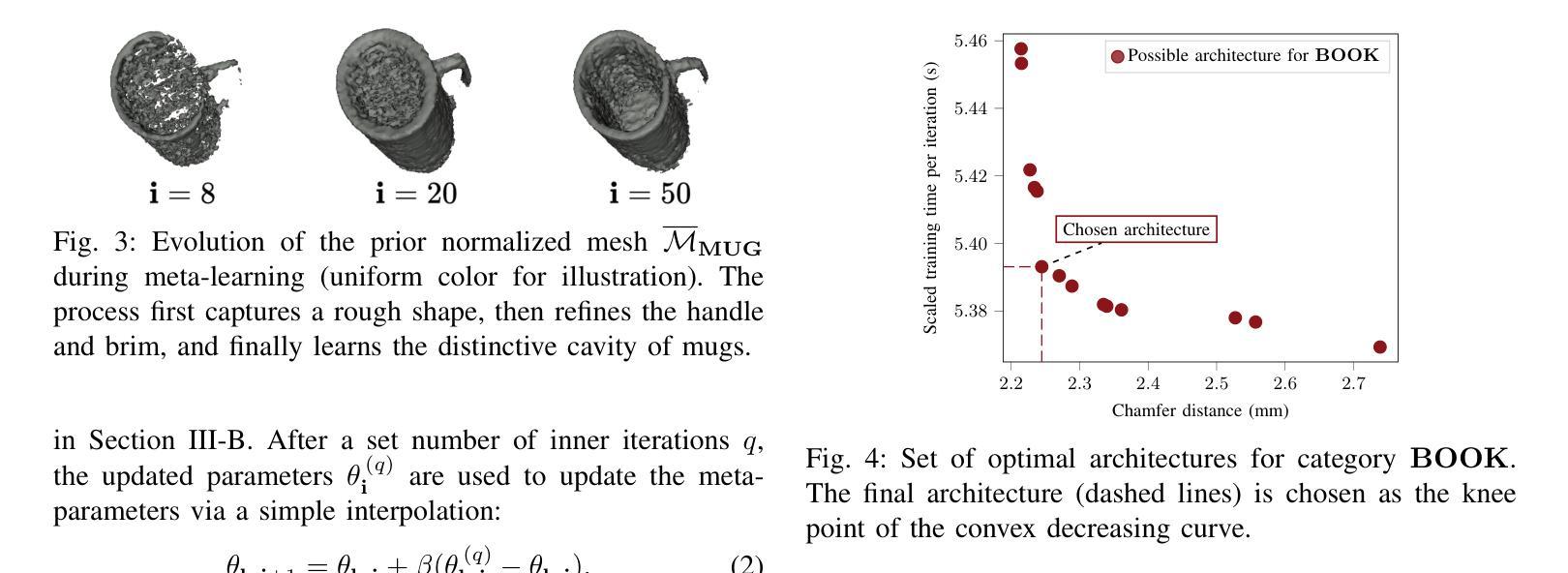
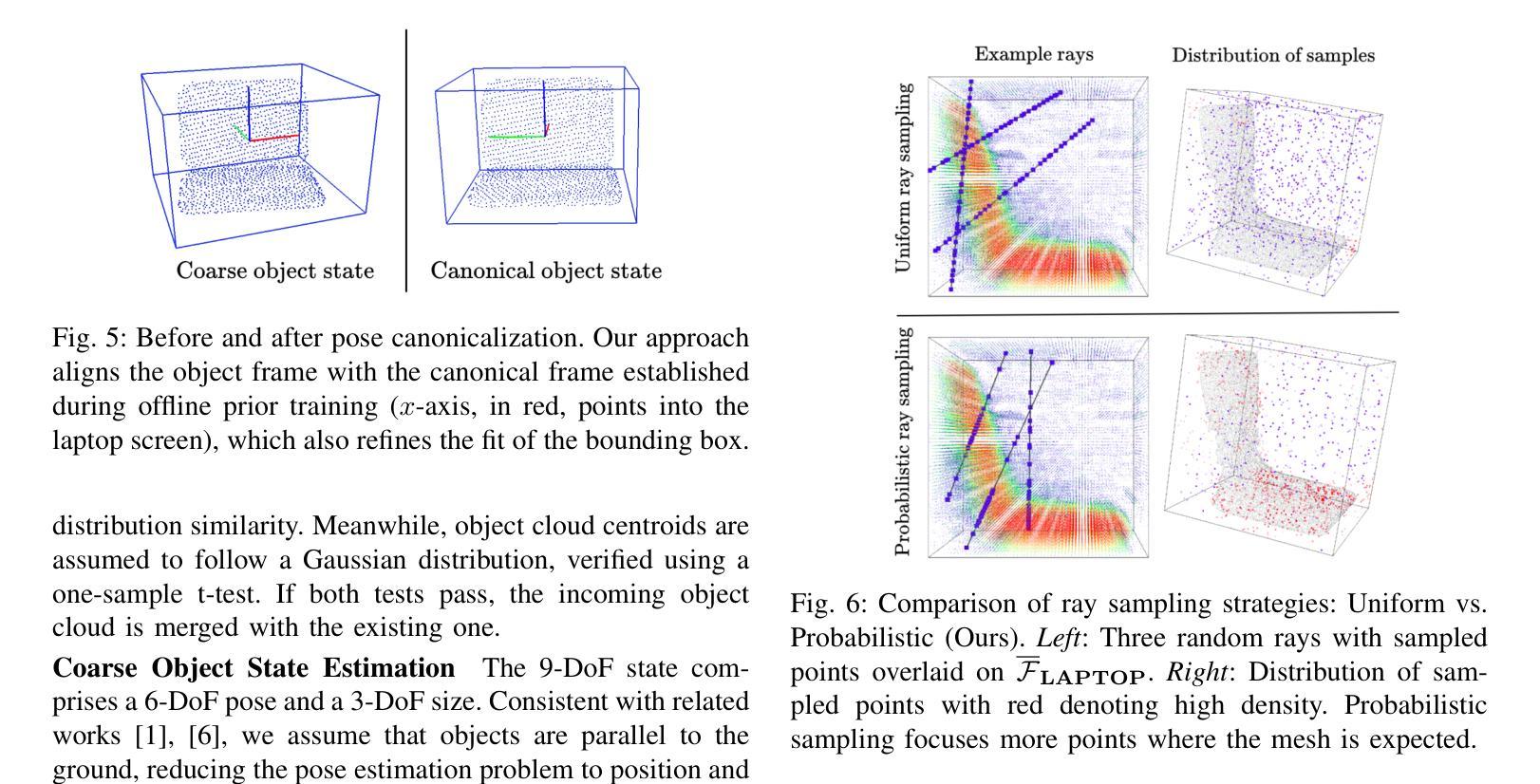
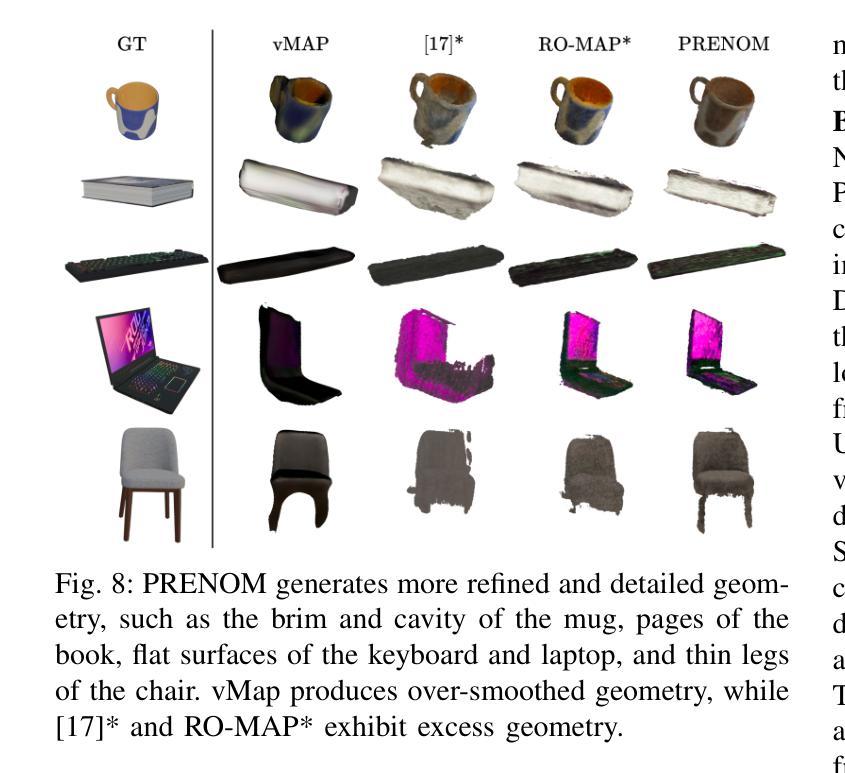
In 3D object mapping, category-level priors enable efficient object reconstruction and canonical pose estimation, requiring only a single prior per semantic category (e.g., chair, book, laptop, etc.). DeepSDF has been used predominantly as a category-level shape prior, but it struggles to reconstruct sharp geometry and is computationally expensive. In contrast, NeRFs capture fine details but have yet to be effectively integrated with category-level priors in a real-time multi-object mapping framework. To bridge this gap, we introduce PRENOM, a Prior-based Efficient Neural Object Mapper that integrates category-level priors with object-level NeRFs to enhance reconstruction efficiency and enable canonical object pose estimation. PRENOM gets to know objects on a first-name basis by meta-learning on synthetic reconstruction tasks generated from open-source shape datasets. To account for object category variations, it employs a multi-objective genetic algorithm to optimize the NeRF architecture for each category, balancing reconstruction quality and training time. Additionally, prior-based probabilistic ray sampling directs sampling toward expected object regions, accelerating convergence and improving reconstruction quality under constrained resources. Experimental results highlight the ability of PRENOM to achieve high-quality reconstructions while maintaining computational feasibility. Specifically, comparisons with prior-free NeRF-based approaches on a synthetic dataset show a 21% lower Chamfer distance. Furthermore, evaluations against other approaches using shape priors on a noisy real-world dataset indicate a 13% improvement averaged across all reconstruction metrics, and comparable pose and size estimation accuracy, while being trained for 5$\times$ less time. Code available at: https://github.com/snt-arg/PRENOM
在3D对象映射中,类别级先验知识能够实现高效的对象重建和规范化姿态估计,只需要每个语义类别(例如椅子、书籍、笔记本电脑等)的一个先验知识即可。DeepSDF主要用作类别级别的形状先验,但在重建锐利几何结构方面存在困难,而且计算成本高昂。相比之下,NeRF可以捕捉精细的细节,但尚未在实时多对象映射框架中有效地与类别级先验相结合。为了弥补这一差距,我们引入了PRENOM(基于先验的高效神经对象映射器),它将类别级先验与对象级的NeRF相结合,提高了重建效率,并实现了规范化对象姿态估计。PRENOM通过在从开源形状数据集生成的合成重建任务上进行元学习来深入了解对象。为了应对对象类别变化,它采用了一种多目标遗传算法来针对每个类别优化NeRF架构,平衡重建质量和训练时间。此外,基于先验的概率射线采样将采样指向预期的对象区域,加快了收敛速度,并在受限资源下提高了重建质量。实验结果表明,PRENOM在高质重建的同时保持计算可行性。具体而言,与合成数据集上无需先验的NeRF方法相比,Chamfer距离降低了21%。此外,在噪声现实世界数据集上与使用形状先验的其他方法进行的评估显示,在所有重建指标上的平均改进为13%,姿态和大小估计的准确性相当,同时训练时间减少了5倍。相关代码可在:https://github.com/snt-arg/PRENOM获取。
论文及项目相关链接
Summary
基于类别先验的高效神经网络对象映射器(PRENOM)结合了类别级别的先验知识和对象级别的NeRF技术,提高了重建效率并实现了对象的标准姿态估计。PRENOM通过元学习在开源重建任务数据集上了解对象,并利用多目标遗传算法优化NeRF架构以平衡重建质量和训练时间。同时,借助基于先验的概率射线采样技术加速收敛,在有限的资源下提高重建质量。实验结果显示,PRENOM在合成数据集上实现了高质量的重建,相较于无先验NeRF方法降低了21%的Chamfer距离。在噪声现实世界数据集上的评估显示,与其他使用形状先验的方法相比,PRENOM平均提高了13%的重建指标准确度,同时姿态和大小估计精度相当,并且训练时间缩短了5倍。
Key Takeaways
- PRENOM结合了类别级别的先验知识和对象级别的NeRF技术,用于3D对象映射和姿态估计。
- PRENOM通过元学习在合成重建任务数据集上了解对象。
- 利用多目标遗传算法针对每个类别优化NeRF架构。
- 基于先验的概率射线采样技术用于加速收敛并改善重建质量。
- 在合成数据集上,PRENOM相较于无先验NeRF方法降低了Chamfer距离。
- 在现实世界数据集上,PRENOM在重建指标、姿态和大小估计精度方面表现出优势,同时训练时间更短。
点此查看论文截图