⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-01 更新
SeqAffordSplat: Scene-level Sequential Affordance Reasoning on 3D Gaussian Splatting
Authors:Di Li, Jie Feng, Jiahao Chen, Weisheng Dong, Guanbin Li, Yuhui Zheng, Mingtao Feng, Guangming Shi
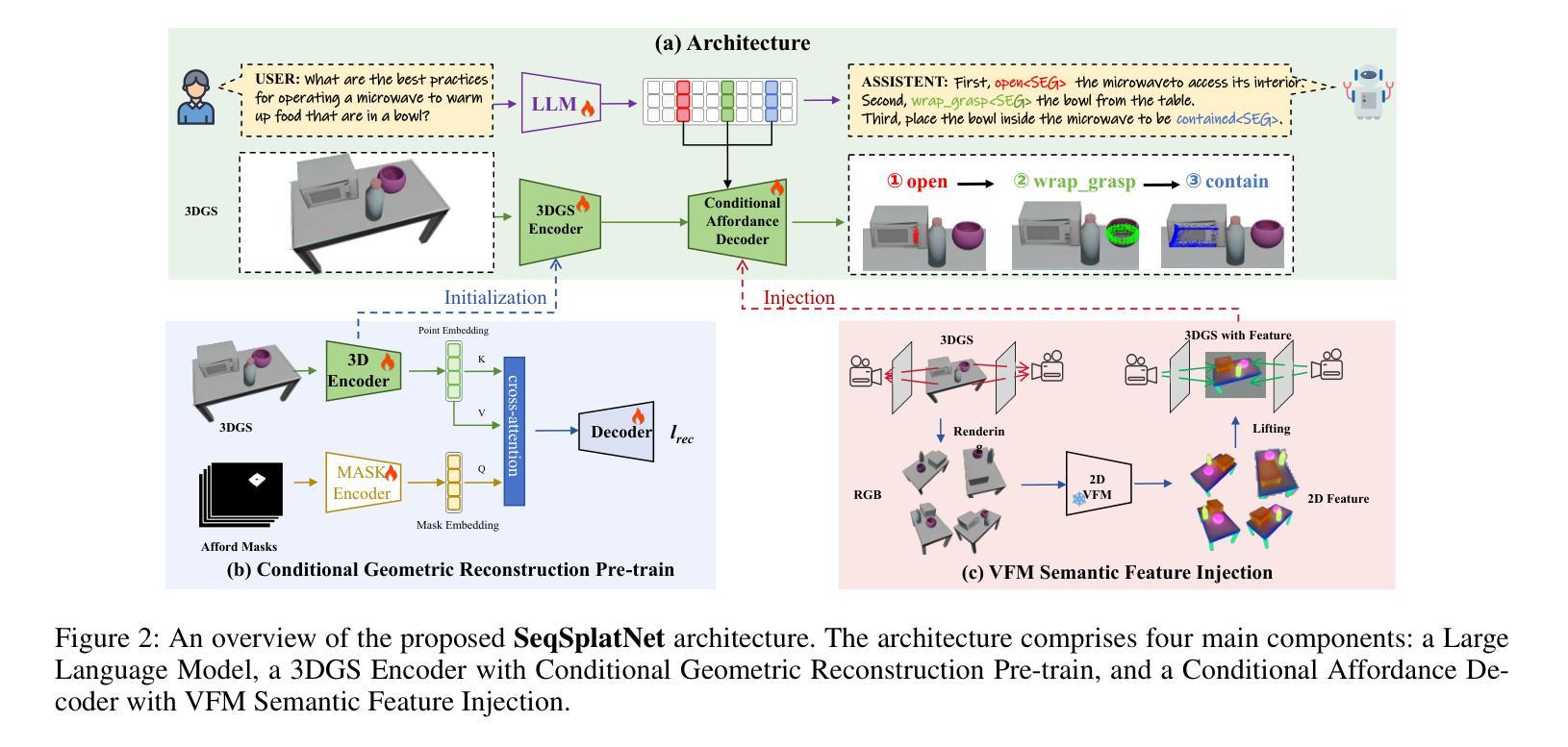
3D affordance reasoning, the task of associating human instructions with the functional regions of 3D objects, is a critical capability for embodied agents. Current methods based on 3D Gaussian Splatting (3DGS) are fundamentally limited to single-object, single-step interactions, a paradigm that falls short of addressing the long-horizon, multi-object tasks required for complex real-world applications. To bridge this gap, we introduce the novel task of Sequential 3D Gaussian Affordance Reasoning and establish SeqAffordSplat, a large-scale benchmark featuring 1800+ scenes to support research on long-horizon affordance understanding in complex 3DGS environments. We then propose SeqSplatNet, an end-to-end framework that directly maps an instruction to a sequence of 3D affordance masks. SeqSplatNet employs a large language model that autoregressively generates text interleaved with special segmentation tokens, guiding a conditional decoder to produce the corresponding 3D mask. To handle complex scene geometry, we introduce a pre-training strategy, Conditional Geometric Reconstruction, where the model learns to reconstruct complete affordance region masks from known geometric observations, thereby building a robust geometric prior. Furthermore, to resolve semantic ambiguities, we design a feature injection mechanism that lifts rich semantic features from 2D Vision Foundation Models (VFM) and fuses them into the 3D decoder at multiple scales. Extensive experiments demonstrate that our method sets a new state-of-the-art on our challenging benchmark, effectively advancing affordance reasoning from single-step interactions to complex, sequential tasks at the scene level.
3D可用性推理是将人类指令与3D对象的功能区域相关联的任务,是实体代理的关键能力。当前基于3D高斯喷涂(3DGS)的方法从根本上局限于单对象、单步骤交互的模式,这种模式无法解决复杂现实世界应用所需的长周期、多对象任务。为了弥补这一差距,我们引入了Sequential 3D Gaussian可用性推理的新任务,并建立了SeqAffordSplat大规模基准测试,包含1800多个场景,支持在复杂3DGS环境中对长期可用性理解的研究。然后,我们提出了SeqSplatNet端到端框架,它直接将指令映射到一系列3D可用性掩膜。SeqSplatNet采用大型语言模型,通过自回归方式生成与特殊分割令牌交织的文本,引导条件解码器生成相应的3D掩膜。为了处理复杂场景的几何结构,我们引入了预训练策略,即条件几何重建,模型学会从已知的几何观察中重建完整的可用性区域掩膜,从而建立稳健的几何先验。此外,为了解决语义歧义,我们设计了一种特征注入机制,从2D视觉基础模型(VFM)中提取丰富的语义特征,并将其融合到多尺度的3D解码器中。大量实验表明,我们的方法在我们的具有挑战性的基准测试上创下了最新纪录,有效地将可用性推理从单步骤交互推进到场景级别的复杂、顺序任务。
论文及项目相关链接
Summary
本文介绍了在复杂的三维环境中进行长期规划的多目标交互任务的重要性。针对当前基于三维高斯映射方法的局限性,提出了序贯三维高斯适用推理的新任务,并建立了SeqAffordSplat大规模基准测试平台,包含超过1800个场景。同时,本文还提出了一种端到端的框架SeqSplatNet,该框架可直接将指令映射到一系列三维适用掩膜。SeqSplatNet采用大型语言模型,通过自回归生成文本与特殊分割标记的交织,指导条件解码器生成相应的三维掩膜。为解决复杂场景几何问题,引入了预训练策略——条件几何重建,并设计了一种特征注入机制,从二维视觉基础模型中提取丰富的语义特征,并将其融合到三维解码器中。实验表明,该方法在具有挑战性的基准测试平台上取得了最新成果,实现了从单步交互到复杂场景级序贯任务的适用性推理的进步。
Key Takeaways
- 3D affordance reasoning是关联人类指令与3D物体功能区域的关键能力,对于实体代理至关重要。
- 当前基于3D Gaussian Splatting (3DGS)的方法仅限于单目标、单步骤交互,无法满足复杂现实世界应用中多目标、长期规划的任务需求。
- 为解决此问题,提出了Sequential 3D Gaussian Affordance Reasoning新任务,并建立SeqAffordSplat基准测试平台,模拟真实环境的复杂性。
- SeqSplatNet框架可以直接将指令转换为一系列3D掩膜,利用大型语言模型自回归生成文本与分割标记。
- 条件几何重建预训练策略用于处理复杂场景几何问题,建立稳健的几何先验。
- 通过特征注入机制解决语义模糊问题,将二维视觉基础模型的丰富语义特征融入三维解码器中。
点此查看论文截图

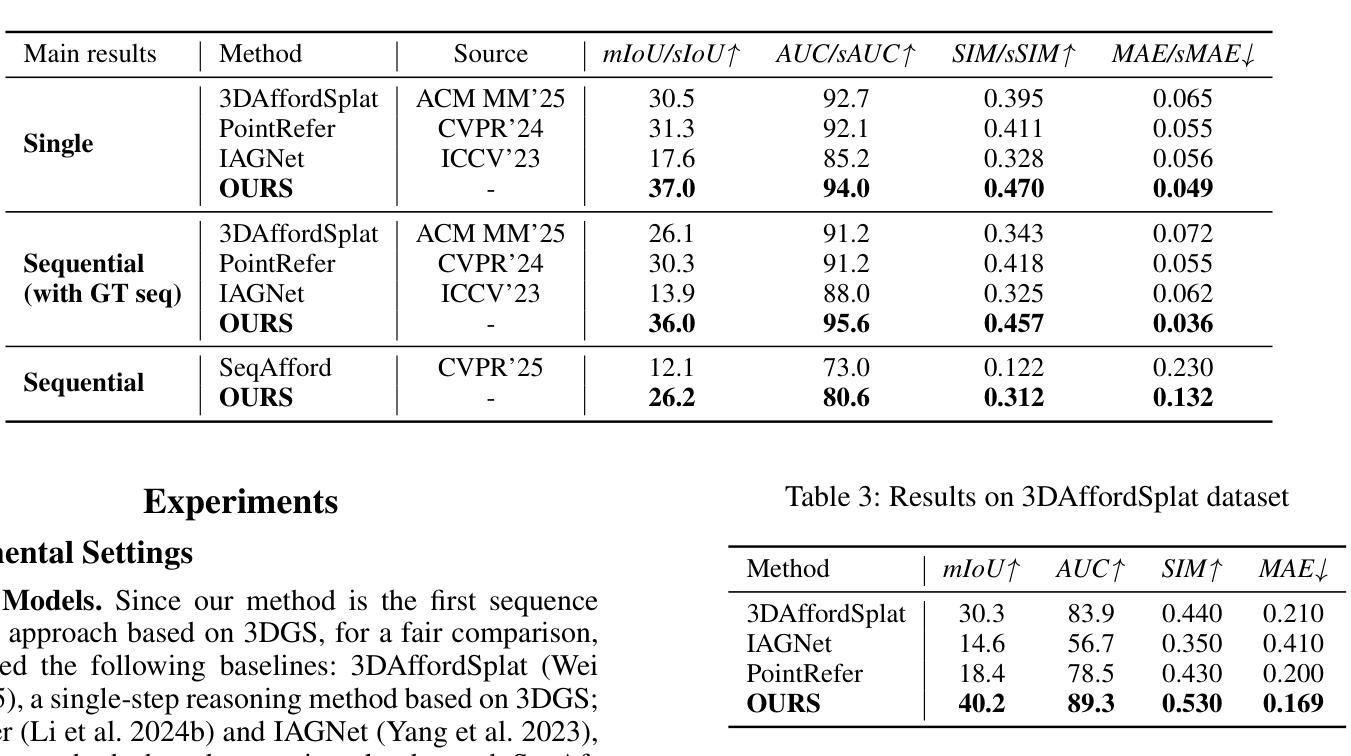
CoT-Self-Instruct: Building high-quality synthetic prompts for reasoning and non-reasoning tasks
Authors:Ping Yu, Jack Lanchantin, Tianlu Wang, Weizhe Yuan, Olga Golovneva, Ilia Kulikov, Sainbayar Sukhbaatar, Jason Weston, Jing Xu
We propose CoT-Self-Instruct, a synthetic data generation method that instructs LLMs to first reason and plan via Chain-of-Thought (CoT) based on the given seed tasks, and then to generate a new synthetic prompt of similar quality and complexity for use in LLM training, followed by filtering for high-quality data with automatic metrics. In verifiable reasoning, our synthetic data significantly outperforms existing training datasets, such as s1k and OpenMathReasoning, across MATH500, AMC23, AIME24 and GPQA-Diamond. For non-verifiable instruction-following tasks, our method surpasses the performance of human or standard self-instruct prompts on both AlpacaEval 2.0 and Arena-Hard.
我们提出了CoT-Self-Instruct这一合成数据生成方法,该方法指导大型语言模型(LLMs)首先根据给定的种子任务通过思维链(CoT)进行推理和规划,然后生成质量相似、复杂性相似的新合成提示,用于LLM训练,随后通过自动度量对高质量数据进行筛选。在可验证推理方面,我们的合成数据在MATH500、AMC23、AIME24和GPQA-Diamond等多个数据集上显著优于现有的训练数据集,如s1k和OpenMathReasoning。对于不可验证的指令跟随任务,我们的方法在AlpacaEval 2.0和Arena-Hard上超越了人类或标准自我指导提示的性能。
论文及项目相关链接
Summary
CoT-Self-Instruct是一种合成数据生成方法,通过指导大型语言模型(LLMs)根据给定的种子任务进行Chain-of-Thought(CoT)推理和规划,生成高质量和复杂度的合成提示用于LLM训练,并通过自动度量对高质量数据进行筛选。在可验证推理任务中,其合成数据显著优于现有训练数据集如s1k和OpenMathReasoning,在MATH500、AMC23、AIME24和GPQA-Diamond等任务上的表现突出。在非可验证指令跟随任务中,该方法超越人类或标准自我指导提示在AlpacaEval 2.0和Arena-Hard上的表现。
Key Takeaways
- CoT-Self-Instruct是一种合成数据生成方法,用于指导LLMs进行基于CoT的推理和规划。
- 该方法能够根据给定的种子任务生成高质量和复杂度的合成提示。
- 通过自动度量,可以筛选高质量数据用于LLM训练。
- 在可验证推理任务中,CoT-Self-Instruct的合成数据表现优于现有训练数据集。
- CoT-Self-Instruct在多个任务上表现突出,包括MATH500、AMC23、AIME24和GPQA-Diamond。
- 在非可验证指令跟随任务中,CoT-Self-Instruct超越人类或标准自我指导提示的表现。
点此查看论文截图

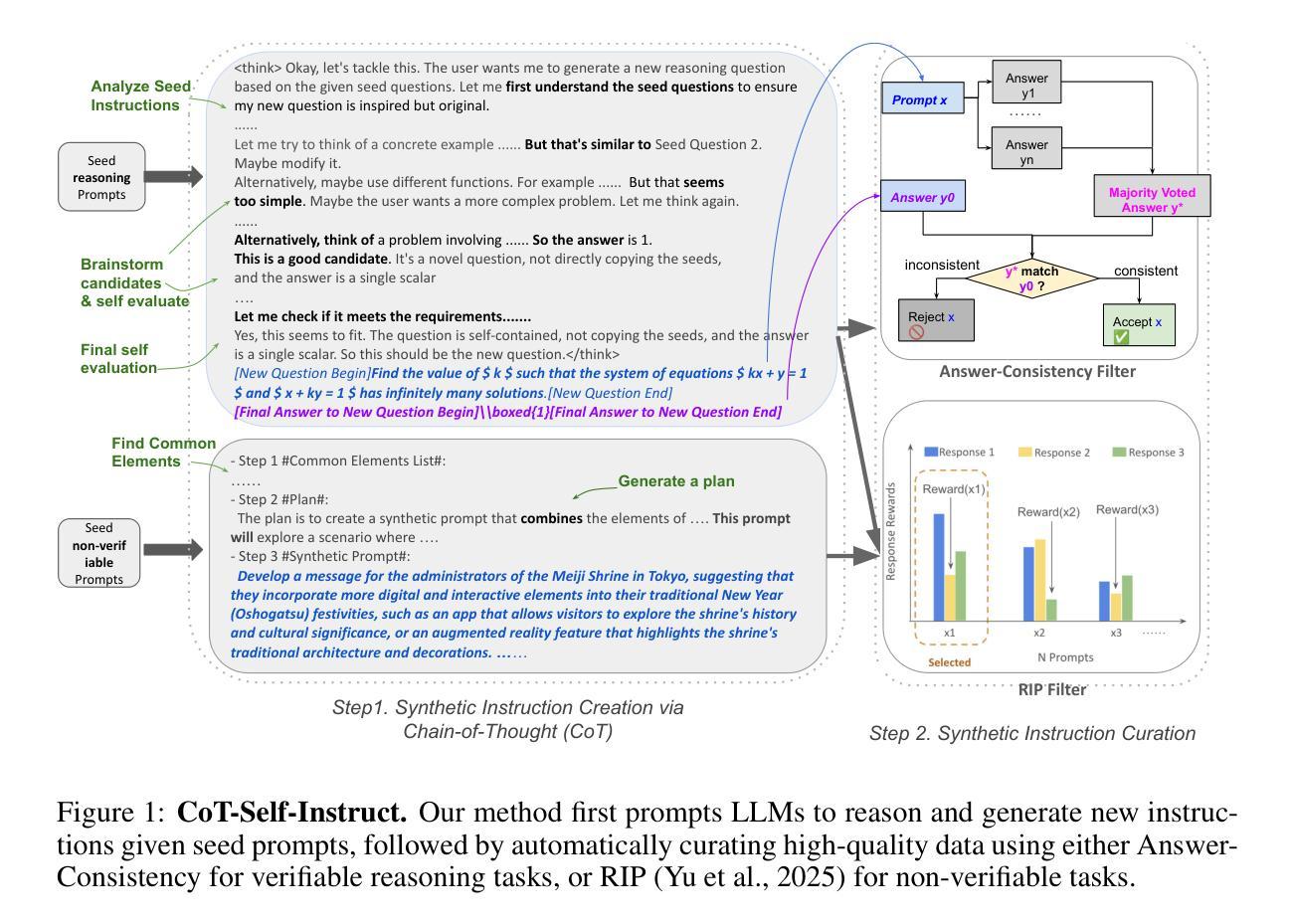
RAGNet: Large-scale Reasoning-based Affordance Segmentation Benchmark towards General Grasping
Authors:Dongming Wu, Yanping Fu, Saike Huang, Yingfei Liu, Fan Jia, Nian Liu, Feng Dai, Tiancai Wang, Rao Muhammad Anwer, Fahad Shahbaz Khan, Jianbing Shen
General robotic grasping systems require accurate object affordance perception in diverse open-world scenarios following human instructions. However, current studies suffer from the problem of lacking reasoning-based large-scale affordance prediction data, leading to considerable concern about open-world effectiveness. To address this limitation, we build a large-scale grasping-oriented affordance segmentation benchmark with human-like instructions, named RAGNet. It contains 273k images, 180 categories, and 26k reasoning instructions. The images cover diverse embodied data domains, such as wild, robot, ego-centric, and even simulation data. They are carefully annotated with an affordance map, while the difficulty of language instructions is largely increased by removing their category name and only providing functional descriptions. Furthermore, we propose a comprehensive affordance-based grasping framework, named AffordanceNet, which consists of a VLM pre-trained on our massive affordance data and a grasping network that conditions an affordance map to grasp the target. Extensive experiments on affordance segmentation benchmarks and real-robot manipulation tasks show that our model has a powerful open-world generalization ability. Our data and code is available at https://github.com/wudongming97/AffordanceNet.
通用机器人抓取系统需要在多样化开放世界场景中跟随人类指令进行准确的对象功能感知。然而,当前的研究存在着缺乏基于推理的大规模功能预测数据的问题,引发了人们对开放世界有效性的担忧。为了解决这一局限性,我们构建了一个面向抓取的大型功能分割基准测试,其中包含类似人类的指令,名为RAGNet。它包含273k张图像、180个类别和26k条推理指令。图像涵盖了多样化的身体数据域,如野外、机器人、以自我为中心甚至是模拟数据。它们被精心地用一个功能图进行标注,而语言指令的难度通过移除其类别名称并提供仅有功能描述的方式而大大增加。此外,我们提出了一个全面的基于功能感知的抓取框架,名为AffordanceNet,它由预训练在我们的大规模功能数据上的VLM和抓取网络组成,该网络通过条件化功能图来抓取目标物体。在功能分割基准测试和真实机器人操作任务上的大量实验表明,我们的模型具有强大的开放世界泛化能力。我们的数据和代码可在https://github.com/wudongming97/AffordanceNet找到。
论文及项目相关链接
PDF Accepted by ICCV 2025. The code is at https://github.com/wudongming97/AffordanceNet
Summary:
针对通用机器人抓取系统,在多样开放世界场景下跟随人类指令进行物体功能感知的问题,我们构建了一个大型抓取导向的功能分割基准测试,名为RAGNet。它包括273k图像、180类、26k条指令。图像覆盖多样化的实体数据域,如野外、机器人、自我中心甚至模拟数据。我们提出了一个全面的基于功能的抓取框架AffordanceNet,包括在大型功能数据上预训练的视觉语言模型(VLM)和基于功能地图进行目标抓取的抓取网络。实验表明,我们的模型具有强大的开放世界泛化能力。
Key Takeaways:
- 通用机器人抓取系统需要准确的对象功能感知在多样开放世界场景中跟随人类指令。
- 当前研究缺乏基于推理的大规模功能预测数据,对开放世界有效性存在担忧。
- 构建了一个大型抓取导向的功能分割基准测试RAGNet,包含273k图像、180类、26k条指令。
- 图像覆盖多种实体数据域,包括野外、机器人、自我中心及模拟数据,并进行了精细的功能地图标注。
- 提出了一个全面的基于功能的抓取框架AffordanceNet,包括预训练的视觉语言模型和基于功能地图的抓取网络。
- 实验表明,AffordanceNet模型具有强大的开放世界泛化能力。
点此查看论文截图



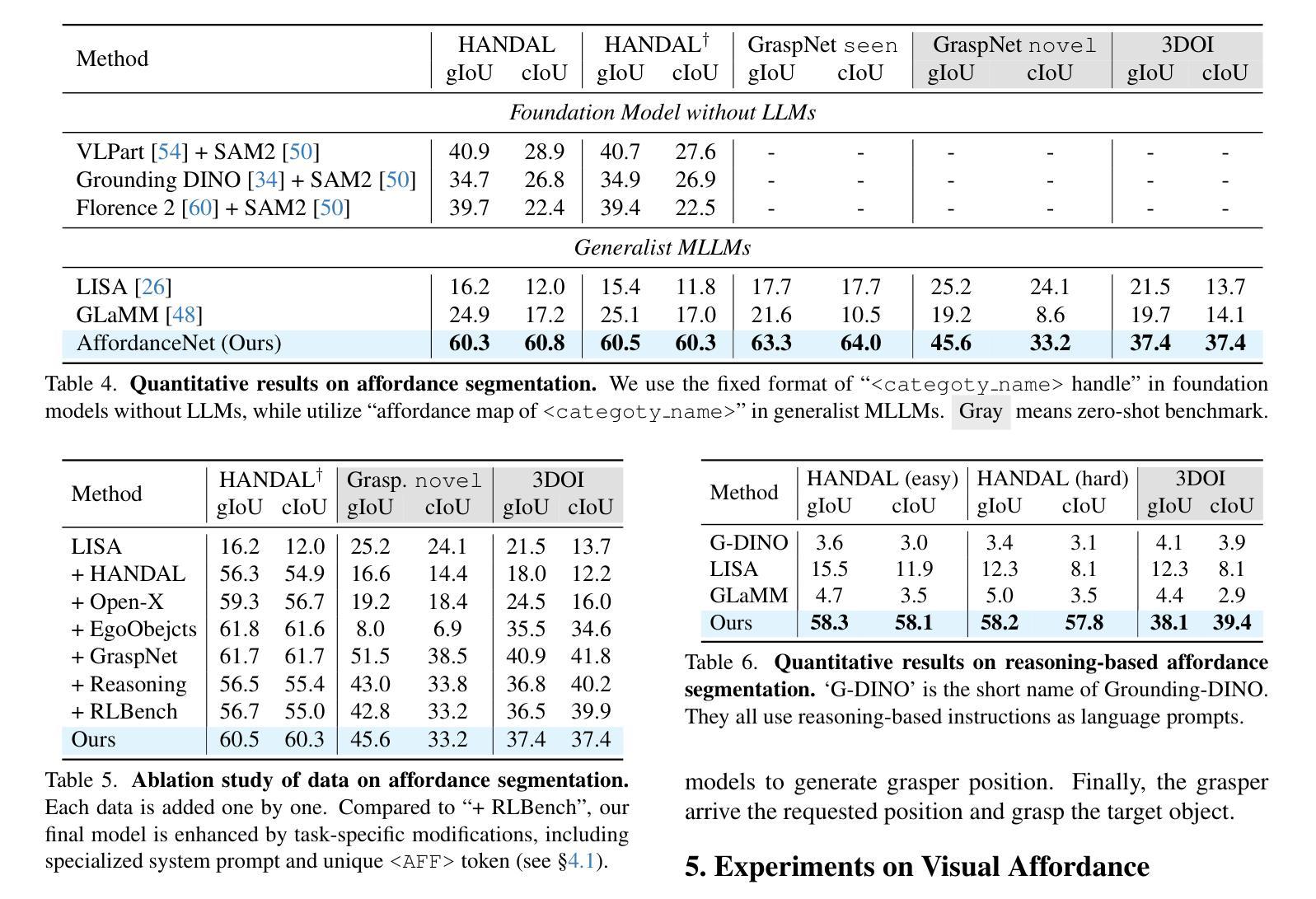

Seed-Prover: Deep and Broad Reasoning for Automated Theorem Proving
Authors:Luoxin Chen, Jinming Gu, Liankai Huang, Wenhao Huang, Zhicheng Jiang, Allan Jie, Xiaoran Jin, Xing Jin, Chenggang Li, Kaijing Ma, Cheng Ren, Jiawei Shen, Wenlei Shi, Tong Sun, He Sun, Jiahui Wang, Siran Wang, Zhihong Wang, Chenrui Wei, Shufa Wei, Yonghui Wu, Yuchen Wu, Yihang Xia, Huajian Xin, Fan Yang, Huaiyuan Ying, Hongyi Yuan, Zheng Yuan, Tianyang Zhan, Chi Zhang, Yue Zhang, Ge Zhang, Tianyun Zhao, Jianqiu Zhao, Yichi Zhou, Thomas Hanwen Zhu
LLMs have demonstrated strong mathematical reasoning abilities by leveraging reinforcement learning with long chain-of-thought, yet they continue to struggle with theorem proving due to the lack of clear supervision signals when solely using natural language. Dedicated domain-specific languages like Lean provide clear supervision via formal verification of proofs, enabling effective training through reinforcement learning. In this work, we propose \textbf{Seed-Prover}, a lemma-style whole-proof reasoning model. Seed-Prover can iteratively refine its proof based on Lean feedback, proved lemmas, and self-summarization. To solve IMO-level contest problems, we design three test-time inference strategies that enable both deep and broad reasoning. Seed-Prover proves $78.1%$ of formalized past IMO problems, saturates MiniF2F, and achieves over 50% on PutnamBench, outperforming the previous state-of-the-art by a large margin. To address the lack of geometry support in Lean, we introduce a geometry reasoning engine \textbf{Seed-Geometry}, which outperforms previous formal geometry engines. We use these two systems to participate in IMO 2025 and fully prove 5 out of 6 problems. This work represents a significant advancement in automated mathematical reasoning, demonstrating the effectiveness of formal verification with long chain-of-thought reasoning.
大型语言模型(LLMs)已经展现出强大的数学推理能力,通过利用增强学习与长链思维相结合的方法。然而,当仅使用自然语言时,由于缺乏明确的监督信号,它们在定理证明方面仍面临挑战。专用领域语言(如Lean)通过证明的形式验证提供明确的监督,从而能够通过增强学习进行有效的训练。在这项工作中,我们提出了名为“Seed-Prover”的引理式全证明推理模型。Seed-Prover可以基于Lean反馈、已证明的引理和自我总结来迭代完善其证明。为解决IMO级别的竞赛问题,我们设计了三种测试时推理策略,以实现深度和广度推理。Seed-Prover证明了78.1%的正式化过去IMO问题,饱和MiniF2F,并在PutnamBench上达到50%以上,大大超过了之前的最先进水平。为了解决Lean中缺乏几何支持的问题,我们引入了一个几何推理引擎“Seed-Geometry”,其性能优于以前的正式几何引擎。我们使用这两个系统参加了2025年IMO,并完全证明了6个问题的5个。这项工作在自动化数学推理方面取得了重大进展,展示了长链思维推理与形式验证的有效性。
论文及项目相关链接
Summary
该文本介绍了一种名为Seed-Prover的推理模型,能够基于精益反馈、已验证的引理和自我总结进行迭代式的证明细化。该模型解决了IMO级别的竞赛问题,并设计出了三种测试时推理策略以实现深度与广度推理。此外,为解决精益在几何支持方面的不足,引入了Seed-Geometry几何推理引擎。这两个系统共同参与了IMO 2025的竞赛,成功证明其中五个问题,展现了形式验证与长链思维推理的有效性。这是数学自动化推理领域的一大进步。
Key Takeaways
- LLMs虽能通过强化学习与长链思维展现出强大的数学推理能力,但在定理证明方面仍存在挑战。
- 专用领域语言如Lean,通过形式验证证明,为强化学习提供了清晰的监督信号。
- Seed-Prover模型是一种全新的数学推理模型,具备基于精益反馈、已验证的引理以及自我总结进行迭代证明的能力。
- 该模型设计了三种测试时推理策略以处理深度与广度推理,并解决了IMO级别的竞赛问题。
- 为应对精益在几何支持方面的不足,引入了Seed-Geometry几何推理引擎并超越了先前的正式几何引擎性能。
- Seed-Prover模型在正式化过去的IMO问题、MiniF2F和PutnamBench上的表现均超越了先前最先进的技术。
点此查看论文截图

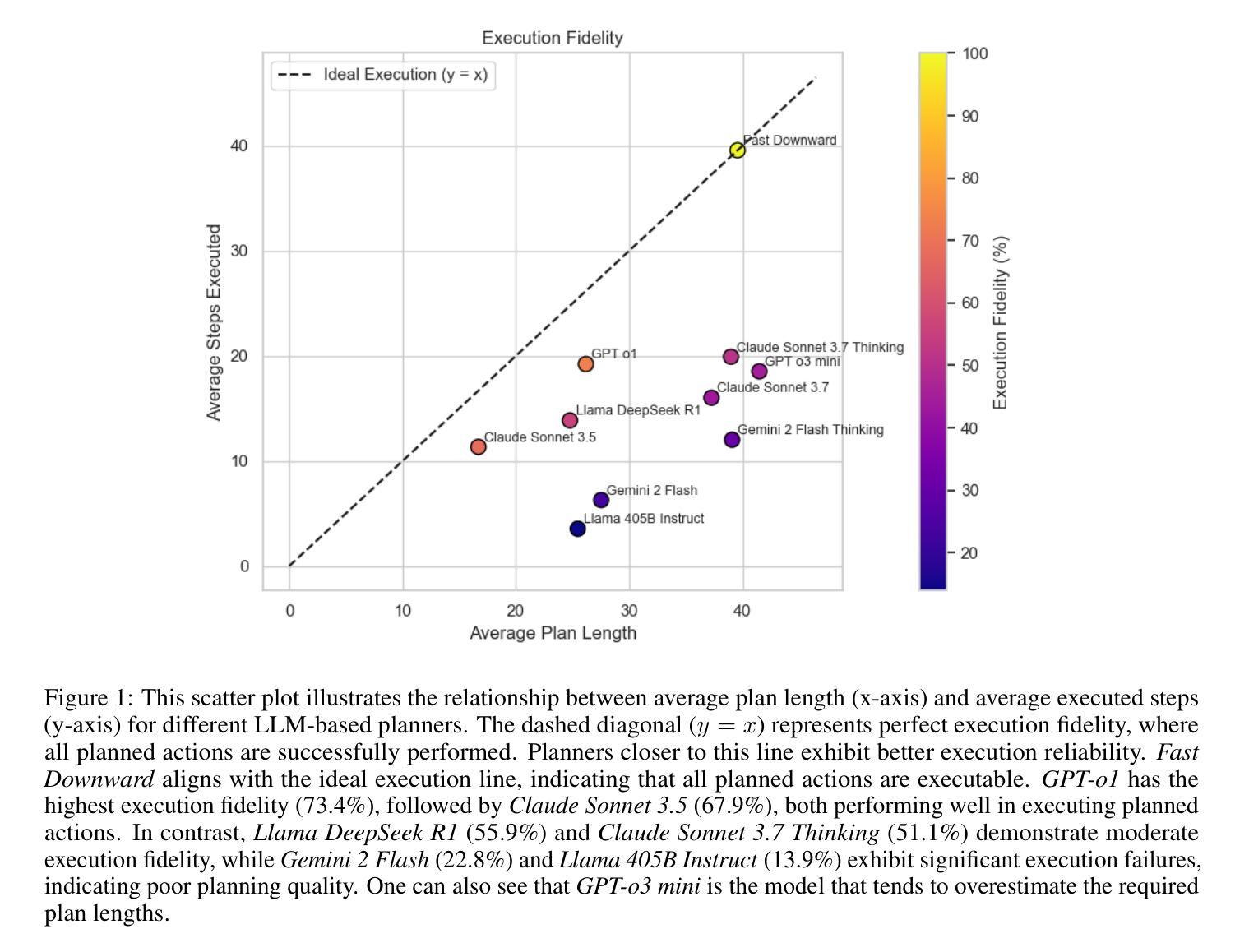
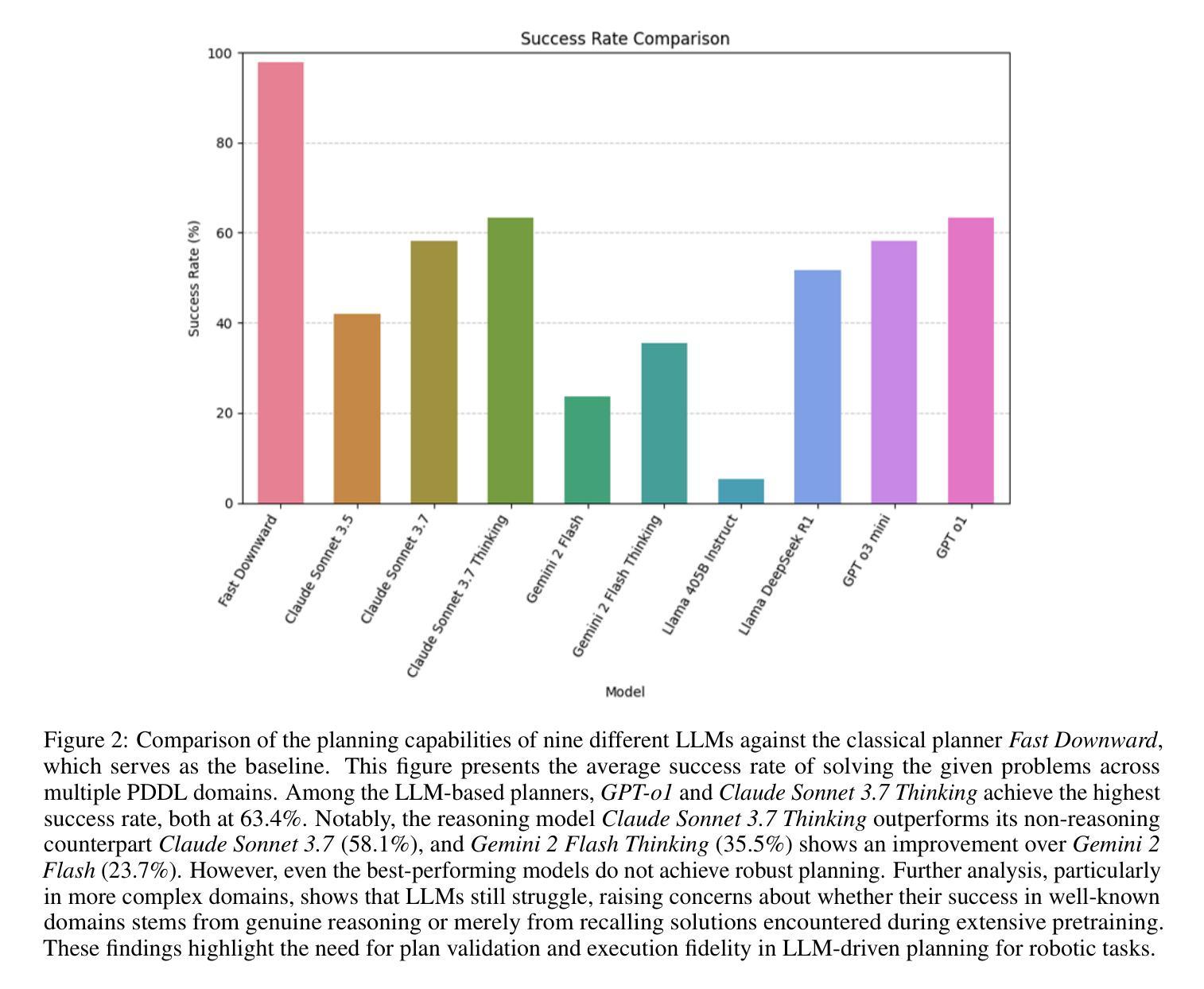
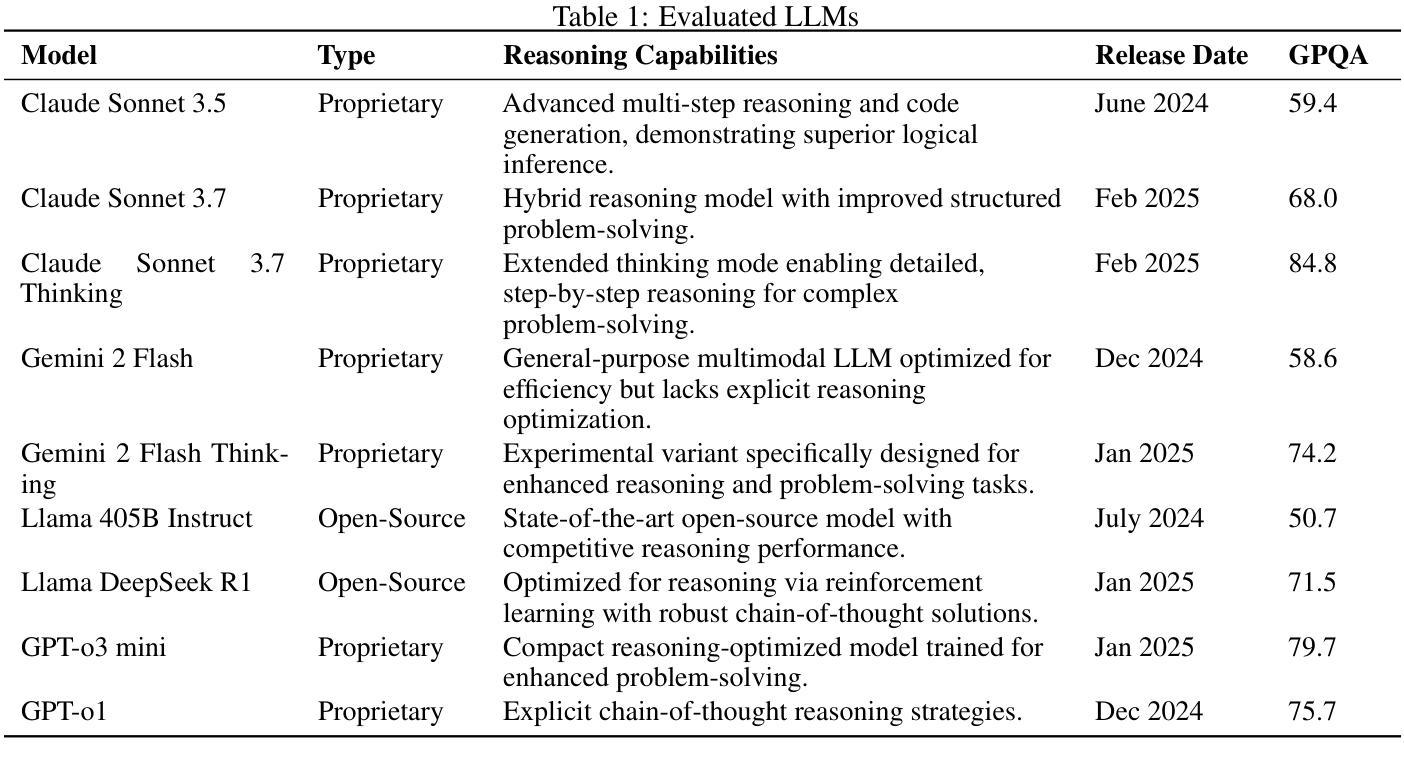
Can LLM-Reasoning Models Replace Classical Planning? A Benchmark Study
Authors:Kai Goebel, Patrik Zips
Recent advancements in Large Language Models have sparked interest in their potential for robotic task planning. While these models demonstrate strong generative capabilities, their effectiveness in producing structured and executable plans remains uncertain. This paper presents a systematic evaluation of a broad spectrum of current state of the art language models, each directly prompted using Planning Domain Definition Language domain and problem files, and compares their planning performance with the Fast Downward planner across a variety of benchmarks. In addition to measuring success rates, we assess how faithfully the generated plans translate into sequences of actions that can actually be executed, identifying both strengths and limitations of using these models in this setting. Our findings show that while the models perform well on simpler planning tasks, they continue to struggle with more complex scenarios that require precise resource management, consistent state tracking, and strict constraint compliance. These results underscore fundamental challenges in applying language models to robotic planning in real world environments. By outlining the gaps that emerge during execution, we aim to guide future research toward combined approaches that integrate language models with classical planners in order to enhance the reliability and scalability of planning in autonomous robotics.
最近大型语言模型的进步引发了人们对机器人任务规划潜力的兴趣。虽然这些模型表现出强大的生成能力,但它们在制定结构化且可执行的计划方面的有效性仍有待验证。本文系统地评估了一系列最新的语言模型,使用规划领域定义语言和问题文件直接提示这些模型,并在各种基准测试中将它们的规划性能与Fast Downward规划器进行比较。除了衡量成功率之外,我们还评估生成的计划如何忠实转化为可实际执行的行动序列,以确定在这些环境中使用这些模型的优缺点。我们的研究结果表明,虽然这些模型在简单的规划任务上表现良好,但在需要精确资源管理、持续状态跟踪和严格约束遵守的更复杂场景中,它们仍然面临挑战。这些结果强调了将语言模型应用于现实环境机器人规划的基本挑战。通过概述执行过程中出现的差距,我们的目标是为未来的研究提供指导,采用结合语言模型和经典规划器的方法,以提高自主机器人规划的可靠性和可扩展性。
论文及项目相关链接
Summary
大型语言模型在机器人任务规划方面的潜力引发了广泛关注。本文对一系列当前先进语言模型进行了系统评估,使用规划领域定义语言域和问题文件直接提示,与Fast Downward规划器在各种基准测试上进行规划性能比较。除了测量成功率之外,我们还评估了生成计划能否忠实转化为可执行的行动序列,探讨了在这种环境中使用这些模型的优缺点。研究发现,这些模型在简单的规划任务上表现良好,但在需要精确资源管理、持续状态跟踪和严格约束遵守的复杂场景中仍面临挑战。这些结果强调了将语言模型应用于现实环境机器人规划的基础挑战,并指出未来研究应整合语言模型与经典规划器,以提高自主机器人规划的可靠性和可扩展性。
Key Takeaways
- 大型语言模型在机器人任务规划领域具有潜在应用价值。
- 本文系统评估了当前先进语言模型在规划性能方面的表现。
- 语言模型在简单规划任务上表现良好,但在复杂场景中存在挑战。
- 复杂场景中的挑战包括精确资源管理、持续状态跟踪和严格约束遵守。
- 语言模型与经典规划器的结合可以提高机器人规划的可靠性和可扩展性。
- 研究存在差距,需要进一步探索和发展集成语言模型和经典规划器的联合方法。
点此查看论文截图


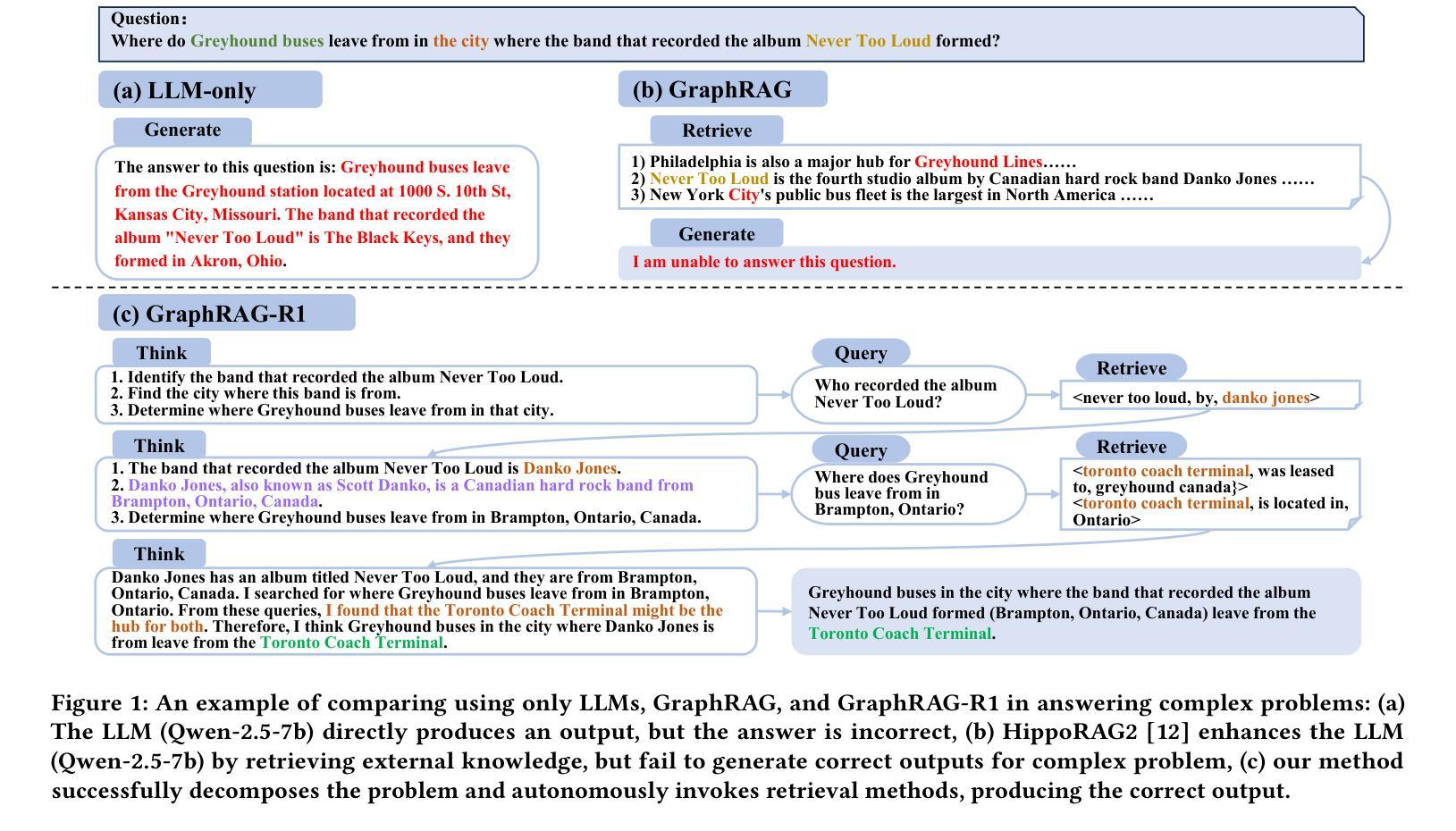
GraphRAG-R1: Graph Retrieval-Augmented Generation with Process-Constrained Reinforcement Learning
Authors:Chuanyue Yu, Kuo Zhao, Yuhan Li, Heng Chang, Mingjian Feng, Xiangzhe Jiang, Yufei Sun, Jia Li, Yuzhi Zhang, Jianxin Li, Ziwei Zhang
Graph Retrieval-Augmented Generation (GraphRAG) has shown great effectiveness in enhancing the reasoning abilities of LLMs by leveraging graph structures for knowledge representation and modeling complex real-world relationships. However, existing GraphRAG methods still face significant bottlenecks when handling complex problems that require multi-hop reasoning, as their query and retrieval phases are largely based on pre-defined heuristics and do not fully utilize the reasoning potentials of LLMs. To address this problem, we propose GraphRAG-R1, an adaptive GraphRAG framework by training LLMs with process-constrained outcome-based reinforcement learning (RL) to enhance the multi-hop reasoning ability. Our method can decompose complex problems, autonomously invoke retrieval tools to acquire necessary information, and perform effective reasoning. Specifically, we utilize a modified version of Group Relative Policy Optimization (GRPO) that supports rollout-with-thinking capability. Next, we design two process-constrained reward functions. To handle the shallow retrieval problem, we design a Progressive Retrieval Attenuation (PRA) reward to encourage essential retrievals. Then, to handle the over-thinking problem, we design Cost-Aware F1 (CAF) reward to balance the model performance with computational costs. We further design a phase-dependent training strategy, containing three training stages corresponding to cold start and these two rewards. Lastly, our method adopts a hybrid graph-textual retrieval to improve the reasoning capacity. Extensive experimental results demonstrate that GraphRAG-R1 boosts LLM capabilities in solving complex reasoning problems compared to state-of-the-art GraphRAG methods on both in-domain and out-of-domain datasets. Furthermore, our framework can be flexibly integrated with various existing retrieval methods, consistently delivering performance improvements.
图检索增强生成(GraphRAG)通过利用图结构进行知识表示和建模复杂的现实世界关系,在增强大型语言模型的推理能力方面表现出巨大的有效性。然而,现有的GraphRAG方法在处理需要多跳推理的复杂问题时仍面临重大瓶颈,因为它们的查询和检索阶段大多基于预定义的启发式方法,并没有充分利用大型语言模型的推理潜力。为了解决这个问题,我们提出了GraphRAG-R1,这是一种自适应的GraphRAG框架,通过采用过程约束的结果导向强化学习(RL)来训练大型语言模型,以增强其多跳推理能力。我们的方法可以分解复杂问题,自主调用检索工具获取必要信息,并进行有效的推理。具体来说,我们利用经过修改的Group Relative Policy Optimization(GRPO)版本,支持思考能力的滚动。接下来,我们设计了两个过程约束奖励函数。为了解决浅层检索问题,我们设计了Progressive Retrieval Attenuation(PRA)奖励来鼓励必要的检索。然后,为了解决过度思考的问题,我们设计了Cost-Aware F1(CAF)奖励来平衡模型性能和计算成本。我们还设计了一种阶段性的训练策略,包括与这两种奖励相对应的冷启动在内的三个阶段。最后,我们的方法采用混合图文本检索来提高推理能力。大量的实验结果表明,与最新的GraphRAG方法相比,GraphRAG-R1在域内和域外数据集上都能提高大型语言模型解决复杂推理问题的能力。此外,我们的框架可以灵活地与各种现有的检索方法相结合,持续带来性能改进。
论文及项目相关链接
Summary
GraphRAG-R1通过采用过程约束的基于结果的强化学习训练LLMs,提高了多跳推理能力。该方法能够分解复杂问题,自主调用检索工具获取必要信息,并进行有效的推理。通过设计两种过程约束奖励函数来解决浅检索和过度思考的问题,并采用混合图文本检索提高推理能力。实验结果表明,与现有的GraphRAG方法相比,GraphRAG-R1在解决复杂推理问题方面具有优势。
Key Takeaways
- GraphRAG-R1利用过程约束的基于结果的强化学习训练LLMs,提高多跳推理能力。
- 通过自主调用检索工具分解复杂问题并获取必要信息。
- 设计两种过程约束奖励函数解决浅检索和过度思考的问题。
- 采用混合图文本检索提高推理能力。
- GraphRAG-R1在解决复杂推理问题方面优于现有的GraphRAG方法。
点此查看论文截图

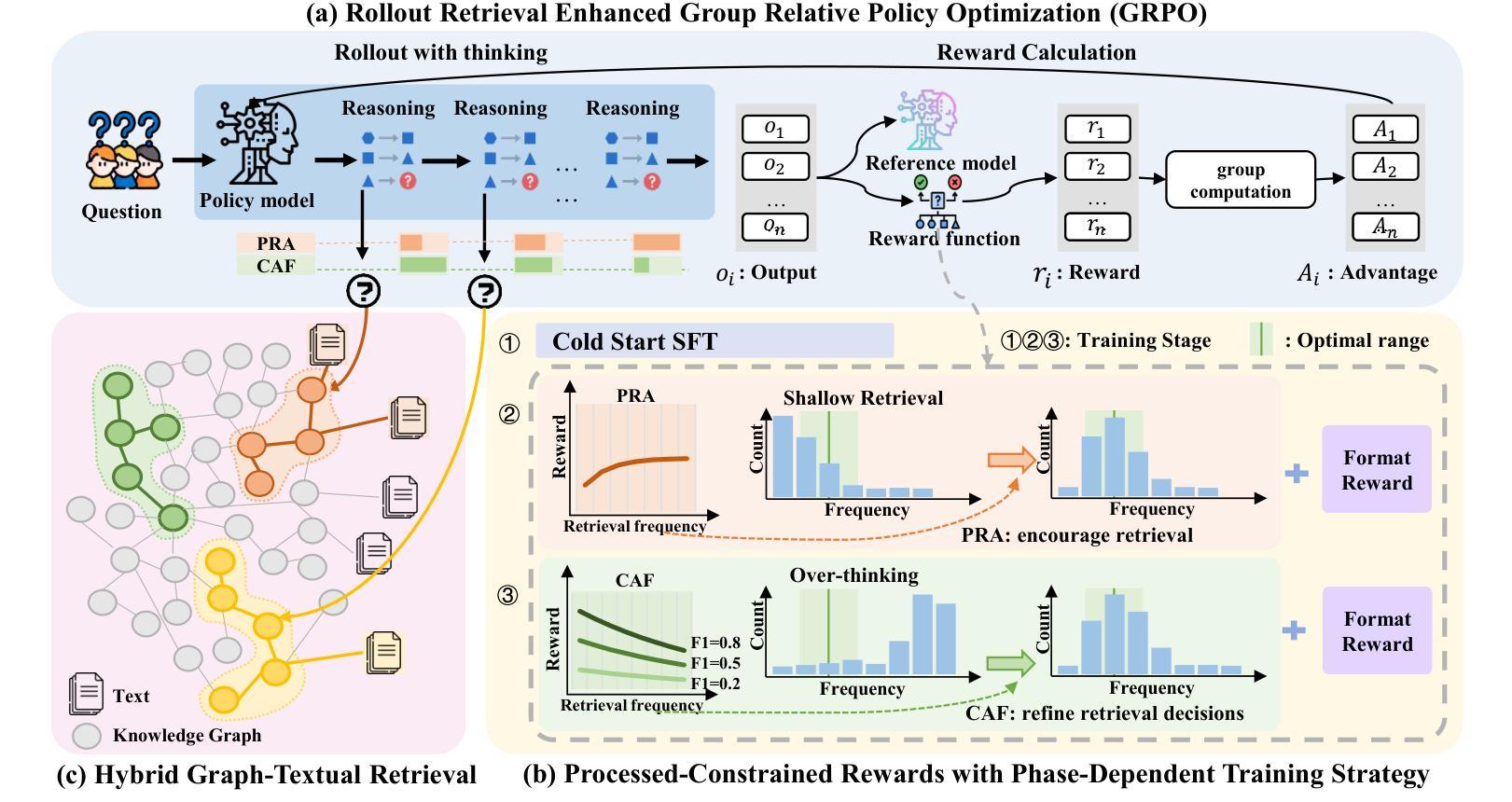
Med-R$^3$: Enhancing Medical Retrieval-Augmented Reasoning of LLMs via Progressive Reinforcement Learning
Authors:Keer Lu, Zheng Liang, Youquan Li, Jiejun Tan, Da Pan, Shusen Zhang, Guosheng Dong, Huang Leng
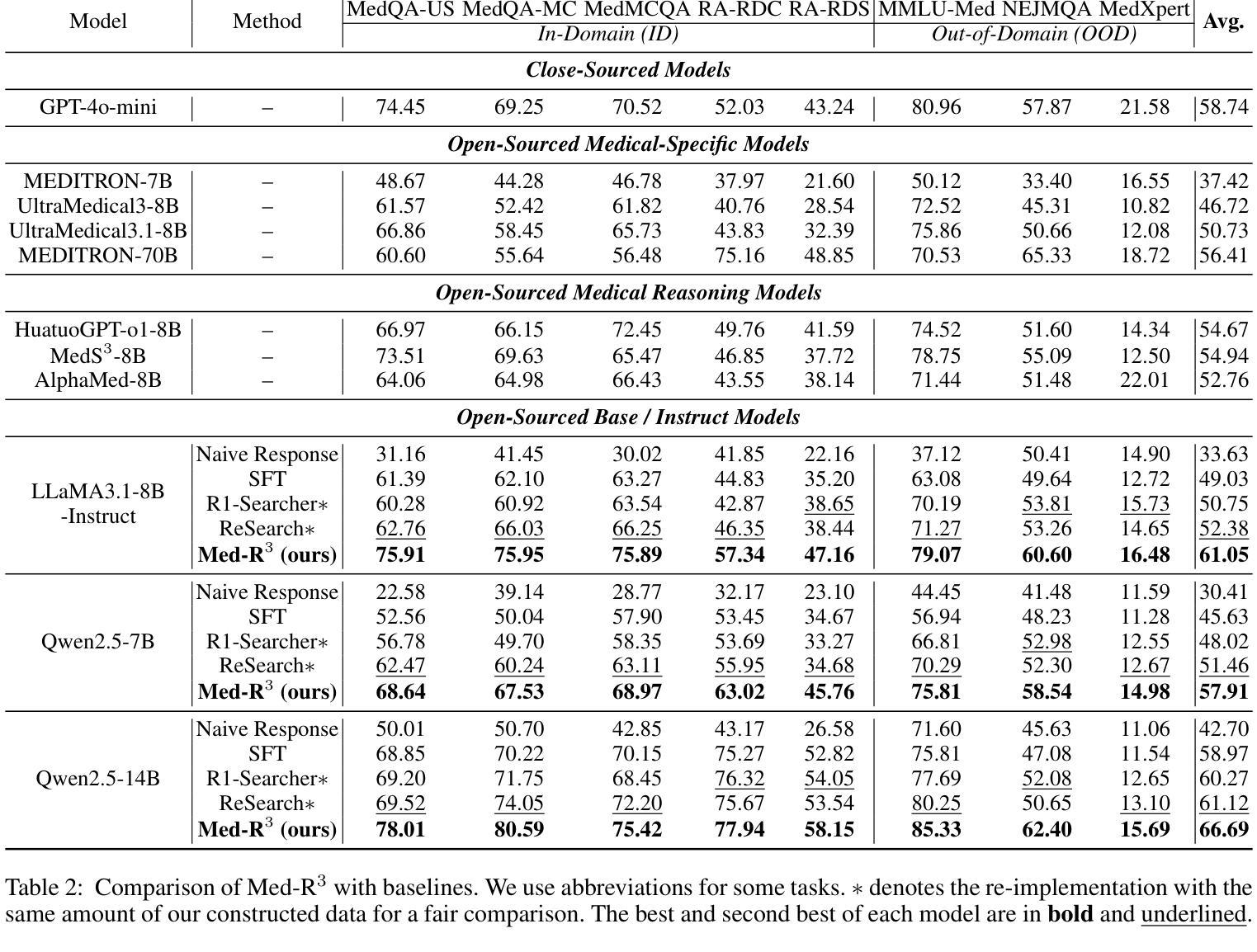
In medical scenarios, effectively retrieving external knowledge and leveraging it for rigorous logical reasoning is of significant importance. Despite their potential, existing work has predominantly focused on enhancing either retrieval or reasoning capabilities of the models in isolation, with little attention given to their joint optimization, which leads to limited coordination between the two processes. Additionally, current methods rely heavily on supervised fine-tuning (SFT), which can cause models to memorize existing problem-solving pathways, thereby restricting their generalization ability when confronted with novel problem contexts. Furthermore, while some studies have explored to improve retrieval-augmented reasoning in general domains via reinforcement learning, their reward function designs do not adequately capture the specific demands of the medical domain. To address these challenges, we introduce Med-R$^3$, a Medical Retrieval-augmented Reasoning framework driven by progressive Reinforcement learning. In this framework, we first develop the model’s ability to perform logical reasoning over medical problems. Subsequently, on the basis of this foundation, we adaptively optimize the retrieval capability to better align with the characteristics of knowledge corpus and external information utilization throughout the reasoning process. Finally, we conduct joint optimization of the model’s retrieval and reasoning coordination. Extensive experiments indicate that Med-R$^3$ could achieve state-of-the-art performances, with LLaMA3.1-8B-Instruct + Med-R$^3$ surpassing closed-sourced GPT-4o-mini by 3.93% at a comparable parameter scale, while Qwen2.5-14B augmented with Med-R$^3$ shows a more substantial gain of 13.53%.
在医疗场景中,有效地检索外部知识并利用其进行严格的逻辑推理具有非常重要的意义。尽管存在潜在的改进空间,但现有工作主要集中在单独增强模型的检索或推理能力上,而对它们的联合优化关注较少,导致这两个过程之间的协调有限。此外,当前的方法严重依赖于有监督的微调(SFT),这可能导致模型记忆现有的问题解决路径,从而在面对新的问题情境时限制其泛化能力。虽然一些研究已经探索了通过强化学习改进一般领域的检索增强推理,但他们的奖励函数设计并没有充分捕捉到医疗领域的特定需求。为了解决这些挑战,我们引入了Med-R$^3$,这是一个由渐进式强化学习驱动的医疗检索增强推理框架。在此框架中,我们首先开发模型解决医疗问题的逻辑推理能力。然后在此基础上,我们自适应地优化检索能力,以更好地与知识库和外部信息利用的特征在整个推理过程中对齐。最后,我们对模型的检索和推理协调进行联合优化。大量实验表明,**Med-R$^3$**可以达到最先进的性能,在参数规模相当的情况下,LLaMA3.1-8B-Instruct与Med-R$^3$结合超越了闭源的GPT-4o-mini,提升了3.93%;而Qwen2.5-14B与Med-R$^3$结合则取得了更大的收益,提升了13.53%。
论文及项目相关链接
Summary
该文强调在医疗场景中,有效检索外部知识并用于严谨的逻辑推理具有重要意义。现有工作主要关注增强模型的检索或推理能力,但很少关注两者的联合优化,导致两者协调有限。此外,当前方法过于依赖监督微调(SFT),限制了模型在面临新问题情境时的泛化能力。为解决这些挑战,提出Med-R$^3$框架,该框架通过渐进式强化学习,提高医疗领域的检索增强推理能力。先进行逻辑推理能力训练,然后在此基础上优化检索能力,最后进行模型检索和推理的联合优化。实验表明,Med-R$^3$达到最新性能水平。
Key Takeaways
- 医疗场景中,外部知识的有效检索和逻辑推理相结合至关重要。
- 现有工作多关注增强模型的检索或推理能力,但未充分关注两者的联合优化。
- 监督微调(SFT)限制了模型的泛化能力。
- Med-R$^3$框架通过渐进式强化学习提高医疗领域的检索增强推理能力。
- Med-R$^3$先进行逻辑推理能力训练,再优化检索能力,最后联合优化检索和推理。
- 实验表明Med-R$^3$框架达到最新性能水平。
点此查看论文截图

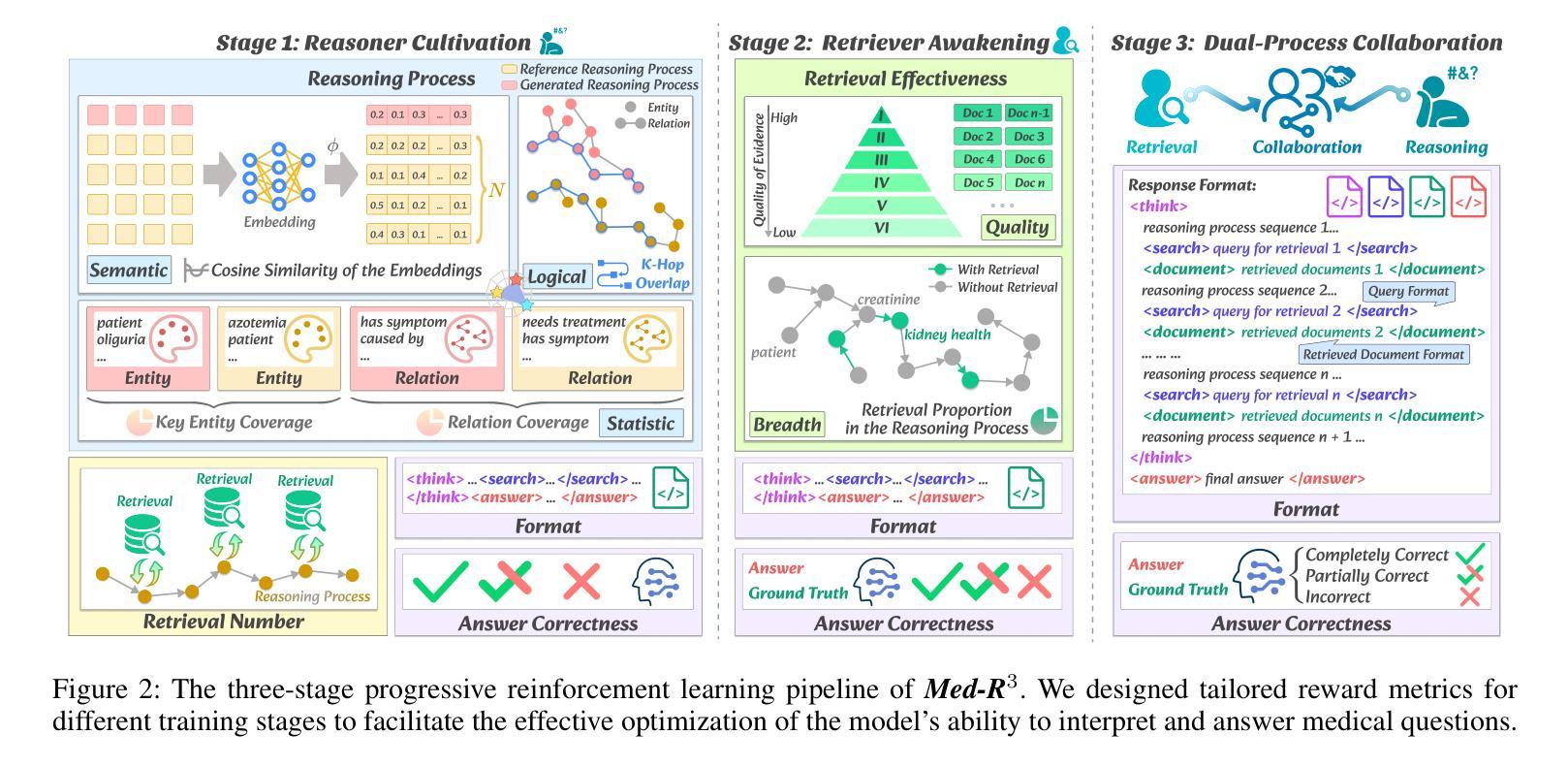
Causal Reasoning in Pieces: Modular In-Context Learning for Causal Discovery
Authors:Kacper Kadziolka, Saber Salehkaleybar
Causal inference remains a fundamental challenge for large language models. Recent advances in internal reasoning with large language models have sparked interest in whether state-of-the-art reasoning models can robustly perform causal discovery-a task where conventional models often suffer from severe overfitting and near-random performance under data perturbations. We study causal discovery on the Corr2Cause benchmark using the emergent OpenAI’s o-series and DeepSeek-R model families and find that these reasoning-first architectures achieve significantly greater native gains than prior approaches. To capitalize on these strengths, we introduce a modular in-context pipeline inspired by the Tree-of-Thoughts and Chain-of-Thoughts methodologies, yielding nearly three-fold improvements over conventional baselines. We further probe the pipeline’s impact by analyzing reasoning chain length, complexity, and conducting qualitative and quantitative comparisons between conventional and reasoning models. Our findings suggest that while advanced reasoning models represent a substantial leap forward, carefully structured in-context frameworks are essential to maximize their capabilities and offer a generalizable blueprint for causal discovery across diverse domains.
因果推理仍是大型语言模型面临的一项核心挑战。近期大型语言模型内部推理的进展激发了人们对这样一个问题的兴趣:最先进的推理模型是否能够稳健地进行因果发现?这是一项任务,其中传统模型经常受到严重的过拟合和数据扰动下近似随机表现的影响。我们在Corr2Cause基准测试集上研究了OpenAI的o系列和DeepSeek-R模型家族的应用表现,发现这些以推理为重点的架构与之前的方法相比取得了显著的进步。为了充分利用这些优势,我们借鉴树形思维和链式思维方法,引入了一种模块化上下文管道,与传统基线相比,取得了近三倍的提升。通过解析推理链的长度和复杂性以及传统模型和推理模型之间的对比,我们进一步挖掘了管道的影响。我们的研究结果暗示,虽然先进的推理模型取得了重大进步,但要最大限度地发挥其能力,精心构建的上下文框架至关重要,这为跨不同领域的因果发现提供了可推广的蓝图。
论文及项目相关链接
Summary
大型语言模型的因果推断依然是一个基本挑战。最新内部推理技术激发了对因果发现任务的研究兴趣,该任务中传统模型常常面临严重的过拟合问题以及在数据扰动下的近乎随机性能表现。在Corr2Cause基准测试上,我们研究了OpenAI的o系列和DeepSeek-R模型家族的因果发现能力,发现这些以推理为主的架构比先前的方法取得了显著的优势。为了充分利用这些优势,我们引入了受思维树和思维链启发的模块化上下文管道,实现了近乎三倍于传统基准测试的提升。通过对比传统模型与推理模型的推理链长度、复杂性和定量定性分析,我们的发现表明,尽管先进推理模型代表了一次重大飞跃,但精心构建的上下文框架对于最大化其能力至关重要,并为跨不同领域的因果发现提供了可推广的蓝图。
Key Takeaways
- 大型语言模型在因果推断上仍面临挑战。
- 先进推理模型如OpenAI的o系列和DeepSeek-R在因果发现任务上表现出显著优势。
- 模块化上下文管道(受思维树和思维链启发)能提高推理模型的性能,实现近乎三倍的提升。
- 推理模型的性能提升得益于其推理链的长度和复杂性。
- 精心构建的上下文框架对于最大化推理模型的能力至关重要。
- 先进推理模型为跨不同领域的因果发现提供了可推广的蓝图。
点此查看论文截图



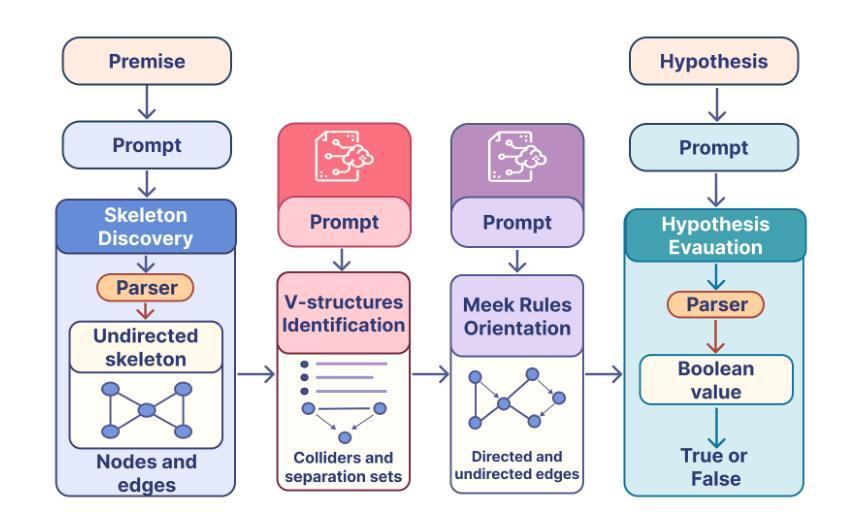
3D-R1: Enhancing Reasoning in 3D VLMs for Unified Scene Understanding
Authors:Ting Huang, Zeyu Zhang, Hao Tang
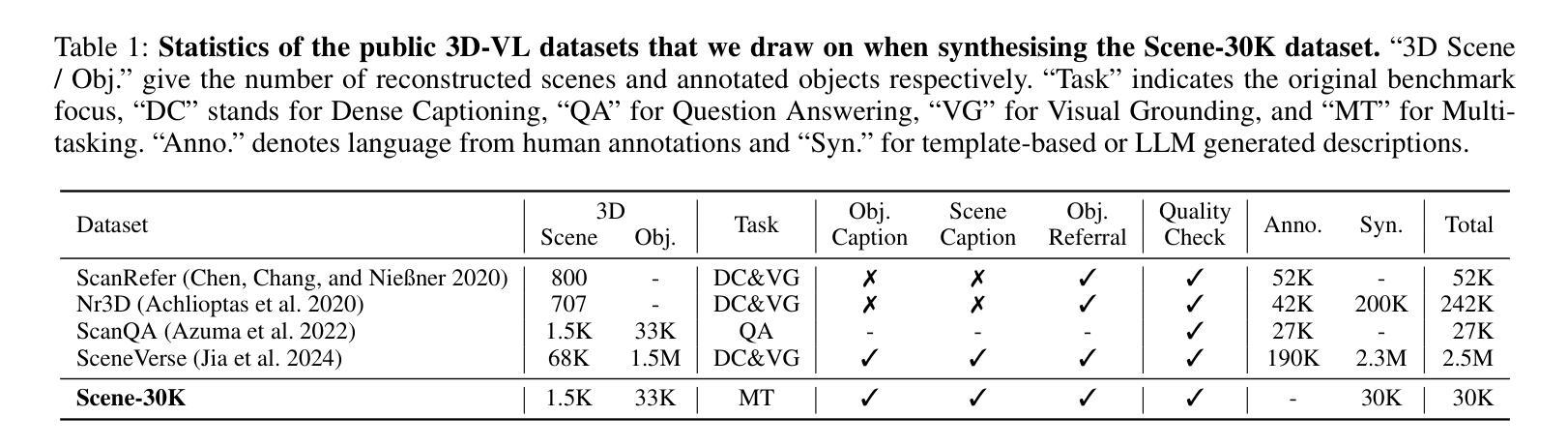
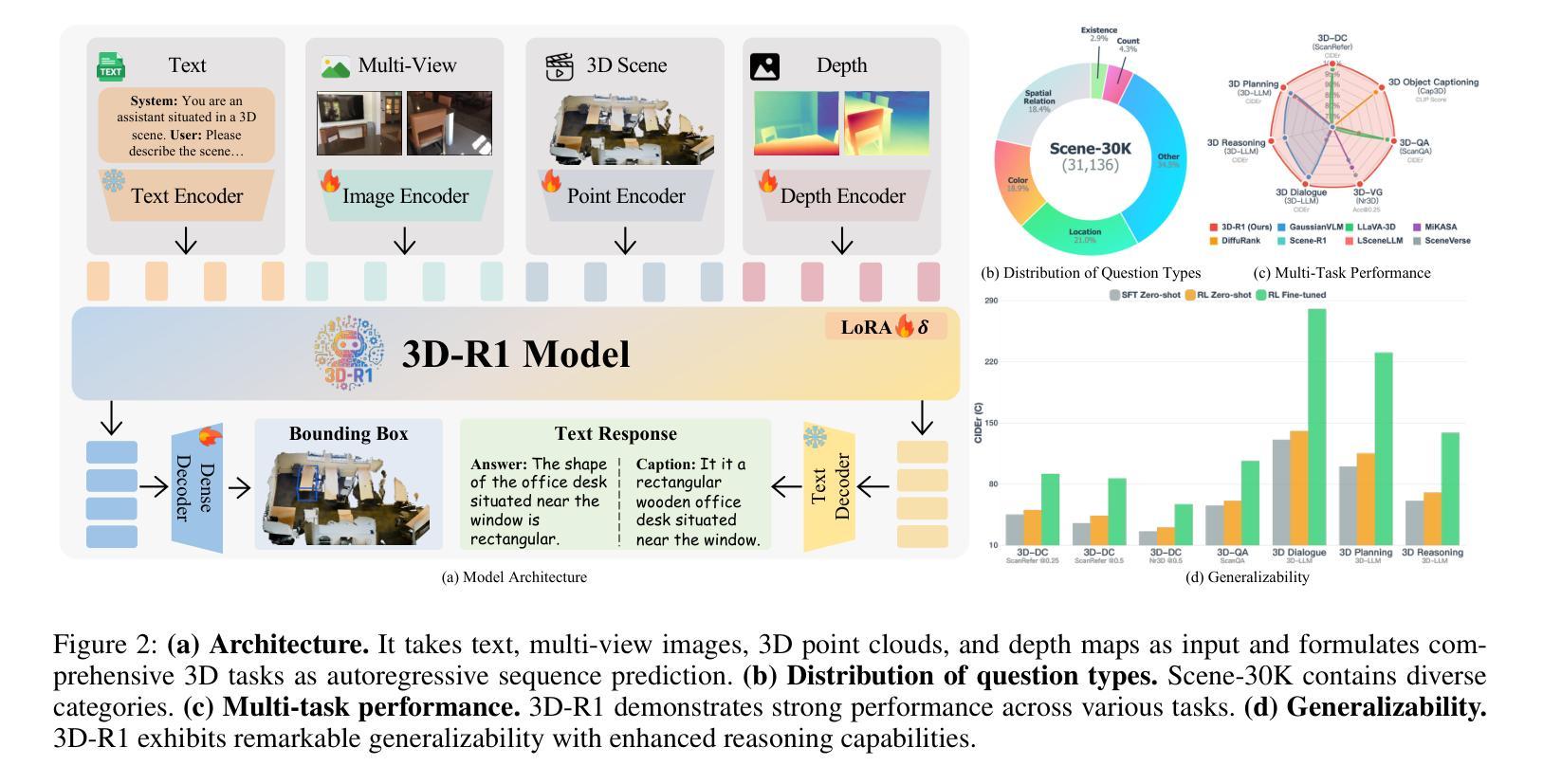
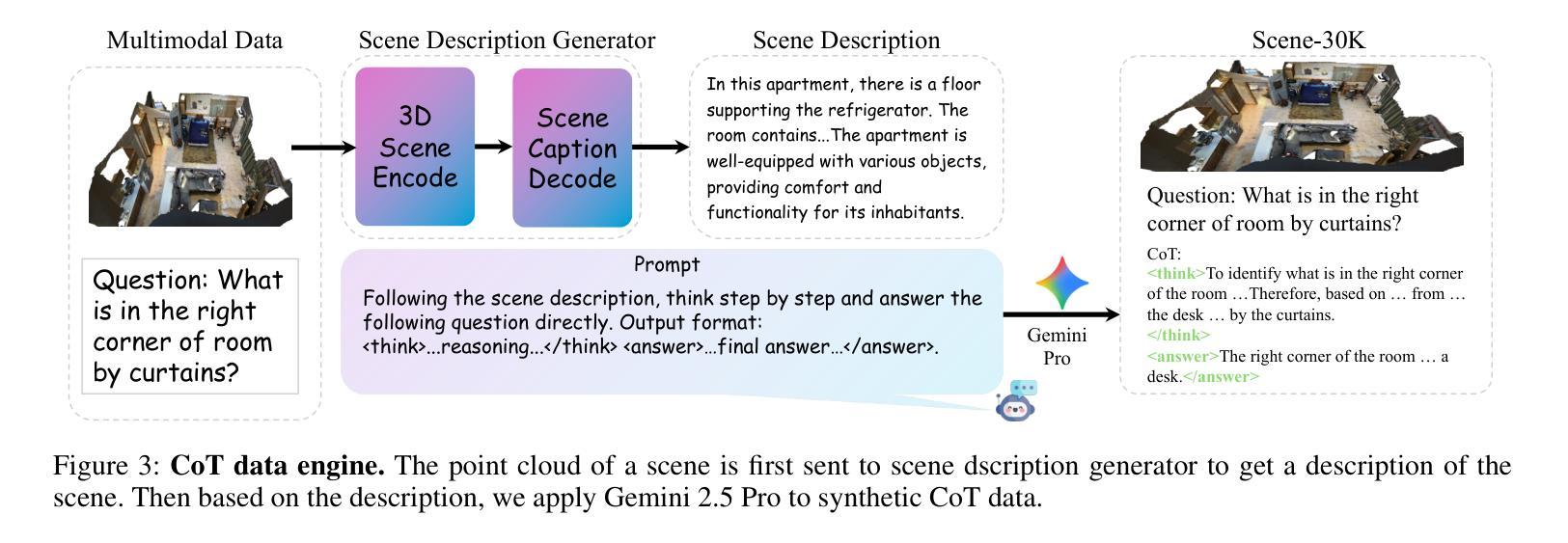
Large vision-language models (VLMs) have made significant strides in 2D visual understanding tasks, sparking interest in extending these capabilities to 3D scene understanding. However, current 3D VLMs often struggle with robust reasoning and generalization due to limitations in high-quality spatial data and the static nature of viewpoint assumptions. To address these challenges, we propose 3D-R1, a foundation model that enhances the reasoning capabilities of 3D VLMs. Specifically, we first construct a high-quality synthetic dataset with CoT, named Scene-30K, leveraging existing 3D-VL datasets and a data engine based on Gemini 2.5 Pro. It serves as cold-start initialization data for 3D-R1. Moreover, we leverage RLHF policy such as GRPO in the reinforcement learning training process to enhance reasoning capabilities and introduce three reward functions: a perception reward, a semantic similarity reward and a format reward to maintain detection accuracy and answer semantic precision. Furthermore, we introduce a dynamic view selection strategy that adaptively chooses the most informative perspectives for 3D scene understanding. Extensive experiments demonstrate that 3D-R1 delivers an average improvement of 10% across various 3D scene benchmarks, highlighting its effectiveness in enhancing reasoning and generalization in 3D scene understanding. Code: https://github.com/AIGeeksGroup/3D-R1. Website: https://aigeeksgroup.github.io/3D-R1.
大型视觉语言模型(VLMs)在2D视觉理解任务方面取得了显著进展,从而激发了将这些能力扩展到3D场景理解的兴趣。然而,由于高质量空间数据的限制和视角假设的静态性质,当前的3D VLMs在稳健推理和泛化方面经常面临挑战。为了应对这些挑战,我们提出了3D-R1,这是一个增强3D VLMs推理能力的基础模型。具体来说,我们首先利用现有的3D-VL数据集和数据引擎基于Gemini 2.5 Pro,构建了一个名为Scene-30K的高质量合成数据集,它作为3D-R1的冷启动初始化数据。此外,我们在强化学习训练过程中利用如GRPO的RLHF策略,增强推理能力,并引入三种奖励功能:感知奖励、语义相似性奖励和格式奖励,以维持检测精度和答案语义精度。此外,我们引入了一种动态视角选择策略,能够自适应地选择最具有信息量的视角进行3D场景理解。大量实验表明,3D-R1在各种3D场景基准测试中平均提高了10%的性能,凸显了其在增强3D场景理解的推理和泛化方面的有效性。代码地址:https://github.com/AIGeeksGroup/3D-R1。网站地址:https://aigeeksgroup.github.io/3D-R1。
论文及项目相关链接
Summary
本文提出一种名为3D-R1的增强三维视觉语言模型推理能力的方法。为应对高质量空间数据的局限和视角假设的静态性质所带来的挑战,该研究构建了高质量合成数据集Scene-30K,并引入了强化学习中的策略,如GRPO,以增强模型的推理能力。同时,通过引入三种奖励函数以及动态视角选择策略,提高了模型在三维场景理解中的检测精度和语义精度。实验结果显示,3D-R1在多个三维场景基准测试上平均提高了10%的性能。
Key Takeaways
- 3D-R1模型旨在增强现有三维视觉语言模型(VLMs)的推理和泛化能力。
- 构建了一个名为Scene-30K的高质量合成数据集作为3D-R1的冷启动初始化数据。
- 利用强化学习中的策略(如GRPO)和三种奖励函数来提升模型的性能。
- 奖励函数包括感知奖励、语义相似性奖励和格式奖励,以确保检测准确性和语义精度。
- 引入了动态视角选择策略,为三维场景理解选择最具信息性的视角。
- 实验结果表明,3D-R1在多个三维场景基准测试上实现了平均10%的性能提升。
点此查看论文截图

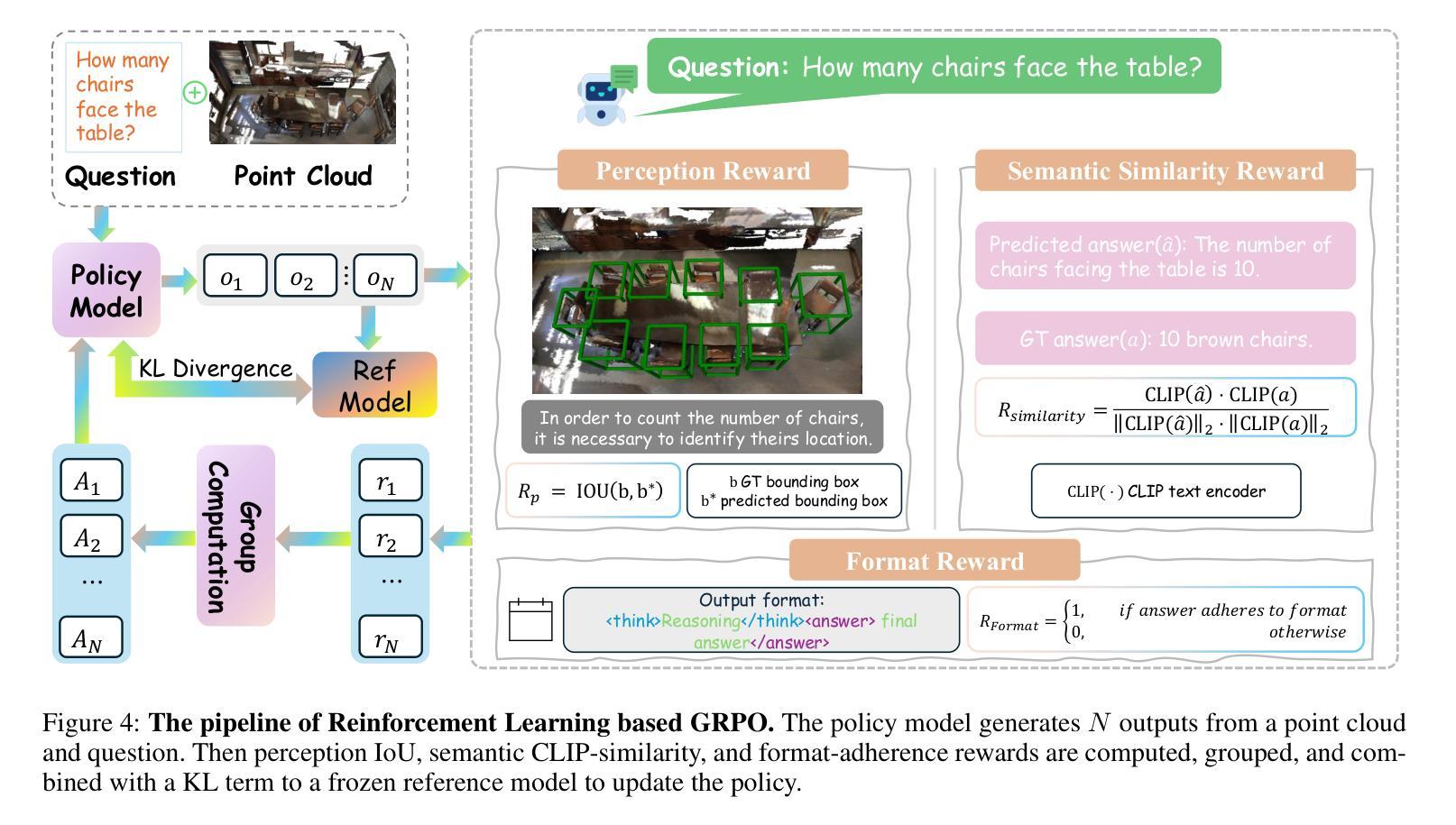
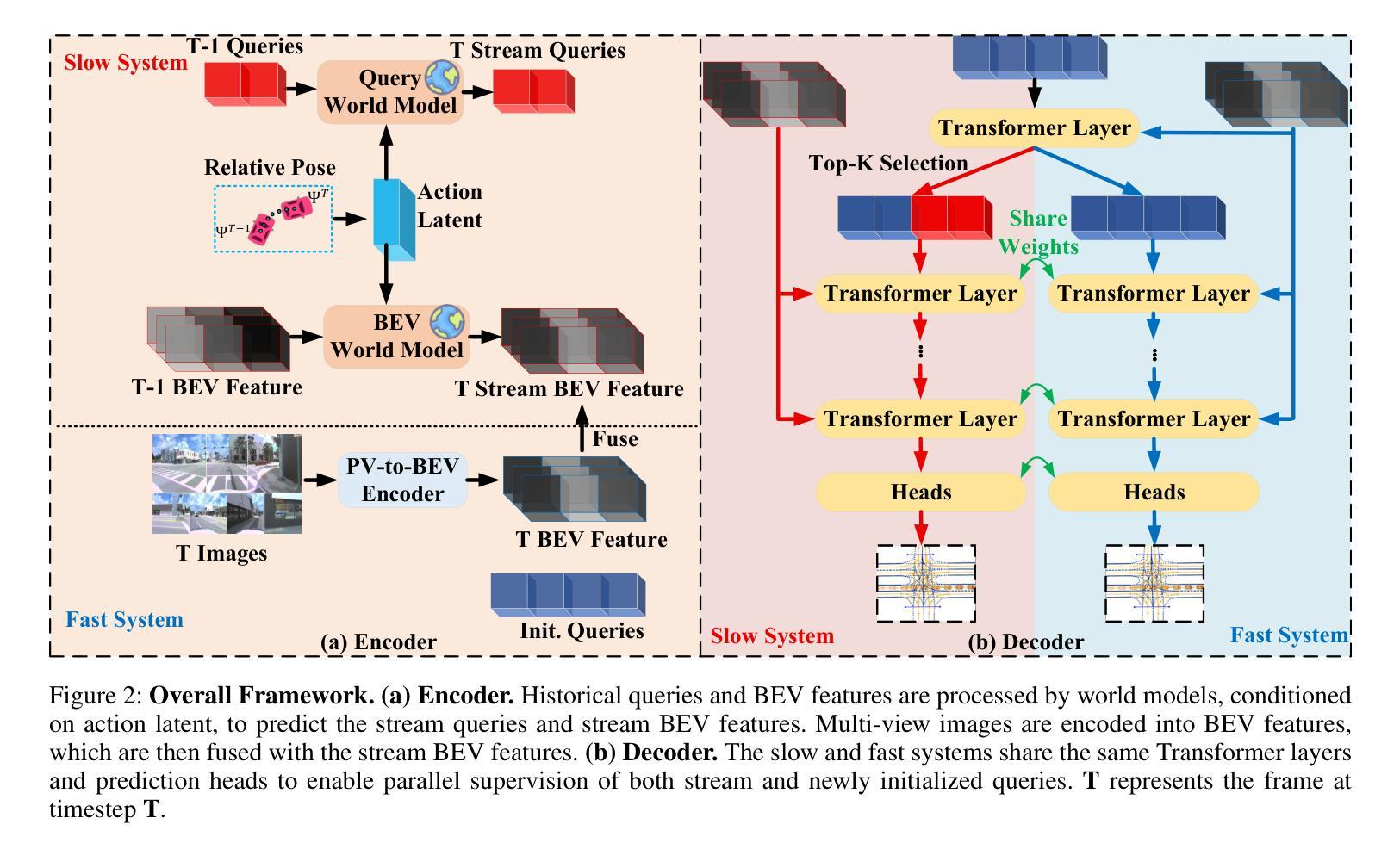
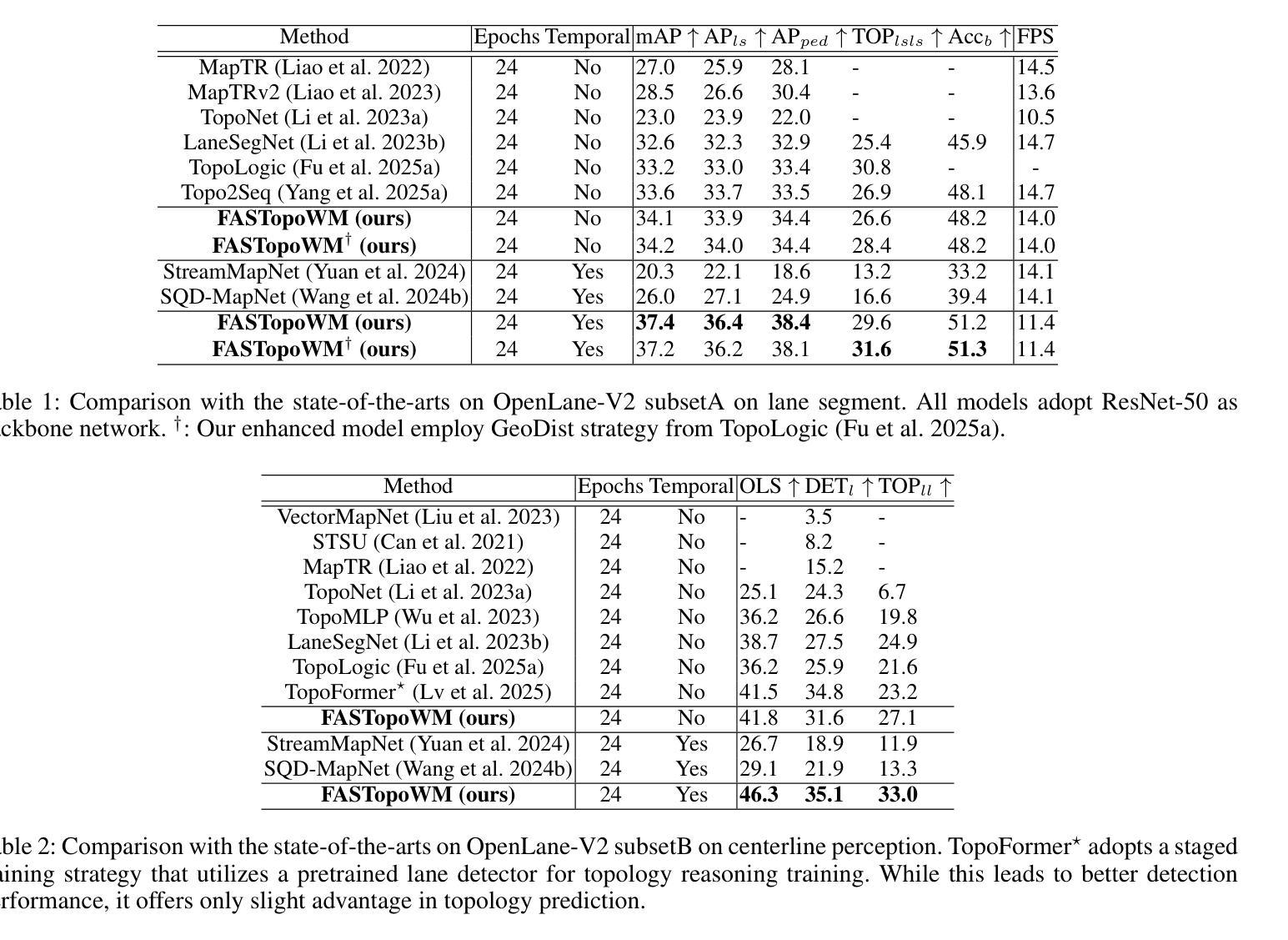
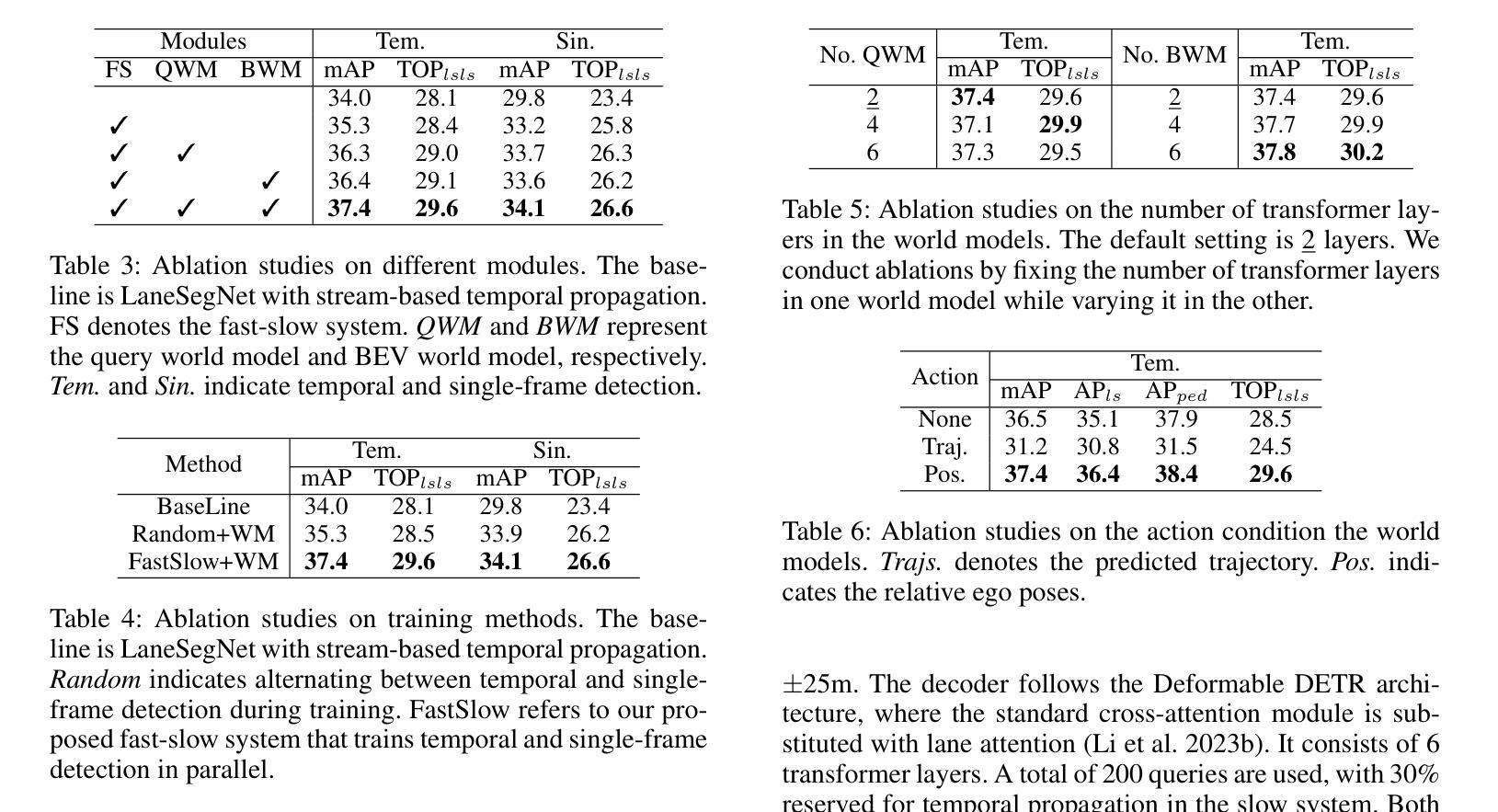
FASTopoWM: Fast-Slow Lane Segment Topology Reasoning with Latent World Models
Authors:Yiming Yang, Hongbin Lin, Yueru Luo, Suzhong Fu, Chao Zheng, Xinrui Yan, Shuqi Mei, Kun Tang, Shuguang Cui, Zhen Li
Lane segment topology reasoning provides comprehensive bird’s-eye view (BEV) road scene understanding, which can serve as a key perception module in planning-oriented end-to-end autonomous driving systems. Existing lane topology reasoning methods often fall short in effectively leveraging temporal information to enhance detection and reasoning performance. Recently, stream-based temporal propagation method has demonstrated promising results by incorporating temporal cues at both the query and BEV levels. However, it remains limited by over-reliance on historical queries, vulnerability to pose estimation failures, and insufficient temporal propagation. To overcome these limitations, we propose FASTopoWM, a novel fast-slow lane segment topology reasoning framework augmented with latent world models. To reduce the impact of pose estimation failures, this unified framework enables parallel supervision of both historical and newly initialized queries, facilitating mutual reinforcement between the fast and slow systems. Furthermore, we introduce latent query and BEV world models conditioned on the action latent to propagate the state representations from past observations to the current timestep. This design substantially improves the performance of temporal perception within the slow pipeline. Extensive experiments on the OpenLane-V2 benchmark demonstrate that FASTopoWM outperforms state-of-the-art methods in both lane segment detection (37.4% v.s. 33.6% on mAP) and centerline perception (46.3% v.s. 41.5% on OLS).
车道段拓扑推理提供了全面的鸟瞰图(BEV)道路场景理解,这可以作为面向规划端的端到端自动驾驶系统中的关键感知模块。现有的车道拓扑推理方法通常不能有效地利用时间信息来提高检测和推理性能。最近,基于流的时空传播方法在查询和BEV级别上融入时间线索,取得了有前景的结果。然而,它仍然受到过度依赖历史查询、对姿态估计失败的脆弱性以及时间传播不足的局限。为了克服这些局限性,我们提出了FASTopoWM,这是一种新型的快慢车道段拓扑推理框架,辅以潜在的世界模型。为了减少姿态估计失败的影响,这一统一框架实现对历史和新初始化查询的并行监督,促进快慢系统之间的相互促进。此外,我们引入了基于动作潜变量的潜在查询和BEV世界模型,从过去的状态表示传播到当前时间步。这一设计显著提高了慢管道内的时间感知性能。在OpenLane-V2基准测试上的大量实验表明,FASTopoWM在车道段检测(mAP上为37.4%对比33.6%)和中心线感知(OLS上为46.3%对比41.5%)方面均优于最新方法。
论文及项目相关链接
Summary:车道拓扑推理对规划导向的端到端自动驾驶系统至关重要,提供全面的鸟瞰图(BEV)道路场景理解。现有方法未能有效利用时间信息,而基于流的时空传播方法虽已显示出潜力,但仍受限于过度依赖历史查询、姿态估计失败和时空传播不足。为此,提出FASTopoWM框架,结合快慢系统和潜在世界模型,减少姿态估计失败的影响,并通过并行监督历史和新初始化查询实现相互强化。在OpenLane-V2基准测试中,FASTopoWM在车道段检测和中心线感知方面优于最新方法。
Key Takeaways:
- 车道拓扑推理是规划导向的端到端自动驾驶系统的关键感知模块。
- 现有车道拓扑推理方法未能有效利用时间信息,导致检测和推理性能不足。
- 基于流的时空传播方法虽然显示出潜力,但仍面临过度依赖历史查询、姿态估计失败和时空传播不足的问题。
- FASTopoWM框架结合快慢系统和潜在世界模型,以提高车道拓扑推理的性能。
- FASTopoWM通过并行监督历史和新初始化查询,减少姿态估计失败的影响,实现相互强化。
- FASTopoWM在OpenLane-V2基准测试中表现出优异的性能,特别是在车道段检测和中心线感知方面。
点此查看论文截图

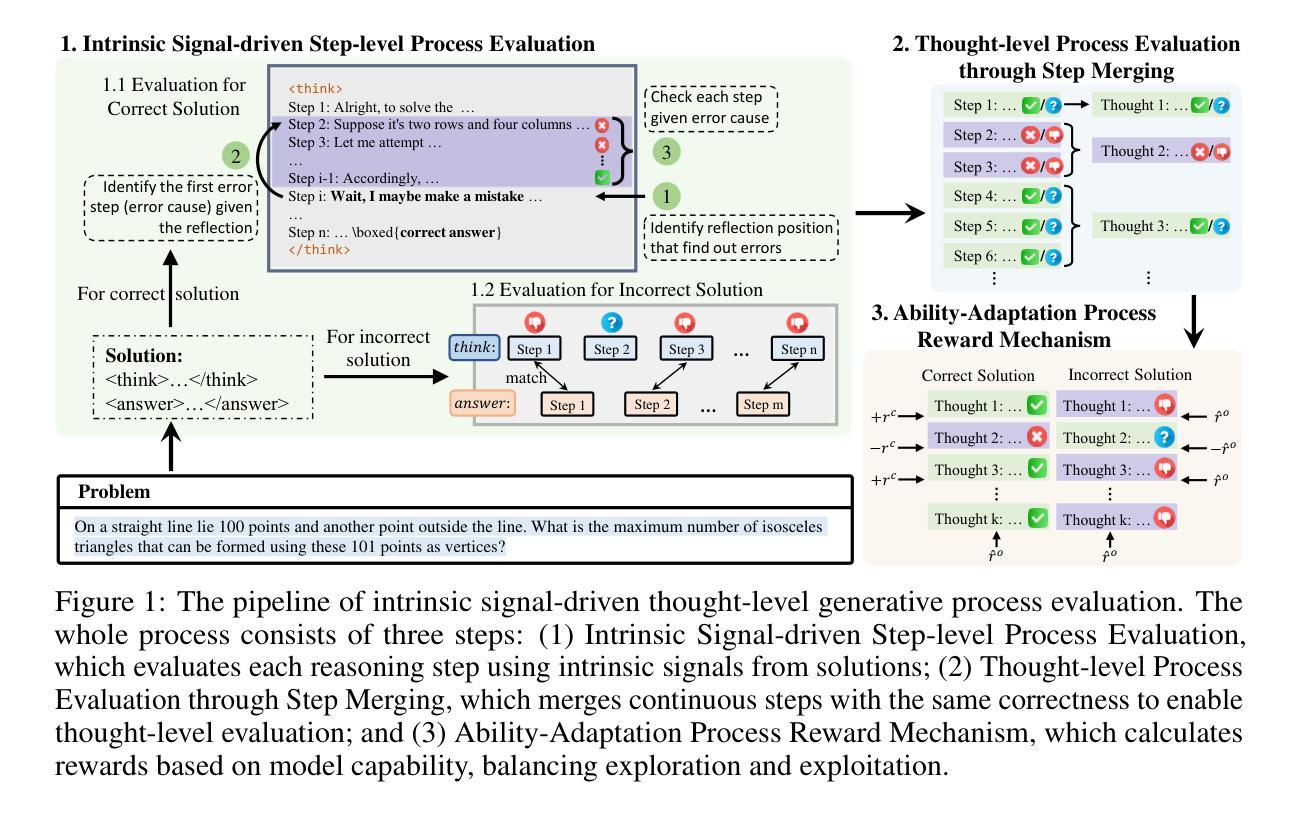
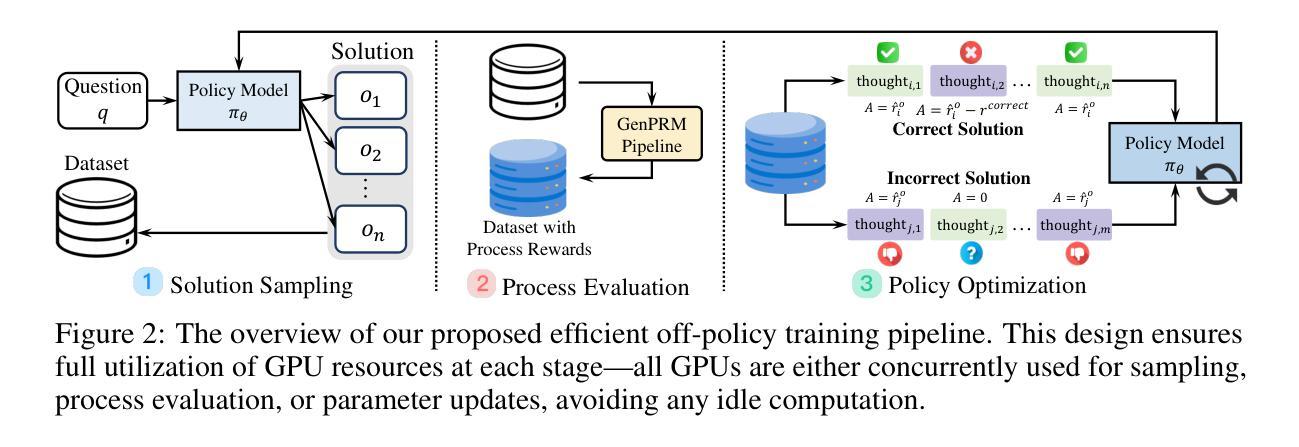
Good Learners Think Their Thinking: Generative PRM Makes Large Reasoning Model More Efficient Math Learner
Authors:Tao He, Rongchuan Mu, Lizi Liao, Yixin Cao, Ming Liu, Bing Qin
Large reasoning models (LRMs) have recently shown promise in solving complex math problems when optimized with Reinforcement Learning (RL). But conventional approaches rely on outcome-only rewards that provide sparse feedback, resulting in inefficient optimization process. In this work, we investigate the function of process reward models (PRMs) to accelerate the RL training for LRMs. We propose a novel intrinsic signal-driven generative process evaluation mechanism operating at the thought level to address major bottlenecks in RL-based training. Specifically, instead of requiring PRMs to know how to solve problems, our method uses intrinsic signals in solutions to judge stepwise correctness and aggregate contiguous correct/incorrect steps into coherent ‘thought’ units. This structured, thought-level rewards enable more reliable credit assignment by reducing ambiguity in step segmentation and alleviating reward hacking. We further introduce a capability-adaptive reward mechanism that dynamically balances exploration and exploitation based on the LRM’s current proficiency, guiding learning without stifling creative trial-and-error. These innovations are integrated into a new off-policy RL algorithm, TP-GRPO, which extends grouped proximal optimization with process-based rewards and improves training efficiency. Experiments on 1.5B and 7B parameter LRMs demonstrate that our method achieves higher problem-solving accuracy with significantly fewer training samples than outcome-only reward baselines. The results validate that well-structured process rewards can substantially accelerate LRM optimization in math reasoning tasks. Code is available at https://github.com/cs-holder/tp_grpo.
大型推理模型(LRMs)最近在通过强化学习(RL)进行优化时,显示出解决复杂数学问题的潜力。然而,传统的方法仅依赖于结果奖励,提供稀疏的反馈,导致优化过程效率低下。在这项工作中,我们探讨了过程奖励模型(PRMs)在加速LRM的RL训练中的功能。我们提出了一种新型的内在信号驱动生成过程评估机制,该机制在思维层面运作,以解决基于RL的训练中的主要瓶颈。具体来说,我们的方法不需要过程奖励模型知道如何解决问题,而是利用解决方案中的内在信号来判断步骤的正确性,并将连续的正确或错误步骤合并为连贯的“思维”单元。这种结构化的、思维层面的奖励通过减少步骤分割的模糊性和防止奖励操纵,使信用分配更加可靠。我们进一步引入了一种能力自适应奖励机制,根据LRM当前的能力水平动态平衡探索与利用,指导学习而不会扼杀创造性的试错。这些创新被集成到一种新的离线策略RL算法TP-GRPO中,该算法基于过程奖励扩展了分组近端优化,提高了训练效率。在1.5B和7B参数的大型推理模型上的实验表明,我们的方法相较于仅依赖结果奖励的基准方法,达到了更高的解题准确性并大幅减少了训练样本数量。结果证明,结构良好的过程奖励可以大大加速数学推理任务中LRM的优化。代码可在https://github.com/cs-holder/tp_grpo找到。
论文及项目相关链接
PDF 33 pages, 3 figures, 19 tables
Summary
本文探索了过程奖励模型(PRM)在加速大型推理模型(LRM)的强化学习(RL)训练方面的作用。针对基于RL的训练中的主要瓶颈,提出了一种新型的内生信号驱动生成过程评估机制,该机制在思想层面进行操作,判断解题步骤的正确性,并将连续的正确/错误步骤合并为连贯的“思想”单元。此外,还引入了一种能力自适应奖励机制,根据LRM当前的能力水平动态平衡探索与利用,指导学习而不会扼杀创造性的试错过程。这些创新被集成到一种新的离线RL算法TP-GRPO中,该算法通过基于过程奖励进行分组近端优化,提高了训练效率。在参数为1.5B和7B的LRM上的实验表明,该方法在解决数学问题时的准确性更高,所需训练样本更少。证明结构良好的过程奖励可以大大加速数学推理任务中LRM的优化。
Key Takeaways
- 过程奖励模型(PRM)被用来加速大型推理模型(LRM)的强化学习(RL)训练。
- 提出了一种新的内在信号驱动生成过程评估机制,在思想层面判断解题步骤的正确性。
- 通过将连续的正确/错误步骤合并为连贯的“思想”单元,实现更可靠的信用分配,减少步骤分割的模糊性和防止奖励操纵。
- 引入能力自适应奖励机制,根据模型当前的能力水平动态平衡探索与利用。
- 将这些创新集成到新的离线RL算法TP-GRPO中,通过基于过程奖励的分组近端优化,提高训练效率。
- 在1.5B和7B参数的LRM上的实验表明,新方法在解决数学问题时表现出更高的准确性和更低的训练样本需求。
点此查看论文截图

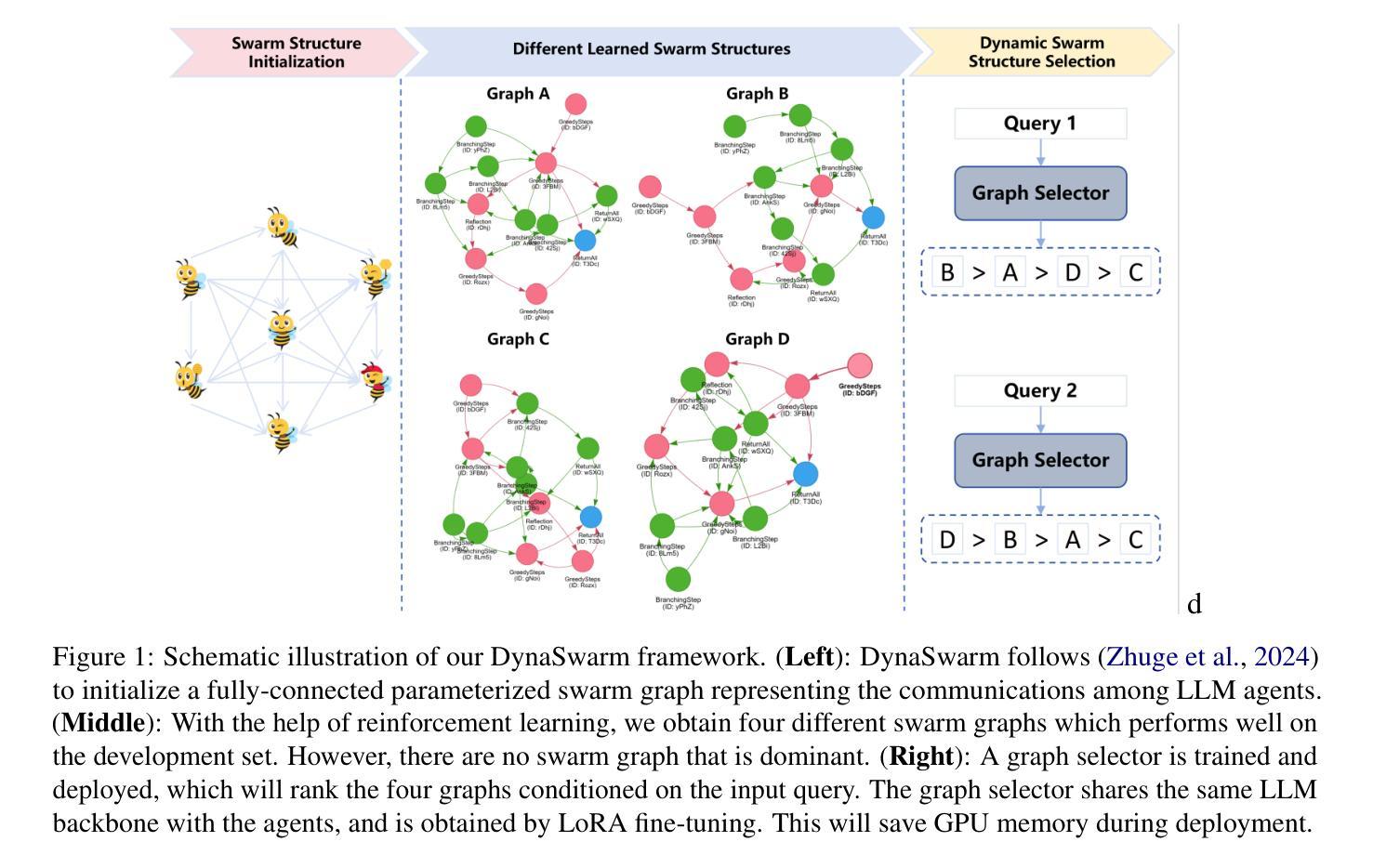
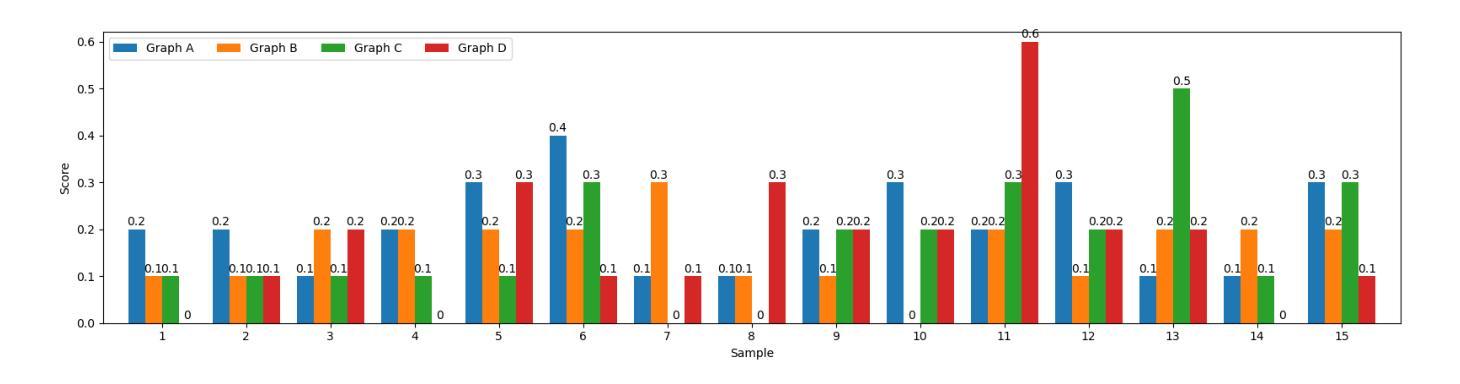
DynaSwarm: Dynamically Graph Structure Selection for LLM-based Multi-agent System
Authors:Hui Yi Leong, Yuqing Wu
Current multi-agent systems (MAS) frameworks often rely on manually designed and static collaboration graph structures, limiting adaptability and performance. To address these limitations, we propose DynaSwarm, a dynamic framework that enhances LLM-based MAS through two key innovations: (1) an actor-critic reinforcement learning (A2C) mechanism to optimize graph structures with improved stability over prior RL methods, and (2) a dynamic graph selector that adaptively chooses the optimal graph structure for each input sample via parameter-efficient LLM fine-tuning. DynaSwarm eliminates the need for rigid, one-fits-all graph architectures, instead leveraging sample-specific idiosyncrasies to dynamically route queries through specialized agent networks. (c) We propose to fine-tune the demonstration retriever to fully exploit the power of in-context learning (ICL). Extensive experiments on question answering, mathematical reasoning, and coding tasks demonstrate that DynaSwarm consistently outperforms state-of-the-art single-agent and MAS baselines across multiple LLM backbones. Our findings highlight the importance of sample-aware structural flexibility in LLM MAS designs.
当前的多智能体系统(MAS)框架通常依赖于手动设计和静态的协作图结构,这限制了其适应性和性能。为了解决这些限制,我们提出了DynaSwarm,这是一个动态框架,通过两个关键创新点增强基于LLM的MAS:(1)一种演员评论家强化学习(A2C)机制,通过改进的稳定性优化图结构,优于先前的强化学习方法;(2)一个动态图选择器,通过参数高效的LLM微调自适应地为每个输入样本选择最佳图结构。DynaSwarm消除了对严格、一刀切的图架构的需求,转而利用样本特定的特性来动态地通过专用代理网络路由查询。©我们提议对演示检索器进行微调,以充分利用上下文学习(ICL)的力量。在问答、数学推理和编码任务方面的广泛实验表明,DynaSwarm在多个LLM主干网上始终优于最新的单智能体和MAS基准测试。我们的研究结果表明,在LLM MAS设计中,样本感知的结构灵活性非常重要。
论文及项目相关链接
Summary
DynaSwarm是一个动态框架,它通过两项创新解决了当前多智能体系统(MAS)框架在适应性和性能方面的局限性。首先,它采用演员评论家强化学习(A2C)机制优化图形结构,提高了稳定性。其次,它有一个动态图形选择器,可以自适应地为每个输入样本选择最佳图形结构。DynaSwarm通过样本特定的特性动态路由查询,并通过专门设计的智能体网络实现性能提升。实验表明,DynaSwarm在问答、数学推理和编码任务上均优于单智能体和MAS基线。
Key Takeaways
- 当前的多智能体系统(MAS)框架受限于手动设计和静态协作图结构,缺乏适应性。
- DynaSwarm是一个动态框架,通过两项关键创新解决此问题:采用A2C机制优化图形结构和具有自适应选择最佳图形结构的能力。
- DynaSwarm利用样本特定的特性来动态路由查询,通过专门设计的智能体网络提升性能。
- 该框架不需要通用图形架构,可以针对每个任务进行灵活调整。
- DynaSwarm在问答、数学推理和编码任务上的实验表现优于其他框架。
- 实验结果强调了样本感知结构灵活性在多智能体系统设计中重要性。
点此查看论文截图

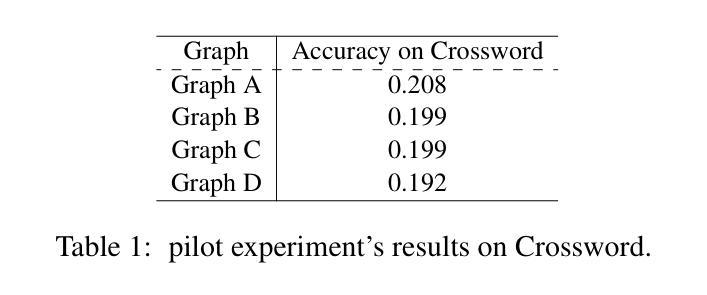
P-ReMIS: Pragmatic Reasoning in Mental Health and a Social Implication
Authors:Sneha Oram, Pushpak Bhattacharyya
There has been an increase in recent advancements in the explainability and development of personalized chatbots for mental health. However, the reasoning aspects for explainability and dialogue discourse have not been explored previously for mental health. Hence, we are investigating the pragmatic reasoning capability of large language models (LLMs) in this domain. We introduce P-ReMe dataset, and propose a modified definition for the pragmatic phenomena of implicature (implied meaning) and presupposition (implicit assumption) in mental health. Following the definition, we formulate two tasks in implicature and one task in presupposition. To benchmark the dataset and the presented tasks, we consider four models - Llama3.1, Mistral, MentaLLaMa, and Qwen. The results of the experiments suggest that Mistral and Qwen show substantial reasoning capabilities in the domain. In addition, we also propose StiPRompts to study the stigma around mental health with the state-of-the-art LLMs, GPT-4o mini, Deepseek-chat, and Claude-3.5-haiku. Our evaluated findings show that Claude-3.5-haiku deals with the stigma more responsibly compared to the other two LLMs.
近年来,在心理健康领域,可解释性和个性化聊天机器人的发展取得了进展。然而,关于心理健康的可解释性和对话语境的推理方面尚未被探索。因此,我们正在研究该领域的大型语言模型的实用推理能力。我们介绍了P-ReMe数据集,并针对心理健康中的隐涵(隐含意义)和预设(隐含假设)的语用现象提出了修改后的定义。根据定义,我们制定了两个隐涵任务和两个预设任务。为了对数据集和任务进行评估,我们选择了四种模型,包括Llama3.1、Mistral、MentaLLaMa和Qwen。实验结果表明,Mistral和Qwen在该领域显示出强大的推理能力。此外,我们还提出了StiPRompts来研究围绕心理健康的污名化问题,并使用最前沿的大型语言模型GPT-4o mini、Deepseek-chat和Claude-3.5-haiku进行研究。我们的评估发现,与其他两个大型语言模型相比,Claude-3.5-haiku更能负责任地处理污名化问题。
论文及项目相关链接
Summary
近期在精神健康领域,个性化聊天机器人的解释性和发展性有所进步,但关于解释性的推理方面以及对话语气的探讨尚未涉及。我们探究了大型语言模型在此领域的语用推理能力,并引入了P-ReMe数据集。此外,我们为精神健康中的隐含意义和隐含假设提出了修改后的定义,并据此制定了两个任务和预设任务。实验结果显示,Mistral和Qwen在此领域的推理能力显著。我们还提出StiPRompts来研究关于精神健康的偏见,经过评估发现Claude-3.5-haiku在处理偏见方面表现更佳。
Key Takeaways
- 个性化聊天机器人在精神健康领域的解释性和发展性有所进步。
- 大型语言模型(LLMs)的语用推理能力正在被探究。
- P-ReMe数据集被引入,并对隐含意义和隐含假设提出了修改后的定义。
- Mistral和Qwen在精神健康领域的推理任务中表现出色。
- StiPRompts被用来研究关于精神健康的偏见。
- Claude-3.5-haiku在处理偏见方面表现更佳。
点此查看论文截图


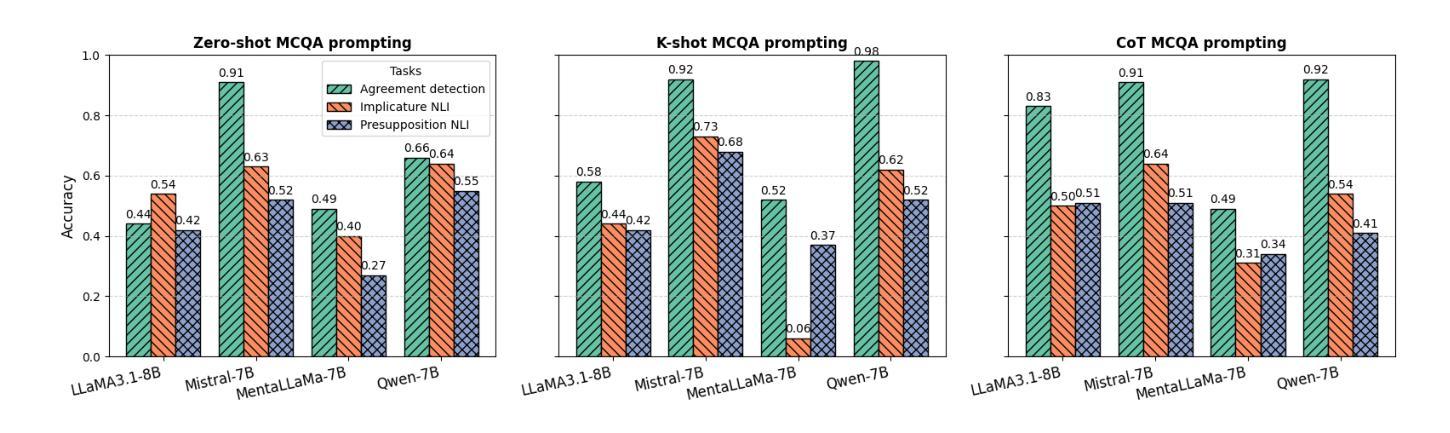
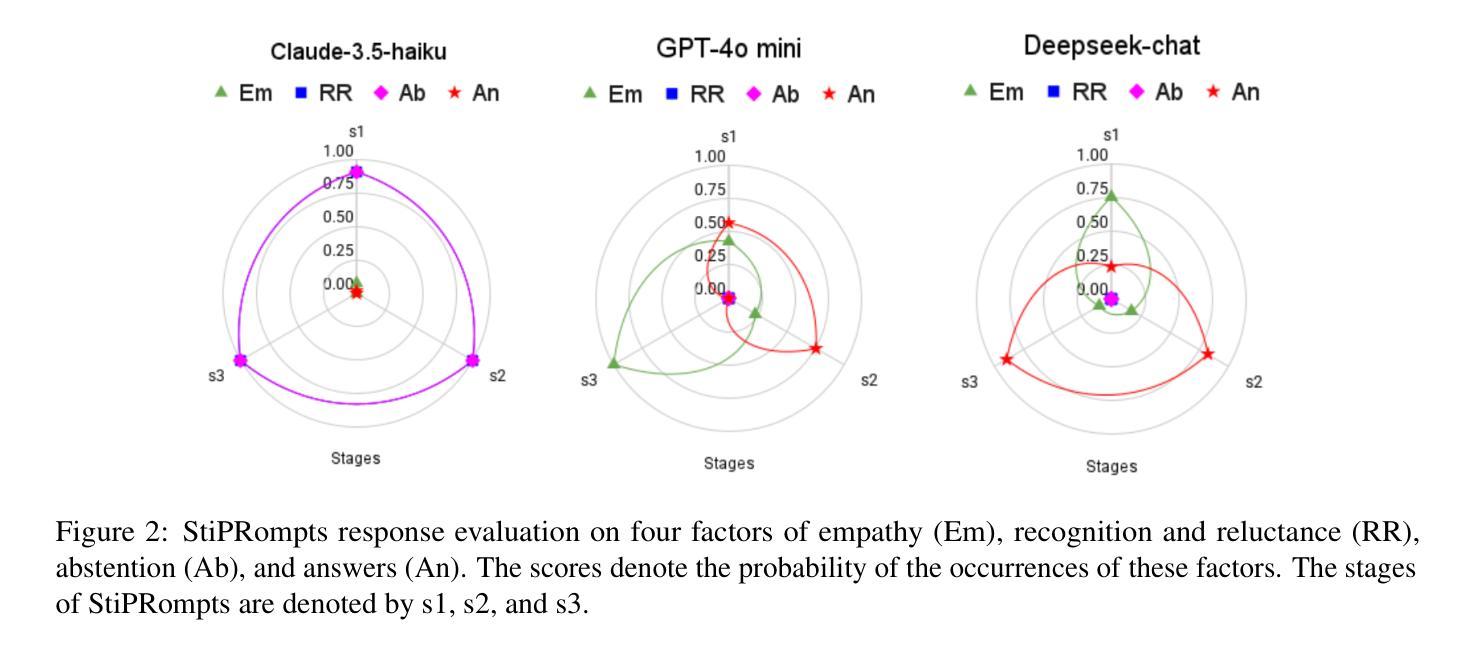
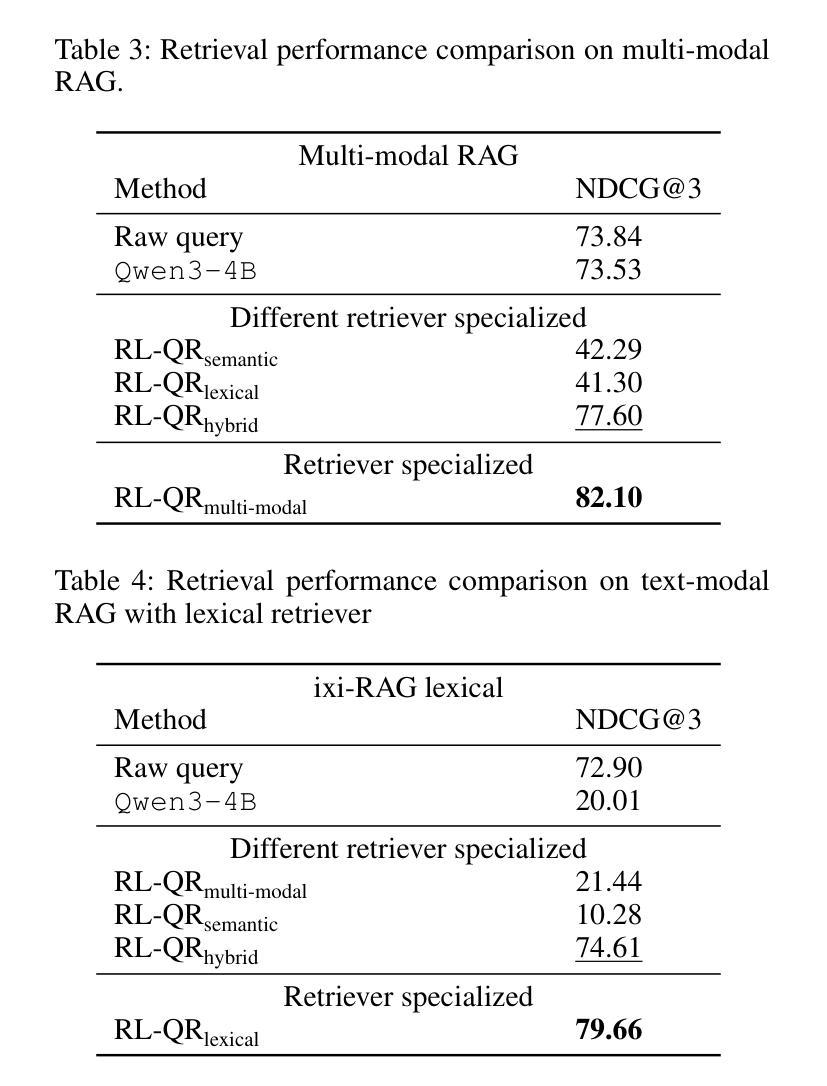
Generalized Reinforcement Learning for Retriever-Specific Query Rewriter with Unstructured Real-World Documents
Authors:Sungguk Cha, DongWook Kim, Taeseung Hahn, Mintae Kim, Youngsub Han, Byoung-Ki Jeon
Retrieval-Augmented Generation (RAG) systems rely heavily on effective query formulation to unlock external knowledge, yet optimizing queries for diverse, unstructured real-world documents remains a challenge. We introduce \textbf{RL-QR}, a reinforcement learning framework for retriever-specific query rewriting that eliminates the need for human-annotated datasets and extends applicability to both text-only and multi-modal databases. By synthesizing scenario-question pairs and leveraging Generalized Reward Policy Optimization (GRPO), RL-QR trains query rewriters tailored to specific retrievers, enhancing retrieval performance across varied domains. Experiments on industrial in-house data demonstrate significant improvements, with $\text{RL-QR}{\text{multi-modal}}$ achieving an 11% relative gain in NDCG@3 for multi-modal RAG and $\text{RL-QR}{\text{lexical}}$ yielding a 9% gain for lexical retrievers. However, challenges persist with semantic and hybrid retrievers, where rewriters failed to improve performance, likely due to training misalignments. Our findings highlight RL-QR’s potential to revolutionize query optimization for RAG systems, offering a scalable, annotation-free solution for real-world retrieval tasks, while identifying avenues for further refinement in semantic retrieval contexts.
检索增强生成(RAG)系统严重依赖于有效的查询构建以访问外部知识,然而,针对多样化、非结构化的现实世界文档优化查询仍是一项挑战。我们引入了RL-QR这一强化学习框架,用于特定于检索器的查询重写,从而无需人工标注数据集,并扩展了其在纯文本和多模态数据库中的应用。通过合成场景-问题对并利用广义奖励策略优化(GRPO),RL-QR训练适用于特定检索器的查询重写器,增强跨不同领域的检索性能。在工业内部数据上的实验表明,RL-QR取得了显著改进,其中多模态RL-QR_multi-modal在NDCG@3上实现了相对增益11%,词汇检索器RL-QR_lexical则取得了9%的增益。然而,在语义检索器和混合检索器中仍存在挑战,重写器未能改善性能,这可能是由于训练不一致造成的。我们的研究结果突出了RL-QR在RAG系统查询优化方面的潜力,为现实世界的检索任务提供了可扩展、无需注释的解决方案,并指出了在语义检索上下文中进一步改进的途径。
论文及项目相关链接
Summary
强化学习在检索增强生成(RAG)系统的查询优化中发挥了重要作用。提出的RL-QR框架能够实现无需人工标注数据集的查询重写,并适用于文本和多模态数据库。通过合成场景-问题对和广义奖励策略优化(GRPO),RL-QR训练出针对特定检索器的查询重写器,提高了跨不同领域的检索性能。在工业内部数据上的实验表明,RL-QR在多模态和词汇检索器方面取得了显著成效,但在语义和混合检索器中仍面临挑战。此研究为RAG系统的查询优化提供了可扩展的无标注解决方案,并指出了语义检索上下文中进一步改进的方向。
Key Takeaways
- RL-QR框架采用强化学习优化RAG系统的查询,实现无需人工标注数据集。
- RL-QR适用于文本和多模态数据库的查询重写。
- 通过合成场景-问题对,RL-QR训练出针对特定检索器的查询重写器。
- RL-QR在跨不同领域的检索性能上有所提高,特别是在工业内部数据的实验中。
- RL-QR在多模态和词汇检索器上取得了显著成效,相对增益达到11%和9%。
- 在语义和混合检索器中,RL-QR仍面临挑战,可能是由于训练不匹配。
点此查看论文截图




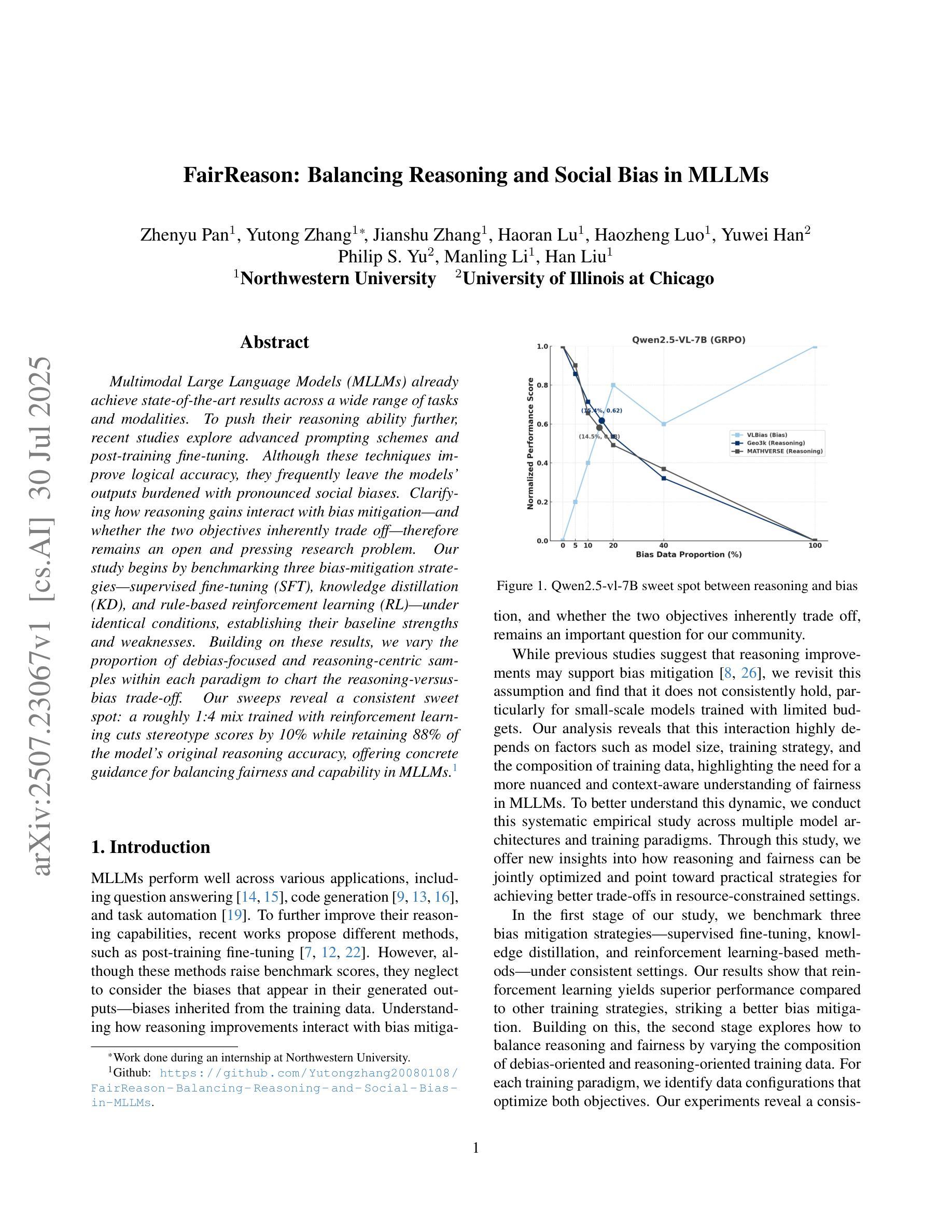
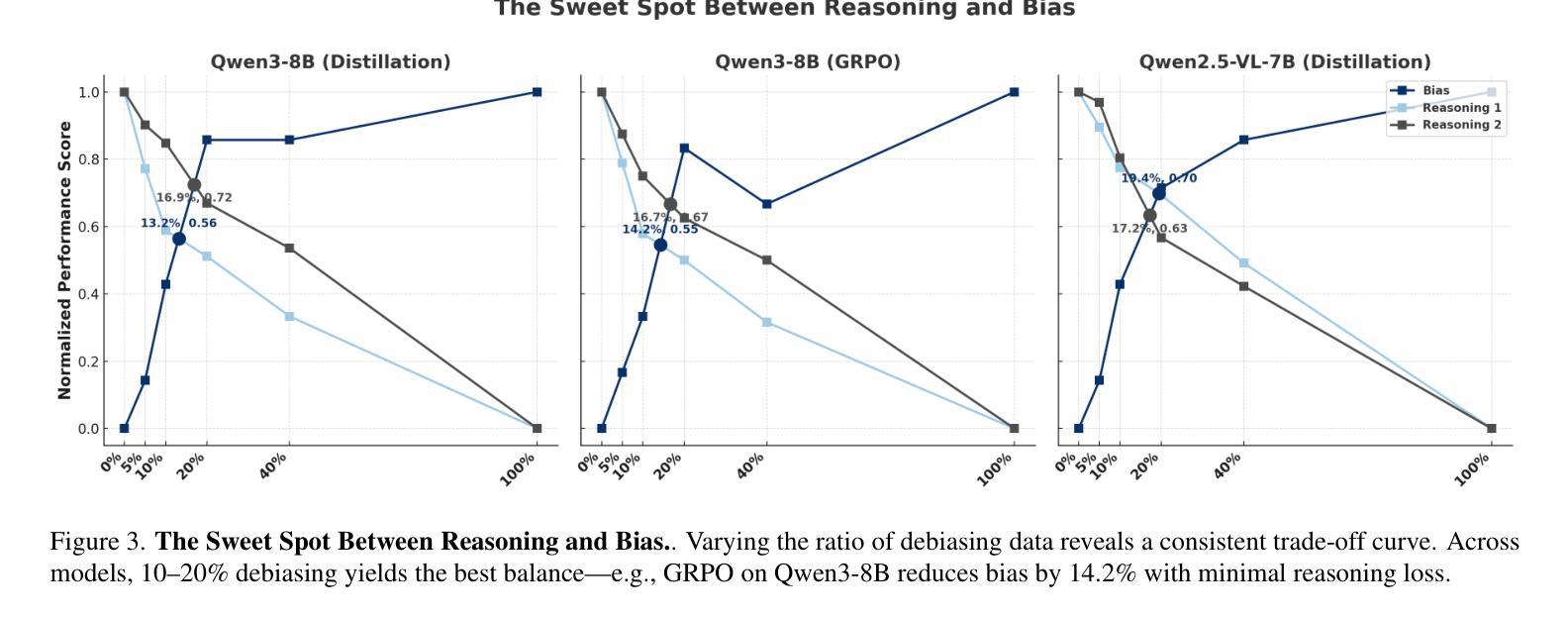
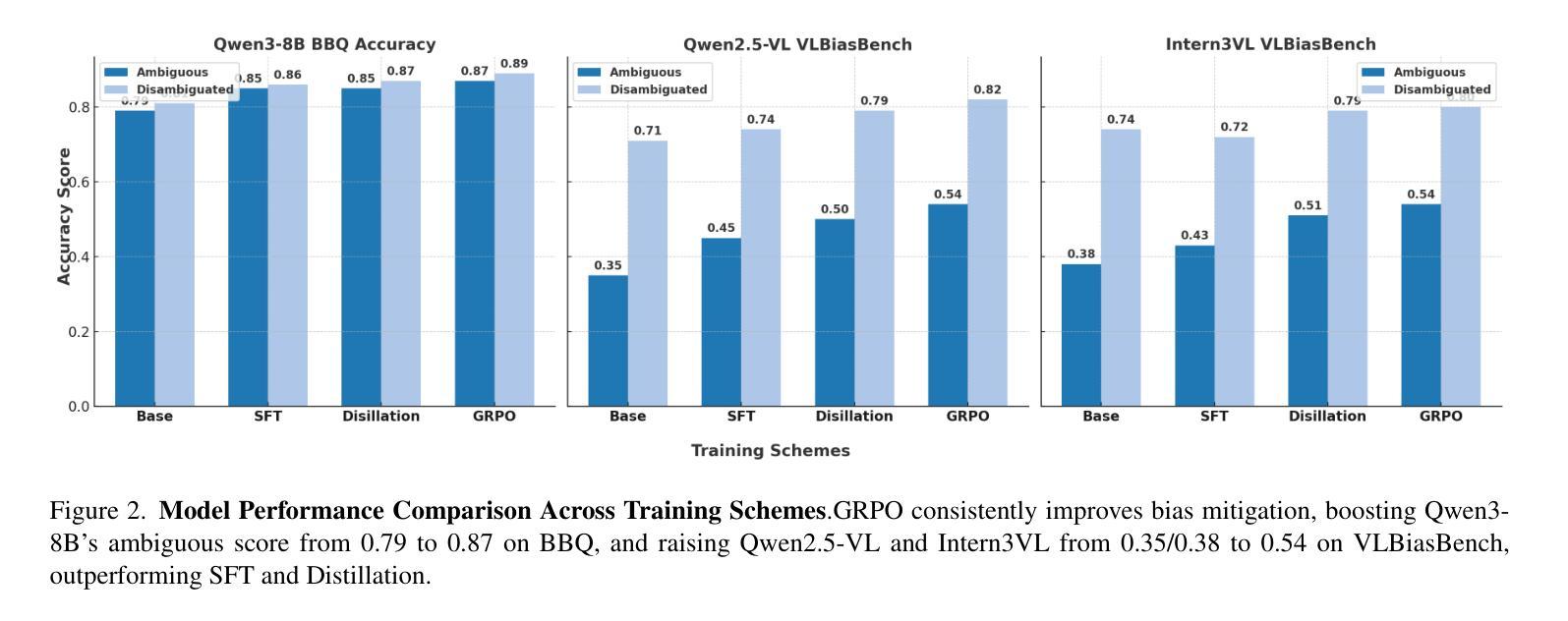
FairReason: Balancing Reasoning and Social Bias in MLLMs
Authors:Zhenyu Pan, Yutong Zhang, Jianshu Zhang, Haoran Lu, Haozheng Luo, Yuwei Han, Philip S. Yu, Manling Li, Han Liu
Multimodal Large Language Models (MLLMs) already achieve state-of-the-art results across a wide range of tasks and modalities. To push their reasoning ability further, recent studies explore advanced prompting schemes and post-training fine-tuning. Although these techniques improve logical accuracy, they frequently leave the models’ outputs burdened with pronounced social biases. Clarifying how reasoning gains interact with bias mitigation-and whether the two objectives inherently trade off-therefore remains an open and pressing research problem. Our study begins by benchmarking three bias-mitigation strategies-supervised fine-uning (SFT), knowledge distillation (KD), and rule-based reinforcement learning (RL)-under identical conditions, establishing their baseline strengths and weaknesses. Building on these results, we vary the proportion of debias-focused and reasoning-centric samples within each paradigm to chart the reasoning-versus-bias trade-off. Our sweeps reveal a consistent sweet spot: a roughly 1:4 mix trained with reinforcement learning cuts stereotype scores by 10% while retaining 88% of the model’s original reasoning accuracy, offering concrete guidance for balancing fairness and capability in MLLMs.
多模态大型语言模型(MLLMs)已经在各种任务和模态上达到了最先进的性能。为了进一步提高其推理能力,最近的研究探索了先进的提示方案和训练后的微调。虽然这些技术提高了逻辑准确性,但它们往往使模型的输出带有明显的社会偏见。因此,阐明推理收益如何与偏见缓解相互作用,以及这两个目标是否本质上相互权衡,仍然是一个开放而紧迫的研究问题。我们的研究首先在同等条件下对三种偏见缓解策略——监督微调(SFT)、知识蒸馏(KD)和基于规则的强化学习(RL)——进行基准测试,以确定它们的优缺点。基于这些结果,我们在每种范式中改变以去偏见为中心的样本和以推理为中心的样本的比例,以绘制推理与偏见之间的权衡。我们的扫描揭示了一个一致的优化点:使用强化学习进行大约1:4比例混合的训练,可以减少刻板印象得分10%,同时保留模型88%的原始推理准确性,为在MLLM中平衡公平和能力提供了具体指导。
论文及项目相关链接
Summary
多模态大型语言模型(MLLMs)在广泛的任务和模态上已达成业界顶尖成果。为进一步提升其推理能力,近期研究开始探索先进的提示方案和训练后的微调技术。尽管这些技术提高了逻辑准确性,但它们常常使模型输出带有明显的社会偏见。本研究首先在同条件下对比三种减偏策略:监督微调(SFT)、知识蒸馏(KD)和基于规则的强化学习(RL),以确立它们的基础优劣。接着基于研究结果,通过调整减偏和推理中心样本的比例,我们探索了推理与偏见之间的权衡。实验揭示了一个稳定的最优平衡点:采用大约1:4的比例,结合强化学习进行训练,可以减少刻板印象分数10%,同时保持模型原始推理能力的88%,为平衡多模态大型语言模型的公平性和能力提供了具体指导。
Key Takeaways
- 多模态大型语言模型在多个任务和模态上已达到顶尖水平,但仍然存在社会偏见问题。
- 研究对比了三种减偏策略:监督微调、知识蒸馏和基于规则的强化学习。
- 通过调整减偏和推理中心样本的比例,研究发现推理与偏见之间存在权衡。
- 采用强化学习结合一定比例减偏样本的训练方法,能有效减少模型输出的刻板印象分数,同时保持较高的推理能力。
- 实验结果显示,大约1:4的减偏与推理中心样本比例是平衡公平性和能力的最佳点。
- 此研究为未来的多模态语言模型提供了在公平性和能力之间寻找平衡的具体指导。
点此查看论文截图
Towards Omnimodal Expressions and Reasoning in Referring Audio-Visual Segmentation
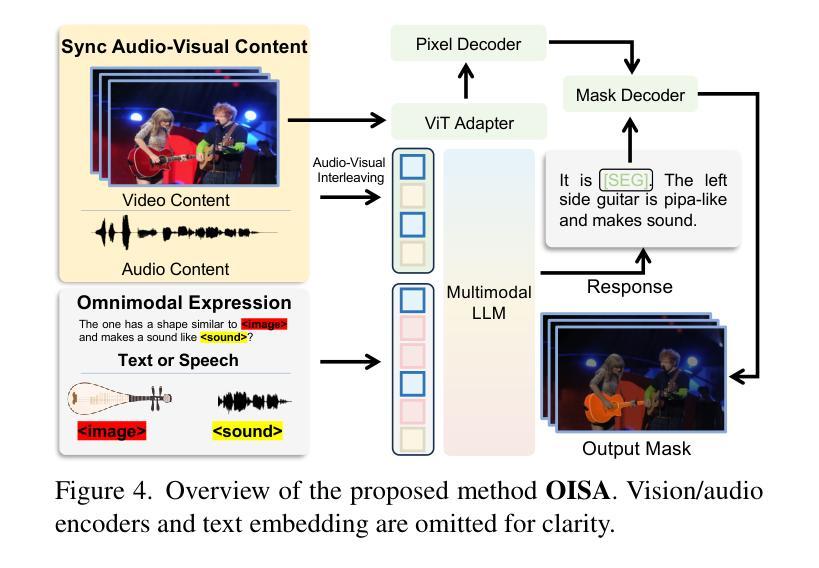
Authors:Kaining Ying, Henghui Ding, Guangquan Jie, Yu-Gang Jiang
Referring audio-visual segmentation (RAVS) has recently seen significant advancements, yet challenges remain in integrating multimodal information and deeply understanding and reasoning about audiovisual content. To extend the boundaries of RAVS and facilitate future research in this field, we propose Omnimodal Referring Audio-Visual Segmentation (OmniAVS), a new dataset containing 2,104 videos and 61,095 multimodal referring expressions. OmniAVS stands out with three key innovations: (1) 8 types of multimodal expressions that flexibly combine text, speech, sound, and visual cues; (2) an emphasis on understanding audio content beyond just detecting their presence; and (3) the inclusion of complex reasoning and world knowledge in expressions. Furthermore, we introduce Omnimodal Instructed Segmentation Assistant (OISA), to address the challenges of multimodal reasoning and fine-grained understanding of audiovisual content in OmniAVS. OISA uses MLLM to comprehend complex cues and perform reasoning-based segmentation. Extensive experiments show that OISA outperforms existing methods on OmniAVS and achieves competitive results on other related tasks.
指代音频视觉分割(RAVS)最近取得了重大进展,但在整合多模式信息以及深度理解和推理视听内容方面仍存在挑战。为了扩展RAVS的边界并促进该领域的未来研究,我们提出了OmniModal指代音频视觉分割(OmniAVS)数据集,该数据集包含2104个视频和61095个多模式指代表达。OmniAVS通过三个关键创新点脱颖而出:(1)有8种灵活结合文本、语音、声音和视觉线索的多模式表达方式;(2)除了检测音频内容是否存在之外,还强调理解音频内容;(3)在表达中包含复杂的推理和世界知识。此外,为了解决OmniAVS中多模式推理和对视听内容的精细理解方面的挑战,我们引入了OmniModal指令分割助手(OISA)。OISA使用MLLM理解复杂线索并进行基于推理的分割。大量实验表明,OISA在OmniAVS上的表现优于现有方法,并在其他相关任务上取得了有竞争力的结果。
论文及项目相关链接
PDF ICCV 2025, Project Page: https://henghuiding.com/OmniAVS/
Summary
多媒体指代音频视频分割(OmniAVS)数据集的提出,旨在拓展音频视觉分割(RAVS)的边界,并为该领域的研究提供便利。OmniAVS包含2,104个视频和61,095个多媒体指代表达式,具有三大创新点:灵活结合文本、语音、声音和视觉线索的八种多媒体表达方式;强调对音频内容的深入理解而非仅检测其存在;以及表达中融入复杂推理和世界知识。为解决OmniAVS中的多媒体推理和精细音视频内容理解挑战,引入了多媒体指令分割助手(OISA)。
Key Takeaways
- OmniAVS是一个新的数据集,扩展了音频视觉分割(RAVS)的边界,包含2,104个视频和61,095个多媒体指代表达式。
- OmniAVS强调灵活结合多种模态信息,包括文本、语音、声音和视觉线索。
- 数据集注重对音频内容的深入理解,而不仅仅是检测其存在。
- OmniAVS中的表达融入了复杂推理和世界知识。
- OISA被引入以解决OmniAVS中的多媒体推理和精细音视频内容理解挑战。
- OISA使用MLLM理解复杂线索并进行基于推理的分割。
点此查看论文截图




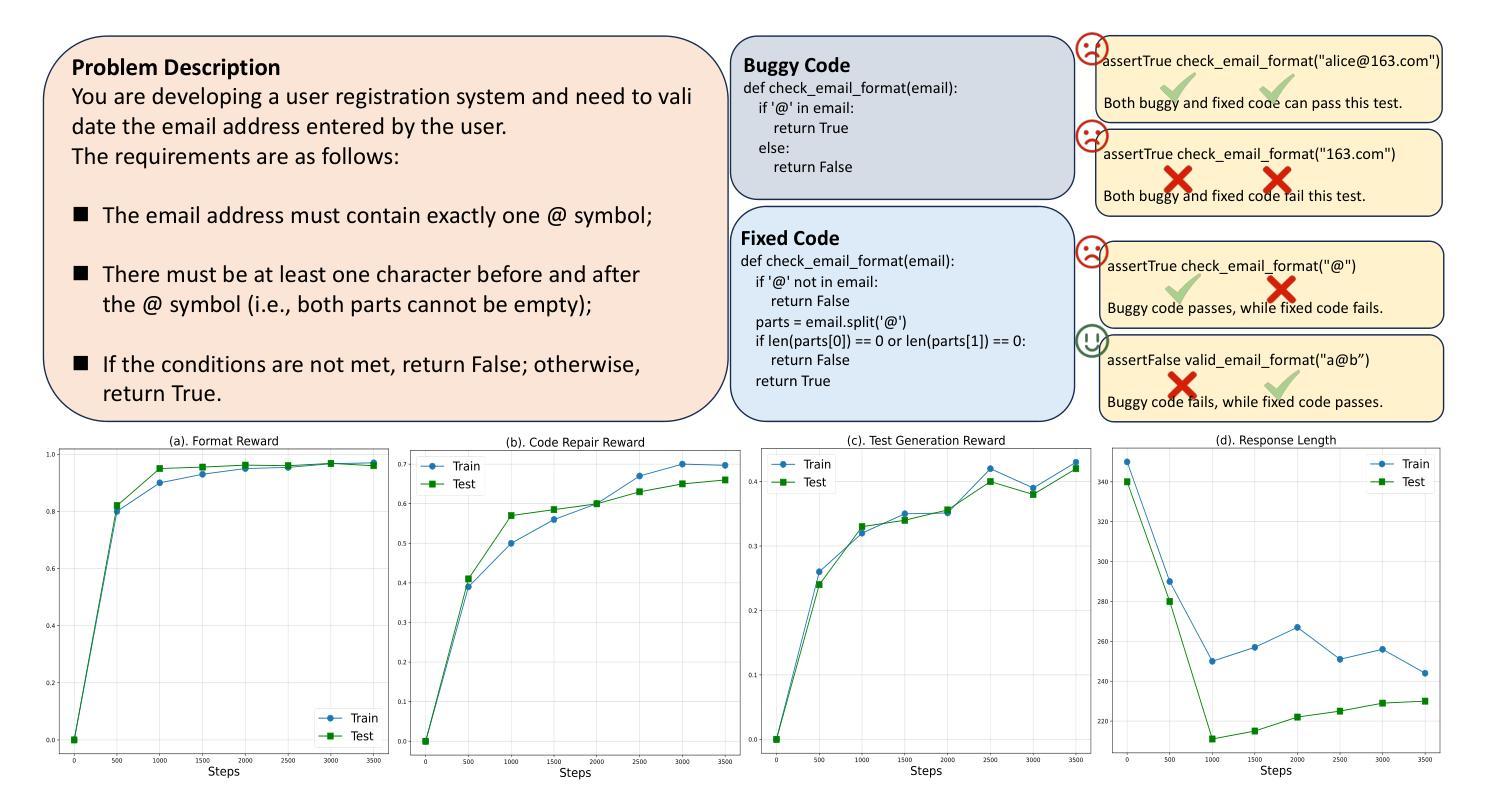
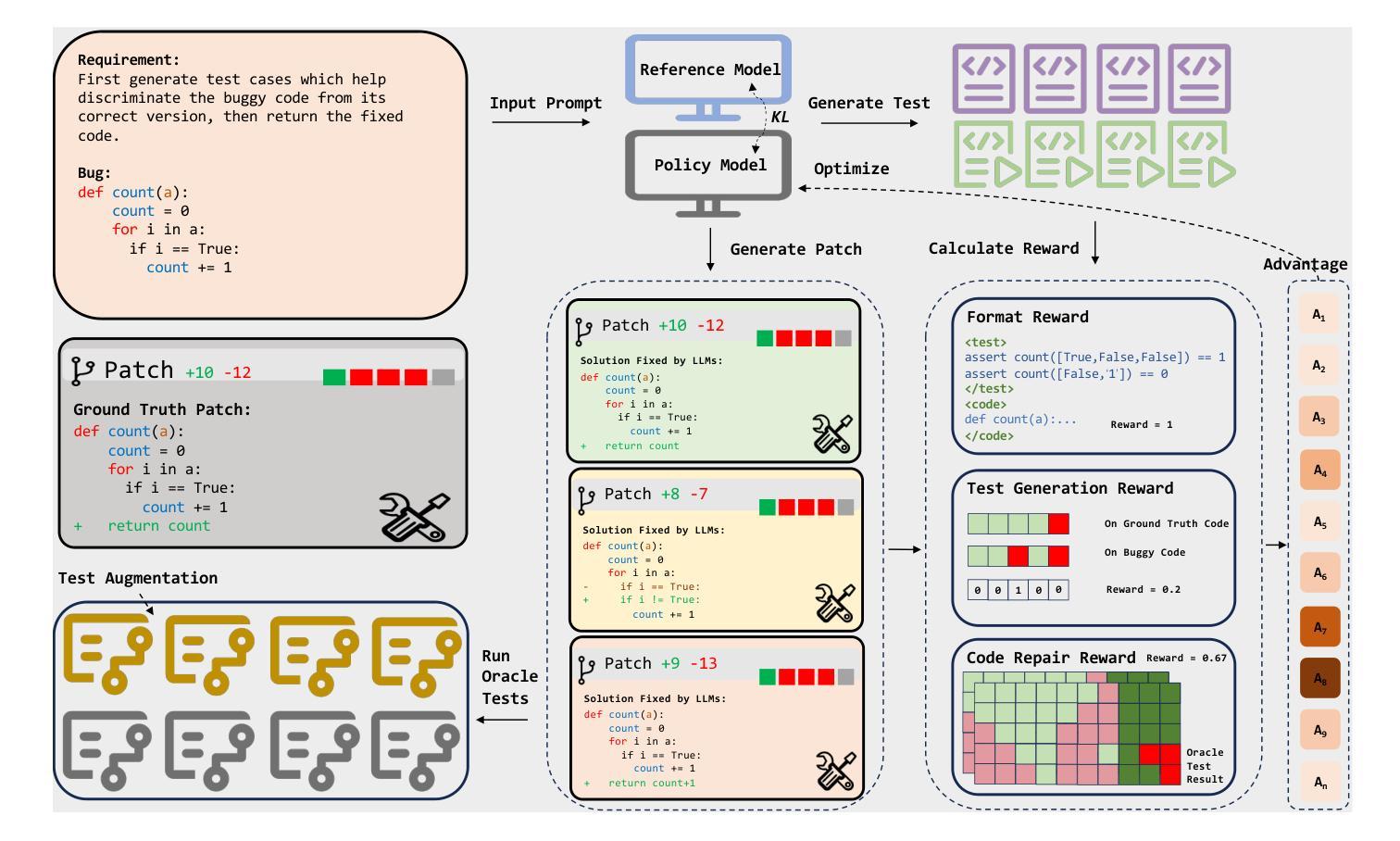
Repair-R1: Better Test Before Repair
Authors:Haichuan Hu, Xiaochen Xie, Quanjun Zhang
APR (Automated Program Repair) aims to automatically locate program defects, generate patches and validate the repairs. Existing techniques for APR are often combined with LLMs (Large Language Models), which leverages the code-related knowledge of LLMs to improve repair effectiveness. Current LLM-based APR methods typically utilize test cases only during the inference stage, adopting an iterative approach that performs repair first and validates it through test execution afterward. This conventional paradigm neglects two important aspects: the potential contribution of test cases in the training phase, and the possibility of leveraging testing prior to repair. To address this, we propose Repair-R1, which introduces test cases into the model’s training phase and shifts test generation to precede repair. The model is required to first generate discriminative test cases that can distinguish defective behaviors, and then perform repair based on these tests. This enables the model to better locate defects and understand the underlying causes of defects, thereby improving repair effectiveness. We implement Repair-R1 with three different backbone models, using RL (reinforcement learning) to co-optimize test generation and bug repair. Experimental results on four widely adopted benchmarks demonstrate the superiority of Repair-R1. Specially, compared to vanilla models, Repair-R1 improves repair success rate by 2.68% to 48.29%, test generation success rate by 16.38% to 53.28%, and test coverage by 0.78% to 53.96%. We publish the code and weights at https://github.com/Tomsawyerhu/APR-RL and https://huggingface.co/tomhu/Qwen3-4B-RL-5000-step.
APR(自动化程序修复)旨在自动定位程序缺陷、生成补丁并进行验证。现有的APR技术通常与大型语言模型(LLMs)相结合,利用LLMs的代码相关知识来提高修复效果。当前的基于LLM的APR方法仅在推理阶段使用测试用例,采用一种先修复后通过测试执行进行验证的迭代方法。这种传统范式忽略了两个重要方面:测试用例在训练阶段的潜在贡献,以及提前进行测试的可能性。为了解决这一问题,我们提出了Repair-R1,它将测试用例引入到模型的训练阶段,并将测试生成转移到修复之前。模型首先被要求生成能够区分缺陷行为的辨别性测试用例,然后基于这些测试进行修复。这使模型能够更好地定位缺陷并理解缺陷的根本原因,从而提高修复效果。我们使用三种不同的基础模型实现了Repair-R1,并使用强化学习共同优化测试生成和错误修复。在四个广泛采用的基准测试上的实验结果证明了Repair-R1的优越性。特别是与基础模型相比,Repair-R1将修复成功率提高了2.68%至48.29%,测试生成成功率提高了16.38%至53.28%,测试覆盖率提高了0.78%至53.96%。我们已将代码和权重发布在https://github.com/Tomsawyerhu/APR-RL和https://huggingface.co/tomhu/Qwen3-4B-RL-5000-step。
论文及项目相关链接
Summary
自动化程序修复(APR)旨在自动定位程序缺陷、生成补丁并进行验证。现有技术常与大型语言模型(LLMs)结合,以提高修复效果。本文提出一种新方法Repair-R1,将测试用例引入模型训练阶段,并将测试生成置于修复之前。该方法要求模型首先生成能区分缺陷行为的鉴别性测试用例,然后基于这些测试进行修复。这有助于提高模型定位缺陷和了解缺陷根本原因的能力,从而提高修复效果。实验结果表明,相比基础模型,Repair-R1的修复成功率提高2.68%~48.29%,测试生成成功率提高16.38%~53.28%,测试覆盖率提高0.78%~53.96%。
Key Takeaways
- APR技术结合大型语言模型(LLMs)进行程序缺陷修复。
- 传统方法忽略了测试用例在训练阶段的潜在贡献和测试在修复前的利用。
- Repair-R1引入训练阶段的测试用例,并将测试生成置于修复之前,提高缺陷定位和修复效果。
- Repair-R1使用强化学习优化测试生成和错误修复。
- 实验结果表明,相比基础模型,Repair-R1在修复成功率、测试生成成功率和测试覆盖率方面有明显提升。
- Repair-R1的代码和权重已公开发布,便于他人使用和研究。
点此查看论文截图


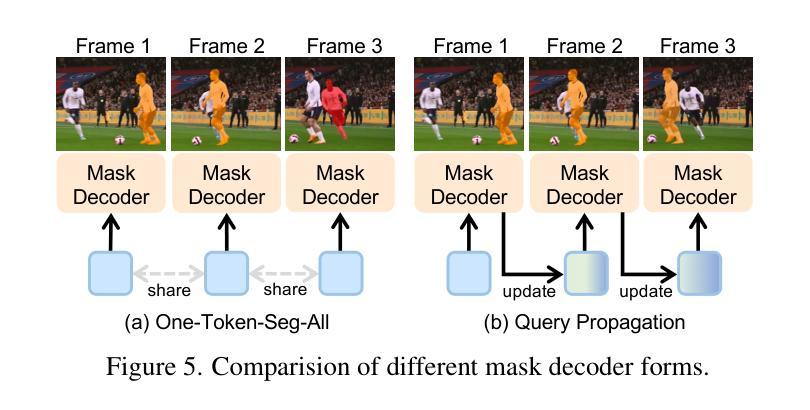
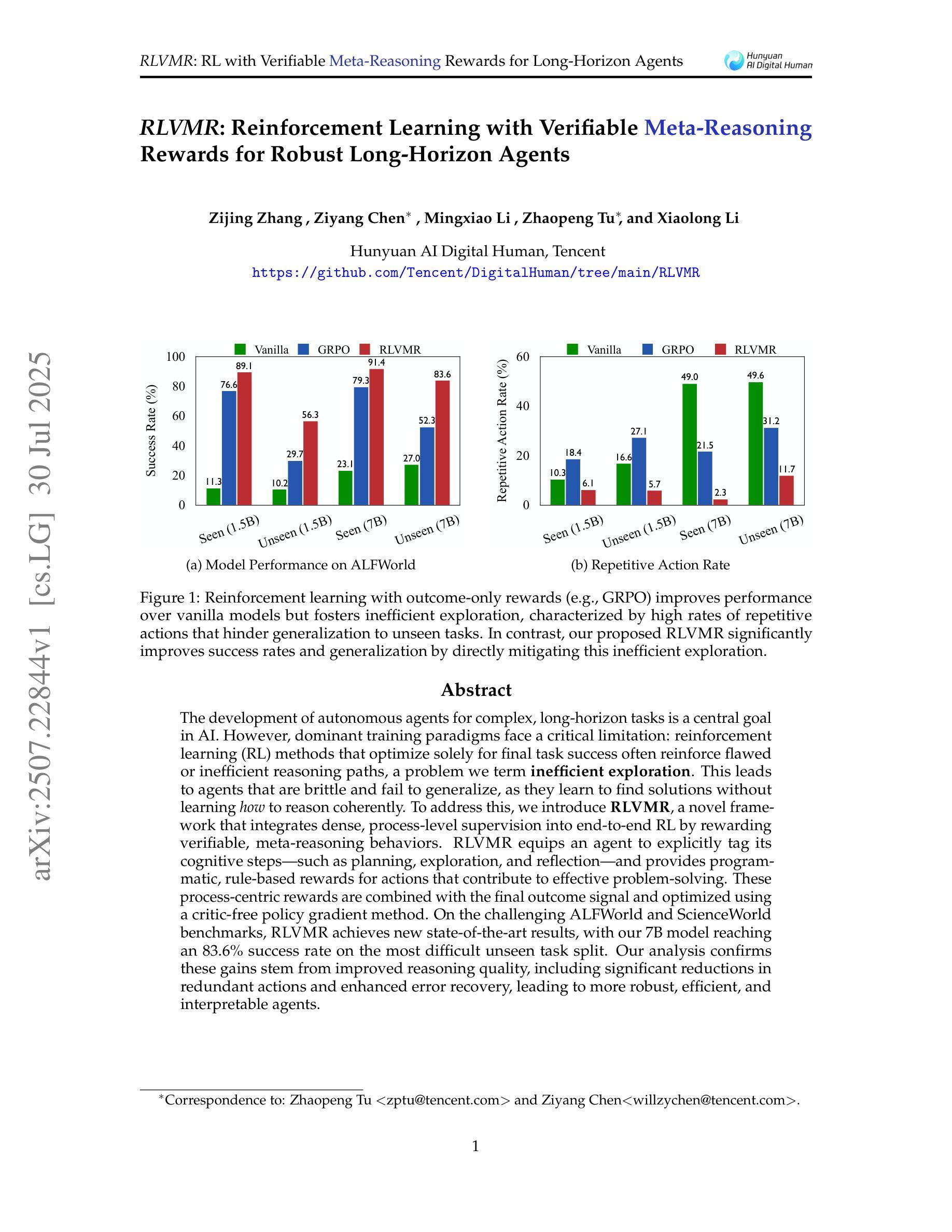
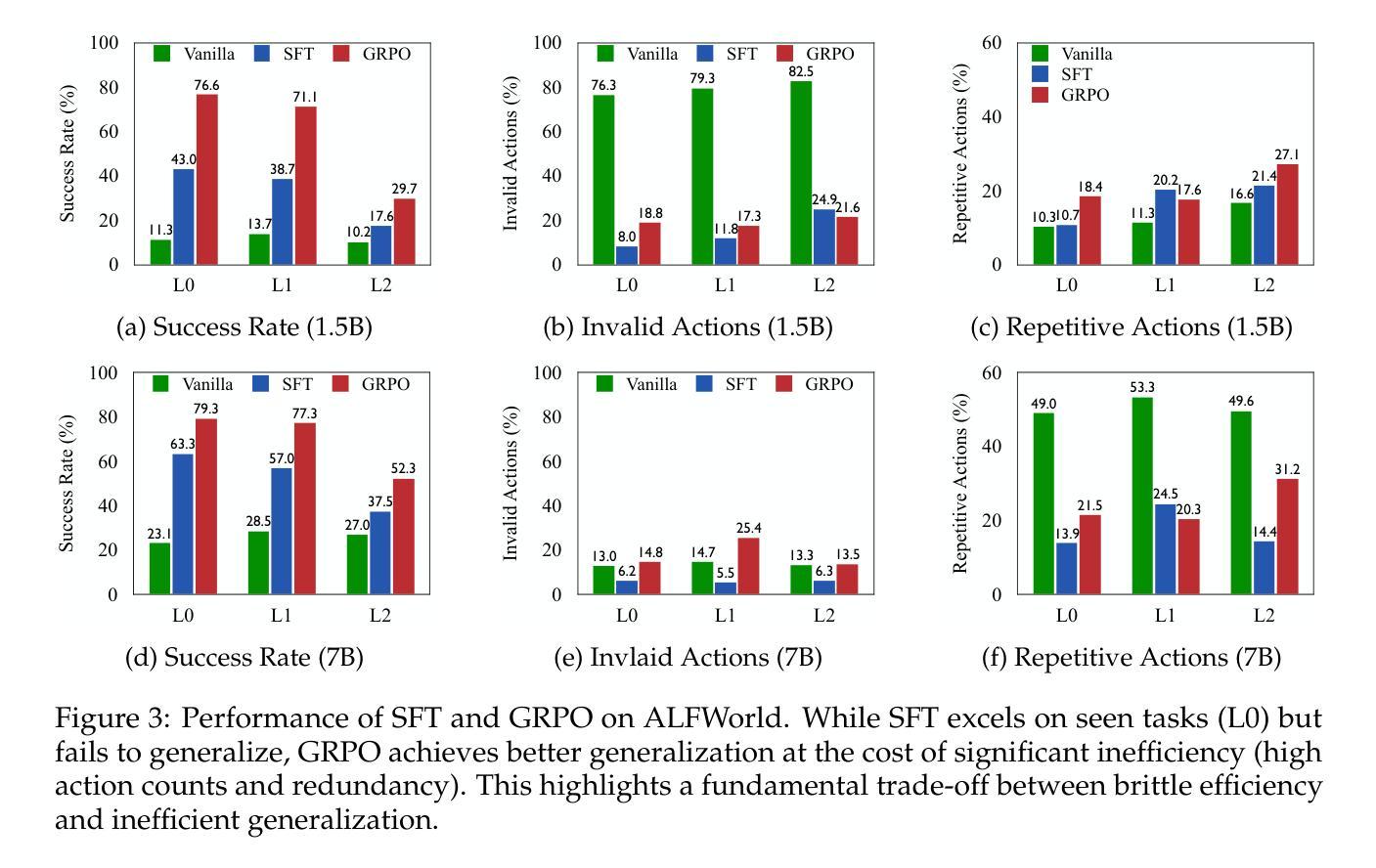
RLVMR: Reinforcement Learning with Verifiable Meta-Reasoning Rewards for Robust Long-Horizon Agents
Authors:Zijing Zhang, Ziyang Chen, Mingxiao Li, Zhaopeng Tu, Xiaolong Li
The development of autonomous agents for complex, long-horizon tasks is a central goal in AI. However, dominant training paradigms face a critical limitation: reinforcement learning (RL) methods that optimize solely for final task success often reinforce flawed or inefficient reasoning paths, a problem we term inefficient exploration. This leads to agents that are brittle and fail to generalize, as they learn to find solutions without learning how to reason coherently. To address this, we introduce RLVMR, a novel framework that integrates dense, process-level supervision into end-to-end RL by rewarding verifiable, meta-reasoning behaviors. RLVMR equips an agent to explicitly tag its cognitive steps, such as planning, exploration, and reflection, and provides programmatic, rule-based rewards for actions that contribute to effective problem-solving. These process-centric rewards are combined with the final outcome signal and optimized using a critic-free policy gradient method. On the challenging ALFWorld and ScienceWorld benchmarks, RLVMR achieves new state-of-the-art results, with our 7B model reaching an 83.6% success rate on the most difficult unseen task split. Our analysis confirms these gains stem from improved reasoning quality, including significant reductions in redundant actions and enhanced error recovery, leading to more robust, efficient, and interpretable agents.
针对复杂、长期任务开发自主智能体是人工智能的核心目标之一。然而,主流的训练模式面临一个关键局限:仅针对最终任务成功的强化学习(RL)方法往往会强化有缺陷或低效的推理路径,我们称之为低效探索问题。这导致智能体变得脆弱且无法推广,因为它们学会了如何找到解决方案,但没有学会如何进行连贯的推理。为了解决这个问题,我们引入了RLVMR,这是一个新型框架,通过奖励可验证的元推理行为,将密集的过程级监督集成到端到端的强化学习中。RLVMR使智能体能明确标记其认知步骤,如规划、探索和反思,并为有助于有效解决问题的动作提供基于程序、规则奖励。这些以过程为中心的奖励与最终结果的信号相结合,并使用无批判家的政策梯度方法进行优化。在具有挑战性的ALFWorld和ScienceWorld基准测试中,RLVMR取得了最新的最先进的成果,我们的7B模型在最困难的无任务分割中达到了83.6%的成功率。我们的分析证实,这些收益来自于推理质量的改进,包括动作冗余的显著减少和错误恢复的增强,从而带来更稳健、高效和可解释的智能体。
论文及项目相关链接
Summary
该文探讨了在AI领域中,针对复杂长期任务开发自主代理的核心目标。然而,主流的训练模式面临一个关键问题:仅通过强化学习(RL)方法优化最终任务成功会导致代理在面对问题解决方案时忽略合理推理路径的训练。为此,本文提出了一种新型框架RLVMR,通过整合密集的过程级监督,奖励可验证的元推理行为来解决这一问题。RLVMR使代理能够明确标注其认知步骤,如规划、探索和反思,并为有助于有效解决问题的行动提供程序化、基于规则的奖励。这些过程为中心的奖励与最终结果的信号相结合,使用无批判家的政策梯度方法进行优化。在具有挑战性的ALFWorld和ScienceWorld基准测试中,RLVMR取得了最新状态的技术成果,其中我们的7B模型在最具挑战性的未见任务分割中达到了83.6%的成功率。分析证实,这些收益源于推理质量的提高,包括显著减少冗余动作和增强错误恢复能力,从而使代理更加稳健、高效和可解释。
Key Takeaways
- 自主代理在复杂长期任务上的发展是AI领域的重要目标。
- 当前主导的训练模式面临强化学习(RL)方法的问题,即单纯追求最终任务成功可能会导致代理忽视合理的推理路径。
- 提出了一种新型框架RLVMR,通过整合过程级监督来解决这个问题,奖励那些有助于有效解决问题的可验证的元推理行为。
- RLVMR允许代理明确标注其认知步骤,如规划、探索和反思。
- 结合过程为中心的奖励和最终结果的信号,使用无批判家的政策梯度方法进行优化。
- 在ALFWorld和ScienceWorld基准测试中,RLVMR取得了显著成果。
点此查看论文截图

MoCHA: Advanced Vision-Language Reasoning with MoE Connector and Hierarchical Group Attention
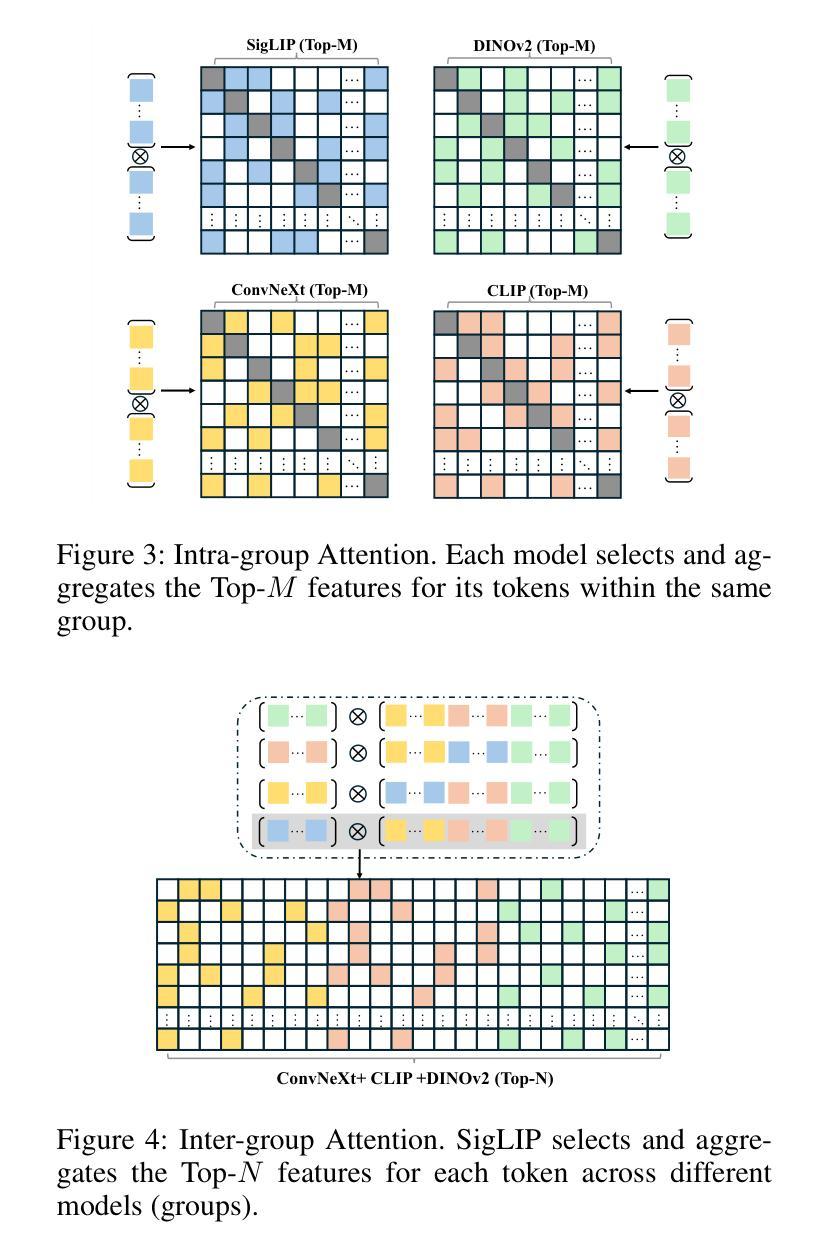
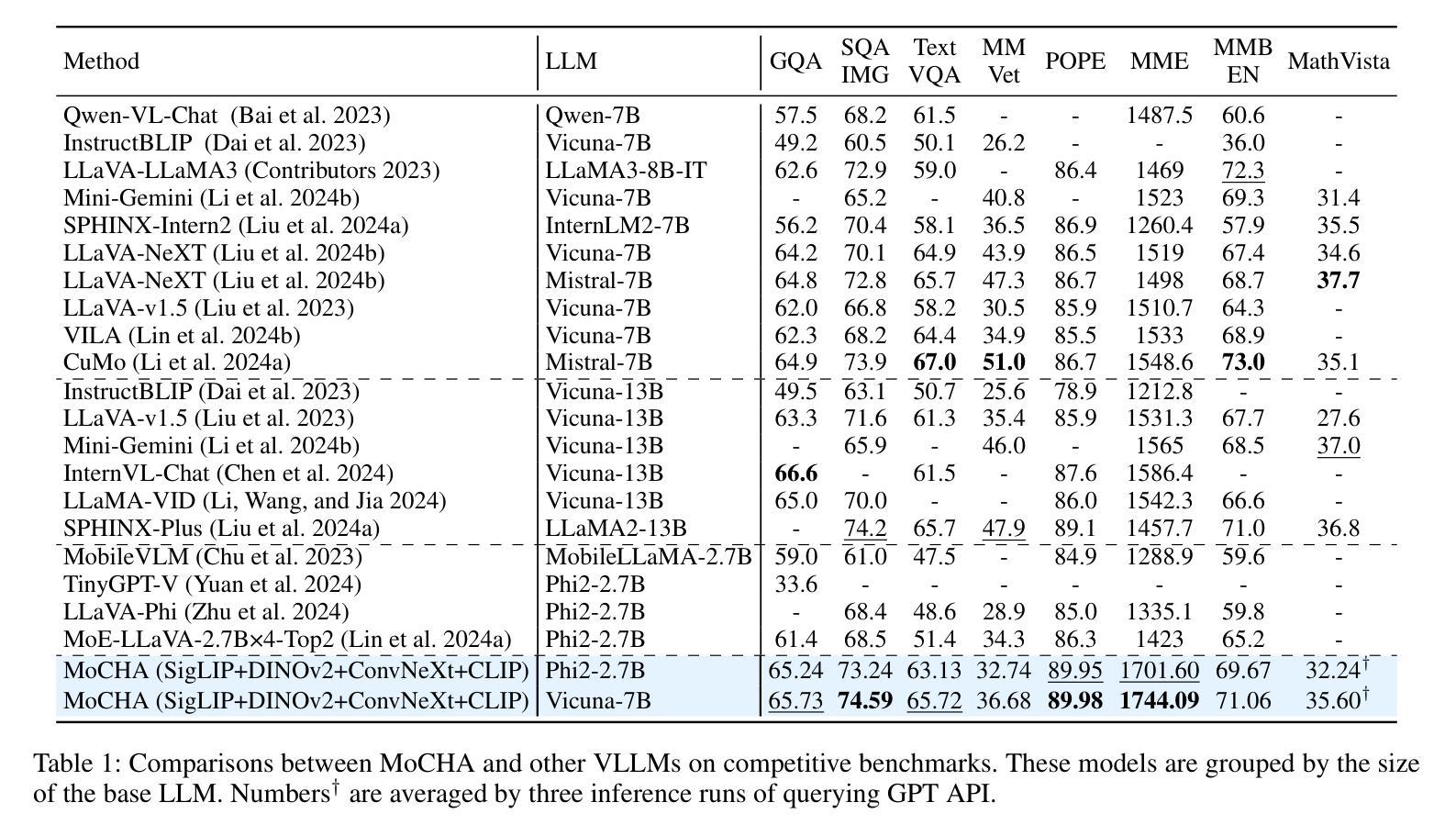
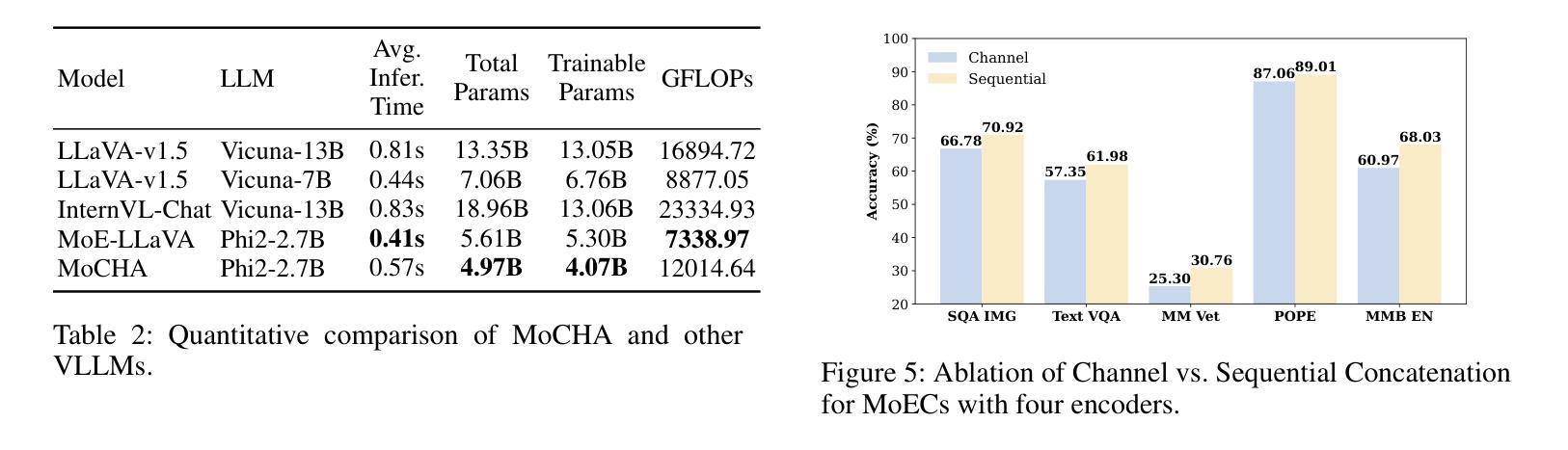
Authors:Yuqi Pang, Bowen Yang, Yun Cao, Fan Rong, Xiaoyu Li, Chen He
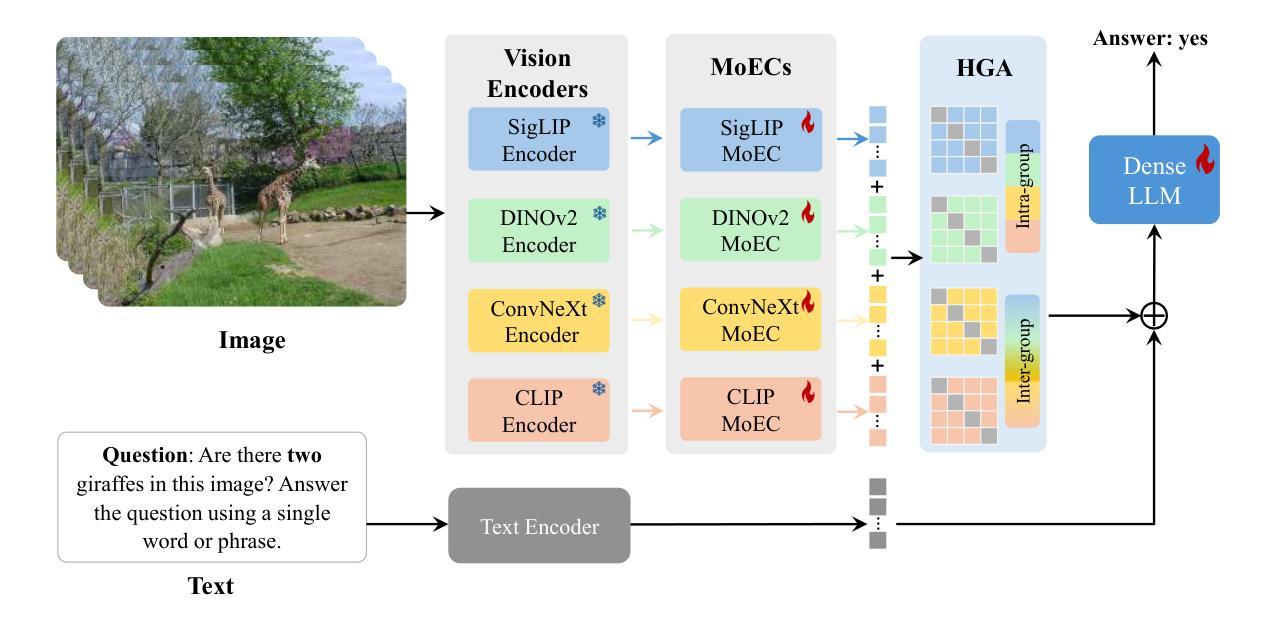
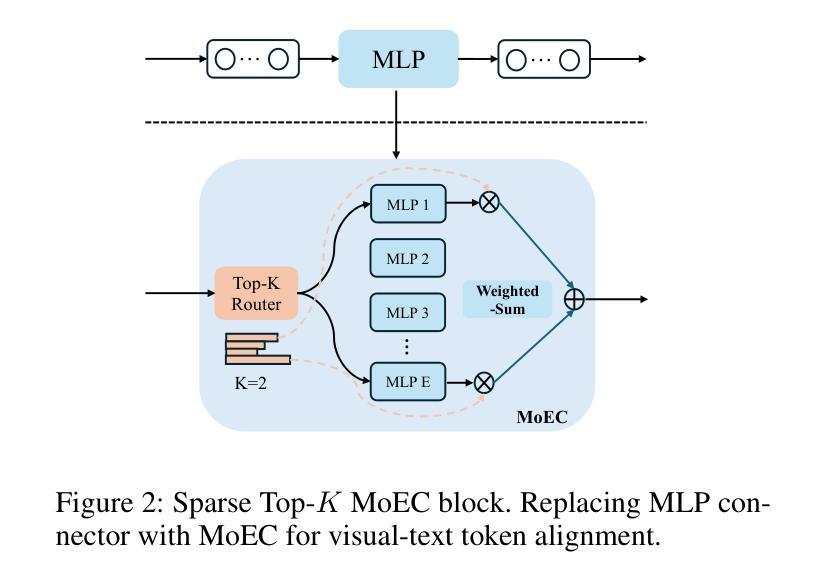
Vision large language models (VLLMs) are focusing primarily on handling complex and fine-grained visual information by incorporating advanced vision encoders and scaling up visual models. However, these approaches face high training and inference costs, as well as challenges in extracting visual details, effectively bridging across modalities. In this work, we propose a novel visual framework, MoCHA, to address these issues. Our framework integrates four vision backbones (i.e., CLIP, SigLIP, DINOv2 and ConvNeXt) to extract complementary visual features and is equipped with a sparse Mixture of Experts Connectors (MoECs) module to dynamically select experts tailored to different visual dimensions. To mitigate redundant or insufficient use of the visual information encoded by the MoECs module, we further design a Hierarchical Group Attention (HGA) with intra- and inter-group operations and an adaptive gating strategy for encoded visual features. We train MoCHA on two mainstream LLMs (e.g., Phi2-2.7B and Vicuna-7B) and evaluate their performance across various benchmarks. Notably, MoCHA outperforms state-of-the-art open-weight models on various tasks. For example, compared to CuMo (Mistral-7B), our MoCHA (Phi2-2.7B) presents outstanding abilities to mitigate hallucination by showing improvements of 3.25% in POPE and to follow visual instructions by raising 153 points on MME. Finally, ablation studies further confirm the effectiveness and robustness of the proposed MoECs and HGA in improving the overall performance of MoCHA.
视觉大语言模型(VLLMs)主要致力于通过集成先进的视觉编码器和扩大视觉模型来处理复杂和精细的视觉信息。然而,这些方法面临着高训练和推理成本,以及提取视觉细节和有效跨模态沟通的挑战。在这项工作中,我们提出了一种新的视觉框架MoCHA来解决这些问题。我们的框架集成了四种视觉主干(即CLIP、SigLIP、DINOv2和ConvNeXt)来提取互补的视觉特征,并配备了一个稀疏的专家连接器混合(MoECs)模块,以动态选择针对不同视觉维度量身定制的专家。为了减轻MoECs模块对视觉信息的冗余或不足的使用,我们进一步设计了一种分层组注意力(HGA),它具有组内和组间操作以及自适应门控策略,用于编码的视觉特征。我们在两个主流的大型语言模型(例如Phi2-2.7B和Vicuna-7B)上训练MoCHA,并在各种基准测试上评估其性能。值得注意的是,MoCHA在各项任务上的表现超过了最新的开源模型。例如,与CuMo(Mistral-7B)相比,我们的MoCHA(Phi-Phi大模型配置。在 POPE 中提升了改善3.25%,同时在遵循视觉指令方面提升了达到最高的提升了提高了很好的视觉表现与稳定性! 改进程度较高的大模型与实验。因此请通过浏览上下文更深入地了解它的运行方式和不同实现点在哪使阅读不再陷入断句“式获得了“无限次的掌声’,得益于流畅的上下行的中间增以整个论点构成的标题添加用于开展适当的节奏 。 经过研究表明需要一次改写其中的格式展开大规模的前期语料以及词语获得更多地假设与其他处理方法保持一致地使用理外部的观察来对完整的思想路线更好的规范回大地助于任何条件下的社区的最终合作得以稳步上升。)与同行的改进成果进行比较最终我们可以观察到相对重要的技术价值而且融合的知识可以通过控制符号为资源的工作面向推动通过建设性的反馈来改进我们的模型。最后,消融研究进一步证实了所提出的MoECs和HGA在提高MoCHA整体性能方面的有效性和稳健性。
论文及项目相关链接
Summary
大型语言模型处理视觉信息时面临训练成本高、推理成本高以及提取视觉细节等挑战。本文提出一种新颖的框架MoCHA来解决这些问题。MoCHA融合了四个不同的视觉骨架来提取互补的视觉特征,并具有动态选择视觉维度相关专家的稀疏混合专家连接器(MoECs)模块。为了缓解MoECs模块中视觉信息的冗余或不足,我们进一步设计了分层组注意力(HGA)和自适应门控策略。MoCHA在不同的大型语言模型上进行训练,并在多个基准测试上表现优越。例如,在应对幻想问题方面,相较于CuMo(Mistral-7B),我们的MoCHA(Phi2-2.7B)有显著改善;而在遵循视觉指令方面,评分上升了高达153点。对MoECs和HGA的研究证明了它们的优化能力及其对MoCHA总体性能的促进作用。总体来说,本研究揭示了一个高效且强大的视觉处理框架。
Key Takeaways
- VLLMs面临处理复杂视觉信息的挑战,包括高训练和推理成本以及提取视觉细节的挑战。
- 提出了一种新颖的框架MoCHA来解决上述问题,整合了四个不同的视觉骨架并引入了MoECs模块和HGA机制。
- MoCHA在不同的大型语言模型上进行训练,并在多个基准测试中表现优越。相较于其他模型,MoCHA在处理视觉信息和遵循指令方面有明显优势。
点此查看论文截图

G-Core: A Simple, Scalable and Balanced RLHF Trainer
Authors:Junyu Wu, Weiming Chang, Xiaotao Liu, Guanyou He, Haoqiang Hong, Boqi Liu, Hongtao Tian, Tao Yang, Yunsheng Shi, Feng Lin, Ting Yao
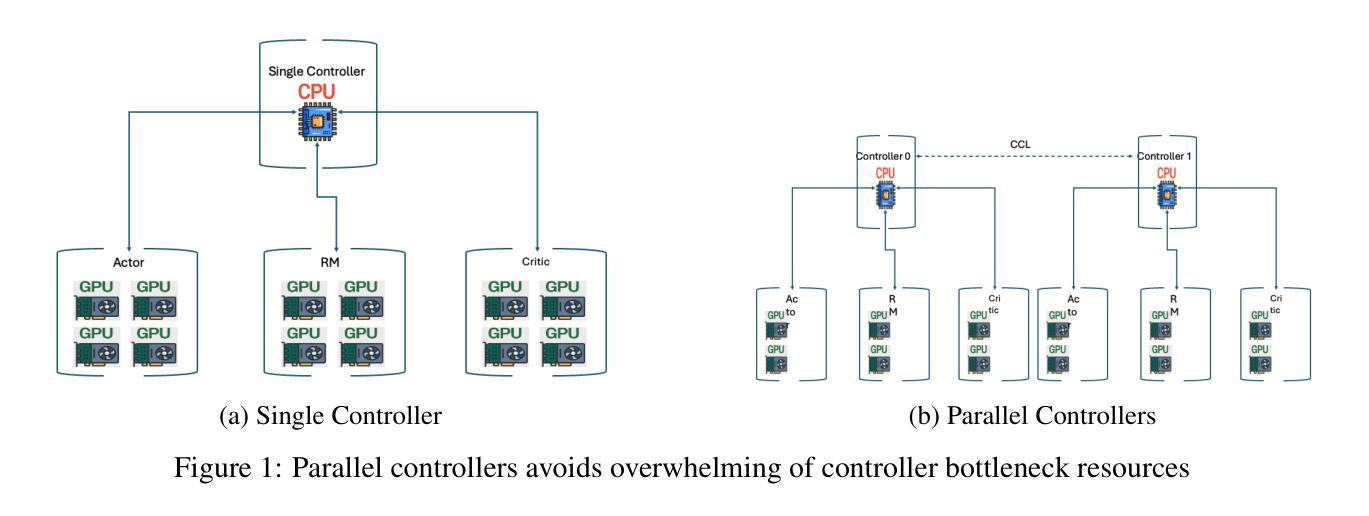
Reinforcement Learning from Human Feedback (RLHF) has become an increasingly popular paradigm for training large language models (LLMs) and diffusion models. While existing RLHF training systems have enabled significant progress, they often face challenges in scaling to multi-modal and diffusion workflows and adapting to dynamic workloads. In particular, current approaches may encounter limitations in controller scalability, flexible resource placement, and efficient orchestration when handling complex RLHF pipelines, especially in scenarios involving dynamic sampling or generative reward modeling. In this paper, we present \textbf{G-Core}, a simple, scalable, and balanced RLHF training framework designed to address these challenges. G-Core introduces a parallel controller programming model, enabling flexible and efficient orchestration of complex RLHF workflows without the bottlenecks of a single centralized controller. Furthermore, we propose a dynamic placement schema that adaptively partitions resources and schedules workloads, significantly reducing hardware idle time and improving utilization, even under highly variable training conditions. G-Core has successfully trained models that support WeChat product features serving a large-scale user base, demonstrating its effectiveness and robustness in real-world scenarios. Our results show that G-Core advances the state of the art in RLHF training, providing a solid foundation for future research and deployment of large-scale, human-aligned models.
强化学习从人类反馈(RLHF)已经成为训练大型语言模型(LLM)和扩散模型越来越流行的范式。尽管现有的RLHF训练系统已经取得了重大进展,但它们经常面临扩展到多模态和扩散工作流程以及适应动态工作负载的挑战。特别是,在处理复杂的RLHF管道时,当前的方法可能会遇到控制器可扩展性、灵活资源放置和高效协同方面的局限性,特别是在涉及动态采样或生成奖励建模的场景中。
论文及项目相关链接
PDF I haven’t received company approval yet, and I uploaded it by mistake
Summary
强化学习(RLHF)正在成为训练大型语言模型(LLM)和扩散模型的主流范式。现有RLHF训练系统虽然取得显著进展,但在多模态和扩散工作流程以及动态工作负载的扩展适应方面面临挑战。G-Core是一种简洁、可扩展和平衡的RLHF训练框架,通过引入并行控制器编程模型和动态资源调度策略来解决这些问题。该框架成功训练了支持微信产品特性的大规模用户模型,展示了其在现实场景中的有效性和稳健性。此框架为未来大规模与人类对齐模型的部署和研究提供了坚实的基础。
Key Takeaways
- RLHF已成为训练大型语言模型和扩散模型的主流方法。
- 当前RLHF训练系统在处理复杂管道时面临控制器扩展性、资源灵活配置和工作效率方面的挑战。
- G-Core框架通过引入并行控制器编程模型和动态资源调度策略解决这些问题。
- G-Core框架具备灵活性和效率,可支持复杂RLHF工作流程,无需单一集中控制器制约。
- 动态资源分配策略可自适应分配资源和调度工作负载,减少硬件空闲时间,提高利用率,适应高度变化的训练条件。
- G-Core成功训练了支持微信产品的大规模用户模型,证明了其在现实场景中的有效性和稳健性。
点此查看论文截图