⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-02 更新
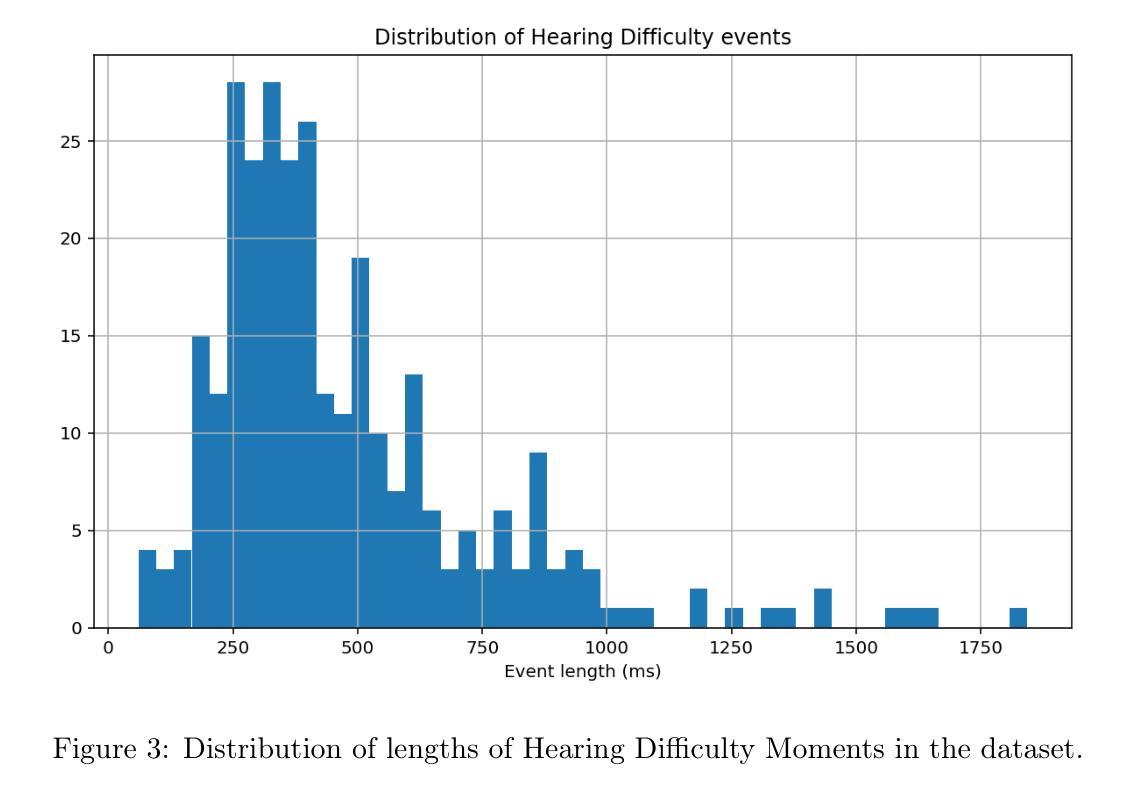
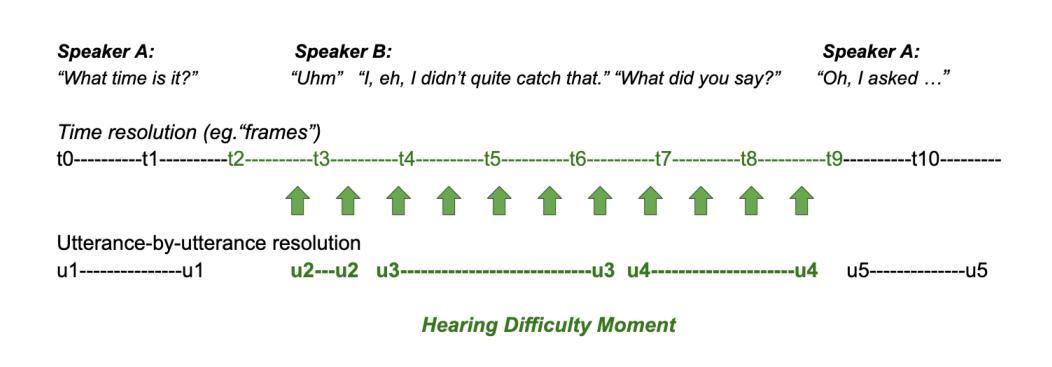
Identifying Hearing Difficulty Moments in Conversational Audio
Authors:Jack Collins, Adrian Buzea, Chris Collier, Alejandro Ballesta Rosen, Julian Maclaren, Richard F. Lyon, Simon Carlile
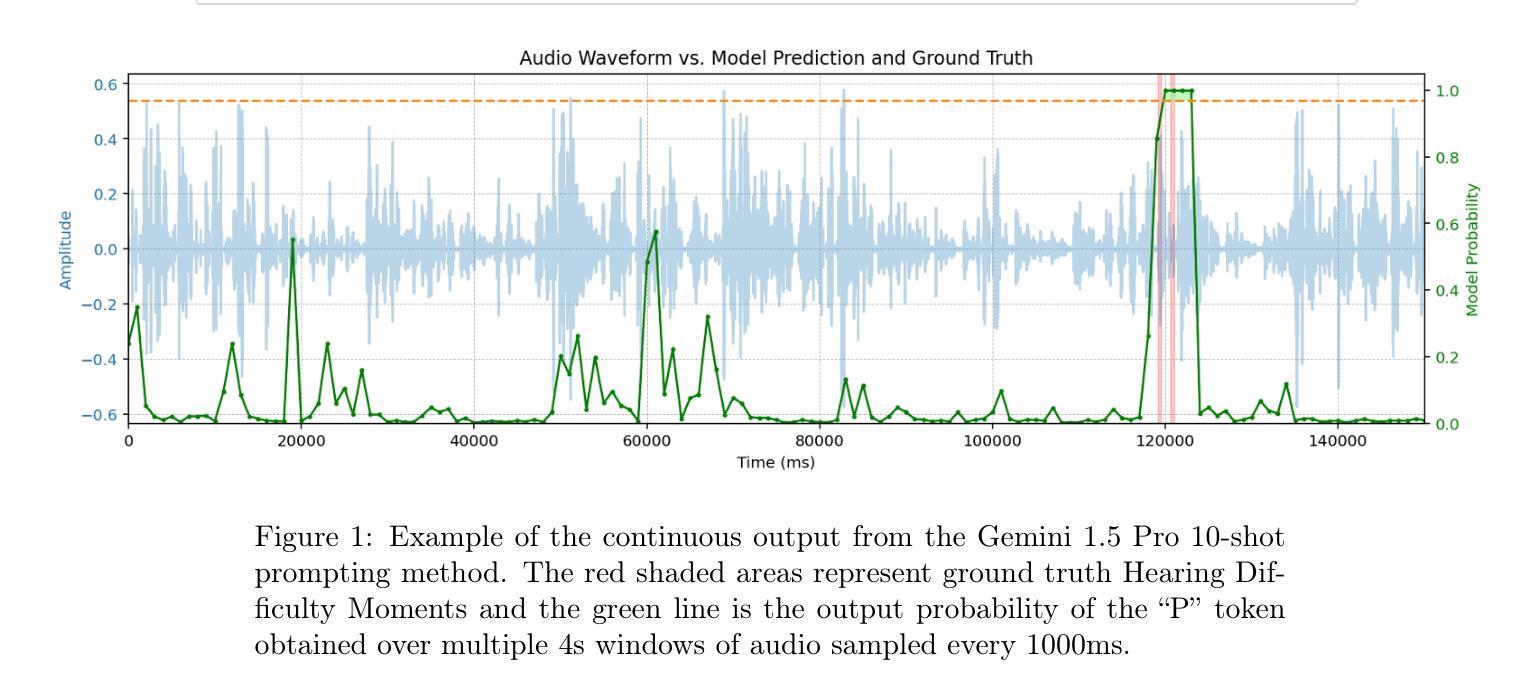
Individuals regularly experience Hearing Difficulty Moments in everyday conversation. Identifying these moments of hearing difficulty has particular significance in the field of hearing assistive technology where timely interventions are key for realtime hearing assistance. In this paper, we propose and compare machine learning solutions for continuously detecting utterances that identify these specific moments in conversational audio. We show that audio language models, through their multimodal reasoning capabilities, excel at this task, significantly outperforming a simple ASR hotword heuristic and a more conventional fine-tuning approach with Wav2Vec, an audio-only input architecture that is state-of-the-art for automatic speech recognition (ASR).
在日常对话中,个人经常会遇到听力困难时刻。识别这些听力困难时刻对于助听技术领域具有重要意义,因为及时的干预对于实时听力辅助至关重要。在本文中,我们提出并比较了用于连续检测对话音频中特定时刻的机器学习方法。我们表明,音频语言模型通过其多模态推理能力在这方面表现出色,显著优于简单的ASR热词启发式方法和更传统的微调方法,使用Wav2Vec(一种仅适用于音频的输入架构,是自动语音识别(ASR)的最新技术)。
论文及项目相关链接
Summary
本文提出并比较了用于持续检测日常对话中的听力困难时刻的机器学习方法。研究发现,具备多模态推理能力的音频语言模型在此任务上表现优异,显著优于简单的ASR热词启发式方法和使用Wav2Vec等传统微调方法。这项研究对于听力辅助技术领域具有重要意义,因为实时干预对于提供实时听力援助至关重要。
Key Takeaways
- 听力困难时刻的识别在日常对话中具有重要价值,特别是在听力辅助技术领域。
- 本文提出并比较了多种机器学习方法来检测听力困难时刻。
- 音频语言模型通过多模态推理能力在此任务上表现突出。
- 音频语言模型显著优于简单的ASR热词启发式方法和使用Wav2Vec等传统微调方法。
- 实时干预对于提供实时听力援助至关重要。
- 机器学习的应用为听力辅助技术提供了新的解决方案。
点此查看论文截图

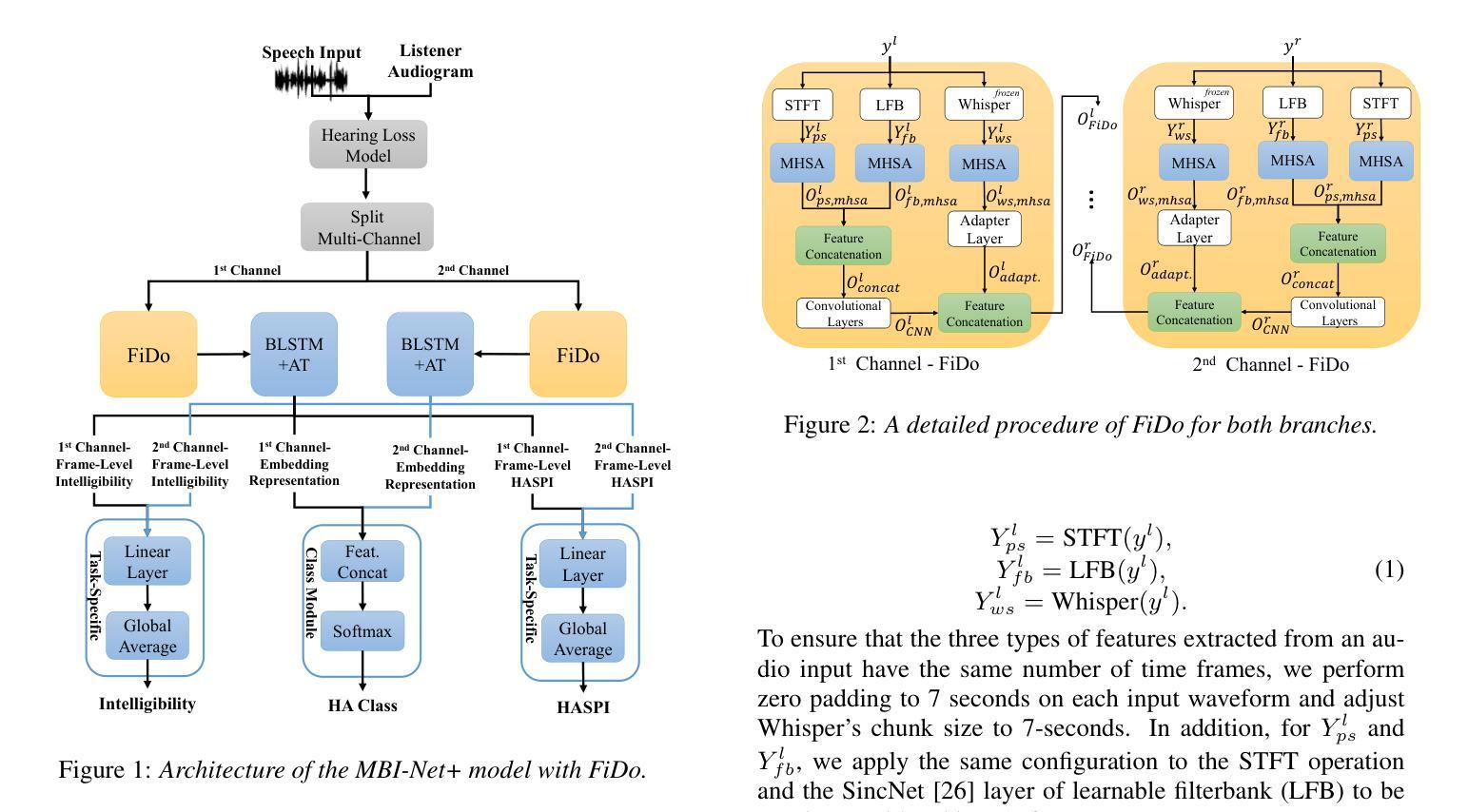
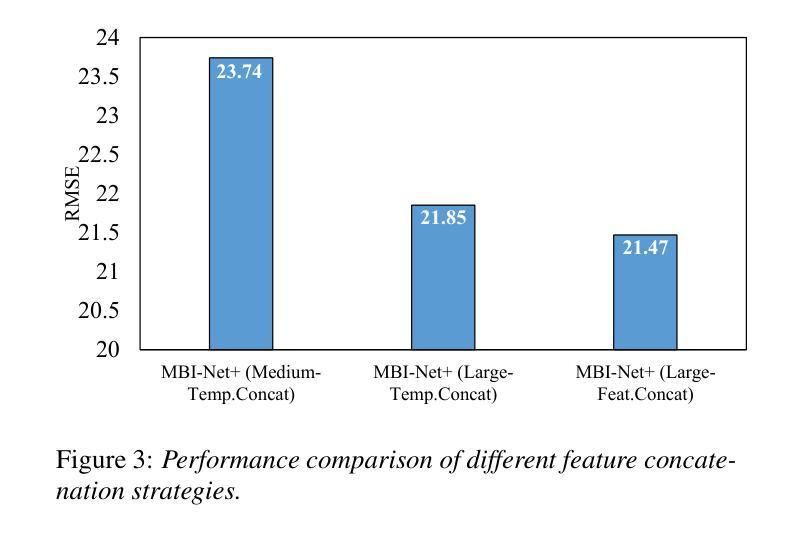
Feature Importance across Domains for Improving Non-Intrusive Speech Intelligibility Prediction in Hearing Aids
Authors:Ryandhimas E. Zezario, Sabato M. Siniscalchi, Fei Chen, Hsin-Min Wang, Yu Tsao
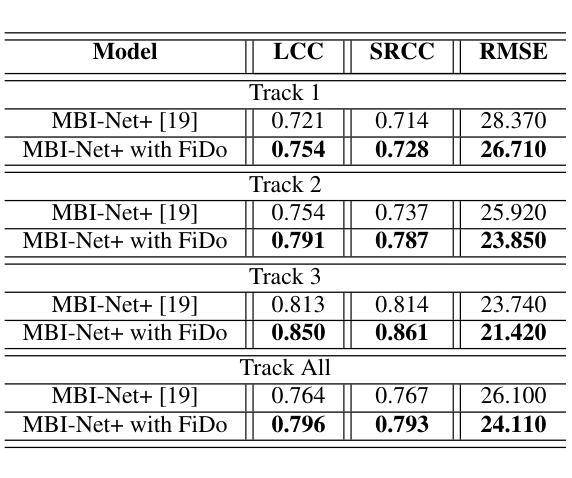
Given the critical role of non-intrusive speech intelligibility assessment in hearing aids (HA), this paper enhances its performance by introducing Feature Importance across Domains (FiDo). We estimate feature importance on spectral and time-domain acoustic features as well as latent representations of Whisper. Importance weights are calculated per frame, and based on these weights, features are projected into new spaces, allowing the model to focus on important areas early. Next, feature concatenation is performed to combine the features before the assessment module processes them. Experimental results show that when FiDo is incorporated into the improved multi-branched speech intelligibility model MBI-Net+, RMSE can be reduced by 7.62% (from 26.10 to 24.11). MBI-Net+ with FiDo also achieves a relative RMSE reduction of 3.98% compared to the best system in the 2023 Clarity Prediction Challenge. These results validate FiDo’s effectiveness in enhancing neural speech assessment in HA.
考虑到非侵入性语音清晰度评估在助听器(HA)中的关键作用,本文通过引入跨域特征重要性(FiDo)来提高其性能。我们估计了频谱和时间域声学特征以及耳语潜在表示的特征重要性。重要性权重是按帧计算的,基于这些权重,特征被投射到新的空间,使得模型能够早期关注重要区域。接下来,进行特征拼接,以在评估模块处理之前结合特征。实验结果表明,当FiDo被纳入到改进的多分支语音清晰度模型MBI-Net+中时,均方根误差(RMSE)可以降低7.62%(从26.10降至24.11)。与2023年清晰度预测挑战赛中的最佳系统相比,MBI-Net+结合FiDo还实现了相对RMSE降低3.98%。这些结果验证了FiDo在提高助听器的神经语音评估中的有效性。
论文及项目相关链接
PDF Accepted to Interspeech 2025
Summary
本论文通过引入跨域特征重要性(FiDo)技术,提高了听力辅助设备中非侵入性语音清晰度评估的性能。论文对频谱和时域声学特征以及whisper的潜在表现进行了特征重要性估算。基于每帧的重要性权重,将特征投影到新的空间中,使得模型能够提前关注重要区域。然后,通过特征拼接将特征合并,以供评估模块处理。实验结果显示,将FiDo纳入改进的多分支语音清晰度模型MBI-Net+后,RMSE可降低7.62%(从26.10降至24.11)。与2023年清晰度预测挑战赛的最佳系统相比,MBI-Net+与FiDo的结合实现了相对RMSE降低3.98%。结果验证了FiDo技术在提高听力辅助设备中神经网络语音评估效果方面的有效性。
Key Takeaways
- 引入跨域特征重要性(FiDo)技术,用于提高非侵入性语音清晰度评估在听力辅助设备中的性能。
- 估算频谱和时域声学特征以及whisper潜在表现的特征重要性。
- 基于每帧的重要性权重,将特征投影到新的空间以突出重要区域。
- 通过特征拼接合并特征,以供评估模块处理。
- FiDo纳入MBI-Net+后,RMSE性能降低7.62%。
- 与现有最佳系统相比,MBI-Net+与FiDo结合实现了相对RMSE降低3.98%。
点此查看论文截图

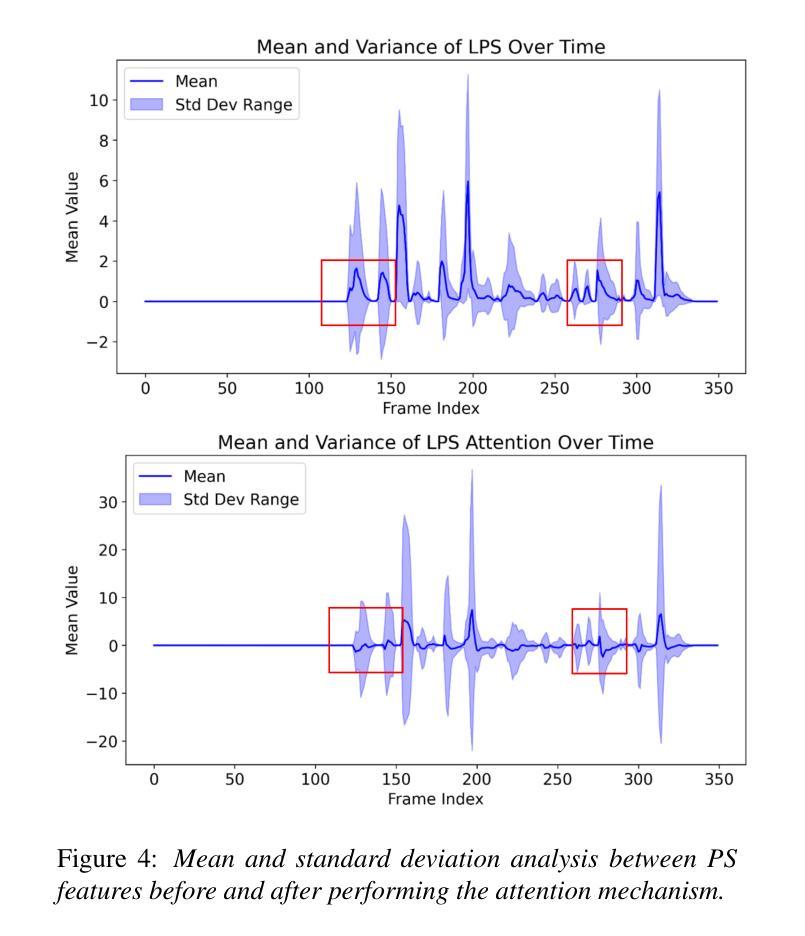

The Interspeech 2025 Speech Accessibility Project Challenge
Authors:Xiuwen Zheng, Bornali Phukon, Jonghwan Na, Ed Cutrell, Kyu Han, Mark Hasegawa-Johnson, Pan-Pan Jiang, Aadhrik Kuila, Colin Lea, Bob MacDonald, Gautam Mantena, Venkatesh Ravichandran, Leda Sari, Katrin Tomanek, Chang D. Yoo, Chris Zwilling
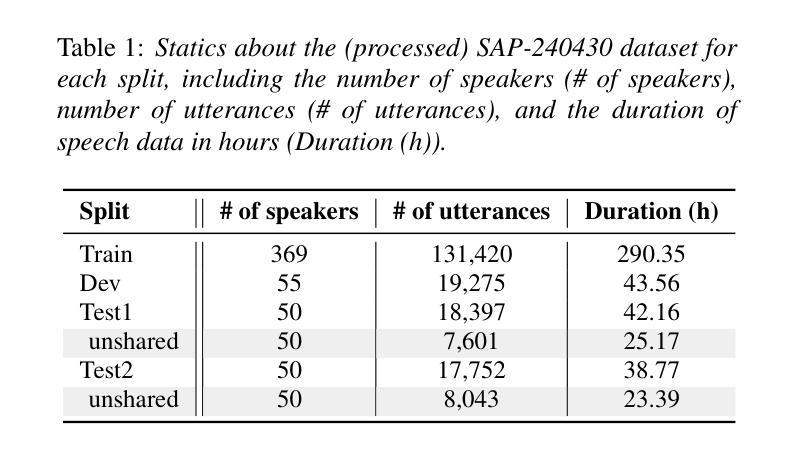
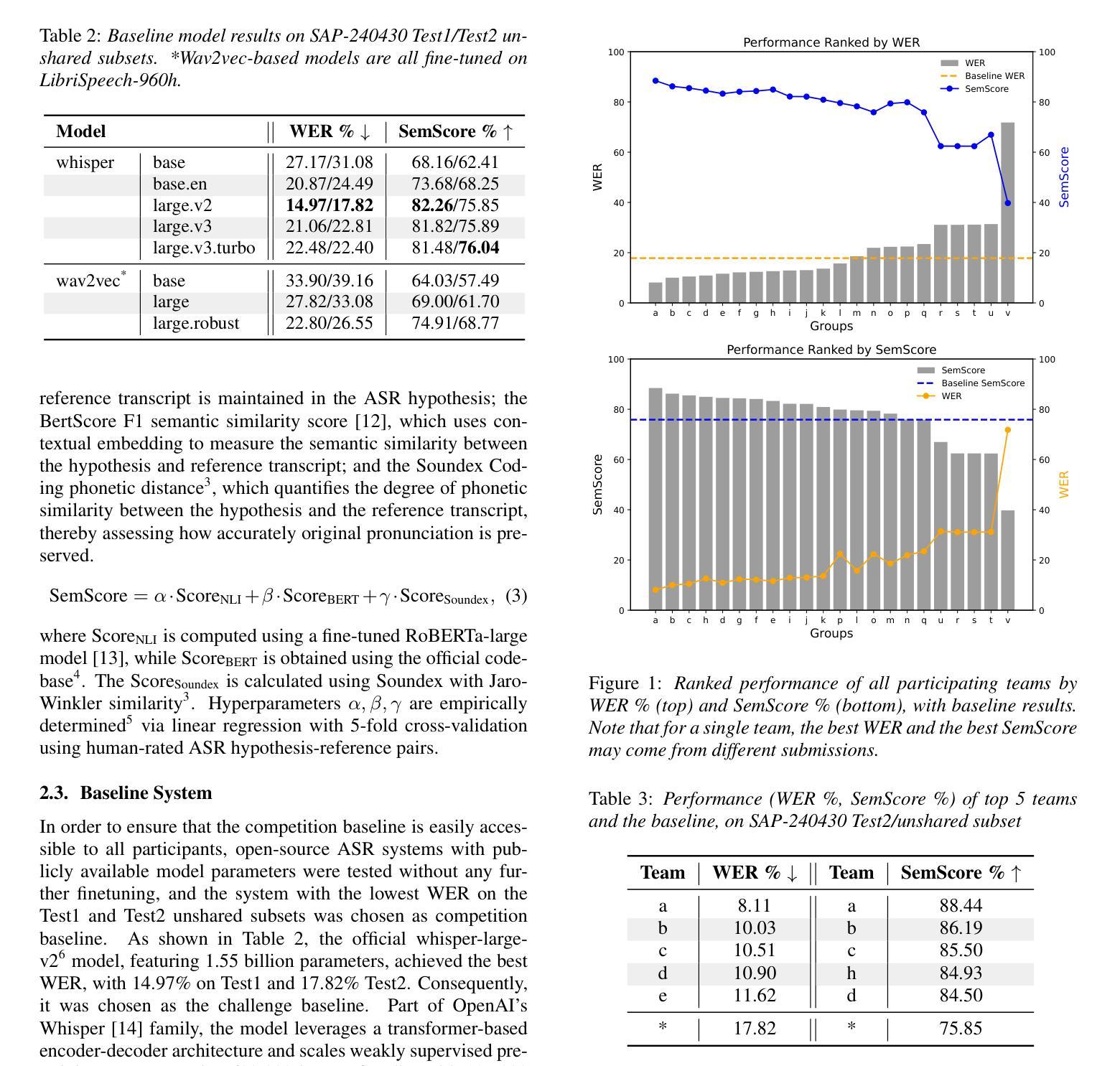
While the last decade has witnessed significant advancements in Automatic Speech Recognition (ASR) systems, performance of these systems for individuals with speech disabilities remains inadequate, partly due to limited public training data. To bridge this gap, the 2025 Interspeech Speech Accessibility Project (SAP) Challenge was launched, utilizing over 400 hours of SAP data collected and transcribed from more than 500 individuals with diverse speech disabilities. Hosted on EvalAI and leveraging the remote evaluation pipeline, the SAP Challenge evaluates submissions based on Word Error Rate and Semantic Score. Consequently, 12 out of 22 valid teams outperformed the whisper-large-v2 baseline in terms of WER, while 17 teams surpassed the baseline on SemScore. Notably, the top team achieved the lowest WER of 8.11%, and the highest SemScore of 88.44% at the same time, setting new benchmarks for future ASR systems in recognizing impaired speech.
尽管过去十年中自动语音识别(ASR)系统取得了重大进展,但对于有言语障碍的个体的性能仍然不足,部分原因是公共训练数据有限。为了弥补这一差距,2025年Interspeech语音无障碍项目(SAP)挑战赛应运而生,该挑战赛使用了超过400小时的SAP数据,这些数据是从500多名具有不同言语障碍的个体身上收集并进行转录的。该挑战赛在EvalAI上托管,并利用远程评估管道进行,根据单词错误率和语义分数对提交的内容进行评估。因此,在WER方面,有12支队伍超过了有效的22支队伍中的whisper-large-v2基线水平;而在SemScore上,有17支队伍超过了基线水平。值得注意的是,排名第一的队伍同时达到了最低的WER为8.11%,以及最高的SemScore为88.44%,为未来ASR系统在识别受损语音方面树立了新的基准。
论文及项目相关链接
PDF To appear in Proceedings of Interspeech, 2025
Summary
近期,尽管自动语音识别(ASR)系统取得了显著进展,但对于有言语障碍的个体的性能仍然不足,部分原因在于公共训练数据的有限性。为弥补这一差距,2025年Interspeech举办了语音无障碍项目(SAP)挑战赛,使用超过400小时的SAP数据,这些数据来自500多名拥有不同言语障碍的个体。该挑战赛基于Word Error Rate和Semantic Score对提交的内容进行评估。结果显示,有12支队伍在WER方面超越了whisper-large-v2基线,有17支队伍在SemScore上超过了基线。尤其值得关注的是,最佳团队同时取得了最低的WER(8.11%)和最高的SemScore(88.44%),为未来ASR系统识别受损语音设定了新的基准。
Key Takeaways
- 自动语音识别(ASR)系统虽有所进步,但对有言语障碍的个体的性能仍然不足。
- 公共训练数据的有限性是导致这一差距的主要原因之一。
- 2025年Interspeech语音无障碍项目(SAP)挑战赛旨在缩小这一差距。
- SAP挑战赛使用了来自500多名拥有不同言语障碍个体的超过400小时的数据。
- 挑战赛基于Word Error Rate和Semantic Score对提交内容进行评估。
- 在SAP挑战赛中,有队伍在性能上超越了现有的whisper-large-v2基线。
点此查看论文截图

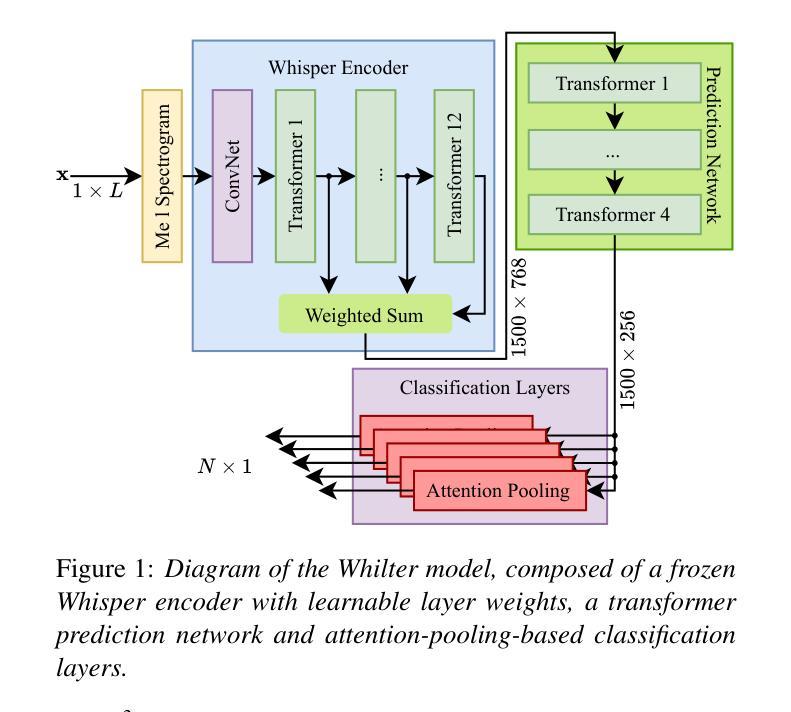
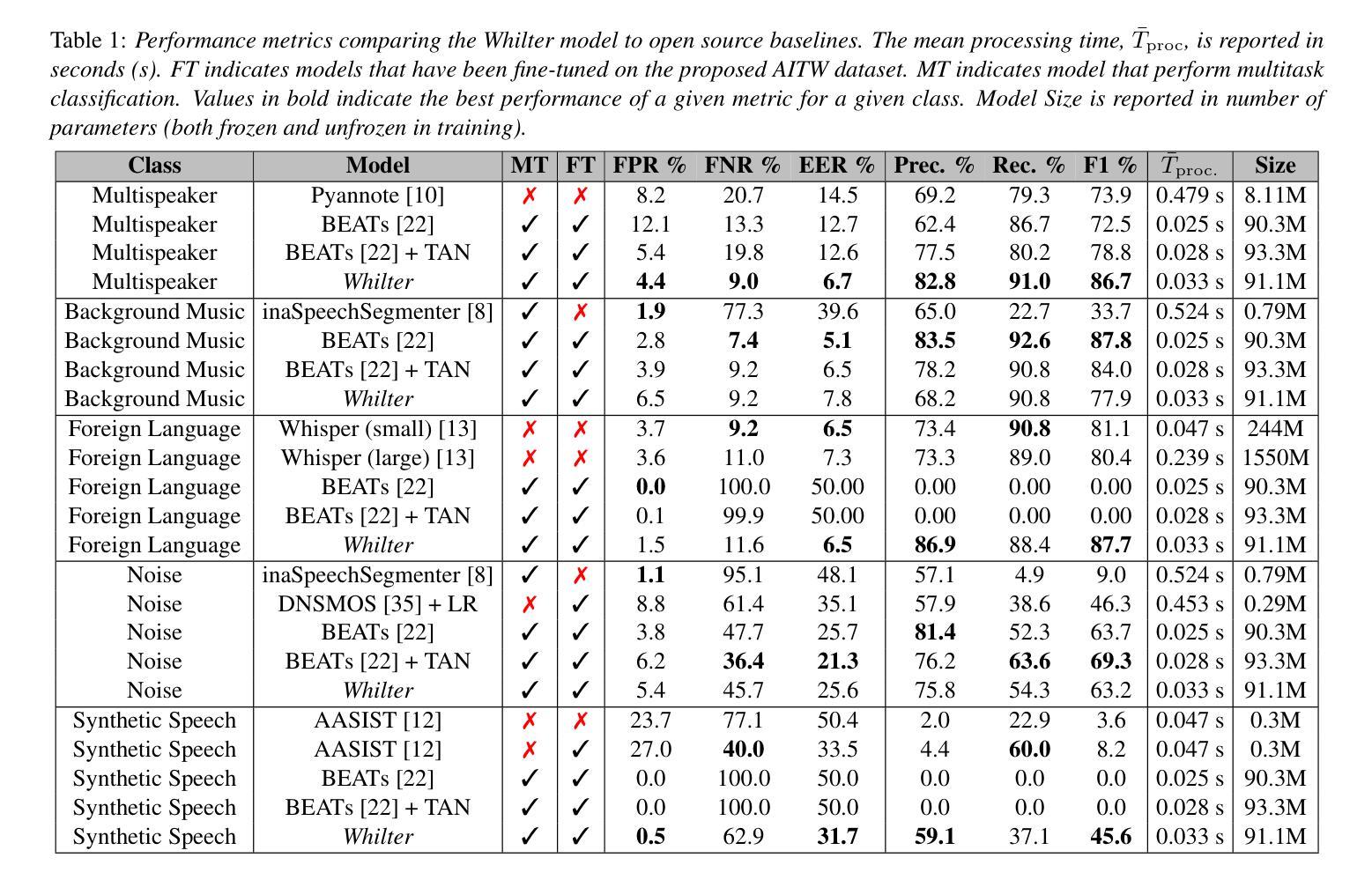
Whilter: A Whisper-based Data Filter for “In-the-Wild” Speech Corpora Using Utterance-level Multi-Task Classification
Authors:William Ravenscroft, George Close, Kit Bower-Morris, Jamie Stacey, Dmitry Sityaev, Kris Y. Hong
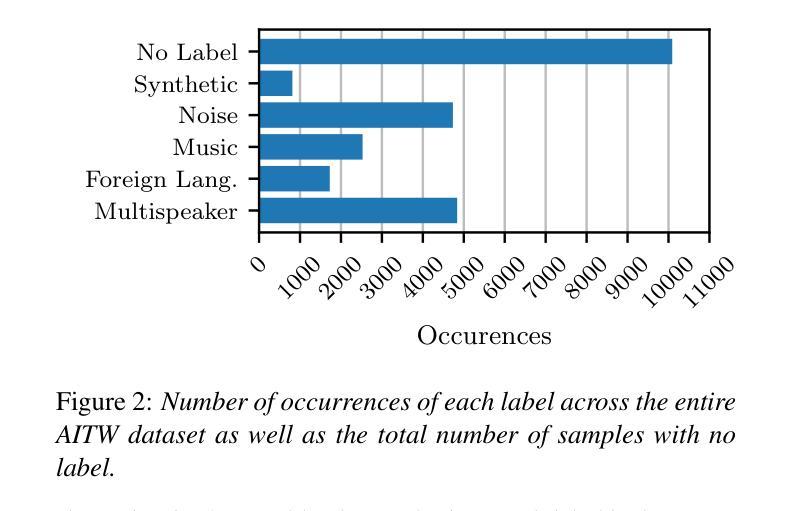
Large-scale in-the-wild speech datasets have become more prevalent in recent years due to increased interest in models that can learn useful features from unlabelled data for tasks such as speech recognition or synthesis. These datasets often contain undesirable features, such as multiple speakers, non-target languages, and music, which may impact model learning. The Whilter model is proposed as a multitask solution to identify these undesirable samples. Whilter uses a Whisper encoder with an attention-based classifier to solve five diverse classification problems at once. In addition, an annotated dataset is published for a subset of two popular in-the-wild corpora. Whilter achieves F1 scores above 85% and equal error rates of 6.5% to 7.8% for three of five subtasks, outperforming a state-of-the-art BEATs classifier on speech-specific classes, with a notable decrease in processing time compared to a combination of single-task alternatives.
近年来,由于模型对从非标记数据中学习有用特征以用于语音识别或合成等任务的兴趣增加,大规模野外语音数据集变得更加普遍。这些数据集往往包含一些不良特征,如多个说话者、非目标语言和音乐等,可能会影响模型学习。因此提出了Whilter模型作为多任务解决方案来识别这些不良样本。Whilter使用一个带有注意力分类器的Whisper编码器同时解决五个不同的分类问题。此外,还为两个流行野外语料库的子集发布了一个带注释的数据集。对于五个子任务中的三个任务,Whilter的F1得分高于85%,并且对于三个子任务的错误率达到了6.5%至7.8%,在语音特定类别上超过了最先进的BEATs分类器,并且相较于单一任务的组合处理方式,处理时间显著减少。
论文及项目相关链接
PDF Accepted for Interspeech 2025
摘要
随着对能从未标记数据中学习有用特征的模型的兴趣增加,用于语音识别或合成等任务的大规模野外语音数据集近年来变得更加普遍。这些数据集往往包含不利的特征,如多个说话者、非目标语言和音乐等,可能会影响模型的学习。Whilter模型被提出作为一种多任务解决方案,用于识别这些不利的样本。Whilter使用一个Whisper编码器和一个基于注意力的分类器来解决五个不同的分类问题。此外,还为两个流行的野外语料库的一个子集发布了一个注释数据集。Whifter在五个子任务中的三个上实现了超过85%的F1分数和6.5%至7.8%的等效错误率,在语音特定类别上优于最新的BEATs分类器,与处理单个任务的组合相比,处理时间显著减少。
要点
- 大规模野外语音数据集的普及推动了对能从未标记数据中学习有用特征的模型的需求。
- 这些数据集常常包含不利的特征,如多个说话者、非目标语言和音乐。
- Whilter模型是一种多任务解决方案,用于识别这些不利的样本。
- Whilter使用Whisper编码器和基于注意力的分类器来解决五个不同的分类问题。
- 一个注释数据集被发布用于两个流行野外语料库的一个子集。
- Whifter在多个关键指标上表现优异,实现了高F1分数和较低的等效错误率。
点此查看论文截图

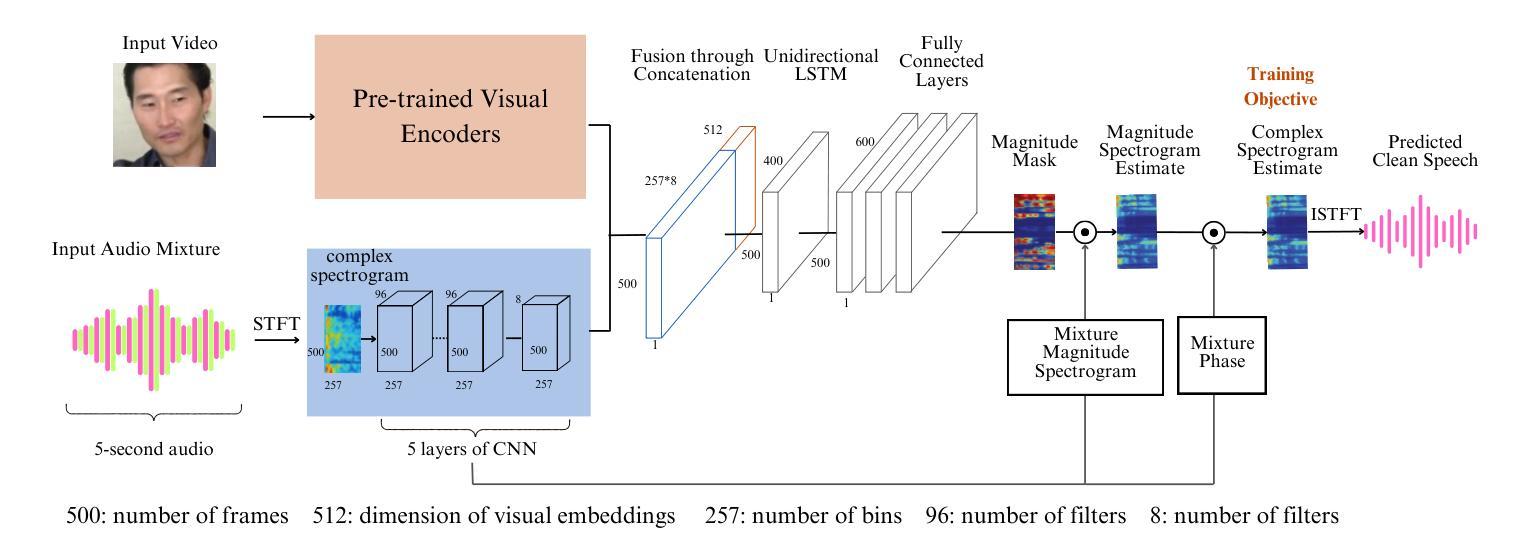
Real-Time Audio-Visual Speech Enhancement Using Pre-trained Visual Representations
Authors: Teng, Ma, Sile Yin, Li-Chia Yang, Shuo Zhang
Speech enhancement in audio-only settings remains challenging, particularly in the presence of interfering speakers. This paper presents a simple yet effective real-time audio-visual speech enhancement (AVSE) system, RAVEN, which isolates and enhances the on-screen target speaker while suppressing interfering speakers and background noise. We investigate how visual embeddings learned from audio-visual speech recognition (AVSR) and active speaker detection (ASD) contribute to AVSE across different SNR conditions and numbers of interfering speakers. Our results show concatenating embeddings from AVSR and ASD models provides the greatest improvement in low-SNR, multi-speaker environments, while AVSR embeddings alone perform best in noise-only scenarios. In addition, we develop a real-time streaming system that operates on a computer CPU and we provide a video demonstration and code repository. To our knowledge, this is the first open-source implementation of a real-time AVSE system.
在只有音频的设定中,语音增强仍然是一个挑战,特别是在存在干扰说话者的情况下。本文提出了一种简单有效的实时视听语音增强(AVSE)系统,名为RAVEN,它能隔离并增强屏幕上的目标说话者,同时抑制干扰说话者和背景噪音。我们研究了从视听语音识别(AVSR)和主动说话者检测(ASD)中学习到的视觉嵌入如何在不同信噪比条件和干扰说话者数量下对AVSE做出贡献。我们的结果表明,在信噪比低、多说话者的环境中,来自AVSR和ASD模型的嵌入物串联提供了最大的改进,而在只有噪音的情况下,AVSR嵌入物单独表现最好。此外,我们开发了一个可在计算机CPU上运行的实时流媒体系统,并提供了视频演示和代码仓库。据我们所知,这是第一个实时AVSE系统的开源实现。
论文及项目相关链接
PDF Accepted into Interspeech 2025
Summary
本文介绍了一种简单有效的实时视听语音增强系统(AVSE)——RAVEN,它能隔离并增强屏幕上的目标说话者声音,同时抑制干扰说话者和背景噪音。研究探讨了视听语音识别(AVSR)和主动说话者检测(ASD)的视觉嵌入对AVSE在不同信噪比条件和干扰说话者数量下的贡献。结果显示,在信噪比低、多说话人的环境中,结合AVSR和ASD模型的嵌入信息表现最佳;而仅使用AVSR嵌入信息在仅存在噪声的场景中表现最好。此外,该研究还开发了一个实时流式系统,可在计算机CPU上运行,并提供视频演示和代码库。这是首个开源的实时AVSE系统。
Key Takeaways
- 语音增强在仅有音频的环境下仍具挑战,特别是在存在干扰说话者的情况下。
- RAVEN系统是一个实时视听语音增强系统,能够隔离并增强目标说话者的声音。
- 研究重点探讨了视听语音识别(AVSR)和主动说话者检测(ASD)的视觉嵌入如何对AVSE做出贡献。
- 在不同的信噪比条件和干扰说话者数量下,结合AVSR和ASD模型的嵌入信息表现最佳。
- 仅使用AVSR嵌入信息在仅存在噪声的场景中表现最好。
- 开发了一个可在计算机CPU上运行的实时流式系统。
点此查看论文截图

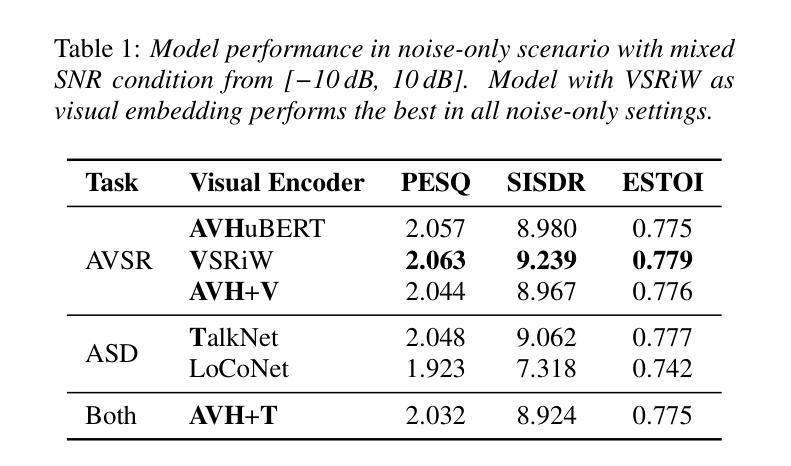
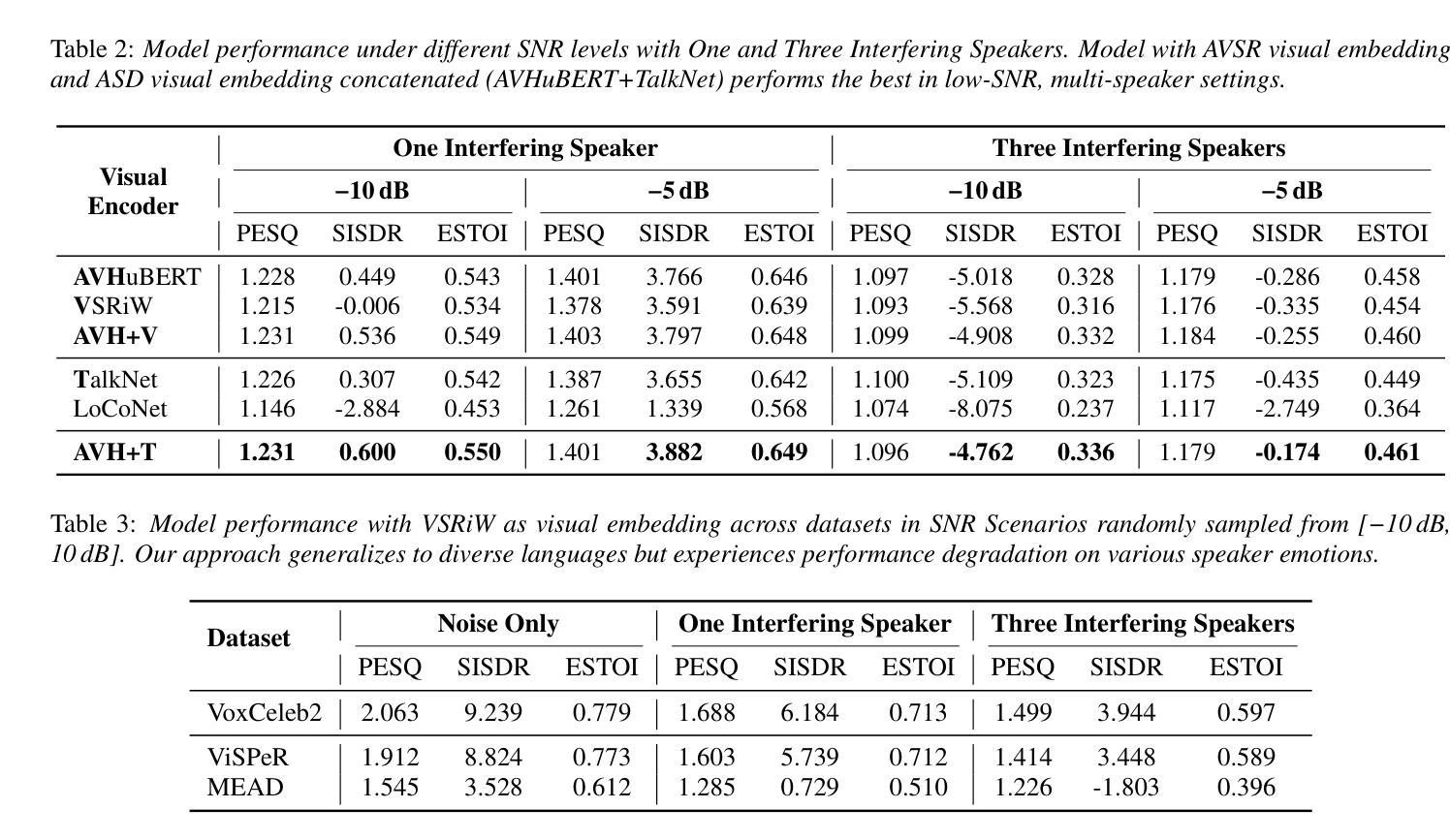
A Deep Learning Automatic Speech Recognition Model for Shona Language
Authors:Leslie Wellington Sirora, Mainford Mutandavari
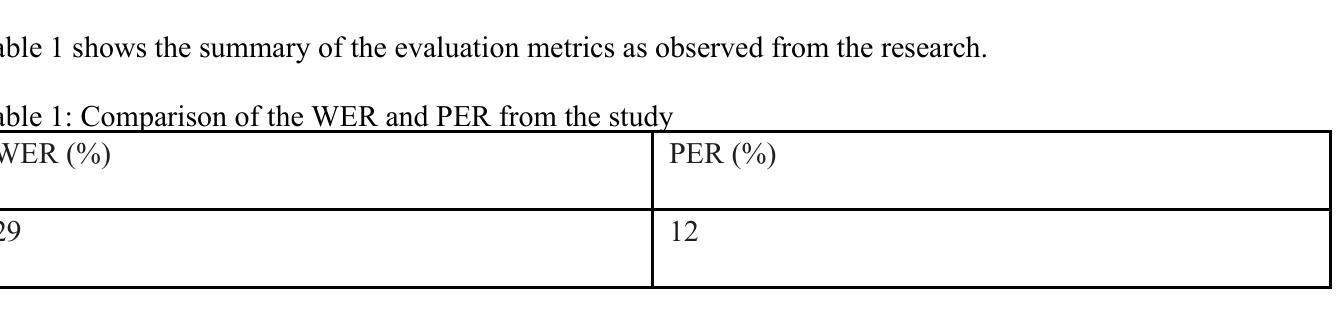
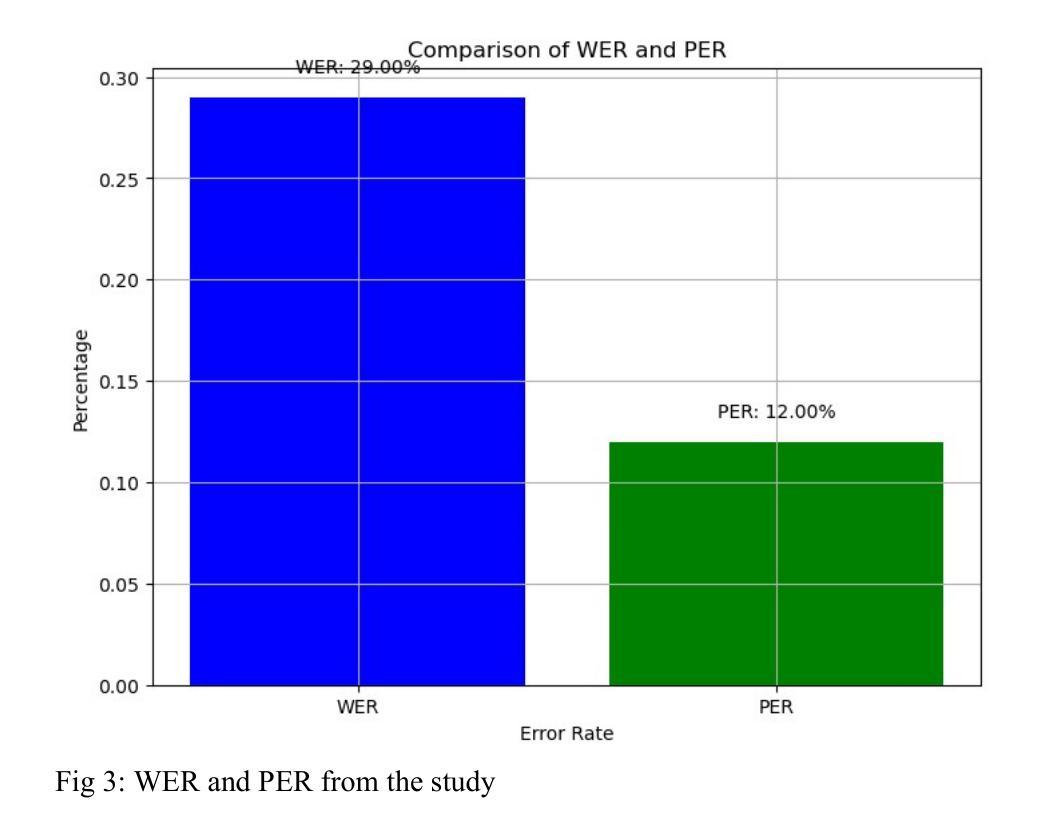
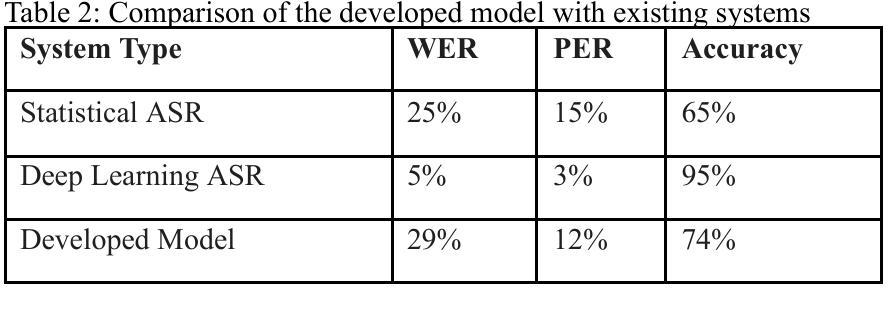
This study presented the development of a deep learning-based Automatic Speech Recognition system for Shona, a low-resource language characterized by unique tonal and grammatical complexities. The research aimed to address the challenges posed by limited training data, lack of labelled data, and the intricate tonal nuances present in Shona speech, with the objective of achieving significant improvements in recognition accuracy compared to traditional statistical models. The research first explored the feasibility of using deep learning to develop an accurate ASR system for Shona. Second, it investigated the specific challenges involved in designing and implementing deep learning architectures for Shona speech recognition and proposed strategies to mitigate these challenges. Lastly, it compared the performance of the deep learning-based model with existing statistical models in terms of accuracy. The developed ASR system utilized a hybrid architecture consisting of a Convolutional Neural Network for acoustic modelling and a Long Short-Term Memory network for language modelling. To overcome the scarcity of data, data augmentation techniques and transfer learning were employed. Attention mechanisms were also incorporated to accommodate the tonal nature of Shona speech. The resulting ASR system achieved impressive results, with a Word Error Rate of 29%, Phoneme Error Rate of 12%, and an overall accuracy of 74%. These metrics indicated the potential of deep learning to enhance ASR accuracy for under-resourced languages like Shona. This study contributed to the advancement of ASR technology for under-resourced languages like Shona, ultimately fostering improved accessibility and communication for Shona speakers worldwide.
本研究开发了一种基于深度学习的用于识别绍纳语的自动语音识别系统。绍纳语是一种具有独特语调及语法复杂性的资源匮乏的语言。研究旨在解决由有限的训练数据和缺乏标记数据所带来的挑战,以及绍纳语中复杂的语调细微差别,目标是实现与传统统计模型相比在识别准确性方面的显著改进。该研究首先探讨了使用深度学习开发准确的绍纳语自动语音识别系统的可行性。其次,它研究了在设计和实施绍纳语音识别的深度学习架构过程中所面临的特定挑战,并提出了解决这些挑战的策略。最后,在准确性方面,将基于深度学习的模型与现有的统计模型进行了比较。开发的自动语音识别系统采用混合架构,包括用于声学建模的卷积神经网络和用于语言建模的长短期记忆网络。为了克服数据缺乏的问题,采用了数据增强技术和迁移学习。还融入了注意力机制以适应绍纳语的语调特点。结果得到的自动语音识别系统取得了令人印象深刻的结果,词错误率为29%,音素错误率为12%,总体准确率为74%。这些指标表明深度学习在提高资源匮乏语言(如绍纳语)的自动语音识别准确性方面具有潜力。本研究推动了自动语音识别技术在资源匮乏语言(如绍纳语)领域的发展,最终促进了全球绍纳语使用者的可访问性和交流。
论文及项目相关链接
Summary
本研究开发了一种基于深度学习的自动语音识别系统,用于对具有独特音调和语法复杂性的低资源语言Shona进行识别。研究旨在解决由有限训练数据和缺乏标签数据所带来的挑战,以及Shona语音中复杂的音调细微差别。通过与传统的统计模型相比,该研究在识别准确性方面取得了显著的改进。研究还探讨了为Shona语音识别设计和实现深度学习架构所面临的特定挑战,并提出了应对策略。最终开发的语音识别系统采用混合架构,包括用于声学建模的卷积神经网络和用于语言建模的长短期记忆网络。通过数据增强技术和迁移学习来克服数据稀缺问题,并融入注意力机制以适应Shona语音的音调特性。结果取得的单词错误率为29%,音素错误率为12%,总体准确率为74%,表明了深度学习在提高低资源语言语音识别准确性方面的潜力。
Key Takeaways
- 本研究旨在解决Shona语言(一种具有独特音调和语法复杂性的低资源语言)在自动语音识别方面的挑战。
- 研究通过深度学习方法开发了一种新的语音识别系统,针对Shona语言的特性进行了优化。
- 研究面临的主要挑战包括有限训练数据、缺乏标签数据和Shona语音中的音调细微差别。
- 为应对这些挑战,研究采用了数据增强技术和迁移学习,并融入了注意力机制。
- 开发的语音识别系统取得了显著的识别准确性,单词错误率为29%,音素错误率为12%,总体准确率为74%。
- 该研究展示了深度学习在低资源语言语音识别方面的潜力。
点此查看论文截图

JAM: A Tiny Flow-based Song Generator with Fine-grained Controllability and Aesthetic Alignment
Authors:Renhang Liu, Chia-Yu Hung, Navonil Majumder, Taylor Gautreaux, Amir Ali Bagherzadeh, Chuan Li, Dorien Herremans, Soujanya Poria
Diffusion and flow-matching models have revolutionized automatic text-to-audio generation in recent times. These models are increasingly capable of generating high quality and faithful audio outputs capturing to speech and acoustic events. However, there is still much room for improvement in creative audio generation that primarily involves music and songs. Recent open lyrics-to-song models, such as, DiffRhythm, ACE-Step, and LeVo, have set an acceptable standard in automatic song generation for recreational use. However, these models lack fine-grained word-level controllability often desired by musicians in their workflows. To the best of our knowledge, our flow-matching-based JAM is the first effort toward endowing word-level timing and duration control in song generation, allowing fine-grained vocal control. To enhance the quality of generated songs to better align with human preferences, we implement aesthetic alignment through Direct Preference Optimization, which iteratively refines the model using a synthetic dataset, eliminating the need or manual data annotations. Furthermore, we aim to standardize the evaluation of such lyrics-to-song models through our public evaluation dataset JAME. We show that JAM outperforms the existing models in terms of the music-specific attributes.
扩散和流匹配模型最近彻底改变了自动文本到音频的生成。这些模型越来越能够生成高质量和忠实的音频输出,捕捉到语音和声音事件。然而,在主要涉及音乐和歌曲的创造性音频生成方面,仍有很大的改进空间。最近的开放歌词到歌曲模型,如DiffRhythm、ACE-Step和LeVo,在娱乐用途的自动歌曲生成方面已经设定了可接受的标准。然而,这些模型缺乏音乐家在其工作流程中通常所需的精细的词语级控制力。据我们所知,我们的基于流匹配的JAM是首次努力赋予歌曲生成中词语级的时序和持续时间控制,允许精细的语音控制。为了提高生成歌曲的质量,以更好地符合人类偏好,我们通过直接偏好优化实现了审美对齐,这迭代地改进了模型,使用合成数据集,消除了对手动数据注释的需求。此外,我们旨在通过我们的公共评估数据集JAME来标准化此类歌词到歌曲模型的评估。我们证明,在特定的音乐属性方面,JAM的表现超过了现有模型。
论文及项目相关链接
PDF https://github.com/declare-lab/jamify
Summary
近期,扩散和流式匹配模型在自动文本到音频生成领域取得了革命性的进展。这些模型能生成高质量、逼真的音频输出,但在音乐创作等创造性音频生成方面仍有提升空间。现有的自动歌曲生成模型如DiffRhythm、ACE-Step和LeVo等虽已设定了娱乐用途的自动歌曲生成标准,但它们缺乏音乐家工作流程中通常所需的精细词级控制。我们的基于流式匹配的JAM模型首次实现了歌曲生成中的词级时序和持续时间控制,实现了精细的声乐控制。为提高生成歌曲的质量以更好地符合人类偏好,我们通过直接偏好优化实施美学对齐,使用合成数据集迭代优化模型,无需手动数据标注。此外,我们致力于通过公开评估数据集JAME来统一此类歌词到歌曲模型的评估标准。实验表明,JAM在音乐特定属性方面优于现有模型。
Key Takeaways
- 扩散和流式匹配模型在自动文本到音频生成中取得显著进展,特别是在语音和声音事件的生成方面。
- 现有自动歌曲生成模型如DiffRhythm、ACE-Step和LeVo等在娱乐用途上表现良好,但缺乏词级控制功能。
- JAM模型首次实现歌曲生成中的词级时序和持续时间控制,为音乐家提供更精细的声乐控制。
- 通过直接偏好优化实施美学对齐,使用合成数据集迭代优化模型,提高生成歌曲质量。
- 提出公开评估数据集JAME,以统一歌词到歌曲模型的评估标准。
- JAM模型在音乐特定属性方面优于现有模型。
点此查看论文截图
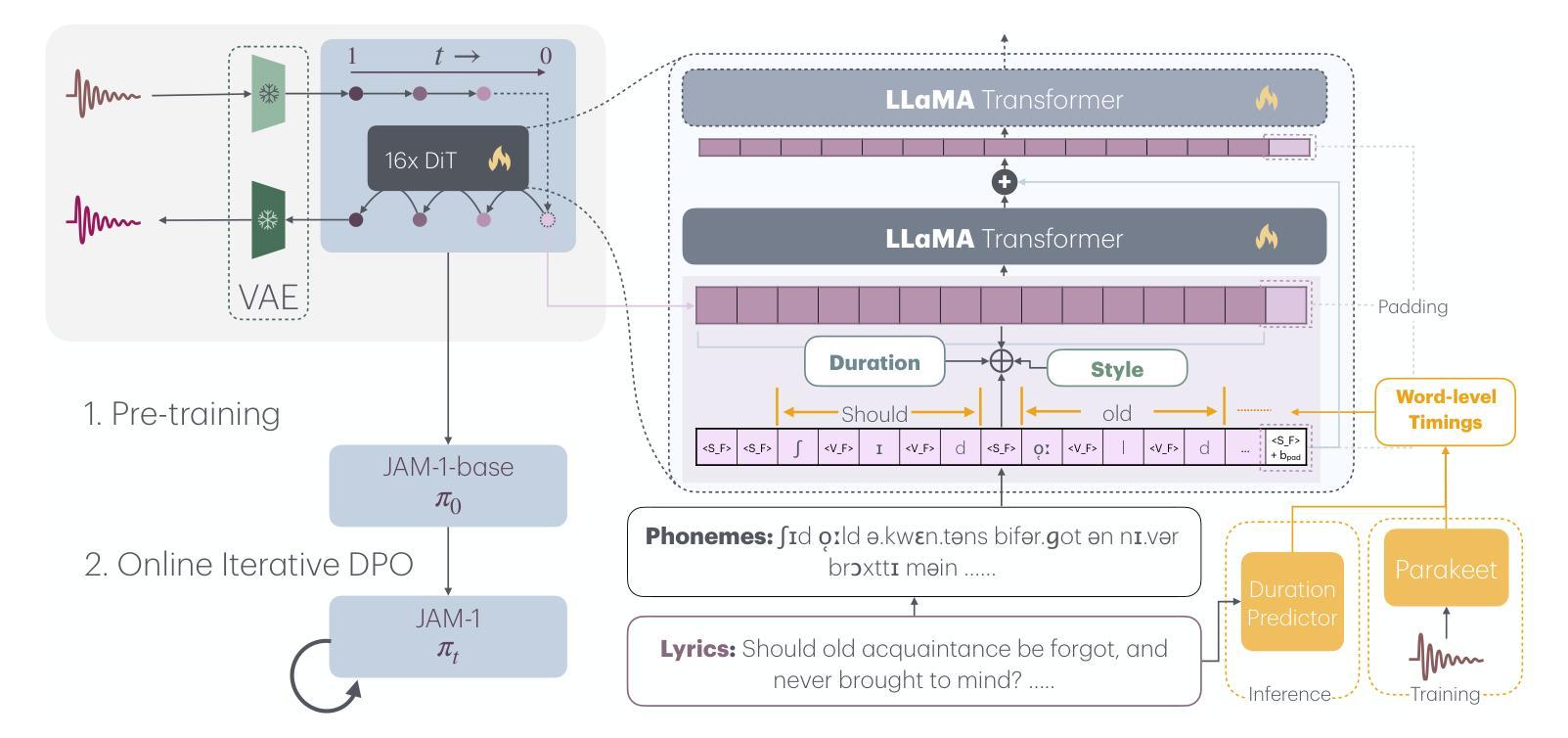

Learning Phonetic Context-Dependent Viseme for Enhancing Speech-Driven 3D Facial Animation
Authors:Hyung Kyu Kim, Hak Gu Kim
Speech-driven 3D facial animation aims to generate realistic facial movements synchronized with audio. Traditional methods primarily minimize reconstruction loss by aligning each frame with ground-truth. However, this frame-wise approach often fails to capture the continuity of facial motion, leading to jittery and unnatural outputs due to coarticulation. To address this, we propose a novel phonetic context-aware loss, which explicitly models the influence of phonetic context on viseme transitions. By incorporating a viseme coarticulation weight, we assign adaptive importance to facial movements based on their dynamic changes over time, ensuring smoother and perceptually consistent animations. Extensive experiments demonstrate that replacing the conventional reconstruction loss with ours improves both quantitative metrics and visual quality. It highlights the importance of explicitly modeling phonetic context-dependent visemes in synthesizing natural speech-driven 3D facial animation. Project page: https://cau-irislab.github.io/interspeech25/
语音驱动的3D面部动画旨在生成与音频同步的真实面部运动。传统方法主要通过将每一帧与地面真实数据进行比对来最小化重建损失。然而,这种逐帧的方法往往无法捕捉到面部运动的连续性,导致由于协同发音而产生抖动和不自然的输出。为了解决这一问题,我们提出了一种新型语音上下文感知损失,该损失能明确建模语音上下文对发音过渡的影响。通过引入发音协同权重,我们根据面部运动随时间变化的动态变化为其分配自适应重要性,确保更平滑和感知一致的动画。大量实验表明,用我们的方法替换传统的重建损失可以提高定量指标和视觉质量。它强调了明确建模语音上下文相关的发音在合成自然语音驱动的3D面部动画中的重要性。项目页面:https://cau-irislab.github.io/interspeech25/
论文及项目相关链接
PDF Accepted for Interspeech 2025 Project Page: https://cau-irislab.github.io/interspeech25/
Summary
语音驱动的3D面部动画旨在生成与音频同步的真实面部动作。传统方法主要通过最小化重建损失来对齐每一帧与真实值,但这种逐帧的方法往往无法捕捉面部动作的连续性,导致输出动作出现抖动和不自然的现象。为解决这一问题,我们提出了一种新颖的语音学语境感知损失函数,该函数显式地建模语音学语境对面部动作的影响。通过引入面部动作权重,我们根据时间动态变化对面部动作进行自适应重要性分配,确保动画更加流畅且视觉感知一致。实验表明,将传统的重建损失函数替换为我们的函数后,既能提升定量指标,也能提高视觉质量。这强调了明确建模依赖于语音学语境的面部动作在合成自然语音驱动的3D面部动画中的重要性。
Key Takeaways
- 语音驱动的3D面部动画旨在生成与音频同步的真实面部动作。
- 传统方法主要通过对齐每一帧与真实值来最小化重建损失,但这种方法无法捕捉面部动作的连续性。
- 提出的语音学语境感知损失函数能显式地建模语音学语境对面部动作的影响。
- 通过引入面部动作权重,该函数能确保动画更加流畅且视觉感知一致。
- 替换传统重建损失函数后,新的函数能提高动画的定量指标和视觉质量。
- 明确建模依赖于语音学语境的面部动作对于合成自然语音驱动的3D面部动画至关重要。
点此查看论文截图

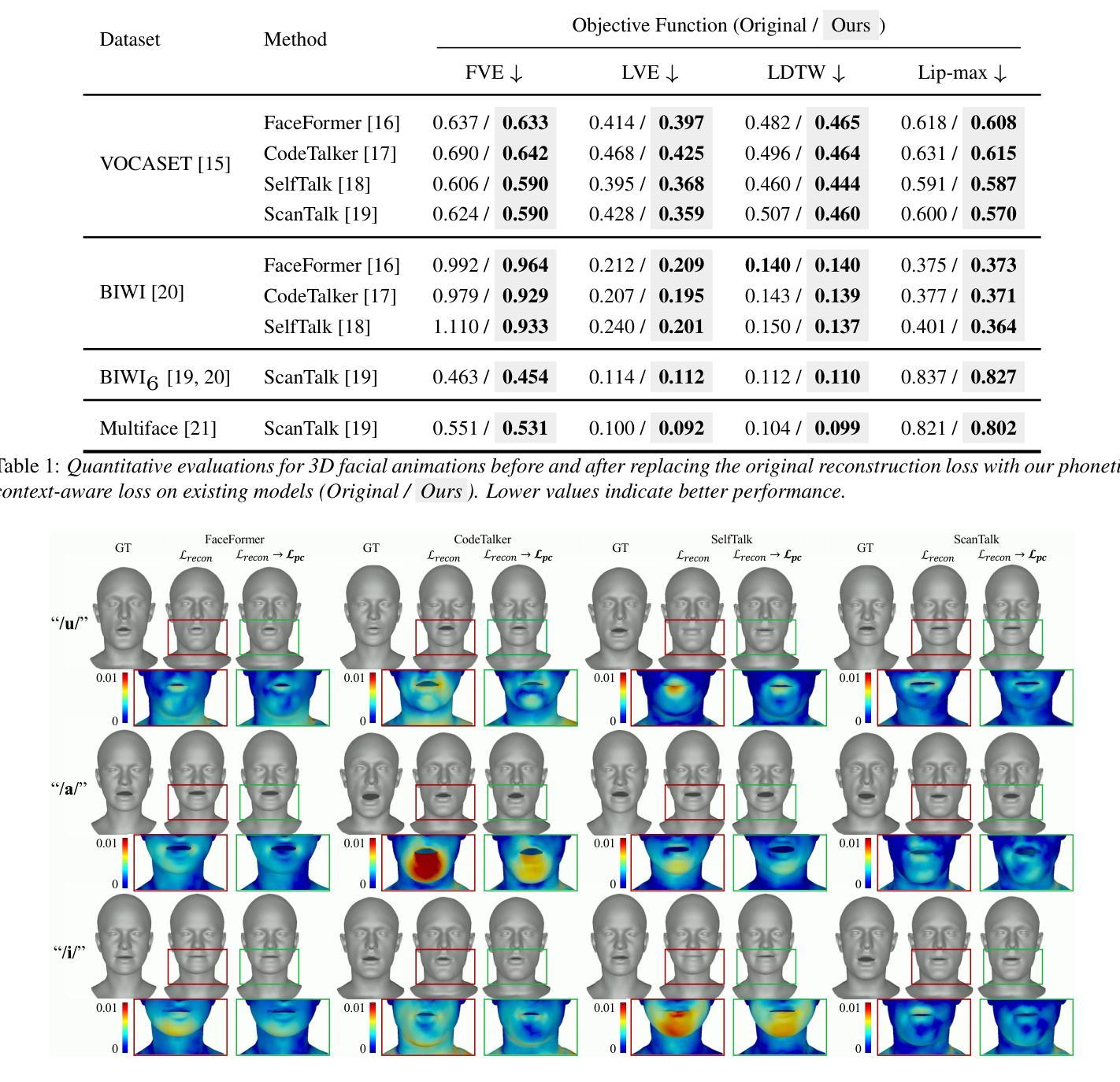
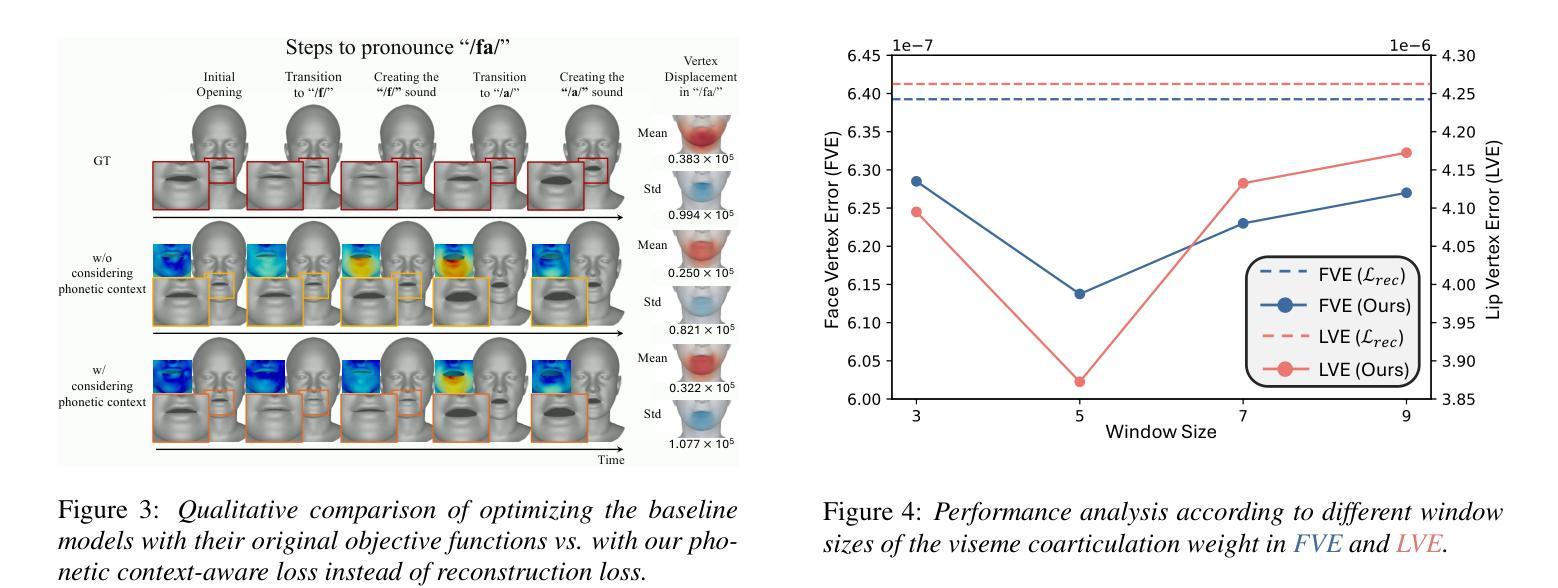
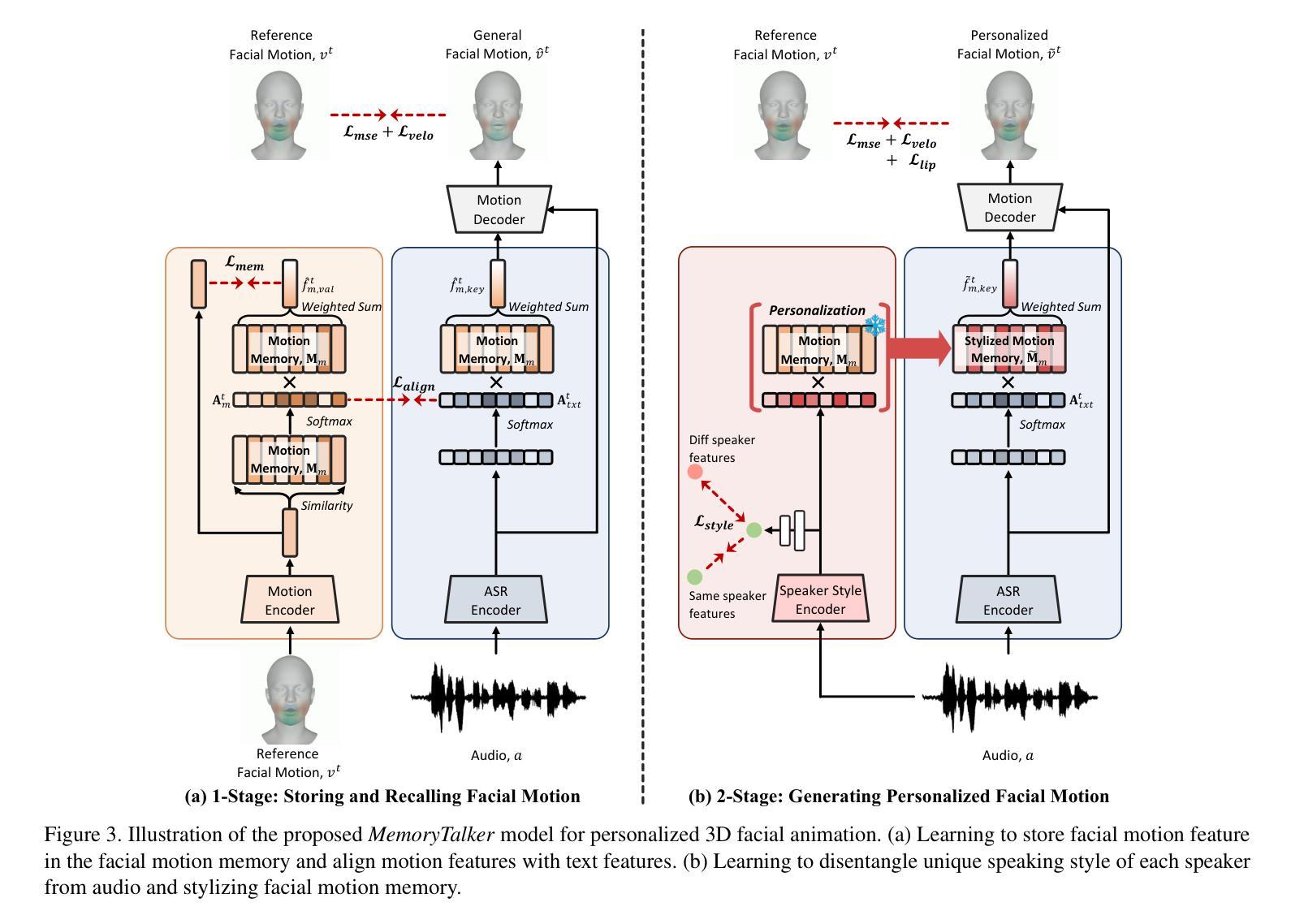
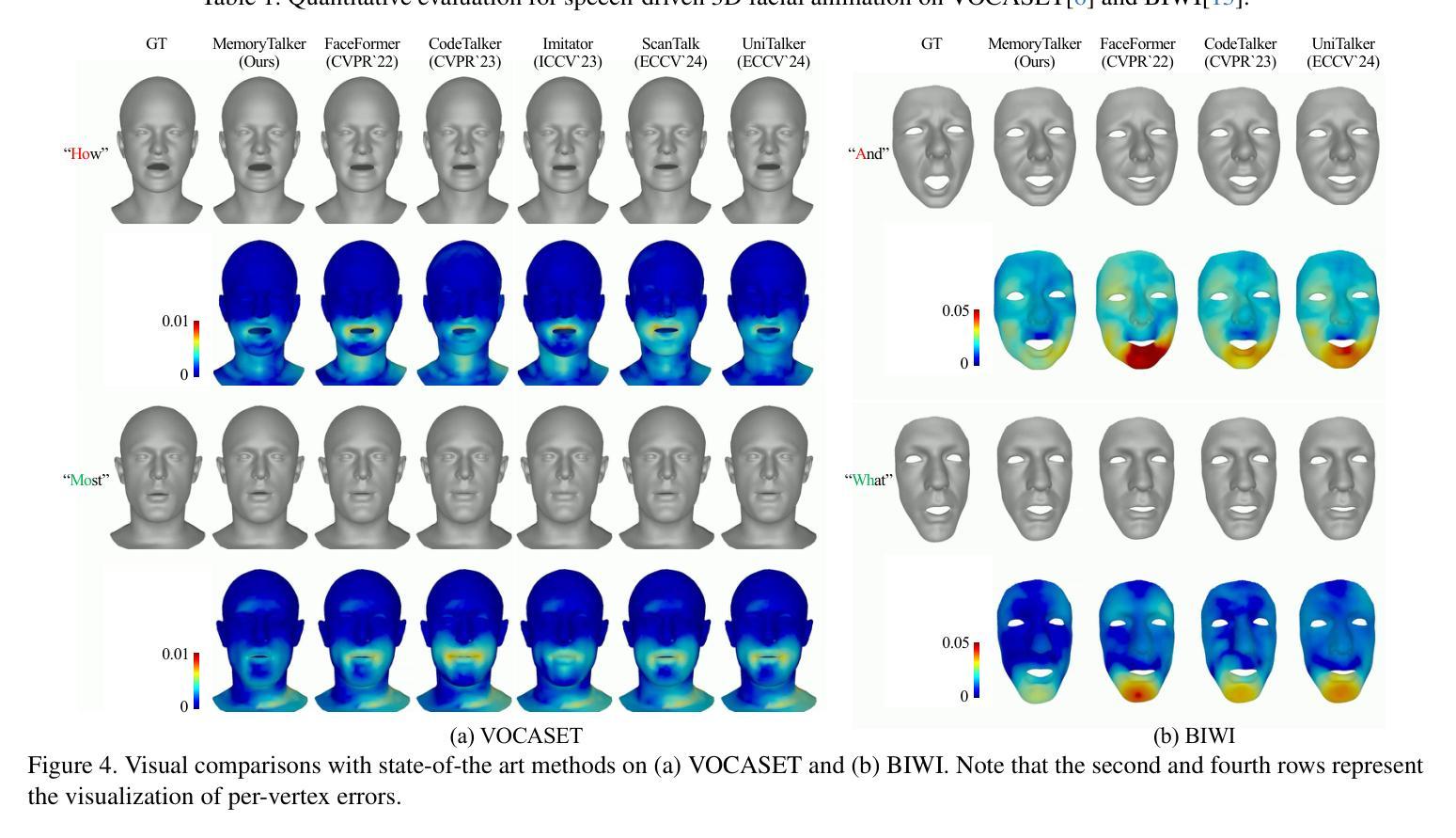
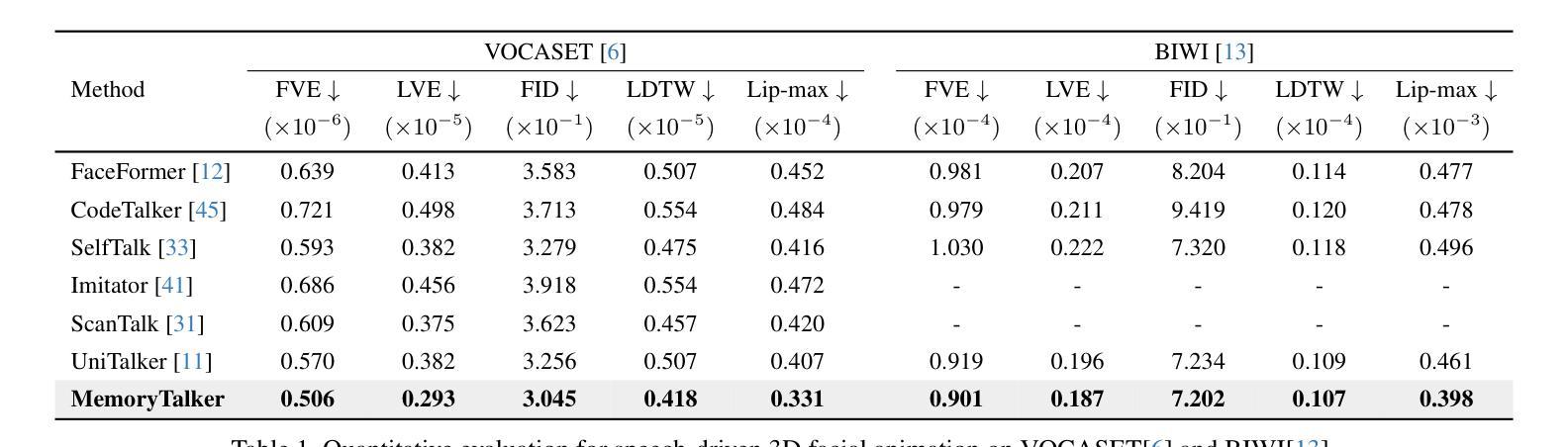
MemoryTalker: Personalized Speech-Driven 3D Facial Animation via Audio-Guided Stylization
Authors:Hyung Kyu Kim, Sangmin Lee, Hak Gu Kim
Speech-driven 3D facial animation aims to synthesize realistic facial motion sequences from given audio, matching the speaker’s speaking style. However, previous works often require priors such as class labels of a speaker or additional 3D facial meshes at inference, which makes them fail to reflect the speaking style and limits their practical use. To address these issues, we propose MemoryTalker which enables realistic and accurate 3D facial motion synthesis by reflecting speaking style only with audio input to maximize usability in applications. Our framework consists of two training stages: 1-stage is storing and retrieving general motion (i.e., Memorizing), and 2-stage is to perform the personalized facial motion synthesis (i.e., Animating) with the motion memory stylized by the audio-driven speaking style feature. In this second stage, our model learns about which facial motion types should be emphasized for a particular piece of audio. As a result, our MemoryTalker can generate a reliable personalized facial animation without additional prior information. With quantitative and qualitative evaluations, as well as user study, we show the effectiveness of our model and its performance enhancement for personalized facial animation over state-of-the-art methods.
语音驱动的3D面部动画旨在从给定的音频中合成逼真的面部运动序列,以匹配说话者的说话风格。然而,之前的工作通常需要先验信息,如说话者的类别标签或推理时的额外3D面部网格,这使得它们无法反映说话风格并限制了其实际应用。为了解决这些问题,我们提出了MemoryTalker,它仅通过音频输入反映说话风格,实现了逼真且准确的3D面部运动合成,以在应用程序中最大限度地提高可用性。我们的框架由两个训练阶段组成:第一阶段是存储和检索一般运动(即记忆),第二阶段是执行个性化的面部运动合成(即动画)与由音频驱动的说话风格特征所形成运动记忆。在第二阶段,我们的模型学习对于特定音频应强调哪些面部运动类型。因此,我们的MemoryTalker可以在没有额外先验信息的情况下生成可靠的个性化面部动画。通过定量和定性评估以及用户研究,我们证明了模型的有效性及其在个性化面部动画方面相较于最新方法的性能提升。
论文及项目相关链接
PDF Accepted for ICCV 2025 Project Page: https://cau-irislab.github.io/ICCV25-MemoryTalker/
Summary
本文介绍了Speech-driven 3D面部动画技术的新进展。针对现有技术需要先验信息(如说话者类别标签或额外的3D面部网格)的问题,提出了一种新的方法MemoryTalker。该方法仅通过音频输入反映说话风格,实现真实且准确的3D面部运动合成,提高了实用性。该方法包括存储和检索通用运动的阶段(即记忆阶段)以及使用音频驱动的说话风格特征进行个性化面部运动合成(即动画阶段)。实验和用户研究证明了该方法的有效性及其在个性化面部动画方面的性能提升。
Key Takeaways
- Speech-driven 3D面部动画旨在从给定的音频中合成逼真的面部运动序列,匹配说话者的说话风格。
- 现有技术通常需要先验信息,如说话者的类别标签或额外的3D面部网格,这限制了其实际应用。
- MemoryTalker方法通过仅使用音频输入反映说话风格,实现了真实且准确的3D面部运动合成。
- MemoryTalker方法包括两个训练阶段:存储和检索通用运动的记忆阶段以及使用运动记忆进行个性化面部运动合成的动画阶段。
- 在动画阶段,模型学习了针对特定音频应强调哪些面部运动类型。
- MemoryTalker能够在没有额外先验信息的情况下生成可靠的个性化面部动画。
点此查看论文截图

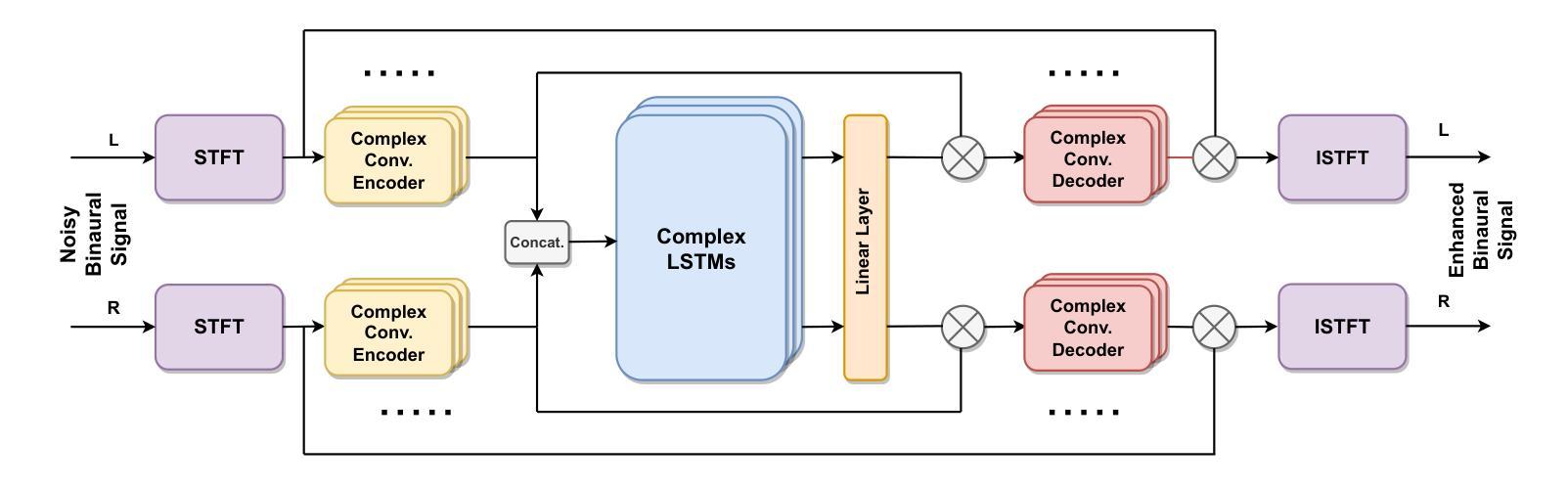
Binaural Speech Enhancement Using Complex Convolutional Recurrent Networks
Authors:Vikas Tokala, Eric Grinstein, Mike Brookes, Simon Doclo, Jesper Jensen, Patrick A. Naylor
From hearing aids to augmented and virtual reality devices, binaural speech enhancement algorithms have been established as state-of-the-art techniques to improve speech intelligibility and listening comfort. In this paper, we present an end-to-end binaural speech enhancement method using a complex recurrent convolutional network with an encoder-decoder architecture and a complex LSTM recurrent block placed between the encoder and decoder. A loss function that focuses on the preservation of spatial information in addition to speech intelligibility improvement and noise reduction is introduced. The network estimates individual complex ratio masks for the left and right-ear channels of a binaural hearing device in the time-frequency domain. We show that, compared to other baseline algorithms, the proposed method significantly improves the estimated speech intelligibility and reduces the noise while preserving the spatial information of the binaural signals in acoustic situations with a single target speaker and isotropic noise of various types.
从助听器到增强和虚拟现实设备,双耳语音增强算法已被确立为最先进的技术,用于提高语音清晰度和听觉舒适度。在本文中,我们提出了一种端到端的双耳语音增强方法,该方法使用具有编码器-解码器架构的复杂循环卷积网络,并在编码器和解码器之间放置了一个复杂的LSTM循环块。除了提高语音清晰度和降低噪声外,还引入了一种损失函数,该函数专注于保留空间信息。该网络在时频域估计双耳听力设备的左右声道个别复杂比率掩模。我们表明,与其他基线算法相比,所提出的方法在单目标说话人和各种类型同向噪声的声学情况下,能显著提高估计的语音清晰度,降低噪声,同时保留双耳信号的空间信息。
论文及项目相关链接
Summary
本文介绍了一种端到端的双耳语音增强方法,采用复杂循环卷积网络,具有编码器-解码器架构,并在编码器和解码器之间设置了一个复杂的LSTM循环块。引入了一种损失函数,侧重于保留空间信息,同时提高语音清晰度并减少噪音。该方法估计双耳听力设备的左右声道的复数比率掩模,在单目标说话人和各种类型同向噪声的声学环境中,相比其他基线算法,显著改善语音清晰度并降低噪音,同时保留双耳信号的空间信息。
Key Takeaways
- 本文提出了一种新的端到端的双耳语音增强方法,采用复杂循环卷积网络和编码器-解码器架构。
- 该方法在编码器和解码器之间使用了复杂的LSTM循环块以提高语音清晰度。
- 引入了一种新的损失函数,该函数在保留空间信息的同时,专注于提高语音清晰度并减少噪音。
- 该方法可以估计双耳听力设备的左右声道的复数比率掩模。
- 在单目标说话人和各种类型同向噪声的声学环境中,该方法相比其他基线算法更有效。
- 实验结果显示,该方法能显著改善语音清晰度并降低噪音。
点此查看论文截图

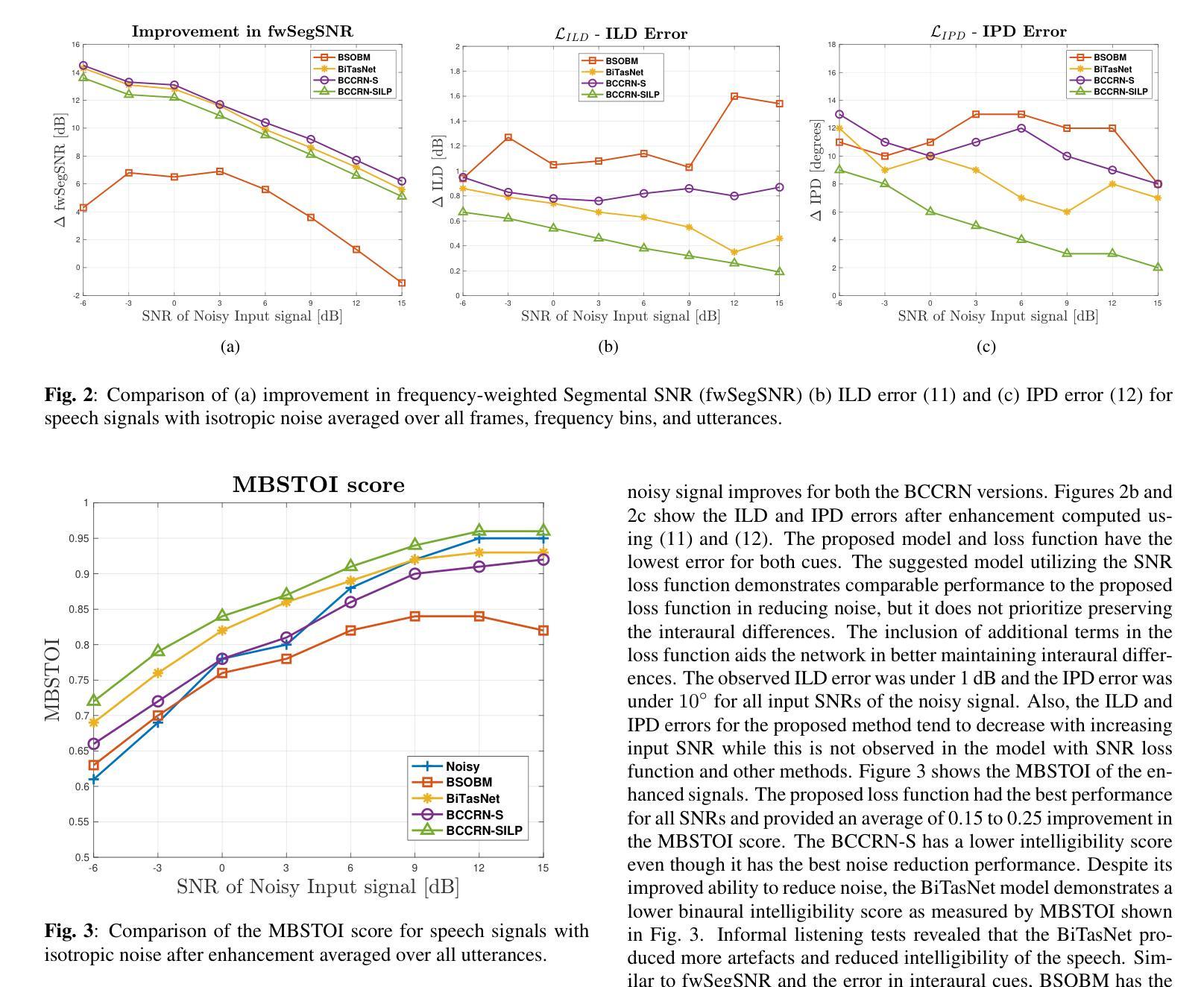
HITSZ’s End-To-End Speech Translation Systems Combining Sequence-to-Sequence Auto Speech Recognition Model and Indic Large Language Model for IWSLT 2025 in Indic Track
Authors:Xuchen Wei, Yangxin Wu, Yaoyin Zhang, Henglyu Liu, Kehai Chen, Xuefeng Bai, Min Zhang
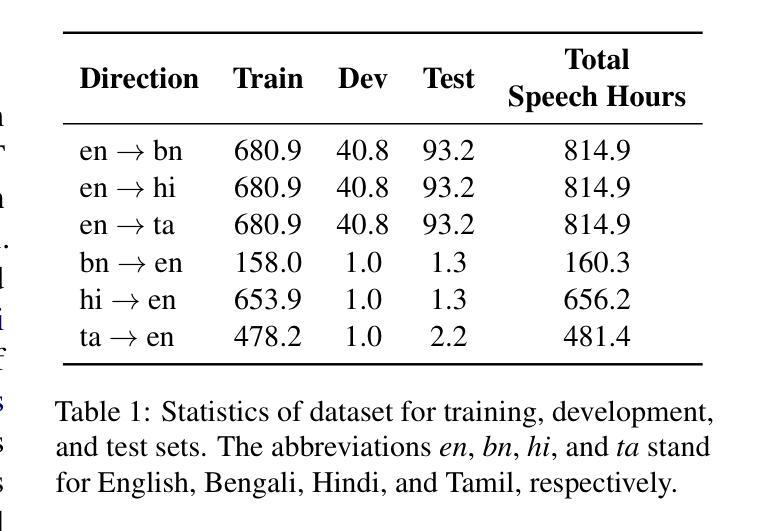
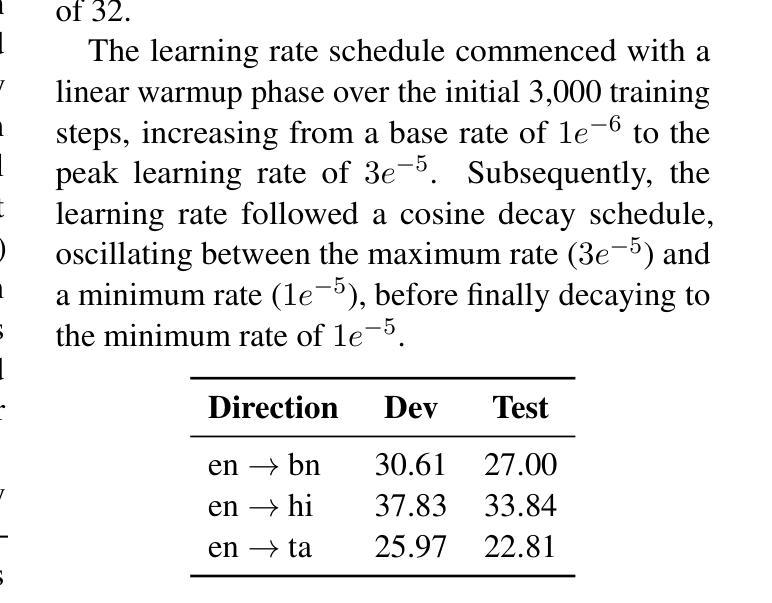
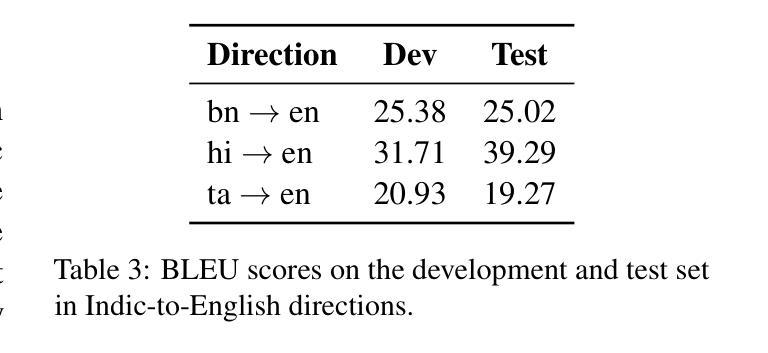
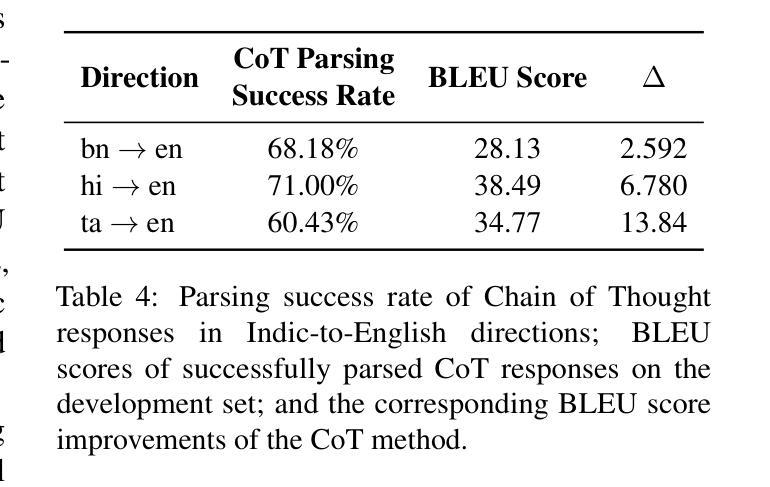
This paper presents HITSZ’s submission for the IWSLT 2025 Indic track, focusing on speech-to-text translation (ST) for English-to-Indic and Indic-to-English language pairs. To enhance translation quality in this low-resource scenario, we propose an end-to-end system integrating the pre-trained Whisper automated speech recognition (ASR) model with Krutrim, an Indic-specialized large language model (LLM). Experimental results demonstrate that our end-to-end system achieved average BLEU scores of $28.88$ for English-to-Indic directions and $27.86$ for Indic-to-English directions. Furthermore, we investigated the Chain-of-Thought (CoT) method. While this method showed potential for significant translation quality improvements on successfully parsed outputs (e.g. a $13.84$ BLEU increase for Tamil-to-English), we observed challenges in ensuring the model consistently adheres to the required CoT output format.
本文介绍了HITSZ为IWSLT 2025印地语赛道提交的方案,重点聚焦英文-印地语和印地语-英文的语音到文本(ST)翻译。为了在这种资源稀缺的场景中提高翻译质量,我们提出了一种端到端的系统,该系统集成了预训练的Whisper自动语音识别(ASR)模型和Krutrim——一款印地语专用的大型语言模型(LLM)。实验结果表明,我们的端到端系统在英文到印地语的翻译方向平均BLEU得分为28.88,印地语到英文的翻译方向平均BLEU得分为27.86。此外,我们还研究了思维链(CoT)方法。虽然该方法在成功解析的输出上显示出提高翻译质量的潜力(例如泰米尔语到英语的BLEU得分提高了13.84),但我们发现在确保模型始终遵循所需的CoT输出格式方面存在挑战。
论文及项目相关链接
PDF 7 pages, 1 figure, submitted to IWSLT 2025
Summary
这篇论文介绍了HITSZ在IWSLT 2025 Indic轨道上的提交内容,聚焦于英语到印地语和印地语到英语的语音识别翻译(ST)。为提升低资源场景下的翻译质量,我们提出了一种端到端的系统,整合了预训练的Whisper自动语音识别(ASR)模型和Krutrim——一款针对印地语的专用大型语言模型(LLM)。实验结果显示,我们的系统在英语到印地语方向平均BLEU得分为28.88,印地语到英语方向为27.86。此外,我们还研究了链式思维(CoT)方法。虽然该方法在成功解析的输出上显示出提高翻译质量的潜力(如泰米尔语到英语的BLEU得分提高了13.84),但我们也面临着确保模型始终遵循所需的CoT输出格式的难题。
Key Takeaways
- HITSZ团队在IWSLT 2025 Indic轨道上的研究集中于英语到印地语和印地语到英语的语音到文本翻译。
- 提出了一种端到端的翻译系统,结合了预训练的Whisper自动语音识别模型和Krutrim大型语言模型。
- 实验结果显示,该系统在英语到印地语和印地语到英语的翻译中取得了较高的BLEU得分。
- 论文探讨了链式思维(CoT)方法在翻译质量提升方面的潜力,尤其在成功解析的输出上表现显著。
- CoT方法面临确保模型遵循所需输出格式的难题。
- 研究表明,在资源有限的情况下,整合现有技术如ASR和LLM能有效提升翻译质量。
点此查看论文截图

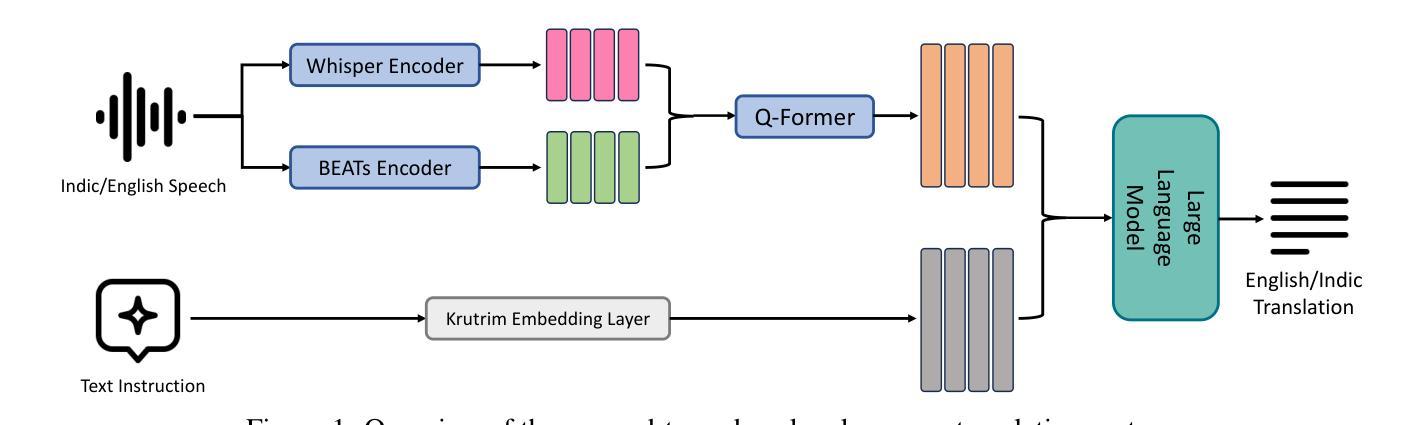
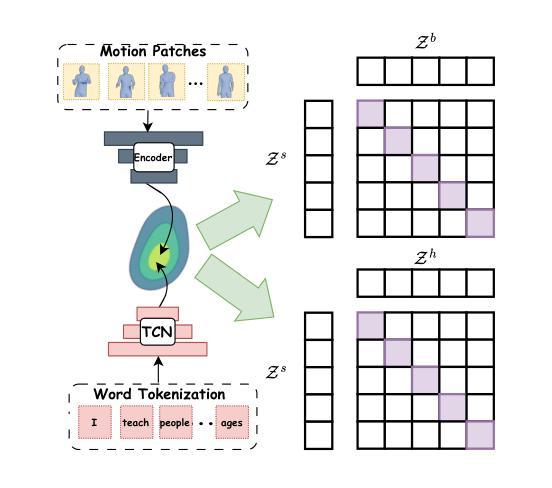
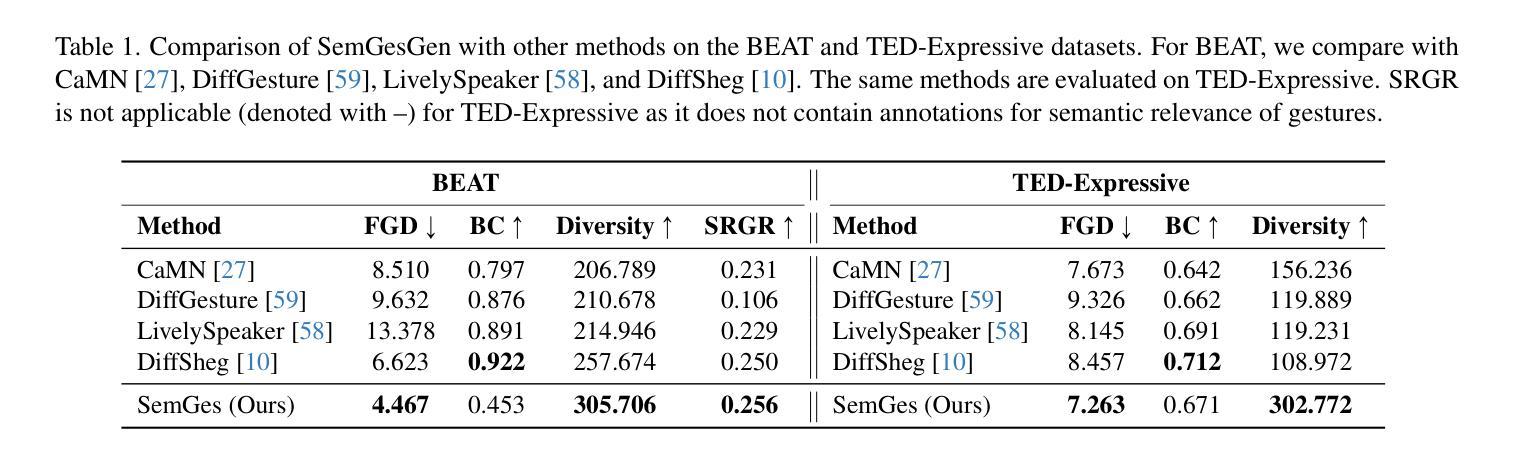
SemGes: Semantics-aware Co-Speech Gesture Generation using Semantic Coherence and Relevance Learning
Authors:Lanmiao Liu, Esam Ghaleb, Aslı Özyürek, Zerrin Yumak
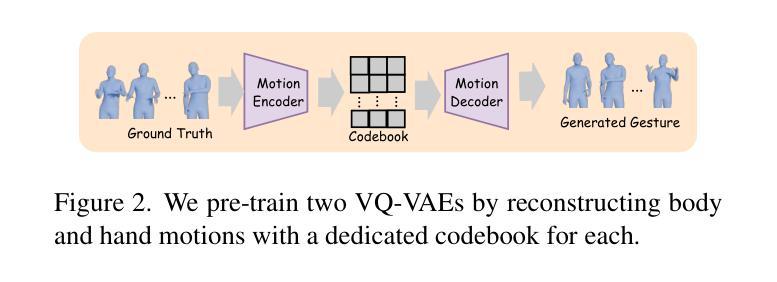
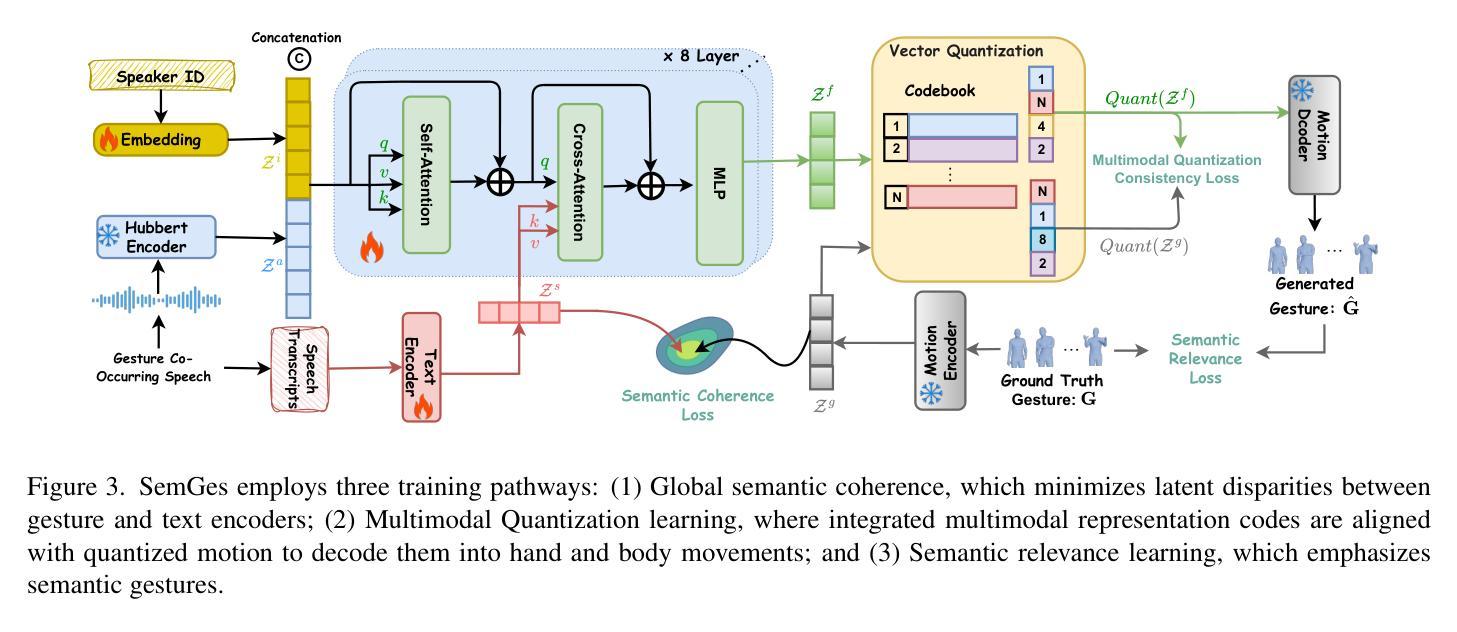
Creating a virtual avatar with semantically coherent gestures that are aligned with speech is a challenging task. Existing gesture generation research mainly focused on generating rhythmic beat gestures, neglecting the semantic context of the gestures. In this paper, we propose a novel approach for semantic grounding in co-speech gesture generation that integrates semantic information at both fine-grained and global levels. Our approach starts with learning the motion prior through a vector-quantized variational autoencoder. Built on this model, a second-stage module is applied to automatically generate gestures from speech, text-based semantics and speaker identity that ensures consistency between the semantic relevance of generated gestures and co-occurring speech semantics through semantic coherence and relevance modules. Experimental results demonstrate that our approach enhances the realism and coherence of semantic gestures. Extensive experiments and user studies show that our method outperforms state-of-the-art approaches across two benchmarks in co-speech gesture generation in both objective and subjective metrics. The qualitative results of our model, code, dataset and pre-trained models can be viewed at https://semgesture.github.io/.
创建与语音对齐的具有语义连贯手势的虚拟化身是一项具有挑战性的任务。现有的手势生成研究主要集中在生成有节奏的节奏手势上,忽视了手势的语义上下文。在本文中,我们提出了一种新颖的协同语音手势生成中的语义定位方法,该方法在精细粒度和全局层面都整合了语义信息。我们的方法首先通过学习运动先验知识,通过向量量化变分自动编码器。在此基础上,应用第二阶段模块,从语音、文本语义和说话人身份自动生成手势,通过语义连贯性和相关性模块确保生成手势的语义相关性与协同发生的语音语义之间的一致性。实验结果表明,我们的方法提高了语义手势的真实性和连贯性。大量的实验和用户研究表明,我们的方法在协同语音手势生成的两个方面都优于最先进的方法,即在客观和主观指标上均有所超越。该模型的定性结果、代码、数据集和预训练模型可在https://semgesture.github.io/查看。
论文及项目相关链接
PDF Accepted to IEEE/CVF International Conference on Computer Vision (ICCV) 2025
Summary
本文提出一种新颖的语义定位协同语音手势生成方法,该方法在精细粒度和全局层面都集成了语义信息。通过向量量化变分自编码器学习运动先验,然后应用第二阶段模块自动从语音、文本语义和说话人身份生成手势,确保生成手势的语义相关性与协同发生的语音语义之间的一致性。实验结果证明,该方法提高了语义手势的真实性和连贯性,并在两个协同语音手势生成基准测试中客观和主观指标上均优于现有技术。
Key Takeaways
- 本文提出了一种新颖的语义定位协同语音手势生成方法。
- 该方法集成了语义信息在精细粒度和全局两个层面。
- 通过向量量化变分自编码器学习运动先验。
- 自动从语音、文本语义和说话人身份生成手势。
- 生成的手势与协同发生的语音语义之间保持一致性。
- 实验和用户研究证明该方法在客观和主观指标上均优于现有技术。
点此查看论文截图

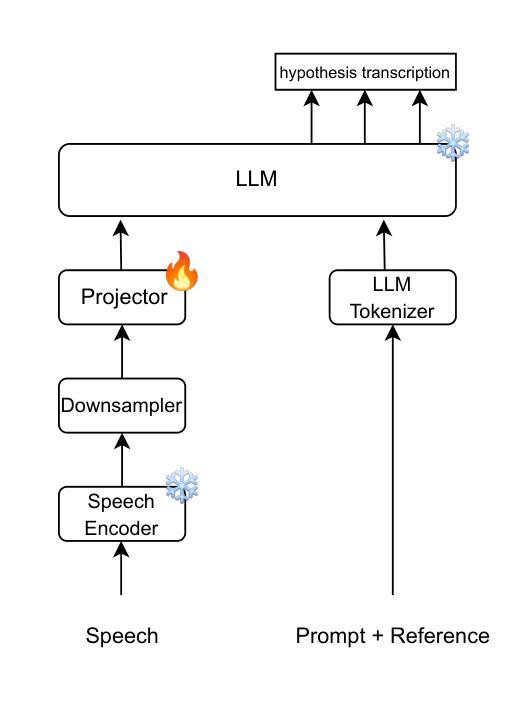
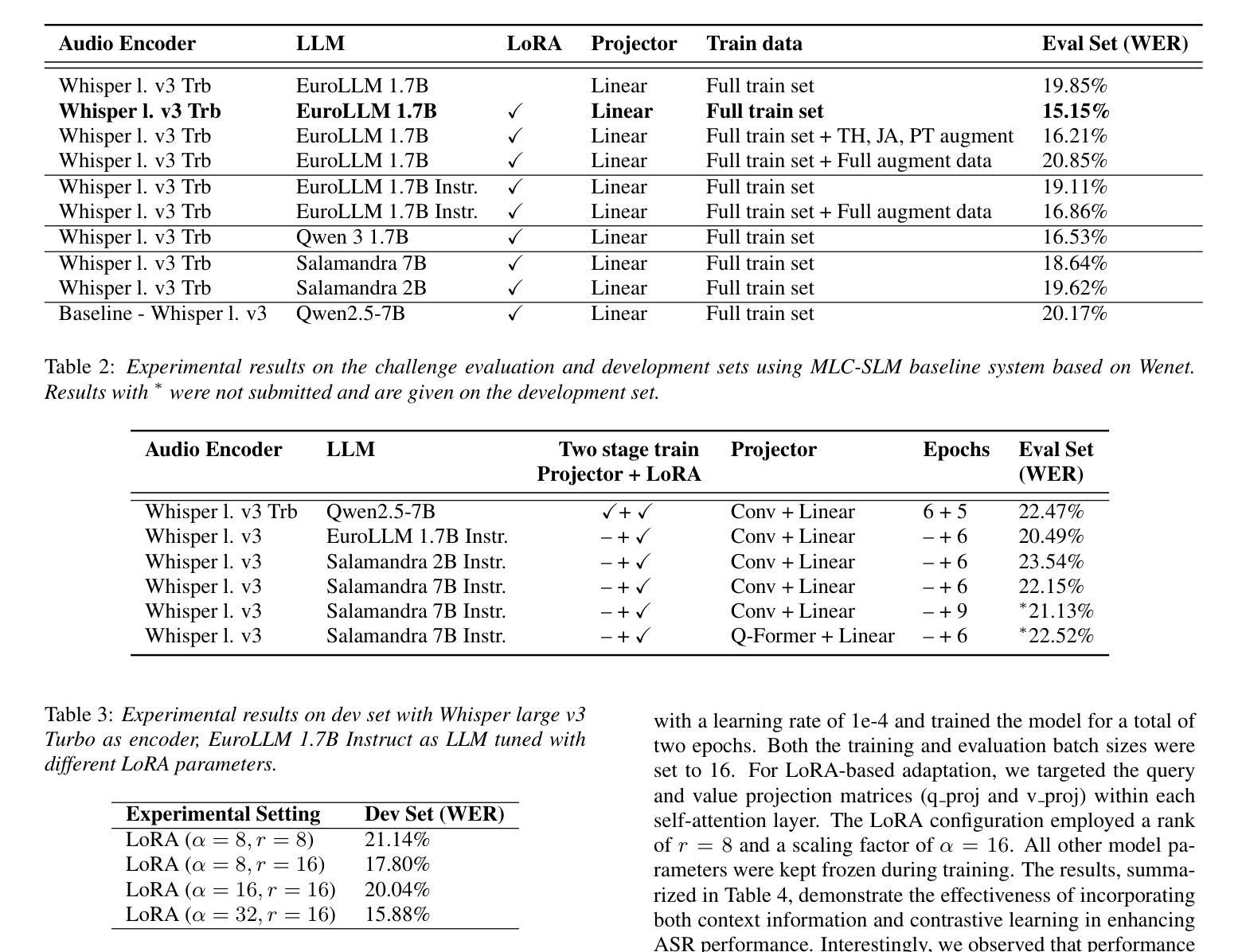
The Eloquence team submission for task 1 of MLC-SLM challenge
Authors:Lorenzo Concina, Jordi Luque, Alessio Brutti, Marco Matassoni, Yuchen Zhang
In this paper, we present our studies and experiments carried out for the task 1 of the Challenge and Workshop on Multilingual Conversational Speech Language Model (MLC-SLM), which focuses on advancing multilingual conversational speech recognition through the development of speech language models architectures. Given the increasing relevance of real-world conversational data for building robust Spoken Dialogue Systems, we explore three approaches to multilingual ASR. First, we conduct an evaluation of the official baseline to better understand its strengths and limitations, by training two projectors (linear and qformer) with different foundation models. Second we leverage the SLAM-ASR framework to train a custom multilingual linear projector. Finally we investigate the role of contrastive learning and the extended conversational context in enhancing the robustness of recognition.
在这篇论文中,我们展示了针对多语言对话语音语言模型挑战与研讨会(MLC-SLM)任务一的研究和实验。该任务旨在通过发展语音语言模型架构,推动多语言对话语音识别的发展。鉴于现实世界对话数据对于构建稳健的口语对话系统越来越重要,我们探索了三种多语言自动语音识别(ASR)的方法。首先,我们通过训练两种投影仪(线性投影仪和Qformer投影仪)来评估官方基线方案的优势和不足,从而更好地了解其优势和局限性。其次,我们利用SLAM-ASR框架训练一个自定义的多语言线性投影仪。最后,我们探讨了对比学习和扩展对话上下文在提高识别稳健性方面的作用。
论文及项目相关链接
PDF Technical Report for MLC-SLM Challenge of Interspeech2025
Summary
该研究论文聚焦于在挑战和研讨会上进行的针对多任务口语语言模型的任务一的实验和研究。研究致力于推进多语种会话语音识别的发展,通过对官方基线模型进行测评来了解其优点和局限性,并探讨了使用不同基础模型的投影器训练方式。同时,研究还采用了SLAM-ASR框架训练了自定义的多语种线性投影器,并探究了对比学习和扩展会话语境在提高识别鲁棒性方面的作用。
Key Takeaways
- 研究关注于多任务口语语言模型任务一的实验和研究,致力于推进多语种会话语音识别技术的发展。
- 通过测评官方基线模型来了解其优点和局限性。
- 研究探讨了使用不同基础模型的投影器训练方法,包括线性投影器和qformer投影器。
- 采用SLAM-ASR框架训练自定义的多语种线性投影器。
- 研究发现对比学习在提高语音识别鲁棒性方面发挥了重要作用。
- 扩展会话语境对增强识别系统的鲁棒性有一定帮助。
点此查看论文截图

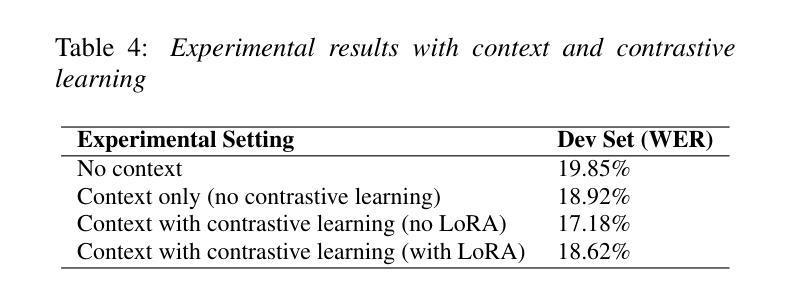
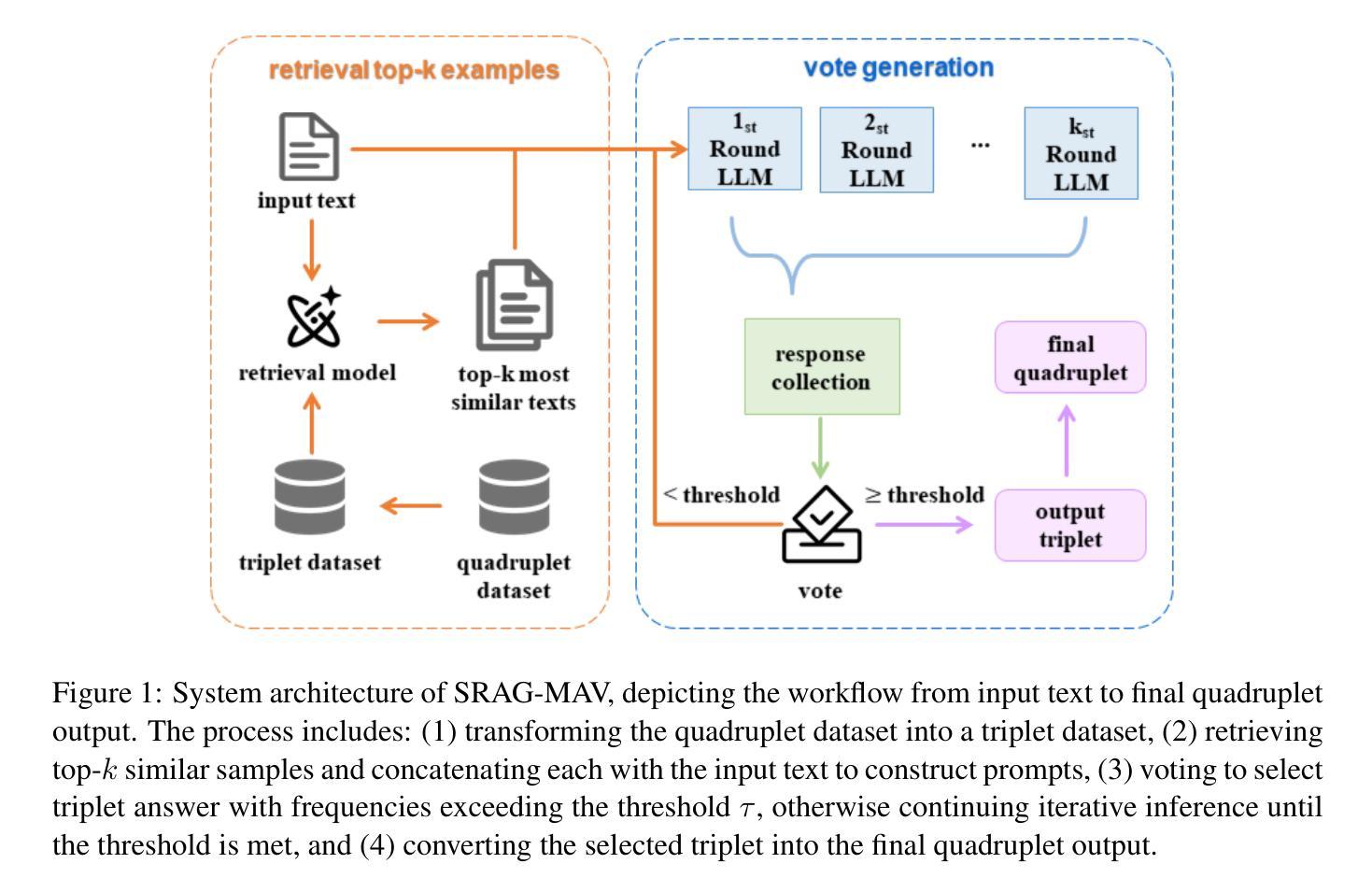
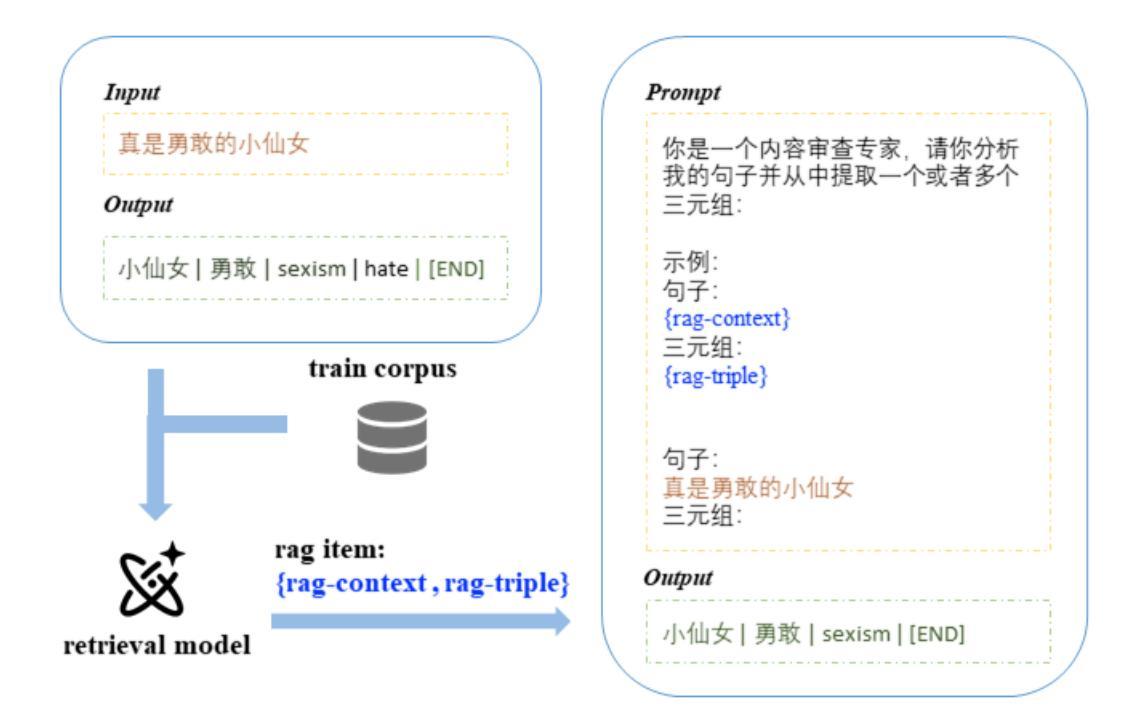
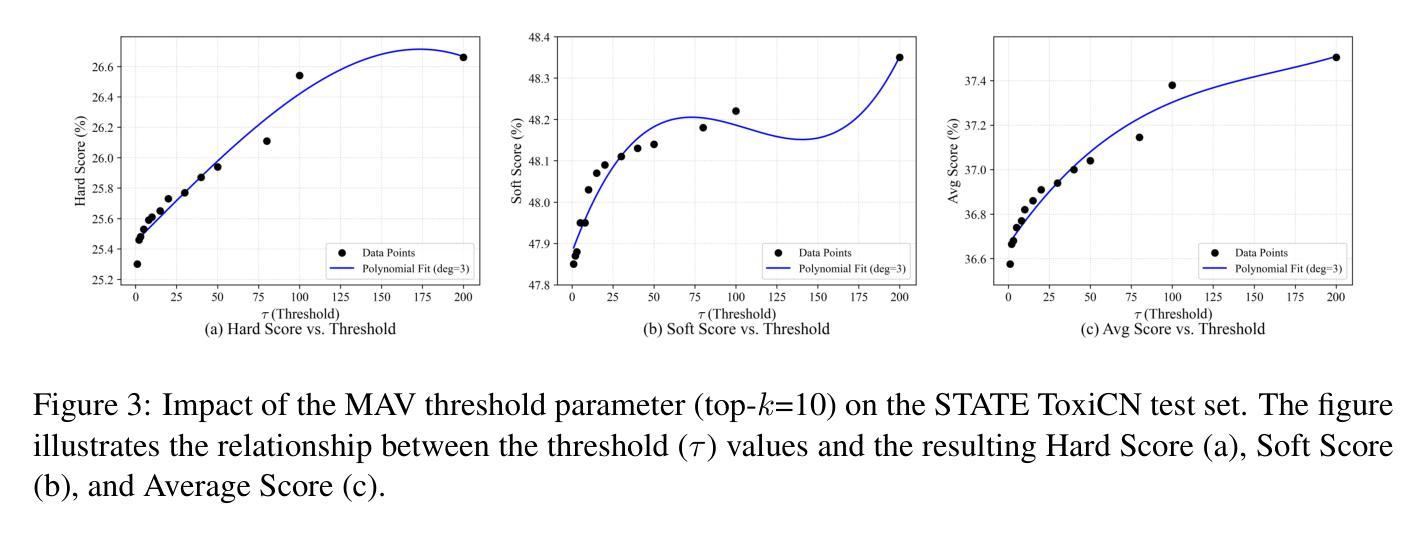
System Report for CCL25-Eval Task 10: SRAG-MAV for Fine-Grained Chinese Hate Speech Recognition
Authors:Jiahao Wang, Ramen Liu, Longhui Zhang, Jing Li
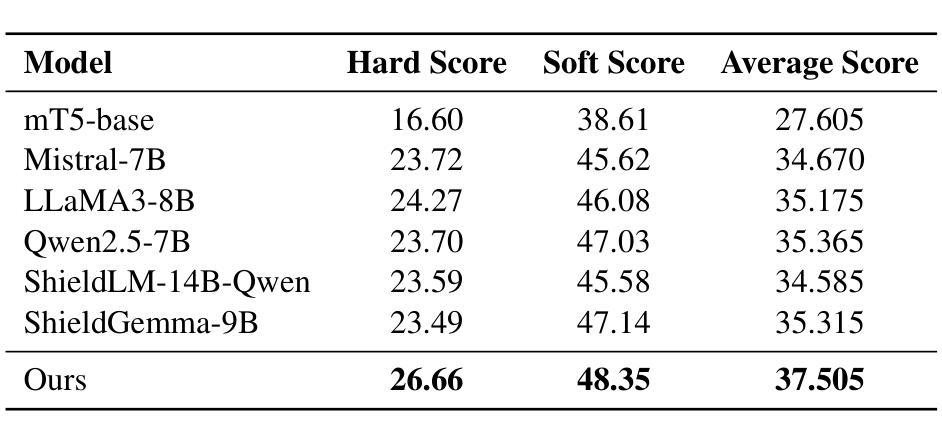
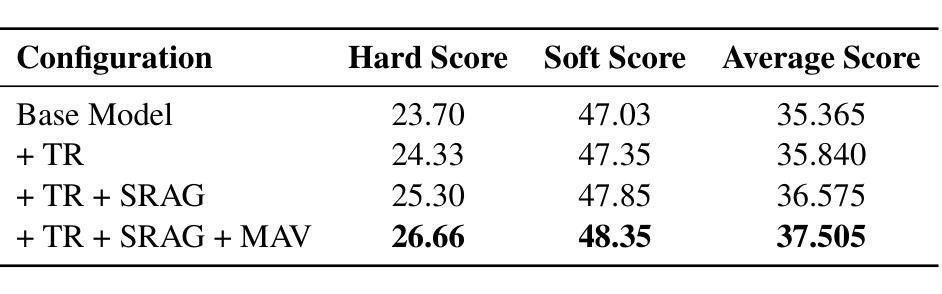
This paper presents our system for CCL25-Eval Task 10, addressing Fine-Grained Chinese Hate Speech Recognition (FGCHSR). We propose a novel SRAG-MAV framework that synergistically integrates task reformulation(TR), Self-Retrieval-Augmented Generation (SRAG), and Multi-Round Accumulative Voting (MAV). Our method reformulates the quadruplet extraction task into triplet extraction, uses dynamic retrieval from the training set to create contextual prompts, and applies multi-round inference with voting to improve output stability and performance. Our system, based on the Qwen2.5-7B model, achieves a Hard Score of 26.66, a Soft Score of 48.35, and an Average Score of 37.505 on the STATE ToxiCN dataset, significantly outperforming baselines such as GPT-4o (Average Score 15.63) and fine-tuned Qwen2.5-7B (Average Score 35.365). The code is available at https://github.com/king-wang123/CCL25-SRAG-MAV.
本文介绍了我们在CCL25-Eval Task 10的系统,该系统专注于精细粒度的中文仇恨言论识别(FGCHSR)。我们提出了一种新颖的SRAG-MAV框架,该框架协同整合了任务重构(TR)、自检索增强生成(SRAG)和多轮累积投票(MAV)。我们的方法将四元组提取任务重新构建为三元组提取,使用训练集的动态检索来创建上下文提示,并应用多轮推理和投票来提高输出稳定性和性能。我们的系统基于Qwen2.5-7B模型,在STATE ToxiCN数据集上实现了硬分数26.66,软分数48.35,平均分数37.505,显著超越了GPT-4o(平均分数15.63)和经过微调后的Qwen2.5-7B模型(平均分数为35.365)。代码可访问于 https://github.com/king-wang123/CCL25-SRAG-MAV。
论文及项目相关链接
PDF 8 pages, 3 figures, accepted as oral presentation at CCL25-Eval
Summary
系统针对精细粒度中文仇恨言论识别任务(FGCHSR)提出新的SRAG-MAV框架,包括任务重新表述(TR)、自我检索增强生成(SRAG)和多轮累积投票(MAV)。通过改革四元组提取任务为三元组提取,使用训练集的动态检索创建上下文提示,并应用多轮推理和投票来提高输出稳定性和性能。在STATE ToxiCN数据集上,基于Qwen2.5-7B模型的该系统取得了显著成绩,平均得分37.505,明显优于GPT-4o和微调后的Qwen2.5-7B基线模型。代码已公开于GitHub。
Key Takeaways
- 系统针对Fine-Grained Chinese Hate Speech Recognition (FGCHSR)任务设计。
- 提出新的SRAG-MAV框架,整合任务重新表述、自我检索增强生成和多轮累积投票技术。
- 改革四元组提取任务为三元组提取以简化处理。
- 使用动态检索从训练集中创建上下文提示以增强模型理解。
- 多轮推理和投票提高输出稳定性和性能。
- 在STATE ToxiCN数据集上取得显著成绩,平均得分优于其他基线模型。
点此查看论文截图

Restoring Rhythm: Punctuation Restoration Using Transformer Models for Bangla, a Low-Resource Language
Authors:Md Obyedullahil Mamun, Md Adyelullahil Mamun, Arif Ahmad, Md. Imran Hossain Emu
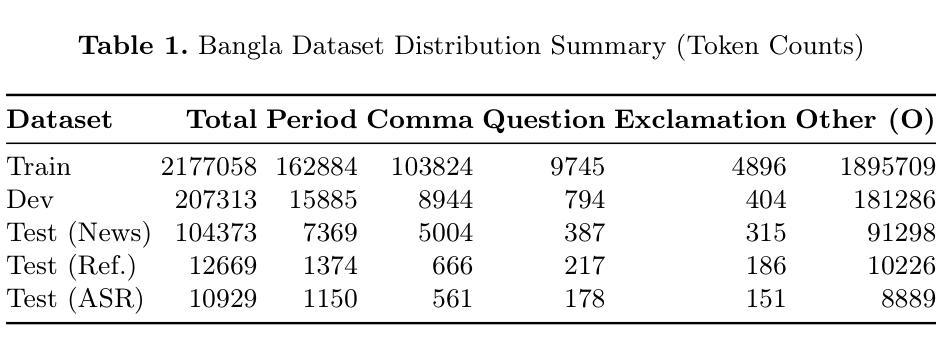
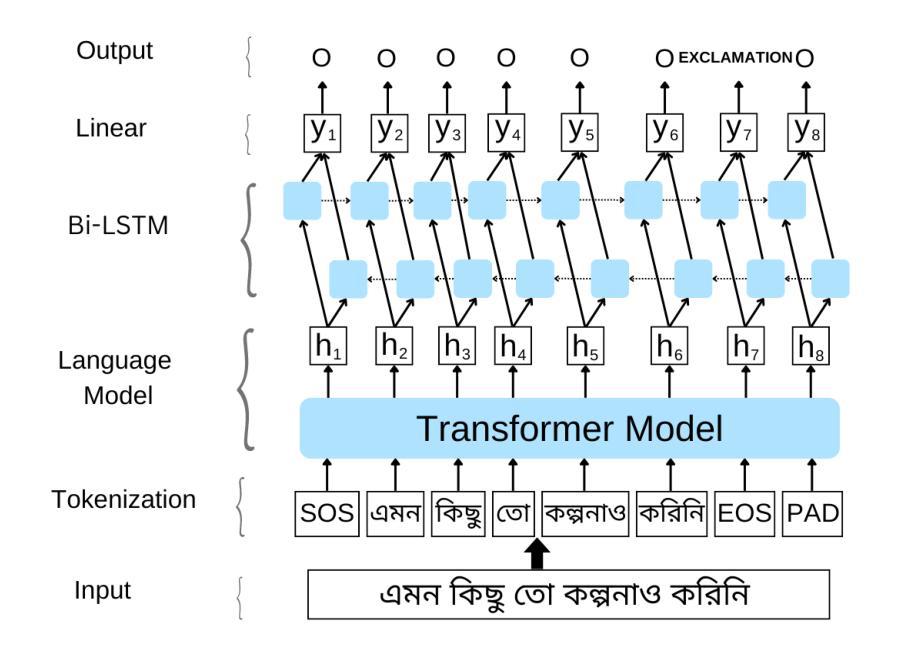
Punctuation restoration enhances the readability of text and is critical for post-processing tasks in Automatic Speech Recognition (ASR), especially for low-resource languages like Bangla. In this study, we explore the application of transformer-based models, specifically XLM-RoBERTa-large, to automatically restore punctuation in unpunctuated Bangla text. We focus on predicting four punctuation marks: period, comma, question mark, and exclamation mark across diverse text domains. To address the scarcity of annotated resources, we constructed a large, varied training corpus and applied data augmentation techniques. Our best-performing model, trained with an augmentation factor of alpha = 0.20%, achieves an accuracy of 97.1% on the News test set, 91.2% on the Reference set, and 90.2% on the ASR set. Results show strong generalization to reference and ASR transcripts, demonstrating the model’s effectiveness in real-world, noisy scenarios. This work establishes a strong baseline for Bangla punctuation restoration and contributes publicly available datasets and code to support future research in low-resource NLP.
标点符号的恢复提高了文本的可读性,对于语音识别(ASR)的后处理任务至关重要,尤其是对孟加拉语等低资源语言而言。在这项研究中,我们探索了基于变换器模型的应用,特别是大型的XLM-RoBERTa模型,以自动恢复未加标点符号的孟加拉语文本中的标点符号。我们专注于预测四个标点符号:句号、逗号、问号和感叹号,涉及不同的文本领域。为了解决标注资源的稀缺问题,我们构建了一个大型、多样化的训练语料库,并应用了数据增强技术。我们表现最佳的模型以alpha=0.2%的扩充因子进行训练,在新闻测试集上的准确率达到了97.1%,在参考集上达到了91.2%,在ASR集上达到了90.2%。结果表明该模型在参考和ASR转录方面的泛化能力强,证明了该模型在现实世界中的嘈杂场景中具有良好的效果。这为孟加拉语标点符号的恢复建立了强大的基线,并为未来低资源NLP的研究提供了公开可用的数据集和代码支持。
论文及项目相关链接
Summary
本研究探讨了基于转换器模型,特别是XLM-RoBERTa-large在孟加拉语无标点文本自动标点恢复中的应用。研究聚焦于预测四种标点:句号、逗号、问号和感叹号在不同文本领域的应用。为解决标注资源匮乏的问题,研究构建了一个大型多样化的训练语料库,并采用了数据增强技术。最优模型在新闻测试集上的准确度达到97.1%,在参考集和语音识别集上的准确度分别为91.2%和90.2%。结果证明模型在真实、嘈杂的场景中具有强大的泛化能力,为孟加拉语标点恢复建立了坚实的基准,并为低资源自然语言处理提供了公开的数据集和代码支持未来研究。
Key Takeaways
- 本研究使用转换器模型XLM-RoBERTa-large进行孟加拉语的标点恢复。
- 研究关注四种标点的预测:句号、逗号、问号、感叹号。
- 构建了一个大型多样化的训练语料库并采用了数据增强技术以解决标注资源匮乏的问题。
- 最优模型在新闻测试集上的准确度为97.1%。
- 模型在参考集和语音识别集上的准确度分别为91.2%和90.2%,显示出强大的泛化能力。
- 研究为孟加拉语标点恢复建立了坚实的基准。
点此查看论文截图

Recent Trends in Distant Conversational Speech Recognition: A Review of CHiME-7 and 8 DASR Challenges
Authors:Samuele Cornell, Christoph Boeddeker, Taejin Park, He Huang, Desh Raj, Matthew Wiesner, Yoshiki Masuyama, Xuankai Chang, Zhong-Qiu Wang, Stefano Squartini, Paola Garcia, Shinji Watanabe
The CHiME-7 and 8 distant speech recognition (DASR) challenges focus on multi-channel, generalizable, joint automatic speech recognition (ASR) and diarization of conversational speech. With participation from 9 teams submitting 32 diverse systems, these challenges have contributed to state-of-the-art research in the field. This paper outlines the challenges’ design, evaluation metrics, datasets, and baseline systems while analyzing key trends from participant submissions. From this analysis it emerges that: 1) Most participants use end-to-end (e2e) ASR systems, whereas hybrid systems were prevalent in previous CHiME challenges. This transition is mainly due to the availability of robust large-scale pre-trained models, which lowers the data burden for e2e-ASR. 2) Despite recent advances in neural speech separation and enhancement (SSE), all teams still heavily rely on guided source separation, suggesting that current neural SSE techniques are still unable to reliably deal with complex scenarios and different recording setups. 3) All best systems employ diarization refinement via target-speaker diarization techniques. Accurate speaker counting in the first diarization pass is thus crucial to avoid compounding errors and CHiME-8 DASR participants especially focused on this part. 4) Downstream evaluation via meeting summarization can correlate weakly with transcription quality due to the remarkable effectiveness of large-language models in handling errors. On the NOTSOFAR-1 scenario, even systems with over 50% time-constrained minimum permutation WER can perform roughly on par with the most effective ones (around 11%). 5) Despite recent progress, accurately transcribing spontaneous speech in challenging acoustic environments remains difficult, even when using computationally intensive system ensembles.
CHiME-7和CHiME-8远程语音识别(DASR)挑战专注于多通道、通用化、联合语音识别(ASR)和对话语音的聚类分析。共有9个团队提交了32个不同的系统参与挑战,为这一领域的最新研究做出了贡献。本文概述了挑战的方案设计、评价指标、数据集和基线系统,同时分析了参与者提交的关键趋势。从分析中可以看出:1)大多数参与者使用端到端(e2e)语音识别系统,而之前的CHiME挑战中混合系统更为普遍。这种转变主要是由于强大的大规模预训练模型的出现,降低了端到端ASR的数据负担。2)尽管神经语音分离与增强(SSE)领域近期取得了进展,但所有团队仍严重依赖导向源分离,这表明当前神经SSE技术仍无法可靠地处理复杂场景和不同录音设置。3)所有最佳系统都通过目标说话人聚类分析技术进行了聚类分析优化。因此,第一次聚类分析过程中的准确说话人数计算至关重要,以避免累积错误,CHiME-8 DASR参与者尤其关注这部分内容。4)通过会议摘要进行的下游评估由于大型语言模型在处理错误方面的显著有效性,可能与转录质量存在微弱的相关性。在NOTSOFAR-1场景中,即使系统的时间约束最小置换错误率超过50%,其表现也可与最佳系统大致相当(约为11%)。5)尽管取得了最新进展,但在充满挑战的声学环境中准确转录非自发表达仍然很困难,即使使用计算密集型的系统集合也是如此。
论文及项目相关链接
摘要
CHiME-7和CHiME-8的远距离语音识别(DASR)挑战关注多通道、通用化、联合自动语音识别(ASR)和对话语音的自动分档。此次挑战吸引了9个团队的参与,共提交了32个多样的系统,为这一领域带来了前沿研究。本文概述了挑战的设计、评估指标、数据集和基线系统,同时分析了参与者提交的关键趋势。分析表明:1)大多数参与者使用端到端(e2e)ASR系统,而混合系统在过去CHiME挑战中较为普遍。这种转变主要是由于稳健的大规模预训练模型的可获得性,降低了e2e-ASR的数据负担。2)尽管神经语音分离和增强(SSE)方面取得了最新进展,所有团队仍然严重依赖于引导源分离,这表明当前神经SSE技术仍然无法可靠地处理复杂场景和不同录音设置。3)所有最佳系统都通过目标说话人分档技术进行分档细化。因此,第一次分档过程中的准确说话人计数至关重要,可以避免累积错误,CHiME-8 DASR参与者尤其关注这部分。4)通过会议总结进行下游评估可能与转录质量存在微弱联系,因为大型语言模型在处理错误方面效果显著。在NOTSOFAR-1场景下,即使系统的时间约束最小置换错误率超过50%,其表现也可能与最出色的系统大致相同(约11%)。5)尽管有最新进展,但在具有挑战性的声学环境中准确转录非自发的语音仍然是一个难题,即使使用计算密集型的系统集合也是如此。
Key Takeaways
- CHiME-7和CHiME-8挑战集中于多通道和通用化的联合自动语音识别和对话语音的自动分档。
- 端到端ASR系统成为多数参与者的选择,这得益于稳健的大规模预训练模型的普及。
- 尽管神经语音分离和增强技术有所进展,但目前仍主要依赖引导源分离技术。
- 说话人分档的准确性在避免累积错误方面至关重要,特别是在复杂的录音环境和设置中。
- 通过会议总结进行的下游评估与转录质量之间的联系可能较为微弱,因为大型语言模型能有效处理错误。
- 在具有挑战性的声学环境中准确转录非自发的语音仍然是一个难题。
点此查看论文截图

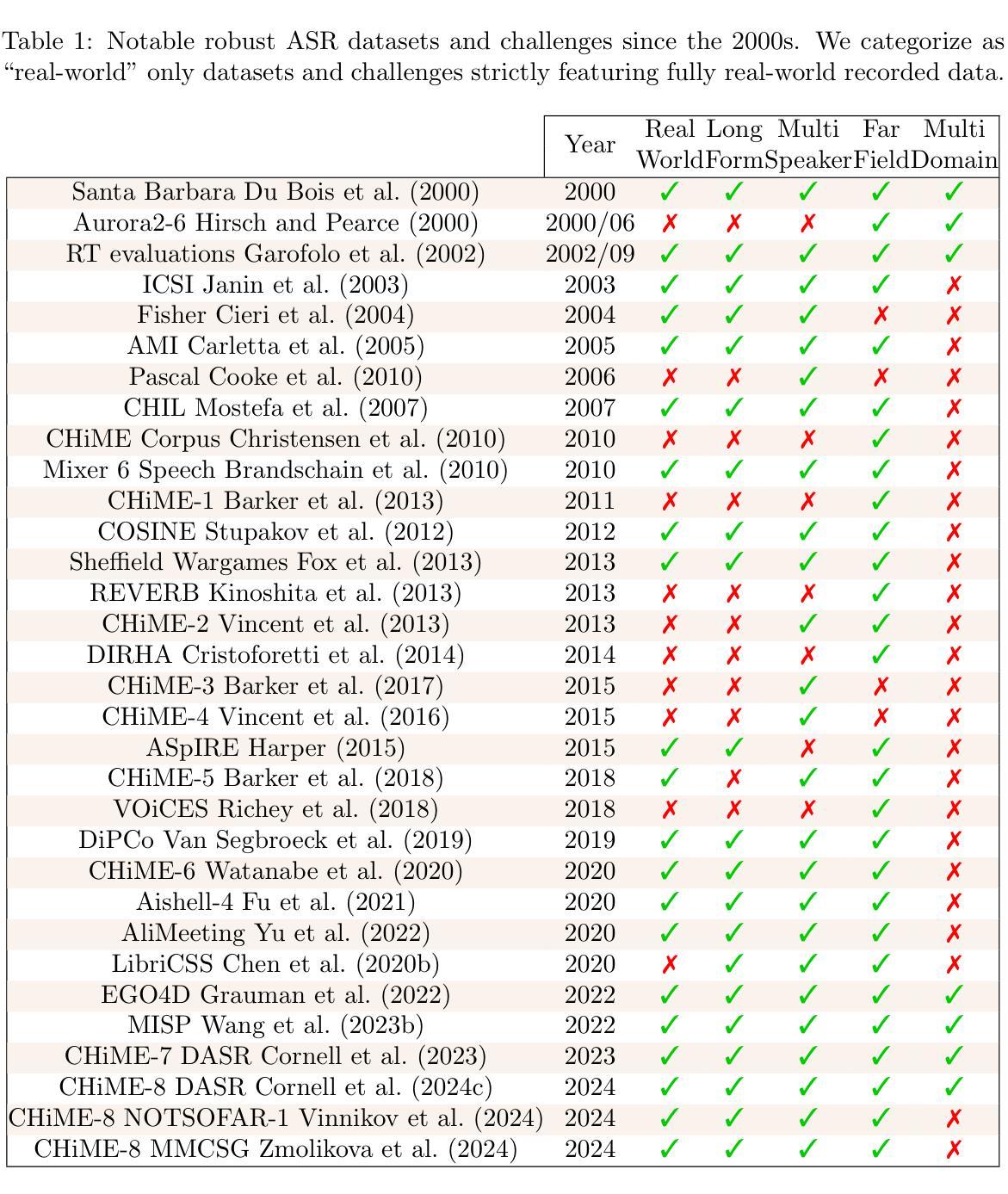
AI Telephone Surveying: Automating Quantitative Data Collection with an AI Interviewer
Authors:Danny D. Leybzon, Shreyas Tirumala, Nishant Jain, Summer Gillen, Michael Jackson, Cameron McPhee, Jennifer Schmidt
With the rise of voice-enabled artificial intelligence (AI) systems, quantitative survey researchers have access to a new data-collection mode: AI telephone surveying. By using AI to conduct phone interviews, researchers can scale quantitative studies while balancing the dual goals of human-like interactivity and methodological rigor. Unlike earlier efforts that used interactive voice response (IVR) technology to automate these surveys, voice AI enables a more natural and adaptive respondent experience as it is more robust to interruptions, corrections, and other idiosyncrasies of human speech. We built and tested an AI system to conduct quantitative surveys based on large language models (LLM), automatic speech recognition (ASR), and speech synthesis technologies. The system was specifically designed for quantitative research, and strictly adhered to research best practices like question order randomization, answer order randomization, and exact wording. To validate the system’s effectiveness, we deployed it to conduct two pilot surveys with the SSRS Opinion Panel and followed-up with a separate human-administered survey to assess respondent experiences. We measured three key metrics: the survey completion rates, break-off rates, and respondent satisfaction scores. Our results suggest that shorter instruments and more responsive AI interviewers may contribute to improvements across all three metrics studied.
随着语音人工智能系统的兴起,定量调查研究人员获得了一种新的数据收集模式:人工智能电话调查。研究人员利用人工智能进行电话采访,可以在扩大定量研究规模的同时,平衡人类般的互动和方法的严谨性这两个目标。不同于早期使用交互式语音应答(IVR)技术自动进行这些调查的努力,语音人工智能在应对中断、纠正以及其他人类语言的特殊特征方面更为强大,能够为受访者提供更自然和适应性更强的体验。我们构建并测试了一个基于大型语言模型(LLM)、自动语音识别(ASR)和语音合成技术的AI系统来进行定量调查。该系统专为定量研究设计,严格遵守研究最佳实践,如问题顺序随机化、答案顺序随机化以及精确措辞。为了验证系统的有效性,我们将其用于开展两项试点调查,并使用人类管理的调查来评估受访者体验。我们衡量了三个关键指标:调查完成率、中断率和受访者满意度得分。我们的结果表明,较短的仪器和反应更快的AI采访者可能在提高所有三个研究指标的方面发挥作用。
论文及项目相关链接
Summary
人工智能电话调查成为定量调查的新模式。利用人工智能进行电话采访,研究者可以在扩大研究规模的同时,平衡人类互动和方法论严谨性的双重目标。新系统基于大型语言模型、自动语音识别和语音合成技术构建,严格遵循研究最佳实践。通过试点调查和后续人工调查,发现更短的问卷和更智能的AI采访者可能有助于提高调查完成率、降低中断率和提高受访者满意度。
Key Takeaways
- AI电话调查是新兴的数据收集模式。
- AI技术能使研究者扩大研究规模同时保持与受访者的互动性和方法严谨性。
- 与传统的互动语音应答系统相比,新的语音AI技术更能适应人类语言的独特性和变化性。
- 新系统基于大型语言模型、自动语音识别和语音合成技术构建。
- 系统设计严格遵循研究最佳实践,如问题顺序随机化、答案顺序随机化和精确措辞。
- 通过试点调查和后续评估,发现更短的问卷和更智能的AI采访者能提高调查效果。
点此查看论文截图


Seed LiveInterpret 2.0: End-to-end Simultaneous Speech-to-speech Translation with Your Voice
Authors:Shanbo Cheng, Yu Bao, Zhichao Huang, Yu Lu, Ningxin Peng, Lu Xu, Runsheng Yu, Rong Cao, Yujiao Du, Ting Han, Yuxiang Hu, Zeyang Li, Sitong Liu, Shengtao Ma, Shiguang Pan, Jiongchen Xiao, Nuo Xu, Meng Yang, Rong Ye, Yiming Yu, Jun Zhang, Ruofei Zhang, Wanyi Zhang, Wenhao Zhu, Liehao Zou, Lu Lu, Yuxuan Wang, Yonghui Wu
Simultaneous Interpretation (SI) represents one of the most daunting frontiers in the translation industry, with product-level automatic systems long plagued by intractable challenges: subpar transcription and translation quality, lack of real-time speech generation, multi-speaker confusion, and translated speech inflation, especially in long-form discourses. In this study, we introduce Seed-LiveInterpret 2.0, an end-to-end SI model that delivers high-fidelity, ultra-low-latency speech-to-speech generation with voice cloning capabilities. As a fully operational product-level solution, Seed-LiveInterpret 2.0 tackles these challenges head-on through our novel duplex speech-to-speech understanding-generating framework. Experimental results demonstrate that through large-scale pretraining and reinforcement learning, the model achieves a significantly better balance between translation accuracy and latency, validated by human interpreters to exceed 70% correctness in complex scenarios. Notably, Seed-LiveInterpret 2.0 outperforms commercial SI solutions by significant margins in translation quality, while slashing the average latency of cloned speech from nearly 10 seconds to a near-real-time 3 seconds, which is around a near 70% reduction that drastically enhances practical usability.
同声传译(SI)是翻译行业中最具挑战性的前沿领域之一,产品级的自动系统长期以来一直面临着难以解决的挑战:转录和翻译质量不佳、缺乏实时语音生成、多说话者混淆,以及在长篇讲话中尤其严重的翻译后语音膨胀问题。本研究中,我们介绍了Seed-LiveInterpret 2.0,这是一个端到端的同声传译模型,具有高保真、超低延迟的语音到语音生成功能,以及语音克隆能力。作为全方位的产品级解决方案,Seed-LiveInterpret 2.0通过我们新颖的双语语音到语音理解生成框架,直接应对这些挑战。实验结果表明,通过大规模预训练和强化学习,该模型在翻译准确性和延迟之间取得了显著的平衡,经人类翻译人员验证,在复杂场景中的正确率超过70%。值得注意的是,Seed-LiveInterpret 2.0在翻译质量上大大优于商业同声传译解决方案,同时将克隆语音的平均延迟从近10秒减少到接近实时的3秒,大约降低了70%,大大提高了实用性。
论文及项目相关链接
PDF Seed-LiveInterpret 2.0 Technical Report
Summary
本文介绍了Simultaneous Interpretation(SI)领域的一个全新解决方案——Seed-LiveInterpret 2.0。作为一款端到端的产品级即时翻译模型,它具备高保真、超低延迟的语音到语音生成能力,并具备语音克隆功能。通过大规模预训练和强化学习,Seed-LiveInterpret 2.0显著提高了翻译准确性并降低了延迟,且复杂性场景下的翻译正确率超过70%,显著优于商业即时翻译解决方案。
Key Takeaways
- Seed-LiveInterpret 2.0是Simultaneous Interpretation领域的一个新产品级解决方案。
- 它具备端到端的语音到语音生成能力,具有高保真和超低延迟的特点。
- 该模型具备语音克隆功能,提高了实用性。
- 通过大规模预训练和强化学习,Seed-LiveInterpret 2.0在翻译准确性和延迟方面取得了显著进步。
- 在复杂性场景下,Seed-LiveInterpret 2.0的翻译正确率超过70%。
- 与商业即时翻译解决方案相比,Seed-LiveInterpret 2.0在翻译质量上表现更优秀。
点此查看论文截图


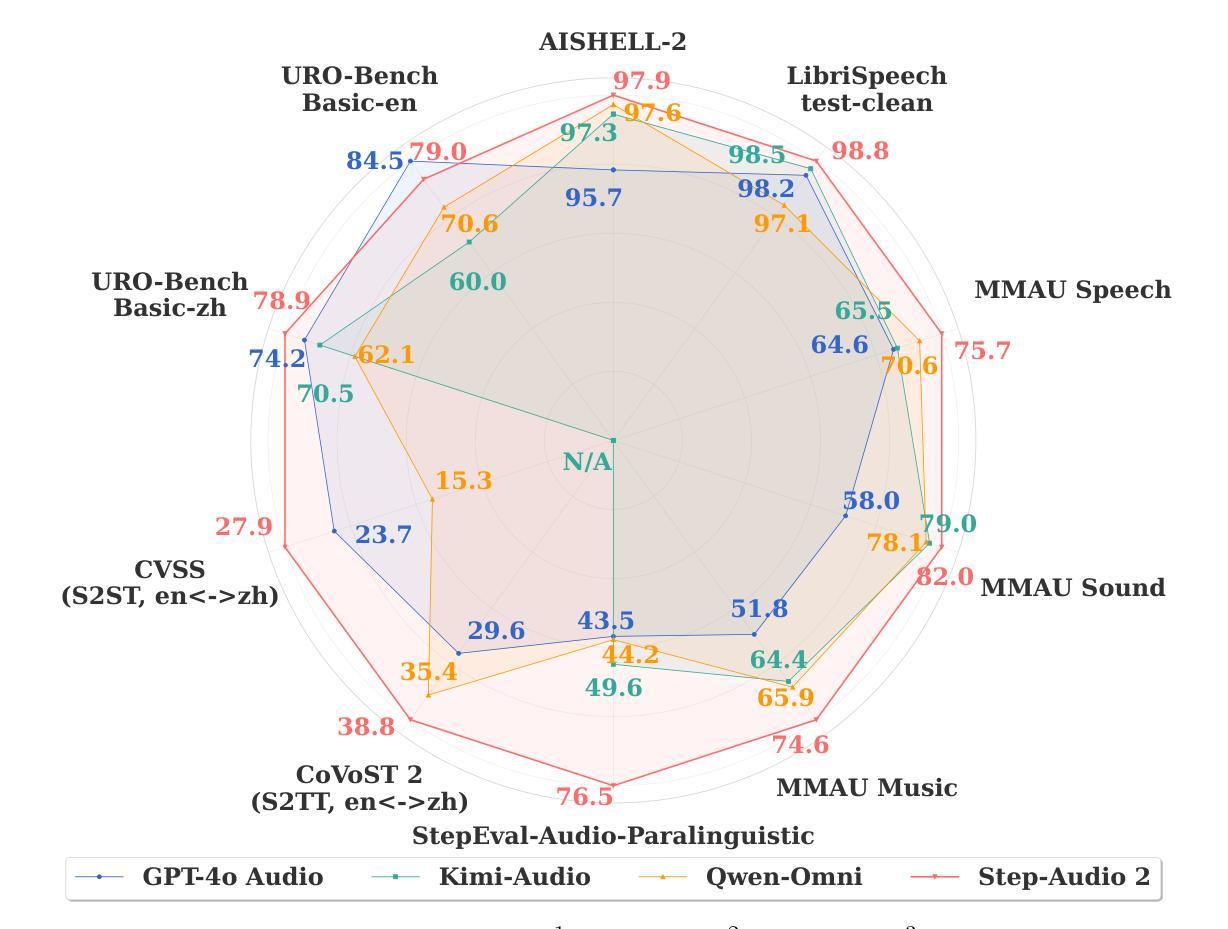
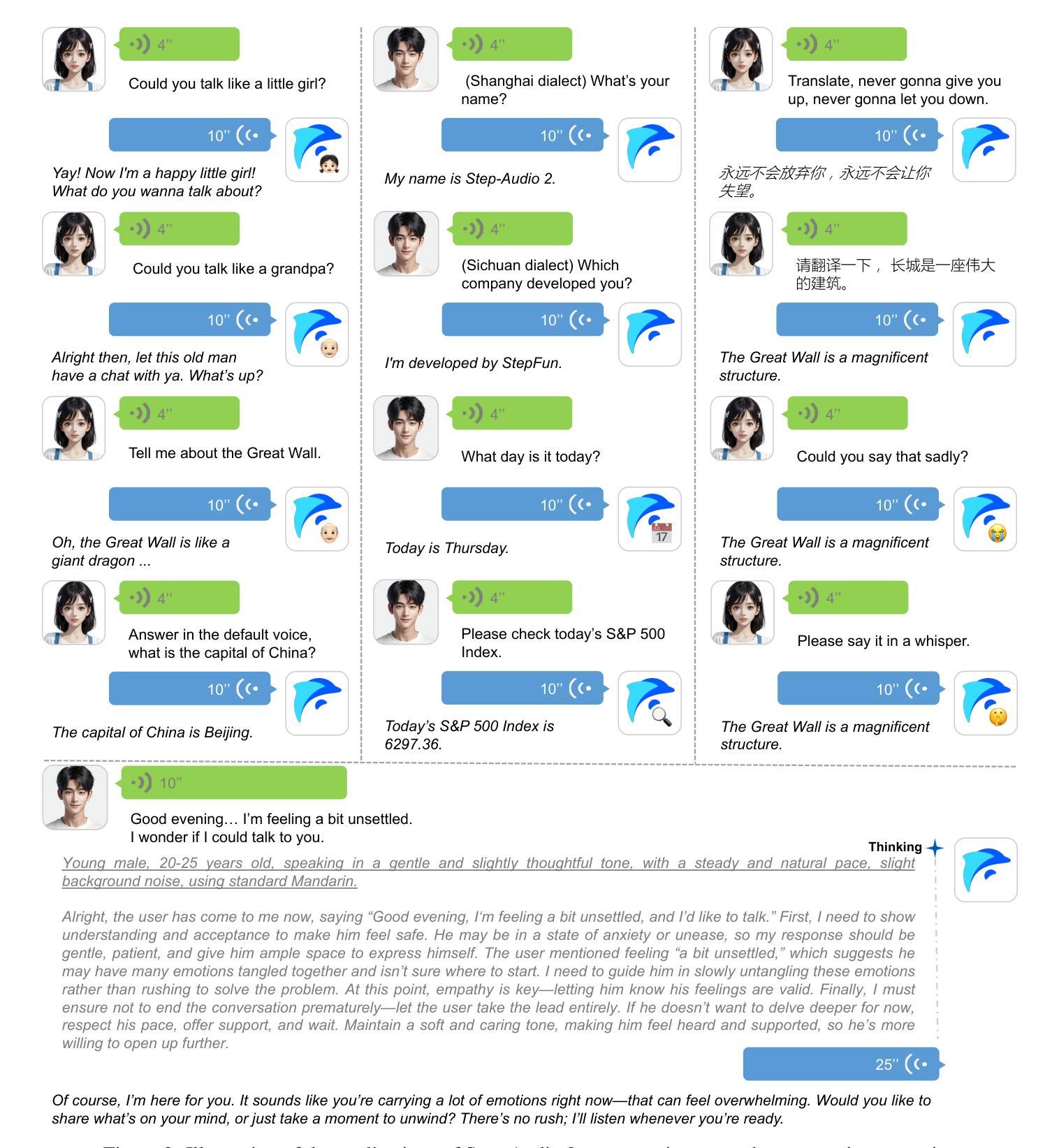
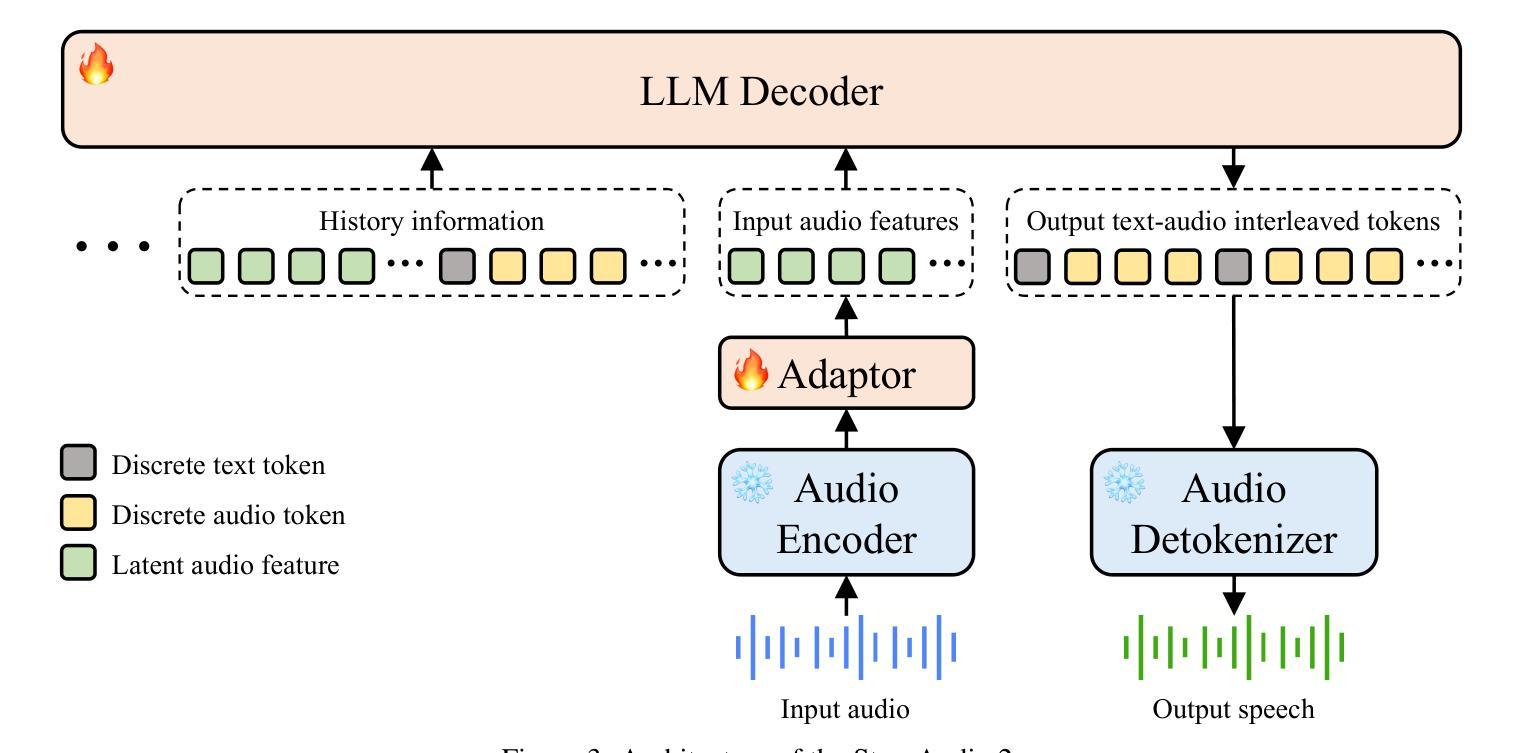
Step-Audio 2 Technical Report
Authors:Boyong Wu, Chao Yan, Chen Hu, Cheng Yi, Chengli Feng, Fei Tian, Feiyu Shen, Gang Yu, Haoyang Zhang, Jingbei Li, Mingrui Chen, Peng Liu, Wang You, Xiangyu Tony Zhang, Xingyuan Li, Xuerui Yang, Yayue Deng, Yechang Huang, Yuxin Li, Yuxin Zhang, Zhao You, Brian Li, Changyi Wan, Hanpeng Hu, Jiangjie Zhen, Siyu Chen, Song Yuan, Xuelin Zhang, Yimin Jiang, Yu Zhou, Yuxiang Yang, Bingxin Li, Buyun Ma, Changhe Song, Dongqing Pang, Guoqiang Hu, Haiyang Sun, Kang An, Na Wang, Shuli Gao, Wei Ji, Wen Li, Wen Sun, Xuan Wen, Yong Ren, Yuankai Ma, Yufan Lu, Bin Wang, Bo Li, Changxin Miao, Che Liu, Chen Xu, Dapeng Shi, Dingyuan Hu, Donghang Wu, Enle Liu, Guanzhe Huang, Gulin Yan, Han Zhang, Hao Nie, Haonan Jia, Hongyu Zhou, Jianjian Sun, Jiaoren Wu, Jie Wu, Jie Yang, Jin Yang, Junzhe Lin, Kaixiang Li, Lei Yang, Liying Shi, Li Zhou, Longlong Gu, Ming Li, Mingliang Li, Mingxiao Li, Nan Wu, Qi Han, Qinyuan Tan, Shaoliang Pang, Shengjie Fan, Siqi Liu, Tiancheng Cao, Wanying Lu, Wenqing He, Wuxun Xie, Xu Zhao, Xueqi Li, Yanbo Yu, Yang Yang, Yi Liu, Yifan Lu, Yilei Wang, Yuanhao Ding, Yuanwei Liang, Yuanwei Lu, Yuchu Luo, Yuhe Yin, Yumeng Zhan, Yuxiang Zhang, Zidong Yang, Zixin Zhang, Binxing Jiao, Daxin Jiang, Heung-Yeung Shum, Jiansheng Chen, Jing Li, Xiangyu Zhang, Yibo Zhu
This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
本文介绍了Step-Audio 2,这是一个为工业级音频理解和语音对话而设计的端到端多模式大型语言模型。通过集成潜在音频编码器和以推理为中心的强化学习(RL),Step-Audio 2在自动语音识别(ASR)和音频理解方面取得了有前景的性能。为了实现真正的端到端语音对话,Step-Audio 2将离散音频符号的生成融入语言建模,极大地提高了对诸如讲话风格和情感等副语言信息的反应能力。为了有效地利用现实数据中丰富的文本和声音知识,Step-Audio 2集成了增强检索生成(RAG)技术,并能够调用外部工具,如网络搜索来减轻虚构性,以及音频搜索来切换音色。在数百万小时的语音和音频数据上进行训练,Step-Audio 2在不同对话场景中展现出智能和表现力。评估结果表明,与其他开源和商业解决方案相比,Step-Audio 2在各种音频理解和对话基准测试上达到了最先进的性能。更多信息请访问 https://github.com/stepfun-ai/Step-Audio2。
论文及项目相关链接
Summary
这篇论文介绍了Step-Audio 2,一个面向工业级音频理解和语音对话的端到端多模态大型语言模型。它通过结合潜在音频编码器和以推理为中心的强化学习,实现了自动语音识别和音频理解的出色性能。此外,它生成离散音频符号以增强对口语风格和情感等非语言信息的响应性。集成检索增强生成方法和可调用外部工具(如网络搜索和音频搜索)以适应现实世界数据的丰富文本和声学知识。经过数百万小时语音和音频数据的训练,Step-Audio 2在多种对话场景中表现出卓越的智能和表现力,并在各种音频理解和对话基准测试中实现了与其他开源和商业解决方案相比的业界领先水平。有关更多信息,请访问 https://github.com/stepfun-ai/Step-Audio2。
Key Takeaways
- Step-Audio 2是一个多模态大型语言模型,适用于工业级音频理解和语音对话。
- 结合潜在音频编码器和以推理为中心的强化学习,提高了自动语音识别和音频理解的性能。
- 生成离散音频符号以增强对口语风格和情感的响应性。
- 集成检索增强生成方法以适应现实世界数据的丰富文本和声学知识。
- 可调用外部工具如网络搜索和音频搜索来增强功能。
- 经过大量语音和音频数据训练,表现出卓越的智能和表现力。
点此查看论文截图

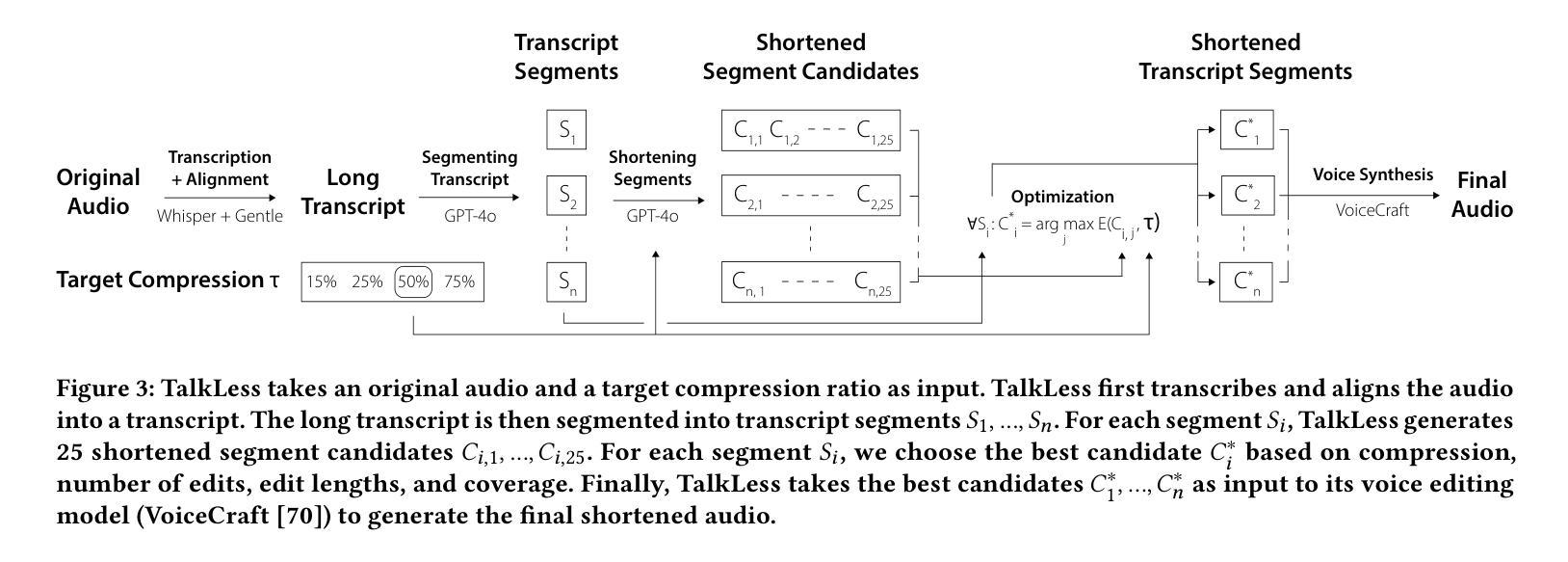
TalkLess: Blending Extractive and Abstractive Speech Summarization for Editing Speech to Preserve Content and Style
Authors:Karim Benharrak, Puyuan Peng, Amy Pavel
Millions of people listen to podcasts, audio stories, and lectures, but editing speech remains tedious and time-consuming. Creators remove unnecessary words, cut tangential discussions, and even re-record speech to make recordings concise and engaging. Prior work automatically summarized speech by removing full sentences (extraction), but rigid extraction limits expressivity. AI tools can summarize then re-synthesize speech (abstraction), but abstraction strips the speaker’s style. We present TalkLess, a system that flexibly combines extraction and abstraction to condense speech while preserving its content and style. To edit speech, TalkLess first generates possible transcript edits, selects edits to maximize compression, coverage, and audio quality, then uses a speech editing model to translate transcript edits into audio edits. TalkLess’s interface provides creators control over automated edits by separating low-level wording edits (via the compression pane) from major content edits (via the outline pane). TalkLess achieves higher coverage and removes more speech errors than a state-of-the-art extractive approach. A comparison study (N=12) showed that TalkLess significantly decreased cognitive load and editing effort in speech editing. We further demonstrate TalkLess’s potential in an exploratory study (N=3) where creators edited their own speech.
成千上万的人聆听播客、音频故事和讲座,但编辑语音仍然是一项乏味且耗时的任务。创作者会删除不必要的词汇、剪裁离题讨论,甚至重新录制语音,以使录音更加简洁、吸引人。之前的工作通过自动移除整个句子(摘录)来进行语音摘要,但僵化的摘录限制了表达力。AI工具可以摘要然后重新合成语音(抽象),但抽象会剥夺说话者的风格。我们推出了TalkLess系统,它灵活地结合了摘录和抽象,浓缩语音的同时保留其内容与风格。为了编辑语音,TalkLess首先生成可能的转录编辑,选择编辑以最大化压缩、覆盖和音频质量,然后使用语音编辑模型将转录编辑转化为音频编辑。TalkLess的界面通过压缩面板提供低级别的措辞编辑,通过大纲面板提供主要内容的编辑,从而实现对自动化编辑的控制。TalkLess的覆盖面更广,能消除比最先进的摘录方法更多的语音错误。一项比较研究(N=12)显示,TalkLess显著降低了语音编辑的认知负荷和编辑工作量。我们在另一项探索性研究(N=3)中进一步展示了TalkLess的潜力,创作者在该研究中编辑了自己的语音。
论文及项目相关链接
Summary
谈到一个名为TalkLess的系统,它结合了提取和抽象技术,能够压缩演讲内容同时保留内容和风格。该系统首先生成可能的文本编辑,选择能最大化压缩、覆盖和音频质量的编辑,然后使用语音编辑模型将文本编辑转化为音频编辑。TalkLess界面分为压缩面板和内容大纲面板,使创作者能分别控制低级别的措辞编辑和主要的内容编辑。TalkLess相比最先进抽取方法能达到更高的覆盖率和减少更多的语音错误。研究发现(N=12),TalkLess能显著降低语音编辑的认知负荷和编辑努力。另外一项探索性研究(N=3)显示创作者能够利用TalkLess编辑自己的语音内容。
Key Takeaways
- TalkLess系统结合了提取和抽象技术,实现了语音内容的压缩并保留了内容和风格。
- TalkLess首先生成可能的文本编辑,然后选择最佳的编辑来提高压缩效率和音频质量。
- TalkLess的编辑界面分为压缩面板和内容大纲面板,方便创作者进行不同层次的编辑操作。
- 与现有技术相比,TalkLess在覆盖率和语音错误处理方面表现更优。
- 研究显示,TalkLess能显著降低语音编辑的认知负荷和编辑努力。
- TalkLess通过一项探索性研究展示了在创作者自我编辑语音方面的潜力。
点此查看论文截图