⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-02 更新
TTS-1 Technical Report
Authors:Oleg Atamanenko, Anna Chalova, Joseph Coombes, Nikki Cope, Phillip Dang, Zhifeng Deng, Jimmy Du, Michael Ermolenko, Feifan Fan, Yufei Feng, Cheryl Fichter, Pavel Filimonov, Louis Fischer, Kylan Gibbs, Valeria Gusarova, Pavel Karpik, Andreas Assad Kottner, Ian Lee, Oliver Louie, Jasmine Mai, Mikhail Mamontov, Suri Mao, Nurullah Morshed, Igor Poletaev, Florin Radu, Dmytro Semernia, Evgenii Shingarev, Vikram Sivaraja, Peter Skirko, Rinat Takhautdinov, Robert Villahermosa, Jean Wang
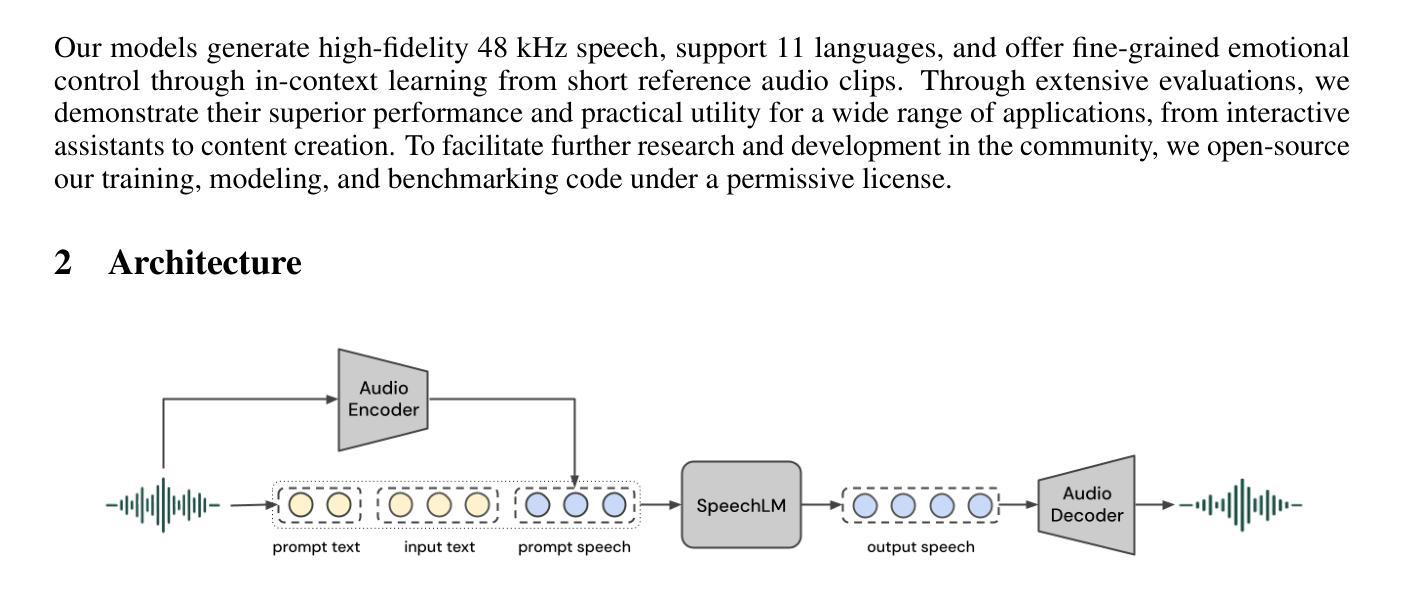
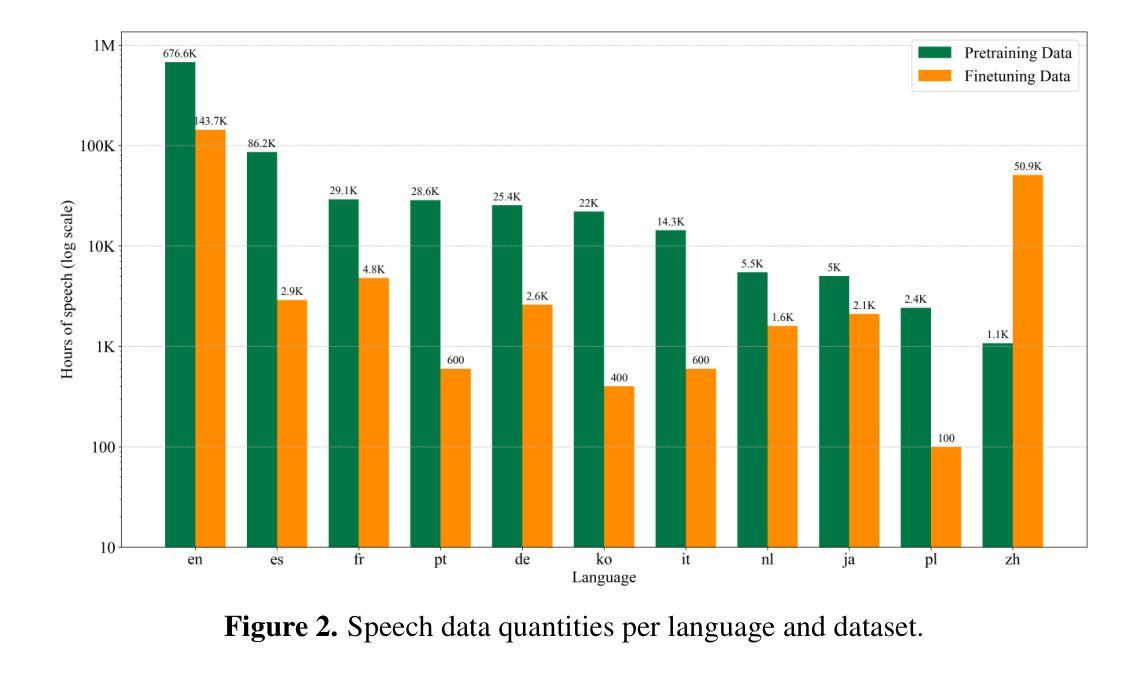
We introduce Inworld TTS-1, a set of two Transformer-based autoregressive text-to-speech (TTS) models. Our largest model, TTS-1-Max, has 8.8B parameters and is designed for utmost quality and expressiveness in demanding applications. TTS-1 is our most efficient model, with 1.6B parameters, built for real-time speech synthesis and on-device use cases. By scaling train-time compute and applying a sequential process of pre-training, fine-tuning, and RL-alignment of the speech-language model (SpeechLM) component, both models achieve state-of-the-art performance on a variety of benchmarks, demonstrating exceptional quality relying purely on in-context learning of the speaker’s voice. Inworld TTS-1 and TTS-1-Max can generate high-resolution 48 kHz speech with low latency, and support 11 languages with fine-grained emotional control and non-verbal vocalizations through audio markups. We additionally open-source our training and modeling code under an MIT license.
我们介绍了Inworld TTS-1,这是一组基于Transformer的自回归文本到语音(TTS)模型。我们的大型模型TTS-1-Max拥有8.8亿个参数,旨在满足高要求和高质量的应用场景。TTS-1则是我们最高效的模型,拥有1.6亿个参数,专为实时语音合成和设备端用例设计。通过扩展训练时间的计算力,对语音语言模型(SpeechLM)组件进行预训练、精细调整和强化学习对齐的序列过程,这两个模型在各种基准测试中都达到了最先进的性能水平,展示了仅凭对说话人声音的上下文学习就能实现的卓越质量。Inworld TTS-1和TTS-1-Max可以生成高分辨率的48kHz语音,具有低延迟,支持使用音频标记进行精细的情绪控制和非言语发声等复杂操作,涵盖多达11种语言。此外,我们还以MIT许可证的形式公开了我们的训练和建模代码。
论文及项目相关链接
PDF 20 pages, 10 figures. For associated modeling and training code, see https://github.com/inworld-ai/tts
Summary
Inworld TTS-1是一款基于Transformer的自回归文本到语音(TTS)模型系列,包含TTS-1和TTS-1-Max两个模型。TTS-1注重实时语音合成和设备端应用场景,拥有1.6B参数;而TTS-1-Max则追求高质量和表达力,适用于高需求应用,拥有8.8B参数。通过扩大训练时的计算规模、对语音语言模型进行预训练、微调及强化学习对齐的序列过程,两个模型在多种基准测试中实现了卓越性能,并凭借语境学习展现出色的声音质量。Inworld TTS-1和TTS-1-Max能生成高分辨率的48kHz语音,具有低延迟特性,支持11种语言,并通过音频标记实现精细的情绪控制和非言语发声。
Key Takeaways
- Inworld TTS-1是一款基于Transformer的文本到语音(TTS)模型系列。
- TTS-1和TTS-1-Max是该系列的两个模型,分别针对实时语音合成和设备端应用场景以及高质量和表达力的高需求应用进行优化。
- 通过扩大训练时的计算规模和对语音语言模型进行预训练、微调及强化学习对齐,两个模型实现了卓越性能。
- Inworld TTS-1和TTS-1-Max能生成高质量、高分辨率的48kHz语音,并具有低延迟特性。
- 模型支持多达11种语言,并具备精细的情绪控制和非言语发声能力。
- 模型采用开源训练和建模代码,遵循MIT许可协议。
点此查看论文截图


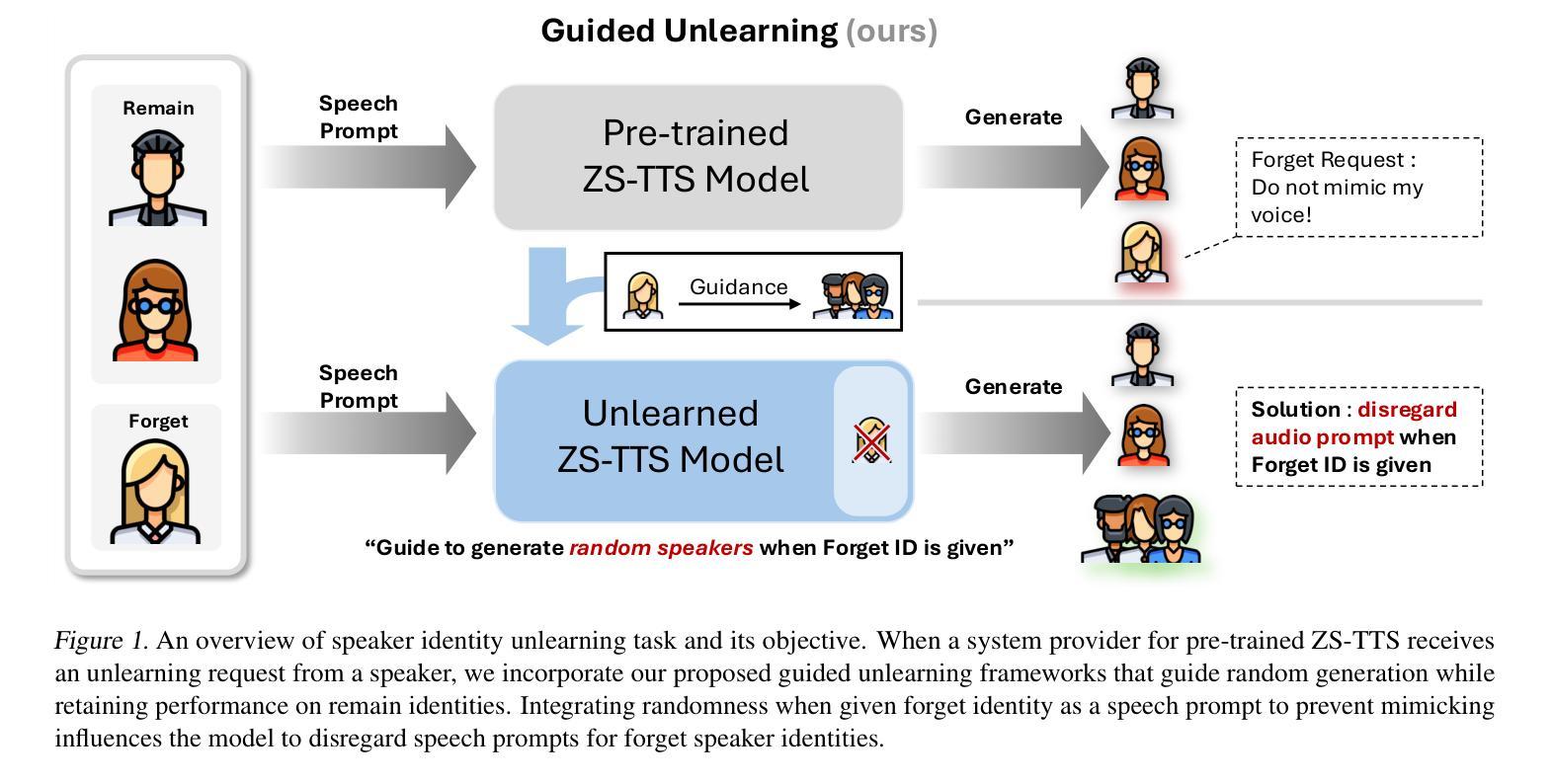
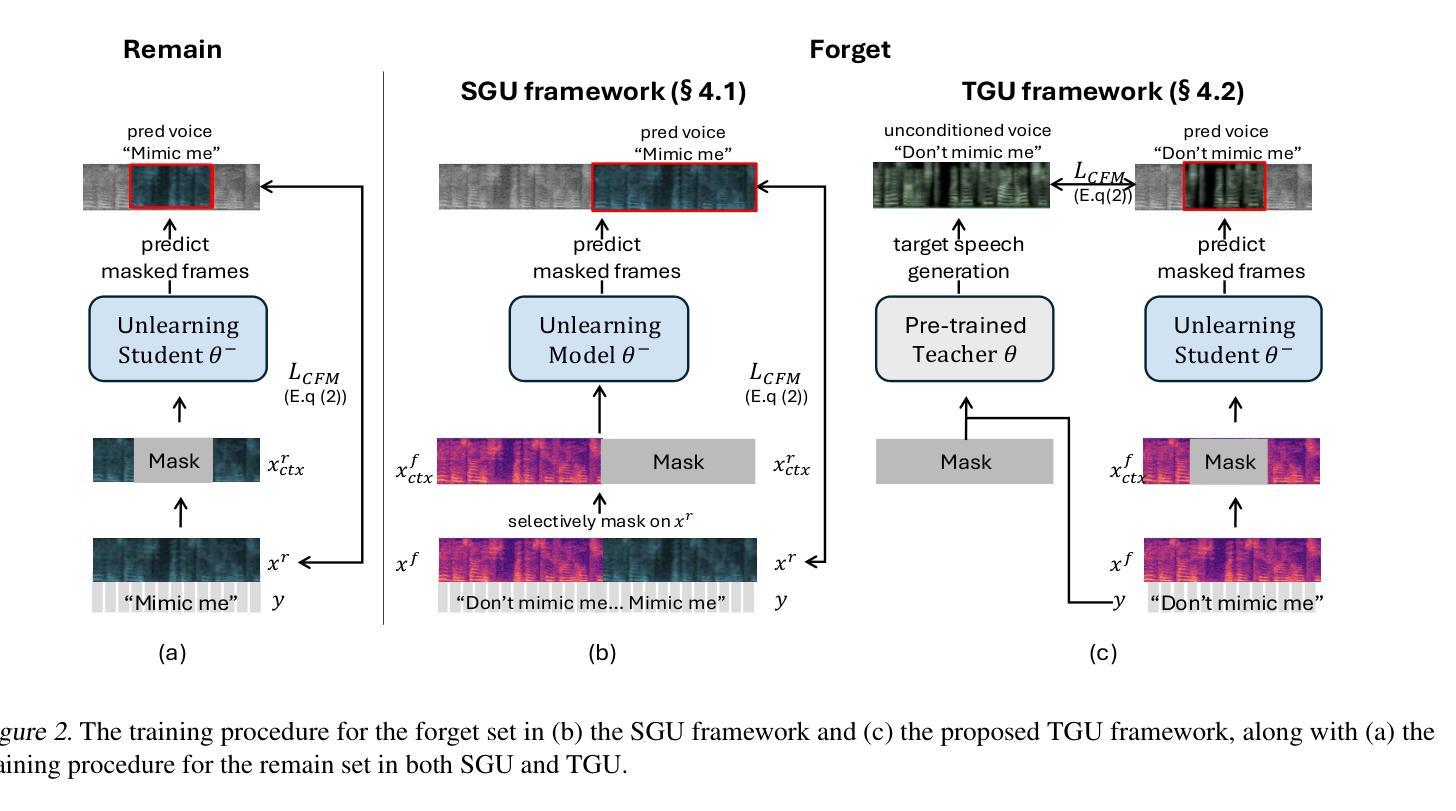
Do Not Mimic My Voice: Speaker Identity Unlearning for Zero-Shot Text-to-Speech
Authors:Taesoo Kim, Jinju Kim, Dongchan Kim, Jong Hwan Ko, Gyeong-Moon Park
The rapid advancement of Zero-Shot Text-to-Speech (ZS-TTS) technology has enabled high-fidelity voice synthesis from minimal audio cues, raising significant privacy and ethical concerns. Despite the threats to voice privacy, research to selectively remove the knowledge to replicate unwanted individual voices from pre-trained model parameters has not been explored. In this paper, we address the new challenge of speaker identity unlearning for ZS-TTS systems. To meet this goal, we propose the first machine unlearning frameworks for ZS-TTS, especially Teacher-Guided Unlearning (TGU), designed to ensure the model forgets designated speaker identities while retaining its ability to generate accurate speech for other speakers. Our proposed methods incorporate randomness to prevent consistent replication of forget speakers’ voices, assuring unlearned identities remain untraceable. Additionally, we propose a new evaluation metric, speaker-Zero Retrain Forgetting (spk-ZRF). This assesses the model’s ability to disregard prompts associated with forgotten speakers, effectively neutralizing its knowledge of these voices. The experiments conducted on the state-of-the-art model demonstrate that TGU prevents the model from replicating forget speakers’ voices while maintaining high quality for other speakers. The demo is available at https://speechunlearn.github.io/
零样本文本转语音(ZS-TTS)技术的快速发展使得可以从极少的音频线索中进行高保真语音合成,从而引发了关于隐私和伦理的重大担忧。尽管语音隐私面临威胁,但关于从预训练模型参数中复制不想要的个人语音的相关知识选择性地消除的研究尚未被探索。在本文中,我们解决了零样本文本转语音系统(ZS-TTS)的说话人身份遗忘的新挑战。为了实现这一目标,我们为ZS-TTS首次提出了机器遗忘框架,特别是教师指导的遗忘(TGU),旨在确保模型忘记指定的说话人身份,同时保留其为其他说话人生成准确语音的能力。我们提出的方法融入了随机性,以防止持续复制遗忘说话者的声音,确保已遗忘的身份无法追踪。此外,我们提出了一种新的评估指标,即说话者零再训练遗忘(spk-ZRF)。这可以评估模型忽略与已遗忘说话者相关的提示的能力,从而有效地中和其对这些声音的了解。在先进模型上进行的实验表明,TGU能够防止模型复制已遗忘说话者的声音,同时保持对其他说话人的高质量语音。演示网站为:https://speechunlearn.github.io/。
论文及项目相关链接
PDF Proceedings of the 42nd International Conference on Machine Learning (ICML 2025), Vancouver, Canada. PMLR 267, 2025. Authors Jinju Kim and Taesoo Kim contributed equally
Summary
零样本文本转语音(ZS-TTS)技术的快速发展带来了对隐私和伦理的重大担忧。为保护语音隐私,本文首次提出了针对ZS-TTS系统的机器遗忘框架,包括教师引导遗忘(TGU)技术,旨在确保模型能够忘记特定说话人的身份同时保留对其他说话人的准确语音生成能力。该方法融入了随机性以确保无法重现遗忘说话人的声音,并引入了新的评估指标——说话者零训练遗忘(spk-ZRF),以评估模型对遗忘说话人的忽视程度。实验证明,TGU能有效防止模型复制遗忘说话人的声音,同时保持对其他说话人的高质量表现。
Key Takeaways
- ZS-TTS技术的快速发展引发了对隐私和伦理的担忧。
- 研究尚未探索从预训练模型中移除特定个体声音复制的知识。
- 本文提出首个针对ZS-TTS系统的机器遗忘框架。
- 教师引导遗忘(TGU)技术确保模型忘记指定说话人身份。
- TGU设计能保留模型对其他说话人的准确语音生成能力。
- 为评估模型对遗忘说话人的忽视程度,引入了新的评估指标——spk-ZRF。
点此查看论文截图

JWST Spectroscopic Confirmation of the Cosmic Gems Arc at z=9.625 – Insights into the small scale structure of a post-burst system
Authors:M. Messa, E. Vanzella, F. Loiacono, A. Adamo, M. Oguri, K. Sharon, L. D. Bradley, L. Christensen, A. Claeyssens, J. Richard, Abdurro’uf, F. E. Bauer, P. Bergamini, A. Bolamperti, M. Bradač, F. Calura, D. Coe, J. M. Diego, C. Grillo, T. Y-Y. Hsiao, A. K. Inoue, S. Fujimoto, M. Lombardi, M. Meneghetti, T. Resseguier, M. Ricotti, P. Rosati, B. Welch, R. A. Windhorst, X. Xu, E. Zackrisson, A. Zanella, A. Zitrin
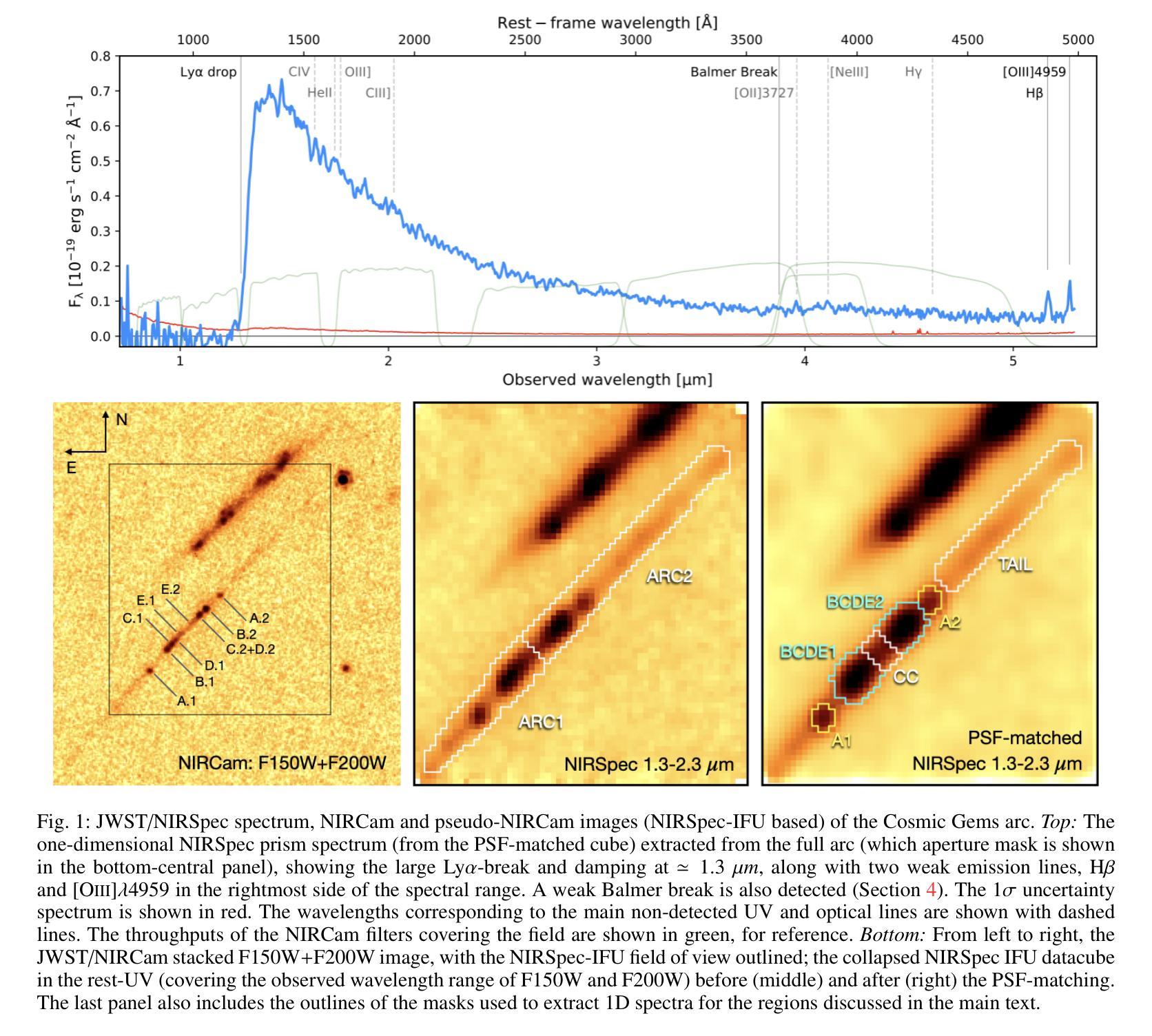
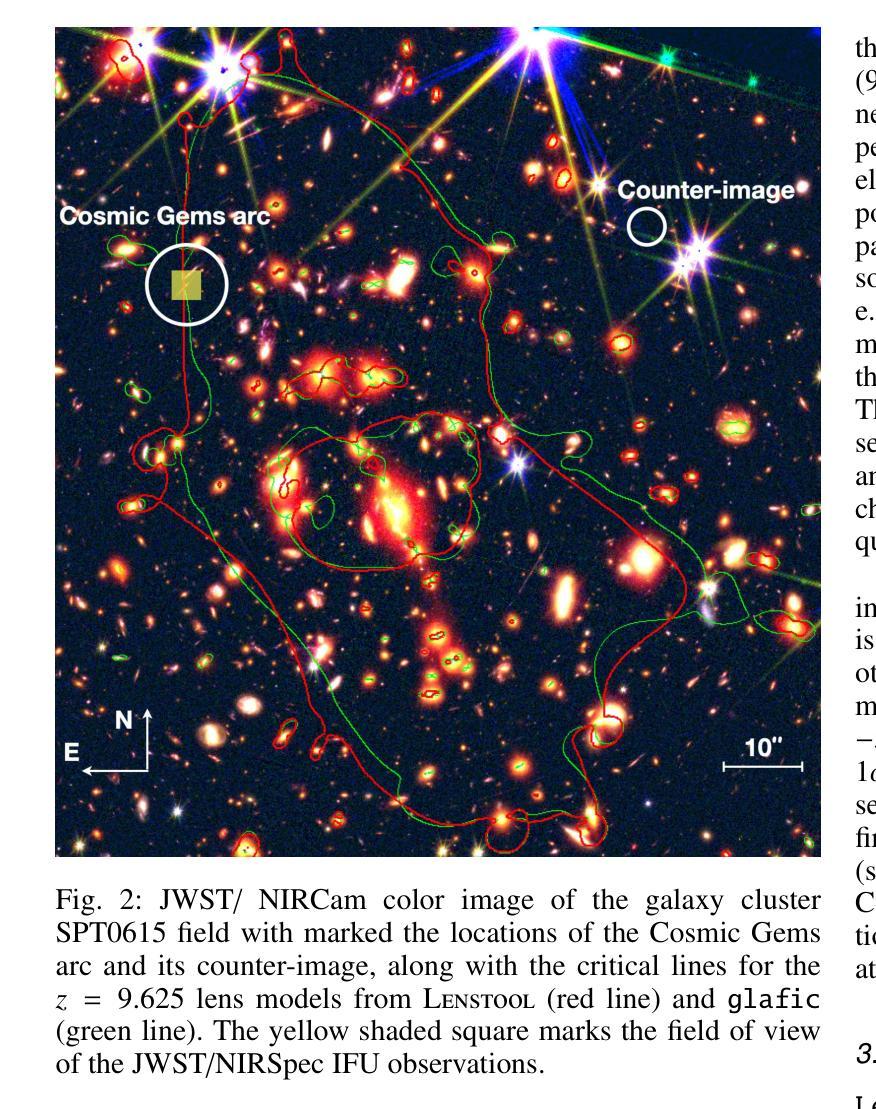
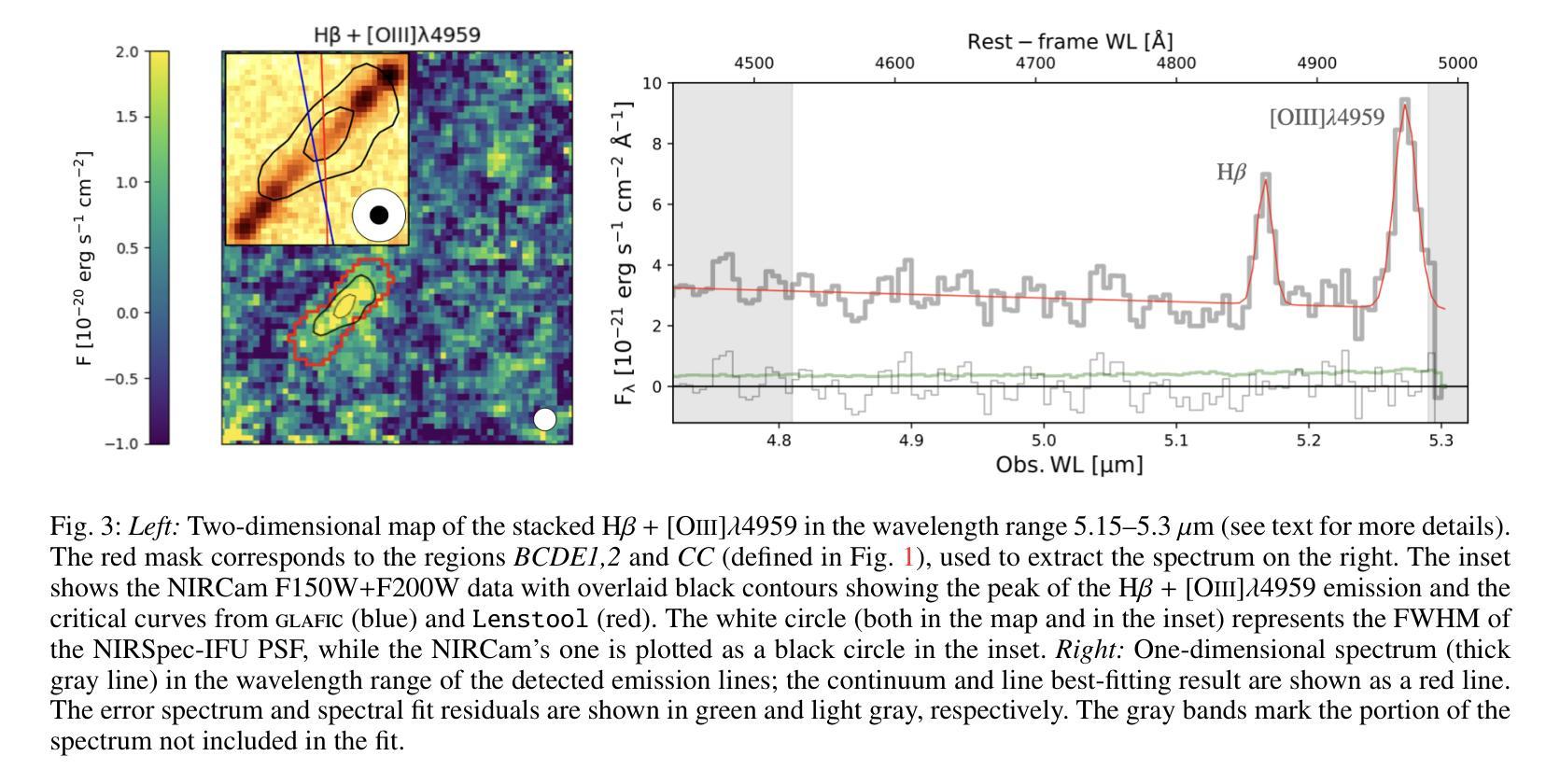
We present JWST/NIRSpec integral field spectroscopy of the Cosmic Gems arc, strongly magnified by the galaxy cluster SPT-CL J0615$-$5746. Six-hour integration using NIRSpec prism spectroscopy (resolution $\rm R\simeq 30-300$), covering the spectral range $0.8-5.3\mu m$, reveals a pronounced $\rm Ly\alpha$-continuum break at $\lambda \simeq 1.3\mu m$, and weak optical $\rm H\beta$ and $\rm [OIII]\lambda4959$ emission lines at $z=9.625\pm0.002$, located in the reddest part of the spectrum ($\lambda > 5.1\mu m$). No additional ultraviolet or optical emission lines are reliably detected. A weak Balmer break is measured alongside a very blue ultraviolet slope ($\beta \leq-2.5$, $\rm F_{\lambda} \sim \lambda^{\beta}$). Spectral fitting with $\tt Bagpipes$ suggests the Cosmic Gems galaxy is in a post-starburst phase, making it the highest-redshift system currently observed in a mini-quenched state. Spatially resolved spectroscopy at tens pc scales shows relatively uniform features across subcomponents of the arc. These findings align well with physical properties previously derived from JWST/NIRCam photometry of the stellar clusters, now corroborated by spectroscopic evidence. In particular, five observed star clusters exhibit ages of $\rm 7-30Myr$. An updated lens model constrains the intrinsic sizes and masses of these clusters, confirming they are extremely compact and denser than typical star clusters in local star-forming galaxies. Additionally, four compact stellar systems consistent with star clusters ($\lesssim10$ pc) are identified along the extended tail of the arc. A sub-parsec line-emitting HII region straddling the critical line, lacking a NIRCam counterpart, is also serendipitously detected.
我们对宇宙宝石弧进行了JWST/NIRSpec积分场光谱观测,该弧受到星系团SPT-CL J0615-5746的强烈放大。使用NIRSpec棱镜光谱法(分辨率R约为30-300)进行六小时积分,覆盖光谱范围0.8-5.3微米,在波长约为1.3微米处显示出明显的Lyα连续统断裂,以及在z=9.625±0.002处的微弱光学Hβ和[OIII]λ4959发射线,位于光谱的红色部分(λ> 5.1微米)。没有检测到其他可靠的紫外或光学发射线。测量到一个微弱的巴尔末断裂以及一个非常蓝的紫外斜率(β≤-2.5,Fλ~λβ)。用Bagpipes进行光谱拟合表明,宇宙宝石星系处于后爆发阶段,使其成为目前观察到的处于最小淬灭状态的红移最高的系统。在数十个天文单位规模上进行空间分解光谱显示,弧的各个子成分的特征相对统一。这些发现与根据JWST/NIRCam对星团的摄影术先前得出的物理性质相符,现在得到了光谱证据的支持。特别是,五个观察到的星团年龄为7-30Myr。更新的透镜模型限制了这些星团的内禀大小和质量,证实它们比本地星系中的典型星团更紧凑、密度更高。此外,在弧的延伸尾迹中发现了四个与星团一致的致密恒星系统(≤10个天文单位)。还意外检测到了一个跨越临界线的亚秒级发射HII区域,它没有NIRCam对应物。
论文及项目相关链接
PDF 21 pages (15 figures, 3 tables). Submitted to A&A; see also the companion work Vanzella et al. 2025. Comments are welcome
Summary:利用JWST/NIRSpec积分场光谱法对宇宙宝石弧进行了观测,该弧被星系团SPT-CL J0615-5746强烈放大。通过NIRSpec棱镜光谱法(分辨率R约为30-300)对谱范围0.8-5.3μm的六小时积分,发现位于λ≈1.3μm处的Lyα连续谱断裂以及位于λ> 5.1μm的弱光学Hβ和[OIII]λ4959发射线。光谱拟合显示宇宙宝石星系处于爆发后的阶段,这是目前在迷淬状态下观察到的红移最高的系统。
Key Takeaways:
- JWST/NIRSpec积分场光谱法揭示了宇宙宝石弧的详细光谱特征。
- 观测到强烈的Lyα连续谱断裂以及弱光学Hβ和[OIII]λ4959发射线。
- 该星系处于爆发后的阶段,是目前在迷淬状态下观察到的红移最高的系统。
- 星系的空间解析光谱显示子成分特征相对均匀。
- 观察到的星团年龄为7-30Myr,与JWST/NIRCam光度计先前对恒星集群的物理性质推导一致。
- 更新后的透镜模型限制了星团的内禀尺寸和质量,证实它们比本地恒星形成星系中的典型星团更紧凑、密度更高。
点此查看论文截图

TTS-VAR: A Test-Time Scaling Framework for Visual Auto-Regressive Generation
Authors:Zhekai Chen, Ruihang Chu, Yukang Chen, Shiwei Zhang, Yujie Wei, Yingya Zhang, Xihui Liu
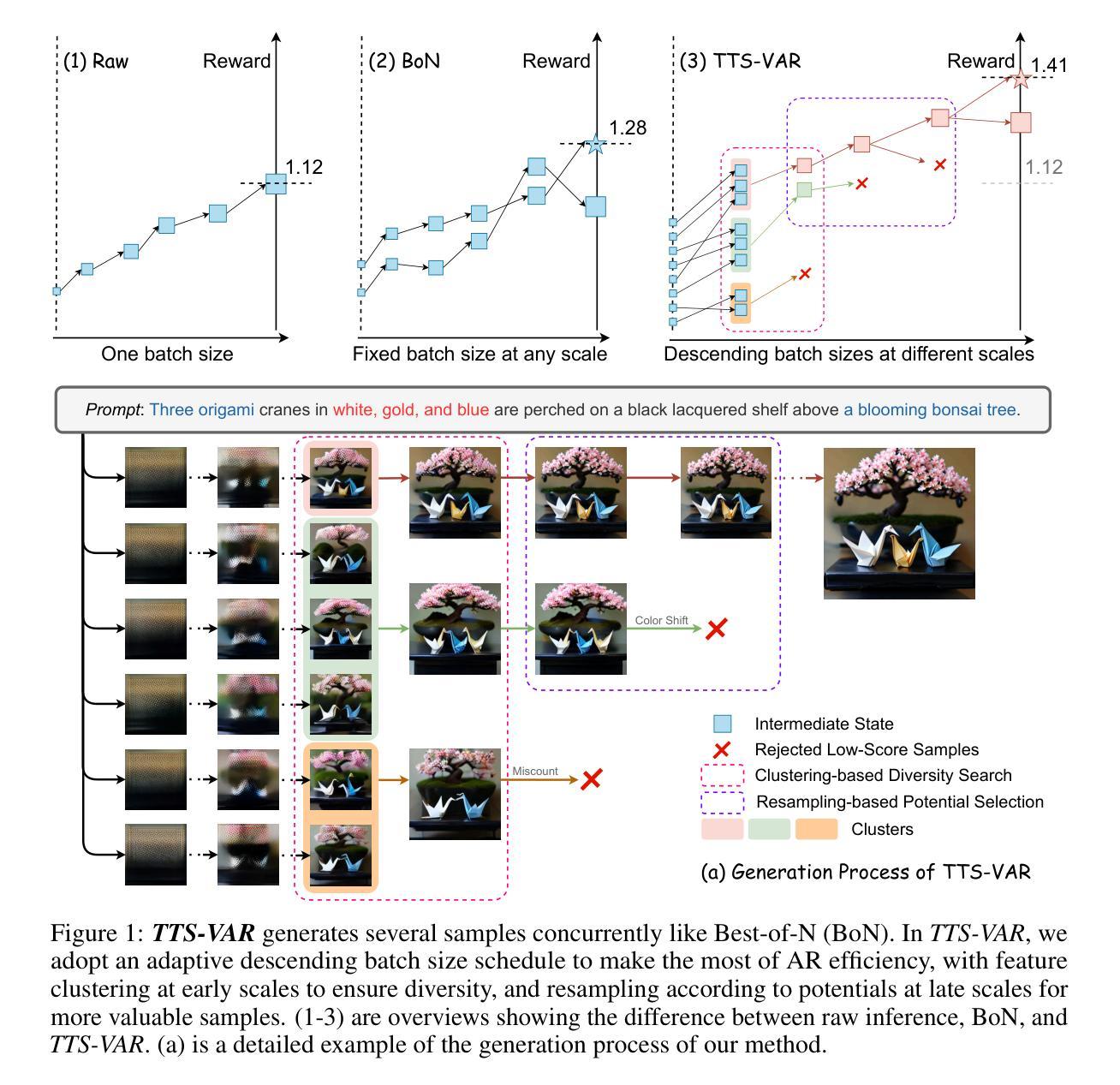
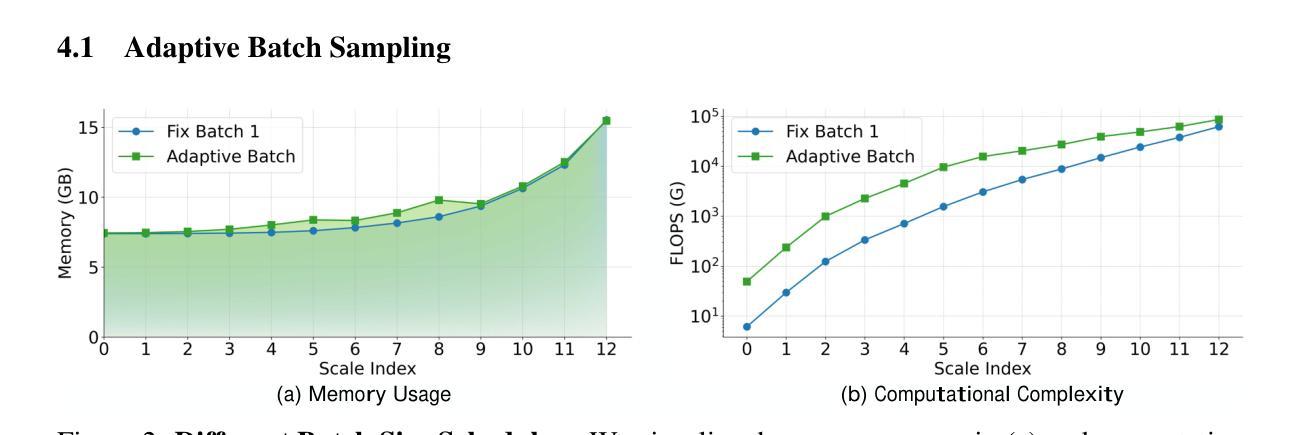
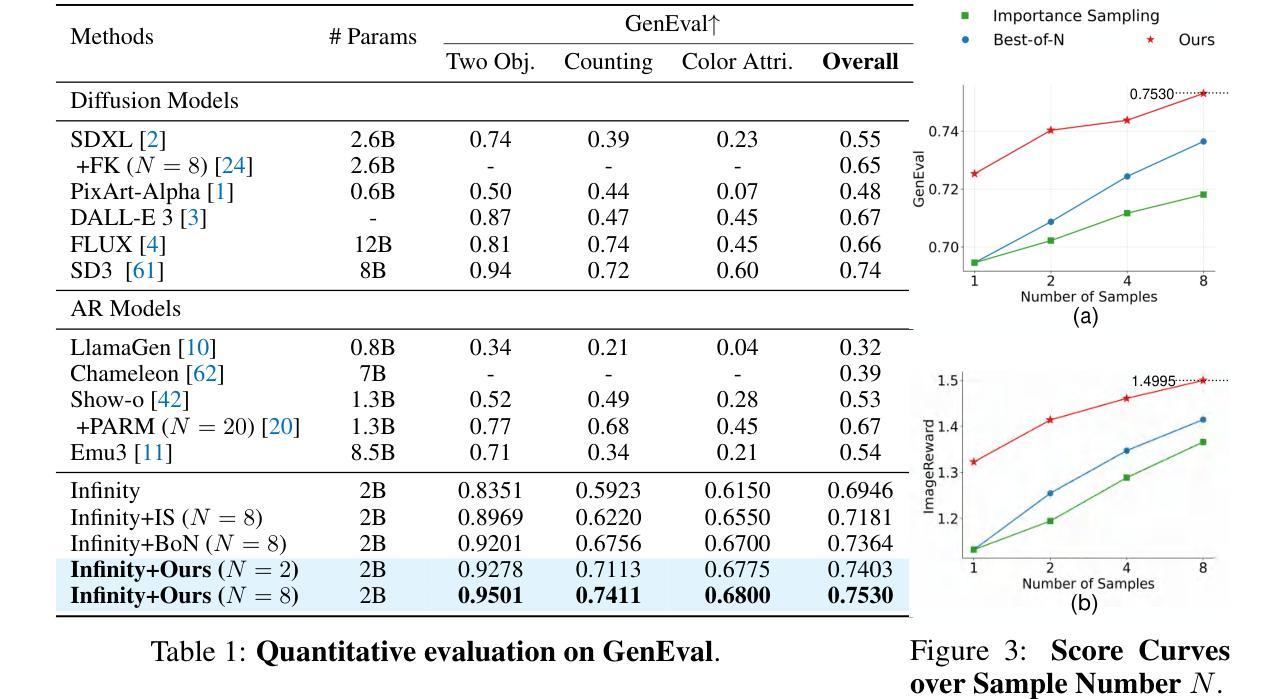
Scaling visual generation models is essential for real-world content creation, yet requires substantial training and computational expenses. Alternatively, test-time scaling has garnered growing attention due to resource efficiency and promising performance. In this work, we present TTS-VAR, the first general test-time scaling framework for visual auto-regressive (VAR) models, modeling the generation process as a path searching problem. To dynamically balance computational efficiency with exploration capacity, we first introduce an adaptive descending batch size schedule throughout the causal generation process. Besides, inspired by VAR’s hierarchical coarse-to-fine multi-scale generation, our framework integrates two key components: (i) At coarse scales, we observe that generated tokens are hard for evaluation, possibly leading to erroneous acceptance of inferior samples or rejection of superior samples. Noticing that the coarse scales contain sufficient structural information, we propose clustering-based diversity search. It preserves structural variety through semantic feature clustering, enabling later selection on samples with higher potential. (ii) In fine scales, resampling-based potential selection prioritizes promising candidates using potential scores, which are defined as reward functions incorporating multi-scale generation history. Experiments on the powerful VAR model Infinity show a notable 8.7% GenEval score improvement (from 0.69 to 0.75). Key insights reveal that early-stage structural features effectively influence final quality, and resampling efficacy varies across generation scales. Code is available at https://github.com/ali-vilab/TTS-VAR.
将视觉生成模型规模化对于现实世界的内容创建至关重要,但这需要大量的训练和计算资源。相对而言,测试时缩放(test-time scaling)因资源效率和高性能表现而备受关注。在这项工作中,我们推出了TTS-VAR,这是第一个用于视觉自回归(VAR)模型的通用测试时缩放框架,将生成过程建模为路径搜索问题。为了在计算效率和探索能力之间实现动态平衡,我们首先引入了自适应递减批大小调度作为因果生成过程的一部分。此外,受VAR层次化从粗到细的多尺度生成的启发,我们的框架集成了两个关键组件:(i)在粗尺度上,我们发现生成的令牌很难进行评估,这可能导致劣质样本的错误接受或优质样本的拒绝。注意到粗尺度包含足够的结构信息,我们提出了基于聚类的多样性搜索。它通过语义特征聚类来保持结构多样性,使后期对潜力更高的样本进行筛选成为可能。(ii)在精细尺度上,基于重采样的潜力选择使用潜力分数优先优秀的候选者,潜力分数被定义为结合多尺度生成历史的奖励函数。在强大的VAR模型Infinity上的实验显示,GenEval得分从0.69提高到0.75,提升了显著的8.7%。关键的见解表明,早期阶段的结构特征有效地影响最终质量,重采样的效果在不同生成尺度上有所不同。代码可通过以下链接获取:https://github.com/ali-vilab/TTS-VAR。
论文及项目相关链接
PDF 10 Tables, 9 Figures
Summary
本文介绍了针对视觉自回归(VAR)模型的测试时缩放框架TTS-VAR。它通过路径搜索问题对生成过程进行建模,并引入自适应递减批大小调度来平衡计算效率和探索能力。此外,该框架包含两个关键组件:在粗尺度上,它观察到生成的标记对于评估很困难,因此提出基于聚类的多样性搜索以保留结构多样性;在精细尺度上,基于重采样的潜力选择则侧重于使用多尺度生成历史的奖励函数来优先选择有前途的候选者。实验显示,在强大的VAR模型Infinity上,TTS-VAR的GenEval得分提高了8.7%。
Key Takeaways
- 测试时缩放(Test-Time Scaling)是一种高效且性能有保证的资源优化方法。对于视觉自回归(VAR)模型,提出了一种新的框架TTS-VAR用于测试时缩放。
- TTS-VAR框架通过将生成过程建模为路径搜索问题来处理视觉内容生成任务的复杂性。它动态平衡计算效率和探索能力。
- 在粗尺度上,TTS-VAR引入基于聚类的多样性搜索来保留结构多样性,解决生成的标记评估困难的问题。
- 在精细尺度上,TTS-VAR采用基于重采样的潜力选择方法,利用多尺度生成历史的奖励函数来选择有前途的候选者。
- 实验结果显示,在强大的VAR模型Infinity上应用TTS-VAR后,GenEval得分显著提高,验证了该框架的有效性。
- 研究强调了早期阶段的结构特征对最终质量的重要影响。这对于进一步改进和优化视觉内容生成模型具有重要的启示意义。
点此查看论文截图

Yume: An Interactive World Generation Model
Authors:Xiaofeng Mao, Shaoheng Lin, Zhen Li, Chuanhao Li, Wenshuo Peng, Tong He, Jiangmiao Pang, Mingmin Chi, Yu Qiao, Kaipeng Zhang
Yume aims to use images, text, or videos to create an interactive, realistic, and dynamic world, which allows exploration and control using peripheral devices or neural signals. In this report, we present a preview version of \method, which creates a dynamic world from an input image and allows exploration of the world using keyboard actions. To achieve this high-fidelity and interactive video world generation, we introduce a well-designed framework, which consists of four main components, including camera motion quantization, video generation architecture, advanced sampler, and model acceleration. First, we quantize camera motions for stable training and user-friendly interaction using keyboard inputs. Then, we introduce the Masked Video Diffusion Transformer~(MVDT) with a memory module for infinite video generation in an autoregressive manner. After that, training-free Anti-Artifact Mechanism (AAM) and Time Travel Sampling based on Stochastic Differential Equations (TTS-SDE) are introduced to the sampler for better visual quality and more precise control. Moreover, we investigate model acceleration by synergistic optimization of adversarial distillation and caching mechanisms. We use the high-quality world exploration dataset \sekai to train \method, and it achieves remarkable results in diverse scenes and applications. All data, codebase, and model weights are available on https://github.com/stdstu12/YUME. Yume will update monthly to achieve its original goal. Project page: https://stdstu12.github.io/YUME-Project/.
Yume旨在利用图像、文本或视频创建互动、逼真、动态的世界,允许使用外围设备或神经信号进行探索和控制。在本报告中,我们展示了\method的预览版,它可以从输入图像中创建一个动态世界,并使用键盘操作探索这个世界。为了实现高保真和互动的视频世界生成,我们引入了一个精心设计的框架,该框架由四个主要组件组成,包括相机运动量化、视频生成架构、高级采样器和模型加速。首先,我们使用键盘输入对相机运动进行量化,以实现稳定的训练和用户友好的互动。然后,我们引入了带有记忆模块的Masked Video Diffusion Transformer(MVDT)以自回归方式进行无限视频生成。之后,我们向采样器引入了无需训练的Anti-Artifact Mechanism(AAM)和基于随机微分方程的Time Travel Sampling(TTS-SDE),以提高视觉质量和更精确的控制。此外,我们通过协同优化对抗蒸馏和缓存机制来研究模型加速。我们使用高质量的世界探索数据集\sekai来训练\method,它在各种场景和应用中取得了显著成果。所有数据、代码库和模型权重均可在https://github.com/stdstu12/YUME上找到。Yume将每月更新以达成其原始目标。项目页面:https://stdstu12.github.io/YUME-Project/。
论文及项目相关链接
Summary
优梦项目旨在使用图像、文本或视频创建互动、真实且动态的世界,可通过外围设备或神经信号进行探索和控制。本次报告预览版的方法通过输入图像创建动态世界,允许使用键盘操作探索世界。为此,我们设计了一个框架,包含相机动作量化、视频生成架构、高级采样器和模型加速等四个主要组件。此外,还探讨了通过对抗蒸馏和缓存机制的协同优化来加速模型。优梦数据集的高质量世界探索成果显著,模型权重及资料均可从公开链接获取。
Key Takeaways
- 优梦项目的核心目标是使用图像、文本或视频来创建一个互动、真实且动态的世界。
- 项目通过输入图像生成动态世界,并允许用户使用键盘操作进行探索。
- 项目采用包含四个主要组件的框架来实现这一功能,包括相机动作量化、视频生成架构、高级采样器和模型加速。
- 采用Masked Video Diffusion Transformer (MVDT)进行无限视频的自回归生成。
- 引入训练外的Anti-Artifact Mechanism (AAM)和基于随机微分方程的Time Travel Sampling (TTS-SDE)以提高视觉质量和控制精度。
- 项目使用优梦数据集进行训练,并在多种场景和应用中取得了显著成果。
点此查看论文截图


AI Telephone Surveying: Automating Quantitative Data Collection with an AI Interviewer
Authors:Danny D. Leybzon, Shreyas Tirumala, Nishant Jain, Summer Gillen, Michael Jackson, Cameron McPhee, Jennifer Schmidt
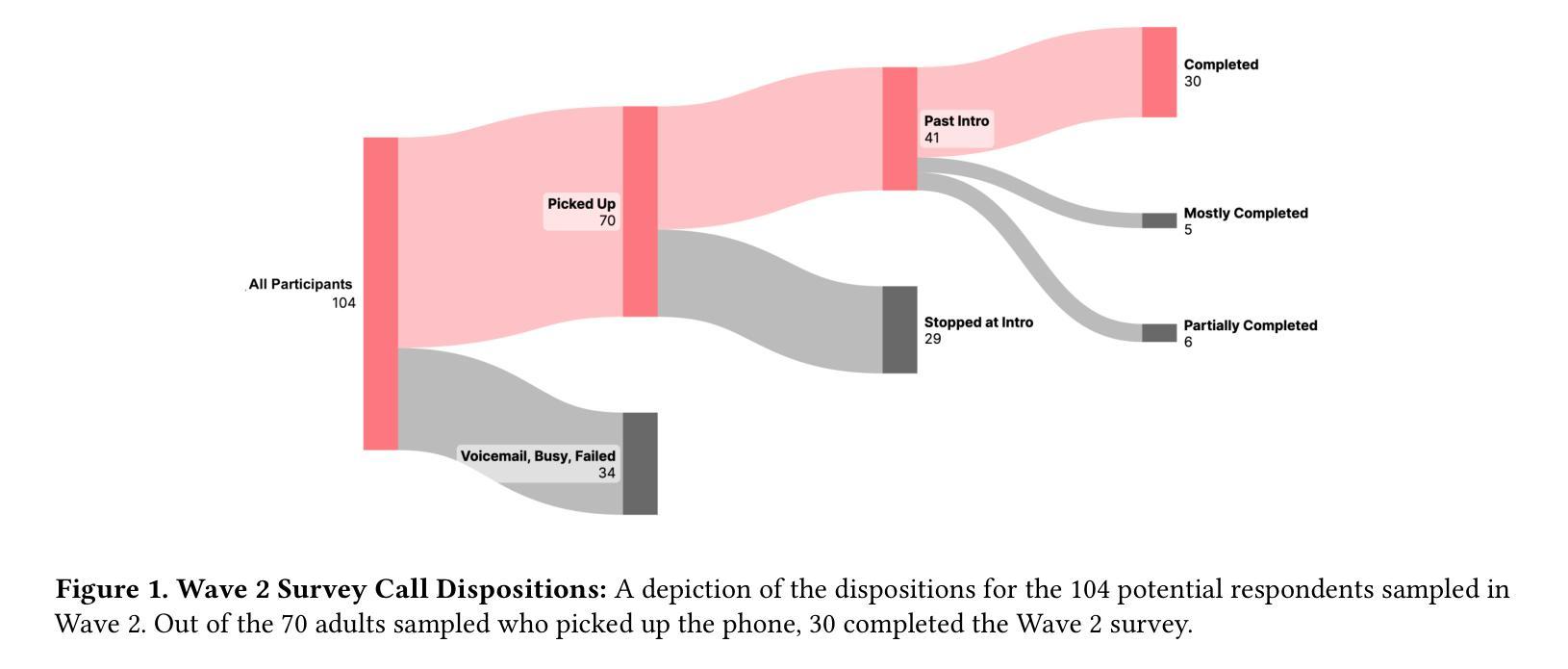
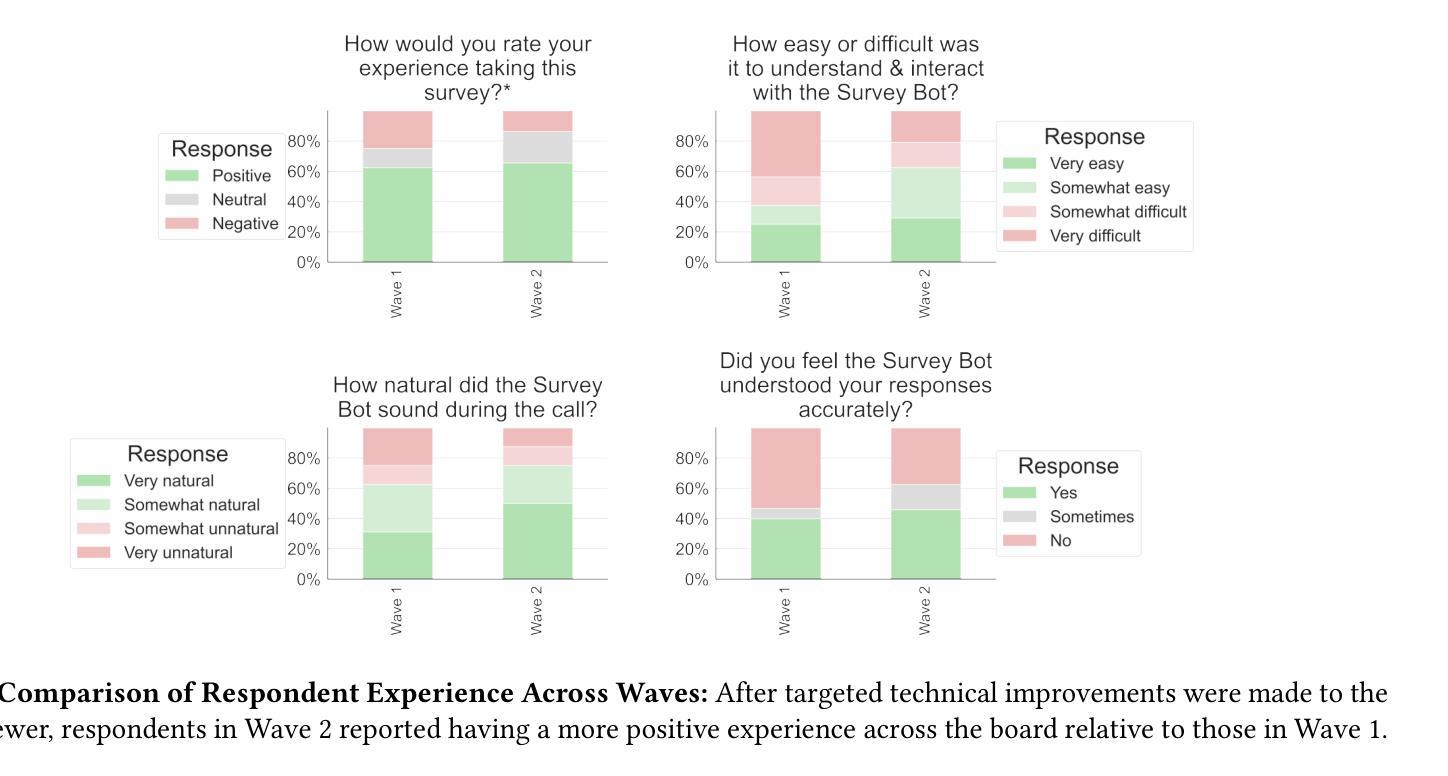
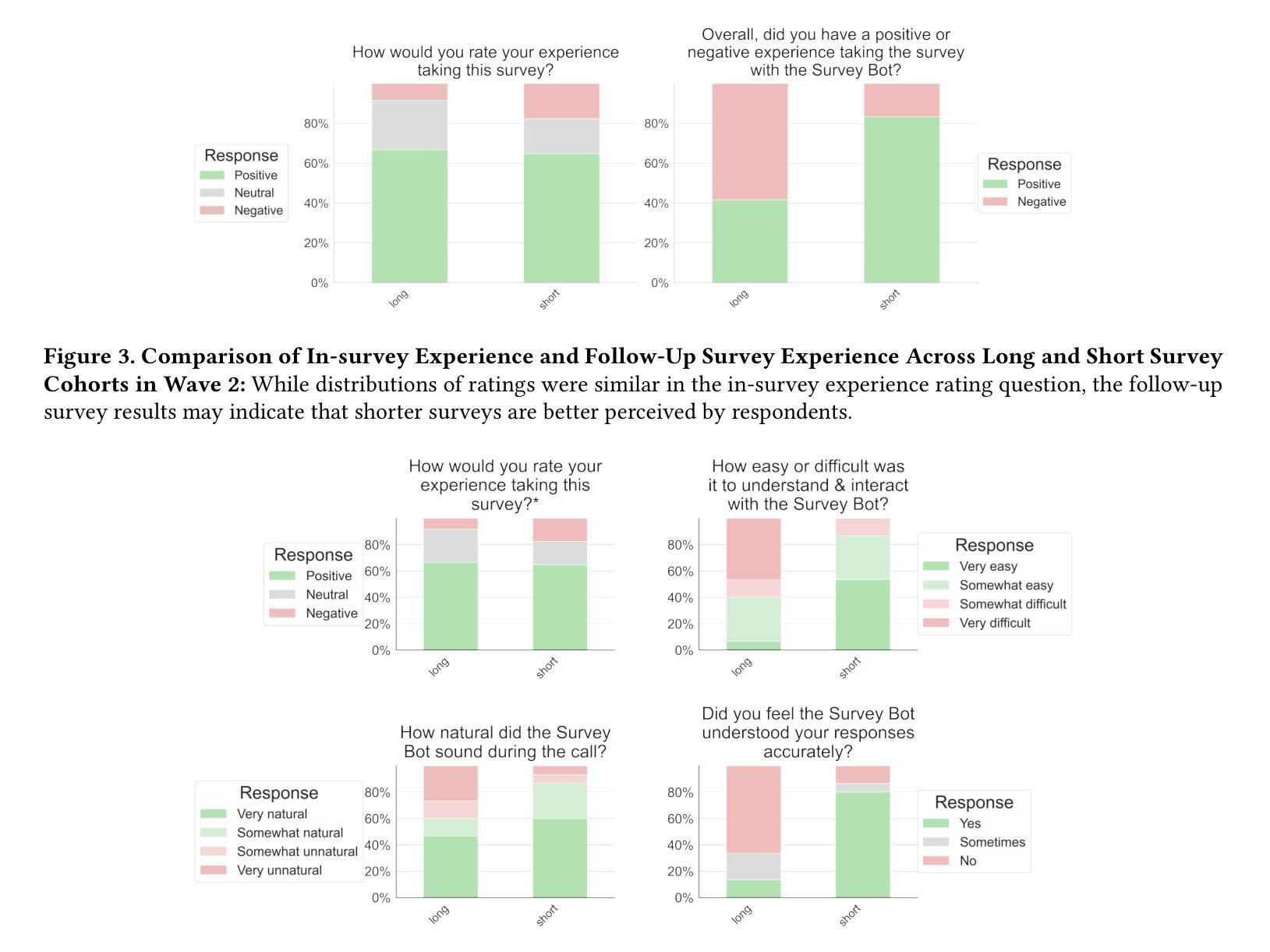
With the rise of voice-enabled artificial intelligence (AI) systems, quantitative survey researchers have access to a new data-collection mode: AI telephone surveying. By using AI to conduct phone interviews, researchers can scale quantitative studies while balancing the dual goals of human-like interactivity and methodological rigor. Unlike earlier efforts that used interactive voice response (IVR) technology to automate these surveys, voice AI enables a more natural and adaptive respondent experience as it is more robust to interruptions, corrections, and other idiosyncrasies of human speech. We built and tested an AI system to conduct quantitative surveys based on large language models (LLM), automatic speech recognition (ASR), and speech synthesis technologies. The system was specifically designed for quantitative research, and strictly adhered to research best practices like question order randomization, answer order randomization, and exact wording. To validate the system’s effectiveness, we deployed it to conduct two pilot surveys with the SSRS Opinion Panel and followed-up with a separate human-administered survey to assess respondent experiences. We measured three key metrics: the survey completion rates, break-off rates, and respondent satisfaction scores. Our results suggest that shorter instruments and more responsive AI interviewers may contribute to improvements across all three metrics studied.
随着语音智能(AI)系统的兴起,定量调查研究人员获得了一种新的数据收集模式:AI电话调查。研究人员可以通过AI进行电话采访,从而在扩大定量研究规模的同时,平衡人性化的互动和方法的严谨性。与早期使用交互式语音应答(IVR)技术自动进行此类调查不同,语音AI能够提供更自然和适应性更强的受访者体验,因为它更能适应中断、更正和人类语言的其它特性。我们构建并测试了一个基于大型语言模型(LLM)、自动语音识别(ASR)和语音合成技术的AI系统来进行定量调查。该系统是专门为定量研究设计的,严格遵守最佳研究实践,如随机问题顺序、随机答案顺序和精确措辞等。为了验证系统的有效性,我们将其部署用于进行两项试点调查,并随后进行一次单独的人工管理调查以评估受访者的体验。我们测量了三个关键指标:调查完成率、中断率和受访者满意度得分。我们的结果表明,更短的工具和反应更迅速的AI面试官可能对这三大指标有所改善。
论文及项目相关链接
Summary
AI电话调查——量化研究的新模式。利用语音人工智能(AI)系统,研究者可规模化开展具有人类交互性的定量研究,实现语音识别的自适应性与连续性。采用大型语言模型(LLM)、自动语音识别(ASR)及语音合成技术构建的AI调查系统遵循研究最佳实践原则,经过初步测试显示,较短的问卷和更灵活的AI采访者可能有助于提高调查完成率、降低中断率和提高受访者满意度。
Key Takeaways
- AI电话调查成为量化研究的新数据收集模式。
- AI系统可平衡人类交互性和方法论严谨性。
- 与早期使用的交互式语音应答(IVR)技术相比,语音AI提供更自然、更适应个体差异的受访者体验。
- 采用大型语言模型(LLM)、自动语音识别(ASR)及语音合成技术构建AI调查系统。
- AI调查系统遵循研究最佳实践原则,如问题顺序随机化、答案顺序随机化及精确措辞。
- 通过初步测试显示,较短的问卷和更灵活的AI采访者有助于提高调查完成率、降低中断率。
点此查看论文截图


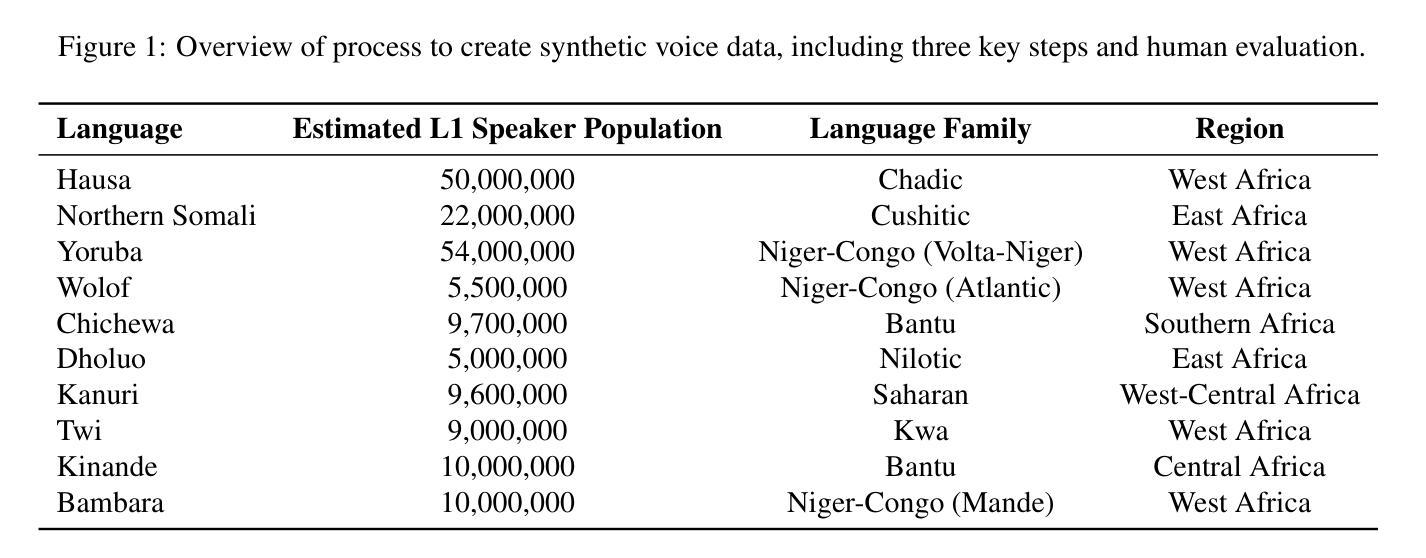
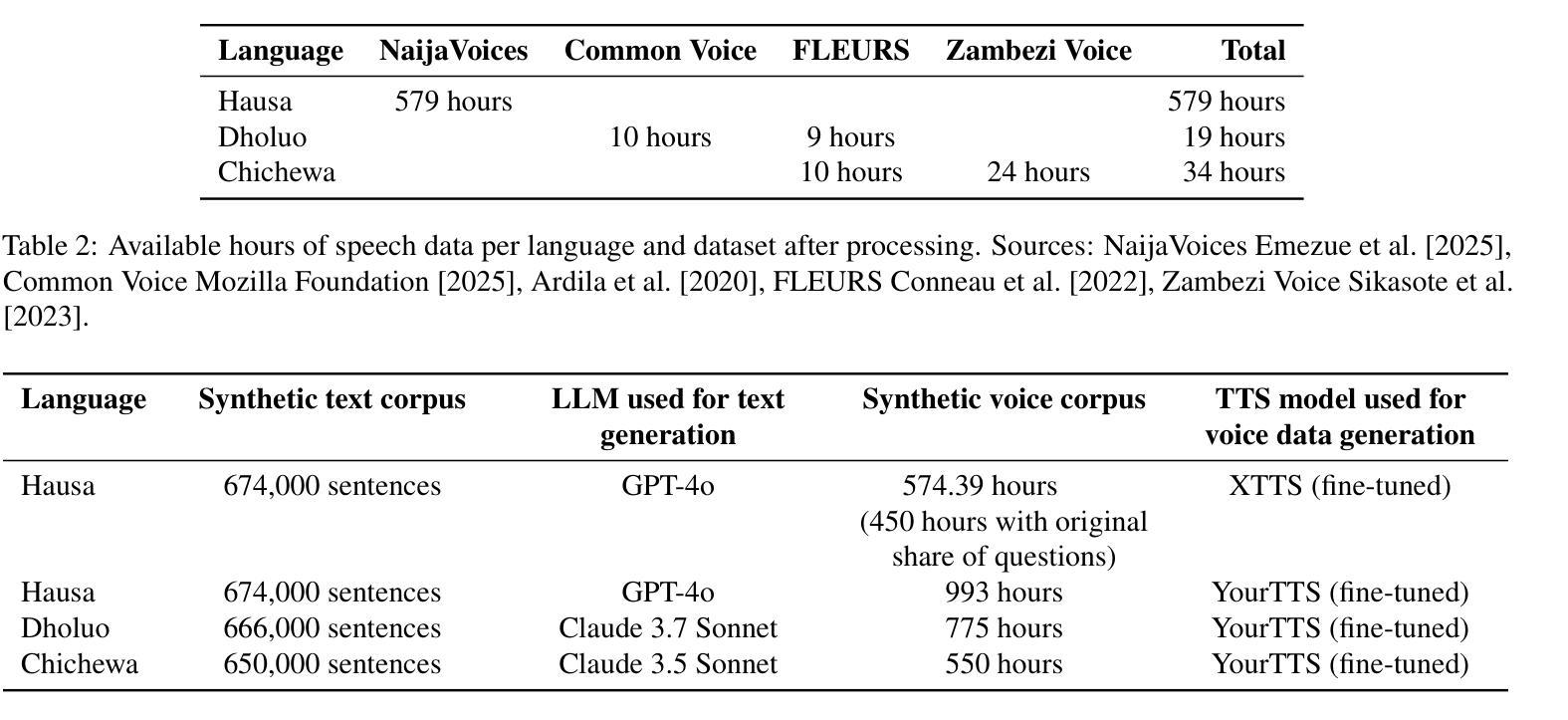
Synthetic Voice Data for Automatic Speech Recognition in African Languages
Authors:Brian DeRenzi, Anna Dixon, Mohamed Aymane Farhi, Christian Resch
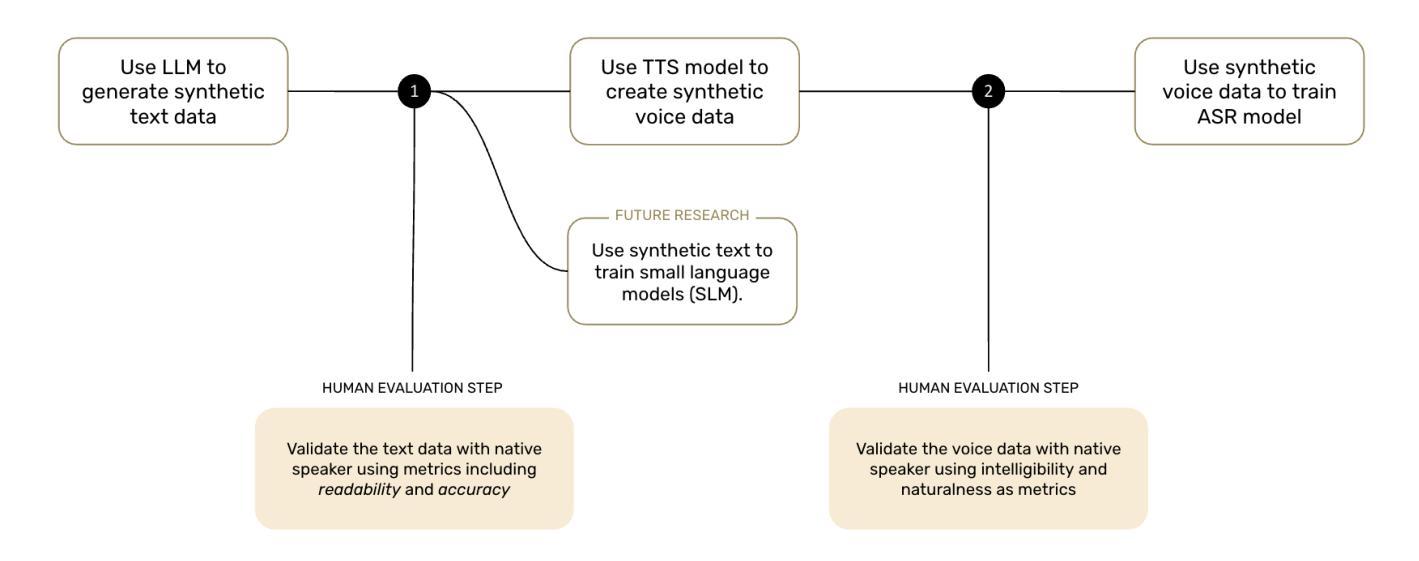
Speech technology remains out of reach for most of the over 2300 languages in Africa. We present the first systematic assessment of large-scale synthetic voice corpora for African ASR. We apply a three-step process: LLM-driven text creation, TTS voice synthesis, and ASR fine-tuning. Eight out of ten languages for which we create synthetic text achieved readability scores above 5 out of 7. We evaluated ASR improvement for three (Hausa, Dholuo, Chichewa) and created more than 2,500 hours of synthetic voice data at below 1% of the cost of real data. Fine-tuned Wav2Vec-BERT-2.0 models trained on 250h real and 250h synthetic Hausa matched a 500h real-data-only baseline, while 579h real and 450h to 993h synthetic data created the best performance. We also present gender-disaggregated ASR performance evaluation. For very low-resource languages, gains varied: Chichewa WER improved about 6.5% relative with a 1:2 real-to-synthetic ratio; a 1:1 ratio for Dholuo showed similar improvements on some evaluation data, but not on others. Investigating intercoder reliability, ASR errors and evaluation datasets revealed the need for more robust reviewer protocols and more accurate evaluation data. All data and models are publicly released to invite further work to improve synthetic data for African languages.
对于非洲的2300多种语言中的大多数而言,语音技术仍是难以触及的领域。我们对非洲ASR的大规模合成语音语料库进行了首次系统性评估。我们采用了三步过程:基于LLM的文本创建、TTS语音合成和ASR微调。在我们创建的合成文本中,有八种语言的可读性得分高于十分之七。我们对三种语言(豪萨语、德洛尔语、契维语)的ASR进行了改进,并以低于真实数据成本的百分之一创建了超过2500小时的合成语音数据。使用250小时真实数据和25sh合成豪萨语的Wav2Vec-BERT-2.0模型微调,匹配了仅使用500小时真实数据的基线,而使用真实数据训练的模型和合成的数据则取得了最佳性能。我们还进行了按性别划分的ASR性能评估。对于资源非常匮乏的语言,收益有所不同:契维语的词错误率相对降低了约百分之六;豪萨语的真实数据与合成数据比例为1:1时,在某些评估数据上显示出相似的改进效果,但在其他方面则没有。调查编码员之间的可靠性、ASR错误和评估数据集揭示了需要更稳健的审查协议和更准确的评估数据。所有数据模型和合成语音都被公开发布,诚邀更多工作来提高非洲语言的合成数据质量。
论文及项目相关链接
PDF 29 pages incl. appendix, 8 tables, 5 figures. Authors are listed in alphabetical order
Summary
本文介绍了针对非洲语言自动语音识别(ASR)系统的合成语音语料库的系统评估。通过三步法创建合成语音:大型语言模型(LLM)驱动文本生成、文本转语音(TTS)语音合成和ASR微调。评估结果显示,八种语言的合成文本可读性得分超过5分(满分7分)。通过合成语音数据改善了三种语言的ASR性能,并创建了超过2,500小时合成语音数据,成本仅为真实数据的1%。同时,公开所有数据模型以邀请更多研究者和开发者共同改进非洲语言的合成数据。
Key Takeaways
- 针对非洲超过2300种语言的语音技术尚未普及。
- 对非洲自动语音识别(ASR)进行了大规模合成语音语料库的系统评估。
- 通过LLM驱动的文本创建、TTS语音合成和ASR微调的三步过程,八种语言的合成文本可读性较高。
- 合成语音数据改善了三种语言的ASR性能,且成本较低。
- 使用真实与合成数据的组合对ASR性能进行了评估,发现最佳性能是在一定比例的真实和合成数据下实现的。
- 进行了性别分类的ASR性能评估。
点此查看论文截图


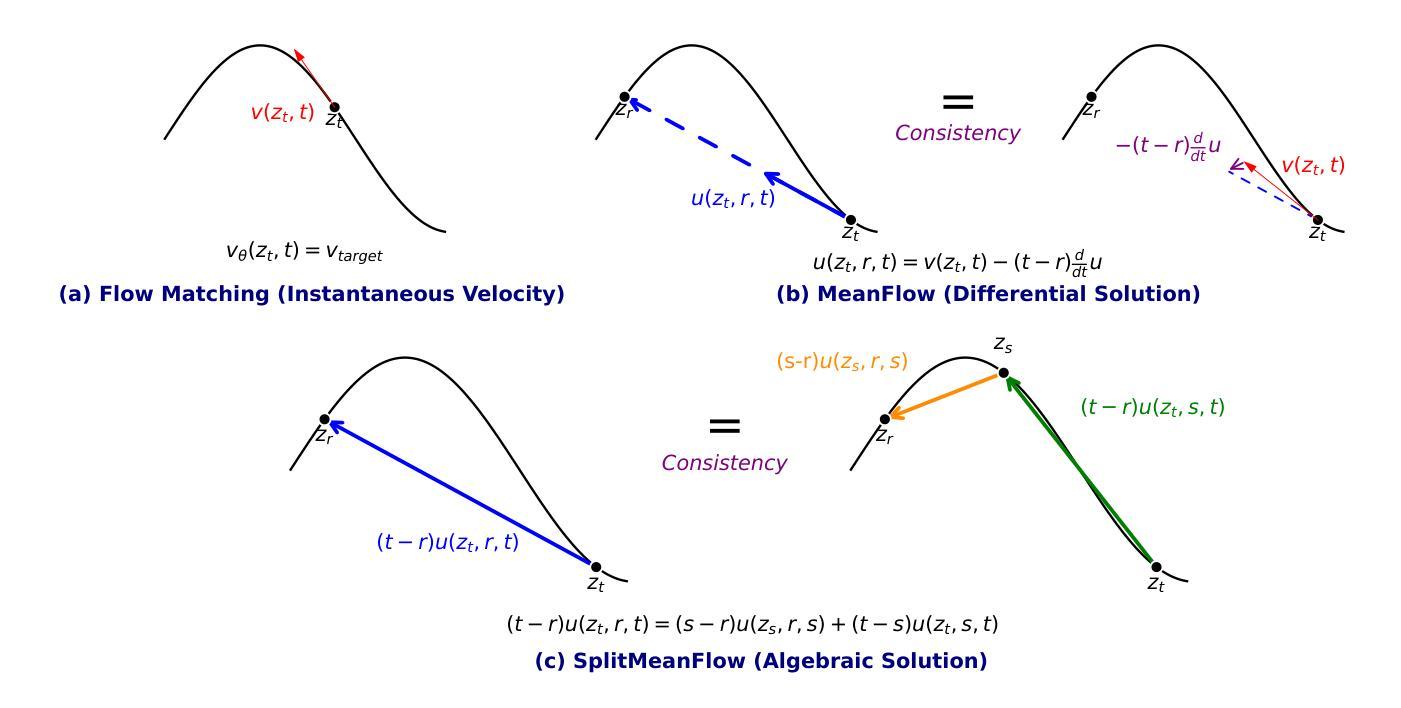
SplitMeanFlow: Interval Splitting Consistency in Few-Step Generative Modeling
Authors:Yi Guo, Wei Wang, Zhihang Yuan, Rong Cao, Kuan Chen, Zhengyang Chen, Yuanyuan Huo, Yang Zhang, Yuping Wang, Shouda Liu, Yuxuan Wang
Generative models like Flow Matching have achieved state-of-the-art performance but are often hindered by a computationally expensive iterative sampling process. To address this, recent work has focused on few-step or one-step generation by learning the average velocity field, which directly maps noise to data. MeanFlow, a leading method in this area, learns this field by enforcing a differential identity that connects the average and instantaneous velocities. In this work, we argue that this differential formulation is a limiting special case of a more fundamental principle. We return to the first principles of average velocity and leverage the additivity property of definite integrals. This leads us to derive a novel, purely algebraic identity we term Interval Splitting Consistency. This identity establishes a self-referential relationship for the average velocity field across different time intervals without resorting to any differential operators. Based on this principle, we introduce SplitMeanFlow, a new training framework that enforces this algebraic consistency directly as a learning objective. We formally prove that the differential identity at the core of MeanFlow is recovered by taking the limit of our algebraic consistency as the interval split becomes infinitesimal. This establishes SplitMeanFlow as a direct and more general foundation for learning average velocity fields. From a practical standpoint, our algebraic approach is significantly more efficient, as it eliminates the need for JVP computations, resulting in simpler implementation, more stable training, and broader hardware compatibility. One-step and two-step SplitMeanFlow models have been successfully deployed in large-scale speech synthesis products (such as Doubao), achieving speedups of 20x.
流匹配等生成模型虽然取得了最先进的性能,但往往受到计算成本高昂的迭代采样过程的制约。为解决这一问题,近期的研究集中在通过学习平均速度场进行几步或一步生成,该场直接将噪声映射到数据。其中,MeanFlow是这个领域的一种领先方法,它通过强制实施一个连接平均速度和瞬时速度的差异恒等式来学习此场。在这项工作中,我们认为这种差异公式是一个更根本原则的限制性特殊情况。我们回到平均速度的第一原理,并利用定积分的可加性属性。这引导我们推导出我们称之为“区间分割一致性”的新型纯代数恒等式。该恒等式在不同时间间隔上建立了平均速度场的自引用关系,无需使用任何微分算子。基于这一原理,我们引入了SplitMeanFlow,这是一种新的训练框架,直接强制实施这种代数一致性作为学习目标。我们正式证明,当区间分割变得无穷小时,MeanFlow核心的微分恒等式是通过我们的代数一致性得到的。这确立了SplitMeanFlow作为学习平均速度场的直接和更一般的基石。从实际的角度来看,我们的代数方法更加高效,因为它消除了对JVP计算的需求,导致实现更简单、训练更稳定、硬件兼容性更广。一步和两步SplitMeanFlow模型已成功部署在大型语音合成产品(如Doubao)中,实现了20倍的加速。
论文及项目相关链接
PDF Tech Report
Summary
近期工作通过平均速度场的学习来解决生成模型如Flow Matching的计算昂贵问题,直接实现噪声到数据的映射。本研究重新审视平均速度的基础原理,利用定积分的可加性属性,推导出一种新的代数恒等式——区间分割一致性。基于此原则,我们引入SplitMeanFlow训练框架,直接强制实施这种代数一致性作为学习目标。SplitMeanFlow方法更为高效,无需计算JVP,简化了实现,提高了训练稳定性并扩大了硬件兼容性。SplitMeanFlow模型在大型语音合成产品(如Doubao)中部署,实现了20倍的加速。
Key Takeaways
- 生成模型如Flow Matching虽达到先进性能,但计算成本高昂,近期工作通过平均速度场学习来解决这一问题。
- MeanFlow方法通过学习平均速度场的微分恒等式来实现,但本研究认为这种方法是一种特殊情形。
- 利用平均速度的基础原理和定积分的可加性属性,推导出新的代数恒等式——区间分割一致性。
- 基于新的代数恒等式,提出SplitMeanFlow训练框架,更高效地学习平均速度场。
- SplitMeanFlow方法避免了微分运算,简化实现、提高训练稳定性并增强硬件兼容性。
- SplitMeanFlow模型已在大型语音合成产品中成功部署,如Doubao,实现了显著的性能提升。
点此查看论文截图

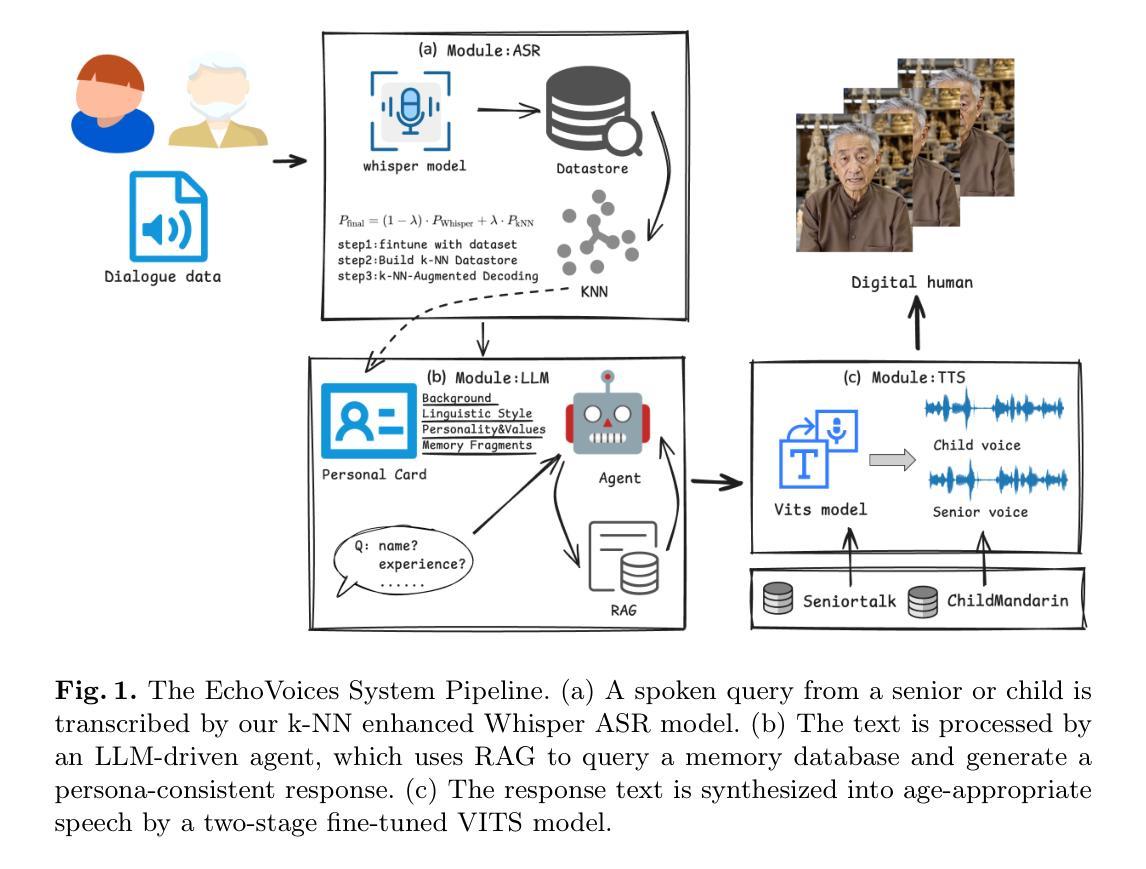
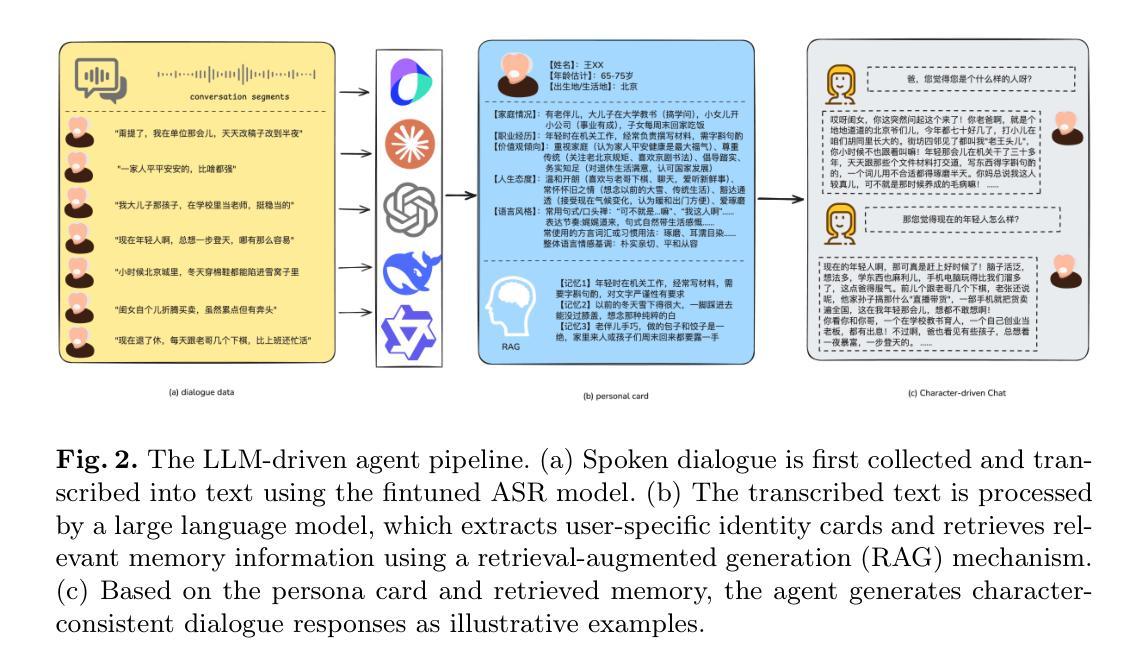
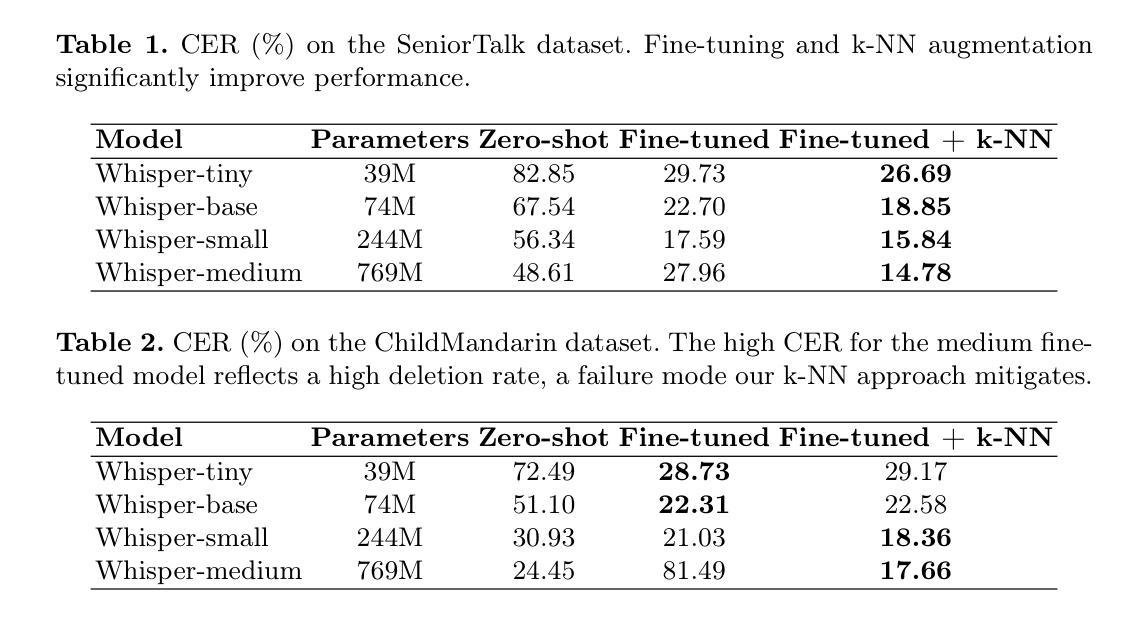
EchoVoices: Preserving Generational Voices and Memories for Seniors and Children
Authors:Haiying Xu, Haoze Liu, Mingshi Li, Siyu Cai, Guangxuan Zheng, Yuhuang Jia, Jinghua Zhao, Yong Qin
Recent breakthroughs in intelligent speech and digital human technologies have primarily targeted mainstream adult users, often overlooking the distinct vocal patterns and interaction styles of seniors and children. These demographics possess distinct vocal characteristics, linguistic styles, and interaction patterns that challenge conventional ASR, TTS, and LLM systems. To address this, we introduce EchoVoices, an end-to-end digital human pipeline dedicated to creating persistent digital personas for seniors and children, ensuring their voices and memories are preserved for future generations. Our system integrates three core innovations: a k-NN-enhanced Whisper model for robust speech recognition of atypical speech; an age-adaptive VITS model for high-fidelity, speaker-aware speech synthesis; and an LLM-driven agent that automatically generates persona cards and leverages a RAG-based memory system for conversational consistency. Our experiments, conducted on the SeniorTalk and ChildMandarin datasets, demonstrate significant improvements in recognition accuracy, synthesis quality, and speaker similarity. EchoVoices provides a comprehensive framework for preserving generational voices, offering a new means of intergenerational connection and the creation of lasting digital legacies.
近期智能语音和数字人技术的突破主要面向主流成年用户,往往忽视了老年人和儿童特有的语音模式和交互风格。这些人群具有独特的语音特征、语言风格和交互模式,对传统的ASR、TTS和LLM系统提出了挑战。为了解决这一问题,我们推出了EchoVoices,这是一个专注于为老年人和儿童创建持久数字人格的端到端数字人管道,确保他们的声音和记忆能够传承给后代。我们的系统集成了三项核心创新:采用k-NN增强的Whisper模型,实现稳健的非常规语音识别;采用年龄自适应的VITS模型,实现高保真、知讲者语音合成;以及一个由LLM驱动的智能代理,可自动生成个人名片,并利用基于RAG的记忆系统实现对话连贯性。我们在SeniorTalk和ChildMandarin数据集上进行的实验,证明了在识别准确性、合成质量和说话人相似性方面的显著改善。EchoVoices提供了一个全面的框架来保存世代之声,为跨代连接和创建持久的数字遗产提供了新的手段。
论文及项目相关链接
Summary
智能语音与数字人技术的最新突破主要集中在主流成年用户上,忽略了老年人和儿童特有的语音模式与交互风格。EchoVoices系统致力于创建针对老年人和儿童的持久数字人格,确保他们的声音与记忆得以传承给未来世代。该系统整合三项核心技术:采用k-NN增强的Whisper模型,实现非典型语音的稳健识别;年龄自适应的VITS模型,实现高保真、具有说话者意识的语音合成;以及基于LLM的代理,自动生成个性卡片并利用RAG为基础的内存系统实现对话连贯性。在SeniorTalk和ChildMandarin数据集上的实验表明,EchoVoices在识别准确率、合成质量和说话者相似性上都有显著提高,为保留世代声音提供了一个综合框架,为跨代连接和创建持久的数字遗产提供了新的手段。
Key Takeaways
- EchoVoices系统致力于创建针对老年人和儿童的持久数字人格。
- 该系统整合三项核心技术:非典型语音的稳健识别、高保真语音合成以及保证对话连贯性的代理技术。
- EchoVoices采用了k-NN增强的Whisper模型来提升对老年人和儿童特有语音模式的识别能力。
- 通过年龄自适应的VITS模型实现高保真、具有说话者意识的语音合成。
- LLM驱动的代理能自动生成个性卡片,并利用RAG为基础的内存系统确保对话连贯性。
- 在SeniorTalk和ChildMandarin数据集上的实验验证了EchoVoices在识别准确率、合成质量和说话者相似性上的显著提高。
点此查看论文截图

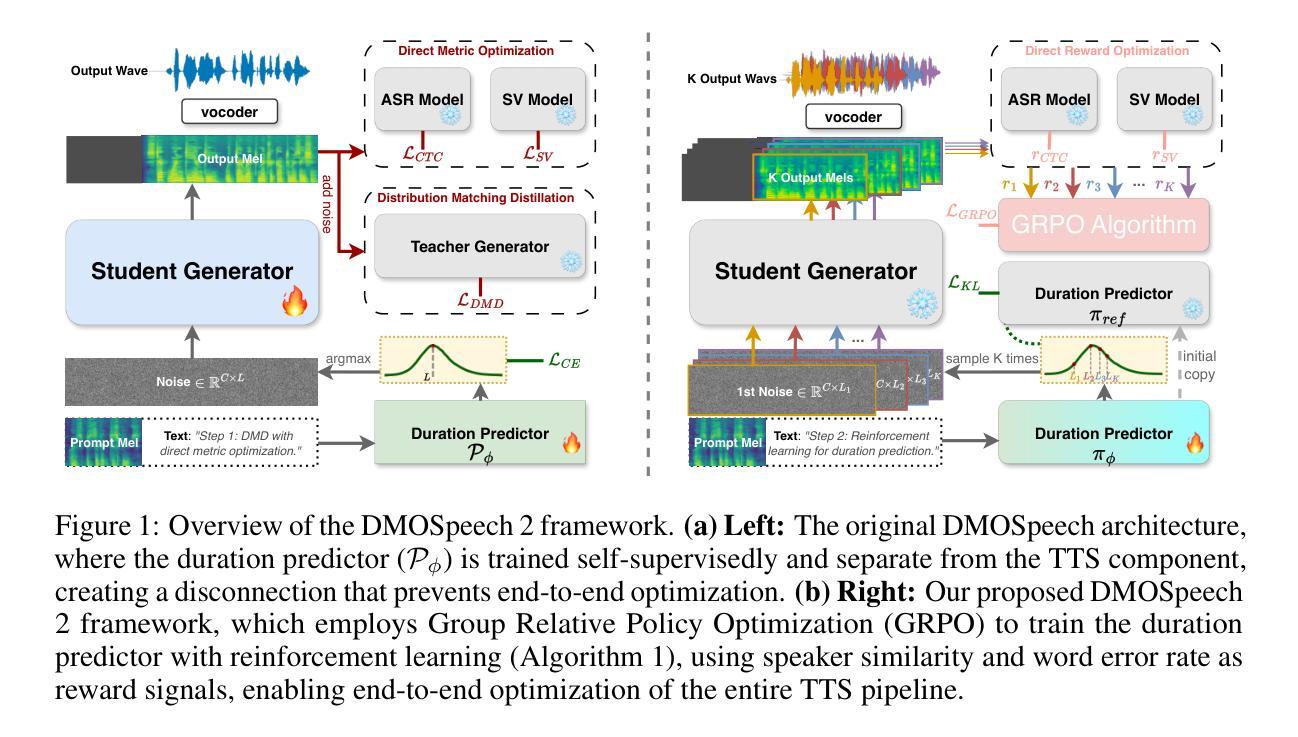
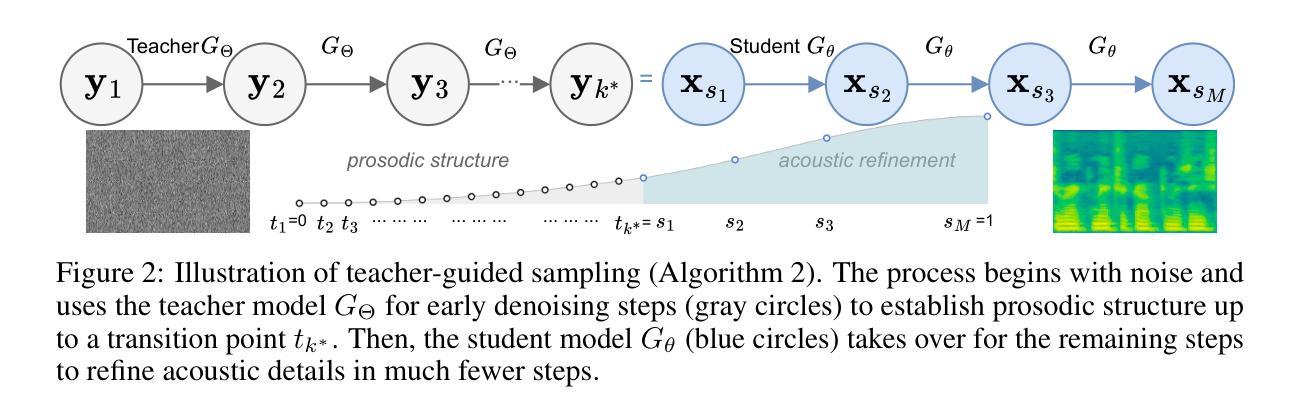
DMOSpeech 2: Reinforcement Learning for Duration Prediction in Metric-Optimized Speech Synthesis
Authors:Yinghao Aaron Li, Xilin Jiang, Fei Tao, Cheng Niu, Kaifeng Xu, Juntong Song, Nima Mesgarani
Diffusion-based text-to-speech (TTS) systems have made remarkable progress in zero-shot speech synthesis, yet optimizing all components for perceptual metrics remains challenging. Prior work with DMOSpeech demonstrated direct metric optimization for speech generation components, but duration prediction remained unoptimized. This paper presents DMOSpeech 2, which extends metric optimization to the duration predictor through a reinforcement learning approach. The proposed system implements a novel duration policy framework using group relative preference optimization (GRPO) with speaker similarity and word error rate as reward signals. By optimizing this previously unoptimized component, DMOSpeech 2 creates a more complete metric-optimized synthesis pipeline. Additionally, this paper introduces teacher-guided sampling, a hybrid approach leveraging a teacher model for initial denoising steps before transitioning to the student model, significantly improving output diversity while maintaining efficiency. Comprehensive evaluations demonstrate superior performance across all metrics compared to previous systems, while reducing sampling steps by half without quality degradation. These advances represent a significant step toward speech synthesis systems with metric optimization across multiple components. The audio samples, code and pre-trained models are available at https://dmospeech2.github.io/.
基于扩散的文本转语音(TTS)系统在零样本语音合成方面取得了显著进步,但优化所有组件以符合感知指标仍然具有挑战性。之前使用DMOSpeech的工作展示了针对语音生成组件的直接指标优化,但持续时间预测尚未优化。本文提出了DMOSpeech 2,它通过强化学习方法将指标优化扩展到持续时间预测器。所提出的系统使用基于群体相对偏好优化(GRPO)的奖励信号来实现新型持续时间策略框架,该策略考虑说话人的相似性和词错误率作为奖励信号。通过优化之前未优化的组件,DMOSpeech 2创建了一个更完整的指标优化合成管道。此外,本文引入了教师引导采样,这是一种混合方法,利用教师模型进行初始去噪步骤,然后过渡到学生模型,在提高输出多样性的同时保持效率。综合评估表明,在所有指标上的性能均优于之前的系统,同时在减半采样步骤的情况下不降低质量。这些进展代表了朝着具有多个组件指标优化的语音合成系统迈出的重要一步。音频样本、代码和预训练模型可在https://dmospeech2.github.io/找到。
论文及项目相关链接
Summary
本文介绍了DMOSpeech 2系统,该系统通过强化学习方法将度量优化扩展到时长预测器上,实现了零样本语音合成的显著进展。通过采用群体相对偏好优化(GRPO)的时长策略框架,同时使用说话人相似度和词错误率作为奖励信号,对时长预测进行优化,创建了一个更完整的度量优化合成管道。此外,引入了教师引导采样法,在初期利用教师模型进行降噪处理,随后过渡到学生模型,以提高输出多样性并维持效率。综合评估表明,DMOSpeech 2在所有指标上的性能均优于之前的系统,且采样步骤减少一半而质量没有降低。这是向多组件度量优化的语音合成系统迈出的重要一步。
Key Takeaways
- DMOSpeech 2系统扩展了度量优化至时长预测器上,通过强化学习方法实现了零样本语音合成的进步。
- 采用群体相对偏好优化(GRPO)的时长策略框架,以优化时长预测。
- 说话人相似度和词错误率被用作奖励信号,以改善语音合成的质量。
- 教师引导采样法的引入提高了输出多样性并维持了效率。
- DMOSpeech 2在多个评估指标上的性能优于先前的系统。
- 采样步骤减少一半,同时保持语音质量不降低。
- 这是朝着多组件度量优化的语音合成系统迈出的重要一步。
点此查看论文截图

NonverbalTTS: A Public English Corpus of Text-Aligned Nonverbal Vocalizations with Emotion Annotations for Text-to-Speech
Authors:Maksim Borisov, Egor Spirin, Daria Diatlova
Current expressive speech synthesis models are constrained by the limited availability of open-source datasets containing diverse nonverbal vocalizations (NVs). In this work, we introduce NonverbalTTS (NVTTS), a 17-hour open-access dataset annotated with 10 types of NVs (e.g., laughter, coughs) and 8 emotional categories. The dataset is derived from popular sources, VoxCeleb and Expresso, using automated detection followed by human validation. We propose a comprehensive pipeline that integrates automatic speech recognition (ASR), NV tagging, emotion classification, and a fusion algorithm to merge transcriptions from multiple annotators. Fine-tuning open-source text-to-speech (TTS) models on the NVTTS dataset achieves parity with closed-source systems such as CosyVoice2, as measured by both human evaluation and automatic metrics, including speaker similarity and NV fidelity. By releasing NVTTS and its accompanying annotation guidelines, we address a key bottleneck in expressive TTS research. The dataset is available at https://huggingface.co/datasets/deepvk/NonverbalTTS.
当前的表情语音合成模型受限于开放源数据集的有限可用性,这些数据集包含各种非言语发声(NVs)。在这项工作中,我们介绍了NonverbalTTS(NVTTS),这是一个包含17小时时长、标注了10种非言语发声类型和8种情绪类别的开放访问数据集。该数据集来源于受欢迎的资源VoxCeleb和Expresso,使用自动检测加人工验证的方式生成。我们提出了一个综合管道,集成了自动语音识别(ASR)、NV标签、情绪分类,以及一个融合算法来合并多个注释器的转录内容。在NVTTS数据集上微调开源文本到语音(TTS)模型,可以实现与人类评估的封闭系统(如CosyVoice2)相当的性能,并通过自动度量指标(包括说话人相似性和NV保真度)来衡量这一点。通过发布NVTTS及其随附的注释指南,我们解决了表情TTS研究中的一个关键瓶颈。该数据集可在链接获取。
论文及项目相关链接
Summary
非言语语音合成模型受限于公开数据集的可访问性和多样性。本研究介绍了NonverbalTTS(NVTTS)数据集,包含17小时时长,标注了10种非言语声音类型和8种情感类别。该数据集来源于VoxCeleb和Expresso等流行来源,采用自动检测加人工验证的方式构建。通过集成自动语音识别(ASR)、非言语标签、情感分类和融合算法等多阶段处理流程,该数据集能够对多重标注进行融合转录。在非言语数据集上微调开放源文本转语音(TTS)模型可实现与闭源系统相近的效果。NVTTS数据集及其标注指南的发布解决了表达性TTS研究的关键瓶颈问题。可通过相关网站访问此数据集。
Key Takeaways
- NVTTS是一个包含多种非言语声音和情感类别的公开数据集。
- 数据集来源于VoxCeleb和Expresso等流行来源,标注了非言语声音和情绪类别。
- NVTTS采用了自动化和人工验证结合的标注方法。
- 数据集提供了一个综合处理流程,包括ASR、NV标签、情感分类等。
- 在NVTTS数据集上微调开放源TTS模型可实现与闭源系统相近的效果。
- NVTTS的发布解决了表达性TTS研究的关键瓶颈问题。
点此查看论文截图

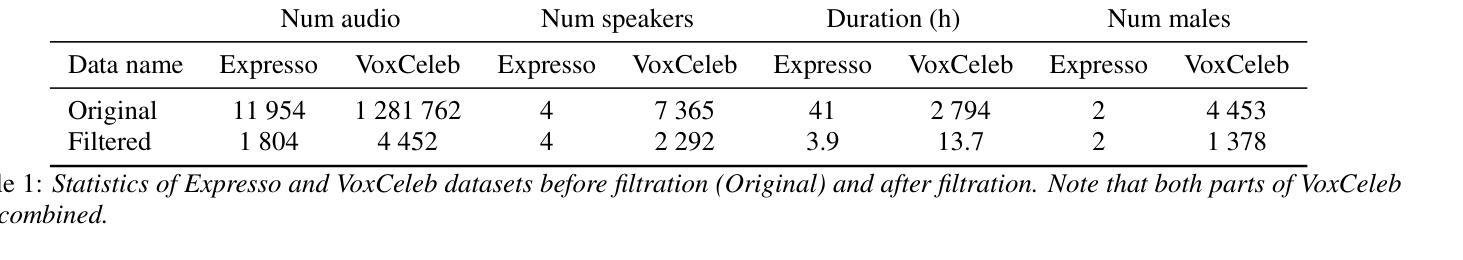





Intelligent Virtual Sonographer (IVS): Enhancing Physician-Robot-Patient Communication
Authors:Tianyu Song, Feng Li, Yuan Bi, Angelos Karlas, Amir Yousefi, Daniela Branzan, Zhongliang Jiang, Ulrich Eck, Nassir Navab
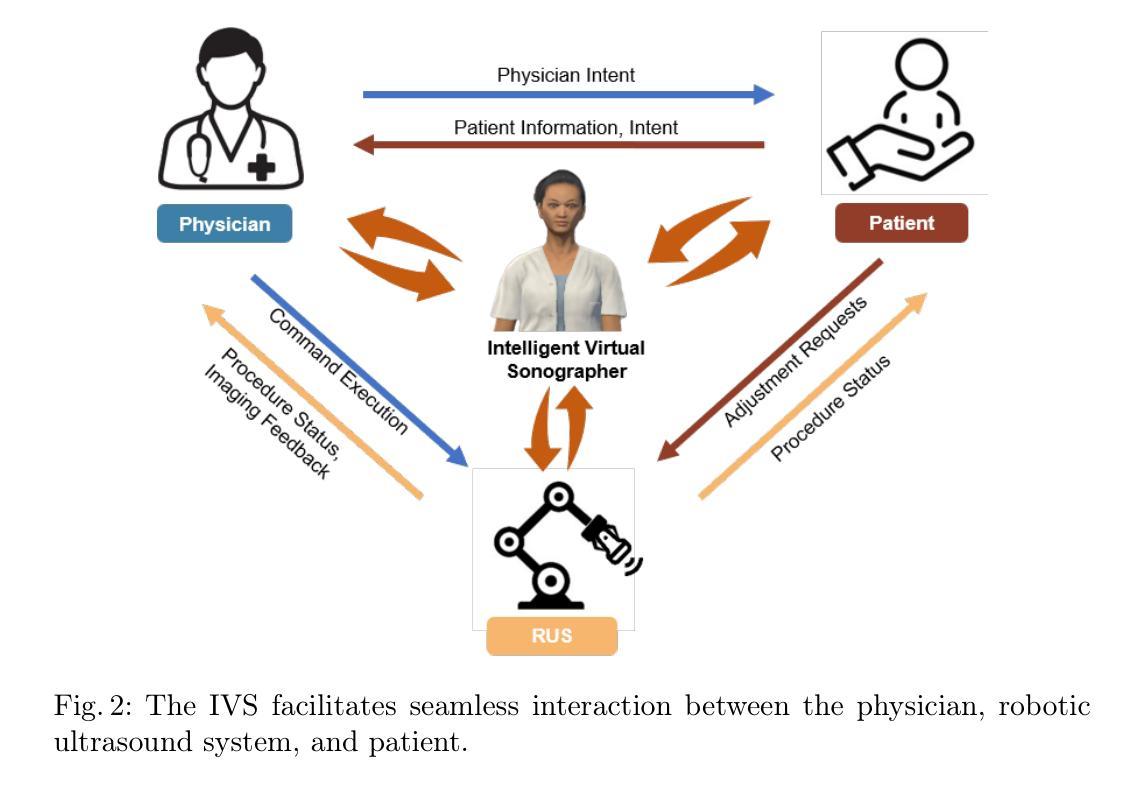
The advancement and maturity of large language models (LLMs) and robotics have unlocked vast potential for human-computer interaction, particularly in the field of robotic ultrasound. While existing research primarily focuses on either patient-robot or physician-robot interaction, the role of an intelligent virtual sonographer (IVS) bridging physician-robot-patient communication remains underexplored. This work introduces a conversational virtual agent in Extended Reality (XR) that facilitates real-time interaction between physicians, a robotic ultrasound system(RUS), and patients. The IVS agent communicates with physicians in a professional manner while offering empathetic explanations and reassurance to patients. Furthermore, it actively controls the RUS by executing physician commands and transparently relays these actions to the patient. By integrating LLM-powered dialogue with speech-to-text, text-to-speech, and robotic control, our system enhances the efficiency, clarity, and accessibility of robotic ultrasound acquisition. This work constitutes a first step toward understanding how IVS can bridge communication gaps in physician-robot-patient interaction, providing more control and therefore trust into physician-robot interaction while improving patient experience and acceptance of robotic ultrasound.
大型语言模型(LLM)和机器人技术的不断进步和成熟,为人机交互,特别是在机器人超声领域,带来了巨大的潜力。尽管现有研究主要关注患者与机器人或医生与机器人的交互,但智能虚拟超声技师(IVS)在医生-机器人-患者沟通中的桥梁作用仍被忽视。本研究引入了一种扩展现实(XR)中的对话式虚拟代理,促进了医生、机器人超声系统(RUS)和患者之间的实时交互。IVS代理以专业的方式与医生沟通,同时向患者提供富有同情心的解释和安慰。此外,它还能主动控制RUS,执行医生的命令,并透明地向患者传达这些行动。通过整合大型语言模型驱动的对话与语音识别、文本到语音转换和机器人控制,我们的系统提高了机器人超声采集的效率、清晰度和可及性。本研究是了解IVS如何弥合医生-机器人-患者沟通中的差距的第一步,为医生-机器人交互提供更多的控制和信任,同时提高患者对机器人超声的体验和接受度。
论文及项目相关链接
PDF Accepted at MICCAI 2025
Summary
新一代大型语言模型(LLM)与机器人技术的成熟为人机交互打开了巨大的潜力,特别是在机器人超声领域。当前研究主要集中在医患机器人或医生机器人交互上,而智能虚拟超声师(IVS)在医生机器人与患者沟通中的桥梁作用尚未得到充分探索。本研究引入了一种基于扩展现实(XR)的对话虚拟智能体,该智能体能促进医生、机器人超声系统(RUS)和患者之间的实时交互。IVS智能体能以专业的方式与医生沟通,同时向患者提供富有同情心的解释和安慰。此外,它还能主动控制RUS执行医生的命令,并向患者透明地传达这些操作。通过整合LLM驱动的对话与语音识别、文本转语音和机器人控制,我们的系统提高了机器人超声采集的效率、清晰度和可及性。本研究是了解IVS如何弥合医生机器人与患者沟通中的差距的第一步,为提高医生机器人交互的控制和信任以及改善患者体验和接受度提供了重要思路。
Key Takeaways
- 大型语言模型(LLM)和机器人技术的成熟促进了人机交互的发展,特别是在机器人超声领域。
- 当前研究忽视了智能虚拟超声师(IVS)在医生机器人与患者沟通中的桥梁作用。
- IVS能够专业地与医生沟通,同时向患者提供富有同情心的解释和安慰。
- IVS能主动控制机器人超声系统(RUS)执行医生的命令。
- 结合LLM、语音识别、文本转语音和机器人控制,提高了机器人超声采集的效率、清晰度和可及性。
- 本研究是了解IVS如何促进医生机器人与患者沟通的第一步。
点此查看论文截图


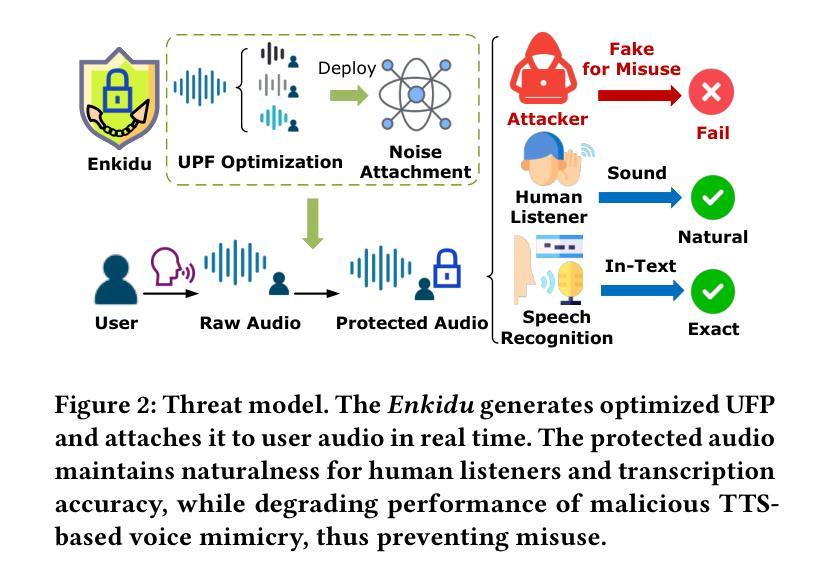
Enkidu: Universal Frequential Perturbation for Real-Time Audio Privacy Protection against Voice Deepfakes
Authors:Zhou Feng, Jiahao Chen, Chunyi Zhou, Yuwen Pu, Qingming Li, Tianyu Du, Shouling Ji
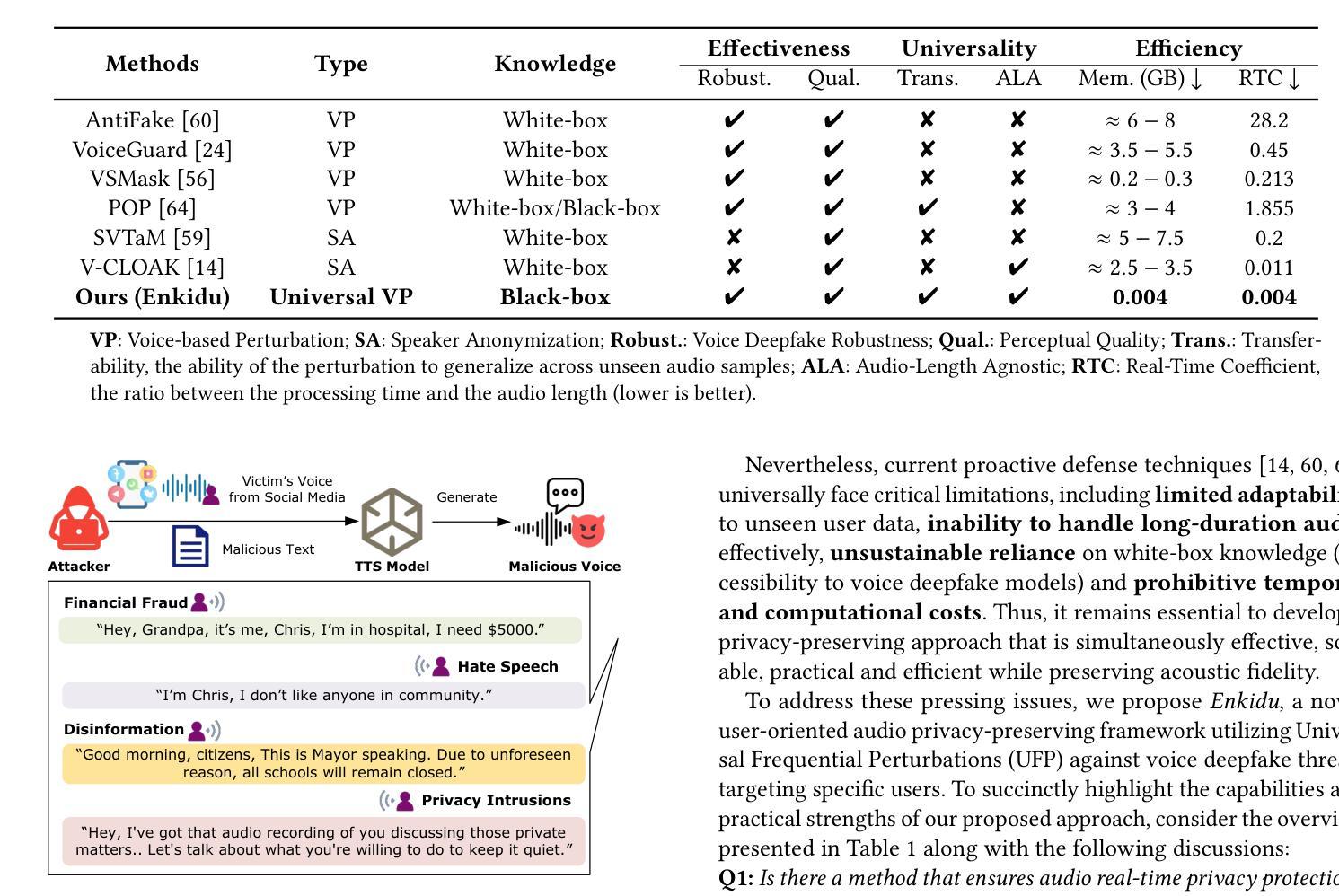
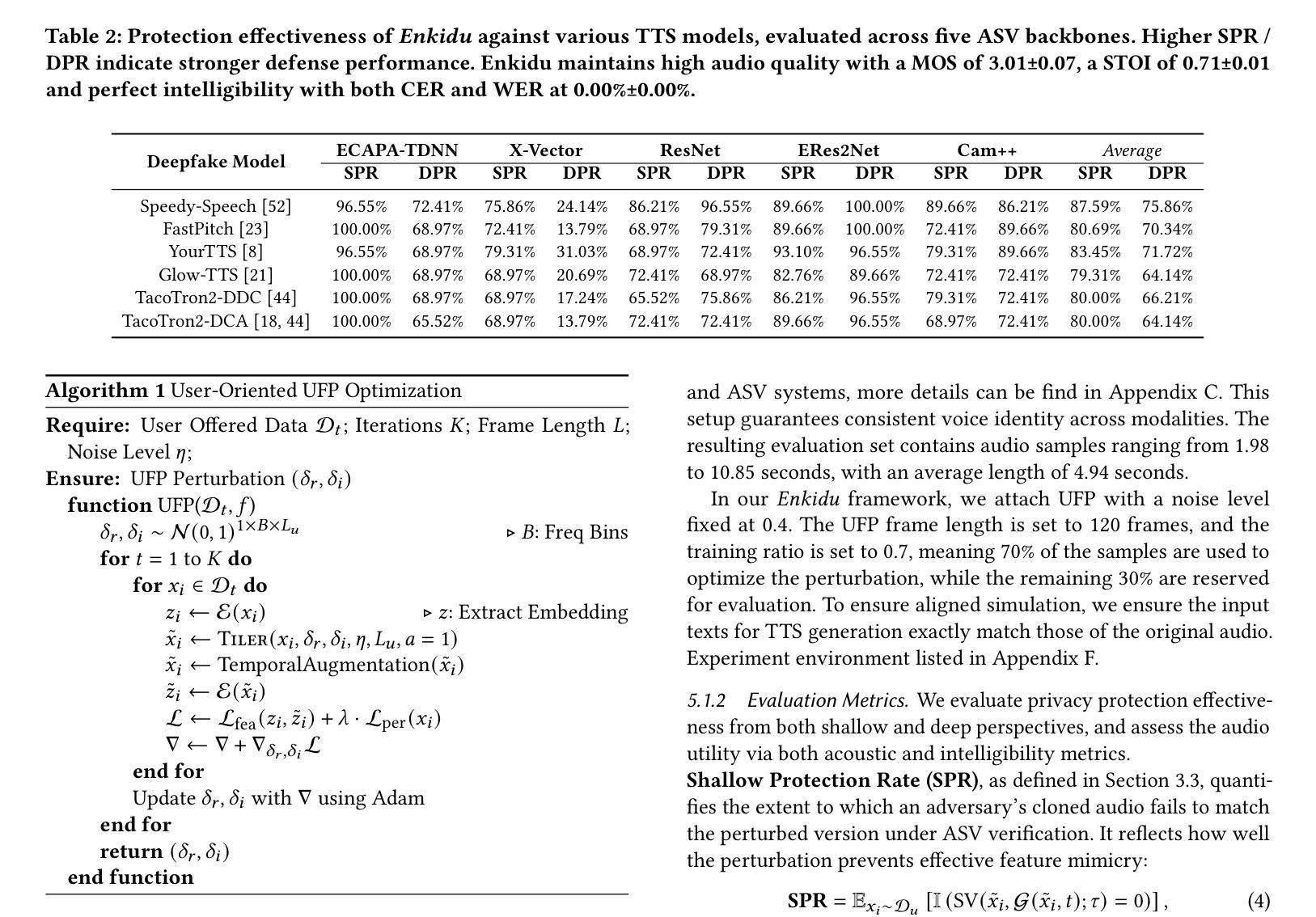
The rapid advancement of voice deepfake technologies has raised serious concerns about user audio privacy, as attackers increasingly exploit publicly available voice data to generate convincing fake audio for malicious purposes such as identity theft, financial fraud, and misinformation campaigns. While existing defense methods offer partial protection, they face critical limitations, including weak adaptability to unseen user data, poor scalability to long audio, rigid reliance on white-box knowledge, and high computational and temporal costs during the encryption process. To address these challenges and defend against personalized voice deepfake threats, we propose Enkidu, a novel user-oriented privacy-preserving framework that leverages universal frequential perturbations generated through black-box knowledge and few-shot training on a small amount of user data. These highly malleable frequency-domain noise patches enable real-time, lightweight protection with strong generalization across variable-length audio and robust resistance to voice deepfake attacks, all while preserving perceptual quality and speech intelligibility. Notably, Enkidu achieves over 50 to 200 times processing memory efficiency (as low as 0.004 gigabytes) and 3 to 7000 times runtime efficiency (real-time coefficient as low as 0.004) compared to six state-of-the-art countermeasures. Extensive experiments across six mainstream text-to-speech models and five cutting-edge automated speaker verification models demonstrate the effectiveness, transferability, and practicality of Enkidu in defending against both vanilla and adaptive voice deepfake attacks.
随着语音深度伪造技术的快速发展,用户音频隐私引起了严重的关注。攻击者越来越利用公开的语音数据生成令人信服的虚假音频,用于身份盗窃、金融欺诈和虚假信息宣传等恶意目的。现有的防御方法虽然提供了一定的保护,但存在关键局限性,包括对新用户数据的适应能力弱、对长音频的可扩展性差、对空白盒知识的刚性依赖以及加密过程中的高计算和时间成本。为了解决这些挑战并防范个性化的语音深度伪造威胁,我们提出了Enkidu,这是一个新型的用户导向的隐私保护框架。它利用通过空白盒知识和少量用户数据的少量训练生成的通用频率扰动。这些高度可塑的频率域噪声斑块能够实现实时、轻量级的保护,具有强大的泛化能力,可跨变长音频使用,并具有抵抗语音深度伪造攻击的稳健性,同时保留感知质量和语音清晰度。值得注意的是,与六种最先进的对策相比,Enkidu的处理内存效率提高了50至200倍(低至0.004GB),运行时效率提高了3至7000倍(实时系数低至0.004)。在六个主流文本到语音模型和五个先进的自动说话人验证模型上的广泛实验证明了Enkidu在防范普通和自适应语音深度伪造攻击方面的有效性、可迁移性和实用性。
论文及项目相关链接
PDF Accepted by ACM MM 2025
Summary
随着语音深度伪造技术的快速发展,用户音频隐私面临严重威胁。攻击者越来越多地利用公开语音数据生成令人信服的虚假音频,用于身份盗窃、金融欺诈和虚假信息宣传等恶意目的。针对现有防御方法面临的关键局限,如不适应未见用户数据、难以处理长音频、过于依赖白盒知识和加密过程中的高计算及时间成本,我们提出了Enkidu这一面向用户的新型隐私保护框架。它通过黑盒知识和少量用户数据的短训练生成通用频域扰动,这些高度灵活的频域噪声块可实现实时、轻量级的保护,具有强大的泛化能力,可抵御个性化语音深度伪造威胁。与其他六种最先进的对策相比,Enkidu在处理内存效率上提高了50至200倍(低至0.004千兆字节),运行时间效率提高了3至7000倍(实时系数低至0.004)。
Key Takeaways
- 语音深度伪造技术带来的用户音频隐私威胁。
- 现有防御方法存在不适应未见用户数据、难以处理长音频、依赖白盒知识和加密过程成本高昂等局限。
- Enkidu是一个面向用户的新型隐私保护框架,利用黑盒知识和少量用户数据短训练生成通用频域扰动。
- Enkidu具有实时、轻量级保护能力,泛化能力强,可抵御个性化语音深度伪造威胁。
- Enkidu在处理内存效率和运行时间效率上相比其他对策有显著提高。
- Enkidu通过广泛实验验证了在抵御传统和适应性语音深度伪造攻击方面的有效性、可迁移性和实用性。
点此查看论文截图

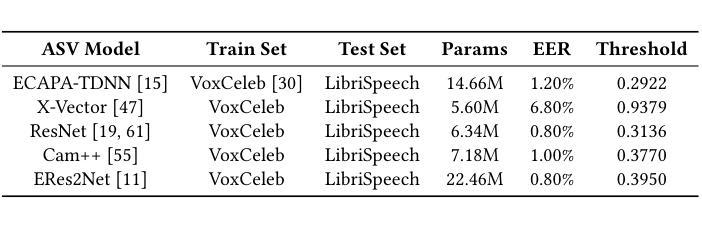
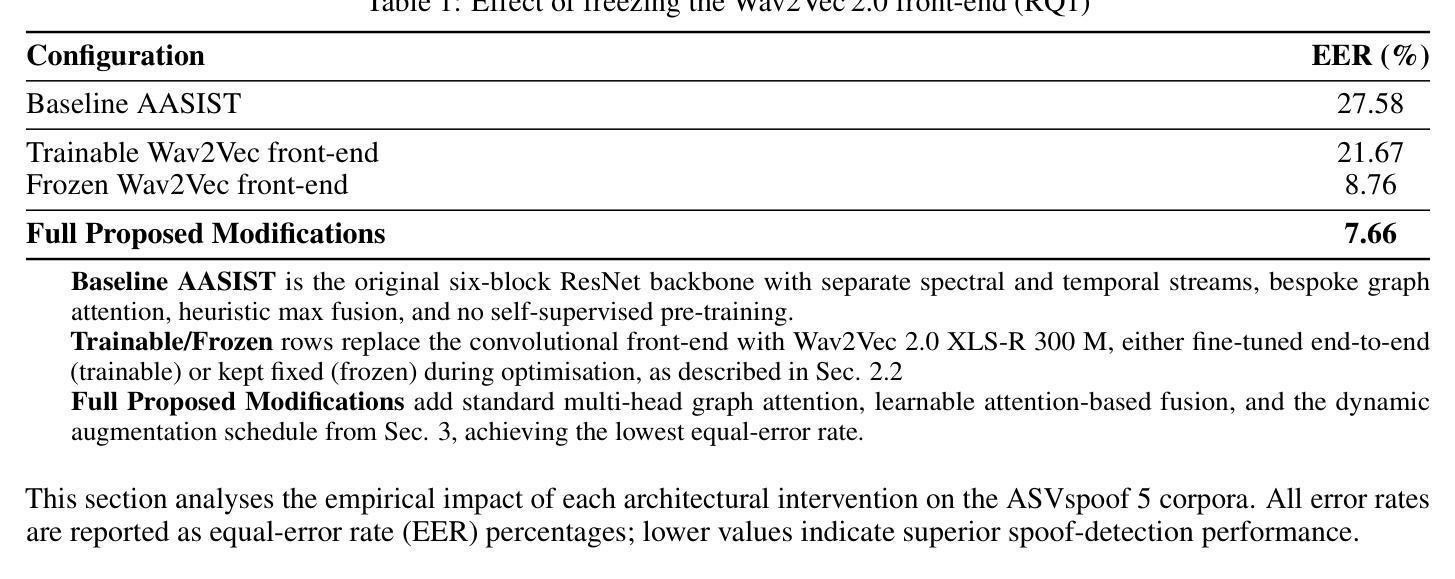
Towards Scalable AASIST: Refining Graph Attention for Speech Deepfake Detection
Authors:Ivan Viakhirev, Daniil Sirota, Aleksandr Smirnov, Kirill Borodin
Advances in voice conversion and text-to-speech synthesis have made automatic speaker verification (ASV) systems more susceptible to spoofing attacks. This work explores modest refinements to the AASIST anti-spoofing architecture. It incorporates a frozen Wav2Vec 2.0 encoder to retain self-supervised speech representations in limited-data settings, substitutes the original graph attention block with a standardized multi-head attention module using heterogeneous query projections, and replaces heuristic frame-segment fusion with a trainable, context-aware integration layer. When evaluated on the ASVspoof 5 corpus, the proposed system reaches a 7.6% equal error rate (EER), improving on a re-implemented AASIST baseline under the same training conditions. Ablation experiments suggest that each architectural change contributes to the overall performance, indicating that targeted adjustments to established models may help strengthen speech deepfake detection in practical scenarios. The code is publicly available at https://github.com/KORALLLL/AASIST_SCALING.
语音转换和文本转语音合成技术的进步使得自动说话人验证(ASV)系统更容易受到欺骗攻击。这项工作探索了AASIST反欺骗架构的适度改进。它结合了冻结的Wav2Vec 2.0编码器,以在数据有限的情况下保留自我监督的语音表示,用标准化的多头注意力模块替代了原始的图注意力块,该模块使用异构图查询投影,并用可训练的、具有上下文意识的集成层替代了启发式帧段融合。在ASVspoof 5语料库上评估时,所提出的系统达到了7.6%的等错误率(EER),在相同的训练条件下改进了重新实现的AASIST基线。消融实验表明,每个架构变化都对整体性能有所贡献,这表明对已有模型的有针对性的调整可能有助于加强实际场景中的语音深度伪造检测。代码公开在https://github.com/KORALLLL/AASIST_SCALING。
论文及项目相关链接
Summary
文本介绍了针对自动说话人验证(ASV)系统的反欺骗架构AASIST的改进。通过引入冻结的Wav2Vec 2.0编码器以在有限数据环境中保留自我监督的语音表示,使用标准化的多头注意力模块替代原始的图注意力块,并用可训练的上下文感知融合层替代启发式帧段融合,提高了系统的性能。在ASVspoof 5语料库上的评估显示,该系统达到了7.6%的等错误率(EER),相较于相同训练条件下的重新实现的AASIST基线有所改善。
Key Takeaways
- 语音转换和文本-语音合成技术的进步使得自动说话人验证系统更容易受到欺骗攻击。
- 对AASIST反欺骗架构进行了适度改进以提高性能。
- 引入冻结的Wav2Vec 2.0编码器以在有限数据环境中保留自我监督的语音表示。
- 使用标准化的多头注意力模块替代了原始的图注意力块。
- 启发式帧段融合被可训练的、上下文感知的融合层所替代。
- 在ASVspoof 5语料库上的评估显示,系统达到了7.6%的等错误率。
点此查看论文截图



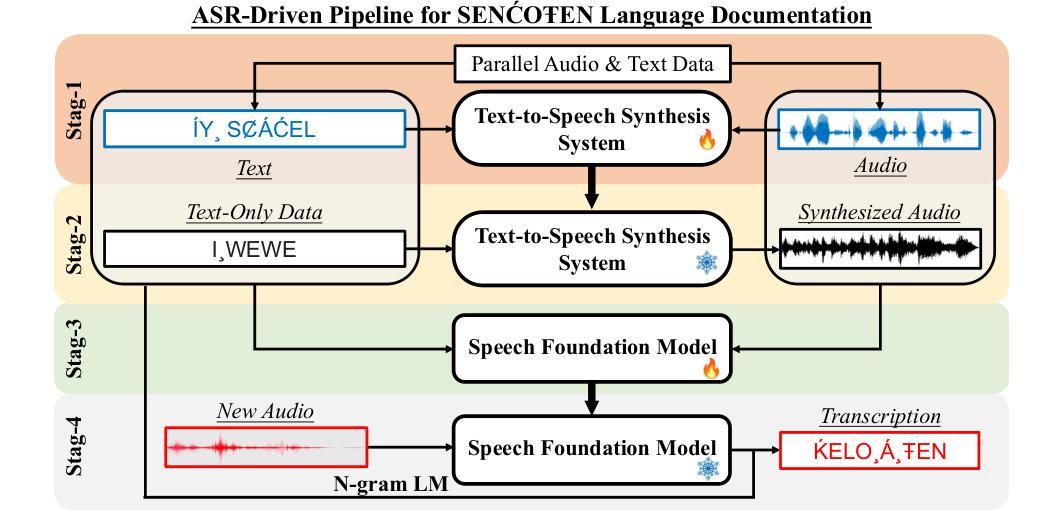
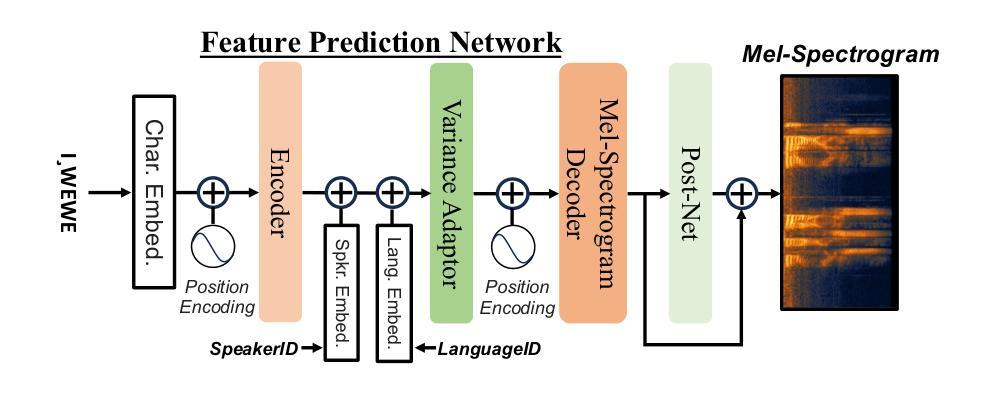
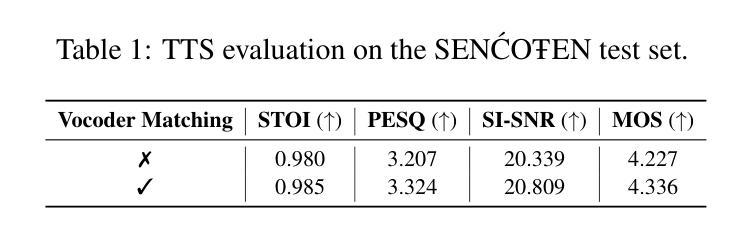
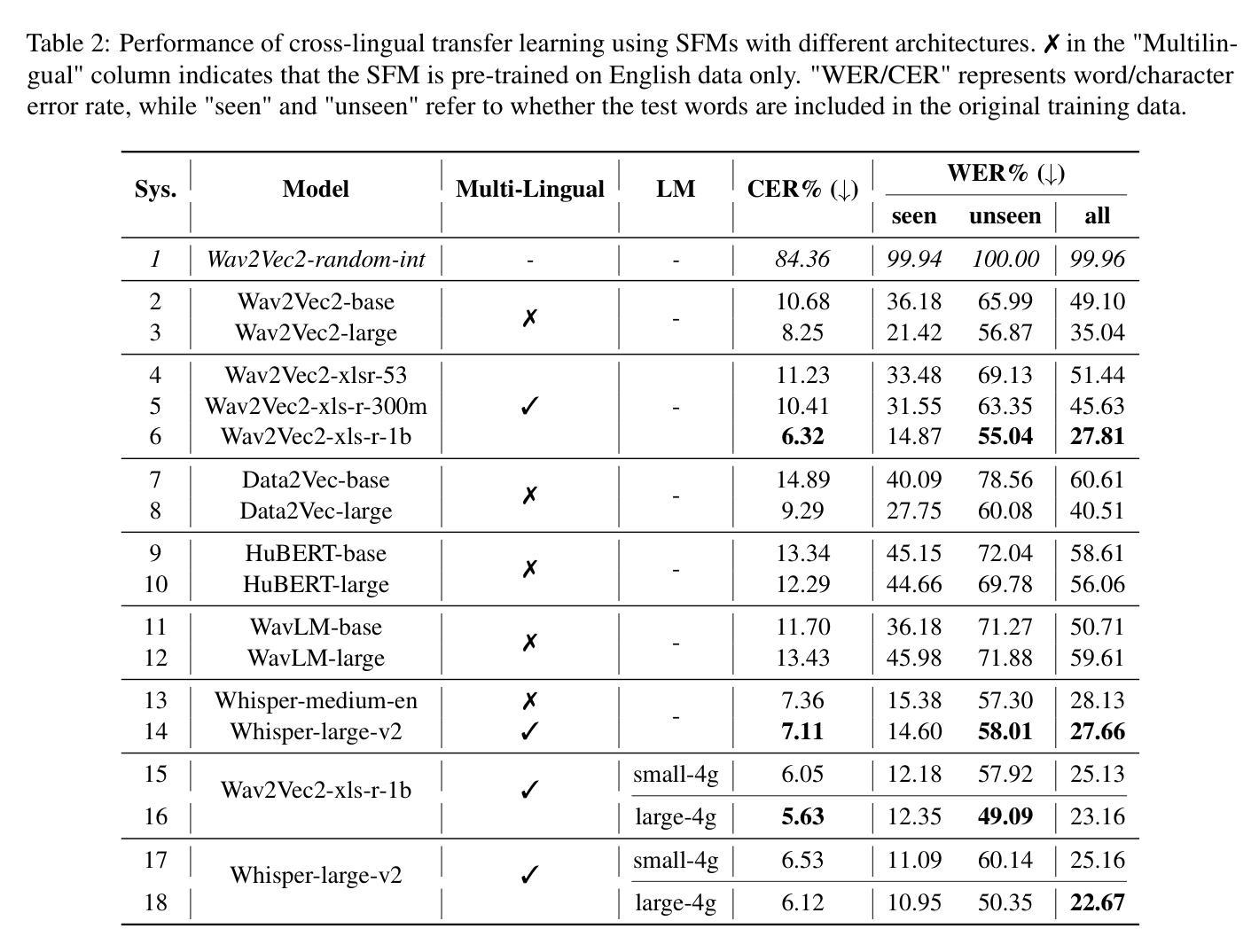
Supporting SENCOTEN Language Documentation Efforts with Automatic Speech Recognition
Authors:Mengzhe Geng, Patrick Littell, Aidan Pine, PENÁĆ, Marc Tessier, Roland Kuhn
The SENCOTEN language, spoken on the Saanich peninsula of southern Vancouver Island, is in the midst of vigorous language revitalization efforts to turn the tide of language loss as a result of colonial language policies. To support these on-the-ground efforts, the community is turning to digital technology. Automatic Speech Recognition (ASR) technology holds great promise for accelerating language documentation and the creation of educational resources. However, developing ASR systems for SENCOTEN is challenging due to limited data and significant vocabulary variation from its polysynthetic structure and stress-driven metathesis. To address these challenges, we propose an ASR-driven documentation pipeline that leverages augmented speech data from a text-to-speech (TTS) system and cross-lingual transfer learning with Speech Foundation Models (SFMs). An n-gram language model is also incorporated via shallow fusion or n-best restoring to maximize the use of available data. Experiments on the SENCOTEN dataset show a word error rate (WER) of 19.34% and a character error rate (CER) of 5.09% on the test set with a 57.02% out-of-vocabulary (OOV) rate. After filtering minor cedilla-related errors, WER improves to 14.32% (26.48% on unseen words) and CER to 3.45%, demonstrating the potential of our ASR-driven pipeline to support SENCOTEN language documentation.
SENCOTEN语言是温哥华岛南部Saanich半岛上的一种语言,正在积极进行语言振兴努力,以扭转因殖民语言政策而导致的语言流失趋势。为了支持这些实地工作,社区正转向数字技术。自动语音识别(ASR)技术在加速语言文档制作和创建教育资源方面具有巨大潜力。然而,由于数据有限以及词汇的显著变化(来自其综合结构和应力驱动的音位变化),开发用于SENCOTEN的ASR系统面临挑战。为了应对这些挑战,我们提出了一种ASR驱动的文档管道,该管道利用文本到语音(TTS)系统的增强语音数据以及跨语言的迁移学习与语音基础模型(SFM)。还通过浅融合或n-best恢复融入了n元语言模型,以最大化利用可用数据。在SENCOTEN数据集上的实验显示,测试集的词错误率(WER)为19.34%,字符错误率(CER)为5.09%,未见词汇(OOV)率为57.02%。过滤掉与cedilla相关的微小错误后,WER提高到14.32%(未见词汇的错误率为26.48%),CER为3.45%,证明了我们的ASR驱动管道在支持SENCOTEN语言文档方面的潜力。
论文及项目相关链接
PDF Accepted by ComputEL-8
摘要
位于温哥华岛南部萨尼奇半岛的森科滕语言正在进行活力恢复工作,旨在扭转因殖民语言政策导致的语言流失趋势。社区正借助数字技术支持这些实地工作,自动语音识别(ASR)技术对于加速语言记录和创建教育资源具有巨大潜力。然而,由于森科滕语言的有限数据和词汇变化多端(来自其合成结构和压力驱动的元音交替),开发ASR系统面临挑战。为解决这些挑战,我们提出了一种ASR驱动的文档处理管道,该管道利用文本到语音(TTS)系统的增强语音数据和跨语言迁移学习与语音基础模型(SFMs)。通过结合n-gram语言模型(通过浅融合或n-best恢复),最大限度地利用可用数据。在森科滕数据集上的实验显示,测试集的词错误率(WER)为19.34%,字符错误率(CER)为5.09%,未见词汇表(OOV)的比率为57.02%。过滤掉与cedilla相关的轻微错误后,WER提高到14.32%(未见词汇的识别率为26.48%),CER降低到3.45%,证明了我们的ASR驱动管道在支持森科滕语言文档方面的潜力。
关键见解
- SENCOTEN语言正在经历活力恢复工作,以应对殖民语言政策导致的语言流失。
- 社区借助数字技术,特别是自动语音识别(ASR)技术,加速语言记录和创建教育资源。
- 开发针对SENCOTEN语言的ASR系统面临挑战,包括有限的数据和词汇变化多端。
- 提出了一种ASR驱动的文档处理管道,结合文本到语音(TTS)系统的增强语音数据、跨语言迁移学习和语音基础模型(SFMs)。
- 通过融入n-gram语言模型优化ASR系统性能。
- 实验结果显示,系统性能在词错误率(WER)和字符错误率(CER)方面取得了显著成果。
点此查看论文截图